
Introducere (Stoian Adriana)stst.elia.pub.ro/news/rc/teme_rc_iva_2011_12/dragan... · Web viewMai...
57
Proiect realizat de: Stoian Adriana Petrache Victor Rata Bogdan Tona Enis Zaharie Bogdan Alfred Dragan Marius Ovidiu
Transcript of Introducere (Stoian Adriana)stst.elia.pub.ro/news/rc/teme_rc_iva_2011_12/dragan... · Web viewMai...

Proiect realizat de:
Stoian Adriana
Petrache Victor
Rata Bogdan
Tona Enis
Zaharie Bogdan Alfred
Dragan Marius Ovidiu
Grupa 441A

Contents1. Introducere (Stoian Adriana)............................................................................................................................4
2. Algoritmul de evitare a congestiunii in TCP (Petrache Victor)..........................................................................5
Controlul congestiunii..........................................................................................................................................6
Lucrari avand ca tema identificarea componentei TCP de evitare a congestiunii.................................................7
Caracteristicile unei componente pentru decongestionare a TCP........................................................................8
Pasii CAAI..............................................................................................................................................................9
Concluzii despre CAAI...........................................................................................................................................9
3. Filtrarea dinamica a pachetelor UDP prin intermediul proxiului nivelui transport (Rata Bogdan).................10
Introducere.........................................................................................................................................................10
Modelul retelei...................................................................................................................................................10
Pasi de rezolvare a problemelor de legatura intre proceduri.............................................................................13
Concluzia............................................................................................................................................................15
4. Alte protocoale de transport prin Internet (Tona Enis)..................................................................................16
Datagram Congestion Control Protocol (DCCP)..................................................................................................16
Tipuri de pachete............................................................................................................................................16
Mecanisme de control al congestiei...............................................................................................................18
Reliable User Datagram Protocol.......................................................................................................................18
Formatul structurii de date.............................................................................................................................19
Descrierea caracteristicilor.............................................................................................................................20
Imbunatatiri viitoare.......................................................................................................................................20
5. Control adaptabil al ratei nivelului de transport (TARC) (Stoian Adriana)......................................................21
Modelul sistemului.............................................................................................................................................21
Rezultate............................................................................................................................................................23
Comparatie cu alte mecanisme......................................................................................................................23
Concluzii.............................................................................................................................................................23
6. Calitatea serviciilor la nivelul Transport (Dragan Marius Ovidiu)....................................................................25
Notiuni generale despre conceptul de calitate a serviciilor (QoS)......................................................................25
Mecanisme pentru controlul congestiei.............................................................................................................28
Lucrul cu cozile in Routere..................................................................................................................................29
Studiu asupra calitatii serviciilor in retelele de ultima generatie........................................................................30
Implementarea practica a QoS intr-o retea de tip WAN.....................................................................................31

Concluzii ale studiului.........................................................................................................................................35
7. Elemente de performanță (Zaharie Bogdan Alfred).......................................................................................36
Îmbunatațirea performanței nivelului de Transport utilizând un nou Protocol de Control de Acces Mediu (MAC) cu “Fast Collision Resolution” în LAN-uri Wireless..................................................................................36
Concluzie............................................................................................................................................................39
Bibliografie.............................................................................................................................................................40

1. Introducere (Stoian Adriana)
Din ce in ce mai mult suntem conectati prin intermediul retelelor. Oamenii comunica online de oriunde.
Tehnologii eficiente si sigure permit retelelor sa fie accesabile oricand si oriunde avem nevoie de ele.
Mai degraba decat dezvolarea de sisteme unice si separate de livrare pentru fiecare nou serviciu,
intrustria retelistica in ansamblul sau a dezvoltat atat mijloace de a analiza platform existent si de a o spori
treptat. Acest lucru garanteaza faptul ca comunicatiile existente sunt mentinute in timp ce sunt introduce noi
servicii, care sunt eficiente atat din punct de vedere al costului cat si al tehnologiei folosite.
Comunicarea incepe cu un mesaj, sau informative, care trebuie sa fie trimisa de la o persoana, sau
dispozitiv, la altul. Oamenii fac schimb de idei folosind multe metode diferite de comunicare. Toate aceste
metode au trei elemente in comun. Primul dintr aceste elemente este sursa mesajului, sau expeditor. Sursele de
mesaj sunt oamenii, sau dispozitivele electronice, care trebuie sa trimita un mesaj catre alte persoane sau
dispositive. Al doilea element al comunicarii este destinatia, sau receptor al mesajului. Destinatia primeste
mesajul si il interpreteaza. Un al treilea element, numit canal, consta in mediul care asigura calea prin care
mesajul poate ajunge de la sursa la destinatie.
Toate mijloacele de comunicare, fie fata in fata sau printr-o retea, sunt guvernate de reguli prestabilite
numite protocoale. Aceste protocoale sunt specific caracteristicilor conversatiei. Comunicarea de success intre
gazde intr-o retea necesita interactiunea dintre mai multe protocoale diferite. Un grup de protocoale
interdependente care sunt necesare pentru a indeplini o functie de comunicare se numeste o suita de
protocoale. Aceste protocale sunt puse in aplicare in software si hardware si sunt incarcate pe fiecare gazda si
dispozitiv de retea.

2. Algoritmul de evitare a congestiunii in TCP (Petrache Victor)
Internetul a evoluat recent de la controlul omogen al congestie la controlul heterogen al congestie. In urma cu cativa ani traficul pe internet era controlat prin algoritmul traditional AIMD (Additive-Increase-Multiplicative-Decrease1 2), pe cand in acest moment, internetul este controlat prin mai multi algoritmi TCP ( algoritm TCP = componenta de evitare a congestiunii a TCP) precum AIMD,BIC,CUBIC3 si CTCP4. Sunt putine lucrari avand ca tema studiul performantei si stabilitatii interentului cu control al congestiunii heterogen. Un motiv fundamental este lipsa informatiilor de implementare a diferitilor algoritmi TCP.
Pentru indentificarea algoritmului TCP utilizat de un server se propune utilizarea CAAI (Congestion Avoidance Algorithm Identification). CAAI poate indentifica toti algoritmii default ai TCP (AIMD, BIC,CUBIC si CTCP) si marea majoritate a algoritmilor non-default TCP ai diferitelor familii de sisteme de operare.
Utilizand CAAI pe primele 5000 cele mai populare servere web s-a observat ca: 16.85% - 25.58% din servere inca utilizeaza algoritmul AIMD. 44.51% folosesc BIC sau CUBIC si 10.27-19% utilizeaza CTCP. Pe langa aceste s-a observat, pentru prima oara ca unele servere folosesc algoritmi pentru congestiune ce nu sunt implementari default. Unele servere folosesc algoritmi TCP necunoscuti care nu se gasesc in familiile principale de sisteme de operare, pe cand alte servere utilizeaza alogritmi ce pornesc anormal de incet.
Conform acestui studiu rezulta ca majoritatea fluxurilor TCP nu mai sunt controlate de AIMD acesta fiind un semn clar ca controlul congestiunii in internet deja a trecut de la omogen la heterogen.
Algoritmii TCP disponibili in familiile principale de sisteme de operare
Sistem de operare Algoritm TCPFamilia Windows MD, si CTCP Familia Linux AIMD, BIC , CUBIC , HSTCP ,
HTCP , HYBLA , ILLINOIS ,LP , STCP , VEGAS , VENO ,WESTWOOD+ , si YEAH
Acest recensamant de algoritmi de decongestionare TCP poate da raspunsul la 2 intrebari fundamentale:
1. Sunt majoritatea fluxurilor TCP controlate in continuare de AIMD?
1 V. Jacobson, “Congestion avoidance and control,” in Proceedings ofACM SIGCOMM, Stanford, CA, August 1988.2 D. Chiu and R. Jain, “Analysis of the increase/decrease algorithmsfor congestion avoidance in computer networks,” Journal of ComputerNetworks and ISDN, vol. 17, no. 1, pp. 1–14, June 1989.3 I. Rhee and L. Xu, “CUBIC: A new TCP-friendly high-speed TCPvariant,” in Proceedings of PFLDNet, France, February 2005.4 K. Tan, J. Song, Q. Zhang, and M. Sridharan, “A compound TCPapproach for high-speed and long distance networks,” in Proceedingsof IEEE INFOCOM, Barcelona, Spain, April 2006.

Aceasta este o intrebare importanta deoarece algoritmilor recent propusi pentru controlul congestiunii (CUBIC, CTCP, DCCP, SCTP) au fost proiectati pentru a da rezultate mai bune decat AIMD dar sa fie de asemenea "prietenosi" cu traficul AIMD cu care concureaza, termen definit in general ca TCP friendliness. Daca majoritatea fluxurilor TCP nu mai sunt controlate de AIMD, este necesara o reevaluare nu numai a performantelor dar si a telurilor de proiectare a acestor algoritmi de control al congestiunii.
2. Care este procentajul a nodurilor din interenet care utilizeaza un algoritm specific TCP.
Acest aspect este important nu numai pentru proiectarea unui noi algoritm de control al congestiunii si a evaluarii algoritmilor deja existenti dar si pentru proiectarea si dimensionarea altor componente ale internetului (proiectarea de mecanisme de Active Queue Management - este o tehnica care consta in droparea sau marcare-ECN a pachetelor inainte ca coada unui router sa fie plina5).
Algoritmul CAAI este propus pentru a identifica in mod activ algoritmul TCP al unui web server. Motivul nesitatii acestei recunoasteri fiind acela ca traficul web reprezinta o parte importanta din traficul total pe internet.
Recensamantul realizat cu ajutorul CAAI a aratat ca o parte importanta din majoritatea fluxurilor TCP nu sunt mai sunt controlate de AIMD, asadar este necesara o reconsiderare a telului de proiectare a compatibilitatii TCP (TCP-friendliness) a unui nou algoritm de control al congestiunii bazata pe majoritatea algoritmilor TCP aflati in utilizare. De asemenea, este un semn ca controlul congestiunii in internet nu mai este omogen (realizat de un singur algoritm de control) ci a devenit eterogen, asadar este necesara o reevaluare a performantei si stabilitatii a internetului bazata pe distributia diferitilor algoritmi TCP).
Controlul congestiunii67
Protocoalele de retea care folosesc retransmisiuni agresive pentru a compensa pierderea de pachete tinnd sa tina reteaua intr-o stare de congestie chiar si dupa ce incarcarea initiala a fost redusa la un nivel care in mod normal nu ar fi indus congestia. Asadar, reltele care folosesc aceste protocoale pot avea doua stari stabile sub aceeasi incarcare. Starea stabila cu throughput mic este numita colaps congestiv.
Retelele moderne utilizeaza controlul congestiunii si evitarea congestiunilor la nivelul retelei pentru a incerca evitarea starii de colaps congestiv. Aceste metode includ: backoff exponential in protocoale precum 802.11's CSMA/CD si in protocolul Ethernet original, reducerea dimensiunii ferestrei in TCP, si asezarea corecta in coada (fair queuing) in sisteme precum routerele. Alta metoda pentru evitarea efectelor negative a congestiunii retelei este implementarea schemelor de prioritati pentru ca unele pachete sa fie transmise cu prioritate mai mare decat altele. Scheme de prioritati nu rezolva problema congestiunii reltelei de unele singure dar ajuta la ameliorarea efecetelor congestiunii pentru anumite servicii.
Controlul congestiunii in TCP consta in cateva componente importante precum :
5 http://en.wikipedia.org/wiki/Active_Queue_Management6 http://en.wikipedia.org/wiki/TCP_congestion_avoidance_algorithm7 http://en.wikipedia.org/wiki/Network_congestion_avoidance

marimea initiala a ferestrei start lent (slow start) evitarea congestiunii recuperarea loss-ului
Marimea initiala a ferestrei poate fi 1,2,3,4 sau 10 pachete Algoritmul de strat lent poate fi standardul start lent, start-ul lent limitat (limited slow start),
start-ul lent hibrid (hybrid slow start) etc. Algoritmul de evitare a congestiunii poate fi AIMD,CUBIC,CTCP. Mecanismul de recuperare al loss-ului poate fi RENO, NEWRENO, SACK, DSACK.
Pot fi creati diferiti algoritmi de control al congestiunii prin diverse combinatii ale acestor algoritmi. De exemplu CUBIC poate fi combinat cu standard slow start sau hybrid slow start sau orice alt algoritm de slow start si poate fi combinat cu NEWRENO sau SACK sau orice alt mecanism de recuperare al loss-ului.
CAAI considera numai identificarea componentei de evitare a congestiunii de pe un server web. Marimea initiala a ferestrei si componenta de recuperare a loss-ului poate fi identificata prin TBIT. Foarte putini alogritmi de slow start au fost implementati in sistemele de operare majore, asadar nu se considera identificarea lor.
Lucrari avand ca tema identificarea componentei TCP de evitare a congestiunii
Deoarece majoritatea algoritmilor aflati in tabela de mai sus sunt propusi recent, sunt foarte putine lucrari avand ca tema identificarea lor.
Oshio8 - propune o metoda bazata pe analiza clusterilor pentru un router pentru a distinge intre doi algoritmi TCP diferiti.
8 J. Oshio, S. Ata, and I. Oka, “Identification of different TCP versions based on cluster analysis,” in Proceedings of IEEE ICCCN, San Francisco, CA, August 2009.

Feyzabadi9 - considera cum se poate face detectia unui algoritm TCP aflat pe un server web daca acesta este AIMD sau CUBIC
Algoritmul CAAI este diferit fata de cele amintite anterior.
1. CAAI poate distinge intre majoritatea algoritmilor TCP utilizati pe sistemele de operare majore pe cand cele anterioare fac distingere intre numai doi algoritmi diferiti.
2. S-au rezolvat mai multe probleme Web si TCP ca sa se poate face experimente pe scara larga pe cand celelalte se bazeaza doar pe simulari.
Caracteristicile unei componente pentru decongestionare a TCP
Un algoritm TCP de evitare a congestiunii poate fi descris prin urmatoarele caracteristici:
Multiplicative Decrease Parameter (β) - determina pragul de slow start (limita dimensiunii ferestrei de congestiune intre starile de slow start si starea de evitare a congestiunii)
Window Growth Function ( g(.) ) - determina cum un algoritm TCP isi mareste fereastre de congestiune in starea de evitare a congestiunii
Fie loss_cwnd marimea ferestrei de congestiune inainte unui eveniment de loss sau un timeout. In cazul unui eveniment de loss, TCP seteaza pragul de slow start si fereastra de congestiune la dimensiunea β x losscwnd. In cazul unui timeout, TCP seteaza pragul de slow start la β x losscwnd si seteaza fereastra de congestiune in mod normal la 1 pachet.
Diferiti algoritmi de decongestionare au parametri de scadere multiplicativi diferiti precum: AIMD - β=0.5 CUBIC - β=0.7 STCP - β=0.875
Unii algoritmi au β variabil, ce depinde de loss_cwnd si mediului retelei precum durata unui round-trip (RTT), RTT minim si RTT maxim. De exemplu:
BIC seteaza β=0.8 daca loss_cwnd > 14 si seteaza β=0.5 daca loss_cwnd <= 14 HSTCP seteaza β intre 0.5 si 0.9 in functie de loss_cwnd HTCP seteaza β intre 0.5 si 0.8 in functie de raportul dintr RTT minim si RTT maxim
Diferiti algoritmi TCP folosesc in mod uzual diferite functii de crestere a ferestrei. Functia de crestere a ferestrei a unui algoritm TCP este in mod uzual o functie numarul de RTT scurs trecut in starea de evitare a congestiunii (notat x) si loss_cwnd. De exemplu AIMD are o crestere a ferestrei liniara definita de x -> g(x,loss_cwnd) = 0.5 * loss_cwnd + x) iar STCP are o crestere a ferestrei exponentiala (g(x,loss_cwnd) = 0.875*loss_cwnd*1.02x pentru ACK ce nu au fost intarziate).
9 S. Feyzabadi and J. Schonwalder, “Identifying TCP congestion controlalgorithms using active probing,” in Passive and Active MeasurementConference (PAM), Poster, Switzerland, April 2010.

Unii algoritmi TCP au o functie de crestere a ferestrei care nu depinde numai de x ci si de mediul retelei. De exemplu: CUBIC are o functie de crestere a ferestrei care depinde atat de x cat si de durata unui RTT pe cand la CTCP functia de crestere a ferestrei depinde atat de x , de durata unui RTT cat si de minimul RTT.
De notat ca diferiti algoritmi TCP pot arata diferite caracteristici intr-un mediu de retea dar pot arata aceleasi caracteristici si in alt mediu, asadar o parte importanta a CAAI este de a emula unele medii de retea in care diferiti algoritmi TCP au diferite caracteristici pentru ca acestia sa fie distinsi unul fata de celalalt.
Pasii CAAI
1. Trace Gathering - CAAI aduna urmele ferestrei de congestiune TCP de pe un server web intr-un mediu de retea emulat.
2. Feature Extraction (extragerea caracteristicilor) - CAAI extrage cele doua caracteristici ale algoritmului TCP din urmele de congestiune adunate.
3. Clasificare Algoritmului - CAAI identifica algoritmul TCP prin compararea caracteristicilor extrase cu caracteristicile de antrenare.
Concluzii despre CAAI
CAAI are in continuare cateva limitari:
CAAI curent nu considera unii algoritmi TCP de control al congestiunii precum FAST , XCP, VCP si PERT (ultimii 3 au fost propusi recent si nu au fost implementati in momentul de fata in nici un sistem de operare).
CAAI curent acopera numai o adresa de ip pe servere si 5000 de servere, ceea ce este in continuare putin compartiv cu numarul total de servere web in internet.

3. Filtrarea dinamica a packetelor UDP prin intermediul proxiului nivelui transport (Rata Bogdan)
IntroducereSuportul de firewall-ul pentru traficului prin intermediu protocolui UDP este inca nesigur si neadecvat. In
acest capitol vom folosi proxiul nivelului de transport (Transport Layer Proxy(TLP)) care ne ofera un firewall securizat pentru protocul UDP. Pentru fiecare asociaţie UDP cu un endpoint separate printr-un server de TLP, serverul TLP efectueaza autentificare user-level sau host-level, filtrarea de pachete, pachete relocare, translatarea optionala a adreselor, sesiune de logare, contorizarea timpului de inactivate, şi alte funcţii de securitate. Nucleul TLP este un TLP în două etape procedura de legare care face o asociere UDP dinamică între un client TLP şi un server TLP. Această procedura de legare are ca suport urmatoarele functionalitati Active UDP Open, Pasive UDP Open, si Source-Specific UDP Open prin care un program local poate produce un socket UDP.
Astăzi, protocolul TCP cuprinde încă marea parte a traficului pe Internet, în principal din cauza protocoalelor HTTP. Cu toate acestea, volumul de trafic UDP este de aşteptat să crească rapid. Acest lucru este parţial din cauza cererilor din ce în ce mai populare pe Internet a aplicatiilor multimedia care se bazează în mare parte pe UDP. Telefonia IP este o alta aplicatie viitoare care vor spori cu siguranta de utilizare a UDP. In afara de asta, multe aplicaţii noi, cum ar fi Internet Key Exchange (IKE) si sesiunea Protocolul de iniţiere (SIP), pot fi de asemenea, bazate pe UDP, în plus faţă de aplicaţiile tradiţionale UDP, cum ar fi NTP şi DNS. În cele din urmă, orice aplicatii multicast trebuie să se bazeze pe UDP.
Prin urmare, firewall-uri, care reprezinta o parte importanta a infracturi Internetului, trebuie să fie capabil să se ocupe de trafic UDP în mod corespunzător şi în siguranţă. În cazurile cele simpliste, firewall-uri, pur şi simplu filtreaza traficul UDP, cu excepţia serviciilor publice, cum ar fi DNS. Pentru o altă extremă, firewall-uri pot deschide porturi fixe (intervale de) pentru traficul UDP de intrare şi ieşire, oferind, astfel, ne oferind nici un fel de securitate. Pe de alta parte Application-level proxies, captureaza starea informatiei pentru a filtra pachetele UDP intr-un mod corespuzator. Gestionarea şi menţinerea unui proxy pe protocol de aplicaţie nu este în mod clar o solutie scalabila. Dinamică de control, o alta alternativa, este de a examina pachetele de iesire pe straturi diferite pentru a capta informaţii de stare necesare pentru a permite traficul sa se întorc pentru a merge printr-un firewall. Această abordare, similară cu Application-level proxies, în general, necesită cunoştinţe de protocoale de aplicare să funcţioneze corect.
În această capitol, vă prezentăm o atenţie proiectat Transport Layer Proxy (TLP) pentru a sprijini aplicaţile pe procoalele TCP si UDP, şi nu se bazează pe informaţiile referitoare la protocol altele decât in afara de IP, hederul TCP si UDP. Un alt avantaj important al operari pe stratul de transport este de a lăsa toate datele venite de la utilizator si datele nivelui de sus nemodificate. Din acest motiv TLP asigură confidenţialitatea datelor, şi nu ar perturba sesiuni end-to-end de mai sus UDP şi TCP, cum ar fi sesiunile IKE de mai sus UDP, şi Secure Socket Layer (SSL) si Real Time Streaming Protocol (RTSP) sesiuni de mai sus TCP.
Modelul reteleiClientul TLP este situat imediat deasupra UDP sau TCP, în termeni de stratificare protocol. O asociaţie
UDP se stabileşte între un program local şi un program de la distanţă. Ne referim la socket corespunzătoare UDP ca socket locale şi socket la distanţă. Cele doua socketuri sunt presupuse a fi separate de cel puţin un server TLP. Un socket local este reprezentat de sfârşitul locală a unei asociaţii UDP cu privire la un server dat TLP. Socket local poate comunica direct cu serverul de TLP, fără a trece prin alte proxy-uri intermediare, şi socketul locale

pot fi de încredere pentru serverul TLP după efectuarea la nivel de utilizator sau host de autentificare. Socketul de la distanta, pe de altă parte, este la capătul îndepărtat al unui UDP este asociere cu privire la un server de date TLP. Socketul de la distanta nu poate fi de incredere pentru un server TLP cu excepţia in care este aprobat de un socket local prin intermediul protocolului TLP.
De asemenea, în Fig. 1 am prezentat două tipuri de relocare a pachetelor UDP realizate de serverul de TLP: cu şi fără NAT. În ambele cazuri, clientul TLP, primind un pachet UDP de la aplicatie, re-directioneaza pachete la server TLP prin intermediul adresei socketului UDP asociere. Aşa cum se arată în Fig. 2, pachetul transmis intre server TLP si client TLP este, de asemenea, adaugă, cu un antet TLP pentru a identifica asociaţiei UDP că acest pachet aparţine. La primirea de pachete de TLP capsulate, serverul TLP elimină antetul TLP, precum şi modificările adresa IP destinaţie şi numărul de port în pachete de adresa de la distanţă curenta. Mai mult decât atât, dacă este nevoie de NAT, serverul TLP schimba adresa IP a sursei şi numărul de port în pachet la adresa unui socket extern pentru UDP asociere. În general, pot exista proxy-uri şi alte firewall-uri între server TLP şi socketul la distanţă. Ca urmare, serverul TLP pot vorbi cu alt proxy, în loc de soclu la distanţă curenta.
Fig 1. Modelul retelei
Fig 2. Encapsularea pachetelor TLP dintre client si server
Pentru a face simplu, vom presupune că socketurile locale se execută un program client, şi socketul de la distanţă, un program server. Astfel, socketul locale iniţiază o asociaţie UDP la serverul de la distanţă prin trimiterea unui primul pachet. Clientul TLP şi server TLP utilizează apoi protocolul TLP pentru a stabili starea pentru această asociere UDP. Un avantaj principal al TLP este faptul că protocolul TLP este transparent la cererea. Programul client face apeluri de obicei socket: socket(), bind(), sendto(), recvfrom(), şi close(). Clientul si serverul TLP sunt capabili de a crea starea pentru asocierea UDP fără ajutorul aplicaţiei. Mai jos, avem în vedere cele patru faze ale TLP-ului.
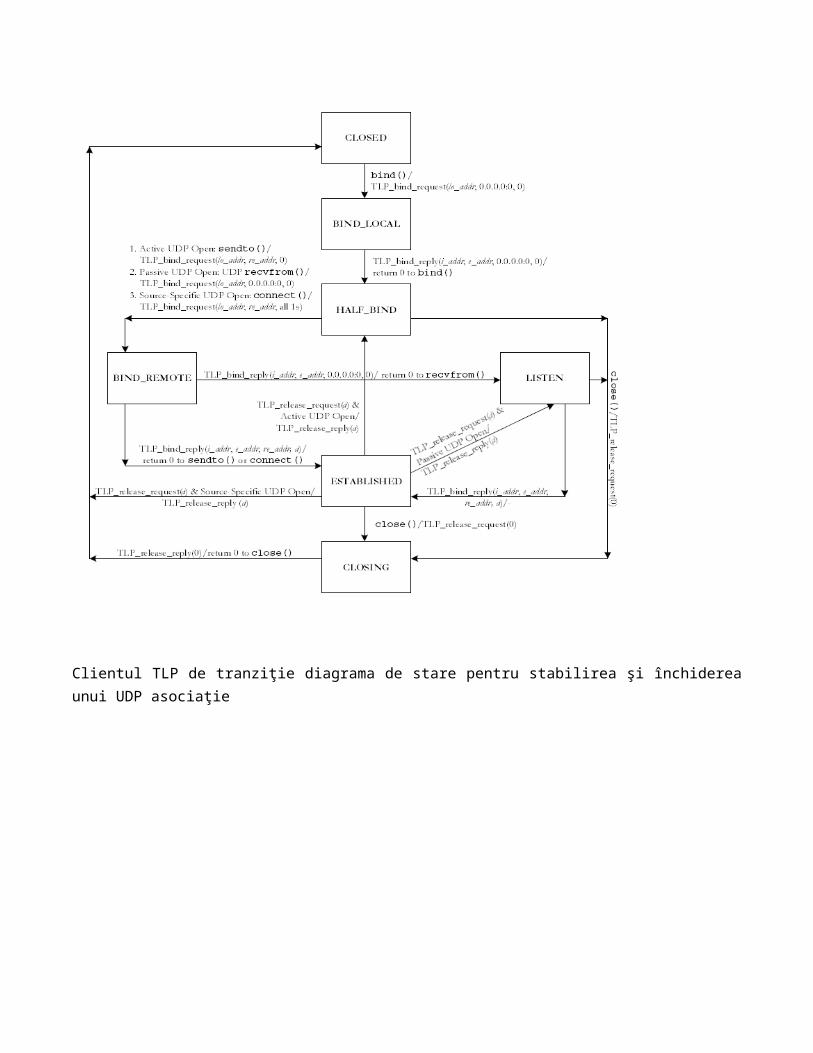
În cazul în care programul face mai întâi un apel bind(), clientul TLP primeşte apelul şi stabileşte un canal de control TLP cu serverul TLP care se bazează pe TCP. Pe acest canal, serverul TLP pote autentifica opţional clientul TLP la nivel de utilizator sau de gazda, şi ambele părţi ar putea negocia, de asemenea, privind autentificarea şi opţiunile de criptare pentru pachetele transportate între client şi server. Mai mult decât atât,

toate subsecventele ulterioare TLP vor schimba mesaje pe acest canal, precum şi fiabilitatea lor este astfel asigurată prin TCP.
Imediat după gazdă locală sau userul local este autentificat, clientul TLP începe prima etapă a unei proceduri de legare TLP. Această procedură obligatorie TLP constă din două etape distincte. Fiecare pas implică două mesaje al protocolului TLP: TLP_bind_request şi TLP_bind_reply. În mesaj TLP_bind_request, clientul TLP specifică o adresă de socket local, în care portul este obţinut prin apelul bind () şi adresa IP se presupune a fi aceeaşi cu cea pentru socletul TCP utilizate pentru canalul de control TLP. La sfârşitul acestei etape, clientul are TLP realizata o legatura un socket externă al server TLP pentru socketul local.
Dacă NAT este va fi efectuate de către serverul de TLP, acest socket se leaga la serverul TLP serveşte ca adresă externă a socketului care urmează să fie utilizate pentru asocierile viitoarelor a UDP-ului folosind socketuri locale. În acest caz, serverul TLP returnează adresa aceastui socket si în plus se returneaza de o adresă internă a socketului, inapoi la client TLP prin mesajul TLP_bind_reply. Dacă NAT nu este folosit, aceasta adresa a socketului va sta in acelasi loc ca adresa de socket local. Ca urmare, un apel getsockname() va întoarce, fie o adresa de socket local fie un o adresa externa a socketului a serverului TLP, precum şi determinarea adresei socket returnat este din nou transparentă programului. In continuare vom presupune NAT-ul ca fiind folosit in caz contrar vom specifica.
Clientul TLP începe o a doua etapă, după primirea unui apel sendto() din program. Asocierea UDP este acum complet specificat prin adresa socket locale al clientului şi adresa de socket la distanţă, care este dat prin apelul sendto (). În această etapă, clientul TLP trimite, prin urmare, un alt mesaj TLP_bind_request cu adresa reală a socketului de la distanţă. În schimb, serverul TLP returnează un număr unic de Asociere ID-ul (AID) pentru a identifica această asociere UDP. Mai mult decât atât, atât serverul, cât şi clientul TLP au creat starea pentru această asociere UDP daca această etapă sa finalizat cu succes, si sunt gata pentru a procesa pachetele care aparţin acestei asociaţii UDP. Pentru pachetele de iesire, clientul TLP încapsulează pachet cu un antet care conţine TLP AID. Serverul de TLP, la primirea de pachete, decapsulates anteturile TLP si se bazeaza pe pachetele venite din reţeaua externă, cu sau fără NAT. Pentru pachetele primite, filtrele serverului TLP se baza pe starea asocierilor UDP active în prezent. Un pachet este permis să intre în reţeaua internă numai atunci când corespunde unui asocieri active a UDP-ului.
În cele din urmă, programul poate face un apel close() pentru a închide socket UDP creat anterior. În acest caz, serverul si client TLP vor folosi alte două mesaje al protocol TLP, TLP_release_request şi TLP_release_reply, pentru a elimina starea pentru acest socketul local şi asocierile UDP realizate.
Similar cu TCP, in cazului protocolui UDP vom folosi Active UDP Open si Pasive UDP Open să diferenţieze diferite acţiuni întreprinse după efectuarea socket () şi bind () solicită pentru socketurile UDP neconectate.
Vom considera ca un program foloseste Active UDP Open în cazul în care creează un nou socket UDP care nu este conectat sau utilizează o socket existentă UDP neconctat pentru a iniţia o asociaţie UDP cu un alt socket cunoscute. Iniţială secventa de socket pentru efectuarea Active UDP Open consta din socket(), bind(), şi sendto(). Prin urmare, orice program client care intenţionează să trimită cereri de la un server cunoscut efectuează Active UDP Open.
Vom considera ca un program foloseste Passive UDP Open în cazul în care creează un socket UDP neconectat, în scopul de a accepta cererile de la orice socket (de obicei, necunoscut). Passive UDP Open corespunde unei scenari al serverul fara conexiune.Segventa iniţială de socket pentru efectuarea Passive UDP Open se compune din socket(), bind(), şi recvfrom().

Un program se spune că foloseste Source-Specific UDP Open, în cazul în care creează un socket UDP conectate cu scopul (1) să iniţieze o asociaţie UDP la un socket specifice, sau (2) să accepte o asociere UDP care urmează să fie iniţiat de la o socket specific. Secventa initiala a socketului care foloseste Source-Specific UDP Open se compune din socket(), bind() şi connect(), şi este apoi urmată de un apel send() in cazul (1) sau un apel recv() pentru caz (2). S Source-Specific UDP Open pentru cazul (1) este similar cu Active UDP Open, cu excepţia faptului că menţine de cele mai multe ori o singură asociaţie UDP.
Oferirea unui pachete de filtrare securizat pentru Active UDP Open este relativ simplă. Deoarece un socket locale trimite primul pachet Active UDP Open, un firewall este în măsură să permită pachetelor de întoarcere să treacă prin înregistrarea adreselor IP a sursei si a destinatiei cat si numerele de port.
Suportul actual pentru un program pentru server pentru UDP-ul local care sa realizeze Passive UDP Open este de a deschide portul serverului la firewall-ul, orice gazdele la distanţă poate ajunge la reţeaua internă printr-un portul. TLP îmbunătăţeşte securitatea şi performanţa serverului prin controlarea viaţă fiecare asociaţii UDP bazat pe time-out, numarul de pachete, sau alţi parametri cuantificabili. În plus, serverul TLP ar putea respinge noile asociaţii de intrare UDP atunci când numărul total de asociaţii UDP activ menţinută pentru un server intern atinge un anumit prag.
Source-Specific UDP Open prezintă probleme majore la nivel de transport prin proxy-uri. Deoarece adresa de socket la distanţă nu pot fi cunoscute de programul local în momentul legari la socketul local. O alta problema care poate sa apara la protocol de aplicaţie si la nivelul transport prin proxi, indiferent dacă NAT este utilizat, de exemplu, între RTSP şi SOCKS [5]. Cele două etape care leaga procedurile ale TLP vor fii discutate in continuare care sunt in masura sa rezolve aceste probleme.
Pasi de rezolvare a problemelor de legatura intre proceduri
Cei doi pasi pentru a rezolva legatura dintre procedurile TLP, care reprezinta nucleul TLP, permite un client TLP şi un server TLP pentru sa stabileasca dinamic asociaţii UDP între ele. Pentru a face simplu, vom presupune doar un singur tranzit complet UDP de asociere în diagrame de tranziţie de stare, ambele Active UDP Open şi Passive UDP Open pentru a permite mai multor asociaţii de UDP care urmează să fie deschise în acelaşi timp la un socket UDP. Mai mult decât atât, noi nu includ tranziţiile de stare atunci când mesajele de eroare sunt generate şi primite. Cu toate acestea, în scopul de claritati, nu ne arată informaţiile referitoare la protocol în alte mesaje, cum ar fi ID-uri de tranzacţii şi codurile de răspuns. Ne concentrăm doar pe treptele TLP obligatoriu în această secţiune, şi se lasă pentru cele pentru închidere de socketuri UDP locale.
Înainte de a face o descriere amanutita a celor două etape este util să înţelegem mai întâi motivele pentru folosirea două etape distincte în cadrul procedurii de legare TLP, în loc de un singur pas ca în SOCKS. Motivul principal este acela de a sprijini Source-Specific UDP Open. Aşa cum sa discutat în ultima secţiune, adresa efectivă socket de la distanţă nu pot fi disponibile atunci când ne legam printr-un socket locale. Prin urmare, mesajul TLP_bind_request invocate de apelul bind() nu va conţine adresa socketului de la distanta. Ca urmare, serverul de TLP nu va returna o adresă extern a socket în cazul in care se foloseste o singură etapă de legare.
Abordarea noastră la rezolvarea acestui conflict este de a serializa sarcina de a obţine adresa extern a socket de la server TLP şi sarcina de a oferi adresa de socket de la distanţă de către client TLP în două etape

distincte. În prima etapă, clientul TLP solicită o evaluare a adresei externe a socket de la server TLP prin furnizarea de o adresă de orice priză de la distanţă (0.0.0.0:0). Prin urmare, acest pas vă permite pur şi simplu clientului TLP (în numele socket local), „creează şi se leagă" un socket, la interfaţa externă a serverului TLP lui. În a doua etapă, clientul TLP stabileşte apoi o asociaţie dinamică a UDP din legatura cu socket la primul pas la un socket de la distanţă cu serverul de TLP prin furnizarea unei adrese socket de la distanţă nonANY. Astfel, a doua etapă este asemănătoare cu apelarea connect() pentru aplicaţii TCP.
Un alt motiv pentru utilizarea aceasta abordare în două etape este de a sprijini reutilizarea socket pentru Active UDP Open. Spre deosebire de socketul TCP, un program local ar putea folosi un socket UDP existent neconectat, care a realizat Active UDP Open pentru a stabili noua asocieri UDP. Cu procedura în două etape legatura TLP, clientul şi serverul TLP trebuie doar să treacă prin ambi pasi pentru a se face o prim apel sendto (). Ei trebuie doar să se stabilească canalul de control TLP şi sa îndeplineasca sarcinile de autentificare şi autorizare doar o singură dată. Apelarea subsecventa sendto(), se foloseste pentru a iniţia noi asocieri UDP,se va invoca numai a doua etapă a procedurii de legare TLP, astfel, asociaţiile dinamică ulterioare UDP poate fi configurat rapid.

Clientul TLP de tranziţie diagrama de stare pentru stabilirea şi închiderea unui UDP asociaţie
Serverul TLP de tranziţie diagrama de stare pentru stabilirea şi închiderea unui UDP asociaţie
ConcluziaFurnizarea de filtrare securizat de pachete UDP şi alte funcţii de securitate la nivelul transport este o
sarcină dificilă. Spre deosebire de proxy-uri la nivel de aplicaţie, un proxy de transport la nivel este transparent pentru activităţi de aplicatiei, cu excepţia apelari secvenţelor de socket. Prin urmare, o provocare majoră este de a sprijini toate UDP Open pentru ca un program sa poata efectua pe un socket UDP. Aşa cum a demonstrat în această capitol, TLP susţine Active UDP Open, Passive UDP Open, Source-Specific UDP Open într-un mod coerent. Serverul şi client TLP stabilesc stari pentru fiecare asociaţie UDP, pot gestiona starile complete UDP asociate pe baza socketului si a ulterioarelor apelurile efectuate de către program şi de perioada de ralanti monitorizată de către serverul de TLP.

4. Alte protocoale de transport prin Internet (Tona Enis)
Datagram Congestion Control Protocol (DCCP)
Datagram Congestion Control Protocol (DCCP) este un protocol de transport care implementeaza conexiuni bidirectionale, unicast de congestie controlata, datagrame nesigure. Concret, DCCP prevede urmatoarele:
Fluxuri nesigure de datagrame “Strangeri de mana” de incredere pentru configurarea conexiunii si teardown Negocierea de incredere a optiunilor, inclusive negocierea unui mecanism adecvat de control al
congestiei Mecanisme care sa permita serverelor sa evite starea de asteptare pentru tentative de conexiune
nerecunoscute si conexiunile deja terminate Controlul congestiei care incorporeaza Explicit Congestion Notification (ECN) si ECN Nonce Mecanisme de recunoastere pentru comunicarea pierderilor de pachete si informatii ECN. ACK-urile sunt
transmise la acelasi nivel de credibilitate ca si cerintele mecanismului de control al congestiei, daca nu chiar complet fiabil.DCCP este destinat pentru aplicatii cum ar fi mass media streaming care nu pot beneficia de control
asupra compromisurilor dintre intarzieri si increderea in comanda de livrare. TCP nu este potrivit pentru aceste aplicatii, deoarece increderea in livrare si controlul congestiei pot cauza intarzieri arbitrare lungi. UDO evita intarzierile lungi, dar cererile UDP care pun in aplicare controlul congestiei trebuie sa faca acest lucru pe cont propriu.
DCCP prevede control al congestiei built-in, inclusiv suport ECN pentru fluxuri de datagrame nesigure, evitand intarzierile arbitrare asociate cu TCP. El pune in aplicare, de asemenea, configurarea fiabila a conexiunii, teardown, si negociere caracteristica.
Dinamica de conexiune de nivel inalt a DCCP mimeaza dinamica de conexiune a TCP. Coneziunile trec prin trei faze: initierea (incluzand three-way handshake), transfer de date si inchiderea conexiunii. Datele circula bidirectional prin conexiunea creata. Un framework de confirmare lasa expeditorii sa afle cate date au fost pierdute si astfel se evita congesionarea pe nedrept a retelei. Bineinteles, DCCP ofera semnatica UDP, nu semantica fiabila bytestream a TCP. Aplicatia trebuie sa isi impacheteze datele in cadre explicite si trebuie sa isi retransmita propriile date cand este necesar. Astfel ne putem gandi la DCCP ca TCP minus semnatica bytestream si fiabilitate, sau ca UDP plus controlul congestiei, handshakes si recunoasteri.
Tipuri de pacheteZece tipuri de pachete implementeaza functiile protocolului DCCP. De exemplu, fiecare incercare noua
de conexiune incepe cu un pachet DCCP-Request trimis de catre client. In acest fel, un pachet DCCP-Request se aseamana TCP SYN, dar fiindca DCCP-Request este un tip de pachet, este imposibil sa se trimita o combinatie neasteptata de fanioane, cum ar fi SYN+FIN+ACK+RST pentru TCP.
Opt tipuri de pachete sunt folosite in timpul une conexiuni tipice.

Cele doua tipuri de pachete ramase sunt folosite pentru resincronizare dupa aparitia spontana a pierderilor.
Fiecare pachet DCCP incepe cu un header generic cu dimensiune fixa. Fiecare tip diferit de pachete include date aditionale in header. Optiunile DCCP si alte aplicatii de date urmeaza headerului de dimensiuni fixe.
Tipurile de pachete sunt urmatoarele:
DCCP-Request – trimisa de client pentru a initia o conexiune (prima parte a three-way handshake in cadrul initierii)
DCCP-Response – trimis de catre server ca raspuns la DCCP-Request (a doua parte a three-way handshake in cadrul initierii)
DCCP-Data – folosit pentru a transmite date
DCCP-Ack – folosit pentru a transmite acknoledgement-uri pure
DCCP-DataAck – folosit pentru a transmite date si aplicatii impreuna cu informatie de acknoledgement
DCCP-CloseReq – trimis de server pentru a cere clientului sa inchida conexiunea
DCCP-Close – folosit fie de catre client fie de catre server pentru a inchide conexiunea
DCCP-Reset – folosit pentru a inchide conexiunea, fie normal fie fortat
DCCP-Sync, DCCP-SyncAck – folosite pentru a resincroniza numarul de secventa dupa aparitia spontana a pierderilor de volum mare
1. Clientul trimite serverului un pachet DCCP-Request specificand clientul si porturile server-ului, serviciul cerut si orice caracteristici care sunt negociate, incluzand CCID-ul pe care clientul doreste sa il foloseasca in cadrul conexiunii.
CLIENT SERVERInitiere
DCCP-REQUEST
DCCP-RESPONSEDCCP-ACK
Transfer de dateDCCP-Data,DCCP-ACK,DCCP-DataAck
DCCP-Data,DCCP-ACK,DCCP-DataAck
Inchiderea conexiunii
DCCP-CloseReq
DCCP-Close
DCCP-Reset

2. Serverul trimite clientului un pachet DCCP-Response in care indica faptul ca este pregatit sa comunice cu clientul. Acest raspuns include caracteristicile negociate dorite.
3. Clientul trimite serverului un pachet DCCP-Ack care confirma primirea pachetului DCCP-Response. Aceasta confirma numarul de secventa initial al serverului.
4. Serverul si clientul schimba intre ei pachetele DCCP-Data, DCCP-Ack care confirma datele primite, si potional DCCP-DataAck. In cazul in care clientul nu are date de trimis, atunci serverul va trimite doar DCCP-Ack.
5. Serverul trimite un pachet DCCP-CloseReq cerand inchiderea conexiunii.6. Clientul trimite un pachet DCCP-Close confirmand inchiderea conexiunii.7. Serverul trimite un pachet DCCP-Reset cu codul de resetare 1 („Closed”) si isi elibereaza starea de
conexiune.8. Clientul primeste pachetul DCCP-Reset si isi mentine starea pentru doua segmente maxime de timp
de viata pentru a permite pachetelor ramase pe retea sa se transmita.
Mecanisme de control al congestieiConexiunile DCCP au control al congestiei, dar spre deosebire de TCP, aplicatiile DCCP isi pot alege
mecanismul de control al congestiei. De fapt, cele doua semiconexiuni pot fi guvernate de mecanisme diferite. Mecanismele sunt indicate de identificatori de control al congestiei pe un bit, sau CCID. Capetele isi negociaza CCID-urle in timpul initierii conexiunii. Fiecare CCID descrie cum HC-Sender limiteaza reatele pachetului de date, cum HC-Receiver trimite feedback-ul congestiei prin intermediul acknoledgement-urilor, samd. CCID 2 si 3 sunt definite, CCID 0,1 si 4-255 sunt rezervate. Alte CCID-uri pot fi definite in viitor.
CCID 2 furnizeaza Controlul Congestiei asemantor TCP. Expeditorul mentine o fereastra de congestie si trimite pachete pana cand fereastra este plina. Pachetele sunt confirmate de catre destinatar. Pachetele pierdute indica congestia; raspunsul la congestie este sa injumatateasca fereastra de congestie. Confirmarile in CCID 2 contin numerele de secventa a tuturor pachetelor trimise in cadrul unei ferestre, similar confirmarilor selective (SACK).
CCID 3 furnizeaza Rata de Control Compatibila TCP (TFRC), o forma de control al congestiei bazata pe ecuatii, care doreste sa raspunda la congestie mult mai lin decat CCID 2. Expeditorul mentine o rata de transmisie, pe care o updateaza folosind estimatul destinatarului la adresa pachetelor pierdute. CCID 3 se comporta relativ diferit fata de TCP pe termen scurt, dar este creat sa opereze bine cu TCP pe termen lung 10.
Reliable User Datagram ProtocolUn protocol de transport fiabil este necesar pentru a transporta semnale telefonice prin retele IP. Acest
transport fiabil trebuie sa fie capabil sa furnizeze o arhitectura pentru o varietate de aplicatii care necesita transport IP.
Protocoalele IP existenta au fost studiate si s-a ajuns la concluzia ca un nou mecanism de incredere pentru transmiterea semnalelor de telecomunicatii este necesar. Acest nou mecanism ar trebui sa respecte urmatoarele criterii:
Ar trebui sa furnizeze livrare de incredere pentru un numar maxim de retransmisii Ar trebui sa furnizeze livrare in ordine
10 . http://www.ietf.org/rfc/rfc4340.txt

Ar trebui sa fie bazat pe mesaj Ar trebui sa furnizeze un mecanism de control al fluxului de date Ar trebui sa fie de inalta performanta, greu de depasit Caracteristicile fiecarei conexiuni virtuale sa fie configurabile Ar trebui sa furnizeze un mecanism de mentinere in „viata” Ar trebui sa furnizeze detectia erorilor Ar trebui sa furnizeze transmisiune sigura
RUDP este creat sa permita configurarea individuala a caracteristicilor fiecarei conexiuni astfel incat sa fie posibila implementarea simultana pe aceeasi platforma a mai multor cerinte de transport.
Formatul structurii de dateFiecare pachet UDP trimis prin RUDP trebuie sa inceapa prin un header de cel putin 6 octeti. Primul
octet contine o serie de fanioane pe un singur bit. Urmatoarele 3 campuri au fiecare dimensiunea de un octet. Aceste sunt: lungimea header-ului, numarul de secventa si numarul de confirmare. Acesti 3 octeti sunt urmati de o suma de verificare de 2 octeti.
Bitii de control
Bitii de control indica ce este prezent in pachet.
SYN – indica daca bitul de sincronizare este prezent ACK – indica daca numarul de confirmare din header este valid EACK – indica daca este prezent un segment de confirmare extinsa RST – indica daca pachetul este un segment de reset NUL – indica daca pachetul este un segment null TCS – indica daca pachetul este un segment de stare a transferului de conexiune (bitii SYN, EACK, RST si
TCS se exclud reciproc, bitul de ACK este setat intotdeauna cand bitul de NUL este setat) CHK – indica daca campul de Checksum contine verificarea sumei header-ului sau header-ul si datele
(corpul). Daca bitul CHK este 0, campul Checksum contine doar verificarea sumei header-ului. Daca bitul CHK este 1, acesta contine suma de verificare a header-ului si a datelor.
Lungimea header-ului
Campul Header length indica unde datele utilizatorului incepe in pachet. Daca lungimea totala a pachetului este mai mare decat valoare din campul Header length, atunci datele sunt prezente in pachet. Datele nu pot fi prezenta in pachete cu bitii EACK, NUL sau RST setati. Un pachet care contine date are intotdeauna bitul ACK setat si este numit segment de date.
Descrierea caracteristicilorUrmatoarele caracteristici sunt suportate de RUDP. Expeditorul si destinatarul se refera fie la clienti fie la
server care trimit sau primesc date prin o conexiune. Client se refera la individul care initiaza conexiunea si server se refera la individul care asculta conexiunea.
1. Timer de retransmisie
Transmitatorul are un timer de retransmisie cu o valoare de time-out configurabila. Acest timer este initiat de fiecare data cand un segment de date, null sau de reset este trimis si nu este nici un segment temporizat in acel moment. Daca o confirmare la aceste segment de date nu este primita pana cand acest timer expira, toate segmentele care au fost trimise dar nu confirmate sunt retransmise. Timerul de retransmisie este restartat cand segmentul temporizat este primit dar daca mai exista pachete trimise dar neconfirmate. Valoarea recomandata este de 600 milisecunde.
2. Confimari de sine statatoare
Un segment de confirmare de sine statatoare este un segment care contine numai informatie de confirmare. Campul cu numarul secventei contine numarul de secventa a datei care urmeaza, null sau segmentul de reset care urmeaza sa fie trimis.
3. Controlul congestiei
RUDP nu prevede control al congestiei sau algoritmi de inceput incet.
4. Porturi UDP
RUDP nu plaseaza restrictii asupra porturilor utilizate.
Imbunatatiri viitoareRUDP ar trebui sa suporte un mod de operare simetric in plus fata de modul curent de operare tip
client/server. Aceasta ar putea permite ca ambele parti sa porneasca activ conexiunea. RUDP ar trebui sa sustina posibilitate de a extinde campurile de secventa si confirmare de la dimensiunea lor actuala de 1 octet la 2 octeti. Aceasta ar permite ferestrei de transmisie sa foloseasca un buffer mai mare de 25511.
11 Partridge, C. and Hinden, R., "Version 2 of the Reliable Data Protocol", RFC 1151, BBN Corporation, April 1990.

5. Control adaptabil al ratei nivelului de transport (TARC) (Stoian Adriana)
Protocoalele de nivel de transport folosite actual au fost create pentru retele cu intarziere mica datorata largimii de banda. Acum ne confruntam cu retele mari (LFN – “Long Fat Networks”) cu intarzieri foarte mari datorate largimii de banda. Datorita acestor conditii, protocoalele vechi de transport nu mai sunt executate cu aceeasi eficienta. Rate de date multi-gigabit sunt deja disponibile la nivelele de legatura de date si retea, dar tranzitul la nivelele superioare este limitat datorita design-urilor arhitecturale create pe tehnologii de generatie invechita. In plus, traficul pe retea in viitor va avea cereri de QoS (quality-of-service) care nu pot fi garantate momentan, precum si noi modele de utilizare cum ar fi multicasting-ul. Pentru a tine pasul cu hardware-ul aparut in domeniul retelisticii, protocoalele de transport nou aparute trebuie sa tine cont de fenomenul de gatuire a procesorului si sa fie de asemenea capabile sa gazduiasca noile aplicatii aparute odata cu disponibilitatea largimii de banda ieftine.
Una dintre ineficientele cele mai presante a protocoalelor de transport implementate actual este cauzata de inadecvarea algoritmilor de control al traficului, care au fost creati sa sustina conditiile de retea din anii `70. In mod clar, noi mecanisme pentru controlul traficului in mod eficient pe nivelul de transport sunt necesare.
TARC (Transport layer Adaptable Rate Control) este un algoritm de control al traficului pentru nivelul de transport, oritentat pe conexiune, bazat pe rata transferului care este capabil sa aloce dinamic largime de banda utilizatorilor. TARC poate fi folosit singur sau in legatura cu un algoritm de control al traficului bazat pe ferestruire, si ofera suport pentru garantia QoS. Un obiectiv major al TARC este sa ofere servicii de transport garantate si best-effort (in termeni de largime de banda), care pot corespunde garantiilor QoS pentru nivelul de retea. De exemplu, in limbajul ATM, o conexiune care transporta trafic CBR la nivelul ATM poate sa obtina o largime de banda garantata echivalenta cu rata de varf a celulelor CBR. O conexiune de transport cu trafic VBR cu rata de varf a celulelor CBR. O conexiune de transport cu trafic VBR poate sa necesite o largime de banda garantata la un nivel intre rata medie a celulelor ATM si rata de varf a celulelor, dar sa fie capabila sa se adapteze la o largime de banda mai mare daca aceasta este existenta in exces. TARC permite o conexiune cu trafic ABR sau UBR sa concureze pentru largimea de banda ramasa disponibila. Apelul controlului de acces in timpul initializarii conexiunii va determina daca pot fi acomodate conexiuni care cer resurse garantate; performanca conxiunilor bets-effort poate fi determinata de catre capabilitatea ramasa largimii de banda a destinatarului. TARC uneste o faza de crestere a ratei in bucla deschisa cu o faza dinamica in bucla inchisa si rezulta intr-o performanta sueprioara algoritmilor de control al traficului pentru nivelul de transport.
Modelul sistemuluiTARC este un hibrid intre algoritmi bucla-deschisa/bucla-inchisa de control al traficului bazat pe rata
pentru conexiunile nivelului de transport care este capabil sa manevreze garantiile largimii de banda la nivel QoS si este capabil sa redistribuie largimea de banda neutilizata catre utilizatorii care o necesita. Sistemul nostru este format din M expeditori, fiecare cu o conexiune la nivel de transport cu un singur destinatar. Expeditorii si destiantarul sunt conectati printr-o retea care cauzeaza intarzieri ale pachetelor. Aceste intarzieri constau in intarzieri de propagare precum si punerea in coada a retelei interne si intarzieri de tranmisiune.
Cuanta de timp utilizata pentru a determina masurarile ratei se va numi cadru. Durata unui cadru ar trebui sa fie destul de mare pentru ca un numar netrivial de pachete sa ajunga la expeditor in timpul unui cadru in care sursa de trafic a expeditorului este activa. De exemplu, daca rata de sosire a traficului in buffer-ul expeditorului este de ordinul megabiti pe secunda, cu un pachet de 500B, o durata resonabila a cadrului va fi intre 5 si 10 ms. Asadar, durata unui cadru este lunga in comparatie cu timpul de transmitere a unui pachet.

Se presupune ca intarzierea retelei este R cadre in ambele directii, unde R>=1. Destinatarul efectueaza detectarea activitatatii de burst pe o baza cadru dupa cadru, astfel incat feedback-ul de la destinatar sa ajunga la expeditor intre 2R si 2R+1 cadre dupa ce pachetul a fost trimis original. Aproximam timpul de dus-intors (RTT) la 2R+1 cadre. Presupunerile deterministe ale intarzierilor pe retea sunt valide pentru retele in care fluctuatia intarzierii este mica in relatie cu intarzierea totala, spre exemplu, o retea necongestionata, sau o retea cu legatura prin satelit12.
Rata la care TARC permite unui expeditor sa trimtia pachete retelei este guvernata de o alocare de credit, care reprezinta cantitatea de trafic pe care emitatorul poate sa o transmita in cadrul urmator. In fiecare cadru, alocarea creditului fiecarui emitator este reactualizata – fie ca raspuns la un mesaj de feedback de la destinatar, fie datorita algoritmului in bucla deschisa. Fiecare credit corespunde cu o permisiune de transmisie pentru un singur „segment”; un singur pachet de transport poate avea lungimea de mai multe segmente, si necesita mai multe credite pentru transmisiune.
Emitatorul are un buffer finit de Y max pachete si o disponibilitate a serviciului de H pachete pe cadru. O portiune din H, notata h f , este dimensiunea creditului care trebuie impartita intre emitatorii activi pentru feedback-ul alocarilor de credit. Ceea ce ramane, H−hf este puterea de procesare pe care destinatarul si-o rezerva pentru a se ocupa de traficul neregulat in bucla deschisa.
Emitatorii au urmatoarele caracteristici: emitatorul m, m=1…M , are un buffer finit de Smaxm pachete.
Traficul ajunge in buffer-ul emitatorului m, intr-un mod modulat sau nu, cu o rata medie de ajungere la timp de λmpachete pe cadru, si o rata de ajungere cu intarziere de 0. Durata medie a perioadei de on/off burst este de
T onm si T off
m cadre. Se presupune ca aceste durate sunt lungi in comparatie cu timpul de intarziere dus-intors.
Fiecare emitator m are garantata o largime de banda minima pentru transmisie, Cminm ; cand emitatorul are
pachete de transmis, va avea intotdeauna credit alocat de cel putin Cminm . Pentru ca fiecare conexiune sa aiba
garantata aceasta Cminm largime de banda trebuie ca h f ≥∑
m=1
M
Cminm . Emitatorul m are de asemenea un increment
de bucla deschisa, αm. Pentru ca nivelul de transport sa sustina serviciile nivelului de retea (CBR sau VBR), Cminm
trebuie sa fie seetate la nivelul de largime de banda calculata la nivelul ATM, cu αm=0.
Faza de bucla deschisa a unui emitator incepe cand nu este primit nici un mesaj de feedback pentru alocarea creditului in cadrul precedent dar bufferul nu este gol. Faza de bucla deschisa se termina cand un feedback al alocarii este primit. In timpul fazei de bucla deschisa, creditul este alocat dupa cum urmeaza: pentru primul cadrul al fazei in bucla deschisa, emitatorului m ii sunt alocate Cmin
m credite. In fiecare cadru care urmeaza, pana cand emitatorul primeste un feedback de alocare de credit de la destinatar, alocarea creditului in bucla deschisa este incrementata cu αm, pana la o alocare maxima de credit in bucla deschisa, notata cu hs. Astfel, un emitator nu este constrans la rata minima cat timp asteapta feedback-ul alocarilor, dar este deasemenea putin probabil sa saurprinda destintarul cu un burst mare.
12 R. Y. C. Brockett, "Transport I aycr Adaptable Rate Control (TARC): A Hybrid Open-LoopK.'loscd Loop Flow ControlAlgorithm for High-speed Tmnsp )rl Level Connections," UCLA Ph.D. Dissertation, October 1997.

Algoritmul de feedback pentru alocarea creditului functioneaza astfel: in fiecare cadru, destinatarul verifica activitatea traficului de la fiecare emitator si trimite mesaje de feedback doar acelora pe care ii considera activi. Cantitatea de credit de feedback alocata unui amitator este determinata de destinatar ca functie de h f , de numarul de emitatori activi si de serviciile garantate de emitatori. Functia de alocare a feedback-ului poate diferi intre emitatori cu servicii garantate (CBR sau VBR) si emitatori cu servicii best-effort (ABR sau UBR). Din plaja de credite de alocare feedback valabile, h f , fiecare emitator activ are garantate Cmin
m credite; ce ramane este impartit echitabil.
Pe scurt, alocam dinamic puterea de procesare nefolosita de destinatar intre emitatorii activi. Avantajul este ca nu toate conexiunile sunt active continuu, si interactiunile intre nivele sau intreconexiuni pot modifica alocarea creditelor de feedback pentru nivelul de transport.
Rezultate
Comparatie cu alte mecanismeAvantajul unui mecanism de control bazat pe rata fluxului de date asupra unui mecanism bazat pe
ferestruire este ca traficul poate sa curga mult mai regulat (si la un volum mai mare) de la emitator la receptor. Unii algoritmi de control al fluxului bazati pe ferestruire includ un mecanism de stimulare in bucla deschisa. TARC foloseste un mecanism de bucla inchisa in plus fata de un mecanism in bucla deschisa. Functia de alocare a ratei de feedback in cazul TARC este versatila si poate fi orientata proactiv catre alocari de rata conservative sau riscante, justificate de conditii. Cu selectia corecta a parametrilor, TARC va depasi intotdeauna un algoritm in bucla deschisa.
Figura indica faptul ca, chiar si fara realocarea largimii de banda neutilizata datorita limitelor secundare ale rate, folosirea feedback-ului in cazul TARC repaseste orice mecamism de control in bucla deschisa, cu intarzieri ale pachetelor mult mai mici si utlizarea mai mare a surselor.
TARC furnizeaza suport pentru trafic multimedia si real-time, permitand garantii minime de largime de banda. Aceasta caracteristica este extrem de importanta datorita cresterii utilizarii retelelor pentru a porta voce, video si alt trafic care necesita servicii real-time.
ConcluziiTARC este un protocol de transport orientat pe conexiune cu un algoritm bazat pe rata fluxului care
opereaza ca un hibrid intr 2 cicluri, unul in bucla deschisa si unul in bucla inchisa, si care garanteaza o rata

minima de tranzitare catre fiecare emitator. TARC imparte alocarea ratei de feedback doar intre conexiunile active. O conexiune care intra intr-o perioada de inactvitate inceteaza sa-i fie alocata rata de feedback. Cand redevine activa, primeste credit de transmisiune prin algoritmul de bucla deschisa, pana cand receptorul realizeaza ca, conexiunea a redevenit activa si o include in calculele pentru alocarea feedback-ului. TARC regularizeaza dinamic fluxul traficului, si poate aplica informatiea despre alocari subutilizate de feedback pentru a redirectiona excesul de largime de banda catre conexiunile care o pot folosi. Resursele destinatarului pot fi impartite total intre conexiunile active, fara a fi irosite pe conexiuni inactive sau pe conexiuni care sunt reduse datorite congestiei la nivel mai mic sau care au impuse limite secundare de rata a transferului13.
TARC poate fi folosit singur sau in legatura cu un algoritm de control al traficului bazat pe ferestruire, si se adreseaza nevoilor semnificative ale protocoalelor nivelului de transport curente sau viitoare. Este echipat cu mecanisme care promoveaza garantii QoS in timp real si foloseste informatie de congestie bazata pe rata de transfer preluata de la nivelele de protocoale inferioare. TARC este adaptabil la diverse nivele de risc/performanta si depaseste algoritmii de control cu fereastra adaptiva in bucla deschisa14.
13 S. Brakmo, L. L. Petcrson, "TCP Vegas: End to End Congestion Avoidance on a Global Internet," IEEE JSAC, Vol. 13, No. 8, October 199514 Transport Layer Adaptable Rate Control (TARC): Analysis of a Transport Layer Flow ControlMechanism for High Speed Networks, Rei Y.C. Brockett and Izhak Rubin

6. Calitatea serviciilor la nivelul Transport (Dragan Marius Ovidiu)
Notiuni generale despre conceptul de calitate a serviciilor (QoS)ISO (Organizația Internațională de Standardizare), una din cele mai importante organizații de standardizare,
a studiat diferite tipuri de rețele existente în acea vreme (DECnet, SNA, TCP/IP) şi a propus în 1984 un model de referință numit OSI - Open System Interconnection). Organizația Internațională de Standardizare defineste calitatea serviciilor QoS pentru modelul de referință OSI (referinta ISO/IEC 7498-1:1994) ca fiind „numele colectiv dat unui set de parametri asociați pentru N transmisii de date între N puncte de access”. De asemenea se face împarțirea parametrilor in 2 categorii: cei pentru serviciile orientate pe conexiune cat si pentru cele neorientate pe conexiune, si parametrii pentru serviciile exclusiv bazate pe conexiune. De asemenea se specifica: „Parametrii individuali sunt definiti pentru fiecare nivel.”
Nivelul transport nu este doar un alt nivel, el este miezul întregii ierarhii de protocoale. Sarcina sa este de a transporta date de la maşina sursă la maşina destinație într-o manieră sigură şi eficace din punctul de vedere al costurilor, independent de rețeaua sau rețelele fizice utilizate. Fără nivelul transport şi-ar pierde sensul întregul concept de ierarhie de protocoale si de aceea unul din aspectele cele mai importante legate de acesta este calitatea serviciilor (Quality of Service - QoS)
Dacă toate rețelele reale ar fi perfecte şi toate ar avea acelaşi set de primitive, atunci probabil că nivelul transport nu ar mai fi fost necesar. Totuşi, în realitate el îndeplineşte funcția de a izola lumea reală de tehnologia, arhitectura şi imperfecțiunile nivelurilor inferioare. Din această cauză se poate face o distincție între nivelurile de la 1 la 4, pe de o parte, şi cele de deasupra pe de altă parte. Primele pot fi văzute ca furnizoare de servicii de transport, în timp ce ultimele ca utilizatoare de servicii de transport. Această distincție între utilizatori şi furnizori are un impact considerabil în ceea ce priveşte proiectarea arhitecturii de niveluri şi conferă nivelului transport o poziție cheie, acesta fiind limita între furnizorul şi utilizatorul serviciilor sigure de transmisie de date.
O posibilitate de a analiza nivelul transport este de a considera că funcția sa de bază este îmbunătățirea QoS (Quality of Service - calitatea serviciului) furnizat de nivelul rețea. Dacă serviciile la nivel rețea sunt impecabile, atunci nivelul transport nu are prea multe de făcut. Dacă totuşi serviciile la nivel rețea sunt necorespunzătpare, nivelul transport trebuie să umple golul între ceea ce aşteaptă utilizatorul nivelului transport şi ceea ce furnizează nivelul rețea.
Pentru imbunatatirea calitatii serviciilor bazate pe modelul de referinta OSI s-au dezvoltat o serie de protocoale care asigura integritatea datelor transmise intre punctele de access dar si mentinerea anumitor parametrii la care a fost convenit serviciul.
Deşi calitatea unui serviciu poate să pâră un concept vag, aceasta poate să fie caracterizată de un număr de parametri specifici. Nivelul transport poate permite utilizatorului să ceară valori preferate, acceptabile sau minime pentru diverşi parametri în momentul stabilirii conexiunii. O parte dintre aceşti parametri sunt aplicabili

şi pentru serviciile de transport neorientate pe conexiune. Este la latitudinea nivelului transport să inspecteze aceşti parametri şi, în funcție de serviciile rețea disponibile, să hotărască dacă poate să furnizeze serviciul cerut.
Cei mai importanți parametrii ce determină calitatea serviciilor sunt:
Întârzierea la stabilirea conexiunii Probabilitatea de insucces la stabilirea conexiunii Productivitatea Întârzierea la transfer Rata reziduală a erorilor Protecția Prioritatea ReziliențaÎntârzierea la stabilirea conexiunii este timpul scurs între cererea unui utilizator al nivelului transport de
alocare a unei conexiuni şi primirea confirmării de stabilire a conexiunii. Ea include timpul de prelucrare al cererii în entitatea de transport aflată la distanță. Ca la orice parametru care măsoară o întârziere, cu cât aceasta este mai mică, cu atât mai bun este serviciul.
Probabilitatea de insucces la stabilirea conexiunii este probabilitatea ca o conexiune să nu fie stabilită într-un interval de timp maxim fixat. Câteva cauze ar putea fi: congestionarea rețelei, lipsa spațiului în tabelele unui nod al rețelei sau alte probleme interne.
Rata de transfer măsoară numărul de octeți de date utilizator transferați de-a lungul unui interval de timp. Rata de transfer este măsurată separat pentru fiecare direcție.
Întârzierea măsoară timpul scurs între trimiterea unui mesaj de către maşina sursă şi recepționarea acestuia la maşina destinație. Ca şi pentru rata de transfer, fiecare direcție este evaluată separat.
Rata reziduală a erorilor măsoară procentul de pachete pierdute sau incorecte din totalul pachetelor trimise. Teoretic, deoarece scopul nivelului transport este de a ascunde toate erorile nivelului rețea, rată reziduală a erorilor ar trebui să fie nulă. în practică ea poate avea şi o valoare (mică) nenulă.
Protecţia furnizează utilizatorului o modalitate de a cere nivelului transport ca datele transmise să fie protejate împotriva accesului neautorizat (citire sau scriere) al terților.
Prioritatea furnizează utilizatorului o modalitate de a indica nivelului transport că unele conexiuni sunt mai importante ca altele şi că, în cazul unei congestii, conexiunile cu prioritate mai mare trebuie servite preferențial.
Rezilienţa indică probabilitatea ca nivelul transport însuşi să închidă spontan o
conexiune datorită unor probleme interne sau datorită congestiilor.
Calitatea serviciilor sau QoS reprezintă pe scurt prioritizarea traficului in functie de protocol. Orice retea mare (cateva sute sau mii de calculatoare) sau orice retea care foloseste o singură iesire spre Internet implementează sau ar trebui să implementeze QoS. Pentru o activitate eficienta traficul trebuie prioritizat in functie de protocolul respectiv. Astfel VoIP(Voice over IP), SSH, protocoalele de remote management sau video

au nevoie de delay minim. Fiecare milisecundă in plus necesara unui pachet să ajungă de la sursă la destinatie poate duce la imposibilitatea de folosire a tehnologiei respective. Există protocoale si servicii care nu necesita delay scăzut cum este cazul email-ului, downloadului, P2P, chiar si Web-ului.
Routerele folosesc principiul FIFO, astfel incat pachetele sunt rutate in ordinea in care au sosit. Se creaza astfel o coada (queue) in care pachetele asteapta sa le vina randul pentru a fi rutate. In acest moment apar intarzieri.
Problema mai sus enuntata este foarte importanta in cazul Internetului, reteaua cu cel mai mare numar de utilizatori din intreaga lume si se poate particulariza pentru orice tip de retea. Problema se poate rezolva prin implementarea si configurarea QoS. Routerele care suporta QoS sunt mult mai scumpe, iar cunostintele implicate in configurarea lor sunt complexe. Regula de baza pentru a scapa de delay este de a fi in masura pentru a controla coada formata si de a o limita. O alta regula este ca poate fi influentat si prioritizat doar traficul de tip upstream dar nu si cel de tip downstream - nu se poate influenta ceea ce primim de la altii, dar poate fi influentat ceea ce se trimite. Apar astfel doua concepte importante in QoS: traffic shaping si traffic policing.
Traffic Shaping reprezinta controlul asupra traficului trimis (upload / upstream) prin delay astfel incat sa nu se formeze coada sau daca se formeaza sa o putem controla. Traffic Policing reprezinta acelasi lucru pentru download / downstream. Implementarea unei politici este extrem de complexa, poate chiar imposibila din simplu motiv ca nu putem influenta ceea ce primim de la altii. Un router care implementeaza intr-un mod profesional traffic shaping face ca eficienta retelei pentru care ruteaza sa creasca cu peste 50%. Asta mai ales daca exista o singura conexiune la internet pentru un intreg LAN - cazul cel mai des intalnit in momentul actual. Tot cu ajutorul QoS se poate configura banda minim garantata pentru fiecare client.
Dezavantajul principal si motivul pentru care QoS nu este implementat peste tot sunt costurile extrem de mari ale routerelor
O retea sau un protocol care suporta QoS defineste un „traffic contract” (contract de trafic) impreuna cu aplicatia software si rezervarea capacitatilor in nodurile retelei in timpul stabilirii unei sesiuni. In timpul sesiunii se poate monitoriza nivelul de performanta atins, de exemplu rata datelor si intarzierilor si sa se controleze dinamic prioritatile programate in nodurile retelei. Mecanismul poate elibera capacitatea rezervata in timpul inchiderii unui anumit canal pentru care fusese in prealabil rezervata banda. O retea de tipul „best-effort” care nu garanteaza parametrii serviciilor oferite nu suporta Quality of Service.
Multe lucruri se pot intampla cu pachetele care traverseaza calea de la origine la destinatie rezultand in urmatoarele probleme din punctual de vedere al transmitatorului si receptorului:
- Pachete aruncate : routerele pot arunca la destinatie anumite pachete cand buffer-ele lor sunt deja pline . Cateva dintre ele sau toate pachetele pot fi aruncate, depinzand de starea retelei si este aproape imposibil sa determine ce se va intampla dinainte. Aplicatia care receptioneaza datele poate cere ca aceste pachete sa fie retransmise .

- Intarzieri: unui pachet ii poate lua un timp mai lung pana sa ajunga la destinatie ,pentru ca trece prin cozi de asteptare destul de lungi sau pentru ca a ales o ruta mai putin directa pentru a evita coliziunile. Altfel ar fi trebuit sa urmeze o ruta mai rapida si mai directa . De aceea intarzierile sunt foarte impredictibile.
- Jitter: pachetele ce pleaca de la sursa vor ajunge la destinatie cu intarzieri diferite. Variatia intarzierilor este cunoscuta ca jitter si poate serios afecta calitatea streaming-ului audio si video.
- Livrare intarziata: cand o colectie de pachete este rutata prin internet , pachete diferite pot urma rute diferite , fiecare avand in final intarzieri diferite. Rezultatul se concretizeaza in faptul ca pachetele sosesc intr-o ordine diferita fata de cea in care au fost trimise. Problema necesita protocoale aditionale responsabile pentru reordonarea pachetelor la destinatie. Acest lucru este cu precadere important in stream-urile de video si VoIP unde calitatea are un impact dramatic din partea intarzierilor sau lipsei sincronizarii.
- Erori: cateodata pachetele sunt indreptate intr-o directie gresita sau sunt combinate sau apar erori in interiorul lor in timpul rutarii. Receptorul trebuie sa detecteze acest lucru si daca pachetul a fost doar aruncat trebuie sa ceara retransmisia acestuia.
De asemenea un rol esential pentru calitatea serviciilor la nivelul transport il au mecanismele pentru controlul congestiei si cele pentru managementul cozilor.
Mecanisme pentru controlul congestieiMecanismele pentru controlul congestiei sunt foarte diverse, motiv pentru care este foarte dificila realizarea
unei clasificari. Mai jos avem trei dintre cele mai importante aspecte ale mecanismelor de control al congestiei, ceea ce ne permite si o oarecare clasificare a acestora.
1.Mecanisme de tip Router-Centric si Host-Centric
Pentru cazul Router-Centric, routerele sunt responsabile atit de ordinea de servire a pachetelor ce le traverseaza cit si de eliminarea lor (in caz de congestie). In caz de congestie, dispozitivele generatoare de trafic care introduc o cantitate prea mare de informatii in retea, vor fi "informate" de acest aspect, ele trebuind sa ia masuri pentru scaderea ratei de transmisie.
2.Mecanisme pe baza de rezervare (Reservation-Based) si mecanisme pe baza de feedback (Feedback-Based)
In mecanismele bazate pe rezervare, la initierea conexiunii, se realizeaza si transmite in retea, o cerere de spatiu in bufferele routerelor care vor fi "strabatute" de pachete pina la destinatie. In cazul in care spatiul solicitat nu este disponibil intr-unul din routere, cererea de conexiune va fi refuzata.
In mecanismele bazate pe feedback sursa incepe sa emita pachetele cu un trafic initial, care urmeaza sa fie ajustat in urma observarii traficului din toate routerele parcurse. Pentru reglarea traficului functie de aglomerarea routerelor sunt disponibile doua tipuri de algoritmi:
- expliciti: cind unul din routere ajunge in stare de congestie va transmite sursei generatoare de trafic un mesaj explicit de micsorare a ratei de transmisie.

- impliciti: sursa generatoare de trafic isi modifica rata de transmisie pe baza rezultatelor propriilor monitorizari ale retelei.
Pentru implementarea unor mecanisme pe baza de rezervare sunt necesare doar adoptarea unor mecanisme de tip Router-Centric pentru a preveni congestia.
La fel, pentru implementarea mecanismelor pe baza de feedback, cu algoritmi impliciti, este necesara doar existenta adoptarii unui mecanism de tip Host-Centric. In cazul algoritmilor impliciti trebuie sa existe ambele tipuri de mecanisme.
3.Mecanisme pe baza de fereastra (Window-Based) si mecanisme pe baa de rata (Rate-Based)
Acest aspect al controlului congestiei este foarte asemanator cu problematica controlului fluxului intr-o retea. Atit controlul congestiei cit si controlul fluxului presupun reglarea vitezei cu care sursa transmite pachete in retea, Diferenta consta in aspectul pe care il rezolva fiecare: controlul congestiei impiedica sursa sa congestioneze reteaua (implicit unul din routerele de pe traseu), in timp ce controlul de flux impiedica sursa sa "innece" cu pachete receptorul.
In principal exista 2 metode de a comunica sursei cu ce rata poate sa emita pachete:
- se indica o fereastra,
- se indica o rata
Lucrul cu cozile in Routere Orice router implementeaza un mecanism de lucru cu cozile. Pachetele ce sosesc la router sunt puse intr-o
coada de asteptare pentru ca, mai apoi, sa fie transmise spre destinatie. Congestia apare atunci cind sosesc foarte multe pachete de date, iar routerul nu mai are spatiu de stocare in bufferele de memorie. Vom descrie, in continuare, doi algoritmi utilizati in lucrul cu cozile.
1.FIFO (First In - First Out)
Dupa cum ii spune si denumirea (primul venit - primul iesit) acest algoritm transmite pachetele in ordinea sosirii lor in buffer. In momentul in care soseste un pachet, este pus in coada de asteptare .Dupa ce vor fi trimise toate pachetele care au sosit inaintea lui, va fi trimis si acesta. In caz de congestie (pachetul soseste, dar bufferul este plin), routerul elimina respectivul pachet fara "sa-si puna problema" carui flux apartine si cit de important este acesta.
In Internet, routerele implementeaza cozi FIFO, dar TCP isi asuma responsabilitatea pentru detectarea si eliminarea congestiei. Totusi, unele routere din Internet nu folosesc doar cozi simple FIFO, ci au implementat si un serviciu, bazat pe bitii TOS (Type Of Service - tip de serviciu - ce se afla in headerul pachetului IP) pentru a putea clasifica pachetele dupa prioritati diferite.
2.FQ (Fair Queuing)

Principalul dezavantaj al cozilor FIFO consta in aceea ca nu se face diferentierea pachetelor functie de sursa emitenta. Acest neajuns incearca sa il elimine cozile FQ. Ideea de baza a acestui "gestionar de cozi" este de a mentine o coada separata pentru fiecare flux de date care traverseaza routerul la un moment dat. Routerul deserveste aceste cozi dupa un algoritm numit jeton-rotitor. In cazul in care pe un flux vin pachete foarte repede, coada asociata se va umple. Routerul preintimpina aceasta situatie si atunci cind coada atinge o marime particulara, pachetele suplimentare, care apartin fluxului respectiv, vor fi eliminate. Din acest motiv, o sursa nu poate acoperi o parte nelimitata din capacitatea retelei, in defavoarea celorlalte fluxuri.
Algoritmul FQ nu presupune ca routerul sa trimita surselor de trafic date despre starea retelei, date care ar putea regla debitul. Cu alte cuvinte FQ a fost proiectat pentru a putea fi folosit impreuna cu un mecanism de control al congestiei.
Studiu asupra calitatii serviciilor in retelele de ultima generatieIn lucrarea A Survey on QoS in Next Generation Networks, autorii Fazal Wahab Karam si Terje Jensen
trateaza problema QoS in retelele eterogene (mixte), cu solutii de implementare si asigurare a QoS dar si perspective de imbnatatire a acestor notiuni.
Dupa descrierea conceptului de calitate a serviciilor numit in continuare QoS se incearca o stabilire a factorilor care influenteaza Qos si a solutiilor gasite pentru implementare in retelele eterogene cu subretele manageriate de diversi furnizori cu tehnologii diferite: cablu, satelit, radio si care implementeaza protocoale diferite pentru transport: TCP/IP, ATM sau MPLS.
Solutii si algoritmi QoS in retele eterogene de ultima generatie.
In lucrare se face o comparatie a algoritmilor pentru calitatea serviciilor din punct de vedere al arhitecturii si al caracteristicilor oferite rezultatul fiind urmatorul:

Arhitectura/Caracteristica
IntServ DiffServ ATM MPLS Eu-QoS Y-comm AN DAIDALOS
Protocoale standard Da Da Da Da Da Nu Da Da
Selectia retelei optime
Da Da Da Da Nu Nu Da Nu
Incorporare tehnologie wireless
Nu Nu Da Da Da Da Da Da
QoS pentru domeniu Da Da Da Da Da Nu Da Nu
Mecanism semnalizare
Protocol dedicat (RSVP)
DiffServ Code Point (DSCP)
Q.2931 Protocol
Label Distributi-on Protocol (LDP)
Legacy si NSIS
Multinivel
Multinivel
Aplicatie
Conditii necesare Rezervarea resurselor pe flux
Edge policing, Priorotizarea traficului, Clasificare de pachete
Serviciu orientat pe conexiune, Multiplexare asincrona, celule de dim. fixa
Orientat pe conexiune
Security, NAT, Failure Recovery
inca in dezvoltare
Security, NAT, Failure Recovery
Security, NAT, Failure Recovery
Concluzia studiului este ca in ultimii zece ani cercetarea din domeniul arhitecturilor bazate pe QoS in retelele eterogene a fost intensa si datorita implicarii Uniunii Europene in proiecte ca Eu-Qos, DAIDALOS sau Smart. In plus, există unele dovezi că astfel de arhitecturi pot livra bunuri utile care rezultă într-un management eficient al QoS. Deci nu există nici un motiv, prin urmare, să presupunem că cercetarea şi dezvoltarea sa nu va continua.
Implementarea practica a QoS intr-o retea de tip WANIn lucrarea Implementing Practical WAN Quality of Service, inginerii de la Intel Blaine Bauer, Tim Verrall, and
Lilin Xie, descriu implementarea unor sisteme de calitate a serviciilor peste reteaua lor WAN pentru a gasi solutia optima in controlul congestiei retelei si imbunatatirea QoS.

Dupa o perioada mai indelungata de teste si incercari ale diferitilor parametrii QoS echipa de la Intel a ajuns la o configuratie satisfacatoare ale carei concluzii sunt prezentate in lucrarea mai sus amintita.
Scopul cercetarii a fost de a suplimenta WAN cu o capacitate QoS care să ofere atât gestionarea lățimii de bandă cat şi prioritizarea latentei. Din moment ce raportul cost-eficiență este unul din scopurile principale ale QoS, soluția nu putea conduce la cheltuieli administrative extinse. Au fost testate şi îmbunătățite politicile, şi soluția finală a îndeplinit cerințele de bază, oferind în acelaşi timp perspective pentru dezvoltarea viitoare.
In cadrul studiului s-au folosit urmatoarele tehnologii QoS:
-Clasificarea si marcarea pachetelor.
Traficul este inspectat şi clasificat cand acesta intra in WAN pentru prima dată. Am clasificat routerele WAN bazate pe listele de acces, care se potrivesc porturilor pentru TCP/UDP, în header-ul pachetului primit. In functie de clasificare, pachetele sunt marcate, stabilindu-se biți specifici în antetul pachetului.
-Priority-Queuing (coadă cu prioritate)
Mecanismul de bază de aşteptare de ieşire în cele mai multe routere este primul intrat, primul ieşit (FIFO), pachetele noi ajungand la sfârşitul cozii de aşteptare. În timp ce această metodă este eficientă şi rapidă, toate pachetele suportă întârziere de aşteptare şi trebuie să aştepte rândul lor să fie transmise. Pe masura ce pachetele traverseaza mai multe hopuri prin routere, o anumită întârziere poate aparea la fiecare hop. Coada cu prioritate in schimb aseaza pachetele cu sensibilitate la latenta cum sunt cele pt VoIP la inceputul cozii.
-Class-based weighted fair queuing
CBWFQ garantează şi / sau limitează lățimea de bandă pe care o poate folosi o clasa de trafic. Aceasta este de obicei realizata prin controlul ratei la care pachetele de tipuri de trafic diferite sunt adăugate la o coadă de ieşire. Procesul garanteaza la clasele de trafic o anumită lățime de bandă şi că traficul cu prioritate mai mică este constrâns, dar nu complet lipsit de lățime de bandă. Dacă o clasă de prioritate mai mare nu are nevoie de toate lățime de bandă alocată, traficul de prioritate mai mică se poate folosi de lățime de bandă rămasă. De exemplu, o coadă cu o garanție de 10 procente obține de cinci ori lățimea de bandă a unei cozi cu o garanție 2 % .

Algoritmi QoS in reteaua Intel
Inginerii de la Intel au respins de asemenea tehnologii ca Fair queuing, weighted fair queuing, and per-flow queuing sau Rate limiting, Congestion avoidance si LAN QoS pentru că nu prezentau avantaje in fata combinatiei alese.
In cadrul testelor effectuate s-a observat că este nevoie de mai multe calibrări datorită faptului ca reteaua este eterogenă si foloseste mai multe tipuri de tehnologii. Dupa efectuarea unor updateuri si upgradeuri atat soft cat si hardware s-a ajuns la soluții satisfăcătoare.
In etapa de implementare au fost prioritizate traficul si lațimea de banda pentru pachetele de voce (VoIP) si s-au folosit algoritmi CBWFQ pentru celelalte clase de pachete. Au fost detectate si tipuri de pachete fara sensibilitate la latența si au fost aplicate criterii corespunzatoare pentru ele restul fiind caracterizate ca sensibile la latență, conform tabelului următor:
Tabel setări initiale pentru QoS
După realizarea unei implementari pilot care să ofere diferite scenarii de trafic in retea si congestie s-a obtinut o serie de rezultate in urma testelor efectuate.

Graficul traficului per coada si a pachetelor aruncate in cursul unei saptamani de teste
După ce s-a avansat la implementarea pe intreaga retea WAN a Intel echipa a trecut la imbunătătirea parametrilor alesi obtinandu-se un nou set de rezultate. In această etapă au descoperit mai multe probleme cu implementarea initiala si cateva dificultăti la clasificarea unor tipuri de trafic:
-Protocoale folosind nespecificat porturile TCP / UDP pentru o anumită aplicație (descoperite de obicei in remote procedure calls - RPC).
-Protocoale folosind un singur port UTP / TCP in scopuri multiple cum este cazul HTTP.
Dupa clasificarea acestora a fost descoperită o problemă cu securitatea retelei si a fost necesară o clasificare si marcare a traficului de tip malware/worm spre un depozitar pentru verificare fiind necesară si folosirea unei noi cozi pentru acest tip de trafic15.
15 Implementing Practical WAN Quality of Service, Blaine Bauer, Tim Verrall, Lilin Xie, Intel Corporation, November 2007

Tabel setari imbunatatite pentru QoS
Concluzii ale studiuluiDupă cum se poate observa si din tabel traficul a fost impărtit in clase cu prioritati specifice, in functie de
acestea rezervandu-se un anumit procent din lătimea de banda disponibilă, astfel incat congestia sa fie minimă in timp ce calitatea serviciilor sa nu fie afectată.
CBWFQ gestionează toate clasele, cu excepția vocii. Aceste clase pot depăşi procentele alocate de lățime de bandă în cazul în care alte clase nu le folosesc. În timpul funcționării practice, clasa de date implicită consumă majoritatea lățimii de bandă.
Au fost testate diferite valori, şi în cele din urmă, s-a ales o adâncime a cozii de 128 de pachete care permite cozilor implicita şi best-effort minimizarea ratei de aruncare a pachetelor(drop-rate).
Rezultatele obtinute in urma implementarii QoS:
-Distribuție mai largă a transmisiunilor video multicast prin garantarea benzii;
-Consolidarea si integritatea pachetelor de date si voce, posibilitatea implementarii viitoare a VoIP datorita prioritizarii si garantarii latimii de banda;
-Control mai bun al hosturilor infectate de virusi/worms.
-Flexibilitate in managementul latimii de banda.
Concluzia studiului este că implementarea unor algoritmi si concepte QoS in rețea este esențială oferind o flexibilitate a lațimii de banda mult mai bună, prioritizare eficientă si minimizand efectele negative ale congestiei rețelei oferind in cele din urma o rețea WAN mult mai performantă si eficientă din punct de vedere al traficului.

7. Elemente de performan ă (Zaharie Bogdan Alfred)ț
Un rol foarte mare ca importanță in rețelele de calculatoare il au elementele de performanță. În
rețelele de scară largă, unde pot fi interconectate sute sau chiar mii de calculatoare, au loc adesea interactiuni
complexe care pot avea consecințe nemaiîntâlnite, ceea ce rezulta deseori in performanțe slabe fără ca cineva
sa ştie de ce.
Din păcate, înțelegerea performanței unei rețele nu poate fi numită o ştiința, ci este considerată mai mult
o „artă”. Puțina teorie care stă la bază nu poate fi folosită cu succes in situații practice. Cel mai bun lucru pe care
îl putem face este sa indicăm reguli rezultate dintr-o experiență îndelungată şi sa prezentăm exemple luate din
lumea reală.
Îmbunata irea performan ei nivelului de Transport utilizând un nou Protocol de ț țControl de Acces Mediu (MAC) cu “Fast Collision Resolution” în LAN-uri Wireless
Dezvoltarea unor protocoale MAC eficiente reprezintă o problemă fundamentală de cercetare in rețelele
locale wireless de mare viteză. Vom aborda un protocol MAC distribuit eficient bazat pe conflict, numit
algoritmul „Fast Collision Resolution” (FCR), şi vom arata ca acest algoritm dezvoltă randament ridicat şi latență
scăzută în timp ce înbunatațeşte performanțele corectitudinii pentru servirea utilizatorilor într-un LAN wireless.
Pentru a creşte performanța tranzitată de un protocol MAC distribuit bazat pe conflict, un algoritm
eficient de descompunere a coliziunii pentru a reduce cheltuielile generale (cum ar fi ciocnirile de pachete şi
sloturi inactive) în fiecare ciclu de dispută. În acest scop, mulți algoritmi noi de descompunere a coliziunii au fost
propuse. De exemplu, algoritmi de revenire îmbunatațiți sunt propusi pentru a ajusta factorii crescătoari şi
descrescătoari de dimensionare a ferestrei conflictuale şi a valorilor de revenire aleatorii, sau pentru ajustarea
dinamică a mărimii ferestrei conflictuale corecte la fiecare stație, bazându-se pe estimarea numărului de stații
active; semnalarea tonului de ocupat a benzii de ieşire este folosita pentru alertarea activă a celorlalți de starea
ocupată a canalului.
Cel mai popular protocol MAC bazat pe conflict este CSMA/CA, care este folosit pe scară largă în LAN-
urile IEEE 802.11. Operațiile de bază a algoritmului CSMA/CA sunt prezentate in Fig.1 .

Fig.1. Operațiile de bază ale algoritmului CSMA/CA
Deficiența majoră a protocolului MAC IEEE 802.11 vine de la scăderea vitezei de descompunere a
coliziunii odată cu creşterea numărului de stații active. O stație activă poate fi în una din două moduri în fiecare
perioada de conflict, mai exact, modul de transmitere atunci când câştigă un conflict şi starea de suspendare
atunci când pierde un conflict. Atunci când o stație transmite un pachet, rezultatul va fi unul dintre următoarele
două cazuri: o transmitere cu succes a pachetului sau o coliziune. Aşadar, o stație se va afla într-una din
următoarele trei stări la fiecare perioada de conflict: o stare de transmisiune cu succes a pachetului, o stare de
coliziune, sau o stare amânată. În majoritatea algoritmilor MAC distribuiți bazați pe conflict, nu există schimbare
a mărimii ferestrei de conflict pentru stațiile amânate, iar cronometrul de revenire va scădea cu un slot de
fiecare dată când un slot inactiv este detectat. În algoritmul FCR, se schimbă marimea ferestrei de conflict
pentru stațiile amânate şi sunt regenerate cronometrele de revenire pentru toate stațiile cu un potențial de
transmitere pentru a evita în mod activ potențialele coliziuni „din viitor”, astfel se pot rezolva mai rapid
posibilele coliziuni de pachete. Algoritmul FCR păstrează simplitatea implementării a IEEE 802.11 MAC.
Algoritmul FCR are următoarele caracteristici:
1. Folosirea unei ferestre minime de conflict inițiala (minCW) mai mica decat cea IEEE 802.11 MAC.
2. Folosirea unei ferestre maxime de conflict (maxCW) mai mare decât cea IEEE 802.11 MAC.
3. Mărirea dimensiunii ferestrei de conflict a unei stații atunci când se afla în starea de coliziune sau de
amânare.
4. Reducerea exponențial de rapid a cronometrelor de revenire când un număr prefixat de sloturi
inactive consecutive sunt detectate
5. Atribuirea limitei de transmisie maxime a pachetelor succesive pentru păstrarea echitații utilizatorilor.

Caracteristicile 1 şi 4 încearcă sa reducă numărul mediu de sloturi inactive de revenire pentru fiecare
perioadă de conflict. Caracteristicile 2 şi 3 sunt folosite pentru creşterea rapidă a cronometrelor de revenire,
astfel reducând rapid probabilitatea de coliziune. În caracteristica 3, algoritmul FCR prezintă diferența majoră de
alte protocoale MAC bazate pe conflict cum ar fi IEEE 802.11 MAC. În protocolul IEEE 802.11 MAC, mărimea
ferestrei de conflict a unei stații este mărită numai în cazul unui eşec de transmisiune (cum ar fi o coliziune). În
algoritmul FCR, mărimea ferestrei de coliziune a unei stații se va mări nu numai în cazul unei coliziuni dar şi când
se află în modul de amânare şi simte startul unei noi perioade ocupate. Aşadar, toate stațiile care au pachete de
transmis (incluzând pe cele care sunt in stare de amânare din cauza revenirii) îşi vor schimba marimile
ferestrelor de conflict la fiecare perioadă de conflict în algoritmul FCR. Caracteristica 5 este folosită pentru
evitarea ca o stație să domine transmisiunea pachetelor pentru o perioadă lungă. Daca o stație reuşeşte să
transmită numărul maxim de pachete succesive, işi schimbă marimea ferestrei de conflict la valoarea maximă
pentru a da oportunitatea accesului mediu celorlalte stații.
Algoritmul FCR detaliat este descris după cum urmează în funție de starea în care se află stația:
1. Procedura de revenire: Toate stațiile active vor monitoriza mediul. Dacă o stație simte mediul inactiv
pentru un slot, atunci acesta îi va decrementa timpul de revenire cu un slot de timp. Atunci când
cronometrul său de revenire ajunge la zero, acesta va transmite un pachet. Dacă sunt detectate
[(minCW+1) x 2 -1] sloturi inactive, cronometrul său de revenire ar trebui să se decrementeze mult
mai rapid sau chiar injumatațit. Efectul net este acela că timpul de revenire pierdut inutil va fi redus
atunci când o stație, care tocmai a transmis cu succes un pachet, rămâne fără pachete de transmis
sau ajunge la numărul maxim limită de pachete transmise succesiv.
2. Transmisiune eşuată (coliziune de pachete): Dacă o stație observă că transmisiunea sa de pachete a
eşuat, posibil din cauza unei coliziuni de pachete ( de exemplu, nu primeşte o confirmare de la stație
receptoare), fereastra de conflict a stație se măreşte si un timp de revenire va fi ales la întâmplare.
3. Transmisia cu succes a pachetelor: Dacă o stație a terminat o transmisie de pachete cu succes, atunci
fereastra sa de conflict se va reduce la mărimea inițială (minCW) şi un timp de revenire va fi ales la
întâmplare. Dacă o stație ajunge, sau chiar depăşeşte limita de pachete succesive transmise, atunci
fereastra sa de conflict va fi mărită la valoarea maximă a ferestrei de conflict maxCW şi un timp de
revenire va fi ales la întâmplare.
4. Starea amânată: Pentru o stație care se află într-o stare de amânare, de fiecare dată când detectează
începutul unei noi perioade ocupate, care indica fie o coliziune, fie un pachet trimis mediului, stația
îşi va mari fereastra de conflict şi işi va alege un timp nou de revenire la întâmplare.

În algoritmul FCR, stația care a transmis cu succes un pachet va avea fereastra de conflict minimă şi un
cronometru de revenire mai mic, astfel va avea o probabilitate mai mare de a primi acces la mediu, cât timp alte
stații prezintă ferestre de conflict si cronometre de revenire mai mari. După un de pachete transmise cu succes
pentru o stație, altă stație poate câştiga un conflict, iar această nouă stație va avea, drept rezultat, probabilitate
mai mare de acces la mediu pentru o perioadă de timp.
Randamentul vs. Capacitatea oferită
Concluzie
Algoritmul FCR poate atige performanțe de randament ridicat cât timp păstrează simpltatea
implementarii unui LAN fără fir. În algoritmul FCR, fiecare stație işi modifică mărimea ferestrei de conflict atât la
o transmisie de succes a pachetelor cât şi la coliziuni pentru toate stațiile active cu scopul de a redistribui
cronometrele de revenire pentru a evita în mod activ coliziunile in viitor. Datorită acestor operații, fiecare stație
poate rezolva rapid problema coliziunilor. Alte idei încorporate în FCR folosesc ferestre de conflict de mărimi
mult mai mici în comparație cu IEEE 802.11 MAC, şi o scădere mai rapidă a cronometrelor de revenire după
detectarea unui număr de sloturi inactive. Aceste modificări pot reduce numărul mediu de sloturi inactive în
fiecare ciclu de conflict, care contribuie la creşterea randamentului.

Bibliografie
1. Retele de calculatoare, Ed. a-III-a, Andrew S. Tanenbaum, Ed. Computer Press Agora – 19982. Retele de comunicatii intre calculatoare, Ion Banica, Ed. Teora, 19983. OSI Reference Model-The IS0 Model of Architecture for Open Systems Interconnection , Hubert
Zimmermann4. ISO/IEC 7498-1:1994, http://www.iso.org/iso/catalogue_detail.htm?csnumber=202695. Retele locale de calculatoare. Proiectare si administrare, Adrian Munteanu, Valerica Greavu Serban, Ed.
Polirom, 20036. Understanding Networking Technologies, Clayton Coulter, http://www.netguru.net/book_ntc.shtml7. TCP/IP, Tim Parker, Mark Sportack, Ed. Teora, 2002.8. Cursuri CISCO CCNA 19. http://en.wikipedia.org/wiki/Transport_layer
10. Partridge, C. and Hinden, R., "Version 2 of the Reliable Data Protocol", RFC 1151, BBN Corporation, April 1990.
11. W. Stevens, RFC 2001 “TCP Slow Start, Congestion Avoidance, Fast Retransmit, and Fast Recovery Algorithms”, January 1997
12. Z. Wang, J. Crowcroft, A Dual-Window Model for Flow and Congestion Control, The Distributed Computing Engineering Journal, Institute of Physics/British Computer Society/IEEE, Vol 1, No 3, page 162-172, May 1994.
13. Larzon, L-A., Degermark, M., Pink, S., Jonsson, L-E.,and G. Fairhurst, "The Lightweight User Datagram Protocol (UDP-Lite)", July 2004.
14. Baugher, M., McGrew, D., Naslund, M., Carrara, E., and K. Norrman, "The Secure Real-time Transport Protocol (SRTP)", RFC 3711, March 2004.
15. http://www.javvin.com/protocolRUDP.html 16. http://www.ietf.org/rfc/rfc4340.txt 17. Curs ARI – CTI anul III semetru al doilea18. TCP Congestion Avoidance Algorithm Identification - Peng Yang, Wen Luo, Lisong Xu, Jitender Deogun si
Ying Lu, Departament of Computer Science and Engineering, University of Nebraska-Lincoln













![[5]stst.elia.pub.ro/.../1_Stroescu_AnRa_DragomirAnMa_CPS.docx · Web viewNivelul mentenabilitatii se stabileste pe baza datelor obtinute in etapele de proiectare, testare si utilizare](https://static.fdocumente.com/doc/165x107/5e24aa713289397680736465/5ststeliapubro1stroescuanradragomiranmacpsdocx-web-view-nivelul.jpg)




