
Un motor eficient de căutare în e-commerce · 2018-06-29 · 2 Rezumat / Abstract Rezumat în...
49
Ministerul Educației Naționale Universitatea „Ovidius” din Constanța Facultatea de Matematică și Informatică Master – Modelare și Tehnologii Informatice Un motor eficient de căutare în e-commerce Lucrare de disertație Coordonator științific: Prof. dr. Popa Constantin Absolvent: Breda Olivian-Claudiu Constanța 2018
Transcript of Un motor eficient de căutare în e-commerce · 2018-06-29 · 2 Rezumat / Abstract Rezumat în...

Ministerul Educației Naționale
Universitatea „Ovidius” din Constanța
Facultatea de Matematică și Informatică
Master – Modelare și Tehnologii Informatice
Un motor eficient de căutare în e-commerce
Lucrare de disertație
Coordonator științific: Prof. dr. Popa Constantin
Absolvent: Breda Olivian-Claudiu
Constanța 2018

2
Rezumat / Abstract Rezumat în limba română: lucrarea curentă are ca temă principală motoarele de
căutare pentru magazine online. Ea e formată dintr-o aplicație practică, care poate
prezice termeni de căutare introduși de utilizatorul programului în mod parțial eronat,
și are și facilitatea de a sorta rezultatele obținute – o listă de laptopuri. De asemenea,
există o parte teoretică, ce își propune să prezinte perspective asupra motoarelor de
căutare, trecând printr-un istoric al lor, prezentând modalitatea de funcționare a unui
motor de căutare, arătând niște limitări ale motoarelor de căutare și aspecte despre
viitorul motoarelor de căutare. În lucrarea teoretică este descrisă și soluția tehnică,
care au fost scopul și obiectivul de la care am pornit, descrierea algoritmului propus.
Domeniu principal: motoarele de căutare pentru magazine online.
Domenii adiacente: e-commerce (comerț electronic), programare C++, algoritmi,
inteligență artificială (artificial intelligence), optimizare pentru motoarele de căutare
(SEO, search engine optimization), machine learning (învățare automatizată).
Tipul lucrării: cercetare.
English language abstract: the current paper has as its main subject search
engines for online stores. The paper consits firstly of a piece of software, which can
correct partially incorrect search terms inserted by the user of the program, and it can
also sort the final results – a list of laptops. There is also a theoretical paper, which
aims to present some perspectives on search engines, going through historical data,
presenting the functioning of a search engine, showing limitations of search engines
and aspects on the future of search engines. In the theoretical paper the technical
solution is also described, what were the aim and objective it started from, and the
description of the proposed algorithm.
Main field: search engines for online stores.
Other fields: e-commerce, C++ programming, algorithms, artificial intelligence,
search engine optimization (SEO), machine learning.
Type of work: research.

3
Cuprins
Rezumat / Abstract ...................................................................................................... 2
Lista figurilor ................................................................................................................ 4
Lista tabelelor .............................................................................................................. 4
1. Introducere .............................................................................................................. 5
2. Istoric și motivație .................................................................................................... 9
2.1 Istoric al căutării informației ................................................................................ 9
2.2 Modalitatea de funcționare a unui motor de căutare ........................................ 17
2.3 Evaluarea eficienței unui motor de căutare ...................................................... 19
2.4 Starea actuală a domeniului ............................................................................. 21
2.5 Limitările unui motor de căutare generalist ...................................................... 25
2.6 Soluții potențiale pentru paginile de rezultate căutări fără niciun rezultat ......... 27
2.7 Viitorul motoarelor de căutare ale magazinelor online ..................................... 28
3. Soluția propusă ..................................................................................................... 31
3.1 Scop și obiective .............................................................................................. 31
3.2 Descrierea algoritmului .................................................................................... 31
3.3 Utilitatea metodei ............................................................................................. 32
3.4 Analiza implementării algoritmului .................................................................... 33
3.5 Posibilități de extindere a algoritmului .............................................................. 36
4. Concluzii ................................................................................................................ 40
Bibliografie................................................................................................................. 42
Anexa 1 – măsurarea complexității codului ............................................................... 45
Anexa 2 – graficul funcțiilor tabelului ......................................................................... 48

4
Lista figurilor
Figura 2.1.1 Graf direcționat, reprezentând o serie de șase pagini (Langville și
Meyer, 2006)..............................................................................................................11
Figura 2.1.2 Graf pentru o rețea de 4 elemente (Langville și Meyer, 2006)...............13
Figura 2.1.3 Cota de piață a căutărilor web, februarie 2018, pentru piața din SUA
(date din partea companiei Jumpshot).......................................................................16
Figura 2.2.1: Unde își încep consumatorii din SUA căutările de produse în online
(Keyes, 2017).............................................................................................................18
Figura 2.4.1 Analiza listei de produse a magazinelor online (Baymard.com, 2015)..24
Figura 3.4.1 Exemplu pentru numărul complex ciclomatic al lui McCabe (Tempero,
2018)..........................................................................................................................36
Lista tabelelor Tabel 2.1.1 Primele câteva iterații ale ecuației anterior prezentate asupra grafului
(Langville și Meyer, 2006)..........................................................................................12
Tabel 2.1.2 Cota de piață la nivel mondial, motoare de căutare (StatCounter Global
Stats, 2018)................................................................................................................15
Tabel 2.4.1 Comparație între funcțiile oferite pentru diferite tipuri de căutări în unele
motoare de căutare.....................................................................................................22
Tabel 2.5.1 Tipuri de conținut web invizibil (Sherman și Price, 2001)..........................26
Tabel 3.4.1 Indicatori pentru a măsura fiabilitatea programului propus (Littlefair,
2018)..........................................................................................................................34

5
1. Introducere Lucrarea de față, prin conținut și aplicația realizată, se încadrează în domeniul de
mare actualitate al motoarelor de căutare. Alegerea temei este motivată și susținută
de experiența de lucru de peste 10 ani în domeniu. Am putut identifica principalele
probleme ale motoarelor de căutare din magazinele online (de exemplu, o persoană
poate naviga pe site-ul Amazon și căuta o carte; unele rezultate, nerelevante, apar mai
sus ca altele, relevante, și uneori nu se obțin prin căutări rezultatele dorite).
Motivația principală a lucrării este dată de experiența negativă avută pe principalele
motoare de căutare pentru magazine online, fie ele din România sau pe plan
internațional. Filtrele Amazon nu funcționează întotdeauna corect (din perspectiva
noastră), iar căutarea de produse pe site uneori nu returnează lucrurile potrivite (o
persoană poate căuta ceva și fie nu obține niciun fel de rezultate, fie obține rezultate
nedorite). Iar aici este vorba de probleme pe site-ului unei companii gigant, care a avut
în 2017 vânzări de 177,9 miliarde de dolari (Kim, 2018). Întreaga piață românească de
e-commerce a fost estimată de GPeC (Gala Premiilor eCommerce, un eveniment
major pentru piața de e-commerce din România) la 2,8 miliarde de euro (Radu, 2018),
așa că, în mod firesc, magazinele online românești au avut bugete mai mici pentru
investiția în motoare de căutare eficiente. Unele probleme sunt mai mari pe site-urile
românești de comerț online. Am vrut să arătăm o modalitate practică prin care se pot
face unele îmbunătățiri la un motor de căutare cu resurse puține. Vom prezenta în
lucrare inclusiv idei noi, potențial utile de folosit pentru magazinele online în viitor.
În ceea ce privește gradul de noutate al lucrării – soluția propusă de noi vine ca
element de noutate cu un grad de predicție asupra termenilor introduși de utilizator.
Soluția există deja în motoare de căutare generaliste (Google, Bing, Yahoo!, Yandex,
Baidu), sau în unele tastaturi pentru telefoanele mobile (SwiftKey pentru Android și
iOS). Ea însă nu a fost implementată în magazinele online suficient de mult. Un
exemplu foarte bun de predicție este cel oferit de tastatura de mobil a celor de la
SwiftKey. Am dorit cu programul propus de noi să simulăm unele din funcționalitățile
de predicție pentru un eventual motor de căutare pentru produsele din magazinele
online. O mare parte din facilitățile prezentate sunt deja incluse în SwiftKey.

6
Scopul de la care am pornit lucrarea a fost atât de a implementa ideile pe care le
am în domeniul căutării pentru motoarele de căutare, de a da un model practic și
verificabil, cât și de a veni cu noi idei, ca posibile rute de prospectat pentru aplicații
viitoare. Acestea au rămas în plan pur teoretic, urmând a fi implementate de alte
entități, în încercarea de a îmbunătăți performanțele motoarelor de căutare din prezent.
Descrierea fiecărui capitol:
• 2. Istoric și motivație - acest capitol are o abordare mai degrabă teoretică, am
prezentat aspecte ce țin de părțile legate de teorie (istoric, motivație) ale unui
motor de căutare pentru magazine online.
• 2.1 Istoric al căutării informației - am prezentat în acest subcapitol evoluția
tehnică, de la primele colecții de documente de pe pereții pictați ai peșterilor,
mai departe pe papirus, pergament, hârtie și, în final, suport electronic. Am
prezentat sistemele de organizare a informației, diferite soluții pentru a cataloga
informațiile. Apoi au fost prezentate detalii despre cum primele motoare de
căutare aveau dificultăți în sortarea informațiilor de pe Internet. S-a continuat cu
doi algoritmi de sortare a datelor - PageRank (1998), motorul din spatele
Google, și HITS (tot 1998), un algoritm folosit inițial de motorul de căutare
Teoma. Am discutat în continuare despre RankBrain, unui sistem de inteligență
artificială bazat pe machine learning pentru a genera rezultatele căutărilor. Au
fost prezentate apoi cotele principalelor motoare de căutare, Google având
peste 90% din piață, și principalele motoare de căutare având aproape 99% din
piața motoarelor de căutare la nivel mondial. Am discutat și despre platforma
de căutare din spatele YouTube și cea a Facebook.
• 2.2 Modalitatea de funcționare a unui motor de căutare - în acest subcapitol am
arătat pentru început unde pornesc căutările internauților (Amazon, alte
motoare de căutare importante, retaileri). S-a prezentat și Teoria Setului Difuz
(Fuzzy Set Theory), o ramură a logicii difuze, și rolul ei în căutări. Au fost
descrise în continuare tipurile de căutări în metodele de obținere a informației -
căutări de proximitate / logică difuză / căutări booleene / puterea dată unor
termeni.
• 2.3 Evaluarea eficienței unui motor de căutare - în subcapitolul 2.3 au fost
prezentați diferiți KPI (indicatori cheie de performanță, key performance

7
indicators) folosiți pentru evaluarea unui motor de căutare - procentul de
utilizatori care folosesc căutarea / numărul de căutări per vizită / procentul de
ieșiri din pagina rezultate căutări / numărul mediu de itemi pentru o vizită cu
căutări vs. vizitele care nu au căutări / procentul căutărilor fără niciun rezultat /
căutările cele mai frecvente / intenția de căutare.
• 2.4 Starea actuală a domeniului – în începutul subcapitolului a fost prezentată
o comparație între funcțiile oferite pentru diferite tipuri de căutări în unele
motoare de căutare - abilitatea de a interpreta termenul scris greșit „Latpop” /
filtrare în rezultate / sortare rezultate / abilitatea de a interpreta „procesor laptop”
(inclusiv în engleză). Motoarele comparate au fost Google.com / Bing.com /
Amazon.com / Target.com / eBay.com / olx.ro / eMAG.ro / Elefant.ro / F64.ro /
evoMAG.ro. A fost descris apoi un studiu de uzabilitate din 2015 realizat de
echipa de la Baymard Institute, în care au fost analizate cele mai importante 50
de site-uri de e-commerce de pe piața Statelor Unite.
• 2.5 Limitările unui motor de căutare generalist - în subcapitolul acesta au fost
expuse unele din limitările motoarelor de căutare generaliste (motoarele de
căutare generaliste sunt motoare de tipul Google, Bing, Yahoo!, care caută în
surse de date diverse, spre deosebire de cele specializate, cum sunt YouTube
sau Amazon, care caută doar anumite tipuri de date). Există diferite tipuri de
conținut care nu sunt indexabile de motoarele de căutare generaliste, și
înțelegerea acestor lucruri ajută la alegerea unui motor de căutare pentru nevoi
specifice. Capitolul și-a propus să arate că există anumite căutări pentru care
motoarele de căutare generaliste (Google, Bing, Yahoo!, Yandex, Baidu etc.)
nu sunt cele optime.
• 2.6 Soluții potențiale pentru paginile de rezultate căutări fără niciun rezultat – în
acest subcapitol am dat niște soluții pentru căutările care în mod tipic nu
returnează niciun rezultat (de exemplu, cineva caută un produs care nu există
pe site, sau tastează un cuvânt greșit, rezultând un cuvânt pentru care nu există
rezultate în mod tipic). De asemenea, am prezentat concluziile unui studiu
comparativ între mai multe motoare de căutare.
• 2.7 Viitorul motoarelor de căutare ale magazinelor online - am prezentat aici
primele încercări de aplicare a unor metode de machine learning asupra
eficienței motoarelor de căutare. Am folosit pentru aceasta o resursă de pe site-

8
ul Loop54, care este un SaaS (software ca serviciu, software as a service)
folosit de diferite site-uri pentru a crește vânzările și ratele de conversie prin
îmbunătățirea experienței vizitatorilor (CX, Customer eXperience).
• 3. Soluția propusă - am scris în acest capitol despre soluția software propusă
de către noi pentru rezolvarea unor părți din problemele identificate în partea
teoretică.
• 3.1 Scop și obiective - în subcapitol au fost descrise, în mod sumar, care a fost
scopul și care au fost obiectivele cercetării noastre - se poate face relativ simplu
un instrument care să folosească predicția rezultatelor posibile, și apoi să
filtreze rezultatele obținute.
• 3.2 Descrierea algoritmului - am descris în acest subcapitol, pas după pas, cum
funcționează algoritmul meu. Se citește de la tastatură un text. Se verifică dacă
programul poate prezice niște termeni alternativi: de exemplu, inversarea unor
litere în cuvânt („latpop” vs. „laptop”) – au fost prezentate mai multe soluții de
acest tip. O altă funcție a programului este de a căuta și sorta cuvintele în
varianta finală introdusă de la tastatură în baza de date de laptopuri.
• 3.3 Utilitatea metodei - în subcapitol am prezentat utilitatea demersului. În
primul rând, funcția de auto-completare termeni, iar apoi, funcția de validare
date. Mai departe, odată realizată procedura pe un set de date (programul a
fost făcut să funcționeze pe o bază de date pentru laptop-uri), se pot imagina
ușor soluții pentru alte tipuri de date de pe site-uri de tip e-commerce.
• 3.4 Analiza implementării algoritmului - subcapitolul prezintă de ce a fost ales
limbajul de programare C++ și paradigma de scriere cod programare
funcțională, apoi procedura, pas cu pas, prin care a fost făcut programul.
Ulterior, au fost prezentați câțiva indicatori folosiți pentru a măsura fiabilitatea
software-ului, folosind un program numit CCCC. Au fost detaliați indicatorii
folosiți, sumar.
• 3.5 Posibilități de extindere a algoritmului - este un subcapitol în care am
prezentat diferite posibile viitoare soluții prin care se poate perfecționa aplicația
noastră.
• Lucrarea se încheie cu un capitol de concluzii și bibliografia aferentă.

9
2. Istoric și motivație
2.1 Istoric al căutării informației Primele colecții de documente au fost înregistrate pe pereții pictați ai peșterilor.
Apoi, până la invenția hârtiei, anticii romani și greci au înregistrat informația pe role de
papirus. Unele artefacte de papirus aveau mici etichete atașate rolelor, care ajutau la
găsirea informației. Cuprinsul unei lucrări au început să apară în rolele din Grecia în
secolul 2 î.Hr. Ulterior, s-a scris pe pergament, straturi subțiri de piele de animale.
Pentru perioada aceasta, cele mai relevante metode de informație erau cele pe cale
orală. (Langville și Meyer, 2006)
Inventarea hârtiei, cel mai bun suport de stocare a informației, a crescut viteza
înregistrării documentelor și au început să apară colecții tematice. Acest lucru a fost
accelerat puternic prin inventarea presei tipografice de către Johann Gutenberg în
1450. În anii 1700 au apărut în America biblioteci publice, la inițiativa lui Benjamin
Franklin. Astfel, a crescut dorința de a ierarhiza informațiile. (Langville și Meyer, 2006)
Primul sistem de organizare a informației a fost atribuit autorului roman Valerius
Maxiums, care l-a folosit în anul 3 d.Hr. pentru a organiza informația unei cărți ale lui.
Ulterior, au apărut sisteme ca sistemul decimal Dewey (1872), cataloagele de cărți
(începutul anilor 1900), microfilmul (anii 1930), sistemul MARC (MAchine Readable
Cataloging – catalog citibil de către mașini) în anii 1960. În ceea ce privește căutările
în baze de date pentru cărți au început cu un sistem SMART (inteligent) al Cornell în
anii 1960. (Langville și Meyer, 2006)
În anul 1989 stocarea, accesare și căutarea colecțiilor de documente a fost
revoluționată de o invenție numită World Wide Web (rețeaua pentru lumea întreagă)
de către fondatorul său, Tim Berners-Lee. Aceasta a devenit semnalul final al
dominației Erei Informației și moartea Erei Industriale. Cu toate acestea, volumul mare
de informație făcea căutările inițiale foarte greoaie. (Langville și Meyer, 2006)
Primele motoare de căutare aveau dificultăți în ierarhizarea informației. Lucrurile s-
au schimbat radical odată cu apariția Google. Într-un document datat 29 ianuarie 1998,
"The PageRank Citation Ranking: Bringing Order to the Web" (ierarhizarea bazată pe

10
citări PageRank: aducând ordine în Internet), autorii, dintre care primii doi au fondat
Google (Lawrence Page, Sergey Brin, Rajeev Motwani și Terry Winograd), prezentau
PageRank, un algoritm care dădea o importanță resurselor găsite în căutări, pe
măsura volumului linkurilor către o anumită resursă (cu precizarea că o resursă putea
acorda o valoare mai mare dacă, la rândul ei, avea multe linkuri). Autorii concluzionau
că "folosind PageRank, putem ordona căutările, în așa fel încât paginile cele mai
importante au poziții preferențiale. În experimentele făcute, asta a dus la rezultate de
calitate ridicată pentru utilizatori". (Page et al., 2018)
Documentul era o continuare a documentului „The Anatomy of a Large-Scale
Hypertextual Web Search Engine” (anatomia unui motor de căutare pe Internet pe
scală largă, și hipertextual), în care Sergey Brin și Lawrence Page prezentau motorul
de căutare în detaliu, inclusiv formula de calculare a PageRank-ului:
„Presupunem că pagina A are linkuri de la paginile T1 ... Tn (aceste pagini o
citează. Parametrul d este un factor de amortizare, care poate fi setat între 0 și 1. În
general, îl stabilim la valoarea 0,85. De asemenea, C(A) este definit ca numărul de
linkuri care pornesc dinspre pagina A spre alte pagini. PageRank-ul paginii A este
definit astfel:
PR(A) = (1-d) + d (PR(T1)/C(T1) + ... + PR(Tn)/C(Tn))
De notat că PageRank-ul formează o distribuție probabilistică peste toate paginile de
Internet, așa că suma tuturor PageRank-urilor va fi 1. PageRank-ul pentru 26 de
milioane de pagini web poate fi calculat în câteva ore pe o stație de lucru medie.” (Brin
și Page, 1998)
Într-o lucrare apărută în 2006 (Langville și Meyer, 2006), formula este
prezentată ca mai jos, o ecuație simplă a sumelor, rădăcina cărei derivă din cercetările
bibliometrice, analiza structurii citațiilor între lucrările academice. PageRank-ul paginii
Pi, numită r(Pi), este suma tuturor PageRank-urilor paginii care direcționează către Pi.
𝑟(𝑃𝑖) = ∑𝑟(𝑃𝑗)
|𝑃𝑗|,
𝑃𝑗∈𝐵𝑃𝑖
unde BPi este setul paginiilor care au trimitere către Pi (trimit backlink către Pi în
cuvintele autorilor Sergey Brin și Lawrence Page), și |Pj| este numărul de linkuri

11
externe (către alte entități) trimise din pagina Pj. De observat că PageRank-ul paginilor
care trimit linkuri către entitate curentă r(Pj) din ecuația anterior menționată este
temperat de numărul de recomandări făcute de Pj, notat |Pj|. Problema cu ecuația
respectivă este că valorile r(Pj), PageRank-ul paginilor care trimit către pagina Pi, sunt
necunoscute. Pentru a trece peste această problemă, autorii ecuației au folosit o
procedură iterativă. Astfel, ei au presupus că, la început, toate paginile au un
PageRank egal una cu cealaltă (să zicem, 1/n, unde n este numărul de pagini din
indexul web al lui Google). Acum regula în ecuația prezentată este urmată pentru a
calcula r(Pi) pentru fiecare pagină Pi din index. Regula dinecuație este aplicată în mod
succesiv, înlocuind valorile iterației anterioare în r(Pj). Introducem și alte notații pentru
a defini această procedură iterativă. Fie rk+1(Pi) PageRank-ul paginii Pi pentru iterația
k + 1. Atunci,
𝑟𝑘+1(𝑃𝑖) = ∑𝑟𝑘(𝑃𝑗)
|𝑃𝑗|.𝑃𝑗∈𝐵𝑃𝑖 (Langville și Meyer, 2006)
Procesul este inițiat cu r0(Pi) = 1/n pentru toate paginile Pi și este repetat, în
speranța că scorurile Page Rank vor converge în final către niște valori stabile.
Aplicând ecuația de mai sus rețelei din figura de mai jos dă următoarele valori pentru
PageRank, după câteva iterații:
Figura 2.1.1 Graf direcționat, reprezentând o serie de șase pagini
(Langville și Meyer, 2006)
1 2
3
6 5
4

12
Iterația 0 Iterația 1 Iterația 2 Rank la iterația 2
R0(P1) = 1/6 R1(P1) = 1/18 R2(P1) = 1/36 5
R0(P2) = 1/6 R1(P2) = 5/36 R2(P2) = 1/18 4
R0(P3) = 1/6 R1(P3) = 1/12 R2(P3) = 1/36 5
R0(P4) = 1/6 R1(P4) = 1/4 R2(P4) = 17/72 1
R0(P5) = 1/6 R1(P5) = 5/36 R2(P5) = 11/72 3
R0(P6) = 1/6 R1(P6) = 1/6 R2(P6) = 14/72 2
Tabel 2.1.1 Primele câteva iterații ale ecuației anterior prezentate asupra grafului
(Langville și Meyer, 2006)
Un alt algoritm al motoarelor de căutare este și HITS. Un acronim pentru
„Hypertext Induced Topic Search” (căutare de subiecte induse prin hipertext), acesta
a fost un algoritm aflat la baza Teoma, un motor de căutare lansat în 2001 și
achiziționat în același an de un alt motor de căutare, Ask Jeeves Inc. (The Globe și
Mail, 2001)
HITS, algoritm inventat de Jon Kleinberg în 1998 (aproximativ în aceeași perioadă
în care Sergey Brin și Lawrence Page lucrau la algoritmul PageRank), asemenea
PageRank, folosește structura de URL-uri pentru a crea scoruri de popularitate
asociate cu paginile web. Totuși, HITS are anumite diferențe (detalii preluate din
Langville și Meyer, 2006):
• Dacă metoda PageRank produce un singur scor de popularitate pentru fiecare
pagină, HITS produce două.
• În timp ce PageRank-ul este independent de căutare, HITS depinde de
căutarea făcută.
• HITS privește paginile ca autorități și huburi. O autoritate este o pagină cu
numeroase linkuri către ea, și un hub este o pagină cu multe linkuri dinspre ea
spre alte pagini. Paginile de autoritate și huburile merită să fie numite „bune”
atunci când următoarea afirmație circulară este validă: „Autoritățile bune au
linkuri către ele din partea unor huburi bune și huburile bune trimit către autorități
bune”. Așadar, fiecare pagină este o măsură a autorității și o măsură a unui
hub.

13
Cum funcționează algoritmul? (Langville și Meyer, 2006) Fiecare pagină i are un
scor de autoritate xi și un scor de hub yi. Fie E setul tuturor marginilor direcționate în
graful de Internet și fie eij marginea direcționată de la nodul i către nodul j. Dat fiind
faptul că fiecărei pagini i-a fost atribuită inițial un scor de autoritate inițială xi și un scor
de hub yi, HITS rafinează în mod succesiv aceste scoruri calculând:
𝑥𝑖(𝑘)
= ∑ 𝑦𝑗(𝑘−1)
𝑗:𝑒𝑗𝑖𝜖𝐸
𝑦𝑖(𝑘)
= ∑ 𝑥𝑗(𝑘)
𝑗:𝑒𝑗𝑖𝜖𝐸
, unde k = 1, 2, 3, ...
Aceste ecuații, care au fost ecuațiile originale ale inventatorului lor, Jon
Kleinberg, pot fi scrise într-o formă matriceală cu ajutorul matricei de adiacență L a
grafului de URL-uri direcționate. (Langville și Meyer, 2006)
1 2
3 4
Figura 2.1.2 Graf pentru o rețea de 4 elemente (Langville și Meyer, 2006)
P1 P2 P3 P4
P1 0 1 1 0
L = P2 1 0 1 0
P3 0 1 0 1
P4 0 1 0 0

14
În notarea matricială, ecuațiile precizate iau forma:
x(k) = LTy(k-1) și y(k) = Lx(k),
unde x(k) și y(k) sunt n x 1 vectori care păstrează autoritatea aproximativă și scorurile
fiecărui hub la fiecare iterație. (Langville și Meyer, 2006)
Algoritmul original HITS: (Langville și Meyer, 2006)
1. Se inițializează y(0) = e, unde e este vectorul coloană al tuturor valorile de 1. Pot
fi folosiți și alți vectori de început pozitivi.
2. Până la convergență, execută:
x(k) = LTy(k-1)
y(k) = Lx(k)
k = k + 1
Se normalizează x(k) și y(k).
Lucrurile au evoluat, pe măsură ce anii au trecut. Algoritmii s-au tot schimbat,
la un moment dat Google afirma că au 200 de factori. Întrebat despre asta, în 2010,
CEO-ul Google, Eric Schmidt, a afirmat că nu îi poate menționa, pentru că sunt într-o
continuă schimbare, și, de asemenea, pentru că sunt un secret comercial al companiei.
(Sullivan, 2010)
Potrivit informațiilor celor de la SearchEngineLand, un site important în lumea
motoarelor de căutare, „RankBrain” este numele dat de către Google unui sistem de
inteligență artificială bazat pe învățare automată (machine-learning artificial
intelligence system) care este folosit pentru a genera rezultatelor căutărilor. Prin
machine learning, un calculator poate să se învețe pe sine însuși cum să facă o
sarcină, mai degrabă decât să urmeze o procedură predefinită. La data apariției
articolului, algoritmul ocupa locul 3 în cele mai importante criterii după care un site era
afișat în rezultatele căutărilor. Scopul lui? Interpretarea rezultatelor care nu conțin
cuvintele căutate în mod exact, ci cuvinte ce ar putea fi similare. Nevoia de a exista a
algoritmului venit din faptul că Google procesa în 2016 3 miliarde de căutări zilnic, iar
în 2007 a afirmat undeva între 20-25% din acele căutări nu au fost observate până
atunci (nu fuseseră probabil căutate niciodată până atunci). În 2016 e posibil să fi ajuns
15
la 15% din căutări, în continuare o valoare mare de căutări pentru care algoritmul își
justifică existența. Sunt căutări în special formate din mulți termeni („long-tail”, căutări
foarte specifice, dar, totuși, numeroase). (Sullivan, 2016)
Luna Google Bing Yahoo! Baidu Yandex
Ru Yandex Alții
2017-02 92,35 2,91 2,17 1,01 0,42 0,35 0,79
2017-03 92,31 2,96 2,2 1,05 0,38 0,35 0,77
2017-04 92,48 2,89 2,01 1,11 0,36 0,35 0,79
2017-05 92,06 2,92 2,07 1,39 0,35 0,34 0,87
2017-06 91,88 2,88 2,18 1,45 0,38 0,38 0,86
2017-07 92,01 2,55 2,23 1,44 0,4 0,49 0,87
2017-08 91,64 2,52 2,32 1,53 0,36 0,5 1,13
2017-09 91,84 2,59 2,33 1,42 0,39 0,41 1,02
2017-10 91,47 2,75 2,25 1,8 0,42 0,41 0,9
2017-11 92,06 2,76 1,73 1,64 0,5 0,36 0,94
2017-12 91,79 2,75 1,61 1,66 0,57 0,39 1,24
2018-01 91,74 2,76 1,83 1,39 0,58 0,36 1,33
2018-02 91,63 2,71 1,94 1,29 0,63 0,33 1,49
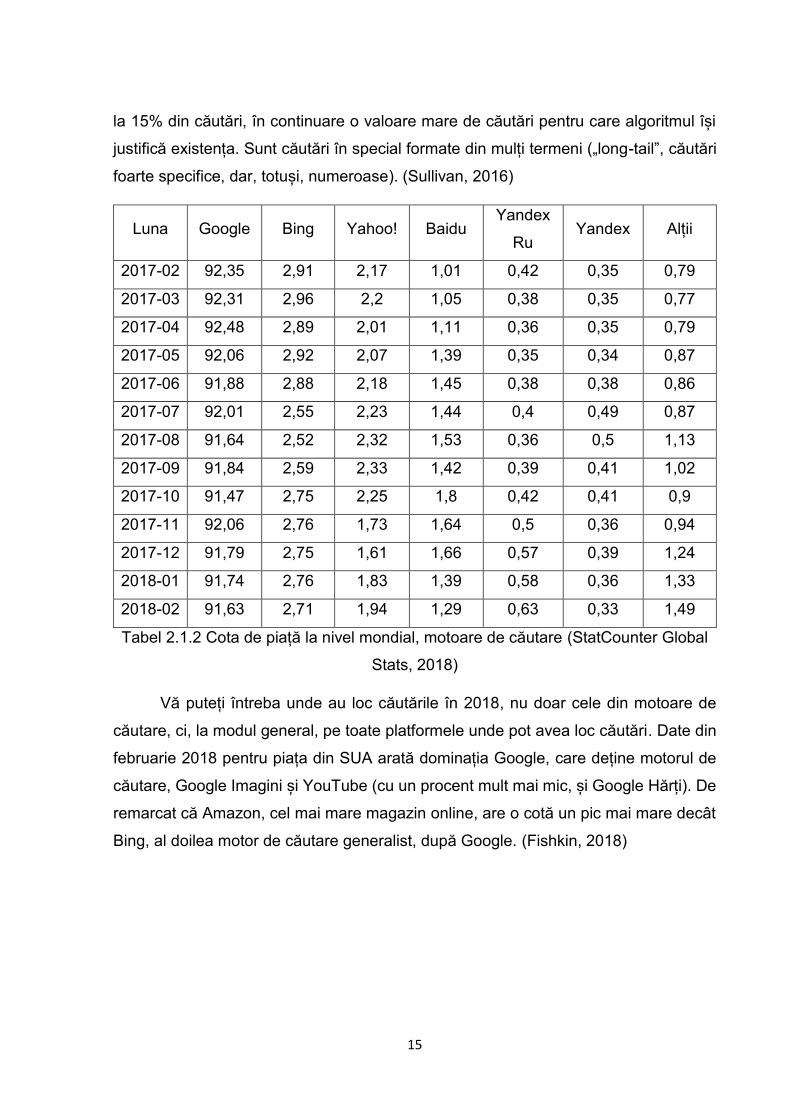
Tabel 2.1.2 Cota de piață la nivel mondial, motoare de căutare (StatCounter Global
Stats, 2018)
Vă puteți întreba unde au loc căutările în 2018, nu doar cele din motoare de
căutare, ci, la modul general, pe toate platformele unde pot avea loc căutări. Date din
februarie 2018 pentru piața din SUA arată dominația Google, care deține motorul de
căutare, Google Imagini și YouTube (cu un procent mult mai mic, și Google Hărți). De
remarcat că Amazon, cel mai mare magazin online, are o cotă un pic mai mare decât
Bing, al doilea motor de căutare generalist, după Google. (Fishkin, 2018)

16
Figura 2.1.3 Cota de piață a căutărilor web, februarie 2018, pentru piața din SUA
(date din partea companiei Jumpshot)
Câte motoare de căutare (generale, pentru tot Internetul) există? Poate, din
diferite surse, ați aflat că există „sute de motoare de căutare”. Majoritatea dintre
acestea sunt însă fie variații ale site-urilor principale (de exemplu, Google.fr pentru
Franța sau Google.co.uk pentru Marea Britanie), fie sunt meta motoare de căutare,
care folosesc rezultatele oferite de alte motoare de căutare (Dogpile, Mamma.com,
Metacrawler). Da, există unele motoare de căutare tematice (Wolfram|Alpha, IMDb),

17
dar motoarele cele mai vizitate au un procent apropiat de 95% din piața motoarelor de
căutare. (Grappone și Couzin, 2011)
Există și alte tipuri de algoritmi care pot susține un motor de căutare. Platforma
de clipuri video YouTube este al doilea motor de căutare, ce-i drept, specializat, după
Google, cu aproximativ 3 miliarde de căutări pe lună, un volum de căutare mai mare
decât cel al Bing, Yahoo!, AOL și Ask.com combinate. (Wagner, 2017) Lucrurile la care
se uită cei 1,5 miliarde de utilizatori înregistrați ai platformei YouTube sunt influențate
de o listă de clipuri asemănătoare. De fiecare dată când un internaut privește un clip
YouTube, i se prezintă într-o bară laterală o listă de clipuri asemănătoare. Acea listă e
considerată cel mai important factor în creșterea cotei de piață a YouTube. În una din
puținele explicații publice despre cum funcționează formula, o lucrare academică care
prezintă rețelele neuronale ale algoritmului, inginerii YouTube o descriu drept una din
"cele mai mari și sofisticate sisteme de recomandare la scală industrială existente în
lume". (Lewis, 2018)
Faptul că Facebook, cea mai folosită rețea socială la nivel mondial – 2,2 miliarde
de utilizatori activi pe lună, în al 4-lea trimestru al lui 2017 (Statista, 2018) –, cu un
potențial enorm în a ajuta utilizatorii în căutarea de produse și servicii pe plan local, cu
un ecosistem format din milioane de pagini de afaceri, date despre locație ale
utilizatorilor, date de comportament, informații demografice, rată de angajament, nu a
reușit în anii recenți să fie un concurent serios pentru Google în căutările de afaceri
locale poate fi un argument că a fi relevant în căutări e o sarcină mai grea decât pare
la o analiză superficială.
2.2 Modalitatea de funcționare a unui motor de căutare
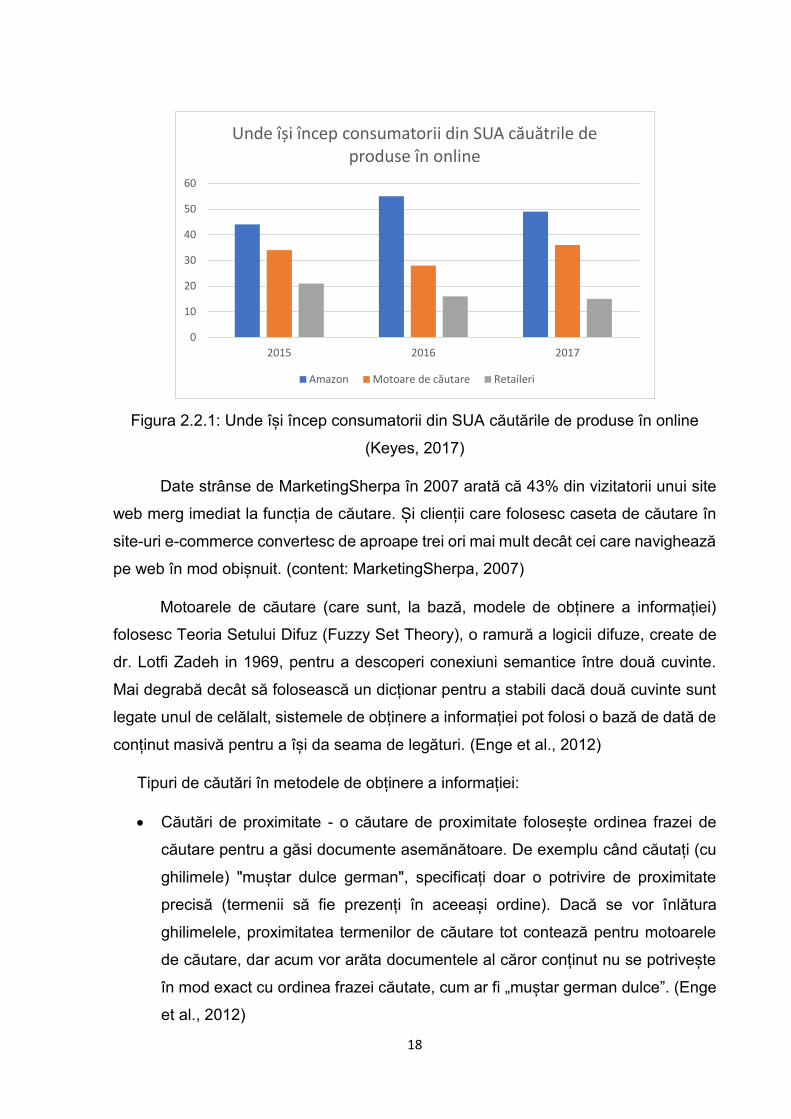
De ce este important, în primul rând, să discutăm despre eficiența unui motor de
căutare? În SUA, cota de piață a celor care își încep căutările de produse de cumpărat
a scăzut pentru Amazon de la 55 la 49% pentru Amazon, în detrimentul motoarelor de
căutare (precum Google), care au crescut de la 28 la 36%, potrivit unui studiu Survata,
citat de Bloomberg. (Keyes, 2017)
18
Figura 2.2.1: Unde își încep consumatorii din SUA căutările de produse în online
(Keyes, 2017)
Date strânse de MarketingSherpa în 2007 arată că 43% din vizitatorii unui site
web merg imediat la funcția de căutare. Și clienții care folosesc caseta de căutare în
site-uri e-commerce convertesc de aproape trei ori mai mult decât cei care navighează
pe web în mod obișnuit. (content: MarketingSherpa, 2007)
Motoarele de căutare (care sunt, la bază, modele de obținere a informației)
folosesc Teoria Setului Difuz (Fuzzy Set Theory), o ramură a logicii difuze, create de
dr. Lotfi Zadeh in 1969, pentru a descoperi conexiuni semantice între două cuvinte.
Mai degrabă decât să folosească un dicționar pentru a stabili dacă două cuvinte sunt
legate unul de celălalt, sistemele de obținere a informației pot folosi o bază de dată de
conținut masivă pentru a își da seama de legături. (Enge et al., 2012)
Tipuri de căutări în metodele de obținere a informației:
• Căutări de proximitate - o căutare de proximitate folosește ordinea frazei de
căutare pentru a găsi documente asemănătoare. De exemplu când căutați (cu
ghilimele) "muștar dulce german", specificați doar o potrivire de proximitate
precisă (termenii să fie prezenți în aceeași ordine). Dacă se vor înlătura
ghilimelele, proximitatea termenilor de căutare tot contează pentru motoarele
de căutare, dar acum vor arăta documentele al căror conținut nu se potrivește
în mod exact cu ordinea frazei căutate, cum ar fi „muștar german dulce”. (Enge
et al., 2012)
0
10
20
30
40
50
60
2015 2016 2017
Unde își încep consumatorii din SUA căuătrile de produse în online
Amazon Motoare de căutare Retaileri

19
• Logică difuză - se referă la un tip de logică ce nu este adevărată sau falsă în
mod categoric. Un exemplu comun este dacă o zi este însorită (spre exemplu,
dacă este acoperită 50% de nori, este în continuare o zi însorită?). Logica de
acest tip este folosită pentru a detecta și procesa cuvintele tastate greșit. (Enge
et al., 2012)
• Căutări booleene - căutările booleene folosesc termeni precum AND (și), OR
(sau) și NOT (nu, negație). Acest tip de logică este folosită pentru a extinde sau
reduce documentele care apar într-o căutare. (Enge et al., 2012)
• Puterea dată unor termeni - acest lucru se referă la importanța unui termen de
căutare particular în cererea transmisă motorului de căutare. Ideea este de a
da un anumit grad de putere unor termeni, pentru a produce rezultate de căutare
superioare. De exemplu, prepozițiile vor primi foarte puțină putere în selectarea
rezultatelor, deoarece apar în majoritatea documentelor. Nu ajută la selectarea
unor documente. (Enge et al., 2012)
2.3 Evaluarea eficienței unui motor de căutare Există mai mule tipuri de metrici care pot evalua eficiența unui motor de căutare.
Mai jos, câteva din acestea, dintr-un articol apărut pe blogul oficial al companiei Adobe
(Simon, 2015). Sunt mai mulți KPI (indicatori cheie de performanță, key performance
indicators):
• Procentul de utilizatori care folosesc căutarea – vizitatorii site-ului de analizat
își petrec timpul navigând pe site înainte de a merge în caseta de căutare, sau
merg la ea direct de la început? Indicatorul, dacă are valori mici pentru cei care
folosesc caseta de căutare, poate indica faptul că există niște experiențe
anterioare neplăcute fie cu acest site, fie cu alte site-uri din nișă sau industrie,
poate sugera că există o casetă de căutare slab vizibilă și insuficient de bine
promovată sau poate arăta că site-ul este atât de prietenos cu vizitatorii, încât
aceștia găsesc informația direct, și nu au nevoie de căutări. Cu instrumente
precum cele de analytics (informații statistice organizate pentru a fi analizate;
exemplu – Google Analytics sau Omniture pe plan internațional; în România,
Trafic.ro sau Brat.ro - Studiul de Audiență și Trafic Internet, SATI) se poate
măsura acest indicator.

20
• Numărul de căutări per vizită – câte căutări face fiecare vizitator. Cea mai bună
situație este în care face doar una – o persoană caută ceva, găsește, și
convertește (adică devine client) imediat. Mai mult de o căutare per vizitator
poate însemna lucruri rele, cum ar fi că o căutare a fost goală sau a găsit lucruri
nepotrivite. Cei de la Google sau alte motoare de căutare pot evalua și ei acest
indicator – să zicem că cineva merge la Google, caută ceva, intră pe un site, e
nemulțumit (probabil), sau e insuficient mulțumit, și se întoarce la Google și face
click pe un alt rezultat. Acest tip de acțiune se numește „bounce” (întoarcere în
urma unui impact). Vizitatorii intră pe un site, nu găsesc, și se întorc în punctul
de plecare, în căutarea unui rezultat mai bun. Iarăși, acesta este un indicator
de bază în instrumentele tip analytics.
• Procentul de ieșiri din pagina rezultate căutări – dacă un vizitator părăsește site-
ul din pagina de rezultate căutări obținută în urma unei căutări în site, în mod
sigur site-ul are niște probleme la care ar trebui ca deținătorul site-ului să se
uite. Căutările ineficiente nu sunt o experiență a consumatorilor pozitivă.
Obiectivul de marketing al zilelor noastre este prezentarea unui vizitator cu
experiență pozitivă în perspectiva sa de client. Clientul ar trebui să găsească ce
căutau încă din prima încercare. De remarcat că acest procent se corelează
puternic cu procentul intrărilor într-un site. Dacă pe un site se intră frecvent pe
o anumită pagină a site-ului, e firesc ca pe acel site să existe și un procent
ridicat al celor care părăsesc site-ul din pagina respectivă. Totul se reduce însă
la procente – este procentul celor care părăsesc pagina în linie cu restul
paginilor sau e ceva radical diferit? În funcție de răspunsul la această întrebare
se poate decide dacă e cazul să se ia măsuri sau nu.
• Numărul mediu de itemi pentru o vizită cu căutări vs. vizitele care nu au căutări.
Cheia în evaluarea acestei diferențe e în procente. Aici intră o doză de bun simț
în comparații, într-o oarecare experiență. Ce se întâmplă pe site-urile principale
de e-commerce este că se testează constant lucruri, în căutarea perfecționării.
• Procentul căutărilor fără niciun rezultat – este una din situațiile în care o veste
proastă poate fi folosită în avantajul magazinului online. E bine ca deținătorul
magazinului să se uite peste ce căutau acele persoane, care e procentul celor
care nu găsesc niciun rezultat, ce fac după ce ajung într-un punct mort cu
căutările? Soluții la aceste probleme am încercat să dăm și în programul nostru

21
– de exemplu, dacă cineva caută 4 termeni și pe site se găsesc doar 3,
programul 3 afișează cele mai relevante rezultate doar pentru cei 3 termeni.
• Căutările cele mai frecvente – ce caută un vizitator? Înțelegerea termenilor cei
mai frecvent folosiți poate să ajute deținătorul magazinului online să înțeleagă
de ce au venit internauții pe site. Cu această informație, se poate îmbunătăți
navigația sau apelurile la acțiune (butoane precum „Adaugă în coș”, „Cumpără”,
„Abonează-te la newsletter” – poștă electronică, „Contactează-ne”), în așa fel
încât vizitatorii să nu apeleze atât de mult la căutări. E bine ca deținătorul
magazinului să folosească instrumentele de tip analytics pentru a îmbunătăți
algoritmii de căutare în site. Tot aici e de menționat și instrumentul Google
Trends (trenduri de căutare din statisticile Google), care permite evaluarea
căutărilor din industrie. Un alt instrument ar putea fi Google Keyword Planner
(planificatorul de cuvinte cheie de la Google), care folosește termenii căutați
pentru vizitatori, și poate da informații de tip sezonalitate, sau costuri per click
pentru campaniile de publicitate plătită.
• Intenția de căutare – un comportament intangibil, și, cu toate acestea critic de
înțeles. Aici este vorba de a măsura la ce se gândea vizitatorul în timpul vizitei
pe site. Acest lucru este legat de ROI (return of investment, rata de rentabilitate
a investiției), pentru că există, de exemplu, unii vizitatori care intră pe un site
doar ca să vadă ce mai e nou, și navighează liber. Alții sunt acolo strict pentru
că au nevoie de informație, și au un model de navigare pentru a obține informații
(de exemplu, detalii tehnice despre un produs, sau link către pagina
producătorului, sau un video explicativ cu produsul). Șansele de conversie
directă a acestor vizitatori sunt mici, dar e de menționat că prin mai multe vizite
pe un site, acesta va rămâne în mintea vizitatorului, care poate converti în client
la un moment ulterior. Totuși, este de preferat ca în instrumentul de Analytics
să existe un diferențiator clar între clienții care fac tranzacții și cei care doar
navighează pe un site în scopul obținerii de informații.
2.4 Starea actuală a domeniului Mai jos, un tabel comparativ între mai multe motoare de căutare, din România, și
pe plan internațional:

22
Motor de
căutare
Abilitatea de a
interpreta
„Latpop”
Filtrare în
rezultate
Sortare
rezultate
Abilitatea de a
interpreta „procesor
laptop” (+engleză)
Google.com Da Nu Nu Da
Bing.com Da Nu Nu Nu
Amazon.com Da Da Da Nu
Target.com Da Da Da Nu
eBay.com Da Da Da Da
olx.ro Nu Da Da Nu
eMAG.ro Da Da Da Nu
Elefant.ro Nu Da Da Nu
F64.ro Da Da Da Nu
evoMAG.ro Da Da Da Nu
Tabel 2.4.1 Comparație între funcțiile oferite pentru diferite tipuri de căutări în unele
motoare de căutare
Am făcut o mică cercetare comparativă între unele magazine online, și motoare
de căutare „clasice”. De asemenea, și două site-uri de anunțuri. Mai jos, câteva
observații.
În primul rând, motoarele de căutare „clasice” se descurcă în general mai bine
la interpretarea căutărilor semantice. De exemplu, dacă scriem „procesor laptop” (sau,
în engleză, „laptop processor”), ne vom aștepta să primim rezultate despre procesoare
de laptop, și nu laptopuri care au procesoare (probabil 100% din laptopuri au
procesoare), nu genți de laptopuri cu anumite procesoare, nu coolere de procesoare
de laptop. Se observă însă că, la această căutare, magazinele online clasice eșuează
în a interpreta căutarea noastră. Soluțiile ar fi două: pe de o parte să folosească
inteligența artificială pentru a învăța din căutările anterioare (spre exemplu, cineva
caută „procesor laptop”, nu e mulțumit de rezultate, apoi merge în categoria
procesoare, subcategoria procesoare laptop; acesta ar putea fi un semnal că acea
categorie e relevantă pentru căutare), sau ar putea face reguli manuale de căutare (toți
cei care caută „procesor laptop” să fie trimiși automat în categoria respectivă).
O a doua observație e că motoarele de căutare „clasice” (Google, Bing) au un
impediment major – nu au indexare instantanee a rezultatelor. Asta înseamnă că pe

23
un site ca Amazon (o căutare site:amazon.com la Google arată că Google a indexat
aproximativ 145 de milioane de pagini) sau eMAG (site:eMAG.ro returnează 25 de
milioane de pagini) Google și Bing sunt nevoiți să indexeze (să parcurgă cu mici roboți
automat – spideri – întregul site) foarte multe pagini pentru a avea o variantă cât mai
recentă a site-ului. Desigur, asta durează zile, uneori săptămâni. Așa că pentru Google
și Bing asta înseamnă că nu au niciodată în index cele mai recente variante ale
paginilor de Internet. Aceste pagini pot suferi modificări, apar noi produse, se schimbă
prețurile, apar promoții. Din acest motiv, sortarea, cel puțin cu tehnologia de astăzi, e
foarte dificilă. Da, Google și Bing pot „ști” care este prețul laptopurilor și să
implementeze o soluție de sortare a rezultatelor după preț. Dar dacă este prețul de
acum câteva zile, sau, mai rău, acum o săptămână, fără nicio informație despre
promoții și schimbări de preț de ultim moment, rezultatele vor avea o relevanță mai
redusă. Prin urmare, se întâmplă ce am observat în cercetarea noastră sumarizată în
tabel – motoarele de căutare „clasice” nu au implementate funcții de filtrare / sortare
rezultate, și ne așteptăm ca situația să nu se schimbe prea devreme, din cauza
limitărilor tehnice (motoarele de căutare indexează relativ greu un site mare de
e-commerce).
Avem și o ultimă observație, despre predicții cuvinte. Google este un motor de
căutare care, din experiența noastră, are abilitatea de a interpreta foarte bine un
termen tastat, chiar dacă e tastat cu greșeli de tipul litere inversate, prea multe litere
într-un cuvânt dorit, prea puține. În unele căutări, mai nou, Google chiar ignoră o parte
din cuvintele introduse, în încercarea de a fi cât mai relevant. În căutarile noastre, am
observat că olx.ro și Elefant.ro nu interpretează căutarea „latpop” (desigur, scrisă fără
ghilimele, altfel și Google o va vedea ca pe o căutare corectă) ca pe o căutare scrisă
greșit. O tastatură numită SwiftKey, disponibilă pe sistemele de operare de mobil iOS
(din 2014) și Android (din 2010) are bune abilități de a prezice cuvinte, de a învăța din
cuvintele pe care utilizatorii le tastează pe mobil. Tehnologia din „spatele” Google, sau,
la o scară mai mică, dar în continuare eficientă, a SwiftKey nu considerăm că se
regăsește încă în toate magazinele online. Faptul că există o tehnologie accesibilă
oricui nu înseamnă și că toate software-urile de predicție cuvinte învață din experiența
altora și le și folosesc.

24
În plus, față de ce am analizat în tabel (pentru că e mai dificil de interpretat) este
și abilitatea de a acorda importanță diferită cuvintelor într-o căutare. De exemplu,
primele cuvinte dintr-o căutare ar trebui să fie mai importante decât restul. Într-un
manual de căutare avansată pe Google, se menționează diferența între [blue sky]
(cerul albastru și compania Blue Sky Studios) și [sky blue] (albastru cer, o denumire
folosită în alte contexte). (Edu.google.com, 2012) Pentru magazinele online ar trebui
să conteze ordinea în care sunt scrise cuvintele, și care sunt cuvintele scrise la
începutul frazei.
Într-un studiu din 2015 realizat de echipa de la Baymard Institute au fost
analizate cele mai importante 50 de site-uri de e-commerce de pe piața Statelor Unite
(Baymard.com, 2015). Rezultatele sintetice ale studiului:
Figura 2.4.1 Analiza listei de produse a magazinelor online (Baymard.com, 2015)
Cofondatorul institutului a scris un articol despre rezultatele cercetării efectuate
asupra magazinelor online respective în revista Smashing Magazine. (Holst, 2015)
Câteva observații din articolul respectiv:
• Doar 16% din site-urile de e-commerce cele mai importante furnizează
utilizatorilor o experiență de filtrare a rezultatelor rezonabil de bună. Acest lucru
se întâmplă din cauza lipsei unor opțiuni de filtrare a rezultatelor importante. Din
datele studiului rezultă că logica de filtrare ineficientă și interfețele nefuncționale
sunt și ele probleme.

25
• 42% din site-urile de e-commerce de top nu au anumite tipuri de filtre specifice
unor categorii pentru câteva din categoriile de produse cele mai importante.
• 20% din site-urile de e-commerce nu au filtre tematice, în ciuda faptului că vând
produse cu atribute tematice evidente (sezon, stil ș.a.m.d.).
• Din site-urile care se ocupă de produse care sunt dependente de o
compatibilitate (de exemplu, o placă de bază e compatibilă doar cu anumite
microprocesoare; sau un încărcător baterii poate lucra doar cu anumite baterii),
32% nu au filtre de comptabilitate.
• Testele au arătat că mai mult de 10 valori filtrate necesită scurtarea (truncation)
rezultatelor pentru a fi afișate în mod corect pe ecran. Cu toate acestea, 32%
din site-uri fie au un design de scurtare insuficient, care face ca utilizatorii să nu
observe valorile truncate (6%), sau se folosesc de ceva ce testele au arătat că
e și mai problematic, zone de scroll intern (24%, se referă la casete în care
vizitatorii dau scroll orizontal și/sau vertical pentru a putea citi toată informația).
• Doar 16 din site-uri promovează în mod activ filtre deasupra listei de produse
(aceasta este o pre-condiție pentru situația când se depinde mai mult de filtre
decât de categorii produse).
• Abilitatea de filtrare eficientă variază puternic de la o industrie la alta,
electronicele și industria confecțiilor suferind de filtre insuficiente (pentru fiecare
din contextele lor specifice), în timp ce site-urile cu bricolaj sau vânzătorii de
produse generaliste au magazinele cu cele mai bune performanțe de filtrare
produse.
2.5 Limitările unui motor de căutare generalist Am discutat în lucrare până acum doar de lucrurile care pot fi găsite de
motoarele de căutări. Totuși, aceste motoare de căutare au limitările lor. Sunt unele
aspecte ce țin de ordin tehnic, pe care o să le discut mai jos, care arată că un motor
de căutare are limitările lui în a găsi informația pe un site. Pe un site de e-commerce,
de exemplu, un motor de căutare clasic (Google, Bing, Yahoo!, Yandex, Baidu) nu
poate adăuga produse în coș, nu poate compara produse, nu poate completa un
formular de cerere ofertă, nu poate interpreta ce înseamnă să ai un discount la
cumpărarea a două produse în același timp.
26
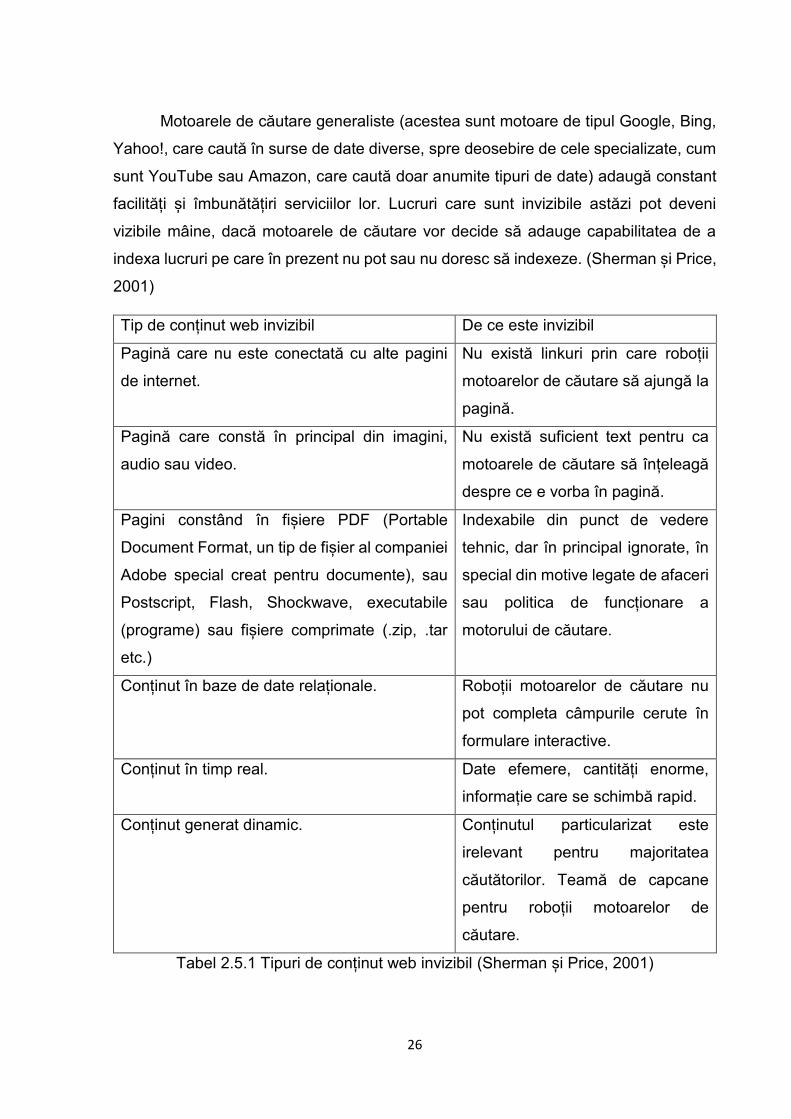
Motoarele de căutare generaliste (acestea sunt motoare de tipul Google, Bing,
Yahoo!, care caută în surse de date diverse, spre deosebire de cele specializate, cum
sunt YouTube sau Amazon, care caută doar anumite tipuri de date) adaugă constant
facilități și îmbunătățiri serviciilor lor. Lucruri care sunt invizibile astăzi pot deveni
vizibile mâine, dacă motoarele de căutare vor decide să adauge capabilitatea de a
indexa lucruri pe care în prezent nu pot sau nu doresc să indexeze. (Sherman și Price,
2001)
Tip de conținut web invizibil De ce este invizibil
Pagină care nu este conectată cu alte pagini
de internet.
Nu există linkuri prin care roboții
motoarelor de căutare să ajungă la
pagină.
Pagină care constă în principal din imagini,
audio sau video.
Nu există suficient text pentru ca
motoarele de căutare să înțeleagă
despre ce e vorba în pagină.
Pagini constând în fișiere PDF (Portable
Document Format, un tip de fișier al companiei
Adobe special creat pentru documente), sau
Postscript, Flash, Shockwave, executabile
(programe) sau fișiere comprimate (.zip, .tar
etc.)
Indexabile din punct de vedere
tehnic, dar în principal ignorate, în
special din motive legate de afaceri
sau politica de funcționare a
motorului de căutare.
Conținut în baze de date relaționale. Roboții motoarelor de căutare nu
pot completa câmpurile cerute în
formulare interactive.
Conținut în timp real. Date efemere, cantități enorme,
informație care se schimbă rapid.
Conținut generat dinamic. Conținutul particularizat este
irelevant pentru majoritatea
căutătorilor. Teamă de capcane
pentru roboții motoarelor de
căutare.
Tabel 2.5.1 Tipuri de conținut web invizibil (Sherman și Price, 2001)

27
2.6 Soluții potențiale pentru paginile de rezultate căutări fără niciun
rezultat În lucrarea "Designing Search: UX Strategies for eCommerce Success", autorul
Greg Nudelman afirmă că nu există un set de reguli clare care să garanteze o
implementare a unei pagini care nu returnează niciun rezultat. Totuși, în lucrare, el
prezintă patru principii generale care pot furniza un bun punct de început (Nudelman,
2011):
1. „Nu vă fie teamă să spuneți că nu ați înțeles. Indicați clar că nu ați obținut niciun
rezultat”, astfel încât clientul să își dea seama că este o problemă, și să o poată
corecta. Dacă vizitatorul înțelege că nu sunt rezultate în pagină, problema se
poate remedia prin tastarea altor termeni cheie.
2. „Axați-vă pe a furniza o rezolvare. Asigurați-vă că fiecare variabilă din pagina
de rezultate de căutare face ceva productiv, pentru a ajuta la rezolvarea
problemei cu niciun rezultat în căutare.” Spre exemplu, cei de la Google, când
cineva introduce cuvinte ce par ar fi scrise greșit, întreabă internauții "Ați dorit
să scrieți ...?" (alt termen decât cel introdus).
3. „Creați o strategie de potrivire parțială robustă. Constrângerile prea mari sunt
unele din greșelile cele mai frecvente pe care le fac oamenii când caută pe site-
uri de e-commerce.” Dacă aveți o strategie de rezultate parțiale robuste, ați
putea, de exemplu, să faceți ca o căutare să răspundă doar la 3 termeni din cei
5 căutați. Google face, de asemenea, și acest lucru.
4. „E bine să aveți mai multe strategii de livrare a răspunsurilor. Obțineți rezultate
din surse diferite, pentru a furniza rezultate care să ajute la căutările fără rezultat
(inițiale), dar în același timp păstrați relevanța căutării inițiale efectuate de
vizitator.” Ce se întâmplă de multe ori în practică este că sunt site-uri care au
un site de e-commerce și o funcție de căutare pentru acesta, au, în plus, și un
blog (deseori pe platforma WordPress), cu o funcție de căutare pentru acesta.
O integrare eficientă ar însemna ca atunci când cineva caută pe site să obțină
și rezultate din articolele puse pe blog, dar acestea să aibă o prioritate mai mică
decât rezultatele cu produse din site.
În concluziile unui studiu ("The effectiveness of Web search engines for retrieving
relevant ecommerce links"), autorii (Bernard J. Jansen și Paulo R. Molina), au tras

28
câteva concluzii despre motoarele de căutare pe care le-au analizat: Excite (un motor
de căutare generalist, existent și astăzi), Froogle (un motor de căutare deținut de
Google, în prezent dispărut de pe piață), Google, Overture (un motor de căutare
generalist, cumpărat de Yahoo! în 2003), Yahoo! Directories (un director web al
Yahoo!, cândva foarte popular, în prezent dispărut; pe baza lui exista un motor de
căutare specializat): (Jansen și Molina, 2006)
1. Froogle și Yahoo! Directories, două site-uri care au pus un accent ceva mai
mare pe e-commerce decât alte site-uri, au avut o relevanță statistică mai mare
decât Excite, Google și Overture (între care nu s-a găsit o diferență statistică).
De asemenea, nu a fost nicio diferență statistică între Froogle și Yahoo!
Directories. Ca răspuns la prima ipoteză a studiului (dacă un motor de căutare
personalizat e mai relevant decât unul generalist), se pare că aceasta este
adevărată, cele mai bune rezultate fiind obținute din site-uri specializate.
2. A doua ipoteză a studiului a fost dacă cumva primele rezultate din pagina de
căutare (de exemplu, rezultatele 1-5) sunt mai relevante decât rezultatele
următoare (6-10). Răspunsul a fost negativ, nu s-a observat că primele rezultate
ar fi mai relevante decât celelalte, pentru toate motoarele de căutare analizate.
3. În fine, o ultimă ipoteză era dacă cumva rezultatele organice (cele care nu sunt
sponsorizate, apar natural, fără a fi plătite, așadar sunt "organice") ar fi mai
relevante decât cele plătite. Răspunsul, în această situație, a fost unul pozitiv.
2.7 Viitorul motoarelor de căutare ale magazinelor online Loop54 este un SaaS (software ca serviciu, software as a service) bazat pe
machine learning folosit de diferite site-uri pentru a crește vânzările și ratele de
conversie prin îmbunătățirea experienței vizitatorilor (CX, Customer eXperience).
Într-un articol de pe site-ul propriu, compania arată cum machine learning va
schimba viitorul căutărilor în e-commerce, unele tendințe fiind deja aplicate.
(Loop54.com, 2017)
Motoarele de căutare clasice pentru magazine online se axează în mod tipic pe
lucruri precum (Loop54.com, 2017):

29
• Indexare eficientă – folosită pentru a localiza rapid datele fără a trebui să caute
în fiecare coloană de tabel de fiecare dată când o tabelă de baze de date este
accesată.
• Reguli de ierarhizare bazate pe atribute - ierarhizează rezultatele pe baza
relevanței așteptate a căutării unui utilizator, folosind o combinație de metode
dependente de căutarea făcută și altele independente de căutarea efectuată.
• Potrivită a căutării relaxată (fuzzy) – potrivire a căutării în mod aproximativ (de
exemplu, „lpatop” pentru „laptop”).
• Variații – obținerea unor cuvinte chiar dacă nu sunt în forma exactă (carte / cărți
/ cărțile / cartea)
• Împărțire pe elemente (tokenization) – procesul prin care o căutare se împarte
în segmente de cuvinte, fraze, simboluri și alte părți relevante, numite elemente
(tokens).
În evoluția machine learning, algoritmii de căutare au putut face avansuri
tehnologice foarte mari în ceea ce privește datele comportamentale. Ele au folosit
comportamentul de click, de adăugare în coș și de cumpărare pentru a influența
sortarea rezultatelor (în acest sens, sortarea nu se face exclusiv bazat pe locația în
metadatele unui produs a unui text căutat). Machine learning a adus abilitatea
motoarelor de căutare de a înțelege relațiile dintre produse, chiar înainte ca orice text
să fie căutat sau să se fie obținut date de comportament. În acest fel, un motor de
căutare poate localiza produse similare sau complementare mai departe decât pe baza
unei simple categorii comune sau a unui brand de producător. Poate identifica tipare
complexe în toate metadatele și construi o arhitectură profundă în catalogul de
produse. Pornind de la aceste elemente de bază, un motor de căutare bazat pe
machine learning poate produce o listă de produse asemănătoare care nu au nicio
legătură cu căutarea efectuată. (Loop54.com, 2017).
Furnizarea unei liste de „produse asemănătoare” care sunt similare cu produsul la
care se uită un client poate duce la rate de conversie (din vizitator în client) crescute
și la valori medii ale coșului de cumpărături mărite, și ele. Machine learning permite
unui motor de căutare să structureze unele relații dintre produse care nu existat
vreodată. Făcând asta, poate realiza o listă inteligentă, auto-perfectibilă de „rezultate
asemănătoare”, care să fie complet diferite de cele oferite în general de sistemele

30
clasice. Mai mult, acest tip de motor de căutare nu are nicio nevoie de a avea date de
comportament pentru a funcționa, eliminând din strat problema unui început de
funcționare mai dificil (de notat, totuși, că datele de comportament sunt necesare, și ar
fi bine să fie adăugate motorului pentru a ajuta la sortarea produselor, pentru o
relevanță crescută). (Loop54.com, 2017)

31
3. Soluția propusă
3.1 Scop și obiective Ne-am propus cu programul la care am lucrat să arăt că se poate face relativ simplu
un instrument care să folosească o căutare într-o bază de date de laptopuri, pe două
planuri – predicția unor termeni introduși la tastatură în mod parțial corect, și apoi
sortarea rezultatelor obținute pe baza unor criterii de relevanță. Soluția găsită în final
este, încă, inferioară la modul general unor soluții dedicate precum cele ale Google,
Amazon sau eMAG, dar pe anumite segmente, soluția propusă le poate depăși și pe
cele dedicate într-o eventuală analiză comparativă.
3.2 Descrierea algoritmului Algoritmul propus urmărește introducerea de date și căutarea într-o bază de date
de laptopuri. Baza de date e formată din numele laptopului și URL-ul aferent de pe
site-ul eMAg.ro. Propunerea noastră e pe două planuri: pe de o parte, am făcut un
algoritm de predicție cuvinte, se introduc unul sau mai mulți termeni, iar algoritmul creat
urmărește dacă acei termeni sunt tastați, cumva greșit, și în a doua parte am făcut o
sortare a rezultatelor care conțin termenii căutați.
În prima etapă în care este construit algoritmul se citește de la tastatură un text,
format doar din anumite caractere (litere, cifre, spațiu, cratimă, punct, virgulă,
ghilimele). Am făcut ca textul introdus să poată fi prelucrat de la tastatură ușor, prin
folosirea unor comenzi speciale, pentru deplasarea cursorului în text, deși textul se
citește literă cu literă, și nu ca string (text). Există un număr maxim de cuvinte pentru
care se afișează predicții, 5, apoi un cuvânt e necesar să aibă între 3 și 14 litere, și tot
stringul introdus de la tastatură trebuie să aibă maxim 60 de caractere cu spații (și alte
semne permise). Pentru a vedea predicții, se apasă tasta TAB, pentru a căuta direct,
fără predicții, se apasă tasta ENTER.
Programul citește apoi dintr-un fișier text predicțiile posibile pentru fiecare din
cuvinte. Predicțiile au fost generate din baza de date folosită (o listă de laptopuri de pe
site-ul eMAG). Se verifică dacă programul poate prezice niște termeni alternativi: de

32
exemplu, inversarea unor litere în cuvânt („latpop” vs. „laptop”). Apoi, pe baza unei
matrici cu poziția fiecărei litere de pe tastatură, programul poate interpreta dacă
cuvântul „laptop” a fost tastat de fapt ca „lstpop” (pe tastatură, litera „s” este lângă litera
„a”). Programul verifică în toate tastele din jurul tastei respective. O altă variantă de
predicție sunt cuvintele care încep cu un string. De asemenea, se caută și dacă un
cuvânt a fost tastat cumva cu o literă în plus față de cuvântul dorit. O altă procedură
verifică dacă un termen are o literă în minus.
Dacă se găsește mai mult de o predicție, programul oferă opțiunea de a alege între
predicțiile găsite.
În partea a doua a programului, se caută cuvintele în varianta finală introdusă de
la tastatură în baza de date de laptopuri. Programul este capabil să înțeleagă anumite
echivalări, de exemplu între termenii „DVD” și „DVD-ROM”, sau „MSDos” și „MS-Dos”
etc.
Dacă un termen va fi mai la începutul stringului introdus, acela va avea prioritate
mai mare în căutări decât un termen aflat la finalul stringului.
Dacă un string are 4 termeni, dar în baza de date de laptopuri sunt doar rezultate
în care apar 3 termeni, vor fi afișați aceia.
3.3 Utilitatea metodei În primul rând, funcția de auto-completare termeni. Dacă se urmează pașii descriși
de noi, se poate obține o funcție de auto-completare termeni foarte bună.
Apoi, funcția de validare date. Când se importă datele din baza de date a eMAG și
se împart datele pe coloane în Excel, și se sortează alfabetic, se pot găsi ușor erori de
introducere date, care pot fi corectate. Am găsit husă de laptop în categoria laptop-uri,
titluri de laptop puse greșit (fără "," ca separator, sau cu virgulă, dar fără spațiul de
după), ordine cuvinte din titlu nerespectată.
Mai departe, odată realizată procedura pe un set de date (noi am făcut procedura
pentru laptop-uri), se pot imagina ușor soluții pentru alte tipuri de date de pe site-uri de
tip e-commerce. Soluția propusă în algoritm este replicabilă.

33
De asemenea, căutarea devine mult mai bună prin procesul de înțelegere a unor
obiceiuri de tastare (notebook, în loc de laptop; 2 Core în loc de Dual Core), și prin
încercarea de înțelegere a sensului unei căutări. Statistici de genul acesta se pot
colecta cu instrumente precum Google Analytics, și apoi folosi pentru a rafina,
constant, căutările. E un proces repetitiv ce ar trebui să fie constant.
3.4 Analiza implementării algoritmului Programul a fost implementat în C++, deoarece am avut experiență ca
programatori cu programele Pascal, C și C++. Avem o oarecare expertiză în PHP și
HTML, dar am preferat să ne axăm pe scrierea de cod și algoritmi, nu neapărat în a
învăța să folosim un limbaj de programare pentru web/Internet.
De asemenea, codul a fost scris în paradigma de scriere programare
funcțională, pentru că avem expertiză în acest tip de programare.
Construcția programului a avut ca prim pas salvarea în calculator a unor pagini
HTML de descriere laptopuri de pe site-ul eMAG. Acestea au fost procesate în
calculator, pentru a obține, în final, o listă cu nume de laptopuri (rândurile impare 1, 3,
5 etc.) și de URL-uri pentru acele laptopuri (rândurile pare 2, 4, 6 etc.).
Apoi, din lista respectivă am extras cele mai folosite cuvinte, și le-am folosit
pentru funcție de autocompletare cuvinte (utilizatorul completează un string, programul
știe la ce e posibil să mă refer).
În continuare, am făcut o listă de conjuncții și prepoziții, care vor fi ignorate în
căutări.
Mai departe, am scris codul pentru a procesa aceste informații.
Pentru că în C++ string-urile funcționează ceva mai atipic decât în Java, și din
cauza faptului că experiența noastră în programare este limitată, am ajuns să scriem
foarte mult cod. Sunt aproximativ 2.500 de linii de cod, și aproape 8.000 de cuvinte
folosite. Ce-i drept, codul are numeroase comentarii, și, pentru debugging ușor, am
lăsat și variantele de testare (sunt multe linii, ulterior comentate, care doar afișează un
status, pentru debugging ușor).

34
Mai jos se prezintă câțiva indicatori folosiți pentru a măsura fiabilitatea software-
ului. Algoritmul a fost testat folosind un program numit CCCC.
Indicator Etichetă Metrică globală Metrică per modul
Număr module NOM 1
Linii de cod LOC 1714 1714
Numărul ciclomatic al lui McCabe MVG 363 363
Linii de comentarii COM 347 347
LOC/COM L_C 4,939
MVG/COM M_C 1,046
Linii de cod respinse de compilator REJ 78
Tabel 3.4.1 Indicatori pentru a măsura fiabilitatea programului propus (Littlefair,
2018)
Detaliere indicatori (sursa pentru textul original este un raport creat de programul
CCCC, în care sunt explicați și indicatorii: Littlefair, 2018):
• NOM = Numărul de module (program principal, biblioteci folosite; noi am folosit
doar un program principal, fără biblioteci). Ne-a fost mai util să lucrăm într-un
singur program, pentru că am putut avea o înțelegere a programului facilă (în
partea de sus funcții de predicție, la mijloc citirea tastelor, în partea de jos
sortare rezultate. Dar dacă am fi lucrat într-o echipă, cu alte persoane să ne
supervizeze codul, ar fi fost mai util să fi lucrat în mai multe programe.
• LOC = Linii de cod, numărul de linii care să nu fie goale, și nici comentate,
numărate de program. Numărul respectiv este ridicat atât pentru că nu sunt încă
un programator profesionist, cât și pentru că am lucrat în C++, care are mici
probleme în gestionarea facilă a string-urilor. Se pot gestiona, doar că este un
pic mai dificil decât în Java, de exemplu.
• COM = Linii de comentarii. De menționat că o mare parte din comentariile făcute
de noi au fost și în continuarea unor linii de cod, așa că numărul este inexact.
Am preferat să punem comentarii cât mai detaliate, pentru a face codul ușor de
înțeles. Am lăsat comentate și diferite instrucțiuni utile pentru debugging. Prin
de-comentarea lor se poate verifica ușor în ce loc al programului vă aflați.

35
• MVG = Complexitatea ciclomatică a lui McCabe. Aceasta este o măsură a
complexității decizionale care formează programul. Definiția strictă a acestei
măsurători este că este un număr de rute linear independente printru grafic
aciclic direcționat, care identifică trecerea controlului unui subprogram.
Software-ul analizator CCCC măsoară aceasta prin înregistrarea rezultatelor
decizionale distincte conținute în fiecare funcție, din care rezultă o bună
aproximare a versiunii definite formal a măsurătorii. Detaliem indicatorul mai
jos. De menționat că recomandarea numărului optim ar fi undeva între 10 și 15,
iar la noi depășește 350. Explicația e că nu am împărțit programul în module
distincte.
• L_C = Linii de cod pentru o linie de comentarii. Prin acest indicator se măsoară
densitatea comentariilor, cu atenție la dimensiunea textului programului.
Indicatorul în cazul de față nu este foarte precis măsurat, deoarece nu ia în
considerare comentariile „inline”, cele scrise în continuarea unei linii de cod.
Totuși, considerăm că și așa se poate vedea că am folosit comentarii în codul
nostru.
• M_C = Complexitatea ciclomatică pe linia de comentarii. Folosind acest
indicator putem afla densitatea comentariilor în ceea ce privește complexitatea
logică a programului. Detaliem mai jos despre acest indicator.
• REJ = Linii de cod respinse de compilator. Indicatorul e unul specific
programului CCCC, în Dev C++ pe Windows x64 nu ni s-a reportat niciun fel de
eroare de cod.
Mai jos, câteva aspecte despre complexitatea ciclomatică a lui McCabe (sursa – o
prezentare dintr-un curs al Universității Auckland - Tempero, 2018).
În primul rând, cu cât este mai complexă structura codului, cu atât este mai dificil
de înțeles, e mai probabil să aibă ceva defect, va fi mai dificil de actualizat, va dura
mai mult timp realizarea lui, și va fi mai dificil de reutilizat.
Apoi, numărul complex ciclomatic al lui McCabe (McCabe’s Cyclomatic Complexity
Number, CCN) măsoară numărul de căi liniare independente prin graful programului
(de văzut imaginea de mai jos, cu un graf).
v(F) = e – n + 2,

36
unde F este graful de parcurgere în cod, n numărul de noduri, e numărul de margini.
Intuitiv, pe măsură ce numărul complex ciclomatic al lui McCabe devine mai
mare, codul devine mai complex. Diferite surse recomandă un CCN nu mai mare de
10-15.
Figura 3.4.1 Exemplu pentru numărul complex ciclomatic al lui McCabe (Tempero,
2018)
3.5 Posibilități de extindere a algoritmului În primul rând, ar fi util un generator automat de filtre, se poate face un sistem care
să folosească filtrele cel mai des folosite de alte persoane care au căutat ceva similar,
și să ne fie afișate cele mai frecvent folosite filtre.
Apoi, pentru produsele în limba română, ar fi util ca textele produselor să poată fi
găsite indiferent dacă scriu sau nu cu diacritice. Diacriticele sunt și ele de două tipuri,
cu virgulă (Ș/ș, Ț/ț) și cu sedilă (Ş/ş și Ţ/ţ). Un motor de căutare ar trebui să poată
interpreta orice variantă de a scrie un cuvânt – cuvântul „țânțari” din „plasă țânțari” ar
putea fi scris în 9 feluri distincte, în funcție de semnul diacritic folosit pentru „ț” (și
numărul se înmulțește cu 4 dacă adăugăm cele 4 feluri de a scrie â: â\î\a\i).
Cum poate „învăța” un site abia lansat pe piață dacă se caută frecvent „notebook”
sau „laptop”? Un răspuns, printre alte posibile soluții, ar putea fi folosirea Google
Trends, un site care permite comparații între termeni. Instrumentul respectiv va oferi și
noi sugestii de căutare. S-ar putea face astfel niște dicționare de echivalență, un motor
de căutare ar putea „înțelege” că „laptop” înseamnă, de fapt, „notebook”. Desigur, ar
putea fi utile și niște dicționare de sinonime, dar pentru termenii mai tehnici e posibil

37
să nu fie suficient de moderne în exprimare, și e posibil să se piardă termeni mai de
argou, sau exprimări imprecise, dar folosite în practică.
Uneori, lucrurile generate automat pot da erori. De exemplu, da, „notebook” poate
însemna „laptop”, dar nu ar trebui să fie egal cu „netbook”, deși, aparent, termenii sunt
similari. Ar trebui ca listele generate automat să fie monitorizate. Sau se poate crea un
algoritm, ceva mai complex, care să învețe din greșeli. Prin studierea
comportamentului vizitatorilor, se poate determina dacă pentru majoritatea „netbook”
= „notebook” – dacă se observă că vizitatorii nu sunt mulțumiți de afișarea de
notebookuri la căutări de netbookuri, sau dacă se observă că au fost multe produse
notebook returnate de către cei care căutau netbookuri, se pot lua măsuri corective.
Dacă acest proces de corecție are loc, atunci predicția ar putea rămâne.
Pentru un site cu trafic ceva mai mare, și cu o prezență stabilită pe o anumită piață,
ar putea fi utilă analiza statisticilor din instrumente precum Google Analytics, care
permit, odată făcută o configurare, monitorizarea căutărilor.
Există și funcții de căutare care sunt specifice anumitor nișe. De exemplu, pentru o
persoană care caută un parfum cu un anumit miros, ar fi relevant să i se prezinte o
serie de parfumuri realmente asemănătoare cu acel parfum.
Filtrele de sortare pot și ele să fie rafinate. Să zicem că discutăm despre un
magazin de ceaiuri. Aici, în plus față de filtre precum „ceaiuri de mentă”, „ceaiuri de
sunătoare” etc., ar putea fi utile filtre pentru diferite metode de a folosi acele ceaiuri –
există ceaiuri de răceală, pentru slăbit, pentru somn liniștit, pentru energie ș.a. În lumea
tehnologiei, laptopurile pot fi de birou, pentru acasă (multimedia), pentru procesare
video, pentru jocuri, pentru condiții de lucru dificile (cu rezistență la praf și căderi). Ar
ajuta dacă filtrele nu ar fi exclusiv axate pe specificații tehnice, ci ar fi și fidele intenției
de căutare a vizitatorilor, așa cum poate fi ea interpretată de deținătorii de magazine
online. Tot legat de laptopuri, „laptopuri noi” ar fi un filtru doar cu laptopuri lansate într-
o anumită perioadă. Similar, o funcție de filtrare pentru „laptopuri ieftine”.
O problemă întâlnită la unele magazine este neconcordanța 100% a filtrelor cu
specificațiile produselor. Pe Amazon.com, de exemplu, unele produse sunt vândute
nu de către Amazon în sine, ci de terțe părți. Este dificil să impui criterii coerente pentru

38
zeci (poate sute) de milioane de produse, introduse de foarte mulți comercianți. Prin
urmare, uneori filtrele Amazon din căutări nu sunt precise.
O funcție de sortare care lipsește multor magazine online e funcția de sortare după
data apariției pe piață. E posibil să ne placă 3 laptopuri în măsură egală. Ar fi un
puternic criteriu diferențiator să pot afla ușor data lansării pe piață a modelelor
respective.
Alte criterii de sortare, care uneori nu apar în magazinele online: sortare după top
vânzări (aceasta ar trebui să fie sortarea implicită), sortare după număr și sentiment
comentarii, traficul pentru anumite produse, istoricul celui care caută, laptopuri
populare în ultima lună, recomandări editoriale (ce recomandă echipa din spatele site-
ului).
Funcția de predicții cuvinte (pe măsură ce scriem un cuvânt, să ni se sugereze
texte în mod automat) ar putea avea ca funcție adițională abilitatea de a învăța care
sunt cele mai des folosite predicții, și să le afișeze prioritar pe acela. Apoi, să învețe
din comportamentul nostru, de utilizatori logați în site, și, odată ce am făcut o selecție,
să o afișeze pe aceea prioritar. Nu în ultimul rând o funcție de tip auto-completare, ca
un utilizator să scrie 2-3 litere și să i se indice cuvinte de 10 litere, să spunem.
Mai departe, se poate lua în considerare comportamentul vizitatorilor - pe ce fac
click când caută, dacă se întorc la rezultatele căutării după ce văd un anumit produs
(ceea ce poate însemna că nu au fost mulțumiți de rezultatul respectiv), ce produse se
cumpără efectiv după o căutare, ce produse sunt recomandate mai departe, care este
sentimentul vizitatorilor, așa cum decurge el din comentariile și notele (ratingurile)
lăsate pentru produse etc. Dacă se intră pe acest proces - cum optimizăm rezultatele
de căutare de pe un site? - se poate ajunge cu perfecționarea la un nivel foarte ridicat.
Pe un magazin online ne-am aștepta să găsim și niște rute predefinite foarte bune.
De exemplu, cine caută „Laptop Asus” ar putea să fie trimis automat în categoria
„Laptopuri”, cu filtru selectat pe „Asus”. Da, e posibil ca vizitatorii să se aștepte să
ajungă într-o pagină de căutări cu filtre posibile, dar e de testat și sugestia noastră.
Suntem aproape siguri că cine introduce un cod produs în funcția de căutare vrea
să ajungă direct la produsul respectiv. Pentru acel tip de căutări, am implementa o

39
funcție de tipul „Mă simt norocos”, prezentă pe motorul de căutare Google, care să
„trimită” automat internauții la primul (deci, cel mai relevant) rezultat găsit.
O funcție pe care am implementat-o în program e ca dacă o căutare nu are niciun
rezultat, să tai din termenii introduși.
Ar fi util ca un motor de căutare să știe că 2 TB = 2.000 GB (pentru hard-diskuri) =
2.048 GB (pentru alte tipuri de căutări, oricum se poate pune ca echivalent). De
asemenea, separatorul ar trebui să fie atât virgulă, cât și punct (să fie echivalente):
„2.048” = „2,048”.
Există și căutări foarte provocatoare: „hard-disk laptop”. Poate vizitatorul dorește
să primească o listă de hard-disk-uri pentru laptopuri. Dar acele hard-diskuri pot fi
interne sau externe. Și căutarea ar putea fi și „laptop care să conțină hard-disk, spre
deosebire de alte laptopuri, cu SSD”.
Conjuncțiile, în general, ar trebui eliminate din funcțiile de căutare. „Cel mai nou
laptop” ar putea fi o excepție, aici ar fi utilă o sortare de la cel mai nou spre cel mai
vechi, cu toate laptopurile din magazin.

40
4. Concluzii Am încercat cu demersul nostru să demonstrăm că se poate face un motor de
căutare laptopuri care să permită predicții cuvinte, și o sortare primară rezultate.
Rămân ca posibilități de explorat diferite sugestii pe care le-am acumulat pe măsură
ce am realizat proiectul, de îmbunătățire a motoarelor de căutare.
Răspundem mai jos principalelor puncte prezentate în partea introductivă:
• "Am vrut să arătăm o modalitate practică prin care se pot face unele îmbunătățiri
la un motor de căutare cu resurse puține." – Am lucrat cu un limbaj de
programare axat mai puțin pe partea de web, C++. A fost o primă variantă a
unui potențial algoritm mult mai complex. Considerăm că am realizat o
mini-performanță – am făcut un algoritm care poate face atât predicții asupra ce
utilizatorul dorește să tasteze, cât și un mic algoritm de sortare a datelor relativ
eficient. Loc de îmbunătățire este suficient, mai ales pe baza unor algoritmi de
machine learning.
• "Vom prezenta în lucrare inclusiv idei noi, potențial utile de folosit pentru
magazinele online în viitor." – partea aceasta a fost una din cele mai consistente
în demersul noastră. Din experiența noastră personală în domeniul optimizării
pentru motoarelor de căutare (SEO), am avut ocazia să interacționăm cu
majoritatea din principalele motoare de căutare, și am acumulat, de-a lungul
anilor, numeroase observații despre cât de ineficiente pot fi unele căutări. Am
căutat în lucrarea noastră să prezentăm unele posibile soluții la aceste
probleme.
• " Am dorit cu programul propus de noi să simulăm unele din funcționalitățile de
predicție pentru un eventual motor de căutare pentru produsele din magazinele
online." – am scris mult cod pentru a face un motor de căutare cu câteva funcții
de predicție distincte. Programul nostru este încă departe de modelul pe care l-
am avut, anume tastatura pentru sistemele de operare pentru mobil Android și
iOS numită SwiftKey. Însă, la nivel primar, am folosit o parte din facilitățile oferite
de tastatură și considerăm că le-am imitat cu succes.

41
• " Scopul de la care am pornit lucrarea a fost atât de a implementa ideile pe care
le am în domeniul căutării pentru motoarele de căutare, de a da un model practic
și verificabil, cât și de a veni cu noi idei, ca posibile rute de prospectat pentru
aplicații viitoare. Acestea au rămas în plan pur teoretic, urmând a fi
implementate de alte entități, în încercarea de a îmbunătăți performanțele
motoarelor de căutare din prezent." – am vorbit anterior despre ideile noi pe
care ne-am propus să le aducem cu lucrarea și cât de bine sau rău am realizat
acest lucru. Legat de testarea abilităților – principala remarcă negativă pe care
o avem este legată de complexitatea codului. Programul este foarte lung,
considerăm că dacă am fi făcut și o a doua variantă am fi putut găsi chiar noi
înșine alte soluții pentru a comprima codul. Iar un programator cu experiență
bogată în programare ar putea realiza un cod semnificativ mai mic. Per
ansamblu, însă, ne declarăm mulțumiți de rezultatul obținut pornind de la
obiectivele inițiale ale cercetării. Un motiv în plus de satisfacție este și faptul că
am comentat o parte însemnată din funcțiile folosite, și am păstrat, în corp de
comentarii, și instrucțiunile folosite pentru debugging (căutare erori) în program,
așa că eventualele erori pot fi reparate mai ușor prin de-comentarea liniilor.
Ca o concluzie finală, considerăm că scopul de la care s-a pornit inițial – acela de
a face o lucrare prin care să arătăm că se poate realiza cu un algoritm realizat cu
resurse puține un program care să aibă abilitatea de a prezice diferite elemente folosite
pentru a introduce date, iar, ulterior, abilitatea de a ierarhiza informația pe baza unor
criterii –, a fost atins, fie doar și parțial. Programul are anumite facilități atât în etapa
de predicție cuvinte, cât și în etapa ulterioară, de căutare și sortare rezultate. Legat de
partea teoretică a demersului nostru, considerăm că și scopul acestuia a fost atins,
așa cum am arătat deja în comparația între obiectivele propuse și cele pe care le-am
îndeplinit în mod practic.

42
Bibliografie Baymard.com. (2015). Top 50 E-Commerce Sites Ranked by Product List Usability -
Baymard Institute. [online] Disponibil la: https://baymard.com/ecommerce-product-
lists/benchmark/site-reviews [Accesat 4 Apr. 2018].
Brin, S. și Page, L. (1998). The Anatomy of a Large-Scale Hypertextual Web Search
Engine - Stanford InfoLab Publication Server. [online] Ilpubs.stanford.edu. Disponibil
la: http://ilpubs.stanford.edu:8090/361/ [Accesat 1 Apr. 2018].
content: MarketingSherpa, M. (2007). How to Improve Your Site’s Internal Search &
Lift ROI - 9 Strategies & Tips. [online] MarketingSherpa. Disponibil la:
https://www.marketingsherpa.com/article/interview/how-to-improve-your-sites
[Accesat 3 Apr. 2018].
Edu.google.com. (2012). Lesson 1.5: Word order matters (Text). [online] Disponibil la:
https://edu.google.com/coursebuilder/courses/pswg/1.2/assets/notes/Lesson1.5/Less
on1.5Wordordermatters_Text_.html [Accesat 2 Apr. 2018].
Enge, E., Spencer, S., Stricchiola, J. și Fishkin, R. (2012). The art of SEO. 2nd ed.
Sebastopol, Calif.: O'Reilly Media, pp.47-48.
Fishkin, R. (2018). New Jumpshot 2018 Data: Where Searches Happen on the Web
(Google, Amazon, Facebook, & Beyond) | SparkToro. [online] SparkToro. Disponibil
la: https://sparktoro.com/blog/new-jumpshot-2018-data-where-searches-happen-on-
the-web-google-amazon-facebook-beyond/ [Accesat 5 Apr. 2018].
Grappone, J. și Couzin, G. (2011). Search engine optimization. 3rd ed. Indianapolis,
Ind.: Wiley Pub., p.70.
Holst, C. (2015). The Current State Of E-Commerce Filtering. [online] Smashing
Magazine. Disponibil la: https://www.smashingmagazine.com/2015/04/the-current-
state-of-e-commerce-filtering/ [Accesat 4 Apr. 2018].
Jansen, B. și Molina, P. (2006). The effectiveness of Web search engines for retrieving
relevant ecommerce links. Information Processing & Management, 42(4), pp.1075-
1098.

43
Keyes, D. (2017). Search engines are weakening Amazon’s hold on product search.
[online] Business Insider. Disponibil la: http://www.businessinsider.com/google-
search-engines-weaken-amazon-hold-on-product-search-2017-12 [Accesat 1 Apr.
2018].
Kim, E. (2018). Amazon shares jump after earnings. [online] CNBC. Disponibil la:
https://www.cnbc.com/2018/02/01/amazon-earnings-q4-2017.html [Accesat 31 Mar.
2018].
Langville, A. și Meyer, C. (2006). Google's PageRank and Beyond. Princeton:
Princeton University Press, pp.1-3; 32-33; 115-116.
Lewis, P. (2018). 'Fiction is outperforming reality': how YouTube's algorithm distorts
truth. [online] The Guardian. Disponibil la:
https://www.theguardian.com/technology/2018/feb/02/how-youtubes-algorithm-
distorts-truth [Accesat 1 Apr. 2018].
Littlefair, T. (2018). CCCC Software Metrics Report. CCCC Software Metrics Report.
Loop54.com. (2017). How machine learning is changing e-commerce site-search for
the better. [online] Disponibil la: https://www.loop54.com/blog/machine-learning-is-
changing-ecommerce-site-search-for-the-better [Accesat 4 Apr. 2018].
Nudelman, G. (2011). Designing search. Ediția 1. Indianapolis, IN: Wiley, p.12.
Page, L., Brin, S., Motwani, R. și Winograd, T. (2018). The PageRank Citation Ranking:
Bringing Order to the Web. - Stanford InfoLab Publication Server. [online]
Ilpubs.stanford.edu. Disponibil la: http://ilpubs.stanford.edu:8090/422/ [Accesat 31
Mar. 2018].
Pelican, E. (2016). Modele de aproximare şi simulare, Curs
Petac, E. (2018). Elaborarea lucrării de disertaţie, Seminar
Radu, A. (2018). Raportul pieței de e-commerce 2017: Românii au cumpărat online de
2,8 miliarde de euro (UPDATE cu infografic). [online] Blogul GPeC. Disponibil la:
https://www.gpec.ro/blog/raportul-pietei-de-e-commerce-2017-romanii-au-cumparat-
online-de-28-miliarde-de-euro [Accesat 31 Mar. 2018].
Sburlan, D. (2016). Modele neconvenţionale de calcul, Curs

44
Sherman, C. și Price, G. (2001). The invisible web. Medford (New Jersey): Information
today, pp.56, 60.
Simon, M. (2015). The Value and Incremental ROI of Internal Site Search | Adobe
Blog. [online] Adobe Blog. Disponibil la: https://theblog.adobe.com/the-value-and-
incremental-roi-of-internal-site-search/ [Accesat 3 Apr. 2018].
StatCounter Global Stats. (2018). Search Engine Market Share Worldwide |
StatCounter Global Stats. [online] Disponibil la: http://gs.statcounter.com/search-
engine-market-shar
Statista. (2018). Facebook users worldwide 2017 | Statista. [online] Disponibil la:
https://www.statista.com/statistics/264810/number-of-monthly-active-facebook-users-
worldwide/ [Accesat 1 Apr. 2018].
Sullivan, D. (2010). Schmidt: Listing Google's 200 Ranking Factors Would Reveal
Business Secrets - Search Engine Land. [online] Search Engine Land. Disponibil la:
https://searchengineland.com/schmidt-listing-googles-200-ranking-factors-would-
reveal-business-secrets-51065 [Accesat 31 Mar. 2018].
Sullivan, D. (2016). FAQ: All about the Google RankBrain algorithm - Search Engine
Land. [online] Search Engine Land. Disponibil la: https://searchengineland.com/faq-
all-about-the-new-google-rankbrain-algorithm-234440 [Accesat 31 Mar. 2018].
Tempero, E. (2018). COMPSCI 702: Software Measurement. McCabe’s Cyclomatic
Complexity Number. [online] Disponibil la:
http://www.dcc.ufmg.br/~mtov/pmcc/cyclomatic_complexity_tempero.pdf [Accesat 3
Apr. 2018].
The Globe și Mail. (2001). AskJeeves acquires Teoma search engine. [online]
Disponibil la: https://www.theglobeandmail.com/technology/askjeeves-acquires-
teoma-search-engine/article1185212/ [Accesat 4 Apr. 2018].
Wagner, A. (2017). Are You Maximizing The Use Of Video In Your Content Marketing
Strategy. [online] Forbes.com. Disponibil la:
https://www.forbes.com/sites/forbesagencycouncil/2017/05/15/are-you-maximizing-
the-use-of-video-in-your-content-marketing-strategy/ [Accesat 1 Apr. 2018].

45
Anexa 1 – măsurarea complexității codului L
inia
Ob
iectu
l
mă
su
rat
LO
Cp
hy
LO
Cb
l
LO
Cp
ro
LO
Cco
m
V
B(x
10
0)
T
N1
N2
n1
n2
D
E
L(x
100
0)
MIw
oc
MIc
w
MI
25
25
pro
gra
m-
v.0
.12
4.c
p
p
25
25
57
9
17
56
33
2
72
61
0
19
04
21
0:3
8:3
5
44
87
38
29
38
38
7
18
8
13
64
96
76
5
50
27
77
12
6
Ste
rge
Ecra
n()
19
1
18
2
31
6
4
0:0
1:1
4
34
34
5
20
4
13
42
23
5
93
24
11
7
15
2
Lite
raM
ica
(
) 28
1
7
20
10
5
3
0:0
0:4
8
16
11
9
6
8
87
0
12
1
92
48
14
0
18
1
Ultim
ele
_2
_S
au
_3_
C
ara
cte
re_
..
.()
43
3
37
5
11
05
42
0:4
1:2
0
12
2
97
15
18
40
44
64
9
25
71
25
96
22
5
Elim
ina
_O
r
ice
_A
ltce
v
a_
Decat_
..
.()
29
3
20
7
91
4
31
0:2
6:1
0
93
80
17
22
31
28
26
2
32
78
34
11
3
25
6
Cuva
ntu
l1
Este
Con
tin
utI
nC
uva
nt
ul2
()
34
2
21
12
51
8
19
0:1
2:4
8
56
45
19
16
27
13
84
2
37
80
40
12
0
29
1
loa
d_
Co
nj
un
ctii_
si_
P
rep
ozitii(
)
30
4
19
7
35
4
7
0:0
3:0
5
37
32
13
22
9
33
46
10
6
85
34
11
9
32
2
loa
d_F
isie
r
_L
ista
_La
p
top
uri
()
96
12
57
29
22
19
74
1:3
5:5
4
20
4
15
8
26
44
47
10
35
78
21
53
38
90
41
9
loa
d_
Arr
ay
_F
rom
_F
il
e_
au
toc_tx
t()
30
4
19
7
35
4
7
0:0
3:0
5
37
32
13
22
9
33
46
10
6
85
34
11
9
45
0
Afisea
za_
Su
ge
stii(
)
16
0
21
13
7
23
32
50
12
4
3:3
0:2
9
30
0
24
8
22
39
70
22
73
36
14
39
28
67
46
61
1
Ca
uta
Po
tri
vir
eE
xa
cta
(
) 43
9
30
8
67
9
19
0:1
2:5
3
72
65
12
19
21
13
93
2
49
75
31
10
6
65
6
Ca
uta
Inve
r
sa
reLite
re(
) 73
9
57
11
13
91
60
1:1
0:0
6
14
4
12
1
18
20
54
75
72
4
18
61
28
89
73
0
Ca
uta
Pozit
iaL
ite
reiP
e
Ta
sta
tura
()
23
5
17
2
31
6
9
0:0
3:5
4
34
34
11
14
13
42
18
75
89
22
11
1
75
4
Ca
uta
Lite
r
eT
asta
teG
r
esit()
85
16
65
9
18
78
69
1:2
6:3
8
18
5
15
5
18
28
50
93
56
5
20
56
24
80
84
1
Cau
taC
uvi
nte
Care
Inc
ep
Cu()
53
12
37
6
84
1
28
0:2
2:2
9
87
77
15
20
29
24
29
0
35
70
25
94
89
7
Cau
taC
uvi
nte
CuL
ite
r
aIn
Plu
s()
68
12
53
9
12
40
50
0:5
3:1
0
12
9
10
9
17
20
46
57
43
6
22
63
27
90
96
7
Cau
taC
uvi
nte
CuL
ite
r
aIn
Min
us()
67
11
51
10
11
77
46
0:4
7:4
3
12
3
10
3
17
20
44
51
53
8
23
63
28
92
10
36
Cau
ta_
Sug
estii(
)
48
16
30
4
58
1
16
0:0
9:2
1
60
50
16
23
17
10
11
1
58
74
22
95
10
85
imp
art
e_
Q
ue
ry_in
_C
uvin
te()
62
15
44
13
12
53
55
1:0
1:2
4
13
0
10
1
22
21
53
66
31
4
19
63
33
96
11
48
Citir
e_
Ta
st
e()
30
7
60
23
2
35
49
17
12
4
3:3
0:5
0
44
7
29
8
23
74
46
22
77
07
22
17
25
42
14
57
Ve
rifica
Da
ca
Te
rme
n
ulA
pa
re..
.()
46
14
26
8
71
7
20
0:1
3:4
3
68
61
19
28
21
14
83
0
48
74
30
10
4
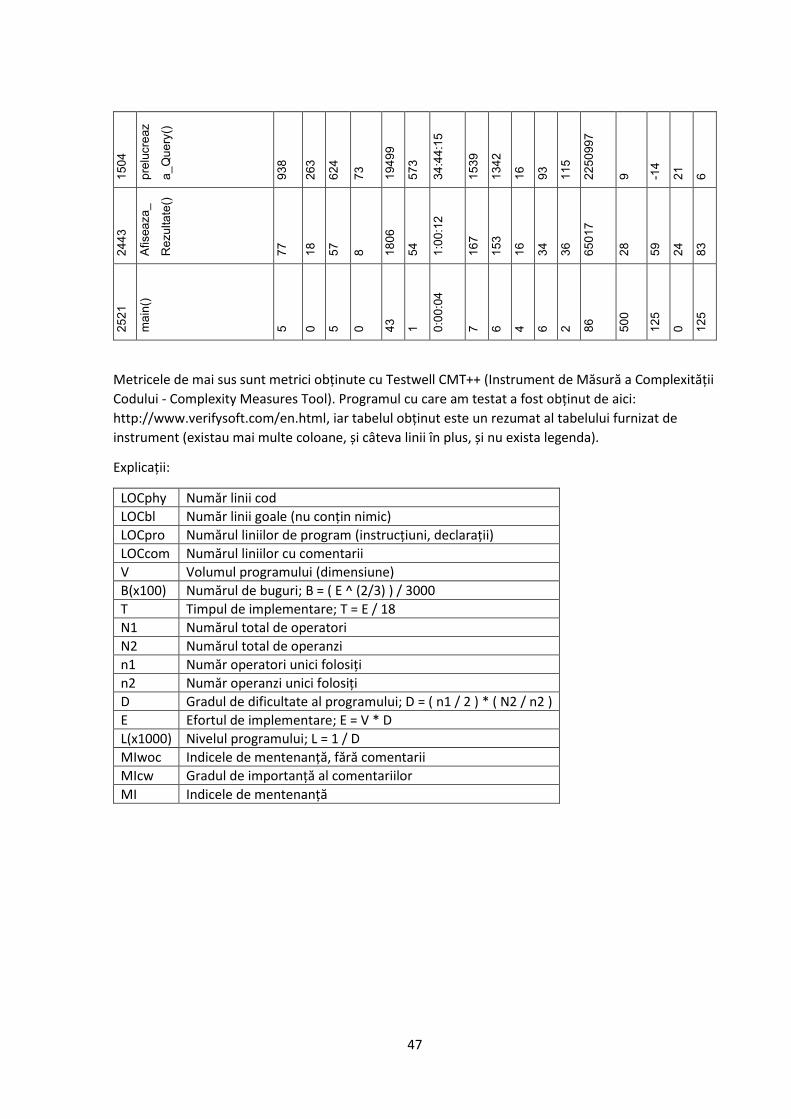
47
15
04
pre
lucre
az
a_
Qu
ery
()
93
8
26
3
62
4
73
19
49
9
57
3
34
:44
:15
15
39
13
42
16
93
11
5
22
50
99
7
9
-14
21
6
24
43
Afisea
za_
Re
zu
lta
te()
77
18
57
8
18
06
54
1:0
0:1
2
16
7
15
3
16
34
36
65
01
7
28
59
24
83
25
21
ma
in()
5
0
5
0
43
1
0:0
0:0
4
7
6
4
6
2
86
50
0
12
5
0
12
5
Metricele de mai sus sunt metrici obținute cu Testwell CMT++ (Instrument de Măsură a Complexității
Codului - Complexity Measures Tool). Programul cu care am testat a fost obținut de aici:
http://www.verifysoft.com/en.html, iar tabelul obținut este un rezumat al tabelului furnizat de
instrument (existau mai multe coloane, și câteva linii în plus, și nu exista legenda).
Explicații:
LOCphy Număr linii cod
LOCbl Număr linii goale (nu conțin nimic)
LOCpro Numărul liniilor de program (instrucțiuni, declarații)
LOCcom Numărul liniilor cu comentarii
V Volumul programului (dimensiune)
B(x100) Numărul de buguri; B = ( E ^ (2/3) ) / 3000
T Timpul de implementare; T = E / 18
N1 Numărul total de operatori
N2 Numărul total de operanzi
n1 Număr operatori unici folosiți
n2 Număr operanzi unici folosiți
D Gradul de dificultate al programului; D = ( n1 / 2 ) * ( N2 / n2 )
E Efortul de implementare; E = V * D
L(x1000) Nivelul programului; L = 1 / D
MIwoc Indicele de mentenanță, fără comentarii
MIcw Gradul de importanță al comentariilor
MI Indicele de mentenanță

48
Anexa 2 – graficul funcțiilor tabelului Mai jos, se pot vedea funcțiile programului – cum se întrepătrund, care dintre ele
folosesc alte funcții, și în ce alte funcții sunt apelate. Săgețile nu au o semnificație
aparte.
49
![SISTEM DE CĂUTARE PERSONALIZATĂ PENTRU REORDONAREA ... · Evaluation. 1. Introducere Un sistem de căutare personalizată [1] este definit ca un tip de sistem de Information Retrieval](https://static.fdocumente.com/doc/165x107/5e4e5d21c9b01b18183ee3db/sistem-de-cutare-personalizat-pentru-reordonarea-evaluation-1-introducere.jpg)

















