
Metode de Optimizare – Curs 14 · Metode de Optimizare – Curs 14 3 pentru k = 0, 1, … execut...
36
Metode de Optimizare – Curs 14 1 VII.3.5. Metode Newton modificate În ultimul algoritm prezentat în cursul trecut în situaţia în care hessiana Hf(x k ) nu era pozitiv definită se folosea drept direcţie de deplasare v k = -∇f(x k ) specifică metodei gradientului. Altă variantă este modificarea ad-hoc a matricei Hf(x k ). Mai precis, folosirea unei direcţii de forma B k = Hf(x k ) + E k unde E k este o matrice aleasă astfel încât Hf(x k ) + E k să fie „suficient de pozitiv definită” (E k = 0 dacă Hf(x k ) este „suficient de pozitiv definită”). Metodele de acest tip poartă numele de metode Newton modificate (sau metode Newton cu modificarea hessianei). Algoritmul asociat metodelor de tip Newton modificate este schiţat mai jos (se presupune x 0 dat) k: = 0; cât timp ||∇f(x k )|| ≠0 execută pasul 1: * se calculează B k = Hf(x k ) + E k , unde E k este o matrice aleasă astfel încât Hf(x k ) + E k să fie „suficient de pozitiv definită” (E k = 0 dacă Hf(x k ) este „suficient de pozitiv definită”) pasul 2: *se rezolvă sistemul B k v k = -∇f(x k ) pasul 3: *se determină pasul de deplasare t k (suboptimal) asociat direcţiei de deplasare v k ; pasul 4: x k+1 = x k + t k v k ; k: = k+1; Pentru determinarea matricei B k putem pleca de la descompunerea spectrală a matricei simetrice Hf(x k ), adică scrierea ei sub forma Hf(x k ) = QDQ t , unde Q este o matrice ortogonală (având pe coloane vectori proprii ai lui Hf(x k )) iar D o matrice diagonală (având pe diagonala principală valorile proprii ale lui Hf(x k )): Se poate lua B k = Hf(x k ) + E k = QD m Q t , unde λ 1 0 0 … 0 0 λ 2 0 … 0 0 0 0 … λ n D =
Transcript of Metode de Optimizare – Curs 14 · Metode de Optimizare – Curs 14 3 pentru k = 0, 1, … execut...

Metode de Optimizare – Curs 14
1
VII.3.5. Metode Newton modificate
În ultimul algoritm prezentat în cursul trecut în situaţia în care hessiana
Hf(xk) nu era pozitiv definită se folosea drept direcţie de deplasare vk = -∇f(xk)
specifică metodei gradientului. Altă variantă este modificarea ad-hoc a matricei
Hf(xk). Mai precis, folosirea unei direcţii de forma Bk = Hf(xk) + Ek unde Ek este o
matrice aleasă astfel încât Hf(xk) + Ek să fie „suficient de pozitiv definită” (Ek = 0
dacă Hf(xk) este „suficient de pozitiv definită”). Metodele de acest tip poartă
numele de metode Newton modificate (sau metode Newton cu modificarea
hessianei).
Algoritmul asociat metodelor de tip Newton modificate este schiţat mai
jos (se presupune x0 dat) k: = 0;
cât timp ||∇f(xk)|| ≠0 execută
pasul 1: * se calculează Bk = Hf(xk) + Ek, unde Ek este o matrice aleasă
astfel încât Hf(xk) + Ek să fie „suficient de pozitiv definită” (Ek
= 0 dacă Hf(xk) este „suficient de pozitiv definită”)
pasul 2: *se rezolvă sistemul Bkvk = -∇f(xk)
pasul 3: *se determină pasul de deplasare tk (suboptimal) asociat
direcţiei de deplasare vk;
pasul 4: xk+1 = xk + tkvk ; k: = k+1;
Pentru determinarea matricei Bk putem pleca de la descompunerea
spectrală a matricei simetrice Hf(xk), adică scrierea ei sub forma Hf(xk) = QDQt,
unde Q este o matrice ortogonală (având pe coloane vectori proprii ai lui Hf(xk))
iar D o matrice diagonală (având pe diagonala principală valorile proprii ale lui
Hf(xk)):
Se poate lua Bk = Hf(xk) + Ek = QDmQt, unde
λ1 0 0 … 0
0 λ2 0 … 0
0 0 0 … λn
D =

Mădălina Roxana Buneci Metode de Optimizare – Curs - 2007
2
cu µi = max (ε, |λi|) pentru orice 1 ≤ i ≤ n (sau eventual, µi = max (ε, λi) pentru
orice 1 ≤ i ≤ n), ε fiind un număr pozitiv „mic” (de exemplu, ε = machε , unde
εmach este precizia maşinii). O astfel de descompunere necesită un volum mare de
calcul dacă n mare. Un volum mai mic de calcul se obţine dacă se estimează doar
cea mai mică valoare proprie λmin(Hf(xk)) a matricei Hf(xk) şi se ia
ε fiind un număr pozitiv „mic”.
Dacă matricea Hf(xk) are o valoare proprie negativă mare în modul şi
restul valorilor proprii pozitive dar mici în modul, atunci se poate întâmpla ca prin
această metodă direcţia de deplasare obţinută să fie esenţial direcţia celei mai
rapide descreşteri.
Alte metode de modificare a hessianei se bazează pe factorizări Cholesky.
Probabil cea mai simplă idee este de a determina un scalar τ >0 cu proprietatea că
Hf(xk) + τIn este „suficient de pozitiv definită”. Un algoritm pentru determinarea
lui τ (bazat pe factorizări Cholesky) este prezentat mai jos (pentru simplitate
notăm Hf(xk) = A, iar elementele de pe diagonala principală cu aii, 1≤i≤n) :
ρ > 0 dat (de exemplu, ρ = 10-3)
dacă min{aii, 1≤i≤n} > 0 atunci τ0 : = 0
altfel τ0 : = - min{aii, 1≤i≤n} + ρ
µ1 0 0 … 0
0 µ2 0 … 0
0 0 0 … µn
Dm =
max(0, ε-λmin(Hf(xk))) 0 0 … 0
0 max(0, ε-λmin(Hf(xk))) 0 … 0
0 0 0 … max(0, ε-λmin(Hf(xk)))
Ek = = max(0, ε-λmin(Hf(xk)))In

Metode de Optimizare – Curs 14
3
pentru k = 0, 1, … execută
* se încearcă factorizarea Cholesky LLt = A + τkIn
dacă factorizarea reuşeşte atunci return L şi STOP
altfel τk+1 : = max (2τk, ρ)
Prezentăm în continuare implementarea în MAPLE ale algoritmului de
mai sus. Procedura are drept parametri funcţia obiectiv f, punctul iniţial, notat x00,
şi precizia ε (criteriul de oprire este ||∇f(xk)|| < ε). Deoarece procedura foloseşte
comenzi (vector, grad, hessian, cholesky, etc.) din pachetul linalg, înainte de
utilizarea ei pachetul trebuie încărcat:
> with(linalg):
Funcţionare procedurii va fi exemplificată pentru funcţiile
> f1:=(x,y)->3*x^2+2*y^2-2*x*y-4*x+2*y-3;
:= f1 → ( ),x y + − − + − 3 x2 2 y2 2 x y 4 x 2 y 3
> f2:=(x,y)->10*(y-x^2)^2+(x-1)^2;
:= f2 → ( ),x y + 10 ( ) − y x22
( ) − x 1 2
> f4:=(x,y)->1/(x-1)^4/4+(y^2-x);
:= f4 → ( ),x y + − 14
1
( ) − x 1 4y2 x
> f6:=(x,y)->x^2*(4-2.1*x^2+x^4/3)+x*y+y^2*(-4+4*y^2);
:= f6 → ( ),x y + + x2
− + 4 2.1 x2 1
3x4 x y y2 ( )− + 4 4 y2
Implementarea unei variante a metodei Newton modificate (pasul de deplasare
este generat prin algoritmul backtracking-Armijo) :
> newton_modif:=proc(f,x00,epsilon)
> local x0,x1,g,H,g0,H0,L,y,v,n,t,z0,tinit,
beta,delta,p,pp,rho,tau,md,test,dd;
> n:=vectdim(x00); x0:=vector(n); x1:=vector(n);y:=vector(n);
>v:=vector(n);beta:=0.5;delta:=0.1;tinit:=1.;
>L:=matrix(n,n);dd:=floor(Digits/2);
> g:=grad(f(seq(x[i],i=1..n)),[seq(x[i],i=1..n)]);
> H:=hessian(f(seq(x[i],i=1..n)),[seq(x[i],i=1..n)]);
> x0:=map(evalf,x00);

Mădălina Roxana Buneci Metode de Optimizare – Curs - 2007
4
> g0:=vector([seq(subs(seq(x[i]=x0[i],i=1..n), g[j]),j=1..n)]);
> while norm(g0,2)>=epsilon do
> H0:=evalm(matrix(n,n,[seq(seq(subs(seq(x[i]=x0[i],i=1..n),
H[j,p]),j=1..n),p=1..n)]));
> rho:=0.001;
>md:=min(seq(H0[i,i],i=1..n));
>if md>0 then tau:=0. else tau:=-md+rho fi;
>test:=1;
>while test=1 do test:=0;
>for p from 1 to n do
>md:=H0[p,p]+tau -sum(L[p,i]^2,i=1..p-1);
>if md<=10^(-dd) then test:=1;tau:=max(rho,2*tau);p:=n+1;
>else L[p,p]:=md^(1/2); for pp from p+1 to n do
>L[pp,p]:=(H0[pp,p]-sum(L[pp,i]*L[p,i],i=1..p-1))/L[p,p] od
>fi
>od;
>od;
> y[1]:=-g0[1]/L[1,1];
> for p from 2 to n do
>y[p]:=(-g0[p]-sum(L[p,j]*y[j],j=1..p-1))/L[p,p] od;
> v[n]:=y[n]/L[n,n];
> for p from n-1 by -1 to 1 do
>v[p]:=(y[p]-sum(L[j,p]*v[j],j=p+1..n))/L[p,p] od;
> z0:=evalf(f(seq(x0[i],i=1..n))); t:=tinit;
>x1:=evalm(x0+t*v);
> while f(seq(x1[i],i=1..n))>z0+t*delta*sum(g0[i]*v[i],i=1..n)
> do t:=t*beta; x1:=evalm(x0+t*v);
> od;
> x0:=evalm(x1);
> g0:=vector([seq(subs(seq(x[i]=x0[i],i=1..n), g[j]),j=1..n)]);
> od;
> RETURN(evalm(x0))
> end;
> newton_modif(f1,vector([0,0]),10^(-4));
[ ],0.6000000001 -0.2000000002
> newton_modif(f2,vector([1,0]),10^(-4));

Metode de Optimizare – Curs 14
5
[ ],1. 1.000000000
> newton_modif(f2,vector([-1,0]),10^(-4));
[ ],0.9999993870 0.9999987218
> newton_modif(f2,vector([-0.5,0.2]),10^(-4));
[ ],1.000000004 0.9999999981
> newton_modif(f3,vector([0,-1]),10^(-4));
[ ],0.4714045208 10-10 0.1 10-8
> newton_modif(f5,vector([2,3]),10^(-4));
[ ],1.565194829 0.1 10-53
> newton_modif(f4,vector([0.5,3]),10^(-4));
[ ],0.12864143 10-5 -0.1 10-62
> newton_modif(f4,vector([-0.5,0.2]),10^(-4));
[ ],0.2439499 10-7 0.1 10-18
> newton_modif(f6,vector([-1,-1]),10^(-4));
[ ],0.08984236139 -0.7126591488
> newton_modif(f6,vector([-1,1]),10^(-4));
[ ],-0.08984201229 0.7126564041
> newton_modif(f6,vector([1,1]),10^(-4));
[ ],-0.08984236139 0.7126591488
Pentru funcţiile f6 cu punctul iniţial (1, -1)t şi f2 cu punctul iniţial (0, 1)t prezentăm
mai jos şi reprezentarea grafică (3D şi contour) a iteraţiilor:
> newton_modif(f6,vector([1,-1]),10^(-4));
[ ],0.08984201229 -0.7126564041
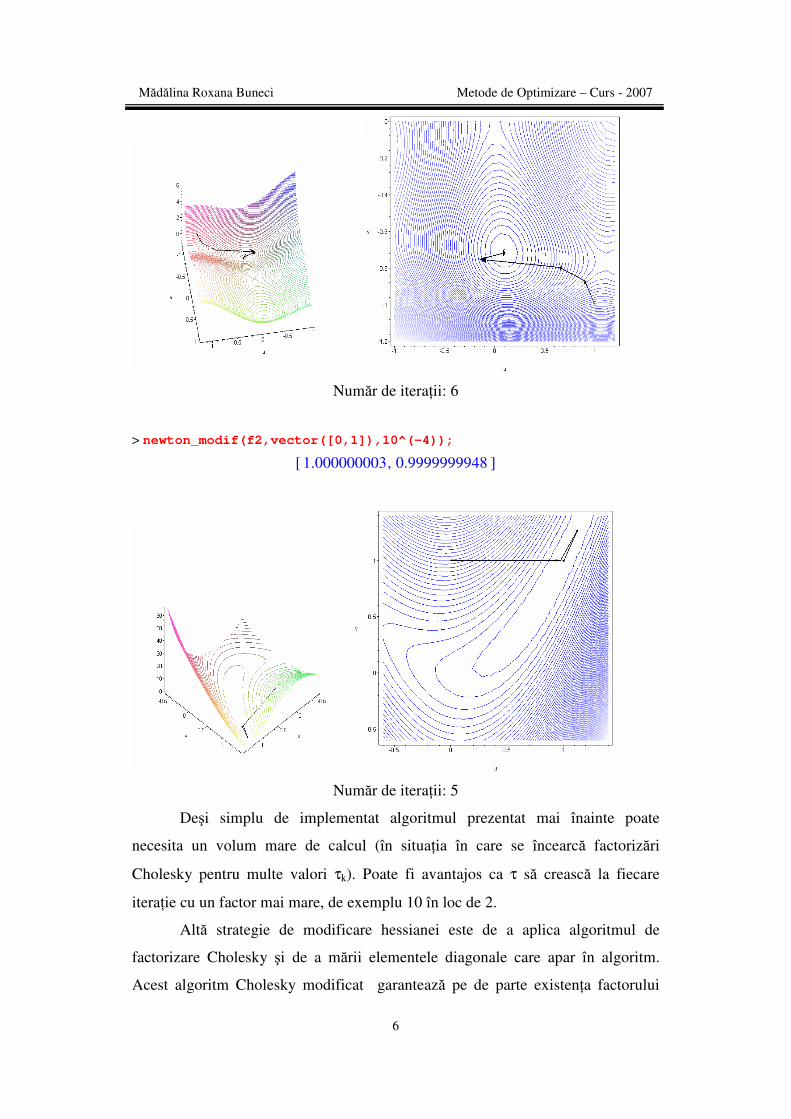
Mădălina Roxana Buneci Metode de Optimizare – Curs - 2007
6
Număr de iteraţii: 6
> newton_modif(f2,vector([0,1]),10^(-4));
[ ],1.000000003 0.9999999948
Număr de iteraţii: 5
Deşi simplu de implementat algoritmul prezentat mai înainte poate
necesita un volum mare de calcul (în situaţia în care se încearcă factorizări
Cholesky pentru multe valori τk). Poate fi avantajos ca τ să crească la fiecare
iteraţie cu un factor mai mare, de exemplu 10 în loc de 2.
Altă strategie de modificare hessianei este de a aplica algoritmul de
factorizare Cholesky şi de a mării elementele diagonale care apar în algoritm.
Acest algoritm Cholesky modificat garantează pe de parte existenţa factorului

Metode de Optimizare – Curs 14
7
Cholesky cu elemente care nu depăşesc în modul norma hessianei, iar pe de altă
parte nu modifică hessiana dacă este „suficient de pozitiv definită”. Începem
descrierea acestei strategii prin recapitularea aşa numitei descompuneri LDLt a
unei matrice simetrice A cu minorii principali nenuli. O scriere a matricei A sub
forma A = LDLt, unde L este o matrice inferior triunghiulară cu elementele de pe
diagonala principală egale cu 1, şi D o matrice diagonală se numeşte factorizare
LDLt. Ţinând cont de relaţiile:
aij = ∑=
j
1kjkkkik LDL = ∑
−
=
1j
1kjkkkik LDL + LijDjj pentru i ≥ j =1,2,…,n.
obţinem următorul algoritm pentru calculul factorizării LDLt a unei matrice A
pentru j=1,2,...,n execută
Djj := ajj - ∑−
=
1j
1kkk
2jk DL
pentru i = j+1, j+2,...,n execută
Lij : = jjD
1(aij - ∑
−
=
1j
1kjkkkik LDL )
Algoritmul funcţionează pentru matrice simetrice cu minorii principali nenuli, în
particular pentru matrice A pozitiv definite. Legătura între factorul Cholesky M al
matricei A (A= MMt cu M =(mij)i,j o matrice inferior triunghiulară cu elementele
de pe diagonala principală pozitive) şi factorizare A = LDLt este
mij = Lij jjD pentru orice i,j.
Algoritmul de factorizare Cholelesky modificat aplicat unei matrice A presupune
date două valori ε > 0 şi η >0. Se calculează A + E = LDLt = MMt astfel încât
Djj ≥ ε şi |mij| ≤ η pentru orice i şi j.
Algoritm Cholesky modificat pentru calculul factorizării A + E = LDLt = MM
t
pentru j=1,2,...,n execută
Cjj : = ajj - ∑−
=
1j
1kkk
2jk DL ; θj := max{cij, j<i≤n}
Djj :=
2
jijmax C , ,
θ ε
η

Mădălina Roxana Buneci Metode de Optimizare – Curs - 2007
8
pentru i = j+1, j+2,...,n execută
Cij : = (aij - ∑−
=
1j
1kjkkkik LDL ); Lij : =
jjD
1Cjj;
Să verificăm că într-adevăr |mij| ≤ η pentru orice i şi j:
|mij| = |Lij| jjD =ij
jj
C
D ≤
ij
j
C η
θ ≤ η.
Pentru a reduce modificările asupra lui A se pot face permutări simetrice de linii şi
coloane (algoritmul Cholesky modificat datorat lui Gill, Murray şi Wright)
obţinându-se factorizarea PAPt + E = LDLt = MMt, unde P este matricea de
permutare.
VII.3.6. Metoda direcţiilor conjugate. Metoda gradientului
conjugat
Fie C ∈Mn,n(R) o matrice pozitiv definită. Matricea C induce un produs
scalar pe Rn, notat <⋅, ⋅>C :
<x, y>C : = <Cx, y>, x, y ∈ Rn.
Doi vectori x, y ∈Rn se numesc conjugaţi în raport cu C (sau C – ortogonali)
dacă <Cx, y> = 0 (sau echivalent, <x, y>C = 0).
Dacă vectorii v1, v2, ..., vk sunt nenuli conjugaţi în raport cu C doi câte doi,
atunci v1, v2, ..., vk sunt liniar independenţi (deoarece conjugarea în raport cu C
înseamnă ortogonalitate în raport cu produsul scalar <⋅, ⋅>C şi într-un spaţiu pre-
Hilbert orice familie de vectori nenuli ortogonali doi câte doi este liniar
independentă). În particular, dacă k = n, vectorii v1, v2, ..., vn constituie o bază în
Rn.
Lema 34. Fie f:Rn→R o funcţie definită prin f(x) = 1
2<x,Cx> + <x, d> cu
C∈Mn,n(R) o matrice pozitiv definită şi d∈Rn un vector fixat, şi fie v0, v1, ..., vn-1
o familie de vectori nenuli conjugaţi în raport cu C doi câte doi. Atunci există şi
este unic un punct de minim global x* al lui f şi

Metode de Optimizare – Curs 14
9
x* = in 1 i
i ii 0
d, vv
Cv , v
−
=
< >− ∑ < >
.
Demonstraţie. Avem ∇f(x) = Cx + d şi Hf(x) = C pentru orice x ∈ Rn.
Deoarece C este pozitiv definită rezultă că f este convexă, deci un punct x* este
punct de minim dacă şi numai dacă x* este punct staţionar. Avem
∇f(x*) = 0 <=> x* = -C-1d,
şi ca urmare x* = -C-1d este unicul punct de minim al lui f. Deoarece v0, v1, ..., vn-1
sunt vectori nenuli conjugaţi în raport cu C doi câte doi, ei constituie o bază în Rn.
În consecinţă, există scalarii α0, α1, ..., αn-1∈R astfel încât
-C-1d = n 1 i
ii 0
v−
=α∑
<-C-1d, vj>C = n 1 i j
i Ci 0
v , v−
=α < >∑
-<C-1d, vj>C = αj <vi, vj>C
-<d, vj> = αj <Cvj, vj>
αj = j
j j
d, v
Cv , v
< >−
< >.
Aşadar x* = -C-1d = in 1 i
i ii 0
d, vv
Cv , v
−
=
< >− ∑ < >
■
Lema 35. Fie f:Rn→R o funcţie definită prin f(x) = 1
2<x,Cx> + <x, d> cu
C∈Mn,n(R) o matrice pozitiv definită şi d∈Rn un vector fixat. Dacă vk∈R
n este un
vector nenul, atunci soluţia optimă a problemei t 0inf
≥f(xk + tvk) este
tk = ( )k k
k k
f x , v
Cv , v
< ∇ >−
< >
Demonstraţie. Pentru orice t avem
f(xk+tvk) = 1
2 t2<vk,Cvk> + t(<vk, Cxk> + <vk, d>)
1
2<xk,Cxk> +
+1
2<xk,Cxk> + <xk,d>

Mădălina Roxana Buneci Metode de Optimizare – Curs - 2007
10
de unde rezultă că tk =k k
k k
Cx d, v
Cv , v
< + >−
< >=
( )k k
k k
f x , v
Cv , v
< ∇ >−
< >.
■
Propoziţie 36. Fie f:Rn→R o funcţie definită prin f(x) = 1
2<x,Cx> +
<x,d> cu C∈Mn,n(R) o matrice pozitiv definită şi d∈Rn un vector fixat, şi fie v0,
v1, ..., vn-1 o familie de vectori nenuli conjugaţi în raport cu C doi câte doi. Se
construieşte şirul (xk)k:
xk+1 = xk + tkvk, x0 dat, 0≤ k ≤n-1
unde tk este pasul optimal asociat direcţiei vk, adică tk este soluţia optimă a
problemei t 0inf
≥f(xk + tvk). Atunci xn = x* unicul punct de minim al lui f.
Demonstraţie. Deoarece v0, v1, ..., vn-1 sunt vectori nenuli conjugaţi în
raport cu C doi câte doi, ei constituie o bază în Rn. În consecinţă, există scalarii α0,
α1, ..., αn-1∈R astfel încât
x0 = n 1 i
ii 0
v−
=α∑
<x0, vj>C = n 1 i j
i Ci 0
v , v−
=α < >∑
<x0, vj>C = αj <vi, vj>C
<Cx0, vj> = αj <Cvj, vj>
αj = 0 j
j j
Cx , v
Cv , v
< >
< >.
Aşadar
x0 = 0 in 1 ii i
i 0
Cx , vv
Cv , v
−
=
< >∑
< > (36.1)
Adunând relaţiile xi+1 = xi + tivi pentru i =0..k-1, obţinem
xk = x0 + k 1 i
ii 0
t v−
=∑ . (36.2)
<xk, vk>C = x0 + k 1 i k
i Ci 0
t v , v−
=< >∑
<Cxk, vk> = <Cx0, vk> (36.3)

Metode de Optimizare – Curs 14
11
Deci
<∇f(xk), vk> = <Cxk + d, vk> = <Cxk, vk> + <d, vk>
( )
=36.3
<Cx0, vk> + <d, vk> (36.4)
Din lema 35 rezultă că tk = ( )k k
k k
f x , v
Cv , v
< ∇ >−
< > ( )
=36.4
0 k k
k k k k
Cx , v d, v
Cv , v Cv , v
< > < >− −
< > < >
pentru orice k, şi înlocuind în (36.2) k cu n şi fiecare ti, obţinem:
xn = x0 + ( )k k
n 1 kk kk 0
f x , vv
Cv , v
−
=
< ∇ > −∑ < >
= x0 + 0 i in 1 ii i i ii 0
Cx , v d, vv
Cv , v Cv , v
−
=
< > < >− − ∑ < > < >
= x0 + 0 in 1 ii i
i 0
Cx , vv
Cv , v
−
=
< >− ∑
< >+
in 1 ii ii 0
d, vv
Cv , v
−
=
< >− ∑ < >
( )
=36.1
x0 – x0 + in 1 i
i ii 0
d, vv
Cv , v
−
=
< >− ∑ < >
(36.5)
Conform lemei 34, f are unic punct de minim
x* = in 1 i
i ii 0
d, vv
Cv , v
−
=
< >− ∑ < >
,
şi în consecinţă ţinând cont şi de (36.5), rezultă xn =x*.
■
Lema 37. Fie f:Rn→R o funcţie definită prin f(x) = 1
2<x,Cx> + <x,d> cu
C∈Mn,n(R) o matrice pozitiv definită şi d∈Rn un vector fixat, şi fie v0, v1, ..., vm-1
(m un număr natural) o familie de vectori conjugaţi în raport cu C doi câte doi. Se
construieşte şirul (xk)k:
xk+1 = xk + tkvk, x0 dat, 0≤ k ≤m
unde tk este pasul optimal asociat direcţiei vk, adică tk este soluţia optimă a
problemei t 0inf
≥f(xk + tvk). Atunci <∇f(xk+1), vi> = 0 pentru orice i ∈ {0, 1, …, k}.
Demonstraţie. Vom face demonstraţia inductiv după k. Pentru k =0 avem
<∇f(x1), v0> = <Cx1 + d, v0> = <Cx0 + t0Cv0, v0> + <d, v0>

Mădălina Roxana Buneci Metode de Optimizare – Curs - 2007
12
= <Cx0, v0> + t0<Cv0, v0> + <d, v0>,
şi ţinând cont că t0 = ( )0 0
0 0
f x , v
Cv , v
< ∇ >−
< >=
0 0 0
0 0 0 0
Cx , v d, v
Cv , v Cv , v
< > < >− −
< > < > (conform,
lemei 35) rezultă că <∇f(x1), v0> = 0. Presupunem afirmaţia adevărată pentru k şi
o demonstrăm pentru k+1. Pentru i = k avem
<∇f(xk+1), vk> = <Cxk+1 + d, vk> = <Cxk + tkCvk, vk> + <d, vk>
= <Cxk, vk> + tk<Cvk, vk> + <d, vk>,
iar din lema 35, tk = ( )k k
k k
f x , v
Cv , v
< ∇ >−
< >=
k k k
k k k k
Cx , v d, v
Cv , v Cv , v
< > < >− −
< > < > . Aşadar
<∇f(xk), vk> = 0. Pentru i ∈ {0, 1, …, k-1}, conform ipotezei de inducţie
<∇f(xk),vi> = 0, şi ca urmare
<∇f(xk+1), vi> = <Cxk+1 + d, vi> = <Cxk + tkCvk + d, vi>
= <∇f(xk), vi> + tk<Cvk, vi> = tk<vk, vi>C = 0.
■
Propoziţie 38. Fie f:Rn→R o funcţie definită prin f(x) = 1
2<x,Cx> +
<x,d> cu C∈Mn,n(R) o matrice pozitiv definită şi d∈Rn un vector fixat, şi fie v0,
v1, ..., vn-1 o familie de vectori nenuli conjugaţi în raport cu C doi câte doi. Se
construieşte şirul (xk)k:
xk+1 = xk + tkvk, x0 dat, 0≤ k ≤n-1
unde tk este pasul optimal asociat direcţiei vk, adică tk este soluţia optimă a
problemei t 0inf
≥f(xk + tvk). Atunci xk+1 este soluţie optimă a problemei
x Ak
inf∈
f(x),
unde Ak = x0 + Sp{v0, v1, …, vk} = x0 + n 1 i
i ii 0
v ,−
=
λ λ ∈∑
R .
Demonstraţie. Adunând relaţiile xi+1 = xi + tivi pentru i =0..k, obţinem
xk+1 = x0 + k i
ii 0
t v=∑ .
Fie x ∈Ak. Atunci există λ0, λ1, ..., λn-1∈R astfel încât x = x0 + n 1 i
ii 0
v−
=λ∑ . Avem
<∇f(xk+1), x-xk+1> = ( ) ( )kk 1 i
i ii 0
f x , t v+
=< ∇ λ − >∑

Metode de Optimizare – Curs 14
13
= ( ) ( )k k 1 i
i ii 0
t f x , v+
=λ − < ∇ >∑
= 0
conform lemei 37. Deci pentru orice x∈Ak avem
f(x) – f(xk+1) ≥ <∇f(xk+1), x-xk+1> = 0,
şi ca urmare xk+1 este punct de minim pentru f pe Ak.
■
În cazul metodei gradientului conjugat vectorii C- conjugaţi v0, v1, ..., vn-1
se construiesc prin ortogonalizarea relativ la produsul scalar <⋅, ⋅>C a sistemului de
vectori –∇f(x0), -∇f(x1), ..., ∇f(xn-1) folosind procedeul Gram-Schmidt. Astfel
v0 = -∇f(x0)
vk = -∇f(xk) + k 1 i
kii 0
v−
=λ∑
unde λki (i=0..k-1) se determină astfel încât pentru orice k şi orice j ≤ k-1, <vk, vj>
= 0. Astfel
λki = ( )i k
C
i iC
v , f x
v , v
< ∇ >
< >=
( )i k
i i
Cv , f x
Cv , v
< ∇ >
< >
Conform lemei 37, pentru orice k ≥ 1 avem
<∇f(xk), ∇f(x0) > = -<∇f(xk), v0 > = 0
şi pentru orice i ≥1 şi k≥ i+1
<∇f(xi),∇f(xk),> = < - vi +i 1 j
i 1, jj 0
v−
−=
λ∑ , ∇f(xk)> = 0.
Pe de altă parte
∇f(xi+1) = Cxi+1 + d = Cxi + tiCvi + d = ∇f(xi) + tiCvi
şi ca urmare pentru orice i ∈{0, 1, …, k-2}
0 = <∇f(xi+1), ∇f(xk)> = <∇f(xi), ∇f(xk)> + ti<Cvi, ∇f(xk)> = ti<Cvi, ∇f(xk)>.
Aşadar <Cvi, ∇f(xk)> = 0 şi deci λki =0 pentru orice i ∈{0, 1, …, k-2}. Deci
vk = -∇f(xk) + k 1 i
kii 0
v−
=λ∑ = -∇f(xk) + λkk-1v
k-1

Mădălina Roxana Buneci Metode de Optimizare – Curs - 2007
14
= -∇f(xk) + ( )k 1 k
k 1 k 1
Cv , f x
Cv , v
−
− −
< ∇ >
< >vk-1.
Deci vk+1 = -∇f(xk+1) + βkvk, unde
βk = ( )k k 1
k k
Cv , f x
Cv , v
+< ∇ >
< >
Cum din lema 35 tk = ( )k k
k k
f x , v
Cv , v
< ∇ >−
< > şi
∇f(xk+1) = Cxk+1 + d = Cxk + tkCvk + d = ∇f(xk) + tkCvk
=∇f(xk) ( )k k
k k
f x , v
Cv , v
< ∇ >−
< > Cvk
rezultă că Cvk = ( )
k k
k k
Cv , v
f x , v
< >
< ∇ >(∇f(xk) - ∇f(xk+1)). În consecinţă
βk = ( ) ( ) ( )
( )
k k 1 k 1
k k
f x f x , f x
f x , v
+ +< ∇ − ∇ ∇ >
< ∇ >
şi ţinând cont că vk = -∇f(xk) + βk-1vk-1, de unde <∇f(xk), vk> = -<∇f(xk), ∇f(xk)>
(conform lemei 37, <∇f(xk), vk-1> = 0), rezultă
βk = ( ) ( ) ( )
( ) ( )
k 1 k k 1
k k
f x f x , f x
f x , f x
+ +< ∇ − ∇ ∇ >
< ∇ ∇ >
Deoarece <∇f(xk), ∇f(xk+1)> = 0, βk poate fi exprimat echivalent:
βk = ( ) ( )
( ) ( )
k 1 k 1
k k
f x , f x
f x , f x
+ +< ∇ ∇ >
< ∇ ∇ >.
În virtutea condiţiei de C-ortogonalitate, în cazul funcţiilor pătratice, metoda
gradientului conjugat converge într-un număr finit de paşi k ≤ n (conform
propoziţiei 36). Deoarece formulele de calcul pentru βk nu depind explicit de
matricea C, metoda poate fi aplicată unor funcţii mai generale. Dacă funcţia f nu
este pătratică atunci cele două formule de calcul ale lui βk nu sunt echivalente.
În cazul în care

Metode de Optimizare – Curs 14
15
βk = ( ) ( )
( ) ( )
k 1 k 1
k k
f x , f x
f x , f x
+ +< ∇ ∇ >
< ∇ ∇ >.
se obţine algoritmul Fletcher-Reeves, iar în cazul în care
βk = ( ) ( ) ( )
( ) ( )
k 1 k k 1
k k
f x f x , f x
f x , f x
+ +< ∇ − ∇ ∇ >
< ∇ ∇ >
se obţine algoritmul Polak-Ribiere. Schiţăm mai jos cei doi algoritmi.
Algoritmul Fletcher-Reeves (se presupune x0 dat)
k: = 0;
v0:=∇f(x0);
cât timp ||∇f(xk)|| ≠0 execută
pasul 1: *se determină pasul de deplasare tk (optimal sau suboptimal)
asociat direcţiei de deplasare vk;
pasul 2: xk+1 = xk + tkvk ;
pasul 3: βk : = ( ) ( )
( ) ( )
k 1 k 1
k k
f x , f x
f x , f x
+ +< ∇ ∇ >
< ∇ ∇ >; vk+1:=-∇f(xk+1) + βkv
k.
k: = k+1;
Algoritmul Polak-Ribiere (se presupune x0 dat)
k: = 0;
v0:=∇f(x0);
cât timp ||∇f(xk)|| ≠0 execută
pasul 1: *se determină pasul de deplasare tk (optimal sau suboptimal)
asociat direcţiei de deplasare vk;
pasul 2: xk+1 = xk + tkvk ;
pasul 3: βk : = ( ) ( ) ( )
( ) ( )
k 1 k k 1
k k
f x f x , f x
f x , f x
+ +< ∇ − ∇ ∇ >
< ∇ ∇ >;
vk+1:=-∇f(xk+1) + βkvk.
k: = k+1;

Mădălina Roxana Buneci Metode de Optimizare – Curs - 2007
16
Prezentăm în continuare implementarea în MAPLE a celor doi algoritmi de mai
sus. Procedurile au drept parametri funcţia obiectiv f, punctul iniţial, notat x00, şi
precizia ε (criteriul de oprire este ||∇f(xk)|| < ε). Procedurile folosesc comenzi din
pachetul linalg. Funcţionare procedurilor va fi exemplificată pentru funcţiile:
> f1:=(x,y)->3*x^2+2*y^2-2*x*y-4*x+2*y-3;
:= f1 → ( ),x y + − − + − 3 x2 2 y2 2 x y 4 x 2 y 3
> f2:=(x,y)->10*(y-x^2)^2+(x-1)^2;
:= f2 → ( ),x y + 10 ( ) − y x22
( ) − x 1 2
> f4:=(x,y)->1/(x-1)^4/4+(y^2-x);
:= f4 → ( ),x y + − 14
1
( ) − x 1 4y2 x
> f6:=(x,y)->x^2*(4-2.1*x^2+x^4/3)+x*y+y^2*(-4+4*y^2);
:= f6 → ( ),x y + + x2
− + 4 2.1 x2 1
3x4 x y y2 ( )− + 4 4 y2
Pentru funcţiile f6 cu punctul iniţial (1, -1)t şi f2 cu punctul iniţial (0, 1)t vom
prezenta şi reprezentarea grafică (3D şi contour) a iteraţiilor (cele două funcţii nu
sunt funcţii convexe!).
Implementarea algoritmului Fletcher-Reeves (pasul optimal de deplasare este
obţinut prin metoda secţiunii de aur) :
> FletcherReeves:=proc(f,x00,epsilon)
> local x0,i,n,g,g0,v,beta,t1,t2,t,
y1,y2,alpha,alpha1,a,b,L,u,w,nmax,j,phi;
> n:=vectdim(x00); x0:=vector(n);v:=vector(n);
>g:=grad(f(seq(x[i],i=1..n)),[seq(x[i],i=1..n)]);
> x0:=map(evalf,x00);
> g0:=vector([seq(subs(seq(x[i]=x0[i],i=1..n), g[j]),j=1..n)]);
>v:=evalm(-g0);
> while norm(g0,2)>=epsilon do
>phi:=t->f(seq(x0[i]+t*v[i],i=1..n));
> t1:=0.; t2:=1.; y1:=phi(t1); y2:=phi(t2);
> if y1<=y2 then a:=t1; b:=t2 else
> while y1>y2 do y1:=y2;t1:=t2;t2:=t2+1;y2:=phi(t2) od;
> a:=t1-1; b:=t2 fi;
> alpha:=evalf((5^(1/2)-1)/2);alpha1:=1-alpha;

Metode de Optimizare – Curs 14
17
> L:=b-a;u:=a+alpha1*L;w:=a+alpha*L;y1:=phi(u);
>y2:=phi(w);nmax:=ceil(ln(epsilon/(10*L))/ln(alpha));j:=0;
> while j<nmax do
> if y1<y2 then b:=w;L:=b-a;
> y2:=y1;w:=u;u:=a+alpha1*L;y1:=phi(u)
> else a:=u;L:=b-a;
> y1:=y2;u:=w;w:=a+alpha*L;y2:=phi(w);
> fi;
>j:=j+1
> od;
> t:=(a+b)/2;beta:=sum(g0[i]*g0[i],i=1..n);
> x0:=evalm(x0+t*v);
> g0:=vector([seq(subs(seq(x[i]=x0[i],i=1..n), g[j]),j=1..n)]);
>beta:=sum(g0[i]*g0[i],i=1..n)/beta;v:=evalm(-g0+beta*v);
> od;
> RETURN(evalm(x0))
> end;
> FletcherReeves(f1,vector([0,0]),10^(-4));
[ ],0.6000128098 -0.2000001602
> FletcherReeves(f2,vector([1,0]),10^(-4));
[ ],0.9999779929 0.9999537039
> FletcherReeves(f2,vector([-1,0]),10^(-4));
[ ],0.9999957029 0.9999902214
> FletcherReeves(f2,vector([-0.5,0.2]),10^(-4));
[ ],0.9999864790 0.9999713199
> FletcherReeves(f3,vector([0,-1]),10^(-4));
[ ],0.28487 10-5 -0.0000111958
> FletcherReeves(f4,vector([0.5,3]),10^(-4));
[ ],0.29674978 10-6 0.00003805865244
> FletcherReeves(f4,vector([-0.5,0.2]),10^(-4));
[ ],-0.633170353 10-5 -0.61905436 10-5
> FletcherReeves(f6,vector([-1,-1]),10^(-4));
[ ],-0.08984210733 0.7126526153
> FletcherReeves(f6,vector([-1,1]),10^(-4));
[ ],1.703604624 -0.7960833832
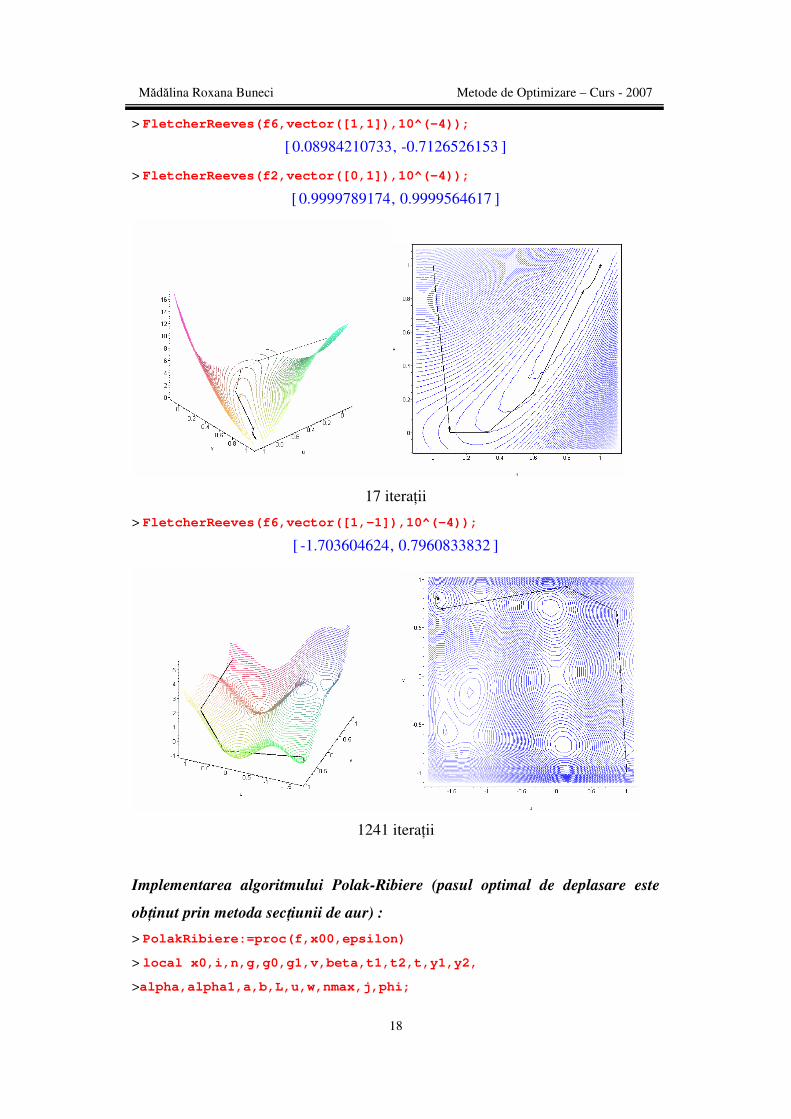
Mădălina Roxana Buneci Metode de Optimizare – Curs - 2007
18
> FletcherReeves(f6,vector([1,1]),10^(-4));
[ ],0.08984210733 -0.7126526153
> FletcherReeves(f2,vector([0,1]),10^(-4));
[ ],0.9999789174 0.9999564617
17 iteraţii
> FletcherReeves(f6,vector([1,-1]),10^(-4));
[ ],-1.703604624 0.7960833832
1241 iteraţii
Implementarea algoritmului Polak-Ribiere (pasul optimal de deplasare este
obţinut prin metoda secţiunii de aur) :
> PolakRibiere:=proc(f,x00,epsilon)
> local x0,i,n,g,g0,g1,v,beta,t1,t2,t,y1,y2,
>alpha,alpha1,a,b,L,u,w,nmax,j,phi;

Metode de Optimizare – Curs 14
19
> n:=vectdim(x00); x0:=vector(n);v:=vector(n);
>g:=grad(f(seq(x[i],i=1..n)),[seq(x[i],i=1..n)]);
> x0:=map(evalf,x00);
> g0:=vector([seq(subs(seq(x[i]=x0[i],i=1..n), g[j]),j=1..n)]);
>v:=evalm(-g0);
> while norm(g0,2)>=epsilon do
>phi:=t->f(seq(x0[i]+t*v[i],i=1..n));
> t1:=0.; t2:=1.; y1:=phi(t1); y2:=phi(t2);
> if y1<=y2 then a:=t1; b:=t2 else
> while y1>y2 do y1:=y2;t1:=t2;t2:=t2+1;y2:=phi(t2) od;
> a:=t1-1; b:=t2 fi;
> alpha:=evalf((5^(1/2)-1)/2);alpha1:=1-alpha;
> L:=b-a;u:=a+alpha1*L;w:=a+alpha*L;y1:=phi(u);y2:=phi(w);
>nmax:=ceil(ln(epsilon/(10*L))/ln(alpha));j:=0;
> while j<nmax do
> if y1<y2 then b:=w;L:=b-a;
> y2:=y1;w:=u;u:=a+alpha1*L;y1:=phi(u)
> else a:=u;L:=b-a;
> y1:=y2;u:=w;w:=a+alpha*L;y2:=phi(w);
> fi;
>j:=j+1
> od;
> t:=(a+b)/2;
> x0:=evalm(x0+t*v);
> g1:=vector([seq(subs(seq(x[i]=x0[i],i=1..n), g[j]),j=1..n)]);
>beta:=sum((g1[i]-g0[i])*g1[i],i=1..n)/sum(g0[i]*g0[i],i=1..n);
>g0:=evalm(g1);v:=evalm(-g0+beta*v);
> od;
> RETURN(evalm(x0))
> end;
> PolakRibiere(f1,vector([0,0]),10^(-4));
[ ],0.6000173636 -0.1999812728
> PolakRibiere(f2,vector([1,0]),10^(-4));
[ ],0.9999999306 0.9999998742
> PolakRibiere(f2,vector([-1,0]),10^(-4));
[ ],0.9999998969 0.9999997969
Mădălina Roxana Buneci Metode de Optimizare – Curs - 2007
20
> PolakRibiere(f2,vector([-0.5,0.2]),10^(-4));
[ ],1.000002020 1.000004631
> PolakRibiere(f3,vector([0,-1]),10^(-4));
[ ],-0.916052101 10-6 -0.366547736 10-5
> PolakRibiere(f4,vector([0.5,3]),10^(-4));
[ ],-0.1120502499 10-5 -0.00001018277
> PolakRibiere(f4,vector([-0.5,0.2]),10^(-4));
[ ],0.832527387 10-5 0.00001060187505
> PolakRibiere(f6,vector([-1,-1]),10^(-4));
[ ],-0.08984347334 0.7126526183
> PolakRibiere(f6,vector([-1,1]),10^(-4));
[ ],-1.703605085 0.7960854846
> PolakRibiere(f6,vector([1,1]),10^(-4));
[ ],0.08984347334 -0.7126526183 > PolakRibiere(f2,vector([0,1]),10^(-4));
[ ],0.9999999059 0.9999997978
9 iteraţii
> PolakRibiere(f6,vector([1,-1]),10^(-4));
[ ],1.703605085 -0.7960854846
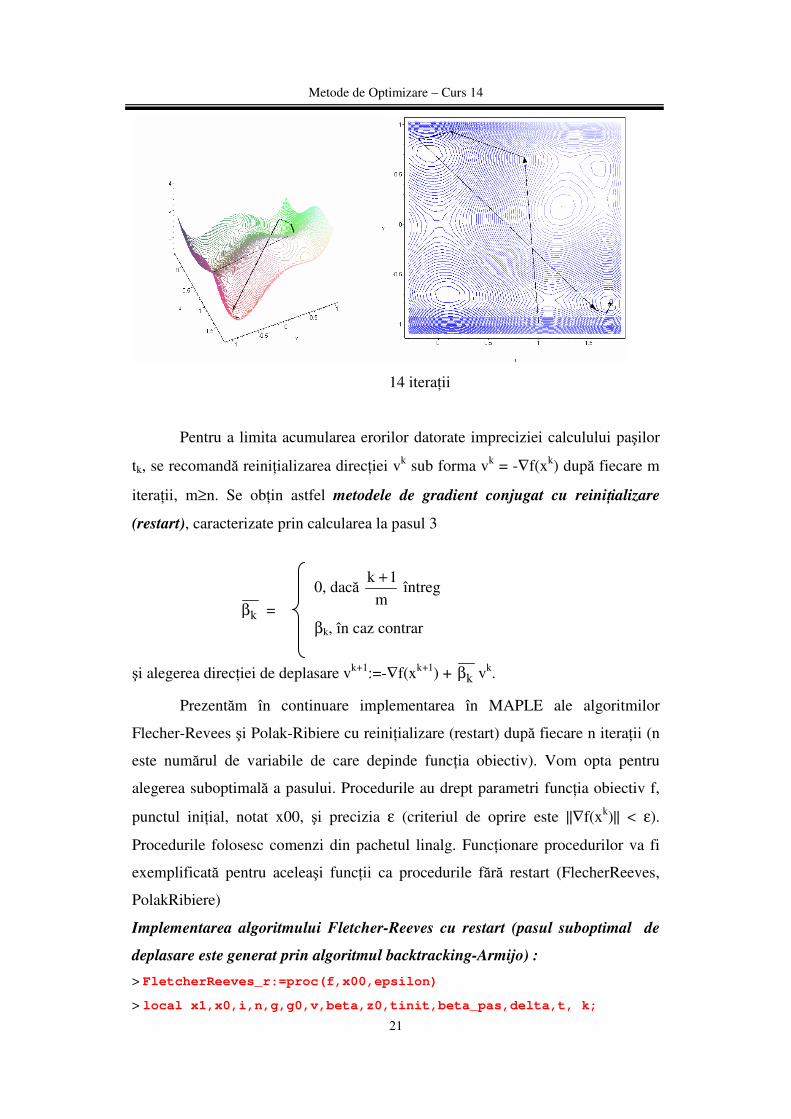
Metode de Optimizare – Curs 14
21
14 iteraţii
Pentru a limita acumularea erorilor datorate impreciziei calculului paşilor
tk, se recomandă reiniţializarea direcţiei vk sub forma vk = -∇f(xk) după fiecare m
iteraţii, m≥n. Se obţin astfel metodele de gradient conjugat cu reiniţializare
(restart), caracterizate prin calcularea la pasul 3
kβ =
şi alegerea direcţiei de deplasare vk+1:=-∇f(xk+1) + kβ vk.
Prezentăm în continuare implementarea în MAPLE ale algoritmilor
Flecher-Revees şi Polak-Ribiere cu reiniţializare (restart) după fiecare n iteraţii (n
este numărul de variabile de care depinde funcţia obiectiv). Vom opta pentru
alegerea suboptimală a pasului. Procedurile au drept parametri funcţia obiectiv f,
punctul iniţial, notat x00, şi precizia ε (criteriul de oprire este ||∇f(xk)|| < ε).
Procedurile folosesc comenzi din pachetul linalg. Funcţionare procedurilor va fi
exemplificată pentru aceleaşi funcţii ca procedurile fără restart (FlecherReeves,
PolakRibiere)
Implementarea algoritmului Fletcher-Reeves cu restart (pasul suboptimal de
deplasare este generat prin algoritmul backtracking-Armijo) :
> FletcherReeves_r:=proc(f,x00,epsilon)
> local x1,x0,i,n,g,g0,v,beta,z0,tinit,beta_pas,delta,t, k;
0, dacă k 1
m
+ întreg
βk, în caz contrar

Mădălina Roxana Buneci Metode de Optimizare – Curs - 2007
22
> n:=vectdim(x00); x0:=vector(n);x1:=vector(n);v:=vector(n);
>g:=grad(f(seq(x[i],i=1..n)),[seq(x[i],i=1..n)]);
>beta_pas:=0.5;delta:=0.1;tinit:=1.;
> x0:=map(evalf,x00);k:=0;
> g0:=vector([seq(subs(seq(x[i]=x0[i],i=1..n), g[j]),j=1..n)]);
>v:=evalm(-g0);
> while norm(g0,2)>=epsilon do
> z0:=evalf(f(seq(x0[i],i=1..n))); t:=tinit;x1:=evalm(x0+t*v);
> while f(seq(x1[i],i=1..n))>z0+t*delta*sum(g0[i]*v[i],i=1..n)
> do t:=t*beta_pas; x1:=evalm(x0+t*v);
> od;
> beta:=sum(g0[i]*g0[i],i=1..n);
> x0:=evalm(x1);k:=k+1;
> g0:=vector([seq(subs(seq(x[i]=x0[i],i=1..n), g[j]),j=1..n)]);
>if irem(k+1,n)=0 then beta:=0 else
>beta:=sum(g0[i]*g0[i],i=1..n)/beta fi;v:=evalm(-g0+beta*v);
> od;
> RETURN(evalm(x0))
> end;
> FletcherReeves_r(f1,vector([0,0]),10^(-4));
[ ],0.6000057569 -0.2000119450
> FletcherReeves_r(f2,vector([1,0]),10^(-4));
[ ],0.9999311774 0.9998613155
> FletcherReeves_r(f2,vector([-1,0]),10^(-4));
[ ],0.9999269533 0.9998499381
> FletcherReeves_r(f2,vector([-0.5,0.2]),10^(-4));
[ ],1.000036412 1.000076377
> FletcherReeves_r(f3,vector([0,-1]),10^(-4));
[ ],-0.876325710 10-6 -0.00001133598715
> FletcherReeves_r(f4,vector([0.5,3]),10^(-4));
[ ],0.44320465 10-5 0.00001173252907
> FletcherReeves_r(f4,vector([-0.5,0.2]),10^(-4));
[ ],0.73348991 10-5 0.
> FletcherReeves_r(f6,vector([-1,-1]),10^(-4));
[ ],-0.08984022516 0.7126573686
Metode de Optimizare – Curs 14
23
> FletcherReeves_r(f6,vector([-1,1]),10^(-4));
[ ],-0.08984151229 0.7126566759
> FletcherReeves_r(f6,vector([1,1]),10^(-4));
[ ],0.08984022516 -0.7126573686
> FletcherReeves_r(f2,vector([0,1]),10^(-4));
[ ],0.9999125593 0.9998228383
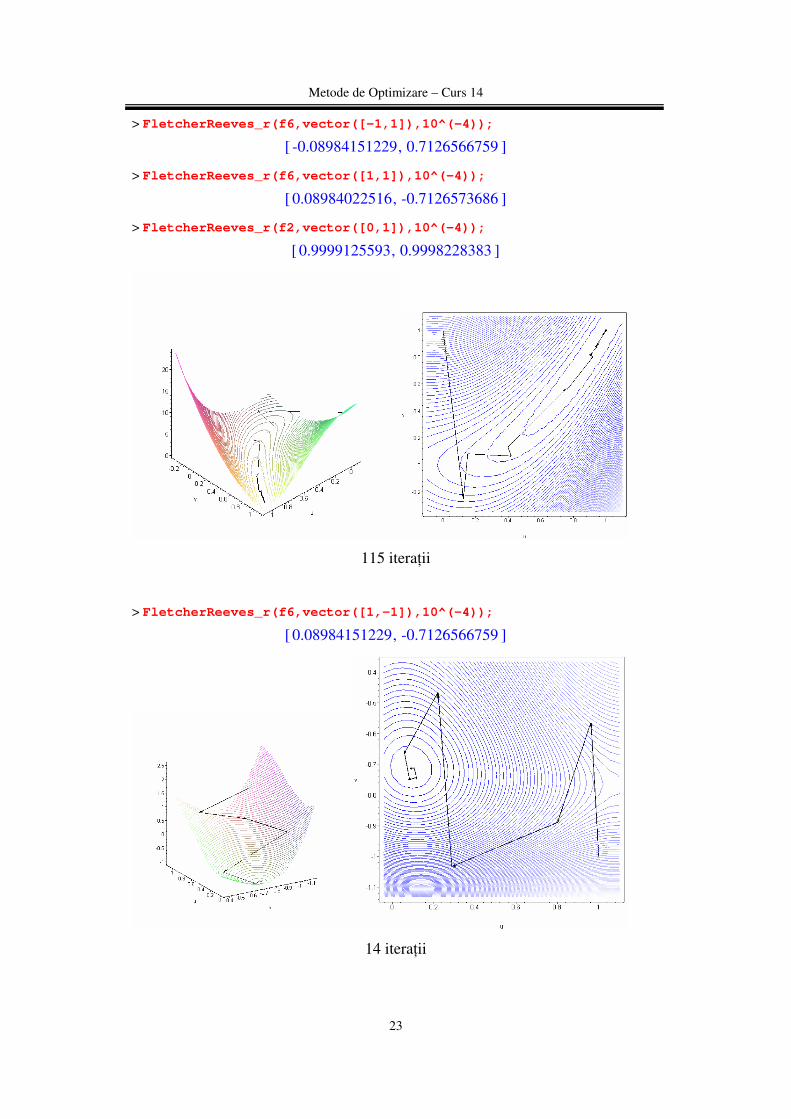
115 iteraţii
> FletcherReeves_r(f6,vector([1,-1]),10^(-4));
[ ],0.08984151229 -0.7126566759
14 iteraţii

Mădălina Roxana Buneci Metode de Optimizare – Curs - 2007
24
Implementarea algoritmului Polak-Ribiere cu restart(pasul suboptimal de
deplasare este generat prin algoritmul backtracking-Armijo) :
> PolakRibiere_r:=proc(f,x00,epsilon)
> local x0,x1,i,n,g,g0,g1,v,beta,z0,tinit,beta_pas,delta,t,k;
> n:=vectdim(x00); x0:=vector(n);x1:=vector(n);v:=vector(n);
>g:=grad(f(seq(x[i],i=1..n)),[seq(x[i],i=1..n)]);
>beta_pas:=0.5;delta:=0.1;tinit:=1.;
> x0:=map(evalf,x00);k:=0;;
> g0:=vector([seq(subs(seq(x[i]=x0[i],i=1..n), g[j]),j=1..n)]);
>v:=evalm(-g0);
> while norm(g0,2)>=epsilon do
> z0:=evalf(f(seq(x0[i],i=1..n))); t:=tinit;x1:=evalm(x0+t*v);
> while f(seq(x1[i],i=1..n))>z0+t*delta*sum(g0[i]*v[i],i=1..n)
> do t:=t*beta_pas; x1:=evalm(x0+t*v);
> od;
> x0:=evalm(x1);
> g1:=vector([seq(subs(seq(x[i]=x0[i],i=1..n), g[j]),j=1..n)]);
>k:=k+1;
>if irem(k+1,n)=0 then
>beta:=sum((g1[i]-g0[i])*g1[i],i=1..n)/sum(g0[i]*g0[i],i=1..n)
else beta:=0 fi;
>g0:=evalm(g1);v:=evalm(-g0+beta*v);
> od;
> RETURN(evalm(x0))
> end;
> PolakRibiere_r(f1,vector([0,0]),10^(-4));
[ ],0.5999894627 -0.1999927775
> PolakRibiere_r(f2,vector([1,0]),10^(-4));
[ ],0.9999408998 0.9998813146
> PolakRibiere_r(f2,vector([-1,0]),10^(-4));
[ ],0.9999400952 0.9998796744
> PolakRibiere_r(f2,vector([-0.5,0.2]),10^(-4));
[ ],0.9999424538 0.9998810721
> PolakRibiere_r(f3,vector([0,-1]),10^(-4));
Metode de Optimizare – Curs 14
25
[ ],-0.274299758 10-5 0.00002535024096
> PolakRibiere_r(f4,vector([0.5,3]),10^(-4));
[ ],-0.00001126654842 -0.3144577122 10-7
> PolakRibiere_r(f4,vector([-0.5,0.2]),10^(-4));
[ ],0.00001096961757 -0.1101010205 10-9
> PolakRibiere_r(f6,vector([-1,-1]),10^(-4));
[ ],-0.08984470254 0.7126608923
> PolakRibiere_r(f6,vector([-1,1]),10^(-4));
[ ],0.08984030100 -0.7126516985
> PolakRibiere_r(f6,vector([1,1]),10^(-4));
[ ],0.08984470254 -0.7126608923
> PolakRibiere_r(f2,vector([0,1]),10^(-4));
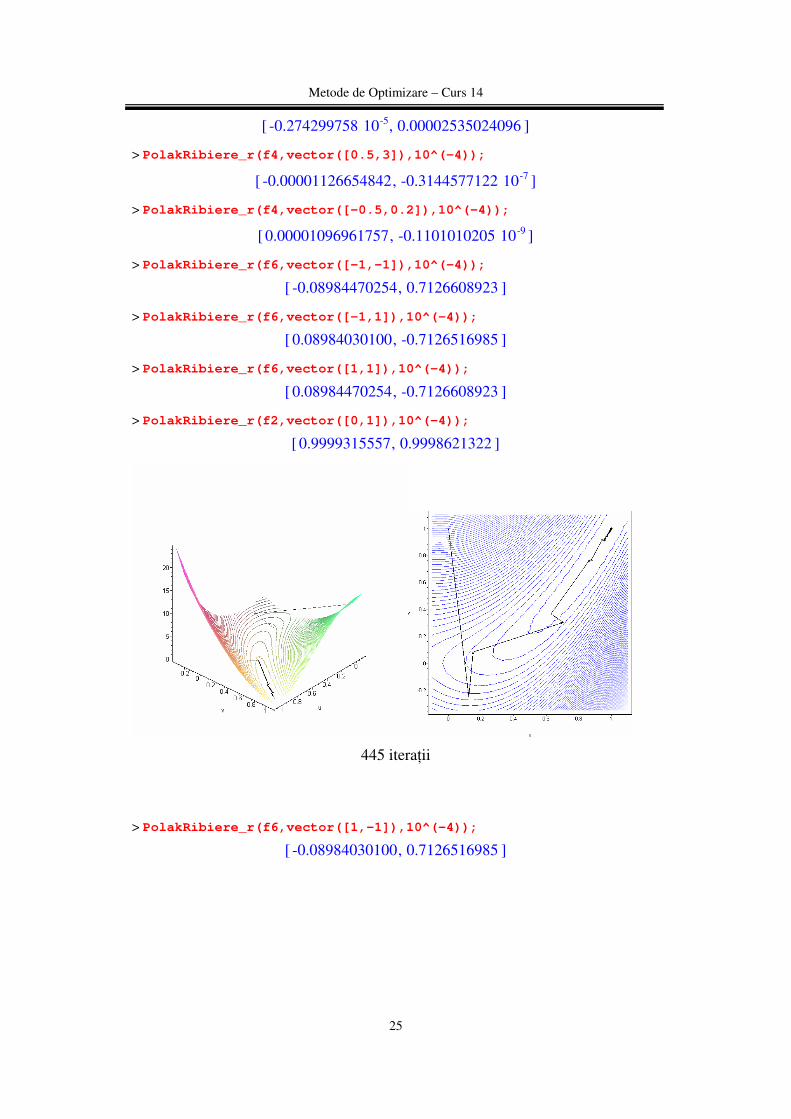
[ ],0.9999315557 0.9998621322
445 iteraţii
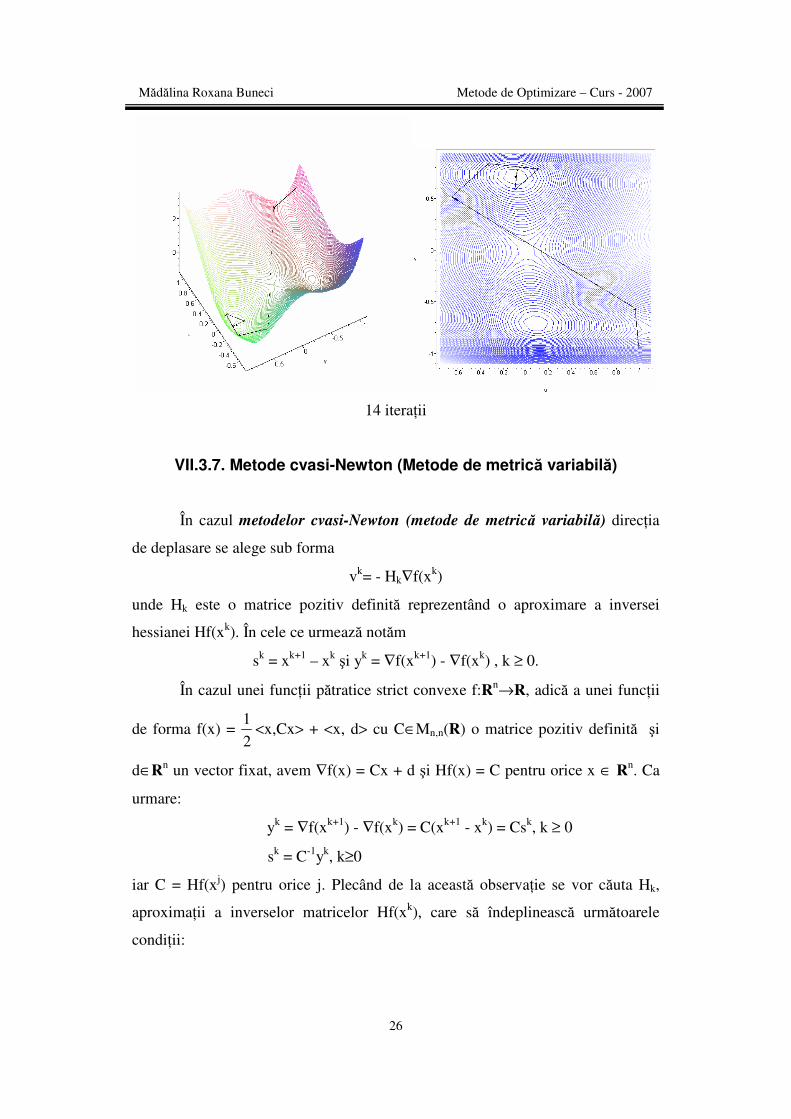
> PolakRibiere_r(f6,vector([1,-1]),10^(-4));
[ ],-0.08984030100 0.7126516985
Mădălina Roxana Buneci Metode de Optimizare – Curs - 2007
26
14 iteraţii
VII.3.7. Metode cvasi-Newton (Metode de metrică variabilă)
În cazul metodelor cvasi-Newton (metode de metrică variabilă) direcţia
de deplasare se alege sub forma
vk= - Hk∇f(xk)
unde Hk este o matrice pozitiv definită reprezentând o aproximare a inversei
hessianei Hf(xk). În cele ce urmează notăm
sk = xk+1 – xk şi yk = ∇f(xk+1) - ∇f(xk) , k ≥ 0.
În cazul unei funcţii pătratice strict convexe f:Rn→R, adică a unei funcţii
de forma f(x) = 1
2<x,Cx> + <x, d> cu C∈Mn,n(R) o matrice pozitiv definită şi
d∈Rn un vector fixat, avem ∇f(x) = Cx + d şi Hf(x) = C pentru orice x ∈ Rn. Ca
urmare:
yk = ∇f(xk+1) - ∇f(xk) = C(xk+1 - xk) = Csk, k ≥ 0
sk = C-1yk, k≥0
iar C = Hf(xj) pentru orice j. Plecând de la această observaţie se vor căuta Hk,
aproximaţii a inverselor matricelor Hf(xk), care să îndeplinească următoarele
condiţii:

Metode de Optimizare – Curs 14
27
1. si = Hk+1yi pentru orice i, 0≤i≤k (condiţia sk = Hk+1y
k se numeşte
condiţia secantei, iar implicaţia „si = Skyi pentru orice i, 0≤i≤k-1 => si
= Sk+1yi pentru orice i, 0≤i≤k-1” se numeşte proprietatea de ereditate)
2. Hk pozitiv definită
Matricele Hk vor fi determinate recursiv:
Hk+1 = Hk + Dk, k ≥0.
Algoritmul generic asociat metodelor cvasi-Newton aplicat funcţiilor
pătratice este schiţat mai jos (se presupune x0 dat şi H0 dat, de exemplu H0 = In )
k: = 0;
cât timp ||∇f(xk)|| ≠0 execută
pasul 1: vk = - Hk∇f(xk)
pasul 2: *se determină pasul de deplasare tk (optimal) asociat direcţiei
de deplasare vk;
pasul 3: xk+1 = xk + tkvk ;
pasul 4: *se alege Dk astfel încât Hk+1 = Hk + Dk să fie pozitiv definită
şi în plus, să fie îndeplinite condiţia secantei ( Hk+1yk = sk) şi
proprietatea de ereditate (Hk+1yi = si pentru orice i , 0≤i≤k-1);
k: = k+1;
Lema 39. Fie f:Rn→R o funcţie definită prin f(x) = 1
2<x,Cx> + <x, d>, cu
C∈Mn,n(R) o matrice pozitiv definită şi d∈Rn un vector fixat, şi fie x0∈R
n. Fie k
un număr natural şi fie (xj)j şirul definit prin xj+1 = xj – tjHj∇f(xj), 0≤ j≤ k unde
- Pentru orice 0≤j≤k, matricele Hj sunt pozitiv definite şi îndeplinesc
condiţia si = Hjyi pentru orice i, 0≤i≤j-1 cu si = xi+1 – xi şi yi = ∇f(xi+1) -
∇f(xi)
- tj este pasul optimal asociat direcţiei vj = - Hj∇f(xj).
Atunci vectorii s0, s1, ..., sk sunt conjugaţi în raport cu C doi câte doi.
Demonstraţie. Observăm că pentru orice k ≥0
sk = xk+1 – xk = tkvk = -tkHk∇f(xk)
iar din faptul că ∇f(x) = Cx+d deducem că
yk = ∇f(xk+1) - ∇f(xk) = Csk = tkCvk = -tkCHk∇f(xk).

Mădălina Roxana Buneci Metode de Optimizare – Curs - 2007
28
Vom face demonstraţia prin inducţie după k. Pentru k = 1, obţinem
<s1, Cs0> = -t0<H1∇f(x1), Cs0> = -t0<∇f(x1), H1Cs0> = -t0<∇f(x1), H1y0>
= -t0<∇f(x1), s0> = <Cx1 + d, v0> = <Cx0 + t0Cv0, v0> + <d, v0>
= <Cx0, v0> + t0<Cv0, v0> + <d, v0>,
şi ţinând cont că t0 = ( )0 0
0 0
f x , v
Cv , v
< ∇ >−
< >=
0 0 0
0 0 0 0
Cx , v d, v
Cv , v Cv , v
< > < >− −
< > < > (conform,
lemei 35) rezultă că <s1, Cs0> = 0.
Presupunem afirmaţia adevărată pentru k şi o demonstrăm pentru k+1.
Avem
<sk+1, Csi> = -tk+1<Hk+1∇f(xk+1), Csi> = -tk+1<∇f(xk+1), Hk+1Csi> =
= -tk+1<∇f(xk+1), Hk+1yi> = -tk+1<∇f(xk+1), si> (39. 1)
Din ipoteza de inducţie rezultă că s0, s1, ..., sk sunt conjugaţi în raport cu C doi
câte doi, şi aplicând lema 37 rezultă că <∇f(xk+1), si> = 0 pentru orice i∈{0,1,
...,k}. Mai departe din (39.1) obţinem
<sk+1, Csi> = -tk+1<∇f(xk+1), si> = 0.
În consecinţă, s0, s1, ..., sk+1 sunt conjugaţi în raport cu C doi câte doi.
■
În condiţiile lemei 39 dacă la un moment dat sk = 0 (k < n) atunci de fapt
vk = 0 sau echivalent ∇f(xk) = 0. Aşadar xk este punctul de minim al lui f (fiind
punct staţionar al funcţiei convexe f). Dacă s0, s1, ..., sn-1 sunt toţi nenuli, atunci
fiind conjugaţi în raport cu C doi câte doi, rezultă că s0, s1, ..., sn-1 sunt liniar
independenţi. Atunci ţinând cont de faptul că si = Hnyi şi că yi = Csi, de unde si
=HnCsi pentru orice i=0..n-1, rezultă că Hn = C-1. Deci vn = -Hn∇f(xn) = -C-1∇f(xn).
Atunci pasul optimal tn asociat direcţiei (Newton) vn = -C-1∇f(xn) este tn = 1. Ca
urmare
xn+1 = xn - tnHn∇f(xn) = xn-C-1(Cxn+d) = -C-1d,
Aşadar xn+1 este punctul de minim al lui f (fiind punct staţionar al funcţiei
convexe f). Deci minimul lui f este determinat în urma a cel mult n+1 iteraţii.
Aşa cum precizat matricele Hk se determină recursiv:
Hk+1 = Hk + Dk, k ≥0.

Metode de Optimizare – Curs 14
29
Prezentăm în continuare trei metode de alegere a matricei Dk. Formula de corecţie
de ordinul I presupune utilizarea pe post de Dk a unei matrice de rang 1. Mai
precis, căutăm Dk de forma Dk = akzk ( )
tkz , unde ak ∈R, ak≠0 şi zk ∈Rn.
Determinăm ak şi zk astfel încât să fie îndeplinită condiţia secantei. Din condiţia
secantei rezultă
(Hk + Dk)yk = sk
Hkyk + ak z
k ( )tkz yk = sk
Înmulţind la stânga cu ( )tky , obţinem
( )tky Hky
k + ak ( )tky zk ( )
tkz yk = ( )tky sk
<yk, Hkyk> + ak (<yk, zk>)2 =<yk, sk>
ak =
( )
k k kk
2k k
y ,s H y
y , z
< − >
< >
Revenind la condiţia secantei Hkyk + ak z
k ( )tkz yk = sk, obţinem
zk = k
1
a k k
1
z , y< >(sk - Hky
k)
de unde,
Dk = akzk ( )
tkz = ak 2k
1
a ( )2k k
1
z , y< >
(sk - Hkyk) (sk - Hky
k)t
= k
1
a ( )2k k
1
z , y< >
(sk - Hkyk) (sk - Hky
k)t
= ( )
2k k
k k kk
y , z
y ,s H y
< >
< − > ( )2k k
1
z , y< >
(sk - Hkyk) (sk - Hkyk)t
= ( ) ( )
tk k k kk k
k k kk
s H y s H y
y ,s H y
− −
< − >

Mădălina Roxana Buneci Metode de Optimizare – Curs - 2007
30
Arătăm prin inducţie după k că dacă funcţia f este pătratică (f(x) = 1
2<x,Cx> +
<x,d>, cu C simetrică), H0 este simetrică şi dacă avem
Dk = ( ) ( )
tk k k kk k
k k kk
s H y s H y
y ,s H y
− −
< − >,
atunci este îndeplinită condiţia Hk+1yi = si pentru orice 0≤i≤k (Hk+1 = Hk + Dk).
Pentru orice k condiţia este îndeplinită pentru i = k din construcţia lui Dk (chiar
dacă funcţia f nu este pătratică). Ca urmare pentru k = 0 afirmaţia este adevărată.
Presupunem afirmaţia adevărată pentru k şi o demonstrăm pentru k +1. Pentru
orice i, 0 ≤ i ≤ k, avem
Hk+2 yi = (Hk+1 + Dk+1) y
i
= Hk+1yi +
( )( )tk 1 k 1 k 1 k 1
k 1 k 1
k 1 k 1 k 1k 1
s H y s H y
y ,s H y
+ + + ++ +
+ + ++
− −
< − >yi
= si +( )k 1 k 1
k 1k 1 k 1 ik 1 k 1 k 1 k 1
k 1
s H ys H y , y
y ,s H y
+ +++ +
+ + + ++
−< − >
< − >
= si + ( )( )k 1 k 1
k 1k 1 i k 1 ik 1 k 1 k 1 k 1
k 1
s H ys , y H y , y
y ,s H y
+ +++ +
+ + + ++
−< > − < >
< − >
= si + ( )( )k 1 k 1
k 1k 1 i k 1 ik 1 k 1 k 1 k 1
k 1
s H ys , y y , H y
y ,s H y
+ +++ +
+ + + ++
−< > − < >
< − >
= si + ( )( )k 1 k 1
k 1k 1 i k 1 ik 1 k 1 k 1
k 1
s H ys , y y , s
y ,s H y
+ +++ +
+ + ++
−< > − < >
< − >
= si + ( )( )k 1 k 1
k 1k 1 i k 1 ik 1 k 1 k 1
k 1
s H ys , Cs Cs , s
y ,s H y
+ +++ +
+ + ++
−< > − < >
< − >
= si + ( )( )k 1 k 1
k 1k 1 i k 1 ik 1 k 1 k 1
k 1
s H yCs , s Cs , s
y ,s H y
+ +++ +
+ + ++
−< > − < >
< − >
= si.
Actualizarea matricei Hk sub forma

Metode de Optimizare – Curs 14
31
Hk+1 = Hk + Dk cu Dk = ( ) ( )
tk k k kk k
k k kk
s H y s H y
y ,s H y
− −
< − >
Poartă denumirea de formula de corecţie de rang 1. Dacă numitorul <yk,sk–
Hkyk> nu este pozitiv, atunci pozitiv definirea matricei Hk+1 nu este garantată.
Formula de corecţie de rang 2 Davidon-Fletcher–Powell (formula DFP)
presupune Hk sub forma Hk+1 = Hk + Dk cu
Dk = ( )
tk k
k k
s s
s , y< >-
( )tk k
k k
k kk
H y y H
y , H y< >
Arătăm că în cazul acestei formule dacă Hk este pozitiv definită şi <sk, yk>
> 0, atunci Hk+1 = Hk + Dk este pozitiv definită.
Lema 40. Fie Hk o matrice pozitiv definită şi sk yk∈Rn astfel încât <sk, yk>
> 0. Atunci Hk+1 = Hk + Dk este pozitiv definită, unde
Dk = ( )
tk k
k k
s s
s , y< >-
( )tk k
k k
k kk
H y y H
y , H y< >
În plus, Hk+1yk = sk.
Demonstraţie. Să observăm mai întâi că dacă z ∈Rn este un vector nenul,
atunci matricea In -tzz
z, z< >este pozitiv semidefinită. Într-adevăr este simetrică şi
pentru orice v∈Rn avem
<v, v-tzz
z, z< >v> = <v, v> - <v,
tzz
z, z< >v> =<v, v> -
t tv zz v
z, z< > =
=<v, v> - ( )
2tz v
z, z< > =
( )2z, z v, v z, v
z, z
< >< > − < >
< >≥0
Dacă H este matrice pozitiv definită şi dacă y ∈Rn este un vector nenul, atunci
H - tHyy H
y,Hy< > =
1
2H
1 1t2 2
nH yy H
Iy,Hy
− < >
1
2H

Mădălina Roxana Buneci Metode de Optimizare – Curs - 2007
32
este pozitiv semidefinită, deoarece
1 1t2 2
nH yy H
Iy,Hy
− < >
= In -tzz
z, z< > cu z =
1
2H y.
În plus, y este vector propriu asociat matricei H = H - tHyy H
y,Hy< > asociat valorii
proprii λ = 0, iar dimensiunea subspaţiului corespunzător este 1. Atunci pentru
orice θ > 0 şi orice s cu proprietatea că <s, y> ≠ 0, rezultă că H +θsst este pozitiv
definită. Înlocuind H prin Hk, y prin yk, s prin sk şi θ prin k k
1
s , y< > se obţine că
Hk -( )
tk kk k
k kk
H y y H
y , H y< > +
( )tk k
k k
s s
s , y< > este pozitiv definită.
Avem
Hk+1yk = (Hk + Dk)y
k = (Hk + ( )
tk k
k k
s s
s , y< >-
( )tk k
k k
k kk
H y y H
y , H y< >)yk
=Hkyk +
( )
( )
tk k k
tk k
s s y
s y-
( )
( )
tk k kk k
tk kk
H y y H y
y H y
=Hkyk + sk – Hky
k = sk
■
Lema 41. Fie f:Rn→R o funcţie definită prin f(x) = 1
2<x,Cx> + <x, d>, cu
C∈Mn,n(R) o matrice pozitiv definită şi d∈Rn un vector fixat, şi fie x0∈R
n. Fie
(xk)k şirul definit prin xk+1 = xk - tkHk∇f(xk), unde
- şirul de matrice (Hk)k este definit prin H0 = In şi Hk+1 = Hk + Dk, cu
Dk = ( )
tk k
k k
s s
s , y< >-
( )tk k
k k
k kk
H y y H
y , H y< >, sk = xk+1 – xk şi yk = ∇f(xk+1) - ∇f(xk)
- tk este pasul optimal asociat direcţiei vk = - Hk∇f(xk).
Atunci pentru orice k≥0, si = Hk+1yi pentru orice i ∈{0, 1, …,k}.
Demonstraţie. Observăm că pentru orice k

Metode de Optimizare – Curs 14
33
sk = xk+1 – xk = tkvk = -tkHk∇f(xk)
iar din faptul că ∇f(x) = Cx+d deducem că
yk = ∇f(xk+1) - ∇f(xk) = Csk = tkCvk = -tkCHk∇f(xk).
Ca urmare <sk, yk> = <sk, Csk> > 0 pentru orice sk ≠ 0. Deci conform lemei 40,
matricele Hk sunt pozitiv definite pentru orice k cu sk ≠ 0 (evident dacă sk = 0,
atunci şi yk = 0; mai mult, în acest caz si=yi =0 pentru orice i ≥ k) .
Vom face demonstraţia prin inducţie după k. Pentru k = 0, obţinem
s0=H1y0, egalitate adevărată conform lemei 40. Presupunem că pentru orice 1≤j ≤k
si = Hjyi pentru orice i ∈{0, 1, …,j-1}
şi demonstrăm că
si = Hk+1yi pentru orice i ∈{0, 1, …,k}.
Conform lemei 39 vectorii s0, s1, ..., sk sunt conjugaţi în raport cu C doi câte doi.
Deoarece pentru orice i∈{0,1, ..., k-1}
<sk, yi> = <sk, Csi> = 0,
<si, yk> = <si, Csk> = 0,
obţinem
Hk+1yi = (Hk + Dk)y
i = (Hk + ( )
tk k
k k
s s
s , y< >-
( )tk k
k k
k kk
H y y H
y , H y< >)yi
= Hkyi +
( )tk k
k k
s s
s , y< >yi -
( )tk k
k k
k kk
H y y H
y , H y< >yi
k is ,y 0< >=
= Hkyi -
( )tk k
k k
k kk
H y y H
y , H y< >yi
i iH y sk =
= si -( )
tk k ik
k kk
H y y s
y , H y< >
k iy ,s 0< >=
= si.
Faptul că Hk+1yk = sk rezultă din lema 40.
■

Mădălina Roxana Buneci Metode de Optimizare – Curs - 2007
34
Ca o consecinţă a lemei 41 (şi lemei 39) rezultă că pentru o funcţie
pătratică f strict convexă algoritmul Davidon-Fletcher–Powell ( DFP) converge la
punctul de minim al lui f după cel mult n+1 iteraţii. Convergenţa algoritmului
pentru clase de funcţii mai generale este o problemă deschisă.
Până acum am optat pentru aproximarea a inversei hessianei Hf(xk) cu o
matrice pozitiv definită Hk verificând condiţiile Hkyi = si pentru orice i ∈{0, 1, ...,
k-1} unde
si = xi+1 – xi şi yi = ∇f(xi+1) - ∇f(xi) , i ≥ 0.
Similar putem opta pentru aproximarea hessianei Hf(xk) cu o matrice
pozitiv definită Bk verificând condiţiile (Bk)-1yi = si (sau echivalent, Bks
i = yi)
pentru orice i ∈{0, 1, ..., k-1}. Se observă că în relaţiile Bksi = yi faţă de relaţiile
Hkyi = si se schimbă rolul lui si cu yi. Schimbând în formula de corecţie de rang 2
Davidon-Fletcher–Powell (formula DFP) rolul lui sk cu yk se obţine formula de
corecţie de rang 2 Broyden-Fletcher–Goldfarb-Shanno (formula BFGS)
Bk+1 = Bk + ( )
tk k
k k
y y
y ,s< >-
( )tk k
k k
k kk
B s s B
s ,B s< >
Similar cu lema 40, dacă sk yk∈Rn astfel încât <sk, yk> > 0, atunci
Bk+1 = Bk + ( )
tk k
k k
y y
y ,s< >-
( )tk k
k k
k kk
B s s B
s ,B s< >
este pozitiv definită. În plus, Bk+1sk = yk. Dacă se folosesc actualizarea matricei Bk
atunci direcţia de deplasare se calculează că vk = - (Bk)-1∇f(xk). Pentru a inversa
matricea Bk putem recurge la aşa numita formulă Sherman-Morrison: pentru o
matrice inversabilă A∈Mn,n(R) şi doi vectori u, v∈Rn cu proprietatea că 1 +
<v,A-1u> ≠0, matricea A + uvt este inversabilă şi
(A+uvt)-1 = A-1 - 1 t 1
t 1
A uv A
1 v A u
− −
−+.
Notăm (Bk)-1 = Hk şi aplicând formula Sherman-Morrison obţinem

Metode de Optimizare – Curs 14
35
( )1tk k
k k k
y yB
y ,s
−
+ < >
= Hk -( )
tk kk k
k k k kk
H y y H
y ,s y , H y< > + < >
Aplicând încă o dată formula Sherman-Morrison obţinem
Hk+1 = (Bk+1)-1
= Hk -( )
tk kk
k k
y H y1
y ,s
+ < >
( )tk k
k k
s s
y ,s< >-
( ) ( )t tk k k k
k k
k k
H y s s y H
y ,s
+
< >
sau echivalent
Hk+1 = Hk + Dk cu
Dk = ( ) ( ) ( )
t t tk k k k k kk k k
k k
s s H y s s y H
y ,s
τ − −
< >
τk = ( )
tk kk
k k
y H y1
y ,s+
< >.
Dacă Hk este matrice pozitiv definită şi dacă <sk, yk> > 0, atunci Hk+1 = Hk
+ Dk este pozitiv definită. În plus, Hk+1yk = sk. Condiţia <sk, yk> > 0 este
echivalentă cu <∇f(xk+1), sk> > <∇f(xk), sk> sau, deoarece sk = tkvk (tk pasul de
deplasare iar vk direcţia de deplasare) ,
<∇f(xk+1), vk> > <∇f(xk), vk>.
Această inegalitate este adevărată dacă pasul tk satisface condiţia Wolfe (17b).
Convergenţa algoritmului Broyden-Fletcher–Goldfarb-Shanno (BFGS) a
fost demonstrată de Powell în 1976.
Algoritmul Broyden-Fletcher–Goldfarb-Shanno (BFGS) (x0 dat)
k: = 0;
H0 := In;

Mădălina Roxana Buneci Metode de Optimizare – Curs - 2007
36
cât timp ||∇f(xk)|| ≠0 execută
pasul 1: vk = - Hk∇f(xk)
pasul 2: *se determină pasul de deplasare tk suboptimal îndeplinind
condiţiile Wolfe (tk asociat direcţiei de deplasare vk)
pasul 3: xk+1 : = xk + tkvk ;
pasul 4: sk: = xk+1 – xk; yk : = ∇f(xk+1) - ∇f(xk);
τk := ( )
tk kk
k k
y H y1
y ,s+
< >.
Dk := ( ) ( ) ( )
t t tk k k k k kk k k
k k
s s H y s s y H
y ,s
τ − −
< >
Hk+1 : = Hk + Dk;
k: = k+1;


















