
Arbori Huffman - Implementare in C++
109
Arbori Huffman. Implementare în C++ -1-
-
Upload
claudiu-stoican -
Category
Documents
-
view
1.118 -
download
21
description
Implementarea algoritmului de compresie Huffman in limbajul cpp
Transcript of Arbori Huffman - Implementare in C++

Arbori Huffman. Implementare în C++
-1-

CUPRINS
INTRODUCERE.................................................................................................. 3CAPITOLUL 1 - CODIFICAREA HUFFMAN................................................ 4 1.1 Concepte generale despre compresia datelor.......................................... 4
1.2 Algoritmi entropici ................................................................................. 8 1.3 Compresie Huffman................................................................................. 10 1.4 Construcţia arborelui Huffman................................................................ 12 1.4.1 Arborele binar Huffman............................................................. 12 1.4.2 Definiţia arborilor binari optimali.............................................. 15
1.4.3 Construcţia arborilor binari optimali......................................... 16 1.4.4 Algoritm de construcţie a arborelui Huffman
optimal........................................................................................ 17 1.5 Coduri Huffman........................................................................................ 19
1.5.1 Codificarea caracterelor............................................................ 20 1.5.2 Obținerea codificării textului.................................................... 22 1.6 Realizarea algoritmul Huffman prin metoda greedy................................ 24 1.6.1 Tehnica greedy.......................................................................... 24 1.6.2 Codificarea Huffman prin metoda greedy................................ 27CAPITOLUL 2-ANALIZA ALGORITMULUI DE CODIFICARE
HUFFMAN........................................................................... 31 2.1 Corectitudinea algoritmului Huffman....................................................... 31 2.2 Coduri prefix............................................................................................ 33 2.2.1 Coduri prefix. Arbore de codificare......................................... 33 2.2.2 Construcţia codificării prefix a lui Huffman............................. 35 2.3 Variante ale algoritmului lui Huffman......................................................................... 37 2.3.1 Metoda de codare dinamică Huffman...................................... 38 2.3.2 Algoritmul FGK......................................................................... 44 2.3.3 Algoritmul V.............................................................................. 47CAPITOLUL 3-IMPLEMENTAREA ALGORITMULUI DE
CODIFICARE/DECODIFICARE HUFFMAN............... 48 3.1. Implementarea algoritmului de compresie.............................................. 48 3.2 Implementarea algoritmului de expandare (de-compresie)....................... 54 3.3 Rezultate obținute……………………………………………………....... 56CONCLUZII.......................................................................................................... 57BIBLIOGRAFIE................................................................................................... 59ANEXA 1 – Program C........................................................................................ 73ANEXA 2 – Program C++.................................................................................... 78
INTRODUCERE
-2-

În lucrarea de fața tratez metodele Huffman de codificare și comprimare a
datelor, necesare pentru elaborarea unor algoritmi optimi care să micşoreze spaţiul
necesar memorării unui fişier.
Tehnicile de compresie sunt utile pentru fişiere text, în care anumite caractere
apar cu o frecvenţă mai mare decât altele, pentru fişiere ce codifică imagini sau sunt
reprezentări digitale ale sunetelor ori ale unor semnale analogice, ce pot conţine
numeroase motive care se repetă. Chiar dacă astăzi capacitatea dispozitivelor de
memorare a crescut foarte mult, algoritmii de compresie a fişierelor rămân foarte
importanţi, datorită volumului tot mai mare de informaţii ce trebuie stocate. În plus,
compresia este deosebit de utilă în comunicaţii, transmiterea informaţiilor fiind mult
mai costisitoare decât prelucrarea lor.
Una dintre cele mai răspândite tehnici de compresie a fişierelor text, care, în
funcţie de caracteristicile fişierului ce urmează a fi comprimat, conduce la reducerea
spaţiului de memorie necesar cu 20%-90%, a fost descoperită de D. Huffman în 1952
şi poartă numele de codificare (cod) Huffman. În loc de a utiliza un cod în care
fiecare caracter să fie reprezentat pe 7 sau pe 8 biţi (lungime fixă), se utilizează un
cod mai scurt pentru caracterele care sunt mai frecvente şi coduri mai lungi pentru
cele care apar mai rar. În unele cazuri această metoda poate reduce dimensiunea
fişierelor cu peste 70%, în special în cazul fişierelor de tip text.
Lucrarea este structurată în trei capitole. Primul capitol prezintă conceptul de
compresie a datelor şi metoda Huffman de compresie statică. Tot aici am
exemplificat aplicarea metodei pe un text şi am construit arborele binar Huffman
corespunzător textului respectiv. În al doilea capitol am demonstrat corectitudine
algoritmului Huffman dedus în primul capitol, am exemplificat modul de codificare
şi decodificare a datelor cu metoda Huffman statică şi am prezentat alte variante ale
algoritmului Huffman. În capitolul trei am implementat algoritmul de codificare şi
decodificare Huffman în limbajul C++. Tot aici am prezentat structurile de date
utilizate pentru implementare şi am explicat în detaliu modul de construcţie al
algoritmului.
-3-

CAPITOLUL 1
CODIFICAREA HUFFMAN
1.1 Concepte generale despre compresia datelor
Noţiunea de comprimare a datelor a apărut din necesitatea evidentă de a
atinge rate mari de transfer în reţele sau de a stoca o cantitate cât mai mare de
informaţii folosind cât mai puţin spaţiu. Compresia datelor este necesară în zilele
noastre şi este foarte des folosită, mai ales în domeniul aplicaţiilor multimedia.
Un compresor de date este o aplicaţie care, pe baza unuia sau mai multor
algoritmi de compresie, diminuează spaţiul necesar stocării informaţiei utile
conţinute de un anumit set de date. Pentru orice compresor de date este necesară
condiţia de existenţă a cel puţin unui decompresor care, pe baza informaţiilor
furnizate de compresor, să poată reconstitui informaţia care a fost comprimată. În
cazul în care nu există un decompresor, atunci datele comprimate devin inutile pentru
utilizator deoarece acesta nu mai are acces la informaţia stocată în arhivă (o arhivă
reprezintă rezultatul obţinut în urma utilizării unui compresor).
Un compresor de date este format din următoarele elemente:
- una sau mai multe surse de informaţie;
- unul sau mai mulţi algoritmi de compresie;
- una sau mai multe transformări.
Sursa de informaţie pentru un compresor poate fi constituită de unul sau mai
multe fişiere sau de un flux de date care a fost transmis compresorului prin
intermediul unei reţele. Datele arhivate urmează să fie stocate într-o arhivă care
urmează să fie păstrată local sau urmează să fie transmisă mai departe.
Există două categorii principale de algoritmi pentru compresia datelor:
1. algoritmi de compresie fără pierderi de date
1.1. algoritmi entropici de compresie a datelor (algoritmi care elimină redundanţa
din cadrul seturilor de date):
-4-

- algoritmul Huffman
- algoritmul Shannon-Fano
- algoritmi de compresie aritmetică (acesta este cel mai performant
algoritm entropic cunoscut).
1.2. algoritmi bazaţi pe dicţionare
- Lempel Ziff 77 (LZ77), Lempel Ziff 78 (LZ78)
- variante ale algoritmilor din categoria LZ
1.3. transformări fără pierderi de date
- Run Length Encoding (RLE)
- Burrow-Wheeler Transform (BWT)
- transformarea delta
2. algoritmi de compresie cu pierderi de date
2.1. algoritmi folosiţi pentru compresia audio care se bazează pe proprietăţile
undelor sonore şi perceperea lor de către om;
2.2. algoritmi utilizaţi pentru compresia imaginilor digitale;
2.3. algoritmi utilizaţi pentru compresia datelor video.
Algoritmii de compresie aparţinând celei de-a doua clase (cea cu pierderi de
date) se folosesc împreună cu cei din prima pentru atingerea unor rate mari de
compresie .
Metodele de compresie text pot fi împărţite în doua categorii: statistice şi ne-
statistice. Metodele statistice utilizează un model probabilistic al sursei de
informaţie. Astfel de coduri sunt Shannon-Fano sau Huffman. Metodele ne-statistice
utilizează alte principii de codare cum sunt cele bazate pe dicţionare, deci nu folosesc
probabilităţile simbolurilor.
In cazul metodelor statistice, un punct important în compresia datelor fără
pierdere de informaţie este dat de posibilitatea organizării/descompunerii compresiei
în două funcţii: modelare şi codificare. Metoda statistică are la bază folosirea
probabilităţilor simbolurilor în stabilirea cuvintelor de cod. Daca modelul sursei este
stabilit înaintea etapei de codare, şi rămâne neschimbat în timpul codării, metoda de
compresie este una statică. Algoritmul de compresie este unul „mecanic” prin
înlocuirea fiecărui simbol la sursei cu cuvântul de cod corespunzător, şi transmiterea
-5-

acestuia pe canal. Metodele statice presupun transmiterea pe canal a informaţiilor
despre modelului sursei şi/sau a codului folosit, astfel încât decodorul să poate
efectua operaţia de decodare. Canalul de comunicaţie se considera fără erori.
O metodă statică este aceea în care transformarea mulţimii mesajelor în
cuvinte de cod este fixată înainte de începerea transmisiei, astfel încât un mesaj dat
este reprezentat prin acelaşi cuvânt de cod de fiecare data când apare în mesajul
global. Un exemplu de codare statică, bazată de cuvinte de cod, este codarea
Huffman (statică). Aici asignarea cuvintelor la mesajele sursei este bazată pe
probabilităţile cu care mesajele sursei apar în mesajul global. Mesajele care apar mai
frecvent sunt reprezentate prin cuvinte de cod mai scurte; mesajele cu probabilităţi
mici sunt reprezentate de cuvinte de cod mai lungi.
La fiecare pas de codare este necesar să se estimeze probabilităţile de utilizare
a simbolurilor sursei. Codorul preia distribuţia de probabilitate şi stabileşte codul
folosit pentru compresie. Se estimează probabilităţile de utilizare a simbolurilor
sursei. Codorul preia distribuţia de probabilitate şi stabileşte codul folosit pentru
compresie.
Figura 1.1 Structura compresiei statice fără pierdere de informaţie
-6-

Figura 1.2 Structura compresiei adaptive fără pierdere de informaţie (lossless compression)
Un cod este dinamic (dynamic) dacă codarea mulţimii mesajelor sursei
primare se schimbă în timp. De exemplu, codarea Huffman dinamică presupune
estimarea probabilităţilor de apariţie în timpul codării, în timp ce mesajul este
procesat. Asignarea cuvintelor de cod mesajului de transmis (de codificat) se bazează
pe frecvenţele de apariţie la fiecare moment de timp. Un mesaj x poate fi reprezentat
printr-un cuvânt de cod scurt la începutul transmisiei pentru că apare frecvent la
începutul transmisiei, chiar dacă probabilitatea sa de apariţie raportată la întreg
ansamblu este mică. Mai târziu, cuvintele de cod scurte pot fi asignate altor mesaje
dacă frecvenţa de apariţie se schimbă.
Codurile dinamice se mai numesc şi coduri adaptive, care va fi folosit mai
departe, întrucât ele se adaptează la schimbările mesajului în timp. Toate metodele
adaptive sunt metode într-un singur pas: numai o singura trecere (scan) a realizării
sursei este necesară. În opoziţie, codarea Huffman statică este în doi paşi: un pas
pentru determinarea probabilităţilor şi determinarea codului, şi – al doilea par, pentru
codare. Metodele într-un singur pas sunt mai rapide. În plus, în cazul metodelor
statice, codul determinat la primul pas trebuie transmis decodorului, împreună cu
mesajul codat. Codul se poate transmite la începutul fiecărei transmisii sau acelaşi
cod poate fi folosit pentru mai multe transmisii.
În metodele adaptive, codorul defineşte şi redefineşte dinamic cuvintele de
cod, în timpul transmisiei. Decodorul trebui să definească şi să redefinească codarea
în acelaşi mod, în esenţa prin „învăţarea” cuvintelor de cod în momentul
-7-

recepţionării acestora. Dificultatea primară a utilizării codării adaptive este
necesitatea folosirii unui buffer între sursă şi canal. Reţelele de date alocă, deci,
resurse de comunicaţie sursei, în sensul alocării de memorie (buffere) ca parte a
sistemului de comunicaţie.
În final există şi metode hibride, care nu sunt complet statice sau complet
dinamice. Într-un astfel de caz simplu, emiţătorul şi receptorul folosesc o mulţime de
coduri statice (codebooks). La începutul fiecărei transmisii, emiţătorul alege şi
trebuie să transmită numărul (numele, identificatorul) codului folosit.
Compresia textelor este un subset al compresiei datelor şi se ocupă cu acei
algoritmi care au proprietatea ca toată informaţia prezentă în fişierul original, fişier
necompresat, este prezentă în fişierul comprimat şi deci în fişierul expandat. Nu se
acceptă o pierdere de informaţie, chiar dacă algoritmul de compresie poate adăuga
informaţie redundantă necesară pentru a efectua în bune condiţii decompresia
(expandarea). Aceste tehnici garantează obţinerea unui fişier expandat identic cu cel
original, existent înaintea compresiei. Aceşti algoritmi se numesc fără pierderi
(lossless), reversibili sau fără zgomot (noiseless).
Termenul text trebuie interpretat în sens larg. Este clar că un text poate fi scris
în limbaj natural sau poate fi generat de translatoare (aşa cum fac diverse
compilatoare). Un text poate fi considerat că o imagine (rezultată dintr-o scanare, aşa
cum este cazul telefaxului) sau alte tipuri de structuri ce furnizează date în fişiere
liniare.
1.2 Algoritmi entropici
Majoritatea surselor de informaţie din domeniul calculatoarelor şi al aplicaţiilor
internet sunt discrete. Pentru a descrie o sursă discretă fără memorie (SDFM) sunt
necesare două mărimi: alfabetul sursei şi probabilităţile de furnizare a fiecărui
simbol:
; (1.1)
-8-

Dacă numărul de simboluri este finit, sursa se numeşte discretă. Dacă la un
moment dat se emite sigur un simbol atunci sursa este completă. Sursa este fără
memorie dacă evenimentele sk sunt independente, adică furnizarea unui simbol la un
moment dat nu depinde de simbolurile furnizate anterior. Totalitatea simbolurilor
unei surse formează alfabetul sursei. Orice succesiune finită de simboluri, în
particular un singur simbol, se numeşte cuvânt. Totalitatea cuvintelor formate cu un
anumit alfabet se numeşte limbaj.
Informaţia furnizată de un simbol al sursei este:
[biţi] (1.2)
Entropia este informaţia medie pe simbol sau, altfel formulat, este
incertitudinea medie asupra simbolurilor sursei S, sau informaţia medie furnizată de
un simbol.
[bit/simbol] (1.3)
Noţiunea de informaţie trebuie legată şi de timp, întrucât, cel puţin din
punct de vedere al utilizatorului informaţiei, nu este indiferent dacă furnizarea unui
simbol are loc într-o oră sau într-un an. În acest sens, se defineşte debitul de
informaţie al unei surse discrete.
Definiţie - Debitul de informaţie cantitatea medie de informaţie furnizată în
unitatea de timp.
(1.4)
unde este durata medie de furnizare a unui simbol:
(1.5)
Definiţie: Redundanţa unei surse discrete de informaţie este diferenţa dintre
valoarea maximă posibilă a entropiei şi entropia sa:
(1.6)
-9-
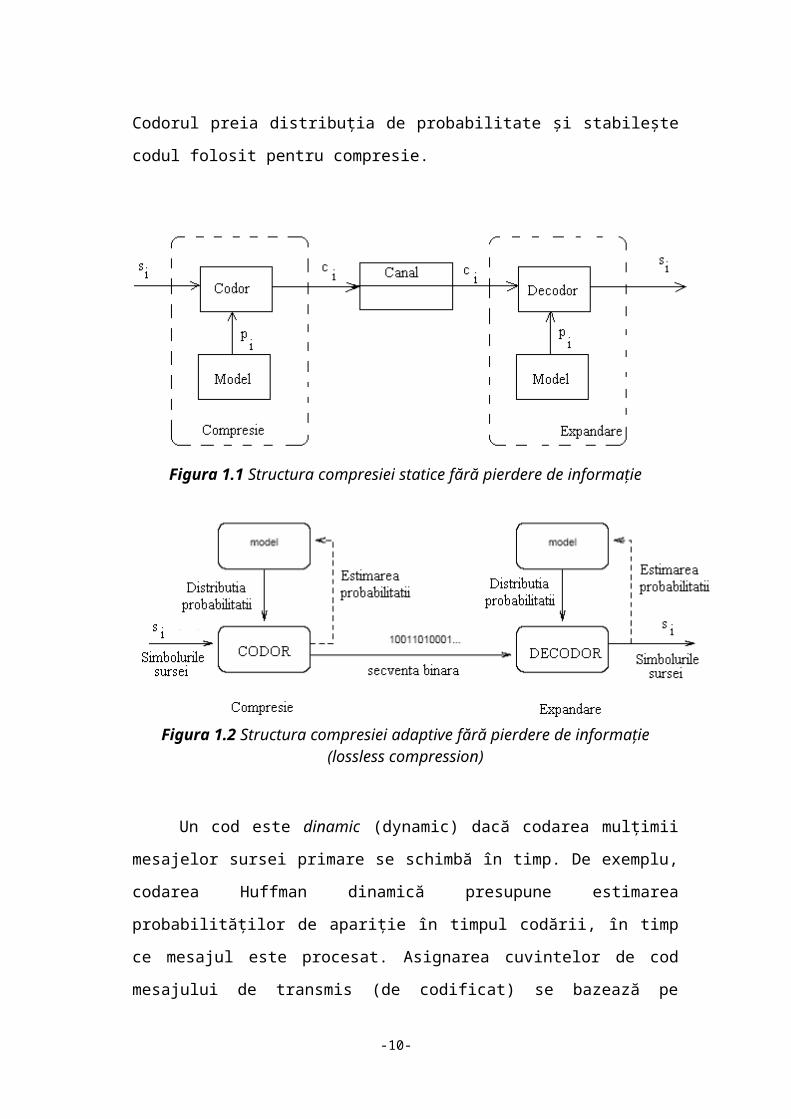
In cadrul compresiei se are în vedere sistemul de transmitere a informaţiei din
figura 1.1.1. Procesul de transformare a mesajelor sursei într-un mesaj codat se
numeşte codare (coding sau encoding, în engleza). Algoritmul care construieşte
transformarea se numeşte codor (encoder, în engleza). Decodorul realizează
transformarea inversă, generând mesajul în forma sa originală.
Canalul se consideră fără erori, deci este canal fără perturbaţii. Alfabetul
codului este, în general, X={xk | k=1,2,...,D}. Pentru cazul compresiei sa va
considera cazul binar.
Codificarea a apărut ca o necesitate de schimbare a formei de prezentare a
informaţiei în scopul prelucrării sau transmiterii acesteia. Codificarea poate fi
uniformă (bloc), dacă se foloseşte aceeaşi lungime a cuvintelor de cod, sau
neuniformă (variabilă), când lungimea cuvintelor de cod nu este constantă. Operaţia
inversă codificării se numeşte decodificare, adică transformarea inversă ce permite
obţinerea formei iniţiale de reprezentare a informaţiei.
1.3 Compresie Huffman
Tehnicile de compresie sunt utile pentru fişiere text, în care anumite caractere
apar cu o frecvenţă mai mare decât altele, pentru fişiere ce codifică imagini sau sunt
reprezentări digitale ale sunetelor ori ale unor semnale analogice, ce pot conţine
numeroase motive care se repetă. Chiar dacă astăzi capacitatea dispozitivelor de
memorare a crescut foarte mult, algoritmii de compresie a fişierelor rămân foarte
importanţi, datorită volumului tot mai mare de informaţii ce trebuie stocate. În plus,
compresia este deosebit de utilă în comunicaţii, transmiterea informaţiilor fiind mult
mai costisitoare decât prelucrarea lor.
Una dintre cele mai răspândite tehnici de compresie a fişierelor text, care, în
funcţie de caracteristicile fişierului ce urmează a fi comprimat, conduce la reducerea
spaţiului de memorie necesar cu 20%-90%, a fost descoperită de D. Huffman în 1952
şi poartă numele de codificare (cod) Huffman. În loc de a utiliza un cod în care
fiecare caracter să fie reprezentat pe 7 sau pe 8 biţi (lungime fixă), se utilizează un
cod mai scurt pentru caracterele care sunt mai frecvente şi coduri mai lungi pentru
cele care apar mai rar.
-10-

Să presupunem că avem un fişier de 100.000 de caractere din alfabetul
{a,b,c,d,e,f}, pe care dorim să-l memorăm cât mai compact. Dacă am folosi un cod
de lungime fixă, pentru cele 6 caractere, ar fi necesari câte 3 biţi. De exemplu, pentru
codul:
a b c d e f
cod fix 000 001 010 011 100 101
ar fi necesari în total 300.000 biţi.
Să presupunem acum că frecvenţele cu care apar în text cele 6 caractere sunt :
a b c d e f
frecvenţă 45 13 12 16 9 5
Considerând următorul cod de lungime variabilă :
a b c d e f
cod variabil 0 101 100 111 1101 1100
ar fi necesari doar 224.000 biţi (deci o reducere a spaţiului de memorie cu
aproximativ 25%).
Problema se reduce deci la a asocia fiecărui caracter un cod binar, în funcţie
de frecvenţă, astfel încât să fie posibilă decodificarea fişierului comprimat, fără
ambiguităţi. De exemplu, dacă am fi codificat a cu 1001 şi b cu 100101, când citim
în fişierul comprimat secvenţa 1001 nu putem decide dacă este vorba de caracterul a
sau de o parte a codului caracterului b.
-11-

Ideea de a folosi separatori între codurile caracterelor pentru a nu crea
ambiguităţi ar conduce la mărirea dimensiunii codificării.
Pentru a evita ambiguităţile este necesar ca nici un cod de caracter să nu fie
prefix al unui cod asociat al unui caracter (un astfel de cod se numeşte cod prefix).
1.4 Constructia arborelui Huffman
D. Huffman a elaborat un algoritm care construieşte un cod prefix optimal,
numit cod Huffman. Prima etapă în construcţia codului Huffman este calcularea
numărului de apariţii ale fiecărui caracter în text.
1.4.1 Arborele binar Huffman
Există situaţii în care putem utiliza frecvenţele standard de apariţie a caracterelor,
calculate în funcţie de limbă sau de specificul textului.
Fie C={c1,c2,...,cn} mulţimea caracterelor dintr-un text, iar f1,f2,...,fn, respectiv,
numărul lor de apariţii. Dacă li ar fi lungimea şirului ce codifică simbolul c i, atunci
lungimea totală a reprezentării ar fi :
Scopul nostru este de a construi un cod prefix care să minimizeze această
expresie. Pentru aceasta, construim un arbore binar complet în manieră bottom-up
astfel :
-Iniţial, considerăm o partiţie a mulţimii C={ {c1,f1},{c2,f2}, ..., {cn,fn}},
reprezentată printr-o pădure de arbori formaţi dintr-un singur nod.
-Pentru a obţine arborele final, se execută n-1 operaţii de unificare.
Unificarea a doi arbori A1 şi A2 constă în obţinerea unui arbore A, al cărui
subarbore stâng este A1, subarbore drept A2, iar frecvenţa rădăcinii lui A este suma
frecvenţelor rădăcinilor celor doi arbori. La fiecare pas unificăm 2 arbori ale căror
rădăcini au frecvenţele cele mai mici.
-12-

De exemplu, arborele Huffman asociat caracterelor {a,b,c,d,e,f} cu
frecvenţele {45,13,12,16,9,5} se construieşte pornind de la cele cinci noduri din
figura 1:
Fig. 1.3
Pas 1: Unific arborii corespunzători lui e şi f, deoarece au frecvenţele cele mai mici:
Fig. 1.4
Pas 2: Unific arborii corespunzători lui b şi c:
Fig. 1.5
Pas 3: Unific arborele corespunzător lui d şi arborele obţinut la primul pas, cu
rădăcina ce are frecvenţa 14:
Fig. 1.6
Pas 4: Unific arborii ce au frecvenţele 25 şi 30.
-13-

Fig. 1.7
Pas 5: Unificând ultimii doi arbori, obţin arborele Huffman asociat acestui set de
caractere cu frecvenţele specificate iniţial.
Fig. 1.8
Nodurile terminale vor conţine un caracter şi frecvenţa corespunzătoare
caracterului; nodurile interioare conţin suma frecvenţelor caracterelor
corespunzătoare nodurilor terminale din subarbori.
Arborele Huffman obţinut va permite asocierea unei codificări binare fiecărui
caracter. Caracterele fiind frunze în arborele obţinut, se va asocia pentru fiecare
deplasare la stânga pe drumul de la rădăcină la nodul terminal corespunzător
caracterului un 0, iar pentru fiecare deplasare la dreapta un 1.
Obţinem codurile :
a b c d e f
cod 0 100 101 110 1110 1111
-14-

Observaţii
- caracterele care apar cel mai frecvent sunt mai aproape de rădăcină şi astfel
lungimea codificării va avea un număr mai mic de biţi.
- la fiecare pas am selectat cele mai mici două frecvenţe, pentru a unifica
arborii corespunzători. Pentru extragerea eficientă a minimului vom folosi un min-
heap. Astfel timpul de execuţie pentru operaţiile de extragere minim, inserare şi
ştergere va fi, în cazul cel mai defavorabil, de O(log n).
- arborii Huffman nu sunt unici. Adică, poţi avea arbori diferiţi, pentru acelaşi
set de frunze cu aceleaşi frecvenţe. De exemplu,dacă ai frunze cu aceeaşi frecvenţă,
poziţia unora fată de celelalte nu este importantă.
1.4.2 Definiţia arborilor binari optimali
Uneori se cunosc probabilităţile de acces la cheile dintr-un arbore, astfel încât
organizarea
arborelui binar le poate lua în calcul.
Se pune problema ca numărul total al paşilor de căutare contorizat pentru un
număr suficient de încercări, să fie minim.
Se defineşte drumul ponderat ca fiind suma tuturor drumurilor de la
rădăcină la fiecare nod, ponderate cu probabilităţile de acces la noduri:
unde - ponderea nodului i
- nivelul nodului i.
-15-

Se urmăreşte minimizarea lungimii drumului ponderat, pentru o distribuţie
dată.
Fig. 1.9
Daca organizarea arborelui binar ia în considerare şi probabilităţile
(ponderile) căutărilor nereuşite, deci notând cu probabilitatea căutării unei chei cu
valoarea între cheile şi , lungimea drumului ponderat va fi:
unde
Se consideră toate structurile de arbori binari care pot fi alcătuiţi pornind de
la setul de chei , având probabilităţile asociate şi . Se numeşte arbore binar
optim, arborele a cărui structură conduce la un cost minim.
1.4.3 Construcţia arborilor binari optimali
Arborii optimali au proprietatea că toţi subarborii lor sunt optimali, sugerând
algoritmul care construieşte sistematic arbori din ce în ce mai mari, pornind de la
nodurile individuale (subarbori de înălţime 1), arborii crescând de la frunze spre
rădăcină, conform metodei "bottom-up".
Notând cu P lungimea drumului ponderat al arborelui, cu PS şi PD lungimile
drumurilor ponderate ale subarborilor stâng şi drept ai rădăcinii şi cu W ponderea
-16-

arborelui, deci numărul de treceri prin rădăcină (tocmai numărul total de căutari în
arbore):
Media lungimii drumului ponderat e P/W.
1.4.4 Algoritm de construcţie a arborelui Huffman optimal
S-a realizat un algoritm cu o eficienţă O(n log n) pentru construirea unui arbore
Huffman, datorită lui Hu şi a lui Tucker. Se foloseşte un vector de noduri ce conţin o
frecvenţă şi pointeri către dreapta şi stânga.
Frunze Număr
1
2
.
.
.
.
.
.
.
.
.
.
f(i) Stânga Dreapta
f1 0 0
f2 0 0
f3 0 0
.
.
.
G
I
V
E
N
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
-17-

.
.
N
Noduri interne
n+1
n+2
.
.
.
Rădăcina 2n-1
. 0 0
fn 0 0
. . .
. . .
. . .
. . .
. . .
. . .
În jumătatea de sus a tabelei, numerotată de la 1 la n, avem frunzele unui
arbore Huffman. Acestea au anumite frecvene date, şi nu au successor stâng sau
drept, De aceea se pune “0” pe coloanele respective. În partea de jos a tabelei, între
n+1 şi 2n-1, avem nodurile interne,incluzând rădăcina, de pe poziţia 2n-1.Frecvenţele
lor pot fi calculate de succesorii lor stâng, respectiv drept. După cum vom vedea mai
departe, cel mai slab caz este de complexitate O(n log n).
Alfabetul este aranjat într-un heap, care are, prin definiţie, cele mai mici
elemente mai sus. Cheile după care este ordonat heap-ul sunt frecvenţele
caracterelor. Heap-ul este iniţial format din n perechi (i, f(i)) corespunzătoare
frunzelor. La fiecare iteraţie, două elemente de frecvenţe minime sunt şterse şi este
creat un nod intern.Frecvenţa acestui nod intern nou format este suma frecvenţelor
succesorilor săi, şi este reprezentat printr-un nou “supercaracter”. Acest nod este
inserat în heap şi procesul se repetă.
-18-

Algoritmul Hu – Tucker
O(n)Se foloseşte heap-ul ce contine perechile
(1,f(1)),..,(n,f(n))
O(n log n)
FOR i = n+1 TO 2n-1 DO
(l,fl) <--- Deletemin(Heap)
(r,fr) <--- Deletemin(Heap)
fi <--- fl + fr
Insert ((i,fi), Heap)
Left[i] <--- l
Right[i] <--- r
RETURN
Instrucţiunea “for” care este executată de n-1 ori pentru un alfabet de n litere
extrage în mod repetat cele două noduri cu cele mai mici frecvenţe şi le înlocuieşte
cu un alt nod, având frecvenţa suma frecventelor celorlalte două noduri. Acest nou
nod are drept descendenţi nodurile anterioare cu frecvenţele cele mai mici. Cel mai
slab caz are complexitatea O(n log n).
1.5 Coduri Huffman
Codurile Huffman constituie un exemplu de utilizare a arborilor binari ca
structuri de date şi reprezintă o variantă de codificare a unor caractere ce apar într-un
limbaj, fiind determinată de probabilităţile de apariţie ale caracterelor, ale căror
valori se cunosc.
1.5.1 Codificarea caracterelor
Codul oricărui caracter e o secvenţă de 0 sau 1, astfel încât să nu fie prefix
pentru codul nici unui alt caracter. Se impune cerinţa ca lungimea medie a codurilor
să fie minimă, deci şi lungimea mesajului codificat să fie minimă.
-19-
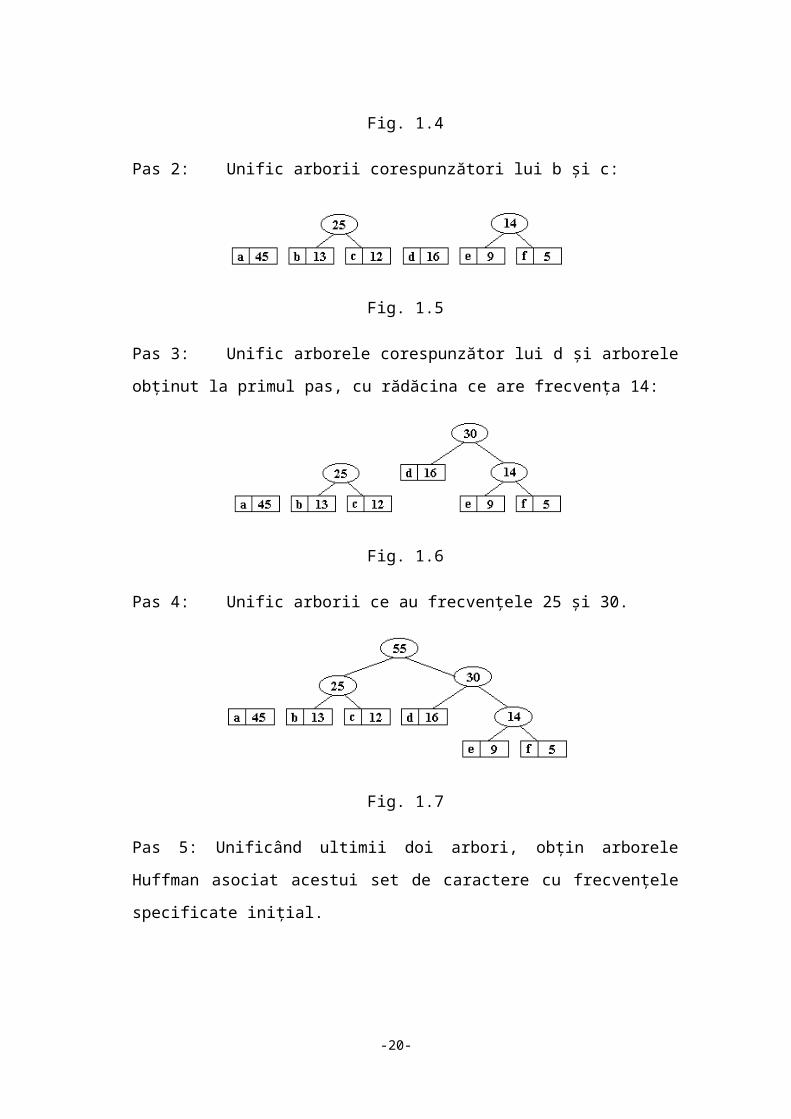
Algoritmul Huffman selectează două caractere a şi b care au probabilităţile
cele mai scăzute de apariţie şi le înlocuieşte cu un caracter imaginar x cu
probabilitatea egala cu suma probabilităţilor lui a și b. Aplicând recursiv aceasta
procedură, se reduce în final setul de caractere la două, cel iniţial cu probabilitatea
cea mai mare şi cel imaginar cu probabilitatea egală cu suma probabilităţilor
celorlalte caractere, cele două caractere codificându-se prin 0 și 1. Codul pentru setul
original de caractere se obţine adăugând la codul lui x un 0 la întâlnirea caracterului a
şi un 1 pentru b.
Un cod prefix se poate asimila cu un drum într-un arbore binar, considerând
că trecerea la fiul stâng al unui nod adaugă un 0 codului, la cel drept, 1.
În implementarea algoritmului lui Huffman se foloseşte o colecţie de arbori
binari, ale căror noduri terminale sunt caractere şi ale căror rădăcini au asociată suma
probabilităţilor de apariţie a caracterelor corespunzătoare tuturor nodurilor terminale,
numita greutatea (ponderea) arborelui.
În continuare se descrie o variantă de structuri de date necesare implementării
algoritmului. Pentru reprezentarea arborelui binar se foloseşte un tablou ARBORE,
fiecărui nod rezervândui-se câte o intrare cu cursorii la fiul stâng, la cel drept şi la
părinte. Variabila de tip indice (cursor) ULTIM_NOD indica ultimul element ocupat
al tabloului. Tabloul ALFABET înregistrează pentru fiecare simbol probabilitatea sa
de apariţie și cursorul la nodul terminal asociat. Tabloul ZONA înregistrează colecţia
de arbori binari, fiecare înregistrare referindu-se la un arbore şi cuprinzând greutatea
arborelui şi un cursor la rădăcina sa din ARBORE; ULTIM_NOD indica ultima
intrare ocupata din ZONA.
var ARBORE:array[1..max1] of record fiu_stâng,
fiu_drept,
parinte :integer
{cursori în ARBORE}
end;
ULTIM_NOD:integer;
-20-

ALFABET:array[1..max2] of record simbol:char;
probabilit:real;
terminal:integer
{cursor în ARBORE}
end;
ZONA:array[1..max3] of record greutate:real;
radacina:integer
{cursor în ARBORE}
end;
ULTIM_ARB:integer; {cursor în ARBORE}
Exemplu: Se considera următorul alfabet, format din simbolurile a,b,c,d, având
probabilităţile: P(a)=15% P(b)=52% P(c)=10% P(d)=23%. Construcţia arborelui de
C Codificare Huffman cuprinde etapele ilustrate în figură.
Fig. 1.9
Pentru codificarea obişnuită a unui alfabet compus din 4 simboluri sunt
necesari câte 2 biţi pentru fiecare simbol. Se observă că, aplicând algoritmul lui
Hufman, simbolurilor care au frecvenţa de apariţie maximă li se atribuie coduri
-21-

scurte, iar celor rar folosite coduri lungi. Astfel, simbolului "b", care este cel mai des
utilizat, i se atribuie un cod format dintr-un bit, iar simbolurilor "a" și "c" coduri pe
trei biţi. La decodificarea unui mesaj, pe măsură ce biţii sunt citiţi, se parcurge
arborele de coduri de la rădăcină până la întâlnirea unei frunze, calea urmând fiul
stâng dacă bitul citit este 0 şi fiul drept dacă bitul citit este 1. De exemplu, dacă se
citeşte mesajul codificat 010110011, se poate reconstitui mesajul iniţial abbdbb.
Proprietatea de prefix a codului Hufmann este deosebit de importantă, permiţând
decodificarea neambiguă a mesajului.
1.5.2 Obținerea codificării textului
Un cod Huffman este un cod unic decodabil (UD). Aceasta înseamnă două
lucruri:
1. Se poate codifica un mesaj uitându-ne la fiecare caracter introdus în
secvenţă. La fiecare pas în parte fiecare caracter pe care-l citim ori intră în
compunerea unei litere, ori corespunde exact uneia.
2. Mesajul codificat este cel mai scurt posibil printre toate schemele de
codare care au proprietatea 1.
Să vedem un exemplu. Presupunem că vrem să codăm mesajul următor: "(C)
2002 Directionsmag.com". Avem codarea Huffman pentru mesaj (în figura şi tabelul
de mai jos):
Mesajul codificat este : 10110 10011 01101 000 1100 1110 1110 1100 000
11010 1000 11011 01111 1010 10111 1000 001 01100 11110 010 01110 10010
11111 1010 001 010. Lungimea lui este de 110 biţi, sau în jur de 4,24 biţi/caracter.
Reprezentarea originală în codul ASCII necesita 8 biţi/caracter, totalizând 208 biţi.
Compresia este aproape 50%.Ideea din spatele acestui cod este evidenţiată în graful
următor: caracterele care apar mai frecvent sunt reprezentate de coduri mai scurte.
Pentru ca un cod să fie unic decodabil trebuie să nu existe ambiguităţi în decodarea
mesajului. Astfel, codul pentru un caracter nu va fi niciodată începutul codului
pentru alt caracter. Ca exemplu, asignând (atribuind) „000” caracterului spaţiu a
însemnat că nici un alt cod nu poate începe cu „000”, putându-se verifica acest lucru.
Un asemenea cod este denumit cod prefix.
-22-

În arborele descris mai jos, zerourile trimise codorului sunt pe ramurile de
sus, iar secvenţele de 1 sunt pe ramurile de jos. Proprietatea unic decodabilă a codului
Huffman corespunde faptului că fiecare cale prin arbore se termină la o literă unică. Cele
mai scurte căi corespund literelor cu frecvenţele cele mai mari.
Caracter Frecvenţă Cod Arbore
' ' 2 000
'(' 1 10110
')' 1 01101
'.' 1 11111
'0' 2 1110
'2' 2 1100
'C' 1 10011
'D' 1 11010
'a' 1 01110
'c' 2 1010
'e' 1 01111
'g' 1 10010
'i' 2 1000
'm' 2 010
'n' 1 01100
'o' 2 001
'r' 1 11011
's' 1 11110
-23-

't' 1 10111
Arborele pentru codul binar Huffman este construit într-un mod direct
şi simplu. Literele cu cele mai mici frecvenţe de apariţie sunt localizate, combinate
ca plecări spre un nod, şi atunci acel nod va fi tratat ca frecvenţa combinata
(însumată) a celor două. Algoritmul necesită în primul rând să găsească cele mai
mici frecvenţe într-o listă potenţial lungă, să o facă în mod repetat, şi apoi să insereze
fiecare frecvenţă nouă înapoi în listă. O eficientă structură de date pentru acest lucru
este coada de priorităţi, care este uşor implementată cu array sau list. Utilizând coada
de priorităţi, întregul algoritm pentru construirea codului Huffman este foarte simplu.
Cea mai mare problemă în implementarea codului Huffman este preocuparea
pentru frecvenţe. Dacă codăm un singur mesaj, o dată şi încă o dată, de mai multe
ori, ca o simplă copiere, asta-i simplu. Dar dacă vrem un mesaj mult mai lung într-un
pachet de mesaje este mai dificil. În acest caz, o soluţie bună este să folosim
frecvenţe tipice pe care dorim să le scriem. Putem implementa rutine pentru
analizarea setului de fişiere text pentru frecvenţele caracterelor lor. Rezultatele sunt
înregistrate într-un fişier special de frecvenţe cu care codul creat Huffman poate fi
folosit pentru citirea şi scrierea fişierelor.
1.6 Realizarea algoritmul Huffman prin metoda greedy
O aplicaţie a strategiei greedy şi a arborilor binari cu lungime externă
ponderată minimă este obţinerea unei codificări cât mai compacte a unui text.
1.6.1 Tehnica greedy
Algoritmii greedy (greedy = lacom) sunt în general simpli şi sunt folosiţi la
probleme de optimizare, cum ar fi: să se găsească cea mai bună ordine de executare a
unor lucrări pe calculator, să se găsească cel mai scurt drum într-un graf etc. În cele
mai multe situaţii de acest fel avem:
o mulţime de candidaţi ( lucrări de executat, vârfuri ale grafului etc);
o funcţie care verifică dacă o anumită mulţime de candidaţi constituie o
soluţie posibilă, nu neapărat optimă, a problemei;
-24-
o funcţie care verifică dacă o mulţime de candidaţi este fezabilă, adică dacă
este posibil să completăm această mulţime astfel încât să obţinem o soluţie
posibilă, nu neapărat optimă, a problemei;
o funcţie de selecţie care indică la orice moment care este cel mai promiţător
dintre candidaţii încă nefolosiţi;
o funcţie obiectiv care dă valoarea unei soluţii (timpul necesar executării
tuturor lucrărilor într-o anumită ordine, lungimea drumului pe care l-am găsit
etc); aceasta este funcţia pe care urmărim să o optimizăm
(minimizăm/maximizăm).
Pentru a rezolva problema noastră de optimizare, căutam o soluţie posibilă
care să optimizeze valoarea funcţiei obiectiv. Un algoritm greedy construieşte soluţia
pas cu pas. Iniţial, mulţimea candidaţilor selectaţi este vidă. La fiecare pas, încercăm
să adăugăm acestei mulţimi cel mai promiţător candidat, conform funcţiei de selecţie.
Dacă, după o astfel de adăugare, mulţimea de candidaţi selectaţi nu mai este fezabilă,
eliminăm ultimul candidat adăugat; acesta nu va mai fi niciodată considerat. Dacă,
după adăugare, mulţimea de candidaţi selectaţi este fezabilă, ultimul candidat
adăugat va rămâne de acum încolo în ea. De fiecare dată când lărgim mulţimea
candidaţilor selectaţi, verificăm dacă această mulţime nu constituie o soluţie posibilă
a problemei noastre. Dacă algoritmul greedy funcţionează corect, prima soluţie găsită
va fi totodată o soluţie optimă a problemei. Soluţia optimă nu este în mod necesar
unică: se poate ca funcţia obiectiv să aibă aceeaşi valoare optimă pentru mai multe
soluţii posibile.
Descrierea formală a unui algoritm greedy general este:
function greedy(C)
{C este mulţimea candidaţilor}
S {S este mulţimea în care construim soluţia}
while not soluţie(S) and C do
x un element din C care maximizează/minimizează select(x)
C C \ {x}
if fezabil(S {x}) then S S {x}
if solutie(S) then return S
else return “nu exista soluţie”
-25-

Este de înţeles acum de ce un astfel de algoritm se numeşte “lacom” (am
putea să-i spunem şi “nechibzuit”). La fiecare pas, procedura alege cel mai bun
candidat la momentul respectiv, fără să-i pese de viitor şi fără să se răzgândească.
Dacă un candidat este inclus în soluţie, el rămâne acolo; dacă un candidat este exclus
din soluţie, el nu va mai fi niciodată reconsiderat. Asemenea unui întreprinzător
rudimentar care urmăreşte câştigul imediat în dauna celui de perspectivă, un algoritm
greedy acţionează simplist. Totuşi, ca şi în afaceri, o astfel de metodă poate da
rezultate foarte bune tocmai datorită simplităţii ei.
Funcţia select este de obicei derivată din funcţia obiectiv; uneori aceste două
funcţii sunt chiar identice.
Un exemplu simplu de algoritm greedy este algoritmul folosit pentru
rezolvarea următoarei probleme. Să presupunem că dorim să dăm restul unui client,
folosind un număr cât mai mic de monezi. În acest caz, elementele problemei sunt:
candidaţii: mulţimea iniţială de monezi de 1, 5, şi 25 unităţi, în care
presupunem că din fiecare tip de monedă avem o cantitate nelimitată;
o soluţie posibilă: valoarea totală a unei astfel de mulţimi de monezi selectate
trebuie să fie exact valoarea pe care trebuie să o dăm ca rest;
o mulţime fezabilă: valoarea totală a unei astfel de mulţimi de monezi
selectate nu este mai mare decât valoarea pe care trebuie să o dam ca rest;
funcţia de selecţie: se alege cea mai mare monedă din mulţimea de candidaţi
rămasă;
funcţia obiectiv: numărul de monezi folosite în soluţie; se doreşte
minimizarea acestui număr.
Se poate demonstra că algoritmul greedy va găsi în acest caz mereu soluţia
optimă (restul cu un număr minim de monezi). Pe de altă parte, presupunând că
există şi monezi de 12 unităţi sau că unele din tipurile de monezi lipsesc din
mulţimea iniţială, se pot găsi contraexemple pentru care algoritmul nu găseşte soluţia
optimă, sau nu găseşte nici o soluţie cu toate că există soluţie.
Evident, soluţia optimă se poate găsi încercând toate combinările posibile de
monezi. Acest mod de lucru necesită însă foarte mult timp.
-26-

Un algoritm greedy nu duce deci întotdeauna la soluţia optimă, sau la o
soluţie. Este doar un principiu general, urmând ca pentru fiecare caz în parte să
determinăm dacă obţinem sau nu soluţia optimă.
1.6.2 Codificarea Huffman prin metoda greedy
Un principiu general de codificare a unui şir de caractere este următorul: se
măsoară frecvenţa de apariţie a diferitelor caractere dintr-un eşantion de text şi se
atribuie cele mai scurte coduri celor mai frecvente caractere, şi cele mai lungi coduri
celor mai puţin frecvente caractere. Acest principiu stă, de exemplu, la baza codului
Morse. Pentru situaţia în care codificarea este binară, există o metodă elegantă pentru
a obţine codul respectiv. Această metodă, descoperită de Huffman (1952) foloseşte o
strategie greedy şi se numeşte codificarea Huffman. O vom descrie pe baza unui
exemplu.
Ex: Fie un text compus din următoarele litere (în paranteze figurează frecvenţele
de apariţie): S(10), I(29), P(4), O(9), T(5). Conform metodei greedy, construim
un arbore binar fuzionând cele două litere cu frecvenţele cele mai mici. Valoarea fiecărui
vârf este dată de frecvenţa pe care o reprezintă.
Etichetăm muchia stânga cu 1 şi muchia dreaptă cu 0. Rearanjăm tabelul de
frecvenţe:
S(10), I(29), O(9), {P, T}(45 = 9)
Mulţimea {P, T} semnifică evenimentul reuniune a celor două evenimente
independente corespunzătoare apariţiei literelor P și T. Continuăm procesul, obţinând
arborele
-27-

În final, ajungem la arborele din figură, în care fiecare vârf terminal corespunde unei
litere din text.
Pentru a obţine codificarea binară a literei P, nu avem decât să scriem
secvenţa de 0-uri şi 1-uri în ordinea apariţiei lor pe drumul de la rădăcina către vârful
corespunzător lui P: 1011. Procedăm similar şi pentru restul literelor:
S(11), I(0), P(1011), O(100), T(1010)
Pentru un text format din n litere care apar cu frecvenţele f1, f2, ..., fn, un
arbore de codificare este un arbore binar cu vârfurile terminale având valorile
f1, f2, ..., fn, prin care se obţine o codificare binară a textului. Un arbore de codificare
nu trebuie în mod necesar să fie construit după metoda greedy a lui Huffman,
alegerea vârfurilor care sunt fuzionate la fiecare pas putându-se face după diverse
criterii. Lungimea externă ponderată a unui arbore de codificare este:
unde ai este adâncimea vârfului terminal corespunzător literei i.
-28-

Fig. 1.10 Arborele de codificare Huffman.
Se observă că lungimea externă ponderată este egală cu numărul total de caractere
din codificarea textului considerat. Codificarea cea mai compactă a unui text
corespunde deci arborelui de codificare de lungime externă ponderată minimă. Se
poate demonstra că arborele de codificare Huffman minimizează lungimea externă
ponderată pentru toţi arborii de codificare cu vârfurile terminale având valorile
f1, f2, ..., fn. Prin strategia greedy se obţine deci întotdeauna codificarea binară cea mai
compactă a unui text.
Arborii de codificare pe care i-am considerat în această secţiune corespund
unei codificări de tip special: codificarea unei litere nu este prefixul codificării nici
unei alte litere. O astfel de codificare este de tip prefix. Codul Morse nu face parte
din aceasta categorie. Codificarea cea mai compactă a unui şir de caractere poate fi
întotdeauna obţinută printr-un cod de tip prefix. Deci, concentrându-ne atenţia asupra
acestei categorii de coduri, nu am pierdut nimic din generalitate.
Algoritmul greedy de construcţie a arborelui Huffman este următorul:
Pas 1. Iniţializare :
- fiecare caracter reprezintă un arbore format dintr-un singur nod;
- organizăm caracterele ca un min-heap, în funcţie de frecvenţele de
apariţie;
Pas 2. Se repetă de n-1 ori :
- extrage succesiv X şi Y, două elemente din heap
- unifică arborii X şi Y :
- crează Z un nou nod ce va fi rădăcina arborelui
- ZA.st := X
- ZA.dr := Y
- ZA.frecv := XA.frecv+YA.frecv
- inserează Z în heap;
Pas 3. Singurul nod rămas în heap este rădăcina arborelui Huffman. Se
generează codurile caracterelor, parcurgând arborele Huffman.
-29-

Iniţializarea heapului este liniară. Pasul 2 se repetă de n-1 ori şi presupune două
operaţii de extragere a minimului dintr-un heap şi de inserare a unui element în heap,
care au timpul de execuţie de O(log n). Deci complexitatea algoritmului de
construcţie a arborelui Huffman este de O(n log n).
CAPITOLUL 2
ANALIZA ALGORITMULUI DE CODIFICARE HUFFMAN
2.1 Corectitudinea algoritmului Huffman
Trebuie să demonstrăm că algoritmul lui Huffman produce un cod prefix
optimal.
-30-

Lema 1.
Fie x, y e C, două caractere care au frecvenţa cea mai mică. Atunci există un
cod prefix optimal în care x şi y au codificări de aceeaşi lungime şi care diferă doar
prin ultimul bit. Demonstraţie:
Fie T arborele binar asociat unui cod prefix optimal oarecare şi fie a, b două
noduri de pe nivelul maxim, care sunt fiii aceluiaşi nod. Putem presupune fără a
restrânge generalitatea că f[a] < f[b] şi f[x] £ f[y]. Cum x şi y au cele mai mici
frecvenţe rezultă că f[x] < f[a] şi f[y] < f[b]. Transformăm arborele T în T',
schimbând pe a cu x :
Fig. 2.1
Notăm cu C(T) costul arborelui T: C(T) = I
f(c) • nivT (c)
ceC
C (T) - C(T') = f (x) • nivT (x) + f (a) • nivT (a) - f (x) • nivT (x) - f (a) •
nivT (a) ^
C(T)-C(T ') = ( f(a)- f (x))• (nivr(a)-nivr(x)) > 0, pentru că {V(X)
În mod analog, construim arborele T, schimbând pe x cu y. Obţinem: C(T ')-
C(T '') = ( f (b)- f (y)) • (nivr(b)- nivr(y)) > 0.
Deci C(T) > C(T''), dar cum T era optimal deducem că T" este arbore optimal şi în
plus x şi y sunt noduri terminale situate pe nivelul maxim, fii ai aceluiaşi nod.
Observaţie:
Din lemă deducem că pentru construcţia arborelui optimal putem începe prin
a selecta după o strategie Greedy caracterele cu cele mai mici frecvenţe.
Lema 2.
Fie T un arbore binar complet corespunzator unui cod prefix optimal pentru
alfabetul C. Dacă x şi y sunt două noduri, fii ai aceluiaşi nod z în T, atunci arborele
T' obţinut prin eliminarea nodurilor x şi y este arborele binar complet asociat unui
cod prefix optimal pentru alfabetul
-31-

C' = (C-{x,y}) u { z}, f[z] fiind f[x]+f[y]. Demonstraţie: VceC-Qr, yV.nivr
(c)=nivr(c) nivr (x)=nivr (y)=nivr (z)+lţrV f (X) • ^(X) + f (^ •nV (y) =
= ( f (x) + f (y)) • (nivr(z) +1) = f (z) • nivr(z) + f (x) + f (y) =
= f (z)• nivr (z) + ( f (x) + f (y)).
Deci,
C(T) = E f(c)• nvr(c) = C(T ') + ( f(x) + f(y))
Dacă presupunem prin reducere la absurd că arborele T' nu este optimal
pentru alfabetul C' = (C-{x,y}) u {z} ^ $ T", ale cărui frunze sunt caractere din C',
astfel încât C(T") < C(T).
Cum z este nod terminal în T", putem construi un arbore Ti pentru alfabetul
C, atârnând pe x [i y ca fii ai lui z. C(Ti) = C(T" )+f(x)+f(y) < C(T), ceea ce
contrazice ipoteza că T este arbore optimal pentru C. Deci, T' este un arbore optimal
pentru C'.
Corectitudinea algoritmului lui Huffman este o consecinţă imediată a celor
două leme.
Observaţie
Metoda de compresie bazată pe arbori Huffman statici are o serie de
dezavantaje:
1. Fişierul de compactat trebuie parcurs de două ori: o dată pentru a calcula numărul
de apariţii ale caracterelor în text, a doua oară pentru a comprima efectiv fişierul.
Deci metoda nu poate fi folosită pentru transmisii de date pentru care nu este
posibilă reluarea.
2.Pentru o dezarhivare ulterioară a fişierului, aşa cum este şi firesc, este necesară
memorarea arborelui Huffman utilizat pentru comprimare, ceea ce conduce la
mărirea dimensiunii codului generat.
3. Arborele Huffman generat este static, metoda nefiind capabilă să se adapteze la
variaţii locale ale frecvenţelor caracterelor.
Aceste dezavantaje au fost în mare parte eliminate în metodele care folosesc
arbori Huffman dinamici, ideea fiind ca la fiecare nouă codificare, arborele Huffman
să se reorganizeze astfel încât caracterul respectiv să aibă eventual un cod mai scurt.
-32-
2.2 Coduri prefix
Vom considera în continuare doar codificarile în care nici-un cuvant nu este prefixul
altui cuvânt. Aceste codificări se numesc codificări prefix. Codificarea prefix este
utila deoarece simplifica atat codificarea (deci compactarea) cât şi decodificarea.
Pentru orice codificare binară a caracterelor se concateneaza cuvintele de cod
reprezentand fiecare caracter al fisierului.
Decodificarea este de asemenea simpla pentru codurile prefix. Cum nici un
cuvânt de cod nu este prefixul altuia, începutul oricarui fisier codificat nu este
ambiguu. Putem sa identificăm cuvantul de cod de la început, sa îl convertim în
caracterul original, sa-l îndepartam din fisierul codificat și să repetăm procesul
pentru fisierul codificat ramas.
2.2.1 Coduri prefix.Arbore de codificare
Algoritmul lui Huffman apartine familiei de algoritmi ce realizeaza codificari cu
lungime variabilă. Aceasta înseamna ca simbolurile individuale (ca de exemplu
caracterele într-un text) sunt înlocuite de secvente de biti (cuvinte de cod) care pot
avea lungimi diferite. Astfel, simbolurilor care se întalnesc de mai multe ori în text
(fisier) li se atribuie o secventa mai scurta de biti în timp ce altor simboluri care se
întâlnesc mai rar li se atribuie o secventa mai mare. Pentru a ilustra principiul, sa
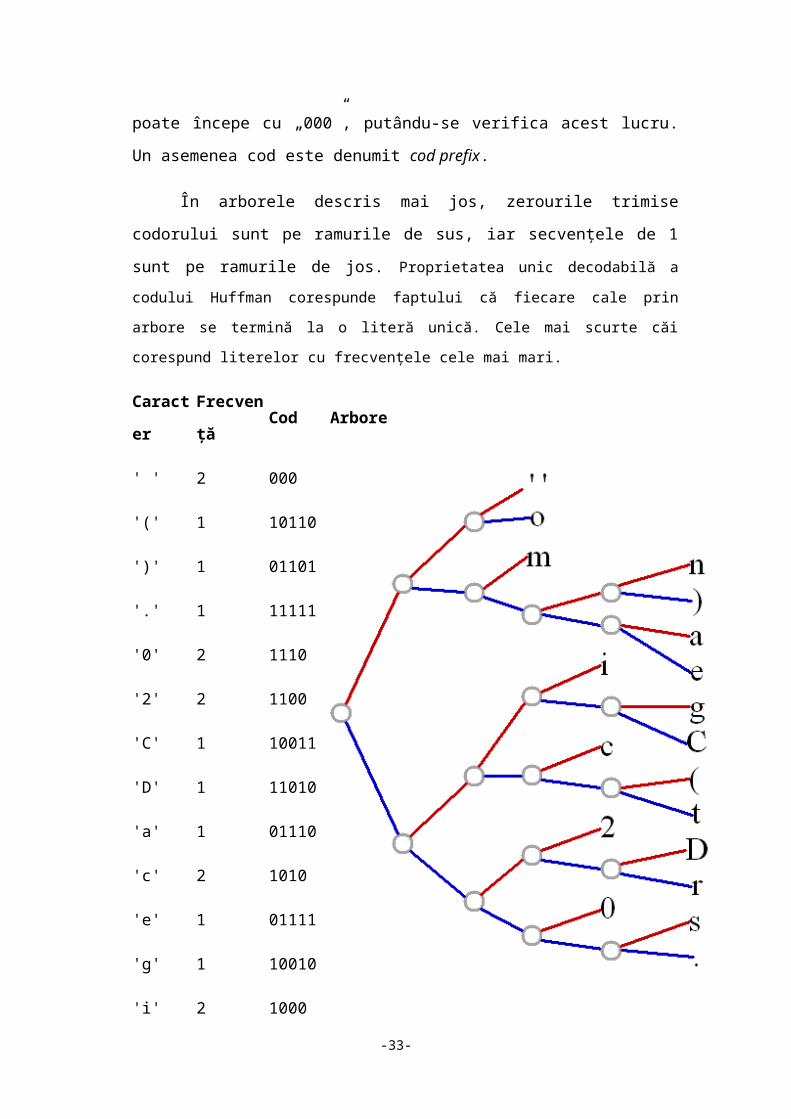
presupunem ca vrem sa compactam următoarea secventa :AEEEEBEEDECDD.
Cum avem 13 caractere (simboluri), acestea vor ocupa în memorie 13 x 8 = 104 biti.
Cu algoritmul lui Huffman, fisierul este examinat pentru a vedea care simboluri apar
cel mai frecvent (în cazul nostru E apare de sapte ori, D apare de trei ori iar A ,B și
C apar cate o data). Apoi se construieste (vom vedea în cele ce urmează cum) un
arbore care înlocuieste simbolurile cu secvente (mai scurte) de biti. Pentru secventa
propusa, algoritmul va utiliza substituie (cuvintele de cod) A =111 , B = 1101, C =
1100, D = 10, E = 0 iar secventa compactata (codificata) obţinuta prin concatenare
va fi 111000011010010011001010. Aceasta înseamna că s-au utilizat 24 biti în loc
de 104, raportul de compresie fiind 24/104.
În cazul exemplului prezentat mai înainte sirul se desparte în
-33-

111 - 0 - 0 - 0 - 0 - 1101 - 0 - 0 - 10 - 0 - 1100 - 10 - 10,
secvența care se decodifică în AEEEBEEDECDD.
Procesul de decodificare necesită o reprezentare convenabilă a codificării
prefix astfel încât cuvantul inițial de cod să poată fi ușor identificat. O astfel de
reprezentare poate fi dată de un arbore binar de codificare, care este un arbore
complet (adica un arbore în care fiecare nod are 0 sau 2 f i i , ale carui frunze sunt
caracterele date. Interpretam un cuvânt de cod binar ca fiind o secventa de biţ
obtinuta etichetând cu 0 sau 1 muchiile drumului de la rădacină până la frunza ce
conține caracterul respectiv: cu 0 se etichetează muchia ce unește un nod cu fiul
stang iar cu 1 se etichetează muchia ce unește un nod cu fiul drept. În figura (2.1)
este prezentat arborele de codificare al lui Huffman corespunzător exemplului
nostru. Notând cu C alfabetul din care fac parte simbolurile (caracterele), un arbore
de codificare are exact |C| frunze, una pentru fiecare litera (simbol) din alfabet și asa
cum se ştie din teoria grafurilor, exact |C| — 1 noduri interne (notăm cu |C| , cardinalul
multimii C).
Dându-se un arbore T, corespunzător unei codificări prefix, este foarte simplu sa
calculăm numărul de biți necesari pentru a codifica un fișier.
Pentru fiecare simbol c C, fie f (c) frecventa (numarul de apariţi) lui c în fisier
și să notăm cu dT (c) adancimea frunzei în arbore. Numărul de biti necesar pentru a
codifica fisierul este numit costul arborelui T și se calculează cu formula :
Figura 2.2: Exemplu de arbore Huffman
-34-

2.2.2 Construcţia codificării prefix a lui Huffman
Huffman a inventat un algoritm greedy care construieste o codificare prefix
optima numită codul Huffman. Algoritmul construieste arborele corespunzator
codificarii optime (numit arborele lui Huffman) pornind de jos în sus. Se începe cu
o multime de |C| frunze și se realizează o secvență de |C| — 1 operaţii de fuzionări
pentru a crea arborele final. În algoritmul scris în pseudocod care urmează, vom
presupune ca C este o multime de n caractere și fiecare caracter are frecventa f (c).
Asimilăm C cu o pădure constituita din arbori formaţi dintr-o singură frunză.Vom
folosi o stiva S formata din noduri cu mai multe câmpuri; un câmp păstrează ca
informaţie pe f (c), alt câmp pastrează rădacina c iar un câmp suplimentar păstrează
adresa nodului anterior (care indică un nod ce are ca informatie pe f (c') cu
proprietatea ca f (c) < f (c'). Extragem din stivă vârful și nodul anterior (adică
obiectele cu frecventa cea mai redusa) pentru a le face sa fuzioneze. Rezultatul
fuzionării celor două noduri este un nou nod care în câmpul informatiei are f (c) + f
(c') adică suma frecventelor celor doua obiecte care au fuzionat. De asemenea în al
doilea câmp apare rădăcina unui arbore nou format ce are ca subarbore stâng,
respectiv drept, arborii de rădăcini c și c'. Acest nou nod este introdus în stiva dar nu
pe pozitia vârfului ci pe poziţa corespunzatoare frecventei sale. Se repetă operaţia
până când în stivă ramâne un singur element. Acesta va avea în campul radacinilor
chiar radăcina arborelui Huffman.
Urmează programul în pseudocod. Ţinand cont de descrierea de mai sus a
algoritmului numele instructiunilor programului sunt suficient de sugestive.
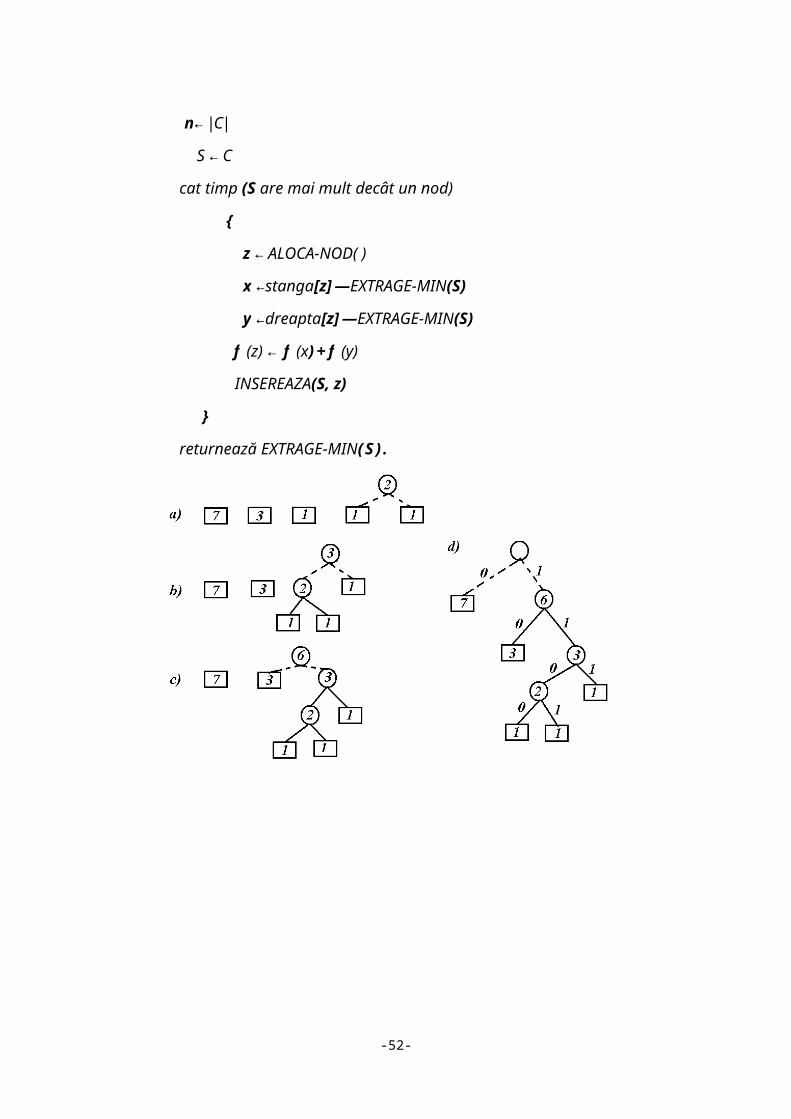
n← |C|
S ← C
cat timp (S are mai mult decât un nod)
{
z ← ALOCA-NOD( )
x ←stanga[z] —EXTRAGE-MIN(S)
y ←dreapta[z] —EXTRAGE-MIN(S)
f (z) ← f (x) + f (y)
-35-

INSEREAZA(S, z)
}
returnează EXTRAGE-MIN(S ) .
Figura 2.3 Construirea arborelui Huffman
În cazul exemplului deja considerat, avem f (E) = 7, f (D) = 3, f (A) = f
(B ) = f (C) = 1. Putem, pentru comoditate sa etichetam frunzele nu cu simbolurile
corespunzătoare, ci cu frecventele lor. în figura (2.2) prezentam arborii aflaţi în
nodurile stivei, după fiecare repetare a instructiunilor din ciclul while. Se pleacă cu o
pădure de frunze, ordonată descrescător dupa frecvențele simbolurilor și se ajunge la
arborele de codificare.
-36-

2.3 Variante ale algoritmului lui Huffman
Există trei variante des aplicate ale acestui algoritm:
• algoritmul Huffman static;
• algoritmul Huffman semi-static;
• algoritmul Huffman dinamic.
Diferenţele dintre cele trei variante sunt următoarele:
• în cazul variantei statice, atât compresorul, cât și decom- presorul deţin acelaşi
arbore de compresie calculat pe baza unor frecvenţe fixe de apariţie și nu mai este
necesară calcularea unui arbore nou și nici transmiterea acestuia. Dezavantajul
acestei metode este că, dacă frecvenţele de apariţie ale simbolurilor generate de o
sursă diferă foarte mult de cele fixe utilizate, atunci s-ar putea ca pentru simboluri
cu frecvenţă mare de apariţie să fie transmise coduri foarte lungi și astfel cantitatea
de informaţie comprimată poate să depăşească cu mult cantitatea de informaţie care
a fost generată de o sursă.
• varianta semi-statică utilizează algoritmul de construire a arborelui de compresie
prezentat anterior. Are ca dezavantaj faptul că şirul simbolurilor generate de o sursă
de informaţie trebuie parcurse de două ori, o dată pentru calcularea frecvenţelor
necesare construirii arborelui și o dată pentru codificarea şirului simbolurilor; în
cazul în care simbolurile au aproximativ aceeaşi frecvenţă de apariţie, algoritmul
nu oferă o compresie bună. Parcurgerea de două ori a şirului simbolurilor generate
de o sursă de informaţie este un inconvenient deoarece acesta trebuie stocat, iar
dimensiunea datelor care trebuie comprimate, în zilele noastre, este foarte mare și
calculatoarele personale (de cele mai multe ori) nu deţin resursele necesare stocării
datelor.
• pentru varianta dinamică există doi algoritmi performanţi: FGK (Faller, Gallager,
Knuth) și V (Vitter). Aceştia au în comun faptul că arborele se construieşte dinamic
pe măsură ce o sursă de informaţie generează simboluri, deci este necesară o
singură parcurgere a şirului simbolurilor și nu este necesară stocarea lor. Doar o
mică parte dintre ele sunt stocate cu scopul de a optimiza procesul de compresie.
Rata de compresie a acestor doi algoritmi variază. În anumite cazuri rezultatele
obţinute sunt cu mult mai bune decât cele date de varianta statică, dar în cazul cel
-37-

mai rău pentru varianta statică, rezultatele variantelor dinamice sunt optime de cele
mai multe ori.
Primele două variante nu mai necesită explicaţii suplimentare, aşadar, în
continuare, vom prezenta în detaliu varianta dinamică FGK, varianta dinamică Vitter
fiind similară.
2.3.1 Metoda de codare dinamică Huffman
Compresia dinamică (sau adaptivă) Huffman folosește un arbore de codare
ce este actualizat de fiecare dată când un simbol este citit din fișierul de intrare.
Arborele creste (se dezvoltă, evoluează) la fiecare simbol citit din fisierul de intrare.
Modul de evolutie al arborelui este identic la compresie și la decompresie. Eficiența
metodei se bazează pe o proprietate a arborilor Huffman, cunoscută sub numele de
proprietatea „fiilor” („sibling property”)
Proprietate (sibling): Fie T un arbore Huffman cu n frunze. Atunci nodurile lui T
pot fi aranjate intr-o secventa (x0, x1, ..., x2n-2) astfel incat:
1. Secvența ponderilor (weight(x0), weight(x1), ..., weight(x2n-2)) sa fie în ordine
descrescatoare;
2. Pentru orice i (0 ≤ i ≤ n-1), nodurile consecutive x2i+1 și x2i+2 sunt siblings (fii
ai aceluiasi parinte).
Compresia și decompresia utilizează arborele dinamic Huffman pornind de la
un caracter virtual, notat – de exemplu – prin VIRT, sau ART. Acesta este
întotdeauna nod terminal (frunză).
Descrierea codării
De fiecare dată când un simbol este citit din fișierul de intrare se efectuează
urmatoarele operatii:
1). se scrie în fisierul destinatie codul simbolului: daca simbolul citit este nou, atunci
se scrie codul caracterului virtual (VIRT) (determinat din arborele de codare) urmat
de codificarea în binar (ASCII) pe 9 biti a simbolului respectiv; în caz contrar, se
scrie cuvantul de cod al simbolului, determinat din arborele de codare. Numai la
primul simbol se scrie direct codul ASCII al acestuia pe 9 biți.
-38-

2). Se introduce simbolul citit în arborele de codare: dacă simbolul curent citit este
nou, atunci din nodul virtual vor pleca doi fii: unul pentru simbolul citit și unul
pentru simbolul virtual. Nodul care a fost folosit ca nod virtual devine nod
intermediar; în caz contrar, se incrementeaza frecventa de aparitie a acestuia, prin
marirea ponderii nodului corespunzator simbolului citit;
3) Se ajusteaza arborele pentru indeplinirea proprietatii sibling. Trebuie considerate
urmatoarele doua aspecte:
o la creșterea ponderii unui nod, frunză sau intermediar, trebuie modificate
și ponderile ancestorilor sai;
o pentru a pastra ordinea descrescatoare a ponderilor se judeca astfel: fie
nodul frunza n ce are ponderea cu unu mai mare decat valoarea anterioră,
deci el este cel care s-a modificat la pasul curent. Pentru indeplinirea
conditiei (1) a proprietatii sibling, nodul n este schimbat cu cel mai
apropiat nod m (m < n) din lista, astfel incat weight(m) < weight(n). Apoi,
aceeasi operatie este efectuată asupra parintelui lui n, pana cand se obține
nodul radacina sau este indeplinită condiția (1).
De obicei se numerotează nodurile iar corespondenta numar nod – eticheta se
obține folosind un vector ale carui elemenete sunt chiar etichetele arborelului de
codare.
Descrierea decodării
La decompresie, textul comprimat este verificat cu arborele de codare. Tehnica se
numeste „parsing”. La inceputul decompresiei, nodul curent este inițializat cu
radacina, ca la algoritmul de compresie, și – apoi – arborele evolueaza simetric. La
fiecare citire a unui simbol 0 se parcurge arborele în jos spre stanga; se parcurge
arborele spre dreapta daca simbolul citit este 1. Cand se ajunge la un nod terminal
(frunza) simbolul asociat este scris în fisierul de iesire și se ajusteaza arborele, la fel
ca în faza de compresie.
Exemplul : Sa se comprime mesajul “astazi” cu Huffman dinamic.
□
-39-

1). Se initializeaza arborele de codare și variabila pentru textul comprimat.
2). Se citeste primul simbol, « a ». Fiind primul simbol nu se scrie codul lui VIRT
(de fapt, nici nu are cod) și se scrie codul lui « a » pe 9 biti. Se actualizeaza arborele
de codare.
3). Se citeste urmatorul simbol, « s ». Fiind simbol nou se scrie codul lui VIRT și
codul lui « s » pe 9 biti. Se actualizeaza arborele de codare. Se observa ca dupa
introducerea nodului nou și numerotarea nodurilor ponderile nodurilor nu sunt
monoton descrescatoare. Trebuie inversate nodurile 1 și 2. Se obtine arborele din
partea dreapta.
4). Se citeste urmatorul simbol, « t ». Fiind simbol nou, în secventa de iesire se scrie
codul lui VIRT, 01, și codul lui « t » pe 9 biti, 0.0111.0100. Se actualizeaza arborele
-40-

de codare. Trebuie inversate nodurile 2 și 4 pentru ca ponderile sa fie ordonate în
sens descrescator.
5). Se citește următorul simbol, « a ». Nefiind simbol nou, în secventa de ieșire se
scrie codul acestuia asa cum rezultă din arbore, 01. Se actualizeaza arborele de
codare. Trebuie inversate nodurile 2 și 4 pentru ca ponderile sa fie ordonate în sens
descrescător.
6). Se citește următorul simbol, « z ». Fiind simbol nou, în secvența de ieșire se scrie
codul lui VIRT, 11, urmat de codul pe 9 biti al lui z, 0.0111.1010. Se actualizează
arborele de codare. Trebuie inversate nodurile 2 și 4 pentru ca ponderile sa fie
ordonate în sens descrescător.
-41-

7). Se citește urmatorul simbol, « i ». Fiind simbol nou, în secvența de ieșire se scrie
codul lui VIRT, 011, urmat de codul pe 9 biti al acetuia, 0.0110.1001. Se
actualizează arborele de codare. Trebuie inversate nodurile 2 și 4 și – apoi – 5 cu 6,
pentru ca ponderile sa fie ordonate în sens descrescător.
-42-

7). Se citește următorul simbol, « END », deci marcatorul sfarșitului de text . Fiind
simbol nou, în secventa de iesire se scrie codul lui VIRT, 101, urmat de codul pe 9
biți al simbolului citit, 1.0000.0000.
În total, secvența comprimată conține 6*9+14=54+14=68 biti. Mesajul
original, reprezentat pe 8 biti/simbol, are o marime de 6*8=48 biti. Raportul de
compresie este 48/68 =0.7.
2.3.2 Algoritmul FGK
Algoritmul FGK precum și algoritmul V se bazează pe proprietatea fraţilor enunţată
și demonstrată de Gallager în anul 1978:
"Un arbore binar cu p frunze care au ponderi (în cazul de faţă frecvenţe)
nenegative este arbore Huffman dacă şi numai dacă următoarele afirmaţii sunt
adevărate:
• cele p frunze au ponderile nenegative w1, w2, ..., w şi ponderea fiecărui nod intern
este egală cu suma ponderilor celor doi fii;
-43-

• nodurilor interne li se pot ataşa numere de ordine în ordinea crescătoare a
ponderilor, astfel încât nodurile cu numerele 2 • j - 1 şi 2 • j să fie fraţi pentru 1 < j <
p - 1 şi părintele lor comun să aibă un număr de ordine mai mare.
• Dacă un arbore este construit pe baza algoritmului prezentat la secţiunea
anterioară, atunci acesta este un arbore Huffman și respectă proprietatea fraţilor.
La început vom avea un arbore A care va conţine un singur nod a cărui pondere
(greutate) este 0 sau 1 în funcţie de implementarea folosită. Acest nod ţine locul
tuturor simbolurilor care pot fi generate de o sursă de informaţie S și care nu au fost
generate încă până la un pas k. Pe acest nod și îl vom numi nodul zero. Vom
considera că pondera acestui nod este 0, deci simbolurile care nu au fost încă
generate de sursa S au apărut de 0 ori (sau în 0% din cazuri). În concluzie, după un
pas k, acest nod este frunză, iar ponderea rădăcinii este egală cu k (sau cu 1 în cazul
în care se folosesc frecvenţele de apariţie ale simbolurilor generate până atunci).
La început arborele A, care conţine doar nodul zero, este un arbore Huffman, deci
respectă proprietatea fraţilor.
Considerăm că la al k-lea simbol generat de o sursă avem un arbore Huffman.
Sursa S generează al (k + 1)-lea simbol care trebuie codificat.
În cazul în care simbolul nu a mai fost încă generat, se va transmite la ieşire codul
nodului zero și simbolul care tocmai a fost generat. Nodul zero va fi înlocuit cu un
nod cu ponderea 1 și ai cărui fii vor fi nodul zero și un alt nod corespunzător
simbolului nou apărut, a cărui pondere va fi tot 1.
În cazul în care sursa a emis un simbol care a mai fost generat, la ieşire se
transmite codul acestuia și se incrementează ponderea nodului corespunzător
simbolului generat.
Codurile simbolurilor din arbore sunt construite la fel ca în cazul variantelor
semi-statice, adică sunt date de drumul parcurs de la rădăcină până la frunza
corespunzătoare simbolului care trebuie codificat.
În continuare trebuie actualizate ponderile celorlalte noduri interne deoarece după
adăugarea unui nod nu mai este respectată proprietatea fraţilor fiindcă ponderea
rădăcinii nu mai este egală cu suma ponderilor frunzelor sub-arborilor ei.
-44-

Aceste două cazuri de apariţie ale unui simbol sunt tratate în mod identic de
algoritmii FGK și V.
În continuare vom prezenta modul în care se actualizează ponderile nodurilor
interne în cadrul algoritmului FGK.
Pentru a menţine proprietatea fraţilor, trebuie parcurs drumul de la frunza
actualizată ultima dată până la rădăcină. Ponderea fiecărui nod din drum trebuie
incrementată cu 1 pentru a fi respectată prima condiţie a proprietăţii fraţilor, iar
pentru a doua condiţie, la fiecare pas trebuie interschimbat nodul curent cu un nod
din arbore care are aceeaşi pondere cu cea a nodului curent și care are cel mai mare
număr de ordine. Părintele nodului curent devine părintele noului nod și invers.
Trebuie avut în vedere faptul că un nod nu se poate interschimba cu un strămoş de-al
său.
-45-

Figura 2.4
În figura alăturată este prezentat modul de construcţie și actualizare a arborelui
folosind algoritmul FGK, pentru şirul "aa bbb c", unde simbolul spaţiu este
reprezentat prin "_".
La fiecare pas, arborii din figură sunt arbori Huffman, deci respectă și a doua
condiţie a proprietăţii fraţilor. Pentru a verifica acest lucru se numerotează nodurile
din arbore în ordine creascătoare începând de la ultimul nivel până la primul și de la
stânga la dreapta.
2.3.3 Algoritmul V
Algoritmul V diferă de algoritmul FGK prin faptul că, în momentul în care se
realizează actualizarea arborelui, se încearcă minimizarea expresiilor SUM(l.) și
-46-

MAX(l.), unde SUM(l.) reprezintă suma lungimilor drumurilor de la rădăcină până la
frunze, iar MAX(li) reprezintă lungimea drumului de la rădăcină până la cea mai
îndepărtată frunză. Cu alte cuvinte, se încearcă minimizarea adâncimii maxime a
arborelui și a lungimii drumului extern.
Complexitatea celor doi algoritmi este aceeaşi, dar algoritmul V este mai
performant în cazul în care probabilităţile de apariţie ale simbolurilor sunt
aproximativ aceleaşi.
Jeffrey S. Vitter a demonstrat faptul că în cel mai rău caz, algoritmul V transmite
la fiecare simbol un bit în plus faţă de metoda semi-statică, în timp ce algoritmul
FGK transmite în cel mai rău caz de două ori mai mulţi biţi pe simbol relativ la
metoda semi-statică.
CAPITOLUL 3
-47-

IMPLEMENTAREA ALGORITMULUI DE
CODIFICARE/DECODIFICARE HUFFMAN
3.1. Implementarea algoritmului de compresie
Structura de bază folosită la implementarea algoritmului de compresie este
structura arbore. Fiecare nod al arborelui este caracterizat de o pondere și o eticheta.
Fiecare nod are doi fii, reprezentati recursiv prin aceeasi structura, de tip arbore.
Structura lista_nodurilor este o listă liniară înlantuita. Fiecare nod din lista
conține un arbore.
În tabelul 1. se prezintă principalele funcții folosite la implementarea
compresiei, în pseudocod și – partial – în C. în Anexa 1 se prezinta codul sursă
complet al programului de compresie.
Tabel 3.1
Pseudocod Exemplu (partial) în C++
Structura arbore(nod):
pondere, nivel, valoare - nr. intregi;
arbore *stanga, * dreapta, *tatal;
END.
typedef struct huffman_nod_t{ int valoare; frecventa_t frecventa; int nivel struct huffman_nod_t *stanga, *dreapta, *tatal;} huffman_nod_t
Structura lista_nodurilor:
nod *t;
lista_nodurilor * urmatorul;
END.
typedef struct cod_lista_t{ octet_t codLungime} cod_lista_t;
-48-

Program Compresie
#1: Stabileste modelul sursei.
#2: Construieste arborele.
#3: Construieste cuvintele de cod.
#4: Codifica arborele și salveaza.
#5: Codifica mesajul și salveaza.
END.
int main(void){arboreHuffman = ArboreGeneratDinFisier (inFisier);if (mod == COMPRESIE){ CodareFisier(arboreHuffman, inFisier, outFisier); } else { TiparireCod(arboreHuffman, outFisier); }}
Functia construieste arborele
#1: Initializeaza lista de noduri cu
simbolurile alfabetului
#2: Cat timp (nr noduri) > 1:
#2.1: Citeste nodul (arbore) 1.
#2.2: Citeste nodul (arbore) 2.
#2.3: Citeste nodul (arbore) 3.
#2.4: Uneste primii doi arbori (cu
cele mai mici ponderi)
#2.5: Pune eticheta nodului.
#2.6: Defineste sub-arborele stang.
#2.7: Defineste sub-arborele drept.
#2.7: Defineste sub-arborele drept.
#2.8: Actualizeaza
int BuildTree(listnode *&list){ BuildList(lleaves, M, freq); listnode *ln1,*ln2,*ln3; tree *t; while (Nodes>1) { ln1=list; // nodul 1 ln2=list->next; // nodul 2 ln3=ln2->next; // nodul 3 t->weight=(ln1->t->weight)+ (ln2->t->weight); t->label=NODE; t->left=ln1->t; //fiu stang t->right=ln2->t; //fiu drept list = ln3; InsertInList(list,t); Nodes -= 2; // actualizez lista } return 0;}
-49-

lista(inserare+sortare); nr_noduri =
nr_noduri + 1;
#2.9: nr_noduri = nr_noduri - 2;
END.
Functia construiste cuvintele de cod
(BCW) corespunzatoare arborelui T
#1: Pentru un nod i al arborelui
DACA i nu este frunza
ATUNCI
k = k + 1;
cod_stanga[k]=’0’;
Parcurg fiul stang al lui i (BCW(fiu
stang))
cod_dreapta[k] = ’1’
Parcurg fiul drept al lui i (BCW(fiu
drept))
k = k - 1;
ALTFEL
cuvant[i]=cod[1:k];
END.
huffman_nod_t *ConstruireArboreHuffman(huffman_nod_t **ah, int elemente){ int min1, min2; for (;;) { min1 = FrecventaMinimuluiGasit(ah, elemente);
if (min1 == NIMIC) { break; }
ah[min1]->ignorat = ADEVARAT;
min2 = FrecventaMinimuluiGasit(ah, elemente);
if (min2 == NIMIC) { break; }
ah[min2]->ignorat = ADEVARAT; ah[min1] = AlocareNodCombinatHuffman(ah[min1], ah[min2]); ah[min2] = NULL; }
return ah[min1];}
Functia codifica arborele (CT) int CodeTree(tree *t)
-50-

#1: Incepe cu nodul radacina.
#2: Pentru un nod k din arbore
DACA k este frunza
ATUNCI
- scrie ’1’;
- scrie codul binar al
etichetei
ALTFEL
- scrie ’0’;
- Parcurg fiul stang al lui
k (CT(fiu stang))
- Parcurg fiul drept al lui
k (CT(fiu drept))
END.
{ if (t->label!=NODE){//t este frunza fprintf(f,"1",t->label); binary(t->label,9,Bits); } else { fprintf(f,"0"); if (t->left) CodeTree(t->left); if (t->right)CodeTree(t->right); } return 0;}
Functia codifica mesajul
#1: Pentru toate simbolurile s[i] ale
mesajului
#1.1: Cauta eticheta label[j] = s[i];
#1.2: Scrie cuvantul de cod
cuvant[j];
#2: Scrie codul caracterului sfarsit;
END.
int CodeMessage(char *txt){ for (i= 0;i < strlen(txt);i++){ for (j = 0;j < NWords;j++) if (Label[j]!=END && txt[i]==Label[j]) break; fprintf(f,"%s",CodeWords[j]); } for (j = 0;j < NWords;j++) if (Label[j]==END) break; fprintf(f,"%s",CodeWords[j]); return 0;}
-51-
3.2 Implementarea algoritmului de expandare (de-compresie)
Pseudocod Exemplu partial C
Program de-compresie
#1: Reconstruieste fisierul de iesire.
#2: Decodifica mesajul.
END.
if (mod == DECOMPRESIE) { DecodareFisier(huffmanTablou, inFisier, outFisier); } if (inFisier == NULL){ fprintf(stderr, "Fisierul de intrare trebuie furnizat\n"); fprintf(stderr, "Intrare \"huffman -?\" pentru ajutor.\n");
exit (EXIT_FAILURE);}
Functia re-construieste arborele (RBT)
#1: Citeste primul caracter din fisier
#2: DACA este nod frunza (valoare
1)
ATUNCI
pondere := 1; eticheta = citeste urmatorii 9
biti;
nu are fii;
ALTFEL
Construiesc fiiul stang (RBT(fiu
stang))
Construiesc fiul drept (RBT(fiu
drept))
void ReBuildTree(tree *T){ fscanf(f,"%c",&ch); if (ch=='0') Bit=0; else Bit=1; if (Bit) { T->left = T->right = NULL; T->weight = 1; T->label = ConvertLabel(); } else { tree *r=new tree,*l=new tree; T->left=l; T->right=r; T->label=NODE; T->weight=1; ReBuildTree(T->left); ReBuildTree(T->right); }}
-52-

END.
Functia decodifica_mesajul
#1: Pentru fiecare caracter al mesajului,
diferit de caracterul fictiv END,
efectueaza
Decodificarea.
END.
void DecodeText(tree *T){ ch2=DecodeChar(T); while (ch2 != END){ printf("%c",(char)ch2); ch2=DecodeChar(T); }}
Functia decodifica_caracter (DC)
#1: Pleaca din nodul radacina
#2: CAT TIMP T nu este frunza,
#2.1: Citeste urmatorul bit b din
mesajul codificat
#2.2: DACA b este 0,
ATUNCI
- parcurgem fiul drept(DC(fiu
stang))
ALTFEL:
- parcurgem fiul stang (DC(fiu
drept))
#3: T este frunza, și contine caracterul
decodificat
END.
int DecodeChar(tree *T){ tree *p=T; while (p->label == NODE){ fscanf(f,"%c",&ch); if (ch=='0') p=p->left; else p=p->right; }return p->label;}
-53-

Functia conversie 9 biti – intreg corespunzator codului ASCII al caracterului#1: PENTRU fiecare bit i, incepand de la stanga la dreapta(MSB pana la LSB): - citesc un bit b din fisier - adun la numarul total 2i*b END.
int ConvertLabel(){ int P=256, Result=0,i; for (i = 8;i >= 0;i--,P /= 2) { fscanf(f,"%c",&ch); if (ch!='0') Bit = 1; else Bit = 0; Result += P*Bit; } return Result;}
3.3 Rezultate obținute
Algoritmul de compresie Huffman este unul relativ simplu de înţeles şi de
implementat, iar în cele ce urmeaza vom arata modul în care se va face codarea.
Presupunem ca fişier de intrare chiar programul în cauză, <huffman.c> şi ca fişier de
ieşire <fisier.out>. Se vor afişa codurile folosite în comprimarea fişierului. Ca
rezultat avem conţinutul fişierului < fisier.out >:
Caracter Frecventa Codat
-------- --------- ------------
0x6F 668 00000
0x2D 165 0000100
0x67 84 00001010
0x3A 85 00001011
0x5F 180 0000110
0x4D 45 000011100
0x5C 22 0000111010
0x3F 5 000011101100
0x25 3 0000111011010
0x6A 3 0000111011011
0x32 12 00001110111
0x55 92 00001111
0x61 1417 0001
-54-

0x3E 93 00100000
0x2C 96 00100001
0x62 192 0010001
0x6D 382 001001
0x3D 196 0010100
0x7B 98 00101010
0x7D 98 00101011
0x49 104 00101100
0x4F 50 001011010
0x09 54 001011011
0x50 27 0010111000
0x58 27 0010111001
0x48 55 001011101
Observăm caracterele cel mai des întâlnite fiind cele corespunzătoare în cod
ASCII lui 0x20 şi 0x2A care va fi codate doar prin doi biţi 10, respectiv trei biţi 010.
Fişierul comprimat va avea o compresie din 30 kbiţi în 17 kbiţi, de aproximativ 57%.
In Anexa 2 este prezentat un program C++ care codifica și decodifica un text
cunoscandu-se ponderile caracterelor (doar pentru caracterele alfabetice)
implementand acelasi algoritm Huffman . Arborele binar Huffman este reprezentat
printr-o clasa C++ iar operatiile prin functii membre. Pentru codarea textului examen
de licenta se obtine urmatorul rezultat:
-55-

Fig. 3.1
CONCLUZII
În compresia datelor un rol important il are teoria codarii și teoria informației.
Compresia se referă la micșorarea redundanței mesajului de transmis. Compresia de
poate face:
cu pierdere de informație, așa cum este cazul surselor continue (analogice)
discretizate, reprezentate numeric în calculator;
fara pierdere de informatie, așa cum este în cazul textelor.
Ca masura a compresiei se foloșeste - cel mai des – marimea numită raportul
de compresie, ca raport intre marimea fișierului comprimat și mărimea fișierului
inițial, necomprimat. Un criteriu complet al calității compresiei trebuie să se
considere însă și complexitatea algoritmilor de codare/decodare.
Compresia datelor este necesară în zilele noastre şi este foarte des folosită,
mai ales în domeniul aplicaţiilor multimedia.
O metodă statică este aceea în care transformarea mulţimii mesajelor în
cuvinte de cod este fixată înainte de începerea transmisiei
Metodele de compresie text pot fi împărţite în doua categorii: statistice şi ne-
statistice. O metodă statică este aceea în care transformarea mulţimii mesajelor în
cuvinte de cod este fixată înainte de începerea transmisiei. Un exemplu de codare
statică, bazată de cuvinte de cod, este codarea Huffman (statică).
Un cod este dinamic (dynamic) dacă codarea mulţimii mesajelor sursei
primare se schimbă în timp. Codarea Huffman dinamică presupune estimarea
probabilităţilor de apariţie în timpul codării, în timp ce mesajul este procesat.
Cea mai mare problemă în implementarea codului Huffman este preocuparea
pentru frecvenţe. Dacă codăm un singur mesaj, o dată şi încă o dată, de mai multe
ori, ca o simplă copiere, asta-i simplu. Dar dacă vrem un mesaj mult mai lung într-un
pachet de mesaje este mai dificil. În acest caz, o soluţie bună este să folosim
frecvenţe tipice pe care dorim să le scriem. Putem implementa rutine pentru
-56-

analizarea setului de fişiere text pentru frecvenţele caracterelor lor. Rezultatele sunt
înregistrate într-un fişier special de frecvenţe cu care codul creat Huffman poate fi
folosit pentru citirea şi scrierea fişierelor.
Structura de bază folosită la implementarea algoritmului de compresie este
structura arbore. Algoritmul de compresie Huffman este unul relativ simplu de
înţeles şi de implementat. Pentru implementarea în limbajele de programare se pot
utilize tipurile de date structurate cum ar fi tipul struct în C sau class în C++.
Metoda de compresie bazată pe arbori Huffman statici are și o serie de
dezavantaje:
1. Fişierul de compactat trebuie parcurs de două ori: o dată pentru a calcula numărul
de apariţii ale caracterelor în text, a doua oară pentru a comprima efectiv fişierul.
Deci metoda nu poate fi folosită pentru transmisii de date pentru care nu este posibilă
reluarea.
2. Pentru o dezarhivare ulterioară a fişierului, aşa cum este şi firesc, este necesară
memorarea arborelui Huffman utilizat pentru comprimare, ceea ce conduce la
mărirea dimensiunii codului generat.
3. Arborele Huffman generat este static, metoda nefiind capabilă să se adapteze la
variaţii locale ale frecvenţelor caracterelor.
Aceste dezavantaje au fost în mare parte eliminate în metodele care folosesc
arbori Huffman dinamici, asa cum am aratat în capitolul 2, ideea fiind ca la fiecare
nouă codificare, arborele Huffman să se reorganizeze astfel încât caracterul respectiv
să aibă eventual un cod mai scurt.
Un algoritm de compresie poate fi evaluat în funcţie de necesarul de memorie
pentru implementarea algoritmului, viteza algoritmului pe o anumită maşină, raportul
de compresie, calitatea reconstrucţiei. De obicei, ultimele două criterii sunt esenţiale
în adoptarea algoritmului de compresie, iar eficienţa lui este caracterizată de
compromisul criteriilor enumerate. Despre metodele de compresie Huffman, în
special cele dinamice, putem spune ca satisfac aceste cerințe.
Deși este cea mai veche metoda de comprimare , algoritmii Huffman sunt
folosiți de către programele de arhivare cu o rată de compresie ridicată mai ales la
comprimarea fișierelor de tip text.
-57-
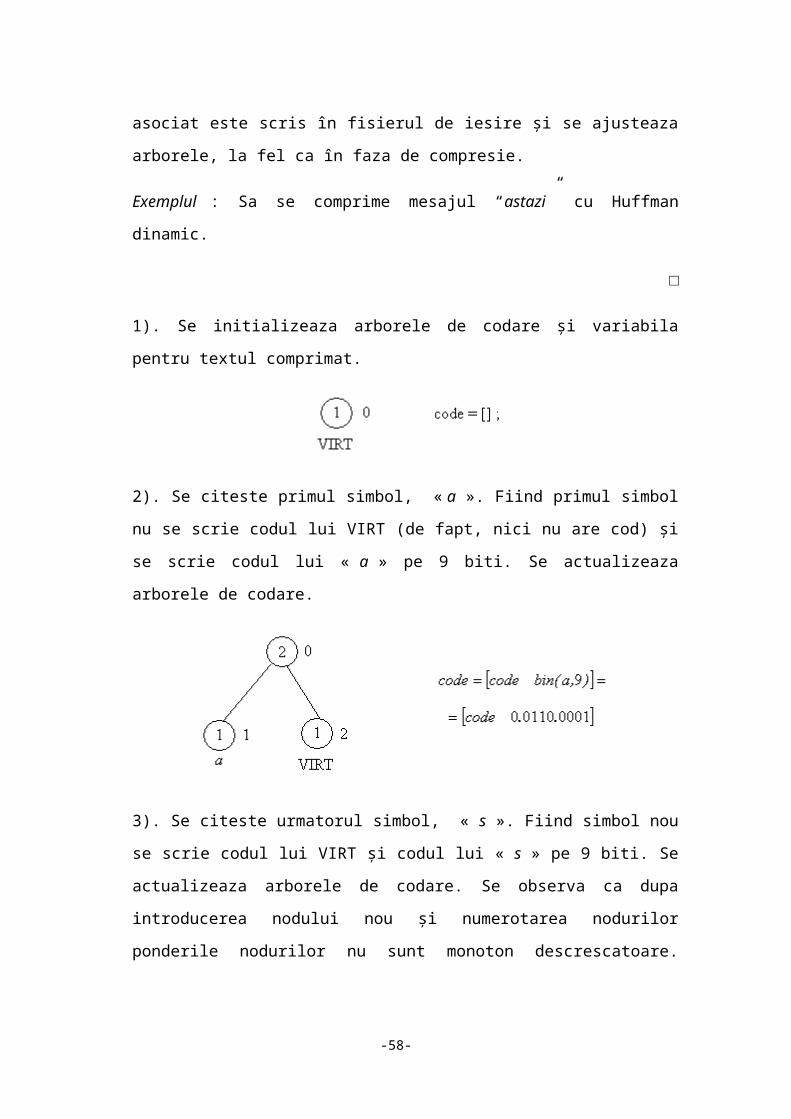
ANEXA 1
- Program C -
/**************************************************************************** Codare și decodare Huffman** Fisier : huffman.c* Scop : Compresia/decompresia fisierelor folosind algoritmul Huffman***************************************************************************/
/**************************************************************************** FISIERE INCLUSE***************************************************************************/#include <stdio.h>#include <stdlib.h>#include <limits.h>#include <string.h>#include "alegopt.h"/**************************************************************************** TIPURI DEFINITE***************************************************************************//* tipurile sistemului */typedef unsigned char octet_t; /* 8 biti fara semn */typedef unsigned short cod_t; /* 16 biti fara semn pentru caracterele codurilor */typedef unsigned int frecventa_t; /* 32 biti fara semn pentru caracterele cautate */
/* foloseste preprocesorul pentru a verifica lungimea tipurilor*/#if (UCHAR_MAX != 255)#error Acest program depaseste tipul char fara semn de 1 octet#endif
#if (USHRT_MAX != 65535)#error Acest program depaseste tipul short fara semn de 2 octeti#endif
/* frecventa_t în tablou al octet_t */typedef union frecventa_octet_t{ frecventa_t frecventa; octet_t octet[sizeof(frecventa_t)];} frecventa_octet_t;
typedef struct huffman_nod_t{ int valoare; /* valoarea caracterului introdus */ frecventa_t frecventa; /* numarul de evenimente al valorii (probabilitati) */ char ignorat; /* ADEVARAT -> deja intalnit sau nu are nevoie sa fie luat */ int nivel; /* nivelul în arbore (radacina are nivelul 0) */ /*********************************************************************** * pointer spre fiu și tatal.
-58-
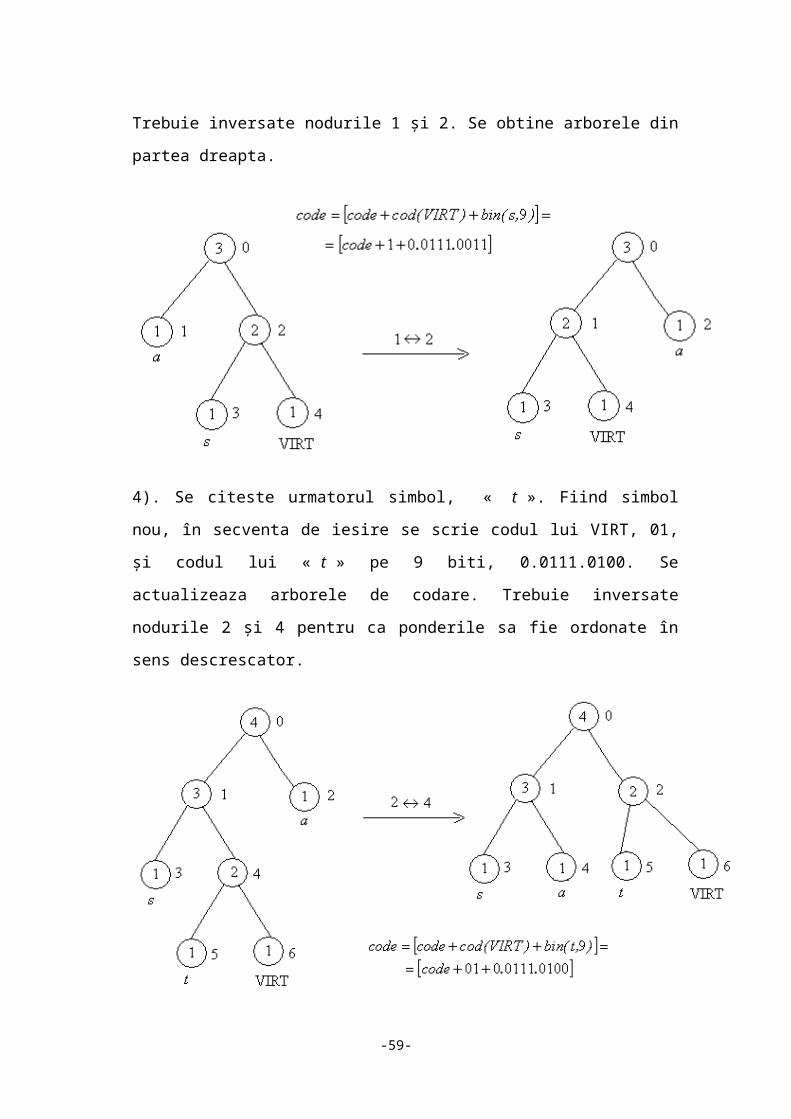
***********************************************************************/ struct huffman_nod_t *stanga, *dreapta, *tatal;} huffman_nod_t;
typedef struct cod_lista_t{ octet_t codLungime; /* numarul de biti folositi în cod */ cod_t cod; /* cod folosit pentru simbol */} cod_lista_t;
typedef enum{ CONSTRUIRE_ARBORE, COMPRESIE, DECOMPRESIE} MODURI;
/**************************************************************************** CONSTANTE***************************************************************************/#define FALS 0#define ADEVARAT 1#define NIMIC -1
#define CARACTERE_T_MAX UINT_MAX /* bazat pe tipul definit frecventa_t */#define NOD_COMBINAT -1 /* nod reprezentand caractere multiple */#define NUM_CARACTERE 256 /* 256 simboluri posibile pe 1 octet */
#define MAX(a, b) ((a)>(b)?(a):(b))
/**************************************************************************** VARIABILE GLOBALE***************************************************************************/huffman_nod_t *huffmanTablou[NUM_CARACTERE]; /* tablou pentru toate caracterele*/frecventa_t totalCaractere = 0; /* numarul total de caractere */
/**************************************************************************** PROTOTIPURI***************************************************************************/
/* alocare/dezalocare rutine */huffman_nod_t * AlocareNodHuffman (int valoare);huffman_nod_t *AlocareNodCombinatHuffman(huffman_nod_t *stanga, huffman_nod_t *dreapta);void EliberareArboreHuffman(huffman_nod_t *ah);
/* constructia și aratarea arborelui */huffman_nod_t *ArboreGeneratDinFisier(char *inFisier);huffman_nod_t *ConstruireArboreHuffman(huffman_nod_t **ah, int elemente);void TiparireCod(huffman_nod_t *ah, char *outFisier);
void CodareFisier(huffman_nod_t *ah, char *inFisier, char *outFisier);void DecodareFisier(huffman_nod_t **ah, char *inFisier, char *outFisier);void CreareCodLista(huffman_nod_t *ah, cod_lista_t *cl);
/* citire-scriere arbore în fisier*/void ScriereHeader(huffman_nod_t *ah, FILE *pf);void CitireHeader(huffman_nod_t **ah, FILE *pf);
-59-

/**************************************************************************** FUNCTII***************************************************************************/
/***************************************************************************** Functia : Main* Descriere : Aceasta este functia main pentru acest program,ea valideaza liniile de * comanda de intrare si, daca sunt valide, ea va construi un arbore huffman * pentru fisierul de intrare, un fisier huffman de codare , sau un fisier de * decodare huffman.* Parametri : argc - numarul de parametri* argv - lista de parametri* Efect : Construieste un arbore huffman pentru fisierul specificat și la iesire* rezulta cod spre stdout.* Returneaza : EXIT_SUCCES pentru succes, altfel returneaza EXIT_FAILURE.****************************************************************************/int main (int argc, char *argv[]){ huffman_nod_t *arboreHuffman; /* radacina arborelui huffman */ int opt; char *inFisier, *outFisier; MODURI mod;
/* initializare variabile */ inFisier = NULL; outFisier = NULL; mod = CONSTRUIRE_ARBORE;
/* analizarea liniilor de comanda */ while ((opt = alegopt(argc, argv, "cdli:o:h?")) != -1) { switch(opt) { case 'c': /* compresie mod */ mod = COMPRESIE; break;
case 'd': /* decompresie mod */ mod = DECOMPRESIE; break;
case 'l': /* doar constructie și afisare arbore*/mod = CONSTRUIRE_ARBORE;break;
case 'i': /* nume fisier de intrare */if (inFisier != NULL){ fprintf(stderr, "Multiple fisiere de intrare nu sunt permise.\n"); free(inFisier);
if (outFisier != NULL) {
free(outFisier); }
exit(EXIT_FAILURE);}
else if ((inFisier = (char *)malloc(strlen(optarg) + 1)) == NULL)
-60-
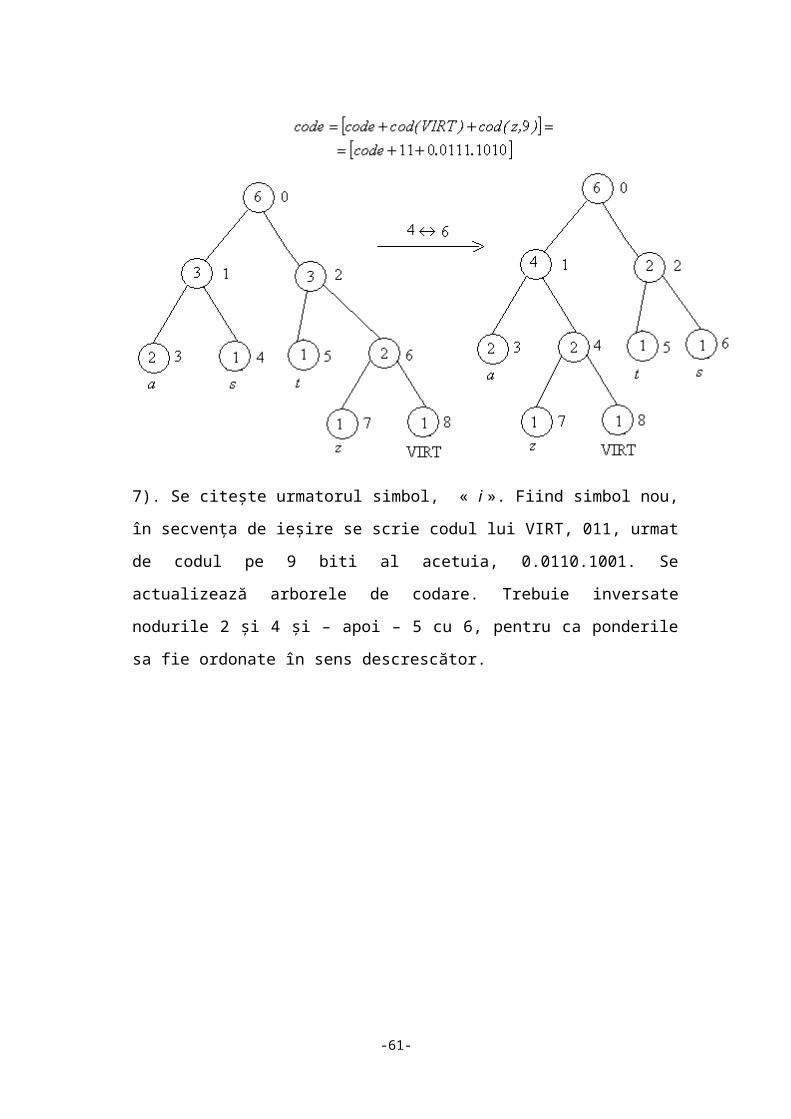
{ perror("Alocarea memoriei");
if (outFisier != NULL) { free(outFisier); }
exit(EXIT_FAILURE);}
strcpy(inFisier, optarg); break;
case 'o': /* nume fisier de iesire */ if (outFisier != NULL) { fprintf(stderr, " Multiple fisiere de iesire nu sunt permise.\n"); free(outFisier);
if (inFisier != NULL) { free(inFisier); }
exit(EXIT_FAILURE); } else if ((outFisier = (char *)malloc(strlen(optarg) + 1)) == NULL) { perror("Alocarea memoriei");
if (inFisier != NULL) { free(inFisier); }
exit(EXIT_FAILURE); }
strcpy(outFisier, optarg); break;
case 'h': case '?': printf("Utilizare: huffman <optiuni>\n\n"); printf("optiuni:\n"); printf(" -c : Fisier intrare codat în fisier de iesire.\n"); printf(" -d : Fisier intrare decodat în fisier de iesire.\n"); printf(" -t : Generare lista coduri fisier intrare în fisier de iesire.\n"); printf(" -i <nume_fisier> : Nume fisier de intrare.\n"); printf(" -o <nume_fisier> : Nume fisier de iesire.\n"); printf(" -h|? : Tiparire optiuni linia de comanda.\n\n");return(EXIT_SUCCESS); } }
/* validare linie de comanda */ if (inFisier == NULL) {
-61-
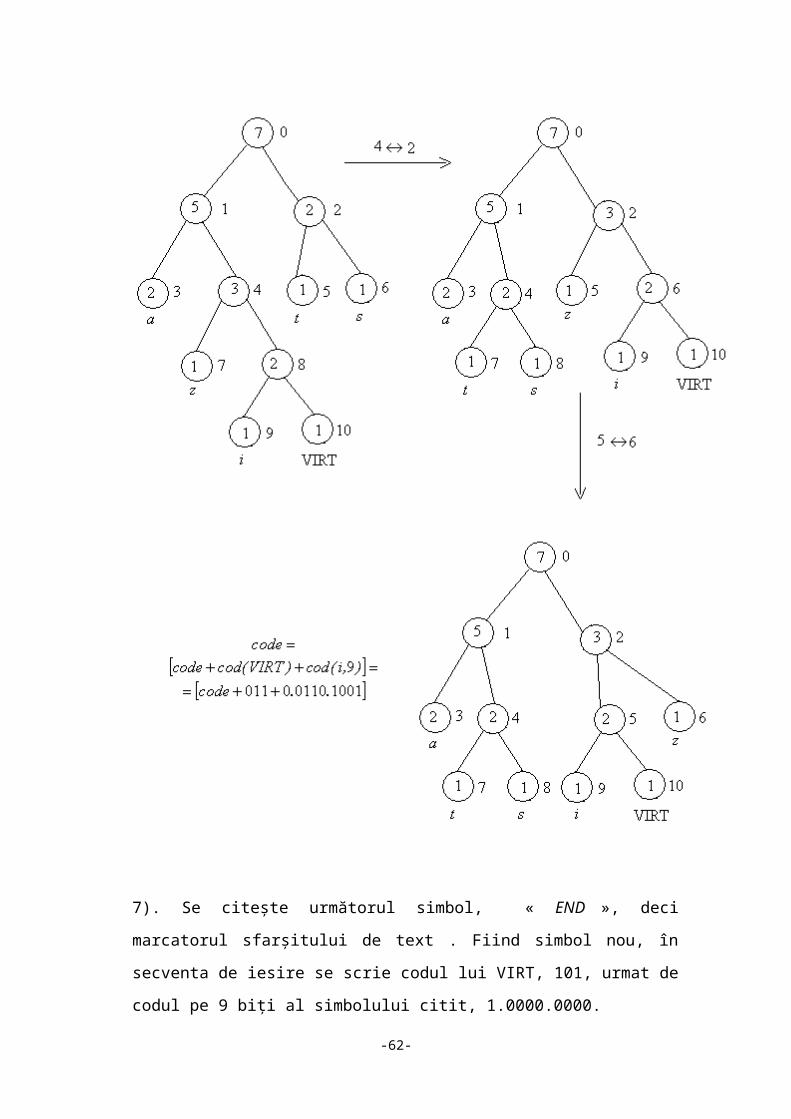
fprintf(stderr, "Fisierul de intrare trebuie furnizat\n"); fprintf(stderr, "Intrare \"huffman -?\" pentru ajutor.\n");
exit (EXIT_FAILURE); }
if ((mod == COMPRESIE) || (mod == CONSTRUIRE_ARBORE)) { arboreHuffman = ArboreGeneratDinFisier(inFisier);
/* determinam ce facem cu arborele */ if (mod == COMPRESIE) { /* scriem fisier de codare */ CodareFisier(arboreHuffman, inFisier, outFisier); } else { /* doar cod de iesire */ TiparireCod(arboreHuffman, outFisier); }
EliberareArboreHuffman(arboreHuffman); /* eliberarea memoriei alocate*/ } else if (mod == DECOMPRESIE) { DecodareFisier(huffmanTablou, inFisier, outFisier); }
/* stergere*/ free(inFisier); if (outFisier != NULL) { free(outFisier); } return(EXIT_SUCCESS);}
/**************************************************************************** Functie : ArboreGeneratDinFisier* Descriere : Aceasta functie creeaza un arbore huffman optim pentru codarea fisieruuil luat * ca parametru.* Parametri : inFisier - numele fisierului pentru creare arbore * Efecte : Arborele Huffman este construit pentru fisier.* Returneza : Pointer spre arborele rezultat.***************************************************************************/huffman_nod_t *ArboreGeneratDinFisier(char *inFisier){ huffman_nod_t *arboreHuffman; /* radacina arborelui huffman */ int c; FILE *pf;
/* deschide fisierul ca binar */ if ((pf = fopen(inFisier, "rb")) == NULL) { perror(inFisier);
exit(EXIT_FAILURE); }
/* alocare tablou pentru toate caracterele posibile */
-62-

for (c = 0; c < NUM_CARACTERE; c++) { huffmanTablou[c] = AlocareNodHuffman(c); }
/* frecventa probabilitati fiecare caracter */ while ((c = fgetc(pf)) != EOF) { if (totalCaractere < CARACTERE_T_MAX) {
totalCaractere++;
/* incrementare frecventa pentru caracter și il includem în arbore */ huffmanTablou[c]->frecventa++; /* cauta pentru depasire */ huffmanTablou[c]->ignorat = FALS; } else { fprintf(stderr, "Numarul de caractere în fisier este prea mare pt. a calcula frecventa. \n");
exit(EXIT_FAILURE); } }
fclose(pf);
/* pune tablou de evenimente intr-un arbore huffman */ arboreHuffman = ConstruireArboreHuffman(huffmanTablou, NUM_CARACTERE);
return(arboreHuffman);}
/**************************************************************************** Functie : AlocareNodHuffman* Descriere : Aceasta rutina aloca și initializeaza memoria pentru un nod (intrare arbore * pentru un singur caracter) în arborele Huffman. * Parametri : valoare - caracterul valoare reprezentat de acest nod* Efect : Memoria pentru huffman_nod_t este alocata din memoria heap* Returneaza : Pointer pentru alocare nod. NULL pentru insuccesul alocarii.***************************************************************************/huffman_nod_t *AlocareNodHuffman(int valoare){ huffman_nod_t *ah;
ah = (huffman_nod_t *)(malloc(sizeof(huffman_nod_t)));
if (ah != NULL) { ah->valoare = valoare; ah->ignorat = ADEVARAT; /* va fi FALS daca se gaseste unul */
/* la acest punct, nodul nu face parte din arbore */ ah->frecventa = 0; ah->nivel = 0; ah->stanga = NULL; ah->dreapta = NULL; ah->tatal = NULL; } else {
-63-

perror("Alocare Nod");exit(EXIT_FAILURE);
}
return ah;}
/***************************************************************************** Functie : AlocareNodCombinatHuffman* Descriere: Aceasta rutina aloca și initializeaza memoria pentru un nod combinat (intrare * arbore pentru multiple caractere) intr-un arbore Huffman .Numarul de * evenimente pentru un nod combinat este suma evenimentelor (probabilitatilor)* fiilor sai.* Parametri : stanga - fiu stanga în arbore* dreapta - fiu dreapta în arbore* Efecte : Memoria pentru un huffman_nod_t este alocata din memoria heap* Returneaza : Pointer spre nodul alocat****************************************************************************/huffman_nod_t *AlocareNodCombinatHuffman(huffman_nod_t *stanga, huffman_nod_t *dreapta){ huffman_nod_t *ah;
ah = (huffman_nod_t *)(malloc(sizeof(huffman_nod_t)));
if (ah != NULL) { ah->valoare = NOD_COMBINAT; /* reprezinta multiple caractere */ ah->ignorat = FALS; ah->frecventa = stanga->frecventa + dreapta->frecventa; /* suma fiilor */ ah->nivel = max(stanga->nivel, dreapta->nivel) + 1;
/* ataseaza fiu */ ah->stanga = stanga; ah->stanga->tatal = ah; ah->dreapta = dreapta; ah->dreapta->tatal = ah; ah->tatal = NULL; } else { perror("Alocare Nod Combinat");
exit(EXIT_FAILURE); }
return ah;}
/***************************************************************************** Functie : EliberareArboreHuffman* Descriere : Aceasta este o rutina recursiva pentru eliberarea memoriei alocate pentru un * nod și a tuturor descendentilor sai.* Parametri : ah - structura de stergere impreuna cu fii sai.* Efecte : Memoria pentru un huffman_nod_t și fii sai este returnata memoriei heap.* Returneaza : Nimic****************************************************************************/void EliberareArboreHuffman(huffman_nod_t *ah){ if (ah->stanga != NULL)
-64-

{ EliberareArboreHuffman(ah->stanga); }
if (ah->dreapta != NULL) { EliberareArboreHuffman(ah->dreapta); }
free(ah);}
/***************************************************************************** Functie : FrecventaMinimuluiGasit* Descriere: Aceasta functie cauta în tablou huffman_struct pentru a gasi elementul activ * (ignorat == FALS) cu cea mai mica frecventa cautata. în ordinea cautarii * arborelui care-l vad, daca doua noduri au aceeasi frecventa, nodul cu nivelul mai * mic este selectat.* Parametri : ah - pointer spre tablou structurii de frecventa* elemente - numar de elemente din tablou* Efect : Nimic* Returneaza : Indicele elementului activ cu cea mai mica frecventa.* Este returnat NIMIC daca nu sunt gasite minime.****************************************************************************/int FrecventaMinimuluiGasit(huffman_nod_t **ah, int elemente){ int i; /* indicele tabloului */ int IndiceleCurent = NIMIC; /* indicele cu cea mai mica frecventa vazut pana în prezent */ int FrecventaCurenta = INT_MAX; /* frecventa cea mai mica pana în prezent */ int NivelulCurent = INT_MAX; /* niveull cautarii celei mai mici pana în prezent */
/* tablou de frecventa secvential */ for (i = 0; i < elemente; i++) { /* cauta pentru cea mai mica frecventa (sau egala ca cea mai mica) */ if ((ah[i] != NULL) && (!ah[i]->ignorat) && (ah[i]->frecventa < FrecventaCurenta || (ah[i]->frecventa == FrecventaCurenta && ah[i]->nivel < NivelulCurent))) { IndiceleCurent = i; FrecventaCurenta = ah[i]->frecventa; NivelulCurent = ah[i]->nivel; } } return IndiceleCurent;}
/***************************************************************************** Functie : ConstruireArboreHuffman* Descriere: Aceasta functie construieste un arbore huffman din tablou huffmann_struct.* Parametri : ah - pointer spre tablou de structuri ce vor fi cautate* elemente - numar de elemente din tablou* Efecte : Tablou huffman_nod_t este construit intr-un abore huffman.* Returneaza : Pointer spre radacina lui Huffman Arbore****************************************************************************/huffman_nod_t *ConstruireArboreHuffman(huffman_nod_t **ah, int elemente){ int min1, min2; /* doua noduri cu cea mai mica frecventa */
-65-

/* sa cautam pana ce nu mai sunt noduri gasite */ for (;;) { /*gaseste nodul cu cea mai mica frecventa */ min1 = FrecventaMinimuluiGasit(ah, elemente);
if (min1 == NIMIC) { /* nu mai sunt noduri de combinat */ break; }
ah[min1]->ignorat = ADEVARAT;
/* gaseste nodul ce cea de a doua frecventa dintre cele mici */ min2 = FrecventaMinimuluiGasit(ah, elemente);
if (min2 == NIMIC) { /* nu mai sunt noduri de combinat */ break; }
ah[min2]->ignorat = ADEVARAT;
/* combina nodurile intr-un arbore */ ah[min1] = AlocareNodCombinatHuffman(ah[min1], ah[min2]); ah[min2] = NULL; }
return ah[min1];}
/***************************************************************************** Functie : TiparireCod* Descriere: Aceasta functie da arborele huffman tiparind la iesire codul nodului fiecarui * caracter intalnit..* Parametri : ah - pointer spre radacina arborelui* outFisier - unde sunt rezultatele de iesire (NULL -> stdout)* Efect : Codul pentru caracterele continute în arbore sunt tiparite în outFisier.* Returneaza : Nimic****************************************************************************/void TiparireCod(huffman_nod_t *ah, char *outFisier){ char cod[50]; int adancime = 0; FILE *pf;
if (outFisier == NULL) {
pf = stdout; } else {
if ((pf = fopen(outFisier, "w")) == NULL) { perror(outFisier); EliberareArboreHuffman(ah);
-66-

exit(EXIT_FAILURE); } }
/* tiparire */ fprintf(pf, "Caracter Frecventa Codat\n"); fprintf(pf, "-------- --------- ------------\n");
for(;;) { /* urmeaza toata calea din stanga */ while (ah->stanga != NULL) { cod[adancime] = '0'; ah = ah->stanga; adancime++; }
if (ah->valoare != NOD_COMBINAT) { /* cand avem nodul unui caracter, i-i tiparim codul */ cod[adancime] = '\0';
/* în cazul de EOF */ fprintf(pf, "0x%02X %5d %s\n", ah->valoare, ah->frecventa, cod);
}
while (ah->tatal != NULL) { if (ah != ah->tatal->dreapta) { /* incercam tatal în dreapta */ cod[adancime - 1] = '1'; ah = ah->tatal->dreapta; break; } else { /* tatal din dreapta am incercat, mergem mai sus un nivel */ adancime--; ah = ah->tatal; cod[adancime] = '\0'; } }
if (ah->tatal == NULL) { /* suntem în varf și nu avem unde sa mai mergem */ break; } }
if (outFisier != NULL) { fclose(pf); }}
/****************************************************************************
-67-

* Functie : CodareFisier* Descriere: Aceasta functie foloseste arborele Huffman furnizat pentru codarea fisierului * luat ca parametru.* Parametri : ah - pointer spre radacina arbore huffman* inFisier - fisier de intrare pentru codare* outFisier - unde se pun rezultatele de iesire (NULL -> stdout)* Efect : inFisier este codat și codul plus rezultatele sunt scrise în fisierul outFisier.* Returneaza : Nimic****************************************************************************/void CodareFisier(huffman_nod_t *ah, char *inFisier, char *outFisier){ cod_lista_t codLista[NUM_CARACTERE]; /* tabel pentru codare */ FILE *pfIn, *pfOut; int c, i, bitFrecventa; cod_t cod, masca; char bitBufer;
/* deschide intrarea binara și fisierul de iesire */ if ((pfIn = fopen(inFisier, "rb")) == NULL) { perror(inFisier);
exit(EXIT_FAILURE); }
if (outFisier == NULL) {
pfOut = stdout; } else {
if ((pfOut = fopen(outFisier, "wb")) == NULL) { perror(outFisier); EliberareArboreHuffman(ah);
exit(EXIT_FAILURE); } }
ScriereHeader(ah, pfOut); /* scriere header pentru refacerea arborelui */ CreareCodLista(ah, codLista); /* converteste cod pentru a folosi usor lista */
/* scrie fisierul codat pe 1 octet */ bitBufer = 0; bitFrecventa = 0;
masca = 1 << ((sizeof(cod_t) * 8) - 1); while((c = fgetc(pfIn)) != EOF) {
cod = codLista[c].cod;
/* deplasare biti */ for(i = 0; i < codLista[c].codLungime; i++) { bitFrecventa++; bitBufer = (bitBufer << 1) | ((cod & masca) != 0); cod <<= 1;
if (bitFrecventa == 8) {
-68-

/* avem un octet în bufer */ fputc(bitBufer, pfOut); bitFrecventa = 0; } } }
if (bitFrecventa != 0) { bitBufer <<= 8 - bitFrecventa; fputc(bitBufer, pfOut); }
fclose(pfIn); fclose(pfOut);}
/***************************************************************************** Functie : CreareCodLista* Descriere: Aceasta functie foloseste un arbore huffman pentru a construi o lista de coduri * și lungimile lor pentru fiecare simbol codat. Aceasta simplifica procesul de * codare. în locul tranversarii arborelui pentru frecventa codului pentru orice * simbol,codul poate fi gasit accesand cl[simbol].cod.* Parametri : ah - pointer spre radacina arborelui huffman* cl - cod lista .* Efect : Valoarile codurilor se afla toate în lista de coduri.* Returneaza : Nimic****************************************************************************/void CreareCodLista(huffman_nod_t *ah, cod_lista_t *cl){ cod_t cod = 0; octet_t adancime = 0;
for(;;) { /* urmeaza toata calea din stanga */ while (ah->stanga != NULL) { cod = cod << 1; ah = ah->stanga; adancime++; }
if (ah->valoare != NOD_COMBINAT) { /* introduse rezultatele în lista */ cl[ah->valoare].codLungime = adancime; cl[ah->valoare].cod = cod;
/* */ cl[ah->valoare].cod <<= ((sizeof(cod_t) * 8) - adancime); }
while (ah->tatal != NULL) { if (ah != ah->tatal->dreapta) { /* incearca tatal este dreapta */ cod |= 1;
-69-

ah = ah->tatal->dreapta; break; } else { /* tatal în dreapta a fost incercat, mergem un nivel mai sus */ adancime--; cod = cod >> 1; ah = ah->tatal; } }
if (ah->tatal == NULL) { /*suntem în varf, nu avem unde sa mai mergem */ break; } }}
/**************************************************************************** Functie : ScriereHeader* Descriere: Aceasta functie scrie fiecare simbol continut în arbore precum și numarul de evenimente în fisierul original în fisierul de iesire specificat. Daca acelasi algoritm care a produs arborele original este folosit cu aceste cautari, o copie exacta a arborelui va fi produsa.* Parametri : ah - pointer spre radacina arborelui huffman * pf - pointer de a deschide fisierul binar în care se scrie.* Efect : Valoarile simbolurilor și cautarile simbolurilor sunt scrise.* Returneaza : Nimic***************************************************************************/void ScriereHeader(huffman_nod_t *ah, FILE *pf){ frecventa_octet_t octetUniune; int i;
for(;;) { /* urmeaza calea din stanga */ while (ah->stanga != NULL) { ah = ah->stanga; }
if (ah->valoare != NOD_COMBINAT) { /* scrie simbolul și cauta dupa header */ fputc(ah->valoare, pf);
octetUniune.frecventa = ah->frecventa; for(i = 0; i < sizeof(frecventa_t); i++) { fputc(octetUniune.octet[i], pf); } }
while (ah->tatal != NULL) { if (ah != ah->tatal->dreapta) {
-70-

ah = ah->tatal->dreapta; break; } else { /* tatal din dreapta este incercat,mergem mai sus un nivel */ ah = ah->tatal; } }
if (ah->tatal == NULL) { /*suntem în varf, nu avem unde sa mergem */ break; } }
/* acum scriem sfarsitul tabelei caracterr 0 */ fputc(0, pf); for(i = 0; i < sizeof(frecventa_t); i++) { fputc(0, pf); }}
/**************************************************************************** Functie : DecodareFisier* Descriere: Aceasta functie decodeaza un fisier codat huffman, scriind rezultatele intr-un * fisier de iesire specificat.* Parametri : ah - pointer spre tablou al poiterilor spre nod arbore * inFisier - fisier de decodare* outFisier - unde sunt rezultatele de iesire (NULL -> stdout)* Efect : inFisier este decodat și rezultatele sunt scrise în outFisier.* Returneaza : Nimic****************************************************************************/void DecodareFisier(huffman_nod_t **ah, char *inFisier, char *outFisier){ huffman_nod_t *arboreHuffman, *NodulCurent; int i, c; FILE *pfIn, *pfOut;
if ((pfIn = fopen(inFisier, "rb")) == NULL) {
perror(inFisier);exit(EXIT_FAILURE);
return; }
if (outFisier == NULL) { pfOut = stdout; } else { if ((pfOut = fopen(outFisier, "wb")) == NULL) { perror(outFisier);
exit(EXIT_FAILURE); }
-71-

}
/* aloca tablou pentru toate posibilele caractere */ for (i = 0; i < NUM_CARACTERE; i++) { ah[i] = AlocareNodHuffman(i); }
CitireHeader(ah, pfIn);
/* pune tabloul intr-un arbore huffman */ arboreHuffman = ConstruireArboreHuffman(ah, NUM_CARACTERE);
/* acum noi avem un arbore Huffman folositt pentru codare */ NodulCurent = arboreHuffman; while ((c = fgetc(pfIn)) != EOF) { /* traversare arbore potrivit gasit pentru caracterele noastre */ for(i = 0; i < 8; i++) { if (c & 0x80) { NodulCurent = NodulCurent->dreapta; } else { NodulCurent = NodulCurent->stanga; }
if (NodulCurent->valoare != NOD_COMBINAT) { /* am gasit un caracter */ fputc(NodulCurent->valoare, pfOut); NodulCurent = arboreHuffman; totalCaractere--;
if (totalCaractere == 0) { /* deja am scris ultimul caracter */ break; } }
c <<= 1; } }
/* inchide toate fisierele */ fclose(pfIn); fclose(pfOut); EliberareArboreHuffman(arboreHuffman); /* memoria alocata este eliberata */}
/**************************************************************************** Functie : CitireHeader* Descriere: Aceasta functie citeste informatiile din ScriereHeader. * Parametri : ah - pointer spre tablou de pointeri spre locurile arborelui * pf – pointer spre tipul FILE* Efect : Informatia frecventa este citita în nodul lui ah
-72-

* Returneaza : Nimic***************************************************************************/void CitireHeader(huffman_nod_t **ah, FILE *pf){ frecventa_octet_t octetUniune; int c; int i;
while ((c = fgetc(pf)) != EOF) { for (i = 0; i < sizeof(frecventa_t); i++) { octetUniune.octet[i] = (octet_t)fgetc(pf); }
if ((octetUniune.frecventa == 0) && (c == 0)) { /* tocmai am citit sfarsitul tabelei marcate */ break; }
ah[c]->frecventa = octetUniune.frecventa; ah[c]->ignorat = FALS; totalCaractere += octetUniune.frecventa; }}
ANEXA 2
- Program C++ -
#include "huffman.h"#include <map>#include <iostream>#include <ostream>#include <algorithm>#include <iterator>#include <string>using namespace std;int ii;std::ostream& operator<<(std::ostream& os, std::vector<bool> vec){ std::copy(vec.begin(), vec.end(), std::ostream_iterator<bool>(os, "")); return os;}
int main(){ std::map<char, double> frecventa; frecventa['e'] = 0.124167; frecventa['a'] = 0.0820011; frecventa['t'] = 0.0969225; frecventa['i'] = 0.0768052;
-73-

frecventa['n'] = 0.0764055; frecventa['o'] = 0.0714095; frecventa['s'] = 0.0706768; frecventa['r'] = 0.0668132; frecventa['l'] = 0.0448308; frecventa['d'] = 0.0363709; frecventa['h'] = 0.0350386; frecventa['c'] = 0.0344391; frecventa['u'] = 0.028777; frecventa['m'] = 0.0281775; frecventa['f'] = 0.0235145; frecventa['p'] = 0.0203171; frecventa['y'] = 0.0189182; frecventa['g'] = 0.0181188; frecventa['w'] = 0.0135225; frecventa['v'] = 0.0124567; frecventa['b'] = 0.0106581; frecventa['k'] = 0.00393019; frecventa['x'] = 0.00219824; frecventa['j'] = 0.0019984; frecventa['q'] = 0.0009325; frecventa['z'] = 0.000599; frecventa[' '] = 0.081599; Hufftree<char, double> hufftree(frecventa.begin(), frecventa.end()); for (char ch = 'a'; ch <= 'z'; ++ch) { std::cout << ch << ": " << hufftree.encode(ch) << "\n"; } std::string source = "sursa"; cout<<"Introduceti un text:"; cin>>source; cout<<"S-a codat:"; std::vector<bool> encoded = hufftree.encode(source.begin(), source.end()); std::cout << encoded << "\n"; cout<<"S-a decodat:"; std::string destination; hufftree.decode(encoded, std::back_inserter(destination)); std::cout << destination << "\n"; cin>>ii;}
#ifndef HUFFMAN_H_INC#define HUFFMAN_H_INC
#include <vector>#include <map>#include <queue>
template<typename DataType, typename Frequency> class Hufftree{public: template<typename InputIterator> Hufftree(InputIterator begin, InputIterator end);
~Hufftree() { delete tree; } template<typename InputIterator> std::vector<bool> encode(InputIterator begin, InputIterator end);
-74-

std::vector<bool> encode(DataType const& value) { return encoding[value]; } template<typename OutputIterator> void decode(std::vector<bool> const& v, OutputIterator iter);
private: class Node; Node* tree;
typedef std::map<DataType, std::vector<bool> > encodemap; encodemap encoding; class NodeOrder;
};
template<typename DataType, typename Frequency>struct Hufftree<DataType, Frequency>::Node{ Frequency frequency; Node* leftChild; union { Node* rightChild; // daca leftChild != 0 DataType* data; // daca leftChild == 0 };
Node(Frequency f, DataType d): frequency(f), leftChild(0), data(new DataType(d)) { } Node(Node* left, Node* right): frequency(left->frequency + right->frequency), leftChild(left), rightChild(right) { } ~Node() { if (leftChild) { delete leftChild; delete rightChild; } else { delete data; } } void fill(std::map<DataType, std::vector<bool> >& encoding, std::vector<bool>& prefix) { if (leftChild) { prefix.push_back(0); leftChild->fill(encoding, prefix);
-75-

prefix.back() = 1; rightChild->fill(encoding, prefix); prefix.pop_back(); } else encoding[*data] = prefix; }};template<typename DataType, typename Frequency> template<typename InputIterator> Hufftree<DataType, Frequency>::Hufftree(InputIterator begin, InputIterator end): tree(0){ std::priority_queue<Node*, std::vector<Node*>, NodeOrder> pqueue; while (begin != end) { Node* dataNode = new Node(begin->second, begin->first); pqueue.push(dataNode); ++begin; } while (!pqueue.empty()) { Node* top = pqueue.top(); pqueue.pop(); if (pqueue.empty()) { tree = top; } else { Node* top2 = pqueue.top(); pqueue.pop(); pqueue.push(new Node(top, top2)); } } std::vector<bool> bitvec; tree->fill(encoding, bitvec);}template<typename DataType, typename Frequency>struct Hufftree<DataType, Frequency>::NodeOrder{ bool operator()(Node* a, Node* b) { if (b->frequency < a->frequency) return true; if (a->frequency < b->frequency) return false; if (!a->leftChild && b->leftChild) return true; if (a->leftChild && !b->leftChild) return false; if (a->leftChild && b->leftChild) { if ((*this)(a->leftChild, b->leftChild)) return true; if ((*this)(b->leftChild, a->leftChild)) return false; return (*this)(a->rightChild, b->rightChild); }
-76-

return *(a->data) < *(b->data); }};template<typename DataType, typename Frequency> template<typename InputIterator> std::vector<bool> Hufftree<DataType, Frequency>::encode(InputIterator begin, InputIterator end){ std::vector<bool> result; while (begin != end) { typename encodemap::iterator i = encoding.find(*begin); result.insert(result.end(), i->second.begin(), i->second.end()); ++begin; } return result;}template<typename DataType, typename Frequency> template<typename OutputIterator> void Hufftree<DataType, Frequency>::decode(std::vector<bool> const& v, OutputIterator iter){ Node* node = tree; for (std::vector<bool>::const_iterator i = v.begin(); i != v.end(); ++i) { node = *i? node->rightChild : node->leftChild; if (!node -> leftChild) { *iter++ = *(node->data); node = tree; } }}#endif
-77-

BIBLIOGRAFIE
1. Appel K. şi Haken W., Algoritmi greedy, 1976
2. Cismaş C. S. , MPEG,- standardul revoluţiei audio-video digitale
3. Craw I., Huffman Coding, 2001-04-27
4. Frîncu C., Caraiman A., PCREPORT,2002
5. Huber A. W., Hoffman Codes, Spring 2002
6. Munteanu V.,Teoria transmisiunii informaţiei, Institutul Politehnic “Gh.Asachi”,
Iaşi ,1979
7.Murgan A.T., Principiile teoriei informaţiei în ingineria informaţiei şi a
comunicaţiilor, Editura Academiei Române, Bucureşti, 1998
8. Schildt H., C manual complet, Editura Teora, 2000
7. Spataru A., Teoria Transmisiunii Informaţiei, Editura Didactică şi Pedagogică,
Bucureşti,1983.
9.Stoian R., Rădescu R., Coduri utilizate în prelucrarea numerică a semnalelor,
Editura U.P.B., 1994
10. Soroiu Claudiu, Compresia datelor, serial Gazeta de informatică nr.13/1, Cluj-
Napoca, ianuarie 2003.
11. Soroiu Claudiu, Compresia datelor, serial Gazeta de informatică nr.13/2, Cluj-
Napoca, februarie 2003.
-78-


















