
carea tiparelor de interes pentru o forma de reprezentare particulara sau pentru un set de astfel de...
65
Transcript of carea tiparelor de interes pentru o forma de reprezentare particulara sau pentru un set de astfel de...

�
�
��������������� �������������� ������������
� ������������ ������� ������
�����
�
�
�
�
�
�
�
�
�
�
�
� �!"��#��$�"� % ��&��'! �(���)%�
�#$ %#%*��"%�$%*�"���$ ���(���
)����#�*�*��
����+����+����,������� ��-�
�
�
�������������������� � �����
�
�
�
�
�
����� ��������.�/� 0�
�
-��/+���+����+�1����2����#��


Cuprins
Cuprins i
1 Introducere 1
1.1 Motivatie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 Structura tezei . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
1.3 Diseminarea rezultatelor . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2 Data mining 10
2.1 Reguli de asociere . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.1.1 Algoritmi secventiali utilizati ın determinarea
regulilor de asociere . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.1.2 Metode de paralelizare ale algoritmilor secventiali . . . . . . . . . 11
2.1.3 Discutii asupra tehnicilor existente de extragere a regulilor de asociere 13
2.2 Reguli de clasificare . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.2.1 Algoritmi secventiali utilizati ın determinarea
regulilor de clasificare . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.3 Segmentarea datelor . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.3.1 Notiuni teoretice fundamentale . . . . . . . . . . . . . . . . . . . . 15
2.3.2 Algoritmi secventiali utilizati ın segmentarea datelor . . . . . . . . 15
2.3.3 Metode de paralelizare ale algoritmilor secventiali . . . . . . . . . 16
2.3.4 Discutii asupra tehnicilor existente de segmentare
a datelor . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.4 Concluzii . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
3 Noi algoritmi si modele de paralelizare pentru determinarea tiparelor
frecvente 18
3.1 Algoritmul Apriori . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
3.1.1 Algoritmul secvential de baza . . . . . . . . . . . . . . . . . . . . . 18
3.1.2 Modificari aduse algoritmului HPA . . . . . . . . . . . . . . . . . . 21
3.1.3 Rezultate si discutii . . . . . . . . . . . . . . . . . . . . . . . . . . 23
3.2 Algoritmul Fast Itemset Miner . . . . . . . . . . . . . . . . . . . . . . . . 24
3.2.1 Algoritmul secvential de baza . . . . . . . . . . . . . . . . . . . . . 24
3.2.2 Algoritmul paralel - modelul simplu . . . . . . . . . . . . . . . . . 26
3.2.3 Algoritmul paralel - modelul generalizat . . . . . . . . . . . . . . . 28
3.2.4 Rezultate si discutii . . . . . . . . . . . . . . . . . . . . . . . . . . 30
i

ii CUPRINS
4 Topologii de comunicare eficiente pentru problema segmentarii datelor 32
4.1 Algoritmul Parallel K-Means . . . . . . . . . . . . . . . . . . . . . . . . . 32
4.2 Modificarea comunicatiilor pentru algoritmul paralel standard . . . . . . . 33
4.2.1 Topologia de tip hipercub . . . . . . . . . . . . . . . . . . . . . . . 34
4.2.2 Partitionarea datelor pe topologia de tip hipercub . . . . . . . . . 34
4.2.3 Tiparul comunicational utilizat ın determinarea centroizilor . . . . 37
4.3 Rezultate si discutii . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
5 Sisteme Grid 41
6 Integrarea aplicatiilor MPI sub forma serviciilor Grid 45
6.1 Justificarea abordarii . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
6.1.1 Model generic pentru serviciile Grid destinate
problemei descoperirii de cunostinte . . . . . . . . . . . . . . . . . 45
6.2 Arhitectura serviciului Grid propus . . . . . . . . . . . . . . . . . . . . . . 46
6.2.1 Modelul Fabrica/Instanta . . . . . . . . . . . . . . . . . . . . . . . 46
6.2.2 Integrarea modulelor MPI ın serviciul Grid . . . . . . . . . . . . . 47
6.3 Consideratii asupra aplicatiilor client . . . . . . . . . . . . . . . . . . . . . 48
6.4 Rezultate importante . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
7 Concluzii, contributii si directii viitoare de cercetare 51
7.1 Concluzii . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
7.2 Contributii . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
7.3 Directii viitoare de cercetare . . . . . . . . . . . . . . . . . . . . . . . . . . 55
Bibliografie 57

Capitolul 1
Introducere
1.1 Motivatie
Un numar din ce ın ce mai mare de domenii stiintifice sau economice se confrunta cu
o crestere impresionanta a volumului de date acumulat. Aceasta stare de fapt este
ıncurajata si de dezvoltarea rapida a tehnicii de calcul si a dispozitivelor si mediilor de
stocare. Extragerea informatiilor relevante din aceste baze de date reprezinta ın contin-
uare un proces laborios, necesitand resurse costisitoare si, uneori, greu accesibile. Toto-
data, timpul necesar pentru obtinerea informatiilor necesare pentru diferite decizii sau
operatii ce trebuie efectuate asupra datelor tinta este din ce ın ce mai mare, implicand
deseori resurse aditionale, ın ciuda cresterii puterii de calcul si a scaderii costurilor echipa-
mentelor de calcul de mare performanta [Two 05, Adamo 00]. Mai mult, datele stocate
pot ıngloba informatii utile ce sunt adeseori ascunse unei analize directe din partea unor
eventuali operatori umani.
In scopul reducerii acestor costuri, precum si pentru micsorarea timpilor necesari, sunt
dezvoltate noi metode pentru analiza detaliata a datelor, metode al caror rezultat este
reprezentat de o restructurare automata/semiautomata a datelor [Adamo 00]. Astfel,
prin dezvoltarea acestor metode avansate de analiza se ıncearca regasirea acelor informatii
suplimentare care pot evidentia moduri noi de grupare a datelor stocate sau relatii noi
ıntre aceste date. Aceste tehnici de analiza sunt cunoscute sub denumirea de tehnici de
descoperire a cunostintelor ın baze de date. Descoperirea de cunostinte ın baze de date
este descrisa ca fiind un proces ce se desfasoara ın mai multe etape si are drept scop
detectarea automata a unor tipare si identificarea unor relatii noi ıntre datele stocate
[Two 05]. Semnificatia rezultatelor obtinute este strict corelata cu domeniul pentru care
se aplica aceste noi tehnici: informatiile noi pot fi utile ın realizarea unor predictii asupra
unor noi ınregistrari de acelasi tip sau pot reprezenta pur si simplu o noua descriere sau
o noua perspectiva asupra datelor existente.
Cu alte cuvinte, descoperirea de cunostinte ınseamna extragerea si interpretarea
informatiilor de interes - netriviale, implicite, necunoscute anterior si potential utile -
sau descoperirea de tipare ın datele stocate sub diferite forme. Procesul ın sine include
urmatoarele etape [Two 05]:
1. ıntelegerea domeniului de aplicatie, a cunostintelor anterioare, precum si a scopu-
1

rilor ce se doresc a fi atinse prin analiza;
2. crearea unui set tinta de date, fapt ce implica selectarea unui set de date, con-
centrarea asupra unui subset de variabile sau modele de date asupra carora sa se
execute procesul de descoperire a cunostintelor;
3. curatarea datelor si preprocesarea acestora: colectarea informatiilor necesare pen-
tru modelarea sau recunoasterea zgomotelor, ınlaturarea acestor zgomote si a datelor
ce nu furnizeaza informatii relevante, generarea de strategii pentru tratarea cam-
purilor de date lipsa sau incomplete;
4. reducerea seturilor de date ce vor fi analizate prin transformarea unui set de
atribute, prin extrapolarea unor valori de interes sau pur si simplu prin restrangerea
setului complet de atribute/caracteristici catre un set minimal de strict interes;
5. alegerea unei metode de extragere a informatiilor, ın functie de telul dorit (ex-
tragerea regulilor de clasificare a datelor, extragerea regulilor de asociere sau analiza
diferitelor secvente ıntalnite ın baza de date);
6. alegerea unui algoritm adecvat: selectarea metodelor de analiza ın functie de even-
tuale constrangeri impuse de particularitatile datelor analizate sau adoptarea unui
model valabil, adecvat domeniului tinta;
7. aplicarea metodelor de analiza si extragerea efectiva a informatiilor noi: identifi-
carea tiparelor de interes pentru o forma de reprezentare particulara sau pentru
un set de astfel de reprezentari, precum reguli sau arbori de clasificare, reduceri,
clusterizari, asocieri, seturi frecvente, s.a.m.d.;
8. validarea si interpretarea rezultatelor extrase;
9. consolidarea informatiilor descoperite.
Etapele descrise anterior sunt sintetizate ın Figura 1.1.
Figura 1.1: Procesul de descoperire de cunostinte (adaptare dupa [Fayyad 96])
2

In mod uzual, procesul de descoperire de cunostinte ın volume mari de date este con-
stituit din urmatoarele metode/modele de analiza (ın engleza: data mining) [Fayyad 96]:
• identificarea gruparilor de date - clusterizare: task descriptiv ce are drept scop
identificarea unui numar finit de categorii (grupuri/clustere) ce descriu mai bine
datele existente pe baza similaritatilor dintre aceste date;
• identificarea regulilor de clasificare: task predictiv ce are drept scop determinarea/
,,ınvatarea”, pe baza datelor existente, a unei functii de mapare (clasificator) cu
rol ın determinarea claselor de apartenenta pentru datele noi ce vor fi analizate;
• regresia: task predictiv ce are drept scop determinarea unei functii de mapare
a valorilor atributelor de interes peste numere reale pentru a prezice un anumit
comportament;
• identificarea tiparelor frecvente si a regulilor de asociere: task descriptiv ce are
drept scop determinarea subseturilor ce apar ımpreuna ıntr-un anumit set de valori
sau determinarea unor relatii (ın mod uzual, relatii de co-existenta) ın cadrul acelui
set de valori;
• analiza secventelor : task descriptiv ce are drept scop determinarea acelor secvente
ce apar ımpreuna ın cadrul unui anumit volum de date. Spre deosebire de deter-
minarea tiparelor frecvente, ın cadrul analizei secventelor entitatile ce pot constitui
o secventa nu sunt ın mod necesar omogene (nu au aceeasi semnificatie). In plus,
o secventa frecventa nu este conditionata de o limita de tip suport minim.
Aplicarea corecta a etapelor descrise anterior, precum si indentificarea corespunza-
toare a metodelor de analiza ce vor fi utilizate si obtinerea unor rezultate de interes nu
este posibila daca nu sunt bine ıntelese limitarile descoperirii de cunostinte. Tehnicile
si modelele utilizate ın descoperirea de cunostinte nu sunt general valabile. Nu ofera
rezultate ,,pe tava”, indiferent de natura domeniului pentru care sunt aplicate. In foarte
mult cazuri, rezultatele obtinute nu sunt valabile fara o eventuala certificare din partea
unui grup de potentiali experti umani pe domeniul de interes abordat. Mai mult, un
set particular de rezultate obtinute pentru un anumit caz nu este general valabil pentru
domeniul din care face parte cazul respectiv. Practic, se poate afirma ca provocarile ın
domeniu deriva si din caracteristicile intrinseci ale procesului ın sine: trebuie cunoscut
ce se cauta si trebuie cunoscute datele ın care se cauta, altfel rezultatele obtinute pot fi
irelevante.
Rezumand cele expuse pana acum, se poate afirma ca domeniul descoperirii de cu-
nostinte ın volume mari de date este un domeniu deosebit de complex, cu un pronuntat
caracter interdisciplinar. Provocarile ridicate de metodele de analiza caracteristice nu
pot fi surmontate fara colaborarea specialistilor din diverse arii de cercetare. Mai mult,
aceste metode de analiza trebuie sa gestioneze un volum din ce ın ce mai mare de date
achizitionate. Astfel, pentru o buna parte dintre algoritmii ce adreseaza problemele
specifice descoperirii de cunostinte trebuie dezvoltate modele de paralelizare si/sau de
distribuire eficiente. Acest fapt implica existenta unor echipamente si a unei infrastruc-
turi hardware si software adecvate, fara a conditiona accesul eventualilor experti ce nu
activeaza ın domeniul IT. O posibila solutie pentru depasirea acestor impedimente este
reprezentata de sistemele Grid. Un exemplu edificator ın acest sens este reprezentat de
3

proiectul Data Mining Grid1. Scopul proiectului este de a expune un framework coe-
rent pentru dezvoltarea si expunerea de aplicatii de descoperire de cunostinte ın cadrul
sistemelor Grid.
Termenul de sistem Grid a fost utilizat pentru prima data la mijlocul anilor ’90 pen-
tru a sintetiza specificatiile unei arhitecturi avansate de calcul distribuit. Ian Foster,
considerat de multi personalitatea numarul unu ın domeniul sistemelor Grid, subliniaza
ın [Foster 01] faptul ca modalitatea anterioara de definire este mult prea sumara pen-
tru a ıncapsula conceptele unui astfel de sistem. Potrivit lui Foster, problemele reale
adresate de Grid-uri sunt reprezentate de partajarea resurselor si rezolvarea problemelor
ın cadrul unui mediu dinamic multi-institutional [Foster 01]. Conceptul de resursa ın
cadrul unui sistem Grid ınglobea-za semnificatii diverse. Astfel, o resursa Grid poate
ınsemna un calculator sau un cluster de calculatoare, un produs software, un set de date
sau mecanismul de acces al unui set de date.
Partajarea resurselor capata ın acest context un plus semnificativ de complexitate fata
de cazul unei partajari uzuale de fisiere. Foster subliniaza faptul ca partajarea resurselor
este realizata ıntr-o maniera colaborativa, ın mod necesar bine controlata [Foster 01].
Pentru fiecare resursa exista unul sau mai multi furnizori si unul sau mai multi utilizatori.
Pentru fiecare dintre cele doua roluri exista un set de reguli ce definesc ın mod clar,
neambiguu, modalitatile acceptate prin intermediul carora se pot accesa resursele oferite,
drepturile de acces asupra acelor resure, mecanismele de utilizare, etc.. In acest context,
se defineste conceptul de Organizatie Virtuala (OV ): grup de indivizi si/sau institutii ce
stabilesc un set comun de reguli pentru partajarea resurselor disponibile.
Sistemele Grid reprezinta sisteme de calcul paralel si distribuit care permit partajarea,
selectia si agregarea resurselor distribuite de-a lungul mai multor domenii administrative
bazate pe disponibilitatea, performanta, capacitatea, costul si cererile utilizatorilor ser-
viciilor de calitate [Craus 05]. Practic, aceste sisteme de calcul de mare performanta sunt
destinate rularii proceselor de mare complexitate. Analizand schema unui proces de des-
coperisre de cunostinte (Figura 1.1), se poate afirma cu certitudine ca sistemele Grid pot
furniza suportul necesar pentru oricare dintre etapele implicate. Un sistem Grid ofera
mecanismele necesare stocarii unui volum mare de informatii, precum si mecanismele de
acces consecvent la acele date. Prin intermediul sistemelor de calcul paralel/distribuit
ınglobate, Grid-urile pot rula cu usurinta modulele de preprocesare a datelor sau orice
algoritm de analiza dorit de catre expertii umani.
Pe de alta parte, viziunea care a condus la dezvoltarea conceptului de sistem Grid
este de a oferi suportul hardware si software necesar colaborarii expertilor din diverse
domenii de cercetare. Asa cum aminteau si Bote-Lorenzo et al. ın [Bote-Lorenzo 03], un
sistem Grid este caracterizat de acces transparent si universal. Acest lucru implica faptul
ca un eventual cercetator fara pregatire profunda ın domeniul calculatoarelor ar trebui sa
fie capabil sa utilizeze diferitele resurse expuse de un sistem Grid ca si cum ar utiliza un
browser instalat pe calculatorul personal. Aceasta consecinta este deosebit de importanta
pentru domeniul descoperirii de cunostinte, ıntrucat oricat de bine automatiza ar fi o
anumita metoda de analiza implicata ın acest proces, rezultatele oferite nu sunt valabile
fara o eventuala re-evaluare din partea unui expert uman. Utilizand un sistem Grid,
acest expert uman se poate concentra pe obtinerea si interpretarea rezultatelor dorite,
accesul la resursele necesare fiind transparent.
1Pentru mai multe detalii: http://www.datamininggrid.org/
4

Aceasta lucrare ısi propune investigarea ambelor domenii prezentate: domeniul des-
coperirii de cunostinte ın volume mari de date si domeniul sistemelor Grid. Pentru
primul dintre acestea, cercetarile cuprinse ın aceasta lucrare sunt axate pe nucleul acestui
proces: algoritmii de analiza a seturilor de date preprocesate. In acest context, se pune
accentul pe determinarea tiparelor frecvente si a regulilor de asociere si pe problemele
legate de identificarea gruparilor similare de date (data clustering). Alegerea este bazata
pe popularitatea celor doua metode de analiza. Pentru ambele componente exista ın
prezent un numar considerabil de algoritmi secventiali si paraleli. Fiecare dintre acestia
exploateaza diversele particularitati ale datelor de lucru sau ale codificarii acestor date
ın vederea obtinerii rapide a unor rezultate de interes coerente.
Pentru problema determinarii tiparelor frecvente si a regulilor de asociere sunt ana-
lizati initial doi algoritmi fundamentali: algoritmul Apriori [Agrawal 94] si algoritmul
FP-Growth [Han 00]. Ambii algoritmi (descrisi pe larg ın subcapitolul 2.1.1) utilizeaza
structuri arborescente si considera ca obiectele de lucru sunt codificate prin index nu-
meric. Cu toate ca ambii algoritmi obtin performante bune din punctul de vedere al
timpului de raspuns oferit, este utila investigarea unor noi modaliati de codificare a
bazei de date tinta. In acest context, este prezentata o noua modalitate de codificare
binara a seturilor de date supuse analizei. Sunt analizate avantajele si dezavantajele
aduse de o astfel de codificare atat pentru cazul secvential, cat si pentru unul dintre
cele mai cunoscute modele de paralelizare ale algoritmului Apriori - Hash Partitioned
Apriori (HPA) [Shintani 96]. Este, de asemenea, analizat un nou model algoritmic pen-
tru determinarea tiparelor frecvente. Acest nou model este axat, similar algoritmului
Apriori, pe generarea si validarea unor seturi candidate. Deosebirea fundamentala fata
de Apriori este aceea ca noii candidati nu sunt generati ıntr-o maniera strict marginita.
Astfel, principiul noului algoritm este de a grupa itemii frecventi/itemseturile frecvente
ın intervale si de a obtine noile itemseturi candidate prin reuniuni de itemseturi frecvente
cu nucleul comun, ce apartin de intervale diferite.
Pentru problema identificarii gruparilor similare de date, ın lucrarea de fata accentul
cade pe analiza algoritmului K-Means Clustering si a uneia dintre cele mai des utilizate
metode de paralelizare ale algoritmului - Parallel K-Means - PKM. Rezultatele cecetarilor
efectuate pentru acest algoritm sunt menite sa evidentieze importanta utilizarii unor
topologii de comunicatie adecvate pentru a obtine implementari eficiente ale paralelizarii
ın discutie. Pentru o parte dintre algoritmii analizti, lucrarea a avut ın vedere abordari
paralele bazate pe implementarea LAM/MPI2 a standardului MPI (Message Passing
Interface).
Partea a doua a acestei lucrari este dedicata sistemelor Grid. Cercetarile efectuate
ın cadrul acestui domeniu vizeaza posibilitatile de expunere a aplicatiilor dezvoltate uti-
lizand standardul MPI sub forma servicii Grid. Primul considerent care trebuie avut ın
vedere ın justificarea acestei alegeri este legat de evolutia sistemelor Grid. Inca de la
ınceputul anilor 2000, Foster utilizeaza notiunea de ,,serviciu” pentru a defini conceptul
de OV [Foster 01]:
...examples of VOs: the application service providers, storage service providers,
cycle providers, and consultants engaged by a car manufacturer to perform
scenario evaluation during planning for a new factory...
2Pentru mai multe detalii http://www.lam-mpi.org/
5

In anul 2002, Foster et al. definesc un prim set de specificatii pentru sistemele Grid
orientate pe servicii [Foster 02c]. Aceste specificatii au devenit standardul de facto ın
cadrul sistemelor Grid bazate pe arhitecturi orientate pe servicii - standard cunoscut ın
prezent sunt numele de Open Grid Services Architecture (OGSA). Unul dintre primele
middleware-uri ce a implementat acest standard este Globus Toolkit (ıncepand cu ver-
siunea 3.0)3. Cu toate ca ın versiunile curente acest middleware asigura suport pentru
aplicatiile Grid dezvoltate utilizand diferite implementari ale standardului MPI (MPICH-
G2, LAM/MPI - prin job-managerul implicit, OpenMPI), experimentele au evidentiat
faptul ca acest suport nu este bine stabilizat pentru expunerea acestui tip de aplicatii
sub forma serviciilor Grid. Avand ın vedere aceasta observatie, este propus un model de
expunere a aplicatiilor paralele dezvoltate utilizand LAM/MPI sub forma unui serviciu
Grid. Acest model este prezentat pe larg ın capitolul 6, implementarea fiind expusa de
Grid-ul GRAI dezvoltat ın cadrul proiectului de cercetare 74 CEEX-II03/31.07.2006.
Un al doilea motiv pentru alegerea acestei directii de cercetare este derivat din mo-
delul propus de Foster et al. pentru abordarea problemelor legate de descoperirea de
cunostinte ın cadrul sistemelor Grid [Foster 02b]. Practic, considerand natura complexa
a procesului amintit anterior, Foster et al. justifica faptul ca metodele de analiza speci-
fice ar trebui implementate sub forma de servicii Grid. Acest fapt atrage dupa sine o
ımbinare mai facila a metodelor de analiza pentru aplicatiile complexe. Modelul descris
ın [Foster 02b] este prezentat ın subcapitolul 6.1.1 si reprezinta puntea de legatura ıntre
cele doua domenii de cercetare abordate.
1.2 Structura tezei
Lucrarea de fata este structurata pe doua parti. Prima parte, intitulata ALGORITMI
PARALELI PENTRU APLICATII DATA MINING, este dedi-cata domeniului
descoperirii de cunostinte ın volume mari de date si cuprinde trei capitole.
In capitolul 2 este analizat stadiul actual al cercetarilor din cadrul acestui domeniu.
Sunt prezentate fundamentele teoretice care stau la baza determinarii tiparelor frecvente
si a regulilor de asociere, a determinarii regulilor de clasificare si, respectiv, a metodelor de
clusterizare. Pentru fiecare dintre aceste metode sunt analizati atat algoritmii secventiali
importanti, cat si metode eficiente de paralelizare ale acestora. In centrul atentiei se afla
algoritmii de identificare a tiparelor frecvente ın volume mari de date si cei utilizati ın
clusterizarea datelor. In cazul determinarii tiparelor frecvente sunt analizati doi dintre
cei mai importanti algoritmi ın domeniu: Apriori si FP-Growth. In ambele cazuri sunt
supuse atentiei atat modelele secventiale cat si cele paralele. In cazul tehnicilor de
clusterizare, analiza este focalizata ın jurul algoritmului K-Means Clustering. Alegerea
este justificata de popularitatea acestui algoritm ın cadrul domeniilor ce necesita astfel
de analize de date. Subcapitolul de concluzii aferent evidentiaza un set suplimentar de
motive ce justifica alegerea temei de cercetare.
Capitolul 3 prezinta modificarile propuse pentru optimizarea algoritmului secvential
Apriori (subcapitolul 3.1). Aceste modificari vizeaza codarea binara a itemitor si, respec-
tiv, a seturilor de itemi. In continuare sunt discutate modalitatile prin care sunt modifi-
cate structurile de date caracteristice algoritmului ın discutie. In subcapitolul urmator
este prezentata o propunere de modificare a algoritmului HPA, propunere care se refera
3Pentru mai multe detalii http://www.globus.org/
6

la implementarile MPI ale HPA. Aceasta vizeaza unul dintre puncte slabe ale modelu-
lui de paralelizare amintit anterior: nivelul ridicat al comunicatiilor implicat de faza de
generare de candidati caracteristica algoritmului secvential de baza. Datorita codificarii
binare amintite anterior, se poate slabi conditia de generare a cheii de dispersie utilizata
ın identificarea seturilor de itemi. Astfel, cheia de dispersie poate fi aplicata asupra
setului generator al candidatului curent, fapt ce atrage dupa sine o reducere semnifica-
tiva a comunicatiilor amintite. In continuare, subcapitolul 3.2 prezinta un nou algoritm
pentru determinarea seturilor frecvente. Acest algoritm este bazat tot pe generarea de
candidati, similar algoritmului Apriori. Spre deosebire de Apriori, candidatii noi nu sunt
generati pe baza combinarii unor seturi frecvente de dimensiune k-1 (unde k reprezinta
lungimea seturilor corespunzatoare iteratiei curente), ci pe a ımparti itemii/itemseturile
frecvente ın intervale initial disjuncte si a genera candidatii noi din reuniuni de itemseturi
ce apartin de intervale diferite.
Capitolul 4 vizeaza ımbunatatirile aduse unor implementari MPI ale algoritmu-
lui Paralel K-Means. Cu toate ca paralelizarea existenta este eficienta, foarte multe
dintre implementarile curente nu tin cont de un factor deosebit de important pentru
paralelizarile bazate pe standardul MPI: topologia de comunicatie dintre noduri. O
topologie adecvata unui anumit algoritm poate reduce considerabil timpul suplimentar
implicat ın comunicatii. In acest sens, ın prima parte a subcapitolului este prezentata ın
detaliu o astfel de topologie, cu perfomante crescute pentru comunicatiile colective im-
plicate de PKM. Peste aceasta topologie sunt detaliate modul de partitionare a datelor si
modificarile aduse ın determinarea colectiva a datelor de lucru pentru o eventuala iteratie
ulterioara. Implementarea astfel modificata este comparata din punctul de vedere al tim-
pului de raspuns oferit cu o implementare ce utilizeaza bibliotecile puse la dispozitie de
implementarea LAM/MPI a standardului MPI.
Partea a doua a tezei, intitulata SOLUTII DE IMPLEMENTARE PENTRU
APLICATII DATA MINING IN SISTEME GRID, vizeaza cerce-tarile efectuate
pentru expunerea metodelor de analiza aferente procesului de descoperire de cunostinte
ın cadrul unui sistem Grid. Aceasta a doua parte cuprinde doua capitole.
Capitolul 5 descrie ın detaliu middleware-ul Globus Toolkit, versiunea 4. Sunt
prezentate arhitectura generala a middleware-ului, standardele pe care se bazeaza acesta
si suportul oferit pentru dezvoltarea serviciilor Grid. Sunt aduse ın discutie si cateva
dintre implementarile cele mai importante ale standardului MPI si este analizat suportul
oferit de GT 4 pentru acestea.
Capitolul 6 este dedicat solutiei propuse pentru integrarea aplicatiilor paralele dez-
voltate utilizand standardul mentionat sub forma de servicii Grid. Accentul se pune
pe aplicatiile dezvoltate utilizand implementarea LAM/MPI a standardului. Motivul
acestei alegeri se bazeaza pe faptul ca LAM/MPI versiunea 7.1.* este printre singurele
versiuni ce ofera suport complet pentru versiunea 2.0 a specificatiilor MPI. Este prezentat
modelul generic propus de Foster et al. pentru servicii Grid destinate analizei datelor.
Pornind de la acest model, a fost dezvoltat un serviciu capabil sa expuna diferite module
de analiza caracteristice data mining, module ce sunt implementate utilizand LAM/MPI.
Managerul de job-uri Grid utilizat este cel predefinit pentru versiunea curenta a toolkit-
ului ın discutie (Fork). Serviciul dezvoltat respecta arhitectura Fabrica/Instanta si poate
fi intergrat usor cu orice instalare standard a GT 4. In finalul capitolului este prezentate
un set de rezultate importante menite sa sublinieze necesitatea unui astfel de serviciu.
In capitolul 7 sunt prezentate sintetic rezultatele obtinute si sunt evidentiate contri-
7

butiile aduse pentru cele doua domenii abordate. Finalul capitolului contine propunerile
de cercetare ce deriva din rezultatele obtinute.
1.3 Diseminarea rezultatelor
Articolele stiintifice ce stau la baza acestei lucrari au fost publicate ın reviste (3), volume
de specialitate (3) sau prezentate la conferinte internationale (6) si sunt indexate ın baze
de date bibliografice recunoscute: Thomson ISI (3), IEEE (1).
A. Archip, M. Craus, and S. Arustei. Efficient Grid Service Design to In-
tegrate Parallel Applications. In Marten van Sinderen, editor, Proceedings of
2nd International Workshop on Architectures, Concepts and Technologies for
Service Oriented Computing held in conjunction with 3rd International Con-
ference on Software and Data Technologies, pages 7-16, Porto PORTUGAL,
2008. INSTICC Press. (ISI)
M. Craus & A. Archip. A generalized parallel algorithm for frequent item-
set mining. In ICCOMP’08: Proceedings of the 12th WSEAS international
conference on Computers, PTS 1-3, pages 520-523. World Scientific and En-
gineering Academy and Society (WSEAS), 2008. (ISI)
S. Arustei, M. Craus, and A. Archip. Towards a Generic Framework for
Deploying Applications as Grid Services. In Marten van Sinderen, editor,
Proceedings of 2nd International Workshop on Architectures, Concepts and
Technologies for Service Oriented Computing held in conjunction with 3rd
International Conference on Software and Data Technologies, pages 17-26,
Porto, Portugal, 2008. INSTICC Press. (ISI)
S. Arustei, A. Archip and C.M. Amarandei. Grid Based Visualization Using
Sort-Last Parallel Rendering. In H.N. Teodorescu and M. Craus, editors,
Scientific and Educational Grid Applications, pages 101-109, Iasi, Romania,
2008. Politehnium.
A.Archip, C.M. Amarandei, S. Arustei, and M. Craus. Optimizing Associa-
tion Rule Mining Algorithms Using C++ STL Templates. Buletinul Institu-
tului Politehnic din Iasi, Automatic Control and Computer Science Section,
LIII(LVII):123-132, 2007.
C.M. Amarandei, A. Archip, and S. Arustei. Performance Study for MySql
Database Access Within Parallel Applications. Buletinul Institutului Po-
litehnic din Iasi, Automatic Control and Computer Science Section, LII(LVI):
127 - 134, 2006.
A. Archip, S. Arustei, C.M. Amarandei and A. Rusan. On the design of
Higher Order Components to integrate MPI applications in Grid Services.
In H.N. Teodorescu and M. Craus, editors, Scientific and Educational Grid
Applications, pages 25-35, Iasi, Romania, 2008. Politehnium.
8

C.M. Amarandei, A. Rusan, A. Archip and S. Arustei. On the Development
of a GRID Infrastructure. In H.N. Teodorescu and M. Craus, editors, Sci-
entific and Educational Grid Applications, pages 13-23, Iasi, Romania, 2008.
Politehnium.
S. Caraiman, A. Archip, and V. Manta. A Grid Enabled Quantum Com-
puter Simulator. In SYNASC’09: Proceedings of the 11th International Sym-
posium on Symbolic and Numeric Algorithms for Scientific Computing, Ti-
misoara, Romania, 2009. IEEE Xplore.
S. Arustei, A. Archip, and C.M. Amarandei. Parallel RANSAC for Plane
Detection in Point Clouds. Buletinul Institutului Politehnic din Iasi, Auto-
matic Control and Computer Science Section, LIII(LVII):139-150, 2007.
M. Craus, H.N. Teodorescu, C. Croitoru, O. Brudaru, D. Arotaritei, M. Calin
& A. Archip. Academic Grid for Complex Applications - GRAI. In Proc.
of 16th International Conference on Control Systems and Computer Science.
POLITEHNICA University of Bucharest, May 22-25 2007.
M. Craus, H.N. Teodorescu, C. Croitoru, O. Brudaru, D. Arotaritei, M. Calin
& A. Archip. The Service Layer of the Academic Grid GRAI. In Proc. of
16th International Conference on Control Systems and Computer Science.
POLITEHNICA University of Bucharest, May 22-25 2007.
Lucrari acceptate spre publicare:
A. Archip, V. Manta & G. Danilet, Parallel K-Means Revisited: A Hy-
percube Approach, In Proceedings of the 10th International Symposium on
Automatic Control and Computer Science, October 2010.
I. Astratiei & A. Archip, A Case Study on Improving the Performance
of Text Classifiers, In Proceedings of the 10th International Symposium on
Automatic Control and Computer Science, October 2010.
O parte dintre cercetarile ce au condus la scrierea acestei teze au fost efectuate ın
cadrul proiectului de cercetare Grid academic pentru aplicatii complexe (GRAI ), contract
74 CEEX-II03/31.07.2006, Parteneri: UT Iasi (coordonator), UAIC Iasi, USAMV Iasi,
IIT Iasi, Director proiect: prof. dr. Mitica Craus, Perioada: 2006 - 2008.
9

Capitolul 2
Data mining
2.1 Reguli de asociere
Problema extragerii regulilor de asociere din baze de date poate fi formulata astfel: Dat
fiind un set de obiecte (itemi) I si un set de tranzactii D (sau colectii/multimi de itemi),
sa se identifice toate regulile de forma:
A⇒ B (2.1)
unde A si B reprezinta colectii disjuncte de obiecte [Agrawal 94, Zaki 99].
O observatie importanta este aceea ca regulile de asociere de forma (2.1) nu trebuie
interpretate ca fiind implicatii ın sensul ”existenta setului A implica existena setului B”.
Aceste reguli au semnificatia coexistentei seturilor A si B.
2.1.1 Algoritmi secventiali utilizati ın determinarea
regulilor de asociere
In prezent exista un numar considerabil de algoritmi secventiali propusi pentru extragerea
regulilor de asociere. Fiecare dintre acestia propune fie noi structuri de date pentru
generarea si testarea seturilor candidate (cazul algoritmilor ce extind Apriori, propus
ın [Agrawal 94]), fie reorganizeaza spatiul de cautare ın forme structurate, fie modifica
organizarea bazei de date propuse spre analiza (cum este cazul algoritmilor bazati pe
Eclat). O sinteza coerenta a algoritmilor dezvoltati pana ın anul 1999, este propusa de
Zaki ın [Zaki 99].
O prima diferenta apare ın modul ın care sunt cautate itemseturile frecvente ın baza
relatiilor de incluziune ce apar ıntre multimi. Astfel, algoritmii bazati pe Apriori, precum
si algoritmii anteriori Apriori (AIS si SETM), folosesc o asa numita cautare bottom-up.
Practic, ın cazul acestor algoritmi se porneste de la itemii frecventi si pe baza acestora
se genereaza apoi itemseturi frecvente de dimensiune din ce ın ce mai mare, pana la
determinarea totala sau partiala a itemseturilor maximale. Exista ınsa situatii cand este
preferata o abordare top-down, pentru indentificarea itemseturilor maximale. In acest
sens au fost dezvoltati algoritmi de cautare hibrizi - cum ar fi, spre exemplu, MaxEclat
si, respectiv, MaxClique. Acest tip de algoritmi identifica, ıntr-o prima etapa, o multime
de itemseturi frecvente de dimensiune variabila. In etapele urmatoare, aceste itemseturi
10

sunt fie combinate pentru obtinerea unor itemseturi maximale, fie sunt sparte pentru
obtinerea subseturilor frecvente incluse.
O alta deosebire importanta, evidentiata de Zaki ın [Zaki 99], este legata de modul ın
care sunt generate seturile candidate si, respectiv, identificate apoi itemseturile frecvente.
Astfel, algoritmii bazati pe Apriori sau pe FP-Growth realizeaza o cautare completa a
spatiului solutiilor, identificand ın final toate itemseturile frecvente si, respectiv, toate
regulile de asociere posibile. Exista, ınsa, cazuri ın care nu este necesara identificarea
tuturor tiparelor frecvente. De asemenea, situatia propusa spre analiza poate impune
regasirea numai a itemseturilor maximale.
Un alt aspect deosebit de important ın diferentierea algoritmilor existenti este orga-
nizarea bazei de date tinta. Majoritatea algoritmilor - Apriori si derivati, FP-Growth,
DHP, SEAR, etc. - sunt orientati pe analiza bazelor de date cu organizare orizontala:
ınregistrarile sunt memorate ın forma [identificator tranzactie (TID), lista itemi inclusi ın
tranzactie]. Exista o grupa de algoritmi - Eclat si derivati, si, respectiv, Clique si derivati
- care sunt orientati pe analiza bazelor de date cu organizare verticala: ınregistrarile sunt
memorate sub forma [item, lista identificatori tranzactii ce includ itemul (TID)].
Unul dintre principalii algoritmi de extragere a regulilor de asociere, folosit si ın
prezent, este algoritmul Apriori, propus ın [Agrawal 94]. Principiul de baza al algo-
ritmului este de a calcula seturile frecvente de itemi de dimensiune k prin combinari
ale seturilor de dimensiune k − 1, pentru k cel putin egal cu 2. In plus, ın partea de
generare a seturilor candidate de dimensiune k, se impune urmatoarea constrangere:
un set candidat de dimensiune k nu poate fi obtinut decat prin combinarea a 2 seturi
frecvente de dimensiune k−1 ce au primele k−2 elemente comune. In plus, se impune si
conditia ca orice subset de dimensiune k−1 inclus ın k-itemsetul candidat sa fie frecvent
[Agrawal 94, Adamo 00, Tan 05].
Zaki nota faptul ca algoritmul propus de Agrawal et al. ın [Agrawal 94] obtine o
complexitate timp liniar marginita fata de dimensiunea listei de tranzactii [Zaki 99].
Un al doilea algoritm deosebit de important pentru problema regasirii tiparelor frec-
vente este reprezentat de algorimul FP-Growth [Han 00]. Acesta este, ın prezent, unul
dintre cei mai rapizi algoritmi folositi ın extragerea tiparelor frecvent. Algoritmul este
bazat pe o reprezentare de tip arbore prefix (arbore FP) a tranzactiilor ınregistrate ın
baza de date tinta, modalitate de reprezentare care reduce considerabil memoria folosita
pentru stocarea tranzactiilor [Han 00]. Ideea de baza a algoritmului este bazata pe o
schema de eliminare recursive [Han 00, Grahne 05]
2.1.2 Metode de paralelizare ale algoritmilor secventiali
In aceasta sectiune sunt prezentate cateva dintre cele mai cunoscute paralelizari pentru
algoritmii prezentati anterior.
Paralelizari ale algoritmului Apriori
Tehnicile de paralelizare ale algoritmului Apriori pot fi ımpartite ın 4 categorii, ın
functie de tinta paralelizarii [Shintani 96, Zaki 99, Kumar 03]:
• distribuirea candidatilor - paralelizari de tip ,,candidate distribution”: generarea
candidatilor este distribuita ıntre nodurile de procesare. Partile bazei de date sunt
memorate pe fiecare procesor ın parte. Multimea de candidati este comunicata
11

celorlalte procesoare printr-un proces de tip gather/broadcast. O observatie impor-
tanta este cea a lui Zaki, care sustine ca acest tip de paralelizare este una extrem
de ineficienta, datorita comunicatiilor excesive [Zaki 99];
• distribuirea calculului suportului minim - paralelizari de tip ,,count distribution”:
ın acest caz, baza de date este partitionata ın subseturi disjuncte ıntre proce-
soare. Fiecare procesor cunoaste integral arborele hash al itemilor si, respectiv,
al candidatilor. Suportul este incrementat local, pentru fiecare candidat ın parte.
Urmeaza apoi o etapa de comunicare, pentru calcularea suportului global. Un astfel
de algoritm este Non Partitioned Apriori, propus ın [Shintani 96];
• distribuirea datelor - paralelizari de tip ,,data distribution”: acest model propune o
generare disjuncta a itemseturilor candidate. Totusi, acest model implica, din nou,
comunicatii excesive, de aceasta data pentru transmiterea candidatilor ıntre proce-
soare si calculul suportului global. Un exemplu de algoritm este Simple Partitioned
Apriori [Shintani 96];
• paralelizari hibride: modelul algoritmic propus ın acest caz este reprezentat de
Hash Partitioned Apriori (HPA) [Shintani 96] si va fi expus pe larg ın contin-
uare.
Algoritmul HPA are la baza, dupa cum indica si numele sau, algoritmul Apriori, fiind
una dintre cele mai eficiente paralelizari ale algoritmului mentionat.
Cum am amintit anterior, ideea algoritmului Apriori este aceea de a genera seturi
candidate de itemi de dimensiune k pe baza seturilor frecvente de itemi de dimensiune
k − 1. Fiecare set de itemi candidat este apoi testat pentru a se determina daca este un
set frecvent de itemi sau nu. Acest pas se repeta pana ın momentul ın care nu mai sunt
gasite seturi frecvente de itemi sau pana cand se ajunge ın imposibilitatea generarii de
seturi candidate.
Algoritmul HPA partitioneaza itemseturile canditate si baza de date ıntre procesoare,
folosind o functia hash caracteristica algoritmului secvential de baza. Se elimina astfel
broadcastul inutil al datelor tranzactionate si se obtin reduceri semnificative din punct
de vedere al timpului consumat ın calculul suportului pentru un set dat [Shintani 96].
Paralelizari ale algoritmului FP-Growth
Una dintre cele mai interesante paralelizari ale algoritmului FP-Growth este propusa
de Zaiane si este prezentata ın continuare [Zaiane 01] . Modelul algoritmic poarta numele
de Multiple Local Frequent Pattern Trees (MLFPT ) si este constituit din doua faze.
Prima dintre acestea consta ın construirea unor arbori FP locali, ın timp ce etapa a doua
consta ın explorarea acestor arbori si construirea seturilor frecvente de itemi.
Pentru construirea arborilor MLP (Multiple Local Pattern), initial se scaneaza baza
de date pentru a se identifica seturile de itemi frecventi de dimensiune 1 (sau, cu alte cu-
vinte, itemii frecventi). In acest scop, baza de date tinta este ımpartita ıntre procesoare
ın mod aproximativ egal. Fiecare procesor va calcula suportul partial al itemilor regasiti
ın subsetul de tranzactii ce i-a fost repartizat din baza de date initiala. Aceasta etapa se
ıncheie cu o operatie colectiva de reducere pentru a determina suportul global al fiecarui
item ın parte. Urmeaza un pas computational de eliminare a itemilor nefrecventi si de
sortare a itemilor frecventi ın ordinea descrescatoare a suportului calculat. Similar algo-
ritmului secvential, tranzactiile sunt de asemenea sortate descrescator relativ la suportul
12

itemilor inclusi si sunt eliminati din tranzactii itemii nefrecventi. Urmeaza o etapa de
calcul, cu scopul de a construi arborii FP locali. Trebuie facuta observatia ca acesti
arbori locali vor avea radacina un element null. Fiecare procesor va scana din nou setul
de tranzactii ce i-a fost asignat pentru determinarea arborilor FP locali. Pasii urmati ın
acest caz sunt similari (la nivel local) cu cei ai algoritmului FP-Growth secvential.
Se construieste apoi baza de tipare conditionale: o lista care contine toti itemii ce
apar ınaintea itemului studiat si pana la radacina (ıntr-o parcurgere bottom-up). Prin
combinarea acestor baze de tipare conditionate se identifica pentru fiecare item ın parte
un sir ce contine toti ceilalti itemi cu care itemul curent poate forma seturi frecvente,
precum si suportul pentru fiecare set ın parte. Se obtin, astfel, arbori FP-conditionali.
Pe baza acestora din urma se determina tiparele frecvente. Aceasta ultima etapa este
una intensiv comunicationala. Pentru fiecare itemset ın parte sunt necesare operatii
de comunictie colective pentru determinarea suportului global pe baza arborilor FP-
conditionali.
2.1.3 Discutii asupra tehnicilor existente de extragere a regulilor de asociere
In subcapitolele anterioare au fost prezentati doi dintre cei mai importanti algoritmi
utilizati ın determinarea regulilor de asociere (Apriori si FP-Growth) si doua dintre cele
mai cunoscute metode de paralelizare pentru algoritmii ın discutie. Cu toate ca ambii
algoritmi sunt eficienti, exista un set de dezavantaje ce ar putea fi eliminate.
Astfel, cu toate ca obtine timpi de raspuns performanti prin reducerea semnificativa
a scanarilor bazei de date tinta (doar doua scanari ale bazei de tranzactii), algorit-
mul FP-Growth implica existenta unor sturcturi de date complexe. Acest fapt atrage
dupa sine o complexitate mult crescuta pentru modelele paralele. Implementarile mod-
elului MLFPT realizate pentru sisteme de calcul paralel bazate pe principiul memoriei
partajate se pot dovedi ineficiente datorita sincronizarilor implicate de construirea arbo-
rilor FP-conditionali. Pe de alta parte, daca sistemul de calcul paralel este unul bazat pe
memorie distribuita si comunicare de mesaje, atunci detereminarea tiparelor frecvente pe
baza arborilor FP-locali implica un necesar crescut de comunicatii ce pot cauza scaderea
performantelor.
Legat de primul algoritm, Apriori, se pot observa rapid doua dezavantaje majore ale
algoritmului. In primul rand, algoritmul interogheaza la fiecare iteratie baza de date tinta,
inclusiv ın faza de generare a k-itemseturilor candidat [Agrawal 94]. In al doilea rand,
functia cheie a algoritmului introduce timpi de calcul suplimentari. Dupa determinarea
celor doua seturilor de dimensiune k − 1 ce vor genera k-itemsetul candidat, trebuie
verificat daca toate (k − 1)-itemseturile incluse ın noul candidat sunt (k − 1)-itemseturi
frecvente. Ordinul de complexitate al functiei de generare este O(rk12· rk· k).
In cazul general, algoritmii existenti utilizati ın extragerea regulilor de asociere pot
fi optimizati doar din punctul de vedere al raspunsului timp. Considerand o astfel de
abordare, Agrawal propune (propunere reluata apoi ın [Adamo 00]) un al doilea algoritm,
AprioriTid [Agrawal 94]. Fata de varianta de baza, algoritmul AprioriTid memoreaza,
pentru fiecare k-itemset frecvent, si un set de identificatori ai tranzactiilor pe baza carora
a fost calculat suportul itemului ın discutie. Totusi, nici aceasta abordare nu obtine un
plus de performante considerabil.
Un alt aspect negativ legat de algoritmii utilizati ın determinarea regulilor de asociere
este ca, ın afara de algoritmul Apriori nu au fost exploatate alte mecanisme de gene-
13

rare a candidatilor ce ar putea reduce considerabil multimea de seturi parcurse. O alta
observatie importanta este ca, desi autorii din [Tan 05] introduc ın mod demonstrativ
codificarea binara a itemseturilor, nu se regasesc publicate nici un set de rezultate care
sa ofere detalii legate de performantele acestei codificari.
2.2 Reguli de clasificare
Formal, extragerea regulilor de clasificare poate fi rezumata la urmatoarea definitie
[Freitas 00, Tan 05]:
Definitia 2.1 (Regula de clasificare). Extragerea regulilor de clasificare dintr-un set
de date reprezinta generarea, pe baza cunostintelor acumulate, a unui set de constrangeri
pentru a sorta datele ulterioare.
2.2.1 Algoritmi secventiali utilizati ın determinarea
regulilor de clasificare
Asa cum am amintit ın capitolul introductiv, prin extragerea unui set de reguli de clasi-
ficare dintr-un set de date tinta se ıncearca identificarea unei functii capabile sa mapeze
corect un set de atribute de intrare pe un set de etichete predefinite, numite clase. In
cazul general, aceasta operatie este compusa din doua etape distincte [Tan 05]:
• prima dintre acestea implica ınvatarea regulilor de clasificare pe baza unui model
predefinit, construit, ın mod uzual, pe baza experientei beneficiarilor finali [Two 05];
• a doua etapa implica aplicarea acestui model de clasificare pe un set de date de test,
pentru a se masura acuratetea modelului. In cazul ın care modelul de clasificare
obtinut este unul satisfacator, atunci se poate trece la aplicarea sa pe bazele de
date de interes. Daca, dimpotriva, acuratetea modelului lasa de dorit, atunci se
ıncearca crearea unui nou set de test, pentru reınvatarea regulilor de clasificare,
eventual prin adaugarea de noi constrangeri.
O alta grupare posibila este legata de specificarea exacta sau nu a claselor rezultat.
Din acest punct de vedere se pot distinge doua clase de algoritmi: algoritmi statici -
clasele si constrangerile pentru fiecare clasa ın parte sunt specificate de la inceput -
si, respectiv, algoritmi dinamici - se ıncearca determinarea automata a claselor si a
numarului acestora.
2.3 Segmentarea datelor
Definitia 2.2 (Clusterizarea datelor). Clusterizarea datelor (sau segmentarea da-
telor) ınseamna, ın sens larg, regasirea unei structuri ıntr-o colectie de date nemarcate/
nestructurate.
Conceptual, procesul de clusterizare/partitionare a datelor poate fi privit ca fiind
organizarea unui set de obiecte (date) ın grupuri ale caror membri sunt similari dupa un
anumit set de restrictii impuse.
In prezent, un numar din ce ın ce mai mare de aplicatii utilizeaza metode de clusteri-
zare pentru a obtine rezultate superioare. Exemplele cele mai uzuale includ clusterizarea
14

documentelor [Li 05] si sistemele de regasire a informatiilor [Grossman 04]. Un studiu
recent a indicat o crestere a acuratetii de clasificare a algoritmului k-nn (k-nearest neigh-
bor) ın cazul ın care setul de antrenament corespunzator a fost generat pe baza unei
clusterizari a documentelor incluse de acest set de antrenament [Astratiei 10]. O prob-
lema comuna care apare ın cazul acestor aplicatii este legata de volumul mare de date
care trebuie procesate. Algoritmii de clusterizare sunt ın general de tipul lazy learner si
trebuie utilizate metode eficiente de paralelizare pentru a obtine timpi de raspuns si o
scalabilitate rezonabile.
2.3.1 Notiuni teoretice fundamentale
Conform definitiei de mai sus (Definitia 2.2, adaptare dupa [Han 06]), clusterizarea
reprezinta o tehnica descriptiva de data mining care urmareste divizarea unui set de
obiecte date ın grupuri distincte. Procesul de ımpartire a setului dat de date este real-
izat pe baza similaritatii intrinseci a itemilor, tinand cont de atributele interesante.
Definitia 2.3 (Similaritate). In mod uzual, similaritatea este definita ca fiind o met-
rica/distanta peste un set de atribute.
Rezultatele clusterizarii ar trebui sa ofere o reprezentare mai buna a setului de date
de intrare, tinand cont de metrica de similaritate (obiectele apartinand aceluiasi grup au
aceleasi caracteristici, ın timp ce doua obiecte apartinand de grupuri diferite ar trebui
sa fie semnificativ diferite). Metodele de clusterizare sunt considerate ın general ca fiind
o forma de ınvatare nesupervizata [Han 06, Berkhin 02]. Din acest punct de vedere,
[Berkhin 02] subliniaza ca rezultatele reprezinta un model ascuns care furnizeaza o noua
reprezentare a datelor existente.
2.3.2 Algoritmi secventiali utilizati ın segmentarea datelor
Unul dintre cei mai des utilizati algoritmi de segmentare, algoritmul K-Means Cluster-
ing (KMC), a fost introdus de catre MacQueen ın anul 1967 [MacQueen 67]. In prezent,
KMC este unul dintre cele mai vechi, si conform [Joshi 03], si unul dintre cei mai populari,
algoritmi de clusterizare. Motivul acestei popularitati este dat de simplitatea ın imple-
mentare, de scalabilitate si de viteza de convergenta. De asemenea, daca se utilizeaza o
metrica adecvata, algoritmul poate fi adaptat pentru o varietate mare de tipuri de date.
Algoritmul KMC reprezinta o metoda de partitionare care are ca scop divizarea setului
de date de intrare de dimunsiune n ın k partitii. Obiectele apartinand unei partitii tre-
buie sa fie asemanatoare ıntre ele, ın timp ce obiectele care apartin unor partitii diferite
trebuie sa difere. M. Joshi ın [Joshi 03], citand [Dhillon 00], prezinta urmatoarele etape
generice pentru algoritmul KMC:
1. initializarea - se selecteaza un set de k itemi din setul de date de intrare pentru a
fi centroizii initiali;
2. calcularea distantelor - pentru fiecare item din setul de date, se calculeaza distanta
pana la centroizii selectati; itemul este distribuit celui mai apropiat centroid;
3. recalcularea centroizilor - pentru fiecare cluster, se recalculeaza centroidul ca fiind
media itemilor atribuiti;
15

4. conditia de convergenta - se repeta etapa 2 si 3 pana la atingerea convergentei.
Din punct de vedere logic, conditia de convergenta pentru etapa 4 poate fi una dintre
urmatoarele variante: atunci cand nu se mai redistribuie nici un item ıntre doua clustere
sau atunci cand coordonatele centroizilor nu s-au modificat ın etapa 3. Din punct de
vedere matematic, convergenta este reprezentata de eroarea patratica calculata conform
relatiei (2.2). In acest caz etapa 4 poate fi definita ca fiind valoarea minima pentru relatia
(2.2) [Han 06] (ın capitolul 8):
E =∑
k
∑
xi∈C(k)
‖xi −mk‖2. (2.2)
Este important de mentionat ca algoritmul KMC este o abordare de tip greedy pentru
metodele de partitionare (datorita modului de alegere a centroizilor ıntre etape). Pentru
diferite variante de alegere a centroizilor initiali, eroarea patratica minima calculata
conform (2.2) poate varia. Daca luam ın considerare k - numarul de clustere, n - numarul
de itemi care trebuie clusterizati si t - numarul de iteratii necesare pentru a atinge
convergenta, algoritmul KMC are o complexitate de timp de ordinul O(nkt) [Han 06]
(capitolul 8). In mod normal, ıntre n, k si t exista urmatoarea relatie (a se vedea
[Han 06] capitolul 8 pentru mai multe detalii):
k ≪ n
t≪ n.(2.3)
Daca luam ın considerare relatia (2.3), se poate observa usor ca numarul total de
itemi n este factorul cu cea mai mare influenta asupra timpului de raspuns pentru orice
implementare KMC.
2.3.3 Metode de paralelizare ale algoritmilor secventiali
Au fost realizate diferite ıncercari de a optimiza paralelizarea algoritmului KMC. Unul
dintre cele mai cunoscute si utilizate modele este Parallel K-Means (prescurtat PKM )
[Dhillon 00, Joshi 03, Stoffle 99]. Cel mai mare consumator de timp este pasul de calcu-
lare a distantelor. Aceasta etapa ın sine presupune O(nk) pasi pentru a calcula distantele
ıntre fiecare item din setul de date (compus din n itemi) si fiecare dintre cei k cen-
trozii. Modelul paralel pentru PKM ımparte ıntregul set de date de intrare ıntre procese
[Dhillon 00, Joshi 03, Stoffle 99]. Considerand p procese, fiecare va primi (n/p) elemente
din setul de intrare. Divizarea itemilor va reduce fazele locale de calculare a distantelor
la complexitatea de timp data de relatia:
O(n· k
p). (2.4)
2.3.4 Discutii asupra tehnicilor existente de segmentare
a datelor
Modelul PKM se bazeaza pe o paradigma de tipul SIMD (Single Instruction Multiple
Data). O prima observatie importanta este faptul ca acest model nu este aplicabil doar
unei metode specifice de implementare. In functie de diferitele cerinte, algoritmul PKM
16

poate fi implementat utilizand fie paralelism la nivel de thread-uri/memorie partajata
sau paralelism la nivel de proces/ memorie distribuita. Totusi, diversi autori sustin faptul
ca ultima metoda ar trebui aleasa, ın special atunci cand avem de-a face cu volume mari
de date [Dhillon 00, Joshi 03, Stoffle 99] (acesta ar fi si cazul aplicarii metodelor bazate
pe KMC ın domeniul clusterizarii documentelor text [Han 06]).
Daca avem ın vedere implementarea efectiva a PKM utilizand o schema de distributie
a memoriei, standardul Message Passing Interface (MPI pe scurt) este considerat cea mai
buna abordare [Joshi 03]. Aceasta alegere este bazata pe o serie de argumente, cum ar
fi [Joshi 03]:
• MPI este un standard pentru calculul paralel bazat pe momorie distribuia si trans-
mitere de mesaje (ın prezent, urmeaza sa fie lansata versiunea 3 a specificatiilor);
• este portabil (cu conditia ca aplicatiile sa fie recompilate ıntre diferitele platforme
de operare), este heterogen si ofera un suport adecvat pentru diferite topologii de
comunicare;
• paralelismul este explicit, programatorului fiindu-i oferita libertate ın implementare;
• o mare varietate de implementari sunt disponibile (exemplele cele mai rapide sunt
MPICH-G2, IntelMPI, LAM/MPI, OpenMPI) pentru toate limbajele de progra-
mare (cum ar fi C/C++ sau FORTRAN).
O deficienta importanta legata de acesata abordare este reprezentata de faptul ca nu
se pune accent pe topologiile de comunicatie ce pot fi manipulate prin intermediul MPI.
Capitolul 4 reia ın detaliu aceasta problema.
2.4 Concluzii
In cadrul acestui capitol au fost evidentiati algoritmii clasici destinati problemei des-
coperirii reguilor de asociere, a regulilor de clasificare, precum si cei destinati seg-
mentarii/clusterizarii datelor. Se observa ın acest fel faptul ca, desi ultimii algoritmi
clasici pentru extragerea de cunostinte din baze de date sunt de data relativ recenta
- 2001 sau 2003, exista putine cercetari legate de ımbunatatirea timpului de raspuns.
Se mai poate observa totodata si faptul ca pentru algoritmii adusi ın discutie nu sunt
epuizate toate posibilitatile de ımbunatatire a performantelor. Parte dintre aceste posi-
bilitati vor fi investigate ın continuare.
17

Capitolul 3
Noi algoritmi si modele de paralelizare
pentru determinarea tiparelor frecvente
3.1 Algoritmul Apriori
In cadrul subcapitolului 2.1 au fost evidentiate un set de dezavantaje ale algoritmu-
lui Apriori. Astfel, algoritmul propus de Agrawal este puternic dependent de metoda
de generare a candidatilor [Agrawal 94]. Aceasta metoda implica un consum de timp
substantial pentru o generare eficienta de candidati. Mai mult, generarea candidatilor
implica un consum suplimentar substantial de memorie.
Cu toate ca HPA reprezinta un model de paralelizare eficient pentru algoritmul
Apriori (implementarile eficiente partitioneaza atat determinarea candidatilor, cat si
tranzactiile bazei de date tinta), exista un set de dezavantaje ale modelului:
• partitionarea candidatilor este realizata ın baza unei chei de dispersie caracteristica
algoritmului secvential de baza. Aceasta cheie nu este, de cele mai multe ori,
determinata astfel ıncat sa realizeze o buna echilibrare a ıncarcarii nodurilor de
lucru.
• considerand ca functia de calcul a cheii de dispersie se aplica la nivel de set de
itemi, acest lucru poate conduce la o crestere substantiala a comunicatiilor pentru
determinarea completa a tuturor seturilor candidate.
• pentru a rezolva orice dezechilibru ce poate aparea ın timpul rularii sau pentru a
determina conditia de oprire, modelul implica existenta unui nod coordonator.
3.1.1 Algoritmul secvential de baza
Considerand observatiile anterioare, o prima modificare propusa pentru algoritmul Apri-
ori vizeaza modul de reprezentare al itemilor/itemseturilor de lucru.
Reprezentarea itemilor
O prima modificare efectuata vizeaza modul de reprezentare al itemilor. Un prim aspect
important este legat de consumul de memorie. Implementarile uzuale ale algoritmului
18

Apriori codeaza itemii fie printr-un caracter alfa-numeric (se poate face, ın acest caz,
distinctie ıntre litere mari si litere mici pentru a mari capacitatea de reprezentare a
metodei), fie printr-un index numeric atribuit itemului (ın general, o valoare ıntreaga
cuprinsa ıntre 0 si nr max− 1, unde nr max reprezinta numarul total de itemi).
Autorul a introdus ın [Archip 07] o metoda de codare binara a itemilor si, respectiv, a
itemset-urilor, similara cu [Tan 05]. Itemii sunt codificti prin intermediul valorilor binare
de 0/1. Considerand o numerotare a itemilor ın intervalul [0, n− 1], un item de index x
este reprezentat de bitul de pe pozitia 2x ıntr-un sir de n biti. Reprezentarea tranzactiilor
si, respectiv, a itemset-urilor este redata ın Tabelul 3.1. Au fost considerati un set de 5
itemi (A, B, C, D, E - itemul A este reprezentat binar prin bitul de pozitie 0, itemul E
prin bitul corespunzator pozitiei 4).
Tabelul 3.1: Reprezentarea binara a tranzactiilor/itemseturilor
Itemset/Tranzactie Reprezentare binara{A, B, C} 00111{A, C, E} 10101{B, D} 01010{C, D, E} 11100{A, B, C, D, E} 11111
In Tabelul 3.1 se poate observa si un aparent dezavantaj al acestei reprezentari:
seturile de itemi/tranzactii au dimensiune fixa, indiferent de numarul de itemi inclusi.
Se poate usor observa ca, ın cazul reprezentarii itemilor prin index numeric (din
punctul de vedere al tipului de data utilizat, ar fi necesari cel putin 2 octeti pentru
reprezentarea unui singur item) consumul de memorie ar fi mult mai mare. Din acest
motiv nu se mai fac comparatii ıntre reprezentarea prin index numeric si reprezentarea
binara propusa ın [Archip 07].
O observatie importanta asupra algoritmului Apriori - observatie care ısi mentine
valabilitatea si pentru algoritmii derivati din Apriori - este aceea ca trateaza tranzactiile
la nivel de multime de itemi. Practic, pentru acesti algoritmi, determinarea suportului
se reduce la problema incluziunii unei submultimi ıntr-o multime data. Din acest punct
de vedere reprezentarea binara ofera din nou un avantaj foarte important: se poate
determina, ın timp constant daca setul curent de itemi este sau nu inclus ın tranzactia
curenta.
Generarea candidatilor
Modelul clasic pentru generarea candidatilor a fost propus ın [Agrawal 94] si are la baza
urmatorul principiu: seturile candidate de itemi de dimensiune k se pot obtine numai
prin combinarea seturilor frecvente de itemi de dimensiune k− 1 ce au primii k− 2 itemi
comuni [Adamo 00].
Dupa cum a fost amintit si ın partea introductiva, functia are la baza principiul
Apriori, conform caruia daca un set de itemi este frecvent, atunci toate subseturile de
itemi ce apartin de acest set sunt seturi frecvente [Tan 05]. Literatura de specialitate
considera aceasta functie ca realizand o eliminare optima a seturilor ce nu pot fi frecvente,
seturi pentru care nu se va mai determina suportul ın cadrul tranzactiilor, ıntrucat aceste
19

seturi contin cel putin un subset nefrecvent [Zaki 99, Adamo 00, Tan 05]. Functia este
totusi una consumatoare de timp si este considerata un dezavantaj major al algoritmului
Apriori.
Unul dintre avantajele utilizarii reprezentarii binare a seturilor de itemi si, respectiv,
a tranzactiilor este cel al vitezei cu care sunt realizate operatiile logice peste multimi de
biti. Aceste operatii binare elementare pot fi mapa rapid orice operatie ar fi necesara ın
lucrul cu multimi de itemi.
Remarcabil ın acest sens este si faptul ca aceste operatii binare elementare nu depind
direct, din punctul de vedere al vitezei de executie, de dimensiunea d a multimilor asupra
carora sunt aplicate, daca d este mai mica decat o anumita valoare maxima specifica
fiecarui procesor ın parte.
Pornind de la aceste considerente, se poate demonstra usor ca determinarea oricaror
itemi necomuni ıntre oricare 2 seturi de itemi se realizeaza ın timp constant. Particu-
larizand, se poate arata ca utilizand o reprezentare binara a seturilor de itemi se poate
identifica setul de dimensiune 2 format din itemii necomuni printr-o singura operatie.
Metoda particulara de generare a candidatilor implementata este bazata pe obser-
vatiile anterioare. Nu se ıncearca, precum ın cazul clasic [Tan 05], generarea tuturor
subseturilor de dimensiune k − 1 ale candidatului curent (de dimensiune k), ci se deter-
mina direct setul format din cei 2 itemi necomuni pentru perechea curenta. Daca acest
set este frecvent, atunci candidatul obtinut va fi adaugat la lista de candidati valizi, iar
daca acest set este nefrecvent, atunci candidatul va fi ignorat. Algoritmul 3.1 prezinta
pseudocodul dezvoltat pentru a implementa aceasta metoda de generare a candidatilor.
Algoritmul 3.1 Generarea candidatilor pentru codificarea binara a itemseturilor
Require: Lk−1
1: for all (set1, set2) in Lk−1 × Lk−1 such that set1.parent == set2.parent do2: test set.code = set1.code ∧ set2.code;3: if isFrequent(test set) then4: candidate.code = set1.code | set2.code5: candidate.parent = min(set1, set2)6: add candidate to candidateList7: end if8: end for
In Algoritmul 3.1 au fost utilizate urmatoarele notatii:
• set1, set2 - variabile generice pentru reprezentarea binara a unui set de itemi;
• set1.parent, set2.parent - notatii folosite pentru a desemna primii k−2 biti comuni
pentru cele 2 seturi frecvente ce pot genera un candidat;
• set1.code, set2.code - codul binar al celor 2 seturi.
Dupa cum se poate usor observa din pseudocodul anterior, singurul test facut asupra
unui candidat este legat de itemii necomuni si anume setul de dimensiune 2 format de
acestia. Desi acest lucru nu conduce la o eliminare optima a candidatilor ce contin
subseturi nefrecvente, functia compenseaza prin scaderea timpilor de raspuns.
20

3.1.2 Modificari aduse algoritmului HPA
Modificarile aduse algoritmului secvential Apriori pot fi utilizate si pentru a solutiona
parte dintre dezavantajele modelului de paralelizare HPA. O prima observatie impor-
tanta este aceea ca modalitatea de reprezentare a itemseturilor si a tranzactiilor prin
intermediul unei codificari binare elimina dependeta algoritmului de un eventual arbore
de dispersie. Acest fapt reprezinta o slabire importanta a conditiilor de generare a cheilor
de dispersie pentru ca aceste chei nu vor mai avea rol de identificator unic al unei anumite
combinatii de itemi.
Un alt punct nevralgic pentru HPA este reprezentat de partitionarea candidatilor
determinati pentru determinarea suportului. In mod uzual, aceasta etapa este una in-
tensiv comunicationala. Mai mult, este posibil ca un set generator sa fie repartizat unui
nod de procesare, ın timp ce perechea sa este repartizata altui nod de calcul. Aceasta
situatie implica din nou comunicatii.
Particularitati ale functiei de dispersie
Considerand observatiile anterioare, functia de dispersie utilizata a fost una de tipmodulo-
bitonic. Cheile hash sunt ın acest caz valori ın clasa de resturimodulo n, unde n reprezinta
numarul total de procesoare implicate ın analiza. Seturile de itemi sunt ımpartite ın or-
dine ıntre procesoare astfel ıncat pentru fiecare item/set de itemi ın parte cheia hash
variaza dupa o alternanta bitona [Archip 07]. In Tabelul 3.2 este prezentat un exemplu
pentru un numar de 10 itemi cu etichete de la 0 la 9 si un total de 3 noduri de procesoare.
Tabelul 3.2: Distribuirea itemilor intiali ıntre procesoare
Eticheta item 0 1 2 3 4 5 6 7 8 9Cheie Hash 0 1 2 2 1 0 0 1 2 2
Un aspect important al acestei functii hash, legat de implementarea practica ın mod
special, este acela ca timpul necesar calculului cheii hash curente trebuie sa fie ın clasa
de complexitate O(1). Algoritmul 3.2 reprezinta pseudocodul utilizat ın implementarile
de test [Archip 07].
Dupa cum se poate usor observa, indiferent ce valoare trebuie generata pentru cheia
curenta, functia propusa realizeaza cel mult 4 pasi: 2 teste si, respectiv, fie o operatie de
atribuire urmata de o operatie de incrementare/decrementare, fie 2 operatii de atribuire.
Mai mult, functia nu este conditionata sub nici o forma de numarul total de itemi, iar
viteza de generare a valorilor rezultat nu este influentata de numarul total de procesoare.
In plus, se poate demonstra usor, prin reducere la absurd, faptul ca indiferent de numarul
de procesoare si de numarul de itemi sau de seturi de itemi ale pasului curent se reali-
zeaza o foarte buna echilibrare a distributiei itemilor/seturilor de itemi ıntre nodurile de
procesare.
Fie k numarul total de itemi/seturi de itemi ai pasului curent si n numarul total de
procesoare (se considera k > n). Din Tabelul 3.2 si Algoritmul 3.2 se observa foarte
rapid ca toate cele n procesoare ar primi un numar de [k/n] itemi/seturi de itemi si doar
[k%n] procesoare ar primi un singur item/set de itemi ın plus fata de restul nodurilor.
21

Algoritmul 3.2 Functia Hash utilizata ın cadrul algoritmului HPA
1: static d = 02: if d = 0 then3: if last key < size− 1 then4: new key = last key ++5: else6: new key = last key7: d = 18: end if9: else
10: if 0 < last key then11: new key = last key −−12: else13: new key = last key14: d = 015: end if16: end if
Partitionarea itemset-urilor
Un alt punct slab al HPA este reprezentat de determinarea si de distribuirea candidatilor
ıntre procese ın vederea calcularii suportului pentru fiecare candidat ın parte. Aceste
doua etape sunt intensiv comunicationale si pot introduce timpi suplimentari considera-
bili.
O prima modificare adusa algoritmului HPA este de a aplica functia de calcul a cheii
de dispersie la nivelul setului parinte al candidatului curent.
Definitia 3.1 (Itemset parinte). Prin conventie, se numeste itemset parinte al unui
candidat de dimensiune k acel itemset care contine primii k-1 itemi din candidatul curent.
Algoritmul 3.3 prezinta modalitatea de generare a candidatilor conform cu modificarile
propuse.
Algoritmul 3.3 Generarea candidatilor - adaptare HPA
Require: Lidk−1 - multimea seturilor frecvente repartizate nodului id
1: for iter = 0 to iter < length(Lidk−1)− 1 do
2: hashKey := nextKey(set[iter])3: for all pairSet in Lid
k−1 such that set[iter].parent == pairSet.parent do4: candidate.code := set[iter].code ∧ pairSet.code5: if true == isFrequent(candidate) then6: candidate.code := set[iter].code | pairSet.code7: candidate.parent := set[iter]8: candidate.hashKey := hashKey9: end if
10: end for11: end for
In Algoritmul 3.3, functia nextKey noteaza o implementare a Algoritmului 3.2.
22

3.1.3 Rezultate si discutii
Testarea algoritmului secvential modificat
Pentru evaluarea modificarilor aduse din punctul de vedere al timpului de raspuns, au
fost realizate un set de 15 teste. Pentru toate cele 15 teste a fost considerata o baza
de date formata din tranzactii generate aleator, cu suport pentru maxim 32 de itemi.
Pentru evaluarea performantelor, au fost considerate seturi de 10, 15 si, respectiv 20 de
itemi, iar limita suportului minim a fost variata ıntre 1%, 5%, 10%, 20% si, respectiv,
35%. In toate cazurile, baza de date contine un numar de 1.000.000 tranzactii. Evaluarile
au urmarit ın principal comportamentul functiei de generare a candidatilor, dar si timpii
totali consumati de analiza.
Rezultatele timp obtinute pentru cazul ın care au fost considerati 10 itemi, iar limita
suportului a fost variata ıntre 1 si, respectiv, 35% evdentiaza obtinuta o scadere pentru
functia de generare a candidatilor. Daca ıntr-un un caz clasic, literatura de specialitate
[Adamo 00, Tan 05] considera metodele de generare a candidatilor ca fiind comparabile
ca rapuns timp cu metodele de selectie ale seturilor frecvente, pentru abordarea pro-
pusa timpii consumati de generarea candidatilor sunt mult inferiori timpilor implicati ın
determinarea seturilor frecvente.
Totusi, acest castig este unul minor pentru cazul secvential. Abordarea propusa
nu se preteaza cazului secvential deoarece renuntarea la structurile de tip ,,hash-tree”
caracteristice abordarilor bazate pe Apriori [Agrawal 94, Adamo 00, Tan 05] conduce
catre timpi de raspuns globali din ce ın ce mai mari. Rezultatele timp pentru aceeasi
baza de date (de 1.000.000 de tranzactii) pentru cazul ın care au fost considerati 15 itemi
de start. Suportul a fost variat si ın acest caz ıntr-o maniera identica testului anterior.
Se observa, ca si ın cazul anterior, un timp foarte mic pentru generarea candidatilor.
Comparand totusi timpii totali implicati se observa ca pentru o cresterea cu doar 5 itemi
a bazei de analizat, timpi cresc cu pana la un ordin de marime. Acest comportament
se datoreaza faptului ca o codificare binara a itemilor/seturilor de itemi atrage dupa
sine o complexitate de O(n· ck) pentru determinarea suportului seturilor candidate (n
reprezinta numarul total de tranzactii, ck reprezinta numarul total de candidati de di-
mensiune k). In foarte multe cazuri, factorul ck este comparabil din punct de vedere al
valorii cu factorul n. Literatura de specialitate sustine pentru aceasta etapa a algorit-
mului o complexitate timp pseudo-liniara ın raport cu dimensiunea bazei de date tinta
[Agrawal 94, Adamo 00, Tan 05].
Rezultatele prezentate nu recomanda, ın mod clar, aceasta abordare pentru modelul
secvential al algoritmului Apriori.
Testarea algoritmului HPA modificat
In vederea testarii modificarilor aduse algoritmului HPA, experimentele au fost conduse
ın aceeasi maniera ca si ın cazul clasic. Astfel a fost utilizata aceeasi baza de date de
1.000.000 de tranzactii, oferind suport pentru 10, 15 sau 20 itemi. Limita de suport
minim a fost variata ıntre 1%, 5%, 10%, 20% si, respectiv, 35%.
Implementarea de test include un set de particularitati importante. Codul algorit-
mului HPA a fost dezvoltat utilizand limbajul C++, suportul pentru paralelizare fiind
oferit de bibliotecile LAM/MPI. Pentru a elimina complet comunicatiile, baza de date
tinta a fost utlizata pentru a stoca si seturile frecvente determinate ın cadrul unei etape
23

k. Astfel, pentru etapa urmatoare, fiecare procesor de rang id selecteaza din baza de
itemseturi frecvente doa acele itemseturi a caror cheie de dispersie este egala cu valoarea
id. Acest lucru este posibil datorita faptului ca, ın urma modificarilor aduse, cheia de
dispersie identifica strict perechile ce pot forma candidati. Serverul suport pentru bazele
de date a fost MySQL, versiunea 4. Atat tabelele de tranzactii cat si tabele rezultat au
folosit suport InnoDB [Amarandei 06]. Este important de retinut ca un astfel de scenariu
poate fi aplicat ın cadrul sistemelor Grid, ın cazul ın care restrictiile impuse ın cadrul
unei organizatii virtuale nu permit migrarea datelor de analizat.
Din analiza rezultatelor obtinute se poate observa ca timpii de lucru pentru fiecare
procesor ın parte sunt timpi foarte apropiati ca valori. Aceste rezultate sustin conside-
ratiile teoretice asupra functiei hash proiectate si implementate si, ın plus, sustin modul
de aplicare al acesteia.
Se poate observa ca, spre deosebire de cazul secvential, unde renuntarea la arborele
hash atragea dupa sine pierderi semnificative ın ceea ce consta performanta timp, versi-
unea paralela a algoritmului mentine stabilitatea timpilor de raspuns. Mai mult, pentru
fiecare procesor ın parte, faptul ca timpul de raspuns este foarte apropiat de timpul
mediu de executie. Acest lucru subliniaza o foarte buna echilibrare a sarcinilor de lucru.
Aceasta echilibrare a fost obtinuta prin utilizarea functiei de dispersie prezentata ın Al-
goritmul 3.2 si prin aplicarea acestei chei la nivel de itemset parinte (conform Definitiei
3.1).
3.2 Algoritmul Fast Itemset Miner
In cadrul subcapitolului 3.1 a fost analizata o abordare noua pentru codarea itemilor
si, respectiv, a itemseturilor pentru algoritmul Apriori. Cu toate ca abordarile re-
cente ın domeniul identificarii tiparelor frecvente evita generarea seturilor candidate
[Tan 05, Han 00], este interesant de observat faptul ca ın literatura de specialitate nu
sunt prezentate alte propuneri pentru aceste abordari. In continuare, este descris un
model algoritmic nou destinat problemei ın discutie. Acest model algoritmic este bazat
tot pe generarea seturilor candidate, dar utilizeaza o euristica noua de generarea acestor
candidati.
Dupa cum este mentionat si ın capitolele anterioare, principiul de baza al algoritmului
Apriori este de a genera seturi candidate de dimensiune k pe baza seturilor frecvente de
dimensiune k−1 [Adamo 00, Zaki 99, Agrawal 94]. Practic, acest lucru implica, la fiecare
etapa, cresterea cu o unitate a dimensiunii seturilor supuse analizei. In cazul algoritmului
Apriori o unitate este echivalenta cu un item. Algoritmul nou, denumit Fast Itemset
Miner (prescurtat FIM ), are la baza cresterea cu o unitate a dimensiunii intervalului
de care apartin seturile candidate aferente unei etape [Craus 07c]. Spre deosebire de
algoritmul Apriori, ın cazul FIM o unitate este echivalenta fie cu un item, fie cu un
index de interval (multime de itemi/itemseturi frecvente) [Craus 08a].
3.2.1 Algoritmul secvential de baza
Ideea fundamentala a algoritmului FIM este de a determina, pas cu pas, itemseturile
frecvente prin a creste treptat intervalul de care apartin itemii individuali ce compun un
itemset candidat [Craus 07c]. Astfel, daca ın pasul k al agoritmului candidatii noi sunt
generati din itemi ce apartin intervalelor [i, i+k] (unde i ∈ {1, 2, ..., n−k}, n reprezentand
24

numarul total de itemi frecventi), ın pasul k+1 candidatii noi vor fi generati din generati
din itemi ce apartin intervalelor [i, i+ k + 1] (unde i ∈ {1, 2, ..., n− k − 1}).
In continuare vor fi utilizate notatiile date de setul de relatii (3.1).
Fi,j −multimea tuturor itemseturilor frecvente ce apartin de intervalul [i, j]
Ci,j −multimea tuturor itemseturilor candidate ce apartin de intervalul[i, j](3.1)
Sunt enuntate urmatoarele doua leme [Craus 07c].
Lema 3.1. Un itemset frecvent inclus ın multimea Fi,j care nu contine simultan itemii
i si j va apartine fie de multimea Fi,j−1, fie de multimea Fi+1,j.
Lema 3.2. Itemseturile frecvente noi ce apartin de multimea Fi,j contin simultan itemii
i si j.
Din Lema 3.2 rezulta ca itemseturile candidate ce apartin de multimea Ci,j vor fi
generate dupa relatia [Craus 07c]:
Ci,j = {X ∪ Y |(X ∈ Fi,j−1 ∧ i ∈ X) ∧ (Y ∈ Fi+1,j ∧ j ∈ X)}. (3.2)
Pseudocodul algoritmului FIM este prezentat ın Algoritmul 3.4 [Craus 07c].
Algoritmul 3.4 Algoritmul Fast Itemset Miner
Require: Fi,j = multimea itemseturilor frecvente din intervalul [i, j]Require: D = multimea de tranzactii, t ⊂ D1: for k = 1 to n− 1 do2: for all i, j : i ∈ 1, ..., n− k; j = i+ k do3: Fi,j ← Fi,j−1 ∪ Fi+1,j
4: Ci,j = {X ∪ Y |(X ∈ Fi,j−1 ∧ i ∈ X) ∧ (Y ∈ Fi+1,j ∧ j ∈ X)}5: for all tranzactiile t ⊂ D do6: Ct ← subset(Ci,j , t) {determinarea candidatilor din intervalul Ci,j inclusi ın
tranzactia t}7: for all candidatii c ∈ Ct do8: c.support++9: end for
10: end for11: Fi,j = Fi,j ∪ {c ∈ Ci,j |c.support ≥ minsupp}12: Fk ← Fk ∪ Fi,j
13: end for14: end for
Definitia 3.2 (Itemset nucleu). In contextul notatiilor (3.1) se numeste itemset nucleu
al unui itemset X ∈ Fi,j acel subset N ⊂ X, N 6= X de dimensiune maxima pentru care
este valabila relatia:
N ∩ {i} = N ∩ {j} = Φ. (3.3)
Lema 3.3. Un itemset nu poate fi frecvent daca itemsetul sau nucleu nu este la randul
lui frecvent.
25

Un rezultat direct al Lemei 3.3 este reprezentat de faptul ca un candidat valid (itemset
candidat ce ar putea satisface conditia de suport minim) trebuie sa fie generat pentru
analiza numai daca nucleul sau este frecvent. Mai mult, un itemset candidat este valid
daca toate subseturile sale, exceptand itemseturile care contin simultan itemii i si j, sunt
itemseturi frecvente.
Pentru simplificare, ın continuare vor fi utilizate urmatoarele notatii:
sufix(X) = X \ {i}
prefix(X) = X \ {j}.(3.4)
In relatia (3.4) i, j reprezinta primul si, respectiv, ultimul item al itemsetuluiX ∈ Fi,j .
Lema 3.4. Un itemset candidat T ∈ Ci,j este valid daca si numai daca se poate obtine
din reuniunea a doua itemseturi X ∈ Fi,j−1 si Y ∈ Fi+1,j care respecta simultan pro-
prietatile:
i ∈ X si j ∈ Y (3.5)
sufix(X) = prefix(Y ). (3.6)
Algoritmul 3.5 prezinta pseudocodul necesar generarii candidatilor ce apartin multimii
Ci,j .
Algoritmul 3.5 Algoritmul de generare a candidatilor specific FIM
Require: Fi,j−1, Fi+1,j
1: for all itemset X ∈ Fi,j−1 do2: for all itemset Y ∈ Fi+1,j do3: if sufix(X) = prefix(Y ) then4: candidat ← X ∪ Y5: adauga candidat ın Ci,j
6: end if7: end for8: end for
Un exemplu detaliat al principiului de functionare al algoritmului FIM este prezentat
ın [Craus 07c].
Considerand aceste observatii, Algoritmul 3.4 este modificat conform Algoritmului
3.6. Aceasta restrangere a multimii de tranzactii de scanat reprezinta un avantaj semni-
ficativ fata de algoritmul Apriori. Spre deosebire de algoritmul Apriori, algoritmul FIM
nu va scana complet multimea de tranzactii de analizat pentru nici o etapa de deter-
minare a tiparelor frecvente. In cadrul Algoritmului 3.6, Di reprezinta acel subset de
tranzactii t ∈ D ce contin itemul i.
3.2.2 Algoritmul paralel - modelul simplu
Avantajul major al acestei metode de paralelizare este ca tiparul comunicational este
cunoscut ınainte de rularea algoritmului [Craus 07c, Craus 08a, Craus 08b]. Un alt avan-
taj important consta ın faptul ca seturile de tranzactii pot fi distribuite procesoarelor
26

Algoritmul 3.6 Algoritmul Fast Itemset Miner - restrangerea setului de tranzactiiscanateRequire: Fi,j = multimea itemseturilor frecvente din intervalul [i, j]Require: D = multimea de tranzactii sortata descrescator relativ la suportul itemilor
frecventi, t ⊂ D1: for k = 1 to n− 1 do2: for all i, j : i ∈ 1, ..., n− k; j = i+ k do3: Fi,j ← Fi,j−1 ∪ Fi+1,j
4: Ci,j = {X ∪ Y |(X ∈ Fi,j−1 ∧ i ∈ X) ∧ (Y ∈ Fi+1,j ∧ j ∈ X)}5: for all tranzactiile t ⊂ Di do6: Ct ← subset(Ci,j , t) {determinarea candidatilor din intervalul Ci,j inclusi ın
tranzactia t}7: for all candidatii c ∈ Ct do8: c.support++9: end for
10: end for11: Fi,j = Fi,j ∪ {c ∈ Ci,j |c.support ≥ minsupp}12: Fk ← Fk ∪ Fi,j
13: end for14: end for
ınainte de ınceputul algoritmului. Acest lucru este posibil deoarece un procesor Pi tre-
buie sa calculeze Fi,j , j ∈ {i, ..., n} si prin urmare sunt necesare doar tranzactiile care
contin itemul frecvent i [Craus 08a, Craus 08b].
Algoritmul 3.7 prezinta pseudocodul aferent modelului de paralelizare descris anterior
[Craus 08a].
Algoritmul 3.7 Algoritmul FIM Paralel - modelul simplu
Require: Fi,i = {itemul frecvent i}Require: Di = multimea de tranzactii repartizata procesorului Pi (multimea de
tranzactii ce contine itemul i)1: for k = 1 to n− 1 do2: for all i : i ∈ 1, ..., n− k parallel do3: j = i+ k4: Fi,j ← Fi,j−1 ∪ Fi+1,j
5: Ci,j = {X ∪ Y |(X ∈ Fi,j−1 ∧ i ∈ X) ∧ (Y ∈ Fi+1,j ∧ j ∈ X)}6: for all tranzactiile t ⊂ Di do7: Ct ← subset(Ci,j , t) {determinarea candidatilor din intervalul Ci,j inclusi ın
tranzactia t}8: for all candidatii c ∈ Ct do9: c.support++
10: end for11: end for12: Fi,j = Fi,j ∪ {c ∈ Ci,j |c.support ≥ minsupp}13: end for14: end for
Se poate observa usor faptul ca si ın cazul Algoritmului 3.7 poate fi utilizat Algoritmul
3.5 pentru a genera candidatii corespunzatori fiecarei etape de calcul.
27

3.2.3 Algoritmul paralel - modelul generalizat
In cazul ın care numarul de procesoare (m) este mai mic decat numarul de itemi frecventi
(n), algoritmul paralel poate fi modificat si generalizat dupa cum urmeaza:
In prima etapa, fiecare procesor Pi, i ∈ {1, ...,m−1} calculeaza secvential itemseturile
frecvente din intervalul Ii = [(i− 1)· p+ 1, i· p], unde p = [ nm]. Procesorul Pm calculeaza
itemseturile frecvente din intervalul Im = [(m− 1)· p+1, n]. Pentru aceasta etapa poate
fi utilizat Algoritmul 3.6.
Pentru cea de-a doua faza, se aplica algoritmul paralel generalizat.
In continuare este utilizat urmatorul set de notatii:
FIi,Ij −multimea tuturor itemseturilor frecvente ce apartin de intervalul
Ii,j = Ii ∪ Ii+1 ∪ ... ∪ Ij
CIi,Ij −multimea tuturor itemseturilor candidate ce apartin de intervalul Ii,j .
(3.7)
In [Craus 08a] sunt enuntate si demonstrate urmatoarele 2 leme:
Lema 3.5. Un itemset frecvent apartinand de FIi,Ij , care nu contine simultan subseturi
de itemi din Ii si Ij, apartine fie de FIi,Ij−1, fie de FIi+1,Ij .
Lema 3.6. Noile itemseturi frecvente FIi,Ij contin simultan subseturi de itemi din Ii si
Ij.
Un rezultat important al Lemei 3.6 este faptul ca noii candidati apartinand interva-
lului Ii,j sunt obtinuti conform relatiei:
CIi,Ij = {X ∪ Y |(X ∈ FIi,Ij−1∧ Ii ∩X 6= Φ) ∧ (Y ∈ FIi+1,Ij ∧ Ij ∩ Y 6= Φ)}. (3.8)
Algoritmul 3.8 prezinta pseudocodul modelului generalizat prezentat anterior.
Algoritmul 3.8 Algoritmul FIM Paralel - modelul generalizat
Require: FIi,Ii = {multimea de itemseturi frecvente ce apartin intervalului Ii}Require: Di = multimea de tranzactii repartizata procesorului Pi (multimea de
tranzactii ce contine itemul i)1: for k = 1 to m− 1 do2: for all Ii : i ∈ 1, ..., n− k parallel do3: Ij = Ii+k
4: FIi,Ij ← FIi,Ij−1∪ FIi+1,Ij
5: CIi,Ij = {X ∪ Y |(X ∈ FIi,Ij−1∧ Ii ∩X 6= Φ) ∧ (Y ∈ FIi+1,Ij ∧ Ij ∩ Y 6= Φ)}
6: for all tranzactiile t ⊂ Di do7: Ct ← subset(CIi,Ij , t) {determinarea candidatilor din intervalul CIi,Ij inclusi
ın tranzactia t}8: for all candidatii c ∈ Ct do9: c.support++
10: end for11: end for12: FIi,Ij = FIi,Ij ∪ {c ∈ CIi,Ij |c.support ≥ minsupp}13: end for14: end for
28

Similar algoritmului paralel simplu, si ın cazul algoritmului generalizat tiparul comu-
nicational este cunoscut ınainte de ınceperea algoritmului. Presupunand m = 5 proce-
soare/nuclee de procesare, Figura 3.1 exemplifica un astfel de tipar de comunicatie.
Figura 3.1: Tiparul de comunicatie pentru algoritmul FIM paralel - modelul generalizat[Craus 08a]
Similar cazului anterior, baza de date poate fi ımpartita ıntre procesoare ınainte de
ınceperea algoritmului. In cazul generalizat, unui procesor Pi ıi vor fi repartizate acele
tranzactii ce cuprind itemseturile incluse ın intervalul Ii (ın Algoritmul 3.8 Di noteaza
submultimea de tranzactii t care include itemseturile ce apartin intervalului Ii).
Pentru generarea candidatilor (linia 5 din Algoritmul 3.8), este necesara adaptarea
Algoritmului 3.5. In acest sens, dat fiind setul X ∈ FIi,Ij , notatiile (3.4) devin:
sufixG(X) = X \ {k|k ∈ Ii}
prefixG(X) = X \ {k′|k′ ∈ Ij}.(3.9)
Utilizand notatiile (3.9), Algoritmul 3.5 este modificat conform Algoritmului 3.9.
Algoritmul 3.9 Algoritmul de generare a candidatilor specific FIM - modelul generalizat
Require: FIi,Ij−1, FIi+1,Ij
1: for all itemset X ∈ FIi,Ij−1do
2: for all itemset Y ∈ FIi+1,Ij do3: if sufixG(X) = prefixG(Y ) then4: candidat ← X ∪ Y5: adauga candidat ın CIi,Ij
6: end if7: end for8: end for
29

Corectitudinea Algoritmului 3.9 este demonstrata de Lema 3.7.
Lema 3.7. Un itemset candidat T ∈ CIi,Ij este valid daca si numai daca se poate obtine
din reuniunea a doua itemseturi X ∈ FIi,Ij−1si Y ∈ FIi+1,Ij care respecta simultan
proprietatile:
X \ sufixG(X) ⊂ Ii (3.10)
Y \ prefixG(Y ) ⊂ Ij (3.11)
sufixG(X) = prefixG(Y ). (3.12)
3.2.4 Rezultate si discutii
Teste comparative: algoritmul FIM secvential vs. algoritmul Apriori secvential
Un prim set de teste au vizat compararea performantelor algoritmilor secventiali FIM si
Apriori. Pentru ambii algoritmi a fost utilizata codificarea binara a itemseturilor/tran-
zactiilor prezentata ın cadrul subcapitolului 3.1.1. Ambii algoritmi au fost rulati pentru
un set de date sintetic (T10I4D100K ) cu 100000 de tranzactii/1000 de itemi, variind
limita de suport minim. Tabelul 3.3 prezinta rezultatele obtinute pentru o limita de
suport minim de 500 de tranzactii. Pentru acest caz de test, ın urma preprocesarii au
rezultat un numar de 569 de itemi frecventi. Pentru algoritmul FIM a fost variat numarul
de intervale astfel ıncat sa poata fi testata atat versiunea simplificata a algoritmului, cat
si cea generalizata (pentru algoritmul FIM coloanele ,,numar intervale” si ,,numar itemi
frecventi pe interval” indica numarul de intervale ın care au fost ımpartiti itemii frecventi
si, respectiv, numarul maxim de itemi pe interval). Pentru fiecare interval ın parte,
pentru determinarea tuturor itemseturilor frecvente cuprinse ın intervalul respectiv a
fost utilizata versiunea simplificata a FIM (Algoritmul 3.4)
O prima observatie importanta este ca algoritmul FIM a obtinut timp mai mic decat
algoritmul Apriori, indiferent de numarul initial de intervale. Se poate observa, de aseme-
nea, faptul timpul de raspuns al algoritmului FIM este dependent de dimensiunea in-
tervalelor initiale. In Tabelul 3.3 se poate observa aceasta variatie ıntre un maxim de
2029.24 secunde (caz pentru care intervalele initiale erau formate dintr-un singur item)
si un minim de 517.19 secunde (caz pentru care itemii frecventi au fost ımpartiti ın 60
de intervale, cu un numar de maxim 10 itemi pe interval). Pentru acest ultim caz se
poate remarca faptul ca algoritmul FIM este de 5.501 ori mai rapid decat algoritmul
Apriori. Acest plus de performanta se datoreaza atat simplificarii metodei de generare a
candidatilor (specifica algoritmului FIM ), cat si reducerii semnificative a submultimilor
de tranzactii ce sunt scanate pentru determinarea suportului itemseturilor candidate.
30
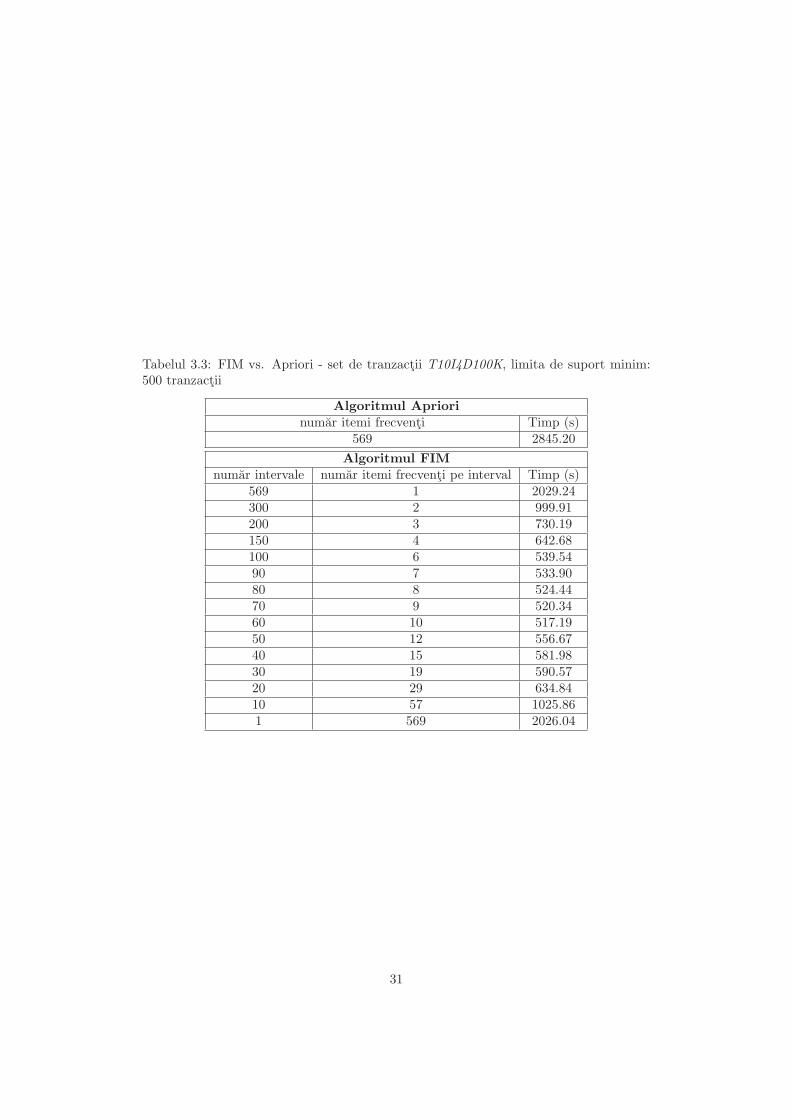
Tabelul 3.3: FIM vs. Apriori - set de tranzactii T10I4D100K, limita de suport minim:500 tranzactii
Algoritmul Apriorinumar itemi frecventi Timp (s)
569 2845.20
Algoritmul FIMnumar intervale numar itemi frecventi pe interval Timp (s)
569 1 2029.24300 2 999.91200 3 730.19150 4 642.68100 6 539.5490 7 533.9080 8 524.4470 9 520.3460 10 517.1950 12 556.6740 15 581.9830 19 590.5720 29 634.8410 57 1025.861 569 2026.04
31

Capitolul 4
Topologii de comunicare eficiente
pentru problema segmentarii datelor
4.1 Algoritmul Parallel K-Means
Algoritmul KMC [MacQueen 67] este unul dintre cei mai des utilizati algoritmi pentru
problema clusterizarii datelor. Popularitatea acestui algoritm se bazeaza pe simplitatea
ın implementare, pe scalabilitatea oferita si pe viteza de convergenta [Joshi 03]. De
asemenea, daca se utilizeaza o metrica adecvata, algoritmul poate fi adaptat pentru o
varietate mare de tipuri de date [Joshi 03, Dhillon 00]. Unul dintre cei mai eficienti
algoritmi paraleli pentru KMC este reprezentat de Parallel K-Means (PKM ) [Joshi 03,
Dhillon 00, Stoffle 99]. In cadrul subcapitolului 2.3.3 am amintit faptul ca algoritmul
PKM a fost dezvoltat pornind de la premiza ca pasul cel mai consumator de timp este
cel destinat determinarii distantelor dintre obiectele de clusterizat si centroizii aferenti
unei etape. Mai mult, un numar considerabil de autori sustin ca implementarile eficiente
ale PKM utilizeaza standardul MPI [Joshi 03, Dhillon 00, Stoffle 99].
Diferitele implementari ale standardului MPI realizeaza operatia colectiva scatter prin
intermediul functiilor MPI Scatter sau MPI Scatterv1. Utilizarea acestor doua functii
pentru a diviza datele stocate de procesul radacina prezinta doua mari dezavantaje.
Primul se refera la faptul ca aceste doua functii nu asigura ıntotdeauna o distributie
egala a datelor. O apelare standard MPI Scatter nu poate fi realizata daca dimensiunea
datelor de intrare nu este divizibila cu numarul total de procese. MPI Scatterv poate
rezolva aceste probleme, dar presupune realizarea unei etape de calcul suplimentare, care
trebuie sa se desfasoare ınainte de comunicatia propriu-zisa, pentru a determina corect
numarul de elemente care trebuie trimise fiecarui procesor ın parte.
Al doilea dezavantaj important este faptul ca MPI Scatter sau MPI Scatterv implica
p − 1 operatii pentru procesul radacina pentru a distribui datele ıntre procese. Con-
siderand tu timpul necesar transmiterii unui mesaj de dimensiune unitate, k = n/p
dimensiunea ın unitati a mesajului de transmis unui nod de procesare si ts timpul nece-
sar stabilirii unei comunicatii ıntre oricare doua noduri, timpul total consumat de nodul
1Pentru mai multe detalii, consultati manualul implementarilor MPICH-G2, LAM/MPI, OpenMPI
32

radacina (acel nod care stocheaza initial datele de transmis) este dat de relatia (4.1)
[Grama 03].
T = (p− 1)· (ts + k· tu). (4.1)
Etapa de reducere inclusa de PKM trebuie de asemenea tratata cu atentie daca
se doreste o implementare eficienta. Manualele diferitelor implementari ale standar-
dului MPI nu ofera detalii specifice pentru implementarea functiilor MPI Reduce si
MPI Allreduce. Mai mult, ın functie de implementarea MPI utilizata, complexitatea
functiilor de reducere poate atinge pe cazurile nefavorabile ordinul O(p). Considerand
aceasta observatie, pe cazul cel mai nefavorabil operatiile de reducere implicate de PKM
se ıncadreaza ın clasa de complexitate data de relatia (4.2) (k noteaza numarul de clus-
tere ın care se doresc a fi grupate datele, p reprezinta numarul de procesoare implicat ın
grupul de lucru):
O(k· p). (4.2)
Considerand ca pasii de reducere trebuie aplicati pana cand nici un obiect nu se mai
deplaseaza ıntre clustere, notand cu t numarul de iteratii efectuate pana la atingerea
convergentei, atunci, pentru cazul cel mai nefavorabil, relatia (4.2) devine:
O(t· k· p). (4.3)
Rezultatele prezentate ın relatiile (2.4) si (4.3) implica faptul ca odata cu cresterea
numarului de procesoare se reduc etapele de calcul ale distantelor, dar, pentru imple-
mentari mai putin eficiente ale primitivelor de reducere, creste liniar, relativ la numarul
de procesoare, timpul necesar pentru determinarea noilor centroizi. Acest lucru va genera
o implementare MPI ineficienta a PKM din moment ce reducerea de timp efectiva ar fi
cu mult mai mica decat estimarea data de relatia (2.4). In plus, implementarile standar-
dului MPI realizeaza functionalitatea operatiei colective de MPI Allreduce ın doua etape
distincte: o prima operatie de reducere, ın urma careia nodul radacina va determina
rezultatul operatiei dorite, urmata de o comunicare de tip broadcast 1-la-toti, ın urma
careia nodul radacina distribuie rezultatul determinat anterior catre celelalte noduri de
lucru. In [Grama 03] este mentionat faptul ca, utilizand o topologie adecvata, cele doua
operatii distincte (operatia colectiva de reducere si operatia colectiva de broadcast) pot
fi cumulate ın cadrul unei singure operatii compuse.
Cu toate ca diversi autori recomanda utilizarea MPI pentru implementarea PKM
[Dhillon 00, Joshi 03, Stoffle 99], ın literatura nu sunt ıntalnite detalii legate de topologiile
de comunicatie utilizate ın implementarile PKM. Dezavantajele mentionate anterior de-
riva tocmai din aceste scapari. Mai mult, eficienta acestor implementari este conditionata
de versiunea MPI utilizata. In [Archip 10] este propusa si analizata o abordare eficienta
a algoritmului PKM, independenta de implementarea efectiva a standardului MPI.
4.2 Modificarea comunicatiilor pentru algoritmul paralel standard
In [Grama 03] sunt prezentate si analizate un set de topologii de comunicatie ce pot fi
implementate ın cadrul sistemelor de calcul paralel ce utilizeaza MPI. Dintre acestea,
topologia de tip hipercub (HC ) se remarca prin dimensiunea logaritmica a numarului de
etape implicate de operatiile colective ın raport cu numarul de procesoare [Grama 03].
33

In baza acestor concluzii, propunem utilizarea HC drept topologie suport pentru imple-
mentarea algoritmului PKM [Archip 10].
4.2.1 Topologia de tip hipercub
Topologia de tip HC presupune exitenta unui numar p = 2d de procesoare distribuite
astfel ıncat fiecare dintre acestea are exact d procesoare vencine. d se numeste dimensi-
unea HC, iar un HC de dimensiune d este denumit un d-HC. Mai mult, fiecare procesor
identificat de un id numeric are exact un procesor vecin pe fiecare dintre cele d dimensi-
uni.
4.2.2 Partitionarea datelor pe topologia de tip hipercub
Pentru a partitiona eficient un volum de date de analizat ıntre procesoarele unui HC,
am recurs la modificarea primitivei colective de baza unul-la-toti nepersonalizat pe HC
(primitiva numita si broadcast), conform propunerilor similare din [Grama 03]. Motivul
alegerii acestui algoritm este dat si de faptul ca procedura de transmitere unul-la-toti pe
HC necesita un numar de exact d pasi pentru finalizare [Grama 03].
Pentru a obtine o functionalitate a primitivei scatter utilizand primitiva unul-la-toti
pe HC, mesajul care urmeaza a fi transmis trebuie sa contina atat datele pentru proce-
sul tinta id (noua radacina pentru subcubul corespunzator), cat si toate datele pentru
procesele ce apartin aceluiasi subcub [Grama 03]. Prin urmare, ın fiecare faza ın care un
procesor are rol de transmitator, acesta trebuie sa trimita jumatate din datele sale catre
nodul pereche din subcubul corespunzator [Grama 03]. In abordarea propusa fiecare
nod transmitator va timite subcubului corespunzator jumatatea superioara a datelor
stocate/primite pentru partitionare [Archip 10].
Un aspect important pentru implementarile MPI eficiente ale primitivelor scatter
este legat de nodul cu rol de receptor. Acesta trebuie sa determine numarul maxim
de elemente ce va fi receptionat. Aceasta determinare trebuie sa fie realizata fara alte
comunicatii suplimentare si, de asemenea, fara sa interpuna etape de calcul complexe cu
etapele implicate de comunicatii. Considerand un HC si primitiva de comunicatie 1-la-
toti peste un HC prezentata ın [Grama 03], se pot determina usor etapele de receptie
pentru fiecare dintre procesoarele participante. Considerand identificatorul de etapa i,
n lungimea mesajului initial (dimensiunea datelor de intrare ce vor fi analizate) si d
dimensiunea HC -ului, numarul maxim de elemente r ce trebuie receptionat de fiecare
procesor ın parte ce compune un HC este dat de relatia [Archip 10]:
r =n
2d−i+ 1. (4.4)
Se remarca faptul ca formula de calcul (4.4) este extrem de simpla si de rapida ın
executie. Utilizand relatia (4.4), Algoritmul 4.1 [Archip 10] prezinta pseudocodul unei
primitive de tip scatter implementata pe un HC de dimendiune d (o abordare similara
este prezentata si ın [Grama 03]). Diferenta fata de abordarea clasica din [Grama 03] este
faptul ca Algoritmul 4.1, prin implementarea relatiei (4.4), nu necesita un calcul initial
pentru determinarea numarului de elemente care vor fi receptionat pe fiecare procesor ın
parte [Archip 10].
In Algoritmul 4.1 variabila n reprezinta lungimea vectorului original de intrare pentru
toate procesele. Dupa fiecare faza de receptie, fiecare proces utilizeaza variabila n pentru
34

Algoritmul 4.1 Primitiva scatter pe un d-HC
procedura HCScatter (vector, d, id)
1: mask := 2d − 12: for i := d− 1 pana la 0 do
3: mask := mask XOR 2i
4: if 0 = (id AND mask) then5: partner := id XOR 2i
6: if 0 = (id AND 2i) then7: s := n/2 {numarul de elemente de transmis}8: n := n− s9: trimite mesaj de la [vector + n] de lungime s la partner
10: else
11: n := n/2d−i + 112: receptioneaza ın vector mesaj de dimensiune maxima n de la partner13: n = numarul de elemente efectiv receptionate14: end if
15: end if
16: end for
a stoca numarul efectiv de elemente pe care trebuie sa-l divida ın urmatoarele etape. La
finalizarea procedurii, fiecare proces utilizeaza aceasta variabila pentru a stoca lungimea
partitiilor proprii din vectorul original.
Pentru a estima costul timp al procedurii prezentate ın Algoritmul 4.1 trebuie tinut
cont de urmatoarea observatie [Grama 03]: costul comunicatiei pentru nodul radacina
(procesorul care contine mesajul de trasnmis) nu poate fi mai mic de:
tminim = (p− 1)· k· tu, (4.5)
unde p, k, tu au aceeasi semnificatie ca ın cazul relatiei (4.1). Acest lucru este evident
deoarece, initial, radacina comunicatiei stocheaza tot volumul de date de dimensiune
n unitati ce trebuie partitionat. Fiecarui procesor din grupul de lucru trebuie sa-i fie
repartizat o subset din aceste date de dimensiune medie k = n/p unitati. Rezulta ca
volumul total de date ce trebuie transmis de nodul radacina are dimensiunea (p − 1)· k
unitati.
Dupa cum s-a mentionat anterior, orice operatie colectiva realizata pe un HC se
realizeaza ın exact d = log2P etape si are un caracter recursiv [Grama 03]. Acest lucru
implica faptul ca timpul total consumat de procesorul radacina ın cazul unei operatii de
tip scatter pe un HC este:
T = d· ts + tminim = d· ts + (p− 1)· k· tu, (4.6)
unde d = log(p). Comparand relatiile (4.1) cu (4.6) se poate estima o reducere de timp
de ((p− 1)− log(p))· ts pentru procesorul radacina al comunicatiei, daca primitva de tip
scatter este implementata pe un HC.
Un al doilea avantaj semnificativ al procedurii prezentate ın Algoritmul 4.1 este
reprezentat de faptul ca procesoarele sunt echilibrate din punctul de vedere al volu-
mului de date ce le este repartizat [Archip 10]. Acest echilibru este atins chiar daca
numarul total de elemente de analizat n nu este divizibil cu numarul de procesoare p
care participa la analiza. Lema 4.1 demonstreaza acest lucru [Archip 10].
35

Lema 4.1. Algoritmul 4.1 partitioneaza un volum de date de dimensiune n ıntre cele
p = 2d procesoare ale unui HC de dimensiune d astfel ıncat diferenta maxima ıntre
oricare doua procesoare din HC este de un singur element.
Demonstratie
Prin inductie matematica:
Pentru d = 1, HC este format din p = 2 procesoare.
Conform (4.4), pentru vectorii V0 si V1, ce rezulta ın urma pasului de divizare, au loc
urmatoarele relatii:
caz 1 - n este par:
numarul total de elemente ale V0:n2 .
numarul total de elemente ale V1:n2 .
caz 2 - n este impar:
numarul total de elemente ale V0: [n2 ] + 1.
numarul total de elemente ale V1: [n2 ].
Presupunem adevarata Lema 4.1 pentru cazul d = k, k natural, mai mare decat 1.
In acest caz, pentru vectorii V0, V1, ..., V2k , repartizati celor 2k subcuburi ın urma a k
divizari, are loc urmatoarea relatie:
|size(Vi)− size(Vj)| ≤ 1, ∀i, j ∈ {0, 1, ..., 2k}, i 6= j, (4.7)
unde prin size(V ) se noteaza dimensiunea vectorului V .
Demonstram Lema 4.1 pentru d = k + 1.
Se noteaza prin Vi0, Vi1, i ∈ {0, 1, ..., 2k} vectorii obtinuti prin divizarea vectorului
Vi, i ∈ {0, 1, ..., 2k}.
Fie doi vectori Vi, Vj (i, j ∈ {0, 1, ..., 2k}, i 6= j) ce respecta relatia (4.7).
Fie size(Vi) = q, size(Vj) = q + 1, unde q = 2· r, r este un numar natural nenul.
Atunci:
size(Vil) = [q
2] = r, ∀l ∈ {0, 1}, (4.8)
size(Vjm) = [q
2] + 1 = r + 1, daca m = 0 sau (4.9)
size(Vjm) = [q
2] = r, daca m = 1. (4.10)
Din relatiile (4.8, 4.9, 4.10) rezulta ca:
|size(Vil)− size(Vjm)| ≤ 1, ∀i, j ∈ {0, 1, ..., 2k}, i 6= j, ∀l,m ∈ {0, 1}. (4.11)
Cazul q = 2· r + 1 se demonstreaza similar. De asemenea, cazurile size(Vi) =
size(Vj) = q se demonstreaza similar, indiferent de natura lui q (par sau impar).
q.e.d
Algoritmul 4.1 descrie o metoda de divizare mult mai simpla si mai directa, aplicabila
pentru toate procesoarele din grupul de lucru, care obtine acelasi efect [Archip 10].
36

4.2.3 Tiparul comunicational utilizat ın determinarea centroizilor
Dupa cum a fost amintit anterior, ın cazurile unor implementari mai putin eficiente ale
standardului MPI este posibil ca functiile de tip MPI Allreduce (utilizate ın mod uzual
pentru implementarea primitivelor colective de reducere) sa atinga o complexitate liniara
relativ la numarul de procesoare p din grupul de lucru (relatia (4.3)). Un exemplu de
astfel de implementare este MPICH-G2, implementare care, desi a fost ıntrerupta din
dezvoltare, este ın prezent utilizata ın cadrul GT 4.
Pentru implementarile curente ale standardului MPI (este vorba despre implemetarile
LAM/MPI si OpenMPI), functaMPI Allreduce ruleaza ın doua etape: o etapa de calcul si
comunicatii, ın care un procesor radacina realizeaza operatia de reducere dorita, urmata
de o etapa de comunicatie, ın care procesorul radacina utilizeaza o primitiva de tip 1-
la-toti nepersonalizat pentru a transmite si celorlalte procesoare rezultatul determinat.
Implementarile ın discutie utilizeaza topologii de tip arbore ın implementarea etapelor
mentionate2. Cu toate ca aceasta abordare obtine o dependeta logaritmica a raspunsului
timp relativ la numarul de procesoare p implicat ın calcul, separarea ın etape a operatiilor
implicate poate atrage timpi suplimentari nedoriti [Grama 03].
Utilizand o topologie de tip HC, primitiva de tip all-reduce necesara poate fi imple-
mentata combinand cele doua etape mentionate anterior [Grama 03]. Astfel, primitiva
generica toti-la-toti prezentata ın [Grama 03] poate fi adapatata astfel ıncat sa imple-
menteze functionalitatile necesare unei primitive all-reduce. Pe baza observatiilor similare
din [Grama 03], Algoritmul 4.2 prezinta pseudocodul necesar implementarii primitivei
all-reduce utilizand o topologie de tip HC [Archip 10].
In Algoritmul 4.2 ⊕ reprezinta fie operatia necesara pentru calculul coordonatelor
noilor centroizi, fie o simpla operatie de adunare utilizata la determinarea valorii MSE.
Algoritmul 4.2 Primitiva all-reduce implementata pe un HC de dimensiune d
procedure CUBEReduce (input, output, d, id)
1: output := input2: for id := 0 to d− 1 do
3: partner id := id XOR 2i
4: trimite output catre partner id5: primeste input de la partner id6: output := ⊕(output, input)7: end for
Se poate observa cu usurinta faptul ca procedura din Algoritmul 4.2 necesita exact
d pasi pentru finalizare (unde d = log2P , unde p este numarul total de procesoare)
[Grama 03, Archip 10].
Avantajul utilizarii acestei abordari pentru operatiile de reducere este reprezentat de
faptul ca limiteaza timpul consumat de aceste operatii, independent de implementarile
standardului MPI utilizate [Archip 10]. Am demonstrat ca ın abordarile clasice, acesti
timpi pot atinge complexitatea O(t· k· p) (relatia (4.3)) pe cazurile cele mai nefavorabile.
Acest lucru se datoreaza faptului ca o singura operatie all-reduce poate atinge timpi de
complexitate O(p). In abordarea propusa o singura operatie de all-reduce necesita pentru
finalizare un timp de ordin O(log2 p) [Grama 03, Archip 10]. Prin urmare complexitatea
timp a unei singure etape de reducere este data de relatia:
2detalii sunt oferite de manualele implementarilor LAM/MPI si OpenMPI
37

O(k· log2 p). (4.12)
Daca PKM atinge convergenta dupa un numar de t etape, utilizand relatia (4.12),
complexitatea timp pentru toate etapele de reducere este data de:
O(k· t· log2 p). (4.13)
Utilizand modificarile propuse anterior, Algoritmul 4.3 descrie pseudocodul algorit-
mului PKM implementat utilizand o topologie de tip HC [Archip 10].
Algoritmul 4.3 Algoritmul PKM implementat utilizand o topologie de tip HC
Require: X vectorul de obiecte de clusterizatRequire: k numarul de clustere1: P := MPI Comm size()2: id := MPI Comm rank()3: MSE := maxim posibil4: length := HCScatter(X, log
2P, id)
5: if id = root then6: alege centroizii initiali {mj}
kj=1
7: end if
8: MPI Bcast({mj}kj=1, root)
9: repeat
10: OldMSE := MSE11: MSE∗ := 012: for j := 1 to k do
13: mj∗ := 0
14: nj∗ := 0
15: end for
16: for i := 1 to length do
17: for j := 1 to k do
18: calculeaza distanta Euclidiana dintre obiectul Xi si centroidul mj d2(Xi,mj)19: end for
20: determina cel mai apropiat centroid ml pentru obiectul Xi
21: ml∗ := ml
∗ +Xi
22: nl∗ := nl
∗ + 123: MSE∗ := MSE∗ + d2(Xi,ml)24: end for
25: for j := 1 to k do
26: CUBEReduce(nj∗, nj , log2 P, id)
27: CUBEReduce(mj∗,mj , log2 P, id)
28: nj := max(nj , 1)29: mj := mj/nj
30: end for
31: CUBEReduce(MSE∗,MSE, log2P, id)
32: until MSE < OldMSE
In Algoritmul 4.3, procedurile CUBEReduce si HCScatter sunt cele descrise ın
Algoritmii 4.2 si 4.1.
38

4.3 Rezultate si discutii
Pentru a testa comparativ abordarea generica a PKM si 4.3, acestia au fost implementati
utilizand C++ si LAM/MPI versiunea 7.1.2. Alegerea implementarii LAM/MPI a stan-
dardului MPI se bazeaza pe faptul ca aceasta furnizeaza o implementare relativ eficienta
a primitivei all-reduce prin intermediul functiei MPI Allreduce (comportamentul aces-
tei functii a fost de descris ın subcapitolul 4.2.3). Seturile de date test au constat ın
5000, 7500 si 10000 puncte generate aleator, avand 4 atribute (coordonatele pe axele
OX,OY ,OZ,OT ). Pentru fiecare dintre cele trei seturi, au fost considerate k = 2000
clustere tinta. Testele au fost realizate pe un sistem multicore cu 8 procesoare. Pentru
fiecare caz ın parte, algoritmii au fost rulati pentru 2, 4, si, respectiv, 8 procesoare.
O particularitate a cazurilor de teste descrise este legata de faptul ca pentru de-
terminarea noilor centroizi atat etapele de comunicatie, cat si gestiunea acestora devin
dominante ın raport cu etapele de calcul.
Pentru toate testele efectuate, Algoritmul 4.3 a obtinut timpi mai buni decat abor-
darea generica standard. Acest lucru se datoreaza faptului ca adoptand o topologie de
tip HC, toate procesoarele participa ın paralel atat ın etapele de comunicare, cat si ın cele
de calcul implicate de o primitiva de tip all-reduce (Algoritmul 4.2). Mai mult, la finalul
etapelor de calcul, toate procesoarele au determinat rezultatul aferent. In cazul functiei
MPI Allreduce (abordarea clasica), numai procesorul cu id = 0 a determinat rezultatul
dorit. Pentru ca si celelalte procesoare din grupul de lucru sa determine acelasi rezultat,
functia MPI Allreduce include un broadcast, fapt ce atrage dupa sine timpi suplimentari.
Din acest punct de vedere rezultatele timp obtinute prin implementarea Algoritmului 4.3
capata un plus de semnificatie. Toate comunicatiile implementate ın cadrul Algoritmului
4.3 au fost implementate prin intermediul functiilor MPI Send/MPI Recv. Prin contrast,
toate comunicatiile implicate de functia MPI Allreduce sunt realizate prin interactiune
directa cu thread-ul de control al mediului LAM/MPI si sunt mai rapide din punctul de
vedere al raspunsului timp. Cu toate acestea, per global, implementarea generica a PKM
obtine timpi de raspuns inferiori implementarii propuse (Algoritmul 4.3).
Un al doilea rezultat important ce se poate observa este legat de variatia timpului de
raspuns o data cu cresterea numarului de procesoare. Astfel, pentru primul set de teste
(5000 puncte /2000 centroizi), daca ın cazul rularii pe 4 procesoare diferenta de timp
este de ≈ 0.06 secunde, aceasta diferenta creste la ≈ 0.10 secunde ın favoarea abordarii
topologiei de tip HC pentru cazul cu 8 procesoare. Aceeasi variatie poate fi observata si
ın cazul celorlalte doua seturi de teste:
• o crestere a diferentei de timp de la ≈ 0.02 secunde la ≈ 0.10 secunde pentru cazul
al doilea de test;
• o crestere a diferentei de timp de la ≈ 0.04 secunde la ≈ 0.16 secunde pentru cazul
al treilea de test.
Se poate observa ca ın ultimile doua cazuri de test convergenta algoritmului PKM
a fost atinsa dupa t = 11 iteratii fata de t = 9 ın primul caz. Acest lucru indica un
comportament mai bun al abordarii propuse (Algoritmul 4.3) fata de cazul clasic.
Rezultatele prezentate au evidentiat faptul ca, prin utilizarea unei topologii de comu-
nicatie eficiente cum este si cazul HC, se pot ımbunatati ın continuare timpii de raspuns
ai unui model paralel dat. Semnificatia acestor rezultate este cu atat mai mare daca
luam ın considerare faptul ca pentru Algoritmul 4.3 am recurs la functiile de baza de tip
39

Send/Receive pentru implementarea comunicatiilor. Chiar daca aceste doua primitive
implica un timp mai mare de deschidere a conexiunilor dintre procesoare si, respectiv,
de transmisie efectiva a mesajelor, marginirea comunicatiilor indusa de topologia de tip
HC s-a dovedit a fi cu mult mai eficienta.
40

Capitolul 5
Sisteme Grid
Primele referiri ale Grid-urilor computationale dateaza din anul 1969. Intuind dezvoltarea
la scara globala a sistemelor de calcul, Len Kleinrock1 a afirmat urmatoarele:
Probabil vom vedea ın viitor o distribuire a utilitatilor de calcul, care, aseme-
nea utilitatilor electrice sau telefonice, vor servi locuintele private si sediile
firmelor dintr-o anume tara. (,,We will probably see the spread of computer
utilities, which, like present electric and telephone utilities, will service indi-
vidual homes and offices across the country.”)
O prima definitie a sistemelor Grid computationale este data de Ian Foster si Carl
Kesselman [Foster 98]: un Grid computational reprezinta o infrastructura hardware si
software care dispune de acces sigur, consecvent, universal si ieftin la resurse de cal-
cul de mare performanta. La foarte scurt timp, aceeasi autori completeaza notiunea de
sistem Grid prin reconsiderarea aspectelor care tin de componenta institutionala impli-
cata de acestea [Foster 01]. Intr-un articol ulterior, Ian Foster definste trei criterii care
caracterizeaza un Grid [Foster 02a]:
1. coordonarea resurselor : resursele sunt coordonate, dar nu sunt controlate ıntr-o
maniera centralizata - un sistem Grid integreaza resurse si utilizatori care apartin
de domenii diferite, controlate si administrate local;
2. utilizarea standardelor, a protocoalelor si a interfetelor deschise, general valabile:
ıntr-un sistem Grid trebuie sa existe protocoale si interfete pentru autentificare,
autorizare, descoperirea si accesul la resurse. Este foarte important ca aceste pro-
tocoale sa fie standardizate si ”vizibile”;
3. furnizarea de servicii netriviale: Conceptul de Grid presupune avantajele resurselor
de grup dar si participare activa la dezvoltarea acestor resurse. Din acest motiv,
ıntr-un sistem Grid exista doua categorii de participanti: consumatori si furnizori
de servicii. Pentru ca sistemul sa functioneze, serviciile trebuie sa fie de calitate;
altfel, consumatorii se orienteaza spre alte sisteme.
1profesor la UCLA’s Henry Samueli School of Engineering and Applied Science, membru al echipeide dezvoltare al ARPANET
41

In prezent, notiunile fundamentale care caracterizeaza un sistem Grid sunt cele de
Organizatie Virtuala (prescurtat OV ), servicii si de resurse Grid [Foster 01]. In acest
context, Grid-urile reprezinta o infrastructura care integreaza resurse distribuite geografic
(putere de calcul, retele de comunicattie, capacitate de stocare a datelor, informattie,
etc.) si mecanismele de partajare a acestor resurse ın scopul de a furniza o platforma
virtuala, colaborativa destinata calculului si gestiunii datelor. Analizand componentele
de tip serviciu Grid, Borja Sotomayor considera ın [Sotomayor 06] urmatoarele grupuri
de servicii ale unui sistem Grid:
• servicii pentru gestiunea OV - destinate managementului nodurilor care fac parte
din OV ;
• servicii pentru descoperirea si gestiunea resurselor Grid - destinate identificarii
resurselor puse la dispozitie si gestiunii acestora;
• servicii pentru gestiunea job-urilor - destinare managementului task-urilor utiliza-
tor ın cadrul sistemelor Grid;
• servicii pentru securitatea informatiilor, managementul datelor, etc.
In cadrul unui astfel de sistem, notiunea de calcul pe Grid (ın engleza: Grid Com-
puting) implica utilizarea de programe organizate pe componente, care necesita o putere
de calcul considerabila si accesul rapid asupra unor resurse variate. Astfel, calculul pe
Grid poate fi gandit ca o forma de calcul paralel pe un cluster de dimensiuni foarte mari
conectate pe principiul rolurilor egale (peer-to-peer) [Aflori 05].
Suportul GT4 pentru aplicatii MPI
GT4 ofera suport pentru aplicatii MPI prin intermediul pachetului MPICH-G2, im-
plementare ce ofera suport pentru versiunea 1.1 a standardului MPI si pentru un set re-
strans de operatii concurente asupra fisierelor. Utilizand aceasta implementare, aplicatiile
MPI pot rula ın cadrul GT4 pe mai multe calculatoare, aflate ın locatii diferite, folosind
aceleasi instructiuni si comenzi care ar fi utilizate pe un calculator paralel. MPICH-G2
extinde implementarea anterioara MPICH pentru utilizarea serviciilor furnizate de GT4
pentru autentificare, autorizare, alocare de resurse, initializarea executiei, operatii de
I/O precum si pentru crearea de procese, monitorizare si control. Diverse operatii critice
din punct de vedere al performantelor, inclusiv initializarea operatiilor colective, sunt
configurate pentru a exploata informatiile legate de topologia retelei [Karonis 03].
MPICH-G2 utilizeaza serviciile GT4 pentru a suporta executia transparenta si efi-
cienta a aplicatiilor ın medii neomogene de tip Grid, permitand ın acelasi timp si gestiunea
acestor aplicatii.
Inaintea lansarii ın executie a unei aplicatii MPICH-G2, utilizatorul apeleaza mo-
dulele GSI (comanda grid-proxy-init) pentru obtinerea unui certificat de autentificare
pentru diverse locatii, furnizandu-se ın acest fel o modalitate de autentificare unica. De
asemenea, utilizatorul poate apela modulele MDS pentru a selecta sistemele pe care va
rula aplicatia pe baza informatiilor legate de configuratie, disponibilitate si interconectare
[Karonis 03].
Odata autentificat, utilizatorul foloseste utilitarul standard mpirun pentru lansarea
aplicatiei. Implementarea MPICH-G2 a acestei comenzi utilizeaza RSL (Resource Spe-
cification Language) pentru descrierea necesarului de resurse fizice al aplicatiei MPI :
42

numarul de procesoare, memorie, timp de executie si parametrii precum localizarea
executabilelor, argumentele din linia de comanda si eventualele variabilele de mediu
[Karonis 03].
Pe baza informatiilor din scripturile RSL, MPICH-G2 apeleaza functiile oferite de
GT4 ın biblioteca DUROC (Dynamically Updated Request Online Coallocator) pentru a
planifica si a lansa ın executie aplicatia pe sistemele specificate de utilizator. La randul ei,
biblioteca DUROC, apeleaza GRAM (Grid Resource Allocation and Management) pen-
tru a starta si gestiona rularea aplicatiei pe fiecare sistem de calcul ın parte [Karonis 03].
GRAM poate utiliza, daca este cazul, GASS (Global Access and Secondary Storage)
pentru a porni executabilele aflate ın diferite locatii si indicate prin adrese URL ın cadrul
scriptului RSL. De asemenea, GASS este utilizat si dupa ce aplicatia a fost pornita pentru
redirectarea iesirilor standard si de eroare (stdout si stderr) catre terminalul utilizatoru-
lui, furnizand acces la fisiere indiferent de locatie, fapt ce ascunde aspectele legate de
distributia geografica. Dupa lansarea ın executie a aplicatiei, MPICH-G2 selecteaza cea
mai eficienta metoda de comunicatie posibila ıntre procese, folosind versiunea de MPI
instalata, utilizand Globus-IO (Globus communication) ımpreuna cu Globus DC (Data
Conversion) peste protocolul TCP ın cazul ın care nu sunt identificate alte mecanisme.
In cadrul acestui capitol au fost prezentate sistemele Grid, punandu-se cu precadere
accent pe middleware-ul GT4. Acest middleware, considerat standardul de facto pentru
sistemele Grid bazate pe SOA, ofera ın prezent un set de specificatii si framework-uri bine
ınchegate pentru construirea platformelor de tip Grid. Fiind un middleware destinat si
aplicatiilor paralele dezvoltate utilizand MPI, GT4 ofera suport pentru implemenatrea si
rularea acestora prin intermediul pachetului MPICH-G2. Cu toate ca pachetul MPICH-
G2 este bine integrat ın middleware-ul GT4 si este folosit de o gama larga de utilizatori
si dezvoltatori de aplicatii Grid, exista un set de dezavantaje care descalifica utilizarea
acestui pachet pentru aplicatii paralele complexe [Archip 08a, Archip 08b]. In continuare
sunt enumerate o parte dintre aceste neajunsuri:
• nu implementeaza decat standardul MPI-1.1 : nu exista suport pentru manipularea
dinamica a numarului nodurilor de procesare, fapt ce face imposibila gestiunea
eficienta a nodurilor de lucru;
• nu ofera decat suport partial pentru limbajul C++: ın timpul rularilor unor
aplicatii de test simpliste, a fost observata lansarea eronata ın executie a codurilor
C++, cu toate ca acestea fusesera compilate si link-editate corect. Aceste rulari
eronate au fost remarcate ın special ın cazul ın care codul C++ continea clase
container specializate, precum bitset, vector sau map;
• nu ofera nici o facilitate suplimentara pentru interactiunea directa ıntre aplicatia
MPI si celelalte servicii Grid;
• lansarea ın executie si gestiunea aplicatiilor MPI ce folosesc MPICH-G2 este ın
continuare realizata prin intremediul modulelor GRAM si DUROC, module ce sunt
mentinute ın actuala distributie GT4 doar din ratiuni de compatibilitate ınapoi cu
GT2.
Ultimul dezavantaj este considerat ca fiind cel mai important. Versiunea 4 a middle-
ware-ului Globus Toolkit realizeaza o migrare a modulelor de gestiune a resurselor catre o
43

abordare SOA. In acest sens a fost dezvoltat un nou modul de gestiune a resurselor - WS-
GRAM (prezentat ın cadrul acestui capitol). Pe langa ımbunatatirea vitezei de lansare
ın executie a aplicatiilor Grid, WS-GRAM aduce o serie de ımbunatatiri ın gestiunea
securitatii aplicatiilor Grid: lansarea ın executie se bazeaza pe implementarea unui modul
de impersonare a utilizatorilor autorizati similar comenzii Unix sudo, spre deosebire de
managerul anterior GRAM pentru care trebuiau setate drepturi speciale de super-user
(ın sistemele Unix/Linux utilizatorul root).
Mai mult, cu toate ca GT4 marcheaza practic migrarea catre sisteme Grid dezvoltate
conform principiilor SOA si cu toate ca se ofera suport complet, la nivel de API-uri si
framework-uri, pentru rularea aplicatiilor MPI din cadrul altor aplicatii Grid complexe
se remarca o slaba dezvoltare a integrarii acestor aplicatii MPI sub forma de servicii
Grid. Aceasta integrare ar oferi suport mai bun pentru procesele complexe precum cel
al descoperirii de cunostinte. Aplicatiile complexe de data mining, ce necesita aplicarea
succesiva a mai multor metode de analiza, pot fi mai usor dezvoltate daca se utilizeaza
compunere de servicii. Capitolul 6 prezinta o propunere menita sa faciliteze integrarea
aplicatiilor MPI sub forma de servicii Grid.
44

Capitolul 6
Integrarea aplicatiilor MPI sub forma
serviciilor Grid
6.1 Justificarea abordarii
Prezentat ın cadrul Capitolului 1, procesul de descoperire de cunostinte este un proces
complex ce se desfasoara ın mai multe etape (reprezentate schematic ın Figura 1.1).
Pentru etapele de analiza efectiva a datelor (etape numite ın mod generic data mining
se remarca o dezvoltare considerabila a algoritmilor paraleli. Sistemele Grid pot sustine
acest proces atat la nivel de etape computationale implicate, cat si la nivel de stocare a
volumului din ce ın ce mai mare de date achizitionate. In acest sens, Ian Foster et al.
propun ın [Foster 02b] un model generic de serviciu Grid, conform specificatiilor OGSA,
pentru a adresa problema descoperirii de cunostinte ın cadrul sistemelor Grid, model ce
poate fi implementat si ın GT4 1.
6.1.1 Model generic pentru serviciile Grid destinate
problemei descoperirii de cunostinte
Capitolele din prima parte a acestei lucrari au evidentiat faptul ca pentru majoritatea
algoritmilor dezvoltati pentru procesul de data mining exista modele de paralelizare. A
fost, de asemenea, evidentiat si faptul ca standardul MPI poate furniza un suport de
implementare adecvat pentru aceste modele. O observatie ın plus este aceea ca imple-
mentarea acestor modele ar trebui realizata ıntr-un limbaj nativ, ın special ın cazul ın
care viteza de rulare este un considerent important.
In cadrul capitolului anterior a fost semnalat un posibil dezavantaj al sistemelor
Grid bazate pe GT4 : middleware-ul ın discutie ofera suport complet pentru aplicatii
MPI prin intermediul MPICH-G2. Aceasta implementare a standardului MPI nu ofera
suport decat pentru versiunea 1.1, cu un set restrans de extensii ce vizeaza accesul
concurent asupra eventualelor fisiere de lucru. In cazul ın care aplicatiile de data mining
implementate ın MPI necesita facilitati avansate ale acestui standard (facilitati precum
gestiunea dinamica de procese - introdusa o data cu versiunea 2.0 a standardului MPI ),
1Modelul ın discutie a reprezentat punctul de start si ın cadrul proiectului Data Mining Grid :http://www.dataminingGrid.org/
45

MPICH-G2 nu poate oferi suport. Totodata a fost indicat faptul ca, desi GT4 ofera
suport extins pentru gestiunea job-urilor Grid din cadrul aplicatiilor Grid complexe
(acest support fiind expus prin includerea diferitelor API-uri ıncapsulate sub forma unor
pachete CoG - Commodity Grid), suportul oferit pentru gestiunea aceluiasi tip de job-uri
din cadrul serviciilor Grid este mai slab dezvoltat.
Subcapitolele urmatoare prezinta o propunere de integrare sub forma de servicii Grid
a aplicatiilor MPI utilizeaza alte implementari ale standardului MPI. Propunerea se
bazeaza pe un model generic prezentat ın [Dunnweber 05].
6.2 Arhitectura serviciului Grid propus
Rolul propunerii ın discutie este acela de a ascunde, pentru un utilizator final sau pentru
un dezvoltator de aplicatii Grid, interactiunea cu componentele implicate de WS-GRAM
pentru gestiunea job-urilor Grid destinate data mining. Din acest punct de vedere,
serviciul Grid propus ın [Archip 08b, Archip 08a] realizeaza o interfata ıntre utilizatorii
finali si serviciile Grid aferente WS-GRAM. Se poate spune ca serviciul Grid propus va
impersona un potential client ın interactiunea cu suita de servicii WS-GRAM.
Implementarea standardului MPI avuta ın vedere este LAM/MPI 2. Aceasta imple-
mentare MPI necesita pentru gestiunea aplicatiilor rularea unui fir de executie de control
(un thread daemon - lamd) ce trebuie sa ruleze pe calculatorul paralel/clusterul tinta.
Serviciul Grid propus va realiza si gestiunea acestuia.
6.2.1 Modelul Fabrica/Instanta
Conform cu observatiile prezentate ın [Foster 02b, Jacob 05, Sotomayor 06], servici-
ile Grid au un pronuntat caracter tranzitoriu. Serviciul Grid destinat ıncapsularii
aplicatiilor MPI are la baza o arhitectura de tip Serviciu fabrica/Serviciu Instanta (ın
englezaa Factory Service/Instance Service), conforma cu specificatiile OGSA (Figura 6.1)
[Archip 08b, Archip 08a].
A fost adoptat acest model ıntrucat respecta specificatiile arhitecturale impuse de
WSRF, specificatii fundamentale pentru sistemele Grid bazate pe SOA. Cele doua com-
ponente ale modelului (serviciul de tip Factory si serviciul de tip Instance) au fost denu-
mite AAFactoryService si, respectiv, AATestService. Avantajul major oferit de aceasta
abordare este acela ca un potential client autorizat poate lansa ın executie mai multe ana-
lize simultan [Archip 08b]. Resursa Grid atasata serviciului Grid ıncapsuleaza aplicatia
MPI ce ruleaza modulul de analiza dorit. Starea resursei Grid este reprezentata de
starea rularii curente a analizei specificate.
Practic, fiecare analiza noua va ınseamna crearea unei resurse noi si, din moment ce
resursele sunt independente, rularile nu se vor influenta reciproc. In plus, o resursa poate
lansa ın executie un job pe un cluster al Grid-ului, ın timp ce analizele ulterioare vor
fi trimise catre alte clustere accesibile si, din acest punct de vedere, se poate obtine o
gestiune eficienta a resurselor de calcul expuse de sistemul Grid [Archip 08b].
2alaturi de OpenMPI saun IntelMPI, acest implementare expune complet specificatiile 2.0 ale stan-dardului ın dicutie
46

Figura 6.1: Arhitectura Factory Service/Instance Service utilizata de serviciul Grid pro-pus pentru ıncapsularea aplicatiilor MPI (adaptare dupa [Sotomayor 06])
6.2.2 Integrarea modulelor MPI ın serviciul Grid
Considerand abordarea propusa (de a ıncapsula aplicatiile MPI ın resurse Grid atasate
serviciilor), trebuie abordata rularea efectiva a job-urilor de analiza de date din cadrul
resurselor Grid. Punctul de start ın rezolvarea acestei probleme a fost propunerea de
integrare prezentata ın [Dunnweber 05] .
Dunnweber et al. propun urmatoarea abordare: din moment ce nu se poate integra
codMPI direct ın serviciile Grid, atunci trebuie implementata o componenta de nivel mai
ınalt sub forma unui serviciu sau a unei aplicatii Grid, astfel ıncat aceasta componenta
sa gestioneze modulul MPI dorit.
In acest sens, pornind de la specificatiile descrise anterior, resursa Grid atasata ser-
viciului Grid este responsabila de gestiunea job-ului de analiza curent. In acest sens
resursa Grid include o referinta catre un obiect de tip Thread (limbajul de programare
adoptat pentru implementarea serviciului a fost limbajul Java) care va interactiona sub
forma de client cu serviciile aferente WS-GRAM pentru lansarea ın rulare si gestiunea
job-ului dorit [Archip 08b].
Pentru o gestiune corecta a job-urilor lansate, resursa Grid include un listener peste
un set de component Java legate (Java Bound Beans) destinate stocarii informatiilor de
stare transmise de modulele WS-GRAM. Fata de abordari similare se obtine avantajul
unei interactiuni mai rapide cu serviciul suport oferit de middleware-ul Globus - Man-
agedJobFactoryService - serviciul de tip Factory inclus ın WS-GRAM pentru rularea job-
urilor Grid [Archip 08b, Archip 08a]. In plus, resursa Grid atasata serviciului instanta
gestioneaza un set de fisiere de tip log, prin intermediul carora este salvata starea curenta
a modulului de analiza ce se afla ın rulare [Archip 08a]. Din acest punct de vedere, trebuie
remarcat faptul ca ın acest caz se ofera o posibilitate de analiza mai detaliata a job-ului
Grid, fata de cazul clasic cand modulul suport oferea doar status-uri de forma Job Active,
Job Pending sau Job Failed. Un alt plus major este acela ca fisierele log gestionate de
resursa permit o mai buna indentificare a eventualelor erori ce pot aparea ın cazul unei
rulari necorespunzatoare a modulului de analiza activ [Archip 08b, Archip 08a].
Un alt avantaj imediat este acela ca, ın caz de functionare eronata a container-
47

ului de servicii Grid suport, nu sunt pierdute informatiile privind starea analizei. In
cadrul testelor efectuate, s-a observat faptul ca ın cazul unei caderi a container-ului
Globus resursa Grid este distrusa si, ın acelasi timp, este distrusa si instanta curenta a
modulului de analiza aflat ın rulare. Fata de abordari similare, ın acest caz, la o repornire
a container-ului Globus job-ul distrus nu mai apare ca si resursa nealocata [Archip 08b].
Un potential client poate, ın acest caz, sa consulte fisierele log partiale pentru a identifica
ultima etapa a analizei dorite si poate reporni analiza ın cauza de la aceasta ultima etapa.
Principiul de functionare al celor doua componente ale serviciului Grid propus este
urmatorul [Archip 08b]:
1. clientul autorizat poate initia o cerere pentru o resursa noua de catre AAFacto-
ryService (cu semnificatia ınceperii unei noi analize) sau se poate conecta direct
pe o resursa deja existenta (prin intermediul serviciului instanta AATestService)
ın scopul consultarii stadiului actual al unei analize ın desfasurare sau ın scopul
consultarii unor rezultate ale unei analize deja ıncheiate;
2. ın cazul ın care clientul autorizat dorsste ınceperea unei analize noi, AAFactory-
Service va initializa o resursa noua, apoi ıntoarce clientului o referinta EPR (End-
pointReference - identificator unic atasat resurselor Grid). Aceasta referinta va fi
salvata pe statia de lucru a clientului, apoi acesta se va conecta, prin intermediul
serviciului de instantta AATestService la resursa nou creata;
3. prin intermediul AATestService se vor specifica setarile specifice analizei dorite si
modalitatea de jurnalizare a aplicatiei;
4. AATestService parcurge urmatorii pasi:
a) scrie fisierele de configurare ale clientului ın locatiile corespunzatoare rularii
modulului de analiza solicitat (prin interactiune directa cu serviciulGridFTP);
b) apeleaza resursa Grid atasata si starteaza job-ul prin intermediul acesteia.
In acest moment, resursa Grid atasata va verifica existenta binarului MPI ce
realizeaza analiza ın cauza, va genera un script RSL (ın XML) corespunzator
analizei curente, apoi va porni job-ul dorit;
5. clientul poate monitoriza apoi starea jobului curent sau al altor job-uri trimise
anterior spre rulare.
O observtie importanta este aceea ca aceasta abordare respecta specificatiile si tiparul
de rulare propus ın [Foster 02b] pentru modulele de data mining.
Aplicatiile MPI de test au fost dezvoltate utilizand implementarea LAM/MPI a
standardului MPI. Trebuie mentionat, de asemenea, si faptul ca la prima instantiere a
unei resurse Grid, serviciul fabrica va verifica starea lamd-ului. In cazul ın care acesta
este oprit, serviciul fabrica ıl va starta. Pentru cazurile ın care eventualele rulari ale
aplicatiilor MPI se ıncheie cu erori sau cazurile ın care se doreste interogarea starii unei
rulari active, serviciul instanta va prelua gestiunea lamd-ului [Caraiman 09].
6.3 Consideratii asupra aplicatiilor client
Utilizarea corecta a modelului propus presupune parcurgerea unui set de pasi de conectare
obligatorii [Archip 08b].
48

Un client Grid autorizat trebuie sa parcurga urmatoarele etape pentru a putea utiliza
serviciul Grid propus:
1. clientul ısi verifica proxy-ul Grid si, ın cazul ın care acest proxy nu exista sau ın
cazul ın care acest proxy a expirat, este reponsabil de reinitializarea sa;
2. dupa setarea parametrilor de securitate corespunzatori, se acceseaza serviciul de tip
Factory pentru crearea unei noi resurse (semnificand ınceperea unei analize noi).
In cazul ın care se doreste accesarea unei resurse instantiate anterior, acest pas
poate fi omis;
3. clientul realizeaza conexiunea cu serviciul de tip Instance. Daca se doreste conectarea
unei resurse existente, atunci clientul va transmite catre acest serviciu un obiect de
tip EPR ce indica resursa Grid dorita. In cazul ınceperii unei noi analize, clien-
tul va transmite catre serviciul instanta obiectul de tip EPR obtinut din apelul
anterior catre serviciul fabrica;
4. pe baza setarilor primite de la client, serviciul instanta va seta corespunzator
parametri analizei, apoi va transmite resursei Grid gestionate un semnal de tip
Submit Job;
5. resursa Grid va seta corespunzator scripturile RSL corespunzatoare analizei dorite,
apoi va lansa ın executie modulul corespunzator;
6. ın cazul modificarii starii executiei pentru rularea curenta, resursa Grid va prelua
notificarile transmise de catre componentele corespunzatoare WS-GRAM ;
7. ın momentul finalizarii analizei, serviciul instanta va trimite un mesaj de tip Notify
client job finished catre client si va transfera eventualele fisiere rezultat catre locatia
indicata de acesta.
6.4 Rezultate importante
Rularea si testarea modelului propus
Dupa cum a fost amintit anterior, aplicatiile MPI au fost dezvoltate utilizand im-
plemenatrea LAM/MPI. Serviciul Grid propus are rolul de intermediar ıntre clientii
autorizati si componentele WS-GRAM utilizate ın gestiunea efectiva a job-urilor Grid.
Pentru a realiza acest lucru ın mod corect, modulele WS-GRAM incluse ın GT4 recurg
la utilizarea unui planificator de job-uri. In mod uzual, GT4 include urmatoarele planifi-
catoare: Fork, PBS, SGE si Condor. Pentru o testare completa a serviciului Grid propus
au fost testate toate cele patru planificatoare aminintite anterior. Au fost observate
urmatoarele rezultate:
• Fork3: a avut cel mai rapid timp pentru lansarea ın executie a aplicatiilor LAM/MPI.
• Condor : acest planificator nu a reusit sa identifice clustere capabile sa ruleze
aplicatii LAM/MPI.
3Planificatorul predefinit pentru GT4
http://www.globus.org/toolkit/docs/4.0/execution/wsgram/developer/internal-components.html
49

• SGE : acest manager a identificat cu succes clusterele pe care a fost startat lamd-ul,
dar lansarea efectiva ın executie a esuat, ıntrucat versiunea SGE testata nu poate
fi configurata sa lanseze ın executie aplicatii LAM/MPI ;
• PBS : acest planificator s-a comportat similar cu planificatorului SGE, cu exceptia
faptului ca a trimis job-ul ıntr-o stare de asteptare si a fost necesara terminarea
fortata a aplicatiei.
Utilizarea serviciului Grid propus ın cadrul Grid-ului GRAI 4
Serviciul Grid pentru gestiunea aplicatiilor LAM/MPI a fost dezvoltat integral ın
cadrul contractului de cerectare cu titlul ,,Grid academic pentru aplicatii complexe”. O
prezentare sumara a acestui contract a fost realizata ın [Craus 07a, Craus 07b].
Scopul initial al acestui serviciu a fost de a dezvolta servicii Grid de data mining ce
utilizeaza implementari MPI ale algoritmilor de tratati ın cadrul acestei teze (sunt avute
ın vedere aplicatiile LAM/MPI corespunzatoare algoritmilor Hash Partitioned Apriori
[Archip 07] si Paralel K-Means [Archip 10]). De asemenea, serviciul Grid dezvoltat poate
fi usor adaptat pentru a fi inclus ın cadrul unor abordari complexe, abordari care necesita
compunerea unui set de servicii. Un astfel de exemplu a fost prezentat ın [Arustei 08].
Caracterul general al abordarii (ın conditiile unor configurari adecvate, resursele Grid
ale serviciului ın discutie pot ıngloba o gama variata de aplicatii LAM/MPI [Archip 08b]),
recomanda aceasta propunere pentru ıncapsularea sub forma de servicii Grid a altor
aplicatii MPI, precum Parallel RANSAC (algoritm de detectie a structurilor planare ın
nori de puncte) [Arustei 07]. Un alt rezultat important obtinut prin utilizarea acestui
serviciu Grid a fost implementarea unui simulator cuantic paralel ın cadrul Grid-ului
GRAI [Caraiman 09].
4http://www.grai.tuiasi.ro/
50

Capitolul 7
Concluzii, contributii si directii viitoare
de cercetare
7.1 Concluzii
Domeniul descoperirii de cunostinte include o componenta deosebit de importanta: data
mining. Importanta si actualitatea acestei componente este recomandata de numarul din
ce ın ce mai mare de domenii ce recurg la utilizarea tehnicilor de analiza specifice (identifi-
carea regulilor de asociere, determinarea regulilor de clasificare, segmentarea/clusterizarea
seturilor de date, etc.) pentru a extrage informatii noi din seturile de date caracteristice
activitatilor desfasurate. Cateva exemple includ domeniul economic, domeniul regasirii
de informatii pe Web sau domeniul geneticii. Cu toate ca aceste domenii sunt diferite
fundamental din punctul de vedere al rezultatelor urmarite, expertii care recurg la uti-
lizarea acestor metode de explorare a datelor de lucru se confrunta cu doua probleme
importante: algoritmii implicati sunt intensiv computationali si volumul de date acu-
mulate este din ce ın ce mai mare. O consecinta directa este reprezentata de faptul ca
pentru algoritmii ce adreseaza problematica data mining trebuie dezvoltate modele efi-
ciente de paralelizare/distribuire. Implementarea acestor modele implica existenta unor
infrastructuri hardware/software dedicate, infrastructuri ce trebuie sa fie caracterizate
de o utilizare facila si de catre expertii ce nu activeza ın domeniul IT. In acest context,
conceptele ce stau la baza dezvoltarii sistemelor Grid pot reprezenta solutii atat pentru
rezolvarea problemelor implicate ın rularea unor aplicatii paralele/distribuite complexe,
cat si pentru furnizarea mecanismelor necesare stocarii unui volum imens de date.
In ceea ce priveste algoritmii implicati ın determinarea tiparelor frecvente si a regulilor
de asociere, o analiza pertinenta a acestora nu poate sa nu includa algoritmul Apriori.
Dezvoltat ın 1994 de catre Agrawal, acest algoritm se remarca prin rezultate rezonabile
din punct de vedere al timpului de raspuns oferit si prin simplitate ın implementare. Prin-
cipiul fundamental al acestui algoritm este de a restrange identificarea tiparelor frecvente
prin generarea de itemseturi candidate. Implementarile algoritmului Apriori se bazeaza
pe utilizarea unor structuri de tip arbore hash pentru reprezentarea itemseturilor si a
tranzactiilor sau pe utilizarea unor structuri de tip arbore prefix. In mod uzual, itemii din
care sunt alcatuite tranzactiile si pe baza carora sunt construite itemseturile sunt ın mod
uzual codificati prin valori numerice. Algoritmii paraleli dezvoltati pornind de la algorit-
51

mul Apriori se bazeaza fie pe divizarea componentei de generare a candidatilor aferenti
unei etape, fie pe divizarea pasilor implicati ın determinarea suportului pentru itemse-
turile candidate, fie pe o combinatia a celor doua. Din ultima categorie mentionata face
parte si algoritmul Hash Partitioned Apriori. Acesta utilizeaza cheia de dispersie carac-
teristica arborelui hash pentru a ımparti diviza ıntre procese atat generarea candidatilor
cat si determinarea suportului pentru acesti candidati. De observat este faptul ca ın
literatura ce trateaza acest algoritm nu exista studii cu privire la utilizarea unor alte
metode de codificare a itemilor si de reprezentare a tranzactiilor si a itemseturilor. In
acest context, prima parte a Capitolului 3 este dedicata investigarii unui model de cod-
ificare binara a datelor de lucru pentru algoritmul Apriori. Codificarea propusa a fost
testata atat pentru algoritmul secvential de baza, cat si pentru algoritmul Hash Parti-
tioned Apriori. Cu toate ca rezultatele testelor efectuate pentru cazul secvential infirma
valididatea unei astfel de abodari, testele efectuate pentru algoritmul paralel indica un
potential avantaj. Utilizarea unei codificari binare pentru reprezentarea itemseturilor
si a tranzactiilor slabeste mult conditiile de generare a cheii de dispersie caracteristica.
Astfel, prin utilizarea unei chei de dispersie modulo bitonic s-a obtinut o echilibrare buna
a sarcinilor de lucru repartizate ıntre procese pentru cazul algoritmului Hash Partitioned
Apriori.
S-a constatat ca algoritmii de data recenta destinati determinarii tiparelor frecvente
abandoneaza problema identificarii itemseturilor frecvente pe baza generarii de itemse-
turi candidat. Un exemplu ın acest sens este algoritmul FP-Growth. Acest algoritm
obtine o reducere substantiala a numarului de scanari ale bazei de tranzactii, fapt ce
conduce la obtinerea unor timpi de raspuns foarte buni. Din nou, se observa faptul ca ın
literatura de specialitate nu au fost investigate alte metode de generare a itemseturilor
candidat. In partea a doua a capitolului al 3-lea este propus un nou astfel de algoritm,
denumit Fast Itemset Miner. Acest algoritm este bazat pe faptul ca itemii supusi anal-
izei sunt divizati pe intervale initial disjuncte. Un interval este constituit din cel putin
un item frecvent. In cazul ın care un interval contine mai mult de un item frecvent,
atunci acesta include si toate itemseturile frecvente ce se pot forma din itemii frecventi
inclusi. Candidatii noi sunt generati prin reuniuni conditionate ale itemseturilor frecevnte
ce apartin de aceste intervale. Rezultatele experimentale obtinute indica doua avantaje
majore fata de algoritmul Apriori. Primul este legat de generarea candidatilor : modal-
itatea de generare propusa pentru algoritmul Fast Itemset Miner este mult simplificata
(si, implicit, mult mai putin consumatoare de timp) fata de algoritmul Apriori. O data ce
un candidat a fost generat, nu mai este necesara generarea subseturilor incluse de acesta
si verificarile suplimentare efectuate asupra acestor subseturi. Un al doilea avantaj ma-
jor este reprezentat de faptul ca algoritmul Fast Itemset Miner nu scaneaza niciodata
complet baza de tranzactii ın cadrul etapelor de determinare a suportului candidatilor.
Acest mod de lucru este posibil daca sunt respectate urmatoarele conditii. Multimea
de itemi trebuie sortata descrescator din punct de vedere al suportului fiecarui item
frecvent ın parte. Totodata, similar algoritmului FP-Growth, baza de tranzactii trebuie
sa includa numai combinatii formate din itemi frecventi, combinatii sortate descrescator
conform aceluiasi criteriu. In aceste conditii, determinarea suportului pentru candidatii
inclusi ıntr-un interval se rezuma la scanarea acelor tranzactii care contin cel mai frecvent
item inclus ın intervalul respectiv. Un alt avantaj important al algoritmului Fast Itemset
Miner este dat de faptul ca paralelizarea acestui algoritm este relativ facila. Modalitatile
de generare a candidatilor si de validare a itemseturilor frecvente caracteristice impun un
52

tipar comunicational predefinit, ce poate fi implementat atat prin utilizarea standardului
MPI, cat si prin utilizarea API-ului OpenMP. Mai mult, algoritmul Fast Itemset Miner
paralalel nu implica alterarea modului de determinare a itemseturilor frecvente (acest
caz este ıntalnit ın cadrul algoritmilor bazati pe FP-Growth - un exemplu ın acest sens
fiind algoritmul Multiple Local Frequent Pattern Trees).
Algoritmii data mining destinati problemei clusterizarii datelor au fost, de aseme-
nea, considerati ın cadrul cercetarilor ce au conturat aceasta lucrare. Aceasta clasa de
metode de analiza este recomandata atat de rezultatele directe oferite, cat si de faptul
ca aceleasi rezultate pot fi utilizate pentru diverse optimizari ın cadrul unui domeniu
de analiza complementar - domeniul determinarii regulilor de clasificare. Un exemplu
important ın acest context este dat de motoarele inteligente de cautare a informatiilor pe
Web (motoare de cautare precum Cuil1 sau Yippy2). Exemplul considerat evidentiaza
si una dintre problemele majore ce trebuie rezolvate de catre algoritmii destinati clus-
terizarii datelor. Astfel, aceasta clasa de algoritmi impune atat existenta unor metode de
paralelizare eficiente, cat si o utilizare adecvata a tehnologiilor de implemnetare a acestor
modele paralele pentru a face fata volumului din ce ın ce mai crescut de date (la ultima
accesare, motorul Cuil raporta un volum de 127 de miliarde de pagini indexate). Printre
algoritmiii utilizati ın clusterizarea datelor se numara si algoritmul K-Means Clustering.
Acest algoritm, fundamentat din punct de vedere teoretic ınca din anul 1967, se remarca
printr-o popularitate crescuta datorita simplitatii, scalabilitatii si vitezei de convergenta.
Este un algoritm adaptabil multor tipuri de date ın conditiile ın care metricile uti-
lizate sunt adecvate acestor tipuri de date. Printre cei mai cunoscuti algoritmi paraleli
bazti pe K-Means Clustering se numara si Parallel K-Means, algoritm analizat ın cadrul
capitolului 4. Acest algoritm a fost conceput initial pentru a fi implementat utilizand
standardul MPI si se bazeaza pe divizarea datelor de analizat ıntre procese. Modelul
de paralelizare ın discutie implica utilizarea operatiilor de tip all-reduce specificate de
standardul amintit. Acest fapt atrage dupa sine un potential dezavantaj al algoritmu-
lui Parallel K-Means : eficienta sa este conditionata puternic de eficienta implementarii
MPI utilizate. Abordarea propusa pentru depasirea acestui obstacol vizeaza un aspect
ce pare a fi omis din abordarile curente ale algoritmilor paraleli destinati clusterizarii
datelor : eficienta operatiilor colective de calcul este direct dependenta de topologia de
comunicatie dintre procese. Prin utilizarea topologiei de tip hipercub ın implementarea
primitivei all-reduce s-a obtinut o scadere a timpilor de rulare fata de abordarile clasice.
Un avantaj major al abordarii propuse este faptul ca topologia virtuala ın discutie poate
fi construita indiferent de implementarea standardului MPI utilizata. Eficienta abordarii
propuse nu este ın acest caz dependenta de eficienta implementarilor MPI utilizate.
Dupa cum s-a aratat ın capitolul 1, sistemele Grid ofera atat mecanismele necesare
rularii algoritmilor complecsi de data mining, cat si resursele destinate stocarii volumului
imens de date ce trebuie analizat prin intermediul acestor metode. Considerat de multi
cercetatori un standard pentru acest tip de ,,supercalculatoare” distribuite, middleware-
ul Globus Toolkit marcheaza ın acelasi timp migrarea sistemelor Grid catre arhitecturi
orientate pe servicii. Implementat initial pentru a deservi aplicatii computationale com-
plexe, Globus Toolkit ınglobeaza ın prezent si un set extins de framework-uri destinate
gestiunii datelor. Pe baza acestor caracteristici, Ian Foster (supranumit ,,parintele Grid-
urilor”) propune ınca de la ınceputul anilor 2000 un model de servicii Grid destinate
1http://www.cuil.com/2http://search.yippy.com/
53

domeniului data mining, model alcatuit din doua componente: un serviciu Grid dedicat
accesarii surselor de date si un serviciu Grid dedicat analizei concrete. In capitolul al
6-lea al acestei lucrari este propusa o abordare noua pentru serviciul Grid de analiza.
Aceasta abordare a fost dezvoltata de la premisa reutilizarii aplicatiilor paralele de data
mining (cazul particular rezolvat fiind cel al aplicatiilor LAM/MPI ), reutilizare moti-
vata de faptul ca aplicatiile de analiza existente sunt aplicatii al caror comportament a
fost deja testat si validat. Astfel, serviciul Grid de analiza este tratat ca si componenta
de nivel ınalt ce ıncapsuleaza setul de aplicatii ın discutie. Implementarea serviciului
utilizeaza framework-ul WSRF inclus ın Globus Toolkit 4 si este conforma specificatiilor
OGSA. Pentru rularea efectiva a aplicatiilor ıncapsulate a fost utilizat planificatorul im-
plicit al Globus Toolkit 4 - Fork. Utilizand aceasta abordare, au fost dezvoltate serviciile
de analiza a datelor pentru Grid-ul GRAI 3. Datorita caracterului generic al modelului
propus, acesta a fost utilizat si pentru implementarea sub forma de serviciu Grid a unui
simulator cuantic paralel.
7.2 Contributii
Sintetizand cele prezentate ın subcapitolul 7.1, contributiile principale aduse ın cadrul
acestei lucrari vizeaza urmatoarele domenii:
1. Data mining :
a) Model de codificare a itemilor/itemseturilor pentru abordarile ba-
zate pe algoritmul Apriori: a fost abordata problema codificarii binare
a tranzactiilor si a itemseturilor pentru algoritmul Apriori. Cu toate ca
aceasta codificare nu este eficienta pentru versiunea secventiala a algorit-
mului Apriori, slabeste restrictiile de generare a cheilor de dispersie carac-
teristice algoritmului. Modificarile aduse acestor chei de dispersie pot con-
duce la obtinerea unor rezultate favorabile din punct de vedere al echilibrarii
nodurilor de lucru ın cazul algoritmului paralel Hash Partitioned Apriori
[Archip 07, Amarandei 06].
b) Algoritmul Fast Itemset Miner reprezinta un algoritm nou pentru prob-
lema identificari itemseturilor frecvente [Craus 07c] pentru care au fost aduse
contributii referitoare la generarea itemseturilor candidat si pentru care a fost
dezvoltat un model de paralelizare generalizat [Craus 08b]. Contributiile refer-
itoare la generarea itemseturilor candidat vizeaza simplificarea determinarii
acestora. Pe baza proprietatii de recurenta Apriori, au fost enuntate si demon-
strate lemele 3.4 si 3.7. Au fost eliminate astfel operatiile suplimentare de
validare a unui itemset candidat, fapt ce conduce la un castig considerabil
din punct de vedere al timpului consumant de aceasta etapa. Rezultatele
teoretice ale acestor leme stau la baza metodelor dezvoltate pentru generarea
itemseturilor candidat.
c) Modificari aduse algoritmului Parallel K-Means: a fost abordata prob-
lema topologiilor de comunincatie utilizate pentru implementarile MPI ale
acestui algoritm. Contributiile constau ın adaptarea primitivelor de comu-
nicatie 1-la-toti personalizat si all-reduce peste o topologie de tip hipercub
3http://www.grai.tuiasi.ro/
54

si marginirea corespunzatoare a etapelor de comunicatii colective implicate
de algoritmul Parallel K-Means, independent de implementarea standardului
MPI utilizata [Archip 10].
2. Sisteme Grid
a) Servicii Grid pentru gestiunea aplicatiilor MPI: a fost propus un servi-
ciu Grid capabil sa ıncapsuleze aplicatii MPI dezvoltate utilizand LAM/MPI.
Serviciul Grid a fost dezvoltat pentru middleware-ul GT4 si respecta specifi-
catiile OGSA si WSRF. Serviciul ın discutie joaca rol de componenta de nivel
ınalt, destinata ıncapsularii aplicatiilor LAM/MPI. Un avantaj al abordarii
propuse este acela de a ıngloba si mecanismele de gestiune specifice thread-ului
de control al LAM/MPI. Pentru lansarea si gestionarea aplicatiilor LAM/MPI
a fost utilizat planificatorul predefinit pentru GT4 (planificatorul Fork), fapt
atrage dupa sine un alt potential avantaj al abordarii propuse: nu sunt nece-
sare configurari suplimentare pentru site-urile unui sistem Grid ce ofera astfel
de servicii utilizatorilor autorizati [Archip 08b, Archip 08a].
O parte dintre cercetarile ce au condus la scrierea acestei teze au fost efectuate ın
cadrul proiectului de cercetare Grid academic pentru aplicatii complexe (GRAI).
7.3 Directii viitoare de cercetare
Dupa cum s-a aratat ın Capitolul 3 al acestei teze, algoritmul FIM prezinta cateva
avantaje majore pentru problema determinarii tiparelor frecvente: simplifica generarea
candidatilor, aceasta devenind astfel si mai putin consumatoare de timp, determinarea
suportului candidatilor nu implica scanarea completa a bazei de date si, nu ın ultimul
rand, paralelizarea algoritmului poate fi realizata facil atat pentru modelul de progra-
mare de tip message-passing cat si shared memory. Aceste aspecte sunt ıncurajatoare
pentru continuarea dezvoltarii algoritmului FIM vizand, ın primul rand, testarea com-
pleta a acestuia. Testele efectuate pana ın prezent au vizat ın principal reprezentarea
prin codificare binara a itemseturilor si a tranzactiilor. Se impune ın acest sens un
set de teste ce vor viza alte metode de reprezentare a componentelor ın discutie. Ast-
fel, reprezentarile de tip arbore prefix vor fi printre primele studiate. Analiza acestui
algoritm din punct de vedere al consumului de momorie relativ la variatia limitei de
suport minim (variatie ce determina implicit si variatia numarului de itemseturi candi-
dat/frecvente) este de asemenea importanta pentru a determina daca acest algoritm este
sau nu unul viabil pentru problema determinarii itemseturilor frecvente pentru seturi de
mari dimensiuni. Algoritmul propus este dependent de preprocesarea tranzactiilor origi-
nale ın vederea determinarii itemilor frecventi, sortarea descrescatoare a acestora relativ
la suportul fiecaruia si reorganizarea bazei de tranzactii de analizat. Realizarea eficienta
a acestor operatii de preprocesare poate fi determinanta ın validarea acestui algoritm.
Multe dintre abordarile algoritmilor paraleli destinati data mining nu considera pro-
blematica topologiei de comunicare dintre procese. Unul dintre rezultatele importante
conturate ın cadrul lucrarii de fata indica faptul ca utilizarea unei topologii adecvate
poate contribui la obtinerea unor perfomante crescute. Particularitatile diferitilor algo-
ritmi paraleli dezvolati pentru data mining pot impune astfel diverse topologii virtuale
55

particulare ce pot contribui la obtinerea unei scalabilitati crescute sau la reducerea timpi-
lor de raspuns. Studiul acestor aspecte este de asemenea considerat pentru cercetarile
viitoare.
O provocare reala ın domeniul data mining este reprezentata de automatizarea me-
todelor de analiza specifice. Ar fi de dorit, de exemplu, ca un algoritm de clusterizare sa
identifice automat sau semiautomat si numarul de clustere, fara interventia unui even-
tual expert. Identificarea unor seturi de antrenament adecvate poate contribui mult la
cresterea performantelor unor algoritmi de clasificare. In acest scop se remarca ın ultima
perioada o crestere a abordarilor ce combina diverse metode de clusterizare a datelor cu
algoritmi de clasificare ın vederea cresterii preciziei celor din urma. Un exemplu ın acest
sens provine din domeniul regasirii informatiilor pe Web. Volumul imens de pagini si
documente Web existente la ora actuala face aproape imposibila generarea unui set de
date de antrenament pentru clasificatorii uzuali. S-a observat totusi ca utilizarea tehni-
cilor de clusterizare pentru a obtine o descriere suplimentara asupra datelor de clasificat
poate contribui la generarea unor seturi de antrenament coerente, fapt ce poate conduce
la cresterea acuratetii clasificatorilor uzuali. In acelasi context pot fi investigate si alte
metode de analiza descriptive pentru a identifica setul de atribute dominante sau setul de
valori dominate ce pot caracteriza mai bine clasele rezultat ale unui eventual clasificator.
Pentru abordarea acestei probleme pot fi utilizate, spre exemplu, metodele de identificare
a tiparelor frecvente.
Sistemele Grid au evoluat catre arhitecturi orientate pe servicii. Implementarile
curente ale serviciilor Grid extind serviciile Web de tip SOAP/XML. Pentru a putea
adapta acest tip de servicii specificului sistemelor Grid au fost dezvoltate mecanisme
prin intermediul carora starea unui serviciu este mentinuta extern, fara a afecta car-
acterul tranzitoriu al serviciului. Un serviciu Grid reprezinta astfel asocierea dintre o
interfata de tip serviciu si o resursa Grid. Din acest punct de vedere se poate spune
ca interactiunea cu un serviciu Grid ınseamna ın fapt gestiunea unui set de resurse si a
tranzitiilor acestor resurse ıntre diferitele stari posibile. Considerand aceasta observatie,
se poate spune ca serviciile Grid au un comportament apropiat serviciilor REST (REpre-
sentational State Transfer). Serviciile REST sunt prin definitie fara stare, au un caracter
tranzitoriu si sunt axate pe gestiunea resurselor asupra carora opereaza. Operatiile ce pot
fi realizate asupra acestor resurse sunt creare, citire, modificare sau stergere. Acest tip de
servicii este restrictionat la utilizarea protocolului HTTP si fiecare dintre operatiile am-
intite anterior este implementata prin metodele HTTP corespunzatoare: POST, GET,
PUT si, respectiv, DELETE. O abordare REST pentru preluarea starii unei resurse
Grid, de exemplu, ar fi mult simplificata fata de metodele actuale. Astfel, ,,citirea” unei
resurse Grid poate implica un apel de metoda HTTP GET, caz ın care identificatorul
asociat resursei poate fi un parametru de tip cale sau un parametru de tip query al cererii
HTTP. Diferentierea operatiilor ce pot fi realizate asupra unei resurse Grid la nivel de
metoda HTTP poate constitui un avantaj ın implementarea si monitorizarea politicilor
de securitate ale unui sistem Grid, componenta legata de securitate fiind una dintre com-
ponentele fundamentale ale acestui tip de sisteme de calcul distribuit. In plus, serviciile
REST nu implica aceeasi ıncarcare a container-ului de servicii necesar unui sistem Grid.
Explorarea posibilitatilor de dezvoltare a serviciilor Grid pe baza serviciilor REST va
constitui o directie importanta de cercetare.
56

Bibliografie
[Adamo 00] Jean-Marc Adamo. Data mining for association rules and sequential pat-
terns: Sequential and parallel algorithms. Springer-Verlag, New York,
2000. [citat la p. 1, 11, 13, 19, 20, 23, 24]
[Aflori 05] Cristian Aflori, Mitica Craus, Ioan Sova, Cristian Butincu, Florin Leon
& Cristian Mihai Amarandei. Grid - tehnologii ıi aplicatii. Politehnium,
2005. [citat la p. 42]
[Agrawal 94] Rakesh Agrawal & Ramakrishnan Srikanta. Fast Algorithms for Mining
Association Rules. In Proceedings of the 20th VLDB Conference, 1994.
[citat la p. 5, 10, 11, 13, 18, 19, 23, 24]
[Amarandei 06] C.M. Amarandei, A. Archip & S. (Caraiman) Arustei. Performance
Study for MySQL Database Access within Parallel Applications. Bulet-
inul Institutului Politehnic din Iasi, Automatic Control and Computer
Science Section, vol. LII(LVI), no. 1-4, pages 127–134, 2006. [citat la p. 24,
54]
[Archip 07] A. Archip, C.M. Amarandei, S. (Caraiman) Arustei & M. Craus. Opti-
mizing Association Rule Mining Algorithms using C++ STL Templates.
Buletinul Institutului Politehnic din Iasi, Automatic Control and Com-
puter Science Section, vol. LIII(LVII), no. 1-4, pages 123–132, 2007.
[citat la p. 19, 21, 50, 54]
[Archip 08a] A. Archip, S. (Caraiman) Arustei, C.M. Amarandei & A. Rusan. On
the design of Higher Order Components to integrate MPI applications
in Grid Services. In H.N. Teodorescu & M. Craus, editeurs, Scientific
and Educational Grid Applications, pages 25–35, Iasi, Romania, 2008.
Politehnium. [citat la p. 43, 46, 47, 55]
[Archip 08b] A. Archip, M. Craus & S. Arustei. Efficient grid service design to
integrate parallel applications. In Marten van Sinderen, editeur, Pro-
ceedings of 2nd International Workshop on Architectures, Concepts and
Technologies for Service Oriented Computing held in conjunction with
3rd International Conference on Software and Data Technologies, 5-8
JUL, 2008 Porto PORTUGAL, pages 7–16, Setubal, Portugal, 2008.
INSTICC Press. [citat la p. 43, 46, 47, 48, 50, 55]
57

[Archip 10] A. Archip, V. Manta & G. Danilet. Parallel K-Means Revisited: A
Hypercube Approach. In Proceedings of the 10th International Sympo-
sium on Automatic Control and Computer Science, october 2010. to be
published. [citat la p. 33, 34, 35, 36, 37, 38, 50, 55]
[Arustei 07] S. (Caraiman) Arustei, A. Archip & C.M. Amarandei. Parallel
RANSAC for Plane Detection in Point Clouds. Buletinul Institutului
Politehnic din Iasi, Automatic Control and Computer Science Section,
vol. LIII(LVII), no. 1-4, pages 139–150, 2007. [citat la p. 50]
[Arustei 08] S. Arustei, M. Craus & A. Archip. Towards a generic framework
for deploying applications as grid services. In Marten van Sinderen,
editeur, Proceedings of 2nd International Workshop on Architectures,
Concepts and Technologies for Service Oriented Computing held in con-
junction with 3rd International Conference on Software and Data Tech-
nologies, 5-8 JUL, 2008 Porto PORTUGAL, pages 17–26, Setubal, Por-
tugal, 2008. INSTICC Press. [citat la p. 50]
[Astratiei 10] I. Astratiei & A. Archip. A Case Study on Improving the Performance
of Text Classifiers. In Proceedings of the 10th International Sympo-
sium on Automatic Control and Computer Science, october 2010. to be
published. [citat la p. 15]
[Berkhin 02] Pavel Berkhin. Survey of Clustering Data Mining Techniques. Disponi-
bil online:
http://www.ee.ucr.edu/˜barth/EE242/clustering survey.pdf, 2002.
[citat la p. 15]
[Bote-Lorenzo 03] Miguel L. Bote-Lorenzo, Yannis A. Dimitriadis & Eduardo Gmez-
snchez. Grid Characteristics and Uses: A Grid Definition. In Across
Grids 2003, LNCS 2970, pages 291 – 298, 2003. [citat la p. 4]
[Caraiman 09] S. Caraiman, A. Archip & V. Manta. A Grid Enabled Quantum Com-
puter Simulator. In Proceedings of the 11th International Symposium on
Symbolic and Numeric Algorithms for Scientific Computing (SYNASC
2009). IEEE Computer Society, 2009. [citat la p. 48, 50]
[Craus 05] Mitica Craus, Cristian Butincu, Cristian Alfori, Ioan Sova, Florin Leon
& Augustin-Ionut Gavrila. Regasirea informatiilor pe web. Editura
Politehnium Iasi, 2005. [citat la p. 4]
[Craus 07a] M. Craus, H.N. Teodorescu, C. Croitoru, O. Brudaru, D. Arotaritei,
M. Calin & A. Archip. Academic Grid for Complex Applications -
GRAI. In Proc. of 16th International Conference on Control Systems
and Computer Science. POLITEHNICA University of Bucharest, May
22-25 2007. [citat la p. 50]
[Craus 07b] M. Craus, H.N. Teodorescu, C. Croitoru, O. Brudaru, D. Arotaritei,
M. Calin & A. Archip. The Service Layer of the Academic Grid
GRAI. In Proc. of 16th International Conference on Control Systems
and Computer Science. POLITEHNICA University of Bucharest, May
22-25 2007. [citat la p. 50]
58

[Craus 07c] Mitica Craus. A New Algorithm for Association Rule Discovery. In
Proceedings of the 9th International Symposium on Automatic Control
and Computer Science, 2007. [citat la p. 24, 25, 26, 54]
[Craus 08a] M. Craus & A. Archip. A generalized parallel algorithm for frequent
itemset mining. In ICCOMP’08: Proceedings of the 12th WSEAS in-
ternational conference on Computers, pages 520–523. World Scientific
and Engineering Academy and Society (WSEAS), 2008. [citat la p. 24, 26,
27, 28, 29]
[Craus 08b] Mitica Craus. A new parallel algorithm for the frequent itemset mining
problem. In Proceedings of the 7th International Symposium on Parallel
and Distributed Computing (ISPDC 2008), 2008. [citat la p. 26, 27, 54]
[Dhillon 00] Inderjit Dhillon & Dharmendra Modha. A Data-Clustering Algorithm
On Distributed Memory Multiprocessors. In In Large-Scale Parallel Data
Mining, Lecture Notes in Artificial Intelligence, pages 245 – 260, 2000.
[citat la p. 15, 16, 17, 32, 33]
[Dunnweber 05] J. Dunnweber, A. Benoit, M. Cole, S. Gorlatch, G. R. Joubert, W. E.
Nagel, F. J. Peters, O. Plata, P. Tirado & E. Zapata. Integrating MPI-
Skeletons with Web services. In In Proceedings of the International
Conference on Parallel Computing, Malaga, 2005. [citat la p. 46, 47]
[Fayyad 96] Usama Fayyad, Gregory Piatetsky-shapiro & Padhraic Smyth. From
Data Mining to Knowledge Discovery in Databases. AI Magazine,
vol. 17, pages 37 – 54, 1996. [citat la p. 2, 3]
[Foster 98] Ian Foster & Carl Kesselman. The grid: Blueprint for a new computing
infrastructure. Morgan Kaufmann Inc., San Francisco, California, 1998.
[citat la p. 41]
[Foster 01] Ian Foster, Carl Kesselman & Steven Tuecke. The Anatomy of the
Grid: Enabling Scalable Virtual Organizations. INTERNATIONAL
JOURNAL OF SUPERCOMPUTER APPLICATIONS, vol. 15, 2001.
[citat la p. 4, 5, 41, 42]
[Foster 02a] Ian Foster. What is the grid? - a three point checklist. GRIDToday,
vol. 6, 2002. [citat la p. 41]
[Foster 02b] Ian Foster, Carl Kesselman, J. Nick & Steven Tuecke. Grid Services for
Distributed System Integration. IEEE Computer, vol. 35, no. 6, pages
37 – 46, June 2002. [citat la p. 6, 45, 46, 48]
[Foster 02c] Ian Foster, Carl Kesselman, Jeffrey M. Nick & Steven Tuecke. The
physiology of the grid: An open grid services architecture for distributed
systems integration. 2002. [citat la p. 6]
[Freitas 00] Alex A. Freitas. Understanding the crucial differences between classi-
fication and discovery of association rules: a position paper. SIGKDD
Explor. Newsl., vol. 2, no. 1, pages 65 – 69, 2000. [citat la p. 14]
59

[Grahne 05] Gsta Grahne & Jianfei Zhu. Fast algorithms for frequent itemset min-
ing using FP-trees. IEEE TRANSACTIONS ON KNOWLEDGE AND
DATA ENGINEERING, vol. 17, no. 10, pages 1347 – 1362, 2005.
[citat la p. 11]
[Grama 03] Ananth Grama, Anshul Gupta, George Karypis & Vipin Kumar. Intro-
duction to parallel computing. Addison Wesley, second edition, 2003.
[citat la p. 33, 34, 35, 37]
[Grossman 04] David A. Grossman & Ophir Frieder. Information retrieval - algorithms
and heuristics. The Information Retrieval Series. Springer, second edi-
tion, 2004. [citat la p. 15]
[Han 00] Jiawei Han, Jian Pei & Yiwen Yin. Mining frequent patterns with-
out candidate generation. In SIGMOD 00: Proceedings of the 2000
ACM SIGMOD international conference on Management of data, 2000.
[citat la p. 5, 11, 24]
[Han 06] Jiawei Han & Micheline Kamber. Data mining - concepts and tech-
niques. Morgan Kaufman Publications, 2006. [citat la p. 15, 16, 17]
[Jacob 05] Bart Jacob, Michael Brown, Kentaro Fukui & Nihar Trivedi. Introduc-
tion to grid computing. IBM Redbooks. IBM Corp, first edition, 2005.
[citat la p. 46]
[Joshi 03] Manasi N. Joshi. Parallel K - Means Algorithm on Distributed Memory
Multiprocessors. Rapport technique, Computer Science Department,
University of Minnesota, Twin Cities, 2003. [citat la p. 15, 16, 17, 32, 33]
[Karonis 03] Nicholas T. Karonis, Brian Toonen & Ian Foster. MPICH-G2: a Grid-
enabled implementation of the Message Passing Interface. J. Parallel
Distrib. Comput., vol. 63, no. 5, pages 551 – 563, 2003. [citat la p. 42, 43]
[Kumar 03] Vipin Kumar. High Performance Data Mining. In In Proceedings of
the 17th International Parallel and Distributed Processing Symposium.
IEEE Computer Society, 2003. [citat la p. 11]
[Li 05] Yanjun Li & Soon M. Chung. Text document clustering based on fre-
quent word sequences. In CIKM ’05: Proceedings of the 14th ACM
international conference on Information and knowledge management,
pages 293 – 294. ACM, 2005. [citat la p. 15]
[MacQueen 67] J. B. MacQueen. Some Methods for Classification and Analysis of Mul-
tiVariate Observations. In L. M. Le Cam & J. Neyman, editeurs, Proc.
of the fifth Berkeley Symposium on Mathematical Statistics and Prob-
ability, volume 1, pages 281 – 297. University of California Press, 1967.
[citat la p. 15, 32]
[Shintani 96] Takahiko Shintani & Masaru Kitsuregawa. Hash Based Parallel Algo-
rithms for Mining Association Rules. In Proceedings of the 4th Inter-
national Conference on Parallel and Distributed Information Systems,
1996. [citat la p. 5, 11, 12]
60

[Sotomayor 06] Borja Sotomayor & Lisa Childers. Globus toolkit 4: Programming
java services. Morgan Kaufmann, San Francisco, California, 2006.
[citat la p. 42, 46, 47]
[Stoffle 99] K. Stoffle & A. Belkonience. Parallel k-Means clustering for large
datasets. Proceedings of EuroPar, 1999. [citat la p. 16, 17, 32, 33]
[Tan 05] Pang-Ning Tan, Michael Steinbach & Vipin Kumar. Introduction to
data mining. Addison - Wesley, first edition, 2005. [citat la p. 11, 14, 19, 20,
23, 24]
[Two 05] Two Crows Corporation. Introduction to Data Mining
and Knowledge Discovery, third edition, 2005. Online:
http://www.twocrows.com/intro-dm.pdf. [citat la p. 1, 14]
[Zaiane 01] Osmar R. Zaiane, Mohammad El-hajj & Paul Lu. Fast Parallel Associ-
ation Rule Mining without Candidacy Generation. In In ICDM, pages
665 – 668, 2001. [citat la p. 12]
[Zaki 99] Mohammed J. Zaki. Parallel and Distributed Association Mining: A
Survey. IEEE Concurrency, vol. 7, no. 4, pages 14 – 25, 1999. [citat la p. 10,
11, 12, 20, 24]
61


















