

Licenta - Final - Cipri
83
Universitatea „Politehnica” din Timişoara Facultatea de Automatică şi Calculatoare Departamentul Calculatoare Analiza semantică a calității proiectării în sisteme orientate pe obiecte Ciprian LUCACI Proiect de diplomă Iunie 2012 Conducător științific Conf. Dr. Ing. Radu MARINESCU
description
Final thesis
Transcript of Licenta - Final - Cipri

Universitatea „Politehnica” din Timişoara Facultatea de Automatică şi Calculatoare
Departamentul Calculatoare
Analiza semantică a calității proiectării în sisteme orientate pe obiecte
Ciprian LUCACI
Proiect de diplomă
Iunie 2012
Conducător științific
Conf. Dr. Ing. Radu MARINESCU

2

3

4

5 CUPRINS
Cuprins
Capitolul 1. Introducere ............................................................................................................ 8
1.1. Context ....................................................................................................................8 1.2. Contribuție ..............................................................................................................9 1.3. Organizarea lucrării................................................................................................ 10
Capitolul 2. Fundamente .........................................................................................................11
2.1 Calitate ................................................................................................................... 11 2.2 Analizabilitatea ....................................................................................................... 11 2.3. Predispoziția la schimbare ..................................................................................... 12 2.4. Tag Cloud ............................................................................................................... 13 2.5. Coeziune ................................................................................................................ 14 2.6. Analiză formală ...................................................................................................... 14 2.7. Mentenanța........................................................................................................... 15 2.8. Lizibilitatea ............................................................................................................ 16 2.9. Metrici ................................................................................................................... 18 2.10. Tool-uri ................................................................................................................ 18
2.10.1. iPlasma ................................................................................................. 18 2.10.2. WordNet .............................................................................................. 19 2.10.3. eRCA .................................................................................................... 19 2.10.4. inFusion................................................................................................ 20 2.10.5. jHotDraw .............................................................................................. 20 2.10.6. ProGuard .............................................................................................. 20 2.10.7. GraphViz .............................................................................................. 20 2.10.8 OpenCloud ............................................................................................ 21
Capitolul 3. Stadiu actual.........................................................................................................22
3.1. Vizualizări .............................................................................................................. 22 3.2. Coeziune ................................................................................................................ 22 3.3. Claritate ................................................................................................................. 23
Capitolul 4. Concepte ................................................................................................................25
4.1. Semantica și Calitatea ............................................................................................ 25 4.2. Word Cloud ........................................................................................................... 26 4.3. Coeziunea semantică ............................................................................................. 27 4.4. Claritatea codului................................................................................................... 28
Capitolul 5. Implementare ......................................................................................................30
5.1. WordCloud ............................................................................................................ 30 5.1.1. Procesarea identificatorilor .................................................................... 30 5.1.2. Method WordCloud ............................................................................... 32 5.1.3. Class WordCloud .................................................................................... 33 5.1.4. Package WordCloud ............................................................................... 34 5.1.5. System WordCloud ................................................................................. 35
5.2. Coeziune Semantică ............................................................................................... 36 5.2.1. Contextul simplu .................................................................................... 36 5.2.2. Contextul extins ..................................................................................... 37 5.2.3. Coeziunea conceptelor ........................................................................... 39

6
5.2.4. Conceptele cheie .................................................................................... 41
5.3. Claritatea Codului .................................................................................................. 43 5.3.1. Claritatea identificatorilor ...................................................................... 43 5.3.2. Claritatea metodelor .............................................................................. 44 5.3.3. Claritatea claselor ................................................................................... 48
Capitolul 6. Studiu experimental ..........................................................................................50
6.1. WordCloud ............................................................................................................ 50 6.1.1. Metode .................................................................................................. 50 6.1.2. Clase ...................................................................................................... 54 6.1.3. Pachete .................................................................................................. 57 6.1.4. Sistem .................................................................................................... 58
6.2. Coeziune ................................................................................................................ 60 6.2.1. jHotDraw vs. ProGuard ........................................................................... 60 6.2.2 Concepte cheie........................................................................................ 61
6.3. Claritate ................................................................................................................. 65 6.3.1. Metode .................................................................................................. 65 6.3.2. Clase ...................................................................................................... 69
Capitolul 7. Concluzii ................................................................................................................70
7.1. WordCloud ............................................................................................................ 70 7.2. Coeziune semantică ............................................................................................... 70 7.3. Claritate ................................................................................................................. 70
Capitolul 8. Dezvoltări ulterioare .........................................................................................72
8.1. WordCloud ............................................................................................................ 72 8.2. Coeziunea semantică ............................................................................................. 72 8.3. Claritatea Codului .................................................................................................. 72
Capitolul 9. Bibliografie ...........................................................................................................74
Anexa A. Claritatea Metodelor ...............................................................................................77
Anexa B. Claritatea Claselor ...................................................................................................78
Anexa C. jHotDraw System Overview...................................................................................79
Anexa D. ProGuard System Overview ..................................................................................80
Anexa E. jHotDraw vs. ProGuard – coeziunea semantică a pachetelor ......................81
Anexa F. jHotDraw vs. ProGuard – claritate .......................................................................82

7 INDEX FIGURI
Index figuri Figura 2.1 – Tag Cloud .................................................................................................................................... 13
Figura 2.2 – Formal context ............................................................................................................................. 15
Figura 3.1 – Tipuri de coeziune sintactică ........................................................................................................ 23
Figura 5.1 – Expresiile regulate pentru divizarea identificatorilor ..................................................................... 30
Figura 5.2 – Procesarea identificatorilor .......................................................................................................... 31
Figura 5.3 – WordCloud pentru metodă ........................................................................................................... 33
Figura 5.4 – WordCloud pentru clasă ............................................................................................................... 34
Figura 5.5 – WordCloud pentru pachet ............................................................................................................ 35
Figura 5.6 – WordCloud pentru sistem ............................................................................................................. 36
Figura 5.7 – NodeFigure – contextul formal simplu .......................................................................................... 37
Figura 5.8 – NodeFigure – contextul formal extins ........................................................................................... 38
Figura 5.9 – RectangleFigure – laticea de concepte ......................................................................................... 40
Figura 5.10 – NodeFigure – laticea de concepte filtrată ................................................................................... 41
Figura 5.11 – NodeFigure – conceptele cheie .................................................................................................. 42
Figura 5.12 – Claritatea metodelor .................................................................................................................. 48
Figura 5.13 – Claritatea claselor ...................................................................................................................... 49
Figura 6.1 – getCappedPath – WordCloud-ul metodei ...................................................................................... 51
Figura 6.2 – fromPathData – WordCloud-ul metodei ....................................................................................... 52
Figura 6.3 – XMLElement – WordCloud-ul clasei .............................................................................................. 55
Figura 6.4 – AttributeKeys – WordCloud-ul clasei ............................................................................................. 56
Figura 6.5 – org.jhotdraw.draw – WordCloud-ul pachetului ............................................................................. 57
Figura 6.6 – org.jhotdraw.gui – WordCloud-ul pachetului ................................................................................ 58
Figura 6.7 – jHotDraw – WordCloud-ul sistemului ............................................................................................ 59
Figura 6.8 – ProGuard – WordCloud-ul sistemului ............................................................................................ 59
Figura 6.9 – jHotDraw vs. ProGuard – coeziune ............................................................................................... 61
Figura 6.10 - AbstractFigure – laticea de bază a conceptelor ............................................................................ 62
Figura 6.11 – AbstractFigure – laticea conceptelor filtrată și conceptele cheie.................................................. 63
Figura 6.12 – RectangleFigure – laticea de bază .............................................................................................. 63
Figura 6.13 – RectangleFigure – laticea filtrată și conceptele cheie .................................................................. 64
Figura 6.14 – codul metodei DoubleStroke.getCappedPath .............................................................................. 66
Figura 6.15 – codul metodei GenericListener.raiseToPublicClass ...................................................................... 66
Figura 6.16 – Distribuția problemelor metodelor în funcție de lizibilitate .......................................................... 67
Figura 6.17 – Distribuția problemelor metodelor în funcție de complexitate ..................................................... 68
Figura 6.18 – Distribuția problemelor metodelor în funcție de claritate ............................................................ 68
Figura 6.19 – Distribuția problemelor claselor în funcție de claritate ................................................................ 69

8 1.1. Context
Capitolul 1. Introducere Sistemele software de astazi sunt intr-o continuă evoluție care duce la o
creștere a complexității lor. Lehman [31] spunea că sistemele software pentru a
trăi într-un mediu care este într-o continuă schimbare trebuie să se adapteze.
Mentenanța și costurile mentenanței sistemelor software sunt o constantă de
neevitat la orice produs software iar calitatea unui produs este cea care
influențează dramatic costurile întreținerii.
1.1. Context
Pentru început încercând să folosim industria auto ca o analogie pentru
industria software am putea să realizăm un studiu legat de diferența de calitate
între două mărci auto. De exemplu, care este diferența dintre Dacia și Mercedes? În
fond și la urma urmei ambele au un singur motor, ambele au patru roți, transportă
tot atâția pasageri, ambele „implementează” aceleași funcționalități esențiale.
Care este totuși diferența? Răspunsul ar fi probabil destul de simplu și ar consta în
diferența dintre numărul de „feature”-uri implementate și „optimizarea
algoritmilor”.
Dacă în cazul celor două mărci diferențele ar fi destul de evidente atunci ce
am putea să spunem în cazul unei comparații între autoturismele VW Golf și
Renault Megane? Ambele automobile fac parte din aceeași categorie, ambele au un
preț apropiat, se adresează aceleași piețe și „implementează” în principiu aceleași
funcționalități. Atunci cum am putea să le diferențiem din perspectiva calității?
Răspunsul se găsește în „detalii”. Ce ați spune dacă la modelele din anul 2008, o
simplă sarcină cotidiană cum ar fi schimbarea unui bec la faza scurtă la faruri ar
dura la una dintre ele 1 minut și la alta 30 de minute chiar și pentru un mecanic
profesionist? Ce ați spune de „arhitectura acelui sistem”, dacă la o mașină ar
trebui pur și simplu ridicată capota, luat un căpăcel și schimbat becul? Dar dacă în
cazul alteia ar trebui ridicată mașina pe cric, dată jos roata din față de pe partea
cu becul, înghesuită mâna printr-un orificiu mic, schimbat becul, pusă roata înapoi
și apoi dată mașina jos de pe cric? Fără a încerca să favorizăm o anumită marcă
auto, aceasta este una dintre diferențele dintre VW Golf și Renault Megane, la VW
schimbarea becului durează un minut iar la Renault durează câteva zeci de
minute.1
Dificultatea mentenaței se datorează în primul rând arhitecturii neinspirate a
componentelor mecanice. În al doilea rând, niciun om obișnuit nu s-ar gândi să
schimbe un bec dând jos roata. Acest lucru se datorează și faptului că cele două
componente, în mod normal nu au legătură unele cu altele. Din punct de vedere
1 Experiment realizat la emisiunea FifthGear, sezonul 14, episodul 2 [Online 01.06.2012
http://www.youtube.com/watch?v=nXCZ2v-nIF4 ]

9 INTRODUCERE
semantic, cele două cuvinte „bec” și „roată” nu sunt foarte apropiate atunci când
este vorba de întreținerea sistemului de iluminare.
Revenind la industria software calitatea unui sistem constă și în ușurința cu
care un sistem poate fi întreținut. Dacă pentru a schimba un „bec” trebuie să
demontăm „roata” am avea suficiente motive să credem că este foarte probabil ca
și în alte locuri să întâlnim carențe de design. În al doilea rând sistemele software
sunt scrise pornind de la cuvinte care au un anumit sens iar rapiditatea cu care se
poate asigura mentenața sistemului depinde și cât de rapid se pot identifica
punctele prin care se face schimbarea.
Când încercăm să comparăm două sisteme software, numărul de feature-uri
implementate și optimizările pot fi evaluate și comparate relativ ușor dar la fel
cum diferențele de calitate se fac până la nivelul detaliilor, la fel este și în
industria software, detaliile fac diferența.
1.2. Contribuție
Pentru că, într-un mod simplist spus, sistemele software pornesc de la cuvinte
scrise într-un editor de text în această lucrare ne-am propus să studiem relația
dintre semantica identificatorilor folosiți în scrierea codului și calitatea sistemului.
Există vreo relație între cuvintele folosite în scrierea codului și calitatea unui
sistem? Sensul cuvintelor și ușurința cu care pot fi înțelese de către un utilizator
uman fac parte din detaliile unui sisttem.
Cuvintele folosite în construirea identificatorilor ar putea fi considerate doar o
preferință și o chestiune legată doar de aspect, fără o funcționalitate directă
asupra sistemului. De asemenea ne-am propus să investigăm dacă alegerea
cuvintelor are vreun impact asupra înțelegerii sistemului și dacă acestea oferă
informații suplimentare utile procesului de mentenanță.
Lucrarea de față urmărește trei obiective. În primul rând, pentru că procesul
de mentenanță este mare consumator de timp, primul obiectiv este investigarea
unei posibile soluții de eficientizare a timpului consumat pornind de la semantica
identificatorilor, „pe unde trebuie schimbat becul?”. În al doilea rând, ne-am
propus să identificăm care este coeziunea semantică a unei clase, care sunt
cuvintele care îi dau „sens” și care este legătura dintre acestea, „ce relație este
între roată și bec, dar capotă și bec”. În al treilea rând, pentru că felul în care sunt
folosite cuvintele într-un text dau claritate acestuia, ne-am propus să construim o
modalitate de a cuantifica numeric claritatea codului unui sistem, „este ușor de
înțeles cum trebuie schimbat becul?”. De asemenea a fost studiată relația dintre
claritatea metodelor și claselor și problemele lor de arhitectură, dacă există vreo
corelație între cele două.
Cele trei tematici sunt abordate sub numele de WordCloud, Coeziune și
Claritate, toate trei bazându-se pe semantica identificatorilor.

10 1.3. Organizarea lucrării
1.3. Organizarea lucrării
Această lucrare este structurată în următoarele capitole:
Capitolul 2 - Fundamente descrie câteva concepte fundamentale folosite pe
parcursul lucării. Baza teoretică constă într-o descriere a elementelor ce constituie
calitatea sistemelor software. Este definit conceptul WordCloud. Sunt prezentate
câteva elemente ale analizei formale și cum este ea folosită în combinație cu
semantica cuvintelor. De asemenea sunt definite câteva metrici folosite pe
parcusul lucrării. În ultimul rând sunt prezentate tool-urile folosite și sistemul
analizat.
Capitolul 3 – Studiu actual prezintă soluții alternative moderne și alte abordări
legate de semantica identificatorilor în domeniul software. De asemenea este
prezentată o scurtă critică la adresa acestora justificând în același timp noile
abordări.
Capitolul 4 – Concepte prezintă conceptual modul de abordare și soluțiile
propuse la obiectivele identificate în introducere.
Capitolul 5 – Implementare continuă prin a detalia modul de implementare a
soluțiilor și particularitățile acestora în funcție de nivelul de analiză al codului,
respectiv metodă, clasă, pachet sau întreg sistemul.
Capitolul 6 – Studiu experimental prezintă rezultatele studiului efectuat
asupra sistemului jHotDraw. De asemenea prezintă observațiile și relațiile
particulare care se pot observa pornind de la datele obținute.
Capitolul 7 – Concluzii prezintă concluziile generale obținute în urma
studiului. Sunt prezentate relațiile și impactul semanticii asupra calității sistemelor
software.
Capitolul 8 – Dezvoltări ulterioare încheie lucrarea prin a prezenta viitoare
direcții de studiu în contextul semanticii și sistemelor software. De asemenea se
prezintă și idei practice pentru posibile funcționalități noi pentru tool-uri deja
existente.

11 FUNDAMENTE
Capitolul 2. Fundamente În acest capitol vor fi prezentate conceptele teoretice fundamentale de la care
s-a pornit în realizarea studiului din lucrarea de față. De asemenea vor fi
prezentate și instrumentele software folosite pentru realizarea studiului.
2.1 Calitate
În cartea sa, Quality Code, Spinnelis [20] spune că putem privi calitatea
software-ului din mai multe perspective. Un punct de plecare poate fi specificațiile
și definirea calității în funcție de conformarea la acele cerințe sau putem lua în
considerare oamenii și să definim calitatea ca măsura în care software-ul satisface
dorințele și așteptările clienților și utilizatorilor. Indiferent cum privim calitatea,
ea este importantă. Calitatea, timpul și costul sunt cei trei factori fundamentali ce
determină succesul sau eșecul oricărui proiect software iar calitatea este doar unul
dintre acei factori care nu pot fi schimbați pe moment de un decret managerial.
Standardul ISO/IEC 9126 [21] definește modelul calității pentru produsele
software pornind de la următoarele categorii de caracteristici interne sau externe
ale calității software-lului: funcționalitate, fiabilitate, utilizabilitate, eficiență,
mentenabilitate și portabilitate.
Spinnelis [20] este de părere că mentenabilitatea unui produs software este
probabil elementul care poate fi cel mai bine abordat la nivel de design și
implementare efectivă a codului. Când vorbim de mentenabilitatea unui sistem,
suntem interesați de analizabilitatea lui, cât de ușor este pentru noi să localizăm
elementele pe care vrem să le îmbunătățim sau să le reparăm; capacitatea de
schimbare, câtă muncă este necesară pentru implementarea unei modificări;
stabilitate, cât de puține lucruri se strică după schimbarea noastră; și
testabilitate, abilitatea de a valida noile modificări.
2.2 Analizabilitatea
Un element important în mentenabilitatea software-ului este analizabilitatea.
Spinnelis [20] afirmă că această proprietate are în vedere două aspecte: când
lucrurile merg rău, vrem să localizăm cauzele erorii iar când vin noi specificații,
vrem să fim capabili să localizăm părțile din software care urmează să fie
modificate.
Multe elemente ale analizabilității unui program sunt legate în mod intim de
procesele cognitive ce se desfășoară în mințile noastre pe măsură ce încercăm să
înțelegem o porțiune de cod. Un element cognitiv de bază ce afectează modul în
care lucrăm cu programele pare a fi numărul limitat de „registre mașină” pe care
le avem în creierele noastre; psihologii le numesc pe acestea memoria de scurtă-
durată. Într-o lucrare clasică intitulată The Magical Number Seven, Plus or Minus

12 2.3. Predispoziția la schimbare
Two: Some Limits on Our Capacity for Processing Information (Numărul magic
șapte, plus sau minus doi: câteva limitări ale capacității noastre de a procesa
informația) [22], George Miller a arătat printr-un număr de experimente că
memoria noastră imediată sau de scurtă durată poate reține aproximativ șapte
(plus sau minus două) elemente discrete.
Pornind de la noua înțelegere dobândită a felului în care mințile noastre
analizează software-ul, Spinnelis [20] spune că acum suntem pregătiți să studiem
analizabilitatea unui sistem la diferite nivele. Când ne uităm la cod în cel mai
restrâns sens posibil vorbim despre lizibilitatea codului. Stilul joacă un rol central
în lizibilitatea unui program; acesta cuprinde formatarea expresiilor și
instrucțiunilor, indentarea, denumirea fișierelor și identificatorilor și comentariile.
Odată ce ne ridicăm ochii de la copaci pentru a vedea pădurea design-ului
sistemului, putem vorbi despre gradul de înțelegere a codului (ușurința de a fi
priceput de procesele noastre cognitive).
În această lucrare soluția propusă pentru a identifica locurile în care un sistem
trebuie schimbat și cât de ușor poate fi această schimbare implementată va porni
de la particularitățile lizibilității codului și particularitățile creierului uman.
Semantica, sensul cuvintelor este un concept intrinsec gândirii și raționamentului
uman. De aceea semantica identificatorilor, sensul cuvintelor care descriu diferite
porțiuni de cod vor fi cruciale în analiza lizibilității unei porțiuni de cod.
2.3. Predispoziția la schimbare
Pe lângă analizabilitatea unui sistem, dificultatea sau ușurința unui sistem de a
se adapta la schimbări este o altă caracteristică a mentenabilității, deci a calității.
Predispoziția unui sistem la schimbare se referă la cât de ușor putem implementa
anumite modificări specifice [20]. Există un număr de proprietăți asociate ce
contribuie la această predispoziției a sistemului: cât de ușor putem identifica
elementele care trebuie schimbate, cât de mult se extind modificările în
comparație cu modificările prevăzute în specificație și în ce măsură implementarea
noastră a modificărilor afectează restul sistemului.
Spinnelis [20] prezintă două procedee pentru identificarea locului unde trebuie
implementată noua funcționalitate. Când vrem să schimbăm un element al unui
sistem software, putem să îl localizăm fie începând de sus în jos (top-down), fie de
jos în sus (bottom-up). Lucrând de sus în jos implică înțelegerea de ansamblu a
structurii pentru a identifica subsistemul unde schimbarea trebuie implementată și
apoi aplicată modificarea în mod recursiv aplicând aceeași tehnică până
identificăm codul care trebuie modificat. Ușurința cu care putem îndeplini această
sarcină depinde de cât de inteligibil este sistemul.
Majoritatea sistemelor sunt mult prea complicate iar sarcinile de mentenanță
sunt mult prea mici pentru a justifica efortul de a învăța întreaga structură a

13 FUNDAMENTE
Figura 2.1 – Tag Cloud
sistemului la un nivel de detaliu care să ne permită identificarea codului care
trebuie schimbat într-o manieră de sus în jos (top-down). În majoritatea cazurilor
este mult mai profitabil adoptarea tehnicii de jos în sus (bottom-up), în care sunt
folosite tehnici euristice și intuiția programatorului pentru a identifica porțiunea
de cod ce trebuie schimbată. Uneori sunt combinate cele două tehnici pentru a
traversa porțiuni mari de cod [20].
Un alt element foarte util pentru identificarea elementelor care trebuie
schimbate este folosirea intuitivă și consistentă a numelor pentru toate elementele
sistemului: pachete, spații de nume, fișiere, clase, metode și funcții [20].
Ținând cont de aceste afirmații legate de schimbarea unui sistem și cum să
identificăm locul, putem să identificăm câteva aspecte despre cum trebuie să
identificăm soluția optimă la obiectivul definit. Pentru a îmbina cele două
procedee, top-down și bottom-up, în identificarea locului unde trebuie făcută o
schimbare vom utiliza conceptul de tag cloud pentru metoda top-down iar apoi
inspectarea vizuală a codului, linie cu linie, pentru bottom-up.
2.4. Tag Cloud
Un tag cloud2 (word
cloud, sau listă ponderată
în design-ul visual) este o
reprezentare vizuală
pentru datele sub formă de
text folosite pentru a
descrie metadate cuvinte
cheie (tags) în pagini web
sau pentru a vizualiza text
liber. Tag-urile sunt de
obicei cuvinte singulare iar
importanța fiecărui tag
este evidențiată prin dimensiunea și culoarea fontului. Acest format este foarte util
pentru observarea rapidă a celor mai proeminenți termeni și pentru a localiza un
termen alfabetic și apoi a determina proeminența lui relativă [23]. Codul fiind în
esență un simplu text se pretează la o astfel de vizualizare.
2 Figura 2.1 reprezintă tag cloud-ul format din cuvintele principale conținute în lucrarea de față în funcție
de ponderea lor. Imaginea a fost generată cu www.wordle.net

14 2.5. Coeziune
2.5. Coeziune
Un alt concept utilizat este cel de coeziune. Din punct de vedere lexical și
gramatical, coeziunea3 reprezintă o relație în cadrul unui text sau unei propoziții.
Coeziunea poate fi definită ca legăturile ce țin un text împreună și îi dau sensul.
Coeziunea este legată de conceptul mai larg coerență.
În programarea calculatoarelor, coeziunea4 este o măsură a cât de strâns
legate sunt fiecare dintre funcționalitățile exprimate de codul sursă al unui modul
software. Coeziunea este o măsurătoare de tip ordinal și este exprimată uzual sub
forma „coeziune ridicată” sau „coeziune scăzută”. Modulele cu o coeziune ridicată
tind să fie de preferat pentru că o coeziune ridicată este asociată cu câteva
trăsături dorite de software ce includ robustețe, fiabilitate, reutilizare și grad de
înțelegere ridicat, în timp ce un grad de coeziune scăzut este asociat cu trăsături
nedorite cum ar fi dificultatea procesului de mentenanță, dificultate ridicată la
testare, reutilizare scăzută și chiar dificultate de înțelegere.
Aplicată în programarea orientată pe obiecte, dacă metodele ce deservesc o
anumită clasă tind să fie similare în multe aspecte, atunci clasa are coeziune
ridicată. Într-un sistem cu o coeziune ridicată, gradul de lizibilitate și de reutilizare
a codului sunt ridicate în timp ce complexitatea este ținută sub control.
Modalitățile de a măsura coeziunea variază de la măsurători calitative ce
clasifică textul sursă analizându-l din punct de vedere hermeneutic până la
măsurători cantitative ce măsoară caracteristicile textuale ale codului sursă pentru
a ajunge la un scor numeric al coeziunii.
2.6. Analiză formală
Pentru coeziunea semantică a fost utilizat conceptul de analiză formală5. În
știința informației, analiza formală [41] a conceptelor este o modalitate de a
deriva ierarhia unui concept sau ontologia formală dintr-o colecție de obiecte și
proprietățile lor. Fiecare concept din ierarhie reprezintă un set de obiecte care
partajează aceleași valori pentru un anumit set de proprietăți și fiecare subconcept
din ierarhie conține un subset de obiecte ale conceptelor superioare.
Din punct de vedere filozofic, un concept este o unitate de idei constând din
două componente, extensia și intenția. Extensia cuprinde toate obiectele care
aparțin conceptului iar intenția cuprinde toate atributele valide pentru acele
obiecte. Prin urmare, obiectele și atributele joacă un rol important alături de
câteva relații între concepte, cum ar fi relațiile ierarhice de tipul „subconcept-
3 Cohesion (linguistics) - http://en.wikipedia.org/wiki/Cohesion_(linguistics) [Online 14.06.2012] 4 Cohesion (computer science) - http://en.wikipedia.org/wiki/Cohesion_(computer_science) [Online
14.06.2012] 5 FCA – Formal Concept Analysis (eng.)

15 FUNDAMENTE
Figura 2.2 – Formal context
superconcept”, relații tip implicație între atribute și relația de tip incidență, „un
obiect are un atribut” [42].
Un tabel cu X-uri reprezintă un tip de date foarte
simplu și des întâlnit. Structura matematică
folosită pentru a descrie formal aceste tabele
este numită un context formal (pe scurt un
context). Vorbind în termeni logici umani,
fiecare concept este reprezentat de un mic cerc
în așa fel încât extensia (intenția) constă din
toate obiectele (atributele) ale căror nume pot
atinse pe o cale ce coboară (urcă) din acel cerc
[42]. Pornind de la un tabel în care sunt descrise
obiecte și proprietățile lor se poate genera un
graf iar pe baza grafului generat, în care fiecare
punct este un concept, prin explorarea lui se
poate ajunge la descoperirea de noi cunoștințe,
cunoștințe care inițial erau implicite (vezi Figura
2.2).
2.7. Mentenanța
Dr. Chong Ho Yu [2] afirmă că există două aspecte ale eficienței. În primul
rând, afirmă el, este vorba de folosirea eficientă a resurselor computaționale.
Definiția eficienței computaționale este următoarea: considerându-se egale
rezultatele a două segmente de programe, un program mai bun este unul care
utilizează mai puține resurse computaționale, ce includ cicluri CPU, RAM sau
utilizarea discului. În al doilea rând, este vorba de folosirea eficientă a resurselor
umane. Dr. Chong definește cel de-al doilea tip de eficiență în felul următor: dacă
două seturi de programe consumă în mod egal aceleași resurse și produc același
rezultat, dar una necesită mai puțin efort uman (scriere, modificare, mentenanță
etc), acel program este considerat mai eficient.
Buse and Wimer [1] rezumă câteva axiome legate de mentenabilitatea unui
produs software. În mod tipic, mentenanța va consuma peste 70% din costul total al
unui produs [5]. Aggarwal afirmă că lizibilitatea, ușurința de a citi codul sursă și
lizibilitatea documentației, ambele sunt critice pentru mentenabilitatea unui
proiect [3]. Alți cercetători au notat faptul că citirea codului este cea mai
costisitoare componentă din punctul de vedere al timpului dintre toate activitățile
de mentenanță [29, 36, 38]. Mai mult, mentenabilitatea software-ului deseori
înseamnă evoluția software-ului și modificarea codului existent înseamnă o mare
parte a ingineriei software moderne [35].

16 2.8. Lizibilitatea
Rober L. Glass [4] afirma că mentenanța software este ...
Complexă intelectual – necesită inovație în timp ce impune constrângeri
severe asupra inovatorului
Dificilă tehnic – responsabilul trebui să fie capabil să lucreze cu un concept,
cu un design cât și cu întreg codul sursă și toate acestea în același timp
Nedreaptă – responsabilul cu mentenanța niciodată nu primește toate
lucrurile de care are nevoie, cum ar fi documentația
Fără câștig – responsabilul cu mentenanța vede doar oameni care au
probleme
Muncă murdară – responsabilul trebuie să lucreze la detalii de implementare
Trăire în trecut – codul a fost scris de cineva înainte de a deveni bun la
codare
Conservatoare – motto-ul mentenanței este „dacă nu este defect, nu repara”
Mentenanța software este foarte complexă și este o activitate istovitoare. Pentru
că lizibilitatea unui program este legată de mentenabilitatea lui, avem motive să
credem că îmbunătățind lizibilitatea în mod implicit se îmbunătățește calitatea
programului.
2.8. Lizibilitatea
Dacă este să ne întrebăm cum își folosește timpul un programator, supriza pe
care o descoperim din practică este faptul că marea parte a timpului nu este
folosită nici pentru scrierea de nou cod, nici pentru modificarea codului existent.
Atunci unde se utilizează resursa timp? Statistic vorbind, din practică se observă că
doar 5% din timp este folosit pentru scrierea de cod nou, 25% din timp este folosit
pentru modificarea codului
existent iar restul de 70% este
folosit pentru înțelegerea codului.
Modificarea codului consumă mult
mai mult din timpul unui
dezvoltator profesionist decât
scrierea de nou cod. Attwood [6] și
Hallam [7] întreabă „De ce este
folosit de 3x mai mult timp în
înțelegerea codului decât în
modificarea codului?” Răspunsul
[7] este că înainte de a modifica în
cod trebuie înțeles ce face exact acesta. Acest lucru este adevărat și despre
refactorizarea codului existent – trebuie să înțelegi comportamentul codului înainte

17 FUNDAMENTE
să poți garanta că refactorizarea nu a schimbat nimic neintenționat. Înțelegerea
codului este de departe activitatea în care dezvoltatorii profesioniști investesc cea
mai mare parte a timpului.
Spinellis [14] remarca faptul că cu patruzeci de ani în urmă, când programarea
calculatorului era o experiență individuală, nevoia unui cod ușor de citit nu era pe
lista de priorități. Însă astăzi, programarea este o activitate de echipă și scrierea
unui cod pe care alții să îl înțeleagă a devenit o necesitate.
O sarcină reprezentativă [7], tipică industriei software, este trimiterea unui
programatator în mijlocul unui cod deja existent pe care nu l-a mai văzut
niciodată, nedocumentat, scris urât, cu o arhitectură deficitară și cu câteva bug-uri
existente. Apoi să i se ceară acestuia adăugarea unei funcționalități încercând să
mențină pe cât posibil comportamentul deja existent. Motivul pentru care
programatorii cred despre codul vechi că este un haos se datorează unei legi
cardinale, fundamentale a programării: este mai greu să citești cod decât să îl scrii
[8].
Martin Fowler [9] afirma că „orice prostănac poate scrie cod pe care
computerul să îl poată înțelege. Programatorii buni scriu cod în așa fel ca oamenii
să îl poată înțelege.” Chiar și așa, cu un cod dificil de citit programul continuă să
funcționeze. Dar, întreabă Fowler, lizibilitatea codului nu este doar o judecată
legată de estetică, o simplă repulsie față de cod urât? Este așa până încercăm să
schimbăm sistemul. Compilatorului nu îi pasă de faptul că sursele sunt murdare,
inestetice sau curate, clare. Dar când schimbăm sistemul, acolo este implicată o
ființă umană și oamenilor le pasă. Un sistem cu un design deficitar este greu de
schimbat. Greu de modificat pentru că este greu de descifrat unde trebuie făcute
schimbările. Pentru că este dificil de identificat ce trebuie schimbat este o șansă
mare ca programatorul să facă o greșeală și să introducă erori [9].
Nakashian [12] afirmă că până la urmă convențiile de formatare a codului sunt
doar convenții. Oricât am dezbate între tab-uri și spații, acestea rămân subiective
și strâns legate de preferințe personale. Totuși sunt unele convenții care chiar
îmbunătățesc calitatea generală a codului. El continuă afirmând că nu doar
calitatea codului contează ci factori importanți sunt de asemenea oboseala ochiului
și citirile accidentale greșite a codului. Fără îndoială ambele sunt de asemenea
factori care afectează calitatea codului în general. Nakashian [12] argumentează
acest fapt pornind de la realitatea că sunt deseori întâlnite situațiile când
programatorii sunt extenuați din cauza unei greșeli care dacă nu s-ar fi datorat
grabei și citirii greșite ar fi putut fi cu totul evitată.
Pe lângă îmbunătățirea utilizării timpului și evitarea greșelilor, Nakashian [12]
aduce și un al treilea argument în favoarea unei lizibilități cât mai bune. El afirmă
că lizibilitatea ridicată facilitează găsirea rapidă a unor biblioteci care
implementează bine o funcționalitate folosită în mod repetat, facilitând astfel

18 2.9. Metrici
reutilizarea codului. Efectul benefic al lizibilității codului este identificarea unor
bug-uri, raportarea lor sau repararea lor pe loc. Astfel, în loc de a crea noi surse de
bug-uri, reutilizarea codului reduce duplicarea de cod și posibil rezolvă vechi
probleme [12].
De fapt, lizibilitatea este atât de importantă, încât Elshoff și Marcotty au propus
adăugarea unei faze de dezvoltare în care programul să fie făcut mai lizibil [11].
Knight și Meyers au sugerat că o fază a inspecției software ar trebui să fie
verificarea codului sursă din perspectiva lizibilității [26]. Haneef a propus
adăugarea la echipa de dezvoltare a unui grup dedicat lizibilității și documentării
[19].
2.9. Metrici
Pentru claritatea codului în implementarea metricii clarității au fost folosite
datele furnizate de câteva metrici deja consacrate în domeniul software. Câteva
dintre acestea sunt:
CYCLO – Complexitatea ciclomatică [25] se referă la numărul total de căi
posibile adunate de la toate operațiile din sistem. Este suma numărului
ciclomatic al lui McCabe [32] pentru toate operațiile. Folosim această
metrică pentru a cuantifica complexitatea funcțională intrinsecă a unui
sistem.
LOC – Numărul de linii de cod
NOA – Numărul atributelor unei clase
NOM – Numărul metodelor unei clase
NOAM – Numărul de metode accesate de o metodă
NOLV – Numărul variabilelor locale pentru o metodă
2.10. Tool-uri
Pentru extragerea datelor unui sistem, pentru analiza codului și problemelor
arhitecturale, pentru generarea de grafului de concepte și diferitelor vizualizări au
fost folosite următoarele tool-uri disponibile online.
2.10.1. iPlasma
iPlasma [28] este un mediu integrat pentru analiza calității sistemelor
orientate pe obiecte, mediu ce include suport pentru toate fazele necesare
analizei: de la extragerea modelului (parsare scalabilă pentru C\C++ și Java) până
la analiză de nivel înalt bazată pe metrici sau detecția de duplicare de cod.
iPlasma a fost dezvoltat în centrul de cercetare LOOSE6 din cadrul Universității
Politehnica Timișoara.
6 http://www.loose.upt.ro/reengineering

19 FUNDAMENTE
Implementarea soluțiilor a fost făcută direct în
iPlasma, soluțiile devenind astfel noi facilități
disponibile plajei de analize disponibile.
2.10.2. WordNet
WordNet® [30] este o mare bază de date lexicală cu cuvinte din limba engleză.
Substantive, verbe, adjective și adverbe sunt grupate în mulțimi de sinonime
cognitive (synsets), fiecare exprimând un concept distinct. Synset-urile sunt
interconectate prin relații lexicale și conceptual-semantice. Structura WordNet
face biblioteca să fie o unealtă folositoare pentru limbajele computaționale și
procesarea limbajelor naturale.
În mod superficial WordNet se aseamănă cu un lexicon prin faptul că grupează
cuvintele pe baza sensului lor. Cu toate acestea, există câteva distincții
importante. În primul rând, WordNet interconectează nu doar forma cuvintelor –
șiruri de litere – ci sensuri specifice ale cuvintelor. Ca rezultat, cuvintele care se
află în proximitate unele față de altele în rețea sunt distinse prin sensul semantic.
În al doilea rând, WordNet identifică relațiile semantice dintre cuvinte, în timp ce
gruparea cuvintelor într-un tezaur nu urmează nici un tipar explicit în afara
similarității cuvintelor.
WordNet a fost creat și continuă să fie dezvoltat în cadrul Laboratorului de
Științe Cognitive al Universității Princeton.
Pentru utilizarea Wordnet s-a utilizat biblioteca RiWordnet [27]. Ea oferă acces
ușor la ontologia WordNet pentru procesarea în Java, oferă distanțe metrice între
termenii ontologiei și asignează ID-uri unici pentru fiecare cuvânt, sens și poziție.
2.10.3. eRCA
eRCA [43] este o bibliotecă gratuită oferită de Google ce
ușureză folosirea Analizei conceptuale formale și relaționale
(eng. Formal and Relational Concept Analysis) și facilitează
tehnicile de clustering.
Câteva facilități oferite de eRCA sunt importarea ușoară a contextelor formale
direct din fișiere .CSV, posibilitatea de a descrie contexte formale direct din cod,
algoritmi pentru construirea laticei de concepte a unui context formal și, pe lângă
altele, exportarea grafului în fișiere cu formatul .DOT.

20 2.10. Tool-uri
eRCA, Eclipse's Relational Concept Analysis, a fost dezvoltată în cadrul
institutului de cercetare fracez LIRMM7.
2.10.4. inFusion
inFusion [45] este un mediu integrat ce execută review-uri de
cod și arhitecturale pentru sisteme orientate pe obiecte și
procedurale. inFusion agregă metrici, vizualizări și alte tipuri de
analize statice pentru a genera recomandări de refactorizare și interpretări legate
de identificarea și adresarea unor probleme de design structural.
Modelul de calitate [45] al inFusion este o unealtă ce oferă mijloacele pentru a
evalua într-un mod cantitativ calitatea design-ului unui sistem. Modelul este
comprehensiv și echilibrat pentru că ia în considerare atât aspecte generale de
design, cum ar fi complexitatea, încapsularea și cuplajul, cât și aspecte ce țin
doar de anumite limbaje, cum ar fi caracteristicile ierarhiilor de clase. inFusion
permite măsurarea calității atât dintr-o perspectivă generală cât și fiecare aspect
individual al calității și oferă o modalitate de monitorizare a evoluției sistemului în
timp.
2.10.5. jHotDraw
JHotDraw [39, 40] este o aplicație Java cu interfață grafică orientată pentru
Grafice structurate și tehnice. A fost dezvoltat ca un „exercițiu de design” dar deja
este foarte dezvoltat. Design-ul său se bazează puternic pe câteva modele de
design (eng. design patterns) foarte bine cunoscute.
2.10.6. ProGuard
ProGuard [47] este un produs opensource gratuit Java ce comprimă fișierele
class, optimizează, obfuschează codul și efectuează o verificare inițială.
Detectează și îndepărtează clasele nefolosite, câmpurile, metodele și atributele.
Optimiează bytecode-ul și îndepărtează instrucțiunile nefolosite. Redenumește
clasele rămase, câmpurile și metodle folosind nume scurte fără nici un sens. În
final, preprocesează codul pentru Java 6 sau pentru Java Micro Edition.
Proguard este un sistem software de dimensiuni similare cu jHotDraw. De
aceea, el va fi folosit în mod comparativ cu jHotDraw în unele analize.
2.10.7. GraphViz Graphviz [33] este un software opensource pentru vizualizarea grafurilor.
Vizualizarea grafurilor este un mod de a reprezenta informația structurală sub
formă de diagrame a grafurilor abstracte sau rețelelor.
7 Laboratoire d'Informatique, de Robotique et de Microélectronique de Montpellier (LIRMM) -
http://www.lirmm.fr/xml/fr/lirmm.html [Online 13.06.2012]

21 FUNDAMENTE
Graphviz preia descrierile grafurilor sub formă de text simplu și construiește
diagrame în formate utile, cum ar fi imagini, SVG pentru pagini web, PDF sau
Postscript pentru includerea în alte documente, sau pentru afișarea ca graf
interactiv într-un browser. (Graphviz de asemenea suportă GXL, un dialect XML).
Graphviz oferă o multitudine de opțiuni pentru diagrame concrete, opțiuni cum ar
fi culori, fonturi, diferite stiluri de linii, hyperlink și altele.
Graphviz a fost folosit pentru a vizualiza laticea de concepte furnizată de erca
pentru clasele analizate pornind de la fișiere .dot generate pentru fiecare clasă.
2.10.8 OpenCloud
Pentru implementarea vizualizării sub forma TagCloud am utilizat biblioteca
gratuită OpenCloud [24]. OpenCloud este o bibliotecă Java pentru generarea de tag
clouds, cunoscute și sub numele de liste ponderate. Cele două clase principale ale
bibliotecii sunt clasa Tag, ea reprezintă un singur tag (în esență un string asociat cu
un URL) și clasa Cloud, ea reprezintă norul de cuvinte în întregime. Clasa Cloud se
comportă ca o colecție pe care o populezi adăugând obiecte Tag.
Fiecare tag are un scor asociat ce reprezintă importanța tag-ului. Tag-urilor cu
un scor mai mare vor avea asociată o pondere mai mare. Când un tag este adăugat
în obiectul Cloud, dacă deja este prezent un tag cu același nume, cele două scoruri
sunt adunate. Clasa Cloud convertește scorurile în ponderi utilizând o transformare
liniară. Utilizatorul poate alege plaja de valori pe care ponderea o poate lua,
așadar ponderile pot fi folosite în mod convenabil în vizualizări [24].

22 3.1. Vizualizări
Capitolul 3. Stadiu actual În acest capitol vor fi prezentate câteva tehnologii și concepte noi din
domeniul ingineriei software care sunt tangențiale tematicii semanticii
identificatorilor.
3.1. Vizualizări
În industria software vizualizările de cod sunt o tematică nouă într-o continuă
schimbare. Acestea au apărut ca o consecință a creșterii din ce în ce mai mult a
complexității sistemelor software și necesității înțelegerii acestora cât mai ușor.
Dacă un sistem are sute de mii de linii de cod și deseori chiar milioane, o citire
linie cu line a codului este total neadecvată.
În [25] sunt descrise mai multe tipuri de vizualizări. Un tip de vizualizare este
Overview Pyramid8 definită în [25] care oferă o imagine de ansamblu a
complexității sistemului. De asemenea există System Complexity View care
afișează ierarhiile claselor din sistem sub formă de arbore. Pentru o clasă în [25] a
fost definită vizualizarea Class blueprint care afișează interacțiunea între diferitele
componente ale clasei în funcție de apelurile efectuate.
Aceste tipuri de vizualizări și altele asemănătoare sunt foarte utile pentru a oferi o
imagine de ansamblu asupra unui sistem. Dar neajunsul lor constă în faptul că
metodele sau clasele sunt porțiuni de text iar vizualizarea este o abstractizare a
entităților prin diferite forme poligonale având diferite caracteristici ale codului
reprezentate prin diferiți parametrii ai poligonului, fără a avea text. Utilizatorul
trebuie să cunoască de la început aceste convenții pentru a putea utiliza în mod
eficient aceste vizualizări și trebuie să creeze mental puntea între cod și
abstractizarea sa.
Alternativa propusă la acest impediment este folosirea cuvintelor din codul
sursă pentru a evidenția anumite caracteristici ale entităților din sistem. Mai mult,
aceste cuvinte cheie sunt reprezentate pe diferite categorii ale informațiilor
afișate și în mod dependent de importanța rolului pe care îl au. Atunci când este
necesară o perspectivă superficială asupra porțiunii unui cod cuvintele pot fi
instrumente foarte utile în a surprinde acele caracteristici.
3.2. Coeziune
În practică există mai multe modalități de evaluare a coeziunii. Majoritatea
acestora evaluează arhitectura sistemului din punctul de vedere al interacțiunii
obiectelor9. Acest tip de coeziune se numeste coeziune sintactică [51]. În Figura
3.1 sunt prezentate principalele tipuri de coeziune sintactică ordonate în funcție
8 vezi Anexa C și D
9 Cohesion metrics - http://www.aivosto.com/project/help/pm-oo-cohesion.html [Online 16.06.2012]

23 STADIU ACTUAL
de calitatea pe care ele o definesc. De exemplu, un modul care are coeziune
funcțională înseamnă că îndeplinește o singură funcționalitate bine definită și are
un scop precis. Din perspectiva coeziunii sintactice codul poate fi scris într-un mod
total neinteligibil pentru programator și totuși să fie coeziv.
Pentru coeziunea unui text au fost
dezvoltate mai multe moduri de măsurare
a similarității semantice bazate pe
taxonomia Wordnet. Aceste măsurări
abordează problema numărând muchiile
ce leagă cuvintele [48], sau ajustează
numărul muchiilor cu altă informație cum
ar fi adâncimea taxonomiei [49] sau
informația calcultată dintr-un obiect [50].
Pentru coeziunea semantică a codului sursă există metrici definite ce
evaluează ierarhia conceptelor unui sistem din punct de vedere semantic [52].
Pentru coeziunea semantică a unei entități în [53] este definită o metrică ce ia în
considerare părțile de vorbire folosite pentru identificatori și folosește o bază de
date lingvistică pentru extragerea părților de vorbire.
În această lucrare, pentru coeziunea semantică abordarea diferă față de
metricile prezentate în primul rând prin faptul că este folosită baza de date
lingvistică oferită de WordNet. De asemenea, pentru construirea grafului de
concepte pentru o entitate se apelează la analiza formală generându-se în mod
automat posibilele sensuri ale entității. Din variantele generate sunt selectate cele
care au coeziunea semantică cea mai bună.
3.3. Claritate
În practică există câteva metrici implementate pentru a măsura lizibilitatea
textului în limbaj natural [1]. Modelul Flesch-Kincaid Grade Level [15], modelul
Gunning-Fox Index [16], modelul SMOG Index [17] și modelul Automated Readability
Index [18] sunt doar câteva dintre exemplele de metrici ale lizibilitatății textului
care au fost dezvoltate pentru text ordinar. Aceste metrici toate sunt bazate pe
factori simpli cum ar fi numărul mediu de silabe pe cuvânt și lungimea medie a
propoziției. În ciuda simplicității lor relative, s-au dovedit a fi chiar foarte utile în
practică [1].
Există un consens asupra faptului că lizibilitatea este o caracteristică esențială
a calității codului [3, 5, 10, 11, 19, 29, 34, 35, 37, 38, 44], dar nu asupra căror
factori contribuie cel mai mult asupra noțiunii umane de lizibilitate a software-ului
[1].
În contextul codului sursă al programelor este important de notat că
lizibilitatea nu este la fel ca și complexitatea, pentru care există câteva metrici
Figura 3.1 – Tipuri de coeziune sintactică

24 3.3. Claritate
despre care s-a demonstrat în mod empiric că sunt folositoare [44,1]. În opinia lui
Brooks, complexitatea este o proprietate „esențială” a software-ului; ea se naște
din cerințele proiectului și nu poate fi eliminată [13]. Pe de altă parte, afirmă
Brooks, lizibilitatea este pur „accidentală”. În modelul lui Brooks, inginerii
software pot doar spera să controleze dificultățile accidentale: lizibilitatea
accidentală poate fi adresată mult mai ușor decât complexitatea intrinsecă.
Buse și Weimer [1] au propus o metrică ce ia în considerare anumite
particularități ale codului în funcție de formatarea lui. Diferite aspecte ale
formatării (ex. numărul mediu și numărul maxim de identificatori pe linie pe o
anumită linie) sunt verificate pe fragmente de cod de dimensiuni în jur de 7 linii
fiecare. Pe baza acestora și comparând cu răspunsul dat de mai mulți utilizatori
umani, aceștia au ajuns la un model ce poate evalua cât de frumos este scrisă o
porțiune de cod.
Spinellis [14] afirmă că singurul factor rezultat ce poate fi citit sau observat
ușor în cod este stilul. El continuă făcând analogia între un cod bun și o proză
bună. Deși un scriitor probabil a învățat că este important să își mențină
propozițiile scurte și să folosească metaforele, făcând acest lucru nu implică în
mod necesar că va rezulta un roman de prima clasă. Autorii excepționali știu
regulile prozei bune dar de asemenea ei știu când să le încalce.
Din moment ce lizibilitatea și complexistatea sunt în principiu două aspecte
diferite, o metrică ce se bazează în primul rând pe formatarea textului codului
sursă considerăm că nu este suficient de sensibilă în a surprinde posibilele
particularități (claritatea identificatorilor, apeluri de metode, căi de execuție) ale
unei anumite porțiuni de cod ce pot îngreuna înțelegerea ei de către un cititor
uman. De exemplu, o porțiune de cod poate fi scrisă într-un mod foarte lizibil,
având o formatare foarte bună dar complexitatea ei să fie ridicată. Un utilizator
uman chiar dacă ar citi ușor porțiunea respectivă de cod, va întâmpina dificultăți în
înțelegerea ei. Cealaltă extremă este cazul în care complexitatea codului nu este
ridicată dar codul este scris în așa manieră încât este foarte greu de descifrat care
este funcționalitatea implementată. Prin urmare am ales să luăm în considerare
simultan ambele aspecte, atât ușurința citirii cât și complexitatea, în construirea
unei noi metrici. În continuare vom propune o nouă soluție, metrica denumită
claritatea codului, care să ia în considerare aceste aspecte.

25 CONCEPTE
Capitolul 4. Concepte În acest capitol vom defini noile conceptele utilizate în studiul impactului
semanticii asupra calității unui sistem. De asemenea va fi prezentat rolul și
importanța fiecărui concept în studiul calității.
4.1. Semantica și Calitatea
Un sistem de calitate este un sistem relativ ușor de întreținut. Este cunoscut
faptul că mentenabilitatea este legată în mod intrinsec de lizibilitatea sistemului și
de arhitectura lui. Mentenabilitatea implică proprietatea unui sistem de a fi
schimbat ușor. Prin urmare cu cât se identifică mai rapid locul în care trebuie
făcută schimbarea cu atât un sistem poate fi considerat mai calitativ. În sistemele
orientate pe obiecte schimbarea se face în primul rând la nivel de metodă, aceasta
având efecte la nivel de clasă pentru ca apoi noile schimbări să se propage la nivel
de pachet și în cele din urmă la nivel de sistem.
Sistemele contemporane se întind de la zeci de mii de linii de cod până la
milioane de linii de cod. Dacă citirea unei singure linii de cod s-ar face într-o
secundă, parcurgerea unui sistem cu un milion de linii de cod ar implica un cost în
termeni de timp mult prea mare pentru cineva care ar trebui să asigure
mentenanța acelui sistem. De aceea avem nevoie de o metodă ca într-un timp cât
mai scurt să reducem numărul de potențial candidați la schimbare la doar câțiva pe
care să îi inspectăm vizual linie cu linie.
Ținând cont de aceste premise pentru a evalua calitatea unui sistem și
impactul semanticii identificatorilor asupra acesteia am abordat problema din trei
perspective. În primul rând, pentru a identifica locul în care trebuie făcută o
schimbare am utilizat vizualizările de cod. În al doilea rând, pentru a înțelege
arhitectura unui sistem și legătura ei cu semantica am construit o metrică ce
reflectă coeziunea din punct de vedere semantic al unei clase. În al treilea rând,
am definit conceptul de claritate a codului ce reflectă ușurința sau greutatea cu
care un programator poate înțelege codul programului. Utilizând acest concept se
va studia impactul semanticii identificatorilor asupra calității.

26 4.2. Word Cloud
4.2. Word Cloud
Sight is a faculty; seeing, an art. Vederea este o înzestrare naturală; a vedea, este o artă.
— George Perkins Marsh
Pentru identificarea aspectelor legate de arhitectura și funcționarea unui
sistem am ales metoda de vizualizare de cod. Marinescu în [25] afirmă că oamenii
sunt învățați să recunoască semnele și pozele, de aceea vizualizarea este o unealtă
excelentă pentru înțelegerea și identificarea aspectelor ascunse în sistemele
software mari.
Vizualizarea de cod este extrem de utilă pentru că într-o singură imagine pot fi
cuprinse o mulțime de informații. Așa cum spune un proverb, „o imagine este cât o
mie de cuvinte”, la fel o imagine poate valora cât o mie de linii de cod. Pentru
ajunge la acest deziderat am folosit conceptul de „tag cloud” sau „word cloud”, în
traducere liberă „nor de cuvinte”. În continuare vom folosi acești termeni în mod
interschimbabil pentru același concept.
Codul programelor este scris în așa manieră încât fiecare identificator
comunică o anumită informație. Chiar dacă pentru mașină caracterele care descriu
un identificator nu au nici o funcționalitate, pentru utilizatorul uman acestea sunt
vehicule ce transportă informație, informație ce la rândul ei descrie
funcționalitatea și arhitectura sistemului. Aceste informații pot fi utilizate în mod
eficient pentru a identifica mult mai rapid unele particularități ale unei porțiuni de
program.
Codul sursă al programelor este în esență un text format din anumite cuvinte cheie
specifice limbajului de programare și alte cuvinte cărora programatorul le atribuie
un anumit sens. În mod special în programele orientate pe obiecte, identificatorii
sunt cuvinte uzuale, deseori compuse, pe care aproape orice persoană le poate
înțelege chiar dacă nu este familiară cu domeniul respectiv.
Pornind de la această premiză din identificatorii prezenți în cod au fost extrase
cuvintele cheie și au fost construți tag cloud-uri pentru metodă, pentru clasă,
pentru pachet și pentru un întreg sistem sistem. Norii rezultați au fost denumiți
NameCloud, TypeCloud, MethodCloud și DataCloud. Categoriile față de care au
fost structurate informațiile sunt:
o name – numele identificatorilor
o type – tipul identificatorilor
o method – metodele, funcțiile apelate
o data – toate informațiile anterioare agregate
Aceste informații afișate pe diferite categorii și la diferite nivele de abstractizare a
sistemului ne vor ajută să combinăm într-un mod eficient abordările top-down și
bottom-up atunci când dorim să identificăm anumite particularități ale unei

27 CONCEPTE
porțiuni de cod. De exemplu, care sunt colaboratorii principali ai metodei
respective? Care sunt cuvintele cheie ce descriu funcționalitatea clasei? În ce
pachet găsim clasele care au în comun un anumit identificator? Care sunt
conceptele de bază cu care lucrează acest sistem? Toate aceste întrebări își pot
găsi răspunsul pornind având ca punct de pornire word cloud-ul descris anterior.
4.3. Coeziunea semantică
Clasele care conțin funcționalități bine relaționate între ele sunt considerate
ca având coeziune ridicată iar scopul inginerului software este să construiască
entități cât mai coezive posibil. McConnell, în cartea consacrată Code Complete
[46], afirmă despre coeziune că este o unealtă utilă pentru a ține sub control
complexitatea pentru că cu cât mai mult cod dintr-o clasă suportă scopul central al
clasei, cu atât este mai ușor pentru creierul programatorului să își amintească tot
ce face codul clasei respective.
Marsic [51] afirmă că este posibil să existe o clasă cu o coeziune sintactică
internă foarte bună dar cu o coeziune semantică scăzută. Clase individuale coezive
din punct de vedere semantic pot fi puse împreună pentru a crea o nouă clasă fără
sens din punct de vedere semantic în timp ce coeziunea sintactică internă este
păstrată. El continuă cu următorul exemplu. Să ne imaginăm o clasă care include
aspecte ce aparțin atât de o persoană cât și de mașina deținută de acea persoană.
Să presupunem că fiecare persoană poate avea doar o singură mașină și că fiecare
mașină poate avea doar un singur proprietar (o asociere de tipul unu-la-unu).
Atunci person_id <—> car_id ar fi echivalentul normalizării datelor. Cu toate
acestea, clasele nu au doar date ci și operații care desfășoară anumite acțiuni. Ele
oferă tipare comportamentale pentru (1) persoană și (2) pentru mașină, ambele
fiind concepte implementate de clasa propusă. Presupunând că nu există nici o
intersecție între funcționalitatea Persoanei și Mașinii, atunci care este înțelesul
clasei, probabil denumită Mașină_Persoană? O asemenea clasă poate fi coezivă
intern și totuși din punct de vedere semantic ca întreg văzut din exterior noțiunea
exprimată (în cazul descris o entitate persoană-mașină) este un non-sens [51].
În lucrarea de față coeziunea a fost studiată în detaliu doar la nivelul de clasă
și din punct de vedere semantic. Coeziunea semantică a unei clase se referă la
identificatorii folosiți în interiorul clasei pentru metode și atribute iar relația
dintre cuvintele folosite în formarea identificatorilor va fi cea care va da formă
conceptului de coeziune semantică. Fiecare identificator fiind compus din unul sau
mai multe cuvinte, scopul studiului semantic este identificarea cuvintelor cheie
față de care toate celelalte cuvinte se relaționează. Cu alte cuvinte, coeziunea
clasei este dată de cuvintele cheie care se relaționează cel mai bine cu cât mai
mulți identificatori ai clasei iar valorea numerică a metricii coeziunii semantice
este numărul acestor cuvinte.

28 4.4. Claritatea codului
Folosind modelul definit de analiza formală, pentru fiecare clasă au fost
extrase atributele și metodele ei și a fost construit contextul formal corespunzător.
Identificatorii compleți ai atributelor și metodelor reprezintă entitățile iar
cuvintele care compun identificatorii reprezintă proprietățile. Între fiecare
entitate și proprietate există un anumit grad de relaționare semantic iar această
relație a fost utilizată pentru construirea contextului formal. Dacă relația de
apropiere dintre o entitate și o proprietate nu depășește un anumit prag atunci
relația dintre cele două nu este introdusă în context.
Pornind de la contextul formal construit se generează laticea de concepte unde
fiecare concept are un număr de entități și un anumit număr de proprietăți.
Extensia conceptului este compusă din identificatorii metodelor și atributelor iar
intenția conceptului este compusă din cuvintele față de care sunt relaționate
metodele și atributele din extensie. Din laticea de concepte sunt eliminate acele
concepte care nu îndeplinesc anumite condiții.
După ce laticea de concepte este filtrată sunt selectate într-un mod cât mai
optim conceptele pentru care reunind entitățile lor cuprind întreaga clasă, adică
implică toate metodele și toate atributele clasei. Toate proprietățile acestor
concepte sunt cuvintele care definesc coeziunea clasei, aceste cuvintele sunt
cuvintele cel mai puternic legate de majoritatea atributelor și metodelor din clasă.
Numărul necesar de concepte reprezintă valoarea metricii pentru coeziunea
semantică.
4.4. Claritatea codului
În acest subcapitol vom explora conceptul de lizibilitate a codului și vom
investiga relația lui cu cel al calității software-ului. Folosind [1] definim
„lizibilitatea” ca o judecată umană a cât de ușor este un text de înțeles, în cazul
de față textul fiind reprezentat de codul sursă.
Pentru că lizibilitatea unui text și complexitatea lui sunt în principiu două
aspecte diferite vom încerca să găsim o soluție de a aduce cele două aspecte
împreună pentru a da funcționalitate unei metrici care să reflecte într-un mod cât
mai fidel cât de greu sau cât de ușor este de citit o anumită porțiune de cod sursă.
Lizibilitatea codului va fi dată de claritatea identificatorilor, ce cuvinte sunt
folosite, dacă acestea pot fi înțelese la o simplă citire. Cuvintele care compun
identificatorii sunt cele care dau claritatea unui identificator. Dacă ele sunt
cuvinte din dicționar atunci identificatorul va avea o claritate mai ridicată.
Complexitatea din punctul de vedere al lizibilității se referă la numărul
identificatorilor. Dacă numărul identificatorilor care trebuie ținuți minte simultan
de către programator este mai mare de un anumit prag (de exemplu, șapte - bazat
pe articolul lui Miller [22]) atunci claritatea va avea de suferit. De asemenea

29 CONCEPTE
complexitatea ciclomatică, numărul de căi posibile ale unui cod influențează
timpul în care programatorul va înțelege acea porțiune de cod.
Am ales conceptul de metrică pentru că, așa cum spune și [25], metricile sunt
foarte eficiente în a rezuma aspectele particulare ale lucrurilor și în a detecta
extremitățile în mulțimi mari de date. Metricile scalează bine și sunt un fundament
bun pentru o sinteză a multor detalii din software.
Având ca punct de plecare metricile putem să ajungem la o strategie de detecție
pentru anumite particulariți ale unei porțiuni de cod. O strategie de detecție [25]
este o condiție compusă logică, bazată pe metrici, ce identifică ce identifică acele
fragmente de design ce îndeplinesc condiția. O strategie de detecție poate fi
utilizată pentru a exprima în mod cantitativ deviațiile de la un set de reguli pentru
un design armonios.
Folosindu-ne de aceste concepte, în continuare va fi descrisă implementarea
unei metrici ce poate fi folosită ulterior ca o bază de pornire pentru o strategie de
detecție a codului scris într-un mod neclar. Pornind de la anumite caracteristici
fundamentale ale unui cod lizibil metrica implementată va identifica acele porțiuni
de cod ce suferă la capitolul ușurința citirii și înțelegirii lui de către un utilizator
uman. Porțiunile de cod studiate au fost analizate la nivel de metodă și la nivel de
clasă. Numărul returnat de metrică va reflecta gradul de claritate al porțiunii de
cod analizate.

30 5.1. WordCloud
Capitolul 5. Implementare În acest capitol vom prezenta soluțiile de implementare pentru conceptele
definite anterior. Prezentarea implementării va fi făcută la nivel de idee
încercându-se cât mai mult o separare de particularitățile limbajului ales deși
implementarea a fost făcută în limbajul Java.
5.1. WordCloud
WordCloud este o modalitate eficientă de afișare sintetizată a informațiilor
oferite de identificatorii unei anumite porțiuni de cod. În acest subcapitol vom
prezenta cum am ales și extras cuvintele care formează identificatorii. Apoi vom
prezenta particularitățile vizualizării pentru fiecare nivel de abstractizare ales,
metodă, clasă, pachet sau sistem.
5.1.1. Procesarea identificatorilor
Codul orientat pe obiecte este scris pornind de la ideea că pentru a descrie
rolul lor, identificatorii pot fi compuși prin alăturarea mai multor cuvinte.
Compunerea acestor identificatori diferă de la o convenție la alta. În Java este
utilizată convenția de a denumi numele de clase începând cu literă mare iar apoi
toate cuvintele alipite încep și ele la rândul lor cu litere mari (ex.
AbstractAttributedRoundFigure). Pentru atribute, metode și variabile este folosită
aceeași convenție cu excepția că numele metodei începe cu literă mică iar restul
cuvintelor încep cu literă mare (ex. getFigureBounds, lowerLimit).
Pentru că identificatorii sunt vehicule transportatoare de informație ce
reflectă funcționalitatea unei anumite părți dintr-un sistem, această informație
trebuie extrasă. Extragerea informației începe cu fracționarea identificatorilor.
Identificatorii fiind construiți din mai multe cuvinte vom considera un tag ca fiind
Figura 5.1 – Expresiile regulate pentru divizarea identificatorilor
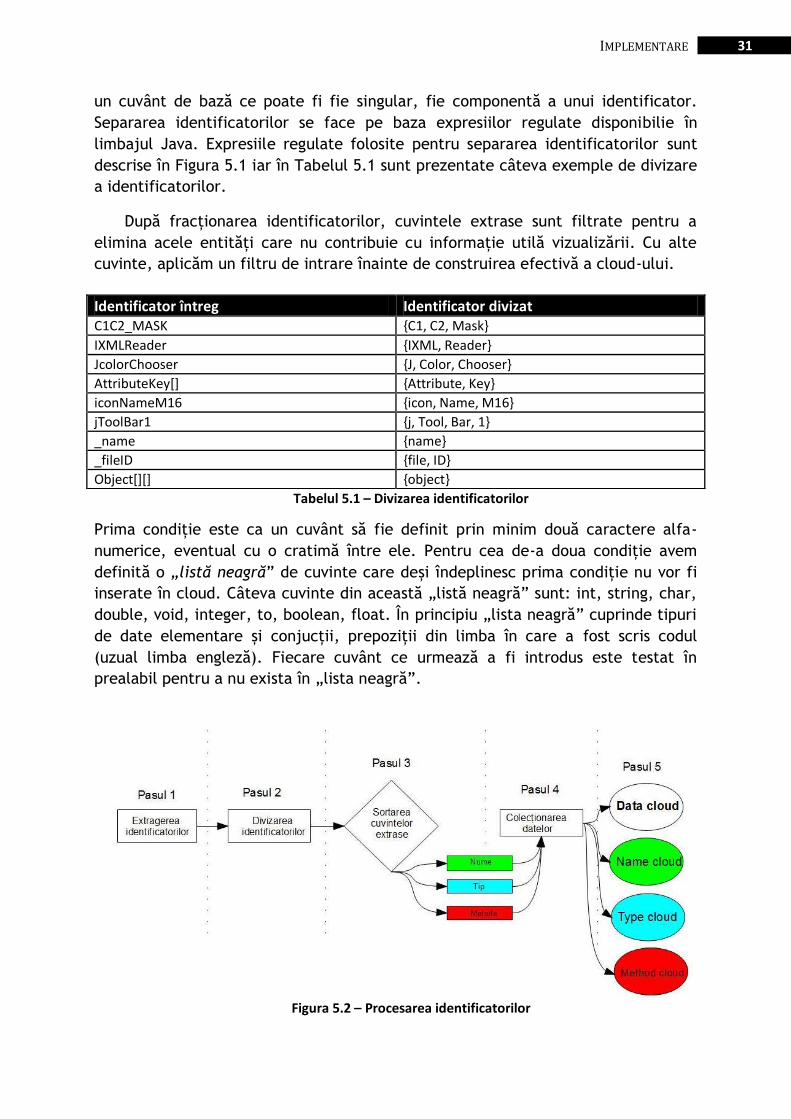
31 IMPLEMENTARE
un cuvânt de bază ce poate fi fie singular, fie componentă a unui identificator.
Separarea identificatorilor se face pe baza expresiilor regulate disponibilie în
limbajul Java. Expresiile regulate folosite pentru separarea identificatorilor sunt
descrise în Figura 5.1 iar în Tabelul 5.1 sunt prezentate câteva exemple de divizare
a identificatorilor.
După fracționarea identificatorilor, cuvintele extrase sunt filtrate pentru a
elimina acele entități care nu contribuie cu informație utilă vizualizării. Cu alte
cuvinte, aplicăm un filtru de intrare înainte de construirea efectivă a cloud-ului.
Tabelul 5.1 – Divizarea identificatorilor
Prima condiție este ca un cuvânt să fie definit prin minim două caractere alfa-
numerice, eventual cu o cratimă între ele. Pentru cea de-a doua condiție avem
definită o „listă neagră” de cuvinte care deși îndeplinesc prima condiție nu vor fi
inserate în cloud. Câteva cuvinte din această „listă neagră” sunt: int, string, char,
double, void, integer, to, boolean, float. În principiu „lista neagră” cuprinde tipuri
de date elementare și conjucții, prepoziții din limba în care a fost scris codul
(uzual limba engleză). Fiecare cuvânt ce urmează a fi introdus este testat în
prealabil pentru a nu exista în „lista neagră”.
Identificator întreg Identificator divizat C1C2_MASK {C1, C2, Mask}
IXMLReader {IXML, Reader}
JcolorChooser {J, Color, Chooser}
AttributeKey[] {Attribute, Key}
iconNameM16 {icon, Name, M16}
jToolBar1 {j, Tool, Bar, 1}
_name {name}
_fileID {file, ID}
Object[][] {object}
Figura 5.2 – Procesarea identificatorilor

32 5.1. WordCloud
Construirea tag cloud-ului se face trecând prin mai multe etape, pași
reprezentați în Figura 5.2. În primul pas se extrag identificatorii de interes în
funcție de tipul vizualizării (metodă, clasă, pachet sau sistem). În al doilea pas se
divizează identificatorii în cuvintele componente. Al treilea pas constă în
distribuirea lor în liste ce corespund informației pe care o poartă (nume, tip sau
metodă). Pasul patru constă în construirea listei cu toate datele generate. Pasul
cinci constă în construirea norilor corespunzători celor patru tipuri de informații
extrase ținând cont de filtrele de intrare pentru cuvintele cheie.
În final, vizualizarea tag-cloud-ului se face cu ajutorul bibliotecii OpenCloud
[24]. Tag-urile vor avea ponderi normalizate pentru fiecare categorie în parte.
Cuvintele vor fi afișate în ordine descrescătoare a frecvenței lor. Astfel că în
partea stângă va fi cel mai mare cuvânt din tag cloud, ceea ce înseamnă că pentru
acea categorie acel cuvânt are ponderea cea mai mare, adică este cel mai
important cuvânt din categoria respectivă.
5.1.2. Method WordCloud
Având modelul general pentru vizualizare, în continuare vom descrie modelul
particular al vizualizării pentru o metodă. Pentru o metodă, în primul rând este
extras numele metodei, sunt analizate cuvintele extrase din identificatorul
metodei, apoi cuvintele extrase sunt introduse în norul DataCloud, nor ce va
cuprinde totalitatea datelor extrase. Este ales identificatorul metodei pentru că în
mod uzual prin numele metodei este transmis scopul acelei metode.
În al doilea pas sunt extrase variabilele locale și pentru variabilele locale sunt
luate în considerare numele lor și tipul lor. Din acestea sunt extrase cuvintele de
bază ce formează identificatorii și tipul variabilelor iar acestea sunt inserate în
NameCloud, respectiv TypeCloud. Variabilele locale oferă informații despre tipul
datelor cu care se operează în metoda respectivă.
În al treilea pas sunt extrași parametrii metodelor și este luată în considerare
informația oferită de numele și tipul lor. Aceste informații, după extragere, sunt
inserate în NameCloud și TypeCloud. Parametrii metodelor în mod evident oferă
informații despre colaboratorii unei metode, care sunt tipurile de date cu care
metoda în cauză colaborează.
În al patrulea pas sunt extrase informațiile oferite prin procesarea tuturor
metodelor apelate în interiorul metodei în cauză. Sunt luați în considerare doar
identificatorii metodelor apelate iar cuvintele extrase sunt inserate în
MethodCloud. Metodele apelate oferă un plus de informații legat de ce fel de
operații se efectuează într-o anumită metodă, dacă sunt operații elementare sau
metoda colaborează cu alte obiecte care îi furnizează servicii.
În ultimul pas sunt extrase informațiile din atributele accesate de metoda
analizată. Sunt luate în considerare identificatorul atributului și tipul său.

33 IMPLEMENTARE
Cuvintele extrase sunt inserate în NameCloud, respectiv TypeCloud. Atributele
accesate din nou oferă informații despre tipul de date care sunt procesate în
interiorul unei metode.
Toate datele extrase pentru cele trei tipuri de informaționale sunt agregate în
DataCloud. Pentru fiecare categorie tag-urile sunt afișate în ordine descrescătoare
în funcție de ponderea lor în cadrul cloud-ului. Figura 5.3 este rezultatul procesării
metodei addFontButtonsTo din clasa org.jhotdraw.action.ToolbarFactory din
sistemul jHotDraw. Metoda are 127 de linii de cod și complexitate ciclomatică 10 și
14 variabile locale.
5.1.3. Class WordCloud
Pentru o clasă procesul de construire a norilor de cuvinte este similar cu cel al
vizualizării pentru metode. În primul rând este extras numele clasei, divizăm
identificatorul, aplicăm filtrele de intrare iar apoi introducem datele în DataCloud.
Numele clasei este ales pentru că numele clasei oferă informații pentru un
utilizator uman despre tipul de date procesat și ce fel de operații ar putea fi
implementate.
În al doilea rând sunt procesate datele pentru metodele clasei. Informațiile din
metode sunt luate în considerare pentru că metodele reprezintă de fapt
„inteligența” clasei, ele reprezintă funcționalitatea ei. Pentru fiecare metodă
obținem DataCloud-ul construit așa cum a fost descris pentru Method WordCloud.
Fiecare DataCloud este inserat în MethodCloud astfel că MethodCloud va conține
toate datele agregate din toate metodele clasei.
Figura 5.3 – WordCloud pentru metodă

34 5.1. WordCloud
În al treilea rând sunt extrase informațiile conținute în atributele clasei.
Atributele sunt cele ce dau sens obiectelor pentru că încapsulează informația
creând noi entități, noi tipuri de date, noi concepte. Pentru fiecare atribut luăm în
considerare informațiile oferite de identificatorul atributului și tipul atributului.
Identificatorul procesat este inserat în NameCloud iar tipul procesat este inserat în
TypeCloud.
În final, toate datele din NameCloud, TypeCloud și MethodCloud sunt agregate
în DataCloud. Figura 5.4 este rezultatul procesării clasaei DefaultDrawingView din
pachetul org.jhotdraw.draw din sistemul jHotDraw. Clasa are 759 linii de cod, 66
metode și 17 atribute.
5.1.4. Package WordCloud
Pachetele sunt procesate din nou în același mod. În primul rând este procesat
numele pachetului și inserat în DataCloud. Apoi, în al doilea pas sunt procesate
toate clasele pachetului.
Pentru fiecare clasă a pachetului sunt extrase mai puține informații ca în cazul
unui cloud dedicat clasei. În acest caz sunt luate în considerare atributele, fiind
procesați identificatorii lor și tipul lor iar informațiile sunt stocate în NameCloud,
respectiv TypeCloud. Apoi sunt luate în considerare și metodele clasei, fiind
procesate numele metodei și tipul returnat. Acestea sunt stocate la rândul lor în
MethodCloud, respectiv TypeCloud.
În cazul metodelor sunt luate în considerare doar numele și tipul returnat al
metodei pentru că dacă ar fi considerată toată informația din interiorul metodei în
Figura 5.4 – WordCloud pentru clasă

35 IMPLEMENTARE
primul rând acest lucru ar cauza ca informația oferită de atribute să fie mult
depășită cantitativ de cea din metode și, în al doilea rând, informația oferită de
atribute ar fi duplicată pentru că metodele cu siguranță vor folosi cel puțin o dată
un atribut. Renunțând la informația oferită de implementarea metodelor poate fi
extrasă mai bine informația despre funcționalitatea unei clase, ce face clasa și nu
cum face ceea ce face clasa respectivă.
În final, din nou toate informațiile sunt agregate în DataCloud și rezultatul este
afișat sub forma a patru tag cloud-uri. Figura 5.5 este rezultatul procesării
pachetului org.jhotdraw.draw, pachet ce conține 134 de clase și conține toată
ierarhia de figuri de bază pentru funcționalitatea sistemului jHotDraw.
5.1.5. System WordCloud
Pentru un sistem sunt considerate toate pachetele conținute. Astfel că pentru
fiecare pachet sunt extrase MethodCloud, TypeCloud și NameCloud definite la
Package WordCloud și toate datele sunt insertate în cloud-ul corespunzător
sistemului. Pentru fiecare pachet este extras și numele său pentru a fi inserat în
DataCloud.
În final toată informația este agregată în DataCloud-ul sistemul și rezultă o
privire de ansamblu a cuvintelor cheie din întreg sistemul. Figura 5.6 este
rezultatul procesării pentru sistemul jHotDraw, sistem format din 25 de pachete,
229 de clase și aproape 30000 de linii de cod.
Figura 5.5 – WordCloud pentru pachet

36 5.2. Coeziune Semantică
Figura 5.6 – WordCloud pentru sistem
Pentru toate nivelele de vizualizare, metodă, clasă, pachet sau sistem,
numărul cuvintelor afișate a fost limitat la 20 din rațiuni estetice. Mai mult de 20
de cuvinte per categorie ar fi făcut afișarea aglomerată cu multe cuvinte prea mici
pentru ochiul uman și care au o pondere scăzută în informația furnizată.
5.2. Coeziune Semantică
În continuare va fi prezentată soluția propusă pentru implementarea metricii
coeziunii semantice. Pentru manipularea conceptelor definite de analiza formală a
fost utilizată biblioteca eRCA [43]. Metrica a fost implementată folosindu-se
modelul codului furnizat de iPlasma, astfel ea devenind o nouă metrică disponibilă
în paleta de metrici implementate în iPlasma.
5.2.1. Contextul simplu
În prima etapă este construit un context formal care inițial nu conține nici o
entitate și nici o proprietate. Contextul formal este reprezentat printr-un tabel în
care prima coloană reprezintă entitățile (atribute și metode) iar prima linie
reprezintă proprietățile (toate cuvintele distincte care formează toți identificatorii
atributelor și metodelor).
După ce a fost creat contextul, urmează a fi extrase atributele clasei analizate.
Atributele clasei au două tipuri de indentificatori: indentificatorul numelui
atributului și identificatorul tipului atributului. Numele atributului este inserat în
lista de entități a clasei și este inserat în context ca o entitate. Apoi identificatorul
numelui și identificatorul tipului atributului sunt fragmentați în cuvintele
componente. Regulile de divizare sunt aceleași ca cele utilizate la formarea
WordCloud-ului (vezi 5.1.1. Procesarea identificatorilor) cu precizarea că sunt
adăugate la „lista neagră” cuvintele „get” și „set”. Acestea sunt eliminate pentru
că ele sunt foarte des întâlnite într-o clasă dar în general nu descriu conceptul
implementat de clasă ci în sunt doar o convenție pentru inserția sau extragerea
datelor încapsulate de acea clasă. După ce cuvintele componente sunt filtrate, ele

37 IMPLEMENTARE
Tabelul 5.2 – distanța dintre cuvinte
sunt inserate în context ca proprietăți ale entității din care au fost extrase.
Ulterior atributelor sunt procesate și metodele. În cazul metodelor sunt procesați
doar identificatorii lor, numele metodei, fără tipul returnat sau parametri.
Identificatorii metodelor sunt procesați în aceeși manieră ca identificatorii
atributelor.
După acest pas contextul formal conține toate entitățile și toate proprietățile care
vor fi folosite în generarea conceptelor și în analizarea coeziunii semantice. Pentru
clasa NodeFigure din sistemul jHotDraw, contextul formal în acest pas arată ca cel
din Figura 5.7.
5.2.2. Contextul extins
A doua etapă este cea de construire a relațiilor, pe
baza apropierii semantice dintre cuvinte, între fiecare
proprietate din context și fiecare entitate în parte. Acest
lucru este făcut cu ajutorul bibliotecii RitaWordNet [27]
ce asigură accesul la dicționarul WordNet. RitaWordNet pune la dispoziție o metodă
ce returnează distanța minimă10 dintre două cuvinte în funcție de sensul lor și
distanța în arborele de cuvinte. Metoda localizează părintele comun al celor două
cuvinte și verifică dacă ele există căutând sensul lor. Dacă unul nu este găsit se
returnează 1.0 (distanța maximă). Dacă există, se calculează cea mai scurtă cale
posibilă de la oricare cuvânt la părintele comun. Apoi se calculează lungimea căii
de la părintele comun la rădăcina ontologiei și se returnează distanța normalizată
cu formula:
Figura 5.7 – NodeFigure – contextul formal simplu
10
http://www.rednoise.org/rita/wordnet/documentation/riwordnet_method_getdistance.htm [Online 14.06.2012] - getDistance(lemma1, lemma2, pos);
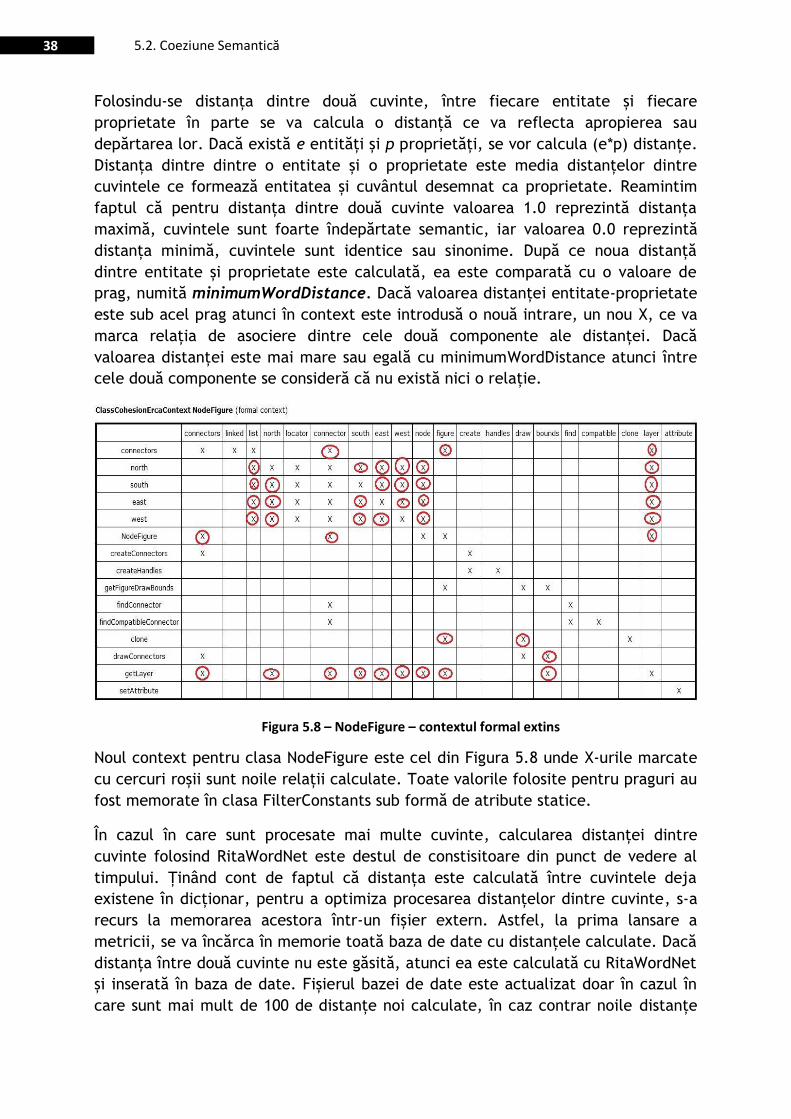
38 5.2. Coeziune Semantică
Folosindu-se distanța dintre două cuvinte, între fiecare entitate și fiecare
proprietate în parte se va calcula o distanță ce va reflecta apropierea sau
depărtarea lor. Dacă există e entități și p proprietăți, se vor calcula (e*p) distanțe.
Distanța dintre dintre o entitate și o proprietate este media distanțelor dintre
cuvintele ce formează entitatea și cuvântul desemnat ca proprietate. Reamintim
faptul că pentru distanța dintre două cuvinte valoarea 1.0 reprezintă distanța
maximă, cuvintele sunt foarte îndepărtate semantic, iar valoarea 0.0 reprezintă
distanța minimă, cuvintele sunt identice sau sinonime. După ce noua distanță
dintre entitate și proprietate este calculată, ea este comparată cu o valoare de
prag, numită minimumWordDistance. Dacă valoarea distanței entitate-proprietate
este sub acel prag atunci în context este introdusă o nouă intrare, un nou X, ce va
marca relația de asociere dintre cele două componente ale distanței. Dacă
valoarea distanței este mai mare sau egală cu minimumWordDistance atunci între
cele două componente se consideră că nu există nici o relație.
Figura 5.8 – NodeFigure – contextul formal extins
Noul context pentru clasa NodeFigure este cel din Figura 5.8 unde X-urile marcate
cu cercuri roșii sunt noile relații calculate. Toate valorile folosite pentru praguri au
fost memorate în clasa FilterConstants sub formă de atribute statice.
În cazul în care sunt procesate mai multe cuvinte, calcularea distanței dintre
cuvinte folosind RitaWordNet este destul de constisitoare din punct de vedere al
timpului. Ținând cont de faptul că distanța este calculată între cuvintele deja
existene în dicționar, pentru a optimiza procesarea distanțelor dintre cuvinte, s-a
recurs la memorarea acestora într-un fișier extern. Astfel, la prima lansare a
metricii, se va încărca în memorie toată baza de date cu distanțele calculate. Dacă
distanța între două cuvinte nu este găsită, atunci ea este calculată cu RitaWordNet
și inserată în baza de date. Fișierul bazei de date este actualizat doar în cazul în
care sunt mai mult de 100 de distanțe noi calculate, în caz contrar noile distanțe

39 IMPLEMENTARE
rămân doar în memorie. În urma rulării analizei pe mai multe sisteme cum ar fi
jHotDraw, ProGuard, Azureus și altele, baza de date conține peste 350000 de
intrări. Utilizând această metodă timpul de calculare a distanței este neglijabil
chiar și atunci când analiza este rulată pentru zeci de clase simultan.
5.2.3. Coeziunea conceptelor
Următorul pas constă în generarea laticei de concepte, grafului de concepte
pornind de la contextul formal. Fiecare concept are cele două componente,
extensia și intenția, formate din entități (atribute și metode) respectiv proprietăți
(cuvintele). eRCA [43] folosește conceptele de bază obținute din context și le
combină generând noi concepte care au o combinări diferite de entități și
proprietăți, noile concepte fiind legate de conceptele de bază.
Pentru fiecare concept va fi calculată coeziunea semantică. Aceasta este definită
ca media distanțelor dintre fiecare entitate și fiecare proprietate în parte.
∑ ∑
Graful generat pe baza contextului clasei NodeFigure este cel din Figura 5.9.
Conceptele cu fundal gri reprezintă conceptele de bază, extrase direct din
contextul formal iar conceptele cu fundal albastru sunt conceptele noi generate.
Vârful grafului este conceptul care are toate entitățile dar nu are nici o
proprietate. Acest lucru se datorează faptului că toate entitățile nu au în comun o
proprietate în același timp. De asemenea la baza grafului să află conceptul care
are toate proprietățile dar nici o entitate iar aceasta din cauză că nu exită nici o
entitate care să aibă toate proprietățile din context. Vizualizarea grafului a fost
făcută cu GraphViz [33].
Odată ce graful conceptelor este generat următorul pas este filtrarea grafului și
ștergea din graf a conceptelor care nu îndeplinesc anumite condiții impuse. Prima
condiție impusă este aceea ca fiecare concept din graf să aibă cel puțin o
proprietate. Această condiție va șterge vârful grafului. A doua condiție este ca
fiecare concept să aibă o anumită coeziune. Toate conceptele care nu depășesc un
anumit prag al coeziunii impus sunt șterse din graf. eRCA permite adăugarea unui
număr nelimitat de filtre la alegere și în același timp permite programatorului să își
definească filtre particularizate. Cele două filtre menționate anterior au fost
definite specific pentru a deservi studiul coeziunii, nefăcând parte din suita de
filtre oferite de eRCA. Odată cu ștergerea conceptelor care nu îndeplinesc
condițiile cerute graful de concepte va fi reactualizat și legăturile refăcute. Figura
5.10 reprezintă laticea conceptelor filtrată și restructurată.
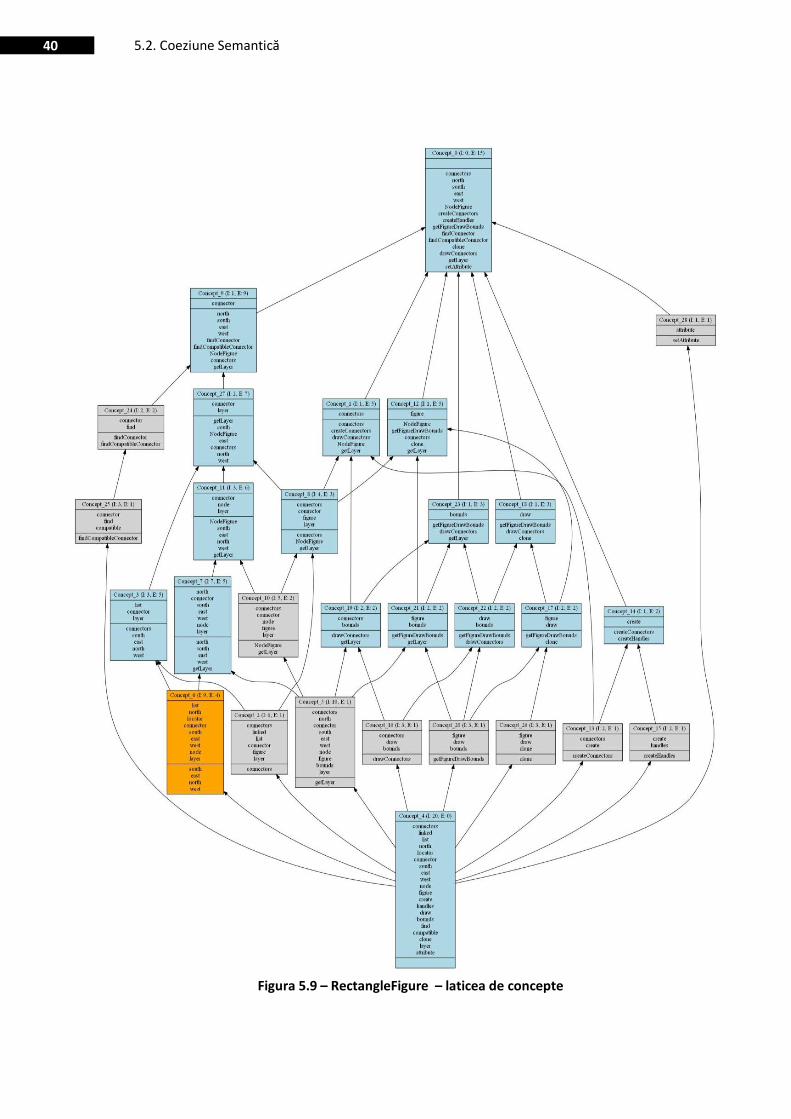
40 5.2. Coeziune Semantică
Figura 5.9 – RectangleFigure – laticea de concepte
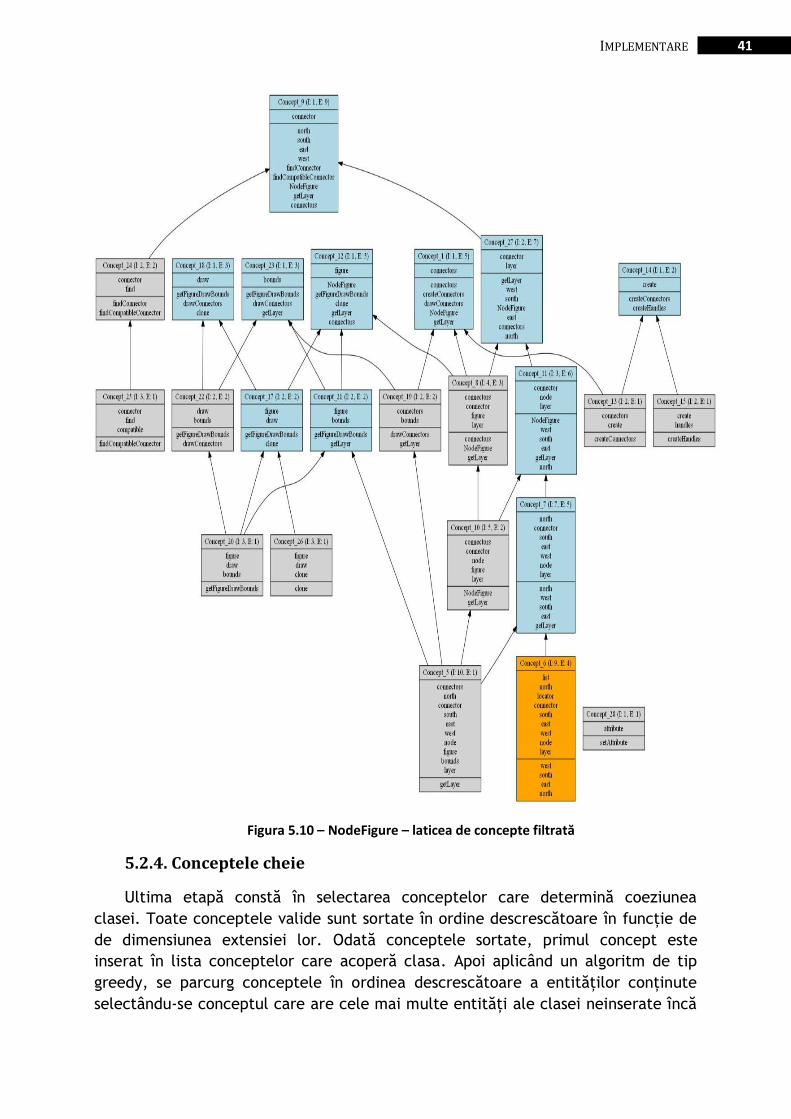
41 IMPLEMENTARE
Figura 5.10 – NodeFigure – laticea de concepte filtrată
5.2.4. Conceptele cheie
Ultima etapă constă în selectarea conceptelor care determină coeziunea
clasei. Toate conceptele valide sunt sortate în ordine descrescătoare în funcție de
de dimensiunea extensiei lor. Odată conceptele sortate, primul concept este
inserat în lista conceptelor care acoperă clasa. Apoi aplicând un algoritm de tip
greedy, se parcurg conceptele în ordinea descrescătoare a entităților conținute
selectându-se conceptul care are cele mai multe entități ale clasei neinserate încă
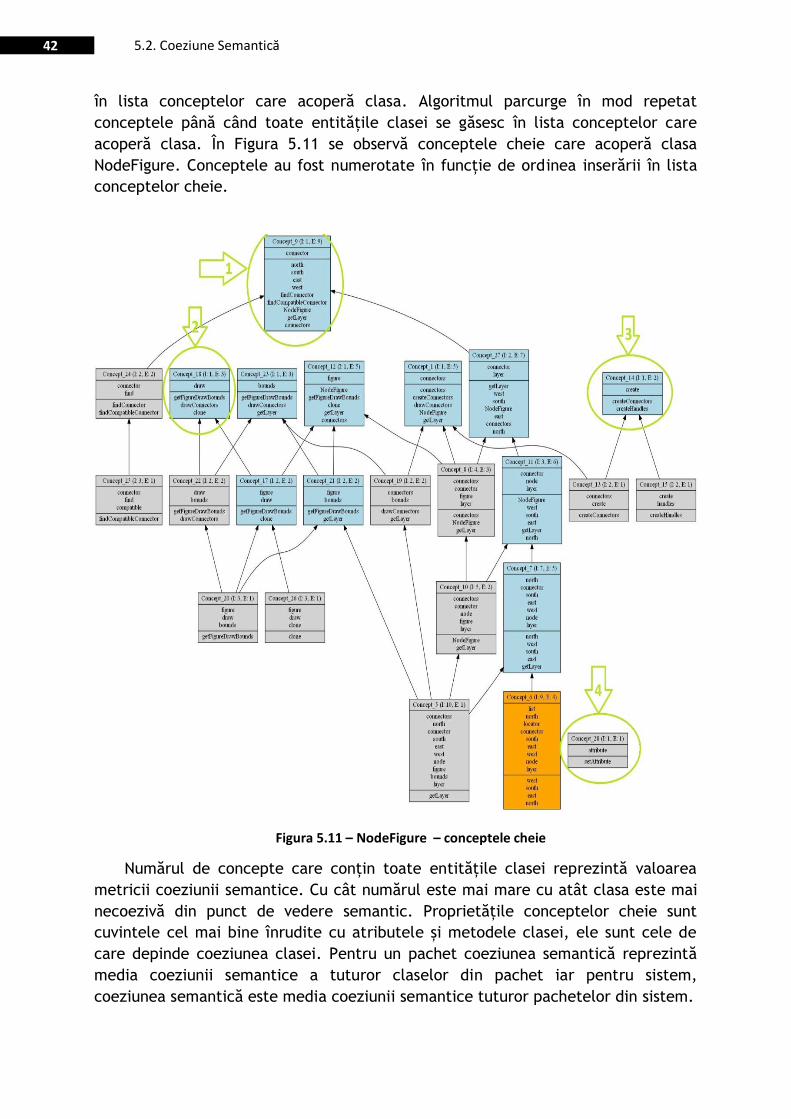
42 5.2. Coeziune Semantică
în lista conceptelor care acoperă clasa. Algoritmul parcurge în mod repetat
conceptele până când toate entitățile clasei se găsesc în lista conceptelor care
acoperă clasa. În Figura 5.11 se observă conceptele cheie care acoperă clasa
NodeFigure. Conceptele au fost numerotate în funcție de ordinea inserării în lista
conceptelor cheie.
Figura 5.11 – NodeFigure – conceptele cheie
Numărul de concepte care conțin toate entitățile clasei reprezintă valoarea
metricii coeziunii semantice. Cu cât numărul este mai mare cu atât clasa este mai
necoezivă din punct de vedere semantic. Proprietățile conceptelor cheie sunt
cuvintele cel mai bine înrudite cu atributele și metodele clasei, ele sunt cele de
care depinde coeziunea clasei. Pentru un pachet coeziunea semantică reprezintă
media coeziunii semantice a tuturor claselor din pachet iar pentru sistem,
coeziunea semantică este media coeziunii semantice tuturor pachetelor din sistem.

43 IMPLEMENTARE
5.3. Claritatea Codului
Claritatea codului depinde de lizibilitatea și de complexitatea lui. Când vorbim
de lizibilitatea codului, cerințele pentru denumirea identificatorilor sunt relativ
modeste. Vrem ca numele identificatorilor să ne ajute să recunoaștem cât mai
rapid rolul lor și vrem ca lungimea lor să fie proporțională cu aria de utilizare a lor
[20]. Un nume scurt de variabilă, cum ar fi i și un nume lung de clasă, cum ar fi
WildcardSessionAttributeMatcherFactory sunt ambele nume acceptabile. În primul
caz, variabila contor pentru ciclu cel mai probabil va fi folosită într-un segment
scurt de cod: vrem să fie scurtă pentru a nu încărca codul și nu ne interesează
descrierea ei, pentru că definiția ei va fi foarte apropiată de utilizarea ei și oricum,
i prin convenție este numele variabilei de control. În cel de-al doilea caz, vrem ca
numele să fie descriptiv, pentru că va fi folosit (ideal doar de câteva ori) într-un
context străin, mult depărtat de locul de definire.
De asemenea, când citim o singură expresie, vrem ca cel puțin să putem
recunoaște măcar rolul unor identificatori ce apar în expresie – acest fapt ne ajută
pe noi oamenii să interpretăm în mod corect expresia fără a ține în minte întreaga
structură a programului.
Ținând cont de câteva dintre aceste convenții larg răspândite în domeniul
programării, în continuare vom descrie modalitatea de implementare a metricii de
claritate a codului metodelor și claselor. Pentru pachete, claritatea pachetului
este implementată ca media clarității claselor conținute de acel pachet. Claritatea
sistemului este media clarității pachetelor acelui sistem.
Valoarea numerică returnată va fi normalizată, astfel că valoarea 1 semnifică
faptul că porțiunea de cod are claritatea maximă iar valoarea 0 semnifică faptul că
porțiunea de cod are claritatea la cote minime. În iPlasma, din cauza unor
constrângeri de afișare și aproximare această valoare a fost înmulțită cu 1000,
astfel că valoarea maximă este 1000 iar cea minimă este 0.
5.3.1. Claritatea identificatorilor
Claritatea unei porțiuni de cod este strâns legată de claritatea
identificatorilor. Considerăm un identificator ca fiind cu atât mai clar cu cât un
utilizator uman poate înțelege scopul acelui identificator într-un timp cât mai
scurt. Pentru că sensul unui identificator este comunicat de cuvintele care
alcătuiesc acel identificator vom analiza cuvintele care compun acel identificator
și pe baza lor vom defini o măsură a clarității identificatorului.
În primul pas identificatorul este divizt în cuvintele componente așa cum s-a
făcut deja la subcapitolul WordCloud (vezi 5.1.1. Procesarea identificatorilor)
folosind aceleași constrângeri pentru cuvinte, folosind aceleași expresii regulate
dar fără alte filtre suplimentare.

44 5.3. Claritatea Codului
În al doilea pas, pornind de la lista de cuvinte extrase este calculată o valoare
normalizată ce va descrie claritatea unui identificator. În cazul în care nu există
nici un cuvânt extras și insertat în lista cuvintelor ce formează identificatorul
considerăm valoarea maximă, 1.00 pentru acel identificator. Biblioteca
RitaWordnet [27] pune la dispoziție o metodă pentru a testa existența unui cuvânt
în dicționarul instalat.
Pentru fiecare cuvânt vom avea un scor în funcție de existența lui. Dacă există,
scorul său este de 1.00, dar dacă există și lungimea lui este mai mică de 3
caractere, atunci scorul său este de 0.25. Am considerat acest caz pentru situația
în care identificatorii sunt acronime sau prescurtări ale altor identificatori mai
lungi. Dacă acest tip de identificatori reprezintă excepția și nu regula atunci
impactul lor asupra clarității nu va fi unul mare. Un utilizator uman poate reține
semnificația unui număr restrâns de acronime fără un efor mare pentru o perioadă
scurtă de timp. Dacă nu există cuvântul în dicționar, atunci scorul său va fi 0.
După ce este calculat scorul fiecărui cuvânt din identificator, se calculează
media aritmetică a acelor valori. Rezultatul obținut este valoarea metricii ce
reflectă claritatea unui anumit identificator. Această metrică este numită în
continuare claritatea identificatorului.
5.3.2. Claritatea metodelor
Metodele sunt porțiuni de cod cu o anumită funcționalitate specifică ce în mod
uzual au doar câteva linii de cod, rareori depășesc câteva zeci de linii dar sunt și
excepții care se pot întinde până peste o sută de linii de cod.
Așa cum am văzut deja, complexitatea și lizibilitatea unei porțiuni de cod sunt
în principiu două aspecte diferite. De aceea am definit două concepte care, din
perspectiva clarității codului, să extragă și să oferă o măsură a calității codului. Am
definit două concepte pentru că o porțiune de cod poate să fie foarte ușor de citit
din perspectiva clarității identificatorilor dar să fie foarte complexă în termeni de
operații efectuate și căi de execuție, sau invers. Ambele aspecte influențează
claritatea unei porțiuni de cod.
Primul concept este cel de Reading Lisibility11. Acest concept urmărește
aspectele ce țin de ușurința citirii și înțelegerii codului din prisma clarității
identificatorilor, numelor metodelor și variabilelor folosite. Acest concept este de
fapt o metrică ce ține cont de următoarele particularități:
o Numele metodei analizate
o Variabilele locale
o Metodele apelate
11 Reading Lisibility – lizibilitatea textului, gradul ușurinței de citire a unui text

45 IMPLEMENTARE
Al doilea concept este numit Reading
Complexity12. Acest concept urmărește
aspectele ce țin de complexitatea unei
porțiuni de cod și influențează claritatea
codului, adică ușurința cu care poate fi
citit și înțeles. Reading Complexity ia în
considerare următoarele aspecte:
o complexitatea ciclomatică
o numărul de metode accesate
o numărul de linii de cod
o numărul de variabile locale
În continuare vom descrie detaliile ce stau la baza conceptului de Reading
Lisibility și modului în care este construită metrica. În primul rând este calculată
claritatea identificatorului metodei, adică este calculată claritatea numelui
metodei folosind metrica claritatea identificatorului. Acest scor va avea o pondere
de 0.1 din rezultatul final. Este considerată această valoare pentru coeficient
deoarece cantitatea de informație utilă din numele unei metode este mult mai
restrânsă comparat cu codul ei atunci când doar metrica este luată în calcul.
În al doilea rând, sunt procesați identificatorii metodelor apelate din corpul
metodei analizate. Pentru numele fiecărei metode este calculată claritatea
identificatorului iar apoi rezultatul este media aritmetică a rezultatelor. În cazul
în care nu există metode apelate, rezultatul este 1.0, ceea ce înseamnă că din
perspectiva metodelor apelate claritatea este maximă pentru că înțelegerea
funcționalității metodei nu este redirectată spre nici o altă porțiune de cod. În
metrica finală, acest scor parțial va avea ponderea de 0.4. Este considerată
această pondere pentru că în general informația utilă necesară înțelegerii este
aproape la același nivel cu informația utilă furnizată de variabilele locale și
atributele locale accesate.
În al treilea rând, sunt procesate variabilele locale. Pentru variabile locale sunt
procesați atât identificatorii variabilelor, numele lor cât și identificatorii tipurilor
lor, tipul declarat al variabilei. Atât pentru identificatorul numelui cât și pentru cel
al tipului este calculat scorul furnizat de claritatea identificatorului. Pentru o
variabilă locală scorul clarității sale va fi compus din 0.25 scorul tipului și 0.75
scorul numelui. Sunt aleste aceste valori pentru coeficienți deoarece în general
numele variabilei este cea care apare în mod repetat în cadrul unei metode și
poartă cea mai multă informație în cadrul procesului din interiorul metodei. Scorul
final al variabilelor locale este media aritmetică a clarității pentru fiecare variabilă
în parte. Dacă nu există variabile locale, atunci scorul este maxim, 1.0, adică
utilizatorul nu trebuie să rețină și să urmărească informații suplimentare oferite și
12 Reading Complexity – complexitate textuală, gradul de complexitate structurală a unui text
Reading Lisibility = 0.1 * claritatea identificatorului metodei + 0.4 * claritatea metodelor apelate + 0.5 * claritatea varirabilelor locale

46 5.3. Claritatea Codului
de variabile pe lângă operațiile
propriu-zise din metodă. Scorul
final pentru variabilele locale va
avea ponderea 0.5 în scorul
clarității metodei.
În final, ultimul pas constă în agregarea informației oferită de numele metodei,
operațiile externe sau interne apelate și variabilele locale. Metrica Reading
Lisibility este așadar compusă din 0.1 claritatea identificatorului metodei, 0.4
claritatea identificatorilor metodelor apelate și 0.5 claritatea variabilelor locale.
Reading Complexity este și ea la rândul ei compusă din mai multe elemente
ce influențează lizibilitatea unei porțiuni de program. În primul rând am luat în
considerare complexitatea ciclomatică (CYCLO) a metodei (vezi 2.9. Metrici). În
urma studiilor din [25] a mai multor sisteme software considerate ca având un
design bun și pe baza valorii complexității ciclomaticii medii descoperite în
limbajul Java în iPlasma [28] s-a considerat că o metodă are complexitate
ciclomatică ridicată dacă are valoarea peste 20. În cazul nostru am considerat
pragul superior, HIGH_cyclo la valoarea 15 pentru că am considerat că o metodă cu
peste 15 căi de execuție distincte posibile este suficient de greu de urmărit și
înțeles într-un timp relativ scurt de către un utilizator uman. Valoarea
complexității ciclomatice este calculată de iPlasma. Dacă valoarea complexității
ciclomatice este peste 15 atunci scorul clarității parțiale este 0.1, în caz contrar
scorul este
. Ponderea complexității
ciclomatice în scorul final este de 0.45 deoarece la citirea unei porțiuni de cod
multitudinea căilor de execuție sunt cele care crează cea mai mare dificultate în
înțelegerea logicii procesului executat.
În al doilea rând am luat în considerare numărul de metode accesate (NOAM –
number of accessed methods) ca o măsură a clarității. În procesul de înțelegere a
unei porțiuni de cod putem considera o metodă apelată din porțiunea analizată ca
un furnizor de servicii și ca o redirectare a procesului de înțelegere a
funcționalității implementate. Prin urmare, cu cât numărul de metode apelate este
mai mare cu atât cel care citește codul va avea mai multe operații secundare de
înțeles, deci codul va fi mai dificil de înțeles din prisma complexității. Dacă nu
există nici o metodă apelată atunci scorul este 1.00. Pentru celelalte cazuri am
considerat pragul superior, HIGH_noam la valoarea 20. Dacă există mai mult de 20
de metode distincte apelate atunci scorul este 0.1, în caz contrat rezultatul este
. Ponderea scorului metodelor
apelate este 0.15 în scorul final.
În al treilea rând am luat în considerare numărul de linii de cod (LOC – lines of
code) al metodei. În iPlasma [28] este considerată o metodă ca fiind lungă dacă ea
are peste 80 de linii de cod. În cazul complexității din prisma lizibilității am
Reading Complexity = 0.45 * raport complexitate ciclomatică + 0.15 * raport număr de operații apelate + 0.20 * raport număr linii de cod + 0.20 * raport număr variabile locale

47 IMPLEMENTARE
considerat pragul superior, HIGH_loc la valoarea 70.
Dacă numărul de linii de cod este mai mare de 70
atunci rezultatul clarității parțiale este 0.1, în caz
contrar valoarea este
. Ponderea acestei caracteristici în scorul
final este de 0.20.
În al patrulea rând am luat în considerare numărul de variabile locale (NOLV –
number of local variables). Ținând cont de faptul că
atunci când este vorba de procesarea codului
mintea umană poate reține un număr limitat de
entități distincte (șapte, plus sau minus doi, spune Miller în [22]) am stabilit pragul
superior, HIGH_nolv la valoarea 10. Dacă există mai mult de 10 variabile locale
distincte procesarea informației oferite de textul codului este făcută cu greutate,
prin urmare vom considera rezultatul acestei caracteristici 0.1. Pe lângă pragul
superior am definit și un prag inferior, LOW_nolv la valoarea 3. Aceasta valoare
reflectă faptul că un număr de maxim 3 variabile locale pot fi reținute și procesate
cu mare ușurință de creierul uman, prin urmare rezultatul va fi 1.0. Dacă numărul
de variabile locale se situează între cele două praguri, atunci rezultatul va fi
. Ponderea acestei caracteristici în
scorul final este de 0.20.
Ultimul pas constă din agregarea scorurilor parțiale pentru a calcula scorul
clarității metodei prin prisma complexității. Metrica Reading Complexity este
așadar compusă din 0.45 scorul complexității ciclomatice, 0.15 scorul numărului
metodelor accesate, 0.20 scorul numărului liniilor de cod și 0.20 scorul numărului
variabilelor locale. Ponderile pentru fiecare componentă au fost alese în mod
orientativ pornind de la cantitatea de informație furnizată atunci când
programatorul citește codul.
După ce am definit cele două concepte acum este foarte ușor să definim
conceptul de claritate pentru o metodă, metrică numită Reading Clarity. Pentru
că dorim să ținem cont atât de lizibilitatea codului cât și de complexitatea codului,
claritatea codului unei metode va consta în agregarea informațiilor oferite de
Reading Lisibility și Reading Complexity. Astfel rezultatul final va fi format din 0.5
Reading Lisibility și 0.5 Reading Complexity. Noua metrică astfel definită
surprinde ambele aspecte definitorii pentru claritatea codului. În Figura 5.12 sunt
surprinse toate caracteristicile care influențează claritatea codului. În capitolul
Studiu experimental vor fi prezentate câteva exemple specifice de cod și valoarea
clarității astfel calculate.
HIGH_cyclo = 15 HIGH_noam = 20 HIGH_loc = 70 HIGH_nolv = 10 LOW_nolv = 3
Tabel 5.1 – Pragurile clarității metodei

48 5.3. Claritatea Codului
Figura 5.12 – Claritatea metodelor
5.3.3. Claritatea claselor
Clasele sunt entitățile fundamentele în orice program orientat pe obiecte. În
principiu ele sunt formate din atribute și metode. Putem spune că atributele sunt
cele care rețin informația în clasă, ele sunt cele care asigură ce-ul clasei, iar
metodele sunt cele care asigură inteligența clasei, funcționalitatea ei, cum. De
aceea atunci când vorbim de claritatea unei clase trebuie să avem în vede ambele
aspecte.
Pentru construcția clarității unei clase am luat în considerare următoarele
aspecte:
o lizibilitatea metodelor
o claritatea atributelor
o numărul de linii de cod
În primul rând, a fost luată în considerare claritatea codului metodelor. Pentru
studiul a fost luată în calcul doar lizibilitatea metodelor, Reading Lisibility,
definită la capitolul anterior. În această situație metrica finală va depinde în
principal de cuvintele folosite, înțelegerea fiind influențată de sensul cuvintelor
folosite. Pentru că o clasă are mai multe metode, scorul lizibilității metodelor este
suma ponderată a lizibilității fiecărei metode, unde ponderea este numărul de linii
de cod a metodei respective raportat la numărul total de linii de cod a tuturor
metodelor. Ponderea acestei valori în rezultatul final este de 0.55.
În al doilea rând, a fost luată în considerare claritatea atributelor. Claritatea
identificatorilor depinde de claritatea numelui atributelor și claritatea tipului lor.
Rezultatul parțial pentru claritatea tipului este media aritmetică a clarității tipului
tuturor atributelor iar rezultatul parțial pentru claritatea numelui este media
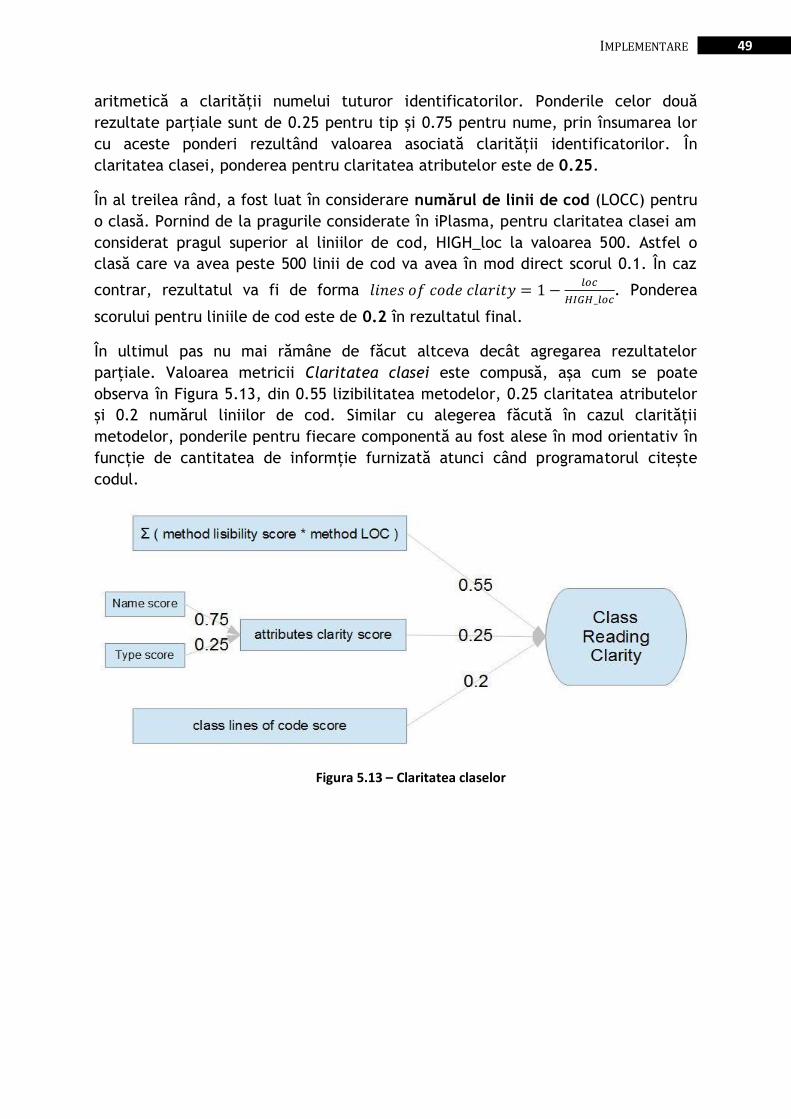
49 IMPLEMENTARE
aritmetică a clarității numelui tuturor identificatorilor. Ponderile celor două
rezultate parțiale sunt de 0.25 pentru tip și 0.75 pentru nume, prin însumarea lor
cu aceste ponderi rezultând valoarea asociată clarității identificatorilor. În
claritatea clasei, ponderea pentru claritatea atributelor este de 0.25.
În al treilea rând, a fost luat în considerare numărul de linii de cod (LOCC) pentru
o clasă. Pornind de la pragurile considerate în iPlasma, pentru claritatea clasei am
considerat pragul superior al liniilor de cod, HIGH_loc la valoarea 500. Astfel o
clasă care va avea peste 500 linii de cod va avea în mod direct scorul 0.1. În caz
contrar, rezultatul va fi de forma
. Ponderea
scorului pentru liniile de cod este de 0.2 în rezultatul final.
În ultimul pas nu mai rămâne de făcut altceva decât agregarea rezultatelor
parțiale. Valoarea metricii Claritatea clasei este compusă, așa cum se poate
observa în Figura 5.13, din 0.55 lizibilitatea metodelor, 0.25 claritatea atributelor
și 0.2 numărul liniilor de cod. Similar cu alegerea făcută în cazul clarității
metodelor, ponderile pentru fiecare componentă au fost alese în mod orientativ în
funcție de cantitatea de informție furnizată atunci când programatorul citește
codul.
Figura 5.13 – Claritatea claselor

50 6.1. WordCloud
Capitolul 6. Studiu experimental În acest capitol vor fi prezentate o parte din rezultatele obținute și concluziile
la care s-a ajuns în urma studiului efectuat pe diferite porțiuni și la diferite nivele
de cod din sistemul jHotDraw. Vizualizările și caracteristicile entităților (linii de
cod, complexitate etc.) au fost obținute cu ajutorul iPlasma iar problemele de
arhitectură au fost identificate cu ajutorul inFusion. Structura capitolului reflectă
cele trei abordări (WordCloud, Coeziune și Claritate) la diferite nivele de
componente determinate de porțiunea de cod studiat (metode, clase, pachete și
sisteme).
6.1. WordCloud
6.1.1. Metode
În continuare vor fi prezentate informațiile care pot fi extrase pornind de la
vizualizarea WordCloud aplicată pe o metodă și de asemenea vor fi enunțate și
beneficiile utilizării unei astfel de vizualizări.
Pentru primul caz analizat la nivel de metodă am luat în considerare metoda
getCappedPath din clasa BezierFigure, din pachetul org.jhotdraw.draw. Metoda
este cea mai lungă din clasă, are 46 linii de cod și are complexitatea ciclomatică
10, cea mai mare din clasa respectivă. Din punctul de vedere al liniilor de cod nu
este o metodă mare dar în urma analizei clarității ea a obținut un scor de 596.50,
penultimul scor comparat cu cel al celorlalte metode din clasă. Acest lucru ne
conduce la indiciul că această metodă s-ar încadra la categoria metodelor dificil de
înțeles.
Pornind de la vizualizarea metodei, Figura 6.1, putem extrage câteva proprietăți
ale metodei fără a fi nevoiți să citim în totalitate codul ei. NameCloud, categorie
compusă din cuvintele scrise cu verde, conține cuvintele cheie care compun
identificatorii variabilelor. Pornind de la aceste cuvinte cheie putem intui ce fel de
concepte sunt folosite de variabile. Doar citind acești identificatori putem observa
că pe lângă primele două cuvinte foarte proemiente, metoda mai are în vedere o
anumită lungime a căii și o anumită rază, detalii oferite de identificatorii length și
radius.
Class Method Loc Cyclo Clarity Complexity Lisibility 1. BezierFigure getCappedPath 46 10 596.50 385 808.09
2. AttributedFigure fromPathData 235 67 422 100 744.44

51 STUDIU EXPERIMENTAL
Figura 6.1 – getCappedPath – WordCloud-ul metodei
Dacă analizăm TypeCloud, categorie compusă din cuvintele scrise cu albastru pe al
treilea rând, putem observa care sunt tipurile predominate cu care această metodă
interacționează. Tipurile proeminente sunt bezier, path și node. Aceste cuvinte
descriu fie un tip distinct fie împreună determină identificatorul unui anumit tip.
Indiferent de situație, ne putem aștepta ca această metodă să returneze un tip
apropiat de aceste cuvinte sau să îi fie transmiși ca parametrii obiecte de tipul
respectiv. Dacă citim codul metodei vom descoperi că tipul returnat este
BezierPath, identificatori care ambii fac parte din tipurile principale identificate în
vizualizare.
În al treilea rând, MethodCloud, categorie compusă din cuvintele scrise cu roșu,
oferă informații legate de operațiile executate de metodă. Pentru că dimensiunea
cuvintelor este direct proporțională cu frecvența lor de apariție în cadrul metodei,
putem trage concluzia că metoda analizată înainte de a returna rezultatul apelează
și la alte surse pentru a construi rezultatul final deoarece cuvântul get este cel mai
proeminent cuvânt, diferența dintre el și restul fiind foarte evidentă. Următoarele
două cuvinte, control și point, au dimensiuni similare, ceea ce ne conduce la
concluzia că probabil sunt fie descriu împreună o acceeași operație, fie descriu
operații diferite dar care se apelează în tandem. Inspectând codul observă că într-
adevăr ele formează împreună identificatorul unei metode. Restul cuvintelor având
o dimensiune a fontului mult mai redusă descriu operații singulare ce intervin
probabil în diverse etape de construire a rezultatului final.
În final, DataCloud, categorie compusă din cuvintele scrise cu negru pe prima linie
din Figura 6.1, conține toate cuvintele cheie extrase din codul metodei. Se observă
faptul faptul că distribuția cuvintelor din cele trei categorii este echilibrată în
DataCloud. Astfel cuvintele cheie din fiecare categorie apar cu un font mai mare
decât restul, cele mai mari cuvinte din NameCloud, TypeCloud și MethodCloud apar
ca având o pondere ridicată și în DataCloud. De asemenea se observă faptul că cele
mai proemintente cuvinte din DataCloud se găsesc și în identificatorul metodei, în

52 6.1. WordCloud
numele metodei. Acest fapt conduce la concluzia că metoda a fost bine denumită.
În caz contrar ar exista dubii că numele metodei reflectă într-adevăr
funcționalitatea ei.
Din perspectiva clarității se observă că rezultatul este mult influențat de
complexitatea metodei. Lizibilitatea identificatorilor folosiți au condus la un scor
ridicat influențând pozitiv nota obținută pentru claritate. Dificultatea înțelegerii
metodei influențată de complexitatea ei poate fi contracarată pornind de la
vizualizarea metodei și informațiile care pot fi extrase din aceasta. Odată ce
utilizatorul uman are bine definite conceptele cheie care trebuie să le urmărească
în codul metodei, acestui îi va fi mult mai ușor să urmărească funcționalitatea de
bază și să nu se „piardă în detalii”.
În cel de-al doilea caz analizat am ales metoda fromPathData din clasa
SVGUtil din pachetul org.jhotdraw.samples.svg. Această metodă, având 235 linii de
cod, este cea mai lungă metodă din întreg sistemul. Complexitatea ciclomatică
este 67, din nou cea mai mare din întreg sistemul. Datele obținute pentru această
figură sunt cele din Figura 6.2.
Figura 6.2 – fromPathData – WordCloud-ul metodei
Spre deosebire de metoda anterioară această metodă are distribuția informațiilor
diferită. NameCloud evidențiază primul cuvânt iar restul cuvintelor sunt toate la
aceeași dimensiune. Acest fapt conduce la concluzia că identificatorii variabilelor
sunt folosiți toți în mod repetat în același număr. TypeCloud are același tipar,
primul cuvânt este mai proeminent ca restul cuvintelor și restul cuvintelor toate
sunt afișate la aceeași dimensiune. În MethodCloud se observă același tipar dar cu
unele variații. În acest caz sunt patru cuvinte care pot fi considerate cuvinte cheie,
ele au aceeși dimensiune iar fontul este mult mai mare în comparație cu celelalte
cuvinte. Diferența dintre cele două seturi de fonturi este una foarte mare ceea ce
conduce la ipoteza că în metodă operațiile descrise de cuvintele exception, io,

53 STUDIU EXPERIMENTAL
next și token sunt cele care asigură funcționalitatea de bază a metodei iar
celelalte cuvinte descriu doar operații în principal singulare în corpul metodei.
Odată agregată toată informația în DataCloud, se observă că informația extrasă
din metodele apelate domină informația extrasă din numele identificatorilor sau
din tipul datelor folosite. O altă particularitate a acestei metode este faptul că
numele ei nu conține nici un cuvânt cheie.
Pentru a intui funcționalitatea metodei se observă faptul că metoda apelează
aceleași operații în mod repetat dar probabil cu parametrii diferiți iar existența
cuvintelor path, stream, tokenizer în categoria tipurilor conduce la ipoteza că
metoda este un parser, este o metodă ce procesează date de mai multe tipuri
dintr-o sursă externă programului. Exception și io sunt cuvinte cheie care se referă
la excepții și la metode de intrare/ieșire. Ipoteza că metoda s-ar putea să fie un
parser este întărită și de complexitatea ciclomatică foarte mare, multitudinea
căilor de execuție fiind explicată de existența mai multor tipuri de date posibile.
Claritatea metodei este influențată puternic în mod negativ de complexitatea
ei, acest fapt conducând la o înțelegere dificilă a funcționalității clasei. Dar
combinând informația extrasă din vizualizare și ipoteza că metoda este un parser,
la inspectarea codului timpul de înțelegere este mult îmbunătățit pentru că
utilizatorul uman se așteaptă la o structură repetitivă, în blocuri a metodei și
presupune o anumită funcționalitate urmărind identificatorii cheie. La inspecția
codului ipoteza se dovedește a fi adevărată, metoda procesează datele primite de
la intrare iar în funcție de anumite caractere efectuează cu mici diferențe aceleași
operații.
În urma acestor exemple se pot afirma următoarele lucruri. Cuvintele cheie din
DataCloud combină cu succes informația din diferitele categorii de cuvinte folosite
pentru a prezenta cuvintele cheie ale funcționalității implemenate de metodă.
Astfel că pe lângă numele metodei aceste cuvinte cheie identificate contribuie
semnificativ la înțelegerea funcționalității metodei. De asemenea, NameCloud și
TypeCloud oferă o imagine de ansamblu asupra colaboratorilor metodei și eventual
asupra tipului returnat.
În al doilea rând, raportul dintre dimensiunea fontului cuvintelor oferă informații
legate de frecveța de apariție a lor. În primul caz studiat dimensiunea fontului a
avut o regresie liniară, iar în al doilea caz dimensiunea fontului a fost în salturi. În
primul caz a fost vorba de un flux de date liniar, nerepetitiv iar în cel de-al doilea
caz a fost vorba de operații care se repetau în funcție de anumiți parametri.
Așadar, pentru metode cu câteva zeci de linii de cod, se poate concluziona că
modelul de regresie a dimensiunii fontului cuvintelor este un indicator că o metodă
are implementată o structură decizională cu operații asemănătoare sau
implementeză un flux de operații aplicate asupra unui tip principal.

54 6.1. WordCloud
În al treilea rând, informația agregată în DataCloud și raportată la celalte categorii
oferă indicii asupra ponderii operațiilor efectuate de intermediari și operațiilor
interne. În primul caz studiat majoritatea operațiilor s-au efectuat intern iar în al
doilea caz o mare parte din operații sunt servicii efectuate de colaboratori ai
metodei. În primul caz s-a observat că DataCloud are cuvintele cheie formate din
cele trei categorii iar în cel de-al doilea caz cuvintele cheie din DataCloud fac
parte doar din MethodCloud.
În al patrulea rând, deși indicatorii clarității sunt influențați negativ de indicatorul
complexității, combinând informațiile obținute din vizualizare, ușurința de
înțelegere a metodei crește semnificativ. Acest lucru este cauzat de faptul că
odată ce un utilizator a pornit în înțelegerea metodei de la vizualizarea
WordCloud, acesta va putea urmări mult mai ușor variabilele cheie. Deși
vizualizarea nu oferă informații exacte asupra cum se face ceea ce face metoda, ea
oferă suficiente informații despre ce face o anumită metodă. Vizualizarea oferă
informații minimale chiar și despre structura codului unei anumite metode.
În concluzie, pentru o metodă vizualizarea oferă informații pornind de la trei
indicatori și anume, cuvintele cheie, raportul dimensiunilor fontului și raportul
densității de informație a celor trei categorii de cuvinte cheie. Acești indicatori
oferă sugestii despre funcționalitatea implementată de metodă, colaboratorii ei și
chiar și structura ei, iar aceste noi informații extrase la rândul lor îmbunătățesc
timpul de înțelegere al metodei când complexitatea ei este ridicată.
6.1.2. Clase
Pentru ilustrarea funcționalității oferite de vizualizarea WordCloud pentru
clase în continuare vor fi descrise clase din sistemul jHotDraw.
În primul rând a fost luată în considerare clasa XMLElement din pachetul
nanoxml. Clasa aceasta are cele mai multe linii de cod din întreg sistemul, 2450 de
linii, are un număr de 71 de metode și 15 atribute. Figura 6.3 reprezintă
rezultatele vizualizării și datele extrase pentru clasa XMLElement. Urmărind în linii
mari aceleași caracteristici ca și în cazul vizualizării pentru metode, se observă că
rata de descreștere a fontului cuvintelor este una liniară, fără salturi. NameCloud
extrage datele din atribute și astfel se pot observa cuvintele cheie ale informațiilor
memorate în clasa analizată. Cuvintele cheie fiind de fapt componente ale
identificatorilor acestea pot descrie mai multe atribute care au date similiare, cu
un înțeles de bază similar dar aplicare diferită.
Continuând cu TypeCloud, acesta este construit pornind de la informațiile oferite
de tipurile atributelor. Pe baza vizualizării se poate concluziona că o mare parte
din atribute sunt de tipul HashMap sau ArrayList sau long. De asemenea se poate
observa un diferență destul de mare între cantitatea de informație din NameCloud
și TypeCloud. Aceasta poate fi explicată în două situații. În primul caz toate
atributele au tipul declarat compus dintr-unul din cuvintele afișate în TypeCloud

55 STUDIU EXPERIMENTAL
sau o parte din atribute sunt tipuri de date elementare iar tipurile acestea sunt
cuvinte ignorate ce fac parte din „lista neagră”.
Figura 6.3 – XMLElement – WordCloud-ul clasei
MethodCloud cuprinde informațiile din metodele clasei. Pornind de la acestea se
poate obține o imagine de ansamblu a funcționalității implementate de clasa
respectivă. Cuvintele afișate nu spun cum face clasa operațiile, ci eventual oferă
indicii despre ce funcționalități implementează clasa. În cazul de față, fiind vorba
de o clasă ce implementează un parser pentru un fișier XML este de așteptat ca în
metodele ei să apară cuvinte care să descrie această funcționalitate. De aceea
această informație despre funcționalitatea clasei este indicată prin cuvintele read,
parse, xml, write, exception, cuvinte ce în majoritatea cazurilor au de a face cu
operațiile cu o sursă de date externe.
Comparând informațiile din DataCloud cu restul categoriilor, pe baza dimensiunii și
ordinii cuvintelor pot fi observate câteva caracteristici. Se observă că informațiile
din MethodCloud sunt cele care domină în mod clar informațiile din DataCloud.
Informațiile din TypeCloud și NameCloud modifică doar foarte puțin proporția unor
cuvinte cu o pondere scăzută în MethodCloud provocând astfel în DataCloud o
reordonare a cuvintelor doar în rândul celor cu pondere scăzută. De exemplu, se
observă apariția cuvintelor map, reader, hash în DataCloud. Tot pe baza raportului
de informații furnizat de diferitele categorii de cuvinte cheie se poate concluziona
că numărul metodelor este mult mai mare decât numărul atributelor, iar unele
dintre acestea implementează o funcționalitate complexă. Această ipoteză este
confirmată de faptul că numărul metodelor este de 71 față de 15, numărul
atributelor. De asemenea, clasa a fost detectată de iPlasma ca suferind de

56 6.1. WordCloud
problema de design BrainClass și că ea are de asemenea o metodă ce suferă de
boala numită BrainMethod.
Al doilea caz ilustrativ este WordCloud-ul clasei AttributeKeys. Clasa are un
număr de 7 metode, 31 de atribute și 427 linii de cod. În cazul acestei clase, în
Figura 6.4, se observă în DataCloud că informațiile oferite de metode sunt
surclasate de informațiile oferite de numele atributelor. Doar bazându-ne pe
această informație se poate concluziona că numărul atributelor este mare
comparat cu numărul metodelor.
De asemenea se observă o diferențiere puternică între mărimea font-ului pentru
primele două cuvinte cheie din TypeCloud și celelalte două cuvinte. Acest fapt
conduce la ipoteza că majoritatea atributelor sunt de tipul AttributeKey sau altă
combinație a acestor termeni.
Figura 6.4 – AttributeKeys – WordCloud-ul clasei
În concluzie, vizualizarea WordCloud pentru o clasă, alături de numele ei,
oferă o imagine de perspectivă asupra funcționalității unei clase și datele cu care
operează aceasta fără ca programatorul să fie nevoit să citească întreg codul clasei
pentru a identifica atributele, metodele și eventual a citi unele comentarii care
deseori se referă la implementarea specifică a unei funcționalități. De asemenea,
ponderea de informație furnizată DataCloud-ului de celelalte categorii de cuvinte
cheie este direct proporțională cu numărul de atribute și numărul de metode a
clasei. Prin urmare vizualizarea, pe lângă informații despre funcționalitatea clasei,
oferă informații și despre structura clasei.

57 STUDIU EXPERIMENTAL
6.1.3. Pachete
Atunci când un programator are de a face cu un sistem nou sau un sistem
mare, o problemă cu care acesta se întâlnește adeseori este faptul că rareori există
o imagine de ansamblu asupra pachetelor. De exemplu, unde se găsește clasa
AttributedFigure sau clasa Figure? Pentru că nici un pachet nu conține în numele
său cuvântul figure, rămâne la intuiția programatorului să parcurgă pachetele
pentru a găsi clasele care îl interesează. Această problemă poate fi depășită
apelând în prealabil la vizualizarea WordCloud pentru un pachet
Pachetul org.jhotdraw.draw conține 134 de clase și este cel mai mare pachet
al sistemului după numărul de clase. În Figura 6.5 se observă în NameCloud
cuvintele cheie figure și handle. Acestea sunt cuvintele cheie extrase din
atributele claselor. Ținând cont de problema enunțată anterior și cuvintele afișate
în DataCloud acest pachet este un candidat foarte viabil pentru a conține clasele
care se ocupă de conceptul figure și astfel să conțină clasele Figure și derivatele ei.
De asemenea din MethodCloud se pot observa cele mai des întâlnite
funcționalități. Pentru un pachet care se ocupă cu figuri cele mai întâlnite operații
sunt cele care se ocupă de draw, bounds, mouse etc.
Figura 6.5 – org.jhotdraw.draw – WordCloud-ul pachetului
Un alt exemplu de vizualizare a pachetului este cea pentru pachetul
org.jhotdraw.gui din Figura 6.6. Acronimul gui din numele pachetului face referire
la graphical user interface și combinând această informație cu vizualizarea
pachetului se poate concluziona că pachetul conține clasele care se ocupă cu
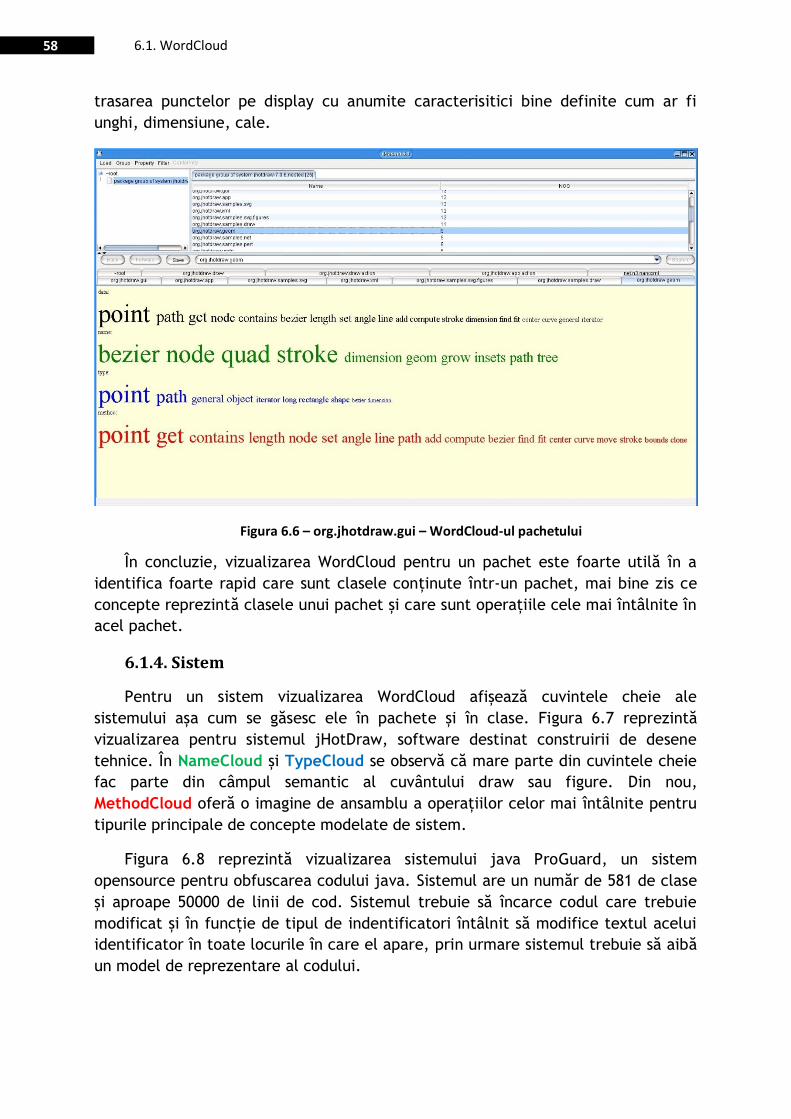
58 6.1. WordCloud
trasarea punctelor pe display cu anumite caracterisitici bine definite cum ar fi
unghi, dimensiune, cale.
Figura 6.6 – org.jhotdraw.gui – WordCloud-ul pachetului
În concluzie, vizualizarea WordCloud pentru un pachet este foarte utilă în a
identifica foarte rapid care sunt clasele conținute într-un pachet, mai bine zis ce
concepte reprezintă clasele unui pachet și care sunt operațiile cele mai întâlnite în
acel pachet.
6.1.4. Sistem
Pentru un sistem vizualizarea WordCloud afișează cuvintele cheie ale
sistemului așa cum se găsesc ele în pachete și în clase. Figura 6.7 reprezintă
vizualizarea pentru sistemul jHotDraw, software destinat construirii de desene
tehnice. În NameCloud și TypeCloud se observă că mare parte din cuvintele cheie
fac parte din câmpul semantic al cuvântului draw sau figure. Din nou,
MethodCloud oferă o imagine de ansamblu a operațiilor celor mai întâlnite pentru
tipurile principale de concepte modelate de sistem.
Figura 6.8 reprezintă vizualizarea sistemului java ProGuard, un sistem
opensource pentru obfuscarea codului java. Sistemul are un număr de 581 de clase
și aproape 50000 de linii de cod. Sistemul trebuie să încarce codul care trebuie
modificat și în funcție de tipul de indentificatori întâlnit să modifice textul acelui
identificator în toate locurile în care el apare, prin urmare sistemul trebuie să aibă
un model de reprezentare al codului.

59 STUDIU EXPERIMENTAL
Figura 6.7 – jHotDraw – WordCloud-ul sistemului
Figura 6.8 – ProGuard – WordCloud-ul sistemului
Comparând vizualizările celor două sisteme, jHotDraw și ProGuard, se observă
că vizualizarea WordCloud surprinde bine diferitele concepte în jurul cărora sunt
construite sistemele (figure, action, tool, icon vs. class, type, method,value).

60 6.2. Coeziune
6.2. Coeziune
În acest subcapitol vor fi prezentate rezultatele studiului coeziunii semantice a
sistemului jHotDraw. Sistemul are un număr de 483 de clase cu media liniilor de
cod 130 (LOC/class), media numărului de metode 10 (NOM/class) iar media
numărului de atribute 2.5 (NOA/class). Metrica paote fi rulată pe clasele sistemului
cu diferite calibrări ale constantelor de filtrare.
Setul de calibrări utilizat pentru filtre a constat în următoarele valori. Pentru
distanța minimă dintre cuvinte s-a utilizat valoarea 0.35 (minimumWordsDistance
= 0.35) iar pentru coeziunea minimă a conceptului s-a utilizat valoarea 0.3
(maximumConceptCohesion = 0.3). Distanța dintre cuvinte este un număr
normalizat cu valoarea 0.0 pentru apropiere maximă și 1.0 pentru depărtare
maximă. Acest mod de reprezentare este reflectat și în modul de reprezentare al
coeziunii conceptelor. Valorea 0.0 reprezintă coeziune maximă a conceptului iar
valoarea 1.0 reprezintă coeziunea minimă pe care o poate avea un concept. Pragul
maximumConceptCohesion reprezintă valoarea maximă din punct de vedere
numerică acceptată pentru coeziunea unui concept. Orice concept care are o
coeziune ce depășește acest prag este considerat necoeziv.
6.2.1. jHotDraw vs. ProGuard
Clasa AbstractFigure, una dintre clasele cu cea mai scăzută coeziune
semantică, în urma analizei cu inFusion a obținut de asemenea un grad de coeziune
sintactică scăzut. Clasa RectangleFigure, una dintre clasele cu o coeziune
semantică bună, în urma analizei cu inFusion a obținut și la coeziunea sintactică un
scor bun.
Sistemul jHotDraw a obținut un deficit de calitate pentru coeziunea sintactică de
5.7. Pentru aceste valori de prag coeziunea semantică a sistemului este 3.01.
Sistemul Proguard în urma analizei cu inFusion a obținut un deficit de calitate
pentru coeziune de 4.3 iar coeziunea semantică este de 2.18. Raportul acestor
valori se poate observa în Figura 6.9. În partea stângă se află sistemul jHotDraw iar
în partea dreaptă se află sistemul ProGuard. Culoarea roșie reprezintă coeziunea
sistemului din punctul de vedere al interacțiunii componentelor iar culoarea
albastră reprezintă coeziunea semantică.
Valoarea calculată de inFusion este folosită pentru a compara două sisteme între
ele. Se observă că raportul coeziunii semantice este foarte asemănător cu raportul
coeziunii sintactice calcultate de inFusion. Plecând de la această observație se
poate concluziona că metrica nou definită poate fi folosită cu succes în compararea
a două sisteme. Pentru cele două sisteme, coeziunea semantică reflectă fidel
gradul de coeziune sintactică a sistemului.
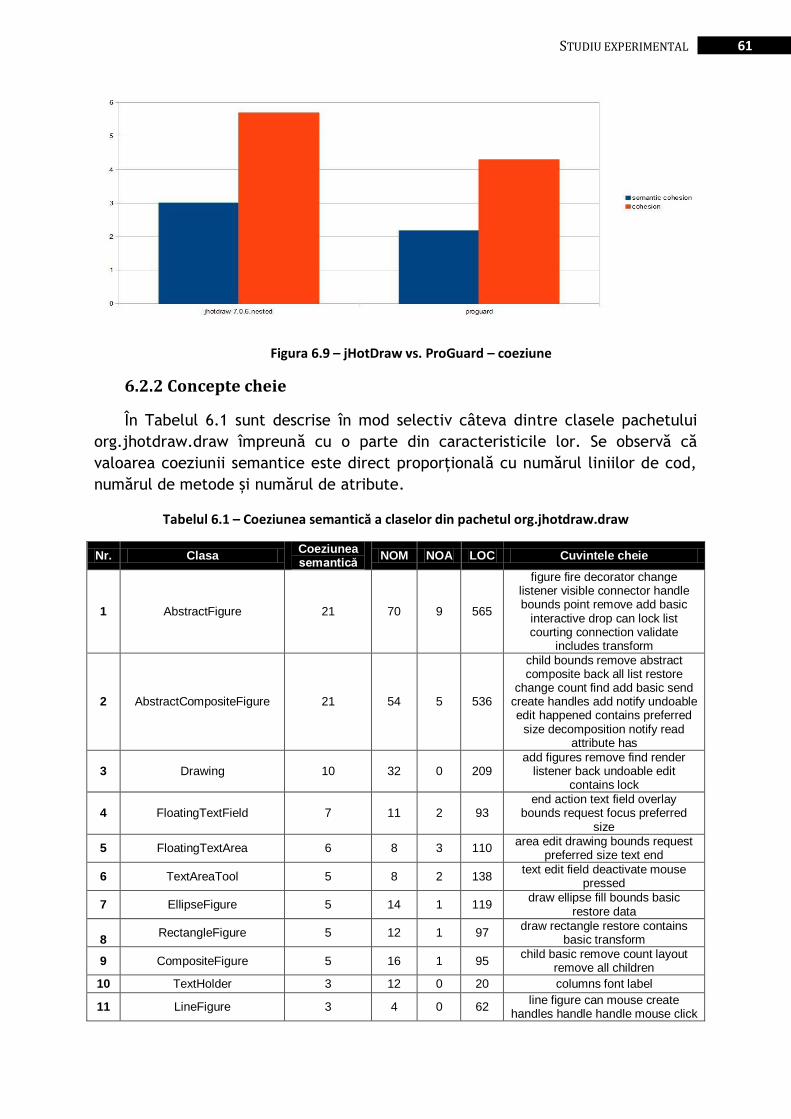
61 STUDIU EXPERIMENTAL
Figura 6.9 – jHotDraw vs. ProGuard – coeziune
6.2.2 Concepte cheie
În Tabelul 6.1 sunt descrise în mod selectiv câteva dintre clasele pachetului
org.jhotdraw.draw împreună cu o parte din caracteristicile lor. Se observă că
valoarea coeziunii semantice este direct proporțională cu numărul liniilor de cod,
numărul de metode și numărul de atribute.
Tabelul 6.1 – Coeziunea semantică a claselor din pachetul org.jhotdraw.draw
Nr. Clasa Coeziunea semantică
NOM NOA LOC Cuvintele cheie
1 AbstractFigure 21 70 9 565
figure fire decorator change listener visible connector handle bounds point remove add basic
interactive drop can lock list courting connection validate
includes transform
2 AbstractCompositeFigure 21 54 5 536
child bounds remove abstract composite back all list restore
change count find add basic send create handles add notify undoable edit happened contains preferred
size decomposition notify read attribute has
3 Drawing 10 32 0 209 add figures remove find render
listener back undoable edit contains lock
4 FloatingTextField 7 11 2 93 end action text field overlay
bounds request focus preferred size
5 FloatingTextArea 6 8 3 110 area edit drawing bounds request
preferred size text end
6 TextAreaTool 5 8 2 138 text edit field deactivate mouse
pressed
7 EllipseFigure 5 14 1 119 draw ellipse fill bounds basic
restore data
88
RectangleFigure 5 12 1 97 draw rectangle restore contains
basic transform
9 CompositeFigure 5 16 1 95 child basic remove count layout
remove all children
10 TextHolder 3 12 0 20 columns font label
11 LineFigure 3 4 0 62 line figure can mouse create
handles handle handle mouse click

62 6.2. Coeziune
În Figura 6.10 este reprezentată laticea de concepte de bază generată
pentru clasa AbstractFigure. În Figura 6.11 laticea de concepte pentru
AbstractFigure este filtrată și sunt sunt evidențiate conceptele cheie care definesc
gradul de coeziune al clasei. AbstractFigure este clasa cu coeziunea semantică cea
mai scăzută din pachet și de asemenea printre clasele cu coeziunea semantică cea
mai scăzută din întreg sistemul.
Figura 6.10 - AbstractFigure – laticea de bază a conceptelor
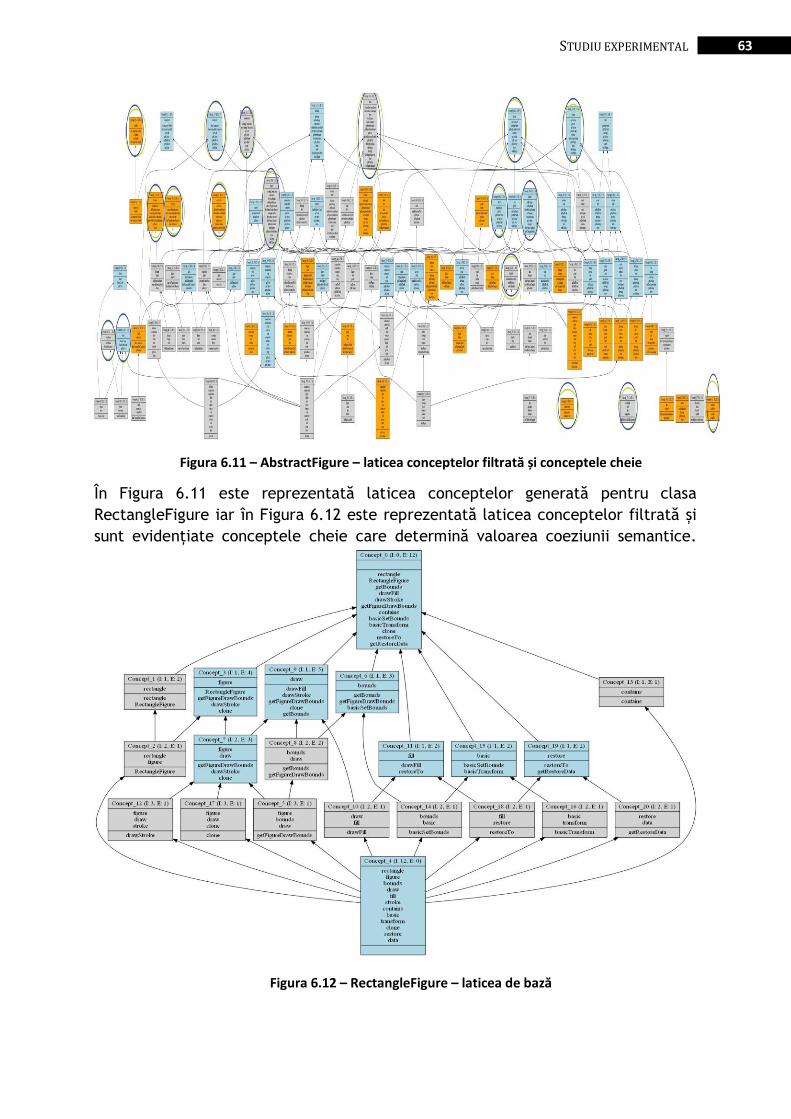
63 STUDIU EXPERIMENTAL
Figura 6.11 – AbstractFigure – laticea conceptelor filtrată și conceptele cheie
În Figura 6.11 este reprezentată laticea conceptelor generată pentru clasa
RectangleFigure iar în Figura 6.12 este reprezentată laticea conceptelor filtrată și
sunt evidențiate conceptele cheie care determină valoarea coeziunii semantice.
Figura 6.12 – RectangleFigure – laticea de bază

64 6.2. Coeziune
Figura 6.13 – RectangleFigure – laticea filtrată și conceptele cheie
Odată cu obținerea conceptelor cheie și a cuvintelor ce definesc coeziunea clasei,
sunt generate și fișierele pentru laticea conceptelor. De asemenea pentru fiecare
clasă pentru care este calculată coeziunea semantică, implementarea din iPlasma
generează un fișier în care sunt descrise conceptele și cuvintele cheie ale fiecărui
concept.
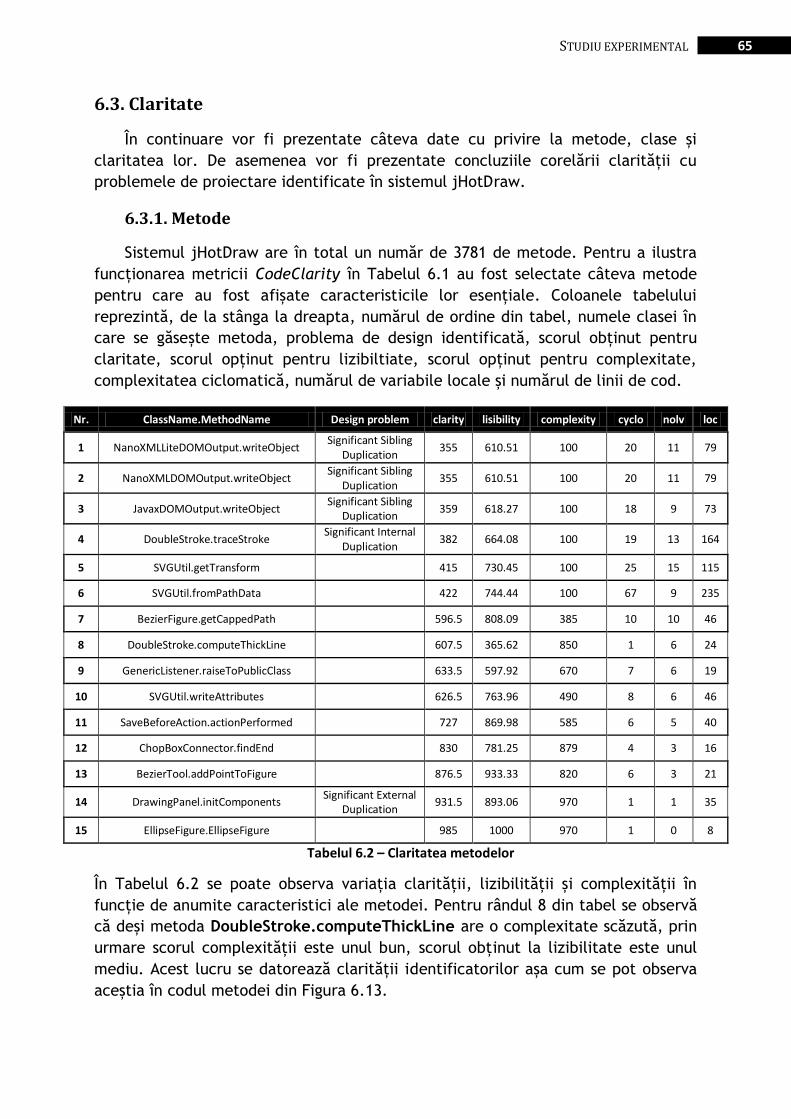
65 STUDIU EXPERIMENTAL
6.3. Claritate
În continuare vor fi prezentate câteva date cu privire la metode, clase și
claritatea lor. De asemenea vor fi prezentate concluziile corelării clarității cu
problemele de proiectare identificate în sistemul jHotDraw.
6.3.1. Metode
Sistemul jHotDraw are în total un număr de 3781 de metode. Pentru a ilustra
funcționarea metricii CodeClarity în Tabelul 6.1 au fost selectate câteva metode
pentru care au fost afișate caracteristicile lor esențiale. Coloanele tabelului
reprezintă, de la stânga la dreapta, numărul de ordine din tabel, numele clasei în
care se găsește metoda, problema de design identificată, scorul obținut pentru
claritate, scorul opținut pentru lizibiltiate, scorul opținut pentru complexitate,
complexitatea ciclomatică, numărul de variabile locale și numărul de linii de cod.
Nr. ClassName.MethodName Design problem clarity lisibility complexity cyclo nolv loc
1 NanoXMLLiteDOMOutput.writeObject Significant Sibling
Duplication 355 610.51 100 20 11 79
2 NanoXMLDOMOutput.writeObject Significant Sibling
Duplication 355 610.51 100 20 11 79
3 JavaxDOMOutput.writeObject Significant Sibling
Duplication 359 618.27 100 18 9 73
4 DoubleStroke.traceStroke Significant Internal
Duplication 382 664.08 100 19 13 164
5 SVGUtil.getTransform
415 730.45 100 25 15 115
6 SVGUtil.fromPathData
422 744.44 100 67 9 235
7 BezierFigure.getCappedPath 596.5 808.09 385 10 10 46
8 DoubleStroke.computeThickLine 607.5 365.62 850 1 6 24
9 GenericListener.raiseToPublicClass 633.5 597.92 670 7 6 19
10 SVGUtil.writeAttributes 626.5 763.96 490 8 6 46
11 SaveBeforeAction.actionPerformed 727 869.98 585 6 5 40
12 ChopBoxConnector.findEnd 830 781.25 879 4 3 16
13 BezierTool.addPointToFigure 876.5 933.33 820 6 3 21
14 DrawingPanel.initComponents Significant External
Duplication 931.5 893.06 970 1 1 35
15 EllipseFigure.EllipseFigure 985 1000 970 1 0 8
Tabelul 6.2 – Claritatea metodelor
În Tabelul 6.2 se poate observa variația clarității, lizibilității și complexității în
funcție de anumite caracteristici ale metodei. Pentru rândul 8 din tabel se observă
că deși metoda DoubleStroke.computeThickLine are o complexitate scăzută, prin
urmare scorul complexității este unul bun, scorul obținut la lizibilitate este unul
mediu. Acest lucru se datorează clarității identificatorilor așa cum se pot observa
aceștia în codul metodei din Figura 6.13.

66 6.3. Claritate
Figura 6.14 – codul metodei DoubleStroke.getCappedPath
În cazul metodei GenericListener.raiseToPublicClass, metoda din rândul 9 din
Tabelul 6.2, se observă că scorul lizibilității este foarte apropiat de cel al
complexității. Codul metodei care a dus la aceste rezultate este cel din Figura
6.14. Metoda nu are o complexitate foarte mare dar din cauza identificatorilor, în
mod special al variabilelor locale declarate prin abrevieri, claritatea ei poate avea
de suferit.
Figura 6.15 – codul metodei GenericListener.raiseToPublicClass
67 STUDIU EXPERIMENTAL
În continuare vor fi prezentate rezultatele corelării clarității, lizibilității și
complexității metodelor cu problemele arhitecturale ale metodelor identificate cu
inFusion. Din cele 3781 de metode au fost identificate 70 de metode care au cel
puțin o problemă de design. Relația dintre claritate, lizibilitate și complexitate a
fost afișată sub forma unui grafic. Pe linia orizontală a fost afișat scorul clarității,
respectiv lizibilității sau complexității pe o scară de la 0 la 1000. Pe axa verticală a
fost reprezentat numărul de probleme pentru o metodă, pe o scară de la 0 la 4.5
pentru metodele analizate.
Figura 6.16 – Distribuția problemelor metodelor în funcție de lizibilitate
În Figura 6.15 este reprezentată distribuția problemelor de structură identificate în
funcție de scorul obținut la capitolul lizibilitate (Reading Lisibility), în Figura 6.16
este reprezentată distribuția problemelor în funcție de scorul obținut la capitolul
complexitate (Reading Complexity) iar în Figura 6.17 este reprezentată distribuția
problemelor în funcție de claritatea metodelor (Reading Clarity).
În Figura 6.15 se observă că toate metodele cu probleme raportate la conceptul de
lizibilitate se găsesc în intervalul 500-1000. În Figura 6.16 problemele sunt
raportate la complexitate și se observă că metodele cu probleme au o distribuție
relativ uniformă pe tot intervalul 0-1000. În Figura 6.17 problemele sunt raportate
la claritate, media scorului lizibilității și complexității, și se observă că metodele
cu probleme din nou au o distribuție uniformă în intervalul 300-1000.
În urma analizei celor peste 3000 de metode ale sistemului jHotDraw, s-a
observat că metodele cu probleme au o distribuție relativ uniformă pe întreg
spectrul clarității, de la un scor scăzut (250-300) până la un scor ridicat (900-1000).
În concluzie, pe baza datelor analizate nu se poate emite concluzia că există o
corelație între claritatea unei metode și problemele ei arhitecturale. Faptul că o
metodă este scrisă într-un mod cât mai lizibil și cât mai ușor de înțeles nu oferă
garanție asupra faptului că acea metodă nu va suferi de o anumită problemă de
design.
68 6.3. Claritate
Figura 6.17 – Distribuția problemelor metodelor în funcție de complexitate
Figura 6.18 – Distribuția problemelor metodelor în funcție de claritate
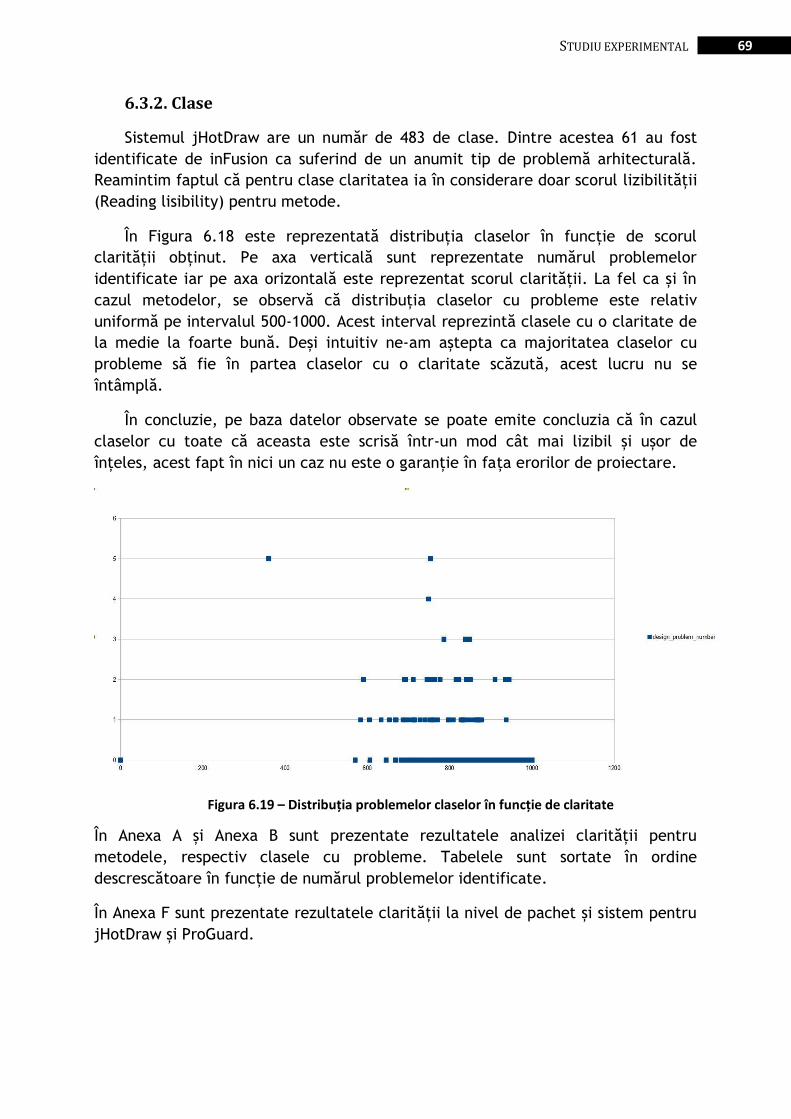
69 STUDIU EXPERIMENTAL
6.3.2. Clase
Sistemul jHotDraw are un număr de 483 de clase. Dintre acestea 61 au fost
identificate de inFusion ca suferind de un anumit tip de problemă arhitecturală.
Reamintim faptul că pentru clase claritatea ia în considerare doar scorul lizibilității
(Reading lisibility) pentru metode.
În Figura 6.18 este reprezentată distribuția claselor în funcție de scorul
clarității obținut. Pe axa verticală sunt reprezentate numărul problemelor
identificate iar pe axa orizontală este reprezentat scorul clarității. La fel ca și în
cazul metodelor, se observă că distribuția claselor cu probleme este relativ
uniformă pe intervalul 500-1000. Acest interval reprezintă clasele cu o claritate de
la medie la foarte bună. Deși intuitiv ne-am aștepta ca majoritatea claselor cu
probleme să fie în partea claselor cu o claritate scăzută, acest lucru nu se
întâmplă.
În concluzie, pe baza datelor observate se poate emite concluzia că în cazul
claselor cu toate că aceasta este scrisă într-un mod cât mai lizibil și ușor de
înțeles, acest fapt în nici un caz nu este o garanție în fața erorilor de proiectare.
Figura 6.19 – Distribuția problemelor claselor în funcție de claritate
În Anexa A și Anexa B sunt prezentate rezultatele analizei clarității pentru
metodele, respectiv clasele cu probleme. Tabelele sunt sortate în ordine
descrescătoare în funcție de numărul problemelor identificate.
În Anexa F sunt prezentate rezultatele clarității la nivel de pachet și sistem pentru
jHotDraw și ProGuard.

70 7.1. WordCloud
Capitolul 7. Concluzii În urma analizei identificatorilor unui sistem software orientat pe obiecte pot
fi enunțate următoarele concluzii.
7.1. WordCloud
Sumarizând informațiile colectate în urma utilizării vizualizării WordCloud
pentru metode se pot afirma următoarele lucruri. Pe baza cuvintelor extrase sunt
identificate conceptele cheie cu care operează metoda analizată. În al doilea rând,
în funcție de informațiile extrase din TypeCloud și MethodCloud pot fi identificați
foarte ușor posibilii colaboratori ai metodei și dacă metoda procesează datele
intern sau apelează la alți furnizori. În al treilea rând, pe baza distribuției de
informație între categorii și diferenței de dimensiune între cuvintele cheie a
fiecărei categorii pot fi făcute anumite presupuneri legate de structura codului. În
al patrulea rând, cuvintele cheie din DataCloud pot fi utilizate pentru a identifica
eventualele metode care au o denumire ce nu reflectă funcționalitatea metodei. În
al cincilea rând, pentru metodele care au un grad de claritate scăzut, identificarea
conceptelor cheie și o eventuală ipoteză legată de structura codului se dovedesc a
fi foarte utile în a îmbunătăți timpul de înțelegere a metodei atunci când este
parcursă linie cu line de către un utilizator uman.
Generalizând concluziile pentru toate nivele de vizualizare, utilizând vizualizarea
WordCloud construită pe baza cuvintelor folosite în identificatori și a frecvenței cu
care ele sunt folosite pot fi extrase informații legate de funcționalitatea,
colaboratorii și structura unei porțiuni de cod. De asemenea, vizualizarea
WordCloud aduce o îmbunătățire a timpului de înțelegere a unui cod scris ilizibil
sau complex. Îmbunătățind capacitatea de înțelegere a codului și reducând timpul
necesar înțelegerii crește eficiența procesului de mentenață, deci crește calitatea.
În concluzie, utilizarea WordCloud aduce un plus de calitate sistemelor software.
7.2. Coeziune semantică
În urma rezultatelor obținute metrica nou definită pentru coeziunea semantică
poate fi utilizată cu succes ca o alternativă pentru compararea a două sisteme
similare. De asemenea în procesul de calculare a valorii metricii sunt obținute și
cuvintele cheie care dau coeziune clasei respective. Acestea pot fi folosite ca
perspectivă asupra funcționalității implementate de metodele clasei respective.
7.3. Claritate
Metrica definită cu numele CodeClarity reușește să evalueze în mod pertinent
claritatea unei metode sau unei clase. Aceasta poate fi foarte utilă atunci când se
dorește obținerea unor informații inițiale într-un mod rapid despre cât de ușor

71 CONCLUZII
poate fi înțeleasă de către un programator o anumită porțiune de cod, o metodă
sau o clasă.
Aceste informații pot fi agregate și astfel poate fi construită o medie a
clarității pentru un întreg sistem. O astfel de informație poate fi utilă de exemplu
când un programator are de ales între utilizarea a două biblioteci similare, cu
funcționalități diferite. Întrebarea la care trebuie să răspundă este: care dintre ele
va fi cea mai ușor de folosit? Comparând valorile clarității obținute pentru cele
două sisteme poate fi o modalitate de a decide între cele două. Sistemul cu cel mai
înalt grad de claritate este foarte probabil să fie cel mai ușor de folosit pentru că
programatorul va putea înțelege și utiliza sistemul într-un timp mai scurt decât în
cazul celuilalt sistem.
Claritatea identificatorilor determină claritatea metodelor și claritatea
claselor. În urma studiului ce a investigat existența unei posibile relații între
claritate și problemele de design existente concluzia la care s-a ajuns este că
problemele de design nu depind în mod direct claritatea codului. Mai degrabă
claritatea codului este rezultatul unui design bun și nu invers. Chiar dacă
identificatorii nu sunt o cauză directă a unei carențe de design, cu siguranță ei
contribuie la o asemenea situație deoarece programatorul poate fi indus în eroare
de informațiile eronate transmise de identificatori.
Concluzia analizei semanticii identificatorilor și calității sistemelor software
orientate pe obiecte este că identificatorii nu sunt doar simple convenții ci ei fac
parte și contribuie semnificativ la o rată cât mai crescută de mentenabilitate
contribuind astfel la calitatea sistemului.

72 8.1. WordCloud
Capitolul 8. Dezvoltări ulterioare În acest capitolu sunt prezentate direcții viitoare de cercetare și îmbunătățiri
care pot fi aduse atât conceptelor prezentate cât și tool-urilor disponibilie
programatorilor.
8.1. WordCloud
O primă direcție posibilă este implementarea unei funcționalități în editoarele
de cod ce verifică în timp real că identificatorul clasei sau metodei conține cuvinte
cheie din codul delimitat de acea clasă sau metodă. De asemenea, pe lângă
verificarea aceasta pot fi sugerate tot în timp real nume alternative ce reflectă cât
mai bine funcționalitatea implementată.
O altă direcție de dezvoltare este ca următoarea versiune de vizualizare pentru
metode pe lângă cuvintele cheie să ofere în mod textual și unele indicii cu privire
la o potențială structură a codului.
În al treilea rând, pentru vizualizarea pachetelor o facilitate foarte utilă ar fi
ca după un scurt interval în care mouse-ul programatorului este deasupra unui
pachet, să fie afișată vizualizarea WordCloud ca un pop-up image. O asemenea
facilitate poate fi implementată cu ușurință ca un plug-in pentru Eclipse sau
inFusion.
8.2. Coeziunea semantică
În primul rând, ca direcție de cercetare poate fi îmbunătățirea algoritmului de
filtrare și selecție a conceptelor din latice.
În al doilea rând, este necesară compararea coeziunii semantice și a coeziunii
arhitecturale între mai multe sisteme similare și investigării gradului de precizie a
coeziunii semantice.
O a treia direcție de cercetare este studiul coeziunii semanticii și relația ei cu
problemele arhitecturale ale claselor unui sistem.
8.3. Claritatea Codului
În programarea orientată pe obiecte există deja câteva convenții pentru
construirea numelor identificatorilor. O problemă importantă cu privire la numele
identificatorilor este alegerea cuvintele folosite în construirea identificatorilor. În
programele orientate pe obiecte o regulă de bază este folosirea substantivelor
pentru numele de clasă și perechilor verb-substantiv (sau doar un verb, dacă
substantivul este numele clasei) pentru numele methodei [20]. Astfel o primă
direcție de dezvoltare este ca în viitor calcularea scorului clarității să țină cont și
de convențiile părților de vorbire utilizate în construirea identificatorilor. Această

73 DEZVOLTĂRI ULTERIOARE
îmbunătățire se poate face tot cu ajutorul bibliotecii RitaWordnet care oferă
suport și pentru părțile de vorbire a cuvintelor.
Buse and Wimer [1] prezintă mai multe posibile utilizări pentru o metrică automată
a lizibilității. O asemenea metrică ar putea ajuta dezvoltatorii să scrie software
mai lizibil prin identificare rapidă a unui cod ce are un scor scăzut. Poate ajuta
managerii de proiect în monitorizarea și menținerea lizibilității. Poate servi ca o
cerință pentru validare. Poate asista inspecțiile de cod prin canalizarea efortului
spre părți de program care ar necesita îmbunătățire.
O altă posibilă direcție de dezvoltare este utilizarea metricii clarității ca
punct de plecare pentru o strategie de detecție ceva identifică porțiunile de cod
scrise într-un mod ilizibil și în același timp oferă sugestii programatorului pentru
îmbunătățirea ei.

74
Capitolul 9. Bibliografie [1] Raymond P.L. Buse and Westley R. Weimer, „A Metric for Software Readability”, ISSTA '08
Proceedings of the 2008 international symposium on Software testing and analysis, pg. 121-130 [Online 17.05.2012: http://dl.acm.org/citation.cfm?id=1390647].
[2] Dr. Chong Ho Yu, „Writing Efficient SAS Codes”, Arizona State University 2012 [Online 17.05.2012: http://www.creative-wisdom.com/computer/sas/efficient.html]
[3] K. Aggarwal, Y. Singh, and J. K. Chhabra, „An integrated measure of software maintainability”, Reliability and Maintainability Symposium, 2002, Proceedings. Annual,
pages 235-241, September 2002.
[4] Robert L. Glass, „Software Conflict 2.0: The Art and Science of Software Engineering”, developer.* Books (March 10, 2006), pg.73, ISBN-10: 0977213307, ISBN-13: 978-
0977213306 [Online 17.05.2012: http://www.codinghorror.com/blog/2006/06/the-noble-art-
of-maintenance-programming.html]
[5] B. Boehm and V. R. Basili, „Software defect reduction top 10 list”, Computer, 34(1):135-137,
2001.
[6] Jeff Atwood, „When Understanding means Rewriting” [Online 17.05.2012:
http://www.codinghorror.com/blog/2006/09/when-understanding-means-rewriting.html]
[7] Peter Hallam, „What Do Programmers Really Do Anyway?” [Online 17.05.2012:
http://blogs.msdn.com/b/peterhal/archive/2006/01/04/509302.aspx ]
[8] Jeff Atwood, „The Noble Art of Maintenance Programming”, [Online 17.05.2012:
http://www.codinghorror.com/blog/2006/06/the-noble-art-of-maintenance-programming.html]
[9] Martin J Fowler, „Refactoring: Improving the Design of Existing Code”, Addison-Wesley
Professional; 1 edition (July 8, 1999)
[10] E. W. Dijkstra, „A Discipline of Programming”, Prentice Hall PTR, 1976.
[11] J. L. Elsho and M. Marcotty, „Improving computer program readability to aid modification”, Commun, ACM, 25(8):512-521, 1982.
[12] Ashod Nakashian, „Why Code Readability Matters”, [Online 17.05.2012
http://blog.ashodnakashian.com/2011/03/code-readability]
[13] J. Frederick P. Brooks, „No silver bullet: essence and accidents of software engineering”,
Computer, 20(4):10-19, 1987.
[14] Diomidis Spinellis, „Reading, Writing, and Code”, Queue - Power Management, Volume 1
Issue 7, 10-01-2003, pg 84 [Online 18.05.2012 http://queue.acm.org/detail.cfm?searchterm=code+readability&id=957782]
[15] R. F. Flesch, „A new readability yardstick”, Journal of Applied Psychology, 32:221-233, 1948.
[16] R. Gunning, „The Technique of Clear Writing”, McGraw-Hill International Book Co, New
York, 1952.
[17] G. H. McLaughlin, „Smog grading - a new readability”, Journal of Reading, May 1969.

75 BIBLIOGRAFIE
[18] J. P. Kinciad and E. A. Smith, „Derivation and validation of the automated readability index
for use with technical materials”, Human Factors, 12:457-464,1970.
[19] N. J. Haneef, „Software documentation and readability: a proposed process improvement”,
SIGSOFT Softw. Eng. Notes, 23(3):75-77, 1998.
[20] Diomidis Spinellis, „Code Quality: The Open Source Perspective”, Addison Wesley Professional, April 03, 2006, ISBN-10: 0-321-16607-8
[21] ISO/IEC 9126 Software engineering — Product quality [Online 28.05.2012 http://webstore.iec.ch/preview/info_isoiec9126-1%7Bed1.0%7Den.pdf]
[22] George A. Miller, „The magical number seven, plus or minus two: Some limits on our capacity for processing information”, Psychological Review, 63:81–97, 1956 [Online
28.05.2012 http://psychclassics.yorku.ca/Miller/ ]
[23] Martin Halvey and Mark T. Keane, „An Assessment of Tag Presentation Techniques”, poster
presentation at WWW 2007, 2007 [Online 29.05.2012
http://en.wikipedia.org/wiki/Tag_cloud#cite_note-0]
[24] OpenCloud - http://opencloud.mcavallo.org/ [Online 29.05.2012]
[25] Radu Marinescu, Michele Lanza, „Object Oriented Metrics in Practice”, Springer 2006
[26] J. C. Knight and E. A. Myers, „Phased inspections and their implementation”, SIGSOFT
Softw. Eng. Notes, 16(3):29-35, 1991.
[27] RitaWordNet - http://www.rednoise.org/rita/wordnet/documentation/ [Online 31.05.2012]
[28] iPlasma - http://loose.upt.ro/reengineering/research/iplasma [Online 31.05.2012]
[29] J. Lionel E. Deimel, „The uses of program reading”, SIGCSE Bull., 17(2):5-14, 1985.
[30] WordNet - http://wordnet.princeton.edu/ [Online 31.05.2012]
[31] M M Lehman, „Laws of Software Evolution Revisited”, 1997.
[32] T.J. McCabe, „A measure of complexity”, IEEE Transactions on Software Engineering,
2(4):308–320, December 1976.
[33] GraphViz - http://www.graphviz.org/ [Online 13.06.2012]
[34] N. Nagappan and T. Ball, „Use of relative code churn measures to predict system defect
density”, in ICSE '05: Proceedings of the 27th international conference on Software
engineering, pg. 284-292, 2005.
[35] C. V. Ramamoorthy and W.-T. Tsai, „Advances in software engineering”, Computer,
29(10):47-58, 1996.
[36] D. R. Raymond, „Reading source code”, in CASCON '91: Proceedings of the 1991 conference
of the Centre for Advanced Studies on Collaborative research, pg. 3-16. IBM Press, 1991.
[37] P. A. Relf, „Tool assisted identifier naming for improved software readability: an empirical
study”, Empirical Software Engineering, 2005. 2005 International Symposium on, November
2005.
[38] S. Rugaber, „The use of domain knowledge in program understanding”, Ann. Softw. Eng.,
9(1-4):143-192, 2000.

76
[39] jHotDraw - http://www.jhotdraw.org/ [Online 09.06.2012]
[40] jHotDraw – sursele http://sourceforge.net/projects/jhotdraw/ [Online 09.06.2012]
[41] Wolff, Karl Erich, „A first course in Formal Concept Analysis", în F. Faulbaum, StatSoft '93,
Gustav Fischer Verlag (1994).
[42] Rudolf Wille, „Restructuring lattice theory: An approach based on hierarchies of concepts”,
retipărit în: ICFCA '09: Proceedings of the 7th International Conference on Formal Concept
Analysis, Berlin, Heidelberg, 2009.
[43] eRCA - http://code.google.com/p/erca/ [Online 13.06.2012]
[44] E. J. Weyuker, „Evaluating software complexity measures”, IEEE Trans. Softw. Eng.,
4(9):1357-1365, 1988.
[45] inFusion - http://www.intooitus.com/products/infusion [Online 14.06.2012]
[46] Steve McConnell, „Code Complete”, Microsoft Press, 2nd ed.
[47] ProGuard - http://proguard.sourceforge.net/ [Online 15.06.2012]
[48] Rada, R., Mili, H., Bicknell, E., Bletner, M., „Development and application of a metric on semantic nets”, IEEE Transactions on Systems, Man and Cybernetics 19(1) (1989) 17 – 30.
[49] Sussna, M., „Word sense disambiguation for free-text indexing using a massive se-mantic network”, CIKM ’93: Proceedings of the second international conference on Information and
knowledge management, New York, NY, USA, ACM (1993), 67–74.
[50] Resnik, P., „Using information content to evaluate semantic similarity in a taxon-omy”,
Proceedings of the 14th International Joint Conference on Artificial Intelli-gence (August
1995) 448 – 453.
[51] Ivan Marsic, „Software Engineering”, Rutgers University, School of Engineering [Online
16.06.2012 http://www.ece.rutgers.edu/~marsic/books/SE/ ]
[52] Haining Yao, Anthony Mark Orme, Letha Etzkorn, „Cohesion Metrics for Ontology Design
and Application”, Journal of Computer Science 1(1): 107-113, 2005, ISSN 1549-3636,
Science Publications, 2005
[53] Cara Stein, Letha Etzokorn, Sampson Gholston, Phillip Farrington, Julie Fortune, „A
Knowledge-Based Cohesion Metric for Object-Oriented Software”, Federal University of Lavras, Department of Computer Science, Brazil [Online 16.06.2012
http://www.dcc.ufla.br/infocomp/artigos/v5.4/art06.pdf ]
77 ANEXA A. CLARITATEA METODELOR
Anexa A. Claritatea Metodelor

78
Anexa B. Claritatea Claselor

79 ANEXA C. JHOTDRAW SYSTEM OVERVIEW
Anexa C. jHotDraw System Overview

80
Anexa D. ProGuard System Overview

81 ANEXA E. JHOTDRAW VS. PROGUARD – COEZIUNEA SEMANTICĂ A PACHETELOR
Anexa E. jHotDraw vs. ProGuard – coeziunea semantică a pachetelor
jHotDraw 3.01 483 ProGuard 2.18 655
package
semantic cohesion
no. classes
package semantic cohesion
no. classes
1 nanoxml 11 2 proguard.optimize.evaluation 4.15 13
2 org.jhotdraw.app 6.15 13 proguard.retrace 4 3
3 org.jhotdraw.gui.datatransfer 5 1 proguard.classfile.io 3.8 10
4 org.jhotdraw.xml 5 12 proguard.classfile.util 3.5 18
5 org.jhotdraw.draw 4.36 134 proguard.classfile 3.2 15
6 org.jhotdraw.geom 3.73 9 proguard.classfile.editor 2.94 53
7 net.n3.nanoxml 3.62 24 proguard 2.87 31
8 org.jhotdraw.samples.net.figures 3 1 proguard.optimize.peephole 2.83 24
9 org.jhotdraw.samples.pert.figures 3 5 proguard.preverify 2.75 4
10 org.jhotdraw.samples.svg 2.92 13 proguard.shrink 2.61 18
11 org.jhotdraw.samples.net 2.89 9 proguard.classfile.attribute.preverification.visitor 2.5 2
12 org.jhotdraw.samples.pert 2.78 9 proguard.optimize 2.44 18
13 org.jhotdraw.samples.draw 2.55 11 proguard.evaluation 2.18 11
14 org.jhotdraw.draw.action 2.22 45 proguard.classfile.attribute.annotation 2.07 14
15 org.jhotdraw.samples.svg.figures 2.17 12 proguard.evaluation.value 2 46
16 org.jhotdraw.io 2 1 proguard.gui 1.97 30
17 org.jhotdraw.gui.event 2 2 proguard.optimize.info 1.93 30
18 org.jhotdraw.undo 2 6 proguard.classfile.attribute 1.91 22
19 org.jhotdraw.app.action 1.82 37 proguard.ant 1.88 8
20 org.jhotdraw.util.prefs 1.6 5 proguard.obfuscate 1.86 28
21 org.jhotdraw.gui 1.54 13 proguard.classfile.attribute.preverification 1.84 19
22 org.jhotdraw.samples.svg.action 1.5 2 proguard.classfile.visitor 1.83 59
23 org.jhotdraw.util 1.43 6 proguard.classfile.instruction 1.82 11
24 org.jhotdraw.beans 1 1 proguard.classfile.instruction.visitor 1.75 4
25
proguard.classfile.constant 1.69 16
26
proguard.classfile.attribute.visitor 1.69 16
27
proguard.classfile.constant.visitor 1.67 6
28
proguard.gui.splash 1.55 38
29
proguard.util 1.41 17
30
proguard.io 1.21 33
31
proguard.classfile.attribute.annotation.visitor 1.17 6
32
proguard.wtk 1 1
average 3.14 15.54 average 2.25 19.5
82
Anexa F. jHotDraw vs. ProGuard – claritate
jhotdraw-7.0.6 818.38 483 ProGuard 870.28 655
package clarity no.
classes package clarity
no. classes
org.jhotdraw.gui.event 975.26 2 proguard.classfile.attribute.preverification.vis
itor 997.82 2
org.jhotdraw.beans 930.6 1 proguard.classfile.attribute.annotation.visitor 979.89 6
org.jhotdraw.samples.svg.figures
912.27 12 proguard.classfile.constant.visitor 957.69 6
org.jhotdraw.util 907.02 6 proguard.io 946.97 33
org.jhotdraw.gui 904.37 13 proguard.classfile.attribute.visitor 939.9 16
org.jhotdraw.draw 899.72 134 proguard.classfile.visitor 939.83 59
org.jhotdraw.undo 896.01 6 proguard.util 938.17 17
org.jhotdraw.draw.action 889.95 45 proguard.classfile.instruction.visitor 933.6 4
org.jhotdraw.util.prefs 889.54 5 proguard.classfile.attribute.preverification 924.32 19
org.jhotdraw.samples.pert.figures
876.62 5 proguard.wtk 921.65 1
org.jhotdraw.samples.net.figures
869.18 1 proguard.optimize.info 920.36 30
org.jhotdraw.app 865.91 13 proguard.obfuscate 919.89 28
org.jhotdraw.io 856.12 1 proguard.classfile.attribute.annotation 915.07 14
org.jhotdraw.app.action 841.87 37 proguard.gui.splash 913.85 38
org.jhotdraw.xml 833.66 12 proguard.optimize 898.85 18
org.jhotdraw.samples.net 823.95 9 proguard.classfile 897.44 15
org.jhotdraw.samples.pert 822.83 9 proguard.evaluation.value 895.78 46
org.jhotdraw.samples.draw 819.69 11 proguard.retrace 893.53 3
net.n3.nanoxml 812.88 24 proguard.classfile.constant 888.81 16
org.jhotdraw.samples.svg 798.4 13 proguard.ant 888.57 8
org.jhotdraw.gui.datatransfer 775.39 1 proguard.shrink 884.93 18
org.jhotdraw.samples.svg.action
770.61 2 proguard.classfile.attribute 884.49 22
org.jhotdraw.geom 769.23 9 proguard 876.99 31
nanoxml 718.4 2 proguard.gui 873.31 30
proguard.evaluation 872.93 11
proguard.classfile.editor 866.72 53
proguard.optimize.peephole 852.9 24
proguard.optimize.evaluation 844.52 13
proguard.classfile.io 843.04 10
proguard.classfile.util 829.52 18
proguard.classfile.instruction 826.86 11
proguard.preverify 751.13 4
average 852.47 15.54 average 897.47 19.5


















