
Departamentul de Comunicatii, Universitatea …3.1.3 Necesităţi de securitate în reţele 30 3.2...
185
Transcript of Departamentul de Comunicatii, Universitatea …3.1.3 Necesităţi de securitate în reţele 30 3.2...


Cuprins 1. Introducere 1 2. Protecţia calculatoarelor neconectate în reţea 3 2.1 Autentificarea utilizatorului 3 2.1.1 Sisteme cu parole 3 2.1.1.1 Avantajele sistemelor cu parole 4 2.1.1.2 Dezavantaje 4 2.1.1.3 Reguli pentru creşterea securităţii asigurate de sistemele cu parole 5 2.1.2 Protecţia prin criptare 5 2.1.2.1 Autentificarea bazată pe chei cifrate 6 2.1.2.2 Autentificarea bazată pe ceva ce utilizatorul este 7 2.1.2.2.1 Sisteme de autentificare biometrice 7 2.1.2.2.1.1 Utilizarea amprentelor în autentificare 7 2.1.2.2.1.1.1 Dispozitive de scanare cu deplasare 7 2.1.2.2.1.1.2. Dispozitive de scanare cu arii de senzori 8 2.1.2.2.1.1.3 Dispozitive de scanare capacitive 9 2.1.2.2.1.1.4 Dispozitive de scanare a amprentelor funcţionând în radio-frecvenţă
9
2.1.2.2.1.1.5 Dispozitive de scanare a amprentelor funcţionând termic
10
2.1.2.2.1.1.6 Dispozitive de scanare piezoelectrică a amprentelor 10 2.1.2.2.1.1.7 Dispozitive de scanare Micro-Electro-Mecanică a amprentelor
10
2.1.2.2.1.1.8 «Potrivirea» amprentelor 10 2.1.2.2.1.1.8.1. Parametrii imaginilor de amprente 12 2.1.2.2.1.2 Utilizarea irisului în autentificare 15 2.1.2.2.1.2.1 Extragerea imaginii irisului din imaginea ochiului 16 2.1.2.2.1.2.2 Codarea imaginii irisului 17 2.1.2.2.1.2.3 Detecţia 19 2.2 Viruşii calculatoarelor 20 2.2.1 Clasificări 21 2.2.2 Moduri de funcţionare a viruşilor 23 2.2.2.1 Activarea viruşilor în cazul calculatoarelor IBM-PC 23 2.2.3 Modalităţi de detectare a viruşilor 24 2.2.4 Programe anti-virus 25 2.2.5 Elaborarea unei politici de protecţie anti-virus 26 3. Protecţia reţelelor 27 3.1 Categorii de atacuri asupra reţelelor 27 3.1.1 Atacuri pasive 27 3.1.2 Atacuri active 27 3.1.2.1. Viermi informatici 28 3.1.2.1.1 Tipuri de viermi informatici 28 3.1.2.1.2 Viermi distrugători 29 3.1.2.1.3 Viermi cu intenţii bune 29 3.12.1.4 Protecţia împotriva viermilor 29

3.1.3 Necesităţi de securitate în reţele 30 3.2 Securitatea LAN-urilor 30 4. Bazele matematice ale criptării 33 4.1 Aritmetica pe clase de resturi modulo specificat 33 4.2 Numere prime 33 4.3 Mica teoremă a lui Fermat 36 4.4 Câmpuri Galois 36 4.5 Matrici MDS 41 4.6 Transformări pseudo-Hadamard 42 4.7 Funcţii hash 42 4.7.1 Descrierea algoritmului MD5 42 5. Criptografia şi securitatea reţelelor 47 5.1 Câţiva termeni utilizaţi în criptografie 47 5.2 Algoritmi criptografici cu cheie secretă 47 5.2.1 Algoritmul DES 49 5.2.1.1 Variante de DES 56 5.2.2 Algoritmul IDEA 57 5.2.3 Algoritmul BLOWFISH 59 5.2.4 Algoritmul TWOFISH 61 5.2.5 Algoritmul RC6 64 5.2.6 Standardul AES, Advanced Encryption Standard (Rijndael) 66 5.3 Algoritmi de criptare cu cheie publică 70 5.3.1 Algoritmul Diffie-Hellman 73 5.3.2 Algoritmul RSA 74 5.3.3 Algoritmul El Gamal 78 5.4 Standardul de criptare cu cheie publică PKCS#1 78 5.5 Algoritmi de semnătură digitală 83 5.5.1 Algoritmi de semnătură digitală bazaţi pe metoda Diffie-Hellman 83 5.5.2 Semnături digitale El-Gamal 84 5.5.3 Standardul de semnătură digitală DSS 85 5.6 Atacuri împotriva sistemelor de criptare 89 6. Securitatea servicilor INTERNET 92 6.1 Protocoale TCP/IP 92 6.1.1 Protocoale de nivel transport 107 6.1.2 Analiza de protocoale 115 6.1.3 Concluzii 117 6.2 Securitatea la nivel IP 119 6.3 Arhitectura securităţii în INTERNET 121 6.3.1 Servicii de securitate 122 6.3.2 Mecanisme de securitate specifice 123 6.3.2.1 Arhitectura securităţii ISO 124 6.3.2.2 Securitatea servicilor TCP/IP 127 6.3.2.2.1 Arhitectura securităţii pentru protocolul IP 127 6.3.2.2.1.1 Mecanisme de securitate la nivel IP 129 6.3.2.2.1.2 Managementul cheilor 131 6.3.2.2.3 Securitatea protocolului TCP 136 6.3.2.2.3.1 O slăbiciune a protocolului TCP 138 6.3.3 Funcţionarea servicilor INTERNET 138 6.4 Servicii de autentificare 146 6.5 Pachetul de programe PGP, Pretty Good Privacy 161

6.6 Sisteme de tip firewall 165 6.6.1. Produse de tip firewall 170 6.6.2. Prinicipii de bază în proiectarea unui dispozitiv de tip firewall 171 6.6.3. Filtrarea pachetelor 171 6.6.4. Studiu de caz 173

1
Introducere
Odată cu dezvoltarea tehnologică înregistrată în ştiinţa calculatoarelor şi în telecomunicaţii, calculatoarele sunt utilizate tot mai mult, crescând riscurile ca informaţia pe care o stochează să fie accesată fraudulos. Uneori acest tip de furt de informaţie poate fi foarte dăunător, din punct de vedere economic, proprietarului acelui calculator. Obiectul securităţii calculatoarelor este scăderea acestor riscuri. Scopurile securităţii calculatoarelor şi reţelelor de calculatoare
- Să asigure cofidenţialitatea; Doar persoanele autorizate să poată avea acces la informaţie. - Să asigure integritatea informaţiei; Aceasta este o sarcină mai dificilă. Atributele
integrităţii sunt: precizia, acurateţea, consistenţa, informaţia să fie modificată doar în moduri permise de persoane autorizate. Există câteva aspecte mai importante ale integrităţii informaţiei:
- Să nu se efectueze decât acţiuni autorizate, - Să se separe şi să se protejeze resursele, - Să se detecteze şi să se corecteze erorile. - Să se asigure disponibilitatea datelor şi servicilor; Şi aceasta este o sarcină mai
dificilă. Principalul atribut al disponibilităţii este utilizabilitatea (capacitatea de a satisface nevoi). Se urmăreşte aceesul cât mai rapid la rezultate şi corectitudinea;
- Să se asigure autenticitatea; să se cunoască originea diferitelor obiecte informaţionale şi modificările pe care le-au suferit acestea; - Să se asigure nerepudierea; autorii unei informaţii să nu se poată dezice de aceasta.
Câţiva dintre termenii utilizaţi frecvent în securitatea calculatoarelor şi reţelelor sunt:
- Sistem de calcul, hard, soft, date; - Expunere; o formă de pierdere de informaţie - Vulnerabilitatea; slăbiciune care poate fi exploatată pentru pierderea de informaţie - Atac; încercarea de a exploata vulnerabilitatea - Control; măsură de reducere a vulnerabilităţii
- Costul controlului; se măsoară în: - Bani; - Timp;
- Cheltuit; - Operaţional;
- de calculator; întârziere în reţea; - disponibilitate; se măsoară în:
- cicluri de unitate centrală de microprocesor; - spaţiu fizic:
- de memorie; - de disc; - Principiul eficienţei: Un control este eficient numai dacă este utilizat corespunzător. "Foloseşte-l sau pierde-l".
-Analiza de risc şi planificarea securităţii; - Asumarea riscului; - Estimarea valorii; se face pe baza răspunsului la întrebările: Care este importanţa
funcţională a misiunii ?; Este capabilă organizaţia să funcţioneze fără acea resursă ?;

2
- Estimarea "inamicului"; se face pe baza răspunsului la întrebarea: Care este cauza pierderii resursei de informaţie ?
- Estimarea slăbiciunilor sistemului de calcul; se face pe baza răspunsului la întrebarea: Care sunt subsistemele cele mai vulnerabile ? - Principiul celei mai uşoare penetrări; Atacatorul va exploata orice vulnerabilitate disponibilă, el va ataca "cea mai slabă za a lanţului"; - Recomandarea controlului; -Realizarea controlului adecvat pentru a reduce: a) vulnerabilităţile periculoase; b) resursele critice; c) ameninţările semnificative; - Tipuri de ameninţări: Întrerupere, Interceptare, Modificare.
- Confidenţialitate; Poate fi realizată prin: Criptare (Cifrare), Controlul accesului la citire. - Integritate; Poate fi realizată prin: Controlul accesului la scriere, Controlul consistenţei. - Disponibilitate; Poate fi realizată prin: Controlul accesului, Redundanţă, Toleranţă la defecţiuni, Monitorizare, Folosirea mecanismelor de prioritate, Autentificare, Secrete (de exemplu parole), Folosirea semnăturilor digitale. - Nerepudiere; Poate fi realizată prin: utilizarea semnăturilor digitale, Contactul cu terţe persoane de încredere, Folosirea mecanismelor de control, Controlul accesului,
- Criptografie; Criptare (Cifrare), Semnături digitale, Protocoale criptografice, Monitorizare, - Detectoare de anomalii, - Control soft:
- Controlul programelor interne (de obicei identificare şi autentificare), - Controlul sistemelor de operare (Identificare şi autentificare, Izolarea proceselor, Protecţia fişierelor), - Controlul dezvoltării, Standarde de calitate (ISO 9000), Revizii, Testare, Separarea sarcinilor, - Politici, Stabilirea politicii, Antrenament, Monitorizare, - Protecţie fizică: Uşi, Lacăte, Scuturi, Surse neinteruptibile, Controlul climatic,… - Protecţie hard: instrucţiuni protejate, protecţie la scriere, - Protecţie soft (bazată pe sistemul de operare): Identificare şi autentificare, grupuri de lucru în reţea; - Protecţia la nivelul aplicaţiei: prin parole, prin criptare
- Eficienţa controalelor -Politică; -Disponibilitate; -Securitatea resurselor; -Costuri operaţionale -Suprapunerea controalelor; - Revizii periodice.
3
Capitolul 2
Protecţia calculatoarelor neconectate în reţea
Modelul de securitate pentru un calculator seamănă cu o ceapă, bazându-se pe mai multe nivele de securitate: 1) Nivelul fizic: interzicerea accesului fizic al persoanelor neautorizate la calculator (încuiere în spaţii protejate), 2) Nivelul logic. La al doilea nivel se efectuează controlul accesului la resursele şi serviciile sistemului de calcul. Controlul accesului presupune să se controleze dacă şi când calculatorul este accesibil altor utilizatori, dacă un utilizator care solicită o conectare este îndreptăţit la aceasta şi ce drepturi are el (sistem de parole). Securitatea serviciilor este asigurată prin controlul accesului la diferitele componente ale sistemului: cozi de aşteptare, intrări-ieşiri, hard-disk sau sistem de gestiune a server-ului.
În continuare se prezintă câteva modalităţi de control al accesului.
2.1. Autentificarea utilizatorului
Autentificarea utilizatorului poate fi realizată pe baza a ceva ce utilizatorul posedă, a ceva ce utilizatorul ştie sau a ceva ce utilizatorul este. De exemplu utilizatorul ştie parola sa. În figura următoare se prezintă fereastra de acces la mesageria electronică Yahoo.
Figura 1.2.1. Fereastra de acces la mesageria electronică Yahoo.
Pentru a putea să-şi acceseze cutia poştală, utilizatorul trebuie să-şi specifice identificatorul şi parola. 2.1.1. Sisteme cu parole
Sunt programe care rulează când se face încărcarea sistemului de operare, cer o parolă şi nu permit continuarea încărcării sistemului de operare până când nu se introduce parola corectă. O metodă obişnuită de a activa programul corespunzător este folosirea unei linii de tipul: DEVICE=PASSWORD.SYS în fişierul CONFIG.SYS. Prin utilizarea unei parole se face identificarea şi autentificarea unui anumit utilizator, program sau operator. În figura următoare este prezentat un exemplu de utilizare al manager-ului de parole al unui
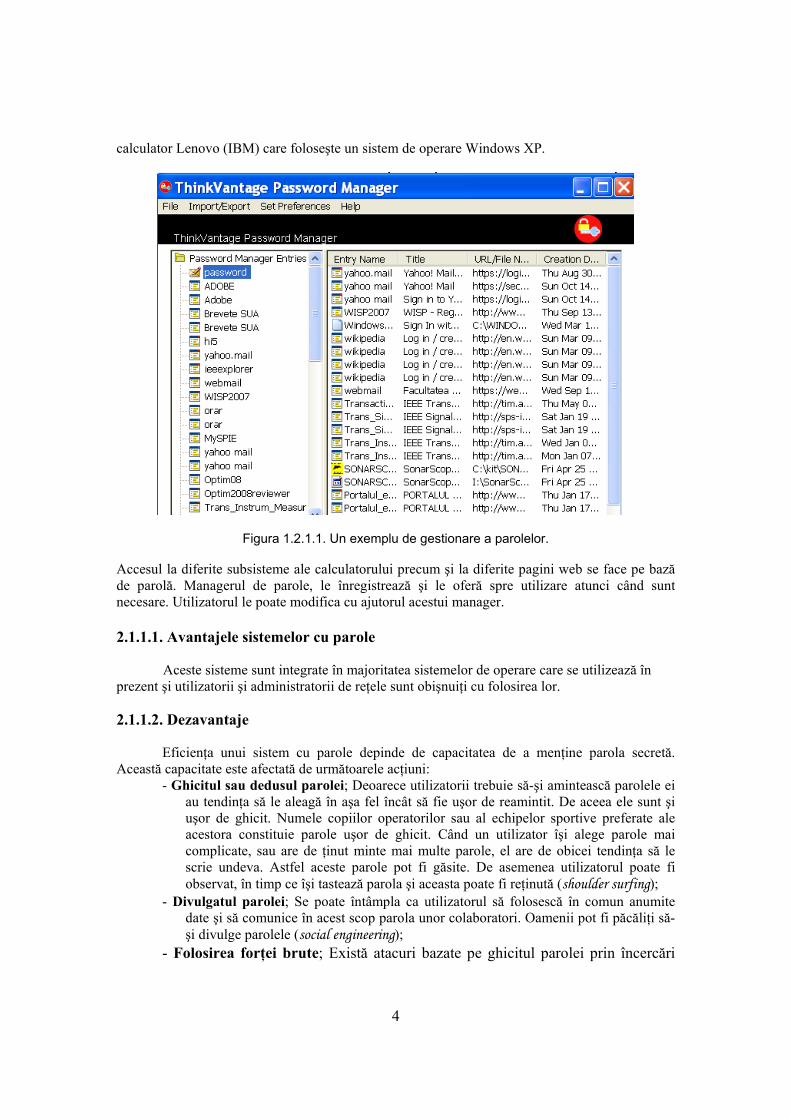
4
calculator Lenovo (IBM) care foloseşte un sistem de operare Windows XP.
Figura 1.2.1.1. Un exemplu de gestionare a parolelor. Accesul la diferite subsisteme ale calculatorului precum şi la diferite pagini web se face pe bază de parolă. Managerul de parole, le înregistrează şi le oferă spre utilizare atunci când sunt necesare. Utilizatorul le poate modifica cu ajutorul acestui manager. 2.1.1.1. Avantajele sistemelor cu parole
Aceste sisteme sunt integrate în majoritatea sistemelor de operare care se utilizează în prezent şi utilizatorii şi administratorii de reţele sunt obişnuiţi cu folosirea lor.
2.1.1.2. Dezavantaje
Eficienţa unui sistem cu parole depinde de capacitatea de a menţine parola secretă. Această capacitate este afectată de următoarele acţiuni:
- Ghicitul sau dedusul parolei; Deoarece utilizatorii trebuie să-şi amintească parolele ei au tendinţa să le aleagă în aşa fel încât să fie uşor de reamintit. De aceea ele sunt şi uşor de ghicit. Numele copiilor operatorilor sau al echipelor sportive preferate ale acestora constituie parole uşor de ghicit. Când un utilizator îşi alege parole mai complicate, sau are de ţinut minte mai multe parole, el are de obicei tendinţa să le scrie undeva. Astfel aceste parole pot fi găsite. De asemenea utilizatorul poate fi observat, în timp ce îşi tastează parola şi aceasta poate fi reţinută (shoulder surfing);
- Divulgatul parolei; Se poate întâmpla ca utilizatorul să folosescă în comun anumite date şi să comunice în acest scop parola unor colaboratori. Oamenii pot fi păcăliţi să-şi divulge parolele (social engineering);
- Folosirea forţei brute; Există atacuri bazate pe ghicitul parolei prin încercări

5
repetate. Acestea recurg la utilizarea unor dicţionare de parole online sau pe epuizarea tuturor combinaţiilor posibile. - Monitorizarea electronică; Poate fi făcută atunci când parolele sunt transmise
calculatorului de către utilizatori; - Accesarea fişierului de parole; Este vorba despre fişierul de parole al unui server; - Evitarea sistemului cu parole; Există posibilitatea încărcării sistemului de operare,
folosind dischete sistem. În acest mod se evită utilizarea fişierelor CONFIG.SYS şi AUTOEXEC.BAT şi deci şi a sistemului cu parole.
2.1.1.3. Reguli pentru creşterea securităţii asigurate de sistemele cu parole
În loc să se aleagă euristic parola, se poate face apel la generatoarele automate de parole. Pentru evitarea atacurilor bazate pe utilizarea forţei brute sistemul de operare poate fi configurat să accepte doar un număr limitat de încercări de introducere a parolei. Dacă după consumarea acestui număr limitat de încercări nu s-a introdus parola corectă atunci calculatorul se decuplează automat. Dacă parola se alege euristic atunci aceasta trebuie să fie de lungime maximă, să conţină toate categoriile de caractere disponibile şi să nu aparţină unui dicţionar de parole online existent. Este bine ca parola să fie schimbată periodic. Se recomandă controlul accesului şi criptarea fişierului de parole de pe server. Alte reguli utile pentru alegerea parolelor sunt prezentate la adresa: http://www.microsoft.com/protect/yourself/password/create.mspx
2.1.2. Protecţia prin criptare
Presupune autentificarea bazată pe criptarea fişierelor de date. În figura următoare se prezintă partiţiile hard-disk-ului calculatorului amintit mai sus.
Figura 1.2.1.2. Discul R este configurat pentru salvarea fişierelor criptate.

6
Prin criptarea fişierelor de date se asigură prevenirea accesului neautorizat la aceste fişiere. Această operaţie este însă antagonică cu un alt deziderat şi anume prevenirea pierderii datelor. Prima operaţie presupune existenţa unui număr minim de copii ale fişierului de date în timp ce cea de a doua necesită existenţa unui număr cât mai mare de copii ale aceluiaşi fişier. Criptarea poate rezolva această contradicţie simplu şi eficient. E necesară doar cifrarea tuturor copiilor fişierului considerat.
2.1.2.1. Autentificarea bazată pe chei criptate
Pentru început se prezintă metode de autentificare bazate pe o combinaţie între ceva ce utilizatorul posedă şi ceva ce utilizatorul ştie. Obiectele pe care utilizatorul le posedă şi care sunt folosite pentru autentificarea sa se numesc tokens. Există două categorii de astfel de obiecte: memory tokens şi smart tokens.
Memory tokens
Sunt obiecte care stochează informaţia fără însă a o prelucra. Există dispozitive speciale de citire-scriere care transferă informaţie dinspre şi înspre memory tokens. Cel mai cunoscut tip de memory token este cartela magnetică. Cartela magnetică de tip ATM este cel mai folosit dispozitiv de tip memory token pentru autentificare într-un sistem de calcul. Un exemplu este prezentat în figura următoare.
Figura 1.2.1.2.1. Un exemplu de memory token.
Această cartelă reprezintă o combinaţie între ceva ce utilizatorul posedă (cartela propriuzisă) şi ceva ce utilizatorul ştie (codul PIN).
Avantajele acestor sisteme
Sunt mult mai sigure decât parolele.

7
Dezavantaje
Problema securităţii PIN-ului este de tipul securitatea parolei. Necesită cititoare speciale, în care trebuie incluse procesoare de verificare a PIN-ului. Pot fi pierdute, furate sau falsificate.
Smart tokens
Diversifică funcţionarea unui memory token adăugând câteva circuite integrate care realizează funcţiile unui calculator. Aceste dispozitive pot fi clasificate după trei criterii: carateristici fizice, tipul de interfaţă folosit şi protocolul folosit.
2.1.2.2 Autentificarea bazată pe ceva ce utilizatorul este
Tehnologiile de autentificare biometrică folosesc trăsături unice ale utilizatorului ca de exemplu: amprentele, geometria mâinii, caracteristici ale retinei, caracteristici ale vocii sau caracteristici ale semnăturii. Ele se folosesc pentru aplicaţiile de login. Ele funcţionează astfel:
-Utilizatorul este "achiziţionat", înregistrându-i-se caracteristicile şi asociând acestora identitatea sa;
-La cererea de autentificare caractersiticile utilizatorului sunt măsurate; -Se compară rezultatele obţinute prin măsurare cu cele înregistrate anterior şi se realizează sau nu autentificarea utilizatorului.
În continuare se face o trecere în revistă a principalelor sisteme de auenitificare biometrică folosite în prezent. 2.1.2.2.1 Sisteme de autentificare biometrice După cum s-a arătat deja, aceste sisteme se diferenţiază prin tipul de trăsătură biometrică utilizată. În continuare se analizează cazul amprentelor şi cel al irisului. 2.1.2.2.1.1 Utilizarea amprentelor în autentificare Amprentele utilizatorului sunt "achiziţionate" prin scanare. Se prezintă principalele rezultate ale studiului: “Solid state fingerprint scanners” elaborat de Philip D. Wasserman de la NIST în decembrie 2005. Un dispozitiv hard de scanare a amprentei măsoara anumite caracteristici fizice ale acesteia şi le transformă într-o imagine. Mai multe tehnologii se pot aplica în acest scop: capacitivă (UPEK), de radiofrecvenţă (Authentec), termică (Atmel), piezorezistivă (Fidelica), ultrasonică (Ultrascan), piezoelectrică (Franhaufer), MEMS. Există mai multe tipuri de dispozitive hard de scanare a amprentelor : - cu deplasare ; utilizatorul îşi deplasează degetul de-a lungul dispozitivului de scanare (care este format dintr-o linie de senzori). - cu arii de senzori ; conţin o arie de senzori care acoperă amprenta utilizatorului. Sunt mai scumpe decât dispozitivele de scanare cu deplasare. 2.1.2.2.1.1.1 Dispozitive de scanare cu deplasare
Sunt formate dintr-o singură linie (sau din doar câteva linii) de senzori. Sunt ieftine, au dimensiuni mici şi consumă puţină energie electrică. Se folosesc la telefoane celulare, la PDA-uri şi la laptop-uri.

8
Utilizatorul îşi deplasează degetul transversal peste linia de senzori, imaginea amprentei construindu-se pe baza mai multor înregistrări făcute de linia de senzori. Viteza şi direcţia deplasării degetului sunt limitate. Un exemplu de astfel de senzor este prezentat în figura următoare.
Figura 1.2.1.2.2.1.1.1. Exemplu de utilizare a unui senzor de scanare a amprentelor. Prin scanare se obţine o imagine intermediară care este ulterior transformată software în imaginea amprentei.
Procesul software de sinteză a imaginii poate produce distorsiuni, neacceptabile în cazul utilizării în criminalistică. O imagine detaliată a senzorului de mai sus este prezentată în figura următoare.
Figura 2.2.1.2.2.1.1.1. Circuit integrat de scanare hard a amprentei cu deplasare de tipul Fujitsu
Microelectronics MBF 320.
2.1.2.2.1.1.2 Dispozitive de scanare cu arii de senzori Capturează una sau mai multe amprente printr-o singură expunere. Dimensiunea imaginii trebuie sa fie suficient de mare. După cum s-a menţionat deja, procesul de scanare are ca rezultat o imagine a amprentei care este supusă unui proces de recunoaştere. Acesta poate avea succes doar dacă dimensiunile imaginii obţinute în urma scanării sunt suficient de mari. Recent a fost publicat de către NIST un studiu dedicat identificării dimensiunii minime a imaginii care permite o rată satisfăcătoare de recunoaştere, « Effect of Image Size and Compression on One-to-One Fingerprint Matching ». Concluzia acestui studiu este: Prin decuparea imaginii performanţele dispozitivului de recunoaştere a amprentei se degradează rapid. Imagini cu dimensiuni mai mici de 320×320 pixeli nu trebuie să fie folosite. Încă nu s-a realizat nici un circuit integrat pentru scanarea

9
amprentei unui singur deget care să satisfacă aceste condiţii. Procesul de scanare poate fi implementat cu diferite tehnologii. În continuare se prezintă câteva dintre acestea. 2.1.2.2.1.1.3 Dispozitive de scanare capacitive În brevetul SUA nr. 5973623 este descris un dispozitiv de scanare a amprentelor capacitiv cu deplasare. Principiul său de funcţionare este prezentat în figura următoare.
Figura 1.2.1.2.2.1.1.3. Schema electrică echivalentă a a unei celulule a dispozitivului de scanare
capacitiv. Fiecare senzor, corespunzător unui pixel din imaginea amprentei, conţine un integrator a cărui capacitate este determinată de prezenţa degetului în apropierea suprafeţei circuitului. Senzorii funcţionează în 2 faze: Prima este de reset-are – scurtcircuitarea condensatorului integratorului. Faza 2 – integratorul primeşte cantitatea de sarcină ΔQ, care produce tensiunea de ieşire E= ΔQ/C, unde C reprezintă capacitatea dintre plăcile de metal, determinată de proximitatea pielii (muchii şi văi). Un exemplu de astfel de sistem de scanare a amprentelor este circuitul MBF 320, amintit deja mai sus. O arie de 256 x 8 electrozi metalici de pe suprafaţa circuitului capturează imaginea unei amprente folosind detecţia de capacitate. Suprafaţa degetului joacă rolul unei armături a condensatorului iar fiecare electrod al ariei acţionează ca şi cealaltă armătură. Suprafaţa circuitului e protejată de un înveliş foarte dur, rezistent chimic, care are rolul de dielectric. Un ghidaj axează degetul pe centrul ariei de senzori. Când un utilzator îşi deplasează degetul de-a lungul suprafeţei circuitului, muchiile şi văile epidermei degetului produc variaţii de capacitate. Circuitul măsoară modificările de tensiune corespunzătoare prin intermediul unui CAN pe 8 biţi. Rezultatul este o imagine de rezoluţie mare. Pachetul de programe oferit de Fujitsu capturează cadrele de imagine de 256 x 8 pixeli produse la o scanare completă şi construieşte o imagine completă a amprentei. 2.1.2.2.1.1.4 Dispozitive de scanare a amprentelor funcţionând în radio-frecvenţă Principiul lor de funcţionare este prezentat în figura următoare. Într-un câmp de radio-frecvenţă generat local muchiile şi văile epidermei degetului modulează în amplitudine semnalul de radio-frecvenţă. Condensatoarele formate între punctele de pe suprafaţa degetului şi electrozii circuitului de scanare acţionează ca nişte antene care recepţionează semnalul modulat în amplitudine. Amplificatoarele din structura circuitului răspund la semnalele de radio-frecvenţă cuplate prin condensatoarele formate între deget şi electrozii circuitului. În urma demodulării acestor semnale se obţine imaginea amprentei care poate fi memorată în vederea unei recunoaşteri ulterioare.

10
Figura 1.2.1.2.2.1.1.4. Schema de principiu a unui dispozitiv de scanare a amprentelor care lucrează în radio-frecvenţă.
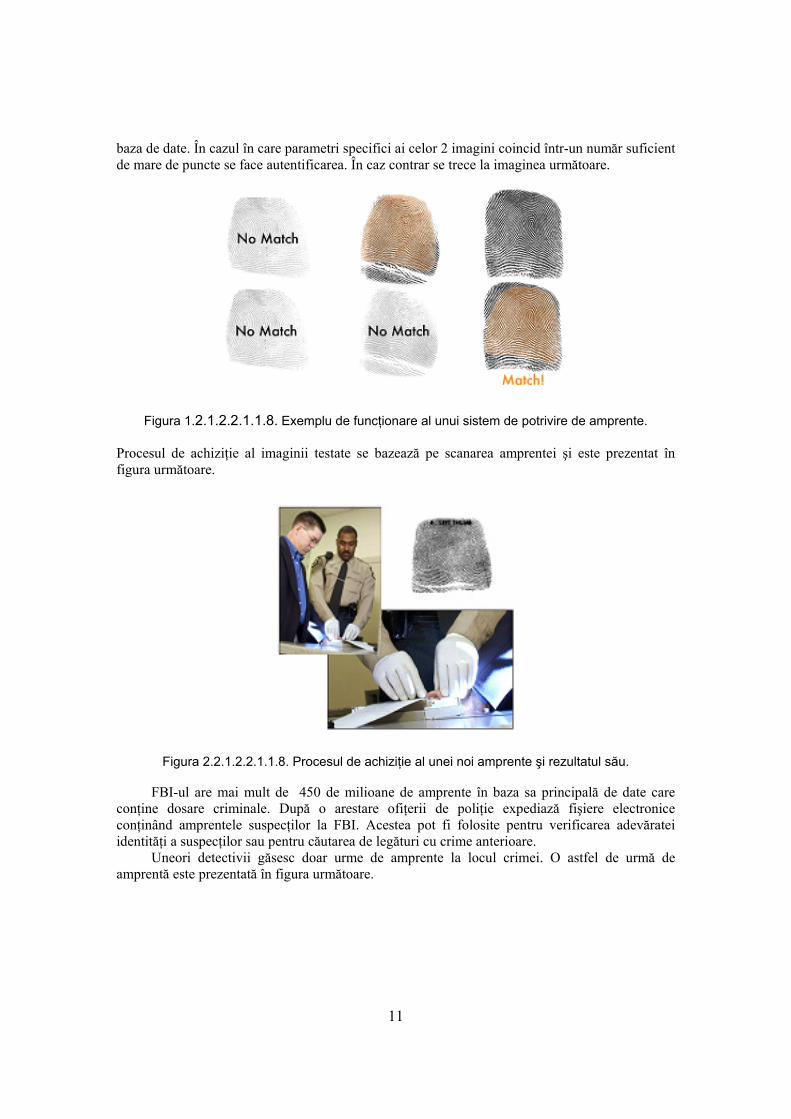
2.1.2.2.1.1.5 Dispozitive de scanare a amprentelor funcţionând termic (Atmel) Măsoară diferenţa de temperatură dintre muchiile şi văile epidermei degetului. Aceasta este tranzitorie (durează aproximativ 100 ms). Constau dintr-o plăcuţă de siliciu presărată cu “pixeli” de material piroelectric, sensibili la diferenţele de temperatură. Aceste diferenţe de temperatură sunt transformate în sarcini electrice, care sunt amplificate şi măsurate. Se obţin doar 16 nivele de gri. 2.1.2.2.1.1.6 Dispozitive de scanare piezoelectrică a amprentelor (Fraunhofer) Acest tip de dispozitive este descris în câteva brevete din SUA : Nr. 6720712 – Scott ş.a., 13 Aprilie 2004, Nr. 6812621 – Scott, 2 Noiembrie 2004, Nr. 6844660 – Scott, 18 Ianuarie 2005. 2.1.2.2.1.1.7 Dispozitive de scanare Micro-Electro-Mecanică a amprentelor Sunt dispozitive mecanice integrate în circuite semiconductoare. Au preţ potenţial scăzut. Odată obţinută, în urma procesului de scanare, imaginea amprentei poate fi utilizată pentru autentificare. În continuare se prezintă câteva tehnici de autentificare bazate pe utilizarea imaginilor de amprente. În general autentificarea se face prin compararea noii imagini achiziţionate cu imaginile dintr-o bază de date. În cazul în care există o imagine în baza de date care se «potriveşte» cu noua imagine, posesorul acesteia este identificat cu posesorul imaginii din baza de date. În acest mod persoana testată este autentificată. 2.1.2.2.1.1.8 «Potrivirea» amprentelor Cea mai importantă aplicaţie a potrivirii amprentelor este rezolvarea crimelor. De mai bine de 35 de ani FBI dezvoltă sisteme de potrivire a amprentelor precum şi tehnici de apreciere a calităţii acestora. În figura următoare se prezintă un exemplu de funcţionare al unui sistem de potrivire a amprentelor. Imaginea de amprentă care se testează este reprezentată folosind culoarea maro. Sunt prezentate şi şase imagini de amprente din baza de date (reprezentate folosind culoarea gri). Imaginea care se testează este suprapusă pe rând peste fiecare din imaginile din
11
baza de date. În cazul în care parametri specifici ai celor 2 imagini coincid într-un număr suficient de mare de puncte se face autentificarea. În caz contrar se trece la imaginea următoare.
Figura 1.2.1.2.2.1.1.8. Exemplu de funcţionare al unui sistem de potrivire de amprente. Procesul de achiziţie al imaginii testate se bazează pe scanarea amprentei şi este prezentat în figura următoare.
Figura 2.2.1.2.2.1.1.8. Procesul de achiziţie al unei noi amprente şi rezultatul său.
FBI-ul are mai mult de 450 de milioane de amprente în baza sa principală de date care conţine dosare criminale. După o arestare ofiţerii de poliţie expediază fişiere electronice conţinând amprentele suspecţilor la FBI. Acestea pot fi folosite pentru verificarea adevăratei identităţi a suspecţilor sau pentru căutarea de legături cu crime anterioare.
Uneori detectivii găsesc doar urme de amprente la locul crimei. O astfel de urmă de amprentă este prezentată în figura următoare.

12
Figura 3.2.1.2.2.1.1.8. Urmă de amprentă prelevată la locul unei infracţiuni.
Folosindu-se un sistem la a cărui dezvoltare a ajutat şi NIST, detectivii pot transmite aceste urme de amprente la un sistem automat de la sediul FBI, care caută potrivirile cu toate amprentele din baza de date amintită deja. Acest proces este ilustrat în figura următoare.
Figura 4.2.1.2.2.1.1.8. Urma de amprentă transmisă de către detectivii din teritoriu (reprezentată în figura anterioară) este comparată cu imaginile de amprentă din baza de date FBI
până la găsirea unei potriviri (Imaginea din baza de date este reprezentată cu maro).
După cum s-a amintit deja pentru a decide dacă două amprente se potrivesc se verifică câţi dintre parametrii celor două imagini aferente coincid. În cazul în care acest număr este suficient de mare se decide că are loc o potrivire.
2.1.2.2.1.1.8.1 Parametrii imaginilor de amprente
Amprentele constau din muchii şi văi ale epidermei degetelor. Pe o imagine de amprentă
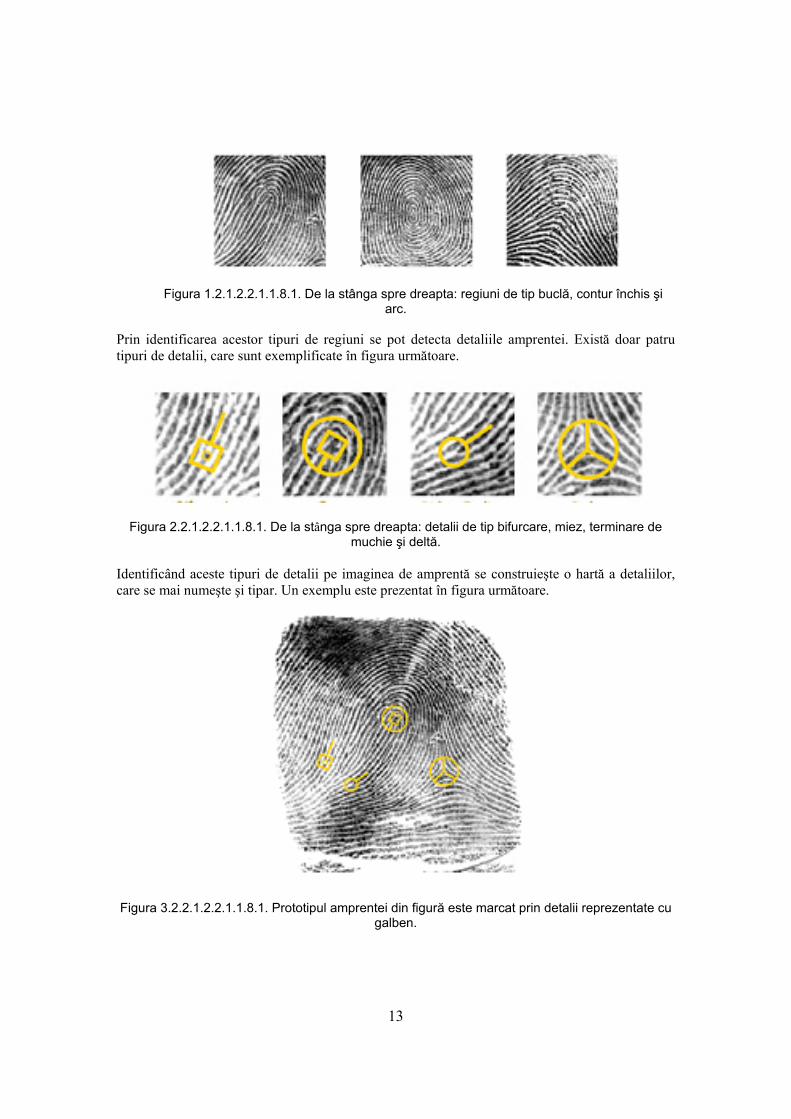
muchiile apar ca şi curbe întunecate iar văile ca şi spaţii luminoase între muchii. Succesul autentificării bazate pe folosirea amprentelor constă într-o proprietate remarcabilă a acestora, unicitatea lor. Nu există două persoane cu amprente identice. Compararea directă a două imagini de amprentă nu conduce la o soluţie fiabilă de autentificare deoarece procesul de scanare nu poate fi controlat riguros. Cele două imagini pot avea orientări diferite şi scări de reprezentare diferite. De aceea se preferă compararea tiparelor celor două imagini de amprente. Programul de potrivire a amprentelor de la FBI asociază un tipar global fiecărei amprente. Există doar câteva tipuri de astfel de tipare. Imaginile de amprentă conţin doar trei feluri de regiuni. Acestea sunt prezentate în figura următoare.
13
Figura 1.2.1.2.2.1.1.8.1. De la stânga spre dreapta: regiuni de tip buclă, contur închis şi arc.
Prin identificarea acestor tipuri de regiuni se pot detecta detaliile amprentei. Există doar patru tipuri de detalii, care sunt exemplificate în figura următoare.
Figura 2.2.1.2.2.1.1.8.1. De la stânga spre dreapta: detalii de tip bifurcare, miez, terminare de muchie şi deltă.
Identificând aceste tipuri de detalii pe imaginea de amprentă se construieşte o hartă a detaliilor, care se mai numeşte şi tipar. Un exemplu este prezentat în figura următoare.
Figura 3.2.2.1.2.2.1.1.8.1. Prototipul amprentei din figură este marcat prin detalii reprezentate cu galben.
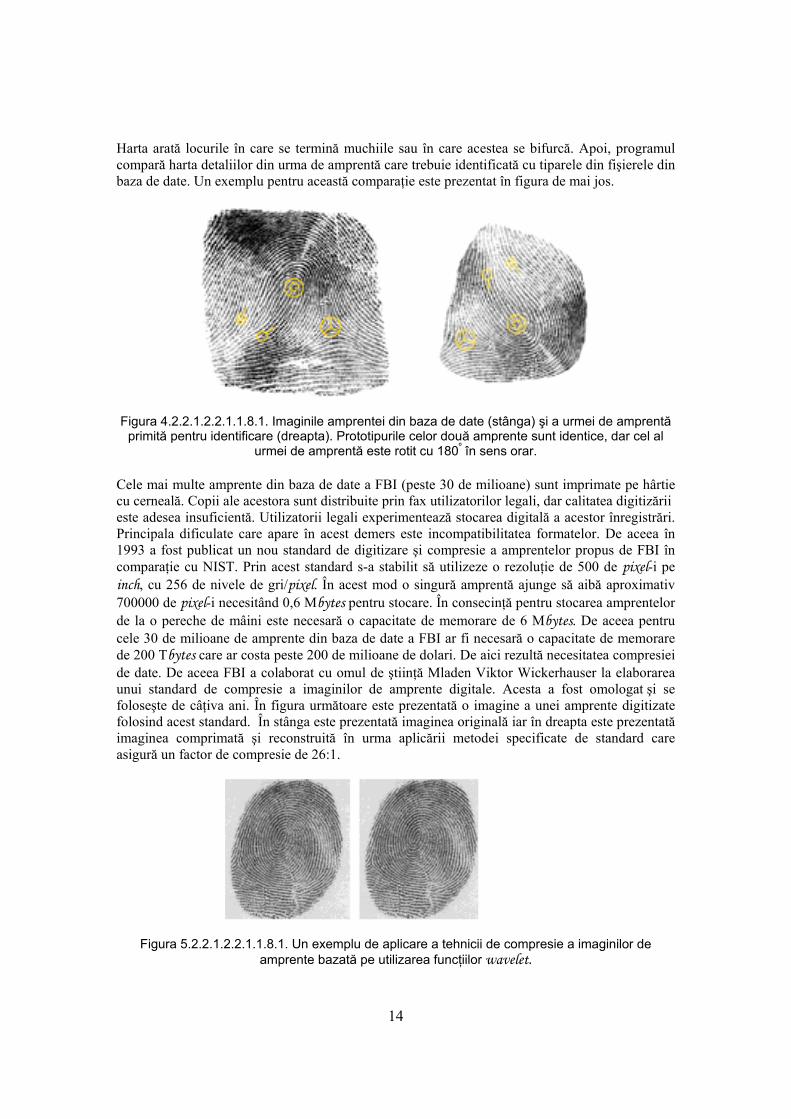
14
Harta arată locurile în care se termină muchiile sau în care acestea se bifurcă. Apoi, programul compară harta detaliilor din urma de amprentă care trebuie identificată cu tiparele din fişierele din baza de date. Un exemplu pentru această comparaţie este prezentat în figura de mai jos.
Figura 4.2.2.1.2.2.1.1.8.1. Imaginile amprentei din baza de date (stânga) şi a urmei de amprentă primită pentru identificare (dreapta). Prototipurile celor două amprente sunt identice, dar cel al
urmei de amprentă este rotit cu 180º în sens orar.
Cele mai multe amprente din baza de date a FBI (peste 30 de milioane) sunt imprimate pe hârtie cu cerneală. Copii ale acestora sunt distribuite prin fax utilizatorilor legali, dar calitatea digitizării este adesea insuficientă. Utilizatorii legali experimentează stocarea digitală a acestor înregistrări. Principala dificulate care apare în acest demers este incompatibilitatea formatelor. De aceea în 1993 a fost publicat un nou standard de digitizare şi compresie a amprentelor propus de FBI în comparaţie cu NIST. Prin acest standard s-a stabilit să utilizeze o rezoluţie de 500 de pixel-i pe inch, cu 256 de nivele de gri/pixel. În acest mod o singură amprentă ajunge să aibă aproximativ 700000 de pixel-i necesitând 0,6 Mbytes pentru stocare. În consecinţă pentru stocarea amprentelor de la o pereche de mâini este necesară o capacitate de memorare de 6 Mbytes. De aceea pentru cele 30 de milioane de amprente din baza de date a FBI ar fi necesară o capacitate de memorare de 200 Tbytes care ar costa peste 200 de milioane de dolari. De aici rezultă necesitatea compresiei de date. De aceea FBI a colaborat cu omul de ştiinţă Mladen Viktor Wickerhauser la elaborarea unui standard de compresie a imaginilor de amprente digitale. Acesta a fost omologat şi se foloseşte de câţiva ani. În figura următoare este prezentată o imagine a unei amprente digitizate folosind acest standard. În stânga este prezentată imaginea originală iar în dreapta este prezentată imaginea comprimată şi reconstruită în urma aplicării metodei specificate de standard care asigură un factor de compresie de 26:1.
Figura 5.2.2.1.2.2.1.1.8.1. Un exemplu de aplicare a tehnicii de compresie a imaginilor de amprente bazată pe utilizarea funcţiilor wavelet.

15
Această valoare consistentă a factorului de compresie reduce de 26 de ori costul amintit mai sus. Metoda de compresie se bazează pe folosirea funcţiilor wavelet şi este descrisă de grupul Amara Graps în raportul său An Introduction to Wavelets. 2.1.2.2.1.2 Utilizarea irisului în autentificare
Recunoaşterea automată sigură a persoanelor este de mult timp o provocare. Ca în toate problemele de recunoaştere a formelor principala dificultate rezidă în relaţia dintre variabilităţile inter-clase şi intra-clasă: obiectele pot fi clasificate corect numai dacă variabilitatea elementelor fiecărei clase este inferioară variabilităţii dintre diferite clase. De exemplu în recunoaşterea feţei, dificultăţile apar din faptul că faţa este un organ social care se modifică, oglindind o varietate de expresii, la fel ca şi din caracterul său de obiect 3D activ, a cărui imagine variază în funcţie de unghiul sub care este privită, de iluminare sau de vârstă. S-a demonstrat că pentru imagini ale feţei luate la interval de 1 an, chiar şi cei mai buni algoritmi de recunoaştere au rate de eroare cuprinse între 43% şi 50%. Împotriva unei astfel de variabilităţi intra-clasă variabilitatea inter-clase este limitată deoarece feţe diferite posedă acelaşi set de parametri de bază în aceeaşi geometrie canonică. Irisul devine interesant pentru recunoaşterea vizuală sigură a persoanelor când imaginea poate fi achiziţionată de la distanţă mai mică de 1 m şi în special atunci când există o nevoie de căutare în baze de date foarte mari, care să nu producă erori de identificare în ciuda numărului imens de posibilităţi. Deşi mic (11 mm), irisul are marele avantaj matematic că variabilitatea formei sale de la persoană la persoană este enormă. Ca şi organ intern (deşi vizibil din exterior) al ochiului, irisul este bine protejat faţă de mediul înconjurător şi stabil în timp. Ca şi obiect planar imaginea sa este relativ insensibilă la unghiul iluminării şi modificări în unghiul de vedere cauzează doar transformări afine ale imaginii, chiar şi distorsiunea de formă ne-afină cauzată de dilatarea pupilei este reversibilă. Uşurinţa localizării ochilor în cadrul feţei şi forma inelară distinctivă a irisului facilitează izolarea precisă şi repetabilă a acestuia şi crearea unor reprezentări invariante la dimensiune. 2.1.2.2.1.2.1 Captura imaginii irisului Sistemul de captură a imaginii irisului folosit în laboratorul de calculatoare al Universităţii Cambridge din Anglia este prezentat în figura următoare.
Figura 1.2.1.2.2.1.2.1. Sistem de achiziţii al imaginilor de iris. Acest sistem este compus din: - camera de tipul Machine Vision ;
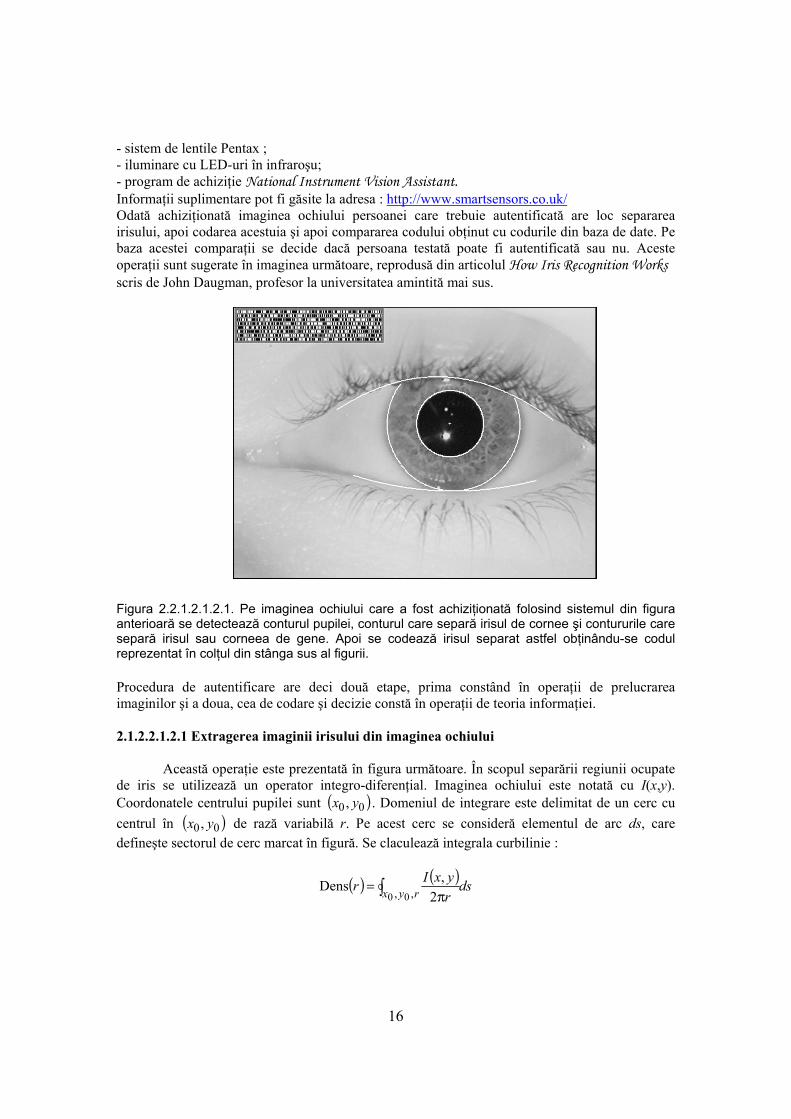
16
- sistem de lentile Pentax ; - iluminare cu LED-uri în infraroşu; - program de achiziţie National Instrument Vision Assistant. Informaţii suplimentare pot fi găsite la adresa : http://www.smartsensors.co.uk/ Odată achiziţionată imaginea ochiului persoanei care trebuie autentificată are loc separarea irisului, apoi codarea acestuia şi apoi compararea codului obţinut cu codurile din baza de date. Pe baza acestei comparaţii se decide dacă persoana testată poate fi autentificată sau nu. Aceste operaţii sunt sugerate în imaginea următoare, reprodusă din articolul How Iris Recognition Works scris de John Daugman, profesor la universitatea amintită mai sus. Figura 2.2.1.2.1.2.1. Pe imaginea ochiului care a fost achiziţionată folosind sistemul din figura anterioară se detectează conturul pupilei, conturul care separă irisul de cornee şi contururile care separă irisul sau corneea de gene. Apoi se codează irisul separat astfel obţinându-se codul reprezentat în colţul din stânga sus al figurii. Procedura de autentificare are deci două etape, prima constând în operaţii de prelucrarea imaginilor şi a doua, cea de codare şi decizie constă în operaţii de teoria informaţiei. 2.1.2.2.1.2.1 Extragerea imaginii irisului din imaginea ochiului Această operaţie este prezentată în figura următoare. În scopul separării regiunii ocupate de iris se utilizează un operator integro-diferenţial. Imaginea ochiului este notată cu I(x,y). Coordonatele centrului pupilei sunt ( )00, yx . Domeniul de integrare este delimitat de un cerc cu centrul în ( )00, yx de rază variabilă r. Pe acest cerc se consideră elementul de arc ds, care defineşte sectorul de cerc marcat în figură. Se claculează integrala curbilinie :
( ) ( )dsryxIr ryx∫ π
= ,, 00 2,Dens
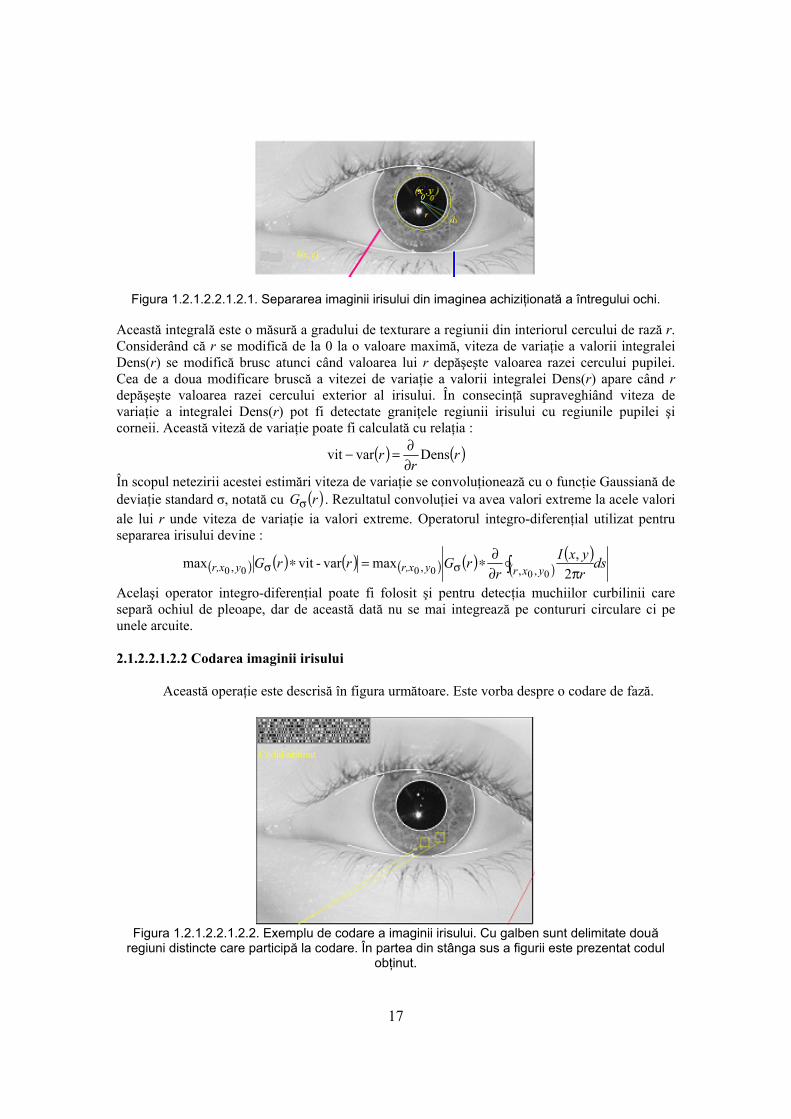
17
Figura 1.2.1.2.2.1.2.1. Separarea imaginii irisului din imaginea achiziţionată a întregului ochi.
Această integrală este o măsură a gradului de texturare a regiunii din interiorul cercului de rază r. Considerând că r se modifică de la 0 la o valoare maximă, viteza de variaţie a valorii integralei Dens(r) se modifică brusc atunci când valoarea lui r depăşeşte valoarea razei cercului pupilei. Cea de a doua modificare bruscă a vitezei de variaţie a valorii integralei Dens(r) apare când r depăşeşte valoarea razei cercului exterior al irisului. În consecinţă supraveghiând viteza de variaţie a integralei Dens(r) pot fi detectate graniţele regiunii irisului cu regiunile pupilei şi corneii. Această viteză de variaţie poate fi calculată cu relaţia :
( ) ( )rr
r Densvarvit∂∂=−
În scopul netezirii acestei estimări viteza de variaţie se convoluţionează cu o funcţie Gaussiană de deviaţie standard σ, notată cu ( )rGσ . Rezultatul convoluţiei va avea valori extreme la acele valori ale lui r unde viteza de variaţie ia valori extreme. Operatorul integro-diferenţial utilizat pentru separarea irisului devine :
( ) ( ) ( ) ( ) ( ) ( )( ) ds
ryxI
rrGrrG yxryr,xyr,x ∫ π∂
∂∗=∗ σσ 000000 ,,,, 2,maxvar-vitmax
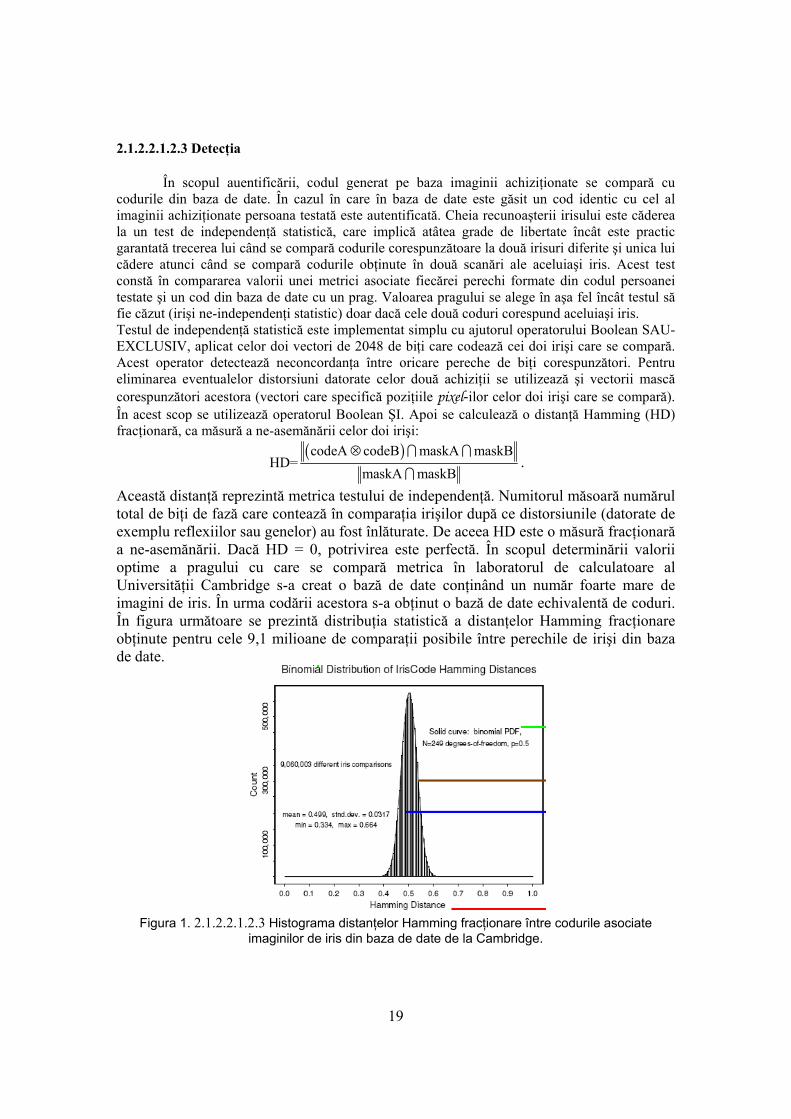
Acelaşi operator integro-diferenţial poate fi folosit şi pentru detecţia muchiilor curbilinii care separă ochiul de pleoape, dar de această dată nu se mai integrează pe contururi circulare ci pe unele arcuite. 2.1.2.2.1.2.2 Codarea imaginii irisului Această operaţie este descrisă în figura următoare. Este vorba despre o codare de fază.
Figura 1.2.1.2.2.1.2.2. Exemplu de codare a imaginii irisului. Cu galben sunt delimitate două
regiuni distincte care participă la codare. În partea din stânga sus a figurii este prezentat codul obţinut.

18
Un număr de 1024 de regiuni locale disjuncte ale imaginii irisului (ca şi cele două demarcate cu galben în figura de mai sus) sunt filtrate cu filtre Gabor, generând coeficienţi complecşi ale căror părţi reale şi imaginare specifică coordonatele unor fazori în planul complex. Interesul pentru semnale complexe apare în legătură cu posibilitatea pe care o oferă acestea de a face o codare în fază. Există cercetători în domeniul prelucrării imaginilor care consideră că cel mai mare conţinut de informaţie poate fi găsit în imaginile de fază. Răspunsul la impuls al unui filtru Gabor este dat de produsul dintre un nucleu, care descrie comportarea sa în domeniul spaţial şi o exponenţială complexă, care îi descrie comportamentul în domeniul frecvenţă, ω. Expresia nucleului este: ( ) 2 2 2 2/ /,h e e−ρ α −φ βρ φ = ⋅ unde ρ reprezintă raza vectoare a pixelului considerat în raport cu
centrul pupilei iar φ reprezintă unghiul pe care îl face această rază vectoare cu axa orizontală. Acest nucleu are doi parametri: α şi β care caracterizează direcţia preferenţială a filtrului. La ieşirea unui filtru Gabor se obţine semnalul complex:
( ) ( ) ( ) ( ) ( ) φρρ⋅⋅⋅φρ=ωθ βφ−θ−αρ−−φ−θω−ρ φ∫ ∫ ddeeeIr ri 22
022
00 //00 ,,,comp ,
dat de convoluţia bidimensională a răspunsului la impuls al filtrului Gabor cu imaginea din regiunea locală curentă. Parametrii θ0 şi r0 reprezintă coordonatele polare ale centrului regiunii locale curente. Aceste semnale complexe au părţile reală:
( ) ( )( ) ( ) ( ) φρρ⋅⋅φ−θω⋅φρ=ωθ βφ−θ−αρ−−ρ φ∫ ∫ ddeeIr r 22
022
0 //000 cos,),,re(
şi imaginară:
( ) ( )( ) ( ) ( ) φρρ⋅⋅φ−θω⋅φρ−=ωθ βφ−θ−αρ−−ρ φ∫ ∫ ddeeIr r 22
022
0 //000 sin,),,im( .
Prin gruparea acestor părţi reală şi imaginară se obţin fazori. Unghiul fiecărui fazor (element al imaginii de fază creată prin utilizarea filtrelor Gabor) este cunatizat pe 2 biţi, fiind alocat într-unul din cele patru cadrane ale planului complex, aşa după cum se vede în figura următoare.
Figura 2. 2.1.2.2.1.2.2. Alocarea celor doi biţi de cod corespunzători celor patru cadrane fiecărui
fazor obţinut în urma unei filtrări Gabor.
Acest proces este repetat pe toată suprafaţa irisului obţinându-se un cod de 2048 de biţi.
19
2.1.2.2.1.2.3 Detecţia În scopul auentificării, codul generat pe baza imaginii achiziţionate se compară cu codurile din baza de date. În cazul în care în baza de date este găsit un cod identic cu cel al imaginii achiziţionate persoana testată este autentificată. Cheia recunoaşterii irisului este căderea la un test de independenţă statistică, care implică atâtea grade de libertate încât este practic garantată trecerea lui când se compară codurile corespunzătoare la două irisuri diferite şi unica lui cădere atunci când se compară codurile obţinute în două scanări ale aceluiaşi iris. Acest test constă în compararea valorii unei metrici asociate fiecărei perechi formate din codul persoanei testate şi un cod din baza de date cu un prag. Valoarea pragului se alege în aşa fel încât testul să fie căzut (irişi ne-independenţi statistic) doar dacă cele două coduri corespund aceluiaşi iris. Testul de independenţă statistică este implementat simplu cu ajutorul operatorului Boolean SAU-EXCLUSIV, aplicat celor doi vectori de 2048 de biţi care codează cei doi irişi care se compară. Acest operator detectează neconcordanţa între oricare pereche de biţi corespunzători. Pentru eliminarea eventualelor distorsiuni datorate celor două achiziţii se utilizează şi vectorii mască corespunzători acestora (vectori care specifică poziţiile pixel-ilor celor doi irişi care se compară). În acest scop se utilizează operatorul Boolean ŞI. Apoi se calculează o distanţă Hamming (HD) fracţionară, ca măsură a ne-asemănării celor doi irişi:
( )codeA codeB maskA maskBHD=
maskA maskB⊗ ∩ ∩
∩.
Această distanţă reprezintă metrica testului de independenţă. Numitorul măsoară numărul total de biţi de fază care contează în comparaţia irişilor după ce distorsiunile (datorate de exemplu reflexiilor sau genelor) au fost înlăturate. De aceea HD este o măsură fracţionară a ne-asemănării. Dacă HD = 0, potrivirea este perfectă. În scopul determinării valorii optime a pragului cu care se compară metrica în laboratorul de calculatoare al Universităţii Cambridge s-a creat o bază de date conţinând un număr foarte mare de imagini de iris. În urma codării acestora s-a obţinut o bază de date echivalentă de coduri. În figura următoare se prezintă distribuţia statistică a distanţelor Hamming fracţionare obţinute pentru cele 9,1 milioane de comparaţii posibile între perechile de irişi din baza de date.
Figura 1. 2.1.2.2.1.2.3 Histograma distanţelor Hamming fracţionare între codurile asociate
imaginilor de iris din baza de date de la Cambridge.

20
Această histogramă corespunde unei distribuţii statistice descrise de o lege binomială. Expresia analitică a densităţii de probabilitate corespunzătoare legii binomiale este:
( ) ( ) ( )! 1! !
N mmNf x p pm N m
−= −−
Parametrii legii binomiale sunt: p (valaorea sa medie), N (numărul său de grade de libertate) şi m. Doi dintre aceşti parametri pot fi identificaţi pe baza histogramei din figură: p=0,5, N=249. Analizând figura se constată că valoarea distanţei Hamming fracţionară care apare cel mai frecvent este de 0,5 şi că valori mai mici de 0,3 sau mai mari de 0,7 apar foarte rar. De aceea s-a ales pentru pragul cu care se compară distanţa Hamming fracţionară în testul de independenţă statistică valoarea de 0,5. Se poate afirma că este extrem de improbabil ca doi irişi diferiţi să se deosebească în mai puţin de o treime din informaţia lor de fază. Exprimând dispersia distribuţiei binomiale ca şi o entropie de discriminare şi folosind diametre pentru pupilă şi iris de 5 mm şi 11 mm, conţinutul de variabilitate statistică între diferite forme de iris corespunde la o densitate de informaţie de aproximativ 3,2 biţi/mm2/iris. Calculând integrala densităţii de probabilitate corespunzătoare legii binomiale (din ultima relaţie) cu parametrii identificaţi pe baza histogramei din figura 1.2.1.2.6 între 0 şi 0,333 se obţine probabilitatea ca distanţa Hamming fracţionară să fie egală cu 0,333. Valoarea acestei probabilităţi este foarte mică fiind egală cu 1/16000000. Deci chiar în cazul în care se observă un grad mare de asemănare între codurile celor doi irişi (de exemplu un grad de asemănare de 70% corespunde la HD=0,3) totuşi testul de independenţă statistică este căzut foarte convingător (probabilitatea ca HD să fie egal cu 0,3 este de 1/10000000000). 2.2. Viruşii calculatoarelor
Termenul de virus de calculator a fost introdus, în anul 1972, de către Fred Cohen, pe baza analogiei cu termenul de virus biologic. Virus este termenul latin pentru otravă. Un virus de calculator este un program (cu lungimea cuprinsă între 200 şi 4000 de octeţi) care îşi copiază propriul cod în unul sau mai multe programe "gazdă" mai mari, atunci când este activat. Când se execută aceste programe, se execută şi virusul, continuându-se răspândirea sa. După cum s-a arătat, viruşii fac parte dintr-o categorie de programe care încearcă să ascundă funcţia pe care o au de îndeplinit (malicious programs). Din această categorie mai fac parte şi programe de tipul Trojan horses (care sub pretextul realizării unei alte funcţii reuşesc să ajungă în memoria calculatorului, de exemplu un astfel de program poate realiza "infiltrarea" unui virus în memoria unui calculator), programe de tip "vierme" care au capacitatea de a trece de pe un sistem de calcul pe un altul şi se execută independent de excuţia altor programe ("gazdă"), programe de tip "bacterie", care se reproduc până absorb întreaga capacitate de memorie a sistemului pe care au fost instalate şi programe de tipul "bombă" care se decleanşează doar atunci când se îndeplinesc anumite condiţii (de exemplu se ajunge într-o zi de vineri la data de 13). În prezent se cunoaşte un număr foarte mare de viruşi de calculator. De exemplu în anul 2002 putea fi procurată de pe Internet o listă a acestora, ordonaţi alfabetic. De exemplu la litera R puteau fi găsiţi următorii viruşi:
Raadioga, Rabbit (First), Radiosys, Rage, Rainbow (Ginger), Ramen, Ramen.A (Ramen), Ramen.B (Ramen), Rape, Rape-10 (Rape), Rape-11 (Rape), Rape-2.2 (Rape), Rapi, Rasek, Raubkopie, Ravage (Dodgy), Ravage (MMIR), Ray (Joke Program), Razer, RC5, RC5 Client (RC5), RD Euthanasia (Hare), Readiosys (Radiosys), Reboot, Reboot Patcher (Lomza), Red Diavolyata, Red Diavolyata-662 (Red Diavolyata), Red Spider (Reverse),

21
Red worm (Adore), Red-Zar (Torn), Redspide (Reverse), Redstar (Karin), RedTeam, RedX (Ambulance), Reggie (Secshift), Reiz, Reizfaktor (Reiz), Reklama, Relzfu, RemExp, Remote_Explorer (RemExp), Rendra, Rendra.A (Rendra), REQ! (W-13), Requires, Rescue, Reset (Omega), Resume, Resume.A@mm (Resume), Resume.A (Resume), ResumeWorm (Resume), Resurrect (Siskin), Reveal, Revenge, Reverse, Reverse.B (Reverse), Rex, Rhubarb (RP), Richard Keil, RICHS (RemExp), Rich (RemExp), Riihi, Ring0 (RingZero), RingZero, Ripper, RITT.6917, RM, RMA-Hammerhead, RMA-hh (RMA-Hammerhead), RNA2, Roach.b (Nymph), Roach (Nymph), Robocop, Robocop.A (Robocop), Robocop.B (Robocop), Rock Steady (Diamond), Rogue, Roma, Romeo-and-Juliet (BleBla), Romeo (BleBla), Romer_Juliet, Rosen (Pixel), RP, RPS, RPS.A (RPS), RPS.B (RPS), RPS.C (RPS), RPVS (TUQ), RraA, rrAa (RRaA), RSY, Russian Mirror, Russian Mutant, Russian New Year, Russian Tiny, Russian Virus 666, Russian_Flag, Russ (Joke.Win32.Russ), Rust, Rut, Rut.A (Rut), RV, RV.A (RV), Ryazan, Rybka (Vacsina).
O porţiune dintr-o listă mai recentă poate fi văzută în figura următoare. Comparând lista şi porţiunea sa prezentată în figură se poate constata evoluţia produsă în generarea de viruşi.
Figura 1.2.2. O listă de viruşi printre care se găseşte şi unul produs în ţara noastră.
De obicei un virus de calculator are pe lângă funcţia de reproducere încă o funcţie distinctă, cea de distrugere.
2.2.1. Clasificări
O clasificare posibilă a viruşilor se bazează pe tipurile de fişiere pe care le pot infecta. Conform acestei clasificări există viruşi care infectează fişiere ordinare de tipul .com sau .exe şi viruşi care infectează fişierele sistem. Dintre fişerele sistem cel mai des atacate sunt cele de boot (de pornire a sistemului). Viruşii care produc astfel de atacuri se numesc viruşi de boot. Există şi viruşi capabili să infecteze ambele categorii de fişiere (ca de exemplu virusul Tequila). Viruşii

22
care afectează fişierele ordinare pot fi cu acţiune directă (ca de exemplu virusul Viena) sau rezidenţi (ca de exemplu virusul Jerusalim). Viruşii rezidenţi, la prima execuţie a unui program pe care l-au contaminat deja, îl părăsesc, se ascund în memorie şi se declanşează doar atunci când sunt îndeplinite anumite condiţii.
O altă clasificare posibilă a viruşilor se bazează pe modul în care aceştia se ataşează la programele pe care le infectează. Conform acestei clasificări există viruşi de tip "shell", viruşi de tip "add-on" şi viruşi de tip "intrusiv".
Viruşii de tip "shell" Formează un înveliş ("shell") în jurul programului "gazdă". Virusul devine program principal iar programul "gazdă" devine o subrutină a virusului. Prima dată se execută virusul şi apoi programul "gazdă". Majoritatea viruşilor de "boot" sunt de tip "shell".
Viruşii de tip "add-on" Se adaugă la începutul sau la sfârşitul codului programului "gazdă". Apoi este alterată informaţia de start a programului "gazdă" şi se rulează pe rând virusul şi apoi programul "gazdă". Programul gazdă este lăsat aproape neatins. Acest tip de viruşi poate fi uşor detectat dacă se compară dimensiunile fişierului corespunzător programului gazdă, înainte şi după o rulare a acestuia.
Viruşii de tip "intrusiv" Distrug o parte a codului asociat programului "gazdă" şi înscriu în acea zonă codul propriu. Ulterior programul "gazdă" nu mai poate funcţiona.
Alte categorii de viruşi
Viruşi de tip STEALTH
Modifică fişierele în funcţie de rezultatul monitorizării funcţiilor sistemului folosite de programe pentru a citi fişiere sau blocuri fizice de pe mediile de înregistrare, pentru a falsifica rezultatele acestor funcţii astfel încât programele care încearcă să citească aceste zone să vadă formele iniţiale neafectate de virus în locul formelor reale, actuale, infectate. În acest fel modificările efectuate de virus rămân neafectate de programele anti-virus.
Viruşi polimorfi
Produc copii neidentice (dar operante) ale variantei iniţiale în speranţa că programul anti-virus nu le va putea detecta pe toate. O modalitate de realizare a diferitelor copii este autocriptarea cu cheie variabilă a variantei iniţiale. Un exemplu este virusul Whale. O altă modalitate de realizare a copiilor multiple se bazează pe modificarea secvenţei de instrucţii, pentru fiecare copie, prin includerea unor instrucţii care funcţionează ca şi zgomot (de exemplu instrucţia No operation sau instrucţii de încărcare a unor regiştrii nefolosiţi cu valori arbitrare). Un exemplu este virusul V2P6.
Viruşi rapizi
Un virus obişnuit se autocopiază în memorie când un program "gazdă" se executăşi apoi infectează alte programe când se declanşează execuţia acestora. Un virus rapid nu infectează, atunci când este activ în memorie, doar programele care se excută ci şi pe cele care sunt doar deschise. În acest mod se infectează mai multe programe deodată. Exemple de astfel de viruşi sunt Dark Avenger şi Frodo.

23
Viruşi lenţi
Sunt viruşi care în faza în care sunt activi în memorie infectează fişierele doar în momentul în care li se aduc modificări sau atunci când sunt create. Un exemplu de astfel de virus este cel numit Darth Vader.
Viruşi împrăştiaţi
Infectează doar ocazional, de exemplu tot al 10-lea program executat sau doar fişierele care au o lungime bine precizată. În acest mod se încearcă îngreunarea detectării lor.
Viruşi însoţitori
În loc să modifice un fişier existent crează un nou program a cărui execuţie este declanşată de către interpretorul liniei de comandă şi nu de programul apelat. La sfârşit se rulează şi programul apelat în aşa fel încât funcţionarea calculatorului să pară normală utilizatorului.
2.2.2. Moduri de funcţionare a viruşilor
Funcţionarea viruşilor, după ce aceştia au ajuns în memoria calculatorului, se bazează pe alterarea întreruperilor standard utilizate de sistemul de operare şi de BIOS (Basic Input/Output System). Aceste modificări se realizează astfel încât virusul să fie apelat de alte aplicaţii când acestea sunt activate. PC-urile uilizează numeroase întreruperi (atât hard cât şi soft) pentru a coopera cu evenimente asincrone. Toate serviciile DOS-ului şi BIOS-ului sunt apelate de utilizator prin parametri stocaţi în regiştri, cauzând întreruperi soft. Când se solicită o întrerupere, sistemul de operare apelează rutina a cărei adresă o găseşte în tabelul de întreruperi. În mod normal acest tabel conţine pointer-i spre regiuni din ROM sau spre regiuni rezidente în memorie din DOS. Un virus poate modifica tabelul de întreruperi astfel încât execuţia unei întreruperi să genereze rularea sa. Un virus tipic interceptează întreruperea specifică DOS-ului şi permite rularea sa înainte de rularea serviciului DOS cerut curent. După ce un virus a infectat un anumit program el încearcă să se împrăştie şi în alte programe sau eventual în alte sisteme. Majoritatea viruşilor aşteaptă îndeplinirea unor condiţii favorabile şi apoi îşi continuă activiatatea.
2.2.2.1. Activarea viruşilor în cazul calculatoarelor IBM-PC
1. Infectarea secvenţei de încărcare (boot) a sistemului de operare
Această secvenţă are 6 componente: a) Rutinele ROM BIOS; b) Executarea codului din tabela partiţiilor; c) Executarea codului din sectorul de boot; d) Executarea codului IO.SYS şi MSDOS.SYS; e) Executarea comenzilor Shell din COMMAND.COM; f) Executarea fişierului batch AUTOEXEC.BAT
a) La boot-are calculatorul execută un set de instrucţii din ROM. Acestea iniţializează hard-ul calculatorului şi furnizează un set de rutine de intrare-ieşire de bază, BIOS-ul. Rutinele din ROM nu pot fi infectate (deoarece în această memorie nu se poate scrie).

24
b) Orice hard-disk poate fi împărţit în mai multe regiuni, numite partiţii, C,D,E,…. Dimensiunea fiecărei partiţii, obţinute astfel, este memorată în tabela partiţiilor. În această tabelă existăşi un program, de 446 de octeţi, care specifică pe care partiţie se află blocul de boot. Acest program poate fi infectat de un virus. Acesta poate, de exemplu (este cazul virusului New Zealand), să mute tabela partiţiilor la o nouă locaţie de pe hard-disk şi să controleze întreg sectorul din care face parte acea locaţie.
c) Programul din tabela partiţiilor localizează blocul de boot. Acesta conţine blocul parametrilor BIOS-ului. (BPB), care conţine informaţii detailate despre organizarea sistemului de operare precum şi un program, de mai puţin de 460 de octeţi, de localizare a fişierului IO.SYS. Acest fişier conţine stadiul următor din secvenţa de boot-are. Evident şi acest program poate fi atacat, aşa cum se întâmplă în prezeţa virusului Alameda. Principalul atu al acestor viruşi de boot este faptul că ei ajung să controleze întregul sistem de calcul înainte ca orice program de protecţie (anti-virus) să poată fi activat.
d) Blocul de boot declanşează încărcarea fişierului IO.SYS, care produce iniţializarea sistemului, după care se încarcă DOS-ul, conţinut în fişierul MSDOS.SYS. Şi aceste două fişiere pot fi infectate de viruşi.
e) Programul MSDOS.SYS declanşează apoi execuţia interpretorului de comenzi COMMAND.COM. Acest program furnizează interfaţa cu utilizatorul, făcând posibilă execuţia comenzilor primite de la tastatură. E clar căşi acest program poate fi infectat aşa cum se întâmplă în prezenţa virusului Lehigh.
f) Programul COMMAND.COM execută o listă de comenzi memorate în fişierul AUTOEXEC.BAT Acesta este un simplu fişier text ce conţine comenzi ce vor fi executate de interpretor. La execuţia acestui fişier un virus poate fi inclus în structura sa.
2. Infectarea unui program utilizator
Acestea sunt programe de tipul .COM sau .EXE. Programele de tipul .COM conţin la început o instrucţiune de tipul jump la o anumită adresă. Viruşii pot înlocui această adresă cu adresa lor. După execuţia virusului se efectuează jump-ul la adresa specificată la începutul programului .COM infectat şi se ruleazăşi acest program.
3. Modalităţi de rezidenţă în memoria sistemului
Cei mai periculoşi viruşi folosesc o varietate de tehnici de rămânere în memorie, după ce au fost executaţi prima oară şi după ce s-a executat pentru prima oară, primul program "gazdă". Toţi viruşii de boot cunoscuţi sunt astfel de viruşi. Dintre aceştia pot fi menţionaţi viruşii: Israeli, Cascade sau Traceback. Această proprietate a viruşilor rezidenţi în memorie este datorată faptului că ei afectează întreruperile standard folosite de programele DOS şi BIOS. De aceea aceşti viruşi sunt apelaţi, involuntar, de către orice aplicaţie care solicită servicii de la sistemul de operare. De fapt, aşa cum s-a arătat deja, în paragraful "Moduri de acţionare a viruşilor", viruşii modifică tabela de întreruperi, astfel încât la fiecare întrerupere să fie executat şi programul virus. Deturnând întreruperea de tastatură, un virus poate intercepta comanda de reboot-are soft CTRL-ALT-DELETE, poate modifica semnificaţia tastelor apăsate sau poate face să fie invocat la fiecare apăsare de tastă. La fel pot fi deturnate şi întreruperile de BIOS sau de DOS.
2.2.3. Modalităţi de detectare a viruşilor
Cele mai importante manifestări ale unui calculator care indică prezenţa unui virus sunt: modificările în dimensiunile fişierelor sau în conţinutul acestora, modificarea vectorilor de întrerupere, sau realocarea altor resurse ale sistemului. Din păcate aceste manifestări sunt sesizate

25
cu dificultate de un utilizator obişnuit. O indicaţie referitoare la memoria sistemului poate fi obţinută folosind utilitarul CHKDSK. Nu este necesară cunoaşterea semnificaţiei fiecărei cifre afişate de către acest utilitar ca şi rezultat al rulării sale, e suficient să se verifice dacă aceste valori s-au modificat substanţial de la boot-are la boot-are. Printre aceste cifre există una care reprezintă capacitatea memoriei disponobile pe calculatorul respectiv. Dacă aceasta s-a modificat cu mai mult de 2 kilo-octeţi atunci este foarte posibil ca pe acel calculator să se fi instalat un virus de boot. Oricum cel mai bine este ca pe fiecare calculator să fie instalat un program anti-virus. Din nefericire aceste programe nu recunosc decât viruşii deja cunoscuţi de către producătorii lor. De aceea ele trebuie schimbate frecvent, căutându-se în permanenţă variantele cele mai noi. Trebuie ţinut seama şi de faptul că producători diferiţi de programe antivirus folosesc denumiri diferite pentru acelaşi virus. Fred Cohen a demonstrat următoarea propoziţie:
Orice detector de viruşi se poate înşela, furnizând alarme false (atunci când clasifică un fişier sănătos ca fiind infectat) sau nedectând unii viruşi sau făcând ambele tipuri de erori.
În consecinţă există situaţii în care utilizarea unui astfel de sistem nu poate conduce la luarea unei decizii corecte. De aceea este recomandabil ca înainte de a lua o decizie să se utilizeze două sau mai multe programe anti-virus. În acest caz însă există riscul ca modificările făcute asupra fişierelor de către unul dintre ele să fie interpretate de către celălalt ca şi posibili viruşi. Un alt pericol este ca însuşi programul anti-virus să fie infectat. De aceea este bine ca aceste programe să fie procurate din surse verificate şi ca rezultatele lor să fie considerate doar dacă ele au fost rulate de pe sisteme neinfectate. Există însă din păcate şi posibilitatea ca să apară rapoarte conform cărora programul anti-virus este el însuşi infectat deşi în realitate el nu este. 2.2.4. Programe anti-virus
Nu există o cea mai bună strategie împotriva viruşilor. Nici un program antivirus nu poate asigura o protecţie totală împotriva viruşilor. Se pot însă stabili strategii anti-virus bazate pe mai multe nivele de apărare. Există trei tipuri principale de programe anti-virus, precum şi alte mijloace de protecţie (ca de exemplu metodele hard de protecţie la scriere). Cele trei tipuri principale de programe anti-virus sunt:
1) Programele de monitorizare. Acestea încearcă să prevină activitatea viruşilor. De exemplu programele: SECURE sau FluShot+. 2) Programele de scanare. Caută şiruri de date specifice pentru fiecare dintre viruşii cunoscuţi dar care să nu poată apărea în programele sănătoase. Unele dintre aceste programe anti-virus folosesc tehnici euristice pentru a recunoaşte viruşii. Un program de scanare poate fi conceput pentru a verifica suporturi de informaţie specificate (hard-disk, dischetă, CD-ROM) sau poate fi rezident, examinând fiecare program care urmează să fie executat. Majoritatea programelor de scanare conţin şi subrutine de îndepărtare a unui virus după ce acesta a fost detectat. Câteva exemple de astfel de programe sunt: FindViru, din cadrul programului Dr Solomon's Anti-Virus Toolkit, programul FPROT al firmei FRISK sau programul VIRUSCAN conceput la firma McAfee. Dintre programele de scanare rezidente pot fi amintite programele V-Shield sau VIRUSTOP realizate la firma McAfee. Dintre programele de scanare euristică poate fi menţionat programul F-PROT.
3) Programe de verificare a integrităţii sau de detectare a modificărilor. Acestea calculează o mică sumă de control sau valoare de funcţie hash (de obicei pe bază de criptare) pentru fiecare fişier, presupus neinfectat. Ulterior compară valorile nou calculate ale acestor mărimi cu valorile iniţiale pentru a vedea dacă aceste fişiere au fost modificate. În acest mod pot fi detectaţi viruşi noi sau vechi, efectuându-se o detecţie"generică". Dar modificările pot apărea şi din alte motive decât activitatea viruşilor. De

26
obicei este sarcina utilizatorului să decidă dacă o anumită modificare a apărut ca urmare a unei operaţii normale sau ca urmare a unei activităţi virale. Există însă programe anti-virus care pot să-l ajute pe utilizator să ia această decizie. La fel ca şi în cazul programelor de scanare şi programelor de verificare a sumelor de control li se poate cere să verifice întregul hard-disk sau doar anumite fişiere sau ele pot fi rezidente verificând fiecare program care urmează să fie executat. De exemplu Fred Cohen ASP Integrity Toolkit, Integrity Master sau VDS sunt programe anti-virus de acest tip. 3a) Antivirusul GENERIC DISINFECTION face parte dintr-o categorie puţin mai aparte. El face ca să fie salvată suficientă informaţie pentru fiecare fişier, astfel încât acesta să poată fi reconstruit în forma sa originală în cazul în care a fost detectată activitate virală, pentru un număr foarte mare de viruşi. Acest program anti-virus face parte din nucleul de securitate V-Analyst 3, realizat de firma izraeliană BRM Technologies.
2.2.5. Elaborarea unei politici de securitate anti-virus
Este bine ca metodele de apărare împotriva viruşilor să fie utilizate pe rând pentru a se creşte securitatea sistemului de calcul folosit.
Un calculator PC ar trebui să includă un sistem de protecţie al tabelei de partiţie a hard-disk-ului, pentru a fi protejat de infectarea la boot-are. Acesta ar trebui să fie de tip hard sau de tip soft dar localizat în BIOS. Şi sisteme soft de tipul DiskSecure sau PanSoft Imunise sunt destul de bune. Acest sistem de protecţie ar trebui să fie urmat de detectoare de viruşi rezidente care să fie încărcate ca şi părţi ale programelor de pornire ale calculatorului, CONFIG.SYS sau AUTOEXEC.BAT, cum sunt de exemplu programele FluShot+ şi/sau VirStop împreună cu ScanBoot. Un program de scanare cum ar fi F-Prot sau McAfee's SCAN poate fi pus în AUTOEXEC.BAT pentru a verifica prezenţa viruşilor la pornirea calculatorului. Noile fişiere ar trebui scanate pe măsură ce ele sosesc în calculator. Este indicat să se folosească comanda PASSWORD din DRDOS pentru a se proteja la scriere toate executabilele de sistem precum şi utilitarele. Pe lângă metodele de protecţie anti-virus deja amintite mai pot fi folosite şi următoarele: (a) Crearea unei liste de partiţii a hard-disk-ului specială astfel încât acesta să fie inaccesibil când se boot-ează de pe o dischetă. Această măsură este utilă deoarece la boot-area de pe dischetă sunt evitate protecţiile hard-disk-ului din CONFIG.SYS şi din AUTOEXEC.BAT. O astfel de listă poate fi realizată de programul GUARD. (b) Utilizarea Inteligenţei Artificiale pentru a învăţa despre viruşi noi, şi pentru a extrage noi caracteristici utile pentru scanare. Astfel de demersuri sunt făcute în cadrul programului V-Care (CSA Interprint Israel; distribuit în S.U.A. de către Sela Consultants Corp.). (c) Criptarea fişierelor (cu decriptare înainte de execuţie).

27
Capitolul 3
Protecţia reţelelor de calculatoare
Orice reţea este realizată conectând mai multe calculatoare. Pentru a proteja reţeaua trebuie să protejăm fiecare calculator. Faţă de mijloacele de protecţie amintite în primul capitol care se referă la protecţia calculatoarelor izolate (neconectate în reţea) în cazul reţelelor trebuie luate măsuri suplimentare datorate comunicării dintre calculatoare. De această dată operaţiile de identificare şi autentificare sunt mai complexe ţinând seama de faptul că acum numărul persoanelor care pot avea acces la datele comune poate fi mult mai mare. De asemenea lupta împotriva viruşilor este mai grea, deoarece oricare dintre calculatoarele reţelei poate fi atacat pentru a fi infectat. În plus există noi tipuri de atac specific pentru reţele. Deoarece scopul reţelelor este de a asigura comunicarea între calculatoare, tocmai această funcţiune poate fi periclitată prin atacuri din exterior. Astfel de atacuri pot să introducă un program într-unul dintre calculatoarele reţelei, care să se autoreproducă şi să se autotransfere pe celelalte calculatoare atât de mult încât să satureze traficul prin reţea. Chiar mai mult un astfel de program poate doar să simuleze creşterea şi mobilitatea sa, "infectând" doar dispozitivele responsabile cu controlul traficului prin reţea. În acest mod transferul de informaţie dintre calculatoarele reţelei este împiedicat fără ca să existe motive reale pentru asta.
3.1. Categorii de atacuri asupra reţelelor
3.1.1. Atacuri pasive
Intrusul în reţea doar observă traficul de informaţie prin reţea, fără a înţelege sau modifica această informaţie. El face deci doar analiza traficului, prin citirea identităţii părţilor care comunică şi prin învăţarea lungimii şi frecvenţei mesajelor vehiculate pe un anumit canal logic, chiar dacă conţinutul acestora este neinteligibil. Caracteristicile atacurilor pasive sunt:
- Nu cauzează pagube, - Pot fi realizate pritr-o varietate de metode, cum ar fi supravegherea legăturilor telefonice sau radio, exploatarea radiaţilor electromagnetice emise, dirijarea datelor prin noduri adiţionale mai puţin protejate.
3.1.2. Atacuri active
Intrusul fură mesaje sau le modifică sau emite mesaje false. El poate şterge sau întârzia mesaje, poate schimba ordinea mesajelor. Există următoarele tipuri de atacuri pasive:
- Mascarada : o entitate pretinde că este o alta. De obicei mascarada este însoţită de înlocuirea sau modificarea mesajelor; - Reluarea: Un mesaj sau o parte a sa sunt repetate. De exemplu este posibilă reutilizarea informaţiei de autentificare a unui mesaj anterior. - Modificarea mesajelor: alterarea datelor prin înlocuire, inserare sau ştergere. - Refuzul serviciului: O entitate nu reuşeşte să-şi îndeplinească propria funcţie sau efectuează acţiuni care împiedică o altă entitate să-şi efectueze propria funcţie. - Repudierea serviciului: O entitate refuză să recunoască serviciul pe care l-a executat. - Viruşii, Caii Troieni, "Bombele" informatice, "Bacteriile" informatice şi mai ales "Viermii" informatici. - Trapele: reprezintă perturbarea acceselor speciale la sistem cum ar fi procedurile de încărcare la distanţă sau procedurile de întreţinere. Ele eludează procedurile de identificare uzuale.

28
3.1.2.1. Viermii informatici
Denumirea de vierme a fost preluată din nuvela SF: The Shockwave Rider, publicată în 1975 de John Brunner. Cercetătorii John F. Shoch şi John A. Huppode la Xerox PARC au propus această denumire într-un articol publicat in 1982: The Worm Programs, Comm ACM, 25(3):172-180, 1982, şi a fost unanim adoptat. Ei au implementat primul vierme în 1978, în scopul detectării procesoarelor mai puţin încărcate dintr-o reţea şi alocării de sarcini suplimentare pentru o mai bună împărţire a muncii în reţea şi pentru îmbunătăţirea eficienţei acesteia. Principala limitare a programului lor a fost răspândirea prea lentă. Primul vierme care s-a propagat la nivel mondial (de fapt un cal troian) a fost Christmas Tree Worm, care a afectat atât reţeaua IBM cât şi reţeaua BITNET în decembrie 1987. Un alt vierme care a afectat funcţionarea Internet-ului a fost Morris worm. Peter Denning l-a numit 'The Internet Worm' într-un articol apărut în American Scientist (martie-aprilie, 1988), în care el făcea distincţia între un virus şi un vierme. Definiţia lui era mai restrictivă decât cele date de alţi cercetători contemporani: (McAfee and Haynes, Computer Viruses, Worms, Data Diddlers, ..., St Martin's Press, 1989). Acest vierme a fost creat de către Robert Tappan Morris, care în acea perioadă era student la Cornell University, şi a fost activat în 2 noiembrie 1988, cu ajutorul calculatorului unui prieten, student la Harvard University. El a infectat rapid un număr foarte mare de calculatoare, conectate la Internet şi a produs pagube importante. Motivul pentru care el nu s-a împrăştiat şi mai departe şi nu a produs mai multe necazuri a fost prezenţa unor erori în implementarea sa. El s-a propagat datorită câtorva bugs-uri ale BSD Unix şi ale programelor asociate acestui sistem de operare, printre care şi câteva variante ale protocolului 'sendmail'. Morris a fost identificat, acuzat şi mai târziu condamnat. 3.1.2.1.1. Tipuri de viermi informatici
De e-mail – se răspândesc cu ajutorul mesajelor e-mail. Mesajul propriuzis sau fişierul ataşat conţin codul viermelui, dar el poate fi de asemenea declanşat de un cod situat pe un site web extern. Majoritatea sistemelor de poştă electronică cer explicit utilizatorului să deschidă fişierul ataşat pentru a activa viermele dar şi tehnica numită "social engineering" poate fi adesea utilizată pentru a încuraja această acţiune, aşa cum a dovedit-o autorul viermelui "Anna Kournikova". Odată activat viermele va emite singur, folosind fie sisteme locale de e-mail (de exemplu servicii MS Outlook, funcţii Windows MAPI), sau direct, folsind protocolul SMTP. Adresele la care expediază el mesaje sunt împrumutate adesea de la sistemul de e-mail al calculatoarelor pe care le-a infectat. Începand cu viermele Klez.E lansat în 2002, viermii care folsesc protocolul SMTP falsifică adresa expeditorului, aşa că destinatarii mesajelor e-mail conţinând viermi trebuie să presupună că acestea nu sunt trimise de către persoana al cărei nume apare în câmpul 'From' al mesajului.
De messenger – împrăştierea se face prin aplicaţii de mesagerie instantanee (IRC, Yahoo-Messenger) prin transmiterea unor legături la site-uri web infectate fiecărui membru al unei liste de contact. Singura diferenţă între aceşti viermi şi viermii de e-mail este calea aleasă pentru transmiterea legăturii la site-ul infectat. De această dată se utilizează canalele de chat IRC dar aceiaşi metodă de infectare/împrăştiere, deja prezentată, se foloseşte şi în acest caz. Transmiterea de fişiere infectate este mai puţin eficientă în acest caz, deoarece destinatarul trebuie să confirme recepţia acestuia, să salveze fişierul infectat şi să-l deschidă, pentru ca să se producă infectarea.

29
De sharing în reţele – Viermii se autocopiază într-un fişier vizibil de întreaga reţea, de obicei localizat pe calculatorul infectat, sub un nume inofensiv. În acest mod viermele este gata sa fie încărcat (download) prin reţea şi împrăştierea infecţiei continuă.
De Internet – Cei care ţintesc direct porturile TCP/IP, fără să mai apeleze la alte protocoale de nivel mai înalt (de exemplu aplicaţie, cum ar fi cel de e-mail sau cel de IRC). Un exemplu clasic este viermele "Blaster" , care a exploatat o vulnerabilitate a protocolului Microsoft RPC. Un calculator infectat scanează agresiv în mod aleator reţeaua sa locală precum şi Internet-ul, încercând să obţină acces la portul 135. Dacă obţine acest acces, împrăştierea viermelui continuă.
3.1.2.1.2. Viermi distrugători Mulţi viermi au fost creaţi doar pentru a se împrăştia. Ei nu distrug sistemele prin care se propagă. Totuşi, aşa cum s-a văzut, viermii Morris şi Mydoom afectează traficul prin reţea şi produc şi alte efecte neintenţionate, care pot produce disfuncţionalităţi majore. Un program de tip payload este conceput să facă mai mult decât împrăştierea viermelui - el poate şterge fişiere de pe un calculator, poate cripta fişiere, în cadrul unui atac de tipul cryptoviral extortion, sau poate să expedieze documente prin e-mail. O acţiune uzuală efectuată de către un program de tip payload este instalarea unui program de tipul backdoor pe calculatorul infectat, care favorizează crearea unui "zombie", controlat de către autorul viermelui. Exemple de viermi care crează zombies sunt Sobig şi Mydoom. Reţelele din care fac parte calculatoarele infectate cu astfel de viermi sunt numite botnets şi se utilizează cu predilecţie de către expeditorii de spam. Un program backdoor, odată instalat, poate fi exploatat şi de alţi viermi. De exemplu, programul de tip backdoor instalat de viermele Mydoom este folosit pentru împrăştierea viermelui Doomjuice. 3.1.2.1.3. Viermi cu intenţii bune Totuşi, viermii pot fi utilizaţi în lupta anti-tero, în cooperare cu tehnici bazate pe ştiinţa calculatoarelor şi pe inteligenţă artificială, începând cu prima cercetare efectuată la Xerox. Familia de viermi Nachi încearcă să transfere (download) şi apoi să instaleze programele de corecţie (patches) de pe site-ul Microsoft pentru a corecta diferite vulnerabilităţi ale calculatorului gazdă – aceleaşi vulnerabilităţi pe care le exploata viermele Nachi. Această acţiune ar putea să facă sistemul afectat mai sigur, dar generează trafic suplimentar considerabil. 3.1.2.1.4. Protecţia împotriva viermilor Viermii se răspândesc exploatând vulnerabilităţile sistemului de operare sau înşelând operatorul (determinându-l să-i ajute). Toţi furnizorii oferă actualizări (updates) de securitate frecvente ("Patch Tuesday"), şi dacă acestea sunt instalate pe un calculator atunci majoritatea viermilor este împiedicată să se împrăştie. Utilizatorii nu trebuie să deschidă mesaje e-mail neaşteptate şi mai ales nu trebuie să ruleze fişierele sau programele ataşate şi nu trebuie să viziteze site-urile web la care îi conectează astfel de programe. Totuşi, aşa cum au dovedit-o viermii ILOVEYOU şi phishing oricând există un procent de utilizatori care sunt înşelaţi. Programele anti-virus şi anti-spyware sunt folositoare, dar este necesară reactualizarea lor aproape zilnică.

30
3.1.3. Necesităţi de securitate în reţele
Organizaţia internaţională de standardizare (ISO) defineşte în modelul OSI (Open System Interconnect) 7 nivele de comunicaţii şi interfeţele dintre ele. Funcţionarea la fiecare nivel depinde de serviciile efectuate la nivelul imediat inferior.
În ultimii 20 de ani au fost concepute şi puse în funcţiune mai multe tipuri de reţele de calculatoare. Reţele separate se integrează în reţele globale. Protocolul CLNP (Connectionless Network Protocol) al ISO, cunoscut şi sub numele ISO IP, defineşte o cale de interconectare virtuală a tuturor reţelelor şi o cale de acces la fiecare nod al acesteia (Network Service Access Point), NSAP din oricare alt NSAP. În prezent familia de protocoale TCP/IP, a Departamentului Apărării din SUA, DoD, prezintă cea mai naturală cale de evoluţie spre adevăratele sisteme deschise. Protocolul IP al DoD, oferă prima cale utilizabilă de interconectare a reţelelor heterogene şi de dirijare a traficului între acestea. Succesorul firesc al protocolului IP va fi protocolul CLNP, care va oferi aceiaşi funcţionalitate dar într-o formă standardizată internaţional şi cu un spaţiu de adresare mai mare şi mai bine structurat. În viitor reţelele de intreprindere sau reţelele cu valoare adăugată (VAN), nu vor mai fi separate fizic ci vor fi reţele virtuale, adică colecţii de NSAP formând o reţea logică. Un anumit NSAP poate aparţine simultan unui număr oricât de mare de astfel de reţele logice. Calculatoare individuale şi staţii de lucru sunt conectate la reţele locale (LAN) rapide. LAN-urile oferă conectivitate completă (posibilitatea de comunicare directă între oricare două staţii din aceeaşi reţea). LAN-urile dintr-o clădire, dintr-un complex de clădiri sau dintr-un cartier pot fi interconectate obţinându-se comunicaţii cu viteze comparabile cu cele din cadrul LAN-urilor componente. Reţele orăşeneşti, MAN ( Metropolitan Area Networks ) se construiesc tot mai frecvent. La acestea pot fi conectate alte LAN-uri sau reţele private PBX (Private Branch Exchanges). Cele mai cuprinzătoare reţele sunt WAN-urile (Wide Area Network). Reţele şi mai cuprinzătoare pot fi construite folosind sisteme ATM de tipul BISDN. În ierarhia reţelelor prezentată majoritatea traficului este local (în cadrul unui aceluiaşi LAN). Pe măsură ce se urcă în ierarhie mărimea traficului scade şi costurile de transmitere a informaţiei cresc dar calitatea şi viteza serviciilor rămân ridicate. Aceste dezvoltări au deschis perspective complet noi pentru proiectanţii de servicii informatice. De exemplu un calculator oarecare, conectat la o reţea locală, poate comunica cu oricare alt calculator (din lumea întreagă) folosind o bandă largă şi cu o întârziere relativ mică. E clar că acest gen de conectivitate conduce la creşterea riscurilor de securitate care trebuie considerate.
3.2. Securitatea LAN-urilor
Deşi reţelele locale au multe proprietăţi utile, cum ar fi banda largă, întârzierile mici, şi costuri independente de traficul de informaţie, ele posedă şi o ameninţare de securitate importantă. Într-o reţea locală toate calculatoarele componente "ascultă" în permanenţă mediul de comunicare, culegând toate mesajele transmise şi le recunosc pe cele care le sunt destinate pe baza adreselor destinatarilor. Asta înseamnă că oricare calculator poate supraveghea, fără a fi detectat, întregul trafic din reţea. De asemenea orice staţie îşi poate asuma o identitate falsă şi să transmită cu o adresă de sursă falsă, şi anume cea a unei alte staţii. Unul dintre atacurile cele mai uşor de realizat este înregistrarea şi retransmiterea secvenţelor de autentificare. Există în prezent posibilităţi (hard şi soft) pentru oricine care are acces într-o reţea locală să monitorizeze traficul, să caute secvenţe de tipul "Username:" sau "Password:" să înregistreze răspunsurile la aceste secvenţe şi mai târziu să acceseze un serviciu cu o identitate falsă. Este uşor să se imagineze şi atacuri mai ingenioase într-o reţea locală. Trebuie remarcat că orice tronson al unei reţele locale poate fi securizat rezonabil folosind o pereche de dispozitive de criptare de încredere, dar şi că pe

31
măsură ce capacitatea unei reţele creşte şi riscurile de securitate cresc. În continuare se consideră exemplul unei reţele locale, deservită de un server. Se prezintă
o colecţie utilă de măsuri de securitate ce se pot lua în cazul unei astfel de reţele. Nu se iau în considerare sistemul de operare al serverului sau al celorlalte calculatoare. Se presupune că reţeaua poate fi ameninţată de următoarele acţiuni:
De forţă majoră: - pierderea personalului; inundaţie; incendiu; praf;
Deficienţe de organizare: - folosirea neautorizată a drepturilor de utilizare ; bandă de frecvenţe aleasă
neadecvat; Greşeli umane:
- Distrugerea din neglijenţă a unor echipamente sau a unor date; Nerespecatrea măsurilor de securitate; Defectarea cablurilor; Defecţiuni aleatoare datorate personalului de întreţinere a clădirii sau datorate unui personal extern; Administrarea necorespunzătoare a sistemului de securitate; Organizarea nestructurată a datelor;
Defecţiuni tehnice: - Întreruperea unor surse de alimentare; Variaţii ale tensiunii reţelei de
alimentare cu energie electrică; Defectarea unor sisteme de înregistrare a datelor; Descoperirea unor slăbiciuni ale programelor folosite; Posibilităţi de acces la sistemul de securitate prea greoaie;
Acte deliberate: -Manipularea sau distrugerea echipamentului de protecţie al reţelei sau a
accesoriilor sale; Manipularea datelor sau a programelor; Furt; Interceptarea liniilor de legătură dintre calculatoarele reţelei; Manipularea liniilor de legătură; Folosirea neautorizată a sistemului de protecţie al reţelei; Încercarea sistematică de ghicire a parolelor; Abuzarea de drepturile de utilizator; Distrugerea drepturilor administratorului; Cai Troieni; Viruşi de calculator; Răspunsuri la mesaje; Substituirea unor utilizatori cu drept de acces în reţea de către persoane fără aceste drepturi; Analiza traficului de mesaje; Repudierea unor mesaje; Negarea serviciilor. Contramăsuri recomandate:
O bună alegere a modulelor de protecţie. Această alegere se face secvenţial, pe baza următoarelor criterii:
Pasul 1: Regulile specifice instituţiei respective pentru Managementul Securităţii, Regulamentul de organizare al instituţiei, Politica de realizare a back-up-urilor şi Conceptele de protecţie anti-virus;
Pasul 2: Criterii arhitecturale şi structurale, care iau în considerare arhitectura clădirii instituţiei respective;
Pasul 3: Criterii constructive ale echipamentelor care constituie reţeaua;
Pasul 4: Criterii de interconectare a echipamentelor din reţea; de exemplu dacă există sau nu echipamente de tip firewall ;
Pasul 5: Criterii de comunicare între echipamentele reţelei, cum ar fi programele de poştă electronică folosite sau bazele de date folosite.

32
Utilizând pe rând toate aceste criterii rezultă modelul de securitate al reţelei considerate. Un astfel de model poate fi prezentat sub forma unui tabel cu următoarele coloane:
Numărul şi numele modulului de protecţie; Obiectul ţintă sau grupul de obiecte ţintă. De exemplu acesta poate fi numărul de identificare al unei componente sau grup de componente din reţea sau numele unei clădiri sau al unei unităţi organizatorice din cadrul instituţiei; Persoana de contact. Persoana de contact nu este nominalizată în faza de modelare ci doar după ce s-a ales o anumită arhitectură de sistem de securitate; Ultima coloană este destinată observaţiilor. Pe baza unei astfel de analize se poate ajunge, pentru server-ul considerat în acest paragraf, la următoarea listă de măsuri de securitate: Sursă de alimentare neinteruptibilă (opţional); Controlul mediilor de păstrare a datelor; Revizii periodice; Interzicerea utilizării unor programe neautorizate; Supravegherea păstrării programelor; Corecta dispunere a resurselor care necesită protecţie; Împrospătarea periodică a parolelor; Existenţa documentaţiei de configurare a reţelei; Desemnarea unui administrator de reţea şi a unui adjunct al său; Existenţa unei documentaţii asupra utilizatorilor autorizaţi şi asupra drepturilor fiecăruia; Existenţa unei documentaţii asupra schimbărilor efectuate în sistemul de securitate; Permanenta căutare a informaţiilor despre slăbiciunile sistemului de protecţie; Stocarea structurată a datelor; Antrenarea personalului înainte de utilizarea unui anumit program; Educarea personalului în legătură cu măsurile de securitate utilizate; Selecţia unor angajaţi de încredere pentru posturile de administrator de reţea şi de adjunct al acestuia; Antrenarea personalului tehnic şi a personalului de întreţinere; Protecţie prin parole; Rularea periodică a unui program anti-virus; Asigurarea unei operaţii de login sigure; Impunerea unor restricţii la accesul la conturi şi sau la terminale; Blocarea sau ştergerea terminalelor, conturilor care nu sunt necesare; Asigurarea unui management de sistem consistent; Verificarea datelor noi care sosesc în reţea împotriva viruşilor; Managementul reţelei; Verificări periodice ale securităţii reţelei; Folosirea corectă a echipamentelor la noi cuplări în reţea; Stocarea corespunzătoare a copiilor (back-up) ale fişierelor de date; Existenţa de copii back-up pentru fiecare program folosit; Verificarea periodică a copiilor back-up. În prezent se urmăreşte integrarea dispozitivelor de securitate izolate ((specifice fiecărui nivel de comunicaţie ISO), de tipul "modulelor" amintite mai sus) în sisteme de securitate complexe, specifice fiecărui tip de reţea.

33
Capitolul 4. Bazele matematice ale criptării
În acest paragraf se prezintă principalele cunoştiinţe de matematică care sunt utilizate în realizarea algoritmilor de criptare.
4.1. Aritmetica pe clase de resturi modulo specificat Se prezintă pentru început tabelele pentru operaţiile de adunare, înmulţire şi ridicare la putere pe mulţimea claselor de resturi modulo 7.
+ | 0 1 2 3 4 5 6 * | 0 1 2 3 4 5 6
^ | 0 1 2 3 4 5 6 0 | 0 1 2 3 4 5 6 0 | 0 0 0 0 0 0 0 1 | 1 2 3 4 5 6 0 1 | 0 1 2 3 4 5 6 1 | 1 1 1 1 1 1 1 2 | 2 3 4 5 6 0 1 2 | 0 2 4 6 1 3 5 2 | 1 2 4 1 2 4 1 3 | 3 4 5 6 0 1 2 3 | 0 3 6 2 5 1 4 3 | 1 3 2 6 4 5 1 4 | 4 5 6 0 1 2 3 4 | 0 4 1 5 2 6 3 4 | 1 4 2 1 4 2 1 5 | 5 6 0 1 2 3 4 5 | 0 5 3 1 6 4 2 5 | 1 5 4 6 2 3 1 6 | 6 0 1 2 3 4 5 6 | 0 6 5 4 3 2 1 6 | 1 6 1 6 1 6 1
Analizând tabelul din stânga se constată că 1 şi 6, 2 şi 5 şi 3 şi 4 sunt inverse în raport cu adunarea. Să luăm prima pereche şi să considerăm că se doreşte transmiterea mesajului 3. În loc de 3 se va emite 4 (trei plus unu). La recepţia se va aduna modulo 7 inversul lui 1, adică 6 şi se va obţine 10 modulo 7, adică 3, adică mesajul care trebuia transmis. Poate că metoda descrisă anterior este cea mai simplă schemă de criptare bazată pe aritmetica claselor de resturi.
Dacă se îndepărtează din tabelul de înmulţire linia şi coloana care conţin doar elemente nule atunci cele şase numere care rămân în fiecare linie şi în fiecare coloană sunt diferite între ele. Se constată că în fiecare linie respectiv coloană pe o anumită poziţie există un 1. De aceea se poate afirma că pentru fiecare număr cuprins între 1 şi 6 există un alt număr cuprins între 1 şi 6 astfel încât produsul acestor două numere, modulo 7, să fie egal cu 1. Cu alte cuvinte, dacă se elimină elementul 0, pe clasa de resturi modulo 7 (fără 0) operaţia de înmulţire este inversabilă. De exemplu inversul lui 2, în raport cu înmulţirea modulo 7 este 4. Această proprietate nu este adevărată pentru orice valoare a modulului. Ea este adevărată în cazul exemplului nostru deoarece modulul utilizat, 7, este un număr prim.
4.2. Numere prime Se numeşte funcţie indicator, totient, a lui Euler şi se notează cu ϕ funcţia care asociază lui N numărul de numere întregi şi pozitive mai mici decât N, relativ prime cu N. E clar că dacă N este prim atunci ϕ(N)=N-1. În cazul din exemplul anterior ϕ(7)=6. Deci dacă modulul N este număr prim, atunci numărul de elemente inversabile la înmulţirea modulo N este ϕ(N). Mai interesant este tabelul de ridicare la putere prezentat în paragraful anterior. Analizând acest tabel se constată că orice număr cuprins între 1 şi 6, ridicat la puterea 6 este egal cu 1. Mai mult, pe baza tabelului de ridicare la putere se constată că această operaţie este periodică. Valorile obţinute prin ridicarea la puterea 0 sunt identice cu valorile obţinute prin ridicarea la puterea a 6-a. În consecinţă doar pentru 6 valori distincte ale exponenţilor (1, 2, 3, 4, 5 şi 6) se obţin valori diferite prin ridicarea la putere modulo 7. Ţinând seama de definiţia anterioară a funcţiei totient a lui Euler, se poate afirma, pe baza acestui exemplu, că numărul de exponenţi pentru care se obţin valori distincte

34
prin ridicarea la putere modulo N este egal cu ϕ(N). Cu alte cuvinte perioada de repetiţie într-un tabel de ridicare la putere modulo N este egală cu ϕ(N). Din acest punct de vedere se poate afirma că la ridicarea la putere modulo 7, (N), exponentul poate fi privit ca fiind un element al clasei de resturi modulo 6 (modulo ϕ(N)). Această proprietate este valabilă, în general, pentru orice clasă de returi modulo un număr prim. În continuare se analizează cazul în care baza nu este număr prim. Dacă se cunoaşte restul împărţirii unui anumit număr cu 5 şi apoi cu 7, se poate determina (deoarece 5 şi 7 sunt numere prime între ele (nu au factori comuni)) restul împărţirii acelui număr la 35. De fapt cele două resturi sunt egale. De aceea se poate spune că proprietăţile aritmeticii modulo 35 sunt o combinaţie a proprietăţilor aritmeticilor modulo 5 şi modulo 7. De aceea, referindu-ne acum la operaţia de ridicare la putere şi ţinând seama de proprietatea amintită anterior, nu este nevoie ca pentru ridicarea la putere modulo 35 (care conform proprietăţii anterioare ar pretinde exponenţi modulo 34) să se folosească exponenţi modulo 34, fiind suficient să se utilizeze exponenţi modulo 24 (pentru ridicarea la puterea a 5-a sunt suficienţi, conform proprietăţii anterioare, coeficienţi modulo 4, iar pentru ridicarea la puterea a şaptea, exponenţi modulo 6 şi produsul dintre 4 şi 6 este 24). Raţionamentul făcut explică rolul numărului (p-1)(q-1) folosit în metoda de criptare cu cheie publică RSA. Această metodă presupune criptarea unui mesaj M, prin ridicarea sa la o putere e modulo N. Perechea (N,e) reprezintă cheia de criptare. Se obţine textul criptat C. Decriptarea se realizează prin ridicarea lui C la o putere d, inversa lui e în raport cu operaţia de înmulţire modulo N. Cheia de decriptare este perechea (N,d). Pentru a aplica această metodă de criptare trebuie calculată puterea d. În continuare se prezintă tabelul corespunzător operaţiei de ridicare la putere modulo 55. Factorii lui 55 sunt 5 şi 11, numere prime între ele şi prime în general. Conform observaţiei anterioare ar trebui să fie folosiţi coeficienţi modulo 40, deoarece tabelul ar trebui să se repete cu perioada 40. Observaţia anterioară este justificată de următoarea propoziţie:
Dacă p şi q sunt două numere relativ prime şi dacă N =p ·q atunci ϕ(N)=(p −1)(q −1).
Într-adevăr, în exemplul prezentat mai sus, valoarea lui N este 55, valoarea lui p este 5 iar valoarea lui q este 11. Numerele relativ prime cu 55, mai mici decât 55 sunt: 1, 2, 3, 4, 6, 7, 8, 9, 12, 13, 14, 16, 17, 18, 19, 21, 23, 24, 26, 27, 28, 29, 31, 32, 34, 36, 37, 38, 39, 41, 42, 43, 46, 47, 48, 49, 51, 52, 53, 54. De aceea ϕ(55)=40. Pe baza analizei acestui tabel se pot face câteva observaţii.
Deşi coloana a 20-a nu conţine doar elemente egale cu 1, coloana a 21-a este identică cu coloana 1-a, ambele conţinînd în ordine numerele cuprinse între 1 şi 45. Asta înseamnă că tabelul se repetă cu perioada 20 în loc de 40. Evident că şi 40 este o valoare bună pentru perioadă (orice multiplu al perioadei prinicpale reprezintă o perioadă). Această comportare are loc întotdeauna când cel mai mare divizor comun al numerelor p-1 şi q-1 este 2. Cu alte cuvinte perioada de repetiţie în tabelul de ridicare la putere modulo N (dat de produsul dintre p şi q) este egală cu (p-1)(q-1)/2, dacă factorii p şi q sunt numere prime. De aceea exponenţii de la ridicarea la putere modulo N, trebuie priviţi ca şi elemente ale clasei de resturi modulo (p-1)(q-1)/2. De aceea se lucrează cu acest modul în metoda RSA pentru determinarea puterii d. Deoarece 55 nu este număr prim e logic ca prin înmulţirea repetată a numerelor divizibile cu 5 şi cu 11 să nu se poată obţine numere nedivizibile cu 5 sau cu 11 cum ar fi de exemplu 1. Doar dacă valoarea produsului este 1 se poate vorbi despre inversare. De aceea numai numere prime cu (p-1)(q-1) pot fi utilizate ca şi exponenţi pentru cifrarea respectiv descifrarea bazate pe metoda de criptare RSA. De aceea pentru cazul analizat trebuiesc excluse toate numerele divizibile cu 2 şi 5.

35
Tabel 1. Ridicarea la putere modulo 55. ^ | 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
1 | 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 | 2 4 8 16 32 9 18 36 17 34 13 26 52 49 43 31 7 14 28 1 2 3 | 3 9 27 26 23 14 42 16 48 34 47 31 38 4 12 36 53 49 37 1 3 4 | 4 16 9 36 34 26 49 31 14 1 4 16 9 36 34 26 49 31 14 1 4 5 | 5 25 15 20 45 5 25 15 20 45 5 25 15 20 45 5 25 15 20 45 5 6 | 6 36 51 31 21 16 41 26 46 1 6 36 51 31 21 16 41 26 46 1 6 7 | 7 49 13 36 32 4 28 31 52 34 18 16 2 14 43 26 17 9 8 1 7 8 | 8 9 17 26 43 14 2 16 18 34 52 31 28 4 32 36 13 49 7 1 8 9 | 9 26 14 16 34 31 4 36 49 1 9 26 14 16 34 31 4 36 49 1 9 10 |10 45 10 45 10 45 10 45 10 45 10 45 10 45 10 45 10 45 10 45 10 11 |11 11 11 11 11 11 11 11 11 11 11 11 11 11 11 11 11 11 11 11 11 12 |12 34 23 1 12 34 23 1 12 34 23 1 12 34 23 1 12 34 23 1 12 13 |13 4 52 16 43 9 7 36 28 34 2 26 8 49 32 31 18 14 17 1 13 14 |14 31 49 26 34 36 9 16 4 1 14 31 49 26 34 36 9 16 4 1 14 15 |15 5 20 25 45 15 5 20 25 45 15 5 20 25 45 15 5 20 25 45 15 16 |16 36 26 31 1 16 36 26 31 1 16 36 26 31 1 16 36 26 31 1 16 17 |17 14 18 31 32 49 8 26 2 34 28 36 7 9 43 16 52 4 1 31 17 18 |18 49 2 36 43 4 17 31 8 34 7 16 13 14 32 26 28 9 52 1 18 19 |19 31 39 26 54 36 24 16 29 1 19 31 39 26 54 36 24 16 29 1 19 20 |20 15 25 5 45 20 15 25 5 45 20 15 25 5 45 20 15 25 5 45 20 21 |21 1 21 1 21 1 21 1 21 1 21 1 21 1 21 1 21 1 21 1 21 22 |22 44 33 11 22 44 33 11 22 44 33 11 22 44 33 11 22 44 33 11 22 23 |23 34 12 1 23 34 12 1 23 34 12 1 23 34 12 1 23 34 12 1 23 24 |24 26 19 16 54 31 29 36 39 1 24 26 19 16 54 31 29 36 39 1 24 25 |25 20 5 15 45 25 20 5 15 45 25 20 5 15 45 25 20 5 15 45 25 26 |26 16 31 36 1 26 16 31 36 1 26 16 31 36 1 26 16 31 36 1 26 27 |27 14 48 31 12 49 3 26 42 34 38 36 37 9 23 16 47 4 53 1 27 28 |28 14 7 31 43 49 52 26 13 34 17 36 18 9 32 16 8 4 2 1 28 29 |29 16 24 36 54 26 39 31 19 1 29 16 24 36 54 26 39 31 19 1 29 30 |30 20 50 15 10 25 35 5 40 45 30 20 50 15 10 25 35 5 40 45 30 31 |31 26 36 16 1 31 26 36 16 1 31 26 36 16 1 31 26 36 16 1 31 32 |32 34 43 1 32 34 43 1 32 34 43 1 32 34 43 1 32 34 43 1 32 33 |33 44 22 11 33 44 22 11 33 44 22 11 33 44 22 11 33 44 22 11 33 34 |34 1 34 1 34 1 34 1 34 1 34 1 34 1 34 1 34 1 34 1 34 35 |35 15 30 5 10 20 40 25 50 45 35 15 30 5 10 20 40 25 50 45 35 36 |36 31 16 26 1 36 31 16 26 1 36 31 16 26 1 36 31 16 26 1 36 37 |37 49 53 36 12 4 38 31 47 34 48 16 42 14 23 26 27 9 3 1 37 38 |38 14 37 31 23 49 47 26 53 34 27 36 48 9 12 16 3 4 42 1 38 39 |39 36 29 31 54 16 19 26 24 1 39 36 29 31 54 16 19 26 24 1 39 40 |40 5 35 25 10 15 50 20 30 45 40 5 35 25 10 15 50 20 30 45 40 41 |41 31 6 26 21 36 46 16 51 1 41 31 6 26 21 36 46 16 51 1 41 42 |42 4 3 16 12 9 48 36 27 34 53 26 47 49 23 31 37 14 38 1 42 43 |43 34 32 1 43 34 32 1 43 34 32 1 43 34 32 1 43 34 32 1 43 44 |44 11 44 11 44 11 44 11 44 11 44 11 44 11 44 11 44 11 44 11 44 45 |45 45 45 45 45 45 45 45 45 45 45 45 45 45 45 45 45 45 45 45 45 46 |46 26 41 16 21 31 51 36 6 1 46 26 41 16 21 31 51 36 6 1 46 47 |47 9 38 26 12 14 53 16 37 34 3 31 27 4 23 36 42 49 48 1 47 48 |48 49 42 36 23 4 27 31 3 34 37 16 53 14 12 26 38 9 47 1 48 49 |49 36 4 31 34 16 14 26 9 1 49 36 4 31 34 16 14 26 9 1 49 50 |50 25 40 20 10 5 30 15 35 45 50 25 40 20 10 5 30 15 35 45 50 51 |51 16 46 36 21 26 6 31 41 1 51 16 46 36 21 26 6 31 41 1 51 52 |52 9 28 26 32 14 13 16 7 34 8 31 17 4 43 36 2 49 18 1 52 53 |53 4 47 16 23 9 37 36 38 34 42 26 3 49 12 31 48 14 27 1 53 54 |54 1 54 1 54 1 54 1 54 1 54 1 54 1 54 1 54 1 54 1 54

36
4.3. Mica teoremă a lui Fermat
Fiind dat numărul întreg a şi numărul prim p, care nu este divizor al lui a, are loc relaţia:
ap-1
= 1 (mod p). Demonstraţie:
Notă istorică Ca de obicei, Fermat nu a dat o demonstraţie nici pentru această teoremă (mărginindu-se
să afirme "Ţi-aş fi trimis şi demonstraţia dacă nu m-aş fi temut că este prea lungă"). Primul care a publicat o demonstraţie a acestei teoreme a fost Euler în anul 1736. A fost găsită însă aceeaşi demonstraţie într-un manuscris al lui Leibniz, redactat înainte de 1683, rămas nepublicat.
Pentru început se scriu primii p-1 multipli pozitivi ai lui a:
a, 2a, 3a, ... (p -1)a Dacă ra şi sa sunt egali modulo p, atunci:
r(mod p)a(mod p) =s (mod p)(a mod p)
deoarece p este număr prim şi nu-l divide pe a. Adică:
r = s (mod p)
Dar numerele r şi s sunt distincte şi mai mici decât p. De aceea ultima egalitate nu poate avea loc. În consecinţă ipoteza făcută este absurdă. De aceea se poate afirma că cei p-1 multipli ai lui a introduşi mai sus sunt distincţi şi nenuli. În consecinţă (fiind vorba de p-1 valori) ei trebuie să fie egali modulo p cu numerele 1, 2, 3, ..., p-1 într-o anumită ordine. Prin înmulţirea membrilor stângi respectiv drepţi ai tuturor acestor egalităţi se obţine egalitatea următoare:
a.
2a.
3a.
... .
(p-1)a =1.
2.
3.
....
(p-1) (mod p)
adică:
a(p-1)
(p-1)! = (p-1)! (mod p)
Împărţind în ambii membri cu (p-1)! mod(p) se obţine tocmai relaţia din enunţ.
4.4. Câmpuri Galois
Un câmp Galois este un câmp finit cu pn
elemente, unde p este un număr prim. Mulţimea elementelor nenule ale câmpului Galois este un grup ciclic în raport cu operaţia de înmulţire. Un element generator al acestui grup ciclic este numit element primitiv al câmpului. Câmpul Galois poate fi generat ca o mulţime de polinoame cu coeficienţi în Z
p
modulo un polinom ireductibil de gradul n.
Valorile unui octet se reprezintă în algoritmii de criptare prin concatenarea biţilor individuali: {b7, b6, b5, b4, b3, b2, b1, b0}. Aceşti octeţi sunt interpretaţi ca şi elemente ale câmpului finit GF(2
8) cu ajutorul unei reprezentări polinomiale:

37
b7 x7 + b6 x
6 + b5 x
5 + b4 x
4 +b3 x
3 + b2 x
2 + b1x + b0 =
7
k0b k
kx
=∑
De exemplu octetul {01100011} se identifică cu polinomul: x6 + x
5 + x+1. Elementele câmpurilor
finite pot fi adunate sau înmulţite. Exemplul 1: GF(2)
GF(2) constă din elementele 0 şi 1 (p=2 şi n=1) şi reprezintă cel mai mic câmp finit. Este generat de polinoame peste Z
2 modulo polinomul x. Polinoamele corespunzătoare elementelor din
GF(2) sunt: 0 şi 1, deoarece x mod x=0 şi x+1 mod x=1. Tabelele sale de adunare şi înmulţire sunt:
+ 0 1 * 0 1 0 0 1 0 0 0 1 1 0 1 0 1
Se constată că operaţia de adunare este identică cu operaţia logică sau-exclusiv şi că înmulţirea este identică cu operaţia logică şi. Câmpul GF(2) este utilizat frecvent la construcţia de coduri deoarece el este uşor reprezentat în calculatoare, fiind necesar un singur bit. Adunarea
Însumarea a două elemente într-un câmp finit Galois al lui 2 la o anumită putere este realizată prin "adunarea" coeficienţilor corespunzători aceleiaşi puteri din polinoamele corespunzătoare celor două elemente. "Adunarea" este efectuată modulo 2 (adică este vorba despre funcţia logică sau exclusiv). În consecinţă scăderea polinoamelor este identică cu adunarea lor. Alternativ adunarea a doi octeţi în GF(2
8
), {a7a6a5a4a3a2a1a0} şi {b7b6b5b4b3b2b1b0}, se face prin adunarea modulo 2 a biţilor lor corespunzători. Se obţine octetul {c7c6c5c4c3c2c1c0}, unde: ci
= ai ⊕ bi , i = 1,7. De exemplu următoarele expresii sunt echivalente:
( ) ( )6 4 2 7 7 6 4 21 1x x x x x x x x x x+ + + + + + + = + + + (notaţie polinomială)
{01010111}
⊕ {10000011} = {11010100} (notaţie binară)
{57} ⊕ {83} = {d4} (notaţie hexazecimală)
Înmulţirea
În reprezentare polinomială, înmulţirea în câmpul lui Galois al lui 2
8
, GF(28
), notată cu •, corespunde înmulţirii polinoamelor corespunzătoare modulo un polinom ireductibil de gradul 8. Un astfel de polinom ireductibil este:
x8 +x
4 +x
3 +x +1 sau {1b} în notaţie hexazecimală. De exemplu:
{57} • {83} = {c1}
deoarece ţinând seama de reprezentările polinomiale ale lui {57} şi {83}:

38
( ) ( )6 4 2 7 13 11 9 8 7 5 3 2
6 4 2
1 1
1
x x x x x x x x x x x x x x x
x x x x
+ + + + • + + = + + + + + + + +
+ + + + +
sau ţinând seama de modul în care a fost definită adunarea:
( ) ( )6 4 2 7 13 11 9 8 6 5 4 31 1 1x x x x x x x x x x x x x+ + + • + + = + + + + + + + +
Dar: ( )
( ) ( ) ( )
13 11 9 8 6 5 4 3 8 4 3 7 61 mod 1 1
x x x x x x x x x x x x x x
P x m x R x
+ + + + + + + + + + + + = + +
deoarece restul împărţirii lui P(x) la m(x) este −x7 −x
6 +1, care este egal cu R(x), deoarece
coeficienţii acestor polinoame trebuie consideraţi din mulţimea claselor de resturi modulo 2 (aşa cum s-a arătat deja când s-a vorbit despre adunare). Dar octetul corespunzător lui R(x) este{0,1,1,0,0,0,0,0,1}sau în notaţie hexazecimală {c1}.
Înmulţirea definită astfel este asociativă, iar elementul său neutru este {01}. Pentru orice polinom binar neidentic nul, de grad inferior lui 8, b(x), există un element invers în raport cu această înmulţire, notat ( )1b x− . Acesta poate fi calculat utilizând algoritmul lui Euclid, şi determinând polinoamele a(x) şi c(x), care au proprietatea:
( ) ( ) ( ) ( ) 1b x a x m x c x⋅ + ⋅ =
adică:
( ) ( ) ( ){ }mod 1b x a x m x• =
ceea ce înseamnă că:
( ) ( ) ( ){ }1 modb x a x m x− =
Mai mult, se poate demonstra că înmulţirea • este distributivă în raport cu adunarea pe GF(28),
adică:
( ) ( ) ( )( ) ( ) ( ) ( ) ( )a x b x c x a x b x a x c x• + = • + • Exemplul 2: GF(3)
GF(3) este constituit din elementele 0, 1, şi -1. El este generat de polinoame peste Z3
modulo polinomul x. Tabelele sale de adunare şi înmulţire sunt:
+ 0 1 -1 * 0 1 -1 0 0 1 -1 0 0 0 0 1 1 -1 0 1 0 1 -1 -1 -1 0 1 -1 0 -1 1

39
Este utilizat la construcţia codurilor ternare. Exemplul 3: GF(4)
Acest câmp Galois este generat de polinoamele peste Z2
modulo polinomul x2
+ x + 1. Elementele sale sunt (0,1,A,B). Tabelele sale de adunare şi înmulţire sunt:
+ 0 1 A B * 0 1 A B 0 0 1 A B 0 0 0 0 0 1 1 0 B A 1 0 1 A B A A B 0 1 A 0 A B 1 B B A 1 0 B 0 B 1 A
Datorită tabelului de înmulţire A se identifică de obicei cu rădăcina cubică a unităţii
2/32/1 i+− . A şi B sunt elemente primitive ale lui GF(4).
Înmulţirea cu monoame pe GF(28
)
Într-un paragraf anterior s-a introdus înmulţirea pe acest câmp Galois, dar nu s-a indicat o metodă numerică simplă pentru efectuarea acestei înmulţiri. Înmulţirea cu monoame este un caz particular important (orice înmulţire de polinoame se bazează pe câteva înmulţiri cu monoame) pentru care există metode numerice simple de implementare.
Înmulţirea polinomului binar b7 x7 +b6 x
6 +b5 x
5 +b4 x
4 +b3 x
3 +b2 x
2 +b1x +b0 , notat
cu b(x), cu x conduce la polinomul b7 x8 +b6 x
7 +b5 x
6 +b4 x
5 +b3 x
4 +b2 x
3 +b1x
2 +b0 x
Rezultatul înmulţirii ( )xbx • se obţine reducând modulo m(x) rezultatul obţinut anterior. Dacă bitul b7 are valoarea 0 atunci rezultatul este deja în formă redusă. Dacă acest bit are valoarea 1 reducerea este realizată prin scăderea (adică prin operaţia logică sau-exclusiv) polinomului m(x). În consecinţă înmulţirea pe GF(2
8
) cu x, (adică {00000010}în formă binară, respectiv {02}, în formă hexazecimală) poate fi implementată la nivel de octet printr-o deplasare la stânga urmată sau nu (în funcţie de valoarea bitului b7) de calculul funcţiei sau-exclusiv dintre rezultatul (obţinut în urma rotirii) şi {1b}. Această operaţie, la nivel de octet, este notată prin xtime(). Înmulţirea cu puteri mai mari ale lui x poate fi implementată prin aplicarea repetată a operaţiei xtime(). Prin adunarea unor astfel de rezultate intermediare poate fi implementată înmulţirea cu orice polinom. De exemplu:
{57} • {13} = {fe} deoarece: {57} • {02} = xtime({57}) = {ae} {57} • {04} = xtime({ae}) = {47} {57} • {08} = xtime({47}) = {8e} {57} • {10} = xtime({8e}) = {07} şi: {57} • {13} = {57} •({01} ⊕{02} ⊕{10}) = {57} ⊕{ae} ⊕{07} = {fe}

40
Polinoame cu coeficienţi în GF(28
)
Până acum coeficienţii polinoamelor erau de valoare unu sau zero, fiind deci vorba despre polinoame binare. În continuare se analizează cazul polinoamelor cu coeficienţi octeţi. Polinoamele cu patru termeni, cu coeficienţi în câmpul specificat, sunt de forma:
( ) 01
22
33 axaxaxaxa +++=
şi se reprezintă ca şi cuvinte de forma [a0 , a1 , a2 , a3]. De data aceasta însă coeficienţii nu mai sunt biţi ci octeţi. De aceea şi polinomul de reducere va fi diferit, aşa cum se va arăta în continuare. Pentru a ilustra operaţiile de adunare şi de înmulţire pentru polinoame cu patru termeni cu coeficienţi octeţi fie cel de al doilea termen (sau factor) al operaţiei:
b(x)=b3 x3
+b2 x2
+b1x +b0. Adunarea este realizată prin adunarea, în câmpul finit al coeficienţilor, a coeficienţilor corespunzători aceleiaşi puteri a lui x. Adunarea în câmpul finit al coeficienţilor este efectuată prin intermediul operaţiei de sau-exclusiv între octeţii corespunzători (de această dată este vorba despre sau-exclusiv între octeţii compleţi şi nu între biţii din componenţa lor). În consecinţă:
( ) ( ) ( ) ( ) ( ) ( )0011
222
333 baxbaxbaxbaxbxa ⊕+⊕+⊕+⊕=+
Înmulţirea celor două polinoame, numită înmulţire modulară, se efectuează în doi paşi. Primul pas presupune dezvoltarea algebrică a produsului celor două polinoame, ( ) ( ) ( )xbxaxc •= , identificarea coeficienţilor fiecărei puteri:
c(x)=c6 x6 +c5 x
5 +c4 x
4 +c3 x
3 +c2 x
2 +c
1 x+c0
unde:
302112233
3362011022
3223510011
3122134000
babababacbacbababac
babacbabacbababacbac
•⊕•⊕•⊕•=•=•⊕•⊕•=
•⊕•=•⊕•=•⊕•⊕•=•=
Acest rezultat, c(x), nu este însă un polinom cu patru termeni. Cel de al doilea pas presupune reducerea lui c(x) modulo un polinom de gradul 4, obţinându-se un polinom de grad mai mic decât patru. De exemplu în cazul algoritmului de criptare simetrică Rijndael, polinomul de reducere este x
4 +1, astfel încât:
( ) mod4 4 1mod ii xxx =+

41
Produsul modular al polinoamelor a(x) şi b(x), notat ( ) ( )xbxa ⊗ , este dat de polinomul cu patru termeni d(x), definit după cum urmează:
( ) 012
23
3 dxdxdxdxd +++= cu:
( ) ( ) ( ) ( )( ) ( ) ( ) ( )( ) ( ) ( ) ( )( ) ( ) ( ) ( )302112033
332011022
322310011
312213000
babababadbabababadbabababadbabababad
•⊕•⊕•⊕•=•⊕•⊕•⊕•=•⊕•⊕•⊕•=•⊕•⊕•⊕•=
Dacă a(x) este un polinom fixat, operaţiile descrise mai sus pot fi exprimate şi matricial:
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
=⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
3
2
1
0
0123
3012
2301
1230
3
2
1
0
bbbb
aaaaaaaaaaaaaaaa
dddd
De aceea se poate afirma că înmulţirea modulară se reduce la o înmulţire matricială.
Deoarece x4 +1 nu este un polinom ireductibil pe GF(2
8
), înmulţirea modulară a polinoamelor cu patru termeni cu coeficienţi octeţi, definită mai sus, nu este neapărat o operaţie inversabilă. În algoritmul Rijndael este totuşi utilizat un polinom cu patru termeni cu coeficienţi octeţi, care trebuie să aibă invers în raport cu această operaţie de înmulţire:
( ) { } { } { } { }02010103 23 +++= xxxxa Inversul său este:
( ) { } { } { } { }exxdxbxa 00900 231 +++=− Un alt polinom utilizat în programul de criptare cu cheie secretă Rijndael este polinomul x
3 .
Efectul înmulţirii modulare cu acest polinom este rotirea octetului cu o poziţie spre stânga. Asta înseamnă că [b0, b1, b2, b3] se transformă în [b1, b2, b3, b0].
4.5. Matrici MDS
Un cod separat la distanţa maximă, maximum distance separable code (MDSC), definit peste un câmp finit, este o corespondenţă între a elemente ale acelui câmp finit şi b elemente ale unui alt câmp finit, care produce un vector compus de a+b elemente, cu proprietatea că numărul minim de elemente nenule din orice vector nenul este de cel puţin b + 1. Altfel spus distanţa dintre oricare doi vectori produşi de corespondenţa MDS (adică numărul de elemente care diferă între cei doi vectori) este de cel puţin b + 1. Poate fi demonstrat că nu există o altă corespondenţă care să aibă o distanţă minimă, între oricare 2 vectori produşi, mai mare. De aceea se foloseşte denumirea de separare la distanţă maximă. O corespondenţă MDS poate fi reprezentată cu ajutorul unei matrici MDS care are a×b elemente. Transformarea MDS corespunzătoare, a unui anumit octet, se realizează prin înmulţirea acelui octet, privit ca şi vector, cu matricea MDS. De exemplu codurile corectoare de erori Reed-Solomon sunt coduri de tip MDS. O condiţie necesară şi suficientă ca o matrice să fie MDS este ca toate submatricele sale pătrate să fie nesingulare. Algoritmul de criptare simetrică Twofish utilizează o matrice MDS peste câmpul Galois a lui 2 la

42
puterea a 8-a.
4.6. Transformări Pseudo-Hadamard
O transformare Pseudo-Hadamard este o simplă operaţie de mixare care poate fi implementată numeric rapid. Fiind date 2 intrări a şi b, transformarea Pseudo-Hadamard pe 32 de biţi este definită prin:
32
32
mod(2 )2 mod(2 )
t
t
a a bb a b
= += +
O astfel de transformare este utilizată în algoritmul Twofish, putând fi execută în două operaţii de microprocesor. 4.7. Funcţii hash
O funcţie hash, notată cu H este o funcţie definită pe o mulţime A, care ia valori într-o mulţime B, formată cu elemente a căror exprimare în binar se face cu acelaşi număr de biţi, n. De obicei mulţimea A reprezintă mulţimea mesajelor. Mulţimea B are 2
n
elemente. Dacă n nu este suficient de mare atunci funcţia nu este injectivă şi deci nu este inversabilă. Caracteristicile funcţiilor hash sunt: - Fiind dat mesajul M, din A, este simplu de calculat h=H(M). - Fiind dat h este dificil de calculat M. - Fiind dat M este dificil să se găsească un alt mesaj M' diferit astfel încât H(M)=H(M'). - Este greu să se găsească două mesaje aleatoare astfel încât H(M)=H(M'). Această proprietate este numită rezistenţă la coliziune. - Prin modificarea unui singur bit din M se modifică mulţi biţi din h.
O funcţie hash de tipul one-way este o funcţie hash care este dificil de inversat. Asta înseamnă că dacă H(a)=b şi dacă se cunoaşte b atunci este foarte dificil să se afle a. Uneori nu există nici o metodă mai rapidă de a-l afla pe a decât cea bazată pe forţa brută (care cere să fie încercate toate elementele din A). Rezultă că funcţiile hash de tipul one-way sunt rezistente la atacuri de tip collision. Funcţiile hash de tipul one-way au numeroase aplicaţii: - autentificare; - controlul integrităţii mesajelor, MIC, message integrity check; - controlul autenticităţii mesajelor, MAC, message authentication check; - generarea şirurilor de chei (astfel de exemple vor fi date când se vor prezenta funcţiile f, din structurile Feistel folosite de diferiţii algoritmi de criptare simetrică); - securitatea parolelor. Cel mai des folosită funcţie hash se numeşte MD5 (Message Digest) şi a fost introdusă de Rivest în 1991. Ea transformă un fişier de lungime arbitrară într-o valoare exprimată pe 128 de biţi. Această funcţie hash se utilizează la generarea semnăturilor digitale, caz în care rezultatul aplicării sale unui mesaj se numeşte rezumatul mesajului, MD. Această funcţie este prezentată în [3].
4.7.1. Descrierea algoritmului MD5
Se consideră că mesajul de intrare (elementul căruia i se aplică funcţia hash) are o lungime de b biţi. Rezultatul aplicării funcţiei hash va fi rezumatul mesajului considerat.

43
Forma mesajului iniţial este: m_0 m_1 ... m_{b-1}
Terminologie şi notaţii
^ - ridicare la putere, x^i înseamnă x la puterea i.
+ - adunarea modulo 2^32 a cuvintelor.
X <<< s - o valoare exprimată pe 32 de biţi obţinută prin rotirea circulară spre stânga cu s poziţii a lui X.
not(X) - complementul lui X obţinut prin complementarea fiecărui bit al său.
X v Y - rezultatul aplicării funcţiei sau cuvintelor X şi Y obţinut prin aplicarea
funcţiei sau fiecărei perechi de biţi (de aceeaşi semnificaţie) din cele două cuvinte.
X xor Y - rezultatul aplicării funcţiei sau-exclusiv cuvintelor X şi Y obţinut prin
aplicarea funcţiei sau-exclusiv fiecărei perechi de biţi (de aceeaşi semnificaţie) din cele
două cuvinte.
XY - rezultatul aplicării funcţiei şi cuvintelor X şi Y obţinut prin aplicarea funcţiei
şi fiecărei perechi de biţi (de aceeaşi semnificaţie) din cele două cuvinte.
Pentru determinarea rezumatului mesajului se fac următorii 5 paşi.
Pasul 1. Adăugare de biţi pentru egalizarea lungimii mesajului
Mesajul este extins astfel încât lungimea sa să devină egală cu 448 modulo 512. Extinderea se face întotdeauna, chiar dacă lungimea mesajului iniţial este egală cu 448 modulo 512. Extinderea se face după cum urmează: se adaugă un singur bit cu valoarea 1 şi apoi se aduagă biţi de valoare 0 până când lungimea mesajului ajunge să fie de valoarea dorită. Numărul de biţi adăugaţi poate varia între 1 şi 512. Pasul 2. Adăugarea lungimii mesajului
O reprezentare pe 64 de biţi a lungimii iniţiale a mesajului, b, este adăugată la rezultatul obţinut în urma efectuării pasului anterior. În ipoteza, puţin probabilă, că valoarea lui b este mai mare decât 2 la puterea 64, se utilizează doar cei mai puţin semnificativi 64 de biţi ai reprezentării binare a valorii b. Acest cuvânt de 64 de biţi se adauagă prin concatenarea a două cuvinte de 32 de biţi, primul fiind cel care conţine biţii mai puţin semnificativi. În acest punct al algoritmului noul mesaj obţinut are o lungime egală cu un multiplu de 512. Deci acest mesaj conţine un număr întreg de cuvinte de 16, respectiv 32 de biţi. Fie M[0 ... N-1] reprezentarea unui cuvânt al mesajului rezultat, unde N este un multiplu de 16.
Pasul 3. Iniţializarea registrului MD

44
Un registru de patru cuvinte (A,B,C,D) se foloseşte pentru calculul rezumatului mesajului. De fapt cu A, B, C, D, au fost notate patru registre de câte 32 de biţi. Aceste registre sunt încărcate iniţial cu următoarele valori, exprimate în hexazecimal (cu biţii cei mai puţin semnificativi la început):
A 01 23 45 67 B 89 ab cd ef C fe dc ba 98 D 76 54 32 10
Pasul 4. Prelucrarea mesajului folosind blocuri de câte 16 cuvinte
Pentru început se definesc 4 funcţii auxiliare fiecare aplicându-se la cîte 3 cuvinte de câte 32 de biţi şi avînd ca valoare câte un cuvânt de 32 de biţi.
F(X,Y,Z) = XY v not(X) Z ; G(X,Y,Z) = XZ v Y not(Z) ; H(X,Y,Z) = X xor Y xor Z; I(X,Y,Z) = Y xor (X v not(Z)).
În fiecare poziţie de bit funcţia F acţionează ca şi o condiţionare: dacă X atunci Y, altfel Z. Funcţia F ar fi putut fi definită şi folosind operaţia + în loc de v deoarece subfuncţiileXY şi not(X)Z nu vor avea niciodată un 1 în aceeaşi poziţie. Este interesant să se observe faptul că dacă biţii operanzilor X, Y, şi Z (priviţi ca şi variabile aleatoare) sunt independenţi şi nepolarizaţi, atunci fiecare bit al lui F(X,Y,Z) va fi independent şi nepolarizat.
Funcţiile G, H, şi I sunt similare cu funcţia F, în sensul că şi ele acţionează la nivel de bit în mod paralel astfel încât dacă X, Y, şi Z au biţii independenţi şi nepolarizaţi atunci biţii rezultatelor G(X,Y,Z), H(X,Y,Z) şi I(X,Y,Z) vor fi independenţi şi nepolarizaţi. Se observă că folosind funcţia H poate fi făcut controlul parităţii variabilelor sale.
Acest pas foloseşte un tabel cu 64 de elemente T[1 ... 64] construit cu ajutorul valorilor funcţiei sinus. Fie T[i] cel de al i-ilea element al tabelului, care este egal cu partea întreagă a produsului dintre 4294967296 şi valoarea absolută a lui sin(i), unde i este exprimat în radiani.
Pentru încheierea acestui pas se efectuează următoarele operaţii:
/* Se prelucrează fiecare bloc de căte 16 cuvinte. */ For i = 0 to N/16-1 do /* Se copiază cel de al i-ilea bloc în X. */ For j = 0 to 15 do Set X[j] to M[i*16+j]. end /* al buclei după j */
/* Salvează A ca şi AA, B ca şi BB, C ca şi CC, şi D ca şi DD. */ AA = A BB = B CC = C DD = D

45
/* Iteraţia 1. */ /* Se notează cu [abcd k s i] operaţia: a = b + ((a + F(b,c,d) +X[k] + T[i]) <<< s). */ /* Se fac următoarele 16 operaţii. */ [ABCD 0 7 1] [DABC 1 12 2] [CDAB 2 17 3] [BCDA 3 22 4] [ABCD 4 7 5] [DABC 5 12 6] [CDAB 6 17 7] [BCDA 7 22 8] [ABCD 8 7 9] [DABC 9 12 10] [CDAB 10 17 11] [BCDA 11 22 12] [ABCD 12 7 13] [DABC 13 12 14] [CDAB 14 17 15] [BCDA 15 22 16] /* Iteraţia 2. */ /* Se notează cu [abcd k s i] operaţia:
a = b + ((a + G(b,c,d) + X[k] + T[i]) <<< s). */ /* Se fac următoarele 16 operaţii. */
[ABCD 1 5 17] [DABC 6 9 18] [CDAB 11 14 19] [BCDA 0 20 20] [ABCD 5 5 21] [DABC 10 9 22] [CDAB 15 14 23] [BCDA 4 20 24] [ABCD 9 5 25] [DABC 14 9 26] [CDAB 3 14 27] [BCDA 8 20 28] [ABCD 13 5 29] [DABC 2 9 30] [CDAB 7 14 31] [BCDA 12 20 32]
/* Iteraţia 3. */ /* Se notează cu [abcd k s t] operaţia: a = b + ((a + H(b,c,d) + X[k] + T[i]) <<< s). */ /* Se fac următoarele 16 operaţii. */ [ABCD 5 4 33] [DABC 8 11 34] [CDAB 11 16 35] [BCDA 14 23 36] [ABCD 1 4 37] [DABC 4 11 38] [CDAB 7 16 39] [BCDA 10 23 40] [ABCD 13 4 41] [DABC 0 11 42] [CDAB 3 16 43] [BCDA 6 23 44] [ABCD 9 4 45] [DABC 12 11 46] [CDAB 15 16 47] [BCDA 2 23 48] /* Iteraţia 4. */ /* Se notează cu [abcd k s t] operaţia: a = b + ((a + I(b,c,d) + X[k] + T[i]) <<< s). */ /* Se fac următoarele 16 operaţii. */
[ABCD 0 6 49] [DABC 7 10 50] [CDAB 14 15 51] [BCDA 5 21 52] [ABCD 12 6 53] [DABC 3 10 54] [CDAB 10 15 55] [BCDA 1 21 56]
[ABCD 8 6 57] [DABC 15 10 58] [CDAB 6 15 59] [BCDA 13 21 60] [ABCD 4 6 61] [DABC 11 10 62] [CDAB 2 15 63] [BCDA 9 21 64] /* Apoi se realizează următoarele adunări. (Acestea incrementează fiecare
dintre cele patru registre cu valorile pe care le-a avut înaintea începerii acestui bloc.) */
A = A + AA ; B = B + BB; C = C + CC ; D = D + DD end /* al buclei după i */
Pasul 5. Livrarea MD
Rezumatul mesajului produs cu algoritmul MD5 este obţinut prin concatenarea conţinuturilor registrelor A, B, C şi D obţinute la sfârşitul pasului anterior. La început se vor găsi biţii cei mai puţin semnificativi ai registrului A iar la sfîrşit biţii cei mai

46
semnificativi ai registrului D. O altă funcţie hash utilizată frecvent este SHA (prescurtarea de la Secure Hash
Algorithm), publicată de Guvernul American în anul 1995. Aceasta transformă un fişier, mai scurt sau mai lung de 160 de biţi, într-o secvenţă de 160 de biţi. Şi această funcţie se utilizează la construcţia semnăturilor digitale, fiind utilizată în standardul DSS, în algoritmul DSA. Şi această funcţie este prezentată în [3] şi în documentul publicat de NIST intitulat FIPS 180-1.

47
Capitolul 5. Criptografia şi securitatea reţelelor
În acest capitol se prezintă principalii algoritmi de criptare utilizaţi în prezent în securitatea reţelelor de calculatoare. 5.1. Câţiva termeni utilizaţi în criptografie
Text clar - mesajul original; Mesaj cifrat, criptogramă - rezultatul operaţiei de criptare efectuate asupra textului clar; Cifrare, criptare - operaţia de secretizare a textului clar al cărei rezultat este mesajul cifrat; Descifrare, decriptare - operaţia inversă operaţiei de criptare. Chei criptografice - secvenţe de caractere care controlează operaţiile de criptare şi de decriptare. Criptoanaliza - Studiul metodelor de decriptare ilegale (fără cunoaşterea cheilor criptografice). Un sistem criptografic este compus din:
- M, text clar;
- C, text cifrat;
- 2 funcţii inverse E şi D;
- un algoritm care produce cheile Ke şi Kd astfel încât:
( ) ( ) şi e dK KC E M M D C= =
Există două tipuri de sisteme criptografice: - simetrice (cu cheie secretă) care folosesc aceeaşi cheie atât la cifrarea cât şi la descifrarea
mesajelor;
- asimetrice (cu chei publice) care folosesc două chei, una publică şi una privată.
5.2. Algoritmi criptografici cu cheie secretă
Dezvoltarea aşa numitei economii informatice, născută prin proliferarea calculatoarelor, a telecomunicaţiilor şi a INTERNET-ului, a transformat radical modul de a face afaceri, de a guverna, de a se distra şi de a conversa cu prietenii şi cu familia. Documente private, care înainte erau realizate pe hârtie, livrate în mână şi ţinute sub lacăt sunt acum create, trimise şi păstrate electronic. Dar majoritatea mijloacelor care asigură această viteză sporită şi această uşurinţă de comunicare au contribuit şi la scăderea, în mare măsură, a confidenţialităţii acestor mesaje. Într-o epocă electronică, o persoană interpusă poate mai uşor intercepta şi altera mesaje decât atunci când comunicările faţă în faţă constituiau baza schimbului de mesaje. Îngrijorarea creată de noile ameninţări ale securităţii a condus la larga adoptare a criptografiei. În ultimii 20 de ani indivizi şi organizaţii au adoptat această tehnologie folosind-o la aproape orice, de la trimiterea de e-mail-uri sau stocarea de date medicale sau legale la conducerea de la distanţă a tranzacţiilor. Cele mai populare browser-e de WWW folosesc algoritmi criptografici care pot fi incluşi şi în majoritatea programelor de e-mail. Dar aşa cum pot indivizii obişnuiţi să cripteze mesaje într-o formă de neatacat aşa pot şi criminalii, teroriştii sau alţi răufăcători. Pe vremuri, poliţia putea să recupereze orice document (în cel mai rău caz forţând un seif). Forţa brută nu este însă utilă pentru a decripta

48
un mesaj de pe un calculator. Această turnură a evenimentelor a condus guvernele din multe ţări să privească această tehnologie ca pe o gravă ameninţare a ordinii sociale şi să încerce controlul răspândirii sale. Regimurilor represive le poate fi teamă că grupuri dizidente folosesc criptarea pentru a promova ideile lor subversive. Şi guvernele democratice se pot teme că criptografia este utilizată de cartelele de droguri şi de alţi inamici ai statului respectiv. Astfel guvernul S.U.A. a caracterizat odată criptarea ca pe o "muniţie controlată" la fel de periculoasă ca şi armele atomice şi până în zilele noastre a controlat exportul celor mai avansate produse criptografice. Această atitudine a guvernelor a stârnit proteste ale avocaţilor dreptului la intimitate, a experţilor în criptografie, şi a companiilor interesate financiar în promovarea criptografiei. Această bătălie, cauzată de criptografie, are loc pe mai multe fronturi: tehnic, legal, etic şi social. Uneori dezbaterile se bazează pe atitudini la fel de rigide sau polarizate ca şi unele dezbateri religioase.
În continuare se dă un exemplu de probleme pe care le ridică utilizarea (respectiv neutilizarea) criptării. Acum câţiva ani, la televiziunea germană a fost prezentat cazul unui surfer de Web al cărui calculator a fost scanat în timp ce era conectat la un anumit site. Operatorii acestui site au constatat, în urma scanării că surfer-ul folosea un anumit program de tranzacţii bancare şi au modificat de la distanţă un fişier al acestui program astfel încât la următoarea utilizare a acestui program de către surfer să se declanşeze o plată către site-ul lor.
Vulnerabilitatea datelor din calculatoare afectează pe oricine. Chiar şi datele pe care utilizatorul le considera şterse sau suprascrise pot fi refăcute. Cea mai bună metodă de protecţie a datelor este criptarea. Scopul criptării este să transforme un document într-o formă de necitit pentru toată lumea, cu excepţia celor autorizaţi să-l citească. Textul clar este modificat folosind un algoritm şi o variabilă (cheie). Cheia este un şir de caractere alese aleator. În general cu cât numărul acestor caractere este mai mare cu atât securitatea textului cifrat obţinut este mai mare.
Multe scheme de criptare utilizate astăzi sunt simetrice (se bazează pe o singură cheie, secretă), aşa cum o arată standardul american DES. În continuare se prezintă câteva dintre cele mai populare astfel de metode. Standardul de criptare a datelor (DES) a fost dezvoltat în anii 70 şi încă se utilizează pe scară largă, urmând să fie înlocuit de Standardul avansat de criptare a datelor Advanced Encryption Standard (AES), care a fost omologat în anul 2000. Triplu DES. Criptând un mesaj deja criptat cu algoritmul DES cu ajutorul unei noi chei creşte securitatea acestuia dar aceasta poate fi crescută şi mai mult dacă se mai efectuează încă o criptare DES. Algoritmul obţinut astfel este mai lent dar mai sigur. Majoritatea implementărilor noului algoritm utilizează doar două chei, cheia 1 este folosită la prima şi la cea de a treia criptare iar cheia 2 la cea de a doua criptare. Algoritmul internaţional de criptare de date (IDEA) foloseşte o cheie de 128 de biţi, concepută la ETH Zurich. IDEA se foloseşte în programele PGP (de poştă electronică criptată) şi Speak Freely (un program care realizează criptarea semnalului vocal digitizat care se transmite pe Internet).
Blowfish este un cod bloc de 64 de biţi care foloseşte chei de lungimi cuprinse între 32 şi 448 de biţi. A fost conceput de către Bruce Schneier de la Counterpane Internet Security Inc., San Jose, California şi este utilizat în peste 100 de produse.
Twofish, de asemenea conceput de Schneier, este un program de criptare foarte bun şi este unul dintre cei cinci candidaţi consideraţi pentru standardul AES.
RC4 este un program de cifrare a şirurilor de date proiectat de către Ronald Rivest de la RSA Security Inc., Bedford, Massachusetts. El adună bit cu bit ieşirea unui generator de numere pseudoaleatoare cu şirul de biţi ai unui text clar. Algoritmul DES este încă popular mai ales în "industria bancară". El este un sistem de cifrare pe blocuri, codând textul în blocuri de lungime fixă, folosind o cheie tot de lungime fixă. Există şi

49
sisteme de cifrare a şirurilor care nu fac segmentarea în blocuri. În anul 2002, Institutul Naţional de Standardizare şi Tehnologii al S.U.A., United States'
National Institute of Standards and Technology (NIST), din Gaithersburg, a declanşat o competiţie pentru conceperea unui nou standard de criptare simetrică numit Standardul de Criptare Avansat, Advanced Encryption Standard (AES), care va înlocui standardul DES. Motivul principal este că există suspiciunea că Guvernul S.U.A. ar avea o "uşă din dos" pentru a controla fişierele criptate folosind algoritmul DES. Cei cinci finalişti ai acestei competiţii au fost: programul Mars, creat de IBM; programul RC6, realizat de RSA Laboratories şi Ronald Rivest de la Massachusetts Institute of Technology; programul Rijndael, creat de doi belgieni, Joan Daemen şi Vincent Rijmen; programul Serpent, creat de Ross Anderson, Eli Biham şi Lars Knudsen, din Marea Britanie, Israel şi Norvegia, şi progamul Twofish, creat de Bruce Schneier, de la Counterpane Internet Security, Inc. Câştigătorul acestui concurs a fost programul Rijndael.
Pentru anumiţi algoritmi de criptare un text clar care se repetă conduce la un text cifrat care se repetă. E clar că o astfel de comportare nu este dorită deoarece în acest caz ieşirea sistemului de criptare trădează informaţii importante despre textul clar. O soluţie posibilă pentru evitarea unui astfel de comportament este să se cripteze textul cifrat şi să se adune, bit cu bit, rezultatul obţinut cu textul clar. O altă problemă care apare atunci când se utilizează criptarea simetrică este că această necesită ca expeditorul şi destinatarul unui mesaj să aibă o posibilitate sigură pentru a-şi comunica cheia de criptare. Asta este dificil în special atunci când cei doi utilizatori se află departe. Această problemă revine ori de câte ori cheile trebuiesc împrospătate. Utilizarea repetată a aceleiaşi chei slăbeşte securitatea acesteia.
În continuare se prezintă algoritmul care stă la baza standardului DES.
5.2.1. Algoritmul DES
Horst Feistel de la IBM a propus în anul 1973 o structură care a fost aleasă pentru algoritmul DES. Aceasta este o structură iterativă, care are un număr fixat de iteraţii. La prima iteraţie se utilizează textul clar iar rezultatul ultimei iteraţii este textul cifrat. Cheia de criptare K este utilizată pentru a genera câte o cheie k_i la fiecare iteraţie, i. În fiecare iteraţie, textul obţinut la sfârşitul iteraţiei anterioare este împărţit în 2 jumătăţi L_i şi R_i. Se folosesc formulele de recurenţă:
L _{i+1} = R_i (1 Feistel)
şi
R_{i+1} = f(R_i,k_i) + L_i, (2 Feistel)
unde cu + s-a notat operaţia de sau-exclusiv şi cu f() s-a notat o funcţie care este dificil de inversat şi care depinde R_i şi k_i. O astfel de corespondenţă se numeşte funcţie hash.
O trăsătură utilă a acestei structuri este că în fiecare iteraţie se utilizează o altă funcţie dacă cheia specifică a iteraţiei este diferită de cheile folosite în iteraţiile anterioare şi că se poate utiliza orice număr de iteraţii.
Frumuseţea acestei structuri este că, deşi f este dificil de inversat, această inversare nu este necesară pentru a descifra L_{i+1} putându-se utiliza tot funcţia f, folosind cheia k_i şi apoi aplica funcţia sau-exclusiv între rezultatul obţinut şi R_{i+1}:
L_i = f(R_i,k_i) + R_{i+1} = f(L_{i+1},k_i) + R_{i+1} (3 Feistel) iar:

50
R_i = L_{i+1} (4 Feistel)
Într-adevăr, calculând sau-exclusiv între f(R_i,k_i) şi R_{i+1}, conform relaţiei (2 Feistel), se obţine L_i, datorită faptului că rezultatul aplicării funcţiei sau-exclusiv la două şiruri de date identice (f(R_i,k_i)) este şirul identic nul. Structura lui Feistel conduce deci la folosirea aceleiaşi structuri hard sau soft atât pentru criptare cât şi pentru decriptare. Algoritmul DES generează blocuri de date de câte 64 de biţi, foloseşte chei de câte 56 de biţi şi face 16 iteraţii ale structurii Feistel. Ordinograma sa este prezentată în figura 1 cprt. Cheile de iteraţie sunt generate din cheia originală de 56 de biţi prin împărţirea acesteia în jumătate, prin rotirea fiecărei jumătăţi cu unul sau doi biţi şi prin alegerea a câte 24 de biţi din fiecare jumătate rotită. Decriptarea utilizează aceleaşi chei în ordine inversă şi cu jumătăţile stângă şi dreaptă ale blocului de 64 de biţi inversate. Cei 64 de biţi ai unui bloc de text clar care urmează să fie criptat suferă o permutare iniţială IP:
58 50 42 34 26 18 10 2 60 52 44 36 28 20 12 4 62 54 46 38 30 22 14 6 64 56 48 40 32 24 16 8 57 49 41 33 25 17 9 1 59 51 43 35 27 19 11 3 61 53 45 37 29 21 13 5 63 55 47 39 31 23 15 7
Primul bit al şirului obţinut după permutarea iniţială este cel de-al 58-lea bit al blocului de text clar, cel de al doilea bit al şirului obţinut după permutarea iniţială este cel de al 50-lea bit al blocului de text clar ş.a.m.d, iar ultimul bit al şirului obţinut după permutarea iniţială este cel de al 7-lea bit al blocului de text clar. Şirul de biţi obţinut în urma permutării iniţiale este prelucrat apoi de o schemă de calcul dependentă de chei, descrisă în continuare.
Prima etapă, Expandarea (E):
În fiecare iteraţie, partea dreaptă este la început expandată de la 32 la 48 de biţi, prin considerarea sa ca o grupare de 8 nybbles (cantitate de 4 biţi) şi prin copierea celor 8 nybbles în centrele (de câte 4 biţi) ale celor 8 grupări de câte 6 biţi (existente în cadrul şirului destinaţie de 48 de biţi). Biţii extremi, din stânga şi din dreapta ai grupărilor de 6 biţi (destinaţie) sunt obţinuţi prin copierea biţilor extremi ai nybble-ului corespunzător din şirul original de 32 de biţi. De exemplu prima grupare de 6 biţi constă din biţii: 31, 0, 1, 2, 3 şi 4 iar cea de a doua constă din biţii 3,4,5,6,7 şi 8.
A doua etapă, Sau-exclusiv (+):
Între aceste 8 grupări de 6 de biţi şi cheia iteraţiei se efectuează sau-exclusiv, rezultatul fiind salvat în una din cele 8 "cutii" de tip S (S-boxe).
A treia etapă, Salvarea (S):
În fiecare cutie de tip S ajunge câte o grupare de 6 biţi căreia folosind un "selector" (construit cu cei doi biţi de la capete) i se aplică una dintre cele 4 substituţii ale celor 4 biţi centrali. Din cele 8 grupări de câte 4 biţi centrali se obţine un şir de 32 de biţi.

51
A patra etapă, Permutarea (P): Acestui şir i se aplică o nouă permutare (se zice că şirul este pus într-o cutie de tip P) şi apoi se calculează sau-exclusiv între rezultat şi partea stângă a structurii Feistel.
Rezultatul acestei scheme de calcul, numit pre-ieşire, este subiectul unei noi permutări, prezentată în continuare, inversa permutării iniţiale:
IP-1
40 8 48 16 56 24 64 32 39 7 47 15 55 23 63 31 38 6 46 14 54 22 62 30 37 5 45 13 53 21 61 29 36 4 44 12 52 20 60 28 35 3 43 11 51 19 59 27 34 2 42 10 50 18 58 26 33 1 41 9 49 17 57 25
Deci primul bit al şirului de biţi obţinut prin aplicarea algoritmului DES este bitul al 40-lea al pre-ieşirii, cel de-al doileea bit al şirului rezultat este cel de-al 8-lea bit al pre-ieşirii ş.a.m.d. În descrierea de mai sus prezentarea funcţiei f a fost implicită. În figura 2 crpt este prezentată ordinograma de construcţie a acestei funcţii.
Figura 1cript. Ordinograma algoritmului DES.

52
Figura 2 cprt. Construcţia funcţiei f din algoritmul DES.
În figură se remarcă cele 4 etape: expandare, sau-exclusiv, salvare şi permutare, descrise mai sus. Operaţia de expandare poate fi descrisă şi cu ajutorul unui tabel de selecţie a biţilor. Funcţia E transformă şirul de 32 de biţi într-un bloc de 48 de biţi. Blocul de 48 de biţi rezultat este reprezentat ca şi o mulţime de 8 blocuri de câte 6 biţi fiecare şi se obţine prin alegerea biţilor din şirul de intrare (de 32 de biţi) în concordanţă cu tabelul următor:
32 1 2 3 4 5 4 5 6 7 8 9 8 9 10 11 12 13 12 13 14 15 16 17 16 17 18 19 20 21 20 21 22 23 24 25 24 25 26 27 28 29 28 29 30 31 32 1
Deci primii trei biţi ai şirului E(R) sunt biţii din poziţile 32, 1 şi 2 ale şirului R în timp ce ultimii 2 biţi ai şirului E(R) sunt biţii din poziţiile 32 şi 1 ale şirului R.
Şi operaţia de salvare S poate fi descrisă cu ajutorul unor tabele de selecţie a biţilor. Fiecare dintre funcţiile de selecţie S1,S2,...,S8, transformă un bloc de intrare de 6 biţi într-un bloc de ieşire de 4 biţi. În acest scop se poate folosi câte un tabel de ordonare a biţilor. Tabelul de selecţie pentru S1 are forma următoare:
Număr coloană Linie 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
0 14 4 13 1 2 15 11 8 3 10 6 12 5 9 0 7 1 0 15 7 4 14 2 13 1 10 6 12 11 9 5 3 8 2 4 1 14 8 13 6 2 11 15 12 9 7 3 10 5 0 3 15 12 8 2 4 9 1 7 5 11 3 14 10 0 6 13

53
Dacă B este un bloc de 6 biţi, atunci S1(B) se determină după cum urmează: Primul şi ultimul bit al lui B reprezintă în baza 2 un număr cuprins între 0 şi 3. Fie acest număr k. Cei 4 biţi din mijlocul lui B reprezintă în baza 2 un număr cuprins între 0 şi 15. Fie acest număr l. Se alege din tabel numărul din linia k şi din coloana l. Acesta este un număr cuprins între 0 şi 15 şi deci este reprezentat pe 4 biţi. Acest bloc de 4 biţi reprezintă şirul S1(B) al lui S1 pentru intrarea B. De exemplu, pentru intrarea 011011 se obţine linia 01, adică 1 şi coloana 1101, adică 13. În linia 1 şi coloana 13 se găseşte 5 şi deci rezultatul este 0101. Tabelele de selecţie pentru cutiile S2,...,S8 sunt:
S2 S3
15 1 8 14 6 11 3 4 9 7 2 13 12 0 5 10 10 0 9 14 6 3 15 5 1 13 12 7 11 4 2 8 3 13 4 7 15 2 8 14 12 0 1 10 6 9 11 5 13 7 0 9 3 4 6 10 2 8 5 14 12 11 15 1 0 14 7 11 10 4 13 1 5 8 12 6 9 3 2 15 13 6 4 9 8 15 3 0 11 1 2 12 5 10 14 7 13 8 10 1 3 15 4 2 11 6 7 12 0 5 14 9 1 10 13 0 6 9 8 7 4 15 14 3 11 5 2 12 S4 S5
7 13 14 3 0 6 9 10 1 2 8 5 11 12 4 15 2 12 4 1 7 10 11 6 8 5 3 15 13 0 14 9 13 8 11 5 6 15 0 3 4 7 2 12 1 10 14 9 14 11 2 12 4 7 13 1 5 0 15 10 3 9 8 6 10 6 9 0 12 11 7 13 15 1 3 14 5 2 8 4 4 2 1 11 10 13 7 8 15 9 12 5 6 3 0 14 3 15 0 6 10 1 13 8 9 4 5 11 12 7 2 14 11 8 12 7 1 14 2 13 6 15 0 9 10 4 5 3
S6 S7
12 1 10 15 9 2 6 8 0 13 3 4 14 7 5 11 4 11 2 14 15 0 8 13 3 12 9 7 5 10 6 1 10 15 4 2 7 12 9 5 6 1 13 14 0 11 3 8 13 0 11 7 4 9 1 10 14 3 5 12 2 15 8 6 9 14 15 5 2 8 12 3 7 0 4 10 1 13 11 6 1 4 11 13 12 3 7 14 10 15 6 8 0 5 9 2 4 3 2 12 9 5 15 10 11 14 1 7 6 0 8 13 6 11 13 8 1 4 10 7 9 5 0 15 14 2 3 12
S8
13 2 8 4 6 15 11 1 10 9 3 14 5 0 12 7 1 15 13 8 10 3 7 4 12 5 6 11 0 14 9 2 7 11 4 1 9 12 14 2 0 6 10 13 15 3 5 8 2 1 14 7 4 10 8 13 15 12 9 0 3 5 6 11
Permutarea P poate fi descrisă cu ajutorul următorului tabel:
16 7 20 21 29 12 28 17 1 15 23 26 5 18 31 10 2 8 24 14
32 27 3 9 19 13 30 6 22 11 4 25
Valoarea P(L) a funcţiei P definită de acest tabel este obţinută pe baza şirului de biţi L considerând că cel de al 16-lea bit al lui L este primul bit al lui P(L), că cel de al 7-lea bit al lui L este cel de al doilea bit al lui P(L), ş.a.m.d.

54
În continuare se explică modul de generare a cheilor, folosite în cadrul algoritmului DES. Cheia K_i (vezi relaţia (2)), pentru 1 6i≤ ≤ , este un bloc de 48 de biţi. Calculul acestui bloc este prezentat în figura 3 crpt.
Analizând această figură se constată că pentru generarea cheilor de criptare se fac două tipuri de operaţii: permutări şi deplasări la stânga. În continuare se prezintă aceste două tipuri de operaţii. Câte un bit din fiecare octet al unei chei poate fi utilizat pentru detecţia de erori în generara cheilor, distribuirea cheilor şi stocarea cheilor. Biţii 8, 16,..., 64 dintr-o cheie se folosesc pentru a asigura imparitatea fiecărui octet. De aceea s-a afirmat că numărul de biţi ai cheii algoritmului DES este 56 deşi în figura 3 crpt blocul iniţial are doar 48 de biţi. Varianta 1 de permutare este realizată cu ajutorul următorului tabel:
PC-1 57 49 41 33 25 17 9 1 58 50 42 34 26 18 10 2 59 51 43 35 27 19 11 3 60 52 44 36 63 55 47 39 31 23 15 7 62 54 46 38 30 22 14 6 61 53 45 37 29 21 13 5 28 20 12 4
Tabelul este împărţit în două părţi, cu cea de sus efectuându-se alegerea biţilor din şirul C() iar cu cea de jos alegerea biţilor din şirul D(). Numerotând biţii CHEII de la 1 la 64, şirul C() este format cu ajutorul celui de al 57-lea bit al CHEII, urmat de cel de al 49-lea bit al CHEII, urmat de cel de al 41lea bit al CHEII,...,urmat de cel de al 44-lea bit al CHEII şi de cel de al 36-lea bit al CHEII. Şirul de biţi D() este format din biţii CHEII cu numerele de ordine 63, 55, 47,..., 12 şi 4. Cu şirurile C() şi D() definite astfel se pot calcula blocurile Cn şi Dn pe baza blocurilor Cn-1 şi Dn-1, pentru n = 1, 2,..., 16. Această sarcină este îndeplinită cu ajutorul operaţiilor de deplasare la stânga ale blocurilor individuale. Numărul de deplasări la stânga cerut în fiecare iteraţie este specificat în tabelul următor:
Numărul iteraţiei Numărul de deplasări la stânga 1 1 2 1 3 2 4 2 5 2 6 2 7 2 8 2 9 1 10 2 11 2 12 2 13 2 14 2 15 2 16 1
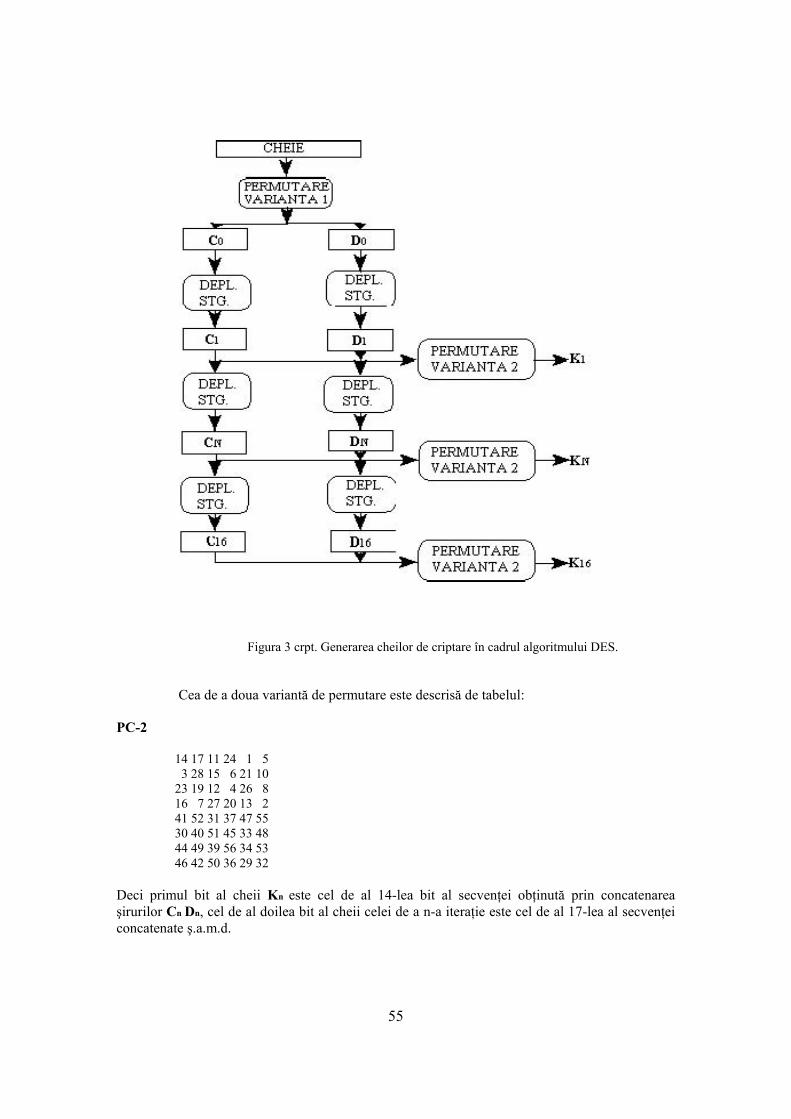
55
Figura 3 crpt. Generarea cheilor de criptare în cadrul algoritmului DES.
Cea de a doua variantă de permutare este descrisă de tabelul:
PC-2
14 17 11 24 1 5 3 28 15 6 21 10 23 19 12 4 26 8 16 7 27 20 13 2 41 52 31 37 47 55 30 40 51 45 33 48 44 49 39 56 34 53 46 42 50 36 29 32
Deci primul bit al cheii Kn este cel de al 14-lea bit al secvenţei obţinută prin concatenarea şirurilor Cn Dn, cel de al doilea bit al cheii celei de a n-a iteraţie este cel de al 17-lea al secvenţei concatenate ş.a.m.d.

56
Moduri de aplicare ale algoritmului DES
ECB -Electronic Code Book - Textul clar al mesajului, M, este împărţit în blocuri de 64 de biţi şi fiecare dintre aceste blocuri este criptat folosind cheia K. Acest mod de aplicare este sensibil la atacuri de tipul cut&paste.
CBC -Cipher Block Chaining -M este din nou segmentat în blocuri de 64 de biţi. Acestea sunt cifrate ca la ECB. Se calculează funcţia sau-exclusiv între blocul curent de text clar şi blocul anterior cifrat. Rezultatul se criptează cu cheia K. La început se calculează sau-exclusiv între primul bloc de text clar şi un vector de iniţializare (IV). În scopul decriptării, fiecare bloc este prima dată descifrat folosind cheia K şi apoi se calculează funcţia sau-exclusiv între rezultat şi anteriorul bloc de text cifrat sau IV. Erorile de transmisie vor afecta două blocuri. Anumiţi biţi dintr-un bloc de text clar vor fi schimbaţi dacă blocul precedent a fost atacat.
OFB -Output Feedback -Un vector de iniţializare este criptat folosind cheia K şi apoi cei mai din stânga k biţi ai rezultatului se utilizează ca şi un şir cheie. Apoi se consideră următorii (spre dreapta) k biţi din vectorul de iniţializare şi acest nou şir este criptat pentru a se obţine noul şir cheie. Pentru a se produce textul cifrat se calculează sau-exclusiv între blocurile textului clar şi şirurile cheie. Decriptarea este foarte simplă. Se generează aceleaşi şiruri cheie şi se calculează sau-exclusiv între blocurile textului cifrat şi aceste şiruri cheie.
5.2.1.1 Variante de DES
DES triplu -Această variantă a fost deja menţionată.
DES cu sub-chei independente- La fiecare iteraţie se utilizează o cheie independentă. Aceste chei nu se mai generează cu metoda descrisă în figura 3 cprt, ci se extrag direct din cheia principală. Această cheie are un număr total de 768 de biţi (16 iteraţii x 48 de biţi). În acest mod atacurile bazate pe forţa brută devin impracticabile.
DESX- Este o variantă dezvoltată la RSA Data Security Inc. bazată pe o tehnică numită de transparenţă. Pe lângă cheia obişnuită de 56 de biţi se mai genereazăşi o cheie de 64 de biţi, numită cheie transparentă. Aceşti 64 de biţi sunt însumaţi cu fiecare bloc de text clar înainte de aplicarea algoritmului DES clasic. După ultima iteraţie a algoritmului DES se face suma modulo 2 între rezultat şi cheia transparentă. Această variantă măreşte securitatea la atacurile prin criptanaliză diferenţialăşi liniară.
DES generalizat (GDES). Această variantă a fost proiectată pentru a mări viteza algoritmului. Se lucrează cu blocuri de text clar de dimensiune mai mare, dar numărul de operaţii de calcul rămâne constant. Blocurile de text clar, de dimensiune variabilă, sunt împărţite în q sub-blocuri de 32 de biţi. La fiecare iteraţie se construieşte funcţia f pentru cel mai din dreapta sub-bloc. Rezultatul este însumat modulo 2 cu toate celelalte sub-blocuri de text clar care sunt apoi rotite spre dreapta. Numărul de iteraţii este variabil. Dacă se alege un număr de 16 iteraţii şi valoarea 2 pentru q se obţine algoritmul DES clasic. Din păcate pentru orice alegere a parametrilor, q şi număr de iteraţii, securitatea asigurată de GDES este mai slabă decât securitatea asigurată de DES.
DES cu cutii S alternative. Este o variantă în care construcţia cutiilor S este diferită de cea descrisă mai sus. În unele cazuri dimensiunile acestor cutii sunt variabile. Dacă construcţia acestor cutii depinde de cheie atunci se obţine varianta de DES numită DES cu cutii S dependente de cheie. Avantajul acestei variante este că poate fi implementată

57
hard.
5.2.2 Algoritmul IDEA A fost conceput în Elveţia de către Xuejia Lai şi James Massey în anul 1992. Patentul său
se găseşte la firma Ascom. Principala sa aplicaţie este programul de criptare PGP. Este unul dintre sistemele de criptare cele mai rapide şi mai sigure disponibile la ora actuală. Foloseşte o cheie de 128 de biţi. Pe baza acesteia se construiesc 52 de sub-chei cu lungimea de 16 biţi fiecare. Câte două dintre acestea se utilizează la fiecare dintre cele 8 iteraţii ale algoritmului, şi câte 4 se utilizează înaintea fiecărei iteraţii şi după ultima iteraţie. Nu foloseşte nici un tabel de alocare de biţi şi nici o cutie de tip S. Cifrarea şi descifrarea se fac pe blocuri de câte 64 de biţi. Se bazează pe utilizarea unor operaţii algebrice utile în operaţiile de criptare cum ar fi suma modulo 2, suma modulo 2
16 , produsul modulo 2
16 +1. În continuare se dau câteva explicaţii referitoare la aceste
înmulţiri. Operaţia de înmulţire cu zero are ca rezultat zero şi nu este o operaţie inversabilă. Dar înmulţirea folosită în acest algoritm trebuie să fie o operaţie inversabilă. Numărul 2
16 +1 are
valoarea 65537 şi este prim. Pe baza tabelului de înmulţire specific mulţimii claselor de resturi modulo 2
16 +1 se constată că această operaţie este inversabilă dacă se evită înmulţirea cu zero (se
elimină din tabel prima linie şi prima coloană). Toate aceste operaţii se efectuează asupra unor sub-blocuri de 16 biţi. S-a dovedit că IDEA este mai sigur decât DES la atacuri de criptanaliză diferenţială. Descrierea algoritmului IDEA Fie cele patru sferturi ale textului clar care trebuie criptat notate cu A, B, C şi D, şi cele 52 de sub-chei notate cu K(1) … K(52). Înainte sau în cursul primei iteraţii se efectuează următoarele operaţii: Se înmulţeşte A cu K(1). Rezultatul va reprezenta noua valoare a lui A. Se adună modulo 2
16 K(2) la B. Rezultatul va reprezenta noua valoare a lui B. Se adună modulo 2
16
K(3) la C. Rezultatul va reprezenta noua valoare a lui C. Se înmulţeşte D cu K(4). Rezultatul va reprezenta noua valoare a lui D. Prima iteraţie propriuzisă constă din executarea următoarelor operaţii: Se calculează suma modulo 2 dintre A şi C (rezultatul se notează cu E). Se calculează suma modulo 2 dintre B şi D (şi se notează cu F). Se înmulţeşte E cu K(5). Rezultatul reprezintă noua valoare a lui E. Se adună modulo 2
16
noua valoare a lui E la F. Rezultatul va reprezenta noua valoare a lui F. Se înmulţeşte noua valoare a lui F cu K(6). Se adună rezultatul, care reprezintă noua valoare a lui F, la E. Se modifică valorile lui A şi C însumând modulo 2 aceste valori cu valoarea curentă a lui E. Noile valori pentru A şi C se substituie una celeilalte obţinându-se astfel două dintre cele 4 blocuri iniţiale ale celei de a doua iteraţii şi anume A şi C. Se modifică valorile lui B şi D, însumând modulo 2 aceste valori cu valoarea curentă a lui F. Noile valori pentru B şi D se substituie una celeilalte obţinându-se astfel celelalte două dintre cele 4 blocuri iniţiale ale celei de a doua iteraţii şi anume B şi D. Prima iteraţie este prezentată în figura 4 crpt. Celelalte 7 iteraţii sunt identice, doar că se folosesc celelalte sub-chei: de la K(7) la K(12) pentru cea de a doua iteraţie şi de la K(43) la K(48) pentru cea de a 8-a iteraţie. La ultima iteraţie nu se mai face substituţia finală dintre A şi C respectiv B şi D. Ultimele operaţii sunt: Se înmulţeşte A cu K(49). Se adună modulo 2
16
K(50) la B. Se adună modulo 216
K(51) la C. Se înmulţeşte D cu K(52). Cele 8 iteraţii ale IDEA sunt prezentate în figura 5 crpt.

58
Figura 4 crpt. Prima iteraţie. Figura 5 crpt. Structura algoritmului IDEA. Decriptarea
Cum se poate inversa o iteraţie a algoritmului IDEA, când toate cele 4 blocuri se modifică în acelaşi timp ? Răspunsul se bazează pe o proprietate a sumei modulo 2. Suma modulo 2 a două variabile A şi C nu se modifică atunci când cele două variabile sunt însumate modulo 2 cu o aceeaşi variabilă, X. D:
An = Av + X ; Cn = Cv + X ; ⇒ An + Cn = Av + Cv + X + X = Av + Cv Se observă că variabila X a dispărut. Aceeaşi proprietate este valabilă şi pentru
variabilele B şi D. Întrucât variabilele folosite în iteraţiile algoritmului IDEA sunt funcţii de A + C şi B + D rezultă că cele 4 variabile pot fi recuperate. Inversarea operaţiei de adunare modulo 2
16
se face prin calculul complementului faţă de 2. Pentru prima iteraţie a algoritmului de decriptare se utilizează următoarele chei: KD(1) = 1/K(49) KD(2) = -K(50) KD(3) = -K(51) KD(4) = 1/K(52) Pentru cheile din următoarele iteraţii procedura următoare se repetă de 8 ori, adunând 6 la fiecare indice al unei chei de decriptare şi scăzând 6 din fiecare indice al unei chei de criptare: KD(5) = K(47) KD(6) = K(48) KD(7) = 1/K(43) KD(8) = -K(45) KD(9) = -K(44) KD(10) = 1/K(46) Generarea sub-cheilor
Primele 8 sub-chei se obţin prin segmentarea cheii originale a algoritmului IDEA în

59
segmente de 16 biţi. Apoi se efectuează o deplasare circulară la stânga a cheii originale cu 25 de poziţii şi o nouă segmentare obţinându-se următoarele 8 chei. Această procedură de deplasare la stânga şi segmentare este repetată până când se obţin toate cele 52 de chei de criptare necesare. 5.2.3. Algoritmul BLOWFISH
Acest algoritm a fost conceput de Bruce Schneier. Este un algoritm de criptare bazat pe o structură Feistel. A fost aleasă o funcţie f mai simplă decât în cazul algoritmului DES obţinându-se aceeaşi securitate dar o eficienţă şi o viteză de calcul sporite. Cea mai impotantă particularitate a algoritmului Blowfish este metoda de generare a cheilor. Cheile iteraţiilor precum şi întregul conţinut al cutiilor de tip S sunt create prin iteraţii multiple ale sistemului de criptare de bloc. În acest mod creşte securitatea sistemului de criptare împotriva atacurilor bazate pe metode exhaustive de căutare a cheilor, chiar şi pentru chei scurte.
Descriere Spre deosebire de DES, Blowfish aplică funcţia f jumătăţii din stânga a blocului de text
clar rezultatul fiind însumat modulo 2 cu jumătatea din dreapta a blocului. Se fac 16 iteraţii. La începutul fiecărei iteraţii se calculează suma modulo 2 dintre blocul din stânga şi sub-cheia corespunzătoare acelei iteraţii. Apoi se aplică funcţia f blocului din stânga şi rezultatul se adună modulo 2 cu blocul din dreapta. La sfârşitul ultimei iteraţii se substituie una celeilalte cele două jumătăţi de bloc obţinute. În fiecare iteraţie se foloseşte o singură sub-cheie, funcţia f nu foloseşte nici o sub-cheie, dar foloseşte cutii S care depind de sub-cheie. După ultima iteraţie se calculează suma modulo 2 a jumătăţii din dreapta a blocului de biţi cu sub-cheia 17 şi se calculează suma modulo 2 a jumătăţii din stânga a blocului de biţi cu sub-cheia 18.
Funcţia f Blowfish foloseşte 4 cutii de tip S. Fiecare are 256 de intrări la care se aduc blocuri de
câte 32 de biţi. Calculul funcţiei f se bazează pe următoarea succesiune de operaţii: Se foloseşte primul octet al blocului de 32 de biţi de intrare pentru a găsi o intrare în prima cutie de tip S, cel de al doilea octet pentru a găsi o intrare în cea de a doua cutie de tip S, ş.a.m.d. Valoarea funcţiei f este :
((S1(B1) + S2(B2)) + S3(B3)) + S4(B4)) unde se foloseşte adunarea modulo 232
, notată cu + .
Decriptarea Decriptarea se realizează la fel ca şi criptarea, folosind cele 18 sub-chei de iteraţie în
ordine inversă. Se poate face aşa deoarece se foloseşte proprietatea sumei modulo 2 demonstrată la prezentarea decriptării algoritmului IDEA. Într-adevăr există două operaţii de adunare modulo 2 după ultima utilizare a funcţiei f şi numai una singură înaintea primei utilizări a funcţiei f.
Generarea sub-cheilor Acest proces converteşte o cheie iniţială de cel mult 448 de biţi în câteva zone de sub-
chei care ocupă un spaţiu de 4168 de octeţi. Blowfish foloseşte un număr mare de sub-chei. Acestea trebuiesc generate înaintea oricărei operaţii de criptare sau de decriptare. În continuare se prezintă zonele de sub-chei.
Zona 1. Este numităşi zona P şi constă din 18 sub-chei de 32 de biţi: P1, P2,..., P18.

60
Zona 2. Este zona cutiilor de tip S. Există 4 cutii de tip S de 32 de biţi, fiecare cu 256 de intrări:
S1,0, S1,1,..., S1,255; S2,0, S2,1,..,, S2,255; S3,0, S3,1,..., S3,255; S4,0, S4,1,..,, S4,255. Generarea sub-cheilor se face folosind algoritmul Blowfish. Etapele de generare a cheilor sunt: 1. Iniţializarea zonelor 1 şi apoi 2, în ordine, cu un şir fixat. Acest şir constă din partea fracţionară a numărului pi exprimată în formă hexa-zecimală. De exemplu: P1 = 0x243f6a88
P2 = 0x85a308d3
P3 = 0x13198a2e
P4 = 0x03707344
2. Se calculează suma modulo 2 între P1 şi primii 32 de biţi ai cheii iniţiale, se calculează suma modulo 2 între P2 şi următorii 32 de biţi ai cheii iniţiale, ş.a.m.d. (e posibil să se depăşeasă P18). Acest ciclu se repetă până când întreaga zonă 1 a fost însumată modulo 2 cu biţi ai cheii iniţiale a algoritmului Blowfish. Pentru orice cheie iniţială scurtă există cel puţin o cheie echivalentă mai lungă; de exemplu dacă A este o cheie de 64 de biţi atunci AA, AAA, etc. sunt chei echivalente. 3. Se criptează texte în clar formate numai din biţi nuli cu algoritmul Blowfish folosind sub-cheile descrise în paşii (1) şi (2). 4. Se înlocuiesc cheile P1 şi P2 cu rezultatul obţinut la pasul (3). 5. Se criptează rezultatul obţinut la pasul (3) folosind algoritmul Blowfish cu cheile obţinute la pasul (4). 6. Se înlocuiesc cheile P3 şi P4 cu rezultatul obţinut la pasul (5). 7. Se continuă procesul, înlocuind toate elementele zonelor 1 şi 2 cu rezultatele aplicării algoritmului Blowfish. Pentru generarea tuturor sub-cheilor de care este nevoie sunt necesare 521 de rulări ale algoritmului Blowfish.
O particularitate a algoritmului Blowfish este utilizarea cutiilor de tip S dependente de chei. Această construcţie are câteva avantaje:
-Se realizează o bună protecţie împotriva atacurilor prin criptanaliză liniară sau diferenţială;
-Implementarea cutiilor variabile este mai simplă decât cea a unor cutii fixe; -Reducerea necesităţii stocării unor structuri de date mari. Există câteva modalităţi de simplificare a algoritmului Blowfish care pot conduce la
reducerea volumului de memorie ocupat precum şi la creşterea vitezei. Acestea sunt prezentate în continuare:
-Utilizarea unui număr mai mic de cutii de tip S, de dimensiuni mai mici ; -Reducerea numărului de iteraţii (de exemplu de la 16 la 8). Numărul de iteraţii necesar pentru asigurarea unui anumit nivel de securitate depinde de lungimea sub-cheilor folosite. - Utilizarea unei metode neiterative de calcul al sub-cheilor. În acest mod s-ar putea obţine chei independente una de cealaltă.

61
5.2.4. Algoritmul TWOFISH
Twofish este un algoritm de criptare a blocurilor de 128 de biţi care lucrează cu o cheie variabilă de lungime maximă de 256 de biţi. Sunt folosite 40 de sub-chei de 32 de biţi. La începutul algoritmului se calculează suma modulo 2 între 4 chei şi blocul de text clar, iar la sfârşitul său se calculează suma modulo 2 între alte 4 chei şi întregul text rezultat. Face 16 iteraţii ale unei structuri Feistel folosind o funcţie f bijectivă construită cu ajutorul a 4 cutii de tip S dependente de chei, cu ajutorul unei matrici fixe de dimensiune 4x4, cu ajutorul unei transformări pseudo-Hadamard, cu ajutorul unor rotaţii de biţi şi cu ajutorul unei scheme de generare a cheilor. În fiecare iteraţie sunt folosite 2 sub-chei.
Acest algoritm poate fi implementat şi hard folosind un număr de 14000 de porţi. Liberatea de proiectare a funcţiei de iteraţie şi a sub-cheilor permite o mare variabilitate a raportului dintre viteza de calcul şi lungimea programului.
O iteraţie a algoritmului Twofish
Blocul de text clar este împărţit în patru sferturi: Q0...Q3. Q3 este rotit cu o poziţie spre stânga. Q0 şi Q1 sunt rotite spre stânga cu 8 poziţii şi sunt trimise la cele 4 cutii de tip S dependente de sub-cheie care au intrări şi ieşiri de 8 biţi. Apoi octeţii din fiecare cutie de tip S sunt "combinaţi" prin înmulţire matricială cu următoarea matrice (numită matrice MDS (Maximum Distance Separation)):
01 EF 5B 5B 5B EF EF 01 EF 5B 01 EF EF 01 EF 5B peste câmpul Galois al lui 2
8. Fiind vorba despre octeţi este vorba despre o înmulţire modulară de
polinoame cu coeficienţii din GF(28) modulo x
8 + x
6 + x
5 + x
3 +1. Acest gen de înmulţire este
definit în paragraful de prezentare a bazelor matematice ale algoritmilor de criptare. Rezultatul acestei înmulţiri este un şir de 16 biţi.
Acesta este redus la un şir de 8 biţi folosind următoarea metodă: Polinomul modul, considerat ca şi şirul binar 101101001, este rotit la stânga până când primul său bit coincide cu primul bit de 1 al rezultatului. Apoi se calculează suma modulo 2 dintre polinomul modul rotit şi rezultat. Acceastă sumă reprezintă noul rezultat. Apoi se roteşte polinomul modul spre dreapta până când primul său bit coincide cu primul bit de 1 din noul rezultat. Apoi se calculează suma modulo 2 dintre rezultat şi polinomul modul rotit. Astfel se obţine noul rezultat. Această procedură se repetă până când lungimea rezultatului devine egală sau mai mică decât 8. În acest fel la ieşirile celor 4 cutii de tip S se obţin 4 şiruri de 8 biţi (adică 32 de biţi pentru Q0 şi 32 de biţi pentru Q1). Aceste două şiruri de 32 de biţi sunt amestecate cu ajutorul unei transformări Pseudo-Hadamard (PHT). Această transformare este descrisă în paragraful referitor la bazele matematice ale criptării.
Apoi prima sub-cheie pentru iteraţie este adunată la cea formată din Q0 şi se calculează suma modulo 2 între rezultatul obţinut şi Q2.
Cea de a doua sub-cheie pentru iteraţie este adunată la cheia formată din Q1 şi se calculează suma modulo 2 între rezultatul obţinut şi Q3.
La sfârşit, Q2 se roteşte cu o poziţie la dreapta şi cele două jumătăţi ale blocului îşi

62
schimbă poziţia (Q0 se schimbă cu Q2 iar Q1 se schimbă cu Q3). La fel ca şi la algoritmul DES cele două jumătăţi nu se schimbă între ele după ultima iteraţie.
Generarea cheilor
Procesul de generare a cheilor începe prin construcţia vectorilor pentru 3 chei, fiecare având o lungime egală cu jumătate din lungimea cheii iniţiale. Primii 2 vectori se construiesc prin împărţirea cheii iniţiale în blocuri de 32 de biţi. Numerotând aceste părţi începând cu zero, cele cu indici pari devin M(e), iar cele cu indici impari devin M(o).
Cel de al treilea vector se formează împărţind cheia iniţială în blocuri de 64 de biţi şi construind o parte de 32 de biţi a vectorului cheie prin înmulţirea fiecărui bloc de 64 de biţi cu matricea RS:
01 A4 55 87 5A 58 DB 9E A4 56 82 F3 1E C6 68 E5 02 A1 FC C1 47 AE 3D 19 A4 55 87 5A 58 DB 9E 03
Această înmulţire matricială corespunde unei înmulţiri peste câmpul Galois al lui 28
cu polinomul
modul x8 + x
6 + x
3 + x
2 +1. Cuvintele rezultante cu lungimea de 32 de biţi sunt apoi plasate în
ordine inversă în vectorul cheie notat S. Fiecare dintre cutiile de tip S fixe, cu intrări şi ieşiri de 8 biţi, notate q(0) şi q(1) este construită pornind de la 4 cutii de tip S cu intrări şi ieşiri de 4 biţi. Pentru q(0), cutiile de tip S sunt:
Intrare 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 T0 8 1 7 13 6 15 3 2 0 11 5 9 14 12 10 4 T1 14 12 11 8 1 2 3 5 15 4 10 6 7 0 9 13 T2 11 10 5 14 6 13 9 0 12 8 15 3 2 4 7 1 T3 13 7 15 4 1 2 6 14 9 11 3 0 8 5 12 10 Pentru q(1), cutiile de tip S sunt:
Intrare 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 T0 2 8 11 13 15 7 6 14 3 1 9 4 0 10 12 5 T1 1 14 2 11 4 12 3 7 6 13 10 5 15 9 0 8 T2 4 12 7 5 1 6 9 10 0 14 13 8 2 11 3 15 T3 11 9 5 1 12 3 13 14 6 4 7 15 2 0 8 10
Fiecare cutie de tip S se construieşte după cum urmează:
� Octetul de intrare este împărţit în părţile sale mai semnificativă şi mai puţin semnificativă, A şi B. � Noua valoare a lui A este suma modulo 2 a vechilor valori ale lui A şi B. � Noua valoare a lui B este suma modulo 2 a vechilor valori ale lui A şi B rotite la dreapta

63
cu o poziţie sau cu opt poziţii dacă vechea valoare a lui A a fost impară. � Noile valori ale lui A şi B substituie vechile valori A şi B la intrările T0 şi T1 ale cutiilor S pe 16 biţi. � Noua valoare a lui A este suma modulo 2 a vechilor valori ale lui A şi B. � Noua valoare a lui B este suma modulo 2 a vechilor valori ale lui A şi B rotite la dreapta cu o poziţie sau cu opt poziţii dacă vechea valoare a lui A a fost impară. � Noile valori ale lui A şi B substituie vechile valori A şi B la intrările T2 şi T3 ale cutiilor S pe 16 biţi. � A şi B sunt combinate apoi în ordine inversă pentru a forma octetul rezultat. Cele 4 cutii de tip S dependente de chei se formează din elementele de 32 de biţi ale vectorului cheie S după cum urmează:
Dacă cheia iniţială are o lungime de 256 de biţi atunci vectorul cheie S are 4 elemente de 32 de biţi, S(0), S(1), S(2), şi S(3). În acest caz utilizarea celor 4 cutii de tip S dependente de cheie este echivalentă cu efectuarea următoarelor operaţii: output = q(0)(S(0,0) xor q(1)(S(1,0) xor q(1)(S(2,0) xor q(0)(S(3,0) xor q(1)(input)))) output = q(1)(S(0,1) xor q(1)(S(1,1) xor q(0)(S(2,1) xor q(0)(S(3,1) xor q(0)(input)))) output = q(0)(S(0,2) xor q(0)(S(1,2) xor q(1)(S(2,2) xor q(1)(S(3,2) xor q(0)(input)))) output = q(1)(S(0,3) xor q(0)(S(1,3) xor q(0)(S(2,3) xor q(1)(S(3,3) xor q(1)(input)))) unde S(2,1) reprezintă octetul 1 al cuvântului 2 din vectorul cheie S.
Dacă cheia iniţială are o lungime de 192 de biţi definirea cutiilor S se simplifică la: output = q(0)(S(0,0) xor q(1)(S(1,0) xor q(1)(S(2,0) xor q(0)(input))) output = q(1)(S(0,1) xor q(1)(S(1,1) xor q(0)(S(2,1) xor q(0)(input))) output = q(0)(S(0,2) xor q(0)(S(1,2) xor q(1)(S(2,2) xor q(1)(input))) output = q(1)(S(0,3) xor q(0)(S(1,3) xor q(0)(S(2,3) xor q(1)(input))) şi dacă cheia iniţială are o lungime de doar 128 definirea cutiilor S se simplifică şi mai mult: output = q(0)(S(0,0) xor q(1)(S(1,0) xor q(1)(input)) output = q(1)(S(0,1) xor q(1)(S(1,1) xor q(0)(input)) output = q(0)(S(0,2) xor q(0)(S(1,2) xor q(1)(input)) output = q(1)(S(0,3) xor q(0)(S(1,3) xor q(0)(input))
Sub-cheile care se adună la ieşirile funcţiilor înainte de a se calcula suma lor modulo 2 cu un alt sfert de bloc sunt generate de un proces asemănător cu o iteraţie a algoritmului Twofish, dar cu cutii de tip S dependente de chei derivate din vectorii M(e) şi M(o) şi nu din vectorul S. Intrările în toţi cei patru octeţi ai unui cuvânt reprezintă numărul obţinut prin înmulţirea numărului iteraţiei cu 2 şi adunarea lui 1 iar paşii de rotire la stânga au loc fie înainte de calculul funcţiei f, fie după: o rotire la stânga cu 8 poziţii se efectuează înainte de PHT iar o rotire cu 9 poziţii la stânga se efectuează după.
Operaţiile descrise pot fi observate în schema de funcţionare a algoritmului Twofish, prezentată în figura următoare.

64
Figura 6 crpt. Ordinograma algoritmului Twofish. 5.2.5. Algoritmul RC6
Proiectat de Ronald C. Rivest, în anul 1998, RC6 se bazează pe iteraţii de structuri Feistel. Acestea nu operează însă asupra celor două jumătăţi ale blocului de date, ci asupra unor perechi de sferturi ale blocului de date. Între aceste iteraţii au loc transferuri de date. Particularitatea cea mai importantă a acestui algoritm este utilizarea unor deplasări circulare cu numere de poziţii dependente de datele de cifrat. Un alt element neliniar utilizat în construcţia funcţiei f, specifică unei structuri Feistel, utilizat în algoritmul RC6 este o funcţie pătratică.
Algoritmul este conceput în aşa fel încât să poată lucra cu blocuri de lungime variabilă, cu o cheie iniţială de lungime variabilă şi să efectueze un număr variabil de iteraţii. În continuare se prezintă varianta propusă pentru competiţia destinată construcţiei standardului AES. Descrierea originală este disponibilă la adresa http://theory.lcs.mit.edu/~rivest .
RC6 foloseşte 44 de sub-chei, notate S0 … S43, fiecare având lungimea de 32 de biţi. Textul în clar este segmentat în blocuri de 128 de biţi. Fiecare bloc obţinut astfel este împărţit în 4 sferturi, de lungimi egale notate A, B, C, şi D. Primii 4 octeţi criptaţi formează noul A, primul octet codat reprezentând cel mai puţin semnificativ octet al noului A.
RC6 începe cu un pas iniţial de albire; se calculează suma modulo 2 între B şi S0, respectiv între D şi S1. Fiecare iteraţie a algoritmului RC6 foloseşte 2 sub-chei; pentru construcţia primeia se utilizează S2 şi S3, iteraţii succesive utilizând chei succesive. O iteraţie a algoritmului RC6 se desfăşoară duă cum urmează: Rezultatul aplicării funcţiei f blocului B (f(x) = x(2x+1)), este rotit la stânga cu 5 poziţii, între noul rezultat şi blocul A calculându-se suma modulo 2. Rezultatul aplicării funcţiei f blocului D este rotit cu 5 poziţii spre stânga şi apoi se calculează suma modulo 2 între noul şir obţinut şi blocul C.

65
Se efectuează o deplasare circulară spre stânga a blocului C. Numărul de poziţii cu care se face această deplasare este specificat de cei mai semnificativi 5 biţi ai şirului obţinut prin aplicarea funcţiei f blocului B şi rotirea la stânga cu 5 poziţii. Se efectuează o deplasare circulară spre stânga a blocului A. Numărul de poziţii cu care este efectuată această deplasare este specificat de cei mai semnificativi 5 biţi ai şirului obţinut prin aplicarea funcţiei f blocului D şi rotirea rezultatului cu 5 biţi spre stânga. Apoi se calculează suma modulo 2 între prima sub-cheie a iteraţiei şi blocul A şi suma modulo 2 între cea de a doua sub-cheie a iteraţiei şi blocul C. Apoi cele 4 sferturi ale blocului sunt rotite după cum urmează: Valoarea lui A este plasată în D, valoarea lui B este plasată în A, valoarea lui C este plasată în B şi valoarea (originală) a lui D este plasată în C. În figura următoare se prezintă ordinograma unei iteraţii a algoritmului RC6.
Figura 7 crpt. O iteraţie a algoritmului RC6.
După încheierea celei de a douăzecea iteraţii are loc un pas suplimentar de albire: se calculează suma modulo 2 între A şi S42, respectiv între C şi S43.
Generarea cheilor în cadrul algoritmului RC6 se realizează cu metoda descrisă în următorul program.
Input: User-supplied b byte key preloaded into the c-v = 3_ maxfc; 2r + 4g word array L[0;…; c - 1] for s = 1 to v do Number r of rounds {Output: w-bit round keys S[0; …;2r + 3] A = S[i] =(S[i] +A + B)<<<3 Procedure: S[0] = Pw B = L[j] =(L[j] +A + B)<<<(A + B) for i = 1 to 2r + 3 do i = (i + 1) mod (2r + 4) S[i] =S[i -1] + Qw j = (j + 1) mod c A = B = i = j = 0 }

66
5.2.6. Standardul AES, Advanced Encryption Standard (Rijndael)
Algoritmul care a câştigat competiţia pentru standardul AES este numit Rijndeal. Acesta realizează doar operaţii pe octeţi întregi. El este foarte flexibil deoarece dimensiunea blocurilor cu care se lucrează poate fi aleasă de valoare 128, 192 sau 256 de biţi. Rijndael are un număr variabil de iteraţii. Acesta poate fi (fără a considera ultima iteraţie, care nu este completă):
� 9 dacă atât blocurile cât şi cheia iniţială au o lungime de 128 de biţi; � 11 dacă fie blocurile fie cheia iniţială au lungimea de 192 de biţi şi nici una dintre ele nu are o lungime superioară acestei valori; � 13 dacă atât blocurile cât şi cheia au o lungime de 256 de biţi. � Pentru a cripta un bloc de date cu algoritmul Rijndael, primul pas presupune calculul unui sau exclusiv între blocul de text clar şi o sub-cheie. Paşii următori sunt iteraţiile care se vor prezenta în continuare. Ultimul pas este constituit de ultima iteraţie care este incompletă, neconţinând operaţia de amestecare a coloanelor, the Mix Column step. În continuare se prezintă varianta care lucrează cu blocuri de 128 de biţi. Iteraţiile algoritmului
Fiecare iteraţie obişnuită se efectuează în 4 paşi, aşa după cum se poate constata analizând figura 8 crpt. Primul pas este cel de substituire al octeţilor, the Byte Sub step. În acest pas fiecare octet al textului clar este substituit cu un octet extras dintr-o cutie de tip S. Cutia de tip S este descrisă de matricea prezentată pe pagina următoare. Cel de al doilea pas al unei iteraţii uzuale se numeşte deplasarea liniilor, the Shift Row step. Considerând că blocul care trebuie construit este alcătuit cu octeţii numerotaţi de la 1 la 16, aceşti octeţi se aranjează într-un dreptunghi şi se deplasează după cum urmează:
De la la 1 5 9 13 1 5 9 13 2 6 10 14 6 10 14 2 3 7 11 15 11 15 3 7 4 8 12 16 16 4 8 12
Cel de al treilea pas al algoritmului de criptare Rijndael este numit amestecarea coloanelor, the Mix Column step. Acest pas se realizează prin înmulţire matricială: fiecare coloană, în aranjamentul pe care l-am observat, este înmulţită cu matricea:
2 3 1 1 1 2 3 1 1 1 2 3 3 1 1 2
Această înmulţire matricială corepunde unei înmuţiri specifică câmpului Galois al lui 28, definită
de polinomul modul x8
+ x4
+ x3
+ x +1. Această înmulţire (folosind acelaşi polinom modul) a fost prezentatăşi exemplificată în paragraful destinat bazelor matematice ale criptării. Octeţii care trebuie înmulţiţi sunt priviţi ca şi polinoame şi nu ca şi numere. De exemplu prin înmulţirea unui octet cu 3 se obţine rezultatul operaţiei sau-exclusiv dintre acel octet şi şi varianta sa obţinută prin rotirea acelui octet cu o poziţie la stânga. Dacă rezultatul acestei înmulţiri are mai mult de 8 biţi,
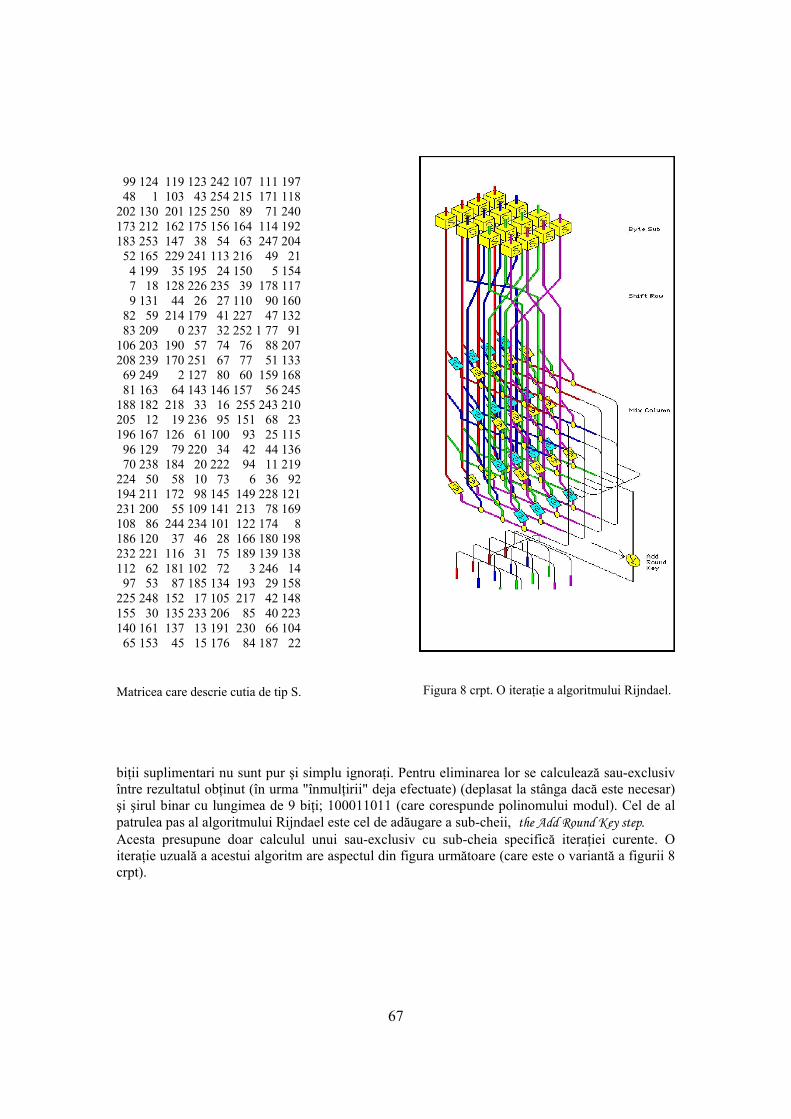
67
99 124 119 123 242 107 111 197 48 1 103 43 254 215 171 118 202 130 201 125 250 89 71 240 173 212 162 175 156 164 114 192 183 253 147 38 54 63 247 204 52 165 229 241 113 216 49 21 4 199 35 195 24 150 5 154 7 18 128 226 235 39 178 117 9 131 44 26 27 110 90 160 82 59 214 179 41 227 47 132 83 209 0 237 32 252 1 77 91 106 203 190 57 74 76 88 207 208 239 170 251 67 77 51 133 69 249 2 127 80 60 159 168 81 163 64 143 146 157 56 245 188 182 218 33 16 255 243 210 205 12 19 236 95 151 68 23 196 167 126 61 100 93 25 115 96 129 79 220 34 42 44 136 70 238 184 20 222 94 11 219 224 50 58 10 73 6 36 92 194 211 172 98 145 149 228 121 231 200 55 109 141 213 78 169 108 86 244 234 101 122 174 8 186 120 37 46 28 166 180 198 232 221 116 31 75 189 139 138 112 62 181 102 72 3 246 14 97 53 87 185 134 193 29 158 225 248 152 17 105 217 42 148 155 30 135 233 206 85 40 223 140 161 137 13 191 230 66 104 65 153 45 15 176 84 187 22
Matricea care descrie cutia de tip S.
Figura 8 crpt. O iteraţie a algoritmului Rijndael.
biţii suplimentari nu sunt pur şi simplu ignoraţi. Pentru eliminarea lor se calculează sau-exclusiv între rezultatul obţinut (în urma "înmulţirii" deja efectuate) (deplasat la stânga dacă este necesar) şi şirul binar cu lungimea de 9 biţi; 100011011 (care corespunde polinomului modul). Cel de al patrulea pas al algoritmului Rijndael este cel de adăugare a sub-cheii, the Add Round Key step. Acesta presupune doar calculul unui sau-exclusiv cu sub-cheia specifică iteraţiei curente. O iteraţie uzuală a acestui algoritm are aspectul din figura următoare (care este o variantă a figurii 8 crpt).

68
Figura 9 crpt. O altă reprezentatre grafică a unei iteraţii a algoritmului Rijndael.
Din ultima iteraţie este omis pasul de amestecare a coloanelor.
Decriptarea
Pentru a decripta mesajul fabricat de algoritmul Rijndael este necesar ca operaţiile descrise să fie înlocuite cu operaţiile lor inverse şi ca acestea să fie aplicate în ordine inversă (prima operaţie din algoritmul de decriptare trebuie să fie inversa ultimei operaţii din algoritmul de criptare). Succesiunea paşilor în algoritmul Rijndael este:
ARK BS SR MC ARK BS SR MC ARK ... BS SR MC ARK BS SR ARK
Deşi această secvenţă nu este simetrică, ordinea unor operaţii poate fi modificată fără ca procesul de criptare să fie afectat. De exemplu pasul de substituire a octeţilor BS (notat cu B în continuare), poate fi la fel de bine făcut şi după pasul de deplasare a liniilor SR (notat cu S în continuare). Această observaţie este utilă pentru procesul de decriptare. Făcând această inversare secvenţa algoritmului, de forma:
A BSMA BSMA ... BSMA BSA
se transformă într-o secvenţă de forma:
A SBMA SBMA ... SBMA SBA (1R)
Pentru fiecare pas s-a folosit notaţia bazată pe prima literă a denumirii engleze a pasului.

69
Dacă se inversează secvenţa care descrie algoritmul se obţine:
ASB AMSB ... AMSB AMSB A (2R)
Comparând secvenţele (1R) şi (2R) se constată că pe lângă diferita poziţionare a spaţiilor (acestea marchează începutul unei noi iteraţii a algoritmului de criptare) singura diferenţă care mai apare este că grupurile "MA" din (1R) sunt înlocuite cu grupuri "AM" în (2R).
E clar că nu este suficientă inversarea ordinii paşilor folosiţi la criptare pentru a se face decriptarea ci trebuie inversate şi operaţiile care compun aceşti paşi. Pentru inversarea pasului ARK trebuie inversată funcţia sau-exclusiv. Dar această inversare se realizează tot cu funcţia sau-exclusiv. De aceea pasul ARK nu trebuie inversat la decriptare. Nu acelaşi lucru se poate spune despre ceilalţi paşi. Este de exemplu cazul pasului de amestecare a coloanelor, MC, (notat cu M în relaţiile (1R) şi (2R)) pentru inversarea căruia, în procesul de decriptare este necesară inversarea matricii cu care se înmulţeşte fiecare vector. La fel trebuie procedat şi cu matricea cutiei de tip S din pasul de substituţie a octeţilor, BS (notat cu B în relaţiile (1R) şi (2R)).
Revenind la relaţiile (1R) şi (2R) este legitimă întrebarea: Trebuie inversată ordinea secvenţei paşilor "MA" şi "AM" pentru decriptare ? Răspunsul este: Nu, deoarece operaţia de înmulţire a matricilor este distributivă în raport cu operaţia de adunare pe câmpul Galois al lui 2
8 .
Operaţia de sau-exclusiv din cadrul pasului MC (M) este de fapt identică cu operaţia de adunare definită pe câmpul Galois al lui 2
8
. De aceea cheile de iteraţie, implicate în procesul de inversare al pasului de amestecare a coloanelor, trebuiesc înmulţite cu inversa matricii de amestecare a coloanelor şi apoi se pot calcula funcţiile sau-exclusiv, la fel ca la criptare (bineînţeles cheile de iteraţie trebuiesc luate în ordine inversă în raport cu ordinea folosită la criptare). Matricea pentru inversarea pasului de amestec al coloanelor este:
14 11 13 9 9 14 11 13
13 9 14 11 11 13 9 14 iar forma sa binară, folosită în algoritmul de decodare este:
1110 1011 1101 1001 01 00 00 00 1001 1110 1011 1101 00 01 00 00 1101 1001 1110 1011 00 00 01 00 1011 1101 1001 1110 00 00 00 01
111 101 110 100 01 01 00 00 110 100 111 101 00 00 01 01 1100 1000 1110 1010 00 00 10 10 1011 1101 1000 1110 01 01 10 10
0 0 1 0 01 01 10 11 Generarea cheilor
Pentru cazul în care se foloseşte o cheie iniţială cu lungimea de 128 biţi sau de 192 de biţi, toate subcheile necesare pentru toate iteraţiile, se obţin din cheia iniţială (prima subcheie fiind chiar cheia iniţială) sau din variante ale cheii iniţiale şi au aceeaşi lungime cu aceasta. Subcheile sunt alcătuite din cuvinte de 4 octeţi. Fiecare cuvânt se obţine calculând sau-exclusiv între cuvântul anterior de 4 octeţi şi cuvântul corespunzător dintr-o variantă anterioară sau rezultatul aplicării unei funcţii acestui cuvânt (din varianta precedentă). Pentru stabilirea primului cuvânt dintr-o anumită variantă, cuvântul iniţial (cel curent pentru iteraţia respectivă) este pentru

70
început rotit cu opt poziţii spre stânga, apoi octeţii săi sunt modificaţi folosind cutia de tip S din pasul de substituţie a biţilor BS (B) corespunzător, iar apoi se calculează sau-exclusiv între primul octet al rezultatului obţinut anterior şi o constantă dependentă de iteraţie. Constantele dependente de iteraţie sunt:
1 2 4 8 16 32 64 128 27 54 108 216 171 77 154 47
94 188 99 198 151 53 106 212 179 125 250 239 197 145 57 114 228 211 189 97... sau în binar: 00000001 00000010 00000100 00001000 00010000 00100000 01000000 10000000 00011011 00110110 01101100 11011000 10101011 01001101 10011010 00101111 01011110 10111100 01100011 11000110 10010111 00110101 01101010 11010100 10110011 01111101 11111010 11101111 11000101 10010001 00111001 01110010 11100100 11010011 10111101 01100001...
puterile lui 2 succesive în reprezentarea din câmpul Galois al lui 28 folosit.
5.3. Algoritmi de criptare cu cheie publică
Algoritmii criptografici prezentaţi până acum erau simetrici: cei doi corespondenţi, expeditorul şi destinatarul cunoşteau amândoi o cheie (secretă pentru orice alt utilizator al reţelei), care se folosea atât pentru criptare cât şi pentru decriptare. De aceea prima problemă de securitate a acestor algoritmi este distribuţia acestei chei secrete. Algoritmii de criptare cu cheie publică pot rezolva această problemă asigurând canale de securitate secrete pentru distribuirea acestei chei. Aceşti algoritmi mai oferă şi o altă funcţie de securitate importantă. Ei oferă o cale pentru ca expeditorul să semneze mesajul pe care doreşte să-l expedieze, semnătura putând fi verificată de oricare dintre ceilalţi utilizatori ai reţelei fără ca aceştia să fie capabili să semneze un alt mesaj şi să pretindă că acesta vine din partea expeditorului considerat.
O schemă ingenioasă care evită multe dintre problemele criptării simetrice a fost propusă în anul 1976 de profesorul Martin Hellman, de la universitatea Stanford şi de fostul său student Whitfield Diffie.
Schema lor de criptare cu cheie publică a fost prima dată prezentată într-un articol din revista IEEE Transactions on Information Theory, permite destinatarului să verifice şi dacă expeditorul este cel declarat în cadrul mesajului şi dacă mesajul a fost cumva falsificat de către un alt utilizator.
Funcţionarea acestei metode de criptare este descrisă în continuare. Bob şi Alice au câte o copie a soft-ului, distribuit liber, de criptare cu cheie publică. Fiecare foloseşte copia proprie pentru a crea o perche de chei. Un mesaj criptat cu una dintre cheile din această pereche de chei poate fi decriptat doar cu cealaltă cheie din aceeaşi pereche. Cea de a doua cheie nu poate fi generată matematic folosind doar prima cheie.
Bob face cunoscută una dintre cheile din perechea sa, aceasta devenind cheia sa publică. Alice face acelaşi lucru. Fiecare păstrează secretă cealaltă cheie din pereche, care devine cheia sa privată.
Dacă Bob vrea să cripteze un mesaj, pe care să-l poată citi doar Alice, atunci el foloseşte cheia publică a lui Alice (care este disponibilă tuturor); dar acest mesaj va putea fi decodat doar cu ajutorul cheii secrete a lui Alice, aşa cum se vede în partea de sus a figurii 10 crpt. Procesul invers; trimiterea unui mesaj criptat de la Alice la Bob este acum clarificat. De fapt, Bob şi Alice pot acum schimba între ei fişiere criptate, fără a avea vreun canal sigur pentru transmiterea cheilor, acesta fiind un avantaj major asupra comunicaţiilor bazate pe criptarea simetrică.
Autentificarea expeditorului este operaţia de verificare a identităţii dintre expeditor şi

71
persoana care pare să fie (pe baza mesajului) expeditorul. Să presupunem că Bob trimite tuturor utilizatorilor reţelei un mesaj, după ce l-a criptat cu cheia sa secretă. Oricare dintre utilizatori poate folosi cheia publică a lui Bob pentru a decripta acest mesaj, adeverind că acesta este un mesaj care ar putea veni numai de la Bob.
Autentificarea mesajului, reprezintă operaţia de validare a faptului că mesajul recepţionat este o copie neatinsă a mesajului trimis. Şi această operaţie poate fi realizată folosind criptarea cu cheie publică. Să presupunem că înainte de a expedia un mesaj, Bob efectuează o operaţie criptografică asupra acestuia, de exemplu îl transformă cu ajutorul unei funcţii, ale cărei valori sunt dificil de calculat cu metode numerice. Denumirea engleză a acestor funcţii este hash functions. Cel mai simplu exemplu de astfel de funcţie este cea care asociază o sumă de control textului clar. Este foarte dificil să se modifice textul clar fără a modifica valoarea obţinută prin aplicarea funcţiei amintită mai sus, figura 11 crpt.
Criptarea cu cheie publică este utilizată de câţiva ani la construcţia oricărui căutător pe INTERNET, Web browser. Această metodă de criptare se utilizează de asemenea atunci când se transmit informaţii referitoare la cartea de credit, la un vânzător on-line sau când se transmite un e-mail folosind protocolul standard S/MIME, sau când se obţine un certificat de securitate, de la un vânzător on-line sau creat local folosind soft specializat.
Un dezavantaj al criptării cu cheie publică este că solicită un volum de calcul mai important decât criptarea simetrică. Pentru a diminua acest dezavantaj majoritatea programelor de securitate folosesc criptarea simetrică pentru a cripta textul clar şi criptarea cu cheie publică pentru a cripta cheia secretă, folosită în criptarea simetrică a textului clar. Apoi fişierele criptate, conţinând mesajul şi cheia secretă, sunt transmise destinatarului.
Dacă ne referim la atacuri bazate pe forţă brută (se face căutarea exhaustivă a cheii încercând toate posibilităţile) atunci se poate afirma că un algoritm de criptare simetrică care foloseşte o cheie secretă (este vorba despre cheia iniţială) de 128 de biţi este la fel de rezistent ca şi un algoritm de criptare cu cheie publică a aceluiaşi text clar care foloseşte chei de 2304 biţi. De fapt cheia publică ar trebui să aibă o lungime şi mai mare deoarece aceeaşi pereche de chei publică şi secretă este folosită pentru a proteja toate mesajele la acelaşi destinatar. Altfel spus, în timp ce "spargerea" unei chei secrete pentru un algoritm de criptare simetrică compromite un singur mesaj, "spargerea" unei perechi de chei pentru un algoritm de criptare cu cheie publică compromite toate mesajele primite de un anumit destinatar. Algoritmii de criptare cu cheie publică pot fi atacaţi şi datorită faptului că cei doi corespondenţi nu au la dispoziţie un canal sigur prin care să-şi poată confirma identitatea unul celuilalt. Este situaţia prezentată în partea de jos a figurii 10crpt. Încă nu se cunoaşte nici o metodă de apărare împotriva unui astfel de atac. Unul dintre algoritmii de criptare cu cheie publică cel mai des folosit este algoritmul RSA, care o vechime de 22 de ani. Denumirea îi vine de la numele creatorilor săi: Ronald Rivest, Adi Shamir, şi Leonard Adleman de la MI, Massachusetts Institute of Technology, Cambridge. Proprietăţile sale de securitate provin din dificulatea de a factoriza numere prime de valorimari. În prezent o cheie cu lungime mai mare sau egală decât 1024 de biţi este, în general, suficient de sigură. Totuşi algoritmul RSA poate fi vulnerabil la "atacuri cu textul clar ales". Acestea sunt atacuri pentru care criptanalistul posedă un fişier de text clar şi textul cifrat corespunzător obţinut prin criptarea cu algoritmul de cifrare investigat. Algoritmul de criptare cu cheie publică Diffie-Hellman este folosit mai ales pentru schimbul de chei. Proprietăţile sale de securitate se bazează pe dificultatea de a discretiza valorile unei funcţii logaritmice într-un câmp finit generat de un număr prim de valoare mare. Se consideră că această operaţie este chiar mai dificilă decât operaţia de factorizare a unor numere foarte mari. Acest algoritm se consideră sigur dacă se utilizează chei suficient de lungi şi generatoare de chei performante.
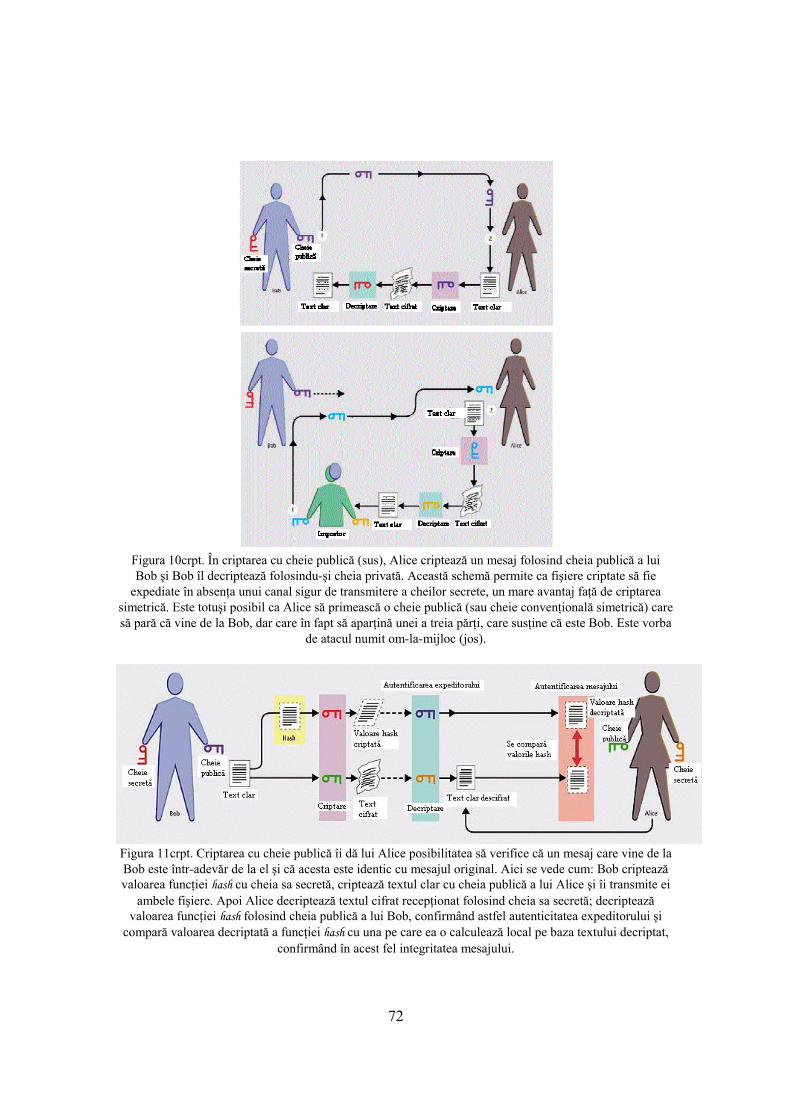
72
Figura 10crpt. În criptarea cu cheie publică (sus), Alice criptează un mesaj folosind cheia publică a lui Bob şi Bob îl decriptează folosindu-şi cheia privată. Această schemă permite ca fişiere criptate să fie
expediate în absenţa unui canal sigur de transmitere a cheilor secrete, un mare avantaj faţă de criptarea simetrică. Este totuşi posibil ca Alice să primească o cheie publică (sau cheie convenţională simetrică) care să pară că vine de la Bob, dar care în fapt să aparţină unei a treia părţi, care susţine că este Bob. Este vorba
de atacul numit om-la-mijloc (jos).
Figura 11crpt. Criptarea cu cheie publică îi dă lui Alice posibilitatea să verifice că un mesaj care vine de la Bob este într-adevăr de la el şi că acesta este identic cu mesajul original. Aici se vede cum: Bob criptează valoarea funcţiei hash cu cheia sa secretă, criptează textul clar cu cheia publică a lui Alice şi îi transmite ei
ambele fişiere. Apoi Alice decriptează textul cifrat recepţionat folosind cheia sa secretă; decriptează valoarea funcţiei hash folosind cheia publică a lui Bob, confirmând astfel autenticitatea expeditorului şi
compară valoarea decriptată a funcţiei hash cu una pe care ea o calculează local pe baza textului decriptat, confirmând în acest fel integritatea mesajului.

73
De departe cea mai populară metodă de criptare cu cheie este PGP, pretty good privacy . Acest algoritm a fost creat în anul 1991 de un programator, pe nume Philip Zimmermann ca un mijloc de protejare al e-mail-urilor. După ce unul dintre colegii săi a publicat pe Internet algoritmul PGP, Departamentul justiţiei din Guvernul S.U.A. a început să-l investigheze pe Zimmermann, pentru posibila violare a legilor S.U.A. privind exportul produselor de criptare. Acuzaţiile împotriva sa au fost anulate în anul 1996. Apoi Zimmermann a fondat o intreprindere pentru comercializarea PGPului.
5.3.1. Algoritmul Diffie-Hellman
De fapt inventatorul acestui algoritm este englezul Malcolm Williamson iar anul primei sale menţionări este 1974. Deşi nu este util la criptarea directă a vreunui mesaj, acest algoritm este folositor pentru trimiterea de mesaje secrete. De fapt cu ajutorul său poate fi generată o cheie secretă pe baza unor chei publice. Funcţionarea sa este următoarea. Cele două părţi, expeditorul şi destinatarul, care cunosc aceeaşi cheie publică, îşi aleg fiecare câte un număr. Fiecare aplică o anumită funcţie hash numărului pe care l-a ales, folosind cheia publică şi transmit rezultatul celeilalte părţi. Aceste rezultate sunt utile deoarece acum fiecare parte posedă rezultatul aplicării funcţiei hash numărului ales de ea precum şi rezultatul aplicării funcţiei hash numărului ales de cealaltă parte iar produsul acestor rezultate este acelaşi. De aceea acest produs poate fi utilizat ca şi o cheie publică de criptare iar produsul celor două numere orignale, alese de cele două părţi, poate fi utilzat ca şi o cheie secretă de criptare. Funcţia hash utilizată în metoda Diffie-Hellman este A la puterea x modulo P. Aceasta nu este o funcţie inversabilă pe mulţimea numerelor întregi.
Figura 12 crpt. Un exemplu practic de aplicare a algoritmului Diffie-Hellman în scopul schimbului de chei
de criptare.
Notând cu x numărul ales de expeditor şi cu y numărul ales de destinatar, primul va transmite A la puterea x modulo P, iar cel de al doilea A la puterea y modulo P. Fiecare parte poate calcula apoi A la puterea x ori y modulo P (expeditorul ridică la puterea x numărul primit

74
de la destinatar iar destinatarul ridică la puterea y numărul primit de la expeditor). Orice alt utilizator al aceleiaşi reţele poate avea acces la numerele A la puterea x modulo P, respectiv A la puterea y modulo P, dar nu poate, pe baza lor, să-l determine pe A la puterea x ori y modulo P. Pentru o funcţionare sigură a metodei Diffie-Hellman trebuie alese cu grijă constantele A şi P. Un exemplu de funcţionare a metodei Diffie-Hellman este prezentat în figura 12 crpt.
5.3.2. Algoritmul RSA (Rivest-Shamir-Adleman)
Metoda RSA este aproape singura metodă "adevărată" de criptare cu cheie publică. Ea a fost publicată în anul 1977. S-a demonstrat însă recent că de fapt această metodă a fost inventată în anul 1973 de către Clifford Cocks. Algoritmul RSA se bazează pe următoarele fapte matematice:
Dacă se ridică un număr la o putere (d), modulo un număr N, numărul original poate fi recuperat prin ridicarea rezultatului la o altă putere (e) modulo acelaşi număr. Cunoscând numărul N utilizat ca şi modul precum şi prima putere folosită se poate determina cu uşurinţă care a fost cea de a doua putere folosită.
Algoritmul RSA are următoarele etape: - criptarea mesajului X;
( ) ( ) modeE X X p q= ⋅
unde p şi q sunt două numere prime foarte mari cu produsul egal cu N, iar cmmdc(e, ϕ(N))=1. Cu ajutorul lui N şi e rezultă cheia publică.
- decriptarea mesajului X; Se calculează d, care reprezintă inversa lui e în raport cu operaţia de înmulţire modulo ϕ(N) (o explicaţie pentru utilizarea acestui modul este prezentată în paragraful referitor la bazele matematice ale criptării, cu care începe capitolul despre criptare),
( ) ( ) ( )mod .d
D X E X p q⎡ ⎤= ⋅⎣ ⎦
Cheia secretă rezultă cu ajutorul lui N şi d. Dacă se doreşte semnarea unui mesaj X atunci semnătura poate fi generată cu formula:
( ) dS X X=
Pentru a verifica o semnătură se calculează:
( )( ) ( )( ) mod ...
eV S X S X N X= = =
şi se compară cu X. În figura următoare se prezintă un exemplu de utilizare al algoritmului RSA. Bineînţeles pentru a putea folosi algoritmul RSA nu este suficientă doar descrierea sumară făcută până acum. E necesar să se găsească răspunsuri la cîteva întrebări: - Cum se pot alege 2 numere prime foarte mari ? - Cum se poate calcula o valoare inversă modulo (p-1)(q-1) ? - Cum se face o ridicare la putere modulo pq ?

75
Figura 13 crpt. Un exemplu de aplicare al algoritmului RSA.
Inversarea lui e
După cum s-a arătat d este inversa lui e modulo (p-1)(q-1), fiind respectată condiţia:
cmmdc(e, (p-1)(q-1))=1 (1 RSA)
Deoarece p şi q sunt două numere prime foarte mari ele trebuie să fie numere impare. De aceea numerele p-1 şi q-1 vor fi pare. În consecinţă aceste numere au pe 2 ca şi factor comun. De aceea o soluţie pentru d va fi şi inversa lui e modulo (p-1)(q-1)/2 (aşa cum s-a arătat în paragraful referitor la bazele matematice ale criptării). Condiţia (1 RSA) devine:
cmmdc(e, (p-1)(q-1)/2)=1 (2 RSA)
De obicei e se alege dintre următoarele numere: 3, 5, 17, 257, sau 65537, pentru a obţine o criptare (prin ridicarea la puterea e modulo pq) convenabilă şi rapidă.
Verificarea condiţiei (2 RSA) poate fi realizată folosind algoritmul lui Euclid, cu ajutorul căruia se poate găsi cel mai mare divizor comun a două numere. E clar că folosirea algoritmului lui Euclid permite şi obţinerea răspunsului la întrebarea legată de găsirea a două numere prime de valori foarte mari. Dacă cel mai mare divizor comun al acestor numere este 1 atunci ele sunt prime. Fie b cel mai mare dintre aceste două numere şi s cel mai mic dintre ele. Pentru cazul algoritmului RSA valoarea iniţială a lui b este (p-1)(q-1)/2 iar valoarea iniţială a lui s este e. În continuare se prezintă paşii algoritmului lui Euclid.
- Se împarte b la s şi restul obţinut se notează cu r. Noua valoare a lui b va fi vechea valoare a lui s şi noua valoare a lui s va fi r.
- Se repetă pasul anterior până când r devine zero. Valoarea lui r din pasul anterior reprezintă cel mai mare divizor comun.
Dacă r devine 1 atunci algoritmul se poate opri mai devreme, putându-se afirma că valoarea celui mai mare divizor comun este 1. Într-adevăr împărţind orice număr la 1 se obţine

76
restul zero. În acest caz cele două numere sunt prime între ele.
Dacă s-a demonstrat că 2 numere sunt prime între ele atunci inversul lui s modulo b poate fi determinat pe baza valorilor intermediare obţinute prin aplicarea algoritmului lui Euclid.
Se doreşte găsirea unei ecuaţii de forma:
1=s(0)*d- b(0)*n (3 RSA)
unde s(0)=e, b(0)=(p-1)(q-1)/2 şi n este un număr întreg arbitrar.
Într-adevăr, d, soluţia acestei ecuaţii, reprezintă inversa modulo b(0) a lui s(0) deorece:
b(0)*n=0 modulo b(0)
Dacă în pasul i al algoritmului lui Euclid se obţine restul 1 (asta înseamnă că s-a ajuns la penultima iteraţie a algoritmului) atunci înseamnă că are loc relaţia:
b(i)-s(i)*q(i)=1 (4 RSA)
unde q(i) este câtul împărţirii efectuate la pasul i. Aceasta este de forma ecuaţiei (3 RSA). Deci când se foloseşte algoritmul lui Euclid pentru determinarea unei valori inverse nu
este suficientă memorarea valorilor b şi s la fiecare pas al algoritmului ci este necesară şi memorarea câtului împărţirii la fiecare pas al algoritmului. Memorarea valorilor câtului trebuie făcută într-o memorie de tip stivă. Din prezentarea anterioară a algoritmului lui Euclid rezultă că acesta este descris de următoarele relaţii:
s(i-1)=b(i); r(i-1)=s(i);
şi:
b(i-1)-s(i-1)*q(i-1)=r(i-1).
De aceea relaţia (3 RSA) se mai poate scrie:
s(i-1)-r(i-1)*q(i)=1 sau:
s(i-1)-(b(i-1)-s(i-1)*q(i-1))*q(i)=1
adică: -q(i)*b(i-1)+(1-q(i)*q(i-1))*s(i-1)=1 (5 RSA)
Se remarcă faptul că şi aceasta este de tipul relaţiei (3 RSA). Folosind relaţiile:
s(i-2)=b(i-1), r(i-2)=s(i-1) şi b(i-2)=s(i-2)*q(i-2)=r(i-2)
se poate substitui din nou ( de data asta în relaţia (5 RSA)) pentru a-l exprima pe 1 ca şi o sumă de multiplii de b(i-2) şi s(i-2). Acest proces se poate repeta mergând înapoi (faţă de sensul în care s-a iterat algoritmul lui Euclid) spre b(0) şi s(0) pentru a găsi inversa dorită, d, pe baza unei relaţii de tipul (3RSA).

77
Ridicarea la putere a numerelor mari
Algoritmul folosit pentru ridicarea la putere a unor numere mari modulo un număr specificat se bazează pe o metodă de înmulţire numită Russian Peasant Multiplication şi presupune înmulţiri repetate. Algoritmul are următoarele etape:
- Fie rezultatul egal cu 1; - Se converteşte puterea dorită în binar şi se notează cu n lungimea obţinută. Se
memorează rezultatul conversiei. Bitul cel mai puţin semnificativ va fi a(1) iar bitul cel mai semnificativ va fi a(n).
- Numărul care se va ridica la putere se numeşte bază. Pentru ridicare la pătrat rezultat=rezultat * bază
-Se repetă pasul anterior până când se ajunge la puterea dorită.
O altă metodă de înmulţire este metoda Schönhage-Strassen. Această metodă merită să fie utilizată doar pentru numere foarte mari (mai mari decât numerele folosite în metoda de criptare RSA). Ea poate fi utilizată de exemplu pentru calculul puterii un million a numărului pi. Această metodă de înmulţire are la bază transformarea Fourier rapidă.
Factorizare Deoarece d poate fi obţinut din e de îndată ce este cunoscut (p-1)(q-1), descompunerea lui
N în factorii săi primi p şi q poate fi o cale de decriptare ilegală, cracking, a unui text criptat cu algoritmul RSA. Factorizarea numerelor mari este o operaţie dificilă. Calea cea mai simplă este să se împartă numărul cu fiecare număr prim mai mic decât el. Dacă restul împărţirii este zero atunci numărul testat care a condus la acest rest este un factor al lui N. O îmbunătăţire a acestei metode se bazează pe faptul că este suficient dacă se încearcă numerele prime mai mici decât radicalul numărului testat. Într-adevăr dacă primul factor identificat ar fi mai mare decât radical din N atunci şi al doilea factor care ar putea fi identificat ar trebui să fie mai mare decât radical din N. Dar în acest caz produsul acestor factori ar fi mai mare decât N, ceea ce este absurd. Există şi alte îmbunătăţiri posibile ale metodei de factorizare. Un algoritm de factorizare îmbunătăţit, relativ uşor de înţeles, este algoritmul lui Fermat. Acesta se bazează pe formula produsului sumei prin diferenţă.
( ) ( ) 22 bababa −=−∗+ (1 Fermat)
Astfel, deoarece numărul care trebuie factorizat este produsul a două numere impare diferenţa acestora va fi un număr par, iar cei doi factori vor fi exprimaţi în forma a+b şi a-b, unde a şi b sunt doi întregi pozitivi. În continuare se prezintă algoritmul lui Fermat pentru factorizarea numărului 319 (care este produsul dintre numerele prime 11 şi 29). Acesta se bazează pe încercări repetate de verificare a relaţiei (1 Fermat) pentru valori consecutive ale lui a. Rădăcina pătrată a lui 319 (care reprezintă membrul stâng al relaţiei (1 Fermat)) este 17,86057.... Dacă i se dă lui a valoarea 18 atunci a la pătrat este egal cu 324 şi conform relaţiei (1 Fermat) valoarea lui b la pătrat este 5. Dar 5 nu este un pătrat perfect. De aceea i se dă lui a valoarea următoare, adică 19. Valoarea lui a la pătrat devine 361. În acest caz valoarea lui b la pătrat devine 42. Dar nici această valoare nu reprezintă un pătrat perfect. De aceea i se dă lui a valoarea 20. Valoarea lui 20 la pătrat este de 400. Diferenţa dintre 400 şi 319 este de 81. Acesta este în sfârşit un pătrat perfect. Deoarece b la pătrat ia valoarea 81 rezultă că valoarea lui b este 9. În consecinţă factorii a+b şi a-b sunt de valori 29 şi 11. Se constată că s-a realizat factorizarea dorită.

78
Algoritmul de factorizare al lui Fermat este rapid doar dacă cei doi factori au valori apropiate. Dacă este necesară factorizarea numărului 321, de exemplu (care este produsul dintre numerele prime 3 şi 107) atunci deoarece iniţializarea algoritmului lui Fermat se realizează cu valoarea 18 (partea întreagă a rădăcinii pătrate a numărului 321 este 17), pentru a ajunge la factorul 107 sunt necesare 89 de iteraţii.
În consecinţă dacă N este suficient de mare şi dacă p şi q sunt aleşi aleator atunci este foarte dificilă factorizarea lui N. Rivest, Shamir şi Adelman au sugerat utilizarea unor numere p şi q de câte 100 de cifre, cea ce face ca N să aibă 200 de cifre. Pentru factorizare ar putea fi necesar un număr mare de ani de calcul.
Un alt atac împotriva metodei de criptare cu cheie publică RSA este aşa numitul atac cu text în clar limitat, limited plain text attack. Dacă există un număr mic de mesaje care trebuiesc transmise, un atacator ar putea să le cripteze pe toate, cu diferite chei publice, folosind algoritmul RSA şi să-l identifice pe cel transmis la un moment dat comparându-l cu toate textele cifrate pe care le-a obţinut.
5.3.3. Algoritmul El Gamal
Algoritmul de schimb de chei Diffie-Hellman a fost descris pe baza următoarelor operaţii: - expeditorul alege numărul x şi transmite A la puterea x modulo P, - destinatarul alege numărul y şi transmite A la puterea y modulo P, - apoi ambele părţi comunică folosind ca şi cheie publică A la puterea xy modulo P.
După cum se vede nimic nu împiedică destinatarul să declare ca şi cheie publică A la puterea y modulo P, permiţând oricărui alt utilizator al reţelei să transmită un mesaj pe care expeditorul să-l citească, după ce l-a ales pe x şi să-l retransmită criptat cu cheia A la puterea xy modulo P, adăugândui la început A la puterea x. Algoritmul El Gamal poate fi considerat ca şi un caz particular al acestei metode.
În algoritmul El Gamal pentru a transmite un mesaj unui corespondent a cărui cheie publică este A la puterea y modulo P, i se transmite propria cheie publică, A la x modulo P şi apoi mesajul, care este criptat prin înmulţirea sa, modulo P, cu A la puterea xy modulo P.
Algoritmul El Gamal poate fi utilizat şi pentru generare şi autentificare de semnături.
5.4. Standardul de criptare cu cheie publică PKCS#1
Standardele de criptare cu cheie publică, PKCS, Public-Key Criptography Standards, sunt specificaţii produse de către laboratoarele RSA, din S.U.A cu scopul de a accelera dezvoltarea criptografiei cu chei publice. Primul a fost publicat în 1991. S-a ajuns în prezent ca în multe lucrări de specialitate să se facă referiri la aceste standarde şi ca ele să fie frecvent implementate. Numeroase contribuţii prezentate în aceste standarde au ajuns să fie părţi ale unor standarde elaborate de institute speciale de standardizare, cum ar fi documentele X9 ale ANSI sau PKIX, SET, S/MIME şi SSL. Aceste standarde sunt publicate la adresa: http://www.rsasecurity.com/rsalabs/pkcs/indexhtml La această adresă se găsesc următoarele documente:
PKCS #1: Standardul criptografic RSA, care dă titlul acestui paragraf. PKCS #2: O notă explicativă referitoare la standardul PKCS#1. PKCS #3: Convenţia de schimbare de chei Diffie-Hellman. PKCS #4: O notă explicativă referitoare la standardul PKCS#3. PKCS #5: Standard de criptografie bazată pe parole.

79
PKCS #6: Standardul de sintaxă a certificatelor (de autentificare) extinse. PKCS #7: Standardul de sintaxă al mesajelor criptografice. PKCS #8:Standardul de sintaxă al cheilor secrete. PKCS #9:Tipuri de atribute selectate.
PKCS #10:Standardul de sintaxă de cerere a unui certificat. PKCS #11:Standardul de interfaţă criptografică de tip token.
PKCS #12:Standardul de sintaxă de schimb de informaţie personală. PKCS #13: Standardul de criptografie cu curbe eliptice. PKCS #15: Standardul de format al informaţiei criptografice de tip token.
Scopul standardului PKCS#1 este să permită cifrarea datelor folosind metoda de criptare cu cheie publică RSA. Se intenţionează ca acest standard să se utilizeze în construcţia semnăturilor digitale şi a "plicurilor" digitale, digital envelopes, aşa cu este prezentat în standardul PKCS #7. � Pentru semnături digitale conţinutul care trebuie semnat este prima dată redus la un rezumat, cu ajutorul unui algoritm de rezumare (ca de exemplu MD5) şi apoi un şir de octeţi, conţinând rezumatul mesajului este criptat cu cheia secretă RSA a semnatarului conţinutului. Conţinutul precum şi rezumatul mesajului criptat sunt reprezentate împreună, conform regulilor de sintaxă prezentate în standardul PKCS #7, formând o semnătură digitală. Această aplicaţie este compatibilă cu metodele de protejare a poştei electronice de tipul PEM, Privacy-Enhanced Mail . � Pentru "plicuri" digitale, conţinutul care trebuie introdus în plic este prima dată criptat cu o metodă de criptare simetrică (care foloseşte o cheie secretă) folosind un algoritm corespunzător (de exemplu DES) şi apoi cheia secretă este criptată folosind cheia publică RSA a destinatarului conţinutului. Conţinutul criptat precum şi cheia secretă criptată sunt reprezentate împreună, conform sintaxei prezentate în standardul PKCS#7, pentru a crea un plic digital. Şi această metodă este compatibilă cu metodele PEM.
Standardul mai descrie şi sintaxa pentru cheile publice şi secrete RSA. Sintaxa cheilor publice se foloseşte la elaborarea certificatelor iar sintaxa cheilor secrete se foloseşte la elaborarea informaţiilor referitoare la cheile secrete prezentate în standardul PKCS#8.
Standardul defineşte şi trei algoritmi de semnare a certificatelor pentru PEM şi a listelor de revocare a certificatelor, a certificatelor extinse, descrise în standardul PKCS#6 şi a altor obiecte care folosesc semnături digitale.
Sintaxa cheilor
În cazul cheilor publice este vorba despre o secvenţă care are pe prima poziţie valorea modulului N, iar pe a doua poziţie, valoarea cheii publice a expeditorului e.
În cazul cheilor secrete este vorba despre o secvenţă care are, în ordine, următoarele elemente: versiunea, modulul N, cheia publică a expeditorului, e, cheia secretă a destinatarului, d, numărul prim p, numărul prim q, valoarea exponentului d modulo (p-1), valoarea exponentului d modulo (q-1), valoarea inversului lui q modulo p şi versiunea. Semnificaţia acestor elemente este următoarea:
-versiunea: este un număr care indică apartenenţa la standard şi care are rolul de a face posibilă compatibilitatea cu standarde viitoare. Are valoarea 0 pentru acest standard.
- N, e, d, p au semnificaţiile din prezentarea metodei RSA, de mai sus.
Lungimea modulului N, în octeţi, este numărul întreg k care satisface condiţia:
28(k−1)
≤ N ≤ 28k
Pentru acest standard valoare minimă a lui k este 12.

80
Observaţii
1 Pentru o cheie secretă RSA sunt suficiente valorile lui N şi d. Prezenţa valorilor p, q, d mod (p-1), d mod (q-1) şi q-1 mod p este justificată de eficienţa sporită obţinută prin utilizarea lor. 2 Prezenţa exponentului cheii publice e, în structura cheii secrete este justificată de crearea posibilităţii de a transforma cheia secretă într-o cheie publică. Procesul de criptare
Acest proces are 4 paşi: - formatarea blocului de criptat, - conversia şirului de octeţi în valori întregi, - calculul specific metodei RSA, - conversia valorilor întregi obţinute într-un şir de octeţi.
Datele iniţiale pentru procesul de criptare sunt: - şirul de octeţi D, care reprezintă datele de transmis, - Valoarea modulului N, - Valoarea unui exponent c. Pentru o operaţie care necesită chei publice exponentul c trebuie să fie identic cu exponentul cheii publice a unui utilizator, e, iar pentru o operaţie care necesită chei secrete el trebuie să fie identic cu exponentul cheii secrete a unui utilizator, d. Datele obţinute în urma procesului de criptare reprezintă un şir de octeţi ED.
Observaţii
1 În aplicaţiile tipice ale acestui standard pentru a genera chei secrete dependente de conţinutul mesajului sau rezumate de mesaj este necesar ca lungimea şirului de octeţi D să fie de 30. De aceea este necesar ca lungimea modulului N, folosit în metoda RSA să fie de cel puţin 41 de octeţi. 2 Procesul de criptare nu presupune şi realizarea unui control de integritate explicit care să uşureze detecţia erorilor care provin din coruperea datelor criptate pe durata transmisiei lor. Totuşi structura blocului de date folosit garantează că probabilitatea de ne-detectare a erorilor este mai mică decât 2 la puterea -16. 3 Aplicarea operaţiilor cu cheie publică aşa cum este definită în acest standard la alte tipuri de date decât şirurile de octeţi care conţin un rezumat al mesajului nu este recomandată şi reprezintă obiectul unor studii viitoare. Formatarea blocului de criptat
Blocul de criptat, EB, encryption block, este un şir de octeţi şi este format din 3 elemente : tipul blocului BT, şirul de egalizare, PS, padding string şi şirul de date D. Acestea sunt concatenate conform formulei :
EB = 00 ||BT ||PS ||00 ||D (1 PKCS#1)
Tipul blocului, BT, trebuie să fie un singur octet şi indică structura blocului de criptare. Pentru această versiune a standardului el poate avea una dintre valorile: 00, 01, sau 02. Pentru o operaţie cu cheie secretă se folosesc valorile 00 sau 01. Pentru o operaţie cu cheie publică valoarea sa este 02. Şirul de egalizare, PS, trebuie să aibă k-3-ll D ll octeţi, unde cu ll D ll s-a notat lungimea

81
şirului de date D. Pentru BT de valoare 00, toţi octeţii din PS vor avea valoarea 00. Pentru BT de valoare 01, toţi octeţii din PS vor avea valoarea FF iar pentru BT de valoare 02, octeţii din PS vor fi generaţi pseudoaleator şi de valoare diferită de 00. În acest fel lungimea blocului de criptat va fi egală cu k. De aceea PS se numeşte şir de egalizare.
Observaţii
1 Cei doi octeţi 00 din formula (1 PKS#1) au fost incluşi pentru a se asigura condiţia ca blocul criptat, convertit într-o valoare întreagă să fie de valoare mai mică decât a modulului. 2 Dacă BT are valoarea 00, şirul de date D trebuie să înceapă cu un octet nenul sau să aibă o lungime cunoscută pentru ca blocul criptat să poată fi interpretat corect (neambiguu). Pentru BT de valori 01 sau 02 blocul criptat poate fi interpretat corect, deoarece şirul egalizator PS nu conţine octeţi de valoare 00 şi este separat de şirul de date D printr-un octet de valoare 00. 3 Valoarea 01 a BT este recomandată pentru operaţii cu chei secrete. Această valoare conduce la o valoare mare a blocului EB, după ce acesta a fost convertit într-o valoare întreagă, ceea ce previne anumite atacuri 4 Valorile 01 şi 02 pentru BT asigură compatibilitatea blocului criptat cu criptarea RSA bazată pe conţinut al cheilor şi al rezumatelor de mesaje, folosită la protecţia poştei electronice, PEM. 5 Pentru valoarea 02 a BT se recomandă ca generarea pseudoaleatoare a octeţilor să se facă independent pentru fiecare proces de criptare, în special dacă este necesară criptarea repetată a aceluiaşi mesaj. 6 Pentru valoarea 02 a BT, şirul de egalizare, PS, trebuie să aibă o lungime minimă de 8 octeţi. Aceasta este o condiţie de securitate pentru operaţii cu chei publice, care previne ca un atacator să poată reconstrui şirul de date prin încercarea tuturor blocurilor criptate posibile. Aceaşi lungime minimă se recomandălşi dacă se utilizează valoarea 01 pentru BT. 7 Acest standard va fi extins în viitor pentru a include şi alte valori posibile pentru BT. Conversia şirului de octeţi într-un întreg
Blocul criptat, EB, se converteşte într-un întreg, x, folosind relaţia :
( )8
12 EB
kk i
ii
x −
=
=∑ (2PKCS#1)
unde EB1, EB2,..., EBk reprezintă octeţii lui EB de la primul la ultimul. Cu alte cuvinte primul octet al lui EB are cea mai mare semnificaţie în întregul x iar ultimul octet al lui EB este cel mai puţin semnificativ pentru întregul x.
Observaţie
Întregul x obţinut prin conversia blocului EB satisface condiţia:
0 x N≤ < (3PKCS#1)
deoarece EB1 = 00 şi 28(k−1)
≤ N.
Criptarea RSA

82
Întregul x, obţinut în pasul anterior este ridicat la puterea c modulo N, obţinându-se întregul y care reprezintă rezultatul criptării în formă de număr întreg, mai mic decât N.
Conversia întreg-şir de octeţi
Întregul y, obţinut în urma criptării este convertit într-un şir de octeţi, ED, de lungime k, care reprezintă mesajul criptat. Şirul ED trebuie să satisfacă relaţia:
( )8
12
kk i
ii
y ED−
=
=∑ (4 PKCS#1)
unde ED1, ED2,..., EDk sunt octeţii şirului ED, de la primul la ultimul.
Procesul de decriptare
Acest proces constă din 4 paşi: conversia şirului de octeţi într-un întreg, decriptarea RSA, conversia întregului într-un şir de octeţi şi formatarerea blocului decriptat.
Pentru efectuarea procesului de decriptare sunt necesare: şirul de octeţi ED, datele criptate, modulul N şi exponentul c. Pentru o operaţie cu chei publice exponentul c trebuie să reprezinte exponentul public al unui utilizator, e, iar pentru o operaţie cu chei secrete coeficientul c trebuie să reprezinte exponentul secret al unui utilizator, d.
În urma procesului de decriptare se obţine un şir de octeţi, D, care reprezintă datele transmise. Dacă lungimea acestui şir de octeţi nu este egală cu k atunci înseamnă că s-a comis o eroare.
Conversia şirului de octeţi într-un întreg
Şirul de date criptate, ED, este convertit într-un întreg y, conform relaţiei (4PKCS#1). Dacă întregul obţinut nu satisface condiţia : 0 ≤ y < N, înseamnă că s-a comis o eroare de transmisie.
Decriptarea RSA
Întregul y, obţinut la pasul anterior este ridicat la puterea c modulo N, obţinându-se un nou întreg, x, inferior lui N.
Conversia întregului într-un şir de octeţi
Întregul x, obţinut la pasul anterior, este convertit într-un şir de octeţi, EB, de lungime k, conform relaţiei (2PKCS#1).
Formatarea blocului decriptat
Blocul decriptat este formatat prin includerea într-o structură formată dintr-un octet BT care specifică tipul blocului, un şir de egalizare, PS, şi un şir de octeţi de date, conform relaţiei (1PKCS#1). Dacă este satisfăcută una dintre condiţiile următoare înseamnă că s-a produs o eroare în procesul de transmisie:
� Blocul decriptat nu poate fi formatat neambiguu.

83
� Şirul de egalizare, PS, este constituit din mai puţin de 8 octeţi, sau nu este în accord cu BT. � Procesul de decriptare este o operaţie cu cheie publică iar BT nu are valorile 00 sau 01, sau procesul de decriptare este o operaţie cu cheie secretă şi BT nu are valoarea 02. 5.5. Algoritmi de semnătură digitală
În paragraful în care s-a prezentat metoda de criptare cu cheie publică RSA s-a explicat şi cum poate fi folosită aceasta la generarea şi verificarea semnăturilor digitale. În standardul PKCS#1 sunt prezentate şi trei metode de semnare digitală, bazate pe utilizarea algoritmului RSA. Cei doi exponenţi d şi e sunt inverşi modulo N. 5.5.1. Algoritmi de semnătură digitală bazaţi pe metoda Diffie-Hellman
Pentru a semna ceva folosind algoritmul Diffie-Hellman este necesară o abordare puţin diferită. Baza algoritmilor de semnătură digitală de acest tip este următoarea : Persoana care îl cunoaşte pe x crează două sau trei numere diferite, care au o anumită legătură într ele, legătură care nu poate fi îndeplinită decât dacă se cunoaşte x, dar a cărei prezenţă poate fi verificată şi de către utilizatorii care îl cunosc doar pe A la puterea x. În continuare se prezintă o implementare ipotetică a acestei metode.
Pentru mesajul m se calculează produsul dintre x şi m modulo Q. Acest produs se notează cu s. Modulul Q se alege în aşa fel încât să fie satisfăcută relaţia P-1 = 2Q, unde P este un număr prim. Atunci un utilizator care cunoaşte doar valoarea lui A la puterea x poate constata că A la puterea s se obţine prin ridicarea lui A la puterea x la puterea m, deoarece un document semnat constă din semnătura s şi mesajul m şi orice utilizator al reţelei poate avea acces la mesajul semnat. Din păcate o astfel de procedură nu este sigură deoarece, Q fiind o valoare publică, utilizatorul care îl cunoaşte pe A la puterea x şi este în posesia perechii (s,m) îl poate deduce pe x, împîrţindu-l pe s la m modulo Q.
Metodele de semnătură digitală utilizate în prezent necesită parametrii suplimentari, astfel încât pe baza semnăturii s să nu se poată afla valoarea x. Aceste metode lucrează aşa cum este descris în continuare.
Se presupune pentru început că sunt satisfăcute relaţiile : P – 1 = 2 * Q unde Q este prim şi în plus : Q – 1 = 2 * R unde şi R este prim.
Asta înseamnă că nu numai P este potrivit pentru valoarea modulului folosit în algoritmul Diffie-Hellman ci şi Q, care este mai mic. Pentru semnarea unui mesaj, m, expeditorul are cheia sa secretă, x, şi se construieşte cheia publică, A la puterea x modulo Q (în loc de A la puterea x modulo P). În plus se mai construieşte o cheie secretă, y, şi cheia ei publică corespunzătoare, A la puterea y modulo P. Baza A este aleasă astfel încât A la puterea Q modulo P să fie egal cu 1. De asemenea se calculează Y, care este egal cu ((A la puterea y modulo P) modulo Q). Atât mesajul cât şi semnătura sunt numere modulo Q. Semnătura se calculează ca şi funcţie de x şi de m. Există diferite scheme de generare a semnăturii, dar toate au în comun trei numere a, b şi c care sunt definite cu ajutorul mărimilor s, Y şi m. Cele trei numere a, b şi c satisfac ecuaţia:
ax + by = c modulo Q (1.SD)
Aceasta arată de ce este atât de important ca pentru fiecare semnătură să se aleagă o altă valoare a lui y. Mărimile a, b şi c sunt toate informaţii publice. De aceea dacă există două seturi de mărimi a, b şi c (de exemplu de la 2 utilizatori) atunci există 2 ecuaţii de tipul (1. SD) şi deci un sistem de

84
2 ecuaţii cu 2 necunoscute. Prin rezolvarea acestuia pot fi obţinute cheile secrete x şi y. Fiind date s, m, A la puterea x modulo P şi A la puterea y modulo P, relaţia dintre a, b şi c
poate fi verificată folosind ecuaţia:
( ) ( ) mod mod mod
bya A Px cA P A P⋅
= (2. SD) Legăturile dintre cele 3 numere a, b şi c şi mărimile s, Y şi m pot fi:
a=m, b=Y, c=s a=Y, b=m, c=s a=s, b=Y, c=m, a=Y, b=s, c=m, a=m, b=s, c=Y, a=s, b=m, c=Y
5.5.2. Semnături digitale El-Gamal
Aşa după cum s-a afirmat deja în paragraful destinat pezentării metodei de criptare cu cheie publică El-Gamal, aceasta poate fi utilizată şi pentru generarea şi verificarea semnăturilor digitale.
Fiecare utilizator al reţelei este în posesia unei perechi de chei (<g,P,T>,S), formată dintr-o cheie publică <g,P,T> şi o cheie secretă S. Legătura dintre acestea este satabilită cu ajutorul algoritmului Diffie-Hellman:
T = gS mod P
Pentru un anumit mesaj m, semnatarul îşi alege un nou număr secret, S’ şi calculează:
T ‘= gS ‘
mod P
Pe baza lui m concatenat cu T ‘, se calculează un rezumat:
d = H(m|T ‘). Apoi se calculează o semnătură X:
X =S’+(d ·S )mod(P −1)
Apoi se transmite mesajul m împreună cu X şi cu T ‘. Pentru verificarea semnăturii destinatarul calculează d cunoscând funcţia H, mesajul m şi
pe T ‘, apoi verifică că:
gX =T’·Td
mod P

85
deoarece :
( )( ) ( )( ) ( ) ( )( )( ) ( )( ) ( )
mod 1' mod P-1 '
mod 1 mod 1
mod mod mod mod
' mod ) ' mod
d S PS d SX S
d PS P d
g P g P g P g P
T g P T T P
⋅ −+ ⋅
−−
= = ⋅ =
= ⋅ = ⋅
Ultima egalitate este corectă deoarece S este mai mic decât P-1 (şi de aceea S mod (P-1)=S). Toate mărimile necesare pentru verificare sunt disponibile deoarece destinatarul cunoaşte g, T, T’, m, X şi H şi poate calcula d şi celelalte valori necesare pe baza acestora.
5.3.3. Algoritmul El Gamal
Algoritmul de schimb de chei Diffie-Hellman a fost descris pe baza următoarelor operaţii:
- expeditorul alege numărul x şi transmite A la puterea x modulo P,
- destinatarul alege numărul y şi transmite A la puterea y modulo P,
- apoi ambele părţi comunică folosind ca şi cheie publică A la puterea xy modulo P.
După cum se vede nimic nu împiedică destinatarul să declare ca şi cheie publică A la puterea y modulo P, permiţând oricărui alt utilizator al reţelei să transmită un mesaj pe care expeditorul să-l citească, după ce l-a ales pe x şi să-l retransmită criptat cu cheia A la puterea xy modulo P, adăugândui la început A la puterea x. Algoritmul El Gamal poate fi considerat ca şi un caz particular al acestei metode.
În algoritmul El Gamal pentru a transmite un mesaj unui corespondent a cărui cheie publică este A la puterea y modulo P, i se transmite propria cheie publică, A la x modulo P şi apoi mesajul, care este criptat prin înmulţirea sa, modulo P, cu A la puterea xy modulo P.
Algoritmul El Gamal poate fi utilizat şi pentru generare şi autentificare de semnături.
5.5.3. Standardul de semnătură digitală DSS
În anul 1994, Institutul naţional de standarde şi tehnologie din S.U.A. , NIST, National Institute of Standards and Technology a publicat standardul de semnătură digitală, Digital Signature Standard (DSS). Acest standard prezintă un algoritm de semnătură digitală, Digital Signature Algorithm (DSA) folositor în aplicaţiile în care este mai potrivită utilizarea unei semnături digitale în locul unei semnături scrise. Semnătura numerică DSA este o pereche de numere foarte mari reprezentate ca şi şiruri de octeţi. Semnătura digitală este calculată folosind o mulţime de reguli şi o mulţime de parametri astfel încât identitatea semnatarului şi integritatea datelor transmise să poată fi verificate. DSA asigură posibilitatea de a genera şi de a verifica semnături digitale. Generarea semnăturilor se bazează pe utilizarea unei chei secrete. Verificarea semnăturii se bazează pe folosirea unei chei publice care corespunde cheii secrete. Fiecare utilizator posedă o perche de chei formată din cheia sa publică şi cheia sa secretă. Cheile publice pot fi cunoscute de către orice utilizator al reţelei. Oricine poate verifica semnătura unui utilizator folosind cheia sa publică. Generarea semnăturii unui utilizator poate fi realizată numai de către acesta deoarece în procesul de generare se foloseşte cheia sa secretă. În procesul de generare a semnăturii se utilizează o funcţie hash, pentru a obţine o variantă condensată (rezumat al mesajului) a datelor

86
care trebuiesc transmise (a se vedea figura 17 crpt). Acestui rezumat i se aplică algoritmul DSA pentru a se genera semnătura digitală. Semnătura digitală împreună cu mesajul semnat sunt transmise celui care trebuie să verifice semnătura digitală. Acesta verifică semnătura digitală cu ajutorul cheii publice a expeditorului. Aceeaşi funcţie hash trebuie folosită şi în procesul de verificare. Proceduri similare trebuie folosite şi pentru generarea şi verificarea semnăturilor digitale pentru date stocate ( nu transmise).
Figura 17 crpt. Procedurile de generare şi de verificare a semnăturii digitale.
Algoritmul DSA se foloseşte pentru poştă electronică, pentru transferul electronic de fonduri, schimbul electronic de date, distribuire de soft, stocare de date şi alte aplicaţii care necesită verificarea integrităţii datelor transmise şi autentificarea expeditorului. Algoritmul DSA poate fi implementat în variante hard, soft sau mixte. NIST dezvoltă un program de validare a acordului dintre aceste implementări şi standardul DSS.
Parametrii algoritmului DSA
Acest algoritm utilizează următorii parametri:
1. p, un număr prim folosit ca şi modul, cu proprietatea:
2L−1 · p < 2
L pentru 512 ≤ L ≤ 1024, L multiplu de 64 ;
1 q, un număr prim, divizor al lui p - 1.
2 1
mod .pqg h p−
= 3 x, un număr generat aleator sau pseudoaleator. 4 y = g
x mod p .
5. k, un întreg generat aleator sau pseudoaleator.

87
Întregii p, q, şi g pot fi publici şi pot fi comuni unui grup de utilizatori. Numărul x reprezintă cheia secretă a unui utilizator iar y cheia sa publică. În mod normal aceste valori rămân fixe pentru o perioadă de timp. Parametrii x şi k se folosesc doar pentru generarea semnăturii şi trebuie păstraţi secreţi. Parametrul k trebuie regenerat pentru fiecare semnătură digitală.
Generarea semnăturii Semnătura unui mesaj M, este perechea de numere r şi s calculate conform următoarelor
ecuaţii: ( )
( )( )( )1
mod mod
mod
kr g p q
s k SHA M x r q−
=
= + ⋅
Cu k la puterea -1 s-a notat inversa lui k pentru înmulţirea modulo q. E necesară verificarea egalităţii cu zero a lui r sau s. Dacă una dintre aceste mărimi este 0 atunci o nouă valoare a lui k trebuie aleasă şi semnătura trebuie recalculată.
Semnătura împreună cu mesajul sunt transmise celui care trebuie să verifice semnătura digitală.
Verificarea semnăturii
Înaintea verificării semnăturii unui mesaj parametrii p, q şi g precum şi cheia publică şi identitatea expeditorului a sunt puse la dispoziţia celui care trebuie să verifice semnătura digitală într-o formă autentificată. Fie M', r' şi s' versiunile recepţionate ale parametrilor M, r, şi s şi fie y cheia publică a semnatrului mesajului. Prima operaţie de verificare se referă la şirul de inegalităţi 0 < r' < s' < q. Dacă una dintre aceste condiţii nu este respectată atunci semnătura este respinsă. Dacă aceste condiţii sunt satisfăcute atunci se continuă verificarea. Se calculează:
( )( )( )( )
( )( )( ) ( )( )( )1 2
1
1
2
' mod
' mod
' mod
mod modu u
w s q
u SHA M w q
u r w q
v g y p q
−=
= ⋅
= ⋅
= ⋅
Dacă v = r', atunci rezultatul verificării semnăturii digitale este pozitiv şi se poate afirma că mesajul a fost trimis de către posesorul cheii secrete x corespunzătoare lui y. Dacă v nu este egal cu r' atunci se poate ca mesajul să fi fost modificat sau să nu fi fost corect semnat de către semnatar sau ca mesajul să fi fost semnat de către un impostor. Oricum mesajul nu trebuie validat. În continuare se demonstrează criteriul de verificare. Cu alte cuvinte se demonstrează că dacă M' = M, r' = r, şi s' = s, atunci v = r' .
Demonstraţia se bazează pe utilizarea următoarei leme.
LEMĂ. Fie p şi q două numere prime astfel încât q să fie p - 1 şi fie h un întreg pozitiv mai mic decît p şi g dat de relaţia:
1
mod pqg h p−
= Atunci:

88
mod 1qg p = (1 L)
şi dacă m mod q = n mod q, atunci:
gm mod p =g
n mod p (2 L)
DEMONSTRAŢIE.
11 mod mod mod mod 1
pq pqg p h p p h p
−−
⎛ ⎞= = =⎜ ⎟⎜ ⎟⎝ ⎠
Ultima egalitate din relaţia anterioară este un rezultat direct al Teoremei mici a lui Fermat (care este demonstrată în paragraful destinat bazelor matematice ale criptării). Egalitatea: m mod q = n mod q, este identică cu relaţia: m = n + kq pentru un anumit întreg k. De aceea se poate scrie:
( ) ( ) ( )( ) mod mod mod mod mod mod km n kq n kq n qg p g p g g p g p g p p+= = ⋅ = ⋅
sau aplicând relaţia (1. L):
( )( ) mod mod 1 mod mod m n ng p g p p g p= ⋅ = Deci şi relaţia (2. L) a fost demonstrată. În consecinţă lema a fost demonstrată. În continuare se demonstrează propoziţia. Se poate scrie:
( ) ( )( )( )( ) ( )( )
( )( )
1 1
1
2
' mod
' mod mod
' mod mod
w s s q
u SHA M w q SHA M w q
u r w q r w q
− −= =
= ⋅ = ⋅
= ⋅ = ⋅
Deoarece y =gx mod p , pe baza lemei enunţate anterior se poate scrie:
( )( ) ( ) ( )( )( )( )( ) ( )( )( ) ( ) ( )( )( )( )
1 2 mod
mod mod
mod mod mod mod
mod mod mod mod
SHA M w qu u
SHA M w q SHA M x r w q
v g y p q g p q
g p q g p q
⋅
⋅ + ⋅ ⋅
= ⋅ = =
= = (1 D)
Dar:
( )( )( )11 mod s k SHA M x r q−−= + ⋅
şi:

89
( ) 1 mod w s q−=
adică:
( )( )( )1mod w k SHA M x r q
−= + ⋅
de unde: ( )( ) mod mod SHA M x r w q k q+ ⋅ ⋅ =
relaţie care înlocuită în (1. D) conduce la: v = (g
k mod q mod p) mod q
Dar:
( )mod mod kr g p q=
Presupunând că valoarea lui k este inferioară valorii lui q, k mod q este egal cu k şi conform ultimelor două relaţii rezultă că v şi r sunt egale.
Propoziţia a fost demonstrată.
În standardul DSS, în anexe, sunt prezentate şi metode de generare a numerelor prime, necesare în algoritmul DSA, precum şi metode de generare a numerelor aleatoare sau pseudoaleatoare, de asemenea necesare în algoritmul DSA. 5.6. Atacuri împotriva sistemelor de criptare
Sistemele de criptare simetrică, ca de exemplu DES au fost construite cu intenţia de a fi foarte greu de atacat (decriptat de către o persoană neautorizată) şi au reuşit pe deplin să satisfacă această necesitate. Chiar având la dispoziţie cantităţi impresionante de text în clar şi text cifrat crespunzător o a treia persoană (neautorizată) nu ar trebui să poată (aceasta este intenţia constructorilor sistemelor de cifrare) să deducă cheia de criptare folosită, decât folosind atacurile bazate pe căutare cu forţă brută (adică generarea tuturor cheilor posibile având un număr fixat de caractere şi încercarea lor pe un text clar al cărui text cifrat corespunzător se află de asemenea în posesia acelei persoane, până la identificarea cheii utilizate de expeditor). Multe sisteme de criptare par să satisfacă această condiţie. Totuşi există două tipuri de atac care ar putea să descopere mai repede o cheie secretă decât metoda de căutare a acesteia bazată pe forţa brută. Acestea sunt atacul bazat pe criptanaliză linarăşi cel bazat pe criptanaliză diferenţială.
Metode de criptanaliză a sistemelor de criptare moderne Existăşi alte tipuri de atacuri bazate pe tehnici de tip hill-climbing sau pe algoritmi genetici.
Criptanaliza diferenţială
Dacă persoana neautorizată are la dispoziţie cantităţi suficiente de text clar şi text criptat corespunzător textului clar pe baza criptanalizei diferenţiale, inventată de Eli Biham şi Adi Shamir, aceasta ar putea obţine unele indicaţii despre anumiţi biţi ai cheii secrete folosite în procesul de criptare, putând în acest fel scurta timpul cerut de căutarea cheii printr-o tehnică exhaustivă (bazată pe forţă brută).
De exemplu după 2 iteraţii ale algoritmului DES, dacă se cunosc atât datele de intrare cât şi cele de ieşire ale acestor iteraţii, este uşor să se găsească cele două subchei folosite (deoarece se

90
cunosc rezultatele aplicării ambelor funcţii f /specifice celor două iteraţii). Pentru fiecare ieşire cunoscută de cutie de tip S există doar patru intrări posibile. Deoarece fiecare subcheie are o lungime de 48 de biţi iar cheia secretă are o lungime de doar 56 de biţi, găsirea intrării adevărate, dintre cele patru posibile identificate anterior este realtiv uşor de înfăptuit.
Însă de îndată ce numărul de iteraţii creşte la 4 problema descoperirii cheii secrete devine mult mai dificilă. Cu toate acestea este încă adevărat că ieşirea unei iteraţii depinde de intrarea sa şi de cheie.
Pentru un număr limitat de iteraţii este inevitabil ca un bit sau o combinaţie de biţi din cuvântul de la ieşirea iteraţiei să fie corelată (într-un anumit fel) cu rezultatul unei combinaţii simple a unor biţi ai cuvântului de intrare în prima iteraţie cu unii biţi ai cheii secrete. Pe baza identificării acestei corelaţii este mai probabil să se determine biţii cheii secrete, deoarece aceasta este unică, decât biţii cuvântului de intrare în prima iteraţie, deoarece pentru aceştia există mai multe combinaţii posibile.
Pe măsură ce numărul de iteraţii creşte, modul de corelare al biţilor cuvântului de intrare în prima iteraţie cu cheia secretă se rafinează, identificarea acestei iteraţii fiind mult mai dificilă. În loc să se spună "dacă acest bit este de valoare 1 în cuvântul de intrare atunci el va fi de valoare 0 (sau 1) în cuvântul de ieşire" se va spune "schimbând acest bit în cuvântul de intrare se va schimba (sau nu se va schimba) acel bit în cuvântul de ieşire". De fapt realizarea unei imagini complete a mecanismului prin care modificarea biţilor din cuvântul de intrare afectează sau nu biţii din cuvântul de ieşire este scopul criptanalizei diferenţiale.
Principiul de bază al criptanalizei diferenţiale, în forma sa clasică, este următorul. Sistemul de criptare, care se doreşte a fi atacat, are o anumită "caracteristică", dacă:
- există o anumită constantă X astfel încât cunoscând multe perechi de text clar, A şi B, cu proprietatea:
B = A xor X
- şi o anumită propoziţie, referitoare la cheia secretă, k, este adevărată, - şi dacă următoarea relaţie:
E(B,k) = E(A,k) xor Y
(unde cu E s-a notat rezultatul criptării), este adevărată, pentru o anumită constantă Y, cu aceeaşi probabilitate cu care ar fi adevărată dacă valoarea lui Y ar fi aleasă aleator.
Criptanaliză liniară
Criptanaliza linară, inventată de către Mitsuru Matsui, este o tehnică înrudită dar diferită. În loc să se analizeze puncte izolate, în care un anumit sistem de criptare se comportă ca şi un altul mai simplu, această metodă de criptanaliză încearcă să creeze o aproximare simplă a întregului sistem de criptare. Pe baza unei perechi text clar-text cifrat, constituită din elemente de lungime mare, se determină cheia secretă care ar fi produs această pereche, folosind sistemul de criptare simplificat, precum şi biţii cheii care au tendinţa să aibă aceeaşi valoare şi în cazul cheii folosite de sistemul de criptare real.
Principiul care stă la baza criptanalizei liniare este asemănător celui care stă la baza tomografiei asistate de calculator: compunerea mai multor scan-ări unidimensionale ale unui obiect în scopul realizării unei imagini bidimensionale a unei bucăţi a acestuia.

91
Extinderi ale criptanalizei diferenţiale
Pornind de la criptanaliza diferenţială clasică au fost concepute câteva metode puternice de criptanaliză. Utilizând aceste metode a devenit posibilă atacarea unor sisteme de criptare simetrică care au fost concepute să fie rezistenete la atacurile prin criptanaliză diferenţială clasică.
Diferenţiale trunchiate
Este bineînţeles posibil ca probabilitatea ca unii dintre biţii lui E(A,k) xor E(B,k) să se potrivească cu biţii lui Y să fie mai mare decât probabilitatea ca alţi biţi ai lui E(A,k) xor E(B,k) să se potrivească cu biţii corespunzători lor din structura lui Y. Dacă cineva poate, în plus, să ignore anumiţi biţi ai textelor A şi B, (şi anume pe aceia care fac potrivirea de care s-a vorbit mai înainte mai puţin probabilă) acela are o diferenţială trunchiată pentru sistemul de criptare atacat şi această tehnică, inventată de Lars R. Knudsen, s-a dovedit a fi foarte puternică. Fiind capabil să ignore anumiţi biţi ai textelor A şi B, atacatorul poate utiliza două sau trei diferenţiale simultan ceea ce sporeşte mult şansele atacului său.
Diferenţiale de ordin superior
O altă extindere importantă a criptanalizei diferenţiale este dată de utilizarea difernţialelor de ordin superior. Această idee a apărut pentru prima dată într-o lucrare a lui Xuejia Lai.
O caracteristică diferenţială de tipul descris deja, unde pentru un număr mare de valori diferite A, B este egal cu A xor X şi variantele criptate cu o anumită cheie secretă k, ale lui A şi B satisfac relaţia E(A,k) = E(B,k) xor Y, dacă o anumită propoziţie referitoare la cheia k este adevărată, poate fi considerată analoagă cu o derivată (a unei anumite funcţii) şi este numită derivata cifrului E în punctul X. La fel poate fi definităşi derivata de ordinul 2. Această definiţie necesită existenţa unei a doua cantităţi, W, astfel încât şirul de egalităţi: B=A xor X, C=A xor W şi D=B xor W să implice ca relaţia: E(A,k) xor E(B,k) = E(C,k) xorE(D,k) xor Z să fie adevărată pentru o anumită constantă Z, cu o probabilitate mai mare decât cea corespunzătoare alegerii aleatoare a lui Z. În acest caz Z reprezintă derivata a doua a cifrului E în punctul (X,W). Formulele prezentate mai sus sunt valabile pe un câmp finit de tip Galois, modulo o putere întreagă a lui 2 (unde operaţia sauexclusiv (xor) este identică cu operaţiile de adunare respectiv de scădere). Pe un câmp finit mai general ar fi trebuit să se folosească relaţiile:
Y=E(A+X,k)-E(A,k) şi:
Z=(E(A+X+W,k)-E(A+W,k))-(E(A+X,k)-E(A,k))
Această relaţie este importantă deoarece o derivată a doua ar putea exista într-un punct pentru a cărui primă coordonată să nu existe o derivată a întâia sau aceasta să nu fie suficientă.
Similar, o derivată de ordinul 3, poate fi dedusă pe baza diferenţei a două derivate de ordinul 2, efectuată pentru o altă diferenţă de constante şi aşa mai departe.

92
6. Securitatea serviciilor INTERNET
INTERNET este cea mai mare reţea de reţele din lume. Când se doreşte accesarea resurselor oferite de INTERNET, nu se face în realitate o conectare la INTERNET, ci se face conectarea la o reţea care este ea însăşi conectată la Internet backbone, care este o reţea foarte rapidă şi incredibil de încărcată.
6.1 Protocoale TCP/IP
Ierarhia protocoalelor INTERNET
Serviciile INTERNET au la bază schimbul de mesaje între o sursă şi un destinatar. Principiul comunicării este inspirat de serviciul poştal. Dacă A doreşte să-i transmită ceva lui B, A împachetează obiectul, scrie pe pachet adresa destinatarului şi a expeditorului şi depune pachetul la cel mai apropiat oficiu poştal. Similar, dacă A doreşte să-i transmită un mesaj electronic lui B atunci mesajul trebuie "împachetat", adică încadrat de anumite informaţii de control. Unitatea de date astfel obţinută se numeşte "pachet", prin analogie cu sistemul poştal obişnuit. Informaţia de control include adresa expeditorului şi a destinatarului, specificate în formă numerică (număr IP): patru numere naturale mai mici decât 256, despărţite între ele prin puncte.
În sistemul poştal obişnuit, în funcţie de localizarea destinatarului, pachetul poate fi transmis prin intermediul mai multor oficii poştale intermediare. Ultimul oficiu poştal livrează pachetul destinatarului. Asemănător, într-o reţea de calculatoare, pachetul este dat unui comutator de pachete, numit şi "ruter", router, care are un rol similar oficiului poştal şi care-l trimite spre destinatar. Eventual pachetul traversează mai multe rutere intermediare. Ultimul comutator livrează mesajul destinatarului.
Dirijarea pachetelor este efectuată automat de către reţea şi respectă un set de reguli şi convenţii numit "protocol". Pentru reţeaua INTERNET acest protocol se numeşte IP, Internet Protocol. Acest protocol asigură livrarea pachetelor numai dacă în reţelele pe care acesta le traversează nu apar erori. Dacă un mesaj este prea lung, IP cere fragmentarea lui în mai multe pachete. Transmiterea pachetelor IP se face între calculatoarele gazdă şi nu direct între programele de aplicaţie. Din acest motiv protocolul IP trebuie completat cu un altul numit protocol de transmisie,TCP, Transmission Control Protocol. Protocolul TCP face fragmentarea mesajului în pachete şi asigură transmiterea corectă a mesajelor între utilizatori. În reţelele intermediare, pe care le traversează un mesaj, o parte din datele acestuia s-ar putea pierde. De aceea protocolul TCP ajută la detectarea erorilor de transmisie şi la detectarea datelor pierdute precum şi declanşează retransmisii ale mesajului până când acesta este recepţionat corect şi complet. Pachetele unui mesaj sunt numerotate, putându-se verifica primirea lor în forma în care au fost trimise şi reconstruirea mesajelor lungi, formate din mai multe pachete.
TCP este un protocol complicat. În unele cazuri, când se transmite un singur mesaj, suficient de scurt pentru a fi conţinut într-un singur pachet, se poate folosi un protocol mai simplu, numit UDP, User Datagram Protocol.
La rândul lor, operaţiile de la nivel aplicaţie se derulează şi ele pe baza unor protocoale. De exemplu protocolul de poştă electronică prin INTERNET se numeşte SMTP, Simple Mail Transfer Protocol. Funcţionarea acestui protocol se bazează pe serviciile oferite de protocoalele IP şi TCP.
Funcţionarea protocoalelor IP şi TCP se bazează pe existenţa unei comunicări directe între noduri (rutere) adiacente din reţea. Această comunicare este realizată conform unor tehnologii diverse şi se supune unor protocoale specifice, bine precizate. Ca urmare protocoalele TCP şi IP se bazează la rândul lor pe protocoale, care depind unele de altele, dar care au ca şi punct central, protocoalele TCP/IP. Termenul TCP/IP se referă la o întreagă familie de protocoale, protocoalele IP şi TCP fiind doar doi membri ai acestei familii. În figura 1 Internet se prezintă pachetul standard de protocoaleTCP/IP. În loc de a construi protocoale monolitice (protocoalele ftp, telnet sau gopher au fiecare câte o implementare completă, care include copii separate ale codului nucleu pentru dispozitivele folosite) proiectanţii seriei de protocoale TCP/IP au preferat să segmenteze munca unui întreg şir de protocoale de reţea într-un număr de sarcini. Fiecare nivel al modelului OSI corespunde la o faţetă diferită a

93
procesului de comunicaţie. Conceptual este util să se reprezinte familia de protocoale TCP/IP ca şi o stivă. În implementări, programatorii ascund de obicei nivelele modelului OSI pentru a creşte performanţele programelor.
Primul, nivelul legătură, este responsabil pentru comunicarea cu hard-ul reţelei. Acesta este locul unde sunt situate "driver-ele" pentru dispozitivele diferitelor interfeţe.
Cel de al doilea, nivelul reţea, este responsabil pentru stabilirea modului în care sunt livrate datele la destinaţie. Fără a oferi garanţii despre modul în care un anumit şir de date va ajunge la destinaţia sa, acest nivel al modelului de referinţă OSI decide unde trebuie transmise datele.
Figura 1 Internet. Nivelurile stivei de protocoale TCP/IP.
Cel de al treilea, nivelul transport, face posibil transferul datelor spre nivelul aplicaţie. Acesta este nivelul la care trebuie date garanţii de fiabilitate.
Cel de al patrulea, nivelul aplicaţie, este locul unde, de obicei, utilizatorii interacţionează cu reţeaua. Acesta este nivelul în care rezidă protocoalele: telnet, ftp, email, IRC, etc.
Protocoalele sunt astfel proiectate încât nivelul N al destinaţiei să primească (fără modificări) obiectul transmis de nivelul N al sursei. Pentru a fi posibilă respectarea acestui principiu, prin proiectarea oricărui protocol trebuie specificate:
- formatul unităţilor de date manipulate, - acţiunile posibile ale entităţilor de protocol care concură la realizarea serviciilor specifice protocolului. Accesul la protocoalele IP şi TCP este asigurat de diferite subrutine care au denumirea generică de Sokets. În modelul unei inter-reţele apar sistemele ce găzduiesc aplicaţiile, numite şi sisteme
terminale, subreţelele la care aceste sisteme sunt conectate şi sistemele intermediare, ruterele, ce conectează între ele subreţelele. De obicei un sistem terminal are o singură interfaţă cu reţeaua la care este conectat, în timp ce un sistem intermediar are mai multe interfeţe, câte una pentru fiecare subreţea la care este conectat. Rolul unui sistem intermediar este de a retransmite pachetele pe care le primeşte de la o subreţea, spre o altă subreţea, situată pe calea aflată spre sistemul terminal destinatar. Sistemul intermediar este legat la ambele subreţele.
Pachetele reprezintă unitatea de bază a unei transmisii pe INTERNET. Ele conţin atât date cât şi informaţii de tip antet (prefix). Informaţiile de tip antet constau din anumite combinaţii de sume de control, identificatoare de protocol, adrese de destinaţie şi de sursă şi informaţii de stare. Fiecare nivel al modelului OSI trebuie să adauge la şirul de date antetul său propriu, astfel încât să se poată interpreta informaţia de către toate nivelele, începând cu cel mai de jos. În figura 2 internet este dat un exemplu de cadru Ethernet. Acest cadru este rezultatul unui pachet care a plecat de la nivelul aplicaţie pe toate căile posibile spre nivelul legătură. Fiecare nivel ia pachetul de la nivelul anterior, putându-l vedea aproape în întregime ca pe un şir de date şi îi adaugă propriul antet.

94
Figura 2 Internet. Un exemplu de cadru Ethernet.
Nivelul legătură
Acesta este nivelul cel mai uşor de înţeles. Compus din hard-ul reţelei şi din driver-ele dispozitivelor, el este cel mai de jos nivel din stiva de protocoale. Când recepţionează date din reţea, el culege datele de pe cablul reţelei, le adaugă un antet specific şi transmite pachetele astfel construite spre nivelul reţea. Când transmite date spre reţea preia pachetele de la nivelul reţea, le adaugă un antet specific şi le transmite pe cablul reţelei. Avantajul separării de hard este că soft-iştii care implementează protocoalele trebuie să programeze legătura cu hard-ul o singură dată. Apoi ei concep o interfaţă comună cu reţeaua, programând diferitele driver-e de dispozitive pentru fiecare tip particular de reţea.
Nivelul reţea Acesta este nivelul unde rezidă, printre alte protocoale, şi protocoalele IP şi ICMP, Internet
Control Message Protocol. Protocolul ICMP este folosit atât pentru a furniza informaţii despre funcţionarea corectă a reţelei cât şi pentru a asigura unele utilităţi ca de exemplu ping sau traceroute.
Protocolul IP este folosit pentru aproape toate comunicaţiile în INTERNET. Când se trimit pachete, el găseşte modul în care acestea sunt transmise spre destinaţie. Când se primesc pachete el află de unde sosesc aceste pachete. Dacă un pachet soseşte fără probleme (de exemplu necorupt) protocolul IP îl transmite. Corectitudinea recepţiei pachetelor este sarcina unor nivele superioare. Pentru prelucrarea pachetului curent nu este relevantă existenţa unor pachete anterioare sau ulterioare. Protocolul IP nu este capabil să sesizeze nici măcar decuplarea, pentru un anumit interval de timp, a cablului de legătură cu reţeaua. Protocolul IP este capabil să conducă pachetele la destinaţia dorită deoarece fiecare interfaţă de reţea din INTERNET are o adresă numerică unică. Aceste numere se numesc adrese IP. Fiecare interfaţă are propria sa adresă. Dacă un calculator are mai multe interfeţe (ca de exemplu în cazul unui ruter) fiecare dintre aceste interfeţe are propria sa adresă IP. Deoarece este dificil să te referi la calculatoare folosind şiruri de numere, proiectanţii protocoalelor TCP/IP, au făcut posibil ca administratorii de reţea să asocieze nume cu adresele IP.
La început fiecare calculator gazdă, conectat la INTERNET, menţinea o copie completă a bazei de date cu toate numerele IP (pe calculatoarele care operau cu sistemul UNIX aceasta se găsea în /etc/hosts). Datorită expansiunii reţelei INTERNET acest lucru nu a mai fost posibil având în vedere atât dimensiunile uriaşe ale unei astfel de baze de date cât şi coşmarul la care ar fi fost supuşi administratorii de reţea pentru continua aducere la zi a acestei baze de date. Atfel s-a născut sistemul numelui de domeniu, DNS, domain name system. Acesta reprezintă o bază de date distribuită, conţinând adrese IP şi numele acestora în limbaj natural, numite nume de gazdă, host names.

95
De fapt la o anumită adresă INTERNET pot fi asociate mai multe nume de gazdă. Când un administrator de reţea adaugă un nou calculator la reţeaua pe care o administrează, el trebuie să reactualizeze tabelul de nume de organizaţie de pe server-ul acelei reţele. Această modificare se propagă rapid. Orice comunicaţie cu un calculator este realizată prin intermediul adreselor IP numerice, de aceea numele de gazdă pentru un calculator este folosit doar la începutul unei conexiuni. Paşii pe care îi face protocolul IP pentru a trimite un pachet sunt:
- pe baza adresei sale IP acesta găseşte modul în care pachetul poate ajunge la destinaţie; - trimite pachetul pe calea indicată. Din fericire, nu trebuie cunoscute toate modalităţile prin care un pachet poate ajunge, să
spunem, în Alaska, fiind suficient să se afle care este ruterul responsabil pentru transmiterea pachetelor spre Alaska. Un ruter este diferit de o gazdă obişnuită din reţea prin aceea că el are cel puţin două interfeţe, care îi permit să se conecteze la două sau mai multe reţele. Pentru o organizaţie mică, tipic există o reţea locală (de exemplu de tipul Ethernet) şi apoi o linie închiriată spre INTERNET. Ruterul acelei organizaţii este conectat atât la reţeaua locală cât şi la legătura INTERNET. Toate pachetele care trebuie transmise în INTERNET sunt transmise la ruter, care le retransmite pe linia închiriată, trimiţându-le spre ruterul următor. De aceea fiecare ruter trebuie să cunoască doar următoarele rutere cu care este conectat. Acestea la rândul lor vor cunoaşte ruterele la care sunt ele conectate. Dacă un ruter este conectat la mai multe alte rutere următoare (pe un anumit drum) atunci el trebuie să decidă la care dintre ele trebuie să transmită pachetul curent. La întrebarea "Cum trebuie să aleagă un anumit ruter ruterul următor ?" nu există un răspuns unic. Traficul poate fi dirijat pe baza algoritmului "în sensul acelor de ceasornic" sau ruterele următoare aflate pe acelaşi drum (adică care pot conduce la aceeaşi destinaţie) pot fi alternate. Există şi algoritmi de dirijare mai complicaţi care ţin seama de încărcarea drumurilor posibile şi care trimit datele pe linia cea mai puţin ocupată. Un ruter local ar putea "spune": "Toate pachetele din reţeaua locală West merg la MIT, de aceea eu le trimit acolo şi las ruterul de la MIT să afle ce trebuie făcut mai departe". Ruterul de la MIT le poate transmite la Cleveland, de acolo pachetele se pot duce la Chicago, San Francisco sau Seattle şi apoi în Alaska, unde au fost trimise de fapt de primul ruter (cel al reţelei locale). Ruterul din fiecare nod al reţelei INTERNET este interesat doar de ruterul următor la care trebuie să trimită pachetele. El nu trebuie să încerce să determine întregul traseu pe care îl vor urma aceste pachete. Pentru a determina următorul ruter la care trebuie să ajungă un pachet, ruterele din INTERNET utilizează tabele de dirijare. Acestea au trei părţi constitutive:
-adrese de rutere, -adrese pe care le pot manipula, -interfeţele destinaţie, la care sunt conectate ruterele respective. În cazul unui calculator dintr-o reţea locală (ca de exemplu cool.cs.umass.edu), e suficient
dacă un astfel de tabel are trei rubrici: una pentru interfaţa cu bucla (care îi permite unui calculator gazdă să se conecteze la el însuşi), una pentru reţeaua locală şi una pentru legătura spre exterior iniţială.
Rubrica pentru reţeaua locală permite protocolului IP să ştie că gazda sa este conectată direct la câteva calculatoare şi să cunoască adresele IP ale acestora. În loc să încerce să dirijeze aceste pachete, protocolul IP găseşte adresa dispozitivului hard cu numărul IP de interfaţă Ethernet corespunzător şi trimite pachetul acolo. Adresele pe care le poate manipula ruterul sunt toate adresele IP din reţeaua locală. Interfaţa destinaţie este o placă Ethernet din reţeaua locală. Toate celelalte adrese identificate din pachetul de transmis, diferite de cele amintite mai sus trebuie să conducă la legătura iniţială spre exterior.
În loc să încerce să livreze un pachet cu destinaţia cool.alaska.edu unui calculator din reţeaua locală, un anumit calculator din reţea trimite acel pachet spre interfaţa ruterului, spunând "Ia, eu nu ştiu unde trebuie să meargă pachetul ăsta, dă-ţi tu seama". Atunci ruterul se uită în tabelul său de dirijare, constată că nu are o legătură directă cu domeniul cool şi de aceea îl trimite la legătura sa iniţială spre exterior, MIT. Şi astfel continuă procesul.
Chiar dacă o linie telefonică dintr-o anumită reţea se defectează, traficul nu se întrerupe, datele putând ajunge la destinaţie pe un alt drum (care exclude legătura întreruptă). După pierderea legăturii între New York şi Chicago datele pot fi trimise de la New York la Atalanta apoi la Los Angeles şi apoi la Chicago. În acest fel se poate asigura un serviciu continuu dar cu performanţe degradate. Acest tip

96
de recuperare a datelor este primul parametru de proiectare al protocolului IP. Defectarea liniei telefonice este imediat sesizată de ruterele din New York şi Chicago, dar într-un anumit mod această informaţie trebuie transmisă şi celorlalte noduri. Altfel, ruterul din Los Angeles ar continua să transmită mesaje spre New York prin Chicago unde ele ar sosi la un "capăt mort". De aceea în fiecare reţea este adoptat un anumit protocol de dirijare care reîmprospătează periodic tabelele de dirijare pentru întreaga reţea pe baza unor informaţii despre schimbările suferite de stările de dirijare.
Când se recepţionează date, protocolul IP preia pachetul de pe nivelul legătură, verifică dacă acesta a fost corupt sau nu şi livrează pachetul procesului corespunzător din nivelul transport.
În această descriere succintă au fost ignorate câteva funcţiuni cum ar fi: fragmentarea pachetelor, manevrarea erorilor de transmisie, sau interacţiunea dintre nivelele reţea şi transport.
Nivelul transport
La acest nivel se uitlizează două protocoale: TCP şi UDP. În timp ce protocolul TCP asigură o comunicaţie sigură între capete, protocolul UDP nu asigură această condiţie. UDP nu este la fel de sigur ca TCP dar permite programatorilor să scrie soft la nivel de utilizator, care să creeze formate particulare de pachete, ceea ce este foarte util când se doreşte conceperea unor noi protocoale, fără a avea la dispoziţie programele sursă pentru nucleele acestora şi nu se doreşte supraveghere din partea protocolului TCP. Protocolul TCP crează un circuit virtual între două procese. El asigură recepţia pachetelor în ordinea în care au fost trimise şi retransmiterea pachetelor pierdute. Programe interactive ca de exemplu ftp sau telnet folosesc acest protocol.
Când sosesc date la un ruter congestionat (care este deja ocupat în proporţie de 100%) nu există nici un loc unde să fie trimise datele în exces. Este resposabilitatea expeditorului să încerce retransmiterea datelor puţin mai târziu şi să insisite până când reuşeşte. Acest tip de reconstrucţie a şirului de date este realizat de protocolul TCP. Acest protocol a fost proiectat să reconstruiască şirul de date şi în cazul în care apar defecţiuni la un nod al reţelei sau la o legătură dintre două noduri. Când se propagă informaţia despre o astfel de defecţiune, tabelele de dirijare ale unor rutere trebuie să se modifice. Deoarece această modificare cere un anumit timp, se poate afirma că protocolul TCP este lent în cazul în care trebuie refăcut şirul de date după o astfel de defecţiune. Deci protocolul TCP nu este dedicat optimizării manipulării pachetelor în cazul congestiei traficului. De fapt strategia tradiţională de rezolvare a problemei congestiei traficului în INTERNET a fost creşterea vitezei liniilor de comunicaţie şi a echipamentelor pentru a exista o rezervă consisitentă în raport cu creşterea cererii de servicii.
Protocolul TCP tratează fluxul de date ca pe un şir de octeţi. El asociază un număr de secvenţă fiecărui octet. Pachetul TCP are un prefix care "spune" de exemplu: "Acest pachet începe cu octetul 379642 şi conţine 200 de octeţi de date". Destinatarul poate detecta absenţa unor pachete sau incorecta indexare a altora. Protocolul TCP validează datele care au fost recepţionate şi retransmite datele care au fost pierdute. Acest protocol asigură mijloace pentru ca datele să fie reconstruite între capete, adică între calculatoarele expeditorului şi destinatarului.
Nu există standarde pentru rezolvarea problemelor care apar în mijlocul unei subreţele care este traversată de un anumit mesaj deoarece în fiecare subreţea sunt adoptate în mod ad-hoc anumite "soluţii".
Până aici s-a discutat adresarea la nivel de calculator gazdă - cum se identifică un anumit calculator. Dar odată această identificare făcută, este necesară o metodă pentru identificarea unui anumit serviciu (pe care să-l efectueze calculatorul gazdă identificat), de exemplu serviciul de poştă electronică. Aceasta este sarcina porturilor - identificarea numerelor incluse în fiecare pachet TCP sau UDP. Porturile TCP/IP nu sunt de natură hard. Ele sunt doar o modalitate de a etichetare a pachetelor. Fiecare proces care poate fi efectuat pe un anumit calculator corespunde unui anumit port TCP/IP. Când nivelul transport primeşte un pachet el verifică numărul de port din acel pachet şi trimite datele procesului corespunzător. Când un anumit proces porneşte, se înregistrează un anumit număr de port cu ajutorul stivei TCP/IP. Un singur proces de protocol poate corespunde unui port dat. Astfel dacă un proces aparţine protocolului UDP şi un alt proces protocolului TCP ele pot corespunde unui acelaşi port, de exemplu 111, nu acelaşi lucru se poate afirma despre două procese care aparţin aceluiaşi

97
protocol, de exemplu TCP. Un număr de porturi sunt rezervate pentru servicii standard. De exemplu protocolul de poştă electronică, SMTP, corespunde întotdeauna portului 25 iar protocolul telnetd portului 23. O listă a porturilor rezervate pe un sistem UNIX se găseşte în fişierul /etc/services.
Până aici s-a prezentat modul în care lucrează porturile la capătul la care este conectat server-ul - se rezervă porturi specifice pentru sarcini specifice. La celălalt capăt are loc o distribuire dinamică a porturilor. Când un client telnet începe să utilizeze acest protocol el dă un nou număr de port (de exemplu 1066). Acesta este portul sursă pe care protocolul TCP al utilizatorului îl include în fiecare pachet. Astfel va putea protocolul telnet daemon, telnetd, de pe server să răspundă corect la procesul telnet iniţiat de utilizator. Combinaţia dintre adresele IP ale sursei şi ale destinaţiei şi porturi crează un identificator unic de conversaţie. Fiecare conversaţie este numită curgere.
UDP-ul se bazează pe protocolul IP şi pe numere de porturi. El dă acces utilizatorului la pachetele de tip IP. Sistemul de fişiere al reţelei, network file system, NFS şi talk sunt două exemple de protocoale bazate pe UDP.
Prezentarea protocoalelor TCP şi UDP, făcută până aici, a fost extrem de sumară. Ea oferă doar o înţelegere aproximativă a modului în care interacţionează într-o reţea nivelele reţea (al cărui protocol specific este IP) şi transport (ale cărui protocoale specifice sunt TCP sau UDP).
Nivelul aplicaţie
Reprezintă locul în care utilizatorul interacţionează cu reţeaua. Toate programele de comunicaţie în reţea ca de exemplu: telnet, ftp, mail, news, şi WWW clients acţionează la acest nivel. Ele folosesc TCP sau UDP pentru a comunica cu alte calculatoare. În continuare se detaliază puţin programul telnet. Acesta este utilizat pentru utilizarea unui calculator de la distanţă, remote login. El înlătură necesitatea de a folosi terminale conectate hard. Un utilizator care tastează, după ce a declanşat acest program, ``telnet cool.alaska.edu'' este conectat rapid la calculatorul cool.alaska.edu, care îi cere să-l acceseze. Apoi utilizatorul poate lucra pe calculatorul cool.alaska.edu. Acest proces se bazează pe următoarele etape:
1 Numele folosit ca şi adresă este convertit numeric, obţinându-se (137.229.18.103), prin intermediul unui server de nume de domeniu. 2 Programul telnet transmite nivelului de transport că doreşte să înceapă o legătură TCP cu 137.229.18.103, la portul 23. 3 Protocolul TCP iniţiază o conversaţie cu calculatorul numit cool. Se foloseşte protocolul IP pentru a dirija pachete. Programul telnet, rulat pe calculatorul pe care lucrează utilizatorul care doreşte serviciul la distanţă, dă un număr de port, de exemplu, 1096. Protocolul TCP plasează numerele de port al sursei şi destinaţiei în prefixul pe care îl adaugă el pachetului, iar protocolul IP adaugă, în prefixul pe care îl adaugă el pachetului, adresa IP. 4 Pachetele sunt apoi dirijate la nivelul IP, care le trimite la nivelul legătură. Ele trec de pe calculatorul utilizatorului pe ruterul organizaţiei sale şi apoi ies în INTERNET. Ele îşi urmează drumul spre calculatorul numit cool, trecând rând pe rând prin toate ruterele situate pe acest drum. 5 Nivelul TCP al calculatorului numit cool răspunde într-un mod similar. 6 Protocolul telnet daemon de pe calculatorul numit cool şi protocolul telnet de pe calculatorul care a solicitat serviciul la distanţă schimbă informaţii de terminal şi alţi parametri necesari unei sesiuni de lucru interactiv. Se transmit mesaje de control de tipul: ecou, stare, tip de terminal, viteză de terminal, controlul traficului sau variabile de mediu. 7 Utilizatorul vede pe monitorul calculatorului său prompter-ul de login. După ce se efectuează operaţia de login începe transferul de date între calculatorul utilizatorului şi calculatorul accesat la distanţă.
De îndată ce sarcina a fost împărţită în mai mulţi paşi se poate constata că ea este relativ simplă. Deoarece nivelul transport realizează o interfaţare standard, nu este necesar ca aplicaţiile de reţea să fie rescrise şi nici măcar recompilate dacă se schimbă programul corespunzător nivelului transport.
Pentru o bună funcţionare a seriei de protocoale TCP/IP este necesar ca elementele acesteia să posede anumite cunoştiinţe. Există trei nivele de cunoştiinţe TCP/IP.

98
Cei care administrează o reţea regională sau naţională trebuie să proiecteze un sistem format din linii telefonice care să permită comunicaţii la foarte mare distanţă, din dispozitive de dirijare dedicate şi din fişiere de configurare foarte mari. Ei trebuie să cunoască numerele IP şi locaţiile fizice a mii de reţele de abonaţi. De asemenea ei trebuie să aibă o strategie de monitorizare a reţelei pentru a detecta problemele care apar şi a le rezolva rapid.
Fiecare companie mare sau universitate, conectată la INTERNET, trebuie să aibă un nivel intermediar de organizare a reţelei. Un număr de şase rutere ar putea fi suficient pentru a conecta câteva duzini de reţele locale de departament, situate în câteva clădiri. Întregul trafic din afara organizaţiei va fi dirijat la o singură conexiune spre un prestator de servicii de reţea regional.
Utilizatorul final (situat la unul dintre capetele reţelei) poate instala seria de protocoale TCP/IP pe un calculator personal fără a avea vreo cunoştiinţă despre reţeaua regională sau despre reţeaua companiei. Totuşi el are nevoie de trei tipuri de informaţie: 1 Adresa IP asociată calculatorului său, 2 Partea din adresa IP (masca subreţelei) care permite să se facă distincţia între diferite calculatoare din aceeaşi reţea locală (pot fi trimise direct mesaje la aceste calculatoare de la alte calculatoare din aceeaşi reţea sau de altundeva din lume (acestea fiind în prealabil transmise ruterului reţelei locale)). 3 Adresa IP a ruterului care conectează acea reţea locală la restul lumii. De exemplu un server de reţea locală poate fi configurat cu următoarele valori:
Adresa sa IP: 130.132.59.234 Masca subreţelei: 255.255.255.0 Adresa ruterului iniţial de conexiune spre exterior: 130.132.59.1 Masca subreţelei specifică server-
ului că orice alt calculator cu o adresă IP care începe cu 130.132.59.* se află în aceeaşi reţea locală departamentală, în consecinţă mesajul putându-i-se transmite direct. Orice adresă IP care începe cu o valoare diferită este accesată indirect transmiţându-i-se mesajul prin ruterul cu adresa 130.132.59.1 .
Au fost trecute în revistă cele patru nivele ale modelului OSI care găzduiesc protocoale din seria TCP/IP şi s-a prezentat modul în care interacţionează elementele acestei serii de protocoale. Multe detalii nu au fost dezvăluite. Acestea pot fi găsite în documente publicate pe INTERNET de tip RFC, Request for Comments. Aceste documente sunt elaborate de către asociaţia de standardizare a INTERNET-ului, Internet Engineering Task Force, IETF şi se găsesc la adresa: http://www.rfc-editor.org/
În continuare se reia prezentarea protocoalelor din familia TCP/IP, puţin mai în detaliu.
Nivelul de interfaţă cu reţeaua
Două protocoale de interfaţă cu reţeaua sunt relevante pentru seria TCP/IP. Acestea sunt: Protocolul de legătură serială, The Serial Line Internet Protocol, SLIP(descris în RFC 1055) şi Protocolul punct la punct, Point-to-Point Protocol , PPP(descris în RFC 1661). Aceste protocoale funcţionează la nivelul legătură de date. Şi unele pachete de programe TCP/IP, destinate calculatoarelor de tip PC, includ aceste două protocoale. Cu ajutorul protocoalelor SLIP sau PPP, un calculator aflat la distanţă se poate conecta la un server gazdă, şi prin intermediul acestuia la INTERNET folosind protocolul IP, în loc de a fi limitat să folosească o conectare asincronă.
Protocolul PPP
Point to Point Protocol este unul dintre protocoalele cel mai des utilizate pentru accesul la INTERNET. După cum îi arată şi numele acest protocol a fost proiectat pentru a fi utilizat pentru legăturile punct la punct. De fapt el reprezintă modalitatea de încapsulare IP pentru sistemele de acces dedicate INTERNETULUI sau bazate pe adresare numerică (ca şi în cazul telefoniei). Una dintre funcţiile de bază ale acestui protocol este negocierea, înainte de conectarea iniţială, a unei serii de aspecte cum ar fi: parole, adrese IP, scheme de compresie, sau scheme de criptare. În plus, PPP ajută utilizarea mai multor protocoale pentru o singură legătură. Acest atribut al protocolului PPP este foarte util în aplicaţii în care utilizatorii de adresare numerică pot folosi atât IP cât şi un alt protocol de nivel reţea. Acest protocol poate fi utilizat şi de reţelele cu integrare de servicii, ISDN, deoarece suportă operaţii specifice pentru acest tip de reţele, cum ar fi multiplexarea inversă sau alocarea dinamică a

99
benzilor de frecvenţă prin intermediul variantei sale Multilink-PPP , ML-PPP, descrisă în RFC 1990 şi în RFC 2125. În figura următoare se prezintă formatul unui cadru pentru protocolul PP.
Figura 3 Internet. Formatul de cadru PPP.
Semnificaţia câmpurilor din acest cadru este următoarea:
Flag (steguleţ indicator): Octetul "01111110" este folosit pentru a delimita începutul şi sfârşitul transmisiei.
Address (adresă): Pentru PPP, se foloseşte octetul de adresă, "11111111". Frame Check Sequence, FCS (secvenţă de verificare a cadrului): este un octet care reprezintă restul
obţinut în urma efectuării unei operaţii de verificare a corectitudinii transmisiei, cyclic redundancy check , CRC, utilizată pentru detecţia erorilor de transmisie.
Protocol: este o valoare exprimată pe 8 sau pe 16 biţi care indică tipul de pachet despre care este vorba în câmpul Information din acelaşi cadru. Acest câmp poate indica utilizarea unui protocol de nivel reţea (cum ar fi IP, IPX, sau DDP), un protocol de control al reţelei, a Network Control Protocol , NCP, în asociere cu un protocol de nivel reţea, sau un protocol de control al nivelului legătură de tip PPP, a PPP Link-layer Control Protocol, LCP.
Information (informaţie): Conţine pachetele pentru protocolul specificat în câmpul Protocol. Acesta cîmp poate conţine între 0 şi 1500 de octeţi (o valoare diferită poate fi negociată).
Padding (egalizare): Lungimea cîmpului Information poate fi egalizată. Această egalizare poate fi cerută în unele implementări ale acestui protocol pentru a asigura o anumită lungime minimă a cadrului şi/sau pentru a asigura o anumită aliniere a marginilor cuvintelor folosite de calculatorul pe care funcţionează acest protocol. Modul de operare al protocolului PPP este următorul: 1 După stabilirea fizică a legăturii, fiecare calculator gazdă trimite pachete LCP pentru a configura şi testa legătura de date respectivă. În această etapă se negociază lungimea maximă a cadrelor, protocolul de autentificare folosit (se poate alege între protocolul de autentificare a parolelor, Password Authentication Protocol, PAP, sau protocolul de autentificare Challenge-Handshake Authentication Protocol, CHAP), protocolul de calitate a legăturii folosit, protocolul de compresie folosit. De asemenea se negociază şi alţi parametri de configurare. Dacă se utilizează autentificarea, aceasta se va face după ce legătura de date a fost stabilită. 2 După ce legătura de date a fost stabilită, se configurează una sau mai multe conexiuni de protocol de nivel reţea folosind protocolul de control al reţelei, NCP, corespunzător. Dacă se utilizează ca şi protocol de nivel reţea protocolul IP, conexiunea corespunzătoare acestuia va fi configurată folosind protocolul de control, specific pentru PPP şi IP, numit IP Control Protocol, IPCP. După ce fiecare protocol de nivel reţea a fost configurat, pachete corepunzătoare acestor protocoale pot fi trimise prin această legătură. Pot fi utilizate protocoale de control pentru protocoalele de nivel reţea: IP, IPX (NetWare), DDP (AppleTalk), DECnet, ş.a.m.d. 3 Legătura va rămâne configurată pentru comunicaţii până când pachete specifice pentru protocoalele LCP şi/sau NCP o vor desface.

100
Nivelul INTERNET
Protocolul INTERNET (descris în RFC 791), oferă servicii echivalente cu cele prevăzute în modelul de referinţă OSI la nivelul reţea. Protocolul IP oferă un serviciu de transport al pachetelor de-a lungul întregii reţele. Despre acest serviciu se afirmă uneori că nu ar fi de încredere deoarece reţeaua nu trebuie să garanteze livrarea corectă şi nici nu trebuie să informeze calculatorul gazdă destinatar al pachetelor de date despre pierderea unor pachete datorită unor erori de transmisie sau datorită congestionării reţelei. Pachetele IP conţin un mesaj sau un fragment de mesaj, care poate fi de o lungime mai mare de 65.535 octeţi. Protocolul IP nu trebuie să prevadă un mecanism de control al curgerii datelor. Formatul antetului pachetului IP este prezentat în figura următoare.
Figura 4 Internet. Formatul antetului protocolului IP.
Biţii antetului acestui protocol sunt numerotaţi de la stânga la dreapta pornind de la 0. Pe fiecare linie este situat un cuvânt de 32 de biţi. Trebuie remarcat că fiecare antet IP va avea o lungime de cel puţin cinci cuvinte (adică 20 de octeţi). Câmpurile conţinute în acest antet şi funcţiile lor sunt: - Version (versiune): Specifică versiunea IP a pachetului. Deoarece versiunea curentă de IP este 4 acest câmp va conţine valoarea în binar 0100. - Internet Header Length (lungimea antetului INTERNET), IHL: indică lungimea antetului pachetului în cuvinte cu lungimea de 4 octeţi. O lungime minimă de antet este de 20 de octeţi. De aceea în acest câmp de obicei este înscrisă o valoare mai mare sau egală cu 5 (0101). Deoarece valoarea maximă care se poate înscrie în acest câmp este de 15, antetul IP al unui pachet nu poate fi mai lung de 60 de octeţi. - Type of Service (tipul de serviciu), TOS: Permite ca un calculator gazdă care transmite pachete să

101
solicite diferite tipuri de servicii pentru pachetele pe care le emite. Deşi această facilitate încă nu este asigurată de toate protocoalele Internet, în cazul protocolului IPv4, câmpul TOS poate fi setat de către calculatorul gazdă expeditor conform specificaţiilor făcute la nivelul interfeţei dintre nivelul transport şi nivelul servicii al reţelei INTERNET şi poate specifica o prioritate a serviciului (0-7) sau poate cere ca dirijarea pachetelor să fie optimizată după criterile: cost, întârziere, sau fiabilitate. - Total Length (lungime totală): indică lungimea în octeţi a întregului pachet, incluzând atât antetul cât şi datele. Lungimea totală maximă a unui pachet IP este de 65.535 de octeţi. În practică dimensiunile pachetelor sunt limitate la unitatea maximă de transmisie, the maximum transmission unit , MTU. - Identification (identificare): Folosit când un pachet este fragmentat în bucăţi mai mici pentru a traversa INTERNET-ul, acest identificator este specificat de către ruterul curent, astfel încât diferitele fragmente care sosesc la destinaţie, să poată fi reasamblate. - Flags (steguleţe): Şi acest câmp se utilizează pentru fragmentare şi reasamblare. Primul bit al acestui câmp este numit bit de continuare a fragmentării, the More Fragments bit , MF şi este folosit pentru a indica ultimul fragment al unui pachet, astfel încât calculatorul care recepţionează pachetul să ştie că acest pachet poate fi reasamblat. Următorul bit al acestui câmp este numit bit de încetare a fragmentării, Don't Fragment bit, DF şi indică faptul că fragmentarea trebuie suprimată. Cel de al treilea bit al acestui câmp nu este folosit, fiind setat în permanenţă pe zero. - Fragment Offset (poziţionarea fragmentului): indică poziţia fragmentului curent în cadrul pachetului original. Pentru primul fragment dintr-un şir de fragmente, valoarea înscrisă în acest câmp va fi zero; pentru fragmentele următoare acest câmp va indica poziţia prin valori obţinute prin incrementarea valorii anterioare cu câte 8 octeţi. - Time-to-Live (timpul de viaţă), TTL: În acest câmp se înscrie o valoare cuprinsă între 0 şi 255, indicând numărul de rutere prin care acest pachet va trece înainte de a fi distrus. Fiecare ruter prin care trece acest pachet va decrementa valoarea înscrisă în acest cîmp. Dacă valoarea curentă ajunge să fie zero pachetul va fi distrus. - Protocol: indică protocolul corespunzător celui mai înalt nivel din modelul de referinţă OSI cu care sunt prelucrate datele din pachetul curent. Sunt posibile următoarele opţiuni: ICMP (1), TCP (6), UDP (17), sau OSPF (89). O listă de implementare a acestor protocoale poate fi găsită în fişierul de protocoale de pe fiecare calculator, numit /etc, pentru calculatoarele care folosesc sistemul de operare Linux/Unix, c:\windows pentru calculatoarele care utilizează sistemul de operare Windows 9x, sau c:\winnt\system32\drivers\etc , pentru calculatoarele care utilizează sistemele de operare Windows NT, sau Windows 2000. - Header Checksum (suma de control a antetului): în acest câmp sunt înscrise informaţii care să asigure că antetul IP al pachetului recepţionat nu este afectat de erori. Acest control se referă doar la antet, nu şi la partea de date conţinută în acel pachet. - Source Address (adresa susrsei): Adresa IP a calculatorului care a trimis pachetul. - Destination Address (adresa destinaţiei): Adresa IP a calculatorului căruia i se transmite pachetul. - Options (opţiuni): O mulţime de opţiuni care pot fi făcute în legătură cu orice pachet, cum ar fi tipul de dirijare specificat de un anumit expeditor, sau tipul de securitate specificat de către acesta. Câmpul conţinând lista de opţiuni poate avea o lungime maximă de 40 de octeţi (care corespunde la un număr de 10 cuvinte).
Adrese IP
Lungimea adreselor Ipv4 este de 32 de biţi. Ele reprezintă o secvenţă de 4 numere, exprimate în zecimal, fiecare reprezentând valorea zecimală a unui octet de adresă. Deoarece aceste valori sunt separate prin puncte, notaţia utilizată pentru scrierea lor este numită zecimală punctată. Un exemplu de adresă IP este următorul: 208.162.106.17.
Adresele IP sunt ierarhizate pentru a face posibilă dirijarea pachetelor de date şi sunt compuse din două subcâmpuri. Subcâmpul de identificare a reţelei, The Network Identifier, NET_ID identifică subreţeaua TCP/IP conectată la INTERNET. Acest identificator este utilizat pentru dirijarea la nivel înalt între subreţele, la fel cum se folosesc prefixurile de ţară, de oraş sau de cartier, în reţeaua

102
telefonică. Cel de al doilea subcâmp, identificatorul calculatorului gazdă, The Host Identifier, HOST_ID indică un anumit calculator gazdă, din cadrul subreţelei (deja identificată).
Pentru a putea funcţiona în reţele de dimensiuni diferite, pentru protocolul IP există câteva clase de adrese. Clasele A, B şi C se folosesc pentru identificarea calculatoarelor gazdă şi singura diferenţă între clase este lungimea subcâmpului NET_ID. O adresă de clasă A are un subcâmp NET_ID cu o lungime de 7 biţi şi un câmp HOST_ID cu o lungime de 24 de biţi. Clasa A de adrese este construită pentru reţele foarte mari şi poate adresa un număr de până la 16.777.216 (2
24)
calculatoare gazdă pentru fiecare reţea. Primul octet al unei adrese de clasă A va fi un număr cuprins între 1 şi 126. O adresă de clasă B are un subcâmp de tipul NET_ID cu o lungime de 14 biţi şi un subcâmp de tipul HOST_ID cu o lungime de 16 biţi. Adresele din această clasă au fost construite pentru reţele de mărime medie şi pot fi folosite pentru identificarea unui număr de până la 65.536 (2
16)
calculatoare într-o singură reţea.
Figura 5 Internet. Formatul adreselor IP.
Primul octet al unei adrese de clasă B este un număr cu valoarea cuprinsă între 128 şi 191. O adresă de clasă C are un sub-câmp de tipul NET_ID cu o lungime de 21 de biţi şi un subcâmp de tipul HOST_ID cu o lungime de 8 biţi. Acest tip de adrese au fost concepute pentru reţelele de dimensiuni mici şi pot adresa doar un număr de până la 254 de calculatoare într-o reţea. Primul octet al unei adrese de clasă C va fi un număr cuprins între 192 şi 223. Majoritatea adreselor folosite în ziua de azi sunt de clasă C.
Ultimele două clase de adrese rămase se utilizează doar pentru funcţii speciale şi nu sunt alocate unor calculatoare gazdă individuale. Adresele de clasă D pot începe cu un octet cu valoarea cuprinsă între 224 şi 239 şi sunt utilizate pentru comunicaţii multipunct (trimiterea unui pachet de date la mai mulţi utilizatori).
Primul octet al adreselor de clasă E are valoarea cuprinsă între 240 şi 255. Aceste adrese sunt utilizate în scop experimental. Câteva adrese sunt rezervate şi/sau au un înţeles special. Când ne referim la o întreagă subreţea putem folosi un HOST_ID de valoare 0. Adresa 208.162.106.0 este una de tip C cu un NET_ID de valoare 208.162.106 . Dacă un sub-câmp de tipul HOST_ID este completat doar cu cifre de valoare 1 (asta se scrie de obicei 255 sau -1) atunci adresa corespunzătoare se referă la

103
toate calculatoarele gazdă dintr-o reţea. Valoarea 127 pentru NET_ID este folosită pentru testarea în buclă închisă iar adresa 127.0.0.1 reprezintă o adresă de calculator gazdă local. Cîteva valori ale subcâmpului NET_ID au fost rezervate prin RFC 1918 pentru reţele private şi pachetele de date nu vor fi dirijate prin INTERNET spre aceste reţele. Printre acestea se găsesc adresele: 10.0.0.0, de clasă A, cele 16 adrese de clasă B, 172.16.0.0172.31.0.0, şi cele 256 de adrese de clasă C, 192.168.0.0-192.168.255.0.
O unealtă suplimentară de adresare este masca de subreţea. Aceste măşti se folosesc pentru a specifica porţiunea din adresă care specifică reţeaua sau subreţeaua, pentru scopuri de dirijare. Şi masca de subreţea este scrisă în zecimal punctat şi numărul de 1-uri indică biţii semnificativi ai subcâmpului NET_ID. Pentru adresele IP din clasele specificate, măştile de subreţea şi numărul de biţi semnificativi de subcâmp NET_ID sunt prezentaţi în tabelul următor.
Clasa Masca de subreţea Numărul de biţi semnificativi A 255.0.0.0 8 B 255.255.0.0 16 C 255.255.255.0 24
Măştile de subreţea pot fi scrise în formă zecimală punctată sau doar ca un număr care reprezintă numărul de biţi semnificativi ai subcâmpului NET_ID al adresei IP. De exemplu adresele, 208.162.106.17 255.255.255.0 şi 208.162.106.17/24 , se referă amândouă la un subcâmp de tipul NET_ID al unei adrese de clasă C cu HOST_ID de valoare 208.162.106. Cineva ar putea citi valoarea acestui subcâmp NET_ID chiar şi în forma "slash-24."
Măştile de subreţea mai pot fi utilizate şi pentru divizarea unui spaţiu de adrese de lungime mare în spaţii pentru subreţele sau pentru a combina mai multe spaţii de adresă de lungime mică. În primul caz o reţea îşi poate diviza spaţiul de adrese pentru a defini mai multe subreţele prin segmentarea subcâmpului său HOST_ID într-un identificator de subreţea, Subnetwork Identifier, SUBNET_ID şi un câmp HOST_ID de lungime mai mică. De exemplu spaţiul de adresă al unei adrese de clasă B, definit de utilizator 172.16.0.0, poate fi segmentat într-un câmp NET_ID cu o lungime de 16 biţi, un câmp SUBNET_ID cu o lungime de 4 biţi, şi un câmp HOST_ID cu o lungime de 12 biţi. În acest caz masca de subreţea, folosită pentru dirijarea în INTERNET, va fi 255.255.0.0 (adică "/16"), în timp ce masca de subreţea folosită pentru dirijarea în reţele individuale, conţinută în spaţiul mai larg al adresei de clasă B va fi 255.255.240.0 (adică "/20").
În continuare se prezintă modul de lucru al măştii de subreţea. Pentru a determina porţiunea corespunzătoare subreţelei a adresei, se calculează funcţia şi logic între biţii măştii şi biţii adresei IP. Se consideră următorul exemplu: se consideră că există un claculator gazdă cu adresa IP 172.20.134.164 şi o mască de subreţea 255.255.0.0 . Se convertesc cele două valori în zecimal şi în binar:
172.020.134.164 10101100.00010100.10000110.10100100
AND 255.255.000.000 11111111.11111111.00000000.00000000
172.020.000.000 10101100.00010100.00000000.00000000
Se poate determina astfel uşor valoarea de NET_ID, 172.20.0.0 . Majoritatea interfeţelor legăturilor cu clientul dintr-o reţea WAN folosesc adresa /30. Ruterul
din reţeaua clientului va avea două adrese IP; una pe interfaţa cu reţeaua LAN, luată din spaţiul de adrese IP publice ale clientului şi una pe interfaţa cu reţeaua WAN care conduce înapoi la calculatoarele gazdă din reţeaua considerată.
Conservarea adreselor IP
Utilizarea claselor de adrese IP întâmpină câteva obstacole. De exemplu să considerăm că o organizaţie are nevoie de 1000 de adrese IP. Nu se pot utiliza adrese de clasă C, deoarece numărul

104
acestora este mai mic decât 1000. De aceea acea organizaţie va trebui să folosească adrese de clasă B. Dar această clasă oferă mai mult de 64000 de adrese, în consecinţă 63.000 de adrese rămân nefolosite. O procedură alternativă este să i se aloce acestei organizaţii un bloc de 4 adrese de clasă C, ca de exemplu 192.168.128.0, 192.168.129.0, 192.168.130.0 şi 192.168.131.0. Prin folosirea unei măşti de subreţea cu lungimea de 22 de biţi, ca de exemplu 255.255.252.0 (adică /22) pentru dirjarea spre acest bloc, subcâmpul de tipul NET_ID alocat acestei organizaţii este 192.168.128.0. Această folosire a unei măşti de subreţea de lungime variabilă se numeşte dirijare interdomeniu fără clasă, Classless Interdomain Routing , CIDR şi este descrisă în RFC 1518 şi RFC 1519. Pentru exemplul prezentat informaţia de dirijare esenţială poate fi specificată într-o singură rubrică a unui tabel de dirijare.
Acest concept, pe baza căruia o adresă dintr-o clasă superioară poate fi înlocuită cu un bloc de adrese de clasă inferioară, folosind în acest scop măşti de subreţea de lungime variabilă, poate fi generalizat. CIDR este o contribuţie importantă la INTERNET deoarece a permis limitarea dimensiunilor tabelelor de dirijare. În prezent, adresele IP nu sunt alocate strict pe baza principiului "Primul venit primul servit" ci ele au fost prealocate diferitelor autorităţi de adresare existente în lume.
Sistemul numelor de domeniu
Deoarece lungimea adreselor Ipv4 este de 32 de biţi, majoritatea utilizatorilor nu memorează adresa calculatorului gazdă pe care lucrează în formă numerică, oamenii se simt mai bine dacă lucrează cu nume de domeniu. De aceea majoritatea calculatoarelor gazdă care utilizează protocolul IP au atât o adresă numerică IP cât şi un nume. Deşi asta este convenabil pentru operatori, totuşi, numele trebuie reconvertit într-o adresă numerică pentru a fi posibilă dirijarea. Pentru a face posibilă înregistrarea numelor noi care apar ca urmare a dezvoltării rapide a INTERNET-ului a fost creat sistemul numelor de domeniu, the Domain Name System, DNS. Acesta este o bază de date distribuită care conţine nume de calculatoare gazdă şi informaţii despre adrese IP pentru toate domeniile din INTERNET. Pentru fiecare domeniu există un singur server de nume autorizat. Acesta conţine toate informaţiile referitoare la DNS din acel domeniu. Fiecare domeniu mai are cel puţin încă un server de nume, numit secundar, care conţine copii ale tuturor informaţiilor conţinute şi pe server-ul autorizat. Treisprezece server-e de dirijare, în toată lumea, menţin câte o listă cu aceste server-e de nume autorizate. Când un calculator gazdă din INTERNET are nevoie de o adresă IP a unui alt calculator gazdă şi cunoaşte doar numele acelui calculator gazdă, este lansată o cerere DNS de către primul calculator gazdă către un server de nume local. Acesta poate fi capabil să răspundă la această cerere fie cu informaţie configurată fie cu informaţie ascunsă; dacă informaţia necesară nu este disponibilă, server-ul local de nume transmite cererea la unul dintre server-ele de dirijare (ruter). Server-ul de dirijare va găsi un server de nume potrivit, pentru calculatorul gazdă ţintă şi cererea DNS va fi trimisă acestuia. Fişierele de date ale server-elor de nume conţin următoarele tipuri de înregistrări: - Înregistrare de tip A, A-record: O înregistrare de adresă care face corespondenţa între un nume de calculator gazdăşi o adresă IP. - Înregistrare de pointer, PTR-record: face corespondenţa între o adresă IP şi un nume de calculator gazdă. - Înregistrare de server de nume: este o listă a server-elor de nume autorizate pentru un anumit domeniu. - Înregistrare de corespondenţă prin poştă electronică, MX-record: este o listă a server-elor de e-mail pentru un anumit domeniu. De exemplu, se consideră adresa de e-mail [email protected]. Porţiunea din adresă "sover.net" este un nume de domeniu nu un nume de calculator gazdă, iar mesajul trebuie transmis unui calculator gazdă specific. Înregistrarea MX din baza de date de nume sover.net specifică faptul că mail.sover.net este server-ul de poştă electronică pentru acest domeniu. - Înregistrare de nume canonic, Canonical name records, CNAME-record: asigură funcţionarea unui mecanism de alocare a unor nume fictive, aliases, numelor de calculator gazdă, astfel încât un anumit calculator gazdă, care are o singură adresă IP, să poată fi cunoscut cu mai multe nume. Conceptele, structura şi drepturile sistemului DNS sunt descrise în RFC 1034 şi în RFC 1591. Pentru aplicaţii de tipul Microsoft NetBIOS, echivalentul sistemului DNS este serviciul WINDOWS de nume INTERNET, the Windows Internet Name Service, WINS, folosit pentru a pune de acord numele

105
NetBIOS al unui calculator (de exemplu \\ALTAMONT) cu o adresă IP. O bază de date locală WINS poate fi creată în fişierul LMHOSTS.
Rezolvarea adreselor
Implementările mai vechi ale protocolului IP rulau pe calculatoare gazdă care erau de obicei în reţele locale de tip Ethernet. Fiecare transmisie printr-o astfel de reţea locală conţinea o adresă pentru controlul accesului, medium acces control, MAC, a nodurilor sursă şi destinaţie. Lungimea adreselor MAC este de 48 de biţi. Aceste adrese nu sunt ierarhizate. De aceea nu poate fi făcută dirijarea pachetelor folosind aceste adrese. Adresele MAC nu sunt niciodată identice cu adresele IP.
Când un calculator gazdă trebuie să transmită un pachet la un alt calculator gazdă din aceeaşi reţea, protocolul de transmisie trebuie să cunoască atât adresa IP cît şi adresa MAC ale destinatarului deoarece adresa IP de destinaţie este plasată în pachetul IP iar adresa de destinaţie MAC este plasată în cadrul de protocol LANMAC. Dacă calculatorul gazdă destinaţie este situat într-o altă reţea, expeditorul va trebui să caute adresa MAC a ruterului de ieşire iniţial al reţelei.
Din nefericire, protocolul IP care rulează pe calculatorul gazdă al expeditorului poate să nu cunoască adresa MAC a destinatarului, dacă acesta este conectat la aceeaşi reţea locală. Protocolul de rezolvare a adresei, The Address Resolution Protocol , ARP, descris în RFC 826, implementează un mecanism prin care un anumit calculator gazdă poate învăţa adresa MAC a unui destinatar, dacă cunoaşte adresa IP a acestuia. Acest mecanism este relativ simplu:
- expeditorul transmite o cerere ARP într-un cadru care conţine adresa de difuzare MAC; - cererea ARP dezvăluie adresa IP de destinaţie şi solicită adresa MAC corespunzătoare; - staţia din reţeaua locală care îşi recunoaşte propria adresă IP va transmite un răspuns ARP cu propria sa adresă MAC. Au fost concepute şi alte proceduri de rezolvare a adreselor. Se amintesc: Reverse ARP (RARP), care permite unui calculator fără hard-disk să-şi afle propria adresă IP pe baza cunoaşterii propriei adrese MAC. Inverse ARP (InARP), care realizează o corespondenţă între o adresă IP şi un identificator de circuit virtual, a frame relay virtual circuit identifier, ATMARP şi ATMInARP, care realizează o corespondenţă între o adresă IP şi un identificator de cale/canal ATM, ATM virtual path/channel identifiers, LAN Emulation ARP (LEARP), care realizează o corespondenţă între o adresă ATM de destinatar şi adresa sa de emulare în reţeaua locală, LAN Emulation (LE) address (care ia forma unei adrese MAC de tipul IEEE 802).
Dirijarea IP: OSPF, RIP şi BGP
La fel ca şi un protocol de nivel reţea, specific pentru modelul OSI, protocolul IP are responsabilitatea de a dirija pachetele de date. El realizează această funcţie căutând într-un tabel de dirijare valoarea din subcâmpul IP NET_ID din structura adresei IP a pachetului curent. Dar completarea tabelelor de dirijare nu este sarcina protocolului IP ci a protocoalelor de dirijare. Există trei protocoale de dirijare asociate de obicei cu protocolul IP şi cu INTERNET-ul: RIP, OSPF şi BGP. Protocoalele de dirijare OSPF şi RIP au fost utilizate la început pentru dirijare în cadrul unui anumit domeniu, ca de exemplu într-o reţea de intreprindere.
Cea de a doua versiune a protocolului numit de "Dirijare a informaţiilor", The Routing Information Protocol version 2 (RIP-2),este descrisă în RFC 2453 şi prezintă modul în care ruterele fac schimb de informaţii de dirijare folosind un algoritm bazat pe vectori de distanţă. Când se utilizează protocolul RIP, ruterele vecine, schimbă între ele periodic, tabelele lor de dirijare, complete. Ca o măsură a costului unei legături, protocolul RIP foloseşte numărul de rutere care trebuiesc traversate pentru realizarea acelei legături. Cea mai scumpă legătură poate fi făcută prin intermediul a 16 rutere intermediare. Datorită creşterii rapide a reţelei INTERNET acest protocol a devenit ineficient. Protocoalele de dirijare în reţele locale care se folosesc în prezent se bazează pe protocolul RIP dar se asociazăşi cu alte programe. Aceste protocoale sunt: NetWare, AppleTalk, VINES şi DECnet. Protocolul numit "Cea mai scurtă legătură mai întâi", The Open Shortest Path First, OSPF, este un

106
algoritm de dirijare bazat pe analiza stărilor legăturilor şi este mai robust decât protocolul RIP, algoritmul care stă la baza sa converge mai rapid, necesită o bandă de frecvenţă a reţelei mai îngustă, şi este mai potrivit pentru implementarea în reţele de mari dimensiuni. Dacă un ruter utilizează acest protocol el trebuie să difuzeze informaţii referitoare doar la schimbarea stărilor legăturilor pe care le guvernează, şi nu întregul său tabel de dirijare. Versiunea a doua a protocolului OSPF este descrisă în RFC 1583 şi a înlocuit protocolul RIP pentru comunicaţiile din reţeaua INTERNET. Cea de a patra versiune a protocolului numit "Poartă la frontieră", The Border Gateway Protocol version 4 , BGP-4, este un protocol de comunicaţii externe, fiind folosit să realizeze schimbul de informaţii între domeniile de dirijare INTERNET. La fel ca şi RIP, protocolul BGP se bazează pe un algoritm de măsurare a unui vector de distanţă, dar spre deosebire de alte protocoale care se bazează pe algoritmi similari, în tabelele de dirijare BGP sunt înscrise informaţii despre drumul care trebuie parcurs spre reţeaua de destinaţie. Protocolul BGP-4 permite şi dirijarea pe baze politice. Acest tip de dirijare permite unui administrator de reţea să creeze politici de dirijare bazate pe aspecte politice, de securitate, legale, sau economice, pe lângă cele tehnice. Protocolul BGP-4 permite şi utilizarea dirijării CIDR. Acest protocol este descris în RFC 1771 în timp ce RFC 1268 descrie utilizarea protocolului BGP în INTERNET.
Ca o alternativă la folosirea unui protocol de dirijare, un tabel de dirijare poate fi întreţinut şi folosind "dirijarea statică". Un exemplu de dirijare statică este configurarea unui ruter de ieşire iniţial al unei reţele locale. Dacă un calculator gazdă dintr-o reţea locală trebuie să transmită un pachet în exteriorul acelei reţele, el transmite "orbeşte" acel pachet la ruterul de ieşire iniţial al acelei reţele.
Toate calculatoarele gazdă care utilizează protocolul IP şi toate ruterele care utilizează acest protocol, întreţin câte un tabel în care sunt înregistrate cele mai proaspete informaţii de dirijare pe care le cunoaşte calculatorul respectiv. În cazul calculatoarelor care utilizează sistemul de operare WINDOWS, acest tabel de dirijare poate fi examinat cu ajutorul unei comenzi de listare a dirijării iar în cazul calculatoarelor care utilizează sistemul de operare UNIX, în acelaşi scop se poate utiliza comanda netstat-r.
Versiunea a 6-a a protocolului IP
La sfîrşitul anului 1995 a fost standardizată această versiune a protocolului IP, IPv6. O primă descriere a acestei versiuni este făcută în RFC 1883. Această versiune a fost concepută ca să înlocuiască şi să dezvolte versiunea anterioară IPv4. Modificările se referă la:
- Creşterea lungimii adresei IP la 128 de biţi,
- Alocarea adreselor nu se mai face cu ajutorul claselor,
- Diferitele utilizări sunt specificate prin prefixe,
- Se pot utiliza prefixe pentru a pune în corespondenţă spaţii de adrese de tip v4 cu spaţii de adrese de tip v6 şi reciproc,
- Reprezentarea standard este făcută prin 8 valori de lungime 16 biţi separate prin coloane. Un exemplu de adresă IP conform acestei variante este 47CD:1234:3200:0000:0000:4325:B792:0428. Dacă adresa conţine un număr mare de zerouri, acestea pot fi omise. De exemplu adresa anterioară se mai poate scrie în forma 47CD:1234:3200::4325:B792:0428.
- Alocarea adreselor în cazul comunicărilor între doi utilizatori, Unicast, se face la fel ca şi la protocolul CIDR,
- Se au în vedere considerente geografice,

107
- Comunicaţia se face cu ajutorul prestatorilor de servicii. Un exemplu de adresă IP , Unicast, este 010, regionID, providerID, subscriberID, subnetID, intefaceID.
- O mai bună implementare a tipurilor de trafic care au diferite obiective de calitate a servicilor,
- Posibilitatea securizării comuncaţiilor prin implementarea unor mecanisme de autentificare, control al integrităţii datelor şi control al respectării confidenţialităţii datelor. Arhitectura şi structura adreselor pentru IPv6 sunt descrise în RFC 2373. Formatul pachetelor Ipv6 este prezentat în figura următoare.
0 4 8 1 2 3
Figura 6 Internet. Protocolul IP v 6. 6.1.1. Protocoale de nivel transport
Şirul de protocoale TCP/IP conţine două protocoale care corespund nivelelor de transport şi de sesiune din modelul de referinţă OSI. Acestea se numesc Protocolul de control al transmisiei, the Transmission Control Protocol, şi Protocolul pachetelor de utilizator, the User Datagram Protocol, UDP.
Porturi
Aplicaţiile de nivel înalt sunt semnalizate în mesajele TCP/UDP printr-un identificator de port. Identificatorul de port şi adresa IP formează împreună un socket, iar comunicaţia capăt la capăt între două calculatoare gazdă este identificată în mod unic în INTERNET prin mulţimea de patru identificatori (portul sursei, adresa sursei, portul destinaţiei şi adresa destinaţiei). Numerele de porturi se exprimă pe 16 biţi. Numerele de port cuprinse între 0 şi 1023 corespund unor porturi numite, porturi

108
foarte bine cunoscute, Well Known Ports. Aceste numere sunt alocate în general server-elor aplicaţiilor şi pot fi utilizate doar de procese privilegiate, cum este de exemplu root sau administrator. Numerele de port din domeniul 1024-49151 corespund unor porturi numite porturi înregistrate, Registered Ports şi aceste numere au fost definite în mod public prin acordul întregii comunităţi INTERNET, pentru a evita conflictul între diferiţi vânzători. Numerele de port din această categorie pot fi folosite atât de aplicaţii de client cât şi de aplicaţii de server. Numerele de port rămase, din domeniul 49152-65535, corespund unor porturi numite dinamice şi/sau private, Dynamic and/or Private Ports şi pot fi folosite liber de orice client sau orice server. Printre numerele de porturi sunt:
Numărul portului Protocolul comun Serviciu 7 TCP Ecou 80 TCP http 9 TCP Eliminare 110 TCP Pop 3 13 TCP Data daytime 111 TCP Sunrpc 19 TCP Chargen 119 TCP nntp 20 TCP ftp-control 123 UDP Ntp 21 TCP ftp-data 137 UDP netbios-ns 23 TCP telnet 138 UDP netbios-dgm 25 TCP Smtp 139 TCP Imap 37 UDP Time 143 TCP Imap 43 TCP Whois 161 UDP Snmp 53 TCP/UDP Dns 162 UDP snmp-trap 67 UDP Bootps 179 TCP Bgp 68 UDP Bootpc 443 TCP https (http/ssl) 69 UDP Tftp 520 UDP Rip 70 TCP Gopher 1080 TCP Socks 79 TCP Finger 33434 UDP Traceroute
Protocolul TCP
Acest protocol este descris în RFC 793 şi realizează un serviciu de comunicaţii prin circuit virtual (orientat pe conexiune) de-a lungul reţelei. TCP include înfiinţarea şi desfinţarea de circuite virtuale, reguli pentru formatarea mesajelor, reguli de segmentare, reguli de controlul traficului şi reguli de corecţie a erorilor. Majoritatea aplicaţiilor din şirul de protocoale TCP/IP funcţionează pe baza serviciului de transport implementat de protocolul TCP. Unitatea de date pentru protocolul TCP este numită segment. Această denumire este justificată de faptul că protocolul TCP nu recunoaşte mesaje, ci transmite blocuri de octeţi din structura şirului de date care trebuie schimbat între expeditor şi

109
destinatar. Câmpurile unui astfel de segment sunt prezentate în figura următoare şi au semnificaţia descrisă în continuare.
Figura 7 Internet. Formatul de segment TCP.
Porturile sursă şi destinaţie, Source Port şi Destination Port: identifică porturile sursă şi destinaţie pentru a identifica legătura capăt la capăt şi aplicaţiile de nivel înalt. Numărul de secvenţă, Sequence Number: conţine numărul primului octet de date al segmentului curent, din cadrul întregului şir de octeţi. Deoarece numărul de secvenţă se referă la o numărătoare de octeţi şi nu la o numărătoare de segmente numerele de secvenţă pentru segmente succesive nu apar în succesiune. Numărul de validare, Acknowledgment Number: Este folosit de expeditor pentru a valida recepţia datelor. Acest câmp indică numărul de secvenţă al următorului octet aşteptat de la destinatar. Alunecarea datelor, Data Offset: Trimite la primul octet de date din segmentul curent. Acest cîmp indică şi lungimea antetului segmentului. Steguleţe de control, Control Flags: O mulţime de steguleţe de control care controlează unele aspecte ale conexiunilor virtuale TCP. Steguleţele includ: Steguleţ de urgenţă maximă, Urgent Pointer Field Significant, URG : Când este setat indică faptul că segmentul curent conţine date de mare prioritate şi că valoarea din câmpul Urgent Pointer este validă. Steguleţ de validare, Acknowledgment Field Significant, ACK: Când este setat, indică faptul că valoarea cuprinsă în câmpul Acknowledgment Number field este validă. De obicei acest bit este setat, cu excepţia perioadei de stabilire a conexiunii pentru primul mesaj. Steguleţ de forţare, Push Function, PSH: Este folosit când aplicaţia de transmisie vrea să forţeze protocolul TCP să transmită imediat datele care sunt în registre, la acel moment, fără a aştepta ca

110
aceste registre să se umple. Acest steguleţ este util pentru transmiterea unor unităţi mici de date. Steguleţ de reset-are a conexiunii, Reset Connection, RST: Când este setat întrerupe imediat conexiunea TCP între capete. Steguleţ de sincronizare cu numărul de secvenţă, Synchronize Sequence Numbers, SYN: setat în segmentele iniţiale folosite pentru stabilirea unei conexiuni, indică faptul că segmentul curent conţine numărul de secvenţă iniţial. Steguleţ de sfârşit, Finish, FIN: Setat cere terminarea normală a conexiunii TCP în direcţia în care segmentul curent traversează reţeaua. Închiderea completă a conexiunii cere să se transmită câte un segment cu steguleţul FIN setat în fiecare direcţie. Steguleţ fereastră, Window: este utilizat pentru controlul traficului, conţine valoarea dimensiunii ferestrei de recepţie adică numărul octeţilor transmişi pe care expeditorul segmentului curent este dispus să-i accepte de la destinatar. Steguleţ de sumă de control, Checksum: Permite o detecţie rudimentară de eroare de bit pentru segment, atât pentru antet cât şi pentru date. Steguleţ de urgenţă, Urgent Pointer: Datele "urgente" reprezintă acele date care au fost marcate ca prioritare de către o aplicaţie de nivel înalt. Aceste date ocolesc de obicei sistemul uzual de registre TCP şi sunt plasate într-un segment între antet şi datele normale. Pointer-ul de urgenţă, care este validat când steguleţul URG este setat, indică poziţia primului octet de date încă neexpediat din segment. Steguleţul opţiuni, Options: este folosit la stabilirea conexiunii pentru a permite negocierea unor opţiuni. Opţiunea cel mai des utilizată este dimensiunea maximă a segmentului, maximum segment size, MSS. Dacă aceasta nu este specificată atunci se alege valoarea iniţială de lungime maximă a segmentului de 536. O altă opţiune este cea de validare selectivă, Selective Acknowledgement (SACK), care permite ca segmente din exteriorul secvenţei de segmente să fie acceptate de către un receptor.
Protocolul UDP
Protocolul UDP, descris în RFC 768, oferă un serviciu de transfer de pachete între capete fără conexiune. Unele aplicaţii, cum ar fi cele care implică o cerere simplă şi un răspuns sunt mai potrivite pentru protocolul UDP deoarece nu se mai pierde timp cu construcţia şi distrugerea circuitului virtual.
Figura 8 Internet. Formatul de pachet UDP.
Cea mai importantă funcţie a protocolului UDP este să adauge un număr de port la adresa IP pentru a se obţine un socket pentru aplicaţia avută în vedere. Câmpurile unui pachet UDP sunt prezentate în figura următoare iar semnificaţia lor este prezentată în continuare. Portul sursă, Source Port: Identifică portul UDP folosit de către expeditorul pachetului. Utilizarea acestui câmp este opţională în protocolul UDP şi poate fi setat pe 0. Portul destinaţie, Destination Port: Identifică portul folosit de către receptorul pachetului. Lungimea, Length: Indică lungimea totală a pachetului UDP.

111
Sumă de control, Checksum: Realizează o detecţie rudimentară pentru pachet, incluzând antetul şi datele.
Protocolul ICMP
Protocolul de control al mesajelor pe INTERNET, descris în RFC 792, este un protocol ajutător pentru IP, care informează expeditorul pachetelor IP despre evenimente anormale. Acest protocol colateral are o importanţă particulară în aplicaţiile IP. ICMP nu este un protocol clasic capăt la capăt ca TCP sau UDP. El este capăt-la capăt în sensul că un dispozitiv (de exemplu un ruter sau un calculator) trimite un mesaj la un alt dispozitiv (de exemplu un alt calculator sau ruter).
Cele mai frecvent utilizate tipuri de mesaje folosite de ICMP sunt: Mesajul Destinaţie de neatins, Destination Unreachable: Indică faptul că un pachet nu poate fi livrat deoarece calculatorul destinaţie nu poate fi atins. Motivul pentru care destinatarul nu poate fi atins este că acel calculator este necunoscut, deşi era cerută fragmentarea, aceasta nu a fost realizată (steguleţul DF este setat), reţeaua sau calculatorul destinaţie nu poate fi atins de acest tip de serviciu. Mesajul Ecou şi răspuns la ecou: Echo and Echo Reply, Aceste două mesaje se folosesc pentru a verifica dacă un anumit calculator gazdă poate fi atins sau nu într-o anumită reţea. Un calculator gazdă trimite un mesaj ecou unui alt calculator gazdă, care poate conţine nişte date şi calculatorul care recepţionează acest mesaj răspunde cu mesajul de răspuns la ecou, care conţine aceleaşi date. Aceste mesaje stau la baza comenzii Ping. Mesajul Probleme, Parameter Problem: Indică faptul că un ruter sau un calculator gazdă întâmpină o anumită problemă referitoare la antetul pachetului curent. Mesajul Redirectare, Redirect: Este folosit de un calculator gazdă sau de un ruter pentru a informa expeditorul că pachetele trebuie transmise la o altă adresă. Din motive de securitate mesajele de redirectare trebuiesc blocate de către dispozitivele de tip firewall. Mesajul de congestie, Source Quench: Este transmis de un ruter pentru a indica faptul că este congestionat, datorită umplerii tuturor registrelor sale de date şi că distruge pachete. Mesajul de depăşire de timp, TTL Exceeded: Indică faptul că un pachet a fost distrus pentru că în câmpul său TTL a fost înscris un 0 sau pentru că nu a fost recepţionat întregul pachet înainte de expirarea timpului de fragmentare. Mesajul de ştampilă temporală şi mesajul de răspuns la ştampila temporală: Aceste mesaje sunt asemănătoare mesajelor de ecou, dar plasează o ştampilă temporală (cu o granularitate de ordinul milisecundelor) în cadrul mesajului, creând o măsură a timpului pierdut de sistemele acţionate la distanţă pentru încărcarea în registre şi prelucrarea pachetelor de date şi un mecanism care să permită calculatoarelor gazdă să-şi sincronozeze ceasurile. Mesajele ICMP sunt transportate de către pachetele IP.
Stabilirea conexiunii TCP şi colaborarea cu ICMP
Pentru a putea folosi protocolul TCP este foarte important să se înţeleagă cum se realizează conexiunea în cadrul acestui protocol. Legăturile TCP au trei părţi importante: stabilirea legăturii, schimbul de date şi terminarea legăturii. În continuare se prezintă un exemplu în care un server POP3 (care ascultă folosind portul TCP 110) este contactat de un client (care foloseşte portul TCP 1067). Fazele realizării acestei conexiuni sunt prezentate în figura următoare.
Faza stabilirii conexiunii începe prin schimbare numărului iniţial de secvenţă, ISN, între client şi server şi validează numărului iniţial de secvenţă al unui al treilea calculator gazdă. În acest exemplu clientul începe prin a trimite server-ului un segment TCP conţinând biţii de sincronizare şi un număr de secvenţă de 800. Biţii de sincronizare îi spun receptorului (sever-ului) că expeditorul (clientul) este în modul de iniţializare ISN şi că ISN-ul nu a fost încă confirmat. Numărul de validare al segmentului nu este arătat deoarece valoarea sa, la acest moment nu este încă fixată. Server-ul răspunde cu un segment cu biţii de sincronizare, syn-bits şi cu biţii de acceptare, ack-bits, setaţi, cu un număr de secvenţă de 1567 şi cu un număr de acceptare, Acknowledge Number de 801. Biţii de sincronizare şi ISN-ul lui 1567 au aceeaşi semnificaţie ca şi mai sus. Bitul de acceptare indică faptul că valoarea din
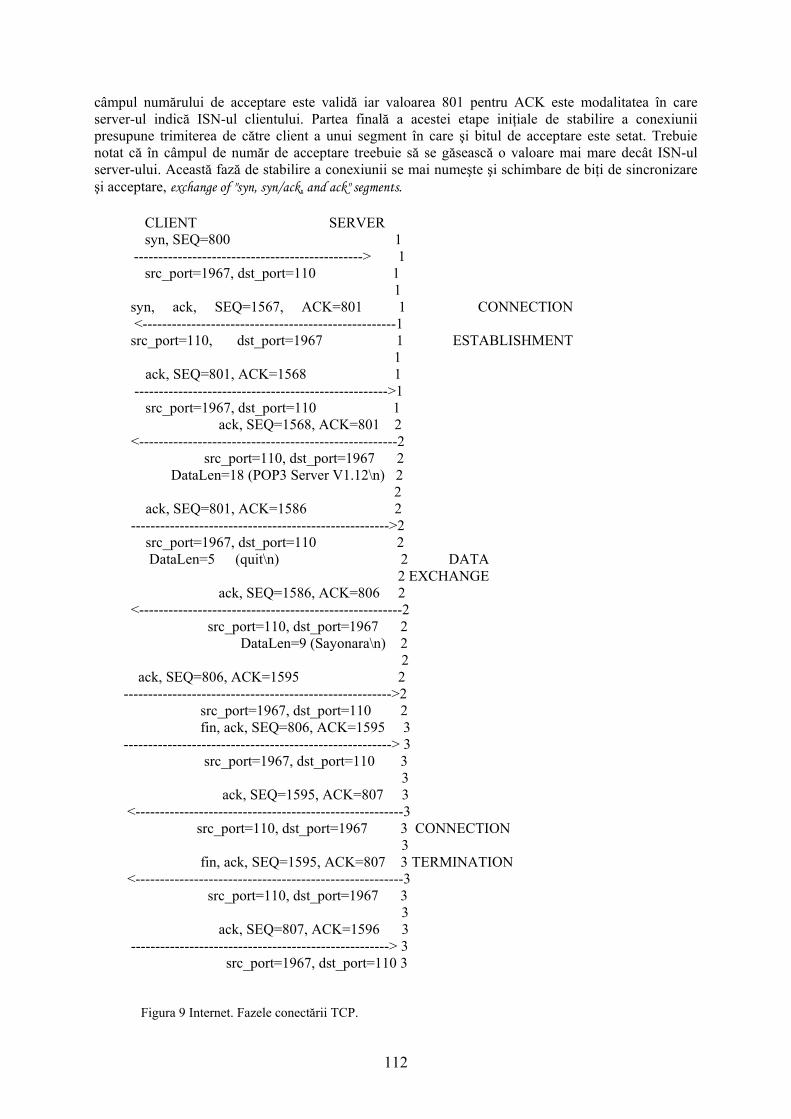
112
câmpul numărului de acceptare este validă iar valoarea 801 pentru ACK este modalitatea în care server-ul indică ISN-ul clientului. Partea finală a acestei etape iniţiale de stabilire a conexiunii presupune trimiterea de către client a unui segment în care şi bitul de acceptare este setat. Trebuie notat că în câmpul de număr de acceptare treebuie să se găsească o valoare mai mare decât ISN-ul server-ului. Această fază de stabilire a conexiunii se mai numeşte şi schimbare de biţi de sincronizare şi acceptare, exchange of "syn, syn/ack, and ack" segments.
CLIENT SERVER syn, SEQ=800 1 -----------------------------------------------> 1 src_port=1967, dst_port=110 1 1 syn, ack, SEQ=1567, ACK=801 1 CONNECTION <----------------------------------------------------1 src_port=110, dst_port=1967 1 ESTABLISHMENT 1 ack, SEQ=801, ACK=1568 1 ---------------------------------------------------->1 src_port=1967, dst_port=110 1
ack, SEQ=1568, ACK=801 2 <-----------------------------------------------------2 src_port=110, dst_port=1967 2 DataLen=18 (POP3 Server V1.12\n) 2 2 ack, SEQ=801, ACK=1586 2 ----------------------------------------------------->2 src_port=1967, dst_port=110 2 DataLen=5 (quit\n) 2 DATA 2 EXCHANGE ack, SEQ=1586, ACK=806 2 <------------------------------------------------------2 src_port=110, dst_port=1967 2 DataLen=9 (Sayonara\n) 2 2 ack, SEQ=806, ACK=1595 2 ------------------------------------------------------->2 src_port=1967, dst_port=110 2 fin, ack, SEQ=806, ACK=1595 3 -------------------------------------------------------> 3 src_port=1967, dst_port=110 3 3 ack, SEQ=1595, ACK=807 3 <-------------------------------------------------------3 src_port=110, dst_port=1967 3 CONNECTION 3 fin, ack, SEQ=1595, ACK=807 3 TERMINATION <-------------------------------------------------------3 src_port=110, dst_port=1967 3 3 ack, SEQ=807, ACK=1596 3 -----------------------------------------------------> 3 src_port=1967, dst_port=110 3
Figura 9 Internet. Fazele conectării TCP.

113
Ea este foarte importantă din mai multe motive. Persoanelor care examinează urmele pachetelor, recunoaşterea fazei de iniţializare le permite găsirea începerii conexiunii.
Pentru dispozitivele de tip firewalls, proxy server, intrusion detector, această fază de stabilire a conexiunii este o cale de cunoaştere a programării direcţiei conexiunii TCP, ceea ce este important deoarece regulile de conectare pot diferi pentru conexiuni din interiorul respectiv cu exteriorul unei reţele.
Următoarea fază a legăturii TCP este schimbul de date. Prezentarea care urmează este destinată doar exemplificării, referindu-se la un POP server, care transmite un mesaj de uz general sitemului client, acesta transmite comanda de terminare, the "quit" command, şi server-ul semnalizează terminarea, sign off. Cu "\n" s-a notat sfârşitul de linie. Aceste segmente ilustrează modificările şi relaţiile dintre numerele de secvenţă ale clientului şi server-ului şi numerele de acceptare ale acestora. Faza finală a legăturii TCP este terminarea conexiunii. Deşi legăturile TCP sunt duplex (chiar dacă o aplicaţie dată nu asigură comunicarea simultană bidirecţională), protocolul TCP vede conexiunea ca şi o pereche de legături simplex. De aceea terminarea conexiunii necesită patru segmente, sau mai precis două perechi de segmente. În acest caz clientul trimite server-ului un segment cu biţii de terminare, fin-bits şi cu biţii de acceptare, ack-bits, setaţi, server-ul răspunde cu un segment în care doar bitul de acceptare este setat iar numărul de validare, the Acknowledgment Number este incrementat. Apoi server-ul transmite un segment de acceptare a finalizării, a fin/ack segment, clientului. Descrierea deja făcută se referă la un "scenariu" normal pentru realizarea unei legături TCP între un client şi un server.
Două calculatoare gazdă UDP comunică într-un mod asemănător; unul dintre ele trimite un pachet UDP celuilalt, care se presupune că "ascultă" la portul indicat pachetul curent. În continuare se explică ce se întâmplă atunci când celălalt calculator nu "ascultă" la portul pe care legătura îl estimează sau atunci când celălalt calculator nu există.
Celălalt calculator gazdă nu "ascultă" la portul TCP: Dacă calculatorul A încearcă să contacteze calculatorul B la un port TCP la care calculatorul B nu "ascultă", calculatorul B răspunde cu un segment TCP cu steguleţele de reset, RST şi de acceptare, acknowledge, ACK, setate.
Celălalt calculator nu ascultă la portul UDP: Dacă calculatorul A încearcă să contacteze calculatorul B la un port UDP la care calculatorul B nu "ascultă", calculatorul B trimite un mesaj de tip ICMP de imposibilitate a atingerii portului, calculatorului A.
Celălalt calculator nu există: Dacă calculatorul A încearcă să contacteze calculatorul B şi acesta nu "ascultă" (de exemplu adresa IP a calculatorului B nu există sau nu este disponibilă), ruterul de subreţea al calculatorului B va transmite un mesaj de tip ICMP de imposilibitate a atingerii calculatorului B, calculatorului A.
Nivelul de aplicaţie TCP/IP
Protocoalele TCP/IP de nivel aplicaţie ajută la implementarea tuturor aplicaţiilor (utilităţilor) pe care le oferă INTERNET-ul. În continuare se va prezenta o listă a acestor aplicaţii.
Aplicaţii TCP şi UDP
În continuare se prezintă protocoalele de acest tip cel mai frecvent utilizate.
Archie: Un utilitar care permite unui utilizator să caute în toate site-urile unde există acces anonymous-ftp toate fişierele aprţinând unei anumite tematici. Acest protocol este actual depăşit moral fiind înlocuit de protocolul World Wide Web.
BGP-4, The Border Gateway Protocol version 4: este un protocol de dirijare bazat pe utilizarea unui vector de distanţă în nodurile care sunt conectate prin mai multe legături.
DNS, The Domain Name System : este un protocol care defineşte structura numelor pe INTERNET şi modul lor de asociere cu adrese IP precum şi asocierea poştei electronice şi a serverelor de nume cu diferite domenii.
Finger: este un protocol folosit pentru determinarea stării altor calculatoare gazdă şi/sau utilizatori (RFC 1288).

114
FTP, The File Transfer Protocol: este un protocol care permite unui utilizator să transfere fişiere spre respectiv dinspre calulatoare gazdă aflate la distanţă, (RFC 959).
Gopher: este un utilitar care permite utilizatorilor să caute date memorate pe alte calculatoare gazdă folosind o interfaţă ierarhizată, comandată printr-un meniu. Acest protocol este deja depăşit moral, fiind înlocuit de protocolul World Wide Web, WWW (RFC 1436).
HTTP, The Hypertext Transfer Protocol : este protocolul de bază pentru schimbul de informaţii prin World Wide Web. În prezent sunt utilizate în INTERNET diferite versiuni de HTTP, dar cea folosită cel mai frecvent este versiunea 1.0 (RFC1945). Paginile WWW sunt de obicei concepute cu ajutorul limbajului Hypertext Markup Language (HTML), care se baează pe codul ASCII şi este un limbaj independent de platforma pe care rulează aplicaţiile sale, (RFC 1866).
IMAP, The Internet Mail Access Protocol : este un protocol care reprezintă o alternativă la protocolul POP, fiind o interfaţă între un utilizator al unui serviciu de poştă electronică şi server-ul de poştă electronică corespunzător. Acest protocol este folosit pentru a tansfera mesaje de poştă electronică de la server la client. El asigură o mare flexibilitate în gestionarea cutiei poştale, mailbox, a utilizatorului. OSPFv2, The Open Shortest Path First version 2 : este un protocol de dirijare a stărilor legăturilor într-o reţea de organizaţie. Este protocolul preferat de dirijare interioară.
Ping, The Packet Internet Groper: este un utilitar care permite unui utilizator să determine starea altor calculatoare gazdă şi întârzierea cu care este livrat un anumit mesaj acelui calculator gazdă. Foloseşte mesaje de ecou ICMP.
POP, The Post Office Protocol : defineşte o interfaţă simplă între un soft de utilizator de tip client de poştă electronică (ca de exemplu Eudora, Outlook sau programul de e-mail al căutătorului pe INTERNET) şi un server de poştă electronică folosit pentru transferul mesajelor de poştă electronică de la un server la un client şi permite utilizatorului să-şi administreze cutia poştală. Versiunea folosită curent este POP3, (RFC 1460).
RADIUS, The Remote Authentication Dial-In User Service, este un protocol de acces la distanţă. RIP, The Routing Information Protocol, este un protocol de dirijare bazat pe măsurare de distanţe
într-o reţea de organizaţie. SSH, The Secure Shell, este un protocol care permite conectarea la un calculator gazdă sau la un
terminal virtual aflat la distanţă prin intermediul INTERNET-ului. Acest protocol seamănă mult cu protocolul Telnet. Spre deosebire de acesta, protocolul SSH presupune criptarea parolelor şi a datelor transmise. Acest protocol permite comunicaţia criptată între claculatoare gazdă care nu sunt considerate de încredere printr-o reţea considerată nesigură. Utilizarea sa presupune că pot exista persoane externe care să "asculte" comunicaţia respectivă. Acest protocol implementează şi unele metode de autentificare. Funcţionarea sa se bazează pe criptarea datelor care sunt schimbate în cadrul acelei comunicaţii. Acest protocol a fost conceput ca să înlocuiască alte protocoale considerate nesigure cum ar fi de exemplu rlogin sau rsh. Pot fi realizate şi transferuri sigure de fişiere folosind acest protocol. Este un protocol foarte popular şi utilizat frecvent, dar nu invulnerabil. Acest protocol suportă trei tipuri de autentificare:
- de tip rhosts: numele utilizatorului sau al sistemului sunt disponibile în directoarele ~/.rhosts, sau ~/.shosts. Acest mod de autentificare este vulnerabil la atacuri asupra IP/DNS şi cere un mod specific de compilare.
- bazat pe calculatoarele gazdă: foloseşte sistemul de criptare RSA pentru a verifica cheile calculatoarelor gazdă şi foloseşte fişierul ~/.rhosts pentru autentificarea utilizatorului.
- bazat atât pe calculatoarele gazdă cât şi pe utilizator: realizează atât verificarea cheilor calculatoarelor gazdă cât şi ale utilizatorilor folosind sistemul de criptare RSA.
- dacă procedura de autentificare dă greş se cere parola clientului. O variantă a acestui protocol SSH1, permite schimbul de chei de criptare. Această variantă este descrisă pe scurt în continuare.
Server-ul are o pereche de chei, una publică şi una privată. Clientul cunoaşte dinainte cheia publică a server-ului. Aceasta trebuie să îi fi fost trimisă printr-un canal sigur. Server-ul trimite cheia publică şi o cheie aleatoare clientului. Clientul verifică cheia publică. Clientul trimite cheia sesiunii (care este aleatoare) criptată folosind cheia clientului şi cheia server-ului. Restul datelor este criptat cu cheia sesiunii.

115
Pentru schimbul de chei poate fi utilizată şi o altă variantă de protocol SSH, numită SSH2. Aceasta este descrisă pe scurt în continuare. De această dată este utilizat algoritmul de schimb de chei publice Diffie-Hellman. Identităţile server-ului şi clientului pot fi verificate folosind semnături digitale. La sfârşitul schimbului de chei, o cheie secretă este împărţită de către cei doi utilizatori aflaţi în comunicaţie, pentru schimbul de date care urmează. Aceste date sunt criptate cu unul dintre algoritmii de cifrare cu cheie secretă: IDEA (algoritmul cu care protocolul este iniţializat), Blowfish, DES, DES triplu, etc. Această variantă de algoritm SSH foloseşte şi verificări de sume de control de tip MD5, pentru stabilirea integrităţii datelor.
SMTP, The Simple Mail Transfer Protocol: este un protocol standard pentru poşta electronică pe INTERNET, (RFC 821). SMTP este folosit între server-e de e-mail, pe INTERNET, sau ca să permită unui client al unui serviciu de poştă electronică să transmită un mesaj spre un server. Formatul mesajului este descris în RFC 822. Extensiile MIME (Multipurpose Internet Mail Extensions), (care se pot adăuga la mesaj) sunt descrise în RFC 1521 şi în RFC 1522. SNMP, The Simple Network Management Protocol: defineşte proceduri şi baze de date conţinând informaţii de management pentru administrarea dispozitivelor de reţea care folosesc protocoalele TCP/IP. Protocolul SNMP, descris în RFC 1157 este utilizat frecvent în reţele LAN şi WAN. Protocolul SNMP Version 2 este descris în RFC 1441 şi adaugă mecanisme de securitate la protocolul SNMP. Este un protocol foarte complex a cărui utilizare se răspândeşte rapid în prezent.
SSL, The Secure Sockets Layer : este proiectat de Netscape şi implementează un mecanism de comunicare sigură pe INTERNET bazat pe criptografie cu chei publice şi certificate. Cea mai cunoscută aplicaţie a SSL este HTTP cu SSL, https. Cea mai nouă versiune de SSL este numită TLS, Transport Layer Security şi este descrisă în RFC 2246. Totuşi această versiune nu are un specific HTTP; protocoale ca IMAP4 (imaps), FTP (ftps), Telnet (telnets), şi POP3 (pop3s) au posibilitatea să opereze în cooperare cu SSL.
TACACS+, The Terminal Access Controller Access Control System plus: este un protocol de acces la distanţă.
Telnet, (prescurtare de la Telecommunication Network): este un protocol de terminal virtual care permite unui utilizator care este deja conectat la un calculator gazdă aflat la distanţă să acceseze şi alte calculatoare gazdă aflate la distanţă, sau alte reţele. Acest protocol este descris în RFC 854.
TFTP, The Trivial File Transfer Protocol, este un protocol specializat pentru unele aplicaţii simple de transfer de fişiere.
Time/NTP, Time and the Network Time Protocol: sunt protocoale utilizate pentru sincronizarea calculatoarelor gazdă cu server-e INTERNET bine cunoscute.
Traceroute: este un utilitar care afişează drumul pe care îl iau pachetele prin INTERNET între un calculator local şi un calculator gazdă aflat la distanţă. Această comandă este disponibilă pe calculatoare înzestrate cu sistemul de operareLinux/Unix. Şi calculatoarele înzestrate cu sistemul de operare Windows, începând cu Windows 95 au un utilitar tracert.
Whois/NICNAME: sunt utilitare de căutare în baze de date. Ele caută informaţii despre domeniile INTERNET şi despre conectarea la acestea. Aceste utilitare sunt descrise în RFC 954.
6.1.2. Analiza de protocoale
În prezent se utilizează tot mai frecvent analizoarele de protocoale. Acestea sunt echipamente soft care funcţionează pe calculatoare de uz general sau reprezintă echipamente de sine stătătoare. Indiferent de construcţie, aceste echipamente folosesc o interfaţă cu reţeaua, the device's network interface card (NIC). Aceasta capturează orice pachet care este transmis pe linia la care este conectată. Majoritatea analizoarelor de protocol realizează şi o afişare a interpretării (măcar parţiale) acestor pachete. În figura următoare se prezintă o astfel de afişare. Este vorba despre o comandă POP3 şi despre răspunsurile obţinute. Pot fi distinse pe verticală 3 regiuni. În regiunea din mijloc se prezintă pachetul decodat. În regiunea de jos este prezentat întregul cadru în forma hexazecimală, aşa cum este transmis pe linie. Acesta este şirul de biţi. Cea mai interesantă este regiunea din mijloc. Aici este interpretat conţinutul pachetului. Aici se prezintă detaliile protocoalelor IP, TCP, şi POP3 ale cadrului 80.
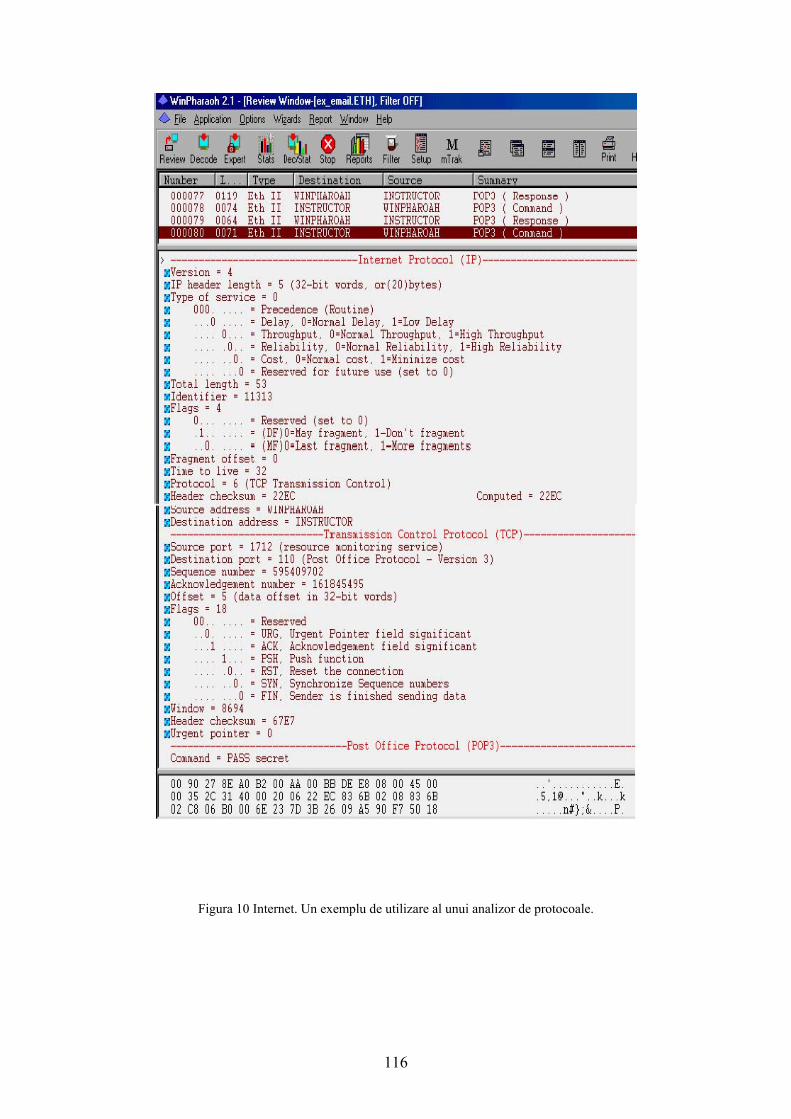
116
Figura 10 Internet. Un exemplu de utilizare al unui analizor de protocoale.

117
Partea de sus prezintă un rezumat al cadrelor care au fost capturate în registrul analizorului de protocoale. În exemplul considerat este vorba despre cadrele cu numerele de ordine cuprinse între 77 şi 80. Aceste numere de ordine sunt afişate pe coloana 1. Pe colana a doua sunt afişate lungimile cadrelor de pe coloana 1 (în octeţi). Este folosit formatul de cadru Ethernet II, (specificat pe coloana a 3-a). Următoarele două coloane prezintă adresele de sursă şi de destinaţie; în acest exemplu sunt două staţii care comunică între ele, numite INSTRUCTOR (server-ul) şi WINPHAROAH (clientul). La dreapta antetului de informaţii Ethernet este antetul de pachet IP. Pachetul din exemplul considerat utilizează protocolul IP varianta 4, are o lungime de 53 de octeţi şi transportă un segment TCP. Mai trebuie notat că acest pachet a fost trimis de la client spre server. După informaţia IP urmează informaţia TCP. Numărul portului destinaţie este 110, adică portul asociat cu un server POP3. Deoarece portul de destinaţie este POP3 înseamnă că pachetul acesta conţine o comandă POP pentru server din partea clientului (pe care o puteam şti şi consultând rezumatul cadrul vecin, cu numărul 80). În sfârşit se vede însăşi comanda POP3. Când un client POP3 se conectează la server, primul lucru pe care el trebuie să-l facă este să trimită numele de utilizator folosind comanda POP3 USER. Dacă numele de utilizator este valid, server-ul cere o parolă, care este transmisă de utilizator cu ajutorul unei comnezi POP3 PASS (care este de asemenea prezentată în figură). Trebuie observat că această parolă este tranmisă în formă necriptată. Cele prezentate mai sus au rolul de a deschide doar apetitul cititorului pentru unul dintre cele mai utile echipamente care pot fi utilizate în comunicaţiile de date, analizorul de protocoale. Acest tip de echipament este foarte util şi pentru managerii de reţele respectiv pentru administratorii de securitate. Există în prezent un număr destul de mare de pachete de programe de analiză de protocoale gratuite sau la preţuri rezonabil de mici atât pentru sistemul de operare Linux cât şi pentru Windows. Unul dintre cele mai populare este: tcpdump (care poate fi achiziţionat de la adresa http://www.tcpdump.org). Analizorul de protocoale cel mai utilizat în prezent este WireShark : http://download.kappa.ro/action__file/id__5157
6.1.3. Concluzii
Cum s-a arătat mai sus, TCP/IP nu reprezintă o pereche de protocoale de comunicaţie ci o familie de protocoale, aplicaţii şi utilitare. Din ce în ce mai des, aceste protocoale sunt numite stivă de protocoale INTERNET dar vechiul nume va mai fi folosit încă multă vreme.
În figura următoare se prezintă relaţiile dintre diferitele niveluri de protocoale TCP/IP.
Figura 10 Internet. Arhitectura familiei de protocoale TCP/IP.

118
Aplicaţiile şi utilitarele se grupează în calculatoarele gazdă sau în sistemele de comunicaţie de capăt. TCP realizează o legătură prin circuit virtual de încredere, între cele două calculatoare gazdă. IP realizează un serviciu de transport al pachetelor prin orice subreţea aflată pe drum (indiferent dacă este de tipul LAN sau WAN. Pentru dispozitivul de interconectare a celor două reţele se foloseşte termenul gateway. Acesta este de obicei un ruter în cazul LAN-urilor sau un sistem intermediar în cazul în care este vorba despre o legătură de tip OSI. În terminologie OSI un dispozitiv de tip gateway este folosit pentru a realiza conversia de protocol între două subreţele şi/sau aplicaţii.
Alte surse de informare
Există numeroase surse de informare despre şirul de protocoale TCP/IP şi despre INTERNET. Specificaţii, rapoarte, umor, lucrări de sinteză sunt distribuite ca şi documente RFC, Request for Comments. Acest tip de documente pot fi obţinute gratuit, prin INTERNET, în format de text ASCII.
O categorie de astfel de documente este destinată standardelor, acestea pot fi identificate prin particula "STD". De exemplu RFC 2026 descrie procesul de standardizare al INTERNET-ului iar documentul STD 1 conţine lista oficială de standarde de INTERNET.
O altă categorie de documente de tip RFC este cea notată FYI, For Your Information. Aceste documente furnizează informaţii de bază pentru comunitatea INTERNET. Această categorie de documente este descrisă în RFC 1150.
O altă categorie de documente utile pentru studiul INTERNET-ului este cea prescurtată cu FAQ, Frequently Asked Question. Pot fi găsite astfel de documente despre diferite subiecte de la ISDN şi criptografie la INTERNET şi Gopher. Două astfel de documente sunt foarte interesante pentru utilizatorii de INTERNET: "FYI on Questions and Answers - Answers to Commonly asked 'New Internet User' Questions" (RFC 1594) şi "FYI on Questions and Answers: Answers to Commonly Asked 'Experienced Internet User' Questions" (RFC 1207).
Toate documentele descrise mai sus fac trimiteri şi către alte surse de documentare.
Prescurtări folosite
ARP-Address Resolution Protocol ARIN-American Registry for Internet Numbers ARPANET-Advanced Research Projects Agency Network ASCII-American Standard Code for Information Interchange ATM-Asynchronous Transfer Mode BGP- Border Gateway Protocol BSD-Berkeley Software Development CCITT-International Telegraph and Telephone Consultative Committee CIX-Commercial Internet Exchange CDPD-Cellular Digital Packet Data protocol CSLIP-Compressed Serial Line Internet Protocol DARPA-Defense Advanced Research Projects Agency DDP-Datagram Delivery Protocol DDS-Digital data service DNS-Domain Name System DOCSIS-Data Over Cable System Interface Specification DoD-U.S. Department of Defense
DWDM-Dense Wave Division Multiplexing FAQ-Frequently Asked Questions lists FDDI-Fiber Distributed Data Interface FTP-File Transfer Protocol FYI-For Your Information series of RFCs GOSIP-U.S. Government Open Systems Interconnection Profile

119
HDLC-High-level Data Link Control HTML-Hypertext Markup Language HTTP-Hypetext Transfer Protocol IAB-Internet Activities Board IANA-Internet Assigned Numbers Authority ICANN-Internet Corporation for Assigned Names and Numbers ICMP-Internet Control Message Protocol IESG-Internet Engineering Steering Group IETF-Internet Engineering Task Force IMAP-Internet Message Access Protocol InterNIC-Internet Network Information Center IP-Internet Protocol IPX-Internetwork Packet Exchange ISDN-Integrated Services Digital Network ISO-International Organization for Standardization ISOC-Internet Society ITU-T - International Telecommunication Union Telecommunication Standardization Sector MAC-Medium (or media) access control Mbps-Megabits (millions of bits) per second NICNAME-Network Information Center name service NSF-National Science Foundation NSFNET-National Science Foundation Network NTP-Network Time Protocol OSI-Open Systems Interconnection OSPF-Open Shortest Path First PING-Packet Internet Groper POP3-Post Office Protocol v3 PPP-Point-to-Point Protocol RADIUS-Remote Authentication Dial-In User Service RARP-Reverse Address Resolution Protocol RIP-Routing Information Protocol RFC-Request For Comments SDH-Synchronous Digital Hierarchy SLIP-Serial Line Internet Protocol SMDS-Switched Multimegabit Data Service SMTP-Simple Mail Transfer Protocol SNAP-Subnetwork Access Protocol SNMP-Simple Network Management Protocol SONET-Synchronous Optical Network SSL-Secure Sockets Layer STD-Internet Standards series of RFCs TACACS+ - Terminal Access Controller Access Control System plus TCP-Transmission Control Protocol TFTP-Trivial File Transfer Protocol TLD-Top-level domain UDP-User Datagram Protocol WAP-Wireless Application Protocol XDSL-Digital Subscriber Line family of technologies 6.2. Securitatea la nivel IP
După anul 1980, calculatoarele conectate la INTERNET au constituit obiectul unor

120
atacuri individuale dintre cele mai diverse. Soluţiile sugerate împotriva acestor pericole constau într-o bună alegere a parolelor, ţinerea confidenţială a conturilor şi folosirea lor doar de către proprietar, precum şi eliminarea unor "găuri" de securitate, detectate la programe de tipul sendmail sau login. Mai târziu, în anii 90, INTERNET-ul a continuat să fie atacat, cu mijloace şi metode mai elaborate:
- Captatorii de parole interceptează parole sau alte informaţii sensibile care trec prin reţea; - Atacurile cu înregistrări IP vechi au fost utilizate pentru a se asigura penetrarea ilegală a unor
calculatoare gazdă, - Furtul conexiunilor a fost folosit pentru a obţine controlul asupra unor sesiuni deschise, - Inserarea de date vechi sau false a fost folosită de atacatori pentru a compromite integritatea
unor fişiere sau programe. Nici protocoalele IP nu sunt suficient de bine protejate împotriva unor astfel de atacuri. Deşi au fost concepute să lucreze în medii ostile, făcând faţă unor căderi de calculatoare pe anumite rute, protocoalele IP sunt vulnerabile la atacuri extinse, provenind din partea unor calculatoare legitime. De asemenea, în structura lor originală nu au fost prevăzute soluţii de securitate cum ar fi autentificarea, secretizarea, etc. Astfel de soluţii sunt pe cale de a fi introduse în noile variante de protocoale IP. Protocoalele IP au fost concepute pentru a permite transferul de pachete între două calculatoare ale reţelei. Ele nu sesizează şi nici nu împiedică ca alte calculatoare ale aceleiaşi reţele să intercepteze şi să citească aceste pachete în timp real. Acest tip de atac se numeşte ascultarea liniei, eavesdropping, sau captarea pachetelor, packet sniffing. În continuare se prezintă câteva dintre vulnerabilităţile specifice diferitelor medii de transmisie a pachetelor între calculatoare:
Ethernet. Posibilitatea interceptării este ridicată, aceste reţele fiind de tip broadcast (orice calculator din reţea poate transmite un mesaj tuturor celorlalte calculatoare din reţea), ceea ce asigură accesul tuturor calculatoarelor la cadrele (secvenţe de pachete) transmise. Cele mai frecvente atacuri de acest tip sunt făcute de programe care se execută pe aceeaşi reţea locală cu router-ul, interceptând pachetele transmise acestuia.
Linii telefonice. Posibilitatea interceptării este medie, deoarece cere o cooperare cu compania de telefoane sau un acces fizic la liniile de telefon. La modemurile de mare viteză interceptarea devine mai dificilă datorită folosirii mai multor frecvenţe.
Cablul TV. Posibilitatea interceptării este ridicată datorită posibilităţii de acces la cablul TV, pe care se tansmit atât semnale de televiziune cât şi date.
Canalul radio (microunde) Posibilitatea interceptării radio este ridicată, datorită faptului că este vorba de un canal pe care se fac frecvent transmisii broadcast. Singura cale de protecţie împotriva interceptării este criptarea. Aceasta poate fi înglobată la diferite nivele arhitecturale.
Cifrarea la nivel legătură de date. Pachetele sunt cifrate automat atunci când sunt transmise între două noduri, ceea ce pune atacatorul în situaţia de a nu putea înţelege traficul. Această metodă se foloseşte în cazul reţelelor radio. Există sisteme dedicate de criptare pentru modemuri şi linii închiriate. Nu se foloseşte în reţele Ethernet.
Cifrarea capăt la capăt. Calculatorul expeditor cifrează datele (nu şi antetul). La calculatorul destinatar datele sunt automat decriptate. Multe organizaţii apelează la această soluţie, folosind, pentru conectarea reţelelor la INTERNET, rutere cu criptare. Acestea criptează întregul trafic al calculatoarelor aceleiaşi organizaţii, singurele care au mijloacele de decriptare necesare. Traficul cu calculatoare din alte organizaţii rămâne necriptat.
Cifrarea la nivelul aplicaţiei. Criptarea este făcută la nivelul programelor de comunicaţii care reprezintă aplicaţii INTERNET. De exemplu versiunea Kerberos a programului telnet criptează datele transmise în ambele direcţii.
Un alt protocol care poate crea probleme de securitate este DNS. Riscul major îl constitutie faptul că nu există mijloace de verificare a corectitudinii informaţiilor returnate ca urmare a unei cereri DNS de rezolvare a unei adrese. De exemplu, dacă DNS spune că un anumit calculator gazdă are o anumită adresă IP, aceasta este laută drept bună şi se transmite informaţie, uneori sensibilă, către acest calculator, care poate fi unul de interceptare. Din păcate adresele IP şi numele de calculatoare gazdă sunt folosite frecvent în INTERNET în scop de autentificare. De exemplu comenzile rsh şi rlogin folosesc numele calculatorului gazdă drept element de autentificare. Ele analizează adresa IP de pe

121
conexiunea TCP, fac operaţia inversă de determinare a numelui asociat de calculatorul gazdă şi îl compară cu valoarea tastată pentru autentificare. Iată câteva posibilităţi de atac la acest nivel:
- Deoarece protocolul DNS foloseşte pachete UDP, un atacator poate cu uşurinţă "inunda" calculatorul gazdă, construind, pentru o cerere de nume de calculator gazdă, nenumărate răspunsuri invalide. Ele pot fi astfel construite încât să pară că vin de la un server DNS. Clientul DNS va accepta răspunsul ca venind de la un server DNS.
- Multe sever-e DNS memorează orice răspuns pe care îl primesc, pentru a putea răspunde mai rapid la eventuale cereri similare care vor veni. Se poate încărca cu uşurinţă un astfel de server cu răspunsuri cu adrese IP incorecte.
- Există posibilitatea ca un atacator să creeze un server DNS fals, pe propriul calculator. El poate apoi infecta şi servere DNS reale.
6.3. Arhitectura securităţii în INTERNET
Abordarea securităţii în sistemele distribuite pleacă de la modelul OSI, al cărui obiectiv îl constituie interconectarea unor sisteme eterogene, în aşa fel încât să se poată realiza comunicaţii sigure (fiabile) între procese (aplicaţii) situate la distanţă. Din punct de vedere al securităţii acest lucru înseamnă: integritatea şi protecţia resurselor (prin controale adecvate) şi implementarea unor servicii şi protocoale de securitate.
Serviciile de securitate, controalele şi protocoalele au ca scop protejarea resurselor şi informaţiilor schimbate între procese. Ele trebuie să facă în aşa fel încât costul obţinerii ilegale a unor date sau al modificării ilegale a acestora să fie superior costului de obţinere legală a acelor date iar timpul necesar pentru efectuarea operaţiilor ilegale să fie atât de lung încât datele obţinute să devină caduce.
Măsurile de securitate pot fi: - procedurale (selectarea personalului, schimbarea periodică a parolelor), - logice (controlul accesului, criptografia), - fizice (camere speciale, uşi blocate). Termenul de securitate este folosit în sensul minimizării vulnerabilităţii informaţiilor şi resurselor. El se referă la un complex de măsuri procedurale, logice şi fizice destinate să prevină, să detecteze şi să corecteze pierderile de informaţii din sistem. Principalele probleme de securitate ce apar într-un sistem deschis distribuit sunt:
- Schimbarea identităţii, care apare atunci când entităţile (utilizatori sau programe), reuşesc să pătrundă în reţea sub o altă identitate;
- Asocieri ilegale, care permit să se realizeze legături logice (asociaţii) între utilizatorii reţelei prin eludarea politicii de autorizare şi autentificare;
- Accese neautorizate, care permit unui utilizator sau proces neautorizat să acceadă la obiecte la care nu are dreptul, eludând serviciile de control al accesului;
- Refuzul de servicii, apare atunci când utilizatorii legali sunt împiedicaţi să execute anumite funcţii;
- Repudierea, apare atunci când utilizatori ai reţelei refuză să participe la asociaţii; - Analiza traficului, apare atunci când entităţile intruse observă protocoalele, lungimea,
frecvenţa, suma şi destinaţia mesajelor transmise; - Modificarea sau distrugerea datelor; - Modificarea secvenţei mesajelor, constă din ştergerea, inserarea, relauarea sau reordonarea
ilegală a secvenţei de mesaje transmise; - Modificarea ilegală a programelor, este realizată de viruşi, "cai Troieni", "viermi", etc.
Politica de securitate constă în a decide : - ce ameninţări se vor elimina şi ce ameninţări vor rămâne; - ce resurse vor fi protejate şi la ce nivel; - cu ce mijloace vor fi implementate cerinţele de securitate; - cu ce costuri vor fi implementate cerinţele de securitate.

122
După ce s-a stabilit politica de securitate se vor selecta serviciile de securitate. Acestea sunt funcţii individuale, care contribuie la creşterea sistemului. Fiecare serviciu de securitate poate fi implementat prin metode variate, numite mecanisme de securitate.
Pentru a implementa eficient serviciile de securitate sunt necesare o serie de activităţi denumite generic gestiunea securităţii, care cuprind controlul şi distribuţia informaţiilor folosite de serviciile şi mecanismele de securitate pentru semnalarea unor evenimente relevante privind securitatea sistemului.
Arhitectura securităţii îşi are originea la Departamentul Apărării al S.U.A., DoD şi are la bază protocoalele TCP/IP.
6.3.1. Servicii de securitate
ISO defineşte cinci servicii principale de securitate: autentificare, confidenţialitate, controlul accesului, integritate şi nerepudiere. În plus se defineşte şi monitorizarea sau auditing-ul - înregistrarea elementelor relevante de securitate. Fiecare dintre serviciile amintite poate fi implementat la oricare dintre nivelele modelului OSI. Pentru asigurarea securităţii unui nivel OSI pot fi combinate unul sau mai multe servicii care, la rândul lor, pot fi compuse din câteva subservicii şi mecanisme.
Autentificarea
a) entităţilor perechi, peer entity authentication, asigură, în momentul cnexiunii, că o entitate este într-adevăr ceea ce pretinde a fi şi că dialogul nu reprezintă o reluare a unei înregistrări vechi;
b) originii datelor, data origin authentication, asigură faptul că sursa datelor este autentică, fără însă a asigura însăşi protecţia împotriva duplicărilor sau a modificării şirurilor de date.
Controlul accesului
Asigură protecţia datelor împotriva accesului neautorizat la resursele OSI sau non-OSI prin intermediul OSI. Se aplică la tipuri variate de acces (citire, scriere, execuţie).
Confidenţialitatea datelor
Asigură protecţia datelor la dezvăluiri neautorizate prin:
a) confidenţialitatea legăturii, connection confidentiality, este vorba despre o linie orientată pe conexiune;
b) confidenţialitatea neorientată conexiune, connectionless confidentiality, este vorba despre confidenţialitatea pachetelor de date; c) confidenţialitatea selectivă a câmpurilor, selective field confidentiality, este vorba despre anumite câmpuri ale unui pachet de date; d) confidenţialitatea traficului, traffic flow confidentiality, este vorba despre informaţia ce provine din analiza traficului de mesaje.
Integritatea datelor
Acest serviciu combate ameninţările active (înlocuire, inserare, ştergere), fiind deseori combinat cu serviciile de autentificare a unităţilor perechi. El asigură că datele nu au fost modificate de-a lungul transmisiei. Există mai multe servicii derivate: a) integritatea conexiunii cu recuperare, connection integrity with recovery; b) integritatea conexiunii fără recuperare, connection integrity without recovery; c) integritatea conexiunii cu câmpuri selectate, selective field connection integrity;

123
d) integritatea neorientată pe conexiune cu câmpuri selectate, selective field connectionless integrity. Ne-repudierea a) ne-repudierea cu probarea originii, non-repudiation with proof of origin, permite receptorului
să dovedească faptul că datele au fost furnizate, împiedicându-se astfel orice încercare a unui emiţător de a nega că datele au fost trimise sau că mesajul nu avea conţinutul respectiv;
b) ne-repudierea cu probarea livrării, non-repudiation with proof of delivery, permite emiţătorului să poată demonstra că mesajele trimise de el au fost recepţionate, împiedicându-se astfel orice încercare a unui receptor că a recepţionat datele sau că mesajul avea conţinutul respectiv.
6.3.2. Mecanisme de securitate specifice
OSI a introdus 8 mecanisme de securitate de bază. Acestea se folosesc fie individual fie combinat pentru a construi mecanisme de securitate. De exemplu serviciul de ne-repudiere cu probarea livrării poate fi combinat cu servicii de integritate a datelor, obţinîndu-se mecanismul de semnătură digitală. Un mecanism poate folosi un alt mecanism. De exemplu mecanismul de autentificare a schimbului poate folosi mecanismul de criptare şi uneori mecanismul de notariat (care presupune existenţa unei a treia părţi, căreia i se acordă încredere).
A. Criptarea Obiectivul acestui mecanism este de a transforma datele în aşa fel încât ele să fie inteligibile
doar pentru entităţile autorizate (care au la dispoziţie o cheie secretă pentru decriptare). Criptarea este folosită pentru a furniza confidenţialitate sau alte servicii de securitate.
B. Mecanismul de semnătură digitală Scopul semnăturii digitale este de a confirma că datele respective au fost generate de către
semnatar. Acest mecanism este utilizat de către sistemele de apreciere a integrităţii datelor respectiv de către sistemele de autentificare a originii datelor. Pentru acest mecanism sunt definite două proceduri:
- cea de semnare, - cea de verificare a semnăturii. Folosindu-se sistemele de criptare cu cheie publică, semnătura poate fi generată prin
calcularea unei funcţii de datele care trebuiesc semnate, care apoi se criptează din nou, folosind cheia secretă a semnatarului. Se recomandă ca această valoare să depindă de momentul emisiei, pentru a preveni falsificarea prin retransmisie a datelor respective. Semnătura trebuie generată folosind doar chei secrete, în timp ce procedura de verificare a semnăturii trebuie să fie publică.
C. Mecanismul de control al accesului
Acest mecanism controlează accesul entităţilor la resurse, presupunând cunoscută identitatea entităţii care solicită accesul. Mecanismul se declanşează atunci când se încearcă un acces neautorizat, fie prin declanşarea unei alarme, fie prin simpla înregistrare a incidentului. Politica de control a accesului poate fi bazată pe unul sau mai multe dintre următoarele elemente:
- lista/matricea drepturilor de acces, - parole, - durata accesului, - timpul de încercare al accesului, - ruta (calea de încercare a accesului).
D. Mecanismul de integritate a datelor
Asigură integritatea pachetelor de date (întreg pachetul sau numai un anumit câmp al acestuia) şi presupune că datele nu pot fi modificate, şterse sau amestecate în timpul transmisiei. Acest

124
mecanism implică două proceduri: - la expediere: expeditorul adaugă la unitatea de date o informaţie adiţională ce depinde
numai de datele transmise ("checkvalue"-aceasta poate fi criptată sau nu); - la recepţie: partea receptoare generează aceeaşi "checkvalue" şi o compară cu cea primită.
Mecanismul de ştampile de timp, time stamping, poate fi folosit pentru transmisiile neorientate conexiune în scopul asigurării actualităţii datelor.
E. Mecanismul de autentificare a schimbului Este folosit pentru a dovedi identitatea entităţilor. Pot fi folosite parole sau tehnici
criptografice (parole cifrate, cartele magnetice sau inteligente, caracteristici biometrice, biochimice). Când sunt folosite tehnicile criptografice de obicei acestea sunt combinate cu protocoale "handshaking", în intenţia de protejare împotriva înlocuirii respectiv reluării datelor. Principiul este următorul: entitatea A trimite identitatea sa (criptată sau nu) entităţii B, care generează o valoare aleatoare şi o trimite (criptat sau nu) lui A. A trebuie să cripteze valoarea aleatoare cu cheia sa secretă şi să o trimită la B, care va verifica corectitudinea acesteia.
F. Mecanismul de umplere a traficului Este folosit pentru a asigura diferite nivele de protecţie împotriva analizei de trafic şi implică
utilizarea uneia dintre următoarele metode: - generarea unui trafic fals, - umplerea pachetelor de date transmise cu date redundante, - transmiterea de pachete de date şi spre alte destinaţii decât cea dorită. G. Mecanismul de control al dirijării Într-o reţea unele drumuri pot fi considerate mai sigure decât altele. Acest mecanism permite
alegerea în mod static sau dinamic a drumurilor celor mai convenabile, în concordanţă cu criterile de securitate (importanţa datelor şi confidenţialitatea legăturii). Acest mecanism trebuie folosit ca suport şi pentru serviciile de integritate cu recuperarea datelor (de exemplu, pentru a pemite selecţia unor rute alternative în vederea protejării în cazul unor atacuri ce ar perturba comunicaţia).
H. Mecanismul de notarizare, notarization mechanism Acest mecanism implică existenţa unei a treia părţi-numită notar-în care au încredere toate entităţile, pentru a asigura garanţii de integritate a originii datelor sau a destinaţiei datelor. Atunci când acest mecanism este folosit datele sunt comunicate prin intermediul notarului.
6.3.2.1. Arhitectura securităţii ISO
În tabelul următor se prezintă legătura între servicile de securitate şi mecanismele de securitate definite de ISO. Pe linii sunt marcate servicile iar pe coloane mecanismele. Prezenţa unui x într-una dintre rubricile tabelului semnifică faptul că mecanismul respectiv poate fi folosit pentru implementarea serviciului corespunzător. Mecanism Serviciu A B C D E F G H
Autentificarea entităţilor perechi x x x Autentificarea originii datelor x x Controlul accesului x Confidenţialitatea conexiunii x x Confidenţialitatea neorientată conexiune x x Confidenţialitatea selectivă a câmpurilor x x x Integritatea conexiunii cu recuperare x x Integritatea conexiunii fără recuperare x x Integritatea conexiunii cu câmpuri selectate x x Integritatea neorientată conexiune x x x Integritatea cu câmpuri selectate neorientată conexiune
x x x
Ne-repudiere, emisie x x x Ne-repudiere, recepţie x x x
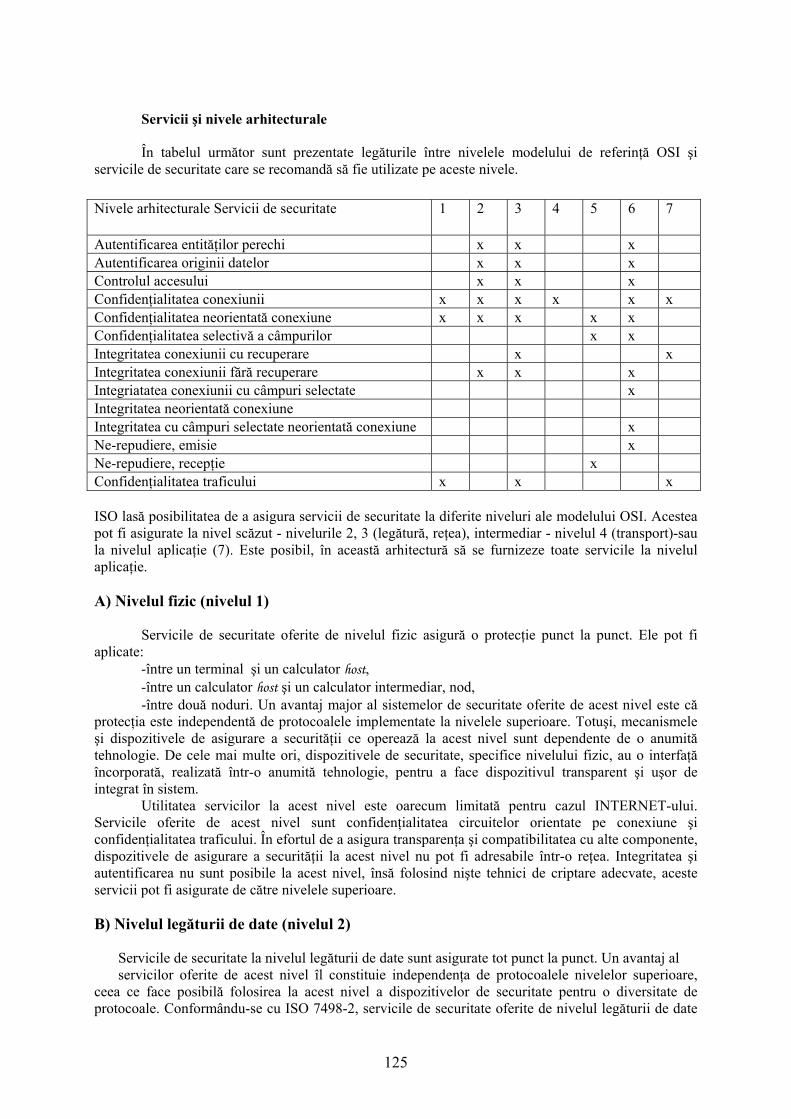
125
Servicii şi nivele arhitecturale
În tabelul următor sunt prezentate legăturile între nivelele modelului de referinţă OSI şi servicile de securitate care se recomandă să fie utilizate pe aceste nivele.
Nivele arhitecturale Servicii de securitate 1 2 3 4 5 6 7
Autentificarea entităţilor perechi x x x Autentificarea originii datelor x x x Controlul accesului x x x Confidenţialitatea conexiunii x x x x x x Confidenţialitatea neorientată conexiune x x x x x Confidenţialitatea selectivă a câmpurilor x x Integritatea conexiunii cu recuperare x x Integritatea conexiunii fără recuperare x x x Integriatatea conexiunii cu câmpuri selectate x Integritatea neorientată conexiune Integritatea cu câmpuri selectate neorientată conexiune x Ne-repudiere, emisie x Ne-repudiere, recepţie x Confidenţialitatea traficului x x x ISO lasă posibilitatea de a asigura servicii de securitate la diferite niveluri ale modelului OSI. Acestea pot fi asigurate la nivel scăzut - nivelurile 2, 3 (legătură, reţea), intermediar - nivelul 4 (transport)-sau la nivelul aplicaţie (7). Este posibil, în această arhitectură să se furnizeze toate servicile la nivelul aplicaţie.
A) Nivelul fizic (nivelul 1)
Servicile de securitate oferite de nivelul fizic asigură o protecţie punct la punct. Ele pot fi aplicate:
-între un terminal şi un calculator host, -între un calculator host şi un calculator intermediar, nod, -între două noduri. Un avantaj major al sistemelor de securitate oferite de acest nivel este că
protecţia este independentă de protocoalele implementate la nivelele superioare. Totuşi, mecanismele şi dispozitivele de asigurare a securităţii ce operează la acest nivel sunt dependente de o anumită tehnologie. De cele mai multe ori, dispozitivele de securitate, specifice nivelului fizic, au o interfaţă încorporată, realizată într-o anumită tehnologie, pentru a face dispozitivul transparent şi uşor de integrat în sistem.
Utilitatea servicilor la acest nivel este oarecum limitată pentru cazul INTERNET-ului. Servicile oferite de acest nivel sunt confidenţialitatea circuitelor orientate pe conexiune şi confidenţialitatea traficului. În efortul de a asigura transparenţa şi compatibilitatea cu alte componente, dispozitivele de asigurare a securităţii la acest nivel nu pot fi adresabile într-o reţea. Integritatea şi autentificarea nu sunt posibile la acest nivel, însă folosind nişte tehnici de criptare adecvate, aceste servicii pot fi asigurate de către nivelele superioare.
B) Nivelul legăturii de date (nivelul 2)
Servicile de securitate la nivelul legăturii de date sunt asigurate tot punct la punct. Un avantaj al servicilor oferite de acest nivel îl constituie independenţa de protocoalele nivelelor superioare,
ceea ce face posibilă folosirea la acest nivel a dispozitivelor de securitate pentru o diversitate de protocoale. Conformându-se cu ISO 7498-2, servicile de securitate oferite de nivelul legăturii de date

126
sunt confidenţialitatea circuitelor orientate pe conexiune precum şi confidenţialitatea circuitelor neorientate pe conexiune. Deoarece majoritatea protocoalelor de la acest nivel au facilităţi de detecţie a erorilor şi de secvenţiere pentru asigurarea retransmisiilor, ele dau impresia că se poate asigura integritatea datelor cu posibilitatea refacerii acestora. Totuşi calitatea unui astfel de serviciu nu ar putea fi prea bună.
Realizarea criptării la acest nivel presupune oferirea unei cantităţi mai mari de informaţie, unui adversar ce interceptează pachete, deoarece câmpurile de control sunt în text clar, lucru ce permite atacuri cum ar fi re-rularea datelor (deoarece câmpurile sursă şi destinaţie sunt citibile). Nivelul 2 nu este recomnadat de OSI pentru implementarea criptării. Principalul dezavantaj al criptării la acest nivel este acela că datele sunt memorate în clar în toate nodurile intermediare. Acest aspect poate fi acceptat numai în reţele private, unde este asigurată securitatea fizică şi utilizatorii sunt de încredere.
C) Nivelul reţea (nivelul 3)
Servicile de securitate asigurate de acest nivel sunt: - confidenţialitatea circuitelor neorientate pe conexiune, - confidenţialitatea circuitelor orientate pe conexiune, - integritatea datelor, - autentificarea, - controlul accesului.
Securitatea nivelului reţea poate fi asigurată atât între sistemele terminale cât şi între un sistem terminal şi un sistem intermediar (de exemplu ruter). Dacă securitatea nivelului reţea este asigurată în funcţie de tehnologia de realizare a reţelei respective, atunci servicile de securitate oferite pot fi independente de protocoalele de nivel superior. Istoric vorbind, servicile de securitate de la nivelele fizic şi legătură de date au fost implementate în hard extern. Este mult mai eficient să se implementeze securitatea nivelului reţea intern în sistemele terminale sau intermediare. O implementare internă evită problemele nivelelor inferioare ce au fost menţionate mai înainte.
La acest nivel este permisă securizarea anumitor rute; tot traficul de pe aceste rute este criptat, chiar dacă nu este necesar. Este criptat însă numai câmpul de date al pachetului şi ca urmare, datele care trec prin nodurile intermediare sunt criptate, pe când altele nu. Acest aspect face să nu fie asigurată confidenţialitatea traficului ci numai integritatea şi confidenţialitatea datelor transmise.
D) Nivelul transport (nivelul 4)
Pentru nivelul transport, ISO 7498-2 identifică câteva servicii de securitate: confidenţialitatea (orientată sau nu pe conexiune), integritatea (completă sau pentru câmpuri selectate), autentificara originii datelor, autentificarea entităţilor perechi şi controlul accesului. Există o singură diferenţă semnificativă între servicile de securitate asigurate de nivelul transport şi cele oferite de nivelul reţea. Aceasta se referă la capacitatea de asigurare unei protecţii şi în sistemele intermediare, atunci când se folosesc mecanismele părţii superioare a nivelului reţea. Servicile de securitate ale nivelului transport orientate pe conexiune pot asigura, în principiu, o protecţie sporită, comparativ cu protecţia asigurată de partea superioară a nivelului reţea, însă în practică, aceste diferenţe sunt minime.
E) Nivelul sesiune (nivelul 5)
ISO 7498-2 nu prevede ca nivelul sesiune să ofere servicii de securitate.
F) Nivelul prezentare (nivelul 6)
Acest nivel este citat adesea ca fiind nivelul ideal de asigurare a protecţiei, întrucât servicile de securitate sunt văzute ca transformări de date asemenea funcţiilor nivelului prezentare. Facilităţile de confidenţialitate oferite aici se pot baza pe legături orientate/ neorientate pe conexiune sau pe variantele de câmp selectat. Deoarece acest nivel este folosit pentru transformarea datelor există un avantaj pentru cifrarea datelor la acest nivel mai curând decât la nivelul aplicaţie.

127
G) Nivelul aplicaţie (nivelul 7)
ISO 7498-2 afirmă că toate servicile de securitate pot fi asigurate de acest nivel iar ne-repudierea mesajelor poate fi oferită numai de acest nivel. Totuşi, servicile de secuirtate oferite de nivelul
aplicaţie pun unele probleme, datorită conflictului cu funcţionalitatea nivelului prezentare. Pentru mulţi, unul dintre motivele cele mai importante pentru asigurarea servicilor de securitate la acest nivel îl constituie posibilitatea de implementare a acestor servicii în afara sistemelor de operare. Astfel, cei ce dezvoltă aplicaţii pot implementa mecanismele de securitate pe care le doresc în interiorul aplicaţilor. Aspectul neplăcut al servicilor de securitate localizate în aplicaţii este că fiecare implementare trebuie să servească doar unei anumite aplicaţii. Ţinând cont de faptul că proiectarea şi implementarea unui mecanism de securitate este un proces complex există riscul ca facilităţile de securitate ale aplicaţiei respective să fie slabe. 6.3.2.2. Securitatea servicilor TCP/IP
Aceste protocoale au propriile lor probleme de securitate, amintite deja mai devreme. Majoritatea acestor probleme sunt datorate faptului că protocoalele nu conţin mecanisme proprii de securitate.
6.3.2.2.1. Arhitectura securităţii pentru protocolul IP
Această arhitectură este prezentată în documentul RFC 1827, elaborat în anul 1995 şi este valabilă atât pentru varianta 4 cât şi pentru varianta 6 a protocolului IP.
Introducere
Există două antete specifice pentru servicile de securitate la nivelul protocolului IPv6. Acestea sunt antetul de autentificare IP, AH şi antetul de încapsulare a sarcinii de securitate, ESP. Mecanismele de securitate, implicate de aceste antete (la fiecare antet corespunde un mecanism de securitate) pot fi folosite în mai multe feluri. Mecanismul corespunzător antetului AH este destinat asigurării integrităţii şi autentificării pachetelor de date, fără însă a le asigura confidenţialitatea. Absenţa confidenţialităţii asigură disponibilitatea fără restricţii pe INTERNET a descrierii mecanismului de la nivelul IP de asigurare a integrităţii şi a autenticităţii. Acest mecanism asigură securitatea unei comunicaţii între două calculatoare terminale, între un calculator terminal şi un ruter sau între două rutere. Un ruter de securitate este unul care face comunicaţii între calculatoare exterioare (considerate ca nefiind de încredere) şi calculatoare interioare (unei subreţele) considerate de încredere. O subreţea este considerată de încredere dacă conţine calculatoare gazdă şi rutere care au încredere unele în celălalte, nu se angajează în atacuri active sau pasive şi cred că au la dispoziţie un canal de comunicaţii de încredere (care nu este atacat). În cazul în care un ruter de securitate efectuează servicii în beneficiul unuia sau mai multor calculatoare gazdă dintr-o reţea de încredere acest ruter de securitate este responsabil pentru asigurarea securităţii acelei subreţele precum şi conectarea sa sigură spre exterior. În acest caz doar ruterul de securitate trebuie să implementeze serviciul AH, toate calculatoarele din subreţeaua de încredere beneficiând de acest serviciu, pentru comunicarea spre exterior. Un ruter de securitate care primeşte un pachet de date conţinând o etichetă sensibilă, de exemplu eticheta IPSO (IP Security Option) de la un calculator de încredere trebuie să o ia în considerare când crează sau selectează o "asociaţie de securitate" pentru folosire împreună cu AH la stabilirea legăturii între acel calculator de încredere şi destinaţie. Într-o astfel de situaţie un ruter de securitate care primeşte un pachet IP conţinând antetul ESP trebuie să adauge autentificarea potrivită incluzând eticheta implicită (conţinută în asociaţia de securitate folosită) sau eticheta explicită (de exemplu eticheta IPSO) pentru pachetul de date decriptat care este trimis spre calculatorul gazdă de încredere, căruia îi este adresat. Antetul AH trebuie utilizat întotdeauna când este vorba despre pachete care conţin etichete sensibile explicite pentru a asigura integritatea comunicaţiei capăt la capăt.
Antetul ESP este conceput pentru a asigura integritatea, autenticitatea şi confidenţialitatea pachetelor de date IP. Mecanismul ESP asigură comunicaţia sigură între două sau mai multe calculatoare gazdă care implementează acest mecanism, între două sau mai multe rutere care

128
implementează acest mecanism, precum şi între un calculator gazdă sau ruter, care implementează acest mecanism şi/sau o mulţime de calculatoare gazdă sau de rutere.
Criptarea de la ruter la ruter este mai valoroasă pentru construcţia reţelelor virtuale private într-o structură în care nu se poate avea încredere, aşa cum este INTERNET-ul. Acest deziderat este îndeplinit prin excluderea calculatoarelor externe. Cu toate acestea criptarea de la ruter la ruter nu poate substitui întotdeauna criptarea de la calculator gazdă la calculator gazdă, cele două tipuri de criptare putând şi adesea trebuind să fie folosite împreună.
Dacă în cadrul legăturii respective nu există rutere de securitate, cele două sisteme aflate în comunicaţie, care trebuie să implementeze mecanismul ESP pot să-l utilizeze pentru a cripta doar datele de utilizator (de exemplu de tip TCP sau UDP) care se transmit între cele două sisteme. Mecanismul ESP este proiectat în aşa fel încât să asigure flexibilitate maximă, adică să permită utilizatorilor să aleagă şi să folosească doar acele servicii de securitate pe care le doresc şi de care au nevoie.
Antetele de dirijare pentru care integritatea nu a fost asigurată, prin criptare, trebuie ignorate de către receptor. Dacă această regulă nu este respectată cu stricteţe atunci sistemul va fi vulnerabil la diferite tipuri de atac, inclusiv la atacuri de redirijare a sursei. Deşi acest document nu se ocupă în mod explicit de difuzare, în cadrul protocolului Ipv6, mecanismele de securitate discutate pot fi folosite şi pentru astfel de comunicaţii. Operaţiile de distribuire a cheilor şi de management al asociaţiilor de securitate sunt complicate pentru cazul acestui tip de comunicaţie. Dacă se folosesc algoritmi de criptare cu cheie secretă atunci valoarea folosirii criptării, pentru pachete care trebuiesc difuzate, este limitată deoarece receptorul poate să ştie doar că pachetul recepţionat vine de la unul sau mai multe sisteme doar dacă ştie cheia secretă corespunzătoare.
Asociaţii de securitate
Conceptul de asociaţie de securitate este fundamental atât pentru mecanismul de securitate IP de tip ESP cât şi pentru mecanismul de securitate AH. O anumită asociaţie de securitate este identificată univoc pe baza unui index de parametrii de securitate , Security Parameter Index, SPI şi a unei adrese de destinaţie. Orice implementare a mecanismelor de securitate AH sau ESP se bazează pe conceptul de asociaţie de securitate, precum şi pe unii parametri ai săi. De obicei o asociaţie de securitate are următorii parametri:
- Algoritm de autentificare şi modul său de utilizare, folosit de mecanismul AH; - Chei, folosite de către algoritmul de autentificare ales; - Algoritm de criptare şi transformare, folosite de mecanismul de securitate ESP; - Chei, folosite de algoritmul de criptare corespunzător mecanismului ESP; - Prezenţa/absenţa şi dimensiunea unui vector de sincronizare sau iniţailizare pentru algoritmul de criptare corespunzător mecanismului de securitate ESP; - Algoritm de autentificare şi modul său de utilizare folosit pentru transformarea
corespunzătoare mecanismului de securitate ESP; - Chei de autentificare, folosite pentru algoritmul de autentificare corespunzător mecanismului ESP, - Timpul de viaţă al cheilor (reprezintă intervalul de timp după care cheile trebuie schimbate); - Timpul de viaţă al asociaţiei de securitate; - Adresa sau adresele asociaţiei de securitate; - Nivelul de sensibilitate al datelor protejate (de exemplu secret sau neclasificat);
Calculatorul gazdă expeditor foloseşte identificatorul utilizatorului şi adresa de destinaţie pentru a alege o asociaţie de securitate corespunzătoare (şi deci valoarea SPI). Calculatorul gazdă receptor foloseşte combinaţia dintre valoarea SPI şi adresa de destinaţie pentru a determina asociaţia corectă de securitate. De aceea, o implementare a mecanismului AH, va fi întotdeauna capabilă să folosească SPI în combinaţie cu adresa de destinaţie pentru a determina asociaţia de securitate şi configuraţia de securitate asociată pentru toate pachetele de date valide care sosesc. Când o asociaţie de securitate devine invalidă, sistemul destinaţie nu trebuie imediat să ignore valoarea corespunzătoare acelei

129
asociaţii de securitate, ci trebuie să aştepte până când sarcinile sale au fost preluate de alte asociaţii de securitate.
De obicei o asociaţie de securitate este unidirecţională. O sesiune de comunicări cu autentificare între două calculatoare gazdă are doi indici de parametri de securitate, SPI, câte unul în fiecare direcţie. Combinaţia dintre un anumit indice de securitate şi o anumită adresă de destinaţie, determină în mod unic o anumită asociaţie de securitate. Adresa de destinaţie poate fi o adresă corespunzătoare unei comunicaţii punct la punct respectiv o adresă de grup (specifică unei comunicaţii multipunct).
Atributul de orientare spre recepţie a unei asociaţii de securitate implică pentru traficul punct la punct selectarea valorii SPI de către sistemul destinatar. În acest mod se evită posibilitatea unui conflict între asociaţile de securitate configurate manual şi asociaţile de securitate configurate
automat (de exemplu printr-un protocol de management al cheilor). Pentru traficul multipunct, există mai multe sisteme destinaţie dar un singur grup de sisteme destinaţie. De aceea un anumit sistem sau o anumită persoană vor trebui să aleagă indicii SPI pentru acest grup de sisteme destinaţie şi apoi să comunice informaţia tuturor membrilor legitimi ai acestui grup de sisteme de destinaţie prin mecanisme care nu sunt specificate în acest document. Expeditori multipli spre un grup de sisteme destinaţie pot utiliza o singură asociaţie de securitate (şi deci un singur indice SPI) pentru întreg traficul cu acest grup. În acest caz un anumit receptor ştie doar că mesajul vine de la un sistem care ştie parametrii asociaţiei de securitate corespunzătoare pentru acel grup de sisteme destinaţie. Receptorul nu poate autentifica care dintre sisteme a generat traficul multipunct dacă se folosesc algoritmi de criptare cu cheie secretă (de exemplu DES sau IDEA). Traficul multipunct se poate baza şi pe folosirea câte unei asociaţii de securitate separate (şi implicit al câte unui indice SPI separat) pentru fiecare componentă punct la punct a traficului cu acel grup. Dacă fiecare expeditor are propria sa asociaţie de securitate şi se folosesc algoritmi de criptare cu cheie publică atunci este posibilă şi efectuarea serviciului de autentificare a sursei datelor.
Obiective de proiectare
În continuare se descriu câteva obiective de proiectare pentru această arhitectură de securitate şi pentru mecanismele de securitate corespunzătoare.
Primul obiectiv al acestui document este să asigure că IPv6 vor avea mecanisme de securitate, bazate pe criptare, solide, disponibile pentru utilizatorii care doresc securitate. Aceste mecanisme sunt concepute pentru a împiedica impactul cu adversari, utilizatori de INTERNET, care nu folosesc aceste mecanisme de securitate pentru traficul lor. Se intenţionează ca aceste mecanisme să fie independente de algoritm, astfel încât algoritmii de criptare să poată fi alteraţi fără a fi afectate alte părţi ale implementării. Aceste mecanisme de securitate trebuie să fie utile pentru întărirea unor politici de securitate. Algoritmi de securitate ca de exemplu MD5 sau DES au fost standardizaţi pentru a se asigura interoperabilitatea în reţeaua INTERNET. Algoritmii recomandaţi pentru protocolul IP sunt aceeaşi cu algoritmi recomandaţi pentru protocolul SNMPv2.
6.3.2.2.1.1. Mecanisme de securitate la nivel IP
După cum s-a arătat deja există două mecanisme de securitate la nivelul IP, AH şi ESP. Aceste mecanisme nu asigură securitate împotriva unui număr de atacuri prin analiză de trafic. Totuşi există câteva tehnici în afara scopului acestui document care pot fi folosite pentru a realiza protecţia împotriva analizei de trafic.
Mecanismul de securitate AH
Antetul de autentificare IP păstrează informaţia de autentificare pentru pachetul de date IP. El realizează această funcţie calculând o funcţie de autentificare criptografică pentru pachetul de date IP. În calcul se utilizează o cheie secretă de autentificare. Expeditorul calculează datele de autentificare înainte de a trimite pachetul IP autentificat. Poate apărea fragmentarea datelor după prelucrarea antetului la pachetele care iasă şi înainte de prelucrarea antetului la pachetele care intră. Receptorul verifică corectitudinea datelor de autentificare după recepţie. Unele câmpuri care trebuie să

130
se schimbe în tranzit, ca de exemplu câmpul "TTL" din cazul protocolului IPv4 sau câmpul "Hop Limit" din cazul protocolului IPv6, sunt omise când se face calculul de autentificare. Serviciul de ne-repudiere poate fi realizat cu ajutorul unor algoritmi de autentificare (de exemplu algoritmi cu cheie publică, situaţie în care se folosesc în calculul de autentificare atît cheia secretă a expeditorului cât şi cheia secretă a destinatarului) care folosesc şi antetul AH dar nu este neapărat implementat de toţi algoritmii de autentificare care se folosesc de antetul AH. Algoritmul de autentificare recomandat este algoritmul MD5 cu cheie, care la fel ca toţi algoritmii cu cheie secretă nu poate implementa de unul singur serviciul de ne-repudiere.
Utilizarea antetului AH va creşte costurile de prelucrare ale protocolului IP şi întârzierea de comunicare. Această creştere a întârzierii este explicată de necesitatea calculului datelor de autentificare de către expeditor şi de necesitatea de calcul şi de comparare a datelor de autentificare de către fiecare receptor, pentru fiecare pachet de date IP care conţine antetul de autentificare AH.
Folosirea antetului AH asigură o securitate mult mai puternică decât cea care există în majoritatea protocoalelor INTERNET şi nu trebuie să afecteze posibilitatea de export sau să conducă la creşterea excesivă a costurilor de implementare. În timp ce mecanismul de securitate bazat pe antetul AH trebuie implementat de un ruter de securitate în beneficiul calculatoarelor gazdă dintr-o reţea de încredere situată în spatele acestui ruter de securitate, acest mod de operare nu este încurajat pentru calculatoarele situate în faţa acestui ruter de securitate.
Toate calculatoarele gazdă care au implementat protocolul IPv6 trebuie să implementeze mecanismul de securitate bazat pe antetul AH folosind cel puţin algoritmul MD5 cu o cheie cu lungimea de 128 de biţi. O implementare particulară poate utiliza şi alţi algoritmi de autentificare diferiţi de algoritmul MD5 cu cheie.
Mecanismul de securitate ESP
Acest mecanism de securitate este proiectat să asigure integritatea, autenticitatea şi confidenţialitatea pachetelor de date IP. El îndeplineşte aceste funcţii încapsulând fie un întreg pachet de date IP fie doar protocolul de nivel superior (de exemplu TCP sau UDP sau ICMP), în interiorul capsulei ESP. Încapsularea se realizează prin criptarea celei mai mari părţi a ESP şi apoi prin adăugarea unui nou antet IP în clar capsulei ESP, care este la acest moment criptată. Noul antet, care reprezintă un text clar, este folosit pentru a transporta datele protejate prin interreţea.
Descrierea modurilor ESP
Există două astfel de moduri. Primul, numit mod tunel, încapsulează un pachet întreg IP sub antetul ESP. Cel de al doilea mod, numit mod transport, încapsulează doar un protocol de nivel mai înalt (de exemplu UDP sau TCP) sub antetul ESP şi apoi necesită adăugarea unui nou antet IP cu text clar.
Utilizarea mecanismului de securitate ESP
Acest mecanism poate fi folosit la comunicaţia între două calculatoare gazdă, între un calculator gazdă şi un ruter de securitate sau între două rutere de securitate. Acest ajutor pentru ruterele de securitate permite reţelelor de încredere situate în spatele unui ruter de securitate să omită criptarea şi deci să înlăture pierderile de performanţă şi creşterea de costuri datorate criptării, cu păstrarea confidenţialităţii traficului care străbate segmente nesigure ale reţelei. Cănd ambele calculatoare gazdă aflate în comunicaţie folosesc mecanismul de securitate EPS şi nu se foloseşte nici un ruter de securitate atunci cele două calculatoare trebuie să folosească modul transport. Acesta reduce atât banda de frecvenţe consumată cât şi costurile de prelucrare ale protocolului pentru utilizatori care nu trebuie să păstreze confidenţial întregul pachet de date. Mecanismul ESP funcţionează atât pentru trafic punct la punct cât şi pentru trafic multipunct.
Performanţele mecanismului de securitate ESP
Metoda de securitate bazată pe antetul ESP poate afecta semnificativ performanţele unei

131
reţele. Utilizarea acestui mecanism de securitate, bazat pe criptare, creşte întârzierea în transmiterea unui mesaj. Costul exact al serviciului de securitate ESP se va modifica în funcţie de implementarea aleasă, incluzând algoritmul de criptare, dimensiunea cheilor şi alţi factori. Algoritmii de criptare pot fi implementaţi şi hard. De obicei, algoritmul de criptare folosit este DES.
Combinarea celor două mecanisme de securitate
Există cazuri când mecanismul de securitate bazat pe antetul AH poate fi combinat cu mecanismul de securitate bazat pe antetul ESP pentru a obţine proprietăţile de securitate dorite. Mecanismul bazat pe antetul AH asigură integritate şi autenticitate şi poate asigura şi nerepudiere dacă se bazează pe anumiţi algoritmi de autentificare prin criptare (ca de exemplu algoritmul RSA). Mecanismul de securitate bazat pe antetul ESP, asigură întotdeauna autenticitate şi confidenţialitate şi poate asigura şi autentificare dacă este folosit împreună cu anumiţi algoritmi de criptare. Adăugarea antetului AH la un pachet de date IP înainte de încapsularea acestuia cu ajutorul mecanismului ESP poate fi de dorit pentru acei utilizatori care doresc o integritate puternică, autenticitate, confidenţialitate şi poate şi pentru utilizatori care cer un serviciu puternic de nerepudiere. Cînd se combină cele două mecanisme poziţia antetului AH specifică partea din şirul de date care este autentificată. Alte mecanisme de securitate
Protecţia împotriva analizei traficului nu este asigurată de nici unul dintre mecanismele descrise mai sus. Nu este clar cum pot fi realizate economic la nivelul INTERNET mecanisme de protecţie împotriva analizei traficului şi se pare că există puţini utilizatori de INTERNET interesaţi de anliza de trafic. O metodă tradiţională de protecţie împotriva analizei de trafic este criptarea liniilor. O altă metodă este de a genera trafic fals în scopul creşterii zgomotului în datele obţinute prin analiza de trafic.
6.3.2.2.1.2. Managementul cheilor
Protocolul de management al cheilor care se foloseşte cu mecanismele de securitate ale protocolului IP nu este specificat în acest document. Totuşi, deoarece protocolul de management al cheilor este cuplat cu mecanismele de securitate AH şi ESP numai prin inermediul indicelui SPI, pot fi definite aceste mecanisme de securitate fără a specifica complet cum se realizează managementul cheilor. Se prevede că pot fi utilizate câteva mecanisme de management al cheilor împreună cu mecanismele de securitate descrise, printre care şi configurarea manuală a cheilor. Se lucrează la specificarea unui standard INTERNET pentru un protocol de management al cheilor. Mecanismele de securitate prezentate în acest document au fost concepute în ipoteza că folosesc metode de management al cheilor unde datele de management al cheilor sunt purtate de un protocol de nivel superior, cum ar fi UDP sau TCP, spre un număr de port specific sau spre punctul în care datele de management al cheilor vor fi distribuite manual.
Această modalitate de proiectare permite o delimitare clară a mecanismelor de management al cheilor de alte mecanisme de securitate şi deci permite includerea unor mecanisme de securitate noi şi îmbunătăţite fără a fi necesară modificarea implementării celorlalte mecanisme de securitate.
În continuare se face o scurtă prezentare a alternativelor de management al cheilor.
Distribuirea manuală a cheilor
Cea mai simplă formă de management al cheilor este cea manuală, în care o persoană configurează fiecare sistem cu propria sa cheie precum şi cu cheile celorlalte sisteme aflate în comunicaţie. Această metodă de distribuţie este practicată în împrejurări statice la reţele de dimensiune mică. Nu este o metodă bună pentru abordările pe termen mediu sau lung dar poate fi aplicată în cazul abordărilor pe termen scurt. De exemplu în cazul unei reţele locale de dimensiuni mici este frecventă configurarea manuală a cheilor pentru fiecare calculator component. În cadrul unui singur domeniu de administrare se practică de asemenea, pentru fiecare ruter, configurarea manuală a

132
cheilor, astfel încât datele dirijate să poată fi protejate şi să se reducă riscul de pătrundere al unei persoane neavizate într-un ruter. Un alt caz este cel al unei organizaţii care foloseşte un dispozitiv de tip firewall, între reţeaua internă şi INTERNET în fiecare dintre sediile sale. În acest caz dispozitivul firewall trebuie să cripteze selectiv traficul cu alte sedii ale acelei organizaţii folosind un sistem manual de configurare a cheilor şi să nu cripteze traficul pentru alte destinaţii. Acest sistem de management al cheilor mai este potrivit şi pentru cazul în care doar anumite comunicaţii selectate trebuie securizate.
Câteva tehnici de management al cheilor existente
Există un număr de algoritmi de management al cheilor care au fost deja descrişi în literatură. Un exemplu este cel al algoritmului folosit în cadrul sistemului de autentificare Kerberos, realizat la M.I.T în cadrul proiectului Athena. Un alt algoritm de management al cheilor a fost dezvoltat de Diffie şi Hellman.
Distribuirea automată a cheilor
Dezvoltarea accelerată şi folosirea pe scară largă a securităţii IP va necesita un protocol de management al cheilor pentru INTERNET standardizat. Ideal ar fi ca un astfel de protocol de management al cheilor să suporte mai multe protocoale de securitate pentru protocoalele din seria TCP/IP şi nu numai protocolul de securitate corespunzător protocolului IP. De exemplu în prezent se lucrează la adăugarea de chei de calculatoare gazdă semnate la protocolul DNS. Cheile DNS permit expeditorilor să autentifice mesaje de management al cheilor între două părţi însărcinate cu managementul cheilor folosind un algoritm de criptare cu cheie publică. Cele două părţi ar avea atunci un canal de comunicaţii autentificabil care ar putea fi folosit pentru a crea o cheie de sesiune (acceptată de ambele părţi) folosind metoda Diffie-Hellman sau alte metode.
Abordări ale sistemului de management al cheilor pentru protocolul IP
Există două astfel de abordări pentru protocolul IP. Prima se numeşte orientată pe gazdă şi presupune ca toţi utilizatorii gazdei 1 să împartă aceeaşi cheie pentru a o folosi în traficul destinat tuturor utilizatorilor gazdei 2. Cea de a doua abordare, numită orientată pe utilizator, permite utilizatorului A de la gazda 1 să aibă una sau mai multe sesiuni unice pentru traficul său destinat gazdei 2; cheile acestor sesiuni nu sunt împărţite cu alţi utilizatori ai gazdei 1. De exemplu sesiunea ftp a utilizatorului A trebuie să folosească o altă cheie decât sesiunea telnet a aceluiaşi utilizator. În sistemele care sunt destinate securităţii multi-nivel, utilizatorul A va avea de obicei cel puţin câte o cheie pe nivel de sensibilitate (de exemplu o cheie pentru traficul neclasificat, o a doua cheie pentru traficul secret şi o atreia cheie pentru traficul foarte secret). Similar în cazul sistemelor de management al cheilor, orientate pe utilizator, trebuie folosite chei separate pentru informaţiile transmise unui grup printr-o comunicaţie multipunct şi pentru mesajele de control trimise aceluiaşi grup. În multe cazuri un singur sistem de calcul va avea cel puţin doi utilizatori A şi B care nu au încredere unul în celălalt. Când se foloseşte un sistem de management al cheilor orientat pe gazdă şi există astfel de utilizatori (care nu au încredere unul în celălalt) e posibil ca utilizatorul A să determine cheia orientată pe gazdă prin metode bine cunoscute cum ar fi atacul cu text în clar selectat. Odată ce utilizatorul A a obţinut fraudulos cheia folosită, el poate citi traficul criptat al utilizatorului B sau să falsifice traficul utilizatorului B. Când se utilizează sisteme de management al cheilor orientate pe utilizator, anumite tipuri de atac ale traficului unui utilizator de către un alt utilizator nu sunt posibile.
Securitatea protocolului IP a fost concepută ca să asigure autenticitate, integritate şi confidenţialitate pentru aplicaţiile care operează cu sisteme conectate capăt la capăt când se utilizează algoritmi potriviţi. Integritatea şi confidenţialitatea pot fi realizate cu sisteme de management al cheilor orientate pe gazdă când se folosesc algoritmi corespunzători. Totuşi autentificarea în principalele aplicaţii pentru sistemele capăt la capăt necesită folosirea asociaţilor de securitate. Astfel aplicaţiile pot folosi facilităţile de distribuire a cheilor care realizează autentificarea. De aceea sistemele de management al cheilor trebuie să fie prezente în toate implementările algoritmului IP.

133
Distribuirea cheilor în sistemele de comunicaţii multipunct
Pentru grupurile de utilizatori ai comunicaţiilor multipunct care au un număr mic de membri, distribuirea manuală a cheilor sau folosirea multiplă a sitemelor de distribuire a cheilor pentru sistemele de comunicaţii punct la punct bazată pe algoritmi cunoscuţi (ca de exemplu o variantă modificată a algoritmului Diffie-Hellman) par soluţii acceptabile. Pentru grupuri cu un număr mare de membri vor fi însă necesare noi tehnici de management al cheilor.
Necesităţi de management ale cheilor pentru protocolul IP
Acest paragraf defineşte necesităţi de management al cheilor pentru toate implementările protocolului IPv6. Toate implementările de acest fel trebuie să permită configurarea manuală a asociaţilor de securitate. Toate implementările de acest fel ar trebui să suporte un protocol de stabilire a asociaţilor de securitate de îndată ce s-ar publica un astfel de standard pentru INTERNET, chiar şi în forma de RFC. Aceste implementări ar trebui să suporte de asemenea şi alte metode de configurare a asociaţilor de securitate. Fiind date două capete trebuie să existe mai mult de o singură asociaţie de securitate pentru comunicaţia între acestea. Toate aceste implementări trebuie să permită configurarea sistemelor de management al cheilor orientate pe gazdă. Un dispozitiv care criptează sau autentifică pachete IP provenind de la alte sisteme, de exemplu un sistem de criptare dedicat sau un ruter de criptare nu poate, în general să realizeze o distribuire a cheilor orientată pe utilizator pentru traficul generat de către un alt sistem. Astfel de sisteme trebuie să implementeze în plus suport pentru managementul cheilor orientat pe utilizator, pentru traficul generat de pe alte sisteme. Metoda prin care cheile sunt configurate pe un sistem particular este definită prin implementare. Geenerarea unui fişier conţinând identificatori ai asociaţilor de securitate şi parametri de securitate, inclusiv cheile este un exemplu pentru o metodă posibilă pentru distribuirea manuală a cheilor. Un sistem IP trebuie să ia măsuri rezonabile pentru a proteja cheile şi alte informaţii referitoare la asociaţiile de securitate de examinarea neautorizată sau de modificări pentru că toată securitatea este depozitată în chei.
Utilizare
Acest paragraf descrie utilizarea posibilă a mecanismelor de securitate oferite de protocolul IP, în împrejurări diferite şi în aplicaţii diferite din dorinţa de a da celui care implementează şi utilizatorului o idee mai clară despre modul în care aceste mecanisme pot fi folosite pentru a reduce riscurile de securitate.
Utilizarea împreună cu dispozitive de tip firewall
Aceste dispozitive se folosesc tot mai frecvent în INTERNET. Deşi mulţi utilizatori nu apreciază folosirea acestor dispozitive, doearece este restricţionată conectivitatea calculatoarelor din reţea, nu este probabil ca utilizarea lor să înceteze în viitorul apropiat. Ambele mecanisme de securitate IP, amintite mai sus, pot fi folosite pentru a creşte securitatea asigurată de dispozitivele de tip firewall. Asociaţiile dintre dispozitive de tip firewal şi mecanismele de securitate IP de obicei trebuie să fie capabile să identifice antetele şi opţiunile din pachetele de date pentru a determina tipul protocolului de transport folosit (de exemplu UDP sau TCP) precum şi numărul de port al acelui protocol. Dispozitivele de tip firewall pot fi utilizate în asociaţie cu mecanismul de securitate IP bazat pe antetul AH, în funcţie de modul în care sunt cuplate cu asociaţia de securitate potrivită. Un dispozitiv de tip firewall care nu este parte a asociaţiei de securitate considerată nu va fi capabil în mod normal să decripteze un protocol de nivel superior criptat pentru a-l analiza şi a extrage numărul de port necesar pentru efectuarea filtrării pachetelor sau pentru a verifica datele (de exemplu sursa, destinaţia, protocolul de transport, numărul de port) folosite pentru verificarea autenticităţii sau corectitudinii decizilor de control al accesului. Deci autentificarea trebuie realizată nu numai într-o organizaţie sau într-un cartier ci şi pentru legăturile capăt la capăt dintre două calculatoare gazdă, care traversează INTERNET-ul. Utilizarea mecanismului de securitate IP bazat pe antetul AH oferă o mai

134
mare credibilitate că datele folosite pentru decizii de control al accesului sunt autentice. Organizaţii care au două sau mai multe site-uri care sunt interconectate folosind servicii IP
comerciale ar putea dori să folosească un dispozitiv de tip firewall cu criptare selectivă. Dacă câte un dispozitiv de tip firewall este plasat între fiecare dinte site-urile companiei respective şi furnizorul de servicii comerciale IP, atunci sistemul de criptare de tip firewall, creat astfel, ar putea fi privit ca şi un tunel între toate site-urile companiei. Acest sistem ar putea cripta de asemenea traficul dintre companie şi furnizorii săi sau clienţii săi. Traficul cu Centrul de informare al reţelei cu arhivele INTERNET publice sau cu alte organizaţii nu trebuie criptat datorită faptului că nu există un protocol standardizat de management al cheilor sau deoarece renunţarea la criptare este o alegere deliberată pentru a se facilita o mai bună comunicare, sau performanţe îmbunătăţite ale reţelei şi o conectivitate crescută. O astfel de abordare ar putea cu uşurinţă să protejeze traficul sensibil al companiei de atacuri sau de modificări.
Unele organizaţii ( de exemplu cele guvernamentale) ar putea dori să utilizeze un dispozitiv de tip firewall, complet criptat, pentru a oferi o reţea virtuală protejată, bazată pe servicii IP comerciale.
Utilizarea la transmisii multipunct
În ultimii ani transmisile multipunct s-au dezvoltat rapid. Numeroase conferinţe electronice se desfăşoară acum multipunct folsind comunicaţii audio şi video în timp real. Se folosesc aplicaţii de tip teleconferinţă bazate pe protocolul IP multipunct în INTERNET sau în reţele interne private. În alte cazuri se folosesc comunicaţiile bazate pe protocolul IP multipunct pentru a face posibile simulările distribuite sau alte aplicaţii. De aceea este important ca serviciile de securitate IP să funcţioneze şi în cazul comunicaţiilor multipunct.
Indicii parametrilor de securitate, SPI, folosiţi în mecanismele de securitate IP sunt orientaţi spre receptor şi de aceea sunt potriviţi pentru aplicaţii IP la comunicaţii multipunct. Din nefericire majoritatea mecanismelor de management al cheilor în comuncaţii multipunct nu se potrivesc prea bine cu mecanismele de securitate ale protocolului IP. Totuşi există cercetări în acest domeniu. Ca şi un pas intermediar, un grup conectat printr-o comunicaţie multipunct ar putea utiliza repetitiv un protocol de distribuire a cheilor pentru comunicaţii punct la punct pentru a distribui cheia tuturor membrilor grupului sau grupul ar putea folosi distribuirea manuală a cheilor.
Utilizarea pentru protecţia calităţii servicilor
Protecţia calităţii serviciilor este o zonă de interes semnificativ. Cele două mecanisme de securitate IP, prezentate mai sus, au fost concepute pentru a asigura un suport important pentru servicile în timp real ca şi pentru comunicaţiile multipunct. În continuare se descrie o abordare posibilă pentru a furniza o astfel de protecţie. Mecanismul de protecţie IP, bazat pe folosirea antetului AH, trebuie folosit, cu un management al cheilor potrivit, pentru a face posibilă autentificarea pachetelor. Această autentificare are un potenţial important pentru clasificarea pachetelor între rutere. Identificatorul de trafic, Flow Identifier, FI, din cadrul protocolului IPv6, trebuie să acţioneze ca şi un identificator de nivel coborât, Low-Level Identifier, LLID. Folosind împreună acest identificator şi serviciul de securitate IP bazat pe antetul AH, clasificarea pachetelor între rutere devine realizabilă dacă ruterele sunt înzestrate cu cheile potrivite. Din motive de performanţă ruterele autentifică doar tot al N-lea pachet de date (şi nu fiecare pachet de date), dar şi aşa se înregistrează o îmbunătăţire semnificativă pentru starea curentă a INTERNET-ului. Calitatea servicilor poate fi protejată şi dacă se foloseşte FI împreună cu un protocol de rezervare a resurselor, ca de exemplu RSVP. Deci, clasificarea pachetelor autentificate poate fi folosită pentru a ajuta la asigurarea manipulării corecte a fiecărui pachet în interiorul ruterelor.
Utilizarea în reţele compartimentate sau multinivel
O reţea multinivel sigură, multi-level secure network, MLS, este o reţea în care se comunică date la diferite nivele de sensibilitate, (de exemplu neclasificat şi secret). Multe guverne au un interes semnificativ în reţele MLS. Acestea cer folosirea controlul accesului mandatat, Mandatory Access

135
Control, MAC, pe care utilizatorii ordinari sunt incapabili să-l implementeze sau să-l violeze. Mecanismul de securitate IP, bazat pe folosirea antetului AH, poate fi folosit pentru a realiza o
bună autentificare a calculatoarelor gazdă în reţele cu un singur nivel. Acest mecanism de securitate poate fi folosit şi pentru a oferi asigurări puternice atât pentru luarea deciziilor referitoare la controlul accesului mandatat în reţele multinivel cât şi pentru luarea decizilor referitoare la controlul accesului discreţional în toate tipurile de reţele. Dacă se utilizează tabele IP explicite de sensibilitate, ca de exemplu IPSO şi se consideră că nu este necesară confidenţialitatea în mediul operaţional considerat, se utilizează mecanismul de securitate bazat pe antetul AH pentru a realiza autentificarea întregului pachet, inclusiv criptarea nivelului de sensibilitate conţinut în antetul IP şi în datele de utilizator. Aceasta este o îmbunătăţire semnificativă faţă de funcţionarea reţelelor bazată pe varianta IPv4 etichetată unde trebuie să se aibă încredere în etichetă chair dacă aceasta nu este de încredere deoarece nu există posibilitatea criptării sale. Varianta IPv6 foloseşte etichete cu sensibilitate implicită care sunt parte a asociaţiei de securitate dar nu se transmit cu fiecare pachet. Orice etichetă IP cu sensibilitate explicită trebuie autentificată folosind mecanismul de securitate bazat pe antetul AH, sau mecanismul de securitate bazat pe antetul ESP, sau amândouă mecanismele.
Mecanismul de securitate bazat pe antetul ESP poate fi combinat cu politici potrivite de management al cheilor pentru a fi create reţele multinivel sigure. În acest caz fiecare cheie trebuie folosită numai la un singur nivel de sensibilitate şi într-un singur compartiment. De exemplu cheia A trebuie folosită doar pentru pachete sensibile neclasificate, în timp ce cheia B este folosită doar pentru pachete clasificate ca secrete dar neaparţinând nici unui compartiment iar cheia C este folosită doar pentru pachete clasificate drept secrete dar care nu se transmit în exterirorul reţelei. Nivelul de sensibilitate al traficului protejat nu trebuie să domine nivelul de sensibilitate al asociaţiei de securitate folosită pentru acel trafic. Nivelul de sensibilitate al asociaţiei de securitate nu trebuie să domine nivelul de sensibilitate al cheii care aparţine acelei asociaţii de securitate. Nivelul de sensibilitate al cheii trebuie să fie identic cu nivelul de securitate al asociaţiei de securitate. Şi mecanismul de securitate bazat pe antetul de autentificare, AH, poate avea chei diferite din aceleaşi motive, cu alegerea cheii depinzând în parte de nivelul de sensibilitate al pachetului de date. Criptarea este foarte utilă şi de dorit chair atunci când toate calculatoarele gazdă se găsesc într-un mediu protejat. Algoritmul de criptare pentru INTERENT standard ar putea fi folosit, în acord cu un management al cheilor potrivit, pentru a asigura controale de acces direcţional, DAC, împreună fie cu etichete de sensibilitate implicite fie cu etichete de sensibilitate explicite (cum ar fi IPSO, folosite în IPv4). În anumite împrejurări algoritmul de criptare standard pentru INTERNET ar putea fi suficient de puternic pentru a asigura controale de acces mandatat, MAC. Criptarea completă trebuie folosită pentru toate comunicaţiile multinivel între calculatoare sau staţii de lucru care funcţionează compartimentat chiar dacă mediul de transmisiuni respectiv este considerat ca fiind protejat.
Consideraţii de securitate
Întregul document care reprezintă subiectul ultimului paragraf discută o structură de securitate pentru protocolul IP. Nu există o arhitectură generală de securitate pentru INTERNET, dar mecanismele de securitate trebuie concentrate la nivelul IP. Transformările de criptare pentru mecanismul de securitate bazat pe antetul ESP care folosesc un algoritm de schimbare a blocurilor şi produc o integritate puternică sunt vulnerabile la atacuri de tip taie şi lipeşte, cut and paste şi trebuiesc evitate. Dacă mai mulţi utilizatori folosesc o asociaţie de securitate în comun cu o destinaţie, atunci sistemul de recepţie poate autentifica doar faptul că pachetul a fost trimis de unul dintre aceşti utilizatori dar nu poate specifica care dintre aceştia l-a trimis. Similar, dacă receptorul nu verifică că asociaţia de securitate folosită pentru un pachet este valabilă pentru adresa sursă identificată de pachet atunci receptorul nu poate autentifica care dintre adresele sursă identificate de pachet este valabilă. De exemplu, dacă expeditorii A şi B au fiecare o unică asociaţie de securitate împreună cu destinaţia D şi dacă B îşi foloseşte asociaţia sa de securitate validă cu D dar indică, în mod fraudulos, adresa sursă a lui A, atunci D va fi păcălit fiind făcut să creadă că pachetul vine de la A. El poate să nu se lase păcălit doar dacă verifică că adresa de sursă identificată în pachetul de date face parte din asociaţia de securitate care a fost folosită. Utilizatorii trebuie să înţeleagă că indicele de calitate al securităţii oferite de mecanismele bazate pe antetele

136
AH şi ESP depinde de puterea algortmului de criptare implementat, de puterea cheilor folosite de corecta implementare a algoritmilor de criptare, de siguranţa mecanismului de management al cheilor şi de corecta implementare a algoritmului IP precum şi de câteva mecanisme de securitate situate în sistemele participante. Securitatea implementării este în parte în legătură cu securitatea sistemului de operare care implemetează mecanismele de securitate. De exemplu, dacă sistemul de operare nu păstrează cheile de criptare secrete, atunci traficul criptat cu aceste chei nu va fi sigur. Deoarece diferiţi utilizatori ai aceluiaşi sistem pot să nu aibă încredere unul în celălalt, fiecare utilizator sau fiecare sesiune trebuiesc criptate folosind chei separate. Şi asta va tinde să crească volumul de muncă cerut pentru a criptanaliza acel trafic deoarece nu întreg traficul va folosi aceeaşi cheie. Anumite proprietăţi de securitate (de exemplu protecţia împotriva analizei traficului) nu sunt realizate de nici unul dintre mecanismele expuse. O posibilă abordare a protecţiei împotriva analizei traficului este utilizarea corectă a criptării liniei de comunicaţii. Utilizatorii trebuie să considere cu grijă care proprietate de securitate o cer şi să ia măsuri active pentru a se asigura că nevoile lor sunt satisfăcute de aceste măsuri de securitate. Anumite aplicaţii (de exemplu poşta electronică) au nevoie probabil de mecanisme de securitate specifice. Informaţii conexe materialului prezentat pot fi găsite în: RFC 1826, RFC 1827, RFC 1636, RFC 1446, RFC 1704, RFC 1422, RFC 1510, RFC 1828 şi RFC 1829.
6.3.2.2.3. Securitatea protocolului TCP
În 1985, Morris a descris o formă de atac bazată pe ghicirea secvenţei de numere TCP care va fi folosită pentru conexiuni viitoare ale unui anumit calculator gazdă. Atacatorul pune sub urmărire un calculator gazdă în care ţinta sa are încredere, modifică adresa IP a acestui calculator gazdă, când acesta comunică cu ţinta şi se conectează la ţintă pe baza ghicirii următorului număr iniţial de secvenţă care va fi folosit de către protocolul TCP. Pentru a obţine informaţii referitoare la starea numărului iniţial de secvenţă se foloseşte o conectare ordinară la calculatorul ţintă. Soluţia recomandată împotriva unui astfel de atac este autentificarea criptografică a expeditorului. Din păcate această soluţie încă nu se foloseşte. De aceea ar fi necesar pentru multe site-uri să se restrângă folosirea protocoalelor care folosesc autentificarea bazată pe adrese, cum sunt de exemplu rlogin sau rsh. Din nefericire şi utilizarea protocolului TELNET este pereclitată de un astfel de atac. Deci INTERNET-ul nu are un mecanism sigur pentru accesarea unui calculator de la distanţă. În continuare se prezintă documentul RFC 1948, care propune o modificare simplă a protocolului TCP care va bloca majoritatea atacurilor bazate pe ghicirea numărului de secvenţă. Mai precis, astfel de atacuri vor rămâne posibile dacă şi numai dacă atacatorul este capabil să lanseze şi atacuri mai devastatoare.
Detalii ale atacului
Din dorinţa de a înţelege cazul particular al ghicirii numărului de secvenţă, trebuie analizat modul de realizare a unei conexiuni cu ajutorul protocolului TCP. Să presupunem că utilizatorul A doreşte să se conecteze la serverul rsh B. Calculatorul A transmite mesajul următor:
A->B: SYN, ISNa
El transmite un pachet conţinând mulţimea de biţi SYN, synchronize sequence number şi numărul iniţial de secvenţă, ISNa. Calculatorul B răspunde cu: B->A: SYN, ISNb, ACK(ISNa)
Pe lângă trimiterea propriului număr iniţail de secvenţă, el validează numărul iniţial de secvenţă al calculatorului A. Trebuie remarcat că valoarea ISNa trebuie să apară în mesaj. Calculatorul A confirmă cererea de comunicaţie trimiţând mesajul:
A->B: ACK(ISNb)
Numerele iniţiale de secvenţă se construiesc într-o manieră aleatoare. Mai precis, în documentul RFC

137
793 se specifică faptul că numărătorul de 32 de biţi folosit trebuie să fie decrementat cu 1 din patru în patru microsecunde. O altă posibilitate este ca acest numărător să fie incrementat la fiecare secundă cu o anumită constantă şi cu o altă constantă la fiecare nouă conectare. Deci dacă se deschide o comunicaţie cu un anumit calculator se va şti cu mare precizie ce număr de secvenţă va folosi acest calculator la următoarea sa conectare. Pe cunoaştere acestei informaţii se bazează atacul amintit mai sus. Atacatorul X deschide pentru început o conexiune reală cu ţinta sa B, de exemplu cu portul de poştă electronică sau cu TCP echo port. Aşa se obţine ISNb. Apoi atacatorul se substituie calculatorului A şi trimite:
Ax->B: SYN, ISNx
unde "Ax" reprezintă un pachet trimis de către X care se pretinde a fi A.
Calculatorul B îi transmite calculatorului A numărul său de sincronizare SYN, adică:
B->A: SYN, ISNb', ACK(ISNx)
Deşi calculatorul X nu vede niciodată acest mesaj el totuşi poate transmite:
Ax->B: ACK(ISNb')
folosind pentru ISNb' valoarea pe care a ghicit-o. Dacă a ghicit corect serverul rsh al lui B crede că are o conexiune legitimă cu A, când de fapt X este cel care trimite pachetele. X nu poate vedea ieşirea din această sesiune dar el poate executa comenzi la fel ca orice utilizator. Aici apare o dificultate minoră. Dacă A vede mesajele lui B el îşi va da seama că B a validat un mesaj pe care el nu l-a trimis niciodată şi va transmite un pachet RST pentru a întrerupe conexiunea. Există mai multe căi de a preveni asta; cea mai uşoară este aşteptarea ca A să fie deconectat (tot ca urmare a unui atac).
Remediul
Alegerea numerelor iniţiale de secvenţă pentru o conexiune nu este aleatoare. Aceste numere trebuie alese în aşa fel încât să se minimizeze probabilitatea apariţiei unor pachete mai vechi care sunt acceptate de noi activări ale aceleiaşi conexiuni. Unele implementări ale protocolului TCP conţin subprograme speciale care se ocupă cu astfel de reactivări când serverul conexiunii originale este încă în starea TIMEWAIT. În consecinţă simpla generare aleatoare a numărului iniţial de secvenţă nu este o soluţie convenabilă. Dar nu există nici o legătură sintactică sau semnatică între numerele de secvenţă a două conexiuni diferite. Atacurile bazate pe ghicirea numărului iniţial de secvenţă pot fi parate prin alocarea câte unui spaţiu separat de număr de secvenţă fiecărei conexiuni, adică fiecărui quadruplet de forma (gazdă locală, port local, gazdă la distanţă, port la distanţă). În fiecare dintre aceste spaţii numărul iniţial de secvenţă este incrementat. Nu există o relaţie evidentă între numerele din spaţii diferite. Calea evidentă de a face asta este memorarea stărilor conexiunilor deja desfăcute, dead connections, şi cea mai simplă modalitate de a face asta este modificarea diagramei TCP de tranziţie a stărilor astfel încât la ambele capete ale tuturor conexiunilor să se treacă în starea TIMEWAIT. Aceasta este o soluţie care funcţionează dar care este ne-elegantă şi consumă spaţiu de stocare. Întradevăr ar trebui folosit temporizatorul curent de 4 microsecunde, M, şi ar trebui făcută setarea:
ISN = M + F(localhost, localport, remotehost, remoteport).
Este vital ca funcţia F să nu poată fi calculată din exterior, altfel un atacator ar putea ghici un număr de secvenţă, pe baza numărului iniţial de secvenţă folosit pentru o altă conexiune. De aceea se sugerează ca F să fie o funcţie hash, al cărui calcul să se bazeze pe numărul de identificare al conexiunii şi pe anumite date secrete. O bună alegere este funcţia hash de tipul MD5, deoarece programe de implementare a acesteia sunt uşor de găsit. Datele secrete pot fi fie un număr aleator fie o combinaţie dintre unele date secrete specifice calculatorului gazdă şi timpul de boot-are al acestuia. Timpul de

138
boot-are este inclus pentru a asigura că secretul se modifică ocazional. Şi alte date, ca de exemplu adresa IP a calculatorului gazdă sau numele său, pot fi incluse în calculul funcţiei hash, pentru a uşura administrarea, permiţând componentelor unei reţele de staţii de lucru să împartă aceleaşi date secrete şi în acelaşi timp să aibă spaţii diferite pentru numerele de secvenţă. De fapt se recomandă ca să se folosească toate aceste trei tipuri de date: un număr atât de aleator cât poate hard-ul să genereze, o parolă instalată de administratorul de reţea şi adresa IP a calculatorului.
Trebuie remarcat că secretul nu poate fi schimbat cu uşurinţă pe un anumit calculator. O astfel de modificare ar afecta valorile numerelor iniţiale de secvenţă folosite pentru conexiunile reactivate; pentru a asigura securitatea ar trebui fie să se memoreze stările conexiunilor deja desfăcute fie să fie observat un anumit timp de linişte, corespunzător la două segmente cu lungime maximă de "timp de viaţă".
6.3.2.2.3.1. O slăbiciune a protocolului TCP
Cum s-a menţionat deja, atacatorii care ghicesc numărul de secvenţă trebuie, în primul rând, să "păcălească", calculatorul de încredere, notat cu A. Deşi pentru acest scop sunt posibile mai multe strategii, majoritatea atacurilor detectate până în prezent se bazează pe o slăbiciune a protocolului TCP. Când se recepţionează pachetele SYN pentru o anumită conexiune, sistemul receptor crează un nou TCB, transfer control block, în starea SYN-RCVD. Pentru a evita irosirea resurselor majoritatea sistemelor permit un număr limitat de TCB în această stare, pentru o conexiune. Odată ce această limită a fost atinsă, următoarele pachete SYN pentru noile conexiuni sunt neglijate, se presupune că ele vor fi retransmise dacă va fi nevoie. La recepţia unui pachet, primul lucru care trebuie făcut este o căutare a TCB-ului pentru conexiunea respectivă. Dacă nu se găseşte nici unul atunci nucleul TCP caută o "wildcard" TCB folosită de servere pentru a accepta conexiuni de la toţi clienţii. Din nefericire în multe nuclee TCP acest cod este cerut pentru orice pachet recepţionat, nu numai pentru pachetele SYN iniţiale. Dacă coada SYN-RCVD este plină la sosirea "wildcard" TCB, orice nou pachet care specifică doar gazda şi numărul de port va fi neglijat, chair dacă nu este vorba despre un pachet SYN. De aceea pentru a păcăli un calculator gazdă, atacatorul trimite câteva zeci de pachete SYN portului rlogin de la diferite numere de port ale unor calculatoare inexistente. În acest fel se umple coada SYNRCVD. Astfel atacul împotriva calculatorului ţintă pare a veni de la portul rlogin al calulatorului considerat de încredere. Răspunsurile din partea ţintei, conţinând secvenţele SYN+ACK, vor fi percepute ca aparţinând unei cozi pline şi vor fi neglijate.
Această comportare poate fi evitată dacă codul cozii pline este verificat pentru bitul ACK, care nu poate fi pus pe 1 în mod legal pentru cereri de deschidere. Dacă se constată că acest bit este pe 1 atunci trebuie să se răspundă cu RST.
Consideraţii de securitate
Alegerea unor numere de secvenţă potrivite nu reprezintă o înlocuire a autentificării bazate pe criptografie. Este în cel mai bun caz o măsură paleativă. Un atacator care poate observa mesajele iniţiale pentru o anumită conexiune, poate determina starea numerelor de secvenţă ale acesteia şi poate fi capabil să lanseze atacuri bazate pe ghicirea numerelor de secvenţă, "păcălind" această conexiune.
Conectarea unui calculator la INTERNET presupune folosirea sistemului de operare UNIX şi a suitei de protocoale TCP/IP. Pentru ca un utilizator să poată lua măsurile de securitate adecvate, la coneectarea în reţea, el trebuie să înţeleagă modul în care sistemul de operare UNIX lucrează cu INTERNET-ul.
6.3.3. Funcţionarea servicilor INTERNET
Cele mai multe servicii sunt furnizate de programe numite server-e. Pentru ca un astfel de program să funcţioneze, el trebuie să folosească un protocol (TCP sau UDP), să aibă alocat un port şi să fie lansat în execuţie - de obicei, la încărcarea sistemului de operare. În UNIX există un fişier cu rol esenţial în execuţia servicilor: /etc/services. El conţine, în fiecare linie, numele unui serviciu, numărul portului, numele protocolului şi o listă de alias-uri. Acest fişier, a cărui securitate este foarte

139
importantă, este folosit atât de server-e cât şi de clienţi. Iată un exemplu de conţinut parţial pentru un astfel de fişier:
#/etc/services # telnet 23 /tcp smtp 25 /tcp mail …
Server-ele determină din acest fişier numărul propriu de port cu care lucrează, folosind un apel sistem special: getservicebyname().
Porturile au alocate numere; cele cuprinse în domeniul 0-1023 se consideră porturi sigure. Ele sunt restricţionate la folosire, fiind accesibile doar superuser-ului. Ca urmare, programele care folosesc aceste porturi trebuie executate ca root. Acest lucru împiedică programele obişnuite să obţină informaţii sensibile de la aceste porturi. Astfel, ar fi posibil pentru un utilizator să creeze, de exemplu, un program care să se prezinte drept telnet, să asculte portul 23 şi să intercepteze parolele altor utilizatori. Există două tipuri distincte de server-e:
-Cele care se execută continuu. Ele sunt pornite automat la lansarea sistemului de operare, pe baza infrmaţilor din /etc/rc
*
. Aceste server-e trebuie să răspundă rapid la cererile care sosesc din reţea, cum ar fi nfsd (Network Filesystem Daemon ) şi sendmail;
-Cele care sunt lansate doar atunci când este nevoie de ele. Ele sunt de obicei pornite de daemon-ul inetd, care poate asculta zeci de porturi şi care lansează în execuţie daemon-ul necesar. În această categorie intră servicii ca fingerd (Finger Daemon) şi popper (Post Office Protocol Daemon).
De exemplu lansarea în execuţie a serviciului SMTP-sendmail se face, în /etc/rc, prin următoarea secvenţă:
if [-f /usr/lib/sendmail -a -f /etc/sendmail/sendmail.cf ]; then /usr/lib/sendmail -bd -qlh && (echo /n 'sendmail') >/dev/console fi
Ea face verificarea existenţei programului sendmail şi a fişierului său de configurare, sendmail.cf, lansează în execuţie programul şi afişează la consolă mesajul "sendmail". După lansare, sendmail se va conecta la port-ul 25 şi va rămâne în ascultarea unor cereri. O dată sosită o astfel de cerere, programul va folosi apelul sistem fork() pentru a se crea un nou proces care va gestiona conexiunea. Programul sendmail original va rămâne în aşteptare pentru alte eventuale cereri de conexiune.
Lansarea în execuţie a server-elor care nu sunt permanent rezidente se face cu ajutorul unui program daemon numit inetd. Cu ajutorul fişierului /etc/inetd.conf , acesta determină servicile reţea care le gestionează. Apoi foloseşte apelurile sistem bind(), pentru a se conecta la mai multe porturi şi select(), pentru a obţine controlul atunci când se face o cerere de conectare la un anumit port. Iată spre exemplificare, câteva linii din fişierul /etc/inetd.conf:
# /etc/inetd.conf # ftp stream tcp nowait root /usr/etc/ftpd ftpd telnet stream tcp nowait root /usr/etc/telnetd telnetd finger stream tcp nowait nobody /usr/etc/fingerd fingerd …
Fiecare linie conţine numele serviciului, tipul soket-ului, tipul protocolului, dacă se aşteaptă sau nu cereri în continuare, după servirea celei care a activat server-ul, numele utilizatorului proprietar al server-ului şi numele comenzii executate la activarea serviciului.
O problemă deosebit de importantă din punctul de vedere al securităţii este aceea a controlului la server-e. Doar o mică parte din programele server au incorporate facilităţi de limitare a accesului, bazate pe controlul corelaţiei dintre adresele IP şi numele de calculator gazdă al celui care face cererea. De exemplu, NFS, permite specificarea calculatoarelor gazdă care au dreptul de a monta anumite sisteme de fişiere, de asemenea, nntp permite precizarea calculatoarelor gazdă care pot citi fişiere. Există însăşi alte modalităţi, exterioare programelor, prin care se poate controla accesul la server-e:
-Programul tcpwrapper, este un utilitar care poate îmbrăca un server INTERNET. El permite restricţionarea accesului unor calculatoare gazdă la server-e;
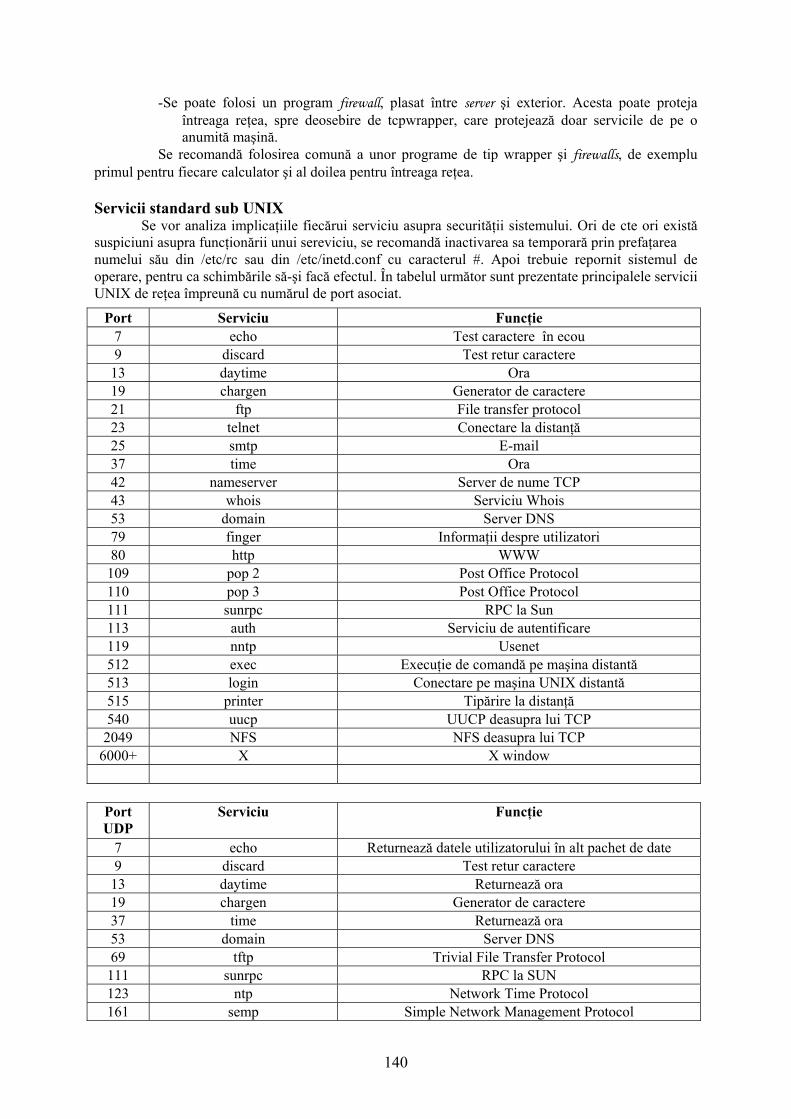
140
-Se poate folosi un program firewall, plasat între server şi exterior. Acesta poate proteja întreaga reţea, spre deosebire de tcpwrapper, care protejează doar servicile de pe o anumită maşină.
Se recomandă folosirea comună a unor programe de tip wrapper şi firewalls, de exemplu primul pentru fiecare calculator şi al doilea pentru întreaga reţea. Servicii standard sub UNIX
Se vor analiza implicaţiile fiecărui serviciu asupra securităţii sistemului. Ori de cte ori există suspiciuni asupra funcţionării unui sereviciu, se recomandă inactivarea sa temporară prin prefaţarea numelui său din /etc/rc sau din /etc/inetd.conf cu caracterul #. Apoi trebuie repornit sistemul de operare, pentru ca schimbările să-şi facă efectul. În tabelul următor sunt prezentate principalele servicii UNIX de reţea împreună cu numărul de port asociat.
Port Serviciu Funcţie 7 echo Test caractere în ecou 9 discard Test retur caractere
13 daytime Ora 19 chargen Generator de caractere 21 ftp File transfer protocol 23 telnet Conectare la distanţă 25 smtp E-mail 37 time Ora 42 nameserver Server de nume TCP 43 whois Serviciu Whois 53 domain Server DNS 79 finger Informaţii despre utilizatori 80 http WWW
109 pop 2 Post Office Protocol 110 pop 3 Post Office Protocol 111 sunrpc RPC la Sun 113 auth Serviciu de autentificare 119 nntp Usenet 512 exec Execuţie de comandă pe maşina distantă 513 login Conectare pe maşina UNIX distantă 515 printer Tipărire la distanţă 540 uucp UUCP deasupra lui TCP
2049 NFS NFS deasupra lui TCP 6000+ X X window
Port UDP
Serviciu Funcţie
7 echo Returnează datele utilizatorului în alt pachet de date 9 discard Test retur caractere
13 daytime Returnează ora 19 chargen Generator de caractere 37 time Returnează ora 53 domain Server DNS 69 tftp Trivial File Transfer Protocol
111 sunrpc RPC la SUN 123 ntp Network Time Protocol 161 semp Simple Network Management Protocol

141
512 biff Alertă de e-mail sosit 513 who Returnează cine este conectat în sistem 517 talk Cerere de discuţie 520 route Routing Information Protocol 533 netwall Scriere pe terminal utilizator
2049 NFS Sistem de fişiere NFS Serviciul FTP
Este implementat în UNIX prin programele client ftp şi prin server-ul /etc/ftpd şi permite utilizatorilor să se conecteze la distanţă şi să facă transfer de fişiere. Porturile folosite sunt 21, pentru trimiterea de comenzi şi 20 sau unul peste 1024, negociat de client şi server, pentru transferuri de date. Versiunile mai vechi ale acestui serviciu (de dinainte de 1988) nu au un grad de securitate prea ridicat.
Fie că este vorba despre un transfer de date sau de listarea conţinutului unui director, transmisia se face pe un canal de date. Cele mai obişnuite implementări crează o nouă legătură pentru fiecare fişier. Clientul ascultă un număr de port aleator şi informează server-ul sistem despre acesta, prin comanda PORT. La înapoiere, server-ul face un apel la portul dat.
Fişerele sunt transferate în mod ASCII. La apelul serviciului ftp, utilizatorul trebuie să furnizeze numele şi parola. Acestea sunt
memorate la maşina server în fişierul /usr/adm/wmtp. Transmiterea în clar a acestor informaţii între calculatoare reprezintă un element de mare vulnerabilitate, fiind cunoscute numeroase cazuri de interceptare. De aceea pe calculatoarele importante acest serviciu trebuie dezactivat sau înlocuit cu variante care implementează protocoale criptografice de autentificare.
Există trei variante de server-e ftp: - ftpd standard; - wuftpd; - aftp.
Toate aceste server-e sunt pornite de către daemon-ul inetd, pe baza intrărilor în fişierul /etc/inetd.conf. Se pot lua unele măsuri de restricţionare a accesului la serviciul ftp standard. Fişierul
/etc/ftpusers conţine o listă a tuturor conturilor care nu pot folosi acest serviciu. Dacă, de exemplu, se blochează prin acest fişier conturi ca root, uucp, news, bin, se previne, pe de o parte, posibilitatea ca, odată sparte aceste conturi, să se facă transferuri de fişiere importante, iar pe de altă parte se împiedică folosirea serviciului ftp de către conturile privilegiate, ceea ce ar face ca să se transfere prin reţea conturile acestora.
Una dintre cele mai utilizate modalităţi de conectare ftp este "anonymous". Aceasta permite unui utilizator, care nu are cont pe o anumită maşină, un acces restrâns, pentru a transfera fişiere dintr-un director specificat. De obicei la un apel de ftp anonim se cere furnizarea numelui solicitatorului iar la parolă, adresa e-mail a acestuia.
Serviciul de ftp anonim a devenit un adevărat standard în INTERNET pentru difuzare de software, documente, imagini. Trebuie însă acordată toată atenţia administrării lui. Prima şi cea mai importantă regulă este ca nici un fişier sau director din aria lui ftp anonim să nu fie cu acces la scriere şi să nu fie controlat de ftp; deoarece ftp anonim se execută cu acest nume. Dacă directorul ftp nu permite acces la scriere, dar este controlat de ftp, pot exista încă modalităţi de atac periculoase: anumite server-e permit utilizatorului de la distanţă să schimbe permisiunile fişierului. Existenţa comenzilor de schimbare a drepturilor de acces (permisiunilor) în server-ul anonymous este un mare neajuns. Se recomandă eliminarea acestor posibilităţi.
Următoarea regulă este de a se evita existenţa unui fişier /etc/passwd real în aria lui ftp anonim.
Există controverse privind crearea unui director cu acces public la scriere, pentru fişierele sosite. Maşina care a creat această facilitate ar putea deveni o gazdă permanentă sau temporară a unui software pirat. Pentru a nu se întâmpla aşa ceva trebuie respectate următoarele reguli:
- Se crează directorul cu acces la scriere dar nu şi la citire. Cel mai simplu mijloc este să se pună directorul în proprietatea lui root şi să se primească modul 1733. Astfel fişierele pot fi

142
depozitate aici de utilizatori anonimi dar nu pot fi listate de alţi utilizatori anonimi; - Se limitează numărul de octeţi ce se admit a fi transferaţi de către utilizatorul ftp; - Se crează un script care să mute automat fiecare fişier depozitat în aceste directoare, la
anumite intervale de timp. Se plasează acest scipt în fişierul /usr/lib/crontab, pentru a fi lansat periodic.
Serviciul TFTP
Se utilizează de obicei pentru a permite calculatoarelor gazdă, fără disc, să boot-eze prin reţea. TFTP este o variantă mai veche de FTP şi nu are mecanisme de autentificare. Conexiunea foloseşte portul 69 şi protocolul UDP.
Serviciul telnet
Asigură accesul de la distanţă la un calculator. Versiunea pentru client se numeşte telnet iar cea pentru server telnetd. Server-ul foloseşte port-ul TCP 23. Daemon-ii telnet apelează serviciul login pentru autentificarea şi iniţializarea sesiunii. Apelantul furnizează un număr de cont şi, de obicei, o parolă de conectare. O sesiune telnet poate avea loc şi între două calculatoare de încredere. În acest caz poate fi utilizat un telnet sigur, care face criptarea întregii sesiuni, protejând conţinutul parolei şi al sesiunii.
Cele mai multe sesiuni telnet sunt însă declanşate de calculatoare situate la distanţă, în care nu se poate avea încredere.
Parolele tradiţionale nu sunt sigure, deoarece orice porţiune a legăturii poate fi ascultată. De aceea se recomandă utilizarea parolelor de unică folosinţă. Se recomandă ca serviciul telnet să nu apeleze serviciul log-in pentru a valida sesiunea. O soluţie recomandată este folosirea server-elor de autentificare. În acest mod poate fi asigurată conectarea sigură, dar nu poate fi protejat restul sesiunii. De exemplu o a treia parte a comunicării (neautorizată), care ascultă conexiunea, poate să o reţină după ce unul dintre actorii autorizaţi ai acelei conexiuni crede că s-a deconectat. Acest tip de atac se numeşte session hijacking. Împotriva unor atacuri de acest tip se poate lupta prin criptarea întregii sesiuni telnet. Este capital ca să se poată avea încredere în calculatoarele de la capetele conexiunii.
Servicile rlogin şi rsh
Aceste programe permit un acces de la distanţă asemănător cu accesul permis de serviciul telnet. Ele folosesc porturile TCP 513 şi 514. Există două deosebiri importante faţă de telnet:
- Utilizatorul lui rlogin nu trebuie să furnizeze numele, acesta fiind transmis automat la iniţierea conexiunii;
- Dacă conexiunea se face de la o maşină de încredere, utilizatorul nu mai trebuie să tasteze parola. Programele rsh şi rshd sunt similare, cu deosebirea că ele dau acces doar de la maşini sau utilizatori de încredere şi permit execuţia doar unei singure comenzi la distanţă.
Numite generic şi comenzi r ele se flosesc pe baza mecanismului de autentificare BSD. Cineva poate da comanda rlogin fără a specifica parola doar dacă sunt folosite următoarele criterii de autentificare:
- Apelul trebuie să provină de la un port privilegiat tcp; - Utilizatorii şi maşinile care apelează trebuie să se găsească la maşina destinaţie într-o listă a partenerilor de încredere (tipic în /etc/hosts.equiv) sau în fişierul HOME/.rhosts al utilizatorului; - Numele celui care a făcut apelul trebuie să corespundă adresei sale IP (implementările
recente verifică această corespondenţă). Din punct de vedere al utilizatorului această schemă lucrează corect. Un utilizator poate accesa maşinile pe care vrea să lucreze, fără a i se cere parola.

143
Serviciul SMPT
Serviciul Simple Mail Transfer Protocol, SMTP, este un standard INTERNET pentru transferul de poştă electronică. El foloseşte port-ul TCP 25. Programul /usr/lib/sendmail implementează atât clientul cât şi server-ul. Alte variante ale acestui program sunt: smail, MMDF sau PMDF.
Programul sendmail permite poştei electronice să fie: - livrată utilizatorilor individuali; - distribuită unor liste de utilizatori, - retransmisă unor alte maşini, - adăugată la un fişier.
O adresă legitimă de e-mail poate fi un nume de utilizator sau un alias. Acestea din urmă sunt prezente într-un fişier aliases, în directoarele /usr/lib,/etc, /etc/mail sau /etc/sendmail. Programul sendmail permite utilizatorilor individuali să seteze un alias pentru contul lor, prin plasarea în directorul home a unui fişier cu numele .forward. Un alt fişier, sendmail.cf , controlează configurarea lui sendmail.
Programul sendmail este foarte complex. El are numeroase probleme de securitate: - acceptă o parolă specială (wizard's password), situată în fişierul de configurare care poate
fi obţinută pentru obţinerea unui saţiu pe maşina distantă pe care să se ruleze un anumit program, de exemplu Shell, fără conectare la aceasta;
- se pot declara utilizatori de încredere, care pot falsifica poşta sosită pe maşina locală; - programul poate fi compilat cu opţiunea debug, lucru care a permis acces nelimitat din partea unor utilizatori externi la maşina pe care se execută sendmail; - poate impune ca recepţia poştei electronice să se facă cu un anumit program, ceea ce permite lansarea la destinaţie a unui anumit program, de exemplu Shell.
Pentru a afla versiunea de sendmail cu care este echipat calculatorul dumneavoastră, conectaţi-vă cu telnet la port-ul 25, lucru care va antrena afişarea versiunii programului. Pentru a obţine cea mai nouă variantă de sendmail, puteţi apela prin ftp următoarea adresă: ftp.cs.berkely.edu/ucb/sendmail info.cert.org/tools/sendmail/
Protocolul SMTP ar putea fi ţinta unor atacuri de refuzare a servicilor. Pentru asigurarea securităţii poştei electronice a fost conceput standardul PEM, Privacy Enhanced Mail.
Serviciul POP
Post Office Protocol, POP, reprezintă un protocol care, folosind porturile 109 şi 110, permite unor utilizatori de maşini client să obţină propria poştă electronică, fără să fie nevoiţi să folosească NFS pentru accesul la un director special de poştă. Există o variantă mai sigură de POP, numită POP3. În general se cere o autentificare prealabilă a utilizatorilor, înainte ca aceştia să acceseze poşta. Acest lucru se realizează în mai multe feluri:
- Se pot folosi parole, prin care clienţii POP se autentifică la server-ele POP. Din păcate însă mai mulţi clienţi folosesc aceeaşi parolă, ceea ce sporeşte vulnerabilitatea acestei metode. Fiind transmise frecvent şi spre acelaşi port, parolele pot face obiectul unor interceptări prin ascultarea pachetelor corespunzătoare. De exemplu atunci când un client se conectează la un server POP3, server-ul trimite un şir care conţine o marcă de timp, iar programul client îşi trimite numele şi parola; - Se poate folosi opţiunea APOP care realizează o autentificare de tipul întrebare/răspuns. Este cazul protocolului POP3. Programul client nu mai trimite comenzile user şi pass. În schimb se trimite comanda APOP care conţine un şir hexa de 128 de biţi, care reprezintă prelucrarea cu funcţia MD5 a adresei şi a unei fraze cunoscute atât de clientul autentic cât şi de server; - Se poate folosi o versiune POP modificată, capabilă să lucreze cu sistemul complex de autentificare Kerberos. Este de exemplu cazul programului de poştă electronică EUDORA.

144
Serviciul DNS
Domain Name Server, DNS, este un serviciu format dintr-o bază de date distribuită, cu ajutorul căreia se determină relaţia existentă între adresa IP şi numele de gazdă precum şi locul în care trebuie livrată poşta electronică în interiorul organizaţiilor. Acest serviciu utilizează portul TCP şi UDP 53. Procesul folosit pentru rezolvarea acestor probleme se numeşte resolver. Atunci când DNS încearcă să localizeze un nume de gazdă, calculatorul apelează mai multe server-e de nume. Unul sau mai multe dintre acestea vor răspunde dacă vor găsi corespondenţa nume-adresă IP.
În DNS se transmit mai multe tipuri de înregistrări care desemnează: - adrese IP sau numele canonic pentru un alias, de pe un calculator gazdă, - diferite calculatoare care pot primi poşta pentru un anumit calculator gazdă; - fac legătura inversă, de la adresa IP la nume;
În afara rezolvării cererilor prezentate anterior, DNS mai furnizează posibilitatea transmiterii unor copii întregi ale bazelor de date ale server-elor de nume. Este vorba despre aşa numitul transfer de zonă, care se utilizează pentru ca server-ele secundare să obţină copii ale bazelor de date localizate pe server-ele principale. DNS foloseşte protocolul UDP pentru rezolvarea unor cereri individuale şi protocolul TCP pentru transferurile de zone.
În ceea ce priveşte securitatea, serviciul DNS are 2 probleme mari: - Riscurile pe care le implică transferurile de zone. Acestea indică modul în care este
structurată o anumită reţea. Transferul ilegal de zone poate fi blocat prin folosirea unui ruter care să interzică accesul la port-ul 53.
- Atacurile la server-ele de nume, prin care se obţine fie controlul asupra acestora fie modificarea conţinutului bazei de date. Există două căi prin care un server de nume să fie făcut să furnizeze informaţii incorecte:
a) informaţia greşită poate fi încărcată în memoria cache a acestuia, de la distanţă, prin răspunsuri false la întrebări privind adresele; b) prin schimbarea fişierelor de configurare a server-ului, pe calculatorul unde se execută acesta.
Se impune respectarea următoarelor recomandări privind server-ele de nume: - să se instaleze server-ul de nume pe un calculator separat, care să nu aibă declarate conturi; - dacă este necesară executarea server-ului de nume pe un calculator folosit şi de alţi utilizatori, atunci este necesar ca toate fişierele şi directoarele server-ului să fie în posesia lui root şi au setate drepturile de acces la 444 sau 400, pentru fişiere şi 755 sau 700 pentru directoare. Serviciul finger
Este conectat la portul TCP 79 şi este folosit în două scopuri: - Dacă este apelat fără argumente el afişează toţi utilizatorii conectaţi în acel moment la
calculator: numele, ora de conectare, numărul de telefon, etc; - Dacă este apelat cu un nume drept argument, programul caută în fişierul /etc/passwd şi
afişează toate informaţiile legate de acel utilizator. În mod normal programul rulează pe calculatorul local. El poate fi lansat şi pe o maşină distantă. Acest program reprezintă o cale foarte simplă de a face publice anumite date personale sau date de interes pentru alte persoane. În acest scop se folosesc două fişiere al căror conţinut, dacă există, este afişat de finger; acestea sunt .plan şi .project. Existenţa acestor fişiere în directorul home al utilizatorului vizat prin finger, va antrena afişarea conţinutului lor.
Dată fiind lipsa de securitate a programului finger, anumite date referitoare la utilizatori pot fi deconspirate prin utilizarea acestui program. De aceea unii administratori de reţea preferă să dezactiveze acest serviciu.
Serviciul HTTP
Programul HyperText Transfer Protocol, HTTP, este folosit pentru cererea şi recepţionarea

145
unor documente de la server-ele WWW. El foloseşte port-ul TCP 80. Clientul contactează un server WWW şi apoi cere un fişier. Server-ul răspunde cu un document multimedia, MIME, în format ASCII sau HTML, HyperText Markup Language. Apoi documentul este afişat. Documentele HTML au trimiteri către imagini şi pot face legături de tip hipertext la alte documente.
Serviciul portmapper
Protocoalele RPC, Remote Procedure Call, de la SUN stau la baza multora din noile servicii. Ele folosesc portul 111, cu protocol TCP sau UDP.
Persoana care crează un serviciu de reţea utilizează un limbaj special pentru specificarea punctelor de intrare şi a parametrilor lor. Un precompilator converteşte aceste specificaţii în ceea ce se cheamă "cioturi", stub, de fapt nişte rutine pentru modulele server şi client. Cu ajutorul acestor rutine, clientul poate face apeluri de subrutine ale unui server aflat la distanţă. Portmapper-ul este programul care implementează aceste RPC-uri. El este oarecum similar daemon-ului inetd, în sensul că mediază comunicaţii între clienţi şi server-e. RPC poate face autentificare criptografică utilizând DES. Acesta este numit Secure RPC. Toate apelurile sunt autentificate utilizând o cheie de sesiune. Aceste chei sunt distribuite folosind metoda Diffie-Hellman. Din păcate RPC-ul autentificat cu DES nu este bine integrat în multe sisteme. Protocolul standard care îl utlizează este NFS.
Serviciul NNTP
Ştirile prin INTERNET sunt cel mai adesea transferate cu NNTP-Network News Transfer Protocol. El foloseşte portul TCP 119. Dialogul este similar celui utilizat pentru SMPT. NNTP poate fi configurrat cu o listă de control al accesului, ACL, care determină ce calculatoare pot folosi acest serviciu. ACL este bazată pe nume de gazde; ca urmare aceste liste pot fi ocolite prin asculatarea pachetelor IP sau prin atacuri la DNS.
Serviciul NTP
Programul Network Time Protocol, NTP, este un ajutor important al maşinilor conectate la INTERNET. Este utilizat pentru sincronizarea ceasurilor maşinilor cu lumea de afară. Este un protocol sofisticat care foloseşte portul UDP 123. Fiecare maşină discută cu unul sau mai mulţi vecini şi maşinile se organizează într-un graf, funcţie de distanţa lor până la o sursă autorizată de timp. Comparaţiile între multiplele surse de informaţie de timp permit server-elor NTP să desopere intrările eronate.
Serviciul X-Window
Este un sistem de ferestre care utilizează reţeaua pentru comunicaţii între aplicaţii şi dispozitive I/O (ecran, mouse), ceea ce permite aplicaţiilor să lucreze pe diferite maşini. Acest serviciu permite folosirea în comun, de către mai multe programe a aceluiaşi display.
Acest serviciu este foarte vulnerabil.
Serviciul systat
Acest program, conectat la port-ul TCP 11, furnizează informaţii despre calculatorul gazdă. De obicei se configurează /etc/inetd.conf astfel încât conectarea la acest port să fie urmată de execuţia comenzilor who sau w. Deoarece acest serviciu poate da informaţii utile atacatorilor despre utilizatorii autorizaţi, este recomandabil ca el să fie invalidat pe calculatoarele importante.

146
6.4. Servicii de autentificare
1. Server-e de autentificare Kerberos
Cel mai puternic şi mai folosit serviciu de autentificare din lume este Kerberos Authentication Server. El a fost creat la MIT. Kerberos oferă un mijloc de verificare a identităţii principalelor calculatoare (de exemplu staţie de lucru sau server de reţea) dintr-o reţea. Autentificarea se face cu ajutorul unei autorităţi de încredere numită terţ de încredere (trusted third-party). Această sarcină (autentificarea) este îndeplinită fără a face apel la autentificarea asigurată de către sistemul de operare al calculatorului gazdă, fără a avea încredere în adresa sa, fără a fi necesară prezenţa unor dispozitive suplimentare de securitate şi pe baza ipotezei că pachetele care traversează reţeaua pot fi citite sau modificate. Totuşi numeroase funcţii ale sistemului Kerberos sunt folosite doar pentru iniţierea unei conexiuni şi presupun absenţa oricărui atac de tipul hijacke. O astfel de utilizare are implicit încredere în adresele calculatoarelor gazdă implicate. În aceste condiţii Kerberos realizează o autentificare de tipul celei oferite de o a treia parte, de încredere. Se folosesc în acest scop metode convenţionale de criptare, cum ar fi algoritmii simetrici. În schema de autentificare a protocolului Kerberos sunt implicate următoarele entităţi:
- Serverul de autentificare Kerberos, AS, - Serverul de acordare a tichetului, TGS, - Clientul C, care tebuie autentificat, pentru a i se acorda acces la un seviciu furnizat de serverul S, - Serverul S, la care se cere acces din partea clientului C.
Procesul de autentificare se desfăşoară după cum urmează: Un client, C, transmite o cerere server-ului de autentificare, AS, cerând acreditări pentru un anumit server, S. AS răspunde cu aceste acreditări, criptate, în cheia clientului C. Aceste acreditări constau în: 1) un "tichet" pentru server; 2) o cheie de criptare temporară (de obicei numită cheie de sesiune).
Clientul transmite "tichetul" (care conţine identitatea clientului şi o copie a cheii sesiunii, ambele criptate în cheia serverului) serverului. Cheia sesiunii (acum împărţită de client şi de server) este folosită pentru autentificarea clientului şi poate fi opţional utilizată pentru autentificarea serverului. Ea poate fi folosită şi pentru a cripta în continuare comunicaţia între cele două părţi sau pentru a permite schimbul unei chei separate de sub-sesiune care să fie folosită pentru criptarea comunicaţiei ulterioare.
Implementarea Kerberos-ului constă din unul sau mai multe servere de autentificare care rulează pe calculatoare gazdă sigure. Serverele de autentificare întreţin o bază de date de utilizatori principali (utilizatori sau servere) şi cheile lor secrete. Există biblioteci de programe pentru realizarea criptării şi implementarea protocolului Kerberos. Din dorinţa de a adăuga posibilitatea autentificării unor tranzacţii, o aplicaţie de reţea tipică adaugă una sau două apeluri la biblioteca Kerberos, pentru a se transmite mesajele necesare pentru realizarea autentificării.
Protocolul Kerberos constă din câteva sub-protocoale (sau schimburi). Exită două metode prin care un client poate cere acreditări unui server Kerberos.
În cazul primeia, clientul trimite la AS un text în clar, cerut pentru generarea unui "tichet" pentru serverul dorit. Răspunsul este trimis criptat în cheia secretă a clientului. De obicei se cere un ticket-granting ticket, (TGT), care poate fi folosit mai târziu împreună cu the ticket-granting server (TGS).
În cea de a doua metodă, clientul trimite o cerere la TGS. Clientul trimite TGT la TGS în acelaşi fel în care el ar fi contactat orice alt server de aplicaţie care necesită solicitarea de acreditări Kerberos. Răspunsul este criptat în cheia sesiunii.
Odată obţinute, acreditările trebuie folosite pentru verificarea identităţii utilizatorilor principali care intervin într-o anumită tranzacţie, pentru a se asigura integritatea mesajelor schimbate între ei, sau pentru a asigura securitatea mesajelor. În aplicaţia curentă poate fi ales nivelul de protecţie necesar.
Pentru a se verifica identităţile utilizatorilor principali dintr-o tranzacţie, clientul trimite "tichetul" serverului. Deoarece "tichetul" poate fi interceptat şi modificat de către un atacator, se transmite informaţie adiţională pentru a se demonstra că mesajul a fost transmis de către utilizatorul principal căruia i-a fost atribuit "tichetul". Această informaţie (numită autentificare) este criptată în cheia sesiunii şi include o ştampilă temporală. Aceasta dovedeşte că mesajul a fost generat recent şi că nu

147
este un răspuns. Criptarea autentificatorului în cheia sesiunii demostrează că aceasta a fost generată de către cineva care posedă această cheie. Deoarece nimeni în afară de utilizatorul principal, care face solicitarea şi server nu cunoaşte cheia sesiunii (aceasta nu este nici odată transmisă în clar în reţea) se obţine garanţia identităţii clientului.
Integritatea mesajelor schimbate între utilizatorii principali mai poate fi garantată şi folosind cheia sesiunii (trecută în "tichet" şi conţinută în acreditări). Această abordare asigură atât detectarea atacurilor de tip răspuns cât şi a atacurilor bazate pe modificarea şirului de date al mesajului. Ea se bazează pe generarea şi transmiterea valorii unei funcţii hash de mesajul clientului, criptată cu cheia sesiunii. Confidenţialitatea şi integritatea mesajelor schimbate între principalii utilizatori pot fi realizate prin criptarea datelor de transmis folosind cheia sesiunii trecută în "tichet" şi conţinută în acreditări.
Schimburile de autentificare, menţionate mai sus, solicită doar accesul la citire în baza de date Kerberos. Uneori, totuşi, intrările în baza de date trebuie modificate, ca de exemplu atunci când se adaugă noi utilizatori principali sau când se schimbă cheia unuia dintre utilizatorii principali. Asta se poate face cu ajutorul unui protocol între un anumit client şi un al treilea server Kerberos, serverul de administrare Kerberos, the Kerberos Administration Server (KADM).
Serviciul de autentificare Kerberos este descris în RFC 1510.
2. Formatul "tichetelor"
Fiecare "tichet" Kerberos conţine mai multe câmpuri care sunt folosite pentru a indica diferite atribute ale acestuia. La obţinerea "tichetului" clientul este interesat de semnificaţia majorităţii acestor câmpuri, câteva dintre ele sunt fixate în mod automat de către serverul care furnizează "tichetul". În continuare se prezintă semnificaţia acestor câmpuri.
2.1 Câmpul iniţial
Indică faptul că acel "tichet" a fost generat folosind protocolul serverului AS şi nu pe baza unui ticket-granting ticket.
2.2. Câmpurile PRE-AUTHENT şi HW-AUTHENT
Oferă informaţie adiţională despre autentificarea iniţială, referitoare la sursa care a emis tichetul. Dacă este vorba despre serverul AS atunci atât aceste câmpuri cât şi câmpul iniţial vor fi setate. Dacă tichetul a fost generat pe baza unei proceduri ticket-granting ticket, câmpul iniţial va conţine valoarea 0, dar câmpurile PRE-AUTHENT şi HW-AUTHENT vor avea valori generate de procedura ticket-granting ticket.
2.3 Câmpul INVALID
Indică dacă un "tichet" este valid sau nu. Serverele de aplicaţii trebuie să invalideze "tichetele" care au acest câmp setat. Este de exemplu cazul unui "tichet" postdatat. "Tichetele" invalidate trebuie revalidate de către serverul Kerberos înainte de folosire. În acest scop ele trebuiesc trimise la acest server într-o cerere TGS cu opţiunea de validare specificată. Acest server va valida astfel de tichete doar după ce a trecut momentul lor de pornire. Validarea este cerută pentru ca postdatarea "tichetelelor" care au fost furate înaintea momentului lor de pornire să poată fi declarate permanent invalide (printr-un mecanism bazat pe o listă). 2.4 Câmpul de reînoire a "tichetului"
Aplicaţiile pot dori să păstreze "tichetele" care pot fi valabile perioade lungi de timp. Totuşi, asta poate expune acreditările lor la posibilitatea de a fi furate pe perioade de timp la fel de lungi. Aceste acreditări furate vor părea valabile până la data expirării "tichetelor" corespunzătoare. Utilizarea simplă a "tichetelor" cu viaţă scurtă şi obţinerea frecventă a unor noi "tichete" va obliga

148
clientul să dea un timp lung de acces la cheia sa secretă şi conduce la riscuri şi mai mari. "Tichetele" care pot fi reînoite au două termene de expirare, primul este unul local, când expiră "tichetul" de această dată iar cel de al doilea este unul global reprezentînd ultima valoare individuală de timp permisă pentru un termen de expirare. Clientul unei aplicaţii trebuie să prezinte periodic (înainte de expirare) un "tichet" reînoibil serverului Kerberos, cu opţiunea de reînoire, din cadrul cererii pentru acest server, setată. Serverul Kerberos va genera un nou tichet cu o nouă cheie de sesiune şi un moment ulterior de expirare. Toate celelalte câmpuri ale "tichetului" sunt lăsate nemodificate de către procesul de reînoire. Când se atinge ultimul termen de expirare permis, acel "tichet" expiră permanent. La fiecare reînoire, serverul Kerberos trebuie să consulte o listă actualizată de "tichete" raportate furate, pentru a determina dacă "tichetul" în cauză a fost raportat furat în intervalul de timp parcurs de la ultima sa reînoire. În acest caz se va refuza reînoirea acelui "tichet". Aşa poate fi redus timpul efectiv de viaţă al unui "tichet" furat.
Câmpul de reînoire al unui "tichet" este interpretat în mod normal doar de către serviciul tiketgranting. El poate fi ignorat de serverele de aplicaţii. Totuşi unele servere de aplicaţii mai prevăzătoare pot dori să nu accepte "tichete" reînoibile.
Dacă un tichet reînoibil nu este trimis la reînoire, înainte de termenul său local de expirare, serverul Kerberos nu îl va reînoi după expirarea acestui termen. Câmpul de reînoire este resetat iniţial, dar un client poate cere ca el să fie setat prin setarea opţiunii de reînoire în mesajul KRB_AS_REQ. Dacă el este setat atunci cîmpul renew-till din "tichet" conţine termenul după care "tichetul" nu va mai fi reînoit.
2.5 Câmpul MAY-POSTDATE
Aplicaţiile pot avea nevoie, ocazional, să obţină "tichete" pe care le vor folosi mult mai târziu. Dar este periculos să se păstreze "tichete" valabile într-o coadă de aşteptare, deoarece ele vor fi mai accesibile atacurilor. Post-datarea "tichetelor" este o cale de a obţine aceste "tichete" de la serverul Kerberos la momentul cererii unei aplicaţii, lăsându-le inactive până la apariţia unei cereri ulterioare de validare din partea serverului Kerberos. Dacă între timp s-a raportat un furt de "tichete", serverul Kerberos va refuza validarea tichetului şi hoţul nu va fi servit.
Câmpul MAY-POSTDATE este interpretat doar de către serviciul ticket-granting. El poate fi ignorat de către serverele de aplicaţie. Acest câmp trebuie setat într-un ticket-granting ticket pentru a crea posibilitatea generării unui "tichet" postdatat pe baza "tichetului" curent. În mod normal acest câmp este resetat, dar poate fi cerută de către un client setarea sa. În acest scop clientul trebuie să seteze opţiunea ALLOW-POSTDATE în mesajul KRB_AS-REQ. Acest câmp nu va permite unui client să obţină un ticket-granting ticket postdatat. Un astfel de "tichet" poate fi obţinut doar dacă se cere post-datarea în mesajul KRB_AS-REQ. Timpul de viaţă al unui "tichet" postdatat va fi egal cu restul timpului de viaţă al "tichetului" de tip ticket-granting ticket, la momentul cererii, cu excepţia cazului când opţiunea RENEWABLE este de asemenea setată. În acest caz timpul de viaţă al "tichetului" postdatat va fi egal cu întregul timp de viaţă al "tichetului" de tip ticket-granting ticket. Serverul Kerberos poate limita cât de departe în viitor poate fi postdatat un "tichet".
Câmpul POSTDATED indică faptul că un "tichet" a fost postdatat. Anumite servicii pot alege să rejecteze "tichetele" postdatate, sau să le accepte doar într-o anumită perioadă după efectuarea autentificării originale. Când serverul Kerberos generează un "tichet" postdatat, acesta va fi marcat şi ca INVALID, astfel încât clientul trebuie să prezinte din nou "tichetul" serverului Kerberos, pentru a fi validat înainte de utilizare. 2.6 Câmpul PROXIABLE
Uneori poate fi necesar ca un utilizator prinicipal să solicite un serviciu pentru sine. Serviciul trebuie să fie capabil să identifice clientul, dar numai pentru un anumit scop. Pentru aceasta serviciul include acel utilizator principal în categoria proxy.
Câmpul PROXIABLE dintr-un "tichet" este interpretat doar de către serviciul ticket-granting. El poate fi ignorat de către serverele de aplicaţie. Când este setat, acest câmp spune serverului ticket-granting că poate fi generat un nou "tichet", dar nu un "tichet" de tipul ticket-granting ticket. "Tichetul"

149
nou, care poate fi generat, va avea o nouă adresă de reţea bazată pe "tichetul" curent. Câmpul PROXIABLE permite unui client să aloce o etichetă proxy unui server pentru a satisface acestuia o cerere de serviciu la distanţă. De exemplu un serviciu de listare, al unui client, poate eticheta ca proxy serverul de listare, permiţându-i acestuia accesul la fişierele clientului, de pe un anumit server de fişiere, pentru a fi satisfăcută o anumită cerere de listare.
În scopul complicării utilizării acreditărilor furate, "tichetele" Kerberos sunt de obicei valide doar pentru acele adrese de reţea incluse în mod explicit în "tichet". Din acest motiv, un client care doreşte să acorde o etichetă proxy trebuie să ceară un nou "tichet" valid pentru adresa de reţea a serviciului care va fi etichetat ca proxy.
Câmpul PROXY este setat într-un "tichet" de către TGS când acesta generează un "tichet" proxy. Serverele de aplicaţie trebuie să verifice acest câmp şi să ceară o autentificare suplimentară de la agentul care prezintă "tichetul" proxy.
2.7 Câmpul FORWARDABLE
Retransmiterea autentificării, Authentication forwarding, este un caz particular de serviciu proxy, când serviciului i se permite completa utilizare a identităţii clientului. Un exemplu, în care acest caz trebuie folosit este când un utilizator se conectează la un sistem la distanţă, şi doreşte autentificarea pentru a lucra de pe acel sistem ca şi cum l-ar fi accesat local.
În mod normal câmpul FORWARDABLE al unui "tichet" este interpretat doar de serviciul ticket-granting. El poate fi ignorat de către serverele de aplicaţie. Interpretarea câmpului FORWARDABLE este similară celei a câmpului PROXIABLE, cu excepţia cazului când se utilizează "tichete" de tipul ticket-granting ticket. La interpretarea câmpului FORWARDABLE, şi "tichetele" de tipul ticket-granting ticket pot fi înzestrate cu diferite adrese de reţea. Acest câmp este resetat iniţial, dar utilizatorii pot cere ca el să fie setat, setând opţiunea FORWARDABLE în cererea către AS, atunci când cer "tichetul" lor iniţial, de tipul ticket-granting ticket. Acest câmp foloseşte la retransmiterea autentificării fără a fi necesară o cerere către utilizator de a-şi reintroduce parola. Dacă acest câmp nu este setat, retransmiterea autentificării nu este permisă, dar la acelaşi rezultat final se poate totuşi ajunge dacă utilizatorul se angajează în schimbul cu serverul AS cu adresele de reţea cerute şi furnizează o parolă.
Câmpul FORWARDED este setat de către TGS când un client prezintă un "tichet" cu câmpul FORWARDABLE setat şi cere setarea câmpului FORWARDED specificând opţiunea FORWARDED KDC şi furnizând un set de adrese pentru noul "tichet". El este de asemenea setat în toate "tichetele" generate pe baza "tichetelor" cu câmpul FORWARDED setat. Serverele de aplicaţie pot dori să prelucreze "tichete" retransmisibile în mod diferit de modul în care prelucrează "tichete" ne-retransmisibile.
3 Schimburi de mesaje
În continuare se descriu interacţiunile între clienţii reţelei şi servere şi mesajele implicate în aceste schimburi. 3.1 Schimburile de mesaje în cadrul serviciului de autentificare
Schimburile de mesaje între client şi serverul de autentificare Kerberos în cadrul serviciului de autentificare, AS, sunt iniţiate de obicei de către client, când acesta doreşte să obţină acreditări de autentificare pentru un anumit server, pentru că nu are astfel de acreditări. Cheia secretă a clientului este folosită pentru criptare şi decriptare. Acest schimb de mesaje este de obicei folosit la iniţierea unei sesiuni de login, pentru a obţine acreditări pentru un server de tipul Ticket-Granting, TS, care va fi folosit apoi pentru a se obţine acreditări pentru alte servere, fără a mai fi necesară folosirea cheii secrete a clientului. Acest schimb este de asemenea folosit pentru a se cere acreditări pentru servicii care nu trebuiesc mediate de către serviciul Ticket-Granting Service, dar în acest caz este necesară cheia secretă a unui utilizator principal aşa cum este serviciul de modificare a parolelor, the password-changing service. (Cererea de schimbare a parolei poate să nu fie onorată dacă cel care solicită nu poate furniza vechea

150
parolă (cheia secretă a utilizatorului). Altfel, ar fi posibil pentru cineva să schimbe parola unui utilizator). Acest schimb de mesaje, nu trebuie, prin sine însuşi, să producă vreo asigurare asupra identităţii utilizatorului. (Pentru a autentifica conectarea locală a unui utilizator acreditările obţinute în cadrul schimbului de mesaje cu serverul de autentificare, AS, trebuie mai întâi folosite într-un schimb de mesaje cu serviciul TGS pentru a obţine acreditări pentru un server local. Aceste acreditări trebuie apoi verificate de către serverul local prin încheierea schimbului de mesaje Client/Server).
Schimburile de mesaje între client şi serverul de autentificare Kerberos se bazează pe două tipuri de mesaje: KRB_AS_REQ care se transmite de la client la serverul Kerberos şi KRB_AS_REP sau KRB ERROR cu care se răspunde. În cerere clientul trimite, ca şi text clar, propria identitate şi identitatea serverului pentru care cere acreditarea. Răspunsul, KRB_AS_REP, conţine un "tichet" pe care clientul să-l prezinte serverului şi o cheie de sesiune care va fi "împărţită" (shared) de către client şi de către server. Cheia sesiunii şi alte informaţii adiţionale sunt criptate în cheia secretă a clientului. Mesajul KRB_AS_REP conţine informaţie care poate fi folosită pentru a se detecta răspunsuri şi pentru a le asocia cu mesajele cărora le răspunde. Pot apărea diferite tipuri de eroare. Acestea sunt indicate printr-un răspuns de eroare, KRB_ERROR, care se transmite în loc de KRB_AS-REP. Mesajul de eroare nu este criptat. El conţine informaţii care pot fi folosite pentru a-l asocia cu mesajul căruia îi răspunde. Lipsa criptării în mesajele KRB_ERROR favorizează abilitatea de a detecta răspunsuri sau fabricarea unor astfel de mesaje. În mod normal serverul de autentificare nu trebuie să ştie care dintre clienţi este utilizatorul principal numit în cerere. El trimite simplu un răspuns. Acesta este acceptabil deoarece nimeni, cu excepţia utilizatorului principal a cărui identitate e dată în cerere, nu va fi capabil să folosească acest răspuns. Informaţia critică din acest răspuns este criptată în cheia acelui utilizator principal. Cererea iniţială conţine un câmp opţional care poate fi folosit pentru a transmite informaţie suplimentară care poate fi necesară pentru schimbul iniţial de mesaje. Acest câmp poate fi folosit pentru preautentificare, dar mecanismul de preautentificare nu este specificat.
3.1.1 Generarea mesajului KRB_AS_REQ
Clientul trebuie să specifice un număr de opţiuni în cererea iniţială. Printre aceste opţiuni este modul în care se realizează preautentificarea, dacă "tichetul" cerut poate fi reînoit, dacă el trebuie să primească eticheta proxy, dacă el va putea fi retransmis, cum trebuie el postdatat sau dacă poate fi folosit pentru post-datarea altor "tichete" derivate şi dacă un "tichet" reînoibil va fi acceptat în locul unui "tichet" nereînoibil dacă termenul de expirare al "tichetului" cerut nu va putea fi satisfăcut de către un "tichet" nereînoibil (datorită constrângerilor de configurare). Clientul generează mesajul KRB_AS_REQ şi îl trimite la serverul Kerberos. 3.1.2 Recepţia mesajului KRB_AS_REQ
Dacă totul merge bine, prin prelucrarea mesajului KRB_AS_REQ se va crea un "tichet" pe care clientul să îl prezinte serverului. Conţinutul "tichetului" se determină după cum urmează.
3.1.3 Generarea mesajului KRB_AS_REP
Serverul de autentificare identifică utilizatorii principali de tip client şi server din baza sa de date, pe baza cheilor lor secrete. Dacă se cere, serverul preautentifică cererea şi dacă controlul de preautentificare conduce la un rezultat negativ se returnează un mesaj de eroare de tipul KDC_ERR_PREAUTH_FAILED. Dacă serverul nu poate asigura tipul de criptare cerut se returnează un mesaj de eroare de tipul KDC_ERR_ETYPE_NOSUPP. În caz contrar se generează, aleator, o cheie de sesiune. Dacă în mesajul de cerere nu este indicat momentul de începere al serviciului, sau dacă acest moment a fost depăşit, atunci momentul de început al "tichetului" este fixat la momentul la care serverul de autentificare transmite răspunsul. Dacă în cerere este specificat un moment de timp viitor, dar opţiunea POSTDATED nu a fost specificată, atunci se răspunde că s-a comis o eroare, cu un mesaj de tipul KDC_ERR_CANNOT_POSTDATE. Altfel, momentul de începere al "tichetului" este fixat cum s-a cerut şi câmpul INVALID este setat în noul "tichet" (cel postdatat). "Tichetul" postdatat trebuie să fie validat înaintea folosirii prin prezentarea sa la serverul Kerberos după ce s-a atins

151
momentul de început. Termenul de expirare al "tichetului" va fi fixat la valoarea minimă dintre următoarele valori:
- termenul de expirare cerut în mesajul KRB_AS-REQ, - suma dintre momentul de început al "tichetului" şi timpul de viaţă maxim obtenabil de către clientul utilizator principal (baza de date a serverului de autentificare include un câmp de timp maxim de viaţă al "tichetului" în fiecare înregistrare a acelui utilizator principal),
- suma dintre momentul de început al "tichetului" şi timpul de viaţă maxim obtenabil asociat cu utilizatorul principal de tip server, - suma dintre momentul de început al "tichetului" şi timpul de viaţă maxim fixat de politica severului reţelei locale. Dacă diferenţa dintre termneul de expirare cerut şi momentul de început este inferioară unui timp de viaţă minim determinat de site, atunci se returnează un mesaj de eroare de tipul KDC_ERR_NEVER_VALID. Dacă termenul de expirare al "tichetului" depăşeşte ceea ce s-a determinat anterior şi dacă opţiunea RENEWABLE-OK a fost specificată atunci câmpul RENEWABLE este setat în noul "tichet" şi valoarea renew-till este setată ca şi cum ar fi fost specificată opţiunea RENEWABLE. Dacă a fost specificată opţiunea RENEWABLE sau opţiunea RENEWABLE-OK şi se generează un "tichet" reînoibil atunci câmpul renew-till este setat la valoarea minimă dintre valorile: - valoarea cerută pentru el, - suma dintre momentul de început al "tichetului" şi valoarea minimă dintre cele două valori maxime de timpi de viaţă reînoibili asociate cu intrările în baza de date a utilizatorului principal. - suma dintre momentul de început al "tichetului" şi maximul timpului de viaţă reînoibil fixat de politica serverului reţelei locale.
Câmpurile noului "tichet" vor avea următoarele opţiuni setate dacă ele au fost solicitate şi dacă se aplică politica serverului reţelei locale: FORWARDABLE, MAY-POSTDATE, POSTDATED, PROXIABLE, RENEWABLE. Dacă noul "tichet" este postdatat (momentul de început este în viitor) şi câmpul său INVALID va fi setat. Dacă toate acţiunile descrise mai sus s-au îndeplinit atunci serverul Kerberos generează un mesaj de tipul KRB_AS_REP, copiind adresele din cerere în câmpul caddr al răspunsului, plasând orice date de preautentificare cerute în câmpul padata al răspunsului şi criptând un text în cheia clientului, folosind metoda de criptare solicitată, pe care-l trimite clientului. 3.1.4 Generarea mesajului KRB_ERROR
Câteva erori pot apărea, caz în care sereverul de autentificare răspunde, returnând clientului un mesaj de eroare, KRB_ERROR, în care câmpurile error-code şi e-text sunt setate cu valori corespunzătoare.
3.1.5 Recepţia mesajului KRB_AS_REP
Dacă mesajul cu care răspunde serverul KERBEROS este de tipul KRB_AS_REP atunci clientul verifică dacă câmpurile cname şi crealm din porţiunea de text clar a răspunsului se potrivesc cu ceea ce s-a cerut. Dacă este prezent vreun câmp de tipul padata, acesta poate fi folosit pentru extragerea cheii corecte pentru decriptarea mesajului. Clientul decriptează partea criptată a răspunsului folosind cheia sa secretă, verifică dacă zona nonce din partea criptată este identică cu conţinutul câmpului nonce din cererea pe care a expediat-o el. El verifică de asemenea dacă câmpurile sname şi srealm din cerere şi din răspuns sunt identice şi dacă câmpul de adresă al gazdei este de asemenea corect. Apoi el stochează "tichetul", cheia sesiunii, momentele de început şi de expirare şi alte informaţii, pentru a le folosi ulterior. Câmpul de expirare a cheii, din partea criptată a răspunsului poate fi verificat pentru a informa utilizatorul despre expirarea eminentă a cheii (programul utilizatorului poate atunci sugera remedii, ca de exemplu o schimbare de parolă).
Decriptarea corectă a mesajului KRB_AS_REP nu este suficientă pentru verificarea identităţii utilizatorului, acesta şi un atacator pot coopera pentru a genera un format de meaj KRB_AS_REP care decriptează corect dar care nu este transmis de serverul Kerberos legal. Dacă gazda vrea să verifice identitatea utilizatorului, ea trebuie să-i ceară utilizatorului să prezinte acreditări pentru aplicaţie, care

152
pot fi verificate folosind o cheie secretă memorată sigur. Dacă aceste acreditări pot fi verificate atunci identitatea utilizatorului poate fi asigurată.
3.1.6 Recepţia mesajului KRB_ERROR
Dacă mesajul recepţionat de la serverul Kerberos este de tipul KRB_ERROR atunci clientul îşi dă seama că în elaborarea sau în recepţia cererii sale de autentificare s-a comis cel puţin o eroare şi o poate corecta.
3.2 Schimburile de mesaje în cadrul procesului de autentificare Client/Server
Procesul de autentificare client/server, CS, este folosit de aplicaţiile de reţea pentru a autentifica clientul serverului şi invers. Clientul trebuie să fi obţinut anterior acreditări pentru server folosind un schimb de mesaje cu serverul AS sau cu serviciul TGS.
3.2.1 Mesajul KRB_AP_REQ
Acest mesaj conţine informaţie de autentificare care trebuie să fie parte din primul mesaj într-o tranzacţie autentificată. El conţine un "tichet", un autentificator, şi informaţie adiţională. Doar "tichetul" nu este suficient pentru autentificarea unui client, deoarece "tichetele" trec prin reţea cu textul în clar ("tichetele" conţin atât o parte criptată cât şi o parte necriptată aşa că prin text clar, aici se înţelege întregul mesaj). Autentificatorul este folosit pentru a preveni răspunsul invalid la "tichete" care ar demonstra serverului că se cunoaşte, de către client, cheia secretă a sesiunii. Mesajul KRB_AP_REQ se mai numeşte şi authentication header.
3.2.2 Generarea mesajului KRB_AP_REQ
Când un client doreşte să iniţieze procesul de autentificare cu un server, el obţine (fie prin intermediul unor acreditări, fie prin itermediul schimbului de mesaje cu serverul AS, fie prin intermediul schimbului de mesaje cu serviciul TGS) un "tichet" şi o cheie de sesiune pentru serviciul dorit. Clientul poate refolosi orice "tichet" pe care el l-a păstrat, dacă acesta nu este expirat. Clientul construieşte un nou autentificator pe baza timpului sistemului, a numelui sistemului şi opţional pe baza unei aplicaţii specifice de sumă de control, o secvenţă iniţială de numere care se utilizează în mesajele de tipul KRB_SAFE sau KRB_PRIV, şi/sau o subcheie de sesiune care se foloseşte la negocieri pentru obţinerea unei chei unice pentru sesiunea curentă. Autentificatorii nu pot fi refolosiţi şi vor fi respinşi dacă se vor folosi în răspunsul către un server . Dacă trebuie inclusă şi o secvenţă iniţială de numere, ea trebuie aleasă aleator, astfel încât chiar şi după multe mesaje schimbate să nu existe riscul coliziunii cu alte secvenţe de numere utilizabile.
Clientul poate indica o cerere de autentificare mutuală sau utilizarea unui "tichet" bazat pe o cheie de sesiune, prin setarea câmpurilor corespunzătoare din zona ap-options a mesajului.
Autentificatorul este criptat în cheia sesiunii şi combinat cu "tichetul" pentru a forma mesajul KRB_AP_REQ care este apoi trimis la serverul destinaţie împreună cu informaţie adiţională specifică pentru aplicaţie.
3.2.3 Recepţia mesajului KRB_AP_REQ
Autentificarea este bazată pe timpul curent al serverului (ceasurile celor două sisteme trebuie să fie sincronizate), pe autentificator şi pe "tichet". Se pot produce mai multe tipuri de erori. Dacă apare o eroare, atunci serverul va răspunde clientului cu un mesaj KRB_ERROR. Acest mesaj poate fi înglobat în protocolul aplicaţiei.
Algoritmul pentru verificarea autenticităţii informaţiei este următorul. Dacă mesajul nu este de tip KRB_AP_REQ serverul returnează mesajul de eroare KRB_AP_ERR_MSG_TYPE. Dacă versiunea de cheie, indicată în KRB_AP_REQ nu este cea pe care o foloseşte serverul (de exemplu s-a indicat o versiune de cheie mai veche) atunci se returnează mesajul de eroare KRB_AP_ERR_BADKEYVER. Dacă în zona ap-options este setat câmpul USE-SESSION_KEY i se

153
indică serverului că "tichetul" şi nu cheia secretă a clientului este criptat în cheia sesiunii. Deoarece este posibil ca serverul de aplicaţie considerat să fie înregistrat pe mai multe servere
de subreţea, cu diferite chei, câmpul srealm, din porţiunea necriptată a "tichetului", din cadrul mesajului KRB_AP_REQ, este folosit pentru a specifica care cheie secretă trebuie folosită pentru decriptare.
Mesajul de eroare KRB_AP_ERR_NOKEY este returnat dacă serverul nu are cheia corespunzătoare pentru decriptarea "tichetului".
"Tichetul" este decriptat folosind versiunea cheii serverului specificată în cadrul său. Dacă rutinele de decriptare detectează o modificare a "tichetului" (fiecare sistem de criptare trebuie să aibă posibilitatea de a verifica dacă a fost modificat textul criptat) atunci se returnează mesajul de eroare KRB_AP_ERR_BAD_INTEGRITY.
Autentificatorul este decriptat folosind cheia de sesiune extrasă din "tichetul" decriptat. Dacă această decriptare dovedeşte că autentificatorul a fost modificat se returnează mesajul de eroare de tip KRB_AP_ERR_BAD_INTEGRITY.
Numele şi câmpul realm ale clientului din cadrul "tichetului" sunt comparate cu câmpurile corespunzătoare din autentificator. Dacă ele nu se potrivesc se returnează mesajul de eroare KRB_AP_ERR_BADAMTCH (ele pot să nu se potrivească dacă de exemplu nu s-a folosit cheia de sesiune corectă pentru criptarea autentificatorului). Apoi se caută adresele din "tichet" (dacă există vreuna) şi se compară cu adresa clientului, găsită de către sistemul de operare. Dacă nu se găseşte nici o potrivire sau dacă serverul insisită asupra adreselor din "tichet" dar acesta nu conţine nici o adresă se returnează mesajul KRB_AP_ERR_BADADDR. Dacă timpul serverului local şi timpul clientului diferă cu mai mult decât un decalaj maxim acceptat (de exemplu 5 minute) atunci se returnează mesajul de eroare KRB_AP_ERR_SKEW. Dacă în autentificator este conţinut un număr de secvenţă, serverul îl salvează, pentru a-l folosi ulterior în prelucrarea mesajelor de tipul KRB_SAFE şi/sau KRB_PRIV. Dacă o subcheie este prezentă, serverul o salvează pentru o utilizare ulterioară sau o foloseşte în scopul generării propriei sale alegeri pentru o subcheie care să fie returnată în mesajul KRB_AP_REP.
Serverul calculează vârsta "tichetului" făcând diferenţa dintre timpul serverului local şi momentul de început al "tichetului", indicat în acesta. Dacă momentul de început este ulterior momentului actual cu un interval de timp mai mare decât timpul de decalaj maxim acceptat sau dacă este setat câmpul INVALID din cadrul "tichetului" atunci se returnează mesajul de eroare KRB_AP_ERR_TKT_NYV. Altfel, dacă momentul curent este ulterior momentului de expirare a "tichetului" cu mai mult decât timpul de decalaj maxim acceptat se returnează mesajul de eroare KRB_AP_ERR_TKT_EXPIRED. Dacă toate controalele descrise nu detectează erori atunci serverul este asigurat că clientul posedă acreditările utilizatorului principal numit în "tichet" şi deci acest client este autentificat de server.
3.2.4 Generarea mesajului KRB_AP_REP
Uzual o cerere de la client va include atât informaţia de autentificare cât şi cererea sa iniţială, în acelaşi mesaj iar serverul nu va trebui să răspundă explicit la mesajul KRB_AP_REQ. Totuşi dacă s-a realizat o autentificare mutuală (nu numai autentificarea clientului de către server ci şi reciproc) atunci în zona ap-option a mesajului KRB_AP_REQ va fi setat câmpul MUTUAL-REQUIERED şi este necesar un mesaj de răspuns KRB_AP_REP. La fel ca şi în cazul mesajelor de eroare acest mesaj poate fi inclus în protocolul de aplicaţie.
Mesajul KRB_AP_REP este criptat în cheia sesiunii extrasă din "tichet".
3.2.5 Recepţia mesajului KRB_AP_REP
Dacă i se returnează un mesaj KRB_AP_REP, clientul foloseşte cheia sesiunii din acreditările obţinute pentru server pentru a decripta acest mesaj. Trebuie remarcat că pentru criptarea mesajului KRB_AP_REP nu se utilizează cheia sesiunii chiar dacă aceasta este prezentă în autentificator. Apoi clientul verifică dacă ştampila temporală şi câmpurile de microsecunde se potrivesc cu zonele corespunzătoare din autentificatorul pe care el l-a trimis serverului. Dacă are loc această potrivire atunci clientul este asigurat că serverul este sigur. Numărul de secvenţă şi cheia (dacă există) sunt

154
reţinute pentru utilizare ulterioară.
3.2.6 Utilizarea cheii de criptare
După ce s-a declanşat schimbul de mesaje KRB_AP_REQ/KRB_AP_REP clientul şi serverul împart o cheie de criptare care poate fi folosită de către aplicaţie. Adevărata cheie de sesiune care trebuie folosită pentru mesajele KRB_PRIV sau KRB_SAFE sau alte measaje specifice aplicaţiilor trebuie aleasă de către aplicaţie pe baza subcheilor din mesajul KRB_AP_REP şi a autentificatorului. Implementări ale protocolului aplicaţiei pot dori să realizeze rutine de alegere a subcheilor, pornind de la cheile de sesiune şi de la numere aleatoare şi să genereze o cheie negociată care să fie returnată în cadrul mesajului KRB_AP_REP. În anumite cazuri utilizarea acestei chei de sesiune va fi implicită, în protocol, în alte cazuri metoda de folosit se alege dintre mai multe alternative. Se organizează negocieri ale protocolului asupra utilizării cheii (de exemplu selectarea unui anumit tip de criptare sau a unui anumit tip de sumă de control). Protocolul Kerberos nu trebuie să impună constrângeri opţiunilor de implementare.
Atât în cazul schimburilor de mesaje de autentificare într-un singur sens cît şi în cazul mesajelor de autentificare mutuale, trebuie luate măsuri de siguranţă să nu se transmită informaţii sensibile între cele două calculatoare (care schimbă mesaje) fără asigurări de securitate corespunzătoare. În particular, aplicaţiile care necesită confidenţialitate sau integritate trebuie să folosească răspunsurile KRB_AP_REP sau KRB_ERROR de la server la client. Dacă un protocol de aplicaţie necesită confidenţialitatea mesajelor sale, el poate utiliza mesajul de tip KRB_PRIV. Mesajul de tip KRB_SAFE poate fi folosit pentru a asigura integritate.
3.3 Schimbul de mesaje în cadrul serviciului Ticket-Granting, TGS
Schimbul de mesaje TGS între un client şi serverul Kerberos Ticket-Granting este iniţiat de un client când el doreşte să obţină acreditări de autentificare pentru un anumit server (care poate fi înregistrat într-un domeniu de securitate aflat la distanţă), când el doreşte să reînoiască sau să valideze un "tichet" existent sau când el vrea să obţină un "tichet" proxy. În primul caz,clientul trebuie să fi obţinut deja un "tichet" pentru serviciul Ticket-Granting, pe baza schimbului de mesaje AS ("tichetul" de tip ticket-granting este de obicei obţinut când un client este deja autentificat de sistem, aşa cum se întâmplă atunci când un utilizator face log-in). Formatul mesajului pentru schimbul TGS este aproape identic cu cel al mesajului pentru schimbul AS. Diferenţa principală este că criptarea şi decriptarea din cazul schimbului TGS nu trebuiesc făcute cu ajutorul cheii clientului. În locul acesteia se folosesc cheia sesiunii pentru "tichetul" de tip ticket-granting, sau de tipul "tichet" reînoibil, sau o cheie de subsesiune de la un autentificator. La fel ca în cazul schimbului de mesaje cu servere de aplicaţie, nu sunt acceptate în cadrul schimbului TGS "tichetele" expirate, aşa că odată ce un "tichet" reînoibil sau un "tichet" de tipul ticket-granting expiră, clientul trebuie să folosească un schimb separat de mesaje pentru a obţine "tichete" valabile. Schimbul de mesaje TGS se bazează pe două tipuri de mesaje: unul de cerere de la client la serverul Kerberos de tipul Ticket-Granting, KRB_TGS_REQ şi unul de răspuns KRB_TGS_REP sau KRB_ERROR.
Mesajul de tip KRB_TGS_REQ include informaţie autentificând clientul şi o cerere de acreditări. Informaţia de autentificare constă dintr-un antet de autentificare, KRB_AP_REQ, care include "tichetele" anterior obţinute de client, de tipul ticket-granting, reînoibil sau invalid. În cazurile în care este vorba despre "tichete" de tipul ticket-granting sau proxy, cererea trebuie să includă şi una sau mai multe dintre următoarele: o listă cu adrese de reţea, o colecţie de date de autorizare care vor fi folosite pentru autentificare de serverul de aplicaţie sau "tichete" adiţionale.
Mesajul de răspuns TGS, KRB_TGS_REP conţine acreditările cerute, criptate în cheia sesiunii din cadrul "tichetului" de tipul ticket-granting sau reînoibil, sau dacă este prezentă, în cheia subsesiunii din autentificator (o parte a antetului de autentificare).
Mesajul de eroare KRB_ERROR conţine un cod de eroare şi un text în care se explică ce s-a greşit. Acest mesaj nu este criptat.
Mesajul de tip KRB_TGS_REP conţine informaţie care poate fi folosită pentru a detecta răspunsuri şi pentru a le asocia cu mesajul care le-a generat.

155
3.3.1 Generarea mesajului KRB_TGS_REQ
Înainte de a trimite o cerere serviciului TGS, clientul trebuie să determine în ce domeniu de securitate este înregistrat serverul de aplicaţie corespunzător. Dacă el nu posedă deja un "tichet" de tipul ticket-granting, pentru acel domeniu de securitate atunci trebuie obţinut un astfel de "tichet". În acest scop se face pentru început o cerere de "tichet" de tipul ticket-granting pentru domeniul de securitate vizat de la serverul Kerberos local (folosind recursiv mesajul KRB_TGS_REQ). Serverul Kerberos poate returna un "tichet" de tip TGT pentru domeniul de securitate dorit, caz în care se poate continua. Dar serverul Kerberos poate returna şi un "tichet" de tip TGT pentru un domeniu de securitate care este apropiat de domeniul de securitate, caz în care acest pas trebuie repetat, apelând la un server Kerberos din domeniul de securitate specificat în "tichetul" de tip TGT returnat. Dacă nu se returnează nici un mesaj, atunci trebuie să se transmită cererea unui server Kerberos pentru un domeniu de securitate superior ierarhic.
După ce clientul a obţinut un "tichet" de tip TGT pentru domeniul de securitate corespunzător, el determină care servere Kerberos, deservesc acest domeniu şi contacteză unul dintre ele. Lista trebuie obţinută printr-un fişier de configurare sau printr-un serviciu de reţea; atât timp cât cheile secrete schimbate între domenii de securitate sunt păstrate secrete, un server Kerberos fals nu poate face altceva decât să nege serviciul.
La fel ca în cazul schimbului de mesaje cu serverul de autentificare, AS, clientul trebuie să specifice un număr de opţiuni în mesajul KRB_TGS_REQ. Clientul pregăteşte mesajul KRB_TGS_REQ, completând un antet de autentificare ca element al zonei padata şi incluzând aceleaşi câmpuri ca şi cele folosite în mesajul KRB_AS_REQ precum şi câteva câmpuri opţionale: câmpul enc-authorization-data pentru utilizarea de către serverul de aplicaţie şi "tichete" adiţionale cerute de anumite opţiuni.
În pregătirea antetului de autentificare, clientul poate selecta o cheie de sub-sesiune cu ajutorul căreia va fi criptat răspunsul de la serverul Kerberos. Dacă cheia de sub-sesiune nu este specificată atunci se va folosi cheia sesiunii din "tichetul" de tip TGT. Dacă data de tipul enc-authorization există, ea trebuie criptată în cheia sub-sesiunii.
După ce antetul de autentificare a fost elaborat, mesajul KRB_TGS_REQ este trimis serverului Kerberos pentru domeniul de securitate de destinaţie.
3.3.2 Recepţia mesajului KRB_TGS_REQ
Mesajul KRB_TGS_REQ este prelucrat asemănător cu modul în care este prelucrat mesajul KRB_AS_REQ, dar există câteva verificări suplimentare, de efectuat. În primul rând, serverul Kerberos trebuie să determine de la care server este "tichetul" care acompaniază mesajul şi el trebuie să selecteze cheia potrivită pentru a-l decripta. Pentru un mesaj KRB_TGS_REQ normal "tichetul" va corespunde unui serviciu de tipul TGS şi va fi folosită cheia TGS. Dacă "tichetul" de tip TGT a fost emis de un alt domeniu de securitate, atunci trebuie folosită cheia potrivită dintre domenii de securitate. Dacă "tichetul" care acompaniază mesajul nu este de tipul TGT pentru domeniul de securitate curent, ci este pentru un server de aplicaţie din domeniul de securitate curent, opţiunile RENEW, VALIDATE sau PROXY sunt specificate în cerere şi serverul pentru care se cere un "tichet" este serverul numit în "tichetul" care acompaniază mesajul, atunci serverul KDC va decripta "tichetul" în antetul de autentificare, folosind cheia serverului pentru care a fost solicitat. Dacă nu poate fi găsit nici un "tichet" în zona padata, atunci se returnează mesajul de eroare KDC_ERR_PADATA_TYPE_NOSUPP.
După ce "tichetul" care acompaniază mesajul KRB_TGS_REQ a fost decriptat trebuie verificată suma de control a utilizatorului din autentificator în acord cu conţinutul cererii, şi mesajul trebuie rejectat dacă această sumă nu se potirveşte. Mesajul de eroare folosit în acest caz este KRB_AP_ERR_MODIFIED. Dacă tipul de sumă de control nu este suportat atunci se returnează mesajul KDC_ERR_SUMTYPE_NOSUPP. Dacă există şi date de autorizare, acestea sunt decriptate folosind cheia de sub-sesiune din autentificator.
Dacă oricare dintre procedurile de decriptare indicate dovedeşte pierderea integrităţii după ce se testează acestă proprietate atunci se returnează mesajul de eroare KRB_AP_ERR_BAD_INTEGRITY.

156
3.3.3 Generarea mesajului KRB_TGS_REP
Acest mesaj îşi împarte (shares) formatul cu mesajele KRB_AS_REP (KRB_KDC_REP), dar câmpul său de tip este setat cu KRB_TGS_REP. Răspunsul va include un "tichet" pentru serverul cerut. Baza de date Kerberos este însărcinată să găsească înregistrarea pentru serverul cerut (inclusiv cheia cu care "tichetul” va fi criptat). Dacă cererea este pentru un tichet de tip TGT pentru un domeniu de securitate aflat la distanţă şi dacă nu există vreo cheie împărţită cu domeniul de securitate cerut, atunci serverul Kerberos va selecta domeniul de securitate cel mai apropiat de domeniul de securitate cerut, cu care se împarte o cheie şi va folosi acest domeniu. Acesta este singurul caz în care răspunsul de la KDC va fi pentru un server diferit de serverul solicitat de client. Automat, câmpul de adrese, numele clientului şi domeniul de securitate, lista domenilor de securitate tranzitate, momentul autentificării iniţiale, momentul expirării şi datele de autorizare ale noului "tichet" generat vor fi copiate din "tichetul" de tip TGT sau reînoibil.
Dacă cererea specifică un timp de terminare atunci timpul de terminare al noului "tichet" este setat la minimul dintre:
(a) timpul de terminare din "tichetul" de tip TGT, (b) timpul de terminare al "tichetului" de tip TGT, (c) suma dinre timpul de începere al "tichetului" de tip TGT şi minimul dintre timpul maxim de viaţă pentru serverul de aplicaţie şi maximul de viaţă pentru domeniul de securitate local. Dacă noul tichet este pentru o reînoire atunci momentul de terminare de mai sus e înlocuit cu
minimul dintre: (a) valoarea câmpului renew-till al "tichetului", (b) suma dintre momentul de pornire al noului "tichet" şi timpul de viaţă al vechiului "tichet". Dacă s-a specificat opţiunea FORWARDED, atunci "tichetul" rezultant va conţine adresele
specificate de client. Această opţiune va fi onorată doar dacă câmpul FORWARDABLE este setat în cadrul "tichetului" de tip TGT. La fel se procedează şi cu opţiunea PROXY. Această opţiune nu va fi onorată în cazul cererilor pentru "tichete" de tipul TGT adiţionale.
Dacă momentul de pornire solicitat este absent sau a trecut deja, atunci momentul de începere al "tichetului" este fixat pe baza timpului curent al serverului de autentificare. Dacă a fost indicat un moment de timp viitor, dar nu a fost specificată opţiunea POSTDATED sau câmpul MAYPOSTDATE nu este setat în cadrul "tichetului" de tip TGT, atunci se returnează mesajul de eroare KDC_ERR_CANNOT_POSTDATE. Altfel, dacă "tichetul" de tip TGT are câmpul MAYPOSTDATE setat, atunci "tichetul" rezultat va fi postdatat şi momentul de început cerut este fixat pe baza politicii domeniului de securitate local. Dacă este acceptabil, momentul de pornire al "tichetului" este setat după cum s-a cerut şi câmpul INVALID este setat. "Tichetul" postdatat trebuie validat înaintea folosirii prin prezentarea sa la serverul Kerberos, KDC, după ce momentul începerii a fost atins. Totuşi, în nici un caz nu trebuie ca momentul de începere, momentul de terminare, sau timpul de tip renew-till, ale unui nou "tichet" postdatat să depăşească timpul de tipul renew-till al "tichetului" de tip TGT.
Dacă s-a specificat opţiunea ENC-TKT-IN-SKEY şi a fost inclus şi un "tichet" adiţional în cerere, atunci serverul Kerberos, KDC, va decripta "tichetul" adiţional folosind cheia pentru serverul pentru care a fost generat "tichetul" adiţional şi va verifica dacă acesta este un "tichet" de tip TGT. Dacă numele serverului cerut lipseşte din cerere, va fi folosit numele clientului din "tichetul" adiţional. Altfel numele serverului cerut va fi comparat cu numele clientului din "tichetul" adiţional şi dacă se vor constata diferenţe cererea va fi respinsă.
Dacă cererea a fost satisfăcută, se va utiliza cheia sesiunii din "tichetul" adiţional pentru a cripta noul "tichet" care se generează, în loc să se folosească cheia serverului pentru care se va folosi noul "tichet". În acest mod se favorizează implementarea autentificării de la utilizator la utilizator, care foloseşte chei de sesiune pentru "tichete" de tip TGT în loc de chei de server în cazurile în care astfel de chei secrete ar putea fi uşor compromise. Dacă numele serverului din "tichetul" care este prezentat la serverul KDC ca o parte a antetului de autentificare nu este cel al serverului Ticket-Granting şi serverul este înregistrat în domeniul de securitate al serverului Kerberos, KDC, şi dacă este specificată opţiunea RENEW, atunci serverul KDC va verifica dacă este setat câmpul RENEWABLE în cadrul "tichetului" şi că momentul renew-till este îmcă în viitor. Dacă este specificată opţiunea VALIDATE,

157
atunci serverul KDC va verifica că momentul de începere a trecut şi că este setat câmpul INVALID. Dacă este specificată opţiunea PROXY atunci serverul KDC va verifica dacă este setat câmpul PROXIABLE din cadrul "tichetului". Dacă toate aceste verificări conduc la rezultate corecte atunci serverul KDC va genera noul tichet corespunzător.
Ori de câte ori se transmite o cerere serverului Ticket-Granting, "tichetul" prezentat este verificat fiind comparat cu cele de pe o listă de "tichete" anulate. Această listă este alcătuită prin memorarea unor date de generare ale "tichetelor" suspecte. Dacă data de generare a "tichetului" prezentat este cuprinsă în intervalul de timp memorat atunci acesta va fi respins. În acest mod un "tichet" de tipul TGT sau de tipul reînoibil, furat, nu poate fi folosit pentru obţinerea de noi "tichete" (reînoite sau de alt tip) de îndată ce furtul a fost raportat. Orice "tichet" obţinut înainte de a se fi raportat că este furat va fi considerat valid (pentru că în cazul său nu va apărea interacţiunea cu serverul KDC), dar numai până la momentul său normal de expirare.
Partea criptată a răspunsului din mesajul KRB_TGS_REP este cifrată cu cheia sub-sesiunii din autentificator, dacă aceasta există, sau cu cheia sesiunii din "tichetul" de tip TGT. Nu se foloseşte pentru criptare cheia secretă a clientului.
3.3.3.1 Codarea câmpurilor tranzitate
Dacă identitatea serverului declarată în "tichetul" de tip TGT care este prezentat serverului KDC ca şi parte a antetului de autentificare este cea a serviciului Ticket-Granting dar "tichetul" de tip TGT a fost generat dintr-un alt domeniu de securitate, atunci serverul KDC va folosi cheia interdomenii de securitate, împărţită cu acel domeniu de securitate, pentru a decripta "tichetul". Dacă "tichetul" este valid atunci serverul KDC va onora cererea, respectând constrângerile specifice schimbului de mesaje cu serverul de autentificare AS. Partea din identitatea clientului, referitoare la domeniile de securitate, va fi luată din "tichetul" de tip TGT. Numele domeniului de securitate care a generat "tichetul" de tip TGT va fi adăugat la câmpul tranzitat, the transited field, al "tichetului" care va fi generat. Asta se realizează citind câmpul tranzitat din "tichetul" de tip TGT (care este tratat ca o mulţime neordonată de nume de domenii de securitate), adăugând noul domeniu de securitate la mulţime, apoi construind şi scriind forma sa codată, shorthand, (asta poate implica o rearanjare a codării existente).
Trebuie notat că serviciul Ticket-Granting nu trebuie să adauge numele propriului său domeniu de securitate. De fapt responsabilitate sa este să adauge numele domeniului de securitate anterior. Asta previne ca un server Kerberos fals să evite declararea propriului său nume (el va putea totuşi să omită numele altor domenii de securitate).
Nici numele domeniului de securitate local şi nici cel al domeniului de securitate al utilizatorului principal nu trebuie incluse în câmpul tranzitat. Ele apar altundeva în cadrul "tichetului" şi ambele se folosesc în autentificarea utilizatorului principal.
Deoarece punctele de capăt nu sunt incluse, atât autentificarea locală cât şi autentificarea inter-domenii de securitate, cu un domeniu vecin vor corespunde la câmpuri de tranzitare vide. Deoarece numele fiecărui domeniu de securitate tranzitat este adăugat la acest câmp, el poate avea o lungime foarte mare. Pentru a descreşte lungimea acestui câmp, conţinutul său se codează. Metoda de codare iniţială este optimizată pentru cazul normal al comunicării inter-domenii de securitate.
3.5 Schimbul de mesaje KRB_PRIV
Mesajul de tip KRB_PRIV poate fi folosit de clienţi care au nevoie de confidenţialitate şi de abilitatea de a detecta modificări ale mesajelor schimbate. El realizează aceste deziderate criptând mesajele şi adăugând informaţie de control.
3.5.1 Generarea mesajului KRB_PRIV
Când o aplicaţie doreşte să trimită un mesaj de tip KRB_PRIV, ea colectează datele sale şi informaţia de control corespunzătoare şi le criptează folosind o cheie (de obicei ultima cheie negociată prin intermediul mecanismului bazat pe subchei, sau cheia sesiunii dacă nu au avut loc negocieri). Ca

158
şi parte a informaţiei de control, clientul trebuie să aleagă fie utilizarea unei ştampile de timp fie utilizarea unui număr de secvenţă (fie amândouă). După ce datele de utilizator şi informaţia de control au fost criptate, clientul transmite textul cifrat şi informaţie de tip "plic".
3.5.2 Recepţia mesajului KRB_PRIV
Când o aplicaţie primeşte un mesaj de tipul KRB_PRIV ea îl verifică după cum urmează. La început se controlează dacă versiunea de protocol şi tipurile de câmpuri folosite se potrivesc cu versiunea curentă şi cu mesajul de tip KRB_PRIV. O nepotrivire generează un mesaj de eroare de tipul KRB_AP_ERR_BADVERSION sau de tipul KRB_AP_ERR_MSG_TYPE. Apoi aplicaţia decriptează textul cifrat şi prelucrează textul clar rezultat. Dacă decriptarea arată că datele au fost modificate, atunci se generează un mesaj de eroare de tip KRB_AP_ERR_BAD_INTEGRITY.
Aplicaţia care a recepţionat mesajul verifică, pe baza raportului sistemului său de operare, referitor la adresa expeditorului, dacă aceasta este identică cu adresa expeditorului din mesaj şi (dacă este specificată o adresă de destinatar sau dacă destinatarul cere o adresă) că una dintre adresele destinatarului apare ca adresă a destinatarului în cadrul mesajului. O nepotrivire de adresă, în unul dintre cele două cazuri expuse, generează un mesaj de eroare de tipul KRB_AP_ERR_BADADDR. Apoi se verifică câmpurile: ştampilă temporală, time stamp, usec şi/sau număr de secvenţă, sequence number.
Dacă se aşteaptă prezenţa câmpurilor timestamp şi usec şi acestea nu sunt prezente, sau ele sunt prezente dar nu sunt setate, atunci se generează mesajul de eroare KRB_AP_ERR_SKEW. Dacă cele patru câmpuri: numele serverului, numele clientului, timp şi microsecond, din cadrul autentificatorului, sunt identice cu o grupare de astfel de câmpuri observată recent, atunci se generează mesajul de eroare KRB_AP_ERR_REPEAT.
Dacă este inclus un număr de secvenţă incorect, sau se aşteaptă un număr de secvenţă, dar acesta nu este prezent, atunci se generează mesajul de eroare KRB_AP_ERR_BADORDER. Dacă nu este prezent nici unul dintre câmpurile: ştampilă de timp, usec, sau număr de secvenţă, atunci se generează mesajul de eroare KRB_AP_ERR_MODIFIED.
Dacă toate controalele descrise mai sus, sunt satisfăcute, atunci aplicaţia poate considera că mesajul a fost transmis de sursa invocată şi că a fost transmis în siguranţă.
3.6 Schimbul de mesaje KRB_CRED
Mesajul de tip KRB_CRED poate fi folosit de clienţii care solicită dreptul de a transmite acreditări Kerberos de la un calculator gazdă la altul. Asta se poate face trimiţând "tichetele" împreună cu date criptate conţinând cheia sesiunii şi alte informaţii asociate cu "tichetele".
3.6.1 Generarea mesajului KRB_CRED
Când o aplicaţie doreşte să transmită un mesaj de tipul KRB_CRED ea obţine în primul rând (folosind schimbul de mesaje KRB_TGS) acreditările care trebuie trimise la calculatorul gazdă de la distanţă. Apoi ea construieşte un mesaj de tipul KRB_CRED folosind "tichetul" sau "tichetele" obţinute astfel, plasând cheia de sesiune, care trebuie folosită de către fiecare "tichet" în câmpul de cheie al secvenţei KrbCredInfo corespunzătoare a părţii criptate a mesajului KRB_CRED.
Alte informaţii asociate cu fiecare "tichet" şi obţinute pe durata schimbului de mesaje KRB_TGS sunt de asemenea plasate în secvenţa KrbCredInfo corespunzătoare din partea criptată a mesajului KRB_CRED. Timpul curent şi, dacă este explicit cerut de către aplicaţie, câmpurile: nonce, s-address, şi raddress, sunt plasate în partea criptată a mesajului KRB_CRED, care este apoi criptată folosind o cheie de criptare, care a fost transmisă în cadrul schimbului de mesaje KRB_AP (de obicei ultima cheie negociată prin mecanismul subcheilor, sau cheia sesiunii dacă nu au avut loc negocieri).
3.6.2 Recepţia mesajului KRB_CRED
Când o aplicaţie primeşte un mesaj de tipul KRB_CRED, ea îl verifică. Dacă a apărut vreo

159
eroare este generat un cod de eroare care se foloseşte de către aplicaţie. Mesajul este verificat controlând dacă versiunea de protocol şi tipurile de câmp se potrivesc cu versiunea curentă şi respectiv cu tipul de mesaj, KRB_CRED. O nepotrivire generează returnarea unui mesaj de eroare de tipul KRB_AP_ERR_BADVERSION sau de tipul KRB_AP_ERR_MSG_TYPE. Apoi aplicaţia decriptează textul cifrat şi prelucrează textul în clar rezultat. Dacă la decriptare se constată că datele au fost modificate, se generează un mesaj de eroare de tipul KRB_AP_ERR_BAD_INTEGRITY.
Dacă sunt prezente sau dacă se cere, destinatarul verifică dacă raportul sistemului său de operare referitor la adresa expeditorului se potriveşte cu adresa expeditorului conţinută în mesaj şi dacă una dintre adresele destinatarului se potriveşte cu adresa destinatarului din mesaj. Dacă la unul dintre aceste controale se sesizează vreo nepotrivire atunci se generează un mesaj de eroare de tipul KRB_AP_ERR_BADADDR. Cîmpurile ştampilă temporală şi usec (şi câmpul nonce dacă se cere) sunt apoi verificate. Dacă primele două câmpuri nu sunt prezente, sau ele sunt prezente dar nu sunt setate, atunci se generează un mesaj de eroare de tipul KRB_AP_EPR_SKEW.
Dacă toate controalele descrise au condus la rezultate satisfăcătoare, aplicaţia stochează fiecare dintre noile "tichete" împreună cu cheia sesiunii şi alte informaţii din secvenţa krbCredInfo corespunzătoare din partea criptată a mesajului KRB_CRED.
4 Baza de date Kerberos
Serverul Kerberos trebuie să aibă acces la o bază de date care să conţină identificatorii şi cheile secrete ale utilizatorilor principali care trebuie autentificaţi. Implementarea serverului nu necesită să se combine baza de date şi serverul propriuzis pe acelaşi calculator; principala bază de date poate fi stocată într-un nume de serviciu de reţea, de exemplu, dar datele, din această bază, trebuie să fie protejate împotriva modificărilor sau a schimbării structurii, efectuate de către părţi neautorizate. Totuşi astfel de strategii nu sunt recomandate, deoarece ele conduc la un management de sistem şi la o analiză a vulnerabilităţii complicate. 4.1 Conţinutul bazei de date
O intrare în baza de date trebuie să conţină cel puţin următoarele câmpuri:
Câmp Valoare
nume Identificatorul utilizatorului principal cheie Cheia secretă a utilizatorului principal p_kvno Versiunea de cheie a utilizatorului principal max_life Timpul de viaţă maxim al "tichetelor" max_renewable_life Timpul total maxim de viaţă pentru "tichete" reînoibile
Câmpul de nume conţine un cod pentru identificatorul principalului utilizator. Câmpul cheie conţine o cheie de criptare. Aceasta este cheia secretă a utilizatorului principal. Ea poate fi criptată înainte de memorare cu ajutorul unei chei de criptate a serviciului Kerberos, numită master key, pentru a o proteja, în cazul în care baza de date este compromisă, dar nu şi cheia master. În acest caz trebuie adăugat un câmp suplimentar, pentru a indica versiunea folosită de master key. Câmpul p-kvno conţine numărul versiunii de cheie secretă a utilizatorului principal. Câmpul max_life conţine timpul de viaţă maxim obtenabil (diferenţa dintre momentul de terminare şi momentul de începere) pentru orice "tichet" generat de acest utilizator principal. Câmpul max_renewable_life conţine timpul de viaţă total maxim obtenabil pentru orice "tichet" reînoibil generat de acest utilizator principal.
Un server poate oferi servicii KDC pentru mai multe domenii de securitate, atât timp cât reprezentarea în baza de date oferă un mecanism de diferenţiere între înregistrările utilizatorului principal cu identificatori care diferă doar la numele domeniului de securitate.
Când se schimbă o cheie a unui server de aplicaţie, dacă este o schimbare de rutină (şi nu rezultatul atacului asupra vechii chei), vechea cheie trebuie reţinută de către server, până când toate "tichetele" care au fost generate folsind vechea cheie au expirat. Din această cauză, este posibil pentru

160
unele chei să fie active pentru un singur utilizator principal. Când mai multe chei sunt active pentru un anumit utilizator principal, acesta va avea mai
multe înregistrări în baza de date Kerberos. Cheile şi versiunile de cheie vor diferi între înregistrări (restul câmpurilor pot să fie identice).
Ori de câte ori Kerberos generează un "tichet" sau răspunde la o cerere iniţială de autentificare, cea mai recentă cheie (cunoscută de serverul Kerberos) va fi folsită pentru criptare. Aceasta este cheia cu cel mai mare număr de versiune.
5. Specificaţii referitoare la criptare şi la sumele de control
Protocoalele Kerberos sunt destinate utilizării unor sisteme de criptare secvenţiale, care pot fi simulate folosind siteme de criptare pe blocuri, care se pot procura mai uşor, cum ar fi sistemul de criptare DES. Aceste sisteme de criptare sunt utilizate împreună cu metode de înlănţuire a blocurilor şi cu metode bazate pe sumele de control.
Criptarea este folosită pentru a demonstra identitatea entităţilor din reţea, care participă la schimburile de mesaje. Centrul de distribuire a cheilor, al fiecărui domeniu de securitate, este considerat de încredere de către toţi utilizatorii principali, înregistraţi în acel domeniu de securitate şi este folosit pentru memorarea câte unei chei secrete. Cunoaşterea acestei chei secrete este folosită pentru verificarea autenticităţii utilizatorilor principali.
Serverul KDC foloseşte cheia utilizatorului principal (în schimbul de mesaje AS) sau o cheie de sesiune împărţită (în schimbul de mesaje TGS) pentru a cripta răspunsurile la cererile de "tichete". Abilitatea de a obţine cheia secretă sau cheia sesiunii implică cunoaşterea cheilor corespunzătoare şi a identităţii serverului KDC.
Protocoalele Kerberos presupun în general că metoda de criptare folosită este sigură; totuşi, în anumite cazuri, ordinea câmpurilor din porţiunile criptate ale mesajelor sunt aranjate pentru a minimiza efectele unor alegeri necorespunzătoare ale cheilor. Este totuşi important să se aleagă chei bune. Dacă cheile sunt derivate din parole de tip utilizator, aceste parole trebuie să fie bine utilizate, pentru a combate atacurile bazate pe forţa brută. Nealegerea corespunzătoare a cheilor face sarcina atacatorilor mai uşoară.
Pentru metodele de criptare, este de obicei de dorit să se plaseze informaţie aleatoare la începutul mesajului.
Anumite sisteme de criptare folosesc o metodă de înlănţuire a blocurilor pentru a îmbunătăţi caracteristicile de securitate ale textului cifrat. Totuşi, aceste metode de înlănţuire, nu asigură, de obicei, controlul integrităţii după decriptare. Sistemele de criptare, cum ar fi de exemplu, DES, trebuie înzestrate cu un mecanism de verificare a sumelor de control, pentru textul în clar obţinut după decriptare, care să fie folosit pentru verificarea integrităţii mesajului. Un astfel de mecanism trebuie să fie bun la detectarea erorilor de tip burst. Dacă se detectează vreo eroare, rutina de decriptare trebuie să returneze un mesaj de eroare, indicând faptul că testul de integritate nu a fost satisfăcut. Fiecărei metode de criptare i se asociază un anumit tip de sumă de control. Prin specificarea metodei de criptare se precizează şi parametrii metodei de verificare a sumei de control aferente.
În sfârşit, când trebuie extrasă o cheie din parola unui utilizator, se foloseşte un algoritm pentru conversie. Este de preferat ca funcţia hash folosită pentru transformarea parolei în cheie să fie de tipul one-way şi să se folosească funcţii hash diferite pentru diferite domenii de securitate. Asta este important deoarece utilizatori care sunt înregistraţi în mai multe domenii de securitate, vor utiliza aceaşi parolă în fiecare dintre aceste domenii şi este de dorit ca un atacator care a reuşit să compromită serverul Kerberos dintr-un domeniu de securitate să nu poată obţine cheia utilizatorului într-un alt astfel de domeniu.

161
6.5 Pachetul de programe PGP, Pretty Good Privacy
Acest pachet de programe reprezintă o exemplificare a conceptului PEM. El a fost conceput de Phil Zimmermann. Deoarece acesta a fost suspectat că ar fi încălcat interdicţia impusă de guvernul american asupra exportului de produse criptografice, el a fost urmărit în justiţie timp de mai mulţi ani. În prezent este patronul unei companii de software care comercializează acest pachet de programe.
Funcţionarea PGP
PGP combină câţiva dintre cei mai buni parametri ai criptografiei simetrice şi asimetrice. El este un sistem de criptare hibrid. Când un utilizator criptează un text în clar cu PGP, acesta comprimă prima dată textul în clar. Compresia creşte rezistenţa la atacuri de criptanaliză. Apoi PGP crează o cheie de sesiune care este folosită o singură dată. Această cheie este un număr aleator. Ea lucrează în acord cu un algoritm de criptare foarte sigur şi rapid pentru a cripta varianta comprimată a textului în clar. Rezultatul este textul criptat. De îndată ce datele au fost criptate, este criptată şi cheia sesiunii, folosindu-se cheia publică a destinatarului. Varianta criptată a cheii sesiunii este transmisă împreună cu textul criptat. Pentru decriptare se aplică operaţiile dscrise în ordine inversă. Destinatarul recepţionează mesajul PGP, îşi foloseşte cheia secretă pentru a reconstrui cheia sesiunii, pe care apoi programele PGP o folosesc pentru a decripta textul criptat.
Chei PGP memoreză cheile în două fişiere de pe hard disk-ul calculatorului gazdă. Unul dintre
ele este folosit pentru cheile secrete iar celălalt pentru cheile publice. Acestea se numesc inele de chei keyrings. Dacă un utilizator îşi pierde cheia secretă, el nu va mai putea să decripteze nici un mesaj PGP pe care îl primeşte.
Semnături digitale
Se folosesc pentru autentificarea sursei mesajului şi pentru verificarea integrităţii acestuia. Ele asigură şi nerepudierea mesajului. În figura următoare este exemplificat modul de generare a unei semnături digitale.
Figura 1. Inserarea unei semnături digitale.

162
În loc să se cripteze informaţia cu cheia publică a cuiva se foloseşte cheia secretă a utilizatorului. Dacă acea informaţie poate fi decriptată cu cheia publică a utilizatorului atunci înseamnă că a fost generată de către acesta.
PGP foloseşte funcţia hash MD-5 pentru a obţine un rezumat (message digest) al textului în clar pe care trebuie să-l semneze utilizatorul. Cu ajutorul acestui rezumat şi al cheii secrete a utilizatorului, acesta crează semnătura. PGP transmite împreună semnătura şi mesajul în clar. După recepţie destinatarul foloseşte PGP pentru a recompune rezumatul, verificând în acest fel semnătura. Mesajul în clar poate fi criptat sau nu. Semnarea unui text în clar este utilă dacă unii dintre destinatari nu sunt interesaţi sau nu sunt capabili să verifice semnătura.
Atât timp cât se utilizează o funcţie hash sigură, nu există nici o posibilitate să se copieze semnătura cuiva dintr-un mesaj şi să se ataşeze într-un altul sau se altereze un mesaj semnat. Cea mai mică modificare a unui document semnat va cauza insuccesul procesului de verificare a semnăturii. Semnăturile digitale joacă un rol important în autentificarea şi validarea cheilor unor noi utilizatori PGP. În figura următoare se prezintă procesul de generare şi inserare a unei semnături digitale.
Figura 2. Generarea şi inserarea unei semnături digitale.
Certificate digitale
După cum s-a arătat la prezentarea algoritmului Diffie-Hellman, o problemă majoră a sistemelor de criptare cu cheie publică este vulnerabilitatea acestora la atacul de tip man-in-the-midle. De aceea în cazul acestor sisteme de criptare este vital ca utilizatorul să fie sigur că foloseşte o cheie publică, pentru criptarea datelor, care aparţine într-adevăr destinatarului mesajului şi nu este o cheie falsificată. Aşa cum s-a arătat la prezentarea sistemului Kerberos, în scopul eliminării cheilor falsificate, pot fi folosite certificatele digitale. Acestea permit autentificarea pe baza colaborării cu o a treia entitate de încredere. Un certificat digital este compus din trei elemente:

163
- o cheie publică, - informaţie proprie (de identificare a utilizatorului), - una sau mai multe semnături digitale.
Scopul utilizării semnăturilor digitale într-un certificat este ca acesta să ateste că informaţia proprie a fost verificată şi confirmată de o a treia entitate de încredere.
Deci un certificat digital este o cheie publică la care se ataşează una sau două forme de identificare şi o aprobare de la o a treia entitate de încredere.
Distribuirea certificatelor
În cazul grupurilor mici se utilizează distribuirea manuală a certificatelor digitale. În cazul grupurilor mai mari trebuie să se folosească server-e de certificare sau alte sisteme mai complexe, de tipul celor prezentate în capitolul destinat standardelor PKCS, ale firmei RSA. Structura unui certificat digital este prezentată în figura următoare.
Figura 3. Anatomia unui certificat digital.
PGP recunoaşte două formate diferite de certificat: - certificate PGP, - certificate X.509.
Formatul de certificat PGP
Un certificat PGP include (dar nu este limitat la) următoarea informaţie: - numărul de versiune PGP. Acesta identifică ce versiune de PGP a fost folosită la generarea cheii asociate la certificatul curent, - cheia publică a certificatului. Partea publică a perechii de chei a utilizatorului,

164
împreună cu algoritmul folosit împreună cu această cheie: RSA, Diffie-Hellman, algortim de semnătură digitală, - partea de informaţie a certificatului. Este vorba despre informaţia de identificare a
utilizatorului, cum ar fi numele său, fotografia sa, etc, - semnătura digitală a distribuitorului de certificate. Se mai numeşte şi autosemnătură şi
se construieşte folosind cheia secretă corespunzătoare cheii publice amintită mai sus, - perioada de valabilitate a certificatului. Se specifică data de generare a certificatului
precum şi data expirării sale, - algoritmul de criptare simetrică preferat pentru criptarea cheii. Se indică care algoritm de criptare, dintre CAST, IDEA sau DES-triplu, este preferat de către autoritatea care eliberează certificatul.
Valabilitate şi încredere
Orice utilizator poate confunda un certificat real cu unul fals. Valabilitatea exprimă gradul de încredere cu care trebuie considerat că un certificat a fost elaborat de o anumită autoritate. Când un utilizator s-a convins că un anumit certificat este valabil el poate semna copia acestuia cu una dintre cheile de pe inelul său de chei, pentru a-i confirma autenticitatea. După cum s-a arătat în paragraful în care a fost prezentat sitemul PEM, există autorităţi de autentificare a certificatelor, CA.
Nivele de încredere în PGP
Cel mai înalt nivel de încredere într-o cheie, încredere implicită, este cel corespunzător perechii proprii de chei. PGP presupune că dacă un utilizator posedă o cheie secretă, el trebuie să aibă încredere în acţiunile efectuate pe baza cheii publice corespunzătoare. Orice cheie semnată cu ajutorul acestei chei publice este de încredere pentru acel utilizator. Există trei nivele de încredere care se poate acorda unei chei publice a unui alt utilizator:
- încredere completă, - încredere marginală, - neîncredere.
În consecinţă există şi trei nivele de validitate: - totală, - marginală, - nulă.
Pentru a considera o cheie validă PGP pretinde fie o semnătură cu încredere completă fie două semnături cu încredere marginală. Revocarea certificatelor
Certificatele digitale sunt folositoare doar atâta vreme cât sunt valabile. Când ele expiră nu mai sunt valabile.
Există şi cazuri când este necesară revocarea unui certificat digital înainte de data expirării sale.
Orice entitate care a semnat un certificat, poate să-şi revoce propria semnătură de pe acesta, de îndată ce are impresia că informaţia proprie şi cheia publică nu mai sunt în corespondenţa corectă sau că a fost atacată cheia publică. În cazul certificatelor PGP poate fi revocat şi întregul certificat (nu numai propria semnătură) de către una dintre entităţile care l-a semnat. Un certificat PGP pot fi revocat doar de către autoritatea care l-a eliberat sau de către o entitate care a fost împuternicită de către aceasta să revoce certificate.

165
Comunicarea revocării unui certificat
La revocarea unui certificat digital este important ca toţi potenţialii săi beneficiari să fie informaţi. Pentru aceasta, în cadrul sistemului PGP se afişează certificatul revocat pe un server de certificare. În acest mod toţi cei care doresc să comunice cu utilizatorul a cărui cheie publică este conţinută în acel certificat pot să fie avertizaţi că acea cheie publică nu mai este validă. Pentru aceasta se folosesc liste de certificate revocate, Certificate Revocation List, CRL, publicate de către CA. Certificatele revocate rămân pe o astfel de listă doar până la data expirării lor. CA distribuie CRL, la utilizatori, periodic. Ce este o parolă de tip frază ?
O parolă de tip frază este o variantă mai lungă de parolă care este folosită de către un utilizator în scop de identificare. Aceasta este mai sigură împotriva atacurilor bazate pe forţa brută. PGP foloseşte o parolă de tip frază pentru criptarea cheii unui utilizator pe propriul calculator. Nu este permis ca utilizatorul să-şi uite parola de tip frază.
Împărtăşirea cheilor
Se spune că un secret nu mai este secret dacă este cunoscut de două persoane. La fel este şi în cazul unei chei secrete. Deşi nu este recomandabil, uneori este necesar să se utilizeze în comun chei secrete. În aceste situaţii este recomandabil ca porţiuni ale cheii secrete să fie făcute cunoscute câte unei persoane, astfel încât acea cheie să poată fi folosită doar cu participarea tuturor acelor persoane. 6.6. Sisteme de tip firewall
Un firewall este un sistem sau un grup de sisteme care impune o politică de control al accesului între două reţele. Metodele de implementare sunt variate dar în principiu dispozitivul de tip firewall poate fi privit ca şi o pereche de două mecanisme: unul de blocare a traficului de date şi celălalt de deblocare a acestui trafic. Denumirea de firewall a fost folosită pentru prima dată la sfârşitul anului 1980, pentru un dispozitiv de limitare a pagubelor. Pentru prima oară termenul firewall a fost folosit pentru a denumi un dispozitiv de securitate în anul 1987. O primă descriere a unui dispozitiv de acest tip a fost făcută în anul 1990.
Cel mai important atribut al unui astfel de dispozitiv este politica de control pe care o implementează. În absenţa unei astfel de politici utilizarea unui dispozitiv de tip firewall nu are sens. Este de asemenea de remarcat că dispozitivul de tip firewall impune politica sa, tuturor dispozitivelor din vecinătate. De aceea responsabilitatea administratorilor de reţea care programează dispozitivele de tip firewall este importantă pentru funcţionarea reţelelor pe care le conectează aceste dispozitive.
Dispozitivul de tip firewall al unei companii poate fi folosit şi pentru a obţine informaţii despre acea companie. Prin intermediul acestui dispozitiv pot fi publicate cataloage de produse, informaţii de uz general,…, dobândirea acestora putându-se face fără a accesa vreun server din reţeaua companiei considerate.
Unele dispozitive de tip firewall permit doar traficul prin poştă electronică, protejând reţeaua de orice atac cu excepţia celor specifice pentru poşta electronică. Alte dispozitive de tip firewall realizează o protecţie mai puţin strictă, blocând doar serviciile despre care se crede că nu sunt suficient de sigure.

166
În general dispozitivele de tip firewall sunt configurate pentru a proteja împotriva accesului neautentificat din lumea externă. Dispozitive de tip firewall mai elaborate blochează traficul dinspre exterior spre interior dar permit utilizatorilor din interior să comunice liber cu exteriorul.
Dispozitivele de tip firewall sunt importante şi deoarece ele pot fi privite ca noduri în care poate fi impusă securitatea. De exemplu atacurile prin modem-uri pot fi respinse, dispozitivul de tip firewall comportându-se ca şi un înregistrator de convorbiri telefonice. El înregistrează mesajul transmis prin modem, verifică securitatea acestuia şi doar dacă mesajul este sigur îl transmite mai departe. Dispozitivele de tip firewall pot oferi administratorilor de reţea şi diferite informaţii referitoare la traficul care le-a străbătut într-un anumit interval de timp (tipul de trafic, numărul de încercări ilegale de a forţa accesul, etc).
Dispozitivele de tip firewall nu pot proteja împotriva atacurilor care nu trec prin ele. Date pot fi furate dintr-o anumită reţea şi prin acces direct (de exemplu pe o bandă magnetică) sau prin intermediul modemurilor. Pentru ca să poată funcţiona corect, un dispozitiv de tip firewall trebuie să reprezinte o parte a unei arhitecturi de securitate bazată pe o politică coerentă. Dacă una dintre celelalte părţi ale acestei arhitecturi de securitate nu funcţionează corect atunci arhitectura respectivă nu este sigură. Politica de securitate a unui dispozitiv de tip firewall trebuie să fie realistă şi să reflecte nivelul de securitate din întreaga reţea. De exemplu un calculator gazdă care deţine informaţii clasificate ca secrete nu necesită un dispozitiv de tip firewall, pur şi simplu acesta nu trebuie conectat în reţea. De asemenea dispozitivele de tip firewall nu pot proteja împotriva atacurilor pornite din interiorul reţelei.
Nici împotriva viruşilor nu poate fi asigurată o protecţie eficientă. Împotriva acestui tip de atacuri trebuie creată o politică specială a întregii reţele. Majoritatea viruşilor sunt inoculaţi prin folosirea dischetelor şi nu prin reţea.
În continuare se prezintă câteva adrese utile pentru informare în domeniul dispozitivelor de tip firewall:
http://www.net.tamu.edu/ftp/security/TAMU/ http://www.cs.purdue.edu/coast/firewalls
Implementare
Eistă câteva decizii, pe care trebuie să le ia un administrator de reţea în legătură cu instalarea unui dispozitiv de tip firewall. În primul rând trebuie cunoscut modul în care se doreşte să se opereze sistemul. E necesar ca administratorul de reţea să ştie dacă dispozitivul de tip firewall trebuie să blocheze toate servicile care nu sunt absolut necesare pentru conectarea reţelei respective la INTERNET sau dacă este suficient ca dispozitivul de tip firewall să ofere o cale obiectivă de dirijare a accesului.
În al doilea rând administratorul de reţea trebuie să ştie care este nivelul de monitorizare, redundanţă şi control necesare pentru reţeaua considerată.
Cel de al treilea este aspectul financiar.
Tipuri de dispozitive firewall
Dispozitivele de tip firewall pot fi clasificate după nivelul din modelul de referinţă OSI, la care acţionează, în două categorii: -dispozitive care acţionează la nivelul reţea, -dispozitive care acţionează la nivelul aplicaţie.

167
Dispozitivele firewall care acţionează la nivele inferioare (reţea) sunt mai rapide dar asigură un nivel de securitate mai scăzut.
Dispozitive firewall care acţionează la nivel reţea
Aceste dispozitive iau decizii pe baza adreselor sursei şi destinaţiei precum şi pe baza porturilor specificate, în adresele IP individuale. Un router obişnuit poate fi privit ca dispozitiv de tip firewall din această categorie. Dispozitivele firewall care acţionează la nivel reţea moderne sunt din ce în ce mai complicate, în prezent acestea menţin informaţii interne despre starea conexiunilor care trec prin ele precum şi despre conţinutul anumitor şiruri de date. Utilizarea unui astfel de dispozitiv este prezentată în figura 6.6.1.
Figura 6.6.1. Utilizarea unui dipozitiv de tip firewall care acţionează la nivelul reţea. După cum se vede în figură accesul la şi de la un singur calculator gazdă este controlat cu ajutorul unui router care operează la nivelul reţea. Singurul calculator gazdă, amintit mai sus este un calculator gazdă de tip Bastion, adică un calculator puternic apărat care realizează un nod cu securitate de nivel înalt pentru a rezista atacurilor. Dispozitivul de tip firewall din figura 6.6.1 este numit screened host firewall. În figura 6.6.2 se prezintă un alt exemplu de dispozitiv de tip firewall care acţionează la nivelul reţea.
Dispozitivul din figura 6.6.2 se numeşte screened subnet firewall. În cazul utilizării unui astfel de sistem este controlat accesul spre şi dinspre o întreagă reţea cu ajutorul unui router care operează la nivel reţea. Sistemul din figura 6.6.2 este similar cu un dispozitiv de tipul screened host, doar că nu este vorba despre un singur dispozitiv ci despre o reţea de dispozitive de tipul screened host.

168
Figura 6.6.2. Utilizarea unui dispozitiv de tipul screened subnet.
Dispozitive firewall care acţionează la nivel aplicaţie
Pot fi folosite ca şi translatoare de adrese de reţea deoarece traficul este dirijat într-o singură direcţie, la un anumit moment de timp, după ce a trecut printr-o aplicaţie care a mascat originea conexiunii iniţiate. Având o aplicaţie într-un anumit sens, la un moment dat, în anumite cazuri pot fi afectate performanţele reţelei iar dispozitivul de tip firewall poate deveni mai puţin transparent. Dispozitivele de tip firewall mai moderne, cu acţiune la nivelul aplicaţie, cum sunt cele construite folosind sistemul de generare a dispozitivelor firewall (toolkit) TIS, nu sunt absolut transparente la nivelul utilizatorilor de la capete şi pot necesita o perioadă de antrenament. Cele mai moderne dispozitive de tip firewall sunt perfect transparente. Dispozitivele de tip firewall care acţionează la nivel aplicaţie tind să asigure un nivel de securitate mai ridicat decât cele care acţionează la nivel reţea. Un exemplu de dispozitiv de tip firewall din această categorie este prezentat în figura 6.6.3. El este numit dual horn gateway. Este vorba despre un calculator gazdă cu un nivel de securitate sporit care rulează software de tip proxy. Are două interfeţe cu reţeaua şi blochează complet traficul care îl străbate.
Figura 6.6.3. Utilizarea unui dispozitiv de tip Dual-Homed Gateway.
Viitorul dispozitivelor de tip firewall se va găsi undeva între categoria care acţionează la nivelul reţea şi categoria care acţionează la nivelul aplicaţie. Vor fi dispozitive care vor asigura un nivel de securitate mai mare decât dispozitivele care acţionează la nivelul reţea şi o transparenţă mai mare decât dispozitivele care acţionează la nivelul aplicaţie. Din ce în ce mai des dispozitivele de tip firewall apelează la metode de criptare pentru protejarea datelor care le străbat. Dispozitivele de tip firewall cu criptare capăt la capăt pot fi folosite de organizaţii care au mai multe puncte de
169
conectare la INTERNET, în acest fel administratorii de reţea ai acestor oraganizaţii, netrebuind să-şi mai facă griji pentru protecţia datelor sau parolelor calculatoarelor organizaţiilor lor.
Server-e proxy
Un server proxy este o aplicaţie care mediază traficul între o reţea protejată şi INTERNET. De obicei astfel de server-e se utilizează în locul controloarelor de trafic baazte pe router-e, pentru a preveni traficul direct între reţele diferite. Multe server-e proxy conţin programe pentru autentificarea utilizatorului. O categorie populară de sever-e proxy este TIS, Internet Firewall Toolkit, care include server-e proxy pentru protocoalele: Telenet, rlogin, FTP, X-window, HTTP/Web şi NNTP/Usenet. Un alt sistem de server-e proxy este numit SOCKS. Acesta poate fi compilat într-o aplicaţie de tip client pentru a fi făcut să lucreze printr-un dispozitiv de tip firewall.
Resurse critice într-un dispozitiv de tip firewall
Resursele critice ale unui dispozitiv de tip firewall tind să varieze de la site la site în funcţie de trafic. Oricum una dintre cele mai importante resurse este capacitatea de memorare a unui astfel de dispozitiv, mai ales atunci când debitul traficului este ridicat. În tabelul următor se prezintă câteva dintre resursele critice pentru servicile de tip firewall în funcţie de principala aplicaţie a acestora.
Serviciu Resursa critică Poştă electronică Dispozitive I/O pentru hard-disck
Reviste electronice Netnews Dispozitive I/O pentru hard-disck Navigaţie Web Performanţele socket-ului sistemului de operare al
calculatorului gazdă Dirijare IP Performanţele socket-ului sistemului de operare al
calculatorului gazdă Web Cache Performanţele socket-ului sistemului de operare al
calculatorului gazdă, Dispozitive I/O pentru hard-disck
Diferite tipuri de atac
În continuare se prezintă câteva tipuri de atac împotriva unei reţele şi modurile în care dispozitivele de tip firewall se pot opune acestor atacuri.
Traficul dirijat de sursă
În mod normal drumul pe care îl parcurge un pachet de date între sursa şi destinaţia sa este fixat de către router-ele pe care le întâlneşte în cale. Pachetul conţine doar adresa destinaţiei. Există însă o opţiune pentru expeditorul de pachete de a include informaţii în pachet care să specifice drumul pe care trebuie să meargă pachetul respectiv. În acest mod se realizează dirijarea traficului de către sursă. Această metodă de dirijare nu este agreată de către dispozitivele de tip firewall, deoarece un atacator poate genera trafic declarând că acesta a fost creat de către un sistem din interiorul dispozitivului de tip firewall. Un astfel de trafic nu poate fi dirijat corect de către dispozitivul de tip firewall deoarece toate router-ele situate între calculatorul atacatorului şi ţintă vor returna traficul pe calea inversă a drumului "indicat" de către sursă (deci tot acest trafic fals va fi îndreptat spre dispozitivul de tip firewall). Deoarece implementarea unui astfel de atac este

170
foarte simplă, constructorii de dispozitive de tip firewall nu trebuie să accepte ca acest tip de dirijare să fie folosit. La construcţia unui dispozitiv de tip firewall trebuie blocată într-un anumit punct dirijarea traficului de către sursă.
Redirecţionare ICMP
O redirecţionare ICMP informează un anumit router că trebuie să modifice ceva în tabelul său de dirijare. În acest fel pot fi evitate de exemplu drumurile blocate (din cauză că, de exemplu, un router de pe acele drumuri s-a defectat, sau este congestionat). E clar că prin falsificarea mesajelor de redirecţionare ICMP poate fi atacat un anumit router şi traficul prin acesta blocat. Redirecţionarea ICMP poate fi folosită şi pentru realizarea unor atacuri de tip negarea serviciului, service denial. De aceea multe dispozitive de tip firewall nu iau în considerare mesajele de redirecţionare ICMP.
Negarea serviciului
Este imposibil, în INTERNET, să se pareze un atac de tipul negarea serviciului, datorită naturii distribuite a acestei reţele. Un dispozitiv de tip firewall poate avea control doar asupra câtorva elemente locale, atacul de tip negarea serviciului putându-se oricând declanşa de la distanţă mai mare.
Saturarea server-ului SMTP
Un atacator poate trimite numeroase copii ale unui aceluiaşi mesaj la o listă de adrese e-mail. Această listă transmite mesajele unui server SMTP pentru a le livra destinatarilor. În acest mod acel server poate fi saturat.
Exploatarea greşelilor din softul de aplicaţie
Majoritatea programelor de aplicaţie folosite pentru reţeaua INTERNET conţin mici greşeli, bugs. Acestea pot fi utilizate pentru atacarea servicilor implementate de aplicaţiile respective. Expunerea la acest risc poate fi redusă prin limitarea la folosirea doar a servicilor strict necesare şi utilizarea acelor programe de implementare a acestor servicii care s-au dovedit în timp cele mai fiabile şi sigure. Aceleaşi considerente sunt valabile şi pentru sistemele de operare.
6.6.1. Produse de tip firewall
În continuare se prezintă o listă de produse de acest tip indicându-se şi producătorii.
Produs Producător
Black Hole Milkyway BorderWare Border Network Technologies Brimstone SOS Corp
CENTRISecure Internet Gateway Cohesive Systems CiscoWorks Cisco Systems Cyberguard Harris Computer Systems
Data Privacy Facility Network Systems Corporation Eagle Raptor Systems

171
Firewall-1 CheckPoint Software Technologies Gauntlet TIS
GFX-94 Internet Firewall Global Technology Associates HSC GateKeeper Herve Schauer Consultants
Interceptor Technologic Interlock ANS
IRX Router Livingston Enterprises KarlBridge KarlNet
NetGate Smallworks NetLOCK(tm) Hughes
NetRanger WheelGroup NetSeer enterWorks.com
Netra Server Sun NetSP IBM
Private Internet Exchange Network Translation PORTUS LSLI
SEAL Digital Secureconnect Morning Star
Sidewinder Secure Computing Corporation Site Patrol BBN Planet Corp SmartWall V-ONE
SunScreen SPF-100 Sun Internet Commerce Group Turnstyle Firewall System Atlantic Systems Group
Tiny Personal Firewall TINY Software 6.6.2. Principii de bază în proiectarea unui dispozitiv de tip firewall
Primul pas în proiectarea unui astfel de dispozitiv este definirea nevoilor pe care trebuie să le satisfacă utilizarea sa. Trebuie identificat rolul său concret, trebuie specificate serviciile care se doreşte să fie efectuate precum şi grupurile de utilizatori pe care trebuie să-i protejeze şi gradul de protecţie oferit de aceştia. Cel de al doilea pas al metodologiei de proiectare presupune evaluarea produselor disponibile pe piaţă. În sfârşit ultimul pas al acestei metodologii presupune îmbinarea principiilor stabilite în paşii anteriori în vederea obţinerii unei soluţii convenanbile. 6.6.3. Filtrarea pachetelor Cea mai simplă soluţie constructivă pentru un dispozitiv de tip firewall prezentată în figura următoare, este filtrarea pachetelor care-l străbat. Această operaţie presupune pentru fiecare pachet identificarea protocoalelor utilizate pentru transmiterea sa, pe baza antetelor pachetului. Pentru a dirija traficul router-ul din figura 6.6.4 foloseşte un tabel de dirijare de tipul IPTABLES. Dirijarea este exemplificată în figura 6.6.5. După cum se vede în această figură există două tipuri de dirijare, la intrare şi la ieşire. Dirijarea la intrare are ca principal scop identificarea acelor pachete care sunt destinate maşinii căreia îi corespunde tabelul IPTABLES considerat şi separarea lor de pachetele destinate altor maşini. Acesta este un exemplu de filtrare de pachete. Un filtru de pachete este o bucăţică de software care se uită la antetul pachetelor pe măsură ce ele intră şi decide soarta întregului pachet. Acest filtru poate să decidă să ignore pachetul (DROP), să îl accepte (ACCEPT) sau poate să ia alte decizii mai complicate.
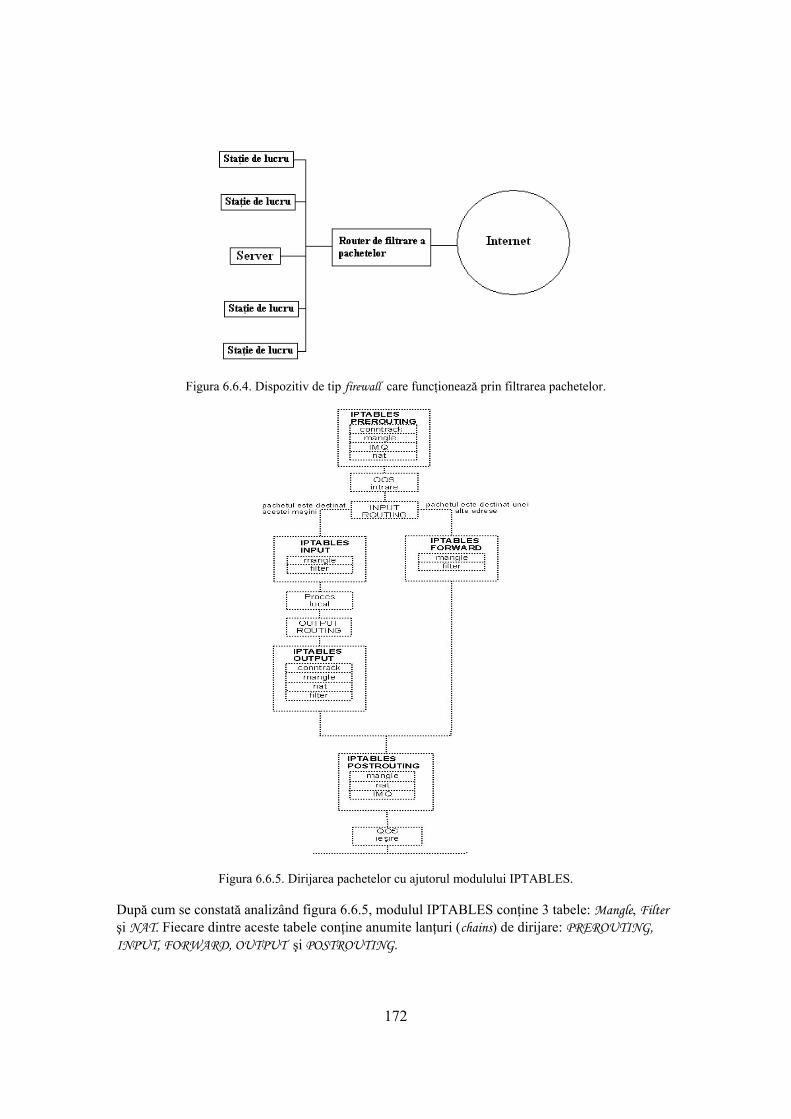
172
Figura 6.6.4. Dispozitiv de tip firewall care funcţionează prin filtrarea pachetelor.
Figura 6.6.5. Dirijarea pachetelor cu ajutorul modulului IPTABLES.
După cum se constată analizând figura 6.6.5, modulul IPTABLES conţine 3 tabele: Mangle, Filter şi NAT. Fiecare dintre aceste tabele conţine anumite lanţuri (chains) de dirijare: PREROUTING, INPUT, FORWARD, OUTPUT şi POSTROUTING.

173
Un lanţ este o listă de verificare cu reguli. Fiecare regulă spune "dacă antetul pachetului arată aşa, atunci iată ce să faci cu pachetul". Dacă regula nu se potriveşte cu pachetul, atunci următoarea regulă din lanţ este examinată. În final, dacă nu mai exista reguli de examinat, nucleul (kernel) Linux se uită la politica acelui lanţ pentru a decide soarta pachetului. Fiecare regulă sau set de reguli are o ţintă. Dacă o regulă se potriveşte, ţinta ei specifică ce se va întâmpla cu acel pachet. Există două ţinte foarte simple incluse: ACCEPT şi DROP. Există şi specificaţii de tipul salt (jump). Această instrucţiune se foloseşte când ţinta unui pachet este un alt lanţ. Sintaxa unei reguli este de forma: Iptables [-t tabel] comandă lanţ [identificatori] [ţintă/salt]. 6.6.4 Studiu de caz În figura următoare se prezintă o reţea de intreprindere protejată de un dispozitiv de tip firewall.
Figura 6.6.6. Protecţia unei reţele de intreprindere formată dintr-o reţea locală (LAN) şi o zonă demilitarizată (DMZ) cu un dispozitiv de tip firewall montat între gateway-ul reţelei şi Internet.
Reţeaua de intreprindere este compusă dintr-o reţea locală (LAN) şi o zonă demilitarizată (DMZ) cu o structură de reţea privată (Virtual Private Network - VPN). Aceasta din urmă este compusă dintr-un server web , un server de rezervă (subversion - SVN), un sistem pe care rulează protocolul LDAP (Lightweight Directory Access Protocol), o bază de date de tip Oracle şi un server de aplicaţii (AS). Dirijarea în reţeaua de intreprindere este realizată cu ajutorul unui sistem de tip gateway, care este protejat de către dispozitivul de tip firewall. De fapt, aşa după cum se vede în figura următoare deoarece dispozitivul de tip gateway are mai multe interfeţe de reţea (cel puţin două) se poate considera că se foloseşte un sistem firewall de tipul dual-homed gateway.
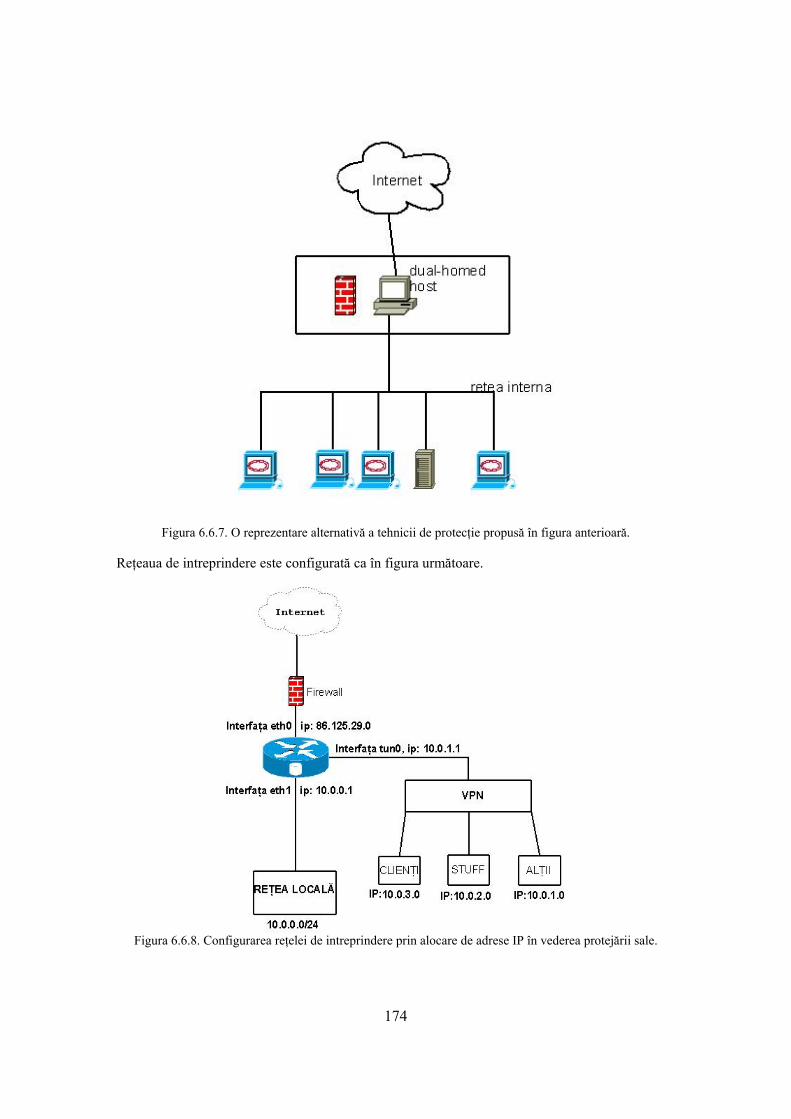
174
Figura 6.6.7. O reprezentare alternativă a tehnicii de protecţie propusă în figura anterioară.
Reţeaua de intreprindere este configurată ca în figura următoare.
Figura 6.6.8. Configurarea reţelei de intreprindere prin alocare de adrese IP în vederea protejării sale.
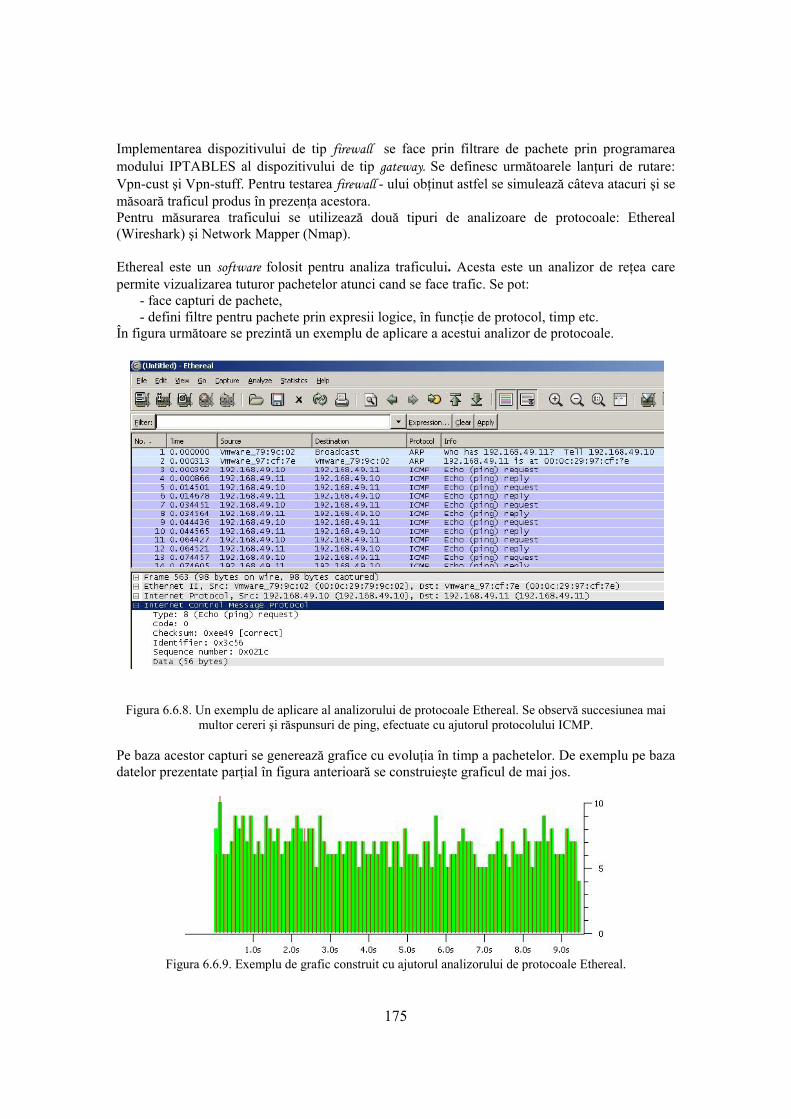
175
Implementarea dispozitivului de tip firewall se face prin filtrare de pachete prin programarea modului IPTABLES al dispozitivului de tip gateway. Se definesc următoarele lanţuri de rutare: Vpn-cust şi Vpn-stuff. Pentru testarea firewall - ului obţinut astfel se simulează câteva atacuri şi se măsoară traficul produs în prezenţa acestora. Pentru măsurarea traficului se utilizează două tipuri de analizoare de protocoale: Ethereal (Wireshark) şi Network Mapper (Nmap). Ethereal este un software folosit pentru analiza traficului. Acesta este un analizor de reţea care permite vizualizarea tuturor pachetelor atunci cand se face trafic. Se pot:
- face capturi de pachete, - defini filtre pentru pachete prin expresii logice, în funcţie de protocol, timp etc.
În figura următoare se prezintă un exemplu de aplicare a acestui analizor de protocoale.
Figura 6.6.8. Un exemplu de aplicare al analizorului de protocoale Ethereal. Se observă succesiunea mai multor cereri şi răspunsuri de ping, efectuate cu ajutorul protocolului ICMP.
Pe baza acestor capturi se generează grafice cu evoluţia în timp a pachetelor. De exemplu pe baza datelor prezentate parţial în figura anterioară se construieşte graficul de mai jos.
Figura 6.6.9. Exemplu de grafic construit cu ajutorul analizorului de protocoale Ethereal.

176
Datele pot fi capturate în timp real din reţele de tipul: Ethernet, FDDI (Fiber Distributed Data Interface), PPP, Token-Ring, IEEE 802.11 (standardul pentru LAN Wireless) şi interfeţe loopback. Ethereal suportă peste 700 de protocoale. Nmap este un utilitar open-source folosit pentru explorarea reţelei şi audit de securitate. Design-ul său permite scanarea rapidă chiar şi a reţelelor de mari dimensiuni, dar funcţionează foarte bine şi pentru un singur calculator gazdă. Nmap utilizează pachete IP brute pentru a determina ce host-uri sunt disponibile într-o reţea, ce servicii (nume de aplicaţii şi versiuni) oferă aceste host-uri, ce sisteme de operare rulează, ce tipuri de filtre de pachete sunt în uz şi multe alte caracteristici. În figura următoare se prezintă un exemplu de raport obţinut la sfârşitul unei rulări a analizorului de protocoale Nmap. [root@krishna ~]# nmap -sS 86.125.29.227 Starting Nmap 4.11 ( http://www.insecure.org/nmap/ ) at 2007-05-20 20:20 EEST Interesting ports on 86-125-29-227.oradea.rdsnet.ro (86.125.29.227): Not shown: 1676 closed ports PORT STATE SERVICE 22/tcp open ssh 53/tcp open domain 80/tcp open http 199/tcp open smux Nmap finished: 1 IP address (1 host up) scanned in 0.615 seconds
Figura 6.6.10. Exemplu de raport furnizat de analizorul de protocoale Nmap.
Nmap este foarte util pentru operaţiuni ca: inventarierea reţelei, monitorizarea host-urilor şi determinarea timpului de funcţionare a serviciilor (uptime). Ieşirea este o listă de ţinte scanate, cu diferite informaţii suplimentare, în funcţie de opţiunile utilizate. În tabel vor fi listate numărul portului, protocolul, numele serviciului şi starea. Starea poate fi: deschis (open), filtrat (filtered), închis (closed) sau nefiltrat (unfiltered). Deschis înseamnă că o aplicaţie de pe maşina ţintă ascultă pe un port. Filtrat înseamnă că un firewall, filtru sau alt obstacol blochează portul. Porturile închise nu au aplicaţii care să le asculte. Dispozitivului de tip firewall implementat i s-au aplicat următoarele teste: - Ping flood,
- Syn flood, - Scanare de porturi de pe maşina pe care e instalat firewall-ul,
- Scanare de porturi de pe o maşină aflată în exteriorul reţelei, - Scanare UDP.
Ping flood este încercarea de inundare cu pachete ICMP echo-request. În firewall există o regulă prin care se limitează rata de răspuns echo-reply, la pachetele de tip request. În figurile următoare se prezintă câteva rezultate obţinute analizând reţeaua studiată cu ajutorul analizorului de protocoale Ethereal în cazul unui astfel de atac. În figura 6.6.11 este prezentat ecranul analizorului Ethereal în prezenţa unui atac de tipul ping-flood în cazul în care nu se foloseşte firewall.
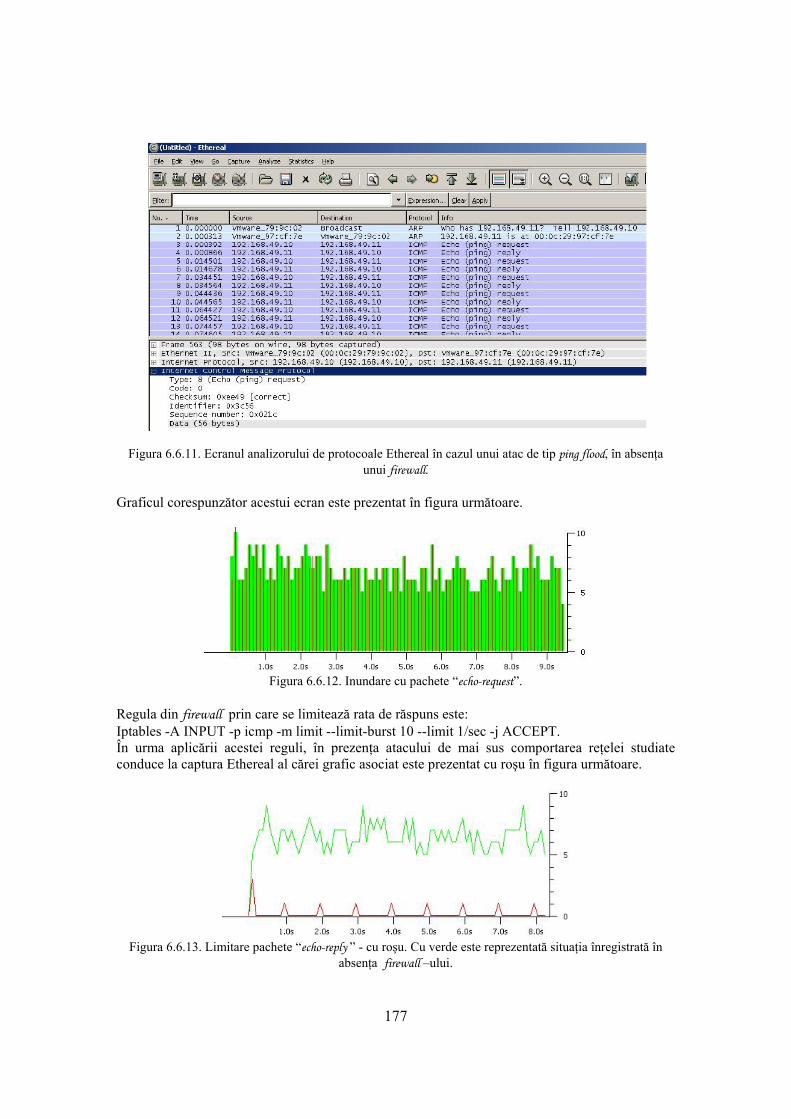
177
Figura 6.6.11. Ecranul analizorului de protocoale Ethereal în cazul unui atac de tip ping flood, în absenţa unui firewall.
Graficul corespunzător acestui ecran este prezentat în figura următoare.
Figura 6.6.12. Inundare cu pachete “echo-request”.
Regula din firewall prin care se limitează rata de răspuns este: Iptables -A INPUT -p icmp -m limit --limit-burst 10 --limit 1/sec -j ACCEPT. În urma aplicării acestei reguli, în prezenţa atacului de mai sus comportarea reţelei studiate conduce la captura Ethereal al cărei grafic asociat este prezentat cu roşu în figura următoare.
Figura 6.6.13. Limitare pachete “echo-reply ” - cu roşu. Cu verde este reprezentată situaţia înregistrată în
absenţa firewall –ului.
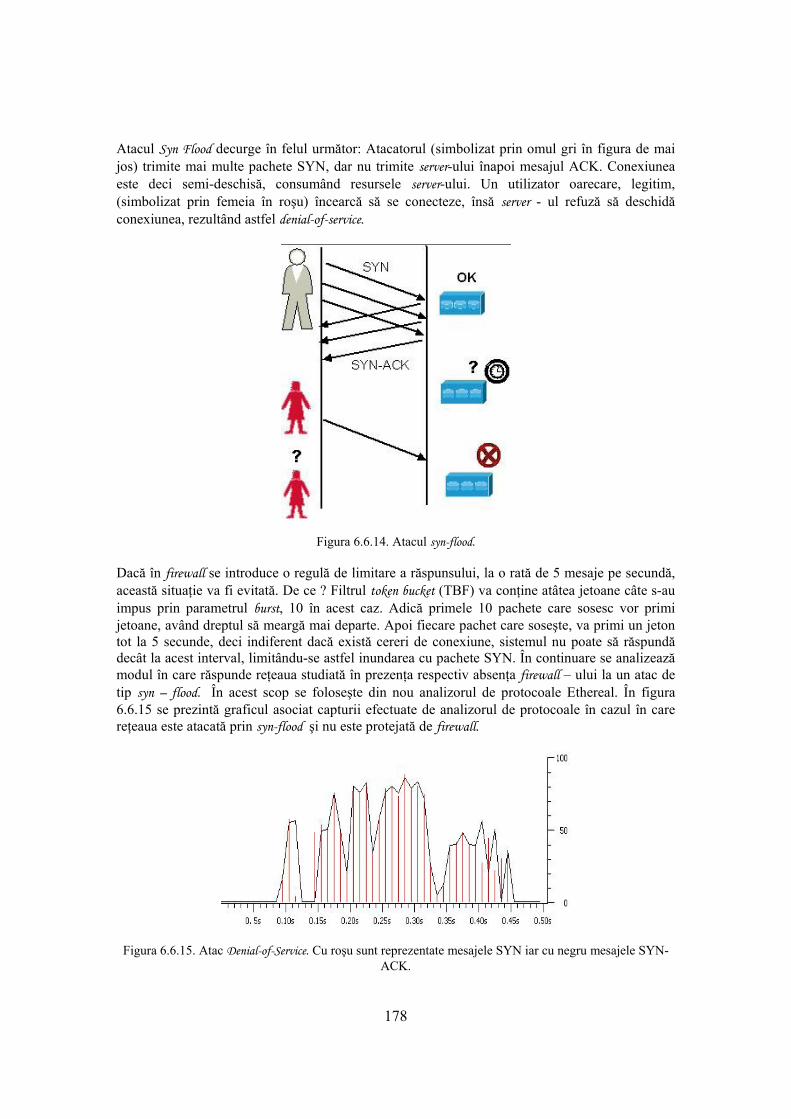
178
Atacul Syn Flood decurge în felul următor: Atacatorul (simbolizat prin omul gri în figura de mai jos) trimite mai multe pachete SYN, dar nu trimite server-ului înapoi mesajul ACK. Conexiunea este deci semi-deschisă, consumând resursele server-ului. Un utilizator oarecare, legitim, (simbolizat prin femeia în roşu) încearcă să se conecteze, însă server - ul refuză să deschidă conexiunea, rezultând astfel denial-of-service.
Figura 6.6.14. Atacul syn-flood.
Dacă în firewall se introduce o regulă de limitare a răspunsului, la o rată de 5 mesaje pe secundă, această situaţie va fi evitată. De ce ? Filtrul token bucket (TBF) va conţine atâtea jetoane câte s-au impus prin parametrul burst, 10 în acest caz. Adică primele 10 pachete care sosesc vor primi jetoane, având dreptul să meargă mai departe. Apoi fiecare pachet care soseşte, va primi un jeton tot la 5 secunde, deci indiferent dacă există cereri de conexiune, sistemul nu poate să răspundă decât la acest interval, limitându-se astfel inundarea cu pachete SYN. În continuare se analizează modul în care răspunde reţeaua studiată în prezenţa respectiv absenţa firewall – ului la un atac de tip syn – flood. În acest scop se foloseşte din nou analizorul de protocoale Ethereal. În figura 6.6.15 se prezintă graficul asociat capturii efectuate de analizorul de protocoale în cazul în care reţeaua este atacată prin syn-flood şi nu este protejată de firewall.
Figura 6.6.15. Atac Denial-of-Service. Cu roşu sunt reprezentate mesajele SYN iar cu negru mesajele SYN-ACK.
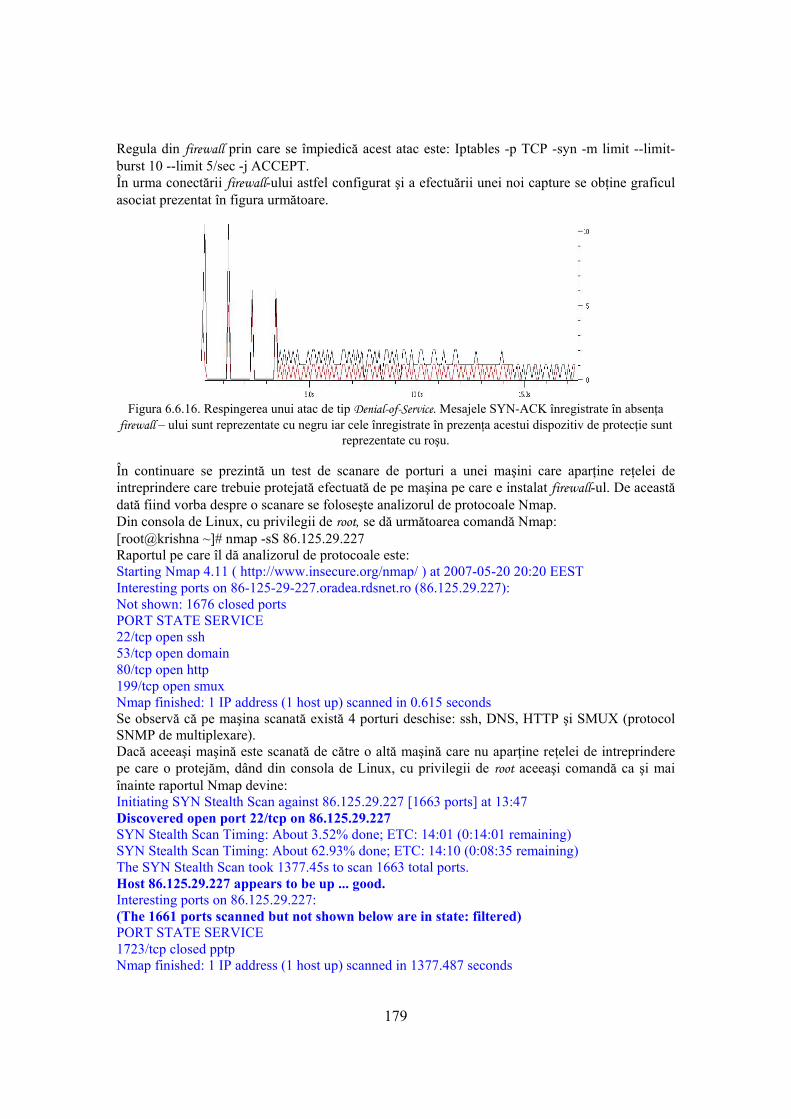
179
Regula din firewall prin care se împiedică acest atac este: Iptables -p TCP -syn -m limit --limit-burst 10 --limit 5/sec -j ACCEPT. În urma conectării firewall-ului astfel configurat şi a efectuării unei noi capture se obţine graficul asociat prezentat în figura următoare.
Figura 6.6.16. Respingerea unui atac de tip Denial-of-Service. Mesajele SYN-ACK înregistrate în absenţa
firewall – ului sunt reprezentate cu negru iar cele înregistrate în prezenţa acestui dispozitiv de protecţie sunt reprezentate cu roşu.
În continuare se prezintă un test de scanare de porturi a unei maşini care aparţine reţelei de intreprindere care trebuie protejată efectuată de pe maşina pe care e instalat firewall-ul. De această dată fiind vorba despre o scanare se foloseşte analizorul de protocoale Nmap. Din consola de Linux, cu privilegii de root, se dă următoarea comandă Nmap: [root@krishna ~]# nmap -sS 86.125.29.227 Raportul pe care îl dă analizorul de protocoale este: Starting Nmap 4.11 ( http://www.insecure.org/nmap/ ) at 2007-05-20 20:20 EEST Interesting ports on 86-125-29-227.oradea.rdsnet.ro (86.125.29.227): Not shown: 1676 closed ports PORT STATE SERVICE 22/tcp open ssh 53/tcp open domain 80/tcp open http 199/tcp open smux Nmap finished: 1 IP address (1 host up) scanned in 0.615 seconds Se observă că pe maşina scanată există 4 porturi deschise: ssh, DNS, HTTP şi SMUX (protocol SNMP de multiplexare). Dacă aceeaşi maşină este scanată de către o altă maşină care nu aparţine reţelei de intreprindere pe care o protejăm, dând din consola de Linux, cu privilegii de root aceeaşi comandă ca şi mai înainte raportul Nmap devine: Initiating SYN Stealth Scan against 86.125.29.227 [1663 ports] at 13:47 Discovered open port 22/tcp on 86.125.29.227 SYN Stealth Scan Timing: About 3.52% done; ETC: 14:01 (0:14:01 remaining) SYN Stealth Scan Timing: About 62.93% done; ETC: 14:10 (0:08:35 remaining) The SYN Stealth Scan took 1377.45s to scan 1663 total ports. Host 86.125.29.227 appears to be up ... good. Interesting ports on 86.125.29.227: (The 1661 ports scanned but not shown below are in state: filtered) PORT STATE SERVICE 1723/tcp closed pptp Nmap finished: 1 IP address (1 host up) scanned in 1377.487 seconds

180
Portul SSH este deschis, deoarece conexiunea la maşină s-a făcut de către un utilizator autentificat (user/parola). Restul porturilor sunt închise, aşa cum şi trebuie ele să apară pentru un utilizator care este în exterior. Deşi cele mai multe servicii în Internet folosesc protocolul TCP, serviciile UDP sunt de asemenea foarte utilizate. DNS (Domain Name System), SNMP (Simple Network Management) şi DHCP (Dynamic Host Configuration Protocol) sunt cele mai cunoscute. Acest tip de scanare este mult mai lentă decât cea TCP, dar este foarte utilă deoarece un atacator sigur nu va ignora acest protocol. Scanarea funcţionează în felul următor: se trimite un antet UDP la portul ţintă. Dacă se returnează o eroare ICMP unreachable (tip 3, cod 3), portul este închis. Alte erori ICMP (tip 3, cod 1,2,9,10 sau 13) marchează portul ca fiind filtrat. Dacă nu se primeşte nici un răspuns, portul este clasificat ca fiind deschis/filtrat. Acest lucru înseamnă că portul poate fi deschis sau că un filtru de pachete blochează comunicaţia. În continuare se prezintă rezultatele scanării UDP a porturilor unei maşini din reţeaua de intreprindere pe care o studiem efectuată de pe două maşini, una din interiorul şi cea de a doua din exteriorul acestei reţele. În cazul scanării UDP din interiorul reţelei, cu privilegii de root se rulează următoarea comandă cu Nmap: [root@krishna tmp]# nmap -sU gw Rezultatul scanării este: Starting Nmap 4.11 ( http://www.insecure.org/nmap/ ) at 2007-05-20 22:30 EEST Interesting ports on 10.0.0.1: Not shown: 1479 closed ports PORT STATE SERVICE 53/udp open|filtered domain 67/udp open|filtered dhcps 68/udp open|filtered dhcpc 123/udp open|filtered ntp 137/udp open|filtered netbios-ns 138/udp open|filtered netbios-dgm 161/udp open|filtered snmp 32768/udp open|filtered omad Nmap finished: 1 IP address (1 host up) scanned in 1.808 seconds Interpretarea scanării: Se observă că porturile 53 (DNS), 67 (DHCPS), 68 (DHCPC), 123 (NTP-Network Time Protocol), 137 (NetBios-NS), 138 (NetBios-DGM) şi 161 (SNMP) sunt în starea open|filtered, ceea ce înseamnă că există un mecanism de filtrare (firewall-ul). Deci regulile de filtrare din firewall funcţionează corect. În cazul scanării din exteriorul reţelei comanda Nmap este urmatoarea: [root@localhost ~]# nmap -vv -sU -F 86.125.29.227 -P0 Aceasta este o scanare rapidă (specificată prin parametrul -F), iar prin parametrul -PO se specifică comanda "No Ping" (pentru a trece peste testul de "descoperire host"). Rezultatul scanării: Initiating SYN Stealth Scan against 86.125.29.227 [1663 ports] at 13:47 Discovered open port 22/tcp on 86.125.29.227 SYN Stealth Scan Timing: About 3.52% done; ETC: 14:01 (0:14:01 remaining) SYN Stealth Scan Timing: About 62.93% done; ETC: 14:10 (0:08:35 remaining) The SYN Stealth Scan took 1377.45s to scan 1663 total ports. Host 86.125.29.227 appears to be up ... good. Interesting ports on 86.125.29.227: (The 1661 ports scanned but not shown below are in state: filtered) PORT STATE SERVICE 22/tcp open ssh 1723/tcp closed pptp

181
Nmap finished: 1 IP address (1 host up) scanned in 1377.487 sec Raw packets sent: 3509 (140KB) | Rcvd: 3392 (156KB) Interpretare: Singurul port care apare deschis este SSH, dar acest lucru este normal deoarece conexiunea s-a făcut prin SSH, însă în mod autorizat (user/parola), pentru a putea efectua testul de la distanţă (nu din reţeaua locală). În cazul în care un atacator ar incerca o astfel de scanare, nu ar reuşi, deoarece mai întâi trebuie să se conecteze la maşină şi nu poate face acest lucru decât dacă obţine (în mod fraudulos) un user şi o parolă. În urma testelor efectuate se constată că soluţia de dispozitiv firewall propusă în acest studiu de caz este eficientă.


















