







Limbile
Pagini
Legal


LABORATORUL DE ANALIZA ŞI PRELUCRAREA IMAGINILOR
C. VERTAN
SEGMENTAREA IERARHICA A IMAGINILOR

LABORATORUL DE ANALIZA ŞI PRELUCRAREA IMAGINILOR
C. VERTAN
Se doreste controlul continuu al variatiei numarului de claseal partitiei si posibilitatea de oprire a clasificarii in orice moment(daca se considera ca numarul de clase este satisfacator), cu pastrareaunei erori minime.
Variantele posibile de construire a ierarhiei de clase:top - down (prin divizare)bottom - up (prin aglomerare)
Criteriul de divizare sau de aglomerare a claselor exprima similaritateaelementelor din fiecare clasa (clase uniforme, compacte, bineseparate).
Algoritmi de clustering ierarhic

LABORATORUL DE ANALIZA ŞI PRELUCRAREA IMAGINILOR
C. VERTAN
Clusteringprin divizare
1. Initializare : toti vectorii fac parte dintr-o clasa unica.Clasa unica este clasa curenta.
2. Daca clasa curenta este “neuniforma” (vectorii continuti inclasa nu sunt suficient de similari), este divizata dupa uncriteriu pre-stabilit in doua clase. Se repeta pentru fiecare clasacurenta de la acealsi nivel al ierarhiei de clase.
3. Se verifica criteriul de oprire (numar final de clase, eroare deaprocximare a claselor prin prototipul lor, …).
LABORATORUL DE ANALIZA ŞI PRELUCRAREA IMAGINILOR
C. VERTAN
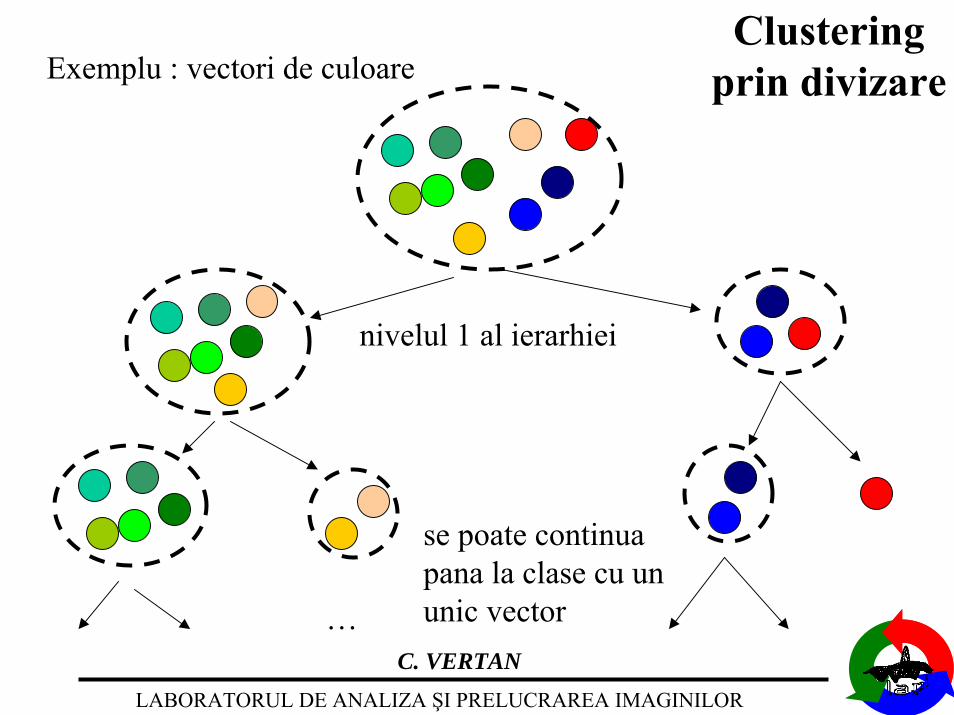
Exemplu : vectori de culoareClustering
prin divizare
nivelul 1 al ierarhiei
…
se poate continuapana la clase cu ununic vector

LABORATORUL DE ANALIZA ŞI PRELUCRAREA IMAGINILOR
C. VERTAN
1. Toti vectorii de culoare fac parte dintr-o clasa unica. Clasa unicaeste clasa curenta.
2. Pentru clasa curenta se determina componenta de culoare (R, G, B)pe care apare variatia maxima de culoare; de-a lungul acesteicomponente spatiul de culoare este “taiat” cu un plan ce treceprin valoarea mediana a componentei. Exceptie : clasele cecontin o unica culoare.
3. Fiecare clasa devine clasa curenta.
4. Algoritmul se opreste dupa K etape, in urma carora sunt 2K clase(culori cuantizate)
Clusteringprin divizare
Median Cut Color Quantization

LABORATORUL DE ANALIZA ŞI PRELUCRAREA IMAGINILOR
C. VERTAN
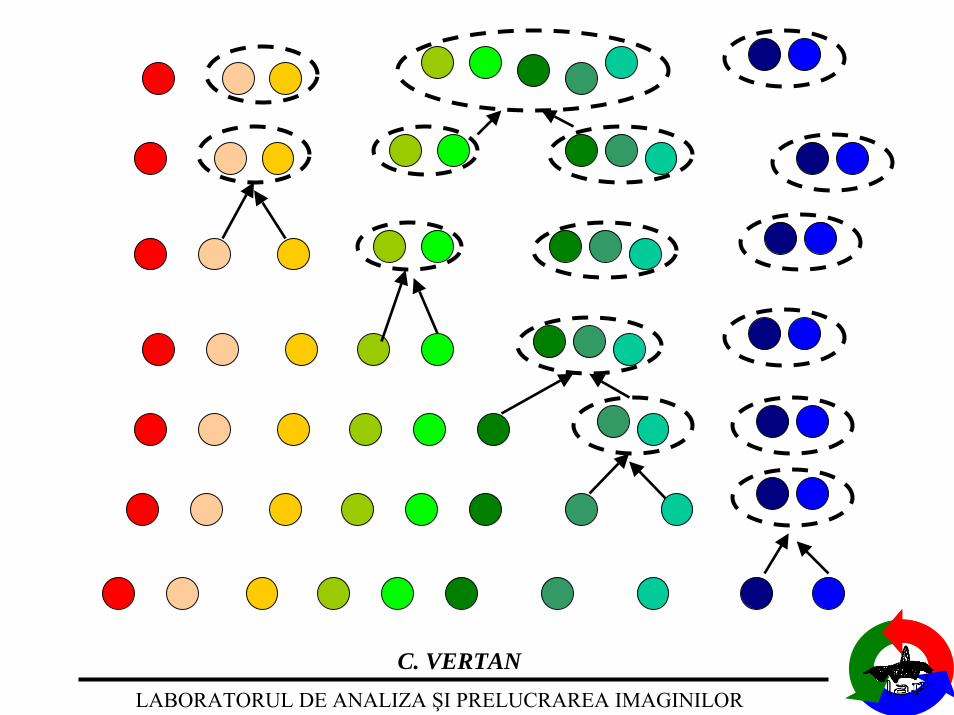
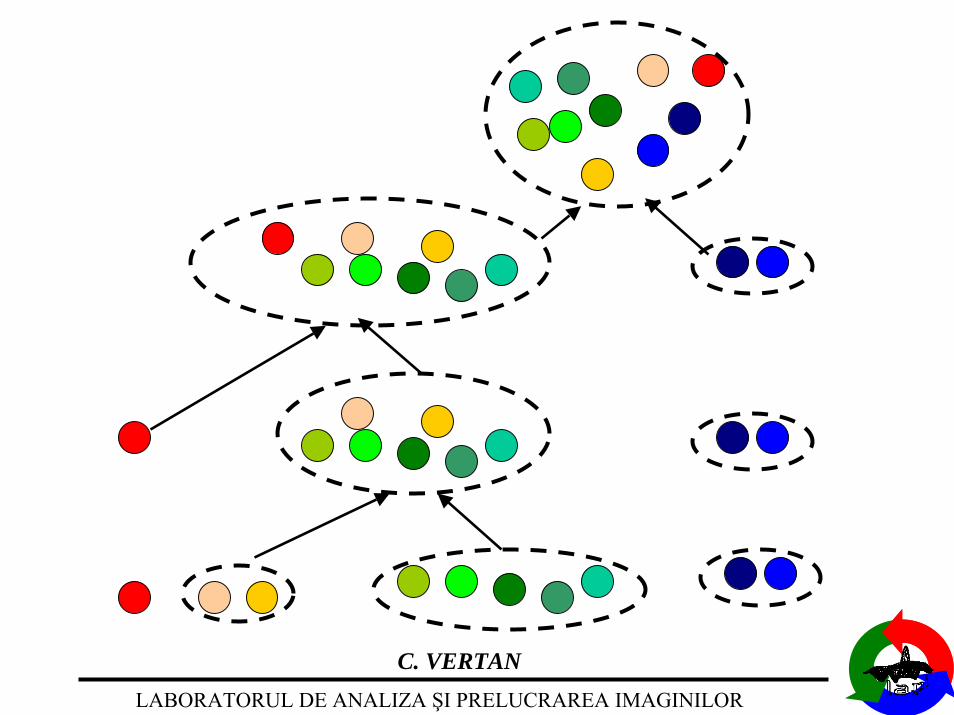
Clusteringprin aglomerare
1. Initializare : fiecare vector constituie o clasa.
2. La fiecare etapa clasele cele mai similare (conform criteriuluiales) sunt fuzionate.
3. Se verifica criteriul de oprire (numar final de clase, eroare deaproximare a claselor prin prototipul lor, …).

LABORATORUL DE ANALIZA ŞI PRELUCRAREA IMAGINILOR
C. VERTAN
),(distmaxD21
j2ki1kkkC,Cij xx
xx ∈∈=
),(distminD21
j2ki1kkkC,Cij xx
xx ∈∈=
Criterii de disimilaritate a claselor Clusteringprin aglomerare
Disimilaritatea dintre clasele i si j poate fi :
∑
∑==
kki
kki
iji2
ij u
u);,(distD kx
xμμμ
),(distnn
nnD ji
2
ji
jiij μμ
+=
“complete link”
“single link”
“centroid”
“minimum variance”

LABORATORUL DE ANALIZA ŞI PRELUCRAREA IMAGINILOR
C. VERTAN
Clusteringprin aglomerare
Dupa construirea clasei aglomerate, disimilaritatile dintre clasele noiipartitii trebuie re-calculate. Dar : modificarile apar numai in ceea cepriveste clasa nou creata (k) si clasele din care aceasta provine (i, j).
Se poate gasi o relatie prin care, pentru orice clasa l :
)D,D,D(FunctieD ijljlilk =
ljliijljlilk DDDDDD −+++= δγβα

LABORATORUL DE ANALIZA ŞI PRELUCRAREA IMAGINILOR
C. VERTAN
0;nnn
nn;
nnnnn
;nnn
nn
lji
ji
lji
lj
lji
li =++
+=
++
+=
+++
= δγβα
0;5.0 ==== γδβα
Clusteringprin aglomerare
complete link
minimum variance
single link 0;5.0 ==−== γδβα
0;)nn(
nn;
nnn
;nn
n2
ji
ji
ji
j
ji
i =+
−=+
=+
= δγβα
centroid

LABORATORUL DE ANALIZA ŞI PRELUCRAREA IMAGINILOR
C. VERTAN
Clusteringprin aglomerare
1. Initializare : fiecare vector constituie o clasa.Se construieste matricea D de disimilaritate intre clase alecarei elemente sunt distantele dintre perechi de vectori
2. Se determina clasele cele mai similare (conform criteriuluiales) : corespund minimului din matricea D. Clasele alese(i, j) se fuzioneaza : se sterg din matricea D liniile si coloanelei si j, se introduce o noua linie si coloana ce corespundeclasei agregate; se calculeaza disimilaritatile clasei agregatefata de clasele ramase prin formula de actualizare.
3. Se verifica criteriul de oprire (numar final de clase, eroare deaprocximare a claselor prin prototipul lor, …).
LABORATORUL DE ANALIZA ŞI PRELUCRAREA IMAGINILOR
C. VERTAN
LABORATORUL DE ANALIZA ŞI PRELUCRAREA IMAGINILOR
C. VERTAN

LABORATORUL DE ANALIZA ŞI PRELUCRAREA IMAGINILOR
C. VERTAN
ABORDARI MIXTE IN SEGMENTARE

LABORATORUL DE ANALIZA ŞI PRELUCRAREA IMAGINILOR
C. VERTAN
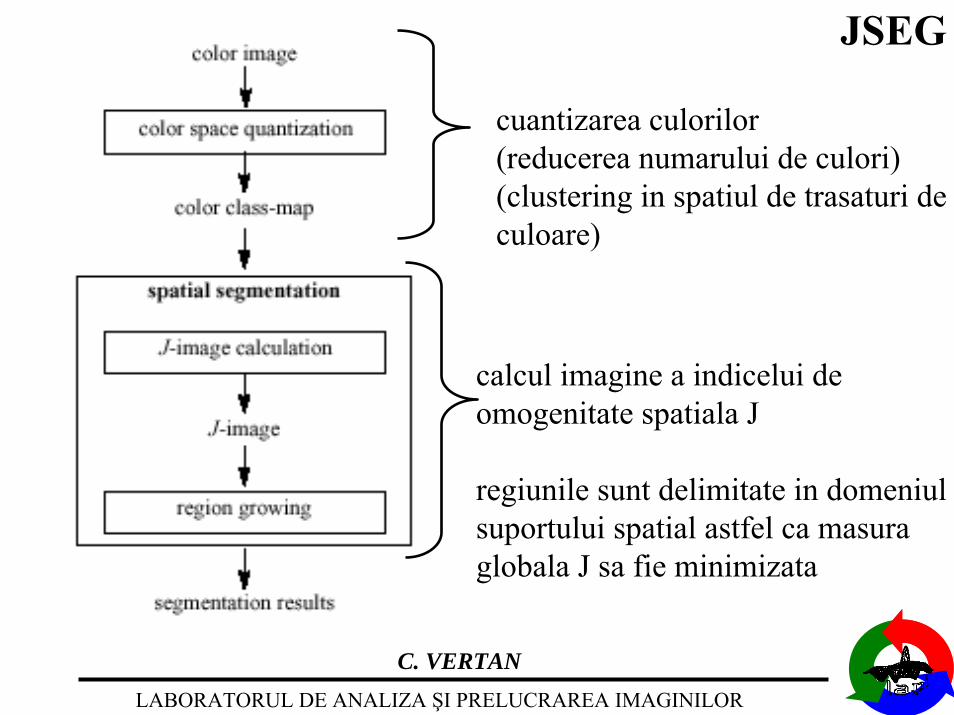
Algoritmul JSEG
Porneste de la o cuantizare de culoare (segmentare in spatiulculorilor) prin care se reduce numarul de culori diferite din imaginesi se stabileste o structura initiala de clase.
Aceasta structura de clase este bazata pe relatii de similaritatein spatiul caracteristicilor (culoare) si nu in suportul spatial alimaginii.
Prima segmentare este rafinata prin introducerea unui criteriude uniformitate si similaritate spatiala (numit J), la mai multescari de rezolutie ale imaginii (piramida de imagini).

LABORATORUL DE ANALIZA ŞI PRELUCRAREA IMAGINILOR
C. VERTAN
JSEGCriteriul J de uniformitate spatiala
Fie partitia cu C clase obtinuta prin clustering in spatiul deculoare.
Pentru fiecare clasa j se calculeaza pozitia centrului de greutate mjin suportul spatial al imaginii; se calculeaza si centrul imaginii, m.
∑∈
=ji C
ij
j N1
zzm ∑
=
=N
1iiN
1 zm
1J C
1j C
2ji
N
1i
2i
ji
−−
−=
∑ ∑
∑
= ∈
=
zmz
mz z sunt coordonate de pozitieale pixelilor
LABORATORUL DE ANALIZA ŞI PRELUCRAREA IMAGINILOR
C. VERTAN
JSEG
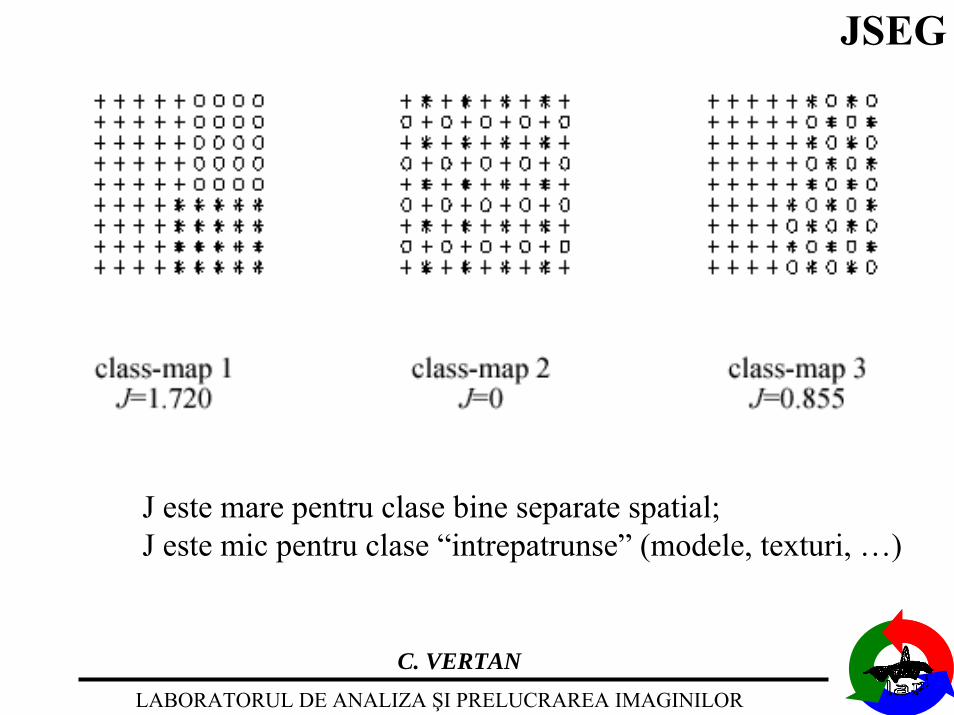
J este mare pentru clase bine separate spatial;J este mic pentru clase “intrepatrunse” (modele, texturi, …)
LABORATORUL DE ANALIZA ŞI PRELUCRAREA IMAGINILOR
C. VERTAN
JSEG
cuantizarea culorilor(reducerea numarului de culori)(clustering in spatiul de trasaturi deculoare)
calcul imagine a indicelui deomogenitate spatiala J
regiunile sunt delimitate in domeniulsuportului spatial astfel ca masuraglobala J sa fie minimizata
LABORATORUL DE ANALIZA ŞI PRELUCRAREA IMAGINILOR
C. VERTAN
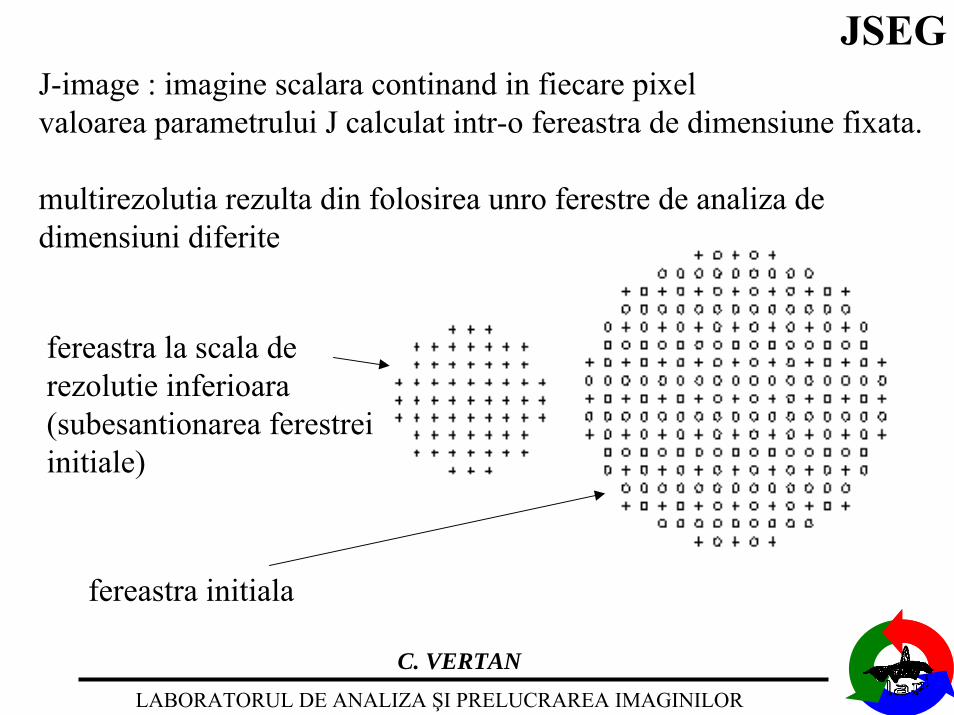
JSEGJ-image : imagine scalara continand in fiecare pixelvaloarea parametrului J calculat intr-o fereastra de dimensiune fixata.
multirezolutia rezulta din folosirea unro ferestre de analiza dedimensiuni diferite
fereastra initiala
fereastra la scala derezolutie inferioara(subesantionarea ferestreiinitiale)
LABORATORUL DE ANALIZA ŞI PRELUCRAREA IMAGINILOR
C. VERTAN
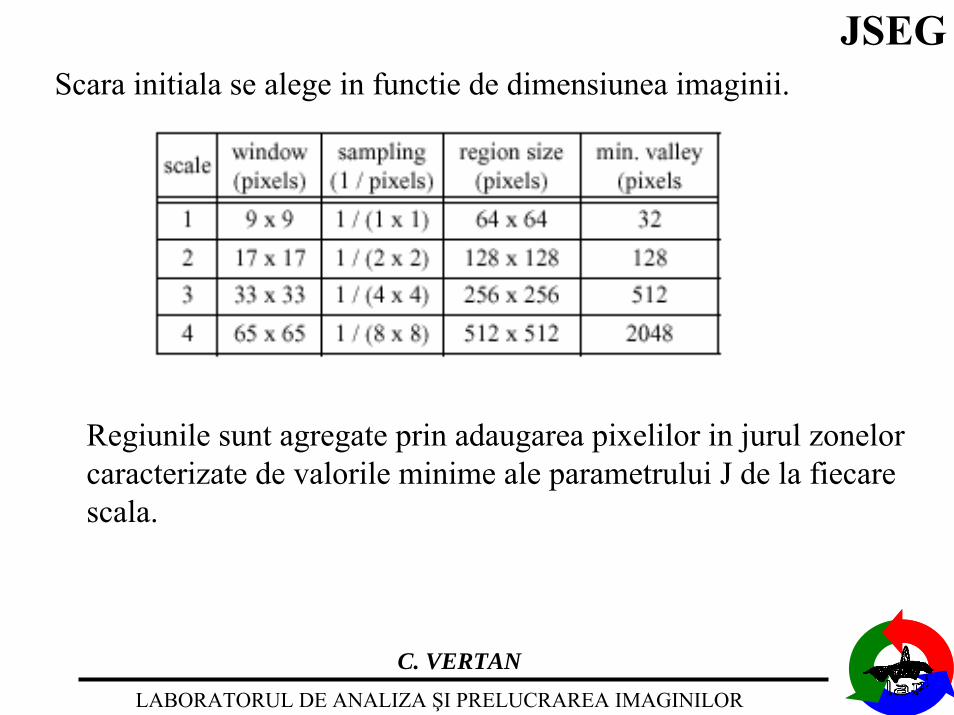
JSEGScara initiala se alege in functie de dimensiunea imaginii.
Regiunile sunt agregate prin adaugarea pixelilor in jurul zonelorcaracterizate de valorile minime ale parametrului J de la fiecarescala.
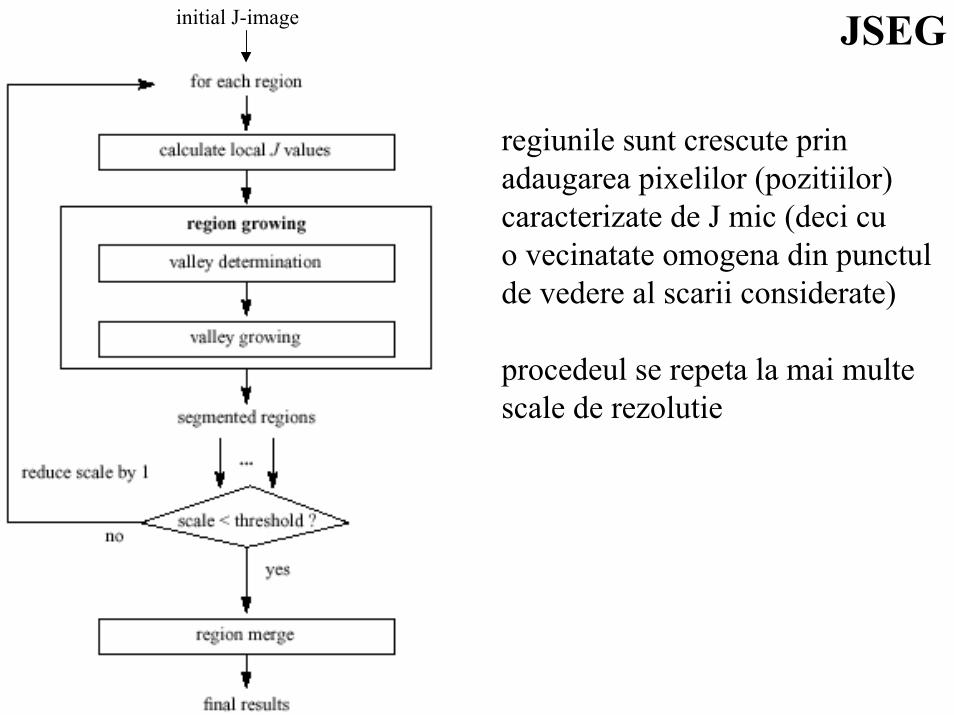
JSEGinitial J-image
regiunile sunt crescute prinadaugarea pixelilor (pozitiilor)caracterizate de J mic (deci cuo vecinatate omogena din punctulde vedere al scarii considerate)
procedeul se repeta la mai multescale de rezolutie
LABORATORUL DE ANALIZA ŞI PRELUCRAREA IMAGINILOR
C. VERTAN
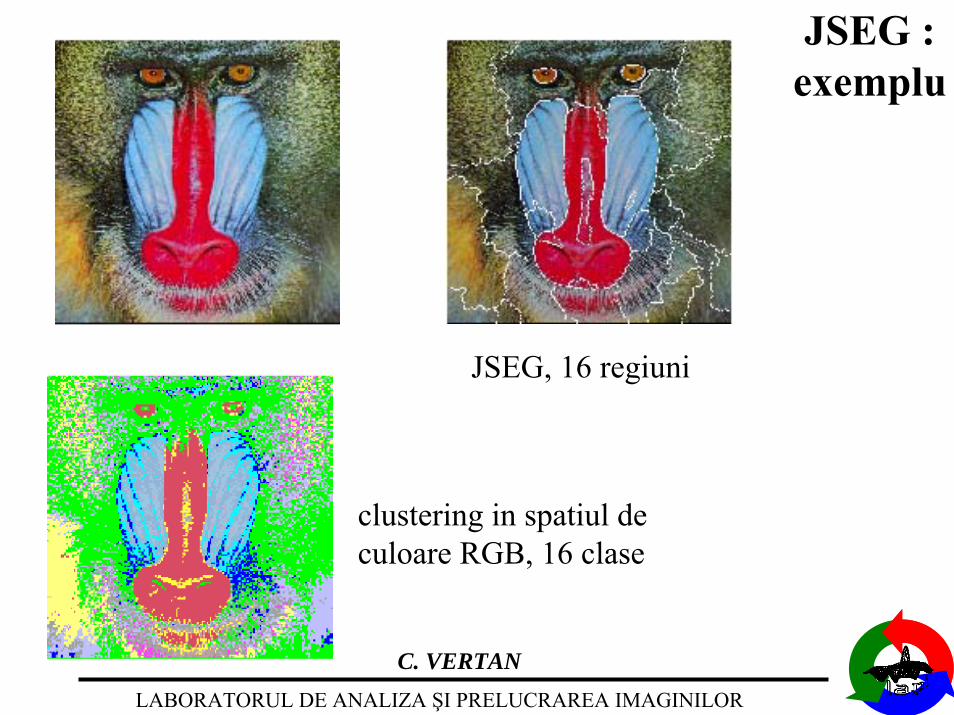
JSEG :exemplu
clustering in spatiul deculoare RGB, 16 clase
JSEG, 16 regiuni

LABORATORUL DE ANALIZA ŞI PRELUCRAREA IMAGINILOR
C. VERTAN
JSEG :exemplu
J-imagela scara 2

LABORATORUL DE ANALIZA ŞI PRELUCRAREA IMAGINILOR
C. VERTAN
JSEG
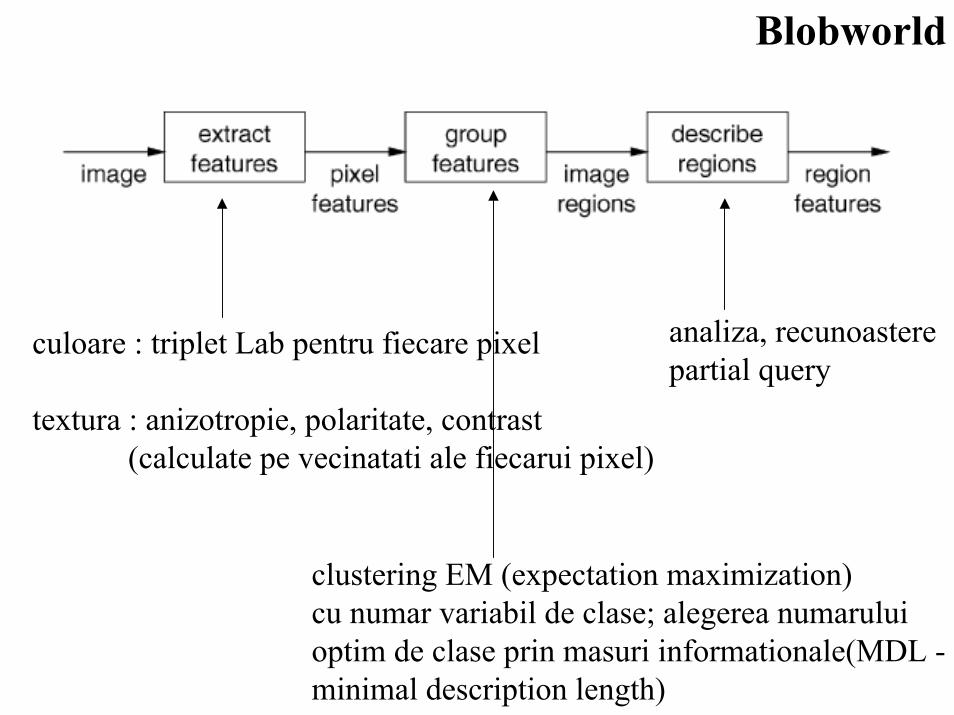
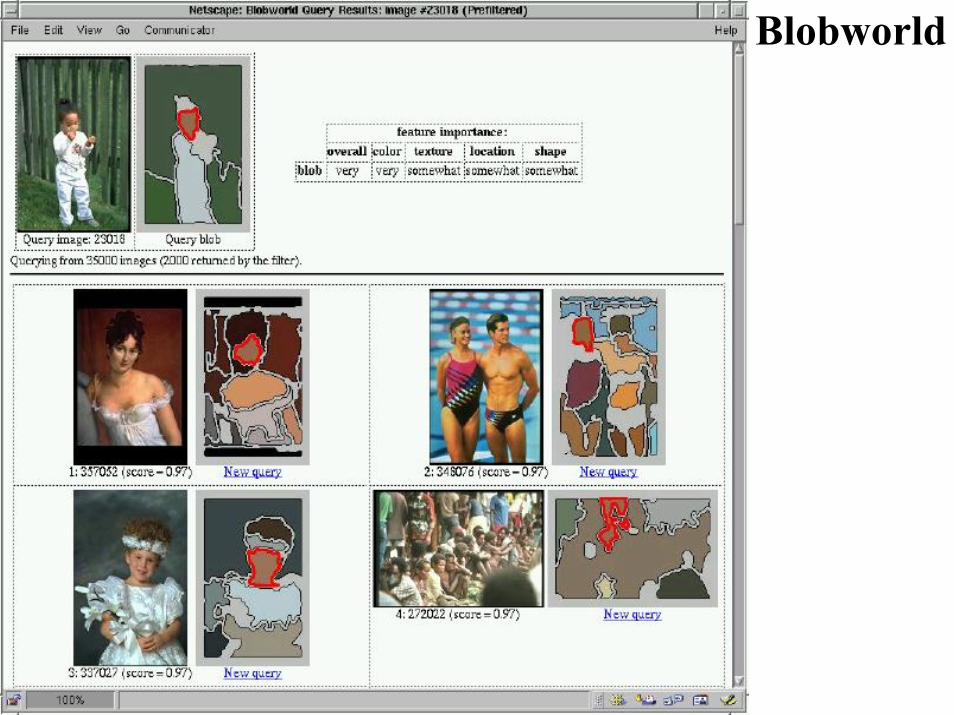
Blobworld
analiza, recunoasterepartial query
culoare : triplet Lab pentru fiecare pixel
textura : anizotropie, polaritate, contrast(calculate pe vecinatati ale fiecarui pixel)
clustering EM (expectation maximization)cu numar variabil de clase; alegerea numaruluioptim de clase prin masuri informationale(MDL -minimal description length)
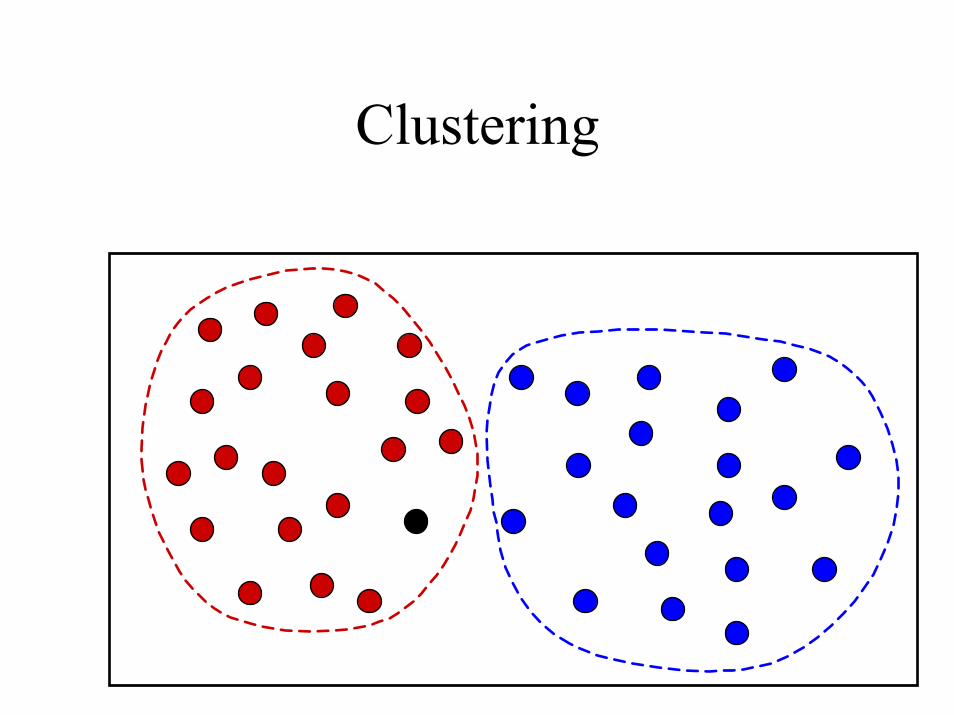
Clustering
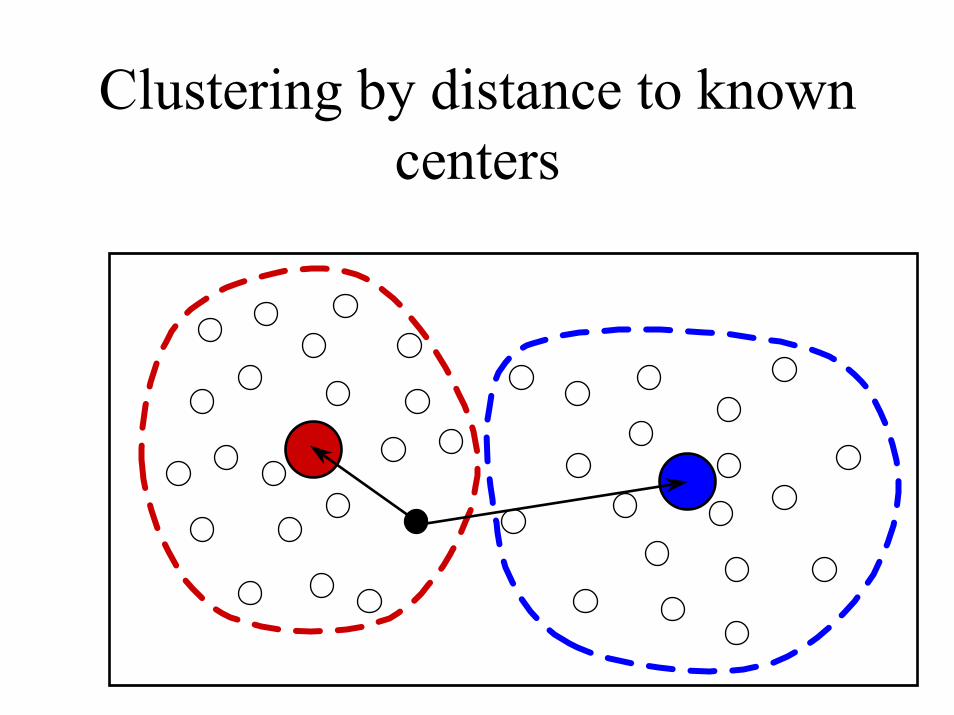
Clustering by distance to known centers
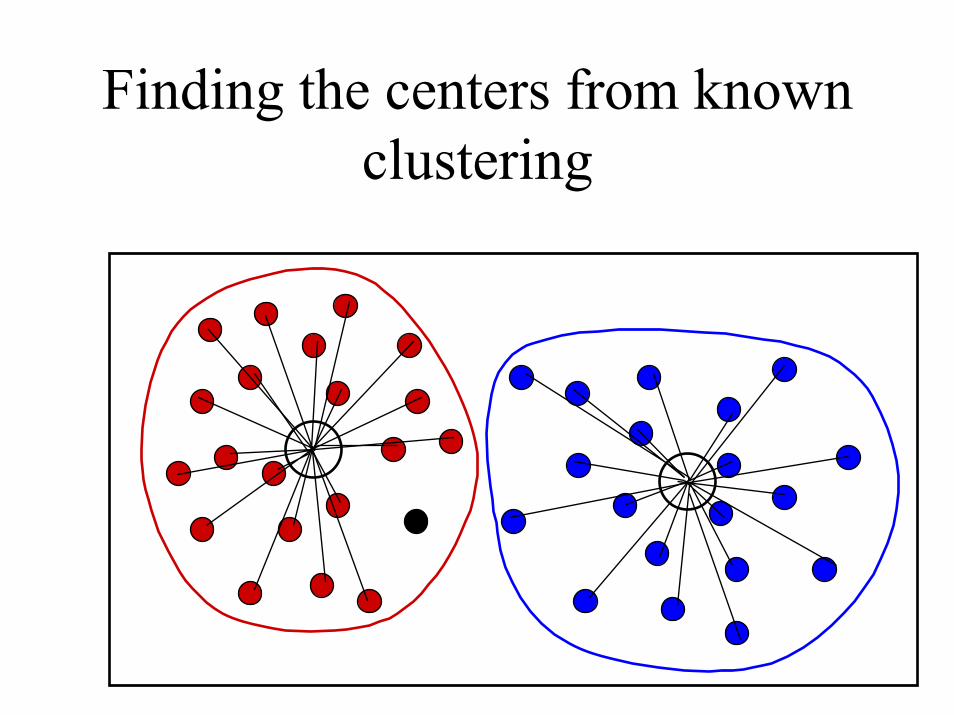
Finding the centers from known clustering
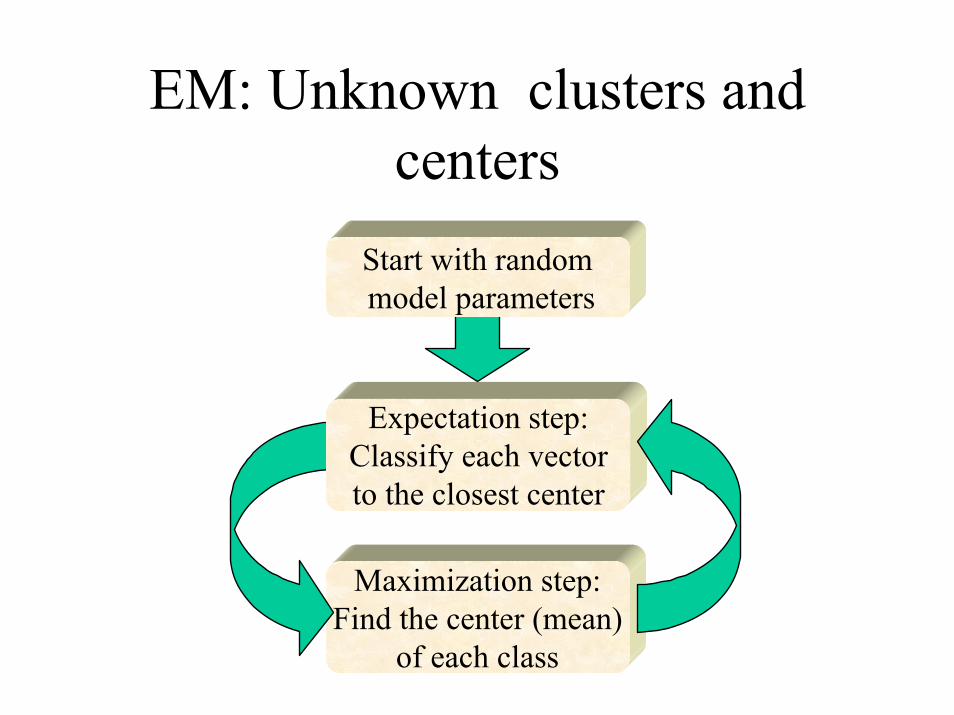
EM: Unknown clusters and centers
Maximization step:Find the center (mean)
of each class
Start with randommodel parameters
Expectation step:Classify each vectorto the closest center
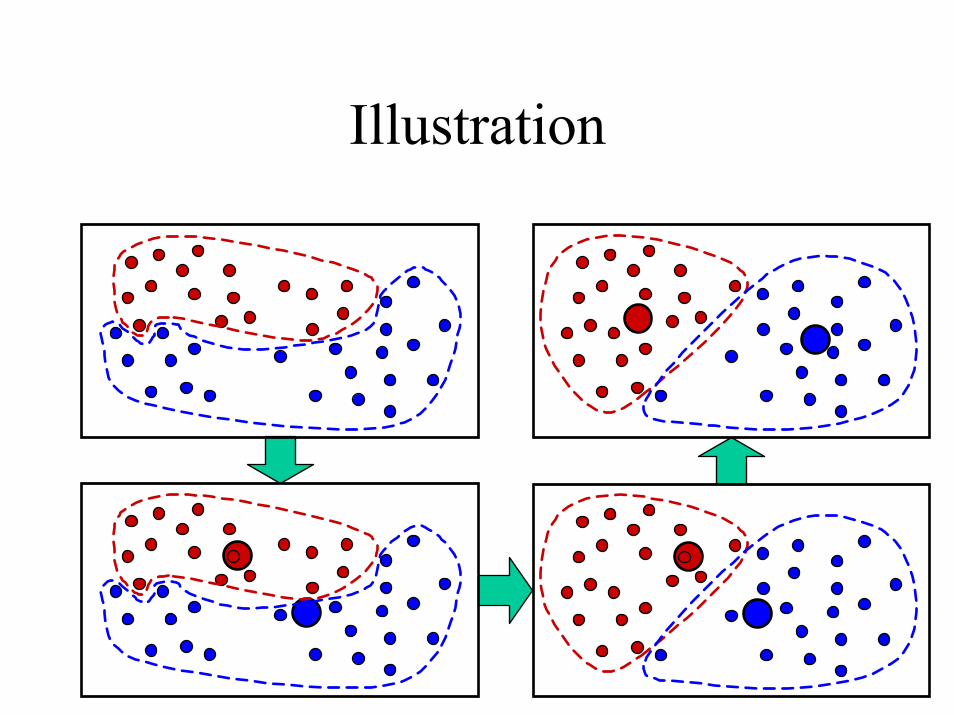
Illustration

EM Characteristics
• Simple to program.• Separates the iterative stage to two
independent simple stages.• Convergence is guaranteed, to some local
minimum.• Speed and quality depend on:
– Number of clusters.– Geometric Shape of the real clusters.– Initial clustering.

EM Algorithm
⎭⎬⎫
⎩⎨⎧ −Σ−−
Σ= − )()(
21exp
)2(1)( 1
2/12/ iiT
ii
ni mxmxxbπGaussian mixture
density:
M Gaussian densities: ∑=
=M
iii xbpxp
1)()|( λ
In Gaussian mixture models, we assume the data sample satisfy the Gaussian distribution.
The mean vectors (mi), covariance matrices (Σi) and mixture weights (pi) of all Gaussian functions together parameterize the complete Gaussian mixture density.

EM Algorithm
)|(1~1∑=
=T
iti xip
Tp
∑
∑
=
== T
tt
T
ttt
i
xip
xxipm
1
1
)|(
)|(~ T
iiT
it
T
i
Tttt
i mmxip
xxxip~~
)|(
)|(~
1
1 −=Σ
∑
∑
=
=
At each iteration, the following reestimation formulas are used which guarantee a monotonic increase in the model’s likelihood value.
)|()()|(
λλ
xpxbpxp kk
k = (Bayes Formula)
EM Algorithm Demo
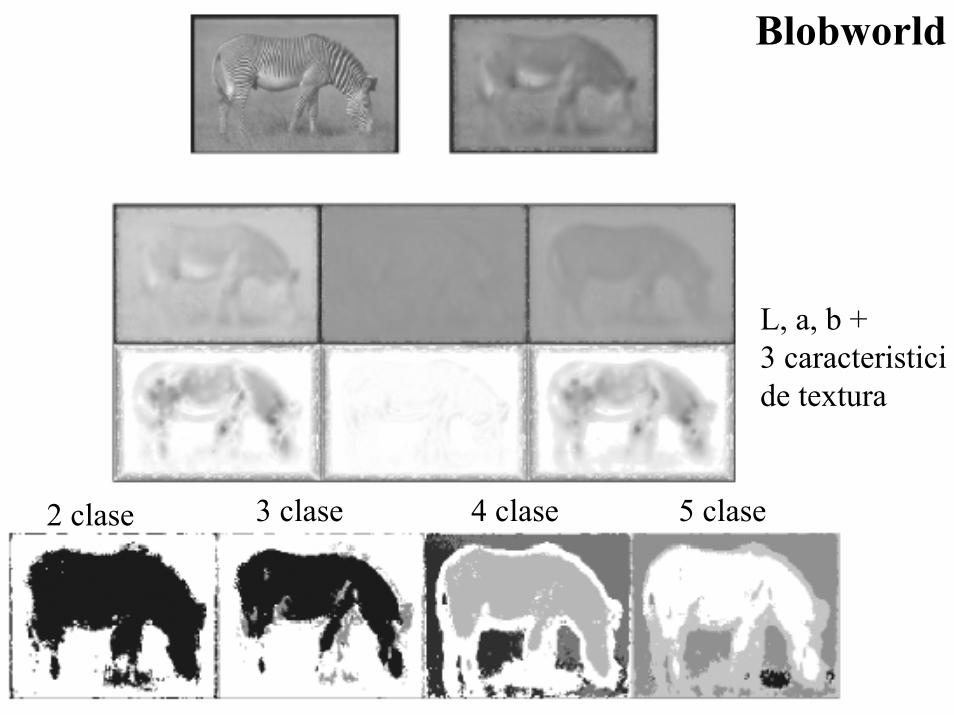
Blobworld
2 clase 3 clase 4 clase 5 clase
L, a, b +3 caracteristicide textura

Blobworld

Blobworld
Blobworld
Top Related