
Lector Doctor Lucian Sasu...Capitolul 1 Defini¸tii. Rezolvarea problemelor prin c˘autare 1.1...
99
Inteligen¸ t˘aartificial˘a Lector Doctor Lucian Sasu 2011-2012 Universitatea Transilvania din Bra¸ sov Facultatea de Matematic˘a¸ siInformatic˘a
Transcript of Lector Doctor Lucian Sasu...Capitolul 1 Defini¸tii. Rezolvarea problemelor prin c˘autare 1.1...

Inteligenta artificiala
Lector Doctor Lucian Sasu
2011-2012
Universitatea Transilvania din Brasov
Facultatea de Matematica si Informatica

2
Versiunea: 2012.40

Cuprins
1 Definitii. Rezolvarea problemelor prin cautare 7
1.1 Definitii . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
1.1.1 Sisteme care actioneaza precum oamenii . . . . . . . . . . . . . . . 7
1.1.2 Sisteme care gandesc ca oamenii . . . . . . . . . . . . . . . . . . . . 8
1.1.3 Sisteme care gandesc rational . . . . . . . . . . . . . . . . . . . . . 8
1.1.4 Sisteme care actioneaza rational . . . . . . . . . . . . . . . . . . . . 9
1.2 Fundamentele inteligentei artificiale . . . . . . . . . . . . . . . . . . . . . . 9
1.3 Starea actuala . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
1.4 Rezolvarea de probleme de catre agenti . . . . . . . . . . . . . . . . . . . . 10
1.5 Formularea unei probleme de cautare . . . . . . . . . . . . . . . . . . . . . 11
1.6 Exemple de probleme de cautare . . . . . . . . . . . . . . . . . . . . . . . . 12
1.6.1 Probleme “de jucarie” . . . . . . . . . . . . . . . . . . . . . . . . . . 12
1.6.2 Probleme “din lumea reala” . . . . . . . . . . . . . . . . . . . . . . 13
1.7 Cautarea solutiei . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
1.8 Masurarea performantelor algoritmilor de cautare . . . . . . . . . . . . . . 18
2 Strategii de cautare neinformata 19
2.1 Cautarea “mai ıntai ın latime” . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.2 Cautarea dupa costul uniform . . . . . . . . . . . . . . . . . . . . . . . . . 21
2.3 Cautarea “mai ıntai ın adancime” . . . . . . . . . . . . . . . . . . . . . . . 22
2.4 Cautarea cu adancime limitata . . . . . . . . . . . . . . . . . . . . . . . . 25
2.5 Cautarea “mai ıntai ın adancime” cu adancire iterativa . . . . . . . . . . . 25
2.6 Cautare bidirectionala . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
2.7 Problema starilor duplicat . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
3 Cautare informata 31
3.1 Strategii de cautare informata . . . . . . . . . . . . . . . . . . . . . . . . . 31
3.2 Cautarea euristica lacoma . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
3.3 Algoritmul A* . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
3

4 CUPRINS
3.4 Variatii ale lui A* . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
3.5 Functii euristice . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
3.6 Algoritmi de cautare locala . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
3.6.1 Cautarea prin metoda ascensiunii . . . . . . . . . . . . . . . . . . . 44
3.6.2 Recoacerea simulata . . . . . . . . . . . . . . . . . . . . . . . . . . 48
3.6.3 Algoritmi genetici . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
3.6.4 Cautare locala ın spatii continue . . . . . . . . . . . . . . . . . . . . 53
4 Probleme de satisfacere a constrangerilor 55
4.1 Probleme de satisfacere a constrangerilor . . . . . . . . . . . . . . . . . . . 55
4.2 Cautare backtracking pentru PSC . . . . . . . . . . . . . . . . . . . . . . . 58
4.2.1 Ordonarea valorilor si a variabilelor . . . . . . . . . . . . . . . . . . 59
4.2.2 Propagarea informatiilor prin constrangeri . . . . . . . . . . . . . . 60
4.3 Cautare locala pentru PSC . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
4.4 Structura problemei . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
5 Agenti logici 69
5.1 Motivatie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
5.2 Agenti bazati pe cunoastere . . . . . . . . . . . . . . . . . . . . . . . . . . 70
5.3 Jocul “lumea monstrului” . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
5.4 Logica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
5.5 Logica propozitionala . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
5.5.1 Sintaxa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
5.5.2 Semantica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
5.5.3 Exemplu: lumea monstrului ın logica propozitionala . . . . . . . . . 75
5.5.4 Inferenta ın logica propozitionala . . . . . . . . . . . . . . . . . . . 75
5.5.5 Echivalenta, validitate si satisfiabilitate . . . . . . . . . . . . . . . . 76
5.6 Tipare de rationament ın logica propozitionala . . . . . . . . . . . . . . . . 77
5.6.1 Rezolutia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
5.7 Forma normala conjunctiva . . . . . . . . . . . . . . . . . . . . . . . . . . 80
5.8 Algoritmul de rezolutie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
5.9 Inlantuirea ınainte si ınapoi . . . . . . . . . . . . . . . . . . . . . . . . . . 82
5.10 Inferenta propozitionala efectiva . . . . . . . . . . . . . . . . . . . . . . . . 84
5.10.1 Algoritm bazat pe backtracking . . . . . . . . . . . . . . . . . . . . 84
5.10.2 Algoritm bazat pe cautare locala . . . . . . . . . . . . . . . . . . . 89
6 Logica de ordinul ıntai 91
6.1 Introducere . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91

CUPRINS 5
6.2 Sintaxa si semantica logicii de ordinul ıntai . . . . . . . . . . . . . . . . . . 92
6.2.1 Modele pentru logica de ordinul ıntai . . . . . . . . . . . . . . . . . 92
6.2.2 Simboluri si interpretari . . . . . . . . . . . . . . . . . . . . . . . . 93
6.2.3 Termeni . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 94
6.2.4 Propozitii atomice . . . . . . . . . . . . . . . . . . . . . . . . . . . 94
6.2.5 Enunturi complexe . . . . . . . . . . . . . . . . . . . . . . . . . . . 94
6.2.6 Cuantificatori . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 94
6.3 Procesul de management al cunostintelor . . . . . . . . . . . . . . . . . . . 95
6.4 Inferenta propozitionala comparata cu inferenta de ordinul ıntai . . . . . . 96
6.4.1 Reguli de inferenta pentru cuantificatori . . . . . . . . . . . . . . . 97
6.4.2 Reducerea la inferenta propozitionala . . . . . . . . . . . . . . . . . 97
Bibliografie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 99

6 CUPRINS

Capitolul 1
Definitii. Rezolvarea problemelor prin
cautare
1.1 Definitii
Dam cateva definitii care au fost formulate de-a lungul timpului ın diverse lucrari,
precum si comentarii asupra lor. Exista patru tipuri de abordari pentru sistemele cu
inteligenta artificiala: sisteme care gandesc precum oamenii, sisteme care gandesc rational,
sisteme care actioneaza precum oamenii, sisteme care actioneaza rational. Remarcam ca
exista o diferenta ıntre a actiona ca un om si a actiona rational; desi inteligenta umana
si rationalitatea nu sunt disjuncte, actiunile oamenilor nu sunt ıntotdeauna ınscrise ın
totalitate ın legile ratiunii.
1.1.1 Sisteme care actioneaza precum oamenii
Definitia 1 Arta crearii de masini care ındeplinesc functii ce necesita inteligenta atunci
cand sunt ındeplinite de catre oameni.
Definitia 2 Studiul asupra cum se poate ca un calculator sa faca lucruri la care, pentru
moment, oamenii sunt mai buni.
Testul Turing, propus de catre Alan Turing ın 1950 a fost conceput pentru a da o
definitie operationala a inteligentei. Testul care trebuie trecut de catre un sistem inteligent
consta ın a pune un om ın imposibilitate de a decide daca interlocutorul (sistemul artificial)
este om sau nu.
Deducem ca un asemenea sistem ar trebui sa posede urmatoarele abilitati:
1. procesarea limbajului natural - pentru a putea comunica ıntr-o limba folosita de
oameni
7

8 CAPITOLUL 1. DEFINITII. REZOLVAREA PROBLEMELOR PRIN CAUTARE
2. reprezentarea cunostintelor - pentru a stoca ceea ce se stie sau afla
3. rationamentul automat - pentru a putea deduce noi concluzii pe baza informatiilor
acumulate si pentru a raspunde ıntrebarilor
4. ınvatarea automata - pentru a se adapta noilor conditii, pentru a detecta modele
sau sabloane (pattern-uri).
Testul de mai sus nu presupune un contact direct ıntre om si sistemul artificial. Daca
acest lucru este dorit, atunci mai e nevoie de:
1. vedere artificiala (engl: computer vision) - pentru perceperea vizuala a obiectelor
2. robotica - pentru a manipula obiecte
Cu toate ca testul Turing nu a fost ınca trecut, exista interes destul de scazut din
partea cercetatorilor ın aceasta directie; exista opinia ca e mai important a se studia
principiile care stau la baza inteligentei decat sa se duplice o functionalitate.
1.1.2 Sisteme care gandesc ca oamenii
Definitia 3 Efortul provocator de a face calculatoarele sa gandeasca [. . . ] masini cu
minte, ın sens literal.
Definitia 4 [Automatizarea] activitatilor pe care le asociem cu gandirea umana, activitati
precum luarea deciziilor, rezolvarea problemelor, ınvatarea[. . . ]
Pentru a putea spune ca un program gandeste precum un om, ar trebui sa stim cum
anume gandesc oamenii - problema deloc simpla. Sunt doua moduri: prin introspectie si
prin experimente psihologice.
1.1.3 Sisteme care gandesc rational
Definitia 5 Studiul facultatilor mentale pe baza utilizarii modelelor computationale.
Definitia 6 Studiul calculelor care fac posibile perceptia, rationamentul, actionarea.
Aceasta abordare se bazeaza pe maturizarea domeniului numit “logica” ın secolul
al 19-lea – introducerea de notatii si silogisme care permit redactarea unor enunturi si
relatii ıntre diferite obiecte. Exista ınsa probleme la trecerea din teorie la practica: de
exemplu, ce se ıntampla cu situatiile ın care exista incertitudine? apoi, exista diferente
ıntre a rezolva o problema “ ın principiu” (teoretic) si a o rezolva ın practica - resursele
computationale necesare pot fi prohibitive chiar pentru probleme de dimensiuni modeste
- a se vedea de exemplu algoritmii si discutiile capitolul 2.

1.2. FUNDAMENTELE INTELIGENTEI ARTIFICIALE 9
1.1.4 Sisteme care actioneaza rational
Definitia 7 Inteligenta computationala este studiul design-ului agentilor inteligenti.
Definitia 8 IA [. . . ] se preocupa de comportamentul inteligent ın artifacte.
Pe aceasta directie se introduce de obicei conceptul de agent - un sistem artificial, care
spre deosebire de programele obisnuite actioneaza autonom, percep mediul, persista pe
o perioada mai mare de timp, se adapteaza la schimbari si care urmaresc un scop. Un
agent rational este unul care actioneaza pentru a obtine cel mai bun rezultat, sau, acolo
unde exista incertitudinea, cel mai bun rezultat mediu.
Nu toate actiunile unui astfel de agent sunt neaparat rationale; exista cazuri ın care se
stie ca nu exista nici o actiune rationala, dar totusi se decide a se actiona cumva. Astfel,
inferentele corecte sunt doar o parte a actiunii rationale.
1.2 Fundamentele inteligentei artificiale
Prezentam succint o lista a disciplinelor care au contribuie la dezvoltarea IA:
1. Filozofie - intervine cu ıntrebari si discutii despre:
• Pot fi regulile formale folosite pentru a extrage concluzii valide?
• Cum se creeaza activitatea mentala plecand de la creier?
• De unde vine cunoasterea?
• Cum duce cunoasterea la actiune?
2. Matematica - trateaza problemele:
• Care sunt regulile formale pentru a extrage concluzii valide?
• Ce poate fi calculat?
• Cum rationam plecand de la informatii nesigure?
3. Stiintele economice - preocupate de:
• Cum ar trebui sa decidem astfel ıncat sa maximizam castigul?
• Cum ar trebui sa decidem atunci cand castigul este pe termen lung?
4. Neurostiinta care ıncearca sa raspunda la “Cum proceseaza creierul informatia?”
5. Psihologia - cum gandesc si actioneaza animalele?
6. Ingineria calculatoarelor - cum putem crea un calculator eficient?
7. Lingvistica - cum este legat limbajul de gandire?

10 CAPITOLUL 1. DEFINITII. REZOLVAREA PROBLEMELOR PRIN CAUTARE
1.3 Starea actuala
Unde este de folos IA? O lista neexhaustiva este data mai jos:
• planificare autonoma - folosita de exemplu ın navetele lansate spre Marte
• jocuri - supercalculatorul Deep Blue de la IBM a fost folosit pentru rularea unui
program specializat ın jocul de sah, ınvingandu-l pe campionul mondial, Garry
Kasparov
• control autonom - folosit pentru a conduce o masina de-a lungul SUA, realizand o
conducere autonoma pentru 98% din perioada totala.
• diagnostic - diagnostic medical bazat pe sisteme expert
• robotica - se folosesc roboti asistenti ın microchirurgie, implant de proteze.
• ıntelegerea limbajului si rezolvarea problemelor - rezolvare de cuvinte ıncrucisate.
1.4 Rezolvarea de probleme de catre agenti
Sa presupunem ca un agent inteligent are de rezolvat o problema: cum anume se
poate ajunge din Arad ın Bucuresti (figura 1.4 este o harta simplificata a Romaniei),
folosind drept cai de comunicatie soselele din Romania. Vom considera faptul ca se cunosc
distantele existente ıntre cateva perechi de orase (cele care sunt direct legate) si ca se pot
schita cateva scenarii de drum pe baza carora sa aleaga o solutie. Ca rezultat se va obtine
o secventa de actiuni a caror ındeplinire duce la rezolvarea problemei.
Pasii care trebuie urmati ın rezolvarea unei probleme de cautare sunt:
1. formularea problemei - ın sectiunea 1.5 se arata modul ın care poate fi exprimata o
problema de cautare;
2. cautarea solutiei - aici se folosesc algoritmi decautare specifici, avand ca rezultat
returnarea unei singure solutii ;
3. executarea - pe baza solutiei ce expliciteaza actiunile ce trebuie executate ın vederea
rezolvarii problemei se implementeaza faza de executie. Dupa ce se atinge scopul
problemei, se poate formula un nou scop.

1.5. FORMULAREA UNEI PROBLEME DE CAUTARE 11
Figura 1.1: O harta simplificata a Romaniei[1]
1.5 Formularea unei probleme de cautare
O problema de cautare poate fi abstractizata precum mai jos, prin intermediul a patru
atribute.
1. Starea initiala - starea din care se porneste cautarea; de exemplu, pentru problema
drumului de la Arad la Bucuresti starea initiala este In(Arad).
2. O descriere a actiunilor pe care le poate ındeplini agentul. Acestea se pot formaliza
sub forma de operatori sau a unei functii succesor ce se aplica pe multimea starilor
si produce ca rezultat o multime de perechi de forma (actiune, stare):
x→ functie− succesor(x) = {(actiune1, stare1), . . . , (actiunen, staren)}
unde actiunei este o actiune ce se poate aplica ın starea x, iar starei este starea ın
care se ajunge din x aplicand actiunei.
Pentru problema exemplificata putem avea de exemplu:
functie− succesor(In(Arad)) = {(Go(Sibiu), In(Sibiu)),
(Go(T imisoara), In(T imisoara)),
(Go(Zerind), In(Zerind))}
Starea initiala si functia succesor determina spatiul starilor problemei - al acelor stari
care sunt accesibile din starea initiala. O cale ın spatiul starilor este o secventa de
stari conectate printr-o secventa de actiuni.

12 CAPITOLUL 1. DEFINITII. REZOLVAREA PROBLEMELOR PRIN CAUTARE
3. Testul de scop - determina daca o stare este stare scop, adica o stare ın care problema
se considera a fi rezolvata. Verificarea atingerii scopului se poate face ın doua
moduri:
(a) prin compararea starii curente cu multimea starilor scop, enuntata explicit; de
exemplu, pentru problema de mai sus multimea starilor scop este In{Bucuresti}.
(b) prin verificarea unor proprietati pe care trebuie sa le ındeplineasca starea pen-
tru a fi considerata stare scop; de exemplu, pentru jocul de sah stare scop este
aceea ın care regele este atacat si nu se mai poate misca fara a fi atacat.
4. O functie de cost a caii care asigneaza o valoare numerica fiecarei cai. Functia
serveste ca masura a performantei succesiunii de actiuni (a solutiei); vom presupune
ca costul unei cai este dat de suma costurilor actiunilor continute, iar costul unei
actiuni este o cantitate nenegativa.
O solutie este o succesiune de actiuni care permite agentului rezolvarea problemei, iar
o solutie optima este una ın care costul solutiei este minim posibil.
1.6 Exemple de probleme de cautare
1.6.1 Probleme “de jucarie”
Sunt folosite ın special pentru demonstrarea conceptelor, avand scop didactic.
1. Problema puzzle-ului: se da o matrice de n linii si tot atatea coloane; ın fiecare
celula se afla un singur numar de la 1 la n2−1, nu exista doua celule care sa contina
acelasi numar, iar una din celule este goala. Pentru cazul n = 3 avem exemplificare
ın figura 1.2(a). Se cere ca prin mutari succesive pe orizontala si pe verticala ale
numerelor ın locul spatiului gol sa se ajunga la o configuratie finala, de exemplu ın
care numerele sunt ordonate (citirea se face linie cu linie), iar spatiul este pe ultima
pozitie.
(a) Starea
initiala
(b) Starea
scop
Figura 1.2: Problema puzzle-ului pentru n = 3

1.6. EXEMPLE DE PROBLEME DE CAUTARE 13
Starea initiala este dispunerea data; functia succesor genereaza toate miscarile prin
care spatiul alb este mutat ın cadrul matricei, pe verticala sau orizontala, cu cate
o sigura pozitie; testul de scop este verificarea faptului ca o stare coincide cu cea
aleasa drept finala; costul caii este egal cu numarul de mutari efectuate, deoarece se
poate considera ca fiecare mutare are costul egal cu 1.
2. Problema reginelor pe tabla de sah: dandu-se o tabla de sah de n linii si tot atatea
coloane, sa se determine o pozitionare a reginelor astfel ıncat sa nu se atace reciproc.
Starea initiala este cea ın care tabla este goala; functia succesor este “adauga o regina
Tabela 1.1: Problema dispunerii reginelor pe o tabla de 5x5
,
,
,
,
,
ıntr-o celula goala” (dar se pot gasi si alte formulari mai inspirate); o stare scop este
aceea ın care reginele nu se ataca reciproc.
1.6.2 Probleme “din lumea reala”
1. Problema determinarii rutei: acest tip de problema apare ıntr-o varietate de aplicatii,
precum crearea unui itinerar bazat pe zboruri cu avionul, planificarea operatiilor mi-
litare, rutare ın retele de calculatoare etc. Complexitatea acestor probleme provine
din multitudinea de factori ce trebuie luati ın considerare. De exemplu, pentru
problema gasirii unui itinerar pe cale aeriana, specificatiile ar putea fi:
• fiecare stare este reprezentata de o locatie (un aeroport) si momentul curent;
• starea initiala: locul si momentul plecarii;
• functie succesor: dependenta de lista zborurilor care sunt programate dintr-o
anumita locatie, la un moment ulterior;
• testul scop: se poate ajunge la destinatie ıntr-o perioada de timp specifi-
cata/pana la un moment maxim specificat?
• costul caii: depinde de costul biletelor ce trebuie achizitionate, timpul de
asteptare, durata totala a calatoriei, calitatea locurilor, tipul serviciului, modul
de rezolvare a ımbarcarii si tranzitului, tipul avionului etc.

14 CAPITOLUL 1. DEFINITII. REZOLVAREA PROBLEMELOR PRIN CAUTARE
Trebuie ınsa considerate posibilitatile (si probabilitatile) de aparitie a unor eveni-
mente nedorite precum anularea/ıntarzierea unor zboruri. Un bun planificator va
considera mai multe variante, va veni cu alternative si solutii de rezerva, ımpreuna
cu costurile suplimentare.
2. Problema comis-voiajorului - o persoana trebuie sa faca un tur al unei multimi de
orase, fara a trece de doua ori prin acelasi loc, cu revenire ın locatia initiala si cu un
cost al drumului minim (ciclu Hamiltonian de cost minim). Se cunoaste faptul ca
problema este NP-completa, dar exista foarte multe studii care ıncearca sa rezolve
problema cat mai eficient, eventual cu sacrificarea optimalitatii solutiei.
3. Dispunerea circuitelor VLSI1, unde pe o placuta de dimensiuni foarte mici trebuie
dispuse componente, realizate conexiuni, astfel ıncat sa nu existe cuplari nedorite
ıntre componente, sa se realizeze cu consum de material minim, sa fie minimizate
lungimile circuitelor de transfer etc. Problemele de cautare sunt complexe datorita
interdependentelor sau restrictiilor.
4. Roboti software pentru cautarea pe Internet; pe langa faptul ca trebuie sa trateze
operarea ıntr-o imensa baza de date cu grad mic de structurare, trebuie sa rezolve
probleme care nu sunt simple nici pentru un om: raspunsuri la ıntrebari, gasirea
preturilor cele mai convenabile, gasirea informatiilor ınrudite cu ceva specificat etc.
1.7 Cautarea solutiei
Rezolvarea problemei este facuta prin cautare ın spatiul starilor. Tehnicile de cautare
prezentate ın acest capitol si ın capitolul 2 folosesc un arbore de cautare care are drept
radacina un nod corespunzand starii initiale a problemei, iar nodurile sunt generate pe
baza actiunilor permise din starea curenta.
Vom considera ca exemplu problema gasirii drumului minim de la Arad la Bucuresti;
pentru moment, permitem existenta unor noduri diferite, dar care au stari identice; o
discutie asupra acestui aspect este prezentata ın sectiunea 2.7.
Considerand cate o stare la un moment dat, vom proceda astfel: testam sa vedem daca
starea curenta este stare scop; daca da, oprim cautarea, construim solutia si o raportam2.
Daca raspunsul este ınsa negativ, atunci se va expanda starea curenta pe baza functiei
succesor, obtinand un nou set de stari. Modul de alegere a nodului determina strategia
de cautare.
1VLSI: Very Large Scale Integration, crearea de circuite integrate prin combinarea de tranzistoare.2De remarcat ca nu ne propunem determinarea tuturor sau macar a mai multor solutii, ci doar a
primeia pe care algoritmul de cautare o descopera.

1.7. CAUTAREA SOLUTIEI 15
Arborele de cautare este format din noduri; un nod consta din urmatoarele compo-
nente:
• Stare: starea caruia ıi corespunde nodul curent
• Nod-Parinte: nodul din arborele de cautare care a generat nodul curent
• Actiune: actiunea care a fost aplicata nodului parinte pentru a produce nodul
curent
• Costul-caii: costul cumulat al actiunilor care duc de la nodul initial la nodul
curent;
• Adancime: numarul de pasi de-a lungul caii de la nodul initial
Nodul initial corespunde starii initiale, parintele si actiunea aferente acestui nod sunt
codificate convenabil (null, valoare neaplicabila etc.). Componenta Costul-caii poate fi
ın unele cazuri omisa, deoarece nu toate problemele cer determinarea unei solutii de cost
optim.
Un exemplu al arborelui de cautare generat pentru a cauta drumul de la Arad la
Bucuresti este dat ın figura 1.4. Mai trebuie sa mentionam ca nu trebuie facuta confuzie
ıntre noduri si stari; ın timp ce multimea starilor poate fi finita (de exemplu multimea
oraselor din Romania), numarul nodurilor poate fi infinit, daca se permite generarea de
cicluri de forma: Arad – Sibiu – Arad, Arad – Sibiu – Arad – Sibiu – Arad etc.
Nodurile care au fost obtinute prin expandarea altora, dar nu au fost la randul lor
expandate (altfel zis: noduri frunza ın arborele de cautare construit pana la momentul
curent) sunt mentinute ıntr-o colectie numita colectieNoduri; natura acestei colectii si
politica de acces fac distinctia ıntre o parte din algoritmii de cautare ce vor fi prezentati
ın capitolul 2.
Forma generala a algoritmului de cautare este data ın figura 1.3.
Cateva comentarii relativ la cod:
1. Functiile insereaza, insereaza-toate, scoate-primul determina: inserare de
nod, inserare de colectie de noduri, extragerea primului element conform politicii de
acces specifice tipului de date corespunzator lui colectieNoduri;
2. Notatia X[Y] reprezinta valoarea atributului (proprietatii) X pentru entitatea Y
3. Parametrul problema reprezinta o codificare a problemei conform celor din sectiunea
1.5.

16 CAPITOLUL 1. DEFINITII. REZOLVAREA PROBLEMELOR PRIN CAUTARE
Figura 1.3: Algoritmul general de cautare.
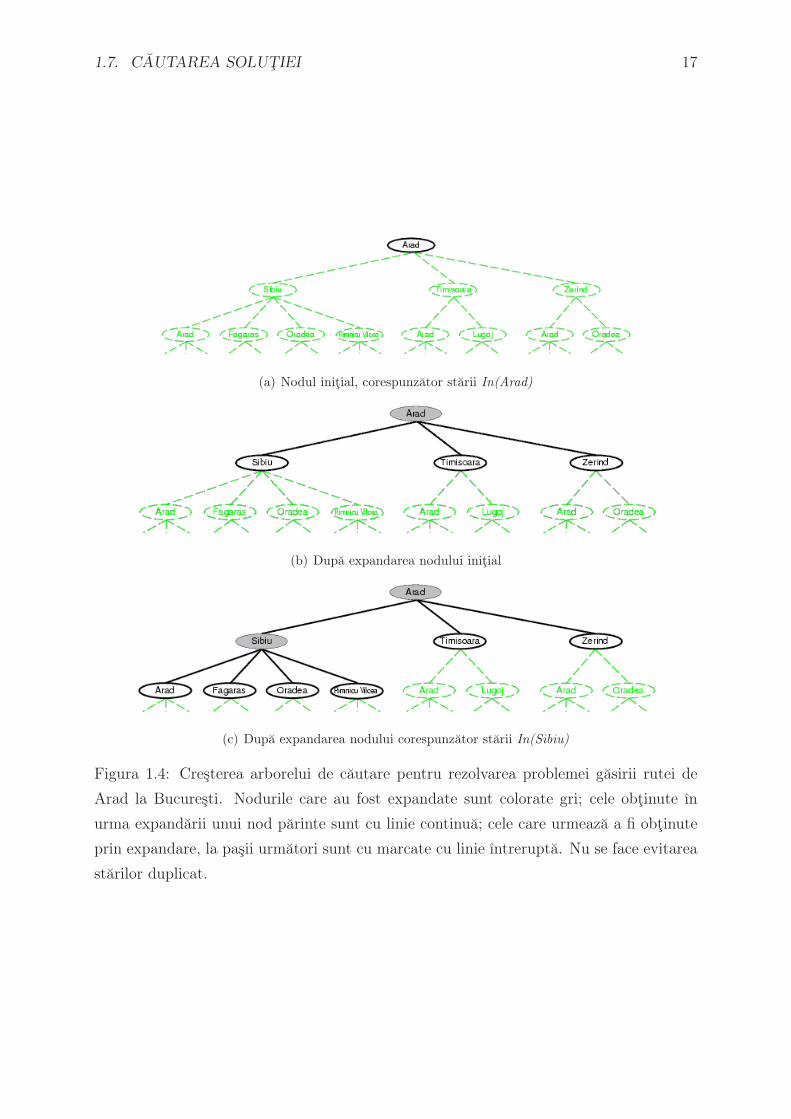
1.7. CAUTAREA SOLUTIEI 17
(a) Nodul initial, corespunzator starii In(Arad)
(b) Dupa expandarea nodului initial
(c) Dupa expandarea nodului corespunzator starii In(Sibiu)
Figura 1.4: Cresterea arborelui de cautare pentru rezolvarea problemei gasirii rutei de
Arad la Bucuresti. Nodurile care au fost expandate sunt colorate gri; cele obtinute ın
urma expandarii unui nod parinte sunt cu linie continua; cele care urmeaza a fi obtinute
prin expandare, la pasii urmatori sunt cu marcate cu linie ıntrerupta. Nu se face evitarea
starilor duplicat.

18 CAPITOLUL 1. DEFINITII. REZOLVAREA PROBLEMELOR PRIN CAUTARE
4. Functia Cautare-in-arbore poate returna si esuare, pentru cazul ın care nu mai
exista nici un nod care sa fie expandat iar iteratiile anterioare nu au descoperit
starea scop printre starile explorate. Trebuie ınsa spus ca exista situatii si strategii
de algoritmi de cautare care pot rula teoretic la infinit, sau din punct de vedere
practic duc la epuizarea memoriei disponibile.
1.8 Masurarea performantelor algoritmilor de cautare
Pentru algoritmii de cautare care urmeaza a fi discutati evaluarea se va face prin
prisma urmatoarelor patru atribute:
• Completitudinea – un algoritm de cautare este complet daca se garanteaza ca gaseste
solutia problemei, ın cazul ın care aceasta exista;
• Optimalitatea – un algoritm este optim daca solutia gasita este cu cost al caii optim;
• Complexitatea ın timp
• Complexitatea de memorie
Complexitatea ın timp este masurata relativ la numarul de noduri generate ın decursul
explorarii, iar complexitatea de memorie este numarul maxim de noduri ce trebuie sa fie
memorat pana la rezolvare.
Cele doua complexitati se cuantifica prin intermediul notatiei O. Prezentam notatia
pentru cazul functiilor reale cu un singur argument. Fie o functie g : N → R+; notam cu
O(g) multimea:
O(g) = {f : N → R+|∃n0 ∈ N, ∃c > 0 : ∀n ≥ n0, f(n) ≤ c · g(n)}
Pentru algoritmii de cautare ce urmeaza a fi prezentati complexitatea este data ın termeni
de:
• b, factor de ramificare reprezentand numarul maxim de succesori ai oricarui nod
• d, adancimea celui mai putin adanc nod solutie (a carui stare este stare scop)
• m, lungimea maxima a oricarei cai ın arborele de cautare.

Capitolul 2
Strategii de cautare neinformata
2.1 Cautarea “mai ıntai ın latime”
Cautarea “mai ıntai ın latime”1 are ca particularitate folosirea structurii de date de tip
coada (colectie ın care politica de acces este FIFO - First In, First Out - primul intrat,
primul iesit) ın cadrul functiei Cautare-in-arbore din sectiunea 1.7. Nodul de start
este expandat, apoi copiii acestui nod sunt expandati, apoi copiii copiilor etc. Functia
Cautare-in-arbore va fi apelata cu parametrul colectieNoduri initializat cu o coada
goala. Expandarea oricarui nod duce la crearea altor noduri care sunt puse la sfarsitul
cozii. In acest fel nodurile de la o adancime mai mica ın arborele de cautare sunt expandate
ınaintea celor cu adancime mai mare. Putem vedea aceasta explorare ca o expandare
radiala ın jurul nodului de plecare. Un exemplu de functionare a acestei strategii este
aratat ın figura 2.1, pentru cazul ın care arborele de cautare este de tip binar.
Se poate vedea faptul ca daca plecand de la nodul initial se ajunge la nodul final prin
urmarirea actiunilor date de functia succesor, atunci functia va duce mai devreme sau
mai tarziu la descoperirea lui; mai mult, drumul de la nodul initial la nodul scop este cu
numar minim de arce; altfel spus, algoritmul descopera un nod scop care are adancimea
minima si atunci opreste cautarea.
Algoritmul este optimal doar daca functia de cost a caii este nedescrescatoare2 fata de
numarul de arce (adancimea nodului). Acest lucru se ıntampla, de exemplu, daca costul
fiecarei actiuni egal cu aceeasi cantitate constanta. Un exemplu de functie de cost a caii
care nu este nedescrescator fata de numarul de arce este dat ın figura 2.1, unde costul caii
din nodul A ın nodul C via B (deci cu doua arce) este 20, pe cand costul drumului direct
A—C (un singur arc) este 30.
Pana acum comportamentul acestui algoritm este ıncurajator. Pentru a vedea de ce
1Engl: breadth-first search2O functie f : R→ R este nedescrescatoare daca ∀x, y ∈ R, x < y avem ca f(x) ≤ f(y).
19
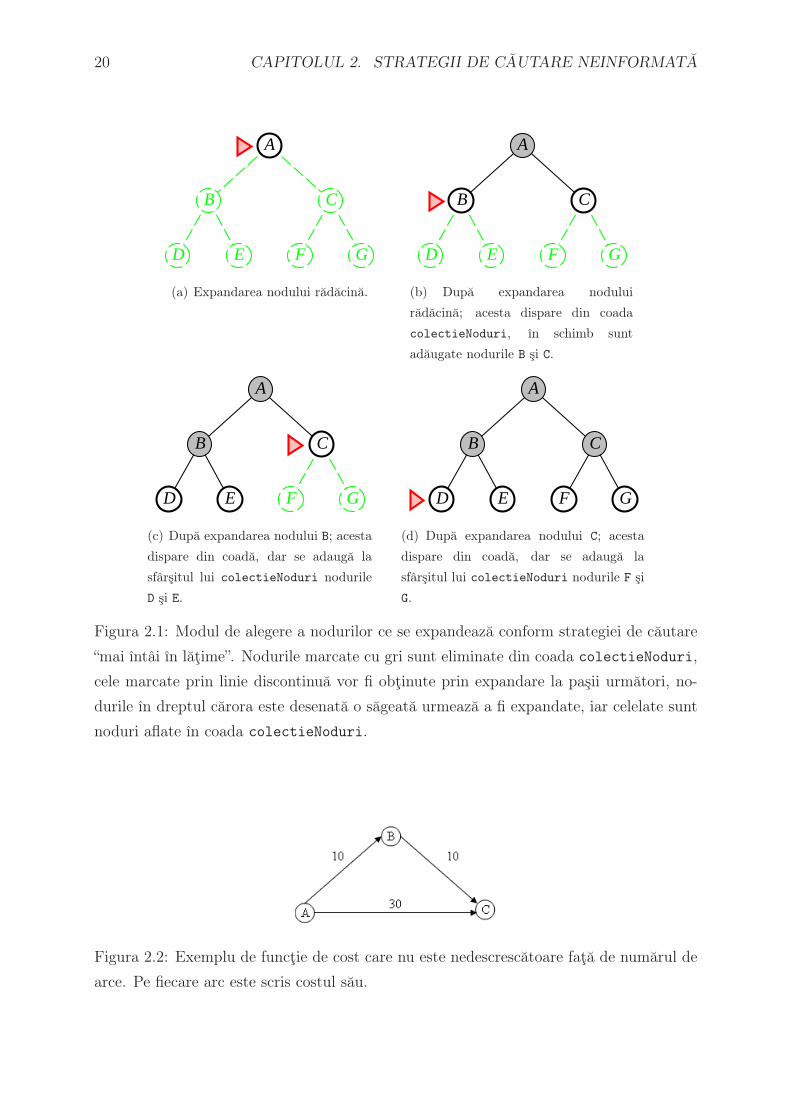
20 CAPITOLUL 2. STRATEGII DE CAUTARE NEINFORMATA
A
B C
D E F G
(a) Expandarea nodului radacina.
A
B C
D E F G
(b) Dupa expandarea nodului
radacina; acesta dispare din coada
colectieNoduri, ın schimb sunt
adaugate nodurile B si C.
A
B C
D E F G
(c) Dupa expandarea nodului B; acesta
dispare din coada, dar se adauga la
sfarsitul lui colectieNoduri nodurile
D si E.
A
B C
D E F G
(d) Dupa expandarea nodului C; acesta
dispare din coada, dar se adauga la
sfarsitul lui colectieNoduri nodurile F si
G.
Figura 2.1: Modul de alegere a nodurilor ce se expandeaza conform strategiei de cautare
“mai ıntai ın latime”. Nodurile marcate cu gri sunt eliminate din coada colectieNoduri,
cele marcate prin linie discontinua vor fi obtinute prin expandare la pasii urmatori, no-
durile ın dreptul carora este desenata o sageata urmeaza a fi expandate, iar celelate sunt
noduri aflate ın coada colectieNoduri.
Figura 2.2: Exemplu de functie de cost care nu este nedescrescatoare fata de numarul de
arce. Pe fiecare arc este scris costul sau.

2.2. CAUTAREA DUPA COSTUL UNIFORM 21
nu este o alegere buna ın toate cazurile facem analiza complexitatilor. Consideram un caz
ın care fiecare stare are exact b succesori. Nodul radacina genereaza b noduri copil, fiecare
dintre acestia are la randul lui b copii (deci la adancimea 2 avem b2 noduri), prin inductie
se poate arata ca la adancimea h avem bh noduri. Sa presupunem ca solutia se afla la
adancimea d. Cazul cel mai defavorabil este acela ın care acest nod corespunzand solutiei
este chiar ultimul care se expandeaza de pe nivelul lui, deci avem: cele bd noduri de pe
nivelul d, fiecare din cele b − 1 noduri de pe nivelul nodului solutie (noduri expandate
ınaintea nodului solutie) produce copii care se pun ın colectieNoduri, deci ınca (bd− 1) · b
noduri de pe nivelul d+ 1. In total numarul de noduri generate este:
1 + b+ b2 + . . .+ bd + (bd+1 − b) = O(bd+1).
Fiecare nod generat trebuie de asemenea sa fie pastrat ın memorie, pentru a putea fi
folosit la reconstituirea drumului - nu avem de unde sa stim care din acestia sunt efectiv
folositi ın refacerea drumului, deci nu ne permitem sa stergem din memorie pana cand se
reface drumul de la starea initiala la cea finala; alfel zis, complexitatea ın spatiu este tot
O(bd+1).
Complexitatile nu sunt ıncurajatoare, deoarece pentru un factor de ramificare b = 10
si adancime a nodului solutie d = 8 este nevoie de 31 de ore de rulare si 1 teraoctet de
memorie RAM (la o rata de producere a nodurilor de 10000 noduri/secunda si 1000 octeti
pentru fiecare nod). Ca atare, acest tip de explorare nu se foloseste ın practica decat
pentru probleme de dimensiuni mici.
2.2 Cautarea dupa costul uniform
Cautarea “mai ıntai ın latime” alege spre expandare cel mai putin adanc nod care nu
este expandat. Pentru cazul ın care costul caii nu este nedescrescator fata de adancimea
nodului, strategia de alegere poate sa rateze gasirea caii optime. Se poate ınsa corecta
acest aspect daca la fiecare pas se alege nu cel mai putin adanc nod neexpandat, ci nodul
neexpandat cu costul caii cel mai mic. Acest lucru se poate face daca colectia de noduri
este mentinuta ca o coada de prioritati (colectie sortata dupa costul caii fiecarui nod; orice
adaugare de nod se face nu neaparat la sfarsit – ca pentru o coada clasica – ci astfel ıncat
sa se pastreze proprietatea de ordonare a colectiei; extragerea produce nodul cu costul
caii cel mai mic).
Astfel, cautarea dupa costul uniform nu favorizeaza caile cu numar minim de arce, ci
pe cel cu cost minim. Daca costul fiecarui pas (actiune) este cel putin egal cu o constanta
ε > 0, atunci cautarea este atat completa cat si optima.
Complexitatea ın timp si spatiu de memorie nu mai poate fi caracterizata de adancimea

22 CAPITOLUL 2. STRATEGII DE CAUTARE NEINFORMATA
nodului; ın schimb este implicat costul solutiei optime, C∗. Complexitatea de timp si
spatiu este O(
b1+[C∗
ε ])
care este deseori mult mai mare decat O(
bd+1)
.
2.3 Cautarea “mai ıntai ın adancime”
Cautarea “mai ıntai ın adancime”3 va alege pentru expandare “cel mai adanc” nod
din arbore care nu a fost expandat. Colectia de noduri neexpandate din algoritmul
Cautare-in-arbore se poate implementa ca o stiva (structura de date cu politica de
acces LIFO - Last In, First Out sau ultimul intrat, primul iesit). Pentru cazul unui
arbore binar ordinea de parcurgere este exemplificata ın figura 2.3.
Necesarul de memorie pentru acest algoritm este deosebit de modest: daca factorul de
ramificare este b si adancimea maxima e m atunci numarul de noduri ce trebuie retinute
ın colectieNoduri este 1 + b ·m, deci complexitatea este O(b ·m).
Exista o varianta si mai redusa ca necesar de memorie bazat pe acest tip de cautare;
algoritmul este cunoscut sub numele de “backtracking” si are particularitatea ca nu obtine
prin expandare toate nodurile copil pentru nodul extras din stiva, ci doar un nod copil;
daca explorarea pe acest copil este nefructuoasa, atunci se ıncearca al doilea copil etc.
Avantajul vine din faptul ca stiva nu se ıncarca decat cu nodurile care chiar fac parte din
calea de cautare curenta. Complexitatea ın spatiu este O(m). Mai mult, se poate doar
mentine nodul curent (daca pasul ınapoi, de la copil spre parinte este usor de refacut)
si atunci complexitatea ın spatiu este O(1) – memorie constanta ocupata, indiferent de
adancimea curenta a nodului.
Problema cu acest tip de cautare este ca poate sa parcurga un numar mare de arce
pana la gasirea nodului solutie, daca ordinea de alegere a nodurilor este “neinspirata”;
de exemplu, strategia de cautare poate sa duca la descoperirea unui nod scop de cost
suboptimal, dar daca ınscrierea ın stiva a nodurilor copil obtinute la expandare s–ar face
dupa alta ordine, atunci s-ar putea ca primul nod solutie descoperit sa fie de cost mai bun
sau chiar optim. Mai mult chiar, poate sa caute la nesfarsit ın arbore, daca nu se face
evitarea starilor duplicat. Pentru problema oraselor, este posibila urmatoarea parcurgere:
Arad, apoi Sibiu, apoi Arad, iar Sibiu etc. Putem deci spune ca algoritmul nu este complet,
nici optimal, iar daca se termina atunci ın cel mai defavorabil caz are complexitatea ın
timp O(bm), unde m este lungimea maxima a unei cai ın arborele de cautare. Mai trebuie
zis ca m poate sa fie mult mai mare decat d, adancimea celui mai putin adanc nod scop,
deci complexitatea de timp poate sa fie mai mare decat cea pentru cautarea “mai ıntai ın
latime” sau chiar si cea a costului uniform. Ramane ınsa de remarcat complexitatea de
memorie ceruta: liniara sau chiar constanta.
3In limba engleza, ın original: depth first search.
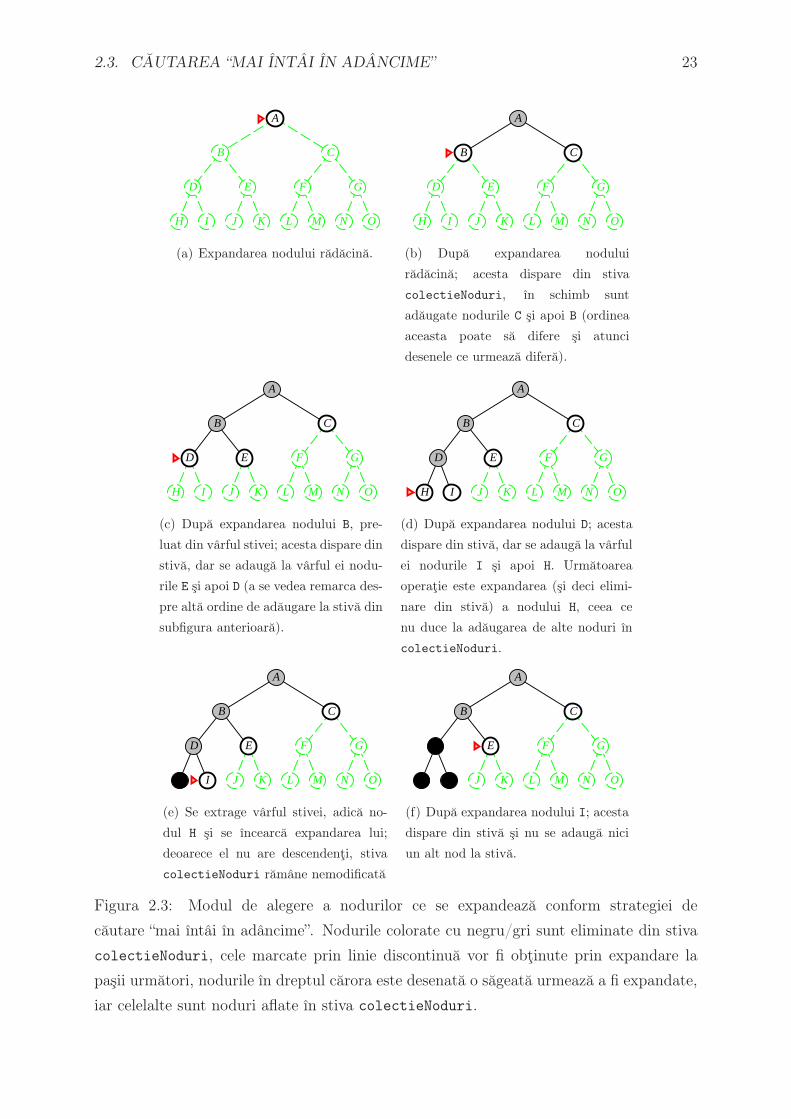
2.3. CAUTAREA “MAI INTAI IN ADANCIME” 23
A
B C
D E F G
H I J K L M N O
(a) Expandarea nodului radacina.
A
B C
D E F G
H I J K L M N O
(b) Dupa expandarea nodului
radacina; acesta dispare din stiva
colectieNoduri, ın schimb sunt
adaugate nodurile C si apoi B (ordinea
aceasta poate sa difere si atunci
desenele ce urmeaza difera).
A
B C
D E F G
H I J K L M N O
(c) Dupa expandarea nodului B, pre-
luat din varful stivei; acesta dispare din
stiva, dar se adauga la varful ei nodu-
rile E si apoi D (a se vedea remarca des-
pre alta ordine de adaugare la stiva din
subfigura anterioara).
A
B C
D E F G
H I J K L M N O
(d) Dupa expandarea nodului D; acesta
dispare din stiva, dar se adauga la varful
ei nodurile I si apoi H. Urmatoarea
operatie este expandarea (si deci elimi-
nare din stiva) a nodului H, ceea ce
nu duce la adaugarea de alte noduri ın
colectieNoduri.
A
B C
D E F G
H I J K L M N O
(e) Se extrage varful stivei, adica no-
dul H si se ıncearca expandarea lui;
deoarece el nu are descendenti, stiva
colectieNoduri ramane nemodificata
A
B C
D E F G
H I J K L M N O
(f) Dupa expandarea nodului I; acesta
dispare din stiva si nu se adauga nici
un alt nod la stiva.
Figura 2.3: Modul de alegere a nodurilor ce se expandeaza conform strategiei de
cautare “mai ıntai ın adancime”. Nodurile colorate cu negru/gri sunt eliminate din stiva
colectieNoduri, cele marcate prin linie discontinua vor fi obtinute prin expandare la
pasii urmatori, nodurile ın dreptul carora este desenata o sageata urmeaza a fi expandate,
iar celelalte sunt noduri aflate ın stiva colectieNoduri.

24 CAPITOLUL 2. STRATEGII DE CAUTARE NEINFORMATA
A
B C
D E F G
H I J K L M N O
(a) Dupa expandarea nodului E; acesta
dispare din stiva colectieNoduri, ın
schimb sunt adaugate nodurile K si apoi
J.
A
B C
D E F G
H I J K L M N O
(b) Dupa expandarea nodului J; acesta
dispare din stiva colectieNoduri si
deoarece nu are descendenti nu produce
noi elemente ın stiva.
A
B C
D E F G
H I J K L M N O
(c) Dupa expandarea nodului K; acesta
dispare din stiva colectieNoduri si
deoarece nu are descendenti nu pro-
duce noi elemente ın stiva.
A
B C
D E F G
H I J K L M N O
(d) Dupa expandarea nodului C; acesta
dispare din stiva, dar se adauga la
varful ei nodurile G si apoi F.
A
B C
D E F G
H I J K L M N O
(e) Se extrage varful stivei, adica no-
dul F si se expandeaza, adaugand-se la
stiva nodurile M si apoi L.
A
B C
D E F G
H I J K L M N O
(f) Expandarile frunzelor M si L re-
duc numarul de elemente din stiva
cu cate o unitate, urmeaza expanda-
rea nodului G (deci scoaterea lui din
stiva colectieNoduri) si introduce-
rea frunzelor O si N. Dupa expandarea
acestor frunze (deci eliminarea lor din
stiva) colectieNoduri devine vida si
cautarea se opreste.
Figura 2.4: Parcurgerea “mai ıntai ın adancime” - continuare.

2.4. CAUTAREA CU ADANCIME LIMITATA 25
2.4 Cautarea cu adancime limitata
Cautarea “mai ıntai ın adancime” din sectiunea 2.3 are un mare atu: foloseste extrem
de putina memorie. Dar are si un dezavantaj major, posibilitatea de a cauta la infinit
ın arbore, datorita starilor duplicat. Acest dezavantaj este eliminat simplu: vom limita
adancimea maxima la care poate sa coboare explorarea ın arbore. Vom folosi deci un
parametrul l (numar ıntreg) reprezentand adancimea maxima de explorare. Nodurile de la
adancimea l sunt tratate ca si cum nu ar avea succesori. Insa acest algoritm mai introduce
un tip de rezultat: taiere4, pentru cazul ın care avem d > l iar cautarea epuizeaza toate
nodurile din subarborele de adancime l; ın acest caz nu se poate spune ca se esueaza,
pentru ca o adancime de cautare mai mare ar fi permis gasirea nodului scop (si deci
problema s–ar fi putut rezolva).
Algoritmul cautarii cu adancime limitata5 este dat ın figura 2.4. Functiile solutie,
expandeaza sunt aceleasi ca la algoritmul de cautare ın arbore (sectiunea 1.3, pagina 16).
Algoritmul nu este complet daca l < d; pentru l ≥ d el este complet, dar nu neaparat
optim. Complexitatea ın timp este O(bl), iar cea ın spatiu O(b·l) (mostenite amandoua de
la parcurgerea “mai ıntai ın adancime”). Ceea ce este ınsa de remarcat e ca nu mai avem
risc de cautare infinita datorata ciclurilor (vizitarii repetate a acelorasi stari). Impreuna
cu consumul de memorie redus ne fac sa speram ca problema de cautare devine rezolvabila
cu cerinte de memorie rezonabile.
Se pune ıntrebarea: de unde stim care este adancimea maxima la care vom permite
cautarea? Pentru destul de multe probleme, din ınsasi enuntul lor se poate deduce care
este o valoare rezonabila pentru limita maxima. De exemplu, pentru problema Arad–
Bucuresti putem observa ca numarul de orase de pe harta este 20, deci l = 19 este o
alegere buna. Chiar mai mult, se poate observa ca pentru orice pereche de orase se poate
sa se ajunga dintr-unul ın celalalt prin maxim 9 pasi, deci adancimea poate fi si mai mult
redusa.
2.5 Cautarea “mai ıntai ın adancime” cu adancire ite-
rativa
Problema necunoasterii apriorice a adancimii la care sa se faca cautarea este tratabila
prin urmatoarea strategie: se dau valori succesive lui l ıncepand cu 0, din ce ın ce mai mari
pana ce rezultatul este de tip esuare sau solutie. Gasirea solutiei ınseamna determinarea
nodului solutie cel mai putin adanc. Varianta de algoritm combina partile bune ale
4In limba engleza, ın original: cutoff5In limba engleza, ın original: depth–limited search

26 CAPITOLUL 2. STRATEGII DE CAUTARE NEINFORMATA
Figura 2.5: Algoritmul cautarii cu adancime limitata.
cautarii ın adancime si ın latime: memorie necesara mica si respectiv, completitudine
si optimalitate pentru cazul ın care functia de cost a caii este nedescrescatoare fata de
numarul de arce pentru cale.
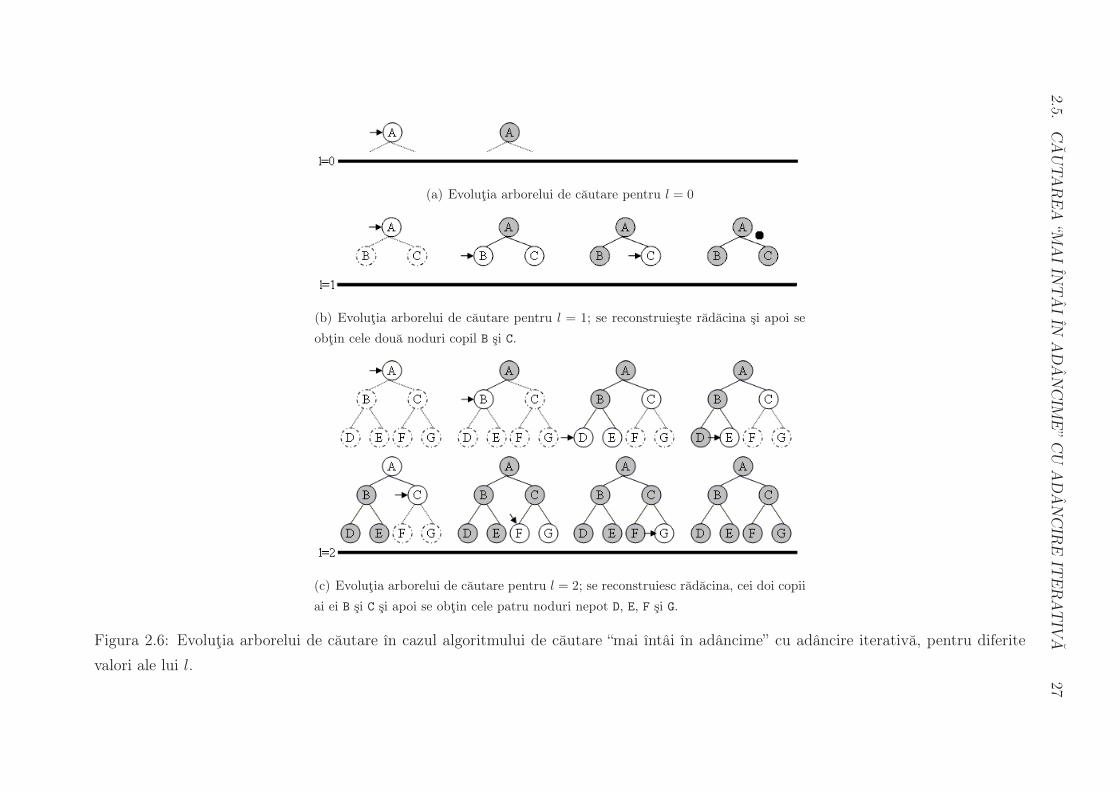
2.5
.C
AU
TA
RE
A“M
AI
INT
AI
INA
DA
NC
IME
”C
UA
DA
NC
IRE
ITE
RA
TIV
A27
(a) Evolutia arborelui de cautare pentru l = 0
(b) Evolutia arborelui de cautare pentru l = 1; se reconstruieste radacina si apoi se
obtin cele doua noduri copil B si C.
(c) Evolutia arborelui de cautare pentru l = 2; se reconstruiesc radacina, cei doi copii
ai ei B si C si apoi se obtin cele patru noduri nepot D, E, F si G.
Figura 2.6: Evolutia arborelui de cautare ın cazul algoritmului de cautare “mai ıntai ın adancime” cu adancire iterativa, pentru diferite
valori ale lui l.

28 CAPITOLUL 2. STRATEGII DE CAUTARE NEINFORMATA
Strategia algoritmului cautarea “mai ıntai ın adancime” cu adancire iterativa6 ar putea
parea neeficienta, deoarece se creeaza toate nodurile de la adancimea i− 1 atunci cand se
cauta la adancimea i. Putem observa ınsa ca cu cat un nivel de noduri se recreeaza mai
des, cu atat este de fapt adancimea lui mai mica (deci numarul de noduri corespunzator
este mai redus). Putem calcula numarul de noduri care sunt expandate astfel: nodurile
de la adancimea d sunt generate o singura data (de fapt, la ultima iteratie s-ar putea sa
nu fie chiar toate generate), cele de la nivelul d− 1 sunt generate de doua ori etc, cele de
la nivelul 0 (adica radacina) de d ori; numarul de noduri este dat ca:
N(CAR) = bd · 1 + bd−1 · 2 + . . .+ b · d+ 1 · (d+ 1) = O(bd)
pe cand la cautarea “mai ıntai ın latime” numarul de noduri generate este O(bd+1).
Am obtinut deci un algoritm de cautare care este complet, este optimal daca costul
fiecarui pas este o constanta, are cerinte de memorie modeste si complexitate ın timp mai
mica decat cea a algoritmilor anterior prezentati. In practica se considera ca algoritmul
de cautare mai ıntai ın adancime cu adancire iterativa este algoritmul preferat de cautare
atunci cand spatiul de cautare este mare iar adancimea nodului solutie este necunoscuta.
2.6 Cautare bidirectionala
Cautarea bidirectionala se bazeaza pe strategia: se ıncep simultan doua cautari, atat
dinspre nodul de start spre scop cat si invers. Daca se produce “ ıntalnirea” celor doua
cautari (si ın acest caz punctul comun celor doua parcurgeri este la distanta d/2 dintre
cele doua noduri de pornire), atunci complexitatea ın timp este O(bd/2 + bd/2) = O(bd/2),
care este mult mai mic decat O(bd). Procedeul este ilustrat ın figura 2.7.
Figura 2.7: Cautare bidirectionala. Aria ınsumata a celor doua cercuri este mai mica
decat aria unui cerc mare care pleaca din nodul de start si ajunge ın nodul de scop.
GoalStart
La fiecare expandare de nod se verifica daca acesta nu a fost cumva atins de cautarea
din sens contrar. Daca da, atunci solutia (secventa de actiuni care duce dinspre nodul
de start spre cel de scop) se reface pe baza drumurilor construite spre nodul comun.
6In limba engleza, ın original: iterative deepening depth-first search.

2.7. PROBLEMA STARILOR DUPLICAT 29
Determinarea faptului ca un nod se gaseste ıntr-o lista de noduri se face ın timp mediu
constant7, daca se foloseste o tabela de dispersie. Dar tocmai faptul ca necesarul de
memorie este O(bd/2) face acest algoritm sa nu poata fi aplicat ın practica. In rest ınsa,
algoritmul este complet si optimal daca fiecare din cele doua cautari este efectuata prin
parcurgere “mai ıntai ın latime” (si desigur, cu ipoteza suplimentara ceruta de algoritmul
mentionat). Alte variante de combinare pot face algoritmul neoptim sau incomplet.
Mai trebuie zis aici ca algoritmul poate fi folosit doar ın cazul ın care se poate calcula
usor functia de predecesor, opusul functiei succesor care face parte din definitia problemei
- lucru care nu se ıntampla la toate problemele. Inca un aspect merita mentionat - daca
exista mai multe noduri scop care pot fi enumerate (nu doar teoretic, ci si practic) atunci
se poate crea o stare scop noua, unica, al carui pas de predecesor sa duca ın starile scop
originale. Daca multimea starilor scop este foarte larga sau validarea nodurilor scop se
face fata de un predicat, atunci cautarea bidirectionala este greu sau imposibil de aplicat,
ın lipsa unei descrieri compacte a proprietatii de a fi stare scop.
2.7 Problema starilor duplicat
Algoritmul general de cautare nu evita explorarea ın mod repetat a acelorasi stari
(deci obtinerea de noduri diferite, dar pentru care starile corepsunzatoare au mai fost
vizitate anterior). Acest lucru face ca, de exemplu, explorarea ın adancime sa poata sa
nu determine solutie, cu toate ca una exista. Pentru ceilalti algoritmi vizitarea repetata
a unor stari se traduce prin ineficienta.
Un exemplu de “explozie” a numarului de noduri datorate starilor duplicat este dat
ın figura 2.8. Din fiecare punct avem 4 variante de continuare; daca nu facem evitarea
starilor duplicat, atunci la o parcurgere de adancime d obtinem 4d noduri; daca se face
evitarea starilor duplicat, atunci obtinem 4 · d2 noduri. Pentru d = 20, diferenta este
uriasa: 1.099.511.627.776 fata de 1600 de noduri!
Figura 2.8: Retea pentru care neevitarea starilor duplicat duce la o explozie exponentiala
a numarului de noduri cu stari repetate.
Detectarea se face prin cautarea starii nodului ce urmeaza a fi expandat ın lista starilor
care au fost deja expandate. Daca un algoritm evita starile duplicat, atunci poate fi vazut
7Daca functia de dispersie este bine aleasa.

30 CAPITOLUL 2. STRATEGII DE CAUTARE NEINFORMATA
ca o cautare ın graf. Algoritmul este dat ın figura 2.9 si foloseste o multime a starilor deja
expandate numita stariVechi. Algoritmul nou obtinut se numeste Cautare-in-graf.
Figura 2.9: Algoritmul de cautare in graf.
Algoritmul Cautare-in-graf nu pune probleme ın privinta completitudinii; comple-
xitatea ın timp si spatiu sunt proportionale cu numarul starilor distincte, iar asta poate sa
fie mult mai mic decat O(bd). Remarcam ınsa ca pentru cautarea “mai ıntai ın adancime”
sau cei derivati din aceasta strategie, datorita mentinerii acestei liste de noduri vechi,
necesarul de memorie nu mai este liniar; se evita ın schimb ciclarea.
In ceea ce priveste optimalitatea, lucrurile stau astfel: algoritmul va elimina noua cale
descoperita catre o stare care a mai fost ıntalnita ınainte. Deoarece prima cale descope-
rita s-ar putea sa fie suboptimala, rezulta ca nu se poate garanta optimalitatea solutiei
determinate. Acest lucru nu se ıntampla atunci cand avem cautarea costului uniform sau
cand se foloseste cautarea “mai ıntai ın latime” pentru cost constant al actiunilor. Pentru
celelate metode ar trebui ca ajungerea la o stare care a mai fost parcursa sa declanseze o
verificare asupra faptului ca noua cale produce un rezultat mai bun; daca este adevarat,
atunci trebuie ca toate nodurile care au ca ascendent (direct sau prin tranzitivitate) nodul
curent sa ısi reactualizeze costurile.

Capitolul 3
Cautare informata
3.1 Strategii de cautare informata
Strategiile euristice prezentate ın acest capitol pornesc de la o idee simpla: ce s-ar
ıntampla daca s-ar explora ıntr-o directie care pare mai promitatoare pentru rezolvarea
problemei? am putea astfel sa evitam explorarea unor noduri care au o sansa mica de
ajungere ın nodul scop, cu efect benefic asupra complexitatii de timp si de spatiu de
memorie folosit. Este o strategie des folosita de expertii umani, care pe baza experientei
si intuitiei evita explorarea tuturor posibilitatilor si decid o cautare ın anumite directii,
cele estimate a fi mai promitatoare.
In cazul problemelor de cautare formalizate ın capitolul 1, vom considera pentru fiecare
nod n capacitatea estimata a lui de a duce spre un nod scop. Concret, se folosesste o
functie de evaluare f(·) si pentru fiecare nod n se calculeaza f(n). Nodul cu cea mai mica
valoare a acestei functii este ales pentru expandare. Ca atare, algoritmul de cautare pe
arbore poate fi folosit cu particularizarea: lista de noduri colectieNoduri este o coada
de prioritati.
Exista o clasa ıntreaga de algoritmi bazati pe aceasta idee. O componenta comuna a
acestora este o functie euristica notata traditional cu h(·). h(n) reprezinta costul estimat
al celei mai “ieftine” cai care duce de la nodul curent n la un nod scop1.
In mod firesc, vom impune ca h(n) = 0 daca n este nod scop.
De exemplu, pentru problema drumului din Arad ın Bucuresti putem sa vedem aceasta
functie ca fiind distanta pe drum drept de la oricare oras catre Bucuresti. Figura 3.1
contine atat harta schematizata a Romaniei, cat si un tabel cu distantele pe drum drept
dintre orase si Bucuresti.
1Daca problema este de minimizare, atunci h(n) este costul estimat al celei mai scurte cai; daca este
problema de maxim, atunci este costul estimat al celei mai “scumpe” cai. In cele ce urmeaza vom lucra
cu probleme de cost minim.
31

32 CAPITOLUL 3. CAUTARE INFORMATA
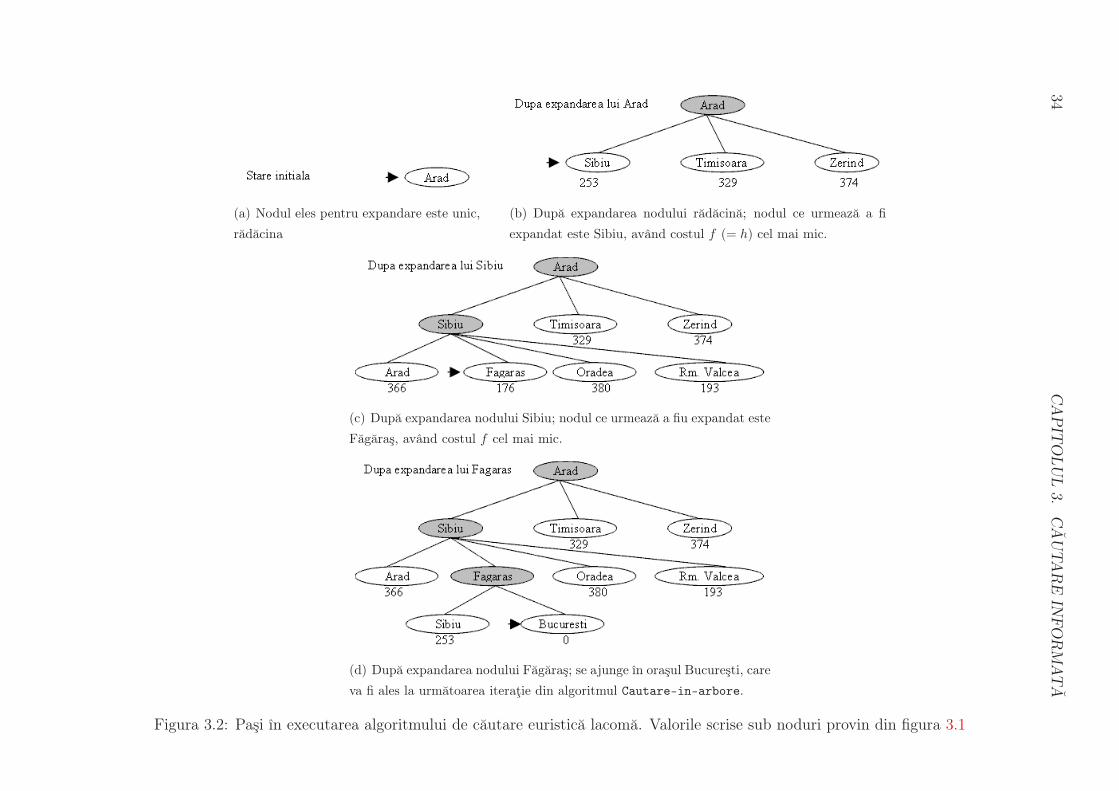
3.2 Cautarea euristica lacoma
Cautarea euristica lacoma2 alege pentru expandare nodul care are valoarea calculata
pentru functia h cea mai mica. Altfel spus, alegem ca f(n) = h(n), pentru orice nod n.
Pentru problema drumului minim de la Arad la Bucuresti pasii sunt dati ın figura
3.2. Distantele folosite drept euristica sunt scrise ın figura 3.1. Primul nod care se
expandeaza este Sibiu, deoarece are distanta pe drum drept de la el la Bucuresti minima,
253 km. Urmatorul nod expandat este Fagaras, deoarece din multimea nodurilor aflate
ın colectieNoduri el este cel mai apropiat de Bucuresti. Expandarea lui Fagaras duce
la obtinerea nodului Bucuresti, care la iteratia urmatoare este cel ales pentru expandare
(avand costul 0) si care termina iteratia din algoritmul Cautare-in-arbore (sectiunea
1.7). Dar drumul optim este urmatorul: Arad — Sibiu — Ramnicu Valcea — Pitesti —
Bucuresti, cu 32 de kilometri mai mic decat cel descoperit anterior.
Putem observa ca explorarea prin cautarea dupa valoarea minima a lui h poate duce
la cautare cu numar infinit de pasi: de exemplu, daca se doreste a se ajunge din Iasi la
Fagaras, prima destinatie este Neamt; dar de aici nu mai exista nici un alt drum, decat
ınapoi ınapoi ın Iasi, ceea ce duce la un ciclu infinit daca nu se evita starile repetate; daca
se evita, atunci se descopera calea optima: Iasi, Vaslui, Urziceni, Bucuresti, Fagaras.
Caracteristicile acestui algoritm sunt: incomplet – deoarece poate intra ıntr–un ciclu
infinit, neoptim – a se vedea exemplul dat mai sus, complexitate de timp si memorie O(bm),
unde m este adancimea maxima a unui drum ın arborele de cautare. In practica ınsa, o
euristica bine aleasa poate sa duca la viteza crescuta si memorie necesara rezonabila, iar
costul solutiei determinate, chiar daca nu e optim, este deseori foarte apropiat de el.
2In limba engleza: greedy best-first search.

3.2
.C
AU
TA
RE
AE
UR
IST
ICA
LA
CO
MA
33
Bucharest
Giurgiu
Urziceni
Hirsova
Eforie
NeamtOradea
Zerind
Arad
Timisoara
LugojMehadia
DobretaCraiova
Sibiu
Fagaras
PitestiRimnicu Vilcea
Vaslui
Iasi
Straight−line distanceto Bucharest
0160242161
77151
241
366
193
178
25332980
199
244
380
226
234
374
98
Giurgiu
UrziceniHirsova
Eforie
Neamt
Oradea
Zerind
Arad
Timisoara
Lugoj
Mehadia
Dobreta
Craiova
Sibiu Fagaras
Pitesti
Vaslui
Iasi
Rimnicu Vilcea
Bucharest
71
75
118
111
70
75120
151
140
99
80
97
101
211
138
146 85
90
98
142
92
87
86
Figura 3.1: Harta Romaniei si distantele pe drum drept dintre orase si Bucuresti.
34C
AP
ITO
LU
L3.
CA
UTA
RE
INFO
RM
AT
A
(a) Nodul eles pentru expandare este unic,
radacina
(b) Dupa expandarea nodului radacina; nodul ce urmeaza a fi
expandat este Sibiu, avand costul f (= h) cel mai mic.
(c) Dupa expandarea nodului Sibiu; nodul ce urmeaza a fiu expandat este
Fagaras, avand costul f cel mai mic.
(d) Dupa expandarea nodului Fagaras; se ajunge ın orasul Bucuresti, care
va fi ales la urmatoarea iteratie din algoritmul Cautare-in-arbore.
Figura 3.2: Pasi ın executarea algoritmului de cautare euristica lacoma. Valorile scrise sub noduri provin din figura 3.1

3.3. ALGORITMUL A* 35
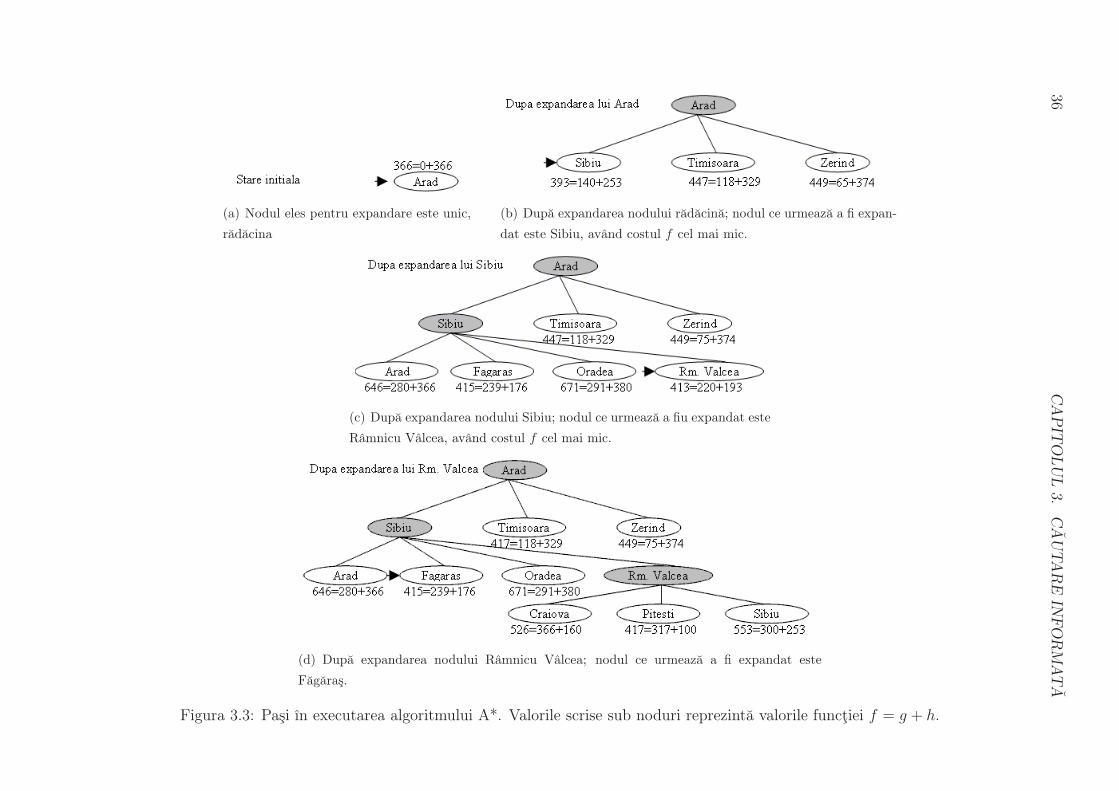
3.3 Algoritmul A*
Cea mai cunoscuta forma a acestor algoritmi de cautare informata este algoritmul A*,
pentru care functia f(n) este data ca:
f(n) = g(n) + h(n)
unde g(n) este costul real al drumului de la nodul de start la nodul n – un nod din
arborele de cautare contine deja aceasta valoare – iar h(n) este, precum anterior, costul
estimat al celei mai bune cai de la nodul n la un nod scop. Avem deci ca f(n) este costul
estimat al celui mai bun drum de la nodul de start la un nod scop, drum ce trece prin n.
Pentru cateva conditii impuse lui h se obtine ca algoritmul A* este optim si complet; ın
practica, rezultatele obtinute sunt foarte bune, prin comparatie cu strategiile de cautare
oarba studiate ın cursul 2.
Vom considera functii h care sunt euristici admisibile, adica h(n) niciodata nu supra-
estimeaza (depaseste) costul unei solutii de la nodul n la nod scop3. Prin natura lor, acest
tip de functii sunt optimiste – ele permanent subestimeaza costul real al drumului. Deoa-
rece functia g cuantifica efortul exact de a ajunge din nodul initial ın nod scop, deducem
ca valoarea f(n) nu supraestimeaza efortul de a ajunge din nodul initial ın nod scop via
nodul intermediar n.
Un exemplu de functie euristica admisibila este cea care estimeaza efortul de ajungere
din nodul n ın Bucuresti ca fiind distanta pe drum drept de la n la Bucuresti. Este evident
ca orice ruta s-ar alege, ea nu poate avea cost mai mic decat costul drumului drept.
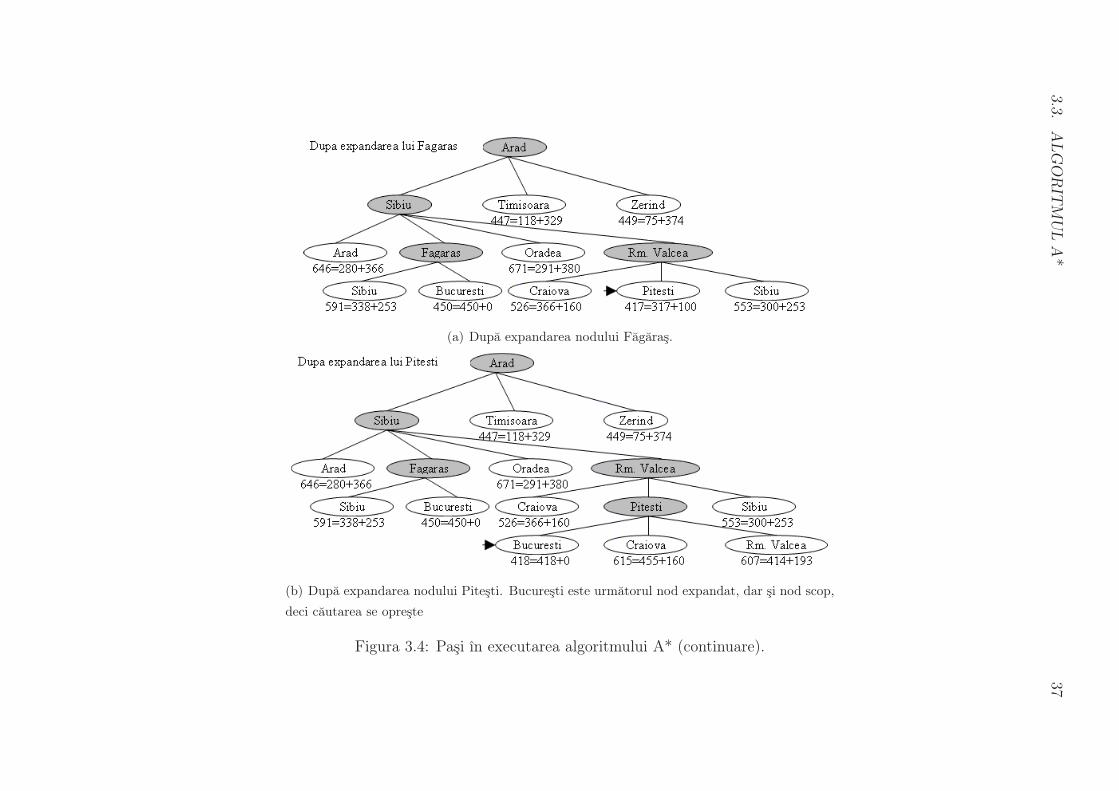
Evolutia algoritmului A* pentru problema ajungerii de la Arad la Bucuresti este re-
prezentata ın figurile 3.3 si 3.4.
3Aceasta este definitia pentru problema ın care se cere minimizarea caii; pentru probleme de maximi-
zare, o euristica admisibila nu subestimeaza efortul real de ajungere la nod scop.
36C
AP
ITO
LU
L3.
CA
UTA
RE
INFO
RM
AT
A
(a) Nodul eles pentru expandare este unic,
radacina
(b) Dupa expandarea nodului radacina; nodul ce urmeaza a fi expan-
dat este Sibiu, avand costul f cel mai mic.
(c) Dupa expandarea nodului Sibiu; nodul ce urmeaza a fiu expandat este
Ramnicu Valcea, avand costul f cel mai mic.
(d) Dupa expandarea nodului Ramnicu Valcea; nodul ce urmeaza a fi expandat este
Fagaras.
Figura 3.3: Pasi ın executarea algoritmului A*. Valorile scrise sub noduri reprezinta valorile functiei f = g + h.
3.3
.A
LG
OR
ITM
UL
A*
37
(a) Dupa expandarea nodului Fagaras.
(b) Dupa expandarea nodului Pitesti. Bucuresti este urmatorul nod expandat, dar si nod scop,
deci cautarea se opreste
Figura 3.4: Pasi ın executarea algoritmului A* (continuare).

38 CAPITOLUL 3. CAUTARE INFORMATA
Vom demonstra urmatoarea propozitie:
Teorema 1 Daca algoritmul A* se termina, atunci nodul scop la care s-a ajuns, folosind
algoritmul Cautare-in-Arbore are cost optim.
Demonstratie Fie G si G2 noduri scop aflate ın colectieNoduri, G2 suboptimal (adica
cu valoarea drumului pana la el mai mare decat este necesar) si G optimal. Avem
urmatoarele:
f(G2) = g(G2) + h(G2) = g(G2)
deoarece am impus ınca de la ınceput ca h(nodScop) = 0. Din acelasi motiv:
f(G) = g(G)
Apoi:
g(G2) > g(G)
deoarece G2 este suboptimal. Din cele de mai sus avem ca:
f(G2) > f(G)
deci G va fi expandat ınaintea lui G2 de catre algoritmul A*.
Conditia din teorema anterioara este satisfacuta daca numarul de noduri n pentru
care f(n) ≤ f(G) este finit.
Daca se foloseste algoritmul Cautare-in-Graf ın locul algoritmului Cautare-in-Arbore,
optimalitatea nu mai este neaparat valabila. Reamintim ca algoritmul parcurgerii pe graf
evita starile repetate astfel: un nod din colectia de noduri se expanda doar daca starea sa
nu se regaseasca ıntr-o colectie de stari deja parcurse. Problema cu aceasta abordare este
ca se poate astfel ca prima ajungere ıntr-o anumita stare sa se faca cu un cost suboptimal,
iar urmatoarele drumuri care conduc la aceeasi stare sunt neglijate, chiar daca ar duce la
ımbunatatirea costului pentru acea stare.
Exista doua solutii care se pot aplica. Prima consta ın mentinerea si actualizarea
permanenta a caii care are costul cel mai bun. Se poate scrie asemenea algoritm, chiar
daca este mai complex (presupune de exemplu ca sa se modifice si costurile nodurilor care
sunt descendenti ai nodurilor cu cost ımbunatatit). A doua solutie cere sa ne asiguram
ca prima cale ce duce la o anumita stare este ıntotdeauna cu cost optim, ca atare putem
neglija drumurile ulterioare care redescopera starea. Vom detalia ın cele ce urmeaza care
sunt conditiile care trebuie sa fie ındeplinite de catre functia h pentru a aplica aceasta
varianta.

3.3. ALGORITMUL A* 39
Definitia 9 O functie h se numeste consistenta daca pentru orice nod n si orice succesor
n′ generat de o actiune a avem ca:
h(n) ≤ c(n, a, n′) + h(n′) (3.1)
unde c(n, a, n′) este costul actiunii a care permite mutarea din starea n ın starea n′ – a
se vedea figura 3.5.
n
c(n,a,n’)
h(n’)
h(n)
G
n’
Figura 3.5: Inegalitatea triunghiului pentru o functie consistenta
Aratam ca daca h este consistenta, atunci valorile lui f de-a lungul unui drum sunt
nedescrescatoare. Fie n′ un succesor al lui n; atunci:
g(n′) = g(n) + c(n, a, n′)
(conform definitiei lui g, unde a este actiunea care permite schimbarea starii curente din
n ın n′) si
f(n′) = g(n′) + h(n′) = g(n) + c(n, a, n′) + h(n′) ≥ g(n) + h(n) = f(n)
O functie consistenta se mai numeste din acest motiv si monotona.
Ecuatia 3.1 este o forma a inegalitatii triunghiului, triunghi format de varfurile n, n′
si nodul scop cel mai apropiat de n. Se poate arata ca orice functie consistenta este si
admisibila. Reciproca nu este adevarata, dar trebuie destul de multa ingeniozitate pentru
a crea o functie care este admisibila si nu este si monotona.
Pentru problema drumului Arad–Bucuresti, functia euristica data de distanta pe drum
drept de la orasul curent la Bucuresti este de asemenea si consistenta, deoarece satisface
inegalitatea triunghiului din geometria plana.
Enuntam fara demonstratie teorema:
Teorema 2 Daca h este consistenta, atunci A* folosind functia Cautare-pe-Graf este
optimal.
Fie C∗ costul solutiei optime. Se mai poate arata ca:

40 CAPITOLUL 3. CAUTARE INFORMATA
• A* expandeaza toate nodurile cu f(n) < C∗;
• se poate ca A* sa expandeze cateva noduri care au f(n) = C∗ ınainte ca sa expandeze
nod scop (si deci sa se termine algoritmul);
• A* nu expandeaza noduri n cu f(n) > C∗.
Ultima observatie este deosebit de importanta, deoarece arata ca se evita expandarea
unui nod care are costul mai mare decat costul optim, chiar daca acest cost optim nu este
cunoscut decat la terminarea algoritmului! De exemplu, nodul aferent orasului Timisoara
nu este niciodata expandat, avand cost prea mare. Datorita monotoniei functiei f avem ca
nici orasele care descind direct din Timisoara nu vor fi expandate, de fapt nici un nod de
pe vreo ruta care include Timisoara ca nod intermediar nu va fi expandat; se face astfel o
“retezare” a arborelui de cautare, prin eliminarea unor variante care nu ar fi dus oricum la
un rezultat optim. Geografic, realizam ca toata partea Banatului este exclusa din arborele
de cautare, deoarece costurile nodurilor din aceasta regiune sunt oricum prea mari fata
de costul optim (momentan necunoscut, determinat doar la sfarsitul algoritmului) C∗.
Algoritmul este complet, daca nu cumva sunt infinit de multe noduri n care au f(n) ≤
C∗. Este si optimal; mai mult decat atat, este optimal eficient pentru orice functie
euristica data – adica nici un alt algoritm optimal nu garanteaza expandarea unui numar
mai mic de noduri decat A*, abstractie facand de numarul de noduri n pentru care
f(n) = C∗. Daca am avea un algoritm care nu expandeaza toate nodurile n cu f(n) < C∗,
atunci ar exista riscul ca sa se rateze o cale optima.
Exista totusi o problema: numarul de noduri care au f(·) < C∗ creste exponential cu
numarul de pasi. Un caz ın care nu se ıntampla asa ceva este cand:
|h(n)− h∗(n)| ≤ O (log (h∗(n)))
unde h∗(n) este costul real al ajungerii de la nodul n la scop. Din pacate, cele mai multe
euristici folosite ın practica sunt macar proportionale cu costul caii, ca atare obtinem
numar de noduri exponential – si toate trebuie tinute ın memorie, pentru a putea reface
solutia. De multe ori algoritmul epuizeaza toata memoria pusa la dispozitie.
3.4 Variatii ale lui A*
Exista cateva variatii ale algoritmului A*, recent obtinute, care determina solutia
optima cu un necesar de memorie neprohibitiv. Primul dintre ele este Recursive best–
first search (RBFS) care are complexitate de memorie liniara, dar sufera de regenerarea
excesiva a nodurilor. Practic, acest algoritm sufera din cauza ca foloseste prea putina
memorie.

3.5. FUNCTII EURISTICE 41
Algoritmii MA* (Memory–bounded A*) si SMA* (Simplified memory–bounded A*)
vin sa corecteze problema, ei folosind toata memoria care li se pune la dispozitie. Algo-
ritmul este complet daca solutia poate fi atinsa cu memoria data; este optimal ın aceeasi
conditie, iar daca memoria pusa la dispozitie este prea putina, atunci va returna cea mai
buna solutie (suboptimala) pe care a putut-o descoperi. Pe de alta parte, ınsa, o problema
poate deveni intratabila datorita complexitatii de timp crescute.
3.5 Functii euristice
Vom studia functii euristice pentru problema puzzle-ului (a se vedea definitia problemei
de la pagina 12). Pentru un puzzle de 3x3, factorul mediu de ramificare este 3 (4 noduri
descendente daca spatiul este la mijloc, 2 noduri descendente daca spatiul este ıntr-un
colt, 3 noduri altfel). Numarul mediu de mutari pentru rezolvare este de 22; o cautare
exhaustiva ar cere vizitarea a 322 adica aproximativ 3.1 · 1010 noduri. Prin eliminarea
starilor duplicat problema s-ar reduce la 9!/2=181.440 noduri. Numarul este acceptabil,
dar pentru un puzzle de 4x4, un calcul asemanator duce la aproximativ 1013 stari distincte.
Ca atare, ne ıntrebam ce functie euristica am putea folosi si cat de buna este ea.
Cele mai populare euristici sunt:
• h1 — numarul de piese pozitionate gresit. h1 este o euristica admisibila, deoarece
este clar ca orice casuta cu pozitionare gresita trebuie sa suporte cel putin o mutare.
• h2 — suma distantelor dintre pozitiile actuale si cele din starea finala a pieselor.
Deoarece piesele se pot misca doar pe orizontala si verticala, nu vom folosi distanta
euclidiana – precum ın problema drumului de la Arad la Sibiu – ci distanta L1 (sau
distanta Manhattan):
L1 ((x1, y1), (x2, y2)) = |x1 − x2|+ |y1 − y2|
Din nou se observa ca este o euristica admisibila, deoarece pentru mutarea unei
piese la pozitia corecta se fac cel putin mutarile pe orizontala si pe verticala.
O modalitate de a caracteriza calitatea unei euristici este factorul efectiv de ramificare,
b∗. Daca numarul de noduri create de algoritmul decautare pentru o instanta particulara
a unei probleme este N , atunci b∗ se defineste ca factorul de ramificare (nu neaparat
numar ıntreg) pentru care un arbore uniform de adancime d contine cele N noduri; pe
scurt, b∗ este solutia ecuatiei:
N = 1 + b∗ + (b∗)2 + . . .+ (b∗)d

42 CAPITOLUL 3. CAUTARE INFORMATA
De exemplu, daca A* descopera solutia la adancime 5 generand 52 de noduri, atunci
b∗ ≃ 1.92. Numarul b∗ se obtine de fapt ca o medie peste diferite instante, dar este o
valoare aleatoare cu dispersie mica. Scopul este de a obtine un factor de ramificare cat
mai apropiat de 1.
De exemplu, pentru instante ın care numarul de pasi este 12, numarul de noduri ge-
nerat pentru cautarea “mai ıntai ın adancime” cu adancire iterativa genereaza 3.644.035
noduri, algoritmul A*(h1) genereaza 227 noduri, iar A*(h2) genereaza 73 noduri. Pen-
tru adancime 24, algoritmul de cautare oarba clacheaza din lipsa de memorie, A*(h1)
genereaza 39135 noduri, iar A*(h2) genereaza 1641 noduri.
Daca exista mai multe euristici ne putem pune problema daca e vreuna mai buna
decat celelalte. Pentru h1 si h2, de pilda, avem ca h2(n) ≥ h1(n), ∀n. Din cauza ca A*
expandeaza fiecare nod care are f(n) < C∗ (echivalent: h(n) < C∗ − g(n)), rezulta ca
orice nod expandat pentru functia h2 este sigur expandat si pentru functia h1. Asta ne
ındeamna a cauta functii euristice care sa aiba valori cat mai mari, dar sa ramana ınca
admisibile (sub valoarea reala a costului h(n)). Problema cu o asemenea abordare este
ca functia, desi devine mai “buna”, poate cere de asemenea resurse computationale prea
mari. Pentru cazul ın care ıntre doua euristici exista relatia h2 ≥ h1 spunem ca h2 domina
pe h14.
Se pune ıntrebarea: cum se pot inventa functii euristice? Este posibil a se inventa
asemenea functii ın mod automat? Modul ın care s–au descoperit cele de mai sus este
simplu: s–au relaxat restrictiile problemei. Daca problema se enunta sub forma unor
conditii, precum: “o piesa se muta din locatia A ın B daca A este vecin orizontal sau
vertical al lui B si B este spatiu” atunci putem realiza trei variante relaxate prin eliminarea
la o parte din conditii:
1. o piesa se poate muta de la pozitia A la B daca A este vecin cu B
2. o piesa se poate muta de la pozitia A la B daca B este spatiu
3. o piesa se poate muta de la pozitia A la B
Prima varianta corespunde euristicii h2, iar cea de-a treia este pentru euristica h1.
Folosind aceasta tehnica de relaxare a conditiilor (si alte strategii), s–a obtinut un program
capabil de a gasi variante relaxate de probleme, unele conducand la euristici superioare
celor cunoscute de rezolvitorii umani.
Ce se ıntampla cand avem mai multe euristici, dar niciuna nu domina pe toate celelelate
(adica: avem h1, h2, . . . , hm si pentru orice i, j, 1 ≤ i, j ≤ m, i 6= j exista x, y astfel ıncat
4Reamintim ca ne-am fixat pe probleme ın care dorim sa obtinem solutie de cost minim. Pentru
probleme de maxim dominarea ınseamna schimbarea sensului inecuatiei.

3.6. ALGORITMI DE CAUTARE LOCALA 43
hi(x) ≤ hj(x) dar hi(y) > hj(y))? Putem considera functia h definita punctual ca:
h(n) = max{h1(n), . . . hm(n)}
care domina pe toate celelalte; mai mult decat atat, se poate arata ca aceasta functie este
si consistenta!
O alta metoda de obtinere a euristicilor este de a pleca de la subprobleme ale problemei
initiale. De exemplu, putem sa ne concentram atentia doar asupra unora din piesele de pe
puzzle, pe care ıncercam sa le aducem la pozitia corecta, ın timp ce celelate pot ajunge ın
orice pozitie. Pentru multe pozitii de start, rezultatul este mai bun decat daca se foloseste
distanta Manhattan.
Se poate merge mai departe pe ideea acestor subprobleme: avand ın vedere ca au
considerabil mai putine stari decat problema originara, se poate sa memoram ıntr-o baza
de date aceste stari, ımpreuna cu costul de ajungere de la ele la starea finala. Construirea
acestei baze5 poate fi laborioasa, dar efortul se amortizeaza rapid daca trebuie rezolvate
mai multe probleme.
3.6 Algoritmi de cautare locala
Algoritmii precedenti fac o cautare mai mult sau mai putin sistematica pentru a des-
coperi daca un nod scop poate fi ajuns plecand de la nodul initial. Cand acest lucru se
ıntampla, se reconstituie calea dintre nodul de start si nodul scop.
De multe ori, ınsa, secventa de pasi care duce din starea initiala ın starea finala este
irelevanta. De exemplu, pentru problema reginelor pe tabla de sah (sectiunea 1.6.1, pa-
gina 12) nu ne intereseaza cum s–a ajuns la plasarea acestor regine, ci doar dispunerea lor
efectiva pe tabla de sah. In aceeasi categorie intra si designul circuitelor integrate, pro-
gramarea itinerarului optim prin magazine, stabilirea rutelor pentru vehicule, optimizarea
retelelor de telecomunicatii etc.
Pentru asemenea cazuri vom considera o clasa diferita de algoritmi. Cautarea locala
foloseste doar o singura stare, cea curenta – ceea ce din start ınseamna ca memoria
consumata este redusa; mutarile se fac doar ın stare vecina cu cea curenta, iar caile
urmate nu se memoreaza. Pe langa cantitatea mica de memorie ceruta, se pot aborda si
probleme unde cautarea sistematica sau euristica nu sunt fezabile (de exemplu probleme
pe spatii continue).
De asemenea, se pot folosi algoritmii prezentati ın aceasta sectiune si pentru cazul
problemelor de optimizare, unde se da o functie obiectiv. Desi nu totdeauna solutiile
obtinute sunt optime, rezultatele practice pot fi satisfacatoare.
5Numita baza de tipare: pattern database.
44 CAPITOLUL 3. CAUTARE INFORMATA
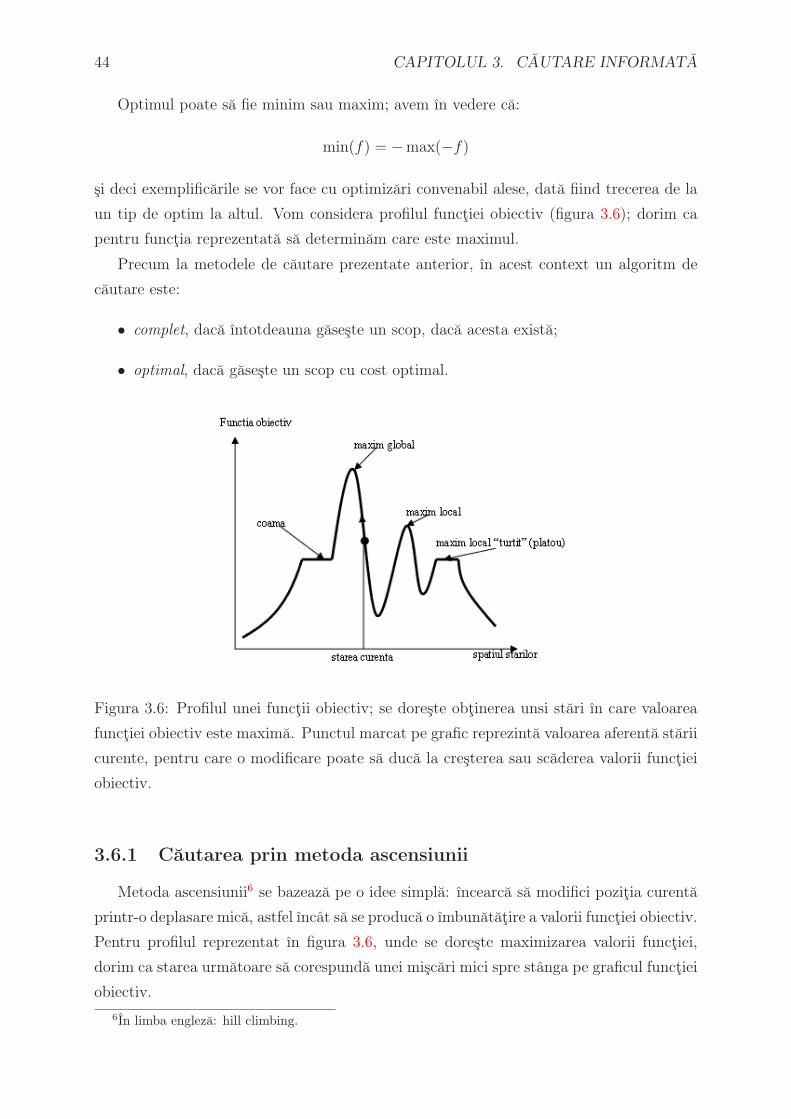
Optimul poate sa fie minim sau maxim; avem ın vedere ca:
min(f) = −max(−f)
si deci exemplificarile se vor face cu optimizari convenabil alese, data fiind trecerea de la
un tip de optim la altul. Vom considera profilul functiei obiectiv (figura 3.6); dorim ca
pentru functia reprezentata sa determinam care este maximul.
Precum la metodele de cautare prezentate anterior, ın acest context un algoritm de
cautare este:
• complet, daca ıntotdeauna gaseste un scop, daca acesta exista;
• optimal, daca gaseste un scop cu cost optimal.
Figura 3.6: Profilul unei functii obiectiv; se doreste obtinerea unsi stari ın care valoarea
functiei obiectiv este maxima. Punctul marcat pe grafic reprezinta valoarea aferenta starii
curente, pentru care o modificare poate sa duca la cresterea sau scaderea valorii functiei
obiectiv.
3.6.1 Cautarea prin metoda ascensiunii
Metoda ascensiunii6 se bazeaza pe o idee simpla: ıncearca sa modifici pozitia curenta
printr-o deplasare mica, astfel ıncat sa se produca o ımbunatatire a valorii functiei obiectiv.
Pentru profilul reprezentat ın figura 3.6, unde se doreste maximizarea valorii functiei,
dorim ca starea urmatoare sa corespunda unei miscari mici spre stanga pe graficul functiei
obiectiv.
6In limba engleza: hill climbing.

3.6. ALGORITMI DE CAUTARE LOCALA 45
Algoritmul este dat ın figura 3.7. Algoritmul nu memoreaza starile prin care trece, iar
cautarea actiunii urmatoare nu se face mai departe de vecinul imediat. Este ındreptatita
deci asemanarea acestui algoritm cu “urcarea pe Everest ıntr-o ceata subtire, suferind de
amnezie”. Metoda se mai numeste si cautare locala lacoma. Algoritmul se termina atunci
cand se ajunge ıntr-un optim, care poate fi local. Cautarea vecinului se face ın imediata
vecinatate, “salturi” prea mari ar putea duce la ratarea unor configuratii cu valoarea buna.
Figura 3.7: Algoritmul de cautare prin ascensiune (urcarea pe panta cea mai abrupta).
Daca pentru nodul curent exista un vecin de valoarea mai buna, atunci el este ınlocuit cu
vecinul.
Strategia se poate folosi pentru problema celor 8 dame pe o tabla de sah (a se vedea
sectiunea 1.6.1, pagina 12). Pentru fiecare patrat se calculeaza care ar fi numarul total de
atacuri de pe tabla de sah care are rezulta dupa plasarea reginei de pe coloana respectiva
ın acel patrat. Evident, dorim sa determinam configuratia ın care numarul de atacuri este
minim, ideal 0. Daca pentru o stare (dispunere a reginelor) oarecare exista mai multe
“cele mai bune mutari” se poate alege aleator oricare dintre ele.
Problemele pe care le are algoritmul bazat pe ascensiune sunt:
1. maximele locale: un maxim local este un varf care este mai ınalt decat punctele
situate ıntr-o vecinatate a lui, dar este mai mic decat maximul global. Algoritmul
se termina atunci cand nodul curent nu poate fi ımbunatatit printr-o mutare ın
apropiere.
2. zona plata: o zona plata este o regiune din spatiul starilor ın care functia de evaluare
este constanta. Poate fi un platou de unde nu exista posibilitate de urcare, sau o
coama de unde se poate obtine un progres. Asa cum este dat algoritmul din figura
3.7, se produce valoarea constanta din platou.

46 CAPITOLUL 3. CAUTARE INFORMATA
(a) O asezare a opt regine pe tabla de
sah, cu costul 17. Pentru fiecare patrat
se arata valorea acestei functii daca s–ar
face mutarea reginei de pe coloana cores-
punzatoare ın ea. Cele mai bune mutari
din aceasta pozitie duc la valoarea 12.
(b) Un minim local pentru problema ce-
lor opt regine. Starea prezentata are va-
loarea 1. Orice mutare din aceasta stare
nu micsoreaza functia obiectiv.
h = 5 h = 2 h = 0
(c) Rezolvarea problemei celor 4 regine. Solutia obtinuta este de cost 0, deci dispunerea este corecta.
Valoarea h reprezinta numarul de atacuri.
Figura 3.8: Rezolvarea problemei reginelor pe tabla de sah prin cautare prin ascensiune.
Se cauta un minim al functiei care contorizeaza numarul de atacuri reciproce pe tabla.

3.6. ALGORITMI DE CAUTARE LOCALA 47
3. creste7; rezulta ın secventa de maxime locale pentru care directia corecta este dificil
de ales (figura 3.9).
Figura 3.9: Creste, una din configuratiile problematice pentru un algoritm de ascensiune.
Pentru problema celor opt regine, cautarea prin ascensiune duce la un optim local ın
86% din cazuri; rezolvare cu functia de cost nula se atinge doar ın 14% din cazuri. Trebuie
sa mentionam totodata ca numarul mediu de mutari ın care se ajunge la un minim local
este 3 iar din 4 mutari (tot numar mediu) se ajunge la o rezolvarea a problemei.
Algoritmul, asa cum a fost enuntat, se opreste atunci cand ajunge ın zona de platou
sau de coama. Pentru coama, ınsa, daca s-ar permite cautarea pe zona plata, s-ar putea
ajunge din nou la o situatie de urcus. O varianta a algoritmului din figura 3.7 este cea
ın care se permit pasi laterali pe zona plata. Pentru a preveni plimbarea la infinit pe un
platou, se poate impune o limita a numarului de pasi succesivi care pastreaza valoarea
functiei obiectiv. De exemplu, daca se stabileste aceasta limita la 100, pentru problema
celor 8 regine se gaseste rezolvare corecta ın 94% din cazuri. Numarul mediu de pasi
creste, ınsa: 21 de pasi pentru o rezolvare si 64 pentru esuare ın minim local.
De asemenea mai exista varianta ascensiunii stochastice: dintr-un punct se alege pro-
babilist panta pe care se face urcarea; cu cat panta este mai abrupta, cu atat este mai
mare sansa de alegere a ei ca directie urmatoare (dar nu e imposibil sa se aleaga pante
7In limba engleza: ridges.

48 CAPITOLUL 3. CAUTARE INFORMATA
de ınclinatie mai mica, adica sa se ajunga ın stari ın care valoarea nu este cea mai mare
dintre toti vecinii).
Algoritmii descrisi pana acum sunt incompleti – ei nu gasesc solutia optima mereu,
deoarece se blocheaza ın optime locale. Ascensiunea cu repornire aleatoare stabileste
puncte de plecare aleator ın spatiul starilor. Abordarea duce la un algoritm care este
complet cu o probabilitate ce tinde catre 1 cand numarul de reporniri aleatoare creste la
infinit, daca punctele de start se aleg conform unei distributii uniforme, din motivul ca
repornirile aleatoare pot duce la alegerea unui nod de start corespunzator unui nod scop.
Daca procentul de succes pentru o problema este p, atunci este nevoie ın medie de 1/p
reporniri. Pentru problema celor opt regine, unde p = 0.14, avem nevoie ın medie de 7
iteratii pentru a gasi o stare scop (de cost 0), adica 6 porniri care duc la minim local si
1 care duce la rezolvare (numerele date trebuie ıntelese ca valori medii). Numarul mediu
de pasi este 6×3+4 = 22. Daca se foloseste algoritmul ce permite pasi laterali, un calcul
asemanator duce la 25 de pasi necesari, ın medie, pentru rezolvarea problemei. Pentru
o problema de 3 milioane de regine, aceasta abordare (repornire aleatoare cu cautare cu
pasi laterali) poate descoperi o solutie ın mai putin de un minut!
Problemele din lumea reala deseori au un profil al functiei obiectiv cu maxime si
minime multiple, “ ındesate” pe domeniul de definitie; algorimul cautarii prin ascensiune
duce, de regula, ıntr-un maxim local suficient de bun pentru tipul de calcul consumat.
3.6.2 Recoacerea simulata
Un algoritm de cautare prin ascensiune este incomplet, deoarece se poate cantona
ıntr-un minim local. Ar fi de dorit sa permitem algoritmului sa efectueze miscari si
ıntr-o directie nefavorabila, ın speranta ca va permite iesirea dintr-un minim local. Ca
suport intuitiv, sa ne imaginam o un relief bidimensional ın care dorim sa descoperim
minimul local. Lasam o bila sa plece dintr-un punct oarecare, dar vom face si scuturarea
suprafetei atunci cand se ajunge ıntr-un minim, cu intentia de a scoate bila din minim.
Aceste scuturari sunt suficient de viguroase pentru a scoate bila din minimul local, dar
totusi nu foarte tari pentru a scoate bila din minim global. O reprezentare este data ın
figura 3.10.
Algoritmul este inspirat din metalurgie, ın care se ıncalzeste un metal pana la o tem-
peratura ınalta; pentru a durifica metalul se lasa apoi sa se raceasca lent, permitand
structurii cristaline sa ajunga ıntr-o stare stabila. Este important ritmul ın care scade
temperatura.
Algoritmul pentru minimizarea unei functii este formalizat ın figura 3.11. Daca muta-
rea curenta duce ıntr-o situatie cu valoarea mai mica, atunci se accepta; daca noua situatie
este defavorabila, atunci se accepta o mutare cu o anumita probabilitate. Probabilitatea

3.6. ALGORITMI DE CAUTARE LOCALA 49
Figura 3.10: Algoritmul recoacerii simulate. Perturbarile vor permite scoaterea bilei din
minimele locale.
scade exponential cu lipsa de calitate a noii configuratii si cu “temperatura” curenta (va-
riabila). Se poate arata ca daca temperatura scade suficient de lent, atunci algoritmul
va gasi un optim local cu probabilitatea 1 [3]. Planificarea care apare ca parametu al
algoritmului este o functie descrescatoare fata de timpul t.
3.6.3 Algoritmi genetici
Sunt inspirati din principiile evolutionismului darwinian, care ıncearca sa explice
evolutia vietuitoarelor pe Pamant. Rolul mediului este preluat de catre functia scop.
Vom detalia algoritmul pentru maximizarea unei functii f : [a, b] → R∗
+. Indivizii care
alcatuiesc populatia se numesc cromozomi si sunt alcatuiti din gene.
Se porneste cu o populatie initiala, care este supusa apoi unui sir de procese de tipul:
1. selectie: indivizii care sunt cei mai adecvati (fata de valoarea functiei ce se vrea
optimizata) sunt favorizati sa apara de mai multe ori ıntr-o populatie noua fata de
indivizii mai putin performanti;
2. ıncrucisare: are loc un schimb de gene ıntre perechi de parinti, formandu-se copii;
acestia se presupune ca mostenesc si combina performantele parintilor.
3. mutatie: se efectueaza niste modificari minore asupra materialului genetic existent.
Pas 1. Crearea unei populatii initiale de cromozomi. Se considera NR valori pen-
tru variabila x ∈ [a, b]. Numarul NR este numit dimensiunea populatiei si reprezinta
un parametrul al algoritmului (ex. NR = 100). Toate valorile sunt cuantificate prin
cromozomi care sunt siruri de k biti (un bit se mai numeste si gena), k fiind alt
parametru al algoritmului.

50 CAPITOLUL 3. CAUTARE INFORMATA
Figura 3.11: Algoritmul de recoacere simulata. Pasii defavorabili sunt permisi, dar proba-
bilitatea acestora este controlata. Parametrul planifiare determina valoarea temperaturii
T pentru timpul t.

3.6. ALGORITMI DE CAUTARE LOCALA 51
Generarea celor NR cromozomi se face aleator, prin setarea fiecarei gene la valoarea
0 sau 1, la ıntamplare. Se obtine astfel o populatie initiala formata din cromozomii
c1, . . . , cNR.
Fiecare cromozom c (adica sir de k biti) va produce un numar x(c) din intervalul
[a, b], astfel: daca valoarea ın baza 10 a cromozomului este v(c), 0 ≤ v(c) ≤ 2k − 1,
atunci valoarea asociata din intervalul [a, b] este:
x(c) = a+ v(c) ·b− a
2k − 1∈ [a, b].
Pas 2. Evolutia populatiei. In acest pas se obtin generatii succesive plecand de la
populatia initiala; populatia de la generatia g + 1 se obtine pe baza populatiei de
la generatia g. Operatorii sunt selectia, ımperecherea (crossover, ıncrucisare) si
mutatia.
Pas 2.1. Selectia. Pentru fiecare cromozom din populatie se calculeaza functia
obiectiv vi = f(x(ci)), 1 ≤ i ≤ NR. Apoi se ınsumeaza valorile functiilor
obiectiv obtinute pentru fiecare cromozom ın parte:
S =NR∑
i=1
vi
Pentru fiecare din cei NR cromozomi se calculeaza probabilitatea de selectie:
pi =viS, 1 ≤ i ≤ NR
Pentru fiecare cromozom se calculeaza probabilitatea cumulativa de selectie:
qj =j∑
i=1
pi, 1 ≤ j ≤ NR
Remarcam ca qNR = 1 iar sirul qi (1 ≤ i ≤ NR) defineste un sir crescator. Cu
cat cromozomul ci produce o valoare mai mare pentru functia f (adica valoarea
f(v(ci)) este mai mare), cu atat diferenta dintre qi si qi−1 este mai mare.
Se selecteaza NR numere aleatoare uniform distribuite ın (0, 1]. Pentru fiecare
numar, pe rand, daca el se gaseste ın intervalul (0, q1] atunci cromozomul c1
este ales si depus ıntr-o populatie noua; daca acest numar se afla ın intervalul
(qi, qi+1] atunci se alege cromozomul ci+1. Remarcam ca numarul de cromozomi
prezenti ın noua populatie este tot NR, iar cu cat valoarea asociata unui cro-
mozom este mai mare, cu atat cresc sansele lui de a fi selectat si depus ın noua
populatie. Este foarte probabil ca un astfel de cromozom valoros (valoarea unui
cromozom este cu atat mai mare cu cat valoarea functiei f calculata pentru

52 CAPITOLUL 3. CAUTARE INFORMATA
cromozomul respectiv este mai mare) sa apara de mai multe ori in populatia
noua; de asemenea, este foarte probabil ca un cromozom cu o valoare mica
pentru functia f sa nu apara deloc.
Pas 2.2. Incrucisarea. Pentru fiecare cromozom care a rezultat la pasul ante-
rior se alege o valoare aleatoare, uniform distribuita ın intervalul (0, 1]. Daca
aceasta valoare este mai mica decat un parametru pc (parametru al aplicatiei,
e.g. 0.1), atunci cromozomul este ales pentru incrucisare. Se procedeaza ast-
fel ıncat sa se obtina un numar par de cromozomi (de exemplu se renunta la
ultimul daca numarul lor este impar).
Cromozomii alesi se ıncruciseaza astfel: primul selectat cu al doilea selectat, al
3-lea cu al 4-lea, etc. Incrucisarea decurge astfel:
• se alege un numar aleator t intre 0 si numarul de gene (toti cromozomii au
acelasi numar de gene k)
• se obtin 2 cromozomi copii astfel: primul va contine primele t gene ale
primului parinte si ultimele k − t gene ale celui de–al doilea parinte; al
doilea copil contine primele t gene ale celui de–al doilea parinte si ultimele
k − t gene ale primului parinte
• cei doi cromozomi copii vor ınlocui ın populatie pe parinti
Pas 2.3. Mutatia. Populatiei obtinute i se aplica operator de mutatie, astfel: pen-
tru fiecare gena a fiecarui cromozom se alege o valoare aleatoare, uniform distri-
buita ın (0, 1]; daca acest numar este mai mic decat o probabilitate de mutatie
pm (parametru al aplicatiei), atunci se modifica valoarea curenta a genei cu
complementul sau fata de 1.
Populatia obtinuta ın pasul 2 reia ciclul de evolutie. Dupa ce se executa cateva astfel
de evolutii (sau numar de generatii, parametru al programului), se raporteaza valoarea
celui mai bun cromozom din ultima generatie8.
Se observa ca se combina cautarea locala cu explorarea aleatoare si schimbul de
informatie ıntre indivizi. Esenta algoritmilor genetici consta ın acest schimb de informatie,
adica schimbarea de blocuri de date care au evoluat astfel ıncat sa se ımbunatateasca va-
loarea produsa. O utilizare eficienta a algoritmilor genetici prespune crearea unor structuri
de date pentru gene si a unor operatori adecvati problemei ce trebuie rezolvate9.
8Sau se foloseste strategia elitista: se returneaza cel mai bun individ al tuturor generatiilor.9S-a stabilit “ecuatia” Algoritmi genetici + structuri de date = programare evolutionista, [4].

3.6. ALGORITMI DE CAUTARE LOCALA 53
3.6.4 Cautare locala ın spatii continue
Algoritmii de cautare prezentati pana acum functioneaza ıntr-un univers discret si ın
care functia succesor returneaza un set finit de pasi care pot fi efectuati dintr-o stare
oarecare. Cele mai multe probleme, ınsa, sunt de tip continuu si deci posibilitatile de
alegere a urmatorilor pasi sunt infinite.
Pentru o functie reala de mai multe variable f(x1, . . . , xn), maximul se regaseste printre
punctele x = (x1, . . . , xn) pentru care ∇f(x) = 0, unde:
∇f(x) =
(
∂f
∂x1
, . . . ,∂f
∂xn
)
De cele mai multe ori acest gradient se poate calcula doar local, nu si global, deci abor-
darea aceasta directa nu este ıntotdeauna posibila. Chiar si asa, se poate aplica metoda
ascensiunii, luand ca stare urmatoare:
x← x+ α∇f(x)
unde α este o constanta mica.
Pentru multe probleme, cel mai bun algoritm este bazat pe metoda Newton–Raphson,
folosita pentru determinarea radacinilor ecuatiilor de forma g(x) = 0 (g fiind functie de o
singura variabila). Se calculeaza o noua estimare a lui x prin:
x← x−g(x)
g′(x)
Pentru a gasi un maxim al lui f (functie de mai multe variabile) urmatoarea valoarea a
lui x se determina astfel:
x← x−H−1
f (x)∇f(x)
unde Hf (x) este matricea hessiana, cu Hij = ∂2f/∂xi∂xj. Totusi, inversarea matricilor
este computational intensiva pentru un numar mare de variabile.

54 CAPITOLUL 3. CAUTARE INFORMATA

Capitolul 4
Probleme de satisfacere a
constrangerilor
Prezentul capitol trateaza probleme ın care starile se supun unor restrictii (con-
strangeri) impuse. Spre deosebire de reprezentarile date la metodele de cautare din capi-
tolele anterioare (reprezentari care tin cont de particularitatile problemei pentru care se
face cautarea solutiei), problemele de satisfacere a constrangerilor au o forma mult mai
generala, iar euristicile sunt larg aplicabile.
4.1 Probleme de satisfacere a constrangerilor
O problema de satisfacere a constrangerilor (PSC) este definita ca un set de variabile
X1, . . . , Xn si un set de constrangeri C1, . . . , Cm. Fiecare variabila are un domeniu nevid
de valori Di. O constrangere se refera la un subset de variabile si exprima conditii asupra
combinatiilor de valori pentru variabilele ın discutie. O stare a problemei este o asignare
de forma {Xi = vi, Xj = vj, . . .}. O stare ın care valorile respecta orice constrangere
Ck, 1 ≤ k ≤ m se numeste stare consistenta sau legala. O solutie a problemei este o
asignare consistenta si care da valori pentru fiecare variabila. Uneori este implicata si o
functie obiectiv care trebuie optimizata.
Tratarea unei probleme ca o PSC poate fi benefica: ın primul rand, se poate formaliza
foarte usor metoda generala de rezolvare, iar aplicarea ei pe o problema concreta ınseamna
scrierea adecvata a functiilor de succesor si a testului de scop (a se vedea algoritmul
general); ın al doilea rand, se dau niste euristici care nu sunt dependente de domeniul
problemei (sectiunea 4.2.1 si urmatoarele).
Exemplu: dorim sa coloram harta regiunilor Australiei (figura 4.1) cu 3 culori, astfel
ıncat sa nu existe doua regiuni vecine care au aceasi culoare. Variabilele pot fi considerate
abrevierile pentru regiuni, respectiv: WA, NT , Q, NSW , V , SA, T , domeniul fiecarei
55

56 CAPITOLUL 4. PROBLEME DE SATISFACERE A CONSTRANGERILOR
variabile este {rosu, verde, albastru}, iar constrangerile se pot exprima sub forma unor
perechi de forma X 6= Y unde X, Y ∈ {WA,NT,Q,NSW, V, SA, T} si X, Y vecine pe
harta.
WesternAustralia
NorthernTerritory
SouthAustralia
Queensland
New South Wales
Victoria
Tasmania
Figura 4.1: Regiuni din Australia.
Deseori se recurge la reprezentarea acestor constrangeri sub forma de graf ın care doua
variabile sunt legate printr-o muchie daca se supun unei constrangeri. De exemplu, pentru
problema colorarii regiunilor se leaga prin muchii noduri reprezentand regiuni vecine (si
care trebuie colorate diferit) - fig 4.2.
Victoria
WA
NT
SA
Q
NSW
V
T
Figura 4.2: Graf de constrangeri pentru problema colorarii hartii Australiei.
O PSC se poate formula astfel:
• stare initiala: multimea vida, corespunzatoare lipsei de asignari de valori oricarei
variabile;
• functie succesor : se asigneaza unei variabile ce nu are valoare data (numita variabila
libera) o valoare din domeniul asociat, cu conditia ca asignarea nou obtinuta sa fie
consistenta (sa nu ıncalce constrangerile impuse);

4.1. PROBLEME DE SATISFACERE A CONSTRANGERILOR 57
• test scop: asignarea curenta este completa, i.e. nu mai exista variabile libere
• costul caii : o constanta pentru fiecare asignare de variabila
Deoarece fiecare solutie are toate cele n variabile cu valori asignate rezulta ca adancimea
solutiei este n. Algoritmii folositi pentru rezolvarea acestui tip de probleme sunt cei de
cautare ın adancime (adancimea se cunoaste, iar cicluri nu putem avea, deoarece la fiecare
pas consideram o alta variabila libera). De asemenea, algoritmii pentru cautare locala dau
rezultate bune.
Domeniile de valori pot fi discrete si finite (precum mai sus) sau nu, si ın acest al
doilea caz constrangerile se dau folosind un limbaj care permite descrierea relatiilor (de
exemplu x+ y < z si x− y = 4). Problemele cu domenii de tip continuu sunt studiate de
catre cercetarile operationale.
O constrangere poate fi unara – daca se refera la o singura variabila – si atunci este
simplu de tratat, pentru ca se modifica corespunzator domeniul de valori asociat prin
excluderea valorilor care nu satisfac constrangerea. Deseori se dau constrangeri binare,
care implica exact doua variabile. De exemplu, pentru graful din figura 4.2 orice muchie
reprezinta o constrangere binara.
Exista si constrangeri de ordin mai mare, implicand cel putin trei variabile. Avem
asemenea situatie ın problema urmatoare1: sa se substituie fiecare litera printr-o cifra
diferita, astfel ıncat ecuatia sa fie adevarata
unu+
patru =
-----
cinci
Constrangerea ca valorile caracterelor diferite sa fie diferite poate fi redusa la mai multe
de tip binar - u 6= i, u 6= n etc; apoi, pentru fiecare din cele cinci coloane avem cate o
constrangere:
u+ u = i+ 10x1
n+ r + x1 = c+ 10x2
u+ t+ x2 = n+ 10x3
a+ x3 = i+ 10x4
p+ x4 = c
(4.1)
unde xi reprezinta (eventualul) transport de la suma de cifre. Constrangerile pot fi re-
prezentate sub forma de hipergraf, precum in figura 4.3. Se poate arata ca problemele
cu domenii finite pot fi reduse la probleme cu constrangeri binare prin introducerea unor
1Problema de criptaritmetica.

58 CAPITOLUL 4. PROBLEME DE SATISFACERE A CONSTRANGERILOR
variabile auxiliare. Din acest motiv ne vom concentra asupra problemelor cu constrangeri
binare.
Figura 4.3: Hipergraf de constrangeri atasat problemei de criptaritmetica. Patratele
definesc constrangeri la care participa variabilele - patratul de pe primul rand este repre-
zentare a conditiei ca valorile caracterelor diferite sa fie diferite, iar cele de pe penultimul
rand reprezinta constrangerile din sistemul 4.1.
4.2 Cautare backtracking pentru PSC
Formularea data pentru PSC (ın special prezenta unei functii succesor) ne permite
sa speram ca putem trata problemele de acest tip prin orice algoritm de cautare de care
dispunem. Totusi, acest tip de probleme trebuie abordat cu o anumita schema de cautare.
Sa plecam de la o PSC ın care avem n variabile care pot lua valori dintr-o multime
finita cu d elemente. Daca vrem sa folosim cautarea ın latime, atunci:
• la nodul radacina (cel care nu are nici o variabila nu are valoare fixata) avem n · d
posibilitati de a continua, deoarece avem n variabile si pentru fiecare poate fi stabilita
o valoare din cele d;
• la nivelul urmator avem (n− 1)d alegeri, pentru ca au ramas mai putine variabile
• ın total obtinem n! · dn frunze
Numarul de frunze este mult mai mare decat dn, care s-ar obtine prin enumerarea tuturor
posibilitatilor de asignare de valori pentru cele n variabile. Ca atare, aplicarea unei metode
de cautare neinspirat alese mareste considerabil numarul de cazuri ce trebuie considerate.
Numarul supraestimat de frunze a aparut din cauza ca la fiecare pas permitem luarea
ın considerare a tuturor variabilelor posibile, pe cand solutia unei PSC nu este senzitiva
la ordine. Este admisibil ca la fiecare pas sa se ia ın considerare doar o variabila. Asa
numarul de frunze devine dn.

4.2. CAUTARE BACKTRACKING PENTRU PSC 59
Cautarea de tip backtracking este de fapt o cautare de tip “mai ıntai ın adancime” care
genereaza un singur nod descendent. Deoarece reprezentarea PSC este standardizata, ea
se poate aplica independent de specificul domeniului. Algoritmul este dat ın figura 4.4.
Figura 4.4: Algoritmul backtracking pentru probleme de satisfacere a constrangerilor.
Fiind un algoritm de cautare neinformata, ın practica el nu se comporta bine pentru
probleme de dimensiune mare. Exista ınsa niste metode generale care maresc eficienta
lor. Metodele reprezinta raspunsuri la urmatoarele ıntrebari:
1. Care variabila ar trebui luata ın considerare la pasul curent si ın ce ordine ar trebui
ıncercate valorile?
2. Care sunt implicatiile asignarii curente de valoare pentru o variabila pentru alte
variabile ce ınca nu au valori asociate?
4.2.1 Ordonarea valorilor si a variabilelor
Algoritmul backtracking contine linia:
var <- selecteaza-variabila-neasignata(variabile[psc], asignare, psc)
dar nu se spune cum anume se face selectarea de variabila. Se poate, desigur, opta,
pentru o ordine fixa a variabilelor. Dar putem observa ca daca asignam WA = rosu si
NT = verde, pentru SA ramane o singura valoare care poate fi asignata, deci are sens
sa consideram la pasul urmator variabila SA, mai degraba decat Q, NSW sau V . Dupa
acest pas, Q, NSW si V au domeniu de alegere al valorilor restrans la cate o variabila.

60 CAPITOLUL 4. PROBLEME DE SATISFACERE A CONSTRANGERILOR
Intuitiv, ar trebui sa consideram la fiecare pas variabila care are cele mai putine valori
candidat.
Strategia numita “minim de valori ramase” (MVR) decide alegerea variabilei care are
cele mai putine variante. Astfel, se ıncearca producerea unei esuari cat mai devreme
posibil ın calea de cautare curenta, astfel ca sa se reteze caile care nu duc la solutii. De
exemplu, daca avem o variabila care are 0 valori ramase, atunci strategia MVR o va alege
pe aceasta si se va detecta esuare. Acest lucru este corect, deoarece oricum mai devreme
sau mai tarziu se ajunge la imposibilitatea de a da valoare pentru variabila ın cauza, deci
se evita niste cautari care nu ar putea produce solutie.
In practica, strategia MVR duce la ımbunatatiri ale vitezei de 3 pana la 3000 de ori.
Se discuta ın sectiunea 4.2.2 modul ın care contorizarea numarului de valori disponibile
ramase se poate face eficient.
Euristica nu este utila la alegerea primei variabile, deoarece fiecare regiune poate avea
la ınceput oricare din cele trei culori. Intr-un asemenea moment se foloseste euristica
gradului care indica alegerea acelei variabile care are cele mai multe contrangeri cu alte
variabile fara valori asignate. Notiunea de grad face aici referire la valoare definita ın
teoria grafurilor. De exemplu, pentru harta din figura 4.1 avem ca SA are gradul 5, alte
variabile au valori 2, 3, 0. Ca atare, se va alege ca prima variabila SA si pasii urmatori,
cu aceeasi euristica, duc la rezolvarea problemei fara a fi nevoie sa se revina. Strategia
MVR este mult mai efectiva decat aceasta, dar euristica gradului este utila la deciderea
urmatorului pas ıntr-o situatie de egalitate.
Odata ce s–a ales variabila pentru care se va da valoare, trebuie determinat care
este ordinea de considerare a valorilor pentru ea. Se aplica strategia celei mai putin
constrangatoare valori. Mai clar, se prefera valorile care produc cele mai putine eliminari
de valori pentru alte variabile neasignate. Ideea este de a se lasa maximum de flexibilitate
(posibilitati) pentru alegerile urmatoare. De exemplu, daca luam WA = verde si NT =
rosu, iar pentru Q setam culoarea albastra, atunci SA ramane fara posibilitate de a i se
atribui valoare. Evident, daca se cere generarea tuturor solutiilor pentru PSC sau daca
problema nu are nicio solutie, strategia este inutila.
4.2.2 Propagarea informatiilor prin constrangeri
Pana acum algoritmul a considerat constrangerile pentru o variabila doar cand ea era
aleasa de catre selecteaza-variabila-neasignata. Daca se iau ın considerare aceste
constrangeri mai repede de acest moment, atunci se poate reduce foarte mult spatiul de
cautare.

4.2. CAUTARE BACKTRACKING PENTRU PSC 61
Verificare ınainte
Ori de cate ori unei variabile X i se asigneaza o valoare, pentru fiecare variabila Y care
este conectata cu X printr–o constrangere se sterg din domeniul lui Y valorile care sunt
inconsistente cu proaspata valoare a lui X. Tabelul 4.1 arata evolutia cautarii cu verificare
ınainte. Se poate observa ca dupa ce se asigneaza WA = rosu si Q = verde, domeniile
pentru NT si SA contin doar un singur element; am redus deci factorul de ramificare
pentru aceste doua variabile. Este clar ca aceasta verificare ınainte face pereche buna cu
strategia MVR, pentru care urmatoarele variabile luate ın considerare sunt SA si NT .
Verificarea ınainte este un mod eficient de calculare a informatiei de care MVR are nevoie.
Mai observam ca dupa ce setam V = albastru2 domeniul lui SA este gol. Verificarea
ınainte a determinat ca asignarea partiala {WA = rosu,Q = verde, V = albastru} este
inconsistenta cu cerintele problemei, necesitand un pas ınapoi.
WA NT Q NSW V SA T
Domeniile initiale RVA RVA RVA RVA RVA RVA RVA
Dupa WA = rosu R VA RVA RVA RVA VA RVA
Dupa Q = verde R A V RA RVA A RVA
Dupa V = albastru R A V R A RVA
Tabela 4.1: Evolutia in problema colorarii hartilor folosind verificarea ınainte. R este
rosu, V este verde, A este albastru.
Propagarea constrangerilor
Cu toate ca verificarea ınainte depisteaza inconsistente, ea nu le depisteaza pe toate.
De exemplu, sa consideram a treia linie a tabelului 4.1: cand WA = rosu si Q = verde,
atat NT cat si SA sunt limitate la culoarea albastra; dar ıntrucat ele sunt si regiuni vecine,
trebuie sa fie de culori diferite. Verificarea ınainte nu este suficient de patrunzatoare ın a
detecta incompatibilitati. Propagarea constrangerilor este un termen general, desemnand
propagarea constrangerilor pentru o variabila conform constrangerilor pentru alte varia-
bile. Mai clar, propagam de la WA si Q la NT si SA (precum la verificarea ınainte),
dar luam ın considerare si constrangerea dintre NT si SA pentru a detecta inconsistenta.
Evident, dorim sa facem o asemenea propagare de constrangeri cu efort computational
cat mai mic.
Consistenta arcului este o metoda rapida de propagare a constrangerilor mai puternica
decat verificarea ınainte. Un arc se refera la o legatura directionata de la o variabila la
alta. Date fiind doua variabile X si Y cu domeniile de valori aferente, un arc de la X
2Am presupus aici ca alegerea urmatoarei variabile nu se face prin strategia MVR.

62 CAPITOLUL 4. PROBLEME DE SATISFACERE A CONSTRANGERILOR
la Y este consistent daca pentru orice valoare din domeniul lui X avem ca exista macar
o valoarea compatibila (consistenta) ın domeniul lui Y . De exemplu, pentru a treia linie
din tabelul 4.1 se observa ca domeniul pentru SA este {albastru}, iar pentru NSW este
{rosu, albastru}. Pentru SA = albastru avem o asignarea consistenta a lui NSW si
anume NSW = rosu. Invers, ınsa, nu este adevarat: pentru NSW = albastru nu avem
nici o valoare potrivita ce poate fi asignata lui SA. Arcul (NSW,SA) poate fi facut
consistent prin eliminarea lui albastru din domeniul de valori al lui NSW .
Acelasi proces se poate aplica si perechii de variabile SA si NT (ele fiind legate printr-
o constrangere): tot din linia 3 a tabelului 4.1 se observa ca amandoua variabilele au
domeniul {albastru} si deci actionarea pentru a mentine consistenta oricarui arc (de la
SA la NT sau invers) duce la domeniu de valori vid pentru una din variabile. Se va
produce deci un pas ınapoi ın algoritm, datorita detectarii din timp a imposibilitatii de
continuare. Consistenta arcului “vede mai departe” decat propagarea ınainte.
Procesul de verificare a consistentei arcelor trebuie aplicat ın mod repetat pana cand
nu mai exista inconsistente. Acest proces se poate face ınainte de ınceperea cautarii
sau dupa fiecare asignare de valoare. Ori de cate ori se face stergerea unei valori din
domeniul unei variabile X, trebuie verificate toate arcele de la variabile Y la X. Algoritmul
consistentei arcelor AC-3 este dat ın figura 4.5 si foloseste o coada care mentine arcele
ce trebuie sa fie verificate din punct de vedere al consistentei. Fiecare arc (Xi, Xj) este
cercetat pe rand pentru consistenta. Daca se sterge vreo valoare din domeniul lui Xi,
atunci toate arcele de forma (Xk, Xi), indicand spre variabila Xi, sunt adaugate la coada.
Complexitatea este O(n2d3) [1]; beneficiile obtinute prin folosirea acestei strategii acopera
efortul computational. Tot ın [1] se explica de ce consistenta arcelor nu determina toate
inconsistentele.
Se pot efectua verificari de k-consistente, ın care pentru orice set de k − 1 variabile
care au o asignare consistenta, o oricare a k-a variabila poate sa primeasca o valoare
consistenta (pentru k = 2 avem obtinem chiar consistenta arcelor). Totusi, cu cat k este
mai mare cu atat verificarile sunt mai complexe.
4.3 Cautare locala pentru PSC
Algoritmii de cautare locala se dovedesc a fi foarte eficienti ın rezolvarea multor PSC.
Ei pornesc de la o asignare aleatoare de valori pentru toate variabilele iar functia succesor
modifica valoarea unei variabile la fiecare pas.
Cea mai evidenta euristica pentru selectarea valorii unei variabile este alegerea de
valoare care produce numarul minim de conflicte cu alte variabile — euristica conflicte-
minime. Algoritmul este dat ın figura 4.6.

4.3. CAUTARE LOCALA PENTRU PSC 63
Figura 4.5: Algoritmul AC-3 pentru consistenta arcelor. Dupa aplicarea lui, fiecare arc
este consistent sau exista variabile al caror domeniu este gol (si ın acest ultim caz PSC
nu poate fi rezolvata).
Figura 4.6: Algoritmul corespunzator euristicii conflicte-minime. Functia conflicte conto-
rizeaza numarul de constrangeri ıncalcate de o valoare particulara.
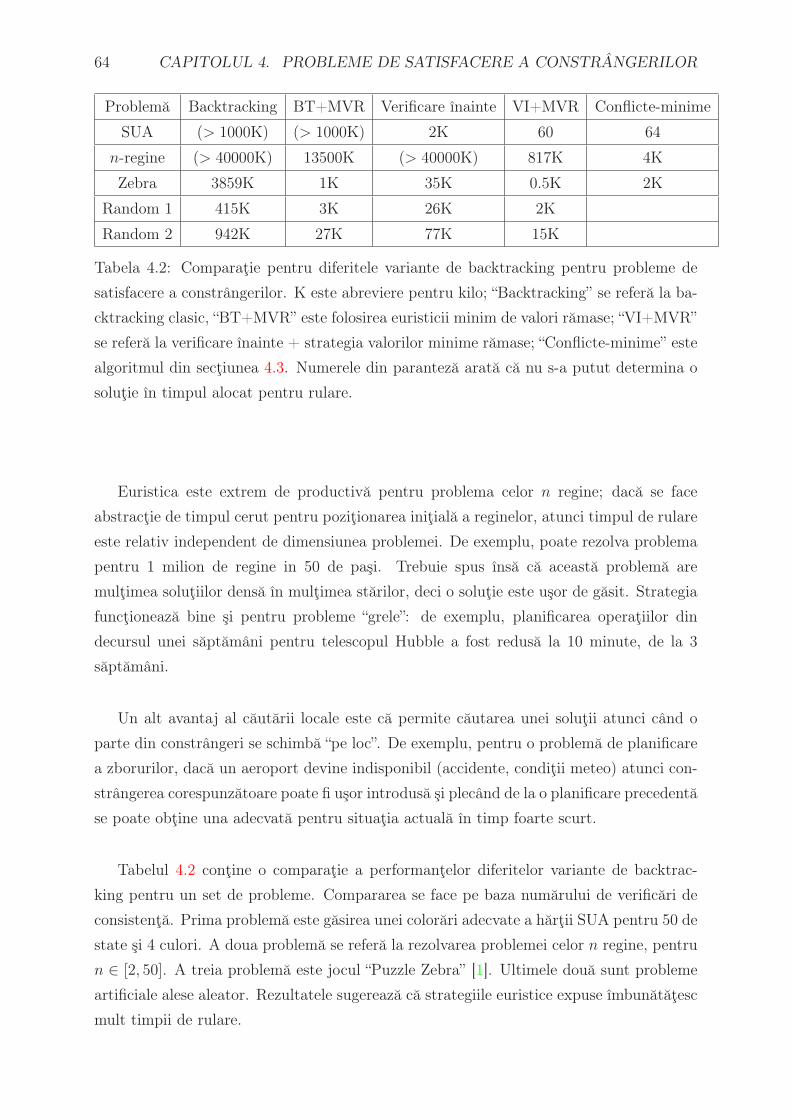
64 CAPITOLUL 4. PROBLEME DE SATISFACERE A CONSTRANGERILOR
Problema Backtracking BT+MVR Verificare ınainte VI+MVR Conflicte-minime
SUA (> 1000K) (> 1000K) 2K 60 64
n-regine (> 40000K) 13500K (> 40000K) 817K 4K
Zebra 3859K 1K 35K 0.5K 2K
Random 1 415K 3K 26K 2K
Random 2 942K 27K 77K 15K
Tabela 4.2: Comparatie pentru diferitele variante de backtracking pentru probleme de
satisfacere a constrangerilor. K este abreviere pentru kilo; “Backtracking” se refera la ba-
cktracking clasic, “BT+MVR” este folosirea euristicii minim de valori ramase; “VI+MVR”
se refera la verificare ınainte + strategia valorilor minime ramase; “Conflicte-minime” este
algoritmul din sectiunea 4.3. Numerele din paranteza arata ca nu s-a putut determina o
solutie ın timpul alocat pentru rulare.
Euristica este extrem de productiva pentru problema celor n regine; daca se face
abstractie de timpul cerut pentru pozitionarea initiala a reginelor, atunci timpul de rulare
este relativ independent de dimensiunea problemei. De exemplu, poate rezolva problema
pentru 1 milion de regine in 50 de pasi. Trebuie spus ınsa ca aceasta problema are
multimea solutiilor densa ın multimea starilor, deci o solutie este usor de gasit. Strategia
functioneaza bine si pentru probleme “grele”: de exemplu, planificarea operatiilor din
decursul unei saptamani pentru telescopul Hubble a fost redusa la 10 minute, de la 3
saptamani.
Un alt avantaj al cautarii locale este ca permite cautarea unei solutii atunci cand o
parte din constrangeri se schimba “pe loc”. De exemplu, pentru o problema de planificare
a zborurilor, daca un aeroport devine indisponibil (accidente, conditii meteo) atunci con-
strangerea corespunzatoare poate fi usor introdusa si plecand de la o planificare precedenta
se poate obtine una adecvata pentru situatia actuala ın timp foarte scurt.
Tabelul 4.2 contine o comparatie a performantelor diferitelor variante de backtrac-
king pentru un set de probleme. Compararea se face pe baza numarului de verificari de
consistenta. Prima problema este gasirea unei colorari adecvate a hartii SUA pentru 50 de
state si 4 culori. A doua problema se refera la rezolvarea problemei celor n regine, pentru
n ∈ [2, 50]. A treia problema este jocul “Puzzle Zebra” [1]. Ultimele doua sunt probleme
artificiale alese aleator. Rezultatele sugereaza ca strategiile euristice expuse ımbunatatesc
mult timpii de rulare.

4.4. STRUCTURA PROBLEMEI 65
4.4 Structura problemei
Vom examina modul ın care structura problemei poate fi de ajutor pentru gasirea
rapida a unei solutii. Un caz simplu este acela ın care problema este compusa din mai
multe subprobleme care se pot rezolva independent; de exemplu, pentru problema colorarii
hartii Australiei, Tasmania este o subproblema care poate fi rezolvata separat: Tasmania
nu e vecina cu nicio alta regiune. Reducerile de complexitate pot fi mari, iar timpii de
rulare obtinuti sunt acceptabili. Singurul impediment este ca o asemenea situatie este rar
ıntalnita.
Un alt caz simplu de rezolvat este acela ın care graful constrangerilor formeaza un
arbore. Se poate arata ca:
Teorema 3 Daca graful de constrangeri nu are cicluri, atunci PSC poate fi rezolvata cu
complexitatea O(n · d2).
Sporul de performanta este evident prin comparatie cu performanta generala a algorit-
mului backtracking, O(dn).
In acest punct ne putem pune problema cum anume reducem o problema la una care
are graful structurat ca un arbore. Exista doua metode: una se bazeaza pe eliminarea
unor variabile, cealalta pe crearea de grupari de noduri.
Prima varianta functioneaza astfel: se determina un set de noduri prin a carui eliminare
se ajunge la un graf de tip arbore; de exemplu, pentru graful din figura 4.2 daca se
elimina nodul corespunzator variabilei SA, atunci graful obtinut este cel din figura 4.7,
pentru care teorema de mai sus ne asigura de existenta unui comportament foarte bun.
Eliminarea nodului se face prin asignarea unei valori din domeniul asociat si stergerea
valorilor incompatibile din domeniile variabilelor care sunt unite prin constrangeri cu
nodul eliminat. Desigur, valoarea aleasa pentru SA poate sa duca la imposibilitatea de
rezolva problema, dar aceste valori pot fi ıncercate pe rand (conform principiului general
al metodei backtracking).
Schitat, algoritmul arata astfel:
1. Alege un subset S din V ariabile[PSC] astfel ıncat graful sa devina un arbore dupa
eliminarea nodurilor din S si a arcelor corespunzatoare. S se va numi set de eliminare
a ciclurilor.
2. Pentru fiecare asignare posibila pentru variabilele din S care satisfac constrangerile
PSC:
(a) elimina din domeniul variabilelor ramase valorile care sunt inconsistente cu
asignarile pentru S

66 CAPITOLUL 4. PROBLEME DE SATISFACERE A CONSTRANGERILOR
(b) daca PSC ramasa are o solutie, returneaz–o ımpreuna cu asignarile pentru S
Gasirea celui mai mic set de eliminare a ciclurilor este o problema NP-grea, dar exista
algoritmi eficienti pentru obtinerea unor aproximari. Daca acest set are dimensiunea c,
atunci complexitatea variantei de mai sus este O(dc · (n− c)d2).
Victoria
WA
NTQ
NSW
V
T
Figura 4.7: Prin eliminarea variabilei SA, graful de constrangeri din figura 4.2 devine un
arbore, pentru care rezolvarea se face ın timp liniar.
A doua varianta porneste de la construirea unei descompuneri a grafului de con-
strangeri ıntr–un arbore format dintr-un set de probleme interconectate. Fiecare sub-
problema se rezolva independent, apoi solutiile rezultate sunt combinate. Figura 4.8
arata descompunerea problemei de colorare a hartii Australiei. Descompunerea trebuie
sa ındeplineasca urmatoarele trei conditii:
1. fiecare variabila din problema originala trebuie sa apara ın cel putin una din sub-
probleme;
2. daca doua variabile sunt conectate printr-o constrangere ın problema originala,
atunci ea trebuie sa apara ımpreuna ın cel putin una dintre subprobleme;
3. daca o variabila apare ın doua subprobleme din arbore, atunci ele trebuie sa apara
ın fiecare subproblema de-a lungul unei cai care conecteaza aceste subprobleme.
Fiecare din subprobleme se rezolva independent; daca una dintre ele nu are solutie,
atunci ıntreaga problema nu are solutie. Constrangerile care trebuie respectate se rezolva
prin interpretarea fiecarei subprobleme ca o variabila mai mare si aplicarea algoritmului

4.4. STRUCTURA PROBLEMEI 67
Figura 4.8: O descompunere sub forma de arbore de subprobleme a grafului de con-
strangeri din figura 4.2
eficient de rezolvare pentru arbore. Constrangerile pentru acest graf arbore reprezinta
conditia ca subprobleme cu variabile comune sa aiba aceeasi valoare pentru variabilele
partajate.

68 CAPITOLUL 4. PROBLEME DE SATISFACERE A CONSTRANGERILOR

Capitolul 5
Agenti logici
5.1 Motivatie
Capitolul introduce agentii bazati pe cunoastere. Conceptele care se discuta sunt
reprezentarea cunoasterii si procesele de rationare – preocupari centrale ale inteligentei
artificiale.
Spre deosebire de agentii care aplica metodele de cautare prezentate ın capitolele
anterioare, agentii logici beneficiaza de cunoastere exprimata ın forme variate, combinand
si recombinand informatia pentru a raspunde unor scopuri diverse. In plus, cunoasterea si
rationarea de asemenea joaca un rol crucial ın lucrul cu medii partial observabile. Un agent
bazat pe cunoastere poate sa produca noi cunostinte pe baza cunostintelor generale si a
perceptiilor ; de exemplu, un medic poate sa puna un diagnostic unui pacient, plecand de
la simptomele acestuia si cunostintele pe care i le-a asigurat formarea medicala. Dar, desi
simptomele sunt cunoscute, un medic nu cunoaste absolut tot despre pacientul tratat – si
de aici rezulta o alta caracteristica a agentilor logici: necesitatea de a lucra cu observatii
partiale.
Un alt motiv pentru care se studiaza agentii bazati pe cunoastere este flexibilitatea
produselor rezultate. Astfel de agenti sunt ın stare sa accepte noi sarcini si sa castige
rapid noi competente prin ınvatare sau prin descoperire de noi informatii.
Principalul mod ın care se abordeaza agentii logici este bazat pe logica (propozitionala,
apoi de ordinul ıntai). Spectrul abordarilor curente este ınsa mai bogat, deoarece ın
lumea reala apar probleme legate de incertitudine, aici intervenind teoria probabilitatilor
si sistemele fuzzy, iar partea de ınvatare se abordeaza de regula prin ınvatare automata -
retele neuronale, arbori de decizie (vezi [5], [6]).
69

70 CAPITOLUL 5. AGENTI LOGICI
5.2 Agenti bazati pe cunoastere
Componenta centrala a unui agent este baza de cunostinte (BC), adica un set de
enunturi care fac parte din domeniul de lucru al agentului. Fiecare enunt este exprimat
ıntr–un limbaj de reprezentare a cunostintelor si reprezinta niste asertiuni despre lume.
Mai este nevoie de un mecanism care sa adauge noi propozitii la BC si unul care sa
determine ce se cunoaste i.e. ce anume trebuie sa se faca la pasul curent. Numele lor este
Spune si Intreaba. Al doilea mecanism presupune inferente – metode prin care pornind
de la cunostinte se deduc altele.
Figura 5.1 contine o schita a unui program bazat pe cunoastere. El preia o perceptie
ca intrare si returneaza o actiune. Agentul mentine o BC care initial este formata din
cunostintele de baza si care se ımbogateste pe masura ce i se comunica perceptii sau
propozitii. Primul pas este de a comunica bazei de cunostinte ceea ce s-a perceput; la
pasul al doilea se ıntreaba ce ar trebui facut. La pasul al treilea i se comunica BC ca s-a
efectuat actiunea indicata la pasul anterior; aceasta a doua comunicare este utila pentru
a tine BC ancorata ın contextul curent.
Figura 5.1: Un agent generic ce actioneaza plecand de la o baza de cunostinte.
Creeaza-enunt-perceptie translateaza ın limbajul formal specific bazei de cunostinte
perceptia curenta; demn de remarcat este ca timpul apare si el ca o dimensiune a perceptiei.
Creeaza-interogare-actiune construieste o propozitie care interogheaza BC ce actiune
ar trebuie sa se execute la momentul curent. In sfarsit, Creeaza-enunt-actiune con-
struieste un enunt care codifica faptul ca actiunea indicata a fost ındeplinita.
Initial, baza de cunostinte este construita printr-o succesiune de apeluri ale lui Spune,
prin care se comunica cunostinte generale si principii. Este un mod declarativ de definire
a unui domeniu, care mareste aria de aplicabilitate a acestor agenti. O alta modalitate
de ımbogatire a BC este prin ınvatare automata pe baza perceptiilor.

5.3. JOCUL “LUMEA MONSTRULUI” 71
5.3 Jocul “lumea monstrului”
Sectiunea contine o descriere a unui joc, folosit ca suport de exemplificare ın restul
capitolului. Se dau mai multe camere dispuse ıntr-o matrice; camerele comunica ıntre
ele; ıntr–o camera se gaseste un monstru care mananca pe oricine intra acolo (si jocul se
termina). In alte camere se afla gropi; daca se intra ıntr–o asemenea groapa, atunci jocul
se termina. Intr-o camera se afla aur; luarea lui determina sfarsitul jocului. Un personaj
ınarmat cu o sageata are posibilitatea de a se muta dintr-o camera ın alta ın cautarea
aurului.
Detaliile sunt:
• masura de performanta este data de suma valorilor atasate fiecarui eveniment: 1000
pentru preluarea aurului, -1000 pentru caderea ıntr–o groapa sau omorarea de catre
monstru, -10 pentru aruncarea sagetii si -1 pentru orice alta actiune;
• mediul: o matrice de camere de 4 pe 4. Agentul (personajul) ıncepe ın camera din
stanga jos, de coordonate [1, 1], cu fata spre dreapta. Locatia camerelor cu aurul,
gaurile si monstrul sunt alese aleator, dar se garanteaza ca nu sunt ın locatia de
pornire.
• actiuni: agentul poate sa se deplaseze ın directia ın care se afla cu fata, poate sa se
ıntoarca la stanga sau la dreapta cu 90◦. Personajul moare daca intra ın camera cu
monstrul viu. Daca exact ın fata lui este un zid, atunci ramane pe loc. Actiunea
“apuca” este folosita pentru preluarea aurului, daca se afla ın aceeasi camera cu el.
Actiunea “trage” se foloseste pentru a lansa sageata ın directia ın care personajul e
orientat; sageata zboara pana se izbeste fie de zid, fie de monstru.
• senzori: agentul are cinci senzori:
– ın patratul care contine monstrul si ın camerele vecine (dar nu pe diagonala)
se percepe miros;
– ın camerele vecine (dar nu pe diagonala) cu o camera care contine o groapa se
simte briza de aer;
– ın camera care contine aurul se percepe stralucire
– cand agentul se izbeste de un zid, se aude bufnitura
– cand monstrul este omorat, se aude tipat
Cele cinci perceptii determina un vector cu cinci elemente care se raporteaza ori de
cate ori agentul intra ıntr–o camera (sau ıncearca sa se deplaseze).

72 CAPITOLUL 5. AGENTI LOGICI
Cunostintele date mai sus se introduc ıntr–o BC. De fiecare data cand agentul viziteaza
o camera se primeste vectorul de perceptii; pe baza acestora si a BC se pot face deductii
de tipul: e posibil ca ın camera [2, 1] sa fie o groapa, sau sigur ın camera [3, 3] nu se
afla monstru, deductii care se adauga la BC, pentru a evita redescoperirea unor elemente
aflate de dinainte.
5.4 Logica
Sectiunea prezenta contine generalitati despre reprezentari logice si rationament. De-
taliile sunt specifice logicilor concrete ce se studiaza (logica propozitiilor, logica predica-
telor, logica temporala, logica fuzzy).
Orice logica trebuie sa clarifice doua aspecte: sintaxa si semantica. Sintaxa reprezinta
o specificare a ceea ce este corect exprimat ın logica respectiva si se poate reprezenta sub
forma de diagrame sau propozitii folosind simboluri.
Semantica defineste ın general semnificatia unui enunt. In cadrul logicii semantica
permite stabilirea unei valori de adevar pentru un enunt care este corect formulat din
punct de vedere sintactic. Mai mult, semantica trebuie sa specifice valoarea de adevar
pentru orice enunt fata de fiecare lume posibila; de exemplu, a > b este adevarata pentru
a = 3 si b = 2, dar falsa pentru a = b = 4.
O “lume posibila” sau set de valori atasat variabilelor se va numi de acum ınainte model
si vom spune ca m este un model al enuntului a daca a este adevarat pentru lumea m.
Rationamentul logic (sau deductia, adica partea de interes major ıntr-o logica) repre-
zinta modul ın care se poate deduce un enunt dintr-un altul. Definitia formala a deductiei
este:
Definitia 10 Spunem ca din α se deduce β si notam α |= β daca ın orice model al
enuntului α avem ca si β este adevarat.
De exemplu, din propozitia a > b se poate deduce si b ≤ a, deoarece pentru orice
combinatie de numere a si b care fac prima propozitie adevarata si al doilea enunt este
adevarat. Pentru jocul cu lumea monstrului, sa presupunem ca agentul nu detecteaza
curent de aer ın pozitia [1, 1] si detecteaza curent de aer ın [2, 1]. Acestea ımpreuna cu
regulile jocului1 formeaza baza de cunostinte. Agentul este interesat daca ın [1, 2], [2, 2],
[3, 1] se afla gauri. Fiecare din camere poate sa contina sau nu gaura, deci ın total avem
8 modele posibile. Vom considera acele modele pentru care baza de cunostinte nu este
contrazisa; exista trei asemenea cazuri din cele 8 posibile si ın toate propozitia “nu exista
1Pentru moment nu ne intereseaza cum anume se exprima formalizat aceste reguli, vom presupune ca
ele sunt reprezentate convenabil.

5.5. LOGICA PROPOZITIONALA 73
groapa ın [1, 2]” este adevarata, pe cand “nu exista groapa ın [2, 2]” si “nu exista groapa
ın [3, 1]” nu sunt adevarate pentru toate cele trei cazuri.
Aceasta metoda de verificare a posibilitatii de deducere se numeste algoritmul veri-
ficarii modelelor. Vom dezvolta mai multi algoritmi de deductie; daca avem un astfel de
algoritm i de deductie, atunci vom scrie α |=i β si vom citi “β este dedus (sau derivat)
din α prin i” sau “i ıl deriveaza pe β din α”.
Un algoritm inferential se numeste temeinic2 daca obtine numai enunturi care sunt
derivabile din baza de cunostinte. Este evident ca algoritmul de verificare a modelelor
este temeinic.
O alta proprietate pentru un algoritm inferential este cea de completitudine – daca
poate sa deduca toate enunturile care sunt derivabile din baza de cunostinte. O examinare
sistematica ın cazul unei probleme ın care multimea de concluzii posibile este finita duce,
evident, la un algoritm complet; proprietatea este ınsa esentiala pentru problemele ın care
multimea concluziilor posibile este infinita.
5.5 Logica propozitionala
5.5.1 Sintaxa
Enunturile atomice din logica propozitionala3 sunt elemente sintactice indivizibile.
Fiecare simbol corespunde unei propozitii care poate sa fie adevarata sau falsa. Exista
doua simboluri propozitionale cu semnificatii fixate: Adevarat este propozitia tot timpul
adevarata si Fals este propozitia tot timpul falsa.
Enunturile complexe sunt compuse din propozitii simple folosind conectorii logici. Cei
cinci conectori sunt:
1. ¬ (non) — o propozitie precum ¬A este negarea lui A. Un literal este fie un enunt
atomic (literal pozitiv), fie negarea a unuia (literal negativ).
2. ∧ (si) — o propozitie formata din doua propozitii legate prin ∧ precum A ∧ B se
numeste conjunctie; A ∧ B se citeste “A si B”
3. ∨ (sau) — o propozitie ce foloseste ∨, precum A ∨B, se numeste disjunctie; A ∨B
se citeste “A sau B”
4. ⇒ (implica) — o propozitie precum A ⇒ B se numeste implicatie. Premisa sau
antecedentul implicatiei este A, iar concluzia sau consecventul este B. A ⇒ B se
citeste “A implica B” sau “daca A atunci B”.
2In limba engleza, ın original: sound.3Numita si logica booleana.

74 CAPITOLUL 5. AGENTI LOGICI
5. ⇔ (echivalent, daca si numai daca) — propozitia A⇔ B se mai numeste biconditionala
si se citeste “A daca si numai daca B” sau “A este echivalent cu B”.
Tabelul 5.1 da sintaxa folosita ın logica propozitionala ın forma BNF (Backus-Naur
Form).
Enunt → Enunt atomic | Enunt complex
Enunt atomic → Adevarat | Fals | simbol
Simbol → P | Q | R | . . .
Enunt complex → ¬ (Enunt)
| (Enunt ∧ Enunt)
| (Enunt ∨ Enunt)
| (Enunt ⇒ Enunt)
| (Enunt ⇔ Enunt)
Tabela 5.1: Gramatica BNF pentru enunturile din logica propozitionala.
Parantezele sunt importante: fiecare propozitie care este construita cu conector binar
este ıncadrata ıntre paranteze. Uneori acestea se pot omite, dar numai daca nu duc
la ambiguitati. Suplimentar, se defineste si prioritatea operatorilor; acestia, ın ordinea
precedentei sunt: ¬, ∧, ∨, ⇒, ⇔. Astfel, A⇒ ¬B ∨ C este totuna cu (A⇒ (¬B ∨ C)).
Suplimentar, semantica ne poate permitem sa scriem A∧B∧C deoarece ((A∧B)∧C)
are ıntotdeauna aceeasi valoare de adevar ca si (A∧ (B ∧C)), dar tot semantica arata ca
este ambigua expresia A⇒ B ⇒ C.
5.5.2 Semantica
Semantica defineste reguli pentru determinarea valorii de adevar a propozitiilor relativ
la un model concret. In logica propozitionala un model reprezinta valorile de adevar ale
simbolurilor propozitionale. De exemplu, daca avem propozitiile P1,2, P2,2, P3,1, atunci
un model posibil este m = {P1,2 = fals, P2,2 = adevarat, P3,1 = adevarat}.
Calculul valorii de adevar se face recursiv, deoarece orice propozitie este alcatuita din
propozitii atomice si conectori. Pentru ınceput, trebuie sa se determine valoarea de adevar
a unei propozitii atomice:
• Adevarat are valoarea de adevar “adevarat” pentru orice model; Fals are valoarea
de adevar “fals” pentru orice model;
• valoarea de adevar a unei unui simbol propozitional trebuie sa rezulte din modelul
curent.

5.5. LOGICA PROPOZITIONALA 75
Pentru propozitiile compuse se foloseste tabela de adevar (data ın tabelul 5.2) care
arata cum se calculeaza valoarea propozitiei plecand de la elementele care o formeaza.
Pe baza celor de mai sus se poate scrie o functie (Este-Adevarat) care stabileste daca
valoarea de adevar a unei expresii s, plecand de la un model dat m este adevarat.
p q ¬p p ∧ q p ∨ q p⇒ q p⇔ q
adevarat adevarat fals adevarat adevarat adevarat adevarat
adevarat fals fals fals adevarat fals fals
fals adevarat adevarat fals adevarat adevarat fals
fals fals adevarat fals fals adevarat adevarat
Tabela 5.2: Tabela de adevar pentru logica propozitionala.
S-a spus anterior ca o baza de cunostinte este o multime de enunturi. Dat fiind modul
de calcul al valorii de adevar pentru o conjunctie, se poate spune ca o BC de forma α1,
. . . , αn se poate scrie ca: α1 ∧ . . . ∧ αn.
5.5.3 Exemplu: lumea monstrului ın logica propozitionala
Pentru fiecare pereche de indici (i, j) corespunzand unei camere, vom seta Pi,j =adevarat
daca si numai daca ın camera de coordonate (i, j) este o groapa si Bi,j va fi adevarata
daca si numai daca se simte curent de aer ın aceeasi camera. Conform regulilor jocului
din sectiunea 5.3, avem ca:
• nu exista nici o groapa in camera din care ıncepe jocul, deci avem regula R1 : ¬P1,1
• ıntr–o camera se simte curent de aer numai daca ın vecinatatea ei se afla o groapa;
deci avem:
R2 : B1,1 ⇔ (P1,2 ∨ P2,1)
si
R3 : B2,1 ⇔ (P1,1 ∨ P2,2 ∨ P3,1)
• introducem perceptiile: nu se simte curent de aer ın prima camera (deci R4 : ¬B1,1)
si se simte curent ın camera (2, 1) (deci R5 : B2,1).
Baza de cunostinte este R1 ∧R2 ∧R3 ∧R4 ∧R5.
5.5.4 Inferenta ın logica propozitionala
Scopul unei inferente este de a detemina daca BC |= α, pentru un α dat. Primul
algoritm pe care ıl dam se bazeaza pe implementarea directa a definitiei 10: se enumera

76 CAPITOLUL 5. AGENTI LOGICI
Figura 5.2: Algoritm de deductie bazat pe construirea tabelei de adevar.
toate modelele si se verifica daca α este adevarata ın toate modelele ın care BC este
adevarata. Pentru logica propozitionala, multimea tuturor modelelor se obtine dand toate
combinatiile de valori de adevar pentru simbolurile propozitionale. In cazul nostru avem
simbolurile B1,1, B2,1, P1,1, P1,2, P2,1, P2,2 si P3,1. Sunt deci 27 = 128 de modele; se poate
verifica faptul ca pentru trei dintre ele BC este adevarata; ın aceste trei modele ¬P1,2
este adevarata, deci nu este groapa ın camera de coordonate (1, 2). P2,2 este adevarata
doar ın doua din cele trei modele, deci nu putem deduce nici P2,2 nici ¬P2,2.
Figura 5.2 contine un algoritm general pentru a determina daca se poate deduce α din
BC. Este o cautare de tip backtracking; algoritmul este temeinic, deoarece implementeaza
direct definitia; este de asemenea si complet deoarece se termina pentru orice baza de
cunostinte si α, numarul de modele fiind finit.
Complexitatea algoritmului este dictata de n, numarul de simboluri. Complexitatea
ın timp este O(2n) iar cea ın spatiu este O(n), deoarece avem o cautare de tipul “mai ıntai
ın adancime”. Vom prezenta algoritmi care ın practica sunt mai eficienti, dar pentru toti
algoritmii inferentiali cunoscuti exista un cel mai defavorabil caz care duce la complexitate
de timp exponentiala.
5.5.5 Echivalenta, validitate si satisfiabilitate
Conceptele urmatoare sunt folosite ın alti algoritmi care urmeaza a fi prezentati.
Primul concept este legat de echivalenta logica, notata cu simbolul ≡. Doua propozitii
α si β sunt echivalente daca si numai daca sunt adevarate ın aceleasi modele. Se poate
vedea de exemplu ca P ∧Q este echivalenta cu Q∧P , prin verificare pe tabela de adevar.
O definitie alternativa a echivalentei este: α ≡ β daca si numai daca α |= β si β |= α.

5.6. TIPARE DE RATIONAMENT IN LOGICA PROPOZITIONALA 77
Tabelul 5.3 contine echivalentele logice standard.
(α ∧ β) ≡ (β ∧ α) comutativitatea lui ∧
(α ∨ β) ≡ (β ∨ α) comutativitatea lui ∨
((α ∧ β) ∧ γ) ≡ (α ∧ (β ∧ γ)) asociativitatea lui ∧
((α ∨ β) ∨ γ) ≡ (α ∨ (β ∨ γ)) asociativitatea lui ∨
¬(¬α) ≡ α eliminarea dublei negatii
(α⇒ β) ≡ (¬β ⇒ ¬α) contrapozitie
(α⇒ β) ≡ (¬α ∨ β) eliminarea implicatiei
(α⇔ β) ≡ ((α⇒ β) ∧ (β ⇒ α)) eliminarea biconditionala
¬(α ∧ β) ≡ (¬α ∨ ¬β) de Morgan
¬(α ∨ β) ≡ (¬α ∧ ¬β) de Morgan
(α ∧ (β ∨ γ)) ≡ ((α ∧ β) ∨ (α ∧ γ)) distributivitatea lui ∧ fata de ∨
(α ∨ (β ∧ γ)) ≡ ((α ∨ β) ∧ (α ∨ γ)) distributivitatea lui ∨ fata de∧
Tabela 5.3: Echivalente logice standard.
Al doilea concept este validitatea. O propozitie este valida daca este adevarata ın orice
model4. Conceptul este util pentru urmatoare teorema de deductie:
Teorema 4 In logica propozitionala, pentru orice propozitii α si β, avem ca α |= β daca
si numai daca propozitia α⇒ β este valida.
Ultimul concept este satisfiabilitatea. O propozitie este satisfiabila daca si numai daca
este adevarata ın cel putin un model. Daca α este adevarata ıntr–un model m, atunci
spunem ca m satisface α, sau ca m este un model al lui α.
A verifica daca β se poate deduce din α (adica daca “α⇒ β” este adevarata) este echi-
valent cu a vedea daca α∧¬β este nesatisfiabila - de fapt regasim procedeul demonstratiei
prin reducere la absurd.
5.6 Tipare de rationament ın logica propozitionala
Prezentam tiparele standard care pot fi aplicate pentru a deriva noi propozitii; aceste
tipare se mai numesc si reguli de inferenta.
Cea mai cunoscuta regula se numeste Modus Ponens si are forma:
α⇒ β, α
β
adica: daca din α se poate deduce β si stim ca α este adevarata, atunci si β este adevarata.
4O astfel de propozitie se mai numeste si tautologie.

78 CAPITOLUL 5. AGENTI LOGICI
Alta regula este eliminarea lui “si” care spune ca dintr–o conjunctie oricare din termeni
poate sa fie dedus:α ∧ β
α
De asemenea, oricare din echivalentele din tabelul 5.3 pot fi folosite ca reguli de
inferenta; de exemplu echivalenta pentru eliminarea biconditionala duce la doua reguli
de inferenta:α⇔ β
(α⇒ β) ∧ (β ⇒ α)si
(α⇒ β) ∧ (β ⇒ α)
α⇔ β
Exemplificam utilizarea regulilor de inferenta si a echivalentelor ın lumea monstrului.
Continuam lista prezentata ın sectiunea 5.5.3. Aplicand eliminarea biconditionala pentru
R3 obtinem:
R6 : (B1,1 ⇒ (P1,2 ∨ P2,1)) ∧ ((P1,2 ∨ P2,1)⇒ B1,1)
Se aplica eliminarea lui “ si” pentru R6 si se ajunge la:
R7 : ((P1,2 ∨ P2,1)⇒ B1,1)
Echivalenta logica pentru contrapozitie da:
R8 : (¬B1,1 ⇒ ¬(P1,2 ∨ P2,1))
Se aplica regula Modus Ponens pentru R8 si faptul dat ın R4, obtinandu–se:
R9 ¬(P1,2 ∨ P2,1)
Din regula lui de Morgan se obtine:
R10 : ¬P1,2 ∧ ¬P2,1
sau altfel zis, nici camera [1, 2] si nici [2, 1] nu contin groapa.
Derivarea precedenta se numeste demonstratie si se bazeaza pe aplicarea unor reguli
de inferenta. Oricare din algoritmii de cautare din capitolele 2 si 3 poate fi folosit pentru
gasirea unei demonstratii, folosind ca stare initiala baza de cunostinte iar ca pas urmator
(actiune) oricare din regulile de inferenta.
Deoarece inferenta ın logica propozitionala este NP-completa, s-ar putea spune ca o
cautare de demonstratie nu poate sa fie mai eficienta decat enumerarea modelelor. In prac-
tica ınsa, gasirea unei demonstratii este mult mai eficienta, deoarece se evita propozitiile
irelevante. De exemplu, ın demonstratia anterioara nu s–a facut referire la propozitiile
care contin simbolurile B2,1 sau P3,1.

5.6. TIPARE DE RATIONAMENT IN LOGICA PROPOZITIONALA 79
5.6.1 Rezolutia
In mod evident, regulile de inferenta expuse anterior sunt temeinice; nu este ınsa evi-
dent daca sunt si complete, adica daca ele permit deducerea a orice poate fi demonstrat
pornind de la o baza de cunostinte. Aplicarea unui algoritm de cautare care este complet
avand drept pasi urmatori regulile de inferenta nu garanteaza obtinerea unui mecanism
inferential complet. De exemplu, daca regula eliminarii biconditionale nu ar fi fost pre-
zenta, atunci concluzia din demonstratia anterioara nu s–ar fi putut dovedi.
Introducem o singura regula de inferenta, numita rezolutie care produce un algoritm
de inferenta complet, daca este folosit ın conjunctie cu un algoritm de cautare complet.
Pentru lumea monstrului adaugam urmatoarele fapte la baza de cunostinte:
R11 : ¬B1,2
si
R12 : B1,2 ⇔ (P1,2 ∨ P2,2 ∨ P1,3)
Printr-o demonstratie asemanatoare cu cea de mai sus, avem ca:
R13 : ¬P2,2
R14 : ¬P1,3
Se aplica eliminarea biconditionala la R3, apoi Modus Ponens cu R5 si se obtine:
R15 : P1,1 ∨ P2,2 ∨ P3,1
Se observa ca literalul ¬P2,2 din R13 se reduce cu literalul P2,2 din R15 si obtinem:
R16 : P1,1 ∨ P3,1
Putem, de asemenea, sa reducem ¬P1,1 din R1 cu P1,1 din R15 si obtinem:
R17 : P3,1
Aceste reduceri exprima regula rezolutiei unitate, care se scrie formalizat astfel:
l1 ∨ · · · ∨ lk, m
l1 ∨ · · · li−1 ∨ li+1 ∨ · · · ∨ lk
unde fiecare lj (1 ≤ j ≤ k) este un literal iar li si m sunt literali complementari (unul este
negarea celuilalt). Deci regula rezolutiei unitate preia o clauza (o disjunctie de literali) si
un literal si produce o noua clauza.
Regula de mai sus admite o generalizare imediata:
l1 ∨ · · · ∨ lk, m1 ∨ · · · ∨mn
l1 ∨ · · · li−1 ∨ li+1 ∨ · · · ∨ lk ∨m1 ∨ · · · ∨mj−1 ∨mj+1 ∨ · · · ∨mn

80 CAPITOLUL 5. AGENTI LOGICI
adica se pleaca de la doua clauze si se ajunge la una noua ın care avem toti literalii
clauzelor initiale, mai putin doi termeni care sunt complementari. Desigur, se presupune
ca se aplica si reducerea literalilor duplicati, adica o expresie de forma A ∨ A ∨ · · · este
redusa la A ∨ · · ·.
Este usor de vazut ca regula de rezolutie este temeinica: daca li este adevarata, atunci
mj este falsa si deci m1 ∨ · · · ∨mj−1 ∨mj+1 ∨ · · · ∨mn trebuie sa fie adevarata; analog,
daca li este falsa, atunci l1 ∨ · · · li−1 ∨ li+1 ∨ · · · ∨ lk este adevarata. Deoarece li este ori
adevarata, ori falsa, obtinem ca una din cele doua concluzii are loc, deci si disjunctia lor
este adevarata; aceasta din urma disjunctie este exact concluzia regulii.
Se poate arata, de asemenea, ca orice algoritm complet de cautare care aplica doar
regula de rezolutie poate sa demonstreze orice concluzie care se poate demonstra plecand
de la o baza de cunostinte ın logica propozitionala.
Exista totusi un aspect practic care trebuie mentionat: daca se da de exemplu propozitia
A adevarata, metoda rezolutiei nu poate sa deduca automat ca si A ∨ B este adevarata.
Mai general, rezolutia poate fi folosita pentru a confirma sau infirma orice propozitie, dar
nu poate sa genereze singura toate propozitiile care pot fi deduse pornind de la baza de
cunostinte.
5.7 Forma normala conjunctiva
Regula de rezolutie se aplica numai disjunctiilor de literali, deci s-ar parea ca se aplica
doar bazelor de cunostinte si interogarilor care constau din asemenea forme. Se poate arata
ca orice expresie din logica propozitionala poate fi rescrisa sub forma unei conjunctii de
disjuntii, asa numita forma normala conjunctiva (FNC).
De exemplu, pentru propozitia: B1,1 ⇔ (P1,2 ∨ P2,1) se obtine FNC echivalenta prin
pasii:
1. Se aplica eliminarea biconditionala:
(B1,1 ⇒ (P1,2 ∨ P2,1)) ∧ ((P1,2 ∨ P2,1)⇒ B1,1)
2. Se elimina ⇒, prin α⇒ β ≡ ¬α ∨ β
(¬B1,1 ∨ P1,2 ∨ P2,1) ∧ (¬(P1,2 ∨ P2,1) ∨ B1,1)
3. Aplicand legea lui de Morgan pentru ¬(α ∨ β) ≡ (¬α ∧ ¬β) obtinem:
(¬B1,1 ∨ P1,2 ∨ P2,1) ∧ ((¬P1,2 ∧ ¬P2,1) ∨ B1,1)
4. Aplicam distributivitatea lui ∨ asupra lui ∧ si obtinem FNC:
(¬B1,1 ∨ P1,2 ∨ P2,1) ∧ (¬P1,2 ∨ B1,1) ∧ (¬P2,1 ∨B1,1)

5.8. ALGORITMUL DE REZOLUTIE 81
Figura 5.3: Algoritm de rezolutie pentru logica propozitionala. Functia LP-Rezolva
returneaza setul de clauze care se obtine prin combinarea celor doua intrari.
5.8 Algoritmul de rezolutie
Procedurile de inferenta bazate pe rezolutie lucreaza pe principiul reducerii la absurd,
adica pentru a arata ca BC |= α, aratam ca (BC ∧ ¬α) este nesatisfiabila.
Algoritmul este aratat ın figura 5.3. Primul pas este de a converti BC ∧ ¬α ın FNC.
Apoi, pentru fiecare pereche care contine literali complementari se produce o noua clauza,
care este adaugata la setul de clauze, daca nu este deja prezenta. Procesul se repeta pana
cand se ıntampla una din:
1. doua clauze produc clauza vida, caz ın care din BC se poate deduce α.
2. nu se ajunge la clauza vida si nu exista noi clauze care sa fie adaugate la setul de
clauze; ın acest caz din BC nu se poate deduce α;
Clauza vida este echivalenta cu Fals, deoarece o clauza este adevarata daca si numai
daca cel putin un termen al ei este adevarat; nefiind cazul, ınseamna ca FNC data de
BC ∧ ¬α evolueaza la un enunt care contine conjunctie cu Fals, deci valoarea de adevar
a ıntregii expresii date ın FNC este falsa. Din principiul reducerii la absurd avem ca
BC |= α.
O aplicare partiala a algoritmului de rezolutie pentru BC = R2 ∧R4 si α = ¬P1,2 este
data ın figura 5.4. Tot din figura observam ca obtinem, de exemplu, ¬B1,1 ∨ P1,2 ∨ B1,1
care se reduce la Adevarat∨P1,2 care se evalueaza la Adevarat. Nu este utila o asemenea

82 CAPITOLUL 5. AGENTI LOGICI
Figura 5.4: Aplicare partiala a algoritmului pentru BC = R2 ∧R4 si α = ¬P1,2. Se arata
evolutia pana ın momentul obtinerii clauzei vide.
clauza, deoarece este cuprinsa ıntr–o conjunctie, iar conform tabelei de adevar 5.2 avem
ca Adevarat ∧X este echivalent cu X, pentru orice expresie X.
Se defineste ınchiderea rezolutiva a unei propozitii aflate ın FNC ca fiind setul tuturor
clauzelor care se obtin din aplicarea repetata a regulii de rezolutie peste propozitie sau
clauze derivate din ea. Acesta multime este finita, deoarece numarul de combinatii ın
disjunctii al unui set finit de simboluri este finit (se aplica si factorizarea).
Completitudinea este data de teorema:
Teorema 5 (Teorema de rezolutie, [1]) Daca un set de clauze este nesatisfiabil, atunci
ınchiderea rezolutiva a acestor clauze contine clauza vida.
5.9 Inlantuirea ınainte si ınapoi
De multe ori, bazele de cunostinte din lumea reala contin clauze ıntr–o forma parti-
culara numita clauza Horn. O clauza Horn este o disjunctie de literali ın care cel mult un
literal are forma pozitiva. De exemplu, ¬A ∨ ¬B ∨ C.
Restrictia poate parea cam dura, dar:
1. Fiecare clauza Horn poate fi scrisa ca o implicatie a carei premisa este o conjunctie cu
literali pozitivi si drept concluzie un singur literal pozitiv. De exemplu, ¬A∨¬B∨C
este echivalenta cu A ∧ B ⇒ C – am aplicat eliminarea implicatiei si regula lui de
Morgan. Aceasta din urma forma este naturala, motiv pentru care clauzele Horn
se regasesc atat de usor ın bazele de cunostinte. Ele sunt element fundamental al
domeniului numit Programare logica.
Daca o clauza Horn nu contine nici un literal pozitiv (de exemplu: ¬A∨¬B), atunci
se poate scrie echivalent ¬A ∨ ¬B ∨ Fals si apoi ca A ∧B ⇒ Fals.
2. Inferentele cu clauze Horn pot fi facute cu doi algoritmi de de inferenta care apar
ca naturali, ınlantuirea ınainte si ınlantuirea ınapoi.
3. Algoritmii de deductie care folosesc clauze Horn sunt liniari ın dimensiunea BC.

5.9. INLANTUIREA INAINTE SI INAPOI 83
Algoritmul de ınlantuire ınainte LP-InlantuireInainte(BC, q) determina daca un
simbol propozitional q poate fi dedus din baza de cunostinte aflate ın forma Horn. Daca
premisele unei implicatii sunt cunoscute ca adevarate, atunci concluzia implicatiei este
adevarata si este adaugata la baza de cunostinte. Procedeul se repeta pana cand fie se
deduce q, fie nu se mai poate adaunga niciun simbol propozitional nou la BC. Algoritmul
este dat ın figura 5.5.
Figura 5.5: Algoritmul de ınlantuire ınainte.
Cel mai bun mod de ıntelegere a algoritmului de ınlantuire ınainte este pe baza unui
exemplu. Sa presupunem ca avem baza de cunostinte exprimata sub forma de enunturi
reductibile la clauze Horn:
P ⇒ Q
L ∧M ⇒ P
B ∧ L⇒M
A ∧ P ⇒ L
A ∧ B ⇒ L
A

84 CAPITOLUL 5. AGENTI LOGICI
B
Acestei baze de cunostinte i se poate asocia un graf de tipul si—sau, construit astfel:
nodurile lui sunt simbolurile propozitionale, arcele de graf unite reprezinta operatorul
∧, ın timp ce arcele neunite corespund disjunctiei. Figura 5.6 reprezinta graful si—sau
asociat bazei de cunostinte date, ımpreuna cu evolutia cunostintelor. In dreptul fiecarui
arc de jonctiune de arce se afla numarul de premise care mai trebuie mai demonstrate
pentru a se putea deduce concluzia aflata la capatul arcului.
Se poate vedea ca ınlantuirea ınainte este temeinica, deoarece reprezinta aplicarea
repetata a regulii Modus Ponens. Este de asemenea si un algoritm complet (a se vedea
[1]).
Inlantuirea ınainte este un exemplu de rationament condus de date, adica al unui
rationament ın care demonstrarea unei concluzii se face pornind dinspre ipoteze. Spre
deosebire de regula rezolutiei, poate fi folosita pentru a genera o lista de concluzii care
pot fi deduse plecand de la o baza de cunostinte.
Inlantuirea ınapoi porneste dinspre interogare spre baza de cunostinte. Daca se cere
a se demonstra ca Q este adevarata, se verifica prima data daca se stie deja valoarea de
adevar a lui Q; daca nu se cunoaste, atunci se gasesc toate implicatiile care ıl produc pe
Q. Daca se poate demonstra ca premisele unei astfel de implicatii sunt toate adevarate,
atunci si Q este adevarata. Procesul de rationament este unul directionat de scop. O
ilustrare a procesului este data ın figura 5.8.
De multe ori, costul unei ınlantuiri ınapoi este mult mai mic decat dimensiunea bazei
de cunostinte (desi o implementare eficienta are costul liniar, ın cel mai defavorabil caz).
5.10 Inferenta propozitionala efectiva
Descriem aici doua variante de algoritmi eficienti pentru inferenta propozitionala ba-
zate pe verificarea de modele: unul este bazat pe cautare backtracking, altul pleaca de la
cautare prin metoda ascensiunii.
Ambele metode verifica satisfiabilitatea, adica determinarea unui model (valori pentru
variabile) astfel ıncat sa se verifice o anumita valoare de adevar. Atat backtracking cat si
cautarea locala rezolva aceste probleme, dar primul este un algoritm determinist, exact,
pe cand al doilea poate sa duca la rezultate incorecte.
5.10.1 Algoritm bazat pe backtracking
Algoritmul, datorat lui Davis si Putnam pleaca de la o propozitie ın forma normala
conjunctiva. Precum cautarea backtracking (sectiunea 4.2) si metoda TA-deductie (figura
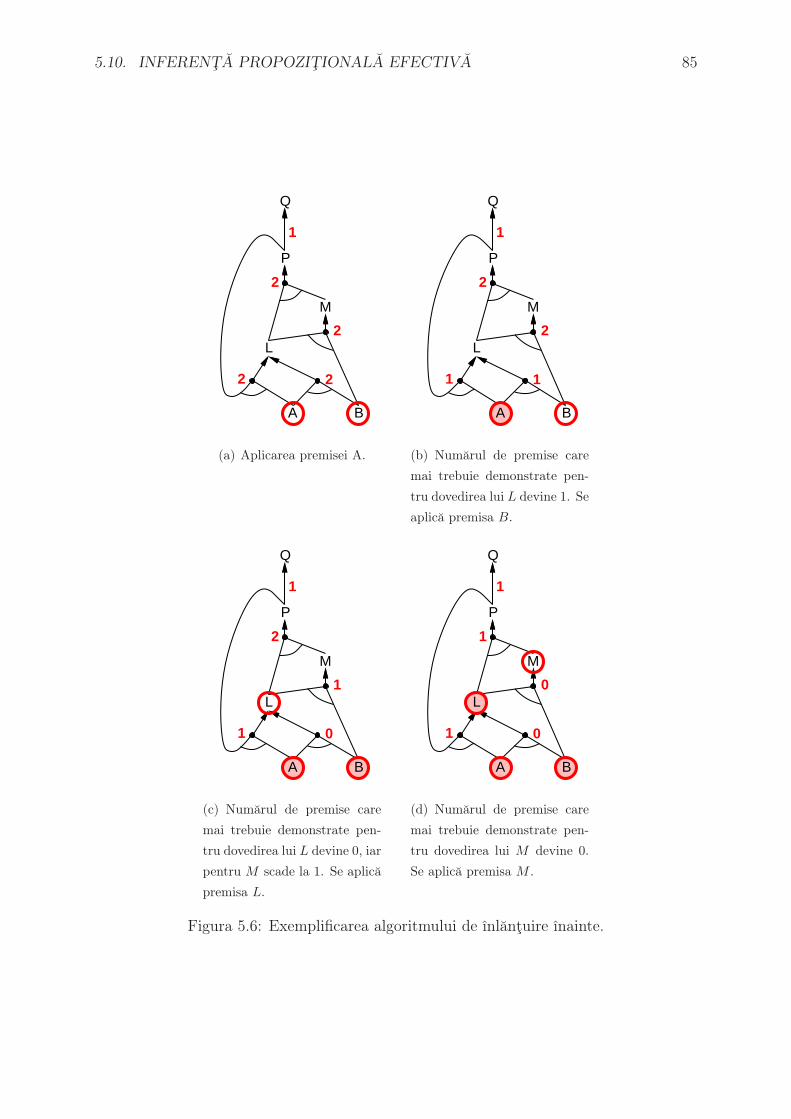
5.10. INFERENTA PROPOZITIONALA EFECTIVA 85
Q
P
M
L
BA
2 2
2
2
1
(a) Aplicarea premisei A.
Q
P
M
L
B
2
1
A
1 1
2
(b) Numarul de premise care
mai trebuie demonstrate pen-
tru dovedirea lui L devine 1. Se
aplica premisa B.
Q
P
M
2
1
A
1
B
0
1L
(c) Numarul de premise care
mai trebuie demonstrate pen-
tru dovedirea lui L devine 0, iar
pentru M scade la 1. Se aplica
premisa L.
Q
P
M
1
A
1
B
0
L0
1
(d) Numarul de premise care
mai trebuie demonstrate pen-
tru dovedirea lui M devine 0.
Se aplica premisa M .
Figura 5.6: Exemplificarea algoritmului de ınlantuire ınainte.

86 CAPITOLUL 5. AGENTI LOGICI
Q
1
A
1
B
0
L0
M
0
P
(a) Numarul de premise care
mai trebuie demonstrate pen-
tru dovedirea lui P devine 0. Se
aplica premisa P .
Q
A B
0
L0
M
0
P
0
0
(b) Numarul de premise care
mai trebuie demonstrate pen-
tru dovedirea lui Q devine 0, la
fel ca si pentru dovedirea lui L
folosind conjunctia (dar despre
L se stie deja ca poate fi de-
monstrat). Astfel, s–a demon-
strat concluzia Q.
Figura 5.7: Exemplificarea algoritmului de ınlantuire ınainte (continuare).
5.2), este o ıncercare pe rand a modelelor, dar cu urmatoarele ımbunatatiri:
• Terminare rapida: algoritmul detecteaza daca o propozitie este adevarata sau falsa,
chiar daca modelul este partial completat. O clauza este adevarata daca un literal
este adevarat, chiar daca ceilalti literali nu au valoare de adevar fixata. Similar, o
conjunctie de clauze este falsa daca o clauza este falsa, indiferent de valorile celorlalte
clauze.
• Euristica simbolurilor pure: un simbol este pur daca apare cu acelasi semn ın fiecare
clauza. Este usor de vazut ca daca o propozitie are un model, atunci acesta are
proprietatea ca simbolul pur are valoarea adevarat.
• Strategia clauzei unitate: o clauza unitate este o clauza cu un singur literal. In
contextul algoritmului, ınseamna si o clauza unde toti literalii, mai putin unul, au
valoare fals. Strategia clauzei unitate asigneaza valori unor asemenea simboluri
ınainte de a se apuca de altele. O astfel de setare de variabila poate de asemenea sa
duca la alte clauze unitate.
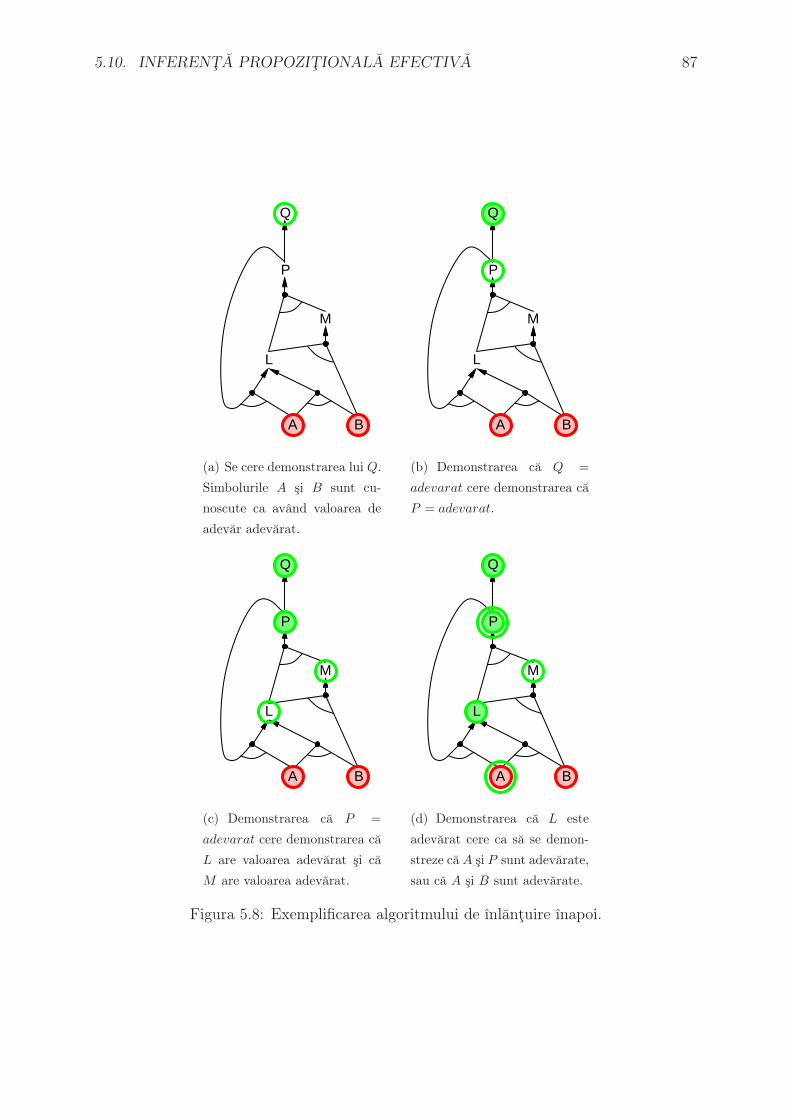
5.10. INFERENTA PROPOZITIONALA EFECTIVA 87
Q
P
M
L
A B
(a) Se cere demonstrarea lui Q.
Simbolurile A si B sunt cu-
noscute ca avand valoarea de
adevar adevarat.
P
M
L
A
Q
B
(b) Demonstrarea ca Q =
adevarat cere demonstrarea ca
P = adevarat.
M
L
A
Q
P
B
(c) Demonstrarea ca P =
adevarat cere demonstrarea ca
L are valoarea adevarat si ca
M are valoarea adevarat.
M
A
Q
P
L
B
(d) Demonstrarea ca L este
adevarat cere ca sa se demon-
streze ca A si P sunt adevarate,
sau ca A si B sunt adevarate.
Figura 5.8: Exemplificarea algoritmului de ınlantuire ınapoi.
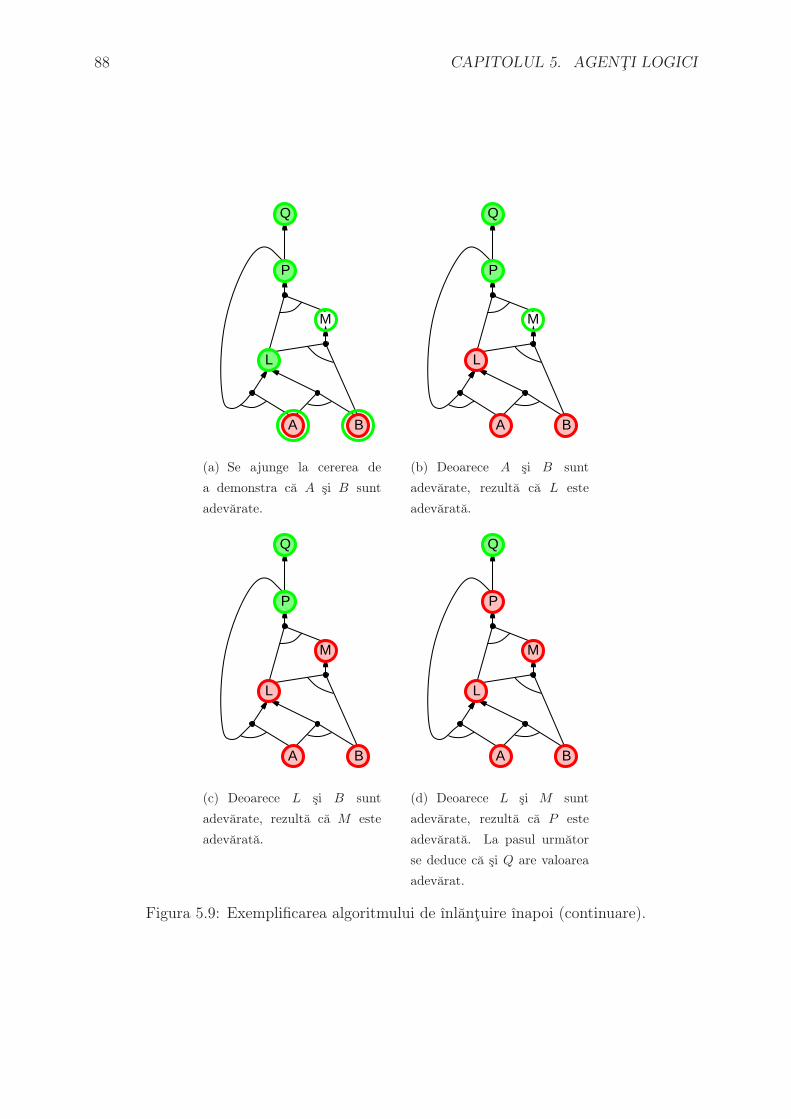
88 CAPITOLUL 5. AGENTI LOGICI
M
A
Q
P
L
B
(a) Se ajunge la cererea de
a demonstra ca A si B sunt
adevarate.
M
A
Q
P
L
B
(b) Deoarece A si B sunt
adevarate, rezulta ca L este
adevarata.
A
Q
P
L
B
M
(c) Deoarece L si B sunt
adevarate, rezulta ca M este
adevarata.
A
Q
P
L
B
M
(d) Deoarece L si M sunt
adevarate, rezulta ca P este
adevarata. La pasul urmator
se deduce ca si Q are valoarea
adevarat.
Figura 5.9: Exemplificarea algoritmului de ınlantuire ınapoi (continuare).

5.10. INFERENTA PROPOZITIONALA EFECTIVA 89
Figura 5.10: Algoritmul Walksat pentru verificarea satisfiabilitatii unui set de clauze.
5.10.2 Algoritm bazat pe cautare locala
Algoritmii de cautare locala pot fi aplicati direct problemelor de satisfiabilitate, daca
se da o functie de evaluare adecvata. Se alege de regula numarul de clauze nesatisfacute.
Algoritmii de acest tip schimba la fiecare pas valoarea unei variabile; pentru a iesi din
minimele locale se folosesc diferite variante de randomizare.
Unul din cei mai simpli si mai eficienti algoritmi rezultati se numeste WalkSat (figura
5.10). La fiecare iteratie algoritmul alege o clauza nesatisfacuta si alege aleator care dintre
variabile sa ısi schimbe valoarea. Alegerea variabilei se face aleator:
• se alege variabila care minimizeaza numarul de clauze nesatisfacute, sau
• se alege simbol ın mod aleator
Daca algoritmul returneaza un model, atunci acest model satisface clauzele. Daca ınsa
se returneaza esuare, atunci nu se poate sti sigur daca expresia este nesatisfiabila sau daca
ar trebui ca algoritmul sa fie lasat sa ruleze mai mult (dar nu se stie cat de mult).

90 CAPITOLUL 5. AGENTI LOGICI

Capitolul 6
Logica de ordinul ıntai
6.1 Introducere
Logica propozitionala se dovedeste a fi un limbaj neadecvat pentru reprezentarea
cunostintelor dintr-un mediu complex, ıntr–un mod concis. De exemplu, pentru a spune
ca ıntr-o camera vecina (pe verticala sau orizontala) cu cea de coordonate [1, 1] ın care
se simte briza de aer exista o groapa, scriem astfel:
B1,1 ⇔ P1,2 ∨ P2,1
si ceva asemanator pentru fiecare camera din joc. Limbajul natural este mai concis
(comparati “camerele vecine cu o camera ın care se simte curent de aer contin o groapa”
cu cele n2 propozitii care trebuie scrise ın logica propozitionala pentru a exprima acelasi
lucru). Pe de alta parte, limbajul natural poate fi si imprecis. Ne dorim deci o varianta
de limbaj care sa fie concis, exact ın exprimare si sa permita deductii.
Alte aspecte pe care le dorim de la un limbaj de reprezentare a cunostintelor sunt:
• natura declarativa — cunostintele dintr–un domeniu vrem sa fie reprezentate separat
de mecanismul inferential; acesta din urma trebuie sa fie cat mai general aplicabil.
Este o abordare diferita de cea a limbajelor procedurale (Java, C#, C++) unde
structurile de date obtinute dupa modelarea problemei sunt puternic cuplate cu
operatorii de prelucrare;
• semantica compozitionala — semantica unui enunt exprimat ıntr–un asemenea lim-
baj trebuie sa fie dictata de semantica partilor care ıl compun;
• independenta de context — se impune obtinerea acelorasi concluzii, daca se reaplica
mecanismul inferential pornind de la o aceeasi baza de cunostinte;
Mai mult, prin compararea cu ceea ce ne pune la dispozitie limbajul natural, ne dam
seama ca dorim sa putem lucra cu:
91

92 CAPITOLUL 6. LOGICA DE ORDINUL INTAI
• obiecte: oameni, culori, numere etc;
• relatii ıntre obiecte: relatii unare (ınalt, rosu, prim) sau n-are: mai mare decat,
frate cu, compus din;
• functii: aplicate pe unul sau mai multe obiecte duc la obtinerea altor obiecte: tatal
lui, succesorul lui etc.
Limbajul logicii de ordinul ıntai trateaza satisfacator toate aceste aspecte.
Cea mai mare diferenta ıntre logica propozitionala si logica predicatelor este ca ın
prima se exprima fapte care au sau nu loc. Fiecare fapt are una din doua valori: adevarat
sau fals. Logica predicatelor ınsa se refera la o multime de obiecte ıntre care exista sau
nu relatii.
6.2 Sintaxa si semantica logicii de ordinul ıntai
6.2.1 Modele pentru logica de ordinul ıntai
Modelele pentru logica propozitionala constau ın perechi de valori de forma simbol =
valoare, unde valoarea poate fi adevarat sau fals. Pentru logica de ordinul ıntai lucrurile
sunt substantial diferite: se lucreaza cu obiecte, care pot lua orice valoare dintr-o multime
specificata, posibil infinita. Domeniul unui model este setul de obiecte pe care le contine.
Sa presupunem ca pornim de la urmatoarea stare: exista doua persoane, John si
Richard, care sunt frati si regi (la momente diferite de timp); exista o coroana care se
afla pe capul unuia dintre ei; se face referire la piciorul stang al oricaruia din cei doi via
o functie, PiciorulStang.
O relatie (cum ar fi frate(John, Richard), frate(Richard, John) si peCap(coroana,
John)) este o multime de tupluri de obiecte care sunt legate prin acea relatie. Mode-
lul poate de asemenea sa contina relatii unare numite si proprietati: rege(John), per-
soana(John), persoana(Richard).
Unele relatii sunt mai natural de vazut ca functii; daca pentru un obiect oarecare
(notat o1), relatia asigura o legatura cu un unic obiect, atunci ea poate fi vazuta ca o
functie de forma relatie(o1)=o2. De exemplu, avem legaturile:
Richard→ piciorul stang al lui Richard
John→ piciorul stang al lui John
Functiile trebuie sa fie totale, adica pentru orice argument sa asocieze un rezultat. Astfel,
piciorul stang al lui John trebuie sa aiba si el un picior stang; o asemenea problema se
rezolva introducand un obiect fictiv care sa fie atasat obiectelor pentru care nu exista,
sub o interpretare rezonabila, ceva corespunzator.

6.2. SINTAXA SI SEMANTICA LOGICII DE ORDINUL INTAI 93
6.2.2 Simboluri si interpretari
Elementele din sintaxa logicii propozitionale sunt:
• constante: John, Richard etc
• relatii (predicate): Frate, > etc
• functii: PiciorulStang, radical etc
• variabile: x, y etc
• conective: ¬, ∧, ∨, ⇒, ⇔
• egalitatea: =
• cuantificatori: ∀, ∃
Gramatica ın forma BNF este data ın tabelul 6.1.
Enunt → Enunt Atomic
| (Enunt Conectiva Enunt)
| Cuantificator Variabila . . . Enunt
| ¬ Enunt
Enunt Atomic → Predicat(Termen, . . . ) | Termen = Termen
Termen → Functie(Termen, . . . )
| Constanta
| Variabila
Conectiva → ⇒ | ∧ | ∨ | ⇔
Cuantificator → ∀ | ∃
Constanta → A | X1 | John | . . .
Variabila → a | x | . . .
Predicat → Frate | . . .
Functie → TatalLui | PiciorulStang | . . .
Tabela 6.1: Forma BNF pentru sintaxa din logica predicatelor.
Semantica trebuie sa lege enunturile de modele pentru a se putea determina valoarea
de adevar. Avem deci nevoie de o interpretare care sa specifice exact care obiecte, relatii
si functii sunt legate simboluri de constante, predicate si functii. Una din interpretarile
posibile si care este adecvata exemplului nostru este:
• constanta Richard se refera la persoana Richard; analog constanta John;

94 CAPITOLUL 6. LOGICA DE ORDINUL INTAI
• predicatul Frate se refera la relatia dintre doua persoane
• functia PiciorulStang se refera la “PiciorulStang” pomenit la pagina 92.
Exista si alte interpretari care se pot face, de exemplu se poate lega constanta Richard
de persoana John sau de coroana; sau se poate ca diferite nume sa se refere la acelasi
obiect.
Valoarea de adevar a fiecarui enunt se defineste ın raport cu un model si o interpre-
tare pentru simbolurile din enunt. Ca atare, deducerea, validitatea, satisfiabilitatea sunt
definite relativ la toate modelele si toate interpretarile posibile. Subliniem ca modelele
pot fi infinite, de exemplu daca se refera la multimea numerelor naturale.
6.2.3 Termeni
Un termen este o expresie logica ce se refera la un obiect – constante, functii, relatii.
Un simbol pentru functii este util pentru a pune ın legatura obiecte (de exemplu constanta
John cu constanta piciorul stang al lui John), cu efect benefic asupra reducerii numarului
de simboluri folosit pentru constante. Este un alt mod de a denumi obiecte, plecand de
la altele.
6.2.4 Propozitii atomice
Sunt folosite pentru a enunta fapte. O propozitie atomica este de regula formata
dintr-un simbol predicativ urmat de o lista de termeni: Frate(John, Richard). Argumen-
tele pot fi si termeni complecsi obtinuti prin aplicare de functii: Casatorit(Tata(John),
Mama(Richard)).
Un enunt atomic este adevarat ıntr–un model dat si sub o anumita interpretare daca
are loc relatia referita de simbolul asociat predicatului ıntre obiectele referite de argu-
mente.
6.2.5 Enunturi complexe
Prin utilizarea conectivelor logice se pot construi enunturi complexe, precum ın calculul
propozitional. Semantica enunturilor complexe formate cu conective logice este identica
cu cea din logica propozitiilor.
6.2.6 Cuantificatori
Cuantificatorii permit exprimarea de proprietati pentru colectii de obiecte, ın loc de a
le enumera pe toate (de aici si dorita concizie a limbajului). Cuantificatorii sunt ınsotiti

6.3. PROCESUL DE MANAGEMENT AL CUNOSTINTELOR 95
de o variabila care poate servi ca argument pentru functii si relatii. Un termen care nu
are variabile se numeste termen legat. Enuntul ∀x P (x) arata ca pentru orice obiect x, P
este adevarata.
Sa considera de exemplu propozitia ∀x Rege(x) ⇒ Persoana(x). Pentru a putea
spune ca este adevarata, toate cele cinci propozitii de mai jos ar trebui sa fie adevarate:
Richard este rege ⇒ Richard este persoana
John este rege ⇒ John este persoana
Piciorul stang al lui Richard este rege ⇒ Piciorul stang al lui Richard este persoana
Piciorul stang al lui John este rege ⇒ Piciorul stang al lui John este persoana
Coroana este rege ⇒ Coroana este persoana
Daca pentru primele doua cazuri nu avem nici o problema din punct de vedere al raportarii
la realitate, ultimele trei propozitii sunt un pic ciudate. Dar sa ne amintim ca ın logica
propozitionala falsul implica orice, asa ca nu se poate spune nimic despre valoarea de
adevar a a concluziilor (“Coroana este persoana” s.a.). Oricum, pornind de la o premisa
falsa, ıntreaga implicatie este adevarata.
Cele cinci propozitii de mai sus care au rezultat din transcrierea ın limbaj propozitional,
conform actiunii lui ∀ formeaza interpretarea extinsa.
Calificatorul existential ∃ are urmatoarea semantica: ∃x P (x) este adevarata ıntr–
un model si sub o intepretare data daca este adevarata pentru cel putin o interpretare
extinsa.
Cuantificatorii pot fi imbricati, iar ordinea de precizare a lor este importanta. De
exemplu, enuntul ∀x ∃y MaiMare(y, x) care e adevarat pentru multimea numerelor na-
turale. Daca inversam ordinea cuantificatorilor, atunci s–ar obtine ∃y ∀xMaiMare(y, x)
care nu este adevarata pentru x si y numere naturale.
Exista o stransa legatura ıntre cei doi cuantificatori. Mai exact, se poate renunta la
oricare dintre ei, deoarece:
∀x P (x) ≡ ¬(∃x ¬P (x))
∃x P (x) ≡ ¬(∀x ¬P (x))
dar ıi mentinem pe amandoi, pentru a obtine exprimari mai naturale.
6.3 Procesul de management al cunostintelor
Proiectele de management al cunostintelor variaza mult, dar toate includ pasii:
1. Identificarea temei de lucru. Inginerul de cunostinte trebuie sa schiteze domeniul
de ıntrebari pentru care baza de cunostinte asigura suport si tipul de fapte care
vor fi disponibile pentru fiecare instanta de problema. De exemplu, pentru lumea

96 CAPITOLUL 6. LOGICA DE ORDINUL INTAI
monstrului, ce anume se doreste: interogarea despre starile diferitelor camere, sau
sa se stie care este actiunea urmatoare?
2. Asamblarea cunostintelor relevante. Inginerul de cunostinte trebuie sa fie expert
ın domeniul abordat, sau sa poata sa colaboreze cu experti umani pentru a putea
extrage ceea ce se cunoaste ın domeniu. La acest pas de achizitie a cunostintelor
nu trebuie sa se formalizeze cunostintele, ci doar sa se ınteleaga care este domeniul
problemei si cum se lucreaza ın el.
3. Deciderea asupra unui vocabular de predicate, functii si constante. Se translateaza
conceptele importante ale domeniului pentru care se aplica procesul ın nume con-
venabil alese. Rezultatul este un vocabular care formeaza ontologia1 domeniului.
4. Codificarea cunostintelor generale despre domeniu. Inginerul de cunostinte scrie
axiomele pentru toti termenii de vocabular. Este bine sa se faca aici si specificarea
semnificatiilor termenilor.
5. Codificarea unei descrieri pentru o problema concreta. Consta ın scrierea enunturilor
atomice despre instante ale conceptelor care sunt deja parte a ontologiei. Este
echivalentul furnizarii datelor pentru programele din limbajele procedurale.
6. Punerea de ıntrebari si obtinerea de raspunsuri. Procedura inferentiala opereaza
asupra axiomelor si faptelor specifice problemei pentru a obtine noi fapte de care
suntem interesati.
7. Depanarea bazei de cunostinte. Daca de exemplu lipseste o axioma, unele interogari
nu vor primi raspuns. Se poate cere unui astfel de sistem sa expliciteze pasii pe care
ıi parcurge, pentru a vedea unde se “blocheaza”.
6.4 Inferenta propozitionala comparata cu inferenta de
ordinul ıntai
Introducem o tehnica care permite realizarea de inferente care pot fi aplicate unor
enunturi cu cuantificatori obtinandu–se enunturi fara cuantificatori. Se poate intui astfel
ca inferenta de ordinul ıntai are o varianta: trecerea la enunturi din logica propozitionala
si folosirea unui mecanism inferential din logica propozitiilor.
1Ontologia studiaza existenta ca atare, trasaturile si principiile comune oricarei existente.

6.4. INFERENTA PROPOZITIONALA COMPARATA CU INFERENTA DE ORDINUL INTAI97
6.4.1 Reguli de inferenta pentru cuantificatori
Sa presupunem ca avem enuntul:
∀x Rege(x) ∧ Lacom(x)⇒ Rau(x)
Data fiind semantica lui ∀ rezulta ca propozitiile urmatoare sunt adevarate:
Rege(John) ∧ Lacom(John)⇒ Rau(John)
Rege(Richard) ∧ Lacom(Richard)⇒ Rau(Richard)
Rege(TatalLui(John)) ∧ Lacom(TatalLui(John))⇒ Rau(TatalLui(John))
Regula instantierii universale spune ca putem deduce orice propozitie obtinuta prin
substituirea unei variabile cu un termen legat (care nu are nicio variabila). Sa notam cu
Subst(θ, α) rezultatul aplicarii substituirii θ ın α. Atunci:
∀v α
Subst({v/g}, α)
Cele trei enunturi propozitionale date anterior sunt obtinute prin substitutiile: {x/John},
{x/Richard}, {x/TatalLui(John)}.
Regula instantierii existentiale este: pentru orice enunt α, pentru orice variabila v si
un simbol constant k care nu apare ın baza de cunostinte avem ca:
∃v α
Subst({v/k}, α)
De exemplu, din enuntul ∃x Coroana(x)∧PeCap(x, John) putem deduce: Coroana(C1)∧
PeCap(C1, John) unde C1 nu mai apare undeva ın baza de cunostinte. Practic, ceea ce
face instantierea existentiala este sa dea un nume pentru obiectul care satisface conditia.
Noul nume se mai cheama si constanta Skolem. Instantierea existentiala poate fi folosita
o singura data si propozitia care are acest cuantificator poate fi eliminata.
6.4.2 Reducerea la inferenta propozitionala
Pe baza mecanismului de mai sus: reducerea unor enunturi cu cuantificatori la unele
fara se poate reduce inferenta de ordinul ıntai la inferenta propozitionala. De fapt, ceea
ce trebuie sa facem este sa ınlocuim un enunt cu care are cuantificator universal cu toate
enunturile ın care variabila este ınlocuita cu toate valorile posibile. De exemplu, baza de
cunostinte din logica predicatelor:
∀x Rege(x) ∧ Lacom(x)⇒ Rau(x)
Rege(John)
Lacom(John)
Frate(Richard, John)

98 CAPITOLUL 6. LOGICA DE ORDINUL INTAI
Se aplica instantierea universala primului enunt folosind toate substituirile de variabile
cu termeni legati din vocabularul BC, deci {x/John} si {x/Richard} si obtinem:
Rege(John) ∧ Lacom(John)⇒ Rau(John)
Rege(Richard) ∧ Lacom(Richard)⇒ Rau(Richard)
Baza de cunostinte rezultata (se adauga, evident, si ultimele 3 propozitii din BC initiala)
este ın forma propozitionala, daca substituim enunturile cu valori legate – Rege(John),
Lacom(John) etc – cu simboluri propozitionale – α, β etc. Se poate aplica oricare din
algoritmii din capitolul precedent si se obtin concluzii – Rau(John).
Exista ınsa o problema: daca BC include un simbol atasat unei functii (de exemplu
TatalLui), atunci prin propozitionalizare se ajunge la o BC infinita, deoarece putem sub-
stitui pe x cu John, TatalLui(John), TatalLui(TatalLui(John)), si tot asa la infinit.
Exista ınsa un raspuns, datorat lui Herbrand care spune ca daca un enunt este implicat
de catre baza de cunostinte initiala, exprimata sub forma de predicate, atunci exista o
demonstratie care pleaca de la un set finit de enunturi ın forma propozitionala, prin care
se poate deduce enuntul respectiv. Se poate genera o astfel de demonstratie plecand de
la ınlocuirea lui x cu John si Richard (deci adancime 0), apoi cu TatalLui(John) si
TatalLui(Richard) (adancime 1) si cu termeni de adancime din ce ın ce mai mare.
Ce se ıntampla daca enuntul dat ca posibila concluzie nu este deductibil din baza
de cunostinte? Teorema lui Herbrand (sau alte rezultate) nu spun nimic ın acest sens.
Procedura descrisa mai sus va genera termeni cu adancime din ce ın ce mai mare, dar
nefiind o limitare data, procedeul se va repeta la nesfarsit. Altfel zis, problema implicatiei
ın logica de ordinul ıntai este semidecidabila – adica exista algoritmi care raspund pozitiv
pentru un enunt care este deductibil din BC, dar nu exista algoritm care de asemenea sa
raspunda negativ la fiecare enunt nedeductibil.

Bibliografie
[1] Artificial Intelligence. A Modern Approach, Prentice Hall, Stuart Russel, Peter Norvig,
3rd edition, 2009
[2] Principiile inteligentei artificiale, Editura Albastra, D. Dumitrescu, 2004
[3] Pattern Classification, editia a doua, Ed. Wiley-Interscience, Richard O. Duda, Peter
E. Hart, David G. Stork, 2000
[4] Genetic Algorithms + Data Structures = Evolution Programs, Ed. Springer-Verlag,
Zbigniew Michalewicz, 1998
[5] Machine Learning, Ed. McGraw–Hill, Tom Mitchell, 1997
[6] Neural Networks and Learning Machines, editia a treia, Simon Haykin, Prentice
Hall, 2008.
[7] Understanding Intelligence, Rolf Pfeifer and Christian Scheier, MIT Press, 1999
99


















