
Statistic Aplicat - math.uaic.rostoleriu/SA2011last.pdf · larea cererii cu ofert , sau pentru a...
210
Transcript of Statistic Aplicat - math.uaic.rostoleriu/SA2011last.pdf · larea cererii cu ofert , sau pentru a...

Iulian STOLERIU
Statistic Aplicat

1 Statistic Aplicat (C1)
Introducere în Statistic
Scurt istoric
Statistica este o ramur a ³tiinµelor ce se preocup de procesul de colectare de date ³i informaµii,de organizarea ³i interpretarea lor, în vederea explic rii unor fenomene reale. În general, prin date(sau date statistice) înµelegem o mulµime de numere ce au o anumit însemn tate. Aceste numerepot legate între ele sau nu. Suntem interesaµi de studiul acestor date, cu scopul de a înµelegeanumite relaµii între diverse tr s turi ce m soar datele culese. De regul , oamenii au anumiteintuiµii despre realitatea ce ne înconjoar , pe care le doresc a conrmate într-un mod cât maiexact. De exemplu, dac într-o anumit zon a µ rii rata somajului este ridicat , este de a³teptatca în acea zon calitatea vieµii persoanelor de acolo s nu e la standarde ridicate. Totu³i, ne-amdori s m cât mai preci³i în evaluarea leg turii dintre rata somajului ³i calitatea vieµii, de aceeane-am dori s construim un model matematic ce s ne conrme intuiµia. Un alt gen de problem :ardem de ner bdare s a m cine va noul pre³edinte, imediat ce secµiile de votare au închis porµile(exit-pole). Chestionarea tuturor persoanelor ce au votat, colectarea ³i unicarea tuturor datelorîntr-un timp record nu este o m sur deloc practic . În ambele probleme menµionate, observaµiile³i culegerea de date au devenit prima treapt spre înµelegerea fenomenului studiat. De cele maimulte ori, realitatea nu poate complet descris de un astfel de model, dar scopul este de a oferio aproximare cât mai del ³i cu costuri limitate. În ambele situaµii menµionate apar erori înaproximare, erori care µin de întâmplare. De aceea, ne-am dori s putem descrie aceste fenomenecu ajutorul variabilelor aleatoare. Plecând de la colecµiile de date obµinute dintr-o colectivitate,Statistica introduce metode de predicµie ³i prognoz pentru descrierea ³i analiza propriet µilorîntregii colectivit µi. Aria de aplicabilitate a Statisticii este foarte mare: ³tiinµe exacte sau sociale,umanistic sau afaceri etc. O disciplin strâns legat de Statistic este Econometria. Aceastaramur a Economiei se preocup de aplicaµii ale teoriilor economice, ale Matematicii ³i Statisticiiîn estimarea ³i testarea unor parametri economici, sau în prezicerea unor fenomene economice.
Statistica a ap rut în secolul al XVIII - lea, din nevoile guvernelor de a colecta date desprepopulaµiile pe care le reprezentau sau de a studia mersul economiei locale, în vederea unei maibune administr ri. Datorit originii sale, Statistica este considerat de unii ca ind o ³tiinµ de sinest t toare, ce utilizeaz aparatul matematic, ³i nu este privit ca o subramur a Matematicii. Darnu numai originile sale au fost motivele pentru care Statistica tinde s devin o ³tiinµ separat de Probabilit µi. Datorit revoluµiei computerelor, Statistica a evoluat foarte mult în direcµiacomputaµional , pe când Teoria Probabilit µilor foarte puµin. A³a cum David Williams scria în[18], "Teoria Probabilit µilor ³i Statistica au fost odat c s torite; apoi s-au separat; în cele dinurm au divorµat. Acum abia c se mai întâlnesc".Din punct de vedere etimologic, cuvântului statistic î³i are originile în expresia latin statisticumcollegium (însemnând consiliul statului) ³i cuvântul italian statista, însemnând om de stat saupolitician. În 1749, germanul Gottfried Achenwall a introdus termenul de Statistik, desemnatpentru a analiza datele referitoare la stat. Mai târziu, în secolul al XIX-lea, Sir John Sinclair aextrapolat termenul la colecµii ³i clasic ri de date.Metodele statistice sunt ast zi aplicate într-o gam larg de discipline. Amintim aici doar câteva

C1 & L1 [Dr. Iulian Stoleriu] 2
exemple:
• în Agricultur , de exemplu, pentru a studia care culturi sunt mai potrivite pentru a folositepe un anumit teren arabil;
• în Economie, pentru studiul rentabilit µii unor noi produse introduse pe piaµ , pentru core-larea cererii cu ofert , sau pentru a analiza cum se schimb standardele de viaµ ;
• în Biologie, pentru clasicarea din punct de vedere ³tiinµic a unor specii de plante saupentru selectarea unor noi specii;
• în tiinµele educaµiei, pentru a g si cel mai ecient mod de lucru pentru elevi sau pentru astudia impactul unor teste naµionale asupra diverselor caregorii de persoane ce lucreaz înînv µ mânt;
• în Meteorologie, pentru a prognoza vremea într-un anumit µinut pentru o perioad de timp,sau pentru a studia efectele înc lzirii globale;
• în Medicin , pentru testarea unor noi medicamente sau vaccinuri;
• în Psihologie, în vederea stabilirii gradului de corelaµie între timiditate ³i singur tate;
• în Politologie, pentru a verica dac un anumit partid politic mai are sprijinul populaµiei;
• în tiinµele sociale, pentru a studia impactul crizei economice asupra unor anumite clasesociale;
• etc.
Pentru a analiza diverse probleme folosind metode statistice, este nevoie de a identica mai întâicare este colectivitatea asupra c reia se dore³te studiul. Aceast colectivitate (sau populaµie)poate populaµia unei µ ri, sau numai elevii dintr-o ³coal , sau totalitatea produselor agricolecultivate într-un anumit µinut, sau toate bunurile produse într-o uzin . Dac se dore³te studiulunei tr s turi comune a tuturor membrilor colectivit µii, este de multe ori aproape imposibil dea observa aceast tr s tur la ecare membru în parte, de aceea este mult mai practic de astrânge date doar despre o submulµime a întregii populaµii ³i de a c uta metode eciente de aextrapola aceste observaµii la toat colectivitatea. Exist o ramur a statisticii ce se ocup cudescrierea acestei colecµii de date, numit Statistic descriptiv . Aceast descriere a tr s turilorunei colectivit µi poate f cut atât numeric (media, dispersia, mediana, cuantile, tendinµe etc),cât ³i grac (prin puncte, bare, histograme etc). De asemenea, datele culese pot procesate într-un anumit fel, încât s putem trage concluzii foarte precise despre anumite tr s turi ale întregiicolectivit µi. Aceast ramur a Statisticii, care trage concluzii despre caracteristici ale întregiicolectivit µi, studiind doar o parte din ea, se nume³te Statistic inferenµial . În contul Statisticiiinferenµiale putem trece ³i urm toarele: luarea de decizii asupra unor ipoteze statistice, descriereagradului de corelare între diverse tipuri de date, estimarea caracteristicilor numerice ale unortr s turi comune întregii colectivit µi, descrierea leg turii între diverse caracteristici etc.
Statistica Matematic este o subramur a Matematicii ce se preocup de baza teoretic abstract a Statisticii. Din datele culese pe cale experimental , Statistica Matematic va c uta s extrag

C1 & L1 [Dr. Iulian Stoleriu] 3
informaµii ³i s le interpreteze. Un cercet tor într-un domeniul teoretic al Statisticii, cum este ³iStatistica Matematic , va c uta s îmbun t µeasc metodele teoretice existente sau s introduc altele noi. Aceasta va utiliza noµiuni din Teoria probabilit µilor, dar ³i noµiuni din alte ramuri aleMatematicii, cum ar : Algebra liniar , Analiza matematic , Teoria optimiz rii. De asemenea,partea computaµional este deosebit de util în studiul Statisticii moderne, f r de care cercetareaar îngreunat sau, uneori, chiar imposibil de realizat. În aceast lucrare vom utiliza pachetele deprograme Matlab pentru efectuarea calculelor, în versiunea Matlab 7.1. Acest software esteintrodus ³i dezvoltat de compania The MathWorks (vezi [9]).
Modelare Statistic
De obicei, punctul de plecare este o problem din viaµa real , e.g., care partid are o susµineremai bun din partea populaµiei unei µ ri, dac un anumit medicament este relevant pentru boal pentru care a fost creat, dac este vreo corelaµie între num rul de ore de lumina pe zi ³i depresie.Apoi, trebuie s decidem de ce tipuri date avem nevoie s colect m, pentru a putea da un r spunsla întrebarea ridicat ³i cum le putem colecta. Modurile de colectare a datele pot diverse: putemface un sondaj de opinie, sau prin experiment, sau prin simpla observare a caracteristicilor. Estenevoie de o metod bine stabilit de colectare a datelor ³i s construim un model statistic potrivitpentru analiza acestora. În general, date culese de noi pot potrivite într-un model statistic princare
Data observat = f(x, θ) + eroare de aproximare, (1.1)
unde f este o funcµie ce veric anumite propriet µi ³i este caracteristic modelului, x este vectorulce conµine variabilele m surate ³i θ e un parametru (sau un vector de parametri), care poate determinat sau nedeterminat. Termenul de eroare apare deseori în pratic , deoarece unele dateculese au caracter stochastic (nu sunt deterministe). Modelul astfel creat este testat, ³i eventualrevizuit, astfel încât s se potriveasc într-o m sur cât mai precis datelor culese.
Denim o populaµie (colectivitate) statistic ca ind o mulµime de elemente ce posed o trasatur comun . Aceasta poate nit sau innit , real sau imaginar . Elementele ce constituie o co-lectivitate statistic se vor numi unit µi statistice sau indivizi. Volumul unei colectivit µi statisticeeste dat de num rul indivizilor ce o constituie. Caracteristica (variabila) unei populaµii statisticeeste o anumit proprietate urm rit la indivizii ei în procesul prelucr rii statistice. Caracteristicilepot : cantitative (m surabile sau variabile) (e.g., 2, 3, 5, 7, 11, . . . ) ³i calitative (nem surabile sauatribute) (e.g., ro³u, verde, albastru etc). La rândul lor, variabilele cantitative pot discrete (nu-m rul de sosiri ale unui tramvai în staµie) sau continue (timpul de a³teptare între dou sosiri aletramvaiului în staµie). Caracteristicile pot depinde de unul sau mai multi parametri, parametriiind astfel caracteristici numerice ale colectivit µii.Suntem interesaµi în a m sura una sau mai multe variabile relative la o populaµie, îns aceasta s-arputea dovedi o munc extrem de costisitoare, atât din punctul de vedere al timpului necesar, cât³i din punctul de vedere al depozit rii datelor culese, în cazul în care volumul colectivit µii estemare sau foarte mare (e.g., colectivitatea este populaµia cu drept de vot a unei µ ri ³i caracteristicaurm rit este candidatul votat la alegerile prezidenµiale). De aceea, este foarte întemeiat alegereaunei selecµii de date din întreaga populaµie ³i s urm rim ca pe baza datelor selectate s putemtrage o concluzie în ceea ce prive³te variabila colectivit µii.
O selecµie (sau e³antion) este o colectivitate parµial de elemente extrase (la întâmplare sau nu)

C1 & L1 [Dr. Iulian Stoleriu] 4
din colectivitatea general , în scopul cercet rii lor din punctul de vedere al unei caracteristici.Dac extragerea se face la întâmplare, atunci spunem c am facut o selecµie întâmpl toare. Nu-m rul indivizilor din selecµia aleas se va numi volumul selecµiei. Dac se face o enumerare sau olistare a ec rui element component al unei a populaµii statistice, atunci spunem c am facut unrecens mânt. Selecµia ar trebui s e reprezentativ pentru populaµia din care face parte. Numito selecµie repetat (sau cu repetiµie) o selecµie în urma c reia individul ales a fost reintrodus dinnou în colectivitate. Altfel, avem o selecµie nerepetat . Selecµia nerepetat nu prezint interesdac volumul colectivit µii este nit, deoarece în acest caz probabilitatea ca un alt individ s eales într-o extragere nu este aceea³i pentru toµi indivizii colectivit µii. Pe de alt parte, dac volumul întregii populaµii statistice este mult mai mare decât cel al e³antionului extras, atunciputem presupune c selecµia efectuat este repetat , chiar dac în mod practic ea este nerepetat .Spre exemplu, dac dorim s facem o prognoz a cine va noul pre³edinte la alegerile din toamn ,e³antionul ales (de altfel, unul foarte mic comparativ cu volumul populaµiei cu drept de vot) seface, în general, f r repetiµie, dar îl putem considera a o selecµie repetat , în vederea aplic riitestelor statistice.Selecµiile aleatoare se pot realiza prin diverse metode, în funcµie de urm torii factori: disponibi-litatea informaµiilor necesare, costul operaµiunii, nivelul de precizie al informaµiilor etc. Mai josprezent m câteva metode de selecµie.
• selecµie simpl de un volum dat, prin care toµi indivizii ce compun populaµia au aceea³i³ans de a ale³i. Aceast metod mininimizeaz riscul de a p rtinitor sau favorabilunuia dintre indivizi. Totu³i, aceast metod are neajunsul c , în anumite cazuri, nu reect componenµa întregii populaµii. Se aplic doar pentru colectivit µi omogene din punctul devedere al tr s turii studiate.
• selecµie sistematic , ce presupune aranjarea populaµiei studiate dup o anumit schem or-donat ³i selectând apoi elementele la intervale regulate. (e.g., alegerea a ec rui al 10-leanum r dintr-o carte de telefon, primul num r ind ales la întâmplare (simplu) dintre primele10 din list ).
• selecµie straticat , în care populaµia este separat în categorii, iar alegerea se face la întâm-plare din ecare categorie. Acest tip de selecµie face ca ecare grup ce compune populaµia s poata reprezentat în selecµie. Alegerea poate facut ³i în funcµie de m rimea ec rui grupce compune colectivitatea total (e.g., aleg din ecare judeµ un anumit num r de persoane,proporµional cu num rul de persoane din ecare judeµ).
• selecµie ciorchine, care este un e³antion straticat construit prin selectarea de selecµii dinanumite straturi (nu din toate).
• selecµia de tip experienµ , care µine cont de elementul temporal în selecµie. (e.g., diver³i timpide pe o encefalogram ).
• selecµie de convenienµ : de exemplu, alegem dintre persoanele care trec prin faµa universit µii.
• selecµie de judecat : cine face selecµia decide cine ramâne sau nu în selecµie.
• selecµie de cot : selecµia ar trebui s e o copie a întregii populaµii, dar la o scar mult maimic . A³adar, putem selecta proporµional cu num rul persoanelor din ecare ras , de ecare

C1 & L1 [Dr. Iulian Stoleriu] 5
gen, origine etnic etc) (e.g., persoanele din Parlament ar trebui s e o copie reprezentativ a persoanelor întregii µ ri, într-o scar mult mai mic ).
Organizarea ³i descrierea datelor
Presupunem c avem o colectivitate statistic , c reia i se urm re³te o anumit caracteristic .(e.g., colectivitatea este mulµimea tuturor studenµilor dintr-o universitate înrolaµi într-un anumitan de studii, iar caracteristica este num rul de credite obµinute de studenµi în decursul acelui an).Vom numi date informaµiile obµinute în urma observaµiei valorilor acestei caracteristici. Datelepot calitative sau cantitative, dup cum caracteristica (sau variabila) observat este calitativ sau, respectiv, cantitativ . Aceste date pot date discrete, dac sunt obµinute în urma observ riiunei caracteristici discrete (o variabila aleatoare discret ), sau date continue, dac aceast carac-teristic este continu (o variabil aleatoare de tip continuu). În cazul din exemplu, datele vor cantitative ³i discrete.Primul pas în analiza datelor proasp t culese este de a le ordona ³i reprezenta grac, dar ³i de acalcula anumite caracteristici numerice pentru acestea. Datele înainte de prelucrare, adic exacta³a cum au fost culese, se numesc date negrupate. De exemplu, num rul de apeluri la 112 în lunaIulie, specicat zilnic, este:
871 822 729 794 523 972 768 758 583 893 598 743 761 858 948
598 912 893 697 867 877 649 738 744 798 812 793 688 589 615 731
De cele mai multe ori, enumerarea tuturor datelor culese este dicil de realizat, de aceea se urm -re³te a se grupa datele, pentru o mai u³oar gestionare. Imaginaµi-v c enumer m toate voturileunei selecµii întâmpl toare de 15000 de votanµi, abia ie³iµi de la vot. Mai degrab , este util s grup m datele dup numele candidaµilor, precizând num rul de voturi ce l-a primit ecare.
Gruparea datelor
Datele prezentate sub form de distribuµie (tabel) de frecvenµe se numesc date grupate. Datelede selecµie obµinute pot date discrete sau date continue, dup cum caracteristicile studiate suntvariabile aleatoare discrete sau, respectiv, continue.
(1) Dac datele de selecµie sunt discrete (e.g., x1, x2, . . . , xn) ³i au valorile distinctex′1, x
′2, . . . , x
′r, r ≤ n, atunci ele pot grupate într-un a³a-numit tabel de frecvenµe (vezi exemplul
din Figura 1.1) sau într-un tablou de frecvenµe, dup cum urmeaz :
data :
(x′1 x′2 . . . x′rf1 f2 . . . fr
)unde fi este frecvenµa apariµiei valorii x′i, (i = 1, 2, . . . , r), ³i se va numi distribuµia empiric deselecµie a lui X. Aceste frecvenµe pot absolute sau de relative. Un tabel de frecvenµe (sau odistribuµie de frecvenµe) conµine toate categoriile ce sunt observate din datele colectate ³i num rulde elemente ce aparµine ec rei categorii în parte, adic frecvenµa absolut . O frecvenµ relativ se obµine prin împ rµirea frecvenµei absolute a unei categorii la suma tuturor frecvenµelor din tabel.

C1 & L1 [Dr. Iulian Stoleriu] 6
nota frecvenµa frecvenµa relativ 2 2 2.22%3 4 4.44%4 8 8.89%5 15 16.67%6 18 20.00%7 17 18.89%8 15 16.67%9 7 7.78%10 4 4.44%
Total 90 100%
Tabela 1.1: Tabel cu frecvenµe pentru date discrete.
Astfel, suma tuturor frecvenµelor relative este egal cu 1. Elementele unui tabel sunt, de regul :valori pentru variabile, frecvenµe sau frecvenµe relative.
În Tabelul 1.1, sunt prezentate notele studenµilor din anul al III-lea la examenul de Statistic .Acesta este exemplu de tabel ce reprezent o caracteristic discret .
Observaµia 1.1 (o glum povestit de G. Pólya,1 despre cum NU ar trebui interpretat frecvenµarelativ )Un individ suferind merge la medic. Medicul îl examineaz îndelung ³i, balansând dezam gitcapul, îi spune pacientului:"Of... drag domnule pacient, am dou ve³ti: una foarte proast ³i una bun . Mai întâi v aducla cuno³tinµ vestea proast : suferiµi de o boal groaznic . Statistic vorbind, din zece pacienµi cecontracteaz aceast boal , doar unul scap ."Pacientul, deja în culmea disper rii, este totu³i consolat de doctor cu vestea cea bun :"Dar, µi pe pace! Dumneavoastr aµi venit la mine, ³i asta v face tare norocos", continu optimist doctorul."Am avut deja nou pacienµi ce au avut aceea³i boal ³i toµi au murit, a³a c ... veµi supravieµui!"
(1) bis. La ecare 5 oameni de pe P mânt, unul este chinez. Asta ar înseamna c , dac la curssunt 23 de persoane, atunci exist m car 4 chinezi printre ei!(2) Dac X este de tip continuu, atunci se obi³nuieste s se fac o grupare a datelor de selecµie înclase. De exemplu, ni se dau datele din Tabelul 1.2, reprezentând timpi (în min.sec) de a³teptarepentru primii 100 de clienµi care au a³teptat la un ghi³eu pân au fost serviµi.
Putem grupa datele de tip continuu într-un tablou de distribuµie de forma:
data :
([a0, a1) [a1, a2) . . . [ar−1, ar)f1 f2 . . . fr
),
sau sub forma unui tabel de distribuµie (vezi Tabelul 1.3). A³adar, putem grupa datele de tip
1György Pólya (1887− 1985), matematician ungur

C1 & L1 [Dr. Iulian Stoleriu] 7
1.02 2.01 2.08 3.78 2.03 0.92 4.08 2.35 1.30 4.50 4.06 3.55 2.63 1.76
0.13 5.32 3.97 3.36 4.31 3.58 5.64 1.95 0.91 1.26 0.74 3.64 4.77 2.14
2.98 4.33 5.08 4.67 0.79 3.14 0.99 0.78 2.34 4.51 3.53 4.55 1.89 3.28
0.94 3.44 1.35 3.64 2.92 2.67 2.86 2.41 3.19 5.41 5.14 2.75 1.67 3.89
1.12 4.75 2.88 4.30 4.55 5.87 0.70 5.04 5.33 2.40 1.50 0.83 3.74 4.85
3.79 1.48 2.65 1.55 3.95 5.88 1.58 5.49 0.48 2.77 3.20 2.51 5.80 4.12
3.12 0.71 2.76 1.95 0.10 4.22 5.69 5.41 1.68 2.46 1.40 2.16 4.98 0.88
5.36 1.32
Tabela 1.2: Date statistice negrupate
clasa frecvenµa valoare medie[a0, a1) f1 x′1[a1, a2) f2 x′2
......
...[ar−1, ar) fr x′r
Tabela 1.3: Tabel cu frecvenµe pentru date continue.
continuu de mai sus în tablou de distribuµie:([0, 1) [1, 2) [2, 3) [3, 4) [4, 5) [5, 6)
14 17 21 18 16 14
). (1.2)
Uneori, tabelul de distribuµie pentru o caracteristic de tip continuu mai poate scris ³i sub forma:
data :
(x′1 x′2 . . . x′rf1 f2 . . . fr
)unde
• x′i =ai−1 + ai
2este elementul de mijloc al clasei [ai−1, ai);
• fi este frecvenµa apariµiei valorilor din [ai−1, ai), (i = 1, 2, . . . , r),r∑i=1
fi = n.
A³adar, dac ne este dat o în³iruire de date ale unei caracteristici discrete sau continue, atuncile putem grupa imediat în tabele sau tablouri de frecvenµe. Invers (avem tabelul sau tabloul derepartiµie ³i vrem s enumer m datele) nu este posibil, decât doar în cazul unei caracteristici detip discret. De exemplu, dac ni se d Tabelul 1.4, ce reprezint rata somajului într-o anumit regiune a µ rii pe categorii de vârste, nu am putea ³ti cu exactitate vârsta exact a persoanelorcare au fost selecµionate pentru studiu.
Observ m c acest tabel are 5 clase: [18, 25), [25, 35), [35, 45), [45, 55), [55, 65). Vom numivaloare de mijloc pentru o clas , valoarea obµinut prin media valorilor extreme ale clasei. Încazul Tabelului 1.4, valorile de mijloc sunt scrise în coloana cu vârsta medie. Frecvenµa cumulat a unei clase este suma frecvenµelor tuturor claselor cu valori mai mici.

C1 & L1 [Dr. Iulian Stoleriu] 8
vârsta frecvenµa frecvenµa relativ frecvenµa cumulat vârsta medie[18, 25) 34 8.83% 8.83% 21.5[25, 35) 76 19.74% 28.57% 30[35, 45) 124 32.21% 60.78% 40[45, 55) 87 22.60% 83.38% 50[55, 65) 64 16.62% 100.00% 60Total 385 100% - -
Tabela 1.4: Tabel cu frecvenµe pentru rata somajului.
Vom numi o serie de timp (sau serie dinamic ori cronologic ) un tablou de forma
data :
(x1 x2 . . . xnt1 t2 . . . tn
),
unde xi sunt variabile de r spuns, iar ti momente de timp (e.g., r spunsurile citite de un electro-cardiograf).
Motive serioase pentru care merit s devii statistician(top 10)
(10) Pentru statisticienii, deviaµiile sunt considerate a normale.
(9) Statisticienii lucreaz discret ³i continuu.
(8) Putem concluziona orice dorim, la un nivel de semnicaµie potrivit.
(7) Nu trebuie s spunem niciodat ca suntem siguri; e sucient doar 95%.
(6) Normalitatea nu este o condiµie sine qua non.
(5) Suntem semnicativ diferiµi.
(4) Putem testa, f r probleme ³i folosind o lege bine stabilit , distribuµia posterioar a cuiva.
(3) Statistica este arta de a nu nevoit s spui vreodat c ai gre³it.
(2) Un statistician poate sta cu capul într-un cuptor incandescent ³i cu picioarele înpte îngheaµ ³i s spun c , în medie, se simte bine.
(1) Aproape nimeni nu dore³te jobul nostru important, deci nu vei avea emoµii c vei r mâne³omer.

Laborator 1 [Dr. Iulian Stoleriu] 9
Statistic Aplicat (Laborator 1)
Reprezent ri grace
Un tabel de frecvenµe sau o distribuµie de frecvenµe (absolute sau relative) sunt de cele mai multeori baza unor reprezent ri grace, pentru o mai bun vizualizare a datelor. Aceste reprezent ripot f cute în diferite moduri, dintre care amintim pe cele mai uzuale.
5 6 7 8 9 100
0.2
0.4
0.6
Figura 1.1: Reprezentarea cu puncte.
Reprezentare prin puncte
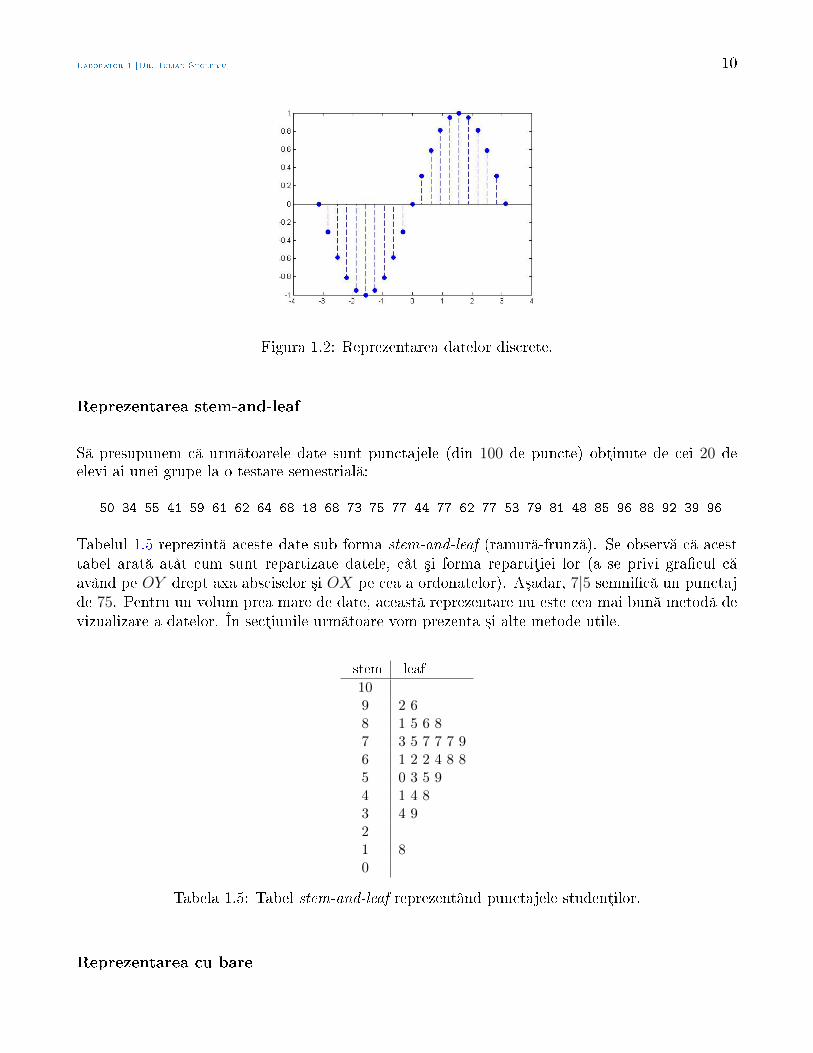
Reprezentarea prin puncte (en., dot plot) este folosit pentru selecµii de dimensiuni mici. Suntreprezentate puncte a³ezate unul peste celalalt, reprezentând num rul de apariµii ale unei valoripentru caracteristica dat . Un astfel de grac este reprezentat în Figura 1.1. Aceste reprezent risunt utile atunci când se dore³te scoaterea în evidenµ a anumitor pâlcuri de date (en., clusters) sauchiar lipsa unor date (goluri). Au avantajul de a conserva valoarea numeric a datelor reprezentate.
O funcµie Matlab util pentru reprezentarea datelor discrete este funcµia stem. Aceast funcµiereprezint datele sub forma unor linii verticale terminate cu un un cerculeµ gol (în mod implicit)la extremitatea opus axei. Are formatul general:
stem(X, Y, 'fill', 'type') % deseneaza pe Y vs. X
Opµiunea 'fill' poate lipsi; dac ea apare, atunci coloreaz cercurile din grac. Opµiunea 'type'se refer la tipul de linie folosit; poate linie continu (în mod implicit), punctat (:) sau de tiplinie-punct (−.). Spre exemplu, linia de cod
x = -pi:pi/10:pi; stem(x, sin(x), 'fill', '--')
produce Figura 1.2.
Laborator 1 [Dr. Iulian Stoleriu] 10
Figura 1.2: Reprezentarea datelor discrete.
Reprezentarea stem-and-leaf
S presupunem c urm toarele date sunt punctajele (din 100 de puncte) obµinute de cei 20 deelevi ai unei grupe la o testare semestrial :
50 34 55 41 59 61 62 64 68 18 68 73 75 77 44 77 62 77 53 79 81 48 85 96 88 92 39 96
Tabelul 1.5 reprezint aceste date sub forma stem-and-leaf (ramur -frunz ). Se observ c acesttabel arat atât cum sunt repartizate datele, cât ³i forma repartiµiei lor (a se privi gracul c având pe OY drept axa absciselor ³i OX pe cea a ordonatelor). A³adar, 7|5 semnic un punctajde 75. Pentru un volum prea mare de date, aceast reprezentare nu este cea mai bun metod devizualizare a datelor. În secµiunile urm toare vom prezenta ³i alte metode utile.
stem leaf109 2 68 1 5 6 87 3 5 7 7 7 96 1 2 2 4 8 85 0 3 5 94 1 4 83 4 921 80
Tabela 1.5: Tabel stem-and-leaf reprezentând punctajele studenµilor.
Reprezentarea cu bare
Laborator 1 [Dr. Iulian Stoleriu] 11
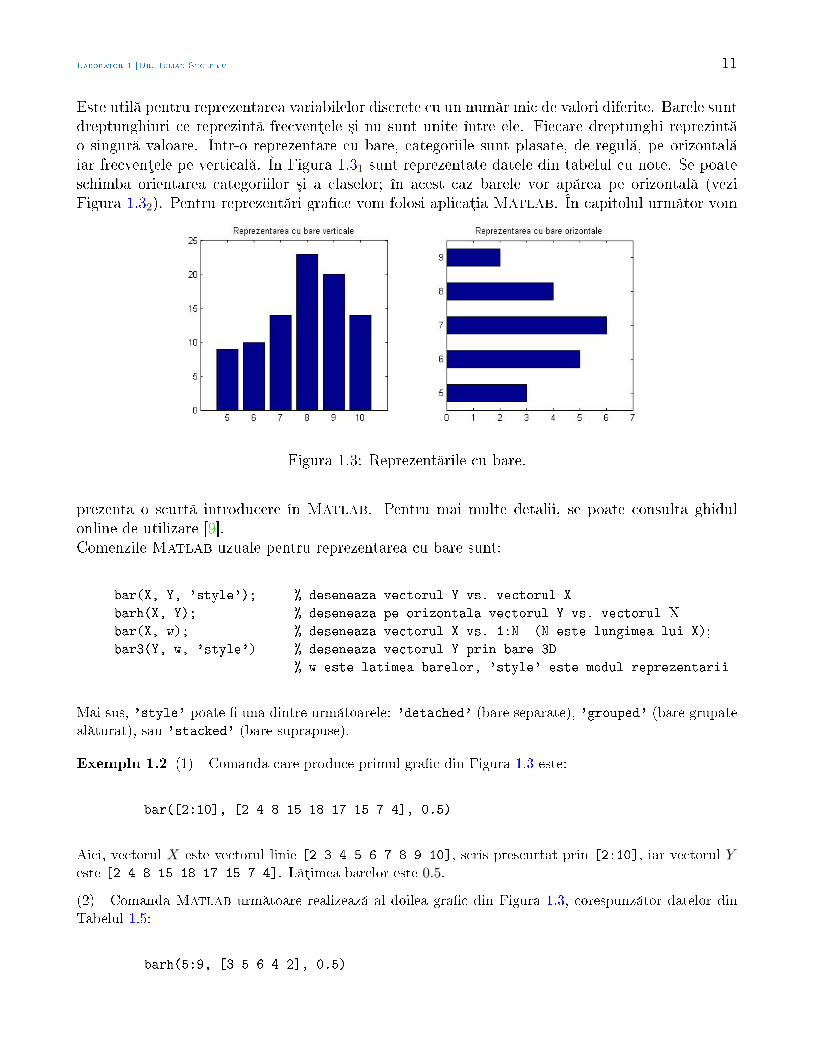
Este util pentru reprezentarea variabilelor discrete cu un num r mic de valori diferite. Barele suntdreptunghiuri ce reprezint frecvenµele ³i nu sunt unite între ele. Fiecare dreptunghi reprezint o singur valoare. Într-o reprezentare cu bare, categoriile sunt plasate, de regul , pe orizontal iar frecvenµele pe vertical . În Figura 1.31 sunt reprezentate datele din tabelul cu note. Se poateschimba orientarea categoriilor ³i a claselor; în acest caz barele vor ap rea pe orizontal (veziFigura 1.32). Pentru reprezent ri grace vom folosi aplicaµia Matlab. În capitolul urm tor vom
Figura 1.3: Reprezent rile cu bare.
prezenta o scurt introducere în Matlab. Pentru mai multe detalii, se poate consulta ghidulonline de utilizare [9].Comenzile Matlab uzuale pentru reprezentarea cu bare sunt:
bar(X, Y, 'style'); % deseneaza vectorul Y vs. vectorul X
barh(X, Y); % deseneaza pe orizontala vectorul Y vs. vectorul Xbar(X, w); % deseneaza vectorul X vs. 1:N (N este lungimea lui X);bar3(Y, w, 'style') % deseneaza vectorul Y prin bare 3D
% w este latimea barelor, 'style' este modul reprezentarii
Mai sus, 'style' poate una dintre urm toarele: 'detached' (bare separate), 'grouped' (bare grupateal turat), sau 'stacked' (bare suprapuse).
Exemplu 1.2 (1) Comanda care produce primul grac din Figura 1.3 este:
bar([2:10], [2 4 8 15 18 17 15 7 4], 0.5)
Aici, vectorul X este vectorul linie [2 3 4 5 6 7 8 9 10], scris prescurtat prin [2:10], iar vectorul Yeste [2 4 8 15 18 17 15 7 4]. L µimea barelor este 0.5.
(2) Comanda Matlab urm toare realizeaz al doilea grac din Figura 1.3, corespunz tor datelor dinTabelul 1.5:
barh(5:9, [3 5 6 4 2], 0.5)
Laborator 1 [Dr. Iulian Stoleriu] 12
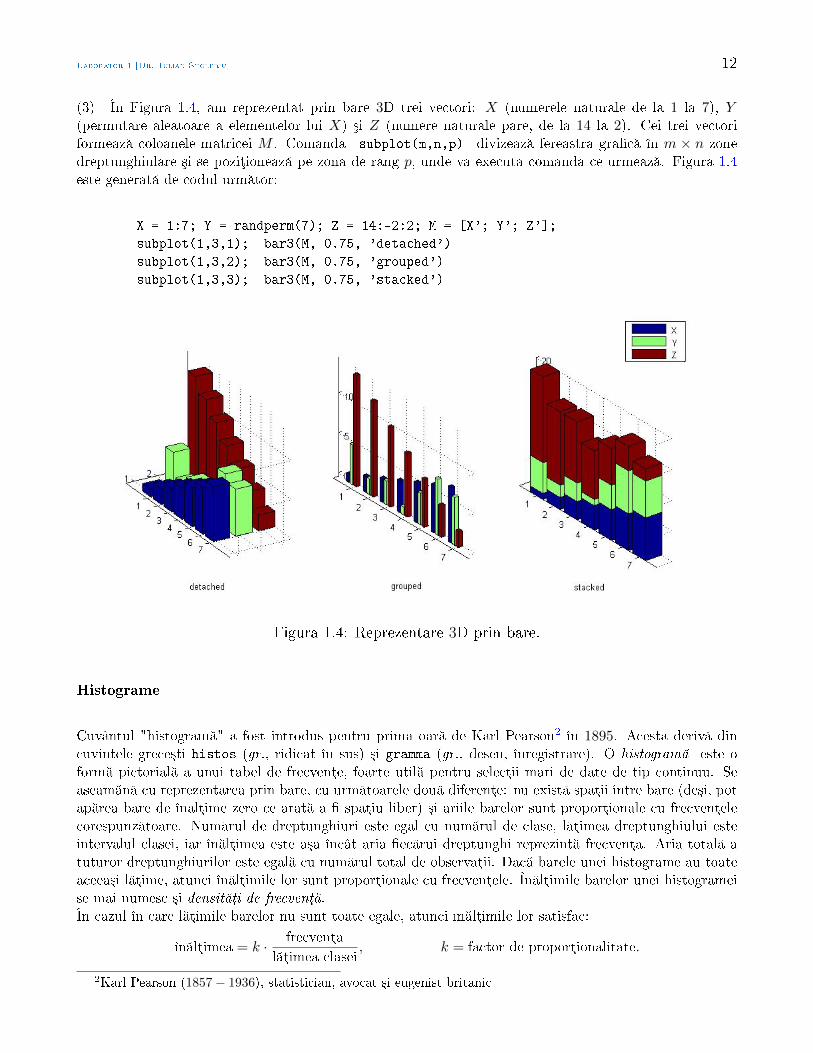
(3) În Figura 1.4, am reprezentat prin bare 3D trei vectori: X (numerele naturale de la 1 la 7), Y(permutare aleatoare a elementelor lui X) ³i Z (numere naturale pare, de la 14 la 2). Cei trei vectoriformeaz coloanele matricei M . Comanda subplot(m,n,p) divizeaz fereastra grac în m × n zonedreptunghiulare ³i se poziµioneaz pe zona de rang p, unde va executa comanda ce urmeaz . Figura 1.4este generat de codul urm tor:
X = 1:7; Y = randperm(7); Z = 14:-2:2; M = [X'; Y'; Z'];
subplot(1,3,1); bar3(M, 0.75, 'detached')
subplot(1,3,2); bar3(M, 0.75, 'grouped')
subplot(1,3,3); bar3(M, 0.75, 'stacked')
Figura 1.4: Reprezentare 3D prin bare.
Histograme
Cuvântul "histogram " a fost introdus pentru prima oar de Karl Pearson2 în 1895. Acesta deriv dincuvintele grece³ti histos (gr., ridicat în sus) ³i gramma (gr., desen, înregistrare). O histogram este oform pictorial a unui tabel de frecvenµe, foarte util pentru selecµii mari de date de tip continuu. Seaseam n cu reprezentarea prin bare, cu urm toarele dou diferenµe: nu exist spaµii între bare (de³i, potap rea bare de înalµime zero ce arat a spaµiu liber) ³i ariile barelor sunt proporµionale cu frecvenµelecorespunz toare. Num rul de dreptunghiuri este egal cu num rul de clase, l µimea dreptunghiului esteintervalul clasei, iar în lµimea este a³a încât aria ec rui dreptunghi reprezint frecvenµa. Aria total atuturor dreptunghiurilor este egal cu num rul total de observaµii. Dac barele unei histograme au toateaceea³i l µime, atunci în lµimile lor sunt proporµionale cu frecvenµele. În lµimile barelor unei histogrameise mai numesc ³i densit µi de frecvenµ .În cazul în care l µimile barelor nu sunt toate egale, atunci în lµimile lor satisfac:
în lµimea = k · frecvenµal µimea clasei
, k = factor de proporµionalitate.
2Karl Pearson (1857− 1936), statistician, avocat ³i eugenist britanic

Laborator 1 [Dr. Iulian Stoleriu] 13
În lµimea (în cm) frecvenµa[0, 5) 5[5, 10) 13[10, 15) 23[15, 20) 17[20, 25) 10[25, 30) 2
Tabela 1.6: Tabel cu în lµimile plantelor.
Tabela 1.7: Histograme pentru datele din Tabelul 1.6.
Comenzile Matlab uzuale pentru crearea histogramelor sunt:
hist(X, n); % unde X este un vector, n este numarul de bare
hist(X, Y); % deseneaza distributia vectorului X, cu numarul de bare egal cu
% lungimea vectorului Y, centrate in elementele lui Y
N = histc(X,E); % returneaza numarul N de valori ale vectorului X, care se afla
% intre elementele vectorului E
bar(E,N,'histc') % reprezinta grafic pe N determinat anterior
hist3(Y) % realizeaza o histogram 3D, unde Y este vector bidimensional
Datele din Tabelul 1.6 reprezint în lµimile unui e³antion de plante culese de un cercet tor dintr-o anu-mit regiune a µ rii. Reprezentarea cu histograme asociat acestor date este cea din Figura 1.7. CodulMatlab care produce acest grac este:
X = [5*rand(5,1); 5*rand(13,1)+5; 5*rand(23,1)+10; 5*rand(17,1)+15; ...
5*rand(10,1)+20; 5*rand(2,1)+25]; % genereaza un vector X ca in Tabelul 1.6C = [2.5 7.5 12.5 17.5 22.5 27.5]; % mijloacele latimilor barelor
hist(X,C); % deseneaza 6 histograme
axis([-1 31 0 30]) % fixeaza axele
S presupunem c altcineva ar grupat datele din Tabelul 1.6 într-o alt manier , în care clasele nusunt echidistante (vezi Tabelul 1.8). În Tabelul 1.8, datele din ultimele dou clase au fost cumulateîntr-o singur clas , de l µime mai mare decât celelalte, deoarece ultima clas din Tabelul 1.6 nu aveasuciente date. Histograma ce reprezint datele din Tabelul 1.8 este cea din Figura 1.9. Conform curegula proporµionalit µii ariilor cu frecvenµele, se poate observa c primele patru bare au în lµimi egalecu frecvenµele corespunz toare, pe când în lµimea ultimei bare este jum tate din valoarea frecvenµeicorespunz toare, deoarece l µimea acesteia este dublul l µimii celorlalte.În general, pentru a construi o histogram , vom avea în vedere urm toarele:− datele vor împ rµite (unde este posibil) în clase de lungime egal . Uneori aceste diviz ri sunt naturale,alteori va trebui s le fabric m.− num rul de clase este, în general, între 5 ³i 20.

Laborator 1 [Dr. Iulian Stoleriu] 14
− înregistraµi num rul de date ce cad în ecare clas (numite frecvenµe).− gura ce conµine histograma va avea clasele pe orizontal ³i frecvenµele pe vertical .
Liniile de cod urm toare simuleaz histograma reprezentat în Figura 1.5:
x = randn(1000, 2); % numere repartizate normal
hist3(x)
Figura 1.5: Histogram 3D.
Observaµia 1.3 (1) Dac lungimea unei clase este innit (e.g., ultima clas din Tabelul 1.8 este[20, ∞)), atunci se obi³nuie³te ca l µimea ultimului interval s e luat drept dublul l µimii intervalu-lui precedent.(2) În multe situaµii, capetele intervalelor claselor sunt ni³te aproxim ri, iar în locul acestora vom puteautiliza alte valori. Spre exemplu, s consider m clasa [15, 20). Aceast clas reprezint clasa acelor plantece au în lµimea cuprins între 15cm ³i 20cm. Deoarece valorile în lµimilor sunt valori reale, valorile 15³i 20 sunt, de fapt, aproxim rile acestor valori la cel mai apropiat întreg. A³adar, este posibil ca aceast clas s conµin acele plante ce au în lµimile situate între 14.5cm (inclusiv) ³i 20.5cm (exclusiv). Amputea face referire la aceste valori ca ind valorile reale ale clasei, numite frontierele clasei. În cazul încare am determinat frontierele clasei, l µimea unei clase se dene³te ca ind diferenµa între frontierele ce-icorespund. În concluzie, în cazul clasei [15, 20), aceasta are frontierele 14.5 - 20.5, l µimea 6 ³i densitateade frecvenµ 17
6 . Pentru exemplicare, în Tabelul 1.10 am prezentat frontierele claselor, l µimile lor ³idensit µile de frecvenµ pentru datele din Tabelul 1.4.
Reprezentare prin sectoare de disc
Se poate desena distribuµia unei caracteristici folosind sectoare de disc (diagrame circulare) (en., piecharts), ecare sector de disc reprezentând câte o frecvenµ relativ . Aceast variant este util în special
Laborator 1 [Dr. Iulian Stoleriu] 15
În lµimea (în cm) frecvenµa[0, 5) 5[5, 10) 13[10, 15) 23[15, 20) 17[20, 30) 12
Tabela 1.8: Tabel cu în lµimile plantelor.
Tabela 1.9: Histograme pentru datele din Tabelul 1.8.
în lµimea (în cm) frontierele l µimea frecvenµa densitatea de frecvenµ [18, 25) 17.5− 25.5 8 34 4.25[25, 35) 24.5− 35.5 11 76 6.91[35, 45) 34.5− 45.5 11 124 11.27[45, 55) 44.5− 55.5 11 87 7.91[55, 65) 54.5− 65.5 11 64 5.82
Tabela 1.10: Tabel cu frontierele claselor.
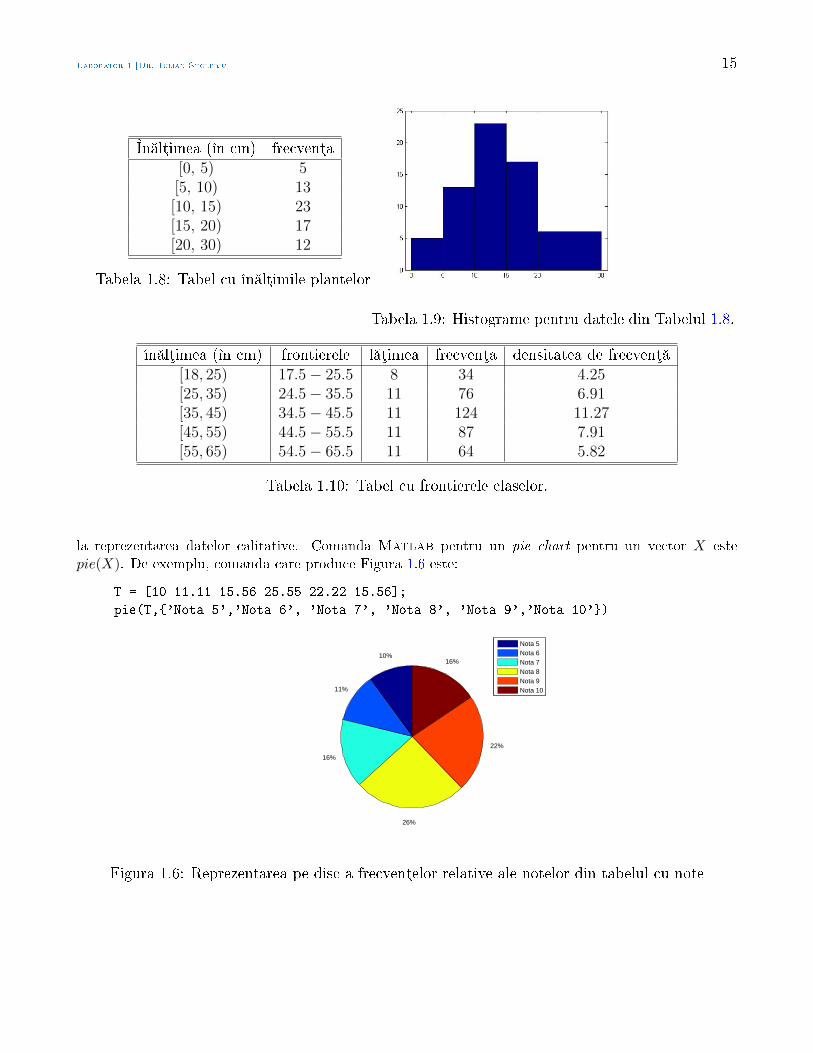
la reprezentarea datelor calitative. Comanda Matlab pentru un pie chart pentru un vector X estepie(X). De exemplu, comanda care produce Figura 1.6 este:
T = [10 11.11 15.56 25.55 22.22 15.56];
pie(T,'Nota 5','Nota 6', 'Nota 7', 'Nota 8', 'Nota 9','Nota 10')
10%
11%
16%
26%
22%
16%
Nota 5Nota 6Nota 7Nota 8Nota 9Nota 10
Figura 1.6: Reprezentarea pe disc a frecvenµelor relative ale notelor din tabelul cu note

STATS 2 [Dr. Iulian Stoleriu] 16
2 Statistic Aplicat (C2)
Elemente de Teoria probabilit µilor
Experienµe aleatoare
Numim experienµ aleatoare (sau experiment aleator) orice act cu rezultat incert, care poate repetat înanumite condiµii date. Opusul noµiunii de experiment aleator este experimentul determinist, semnicândun experiment ale c rui rezultate sunt complet determinate de condiµiile în care acesta se desf ³oar . Re-zultatul unui experiment aleator depinde de anumite circumstante întâmpl toare ce pot aparea. Exemplede experienµe aleatoare: jocurile de noroc, aruncarea zarului, observarea duratei de viaµ a unui individ,observarea vremii de a doua zi, observarea num rului de apeluri telefonice recepµionate de o centralatelefonic într-un timp dat. Aplicarea experienµei asupra unei colectivit µi date se nume³te prob . Re-zultatul potenµial al unei experienµe aleatoare se nume³te eveniment aleator. De exemplu: apariµia uneiduble (6, 6) la aruncarea a dou zaruri, extragerea unei bile albe dintr-o urn . Se nume³te caz favorabilpentru evenimentul aleator un caz în care respectivul eveniment se realizeaz . Un eveniment aleator poateavea mai multe cazuri favorabile. Un eveniment aleator cu un singur caz favorabil se nume³te evenimentelementar.Fie Ω o mulµime nevid , pe care o vom numi mulµimea tuturor evenimentelor elementare. Un elemental lui Ω îl vom nota cu ω. Vom numi evenimentul sigur, acel eveniment care se poate realiza în urmaoric rei experienµe aleatoare. Evenimentul imposibil este acel eveniment ce nu se realizeaz în nicio prob .Evenimentele aleatoare le vom nota cu A, B, C, . . . . Prin Ac vom nota evenimentul complementar lui A,care se realizeaz atunci când A nu se realizeaz . Avem: Ac = Ω \A.Pentru a putea cuantica ³ansele de realizare a unui eveniment aleator, s-a introdus noµiunea de probabi-litate. În literatura de specialitate, probabilitatea este denit în mai multe moduri: cu deniµia clasic (apare pentru prima oar în lucr rile lui P. S. Laplace3), folosind o abordare statistic (cu frecvenµerelative) sau utilizând deniµia axiomatic (Kolmogorov).
Probabilitatea clasic este denit doar pentru cazul în care experienµa aleatoare are un num r nit decazuri posibile ³i echiprobabile (toate au aceea³i ³ans de a se realiza). În acest caz, probabilitatea derealizare a unui eveniment este raportul dintre num rul cazurilor favorabile realiz rii evenimentului ³inum rul cazurilor egal posibile ale experimentului aleator.
Exemplu 2.1 Se cere probabilitatea obµinerii unei duble la o singur aruncare a unei perechi de zaruriideale. Mulµimea cazurilor posibile este mulµimea tuturor perechilor (i, j); i, j = 1, 6, care are 36 deelemente. Cazurile favorabile sunt cele din mulµimea (1, 1), (2, 2), (3, 3), (4, 4), (5, 5), (6, 6), adic 6elemente. Probabilitatea apariµiei unei duble este P = 6
36 = 16 .
Sunt îns foarte multe cazuri în care deniµia clasic nu mai poate utilizat . Spre exemplu, în cazulîn care se cere probabilitatea ca, alegând la întâmplare un punct din p tratul [0, 1] × [0, 1], acesta s sesitueze deasupra primei bisectoare. În acest caz, atât num rul cazurilor posibile, cât ³i num rul cazurilorfavorabile este innit, f când deniµia clasic a probabilit µii inutilizabil .
Probabilitatea statistic exprim probabilitatea cu ajutorul frecvenµelor de realizare a unui eveniment într-un num r mare de experimente aleatoare realizate în acelea³i condiµii.
3Pierre-Simon, marquis de Laplace (1749− 1827), matematician ³i astronom francez

STATS 2 [Dr. Iulian Stoleriu] 17
S consider m o experienµ aleatoare (e.g., aruncarea unui zar) al c rei rezultat posibil este evenimentulaleator A (e.g., apariµia feµei cu 6 puncte). Aceste experiment aleator îl putem efectua de N ori încondiµii identice (spunem c efectu m N probe ale experimentului), astfel încât rezultatul unei probe s nu inuenµeze rezultatul alteia (probe independente). S not m cu νN (A) frecvenµ absolut de realizare
a lui A în cele N probe independente. RaportulνN (A)
Nse va numi frecvenµ relativ . Not m cu fN (A)
acest raport, ce are urm toarele propriet µi:
(a) 0 ≤ fN (A) ≤ 1;
(b) fN (Ω) = 1;
(c) fN (Ac) = 1− fN (A), ∀A;
(d) fN (A⋃B) = fN (A) + fN (B), dac A
⋂B = ∅.
Mai mult, exist limN→∞
fN (A) ³i aceasta este denit ca ind probabilitatea de realizare a evenimentului A,
notat P (A). A³adar, în cazul deniµiei statistice a probabilit µii, aceasta este limit ³irului frecvenµelorrelative de producere a respectivului eveniment când num rul de probe tinde la innit (vezi Teorema 4.6).
În cele ce urmeaz , vom deni noµiunea de probabilitate din punct de vedere axiomatic. Aceast axioma-tic a fost introduse de matematicianul rus A. N. Kolmogorov4 (1929) ³i are la baza teoria m surii.
Deniµia axiomatic a probabilit µii
Reamintim, Ω este o mulµime abstract , nevid .
Deniµia 2.2 Numim algebr sau câmp o colecµie F de submulµimi ale lui Ω astfel încât:(a) ∅ ∈ F ;(b) dac A ∈ F , atunci Ac ∈ F ; (Ac = Ω \A) (închidere la complementariere)(c) dac A, B ∈ F , atunci A
⋃B ∈ F (închidere la reuniune nit ).
Propoziµia 2.3 (c) implic
(c') dac (Ai)i=1, n ∈ F , atuncin⋃i=1
Ai ∈ F . (2.1)
Deniµia 2.4 Numim σ−algebr sau σ−câmp (sau corp borelian) o colecµie F de submulµimi ale lui Ωastfel încât (a), (b) din deniµia anterioar sunt satisf cute ³i, în plus, avem
(c') dac (An)n∈N ∈ F , atunci∞⋃n=1
An ∈ F ; (închidere la reuniune num rabil ) (2.2)
Exemplu 2.5 (1) Ω = R ³i F = A; A ⊂ R este o σ−algebr ;(2) F = Ω, ∅ este o algebr ;(3) Dac A ∈ Ω, F = A, Ac, Ω, ∅ este o algebr ;(4) Dac A ⊂ R, atunci mulµimea tuturor p rµilor lui A, P(A), formeaz o σ-algebr .(5) Dac Ω e o mulµime nevid ³i F este o σ−algebr pe Ω, atunci perechea (Ω, F) se nume³te spaµium surabil. Elementele unei σ-algebre se numesc mulµimi m surabile.
4Andrei Nikolaevich Kolmogorov (1903− 1987), matematician rus

STATS 2 [Dr. Iulian Stoleriu] 18
Deniµia 2.6 Fie F o colecµie de submulµimi ale lui Ω. Numim σ−algebr generat de F cea mai mic σ−algebr ce conµine F . O not m prin σ(F) ³i este, de fapt,
σ(F) =⋂A⊃F
A. (2.3)
Dac E e un spaµiu topologic, vom numi σ-algebr Borel5, notat B(E), σ-algebra generat de familiamulµimilor deschise din E, i.e., cea mai mic σ-algebr ce conµine deschi³ii lui E.Dac E = Rd, atunci B(Rd) (sau Bd) este σ-algebra generat de cuburile deschise din Rd. O mulµimeA ∈ Bd se nume³te mulµime borelian .
Deniµia 2.7 O funcµie P : (Ω, F)→ R, care asociaz oric rui eveniment A ∈ F num rul real P (A), cupropriet µile:
(a) P (A) ≥ 0, ∀A ∈ F ;
(b) P (Ω) = 1;
(c) P (A⋃B) = P (A) + P (B),∀A, B ∈ F , A
⋂B = ∅,
se nume³te probabilitate.
Aceasta este deniµia axiomatic dat de A. N. Kolmogorov. Un câmp de evenimente (Ω, F) înzestrat cuo probabilitate P se nume³te câmp de probabilitate în sens Kolmogorov ³i îl vom nota cu (Ω, F , P ).
Observaµia 2.8 Dac în locul condiµiei (c) avem:(c)′ dac (An)n∈N ∈ F disjuncte dou câte dou (Ai
⋂Aj = ∅, ∀i 6= j) ³i P (
⋃n∈N
An) ∈ F , atunci
P (⋃n∈N
An) =∑n∈N
P (An). (σ − aditivitate) (2.4)
atunci P se va numi probabilitate σ−aditiv pe corpul borelian (Ω, F), iar (Ω, F , P ) se va numi câmpborelian de probabilitate.
Observaµia 2.9 (1) Fie Ω o mulµime cu n elemente, F = P(Ω) ³i A ∈ Ω. Atunci
P (A) =card Acard Ω
(2.5)
dene³te o m sur de probabilitate pe F (probabilitatea în sens clasic).(2) În cazul în care condiµia (b) din deniµia probabilit µii lipse³te, atunci spunem ca P dene³te o m sur pe spaµiul m surabil (Ω, F ), iar tripletul (Ω, F , P ) se va numi spaµiu cu m sur . O probabilitate esteastfel un caz particular al noµiunii de m sur , în cazul în care m sura întregului spaµiu este P (Ω) = 1.
Spunem c o proprietate are loc a.s. (aproape sigur) dac are loc întotdeauna, cu excepµia unei mulµimiA pentru care P (A) = 0. O astfel de mulµime se va numi mulµime P -nul .
5Félix Édouard Justin Émile Borel (1871− 1956), matematician si politician francez

STATS 2 [Dr. Iulian Stoleriu] 19
Câmp de probabilitate
Principalul concept al teoriei probabilit µilor este spaµiu probabilistic sau câmp de probabilitate. În cele ceurmeaz , când ne vom referi la câmp de probabilitate, vom înµelege un triplet (Ω, F , P ), cu urm toarelepropriet µi:
(i) Ω este o mulµime abstract (mulµimea tuturor evenimentelor elementare ale unui experimentstochastic);
(ii) F ⊂ P(Ω) este o σ-algebr , i.e., sunt îndeplinite urm toarele condiµii:(σ1) Ω ∈ F ;(σ2) A ∈ F =⇒ Ac ∈ F ;(σ3) ∀(An)n∈N ∈ F =⇒
⋃n∈N
An ∈ F ;
(iii) P : F → R e o funcµie satisf când condiµiile:(P1) P (Ω) = 1;(P2) ∀A ∈ F , P (A) ≥ 0;(P3) ∀(An)n∈N, An
⋂Am = ∅,∀n 6= m, avem P (
⋃n∈N
An) =∑n∈N
P (An).
Terminologie:(i) Elementele lui F se numesc evenimente iar ω ∈ Ω sunt elemente de prob .(ii) O mulµime A ⊂ F , cu A− σ-algebr , o vom numi sub-σ-algebr a lui F .(iii) ∀A ∈ F , P (A) se va numi probabilitatea lui A.(iv) Dac P (A) = 0, atunci A se va numi mulµime P -nul .(v) Dac P (A) = 1, atunci A este evenimentul sigur, sau spunem ca A se realizeaz aproape sigur (a.s.).
Dat ind un ³ir (An)n∈N în Ω, denim
lim infn→∞
An =
∞⋃n=1
⋂m≥n
Am ³i lim supn→∞
An =
∞⋂n=1
⋃m≥n
Am. (2.6)
În general, lim infn→∞
An ⊆ lim supn→∞
An. În caz de egalitate vom spune c ³irul (An)n∈N are limit ³i vom scrie
limn→∞
An = lim infn→∞
An = lim supn→∞
An. (2.7)
Observaµia 2.10 Din punct de vedere euristic, lim infn→∞
An reprezint evenimentul care se realizeaz când
toate An se realizeaz , mai puµin un num r nit. Pe de alt parte, lim supn→∞
An înseamn realizarea unei
innit µi de evenimente din ³irul A1, A2, . . . .
Teorema 2.11 (Borel-Cantelli6)Fie (An)n∈N ∈ Ω, un ³ir de evenimente. Atunci:
(i) Dac ∞∑n=1
P (An) <∞, atunci P
(lim supn→∞
An
)= 0.
(ii) Dac ∞∑n=1
P (An) =∞ ³i evenimentele Ann sunt independente, atunci
6Francesco Paolo Cantelli (1875− 1966), matematician italian

STATS 2 [Dr. Iulian Stoleriu] 20
P
(lim supn→∞
An
)= 1.
Câmp de probabilitate geometric
S presupunem c am dispune de un procedeu prin care putem alege la întâmplare un punct dintr-uninterval [a, b]. În plus, vom presupune c acest procedeu ne asigur c nu exist porµiuni privilegiate aleintervalului [a, b], i.e., oricare ar dou subintervale de aceea³i lungime, este la fel de probabil ca punctuls cad în oricare dintre aceste intervale. Dac am folosi de mai multe ori procedeul pentru a alege unnum r mare de puncte, acestea vor repartizate aproximativ uniform în [a, b], i.e., nu vor exist puncteîn vecin tatea c rora punctul ales s cad mai des, ori de câte ori este ales. De aici reiese c probabilitateaca un punct s cad într-un subinterval al lui [a, b] este dependent de lungimea acelui subinterval ³i nu depoziµia sa în interiorul lui [a, b]. Mai mult, aceasta este chiar proporµional cu lungimea subintervalului.
Se poate observa analogia cu experienµa alegerii dintr-un num r de cazuri egal posibile.
Dac [a, b] e mulµimea cazurilor egal posibile ³i [c, d] ⊂ [a, b] este mulµimea cazurilor favorabile, atunciprobabilitatea ca punctul ales s cad în [c, d] este
P (A) =m sura ([c, d])
m sura ([a, b])=d− cb− a
.
În particular, dac x ∈ (c, d), atunci probabilitatea ca punctul ales aleator dintr-un interval s coincid cu un punct dinainte stabilit este zero ³i, astfel, întrez rim posibilitatea teoretic ca un eveniment s aib probabilitatea nul , far ca el s e evenimentul imposibil ∅.
În mod cu totul analog, dac se ia la întâmplare un punct dintr-un domeniu planar D, astfel ca s nu existepuncte sau porµiuni privilegiate în acest domeniu, atunci probabilitatea ca punctul s cad în subdomeniulD′ ⊂ D este aria D′
aria D .
În trei dimensiuni, o probabilitate similar este raportul a dou volume: volumul mulµimii cazurilor favo-rabile ³i volumul mulµimii cazurilor egal posibile.
Probabilit µi condiµionate
Fie spaµiul probabilistic (Ω, F , P ) ³i A, B ∈ F , cu P (B) > 0. Denim probabilitatea evenimentului Acondiµionat de realizarea evenimentului B, notat P (A|B) sau PB(A), prin:
PB(A) =P (A
⋂B)
P (B). (2.8)
Observaµia 2.12 PB(A) astfel denit va o probabilitate pe F , iar tripletul (Ω, F , PB) este un câmpde probabilitate.
Propoziµia 2.13 (a) (formula probabilit µilor totale) Fie (Bi)i∈I , (I ⊂ N) o partiµie a lui Ω, astfel încâtP (Bi) > 0, ∀i ∈ I. Atunci
P (A) =∑i∈I
P (Bi) · PBi(A), ∀A ∈ F . (2.9)

STATS 2 [Dr. Iulian Stoleriu] 21
(b) (formula lui Bayes7) În condiµiile de la (a) ³i, în plus, P (A) > 0, avem:
PA(Bi) =P (Bi) · PBi(A)∑
j∈IP (Bj) · PBJ (A)
, ∀i ∈ I. (2.10)
(c) Dac B1, B2, . . . , Bn ∈ F , astfel încât P (B1⋂B2⋂· · ·⋂Bn) > 0, atunci:
P (B1
⋂B2
⋂· · ·⋂Bn) = P (B1) · PB1(B2) · . . . · PB1
⋂···⋂Bn−1
(Bn). (2.11)
Variabile aleatoare
Din punct de vedere euristic, o variabil aleatoare este o funcµie ce ia valori întâmpl toare. În viaµ dezi cu zi întâlnim numeroase astfel de funcµii, e.g., numerele ce apar la extragerea loto, num rul clienµilordeserviµi la un anumit ghi³eu într-o anumit perioad , timpul de a³teptare a unei persoane într-o staµie deautobuz pân la sosirea acestuia etc. Variabilele aleatoare le vom nota cu litere de la sfâr³itul alfabetuluiX, Y, Z sau ξ, η, ζ ³i altele.
Fie (Ω,F , P ) un câmp de probabilitate ³i (E, E) un spaµiu m surabil.O funcµie X : (Ω,F , P )→ (E, E) se nume³te variabil aleatoare (v.a.) dac
pentru orice B ∈ E , X−1(B) ∈ F (2.12)
(mai spunem c X este o funcµie F−m surabil ).În particular, dac :
• (E, E) ≡ (R,B(R)), atunci X este o variabil aleatoare real ;
• (E, E) ≡ (Rd,B(Rd)), atunci X este vector aleator (sau v.a.) d-dimensional( );
• (E, E) ≡ (Rn×m,B(Rn×m), atunci X este o matrice aleatoare.
Deoarece mulµimile (−∞, x], x ∈ R genereaz B(R), pentru ca X : (Ω,F , P ) → R s e o v.a. real este sucient ca
∀x ∈ R, ω ∈ Ω | X(ω) ≤ x ∈ F . (2.13)
Vom utiliza notaµiile X ≤ x not= ω ∈ Ω | X(ω) ≤ x ³i, în general,
X ∈ B not= ω ∈ Ω | X(ω) ∈ B
Dac X : (Ω,F , P )→ Rd este o v.a., atunci
F(X) = X−1(B), B ∈ Bd
este o σ−algebr , denumit σ−algebra generat de v.a. X. Astfel, σ(X) este cea mai mic sub−σ−algebr a lui F astfel încât X este m surabil .
Dac (Xn)n∈N este un ³ir de v.a. reale astfel încât Xk(ω)→ X(ω), aproape pentru toµi ω ∈ Ω, atunci Xeste tot o v.a. real .
7Thomas Bayes, (1702− 1761) matematician britanic

STATS 2 [Dr. Iulian Stoleriu] 22
Fie Xi : (Ω,F , P )→ (E, E), (i ∈ I) o familie de v.a.. Denim σ−algebra generat de familia Xi, i ∈ N,notat σ(Xi, i ∈ I), cea mai mic σ−algebr pentru care Xi, i ∈ I, sunt m surabile.
Variabilele aleatoare pot lua o mulµime cel mult num rabil de valori (³i le numim v.a. discrete) saupoate lua o mulµime continu de valori (un interval nit sau innit din R), ³i le vom numi (v.a. de tipcontinuu). Exemple de v.a. discrete: num rul feµei ap rute la aruncarea unui zar, num rul de apariµiiale unui tramvai într-o staµie într-un anumit interval, num rul de insuccese ap rute pân la primul succesetc. Din clasa v.a. de tip continuu amintim: timpul de a³teptare la un ghi³eu pân la servire, preµul unuiactiv nanciar într-o perioad bine determinat .O v.a. discret X se poate scrie sub forma
X(ω) =∑i∈J
xiχAi(ω), ∀ω ∈ Ω, J ⊂ N. (2.14)
Aici χA este funcµia indicatoare a mulµimii A, iar Ak = X−1(xk). Observ m cu u³urinµ c
n⋃i=1
Ai = Ω ³i Ai⋂Aj = ∅, ∀i 6= j.
Uneori, unei o v.a. discrete i se atribuie urm torul tablou de repartiµie:
X :
(xipi
), (2.15)
unde pi = P (X = xi), i ∈ J ⊂ N,n∑i=1
pi = 1. Spre exemplu, tabloul de repartiµie pentru v.a. ce reprezint
num rul de puncte ce apare la aruncarea unui zar ideal este:(1 2 3 4 5 6
1/6 1/6 1/6 1/6 1/6 1/6
),
O v.a. X real se nume³te de tip continuu dac exist f : Rd → R m surabil Borel ce îndepline³tecondiµiile:
(a) f(x) ≥ 0, a.s.
(b)
∫Rf(x) dx = 1
(c) PX(B) =
∫Bf(x) dx, ∀B ∈ F .
Funcµia f se nume³te densitatea de repartiµie a lui X.
În urm toarele dou secµiuni, vom deni cele mai importante caracteristici funcµionale ³i numerice aleunei variabile aleatoare X : (Ω,F , P )→ (Rd, B(Rd)).

STATS 2 [Dr. Iulian Stoleriu] 23
Caracteristici funcµionale ale variabilelor aleatoare
Repartiµia
Repartiµia (sau legea, sau distribuµia) lui X este o m sur de probabilitate pe Bd, PX : Bd → [0, 1], dat prin
PX(B) = P (X ∈ B), ∀B ∈ Bd. (2.16)
Repartiµia unei v.a. de tip discret (de forma 2.14) este astfel:
PX(B) =∑j∈J
P (Aj)δxj (B), (2.17)
unde
δa(B) =
1, dac a ∈ B0, în rest
Repartiµia unei v.a. X de tip continuu este:
PX(B) =
∫Bf(x) dx, ∀B ∈ Bd, (2.18)
unde f(x) este densitatea de repartiµie a lui X. În limba englez , pentru repartiµie se folosesc termenii:distribution sau law.
Funcµia de repartiµie (sau funcµia de repartiµie cumulat )
Numim funcµie de repartiµie ata³at v.a reale X o funcµie F : R→ [0, 1], dat prin
F (x) = P (X ≤ x).
Astfel, F (x) = PX((−∞, x]), adic este repartiµia mulµimii (−∞, x].Termenul în englez pentru funcµia de repartiµie este cumulative distribution function (cdf).Dac X = (X1, X2, . . . , Xd) : (Ω, F , P ) → Rd este un vector aleator, atunci funcµia de repartiµie sedene³te ca ind F : Rd → [0, 1], dat prin
F ((x1, x2, . . . , xd)) = P (X1 ≤ x1;X2 ≤ x2; . . . , Xd ≤ xd).
Propriet µi ale funcµiei de repartiµie:
• este cresc toare (F (x) ≤ F (y), ∀x, y ∈ R, x ≤ y);
• este continu la dreapta ( limyx
F (y) = F (x), ∀x ∈ R);
• limx→−∞
F (x) = 0 ³i limx→∞
F (x) = 1.
În cazul unei variabile aleatoare discrete, cu tabloul de repartiµie dat de (2.15), funcµia sa de repartiµiaîntr-un punct x este:
F (x) =∑
i;xi≤x
pi. (2.19)

STATS 2 [Dr. Iulian Stoleriu] 24
Dac X este o variabil aleatoare continu ³i f este densitatea sa de repartiµie, atunci funcµia de repartiµieeste dat de formula:
F (x) =
x∫−∞
f(t) dt, x ∈ R. (2.20)
Observaµia 2.14 Deseori în calcule probabilistice, avem de calculat evenimentul P (X > x), pentru unx ∈ R dat. Numim funcµie de repartiµie complementar , funcµia Fc : R→ [0, 1], dat prin F (x) = P (X >x) = 1− F (x), ∀x ∈ R.
Funcµia caracteristic
Numim funcµie caracteristic ata³at v.a reale X o funcµie φX : R→ C, dat prin:
φX(t) =∑k∈J
ei t xk pk, dac X =∑k∈J
xk χAk , (X = discret )
φX(t) =
∫Rei t xf(x) dx, dac X = variabil aleatoare continu .
Aici, i este num rul imaginar, (i2 = −1).Propriet µi ale funcµiei caracteristice:
• |φX(t)| = 1, ∀t ∈ R;
• φaX(t) = φX(a t), ∀t ∈ R, a ∈ R;
• φaX+b(t) = φX(a t)eibt, ∀t ∈ R, a ∈ R;
• φX(−t) = φX(t), ∀t ∈ R;
• φX : R→ C este uniform continu ;
• ∀ti, tj ∈ R, ∀zi, zj ∈ C avemn∑
i, j=1
φX(ti − tj)zizj ≥ 0.
Funcµia de probabilitate (sau de frecvenµ )
Fie X o variabil aleatoare discret , X(ω) =∑i∈J
xiχAi(ω), ∀ω ∈ Ω, Ai ∈ F , J ⊂ N. Numim funcµie de
probabilitate (de frecvenµ ) ata³at variabilei aleatoare discrete X o funcµie f : R→ R, denit prin
f(xi) = pi, unde pi = P (Ai), i ∈ J.
Funcµia de probabilitate (en., probability distribution function) pentru o variabil aleatoare discret estesimilara densit µii de repartiµie pentru o variabil aleatoare continu . Într-adevar, propriet µile pe care lesatisface funcµia de probabilitate sunt:
f(xi) ≥ 0, ∀i ∈ J,n∑i=1
f(xi) = 1.

Laborator 2 [Dr. Iulian Stoleriu] 25
Statistic Aplicat (Laborator 2)
Experienµe aleatoare în Matlab
Generarea de numere (pseudo-)aleatoare
Numerele generate de Matlab sunt rezultatul compil rii unui program deja existent în Matlab, a³adarel vor pseudo-aleatoare. Putem face abstracµie de modul programat de generare ale acestor numere ³is consider m c acestea sunt numere aleatoare.
Generarea de numere uniform repartizate într-un interval, U(a, b)
Funcµia rand
• Funcµia rand genereaz un num r aleator repartizat uniform în [0, 1].De exemplu, comanda
X = (rand < 0.5)
simuleaz aruncarea unei monede ideale. Mai putem spune ca num rul X astfel generat este unnum r aleator repartizat B(1, 0.5).
• De asemenea, num rul
Y = sum(rand(10,1) < 0.5)
urmeaz repartiµia B(10, 0.5) (simularea a 10 arunc ri ale unei monede ideale).
• rand(m, n) genereaz o matrice aleatoare cu m× n componente repartizate U(0, 1).
• Comanda a+ (b− a) ∗ rand genereaz un num r pseudo-aleator repartizat uniform în [a, b].
• Folosind comanda s = rand('state'), i se atribuie variabilei s un vector de 35 de elemente, repre-zentând starea actual a generatorului de numere aleatoare uniform (distribuite). Pentru a schimbastarea curent a generatorului sau iniµializarea lui, putem folosi comanda
rand(method, s)
unde method este metoda prin care numerele aleatoare sunt generate (aceasta poate 'state','seed' sau 'twister'), iar s este un num r natural între 0 ³i 232 − 1, reprezentând starea iniµiali-zatorului. De exemplu,
rand('state', 125)
xeaz generatorul la starea 125.

Laborator 2 [Dr. Iulian Stoleriu] 26
Observaµia 2.15 Printr-o generare de numere aleatoare uniform distribuite în intervalul (a, b) înµelegemnumere aleatoare care au aceea³i ³ans de a oriunde în (a, b), ³i nu numere la intervale egale.
Figura 2.1 reprezint cu histograme date uniform distribuite în intervalul [−2, 3], produse de comandaMatlab:
hist(5*rand(1e4,1)-2,100)
Figura 2.1: Reprezentarea cu histograme a datelor uniforme.
Generarea de numere repartizate normal, N (µ, σ)
Funcµia randn
• Funcµia randn genereaz un num r aleator repartizat normal N (0, 1).
• randn(m, n) genereaz o matrice aleatoare cu m× n componente repartizate N (0, 1).
• Pentru a schimba metoda prin care sunt generate numerele aleatoare normale sau starea generato-rului, folosim comanda:
randn(method, s)
unde unde method este metoda prin care numerele aleatoare sunt generate (aceasta poate 'state'
sau 'seed'), iar s este un num r natural între 0 ³i 232 − 1, reprezentând starea iniµializatorului.
• Comanda m+σ∗randn genereaz un num r aleator repartizat normal N (m, σ). De exemplu, codulurm tor produce Figura 2.2:
x = 0:0.05:10;
y = 5 + 1.1*randn(1e5,1); % date distribuite N (5, 1.1)hist(y,x)

Laborator 2 [Dr. Iulian Stoleriu] 27
0 2 4 6 8 100
50
100
150
200
250
Figura 2.2: Reprezentarea cu histograme a datelor normale.
Generarea de numere aleatoare de o repartiµie dat
Comenzile Matlab
legernd(<param>, m, n)
³i
random('lege', <param>, m, n).
Oricare dintre cele dou comenzi genereaz o matrice aleatoare, cu m linii ³i n coloane, având componentenumere aleatoare ce urmeaz repartiµia lege. În loc de lege putem scrie oricare dintre expresiile din tabeluldin Figura 4.1. De exemplu,
normrnd (5, 0.2, 100, 10);
genereaz o matrice aleatoare cu 100× 10 componente repartizate N (5, 0.2).
random ('poiss',0.01, 200, 50);
genereaz o matrice aleatoare cu 200× 50 componente repartizate P(0.01).
Utilizând comanda
randtool
putem reprezenta interactiv selecµii aleatoare pentru diverse repartiµii. Comanda deschide o interfaµ grac ce reprezint prin histograme selecµiile dorite, pentru parametrii doriµi (vezi Figura 2.3). Datelegenerate deMatlab pot exportate în ³ierulWorkspace cu numele dorit. De exemplu, folosind dateledin Figura 2.3, am generat o selecµie aleatoare de 10000 de numere ce urmeaz repartiµia lognormal deparametri µ = 2 ³i σ = 0.5 ³i am salvat-o (folosind butonul Export) într-un vector L.

Laborator 2 [Dr. Iulian Stoleriu] 28
Figura 2.3: Interfaµ pentru generarea de numere aleatoare de o repartiµie dat .
Simularea arunc rii unei monede
• Comanda
X = (rand < 0.5);
simuleaz aruncarea unei monede ideale. Vom mai spunem c num rul X astfel generat este unnum r aleator repartizat B(1, 0.5) (similar cu schema bilei revenite, în cazul în care o urn are bilealbe ³i negre în num r egal ³i extragem o bil la întâmplare)
• Num rul
Y = sum (rand(30,1)<0.5)
urmeaz repartiµia B(30, 0.5) (simularea a 30 arunc ri ale unei monede ideale).
• Acela³i experiment poate modelat ³i prin comanda
round(rand(30,1))
Pentru a num ra câte feµe de un anumit tip au ap rut, folosim
sum(round(rand(30,1)))
Exemplu 2.16 Dorim s scriem o funcµie MATLAB care s simuleze aruncarea repetat a unei monedem sluite, pentru care probabilitatea teoretic de a obµine o anumit faµ este p ∈ (0, 1). S se determine
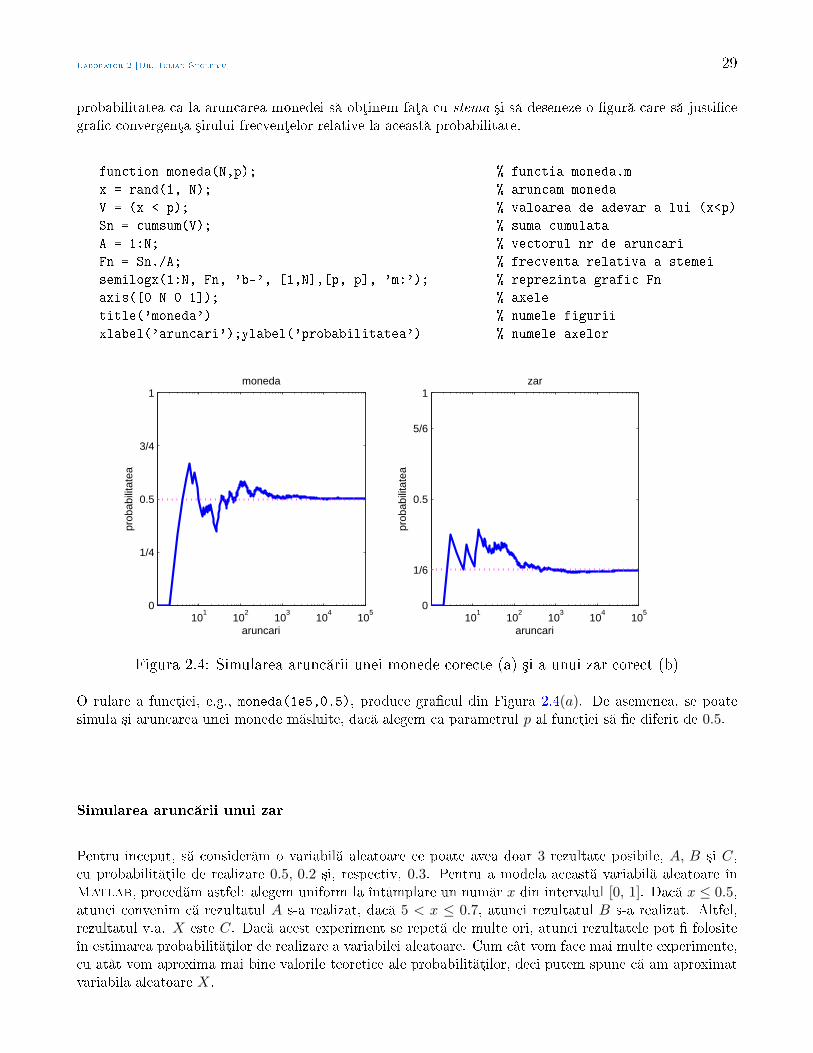
Laborator 2 [Dr. Iulian Stoleriu] 29
probabilitatea ca la aruncarea monedei s obµinem faµa cu stema ³i s deseneze o gur care s justicegrac convergenµa ³irului frecvenµelor relative la aceast probabilitate.
function moneda(N,p); % functia moneda.m
x = rand(1, N); % aruncam moneda
V = (x < p); % valoarea de adevar a lui (x<p)
Sn = cumsum(V); % suma cumulata
A = 1:N; % vectorul nr de aruncari
Fn = Sn./A; % frecventa relativa a stemei
semilogx(1:N, Fn, 'b-', [1,N],[p, p], 'm:'); % reprezinta grafic Fn
axis([0 N 0 1]); % axele
title('moneda') % numele figurii
xlabel('aruncari');ylabel('probabilitatea') % numele axelor
101
102
103
104
105
0
1/4
0.5
3/4
1
aruncari
prob
abili
tate
a
moneda
101
102
103
104
105
0
1/6
0.5
5/6
1
aruncari
prob
abili
tate
a
zar
Figura 2.4: Simularea arunc rii unei monede corecte (a) ³i a unui zar corect (b)
O rulare a funcµiei, e.g., moneda(1e5,0.5), produce gracul din Figura 2.4(a). De asemenea, se poatesimula ³i aruncarea unei monede m sluite, dac alegem ca parametrul p al funcµiei s e diferit de 0.5.
Simularea arunc rii unui zar
Pentru început, s consider m o variabil aleatoare ce poate avea doar 3 rezultate posibile, A, B ³i C,cu probabilit µile de realizare 0.5, 0.2 ³i, respectiv, 0.3. Pentru a modela aceast variabil aleatoare înMatlab, proced m astfel: alegem uniform la întâmplare un num r x din intervalul [0, 1]. Dac x ≤ 0.5,atunci convenim c rezultatul A s-a realizat, dac 5 < x ≤ 0.7, atunci rezultatul B s-a realizat. Altfel,rezultatul v.a. X este C. Dac acest experiment se repet de multe ori, atunci rezultatele pot folositeîn estimarea probabilit µilor de realizare a variabilei aleatoare. Cum cât vom face mai multe experimente,cu atât vom aproxima mai bine valorile teoretice ale probabilit µilor, deci putem spune c am aproximatvariabila aleatoare X.

Laborator 2 [Dr. Iulian Stoleriu] 30
La aruncarea unui zar ideal, avem 6 rezultate posibile, ³i anume, apariµia unei feµe cu 1, 2, 3, 4, 5 sau 6puncte. Pentru a simula acest experiment, modic m în mod convenabil problema. Vom considera c punctele din intervalul [0, 1] formeaz mulµimea tuturor cazurilor posibile ³i împ rµim intervalul [0, 1] în6 subintervale de lungimi egale:
(0,1
6), (
1
6,
2
6), (
2
6,
3
6), (
3
6,
4
6), (
4
6,
5
6), (
5
6, 1)
.
corespunz toare, respectiv, celor ³ase feµe, s zicem în ordinea cresc toare a punctelor de pe ele. Vomvedea mai târziu (vezi metoda Monte Carlo) ca alegerea acestor intervale cu capete închise, deschisesau mixte nu are efect practic asupra calculului probabilit µii dorite. Acum, dac dorim s simul m înMatlab apariµia feµei cu 3 puncte la aruncarea unui zar ideal, vom alege (comanda rand) un num r "laîntâmplare" din intervalul [0, 1] ³i veric m dac acesta se a în intervalul (2
6 ,36). A³adar, comanda
Matlab
u = rand; (u < 3/6 & u > 2/6)
simuleaz aruncarea unui zar ideal. Ca o observaµie, deoarece cele 6 feµe sunt identice, putem simplicaaceast comanda ³i scrie
(rand < 1/6).
Exemplu 2.17 Dorim s simuleze în Matlab aruncarea repetat a unui zar corect. S se determineprobabilitatea ca la aruncarea zarului s obµinem faµa cu trei puncte ³i s deseneze o gura care s justicegrac convergenµa ³irului frecvenµelor relative la aceast probabilitate (vezi Figura 2.4(b)).
function dice(N); % functia dice.m
u = rand(1, n); % probabilitatea aparitiei fetei ∴Z1 = (u < 3/6 & u > 2/6); % aparitia fetei ∴freq = cumsum(Z1)./(1:n); % frecventa relativa
subplot(1,2,2); % activeaza fereastra din stanga
semilogx(1:n, freq, 'b-', [1, n], [1/6,1/6], 'm:');
axis([0 n 0 1]); % axele
title('zar') % numele figurii
xlabel('aruncari');ylabel('probabilitatea')
Fi³ierul dice.m simuleaz aruncarea unui zar corect de un num r N de ori. O rulare a funcµiei, e.g.,dice(1e5) produce gracul din Figura 2.4(b).

STATS 3 [Dr. Iulian Stoleriu] 31
3 Statistic Aplicat (C3)
Elemente de Teoria probabilit µilor
Caracteristici numerice ale variabilelor aleatoare
Media
Deniµia 3.1 Dac X este o v.a. de tip discret, X(ω) =∑i∈J
xiχAi(ω), ∀ω ∈ Ω, J ⊂ N, atunci media
acestei v.a. se dene³te prin:E(X) =
∑i∈J
xiP (Ai). (3.1)
Deniµia 3.2 Dac X este o v.a. de tip continuu, cu densitatea de repartiµie f : R → R, atunci media(teoretic ) acestei v.a., dac exist (!) (nu toate v.a. de tip continuu admit medie - vezi repartiµia Cauchy),se dene³te astfel:
E(X) =
∫Rxf(x)dx, (dac aceast integral exist ). (3.2)
Observaµia 3.3 Deniµia mediei poate dat într-un cadru mult mai general, folosind integrala Lebesque.Aceast integral este generalizarea integralei Riemann. Sumariz m mai jos, gradual ³i f r demonstraµiileaferente, construcµia mediei unei v.a. reale.
Pasul 1: O v.a. X cu X(ω) =n∑i=1
xiχAi(ω) se nume³te v.a. simpl . Pentru v.a. simpl X denim
media (notat cu E(X)) astfel:
E(X)not=
∫ΩX(ω) dP (ω) =
n∑i=1
xiP (Ai).
Pasul 2: Dac X : Ω → R ³i X ≥ 0, atunci exist un ³ir Xn : Ω → R, (n ∈ N) de v.a. simple astfelîncât
0 ≤ X1(ω) ≤ · · · ≤ Xn(ω) ≤ X(ω), ∀ω ∈ Ω
³ilimn→∞
Xn(ω) = X(ω).
DenimE(X) = lim
n→∞E(Xn).
Pasul 3: Fie X : Ω→ R o v.a.. Atunci X = X+ −X−, unde
X+(ω) = maxX(ω), 0, X−(ω) = max−X(ω), 0 = (−X)+(ω).
În acest caz denim media lui X,E(X) = E(X+)− E(X−),

STATS 3 [Dr. Iulian Stoleriu] 32
ori de câte ori m car una dintre E(X+) ³i E(X−) este nit . Când ambele sunt nite, atunci spunem c X este o v.a. integrabil .Dac X = X1 + iX2 : Ω→ C, denim media v.a. complexe X prin
E(X) = E(X1) + iE(X2),
ori de câte ori ambele medii exist ³i sunt nite.Dac X este un vector aleator, X = (X1, X2, . . . , Xd)
T : Ω→ Rd, atunci denim media lui X prin
E(X) = (E(X1), E(X2), . . . , E(Xd))T .
Propoziµia 3.4 Fie X : Ω→ Rd o v.a. cu densitatea de repartiµie f ³i o funcµie m surabil g : Rd → R.Atunci
E(g(X)) =
∫Rdg(x)f(x) dx.
În particular, dac g : R→ R este funcµia identic , atunci:
E(X) =
∫ΩX(ω) dP (ω) =
∫Rxf(x) dx,
³i astfel redescoperim deniµia mediei unei v.a. de tip continuu din Deniµia 3.2.Relaµia anterioar se mai nume³te ³i formula de transport pentru integral , deoarece integrala abstract pe mulµimea Ω este "transportat " într-o integrala Riemann pe R.
Dispersia (sau varianµa) ³i abaterea standard
Dac X este o variabil aleatoare ³i X = X − E(X) (numit abaterea lui X de la media sa), atunciE(X) = 0. A³adar, nu putem m sur gradul de împr ³tiere a valorilor lui X în jurul mediei sale doarcalculând X − E(X). Avem nevoie de o alt m sur . Aceasta este dispersia variabilei aleatoare.
Deniµia 3.5 Dac X este o v.a. discret , X(ω) =∑i∈J
xiχAi(ω), ∀ω ∈ Ω, J ⊂ N, cu media E(X) = m,
denim dispersia lui X ca ind:
D2(X) =∑i∈J
(xi −m)2pi, unde pi = P (Ai), ∀i ∈ J. (3.3)
Deniµia 3.6 Fie X : Ω→ R o v.a. de tip continuu pentru care media poate denit (exist E(X) =m ∈ R). Denim dispersia lui X (sau varianµa lui X) cantitatea
D2(X) = E[(X −m)2] =
∫R
(x−m)2f(x) dx. (3.4)
Notaµiile consacrate pentru dispersie sunt D2(X) sau σ2.
Observaµia 3.7 Dispersia scris ca integral abstract (vezi propoziµia anterioar ) este:
σ2 =
∫Ω
(X(ω)−m)2 dP (ω).

STATS 3 [Dr. Iulian Stoleriu] 33
Numim abatere standard (sau deviaµie standard) cantitatea σ =√σ2.
Momente
Pentru o v.a. X de tip discret, X(ω) =∑i∈J
xiχAi(ω), ∀ω ∈ Ω, J ⊂ N,
cu E(X) = m ³i pi = P (Ai), i ∈ J , denim momentele:
αk(X) = E(Xk) =∑i∈J
xki pi (momente iniµiale de ordin k);
βk(X) = E(|X|k) =∑i∈J|xi|kpi (momente absolute de ordin k);
µk(X) = E((X −m)k) =∑i∈J
(xi −m)kpi (momente iniµiale centrate de ordin k);
γk(X) = E(|X −m|k) =∑i∈J|xi −m|kpi (momente absolute centrate de ordin k);
Pentru o v.a. X de tip continuu ce admite medie m = E(X) <∞, denim momentele:
αk(X) = E(Xk) =
∫Rxkf(x) dx =
∫ΩXkdP (momente iniµiale de ordin k);
βk(X) = E(|X|k) =
∫R|x|kf(x) dx =
∫Ω|X|kdP (momente absolute de ordin k);
µk(X) = E((X −m)k) =
∫R
(x−m)kf(x) dx =
∫Ω
(X −m)kdP (momente iniµiale centrate);
γk(X) = E(|X −m|k) =
∫R|x−m|kf(x) dx =
∫Ω|X −m|kdP (momente absolute centrate);
Cuantile
Fie o v.a. X cu funcµia de repartiµie F (x).
Deniµia 3.8 Pentru α ∈ (0, 1), denim cuantila de ordin α valoarea xα astfel încât:
F (xα) = P (X ≤ xα) = α. (3.5)
Observaµia 3.9 (1) Cuantilele sunt m suri de poziµie, ce m soar locaµia unei anumite observaµii faµ de restul datelor. A³a cum se poate observa din Figura 3.1, valoarea xα este acel num r real pentru carearia ha³urat este chiar α.(2) În cazul în care X este o variabil aleatoare discret , atunci (3.5) nu poate asigurat pentru oriceα. Îns , dac exist o soluµie a acestei ecuaµiei F (x) = α, atunci exist o innitate de soluµii: intervalulce separ dou valori posibile.
(3) Cazuri particulare de cuantile: mediana (α = 1/2), cuartile (α = i/4, i = 1, 4), decile (α =j/10, i = 1, 10), percentile (α = k/100, k = 1, 100), promile (α = l/1000, l = 1, 1000).

STATS 3 [Dr. Iulian Stoleriu] 34
Figura 3.1: Cuantila de ordin α.
Modul (valoarea cea mai probabil )
Este acea valoare x∗ pentru care f(x∗) (densitatea de repartiµie sau funcµia de probabilitate) este maxim .O repartiµie poate s nu aib niciun mod, sau poate avea mai multe module.
Inegalit µi între momente
(a) βr(X + Y ) ≤ cr(βr(X) + βr(Y )), unde cr = 1 pentru r ∈ (0, 1] ³i cr = 2r−1 pentru r > 1.
(b) (βr(X))1/r ≤ (βs(Y ))1/s, ∀0 ≤ r ≤ s; (Lyapunov8)
(c) E|XY | ≤ (E|X|r)1/r(E|Y |s)1/s, ∀r, s > 1, r−1 + s−1 = 1; (Hölder9);
(d) (E|X + Y |r)1/r ≤ (E|X|r)1/r + (E|Y |r)1/r; (Minkowski10)
(e) Fie g : R→ R convex . Atunci avem g(E(X)) ≤ E(g(X)). (Jensen11)
(f) Dac a > 0, p ∈ N∗, atunci avem:
P (|X| ≥ a) ≤ βp(X)
ap; (Markov12)
În particular, pentru p = 2 ³i X e înlocuit cu variabila aleatoare (X −m), (m = E(X)), obµinem:
P (|X −m| ≥ a) ≤ σ2
a2. (Cebî³ev13) (3.6)
8Aleksandr Mikhailovich Lyapunov (1857− 1918), matematician rus, student al lui Cebî³ev9Otto Ludwig Hölder (1859− 1937), matematician german10Hermann Minkowski (1864− 1909), matematician german11Johan Ludwig William Valdemar Jensen (1859− 1925), matematician si inginer danez12Andrei Andreyevich Markov (1856− 1922), matematician rus, student al lui Cebî³ev13Pafnuty Lvovich Chebyshev (1821− 1894), matematician rus

STATS 3 [Dr. Iulian Stoleriu] 35
Dac în inegalitatea lui Cebî³ev lu m a = kσ, unde k ∈ N, atunci obµinem:
P (|X −m| ≥ kσ) ≤ 1
k2, (3.7)
sau, echivalent:
P (|X −m| < kσ) ≥ 1− 1
k2. (3.8)
În cazul particular k = 3, obµinem regula celor 3σ:
P (|X −m| ≥ 3σ) ≤ 1
9≈ 0.1.
sauP (m− 3σ < X < m+ 3σ) ≥ 8
9, (3.9)
semnicând c o mare parte din valorile posibile pentru X se a în intervalul [m− 3σ, m+ 3σ].
Standardizarea unei variabile aleatoare
Fie variabila aleatoare X, de medie m ³i dispersie σ2.
Deniµia 3.10 Variabila aleatoare X =X −mσ
se nume³te variabila aleatoare standardizat (sau nor-
mat ).
Propriet µile variabilei aleatoare standardizate:
E(X) = 0, D2(X) = 1.
Corelaµia ³i coecientul de corelaµie
Conceptul de corelaµie (sau covarianµ ) este legat de modul în care dou variabile aleatoare tind s semodice una faµ de cealalt ; ele se pot modica e în aceea³i direcµie (caz în care vom spune c X ³i Ysunt direct <sau pozitiv> corelate) sau în direcµii opuse (X ³i Y sunt invers <sau negativ> corelate).Fie X, Y v.a. cu mediile, respectiv, mX , mY ³i dispersiile σ2
X , respectiv, σ2Y . Calculând dispersia sumei
X + Y , obµinem:
D2(X + Y ) = E[(X + Y − (mX +mY )2)]
= E[(X −mX)2] + E[(Y −mY )2] + 2E[(X −mX)(Y −mY )]
= D2(X) +D2(Y ) + 2E[(X −mX)(Y −mY )].
Deniµia 3.11 Denim corelaµia (sau covarianµa) v.a. X ³i Y , notat prin cov(X, Y ), cantitateacov(X, Y ) = E[(X −mX)(Y −mY )].

STATS 3 [Dr. Iulian Stoleriu] 36
Proprietatea 3.12 (a) Continuând ³irul anterior de egalit µi, putem scrie:
D2(X + Y ) = D2(X) +D2(Y ) + 2 cov(X, Y ). (3.10)
(b) cov(X, Y ) = cov(Y, X) = E[(X −mX)(Y −mY )] = E(XY )−mXmY .(c) cov(X, X) = D2(X), pentru orice v.a. X.(d) cov(X + Y, Z) = cov(X,Z) + cov(Y, Z), pentru orice v.a. X,Y, Z.(e) Dac X ³i Y sunt v.a. independente (i.e., realiz rile lui X nu depind de realiz rile
lui Y ), atunci cov(X, Y ) = 0. Reciproca nu este întotdeauna adev rat .
Fie v.a. X ³i Y , pentru care presupunem c variaµiile σ2X ³i σ2
Y sunt nite ³i nenule. Consider m v.a.
standardizate, X =X −mX
σX³i Y =
Y −mY
σY.
Deniµia 3.13 Se nume³te coecient de corelaµie (teoretic) al v.a. X ³i Y covarianµa variabilelor stan-dardizate X ³i Y . Not m astfel:
ρ(X, Y ) = cov(X, Y ) =cov(X, Y )
σXσY. (3.11)
Observaµia 3.14 (a) Dac X ³i Y sunt independente (i.e., realiz rile uneia sunt independente derealiz rile celeilalte − vezi secµiunea urm toare), atunci
ρ(X, Y ) = 0.
(b) − 1 ≤ ρ(X, Y ) ≤ 1, pentru orice v.a. X ³i Y .(c) Dac Y = aX + b (a, b ∈ R), atunci
ρ(X, Y ) =
+1, dac a = 1;
−1, dac a = −1.
Independenµa
Conceptul de independenµ a v.a. sau a evenimentelor este foarte important din punctul de vedere alcalculului probabilit µilor evenimentelor compuse din evenimente mai simple. Independenµa este unuldintre conceptele principale care deosebesc Teoria probabilit µilor de Teoria m surii, neavând echivalentîn teoria din urm .
Deniµia 3.15 Fie (Ω, F , P ) un câmp de probabilitate, A, B ∈ F dou evenimente arbitrare.(1) Dac anumite informaµii despre evenimentul B au inuenµat în vreun fel realizarea evenimentuluiA, atunci vom spune c A ³i B sunt evenimente dependente. De exemplu, evenimentele A = mâine plou ³i B = mâine mergem la plaj sunt dependente.(2) S presupunem c evenimentul B satisface relaµia P (B) > 0. Vom spune c evenimentele A ³iB sunt independente dac probabilitatea lui A este independent de realizarea evenimentului B, adic probabilitatea condiµionat
P (A| B) = P (A), (3.12)
echivalent cuP (A
⋂B)
P (B)= P (A).

STATS 3 [Dr. Iulian Stoleriu] 37
Putem rescrie ultima egalitate sub forma simetric :
P (A⋂B) = P (A) · P (B). (3.13)
Deoarece în relaµia (3.13) nu mai este nevoie de condiµie suplimentara pentru P (B), este preferabil s denim independenµ a dou evenimente arbitrare astfel:
Dou evenimente, A, B ∈ F se numesc independente (stochastic) dac relaµia (3.13) are loc.
Deniµia 3.16 (i) Evenimentele A1, A2, . . . , An se numesc independente în ansamblu dac pentru e-care submulµime i1, i2, . . . , ik a mulµimii 1, 2, . . . , n avem
P (Ai1⋂Ai1
⋂· · ·⋂Aik) = P (Ai1) · P (Ai2) · . . . · P (Aik). (3.14)
(ii) Spunem c evenimentele A1, A2, . . . , An sunt independente dou câte dou dac pentru oricare dou evenimente, Ai ³i Aj , din aceast mulµime, avem
P (Ai⋂Aj) = P (Ai) · P (Aj)). (3.15)
(iii) În general, evenimentele (Ai)i∈I ⊂ F , (I ⊂ N), se numesc independente dac
P (⋂j∈J
Aj) =∏j∈J
P (Aj), (3.16)
pentru orice J ⊂ I, J−nit .
Observaµia 3.17 Independenµ dou câte dou a evenimentelor nu implic independenµa în ansamblu.S exemplic m considerând urm toarea experienµ .Consider m aruncarea a dou monede ideale. Fie A evenimentul ca "faµa ce apare la prima moned estestema", B evenimentul ca "faµa ce apare la a doua moned este stema", iar C evenimentul ca "doar la omoned din cele dou a ap rut faµa cu stema". Se observ cu u³urinµ c evenimentele A, B ³i C suntindependente dou câte dou , deoarece:
P (A⋂C) = P (A) · P (C) =
1
4; P (B
⋂C) = P (B) · P (C) =
1
4; P (A
⋂B) = P (A) · P (B) =
1
4.
Totodat , mai observ m c oricare dou dintre ele determina în mod unic pe al treilea. A³adar, indepen-denµa a dou câte dou nu implic independenµa celor trei evenimente în ansamblu, fapt observat ³i dinrelaµia
0 = P (A⋂B⋂C) 6= P (A) · P (B) · P (C) =
1
8.
Deniµia 3.18 Dac Mi, i ∈ I ⊂ N, cu Mi ⊂ F , este o familie de σ−corpuri, atunci spunem c acestea sunt independente (stochastic) dac pentru orice submulµime nit J ⊂ I ³i pentru orice alegerede evenimente Aj ∈Mj , este îndeplinit condiµia
P (⋂j∈J
Aj) =∏j∈J
P (Aj). (3.17)
Deniµia 3.19 (1) Spunem c v.a. (Xi)i∈I : (Ω,F) → R, (I ⊂ N), sunt independente (în ansamblu)dac σ−corpurile generate de Xi, σ(Xi)i∈I , formeaz o familie de σ−corpuri independente.(2) Spunem c v.a. (Xi)i∈I : (Ω,F)→ R, (I ⊂ N), sunt independente dou câte dou dac oricare ar dou variabile aleatoare din aceast familie, acestea sunt independente în sensul deniµiei de la (1).

STATS 3 [Dr. Iulian Stoleriu] 38
Observaµia 3.20 Deniµia variabilelor aleatoare independente (în ansamblu) este echivalent cu:
Pentru orice k ≥ 2 ³i orice alegere a mulµimilor boreliene B1, B2, . . . , Bk ∈ F , avem:
P(X1 ∈ B1
⋂X2 ∈ B2
⋂· · ·⋂Xk ∈ Bk
)= P (X1 ∈ B1) ·P (X2 ∈ B2) · . . . ·P (Xk ∈ Bk), (3.18)
sau, cu alte cuvinte, evenimentele X1 ∈ B1, X2 ∈ B2, . . . , Xk ∈ Bk sunt independente în ansamblu.
Exemplu 3.21 S consider m aruncarea unui zar. Arunc m zarul de dou ori ³i not m cu X1, respectiv,X2, v.a. ce reprezint num rul de puncte ap rute la ecare aruncare. Evident, valorile acestor v.a. suntdin mulµimea 1, 2, 3, 4, 5, 6. A³adar,
Xi : Ω→ 1, 2, 3, 4, 5, 6, i = 1, 2.
Avem:
P(X1 = i
⋂X2 = j
)= P (X1 = i, X2 = j) =
1
36= P (X1 = i) · P (X2 = j), ∀i, j ∈ 1, 2, 3, 4, 5, 6,
aceast însemnând c variabilele aleatoare X1 ³i X2 sunt independente stochastic (arunc rile au fostefectuate independent una de cealalt ).
Teorema 3.22 Consider m familia de v.a. X1, X2, . . . , Xn, Xi : (Ω,F)→ R, i = 1, n.Urm toarele armaµii sunt echivalente:
(i) X1, X2, . . . , Xn sunt v.a. independente stochastic;
(ii) P (X1 ∈ B1, X2 ∈ B2, . . . , Xn ∈ Bn) = P (X1 ∈ B1) · P (X2 ∈ B2) · . . . · P (Xn ∈ Bn), ∀Bi;(iii) F(X1, X2,..., Xn)(x1, x2, . . . , xn) = FX1(x1) · FX2(x2) · . . . · FXn(xn), ∀x1, x2, . . . , xn ∈ R;
(iv) φ(X1, X2,..., Xn)(t) = φX1(t1) · φX2(t2) · . . . · φXn(tn), ∀t = (t1, t2, . . . , tn) ∈ Rn. (3.19)
Dou dintre dintre cele mai importante propriet µi ale v.a. independente sunt urm toarele:
Teorema 3.23 Dac X1, X2, . . . , Xn sunt v.a. reale, independente, astfel încât
E(|Xk|) <∞, ∀k = 1, 2, . . . , n,
atunci E(|X1 ·X2 · . . . ·Xn|) <∞ ³i:
E(X1 ·X2 · . . . ·Xn) = E(X1) · E(X2) · . . . · E(Xn). (3.20)
Teorema 3.24 Dac X1, X2, . . . , Xn sunt v.a. reale, independente, astfel încât
D2(Xk) <∞, ∀k = 1, 2, . . . , n,
atunci D2(X1 +X2 + . . . +Xn) <∞ ³i:
D2(X1 +X2 + . . . +Xn) = D2(X1) +D2(X2) + . . . +D2(Xn). (3.21)

Laborator 3 [Dr. Iulian Stoleriu] 39
Statistic Aplicat (Laborator 3)
Metode Monte Carlo
Metoda Monte Carlo
Metoda Monte Carlo este o metod de simulare statistic , ce produce soluµii aproximative pentru o marevarietate de probleme matematice prin efectuarea de experimente statistice pe un computer. Se poateaplica atât problemelor cu deterministe, cât ³i celor probabilistice ³i este folositoare în obµinerea de soluµiinumerice pentru probleme care sunt prea dicile în a rezolvate analitic. Este o metod folosit de secole,dar a c p tat statutul de metod numeric din anii 1940. În 1946, S. Ulam14 a devenit primul matema-tician care a dat un nume acestui procedeu, iar numele vine de la cazinoul Monte Carlo din principatulMonaco, unde se practic foarte mult jocurile de noroc, în special datorit jocului de rulet (ruleta = ungenerator simplu de numere aleatoare). De asemenea, Nicholas Metropolis15 a adus contribuµii importantemetodei.Are la baz generarea de numere aleatoare convenabile ³i observarea faptului c o parte dintre acesteaveric o proprietate sau anumite propriet µi. În general, orice metod care are la baz generarea de nu-mere aleatoare în vederea determin rii rezultatului unui calcul este numit o metod Monte Carlo. Oriceeveniment zic care poate v zut ca un proces stochastic este un candidat în a modelat prin metoda MC.
Integrarea folosind metoda Monte Carlo
Dorim s folosim metode Monte Carlo pentru evaluarea integralei
I =
∫ b
af(x) dx. (3.22)
În general, pentru a evalua numeric integral , metoda Monte Carlo nu este prima alegere, însa este foarteutil în cazul în care integral este dicil (sau imposibil) de evaluat. Aceast metoda devine mai ecient decât alte metode de aproximare când dimensiunea spaµiului e mare.
Dac dorim aplicarea metodei MC, atunci avem de ales una din urm toarele variante:
Varianta 1 (poate aplicat doar pentru f ≥ 0. Dac f ³i valori negative, dar este m rginit inferior,atunci putem utiliza o translaµie, astfel încât s avem de integrat o funcµie nenegativ ) Încadr m graculfuncµiei f într-un dreptunghi
D = [a, b]× [0, d],
unde d > sup[a, b]
f . Evalu m integrala folosindu-ne de calculul probabilit µii evenimentului A, c un punct
ales la întâmplare în interiorul dreptunghiului D s se ae sub gracul funcµiei f(x). Facem urm toareaexperienµ aleatoare: alegem în mod uniform (comanda rand ne ofer aceast posibilitate în Matlab)un punct din interiorul dreptunghiului ³i test m dac acest punct se a sub gracul lui f(x). Repet mexperienµa de un num r N (mare) de ori ³i contabiliz m num rul de apariµii f(N) ale punctului sub grac.
14Stanislaw Marcin Ulam (1909− 1984), matematician de origine polonez , n scut în Lvov, Ucraina15Nicholas Constantine Metropolis (1915− 1999), zician grec

Laborator 3 [Dr. Iulian Stoleriu] 40
Pentru un num r mare de experienµe, probabilitatea ca un punct generat aleator în interiorul dreptun-ghiului s se ae sub gracul funcµiei va aproximat de frecvenµa relativ a realiz rii evenimentului,adic
P ' f(N)
N.
Pe de alt parte, probabilitatea teoretic este
P =I
aria dreptunghi,
de unde aproximarea
I ' aria dreptunghi · f(N)
N. (3.23)
Totu³i, aceast metod nu e foarte ecient , deoarece N trebuie s e foarte mare pentru a avea o preciziebun .
Exemplu 3.25 Utilizând metoda Monte Carlo, s se evalueze integrala
I =
5∫−2
e−x2dx.
Soluµie: Gener m 106 puncte aleatoare în interiorul p tratului [−2, 5] × [0, 1] ³i veric m care dintreacestea se a sub gracul funcµiei f(x) = e−x
2, x ∈ [0, 1]. Urm toarea funcµie Matlab calculeaz inte-
grala dorit :
function I = integrala(N) % functia integrala.m
x = 7*rand(N,1)-2; y = rand(N,1); % genereaza N numere aleatoare in [−2, 5]× [0, 1]f = find(y < exp(-x.^2)); % numar punctele aflate sub graficul functiei e−x
2
I = 7* length(f)/N; % formula (3.23)
O rulare a funcµiei, integrala(1e6), ne furnizeaz rezultatul I = 1.7675.
Varianta 2 Putem rescrie integrala în forma
I = (b− a)
∫ b
af(x)h(x) dx, (3.24)
unde
h(x) =
1
b− a, dac x ∈ [a, b],
0 , altfel.
Funcµia h(x) denit mai sus este densitatea de repartiµie a unei v.a. X ∼ U [a, b], iar relaµia (3.22) serescrie
I = (b− a)E(f(X)). (3.25)
Folosind legea slab a numerelor mari, putem aproxima I prin:
I ' b− aN
N∑k=1
f(Xk), (3.26)

Laborator 3 [Dr. Iulian Stoleriu] 41
unde Xk sunt numere aleatoare ce urmeaz repartiµia U [a, b].
Putem generaliza aceast metod pentru calculul integralelor de tipul∫Vf(x) dx, unde V ⊂ Rn.
Exemplu 3.26 S se evalueze integrala din Exemplul (3.25) folosind formula (3.26).
Soluµie: Codul Matlab este urm torul:
x = 7*rand(1e6,1)-2; % genereaza 106 numere aleatoare U(−2, 5)g = exp(-x.^2); % g(x) = e−x
2
I = 7*mean(g) % 7*media lui g(x)
sau, restrâns, putem apela urm toarea comand :
estimate = 7*mean(exp(-((7*rand(10^6,1)-2).^2))) % I ≈ 1.7671
√
Exemplu 3.27 Evaluând integrala
I =
1∫0
ex dx
printr-o metod Monte Carlo s se estimeze valoarea num rului transcendent e. (e = I + 1).
Soluµie: estimate = mean(exp(rand(10^6,1))) + 1 % e ≈ 2.7183
√
Exemplu 3.28 (aproximarea lui π folosind jocul de darts)În ce const jocul? S presupunem c suntem la nivelul încep tor. Avem de aruncat o s geat ascuµit ,ce poate penetra cu u³urinµ lemnul, spre o tabl p trat din lemn, în interiorul c ruia se a desenatun cerc circumscris p tratului. Dac s geata se înnge în interiorul discului atunci aµi câ³tigat un punct,dac nu - nu câ³tigaµi nimic. Repet m jocul de un num r N de ori ³i contabiliz m la sfâr³it num rul depuncte acumulate, s zicem c acest num r este νN .
S presupunem c sunteµi un juc tor slab de darts (asta implic faptul c orice punct de pe tabl areaceea³i ³ans de a µintit), dar nu a³a de slab încât s nu nimeriµi tabla. Cu alte cuvinte, presupunemc de ecare dat când aruncaµi s geata, ea se înnge în tabl .
Se cere s se aproximeze valoarea lui π pe baza jocului de mai sus ³i s se scrie un program în Matlabcare s simuleze experimentul.
Soluµie: S not m cu A evenimentul ca s geata s se înng chiar în interiorul discului. În cazul în carenum rul de arunc ri N e foarte mare, atunci probabilitatea evenimentului A, P (A), este bine aproximat
de limit ³irului frecvenµelor relative, adic limn→∞
νNN
.

Laborator 3 [Dr. Iulian Stoleriu] 42
Pe de alt parte, P (A) = aria discaria perete
= π4 . A³adar, putem aproxima π prin
π ' 4νNN
(pentru N 1). (3.27)
Funcµia Matlab care aproximeaz pe π este prezentat mai jos. Metoda care a stat la baza aproxim riilui π este o metoda Monte Carlo.
function Pi = darts(N) % numar de aruncari
theta = linspace(0,2*pi,N); % genereaza vectorul theta
x = rand(N,1); y = rand(N,1); % (x,y) - intepaturi
X = 1/2+1/2*cos(theta); Y = 1/2+1/2*sin(theta); % cerc in polar
plot(x,y,'b+',X,Y,'r-'); % deseneaza cercul si punctele
S = sum((x-.5).^2 + (y-.5).^2 <= 1/4); % numarul de succese
Prob = S/N; % frecventa relativa
approxpi = 4*Prob; % aproximarea lui pi
axis([0 1 0 1]); % deseneaza axele
title([int2str(N),' aruncari, \pi \approx ', num2str(approxpi)]);
O simpl rulare a funcµiei, darts(2000), ne genereaz Figura 3.2. √
Figura 3.2: Simularea jocului de darts.

STATS 4 [Dr. Iulian Stoleriu] 43
4 Statistic Aplicat (C4)
Elemente de Teoria probabilit µilor
Tipuri de convergenµ a ³irurilor de variabile aleatoare
Fix m (Ω, F , P ) un câmp de probabilitate ³i Xn, X : Ω→ R variabile aleatoare cu media m ³i dispersiaσ2 nite.
Deniµia 4.1 Spunem c :
(1) Xn converge aproape sigur la X (notat Xna.s.−→ X) dac
P ( limn→∞
Xn = X) = 1,
echivalent cu relaµia
∃Ω0 ∈ F , P (Ω0) = 1, astfel încât limn→∞
Xn(ω) = X(ω), ∀ω ∈ Ω0.
(2) Xn converge în probabilitate la X (notat Xnprob−→ X), dac
∀ε > 0, limn→∞
P (ω : |Xn(ω)−X(ω)| ≥ ε) = 0.
(3) Xn converge în medie de ordin r la X (notat XnLr−→ X), dac
limn→∞
∫Ω|Xn(ω)−X(ω)|r dP (ω) = 0,
echivalent cu
limn→∞
∫R|xn − x|rf(x)dx = 0.
(4) Xn converge în repartiµie la X (notatrep−→ X, sau Xn ⇒ X) dac
limn→∞
E(g(Xn)) = E(g(X)), ∀g : R→ R, continu ³i m rginit .
(5) Xn converge la X în sensul funcµiei de repartiµie dac
limn→∞
FXn(x) = FX(x), ∀x punct de continuitate pentru FX .
(6) Xn converge la X în sensul funcµiei caracteristice dac
limn→∞
φXn(t) = φX(t), ∀t ∈ R.
Teorema 4.2 (leg turi între diverse tipuri de convergenµ )
(a) Xna.s.−→ X implic Xn
prob−→ X.
(b) XnLr−→ X implic Xn
prob−→ X (din inegalitatea lui Markov).
(c) Xnprob−→ X implic Xn ⇒ X.
(d) Urm toarele tipuri de convergenµ sunt echivalente: convergenµa în repartiµie, convergenµa în funcµiede repartiµie ³i convergenµa în funcµie caracteristic .

STATS 4 [Dr. Iulian Stoleriu] 44
Teoreme limit
Fie (Ω, F , P ) un câmp de probabilitate ³i X : (Ω, F , P )→ R o v.a. ce înregistreaz rezultatele posibileale unui anumit experiment aleator. Putem modela repetiµia acestui experiment prin introducerea unui³ir de v.a., (Xn)n∈N : (Ω, F , P )→ R. Ne-am dori ca acest ³ir s deµin aceea³i informaµie (din punct devedere probabilistic) ca ³i X. În acest scop, introducem noµiunea de variabile aleatoare identic repartizate.
Deniµia 4.3 Variabilele aleatoare X1, X2, . . . , Xn, . . . se numesc identic repartizate dac funcµiile co-respunz toare de repartiµie satisfac ³irul de egalit µi:
FX1(x) = FX2(x) = . . . = FXn(x) = . . . , ∀x ∈ R. (4.1)
Dac , în plus, presupunem c v.a. din ³irul de mai sus sunt independente stochastic, atunci putem priviacest ³ir de v.a. ca un model pentru repet ri independente ale experimentului în aceleasi condiµii. De³iavem de-a face cu un ³ir de funcµii ce iau valori întâmpl toare, suma unui num r sucient de mare devariabile aleatoare î³i pierde caracterul aleator.
Teoremele limit clasice descriu comportarea asimptotic a sumei Sn =n∑k=1
Xk, potrivit normalizat .
Spunem c ³irul (Xn)n urmeaz legea slab (respectiv, tare) a numerelor mari dac :
Sn − E(Sn)
n
prob−→ 0, (respectiv,Sn − E(Sn)
n
a.s.−→ 0), (n→∞)
În Teoria Probabilit µilor exist mai multe rezultate care stabilesc condiµiile în care una sau cealalt dintrelegile anterioare au loc. Prezent m în continuare doar cele mai importante dintre ele, ³i anume: teoremelelui Cebî³ev ³i Hincin, pentru legea slab , ³i teorema lui Kolmogorov pentru legea tare.
Teorema 4.4 (Cebî³ev)Dac v.a. (Xn)n∈N∗ satisfac condiµiile:
(i) toate Xn admit momente absolute de ordin 2 (i.e., β2(Xn) <∞);
(ii) limn→∞
1
n2D2(Sn) = 0,
atunciSn − E(Sn)
n
prob−→ 0, când n→∞.
Demonstraµie. Pentru orice a > 0 xat, conform inegalit µii lui Cebî³ev aplicate variabilei aleatoareSnn,
avem:
P (
(∣∣∣∣Snn − E(Snn
)∣∣∣∣ ≥ a) ≤ 1
a2D2
(Snn
)=
1
a2
1
n2D2(Sn)→ 0, când n→∞.
2
Observaµia 4.5 În plus, dac Xn sunt identic repartizate, cu E(Xn) = m, ∀n ∈ N, atunci concluziaanterioar devine:
Snn
prob−→ m.
Astfel, teorema ne spune c , de³i variabilele aleatoare independente pot lua valori dep rtate de mediile lor,media aritmetic a unui num r sucient de mare de astfel de variabile aleatoare ia valori în vecin tatealui m, cu o probabilitate foarte mare.

STATS 4 [Dr. Iulian Stoleriu] 45
Teorema 4.6 (Teorema lui Bernoulli)S consider m o experienµ în care probabilitatea de realizare a unui eveniment A este P (A) = p. Se facN experienµe independente. Dac νN este num rul de realiz ri ale lui A din cele N experienµe atunci,pentru orice ε > 0, avem:
limn→∞
P(∣∣∣νNN− p∣∣∣ ≤ ε) = 1. (4.2)
Cu alte cuvinte, ³irul frecvenµelor relative converge în probabilitate la probabilitatea p. Asta înseamn c ,dac se efectueaz o selecµie de volum mare N ³i se obµin νN cazuri favorabile, atunci, cu o probabilitateapropiat de 1, putem arma c probabilitatea evenimentului cercetat este egal cu frecvenµa relativ .
Demonstraµie. Vom asocia ec rei experienµe i o variabil aleatoare Xi, astfel încât
Xi =
1, dac în experienµa i evenimentul A s-a realizat;
0, dac experienµa i evenimentul A nu s-a realizat.
Observ m c Xi ∼ B(1, p). Atunci, deoarece experimentele sunt independente, avem:
n∑i=1
Xi = νN ∼ B(N, p), E(νN ) = Np, D2(νN ) = Np(1− p).
Aplicând inegalitatea lui Cebî³ev variabilei aleatoareνNN
, obµinem:
P(∣∣∣νNN− E
(νNN
)∣∣∣ ≤ ε) ≥ 1−D2(νNN
)ε2
,
echivalent cu
P(∣∣∣νNN− p∣∣∣ ≤ ε) ≥ 1− p(1− p)
Nε2,
de unde concluzia dorit . 2
Teorema 4.7 (Hincin16) (legea slab a numerelor mari)Dac Xn, n ≥ 1, sunt variabile aleatoare ce admit momente absolute de ordin 1, sunt independente dou câte dou ³i identic repartizate, atunci ³irul (Xn)n urmeaz legea slab a numerelor mari, i.e.,
1
n
n∑k=1
Xkprob−→ m, (n→∞), (4.3)
unde m = E(Xn), ∀n ∈ N∗.
Teorema 4.8 (Kolmogorov) (legea tare a numerelor mari)Fie ³irul de v.a. (Xn)n∈N∗ , independente, sunt identic repartizate ³i E(|X1|) <∞.Fie E(Xn) = m, ∀n ∈ N∗. Atunci ³irul (Xn)n satisface legea tare a numerelor mari, adic :
1
n
n∑k=1
Xka.s−→ m, (n→∞). (4.4)
16Aleksandr Yakovlevich Khinchin (1894− 1959), matematician rus

STATS 4 [Dr. Iulian Stoleriu] 46
Observaµia 4.9 Concluzia legii slabe a numerelor mari se mai poate scrie ³i sub forma:
P
(limn→∞
X1 +X2 + · · ·+Xn
n= m
)= 1.
Teorema 4.10 (TLC) (teorema limit central )Dac v.a. (Xn)n∈N sunt independente ³i identic repartizate, cu m ³i σ2 nite, atunci:
1
σ√n
(n∑k=1
Xk − nm
)⇒ Y ∼ N (0, 1), pentru n→∞.
Observaµia 4.11 (a) Teorema TLC ne spune c , dac avem un ³ir de v.a. independente stochastic ³iidentic repartizate, atunci, pentru n sucient de mare, suma standardizat ,
Sn =Sn − nmσ√n
(4.5)
este o v.a. de repartiµie N (0, 1).
Sau, mai putem spune c distribuµia v.a. X =1
n
n∑k=1
Xk este aproximativ normal N (m,σ√n
).
(b) Not m cu
Znnot=
1
σ√n
(n∑k=1
Xk − nm
).
Atunci, convergenµa din teorema limit central este echivalent cu
limn→∞
P (Zn ≤ x) = Θ(x), ∀x ∈ R, (4.6)
unde Θ(x) este denit în (16.3), sau
limn→∞
P
(a ≤ Sn − nm
σ√n≤ b)
=1√2π
∫ b
ae−x
2dx = Θ(b)−Θ(a). (4.7)
(b) Dac m = 0, σ2 = 1, atunci TLC devine
1√n
n∑k=1
Xk ⇒ Y ∼ N (0, 1), pentru n→∞.
(c) TLC ne permite s aproxim m sume de v.a. identic repartizate, avînd orice tip de repartiµii (atâttimp cât variaµia lor e nit ), cu o v.a. normal . Un exemplu ar aproximarea repartiµiei normale curepartiµia binomial când num rul de încerc ri e foarte mare (vezi teorema lui de Moivre-Laplace de maijos).Se pune problema: Cât de mare ar trebui s e n, în practic , pentru c teorema limit central s eaplicabil ? Dac variabilele aleatoare Xkk sunt deja normal repartizate, atunci teorema aproximareasumei standardizate cu o variabil normal este, de fapt, o egalitate, ind adevarat pentru orice n ∈ N∗.Dac Xkk nu sunt normal repartizate, atunci un num r n astfel încât n ≥ 30 ar sucicient pentruaproximarea cu repartiµia normal de³i, dac repartiµia lui Xk este simetric , aproximarea ar putea bun ³i pentru un num r n mai mic de 30.
(d) Legea tare a numerelor mari e foarte util în metode de simulare tip Monte Carlo.

STATS 4 [Dr. Iulian Stoleriu] 47
Teorema 4.12 (de Moivre17 - Laplace)Fie X1, X2, . . . , Xn, . . . un ³ir de v.a. independente stochastic, identic repartizate B(1, p) ³i e Sn =X1 +X2 + · · ·+Xn. Atunci, pentru orice −∞ < a < b <∞, avem:
limn→∞
P
(a ≤ Sn − np√
npq≤ b)
=1√2π
∫ b
ae−x
2dx. (q = 1− p) (4.8)
Demonstraµie. Demonstraµia rezult imediat din (4.7), µinând cont c
E(Sn) = np ³i D2(Sn) = npq.
2
Observaµia 4.13 (1) A³adar, dac parametrul n este sucient de mare, atunci o repartiµie binomial poate aproximat cu una normal , cu media np ³i dispersia npq. În practic ,
• aproximarea este una sucient de bun dac np ≥ 5 ³i n(1− p) ≥ 5;
• aceast aproximare poate îmbun t µit dac aplic m factori de corecµie.
Putem aproxima funcµia de repartiµie a repartiµiei binomiale prin:
P (X ≤ k) ≈ Θ
(k + 1
2 − np√npq
), (4.9)
unde Θ este funcµia de repartiµie pentru repartiµia normal standard, i.e.,
Θ(x) =1√2π
∫ x
−∞e−
y2
2 dy, x ∈ R.
Termenul 12 din (4.9) este folosit ca o valoare de ajustare când se face aproximarea unei variabile aleatoare
discrete cu una continu .În acela³i mod, putem aproxima funcµia de probabilitate a repartiµiei binomiale folosind densitatea repar-tiµiei normale standard:
P (X = k) ≈ 1√npq
Φ
(k − np√npq
), (4.10)
unde Φ(x) = ddxΘ(x) este densitatea de repartiµie a repartiµiei normale standard.
O variant îmbun t µit a aproxim rii (4.10) este:
P (X = k) = P (k − 1
2< X < k +
1
2)
= P
(k − 1
2 − np√npq
<X − np√npq
<k + 1
2 − np√npq
)
≈ Θ
(k + 1
2 − np√npq
)−Θ
(k − 1
2 − np√npq
).
17Abraham de Moivre (1667− 1754), matematician francez

STATS 4 [Dr. Iulian Stoleriu] 48
(2) În general, dac dorim s aproxim m o repartiµie discret (ce are media µ ³i dispersia σ2) cu unanormal , atunci scriem:
P (X ≤ k) ≈ Θ
(k + 1
2 − µσ
)(4.11)
³i
P (X = k) ≈ 1
σΦ
(k − µσ
). (4.12)
Funcµii de variabile aleatoare
Funcµii de o singur variabil aleatoare
Presupunem c X este o variabil aleatoare continu , c reia i se cunoa³te densitatea de repartiµie, fX(x).Not m cu FX(x) funcµia sa de repartiµie.Fie g(x) este o funcµie m surabil (Borel). Atunci Y = g(X) dene³te o alt variabil aleatoare. Dorims g sim densitatea de repartiµie pentru g(X). S not m cu DY = x ∈ R; g(x) ≤ y. Putem scrie:
Y ≤ y = g(X) ≤ y = ω ∈ Ω, X(ω) ∈ DY (not= X ∈ DY ).
Atunci,
FY (y) = P (X ∈ DY ),
=
∫DY
fX(x) dx. (4.13)
Dac g(x) este bijectiv ³i x = h(y)not= g−1(y), atunci densitatea de repartiµie a lui Y este dat de:
fY (y) = fX(h(y))
∣∣∣∣dh(y)
dy
∣∣∣∣ . (4.14)
Exemplu 4.14 Consider m funcµiag(x) = ax+ b, a 6= 0.
Dac fX(x) este densitatea de repartiµie a unei variabile aleatoare continue X, atunci densitatea derepartiµie a variabilei aleatoare Y = g(X) este
fY (y) =1
|a|fX
(y − ba
).
Alternativ, putem calcula densitatea lui g(X) astfel:Not m cu FY (y) funcµia de repartiµie pentru Y ³i cu fY (y) densitatea sa de repartiµie. Atunci:
FY (y) = P (aX+b ≤ y) =
P
(X ≤ y − b
a
), a > 0;
P
(X ≥ y − b
a
), a < 0;
=
FX
(y − ba
), a > 0;
1− FX(y − ba
), a < 0;
Dac FX este continu , atunci:
fY (y) =dFY (y)
dy=
1
|a|fX
(y − ba
).

Laborator 4 [Dr. Iulian Stoleriu] 49
Statistic Aplicat (Laborator 4)
Repartiµii probabilistice în Matlab
Funcµia de probabilitate (pentru v.a. discrete) ³i densitatea de repartiµie (pentru v.a. continue) (ambelenotate anterior prin f(x)) se introduc în Matlab cu ajutorul comenzii pdf, astfel:
pdf('LEGE', x, <param>) sau LEGEpdf(x, <param>).
Funcµia de repartiµie F (x) a unei variabile aleatoare se poate introduce în Matlab cu ajutorul comenziicdf, astfel:
cdf('LEGE', x, <param>) sau LEGEcdf(x, <param>).
Inversa funcµiei de repartiµie pentru repartiµii continue, F−1(y), se introduce cu comanda icdf, astfel:
icdf('LEGE', y, <param>) sau LEGEinv(y, <param>).
În comenzile de mai sus, LEGE poate oricare dintre legile de repartiµie din Tabelul 4.1, x este un scalar sauvector pentru care se calculeaz f(x) sau F (x), y este un scalar sau vector pentru care se calculeaz F−1(y),iar <param> este un scalar sau un vector ce reprezint parametrul (parametrii) repartiµiei considerate.
Observaµia 4.15 Fie X o variabil aleatoare ³i F (x, θ) funcµia sa de repartiµie, θ ind parametrulrepartiµiei. Pentru un x ∈ R, relaµia matematic
P (X ≤ x) = F (x)
o putem scrie astfel în Matlab:
cdf('numele repartiµiei lui X',x,θ). (4.15)
Problema poate aparea la evaluarea în Matlab a probabilit µii P (X < x). Dac repartiµia considerat este una continu , atunci corespondentul în Matlab este tot (4.15), deoarece în acest caz
P (X ≤ x) = P (X < x) + P (X = x) = P (X < x).
De exemplu, dac X ∼ N (5, 2), atunci
P (X < 4) = cdf('norm', 4, 5, 2).
Dac X este de tip discret, atunci
P (X < x) =
P (X ≤ [x]) , x nu e întreg
P (X ≤ m− 1) , x = m ∈ Z,

Laborator 4 [Dr. Iulian Stoleriu] 50
unde [x] este partea întreag a lui x.De exemplu, dac X ∼ B(10, 0.3), atunci
P (X < 5) = P (X ≤ 4)
= cdf('bino', 4, 10, 0.3) = 0.8497.
Tabelul 4.1 conµine câteva repartiµii uzuale ³i funcµiile corespunz toare în Matlab.
repartiµii probabilistice discrete repartiµii probabilistice continue
norm: repartiµia normal N (µ, σ)bino: repartiµia binomial B(n, p) unif: repartiµia uniform continu U(a, b)nbin: repartiµia binomial negativ BN(n, p) exp: repartiµia exponenµial exp(λ)poiss: repartiµia Poisson P(λ) gam: repartiµia Gamma Γ(a, λ)unid: repartiµia uniform discret U(n) beta: repartiµia Beta β(m,n)geo: repartiµia geometric Geo(p) logn: repartiµia lognormal logN (µ, σ)hyge: repartiµia hipergeometric H(n, a, b) chi2: repartiµia χ2(n)
t: repartiµia student t(n)f: repartiµia Fisher F(m, n)
wbl: repartiµia Weibull Wbl(k, λ)
Tabela 4.1: Repartiµii uzuale în Matlab
Exerciµiu 4.1 O moned ideal este aruncat de 100 de ori, iar X este variabila aleatoare ce reprezint num rul de feµe cu stema ap rute.(a) Care este probabilitatea de a obµine exact 52 de steme?(b) S se calculeze P (45 ≤ X ≤ 55). Folosiµi aproximarea cu o variabil aleatoare normal .
Soluµie: (a) Avem de calculat P = P (X = 52). Îns X este o variabil aleatoare distribuit B(100, 0.5), a³adar rezultatul exact este:
P = C52100 · (0.5)52 · (0.5)48 = 0.0735.
Dac aproxim m rezultatul folosind formula (4.11), obµinem:
P =1√
100 · 0.5 · 0.5Φ
(52− 50√
100 · 0.5 · 0.5
)≈ 0.0737.
Cu varianta îmbun t µit , obµinem:
P = Θ
(52 + 1
2 − 50√
25
)−Θ
(52− 1
2 − 50√
25
)≈ 0.0736.

Laborator 4 [Dr. Iulian Stoleriu] 51
(b) Not m cu FX funcµia de repartiµie pentru variabila aleatoare binomial X. Atunci,
P (45 ≤ X ≤ 55) = P (X ≤ 55)− P (X < 45)
= FX(55)− FX(44)
=55∑
k=45
Ck100 · (0.5)k · (0.5)100−k = 0.7287.
Dac folosim aproximarea cu repartiµia normal , obµinem:
P (45 ≤ X ≤ 55) ≈ Θ
(55 + 1
2 − 50√
25
)−Θ
(45− 1
2 − 50√
25
)= 0.7287.
Codul Matlab urm tor calculeaz probabilit µile cerute, calculate analitic anterior.
P1 = nchoosek(100,52)*(0.5)^52*(0.5)^48 % solutia exacta
P1 = 1/5*normpdf(2/5) % solutia aproximativa 1
P1 = normcdf(2.5/5) - normcdf(1.5/5) % solutia aproximativa 2
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
P2 = binocdf(55,100,0.5) - binocdf(44,100,0.5) % solutia exacta
P2 = normcdf(5.5/5) - normcdf(-5.5/5) % solutia aproximativa √
Exerciµiu 4.2 Cineva a înregistrat zilnic timpul între dou sosiri succesive ale tramvaiului într-o anumit staµie ³i a g sit c , în medie, acesta este de 20 de minute. Se ³tie c acest timp este distribuit exponenµial.Dac o persoan a ajuns în staµie exact când tramvaiul pleca, aaµi care sunt ³ansele ca ea s a³tepte celpuµin 15 minute pân vine urm torul tramvai.
Soluµie: Not m cu T timpul de a³teptare în staµie între dou sosiri succesive ale tramvaiului ³i cu FTfuncµia sa de repartiµie. tim c T ∼ exp(λ), unde λ = 20. A³adar, avem de calculat P (T ≥ 15), careeste:
P (T ≥ 15) = 1− P (T < 15) = 1− FT (15),
³i aceasta este1 - cdf('exp',15, 20) = 0.4724,
ceea ce implic 47.24% ³anse. √
Exerciµiu 4.3 (a) Simulaµi în Matlab o variabil aleatoare discret X ce poate lua doar dou valori,X = 1, cu P (X = 1) = p ³i X = −1, cu P (X = −1) = 1− p, (p ∈ (0, 1)).(b) Consider m urm torul joc: se arunc o moned corect de N ori ³i dac apare stema câ³tig m1 RON , iar dac apare banul, pierdem 1 RON . S se reprezinte v.a. care reprezint câ³tigul S(n) cumu-lat la ecare aruncare. De asemenea, s se contabilizeze de câte ori s-a întors balanµa la 0.
Soluµie: (a) Stabilim un p ∈ [0, 1]. Cu comanda rand, gener m un num r aleator dup repartiµiaU(0, 1). Atunci, comanda Matlab
(rand < p)
ne a³eaz valoarea de adevar a propoziµiei rand < p. A³adar, Matlab a³eaz 1 dac rand < p (pro-babilitatea ca aceasta s se întâmple este p) ³i a³eaz 0 dac rand > p (probabilitatea evenimentului

Laborator 4 [Dr. Iulian Stoleriu] 52
este 1− p). Prin urmare, pentru a simula variabila aleatoare Bernoulli cerut folosim codul:
p = input('p = '); % introduc probabilitatea pX = 2*(rand < p)-1; % variabila aleatoare X
0 1 2 3 4 5 6 7 8 9 10
x 104
−100
−50
0
50
100
150
200
aruncari
S(n
)
Figura 4.1: Suma cumulat - mi³care aleatoare (brownian ) 1D.
(b) Proced m astfel: mai întâi iniµializez un vector ce are toate componentele egale cu −1. Arunc omoned de N ori. Dac apare evenimentul favorabil, atunci pentru aruncarea (componenta) respectiv schimb m valoarea −1 (pierdere) în +1 (castig). La nal, fac suma cumulat la ecare pas ³i o reprezintgrac (vezi Figura 4.1). Pentru a contabiliza num rul de zerouri ale vectorului Castig, calcul m lungi-mea vectorului ce are drept componente rangurile pentru care vectorul Castig este 0. CodulMatlab este:
N = input('N = '); % numar de repetitii ale jocului
S = -1*ones(N,1); % un vector cu toate componentele egale cu -1
u = rand(N,1); % un vector cu N numere U(0, 1)S(u < 0.5) = 1; % aruncare favorabila => schimb componenta -1 cu 1
Castig = cumsum(S); % suma cumulata la fiecare moment
plot(1:N, Castig, '*') % deseneaza graficul
Z=length(find(Castig == 0)) % numarul de componente nule √
Exerciµiu 4.4 Un cet µean turmentat pleac de la bar spre cas . S presupunem c punctul de plecareeste punctul O de pe axa orizontal ³i se mi³c doar pe aceast ax astfel: în ecare unitate de timp,acesta ori face un pas la stânga, cu probabilitatea 0.5, ori face un pas la dreapta, cu probabilitatea 0.5,independent de pa³ii anteriori. Folosind Teorema limit central , estimaµi probabilitatea ca, dup 100 depa³i, acesta nu a ajuns la mai mult de doi pa³i de punctul de plecare.
Soluµie: Fie Xi variabila aleatoare ce reprezint pasul pe care cet µeanul îl face la momentul i (i ∈ N).S atribuim X = −1, dac face un pas la stânga, ³i X = 1, dac face un pas la dreapta. A³adar, X esteo variabil aleatoare discret ce poate lua doar dou valori, −1 ³i 1, ambele cu probabilitatea 0.5. Secalculeaz cu u³urinµ , E(X) = 0 ³i D2(X) = 1. Suntem interesaµi s a m ce se întâmpl dup 100 de
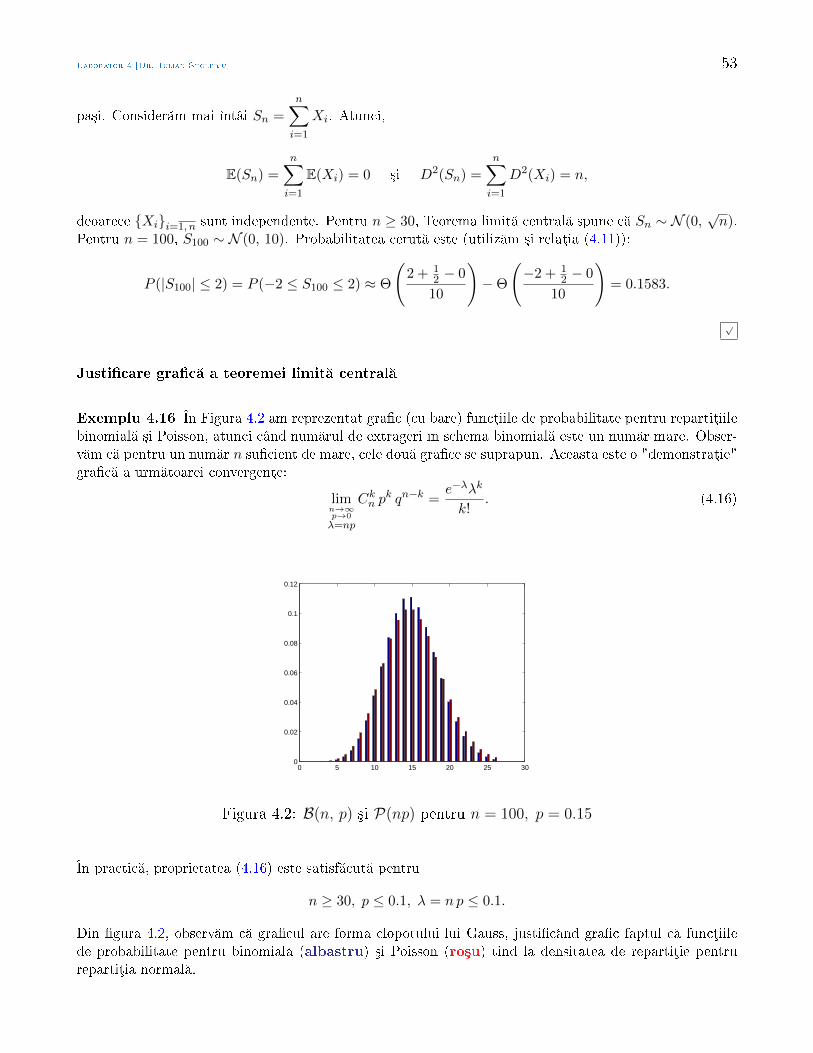
Laborator 4 [Dr. Iulian Stoleriu] 53
pa³i. Consider m mai întâi Sn =n∑i=1
Xi. Atunci,
E(Sn) =n∑i=1
E(Xi) = 0 ³i D2(Sn) =n∑i=1
D2(Xi) = n,
deoarece Xii=1, n sunt independente. Pentru n ≥ 30, Teorema limit central spune c Sn ∼ N (0,√n).
Pentru n = 100, S100 ∼ N (0, 10). Probabilitatea cerut este (utiliz m ³i relaµia (4.11)):
P (|S100| ≤ 2) = P (−2 ≤ S100 ≤ 2) ≈ Θ
(2 + 1
2 − 0
10
)−Θ
(−2 + 1
2 − 0
10
)= 0.1583.
√
Justicare grac a teoremei limit central
Exemplu 4.16 În Figura 4.2 am reprezentat grac (cu bare) funcµiile de probabilitate pentru repartiµiilebinomial ³i Poisson, atunci când num rul de extrageri în schema binomial este un num r mare. Obser-v m c pentru un num r n sucient de mare, cele dou grace se suprapun. Aceasta este o "demonstraµie"grac a urm toarei convergenµe:
limn→∞p→0
λ=np
Ckn pk qn−k =
e−λλk
k!. (4.16)
0 5 10 15 20 25 300
0.02
0.04
0.06
0.08
0.1
0.12
Figura 4.2: B(n, p) ³i P(np) pentru n = 100, p = 0.15
În practic , proprietatea (4.16) este satisf cut pentru
n ≥ 30, p ≤ 0.1, λ = n p ≤ 0.1.
Din gura 4.2, observ m c gracul are forma clopotului lui Gauss, justicând grac faptul c funcµiilede probabilitate pentru binomial (albastru) ³i Poisson (ro³u) tind la densitatea de repartiµie pentrurepartiµia normal .

Laborator 4 [Dr. Iulian Stoleriu] 54
n = input('n='); p = input('p=');
lambda = n*p;
a=fix(lambda-3*sqrt(lambda)); b=fix(lambda+3*sqrt(lambda));
% a si b sunt valorile din problema celor 3σx=a:b; fB=binopdf(x,n,p); fP=poisspdf(x,lambda);
bar(x',[fB',fP'])

STATS 5 [Dr. Iulian Stoleriu] 55
5 Statistic Aplicat (C5)
Funcµii de argumente aleatoare
Funcµii de o singur variabil aleatoare
Presupunem c X este o variabil aleatoare continu , c reia i se cunoa³te densitatea de repartiµie, fX(x).Not m cu FX(x) funcµia sa de repartiµie.Fie g(x) este o funcµie m surabil (Borel). Atunci Y = g(X) dene³te o alt variabil aleatoare. Dorims g sim densitatea de repartiµie pentru g(X). S not m cu DY = x ∈ R; g(x) ≤ y. Putem scrie:
Y ≤ y = g(X) ≤ y = ω ∈ Ω, X(ω) ∈ DY (not= X ∈ DY ).
Atunci,
FY (y) = P (X ∈ DY ),
=
∫DY
fX(x) dx. (5.1)
Dac g(x) este bijectiv ³i x = h(y)not= g−1(y), atunci densitatea de repartiµie a lui Y este dat de:
fY (y) = fX(h(y))
∣∣∣∣dh(y)
dy
∣∣∣∣ . (5.2)
Exemplu 5.1 Fie X ∼ N (0, 1). Se cere densitatea de repartiµie a v.a. X2.
- Funcµia densitate de repartiµie pentru X este dat de
fX(x) =1√2πe−
x2
2 , x ∈ R. (5.3)
Not m cu FX2(y) funcµia de repartiµie pentru X2 ³i cu fX2(y) densitatea sa de repartiµie. Nu putemfolosi formula (5.2) deoarece funcµia g(x) = x2, x ∈ R, nu este bijectiv . Pentru a calcula densitatea luiX2, putem proceda astfel:
FX2(y) = P (X2 ≤ y) =
0 , y ≤ 0;
P (−√y ≤ X ≤ √y) , y > 0,
de unde
fX2(y) = F ′X2(y) =
0 , y ≤ 0;1
2√y
[fX(√y) + fX(−√y)] , y > 0,
=
0 , y ≤ 0;1√yfX(√y) , y > 0.

STATS 5 [Dr. Iulian Stoleriu] 56
=
0 , y ≤ 0;1√2πy
e−y2 dy , y > 0.
√
Funcµii de dou variabile aleatoare:
Fie X, Y variabile aleatoare reale denite pe câmpul de probabilitate (Ω, F , P ).
Deniµia 5.2 O funcµie m surabil fX,Y (x, y) se nume³te densitate de repartiµie bivariat dac :
(i) fX,Y (x, y) ≥ 0, pentru orice x, y ∈ R; (5.4)
(ii)
∫ ∞−∞
∫ ∞−∞
fX,Y (x, y) dx dy = 1. (5.5)
În acest caz, funcµia F (x, y) = P (X ≤ x, Y ≤ y) =
∫ x
−∞
∫ y
−∞fX,Y (u, v) du dv se nume³te funcµie de
repartiµie bivariat .
Dac f(x) este densitatea de repartiµie a lui X ³i g(y) este densitatea de repartiµie a lui Y , iar X, Y suntindependente stochastic, atunci
vectorul bidimensional V = (X, Y ) are densitatea de repartiµie fX,Y (x, y) = f(x)g(y).
Invers, dac fX,Y (x, y) = f(x)g(y), atunci X, Y sunt independente stochastic.În cazul general (în care X ³i Y nu sunt independente), dac fX,Y (x, y) este densitatea de repartiµie avectorului bidimensional V = (X, Y ), atunci densit µile de repartiµie a lui X, respectiv Y , sunt:
f(x) =
∫RfX,Y (x, y) dy ³i, respectiv, g(y) =
∫RfX,Y (x, y) dx. (5.6)
Urm toarea propoziµie determin care este densitatea de repartiµie a unei funcµii de un vector aleator ceare densitatea de repartiµie cunoscut .
Propoziµia 5.3 Fie vectorul aleator V = (X, Y ) de tip continuu, cu densitatea de repartiµie cunoscut ,f(x, y) ³i e vectorul aleator de tip continuuW = (U, V ), cu densitatea de repartiµie necunoscut g(u, v).Dac
X = α(U, V ), Y = β(U, V ),
atunci are loc:g(u, v) = f(α(u, v), β(u, v)) |J |, (5.7)
unde J este determinantul funcµional (Jacobianul) al lui (x, y) în raport cu (u, v), adic :
J =∂(x, y)
∂(u, v)=∂x
∂u
∂y
∂v− ∂x
∂v
∂y
∂u.
Observaµia 5.4 Putem apoi determina ³i densit µile de repartiµie marginale pentru U ³i V . Astfel, acesteformule au ca aplicaµii determinarea formulei densit µii de repartiµie pentru suma, produsul, diferenµa saucâtul a dou variabile aleatoare.

STATS 5 [Dr. Iulian Stoleriu] 57
Exemplu 5.5 (repartiµia raportului a dou variabile aleatoare)Fie vectorul aleator (X, Y ), ce are densitatea de repartiµie f(x, y) ³i e transformarea:
u = x/y;
v = y.
Transformarea invers este: x = u · v := α(u, v);
y = v := β(u, v).
Jacobianul transform rii este J =∂(x, y)
∂(u, v)= v. G sim c densitatea de repartiµie a câtului
X
Y,
fXY
(u) =
∞∫−∞
f(u v, v) |v| dv. (5.8)
Dac , în plus, X ³i Y sunt v.a. independente, atunci f(x, y) = f1(x) f2(y) ³i
fXY
(u) =
∞∫−∞
f1(u v)f2(v) |v| dv. (5.9)
Elemente de Statistic descriptiv
S consider m o populaµie statistic de volum N ³i o caracteristic a ei, X, ce are funcµia de repartiµieF . Asupra acestei caracteristici facem n observaµii, în urma c rora culegem un set de date statistice.Dup cum am v zut anterior, datele statistice pot prezentate într-o form grupat (descrise prin tabelede frecvenµe) sau pot negrupate, exact a³a cum au fost culese în urma observ rilor. Pentru analizaacestora, pot utilizate diverse tehnici de organizare ³i reprezentare grac a datelor statistice îns , decele mai multe ori, aceste metode nu sunt suciente pentru o analiz detaliat . Suntem interesaµi în aatribui acestor date anumite valori numerice reprezentative. Pot denite mai multe tipuri de astfel devalori numerice, e.g., m suri ale tendinµei centrale (media, modul, mediana), m suri ale dispersiei (dis-persia, deviaµia standard), m suri de poziµie (cuantile, distanµa intercuantilic ) etc. În acest capitol, vomintroduce diverse m suri descriptive numerice, atât pentru datele grupate, cât ³i pentru cele negrupate.
M suri descriptive ale datelor negrupate
Consider m un set de date statistice negrupate, x1, x2, . . . , xn (xi ∈ R, i = 1, 2 . . . , n, n ≤ N), cecorespund unor observaµii f cute asupra variabilei X. Denim urm toarele:
(1) Valoarea medie empiric
Este o m sur a tendinµei centrale a datelor. Pentru o selecµie x1, x2, . . . , xn, denim:
x =1
n
n∑i=1
xi,

STATS 5 [Dr. Iulian Stoleriu] 58
ca ind media empiric . Dac x1, x2, . . . , xN sunt toate cele N observaµii (recens mânt) asupra carac-teristicii populaµiei, atunci m rimea
µ =1
N
N∑i=1
xi
se nume³te media (empiric a) populaµiei. Vom vedea mai târziu c , pentru a estima media µ a întregiipopulaµii statistice, nu este necesar s avem toate valorile x1, x2, . . . , xN, ci doar o selecµie a ei, ³i vomputea folosi x ca un estimator pentru µ.Pentru ecare i, cantitatea di = xi − x se nume³te deviaµia faµ de medie. Aceasta nu poate denit cao m sur a gradului de împr ³tiere a datelor, deoarece
n∑i=1
(xi − x) = 0.
(2) Momentele empirice
Momentele empirice de ordin k se denesc astfel:
αk =1
n
n∑i=1
xki (pentru selecµie).
Aceast formul mai este cunoscut ³i sub denumirea de formula generalizat a mediilor. Pentru k = 1,obµinem media empiric (aritmetic ) (x), pentru k = −1, obµinem media armonic (xh), pentru k = 2avem media p tratic (xq). Dac µinem cont ³i de media geometric ,
xg = n√x1 · x2 · · · · · xn,
atunci relaµia dintre aceste medii este:xh ≤ xg ≤ x ≤ xq.
Pentru întreaga colectivitate, momentele de ordin k sunt
mk =1
N
N∑i=1
xki , (k ∈ N).
Pentru ecare k ∈ N, momentele empirice centrate de ordin k se denesc astfel:
µk =1
n
n∑i=1
(xi − x)k, pentru selecµie,
³i
µk =1
N
N∑i=1
(xi − µ)k, pentru populaµie.
(3) Dispersia empiric
Aceasta este o m sur a împr ³tierii datelor în jurul valorii medii. Pentru o selecµie x1, x2, . . . , xn,denim dispersia empiric :
s2 =1
n− 1
n∑i=1
(xi − x)2
(=
1
n− 1[
n∑i=1
x2i − n(x)2]
).

STATS 5 [Dr. Iulian Stoleriu] 59
Pentru întreaga populaµie de volum N , dispersia populaµiei este denit prin m sura
σ2 =1
N
N∑i=1
(xi − µ)2.
Observaµia 5.6 Cantitatea1
n
n∑i=1
(xi − x)2 este tot o m sur a dispersiei (empirice) de selecµie. Vom
vedea mai târziu c alegerea lui s2 este mai potrivit într-un anume sens. De altfel, ambele valori pot folosite ca estimatori ai dispersiei populaµiei, σ2.
(4) Deviaµia empiric standard
Este tot o m sur a împr ³tierii datelor în jurul valorii medii. Pentru o selecµie x1, x2, . . . , xn, denimdeviaµia empiric standard:
s =
√√√√ 1
n− 1
n∑i=1
(xi − x)2.
Pentru întreaga populaµie de volum N , deviaµia standard a populaµiei este denit prin m sura
σ =
√√√√ 1
N
N∑i=1
(xi − µ)2.
(5) Amplitudinea (plaja de valori, range)
Pentru un set de date, amplitudinea (en., range) este denit ca ind diferenµa dintre valoarea cea maimare ³i valoarea cea mai mic a datelor, i.e., xmax − xmin.
(6) Scorul Z
Este num rul deviaµiilor standard pe care o anumit observaµie, x, le are sub sau deasupra mediei. Pentruo selecµie x1, x2, . . . , xn, scorul Z este denit astfel:
z =x− xs
.
Pentru o populaµie, scorul Z este:
z =x− µσ
.
(7) Corelaµia (covarianµa) empiric
Dac avem n perechi de observaµii, (x1, y1), (x2, y2), . . . (xn, yn), denim corelaµia (covarianµa) empiric (de selecµie):
covsel =1
n− 1
n∑i=1
(xi − x)(yi − y). (5.10)
Covarianµa empiric pentru întreaga populaµie este:
covpop =1
N
N∑i=1
(xi − µx)(yi − µy). (5.11)

STATS 5 [Dr. Iulian Stoleriu] 60
(8) Coecientul de corelaµie empiric
r =covselsxsy
, coecient de corelaµie de selecµie,
r =covpopσxσy
, coecient de corelaµie pentru populaµie.
(9) Funcµia de repartiµie empiric
Se nume³te funcµie de repartiµie empiric asociat unei variabile aleatoareX ³i unei selecµii x1, x2, . . . , xn,funcµia F ∗n : R −→ R, denit prin
F ∗n(x) =cardi; xi ≤ x
n. (5.12)
Propoziµia de mai jos arat c funcµia de repartiµie empiric aproximeaz funcµia de repartiµie teoretic (vezi Figura 5.1).
Propoziµia 5.7 Fie Ω o colectivitate statistic ³i X o caracteristic a sa, ce se dore³te a studiat . Notezcu F (x) funcµia de repartiµie a lui X. Pentru o selecµie de valori ale lui X, x1, x2, . . . , xn, construimfuncµia de repartiµie empiric , F ∗n(x). Atunci:
F ∗n(x)prob−→ F (x), când n→∞, ∀x ∈ R.
Demonstraµie. Notez cu A evenimentul X ≤ x ³i cu p = P (A). Se fac n repetiµii ale acestui eveniment³i frecvenµa relativ a realiz rii evenimentului A este
νnn
=cardi; xi ≤ x
n= F ∗n(x).
Astfel, concluzia propoziµiei este o consecinµ imediat a teoremei lui Bernoulli, Teorema 4.6. 2
(10) Coecientul de asimetrie (en., skewness) este al treilea moment standardizat, care se dene³te prin
γ1 =µ3
µ3/22
.
O repartiµie este simetric dac γ1 = 0. Vom spune c asimetria este pozitiv (sau la dreapta) dac γ1 > 0³i negativ (sau la stânga) dac γ1 < 0. A³adar, vom avea:
γ1 =
n1/2n∑i=1
(xi − x)3
(
n∑i=1
(xi − x)2)3/2
(pentru selecµie) ³i γ1 =1
nσ3
N∑i=1
(xi − µ)3 (pentru populaµie).
(11) Excesul (coecientul de aplatizare sau boltire) (en., kurtosis) se dene³te prin
K =µ4
µ22
− 3.
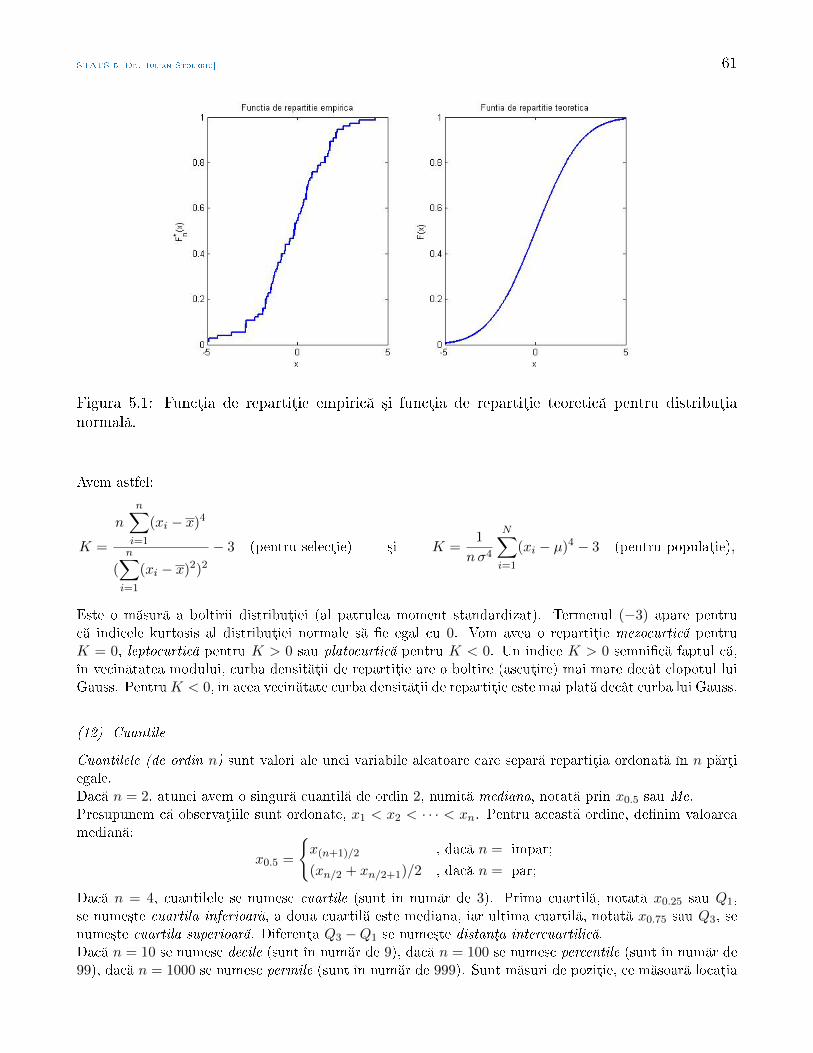
STATS 5 [Dr. Iulian Stoleriu] 61
Figura 5.1: Funcµia de repartiµie empiric ³i funcµia de repartiµie teoretic pentru distribuµianormal .
Avem astfel:
K =
n
n∑i=1
(xi − x)4
(n∑i=1
(xi − x)2)2
− 3 (pentru selecµie) ³i K =1
nσ4
N∑i=1
(xi − µ)4 − 3 (pentru populaµie),
Este o m sur a boltirii distribuµiei (al patrulea moment standardizat). Termenul (−3) apare pentruc indicele kurtosis al distribuµiei normale s e egal cu 0. Vom avea o repartiµie mezocurtic pentruK = 0, leptocurtic pentru K > 0 sau platocurtic pentru K < 0. Un indice K > 0 semnic faptul c ,în vecin tatea modului, curba densit µii de repartiµie are o boltire (ascuµire) mai mare decât clopotul luiGauss. PentruK < 0, în acea vecin tate curba densit µii de repartiµie este mai plat decât curba lui Gauss.
(12) Cuantile
Cuantilele (de ordin n) sunt valori ale unei variabile aleatoare care separ repartiµia ordonat în n p rµiegale.Dac n = 2, atunci avem o singur cuantil de ordin 2, numit mediana, notat prin x0.5 sau Me.Presupunem c observaµiile sunt ordonate, x1 < x2 < · · · < xn. Pentru aceast ordine, denim valoareamedian :
x0.5 =
x(n+1)/2 , dac n = impar;
(xn/2 + xn/2+1)/2 , dac n = par;
Dac n = 4, cuantilele se numesc cuartile (sunt în num r de 3). Prima cuartil , notat x0.25 sau Q1,se nume³te cuartila inferioar , a doua cuartil este mediana, iar ultima cuartil , notat x0.75 sau Q3, senume³te cuartila superioar . Diferenµa Q3 −Q1 se nume³te distanµa intercuartilic .Dac n = 10 se numesc decile (sunt în num r de 9), dac n = 100 se numesc percentile (sunt în num r de99), dac n = 1000 se numesc permile (sunt în num r de 999). Sunt m suri de poziµie, ce m soar locaµia

STATS 5 [Dr. Iulian Stoleriu] 62
unei anumite observaµii faµ de restul datelor.
(13) Modul
Modul (sau valoarea modal ) este acea valoare x∗ din setul de date care apare cel mai des. În anumitecazuri, dac datele sunt deja grupate, putem doar estima modul sau, alternativ, s preciz m clasa careîl conµine, numit clasa modal . De exemplu, pentru datele din Tabelul 1.1 este 6, iar pentru datele dinTabelul 1.4 clasa modal este [35, 45). Un set de date poate avea mai multe module. Dac apar dou astfel de valori, atunci vom spune c setul de date este bimodal, pentru trei astfel de valori avem un setde date trimodal etc. În cazul în care toate valorile au aceea³i frecvenµ de apariµie, atunci spunem c nuexist mod. De exemplu, setul de date
1 3 5 6 3 2 1 4 4 6 2 5
nu admite valoare modal . Nu exist un simbol care s noteze distinctiv modul unui set de date.
M suri descriptive ale datelor grupate
Consider m un set de date statistice grupate (de volum n), ce corespund celor n observaµii asupra variabileiX. Datele grupate sunt în genul celor prezentate în Figurile 1.1 ³i 1.4.
Pentru o selecµie cu valorile de mijloc x1, x2, . . . , xn ³i frecvenµele absolute corespunz toare, f1, f2,
. . . , fn, cun∑i=1
fi = n, denim:
xf =1
n
n∑i=1
xifi, media (empiric ) de selecµie, (sau, media ponderat )
s2 =1
n− 1
n∑i=1
fi(xi − xf )2 =1
n− 1
(n∑i=1
x2i fi − n x2
f
), dispersia empiric ,
s =√s2, deviaµia empiric standard.
Formule similare se pot da ³i pentru m surile descriptive ale întregii populaµii.Mediana pentru un set de date grupate este acea valoare ce separ toate datele în dou p rµi egale. Sedetermin mai întâi clasa ce conµine mediana (numit clas median ), apoi presupunem c în interiorulec rei clase datele sunt uniform distribuite (vezi Exerciµiu 5.2). O formul dup care se calculeaz mediana este:
Me = l +n2 − FMe
fMec,
unde: l este limita inferioar a clasei mediane, n este volumul selecµiei, FMe este suma frecvenµelor pân la (exclusiv) clasa median , fMe este frecvenµa clasei mediane ³i c este l µimea clasei.
Pentru a aa modul unui set de date grupate, determin m mai întâi clasa ce conµine aceast valoare (clas modal ), iar modul va calculat dup formula:
Mod = l +d1
d1 + d2c,

STATS 5 [Dr. Iulian Stoleriu] 63
unde d1 ³i d2 sunt frecvenµa clasei modale minus frecvenµa clasei anterioare ³i, respectiv, frecvenµa claseimodale minus frecvenµa clasei posterioare, l este limita inferioar a clasei modale ³i c este l µimea claseimodale.
Observaµia 5.8 S consider m urm toarea problem . La brut ria din colµ a fost adus o ma³in nou defabricat pâine. Aceast ma³in de pâine ar trebui s fabrice pâini care s aiba în medie m = 400 de grame.Pentru a testa dac ma³ina respectiv îndepline³te norma de gramaj, am pus deoparte (la întâmplare)n pâini produse într-o zi lucratoare, în scopul de a le cânt ri. Spunem astfel c am facut o selecµie devolum n din mulµimea pâinilor produse în acea zi. Dorim s decidem dac , într-adev r, ma³ina este setat la parametrii potriviµi. În urma cânt ririi celor n pâini, obµinem datele (empirice): x1, x2, . . . , xn (îngrame). Calcul m media masei acestora ³i obµinem:
x =1
n
n∑i=1
xi.
Intuitiv, ar de a³teptat ca acest x s aproximeze (într-un anumit sens) masa medie (teoretic ) a pâinilorproduse de aceast ma³in . Pentru a putea obµine aceast aproximare, am avea nevoie de un criteriu cares ne spun c x ≈ m. Mai mult, am dori s m convin³i c aceast aproximare nu depinde de e³antionulde pâini ales, adic , dac am ales alte pâini ³i facut media maselor lor, am obµinut din nou o valoareafoarte apropiat de m. Pentru a construi un astfel de criteriu, avem nevoie de un cadru teoretic maiabstract pentru modelarea datelor statistice. Acest cadru îl vom construi în capitolele ce urmeaz .
În Tabelul 5.1, am prezentat câteva funcµii Matlab specice pentru m surile descriptive.
mean(x) % media valorilor elementelor lui x;geomean(x) % media geometric a elementelor lui x;harmmean(x) % media armonic a elementelor lui x;quantile(x,alpha) % cuantila de ordin α a vectorului x;iqr(x) % distanµa intercuantilic , x0.75 − x0.25;median(x) % valoarea median a lui x;std(x), var(x) % deviaµia standard ³i dispersia valorilor lui x;range(x) % amplitudinea (range) vectorului x;mode(x) % modul lui x;zscore(x) % realizeaz scorul elementelor lui x;moment(x,k) % momentul de ordin k al lui x;sort(x) % sorteaza crescator elementele vectorului x;max(x), min(x) % maximum ³i minimum pentru elementele lui x;skewness(x) % skewness pentru elementele lui x;kurtosis(x) % kurtosis pentru elementele lui x;prctile(x,p) % percentilele de ordin p ale lui x;cdfplot(x) % reprezint grac funcµia de repartiµie empiric a lui x;cov(x,y) % covarianµa dintre x ³i y;corrcoef(x,y) % coecientul de corelaµie dintre x ³i y;LEGEstat(<param>) % a³eaz media ³i dispersia pentru LEGE(<param>);
Tabela 5.1: Funcµii Matlab specice pentru m suri descriptive.

Laborator 5 [Dr. Iulian Stoleriu] 64
Statistic Aplicat (Laborator 5)
Exerciµii rezolvate
Exerciµiu 5.1 Urm torul set de date reprezint preµurile (în mii de euro) a 20 de case, vândute într-oanumit regiune a unui ora³:
113 60.5 340.5 130 79 475.5 90 100 175.5 100
111.5 525 50 122.5 125.5 75 150 89 100 70
Determinaµi amplitudinea, media, mediana, modul, cuartilele ³i distanµa intercuartilic pentru acestedate. Care valoare este cea mai reprezentativ ?
Soluµie: Rearanj m datele în ordine cresc toare:
50 60.5 70 75 79 89 90 100 100 100 111.5
113.5 122.5 125.5 130 150 175.5 340.5 475.5 525
Amplitudinea este 525 − 50 = 475, media lor este 154.15, mediana este 105.75, modul este 100, cuartilainferioar este Q1 = 84, cuartila superioar este Q3 = 140, Q2 = Me ³i distanµa intercuartilic ested = Q3 −Q1 = 56.Mediana este valoarea cea mai reprezentativ în acest caz, deoarece cele mai mari trei preµuri, anume340.5, 475.5, 525, m resc media ³i o fac mai puµin reprezentativ pentru celelalte date. În cazul în caresetul de date nu este simetric, valoarea median este cea mai reprezentativ valoare a datelor. ÎnMatlab,
X = [113; 60.5; 340.5; 130; 79; 475.5; 90; 100; 175.5; 100; ...
111.5; 525; 50; 122.5; 125.5; 75; 150; 89; 100; 70
a = range(X); m = mean(X); Me = median(X); Mo = mode(X);
Q1 = quantile(X,0.25); Q2 = quantile(X,0.5); Q3 = quantile(X,0.75); d = Q3 - Q1;√
Exerciµiu 5.2 Consider m datele din Tabelul 1.6. Determinaµi amplitudinea, media, mediana, modul,dispersia ³i prima cuartil pentru aceste date.
Soluµie: Amplitudinea este a = 30. Media este
x =
∑(x · f)
n=
1
70(2.5× 5 + 7.5× 13 + 12.5× 23 + 17.5× 17 + 22.5× 10 + 27.5× 2) = 13.9286.
Dispersia este:
s2 =1
n− 1(∑
(x2 · f)− n · x2)
=1
69(2.52 × 5 + 7.52 × 13 + 12.52 × 23 + 17.52 × 17 + 22.52 × 10 + 27.52 × 2 − 70 · 13.92862)
= 37.06.

Laborator 5 [Dr. Iulian Stoleriu] 65
Clasa median este clasa [10, 15). Deoarece în clasele anterioare ([0, 5) ³i [5, 10)) se a deja 5 + 13 = 18date mai mici decât mediana, pentru a aa în lµimea median a plantelor (i.e., acea valoare care estemai mare decât în lµimea a 35 de plante ³i mai mic decât în lµimea a alte 35 de plante), va trebuis determin m acea valoare din clasa median ce este mai mare decât alte 17 valori din aceast clas .A³adar, avem nevoie de a determina o fracµie 17
23 dintre valorile clasei mediane. În concluzie, valoareamedian este
Me = 10 +17
23× 5 = 13.6957.
Clasa modal este [10, 15), iar modul este valoarea central a clasei, 12.5.Calcul m acum prima cuartil . Împ rµim setul de date în patru. Prima cuartil este acea valoare dintrecele 70 care este mai mare decât alte 18 valori, adic Q1 = 10. Implementarea în Matlab:
x = [2.5; 7.5; 12.5; 17.5; 22.5; 27.5]; % centrele claselor
f = [5; 13; 23; 17; 10; 2]; % frecventele
n = 70; m = sum(x.*f)/n; s2 = (sum(x.^2.*f) - n*m^2)/(n-1); √
Exerciµiu 5.3 O companie de asigur ri a înregistrat num rul de accidente pe s pt mân ce au avut locîntr-un anumit sat, în decurs de un an (52 de s pt mâni). Acestea sunt, în ordine:
1, 0, 2, 3, 4, 1, 4, 0, 4, 2, 3, 0, 3, 3, 1, 2, 3, 0, 1, 2, 3, 1, 3, 2, 3, 2,
4, 3, 4, 2, 3, 4, 4, 3, 2, 4, 1, 2, 0, 1, 3, 2, 0, 4, 1, 0, 2, 2, 4, 1, 2, 2
(a) Construiµi un tabel de frecvenµe care s conµin num rul de accidente, frecvenµele absolute ³i relative.(b) G siµi media empiric , mediana ³i deviaµia standard empiric .(c) Reprezentaµi prin bare rezultatele din tabelul de frecvenµe.(d) G siµi ³i reprezentaµi grac (cdfplot) funcµia de repartiµie empiric a num rului de accidente.(e) Aproximaµi probabilitatea ca într-o s pt mân aleas la întâmplare s avut cel puµin dou accidente.
Soluµie: (a) Tabelul de frecvenµe este Tabelul 5.2.
num rul 0 1 2 3 4frecv. abs. 7 9 14 12 10frecv. rel. 0.1346 0.1731 0.2692 0.2308 0.1923
Tabela 5.2: Tabel de frecvenµe pentru Exerciµiu 5.3
(b) Avem:
x =
52∑i=1
xi = 2.1731, s =
√√√√ 1
51
52∑i=1
(xi − x)2 = 1.3094, Me = 2.
(c) Reprezentarea prin bare a num rului de accidente ³i gracul lui F ∗n(x) sunt reprezentate în Figura5.2.
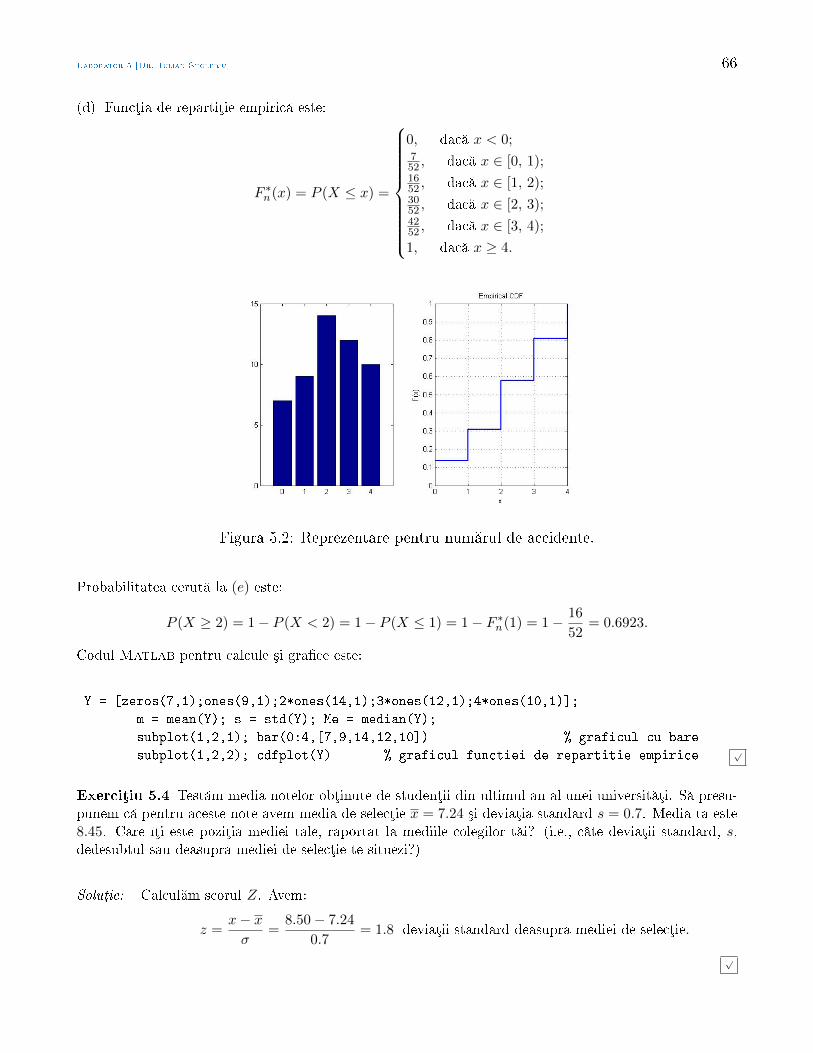
Laborator 5 [Dr. Iulian Stoleriu] 66
(d) Funcµia de repartiµie empiric este:
F ∗n(x) = P (X ≤ x) =
0, dac x < 0;752 , dac x ∈ [0, 1);1652 , dac x ∈ [1, 2);3052 , dac x ∈ [2, 3);4252 , dac x ∈ [3, 4);
1, dac x ≥ 4.
Figura 5.2: Reprezentare pentru num rul de accidente.
Probabilitatea cerut la (e) este:
P (X ≥ 2) = 1− P (X < 2) = 1− P (X ≤ 1) = 1− F ∗n(1) = 1− 16
52= 0.6923.
Codul Matlab pentru calcule ³i grace este:
Y = [zeros(7,1);ones(9,1);2*ones(14,1);3*ones(12,1);4*ones(10,1)];
m = mean(Y); s = std(Y); Me = median(Y);
subplot(1,2,1); bar(0:4,[7,9,14,12,10]) % graficul cu bare
subplot(1,2,2); cdfplot(Y) % graficul functiei de repartitie empirice √
Exerciµiu 5.4 Test m media notelor obµinute de studenµii din ultimul an al unei universit µi. S presu-punem c pentru aceste note avem media de selecµie x = 7.24 ³i deviaµia standard s = 0.7. Media ta este8.45. Care îµi este poziµia mediei tale, raportat la mediile colegilor t i? (i.e., câte deviaµii standard, s,dedesubtul sau deasupra mediei de selecµie te situezi?)
Soluµie: Calcul m scorul Z. Avem:
z =x− xσ
=8.50− 7.24
0.7= 1.8 deviaµii standard deasupra mediei de selecµie.
√

STATS 6 [Dr. Iulian Stoleriu] 67
6 Statistic Aplicat (C6)
Noµiuni de Teoria selecµiei statistice
Deniµia 6.1 Numim colectivitate statistic (sau populaµie) o mulµime nevid Ω de elemente care estecercetat din punct de vedere al uneia sau mai multor caracteristici. Elementele colectivit µii le vomnumi indivizi (sau unit µi statistice). Vom nota cu ω o unitate statistic . Dac populaµia este nit ,atunci num rul n al unit µilor statistice ce o compun (i.e., card(Ω)) îl vom numi volumul colectivit µii(sau volumul populaµiei).
Consider m o populaµie (colectivitate statistic ) Ω. Studiem populaµia Ω din punctul de vedere al uneicaracteristici a sale, X. Aceast caracteristic este o anumit proprietate urm rit la indivizii ei înprocesul prelucr rii statistice ³i o vom asimila cu o variabil aleatoare denit pe Ω. Problema esenµial a Statisticii Matematice este de a stabili legea de probabilitate pe care o urmeaz caracteristica X.Pentru a g si aceast lege (repartiµie), avem nevoie mai întâi de un num r reprezentativ de observaµiiasupra colectivit µii Ω. Pe baza acestor observaµii, vom determina prin inferenµ o lege care s reprezintevariabila X.
Deniµia 6.2 Vom numi selecµie (sau sondaj) o subcolectivitate a colectivit µii cercetate Ω. Num rulelementelor selecµiei poart numele de volumul selecµiei (sondajului). Selecµiile pot repetate sau ne-repetate. O selecµie se nume³te repetat (sau bernoullian ) dac dup examinarea individului acesta sereintroduce în colectivitate; în caz contrar avem o selecµie nerepetat . În practic , volumul colectivit µiiΩ este mult mai mare decât volumul selecµiei. În aceste cazuri, selecµia nerepetat poate considerat caind selecµie repetat . Selecµiile pe care le vom considera în continuare sunt numai selecµii repetate dincolectivitatea statistic .
Dorim acum s introducem un cadru matematic abstract pentru aceste selecµii repetate (pentru o abordaremai detaliat , se poate consulta [11]).Consider m spaµiul m surabil (Ω, F), unde F este un corp borelian de p rµi ale lui Ω. Caracteristica Xurm rit poate reprezentat de o variabil aleatoare denit pe (Ω, F). Dorim s denim matematico selecµie repetat de volum n. Euristic, ideea este urm toarea: a efectua n sondaje repetate dintr-omulµime Ω, este echivalent cu a considera o singur selecµie dintr-o populaµie de genul "Ω multiplicat den ori". Construim astfel:
Ω(n) = Ω× Ω× · · · × Ω, F (n) = F × F × · · · × F ,
produs cartezian de n ori. Un element al lui Ω(n) va
ω(n) = (ω1, ω2, . . . , ωn),
numit selecµie repetat de volum n. Cuplul (Ω(n), F (n)) se nume³te spaµiul selecµiilor repetate de volumn. Consider m variabilele aleatoare
Xi : Ω(n) → R, Xi(ω(n)) = X(ωi), ∀i = 1, n.

STATS 6 [Dr. Iulian Stoleriu] 68
Acestea sunt variabile aleatoare denite pe (Ω(n), F (n)), sunt independente stochastic (pentru c v.a.X(ωi)i=1, n sunt independente) ³i sunt identic repartizate, cu funcµia de repartiµie comun FX (severic usor c FXi = FX , ∀i = 1, n). Vom numi Xi, i = 1, n, variabile aleatoare de selecµie repetat devolum n. Vom numi vector de selecµie repetat de volum n, vectorul Y , astfel încât:
Y : Ω(n) → R, Y (ω(n)) = (X1(ω(n)), X2(ω(n)), . . . , Xn(ω(n))).
Pentru un ω(n) xat, componentele vectorului Y (ω(n)) se numesc valori de selecµie repetat de volum n.Vom nota cu
Ln = Y (Ω(n)) ⊂ Rn,
³i-l vom numi spaµiul valorilor de selecµie repetat de volum n. Elementele lui Ln le vom nota prin
x = (x1, x2, . . . , xn),
(xi = Xi(ω(n)), pentru ω(n) xat, i = 1, 2, . . . , n).
Deniµia 6.3 Vom numi statistic (sau funcµie de selecµie) variabila aleatoare
Sn(X) = g(X1, X2, . . . , Xn),
unde g este o funcµie g : Rn → R m surabil (i.e., ∀B ∈ B(R), g−1(B) ∈ B(Rn)).Ca o observaµie, numele de "statistic " este folosit în literatura de specialitate atât pentru variabila alea-toare de mai sus, cât ³i pentru valoarea ei, înµelesul exact desprinzându-se din context. Repartiµia uneistatistici se mai nume³te ³i repartiµia (distribuµia) de selecµie.
Notaµii: În literatur , statistica este notat cu una dintre urm toarele:
Sn(X), S(X, ω(n)), S(X, n), S(X1, X2, . . . , Xn).
Valoarea numeric Sn(x) = g(x1, x2, . . . , xn)
se nume³te valoarea funcµiei de selecµie pentru un ω(n) xat.
Observaµia 6.4 A³adar, o statistic este o funcµie de variabilele aleatoare de selecµie. Prin intermeniulstatisticilor putem trage concluzii despre populaµia Ω, din care a provenit e³antionul ω(n). Teoria pro-babilit µilor ne ofer procedee de determinare atât a repartiµiei exacte a lui Sn(X), cât ³i a repartiµieiasimptotice a lui Sn(X). Repartiµia exact este acea repartiµie ce poate determinat pentru orice volumal selecµiei. În general, dac se lucreaz cu selecµii de volum redus (n < 30), atunci repartiµia exact artrebui s e cunoscut a priori, dac se dore³te luarea de decizii prin inferenµ . Repartiµia asimptotic este repartiµia limit a Sn(X) când n→∞, iar utilizarea acesteia conduce la rezultate bune doar pentrun ≥ 30.De cele mai multe ori, o funcµie de selecµie (statistic ) este utilizat în urm toarele cazuri:
• în probleme de estimare punctual a parametrilor;
• în obµinerea intervalelor de încredere pentru un parametru necunoscut;
• ca o statistic test pentru vericarea ipotezelor statistice.

STATS 6 [Dr. Iulian Stoleriu] 69
Exemple de statistici
Fie (Ω, F) o colectivitate statistic ³i X o caracteristic cercetat a sa. S not m cu f(x) ³i F (x) densi-tatea de repartiµie (sau funcµia de probabilitate), respectiv, funcµia de repartiµie pentru X. Acestea pot cunoscute sau necunosctute a priori ³i le vom numi funcµii teoretice (densitate de repartiµie teoretic ,funcµie de probabilitate teoretic sau funcµie de repartiµie teoretic ). Dac se cunoa³te f(x), atunci putemdetermina µ = E(X) ³i σ2 = D2(X), dac acestea exist , ³i le vom numi medie teoretic ³i dispersieteoretic .În cazul în care una sau mai multe caracteristici teoretice corespunz toare lui X nu ne sunt a prioricunoscute, vom c uta s le determin m prin inferenµ , adic prin extragerea unor selecµii de date dincolectivitate, calculând caracteristicile respective pentru selecµiile considerate ³i apoi extrapolând (în anu-mite condiµii ³i dup anumite criterii) la întreaga colectivitate.S consider m ω(n) o selecµie repetat de volum n din colectivitatea dat ³i Xi, i = 1, n, variabilelealeatoare de selecµie. Cu ajutorul acestora, putem construi diverse funcµii de selecµie.
Media de selecµie (mean)
Deniµia 6.5 Numim medie de selecµie (repetat de volum n), statistica
X(ω(n)) =1
n
n∑i=1
Xi(ω(n)), ω(n) ∈ Ω(n). (6.1)
Pentru un ω(n) xat, s not m cu x1, x2, . . . , xn valorile de selecµie corespunz toare variabilelor alea-toare de selecµie X1, X2, . . . , Xn. Atunci valoarea mediei de selecµie pentru un ω(n) xat este:
x =1
n
n∑i=1
xi (media empiric ).
Propoziµia 6.6 Media de selecµie satisface urm toarele propriet µi:
E(X) = E(X), D2(X) =D2(X)
n; (6.2)
1
n
n∑i=1
Xia.s.−→ E(X), când n→∞. (conform LTNM) (6.3)
Observaµia 6.7 (1) În capitolele urm toare vom scrie relaµia (6.4) sub forma restrâns :
X =1
n
n∑i=1
Xi. (6.4)
Pentru simplitatea formulelor, de acum înainte vom face abstraµie de dependenµa de ω(n) în formule, carese va subînµelege.
(2) Propoziµia 6.22 precizeaz care este repartiµia mediei de selecµie pentru variabile aleatoare de selecµiedintr-o colectivitate normal , iar Propoziµia 6.24 precizeaz care este repartiµia asimptotic a mediei deselecµie pentru variabile de selecµie într-o colectivitate oarecare.

STATS 6 [Dr. Iulian Stoleriu] 70
Momente de selecµie
Deniµia 6.8 Numim moment de selecµie (repetat de volum n) de ordin k, (k ∈ N∗), statistica
αk(X) =1
n
n∑i=1
Xki .
Valoarea momentului de selecµie de ordin k pentru un ω(n) xat este:
αk(x) =1
n
n∑i=1
xki (moment iniµial empiric de ordin k).
În cazul particular k = 1, avem:α1(X) = X.
Propoziµia 6.9 Pentru oricare k xat, k ∈ N∗, avem:
E(αk(X)) = E(Xk) = αk(X), (momente iniµiale teoretice pentru X)
D2(αk(X)) =D2(Xk)
n,
1
n
n∑i=1
Xki
a.s.−→ αk(X), când n→∞.
Momente de selecµie centrate
Deniµia 6.10 Numim moment de selecµie centrat de ordin k, statistica
µk(X) =1
n
n∑i=1
[Xi −X]k.
Valoarea momentului de selecµie de ordin k pentru un ω(n) xat este:
µk(x) =1
n
n∑i=1
[xi − x]k (moment centrat empiric de ordin k).
Propoziµia 6.11 Pentru oricare k xat, k ∈ N∗, avem:
E(µk(X)) = E([X − µ]k) = µk(X), (momente centrate teoretice pentru X)
1
n
n∑i=1
(Xi −X)ka.s.−→ µk(X), când n→∞.

STATS 6 [Dr. Iulian Stoleriu] 71
Dispersie de selecµie (var)
Deniµia 6.12 Numim dispersie de selecµie (repetat de volum n), statistica
d2(X) = µ2(X) =1
n
n∑i=1
[Xi −X]2.
Pentru simplitate, o vom nota cu d2(X), iar valoarea acesteia pentru un ω(n) xat este:
d2(x) =1
n
n∑i=1
[xi − x]2 (dispersia empiric ). (6.5)
De cele mai multe ori, în locul lui d2(X) se utilizeaz statistica d2∗(X), denit prin:
d2∗(X) =
1
n− 1
n∑i=1
[Xi −X]2. (6.6)
Aceasta se mai nume³te ³i dispersie de selecµie modicat , iar valoarea ei pentru un ω(n) xat este:
s2 = d2∗(x) =
1
n− 1
n∑i=1
[xi − x]2 (dispersia empiric modicat ).
Motivaµia pentru considerarea statisticii d2∗(X) este dat de propriet µile din propoziµia urm toare:
Propoziµia 6.13 Dispersiile de selecµie veric urm toarele relaµii:
E(d2(X)) =n− 1
nD2(X), E(d2
∗(X)) = D2(X) (6.7)
d2∗(X)
prob−→ D2(X), când n→∞. (6.8)
Observaµia 6.14 (i) Dup cum vom vedea în capitolul urm tor, primele dou relaµii arat c statisticad2∗(X) este un estimator nedeplasat pentru dispersia teoretic , pe când d2(X) este estimator deplasat.(ii) Dac media teoretic a colectivit µii este cunoscut a priori, E(X) = µ ∈ R, atunci dispersia deselecµie d2(X) devine:
d2(X) =1
n
n∑i=1
[Xi − µ]2. (6.9)
Propoziµia 6.28 precizeaz care este repartiµia acestei statistici.
Funcµia de repartiµie de selecµie (cdfplot)
Deniµia 6.15 Fie X1, X2, . . . , Xn variabile aleatoare de selecµie repetat de volum n. Numim funcµiede repartiµie de selecµie (repetat de volum n), funcµia
F ∗n : R× Ω(n) → R, F ∗n(x, ω(n)) =n(x)
n, ∀ (x, ω(n)) ∈ R× Ω(n),

STATS 6 [Dr. Iulian Stoleriu] 72
unde n(x) = card i, Xi(ω(n)) ≤ x reprezint num rul de elemente din selecµie mai mici sau egale cu x.
Relaµia din deniµie poate scris ³i sub forma:
F ∗n(x) =1
n
n∑i=1
χ(−∞, x](Xi), ∀x ∈ R,
unde χA este funcµia indicatoare a mulµimii A.Pentru un x ∈ R xat, F ∗n(ω(n)) este o variabil aleatoare repartizat binomial B(n, F (x)).Pentru ecare ω(n) ∈ Ω(n) xat, F ∗n(x) ia valorile:
F ∗n(x) =card i, xi ≤ x
n,
(i.e., este funcµia de repartiµie empiric denit în 5.12).
Propoziµia 6.16 Funcµia de repartiµie de selecµie satisface urm toarele relaµii:
E(F ∗n(x)) = F (x), ∀x ∈ R;
D2(F ∗n(x)) =1
n[F (x)(1− F (x))], ∀x ∈ R;
În Statistic , exist o serie de criterii care permit s se aprecieze apropierea lui F ∗n(x) de F (x). Mai jos,amintim doar câteva dintre ele.
Propoziµia 6.17 Funcµia de repartiµie de selecµie satisface convergenµa
F ∗n(x)a.s.−−−→n→∞
F (x), x xat în R.
Demonstraµie. Rezultatul este o consecinµ direct a legii tari a numerelor mari. 2
Propoziµia 6.18 Funcµia de repartiµie de selecµie satisface proprietatea
√n(F ∗n(x)− F (x)) ∼ N ( 0, F (x)(1− F (x)) ), x xat în R.
Demonstraµie. Rezultatul este o consecinµ direct a Propoziµiei 6.16 ³i a teoremei limit central . 2
Teorema 6.19 (Glivenko-Cantelli) Fie X o caracteristic , F (x) funcµia sa de repartiµie ³i F ∗n(x) funcµiade repartiµie empiric corespunz toare unei selecµii de volum n. Atunci F ∗n(x) converge uniform la F (x),adic :
supx∈R|F ∗n(x)− F (x)| −−−→
n→∞0, cu probabilitatea 1.
Statistici de ordine
Deniµia 6.20 Dac variabilele aleatoare din selecµia X1, X2, . . . , Xn le rearanj m în ordinea m rimiilor ³i scriem
X(1) ≤ X(2) ≤ · · · ≤ X(n),

STATS 6 [Dr. Iulian Stoleriu] 73
atunci vom numi variabila aleatoare X(i)) statistica de ordine de ordin i, pentru orice i = 1, 2, . . . , n.Pentru o selecµie dat , valoarea statisticii de ordine de ordin i o vom nota prin x(i), pentru orice i =1, 2, . . . , n.Statistica X(1) se nume³te prima statistic de ordine ³i este întotdeauna minimumul selecµiei, i.e.,
X(1) = minX1, X2, . . . , Xn.
Statistica X(n) se nume³te ultima statistic de ordine ³i este întotdeauna maximumul selecµiei, i.e.,
X(n) = maxX1, X2, . . . , Xn.
De exemplu, dac avem valorile de selecµie
x1 = 8, x2 = 7, x3 = 9, x4 = 5, x5 = 3,
atuncix(1) = 3, x(2) = 5, x(3) = 7, x(4) = 8, x(5) = 9.
Dac n = 2m+ 1, atunci X(m) = X(n+12
) = X, adic media de selecµie este o statistic de ordine în acest
caz. Dac n = 2m, atunci avem dou valori de mijloc, X(m) ³i X(m+1). Deoarece X = 12(X(m) +X(m+1)),
media de selecµie nu este statistic de ordine pentru n par.Denim amplitudinea (range) selecµiei ca ind statistica A = X(n)−X(1). Statisticile X(n)−X ³i X(1)−Xse numesc deviaµiile extreme ale selecµiei.De³i variabilele aleatoare de selecµie sunt independente, totu³i statisticile de ordine sunt dependente.S presupunem c F (x) este funcµia de repartiµie a selecµiei date ³i f(x) densitatea de reparticµie. Urm -toarea propoziµie stabile³te funcµiile de repartiµie pentru statisticile de ordine.
Propoziµia 6.21 Pentru un k xat, funcµia de repartiµie pentru X(k) este:
FX(k)(x) =
n∑j=k
CjnF (x)j [1− F (x)]n−j , pentru orice x ∈ R.
Demonstraµie. Avem succesiv:
FX(k)(x) = P (X(k) ≤ x)
= P (cel puµin k v.a. din cele n nu dep ³esc pe x)= P (cel puµin k succese în n încerc ri)
=n∑j=k
Cjn[P (X ≤ x)]j [1− P (X ≤ x)]n−j
=
n∑j=k
CjnF (x)j [1− F (x)]n−j , pentru orice x ∈ R.
2
În particular, pentru k = 1, obµinem c funcµia de repartiµie a celui mai mic element al selecµiei:
FX(1)(x) = 1− [1− F (x)]n, pentru orice x ∈ R.

STATS 6 [Dr. Iulian Stoleriu] 74
Funcµia de repartiµie a celui mai mare element al selecµiei este:
FX(n)(x) = [F (x)]n, pentru orice x ∈ R.
Selecµii aleatoare dintr-o colectivitate normal
S consider m Ω o colectivitate statistic ³i X o caracteristic a sa, ce urmeaz a studiat din punct devedere statistic. Fie X1, X2, . . . , Xn variabile aleatoare de selecµie repetat de volum n. În cele maimulte cazuri practice, X urmeaz o repartiµie normal (gaussian ). De regul , dac volumul populaµieieste mic (n < 30), atunci consider m doar populaµii normale, iar pentru n > 30 putem considera orice tipde repartiµie pentru colectivitate. Mai jos, prezent m câteva rezultate utile referitoare la selecµia dintr-ocolectivitate gaussian .
Propoziµia 6.22 (repartiµia mediei de selecµie pentru o selecµie gaussian )Dac Xi ∼ N (µ, σ), ∀i = 1, 2, . . . , n, atunci statistica X satisface:
X ∼ N(µ,
σ√n
). (n ∈ N∗)
Demonstraµie. Vom folosi metoda funcµiei caracteristice. Pentru o variabil aleatoare N (µ, σ) funcµiacaracteristic este:
φ(t) = ei µ t−12σ2t2 . (6.10)
Folosind propriet µile funcµiei caracteristice ³i relaµia
φaX(t) = φX(at),
obµinem c funcµia caracteristic a lui X este:
φX (t) =
n∏k=1
ei µtn− σ2t2
2n2 = ei µ t− 1
2
(σ√n
)2t2,
adic X urmeaz legea de repartiµie N (µ, σ√n
). 2
O consecinµ direct a acestei propoziµii este urm toarea:
Propoziµia 6.23 Dac Xi ∼ N (µ, σ), ∀i = 1, 2, . . . , n sunt variabile aleatoare de selecµie, atunci
Z =X − µσ√n
∼ N (0, 1).
Propoziµia 6.24 (repartiµia mediei de selecµie pentru o selecµie oarecare)Dac X1, X2, . . . , Xn variabile aleatoare de selecµie repetat de volum n, ce urmeaz o repartiµie dat ,atunci pentru un volum n sucient de mare, statistica X satisface:
X ∼ N(µ,
σ√n
). (n > 30)

STATS 6 [Dr. Iulian Stoleriu] 75
Demonstraµie. Acest rezultat este o consecinµ imediat a concluziei teoremei limit central . 2
Observaµia 6.25 Dac n este sucient de mare, atunci concluzia Propoziµiei 6.23 ramâne valabil ³iîn cazul în care avem o selecµie repetat de volum n dintr-o colectivitate statistic ce nu este neap ratgaussian .
Propoziµia 6.26 Dac ξi ∼ N (µi, σi) sunt variabile aleatoare independente stochastic ³i ai ∈ R, i =
1, n, atunci variabila aleatoare ξ =n∑i=1
aiξi satisface proprietatea:
ξ ∼ N
n∑i=1
aiµi,
√√√√ n∑i=1
a2iσ
2i
.
Demonstraµie. Demonstraµia este bazat pe metoda funcµiei caracteristice. [Exerciµiu!] 2
Propoziµia 6.27 Fie ξi ∼ N (µi, σi) variabile aleatoare independente stochastic ³i ai ∈ R, i = 1, n.Pentru ecare caracteristic ξi consider m câte o selecµie repetat de volum ni, ³i not m cu ξi mediade selecµie corespunz toare ec rei selecµii. Atunci statistica Y = a1ξ1 + a2ξ2 + . . . + anξn satisfaceproprietatea:
Y ∼ N
n∑i=1
aiµi,
√√√√ n∑i=1
a2i
σ2i
ni
.
Demonstraµie. Deoarece ξi ∼ N (µi, σi), din Propoziµia 6.22 obµinem c media de selecµie corespunz toare,ξi, satisface:
ξi ∼ N(µi,
σi√ni
).
Aplicând rezultatul Propoziµiei 6.26 variabilelor aleatoare independente ξ1, ξ2, . . . , ξn, obµinem conclu-zia dorit . 2
Urm toarea propoziµie este un caz particular al Propoziµiei 6.27.
Propoziµia 6.28 (repartiµia diferenµei mediilor de selecµie pentru colectivit µi gaussiene)Consider m o selecµie de volum n1 dintr-o populaµie normal N (µ1, σ1) ³i o selecµie de volum n2 dintr-o colectivitate N (µ2, σ2), cele dou selecµii ind alese independent una de cealalt . Not m cu ξ1 ³i,respectiv, ξ2 mediile de selecµie corespunz toare selecµiilor alese. Atunci statistica
ξ1 − ξ2 ∼ N
µ1 − µ2,
√σ2
1
n1+σ2
2
n2
.
Demonstraµie. Aplic m rezultatul Propoziµiei 6.27 pentru cazul particular în care avem doar dou variabilealeatoare, ξ1 ³i ξ2, iar a1 = 1, a2 = −1. 2

STATS 6 [Dr. Iulian Stoleriu] 76
Observaµia 6.29 (1) Concluzia propoziµiei anterioare se mai poate scrie astfel:
Z =(ξ1 − ξ2)− (µ1 − µ2)√
σ21n1
+σ22n2
∼ N (0, 1).
(2) S presupunem c avem dou populaµii statistice normale, Ω1 ³i Ω2, iar ξ este o caracteristic comun a celor dou populaµii, ce urmeaz a studiat . (De exemplu, populaµiile statistice s e mulµimeapieselor produse de dou strunguri într-o zi de lucru, iar caracteristica comun s e masa lor). S maipresupunem c deviaµiile standard ale caracteristicilor considerate sunt cunoscute (i.e., deviaµiile sunt datedeja în cartea tehnic a celor dou strunguri). Pentru ecare dintre cele dou colectivit µi, consider mcâte o selecµie repetat , de volume n1, respectiv, n2 (adic , vom selecta n1 dintre piesele produse destrungul întâi ³i n2 piese produse de cel de-al doilea strung). S not m cu ξ1, respectiv, ξ2 mediile deselecµie corespunz toare. Propoziµia anterioar precizeaz care este repartiµia diferenµei standardizate alecelor dou medii de selecµie. Aceasta ne va deosebit de util , spre exemplu, în vericarea ipotezei c masele medii ale pieselor produse de cele dou strunguri coincid.

Laborator 6 [Dr. Iulian Stoleriu] 77
Statistic Aplicat (Laborator 6)
Utilizând funcµiilelegernd(< param >, m, n) (6.11)
³irandom(′lege′, < param >,m, n) (6.12)
introduse anterior, putem genera variabile aleatoare de selecµie de un volum dat, n. Pentru aceasta, vatrebui ca m = n în (6.11) ³i (6.12). Astfel, comanda
random('norm',100,6, 50,50)
genereaz o matrice p tratic , de dimensiune 50. Putem privi aceast matrice aleatoare astfel: ecarecoloan a sa corespunde unei variabile aleatoare de selecµie de volum 50, c reia îi preciz m cele 50 devalori ale sale obµinute la o observaµie. În total, avem 50 de coloane, corespunzând celor 50 de variabilealeatoare de selecµie. A³adar, am generat 50 de variabile aleatoare de selecµie de volum 50, ce urmeaz repartiµia N (100, 6).
Exerciµii rezolvate
Exerciµiu 6.1 S consider m c masa medie a unor batoane de ciocolat produse de o ma³in esteo caracteristic X ∼ N (100, 0.65). În vederea veric rii parametrilor ma³inii, dintre sutele de mii debatoane produse în acea zi s-au ales la întâmplare 1000 dintre acestea.
• Calculaµi masa medie ³i deviaµia standard ale mediei de selecµie, X.
• Calculaµi P (98 < X < 102).
• Un baton este declarat rebut dac masa sa este sub 98 de grame sau peste 102 de grame. Calculaµiprocentul de rebuturi avute.
Soluµie: Din teorie, ³tim c media de selecµie X urmeaz repartiµia N (100, 0.65/√
1000) (vezi Propoziµia6.22). A³adar,
µX = 100, σX ≈ 0.02.
Probabilitatea P1 = P (98 < X < 102) este
P1 = P (X < 102)− P (X ≥ 98) = FX(102)− FX(98) ≈ 1.
Probabilitatea de a avea un rebut este:
P2 = P(X < 98
⋃X > 102
)= P (X < 98) + P (X > 102)
= FX(98) + 1− FX(102),
de unde, procentul de rebuturi este
r = P2 · 100% ≈ 0.2091%,

Laborator 6 [Dr. Iulian Stoleriu] 78
adic aproximativ 2 rebuturi la 1000 de batoane.În Matlab, acestea pot calculate astfel:
mu = 100; sigma = 0.65; n=1000; % n = volumul selectiei
X = normrnd(mu, sigma, n,n); % am generat selectia de volum n
Xbar = mean(X); S = sigma/sqrt(n); % Xbar = media de selectie
m = mean(Xbar); s = std(Xbar); % media si deviatia standard
P1 = normcdf(102, mu, S) - normdf(98, mu, S);
P2 = normcdf(98,mu,sigma) + 1 - normcdf(102,mu,sigma);
rebut = P2*100; √
Exerciµiu 6.2 În vederea studierii unei caracteristici X ce are densitatea de repartiµie
f(x) =
2x, x ∈ (0, 1);
0, x 6∈(0, 1).
s-a efectuat o selecµie repetat de volum n = 100. Se cere s se determine probabilitatea P (X < 0.65),unde X este media de selecµie.
Soluµie: Se observ cu u³urinµ c f(x) îndepline³te condiµiile unei funcµii de repartiµie, adic estem surabil , nenegativ ³i ∫
Rf(x) dx =
∫ 1
02x dx = 1.
Pentru a calcula probabilitatea cerut , avem nevoie de E(X) ³i D2(X). Avem:
E(X) =
∫Rx f(x) dx =
∫ 1
02x2 dx =
2
3,
D2(X) = E(X2)− (E(X))2 =
∫Rx2 f(x) dx− 4
9=
1
18.
A³adar, repartiµia mediei de selecµie X este
X ∼ N(
2
3,
1√18 ·√
100
).
Putem acum calcula probabilitatea cerut . Ea este:
P (X < 0.65) = FX(0.65) = normcdf(0.65, 2/3, 1/(30*sqrt(2))) = 0.2398.
√
Exerciµiu 6.3 O pereche de zaruri ideale este aruncat de 200 de ori. Care este probabilitatea s obµinemo sum de 7 în cel puµin 20% dintre cazuri?
Soluµie: Probabilitatea de apariµie a sumei 7 într-o singur aruncare a dou zaruri este p = 1/6. FieX v.a. ce reprezint num rul de apariµii ale sumei 7 la aruncarea a dou zaruri ideale în 200 de arunc ri.

Laborator 6 [Dr. Iulian Stoleriu] 79
Atunci, X ∼ B(200, 1/6). Probabilitatea ca sum de 7 s apar în cel puµin 20% dintre cazuri (i.e., în celpuµin 40 dintre cazuri) este:
P = P (X ≥ 40) = 1− P (X ≤ 39) = 1−39∑k=0
Ck200pk(1− p)200−k = 0.1223.
În Matlab,1 - binocdf(39,200,1/6) √
Exerciµiu 6.4 Un sondaj preliminar a determinat c 42% dintre persoanele cu drept de vot dintr-oanumit µar ar vota candidatul C pentru pre³edinµie. Alegem la întâmplare 200 de votanµi. Care esteprobabilitatea ca un procent dintre ace³tia, situat între 40% ³i 50%, îl vor vota pe C la pre³edinµie?
- S not m cu p = 0.42 ³i cu X variabila aleatoare ce reprezint num rul de votanµi ce au alescandidatul C, din selecµia aleatoare de volum n = 200 considerat . Este clar c X ∼ B(n, p). Se cereprobabilitatea P (80 ≤ X ≤ 100) (deoarece 40% din 200 înseamn 80 etc). Deoarece X este o variabil aleatoare discret , avem c :
P = P (80 ≤ X ≤ 100) = P (X ≤ 100)− P (X < 80) = FX(100)− FX(79),
unde FX este funcµia de repartiµie a lui X.În Matlab, avem:
P = binocdf(100, 200, 0.42) - binocdf(79, 200, 0.42) = 0.7303. √

STATS 7 [Dr. Iulian Stoleriu] 80
7 Statistic Aplicat (C7)
Noµiuni de Teoria selecµiei (continuare)
Propoziµia 7.1 Fie X1, X2, . . . , Xn variabile aleatoare independente stochastic, astfel încât Xi ∼N (0, 1) , i = 1, 2, . . . , n. Atunci variabila aleatoare
H2 =n∑i=1
X2k ∼ χ2(n).
Demonstraµie. Pentru a demonstra propoziµia, folosim metoda funcµiei caracteristice. Pentru aceasta,avem nevoie de funcµia caracteristic pentru X2, unde X ∼ N (0, 1).S not m cu f(x) funcµia densitate de repartiµie pentru X, dat de relaµia (16.2) cu µ = 0. Not m cuG(y) funcµia de repartiµie pentru X2 ³i cu g(y) densitatea sa de repartiµie. Avem:
G(y) = P (X2 ≤ y) =
0 , y ≤ 0;
P (−√y ≤ X ≤ √y) , y > 0,
de unde
g(y) = G′(y) =
0 , y ≤ 0;
12√y [f(√y) + f(−√y)] , y > 0,
=
0 , y ≤ 0;
1√yf(√y) , y > 0.
Funcµia caracteristic pentru X2 va :
φX2(t) = E(ei tX
2)
=1√2π
∫ ∞0
y−12 eity
2− y2 dy
= (1− 2it)−12 .
Deoarece variabilele aleatoare Xii sunt independente stochastic, putem aplica relaµia (3.19) ³i obµinem:
φH2(t) = E(eit∑ni=1X
2i ) =
n∏i=1
E(eitX
2i
)=
n∏i=1
φX2i(t) = (1− 2it)−
n2 .
Aceasta este funcµia caracteristic pentru o v.a. χ2(n). 2
Observaµia 7.2 O consecinµ imediat a acestei propoziµii este c , dac X ∼ N (0, 1), atunci v.a. X2 ∼χ2(1). Urm toarea propoziµie este tot o consecinµ direct a Propoziµiei 7.1.

STATS 7 [Dr. Iulian Stoleriu] 81
Propoziµia 7.3 (repartiµia dispersiei de selecµie când media colectivit µii este cunoscut )Fie X1, X2, . . . , Xn variabile aleatoare independente stochastic, astfel încât Xi ∼ N (µ, σ), pentrui = 1, 2, . . . , n. Atunci variabila aleatoare
H2 =1
σ2
n∑i=1
(Xi − µ)2 ∼ χ2(n).
Demonstraµie. Pentru ecare i = 1, 2, . . . , n, consider variabilele aleatoare
Yi =Xi − µσ
.
Conform Propoziµiei 6.23, avem Yi ∼ N (0, 1), ∀i = 1, n. Aplic m rezultatul propoziµiei 7.1 pentruvariabilele aleatoare Y1, Y2, . . . , Yn ³i obµinem concluzia dorit . 2
Lema 7.4 Dac X ³i Y sunt variabile aleatoare independente stochastic, astfel încât X ∼ χ2(n) ³iX + Y ∼ χ2(n+m), atunci Y ∼ χ2(m).
Demonstraµie. Demonstraµia se bazeaz pe metoda funcµiei caracteristice, folosind faptul c
φX(t) · φY (t) = φX+Y (t), ∀t ∈ R.
2
Lema 7.5 Fie X caracteristica unei colectivit µi statistice N (µ, σ), X media de selecµie repetat devolum n ³i d2
∗(X) dispersia de selecµie repetat . Atunci, statisticile
X − µσ√n
=
√n
σ(X − µ) ³i
n− 1
σ2d2∗(X) =
1
σ2
n∑i=1
(Xi −X)2 sunt independente stochastic.
Demonstraµie. Demonstraµia este tehnic ³i nu am inclus-o în acest material. Aceast lem este demon-strat în [4] (Teorema I.2.5). 2
Propoziµia 7.6 FieX ∼ N (µ, σ) caracteristica unei populaµii statistice ³i e X1, X2, . . . , Xn variabilealeatoare de selecµie repetat de volum n. Atunci statistica
χ2 =1
σ2
n∑i=1
(Xi −X)2 ∼ χ2(n− 1).
Demonstraµie. Putem scrie:
1
σ2
n∑i=1
(Xi − µ)2 =1
σ2
n∑i=1
(Xi −X)2 +n
σ2(X − µ)2 (7.1)
sau,n∑i=1
Z2i =
n− 1
σ2d2∗(X) + Z
2, (7.2)

STATS 7 [Dr. Iulian Stoleriu] 82
unde:
Zi =Xi − µσ
∼ N (0, 1) ³i Z =X − µ
σ√n
∼ N (0, 1).
Utilizând Propoziµia 7.3, observ m c membrul stang al egalit µii (7.1) este o variabil aleatoare reparti-zat χ2(n). Folosind Observaµia 7.2, concluzion m c al doilea termen din membrul drept este repartizatχ2(1). Utilizând lema anterioar ³i folosind rezultatul Exerciµiului ??, deducem c variabilele aleatoare Z
2
³i n−1σ2 d2
∗(X) sunt independente stochastic. Facem apel la Lema 7.4, ³i ajungem la concluzia propoziµiei.2
Observaµia 7.7 Concluzia propoziµiei 7.6 se poate rescrie astfel:
n− 1
σ2d2∗(X) ∼ χ2(n− 1), (7.3)
unde d2∗(X) este dispersia de selecµie.
Lema 7.8 Dac X ³i Y sunt variabile aleatoare independente stochastic, cu X ∼ N (0, 1) ³i Y ∼ χ2(n),atunci statistica
T =X√Yn
∼ t (n).
Demonstraµie. Fie f(x) ³i g(y) densit µile de repartiµie pentru X, respectiv, Y . Avem:
f(x) =1√2πe−
x2
2 , x ∈ R,
g(y) =
yn2−1 e−
y2
2n2 Γ(n2 )
, y > 0;
0 , y ≤ 0.
Din independenµ , g sim c densitatea de repartiµie a vectorului (X, Y ) este:
h(x, y) = f(x)g(y) =yn2−1 e−
x2+y2
2n+12√π Γ(n2
) , (x, y) ∈ R× (0, ∞).
Consider m o transformare a acestui vector,
τ :
t =
x√yn
v = y,
în vectorul (T, Y ). Densitatea de repartiµie a acestui vector este (vezi Propoziµia 5.3):
k(t, v) =vn2−1 e−
v2
(1+ t2
n)
2n+12√π Γ(n2
) √ v
n, (t, v) ∈ R× (0, ∞).
Densitatea de repartiµie marginal pentru T este:
k1(t) =
∫ ∞0
k(t, v) dv
=Γ(n+1
2
)√nπ Γ
(n2
) (1 +t2
n
)−n+12
, t ∈ R,
adic tocmai densitatea de repartiµie a unei variabile aleatoare t(n). 2

STATS 7 [Dr. Iulian Stoleriu] 83
Propoziµia 7.9 Dac X1, X2, . . . , Xn sunt variabile aleatoare de selecµie repetat de volum n, ceurmeaz repartiµia unei caracteristici X ∼ N (µ, σ) a unei colectivit µi statistice, atunci statistica
t =X − µd∗(X)√n− 1
∼ t(n− 1).
(Aici, t(n− 1) este repartiµia Student cu (n− 1) grade de libertate, iar d∗(X) =√d2∗(X) ).
Demonstraµie. Aplic m lema anterioar pentru variabilele aleatoare
X =X − µ
σ√n
∼ N (0, 1) ³i Y =n− 1
σ2d2∗(X) ∼ χ2(n− 1).
2
Observaµia 7.10 Aceasta propoziµie va folosit în teoria deciziei statistice, în problema test rii medieiteoretice când dispersia teoretic este necunoscut a priori.
Propoziµia 7.11 Dac variabilele aleatoare X0, X1, . . . , Xn sunt independente stochastic, identic re-partizate N (0, 1), atunci variabila aleatoare
T =X0√
X21+X2
2+ ...+X2n
n
∼ t (n).
Demonstraµie. Concluzia rezult prin aplicarea Propoziµiei 7.1 ³i Lemei 7.8. 2
Propoziµia 7.12 (repartiµia diferenµei mediilor de selecµie când dispersiile sunt necunoscute, egale)Consider m o selecµie de volum n1 dintr-o populaµie normal N (µ1, σ1) ³i o selecµie de volum n2 dintr-ocolectivitate N (µ2, σ2), cele dou selecµii ind alese independent una de cealalt . Not m cu ξ1, ξ2 ³id2∗1 = d2
∗(X1), d2∗2 = d2
∗(X2) mediile de selecµie ³i dispersiile de selecµie corespunz toare selecµiilor alese.Atunci statistica
T =(ξ1 − ξ2)− (µ1 − µ2)√
(n1 − 1)d2∗1 + (n2 − 1)d2
∗2
√n1 + n2 − 2
1n1
+ 1n2
∼ t (n1 + n2 − 2).
Demonstraµie. Consider m variabila aleatoare
U =(ξ1 − ξ2)− (µ1 − µ2)
σ√
1n1
+ 1n2
.
Se veric cu u³urinµ c U ∼ N (0, 1). Fie variabila aleatoare
V =(n1 − 1) d2
∗1σ2
+(n2 − 1) d2
∗2σ2
.
Conform relaµiei (7.3), avem c (n1−1) d2∗1σ2 ∼ χ2(n1 − 1) ³i (n2−1) d2∗2
σ2 ∼ χ2(n2 − 1). Deoarece aceste dou statistici sunt independente, atunci c suma lor, statistica V , satisface V ∼ χ2(n1 + n2 − 2). Concluziapropoziµiei rezult prin simpla aplicare a Lemei 7.8 variabilelor aleatoare U ³i V . 2

STATS 7 [Dr. Iulian Stoleriu] 84
Propoziµia 7.13 Dac X ∼ χ2(m) ³i Y ∼ χ2(n) sunt variabile aleatoare independente, atunci variabilaaleatoare
F =n
m
X
Y∼ F(m, n).
Demonstraµie. Fie f(x) ³i g(y) densit µile de repartiµie pentru X ³i, respectiv, Y . Avem:
f(x) =
xm2 −1 e−
x2
2m2 Γ(m2 )
, x > 0;
0 , x ≤ 0.
g(y) =
yn2−1 e−
y2
2n2 Γ(n2 )
, y > 0;
0 , y ≤ 0.
Din independenµa celor dou variabile aleatoare, g sim c densitatea de repartiµie a vectorului (X, Y )este:
h(x, y) = f(x)g(y) =xm2−1y
n2−1 e−
x+y2
2m+n
2 Γ(m2
)Γ(n2
) , (x, y) ∈ (0, ∞)× (0, ∞).
Consider m o transformare a acestui vector,
τ :
t =n
m
x
yv = y,
în vectorul (F, Y ). Densitatea de repartiµie a acestui vector este (vezi Propoziµia 5.3):
k(u, v) =
(mn
)m2 u
m2−1v
m+n2−1 e−
v2
(1+mnu)
2m+n
2 Γ(m2
)Γ(n2
) , (t, v) ∈ (0, ∞)× (0, ∞).
Densitatea de repartiµie marginal pentru F este:
k1(u) =
∫ ∞0
k(u, v) dv
=
(mn
)m2 Γ(m+n
2
)Γ(m2
)Γ(n2
) um2−1(
1 +m
nu)−m+n
2, u > 0,
adic tocmai densitatea de repartiµie a unei variabile aleatoare F(m, n). 2
Propoziµia 7.14 Dac X1, X2, . . . , Xm+n sunt variabile aleatoare independente, identic repartizateN (0, 1), atunci variabila aleatoare
F =n
m
X21 +X2
2 + . . . +X2m
X2m+1 +X2
m+2 + . . . +X2m+n
∼ F(m, n).
Demonstraµie. Demonstraµia rezult imediat prin aplicarea rezultatelor Propoziµiilor 7.1 ³i 7.13. 2
Propoziµia 7.15 (repartiµia raportului dispersiilor pentru colectivit µi gaussiene)Fie X1 ∼ N (µ1, σ1) ³i X2 ∼ N (µ2, σ2) caracteristicile a dou populaµii statistice, Ω1 ³i Ω2. Din ecarepopulaµie extragem câte o selecµie repetat , de volume n1, respectiv, n2, ³i consider m d2
∗1 = d2∗1(X1) ³i
d2∗2 = d2
∗2(X2) dispersiile de selecµie corespunz toare celor dou selecµii repetate. Atunci statistica
F =σ2
2
σ21
d2∗1d2∗2∼ F(n1 − 1, n2 − 1).

STATS 7 [Dr. Iulian Stoleriu] 85
Demonstraµie. Rescriem F în forma echivalent :
F =n2 − 1
n1 − 1
χ21
χ22
,
unde
χ21 =
1
σ21
n1∑i=1
(X1 i −X1)2, χ22 =
1
σ22
n2∑j=1
(X2 j −X2)2,
X1 ii=1, n1³i X2 ii=1, n2
sunt variabile de selecµie repetat de volume n1, respectiv, n2, ce urmeaz repartiµia variabilelor aleatoare X1, respectiv, X2. Statisticile X1 ³i X2 sunt mediile de selecµie corespun-z toare.Folosind concluzia Propoziµiei 7.6, avem c
χ21 ∼ χ2(n1 − 1), χ2
2 ∼ χ2(n2 − 1).
Concluzia acestei propoziµii urmeaz în urma aplic rii rezultatului Propoziµiei 7.14. 2
Propoziµia 7.16 (repartiµia raportului dispersiilor pentru colectivit µi gaussiene)Suntem în condiµiile Propoziµiei 7.15, cu menµiunea c mediile teoretice µ1 ³i µ2 sunt cunoscute a priori.Atunci
F1 =σ2
2
σ21
d21
d22
∼ F(n1, n2),
unde d21 ³i d2
2 sunt date de:
χ21 =
1
n1
n1∑i=1
(X1 i − µ1)2 ∼ χ2(n1), χ22 =
1
n2
n2∑j=1
(X2 j − µ2)2 ∼ χ2(n2).
Demonstraµie. Demonstraµia este similar cu cea de mai înainte. Se folosesc rezultatele Propoziµiilor 7.3³i 7.14. 2

STATS 8 [Dr. Iulian Stoleriu] 86
8 Statistic Aplicat (C8)
Noµiuni de Teoria estimaµiei
Punerea problemei
S presupunem c avem un set de observaµii aleatoare x1, x2, . . . , xn asupra unei caracteristici X a uneipopulaµii statistice. Funcµia de probabilitate (respectiv densitatea de repartiµie) a caracteristicii poate :
• complet specicat , de exemplu, X ∼ U(0, 1);
• specicat , dar cu parametru(i) necunoscut(i). De exemplu, X ∼ P(λ) sau X ∼ N (µ, σ);
• necunoscut , caz în care se poate pune problema de a estimat .
În mod evident, în primul caz de mai sus nu avem nimic de estimat. Dac funcµia de probabilitate(densitatea de repartiµie) este deja cunoscut , dar cel puµin unul dintre parametrii s i este necunoscut apriori, se pune problema s estim m valoarea parametrilor de care aceasta depinde. Vom spune astfel c avem o problem de estimare parametric . În acest capitol, ne vom ocupa de estimarea parametrilor uneirepartiµii date.S presupunem c avem caracteristica X care urmeaz repartiµia dat de funcµia de probabilitate (saudensitate de repartiµie) f(x, θ), unde θ este un parametru necunoscut. În general, acest parametru poate un vector (θ ∈ Θ ⊂ Rp), ale c rui componente sunt parametrii repartiµiei lui X. Mai sus, f este funcµiade probabilitate dac variabila aleatoare X este de tip discret, iar f este densitatea de repartiµie a lui X,dac este o variabil aleatoare de tip continuu.Scopul teoriei estimaµiei este de a evalua parametrii de care depinde f , folosind datele de selecµie ³ibazându-ne pe rezultatele teoretice prezentate în capitolele anterioare.Fie X1, X2, . . . , Xn variabile aleatoare de selecµie repetat de volum n, ce urmeaz repartiµia lui X.Presupunem totodat c X admite medie ³i not m cu µ = E(X) ³i σ2 = D2(X).
Deniµia 8.1 (1) Se nume³te funcµie de estimaµie (punctual ) sau estimator al lui θ, o funcµie de selecµie(statistic )
θ = θ(X1, X2, . . . , Xn),
cu ajutorul c reia dorim s îl aproxim m pe θ. În acest caz, ne-am dori s ³tim în ce sens ³i cât de bineeste aceast aproximaµie.
(2) O statistic θ este un estimator nedeplasat (en., biased estimator) pentru θ dac
E(θ) = θ.
Altfel, spunem c θ este un estimator deplasat pentru θ, iar deplasarea (distorsiunea) se dene³te astfel:
b(θ, θ) = E(θ)− θ.
Astfel, b(θ, θ) este o m sur a erorii pe care o facem în estimarea lui θ prin θ.

STATS 8 [Dr. Iulian Stoleriu] 87
Exemplu 8.2 (1) Dispersia de selecµie modicat
d2∗(X) =
1
n− 1
n∑i=1
[Xi −X]2
este un estimator nedeplasat pentru dispersia teoretic σ2 = D2(X), iar dispersia de selecµie
d2(X) =1
n
n∑i=1
[Xi −X]2
este un estimator deplasat pentru σ2 = D2(X), deplasarea ind
b(s2, σ2) = −σ2
n. [Exerciµiu!]
(3) Dac x1, x2, . . . , xn sunt date observate, atunci θ(x1, x2, . . . , xn) se nume³te estimaµie a lui θ.A³adar, o estimaµie pentru un parametru necunoscut este valoarea estimatorului pentru selecµia observat .Prin abuz de notaµie, vom nota atât estimatorul cât ³i estimaµia cu θ ³i vom face diferenµa între ele prinprecizarea variabilelor de care depind.
(4) Numim eroare în medie p tratic a unui estimator θ pentru θ (en., mean squared error) cantitatea
MSE(θ, θ) = E([θ − θ
]2).
Observaµia 8.3 Putem scrie:
E([θ − θ
]2)
= E([θ − E(θ) + E(θ)− θ
]2)
= D2(θ) + 2E([θ − E(θ)] · [E(θ)− θ
])+ E
([E(θ)− θ
]2)
= D2(θ) + 0 + (b(θ, θ))2.
A³adar, MSE pentru un estimator nedeplasat este D2(θ).
(5) Fie θ1 ³i θ2 doi estimatori pentru θ. Atunci, valoarea
MSE(θ1, θ)
MSE(θ2, θ)
se nume³te ecienµa relativ (en., relative eciency) a lui θ1 în raport cu θ2. Vom spune c un estimatorθ1 este mai ecient decât θ2 dac MSE(θ1, θ) ≤ MSE(θ2, θ) pentru toate valorile posibile ale lui θ ∈ Θ ³iMSE(θ1, θ) < MSE(θ2, θ) pentru m car un θ.
(6) Un estimator nedeplasat θ pentru θ, θ ∈ Θ, se nume³te estimator nedeplasat uniform de dispersieminim (en., Uniformly Minimum Variance Unbiased Estimator - UMVUE) dac pentru orice alt estimatornedeplasat pentru θ, θ∗, avem
D2(θ) ≤ D2(θ∗), pentru orice θ ∈ Θ.

STATS 8 [Dr. Iulian Stoleriu] 88
(7) Estimatorul θ pentru θ este un estimator consistent dac
θ(X1, X2, . . . , Xn)prob−→ θ, când n −→∞.
În acest caz, valoarea numeric a estimatorului, θ(x1, x2, . . . , xn), se nume³te estimaµie consistent pentruθ.
(8) Estimatorul θ pentru θ este un estimator absolut corect dac
(i) E(θ) = θ;
(ii) limn→∞
D2(θ) = 0.
În acest caz, valoarea numeric a estimatorului, θ(x1, x2, . . . , xn), se nume³te estimaµie absolut corect pentru θ.
(9) Estimatorul θ pentru θ este un estimator corect dac
(i) limn→∞
E(θ) = θ;
(ii) limn→∞
D2(θ) = 0.
În acest caz, valoarea numeric a estimatorului, θ(x1, x2, . . . , xn), se nume³te estimaµie corect pentru θ.
Propoziµia 8.4 Statistica d2∗(X) este un estimator absolut corect pentru σ2 = D2(X), iar statistica
d2(X) este un estimator corect, dar nu absolut corect, pentru D2(X). [Exerciµiu!]
Demonstraµie. Se arat c :
E(d2∗(X)) = E
(1
n− 1
n∑i=1
[Xi −X]2
)= D2(X),
D2(d2∗(X)) =
µ4
n− n− 3
n(n− 1)µ2
2 → 0, când n→∞.
³i
E(d2(X)) = E
(1
n
n∑i=1
[Xi −X]2
)=n− 1
nD2(X)
n→∞−→ D2(X),
D2(d2(X))→ 0, când n→∞.
2
Propoziµia 8.5 Dac θ este un estimator absolut corect pentru θ, atunci estimatorul este consistent.
Demonstraµie. Utiliz m inegalitatea lui Cebî³ev în forma:
P (|θ − θ| ≤ ε) ≥ 1− D2(θ)
ε2, ∀ε > 0. (8.1)
inând cont c limn→∞
D2(θ) = 0 obµinem concluzia dorit . 2

STATS 8 [Dr. Iulian Stoleriu] 89
Observaµia 8.6 Fie θ un estimator pentru θ. P tratul acestui estimator, θ2 nu este, în general, estima-torul pentru θ2.De exemplu, s presupunem c X ∼ N (0, 1) ³i avem urm toarele 20 de observaµii asupra lui X:
0.3617; -2.0587; -2.3320; -0.3709; 1.2857; 0.5570; -0.1802; -0.0357; 1.9344; 1.3056
0.0831; -0.3277; -0.3558; 0.4334; -1.2230; -1.0381; -2.7359; -0.0312; 2.0718; -0.5944
0.6286; -0.5350; 2.2090; -0.6057; 1.4352; 1.1948; 0.7431; -0.1214; 0.8678; -1.0030
Un estimator absolut corect pentru media teoretic a lui X, µX = 0, este X.(pentru selecµia dat , X = 0.0521). Variabila aleatoare X2 urmeaz repartiµia χ2(1) ³i are media µX2 = 1(vezi repartiµia χ2). Un estimator absolut corect pentru µX2 este X2. Pe de alt parte, pentru selecµiadat avem c X2 ≈ 1.4 iar
(X)2
= 0.027.
A³adar, în general X2 6=(X)2.
Observaµia 8.7 Pentru un anumit parametru pot exista mai mulµi estimatori absolut corecµi. De exem-plu, pentru parametrul λ din repartiµia Poisson P(λ) exist urm torii estimatori:
X ³i d2∗(X).
Se pune problema: Cum alegem pe cel mai bun estimator ³i pe ce criteriu? Dac utiliz m inegalitatea luiCebî³ev în forma (8.1), atunci ar resc ca "cel mai bun estimator" s e cel de dispersie minim .
(10) Se nume³te funcµie de verosimilitate (sau, simplu, verosimilitate), statistica
L(X1, X2, . . . , Xn; θ) =n∏k=1
f(Xk, θ).
Pentru Xk = xk, k = 1, n, funcµia L(x1, x2, . . . , xn; θ) este densitatea de repartiµie pentru vectorulaleator V = (X1, X2, . . . , Xn).
Putem scrie informaµia Fisher în funcµie de verosimilitate astfel:
(11) Numim cantitate de informaµie relativ la parametrul θ conµinut în selecµia corespunz toare devolum n (informaµie Fisher) expresia:
In(θ) = E
([∂ lnL(X1, X2, . . . , Xn; θ)
∂θ
]2). (8.2)
Teorema 8.8 (Rao18-Cramer19)Consider m caracteristica X cu funcµia de probabilitate (densitatea de repartiµie) f(x, θ), cu θ ∈ (a, b) ³ipentru care exist ∂f
∂θ . Consider m θ = θ(X1, X2, . . . , Xn), un estimator absolut corect pentru θ. Atunci,
D2(θ) ≥ 1
In(θ). (8.3)
18Calyampudi Radhakrishna Rao (1920−), statistician indian19Harald Cramér (1893− 1985), matematician ³i statistician suedez

STATS 8 [Dr. Iulian Stoleriu] 90
(12) Numim ecienµa unui estimator absolut corect θ pentru θ, valoarea:
e(θ) =I−1n (θ)
D2(θ). (8.4)
(13) Un estimator absolut corect θ pentru θ se nume³te estimator ecient dac e(θ) = 1, adic
D2(θ) = I−1n (θ).
Propoziµia 8.9 Media de selecµie X pentru o selecµie dintr-o colectivitate normal este un estimatorecient pentru media teoretic E(X). [Exerciµiu!]
(14) Un estimator corect θ pentru θ se nume³te estimator sucient (exhaustiv) dac densitatea vectoruluiV = (X1, X2, . . . , Xn), adic L(x1, x2, . . . , xn; θ), se poate scrie în forma:
L(x1, x2, . . . , xn; θ) = g(x1, x2, . . . , xn)h(θ(x), θ), (8.5)
unde g : Rn → R+ este m surabil ³i nu depinde de θ, iar funcµia h : R × R → R+ este m surabil ³idepinde de observaµii doar prin intermediul lui θ(x). Funcµiile g ³i h nu sunt unice. Din punct de vederepractic, un estimator este sucient pentru parametrul pe care îl estimeaz dac acest estimator conµinetoat informaµia relevant despre θ ce se poate obµine din selecµia considerat .
Propoziµia 8.10 Media de selecµie X pentru o selecµie dintr-o anumit colectivitate este un estimatorsucient pentru media teoretic E(X). [Exerciµiu!]
Observaµia 8.11 Orice estimator ecient pentru un parametru θ este ³i estimator sucient pentru θ.[Exerciµiu!]
În continuare, discut m urm toarele metode de estimare punctual a parametrilor:
• metoda verosimilit µii maxime;
• metoda momentelor;
• metoda minimului lui χ2;
• metoda celor mai mici p trate;
• metoda intervalelor de încredere.
Metoda verosimilit µii maxime
Fie caracteristica X studiat , care are funcµia de probabilitate f(x; θ) (unde θ = (θ1, θ2, . . . , θp) suntparametri necunoscuµi). S presupunem c avem n observaµii asupra caracteristicii X, adic am ales oselecµie de date,
x1, x2, . . . , xn.
Fie X1, X2, . . . , Xn variabilele aleatoare de selecµie repetat de volum n.

STATS 8 [Dr. Iulian Stoleriu] 91
Deniµia 8.12 (1) Numim estimator de verosimilitate maxim (maximum likelihood estimator) pentruθ o statistic θ = θ(X1, X2, . . . , Xn) pentru care se obµine maximumul funcµiei de verosimilitate,
L(X1, X2, . . . , Xn; θ) =
n∏k=1
f(Xk, θ).
(2) Valoarea unei astfel de statistici pentru o observaµie dat se nume³te estimaµie de verosimilitatemaxim pentru θ.
Observaµia 8.13 Aceasta metod estimeaz "valoarea cea mai verosimil " pentru parametrul θ.
Nu este necesar ca∂L∂θ
s existe pentru ca estimatorul de verosimilitate maxim s e calculat. Dac
aceasta exist , atunci acest estimator se obµine ca soluµie a sistemului de ecuaµii:
∂L(X1, X2, . . . , Xn; θ)
∂θk= 0, k = 1, 2, . . . , p, (8.6)
care este echivalent cu urm torul sistem:
∂ lnL(X1, X2, . . . , Xn; θ)
∂θk=
n∑i=1
∂ ln f(Xi; θ)
∂θk= 0, k = 1, 2, . . . , p. (8.7)
Exemplu 8.14 Estimaµi prin metoda verosimilit µii maxime parametrii unei caracteristici X ∼ N (µ, σ).
Soluµie: Legea de probabilitate pentru X ∼ N (µ, σ) este
f(x, µ, σ) =1
σ√
2πe−
(x−µ)2
2σ2 , x ∈ R.
Alegem o selecµie repetat de volum n, pe care o vom nota (XK)k=1, n.Parametrii caracteristicii X sunt θ = (µ, σ) ³i funcµia de verosimilitate asociat selecµiei este
L(X1, X2, . . . , Xn; µ, σ) =∏k=1
f(Xk, µ, σ)
=1
σn(2π)n2
e
−n∑k=1
(Xk − µ)2
2σ2
.
Astfel,
lnL(X1, X2, . . . , Xn; µ, σ) = ln
(1
σn(2π)n2
)− 1
2σ2
n∑k=1
(Xk − µ)2.
A³adar, pentru a g si estimatorii de verosimilitate maxim pentru µ ³i σ, avem de rezolvat sistemul:∂L∂µ
=1
σ2
n∑k=1
(Xk − µ) = 0;
∂L∂σ
= −nσ
+1
σ3
n∑k=1
(Xk − µ)2 = 0.

STATS 8 [Dr. Iulian Stoleriu] 92
Se observ cu usurinµ c soluµia sistemului ce convine (µinem cont c σ > 0) este
µ =1
n
n∑k=1
Xk = X, σ =
√√√√ 1
n
n∑k=1
(Xk −X)2 = d(X). (8.8)
Veric m acum dac valorile g site sunt valori de maxim. Pentru aceasta, matricea hessian calculat pentru valorile obµinute trebuie s e negativ denit . Mai întâi, calcul m matricea hessian . Aceastaeste:
H(µ, σ) =∂2L∂µ∂σ
=
− n
σ2− 2
σ3
n∑k=1
(Xk − µ)
− 2
σ3
n∑k=1
(Xk − µ)n
σ2
(1− 3
nσ2
n∑k=1
(Xk − µ)2
) .
Acum calcul m H(µ, σ).
H(µ, σ) =∂2L∂µ∂σ
|µ=µ, σ=σ =
− n
σ20
0 −2n
σ2
,
care este o matrice negativ denit , deoarece valorile sale proprii, adic r d cinile polinomului caracteristic
det(H(µ, σ)− λ I2) = 0,
suntλ1 = − n
σ2< 0 ³i λ2 = −2n
σ2< 0.
Deci, estimatorii µ ³i σ obµinuµi prin metoda verosimilit µii maxime sunt
µ = X ³i σ = d(X). √
Observaµia 8.15 De remarcat faptul c estimatorul d(X) obµinut prin metoda verosimilit µii maximenu este absolut corect, ci doar corect.
Metoda momentelor (K. Pearson)
În anumite cazuri, valorile critice pentru funcµia de verosimilitate sunt dicil de calculat. De aceea, enevoie de alte metode pentru a g si estimatori pentru parametri.Fie caracteristica X care are funcµia de probabilitate f(x; θ) (unde θ = (θ1, θ2, . . . , θp) sunt parametrinecunoscuµi) ce admite momente pân la ordinul p (adic , αp = E(Xp) < ∞). Dorim s g sim esti-matori (estimaµii) punctuale ale parametrilor necunoscuµi. Pentru aceasta, efectu m observaµii asupracaracteristicii, adic alegem o selecµie de date,
x1, x2, . . . , xn.
Fie X1, X2, . . . , Xn variabilele aleatoare de selecµie repetat de volum n. Metoda momentelor const înestimarea parametrilor necunoscuµi din condiµiile ca momentele iniµiale de selecµie s e egale cu momenteleiniµiale teoretice respective, ale lui X. Aceasta înseamn c avem de rezolvat un sistem de ecuaµii în carenecunoscutele sunt parametrii ce urmeaz a estimaµi.

STATS 8 [Dr. Iulian Stoleriu] 93
Deniµia 8.16 Numim estimator (punctual) pentru θ obµinut prin metoda momentelor soluµiaθ = (θ1, θ2, . . . , θp) (aici θk = θk(X1, X2, . . . , Xn), k = 1, p) a sistemului:
α1(X1, X2, . . . , Xn) = α1(X), (8.9)
α2(X1, X2, . . . , Xn) = α2(X),
...
αp(X1, X2, . . . , Xn) = αp(X),
unde αk(X1, X2, . . . , Xn) sunt momentele de selecµie de ordin k pentru X,
α1(X1, X2, . . . , Xn) =1
n
n∑i=1
Xki ,
³i αk(X) sunt momentele teoretice pentru X (care depind de θ), adic :
αk = E(Xk), k = 1, 2, . . . , p.
O estimaµie (punctual ) pentru θ va o realizare a estimatorului θ = (θ1, θ2, . . . , θp), unde componentelesunt θk = θk(x1, x2, . . . , xn), k = 1, p).
Observaµia 8.17 Aceasta metod este fundamentat teoretic pe faptul c momentele de selecµie suntestimatori absolut corecµi pentru momentele teoretice corespunz toare. Metoda nu poate aplicat repartiµiilor care nu admit medie (e.g., repartiµia Cauchy).
Exemplu 8.18 Fie X ∼ U(a, b) caracteristica unei populaµii, unde a < b sunt numere reale. Utilizândmetoda momentelor, determinaµi estimatori pentru capetele intervalului.
Soluµie: Dac X ∼ U(a, b), atunci
E(X) =a+ b
2, D2(X) =
(b− a)2
12,
de unde
E(X2) = D2(X) + [E(X)]2 =a2 + ab+ b2
3.
Sistemul (8.9) se scrie astfel în acest caz:
α1(X1, X2, . . . , Xn) = E(X) (8.10)
α2(X1, X2, . . . , Xn) = E(X2),
unde
α1 =1
n
n∑i=1
Xi, α2 =1
n
n∑i=1
X2i .
Inlocuind în relaµiile (8.10), avem de g sit soluµia (a, b) a urm torului sistem:
a+ b = 2α1
a · b = 4α21 − 3α2.

STATS 8 [Dr. Iulian Stoleriu] 94
Aceasta este:a = α1 −
√3√α2 − α2
1; b = α1 +√
3√α2 − α2
1.
F când calculele ³i µinând cont c α1 = X, obµinem estimatorii pentru a ³i, respectiv, b:
a = X −√
3 s; b = X +√
3 s,
unde
X =1
n
n∑i=1
Xi ³i s =
√√√√ 1
n
n∑i=1
(Xi −X)2.
Estimaµiile punctuale pentru a ³i b sunt:
a =1
n
n∑i=1
xi −
√√√√ 3
n
n∑i=1
(xi − x)2, b =1
n
n∑i=1
xi +
√√√√ 3
n
n∑i=1
(xi − x)2 √
Metoda celor mai mici p trate
Este o metod de estimare a parametrilor în cazul modelelor liniare, adic atunci când avem un set devariabile aleatoare Yi, i = 1, n ce depind liniar de parametrii necunoscuµi. Fie θ = (θ1, θ2, . . . , θp)vectorul ce conµine parametrii necunoscuµi ³i presupunem c Yi depind de ace³tia dup urm torul sistem:
Yi =
p∑j=1
xijθj + εi, i = 1, 2, . . . , n, (8.11)
sau, scris sub form matriceal :
Y = X · θ + ε, X = (xij) ∈ Rn×p.
Variabilele aleatoare εi sunt erori, despre care presupunem c :
E(εi) = 0
D2(εi) = σ2, i = 1, 2, . . . , n;
cov (εi, εj) = 0, ∀i 6= j. (8.12)
Metoda celor mai mici p trate const în determinarea parametrilor θi astfel încât suma p tratelor erorilors e minim . Asta înseamn c avem de rezolvat problema de minim:
minθ
n∑i=1
ε2i = min
θ
n∑i=1
Yi − p∑j=1
xijθj
2
.
Astfel, un estimator θ = (θ1, θ2, . . . , θp) prin metoda celor mai mici p trate este soluµia sistemului:
∂
∂θj
n∑i=1
Yi − p∑j=1
xijθj
2
= 0, j = 1, 2, . . . , p,
echivalent,n∑i=1
p∑j=1
xikxijθj =
n∑i=1
xikYi, k = 1, 2, . . . , p.

STATS 8 [Dr. Iulian Stoleriu] 95
Ultimul sistem poate scris sub forma matriceal :
X′ ·X · θ = X′ ·Y,
de unde g sim c estimatorul θ este
θ = (X′ ·X)−1 ·X′ ·Y.
Exemplu 8.19 Fie X o caracteristic ce admite medie, µ = E(X), ³i e X1, X2, . . . , Xn variabilelealeatoare de selecµie repetat de volum n. Statistica µ = X este estimatorul obµinut prin metoda celormai mici p trate pentru media teoretic µ, adic este soluµia problemei de minimizare
minµ
n∑i=1
(Xi − µ)2. (8.13)
Soluµie: Deoarece µ este media variabilelor aleatoare de selecµie, putem considera c ecare variabil oputem scrie sub forma
Xi = µ+ εi, i = 1, 2, . . . , n, (8.14)
cu εi satisfacând condiµiile (8.12). Soluµia problemei (8.13) este soluµia ecuaµiei
∂
∂µ
n∑i=1
(Xi − µ)2 = 0,
adic
µ =1
n
n∑i=1
Xi.√
Metoda minimului lui χ2
Consider m caracteristica X ce urmeaz a studiat , ce urmeaz legea de probabilitate dat de f(x, θ),unde θ = (θ1, θ2, . . . , θp) ∈ Θ ⊂ Rp sunt parametri necunoscuµi. Fie X1, X2, . . . , Xn variabilele aleatoarede selecµie repetat de volum n. Pentru a obµine un estimator θ prin metoda minimului lui χ2 pentru θ,proced m dup cum urmeaz .Descompunem mulµimea valorilor lui X, X(Ω), în clase, astfel:
X(Ω) =
k⋃i=1
Oi, Oi⋂Oj = ∅, ∀i 6= j.
Construim evenimentele
Ai = ω(n) ∈ Ω(n); X(ωi) ∈ Oi, i = 1, 2, . . . , k.
Se observ cu u³urinµ c
Ω(n) =k⋃i=1
Ai, Ai⋂Aj = ∅, ∀i 6= j.
Not m cupi(θ) = P (n)(Ai), i = 1, 2, . . . , k,

STATS 8 [Dr. Iulian Stoleriu] 96
i.e., probabilitatea ca un individ luat la întâmplare s aparµin clasei Oi. Atunci,
k∑i=1
pi(θ) = 1.
Mai facem urm toarele notaµii:− ni = frecvenµa absolut a evenimentului Ai în orice selecµie repetat de volum n;− Ni = variabilele aleatoare de selecµie corespunz toare lui ni (i = 1, k).
Observaµia 8.20 Vectorul aleator N = (N1, N2, . . . , Nk) urmeaz o repartiµie multinomial de parame-tri pi(θ), i = 1, k.
Deniµia 8.21 Statistica θ se nume³te estimator obµinut prin metoda minimului lui χ2 pentru θ dac θeste soluµie a problemei de minim
minθ
k∑i=1
[Ni − n · pi(θ)]2
n · pi(θ)
.
Propoziµia 8.22 Repartiµia urm toarei statistici este
k∑i=1
[Ni − n · pi(θ)]2
n · pi(θ)∼ χ2(k − p− 1).

Laborator 8 [Dr. Iulian Stoleriu] 97
Statistic Aplicat (Laborator 8)
Estimaµii prin Matlab
Estimarea parametrilor prin metoda verosimilit µii maxime poate realizat în Matlab folosind funcµiamle. Formatul general al funcµiei este:
[p, pCI] = mle(X,'distribution','lege','nume_1','val_1','nume_2','val_2',...)
unde:
• p este parametrul (sau parametrii) (sau vectorul de parametri) ce urmeaz a estimat punctual;
• pCI este variabila de memorie pentru intervalul (intervalele) de încredere ce va estimat;
• X este un vector ce conµine datele ce urmeaz a analizate;
• distribution este parte din formatul comenzii iar lege poate oricare dintre legile din Tabelul4.1;
• nume_i/val_i sunt perechi opµionale de argumente/valori, dintre care amintim:
alpha reprezint nivelul de condenµ pentru intervalul de încredere. Valoarea implicit înMatlab este α = 0.005;
ntrials (utilizat doar pentru repartiµia binomial , reprezint num rul de repetiµii ale ex-perimentului.
Dac urm rim s estim m parametrii unei caracteristici gaussiene, atunci putem folosi comanda simpli-cat :
[p, pCI] = mle(X)
f r a mai preciza legea de distribuµie.
De exemplu, s lu m drept obiect de lucru datele din Tabelul 1.4. Acestea sunt reprezentate prin bare înFigura 1.32. O estimare a parametrilor µ ³i σ prin metoda verosimilit µii maxime este
X=[7*rand(34,1)+18;10*rand(76,1)+25;10*rand(124,1)+35;10*rand(87,1)+45;10*rand(64,1)+55]
[p, pCI] = mle(X)
³i obµinem estim rile:
p =
41.9716 12.0228 % estimari punctuale pentru µ si σ
pCI =
40.7653 11.2439 % intervale de incredere

Laborator 8 [Dr. Iulian Stoleriu] 98
43.1779 12.9547
unde prima coloan reprezint estimarea punctual ³i un interval de încredere pentru µ, iar a doua coloan estimarea punctual ³i un interval de încredere pentru σ.
Estim ri punctuale ³i cu intervale de încredere mai putem obµine ³i utilizând funcµia
LEGEfit(X,alpha)
unde, în locul cuvântului LEGE punem o lege de probabilitate ca în Tabelul 4.1, X reprezint observaµiile³i alpha este nivelul de condenµ . (Exemple: normfit, binofit, poissfit, expfit etc).
Exerciµiu 8.1 S se arate c media de selecµie X constituie un estimator absolut corect ³i ecient alparametrului λ din repartiµia Poisson P(λ).
Soluµie: Deoarece X ∼ P(λ), urmeaz c E(X) = D2(X) = λ. Atunci,
E(X) =1
nE
(n∑i=1
Xi
)=
1
n
(n∑i=1
E(Xi)
)=
1
n(n∑i=1
λ) = λ,
D2(X) =1
n2D2
(n∑i=1
Xi
)=
1
n2
(n∑i=1
D2(Xi)
)=
1
n2(
n∑i=1
λ) =λ
n−→ 0, când n→∞.
A³adar, conform deniµiei, media de selecµie este un estimator absolut corect pentru parametrul λ. Funcµiade probabilitate este
f(x, λ) = e−λλx
x!, x ∈ N,
de unde∂ ln f(x, λ)
∂λ= −1 +
x
λ.
Calcul m ecienµa estimatorului. Avem
In(λ) = n · E
([∂ ln f(X, λ)
∂λ
]2)
= nE(
1− 2X
λ+X2
λ2
)= n
(1− 2
λ
λ+
1
λ2(λ2 + λ)
)=n
λ.
Se observ c D2(X) · In(λ) = 1, deci estimatorul X pentru λ este ecient. √
Exerciµiu 8.2 Fie Xi ∼ B(1, p), i = 1, n ³i
θ = nX =n∑i=1
Xi, num rul de succese în n incerc ri.
S se arate c θ este un estimator sucient pentru p.

Laborator 8 [Dr. Iulian Stoleriu] 99
Soluµie: Pentru vericarea sucienµei, utiliz m deniµia. Avem succesiv:
L(x1, x2, . . . , xn; p) =n∏i=1
pxi(1− p)1−xi
= p
n∑i=1
xi
(1− p)n−
n∑i=1
xi
= g(x) · h(θ(x), p),
unde g(x) ≡ 1 ³i h(θ(x), p) = pθ(x)(1− p)n−θ(x). √
Exerciµiu 8.3 S presupunem c arunc m o moned despre care nu ³tim dac este sau nu corect (adic ,probabilitatea de apariµie a feµei cu stema nu este neap rat 0.5). Fie X variabila aleatoare ce reprezint num rul de apariµii ale feµei cu stema la aruncarea repetat a unei monede. Not m cu p probabilitateaevenimentului ca la o singur aruncare a monedei apare stema. Realiz m 80 de arunc ri ale acelei monede³i obµinem valorile (1 înseamn c faµa cu stema a ap rut iar 0 dac nu a ap rut):
0 1 0 0 1 0 1 1 0 1 0 0 1 0 1 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 1 1 0 1 0 1 1 0
1 0 1 0 1 0 0 0 1 1 0 0 1 0 1 1 0 1 1 0 0 0 1 1 0 1 0 1 1 0 1 1 1 0 0 0 1 0 1 0
(1) S se g seasca un estimator absolut corect pentru p ³i a se studieze ecienµa acestuia.(2) S se g seasc estimaµii punctuale ³i intervale încredere pentru p, folosind funcµiile mle ³i binofitdin Matlab.
Soluµie: (1) Repartiµia lui X este Bernoulli, B(1, p). Astfel,
E(X) = p, D2(X) = p(1− p).
Consider m variabilele de selecµie repetat de volum, (Xk)k=1n.Un estimator absolut corect pentru medie este X, deoarece
E(X) = E(X) ³i D2(X) =p(1− p)n2
−−−−→n→∞
0.
A³adar, pentru selecµia dat , valoarea x =
n∑k=1
xk = 0.5125.
(2) Utilizând funcµiile Matlab astfel:
[p,pCI] = mle(Y,'distribution','bino','ntrials',1,'alpha',0.05)
cu rezultatul:
p = pCI =
0.5125 0.3981
0.6259

Laborator 8 [Dr. Iulian Stoleriu] 100
sau, folosind comanda binofit,
[p,pCI] = binofit(sum(Y),length(Y),0.05)
cu rezultatul:
p = pCI =
0.5125 0.3981
0.6259 √

STATS 8 [Dr. Iulian Stoleriu] 101
9 Statistic Aplicat (C9)
Estimarea parametrilor prin intervale de încredere(o singur populaµie)
S consider m o caracteristic X a c rei lege de probabilitate este dat de f(x, θ), cu θ parametrunecunoscut. Pentru a estima valoarea real a lui θ, efectu m n observaµii, obµinând selecµia:
x1, x2, . . . , xn.
Dup cum am v zut anterior, putem g si o estimaµie punctual a parametrului, θ(x1, x2, . . . , xn). Îns , oestimaµie punctual nu ne precizeaz cât de aproape se g se³te estimaµia θ(x1, x2, . . . , xn) faµ de valoareareal a parametrului θ. De exemplu, dac dorim s estim m masa medie a unor produse alimentarefabricate de o anumit ma³in , atunci putem g si un estimator punctual (e.g., media de selecµie) care s ne indice c aceasta este de 500 de grame. Ideal ar dac aceast informaµie ar prezentat sub forma:masa medie este 500g±10g.Putem obµine astfel de informaµii dac vom construi un interval în care, cu o probabilitate destul de mare,s g sim valoarea real a lui θ.S consider m o selecµie repetat de volum n, X1, X2, . . . , Xn, ce urmeaz repartiµia lui X. Dorim s g sim un interval aleator care s acopere cu o probabilitate mare (e.g., 0.95, 0.98, 0.99 etc) valoareaposibil a parametrului necunoscut.
Deniµia 9.1 Fie α ∈ (0, 1), foarte apropiat de 0 (de exemplu, α = 0.01, 0.02, 0.05 etc). Numiminterval de încredere (en., condence interval) pentru parametrul θ cu probabilitatea de încredere 1− α,un interval aleator (θ, θ), astfel încât
P (θ < θ < θ) = 1− α, (9.1)
unde θ(X1, X2, . . . , Xn) ³i θ(X1, X2, . . . , Xn) sunt statistici.Pentru o observaµie ω(n) xat , capetele intervalului (aleator) de încredere vor funcµii de valorile deselecµie. De exemplu, pentru datele observate, x1, x2, . . . , xn, intervalul(
θ(x1, x2, . . . , xn), θ(x1, x2, . . . , xn))
se nume³te valoare a intervalului de încredere pentru θ. Pentru simplitate îns , vom folosi termenulde "interval de încredere" atât pentru intervalul propriu-zis, cât ³i pentru valoarea acestuia, înµelesuldesprinzându-se din context.Valoarea α se nume³te nivel de semnicaµie sau probabilitate de risc.
Observaµia 9.2 Pentru a determina un interval de încredere, metoda de lucru este dup cum urmeaz :se va considera funcµie de selecµie S(X1, X2, . . . , Xn; θ), convenabil aleas , care s urmeze o lege cunos-cut ³i independent de θ. S not m cu g(s) aceast repartiµie. Se determin apoi valorile s1 ³i s2 (caredepind de α), astfel încât
P (s1 < S < s2) =
s2∫s1
g(s) ds = 1− α. (9.2)

STATS 8 [Dr. Iulian Stoleriu] 102
Cum statistica S depinde de θ, relaµia (9.2) determin un interval aleator (θ, θ) ce satisface (9.1).Intervalul de încredere variaz de la o selecµie la alta.
Cu cât α este mai mic (de regul , α = 0.01 sau 0.02 sau 0.05), cu atât ³ansa (care este (1 − α) · 100%)ca valoarea real a parametrului θ s se g seasc în intervalul g sit este mai mare. De³i ³ansele 99%sau 99.99% par a foarte apropiate ³i ar da rezultate asem n toare, sunt cazuri în care ecare sutimeconteaz . De exemplu, s presupunem c într-un an calendaristic un eveniment are ³ansa de 99% de a serealiza, în orice zi a anului, independent de celelalte zile. Atunci, ³ansa ca acest eveniment s se realizezeîn ecare zi a anului în tot decursului acestui an este de 0.99365 ≈ 2.55%. Dac ³ansa de realizare înecare zi ar fost de 99.99%, atunci rezultatul ar fost ≈ 96.42%, ceea ce înseamn o diferenµ foartemare generat de o diferenµ iniµial foarte mic .
Intervalul de încredere pentru valoarea real a unui parametru nu este unic. Dac ni se dau condiµiisuplimentare (e.g., xarea unui cap t), atunci putem obµine intervale innite la un cap t ³i nite lacel lalt cap t.
În continuare, vom c uta intervale de încredere pentru parametrii unor caracteristici normale.
Interval de încredere pentru medie, când dispersia este cunoscut
FieX ∼ N (µ, σ) caracteristica unei populaµii statistice, unde µ este necunoscut ³i σ este cunoscut. Pentrua construi un interval de încredere pentru media teoretic µ, efectu m o selecµie repetat de volum n ³ix m nivelul de încredere 1− α ≈ 1, α ∈ (0, 1). Alegem urm toarea statistic :
Z =X − µσ√n
∼ N (0, 1) (conform Propoziµiei 6.23). (9.3)
Putem determina un interval numeric (z1, z2) astfel încât
P (z1 < Z < z2) = Θ(z2)−Θ(z1) = 1− α, (9.4)
unde Θ : R→ [0, 1] este funcµia lui Laplace,
Θ(x) =1√2π
∫ x
−∞e−
y2
2 dy. (9.5)
De îndat ce intervalul (z1, z2) este determinat, putem scrie:
P (z1 <X − µσ√n
< z2) = 1− α,
echivalent cu
P
(X − z2
σ√n< µ < X − z1
σ√n
)= 1− α,
de unde intervalul de încredere pentru µ cu nivelul de semnicaµie (1− α) este
(µ, µ) =
(X − z2
σ√n, X − z1
σ√n
).
Mai ramâne de stabilit cum determin m valorile z1 ³i z2.
Distingem trei cazuri:

STATS 8 [Dr. Iulian Stoleriu] 103
(1) Dac nu se cunoa³te o alt informaµie suplimentar despre µ, atunci alegem (z1, z2) ca ind intervalde lungime minim pentru α xat. Aceasta se obµine când z1 = −z2 (vezi Observaµia 9.3), de unde:
Θ(z2)−Θ(−z2) = 1− α.
Tinând cont c Θ(−z) = 1−Θ(z), ultima relaµie se reduce la
Θ(z2) = 1− α
2,
de unde g sim pe z2 ca ind cuantila de ordin 1− α2 , ³i anume z1−α
2.
A³adar,z1 = −z1−α
2, z2 = z1−α
2,
³i intervalul de încredere pentru media teoretic µ când σ este cunoscut este:
(µ, µ) =
(X − z1−α
2
σ√n, X + z1−α
2
σ√n
). (9.6)
(2) Dac pentru media teoretic nu se precizeaz o limit superioar , atunci în (9.4) aleg intervalulaleator (z1, z2) de forma (−∞, z2). Înlocuind în (9.4) obµinem:
P (−∞ < Z < z2) = Θ(z2)−Θ(−∞)︸ ︷︷ ︸= 0
= 1− α,
de unde z2 = z1−α. În acest caz, intervalul de încredere este:
(µ, ∞) =
(X − z1−α
σ√n, ∞
).
(3) Dac pentru media teoretic nu se precizeaz o limit inferioar , atunci în (9.4) aleg intervalulaleator (z1, z2) de forma (z1, ∞). Înlocuind în (9.4) obµinem:
P (z1 < Z <∞) = Θ(∞)︸ ︷︷ ︸= 1
−Θ(z1) = 1− α,
de unde z1 = zα = −z1−α. În acest caz, intervalul de încredere este:
(−∞, µ) =
(−∞, X + z1−α
σ√n
).
Observaµia 9.3 În cazul (1) de mai sus, am ales intervalul aleator de lungime minim , unde aceast lungime este
l =σ√n
(z2 − z1).
Pentru a g si acest interval, avem de rezolvat problema:min
σ√n
(z2 − z1)
z2∫z1
g(z) dz = 1− α,

STATS 8 [Dr. Iulian Stoleriu] 104
unde g este desitatea de repartiµie pentru N (0, 1).Pentru a o rezolva, folosim metoda multiplicatorilor lui Lagrange. Fie funcµia
L(z1, z2; λ) =σ√n
(z2 − z1) + λ
∫ z2
z1
g(z) dz. (9.7)
Dorim s a m z1 ³i z2 ce realizeaz minL(z1, z2; λ). Acestea sunt soluµiile sistemului:∂L
∂z1= 0
∂L
∂z2= 0,
adic − σ√
n− λg(z1) = 0
σ√n
+ λg(z2) = 0.
Deoarece funcµia g este simetric , soluµiile sunt z1 = z2 (ce nu convine) ³i z1 = −z2.
Observaµia 9.4 (1) În cazul în care volumul selecµiei este mare (de cele mai multe ori în practic ,aceasta înseamn n ≥ 30) metoda de determinare a unui interval de încredere prezentat mai sus sepoate aplica ³i pentru selecµii dintr-o colectivitate ce nu este neap rat normal . Aceasta este o consecinµ faptului c , pentru n mare, statistica Z urmeaz repartiµia N (0, 1) pentru orice form a repartiµieicaracteristicii X (conform teoremei limit central ).(2) Intervalele de încredere determinate mai sus sunt valide pentru selecµia (repetat sau nerepetat ) dintr-o populaµie innit , sau pentru selecµii repetate dintr-o populaµie nit . În cazul selecµiilor nerepetatedin colectivit µi nite, în estimarea intervalelor de încredere vom µine cont ³i de volumul N al populaµiei.Spre exemplu, dac selecµia de volum n se face dintr-o populaµie nit de volum N ³i n ≥ 0.005N , atunciun inteval de încredere centrat pentru media populaµiei este:
(µ, µ) =
(X − z1−α
2
σ√n
√N − nN − 1
, X + z1−α2
σ√n
√N − nN − 1
). (9.8)
Interval de încredere pentru medie, când dispersia este necunoscut
Ne a m în condiµiile din secµiunea precedent (i.e., o caracteristic normal , X ∼ N (µ, σ)), mai puµinfaptul c σ este cunoscut. Dac deviaµia standard σ nu este cunoscut , atunci ea va trebui estimat . timdeja c o estimaµie absolut corect pentru σ este statistica d∗(X), dat prin
d∗(X) =
√√√√ 1
n− 1
n∑i=1
(Xi −X)2.
Pentru a estima media teoretic necunoscut µ printr-un interval de încredere, alegem statistica
T =X − µd∗(X)√
n
∼ t(n− 1), (conform Propoziµiei 7.9). (9.9)
În mod analog cu cazul precedent, g sim intervalul de încredere în funcµie de cele trei cazuri amintite maisus:

STATS 8 [Dr. Iulian Stoleriu] 105
(1) Dac nu se cunoa³te o alt informaµie suplimentar despre µ, atunci intervalul de încredere pentrumedia teoretic µ când σ este necunoscut este:
(µ, µ) =
(X − t1−α
2;n−1
d∗(X)√n
, X + t1−α2
;n−1d∗(X)√
n
). (9.10)
(2) Dac pentru media teoretic nu se precizeaz o limit superioar , atunci intervalul de încredereeste:
(µ, ∞) =
(X − t1−α;n−1
d∗(X)√n
, ∞).
(3) Dac pentru media teoretic nu se precizeaz o limit inferioar , atunci intervalul de încredere este:
(−∞, µ) =
(−∞, X − tα;n−1
d∗(X)√n
).
Aici, prin tα;n−1 am notat cuantila de ordin α pentru repartiµia t cu (n− 1) grade de libertate.
Observaµia 9.5 Formulele din aceast secµiune sunt practice atunci când selecµia se face dintr-o colecti-vitate gaussian de volum n mic. Când n este mare, atunci va o diferenµ foarte mic între valorile z1−α
2
³i t1−α2
;n−1, de aceea am putea folosi z1−α2în locul valorii t1−α
2;n−1. Mai mult, pentru un n mare (n ≥ 30),
intervalele de încredere obµinute mai sus r mân acelea³i pentru orice form a repartiµiei caracteristicii X,nu neap rat pentru una gaussian . A³adar, pentru o selecµie de volum mare dintr-o colectivitate oarecare,un interval de încredere pentru media populaµiei, când dispersia nu este cunoscut , este:
(µ, µ) =
(X − z1−α
2
d∗(X)√n
, X + z1−α2
d∗(X)√n
). (9.11)
Interval de încredere pentru dispersie, când media este cunoscut
Fie X ∼ N (µ, σ) o caracteristic a unei populaµii studiate, pentru care cunoa³tem media teoretic µ darnu ³i dispersia σ2. Dorim s estim m dispersia prin construirea unui interval de încredere. Alegem oselecµie repetat X1, X2, . . . , Xn ce urmeaz repartiµia lui X. Fix m nivelul de semnicaµie α.Pentru estimarea punctual a lui σ2 când media este cunoscut folosim statistica d2(X) denit prin
d2(X) =1
n
n∑i=1
[Xi − µ]2.
Intervalul de încredere pentru dispersie se construie³te cu ajutorul statisticii
n
σ2d2(X) =
1
σ2
n∑i=1
(Xi − µ)2 ∼ χ2(n), (conform Propoziµiei 7.3).
Determin m intervalul aleator din condiµia:
P(χ2
1 <n
σ2d2(X) < χ2
2
)= Gn(χ2
2)−Gn(χ21) = 1− α,
unde aici Gn(x) reprezint funcµia de repartiµie teoretic pentru repartiµia χ2 cu n grade de libertate.În funcµie de faptul dac avem sau nu informaµii suplimentare despre dispersie (analog ca anterior), g simc intervalul de încredere pentru σ2, dup cum urmeaz :

STATS 8 [Dr. Iulian Stoleriu] 106
(1) nu avem informaµii suplimentare despre dispersie:
(σ2, σ2) =
(nd2(X)
χ21−α
2;n
,n d2(X)
χ2α2
;n
); (9.12)
(2) avem informaµii c dispersia este nem rginit superior:
(σ2, σ2) =
(nd2(X)
χ2α;n
, +∞)
; (9.13)
(3) avem informaµii c dispersia este nem rginit inferior:
(σ2, σ2) =
(−∞, n d2(X)
χ21−α;n
), (9.14)
unde prin χ2α;n am notat cuantila de ordin α pentru repartiµia χ2 cu n grade de libertate.
Interval de încredere pentru dispersie, când media este necunoscut
Fie X ∼ N (µ, σ) o caracteristic a unei populaµii studiate, pentru care nu cunoa³tem media sau dispersia.De exemplu, X reprezint timpul de producere a unei reacµii chimice. Dorim s estim m dispersia princonstruirea unui interval de încredere. Alegem o selecµie repetat X1, X2, . . . , Xn ce urmeaz repartiµialui X. Fix m nivelul de semnicaµie α.Pentru estimarea punctual a lui σ2 când media este necunoscut folosim statistica d2
∗(X) denit prin
d2∗(X) =
1
n− 1
n∑i=1
[Xi −X]2.
Intervalul de încredere pentru dispersie se construie³te cu ajutorul statisticii
n− 1
σ2d2∗(X) =
1
σ2
n∑i=1
(Xi −X)2 ∼ χ2(n− 1), (conform Propoziµiei 7.6).
Determin m intervalul aleator din condiµia:
P
(χ2
1 <n− 1
σ2d2∗(X) < χ2
2
)= Gn−1(χ2
2)−Gn−1(χ21) = 1− α,
unde Gn−1(x) reprezint funcµia de repartiµie teoretic pentru repartiµia χ2 cu (n− 1) grade de libertate.În funcµie de faptul dac avem sau nu informaµii suplimentare despre dispersie, g sim c intervalul deîncredere pentru σ2 este:
(1) nu avem informaµii suplimentare despre dispersie:
(σ2, σ2) =
((n− 1)d2
∗(X)
χ21−α
2;n−1
,(n− 1)d2
∗(X)
χ2α2
;n−1
), (9.15)
unde prin χ2α;n−1 am notat cuantila de ordin α pentru repartiµia χ2 cu (n− 1) grade de libertate.

STATS 8 [Dr. Iulian Stoleriu] 107
(2) avem informaµii c dispersia este nem rginit superior:
(σ2, σ2) =
((n− 1)d2
∗(X)
χ2α;n−1
, +∞
); (9.16)
(3) avem informaµii c dispersia este nem rginit inferior:
(σ2, σ2) =
(−∞, (n− 1)d2
∗(X)
χ21−α;n−1
). (9.17)
Observaµia 9.6 Intervale de încredere pentru deviaµia standard se obµin prin extragerea r d cinii p -trate din capetele de la intervalele de încredere pentru dispersie.
Interval de încredere pentru proporµii într-o populaµie binomial
Pentru o populaµie statistic , prin proporµie a populaµiei vom înµelege procentul din întreaga colectivitatece satisface o anumit proprietate (sau are o anumit caracteristic ) (e.g., proporµia de studenµi integrali³tidintr-o anumit facultate). Pe de alt parte, prin proporµie de selecµie înµelegem procentajul din valorile deselecµie ce satisfac o anumit proprietate (e.g., proporµia de studenµi integrali³ti dintr-o selecµie aleatoarede 40 de studenµi ai unei facult µi). Proporµia unei populaµii este un parametru (pe care îl vom nota cup), iar proporµia de selecµie este o statistic (pe care o not m aici prin p).
Fie X o caracteristic binomial a unei colectivit µi, cu probabilitatea de succes p (e.g., num rul desteme ap rute la aruncarea unei monede ideale, caz în care p = 0.5). Dorim s construim un intervalde încredere pentru proporµia populaµiei, p. Pentru aceasta, avem nevoie de selecµii de volum mare dinaceast colectivitate. Un estimator potrivit pentru p este proporµia de selecµie, adic
p = p =X
n.
Printr-un "volum mare" vom înµelege un n ce satisface: n ≥ 30, n p > 5 ³i n (1 − p) > 5. Mediavariabilei aleatoare X este E(X) = np, iar dispersia este D2(X) = np(1 − p). Putem scrie pe X ca
ind X =n∑i=1
Xi, unde Xi sunt variabile aleatoare Bernoulli B(1, p). Pentru un volum n mare, variabila
aleatoare X satisface (conform teoremei limit central aplicat ³irului Xii):
X − n p√n p (1− p)
=Xn − p√p (1− p)
n
=p − p√p (1− p)
n
∼ N (0, 1).
Pe baza acestui rezultat, putem construi un interval de încredere pentru p, de forma:(p− z1−α
2
√p (1− p)
n, p+ z1−α
2
√p (1− p)
n
). (9.18)
Deoarece p nu este a priori cunoscut, p a fost înlocuit sub radical cu estimatorul s u. Valoarea
E = z1−α2
√p (1− p)
n(9.19)
se nume³te eroarea standard a proporµiei. E este eroarea care se face prin estimarea lui p prin intervalulde încredere dat de (9.18).

STATS 8 [Dr. Iulian Stoleriu] 108
Observaµia 9.7 Acest interval de încredere este valabil pentru selecµie dintr-o populaµie innit (saun N , de regul n < 0.05N) sau pentru selecµia cu repetiµie dintr-o populaµie nit . Dac selecµiase realizeaz f r repetiµie dintr-o populaµie nit (cu N astfel înât n ≥ 0.05N), atunci intervalul deîncredere este: (
p− z1−α2
√p (1− p)
n
√N − nN − 1
, p+ z1−α2
√p (1− p)
n
√N − nN − 1
). (9.20)

Laborator 9 [Dr. Iulian Stoleriu] 109
Statistic Aplicat (Laborator 9)
Estimaµii prin intervale de încredere în Matlab
Exemplu 9.8 O ma³in de îngheµat umple cupe cu îngheµat . Se dore³te ca îngheµat din cupe s aib masa de µ = 250g. Desigur, este practic imposibil s umplem ecare cup cu exact 250g de îngheµat .Presupunem c masa conµinutului din cup este o variabil aleatoare repartizat normal, cu masa ne-cunoscut ³i dispersia cunoscut , σ = 3g. Pentru a verica dac ma³ina este ajustat bine, se aleg laîntâmplare 30 de înghetate ³i se cânt re³te conµinutul ec reia. Obµinem astfel o selecµie repetat , x1, x2,. . . , x30 dup cum urmeaz :
257 249 251 251 252 251 251 249 248 248 251 253 248 245 251
248 256 247 250 247 251 247 252 248 253 251 247 253 244 253
Se ³tie c un estimator absolut corect pentru masa medie este media de selecµie, X = 250.0667.Se cere s se g seasc un interval de încredere pentru µ, cu nivelul de condenµ 0.99.
Soluµie: Dup cum am v zut mai sus, un interval de încredere pentru µ este:
(µ, µ) =
(x− z1−α
2
σ√n, x+ z1−α
2
σ√n
).
Urm torul cod Matlab furnizeaz un interval de încredere bazat pe datele de selecµie observate.
n=30; sigma=3; alpha = 0.01;
x=[257 249 251 251 252 251 251 249 248 248 251 253 248 245 251 ...
248 256 247 250 247 251 247 252 248 253 251 247 253 244 253];
z = icdf('norm',1-alpha/2,0,1); % cuantila de ordin 1-alpha/2 pentru normala
m1 = mean(x)-z*sigma/sqrt(n); m2 = mean(x)+z*sigma/sqrt(n); % capetele intervalului
fprintf('(m1,m2)=(%6.3f,%6.3f)\n',m1,m2); % afiseaza intervalul dupa modul dorit
Rulând codul, obµinem intervalul de încredere pentru µ când σ este cunoscut:
(µ, µ) = (248.659, 251.478). √
Observaµia 9.9 Exist funcµii predenite în Matlab ce furnizeaz estimatori punctuali ³i intervale deîncredere. A se compara rezultatul din acest exerciµiu cu cel din Exemplul 9.10 (estimare a intervalului deîncredere când σ nu este cunoscut) sau Exerciµiul 9.12 (intervale furnizate de funcµiiMatlab predenite).
Exemplu 9.10 S se g seasc un interval de încredere pentru masa medie din Exerciµiul 9.8, în cazul încare abaterea standard σ nu mai este cunoscut .

Laborator 9 [Dr. Iulian Stoleriu] 110
Figura 9.1: Intervalul de încredere pentru Exerciµiu 9.8.
Soluµie: Dup cum am v zut mai sus, un interval de încredere pentru µ este:
(µ, µ) =
(x− t1−α
2;n−1
d∗(X)√n
, x+ t1−α2
;n−1d∗(X)√
n
).
Urm torul cod Matlab furnizeaz un interval de încredere bazat pe datele de selecµie observate.
n=30; alpha = 0.01;
x=[257 249 251 251 252 251 251 249 248 248 251 253 248 245 251 ...
248 256 247 250 247 251 247 252 248 253 251 247 253 244 253];
dev = std(X); % deviatia standard de selectie
t = icdf('t',1-alpha/2,n-1); % cuantila de ordin 1-alpha/2 pentru t(n-1)
m1 = mean(x)-t*dev/sqrt(n); m2 = mean(x)+t*dev/sqrt(n); % capetele intervalului
fprintf('(m1,m2)=(%6.3f,%6.3f)\n',m1,m2); % afiseaza intervalul dupa modul dorit
Rulând codul, obµinem intervalul de încredere pentru µ când σ este cunoscut:
(µ, µ) = (248.572, 251.561). √
Observaµia 9.11 A se compara rezultatul din acest exemplu cu cel din Exemplul 9.8 (estimare a in-tervalului de încredere când σ este cunoscut) sau Exerciµiul 9.12 (intervale furnizate de funcµii Matlabpredenite).
Exemplu 9.12 Suntem, din nou, în cadrul Exerciµiului 9.8, cu menµiunea c dispersia nu este cunoscut a priori (vezi Exerciµiu 9.10). Dorim s obµinem o estimaµie printr-un interval de încredere pentru µ cândσ nu este cunoscut . Folosind funcµia normfit obµinem chiar mai mult decât ne propunem, ³i anume:estimaµii punctuale pentru µ ³i σ ³i câte un interval de încredere pentru ambele. Rulând funcµia, adic
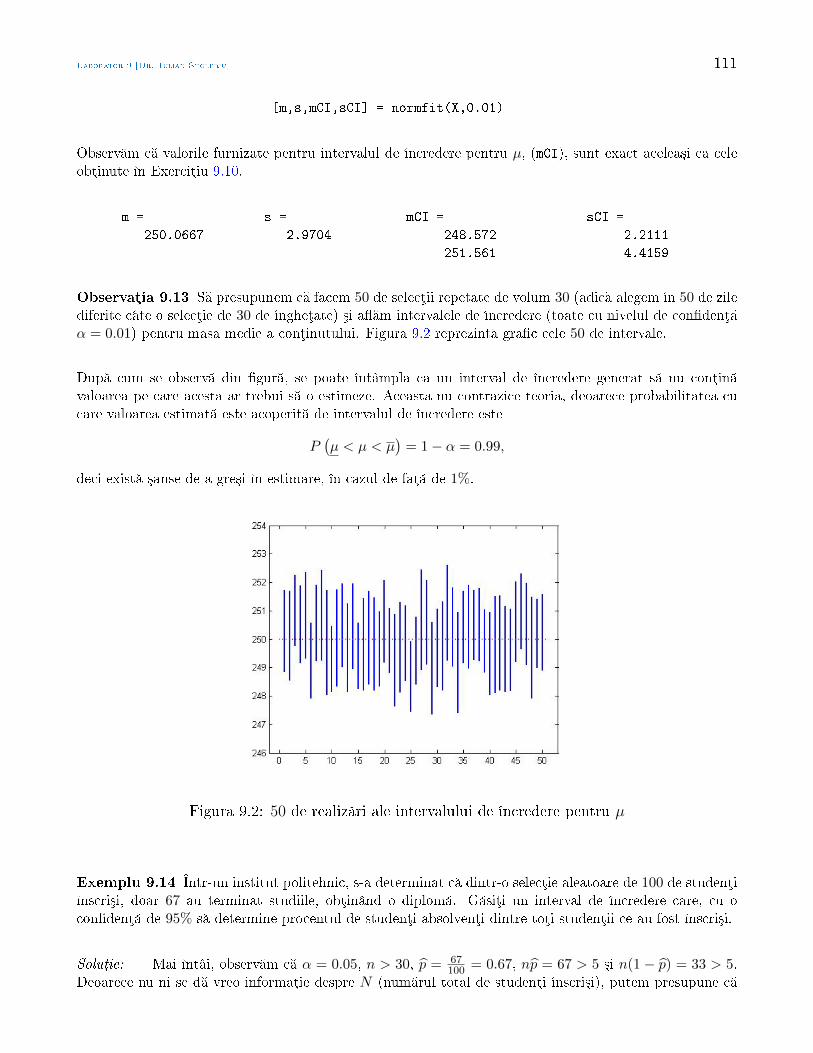
Laborator 9 [Dr. Iulian Stoleriu] 111
[m,s,mCI,sCI] = normfit(X,0.01)
Observ m c valorile furnizate pentru intervalul de încredere pentru µ, (mCI), sunt exact acelea³i ca celeobµinute în Exerciµiu 9.10.
m = s = mCI = sCI =
250.0667 2.9704 248.572 2.2111
251.561 4.4159
Observaµia 9.13 S presupunem c facem 50 de selecµii repetate de volum 30 (adic alegem în 50 de zilediferite câte o selecµie de 30 de îngheµate) ³i a m intervalele de încredere (toate cu nivelul de condenµ α = 0.01) pentru masa medie a conµinutului. Figura 9.2 reprezint grac cele 50 de intervale.
Dup cum se observ din gur , se poate întâmpla ca un interval de încredere generat s nu conµin valoarea pe care acesta ar trebui s o estimeze. Aceasta nu contrazice teoria, deoarece probabilitatea cucare valoarea estimat este acoperit de intervalul de încredere este
P(µ < µ < µ
)= 1− α = 0.99,
deci exist ³anse de a gre³i în estimare, în cazul de faµ de 1%.
Figura 9.2: 50 de realiz ri ale intervalului de încredere pentru µ
Exemplu 9.14 Într-un institut politehnic, s-a determinat c dintr-o selecµie aleatoare de 100 de studenµiînscri³i, doar 67 au terminat studiile, obµinând o diplom . G siµi un interval de încredere care, cu ocondenµ de 95% s determine procentul de studenµi absolvenµi dintre toµi studenµii ce au fost înscri³i.
Soluµie: Mai întâi, observ m c α = 0.05, n > 30, p = 67100 = 0.67, np = 67 > 5 ³i n(1− p) = 33 > 5.
Deoarece nu ni se d vreo informaµie despre N (num rul total de studenµi înscri³i), putem presupune c

Laborator 9 [Dr. Iulian Stoleriu] 112
n < 0.005N ³i putem aplica formula (9.18). G sim c intervalul de încredere c utat este:(0.67− z0.975
√0.67 (1− 0.67)
100, 0.67 + z0.975
√0.67 (1− 0.67)
100
)= (59.27%, 74.73%). √
Exemplu 9.15 Dintr-o selecµie de 200 de elevi ai unei ³coli cu 1276 de elevi, 65% arm c deµin celpuµin un telefon mobil. S se g seasc un interval de încredere pentru procentul de copii din respectiva³coal ce deµin cel puµin un telefon mobil, la nivelul de semnicaµie α = 0.05.
Soluµie: Avem: n = 200, N = 1276, p = 0.65. Deoarece n ≥ 0.05N , folosind (9.20) ³i g sim c uninterval de încredere la nivelul de semnicaµie 0.05 este(
0.65− 1.96
√0.65 (1− 0.65)
200
√1276− 200
1276− 1, 0.65 + 1.96
√0.65 (1− 0.65)
200
√1276− 200
1276− 1
)= (58.93%, 71.07%). √
Observaµia 9.16 Dac se dore³te estimarea volumului selecµiei pentru care se obµine estimarea proporµieip printr-un interval de încredere cu o eroare maxim E , atunci folosim formula (9.19). Dac am puteaghici proporµia populaµiei, p, atunci g sim urm toarea estimare a volumului selecµiei:
n =
[p(1− p)
(z1−α
2
E
)2], (9.21)
unde [ · ] este partea întreag . Dac p nu poate ghicit, atunci folosim faptul c p(1 − p) este maximpentru p = 0.5 ³i estim m pe n prin
n =
[1
4
(z1−α
2
E
)2].
Exemplu 9.17 Un studiu susµine c între 35% ³i 40% dintre elevii de liceu din µar fumeaz . Cât demare ar trebui s e volumul unei selecµii dintre elevii de liceu pentru a estima procentul real de elevi cefumeaz , cu o eroare de estimare maxim de 0.5%. Se va alege nivelul de semnicaµie α = 0.1.
Soluµie: Folosim formula (9.21), pentru p = 0.4 (se alege valoarea 40%, cea mai apropiat de 50%).Cuantila este z0.95 = 1.28. G sim c o estimaµie pentru n este:
n =
[0.4(1− 0.4)
(1.64
0.005
)2]
= 25820. √
Exemplu 9.18 O fabric produce batoane de ciocolat cânt rind 100g ecare. Pentru a se estima aba-terea masei de la aceast valoare, s-a f cut o selecµie de 35 de batoane, obµinându-se valorile:
100.12; 99.92; 100.1; 99.89; 100.07; 99.88; 100.11; 99.90; 99.97; 100.2;
99.89; 100.15; 99.9; 99.7; 100.2; 99.7; 100.2; 100.1; 100.04; 99.89;
99.76; 100.1; 99.24; 98.19; 100.15; 100.5; 99.79; 98.95; 100.23; 99.89;
100.12; 98.63; 99.03; 100.3; 98.68.

Laborator 9 [Dr. Iulian Stoleriu] 113
G siµi un interval de încredere (cu α = 0.05) pentru deviaµia standard masei batoanelor produse de res-pectiva fabric .
Soluµie: Mai întâi, calcul m d2(x). Avem:
d2(x) =1
35
35∑i=1
[Xi − 100]2 = 0.3.
Din tabele, sau utilizând Matlab, g sim cuantilele:
χ20.975; 35 = 53.2033; χ2
0.025; 35 = 20.5694.
În Matlab, cuantilele se calculeaz astfel:
icdf('chi2',0.975, 35); icdf('chi2',0.025, 35)
Intervalul de încredere pentru dispersie este (folosind formula (9.12)):
(σ2, σ2) = (0.20, 0.51).
Pentru variaµia standard, intervalul de încredere este:
(σ, σ) = (√
0.2,√
0.51) = (0.44, 0.71). √
Exemplu 9.19 G siµi un interval de încredere (cu α = 0.05) pentru deviaµia standard a conµinutului denicotin a unui anumit tip de µig ri, dac o selecµie de 24 de buc µi are deviaµia standard a conµinutuluide nicotin de 1.6mg.
Soluµie: Mai întâi, s = d∗(x) = 1.6. Din tabele, sau utilizând Matlab, g sim:
χ20.975; 24 = 39.3641; χ2
0.025; 24 = 12.4012.
Intervalul de încredere pentru dispersie este (folosind formula (9.15)):
(σ2, σ2) = (1.56, 4.95).
Pentru variaµia standard, intervalul de încredere este:
(√
1.5608,√
4.9544) = (1.25, 2.22). √
Tabelul 9.1 sumarizeaz intervalele de încredere prezentate pân acum. În ecare caz, nivelul de semni-caµie este α.

Laborator 9 [Dr. Iulian Stoleriu] 114
Param. Alµi param. Interval de încredere cu nivelul de semnicaµie α
µ
(X − z1−α
2
σ√n, X + z1−α
2
σ√n
)σ2 (
X − z1−ασ√n, +∞
)cunoscut (
−∞, X + z1−ασ√n
)
µ
(X − t1−α
2; n−1
d∗(X)√n, X + t1−α
2; n−1
d∗(X)√n
)σ2 (
X − z1−ασ√n, ∞
);
necunoscut (−∞, X − tα; n−1
d∗(X)√n
)
σ2
(nd2(X)χ21−α2 ;n
, nd2(X)χ2α2 ;n
)µ (
nd2(X)χ2α;n
, +∞)
cunoscut (−∞, nd2(X)
χ21−α;n
)
σ2
((n−1) d2∗(X)χ21−α2 ;n−1
, (n−1) d2∗(X)χ2α2 ;n−1
)µ
((n−1) d2∗(X)χ2α;n−1
, +∞)
necunoscut (−∞, (n−1) d2∗(X)
χ21−α;n−1
)p n
(p− z1−α
2
√p (1−p)
n , p+ z1−α2
√p (1−p)
n
)mare
σ21/σ2
2µ1, µ2
(d2∗1d2∗2fn1−1, n2−1; α
2,d2∗1d2∗2fn1−1, n2−1; 1−α
2
)necunoscuµi
µ1 − µ2 σ21, σ
22
X1 −X2 − z1−α2
√σ2
1
n1+σ2
2
n2, X1 −X2 + z1−α
2
√σ2
1
n1+σ2
2
n2
cunoscuµi
µ1 − µ2 σ21 6= σ2
2
X1 −X2 − t1−α2
; N
√d2∗1n1
+d2∗2n2, X1 −X2 + t1−α
2; N
√d2∗1n1
+d2∗2n2
necunoscuµi
µ1 − µ2 σ21 = σ2
2
(X1 −X2 − t1−α
2; n1+n2−2 d(X1, X2), X1 −X2 + t1−α
2; n1+n2−2 d(X1, X2)
)necunoscuµi
p1 − p2 n1, n2
(p1 − p2 − z1−α
2
√p1 (1−p1)
n1+ p2 (1−p2)
n2, p1 − p2 + z1−α
2
√p1 (1−p1)
n1+ p2 (1−p2)
n2
)mari
Tabela 9.1: Tabel cu intervale de încredere.
Mai sus, prin d(X1, X2) am notat:
d(X1, X2) =√
(n1 − 1)d2∗1 + (n2 − 1)d2
∗2
(n1 + n2 − 2
1n1
+ 1n2
)− 12
.

STATS 10 [Dr. Iulian Stoleriu] 115
10 Statistic Aplicat (C10)
Estimarea parametrilor prin intervale de încredere(dou populaµii)
Interval de încredere pentru diferenµa mediilor
Fie X1 ³i X2 caracteristicile a dou populaµii normale, N (µ1, σ1), respectiv, N (µ1, σ1), pentru care nuse cunosc mediile teoretice. Alegem din prima populaµie o selecµie repetat de volum n1, notat prin(X1k)k=1, n1
, ce urmeaz repartiµia lui X1, iar din a doua populaµie alegem o selecµie repetat de volumn2, notat prin (X2k)k=1, n2
, ce urmeaz repartiµia lui X2. Fix m nivelul de semnicaµie α. S not mdispersiile de selecµie pentru ecare caracteristic prin
d2∗1 =
1
n1 − 1
n1∑i=1
(X1k −X1)2 ³i d2∗2 =
1
n2 − 1
n2∑i=1
(X2k −X2)2.
Pentru a g si un interval de încredere pentru diferenµa mediilor, preciz m mai întâi statisticile care staula baza construirii intervalului. Putem avea urm toarele trei cazuri:
(1) dispersiile σ21 ³i σ2
2 sunt cunoscute a priori. Alegem statistica
Z =(X1 −X2)− (µ1 − µ2)√
σ21
n1+σ2
2
n2
∼ N (0, 1). (conform Propoziµiei 6.27). (10.1)
Intervalul de încredere pentru diferenµa mediilor este:X1 −X2 − z1−α2
√σ2
1
n1+σ2
2
n2, X1 −X2 + z1−α
2
√σ2
1
n1+σ2
2
n2
.
(2) dispersiile σ21 = σ2
2 = σ2 ³i necunoscute. Pentru a g si un interval de încredere pentru diferenµamediilor, alegem statistica (vezi Propoziµia 7.12):
T =(X1 −X2)− (µ1 − µ2)√(n1 − 1)d2
∗1 + (n2 − 1)d2∗2
√n1 + n2 − 2
1n1
+ 1n2
∼ t (n1 + n2 − 2), (10.2)
Intervalul de încredere pentru µ1 − µ2 este:X1 −X2 − t1−α2
; n1+n2−2
√(n1 − 1)d2
∗1 + (n2 − 1)d2∗2
(n1 + n2 − 2
1n1
+ 1n2
)− 12
,
X1 −X2 + t1−α2
; n1+n2−2
√(n1 − 1)d2
∗1 + (n2 − 1)d2∗2
(n1 + n2 − 2
1n1
+ 1n2
)− 12
.

STATS 10 [Dr. Iulian Stoleriu] 116
(3) dispersiile σ21 6= σ2
2, necunoscute. Pentru un interval de încredere pentru µ1 − µ2, alegem statistica
T =(X1 −X2)− (µ1 − µ2)√
d2∗1n1
+d2∗2n2
∼ t(N), (10.3)
unde
N =
(s2
1
n1+s2
2
n2
)2
(s2
1
n1
)21
n1 − 1+
(s2
2
n2
)21
n2 − 1
− 2(s2
1 = d2∗(x1), s2
2 = d2∗(x2)
). (10.4)
În acest caz, un interval de încredere pentru µ1 − µ2 la nivelul de semnicaµie α este:X1 −X2 − t1−α2
; N
√d2∗1n1
+d2∗2n2, X1 −X2 + t1−α
2; N
√d2∗1n1
+d2∗2n2
.
Observaµia 10.1 Pentru un volum de selecµie n mare (n ≥ 30), intervalele de încredere obµinute mai susr mân acelea³i pentru orice form a repartiµiei caracteristicii X, nu neap rat pentru una gaussian .
Interval de încredere pentru raportul dispersiilor
Fie X1 ³i X2 caracteristicile a dou populaµii normale, N (µ1, σ1), respectiv, N (µ2, σ2), pentru care nuse cunosc mediile ³i dispersiile teoretice. Alegem din prima populaµie o selecµie repetat de volum n1 ceurmeaz repartiµia lui X1, iar din a doua populaµie alegem o selecµie repetat de volum n2 ce urmeaz repartiµia lui X2. Fix m nivelul de semnicaµie α. Pentru a g si un interval de încredere pentru raportuldispersiilor,
σ21/σ2
2
consider m statistica
F =σ2
2
σ21
d2∗1d2∗2∼ F(n1 − 1, n2 − 1), (conform Propoziµiei 7.15). (10.5)
Determin m apoi un interval aleator (f1, f2) astfel încât
P (f1 < F < f2) = Fn1−1, n2−1(f2)− Fn1−1, n2−1(f1) = 1− α,
unde Fn,m este funcµia de repartiµie pentru repartiµia Fisher cu (n, m) grade de libertate. Alegem:
f1 = fn1−1, n2−1; α2
³i f2 = fn1−1, n2−1; 1−α2,
unde fn,m;α reprezint cuantila de ordin α pentru repartiµia Fisher cu (n, m) grade de libertate.Intervalul de încredere pentru raportul dispersiilor, σ2
1/σ22 este:(
d2∗1d2∗2fn1−1, n2−1; α
2,
d2∗1d2∗2fn1−1, n2−1; 1−α
2
). (10.6)

STATS 10 [Dr. Iulian Stoleriu] 117
Interval de încredere pentru diferenµa proporµiilor într-o populaµie binomial
Fie X1 ³i X2 dou caracteristici binomiale independente ale unei populaµii, cu volumele ³i probabilit µilede succes n1, p1 ³i, respectiv, n2, p2. Dorim s a m un interval de încredere pentru diferenµa proporµiilor,p1− p2. Pentru a reu³i aceasta, avem nevoie de selecµii mari, de aceea utilizarea testului Z este oportun .Condiµiile testului sunt: n1 ≥ 30, n2 ≥ 30, n1p1 > 5, n2p2 > 5, n1(1 − p1) > 5, n2(1 − p2) > 5. La unnivel de semnicaµie α, un interval de încredere pentru p1 − p2 este:p1 − p2 − z1−α
2
√p1 (1− p1)
n1+p2 (1− p2)
n2, p1 − p2 + z1−α
2
√p1 (1− p1)
n1+p2 (1− p2)
n2
. (10.7)
Vericarea ipotezelor statistice
[Ambiµia de o viaµ a unui statistician este de a nu da gre³. . . în mai mult de 5% din cazuri.]
Punerea problemei
Testarea ipotezelor statistice este o metod prin care se iau decizii statistice, utilizând datele experimentaleculese. Testele prezentate mai jos au la baz noµiuni din teoria probabilit µilor. Aceste teste ne permitca, plecând de la un anumit sau anumite seturi de date culese experimental, s se putem valida anumiteestim ri de parametri ai unei repartiµii sau chiar putem prezice forma legii de repartiµie a caracteristiciiconsiderate.Presupunem c X este caracteristica studiat a unei populaµii statistice ³i c legea sa de probabilitateeste dat de f(x, θ), unde θ ∈ Θ ⊂ Rp. Dup cum precizam în capitolul anterior, aceast funcµie poate specicat (adic îi cunoa³tem forma, dar nu ³i parametrul θ), caz în care putem face anumite ipotezeasupra acestui parametru, sau f(x, θ) este necunoscut , caz în care putem face ipoteze asupra formeisale.S presupunem c (xk)k=1, n sunt datele observate relativ la caracteristica X.
Deniµia 10.2 (1) Numim ipotez statistic o presupunere relativ la valorile parametrilor ce apar înlegea de probabilitate a caracteristicii studiate sau chiar referitoare la tipul legii caracteristicii.(2) O ipotez neparametric este o presupunere relativ la forma funcµional a lui f(x, θ). De exemplu,o ipotez de genul X ∼ Normal .(3) Numim ipotez parametric o presupunere f cut asupra valorii parametrilor unei repartiµii. Dac mulµimea la care se presupune c aparµine parametrul necunoscut este format dintr-un singur element,avem de-a face cu o ipotez parametric simpl . Altfel, avem o ipotez parametric compus .(4) O ipotez nul este acea ipotez pe care o intuim a cea mai apropiat de realitate ³i o presupunem apriori a adev rat . Cu alte cuvinte, ipoteza nul este ceea ce dore³ti s crezi, în cazul în care nu exist suciente evidenµe care s sugereze contrariul. Un exemplu de ipotez nul este urm toarul: "presupusnevinovat, pân se g sesc dovezi care s ateste o vin ". O ipotez alternativ este orice alt ipotez

STATS 10 [Dr. Iulian Stoleriu] 118
admisibil cu care poate confruntat ipoteza nul .De exemplu, în Exerciµiul 9.8, putem presupune c ipoteza (parametric ) nul este
(H0) µ = 250 grame,
iar o ipotez alternativ (bilateral ) poate
(H1) µ 6= 250 grame.
În general, pentru teste parametrice consider m
θ ∈ A = A0
⋃A1, A0
⋂A1 = ∅
³i spunem c (H0) θ ∈ A0 este ipoteza nul ,
iar(H1) θ ∈ A1 este ipoteza alternativ .
(5) A testa o ipotez statistic (en., statistical inference) înseamn a lua una dintre deciziile:
− ipoteza nul se respinge− ipoteza nul se admite (sau, nu sunt motive pentru respingerea ei)
(6) În Statistic , un rezultat se nume³te semnicativ din punct de vedere statistic dac este improbabil cael s se realizat datorit ³ansei. Între dou valori exist o diferenµ semnicativ dac exist sucientedovezi statistice pentru a dovedi diferenµa, ³i nu datorit faptului c diferenµa ar mare. Numim nivel desemnicaµie probabilitatea de a respinge ipoteza nul când, de fapt, aceasta este adev rat . În general,nivelul de semnicaµie este ales ca ind una dintre valorile: α = 0.01, 0.02, 0.05 etc.Vom numi regiune critic mulµimea tuturor valorilor care cauzeaz respingerea ipotezei nule. Matematic,o submulµime U ⊂ R se nume³te regiune critic cu un nivel de semnicaµie α ∈ (0, 1) dac
P ((x1, x2, . . . , xn) ∈ U | H0 admis) = α.
Dac putem scrie regiunea critic sub forma
U = (x1, x2, . . . , xn) ∈ Rn | S(x1, x2, . . . , xn) ≥ c,
atunci valoarea c se nume³te valoare critic iar S(x1, x2, . . . , xn) se nume³te statistic test sau criteriu.Construirea unui test statistic revine la construirea unei astfel de mulµimi critice. Folosind datele observate³i U determinat ca mai sus, putem avea dou cazuri:
(i) (x1, x2, . . . , xn) 6∈ U , ceea ce implic faptul c (H0) este acceptat (pân la o alt testare);
(ii) (x1, x2, . . . , xn) ∈ U , ceea ce implic faptul c (H0) este respins (adic (H1) este acceptat );
În urma unor astfel de decizii pot aparea dou tipuri de erori:
• eroarea de speµa (I) sau riscul furnizorului (en., false positive) − este eroarea care se poate comiterespingând o ipotez (în realitate) adev rat . Se mai nume³te ³i risc de genul (I). Probabilitateaacestei erori este nivelul de semnicaµie, adic :
α = P ((x1, x2, . . . , xn) ∈ U | H0 admis).

STATS 10 [Dr. Iulian Stoleriu] 119
• eroarea de speµa a (II)-a sau riscul beneciarului (en., false negative) − este eroarea care se poatecomite acceptând o ipotez (în realitate) fals . Se mai nume³te ³i risc de genul al (II)-lea. Proba-bilitatea acestei erori este
β = P ((x1, x2, . . . , xn) 6∈ U | H1 admis).
Gravitatea comiterii celor dou erori depinde de problema studiat . De exemplu, riscul de genul (I) estemai grav decât riscul de genul al (II)-lea dac veric m calitatea unui articol de îmbrac minte, iar ris-cul de genul al (II)-lea este mai grav decât riscul de genul (I) dac veric m concentraµia unui medicament.
Fie X o caracteristic ce urmeaz legea de probabilitate f(x; θ), cu θ ∈ Θ ⊂ R ³i (x1, x2, . . . , xn) valoride selecµie de volum n.
Deniµia 10.3 Vom numi puterea unui test probabilitatea respingerii unei ipoteze false (sau, probabili-tiatea de a nu comite eroarea de speµa a II-a). Not m prin
π = 1− β = P ((x1, x2, . . . , xn) ∈ U | H0 − fals) . (10.8)
Deniµia 10.4 Denumim valoare P sau P−valoare (en., P-value) probabilitatea de a obµine un rezultatcel puµin la fel de extrem ca cel observat, presupunând c ipoteza nul este adev rat . Valoarea P estecea mai mic valoare a nivelului de semnicaµie α pentru care ipoteza (H0) ar respins , bazându-nepe observaµiile culese. Dac Pv ≤ α, atunci respingem ipoteza nul la nivelul de semnicaµie α, iar dac Pv > α, atunci admitem (H0). Cu cât Pv este mai mic , cu atât mai mari ³anse ca ipoteza nul s erespins . De exemplu, dac valoarea P este Pv = 0.045 atunci, bazându-ne pe observaµiile culese, vomrespinge ipoteza (H0) la un nivel de semnicaµie α = 0.05 sau α = 0.1, dar nu o putem respinge la unnivel de semnicaµie α = 0.02. Dac ne raport m la P−valoare, decizia într-un test statistic poate f cut astfel: dac aceasta valoare este mai mic decât nivelul de semnicaµie α, atunci ipoteza nul esterespins , iar dac P−value este mai mare decât α, atunci ipoteza nul nu poate respins . De reµinutfaptul c , cu cât valoarea P este mai mic , cu atât mai semnicativ este rezultatul testului.
Un exemplu simplu de test este testul de sarcin . Acest test este, de fapt, o procedur statistic ce ned dreptul s decidem dac exist sau nu suciente evidenµe s concluzion m c o sarcin este prezent .Ipoteza nul ar lipsa sarcinii. Majoritatea oamenilor în acest caz vor c dea de acord cum c un falsenegative este mai grav decât un false positive.
S presupunem c suntem într-o sal de judecat ³i c judec torul trebuie s decid dac un inculpat estesau nu vinovat. Are astfel de testat urm toarele ipoteze:
(H0) inculpatul este nevinovat;
(H1) inculpatul este vinovat.
Posibilele st ri reale (asupra c rora nu avem control) sunt:
[1] inculpatul este nevinovat (H0 este adev rat ³i H1 este fals );
[2] inculpatul este vinovat (H0 este fals ³i H1 este adev rat )
Deciziile posibile (asupra c rora avem control − putem lua o decizie corect sau una fals ) sunt:

STATS 10 [Dr. Iulian Stoleriu] 120
[i] H0 se respinge (dovezi suciente pentru a încrimina inculpatul);
[ii] H0 nu se respinge (dovezi insuciente pentru a încrimina inculpatul);
În realitate, avem urm toarele posibilit µi, sumarizate în Tabelul 10.1:
Situaµie real Decizii H0 - adev rat H0 - fals
Respinge H0 [1]&[i] [2]&[i]Accept H0 [1]&[ii] [2]&[ii]
Tabela 10.1: Posibilit µi decizionale.
Interpret rile datelor din Tabelul 10.1 se g sesc în Tabelul 10.2.
Situaµie real Decizii H0 - adev rat H0 - fals
Respinge H0 închide o persoana nevinovat închide o persoana vinovat Accepta H0 elibereaz o persoana nevinovat elibereaz o persoana vinovat
Tabela 10.2: Decizii posibile.
Erorile posibile ce pot aparea sunt cele din Tabelul 10.3.
Situaµie real Decizii H0 - adev rat H0 - fals
Respinge H0 α judecat corect Accepta H0 judecat corect β
Tabela 10.3: Erori decizionale.
Tipuri de teste statistice
Tipul unui test statistic este determinat de ipoteza alternativ (H1). Avem astfel:
• test unilateral stânga, atunci când ipoteza alternativ este θ < θ0 (vezi Figura 10.1 (a));
• test unilateral dreapta, atunci când ipoteza alternativ este θ > θ0 (vezi Figura 10.1 (b));
• test bilateral, atunci când ipoteza alternativ este θ 6= θ0 (vezi Figura 10.2);
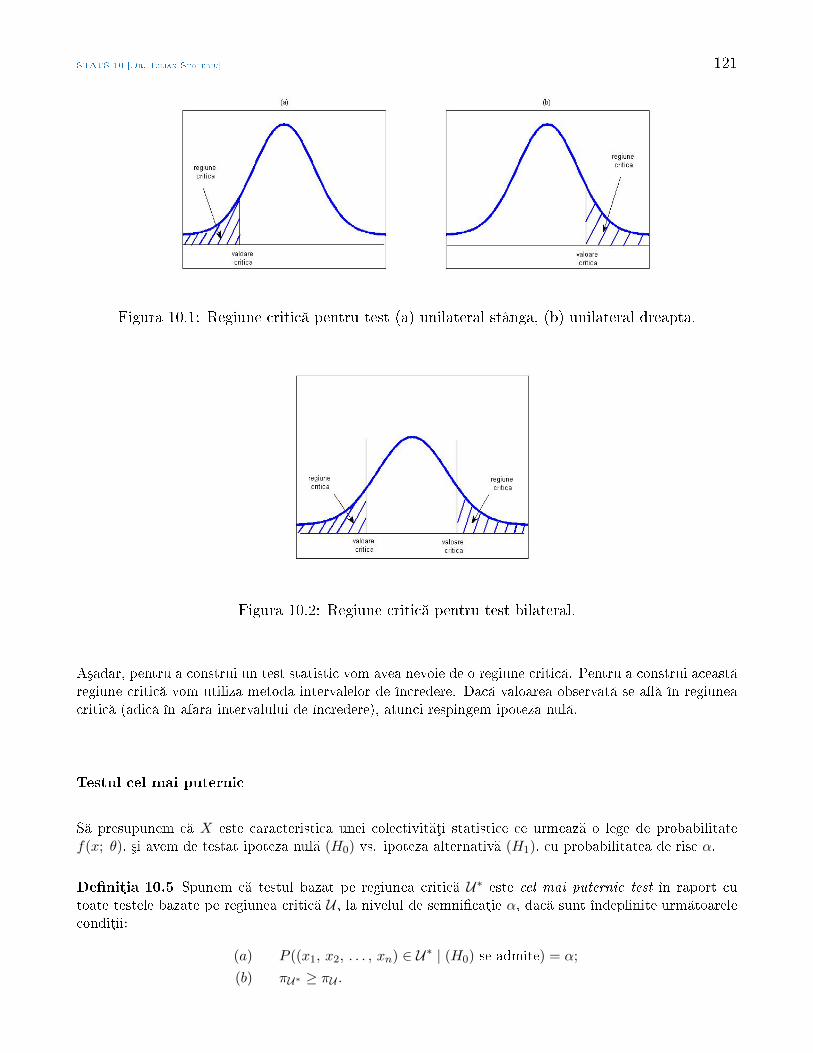
STATS 10 [Dr. Iulian Stoleriu] 121
Figura 10.1: Regiune critic pentru test (a) unilateral stânga, (b) unilateral dreapta.
Figura 10.2: Regiune critic pentru test bilateral.
A³adar, pentru a construi un test statistic vom avea nevoie de o regiune critic . Pentru a construi aceast regiune critic vom utiliza metoda intervalelor de încredere. Dac valoarea observat se a în regiuneacritic (adic în afara intervalului de încredere), atunci respingem ipoteza nul .
Testul cel mai puternic
S presupunem c X este caracteristica unei colectivit µi statistice ce urmeaz o lege de probabilitatef(x; θ), ³i avem de testat ipoteza nul (H0) vs. ipoteza alternativ (H1), cu probabilitatea de risc α.
Deniµia 10.5 Spunem c testul bazat pe regiunea critic U∗ este cel mai puternic test în raport cutoate testele bazate pe regiunea critic U , la nivelul de semnicaµie α, dac sunt îndeplinite urm toarelecondiµii:
(a) P ((x1, x2, . . . , xn) ∈ U∗ | (H0) se admite) = α;
(b) πU∗ ≥ πU .

STATS 10 [Dr. Iulian Stoleriu] 122
(adic , dintre toate testele de nivel de semnicaµie α xat, cel mai puternit test este cel pentru careputerea testului este maxim ). Regiunea U∗ se nume³te regiunea critic cea mai bun .
Observaµia 10.6 Nu întotdeauna exist un cel mai puternic test.
În cazul ipotezelor simple, lema urm toare ne confer un cel mai bun test. În cazul general, nu se poateconstrui un astfel de criteriu.
Lema 10.7 (Neyman20-Pearson) Presupunem c avem de testat
(H0) : θ = θ0 vs. (H1) : θ = θ1,
la nivelul de semnicaµie α. Not m cu L(x; θ) = L(x1, x2, . . . , xn; θ) funcµia de verosimilitate ³i e
S(x) =L(x; θ1)
L(x; θ0).
Atunci regiunea U denit prinU = x ∈ Rn | S(x) ≥ c,
cu c astfel încât P (x ∈ U | (H0) − adev rat ) = α, este cea mai bun regiune critic la nivelul desemnicaµie α.
Exemplu 10.8 Fie x1, x2, . . . , xn valori de selecµie pentru o caracteristic X ∼ N (µ, σ), unde µ estecunoscut. Dorim s test m ipoteza nul :
(H0) : σ = σ0
versus ipoteza alternativ simpl (H1) : σ = σ1.
Soluµie: Funcµia de verosimilitate asociat selecµiei este:
L(x1, x2, . . . , xn; σ) =1
σn(2π)n2
e
− 12σ2
n∑k=1
(xk − µ)2
.
Calculând S(x), obµinem:
S(x) =L(x; σ1)
L(x; σ0)=
(σ0
σ1
)ne
− 12
(1
σ21− 1
σ20
) n∑k=1
(xk − µ)2
.
Utilizând Lema Neyman-Pearson, cel mai puternit test este bazat pe o regiune ce depinde den∑i=1
(xi − µ)2.
De asemenea, observ m c dac σ1 > σ0, atunci S(x) este o funcµie cresc toare den∑i=1
(xi − µ)2. A³adar,
vom respinge ipoteza (H0) dac n∑i=1
(xi − µ)2 este sucient de mare. √
20Jerzy Neyman (1894− 1981), matematician polonez

Laborator 10 [Dr. Iulian Stoleriu] 123
Statistic Aplicat (Laborator 10)
Estimaµii prin intervale de încredere în Matlab
Exemplu 10.9 Dou strunguri sunt potrivite s produc piese identice pentru o comand . Pentru aestima dac abaterile diametrelor pieselor produse de cele dou ma³ini sunt sensibil egale, s-au luat laîntamplare dou seturi de volume n1 = 7 ³i n2 = 10 de piese din cele dou loturi. M sur torile au condusla urm toarele rezultate:
Lotul 1 25.06 24.95 25.01 25.05 24.98 24.97 25.02 − − −Lotul 2 25.01 25.09 25.02 24.95 24.97 25.03 24.99 24.97 25.03 24.98
S se determine un interval de încredere pentru raportul dispersiilor diametrelor pieselor produse de celedou loturi (α = 0.1). Se va presupune c diametrele pieselor urmeaz o repartiµie normal .
Soluµie: Folosim (10.6). Determin m mai întâi dispersiile empirice. Acestea sunt:
d2∗1 =
1
6
7∑i=1
(L1i − L1i)2 = 0.0412 ³i d2
∗2 =1
9
10∑j=1
(L2j − L2j)2 = 0.0409.
Cuantilele sunt:f6, 9; 0.05 = 0.2440 ³i f6, 9; 0.95 = 3.3738.
Folosind Matlab, putem calcula cuantilele astfel:
f1 = finv(0.05, 6, 9); f2 = finv(0.95, 6, 9);
G sim intervalul de încredere:
(f1, f2) ≈ (0.25, 3.4). √
Exemplu 10.10 Dintr-o selecµie de 45 de baieµi ai unei ³coli, 21 au spus c le place Matematica, iardintr-o selecµie de 65 de fete ale aceleia³i ³coli, 37 au susµinut c le place aceast disciplin . Construiµi uninterval de încredere la nivelul de semnicaµie α = 0.02 pentru diferenµa proporµiilor de baieµi ³i fete dinrespectiva ³coal c rora le place Matematica.
Soluµie: Folosim formula (10.7). Mai întâi, p1 = 2345 , p2 = 37
65 ³i z0.99 ≈ 2.33. Intervalul c utat este:21
45− 37
65− 2.33
√2145 ·
2445
45+
3765 ·
2865
65,
21
45− 37
65+ 2.33
√2145 ·
2445
45+
3765 ·
2865
65
= (−0.1990, −0.0061).
√

Laborator 10 [Dr. Iulian Stoleriu] 124
Exerciµiu 10.11 O selecµie aleatoare de volum n = 25 cu media se selecµie x = 50 se ia dintr-o populaµiede volum N = 1000, ce are deviaµia standard σ = 2.(a) Dac presupunem c populaµia este normal , g siµi un interval de încredere pentru media populaµiei,cu α = 0.05.(b) G siµi un interval de încredere pentru media populaµiei (α = 0.05) în cazul în care populaµia nu estenormal .
Soluµie: (a) Folosim formula (9.6). G sim intervalul de încredere
(µ, µ) =
(50− z0.975
2√25, 50 + z0.975
2√25
)= (48.4, 51.6).
(b) Deoarece populaµia nu este normal distribuit ³i nici volumul populaµiei nu este mare (n < 30), vomestima intervalul de încredere bazându-ne pe inegalitatea lui Cebî³ev (3.8). Avem c probabilitatea cavalorile lui X s e aproximate prin x cu o eroare de cel mult k deviaµii standard este:
P (|X − x| < kσ) ≥ 1− 1
k2.
Luând 1− 1
k2= 0.95, g sim k =
√20. Astfel, un interval de încredere pentru media populaµiei va
(µ, µ) =
(x− k σ√
n, x+ k
σ√n
)=
(50−
√20
2√25, 50 +
√20
2√25
)= (46.42, 53.58).
Am folosit faptul c D2(X) =σ2
n. Observ m c acest interval este mai mare decât cel g sit anterior,
de aceea inegalitatea lui Cebî³ev este rar folosit pentru a determina intervale de încredere. Totu³i,în acest caz nu aveam o alt alternativ de calcul. Dac se dore³te o precizie mai bun , ar indicat cavolumul selecµiei s e de cel puµin 30, caz în care putem folosi aproximarea cu repartiµia normal . √
Testarea tipului de date experimentale
Pentru a putea efectua un test statistic în mod corect, este necesar s ³tim care este tipul (tipurile) dedate pe care le avem la dispoziµie. Pentru anumite teste statistice (e.g., testul Z sau testul t, dateletestate trebuie s e normal distribuite ³i independente. De multe ori, chiar ³i ipoteza ca datele s enormal repartizate trebuie vericat . De aceea, se pune problema realiz rii unei leg turi între funcµiade repartiµia empiric ³i cea teoretic (teste de concordanµ ). Vom discuta mai pe larg aceste teste deconcordanµ într-o secµiune urm toare.ÎnMatlab sunt deja implementate unele funcµii ce testeaz dac datele sunt normal repartizate. Funcµianormplot(X) reprezint grac datele din vectorul X versus o repartiµie normal . Scopul acestei funcµiieste de a determina grac dac datele din observate sunt normal distribuite. Dac aceste date sunt selec-tate dintr-o repartiµie normal , atunci acest grac va liniar, dac nu, atunci va un grac curbat. Deexemplu, s reprezent m cu normplot vectorii X ³i Y de mai jos. Gracele sunt cele din Figura 10.3.
X = normrnd(100,2,200,1);
subplot(1,2,1); normplot(X)
Y = exprnd(5,200,1);
subplot(1,2,2); normplot(Y)
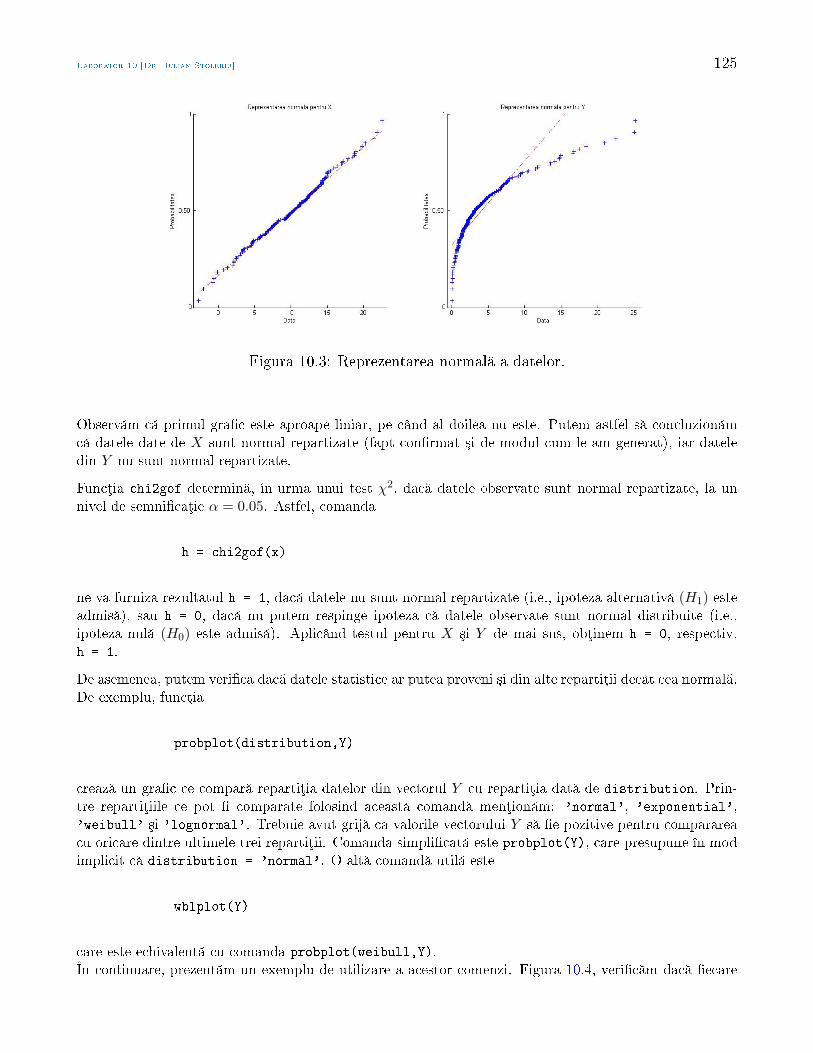
Laborator 10 [Dr. Iulian Stoleriu] 125
Figura 10.3: Reprezentarea normal a datelor.
Observ m c primul grac este aproape liniar, pe când al doilea nu este. Putem astfel s concluzion mc datele date de X sunt normal repartizate (fapt conrmat ³i de modul cum le-am generat), iar dateledin Y nu sunt normal repartizate.
Funcµia chi2gof determin , în urma unui test χ2, dac datele observate sunt normal repartizate, la unnivel de semnicaµie α = 0.05. Astfel, comanda
h = chi2gof(x)
ne va furniza rezultatul h = 1, dac datele nu sunt normal repartizate (i.e., ipoteza alternativ (H1) esteadmis ), sau h = 0, dac nu putem respinge ipoteza c datele observate sunt normal distribuite (i.e.,ipoteza nul (H0) este admis ). Aplicând testul pentru X ³i Y de mai sus, obµinem h = 0, respectiv,h = 1.
De asemenea, putem verica dac datele statistice ar putea proveni ³i din alte repartiµii decât cea normal .De exemplu, funcµia
probplot(distribution,Y)
creaz un grac ce compar repartiµia datelor din vectorul Y cu repartiµia dat de distribution. Prin-tre repartiµiile ce pot comparate folosind aceast comand menµion m: 'normal', 'exponential','weibull' ³i 'lognormal'. Trebuie avut grij ca valorile vectorului Y s e pozitive pentru comparareacu oricare dintre ultimele trei repartiµii. Comanda simplicat este probplot(Y), care presupune în modimplicit c distribution = 'normal'. O alt comand util este
wblplot(Y)
care este echivalent cu comanda probplot(weibull,Y).În continuare, prezent m un exemplu de utilizare a acestor comenzi. Figura 10.4, veric m dac ecare
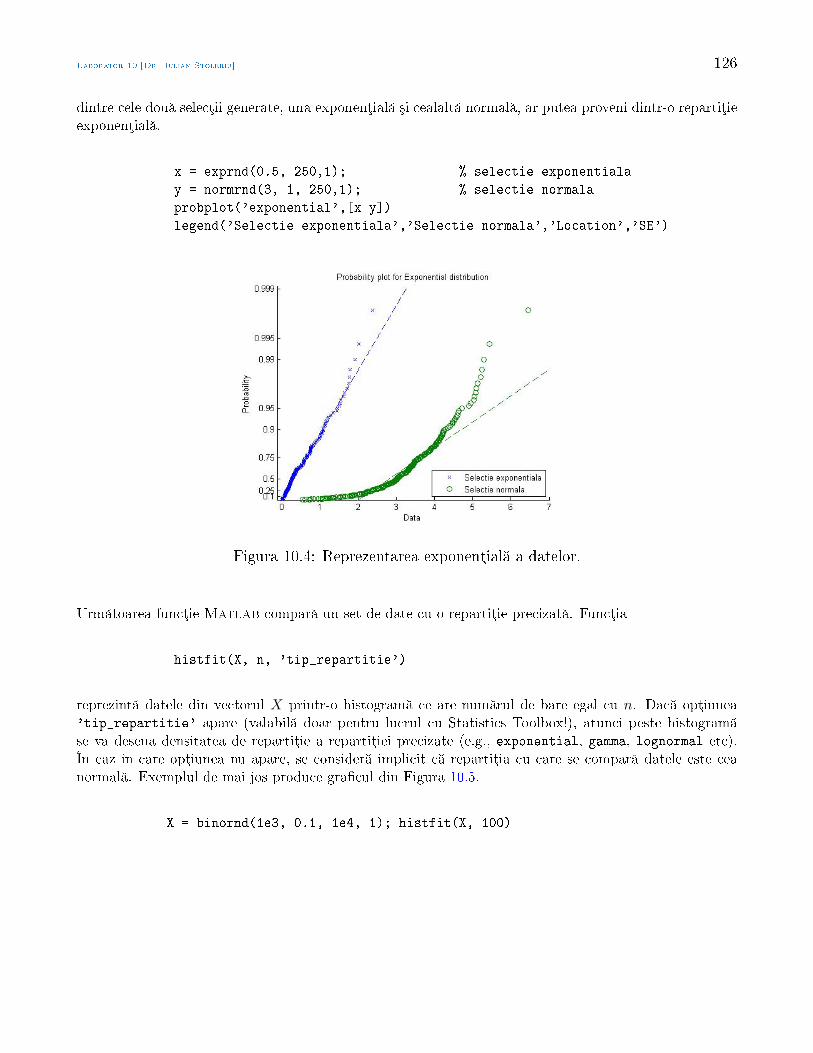
Laborator 10 [Dr. Iulian Stoleriu] 126
dintre cele dou selecµii generate, una exponenµial ³i cealalt normal , ar putea proveni dintr-o repartiµieexponenµial .
x = exprnd(0.5, 250,1); % selectie exponentiala
y = normrnd(3, 1, 250,1); % selectie normala
probplot('exponential',[x y])
legend('Selectie exponentiala','Selectie normala','Location','SE')
Figura 10.4: Reprezentarea exponenµial a datelor.
Urm toarea funcµie Matlab compar un set de date cu o repartiµie precizat . Funcµia
histfit(X, n, 'tip_repartitie')
reprezint datele din vectorul X printr-o histogram ce are num rul de bare egal cu n. Dac opµiunea'tip_repartitie' apare (valabil doar pentru lucrul cu Statistics Toolbox!), atunci peste histogram se va desena densitatea de repartiµie a repartiµiei precizate (e.g., exponential, gamma, lognormal etc).În caz în care opµiunea nu apare, se consider implicit c repartiµia cu care se compar datele este ceanormal . Exemplul de mai jos produce gracul din Figura 10.5.
X = binornd(1e3, 0.1, 1e4, 1); histfit(X, 100)

Laborator 10 [Dr. Iulian Stoleriu] 127
Figura 10.5: Compararea prin histograme.
.

STATS 11 [Dr. Iulian Stoleriu] 128
11 Statistic Aplicat (C11)
Teste parametrice
S presupunem c datele statistice colectate provin dintr-o repartiµie probabilistic dat , îns nu cu-noa³tem parametrul sau parametrii acestei repartiµii. De multe ori, avem anumite intuiµii asupra valorilorparametrilor ce intr în formula densit µii de repartiµie, pe care dorim s le veric m într-un cadru riguros.Astfel de teste, ce au la baz testarea parametrilor unor repartiµii cunoscute, se numesc teste parametrice.În continuare, vom prezenta cele mai folosite teste parametrice. Începem prin a prezenta pa³ii care aparîntr-o testare parametric .
Etapele unei test ri parametrice
• Colect m o selecµie întâmpl toare x1, x2, . . . , xn. De multe ori, aceast selecµie provine dintr-orepartiµie normal . În caz contrar, va trebui ca volumul selecµiei s e mare, de regula n ≥ 30. FieX1, X2, . . . , Xn variabile aleatoare de selecµie;
• Alegem o statistic (criteriu) S(X1, X2, . . . , Xn) care, dup acceptarea ipotezei (H0), aceast areo repartiµie cunoscut , independent de parametrul testat;
• Alegem un nivel de semnicaµie α apropiat de 0. De regul , α = 0.01, 0.02, 0.05.
• G sim regiunea critic U ;
• Calcul m valoarea s0 a statisticii S(X1, X2, . . . , Xn) pentru selecµia considerat ;
• Lu m decizia:
Dac s0 ∈ U , atunci ipoteza nul , (H0), se respinge;
Dac s0 6∈ U , atunci ipoteza nul , (H0), se admite (mai bine zis, nu avem motive s o respingem³i o admitem pân la efectuarea eventual a unui test mai puternic).
Observaµia 11.1 O alt modalitate de testare a unei ipoteze statistice parametrice este prin intermediulvalorii P (sau P−valoarea sau valoare critic ). Reamintim, P−valoarea este probabilitatea de a obµineun rezultat cel puµin la fel de extrem ca cel observat, presupunând c ipoteza nul este adev rat . Pentrutestul bilateral, P−valoarea se poate calcula dup formula:
Pv = P (|S| > |s0|) = P (S > |s0|) + P (S < −|s0|), (11.1)
unde S este statistica folosit în testare ³i s0 este valoarea acestei statistici pentru selecµia dat (respectiv,selecµiile date, în cazul test rii cu dou selecµii).
Pentru testul unilateral stânga, P−valoarea se poate calcula dup formula:
Pv = P (S < s0), (11.2)
iar pentru testul unilateral dreapta, P−valoarea este dat de:
Pv = P (S > s0), (11.3)

STATS 11 [Dr. Iulian Stoleriu] 129
Utilizând P−valoarea, testarea se face astfel:Ipoteza nul va respins dac Pv < α ³i va admis dac Pv ≥ α. A³adar, cu cât Pv este mai mic, cuatât mai multe dovezi de respingere a ipotezei nule.
Testul Z pentru medie (o selecµie)
Testul Z bilateral
Testul Z pentru medie se folose³te pentru selecµii normale sau pentru selecµii de volum mare (n ≥ 30) dinorice tip de variabile aleatoare, atunci când dispersia populaµiei este cunoscut a priori.Fie caracteristica X ce urmeaz legea normal N (µ, σ) cu µ necunoscut ³i σ > 0 cunoscut. Presupunemc avem deja culese datele de selecµie (observaµiile) asupra lui X:
x1, x2, . . . , xn.
Dorim s veric m ipoteza nul (H0) : µ = µ0
vs. ipoteza alternativ (H1) : µ 6= µ0,
cu probabilitatea de risc α. Pentru a efectua acest test, consider m statistica
Z =X − µσ√n
. (11.4)
Dac ipoteza (H0) se admite, atunci Z ∼ N (0, 1), (conform Propoziµiei 6.23). Caut m un interval (z1, z2)astfel încât
P (z1 < Z < z2) = 1− α. (11.5)
G sim c acest interval este: (−z1−α
2, z1−α
2
),
unde zα este cuantila de ordin α pentru repartiµia N (0, 1).Denim regiunea critic pentru ipoteza nul (relativ la valorile statisticii Z) ca ind acea regiune pentrucare ipoteza (H0) se respinge, dac media µ aparµine acelui interval. tim c un interval de încrederepentru µ va conµine valoarea real µ0 cu o probabilitate destul de mare, 1−α. Este de a³teptat ca regiuneacritic s e complementara acestui interval, adic
U =z ∈ R; z 6∈
(−z1−α
2, z1−α
2
)= z; |z| ≥ z1−α
2. (11.6)
Astfel, U este acea regiune în care:
X ≥ µ0 + z1−α2
σ√n
³i X ≤ µ0 − z1−α2
σ√n.
Not m cu z0 valoarea statisticii Z pentru observaµia considerat .Decizia nal se face astfel:
• dac z0 ∈(−z1−α
2, z1−α
2
), (echivalent, z0 6 ∈ U), atunci admitem (H0) (pentru c nu sunt su-
ciente dovezi s o respingem).

STATS 11 [Dr. Iulian Stoleriu] 130
• dac z0 6∈(−z1−α
2, z1−α
2
), (echivalent, z0 ∈ U), atunci respingem (H0) (exist suciente dovezi
s o respingem).
Etapele testul Z bilateral
(1) Se dau: x1, x2, . . . , xn (date repartizate normal), µ0, σ, α;(2) Determin m valoarea z1−α
2astfel încât
Φ(z1−α
2
)= 1− α
2.
(3) Calculez valoarea
z0 =x− µ0
σ√n
.
(4) Dac :(i) |z0| < z1−α
2, atunci (H0) este admis (nu poate respins );
(ii) |z0| ≥ z1−α2, atunci (H0) este respins (adic (H1) este admis );
Testul Z unilateral
În condiµiile din secµiunea anterioar , dorim s veric m ipoteza nul
(H0) : µ = µ0
vs. ipoteza alternativ (H1)s : µ < µ0, (unilateral stânga)
sau ipoteza alternativ (H1)d : µ > µ0, (unilateral dreapta)
cu probabilitatea de risc α.Pentru a realiza testele, avem nevoie de denirea unor regiuni critice corespunz toare. Acestea vor chiarintervalele de încredere pentru condiµiile din ipotezele alternative. Cu alte cuvinte, o regiune critic pentruipoteza nul (ceea ce semnic o regiune în care, dac ne a m, atunci respingem ipoteza nul la pragulde semnicaµie α) este o regiune în care realizarea ipotezei alternative este favorizat . Dac ipoteza nul este vericat vs. ipoteza alternativ (H1)s, atunci regiunea critic va regiunea acelor posibile valori alestatisticii Z pentru care (H1)s se realizeaz cu probabilitatea 1− α ≈ 1, adic :
U = (−∞, z1−α). (11.7)
Într-adev r, se observ cu u³urinµ c :
P (z ∈ U) = P (−∞ < Z < z1−α) = Φ(z1−α) = 1− α.
În mod similar, dac avem ipoteza alternativ (H1)d, atunci alegem regiunea critic :
U = (−z1−α, +∞). (11.8)
La fel ca mai sus, decizia se determin astfel (în ambele cazuri):

STATS 11 [Dr. Iulian Stoleriu] 131
• dac z0 =x− µ0
σ√n
6∈ U , atunci admitem (H0).
• dac z0 =x− µ0
σ√n
∈ U , atunci respingem (H0).
Observaµia 11.2 Testul Z (bilateral sau unilateral) poate aplicat cu succes ³i pentru populaµii non-normale, dac volumul selecµiei observate este n ≥ 30.
Testul Z pentru diferenµa mediilor a dou selecµii
Testul Z pentru diferenµa mediilor se folose³te pentru selecµii independente de volum mare (n ≥ 30) dinorice tip de variabile aleatoare, atunci când dispersiile populaµiilor considerate sunt cunoscute a priori.Fie X1 ³i X2 caracteristicile (independente) a dou populaµii normale, N (µ1, σ1), respectiv, N (µ2, σ2),pentru care nu se cunosc mediile teoretice. Alegem din prima populaµie o selecµie repetat de volum n1,x1 = x1 1, x1 2, . . . , x1n1, ce urmeaz repartiµia lui X1, iar din a dou populaµie alegem o selecµierepetat de volum n2, x2 = x2 1, x2 2, . . . , x2n2, ce urmeaz repartiµia lui X2. Fie (X1i)i=1, n1
³i(X2j)j=1, n2
variabilele aleatoare de selecµie corespunz toare ec rei selecµii. Fix m pragul de semnicaµieα. Dorim s test m ipoteza nul c mediile sunt egale
(H0) : µ1 = µ2
vs. ipoteza alternativ (H1) : µ1 6= µ2.
Pentru a testa aceast ipotez , alegem statistica
Z =(X1 −X2)− (µ1 − µ2)√
σ21
n1+σ2
2
n2
. (11.9)
Dac (H0) este admis (adic admitem c µ1 = µ2), atunci (vezi (10.3)):
Z ∼ N (0, 1). (conform Propoziµiei 6.28). (11.10)
Fie z0 =(u1 − u2)√σ21n1
+σ22n2
. Regiunea critic pentru ipoteza nul , exprimat în valori ale statisticii Z este:
U =z; z 6∈
(−z1−α
2, z1−α
2
).
• Dac valoarea statisticii Z pentru selecµiile date nu se a în U , atunci admitem (H0).
• Dac valoarea statisticii Z pentru selecµiile date se a în U , atunci respingem (H0).
Etapele testul Z pentru diferenµa mediilor

STATS 11 [Dr. Iulian Stoleriu] 132
(1) Se dau datele normale x1 1, x1 2, . . . , x1n1, x2 1, x2 2, . . . , x2n2 ³i µ0, σ1, σ2, α;(2) Determin m valoarea z1−α
2astfel încât, funcµia lui Laplace,
Φ(z1−α
2
)= 1− α
2.
(3) Calculez valoarea
z0 =x1 − x2√σ21n1
+σ22n2
.
(4) Dac :(i) |z0| < z1−α
2, atunci µ1 = µ2;
(ii) |z0| ≥ z1−α2, atunci µ1 6= µ2.
Observaµia 11.3 (1) În cazul în care σ1, σ2 sunt necunoscute, atunci utilizam testul t pentru dou selecµii, prezentat mai jos.(2) Regiunile critice pentru testele unilaterale sunt prezentate în Tabelul 11.2.(3) Testul Z pentru dou selecµii, bilateral sau unilateral, poate aplicat cu succes ³i pentru populaµiinon-normale, dac volumele selecµiilor observate sunt n1 ≥ 30, n2 ≥ 30.(4) Pentru testul Z, P−valoarea se poate calcula dup urm toarele formule:
Pv = P (|Z| > |z0|) = 1−Θ(|z0|) + Θ(−|z0|) (pentru testul Z bilateral); (11.11)
Pv = P (Z < z0) = Θ(z0) (pentru testul Z unilateral stânga); (11.12)
Pv = P (Z > z0) = 1−Θ(z0) (pentru testul Z unilateral dreapta). (11.13)
Testul t pentru medie (o selecµie)
Testul t pentru medie se folose³te pentru selecµii normale de volum mic, de regul n < 30, când dispersiapopulaµiei este necunoscut a priori.Fie caracteristica X ce urmeaz legea normal N (µ, σ) cu µ necunoscut ³i σ > 0 necunoscut. Consider mdatele de selecµie (observaµiile) asupra lui X:
x1, x2, . . . , xn.
Vrem s veric m ipoteza nul (H0) : µ = µ0
vs. ipoteza alternativ (H1) : µ 6= µ0,
cu probabilitatea de risc α. Pentru a efectua acest test, consider m statistica
T =X − µd∗(X)√
n
. (11.14)
Dac ipoteza (H0) se admite (adic µ ia valoarea µ0), atunci T ∼ t(n − 1), (conform Propoziµiei 7.9).C ut m un interval (t1, t2) astfel incât
P (t1 < T < t2) = 1− α. (11.15)
G sim c acest interval este: (−t1−α
2; n−1, t1−α
2; n−1
),
unde tα; n reprezint cuantila de ordin α pentru repartiµia t(n).Regiunea critic este complementara intervalului de încredere. Decizia se ia astfel:

STATS 11 [Dr. Iulian Stoleriu] 133
• dac t0 =x− µ0
d∗(X)√n
∈(−t1−α
2; n−1, t1−α
2; n−1
)(echivalent, t0 6∈ U), atunci admitem (H0).
• dac t0 =x− µ0
d∗(X)√n
6∈(−t1−α
2; n−1, t1−α
2; n−1
)(echivalent, t0 ∈ U), atunci respingem (H0).
Etapele testul t bilateral
(1) Se dau: x1, x2, . . . , xn (date normale), µ0, α;(2) Determin m valoarea t1−α
2; n−1 astfel încât funcµia de repartiµie pentru t(n− 1),
Fn−1
(t1−α
2; n−1
)= 1− α
2.
(3) Calculez valoarea
t0 =x− µ0
d∗(X)√n
, unde, d∗(X) =
√√√√ 1
n− 1
n∑k=1
(xi − x)2.
(4) Dac :(i) |t0| < t1−α
2; n−1, atunci (H0) este admis (nu poate respins );
(ii) |t0| ≥ t1−α2
; n−1, atunci (H0) este respins (adic (H1) este admis );
Testul t unilateral
În condiµiile de mai sus, dorim s veric m ipoteza nul
(H0) : µ = µ0
vs. ipoteza alternativ (H1)s : µ < µ0, (unilateral stânga)
sau ipoteza alternativ (H1)d : µ > µ0, (unilateral dreapta)
cu probabilitatea de risc α.Pentru a realiza testele, avem nevoie de regiuni critice corespunz toare.Regiunea critic pentru ipoteza nul va trebui s e mulµimea valorilor favorabile realiz rii ipotezei alter-native, adic este acel interval ce conµine doar valori ale statisticii T ce vor duce la respingerea ipotezeinule ³i acceptarea ipotezei alternative. A³adar, dac alegem ipoteza alternativ (H1)s, atunci regiuneacritic pentru ipoteza nul va mulµimea valorilor favorabile realiz rii ipotezei alternative (H1)s, adic intervalul:
U = (−∞, t1−α; n−1). (11.16)
Dac alegem ipoteza alternativ (H1)d, atunci regiunea critic pentru ipoteza nul va :
U = (tα; n−1, +∞). (11.17)
La fel ca mai sus, testarea este (în ambele cazuri):

STATS 11 [Dr. Iulian Stoleriu] 134
• dac t0 =x− µ0
d∗(X)√n
6∈ U , atunci admitem (H0).
• dac t0 =x− µ0
d∗(X)√n
∈ U , atunci respingem (H0).
Observaµia 11.4 Testul t (bilateral sau unilateral) poate aplicat cu succes ³i pentru populaµii non-normale, dac volumul selecµiei observate este n ≥ 30.
Alµi parametri(H0) : µ = µ0 Tipul testului
(H1) Regiunea critic
σ µ 6= µ0
(−∞, −z1−α
2
]⋃[z1−α
2, +∞
)Testul Z bilateral
cunoscut µ < µ0 (−∞, z1−α) Testul Z unilateral stângaµ > µ0 (−z1−α, +∞) Testul Z unilateral dreapta
σ µ 6= µ0
(−∞, −t1−α
2; n−1
]⋃[t1−α
2; n−1, +∞
)Testul t bilateral
necunoscut µ < µ0 (−∞, t1−α; n−1) Testul t unilateral stângaµ > µ0 (−t1−α; n−1, +∞) Testul t unilateral dreapta
Tabela 11.1: Teste pentru valoarea medie a unei colectivit µi.
Testul t pentru diferenµa mediilor a dou selecµii
Testul t pentru diferenµa mediilor se folose³te pentru selecµii normale independente de volum mic (n < 30),atunci când dispersiile populaµiilor considerate sunt necunoscute a priori.Fie X1 ³i X2 caracteristicile (independente) a dou populaµii normale, N (µ1, σ1), respectiv, N (µ2, σ2),pentru care nu se cunosc mediile teoretice. Alegem din prima populaµie o selecµie repetat de volum n1,x1 = x1 1, x1 2, . . . , x1n1, ce urmeaz repartiµia lui X1, iar din a dou populaµie alegem o selecµierepetat de volum n2, x2 = x2 1, x2 2, . . . , x2n2, ce urmeaz repartiµia lui X2. Fie (X1i)i=1, n1
³i(X2j)j=1, n2
variabilele aleatoare de selecµie corespunz toare ec rei selecµii. Fix m pragul de semnicaµieα. Dorim s test m ipoteza nul c mediile sunt egale
(H0) : µ1 = µ2
vs. ipoteza alternativ (H1) : µ1 6= µ2.
Cazul I Presupunem c σ1 6= σ2 sunt necunoscute. Pentru a testa aceast ipotez , alegem statistica
T =(X1 −X2)− (µ1 − µ2)√
d2∗1n1
+d2∗2n2
. (11.18)
Aici, d2∗1 ³i d
2∗1 sunt dispersiile de selecµie (modicate). Dac (H0) este admis (adic admitem c µ1 = µ2),
atunci (vezi relaµia (10.3)):T ∼ t(N), (11.19)

STATS 11 [Dr. Iulian Stoleriu] 135
cu N ca în relaµia (10.4). Regiunea critic este complementara intervalului de încredere pentru diferenµamediilor, adic :
U = R \(−t1−α
2; N , t1−α
2; N
).
Cazul II Presupunem c σ1 = σ2 ³i sunt necunoscute. Pentru a testa aceast ipotez , alegem statistica
T =(X1 −X2)− (µ1 − µ2)√(n1 − 1)d2
∗1 + (n2 − 1)d2∗2
√n1 + n2 − 2
1n1
+ 1n2
. (11.20)
Dac (H0) este admis (adic admitem c µ1 = µ2), atunci (vezi relaµia (10.2)):
T ∼ t (n1 + n2 − 2). (11.21)
Regiunea critic este complementara intervalului de încredere pentru diferenµa mediilor, adic :
U = R \(−t1−α
2; n1+n2−2, t1−α
2; n1+n2−2
).
Etapele testul t pentru diferenµa mediilor
(1) Se dau: x1 1, x1 2, . . . , x1n1, x2 1, x2 2, . . . , x2n2 (date normale), µ0, α;(2) Determin m valoarea t1−α
2; m (unde m = N sau m = n1 + n2 − 2, dup caz) astfel încât
funcµia de repartiµie pentru repartiµia Student t(m),
Fm
(t1−α
2; m
)= 1− α
2.
(3) Calculez valoarea
t0 =
x1 − x2√d2∗1n1
+d2∗2n2
, dac σ1 6= σ2
x1 − x2√(n1 − 1)d2
∗1 + (n2 − 1)d2∗2
√n1 + n2 − 2
1n1
+ 1n2
, dac σ1 = σ2
(4) Dac :(i) |t0| < t1−α
2; m, atunci µ1 = µ2;
(ii) |t0| ≥ t1−α2
; m, atunci µ1 6= µ2.
Observaµia 11.5 (1) În practic , nu putem ³ti a priori dac dispersiile teoretice a celor dou populaµiice urmeaz a testate sunt egale sau nu. De aceea, pentru a ³ti ce test s folosim, va trebui s test mmai întâi ipoteza c cele dou dispersii sunt egale, vs. ipoteza ca ele difer . Pentru aceasta, va trebui s utiliz m un test pentru raportul dispersiilor. Dup ce acest prim test a fost realizat, putem decide dac în testarea egalit µii mediilor folosim statistica (11.18) sau statistica (11.20).(2) În cazul în care dispersiile sunt cunoscute, atunci se utilizeaz testul Z pentru diferenµa mediilor,care urmeaz pa³ii testului t pentru diferenµa mediilor, cu diferenµa c statistica ce se consider este dat de relaµia (10.1) care, dup acceptarea ipotezei nule, urmeaz repartiµia N (µ, σ).(3) Testul t pentru dou selecµii, bilateral sau unilateral, poate aplicat cu succes ³i pentru populaµii

STATS 11 [Dr. Iulian Stoleriu] 136
non-normale, dac volumele selecµiilor observate sunt n1 ≥ 30, n2 ≥ 30.(4) Pentru testul Z, P−valoarea se poate calcula dup urm toarele formule:
Pv = P (|T | > |t0|) = 1− Fm(|t0|) + Fm(−|t0|) (pentru testul T bilateral); (11.22)
Pv = P (T < t0) = Fm(t0) (pentru testul T unilateral stânga); (11.23)
Pv = P (T > t0) = 1− Fm(t0) (pentru testul T unilateral dreapta). (11.24)
unde m = N sau m = n1 + n2 − 2, dup caz.
Alµi parametri(H0) : µ1 = µ2 Tipul testului
(H1) Regiunea critic
σ1, σ2 µ1 6= µ2 |X1 −X2| ≥ z1−α2
√σ21n1
+σ22n2
Testul Z bilateral
cunoscute µ1 < µ2 X1 −X2 < z1−α
√σ21n1
+σ22n2
Testul Z unilateral stânga
µ1 > µ2 X1 −X2 > −z1−α
√σ21n1
+σ22n2
Testul Z unilateral dreapta
σ1 6= σ2 µ1 6= µ2 |X1 −X2| ≥ t1−α2
;N
√d2∗(X1)n1
+ d2∗(X2)n2
Testul t bilateral
necunoscute µ1 < µ2 X1 −X2 < t1−α;N
√d2∗(X1)n1
+ d2∗(X2)n2
Testul t unilateral stânga
µ1 > µ2 X1 −X2 > −t1−α;N
√d2∗(X1)n1
+ d2∗(X2)n2
Testul t unilateral dreapta
Tabela 11.2: Teste pentru egalitatea a dou medii.
Testul χ2 pentru dispersie
Fie caracteristica X ce urmeaz legea normal N (µ, σ) cu µ ³i σ > 0 necunoscute. Consider m datele deselecµie (observaµiile) asupra lui X, x1, x2, . . . , xn.Vrem s veric m
(H0) : σ2 = σ20 vs. ipoteza alternativ (H1) : σ2 6= σ2
0,
cu probabilitatea de risc α. Pentru a efectua acest test, consider m statistica
χ2 =n− 1
σ2d2∗(X), (11.25)
care, dup acceptarea ipotezei (H0) (adic σ2 ia valoarea σ20), atunci χ
2 ∼ χ2(n−1), (conform Propoziµiei(7.6). Intervalului de încredere pentru σ2 este(
χ2α2
;n−1, χ21−α
2;n−1
),
unde χ2α;n−1 este cuantila de ordin α pentru repartiµia χ2(n).
Regiunea critic U va complementara acestui intervalul de încredere.
S not m prin χ20 =
n− 1
σ20
d2∗(x) valoarea statisticii χ2 pentru selecµia dat . Atunci, regula de decizie este
urm toarea:
• dac χ20 ∈
(χ2α2
;n−1, χ21−α
2;n−1
), atunci admitem (H0) (i.e., σ2 = σ2
0);

STATS 11 [Dr. Iulian Stoleriu] 137
• dac χ20 6∈
(χ2α2
;n−1, χ21−α
2;n−1
), atunci respingem (H0) (i.e., σ2 6= σ2
0).
Observaµia 11.6 Se pot considera, dup caz, ³i ipotezele alternative unilaterale
(H1)s : σ2 < σ20 ³i (H1)d : σ2 > σ2
0.
Regiunile critice (pe baza c rora se pot face decizii) pentru acestea se g sesc în Tabelul 11.3.
(H0) : σ2 = σ20 Tipul testului
(H1) Regiunea critic
µ σ2 6= σ20
(−∞, χ2
α2
;n−1
]⋃[χ2
1−α2
;n−1, +∞)
Testul χ2 bilateral
necunoscut σ2 < σ20
(−∞, χ2
1−α;n−1
)Testul χ2 unilateral stânga
σ2 > σ20
(χ2α;n−1, +∞
)Testul χ2 unilateral dreapta
Tabela 11.3: Teste pentru dispersie.
Testul F pentru raportului dispersiilor
Fie X1 ³i X2 caracteristicile (independente) a dou populaµii normale, N (µ1, σ1), respectiv, N (µ2, σ2),pentru care nu se cunosc mediile teoretice. Alegem din prima populaµie o selecµie repetat de volum n1,x1 = x1 1, x1 2, . . . , x1n1, ce urmeaz repartiµia lui X1, iar din a doua populaµie alegem o selecµierepetat de volum n2, x2 = x2 1, x2 2, . . . , x2n2, ce urmeaz repartiµia lui X2. Fie (X1i)i=1, n1
³i(X2j)j=1, n2
variabilele aleatoare de selecµie corespunz toare ec rei selecµii. Fix m pragul de semnicaµieα. Dorim s test m ipoteza nul c dispersiile sunt egale
(H0) : σ21 = σ2
2
vs. ipoteza alternativ (H1) : σ2
1 6= σ22.
Pentru a testa aceast ipotez , alegem statistica
F =σ2
2
σ21
d2∗(X1)
d2∗(X2)
. (11.26)
Dac (H0) este admis (adic σ21 = σ2
2), atunci:
F ∼ F(n1 − 1, n2 − 1) (repartiµia Fisher). (11.27)
Intervalul de încredere pentru raportul dispersiilor este(fα
2; n1−1, n2−1, f1−α
2; n1−1, n2−1
)³i se determin astfel încât
P(fα
2; n1−1, n2−1 ≤ F ≤ f1−α
2; n1−1, n2−1
)= 1− α.

STATS 11 [Dr. Iulian Stoleriu] 138
Extremit µile intervalului se determin din relaµiile
Fn1−1;n2−1
(fα
2; n1−1, n2−1
)=α
2³i Fn1−1;n2−1
(f1−α
2; n1−1, n2−1
)= 1− α
2.
(fα; n1−1, n2−1 este cuantila de ordin α pentru repartiµia Fisher F(n1 − 1, n2 − 1)).Regiunea critic U este complementara intervalului de încredere pentru raportul dispersiilor.Not m prin f0 valoarea lui F pentru observaµiile date, x1 ³i x2. Avem:
f0 =d2∗(x1)
d2∗(x2)
.
Regula de decizie este:
• dac f0 ∈(fα
2; n1−1, n2−1, f1−α
2; n1−1, n2−1
), atunci admitem (H0) (i.e., σ1 = σ2);
• dac f0 6∈(fα
2; n1−1, n2−1, f1−α
2; n1−1, n2−1
), atunci respingem (H0) (i.e., σ1 6= σ2).
Observaµia 11.7 Se pot considera, dup caz, ³i ipotezele alternative unilaterale
(H1)s : σ21 < σ2
2, ³i (H1)d : σ21 > σ2
2.
Regiunile critice (pe baza c rora se pot face decizii) pentru acestea se g sesc în Tabelul 11.4.
(H0) : σ21 = σ2
2 Tipul testului(H1) Regiunea critic
µ1, µ2 σ21 6= σ2
2
(−∞, fα
2; n1−1, n2−1
]⋃[f1−α
2; n1−1, n2−1, +∞
)Testul F bilateral
necunoscute σ21 < σ2
2 (−∞, f1−α; n1−1, n2−1) Testul F unilateral stângaσ2
1 > σ22 (−f1−α; n1−1, n2−1, +∞) Testul F unilateral dreapta
Tabela 11.4: Teste pentru raportul dispersiilor.
Teste pentru proporµii într-o populaµie binomial
O singur populaµie
Fie X o caracteristic binomial a unei colectivit µi, cu probabilitatea de succes p. Pe baza unor selecµiiale populaµiei, dorim s test m urm toarea ipotez asupra lui p:
(H0) : p = p0 vs. (H1) : p 6= p0.
De asemenea, putem considera ³i ipoteze alternative unilaterale:
(H1)s : p < p0 sau (H1)d : p > p0.

STATS 11 [Dr. Iulian Stoleriu] 139
Pentru a putea testa acest ipotez , ne vom folosi de rezultatele din cursul precedent. S presupunemc volumul populaµiei (N) este mult mai mare posibil innit) decât volumul n al selecµiilor considerate.Fix m un nivel de semnicaµie α. Vom construi testul pentru proporµia populaµiei pe baza intervaluluide încredere (9.18).
Etapele testului sunt:
• Pe baza selecµiei, calcul m proporµia de selecµie p, care este o estimare a proporµiei populaµiei, p;
• Calcul m valoarea
P0 =p − p0√p0 (1− p0)
n
;
• Calcul m cuantila z1−α2;
• Dac P0 ∈
(−z1−α
2, z1−α
2
),
atunci admitem ipoteza nul la acest nivel de semnicaµie. Altfel, o respingem. Regiunea critic este complementara intervalului de încredere.
Observaµia 11.8 Pentru testul unilateral stânga regiunea critic pentru P0 este (−∞, z1−α), iar pentrutestul unilateral dreapta este (−z1−α, ∞).
Testul proporµiilor pentru dou populaµii
Fie X1 ³i X2 dou caracteristici binomiale independente ale unei populaµii, cu volumele ³i probabilit µilede succes n1, p1 ³i, respectiv, n2, p2. Pe baza unor selecµii, dorim s test m ipotezele:
(H0) : p1 = p2 vs. (H1) : p1 6= p2.
De asemenea, putem considera ³i ipoteze alternative unilaterale:
(H1)s : p1 < p2 sau (H1)d : p1 > p2.
Pentru a putea testa acest ipotez , ne vom folosi de rezultatele din cursul precedent. S presupunem c volumul populaµiei (N) este mult mai mare (posibil innit) decât volumele selecµiilor considerate. Fix mun nivel de semnicaµie α. Dac ipoteza nul este admis , atunci p1 = p2 = p. Un estimator pentru peste frecvenµa relativ a num rului de succese cumulate în cele dou selecµii, i.e.,
p∗ =n1widehatp1 + n2p2
n1 + n2.
Etapele testului sunt:
• Calcul m proporµiile de selecµie p1 ³i p2, care sunt estim ri pentru p1, respectiv, p2;
• Calcul m valoarea
P0 =p1 − p2√
p∗(1− p∗)(
1n1
+ 1n2
) ;

STATS 11 [Dr. Iulian Stoleriu] 140
• Calcul m cuantila z1−α2;
• Dac P0 ∈
(−z1−α
2, z1−α
2
),
atunci admitem ipoteza nul la acest nivel de semnicaµie. Altfel, o respingem. Regiunea critic este complementara intervalului de încredere.

Laborator 11 [Dr. Iulian Stoleriu] 141
Statistic Aplicat (Laborator 11)
Teste parametrice rezolvate în Matlab
Testul Z în Matlab
Testul Z pentru o selecµie poate simulat în Matlab utilizând comanda
[h, p, ci, zval] = ztest(X,m0,sigma,alpha,tail)
unde:
• h este rezultatul testului. Dac h = 1, atunci ipoteza nul se respinge, dac h = 0, atunci ipotezanul nu poate respins pe baza observaµiilor facute (adic , se admite, pân la un test mai puternic);
• p este valoarea P (P− value);
• ci este un interval de încredere pentru µ, la nivelul de semnicaµie α;
• zval este valoarea statisticii Z pentru observaµia considerat ;
• X este un vector sau o matrice, conµinând observaµiile culese. Dac X este matrice, atunci maimulte teste Z sunt efectuate, de-alungul ec rei coloane a lui X;
• m0 = µ0, valoarea testat ;
• sigma este deviaµia standard teoretic a lui X, a priori cunoscut ;
• alpha este nivelul de semnicaµie;
• tail poate unul dintre urm toarele ³iruri de caractere:
'both', pentru un test bilateral (poate s nu e specicat , se subînµelege implicit);
'left', pentru un test unilateral stânga (µ < µ0);
'right', pentru un test unilateral dreapta (µ > µ0);
Exemplu 11.9 Spre exemplicare, s presupunem c datele discrete din Tabelul 1.1 sunt obµinute înurma unui sondaj care contabilizeaz notele la Matematic obµinute de elevii unei anumite ³coli. Dorims test m, la nivelul de semnicaµie α = 0.05, dac media tuturor notelor la Matematic a elevilor ³coliieste µ = 6.8 sau mai mare. Se ³tie c deviaµia standard este σ = 2.5.
Soluµie: A³adar, avem de testat
(H0) µ = 6.8 vs. (H1) µ > 6.8.
Vectorul X de mai jos cuprinde toate notele obµinute în urma sondajului.

Laborator 11 [Dr. Iulian Stoleriu] 142
X = [2*ones(2,1); 3*ones(4,1); 4*ones(8,1); 5*ones(15,1); 6*ones(18,1); ...
7*ones(17,1); 8*ones(15,1); 9*ones(7,1); 10*ones(4,1)];
[h, p, ci, zval] = ztest(X, 6.8, 2.5, 0.05, 'right')
Acest cod a³eaz
h = p = ci = stats =
0 0.9500 5.9332 -1.6444
Inf
Aceasta înseamn faptul c ipoteza nul este admis la acest nivel de semnicaµie. √
Observaµia 11.10 (1) Dac ipoteza alternativ este bilateral ((H1) : µ 6= 6.8), atunci comanda ar :
[h, p, ci, zval] = ztest(X, 6.8, 2.5)
În acest caz, g sim c ipoteza nul este respins (i.e., rezultatul este h = 1).
(2) Decizia testului putea luat ³i pe baza P−valorii. Aceasta este:
Pv = P (Z > z0) = 1− P (Z ≤ z0) = 1−Θ(z0) = 0.95 > 0.05 = α.
În Matlab, aceast valoare poate calculat astfel:
m0 = 6.8; sigma = 2.5; n = 90; z0 = (mean(X) - m0)/(sigma/sqrt(n));
Pv = 1 - normcdf(z0, 0, 1)
(3) Pentru efectuarea testului, nu este neap rat necesar s a³ m toate cele patru variabile din membrulstâng. Putem a³a, dup preferinµ , doar trei, dou , sau numai o variabil , dar doar în ordinea precizat .De exemplu, comanda
h = ztest(X, m0, sigma, alpha, tail)
ne va furniza doar rezultatul testului (h = 0 sau h = 1), f r a a³a alte variabile.(4) Nu exist o funcµie în Matlab care s simuleze testul Z pentru dou selecµii.
Testul t în Matlab
Testul t pentru o selecµie
Testul t poate simulat în Matlab utilizând comanda general

Laborator 11 [Dr. Iulian Stoleriu] 143
[h, p, ci, stats] = ttest(X,m0,alpha,tail)
unde:
• h, p, ci, m0, alpha, tail sunt la fel ca în funcµia ztest;
• variabila stats înmagazineaz urm toarele date:
tstat - este valoarea statisticii T pentru observaµia considerat ;
df - num rul gradelor de libertate ale testului;
sd - deviaµia standard de selecµie;
Exemplu 11.11 Dorim s test m dac o anumit moned este corect , adic ³ansele ec rei feµe de aapare la orice aruncare sunt 50%− 50%. Arunc m moneda în caza de 100 de ori ³i obµinem faµa cu stemade exact 59 de ori. Pe baza acestei experienµe, c ut m s test m ipoteza nul
(H0) : moneda este corect
vs. ipoteza alternativ (H1) : monedal este m sluit ,
la un prag de semnicaµie α = 0.05.
Soluµie: Fie X variabila aleatoare ce reprezint faµa ce apare la o singur aruncare a monedei. S spunem c X = 1, dac apare faµa cu stema ³i X = 0, dac apare faµa cu banul. Teoretic, X ∼ B(1, 0.5),de unde E(X) = 0.5, D2(X) = 0.25.Prin ipotez , ni se d o selecµie de volum n = 100 ³i scriem observaµiile f cute într-un vector x ce conµine59 de 1 ³i 41 de valori 0. Deoarece n = 100 > 30, putem utiliza testul t pentru o selecµie. Rescriemipotezele (H0) ³i (H1) astfel:
(H0) : µ = 0.5
(H1) : µ 6= 0.5.
Dac X1, X2, . . . , Xn sunt variabilele aleatoare de selecµie, atunci alegem statistica
T =X − µd∗(X)√
n
.
Dac ipoteza (H0) se admite, atunci µ este xat, µ = 0.5 ³i statistica T ∼ t(n − 1). Valoarea acesteistatistici pentru selecµia dat este:
t0 =x− µd∗(X)√
n
= 1.8207.
Din t1−α2
; n−1 = t0.975; 99 = 1.9842, rezult c |t0| < t1−α2
; n−1, ³i decidem c ipoteza (H0) este admis (nupoate respins la nivelul de semnicaµie α).P−valoarea este
Pv = 1− Fn−1(t0) + Fn−1(−t0) = 1− F99(1.8207) + F99(−1.8207) = 0.0717.
Codul Matlab pentru calculul analitic de mai sus este urm torul:

Laborator 11 [Dr. Iulian Stoleriu] 144
n=100; mu = 0.5; alpha = 0.05; x = [ones(59,1); zeros(41,1)];
t0 = (mean(x) - mu)/(std(x)/sqrt(n));
tc = tinv(1-alpha/2, n-1); % cuantila
if (abs(t0) < tc)
disp('moneda este corecta')
else disp('moneda este masluita')
end
Pv= 1 - tcdf(t0,n-1) + tcdf(-t0,n-1) % P-valoarea
Rulând codul, obµinem rezultatul:
moneda este corecta
În loc s folosim codul de mai sus, am putea folosi funcµia ttest din Matlab, dup cum urmeaz :
[h, p, ci, stats] = ttest(X,0.5,0.05,'both')
³i obµinem
h = p = ci = stats =
0 0.0717 0.4919 tstat: 1.8207
0.6881 df: 99
sd: 0.4943 √
Observaµia 11.12 (1) Deoarece P−valoarea este p = 0.0717, deducem c la un prag de semnicaµieα ≥ 0.08, ipoteza nul ar fost respins .(2) Dac dintre cele 100 de observ ri aveam o apariµie în plus a stemei, atunci ipoteza nul ar respins ,adic moneda ar fost catalogat a m sluit .
Testul t pentru dou selecµii
Testul t pentru egalitatea a dou medii poate simulat în Matlab utilizând comanda
[h, p, ci, stats] = ttest2(X, Y, alpha, tail, vartype)
unde:
• h, p, ci, alpha, stats ³i tail sunt la fel ca mai sus;
• X ³i Y sunt vectori sau o matrice, conµinând observaµiile culese. Dac ele sunt matrice, atunci maimulte teste Z sunt efectuate, de-alungul ec rei coloane;
• vartype ia valoarea equal dac dispersiile teoretice sunt egale sau unequal pentru dispersii inegale.

Laborator 11 [Dr. Iulian Stoleriu] 145
Exemplu 11.13 Caracteristicile X1 ³i X2 reprezint notele obµinute de studenµii de la Master MF ′08,respectiv,MF ′09 la examenul de Statistic Aplicat . Conducerea universit µii recomand ca aceste note s urmeze repartiµia normal ³i examinatorul se conformeaz dorinµei de sus. Presupunem c X1 ∼ N (µ1, σ1)³i X2 ∼ N (µ2, σ2), cu σ1 6= σ2, necunoscute a priori. Pentru a verica modul cum s-au prezentat studenµiila acest examen în doi ani consecutivi, select m aleator notele a 25 de studenµi din prima grup ³i 30 denote din a doua grup . distribuctii de frecvenµe ale notelor sunt cele din Tabelul 11.5.(i) Vericaµi dac ambele seturi de date provin dintr-o repartiµie normal ;(ii) G siµi un interval de încredere pentru diferenµa mediilor, la nivelul de semnicaµie α = 0.05;(ii) S se testeze (cu α = 0.01) ipoteza nul
(H0) : µ1 = µ2, (în medie, studenµii sunt la fel de buni)
versus ipoteza alternativ
(H1) : µ1 < µ2, (în medie, studenµii au note din ce în ce mai mari)
Nota obµinut Frecvenµa absolut
Grupa MF ′08 Grupa MF ′09
5 3 5
6 4 6
7 9 8
8 7 6
9 2 3
10 0 2
Tabela 11.5: Tabel cu note.
Soluµie: (i) h = chi2gof(u) % h = 0, deci u ∼ Nk = chi2gof(v) % k = 0, deci v ∼ N
(ii) Un interval de încredere la acest nivel de semnicaµie se obµine apelând funcµia Matlab
[h, p, ci, stats] = ttest2(u, v, 0.05, 'both', 'unequal')
Acesta este:(-0.7294, 0.6760)
Altfel, se calculeaz intervalul de încredere (vezi Tabelul 9.1)x1 − x2 − t1−α2
; N
√d2∗1n1
+d2∗2n2, x1 − x2 + t1−α
2; N
√d2∗1n1
+d2∗2n2
Codul Matlab:

Laborator 11 [Dr. Iulian Stoleriu] 146
n1=25; n2=30; alpha = 0.05;
u = [5*ones(3,1);6*ones(4,1);7*ones(9,1);8*ones(7,1);9*ones(2,1)];
v = [5*ones(5,1);6*ones(6,1);7*ones(8,1);8*ones(6,1);9*ones(3,1);10*ones(2,1)];
d1 = var(u); d2 = var(v); N = (d1/n1+d2/n2)^2/((d1/n1)^2/(n1-1)+(d2/n2)^2/(n2-1))-2;
t = tinv(1-alpha/2,N);
m1 = mean(u)-mean(v)-t*sqrt(d1/n1+d2/n2); m2 = mean(u)-mean(v)+t*sqrt(d1/n1+d2/n2);
fprintf('(m1,m2)=(%6.3f,%6.3f)\n',m1,m2);
(iii) Comanda Matlab este:
[h,p,ci,stats] = ttest2(u, v, 0.01, 'left', 'unequal')
În urma rul rii comenzii, obµinem:
h = p = ci = stats =
0 0.4698 -Inf tstat: -0.0761
0.8137 df: 52.7774
sd: 2x1 double √
Observaµia 11.14 Valoarea P poate calculat ³i cu formula:
Pv = P (T < t0) = FN−1(t0) = 0.4698.
În Matlab,
t0 = (mean(u)-mean(v))/sqrt(d1/n1+d2/n2); Pv = tcdf(t0, N-1)
Testul χ2 pentru dispersie în Matlab
Exemplu 11.15 Se cerceteaz caracteristica X, ce reprezint diametrul pieselor (în mm) produse de unstrung. tim c X urmeaz legea normal N (µ, σ). Alegem o selecµie de volum n = 11 ³i obµinemdistribuµia empiric : (
10.50 10.55 10.60 10.652 3 5 1
).
S se testeze (cu α = 0.1) ipoteza nul
(H0) : σ2 = 0.003,
versus ipoteza alternativ (H1) : σ2 6= 0.003.
Soluµie: Intervalul de încredere pentru σ este (3.9403, 18.3070) iar valoarea critic este χ20 = 7.2727.
Deoarece aceasta aparµine intervalului de încredere, concluzion m c ipoteza nul nu poate respins la

Laborator 11 [Dr. Iulian Stoleriu] 147
acest nivel de semnicaµie.Aceea³i concluzie poate luat în urma inspecµiei valorii P , care este mai mare decât nivelul α. Avem:
Pv = P (|χ2| > |χ20|) = P (χ2 > χ2
0) = 1− Fn−1(7.2727) = 0.6995. √
Testul χ2 poate simulat în Matlab utilizând comanda
[h, p, ci, stats] = vartest(X,var,alpha,tail)
unde:
• h, p, ci, m0, alpha, stats, tail sunt la fel ca în funcµia ttest;
• var este valoarea testat a dispersiei;
Spre exemplicare, codul Matlab pentru exerciµiul anterior este:
X = [10.50*ones(2,1); 10.55*ones(3,1); 10.60*ones(5,1); 10.65];
[h, p, ci, stats] = vartest(X,0.003,0.1,'both')
Rularea acestuia ne d :
h = p = ci = stats =
0 0.6011 0.0012 chisqstat: 7.2727
0.0055 df: 10
adic ipoteza nul este acceptat la acest nivel de semnicaµie.Folosind Matlab, putem calcula P−valoarea astfel:
c0 = (n-1)/0.003*var(X); Pv = 1 - chi2cdf(c0,10)
Testul F în Matlab
Testul raportului dispersiilor poate simulat în Matlab utilizând comanda
[h, p, ci, stats] = vartest2(X, Y, alpha, tail)
unde variabilele sunt la fel ca în funcµia ttest2.
Exemplu 11.16 Revenim la Exerciµiul 11.13 ³i veric m dac cele dou selecµii de note (Tabelul 11.5)

Laborator 11 [Dr. Iulian Stoleriu] 148
provin din populaµii cu dispersii egale. A³adar, avem de testat (la nivelul de semnicaµie α = 0.01)
(H0) σ21 = σ2
2 vs. (H1) σ21 6= σ2
2.
Soluµie: Utilizând notaµiile din Exerciµiul 11.13, comanda Matlab care rezolv acest test este:
[h, p, CI, stats] = vartest2(u, v , 0.01 , 'both')
(pentru teste unilaterale, folosim 'left' sau 'right' în locul lui 'both'.)Rezultatul comenzii anterioare este:
h = p = CI = stats =
0 0.2119 0.2191 fstat: 0.6047
1.7426 df1: 24
df2: 29
Deoarece h = 0, decidem c dispersiile teoretice ale celor dou populaµii pot considerate a egale lanivelul de semnicaµie α = 0.01. √
Observaµia 11.17 Decizia testului poate luat ³i pe baza inspecµiei valorii P , observând c aceastaeste mai mare decât α. Aceasta este:
Pv = 1− Fn1−1, n2−1(|f0|) + Fn1−1, n2−1(−|f0|) = 1− Fn1−1, n2−1(|f0|).
În Matlab, calcul m astfel:
f0 = var(u)/var(v); Pv = 1 - fcdf(abs(f0),n1-1,n2-1)
Teste parametrice pentru proporµii
Exemplu 11.18 Într-un sondaj naµional de opinie, 5000 de persoane au fost rugate s r spund la oîntrebare legat de apartenenµa religioas . La întrebarea "Sunteµi cre³tini?", r spunsul a fost armativ în4893 dintre cazuri. Rezultatul acestui sondaj este utilizat în estimarea procentului de cre³tini din µar .S not m cu p acest procent. La nivelul de semnicaµie α = 0.05, testaµi dac p este de 95% sau mai mare.
Soluµie: Avem de testat ipoteza
(H0) : p = 0.95 vs. (H1) : p > 0.95.
Procentul de selecµie este p = 48935000 = 0.9786, cuantila este z1−α = 1.6449 ³i valoarea statisticii este
P0 =0.9786 − 0.95√0.95 (1− 0.95)
5000
= 9.2791 ∈ [−1.6449, ∞),

Laborator 11 [Dr. Iulian Stoleriu] 149
a³adar ipoteza nul este respins la acest nivel de semnicaµie. Admitem c p > 0.95.Aceea³i concluzie poate dedus ³i prin inspecµia P−valorii. Aceasta este
Pv = P (Z > P0) = 1− P (Z ≤ P0) = 1−Θ(9.2791) ≈ 0 < α = 0.05.
A³adar, ipoteza nul va respins la toate nivele de semnicaµie practice. √
Exemplu 11.19 Revenim la Exemplul 10.10. S se testeze, la nivelul de semnicaµie α = 0.02 dac exist diferenµe semnicative între proporµiile de baieµi ³i fete din respectiva ³coal c rora le place Mate-matica.
Soluµie: Avem: p1 = 2345 , p2 = 37
65 , p∗ = 23+37
45+65 = 611 ³i z0.99 ≈ 2.33. Valoarea statisticii este:
P0 =2345 −
3765√
p∗(1− p∗)(
1n1
+ 1n2
) = −0.6019 ∈ [−2.3263, 2.3263],
deci ipoteza nul nu poate respins la acest nivel de semnicaµie.Aceea³i concluzie o putem lua dac veric m P−valoarea. Aceasta este:
Pv = P (|Z| > |P0|) = 1− P (Z < |P0|) + P (Z < −|P0|) = 0.5472 > 0.02 = α.
√

Laborator 11 [Dr. Iulian Stoleriu] 150

STATS 12 [Dr. Iulian Stoleriu] 151
12 Statistic Aplicat (C12)
Teste de concordanµ
Testele de concordanµ (en., goodness-of-t tests) realizeaz concordanµa între repartiµia empiric (repar-tiµia datelor observate) ³i repartiµia teoretic . Dou dintre cele mai des utilizate teste de concordanµ sunt testul χ2 de concordanµ ³i testul Kolmogorov-Smirnov.
Testul χ2 de concordanµ
Acest test de concordanµ poate utilizat ca un criteriu de vericare a ipotezei potrivit c reia un an-samblu de observaµii urmeaz o repartiµie dat . Se aplic la vericarea normalit µii, a exponenµialit µii,a caracterului Poisson, a caracterului Weibull etc. Testul mai este numit ³i testul χ2 al lui Pearson sautestul χ2 al celei mai bune potriviri (en., goodness of t test). Acest test poate aplicat pentru orice tipde date pentru care funcµia de repartiµie empiric poate calculat .
Cazul neparametric
S consider m o caracteristic X a unei populaµii statistice Ω. Repartiµia variabilei aleatoare X estenecunoscut a priori, îns intuim (sau avem anumite informaµii) cum c aceasta ar dat de legeade probabilitate complet specicat f(x, θ) (e.g., f(x) = e−2 2x
x! , x ∈ N (X ∼ P(2) ) sau f(x) =
13√
2πe
(x−5)2
18 (X ∼ N (5, 3) )).Deoarece legea de probabilitate ipotetic este complet specicat , θ este cunoscut ³i vom omite s maipunem în evidenµ dependenµa lui f de acesta în decursul aceste secµiuni.Pentru a verica ipoteza f cut asupra repartiµiei lui X, consider m un set de observaµii asupra lui X ³itest m concordanµa dintre repartiµia empiric a datelor observate cu legea teoretic dat de f(x). Fiex1, x2, . . . , xn setul de date observate. S not m cu F (x) funcµia de repartiµie teoretic , i.e., F ′ = f . Încele ce urmeaz , urm rim s aplic m testul χ2 de concordanµ , ale c rui etape sunt:
• Descompunem în clase mulµimea observaµiilor f cute asupra lui X, astfel încât ecare element almulµimii aparµine unei singure clase. Scriem a³adar,
x1, x2, . . . , xn =
k⋃i=1
Oi, Oi⋂Oj = ∅, ∀i 6= j.
Determin m frecvenµele empirice absolute, i.e., numerele ni de observaµii ce aparµin ec rei clase
Oi. În mod evident, va trebui s avem c k∑i=1
ni = n.
În general, se dore³te ca n ≥ 30 ³i ni ≥ 5, pentru ca testul s e concludent. În cazul în carenum rul de apariµii într-o anumit clas nu dep ³e³te valoarea 5, atunci se vor cumula dou saumai multe clase, astfel încât în noua clas s e respectat condiµia. De³i, dac avem cel puµin 5clase, atunci sunt suciente cel puµin 3 valori în ecare clas . În ambele cazuri, trebuie µinut contde modicarea num rului de clase, iar num rul k trebuie modicat corespunz tor (îl înlocuim cunoul num r, notat aici tot cu k).

STATS 12 [Dr. Iulian Stoleriu] 152
• Pentru ecare i ∈ 1, 2, . . . , k, determin m probabilitatea teoretic pi ca un element al populaµieis se ae în clasa Oi. Aceast probabilitate este obµinut cu ajutorul funcµiei f(x). Astfel, frecven-µele teoretice absolute sunt n pi, i ∈ 1, 2, . . . , k. Altfel spus, n pi este num rul estimat de valoriale repartiµiei cercetate ce ar c dea în clasa Oi.
• Formul m ipoteza nul ,
(H0) : Funcµia de repartiµie a lui X este F (x).
Aceasta este echivalent cu
(H0) : probabilitatea unei observaµii de a aparµine clasei Oi este pi. (i = 1, 2, . . . , k).
• Ipoteza alternativ este negaµia ipotezei nule.
• Deviaµia între cele dou situaµii (empiric ³i teoretic ) este m surat de statistica
χ2 =
k∑i=1
(ni − n pi)2
n pi. (12.1)
(Fiecare dintre termenii(ni − n pi)2
n pipoate privit ca ind o eroare relativ de aproximare a valorilor
a³teptate ale repartiµiei cu valorile observate.)Statistica χ2 urmeaz repartiµia χ2(k − 1). Uneori, statistica χ =
√χ2 se nume³te discrepanµ .
• Alegem nivelul de semnicaµie α, de regul , foarte apropiat de zero.
• Alegem regiunea critic , ca ind regiunea pentru care valoarea χ20 a acestei statistici pentru obser-
vaµiile date satisfaceχ2
0 > χ21−α; k−1,
unde χ21−α; k−1 este cuantila de ordin 1− α pentru repartiµia χ2(k − 1).
• Dac ne a m în regiunea critic , atunci ipoteza nul (H0) se respinge la nivelul de semnicaµie α.Altfel, nu sunt dovezi statistice suciente s se resping .
Cazul parametric
Când probabilit µile teoretice pi nu sunt a priori cunoscute, atunci ele vor trebui estimate. Acest caz apareatunci când legea de probabilitate f(x, θ) nu este complet specicat , ci doar specicat (³tim forma luif , dar nu ³tim unul sau, eventual, mai mulµi parametri ai s i). Folosind datele observate, va trebui s estim m parametrii necunoscuµi ai repartiµiei ipotetice. Fiecare estimare ne va costa un grad de libertate.Cu alte cuvinte, dac avem de estimat un singur parametru, atunci pierdem un grad de libertate, pentrudoi parametri, pierdem dou grade etc.S presupunem c legea de probabilitate a lui X de mai sus este f(x, θ), unde θ = (θ1, θ2, . . . ,θp) ∈ Θ ⊂ Rp sunt parametri necunoscuµi. Pentru a aproxima ace³ti parametri, folosim observaµiileculese asupra lui X. O metod la îndemân pentru estim ri parametrice este metoda verosimilit µii ma-xime.Dup ce am estimat parametrii repartiµiei teoretice ipotetice, determin m probabilit µile estimate. Sta-bilim apoi ipoteza nul :
(H0) : pi = pi, (i = 1, 2, . . . , k),

STATS 12 [Dr. Iulian Stoleriu] 153
unde pi este probabilitatea unei observaµii de a aparµine clasei i ³i pi sunt valorile estimate.Din acest moment, etapele testului χ2− cazul parametric sunt asem n toare cu cele din cazul neparame-tric, cu deosebirea c statistica χ2 dat prin (12.1) urmeaz repartiµia χ2 cu (k−p−1) grade de libertate.Aceasta este urmare a faptului c se pierd p grade de libertate din cauza folosirii observaµiilor date pentruestimarea celor p parametri necunoscuµi.
Etapele aplic rii testului χ2 de concordanµ (neparametric sau parametric)
• Se dau: α, x1, x2, . . . , xn. Intuim F (x; θ1, θ2, . . . , θp);
• Formul m ipotezele statistice:
(H0) funcµia de repartiµie teoretic a variabilei aleatoare X este F (x)(H1) ipoteza nul nu este adev rat .
• Dac θ1, θ2, . . . , θk (k ≤ p) nu sunt parametri cunoscuµi, atunci determin m estim rile de vero-similitate maxim θ1, θ2, . . . , θk pentru ace³tia (doar în cazul parametric; altfel s rim peste acestpas);
• Scriem distribuµia empiric de selecµie (tabloul de frecvenµe),(clasa Oini
)i=1, n
,n∑i=1
ni = n, ni ≥ 5;
• Se calculeaz probabilitatea pi, ca un element luat la întâmplare s se ae în clasa Oi. Dac Oi =[ai−1, ai), atunci pi = F (ai; θ) − F (ai−1; θ), în cazul parametric ³i pi = F (ai; θ) − F (ai−1; θ),în cazul neparametric.
• Se calculeaz χ20 =
k∑i=1
(ni − n pi)2
n pi;
• Determin m valoarea χ∗, care este
χ∗ =
χ2
1−α; k−1 , în cazul neparametric,
χ21−α; k−p−1 , în cazul parametric,
unde χ2α; n este cuantila de ordin α pentru repartiµia χ2(n);
• Dac χ20 < χ∗, atunci accept m (H0), altfel o respingem.
Test de independenµ folosind tabele de contingenµ
În aceast secµiune, vom prezenta un test de independenµ între dou criterii dup care se face împ rµireadatelor observate. S presupunem c avem un set de observaµii ce sunt împ rµite în categorii determinatede dou criterii diferite. De exemplu, conducerea unui liceu este indecis în ce prive³te alegerea unui cursde limbi str ine potrivit pentru introducerea în programa ³colar . Pentru aceasta, s-a realizat un sondajde opinie la care au participat 350 de elevii, în care ace³tia au avut de precizat cursul de limbi str inepreferat ³i nivelul de studiu ce consider c li s-ar potrivi. Identic m aici dou caracteristici (atribute):X este limba str in (e.g., Englez , Francez , German , Italian , Spaniol ³i Rus ) ³i Y reprezint nivelul

STATS 12 [Dr. Iulian Stoleriu] 154
Nivel@@Limba Englez Francez German Italian Spaniol Rus Total
încep tor 33 19 11 12 11 6 92
mediu 65 37 10 14 24 7 157
avansat 43 15 7 17 12 7 101
Total 141 71 28 43 47 20 350
Tabela 12.1: Tabel cu repartizarea elevilor la cursurile de limbi str ine.
de studiu (e.g., încep tor, mediu ³i avansat). Num rul de elevi ce intr în ecare categorie este a³at înTabelul 12.1.
În general, dac datele observate sunt clasicate în categorii ce depind de dou atribute diferite, atunciputem forma un tabel de genul Tabelului 12.2, numit tabel de contingenµ . Aici X ³i Y sunt atributele ³iXi, i = 1, r, Yj , j = 1, s sunt diverse categorii în care ecare atribut în parte poate împ rµit.
X @@Y Y1 Y2 . . . Yj . . . Ys Suma pe linie
X1 n11 n12 . . . n1j . . . n1s n1∗X2 n21 n22 . . . n2j . . . n2s n2∗...
...... · ... · ... · ... · ...
...
Xi ni1 ni2 . . . nij . . . nis ni∗...
...... · ... · ... · ... · ...
...
Xr nr1 nr2 . . . nrj . . . nrs nr∗
Suma pe coloan n∗1 n∗2 . . . n∗j . . . n∗s n (suma total )
Tabela 12.2: Tabel de contingenµ .
În Tabelul 12.2 am folosit urm toarele notaµii: nij pentru num rul (frecvenµa absolut ) de observaµii ceau valoarea Xi pentru atributul X ³i valoarea Yj pentru atributul Y (i = 1, r, j = 1, s), iar n∗j , ni∗ ³i nsunt
n∗j =r∑i=1
nij , ni∗ =s∑j=1
nij , n =r∑i=1
s∑j=1
nij .
Fiecare individ din selecµia aleas aparµine unei singure categorii caracterizate de atributul X ³i unei sin-gure categorii caracterizat de atributul Y . În concluzie, ecare individ poate aparµine doar uneia dintrecele r × s celule.
Dorim acum s test m dac atributele X ³i Y sunt independente (în exemplul de mai sus, aceasta arînsemna determinarea faptului dac alegerea cursului de limba str in este independent de nivelul destudiu).S not m prin pij probabilitatea ca o dat observat s cad în categoriile Xi, Yj , ³i prin pi∗ ³i p∗j

STATS 12 [Dr. Iulian Stoleriu] 155
probabilit µile marginale,
pi∗ =s∑j=1
pij , p∗j =r∑i=1
pij .
Avem c r∑i=1
s∑j=1
pij =r∑i=1
pi∗ =s∑j=1
p∗j = 1.
În general, valorile reale pentru pij , pi∗ ³i p∗j nu sunt cunoscute (specicate) a priori ³i se vor estimafolosind datele din tabelul de contingenµ . Vom nota prin pij , pi∗ ³i, respectiv, p∗j estimaµiile lor. Valorileprobabilit µilor marginale le estim m prin:
pi∗ =ni∗n
(i = 1, r) ³i p∗j =n∗jn
(j = 1, s). (12.2)
Ipoteza nul este:
(H0) : pij = pi∗p∗j , i = 1, r, j = 1, s (i.e., nu exist nicio asociere între atributele X ³i Y ).
(H1) : (H0) nu este adev rat .
Astfel, pentru i ³i j xaµi, valoarea a³teptat în celula (i, j) este
Eij = n pij =ni∗n∗jn
, i = 1, r, j = 1, s. (12.3)
Calcul m num rul
H2 =∑i, j
(nij −
ni∗n∗jn
)2
ni∗n∗jn
=∑i, j
(Oij − Eij)2
Eij
, (12.4)
unde, în parantez , Oij = nij este num rul de valori observate în celula (i, j) iar Eij num rul de valoria³teptate (en., expected) în celula (i, j).Dac în ecare celul num rul de valori ce îi apaµin este de cel puµin 5, atunci statistica H2 urmeaz repartiµia χ2 cu (r − 1)(s− 1) grade de libertate.
Etapele testului de independenµ sunt urm toarele:
• Se dau nij , i = 1, r, j = 1, s ³i pragul de semnicaµie α;
• Pe baza observaµiilor nij , calcul m estimaµiile (12.2);
• Calcul m H2 cu formula (12.4);
• Dac Eij ≥ 5, ∀i, j ³i H2 ≤ χ2α; (r−1)(s−1), atunci se admite (H0) la pragul de semnicaµie α.
Altfel, respingem (H0) la acest prag de semnicaµie.
Exemplu 12.1 Revenim la datele din Tabelul 12.1. Pentru a stabili dac , la un nivel de semnicaµieα = 0.05, alegerea cursului de limba str in este independent de nivelul de studiu, calcul m mai întâiestimaµiile Eij . Acestea sunt scrise în paranteze în Tabelul 12.3.

STATS 12 [Dr. Iulian Stoleriu] 156
Calcul m H2:
H2 =
3∑i=1
6∑j=1
(nij − Eij)2
Eij=
(33− 37.06)2
37.06+ · · ·+ (7− 5.77)2
5.77
= 10.1228 > 3.9403 = χ20.05, 10
deci respingem ipoteza nul conform c reia tipul cursului ³i nivelul s u sunt atribute independente.Pentru calculul acestor valori în Matlab, putem proceda astfel:
n = [33 19 11 12 11 6; 65 37 10 14 24 7; 43 15 7 17 12 7];E = [37.06 18.66 7.36 11.30 12.35 5.26; 63.25 31.85 12.56...
19.29 21.08 8.97; 40.69 20.49 8.08 12.41 13.56 5.77];
H2 = sum(sum((n-E).^2./E)); crit = chi2inv(0.05,2*5);
Nivel@@Limba Englez Francez German Italian Spaniol Rus Total
încep tor33
(37.06)19
(18.66)11
(7.36)12
(11.30)11
(12.35)6
(5.26)92
mediu65
(63.25)37
(31.85)10
(12.56)14
(19.29)24
(21.08)7
(8.97)157
avansat43
(40.69)15
(20.49)7
(8.08)17
(12.41)12
(13.56)7
(5.77)101
Total 141 71 28 43 47 20 350
Tabela 12.3: Tabel cu repartizarea ³i estimaµia elevilor la cursurile de limbi str ine.
Cazul tabelelor de contingenµ 2× 2. Testul exact al lui Fisher
În cazul particular în care r = s = 2, tabelul de contingenµ este de forma:
X @@Y Y1 Y2 Suma pe linie
X1 a b a+ b
X2 c d c+ d
Suma pe coloan a+ c b+ d a+ b+ c+ d
Tabela 12.4: Tabel de contingenµ 2× 2.
unde a, b, c, d sunt valorile observate pentru ecare celul în parte. Valorile a³teptate Eij (vezi formula(12.3)) sunt:
E11 =(a+ b)(a+ c)
n, E12 =
(a+ b)(b+ d)
n, E21 =
(c+ d)(a+ c)
n, E22 =
(c+ d)(b+ d)
n,

STATS 12 [Dr. Iulian Stoleriu] 157
unde n = a+ b+ c+ d. Statistica H2 dat de relaµia (12.4) devine:
H2 =
(ad− bcn
)2( 1
E11+
1
E12+
1
E21+
1
E22
),
³i urmeaz repartiµia χ2(1). Din faptul c H2 ∼ χ2(1), rezult c statistica H =√H2 ∼ N (0, 1), ³i se
poate utiliza H pentru testul statistic de independenµ .De³i acest test poate realizat, în cazul tabelelor de contingenµ 2 × 2 se utilizeaz testul exact al luiFisher. Acest test poate utilizat chiar ³i în cazul în care valorile observaµiilor sunt mai mici decât 5. S alegem un prag de semnicaµie α.Test m ipoteza nul
(H0) : nu exist nicio asociere între atributele X ³i Y.
versus ipoteza alternativ
(H1) : (H0) nu este adev rat . (test bilateral)
Rezultatele obµinute le putem scrie sub forma unei matrice, pe care o vom numi matricea conguraµiei.Aceasta este:
M =
(a bc d
).
S presupunem acum c , pentru o matrice 2 × 2, sumele valorilor pe linii ³i pe coloane sunt xate apriori. Atunci, putem alege elementele matricei ce satisface aceste condiµii în mai multe moduri (estegreu de precizat în câte moduri, în cazul cel mai general). În cazul problemei de faµ , s presupunem c a+ b, c+d, a+ c ³i b+d sunt xate. Atunci, dac ipoteza nul este adev rat , probabilitatea de a obµineexact valorile din Tabelul 12.4 este:
P =Caa+bC
cc+d
Ca+cn
. (12.5)
Aceast probabilitate se obµine prin utilizarea schemei hipergeometrice.Exist îns mai multe matrice de tip 2 × 2 care au o conguraµie xat a sumelor pe ecare linie ³ipe ecare coloan (i.e., a + b, c + d, a + c ³i b + d sunt xate). Pentru ecare matrice de acest tip,putem calcula o probabilitate (condiµionat de realizarea ipotezei nule) de genul celei de mai sus. În cazultestului bilateral, P−valoarea testului (notat prin Pv) este suma tuturor probabilit µilor condiµionateastfel calculate, care sunt mai mici sau egale cu probabilitatea obµinut pentru conguraµia dat .Dac P−valoarea este mai mare decât α, atunci ipoteza nul este admis la acest prag de semnicaµie.Dac Pv ≤ α, atunci respingem (H0).În cazul în care ipoteza alternativ este una specic (e.g., unul dintre atribute este preferat celuilalt),atunci P−valoarea este doar jum tate din suma anterioar . Spunem în acest caz c avem un test unilateral.
Exemplu 12.2 Se testeaz efectele unui anumit tip de medicamente pe un grup de voluntari ce prezint simptome de r ceal . Ace³tia sunt în num r de 14 ³i au fost împ rµiµi în dou grupuri de 7 persoane.Pacienµilor din primul grup, G1, li s-au administrat medicamentul iar pacienµilor din grupul G2 nu li s-auadministrat nimic. Dup o s pt mân , s-a testat starea s n t µii celor 14 pacienµi, rezultatele ind celedin Tabelul 12.5. S se determine dac administrarea medicamentului are vreun efect asupra st rii des n tate a voluntarilor. Se va folosi nivelul de semnicaµie α = 0.05.
- Ipoteza nul este:
(H0) : Starea de s n tate a voluntarilor este independent de administrarea medicamentului.

STATS 12 [Dr. Iulian Stoleriu] 158
X @@Y s n tos bolnav Suma pe linie
G1 6 1 7
G2 4 3 7
Suma pe coloan 10 4 14
Tabela 12.5: Tabel de contingenµ pentru testarea unui medicament.
Ipoteza alternativ (bilateral ) este:
(H1) : Ipoteza (H0) este fals .
Matricea conguraµiei este
M1 =
(6 14 3
)Folosind relaµia (12.5), probabilitatea apariµiei acestei conguraµii, ³tiind c sumele pe linii ³i pe coloanesunt xate, este
P1 =C6
7 C47
C1014
= 0.2448.
Alte conguraµii cu suma 7 pe ecare linie ³i sumele 10 pe prima coloan ³i 4 pe a doua coloan sunt:
M2 =
(4 36 1
), M3 =
(5 25 2
), M4 =
(3 47 0
), M5 =
(7 03 4
).
Probabilit µile condiµionate corespunz toare acestora sunt:
P2 = 0.2448; P3 = 0.4404, P4 = 0.0350, P5 = 0.0350.
P−valoarea este suma tuturor probabilit µilor mai mici sau egale cu P1:
Pv = P1 + P2 + P4 + P5 = 0.2448 + 0.2448 + 0.0350 + 0.0350 = 0.5596 > 0.05 = α.
A³adar, la acest prag de semnicaµie admitem ipoteza nul . √
Observaµia 12.3 (1) A se observa c suma P1 + P2 + P3 + P4 + P5 = 1, ceea ce era de a³teptat.(2) Dac rezultatul experimentului ar matriceaM5 ³i ipoteza alternativ este
(H1) : exist evidenµe c medicamentul are efecte benece,
atunci avem un test unilateral. În acest caz, P−valoarea este Pv = P5 = 0.0305 < α, ceea ce conduce larespingerea ipotezei nule ³i, deci, exist evidenµe c medicamentul are efecte benece.

Laborator 12 [Dr. Iulian Stoleriu] 159
Statistic Aplicat (Laborator 12)
Teste de concordanµ (probleme)
Exemplu 12.4 Se arunc un zar de 60 de ori ³i se obµin rezultatele din Tabelul 12.6. S se decid , lanivelul de semnicaµie α = 0.02, dac zarul este corect sau fals.
Faµa (clasa Oi) Frecvenµa absolut (ni)1 152 73 44 115 66 17
Tabela 12.6: Tabel cu num rul de puncte obµinute la aruncarea zarului.
Soluµie: (aplic m testul χ2 de concordanµ , cazul neparametric)Zarul este corect doar dac ecare faµ a sa are aceea³i ³ans de a aparea, adic probabilit µile ca ecarefaµ în parte s apar sunt:
(H0) : pi =1
6, (i = 1, 2, . . . , 6).
Altfel, not m cu X variabila aleatoare ce are valori num rul punctelor ce apar la aruncarea zarului. Unzar corect ar însemna c X urmeaz repartiµia uniform discret U(6).Toate cele 60 de rezultate obµinute în urma arunc rii zarului pot împ rµite în ³ase clase. Aceste clasesunt: Oi = i, i ∈ 1, 2, . . . , 6. Ipoteza nul este (H0) sau, echivalent,
(H0) : Funcµia de repartiµie a lui X este U(6).
Ipoteza alternativ este "(H0) nu are loc", adic :
(H1) : Exist un j, cu pj 6=1
6, (j ∈ 1, 2, . . . , 6).
Calculez valoarea statisticii χ2 dat de (12.1) pentru observaµiile date:
χ20 =
(15− 10)2
10+
(7− 10)2
10+
(4− 10)2
10+
(11− 10)2
10+
(6− 10)2
10+
(17− 10)2
10= 13.6.
Repartiµia statisticii χ2 dat de (12.1) este χ2 cu k − 1 = 5 grade de libertate. Regiunea critic este:
U = (χ20.98; 5; +∞) = (13.3882, +∞).
Deoarece χ20 se a în regiunea critic , ipoteza nul se respinge la nivelul α = 0.02, a³adar zarul este fals.
Codul Matlab:
n = 60; k=6; alpha = 0.02; x = 1:6; f = [15,7,4,11,6,17]; p = 1/6*ones(1,6);
chi2 = sum((f-n*p).^2)./(n*p)); % valoarea χ20
val = chi2inv(1-alpha,k-1); % cuantila χ20.99; 5
H = (chi2 > val) % afiseaza 1 daca zarul e corect si 0 daca nu √

Laborator 12 [Dr. Iulian Stoleriu] 160
Observaµia 12.5 Dac nivelul de semnicaµie este ales α = 0.01, atunci χ20.99; 5 = 15.0863, ceea ce de-
termin acceptarea ipotezei nule (adic zarul este corect) la acest nivel.
Teste de concordanµ în Matlab
Am v zut deja c funcµia chi2gof(x) testeaz (folosind testul χ2 al lui Pearson) dac vectorul x provinedintr-o repartiµie normal , cu media ³i dispersia estimate folosind x.
Pentru testul χ2, forma general a funcµiei Matlab este:
[h,p,stats] = chi2gof(X,name1,val1,name2,val2,...)
unde:− h, p sunt la fel ca în exemplele anterioare;− perechile namei/valuei sunt opµionale. Variabilele namei pot : num rul de clase, 'nbins', un vectorde valori centrale ale intervalelor ce denesc clasele, 'ctrs', sau un vector cu capetele claselor, 'edges'.Alte variabile ce pot utilizate: 'cdf', 'expected', 'nparams', 'emin', 'frequency', 'alpha'.− variabila de memorie stats a³eaz : chi2stat - statistica χ2, df - gradele de libertate, edges - unvector cu capetele intervalelor claselor dup triere, O - num rul de valori observate în ecare clas , E -num rul de valori a³teptate în ecare clas .
Exemplu 12.6 Spre exemplicare, revenim la Exerciµiul 12.4, dar cu valoarea nivelului de încredere dinObservaµia 12.5. Codul Matlab ce folose³te funcµia de mai sus este:
x = 1:6; f = [15,7,4,11,6,17]; p = 1/6*ones(1,6); e = N*p; alpha = 0.01;
[h, p, stats] = chi2gof(x,'ctrs', x,'frequency', f,'expected',e, 'alpha',alpha)
Acest cod returneaz :
h = p = stats =
0 0.0184 chi2stat: 13.6000
df: 5
edges: [0.5000 1.5000 2.5000 3.5000 4.5000 5.5000 6.5000]
O: [15 7 4 11 6 17]
E: [10 10 10 10 10 10]
Acest rezultat conrm c ipoteza nul (zarul este corect) este acceptat la nivelul α = 0.01. √
Exemplu 12.7 (din [3]) La campionatul mondial de fotbal din 2006 au fost jucate în total 64 de meciuri,iar repartiµia num rului de goluri înscrise într-un meci are tabelul de distribuµie ca în Tabelul 12.7.Determinaµi (la nivelul de semnicaµie α = 0.05) dac num rul de goluri pe meci urmeaz o distribuµiePoisson.
Soluµie: (aplic m testul de concordanµ χ2 parametric) Fie X variabila aleatoare ce reprezint num rulde goluri înscrise într-un meci. Teoretic, X poate lua orice valoare din mulµimea N. Mulµimea observaµiilor

Laborator 12 [Dr. Iulian Stoleriu] 161
Nr. de goluri pe meci Nr. de meciuri0 81 132 183 114 105 26 2
Tabela 12.7: Tabel cu num rul de goluri pe meci la FIFA WC 2006.
f cute asupra lui X este 1, 2, 3, 4, 5, 6, cu frecvenµele respective din tabel. În total, au fost inscrise 144de goluri. Estim m num rul de goluri pe meci prin media lor, adic λ = x = 144
64 = 2.25. Pe baza datelorobservate, dorim s test m dac X urmeaz o repartiµie Poisson. Avem astfel de testat ipoteza nul :
(H0) : X urmeaz o lege Poisson P(λ).
vs. ipoteza alternativ (H1) : X nu urmeaz o lege Poisson P(λ).
Dac admitem ipoteza (H0) (adic X ∼ P(2.25), atunci pi = pi(λ) ³i distribuµia valorilor variabilei este
Clasa ni pi n pin1 − n pin pi
0 8 0.1054 6.7456 0.23331 13 0.2371 15.1775 0.31242 18 0.2668 17.0747 0.05013 11 0.2001 12.8060 0.25474 10 0.1126 7.2034 1.08575 2 0.0506 3.2415 −≥ 6 2 0.0274 1.7514 −≥ 5 4 0.0780 4.9926 0.1973
Tabela 12.8: Tablou de distribuµie pentru P(2.25).
dat de Tabelul 12.8. Valoarea pi este P (X = i), adic probabilitatea ca variabila aleatoare X ∼ P(2.25)s ia valoarea i (i = 0, 1, 2, 3, 4). Am putea forma 7 clase. Deoarece pentru ultimele dou clase dinTabelul 12.8, anume X = 5 ³i X ≥ 6, numerele ni nu dep ³e³c valoarea 3, le ³tergem din tabel ³i leunim într-o singur clas , în care X ≥ 5, cu ni = 4 > 3. Vom nota prin p≥5 probabilitatea
p≥5 = P (X ≥ 5) = 1− P (X < 5) = 1− P (X ≤ 4) = 1−4∑i=0
P (X = i).
R mânem a³adar cu 6 clase. Ipoteza nul (H0) se poate rescrie astfel:
(H0) : p0 = 0.1054, p1 = 0.2371, p2 = 0.2668, p3 = 0.2001, p4 = 0.1126, p≥5 = 0.0780.
Ipoteza alternativ este(H1) : ipoteza (H0) nu este adev rat .

Laborator 12 [Dr. Iulian Stoleriu] 162
Calcul m acum valoarea statisticii (12.1) pentru observaµiile date:
χ20 =
(8− 6.7456)2
6.7456+
(13− 15.1775)2
15.1775+
(18− 17.0747)2
17.0747+
(11− 12.8060)2
12.8060+ . . .
+(10− 7.2034)2
7.2034+
(4− 4.9926)2
4.9926= 2.1337.
Deoarece avem 6 clase ³i am estimat parametrul λ, deducem c num rul gradelor de libertate este6 − 1 − 1 = 4. Cuantila de referinµ (valoarea critic ) este χ2
0.95; 4 = 9.4877. Regiunea critic pentruχ2 este intervalul (χ2
0.95; 4, +∞). Deoarece χ20 < χ2
0.95; 4, urmeaz c ipoteza nul (H0) nu poate respins la nivelul de semnicaµie α. A³adar, este rezonabil s arm m c num rul de goluri marcateurmeaz o repartiµie Poisson. Prezent m mai jos un cod Matlab ce rezolv aceast problem .
X = [0*ones(8,1);1*ones(13,1);2*ones(18,1);3*ones(11,1);4*ones(10,1);...
5*ones(2,1);6*ones(2,1)];
f = [8 13 18 11 10 4]; % vectorul de frecvente absolute
n = 64; alpha = 0.05; lambda = mean(X);
for i=1:5 % probabilitatile P(X=i), i=0,1,2,3,4
p(i) = poisspdf(i-1,lambda);
end
p(6)= 1 - poisscdf(4,lambda); % probabilitatea P(X≥5)H2 = sum((f-n*p).^2./(n*p)); Hstar = chi2inv(1-alpha,4);
if (H2 < Hstar)
disp('X urmeaza repartitia Poisson');
else
disp('X nu urmeaza repartitia Poisson');
end √
Observaµia 12.8 Dac ipoteza nul este respins , atunci motivul poate acela c unele valori observateau deviat prea mult de la valorile a³teptate. În acest caz, este interesant de observat care valori suntextreme, cauzând respingerea ipotezei nule. Putem deni astfel reziduurile standardizate:
ri =Oi − n pi√n pi (1− pi)
=Oi − Ei√Ei (1− pi)
,
unde prin Oi am notat valorile observate ³i prin Ei valorile a³teptate. Dac ipoteza nul ar adev rat ,atunci ri ∼ N (0, 1). În general, reziduuri standardizate mai mari ca 2 sunt semne pentru numere observateextreme.
Exemplu 12.9 Într-o anumit zi de lucru, urm rim timpii de a³teptare într-o staµie de tramvai, pân laîncheierea zilei de lucru (adic , pân trece ultimul tramvai). Fie T caracteristica ce reprezint num rul deminute a³teptate în staµie, pân sose³te tramvaiul. Rezultatele observaµiilor sunt sumarizate în Tabelul12.9. Se cere s se cerceteze (α = 0.05) dac timpii de a³teptare sunt repartizaµi exponenµial.
Soluµie: (folosim testul χ2 de concordanµ , parametric) Avem de testat ipoteza nul
(H0) F (x) ∼= F0(x) = 1− e−λx, x > 0
vs. ipoteza alternativ (H1) ipoteza (H0) este fals .

Laborator 12 [Dr. Iulian Stoleriu] 163
Durata 0− 5 5− 10 10− 15 15− 20 20− 25
ni 39 35 14 7 5
Tabela 12.9: Timpi de a³teptare în staµia de tramvai.
Deoarece parametrul λ este necunoscut, va trebui estimat pe baza selecµiei date. Pentru aceasta, folosimmetoda verosimilit µii maxime. Funcµia de verosimilitate pentru exp(λ) este
L(t1, t2, . . . , tn; λ) =n∏k=1
λe−λ ti = λne−λn t.
Mai sus, am notat prin t1, t2, . . . , tn valorile de selecµie pentru variabila aleatoare T .Punctele critice pentru L(λ) sunt date de ecuaµia
∂ lnL
∂λ= 0 =⇒ ∂
∂λ
(n lnλ− λn t
)=⇒ λ =
1
t.
Se observ cu u³urinµ c ∂2 lnL
∂λ2|λ=λ = −n t2 < 0,
de unde concluzion m c λ este punct de maxim pentru funcµia de verosimilitate.Tabelul de distribuµie pentru caracteristica T este:(
2.5 7.5 12.5 17.5 22.539 35 14 7 5
).
Calcul m media de selecµie, t = 1100(2.5 ·39+7.5 ·35+12.5 ·14+17.5 ·7+22.4 ·5) = 7.7, adic λ = 0.1299.
Dac variabila T ar urma repartiµia exponenµial exp(λ), atunci probabilit µile ca T s ia valori în ecareclas sunt, în mod corespunz tor:
pi = pi(λ) = P (X ∈ (ai, ai+1] | F = F0) = F0(ai+1; λ)− F0(ai; λ), i = 1, 2, 3, 4, 5.
unde a6 = +∞.În Tabelul 12.10 am înregistrat urm toarele date:
• clasele (de notat c ultima clas este (20, +∞), deoarece se dore³te o concordanµ a datelor observatecu date repartizate exponenµial, iar mulµimea valorilor pentru repartiµia exponenµial este R+),
• extremit µile din stânga ale claselor (ai),
• frecvenµele absolute ni (sau valorile observate în ecare clas ),
• probabilit µile pi, valorile a³teptate în ecare clas (n pi),
• erorile relative de aproximare ale datelor a³teptate cu cele observate.
Num rul gradelor de libertate este k − p − 1 = 3. Calcul m valoarea critic χ20.95; 3 = 7.8147 ³i, de
asemenea, valoarea
H0 =k∑i=1
(ni − n pi)2
n pi= 6.5365.

Laborator 12 [Dr. Iulian Stoleriu] 164
Deoarece χ20 < χ2
0.95; 3, ipoteza (H0) nu poate respins la acest nivel de semnicaµie.
Codul Matlab este urm torul:
T = [2.5*ones(39,1);7.5*ones(35,1);12.5*ones(14,1);17.5*ones(7,1);22.5*ones(5,1)];
% sau
% T = [5*rand(39,1);5+5*rand(35,1);10+5*rand(14,1);15+5*ones(7,1);20+5*ones(5,1)];
n = 100; alpha = 0.05; m = mean(T); lambda = 1/m;
a = [0, 5, 10, 15, 20, Inf]; f = [39, 35, 14, 7, 5];
for i =1:5
p(i) = expcdf(a(i+1),m)-expcdf(a(i),m);
end
H2 = sum((f-n*p).^2./(n*p)); cuant = chi2inv(0.95,3);
if (H2 < cuant)
disp('Timpii de asteptare sunt exponential repartizati');
else
disp('ipoteza (H0) se respinge');
end √
Clasa ai ni pi n pini − n pin pi
(0, 5] 0 39 0.4776 47.7615 1.6072(5, 10] 5 35 0.2495 24.9499 4.0483(10, 15] 10 14 0.1303 13.0334 0.0717(15, 20] 15 7 0.0681 6.8085 0.0054(20, +∞) 20 5 0.0745 7.4467 0.8039
(0, +∞) − 100 1 100 6.5365
Tabela 12.10: Tabel de distribuµie pentru timpii de a³teptare.

STATS 13 [Dr. Iulian Stoleriu] 165
13 Statistic Aplicat (C13)
Teste neparametrice
Multe dintre testele discutate anterior au ca cerinµ ca datele selectate s urmeze o repartiµie normal (dac selecµia este mic ). Se pune problema urm toare: Ce se întâmpl dac aceast cerinµ (posibil³i altele) nu este vericat ³i nu ³tim nimic despre repartiµia datelor sau despre parametrii variabilei?Testele neparametrice sunt cele în cadrul c rora nu se fac presupuneri asupra formei repartiµiei. Acesteteste nu estimeaz parametrii necunoscuµi, de aceea mai sunt cunoscute ³i sub titulatura de metode f r parametri (en., parameter-free methods) sau metode f r repartiµie (en., distribution-free methods). Sepot construi teste neparametrice corespunz toare ec rui test parametric studiat mai sus, îns aceste testeneparametrice sunt, în general, grupate în urm toarele categorii:
• teste pentru diferenµa dintre grupuri (pentru selecµii independente). Este cazul compar rii mediilora dou selecµii ce provin din populaµii independente. De regul , se utilizeaz testul t dac ipotezeleacestuia sunt îndeplinite. Variante neparametrice ale acestui test sunt: testul Wald-Wolfowitz,testul Mann-Whitney sau testul Kolmogorov-Smirnov pentru dou selecµii;
• teste pentru diferenµa dintre variabile (pentru selecµii dependente). Utilizat la compararea a dou variabile ce caracterizeaz populaµia din care s-a luat selecµia. Teste neparametrice utilizate: testulsemnelor, testul Wilcoxon.
• teste pentru relaµii între variabile. Pentru a g si corelaµia între variabile, se utilizeaz coecientul decorelaµie. Exist variante neparametrice ale coecientului de corelaµie standard, e.g., coecientul R(Spearman), coecientul τ (Kendall) sau coecientul Gamma. Exist , de asemenea, ³i teste privindcoecientul de corelaµie: χ2 sau testul Fisher exact.
Testul semnelor
Este un test neparametric bazat pe semnele anumitor caracteristici ³i nu pe valorile lor. Este unul dintrecele mai simple teste statistice neparametrice.
Exemplu 13.1 Dorim s test m preferinµele clienµilor dintr-o anumit pizzerie pentru pizza cu blatsubµire sau gros. S spunem c aceste preferinµe sunt reprezentate în Tabelul 13.1. În acest tabel, ec rei
marime subµire gros gros gros subµire gros gros subµire gros grossemn − + + + − + + − + +
Tabela 13.1: Tabel cu preferinµe pentru blatul de pizza.
preferinµe i se atribuie un semn, + pentru "blat gros" ³i − pentru "blat subµire". Dintr-o privire în tabel,se pare c marea parte (70%) a clienµilor prefer blatul gros. Dorim s test m semnicaµia acestor date.Cu alte cuvinte, care este ³ansa obµinerii acestor rezultate dac , de fapt, nu exist vreo diferenµ întrepreferinµe? Sau, dac am presupune c preferinµele pentru cele dou tipuri sunt împ rµite în mod egal,care sunt ³ansele de a obµine un rezultat de genul prezentat în tabelul de mai sus?

STATS 13 [Dr. Iulian Stoleriu] 166
Soluµie: Stabilim ipoteza nul
(H0) : preferinµele pentru cele dou blaturi sunt 50%− 50%;
versus ipoteza alternativ bilateral
(H1) : exist diferenµe semnicative în preferinµele pentru cele dou blaturi;
Pot considerate ³i teste unilaterale (stânga sau dreapta). Alegem pragul de semnicaµie α = 0.05.Ca de obicei, presupunem c ipoteza nul este adev rat ³i, atunci, ³ansa ca cineva s aleag un blat subµireeste p = 0.5. Dac not m cu X variabila aleatoare ce reprezint alegerea blatului, f cut de clienµii careau comandat pizza, atunci X ∼ B(10, 0.5) (aici avem o selecµie de n = 10). Calcul m P−valoarea, adic valoarea maxim pentru pragul de semnicaµie pentru care ipoteza nul nu poate respins . Aceastavaloare este de dou ori probabilitatea P (X ≤ 3) (de dou ori, pentru ca testul este bilateral), adic pro-babilitatea de a obµine un rezultat ca cel din tabel. G sim c P−valoarea este Pv = 2P (X ≤ 3) = 0.3438.Deoarece α < Pv, concluzion m c ipoteza nul nu poate respins la acest nivel de semnicaµie. √
Testul seriilor pentru caracterul aleator
Dac o anumit valoare a unui anumit ³ir de caractere este inuenµat de poziµia sa sau de valorilece o preced, atunci selecµia generat nu poate aleatoare. Testul seriilor (en., runs test) este un testneparametric ce veric ipoteza c un ³ir de date bivariate este aleator generat.
Denim noµiunea de serie sau faz (en., run) ca ind o succesiune a unuia sau mai multe simboluri deacela³i tip, care sunt precedate ³i urmate de simboluri de alt tip sau niciun simbol. De exemplu:
001111010010 sau MFFFFFMMMF sau ++-+---++++--+--++-
Num rul de faze ³i lungimea lor pot folosite în determinarea gradului de stochasticitate a unui ³ir desimboluri. Prea puµine sau prea multe faze, sau de lungimi excesiv de mari sunt rare în serii cu adev rataleatoare, de aceea ele pot servi drept criterii statistice pentru testarea stochasticit µii. Aceste criteriisunt adiacente: prea puµine faze implic faptul c unele faze sunt prea lungi, prea multe faze implic prea multe secvenµe. A³adar, ne vom preocupa doar de num rul total de faze. Fiecare num r din ³ireste comparat cu mediana sau valoarea medie a ³irului, scriind astfel + pentru numere mai mari decâtmediana ³i − pentru cele mai mici. Numerele egale cu mediana nu sunt considerate în calcul. Fie n1 ³i n2
num rul de semne +, respectiv, − din ³ir, ³i e n = n1 + n2. Fie R1 ³i R2 num rul de faze ce corespundsemnului +, respectiv, − din ³ir. Num rul total de faze este R = R1 +R2.Alegem ipoteza nul :
(H0) : ³irul este aleator (ecare aranjament de + ³i − este echiprobabil).
vs. ipoteza alternativ
(H1) : ³irul nu este aleator.

STATS 13 [Dr. Iulian Stoleriu] 167
Putem g si repartiµiile vectorilor aleatori (R1, R2), R1, R2 sau R. Pentru R avem densitatea de repartiµie:
f(r) =
Cr/2−1n1−1 C
r/2−1n2−1
Cn1n
, dac r = par;
[C
(r−1)/2n1−1 C
(r−3)/2n2−1 + C
(r−3)/2n1−1 C
(r−1)/2n2−1
]Cn1n
, dac r = impar.
Când n1 ³i n2 sunt mari, atunci R ∼ N (µ, σ), unde
µ = 2n1 n2
n+ 1, σ =
√2n1 n2 (2n1 n2 − n)
n2(n− 1).
A³adar,R− µσ∼ N (0, 1).
Aceast statistic poate utilizat în testarea ipotezei nule (H0).
Corelaµie ³i regresie
Introducere
În acest capitol vom discuta m suri ³i tehnici de determinare a leg turii între dou sau mai multe variabilealeatoare. Pentru lecturi suplimentare, se pot consulta materialele [13], [14], [15].Primele metode utilizate în studiul relaµiilor dintre dou sau mai multe variabile au ap rut de la începutulsecolului al XIX-lea, în lucr rile lui Legendre21 ³i Gauss22, în ce prive³te metoda celor mai mici p tratepentru aproximarea orbitelor astrelor în jurul Soarelui. Un alt mare om de ³tiinµ al timpului, FrancisGalton23, a studiat gradul de asem nare între copii ³i p rinµi, atât la oameni, cât ³i la plante, observând c în lµimea medie a descendenµilor este legat liniar de în lµimea ascendenµilor. Este primul care a utilizatconceptele de corelaµie ³i regresie ( (lat.) regressio - întoarcere). Astfel, a descoperit c din p rinµi ac ror în lµime este mai mic decât media colectivit µii provin copii cu o în lµime superioar lor ³i vice-versa. Astfel, a concluzionat c în lµimea copiilor ce provin din p rinµi înalµi tinde s "regreseze" spreîn lµimea medie a populaµiei. Din lucr rile lui Galton s-a inspirat un student de-al s u, Karl Pearson, carea continuat ideile lui Galton ³i a introdus coecientul (empiric) de corelaµie ce îi poart numele. Acestcoecient a fost prima m sur important introdus ce cuantica t ria leg turii dintre dou variabile aleunei populaµii statistice.
Un ingredient fundamental în studiul acestor dou concepte este diagrama prin puncte, a³a-numita scatterplot. În probleme de regresie în care apare o singur variabila r spuns ³i o singur variabil observat ,diagrama scatter plot (r spuns vs. predictor) este punctul de plecare pentru studiul regresiei. O diagram scatter plot ar trebui reprezentat pentru orice problem de analiz regresional , deoarece aceasta ne vada o prim idee despre ce tip de regresie vom folosi. Un exemplu de astfel de diagram este reprezentatîn Figura 13.1, în care am reprezentat coecientul de inteligenµ (IQ) a 200 de perechi soµ-soµie. Fiecarecruciuliµ din diagram reprezint IQ-ul pentru o pereche soµ-soµie.
21Adrien-Marie Legendre (1752− 1833), matematician francez22Johann Carl Friedrich Gauss (1777− 1855), matematician ³i zician german23Sir Francis Galton (1822− 1911), om de ³tiinµ britanic
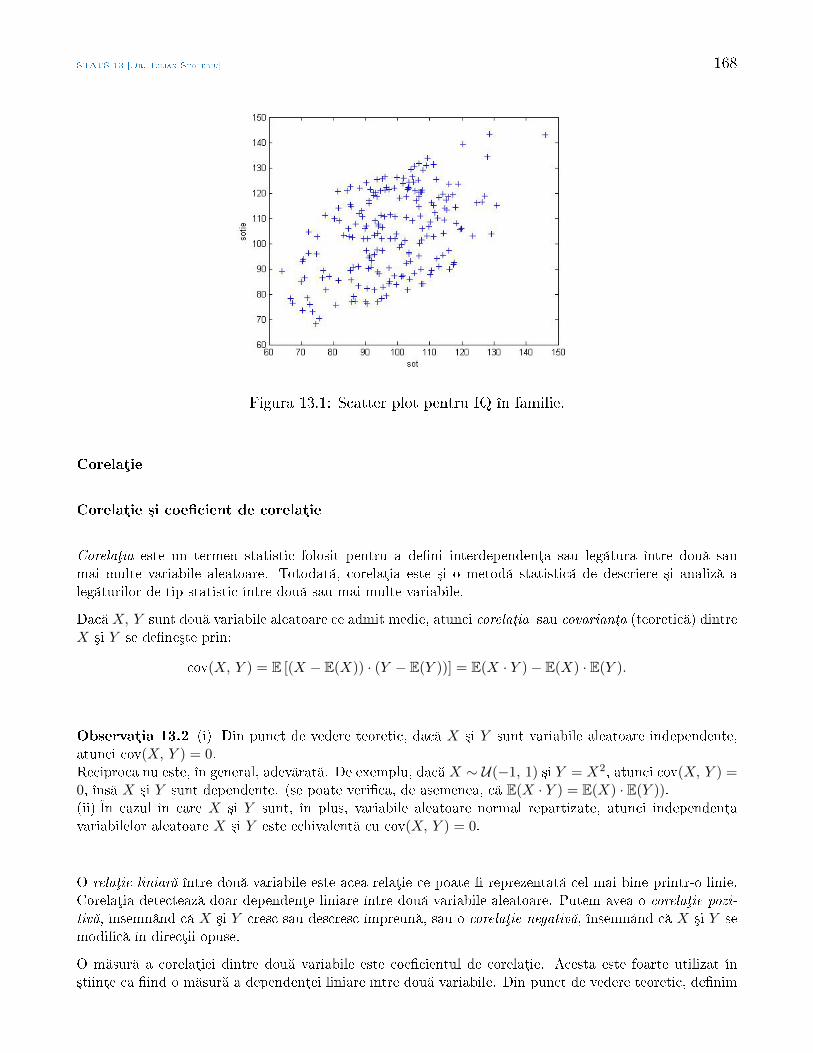
STATS 13 [Dr. Iulian Stoleriu] 168
Figura 13.1: Scatter plot pentru IQ în familie.
Corelaµie
Corelaµie ³i coecient de corelaµie
Corelaµia este un termen statistic folosit pentru a deni interdependenµa sau leg tura între dou saumai multe variabile aleatoare. Totodat , corelaµia este ³i o metod statistic de descriere ³i analiz aleg turilor de tip statistic între dou sau mai multe variabile.
Dac X, Y sunt dou variabile aleatoare ce admit medie, atunci corelaµia sau covarianµa (teoretic ) dintreX ³i Y se dene³te prin:
cov(X, Y ) = E [(X − E(X)) · (Y − E(Y ))] = E(X · Y )− E(X) · E(Y ).
Observaµia 13.2 (i) Din punct de vedere teoretic, dac X ³i Y sunt variabile aleatoare independente,atunci cov(X, Y ) = 0.Reciproca nu este, în general, adev rat . De exemplu, dac X ∼ U(−1, 1) ³i Y = X2, atunci cov(X, Y ) =0, îns X ³i Y sunt dependente. (se poate verica, de asemenea, c E(X · Y ) = E(X) · E(Y )).(ii) În cazul în care X ³i Y sunt, în plus, variabile aleatoare normal repartizate, atunci independenµavariabilelor aleatoare X ³i Y este echivalent cu cov(X, Y ) = 0.
O relaµie liniar între dou variabile este acea relaµie ce poate reprezentat cel mai bine printr-o linie.Corelaµia detecteaz doar dependenµe liniare între dou variabile aleatoare. Putem avea o corelaµie pozi-tiv , însemnând c X ³i Y cresc sau descresc împreun , sau o corelaµie negativ , însemnând c X ³i Y semodic în direcµii opuse.
O m sur a corelaµiei dintre dou variabile este coecientul de corelaµie. Acesta este foarte utilizat în³tiinµe ca ind o m sur a dependenµei liniare între dou variabile. Din punct de vedere teoretic, denim

STATS 13 [Dr. Iulian Stoleriu] 169
coecientul de corelaµie a dou variabile aleatoare X ³i Y prin:
ρX,Y =cov(X, Y )
σX · σY= cov(X, Y ),
unde X ³i Y sunt variabilele aleatoare standardizate iar σX =(E(X −X)2
)1/2³i σY =
(E(Y − Y )2
)1/2sunt deviaµiile standard corespunz toare variabilelor aleatoare X, respectiv Y . Propriet µile coecientuluide corelaµie au fost prezentate anterior.
În practic , pentru a stabili dac exist sau nu vreo leg tura între dou variabile aleatoare, se fac observaµiiasupra acestora, urmând apoi a cuantica relaµia dintre observaµii.
Fie (xk, yk), k ∈ 1, 2, . . . , n un set de date bidimensionale, ce reprezint observaµii asupra vectoruluialeator (X, Y ). O m sur a leg turii dintre xkk ³i ykk este coecientul de corelaµie empiric introdusde K. Pearson (în literatura de specialitate mai este cunoscut ³i sub denumirea de coecientul r):
r =
n∑k=1
(xk − x)(yk − y)√√√√ n∑k=1
(xk − x)2
√√√√ n∑k=1
(yk − y)2
(13.1)
=cove(x, y)
sx · sy, (13.2)
unde
cove(x, y) =1
n− 1
n∑k=1
(xk − x)(yk − y), sx =
√√√√ 1
n− 1
n∑k=1
(xk − x)2, sy =
√√√√ 1
n− 1
n∑k=1
(yk − y)2
sunt covarianµa (corelaµia) empiric ³i deviaµiile standard empirice pentru X ³i Y .Spre exemplu, pentru selecµiile
x = [0.49 -0.45 0.39 0.05 -0.49 0.24 0.72 0.15 0.13 -1.01];
y = [1.31 1.20 -2.58 -2.09 0.39 -0.86 -1.23 2.64 -0.90 -1.22];
coecientul r al lui Pearson ester = −0.0905.
Asemeni coecientului de corelaµie teoretic, ρX,Y, coecientul r al lui Pearson ia valori doar în intervalul[−1, 1]. Cazurile limit pentru r sunt r = 1 sau r = −1, cazuri în care putem trage concluzia c variabileleX ³i Y sunt pozitiv, respectiv, negativ) perfect corelate (vezi Figura 13.2). Pentru valori ale lui r între−1 ³i 1, nu putem vorbi de gradul de corelare între X ³i Y f r a efectua un test statistic asupra valoriicoecientulul teoretic de corelaµie, ρ. De multe ori îns , putem arma ca avem o corelaµie pozitiv dac r este apropiat de valoarea 1 (e.g., r = 0.85, caz în care norul de date are panta ascendent ) ³i avemo corelaµie negativ dac r este apropiat de valoarea −1 (e.g., r = −0.98, caz în care norul de date arepanta descendent ).Rezultatul r = −0.0905 de mai sus ar putea sugera faptul c cele dou selecµii au fost obµinute independentuna faµ de cealalt (i.e., ρ = 0), fapt ce va trebui conrmat folosind un test statistic în care test m ipotezanul ρ = 0, cu ipoteza alternativ ρ 6= 0.

STATS 13 [Dr. Iulian Stoleriu] 170
Figura 13.2: Scatter plots ³i coecienµi de corelaµie.
Test statistic pentru coecientul de corelaµie
Presupunem c avem un set de date bidimensionale (xk, yk), k ∈ 1, 2, . . . , n asupra variabilelor alea-toare X, Y , ³i am calculat r, obµinând o valoare r0 apropiat de 0. Plecând doar de la acest informaµie,nu putem extrapola ³i decide gradul de corelare între X ³i Y . Pentru aceasta, vom construi un test sta-tistic, care va decide dac valoarea real a lui ρ (coecientul teoretic de corelaµie) este 0 sau semnicativdiferit de 0.
Consider m ipoteza nul
(H0) ρX,Y = 0 (variabilele aleatoare nu sunt corelate)
vs. ipoteza alternativ
(H1) ρX,Y 6= 0 (variabilele aleatoare sunt corelate)
Alegem un nivel de semnicaµie α << 1 (e.g., α = 0.05) ³i consider m statistica
T = r
√n− 2
1− r2∼ t(n− 2).
Calculez valoarea statisticii T pentru r = r0 (o not m cu T0) ³i, de asemenea, calcul m cuantila t1−α2
;n−2,de ordin 1− α
2 a repartiµiei t cu (n− 2) grade de libertate.Decizia nal este urm toarea:
|T0| < t1−α2
;n−2 , atunci ipoteza (H0) este acceptat ;
|T0| ≥ t1−α2
;n−2 , atunci ipoteza (H0) este respins .

STATS 13 [Dr. Iulian Stoleriu] 171
Observaµia 13.3 (i) Coecientul lui Pearson, r, este un num r adimensional ce stabile³te doar dac exist o leg tura liniar între dou seturi de date statistice. Totodat , în denirea acestui coecient sepresupune c datele statistice urmeaz o repartiµie normal . De multe ori, în practic , doar coecientulr sigur nu poate edicator asupra t riei leg turii între dou seturi de date statistice, ba chiar poategenera informaµii false în cazul în care cele dou seturi date nu depind liniar unul de cel lalt. De aceea,³i alµi coecienµi pentru determinarea corelaµiei sunt luaµi în consideraµie, cum ar :
• r2, coecientul de determinare (notat în Statistic prin R2), care stabile³te care este procentul dinvariaµia uneia dintre datele statistice ce determina (sau explic ) pe celelalte date. De exemplu, uncoecient de determinare R2 = 0.42 semnic faptul c variabila independent explic doar 42%din variaµia variabilei dependente. În Statistic , acest coecient este denit în mai multe moduri,unele nu tocmai într-un mod echivalent;
• coecientul lui Spearman24, coecientul lui Kendall25 etc. (acestea nu presupun c datele statisticesunt normale)
(ii) Se poate testa, de asemenea, ipoteza nul
(H0) : ρX, Y = ρ0, cu ρ0 6= 0,
îns aceasta nu este foarte des întâlnit în practic .(iii) Corelaµia a dou variabile aleatoare nu implic o cauzare. Cu alte cuvinte, exist o corelaµie întrevârst ³i în lµime la copii, îns niciuna dintre aceastea nu o cauzeaz pe cealalt . Corelaµia poate luat în evidenµ pentru o posibil relaµie cauzal , îns nu este determinant ³i nu poate preciza relaµia cauzal ,dac aceast exist .(iv) Volumul selecµiei este un factor foarte important în testarea ipotezei c dou variabile aleatoaresunt necorelate. Spre exemplu, o relaµie poate puternic (având un r nu foarte aproape de 0), îns nusemnicativ , dac valoarea lui n nu este sucient de mare. Invers, o relaµie poate slab (un r aproapede 0), dar semnicativ . Exemplul (13.4) poate edicator.
Exemplu 13.4 S presupunem c dorim s stabilim dac exist vreo leg tura între vârst unei persoane³i coecientul s u de inteligenµ . Culegem astfel dou seturi de datele asupra acestor caracteristici, devolum n = 10, ³i s presupunem c am g sit un coecient de corelaµie empiric r = 0.62. Se cere:(a) Este aceast leg tur puternic ?(b) Este aceast leg tur semnicativ ?
Soluµie: (a) Calcul m coecientul de determinare, R2, ³i g sim R2 = 0.3844. Asta semnic faptul c doar 38.44% din variaµia coecientului de inteligenµ este explicat de vârst .(b) Aplic m testul pentru coecientul de corelaµie la un nivel de semnicaµie α = 0.05. Statistica
considerat va avea 8 grade de libertate, T0 = 0.62√
80.3844 = 2.2351 < 2.3060 = t0.975; 8, de unde
concluzion m c ipoteza nul ρ = 0 este admis (i.e., nu sunt dovezi suciente pentru ca ipoteza s poate respins la acest nivel de semnicaµie). √
24Charles Edward Spearman (1863− 1945), psiholog britanic25Sir Maurice George Kendall (1907− 1983), statistician britanic

STATS 13 [Dr. Iulian Stoleriu] 172
Coecientul de corelaµie Spearman
În cazul datelor calitative, unde nu se pot asocia valori numerice pentru caracteristica de interes, coecien-tul de corelaµie Pearson nu mai poate calculat. Pentru aceste date, este util de calculat coecientul decorelaµie Spearman, sau coecientul de corelaµie a rangurilor. Acest coecient poate calculat atât pentrudate calitative, cât ³i pentru date cantitative. Pentru a calcula acest coecient, ec rui atribut sau ec reivalori a caracteristicii i se desemneaz un rang. Coecientul de corelaµie Spearman este coecientul decorelaµie Pearson pentru aceste ranguri.În general, dac (xi, yi)i=1, n este un set de date bidimensionale, reprezentând rangurile corespunz toarevariabilelor cercetate, ³i not m cu rS coecientul de corelaµie Spearman, atunci
rS =
n∑k=1
(xk − x)(yk − y)√√√√ n∑k=1
(xk − x)2
√√√√ n∑k=1
(yk − y)2
. (13.3)
La fel ca ³i coecientul lui Pearson, coecientul Spearman ia valori reale în intervalul [−1, 1]; valoarea 1însemnând corelaµie pozitiv perfect a rangurilor, iar valoarea −1 însemnând corelaµie negativ perfect a rangurilor.În cazul în care avem n perechi de observaµii ³i nu exist valori egale pentru rangurile aceleia³i variabile,atunci formula alternativ pentru calcului lui rS este:
rS = 1−6
n∑i=1
d2i
n(n2 − 1), (13.4)
unde di = xi − yi, i.e., diferenµa dintre rangurile corespunz toare pentru poziµia i. Vezi exemplele (13.5)³i (13.6).
Exemplu 13.5 Doi degust tori de vinuri (denumiµi D1 ³i D2) au fost rugaµi s testeze 9 soiuri de vin ³is le claseze în ordinea preferinµelor. S not m mostrele testate cu A, B, C, D, E, F ³i G. Preferinµeleacestora sunt cele din Tabelul 13.2, în ordinea descresc toare a preferinµelor. Tabelul 13.3 conµine rangurilepreferinµelor celor doi degust tori, iar Figura 13.3 reprezint grac rangurile (diagrama scatter plot).
Mostra A B C D E F G H ID1 E B A G C H F D ID2 B E C G A H D I F
Tabela 13.2: Preferinµele degust torilor devin.
Mostra rang D1 rang D2
A 3 5B 2 1C 5 3D 8 7E 1 2F 7 9G 4 4H 6 6I 9 8
Tabela 13.3: Tabel cu rangurile preferinµelor.

STATS 13 [Dr. Iulian Stoleriu] 173
Din diagrama scatter plot se observ o corelaµie pozitiv între ranguri, ceea ce implic o oarecare con-cordanµ între preferinµele celor doi degust tori. Coecientul de corelaµie Spearman va atribui o valoarenumeric acestei concordanµe, aceasta ind rS = 0.8667.
Figura 13.3: Scatter plot pentru ranguri.
Exist cazuri (în special pentru date cantitative) când valorile caracteristicii se repet , a³a încât pentruvalori egale desemn m acela³i rang. În aceste cazuri nu mai putem utiliza formula (13.4) pentru calcululcoecientului Spearman, ci va trebui s utiliz m formula (13.3) (vezi exemplul urm tor).
Exemplu 13.6 Datele din Tabelul 13.4 reprezint num rul de accidente rutiere (A) ³i num rul de decese(D) înregistrate într-un anumit ora³, în primele 6 luni ale anului. Rangurile corespunz toare valorilor suntprezentate în Tabelul 13.5. Datele au fost introduse în tabel în ordinea invers a num rului de accidente.De notat c , deoarece num rul de decese înregistrate în luna Mai este egal cu num rul de decese dinAprilie, rangul pentru ecare dintre cele dou luni este media celor dou poziµii în care s-ar aa. Folosindformula (13.3), calcul m coecientul de corelaµie Spearman. Acesta este rS = 0.8117.
Luna Ian. Feb. Mar. Apr. Mai Iun.A 27 24 15 11 17 12D 8 6 5 3 3 2
Tabela 13.4: Evenimente rutiere în primele 6 luni.
Luna A rang A D rang D
Ian. 27 6 8 6Feb. 24 5 6 5Mai 17 4 3 2+3
2 = 2.5Mar. 15 3 5 4Iun. 12 2 2 1Apr. 11 1 3 2+3
2 = 2.5
Tabela 13.5: Tabel cu rangurile pentru accidente.

STATS 13 [Dr. Iulian Stoleriu] 174
Regresie
Punerea problemei
Regresia este o metod statistic utilizat pentru descrierea naturii relaµiei între variabile. De fapt, regresiastabile³te modul prin care o variabil depinde de alt variabil , sau de alte variabile. Analiza regresional cuprinde tehnici de modelare ³i analiz a relaµiei dintre o variabil dependent (variabila r spuns) ³i unasau mai multe variabile independente. De asemenea, r spunde la întreb ri legate de predicµia valorilorviitoare ale variabilei r spuns pornind de la o variabil dat sau mai multe. În unele cazuri se poate precizacare dintre variabilele de plecare sunt importante în prezicerea variabilei r spuns. Se nume³te variabil independent o variabil ce poate manipulat (numit ³i variabil predictor, stimul sau comandat ), iaro variabil dependent (sau variabila prezis ) este variabila care dorim s o prezicem, adic o variabil c rei rezultat depinde de observaµiile f cute asupra variabilelor independente. S lu m exemplul unei cutiinegre (black box) (vezi Figura 13.4). În aceasta cutie intr (sunt înregistrate) informaµiile x1, x2, . . . , xm,care sunt prelucrate (în timpul prelucr rii apar anumiµi parametri, β1, β2, . . . , βk), iar rezultatul nal esteînregistrat într-o singur variabila r spuns, y. De exemplu, se dore³te a se stabili o relaµie între valoareapensiei (y) în funcµie de num rul de ani lucraµi (x1) ³i salariul avut de-alungul carierei (x2). Variabileleindependente sunt m surate exact, f r erori. În timpul prelucr rii datelor sau dup aceasta pot ap radistorsiuni în sistem, de care putem µine cont dac introducem un parametru ce s cuantice eroarea cepoate ap rea la observarea variabilei y. Se stabile³te astfel o leg tur între o variabil dependent , y,³i una sau mai multe variabile independente, x1, x2, . . . , xm, care, în cele mai multe cazuri, are formamatematic general
y = f(x1, x2, . . . , xm; β1, β2, . . . , βk) + ε, (13.5)
unde β1, β2, . . . , βk sunt parametri reali necunoscuµi a priori (denumiµi parametri de regresie) ³i ε este operturbaµie aleatoare. În cele mai multe aplicaµii, ε este o eroare de m sur , considerat modelat printr-ovariabil aleatoare normal de medie zero. Funcµia f se nume³te funcµie de regresie. Dac aceasta nu estecunoscut a priori, atunci poate greu de determinat iar utilizatorul analizei regresionale va trebui s ointuiasc sau s o aproximeze utilizând metode de tip trial and error (prin încerc ri). Dac avem doaro variabila independent (un singur x), atunci spunem c avem o regresie simpl . Regresia multipl facereferire la situaµia în care avem multe variabile independente.
Figura 13.4: Black box.
Dac observarea variabilei dependente s-ar face f r vreo eroare, atunci relaµia (13.5) ar deveni (cazulideal):
y = f(x1, x2, . . . .., xm; β1, β2, . . . , βk). (13.6)
Forma vectorial a dependenµei (13.5) este:
y = f(x; β) + ε. (13.7)

STATS 13 [Dr. Iulian Stoleriu] 175
Pentru a o analiz complet a regresiei (13.5), va trebui sa intuim forma funcµiei f ³i apoi s determin m(aproxim m) valorile parametrilor de regresie. În acest scop, un experimentalist va face un num r sucientde observaµii (experimente statistice), în urma c rora va aproxima aceste valori. Dac not m cu n num rulde experimente efectuate, atunci le putem contabiliza pe acestea în urm torul sistem stochastic de ecuaµii:
yi = f(x, β) + εi, i = 1, 2, . . . , n. (13.8)
În ipoteze uzuale, erorile εi sunt variabile aleatoare identic repartizate N (0, σ), independente stochasticdou câte dou (σ > 0). Astfel, sistemul (13.8) cu n ecuaµii stochastice algebrice are necunoscutele βjj³i σ.
În cazul în care num rul de experimente este mai mic decât num rul parametrilor ce trebuie aproximaµi(n < k), atunci nu avem suciente informaµii pentru a determina aproxim rile. Dac n = k, atunciproblema se reduce la a rezolva n ecuaµii cu n necunoscute. În cel de-al treilea caz posibil, n > k, atunciavem un sistem cu nedeterminate.
În funcµie de forma funcµiei de regresie f , putem avea:
• regresie liniar simpl , în cazul în care avem doar o variabil independent ³i
f(x; β) = β0 + β1x.
• regresie liniar multipl , dac
f(x; β) = β0 + β1x1 + β2x2 + · · ·+ βmxm.
• regresie p tratic multipl (cu dou variabile), dac
f(x; β) = β0 + β1x1 + β2x2 + β11x21 + β12x1x2 + β22x
22.
• regresie polinomial , dac
f(x; β) = β0 + β1x+ β2x2 + β3x
3 + · · ·+ βkxk.
Vom avea regresie p tratic pentru k = 2, regresie cubic pentru k = 3 etc.
• regresie exponenµial , cândf(x; β) = β0 e
β1 x.
• regresie logaritmic , dac f(x; β) = β0 · logβ1 x.
• ³i altele.
De remarcat faptul c primele patru modele sunt liniare în parametri, pe când ultimele dou nu sunt liniareîn parametri. Modelele determinate de aceste funcµii se vor numi modele de regresie (curbe, suprafeµe etc).
În cadrul analizei regresionale, se cunosc datele de intrare, xii, ³i c ut m s estim m parametrii deregresie βjj ³i deviaµia standard a erorilor, σ. Dac funcµia de regresie f este cunoscut (intuit ),atunci metode statistice folosite pentru estimarea necunoscutelor sunt: metoda verosimilit µii maxime,metoda celor mai mici p trate ³i metoda lui Bayes. Dac f este necunoscut , metode ce duc la estimareanecunoscutelor sunt: metoda celor mai mici p trate sau metoda minimax.

Laborator 13 [Dr. Iulian Stoleriu] 176
Statistic Aplicat (Laborator 13)
Teste neparametrice (probleme)
Testul semnelor în Matlab
În Matlab, testul semnelor poate realizat cu ajutorul funcµiei
[p, h] = signtest(x, m)
unde:
• m este un num r real;
• x este un ³ir de caractere sau vector, asupra c ruia facem testul semnelor;
• variabila de memorie h este rezultatul testului. Dac rezultatul a³at este h = 0, atunci ipotezanul , (H0): setul de date x provine dintr-o distribuµie continu de median egal cu m, este admis la acest nivel de semnicaµie. Dac rezultatul a³at este h = 1, atunci ipoteza nul este respins .Se va admite astfel ipoteza alternativ (H1): setul de date x provine dintr-o distribuµie continu care nu are median egal cu m. Dac m nu apare, atunci se subînµelege c m = 0.
• variabila de memorie p este P- valoarea, adic valoarea maxim pentru pragul de semnicaµie αpentru care ipoteza nul este admis . Deoarece aici α = 0.05 este subînµeles, pentru un p > 0.05 sea³eaz h = 0. Altfel, se a³eaz h = 1.
O variant îmbun t µit a comenzii anterioare este urm toarea:
[p, h, stats] = signtest(x, y,'alpha',alpha,'method',method)
Aici, în plus faµ de preciz rile de mai sus, mai ad ug m c :
• Ipoteza nul este (H0): setul de date x− y provine dintr-o distribuµie continu de median egal cu0, cu ipoteza alternativ c mediana lui x− y nu este 0;
• variabila stats înmagazineaz urm toarele date:
zval - este valoarea statisticii Z pentru observaµia considerat (apare doar pentru selecµii devolum mare, n ≥ 30);
sign - este valoarea statisticii test;
• alpha este nivelul de semnicaµie;
• method este metoda folosit în testare. Putem avea o metod exact , când method este 'exact',sau aproximativ pentru 'approximate';

Laborator 13 [Dr. Iulian Stoleriu] 177
Exemplu 13.7 Pentru problema cu pizza, de mai sus, codul Matlab ce genereaz testul semnelor este:
x = [-1 1 1 1 -1 1 1 -1 1 1];
[p, h, stats] = signtest(x, 0)
Rezultatul testului este:
p = h = stats =
0.3438 0 sign: 3
Observaµia 13.8 Revenim la Exerciµiul 12.4 ³i urm rim testarea ipotezei nule folosind funcµia signtest.
Soluµie: Codul Matlab este simplu:
x = [ones(59,1); zeros(41,1)];
[p, h, stats] = signtest(x,.5)
Obµinem rezultatele:
p = h = stats =
0.0891 0 zval: 1.7000
sign: 41
ceea ce conrm c ipoteza nul este admis la nivelul de semnicaµie α = 0.05. √
Testul seriilor în Matlab
Funcµia Matlab ce simuleaz testul de vericare a stochasticit µii unui ³ir de caractere este
[h, p, stats] = runstest(x)
Acesta este un test ce veric dac valorile ce compun ³irul de caractere x apar în ordine aleatoare. Vari-abilele h, p ³i x sunt ca în testul signtest. Aici, variabila stats a³eaz urm toarele: num rul de faze,lungimile ec rei faze ³i valoarea statisticii pentru selecµia considerat .În urma rul rii comenzii, se va a³a valoarea h = 0 dac ipoteza c valorile apar în ordine aleatoare nupoate respins (este acceptat la nivelul de semnicaµie α = 0.05) ³i h = 1 în caz contrar. De exemplu,rularea codului
x = '011010100010001001010101110010101001010101010010111';
[h, p, stats] = runstest(x)

Laborator 13 [Dr. Iulian Stoleriu] 178
a³eaz
h = p = stats =
1 0.0014 nruns: 38
n1: 24
n0: 27
z: 3.2899
Acest rezultat se traduce astfel: ipoteza c ³irul considerat este aleator generat este respins la nivelulde semnicaµie α = 0.05 (subînµeles), P−valoarea este Pv = 0.0014 (asta însemnând c doar pentru unnivel de semnicaµie mai mic de Pv ³irul poate considerat aleator). Variabila de memorie stats a³eaz datele folosite în aplicarea testului.
Comanda urm toare
[h, p, stats] = runstest(x, v, alpha, tail)
a³eaz
• decizia testului, ori h = 0 ori h = 1, cu semnicaµia de mai sus;
• v este valoarea de referinµ a ³irului de caractere. Sunt num rate valorile ce sunt mai mici sau maimari decât v, cele care sunt exact egale cu v nu sunt contabilizate;
• alpha este nivelul de semnicaµie;
• tail poate una dintre urm toarele ipoteze alternative:
'both', ³irul nu este aleator (test bilateral). Aceasta opµiune poate s nu e specicat ,deoarece se subînµelege implicit.
'left', dac valorile tind s se adune în ciorchine (test unilateral stânga);
'right', dac valorile tind s se separe (test unilateral dreapta);
De exemplu, s consider m urm toarele comenzi:
y = 0:10; [h, p] = runstest(y,median(y),0.02,'left')
y = 0:10; [h, p] = runstest(y,median(y),0.02,'right')
y = 0:10; [h, p] = runstest(y,median(y),0.02,'both')
Rezultatele rul rii lor sunt (în ordine):
h = 1 p = 0.0043
h = 0 p = 1
h = 1 p = 0.0087
Ipoteza nul este aceea c valorile din ³irul [0 1 2 3 4 5 6 7 8 9 10] sunt aleatoare în jurul valorii mediane,median(y) = 5.

Laborator 13 [Dr. Iulian Stoleriu] 179
Observ m mai sus c testul unilateral stânga respinge ipoteza nul ³i admite ipoteza c valorile ³irului sestrâng ciorchine în jurul acestei valori. Testul unilateral dreapta admite ipoteza nul , iar testul bilateralo respinge, admiµând ipoteza c numerele nu vin în ordine aleatoare, raportat la valoarea median .

STATS 14 [Dr. Iulian Stoleriu] 180
14 Statistic Aplicat (C14)
Regresie
Regresie liniar simpl
Este cel mai simplu tip de regresie, în care avem o singur variabil independent , x, ³i variabila depen-dent y. S presupunem c ni se d familia de date bidimensionale (xi, yi)i=1, n. Reprezent m gracaceste date într-un sistem x0y (de exemplu, vezi Figura 14.1 (a)) ³i observ m o dependenµ aproapeliniar a lui y de x. Dac valoarea coecientului de corelaµie liniar , r, este aproape de 1 sau −1 (indicândo corelaµie liniar strâns ), atunci se pune problema stabilirii unei relaµii numerice exacte între x ³i y deforma
y = β0 + β1x. (14.1)
O astfel de dreapt o vom numi dreapta de regresie a lui y în raport cu x. Pentru un set de datebidimensionale ca mai sus, putem reprezenta aceast dreapt ca în Figura 14.1 (b).
Figura 14.1: Aproximarea unui nor de date prin dreapta de regresie.
Exemplu 14.1 Te hot r ³ti s cumperi ma³ina favorit , ce se vinde acum la preµul de 12500EUR. Lasemnarea contractului de vânzare-cump rare, pl te³ti suma iniµial de 10000RON ³i apoi rate lunare de85RON, timp de 5 ani. Dac not m cu X num rul lunilor pân la ultima rat ³i cu Y suma total pl tit pe ma³in , atunci între X ³i Y exist relaµia:
Y = 10000 + 85X.
În acest exemplu, relaµia între X ³i Y este una perfect liniar . O relaµie perfect liniar între datelebidimensionale (xi, yi)i=1, n reprezentate în Figura 14.1 ar însemna c toate acestea s-ar aa pe dreaptade regresie, ceea ce nu se întâmpl . De cele mai multe ori, datele reale nu urmeaz o astfel de relaµieperfect (spre exemplu, rata lunar poate una variabil , în funcµie de rata de schimb EUR-RON), caz încare parametrii din dependenµa liniar trebuie a estimaµi.

STATS 14 [Dr. Iulian Stoleriu] 181
A³adar, va trebui s µinem cont ³i de eventualele perturbaµii din sistem. Putem presupune astfel c dependenµa lui y de x este de forma
y = β0 + β1x+ ε, (14.2)
cu ε o variabil aleatoare repartizat N (0, σ).Plecând de la xi, yii, µelul nostru este s g sim o dreapt ce se apropie cel mai mult (într-un sens bineprecizat) de aceste date statistice. Cu alte cuvinte, va trebui s estim m valorile parametrilor de regresieβ0 ³i β1. Proced m dup cum urmeaz .Înlocuind datele bidimensionale în (14.2), avem urm torul sistem:
yi = β0 + β1xi + εi, i = 1, n, (14.3)
undeεi ∼ N (0, σ), ∀i ³i εi sunt independente stochastic.
Deoareceεi = yi − (β0 + β1xi), i = 1, n,
putem interpreta εi ca ind erorile de aproximare a valorilor observate (yi) cu cele prezise de dreapta deregresie (adic de valorile β0 + β1xi).inând cont c εi ∼ N (0, σ) ³i β0, β1 sunt valori deterministe, din (14.3) rezult c :
yi ∼ N (β0 + β1xi, σ), pentru ecare i,
de unde, probabilitatea ca într-o singur m sur toare a xi s obµinem r spunsul yi este
Pi =1
σ√
2πexp
(−(yi − β0 − β1xi)
2
2σ2
).
Deoarece εii sunt independente stochastic, probabilitatea ca în cele n observaµii independente s obµinemvectorul de valori (y1, y2, , . . . , yn) este (funcµia de verosimilitate):
L(β0, β1, σ) =
n∏i=1
Pi =1
σn(2π)n/2exp
(−
n∑i=1
(yi − β0 − β1xi)2
2σ2
).
Avem de estimat urm toarele cantit µi: β0, β1 ³i σ. Pentru aceasta, vom folosi metoda verosimilit µiimaxime. Urm rim s g sim acele valori ale parametrilor β0, β1 ³i σ care maximizeaz funcµia de verosi-militate. A³adar, problema de maximizare este urm toarea:
maxβ0, β1, σ
L(β0, β1, σ).
Condiµiile de extrem (impuse pentru lnL) sunt:
∂ lnL
∂β0=
1
2σ2
n∑i=1
(yi − β0 − β1xi) = 0;
∂ lnL
∂β1=
1
2σ2
n∑i=1
xi(yi − β0 − β1xi) = 0;
∂ lnL
∂σ= −n
σ+
1
σ2
n∑i=1
(yi − β0 − β1xi)2 = 0.
Rezolvând primele dou ecuaµii în raport cu β0 ³i β1, obµinem estimaµiile:
β1 =sxys2x
³i β0 = y − β1 x, (14.4)

STATS 14 [Dr. Iulian Stoleriu] 182
Figura 14.2: Estimarea dreptei de regresie.
unde,
x =1
n
n∑i=1
xi, y =1
n
n∑i=1
yi, s2x =
1
n− 1
n∑i=1
(xi − x)2, sxy =1
n− 1
n∑i=1
(xi − x)(yi − y).
Astfel, g sim c dreapta de regresie a lui y în raport cu x este aproximat de dreapta:
y = y − β1 x+sxys2x
x, (14.5)
sau, altfel scris ,y = y +
sxys2x
(x− x). (14.6)
Din ultima condiµie de extrem, g sim c o estimaµie pentru dispersia σ2 este:
σ2 =1
n
n∑i=1
(yi − β0 − β1xi)2. (14.7)
Îns , estimaµia pentru σ2 dat prin formula (14.7) este una deplasat . În practic , în locul acestei estimaµiise utilizeaz urm toarea estimaµie nedeplasat :
σ2 =1
n− 2
n∑i=1
(yi − β0 − β1xi)2. (14.8)
Observaµia 14.2 (1) Terminologie:
• dreapta de regresie, y = β0 + β1 x, este dreapta ce determin dependenµa liniar a lui y de valorilelui x, pentru întreaga populaµie de date;

STATS 14 [Dr. Iulian Stoleriu] 183
• dreapta de tare (tting line), y = β0 + β1 x, este dreapta care se apropie cel mai mult (în sensulmetodei celor mai mici p trate) de datele experimentale (de selecµie) xi, yii. Aceast dreapt este o aproximare a dreptei de regresie;
• Valorile yi se numesc valori observate, iar valorile yi = β0 + β1 xi, i = 1, n se numesc valori prezise(i = 1, n);
• valorile εi = yi − yi se numesc reziduuri. Un reziduu m soar deviaµia unui un punct observat dela valoarea prezis de estimarea dreptei de regresie (dreapta de tare);
• suma p tratelor erorilor,n∑i=1
ε2i , se noteaz de obicei prin SSE (sum of squared errors);
• eroarea medie p tratic sau rezidual esteSSE
n− 2, notat MSE (mean squared error);
• r d cina p trat a MSE se nume³te eroarea standard a regresiei;
• se poate demonstra c SSE
σ2= (n− 2)
σ2
σ2∼ χ2(n− 2).
cu autorul acestei relaµii se pot g si intervale de încredere pentru valoarea real a lui σ2.În formula (14.8), (n− 2) reprezint num rul gradelor de libertate ale variabilei SSE.
(2) Estimaµia dispersiei este o m sur a gradului de împr ³tiere a punctelor (x, y) în jurul dreptei deregresie. Mai subliniem faptul c valorile din formulele (14.4) ³i (14.8) sunt doar estimaµii ale parametrilornecunoscuµi, ³i nu valorile lor exacte. Formula pentru β1 mai poate scris sub forma:
β1 = ρxysysx.
(3) Dac deviaµia standard σ ar cunoscut a priori, atunci putem estima parametrii β0 ³i β1 în urm torulmod. Estim m ace³ti doi parametri prin acele valori ce realizeaz minimumul sumei p tratelor erorilorSSE. Vom avea astfel problema de minimizare (metoda celor mai mici p trate):
minβ0, β1
n∑i=1
(yi − β0 − β1xi)2.
Notând cu F (β0, β1) =n∑i=1
(yi − β0 − β1xi)2, condiµiile de extrem sunt:
∂F
∂β0= −2
n∑i=1
(yi − β0 − β1xi) = 0;
∂F
∂β1= −2
n∑i=1
xi(yi − β0 − β1xi) = 0.
Rezolvând acest sistem de ecuaµii algebrice în raport cu β0 ³i β1, g sim soluµiile β0 ³i, respectiv, β1 demai sus. Aceasta dovede³te c , în cazul în care erorile sunt identic normal repartizate ³i independentestochastic, metoda verosimilit µii maxime este, în fapt, totuna cu metoda celor mai mici p trate.

STATS 14 [Dr. Iulian Stoleriu] 184
Caracteristici ale parametrilor de regresie
Estimaµiile pentru parametrii de regresie β0 ³i β1 depind de observaµiile folosite. Pentru a decide dac va-lorile calculate pe baza datelor experimentale xi, yii pot considerate valorile potrivite pentru întreagapopulaµie, se vor utiliza test ri statistice. Mai jos, vom construi teste statistice cu privire la testareavalorilor ambilor parametri, β0 ³i β1, îns cel mai uzual test este testul pentru vericarea valorii panteidreptei de regresie, β1.
Mai întâi, vom calcula media ³i dispersia pentru ecare dintre β1 ³i β0.
Avem succesiv,
E(β1) = E(sxys2x
)= E
n∑i=1
(xi − x)(yi − y)
n∑i=1
(xi − x)2
.
Aici, xi sunt valori deterministe, iar yi variabile aleatoare. Deoarece
y = β0 + β1x+1
n
n∑i=1
εi,
obµinem c E(y) = β0 + β1x. Îns ,
E(yi − y) = β0 + β1xi − (β0 + β1x) = β1(x1 − x), ∀i.
A³adar,
E(β1) =
n∑i=1
(xi − x)E[yi − y]
n∑i=1
(xi − x)2
=
β1
n∑i=1
(xi − x)2
n∑i=1
(xi − x)2
= β1.
Pentru β0 avem:E(β0) = E(y)− xE(β1) = β0 + β1x− xβ1 = β0.
Prin urmare, atât β0, cât ³i β1, sunt stimatori nedeplasaµi pentru β0 ³i, respectiv, β1.
Calcul m acum dispersiile D2(β1
)³i D2
(β0
). Deoarece
n∑i=1
(xi − x)y = 0, avem:
D2(β1
)= D2
n∑i=1
(xi − x)yi
n∑i=1
(xi − x)2
=
n∑i=1
(xi − x)2D2(yi)(n∑i=1
(xi − x)2
)2 =σ2s2
x
s4x
=σ2
s2x
. (14.9)
Utilizând urm toarea proprietate,
D2(X + Y ) = D2(X) + 2 cov(X, Y ) +D2(Y ),
putem scrie:
D2(β0
)= D2(y − β1x) = D2(y)− 2x cov(y, β1) + x2D2
(β1
). (14.10)

STATS 14 [Dr. Iulian Stoleriu] 185
Dar,
D2(y) = D2
(1
n
n∑i=1
εi
)=
1
n2nσ2 =
σ2
n
³i
cov(y, β1
)= cov
1
n
n∑i=1
εi,
n∑i=1
(xi − x)(β0 + β1xi + εi)
b∑i=1
(xi − x)2
= cov
1
n
n∑i=1
εi,
n∑i=1
(xi − x)εi
n∑i=1
(xi − x)2
=1
nn∑i=1
(xi − x)2
cov
(n∑i=1
εi,n∑i=1
(xi − x)εi
)
=
n∑i=1
(xi − x)σ2
n
n∑i=1
(xi − x)2
= 0.
Înlocuind în (14.10), g sim c
D2(β0
)= x2σ
2
s2x
+σ2
n= σ2
(1
n+x2
s2x
). (14.11)
inând cont c estimatorii β0 ³i β1 sunt nedeplasaµi, de relaµiile (14.11) ³i (14.9), ³i de estimatorul σ2
pentru σ2, se poate demonstra c :β0 − β0
σ√
1n + x2
s2x
∼ t(n− 2) (14.12)
³iβ1 − β1
σsx
∼ t(n− 2). (14.13)
Aici, am notat prin σ cantitatea:
σ =
(1
n− 2
n∑i=1
(yi − β0 − β1xi)2
) 12
.
Putem folosi aceste statistici pentru a determina intervale de încredere pentru β0 ³i β1. Un interval deîncredere pentru β0 la nivelul de semnicaµie α este:[
β0 − t1−α2
;n−2 σ
√1
n+x2
s2x
, β0 + t1−α2
;n−2 σ
√1
n+x2
s2x
]. (14.14)

STATS 14 [Dr. Iulian Stoleriu] 186
Un interval de încredere pentru β1 la nivelul de semnicaµie α este:[β1 − t1−α
2;n−2
σ
sx, β1 + t1−α
2;n−2
σ
sx
]. (14.15)
Observaµia 14.3 (1) În general, dispersia σ2 a erorilor de regresie nu este cunoscut a priori. În cazulîn care aceasta este cunoscut , atunci în loc de (14.12) ³i (14.13) am avea:
β0 − β0
σ√
1n + x2
s2x
∼ N (0, 1), ³iβ1 − β1
σsx
∼ N (0, 1). (14.16)
În acest caz, intervalele de încredere pentru β0 ³i β1 vor similare cu cele din relaµiile (14.14) ³i (14.15),cu diferenµa c t1−α
2;n−2 este înlocuit prin z1−α
2. Oricum, pentru n sucient de mare, valorile t1−α
2;n−2
³i z1−α2sunt foarte apropiate.
(2) Coecientul de determinare R2 (= r2) se poate calcula ³i folosind urm toarea formul :
R2 = 1−s2y/x
s2y
, (14.17)
unde
s2y/x =
1
n− 1
n∑i=1
(yi − β0 − β1xi)2, s2
y =1
n− 1
n∑i=1
(yi − y)2.
În analiza regresional , coecientul R2 este folosit pentru a determina cât de bine poate construit ovaloare prezis pe baza valorilor independente.
Test statistic pentru β1
Mai jos prezent m testul ce veric dac β1 ia o valoare dat β10 sau nu, la un nivel de semnicaµie α.Dispersia erorilor de regresie este necunoscut .Test m
(H0) : β1 = β10 versus (H1) : β1 6= β10.
Consider m statistica
T =β1 − β1
σsx
,
care urmeaz repartiµia t(n− 2). Etapele testului sunt urm toarele:
• Calcul m valoarea critic
T0 =β1 − β10
σsx
.
• Calcul m cuantila de ordin 1− α2 pentru repartiµia t cu (n− 2) grade de libertate, t1−α
2;n−2;
• Dac |T0| < t1−α
2;n−2, atunci accept m ipoteza (H0);
Dac |T0| ≥ t1−α
2;n−2, atunci accept m ipoteza (H1);

STATS 14 [Dr. Iulian Stoleriu] 187
Observaµia 14.4 (1) O ipotez alternativ poate considerat ³i una dintre urm toarele:
(H1)s : β1 < β10, (H1)d : β1 > β10.
(2) Dac β10 = 0, atunci ipoteza alternativ β1 6= 0 este ipoteza c între x ³i y exist o dependenµ liniar .
Test statistic pentru β0
Mai jos prezent m testul ce veric dac β0 ia o valoare dat β∗0 sau nu, la un nivel de semnicaµie α.Dispersia erorilor de regresie este necunoscut .Test m
(H0) : β0 = β∗0 versus (H1) : β0 6= β∗0 .
Consider m statistica
T =β0 − β0
σ√
1n + x2
s2x
∼ t(n− 2),
care urmeaz repartiµia t(n− 2). Etapele testului sunt urm toarele:
• Calcul m valoarea critic
T0 =β0 − β∗0σ√
1n + x2
s2x
∼ t(n− 2).
• Calcul m cuantila de ordin 1− α2 pentru repartiµia t cu (n− 2) grade de libertate, t1−α
2;n−2;
• Dac |T0| < t1−α
2;n−2, atunci accept m ipoteza (H0);
Dac |T0| ≥ t1−α
2;n−2, atunci accept m ipoteza (H1);
Observaµia 14.5 De asemenea, teste unilaterale pot considerate ³i în cazul test rii valorii lui β0.În cazul în care σ2 este cunoscut a priori atunci, graµie relaµiilor (14.16), putem utiliza testul Z pentrutestarea ipotezelor de mai sus, atât pentru β0, cât ³i pentru β1.
Predicµie prin regresie
[Pe scurt, predicµia prin regresie este precum ai conduce ma³ina legat la ochi,ghidat de un copilot care prive³te doar în lunet ]
În anumite cazuri, putem folosi regresia în predicµia unor valori ale variabilei dependente. De exemplu,putem prezice temperatura într-un anumit ora³ plecând de la observaµiile temperaturilor din ora³eleînvecinate. Regresia poate utilizat pentru predicµie dup cum urmeaz . S presupunem ca datele pecare le deµinem, (xi, yii=1, n, pot modelate de o dreapt de regresie de forma (14.1). Dat ind ovaloarea xp ce nu se a printre valorile xi, dar este o valoare cuprins între valorile extreme ale variabileiindependente, xmin ³i xmax, dorim s prezicem valoarea r spuns,
yp = β0 + β1 xp + εp.
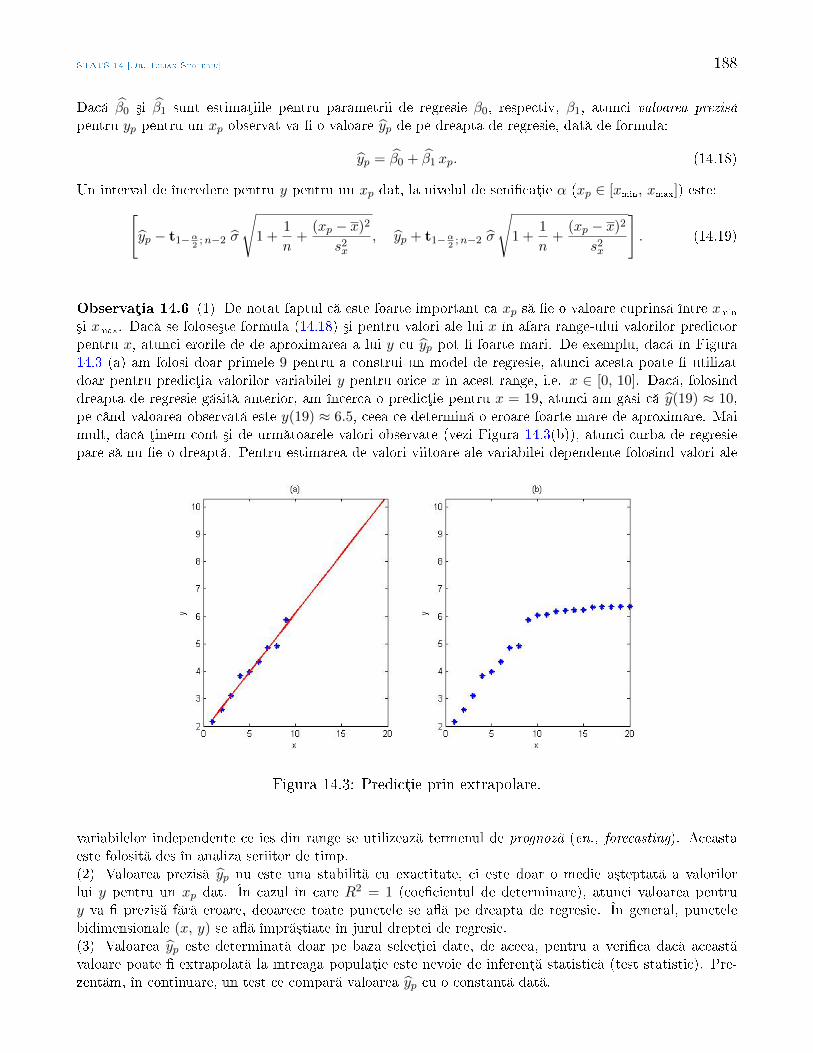
STATS 14 [Dr. Iulian Stoleriu] 188
Dac β0 ³i β1 sunt estimaµiile pentru parametrii de regresie β0, respectiv, β1, atunci valoarea prezis pentru yp pentru un xp observat va o valoare yp de pe dreapta de regresie, dat de formula:
yp = β0 + β1 xp. (14.18)
Un interval de încredere pentru y pentru un xp dat, la nivelul de senicaµie α (xp ∈ [xmin, xmax]) este:[yp − t1−α
2;n−2 σ
√1 +
1
n+
(xp − x)2
s2x
, yp + t1−α2
;n−2 σ
√1 +
1
n+
(xp − x)2
s2x
]. (14.19)
Observaµia 14.6 (1) De notat faptul c este foarte important ca xp s e o valoare cuprins între xmin
³i xmax. Dac se folose³te formula (14.18) ³i pentru valori ale lui x în afara range-ului valorilor predictorpentru x, atunci erorile de de aproximarea a lui y cu yp pot foarte mari. De exemplu, dac în Figura14.3 (a) am folosi doar primele 9 pentru a construi un model de regresie, atunci acesta poate utilizatdoar pentru predicµia valorilor variabilei y pentru orice x în acest range, i.e. x ∈ [0, 10]. Dac , folosinddreapta de regresie g sit anterior, am încerca o predicµie pentru x = 19, atunci am g si c y(19) ≈ 10,pe când valoarea observat este y(19) ≈ 6.5, ceea ce determin o eroare foarte mare de aproximare. Maimult, dac µinem cont ³i de urm toarele valori observate (vezi Figura 14.3(b)), atunci curba de regresiepare s nu e o dreapt . Pentru estimarea de valori viitoare ale variabilei dependente folosind valori ale
Figura 14.3: Predicµie prin extrapolare.
variabilelor independente ce ies din range se utilizeaz termenul de prognoz (en., forecasting). Aceastaeste folosit des în analiza seriitor de timp.(2) Valoarea prezis yp nu este una stabilit cu exactitate, ci este doar o medie a³teptat a valorilorlui y pentru un xp dat. În cazul în care R2 = 1 (coecientul de determinare), atunci valoarea pentruy va prezis f r eroare, deoarece toate punctele se a pe dreapta de regresie. În general, punctelebidimensionale (x, y) se a împr ³tiate în jurul dreptei de regresie.(3) Valoarea yp este determinat doar pe baza selecµiei date, de aceea, pentru a verica dac aceast valoare poate extrapolat la întreaga populaµie este nevoie de inferenµ statistic (test statistic). Pre-zent m, în continuare, un test ce compar valoarea yp cu o constant dat .

STATS 14 [Dr. Iulian Stoleriu] 189
Test m(H0) yp = y0 versus (H1) yp 6= y0.
Etapele testului sunt urm toarele:
• Estim m yp utilizând formula (14.18).
• Consider m statistica
T =yp − y√
MSE( 1n +
(xp−x)2∑i(xi−x)2
)∼ t(n− 2);
• Calculez valoarea T0 =yp − y0√
MSE( 1n +
(xp−x)2∑i(xi−x)2
);
• Dac |T0| < t1−α
2;n−2, atunci accept m ipoteza (H0);
Dac |T0| ≥ t1−α
2;n−2, atunci accept m ipoteza (H1);
(4) În concluzie, regresia este o unealt dibace pentru predicµie. Economi³tii care o utilizeaz pot prezicecu succes chiar 10 dintre ultimele 2 recesiuni! ,
Exemplu 14.7 Un interval de încredere pentru yp la nivelul de încredere 1− α este:[yp − S t1−α
2;n−2, yp + S t1−α
2;n−2
], (14.20)
unde
S =
√MSE
(1 +
1
n+
(xp − x)2∑i(xi − x)2
).
(de vericat!)
Observaµia 14.8 Pân acum am v zut cum putem estima valoarea lui y folosind pe x. În unele cazuri,putem inversa rolurile lui x ³i y, ³i putem vorbi astfel de regresie a lui x în raport cu y. De exemplu,în Exerciµiul 14.9 am putea estima notele la Probabilit µi în funcµie de notele la Statistic . Formuleleobµinute pentru dreapta de regresie a lui x în raport cu y sunt cele g site anterior pentru dreapta deregresie a lui y în raport cu x, în care rolurile lui x ³i y sunt inversate.

Laborator 104 [Dr. Iulian Stoleriu] 190
Statistic Aplicat (Laborator 14)
Regresie (exerciµii rezolvate)
Fie X ³i Y doi vectori de acela³i tip. Urm toarele funcµii din Matlab sunt utile pentru analiza corelaµiei³i regresiei:
• scatter(X,Y) reprezint grac valorile lui Y vs. valorile lui X;
• R = corrcoef(X,Y) calculeaz coecientul de corelaµie între X ³i Y. Rezultatul este a³at sub forma:>> ans =
1.0000 ρρ 1.0000
unde 1.0000 este coecientul de corelaµie dintre X ³i X, respectiv Y ³i Y, iar ρ este coecientul c utat.
• cov(X,Y) pentru matricea de covarianµ empiric dintre X ³i Y (formula (5.10));Funcµia cov(X,Y,1) este tot matrice de covarianµ , îns în acest caz formula folosit este (5.11).
• b = regress(Y,X) a³eaz estimarea coecienµilor pentru care Y = bX. Aici, X este o matricen× k ³i Y un vector coloana n× 1. Coloanele vectorului X corespund observaµiilor (i.e., variabilelorindependente).Dac X este un vector coloan de aceea³i dimensiune cu Y, atunci b este doar un scalar.Dac X este matrice, atunci putem folosi aceast comand pentru a estima coecienµii de regresieliniar multipl . Spre exemplu, s presupunem c se dore³te estimarea coecienµilor de regresieliniar simpl , i.e., β0 ³i β1 pentru care y = β0 + β1 x, unde pentru ecare dintre x ³i y avem nobservaµii. În acest caz, k = 2. Fie X, respectiv, Y vectorii ce conµin aceste observaµii. ComandaMatlab care estimeaz cei doi coecienµi este
B = regress(Y', [ones(n,1)'; X]')
Comanda furnizeaz aproxim ri pentru parametrii β0 ³i β1 ce fac urm toarea aproximare cât maibun :
y1
y2...yn
≈ β0
11...1
+ β1
x1
x2...xn
.
• p = polyfit(X,Y,n) g se³te coecienµii unui polinom p(x) de grad n ale c rui valori p(xi) se apropiecel mai mult de datele observate yi, în sensul celor mai mici p trate. Matlab va a³a în acestcaz un vector linie de lungime n+ 1, conµinând coecienµii polinomiali în ordinea descresc toare aputerilor. Spre exemplu, dac
p(x) = β0 + β1x+ β2x2 + · · ·+ βnx
n,
atunci Matlab va a³aβn, . . . , β1, β0.

Laborator 104 [Dr. Iulian Stoleriu] 191
• Y = polyval(p,X) a³eaz valorile unui polinom p(x) pentru valorile din vectorul X. Polinomulp(x) este dat prin coecienµii s i, ordonaµi în ordine descresc toare a puterilor. De exemplu, dac p(x) = 3x2 + 2x+ 4 ³i dorim s evalu m acest polinom pentru trei valori, 1, 5 ³i 7, atunci scriem înMatlab:
p = [3 2 4]; polyval(p,[-3 1 5])
obµinând rezultatul:ans = 37 5 69
Exerciµiu 14.9 Se dore³te s decid dac exist vreo corelaµie între notele la examenul de Probabilit µi³i cele de la Statistic obµinute de studenµii unui an de studiu. În acest sens, au fost observate noteleobµinute de 10 studenµi la aceste dou discipline ³i au fost trecute în Tabelul 14.1 de mai jos. Se cere:(a) Stabiliµi dac exist o leg tur puternic între aceste note (r ³i r2);(b) Determinaµi dreapta de regresie a notelor de la Statistic în raport cu notele la Probabilit µi ³idesenaµi-o în acela³i sistem de axe ca ³i notele obµinute (scatter plot).(c) Testaµi dac exist sau nu vreo corelaµie între notele de la Statistic ³i Probabilit µi.
Student A B C D E F G H I JProbabilit µi 82 36 72 58 70 48 44 94 60 40Statistic 84 42 50 64 68 54 46 80 60 32
Tabela 14.1: Notele la Statistic ³i Probabilit µi.
Soluµie: (a) Calcul m r cu formula (13.1). Funcµia Matlab pentru coecientul Pearson este corrcoef.În codul Matlab de mai jos l-am calculat pe r folosind aceast funcµie, dar ³i în dou alte modalit µi,folosind formula (13.2) sau scriind desf ³urat expresia lui r.
(b) Coecienµii de regresie se pot obµine în 3 moduri, e folosind funcµiaMatlab polyfit, care realizeaz tarea datelor cu un polinom, în cazul liniar ind un polinom de forma S(P ) = β0 +β1 P . O alt variant de calcul a coecienµilor β0 ³i β1 este simpla implementare în Matlab a formulelor pentru ace³tia. Atreia variant este folosirea funcµiei regress din Matlab.Reprezentarea grac a datelor poate realizat folosind ori funcµia plot, ori funcµia "scatter", ambelefuncµii predenite din Matlab. Gracul este cel din Figura 14.4.
P = [82,36,72,58,70,48,44,94,60,40]; S = [84,42,50,64,68,54,46,80,40,32];
mp = mean(P); ms = mean(S);
%%%~~~~~~~~~~~~~~ Calculez coeficientul de corelatie empiric ~~~~~~~~~~~~~~~~~~~~~~~~~~
CC = corrcoef(P,S); r = CC(1,2)
%%%~~~~~~~~~~~~~~~~~~~~ Alte variante de calcul pentru r ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
% C = cov(P,S)/(std(P)*std(S)); r = C(1,2);
% r = sum((P-mp).*(S-ms))/sqrt(sum((P-mp).^2)*sum((S-ms).^2));
%%%~~~~~~~~~~~~~~~~~~~~~~~~ Calculez coeficientii de regresie ~~~~~~~~~~~~~~~~~~~~~~~
B = polyfit(P,S,1)
%%%~~~~~~~~~~~~~~~~~~~~ Alte variante de calcul pentru B ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
% b1 = sum((P-mp).*(S-ms))/sum((P-mp).^2); b0 = ms - b1*mp;
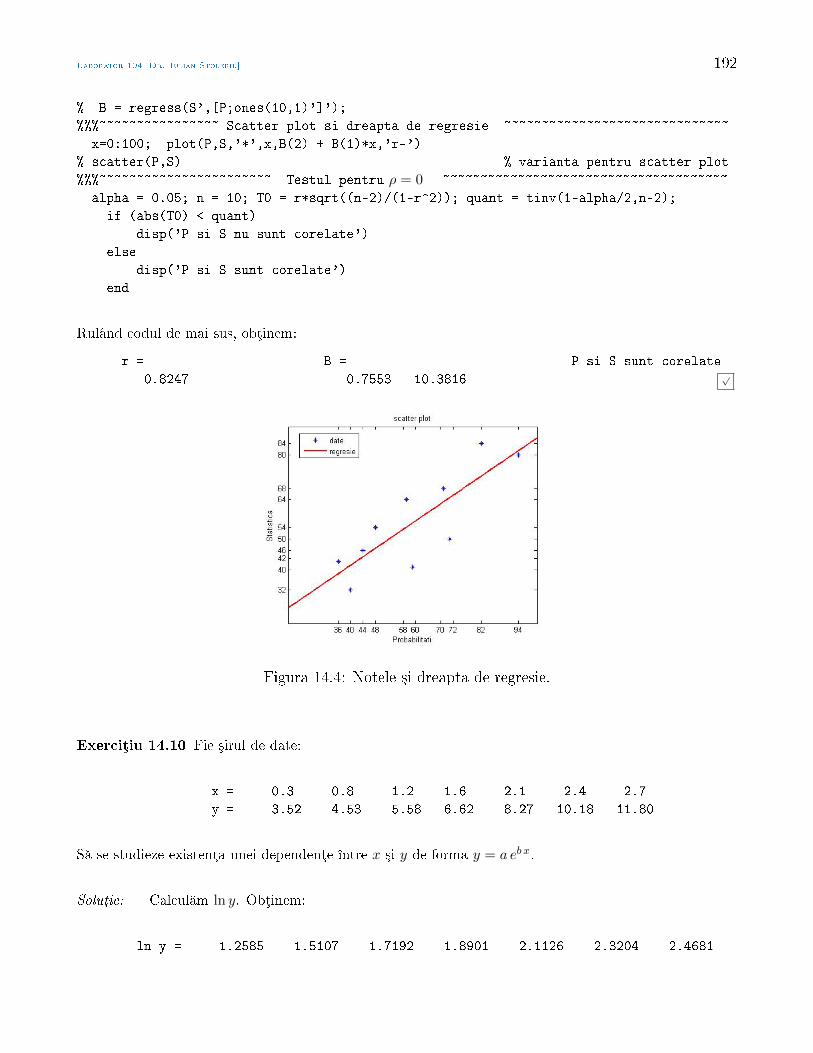
Laborator 104 [Dr. Iulian Stoleriu] 192
% B = regress(S',[P;ones(10,1)']');
%%%~~~~~~~~~~~~~~~~ Scatter plot si dreapta de regresie ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
x=0:100; plot(P,S,'*',x,B(2) + B(1)*x,'r-')
% scatter(P,S) % varianta pentru scatter plot
%%%~~~~~~~~~~~~~~~~~~~~~~~ Testul pentru ρ = 0 ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
alpha = 0.05; n = 10; T0 = r*sqrt((n-2)/(1-r^2)); quant = tinv(1-alpha/2,n-2);
if (abs(T0) < quant)
disp('P si S nu sunt corelate')
else
disp('P si S sunt corelate')
end
Rulând codul de mai sus, obµinem:
r = B = P si S sunt corelate
0.8247 0.7553 10.3816 √
Figura 14.4: Notele ³i dreapta de regresie.
Exerciµiu 14.10 Fie ³irul de date:
x = 0.3 0.8 1.2 1.6 2.1 2.4 2.7
y = 3.52 4.53 5.58 6.62 8.27 10.18 11.80
S se studieze existenµa unei dependenµe între x ³i y de forma y = a eb x.
Soluµie: Calcul m ln y. Obµinem:
ln y = 1.2585 1.5107 1.7192 1.8901 2.1126 2.3204 2.4681
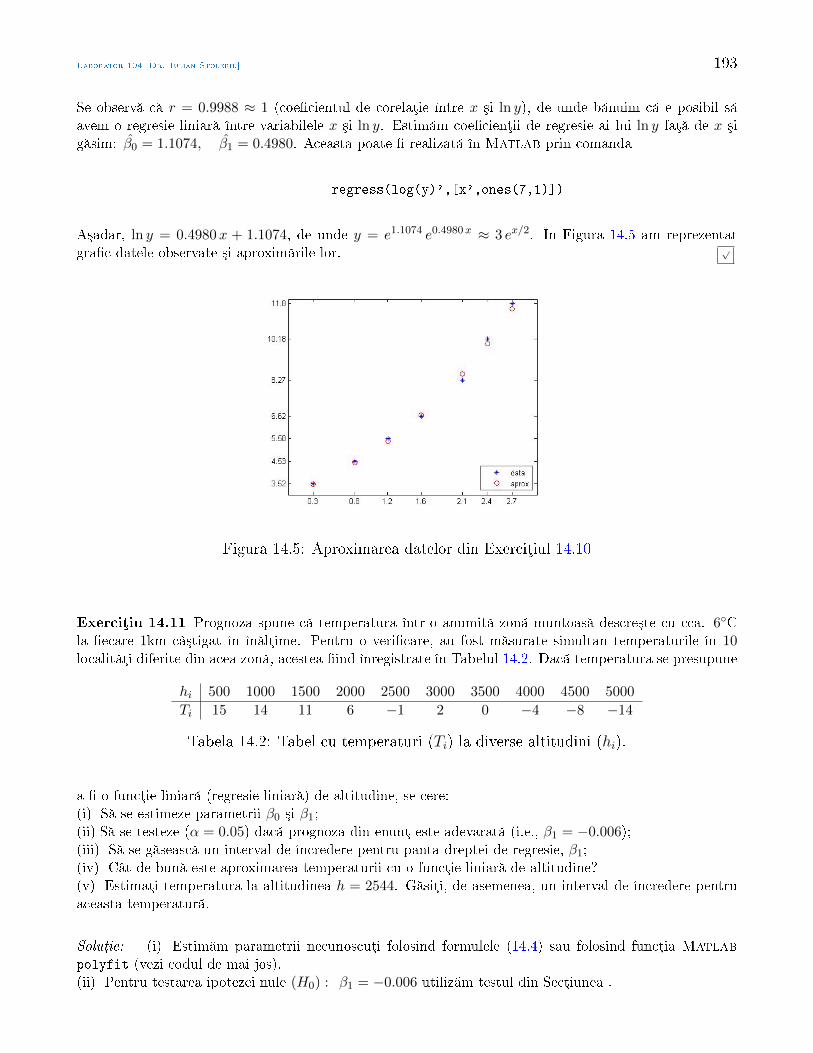
Laborator 104 [Dr. Iulian Stoleriu] 193
Se observ c r = 0.9988 ≈ 1 (coecientul de corelaµie între x ³i ln y), de unde b nuim c e posibil s avem o regresie liniar între variabilele x ³i ln y. Estim m coecienµii de regresie ai lui ln y faµ de x ³ig sim: β0 = 1.1074, β1 = 0.4980. Aceasta poate realizat în Matlab prin comanda
regress(log(y)',[x',ones(7,1)])
A³adar, ln y = 0.4980x + 1.1074, de unde y = e1.1074 e0.4980x ≈ 3 ex/2. În Figura 14.5 am reprezentatgrac datele observate ³i aproxim rile lor. √
Figura 14.5: Aproximarea datelor din Exerciµiul 14.10
Exerciµiu 14.11 Prognoza spune c temperatura într-o anumit zon muntoas descre³te cu cca. 6Cla ecare 1km câ³tigat în în lµime. Pentru o vericare, au fost m surate simultan temperaturile în 10localit µi diferite din acea zon , acestea ind înregistrate în Tabelul 14.2. Dac temperatura se presupune
hi 500 1000 1500 2000 2500 3000 3500 4000 4500 5000
Ti 15 14 11 6 −1 2 0 −4 −8 −14
Tabela 14.2: Tabel cu temperaturi (Ti) la diverse altitudini (hi).
a o funcµie liniar (regresie liniar ) de altitudine, se cere:(i) S se estimeze parametrii β0 ³i β1;(ii) S se testeze (α = 0.05) dac prognoza din enunµ este adevarat (i.e., β1 = −0.006);(iii) S se g seasc un interval de încredere pentru panta dreptei de regresie, β1;(iv) Cât de bun este aproximarea temperaturii cu o funcµie liniar de altitudine?(v) Estimaµi temperatura la altitudinea h = 2544. G siµi, de asemenea, un interval de încredere pentruaceasta temperatur .
Soluµie: (i) Estim m parametrii necunoscuµi folosind formulele (14.4) sau folosind funcµia Matlabpolyfit (vezi codul de mai jos).(ii) Pentru testarea ipotezei nule (H0) : β1 = −0.006 utiliz m testul din Secµiunea .

Laborator 104 [Dr. Iulian Stoleriu] 194
(iii) Un interval de încredere pentru β1 se poate calcula folosind formula (14.15).(iv) Pentru a decide cât de bun este aproximarea, calcul m coecientul de determinare, R2. Acesta esteR2 = 94.83, ceea ce înseamn c temperatura real este foarte aproape de cea prognozat .(v) Utiliz m formulele (14.18) ³i (14.19), pentru xp = 2544. (vezi rezultatele generate de codul de maijos)Codul Matlab este urm torul:
h = [500 1000 1500 2000 2500 3000 3500 4000 4500 5000];
T = [15 14 11 6 -1 2 0 -4 -8 -14]; mh = mean(h); mT = mean(T);
%%%~~~~~~ Calculez coeficientul de corelatie empiric si coeficientul de determinare ~~~
CC = corrcoef(h,T); r = CC(1,2)
R2 = r^2
%%%~~~~~~~~~~~~~~~~~~~ Calculez coeficientii de regresie ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
B = polyfit(h,T,1)
%%%~~~~~~~~~~~~~~~~~~~~ Alte variante de calcul pentru B ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
% B = regress(T',[h;ones(10,1)']');
% b1 = sum((h-mh).*(T-mT))/sum((h-mh).^2); b0 = mT - b1*mh;
%%%~~~~~~~~~~~~~~~~~~~~ Scatter plot si dreapta de regresie ~~~~~~~~~~~~~~~~~~~~~~~~~
x=0:5600; plot(h,T,'*',x,B(2) + B(1)*x,'r-')
%%%~~~~~~ Testul pentru panta dreptei de regresie, (H0) : β1 = −0.006 ~~~~~~~~~~~~~~~~
alpha = 0.05; n = 10;
sigmahat = sqrt(sum((T-B(2) - B(1)*h).^2)/(n-2)); sigmax = std(h);
T0 = (B(1)+0.006)*sigmax/sigmahat; quant = tinv(1-alpha/2,n-2);
if (abs(T0) < quant)
disp('ipoteza (H0) se accepta')
else
disp('ipoteza (H0) se respinge')
end
%%%~~~~~~~~~~~~~~~ Interval de incredere pentru β1 ~~~~~~~~~~~~~~~~~~~~~~~
CI = [B(1) - quant*sigmahat/sigmax,\;B(1) + quant*sigmahat/sigmax]
hp = 2544; Tp = B(2) + B(1)*hp
CI_T = [Tp - quant*sigmahat*sqrt1 + 1/n + (hp-mh)^2/sigmax^2, ...
Tp + quant*sigmahat*sqrt1 + 1/n + (hp-mh)^2/sigmax^2]
Rulând codul de mai sus, obµinem:
r = R2 = B = CI =
-0.9738 94.83 [-0.0061, 18.9333] [-0.0096, -0.0026]
Tp = CI_T =
3.3610 [-2.2335, 8.9555]
ipoteza nula se accepta √
Alte funcµii utile în Matlab pentru analiza regresional (unele disponibile doar în pachetul de programeStatistics Toolbox):
• polytool(x, y) - determin o dreapt de regresie pentru datele conµinut în vectorii x ³i y. Desenula³at este interactiv ³i apare într-o interfaµ grac .
• polytool(x, y, n, alpha, xname, yname) - aproximeaz datele bivariate (x, y) cu un polinom
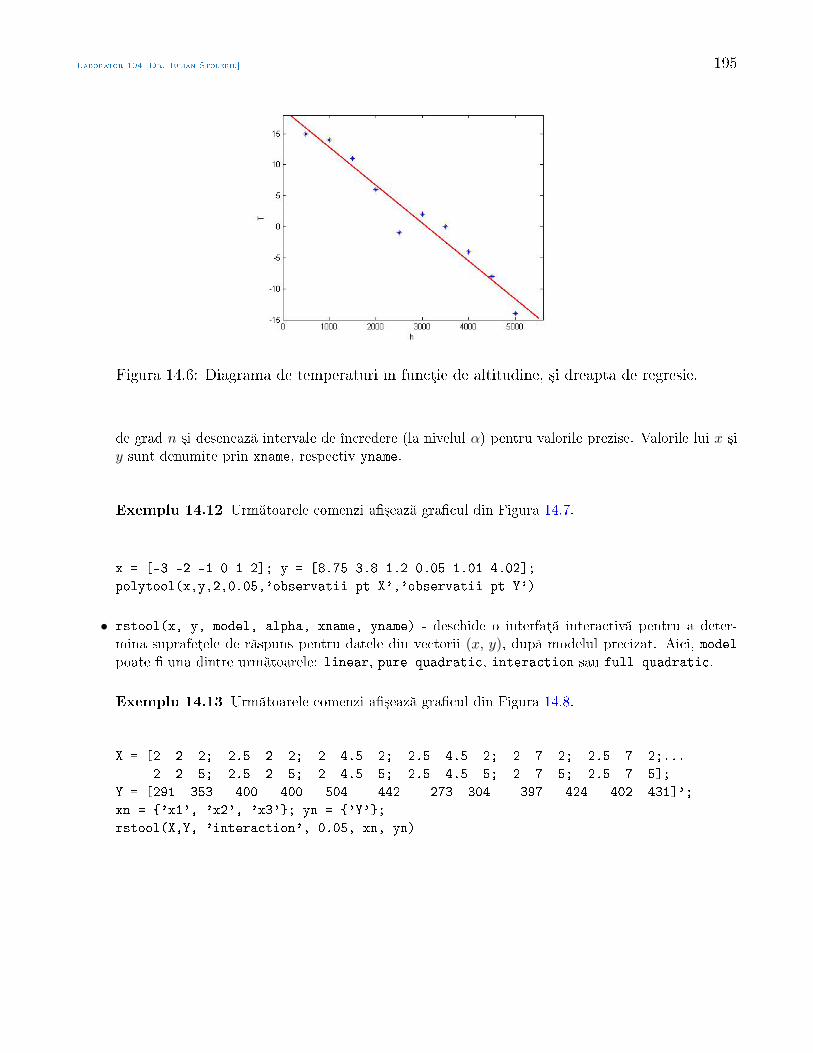
Laborator 104 [Dr. Iulian Stoleriu] 195
Figura 14.6: Diagrama de temperaturi în funcµie de altitudine, ³i dreapta de regresie.
de grad n ³i deseneaz intervale de încredere (la nivelul α) pentru valorile prezise. Valorile lui x ³iy sunt denumite prin xname, respectiv yname.
Exemplu 14.12 Urm toarele comenzi a³eaz gracul din Figura 14.7.
x = [-3 -2 -1 0 1 2]; y = [8.75 3.8 1.2 0.05 1.01 4.02];
polytool(x,y,2,0.05,'observatii pt X','observatii pt Y')
• rstool(x, y, model, alpha, xname, yname) - deschide o interfaµ interactiv pentru a deter-mina suprafeµele de r spuns pentru datele din vectorii (x, y), dup modelul precizat. Aici, modelpoate una dintre urm toarele: linear, pure quadratic, interaction sau full quadratic.
Exemplu 14.13 Urm toarele comenzi a³eaz gracul din Figura 14.8.
X = [2 2 2; 2.5 2 2; 2 4.5 2; 2.5 4.5 2; 2 7 2; 2.5 7 2;...
2 2 5; 2.5 2 5; 2 4.5 5; 2.5 4.5 5; 2 7 5; 2.5 7 5];
Y = [291 353 400 400 504 442 273 304 397 424 402 431]';
xn = 'x1', 'x2', 'x3'; yn = 'Y';
rstool(X,Y, 'interaction', 0.05, xn, yn)
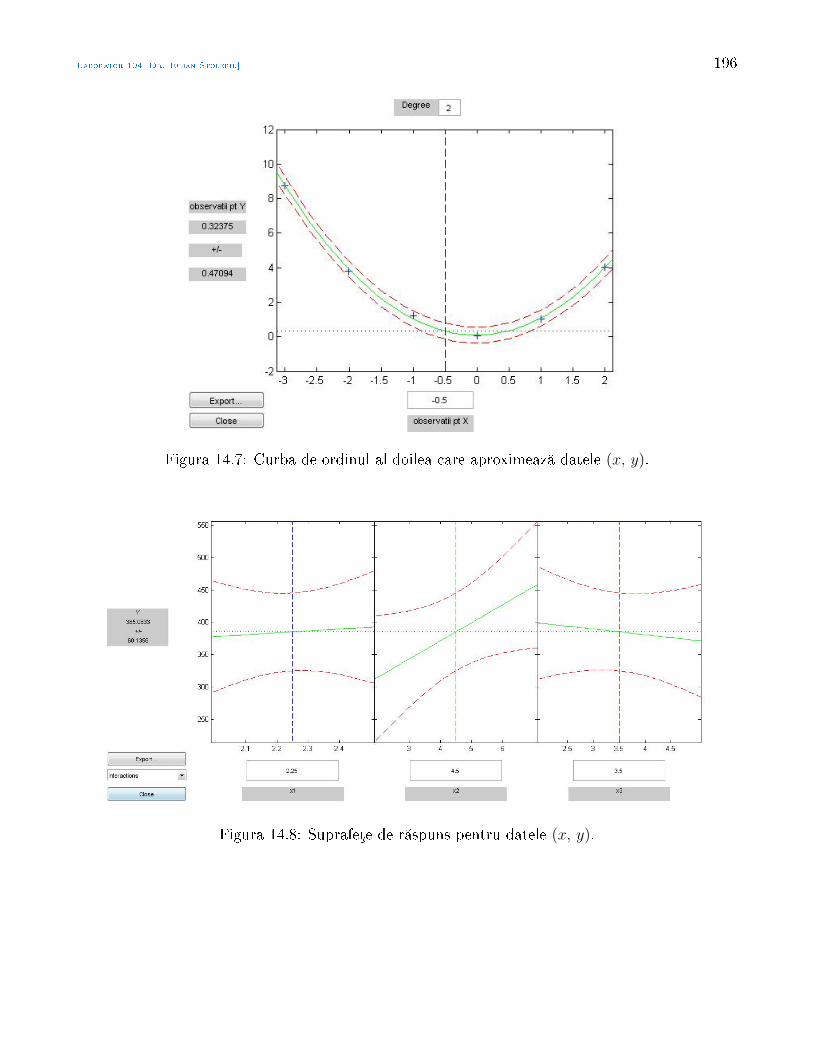
Laborator 104 [Dr. Iulian Stoleriu] 196
Figura 14.7: Curba de ordinul al doilea care aproximeaz datele (x, y).
Figura 14.8: Suprafeµe de r spuns pentru datele (x, y).

Anexa 1 [Dr. Iulian Stoleriu] 197
15 Anexa 1
Scurt introducere în Matlab
Matlab este un pachet comercial de programe de înalt performanµ produs de The MathWorks, Inc.,dedicat calculului numeric ³i reprezent rilor grace în domeniul ³tiinµelor ³i ingineriei. Elementul de baz cu care opereaz Matlab-ul este matricea (Matlab este acronim de laMATrix LABoratory). Matlabeste un software standard în mediile universitare, precum ³i în domeniul cercet rii ³i rezolv rii practice aproblemelor legate de procesarea semnalelor, identicarea sistemelor, calculul statistic, prelucrarea datelorexperimentale, matematici nanciare, matematici aplicate în diverse domenii etc. Cea mai important caracteristic a Matlab-ului este u³urinµa cu care poate extins. La programele deja existente înMatlab, utilizatorul poate ad uga propriile sale coduri, dezvoltând aplicaµii specice domeniului în carelucreaz . Matlab-ul include aplicaµii specice, numite Toolbox-uri. Acestea sunt colecµii extinse defuncµii Matlab (³iere M) care dezvolt mediul de programare de la o versiune la alta, pentru a rezolvaprobleme din domenii variate. Structural, Matlab-ul este realizat sub forma unui nucleu de baz , cuinterpretor propriu, în jurul c ruia sunt construite toolbox-urile.
Prezent m mai jos o scurt introducere în Matlab a principalelor funcµii ³i comenzi folosite în aceast lucrare. Pentru o tratare mai detaliat , puteµi consulta un manual de utilizare sau [9]. Mai menµion maici ³i lucrarea [1], unde puteµi g si diverse modalit µi de implementare în Matlab ale unor noµiuni deTeoria Probabilit µilor ³i Statistic matematic .Folosind comanda demo din Matlab, puteµi urm ri o demonstraµie a principalelor facilit µi din Matlab,cât ³i a pachetelor de funcµii (toolbox) de care aµi putea interesaµi. Dintre acestea, amintim StatisticsToolbox, care este o colecµie de funcµii folosite pentru analiza, modelarea ³i simularea datelor. Conµine:analiza gracelor (GUI), diverse repartiµii probabilistice (beta, binomial , Poisson, χ2), generarea nume-relor aleatoare, analiza regresional , descrieri statistice.
• ComenzileMatlab pot scrise în ³iere cu extensia .m, ce urmeaz apoi a compilate. Un ³ier-mconst dintr-o succesiune de instrucµiuni, cu posibilitatea apel rii altor ³iere-M precum ³i a apel riirecursive. De asemenea, Matlab poate folosit ca pe un mediu computaµional interactiv, caz încare ecare linie este prelucrat imediat. Odat introduse expresiile, acestea pot vizualizate sauevaluate imediat. De exemplu, introducând la linia de comand
>> a = sqrt((sqrt(5)+1)/2)
Matlab dene³te o variabil de memorie a, c reia îi atribuie valoareaa =
1.2720
• Variabilele sunt denite cu ajutorul operatorului de atribuire, =, ³i pot utilizate f r a declarade ce tip sunt. Valoarea unei variabile poate : o constant , un ³ir de caractere, poate reie³i dincalculul unei expresii sau al unei funcµii.
• Pentru a g si informaµii imediate despre vreo funcµie predenit , comanda help va vine în ajutor.De exemplu,

Anexa 1 [Dr. Iulian Stoleriu] 198
>> help length
a³eaz urm toarele:
LENGTH Length of vector.
LENGTH(X) returns the length of vector X. It is equivalent
to MAX(SIZE(X)) for non-empty arrays and 0 for empty ones.
See also numel.
• Comanda help poate utilizat doar dac se cunoa³te exact numele funcµiei. Altfel, folosirea co-menzii lookfor este recomandat . De exemplu, comanda
>> lookfor length
produce:
NAMELENGTHMAX Maximum length of MATLAB function or variable name.
VARARGIN Variable length input argument list.
VARARGOUT Variable length output argument list.
LENGTH Length of vector.
• Matlab este un mediu computaµional orientat pe lucru cu vectori ³i matrice. O linie de cod deforma
>> v = [1,3,5,7,9] % sau v = [1 3 5 7 9]
dene³te un vector linie ce are componentele 1, 3, 5, 7, 9. Aceasta poate realizat ³i folosindcomanda v = 1:2:9 adic a³eaz numerele de la 1 la 9, cu pasul 2. Pentru un vector coloan ,folosim punct-virgul între elemente, adic
>> v = [1;3;5;7;9] % vector coloana
O alt variant de a deni un vector este
>> v = linspace(x1,x2,n)
adic v este un vector linie cu n componente, la intervale egale între x1 ³i x2.
• Denirea matricelor se poate face prin introducerea explicit a elementelor sale sau prin instruc-µiuni ³i funcµii. La denirea explicit , trebuie µinut cont de urm toarele: elementele matricei suntcuprinse între paranteze drepte ([ ]), elementele unei linii trebuie separate prin spaµii libere sauvirgule, liniile se separ prin semnul punct-virgul . De exemplu, comanda
>> A = [1 2 3; 4, 5, 6]

Anexa 1 [Dr. Iulian Stoleriu] 199
dene³te matriceaA =
1 2 3
4 5 6
• Apelul elementelor unei matrice se poate face prin comenzile A(i,j) sau A(:,j) (elementele decoloan j) sau A(i,:) (elementele de linia i);
• Funcµia Matlab ones(m,n) dene³te o matrice m × n, având toate componentele egale cu 1.Funcµia zeros(m,n) dene³te o matrice zero m× n. Funcµia eye(n) dene³te matricea unitate deordin n.
• Dup cum vom vedea mai jos, Matlab permite denirea unor funcµii foarte complicate prin scri-erea unui cod. Dac funcµia ce o avem de denit este una simpl , atunci avem varianta utiliz riicomenzii inline. Spre exemplu, denim funcµia f(x, y) = e5x sin 3y:
>> f = inline('exp(5*x).*sin(3*y)')
f =
Inline function:
f(x,y) = exp(5*x).*sin(3*y)
Putem apoi calcula f(7, π) prin
>> f(7,pi)
0.5827
• Un program Matlab poate scris sub forma ³ierelor script sau a ³ierelor de tip funcµie. Ambeletipuri de ³iere sunt scrise în format ASCII. Aceste tipuri de ³iere permit crearea unor noi funcµii,care le pot completa pe cele deja existente. Un ³ier script este un ³ier extern care conµine o sec-venµ de comenziMatlab. Prin apelarea numelui ³ierului, se execut secvenµaMatlab conµinut în acesta. Dup execuµia complet a unui ³ier script, variabilele cu care acesta a operat r mânîn zona de memorie a aplicaµiei. Fi³ierele script sunt folosite pentru rezolvarea unor probleme carecer comenzi succesive atât de lungi, încât ar putea deveni greoaie pentru lucrul în mod interactiv,adic în modul linie de comand .
Pentru a introduce date în Matlab, putem copia datele direct într-un ³ier Matlab, prin denirea unuivector sau a unei matrice de date. De exemplu, urm toarele date au fost introduse prin "copy-paste" înmatricea data:
>> data = [ % atribuirea valorilor matricei data21.3 24.1 19.9 21.0 % prima linie a datelor copiate
18.4 20.5 17.5 23.2
22.1 16.6 23.5 19.7 % ultima linie a datelor copiate
]; % inchidem paranteza ce defineste matricea de date
Datele din Matlab pot salvate astfel:

Anexa 1 [Dr. Iulian Stoleriu] 200
>> cd('c:\fisierul_de_lucru'); % alegem fisierul unde salvam datele
>> save Timpi_de_reactie data; % salveaza in fisierul Timpi_de_reactie.mat
Datele pot reînc rcate folosind comanda
load Timpi_de_reactie % incarca datele din fisier
Timpi_de_reactie % afiseaza datele incarcate
Fi³ierele funcµie
Matlab creaz cadrul propice extinderii funcµiilor sale, prin posibilitatea cre rii de noi ³iere. Astfel,dac prima linie a ³ierului .m conµine cuvântul function, atunci ³ierul respectiv este declarat ca ind³ier funcµie. Variabilele denite ³i manipulate în interiorul ³ierului funcµie sunt localizate la nivelulacesteia. Prin urmare, la terminarea execuµiei unei funcµii, în memoria calculatorului nu r mân decâtvariabilele de ie³ire ale acesteia. Forma general a primei linii a unui ³ier este:
function[param_iesire] = nume_functie(param_intrare)
unde:
• function este este cuvântul care declar ³ierul ca ³ier funcµie;
• nume_functie este numele funcµiei, care este totuna cu numele sub care se salveaz ³ierul;
• param_iesire sunt parametrii de ie³ire;
• param_intrare sunt parametrii de intrare.
Comenzile ³i funcµiile care sunt utilizate de nou funcµie sunt înregistrate într-un ³ier cu extensia .m.
Exemplu 15.1 Fisierul medie.m calculeaz media aritmetic a sumei p tratelor componentelor unui vec-tor X (alternativ, aceast lucru poate realizat prin comanda mean(X.^2)):
function m2 = medie(X)
n = length(X); m2 = sum(X.^2)/n;
Matlab-ul include aplicaµii specice, numite Toolbox-uri. Acestea sunt colecµii extinse de funcµiiMatlab(³iere-m) care dezvolt mediul de programare de la o versiune la alta, pentru a rezolva probleme dindomenii variate. Statistics Toolbox reprezint o colecµie de funcµii folosite pentru analiza, modelarea ³isimularea datelor ³i conµine: generarea de numere aleatoare; distribuµii, analiza grac interactiv (GUI),analiza regresional , descrieri statistice, teste statistice.
În Tabelul 15.1 am adunat câteva comenzi utile în Matlab.

Anexa 1 [Dr. Iulian Stoleriu] 201
% % permite adaugarea de comentarii in codhelp rand % help specic pentru funcµia randlookfor normal % cauta intrarile în Matlab pentru normalX=[2 4 6 5 2 7 10] % vector linie cu 7 elementeX=[3; 1; 6.5 ;0 ;77] % vector coloan cu 5 elementeX = -10:2:10 % vector cu numerele intregi de la −10 la 10, din 2 în 2length(X) % lungimea vectorului Xt=0:0.01:3*pi % dene³te o diviziune a [0, 3π] cu diviziunea 0.01X.^2 % ridic toate componentele vectorului X la puterea a douaX.*Y % produsul a doi vectoricumsum(X) % suma cumulat a elementelor vectorului Xcumprod(X) % produsul cumulativ al elementelor vectorului Xmin(X) % realizeaz minimum dintre componentele lui Xmax(X) % realizeaz maximum dintre componentele lu Xsort(X) % ordoneaz componentele lui X în ordine crescatoaresort(X, 'descend') % ordoneaz componentele lui X în ordine descrescatoareerf(X) % funcµia eroareexp(x) % calculeaz exponenµial ex
log(x) % calculeaz logaritmul natural ln(x)sqrt(x) % calculeaz radicalul ordinului doi dintr-un num rnum2str(x) % furnizeaz valoarea numeric a lui xfactorial(n) % n!A = ones(m,n) % A e matrice m× n, cu toate elementele 1B = zeros(m,n) % matrice m× n zeroI = eye(n) % matrice unitate, n× nA = [3/2 1 3 7; 6 5 8 8; 3 6 9 12] % matrice 3× 3size(A) % dimensiunea matricei Adet(A) % determinantul matricei Ainv(A) % inversa matricei AA' % transpusa matricei AA(:,7) % coloana a 7-a a matricei AA(1:20,1) % scoate primele 20 de linii ale lui Anchoosek(n,k) % combin ri de n luate câte k1e5 % numarul 105
exp(1) % numarul ebar(X) sau barh(X) % reprezentarea prin barehist(X) % reprezentarea prin histogramehist3(x,y,z) % reprezentarea prin histograme 3-Dplot(X(1:5),'*m') % deseneaz primele 5 componente ale lui X, cu * magenta
plot(t,X,'-') % deseneaz gracul lui X versus t, cu linie continuaplot3(X,Y,Z) % deseneaz un grac în 3-Dstairs(X) % deseneaz o funcµie scarasubplot(m,n,z) % împarte gracul în m× n zone & deseneaz în zona zsemilogx ³i semilogy % logaritmeaz valorile de pe absci , resp., ordonatahold on % reµine gracul pentru a realiza o nou guraclf % ³terge guraclear all % ³terge toate variabilele denitetitle('Graficul functiei') % adaug titlu guriifind % g se³te indicii elementelor nenule ale unui vectorlegend % ata³eaz o legend la un grac
Tabela 15.1: Funcµii Matlab utile

Anexa 2 [Dr. Iulian Stoleriu] 202
16 Anexa 2
Exemple de repartiµii discrete
În dreptul ec rei repartiµii, în parantez , apare numele cu care aceasta care poate apelat în Matlab.
(1) Repartiµia uniform discret , U(n) (unid)
Scriem c X ∼ U(n), dac valorile lui X sunt 1, 2, . . . , n, cu probabilit µile
P (X = k) =1
n, k = 1, 2, . . . , n.
Media ³i dispersia sunt: E(X) = n+12 , D2(X) = n2−1
12 .Exemplu: num rul de puncte care apar la aruncarea unui zar ideal este o valoare aleatoare repartizat U(6).
(2) Repartiµia Bernoulli26, B(1, p) (bino)
Scriem X ∼ B(1, p). V.a. de tip Bernoulli poate lua doar dou valori, X = 1 (succes) sau X = 0(insucces), cu probabilit µile P (X = 1) = p; P (X = 0) = 1− p.Media ³i dispersia sunt: E(X) = p; D2(X) = p(1− p).Exemplu: aruncarea o singur dat a unei monede ideale poate modelat ca ind o v.a. B(1, 0.5).
(3) Repartiµia binomial , B(n, p): (bino)
Scriem X ∼ B(n, p) (schema bilei revenite sau schema extragerilor cu repetiµie) (n > 0, p ∈ (0, 1)),dac valorile lui X sunt 0, 1, . . . , n, cu probabilit µile
P (X = k) = Cknpk(1− p)n−k, k = 0, 1, . . . , n.
Media ³i dispersia sunt: E(X) = np; D2(X) = np(1− p).
Dac (Xk)k=1,n ∼ B(1, p) ³i (Xk)k independente stochastic, atunci X =
n∑k=1
Xk ∼ B(n, p).
Exemplu: aruncarea de 15 ori a unei monede ideale poate modelat ca ind o v.a. binomial B(15, 0.5).
(4) Repartiµia hipergeometric , H(n, a, b) (hyge)
X ∼ H(n, a, b) (schema bilei nerevenite sau schema extragerilor f r repetiµie) (n, a, b > 0) dac
P (X = k) =CkaC
n−kb
Cna+b
, pentru orice k ce satisface max(0, n− b) ≤ k ≤ min(a, n).
26Jacob Bernoulli (1654− 1705), matematician elveµian

Anexa 2 [Dr. Iulian Stoleriu] 203
Media ³i dispersia sunt: EX =n∑i=0
E(Xi) = np; D2(X) = np(1− p)a+ b− na+ b− 1
.
Observaµia 16.1 (i) Dac (Xk)k=0,n ∼ B(1, n), cu p = aa+b (v.a. dependente stochastic), atunci
X =
n∑i=1
Xi ∼ H(n, a, b).
În cazul schemei bilei nerevenite, nu mai putem scrie egalitate între D2(X) ³in∑i=0
D2(Xi), deoarece (Xi)i
nu sunt independente stochastic.(ii) Pentru N = a+ b n, putem face aproximarea a+b−n
a+b−1 ≈a+b−na+b = 1− n
N , de unde
D2(X) ≈ np(1− p)(
1− n
N
). (16.1)
Observ m c repartiµiile binomial ³i hipergeometric au aceea³i medie, îns dispersiile difer prin terme-nul N−nN−1 . În cazul în care num rul de bile este mult mai mare decât num rul de extrageri (N n), atunciacest termen devine aproximativ
(1− n
N
). În plus, dac N este foarte mare, atunci trecând N → ∞ în
(16.1), g sim c ³i dispersiile celor dou repartiµii coincid. Cu alte cuvinte, când num rul de bile din urn este foarte mare, nu mai conteaz dac extragerea bilelor se face cu repetiµie sau nu. Acest fapt îl vomutiliza în Teoria selecµiei, când extragerile se fac dintr-o colectivitate de volum foarte mare.
(5) Repartiµia Poisson27, P(λ) (poiss)
Valorile sale reprezint num rul evenimentelor spontane (cu intensitatea λ) realizate într-un anumit inter-val de timp. Pentru un λ > 0, spunem c X ∼ P(λ) (legea evenimentelor rare) dac X ia valori naturale,cu probabilit µile
P (X = k) = e−λλk
k!, ∀k ∈ N.
E(X) = λ; D2(x) = λ.
(6) Repartiµia geometric , Geo(p) (geo)
Valorile sale reprezint num rul de insuccese avute pân la obµinerea primului succes,stiind probabilitatea de obµinere a unui succes, p.
Spunem c X ∼ Geo(p), (p ∈ (0, 1)) dac X ia valori în N, cu probabilit µile
P (X = k) = p(1− p)k, pentru orice k ∈ N, unde p ≥ 0.
E(X) =1− pp
; D2(X) =1− pp2
.
Observaµia 16.2 Dac X ∼ Geo(p), atunci variabila aleatoare Y = X + 1 reprezint a³teptarea pân laprimul succes.
27Siméon-Denis Poisson (1781− 1840), matematician ³i zician francez, student al lui Laplace

Anexa 2 [Dr. Iulian Stoleriu] 204
(7) Repartiµia binomial cu exponent negativ, BN (m, p) (nbin)
Valorile sale reprezint num rul de insuccese obµinute înainte de a se realiza succesul de rang m.În cazul particular m = 1, obµinem repartiµia geometric .
Pentru m ≥ 1, p ∈ (0, 1), spunem c X ∼ BN (m, p) dac X ia valorile m, m + 1, m + 2, . . . , cuprobabilit µile
P (X = k) = Cm−1m+k−1p
m(1− p)k, ∀k ≥ m, p ≥ 0.
Media ³i dispersia sunt: E(X) =m(1− p)
p; D2(X) =
m(1− p)p2
.
Exemple de repartiµii continue
(1) Repartiµia uniform , U(a, b) (unif)
V.a. X ∼ U(a, b) (a < b) dac funcµia sa de densitate este
f(x; a, b) =
1b−a , dac x ∈ (a, b)
0 , altfel.
E(X) =a+ b
2, D2(X) =
(b− a)2
12.
Exemplu: Alegerea la întâmplare a unei valori din intervalul (0, 1), în cazul în care orice valoare areaceea³i ³ans de a aleas , urmeaz o repartiµie U(0, 1). Comanda rand din Matlab realizeaz acestexperiment (vezi capitolul urm tor).
(2) Repartiµia normal , N (µ, σ) (norm)
Spunem c X ∼ N (µ, σ), dac X are densitatea:
f(x; µ, σ) =1
σ√
2πe−
(x−µ)2
2σ2 , x ∈ R.
E(X) = µ ³i D2(X) = σ2.Se mai nume³te ³i repartiµia gaussian . În cazul µ = 0, σ2 = 1 densitatea de repartiµie devine:
f(x) =1√2πe−
x2
2 , x ∈ R. (16.2)
În acest caz spunem c X urmeaz repartiµia normal standard, N (0, 1).Gracul densit µii de repartiµie pentru repartiµia normal este clopotul lui Gauss (vezi Figura 16.1). Dingrac (pentru σ = 1), se observ c majoritatea valorilor nenule ale repartiµiei normale standard se a în intervalul (µ− 3σ, µ+ 3σ) = (−3, 3). Aceast armaµie se poate demonstra cu ajutorul relaµiei (3.9).
Dac Z ∼ N (0, 1), atunci X = σZ + µ ∼ N (µ, σ). În mod similar, dac X ∼ N (µ, σ), atunci Z =X−µσ ∼ N (0, 1). Pentru o v.a. N (0, 1) funcµia de repartiµie este tabelat (valorile ei se g sesc în tabele)
³i are o notaµie special , Θ(x). Ea e denit prin:
Θ(x) =1√2π
∫ x
−∞e−
y2
2 dy. (16.3)

Anexa 2 [Dr. Iulian Stoleriu] 205
Figura 16.1: Clopotul lui Gauss pentru X ∼ N (0, σ), (σ = 1, 2, 3)
Funcµia de repartiµie a lui X ∼ N (µ, σ) este dat prin
F (x) = Θ(x− µσ
), x ∈ R. (16.4)
(3) Repartiµia log-normal , logN (µ, σ) (logn)
Repartiµia log-normal este foarte util în Matematicile Financiare, reprezentând o repartiµie de preµuriviitoare pentru un activ nanciar. Dac X ∼ N (µ, σ), atunci Y = eX este o v.a. nenegativ , avânddensitatea de repartiµie
f(x; µ, σ) =
1
xσ√
2πe−
(ln x−µ)2
2σ2 , dac x > 0
0 , dac x ≤ 0
A³adar, Y ∼ logN (µ, σ) dac lnY ∼ N (µ, σ).Media ³i dispersia sunt date de E(X) = eµ+σ2/2, D2(X) = e2µ+σ2
(eσ2 − 1).
(4) Repartiµia exponenµial , exp(λ) (exp)
Valorile sale sunt timpi realizaµi între dou valori spontane repartizate P(λ).
Spunem c X ∼ exp(λ) (λ > 0) dac are densitatea de repartiµie
f(x; λ) =
λe−λx , dac x > 00 , dac x ≤ 0
Media ³i dispersia sunt: E(X) =1
λ³i D2(X) =
1
λ2.
Observaµia 16.3 Repartiµia exponenµial satisface proprietatea a³a-numitei lips de memorie, i.e.,
P (X > x+ y|X > y) = P (X > x), ∀x, y ≥ 0.

Anexa 2 [Dr. Iulian Stoleriu] 206
Este unica distribuµie continu cu aceast proprietate. Distribuµia geometric satisface o variant discret a acestei propriet µi. [Vericaµi!]
(5) Repartiµia Gamma, Γ(a, λ) (gam)
O v.a. X ∼ Γ(a, λ), a, λ > 0, dac densitatea sa de repartiµie este:
f(x; a, λ) =
λa
Γ(a)xa−1e−λx , dac x > 0,
0 , dac x ≤ 0.
unde Γ este funcµia lui Euler,
Γ : (0, ∞)→ (0, ∞), Γ(a) =
∫ ∞0
xa−1e−xdx.
Media ³i dispersia sunt: E(X) =a
λ, D2(X) =
a
λ2.
Observaµia 16.4 (i) Γ(1, λ) ≡ exp(λ).
(ii) Dac v.a. Xkk=1,n ∼ exp(λ) sunt independente stochastic, atunci suma lorn∑k=1
Xk ∼ Γ(n, λ).
(6) Repartiµia Weibull28, Wbl(k, λ) (wbl)
Aceast repartiµie este asem n toare cu repartiµia exponenµial (aceast obµinându-se în cazul particulark = 1) ³i poate modela repartiµia m rimii particulelor. Când k = 3.4, distribuµia Weibull este asem n -toare cu cea normal . Când k →∞, aceast repartiµie se apropie de funcµia lui Dirac.Vom spune c X ∼Wbl(k, λ) (k > 0, λ > 0) dac are densitatea de repartiµie
f(x; k, λ) =
kλ
(xλ
)k−1e−( xλ)
k
, dac x ≥ 00 , dac x < 0.
Media pentru repartiµia X ∼Wbl(k, λ) este E(X) = λΓ
(1 +
1
k
).
(7) Repartiµia χ2, χ2(n) (chi2)
O v.a. X ∼ χ2(n) (se cite³te repartiµia hi-p trat cu n grade de libertate) dac densitatea sa de repartiµieeste:
f(x; n) =
1
Γ(n2
)2n2xn2−1e−
x2 , dac x > 0,
0 , dac x ≤ 0.
unde Γ este funcµia lui Euler. Gracul acestei repartiµii (pentru diverse valori ale lui n) este reprezentatîn Figura 16.2.Media ³i dispersia sunt: E(χ2) = n, D2(χ2) = 2n.
28Ernst Hjalmar Waloddi Weibull (1887− 1979), matematician ³i inginer suedez

Anexa 2 [Dr. Iulian Stoleriu] 207
Observaµia 16.5 (a) Repartiµia χ2(n) este, de fapt, repartiµia Γ(n2 ,12).
(b) Dac v.a. independente Xk ∼ N (0, 1) pentru k = 1, 2, . . . , n, atunci
X21 +X2
2 + · · ·+X2n ∼ χ2(n).
În particular, dac X ∼ N (0, 1), atunci X2 ∼ χ2(1).
Figura 16.2: Repartiµia χ2(n) pentru patru valori ale lui n.
(8) Repartiµia Student (W. S. Gosset29), t(n) (t)
Spunem c X ∼ t(n) (cu n grade de libertate) dac densitatea de repartiµie este:
f(x; n) =Γ(n+1
2
)√nπ Γ
(n2
) (1 +x2
n
)−n+12
, x ∈ R.
E(X) = 0, D2(X) =n
n− 2.
(9) Repartiµia Fisher30, F(m, n) (f)
Spunem c X ∼ F(m, n) (cu m, n grade de libertate) dac densitatea de repartiµie este:
f(x) =
(mn )m2 Γ(m+n
2 )Γ(m2 )Γ(n2 )
xm2−1(1 + m
n x)−m+n
2 , x > 0;
0 , x ≤ 0.
E(X) =n
n− 2, D2(X) =
2n2(n+m− 2)
m(n− 2)2(n− 4).
29William Sealy Gosset (1876− 1937), statistician britanic, care a publicat sub pseudonimul Student30Sir Ronald Aylmer Fisher (1890− 1962), statistician, eugenist, biolog ³i genetician britanic

Anexa 2 [Dr. Iulian Stoleriu] 208
(10) Repartiµia Cauchy31, C(λ, µ) (f r corespondent în Matlab)
Spunem c X ∼ C(λ, µ) dac densitatea de repartiµie este:
f(x; λ, µ) =λ
π[(x− µ)2 + λ2], x ∈ R.
NU admite medie, dispersie sau momente!!!
31Augustin Louis Cauchy (1789− 1857), matematician francez

Bibliografie [Dr. Iulian Stoleriu] 209
Bibliograe
[1] Petru Blaga, Statistic . . . prin Matlab, Presa universitar clujean , Cluj-Napoca, 2002.
[2] David Brink, Statistics compendium, David Brink & Ventus Publishing ApS, 2008.
[3] David Brink, Statistics exercises, David Brink & Ventus Publishing ApS, 2008.
[4] Gheorghe Ciucu, Virgil Craiu, Teoria estimaµiei ³i vericarea ipotezelor statistice, Editura Didactic ³i Pedagogic , Bucure³ti, 1968.
[5] Steve Dobbs, Jane Miller, Statistics 1, Cambridge University Press, Cambridge 2000.
[6] Jay L. DeVore, Kenneth N. Berk, Modern Mathematical Statistics with Applications (with CD-ROM),Duxbury Press, 2006.
[7] Robert V. Hogg, Allen Craig, Joseph W. McKean, Introduction to Mathematical Statistics, PrenticeHall, 6th edition, 2004.
[8] Marius Iosifescu, Costache Moineagu, Vladimir Trebici, Emiliana Ursianu, Mic enciclopedie de sta-tistic , Editura ³tiinµic ³i enciclopedic , Bucure³ti, 1985.
[9] http://www.mathworks.com
[10] Gheorghe Mihoc, N. Micu, Teoria probabilit µilor ³i statistica matematic , Bucuresti, 1980.
[11] Elena Nenciu, Lecµii de statistic matematic , Universitatea A. I. Cuza, Ia³i, 1976.
[12] Octavian Petru³, Probabilit µi ³i Statistica matematic - Computer Applications, Ia³i, 2000.
[13] Sanford Weisberg, Applied Linear Regression, Wiley series in Probability and Statistics, 3rd ed.,2005.
[14] Larry J. Stephens, Theory and problems of Beginning Statistics, Schaum's Outline Series, 2nd ed.,The McGraw-Hill Companies, Inc., 1998.
[15] Dominick Salvatore, Derrick Reagle, Theory and problems of Statistics and Econometrics, Schaum'sOutline Series, 2nd ed., The McGraw-Hill Companies, Inc., 2002.
[16] Iulian Stoleriu, Statistic prin Matlab. MatrixRom, Bucure³ti, 2010.
[17] Gábor Székely, Paradoxes in Probability Theory and Mathematical Statistics, (Mathematics and itsApplications), Springer Verlag, 1987.
[18] David Williams, Weighing the Odds: A Course in Probability and Statistics, Cambridge UniversityPress, 2001.


















