







Limbile
Pagini
Legal


Universitatea Politehnica Bucureşti
Facultatea de Automatică şi Calculatoare
Catedra de Automatică şi Ingineria Sistemelor
LUCRARE DE LICENŢĂ
Prelucrare neuronală de imagini pentru
controlul unui vehicul
Absolvent:
Daniel CAZACU
Coordonator:
Prof.dr.ing. Dan ȘTEFĂNOIU
Bucureşti, 2013

1
Cuprins:
1. Introducere ...................................................................................................................... 5 2. Rețele neuronale artificiale ............................................................................................ 7
2.1 Modele ale neuronului artificial ........................................................................... 8
2.2 Arhitecturi ........................................................................................................... 10
2.3 Algoritmi de învățare .......................................................................................... 11
2.4 Aplicații din viața de zi cu zi .............................................................................. 12
2.5 Dezavantaje ale rețelelor neuronale .................................................................... 12
3. Descrierea componentelor hardware ale sistemului ................................................. 13 3.1 Vehiculul ............................................................................................................ 13
3.2 Camera pentru înregistrarea imaginilor .............................................................. 13
3.3 Modulul de procesare ......................................................................................... 14
3.4 Arduino Duemilanove ........................................................................................ 15
3.5 Conexiunile hardware ......................................................................................... 16
4. Descrierea modulelor software .................................................................................... 18 4.1 Software Arduino ............................................................................................... 19
4.2 Software Android ............................................................................................... 20
4.3 Aplicatie Java VACRN ...................................................................................... 23
5. Antrenarea rețelei neuronale ....................................................................................... 31 5.1 Propagare înainte și Propagare inversă ............................................................... 32
5.2 Metode de generalizare ....................................................................................... 35
5.3 Determinarea numărului de neuroni din stratul ascuns ...................................... 36
5.4 Metoda Gradient cu Propagare Inversă (traingd) ............................................... 39
5.5 Propagare inversă flexibilă (trainrp) ................................................................... 40
5.6 Propagarea inversă BFGS quasi-Newton (trainbfg) ........................................... 42
5.7 Propagarea inversă OSS (trainoss) ..................................................................... 43
5.8 Propagarea inversă Levenberg-Marquardt (trainlm) .......................................... 44
ALGORITMI CU GRADIENT-CONJUGAT ............................................................. 46
5.9 Actualizarea Fletcher-Reeves (traincgf) ............................................................. 47
5.10 Actualizarea Polak-Ribiere (traincgp) ................................................................ 49
5.11 Resetarea Powell-Beale (traincgb) .................................................................... 50
5.12 Algoritmul Gradientului Conjugat Scalat (trainscg) .......................................... 51
6. Concluzii și planuri de viitor ....................................................................................... 56
7. Bibliografie .................................................................................................................... 60

2
Lista figurilor Figura 2.1 Model simplu al neuronului artificial 8
Figura 2.2 Modelul MCP (McCulloch – Pitts) al neuronului artificial 9
Figura 2.3 Funcția de activare treaptă 9
Figura 2.4 Funcția de activare liniară 10
Figura 2.5 Funcția de activare log-sigmoid 10
Figura 2.6 Funcția de activare tan-sigmoid 10
Figura 2.7 Arhitectura RNA 11
Figura 2.8 Mecanismul de învățare supervizată 12
Figura 3.1 Vehiculul utilizat 13
Figura 3.2 Telefon HTC Droid Eris 14
Figura 3.3 Utilizare Apache Ant 14
Figura 3.4 Arduino Duemilanove 15
Figura 3.5A Schema electrică a telecomenzii 16
Figura 3.5B Microcipurile de Transmisie-Receptie 17
Figura 3.6 Conectarea telecomenzii la Arduino 17
Figura 3.7 Schema comunicațiilor din sistem 18
Figura 4.1 Formatul YUV420 22
Figura 4.2 Informații accelerometru Android 23
Figura 4.3 Interfața sistemului 28
Figura 4.4 Comunicația între limbajele de programare 31
Figura 5.1 Legătura dintre matricele X și y 32
Figura 5.2 Mecanismul de propagare înainte 32
Figura 5.3 Algoritmul de propagare inversă 33
Figura 5.4 Reprezentarea funcțiilor convexe/non-convexe 34
Figura 5.5 Reprezentarea schematică a problemei generalizării 35
Figura 5.6 Determinarea numărului de neuroni din stratul ascuns 37
Figura 5.7 Vizualizarea conexiunilor din Theta1 38
Figura 5.8 Importanța punctului inițial în determinarea parametrilor θ 39
Figura 5.9 Performanțele Metodei Gradient pe setul de date 40
Figura 5.10 Performanțele Metodei Propagare inversă flexibilă pe setul de date 41
Figura 5.11 Clasificarea rezultatelor folosind RProp 42
Figura 5.12 Performanțele Metodei OSS pe setul de date 44
Figura 5.13 Clasificarea rezultatelor folosind OSS 44
Figura 5.14 O comparație între viteza de convergența a metodei gradient (verde) și metoda
gradienților conjugați (roșu) 46
Figura 5.15 Modul de funcționare a metodelor cu gradient conjugat. 47
Figura 5.16 Performanțele Metodei Gradient Conjugat cu actualizarea Fletcher-Reves pe setul
de date 48
Figura 5.17 Clasificarea rezultatelor folosind CGF 49
Figura 5.18 Clasificarea rezultatelor folosind CGP 50
Figura 5.19 Performanțele Metodei Gradient Conjugat cu actualizarea Polak-Ribiere pe setul
de date 50
Figura 5.20 Performanțele Metodei Gradient Conjugat cu resetarea Powell-Beale pe setul de
date 51
Figura 5.21 Antrenarea rețelei cu metoda SCG 55
Figura 5.22 Performanțele Metodei Gradient Conjugat pe setul de date 56
Figura 5.23 Clasificarea rezultatelor folosind SCG 56
Figura 5.24 Gradul de utilizare al sistemului în timpul antrenării cu algoritmi cu gradient
conjugat 57
Figura 6.1 Exemplu de traseu pentru antrenare 58
Figura 6.2 Interfața sistemului. 59

3
Notații și convenții
Vectori – se vor nota cu litere mici ale alfabetului latin
mulțimea numerelor reale;
spațiul Euclidian n dimensional al vectorilor coloană x cu n componente reale
∈ pentru orice i =
produsul scalar a doi vectori ∈
norma Euclidiană a vectorului ∈
Matrici – se vor nota cu litere mari ale alfabetului latin
spațiul Euclidian al matricilor cu m linii și n coloane cu elemente ∈
pentru orice i = și j =
matrice pozitiv (semi) definită
matricea identitate de ordinul n
elementul matricei A situat pe linia i și coloana j
transpusa matricei A
- inversa/pseudoinversa matricei A
Funcții
∈ gradientul funcției , adică
pentru orice
i =
∈ Hessiana funcției , adică
pentru orice
i,j =
∈ Jacobianul funcției vectoriale cu ,
adică
pentru orice i = și j =

4
Abrevieri
engl. – traducerea cuvântului/expresiei în engleză
RNA/RN – rețea neuronală artificială/rețea neuronală
VACRN – vehicul autonom controlat cu rețele neuronale
BP – propagare inversă (backpropagation)
GD – gradient descendent (gradient descent)
Rprop – propagare inversă flexibilă (resilient backpropagation)
BFGS – algoritmul Broyden-Fletcher-Goldfarb-Shanno
OSS – algoritmul One Step Secant
LM – algoritmul Levenberg-Marquandt
CGF – gradient conjugat cu actualizarea Fletcher-Reeves
CGP – gradient conjugat cu actualizarea Polak-Ribiere
CGB – gradient conjugat cu resetarea Powell-Beale
SCG – gradient conjugat scalat
Mph – mile pe oră

5
1. Introducere
Nu există niciun dubiu că de la începutul anilor ‘90 până în prezent, omenirea a făcut un
progres uimitor în domeniul roboticii. Roboții moderni pot replica mișcările și acțiunile
oamenilor, iar pasul următor constă în învățarea roboților să gândească și să reacționeze în
condiții cât mai diverse. Inteligența artificială promite să ofere aparatelor abilitatea de a gândi
analitic, folosind ultimele concepte și descoperiri din domeniul calculatoarelor, robotizărilor
și matematicii.
Se dorește ca roboții să preia acțiunile monotone cum ar fi tunderea ierbii, datul cu
aspiratorul sau executarea task-urilor de precizie cum ar fi asamblarea anumitor obiecte din
fabrici și uzine. Astfel de automatizări ar trebui să permită mașinăriilor să execute sarcini
periculoase pentru oameni, cum ar fi mineritul sau stinsul incendiilor. Unele țări au început
deja să folosească roboți inteligenți pentru dezarmarea minelor de teren sau prelucrarea
materialelor radioactive pentru a limita riscul pentru oameni. Tot pentru protecția umană se
fac multe cercetări și în domeniul vehiculelor autonome. Există deja multe mașini dotate cu
senzori și echipamente capabile să evite accidente sau dacă nu, măcar să atenționeze șoferul
de potențialele pericole. În acest domeniu, cele mai avansate modele de mașini care au reușit
cu succes să se conducă singure, chiar și în condiții de trafic intens, sunt cele construite de
compania Google. Mașinile Google sunt la bază mașini Toyota Prius dotate cu camere,
senzori și radare. Toate aceste dotări de ultimă generație au ca scop depistarea tuturor
celorlalți participanți la trafic, dar și diferite obstacole, astfel încât mașina să meargă singură,
fără ca șoferul să intervină în direcția ei și în frânare. Dar acestea au sisteme destul de
complexe care nu pot fi construite la scară industrială încă și au un cost destul de mare, motiv
pentru care cred că va mai dura cel puțin 10-20 ani până când publicul va avea acces la ele.
Deși cele mai bune rezultate din acest punct de vedere , al vehiculelor autonome, a fost
înregistrat de curând, el este un subiect care i-a intrigat tot timpul pe cercetători. Un exemplu
în acest sens este proiectul ALVINN (Autonomous Land Vehicle In a Neural Network)
desfășurat în anii ‘95 de către Universitatea Carnegie Mellon în colaborare cu armata
americană, proiect care avea ca scop realizarea unui vehicul care să ia decizii de control
folosind rețele neuronale. ALVINN este un sistem care învață să controleze vehiculul prin
urmărirea unui om conducând. Abordarea pentru acest sistem este diferită deoarece el nu se
bazează pe senzori, radare, laser și GPS, ci are ca date de intrare imagini de dimensiune 30x32
pixeli de la o cameră video montată deasupra mașinii. Ca date de ieșire, sistemul ar trebui să
genereze direcția în care vehiculul ar trebui să meargă pentru a rămâne pe drum. Deși modelul
este unul destul de simplu în comparație cu cel de la Google, el a înregistrat rezultate destul
de bune. ALVINN a reușit să conducă cu o viteză maximă de 70 de mph pe o autostradă
publică de lângă orasul Pittsburg, USA. De asemenea, vehiculul s-a deplasat cu o viteză
normală de 30-40 mph pe drumuri nepavate și pe străzi cu benzi din suburbii. Limitările erau
faptul că nu putea conduce eficient pe tipuri de drum pe care nu a fost antrenat și că nu era
prea robust la schimbări de luminozitate. Cu toate acestea, în comparație cu algoritmii
tradiționali de prelucare de imagini, care aveau nevoie să proceseze imaginea pentru a găsi
drumul și apoi să îl urmărească, ajungând la viteze de doar 3-4 mph, ALVINN era mult mai
rapid.
Unul dintre motivele pentru care m-am înscris la Facultatea de Automatică și Calculatoare
a fost pentru a crea sisteme inteligente de conducere și a aplica concepte matematice cu
ajutorul cărora să pot implementa soluții care ușurează munca oamenilor și previn accidentele
provenite din erori umane. ALVINN reprezintă modelul pe care se bazează realizarea acestei
lucrări, în care, folosind obiecte accesibile oricui dar și puterea de calcul existentă în zilele
noastre, am reușit să construiesc un sistem, care după doar 2-3 minute de înregistrare de date,
a reușit să funcționeze în mod autonom, reproducând mișcările din timpul antrenării.

6
Am ales această temă și acest proiect deoarece pentru o asemenea lucrare sunt necesare
cunoștințe din diferite domenii pe care le-am studiat în timpul facultății, dar și în afara ei, cum
ar fi cele de electronică, programare orientată pe obiecte, tehnici de optimizare, sisteme
avansate de control, programare în timp real și chiar programarea pe sisteme de tipul Android
și microcontrolere pe platforma Arduino.
Lucrarea este divizată în 5 capitole, fără a-l include și pe acesta, în care este explicat
demersul științific pentru realizarea proiectului :
În capitolul doi, intitulat Rețele neuronale artificiale, este realizată o scurtă descriere a
rețelelor neuronale pentru a familiariza cititorul cu acestă tehnică și a oferi o viziune asupra
modului în care funcționează. Sunt prezentate elemente de bază ale unei rețele neuronale cum
ar fi :
- neuronul artificial, modele ale acestuia și cum afecteză alegerea modelului rezultatul
final
- arhitecturi, adică structuri de legătură între diferiți neuroni și problemele care pot
apărea din alegerea unei arhitecturi inadecvate
- algoritmi de învățare, sunt exemplificate diferite metode de învățare și se justifică
alegerea uneia dintre ele pentru cazul nostru
În finalul capitolului sunt exemplificate câteva aplicații ale rețelelor neuronale pentru a
ilustra utilitatea acestora dar și câteva probleme care apar când se folosește o astfel de tehnică.
În capitolul trei, sunt prezentate componentele hardware necesare realizării unui model în
miniatură capabil să funcționeze ca ALVINN. Sunt descrise detalii despre vehiculul ales,
structura și limitările acestuia, despre senzorul folosit pentru captarea imaginilor și despre
modulul central de procesare. Tot aici sunt oferite detalii despre mediile de
programare/interpretare de pe unitatea de procesare. În ultimele două subcapitole este precizat
modul în care cele trei componente descrise anterior comunică, componentele hardware
necesare pentru realizarea comunicației și conexiunile fizice pe care le implică această
comunicare. În finalul capitolului, sunt expuse implicațiile pe care le are arhitectura fizică
aleasă asupra programelor ce vor prelucra datele.
În capitolul patru, sunt descrise modulele software necesare pentru implementarea
sistemului. La începutul capitolului, sunt fixate unele obiective ce țin de modul în care trebuie
sa funcționeze aplicația principală pentru ca aceasta să fie cât mai flexibilă și ușor de
implementat pe orice sistem. Pe tot parcursul capitolului se va urmări ca aceste obiective să
fie atinse ținându-se evident cont și de restricțiile impuse de hardware, menționate în capitolul
precedent. Capitolul acesta este divizat în trei subcapitole, în primul se prezintă programul de
pe microcontrolerul ATMega cu ajutorul căruia se vor transmite comenzi către vehicul și se
va impune un protocol de comunicație între acesta și aplicația centrală. În cel de-al doilea
subcapitol, este prezentat programul conceput pentru captarea și transmiterea imaginilor de pe
un telefon ce folosește sistemul Android către un server prin intermediul internetului wireless
și la fel ca mai sus se impune un protocol de transmitere a informațiilor. În ultimul subcapitol
este expus modul de funcționare a aplicației centrale, cea care va rula pe modulul de procesare
și va fi responsabilă de primirea imaginilor, de la aplicația descrisă anterior, să genereze
comenzi prin intermediul rețelei neuronale pe baza imaginilor și să transmită comenzi prin
serial către microcontroler care la rândul lui va acționa vehiculul. Pentru a face acest lucru,
aplicația centrală va trebui în prealabil să poată înregistra imagini și comenzi care vor
constitui setul de antrenament pentru rețea și să încarce apoi rețeaua antrenată în Matlab prin
intermediul unor fișiere.
Capitolul cinci, cel mai întins capitol (12 subcapitole) , este cel în care se prezintă modul
în care este antrenată rețeaua neuronală. Folosind un set de date obținut cu ajutorul sistemului
descris anterior și o învățare supervizată, se parcurg diferiți algoritmi pentru a găsi cel mai

7
eficient mod de antrenare. În primul subcapitol se explică concepte de bază din teoria rețelelor
neuronale cum ar fi cele de propagare înainte și propagare inversă, ce înseamnă acestea, cum
funcționează aceste mecanisme și cum se aplică algoritmul de propagare inversă din punct de
vedere matematic. Tot în prima parte, s-au stabilit definiții pentru anumite elemente
matematice ce vor fi folosite de-a lungul capitolului. În cel de-al doilea, subcapitol sunt
prezentate două metode de generalizare a rețelei, modul în care se aplică acestea pentru cazul
nostru și care sunt avantajele și dezavantajele lor. Următorul subcapitol este dedicat explicării
modului în care a fost determinat numărul de neuroni din stratul ascuns și tot aici se realizează
primele teste de performanță a rețelei. În următoarele nouă subcapitole, sunt descrise diferite
tehnici de optimizare cu ajutorul cărora este antrenată rețeaua neuronală începând cu tehnici
de ordinul 1, cum ar fi cea de gradient descendent, până la tehnici mai complicate cum ar fi
algoritmul Levenberg-Marquardt sau algoritmul Gradientului Conjugat Scalat. După
descrierea matematică a proceselor ce au loc folosind tehnicile respective, în fiecare din cele
nouă subcapitole s-a efectuat câte o simulare pe setul de antrenament, care au produs rezultate
mai mult sau mai puțin satisfăcătoare.
În capitolul șase și ultimul al acestei lucrări, sunt analizate și comparate rezultatele
obținute în simulări, atât cele numerice cât și cele practice (efectiv prin folosirea rețelei
antrenate). Se prezintă câteva detalii legate de performanță, din punct de vedere al vitezei de
procesare, dar și justificarea unor alegeri făcute de-a lungul lucrării care au fost ulterior
demonstrate prin rezultate. Tot aici sunt analizate potențiale probleme ale sistemului și
eventuale soluții, dar și metode de îmbunătățire și planuri de viitor ce ar putea fi aplicate.
Lucrarea de față constituie un experiment în ceea ce privește utilizarea rețelelor neuronale
pentru controlul unui vehicul prin utilizarea unor componente relativ simple și o putere de
calcul specifică secolului XXI și are ca scop demonstrarea cunoștințelor dobândite din
domeniul automaticii dar și din domeniile conexe.
2. Rețele neuronale artificiale
Rețelele neuronale artificiale (RNA, engl. ANN - artificial neural network) sunt o
ramură din știința inteligenței artificiale, și constituie totodată, principial, un obiect de
cercetare și pentru neuroinformatică. Rețelele neuronale artificiale caracterizează ansambluri
de elemente de procesare simple, puternic interconectate și operând în paralel, care urmăresc
să interacționeze cu mediul înconjurător într-un mod asemănător creierelor biologice și care
prezintă capacitatea de a învăța. Ele sunt compuse din neuroni artificiali, sunt parte a
inteligenței artificiale și își au, concepțional, originea ca și neuronii artificiali, în biologie. Nu
există pentru RNA o definiție general acceptată a acestor tipuri de sisteme, dar majoritatea
cercetătorilor sunt de acord cu definirea rețelelor neuronale artificiale ca rețele de elemente
simple puternic interconectate prin intermediual unor legături numite interconexiuni prin care
se propagă informație numerică.
Originea acestor rețele trebuie căutată în studierea rețelelor bioelectrice din creier
formate de neuroni și sinapsele acestora. Principala trăsătură a acestor rețele este capacitatea
de a învăța pe bază de exemple, folosindu-se de experiența anterioară pentru a-și îmbunătăți
performanțele.
Caracteristicile RNA :

8
reprezentarea distribuită a informației : informația din rețea este stocată în mod
distribuit ( în structura de ponderi ), ceea ce face ca efectul unei anumite intrări asupra
ieșirii să depindă de toate ponderile din rețea.
capacitatea de generalizare în cazul unor situații care nu apar în datele de instruire:
această caracteristică depinde de numărul de ponderi, adică de dimensiunea rețelei . Se
constată că o creștere a dimensiunii rețelei duce la o bună memorare a datelor de
instruire , dar scad performanțele asupra datelor de testare , ceea ce înseamna că RNA
a pierdut capacitatea de generalizare . Stabilirea numărului optim de neuroni din
stratul ascuns , care este o etapă-cheie în proiectarea unei RNA , se poate face alegând
valoarea de la care începe să descrească performanța RNA pe setul de testare. Există
desigur și alte tehnici prin care se poate îmbunătăți capacitatea de generalizare a unei
RNA din timpul antrenării.
toleranța la zgomot : RNA pot fi instruite , chiar dacă datele sunt afectate de zgomot ,
diminuându-se, evident, performanța ei. Cu cât setul de date este mai mare cu atât
zgomotul va fi mai bine tolerat și se vor obține rezultate mai bune în momentul
utilizării rețelei.
rapiditate în calcul : RNA consumă mult timp pentru instruire , dar odată antrenate vor
calcula rapid ieșirea rețelei pentru o anumită intrare.
Rețelele neuronale artificiale se pot caracteriza pe baza a 3 elemente:
modelul adoptat pentru elementul de procesare individual
structura particulară de interconexiuni (arhitectura)
mecanismele de ajustare a legăturilor (de învățare).
2.1 Modele ale neuronului artificial
Sunt mai multe criterii de clasificare a modelelor neuronului elementar, ce implică:
domeniul de definiție a semnalelor folosite, natura datelor folosite, tipul funcției de activare,
prezența memoriei.
Figura 2.1 Model simplu al neuronului artificial
În cazul de față, modelul neuronului este cel din Figura 2.1 , adică un model aditiv , în
care fiecare intrare xi contribuie prin însumare la ieșirea y. Acest lucru este determinat de
ponderile w determinate în timpul antrenării rețelei. Vectorul de intrare din figura de mai sus
este x=[x1 x2…xn] la care a fost adăugat si elementul x0 , element de deplasare, pe care îl vom
nota în continuare cu ‘b’ din englezescul bias.

9
Figura 2.2 Modelul MCP (McCulloch – Pitts) al neuronului artificial
Un neuron cu un vector de intrare având n elemente este prezentat în figura 2.2.
Intrările individuale x1, x2…xn sunt înmulțite cu ponderile w1,w2…wn și valorile ponderate se
însumează. Suma se poate nota Wp, adică produsul scalar al matricei W (cu o linie) și
vectorul x.
Neuronul are deplasarea b, care se adună cu intrările ponderate, rezultând argumentul
sum al funcției de activare(transfer) f : (2.1)
Această expresie poate fi scrisă în codul MATLAB: sum = W*x + b ; a = f ( sum ) . (2.2)
Descrierea elementelor din figura 2.2 :
n este numărul elementelor din vectorul de intrare;
vectorul de intrare x este reprezentat de bara groasă verticala din stânga, dimensiunile
lui x sunt indicate sub simbolul x (n×1);
constanta 1 intră în neuron și multiplică deplasarea b;
intrarea sum în funcția de activare (transfer) f este dată de (2.1);
a este ieșirea neuronului.
Neuronul biologic se activează (dă un semnal la ieșire) numai dacă semnalul de intrare
depășește un anumit prag. În RNA acest efect este simulat aplicând sumei ponderate a
intrărilor (sum) o funcție de transfer (activare) f, pentru a obține semnalul a la ieșire.
Patru dintre cele mai utilizate funcții de activare sunt reprezentate mai jos :
a) Funcția treaptă
Figura 2.3 Funcția de activare treaptă
b) Funcția de activare liniară

10
Figura 2.4 Funcția de activare liniară
c) Funcția log-sigmoid
Figura 2.5 Funcția log-sigmoid
d) Funcția tan-sigmoid
Figura 2.6 Funcția tan-sigmoid
În pătratul din dreapta fiecărui grafic se prezintă simbolul asociat funcției de activare.
Aceste simboluri vor înlocui simbolul general f în schemele RNA pentru a arăta funcția
particulară de transfer care este folosită. Pentru aplicația prezentată a fost folosită doar
funcția log-sigmoid.
2.2 Arhitecturi
Arhitectura unei rețele neuronale reprezintă modul în care sunt realizate conexiunile
dintre neuronii ce compun această rețea. Există numeroase modalități de interconectare a
neuronilor elementari, dar pot fi identificate două clase de arhitecturi:
cu propagare a informației numai dinspre intrare spre ieșire, rețele de tip feedforward
rețele recurente (cu reacție).
Un dezavantaj al rețelelor neuronale îl constituie lipsa teoriei care să precizeze tipul
rețelei și numărul de neuroni elementari, precum și modalitatea de interconectare. Există
câteva tehnici de tip “reducere” (engl. pruning) sau de tip “învață și crește” (engl. learn and
grow), dar acestea sunt în intense cercetări.

11
Proiectarea structurii rețelei (tip, nr. straturi, nr. neuroni , nr. intrări, conexiunile între
neuroni) – factori avuţi în vedere:
• scopul urmărit – natura problemei,
• complexitatea,
• datele disponibile.
În acest caz, rețeaua este una de tip propagare-înainte (engl. feedforward) cu arhitectura
din Figura.2.7 . Motivele pentru care am ajuns la o astfel de arhitectură vor fi detaliate
ulterior, în urma analizării datelor problemei.
Figura 2.7 Arhitectura RNA
2.3 Algoritmi de învățare
Principala deosebire a rețelelor neuronale față de alte sisteme (electronice) de
prelucrare a informațiilor îl constituie capacitatea de învățare în urma interacțiunii cu mediul
înconjurător, și îmbunătățirii performanțelor. O reprezentare corectă a informațiilor, care să
permită interpretarea, predicția și răspunsul la un stimul extern, poate permite rețelei să
construiască un model propriu al procesului analizat. Acest model va putea răspunde astfel
unor stimuli neutilizați în procesele anterioare de învățare ale rețelei RNA. Informațiile
utilizate în procesul de învățare pot fi informații disponibile a priori sau perechi intrare-ieșire
(care stabilesc relații de tipul cauză-efect), iar modul de reprezentare internă urmărește un set
de reguli bine documentate. Acești algoritmi pot fi clasificați după mai multe criterii cum ar
fi: disponibilitatea răspunsului dorit la ieșirea rețelei, existența unui model analitic, tipul
aplicației în care sunt utilizați, dar cele mai multe documentații se rezumă la două clase
mari: învățarea supravegheată (care presupune existența în orice moment a unei valori dorite a
fiecărui neuron din stratul de ieșire) și învățarea nesupravegheată (în care rețeaua extrage
singură anumite caracteristici importante ale datelor de ieșire, în urma unui tip de competiție
între neuronii elementari).

12
Învăţarea supravegheată a RNA presupune existenţa perechilor de învățare intrări –
ieşiri. Se adaptează ponderile sinapselor astfel că la aplicarea intrărilor, RNA să calculeze
tocmai ieşirile pereche. Apare o problema de minimizare a unei funcții a erorilor unde eroarea
(depinde de ponderile sinapselor) este egală cu diferenţa între ieşirea furnizată de RNA prin
calcul şi valoarea “aşteptată” din setul de antrenament.
Figura 2.8 Mecanismul de învățare supervizată
Condiţii necesare antrenamentului sunt ca mulţimea de antrenament să fie
reprezentativă adică să se poată obține informații utile din setul de date , numărul de perechi
intrări-ieşire să fie suficient de mare, metoda (algoritmul) de învăţare să fie eficient și să se
utilizeze calculatoare performante capabile să prelucreze multe date și să execute mai multe
operații în paralel.
În acest caz este vorba despre o învățare supravegheată, în care în fiecare moment unui
set de date de intrare (o imagine) îi este asociată o comandă de ieșire (direcția vehiculului).
Pentru acest tip de învățare, cea mai populară metodă de antrenare este propagarea inversă
(engl. back-propagation) care presupune determinarea ponderilor w prin micșorarea erorilor
obținute din diferențele dintre ținta impusă de utilizator și ieșirea rețelei. Rolul antrenării din
această aplicație este găsirea unui tipar, a unui model pentru ca rețeaua să fie capabilă să
acționeze în modul dorit la apariția unei imagini, astfel obținându-se un clasificator (anumite
imagini vor fi asociate cu anumite comenzi).
2.4 Aplicații din viața de zi cu zi
Domeniile în care rețelele neuronale realizează modele eficiente sunt : aproximări de
funcții, predicții a unor serii temporale, clasificări, recunoaștere de tipare, recunoaștere
vocală, scanarea retinei.
Alte implementari ale rețelelor neuronale, legate de sectorul business, se întâlnesc în:
previziuni financiare, controlul proceselor industriale, cercetări de piață, validări de date pe
bază de clasificări și de tipare, management de risc, previziuni de marketing. Rețele neuronale
folosind algoritmi genetici pot fi folosite în controlul roboților industriali. Un alt domeniu de
interes pentru rețelele neuronale este medicina și stemele biomedicale. În acest moment se
utilizează rețele neuronale pentru descoperirea de boli, prin recunoașterea unor tipare de
pe cardiograme etc.
2.5 Dezavantaje ale rețelelor neuronale
Procesul de învăţare la RNA este complicat din cauza dificultății în a alege setul de
antrenament, de lungă durată în funcție de metoda de antrenare și de mărimea setului de
antrenament și din cauză că necesită mijloace de calcul deosebit de performante. Pentru

13
antrenament este nevoie de un volum extrem de mare de date, iar stabilirea bazei de
antrenament este o operaţie dificilă, ea trebuie să acopere satisfăcător tot domeniul de căutare
a soluției. Fenomenele care se petrec în cadrul unei RNA (modificarea ponderilor pentru
fiecare neuron al rețelei) nu au putut încă să fie explicate satisfăcător din punct de vedere
formal.
3. Descrierea componentelor hardware ale sistemului
La fel ca la ALVINN, se dorește construirea unui sistem inteligent și adaptiv de
urmărire a drumului (engl. road follower). Componentele sistemului sunt:
3.1 Vehiculul
Elementul de acționare din acest sistem este desigur vehiculul, reprezentat de o
mașinuță electrică ce este comandată cu o telecomandă prin unde radio. Modelul este unul
destul de simplu, cu o rază suficient de mare pentru a parcurge un traseu de 5-8 metri, cu un
motor la roțile din spate care controlează sensul de mers față/spate și un motor cu 3 trepte în
partea din față ( 45 grade spre stânga , 0 grade - normal , 45 grade spre dreapta) pentru
setarea direcției de mers. Dezavantajele acestei mașinuțe simple sunt existența a doar 3 trepte
de direcție, puterea relativ mică (motorul de sens este de ~ 3.3 V) și dimensiunea destul de
mare (~21 cm lungime si ~9 cm latime) ceea ce face destul de dificilă conducerea ei și mai
ales executarea întoarcerilor. Telecomanda este și ea una destul de simplă. Conține 4 butoane
pentru față/spate , stânga/dreapta și transmite prin unde radio pe frecvența 27.145 MHz către
receptorul mașinuței comenzile aplicate.
Figura 3.1 Vehiculul utilizat
3.2 Camera pentru înregistrarea imaginilor
Senzorul sistemului trebuia să fie o cameră capabilă să înregistreze imagini video, dar
să le înregistreze nu era suficient , acestea trebuiau și prelucrate/interpretate. Ca primă soluție
am luat în considerare folosirea unei camere web wireless, care capta imaginile și le trimitea
către un laptop prin wireless. Problemele cu această soluție erau faptul că o astfel de cameră
era scumpă și avea nevoie de o sursă de alimentare. Având un consum destul de mare, nu se
preta la folosirea unor baterii. Următoarea soluție, cea pe care am și implementat-o, a fost
folosirea camerei unui telefon. Majoritatea telefoanelor din ziua de azi este dotată cu camere
suficient de performante, capabile să înregistreze, iar dacă telefonul este destul de puternic,
prelucrarea/interpretarea imaginilor poate fi facută chiar pe el, dar ar fi o soluție complicată.

14
Figura 3.2 Telefon HTC Droid Eris
Am folosit un telefon HTC Droid Eris (Figura 3.2), capabil să se conecteze la rețele
wireless și deci capabil să comunice cu alte aparate conectate la rețea. Camera este una ce
suportă înregistrarea captărilor video în trei rezoluții: mare (352x288), medie (320x240) și
mică (176x144). Am optat pentru cea mică pentru a scădea din puterea de calcul necesară
pentru prelucrarea imaginilor. Din nefericire, acest telefon nu este echipat și cu o laternă
pentru filmarea imaginilor în condiții de luminozitate scazută, lucru care l-ar fi făcut mai bine
echipat la schimbările de luminozitate care, vom vedea, afectează precizia rețelei.
3.3 Modulul de procesare
Modulul de procesare și responsabilul de antrenarea rețelei/controlarea
vehiculului/recepționarea și prelucrarea imaginilor a fost laptopul meu personal, echipat cu un
procesor Intel i5 – M460 de 2.67 Ghz , 8 Gb de RAM și bineînțeles capabil să se conecteze și
el la o rețea wireless. Mediile de dezvoltare în care am lucrat au fost “Java (TM) SE Runtime
Environment (build 1.7.0_10-b18)” și „MATLAB 7.11.0.584 (R2010b)”.
Figura 3.3 Utilizare Apache Ant

15
Rularea programelor scrise in mediul Java a fost facută cu ajutorul pachetului
„Apache Ant(TM) Version 1.8.4”. Apache Ant (Figura 3.3) este o unealtă open-source de
dezvoltare a software-ului scrisă în întregime în Java, ce poate fi rulată din linia de comandă
în urma unor configurări rapide. Fișierele de configurare se bazează pe XML care pot fi
generate de către IDE de Java Eclipse. Am optat pentru o astfel de soluție deoarece avem de-a
face cu un sistem în timp real în care resursele sunt foarte prețioase, iar Ant folosește mult
mai puține resurse decât ar face orice altă unealtă, încărcand doar librăriile specificate în
fișierul xml. Un alt avantaj al acestei distribuții este faptul că fișierele modificate (actualizate)
sunt recompilate utilizând o singură comandă și într-un timp foarte scurt. Ultimele versiuni
ale acestei unelte includ și compilatoare pentru Android (dacă au fost instalate librăriile
necesare) și poate fi folosit pentru a genera aplicații pentru Android ce pot fi foarte ușor
instalate apoi pe telefoanele cu acest sistem.
În concluzie, acest sistem este rapid, relativ ușor de folosit, permite rularea aplicațiilor
în timp real și poate fi rulat pe diverse sisteme de operare (Windows, Linux, MacOS etc.)
dând proiectului portabilitate indiferent de mediul în care este utilizat.
3.4 Arduino Duemilanove
Arduino este o platformă electronică de tipul single-board microcontroler, adică acest
tip de plăcuță conține toate circuitele necesare pentru a realiza ușor task-uri de control.
Arduino a fost creat pentru a face proiectele multidisciplinare, ce folosesc componente
electronice interconectate, cât mai simple.
Arduino Duemilanove folosit în cadrul proiectului conține un microcontroler
ATMega328. Pe plăcuța Arduino (Figura 3.4) există 14 pini digitali intrare/ieșire , 6 pini de
ieșire analogici, un oscilator cu frecvența de 16 MHz, o mufă pentru conexiune USB (prin
care se face programarea microcontrolerului) , o mufă de alimentare (deși el poate fi alimentat
și prin USB) și un buton de resetare.
Figura 3.4 Arduino Duemilanove
Domeniul de alimentare a plăcuței este între 6 și 20 de volți. Dacă se alimentează la o
tensiune mai mică de 7 volți, este posibil ca stabilizatorul de tensiune intern să nu asigure o
tensiune de 5 volți constantă și astfel se ajunge la instabilitatea platformei Arduino. Prin
alimentarea acesteia la o tensiune de peste 12 volți se riscă supraîncălzirea sau chiar
deteriorarea stabilizatorului de tensiune și poate chiar a altor componente. Având în vedere
acestea, tensiunea de alimentare optimă a plăcuței poate fi între 7 si 12 volți.
Microcontroler-ul ATMega328 are o memorie flash de 32KB, în care va fi încărcat
codul ce trebuie rulat (2 KB sunt folosiți de către bootloader) și 2 KB de memoria SRAM

16
(Static Random Acces Memory) și 1 KB de memorie EEPROM (Electrically Erasable
Programmable Read-Only Memory).
Printre principalele funcționalități importante ale microprocesorului ATmega 328 se
numără următoarele: 32 de regiștrii de 8 biți, performanțe foarte bune cu un consum foarte
mic de energie, enduranța memoriilor non-volatile ( reținerea datelor timp de 25 de ani la o
temperatură de 85 grade Celsius și 100 de ani la 25 de grade Celsius), 2 timere/countere pe 8
biți, 1 timer/counter pe 16 biți, 6 canale PWM pe 8 biți, șase moduri de economisire a energiei
electrice, gradarea vitezei de procesare (0-20 MHz la 4,5 V– 5,5 V).
Pentru a programa microcontrolerul folosind plăcuța Arduino trebuie descărcat
software-ul open-source de pe pagina lor principală. Acesta este un mic program realizat în
Java care folosește cod C/C++, compilează și generează un fisier .hex . După ce este generat,
acesta poate fi scris pe microcontroler prin intermediul USB-ului sau a pinilor ICSP.
Având în vedere că scopul microcontrolerului va fi doar interfațarea telecomenzii cu
laptop-ul/pc-ul consider că această platforma este ideală deoarece este ușor de folosit, are un
preț relativ mic și performanțe foarte bune (pentru acest proiect).
3.5 Conexiunile hardware
Următorul pas al proiectului este conectarea componentelor alese din punct de vedere
hardware. Componentele sunt compatibile și se poată face o conexiune între ele cât mai
simplu și rapid. Dorim ca sistemul să poată fi rulat de la distanță și să aibă un sistem central
de procesare, ceea ce presupune ca datele de la senzori și comenzile către elementele de
acționare să poată fi recepționate/transmise wireless de către sistemul nostru de prelucrare.
Prima parte, achiziția de date, adică preluarea imaginilor de pe camera telefonului pe
laptop, va fi destul de ușoară din punct de vedere hardware întrucât atât laptopul cât și
telefonul conțin echipamente capabile să transmită/primească informații într-o rețea wireless.
Ca mediu de test va fi folosită o rețea locala wireless, creată cu ajutorul unui rooter TP-Link
300M, în care ne vom baza strict pe accesul la W-LAN și nu pe internet deoarce acest lucru
nu servește scopului proiectului. Pentru acest tip de abordare va trebui configurat un server
(laptopul) și un client (telefonul) și bineînțeles un protocol de recepționare/transmitere a
datelor, lucruri care țin de software și vor fi abordate într-un alt capitol.
Figura 3.5A Schema electrică a telecomenzii

17
Elementele de execuție pentru acest sistem sunt cele 2 motoare ale vehiculului.
Acestea sunt deja comandate prin unde radio pe frecvența 27 MHz de către telecomanda
mașinuței. Așadar ce rămâne de făcut este conectarea telecomenzii la laptop, și așa cum am
menționat la sfârșitul capitolului 3.4 vom folosi platforma Arduino pentru a realiza
interfațarea între cele 2 componente. Altfel spus, dorim ca în loc să fie apasate butoanele
stânga-dreapta ale telecomenzii, să poată fi apăsate butoanele tastaturii laptopului (săgeată
stanga – săgeată dreapta) și ulterior sa fie generate comenzi de către rețeaua neuronală.
Analog pentru butoanele de față-spate. Telecomanda funcționează în modul următor: atunci
când este apăsat un buton, acesta închide o porțiune din circuit și conectează microcipul de
transmisie TX-2B la GND (vezi Figura 3.5), iar acest microcip transmite un semnal către
microcipul din interiorul mașinuței (RX-2B) și astfel sunt acționate motoarele. Dacă nu este
apasăsat niciun buton atunci mașinuța rămâne nemișcată. Deci ar fi suficient să folosim un
pin al plăcuței Arduino pentru a simula apăsarea butonului. Având în vedere faptul că
telecomanda este alimentată la 3V, iar Arduino este alimentat cu 5V (via USB), putem să
renunțăm la bateriile telecomenzii și să utilizăm doar alimentarea prin USB , simplificând
structura electrică.
Figura 3.5B Microchipurile de Transmisie-Receptie
În continuare, voi explica modul în care au fost realizate legăturile (Figura 3.6). A fost
conectat pin-ul VCC-ul de pe plăcuța telecomenzii la VCC-ul de pe plăcuța Arduino (firul
roșu) și la fel pentru pinul de GND (firul negru). După care am conectat pinii RIGHT și LEFT
la pinii 12 și 11 digitali de pe plăcuța Arduino și respectiv pinii FORW și BACK la pinii 9 și
10 (banda gri). Am evitat adăugarea de rezistențe suplimentare sau a unui stabilizator de
tensiune prin programarea eficientă a microcontrolerului de pe Arduino. Un efect neplăcut al
faptului că am scos partea de plastic din jurul plăcuței din telecomandă a fost faptul că am
eliminat suportul pentru antenă și am înlocuit-o cu un fir (alb-albastru) și deci am pierdut din
raza de control.
Figura 3.6 Conectarea telecomenzii la Arduino

18
În acest moment, avem toate componentele fizice necesare pentru a realiza un model
în miniatură al unui vehicul controlat cu o rețea neuronală în urma prelucrarii unor imagini. În
figura 3.7 este o schiță a modului în care va funcțion sistemul. Telefonul montant pe mașinuță
transmite imagini prin rețeaua wireless către laptop, care le prelucrează și transmite comenzi
către telecomanda mașinuței prin intermediul platformei Arduino. Deci ce urmează este
scrierea unui program pe microcontrolerul ATMega368 capabil să interpreteze comenzile
provenite de la laptop, un soft pentru sistemul Android ce va fi pus pe telefon, capabil să
captureze și să transmită imagini către un program server de pe laptop și un program pe laptop
capabil să primească imaginile transmise de către telefon, să transmită semnalele potrivite
către plăcuța Arduino prin USB și să fie capabil să genereze comenzi folosind o rețea
neuronală.
Figura 3.7 Schema comunicațiilor din sistem
4. Descrierea modulelor software
Înainte de a detalia modul de funcționare a programelor software trebuie descrise
unele caracteristici pe care ar trebui să le aibă întreg sistemul. Acesta ar trebui:
să funcționeze in timp-real
să fie portabil – adică să poată fi implementat pe orice sistem (atât din punct de vedere
hardware cat si software – sistem de operare)
să consume minimul de resurse – interfața grafică va fi redusă la minim oferind doar
informații cu adevărat utile utilizatorului astfel încât resursele să fie folosite pentru a
finaliza operațiile necesare conducerii vehicului
să fie modularizat – adică dacă există mai multe procese în paralel acestea să fie
independente unul de celălalt
să fie adaptiv – să poată funcționa indiferent de arhitectura rețelei (se referă la numărul
de neuroni, nu la numărul de straturi)

19
să funcționeze atât în mod manual (pentru a strânge date pentru antrenarea rețelei), cât
și în mod automat (cu comenzi generate de rețeaua neuronală)
antrenarea rețelei va fi făcută offline – ceea ce înseamnă ca vor trebui înregistrate date
inițial și apoi folosite pentru antrenarea rețelei
antrenarea rețelei să fie făcută în mediul Matlab/Octave – am impus aceeastă condiție
deoarece Matlab este unul dintre cele mai puternice limbaje de programare din punct
de vedere computațional și am dezvoltat mai multe aplicații pentru rețele neuronale cu
ajutorul lui, iar Octave este varianta open-source Matlab, puțin mai slab.
Având aceste caracteristici în minte, putem concepe acum un software pentru acest
sistem.
4.1 Software Arduino
Cum am menționat și în capitolul 3.4, Arduino este un IDE special conceput pentru
scrierea programelor pe Platformele Arduino, este scris in Java iar codul este unul similar cu
cel de C/C++. Conține multe librării cu funcții ce fac folosirea platformei cât mai intuitivă.
Ca principiu de funcționare, dacă dorim să mișcăm mașinuța înainte, vom aplica o tensiune pe
pinul 9 – cel conectat la pinul FORW de pe microchipul TX-2B, altfel nu vom aplica nimic.
De aceea am făcut următoarele două funcții pentru activare și respectiv dezactivare:
#define on(pin) {pinMode(pin,OUTPUT); digitalWrite(pin, LOW);} – care are rolul de a
seta pinul selectat ca pin de output și apoi aplică tensiune pe el, deci comandă vehiculul într-o
anumită direcție,
#define off(pin) {pinMode(pin,INPUT);} – setează pinul selectat ca pin de input, ceea ce îl
pune într-o stare de impendanță mărită și nu permite curentului să treacă, deci oprește
transmisia pentru direcția respectivă.
Funcțiile pinMode și digitalWrite sunt funcții specifice librăriilor Arduino.
Următorul pas este asocierea unei “variabile” către fiecare pin folosit printr-o
declarație de tipul #define dreapta 12 , pentru a face codul cât mai intuitiv. Toate programele
Arduino conțin obligatoriu două funcții, una cu denumirea de setup() în care se setează starea
inițială a microcontrolerului și se inițializează componentele folosite – în cazul nostru se
setează toți pinii pe off și se inițializează portul serial pentru o transmisie de 9600 baud.
Aceasta este prima funcție apelată la deschiderea microcontrolerului sau evident după o
resetare. Cea de-a doua funcție se numește loop() și începe imediat după finalizarea funcției
setup() , după care rulează permanent cât timp este alimentat cu energie microcontrolerul. În
funcția loop vom face urmatoarele operații: vom verifica dacă s-a transmis ceva pe serial de la
laptop. Dacă s-a transmis, în funcție de octetul primit, se execută instrucțiunea.
Semnalele primite vor fi de felul următor : 0000 0001 = 0x01 stânga, 0000 0010 = 0x02
dreapta, 0000 0100 = 0x04 față , 0000 1000 = 0x08 spate , dacă bitul corespunzător este 1
atunci execută comanda, dacă este 0 nu o execută, adică o codificare binară. Un alt avantaj al
acestei codificări este că se pot forma cuvinte de tipul 0000 1001 care ar comanda vehiculul
spate pe motorul de sens față-spate și stânga pe motorul de direcție stânga-dreapta, adică se
pot acționa ambele motoare simultan. Un alt lucru ce trebuie făcut în funcția loop() este
includerea unor măsuri de siguranță cum ar fi: să nu se acționeze și stânga și dreapta simultan
sau față-spate (condiții care erau puse fizic în vechiul mecanism). O altă condiție impusă aici
a fost acționarea motorului de sens (față-spate) pentru un timp predefinit (forwardPulse a fost
setat 120 ms) pentru ca mișcarea să funcționeze pe bază de impulsuri. Timpul acesta a fost
găsit empiric și a fost ales așa încât mișcarea să fie fluentă cand vehiculul primește comenzi
de la rețeaua neuronală.

20
4.2 Software Android
În capitolul 3.2 am specificat faptul că telefonul utilizat folosește sistemul de operare
Android. Android este o platformă software și un sistem de operare pentru dispozitive și
telefoane mobile bazată pe nucleul Linux, dezvoltată inițial de compania Google, iar mai
târziu de consorțiul comercial Open Handset Alliance. Android permite dezvoltatorilor să
scrie cod gestionat în limbajul Java, controlând dispozitivul prin intermediul bibliotecilor Java
dezvoltate de Google. Pentru a dezvolta aplicații pentru Android este necesară folosirea sdk-
ului (software development kit) acesta este open-source și se poate downloada de pe site-ul
lor oficial (http://developer.android.com/sdk/) . SDK-ul Android include un set complet de
instrumente de dezvoltare. Acestea includ un program de depanare, biblioteci, un emulator de
dispozitiv , documentație, mostre de cod și tutoriale. Platformele de dezvoltare sprijinite în
prezent includ calculatoare bazate pe x86 care rulează Linux (orice distribuție Linux desktop
modernă), Mac OS X 10.4.8 sau mai recent, Windows XP , Vista sau Seven. Cerințele includ,
de asemenea, Java Development Kit și Apache Ant. Mediul de dezvoltare (IDE) suportat
oficial este Eclipse (3.2 sau mai recent), utilizând plug-in-ul Android Development Tools
(ADT), deși se poate folosi orice editor de text pentru a edita fișiere XML și Java și apoi să
utilizeze unelte din linia de comandă pentru a crea sau depana aplicații Android. Trebuie
menționat că acesta a fost primul meu proiect scris în Android dar exista foarte multă
documentanție în ceea ce privește acest subiect, iar faptul că folosește limbajul Java a fost un
mare plus.
Rolul aplicației este acela de a captura și transmite imagini către un server. Așadar am
structurat proiectul în trei clase : TransmisieDate , AplicațieVACRN (VACRN = Vehicul
Autonom Controlat cu Rețele Neuronale) și TransmiteImaginiVideo pe care le voi detalia în
continuare.
TransmisieDate creează un obiect responsabil de stabilirea unei conexiuni cu un
server (introdus de utilizator) și transmite datele într-o ordine prestabilită (un fel de protocol
de transmisie). Obiectul de tip TransmisieDate are două atribute :
Socket (denumirea clasei) socket (denumirea obiectului) – prin obiectele de tip socket
se lansează o conexiune către un server pe un anumită adresă ip și un anumit port,
conexiunea este una de tipul TCP/IP;
DataOutputStream (denumirea clasei) streamTransmisie (denumirea obiectului) – prin
obiectele de tip DataOutputStream se realizează transmisia de date către serverul de pe
socket;
și patru metode :
TransmisieDate() – constructorul clasei , este gol nu conține nimic
conecteaza(String adresa, int port) – metoda prin care se fixează adresa și portul și se
stabilește o conexiune
transmiteDate(int latime, int inaltime, byte[] date, float[] acceleratii) – metoda prin
care se transmit datele în ordinea definită, datele transmise se vor detalia ulterior
close() – metoda prin care se închide conexiunea la închiderea aplicației
TransmiteImaginiVideo creeaza un obiect responsabil de capturarea imaginilor,
formatarea lor și transmisa lor cu ajutorul obiectului de tip TransmisieDate. Această clasă
extinde clasa ViewGroup – creează un view special care poate conține și alte view-uri în
interior numiți copii și implementeză SurfaceHolder.Callback - primește informații atunci
când suprafața pe care se afișează este modificată, și PreviewCallback - interfață folosită
pentru a prelua cadre de pe cameră în timp ce ele sunt afișate pe ecran. În continuare voi
descrie atributele și metodele clasei.
Atributele :

21
SurfaceView mSurfaceView – oferă o suprafață dedicată pentru desenarea obiectelor
încorporate într-un view
SurfaceHolder mSurfaceHolder – obiect prin care se va apela metoda Callback , care
ne va anunța atunci când suprafața este modificată
Size marimeImagini – reprezintă dimensiunea în pixeli a imaginii, are o componentă
pentru lățime și una pentru lungime
List<Size> listaMarimiSuportate – listă ce va conține toate dimensiunile (rezoluțiile)
la care poate fi folosită camera
Camera mCamera – obiect prin intermediul căruia se apelează camera
byte[] pixeli – un șir/vector de bytes în care se vor reține pixeli imaginii și ulterior vor
fi transmiși
float[] aceleratii – un șir/vector de float în care se vor reține și transmite valorile
accelerației
TransmisieDate td – obiect al clasei TransmisieDate prin care se stabilește conexiunea
cu un server și se transmit datele
Metode :
TransmiteImaginiVideo(Context context, TransmisieDate td) - reprezintă
constructorul clasei , se definește contexul și transmisia de date aici
actualizeazaAcceleratii(float[] date) – metodă pentru actualizarea acelerațiilor
setCamera(Camera camera) - metodă pentru setarea camerei și găsirea listei de mărimi
suportate
switchCamera(Camera camera) – metodă prin care se seteaza camera , se setează
suprafața unde vor fi afișate imaginile și se setează parametrii camerei
onMeasure(int widthMeasureSpec, int heightMeasureSpec) – suprascrie metoda
onMeasure, cu această metodă se setează dimensiunea minimă pentru rezoluția
camerei
onLayout(boolean schimbat, int stanga, int sus, int dreapta, int jos) – suprascrie
metoda onLayout , cu această metodă se setează dimensiunile layoutului astfel încât
imaginea afișată să fie în interiorul suprafeței în care se face afișarea
surfaceCreated(SurfaceHolder holder) - metodă care se ocupă cu preluarea imaginilor
de pe camera și proiectarea acestora pe suprafața creată
surfaceDestroyed(SurfaceHolder holder) - metodă pentru distrugerea suprafeței create
anterior și oprirea afișării imaginilor
cautaDimensiuneMinima(List<Size> valori, int w, int h) – metodă ce caută în lista de
rezoluții care pot fi afișate de cameră și returnează dimensiunea minimă
surfaceChanged(SurfaceHolder holder, int format, int w, int h) – metodă apelată dacă
este modificată dimensiunea imaginilor, după apelarea acestei metode se începe
afișarea cadrelor pe display-ul telefonului, tot aici este alocată memorie pentru
vectorul pixeli în funcție de dimensiunile imaginilor
onPreviewFrame(byte[] data, Camera camera) – acestă metodă este apelată în mod
continuu în timpul funcționării programului, atunci când se primește de la cameră un
set complet de date (o imagine de dimensiunea stabilită), aceasta este prelucrată cu
funcția transformaRGB și transmisă cu ajutorul obiectului td
transformaRGB(byte[] rgb, byte[] yuv420sp, int latime, int inaltime) – camera
telefonului transmite date în formatul YUV420sp , transformarea în format RGB este
destul de simplă mai ales având în vedere că ne interesează doar transformarea pentru
o componentă și nu toate trei pentru a obține nunațe de alb-negru , este suficient să
aplicăm formula 0xff & ((int) yuv420sp[i] – 16 și să avem grijă ca valorile să fie doar
între 0 și 255 (o reprezentare a modului în care funcționează formatul yuv420 se poate
observa în Figura 4.1)

22
Figura 4.1 Formatul YUV420
AplicatieVACRN creează obiectul care este apelat în momentul în care utilizatorul
deschide aplicația de pe telefon. Această clasă extinde clasa Activity, ce reprezintă interfața
vizualizată de utilizator, și implementează SensorEventListener care permite accesul la
senzorii telefonului.
Atributelele clasei sunt următoarele :
TransmiteImaginiVideo vizualizareImagini - obiect prin care se afișează imaginile și
sunt transmise către server , împreună cu accelerațiile
Camera mCamera - obiect care permite accesul la camerele telefonului
int numarDeCamere - reprezintă numărul de camere de pe telefon
int cameraUtilizata – reprezintă id-ul camerei care va fi utilizată
int standardCameraId – reprezintă id-ul default al camerei , prima cameră, cea din
spatele telefonului
String NUME_PREF_FILE – string în care se salvează numele fișierului în care vor fi
salvate informațiile introduse de utilizator
TransmisieDate td - obiect al clasei TransmisieDate prin care se stabilește conexiunea
cu un server și se transmit datele
SensorManager managerSenzori - obiectul care va permite accesul la senzori
double calibrare - variabila de calibrare a senzorului de accelerație
float[] gravity – un șir/vector de float de 3 componente în care se va reține accelerația
gravitațională a telefonului
float[] linear_acceleration – un șir/vector de float în care se va reține accelerația liniară
a telefonului
Metodele clasei :
onCreate(Bundle savedInstanceState) – aceasta este prima metodă care este apelată la
deschiderea aplicației, practic este contructorul clasei. În momentul apelării se creează
interfața, se seteză suprafața în care vor fi afișate imagini pentru obiectul
vizualizareImagini, se detectează camera din spatele telefonului (camera principală) ,
se accesează senzorii telefonului (inclusiv cel de accelerație), se creează căsuțe pentru
input în care utilizatorul va introduce adresa serverului la care se conectează și tot aici,
după introducerea adresei, se realizează conexiunea prin intermediul obiectului td
salveazaAdresaIPinFisier(Context context, String text) – după ce utilizatorul introduce
adresa ip și încearcă să se conecteze la server, aceasta este automat salvată în fișierul
NUME_PREF_FILE
incarcaAdresaIPdinFisier(Context context) - dacă există o adresă de IP salvată în
fisierul NUME_PREF_FILE, atunci aceasta va fi încarcată automat în căsuța în care
utilizatorul introduce IP-ul și poate fi refolosită în cazul în care serverul este același
onResume() – metodă care este apelată atunci când telefonul revine din modul stand-
by și aplicația este deschisă , se reîncarcă ultimele informații din sistem

23
onPause() – metodă apelată atunci cand telefonul intră în stand-by , camera și senzorii
sunt opriți pentru conservarea energiei
onAccuracyChanged(Sensor sensor, int accuracy) – metodă apelată atunci când este
modificată acuratețea senzorului , acest caz nu a fost tratat dar funcția trebuia rescrisă
fiindcă este implementată interfața EventSensorListener și era obligatoriu
onSensorChanged(SensorEvent event) – metodă apelată atunci când senzorul primește
informații noi, se aplică formule (se filtrează accelerația gravitațională și se determină
accelerația liniară pe o anumită direcție , figura 4.2) pentru determinarea accelerației
liniare și aceasta este transmisă către server pentru prelucrări ulterioare .
Figura 4.2 Informații accelerometru Android
Având aplicația construită, folosind Apache Ant, construim fișierul VACRN.apk care
se poate instala folosind o aplicație care se găsește gratuit pe GooglePlay cum ar fi
AppInstaller. Pentru ca aplicația să poată fi rulată pe telefon trebuie să specificăm în fișierul
project.proprerties versiunea minimă a sistemului de operare Android pe care poate fi rulată și
în fișierul AndroidManifest.xml specificat că aplicația are nevoie de acces la Camera și la
Internet, printre altele.
4.3 Aplicatie Java VACRN
Aceasta va fi aplicația centrală a proiectului și trebuie să fie compatibilă cu restul
sistemului, adică :
- să comunice cu telecomanda mașinuței așa cum am stabilit în capitolul 4.1, să
transmită pe interfața serială octeți cu 0 și 1 pentru a comanda motoarele cum dorim
- să fie un server pentru aplicația Android și să primească datele în formatul și ordinea
stabilită în capitolul 4.2
- să înregistreze cadrele și comenzile într-un fișier care să fie apoi prelucrat un Matlab
pentru antrenarea rețelei
- să prelucreze imaginile primite de la telefon , adică să le trecă prin rețeaua neuronală
astfel încât să se obțină comenzi și vehiculul să fie autonom
- să poată încărca fișierele exportate din Matlab pentru a folosi rețeaua determinată
indiferent de arhitectura rețelei

24
Prin folosirea limbajului Java se verifică una din condițiile impuse la începutul capitolului
și anume portabilitate. Java este un limbaj de programare orientat-obiect, puternic tipizat,
conceput de către James Gosling la Sun Microsystems (acum filială Oracle) la începutul
anilor ʼ90, fiind lansat în 1995. Cele mai multe aplicații distribuite sunt scrise în Java, iar
noile evoluții tehnologice permit utilizarea sa și pe dispozitive mobile precum telefon, agendă
electronică, palmtop etc. În felul acesta, se creează o platformă unică, la nivelul
programatorului, deasupra unui mediu eterogen extrem de diversificat. Limbajul împrumută o
mare parte din sintaxă de la C și C++, dar are un model al obiectelor mai simplu și prezintă
mai puține facilități low-level. Un program Java compilat, corect scris, poate fi rulat fără
modificări pe orice platformă care are instalată o mașină virtuală Java (engleză Java Virtual
Machine, prescurtat JVM). Acest nivel de portabilitate (inexistent pentru limbaje mai vechi
cum ar fi C) este posibil deoarece sursele Java sunt compilate într-un format standard numit
cod de octeți (engleză byte-code) care este intermediar între codul mașină (dependent de tipul
calculatorului) și codul sursă. Ca mediu de dezvoltare, am folosit același IDE ca și la aplicația
Android și anume Eclipse.
Proiectul pentru această aplicație este format din șapte clase, două interfețe și o clasă
pentru testarea conexiunii seriale despre care nu voi intra în detalii. Voi prezenta fiecare
clasă/interfață pentru a descrie funcționarea programului.
Conexiunea serială a fost realizată folosind o interfață – InterfataSeriala care conține
două metode print(char c) – pentru transmiterea caracterelor via serial și close() – pentru
închiderea conexiunii. Apoi am importat în proiect pachetul RXTXcomm.jar (versiunea
pentru Windows de 64 de biți). Acesta este un pachet open-source care realizează prin
funcțiile sale comunicația între o aplicație Java și un dispozitiv conectat la PC printr-un port
serial (USB). Acest pachet este inclus și in IDE-ul Arduino și este recomandat chiar si pe site-
ul lor (http://playground.arduino.cc/Interfacing/Java), unde apar și secvențe de cod în care se
explică și cum funcționează metodele din pachet. Având interfața definită și librăria
importată, am creat o clasă RxTxInterfataSeriala care implementează interfața definită
anterior și interfața SerialPortEventListener (din pachetul RXTXcomm) pentru ascultarea
portului serial pentru date primite. Clasa aceasta are două atribut :
- SerialPort port – un obiect de tipul SerialPort , aici va fi reținut portul pe care se
efectuează transferul de date via Serial și se vor seta parametri conexiunii
(BaudRate,DataBits,StopBits,etc)
- PrintStream ps – un obiect de tipul PrintStream care preia date din aplicație și le
transmite pe port
Metode :
- RxTxInterfataSeriala(String numePort) – constructorul clasei primește ca parametru
numele portului (ex COM1), se caută prin toate porturile seriale deschise și se încearcă
conectarea pe cel cu numele numePort , dacă reușește conexiunea atunci se setează toți
parametrii și se setează obiectul ps ca Stream pentru portul numePort
- print(char c) – metodă suprascrisă de la interfața InterfataSeriala, transmite caraterul c
în streamul din ps
- close() – transmite tot ce este în stream și închide stream-ul și portul și deci și
conexiunea
- serialEvent(SerialPortEvent event) – metodă pentru debugging, afișează un mesaj
după transmiterea unui șir de date pe serial, în cazul acesta metoda este apelată după
transmiterea fiecărei comenzi.
Pentru conexiunea prin Wi-Fi este necesar ca acestă aplicație sa funcționeze ca un server
așa cum am specificat și în capitolul 4.2, dar avem nevoie de un mecanism pentru apelarea
datelor primite de către server. De aceea am creat interfața ApeleazaDate care are metoda

25
void date(byte[] pixeli, int latime, int inaltime, float[] acceleratii) prin care se vor accesa
datele primite. Pentru server am creat o clasă ServerDate , această clasă reprezintă serverul
TCP care ascultă portul 6666(același port a fost setat și în aplicația Android) pentru transmisii
de la telefon. Atributele clasei sunt următoarele:
- ServerSocket server – reprezintă portul serverului, prin acest obiect va fi creat serverul
- ApeleazaDate callback – obiect prin care se apelează datele primite
- ThreadInterpretator t – am creat o clasă nouă în interiorul clasei SeverDate, această
clasă este de tipul Thread și în ea este specificat tipul și ordinea în care sunt primite
date pe un socket s (variabilă a clasei ThreadInterpretator). Cât timp este pornit
Threadul, acesta preia date de pe socketul s (în ordinea stabilită în programul Android)
iar după ce primește un set complet de date (adică 25344 de bytes și 3 numere float) ,
acestea sunt trimise către interfața Apelează date prin obiectul callback.
Observație: Bytes primiți sunt de tipul signed bytes ceea ce înseamnă ca înainte să folosim
aceste date pentru calcule, pentru afișarea imaginii etc, aceștia trebuie aduși în intervalul
[0,255]
Este important ca serverul să funcționeze după un thread propriu deoarece el este
independent de restul acțiunilor din sistem și trebuie să fie capabil să primească date în orice
moment de timp.
Ca metode clasa folosește următoarele:
- ServerDate(ApeleazaDate ad) – constructorul cu parametrul interfața , în constructor
se deschide un server pe portul 6666
- startInterpretarea() – cu acestă metodă se acceptă conexiuni pe portul serverului, se
creează un thread de tipul ThreadInterpretator pentru portul serverului și se pornește
threadul, metoda va rula în mod continuu cât este deschisă aplicația.
În continuare voi prezenta clasele responsabile pentru exportarea datelor din aplicație
într-un fișier, astfel încât să fie prelucrate ulterior în Matlab. Pentru acesta avem nevoie de un
obiect care să asocieze imaginea și accelerațiile cu comanda la un anumit moment de timp.
Pentru aceasta am făcut clasă PachetInformatii care conține următoarele atribute:
- byte[] pixeli;
- float[] acceleratie;
- boolean stanga;
- boolean dreapta;
- boolean fata;
- boolean spate;
- int timpModificareStanga;
- int timpModificareDreapta;
- int timpModificareFata;
- int timpModificareSpate;
Nu voi detalia funcțiile lor, întrucât este destul de evident. Metodele :
- int gettimpModificareStanga()
- int gettimpModificareDreapta()
- int gettimpModificareFata()
- int gettimpModificareSpate()
(metode pentru accesarea timpului la care a fost făcut pachetul)
- PachetInformatii(byte[] pixeli, boolean stanga, boolean dreapta, boolean fata, boolean
spate, int timpStanga, int timpDreapta, int timpFata, int timpSpate, float[] acceleratie)
este constructorul clasei, formează pachetul
- byte[] getPixeli()
- float getAcceleratie(int i)

26
(metode pentru accesul la atributele obiectului)
- boolean mergeStanga()
- boolean mergeDreapta()
- boolean mergeFata()
- boolean mergeSpate()
(returnează 1 sau 0 dacă comanda pe direcția respectivă este activă sau nu)
Pentru scrierea efectivă a informațiilor, am creat un obiect care să se ocupe de această
sarcină folosind clasa ScriitorInformatii care implementează intefața Runnable deoarece
vrem ca acest obiect să ruleze în propriul ei Thread și să fie independentă de celelalte obiecte,
scrierea informațiilor se va face asincron. Atributele acestei clase sunt :
- long last – acestă variabilă reține momentul de timp la care a fost scris ultimul pachet
- PrintStream informatiiOut – variabilă prin care se efectuează scrierea în fișier, fluxul
de ieșire a informațiilor
- Queue<PachetInformatii> deScris – reprezintă o coadă de tip FIFO (first in first out)
în care sunt puse pachetele ce urmează să fie scrise în fișier, informațiile vor fi scrise
în fișier în ordinea în care au fost puse în coadă, adică în ordinea apariției lor.
Metodele :
- ScriitorInformatii(PrintStream informatiiOut) – constructorul clasei, aici se setează
fluxul de ieșire
- run() – metodă cerută de interfața Runnable, cât timp există pachete în coadă acestea
sunt scoase pe rând și scrise în fișier cu ajutorul metodei scrieInformații(pachet)
- scrieInformatii(PachetInformatii pachet) – metodă pentru scrierea informațiilor din
pachet, atributele pachetului sunt extrase cu metodele menționate mai sus și apoi
transferate pe fluxul de ieșire, tot aici este afișat timpul de scriere dintre două pachete
consecutive
- adauga(PachetInformatii pachet) – metodă pentru adăugarea pachetelor în coada
deScris
Voi expune în continuare clasele care se ocupă de generarea comenzii. Pentru aceasta
am făcut o clasă pe care am denumit-o ReteaNeuronala, scopul ei este acela de a face obiecte
cu caracteristicile unei rețele neuronale și cu ajutorul ei să putem calcula comanda pentru un
set de intrare. Pentru a ușura implementarea și a mai apropia codul de cel din Matlab am
importat pachetul Apache commons-math3-3.0.jar. Acesta este un pachet open-source și
conține funcții pentru calcul statistic, generare de date (secvențe criptografice, secvențe spab
etc), transformate (FFT, FastCosineTransformer, FastSineTransformer etc) și multe altele, dar
pentru acestă aplicație am avut nevoie de funcțiile de algebră liniară. Aceste funcții permit
crearea obiectelor de tip matrice reală sau vectori reali pe care se pot efectua operații cum ar fi
adunare, înmulțire sau scădere de matrici, înmulțire sau adunare de scalari cu matrice,
transpunerea unei matrici și calcularea normei sau a urmei unei matrici. Pachetul este unul
complex care permite chiar operații de tipul factorizare LU și Cholesky, factorizare QR sau
chiar SVD. Clasa a fost gândită astfel încât rețeaua neuronală să fie cu un singur strat ascuns
dar numărul de neuroni să fie variabil, acesta se va încărca din fișierele din Matlab. Atributele
acestei funcții sunt următoarele:
- RealMatrix theta1Transpus - o matrice de tipul RealMatrix care conține ponderile
pentru conexiunile dintre neuronii de intrare și neuronii ascunși
- RealMatrix theta2Transpus - o matrice de tipul RealMatrix care conține ponderile
pentru conexiunile dintre neuronii din stratul ascuns și neuronii de ieșire.
Au fost denumiți transpuși deoarece operațiunea de transpunere a matricilor se face chiar
de la construirea obiectului.
Metodele acestei clase sunt:

27
- RealMatrix sigmoid(RealMatrix z) - returnează o matrice de tipul RealMatrix care are
aplicată funcția sigmoid pe fiecare valoare
- RealMatrix sigmoidCuTermeniLiberi(RealMatrix z) - aceasta funcție returnează o
matrice de tipul RealMatrix cu 1 pe prima coloană și restul valorilor calculate cu
ajutorul funcției sigmoid
- RealMatrix incarcaMatriceDinFisierMatlab(String numeFisier) – funcție folosită
pentru încărcarea datelor din fișierele exportate din Matlab, formatul fișierelor trebuie
să fie de felul următor :
%% linii: 4
%% coloane: 148
2.9543194e+000 5.5126851e-001 -3.7455494e-001 …
- double[] calculComanda(byte[] date) – funcție folosită pentru calcularea comenzii,
pentru un set de intrare calculează neuroni din stratul de ieșire, funcția returnează un
vector de tipul double cu 4 elemente
Având obiectele de tip ReteaNeuronala cu ajutorul cărora putem să definim rețeaua și să
calculăm ieșirea ei pentru un set de date de intrare, putem acum crea un obiect capabil să
facă acest lucru în orice moment de timp. Am denumit clasa acestui obiect
GeneratorComanda și acestă clasa implementează si ea ca și clasa ScriitorInformații
interfața Runnable și tot la fel ca la aceasta vom forma o coadă de tipul FIFO în care vom
introduce datele de intrare și pe baza cărora vom genera comenzi. Atributele clasei sunt
următoarele :
- double PRAG_INCREDERE – avem nevoie de un prag de încredere un treshhold cu
care să comparăm ieșirile din rețea deoarce comanda poate fi doar 0 sau 1
- în interiorul clasei am creat o interfață denumită CommandListener, adică
“ascultătorul de comenzi” care conține metoda void inTimpulGenerariiComenzii
(double[] comanda, boolean stanga, boolean dreapta, boolean fata, boolean spate),
acestă interfață va fi apelată din programul principal și cu ajutorul ei putem prelua
comenzile generate de obiectul generator de comenzi
- Queue<byte[]> listaImagini – reprezintă coada de tip FIFO din care se vor lua
imaginile (adică datele de intrare pentru rețea) pentru generarea comenzii
- Thread commandThread – reprezintă threadul responsabil de generarea comenzii,
comanda trebuie generată în timp real deci are nevoie de un thread propriu care să
funcționeze în paralel cu restul programului
- CommandListener listener - obiectul listener ce va asculta comenzile și poate acționa
la primirea unor noi comenzi prin metoda inTimpulGenerariiComenzii
- ReteaNeuronala rn – reprezintă rețeaua neuronală.
Iar ca metode acestă clasa are:
- GeneratorComanda(CommandListener listener, ReteaNeuronala rn) – constructorul în
care se setează rețeaua neuronală și “ascultătorul de comenzi” și se pornește threadul
commandThread care va executa operațiile din metoda run()
- void run() – metodă executată în mod continuu de threadul commandThread, dacă
există “imagini” (seturi de date) în listaImagini se va genera comanda folosind metoda
comanda() folosind doar ultima imagine din listă pentru a fi mereu la curent cu ce se
vede pe cameră și să nu generăm comenzi pentru momente anterioare, dacă nu există
“imagini” în listă atunci threadul așteaptă
- adaugaImagini(byte[] date) - metodă ce va fi folosită pentru adăugarea de imagini în
listă ca și în metoda Run a fost folosită specificația synchronized pentru a nu se
încerca nici adăugarea și nici scoaterea de imagini din listă în același timp
- void comanda(byte[] date) - metodă resposabilă cu generarea de comandă, se folosește
metoda calculComanda a rețelei neuronale pentru a determina neuronii de ieșire a
28
rețelei și apoi toate cele patru elemente ale vectorului de ieșire sunt comparate cu
PRAG_INCREDERE astfel obținându-se comenzi pe direcțiile (față , spate , stânga și
dreapta), rezultatele comenzii vor fi transmise prin intermediul obiectului listener către
programul principal .
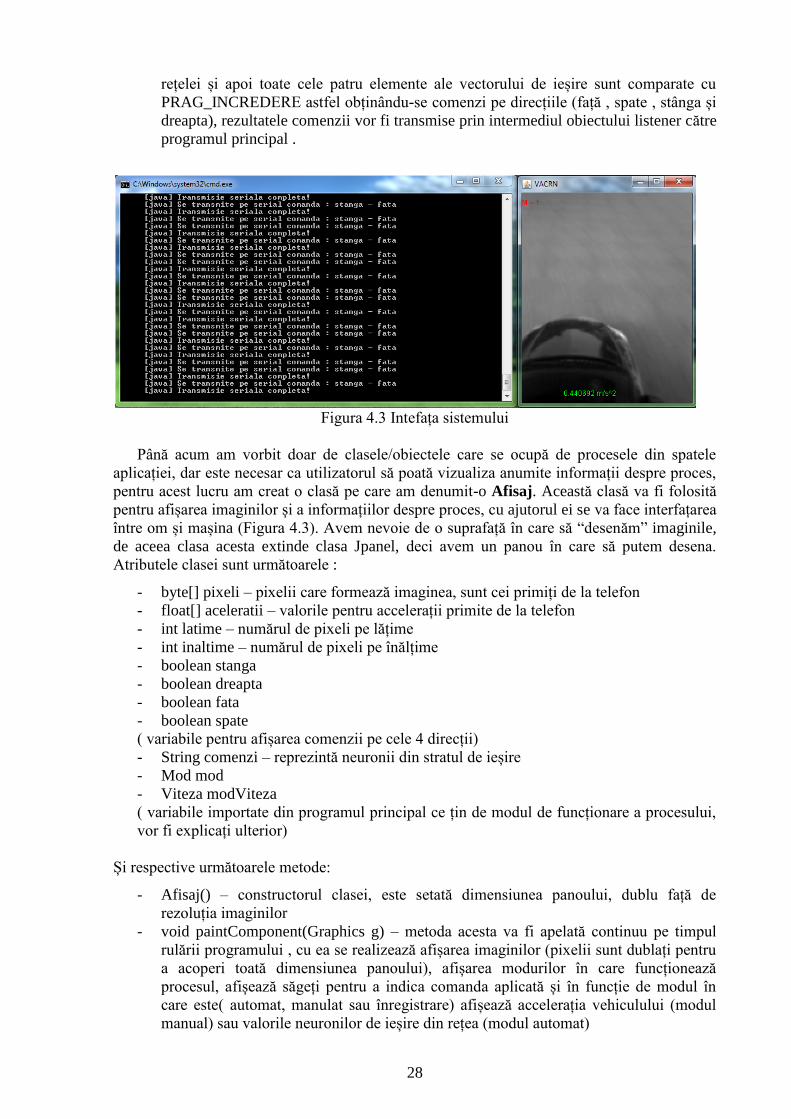
Figura 4.3 Intefața sistemului
Până acum am vorbit doar de clasele/obiectele care se ocupă de procesele din spatele
aplicației, dar este necesar ca utilizatorul să poată vizualiza anumite informații despre proces,
pentru acest lucru am creat o clasă pe care am denumit-o Afisaj. Această clasă va fi folosită
pentru afișarea imaginilor și a informațiilor despre proces, cu ajutorul ei se va face interfațarea
între om și mașina (Figura 4.3). Avem nevoie de o suprafață în care să “desenăm” imaginile,
de aceea clasa acesta extinde clasa Jpanel, deci avem un panou în care să putem desena.
Atributele clasei sunt următoarele :
- byte[] pixeli – pixelii care formează imaginea, sunt cei primiți de la telefon
- float[] aceleratii – valorile pentru accelerații primite de la telefon
- int latime – numărul de pixeli pe lățime
- int inaltime – numărul de pixeli pe înălțime
- boolean stanga
- boolean dreapta
- boolean fata
- boolean spate
( variabile pentru afișarea comenzii pe cele 4 direcții)
- String comenzi – reprezintă neuronii din stratul de ieșire
- Mod mod
- Viteza modViteza
( variabile importate din programul principal ce țin de modul de funcționare a procesului,
vor fi explicați ulterior)
Și respective următoarele metode:
- Afisaj() – constructorul clasei, este setată dimensiunea panoului, dublu față de
rezoluția imaginilor
- void paintComponent(Graphics g) – metoda acesta va fi apelată continuu pe timpul
rulării programului , cu ea se realizează afișarea imaginilor (pixelii sunt dublați pentru
a acoperi toată dimensiunea panoului), afișarea modurilor în care funcționează
procesul, afișează săgeți pentru a indica comanda aplicată și în funcție de modul în
care este( automat, manulat sau înregistrare) afișează accelerația vehiculului (modul
manual) sau valorile neuronilor de ieșire din rețea (modul automat)

29
- void actualizeaza(byte[] pixeli, int latime, int inaltime, float[] aceleratii) – metodă prin
care imaginea este actualizată în Afisaj
- void actualizeaza(boolean stanga, boolean dreapta, boolean fata, boolean spate, Mod
modProces,Viteza modViteza) – metodă prin care informațiile de proces sunt
actualizate în Afisaj
- void actualizeaza(double[] comenzi) – metodă prin care ieșirile rețelei neuronale sunt
actualizate în Afisaj
Avem în acest moment toate instrumentele necesare pentru a realiza un program cu
caracteristicile descrise la începutul acestui capitol. Am construit o clasă VACRN (vehicul
autonom controlat cu rețele neuronale) care extinde clasa JFrame (avem nevoie să creăm o
fereastră, un cadru în care să punem panoul din clasa Afisaj) și implementează interfețele
ApeleazaDate (preia datele primite pe server) , KeyListener (preia inputul utilizatorului de la
tasatatură) și CommandListener (preia comenzile generate de generatorul de comenzi).
Această clasa va reprezenta programul principal, cel care combină toate elementele descrise
până acum.
Atributele acestei clase sunt obiecte din clasele descrise anterior:
- Afisaj display – panoul pentru afișarea informațiilor
- InterfataSeriala serial – interfața serială pentru transmiterea informațiilor pe serial
- Mod modProces – acesta va fi modul de funcționare a procesului, are trei valori
MANUAL în care utilizatorul conduce vehiculul prin intermediul tastaturii , RECORD
în care datele primite/acționate (imagini/comenzi) sunt salvate într-un fișier pe disc,
AUTOMAT imaginile primite de către serverul TCP sunt transmise direct rețelei
neuronale, iar outputul rețelei este interpretat și comenzile sunt transmise către vehicul
prin interfața serial
- Viteza modViteza – acesta va fi tot un mod de funcționare a procesului, valabil doar
pentru modul AUTOMAT, are două valori NORMAL și FAST. În funcție de acest
mod se vor genera comenzi mai rapid, dar mai imprecis (FAST) sau mai lent
(NORMAL) adică se va impune un delay între comenzi pentru a crește acuratețea
comenzilor
- boolean stanga;
- boolean dreapta;
- boolean fata;
- boolean spate;
( comenzile pentru vehicul 0 oprit, 1 acționează pe direcția respectivă)
- long ultimaModificareStanga
- long ultimaModificareDreapta
- long ultimaModificareFata
- long ultimaModificareSpate
- long ultimaModificare
( variabile ce rețin ultima schimbare de direcție pentru fiecare dintre comenzi, necesar
pentru scrierea în fișier și pentru modul Viteză)
- PrintStream informatiiOut;
- ScriitorInformatii listaPachete;
( variabile necesare pentru salvarea informațiilor în fișier)
- ReteaNeuronala rn
- GeneratorComanda predictor
( variabile necesare pentru generarea comenzii)
Metodele acestei clase sunt :

30
- VACRN(InterfataSeriala serial, File fisierOut, String fisierTheta1,String fisierTheta2)
constructorul clasei, aici se setează interfața serială, se setează fișierul în care se vor
salva datele, se încearcă încărcarea datelor din fișierele din Matlab dacă acestea există,
se va seta dimensiunea cadrului (egală cu dimensiunea panoului display) și se adaugă
panoul display, se adaugă un keyListener pentru a prelua input de la tastatură, se
creează o listaPachete în care se vor introduce pachetele ce trebuie scrise în fișier, se
crează și se pornește un thread pentru scrierea informațiilor în fișier așa cum a fost
definit în clasa ScriitorInformatii și se creeză un predictor de tipul GeneratorComandă
care folosește rețeaua neuronală încărcată anterior
- scriePachet(PachetInformatii pachet) – metodă pentru adăugare de pachete în lista de
pachete și deci pentru a-l scrie în fișier
- comandaPeBazaImaginei(byte[] pixeli) – metodă pentru adăugarea de imagini în lista
de imagini a obiectului predictor , care va genera comenzi pe baza lor
- trimiteComanda(boolean stanga, boolean dreapta, boolean fata, boolean spate) –
metodă prin care este transmisă comanda prin serial , codarea informațiilor va fi făcută
la fel ca în programul arduino (ex (fata + stanga) : 0000 0101)
- keyPressed(KeyEvent e) - metodă din interfața KeyListener , este apelată atunci când
este apăsată o tastă, dacă este apăsată una din săgeti de pe tastatură atunci se setează
variabila de direcție (ex dacă este apăsată sageată stânga atunci variabila stanga este
făcută 1), se reține timpul modificării, se transmite comanda pe serial cu funcția
trimiteComanda și se actualizează display-ul cu noile informații
- keyReleased(KeyEvent e) - metodă din interfața KeyListener, este apelată după
apăsarea unei taste, ca o convenție schimbările de mod se vor face doar pe
keyReleased (ridicarea degetului de pe tastatura) , face același lucru ca și keyPressed
dar inclusiv pentru modificarea modProces și modViteză
- keyTyped(KeyEvent e) – metodă din intefața KeyListner, nu este necesară așa că nu
am adăugat operații
- void date(byte[] pixeli, int latime, int inaltime,float[] aceleratii) – metodă din intefața
ApelezaDate, este apelată de fiecare dată când se primește un nou set de date pe
serverul TCP, dacă sistemul se află în modul INREGISTRARE atunci se creează un
pachet nou cu datele primite și se apelează funcția scriePachet, dacă sistemul se află în
modul AUTOMAT se apelează funcția comandaPeBazaImaginei cu argument ultima
imagine primită și actualizează informația afișată pe display (imaginea și accelerația)
- inTimpulGenerariiComenzii(double[] comenzi, boolean stangaNou, boolean
dreaptaNou,boolean fataNou, boolean spateNou) – metodă din intefața
CommandListener , este apelată de fiecare dată când se generează un set de comenzi,
se verifică modul Viteză și în funcție de acesta se setează timpul de delay dintre
comenzi transmise către serial , dacă ultima comandă este diferită de cea anterioară
aceasta este transmisă către serial indiferent de delay, se salvează noile comenzi și
dacă se respectă condițile menționate mai sus se apelează funcția trimiteComanda și se
salvează momentul la care a fost transmis, tot aici se actualizează display-ul cu
informațiile despre proces
- main(String[] args) – funcția principală a aplicației, va fi apelată la deschiderea
aplicației, dacă nu este specificat portul pe care se face comunicația între aplicație și
Arduino, atunci aplicația nu va fi lansată și utilizatorul va fi avertizat de acest lucru
printr-un mesaj, se creează un fișier temporar în care se vor salva informațiile scrise în
modul INREGISTRARE, se creează un obiect de tipul VACRN pentru care se
specfică interfața serială RxTxInterfataSeriala, fișierul de output, cel creat tot aici și
calea către fișierele exportate din Matlab, și un obiect de tipul ServerDate care
comunică cu obiectul VACRN prin intefața ApeleazaDate, se pornește thread-ul
pentru ascultarea portului pentru date .

31
Figura 4.4 Comunicația între limbaje
Avem acum un sistem capabil să conducă un vehicul printr-o interfață serială, să
primească imagini și alte informații de la senzori, acționând ca un server și să înregistreze
date despre modul în care a fost condus acest vehicul. Aceste date sunt salvate într-un fișier pe
disc, prelucrate folosind un mic script Python și apoi importate în Matlab. Aici avem modulul
de Inteligența Artificială, aici este creată rețeaua neuronală propriu-zisă. În urma antrenării
rețelei, se pot extrage două fișiere care reprezintă legăturile dintre neuronii rețelei (theta1 și
theta2) și cu ele putem genera acum cu succes comenzi pentru controlul vehicului. Acuratețea
comenzilor depinde de cât de eficientă este rețeaua și de tehnicile folosite în antrenarea ei,
lucru pe care îl vom vedea în capitolul următor. În Figura 4.4 avem ilustrată o diagramă a
modului de comunicație între diferitele limbaje din proiect.
Scriptul Phyton a fost folosit pentru a converti fișierul în care sunt informațiile salvate
de aplicația Java VACRN în două fișiere X.dat pentru neuronii de intrare în rețea și respectiv
y.dat pentru neuronii de ieșire din rețea. Ele sunt formatate pentru a putea fi ușor citite în
Matlab folosind doar comanda load(). Tot aici au fost eliminate cadrele care nu au comenzi
(adică au doar comenzi cu 0) și se pot face și alte prelucrări cum ar fi eliminarea comenzilor
de mers înapoi sau limitarea comenzilor de mers înainte până la un anumit număr pentru a
elimina redundanța informațiilor.
5. Antrenarea rețelei neuronale
Cum am menționat și în capitolul 2, rețeaua este una de tip propagare înainte, cu
25345 neuroni de intrare obținuți din 176x144 pixeli (25344, fiecare pixel reprezintă câte un
neuron de intrare) și un termen liber (bias), un singur strat ascuns și stratul de ieșire format
din 4 neuroni, fiecare responsabil de comanda pe o direcție. Fiecare imagine va fi o linie în
matricea X și respectiv fiecare linie din matricea y comanda asociată imaginii, în Figura 5.1
avem un exemplu de aranjare a datelor în termeni de X și y pentru o rețea cu m exemple de
învățare.

32
Figura 5.1 Matricele X și y
5.1 Propagare înainte și Propagare inversă
În Figura 5.2 se poate observa o reprezentare a rețelei neuronale în care au fost
reprezentați inclusiv neuronii de bias, aceasta este o bună reprezentare a fenomenului de
propagare înainte. Ca simbolistică Θ(i) reprezintă conexiunile dintre straturile i și i+1,
matricea ponderilor cea pe care vrem sa o aflăm, a(i) reprezintă valoarea neuronului din
stratul i după aplicarea funcției de activare, funcția de activare nu se aplică pe neuroni de bias,
z(i) reprezintă valoarea obținută prin aplicarea ponderilor din Θ(i) asupra valorilor neuronilor
din stratul i-1, g(z) reprezintă funcția sigmoid funcției sigmoid și h(x) reprezintă output-ul
rețelei la aplicarea datelor de intrare x. Acesta este mecansimul cunoscut sub denumirea de
propagare înainte ( engl. feedforward ).
Figura.5.2 Modelul rețelei
Învățarea va fi una supervizată și se va face cu algoritmul de propagare inversă ( engl.
backpropagation BP). Ideea principală din acest algoritm este că dacă avem o pereche de
intrare-ieșire X(t)-y(t) , întâi trecem datele prin rețeaua neuronală (conexiunile dintre straturi
au fost inițializate în mod aleatoriu) inclusiv aplicând funcțiile de activare ale neuronilor (în

33
cazul acesta funcția sigmoid) și determinăm valorile de ieșire. Apoi pentru fiecare neuron j
din stratul l vrem să găsim diferența d(j,l) care va măsura cât de mult este responsabil
neuronul respectiv pentru erorile de la ieșire. O reprezentare a modului în care funcționează
algoritmul de back-propagation putem vedea în Figura 5.3 , unde g’(z) este derivata funcției
sigmoid ( , iar d(j,l) este „eroarea” neuronului j din stratul l față de
traget-ul dorit, restul elementelor au aceeași semnificație ca cele din Figura 5.2.
Figura 5.3 Algoritmul de propagare inversă
Reprezentând matematic ecuațiile sistemului obținem :
∈ (5.1)
(5.2)
Atunci putem să scriem următoarea funcție cost pentru toate exemplele pe care se
efectuează antrenarea :
(5.3)
Dacă am scrie
adică clasica funcție de eroare
medie pătratică ( engl. mean squared error) atunci am obține o funcție cost non-convexă
ca cea din Figura 5.4 a), adică cu mai multe minime locale, iar acest lucru apare din cauza
funcției neliniare sigmoid. Pe o astfel de funcție utilizarea unei metode simple ca cea de
gradient nu ar garanta convergența către minimul global. De aceea vrem să găsim o funcție ca
cea din figura 5.4 b) pe care convergența către minimul global este garantată.
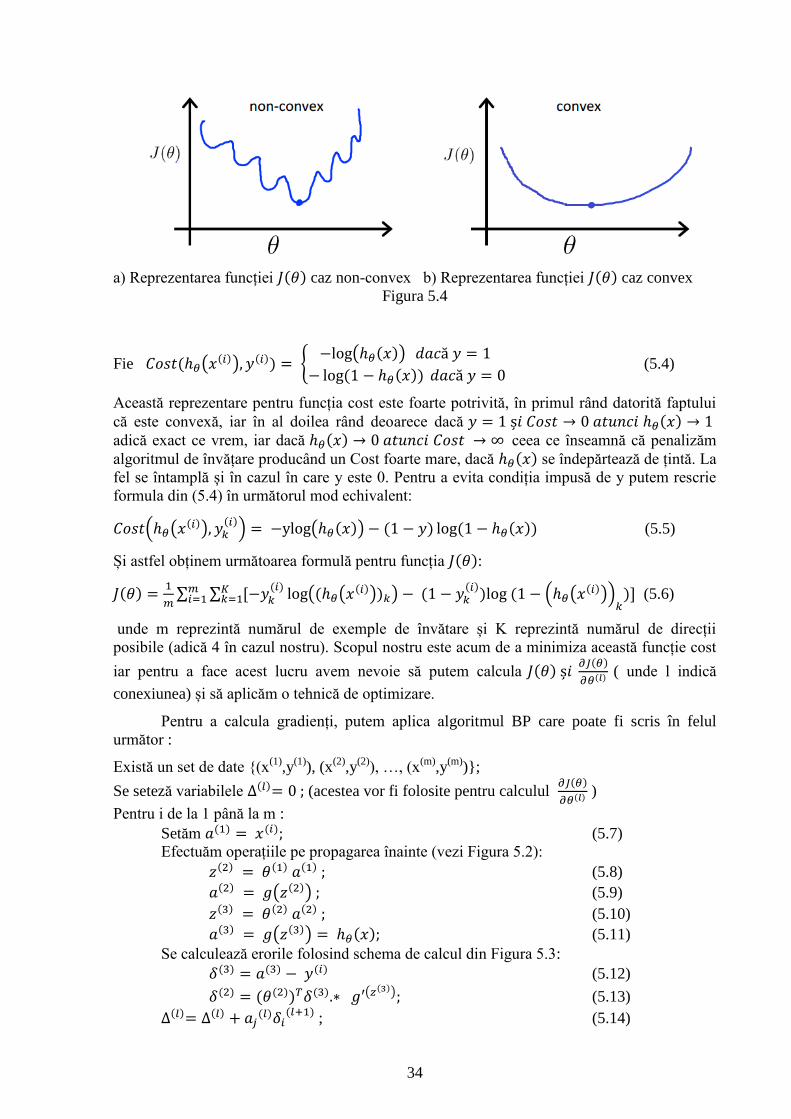
34
a) Reprezentarea funcției caz non-convex b) Reprezentarea funcției caz convex
Figura 5.4
Fie
(5.4)
Această reprezentare pentru funcția cost este foarte potrivită, în primul rând datorită faptului
că este convexă, iar în al doilea rând deoarece dacă adică exact ce vrem, iar dacă ceea ce înseamnă că penalizăm
algoritmul de învățare producând un Cost foarte mare, dacă se îndepărtează de țintă. La
fel se întamplă și în cazul în care y este 0. Pentru a evita condiția impusă de y putem rescrie
formula din (5.4) în următorul mod echivalent:
(5.5)
Și astfel obținem următoarea formulă pentru funcția :
(5.6)
unde m reprezintă numărul de exemple de învătare și K reprezintă numărul de direcții
posibile (adică 4 în cazul nostru). Scopul nostru este acum de a minimiza această funcție cost
iar pentru a face acest lucru avem nevoie să putem calcula
( unde l indică
conexiunea) și să aplicăm o tehnică de optimizare.
Pentru a calcula gradienți, putem aplica algoritmul BP care poate fi scris în felul
următor :
Există un set de date {(x(1)
,y(1)
), (x(2)
,y(2)
), …, (x(m)
,y(m)
)};
Se seteză variabilele (acestea vor fi folosite pentru calculul
)
Pentru i de la 1 până la m :
Setăm (5.7)
Efectuăm operațiile pe propagarea înainte (vezi Figura 5.2):
(5.8)
(5.9)
(5.10)
(5.11)
Se calculează erorile folosind schema de calcul din Figura 5.3:
(5.12)
(5.13)
; (5.14)
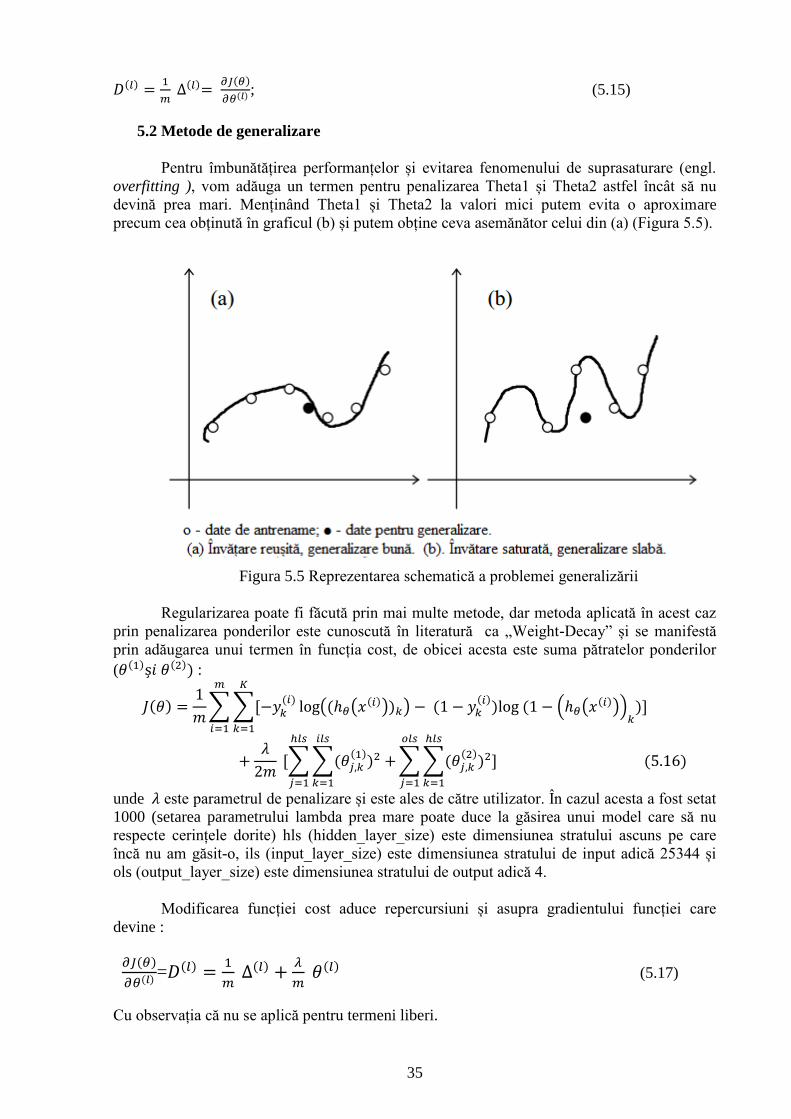
35
; (5.15)
5.2 Metode de generalizare
Pentru îmbunătățirea performanțelor și evitarea fenomenului de suprasaturare (engl.
overfitting ), vom adăuga un termen pentru penalizarea Theta1 și Theta2 astfel încât să nu
devină prea mari. Menținând Theta1 și Theta2 la valori mici putem evita o aproximare
precum cea obținută în graficul (b) și putem obține ceva asemănător celui din (a) (Figura 5.5).
Figura 5.5 Reprezentarea schematică a problemei generalizării
Regularizarea poate fi făcută prin mai multe metode, dar metoda aplicată în acest caz
prin penalizarea ponderilor este cunoscută în literatură ca „Weight-Decay” și se manifestă
prin adăugarea unui termen în funcția cost, de obicei acesta este suma pătratelor ponderilor
( :
unde este parametrul de penalizare și este ales de către utilizator. În cazul acesta a fost setat
1000 (setarea parametrului lambda prea mare poate duce la găsirea unui model care să nu
respecte cerințele dorite) hls (hidden_layer_size) este dimensiunea stratului ascuns pe care
încă nu am găsit-o, ils (input_layer_size) este dimensiunea stratului de input adică 25344 și
ols (output_layer_size) este dimensiunea stratului de output adică 4.
Modificarea funcției cost aduce repercursiuni și asupra gradientului funcției care
devine :
=
(5.17)
Cu observația că nu se aplică pentru termeni liberi.

36
Proprietatea de generalizare reprezintă capabilitatea unei reţele neuronale de a
răspunde la date de intrare ce nu au făcut parte din mulţimea de antrenament. Este evident
faptul că scopul învăţării unei reţele neuronale trebuie să fie obţinerea unei bune capacităţi de
generalizare. Generalizarea poate fi privită, dacă considerăm reţeaua neuronală ca o aplicaţie
între spaţiul datelor de intrare şi spaţiul datelor de ieşire (obţinute la stratul de ieşire), ca fiind
abilitatea de interpolare a aplicaţiei respective. Termenul de penalizare face ponderile să
conveargă la o valoare mai mică decât ar face-o dacă acesta nu ar exista ( . Valori ale
ponderilor mari pot fi dăunătoare pentru generalizarea rezultatului în două moduri. Ponderi
foarte mari către neuronii ascunși pot face ca outputul funcției să fie cu diferențe mari, posibil
chiar cu discontinuități. Ponderi foarte mari care duc la stratul de ieșire pot determina ca unii
neuroni din output sa fie mult mai mari decât restul datelor, dacă funcția de activare nu are un
codomeniu finit. Ponderi mari pot cauza varianță excesivă către output (Geman, Bienenstock,
and Doursat 1992). Conform lui Bartlett (1997), mărimea (norma 1) a ponderilor este mai
importantă decat numărul ponderilor când vine vorba de generalizare.
O altă metodă pe care am folosit-o pentru a îmbunătăți generalizarea este cunosctută în
literatură ca “early-stopping” și se poate aplica folosind următorul algoritm :
1. Se împart datele disponibile în seturi de antrenare și validare.
2. Se utilizează un număr mare de unități ascunse ( nu e neapărat necesar).
3. Se folosesc valori foarte mici și aleatorii pentru inițializarea ponderilor.
4. Se folosește o rată de învățare lentă (un pas mic).
5. Se caculează rata de eroare pe setul de validare periodic în timpul anternării.
6. Se oprește antrenarea dacă eroarea de validare începe să crească.
Avantajele acestei metode ar fi faptul că este rapidă și ușor de implementat, depinde doar
dintr-un singur punct de vedere de utilizator și anume în alegerea setului de validare.
Dezavantajul este că alegerea setului de validare este o sarcină destulă de dificilă și nu există
teorie care să ne spună cum se face acest lucru.
5.3 Determinarea numărului de neuroni din stratul ascuns
O problemă pe care nu am abordat-o încă este determinarea numărului de neuroni din
stratul ascuns. Aceasta este tot o problemă ce ține de generalizarea rezultatului dar nu numai.
Determinarea numărului de neuroni din stratul ascuns depinde într-un mod complex de :
- Numărul de neuroni de intrare și neuroni de ieșire
- Numărul de exemple de învățare
- Complexitatea clasificării
- Arhitectura rețelei
- Tipul funcției de activare
- Algoritmul cu care se face antrenarea
- Metodele de regularizare
Dar încă nu există în literatură specificat clar cum acesta poate fi găsit. Există metode
determinate mai mult empiric, unii spun că numărul de neuroni ar trebui să fie undeva între
dimensiunea stratului de intrare și dimensiunea celui de ieșire, alții spun că ar trebui să fie
exact 2/3 din suma acestora , iar alții spun că pot depăși dimensiunea de intrare dar nu mai
mult decât dublul ei. Având în vedere că părerile sunt împărțite și nu există nici măcar un
rezultat clar după care ar trebui să se facă acestă alegere, vom merge pe o abordare empirică
adică prin încercarea diferitelor dimensiuni se va alege cea care produce o eroare cât mai
mică. Pentru a face acest lucru trebuie importat un set de date din aplicația Java VACRN
(pixelii salvați în fișiere au fost și ei salvați ca signed bytes așa că trebuie făcută conversia
după încărcarea datelor din fișier) și realizat un set de funcții în Matlab :
pentru inițializarea ponderilor ( după formula
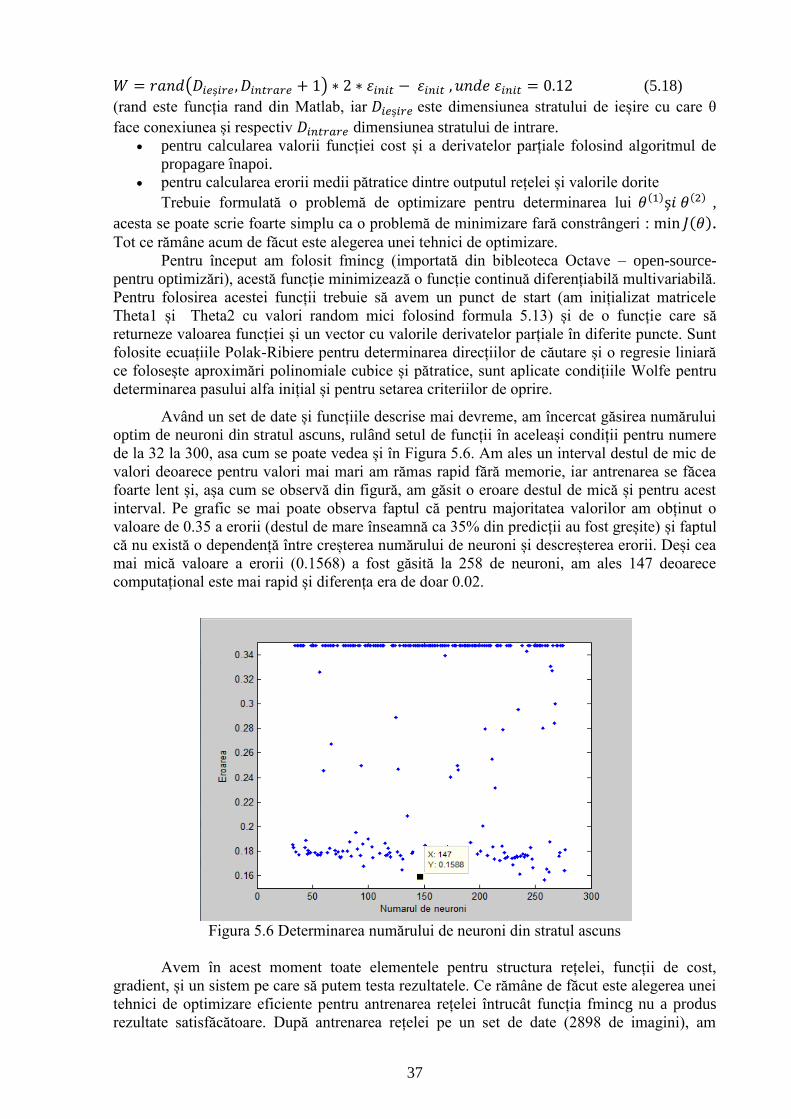
37
(5.18)
(rand este funcția rand din Matlab, iar este dimensiunea stratului de ieșire cu care θ
face conexiunea și respectiv dimensiunea stratului de intrare.
pentru calcularea valorii funcției cost și a derivatelor parțiale folosind algoritmul de
propagare înapoi.
pentru calcularea erorii medii pătratice dintre outputul rețelei și valorile dorite
Trebuie formulată o problemă de optimizare pentru determinarea lui ,
acesta se poate scrie foarte simplu ca o problemă de minimizare fară constrângeri : . Tot ce rămâne acum de făcut este alegerea unei tehnici de optimizare.
Pentru început am folosit fmincg (importată din bibleoteca Octave – open-source-
pentru optimizări), acestă funcție minimizează o funcție continuă diferențiabilă multivariabilă.
Pentru folosirea acestei funcții trebuie să avem un punct de start (am inițializat matricele
Theta1 și Theta2 cu valori random mici folosind formula 5.13) și de o funcție care să
returneze valoarea funcției și un vector cu valorile derivatelor parțiale în diferite puncte. Sunt
folosite ecuațiile Polak-Ribiere pentru determinarea direcțiilor de căutare și o regresie liniară
ce folosește aproximări polinomiale cubice și pătratice, sunt aplicate condițiile Wolfe pentru
determinarea pasului alfa inițial și pentru setarea criteriilor de oprire.
Având un set de date și funcțiile descrise mai devreme, am încercat găsirea numărului
optim de neuroni din stratul ascuns, rulând setul de funcții în aceleași condiții pentru numere
de la 32 la 300, asa cum se poate vedea și în Figura 5.6. Am ales un interval destul de mic de
valori deoarece pentru valori mai mari am rămas rapid fără memorie, iar antrenarea se făcea
foarte lent și, așa cum se observă din figură, am găsit o eroare destul de mică și pentru acest
interval. Pe grafic se mai poate observa faptul că pentru majoritatea valorilor am obținut o
valoare de 0.35 a erorii (destul de mare înseamnă ca 35% din predicții au fost greșite) și faptul
că nu există o dependență între creșterea numărului de neuroni și descreșterea erorii. Deși cea
mai mică valoare a erorii (0.1568) a fost găsită la 258 de neuroni, am ales 147 deoarece
computațional este mai rapid și diferența era de doar 0.02.
Figura 5.6 Determinarea numărului de neuroni din stratul ascuns
Avem în acest moment toate elementele pentru structura rețelei, funcții de cost,
gradient, și un sistem pe care să putem testa rezultatele. Ce rămâne de făcut este alegerea unei
tehnici de optimizare eficiente pentru antrenarea rețelei întrucât funcția fmincg nu a produs
rezultate satisfăcătoare. După antrenarea rețelei pe un set de date (2898 de imagini), am

38
obținut un . Trecând datele prin rețea, am obținut o matrice de ieșire PRED (ieșire
predictată) de 2898x4 cu valori în intervalul (0,1). Am comparat aceste rezultate cu un prag de
încredere (am setat 0.4, același ca cel din clasa GeneratorComanda capitolul 4.3) pentru a
obține doar rezultate de 0 și 1 la fel ca în matricea pe care s-a facut antrenarea. În urma
comparării rezultatelor din matricea PRED cu matricea inițială y, am obținut următoarele
rezulatate :
Acuratețea setului de date: 81.380368 – stânga
Acuratețea setului de date: 67.361963 – dreapta
Acuratețea setului de date: 95.920245 – față
Acuratețea setului de date: 100.000000 – spate
Aceste date reprezezintă procentajul cu care rețeaua a reușit să identifice corect
comanda pentru imaginea respectivă. Mașina a reușit să se descurce relativ bine pe traseu, dar
nu suficient pentru toate situațiile.
În figura 5.6 este o reprezentare a conexiunilor obținute, se poate observa cum ele se
pot aplica aproape ca niște filtre asupra imaginilor introduse pentru obținerea direcției dorite.
Figura 5.7 Vizualizarea legaturile din Theta1
În continuare vom încerca antrenarea rețelei folosind diferite tehnici de optimizare cu
ajutorul librăriei de RNA din Matlab. Aceasta este o librărie ușor de folosit care permite
crearea unui obiect de tipul rețea neuronală pentru determinarea unui model și rezolvarea
problemelor de clasificare (engl. patternent). Librăria permite și folosirea procesării paralele
pe mai multe procesoare dar și folosirea unității grafice de procesare pentru a mări viteza
calculelor. Conține funcțiile menționate mai sus pentru generalizarea rezultatelor, module de
preprocesare și postprocesare a datelor, dar și o suită mare de tehnici pentru determinarea
parametrilor theta folosind BP. Am creat o rețea cu 25345 de neuroni în stratul de intrare,
147 în stratul ascuns și 4 neuroni în stratul de ieșire. Am setat funcțiile de activare (funcția
sigmoid) și tot ce urmează este găsirea unei tehnici potrivite pentru antrenarea rețelei. Nu se
vor implementa toate tehnicile existente în librărie, ci am ales dintre ele 9 care am considerat
că merită investigate.
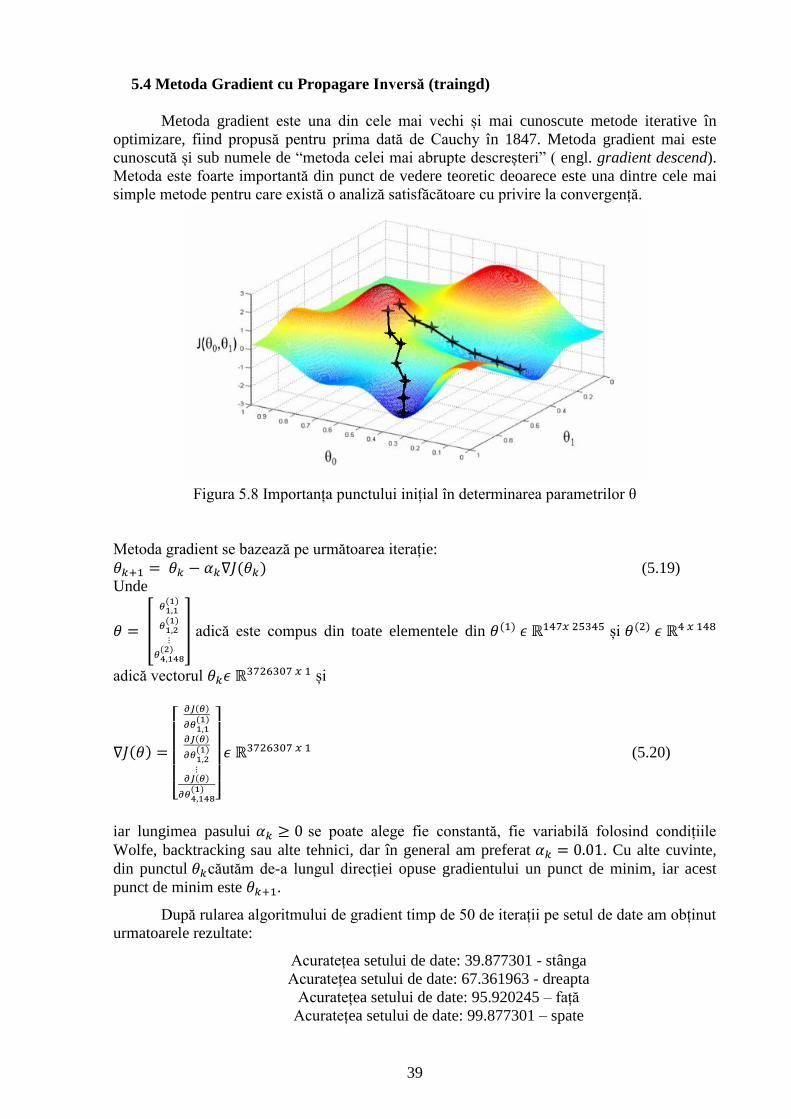
39
5.4 Metoda Gradient cu Propagare Inversă (traingd)
Metoda gradient este una din cele mai vechi și mai cunoscute metode iterative în
optimizare, fiind propusă pentru prima dată de Cauchy în 1847. Metoda gradient mai este
cunoscută și sub numele de “metoda celei mai abrupte descreșteri” ( engl. gradient descend).
Metoda este foarte importantă din punct de vedere teoretic deoarece este una dintre cele mai
simple metode pentru care există o analiză satisfăcătoare cu privire la convergență.
Figura 5.8 Importanța punctului inițial în determinarea parametrilor θ
Metoda gradient se bazează pe următoarea iterație:
(5.19)
Unde
adică este compus din toate elementele din și
adică vectorul și
(5.20)
iar lungimea pasului se poate alege fie constantă, fie variabilă folosind condițiile
Wolfe, backtracking sau alte tehnici, dar în general am preferat . Cu alte cuvinte,
din punctul căutăm de-a lungul direcției opuse gradientului un punct de minim, iar acest
punct de minim este .
După rularea algoritmului de gradient timp de 50 de iterații pe setul de date am obținut
urmatoarele rezultate:
Acuratețea setului de date: 39.877301 - stânga
Acuratețea setului de date: 67.361963 - dreapta
Acuratețea setului de date: 95.920245 – față
Acuratețea setului de date: 99.877301 – spate

40
Figura 5.9 Performanțele Metodei Gradient pe setul de date
În figura 5.9, în partea din stânga, se poate observa evoluția funcției cost (funcția cost
este msereg adică Mean squared error with regularization – eroarea medie pătratică cu
regularizare, adică cea din formula 5.16) pe parcursul celor 50 de iterații și cum acesta a
rămas probabil blocată într-un minim local. În partea din dreapta se observă că și valoarea
gradientului este aproape constantă în 90% dintre iterații, iar în partea de jos avem ilustrat
fenomenul de oprire rapidă ( engl. early-stopping ) care însă nu a produs nicio modificare.
5.5 Propagare inversă flexibilă (trainrp)
Rețeaua noastră folosește funcții de activare sigmoid. Așa cum am precizat și la
începutul lucrării, aceste funcții sunt numite și funcții de “comprimare”, pentru că ele
comprimă un domeniu infinit de la intrare într-un domeniu finit la ieșire. Funcțiile sigmoidale
sunt caracterizate de faptul că panta lor trebuie să fie zero, când intrarea este mare. Aceasta
duce la apariția unei probleme atunci când se folosește gradientul descent la antrenarea unei
rețele multi-strat cu funcții sigmoidale, anume că gradientul fiind foarte mic, provoacă mici
modificări ale valorilor ponderilor și deplasărilor, chiar când acestea sunt departe de valorile
lor optimale, cum am văzut și în exemplul de mai sus ( Capitolul 5.3).
Scopul algoritmului de antrenare prin propagare inversă flexibilă (Rprop) este acela de
a elimina efectele nedorite cauzate de derivatele parțiale. Se folosește numai semnul derivatei
pentru a afla direcția actualizării ponderii; mărimea derivatei nu are niciun efect asupra
actualizării ponderii. Mărimea variației ponderii se determină cu o valoare de actualizare
separată. Valoarea actualizării pentru fiecare pondere și deplasare se amplifică cu un factor
delt-inc dacă derivata funcției cost(de performanță) în raport cu acea pondere are același semn
în două iterații successive. Valoarea actualizată se micșorează cu factorul delt-dec când
derivata în raport cu acea pondere își schimbă semnul față de iterația anterioară. Dacă derivata
are valoarea zero, atunci valoarea actualizată rămâne aceeași. Când ponderile oscilează,
variația ponderii va fi redusă. Daca ponderea continuă să se modifice în aceeași direcție pe
parcursul mai multor iterații, atunci mărimea variației ponderii se va amplifica. Matematic,
acest lucru se poate scrie în următorul fel :
(5.21)
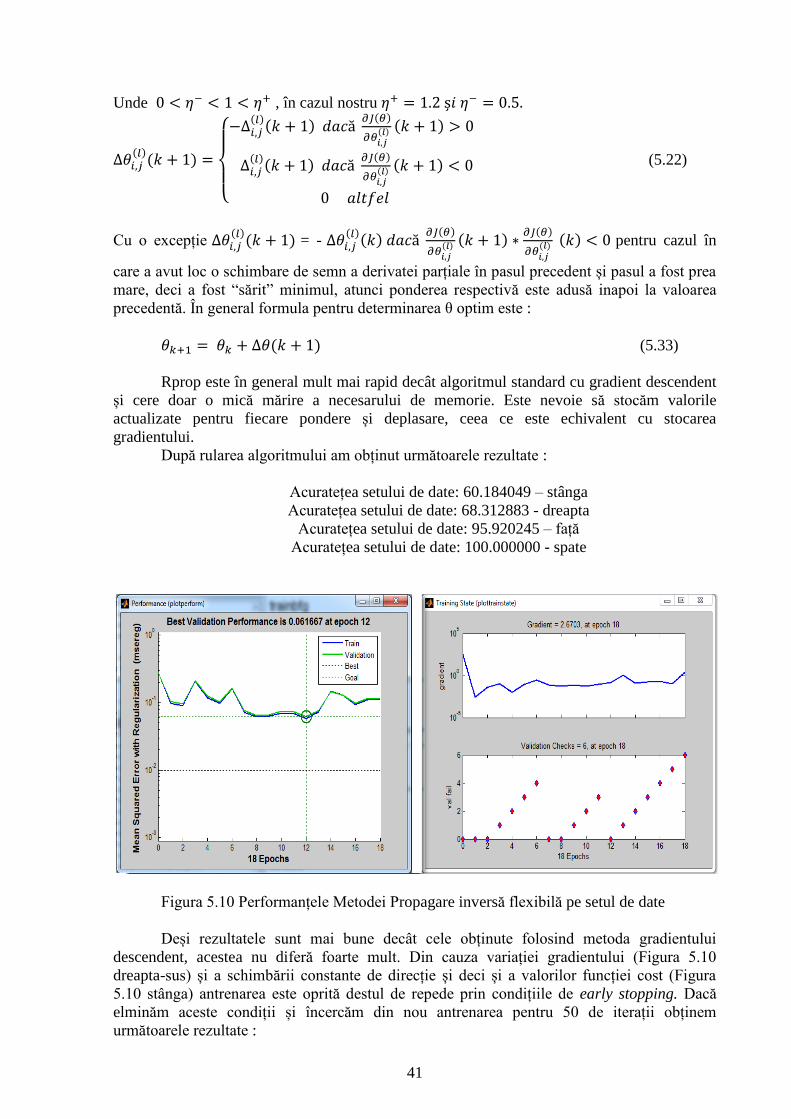
41
Unde , în cazul nostru
(5.22)
Cu o excepție = -
pentru cazul în
care a avut loc o schimbare de semn a derivatei parțiale în pasul precedent și pasul a fost prea
mare, deci a fost “sărit” minimul, atunci ponderea respectivă este adusă inapoi la valoarea
precedentă. În general formula pentru determinarea θ optim este :
(5.33)
Rprop este în general mult mai rapid decât algoritmul standard cu gradient descendent
și cere doar o mică mărire a necesarului de memorie. Este nevoie să stocăm valorile
actualizate pentru fiecare pondere și deplasare, ceea ce este echivalent cu stocarea
gradientului.
După rularea algoritmului am obținut următoarele rezultate :
Acuratețea setului de date: 60.184049 – stânga
Acuratețea setului de date: 68.312883 - dreapta
Acuratețea setului de date: 95.920245 – față
Acuratețea setului de date: 100.000000 - spate
Figura 5.10 Performanțele Metodei Propagare inversă flexibilă pe setul de date
Deși rezultatele sunt mai bune decât cele obținute folosind metoda gradientului
descendent, acestea nu diferă foarte mult. Din cauza variației gradientului (Figura 5.10
dreapta-sus) și a schimbării constante de direcție și deci și a valorilor funcției cost (Figura
5.10 stânga) antrenarea este oprită destul de repede prin condițiile de early stopping. Dacă
elminăm aceste condiții și încercăm din nou antrenarea pentru 50 de iterații obținem
următoarele rezultate :

42
Acuratețea setului de date: 87.515337 - stanga
Acuratețea setului de date: 88.343558 - dreapta
Acuratețea setului de date: 95.920245 – față
Acuratețea setului de date: 100.000000 - spate
Figura 5.11 Clasificarea rezultatelor folosind RProp
Deși am obținut rezultate numerice mai bune, am renunțat la condițiile de
generalizare, ceea ce s-ar putea dovedi foarte dăunător în practică.
5.6 Propagarea inversă BFGS quasi-Newton (trainbfg)
În analiza numerică și optimizare, metoda lui Newton (sau metoda Newton-Raphson)
este o metodă de calcul a rădăcinilor unui sistem de ecuații care are la bază următoarea relație
de recurență :
(5.24)
unde este matricea Hessiana (cu derivatele secunde ale funcției de performanță în
raport cu valorile curente ale ponderilor si deplasărilor). Metoda lui Newton converge deseori
mai rapid decat metodele din capitolele 5.3 și 5.4. Din păcate, este complicat și costisitor să se
calculeze matricea Hessiana pentru o rețea neuronală, mai ales una cu dimensiunile acestea.
Exista însă o categorie de algoritmi bazați pe metoda lui Newton, dar care nu necesită
calcularea derivatelor secundare. Acestea sunt numite metode quasi-Newton. Aceste metode
actualizează la fiecare iterație o matrice Hessiana aproximativă. Actualizarea este calculată ca
o funcție de gradient. O astfel de aproximare este cea Broyden-Fletcher-Goldfarb-Shanno
(BFGS) :
(5.25)
unde
din care se poate obține ușor inversa :

43
(5.26)
Algoritmul funcționează în felul următor :
Cât timp > 0 :
Calculează direcția
Calculează direcția noua iterație și
Evaluează și calculează
Calculează
Algoritmul BFGS necesită multe calcule în fiecare iterație si mai multă memorie decât
metodele cu gradient, deși în general converge în mai puține iterații. Hessianul aproximativ
trebuie stocat, iar dimensiunile sale sunt n× n, unde n este egal cu numărul ponderilor și al
deplasărilor din rețea ( .
Din nefericire, acest algoritm nu a putut fi rulat pentru acestă problemă deoarece
necesită prea multe resurse din punct de vedere al memoriei utilizate. Nici după diminuarea
setului de date și utilizarea opțiunilor pentru optimizare a memoriei nu s-a putut realiza
antrenarea cu acest algoritm. Totuși, pentru rețelele mai mici, trainbfg poate fi o funcție de
antrenare eficientă și îl vom avea în vedere (în funcțiile din matlab) în cazul în care, în viitor,
se va putea utiliza o mașină de calcul mai puternică.
5.7 Propagarea inversă OSS (trainoss)
Din moment ce algoritmul BFGS necesită foarte multă memorie și implică multe
calcule complexe la fiecare iterație, este necesară găsirea unei metode cvasi-Newton care
necesită mai puține resurse. Metoda one step secant (OSS) este o metodă prin care se încearcă
acest lucru. Acest algoritm nu păstrează întreaga hesiană, ci se presupune mereu că la iterația
precedentă Hessiana a fost matricea identitate I. Acestă abordare are ca avantaj faptul că noua
direcție de căutare poate fi calculată fără a se efectua inversări de matrici. Ca și la celelalte
metode, se pornește de la o ecuație iterativă :
, unde reprezintă direcția de căutare și are următoarea formulă :
(5.27)
Unde și
(5.28)
(5.29)
Este ușor de observat ca ecuația (5.27) are nevoie doar de n operații (odată ce este calculat
gradientul folosind BP) pentru calcularea produselor de tipul xTy. Așadar avem de a face cu
un algoritm foarte rapid care ar trebui să fie și eficient.
După antrenarea rețelei am obținut următoarele rezultate :
Acuratețea setului de date: 81.012270 - stânga
Acuratețea setului de date: 67.453988 - dreapta
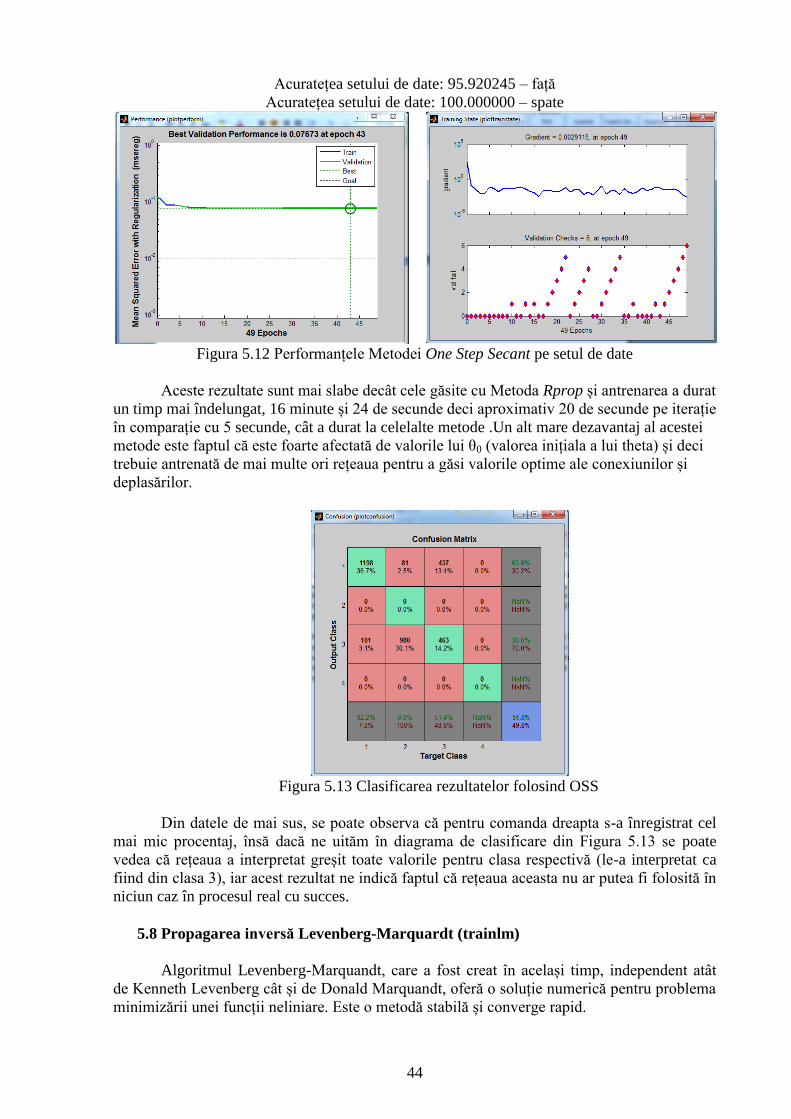
44
Acuratețea setului de date: 95.920245 – față
Acuratețea setului de date: 100.000000 – spate
Figura 5.12 Performanțele Metodei One Step Secant pe setul de date
Aceste rezultate sunt mai slabe decât cele găsite cu Metoda Rprop și antrenarea a durat
un timp mai îndelungat, 16 minute și 24 de secunde deci aproximativ 20 de secunde pe iterație
în comparație cu 5 secunde, cât a durat la celelalte metode .Un alt mare dezavantaj al acestei
metode este faptul că este foarte afectată de valorile lui θ0 (valorea inițiala a lui theta) și deci
trebuie antrenată de mai multe ori rețeaua pentru a găsi valorile optime ale conexiunilor și
deplasărilor.
Figura 5.13 Clasificarea rezultatelor folosind OSS
Din datele de mai sus, se poate observa că pentru comanda dreapta s-a înregistrat cel
mai mic procentaj, însă dacă ne uităm în diagrama de clasificare din Figura 5.13 se poate
vedea că rețeaua a interpretat greșit toate valorile pentru clasa respectivă (le-a interpretat ca
fiind din clasa 3), iar acest rezultat ne indică faptul că rețeaua aceasta nu ar putea fi folosită în
niciun caz în procesul real cu succes.
5.8 Propagarea inversă Levenberg-Marquardt (trainlm)
Algoritmul Levenberg-Marquandt, care a fost creat în același timp, independent atât
de Kenneth Levenberg cât și de Donald Marquandt, oferă o soluție numerică pentru problema
minimizării unei funcții neliniare. Este o metodă stabilă și converge rapid.

45
Acest algoritm reprezintă o combinație a metodei gradient (metoda celei mai abrupte
descreșteri) cu algoritmul Gauss-Newton. Din fericire, ea moștenește viteza rapidă de
convergență a algoritmului Gauss-Newton și stabilitatea metodei gradient. Este mai robustă
decât Gauss-Newton, deoarece în multe cazuri poate converge bine chiar dacă suprafața pe
care se face căutarea este una mai complexă cu minime locale.
La fel ca toate variantele cvasi-Newton, şi această variantă a fost proiectată să
aproximeze antrenarea de ordinul doi fără a fi nevoie să calculeze matricea hessiană. Atunci
când funcţia de performanţă are forma unei sume de pătrate, matricea hessiană poate fi
aproximată astfel:
(5.30)
(5.31)
Unde :
e – reprezintă vectorul erorilor
t – ținta
y – valoarea outputului rețelei
k – numărul de clase
m – numărul de exemple
(5.32)
Matricea Jacobiană (Ja) este calculată folosind o tehnică BP, care este mult mai puţin
complexă decât calculul matricei Hessiene, dar cu mici diferențe față de tehnica standard. În
primul rând, pentru fiecare model, în algoritmul BP, este nevoie de un singur proces de
propagare inversă, în timp ce în algoritmul Levenberg-Marquardt procesul propagării înapoi
trebuie repetat pentru fiecare ieșire separat pentru a obține rândurile consecutive ale matricei
Jacobiene. Și în al doilea rând, pentru antrenarea LM se folosește o funcție cost de tipul suma
erorilor la pătrat (SSE – sum squared error).
Algoritmul LM foloseşte următoarea actualizare:
(5.33)
Atunci când scalarul μ este zero, algoritmul este chiar metoda Newton cu matricea
hessiană aproximată. Cand μ este mare, aceasta devine “gradientul descendent”, cu un pas
mic. Metoda Newton este mai rapidă și mai precisă în privința minimului erorii, astfel că
ideea este de a ne deplasa către metoda lui Newton, cât mai repede posibil. Ca atare, μ este
micșorat după fiecare pas realizat cu succes (care face o reducere în funcție de performanță) și
este mărit doar când, în urma realizării pasului, crește funcția de performanță. În acest fel,
funcția de performanță va fi întotdeauna redusă la fiecare iterație a algoritmului.

46
Inconvenientul algoritmului Levenberg-Marquardt este cantitatea mare de memorie
necesară în calculul Jacobianului, astfel, în cazul reţelei neuronale implementate acest
algoritm nu poate fi aplicat.
Pentru că aceste tehnici de ordinul doi s-au dovedit prea pretențioase din punct de
vedere computațional, vom explora în continuare câteva tehnici de ordinul unu și anume
metode de gradient conjugat.
ALGORITMI CU GRADIENT-CONJUGAT
În matematică, metoda gradientului conjugat este un algoritm pentru rezolvarea
numerică a unor sisteme de ecuații liniare, și anume cele ale căror matrice este simetrică și
pozitiv-definită. Metoda gradientului conjugat este o metodă iterativă, astfel încât poate fi
aplicată la sisteme rare, care sunt prea mari pentru a fi manipulate prin metode directe, cum ar
fi descompunerea Cholesky. Astfel de sisteme apar de multe ori la rezolvarea numerică a
ecuațiilor cu derivate parțiale.
Metoda gradientului conjugat poate fi, de asemenea, folosit pentru a rezolva
problemele de optimizare fără restricții, cum ar fi minimizarea energiei. Acesta a fost introdus
prima dată de către Magnus Hestenes și Eduard Stiefel.
Figura 5.14 O comparație între viteza de convergența a metodei gradient (verde) și
metoda gradienților conjugați (roșu)
Pentru o problemă generală neconstrânsă ∈ , putem aplica metoda
gradienților conjugați folosind aproximări adecvate. Voi prezenta în cele ce urmează câteva
abordări în această direcție. Voi face următoarele notații: .
Aceste asocieri sunt reevaluate la fiecare pas al metodei. Când aplicăm această metodă la
probleme nepătratice (cum este aceasta), ea nu va produce o soluție în n pași ( ∈ . În
acest caz se continuă procedura, găsind noi direcții și terminând atunci când un anumit criteriu
este satisfăcut ( . Este de asemenea posibil ca după n sau n+1 pași, să reinițializăm
algoritmul cu și să începem metoda gradienților conjugați cu un pas de gradient.
Pentru astfel de probleme fără constrângeri, algoritmul gradienților conjugați ar fi
următorul:
1.
2.
3.
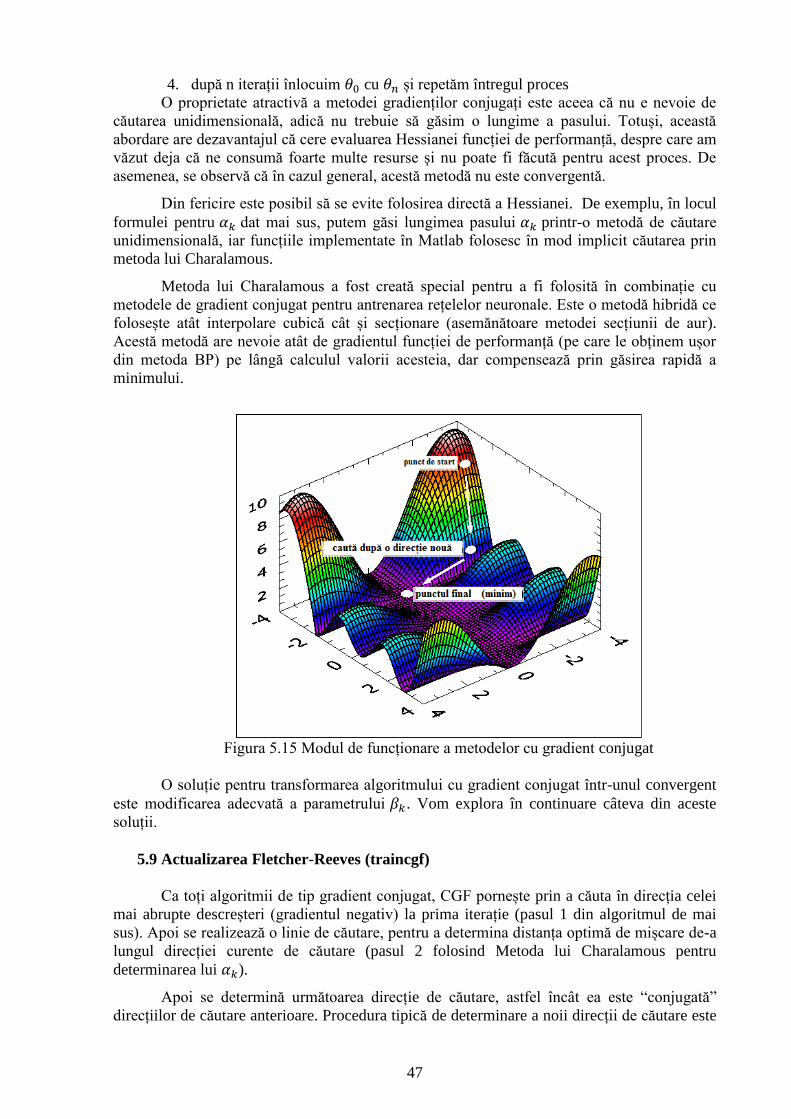
47
4. după n iterații înlocuim cu și repetăm întregul proces
O proprietate atractivă a metodei gradienților conjugați este aceea că nu e nevoie de
căutarea unidimensională, adică nu trebuie să găsim o lungime a pasului. Totuși, această
abordare are dezavantajul că cere evaluarea Hessianei funcției de performanță, despre care am
văzut deja că ne consumă foarte multe resurse și nu poate fi făcută pentru acest proces. De
asemenea, se observă că în cazul general, acestă metodă nu este convergentă.
Din fericire este posibil să se evite folosirea directă a Hessianei. De exemplu, în locul
formulei pentru dat mai sus, putem găsi lungimea pasului printr-o metodă de căutare
unidimensională, iar funcțiile implementate în Matlab folosesc în mod implicit căutarea prin
metoda lui Charalamous.
Metoda lui Charalamous a fost creată special pentru a fi folosită în combinație cu
metodele de gradient conjugat pentru antrenarea rețelelor neuronale. Este o metodă hibridă ce
folosește atât interpolare cubică cât și secționare (asemănătoare metodei secțiunii de aur).
Acestă metodă are nevoie atât de gradientul funcției de performanță (pe care le obținem ușor
din metoda BP) pe lângă calculul valorii acesteia, dar compensează prin găsirea rapidă a
minimului.
Figura 5.15 Modul de funcționare a metodelor cu gradient conjugat
O soluție pentru transformarea algoritmului cu gradient conjugat într-unul convergent
este modificarea adecvată a parametrului . Vom explora în continuare câteva din aceste
soluții.
5.9 Actualizarea Fletcher-Reeves (traincgf)
Ca toți algoritmii de tip gradient conjugat, CGF pornește prin a căuta în direcția celei
mai abrupte descreșteri (gradientul negativ) la prima iterație (pasul 1 din algoritmul de mai
sus). Apoi se realizează o linie de căutare, pentru a determina distanța optimă de mișcare de-a
lungul direcției curente de căutare (pasul 2 folosind Metoda lui Charalamous pentru
determinarea lui ).
Apoi se determină următoarea direcție de căutare, astfel încât ea este “conjugată”
direcțiilor de căutare anterioare. Procedura tipică de determinare a noii direcții de căutare este
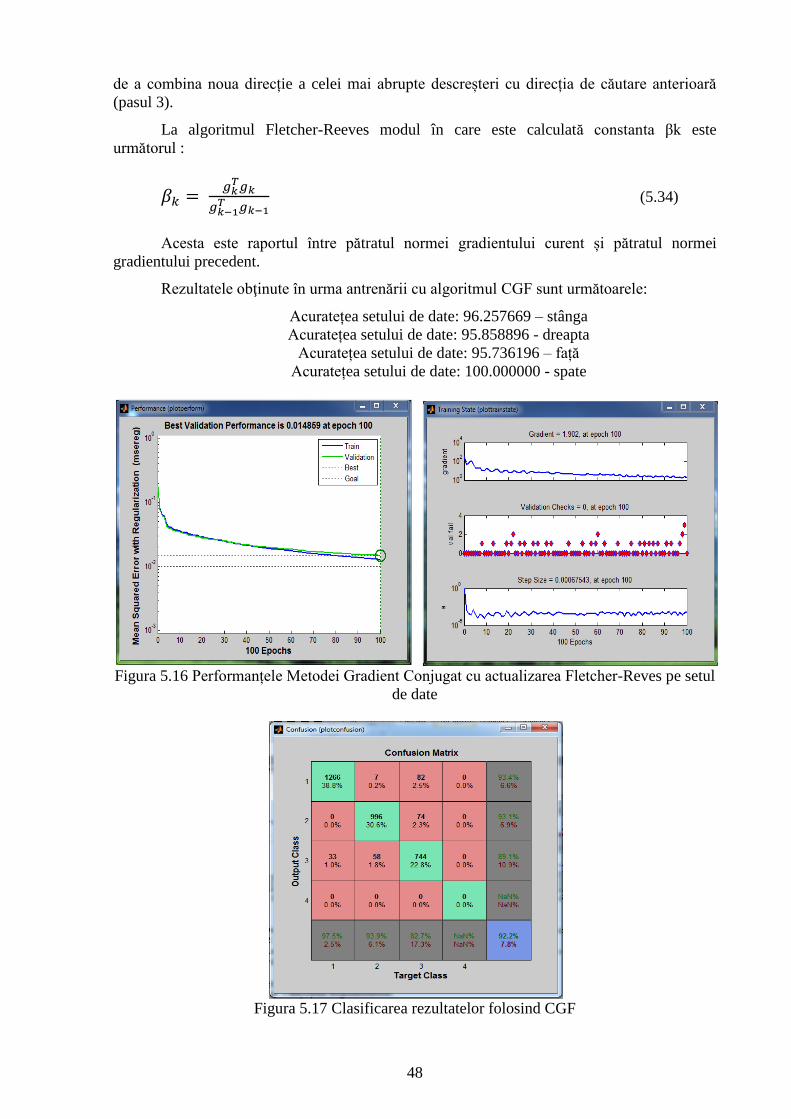
48
de a combina noua direcție a celei mai abrupte descreșteri cu direcția de căutare anterioară
(pasul 3).
La algoritmul Fletcher-Reeves modul în care este calculată constanta βk este
următorul :
(5.34)
Acesta este raportul între pătratul normei gradientului curent și pătratul normei
gradientului precedent.
Rezultatele obţinute în urma antrenării cu algoritmul CGF sunt următoarele:
Acuratețea setului de date: 96.257669 – stânga
Acuratețea setului de date: 95.858896 - dreapta
Acuratețea setului de date: 95.736196 – față
Acuratețea setului de date: 100.000000 - spate
Figura 5.16 Performanțele Metodei Gradient Conjugat cu actualizarea Fletcher-Reves pe setul
de date
Figura 5.17 Clasificarea rezultatelor folosind CGF

49
Se poate observa că aceste rezultate sunt foarte bune, cu o medie de peste 95% din
comenzi identificate corect. Minimizarea a fost oprită deoarece a ajuns la numărul maxim de
iterații permise și anume 100, dar se poate observa din graficul din partea stângă că atât
valorile funcției cost pe setul de date pe care se face antrenarea, cât și pe setul de validare au
fost în continuă descreștere pe tot parcursul antrenării. Același lucru se poate spune și despre
valoarea gradientului dacă ne uităm în graficul din dreapta sus, totuși putem constata că
valorile pentru αk au fost aproape constante și foarte mici în intervalul , ceea ce
înseamnă că convergența este una destul de lentă. Ca timp de antrenare, acest algoritm a avut
o medie de 15 secunde pe iterație, una de 3 ori mai mare față de Rprop.
5.10 Actualizarea Polak-Ribiere (traincgp)
Polak si Ribiere au propus o altă variantă a algoritmului cu gradient conjugat. Ca și în
cazul Fletcher-Reeves, direcția de căutare la fiecare iterație se determină cu:
Pentru actualizarea Polak-Ribiere, constanta βk
se calculează cu:
,
(5.35)
Acesta este produsul scalar al variațiilor anterioare în gradient cu gradientul curent,
divizat cu pătratul normei gradientului precedent. În esență, algoritmul este asemănător cu cel
din capitolul 5.8 și ne așteptăm la performanțe similare.
Acuratețea setului de date: 96.196319 - stânga
Acuratețea setului de date: 95.981595 - dreapta
Acuratețea setului de date: 95.920245 – față
Acuratețea setului de date: 99.877301 – spate
Așa cum am menționat, performanțele sunt asemănătoare și destul de ridicate. Acest
lucru se poate observa și mai bine comparând datele din Figura 5.17 cu cele din figura 5.18.
Figura 5.18 Clasificarea rezultatelor folosind CGP
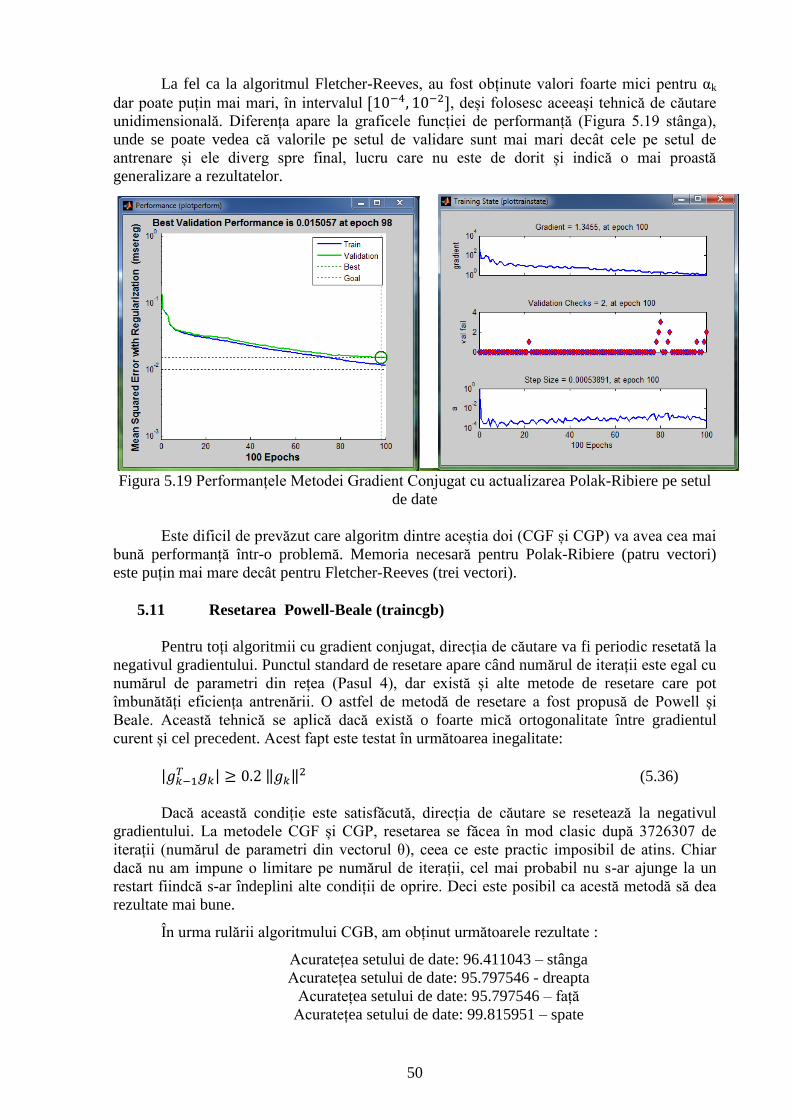
50
La fel ca la algoritmul Fletcher-Reeves, au fost obținute valori foarte mici pentru αk
dar poate puțin mai mari, în intervalul , deși folosesc aceeași tehnică de căutare
unidimensională. Diferența apare la graficele funcției de performanță (Figura 5.19 stânga),
unde se poate vedea că valorile pe setul de validare sunt mai mari decât cele pe setul de
antrenare și ele diverg spre final, lucru care nu este de dorit și indică o mai proastă
generalizare a rezultatelor.
Figura 5.19 Performanțele Metodei Gradient Conjugat cu actualizarea Polak-Ribiere pe setul
de date
Este dificil de prevăzut care algoritm dintre aceștia doi (CGF și CGP) va avea cea mai
bună performanță într-o problemă. Memoria necesară pentru Polak-Ribiere (patru vectori)
este puțin mai mare decât pentru Fletcher-Reeves (trei vectori).
5.11 Resetarea Powell-Beale (traincgb)
Pentru toți algoritmii cu gradient conjugat, direcția de căutare va fi periodic resetată la
negativul gradientului. Punctul standard de resetare apare când numărul de iterații este egal cu
numărul de parametri din rețea (Pasul 4), dar există și alte metode de resetare care pot
îmbunătăți eficiența antrenării. O astfel de metodă de resetare a fost propusă de Powell și
Beale. Această tehnică se aplică dacă există o foarte mică ortogonalitate între gradientul
curent și cel precedent. Acest fapt este testat în următoarea inegalitate:
(5.36)
Dacă această condiție este satisfăcută, direcția de căutare se resetează la negativul
gradientului. La metodele CGF și CGP, resetarea se făcea în mod clasic după 3726307 de
iterații (numărul de parametri din vectorul θ), ceea ce este practic imposibil de atins. Chiar
dacă nu am impune o limitare pe numărul de iterații, cel mai probabil nu s-ar ajunge la un
restart fiindcă s-ar îndeplini alte condiții de oprire. Deci este posibil ca acestă metodă să dea
rezultate mai bune.
În urma rulării algoritmului CGB, am obținut următoarele rezultate :
Acuratețea setului de date: 96.411043 – stânga
Acuratețea setului de date: 95.797546 - dreapta
Acuratețea setului de date: 95.797546 – față
Acuratețea setului de date: 99.815951 – spate
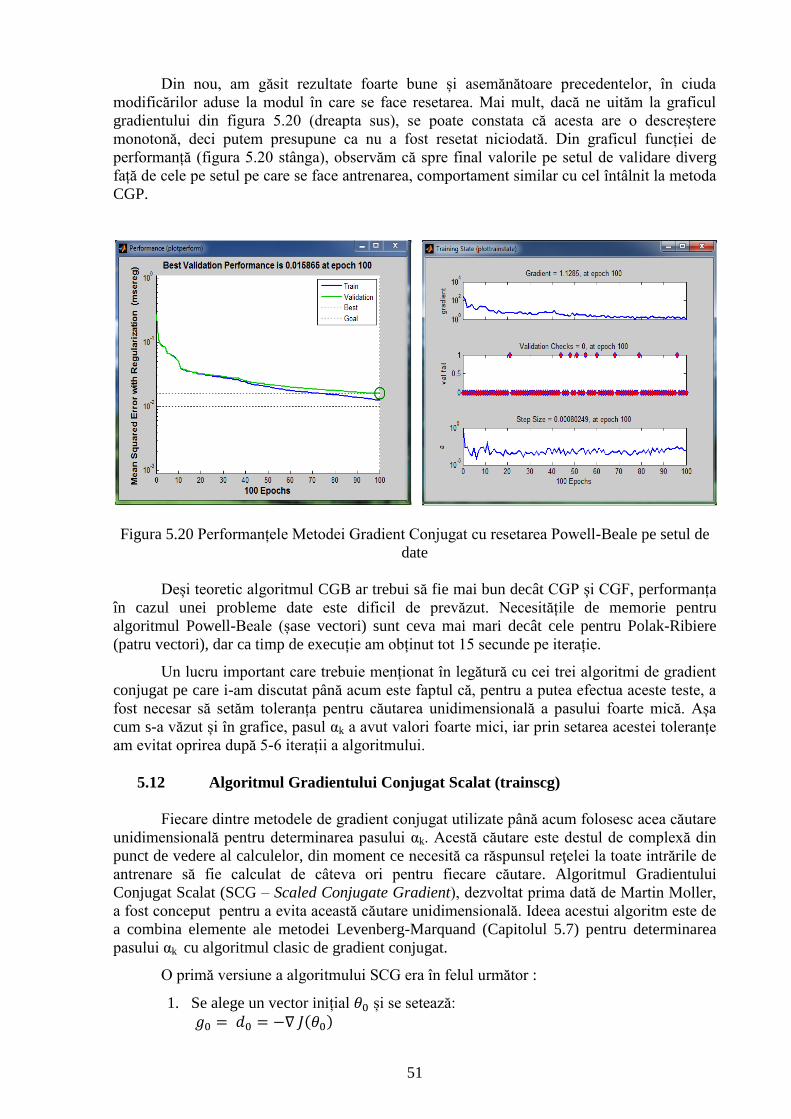
51
Din nou, am găsit rezultate foarte bune și asemănătoare precedentelor, în ciuda
modificărilor aduse la modul în care se face resetarea. Mai mult, dacă ne uităm la graficul
gradientului din figura 5.20 (dreapta sus), se poate constata că acesta are o descreștere
monotonă, deci putem presupune ca nu a fost resetat niciodată. Din graficul funcției de
performanță (figura 5.20 stânga), observăm că spre final valorile pe setul de validare diverg
față de cele pe setul pe care se face antrenarea, comportament similar cu cel întâlnit la metoda
CGP.
Figura 5.20 Performanțele Metodei Gradient Conjugat cu resetarea Powell-Beale pe setul de
date
Deși teoretic algoritmul CGB ar trebui să fie mai bun decât CGP și CGF, performanța
în cazul unei probleme date este dificil de prevăzut. Necesitățile de memorie pentru
algoritmul Powell-Beale (șase vectori) sunt ceva mai mari decât cele pentru Polak-Ribiere
(patru vectori), dar ca timp de execuție am obținut tot 15 secunde pe iterație.
Un lucru important care trebuie menționat în legătură cu cei trei algoritmi de gradient
conjugat pe care i-am discutat până acum este faptul că, pentru a putea efectua aceste teste, a
fost necesar să setăm toleranța pentru căutarea unidimensională a pasului foarte mică. Așa
cum s-a văzut și în grafice, pasul αk a avut valori foarte mici, iar prin setarea acestei toleranțe
am evitat oprirea după 5-6 iterații a algoritmului.
5.12 Algoritmul Gradientului Conjugat Scalat (trainscg)
Fiecare dintre metodele de gradient conjugat utilizate până acum folosesc acea căutare
unidimensională pentru determinarea pasului αk. Acestă căutare este destul de complexă din
punct de vedere al calculelor, din moment ce necesită ca răspunsul reţelei la toate intrările de
antrenare să fie calculat de câteva ori pentru fiecare căutare. Algoritmul Gradientului
Conjugat Scalat (SCG – Scaled Conjugate Gradient), dezvoltat prima dată de Martin Moller,
a fost conceput pentru a evita această căutare unidimensională. Ideea acestui algoritm este de
a combina elemente ale metodei Levenberg-Marquand (Capitolul 5.7) pentru determinarea
pasului αk cu algoritmul clasic de gradient conjugat.
O primă versiune a algoritmului SCG era în felul următor :
1. Se alege un vector inițial și se setează:

52
2. Se calculează informația de ordinul doi:
(5.37)
(5.38)
3. Se calculează mărimea pasului:
(5.39)
(5.40)
4. Se actualizează vectorul ponderilor:
(5.41)
(5.42)
5. Dacă k mod N este 0 atunci se resetează algoritmul:
Altfel se creează o nouă direcție conjugată:
(5.43)
(5.44)
Acesta este oarecum algoritmul clasic de gradient conjugat adaptat pentru calcularea
direcției prin evitarea folosirii hessianei. Dar tot avem nevoie de hessiană în calcularea lui
cel pe care vrem să îl eliminăm. Pentru a face acest lucru, utilizăm definiția derivatei :
(5.45)
Dar nici această aproximare nu este eficientă deoarece ea funcționează (adică
algoritmul converge) doar în cazurile în care hessiana este pozitiv definită. S-a demonstrat că
hessiana funcției de performanță poate ajunge la valori infinite-nedefinite (NaN – not a
number) în diferite zone din spațiul ponderilor, ceea ce explică de ce alogritmul eșuează în
încercarea de a minimiza J. De aceea,încercăm o abordare din metoda LM pentru a modifica
algoritmul. Ideea este să introducem un scalar (multiplicator Lagrange), al cărui rol este de
a regula valorile lui .
(5.46)
Iar la fiecare iterație, este ajustat în funcție de semnul lui (5.38), care ne indică dacă
este pozitiv definită sau nu. Dacă atunci este mărit și este reestimat. Fie
noul notat cu și noul notat cu atunci :
(5.47)
Pentru a determina cu cât trebuie mărit , pornim de la condiția :
(5.48)
Ceea ce înseamnă că dacă vrem ca hessiana să fie pozitiv definită, trebuie să mărim cu
. Nu se cunoaște exact cu cât ar fi optimal să creștem pe , dar o alegere rezonabilă
ar fi :
) (5.49)

53
Aceasta duce la :
(5.50)
Și atunci putem calcula mărimea pasului :
(5.51)
Se poate observa din ecuația (5.51) dependența dintre și și anume faptul că,
dacă crește, scade ceea ce era de așteptat. Totuși, pentru a găsi o bună aproximare a
hessianei, ar trebui găsit un mecanism pentru modificarea lui chiar și când hessiana este
pozitiv definită.
Fie :
(5.52)
Unde
reprezintă o aproximare
Taylor a unui punct din vecinătatea lui . Deci reprezintă un factor ce măsoară cât de
bine aproximează pe , adică cu cât e mai apropiat de 1, cu atât e
mai bună aproximarea. Astfel putem mări și micșora pe după următoarea regulă:
Varianta finală a algoritmului SCG este următoarea :
1. Se alege un vector inițial și scalarii , se setează:
și Test = Adevărat
2. Dacă Test este Adevărat atunci:
3. Se scalează :
4. Dacă , atunci facem hessiana pozitiv definită :
5. Se calcuează pasul:

54
6. Se calculează factorul
7. Dacă atunci:
a. Dacă k mod N este 0 atunci se restează algoritmul :
Altfel se creează o nouă direcție conjugată:
b. Dacă atunci:
8. Dacă atunci:
9. Dacă mergi la pasul 2
Altfel returnează ca fiind minimul căutat.
Pentru fiecare iterație este necesar un calcul pentru și două pentru , ceea
ce înseamnă că algoritmul se poate implementa cu o complexitate de O(2N2) , unde N este
numărul de parametri din Theta. Acesta este mult redus față de algoritmii CGF, CGP, CGB
sau BFGS, care au o complexitate O(2-15 N2) pe iterație din cauza căutarii unidimensionale.
Deși este posibil ca algoritmul SCG să aibă nevoie de mai multe iterații pentru a converge,
numărul de calcule este mai mic și deci compensează. Ca cerințe de memorie SCG nu este
foarte pretențios având aproximativ aceleași cerințe ca CGF.
Rezultatele obținute cu acest algoritm sunt următoarele:
Acuratețea setului de date: 97.975460 – stânga
Acuratețea setului de date: 97.453988 - dreapta
Acuratețea setului de date: 95.797546 – față
Acuratețea setului de date: 100.000000 - spate
Acestea sunt cele mai bune performanțe de până acum, oprirea fiind făcută atât
datorită condiției ca valoarea funcției de performanță să fie mai mică decât 0.01, cât și datorită
fenomenului de oprire rapidă (Figura5.21).
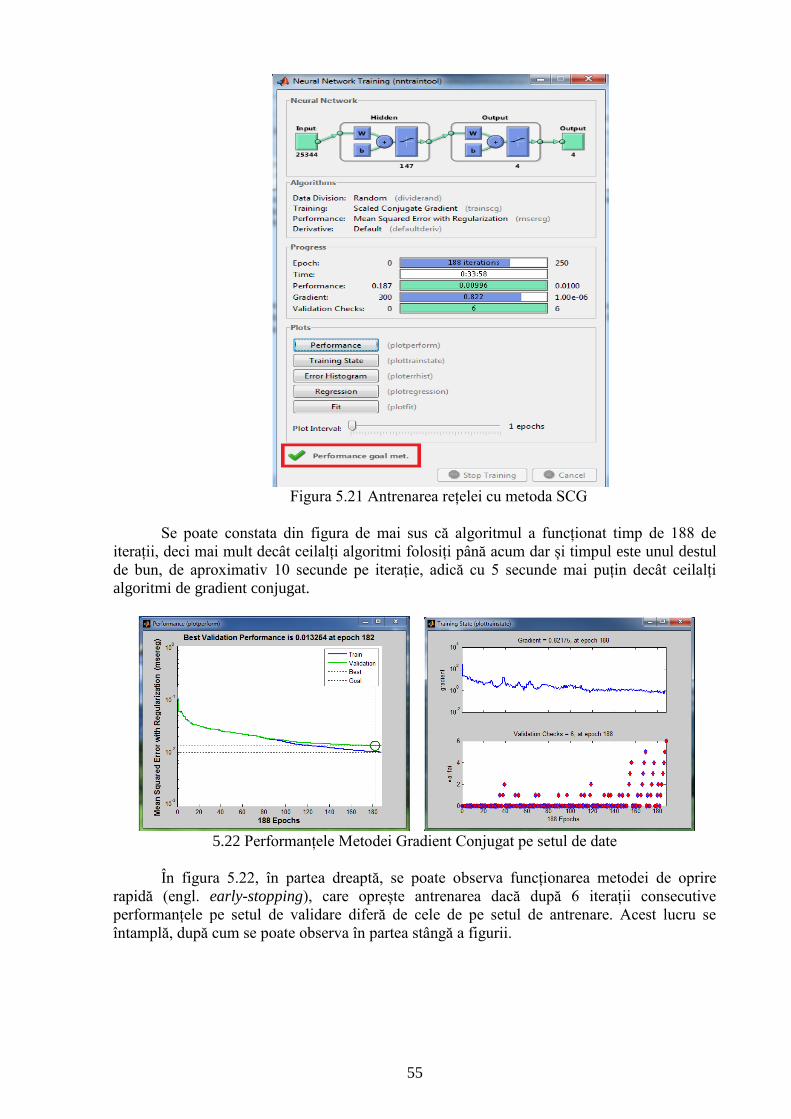
55
Figura 5.21 Antrenarea rețelei cu metoda SCG
Se poate constata din figura de mai sus că algoritmul a funcționat timp de 188 de
iterații, deci mai mult decât ceilalți algoritmi folosiți până acum dar și timpul este unul destul
de bun, de aproximativ 10 secunde pe iterație, adică cu 5 secunde mai puțin decât ceilalți
algoritmi de gradient conjugat.
5.22 Performanțele Metodei Gradient Conjugat pe setul de date
În figura 5.22, în partea dreaptă, se poate observa funcționarea metodei de oprire
rapidă (engl. early-stopping), care oprește antrenarea dacă după 6 iterații consecutive
performanțele pe setul de validare diferă de cele de pe setul de antrenare. Acest lucru se
întamplă, după cum se poate observa în partea stângă a figurii.
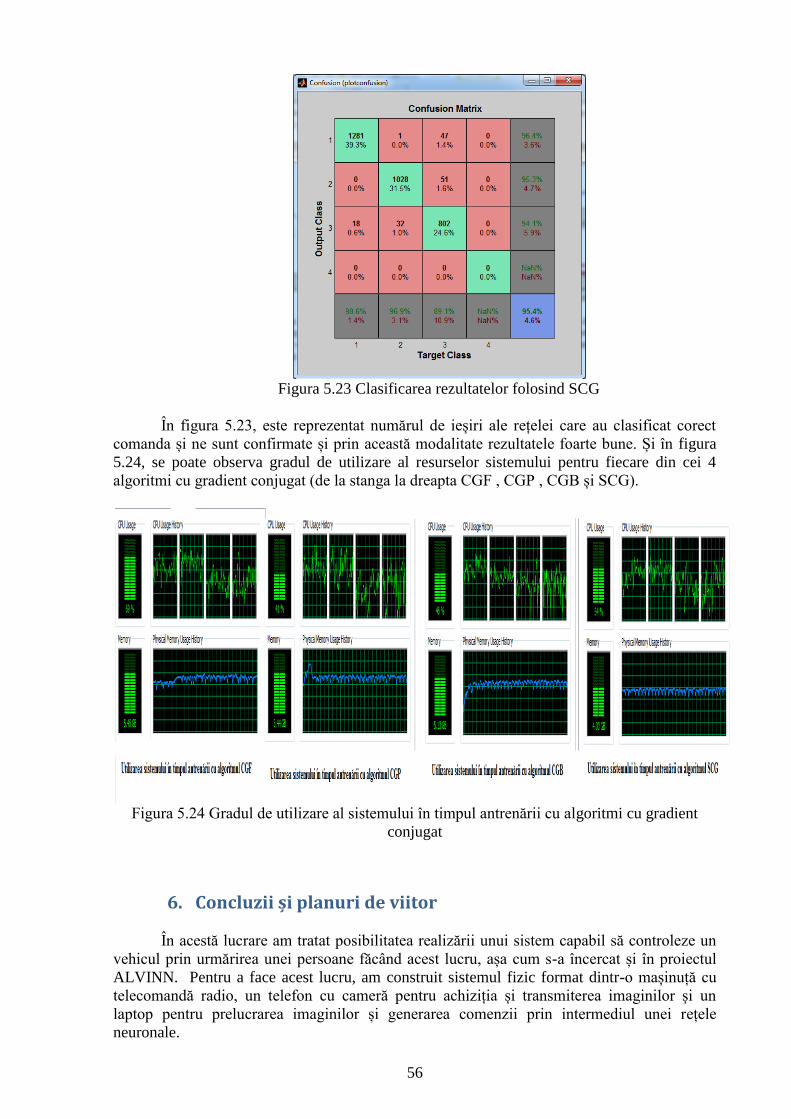
56
Figura 5.23 Clasificarea rezultatelor folosind SCG
În figura 5.23, este reprezentat numărul de ieșiri ale rețelei care au clasificat corect
comanda și ne sunt confirmate și prin această modalitate rezultatele foarte bune. Și în figura
5.24, se poate observa gradul de utilizare al resurselor sistemului pentru fiecare din cei 4
algoritmi cu gradient conjugat (de la stanga la dreapta CGF , CGP , CGB și SCG).
Figura 5.24 Gradul de utilizare al sistemului în timpul antrenării cu algoritmi cu gradient
conjugat
6. Concluzii și planuri de viitor
În acestă lucrare am tratat posibilitatea realizării unui sistem capabil să controleze un
vehicul prin urmărirea unei persoane făcând acest lucru, așa cum s-a încercat și în proiectul
ALVINN. Pentru a face acest lucru, am construit sistemul fizic format dintr-o mașinuță cu
telecomandă radio, un telefon cu cameră pentru achiziția și transmiterea imaginilor și un
laptop pentru prelucrarea imaginilor și generarea comenzii prin intermediul unei rețele
neuronale.

57
Rețelele neuronale sunt capabile de a realiza corect orice calcul liniar sau neliniar și pot
face clasificări pentru aproape orice set de date. Totuși, deși o rețea antrenată este, teoretic,
capabilă de realizări corecte, este posibil ca propagarea înapoi și variațiile ei să nu găsească
întotdeauna soluția. O rată de instruire prea mare duce la o instruire instabilă. Reciproc, o rată
de instruire prea mică, duce la un timp de antrenare foarte lung. Alegerea unei bune rate de
instruire pentru o rețea multistrat neliniară nu este deloc ușoară. În cazul algoritmilor de
antrenare rapidă, este indicat să se aleagă valorile implicite ale parametrilor.
Suprafața de eroare a unei rețele neliniare este complexă. Problema este că funcțiile de
transfer nenliniare ale rețelelor neuronale introduc multe minime locale în suprafața de eroare.
Cum gradientul coborâtor se realizează pe suprafața de eroare, este posibil ca soluția să cadă
într-unul din aceste minime locale. Aceasta se poate întâmpla în funcție de condițiile inițiale
de plecare. Căderea într-un minim local poate fi bună sau rea, depinzând de cât de aproape
este minimul local de cel global si cât de mică eroare se cere. În orice caz, trebuie reținut că
deși o rețea multistrat cu propagare inversă și cu suficienți neuroni poate implementa aproape
orice funcție, propagarea inversă nu va gasi întotdeauna ponderile corecte pentru soluția
optimă. Rețeaua va trebui reinițializată și reantrenata de câteva ori pentru a avea garanția
obținerii celei mai bune soluții. Efectuarea mai multor antrenări pe seturi mari de date poate
dura destul de mult, de aceea este importantă găsirea unui algoritm rapid și eficient. În urma
experimerimentării cu diferite tehnici de optimizare, am constatat următoarele lucruri:
- algoritmul cu gradient coborâtor este în general foarte lent, întrucât pentru o instruire
stabilă cere rate de instruire mici
- metoda Rprop este cel mai rapid algoritm în problemele de recunoaștere a formelor, în
acest caz a imaginilor, performanța ei scade pe măsura ce se reduce eroarea impusă.
Cererile de memorie pentru acest algoritm sunt relativ mici în comparatie cu ceilalți
algoritmi.
- algoritmii cu gradient conjugat, în particular SCG, funcționează bine într-o varietate
largă de probleme, în special pentru rețelele cu un număr mare de ponderi, cum este și
acesta. Algoritmul SCG este aproape la fel de rapid ca Rprop în problemele de
recunoaștere a formelor. Performanța lui nu scade la fel de repede ca la Rprop când se
reduce eroarea.
- Algoritmii cu gradient conjugat au cereri relativ mici de memorie și au demonstrat
rezultate foarte bune numerice, cu toate acestea în practică ponderile antrenate cu
metoda SCG s-au dovedit cele mai eficiente
- Algoritmii BFGS și LM sunt teoretic foarte rapizi, dar sunt aproape imposibil de
implementat pe o rețea cu un număr mare de ponderi cum este și cazul acesta, nici
dacă se aplică o tehnică de reducere a memoriei (prin care se reduce de fapt
dimensiunea Jacobianului, prin împărțirea acestuia în două submatrici egale, la
algoritmul LM) nu s-a putut realiza antrenarea
Într-un final, am ales ca algoritm de bază pentru antrenare metoda SCG. În cazul în care
acesta nu dovedește rezultate foarte bune pentru un set de date, se poate oricând încerca o altă
metodă de gradient conjugat sau chiar metoda RProp, care a demonstrate rezultate destul de
bune.

58
Figura 6.1 Exemplu de traseu pentru antrenare
În urma utilizării sistemului final pe diferite trasee ce conțin un drum cu o singură
bandă de tipul celei din Figura 6.1, am remarcat că vehiculul (mașinuța) se poate deplasa cu o
viteză destul de mare, chiar și pe drumuri mai înguste, rețeaua fiind capabilă să genereze
comenzi suficient de bune pentru a urmări traseul impus. Chiar dacă antrenarea s-a făcut pe
un anumit traseu și testarea pe altul, sistemul s-a descurcat destul de bine, singura condiție
este ca drumul și respectiv benzile care îl delimitează să fie de culori diferite și de contrast cât
mai mare. Pentru a evita ieșirea de pe traseu, s-a impus o rată de eșantionare mică astfel încât,
chiar dacă sunt generate eronat unele comenzi, vehiculul să fie redresat în timp util. Un mare
avantaj al acestei metode de generare al comenzilor cu rețea neuronală este faptul că acest
lucru se face foarte rapid (sunt necesare 3726307 de înmulțiri și aplicarea funcției sigmoid pe
151 de numere pe un procesor de 2.53 Ghz deci ~ 20 ms , dar la care se adună timpul în care
se face achiziția și transmisia), permițând impunerea unei rate de eșantionare mică.
După numai 2-3 minute de “condus” și înregistrat exemple, se pot găsi ponderi pentru
o rețea destul de eficientă. O problemă care apare este faptul că în general “șoferul” nu va
părăsi traseul, iar în cazul în care acest lucru se va întâmpla (când sistemul funcționează
automat), rețeaua nu va ști cum să revină pe traseu din moment ce nu a mai întâlnit acest caz
înainte. Acest lucru poate fi rezolvat prin crearea de exemple sintetice prin rotirea imaginilor
pentru a simula cum ar arăta drumul către stânga sau către dreapta. O altă problemă pe care
am întâlnit-o, este faptul că întreg procesul depinde și de luminozitate și pentru aceasta există
două posibile rezolvări. Una prin creerea unor imagini sintetice cu valori ale pixelilor mai
mici (adică mai apropiate de negru, mai întunecate) și antrenarea rețelei și pe aceste exemple.
Cea de-a doua soluție este instalarea unei surse de lumină lângă cameră, astfel încât
luminozitatea să fie constantă.

59
Figura 6.2 Interfața sistemului
În figura 6.2, apare interfața cu care interacționează utilizatorul. În partea stângă sunt
afișate mesaje de control pentru diagnosticarea sistemului, iar în partea dreaptă sunt afișate
imaginile pe care le primește rețeaua. Se poate observa în colțul din stânga sus, cu roșu, că
sistemul este în modul automat (A) și comanda la momentul respectiv este înainte și dreapta
(săgețile), cum ne și asteptam, având în vedere imaginea. În partea de jos numerele afișate
sunt chiar ieșirile rețelei, evident cele mai mari reprezintă și comenzile. În dreapta jos este
afișat cuvântul “NORMAL” care semnifică modul de viteză (NORMAL / RAPID) despre
care am menționat și în capitolul 4.3.
În timpul execuției aplicației, a fost utilizat sub 40% din capacitatea procesorului și
sub 3 Gb de memorie RAM, ceea ce înseamnă că în paralel se pot executa și alte sarcini pe
aceeași unitate de procesare.
Consider că acest experiment a fost unul de succes deoarece condusul unui vehicul
este un proces dintr-un domeniu plin de zgomote și incertitudini în care aproape toate
elementele din jur contribuie cu informație iar rețelele neuronale au acestă capacitate de a
absorbi un volum mare de informații și a păstra doar elementele utile. Un alt argument este
faptul că nu există nicio teorie care să ne spună exact cum să conducem, dar este ușor de
învățat din exemple lucru care ne duce cu gândul la o metodă care poate învăța din exemple,
iar RNA sunt printre candidații principali.
Ca în orice proiect există încă lucruri de îmbunătățit, unul dintre ele ar fi antrenarea
rețelei on-line, lucru care ar duce la rezultate mai bune datorită numărului mare de exemple,
dar ar putea creea și unele inconveninte prin prisma resurselor (computaționale) necesare. O
altă temă de cerecetare pentru viitor este încercarea reducerii dimensiunii imaginilor prin
utilizarea algoritmilor de compresie de date și verificarea dacă vehiculul va păstra aceleași
rezultate bune sau va eșua în urmărirea traseului. Altă idee, poate puțin mai ușor de
implementat, este folosirea tuturor senzorilor, cum ar fi cel de accelerometru (pe care îl avem
achiziționat deja) pentru reglarea vitezei dar și a GPS-ului pentru crearea unor hărți.
La o scară mai mare, adică pe mașini reale, cred că această soluție ar putea fi
implementată cu succes, pentru transportul substanțelor toxice în fabrici pe un traseu
predefinit, transportul minereurilor în mine sau chiar a oamenilor via tren, toate cu
supraveghere umană de la distanță bineînțeles.

60
7. Bibliografie
Ben Krose and Patrick van der Smagt. 1996. An introduction to Neural Network.
University of Amsterdam, Amsterdam
Dumitrescu, D., Costin, H., 1996. Retele neuronale; teorie si aplicatii. Teora. Bucuresti,.
Dumitrache I. 2010. Ingineria reglarii automate. Ed. Politehnica Press, Bucuresti
Andrew Ng. 2010. Machine Learning Course. Stanford, California
Necoara Ion. 2013. Metode de optimizare numerică. Universitatea Politehnica. București
Popa V., Demeter S., Oancea R., Hangan A. 2006. Aplicatii ale reţelelor neuronale în
prelucrarea imaginilor. Bucuresti
Pomerleau, D.A. (1991) Efficient Training of Artificial Neural Networks for Autonomous
Navigation. In Neural Computation 3:1 pp. 88-97.
Reto Meier. 2008. Professional Android™ Application Development. Wiley Publishing.
Indianopolis
Stefan Tanasa, Cristian Olaru, Stefan Andrei. 2003. Java de la 0 la expert. Polirom.
Bucuresti
Bishop, C.M. 1995. Neural Networks for Pattern Recognition. Oxford University Press.
Oxford
Moller F. 1993, A Scaled Conjugate Gradient Algorithm for Fast Supervised Learning.
Neural Networks, Vol. 6, pp. 525-533
Sjöberg, J. and Ljung, L. 1992, Overtraining, Regularization, and Searching for minimum
in Neural Networks. Technical Report LiTH-ISY-I-1297. Department of Electrical
Engineering, Linkoping University. S-581 83 Linkoping. Suedia
Enăchescu, C., 1995 Learning the Neural Networks from the Approximation Theory
Perspective. Intelligent Computer Communication ICC'95 Proceedings, 184-187, Technical
University of Cluj-Napoca, Romania.
Powell, M.J.D.,1977, Restart procedures for the conjugate gradient method. Mathematical
Programming, Vol. 12, pp. 241-254
Scales, L.E., 1985. Introduction to Non-Linear Optimization, New York, Springer-Verlag
Battiti, R. 1992. First and second order methods for learning: Between steepest descent and
Newton's method. Neural Computation, Vol. 4, No. 2, pp. 141-166
Riedmiller. 1993. Proceedings of the IEEE International Conference on Neural Networks
(ICNN), San Francisco. pp. 586-591
BALAN, C. G., 2006 Metode ale Inteligentei Artificiale in Studiul Sistemelor Mecanice, E-
Book, in WEB site: www.ugal.ro – Faculties - Faculty of Mech. Eng.
Engineering Guideline EG 28. 1993. Annotated Glossary of Essential Terms for Electronic
Production SMPTE.
Open Handset Alliance (5 noiembrie 2007). Industry Leaders Announce Open Platform for
Mobile Devices. Press release
Arduino Duemilanove.2009, http://arduino.cc/en/Main/arduinoBoardDuemilanove
Top Related