Geostatistica˘stoleriu/Geostatistica.pdf · (masurate) pentru o anumita caracteristica de interes,...
130
Geostatistic˘ a Iulian Stoleriu
Transcript of Geostatistica˘stoleriu/Geostatistica.pdf · (masurate) pentru o anumita caracteristica de interes,...

Geostatistica
Iulian Stoleriu

Copyright © 2019 Iulian Stoleriu

Cuprins
1 Introducere . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2 Elemente de Statistica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.1 Scurt istoric 112.2 Modelare Statistica 132.3 Populatie si selectie 132.4 Organizarea si descrierea datelor 162.5 Gruparea datelor 172.6 Reprezentarea datelor statistice 202.6.1 Reprezentare prin puncte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 202.6.2 Reprezentarea stem-and-leaf . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 212.6.3 Reprezentarea cu bare (bar charts) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 212.6.4 Histograme . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 222.6.5 Reprezentare prin sectoare de disc (pie charts) . . . . . . . . . . . . . . . . . . . . 242.6.6 Poligonul frecventelor . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 252.6.7 Ogive . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 252.6.8 Diagrama Q-Q sau diagrama P-P . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 262.6.9 Diagrama scatter plot . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
2.7 Masuri descriptive ale datelor statistice (indicatori statistici) 262.7.1 Date negrupate . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 262.7.2 Date grupate . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
2.8 Transformari de date 35

3 Notiuni teoretice de Statistica . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
3.1 Evenimente aleatoare 393.1.1 Operatii cu evenimente . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 403.1.2 Relatii intre evenimente . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
3.2 Probabilitate 403.3 Variabile aleatoare 423.3.1 Functia de repartitie (sau functia de repartitie cumulata) . . . . . . . . . . . . 443.3.2 Caracteristici numerice ale unei variabile aleatoare (parametri) . . . . . 443.3.3 Independenta . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 493.3.4 Teorema limita centrala . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 503.3.5 Repartitii probabilistice . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
4 Estimatori . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
4.1 Estimatori punctuali 564.1.1 Exemple de estimatori punctuali . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
4.2 Estimarea parametrilor prin intervale de încredere 584.2.1 Intervale de încredere pentru medie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 594.2.2 Interval de încredere pentru dispersie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 604.2.3 Interval de încredere pentru proportie . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
5 Teste statistice . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
5.1 Tipuri de teste statistice 655.1.1 Testul t pentru medie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 665.1.2 Test pentru dispersie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 675.1.3 Testul χ2 de concordanta . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 685.1.4 Testul de concordanta Kolmogorov-Smirnov . . . . . . . . . . . . . . . . . . . . . . . 69
6 Corelatie si regresie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
6.1 Punerea problemei 73
7 Metode de interpolare spatiala . . . . . . . . . . . . . . . . . . . . . . . . . 77
7.1 Metode deterministe de interpolare spatiala 77
8 Procese stochastice spatiale . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
8.1 Procese stochastice stationare 848.1.1 Ergodicitate . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
8.2 Functia de covarianta 858.3 Variograma 868.4 Modelarea variogramei teoretice 908.4.1 Proprietati ale functiilor de corelatie spatiale . . . . . . . . . . . . . . . . . . . . . . 908.4.2 Comportamentul variogramei in jurul originii . . . . . . . . . . . . . . . . . . . . . . . 918.4.3 Modele de variograma . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92

8.4.4 Estimator pentru variograma . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 958.4.5 Pasi in estimarea variogramei . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 968.4.6 Sfaturi practice pentru construirea unei variograme . . . . . . . . . . . . . . . . 998.4.7 Indicatorul Akaike . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 998.4.8 Metode de estimare a variogramei teoretice . . . . . . . . . . . . . . . . . . . . . 1008.4.9 Anizotropia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100
9 Kriging . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103
9.1 Introducere 1039.2 Kriging simplu 1049.3 Kriging ordinar 1089.4 Kriging lognormal 1119.5 Kriging universal (sau kriging cu drift) 1129.6 Kriging indicator 1139.7 Cokriging 1149.8 Cross-validare (validarea incrucisata) 1159.9 Simulare stochastica 116
10 Anexe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 121
10.1 Tabele cu cuantile pentru repartitii uzuale 12110.2 Exemplu de date statistice spatiale 12310.3 Tabel cu intervale de încredere 125
Bibliografie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 127
Index 129


1. Introducere
Geostatistica poate fi privita ca fiind o subramura a Statisticii, ce se preocupa cu analiza siinterpretarea datelor cu caracter geografic. Îsi are originile in industriile miniera si petroli-era, incepand cu studiile inginerului sud-african Danie Krige in anii ’50 si au fost ulteriorcontinuate si dezvoltate de inginerul Georges Matheron ([matheron1], [matheron2]) inanii ’60, care le-a aplicat direct in evaluarea rezervelor miniere. Totusi, anterior anului1950 au existat si alte lucrari importante, nu neaparat legate de fenomene geologice, darcare au contribuit ulterior la conturarea Geostatisticii ca o disciplina de sine statatoare.Prefixul Geo provine de la Geologie si este datorat originilor cercetarilor datelor spatiele.Metodele actuale din Geostatistica au aplicatii in diverse alte domenii, cum ar fi: Hidro-logie, Oceanografie, Meteorologie, Industria forestiera, Epidemiologie, Agricultura etc.Obiectivul principal al acestei discipline este caracterizarea sistemelor spatiale care suntincomplet cunoscute/descrise. In acest scop, Geostatistica contine o colectie de tehnicinumerice si matematice care se ocupa cu caracterizarea sistemelor (datelor) spatiale sauspatio-temporale care nu sunt complet cunoscute, cum ar fi sistemele spatiale ce apar inGeologie. Prin date spatiale intelegem acele date statistice ce sunt asociate cu o locatiein spatiu; pentru datele spatio-temporale mai apare si referirea la variabila timp (dateleobservate depind de momentul cand au fost culese). Exemple de fenomene spatiale sauspatio-temporale de interes in Geostatistica: concentratia poluarii solului, rata infiltrariiapei in sol, porozitatea solului, pretul titeiului etc. Multe dintre fenomenele din Geologiesunt extrem de diversificate si vaste. Geologii au ca sarcina realizarea unui model geologiccomplet plecand de la un numar de observatii/masuratori care, de regula, reprezinta doar omica fractiune din aria sau volumul de interes. Din cauza complexitatii sistemelor spatialece apar in Geologie, realizarea unei descrieri complete a unui sistem spatial este practicimposibila. Mai mult, obtinerea unui numar foarte mare de masuratori este costisitoare.Geostatistica ofera unelte si tehnici de interpolare si extrapolare (atat determinista cat sistochastica), necesare determinarii (prezicerii) valorilor de interes in locatii unde nu aufost facute masuratori.

8 Capitolul 1. Introducere
Spre deosebire de Statististica clasica, in care masuratorile (observatiile statistice)sunt privite ca fiind observatii independente si identic repartizate asupra unei aceleiasicaracteristici, datele de interes din Geostatistica sunt spatial corelate (i.e., ipoteza deindependenta a datelor nu este satisfacuta). Daca nu ar exista o asemenea corelare spatiala,aplicarea metodelor geostatistice nu ar fi oportuna; Statistica clasica singura ar putea oferiraspunsurile necesare. Totodata, vom vedea ca datele spatiale din Geostatistica nu pot fitoate generate de o aceeasi repartitie probabilistica.
Spre exemplu, se doreste a realiza o harta a ratei infiltrarii apei intr-o anumita regiune, cecuprinde atat zone rurale cat si urbane. Deoarece solul nu este acelasi in interiorul regiunii,rata infiltrarii apei va avea diverse valori in acest areal. Este de asteptat ca masuratorileobtinute din locatii foarte apropiate sa fie similare, fapt foarte familiar geologilor. Intermeni statistici, acest fapt se traduce printr-o corelare a valorilor ratelor infiltrarii apeimasurate in locatii diferite. Vom vedea mai tarziu ca in analiza acestor date va trebui satinem cont de corelatiile dintre ele, fapt ce va fi realizat prin analiza variogramei (sau acorelogramei) datelor empirice. Totodata, datorita variabilitatii solului, este de asteptat caratele astfel masurate sa nu urmeze toate o aceeasi repartitie normala. Din acest motiv,fiecare data spatiala din Geostatistica poate privita ca fiind o singura observatie (masurare)a unei anumite repartitii, nu neaparat una normala. Astfel, Geostatistica tine cont atatde repartitiile datelor obtinute cat si de corelatiile intre aceste date, nefiind constransa saconsidere faptul ca toate datele observate au o aceeasi repartitie probabilistica.
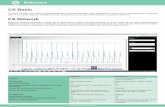
Unul dintre scopurile Geostatisticii este ca, plecand de la o colectie de valori observate(masurate) pentru o anumita caracteristica de interes, sa poata prezice repartitia spatialaintr-un punct de unde nu avem date observate (nu s-au facut masuratori). Spre exemplu, inFigura 1.1 sunt reprezentate 7 masuratori efectuate intr-un regiune in care valorile masurateale caracteristicii de interes sunt aleatoare.
Se doreste prezicerea valorii in punctulmarcat cu culoare rosie. In practica, inurma unor astfel de predictii se pot creaharti care sa descrie grafic caracteristica deinteres. Pentru ca aceste harti sa fie cat maidetaliate, este deseori nevoie de compu-tere si de un software specializat. Valorileprezise pot fi: estimate (folosind metodegeostatistice) sau simulate (folosind me-tode Monte Carlo). Valoarea estimata va fideterminata pe baza unei metode specificeGeostatisticii, numita kriging, si se bazeazape valorile observate (masurate) deja si pecorelatia dintre aceste valori observate (nu-mita corelograma/variograma). Figura 1.1: Valori ale unei caracteristici
intr-un camp aleator.Foarte pe scurt, o analiza geostatistica urmeaza urmatoarele trei etape principale: (1)
analiza descriptiva a datelor spatiale, (2) construirea variogramei empirice si aproximareaei cu un model teoretic (estimarea variogramei teoretice), (3) predictia (prin metodekriging sau simulari stochastice) valorilor caracteristicii de interes in locatiile unde nu aufost facute masuratori. In functie de natura datelor spatiale studiate, pentru fiecare etapa in

9
parte exista metode specifice de analiza, etape ce le vom studia in detaliu in cursurile ceurmeaza.
Dupa cum am mentionat mai sus, pentru locatiile de unde nu au fost culese date sepot face predictii folosind metode de interpolare sau metode kriging. Pe langa acestea,se mai pot folosi metode de simulare stochastica (care au la baza Teoria Probabilitatilor)pentru a produce valori ale caracteristicii in pozitia dorita. Modelele probabilistice pot fiaplicate pentru datele spatiale intr-o maniera asemanatoare analizei seriilor de timp. Astfel,se pot realiza predictii pentru valorile caracteristicii de interes in locatiile unde nu au fostfacute masuratori. Geostatistica este o strans legata de metodele de interpolare, dar continemetode de analiza mult mai elaborate decat simplele de interpolare. In scopul de a modelaincertitudinea asociata cu estimarea spatiala, aceste metode au la baza functii sau variabilealeatoare.
Principalele diferente dintre Statistica clasica si Geostatistica sunt:• Datele statistice din Geostatistica tin cont de locatia de unde au fost culese si pot
fi corelate cu datele obtinute din alte locatii. Datele din Statistica clasica nu suntdependente de locatie si se presupune ca acestea sunt observatii independente aleunei variabile studiate.
• In Geostatistica, datele culese sunt independente intre ele si nici identic repartizate;• In Statistica clasica, o selectie aleatoare contine date ce sunt considerate a fi multiple
realizari independente si identic repartizate ale unei singure variabile. In schimb, inGeostatistica, fiecare data dintr-o selectie este privita ca o singura realizare a uneivariabile, iar aceasta variabila difera cu locatia;
• Multe rezultate din Geostatistica nu presupun cunoasterea repartitiei datelor obser-vate, desi normalitatea datelor ar fi un avantaj pentru analiza. Pentru analiza datelordin Statistica clasica este deseori nevoie ca distributia datelor sa fie cunoscuta. Multedintre rezultatele din Statistica clasica se bazeaza pe ipoteza de normalitate a datelor.
• De regula, datele geostatistice sunt culese in urma impartirii domeniului de masuratin forme regulate (cubice, hexagonale etc.), asadar locatiile de unde se iau masuratorinu sunt alese in mod cu totul aleator. Datele din Statistica clasica nu sunt neaparatlegate de forma regiunii de unde au fost culese.
Deoarece datele statistice spatiale pot foarte numeroase, pentru analiza lor este nevoiede ajutorul computerelor si de un software specializat. Exemple de software ce analizeazadate geostatistice sunt: ArcMap, MATLAB (MAThematics LABoratory), R, GSLIB (Geos-tatistical Software Library), Gstat, SGeMS (Stanford Geostatistical Modeling Software),GS+, Geopack, GeoEAS, Variowin etc.


2. Elemente de Statistica
2.1 Scurt istoric
Statistica este o ramura a stiintelor ce se preocupa de procesul de colectare de date siinformatii, de organizarea si interpretarea lor, în vederea explicarii unor fenomene reale.În Economie si Business, informatiile extrase din datele statistice vor fi utile în evaluareaafacerilor sau a mediului economic în care activeaza, ajutându-i astfel în luarea deciziilor.În general, prin date (sau date statistice) întelegem o multime de numere sau caracterece au o anumita însemnatate pentru utilizator. Utilizatorul este interesat în a extrageinformatii legate de multimea de date pe care o are la îndemâna. Datele statistice pot filegate între ele sau nu. Suntem interesati de studiul acestor date, cu scopul de a întelegeanumite relatii între diverse trasaturi ce masoara datele culese. De regula, oamenii auanumite intuitii despre realitatea ce ne înconjoara, pe care le doresc a fi confirmate într-unmod cât mai exact. De exemplu, daca într-o anumita zona a tarii rata somajului esteridicata, este de asteptat ca în acea zona calitatea vietii persoanelor de acolo sa nu fie lastandarde ridicate. Totusi, ne-am dori sa fim cât mai precisi în evaluarea legaturii dintrerata somajului si calitatea vietii, de aceea ne-am dori sa construim un model matematic cesa ne confirme intuitia. Un alt gen de problema: ardem de nerabdare sa aflam cine va finoul presedinte, imediat ce sectiile de votare au închis portile (exit-pole). Chestionareatuturor persoanelor ce au votat, colectarea si unificarea tuturor datelor într-un timp recordnu este o masura deloc practica. În ambele probleme mentionate, observatiile si culegereade date au devenit prima treapta spre întelegerea fenomenului studiat. De cele mai multeori, realitatea nu poate fi complet descrisa de un astfel de model, dar scopul este de aoferi o aproximare cât mai fidela si cu costuri limitate. În ambele situatii mentionate aparerori în aproximare, erori care tin de întâmplare. De aceea, ne-am dori sa putem descrieaceste fenomene cu ajutorul variabilelor aleatoare. Plecând de la colectiile de date obtinutedintr-o colectivitate, Statistica introduce metode de predictie si prognoza pentru descriereasi analiza proprietatilor întregii colectivitati. Aria de aplicabilitate a Statisticii este foarte

12 Capitolul 2. Elemente de Statistica
mare: stiinte exacte sau sociale, umanistica sau afaceri etc. O disciplina strâns legata deStatistica este Econometria. Aceasta ramura a Economiei se preocupa de aplicatii aleteoriilor economice, ale Matematicii si Statisticii în estimarea si testarea unor parametrieconomici, sau în prezicerea unor fenomene economice.
Statistica a aparut în secolul al XVIII - lea, din nevoile guvernelor de a colecta datedespre populatiile pe care le reprezentau sau de a studia mersul economiei locale, în vedereaunei mai bune administrari. Datorita originii sale, Statistica este considerata de unii cafiind o stiinta de sine statatoare, ce utilizeaza aparatul matematic, si nu este privita ca osubramura a Matematicii. Dar nu numai originile sale au fost motivele pentru care Statisticatinde sa devina o stiinta separata de Teoria Probabilitatilor. Datorita revolutiei computerelor,Statistica a evoluat foarte mult în directia computationala, pe când Teoria Probabilitatilorfoarte putin. Asa cum David Williams scria în [williams], "Teoria Probabilitatilor siStatistica au fost odata casatorite; apoi s-au separat; în cele din urma au divortat. Acumabia ca se mai întâlnesc".Din punct de vedere etimologic, cuvântului statistica îsi are originile în expresia latinastatisticum collegium (însemnând consiliul statului) si cuvântul italian statista, însemnândom de stat sau politician. În 1749, germanul Gottfried Achenwall a introdus termenulde Statistik, desemnat pentru a analiza datele referitoare la stat. Mai târziu, în secolul alXIX-lea, Sir John Sinclair a extrapolat termenul la colectii si clasificari de date.Metodele statistice sunt astazi aplicate într-o gama larga de discipline. Amintim aici doarcâteva exemple:
• în Geografie, spre exemplu, pentru a studia efectul incalzirii globale asupra repartitieipadurilor pe glob;
• în Geologie, pentru a determina o harta a ratei infiltrarii apei intr-o anumita zonaubana;
• în Agricultura, de exemplu, pentru a studia care culturi sunt mai potrivite pentru a fifolosite pe un anumit teren arabil;
• în Economie, pentru studiul rentabilitatii unor noi produse introduse pe piata, pentrucorelarea cererii cu oferta, sau pentru a analiza cum se schimba standardele de viata;
• în Contabilitate, pentru realizarea operatiunilor de audit pentru clienti;• în Biologie, pentru clasificarea din punct de vedere stiintific a unor specii de plante
sau pentru selectarea unor noi specii;• în Stiintele educatiei, pentru a gasi cel mai eficient mod de lucru pentru elevi sau
pentru a studia impactul unor teste nationale asupra diverselor caregorii de persoanece lucreaza în învatamânt;
• în Meteorologie, pentru a prognoza vremea într-un anumit tinut pentru o perioada detimp, sau pentru a studia efectele încalzirii globale;
• în Medicina, pentru testarea unor noi medicamente sau vaccinuri;• în Psihologie, în vederea stabilirii gradului de corelatie între timiditate si singuratate;• în Politologie, pentru a verifica daca un anumit partid politic mai are sprijinul
populatiei;• în Stiintele sociale, pentru a studia impactul crizei economice asupra unor anumite
clase sociale;• etc.Pentru a analiza diverse probleme folosind metode statistice, este nevoie de a identifica
mai întâi care este colectivitatea asupra careia se doreste studiul. Aceasta colectivitate

2.2 Modelare Statistica 13
(sau populatie) poate fi populatia unei tari, sau numai elevii dintr-o scoala, sau totalitateaproduselor agricole cultivate într-un anumit tinut, sau toate bunurile produse într-o uzina.Daca se doreste studiul unei trasaturi comune a tuturor membrilor colectivitatii, este demulte ori aproape imposibil de a observa aceasta trasatura la fiecare membru în parte, deaceea este mult mai practic de a strânge date doar despre o submultime a întregii populatiisi de a cauta metode eficiente de a extrapola aceste observatii la toata colectivitatea. Existao ramura a statisticii ce se ocupa cu descrierea acestei colectii de date, numita Statisticadescriptiva. Aceasta descriere a trasaturilor unei colectivitati poate fi facuta atât numeric(media, dispersia, mediana, cuantile, tendinte etc), cât si grafic (prin puncte, bare, histo-grame etc). De asemenea, datele culese pot fi procesate într-un anumit fel, încât sa putemtrage concluzii foarte precise despre anumite trasaturi ale întregii colectivitati. Aceastaramura a Statisticii, care trage concluzii despre caracteristici ale întregii colectivitati, studi-ind doar o parte din ea, se numeste Statistica inferentiala. În contul Statisticii inferentialeputem trece si urmatoarele: luarea de decizii asupra unor ipoteze statistice, descriereagradului de corelare între diverse tipuri de date, estimarea caracteristicilor numerice aleunor trasaturi comune întregii colectivitati, descrierea legaturii între diverse caracteristicietc.
2.2 Modelare StatisticaDe obicei, punctul de plecare este o problema din viata reala, e.g., care partid are o sustineremai buna din partea populatiei unei tari, daca un anumit medicament este relevant pentruboala pentru care a fost creat, daca este vreo corelatie între numarul de ore de lumina pe zisi depresie. Apoi, trebuie sa decidem de ce tipuri date avem nevoie sa colectam, pentru aputea da un raspuns la întrebarea ridicata si cum le putem colecta. Modurile de colectarea datele pot fi diverse: putem face un sondaj de opinie, sau prin experiment, sau prinsimpla observare a caracteristicilor. Este nevoie de o metoda bine stabilita de colectare adatelor si sa construim un model statistic potrivit pentru analiza acestora. În general, datele(observatiile sau masuratorile) culese pot fi potrivite într-un model statistic prin care
Data observata = f (x, θ)+ eroare de aproximare, (2.2.1)
unde f este o functie ce verifica anumite proprietati si este specifica modelului, x estevectorul ce contine variabilele masurate si θ este un parametru (sau un vector de parametri),care poate fi determinat sau nedeterminat. Termenul de eroare apare deseori în pratica,deoarece unele date culese au caracter stochastic (nu sunt deterministe, in sensul ca valorilelor nu pot fi prevazute a priori). Modelul astfel creat este testat, si eventual revizuit, astfelîncât sa se potriveasca într-o masura cât mai precisa datelor culese.
2.3 Populatie si selectieDefinim o populatie (colectivitate) statistica ca fiind o multime de elemente ce poseda otrasatura comuna ce urmeaza a fi studiata. Aceasta poate fi finita sau infinita, reala sauimaginara. Elementele ce constituie o colectivitate statistica se vor numi unitati statisticesau indivizi. Volumul unei colectivitati statistice este dat de numarul indivizilor ce oconstituie.

14 Capitolul 2. Elemente de Statistica
Prin variabila (sau caracteristica) unei populatii statistice întelegem o anumita pro-prietate urmarita la indivizii ei în procesul prelucrarii statistice si care constituie obiectulmasurarii. Din punct de vedere statistic, ea este o trasatura sau cantitate legata de populatiastudiata, ce poate lua orice valoare dintr-o multime data, fiecarei valori atribuindu-se oanumita pondere (frecventa relativa). Spre exemplu: numarul de clienti ce intra intr-unmagazin intr-o anumita zi de lucru, inaltimea barbatilor dintr-o anumita tara, rata infiltrariiapei in solul urban, media la Bacalaureat, altitudinea, culoarea frunzelor, nationalitateaparticipantilor la un congres international etc. Variabilele pot fi: cantitative (masurabile)(e.g., 2, 3, 5, 7, 11, . . . ) si calitative (sau categoriale) (e.g., albastru, foarte bine, germanetc). La rândul lor, variabilele cantitative pot fi discrete (numarul de sosiri ale unui tramvaiîn statie) sau continue (timpul de asteptare între doua sosiri ale tramvaiului în statie).Datele calitative mai pot fi nominale sau ordinale. Variabilele nominale au nivele distincte,fara a avea o anumita ordine. De exemplu, culoarea parului, sau genul unei persoane.Pe de alta parte, valorile ordinale fac referinta la ordinea lor. De exemplu: schimbareastarii unui pacient dupa un anumit tratamen (aceasta poate fi: imbunatatire semnificativa,imbunatatire moderata, nicio schimbare, inrautatire moderata, inrautatire semnificativa).
Parametrii populatiei sunt masuri descriptive numerice ce reprezinta populatia. Deoa-rece nu avem acces la intreaga populatie, parametrii sunt niste constante necunoscute, ceurmeaza a fi explicate sau estimate pe baza datelor. Spre exemplu, daca populatia formataeste formata din multimea persoanelor dintr-o anumita tara, parametrii pot fi: inaltimeamedie, culoarea predominanta a ochilor, deviata standard a masei corporale, varsta medie,procentul de someri, coeficientul de corelatie dintre conditiile de trai pentru cei care locu-iesc in mediul urban si cei din mediul rural etc. Pentru variabilele cantitative ale populatiei,putem avea urmatoarele tipuri de parametri: parametri care sa descrie tendinta centrala apopulatiei (e.g., media, mediana, momente), parametri care descriu gradul de imprastiere adatelor in jurul unei valori centrale (e.g., dispersia, deviatia standard, coeficient de variatie),parametri de pozitie (e.g., cuantile), parametri ce descriu forma (e.g., skewness, kurtosis).De asemenea, pot fi definiti parametri ce descriu legatura intre doua variabile ce caracteri-zeaza populatia de interes. De exemplu corelatia sau coeficientul de corelatie dintre nivelulde studii si salariul net.Pentru date calitative (categoriale), cei mai des utilizati parametri sunt: π− proportia dinpopulatie ce are caracteristica de interes (e.g., proportia de fumatori din tara), cote (sanseteoretica pentru observarea caracteristicii de interes la intreaga populatie) (e.g., exista 70%sanse sa ploua maine).
O variabila a unei populatii poate depinde de unul sau mai multi parametri, parametriifiind astfel trasaturi ce descriu colectivitatea. Spre exemplu, o variabila normala poate fidescrisa de doi parametri: media si deviatia standard.
Suntem interesati în a masura una sau mai multe variabile relative la o populatie, însaaceasta s-ar putea dovedi o munca extrem de costisitoare, atât din punctul de vedere altimpului necesar, cât si din punctul de vedere al depozitarii datelor culese, în cazul în carevolumul colectivitatii este mare sau foarte mare (e.g., colectivitatea este populatia cu dreptde vot a unei tari si caracteristica urmarita este candidatul votat la alegerile prezidentiale).De aceea, este foarte întemeiata alegerea unei selectii de date din întreaga populatie sisa urmarim ca pe baza datelor selectate sa putem trage o concluzie în ceea ce privestevariabila colectivitatii.
O selectie (sau esantion) este o colectivitate partiala de elemente extrase (la întâmplare

2.3 Populatie si selectie 15
sau nu) din colectivitatea generala, în scopul cercetarii lor din punctul de vedere al uneicaracteristici. Daca extragerea se face la întâmplare, atunci spunem ca am facut o selectieîntâmplatoare. Numarul indivizilor din selectia aleasa se va numi volumul selectiei. Dacase face o enumerare sau o listare a fiecarui element component al unei a populatii statistice,atunci spunem ca am facut un recensamânt. Numim o selectie repetata (sau cu repetitie) oselectie în urma careia individul ales a fost reintrodus din nou în colectivitate. Altfel, avemo selectie nerepetata. Selectia nerepetata nu prezinta interes daca volumul colectivitatii estefinit, deoarece în acest caz probabilitatea ca un alt individ sa fie ales într-o extragere nu esteaceeasi pentru toti indivizii colectivitatii. Pe de alta parte, daca volumul întregii populatiistatistice este mult mai mare decât cel al esantionului extras, atunci putem presupune caselectia efectuata este repetata, chiar daca în mod practic ea este nerepetata. Spre exemplu,daca dorim sa facem o prognoza a cine va fi noul presedinte în urma alegerilor din toamna,esantionul ales (de altfel, unul foarte mic comparativ cu volumul populatiei cu drept devot) se face, în general, fara repetitie, dar îl putem considera a fi o selectie repetata, învederea aplicarii testelor statistice.Selectiile aleatoare se pot realiza prin diverse metode, în functie de urmatorii factori: dis-ponibilitatea informatiilor necesare, costul operatiunii, nivelul de precizie al informatiiloretc. Mai jos prezentam câteva metode de selectie.
• selectie simpla de un volum dat, prin care toti indivizii ce compun populatia auaceeasi sansa de a fi alesi. Aceasta metoda mininimizeaza riscul de a fi partinitor saufavorabil unuia dintre indivizi. Totusi, aceasta metoda are neajunsul ca, în anumitecazuri, nu reflecta componenta întregii populatii. Se aplica doar pentru colectivitatiomogene din punctul de vedere al trasaturii studiate. In cazul datelor spatiale, se potalege prin selectie simpla coordonatele locatiilor de unde se vor efectua masuratoripentru caracteristica de interes.
• selectie sistematica, ce presupune aranjarea populatiei studiate dupa o anumitaschema ordonata si selectând apoi elementele la intervale regulate. (e.g., alegerea afiecarui al 10-lea numar dintr-o carte de telefon, primul numar fiind ales la întâmplare(simplu) dintre primele 10 din lista).
• selectie stratificata, în care populatia este separata în categorii, iar alegerea se facela întâmplare din fiecare categorie. Acest tip de selectie face ca fiecare grup cecompune populatia sa poata fi reprezentat în selectie. Alegerea poate fi facuta siîn functie de marimea fiecarui grup ce compune colectivitatea totala (e.g., aleg dinfiecare judet un anumit numar de persoane, proportional cu numarul de persoane dinfiecare judet).
• selectie ciorchine, care este un esantion stratificat construit prin selectarea de indivizidin anumite straturi (nu din toate).
• selectia de tip experienta, care tine cont de elementul temporal în selectie. (e.g.,diversi timpi de pe o encefalograma).
• selectie de convenienta: de exemplu, alegem dintre persoanele care trec prin fatauniversitatii.
• selectie de judecata: cine face selectia decide cine ramâne sau nu în selectie.• selectie de cota: selectia ar trebui sa fie o copie a întregii populatii, dar la o scara
mult mai mica. Asadar, putem selecta proportional cu numarul persoanelor dinfiecare rasa, de fiecare gen, origine etnica etc) (e.g., persoanele din Parlament artrebui sa fie o copie reprezentativa a persoanelor întregii tari, la o scara mai mica).

16 Capitolul 2. Elemente de Statistica
Pe baza unei selectii, putem construi diversi indicatori statistici care sa estimezeparametrii necunoscuti, obtinand descrieri numerice sau calitative pentru populatie. Astfelde indicatori se numesc statistici. Prin intermeniul statisticilor putem trage concluziidespre populatia din care a provenit esantionul observat. Teoria probabilitatilor ne oferaprocedee de determinare a repartitiei asimptotice a unei statistici, sau chiar, in anumitecazuri, a statisticii exacte. Repartitia exacta este acea repartitie ce poate fi determinatapentru orice volum al selectiei. În general, daca se lucreaza cu selectii de volum redus(sub 30 de masuratori), atunci repartitia exacta ar trebui sa fie cunoscuta a priori, dacase doreste luarea de decizii prin inferenta. Repartitia asimptotica este repartitia limitaa statisticii când volumul esantionului tinde la volumul populatiei. Practic, utilizarearepartitiei asimptotice conduce la rezultate bune doar pentru un esantion suficient de mare(peste 30 de masuratori).De cele mai multe ori, o statistica este utilizata în urmatoarele cazuri:
• în probleme de estimare punctuala a parametrilor;• în obtinerea intervalelor de încredere pentru un parametru necunoscut;• ca o statistica test pentru verificarea ipotezelor statistice. Prin ipoteza statistica
intelegem o presupunere facuta referitor la valoarea unui parametru sau la fostrepartitiei observatiilor. Vom reveni la acest subiect mai tarziu in acest material.
In concluzie, plecand de la o multime de date, Statistica isi propune sa extraga anumiteinformatii din acestea. Mai concret, Statistica detine uneltele si metodele necesare de arealiza urmatoarele cerinte: sa descrie cat mai fidel si sugestiv acele date (prin graficesau indicatori statistici), sa estimeze anumiti parametri de interes (e.g., media teoretica,deviatia standard, asimetria ale caracteristicii), sa verifice prin inferenta ipotezele ce se potface referitoare la anumiti parametri ai caracteristicii sau chiar la forma acesteia.
2.4 Organizarea si descrierea datelorPresupunem ca avem o colectivitate statistica, careia i se urmareste o anumita caracteristica(sau variabila). Spre exemplu, colectivitatea este multimea tuturor studentilor dintr-ouniversitate înrolati în anul întâi de master, iar caracteristica este media la licenta obtinutade fiecare dintre acesti studenti. Teoretic, multimea valorilor acestei caracteristici esteintervalul [6, 10], iar aceasta variabila poate lua orice valoare din acest interval.
Vom numi date (sau date statistice) informatiile obtinute în urma observarii valoriloracestei caracteristici. In cazul mentionat mai sus, datele sunt mediile la licenta observate.În general, datele pot fi calitative (se mai numesc si categoriale) sau cantitative, dupa cumcaracteristica (sau variabila) observata este calitativa (exprima o calitate sau o categorie)sau, respectiv, cantitativa (are o valoare numerica). Totodata, aceste date pot fi date detip discret, daca sunt obtinute în urma observarii unei caracteristici discrete (o variabilaaleatoare discreta, sau o variabila ale carei posibile valori sunt in numar finit sau celmult numarabil), sau date continue, daca aceasta caracteristica este continua (o variabilaaleatoare de tip continuu, sau o variabila ce poate lua orice valoare dintr-un interval sauchiar de pe axa reala). În cazul din exemplul de mai sus, datele vor fi cantitative si continue.
În Statistica clasica, se obisnuieste a se nota variabilele (caracteristicile) cu litere mari,X , Y, Z, . . ., si valorile lor cu litere mici, x, y, z, . . .. In mare parte din acest curs vom folosinotatia Z pentru variabila aleatoare si cu z o posibila valoare (sau realizare) a sa. Daca inexemplul de mai sus notam cu Z variabila medie la licenta, atunci un anume z observat va

2.5 Gruparea datelor 17
fi media la licenta pentru un student din colectivitate ales aleator.În Geostatistica, datele observate au caracter spatial, adica sunt legate de pozitie. Pozitia
spatiala poate fi unu, doi sau trei-dimensionala. Majoritatea datelor spatiale din acest cursvor avea pozitie doi-dimensionala (sau bidimensionala). Vom nota cu x = (x1, x2) vectorulde coordonate bidimensionale. Astfel prin Z(x) sau Z(x1, x2) vom nota variabila Z inlocatia x, iar prin z(x) sau z(x1, x2) vom nota valoarea variabilei Z in locatia x. Dacaavem mai multe valori ale variabilei Z, le vom nota prin z1, z2, z3, . . . . În Geostatistica,se foloseste termenul de variabila pentru a caracteriza o valoare necunoscuta pe care otrasatura unei populatii o poate lua in locatii spatio-temporale.
Primul pas în analiza datelor empirice observate este o analiza descriptiva, ce constain ordonarea si reprezentarea grafica a datelor, dar si în calcularea anumitor caracteristicinumerice pentru acestea. Datele înainte de prelucrare, adica exact asa cum au fost culese,se numesc date negrupate. Un exemplu de date negrupate (de tip continuu) sunt celeobservate in Tabelul 2.1, reprezentând timpi (în min.sec) de asteptare pentru primii 100de clienti care au asteptat la un ghiseu pâna au fost serviti.
1.02 2.01 2.08 3.78 2.03 0.92 4.08 2.35 1.30 4.50 4.06 3.55 2.63
0.13 5.32 3.97 3.36 4.31 3.58 5.64 1.95 0.91 1.26 0.74 3.64 4.77
2.98 4.33 5.08 4.67 0.79 3.14 0.99 0.78 2.34 4.51 3.53 4.55 1.89
0.94 3.44 1.35 3.64 2.92 2.67 2.86 2.41 3.19 5.41 5.14 2.75 1.67
1.12 4.75 2.88 4.30 4.55 5.87 0.70 5.04 5.33 2.40 1.50 0.83 3.74
3.79 1.48 2.65 1.55 3.95 5.88 1.58 5.49 0.48 2.77 3.20 2.51 5.80
3.12 0.71 2.76 1.95 0.10 4.22 5.69 5.41 1.68 2.46 1.40 2.16 4.98
5.36 1.32 1.76 2.14 3.28 3.89 4.85 4.12 0.88
Tabela 2.1: Date statistice negrupate
De cele mai multe ori, enumerarea tuturor datelor culese este dificil de realizat, deaceea se urmareste a se grupa datele, pentru o mai usoara gestionare. Imaginati-va caenumeram toate voturile unei selectii întâmplatoare de 15000 de votanti, abia iesiti dela vot. Mai degraba, ar fi mai util si practic sa grupam datele dupa numele candidatilor,precizând numarul de voturi ce l-a primit fiecare. Asadar, pentru o mai buna descriere adatelor, este necesara gruparea lor in clase de interes.
2.5 Gruparea datelorDatele prezentate sub forma de tabel (sau tablou) de frecvente se numesc date grupate.Datele de selectie obtinute pot fi date discrete sau date continue, dupa cum caracteristicilestudiate sunt variabile aleatoare discrete sau, respectiv, continue.
(1) Date de tip discret: Daca datele de selectie sunt discrete (e.g., z1, z2, . . . , zn),este posibil ca multe dintre ele sa se repete. Presupunem ca valorile distincte ale acestordate sunt z′1, z′2, . . . , z′r, r ≤ n. Atunci, putem grupa datele într-un asa-numit tabel defrecvente (vezi exemplul din Tabelul 2.2). Alternativ, putem organiza datele negrupateîntr-un tabel de frecvente, dupa cum urmeaza:
data z′1 z′2 . . . z′rfrecventa f1 f2 . . . fr
(2.5.2)

18 Capitolul 2. Elemente de Statistica
nota frecventa absoluta frecventa cumulata frecventa relativa frecventa relativa cumulata2 2 2 2.22% 2.22%3 4 6 4.44% 6.66%4 8 14 8.89% 15.55%5 15 29 16.67% 32.22%6 18 47 20.00% 52.22%7 17 64 18.89% 71.11%8 15 79 16.67% 87.78%9 7 86 7.78% 95.56%
10 4 90 4.44% 100%Total 90 - 100% -
Tabela 2.2: Tabel cu frecvente pentru date discrete.
unde fi este frecventa aparitiei valorii z′i, (i = 1, 2, . . . , r), si se va numi distributia empiricade selectie a lui Z. Aceste frecvente pot fi absolute sau de relative. Un tabel de frecvente(sau o distributie de frecvente) contine cel putin doua coloane: o coloana ce reprezintadatele observate (grupate în clase) si o coloana de frecvente. În prima coloana apar clasele,adica toate valorile distincte observate. Datele din aceasta coloana nu se repeta. Prinfrecventa absoluta a clasei întelegem numarul de elemente ce apartine fiecarei clase înparte. De asemenea, un tabel de frecvente mai poate contine frecvente relative sau cumulate.O frecventa relativa se obtine prin împartirea frecventei absolute a unei categorii la sumatuturor frecventelor din tabel. Astfel, suma tuturor frecventelor relative este egala cu 1.Frecventa (absoluta) cumulata a unei clase se obtine prin cumularea tuturor frecventelorabsolute pâna la (inclusiv) clasa respectiva. Frecventa relativa cumulata a unei clase seobtine prin cumularea tuturor frecventelor relative pâna la (inclusiv) clasa respectiva.
Asadar, elementele unui tabel de frecvente pot fi: clasele (ce contin valori pentruvariabile), frecvente absolute, frecvente relative sau cumulate. Într-un tabel, nu esteobligatoriu sa apara toate coloanele cu frecvente sau ele sa apara în aceasta ordine.
Vom numi o serie de timpi (sau serie dinamica ori cronologica) un set de date culese lamomente diferite de timp. O putem reprezenta sub forma unui tablou de forma
data :
(z1 z2 . . . znt1 t2 . . . tn
),
unde zi sunt valorile caracteristicii, iar ti momente de timp (e.g., raspunsurile citite de unelectrocardiograf).
În Tabelul 2.2, sunt prezentate notele studentilor din anul al III-lea la examenul deStatistica. Acesta este exemplu de tabel ce reprezenta o caracteristica discreta.
(o gluma povestita de G. Pólya,1 despre cum NU ar trebui interpretata frecventa relativa)Un individ suferind merge la medic. Medicul îl examineaza îndelung si, balansând dezamagit capul,îi spune pacientului:"Offf... draga domnule pacient, am doua vesti: una foarte proasta si una buna. Mai întâi va aducla cunostinta vestea proasta: suferiti de o boala groaznica. Statistic vorbind, din zece pacienti ce
1György Pólya (1887−1985), matematician ungur

2.5 Gruparea datelor 19
contracteaza aceasta boala, doar unul scapa."Pacientul, deja în culmea disperarii, este totusi consolat de doctor cu vestea cea buna:"Dar, fiti pe pace! Dumneavoastra ati venit la mine, si asta va face tare norocos", continua optimistdoctorul."Am avut deja noua pacienti ce au avut aceeasi boala si toti au murit, asa ca... veti supravietui!"
(2) Date de tip continuu: Daca datele statistice sunt realizari ale unei variabile Zde tip continuu, atunci se obisnuieste sa se faca o grupare a datelor de selectie în clase.Datele de tip continuu pot fi grupate într-un tablou de distributie sau sub forma unui tabelde distributie, dupa cum urmeaza:
data [a0,a1) [a1,a2) . . . [ar−1,ar)
frecventa f1 f2 . . . fr
clasa frecventa valoare medie[a0,a1) f1 z′1[a1,a2) f2 z′2
......
...[ar−1,ar) fr z′r
Tabela 2.3: Tabel cu frecvente pentrudate de tip continuu.
În particular, putem grupa datele de tip continuu din Tabelul 2.1 în tabloul de distributieurmator:
data [0, 1) [1, 2) [2, 3) [3, 4) [4, 5) [5, 6)frecventa 14 17 21 18 16 14
Aceasta grupare nu este unica; intervalele ce reprezinta clasele pot fi modificate dupacum doreste utilizatorul. Uneori, tabelul de distributie pentru o caracteristica de tipcontinuu mai poate fi scris si sub forma unui tabel ca in (2.5.2), unde
• z′i =ai−1 +ai
2este elementul de mijloc al clasei [ai−1, ai);
• fi este frecventa aparitiei valorilor din [ai−1, ai), (i = 1, 2, . . . , r),r
∑i=1
fi = n.
Pentru definirea claselor unui tabel de frecvente, nu exista o regula precisa. Fiecareutilizator de date îsi poate crea propriul tabel de frecvente. Scopul final este ca acesttabel sa scoata în evidenta caracteristicele datelor, cum ar fi: existenta unor grupe (clase)naturale, variabilitatea datelor într-un anumit grup (clasa), informatii legate de existentaunor anumite date statistice care nu au fost observate in selectia data etc. În general, acestecaracteristici nu ar putea fi observate privind direct setul de date negrupate. Totusi, pentrucrearea tabelelor de frecvente, se recomanda urmatorii pasi:
1. Determinarea numarului de clase (disjuncte). Este recomandat ca numarul claselorsa fie între 5 si 20. Daca volumul datelor este mic (e.g., n < 30), se recomandaconstituirea a 5 sau 6 clase. De asemenea, daca este posibil, ar fi util ca fiecareclasa sa fie reprezentata de cel putin 5 valori (pentru un numar mic de clase). Dacanumarul claselor este mai mare, putem avea si mai putine date într-o clasa, dar nu maiputin de 3. O clasa cu prea putine valori (0, 1 sau 2) poate sa nu fie reprezentativa.
2. Determinarea latimii claselor. Daca este posibil, ar fi bine daca toate clasele ar aveaaceeasi latime. Acest pas depinde, în mare masuraa, de alegerea din pasul anterior.
3. Determinarea frontierelor claselor. Frontierele claselor sunt construite astfel încâtfiecare data statistica sa apartine unei singure clase.

20 Capitolul 2. Elemente de Statistica
vârsta frecventa frecventa relativa frecventa cumulata vârsta medie[18,25) 34 8.83% 8.83% 21.5[25,35) 76 19.74% 28.57% 30[35,45) 124 32.21% 60.78% 40[45,55) 87 22.60% 83.38% 50[55,65) 64 16.62% 100.00% 60
Total 385 100% - -
Tabela 2.4: Tabel cu frecvente pentru rata somajului.
În practica, un tabel de frecvente se realizeaza prin încercari, pâna avem convingerea cagruparea facuta poate surprinde cât mai fidel datele observate.
Asadar, daca ne este data o însiruire de date ale unei caracteristici discrete sau continue,atunci le putem grupa imediat în tabele sau tablouri de frecvente. Invers (avem tabelulsau tabloul de repartitie si vrem sa enumeram datele) nu este posibil, decât doar în cazulunei caracteristici de tip discret. De exemplu, daca ni se da Tabelul 2.4, ce reprezinta ratasomajului într-o anumita regiune a tarii pe categorii de vârste, nu am putea sti cu exactitatevârsta exacta a persoanelor care au fost selectionate pentru studiu.
Observam ca acest tabel are 5 clase: [18, 25), [25, 35), [35, 45), [45, 55), [55, 65).Vom numi valoare de mijloc pentru o clasa, valoarea obtinuta prin media valorilor extremeale clasei. În cazul Tabelului 2.4, valorile de mijloc sunt scrise în coloana cu vârsta medie.Frecventa cumulata a unei clase este suma frecventelor tuturor claselor cu valori mai mici.
2.6 Reprezentarea datelor statistice
Un tabel de frecvente sau o distributie de frecvente (absolute sau relative) sunt de cele maimulte ori baza unor reprezentari grafice, pentru o mai buna vizualizare a datelor. Acestereprezentari pot fi facute în diferite moduri, dintre care amintim pe cele mai uzuale.
2.6.1 Reprezentare prin puncte
Reprezentarea prin puncte (en., dot plot)este folosita, de regula, pentru selectii dedate de tip discret de dimensiuni mici. Suntreprezentate puncte asezate unul peste celalalt,reprezentând numarul de aparitii ale uneivalori pentru caracteristica data. Un astfelde grafic este reprezentat în Figura 2.1.Aceste reprezentari sunt utile atunci cândse doreste scoaterea în evidenta a anumitorpâlcuri de date (en., clusters) sau chiar lipsaunor date (goluri). Au avantajul de a con-serva valoarea numerica a datelor reprezentate.
Figura 2.1: Reprezentarea prin puncte.

2.6 Reprezentarea datelor statistice 21
2.6.2 Reprezentarea stem-and-leaf
Este folosita, de asemenea, pentru date de tip discret, de selectii de volum relativ mic.Urmatorul set de date negrupate reprezinta punctajele (din 100 de puncte) obtinute de cei20 de elevi ai unui an de studiu la o testare semestriala:
50 34 55 41 59 61 62 64 68 18 68 73 75 77 44 77 62 77 53 79 81 48 85 96 88 92 39 96
Tabelul 2.3 reprezinta aceste date sub forma stem-and-leaf (ramura-frunza). Se observaca acest tabel arata atât cum sunt repartizate datele, cât si forma repartitiei lor (a se privigraficul ca având pe OY drept axa absciselor si OX pe cea a ordonatelor). Asadar, 7|5semnifica un punctaj de 75. Pentru un volum prea mare de date, aceasta reprezentare nueste cea mai buna metoda de vizualizare a datelor. În sectiunile urmatoare vom prezenta sialte metode utile.
Figura 2.2: Reprezentarea datelor discrete.
stem leaf109 2 68 1 5 6 87 3 5 7 7 7 96 1 2 2 4 8 85 0 3 5 94 1 4 83 4 921 80
Figura 2.3: Tabel stem-and-leaf reprezentândpunctajele studentilor.
2.6.3 Reprezentarea cu bare (bar charts)
Este utila pentru reprezentarea variabilelor discrete cu un numar mic de valori diferite.Barele sunt dreptunghiuri ce reprezinta frecventele si nu sunt unite între ele. Fiecaredreptunghi reprezinta o singura valoare. Într-o reprezentare cu bare, categoriile sunt plasate,de regula, pe orizontala iar frecventele pe verticala. În Figura 2.41 sunt reprezentate dateledin tabelul cu note. Se poate schimba orientarea categoriilor si a claselor; în acest cazbarele vor aparea pe orizontala (vezi Figura 2.42). Figura 2.5 contine o reprezentare dedate folosind bare 3D.

22 Capitolul 2. Elemente de Statistica
Figura 2.4: Reprezentarile cu bare.
Figura 2.5: Reprezentare 3D prin bare.
2.6.4 Histograme
Cuvântul "histograma" a fost introdus pentru prima oara de Karl Pearson2 în 1895. Acestaderiva din cuvintele grecesti histos (gr., ridicat în sus) si gramma (gr., desen, înregistrare).O histograma este o forma pictoriala a unui tabel de frecvente, foarte utila pentru selectiimari de date de tip continuu. Se aseamana cu reprezentarea prin bare, cu urmatoarele douadiferente: nu exista spatii între bare (desi, pot aparea bare de înaltime zero ce arata a fispatiu liber) si ariile barelor sunt proportionale cu frecventele corespunzatoare. Numarulde dreptunghiuri este egal cu numarul de clase, latimea dreptunghiului este intervalulclasei, iar înaltimea este asa încât aria fiecarui dreptunghi reprezinta frecventa. Aria totalaa tuturor dreptunghiurilor este egala cu numarul total de observatii. Daca barele uneihistograme au toate aceeasi latime, atunci înaltimile lor sunt proportionale cu frecventele.Înaltimile barelor unei histogramei se mai numesc si densitati de frecventa.
2Karl Pearson (1857−1936), statistician, avocat si eugenist britanic

2.6 Reprezentarea datelor statistice 23
Înaltimea (în cm) frecventa[0, 5) 5[5, 10) 13[10, 15) 23[15, 20) 17[20, 25) 10[25, 30) 2
Tabela 2.5: Tabel cu înaltimile plantelor
Tabela 2.6: Histograme pentru datele din Tabelul 2.5
În cazul în care latimile barelor nu sunt toate egale, atunci înaltimile lor satisfac:
înaltimea = k · frecventalatimea clasei
, k = factor de proportionalitate.
Sa presupunem ca am fi grupat datele din Tabelul 2.5 într-o alta maniera, în care claselenu sunt echidistante (vezi Tabelul 2.7). În Tabelul 2.7, datele din ultimele doua clase aufost cumulate într-o singura clasa, de latime mai mare decât celelalte, deoarece ultima clasadin Tabelul 2.5 nu avea suficiente date. Histograma ce reprezinta datele din Tabelul 2.7este cea din Figura 2.8. Conform cu regula proportionalitatii ariilor cu frecventele, se poateobserva ca primele patru bare au înaltimi egale cu frecventele corespunzatoare, pe cândînaltimea ultimei bare este jumatate din valoarea frecventei corespunzatoare, deoarecelatimea acesteia este dublul latimii celorlalte.
În general, pentru a construi o histograma,vom avea în vedere urmatoarele:− datele vor fi împartite (unde este posibil)în clase de lungimi egale. Uneori acestedivizari sunt naturale, alteori va trebui sale fabricam.− numarul de clase este, în general, între5 si 20.− înregistrati numarul de date ce cad înfiecare clasa (numite frecvente).− figura ce contine histograma va aveaclasele pe orizontala si frecventele pe ver-ticala. Figura 2.6: Histograma 3D
Observatia 2.1 (1) Daca lungimea unei clase este infinita (e.g., ultima clasa din Tabelul2.7 este [20, ∞)), atunci se obisnuieste ca latimea ultimului interval sa fie luata drept dublullatimii intervalului precedent.(2) În multe situatii, capetele intervalelor claselor sunt niste aproximari, iar în loculacestora vom putea utiliza alte valori. Spre exemplu, sa consideram clasa [15, 20). Aceasta

24 Capitolul 2. Elemente de Statistica
clasa reprezinta clasa acelor plante ce au înaltimea cuprinsa între 15cm si 20cm. Deoarecevalorile înaltimilor sunt valori reale, valorile 15 si 20 sunt, de fapt, aproximarile acestorvalori la cel mai apropiat întreg. Asadar, este posibil ca aceasta clasa sa contina acele plantece au înaltimile situate între 14.5cm (inclusiv) si 20.5cm (exclusiv). Am putea face referirela aceste valori ca fiind valorile reale ale clasei, numite frontierele clasei. În cazul în caream determinat frontierele clasei, latimea unei clase se defineste ca fiind diferenta întrefrontierele ce-i corespund. În concluzie, în cazul clasei [15, 20), aceasta are frontierele14.5 - 20.5, latimea 6 si densitatea de frecventa 17
6 . Pentru exemplificare, în Tabelul 2.9am prezentat frontierele claselor, latimile lor si densitatile de frecventa pentru datele dinTabelul 2.4.
Înaltimea (în cm) frecventa[0, 5) 5[5, 10) 13[10, 15) 23[15, 20) 17[20, 30) 12
Tabela 2.7: Tabel cu înaltimile plantelor
Tabela 2.8: Histograme pentru datele din Tabelul 2.7
înaltimea (în cm) frontierele latimea frecventa densitatea de frecventa[18,25) 17.5−25.5 8 34 4.25[25,35) 24.5−35.5 11 76 6.91[35,45) 34.5−45.5 11 124 11.27[45,55) 44.5−55.5 11 87 7.91[55,65) 54.5−65.5 11 64 5.82
Tabela 2.9: Tabel cu frontierele claselor.
2.6.5 Reprezentare prin sectoare de disc (pie charts)
Se poate reprezenta distributia unei caracteristici si folosind sectoare de disc (diagramecirculare) (en., pie charts), fiecare sector de disc reprezentând câte o frecventa relativa.Aceasta varianta este utila în special la reprezentarea datelor calitative.
Exista si posibilitatea de a reprezenta datele prin sectoare 3 dimensionale. În Figura2.8 am reprezentat datele din Tabelul 2.4.

2.6 Reprezentarea datelor statistice 25
Figura 2.7: Reprezentarea pe disc a frecventelorrelative ale notelor din tabelul cu note
Figura 2.8: Reprezentare pe disc 3D
2.6.6 Poligonul frecventelor
Un poligon de frecventa este similar cu o reprezentarecu bare, dar în loc sa foloseasca barele, se creeazaun poligon prin trasarea frecventelor si conectareaacestor puncte cu o serie de segmente.
Figura 2.9: Exemplu de polygon alfrecventelor
2.6.7 Ogive
Pentru frecventele cumulate pot fi folosite ogive. Oogiva reprezinta graficul unei frecvente cumulate(absoluta sau relativa).
Figura 2.10: Ogiva pentru frecventeleabsolute cumulate din Tabelul 2.2

26 Capitolul 2. Elemente de Statistica
2.6.8 Diagrama Q-Q sau diagrama P-P
Q-Q plot (diagrama cuantila-cuantila) si P-P plot (diagrama probabilitate-probabilitate)sunt utilizate in a determina apropierea dintredoua seturi de date (repartitii). Daca dateleprovin dintr-o acceasi repartitie, atunci elese aliniaza dupa o dreapta desenata in figura.Diagrama Q-Q este bazata pe rangurile valo-rilor, iar diagrama P-P este bazata pe functiilede repartitie empirice. Figura 2.11: Exemplu de diagrama Q-Q plot
2.6.9 Diagrama scatter plot
Daca (xk, yk), k ∈ 1, 2, . . . , n este un set dedate bidimensionale, ce reprezinta observatiiasupra vectorului aleator (X , Y ), atunci o ma-sura a legaturii dintre variabilele X si Y estecoeficientul de corelatie empiric introdus deK. Pearson. Primul pas în analiza regresio-nala este vizualizarea datelor. Pentru aceastase foloseste reprezentarea scatter plot.
Figura 2.12: Exemplu de scatter plot
2.7 Masuri descriptive ale datelor statistice (indicatori statistici)Sa consideram o populatie statistica de volum N si o caracteristica a sa, Z, ce are functiade repartitie F . Asupra acestei caracteristici facem n observatii, în urma carora obtinemun set de date statistice. Dupa cum am vazut anterior, datele statistice pot fi prezentateîntr-o forma grupata (descrise prin tabele de frecvente) sau pot fi negrupate, exact asacum au fost culese în urma observarilor. Pentru analiza acestora, pot fi utilizate diversetehnici de organizare si reprezentare grafica a datelor statistice însa, de cele mai multeori, aceste metode nu sunt suficiente pentru o analiza detaliata. Suntem interesati în aatribui acestor date anumite valori numerice reprezentative. Pot fi definite mai multe tipuride astfel de valori numerice, e.g., masuri ale tendintei centrale (media, modul, mediana),masuri ale dispersiei (dispersia, deviatia standard), masuri de pozitie (cuantile, distantaintercuantilica) etc. În acest capitol, vom introduce diverse masuri descriptive numerice,atât pentru datele grupate, cât si pentru cele negrupate.
2.7.1 Date negrupateConsideram un set de date statistice negrupate, z1, z2, . . . , zn (zi ∈R, i= 1, 2 . . . , n, n≤N),ce corespund unor observatii facute asupra variabilei Z. Pe baza acestor observatii, definimurmatorii indici statistici, in scopul de a estima parametrii reali ai caracteristicilor populatiei.Printr-un estimator pentru un parametru al populatiei intelegem o statistica alecarei valori

2.7 Masuri descriptive ale datelor statistice (indicatori statistici) 27
se apropie foarte mult de valoarea parametrului atunci cand volumul selectiei este suficientde mare. Deoarece ele se bazeaza doar pe observatiile culese, acesti indici statistici se mainumesc si masuri empirice.
• Valoarea medieEste o masura a tendintei centrale a datelor. Pentru o selectie z1, z2, . . . , zn,definim:
z =1n
n
∑i=1
zi,
ca fiind media datelor observate. Aceasta medie empirica este un estimator pentrumedia teoretica, µ = EZ, daca aceasta exista.
• Pentru fiecare i, cantitatea di = zi− z se numeste deviatia valorii zi de la medie.Aceasta nu poate fi definita ca o masura a gradului de împrastiere a datelor, deoarece
n
∑i=1
(zi− z) = 0.
• MomentelePentru fiecare k ∈ N∗, momentele centrate de ordin k se definesc astfel:
mk =1n
n
∑i=1
(zi− z)k.
• DispersiaAceasta este o masura a gradului de împrastiere a datelor în jurul valorii medii. Esteun estimator pentru dispersia populatiei. Pentru o selectie z1, z2, . . . , zn, definimdispersia astfel:
s2 = m2 =1
n−1
n
∑i=1
(zi− z)2
(=
1n−1
[n
∑i=1
z2i −n(z)2]
).
Faptul ca apare n−1 la numitor face ca aceasta masura empirica sa estimeze dispersiateoretica fara deplasare, in sensul ca valoarea medie a lui s2 este chiar σ2. Acest faptnu ar mai fi fost valabil daca in loc de n−1 ar fi fost n.
• Deviatia standardEste tot o masura a împrastierii datelor în jurul valorii medii, care estimeaza parame-trul σ . Pentru o selectie z1, z2, . . . , zn, definim deviatia standard:
s =
√1
n−1
n
∑i=1
(zi− z)2.
• Coeficientul de variatie (sau de dispersie)Aceste coeficient (de obicei, exprimat în procente) este util atunci când comparamdoua repartitii având unitati de masura diferite. Nu este folosit atunci când z sau µ
este foarte mic. Pentru doua populatii care au aceeasi deviatie standard, gradul devariatie a datelor este mai mare pentru populatie ce are media mai mica.
cv =sz.

28 Capitolul 2. Elemente de Statistica
• Amplitudinea (plaja de valori, range)Pentru un set de date, amplitudinea (en., range) este definita ca fiind diferenta dintrevaloarea cea mai mare si valoarea cea mai mica a datelor, i.e., a = zmax− zmin.
• Scorul ζ
Este numarul deviatiilor standard pe care o anumita observatie, z, le are sub saudeasupra mediei. Pentru o selectie z1, z2, . . . , zn, scorul Z este definit astfel:
ζ =z− z
s.
• Corelatia (covarianta)Presupunem acum ca avem doua variabile de interes relative la o populatie statistica,Z1 si Z2, pentru care avem n perechi de observatii, (z1, z′1), (z2, z′2), . . . , (zn, z′n).Definim corelatia (covarianta):
cove =1
n−1
n
∑i=1
(zi− z)(z′i− z′). (2.7.3)
In cazul în care lucram cu mai multe variabile si pot exista confuzii, vom notacovarianta prin cove(Z1, Z2). Daca Z1 si Z2 coincid, sa spunem ca Z1 = Z2 = Z,atunci cove(Z, Z) = s2.O relatie liniara între doua variabile este acea relatie ce poate fi reprezentata cel maibine printr-o linie. Corelatia detecteaza doar dependente liniare între doua variabilealeatoare. Putem avea o corelatie pozitiva, însemnând ca Z1 si Z2 cresc sau descrescîmpreuna (pentru cove > 0), sau o corelatie negativa, însemnând ca Z1 si Z2 semodifica în directii opuse (pentru cove < 0). În cazul în care cove = 0, putem banuica variabilele nu sunt corelate.
• Coeficientul de corelatie
r =cove
sxsy.
In cazul în care lucram cu mai multe variabile si pot exista confuzii, vom notacoeficientul de corelatie prin r(Z1, Z2). La fel ca în cazul coeficientulul de corelatieteoretic, r ia valori între −1 si 1. Dupa cum vom vedea mai târziu, pe baza valoriilui r putem testa valoarea reala aparametrului ρ (coeficientul teoretic de corelatie,care reprezinta întreaga populatie).
• Functia de repartitie empiricaSe numeste functie de repartitie empirica asociata unei variabile aleatoare Z si uneiselectiiz1, z2, . . . , zn, functia F∗n : R−→ [0, 1], definita prin
F∗n (z) =numarul observatiilor mai mici au egale cu z
n. (2.7.4)
Când volumul selectiei (n) este suficient de mare, functia de repartitie empirica(F∗n (z)) aproximeaza functia de repartitie teoretica F(z) (vezi Figura 2.13). Insa,pentru a stabili exact daca ele sunt semnificativ apropiate, este nevoie de un teststatistic.

2.7 Masuri descriptive ale datelor statistice (indicatori statistici) 29
Figura 2.13: Functia de repartitie empirica si functia de repartitie teoretica pentru distribu-tia normala.
• Coeficientul de asimetrie (en., skewness) este al treilea moment standardizat, care sedefineste prin
g1 =µ3
s3 =
1n
n
∑i=1
(zi− z)3
[1
n−1
n
∑i=1
(zi− z)2
]3/2 .
Putem spera ca o repartitie sa fie simetrica daca g1 este foarte apropiat de valoarea 0.Vom spune ca asimetria este pozitiva (sau la dreapta) daca g1 > 0 si negativa (sau lastânga) daca g1 < 0. Coeficientul empiric de asimetrie g1 va fi utilizat în estimareacoeficientului teoretic de asimetrie γ1, care este un parametru al populatiei.
• Excesul (coeficientul de aplatizare sau boltire) (en., kurtosis) se defineste prin
κ =µ4
s4 −3 =
1n
n
∑i=1
(zi− z)4
(1n
n
∑i=1
(zi− z)2
)2 −3.
Este o masura a boltirii distributiei (al patrulea moment standardizat). Termenul(−3) apare pentru ca indicele kurtosis al distributiei normale sa fie egal cu 0. Vomavea o repartitie mezocurtica pentru κ = 0 (sau foarte apropiat de aceasta valoare),leptocurtica (boltita) pentru κ > 0 sau platocurtica pentru κ < 0. Un indice κ > 0semnifica faptul ca, în vecinatatea modului, curba densitatii de repartitie are o boltire(ascutire) mai mare decât clopotul lui Gauss. Pentru κ < 0, în acea vecinatate curbadensitatii de repartitie este mai plata decât curba lui Gauss. Coeficientul empiric deaplatizare κ va fi utilizat în estimarea coeficientului teoretic de aplatizare K, careeste un parametru al populatiei.
• CuantileCuantilele (de ordin r) sunt valori ale unei variabile aleatoare care separa repartitiaordonata în r parti egale. Aceste valori sunt estimari pentru cuantilele teoretice(parametrii). Vom utiliza notatia cu litera mica pentru cuantilele empirice, pentru ale diferentia de parametrii corespunzatori.

30 Capitolul 2. Elemente de Statistica
Pentru r = 2, cuantila ce imparte setul de date in doua clase cu acelasi numar devalori se numeste mediana (empirica), notata prin me.Presupunem ca observatiile sunt ordonate, z1 < z2 < · · ·< zn. Pentru aceasta ordine,definim valoarea mediana:
me =
z(n+1)/2 , daca n = impar;(zn/2 + zn/2+1)/2 , daca n = par.
Pentru r = 4, cuantilele se numesc cuartile (sunt în numar de 3). Prima cuartila,notata q1, se numeste cuartila inferioara, a doua cuartila este mediana, iar ultimacuartila, notata prin q3, se numeste cuartila superioara. Diferenta q3−q1 se numestedistanta intercuartilica.Pentru r = 10 se numesc decile (sunt în numar de 9), pentru r = 100 se numescpercentile (sunt în numar de 99), pentru r = 1000 se numesc permile (sunt în numarde 999). Sunt masuri de pozitie, ce masoara locatia unei anumite observatii fata derestul datelor.
• ModulModul (sau valoarea modala) este acea valoare z∗ din setul de date care apare celmai des (adica are frecventa cea mai mare). Un set de date poate avea mai multemodule. Daca apar doua astfel de valori, atunci vom spune ca setul de date estebimodal, pentru trei astfel de valori avem un set de date trimodal etc. În cazul încare toate valorile au aceeasi frecventa de aparitie, atunci spunem ca nu exista mod.De exemplu, setul de date
1 3 5 6 3 2 1 4 4 6 2 5
nu admite valoare modala. Nu exista un simbol care sa noteze distinctiv modul unuiset de date.
• Valori aberante (en. outliers)Dupa cum am vazut anterior, teorema lui Cebâsev ne asigura ca probabilitatea ca odata observata sa devieze de la medie cu mai mult de k deviatii standard este maimica decat 1
k2 . Valorile aberante sunt valori statistice observate care sunt îndepartatede marea majoritate a celorlalte observatii. Ele pot aparea din cauza unor masuratoridefectuoase sau în urma unor erori de masurare. De cele mai multe ori, ele vor fiexcluse din analiza statistica. Din punct de vedere matematic, valorile aberante suntvalorile ce nu apartin intervalului urmator:
[q1−1.5 iqr, q3 +1.5 iqr],
unde iqr = q3− q1 este distanta intercuartilica. Daca valoarea 1.5 se inlocuiestecu 3, atunci orice valoare care iese din acest interval se va numi valoare aberantaextrema.
• Sinteza prin cele cinci valori statistice (five number summary)Reprezinta cinci masuri statistice empirice caracteristice unui set de date statistice.Acestea sunt:
valoarea minima < prima cuartila (q1) < mediana (me) < a treia cuartila (q3) < valoarea maxima
Acesti cinci indicatori pot fi reprezentati grafic într-o diagrama numita box-and-whiskersplot.

2.7 Masuri descriptive ale datelor statistice (indicatori statistici) 31
Datele din Tabelul 2.4 sunt reprezentate în prima figura de mai jos prin doua diagramebox-and-whiskers. În prima diagrama (numerotata cu 1) am folosit datele negrupate; îna doua diagrama am folosit reprezentarea datelor din acelasi tabel prin centrele claselor.Reprezentarile sunt cele clasice, cu dreptunghiuri. Valorile aberante sunt reprezentate prinpuncte în diagrama box-and-whisker plot.
vârsta f. abs. f. rel. f. cum. mijlocul clasei[18,25) 34 8.83% 8.83% 21.5[25,35) 76 19.74% 28.57% 30[35,45) 124 32.21% 60.78% 40[45,55) 87 22.60% 83.38% 50[55,65) 64 16.62% 100.00% 60
Total 385 100% - -
Tabela 2.10: Tabel cu frecvente.Figura 2.14: Box-an-whiskers plot pentrudatele din Tabelul 2.10
În Figura 2.15, am reprezentat prin box-and-whiskers un set de date discrete ce continedoua valori aberante. Aici dreptunghiul afost crestat (notched box-and whisker plot);lungimea crestaturii oferind un interval deîncredere pentru mediana. Valorile aberantesunt reprezentate in figura prin puncte inafara range-ului datelor.
Figura 2.15: Box-an-whisker plot pentru un setde date discrete
Tabelul 2.11 contine cativaparametri uzuali ce caracte-rizeaza o populatie, alaturide estimatorii corespunza-tori.
parametru indicator statistic (estimator)caracterizeaza populatia format cu date de selectie
µ− media mσ2− dispersia s2
σ− deviatia standard sCV − coef. de variatie cv
cov− covarianta coveρ− corelatia rγ1− skewness g1K− kurtosis κ
Qi− cuantile qiMe− mediana me
F(z)− fct. de repartitie F∗n (z)
Tabela 2.11: Tabel cu parametri si estimatorii sai

32 Capitolul 2. Elemente de Statistica
Exercitiu 2.1 Urmatorul set de date reprezinta preturile (în mii de euro) a 20 de case,vândute într-o anumita regiune a unui oras:
113 60.5 340.5 130 79 475.5 90 100 175.5 100
111.5 525 50 122.5 125.5 75 150 89 100 70
(a) Determinati amplitudinea, media, mediana, modul, deviatia standard, cuartilele sidistanta intercuartilica pentru aceste date. Care valoare este cea mai reprezentativa?(b) Desenati diagrama box-and-whiskers si comentati-o. Exista valori aberante?(c) Calculati coeficientii de asimetrie si de aplatizare.Solutie: Rearanjam datele în ordine crescatoare:
50 60.5 70 75 79 89 90 100 100 100 111.5
113.5 122.5 125.5 130 150 175.5 340.5 475.5 525
Amplitudinea datelor este 525− 50 = 475, media lor este 154.15, mediana este100+111.5
2= 105.75, modul este 100, cuartila inferioara este q1 =
79+892
= 84, q2 =
me, cuartila superioara este q3 =130+150
2= 140 si distanta intercuartilica este d =
q3−q1 = 56. Mediana este valoarea cea mai reprezentativa în acest caz, deoarece cele maimari trei preturi, anume 340.5, 475.5, 525, maresc media si o fac mai putin reprezentativapentru celelalte date.
Figura 2.16: Box-an-whisker plotpentru datele din Exercitiul 2.1
În cazul în care setul de date nu este simetric,valoarea mediana este cea mai reprezentativavaloare a datelor. Deviatia standard este
s =
√1
n−1
n
∑i=1
(zi− z)2 = 133.3141.
Folosind formulele, gasim ca g1 = 1.9598 (asi-metrie la dreapta) si κ = 5.4684 (boltire pro-nuntata). Valorile aberante sunt cele ce se aflain afara intervalului [q1 − 1.5(q3 − q1), q3 +1.5(q3−q1)] = [0, 178]. Se observa ca valorile340.5,475.5,525 sunt valori aberante, repre-zentate prin puncte in figura alaturata. √
2.7.2 Date grupateConsideram un set de date statistice grupate (de volum n), ce reprezinta observatii asupravariabilei Z.
Pentru o selectie cu valorile de mijloc z1, z2, . . . , zr si frecventele absolute corespun-
zatoare, f1, f2, . . . , fr, cur
∑i=1
fi = n, definim:
z f =1n
r
∑i=1
zi fi, media (empirica) de selectie, (sau, media ponderata)

2.7 Masuri descriptive ale datelor statistice (indicatori statistici) 33
s2 =1
n−1
r
∑i=1
fi(zi− z f )2 =
1n−1
(r
∑i=1
z2i fi−nz2
f
), dispersia empirica,
s =√
s2, deviatia empirica standard.
Mediana pentru un set de date grupate este acea valoare ce separa toate datele în douaparti egale. Se determina mai întâi clasa ce contine mediana (numita clasa mediana), apoipresupunem ca în interiorul fiecarei clase datele sunt uniform distribuite. O formula dupacare se calculeaza mediana este:
me = l +n2 −Fme
fmec,
unde: l este limita inferioara a clasei mediane, n este volumul selectiei, Fme este sumafrecventelor pâna la (exclusiv) clasa mediana, fme este frecventa clasei mediane si c estelatimea clasei.
Similar, formulele pentru cuartile sunt:
q1 = l1 +n4 −Fq1
fq1
c si q3 = l3 +3n4 −Fq3
fq3
,
unde l1 si l3 sunt valorile inferioare ale intervalelor in care se gasesc cuartilele respective,iar Fq este suma frecventelor pâna la (exclusiv) clasa ce contine cuartila, fq este frecventaclasei unde se gaseste cuartila.
Pentru a afla modul unui set de date grupate, determinam mai întâi clasa ce contineaceasta valoare (clasa modala), iar modul va fi calculat dupa formula:
mod = l +d1
d1 +d2c,
unde d1 si d2 sunt frecventa clasei modale minus frecventa clasei anterioare si, respectiv,frecventa clasei modale minus frecventa clasei posterioare, l este limita inferioara a claseimodale si c este latimea clasei modale.Exercitiu 2.2 Datele din Tabelul 2.12 reprezinta inaltimile (in cm) pentru o selectie de 70de plante dintr-o anumita regiune.(a) Reprezentati datele printr-o histograma.(b) Folosind formulele pentru indicatori statistici pentru date grupate, determinati amplitu-dinea, media, mediana, modul, dispersia si distanta intercuartilica.(b) Desenati diagrama box-and-whiskers si comentati-o. Exista valori aberante?Solutie: Amplitudinea este A = 30. Folosind centrele claselor, media este
z =1
100(1.52×5+4.52×9+7.52×8+10.52×14+13.52×15+
+16.52×19+19.52×15+22.52×8+25.52×4+28.52×3) = 14.31.
Dispersia este:
s2 =1
n−1(∑(z2 · f )−n · z2)
=1
69(1.52×5+4.52×9+7.52×8+10.52×14+13.52×15+16.52×19+
+19.52×15+22.52×8+25.52×4+28.52×3 − 70 ·14.312)
= 44.5191.

34 Capitolul 2. Elemente de Statistica
Înaltimea (în cm) frecventa[0, 3) 5[3, 6) 9[6, 9) 8[9, 12) 14[12, 15) 15[15, 18) 19[18, 21) 15[21, 24) 8[24, 27) 4[27, 30) 3
Tabela 2.12: Tabel cu date de tip continuuFigura 2.17: Histograma pentru datele dinTabelul 2.12.
Clasa mediana este clasa [12, 15), deoarece în clasele anterioare ([0, 3), [3, 6) si [6, 9))se afla 5+9+8+14 = 36 date mai mici decât mediana, iar la dreapta clasei [12, 15) seafla 19+15+8+4+3 = 49 de date. Valoarea mediana este
Me = 12+50−36
15×3 = 14.8.
Clasa modala este [15, 18), iar modul este Mo = 15+ 44+4 ×3 = 16.5.
Calculam acum prima cuartila dupa formula q1 = l1 +n4 −Fq1
fq1
. Clasa in care se gaseste
prima cuartila este [9, 12) (o valoare din acest interval va avea la stanga sa 100/4 = 25dintre valorile observate). Avem: Fq1 = 22, fq1 = 14, c = 3, de unde q1 = 9.6429.Similar, clasa in care se gaseste a treia cuartila este [18, 21) (o valoare din acest interval vaavea la dreapta sa 100/4 = 25 dintre valori. Avem: Fq3 = 70, fq3 = 15, c = 3, de undeq3 = 19. Astfel, distanta intercuartilica observata este iqr = q3−q1 = 9.3571. √
Tabelul 2.13 reprezinta o sumarizare a statisticilor importante pentru aceste date:
Statistica valoarea parametrul estimatMinimum 0.5 zminMaximum 29.5 zmaxMedia 14.31 µ
Mediana 14.8 MeDeviatia standard 6.6723 σ
Dispersia 44.5191 σ2
Skewness −0.0495 γ1Kurtosis 2.4186 KNumarul de observatii 100 nχ2 pentru testul de normalitate (cu 7 grade de libertate) 33.5440 −
Tabela 2.13: Statistici pentru datele din Tabelul 2.12

2.8 Transformari de date 35
Valorile aberante sunt cele ce se afla in afaraintervalului[q1 − 1.5(q3 − q1), q3 + 1.5(q3 − q1)] =[−5.2264, 34.1501]. Cum toate datele din tabelapartin acestui interval, nu exista valori aberante,fapt care se observa si din Figura 2.18.
Figura 2.18: Box-an-whisker plot pentrudatele din Tabelul 2.12
2.8 Transformari de dateUneori valorile masurate nu sunt normale si este necesara o transformare a lor pentru aobtine valori apropiate de normalitate. Transformarile uzuale sunt: logaritmarea valorilorobservate (folosind functiile ln sau log10, daca valorile sunt toate pozitive), radacina patrataa valorilor, transformarea logit, radacini de ordin superior etc. In Tabelul 2.14 am sugerattipul de transformare ce poate fi utilizat in functie de coeficientul de skewness γ1.
In ce conditii. . . skewness formuladate aproape simetrice −0.5 < γ1 < 0.5 nicio transformareskewness moderat pozitiv, date nenegative 0.5≤ γ1 < 1 yi =
√zi
skewness moderat pozitiv, exista date < 0 0.5≤ γ1 < 1 yi =√
zi +Cskewness moderat negativ −1 < γ1 ≤ 0.5 yi =
√C− zi
skewness mare negativ γ1 ≤−1 yi = ln(C− zi) sau yi = log10(C− zi)skewness mare pozitiv, date pozitive γ1 ≥ 1 yi = lnzi sau yi = log10 ziskewness mare pozitiv, exista date ≤ 0 γ1 ≥ 1 yi = ln(zi +C) sau yi = log10(zi +C)
Tabela 2.14: Exemple de transformari de date statistice
unde C > 0 este o constanta ce poate fi determinata astfel incat datele transformate sa aibaun skewness cat mai aproape de 0. Aceasta constanta va fi aleasa astfel incat functia ceface transformarea este definita.
De exemplu, presupunem ca datele observate sunt z1, z2, . . . , zn si acestea nu sunt toatepozitive, cu un coeficient de asimetrie (skewness) γ1 = 1.3495. Ne uitam la valoareaminima a datelor; aceasta este zmin =−0.8464. Pentru a obtine un set de valori pozitive,vom adauga valoarea 1 la toate datele observate. Apoi, logaritmam valorile obtinute. Celedoua procedee cumulate sunt echivalente cu folosirea directa a formulei ln(1+zi) (adunandvaloarea 1, am facut toate argumentele logaritmului pozitive). Obtinem astfel un nou set dedate, si anume y1, y2, . . . , yn, unde yi = ln(1+ zi). Un exemplu este cel din Figura 2.19. Seobserva ca datele logaritmate sunt aproape normale. O analiza statistica poate fi condusapentru datele yi, urmand ca, eventual, la final sa aplicam transformarea inversa zi = eyi−1pentru a transforma rezultatele pentru datele initiale.

36 Capitolul 2. Elemente de Statistica
Figura 2.19: Datele intiale si datele logaritmate
Dupa transformarea datelor si analiza datelor transformate (de exemplu, prezicerea valorilorin punctele neselectate), de multe ori este necesara transformarea inversa a datelor, pentrua determina proprietatile datelor originale. De aceea, ar fi potrivit de a exprima indicatoriistatistici atat pentru datele transformate, cat si pentru datele originale. Un exemplu este celdin Tabelul 2.15.
Indicatorul datele originale datele tranformatezi yi = ln(1+ zi)
Minimum −0.8464 −1.8734Maximum 14.1107 2.7154Media 6.02142 1.51Cuartila Q1 3.1152 0.6532Mediana 6.5200 1.2512Cuartila Q3 8.7548 1.5785Deviatia standard 5.2511 0.7524Dispersia 27.5741 0.5661Skewness 6.2322 0.0233Kurtosis 78.6077 2.9786Numarul de observatii 100 100χ2 pentru testul de normalitate (cu 7 grade de libertate) − 7.1445
Tabela 2.15: Indicatori pentru datele originale si pentru datele transformate 2.12

2.8 Transformari de date 37


3. Notiuni teoretice de Statistica
3.1 Evenimente aleatoareNumim experiment aleator (sau experienta aleatoare) orice act cu rezultat incert, care poatefi repetat în anumite conditii date. Opusul notiunii de experiment aleator este experimentuldeterminist, semnificând un experiment ale carui rezultate sunt complet determinate deconditiile în care acesta se desfasoara. Rezultatul unui experiment aleator depinde deanumite circumstante întâmplatoare ce pot aparea. Exemple de experiente aleatoare:extragerea LOTO, aruncarea zarului, observarea ratei infiltrarii apei in sol in diverse locatiidintr-o anumita regiune, determinarea concentratiei de nutrienti in sol, observarea durateide viata a unui individ, observarea vremii de a doua zi, observarea numarului de apeluritelefonice receptionate de o centrala telefonica într-un timp dat etc.
Vom numi multime (sau spatiu) de selectie asociat unui experiment multimea tuturorrezultatelor posibile ale acelui experiment. Notam acasta multime cu Ω. Aplicareaexperientei asupra unei colectivitati date se numeste proba. Vom numi eveniment aleatororice colectie de rezultate posibile asociate experimentului aleator. Vom numi evenimentaleator elementar (sau eveniment aleator simplu) un eveniment aleator care are un singurrezultat posibil. Un eveniment aleator cu mai mult de un rezultat posibil se va numieveniment aleator compus.
Exemple de evenimente aleatoare: aparitia unei duble (6, 6) la aruncarea a doua zarurieste un eveniment aleator elementar, iar obtinerea unei duble la aruncarea a doua zarurieste un eveniment aleator compus.
Vom numi evenimentul sigur acel eveniment care se poate realiza în urma oricareiexperiente aleatoare. Evenimentul sigur este, in fapt, chiar multimea de selectie Ω, ceeste multimea tuturor evenimentelor elementare. Prin eveniment imposibil intelegem aceleveniment ce nu se realizeaza în nicio proba. Evenimentul imposibil asociat unei experientealeatoare se noteaza prin ∅.Se numeste caz favorabil pentru evenimentul aleator un caz în care respectivul eveniment

40 Capitolul 3. Notiuni teoretice de Statistica
se realizeaza macar intr-o proba a sa.Evenimentele aleatoare le vom nota cu A, B,C, . . . . Prin A (care se citeste non A) vom notaevenimentul complementar lui A, care se realizeaza atunci când A nu se realizeaza. Avem:A = Ω\A.
3.1.1 Operatii cu evenimentePresupunem ca A si B sunt doua evenimente legate de un anumit experiment aleator. Putemdefini urmatoarele evenimente:
• evenimentul A⋃
B (citit A sau B) este evenimentul care se realizeaza ori de cate orise realizeaza cel putin unul dintre evenimentele A si B.
• evenimentul A⋂
B (citit A si B) este evenimentul care se realizeaza ori de cate ori serealizeaza simultan evenimentele A si B.
• evenimentul A\B (citit A minus B) este evenimentul care se realizeaza ori de cateori se realizeaza A, dar nu se realizeaza B.
3.1.2 Relatii intre evenimente• Notam prin A⊂ B (citit A implica B) si spunem ca realizarea lui A implica realizarea
lui B.• Spunem ca A = B (citit A egal B) daca A⊂ B si B⊂ A.• Spunem ca A si B sunt evenimente incompatibile daca ele nu se pot realiza simultan
in nicio proba. Scriem astfel: A⋂
B =∅.• Spunem ca A si B sunt evenimente compatibile daca ele se pot realiza simul-
tan. Scriem astfel: A⋂
B 6= ∅. De exemplu, la aruncarea unui zar, evenimenteleA =evenimentul aparitiei unui numar impar si B =evenimentul aparitiei unui numarprim sunt compatibile.
• Spunem ca A si B sunt evenimente echiprobabile daca ele au aceeasi sansa derealizare. Spre exemplu, la aruncarea unei monede ideale, orice fata are aceeasisansa de aparitie.
3.2 ProbabilitatePentru a putea cuantifica sansele de realizare a unui eveniment aleator, s-a introdus notiuneade probabilitate. Presupunem ca pentru un anume experiment, am construit spatiul deselectie Ω. Atunci, fiecarui eveniment A în putem asocia un numar P(A), numit probabili-tatea realizarii evenimentului A (sau, simplu, probabilitatea lui A), fiind o masura precisa asanselor ca A sa se realizeze. Probabilitatea este o valoare cuprinsa intotdeauna intre 0 si 1,cu P(∅) = 0 (probabilitatea ca evenimentul imposibil sa se realizeze este 0) si P(Ω) = 1(probabilitatea ca evenimentul sigur sa se realizeze este 1).
Daca evenimentele A si B nu se pot realiza simultan (i.e., A⋂
B=∅), atunci P(A⋃
B)=P(A) +P(B). Daca A si B se pot realiza simultan, atunci P(A
⋃B) = P(A) +P(B)−
P(A⋂
B).În literatura de specialitate, probabilitatea este definita în mai multe moduri: cu definitia
clasica (apare pentru prima oara în lucrarile lui P. S. Laplace1), folosind o abordarestatistica (cu frecvente relative), probabilitatea definita geometric, probabilitatea bayesiana
1Pierre-Simon, marquis de Laplace (1749−1827), matematician si astronom francez

3.2 Probabilitate 41
(introdusa de Thomas Bayes2) sau utilizând definitia axiomatica (Kolmogorov). Aici vomprezenta doar primele trei moduri.
(I) Probabilitatea clasica este definita doar pentru cazul în care experienta aleatoareare un numar finit de cazuri posibile si echiprobabile (toate au aceeasi sansa de a se realiza).În acest caz, probabilitatea de realizare a unui eveniment A este
P(A) =numarul cazurilor favorabile realizarii evenimentului
numarul cazurilor egal posibile.
De exemplu, dorim sa determinam probabilitatea obtinerii unei duble la o singura aruncarea unei perechi de zaruri ideale. Multimea cazurilor posibile este multimea tuturor perechilor(i, j); i, j = 1, 6, care are 36 de elemente. Multimea cazurilor favorabile este formatadin adica 6 elemente, si anume: (1, 1), (2, 2), (3, 3), (4, 4), (5, 5), (6, 6). Probabilitateaaparitiei unei duble este P = 6
36 = 16 .
Sunt însa foarte multe cazuri în care definitia clasica nu mai poate fi utilizata. Spreexemplu, în cazul în care se cere probabilitatea ca, alegând la întâmplare un punct dinpatratul [0, 1]× [0, 1], acesta sa se situeze deasupra primei bisectoare. În acest caz, atâtnumarul cazurilor posibile, cât si numarul cazurilor favorabile este infinit, facând definitiaclasica a probabilitatii inutilizabila.
(II) Probabilitatea definita statistic (probabilitate frecventiala) exprima probabilitateacu ajutorul frecventelor de realizare a unui eveniment într-un numar mare de experimentealeatoare realizate în aceleasi conditii. Pentru a putea evalua aceasta probabilitate, estenecesara repetarea în aceleasi conditii a experimentului legat de evenimentul aleator ce sedoreste a fi cuantificat.Sa consideram o experienta aleatoare (e.g., aruncarea unui zar) al carei rezultat posibil esteevenimentul aleator A (e.g., aparitia fetei cu 6 puncte). Aceste experiment aleator îl putemefectua de n ori în conditii identice (spunem ca efectuam n probe ale experimentului),astfel încât rezultatul unei probe sa nu influenteze rezultatul alteia (probe independente).Sa notam cu νn(A) frecventa absoluta de realizare a lui A în cele N probe independente.
Raportul fn(A) =νn(A)
nse va numi frecventa relativa. Acest raport are intotdeauna valori
intre 0 si 1. Mai mult, sirul frecventelor relative fn(A)n∈N are limita si aceasta estedefinita ca fiind probabilitatea de realizare a evenimentului A, notata P(A). Asadar, încazul definitiei statistice a probabilitatii, probabilitatea unui eveniment A este
P(A) = limn→∞
fn(A),
adica limita sirului frecventelor relative de producere a respectivului eveniment cândnumarul de probe tinde la infinit.
(III) Probabilitate definita geometric Sa presupunem ca am dispune de un procedeuprin care putem alege la întâmplare un punct dintr-un interval [a, b]. În plus, vom presupuneca acest procedeu ne asigura ca nu exista portiuni privilegiate ale intervalului [a, b], i.e.,oricare ar fi doua subintervale de aceeasi lungime, este la fel de probabil ca punctul sa cadaîn oricare dintre aceste intervale. Daca am folosi de mai multe ori procedeul pentru a alegeun numar mare de puncte, acestea vor fi repartizate aproximativ uniform în [a, b], i.e., nuvor exista puncte în vecinatatea carora punctul ales sa cada mai des, ori de câte ori este
2Thomas Bayes (1701−1761), statistician si filosof englez

42 Capitolul 3. Notiuni teoretice de Statistica
ales. De aici reiese ca probabilitatea ca un punct sa cada într-un subinterval al lui [a, b]este dependenta de lungimea acelui subinterval si nu de pozitia sa în interiorul lui [a, b].Mai mult, aceasta este chiar proportionala cu lungimea subintervalului. Se poate observaanalogia cu experienta alegerii dintr-un numar de cazuri egal posibile.
Daca [a, b] e multimea cazurilor egal posibile si [c, d]⊂ [a, b] este multimea cazurilorfavorabile, atunci probabilitatea ca punctul ales sa cada în [c, d] este
P(A) =lungimea([c, d])lungimea([a, b])
=d− cb−a
.
În particular, daca z ∈ (c, d), atunci probabilitatea ca punctul ales aleator dintr-un intervalsa coincida cu un punct dinainte stabilit este zero si, astfel, întrezarim posibilitatea teoreticaca un eveniment sa aiba probabilitatea nula, fara ca el sa fie evenimentul imposibil ∅.Exemplu 3.1 Sa presupunem ca experimentul aleator consta în alegerea la întâmplare aunui numar real din intervalul (0, 1), asa încât fiecare punct din acest interval are aceeasisansa de a fi ales. Daca notam cu Z v.a. care reprezinta numarul ales, atunci Z va urmarepartitia uniform continua U (0, 1). Notam cu A evenimentul ca Z sa nu ia valoarea 0.5.Matematic, scriem evenimentul astfel:
A = ω ∈Ω; Z(ω) 6= 0.5 sau, prescurtat, Z 6= 0.5.
Atunci, P(A) = 1, dar A nu este evenimentul sigur, ci doar un eveniment aproape sigur.Practic, este posibil ca, din mai multe probe independente ale experimentului, sa obtinemvaloarea 0.5.
În mod cu totul analog, daca se alege la întâmplare si în mod uniform un punct dintr-oregiune planara R, astfel ca sa nu existe puncte sau portiuni privilegiate în aceasta regiune,atunci probabilitatea ca punctul sa cada în subregiunea R ′ ⊂R este aria R′
aria R.
În trei dimensiuni, o probabilitate similara este raportul a doua volume: volumulmultimii cazurilor favorabile realizarii experimentului si volumul multimii cazurilor egalposibile.
3.3 Variabile aleatoareÎn general, rezultatul posibil al unui experiment aleator poate fi asociat unei valori reale,precizând regula de asociere. O astfel de regula de asociere se numeste variabila aleatoare(prescurtat, v.a.). Se numeste ”variabila” deoarece poate lua valori diferite, se numeste”aleatoare” deoarece valorile observate depind de rezultatele experimentului aleator, sieste "reala" deoarece valoarea numerica este un numar real. Asadar, din punct de vedereeuristic, o variabila aleatoare este o cantitate ce poate avea orice valoare dintr-o multimedata, fiecarei valori atribuindu-se o anumita pondere (frecventa relativa). În viata de zicu zi întâlnim numeroase astfel de functii, e.g., numerele ce apar la extragerea loto, re-zultatul masurarii fertilitatii solului in diverse locatii, numarul clientilor deserviti la unanumit ghiseu într-o anumita perioada, timpul de asteptare a unei persoane într-o statie deautobuz pâna la sosirea acestuia, calificativele obtinute de elevii de clasa a IV-a la un testde matematica etc.De regula, variabilele aleatoare sunt notate cu litere de la sfârsitul alfabetului, X , Y, Z

3.3 Variabile aleatoare 43
sau ξ ,η , ζ etc. Cum am mai precizat anterior, in acest material vom volosi notatia Zpentru o variabila (Z(x) pentru o variabila spatiala) si z pentru realizarea sa (respectiv, z(x)).
Exemplu 3.2 Un exemplu simplu de variabila aleatoare este urmatorul. Consideramexperimentul aleator al aruncarii unei monede. Acest experiment poate avea doar douarezultate posibile, notate S (stema) si B (banul). Asadar, spatiul selectiilor este Ω = S, B.Acestui experiment aleator îi putem atasa variabila aleatoare reala Z, care asociaza fetei Svaloarea 1 si fetei B valoarea 0. Matematic, scriem astfel: Z : Ω→R, Z(S) = 1, Z(B) = 0.Astfel, valorile 1 si 0 pentru Z vor indica fata aparuta la aruncarea monedei. O astfel devariabila aleatoare se numeste variabila aleatoare Bernoulli si poate fi atasata oricaruieveniment aleator ce are doar doua rezultate posibile, numite generic succes si esec.
Variabilele aleatoare (prescurtat v.a.) pot fi discrete sau continue. Variabilele aleatoarediscrete sunt cele care pot lua o multime finita sau cel mult numarabila (adica, o multimecare poate fi numarata) de valori. O variabila aleatoare se numeste variabila aleatoarecontinua (sau de tip continuu) daca multimea tuturor valorilor sale este totalitatea numerelordintr-un interval real (posibil infinit) sau toate numerele dintr-o reuniune disjuncta de astfelde intervale, cu precizarea ca pentru orice posibila valoare c, P(Z = c) = 0.
Exemple de v.a. discrete: numarul fetei aparute la aruncarea unui zar, numarul deaparitii ale unui tramvai într-o statie într-un anumit interval, numarul de insuccese aparutepâna la primul succes etc. Din clasa v.a. de tip continuu amintim: timpul de asteptare la unghiseu pâna la servire, pretul unui activ financiar într-o perioada bine determinata.
Pentru a specifica o v.a. discreta, va trebui sa enumeram toate valorile posibile pe careaceasta le poate lua, împreuna cu probabilitatile corespunzatoare. Suma tuturor acestorprobabilitati va fi întotdeauna egala cu 1, care este probabilitatea realizarii evenimentuluisigur. Când se face referire la repartitia unei v.a. discrete, se întelege modul în careprobabilitatea totala 1 este distribuita între toate posibilele valori ale variabilei aleatoare.Pentru o scriere compacta, adeseori unei v.a. discrete i se atribuie urmatoarea reprezentareschematica:
tabelul de repartitie
Z z1 z2 z3 . . . znpk p1 p2 p3 . . . zn
(3.3.1)
unde pk este probabilitatea cu care variabila Z ia valoarea zk (matematic, scriem pk =P(Z = zk)) si suma tuturor probabilitatilor corespunzatoare variabilei discrete este egala
cu 1 (scriem can
∑i=1
pi = 1).
Exemplu 3.3Presupunem ca Z este v.a. ce reprezintanumarul de puncte ce apare la aruncareaunui zar ideal. Aceasta variabila o putemreprezenta schematic ca in tabelul alaturat.
tabelul de repartitie
Z 1 2 3 4 5 6pk 1/6 1/6 1/6 1/6 1/6 1/6
Daca Z este o v.a. discreta de forma (3.3.1), atunci definim functia de probabilitate (defrecventa) (en., probability mass function) atasata variabilei aleatoare discrete Z ca fiindo functie ce ataseaza fiecarei realizari ale unei variabile probabilitatea cu care aceastarealizare este observata. Matematic, scriem ca
f (zi) = pi, i ∈ 1, 2, . . . , n.

44 Capitolul 3. Notiuni teoretice de Statistica
În cuvinte, pentru fiecare posibila valoare a unei v.a. discrete, functia de probabilitateataseaza probabilitatea cu care Z ia aceasta valoare. Functia de probabilitate este pentru ov.a. discreta ceea ce o densitate de repartitie este pentru o variabila aleatoare continua.
Dupa cum am mentionat anterior, o variabila aleatoare continua poate lua orice valoareintr-un interval a chiar din R. Deoarece in aceste multimi exista o infinitate de valori,nu mai putem defini o variabila aleatoare continua la fel ca in cazul discret, precizandu-ifiecare valoare pe care o ia si ponderea corespunzatoare. In schimb, pentru o variabilaaleatoare continua, putem preciza multimea in care aceasta ia valori si o functie care sadescrie repartizarea acestor valori. O astfel de functie se numeste functie de densitate arepartitiei, sau simplu, densitate de repartitie (en., probability density function).Exemplu 3.4 Vom spune ca o variabila aleatoare Z are o repartitie (sau distributie)normala de medie µ si deviatie standard σ (notam aceasta prin Z ∼N (µ, σ)) daca Zpoate lua orice valoare reala si are densitatea de repartitie data de:
f (x; µ, σ) =1
σ√
2πe−
(x−µ)2
2σ2 , pentro orice x ∈ R.
Aceasta repartitie se mai numeste si repartitia gaussiana sau distributia gaussiana.Functia de probabilitate sau densitatea de repartitie poate depinde de unul sau mai
multi parametri reali. Spre exemplu, repartitia normala are doi parametri, µ si σ .
3.3.1 Functia de repartitie (sau functia de repartitie cumulata)Numim functie de repartitie atasata v.a reale Z o functie F : R→ [0, 1], definita prin
F(z) = P(Z ≤ z), pentru orice x ∈ R.
Termenul din engleza pentru functia de repartitie este cumulative distribution function(cdf). Functia de repartitie asociaza fiecarei valori reale z probabilitatea cu care variabila Zia valori mai mici sau egale cu z. Ea este o functie crescatoare, care ia valori intre 0 si 1.
În cazul unei variabile aleatoare discrete, cu tabelul de repartitie dat de (3.3.1), functiade repartitie este:
F(z) = ∑i;zi≤z
pi, (3.3.2)
adica suma tuturor probabilitatilor corespunzatoare valorilor lui Z care nu-l depasesc pe z.Daca Z este o variabila aleatoare continua si f este densitatea sa de repartitie, atunci
functia de repartitie este data de formula:
F(z) =z∫
−∞
f (t)dt, z ∈ R. (3.3.3)
Mai mult, F ′(z) = f (z), pentru orice z ∈ R.
3.3.2 Caracteristici numerice ale unei variabile aleatoare (parametri)O colectivitate statistica poate fi descrisa folosind una sau mai multe variabile. Pentrufiecare dintre aceste variabile se pot determina anumite cantitati sau calitati specifice,

3.3 Variabile aleatoare 45
numite parametri. Astfel, acesti parametri sunt niste trasaturi caracteristice colectivitatii,ce pot fi determinate sau estimate pe baza unor masuratori (observatii) ale variabilelor. Incontinuare vom prezenta cativa parametri numerici importanti pentru o variabila aleatoare,folositi in analiza statistica. Vom denumi acesti parametri caracteristici numerice ale uneivariabile aleatoare.
Media (sau valoarea asteptata)(en., expected value; fr., espérance; ger., Erwartungswert)
Pentru o variabila, media este o masura a tendintei centrale a valorilor sale. De remarcatfaptul ca exista variabile (atat discrete cat si continue) care nu admit o valoare medie.
• Daca Z este o v.a. discreta având tabelul de repartitie (3.3.1), atunci media acesteiv.a. (daca exista!) se defineste prin:
µ =n
∑i=1
zi pi. (3.3.4)
Daca U(z) este o functie, atunci media pentru variabila aleatoare U(Z) se definesteprin
E(U(Z)) =n
∑i=1
U(zi)pi.
• Daca Z este o v.a. de tip continuu, cu densitatea de repartitie f (z), atunci media(teoretica) acestei v.a., daca exista (!), se defineste astfel:
µ =∫
∞
−∞
z f (z)dz. (3.3.5)
Daca U(z) este o functie, atunci media pentru variabila aleatoare U(Z) (daca exista!)se defineste prin
E(U(Z)) =∫
∞
−∞
U(z) f (z)dz.
Notatii: În cazul în care poate fi pericol de confuzie (spre exemplu, atunci când lucramcu mai multe variabile în acelasi timp), vom folosi notatia µZ . Pentru media teoretica aunei variabile aleatoare se mai folosesc si notatiile: m, M(Z) sau E(Z).
Dispersia (sau varianta) (en., variance) si abaterea standard (en., standard deviation)
Consideram Z o variabila aleatoare care admite medie finita µ . Dorim sa stim in cemasura valorile aceste variabile sunt imprastiate in jurul valorii medii. Variabila aleatoareZ0 = Z−µ (numita abaterea lui Z de la media sa), atunci E(Z0) = 0. Asadar, nu putemmasura gradul de împrastiere a valorilor lui Z în jurul mediei sale doar calculând Z−µ .Avem nevoie de o alta masura. Aceasta este dispersia variabilei aleatoare, notata prin σ2
Zsau Var(Z). În cazul în care poate fi pericol de confuzie (spre exemplu, atunci când lucramcu mai multe variabile în acelasi timp), vom folosi notatia σ2
Z .
σ2 =
n
∑i=1
(zi−µ)2 pi
(in cazul unei v.a. discrete).
σ2 =
∫∞
−∞
(z−µ)2 f (z)dz
(in cazul unei v.a. continue).

46 Capitolul 3. Notiuni teoretice de Statistica
Alte formule pentru dispersie:
σ2 = E[Z2]−µ
2 =
n
∑i=1
z2i pi−µ
2 , în cazul discret∫∞
−∞
z2 f (z)dz−µ2 , în cazul continuu
Numim abatere standard (sau deviatie standard) cantitatea σ =√
σ2. Are avantajulca unitatea sa de masura este aceeasi cu a variabilei Z.
În conformitate cu teorema lui Cebâsev3, pentru orice variabila aleatoare Z ce admitemedie si orice a > 0, are loc inegalitatea:
P(|Z−µ| ≥ kσ) ≤ 1k2 . (3.3.6)
În cuvinte, probabilitatea ca valorile variabilei Z sa devieze de la medie cu mai mult de kdeviatii standard este mai mica decat 1
k2 . În cazul particular k = 3, obtinem regula celor3σ :
P(|Z−µ| ≥ 3σ) ≤ 19≈ 0.1.
sau
P(µ−3σ < Z < µ +3σ) ≥ 89, (3.3.7)
semnificând ca o mare parte din valorile posibile pentru Z se afla în intervalul [µ−3σ , µ +3σ ].
Coeficientul de variatie
Este definit prin CV =σ
µsau, sub forma de procente, CV = 100
σ
µ%. Este util in
compararea variatiilor a doua sau mai multe seturi de date ce tin de aceeasi variabila. Dacavariatiile sunt egale, atunci vom spune ca setul de observatii ce are media mai mica estemai variabil decat cel cu media mai mare.
Standardizarea unei variabile aleatoare
Pentru o variabila aleatoare Z de medie µ si dispersie σ2, variabila aleatoare Y =Z−µ
σse numeste variabila aleatoare standardizata (sau normata). Astfel, prin standardizareaunei variabile, vom obtine urmatoarele proprietati ale sale: E(Y ) = 0, D2(Y ) = 1.Daca Z este o variabila normala (scriem asta prin Z ∼N (µ, σ)), atunci standardizarea saeste o variabila normala standard, adica Z−µ
σ∼N (0, 1).
Momente centrate
3Pafnuty Lvovich Chebyshev (1821−1894), matematician rus

3.3 Variabile aleatoare 47
Pentru o v.a. Z (discreta sau continua), ce admite medie, momentele centrate suntvalorile asteptate ale puterilor lui Z−µ . Definim astfel µk(Z) =E((Z−µ)k). In particular,
µk(Z) =n
∑i=1
(zi−µ)k pi;
(in cazul unei v.a. discrete).
µk(Z) =∫
∞
−∞
(x−µ)k f (x)dx;
(in cazul unei v.a. continue).
Momente speciale:• µ2(Z) = σ2. Se observa ca al doilea moment centrat este chiar dispersia.
• γ1 =µ3(Z)
σ3 este coeficientul de asimetrie (en., skewness);Coeficientul γ1 este al treilea moment centrat standardizat. O repartitie este simetricadaca γ1 = 0. Vom spune ca asimetria este pozitiva (sau la dreapta) daca γ1 > 0 sinegativa (sau la stânga) daca γ1 < 0.
• K =µ4(Z)
σ4 −3 este excesul (coeficientul de aplatizare sau boltire) (en., kurtosis).
Este o masura a boltirii distributiei (al patrulea moment standardizat). Termenul (−3)apare pentru ca indicele kurtosis al distributiei normale sa fie egal cu 0. Vom aveao repartitie mezocurtica pentru K = 0, leptocurtica pentru K > 0 sau platocurticapentru K < 0. Un indice K > 0 semnifica faptul ca, în vecinatatea modului, curbadensitatii de repartitie are o boltire (ascutire) mai mare decât clopotul lui Gauss.Pentru K < 0, în acea vecinatate curba densitatii de repartitie este mai plata decâtcurba lui Gauss.
Cuantile
Fie o v.a. Z ce are functia de repartitie F(z). Pentru un α ∈ (0, 1), definim cuantila deordin α acea valoare reala zα ∈ R pentru care
F(zα) = P(Z ≤ zα) = α. (3.3.8)
(1) Cuantilele sunt masuri de pozitie, ce ma-soara locatia unei anumite observatii fata de res-tul datelor. Asa cum se poate observa din Figura3.1, valoarea xα este acel numar real pentru carearia hasurata este chiar α .(2) În cazul în care Z este o variabila aleatoarediscreta, atunci (3.3.8) nu are solutie pentru oriceα . Însa, daca exista o solutie a acestei ecuatieiF(x) = α , atunci exista o infinitate de solutii, sianume intervalul ce separa doua valori posibile.
Figura 3.1: Cuantila de ordin α .(3) Cazuri particulare de cuantile:• pentru α = 1/2, obtinem mediana. Astfel, F(Me) = 0.5. Mediana (notata Me)
este valoarea care imparte repartitia in doua parti in care variabila Z ia valori cuprobabilitati egale. Scriem asta astfel:
P(Z ≤Me) = P(Z > Me) = 0.5.

48 Capitolul 3. Notiuni teoretice de Statistica
Pentru o variabila care nu este simetrica, mediana este un indicator mai bun decatmedia pentru tendinta centrala a valorilor variabilei.
• pentru α = i/4, i ∈ 1, 2, 3, obtinem cuartilele. Prima cuartila, Q1, este aceavaloare pentru care probabilitatea ca Z sa ia o valoare la stanga ei este 0.25. Scriemasta astfel: P(Z ≤ Q1) = 0.25. Cuartila a doua este chiar mediana, deci Q2 = Me.Cuartila a treia, Q3, este acea valoare pentru care probabilitatea ca Z sa ia o valoarela stanga ei este 0.75. Scriem asta astfel: P(Z ≤ Q3) = 0.75.
• pentru α = j/10, j ∈ 1, 2, . . . , 9, obtinem decilele. Prima decila este acea valoarepentru care probabilitatea ca Z sa ia o valoare la stanga ei este 0.1. S.a.m.d.
• pentru α = j/100, j ∈ 1, 2, . . . , 99, obtinem centilele. Prima centila este aceavaloare pentru care probabilitatea ca Z sa ia o valoare la stanga ei este 0.01. S.a.m.d.
(4) Daca Z ∼N (0, 1), atunci cuantilele de ordin α le vom nota prin zα .
Modul (valoarea cea mai probabila)
Este valoarea cea mai probabila pe care o lua variabila aleatoare Z. Cu alte cuvinte,este acea valoare x∗ pentru care f (x∗) (densitatea de repartitie sau functia de probabilitate)este maxima. O repartitie poate sa nu aiba niciun mod, sau poate avea mai multe module.
Covarianta si coeficientul de corelatie
Conceptul de corelatie (sau covarianta) este legat de modul în care doua variabilealeatoare tind sa se modifice una fata de cealalta; ele se pot modifica fie în aceeasi directie(caz în care vom spune ca Z1 si Z2 sunt direct <sau pozitiv> corelate) sau în directii opuse(Z1 si Z2 sunt invers <sau negativ> corelate).Consideram variabilele Z1, Z2 ce admit mediile, respectiv, µ1, µ2.
Definim corelatia (sau covarianta) variabilelor Z1 si Z2, notata prin cov(Z1, Z2),cantitatea
cov(Z1, Z2) = E[(Z1−µ1)(Z2−µ2)].
Daca Z1 si Z2 coincid, sa spunem ca Z1 = Z2 = Z, atunci cov(Z, Z) = σ2Z .
O relatie liniara între doua variabile este acea relatie ce poate fi reprezentata cel mai bineprintr-o linie. Corelatia detecteaza doar dependente liniare între doua variabile aleatoare.Putem avea o corelatie pozitiva, însemnând ca Z1 si Z2 cresc sau descresc împreuna (vezicazurile in care ρ = 0.85 sau ρ = 1 in Figura 3.2), sau o corelatie negativa, însemnând ca Z1si Z2 se modifica în directii opuse (vezi cazul ρ =−0.98 in Figura 3.2). In cazul ρ =−0.16din Figura 3.2, nu se observa nicio tendinta, caz in car putem banui ca variabilele nu suntcorelate.
O masura a corelatiei dintre doua variabile este coeficientul de corelatie. Acesta estefoarte utilizat în stiinte ca fiind o masura a dependentei liniare între doua variabile. Senumeste coeficient de corelatie al v.a. Z1 si Z2 cantitatea
ρ =cov(Z1, Z2)
σ1σ2,
unde σ1 si σ2 sunt deviatiile standard pentru Z1, respectiv, Z2. Uneori se mai noteaza prinρ(Z1, Z2) sau ρZ1,Z2 . Coeficientul de corelatie ia valori intre −1 (perfect negativ corelate)si 1 (perfect pozitiv corelate) si masoara gradul de corelatie liniara dintre doua variabile.

3.3 Variabile aleatoare 49
Figura 3.2: Reprezentare de date bidimensionale.
3.3.3 IndependentaConceptul de independenta a variabilelor aleatoare sau a evenimentelor este foarte impor-tant din punctul de vedere al calculului statistic, atunci cand avem de calculat probabilitatileevenimentelor compuse din evenimente mai simple.
Consideram A si B doua evenimente aleatoare arbitrare.(1) Daca anumite informatii despre evenimentul B au influentat în vreun fel realizareaevenimentului A, atunci vom spune ca A si B sunt evenimente dependente. De exemplu,evenimentele A = mâine ploua si B = mâine mergem la plaja sunt dependente.(2) Sa presupunem ca evenimentul B satisface relatia P(B) > 0. Vom spune ca eveni-mentele A si B sunt independente daca probabilitatea lui A este independenta de realizareaevenimentului B, adica probabilitatea conditionata
P(A| B) = P(A), (3.3.9)
echivalent cuP(A
⋂B)
P(B)= P(A).
Aici am notat prin P(A| B) probabilitatea ca evenimentul A sa se realizeze stiind ca B s-arealizat. Putem rescrie ultima egalitate sub forma simetrica:
P(A⋂
B) = P(A) ·P(B). (3.3.10)
Deoarece în relatia (3.3.10) nu mai este nevoie de conditie suplimentara pentru P(B), estepreferabil sa definim independenta a doua evenimente arbitrare astfel:
Doua evenimente A si B se numesc independente daca relatia (3.3.10) are loc. Altfel, elesunt dependente, in sensul ca realizarea uneia depinde de realizarea/nerealizarea celeilalte.

50 Capitolul 3. Notiuni teoretice de Statistica
In general, o multime de evenimente se numesc independente daca oricum am alegeevenimente din aceasta multime, probabilitatea ca acestea sa se realizeze simultan esteegala cu produsul probabilitatilor fiecarui eveniment in parte.
Doua variabile aleatoare Z1 si Z2 sunt independente daca realizarile lor sunt evenimenteindependente intre ele. De asemenea, vom spune ca o multime variabile aleatoare suntindependente daca realizarile oricarei submultimi dintre ele sunt evenimente independenteintre ele.
Exemplu: Sa consideram aruncarea unui zar. Aruncam zarul de doua ori si notam cuZ1, respectiv, Z2, v.a. ce reprezinta numarul de puncte aparute la fiecare aruncare. Evident,valorile acestor v.a. sunt din multimea 1, 2, 3, 4, 5, 6. Aceste doua variabile aleatoaresunt independente, deoarece aparitia unei fete la aruncarea primului zar este independentade aparitia oricarei fete la aruncarea celui de-al doilea.
O consecinta importanta a independentei variabilelor este faptul ca media produsuluia doua sau mai multe variable independente este egala cu produsul mediilor celor douavariabile. De asemenea, daca variabilele sunt independente, dispersia sumei variabileloreste egala cu suma dispersiilor fiecarei variabile in parte. Aceste proprietati nu au loc incazul in care ipoteza de independenta nu este verificata.
De remarcat faptul ca independenta a doua variabile implica faptul ca ele sunt necore-late, adicacov(Z1, Z2) = 0 si, implicit, ρZ1,Z2 = 0. Propozitia reciproca nu este adevarata. Aceastainseamna ca exista variabile care sunt necorelate dar nu sunt independente.
Este important de notat faptul ca in Geostatistica datele spatiale sunt necorelate, decinu pot fi independente. Observatiile facute in locatii apropiate tind sa aiba valori apropiate.
3.3.4 Teorema limita centralaTeorema limita centrala este un rezultat foarte important in Statistica. Ea ne permite saaproximam sume de variabile aleatoare identic repartizate, avînd orice tip de repartitii (atâttimp cât variatia lor e finita), cu o variabila aleatoare normala.Presupunem ca in urma unor masuratori am obtinut datele z1, z2, . . . , zn si ca aceste datesunt realizarile unor variabile Z1, Z2, . . . , Zn. Daca aceste variabile sunt normale, atunci
suma acestora (Sn =n
∑i=1
Zi) cat si media lor (Z =1n
n
∑i=1
Zi) sunt tot variabile normale, pentru
orice volum al selectiei, n.Teorema limita centrala spune ca, daca variabilele Z1, Z2, . . . , Zn nu sunt normal
repartizate, atunci, pentru un volum n este suficient de mare, repartitiile pentru Sn si Z tindsa fie tot normale. Spunem astfel ca repartitiile asimptotice (la limita) pentru Sn si Z suntnormale. Cu cat volumul observatiilor este mai mare, cu atat suma sau media lor sunt maiaproape de repartitia normala.
Mai mult, daca variabilele Zi au aceeasi medie (µ) si aceeasi deviatie standard σ , atuncimedia Z este o variabila normala de medie µZ = µ si deviatie standard σZ =
σ√n
. Se
observa ca, daca n este foarte mare, atunci deviatia standard a lui Z scade, astfel ca valorilesale vor deveni foarte apropiate de µ .
Se pune problema: Cât de mare ar trebui sa fie n, în practica, pentru ca teorema limitacentrala sa fie aplicabila? Se pare ca un numar n astfel încât n≥ 30 ar fi suficicient pentru

3.3 Variabile aleatoare 51
aproximarea cu repartitia normala desi, daca variabilele sunt simetrice, aproximarea arputea fi buna si pentru un numar n mai mic de 30.
3.3.5 Repartitii probabilistice• Repartiµia binomial , B(n, p):
Este o repartitie pentru o variabila aleatoare discreta. Modeleaza numarul de succeseobtinute in urma unui experiment aleator care se desfasoara in aceleasi conditii deun numar de ori. Fie n numarul de repetitii ale experimentului si fie p probabilitateade succes la o singura efectuare a experimentului. Spunem ca o variabila aleatoare Zurmeaza repartitia binomiala de parametri n si p, scriem Z ∼B(n, p), (n > 0, p ∈(0, 1)), daca valorile lui Z sunt 0, 1, . . . , n, cu probabilitatile
P(Z = k) =Ckn pk(1− p)n−k, k = 0, 1, . . . , n.
Media si dispersia pentru o astfel de variabila binomiala sunt: µZ = np; σ2Z =
np(1− p).Spre exemplu, aruncarea de 15 ori a unei monede ideale poate fi modelata ca fiind ov.a. binomiala B(15, 0.5).
• Repartiµia normal , N (µ, σ)Repartitia normala este cea mai cunoscuta si des utilizata repartitie probabilistica.Spunem ca o variabila aleatoare urmeaza o repartitie normala de medie µ si deviatiestandard σ (vom scrie Z ∼N (µ, σ), daca Z are densitatea de repartitie
f (z) =1
σ√
2πe−(z−µ)2
2σ2 , z ∈ R.
Media variabilei Z este E(Z) = µ si dispersia sa este σ2Z = σ2.
Repartitia normala se mai numeste si repartitia gaussiana, dupa numele matemati-cianului german C. F. Gauß. În cazul µ = 0, σ2 = 1 densitatea de repartitie devine:
f (z) =1√2π
e−z22 , x ∈ R. (3.3.11)
În acest caz spunem ca Z urmeaza repartitia normala standard, N (0, 1).Graficul densitatii de repartitie pentru repartitia normala este clopotul lui Gauss (veziFigura 3.3). Din grafic (pentru σ = 1), se observa ca majoritatea valorilor nenuleale repartitiei normale standard se afla în intervalul (µ − 3σ , µ + 3σ) = (−3, 3).Aceasta afirmatie rezulta din relatia (3.3.7).
Daca Z ∼ N (0, 1), atunci Z = σZ + µ ∼ N (µ, σ). În mod similar, daca Z ∼N (µ, σ), atunci Z =
Z−µ
σ∼N (0, 1). Pentru o v.a. N (0, 1) functia de repartitie
este tabelata (valorile ei se gasesc în tabele) si are o notatie speciala, Θ(z). Ea edefinita prin:
Θ(z) =1√2π
∫ z
−∞
e−y22 dy. (3.3.12)

52 Capitolul 3. Notiuni teoretice de Statistica
Functia de repartitie a lui Z ∼N (µ, σ) este data prin
F(z) = Θ
(z−µ
σ
), z ∈ R. (3.3.13)
Figura 3.3: Clopotul lui Gauss pentru o variabila Z ∼N (0, σ), (σ = 1, 2, 3)
• Repartiµia log-normal , logN (µ, σ)
Repartitia log-normala este foarte utila în practica atunci cand observatiile nu suntnormale. In acest caz, este posibil ca logaritmul acestor observatii sa urmeze orepartitie normala. In general, daca datele observate sunt asimetrice (coeficientulskewness este mare), atunci este necesara o logaritmare a datelor. Majoritateamineralelor sau elementelor chimice au repartitii lognormale. Vom spune ca variabilaZ urmeaza o repartitie log-normala, scriem Z ∼ logN (µ, σ), daca variabila lnZurmeaza o repartitie normala, adica lnZ ∼N (µ, σ).Densitatea de repartitie pentru o repartitie lognormala de parametri µ si σ este:
f (z) =
1
zσ√
2πe−(lnz−µ)2
2σ2 , daca z > 0;
0 , daca z≤ 0.
Media si dispersia pentru o variabila Z ∼ logN (µ, σ) sunt date de
µZ = eµ+σ2/2, σ2Z = e2µ+σ2
(eσ2−1).
• Repartiµia χ2, χ2(n)
Repartitia χ2(n) (cu n grade de liberate) apare in urma insumarii unui numar den variabile normale standard independente. Vom spune ca o variabila Z urmeaza

3.3 Variabile aleatoare 53
repartitia χ2(n) (scriem ca Z ∼ χ2(n) si se citeste repartitia hi-patrat cu n grade delibertate) daca densitatea sa de repartitie este:
f (z; n) =
1
Γ(n2)2
n2
zn2−1e−
z2 , daca z > 0,
0 , daca z≤ 0.
unde Γ este functia lui Euler. Graficul acestei repartitii (pentru diverse valori ale luin) este reprezentat în Figura 3.4.(a) Media si dispersia unei repartitii χ2(n) sunt:
E(χ2) = n, D2(χ2) = 2n.
(b) Daca variabilele Zk ∼N (0,1) pentru k = 1, 2, . . . ,n sunt independente, atunci
Z21 +Z2
2 + · · ·+Z2n ∼ χ
2(n).
(c) În particular, daca variabila Z este normala standard, atunci patratul acesteiaeste o variabila χ2(1). Matematic, scriem astfel:
Daca Z ∼N (0,1), atunci Z2 ∼ χ2(1).
Figura 3.4: Repartitia χ2(n) pentru patru valori ale lui n.
• Repartiµia Student (W. S. Gosset4), t(n)
4William Sealy Gosset (1876−1937), statistician britanic, care a publicat sub pseudonimul Student

54 Capitolul 3. Notiuni teoretice de Statistica
Spunem ca Z ∼ t(n) (cu n grade de libertate) daca densitatea de repartitie este:
f (z; n) =Γ
(n+1
2
)√
nπ Γ
(n2
) (1+z2
n
)− n+12
, z ∈ R.
Media si dispersia unei repartitii t(n) sunt: µZ = 0, σ2Z =
nn−2
.
• Repartiµia Fisher5, F (m, n)
Spunem ca Z ∼F (m, n) (cu m, n grade de libertate) daca densitatea de repartitieeste:
f (z) =
(m
n
)m2
Γ
(m+n
2
)Γ
(m2
)Γ
(n2
) zm2−1 (1+ m
n z)−m+n
2 , z > 0;
0 , z≤ 0.
Media si dispersia unei repartitii F (m, n) sunt: µZ =n
n−2, σ
2Z =
2n2(n+m−2)m(n−2)2(n−4)
.
5Sir Ronald Aylmer Fisher (1890−1962), statistician, eugenist, biolog si genetician britanic

4. Estimatori
Presupunem ca Z este variabila de interes a unei colectivitati statistice si ca, in urma unormasuratori, am obtinut rezultatele z1, z2, . . . , zn. Deoarece in urma acestor masuratoripot aparea erori, in Statistica se considera ca aceste date sunt realizarile unor variabileZ1, Z2, . . . , Zn. Se presupune ca aceste variabile sunt independente si au toate aceeasirepartitie (adica sunt toate copii independente ale aceleasi variabile). Aceste variabile levom numi variabile aleatoare de selectie. Pe baza acestor observatii, dorim sa estimamanumiti parametri ai colectivitatii, de exemplu media µ sau deviatia standard σ ale lui Z.
O functie f (Z1, Z2, . . . , Zn) ce depinde de variabilele de selectie se va numi genericstatistica. In caz ca nu este pericol de confuzie, valoarea statisticii pentru un esantion,f (z1, z2, . . . , zn), se numeste tot statistica. Exemple de statistici:
1. Media selectiei:
Z =1n
n
∑i=1
Zi.
O valoare observata pentru Z este z =1n
n
∑i=1
zi.
(∗) Daca variabilele de selectie Zi au media µ si deviatia standard σ , atunci mediamediei selectiei este tot µ si deviatia sa standard este σ√
n . Scriem asta astfel:
µZ = µ si σZ =σ√
n.
(∗∗) In cazul in care variabilele Zi sunt normale N (µ, σ), atunci media selectieieste tot o variabila normala, Z ∼N (µ, σ√
n).(∗∗∗) Daca numarul variabilelor de selectie este suficient de mare, atunci variabilaZ este normala, fara ca Zi sa fie neaparat normale. Acest fapt este o consecinta ateoremei limita centrala.

56 Capitolul 4. Estimatori
2. Dispersia selectiei,
S2 =1
n−1
n
∑i=1
[Zi−Z]2
O valoare observata pentru S2 este s2 =1
n−1
n
∑i=1
[zi− z]2.
3. Deviatia standard a selectiei, S =√
S2. O valoare observata pentru S este s =√
s2.
4.1 Estimatori punctualiConsideram acum un parametru generic al populatiei, notat cu θ , pe care dorim sa-lestimam.
• Prin estimator punctual (sau, simplu, estimator) pentru parametrul θ intelegem ostatistica (independenta de θ ) care se apropie de θ atunci cand volumul selectieieste suficient de mare. Un estimator pentru parametrul θ este notat simbolic prinθ . Valoarea unui astfel de estimator intr-o masurare se va numi estimatie. Pentrusimplitate, atunci cand nu este pericol de confuzie, vom nota estimatorul si estimatiatot cu θ . De remarcat faptul ca estimatorul este o variabila aleatoare si estimatia esteun numar real.
Deoarece estimarile sunt bazate doar pe valorile unei submultimi din colectivitate, ele nupot fi exacte. Apar astfel erori de aproximare. Ne-am dori sa stim în ce sens si cât de bineun estimator aproximeaza (se apropie) de valoarea estimata. Pentru aceasta, avem nevoiede anumite cantitati care sa cuantifice erorile de aproximare. In acest sens, vom discutaaici despre: deplasare, eroarea medie patratica si eroarea standard.
• Un estimator θ se numeste estimator nedeplasat (en., unbiased estimator) pentruparametrul θ daca media estimatorului este chiar valoarea parametrului pe careestimeaza. Matematic, scriem astfel:
E(θ) = θ .
• Altfel, spunem ca θ este un estimator deplasat pentru θ , iar deplasarea (distorsiunea)se defineste prin:
b(θ , θ) = E(θ)−θ .
Cantitatea b(θ , θ) este o masura a erorii pe care o facem în estimarea lui θ prin θ .• O alta masura a incertitudinii cu care un estimator aproximeaza parametrul este
eroarea standard (en., standard error), notata aici prin σ(θ) sau σθ
. Spre exemplu,daca estimatorul θ este Z, atunci
σZ =σ√
n,
unde σ este deviatia standard a unei singure observatii. Se observa de aici ca σZ vatinde la 0 daca n creste nemarginit. Astfel, daca numarul de masuratori creste, mediaacestor masuratori se apropie mult de valoarea parametrului µ .
• Numim eroare medie patratica a unui estimator θ pentru θ (en., mean squared error)cantitatea
MSE(θ , θ) = E([
θ −θ]2)
.

4.1 Estimatori punctuali 57
Aceasta cantitate ne va indica valoarea medie a patratului diferentei dintre estimatorsi valoarea parametrului estimat. Pentru un estimator nedeplasat, MSE este chiardispersia estimatorului, σ2
θ.
• Un estimator nedeplasat θ pentru θ se numeste estimator nedeplasat uniform dedispersie minima (en., Uniformly Minimum Variance Unbiased Estimator - UMVUE)daca pentru orice valori ale parametrului θ si pentru orice alt estimator nedeplasatpentru θ , notat cu θ ∗, estimatorul θ are varianta minima. Matematic, scriem astfel:
σ2θ≤ σ
2θ∗, pentru orice valoarea a lui θ .
• Pentru un anumit parametru pot exista mai multi estimatori nedeplasati. Dintreacestia, cel mai bun estimator va fi acela care are varianta minima.
4.1.1 Exemple de estimatori punctualiPresupunem ca Z este variabila de interes a unei populatii statistice, pentru care dorimsa estimam anumiti parametri, e.g., media µ , varianta (dispersia) σ2, deviatia standard σ
etc. Plecand de la o multime de valori observate pentru Z, si anume z1, z2, . . . , zn, putemconstrui urmatorii estimatori:
1. Un estimator pentru media µ este media selectiei Z = Z =1n
n
∑i=1
Zi. O estimatie
pentru µ este z.Concret, daca dorim sa determinam concentratia medie de azotati din sol intr-oanumita regiune, vom stabili mai intai locatiile x1, x2, . . . , xn de unde vom culegeprobe, urmand ca apoi sa le culegem efectiv si, pe baza valorilor obtinute, facemmedia acestora. Astfel, fiecare variabila Zi = Z(xi) reprezinta concentratia in locatiaxi, care este o variabila aleatoare. Valoarea masurata in aceasta locatie este zi = z(xi).
Estimatorul Z =1n
n
∑i=1
Zi este media concentratiilor din locatiile stabilite (este criteriul
dupa care se estimeaza media), iar estimatia z =1n
n
∑i=1
zi este valoarea medie a
concentratiilor masurate.
2. Dispersia selectiei, S2 =1
n−1
n
∑i=1
[Zi−Z]2, este un estimator pentru dispersia teore-
tica, σ2.3. Deviatia standard a selectiei, S =
√S2 este un estimator pentru deviatia standard
teoretica, σ .4. Un estimator pentru eroarea standard σZ =
σ√n
este sZ =s√n
.
5. Dispersia stratificata In cazul unui camp aleator, exista cazuri in care estimatiiledeviatiei standard s sunt foarte mari, fapt care duce la o eroare standard
s√n
mare.
Acest lucru poate fi datorat faptului ca unele regiuni din campul aleator sunt foarteslab reprezentate prin masuratori, pe cand altele contin prea multe masuratori. Oidee pentru reducerea erorii este cresterea volumului observatiilor, n. Insa, de multeori, acest lucru nu este convenient. Totusi, problema poate fi remediata daca se faceo selectie stratificata a locatiilor masuratorilor, dupa cum urmeaza.Sa presupunem ca regiunea R de interes este impartita in m subregiuni (numite

58 Capitolul 4. Estimatori
straturi). Pentru fiecare astfel de strat, k se vor face nk ≥ 2 masuratori. Pentru fiecarestrat in parte, putem calcula varianta masuratorilor prin formula:
s2k =
1nk−1
nk
∑i=1
[zik− zk]2.
O estimatie pentru varianta mediei in regiunea R este
s2z =
1k2
m
∑j=1
s2k
nk.
O estimatie pentru eroarea standard a lui z este sz =√
s2z .
6. Presupunem acum ca avem doua variabile de interes, Z si Z′. Am vazut anteriorca legatura dintre aceste variabile poate fi descrisa de covarianta, cov(Z, Z′) =E [(Z−µZ)(Z′−µZ′)]. Pentru a construi un estimator pentru covarianta este avemnevoie de n perechi de observatii. Presupunem ca acestea sunt (z1, z′1), (z2, z′2),. . . , (zn, z′n). O estimatie pentru cov(Z,Z′) este covarianta (sau corelatia) empirica,
cove =1
n−1
n
∑i=1
(zi− z)(z′i− z′),
unde
z =1n
n
∑i=1
zi si z′ =1n
n
∑i=1
z′i.
4.2 Estimarea parametrilor prin intervale de încredereO singura populatie
Dupa cum am vazut anterior, putem determina estimatii punctuale pentru parametriiunei populatii însa, o estimatie punctuala, nu precizeaza cât de aproape se gaseste estimatiaθ(x1, x2, . . . , xn) fata de valoarea reala a parametrului θ . De exemplu, daca dorim saestimam valoarea medie a pH din sol, atunci putem gasi un estimator punctual (e.g., mediade selectie) care sa ne indice ca aceasta este de 8.1. Ideal ar fi daca aceasta informatie ar fiprezentata sub forma: pH mediu din sol este 8±0.2.Putem obtine astfel de informatii daca vom construi un interval în care, cu o probabilitatedestul de mare, sa gasim valoarea reala a lui θ .Dorim sa determinam un interval (aleator) care sa acopere cu o probabilitate mare (e.g.,0.95, 0.98, 0.99 etc) valoarea posibila a parametrului necunoscut.
Pentru un α ∈ (0, 1), foarte apropiat de 0 (de exemplu, α = 0.01, 0.02, 0.05 etc). Nu-mim interval de încredere (en., confidence interval) pentru parametrul θ cu probabilitateade încredere 1−α , un interval aleator (θ , θ), astfel încât
P(θ < θ < θ) = 1−α, (4.2.1)
unde θ(Z1, Z2, . . . , Zn) si θ(Z1, Z2, . . . , Zn) sunt statistici.Pentru o observatie fixata, capetele intervalului (aleator) de încredere vor fi statistici. De

4.2 Estimarea parametrilor prin intervale de încredere 59
exemplu, pentru datele observate, z1, z2, . . . , zn, intervalul(θ(z1, z2, . . . , zn), θ(z1, z2, . . . , zn)
)se numeste valoare a intervalului de încredere pentru θ . Pentru simplitate însa, vom folositermenul de "interval de încredere" atât pentru intervalul propriu-zis, cât si pentru valoareaacestuia, întelesul desprinzându-se din context.Valoarea α se numeste nivel de semnificatie sau probabilitate de risc.
Cu cât α este mai mic (de regula, α = 0.01 sau 0.02 sau 0.05), cu atât sansa (care este(1−α) ·100%) ca valoarea reala a parametrului θ sa se gaseasca în intervalul gasit estemai mare.
Intervalul de încredere pentru valoarea reala a unui parametru nu este unic. Daca ni sedau conditii suplimentare (e.g., fixarea unui capat), atunci putem obtine intervale infinitela un capat si finite la celalalt capat.
În continuare, vom preciza intervale de încredere pentru parametrii unor caracteristicinormale. Vom nota cu (generic) prin xα cuantila de ordin α pentru repartitia variabilei Z.Cuantilele xα pot fi gasite in tabele specifice repartitiei cautate, sau pot fi calculate folosindun soft specializat.
Daca variabila Z urmeaza o repartitie normala N (0, 1), atunci cuantilele corespunza-toare le vom nota prin zα si le vom gasi in Tabelul 10.1.
Daca variabila Z urmeaza o repartitie Student t(n), atunci cuantilele corespunzatoarele vom nota prin tα,n si le vom gasi in Tabelul 10.2.
Daca variabila Z urmeaza o repartitie χ2(n), atunci cuantilele corespunzatoare le vomnota prin χ2
α,n si le vom gasi in Tabelul 10.3.
4.2.1 Intervale de încredere pentru medieDistingem aici doua cazuri: (1) cand volumul selectiei este suficient de mare (de multe ori,aceasta inseamna peste 40 de observatii), sau (2) cand volumul selectiei este mic. Dupacum am vazut anterior, pentru estimarea punctuala a mediei pe baza unei selectii folosim:
z =1n
n
∑i=1
zi.
(1) daca n≥ 40, atunci un interval de incredere pentru medie la nivelul de semnificatieα este(
z− z1−α
2
s√n, z+ z1−α
2
s√n
), (4.2.2)
unde z1−α
2este cuantila de ordin 1− α
2 pentru repartitia N (0, 1). Spre exemplu, dacanivelul de semnificatie este α = 0.05, atunci din Tabelul 10.1 gasim ca z0.975 = 1.96.
(2) pentru observatii normale de volum mic, un interval pentru medie la nivelul desemnificatie α este(
z− t1−α
2 ;n−1s√n, z+ t1−α
2 ;n−1s√n
). (4.2.3)
Aici, s este o estimatie pentru deviatia standard,
s =
√1
n−1
n
∑i=1
(zi− z)2

60 Capitolul 4. Estimatori
si t1−α
2 ,n−1 este cuantila de ordin 1− α
2 pentru repartitia t(n− 1). Spre exemplu,daca nivelul de semnificatie este α = 0.05 si volumul selectiei este n = 35, atuncidin Tabelul 10.2 gasim ca t0.975,34 = 2.032.
Când volumul n este mare, atunci va fi o diferenta foarte mica între valorile z1−α
2si
t1−α
2 ;n−1, de aceea am putea folosi z1−α
2în locul valorii t1−α
2 ;n−1.Intervalele de încredere de mai sus sunt valide pentru selectia (repetata sau nerepetata)
dintr-o populatie infinita, sau pentru selectii repetate dintr-o populatie finita. În cazulselectiilor nerepetate din colectivitati finite, în estimarea intervalelor de încredere vom tinecont si de volumul N al populatiei. Spre exemplu, daca selectia de volum n se face dintr-opopulatie finita de volum N si n ≥ 0.05N, atunci un inteval de încredere centrat pentrumedia populatiei este:(
z− t1−α
2 ;n−1s√n
√N−nN−1
, z+ t1−α
2 ;n−1s√n
√N−nN−1
). (4.2.4)
Factorul√
N−nN−1 va fi aproximativ egal cu 1 atunci cand N este infinit sau N n, obtinandu-
se astfel intervalul (4.2.3). Formula (4.2.4) nu este practica in Geostatistica, deoarece uncamp aleator are o multime infinita de puncte, asadar selectia de masuratori se face dintr-opopulatie de volum N = ∞.
O alta observatie este faptul ca este posibil ca σ sa fie un parametru cunoscut pentru Z,caz in care pentru intervalul de incredere pentru medie se foloseste formula (4.2.2) cu σ
inlocuindu-l pe s.Exemplu 4.1 O masina de înghetata umple cupe cu înghetata. Se doreste ca înghetata dincupe sa aiba masa de µ = 250g. Desigur, este practic imposibil sa umplem fiecare cupacu exact 250g de înghetata. Presupunem ca masa continutului din cupa este o variabilaaleatoare repartizata normal. Pentru a verifica daca masina este ajustata bine, se aleg laîntâmplare 30 de înghetate si se cântareste continutul fiecareia. Obtinem astfel o selectierepetata, z1, z2, . . . , z30 dupa cum urmeaza:
257 249 251 251 252 251 251 249 248 248 251 253 248 245 251
248 256 247 250 247 251 247 252 248 253 251 247 253 244 253
Se cere sa se scrie un interval de încredere pentru µ , cu nivelul de incredere de 0.99.Solutie: Dupa cum am vazut mai sus, un interval de încredere pentru µ este (deoareceN este necunoscut, il presupunem mult mai mare decat n):(
x− t1−α
2 ;n−1s√n, x+ t1−α
2 ;n−1s√n
).
Aici, nivelul de risc este α = 0.01, cuantila teoretica este t1−α
2 ;n−1 = t0.995,29 = 2.7564,media valorilor este z = 250.0667 si deviatia standard este s = 2.9704. Astfel, obtinemintervalul de încredere pentru µ:
(248.572, 251.561).
4.2.2 Interval de încredere pentru dispersieDupa cum am vazut anterior, pentru estimarea punctuala a lui σ2 se foloseste
s2 =1
n−1
n
∑i=1
[zi− z]2.

4.2 Estimarea parametrilor prin intervale de încredere 61
Un interval pentru σ2 la nivelul de semnificatie α este:((n−1)s2
χ21−α
2 ;n−1
,(n−1)s2
χ2α
2 ;n−1
). (4.2.5)
Intervale de încredere pentru deviatia standard se obtin prin extragerea radacinii patratedin capetele de la intervalele de încredere pentru dispersie.Exemplu 4.2 Gasiti un interval de încredere (cu α = 0.05) pentru deviatia standard acontinutului de nicotina pentru un anumit tip de tigari, stiind ca pentru o selectie de 25 debucati, deviatia standard a continutului de nicotina este de 1.6mg.Solutie: Observam ca s = 1.6mg. Din tabele, gasim ca:
χ20.975;24 = 39.3641; χ
20.025;24 = 12.4012.
Intervalul de încredere pentru dispersie este:
(σ2, σ2) = (1.5608, 4.9544).
Pentru variatia standard, intervalul de încredere este:
(√
1.5608mg,√
4.9544mg) = (1.25mg, 2.22mg).
4.2.3 Interval de încredere pentru proportiePentru o populatie statistica, prin proportie a populatiei vom întelege procentul din întreagacolectivitate ce satisface o anumita proprietate (sau are o anumita caracteristica) (e.g.,proportia de studenti integralisti dintr-o anumita facultate). Pe de alta parte, prin proportiede selectie întelegem procentajul din valorile de selectie ce satisfac o anumita proprietate(e.g., proportia de studenti integralisti dintr-o selectie aleatoare de 40 de studenti ai uneifacultati). Proportia unei populatii este un parametru (pe care îl vom nota cu p), iarproportia de selectie este o statistica (pe care o notam aici prin p).
Fie Z o caracteristica binomiala a unei colectivitati, cu probabilitatea de succes p (e.g.,numarul de steme aparute la aruncarea unei monede ideale, caz în care p = 0.5). Dorim saconstruim un interval de încredere pentru proportia populatiei, p. Pentru aceasta, avemnevoie de selectii de volum mare din aceasta colectivitate. Un estimator potrivit pentru peste proportia de selectie, adica
p = p =Zn.
Printr-un "volum mare" vom întelege un n ce satisface: n≥ 30, n p > 5 si n(1− p)> 5.Bazat pe o selectie de volum n, un interval de încredere pentru p la nivelui de semnifi-
catie α , este de forma:(p− z1−α
2
√p(1− p)
n, p+ z1−α
2
√p(1− p)
n
). (4.2.6)
Acest interval de încredere este valabil pentru selectie dintr-o populatie infinita (sau n N,de regula n < 0.05N) sau pentru selectia cu repetitie dintr-o populatie finita. Daca selectiase realizeaza fara repetitie dintr-o populatie finita (cu N astfel înât n ≥ 0.05N), atunciintervalul de încredere este:(
p− z1−α
2
√p(1− p)
n
√N−nN−1
, p+ z1−α
2
√p(1− p)
n
√N−nN−1
). (4.2.7)

62 Capitolul 4. Estimatori
Exemplu 4.3 Dintr-o selectie de 200 de elevi ai unei scoli cu 1276 de elevi, 65% afirma cadetin cel putin un telefon mobil. Sa se gaseasca un interval de încredere pentru procentulde copii din respectiva scoala ce detin cel putin un telefon mobil, la nivelul de semnificatieα = 0.05.Solutie: Avem: n = 200, N = 1276, p = 0.65. Deoarece n ≥ 0.05N, gasim ca uninterval de încredere la nivelul de semnificatie 0.05 este(
0.65−1.96
√0.65(1−0.65)
200
√1276−2001276−1
, 0.65+1.96
√0.65(1−0.65)
200
√1276−200
1276−1
)= (58.93%, 71.07%).
Exemplu 4.4 Într-un institut politehnic, s-a determinat ca dintr-o selectie aleatoare de 100de studenti înscrisi, doar 67 au terminat studiile, obtinând o diploma. Gasiti un intervalde încredere care, cu o confidenta de 90%, sa determine procentul de studenti absolventidintre toti studentii ce au fost înscrisi.Solutie: Mai întâi, observam ca α = 0.1, n > 30, p = 67
100 = 0.67, np = 67 > 5 sin(1− p) = 33 > 5. Deoarece nu ni se da vreo informatie despre N (numarul total destudenti înscrisi), putem presupune ca n < 0.05N. Cuantila teoretica este z0.95 = 1.6449.Gasim ca intervalul de încredere cautat este:(
0.67−1.6449
√0.67(1−0.67)
100, 0.67+1.6449
√0.67(1−0.67)
100
)= (57.78%, 76.22%).

5. Teste statistice
Testarea ipotezelor statistice este o metoda prin care se iau decizii statistice, utilizânddatele experimentale culese. Testele prezentate mai jos au la baza notiuni din teoriaprobabilitatilor. Aceste teste ne permit ca, plecând de la un anumit sau anumite seturi dedate culese experimental, sa se putem valida anumite estimari de parametri ai unei repartitiisau chiar putem prezice forma legii de repartitie a caracteristicii considerate.Presupunem ca Z este variabila de interes a unei populatii statistice si ca legea sa deprobabilitate este data de depinde de un parametru θ . In general, o repartitie poate depindede mai multi parametri, insa aici vom discuta doar cazul unui singur parametru. Deasemenea, sa presupunem ca (zk)k=1,n sunt datele observate relativ la caracteristica Z.
• Numim ipoteza statistica o presupunere relativa la valorile parametului θ sau chiarreferitoare la tipul legii caracteristicii.
• O ipoteza neparametrica este o presupunere relativa la repartitia lui Z. De exemplu,o ipoteza de genul Z ∼ Normala.
• Numim ipoteza parametrica o presupunere facuta asupra valorii parametrilor uneirepartitii. Daca multimea la care se presupune ca apartine parametrul necunoscut esteformata dintr-un singur element, avem de-a face cu o ipoteza parametrica simpla.Altfel, avem o ipoteza parametrica compusa.
• O ipoteza nula este acea ipoteza pe care o intuim a fi cea mai apropiata de realitatesi o presupunem a priori a fi adevarata. Cu alte cuvinte, ipoteza nula este ceeace doresti sa crezi, în cazul în care nu exista suficiente evidente care sa sugerezecontrariul. Un exemplu de ipoteza nula este urmatoarul: "presupus nevinovat, pânase gasesc dovezi care sa ateste o vina". O ipoteza alternativa este orice alta ipotezaadmisibila cu care poate fi confruntata ipoteza nula.
• A testa o ipoteza statistica (en., statistical inference) înseamna a lua una dintredeciziile:
− ipoteza nula se respinge (caz in care ipoteza alternativa este admisa)− ipoteza nula se admite (sau, nu sunt motive pentru respingerea ei)

64 Capitolul 5. Teste statistice
• În Statistica, un rezultat se numeste semnificativ din punct de vedere statistic dacaeste improbabil ca el sa se fi realizat datorita sansei. Între doua valori exista o dife-renta semnificativa daca exista suficiente dovezi statistice pentru a dovedi diferenta,si nu datorita faptului ca diferenta ar fi mare.
• Numim nivel de semnificatie probabilitatea de a respinge ipoteza nula când, de fapt,aceasta este adevarata. În general, nivelul de semnificatie este o valoare pozitivaapropiata de 0, e.g., una dintre valorile: α = 0.01, 0.02, 0.05 etc. Intr-o analizastatistica sau soft statistic, valoarea implicita pentru α este 0.05.
• În urma unui test statistic pot aparea doua tipuri de erori:1. eroarea de speta (I) sau riscul furnizorului (en., false positive) − este eroarea
care se poate comite respingând o ipoteza (în realitate) adevarata. Se mainumeste si risc de genul (I). Probabilitatea acestei erori este egala chiar nivelulde semnificatie α , adica:
α = P(H0 se respinge | H0 este adevarata).
2. eroarea de speta a (II)-a sau riscul beneficiarului (en., false negative) − esteeroarea care se poate comite acceptând o ipoteza (în realitate) falsa. Se mainumeste si risc de genul al (II)-lea. Probabilitatea acestei erori este
β = P(H0 se admite | H0 este falsa).
Gravitatea comiterii celor doua erori depinde de problema studiata. De exemplu,riscul de genul (I) este mai grav decât riscul de genul al (II)-lea daca verificamcalitatea unui articol de îmbracaminte, iar riscul de genul al (II)-lea este mai gravdecât riscul de genul (I) daca verificam concentratia unui medicament.
• Denumim valoare P sau P−valoare sau nivel de semnificatie observat (en., P-value)probabilitatea de a obtine un rezultat cel putin la fel de extrem ca cel observat,presupunând ca ipoteza nula este adevarata. Valoarea P este cea mai mica valoarea nivelului de semnificatie α pentru care ipoteza (H0) ar fi respinsa, bazându-nepe observatiile culese. Daca Pv ≤ α , atunci respingem ipoteza nula la nivelul desemnificatie α , iar daca Pv > α , atunci admitem (H0). Cu cât Pv este mai mica, cuatât mai mari sanse ca ipoteza nula sa fie respinsa. De exemplu, daca valoarea P estePv = 0.045 atunci, bazându-ne pe observatiile culese, vom respinge ipoteza (H0)la un nivel de semnificatie α = 0.05 sau α = 0.1, dar nu o putem respinge la unnivel de semnificatie α = 0.02. Daca ne raportam la P−valoare, decizia într-un teststatistic poate fi facuta astfel: daca aceasta valoare este mai mica decât nivelul desemnificatie α , atunci ipoteza nula este respinsa, iar daca P−value este mai maredecât α , atunci ipoteza nula nu poate fi respinsa.
Un exemplu simplu de test este testul de sarcina. Acest test este, de fapt, o procedurastatistica ce ne da dreptul sa decidem daca exista sau nu suficiente evidente sa concluzionamca o sarcina este prezenta. Ipoteza nula ar fi lipsa sarcinii. Majoritatea oamenilor în acestcaz vor cadea de acord cum ca un false negative este mai grav decât un false positive.
Sa presupunem ca suntem într-o sala de judecata si ca judecatorul trebuie sa decidadaca un inculpat este sau nu vinovat. Are astfel de testat urmatoarele ipoteze:
(H0) inculpatul este nevinovat;(H1) inculpatul este vinovat.

5.1 Tipuri de teste statistice 65
Posibilele stari reale (asupra carora nu avem control) sunt:[1] inculpatul este nevinovat (H0 este adevarata si H1 este falsa);[2] inculpatul este vinovat (H0 este falsa si H1 este adevarata)
Deciziile posibile (asupra carora avem control− putem lua o decizie corecta sau una falsa)sunt:
[i] H0 se respinge (dovezi suficiente pentru a încrimina inculpatul);[ii] H0 nu se respinge (dovezi insuficiente pentru a încrimina inculpatul);
În realitate, avem urmatoarele posibilitati, sumarizate în Tabelul 5.1:
Situatie realaDecizii H0 - adevarata H0 - falsa
Respinge H0 [1]&[i] [2]&[i]Accepta H0 [1]&[ii] [2]&[ii]
Tabela 5.1: Posibilitati decizionale.
Interpretarile datelor din Tabelul 5.1 se gasesc în Tabelul 5.2.
Situatie realaDecizii H0 - adevarata H0 - falsa
Respinge H0 închide o persoana nevinovata închide o persoana vinovataAccepta H0 elibereaza o persoana nevinovata elibereaza o persoana vinovata
Tabela 5.2: Decizii posibile.
Erorile posibile ce pot aparea sunt cele din Tabelul 5.3.
Situatie realaDecizii H0 - adevarata H0 - falsa
Respinge H0 α judecata corectaAccepta H0 judecata corecta β
Tabela 5.3: Erori decizionale.
5.1 Tipuri de teste statisticeTipul unui test statistic este determinat de ipoteza alternativa (H1). Astfel, putem avea:
• test unilateral stânga, atunci când ipoteza alternativa este θ < θ0;• test unilateral dreapta, atunci când ipoteza alternativa este θ > θ0;• test bilateral, atunci când ipoteza alternativa este θ 6= θ0.Pentru a lua decizii statistice se poate utiliza metoda intervalelor de încredere pentru
parametri.

66 Capitolul 5. Teste statistice
5.1.1 Testul t pentru medieTestul t pentru medie se foloseste pentru selectii normale de volum mic, de regula n < 30,când dispersia populatiei este necunoscuta a priori.Fie caracteristica Z ce urmeaza legea normala N (µ, σ) cu µ necunoscut si σ > 0 necu-noscut.
Vrem sa verificam ipoteza nula
(H0) : µ = µ0
versus ipoteza alternativa(H1) : µ 6= µ0,
cu probabilitatea de risc α .Metoda I: Etapele testului sunt urmatoarele:• Obtinem o multime de masuratori asupra variabilei Z: z1, z2, . . . , zn.• Pe baza acestor masuratori putem calcula media si deviatia standard:
z =1n
n
∑i=1
zi si s =
√1
n−1
n
∑i=1
(zi− z)2.
• Calculam statistica ce masoara discrepanta dintre valoarea medie observata si valoarea mediepe care o testam:
T0 =z−µ0
s√n
. (5.1.1)
• Calculam cuantila de ordin 1− α
2 pentru repartitia t(n−1), notata aici prin t1− α
2 ; n−1 Este unprag teoretic ce poate fi determinat din tabelele pentru repartitia Student sau calculat cu unsoft matematic (e.g., MATLAB). Decizia se ia astfel:
– daca |T0|< t1− α
2 ; n−1 (adica T0 este suficient de mic in valoare absoluta), atunci admi-tem (H0).
– daca |T0| ≥ t1− α
2 ; n−1, atunci respingem (H0).
Metoda a II-a: O alta modalitate de testare a unei ipoteze statistice parametrice esteprin intermediul P−valorii, Pv. Reamintim, P−valoarea este probabilitatea de a obtineun rezultat cel putin la fel de extrem ca cel observat, presupunând ca ipoteza nula esteadevarata. Aceasta valoare este afisata de orice soft statistic folosit in testarea ipotezelor.Utilizând P−valoarea, testarea se face astfel:Ipoteza nula va fi respinsa daca Pv < α si va fi admisa daca Pv ≥ α . Asadar, cu cât Pv estemai mic, cu atât mai multe dovezi de respingere a ipotezei nule.Exemplu 5.1 Pentru a determina media notelor la teza de Matematica a elevilor dintr-unanumit oras, s-a facut un sondaj aleator de volum n = 90 printre elevii din oras. Noteleobservate in urma sondajului sunt grupate in Tabelul 2.2. Dorim sa testam, la nivelul desemnificatie α = 0.05, daca media tuturor notelor la teza de Matematica a elevilor din oraseste µ = 6.5.Solutie: Asadar, avem de testat
(H0) µ = 6.5 vs. (H1) µ 6= 6.5.

5.1 Tipuri de teste statistice 67
Media si deviatia standard a notelor din tabel sunt:
z = 6.3667, s = 1.8570.
Valoarea statisticii t0 si pragul teoretic de referinta (cuantila) sunt:
t0 =z−µ0
s√n
=−0.6812, t1−α
2 ; n−1 = t0.975; 89 = 1.9870.
Deoarece |t0|< t0.975; 89, luam decizia ca ipoteza (H0) este admisa la acest nivel de semni-ficatie.
Metoda a II-a: Decizia testului putea fi luata si pe baza P−valorii. Aceasta poatefi calculata de un soft statistic, valoarea ei fiind Pv = 0.4975, care este mai mare decatvaloarea lui α . Astfel, ipoteza nula este admisa in acest caz.
5.1.2 Test pentru dispersiePentru variabila Z ca mai sus dorim sa testam ipoteza:
(H0) : σ2 = σ
20 vs. ipoteza alternativa (H1) : σ
2 6= σ20 ,
cu probabilitatea de risc α . Etapele testului sunt urmatoarele:• Obtinem o multime de masuratori asupra variabilei Z: z1, z2, . . . , zn.• Pe baza acestor masuratori putem calcula media si deviatia standard:
z =1n
n
∑i=1
zi si s =
√1
n−1
n
∑i=1
(zi− z)2.
• Calculam statistica
χ20 =
n−1σ2 S2, (5.1.2)
• Determinam cuantilele de ordine α/2 si 1−α/2 pentru repartitia χ2(n−1) (se pot obtinedin tabele pentru repartitia χ2). Luarea deciziei se face astfel:
– daca χ20 ∈
(χ
2α
2 ;n−1, χ21− α
2 ;n−1
), atunci admitem (H0) (i.e., σ2 = σ2
0 );
– daca χ20 6∈
(χ
2α
2 ;n−1, χ21− α
2 ;n−1
), atunci respingem (H0) (i.e., σ2 6= σ2
0 ).
Exemplu 5.2 Se cerceteaza caracteristica Z, ce reprezinta diametrul pieselor (în mm)produse de un strung. Presupunem ca valorile observate urmeaza o repartitie normala.Pentru o selectie de piese de volum n = 11 si obtinem distributia empirica:(
10.50 10.55 10.60 10.652 3 5 1
).
Sa se testeze (cu α = 0.1) ipoteza nula
(H0) : σ2 = 0.003,
versus ipoteza alternativa(H1) : σ
2 6= 0.003.

68 Capitolul 5. Teste statistice
Solutie: Calculam mai intai s2 si apoi valoarea statisticii test. Obtinem s2 = 0.0022 si,astfel,χ2
0 = 100.003 ·0.0022 = 7.2727. Cuantilele sunt:
χ2α
2 ;n−1 = 3.9403; χ21−α
2 ;n−1 = 18.3070.
Astfel, intervalul teoretic de referinta este
χ20 ∈
(χ
2α
2 ;n−1, χ21−α
2 ;n−1
)= (3.9403, 18.3070).
Cum valoarea χ20 = 7.2727 se afla in acest interval, tragem concluzia ca ipoteza nula nu
poate fi respinsa. (o acceptam).
Metoda a II-a: Decizia testului putea fi luata si pe baza P−valorii. Aceasta poatefi calculata de un soft statistic, valoarea ei fiind Pv = 0.6995, care este mai mare decatvaloarea lui α . Astfel, ipoteza nula este admisa in acest caz.
5.1.3 Testul χ2 de concordantaTestele de concordanta (en., goodness-of-fit tests) realizeaza concordanta între reparti-tia empirica (repartitia datelor observate) si repartitia teoretica a unei variabile. Douadintre cele mai des utilizate teste de concordanta sunt testul χ2 de concordanta si testulKolmogorov-Smirnov.
Testul χ2 de concordanta poate fi utilizat ca un criteriu de verificare a ipotezei potrivitcareia un ansamblu de observatii urmeaza o repartitie data. Se aplica la verificareanormalitatii, a exponentialitatii, a caracterului Poisson, a caracterului Weibull etc. Testulmai este numit si testul χ2 al lui Pearson sau testul χ2 al celei mai bune potriviri (en.,goodness of fit test). Acest test poate fi aplicat pentru orice tip de date pentru care functiade repartitie empirica poate fi calculata. Pentru acest test, ipoteza nula este:
(H0) : Functia de repartitie a lui Z este F(z).
Ipoteza alternativa este negatia ipotezei nule.Etapele testului sunt urmatoarele:1. Stabilim pragul de risc α . Facem masuratorile asupra variabilei Z : z1, z2, . . . , zn.2. Pe baza masuratorilor intuim natura repartitiei lui Z (si, implicit, forma functiei de repartitie
a lui Z). Aceasta functie poate depinde de unul sau mai multi parametri, notati generic cu θ .Formulam ipotezele statistice:
(H0) functia de repartitie teoretica a variabilei aleatoare Z este F(z; θ1, θ2, . . . , θp)(H1) ipoteza nula nu este adevarata.
3. Daca θ1, θ2, . . . , θk (k ≤ p) nu sunt parametri cunoscuti, atunci determinam estimarileθ1, θ2, . . . , θk pentru acestia. Altfel, sarim peste acest pas;
4. Grupam datele in clase si scriem distributia empirica de selectie (tabloul de frecvente),(clasa Oi
ni
)i=1,n
, unden
∑i=1
ni = n, ni ≥ 5;
5. Se calculeaza probabilitatea pi, ca un element luat la întâmplare sa se afle în clasa Oi. DacaOi = [ai−1, ai), atunci

5.1 Tipuri de teste statistice 69
6. Se calculeaza statistica χ20 =
k
∑i=1
(ni−n pi)2
n pi, care reprezinta discrepanta dintre valorile
observate si cele teoretice;7. Determinam valoarea χ∗, care este
χ∗ =
χ2
1−α; k−1 , în cazul in care nu avem de estimat parametrii repartitiei,χ2
1−α; k−p−1 , în cazul in care am estimat p parametri pentru repartitie,
unde χ2α; n este cuantila de ordin α pentru repartitia χ2(n);
8. Daca χ20 < χ
∗, atunci acceptam (H0), altfel o respingem.Exemplu 5.3 În urma unui recensamânt, s-a determinat ca proportiile persoanelor dinRomânia ce apartin uneia dintre cele patru grupe sanguine sunt: O : 34%, A : 41%, B :19%, AB : 6%. S-au testat aleator 450 de persoane din România, obtinându-se urmatoarelerezultate:
Verificati, la nivelul de risc α = 0.05,compatibilitatea datelor cu rezultatul teoretic.
Grupa sanguina O A B ABFrecventa 136 201 82 31
Solutie: Ipotezele statistice sunt:
(H0) : Rezultatul observat este compatibil cu cel teoretic,
(H1) : Exista diferente semnificative între rezultatul teoretic si observatii.
Daca ipoteza nula ar fi adevarata, atunci valorile asteptate pentru cele patru grupe sanguine(din 450 de persoane) ar fi: O : 153.5, A : 184.5, B : 85, AB : 27.
Calculez valoarea statisticii χ2 pentru observatiile date. Ponderile pi sunt: p1 =0.34, p2 = 0.41, p3 = 0.19, p4 = 0.06. Folosind formula, gasim ca:
χ20 =
(136−450 ·0.34)2
450 ·0.34+
(201−450 ·0.41)2
450 ·0.41+
(82−450 ·0.19)2
450 ·0.19+
(31−450 ·0.06)2
450 ·0.06
=(136−153.5)2
153.5+
(201−184.5)2
184.5+
(82−85)2
85+
(31−27)2
27= 4.1004.
Aici n = 4, p = 0. Valoarea teoretica a statisticii de referinta este χ∗ = χ20.95; 3 = 7.8147.
Deoarece χ20 < χ
∗, atunci acceptam (H0) la acest nivel de semnificatie. Asadar, observati-ile sunt compatibile cu cele teoretice.
5.1.4 Testul de concordanta Kolmogorov-SmirnovTestul de concordanta Kolmogorov-Smirnov poate fi utilizat în compararea unor observatiidate cu o repartitie cunoscuta (testul K-S cu o selectie) sau în compararea a doua selectii(testul K-S pentru doua selectii). Spre deosebire de criteriul χ2 al lui Pearson, care folosestedensitatea de repartitie, criteriul Kolmogorov-Smirnov utilizeaza functia de repartitieempirica, F∗n (x). În cazul unei singure selectii, este calculata distanta dintre functia derepartitie empirica a selectiei si functia de repartitie teoretica pentru repartitia testata, iarpentru doua selectii este masurata distanta între doua functii empirice de repartitie. Înfiecare caz, repartitiile considerate în ipoteza nula sunt repartitii de tip continuu. TestulKolmogorov-Smirnov este bazat pe rezultatul teoremei urmatoare:

70 Capitolul 5. Teste statistice
Teorema 5.1.1 (Kolmogorov) Fie caracteristica X de tip continuu, care are functia derepartitie teoretica F si fie functia de repartitie de selectie F∗n (x). Atunci, distanta dn =supx∈R|F∗n (x)−F(x)| satisface relatia:
limn→∞
P(√
n ·dn < x) = K(x) =∞
∑k=−∞
(−1)ke−2k2 x2, x > 0. (5.1.3)
Testul K-S pentru o selectie
În cazul în care ipotezele testului sunt satisfacute, acest test este mai puternic decâttestul χ2.Avem un set de date statistice independente, pe care le ordonam crescator, x1 < x2 < · · ·<xn. Aceste observatii independente provin din aceeasi populatie caracterizata de variabilaaleatoare X , pentru care urmarim sa îi stabilim repartitia. Mai întâi, cautam sa stabilimipoteza nula. De exemplu, daca intuim ca functia de repartitie teoretica a lui X ar fi F(x),atunci stabilim:
(H0) : functia de repartitie teoretica a variabilei aleatoare X este F(x).Ipoteza alternativa (H1) este, de regula, ipoteza ce afirma ca (H0) nu este adevarata.
Alegem un nivel de semnificatie α 1.În criteriul K-S pentru o singura selectie, se compara functia F(x) intuita a priori cu functiade repartitie empirica, F∗n (z). Reamintim,
F∗n (x) =cardi; xi ≤ x
n.
Studiind functia empirica de repartitie a acestui set de date, Kolmogorov a gasit ca distantadn = sup
x∈R|F∗n (x)−F(x)| satisface relatia (5.1.3)), unde K(λ ), λ > 0, este functia lui
Kolmogorov (tabelata). În testul K-S, masura dn caracterizeaza concordanta dintre F(x) siF∗n (x). Daca ipoteza (H0) este adevarata, atunci diferentele dn nu vor depasi anumite valori.
Etapele aplicarii testului lui Kolmogorov-Smirnov pentru o selectie:• Se dau α si x1 < x2 < · · ·< xn. Consideram cunoscuta (intuim) F(x);• Ipotezele statistice sunt:
(H0) functia de repartitie teoretica a variabilei aleatoare Z este F(x)(H1) ipoteza nula nu este adevarata.
• Calculam λ1−α;n, cuantila de ordin 1−α pentru functia lui Kolmogorov. Aceasta cuuantilaverifica relatia K(λ1−α) = 1−α .
• Se calculeaza dn = maxx|F∗n (x)−F(x)|;
• Daca dn satisface inegalitatea√
ndn < λ1−α , atunci admitem ipoteza (H0), altfel o respingem.Exercitiu 5.1 (test de verificare a normalitatii)Consideram selectia −2;−0.5; 0; 1; 1; 2; 2; 3, extrasa dintr-o anumita colectivitate. Lanivelul de semnificatie α = 0.1, sa se decida daca populatia din care provine selectia estenormala de medie 1 si dispersie 2 (i.e., X ∼N (1,
√2)).
Solutie: (folosim testul Kolmogorov-Smirnov) Mai întâi, calculam functia de reparti-

5.1 Tipuri de teste statistice 71
tie empirica. Avem:
F∗n (x) = P(X ≤ x) =
0, daca x <−2;18 , daca x ∈ [−2,−0.5);28 , daca x ∈ [−0.5, 0);38 , daca x ∈ [0, 1);58 , daca x ∈ [1, 2);78 , daca x ∈ [2, 3);1, daca x≥ 3.
Pentru α = 0.1 si n = 8, cautam în tabelul pentru inversa functiei lui Kolmogorov acelx1−α;8 = x0.9;8 astfel încât K(x1−α;8) = 1−α . Gasim ca x0.9;8 = 0.411.Pe de alta parte, F(x) = Θ(x−1√
2), unde Θ(x) este functia de repartitie pentru legea normala
N (0, 1).Ipoteza ca X urmeaza repartitia normala N (1,
√2) este acceptata daca
√ndn < x1−α .
Calculele pentru determinarea valorii dn sunt date de Tabelul 5.4. În Figura 5.1, putemobserva reprezentarile acestor doua functii pentru setul de date observate.
xi −∞ −2 −0.5 0 1 2 3 ∞
F(xi) 0 0.0169 0.1444 0.2398 0.5 0.7602 0.9214 1F∗n (xi−0) 0 0 0.125 0.25 0.375 0.625 0.875 1
F∗n (xi) 0 0.125 0.25 0.375 0.625 0.875 1 1|F∗n (xi−0)−F(xi)| 0 0.0169 0.0194 0.0102 0.125 0.1352 0.0464 0|F∗n (xi)−F(xi)| 0 0.1081 0.1056 0.1352 0.125 0.1148 0.0786 0
Tabela 5.4: Tabel de valori pentru testul Kolmogorov-Smirnov.
Pentru a calcula dn, notam faptul ca cea mai mare diferenta între F(x) si F∗n (x) poate firealizata ori înainte de salturile functiei F∗n , ori dupa acestea, i.e.,
supx∈R|F(x)−F∗n (x)|= max
i
|F(xi)−F∗n (xi−0)|, înainte de saltul i;|F(xi)−F∗n (xi +0)|, dupa saltul i.
Din tabel, observam ca dn = 0.1352. Deoarece√
n · dn =√
8 · 0.1352 = 0.3824 < 0.411,concluzionam ca putem accepta ipoteza (H0) la pragul de semnificatie α = 0.1.Observatia 5.1 În cazul în care avem de comparat doua repartitii, procedam astfel. Sapresupunem ca F∗m(z) este functia de repartitie empirica pentru o selectie de volum mdintr-o populatie ce are functia teoretica de repartitie F(z)) si ca G∗n(z) este functia derepartitie empirica pentru o selectie de volum n dintr-o populatie ce are functia teoretica derepartitie G(z). Dorim sa testam
(H0) : F = G versus (H1) : F 6= G.
(eventual, în (H1) putem considera F > G sau F < G.) Consideram statistica
dm,n = supz|F∗m(z)−G∗n(z)|,

72 Capitolul 5. Teste statistice
ce reprezinta diferenta maxima între cele doua functii (vezi Figura 5.2). Etapele testuluiurmeaza îndeaproape pe cele din testul K-S cu o singura selectie. Decizia se face pe bazacriteriului √
mnm+n
dm,n < qα .
Testul Kolmogorov-Smirnov pentru doua selectii este unul dintre cele mai utile teste decontingenta pentru compararea a doua selectii. Acest test nu poate specifica natura celordoua repartitii.
Etapele aplicarii testului lui Kolmogorov-Smirnov pentru doua selectii:• Se dau α , x1 < x2 < · · ·< xm si y1 < y2 < · · ·< yn. Consideram cunoscute (intuim) F(x) si
G(x);• Ipotezele statistice sunt:
(H0) F = G vs. (H1) F 6= G.• Determinam pragul teoretic qα corespunzator valorii α din tabelul urmator:
α 0.10 0.05 0.025 0.01 0.005 0.001qα 1.22 1.36 1.48 1.63 1.73 1.95
• Se calculeaza dm,n = supz|F∗m(z)−G∗n(z)|.
• Daca dm,n satisface inegalitatea√
mnm+n dm,n < qα , atunci admitem ipoteza (H0), altfel ipoteza
nula este respinsa la acest prag de semnificatie.
Figura 5.1: F∗n (x) si F(x) pentru testulKolmogorov-Smirnov cu o selectie.
Figura 5.2: Exemplu de functiile empiricede repartitie în testul K-S cu doua selectii.

6. Corelatie si regresie
6.1 Punerea problemeiÎn acest capitol vom discuta masuri si tehnici de determinare a legaturii între doua saumai multe variabile aleatoare. Primele metode utilizate în studiul relatiilor dintre douasau mai multe variabile au aparut de la începutul secolului al XIX-lea, în lucrarile luiLegendre1 si Gauss2, în ce priveste metoda celor mai mici patrate pentru aproximareaorbitelor astrelor în jurul Soarelui. Un alt mare om de stiinta al timpului, Francis Galton3, astudiat gradul de asemanare între copii si parinti, atât la oameni, cât si la plante, observândca înaltimea medie a descendentilor este legata liniar de înaltimea ascendentilor. Esteprimul care a utilizat conceptele de corelatie si regresie ( (lat.) regressio - întoarcere).Astfel, a descoperit ca din parinti a caror înaltime este mai mica decât media colectivitatiiprovin copii cu o înaltime superioara lor si vice-versa. Astfel, a concluzionat ca înaltimeacopiilor ce provin din parinti înalti tinde sa "regreseze" spre înaltimea medie a populatiei.Din lucrarile lui Galton s-a inspirat un student de-al sau, Karl Pearson, care a continuatideile lui Galton si a introdus coeficientul (empiric) de corelatie ce îi poarta numele. Acestcoeficient a fost prima masura importanta introdusa ce cuantifica taria legaturii dintre douavariabile ale unei populatii statistice.
Un ingredient fundamental în studiul acestor doua concepte este diagrama prin puncte,asa-numita scatter plot. În probleme de regresie în care apare o singura variabila raspuns sio singura variabila observata, diagrama scatter plot (raspuns vs. predictor) este punctul deplecare pentru studiul regresiei. O diagrama scatter plot ar trebui reprezentata pentru oriceproblema de analiza regresionala; aceasta va oferi o prima idee despre ce tip de regresievom folosi. Exemple de astfel de diagrame sunt cele din Figura 3.2.
Regresia este o metoda statistica utilizata pentru descrierea naturii relatiei între variabile.
1Adrien-Marie Legendre (1752−1833), matematician francez2Johann Carl Friedrich Gauss (1777−1855), matematician si fizician german3Sir Francis Galton (1822−1911), om de stiinta britanic

74 Capitolul 6. Corelatie si regresie
De fapt, regresia stabileste modul prin care o variabila depinde de alta variabila, sau dealte variabile. Analiza regresionala cuprinde tehnici de modelare si analiza a relatiei dintreo variabila dependenta (variabila raspuns) si una sau mai multe variabile independente.De asemenea, raspunde la întrebari legate de predictia valorilor viitoare ale variabileiraspuns pornind de la o variabila data sau mai multe. În unele cazuri se poate preciza caredintre variabilele de plecare sunt importante în prezicerea variabilei raspuns. Se numestevariabila independenta o variabila ce poate fi manipulata (numita si variabila predictor,stimul sau comandata), iar o variabila dependenta (sau variabila prezisa) este variabilacare dorim sa o prezicem, adica o variabila carei rezultat depinde de observatiile facuteasupra variabilelor independente.
Sa luam exemplul unei cutii negre (black box) (vezi Fi-gura 6.1). În aceasta cutie intra (sunt înregistrate) infor-matiile x1, x2, . . . , xm, care sunt prelucrate (în timpulprelucrarii apar anumiti parametri, β1, β2, . . . , βk), iarrezultatul final este înregistrat într-o singura variabilaraspuns, y. Figura 6.1: Black box.
De exemplu, se doreste a se stabili o relatie între valoarea pensiei (y) în functie denumarul de ani lucrati (x1) si salariul avut de-alungul carierei (x2). Variabilele independentesunt masurate exact, fara erori. În timpul prelucrarii datelor sau dupa aceasta pot aparadistorsiuni în sistem, de care putem tine cont daca introducem un parametru ce sa cuantificeeroarea ce poate aparea la observarea variabilei y. Se stabileste astfel o legatura între ovariabila dependenta, y, si una sau mai multe variabile independente, x1, x2, . . . , xm, care,în cele mai multe cazuri, are forma matematica generala
y = f (x1, x2, . . . , xm; β1, β2, . . . , βk)+ ε, (6.1.1)
unde β1, β2, . . . , βk sunt parametri reali necunoscuti a priori (denumiti parametri deregresie) si ε este o perturbatie aleatoare. În cele mai multe aplicatii, ε este o eroare demasura, considerata modelata printr-o variabila aleatoare normala de medie zero. Functiaf se numeste functie de regresie. Daca aceasta nu este cunoscuta a priori, atunci poatefi greu de determinat iar utilizatorul analizei regresionale va trebui sa o intuiasca sau sao aproximeze utilizând metode de tip trial and error (prin încercari). Daca avem doar ovariabila independenta (un singur x), atunci spunem ca avem o regresie simpla. Regresiamultipla face referire la situatia în care avem multe variabile independente.
Daca observarea variabilei dependente s-ar face fara vreo eroare, atunci relatia (6.1.1)ar deveni (cazul ideal):
y = f (x1, x2, . . . .., xm; β1, β2, . . . , βk). (6.1.2)
Forma vectoriala a dependentei (6.1.1) este:
y = f (x; β )+ ε. (6.1.3)
Pentru a o analiza completa a regresiei (6.1.1), va trebui sa intuim forma functiei fsi apoi sa determinam (aproximam) valorile parametrilor de regresie. În acest scop, unexperimentalist va face un numar suficient de observatii (experimente statistice), în urma

6.1 Punerea problemei 75
carora va aproxima aceste valori. Daca notam cu n numarul de experimente efectuate,atunci le putem contabiliza pe acestea în urmatorul sistem stochastic de ecuatii:
yi = f (x, β )+ εi, i = 1, 2, . . . , n. (6.1.4)
În ipoteze uzuale, erorile εi sunt variabile aleatoare identic repartizate normal, independentede medie µ = 0 si deviatie standard σ > 0. Astfel, sistemul (6.1.4) cu n ecuatii arenecunoscutele β j j si σ .
În cazul în care numarul de experimente este mai mic decât numarul parametrilor cetrebuie aproximati (n < k), atunci nu avem suficiente informatii pentru a determina aproxi-marile. Daca n = k, atunci problema se reduce la a rezolva n ecuatii cu n necunoscute. Încel de-al treilea caz posibil, n > k, atunci avem un sistem cu valori nedeterminate.
Exemple de regresii:
În functie de forma functiei de regresie f , putem avea:• regresie liniara simpla, în cazul în care avem doar o variabila independenta si
f (x; β ) = β0 +β1x.
• regresie liniara multipla, daca
f (x; β ) = β0 +β1x1 +β2x2 + · · ·+βmxm.
• regresie patratica multipla (cu doua variabile), daca
f (x; β ) = β0 +β1x1 +β2x2 +β11x21 +β12x1x2 +β22x2
2.
• regresie polinomiala, daca
f (x; β ) = β0 +β1x+β2x2 +β3x3 + · · ·+βkxk.
Vom avea regresie patratica pentru k = 2, regresie cubica pentru k = 3 etc.• regresie exponentiala, când
f (x; β ) = β0 eβ1 x.
• regresie logaritmica, daca
f (x; β ) = β0 · logβ1x.
• si altele.De remarcat faptul ca primele patru modele sunt liniare în parametri, pe când ultimele douanu sunt liniare în parametri. Modelele determinate de aceste functii se vor numi modele deregresie (curbe, suprafete etc).
În cadrul analizei regresionale, se cunosc datele de intrare, xii, si cautam sa estimamparametrii de regresie β j j si deviatia standard a erorilor, σ . De regula, functia f estenecunoscuta si va trebui sa fie intuita de statistician.


7. Metode de interpolare spatiala
Dupa cum am mentionat anterior, in Geostatistica, datele observate sunt legate de po-zitie. Spunem astfel ca au un caracter spatial. Pozitia spatiala poate fi unu, doi sautrei-dimensionala. Vom considera aici doar date bi-dimensionale. Vom nota generic cux = (ζ1, ζ2) vectorul de coordonate bidimensionale. tre aceste metode, distingem metodeledeterministe si cele geostatistice (sau stochastice). In cazul metodelor deterministe nu setine cont de erorile cu care pot fi colectate masuratorile si de corelatiile dintre valorile ma-surate. In cazul metodelor stochastice, tinem cont de erorile masuratorilor si de corelatiiledintre date.
7.1 Metode deterministe de interpolare spatiala
Generic, vom nota prin z o valoare prezisa a variabilei Z. O formula generala de estimare avalorii z0 = z(x0) pe baza masuratorilor este media ponderata:
z(x0) =n
∑i=1
λiz(xi), (7.1.1)
unde λi sunt ponderile ce trebuie determinate.1. Metoda diagramei Voronoi (sau Thiessen, sau Dirichlet): Pentru un camp aleator R,
vom numi o diagrama Voronoi indusa de un set de locatii x1, x2, . . . , xn (numite sisituri) o diviziune a lui R in subregiuni, astfel incat pentru fiecare locatie, regiuneacare o contine este formata din punctele cele mai apropiate locatiei. Pentru fiecarepunct xi, sa notam cu Vi regiunea ce o contine.

78 Capitolul 7. Metode de interpolare spatiala
Se considera ca zi este valoarea variabilei Z pen-tru fiecare locatie din regiunea Vi. In cazul uneidiagrame Voronoi, se pot considera ponderile λica fiind
λi =
1 , daca xi ∈Vi,
0 , daca xi 6∈Vi.
Totusi, astfel de predictii sunt grosiere, deoarecein fiecare subregiune avem doar o valoare sinicio indicatie a erorii cu care a fost observata.De asemenea, nu se tine cont de configuratialocatiilor masuratorilor. Figura 7.1: O diagrama Voronoi
2. Metoda triangularii (Delaunay):Pentru o regiune R in care avem un set de locatii x1, x2, . . . , xn, o triangulareDelaunay este o impartire a regiunii R in subregiuni triunghiulare, astfel incatnicio locatie data nu se afla in cercul circumscris vreunui triunghi din diviziune.
O astfel de triangulare este unica pentru un setde locatii aflate in pozitie generala (nu se afla peo aceeasi linie). In cazul unei triangulari, pon-derile pentru fiecare regiune triunghiulara suntobtinute prin interpolarea liniara a coordonatelorvarfurilor triunghiului. Aceasta forma de inter-polare este mai buna decat cea anterioara, darnu suficient de folositoare. De asemenea, o pre-dictie folosind aceasta metoda nu tine cont deerorile de masurare.
Figura 7.2: O triangulare Delaunay3. Metoda vecinilor naturali:
Este o metoda de interpolare introdusa de matematicianul Robin Sibson, care sebazeaza pe diagrama Voronoi. Pe baza locatiilor unde au fost facute masuratori, seconstruieste diagrama Voronoi.

7.1 Metode deterministe de interpolare spatiala 79
Presupunem ca se doreste prezicerea valoriiz0 a variabilei Z intr-o alta locatie decat ceadeja observata, fie ea x0. Pe baza locatiilorx0, x1, . . . , xn, se construieste o alta diagrama Vo-ronoi, care incorporeaza si aceasta noua locatie.Vom nota cu A aria regiunii care contine loca-tia x0 (este regiunea hasurata din Figura 7.3) si,pentru fiecare i, notez cu Ai intersectia regiuniicare contine pe x0 cu regiunea ce contine locatiaxi din vechea retea Voronoi. Presupunem ca re-giunea de arie A intersecteaza r astfel de regiuni.In mod clar, avem ca A1 +A2 + . . .+Ar = A. Figura 7.3: Diagrama pentru
metoda vecinilorPonderile λi sunt considerate astfel:
λi =Ai
A1 +A2 + . . .+Ar,
unde suma se face dupa indicii locatiilor invecinate locatiei x0. Astfel, ponderea λiva fi nenula daca locatia xi este vecin natural cu x0, si λi = 0 daca xi nu este vecinnatural cu x0.
4. Metoda ponderilor inverselor distantelor:
Notam cu di distanta dintre punctele xi si x0. Aceasta metoda foloseste interpolarea(7.1.1) cu ponderile
λi =d−r
in
∑i=1
d−ri
, i = 1, 2, . . . , n,
unde r > 0 este o valoare aleasa de investigator. Valoarea cea mai utilizata este r = 2.Rezultatul acestei interpolari este ca punctele mai apropiate de punctul de interpolareau o pondere mai mare decat cele mai indepartate. Cu cat r este mai mare, cu atatponderea punctelor apropiate creste. Astfel, valoarea variabilei in locatia x0 poate fiestimata prin:
z(x0) =
n
∑i=1
d−ri
n
∑i=1
d−ri
zi , daca di 6= 0,
zi , daca di = 0.
Pentru r = 2, valoarea variabilei in locatia x0 poate fi estimata prin:
z(x0) =
n
∑i=1
λizi , daca distanta dintre xi si x0 este nenula,
zi , daca distanta dintre xi si x0 este0,

80 Capitolul 7. Metode de interpolare spatiala
unde
λi =
1d2
i1d2
1+
1d2
2+ · · ·+ 1
d2n
, pentru fiecare i = 1, 2, . . . , n.
Un mare dezavantaj al acestui tip de interpolare este ca nu tine cont de configuratiaselectiei alese.
5. Metoda determinarii suprafetelor de raspuns (regresie sau trend):
Aceasta metoda este asemanatoare cu metoda regresiei multiple. Sa presupunem cadorim sa dorim sa prezicem valorile pe care o variabila Z le ia intr-o anumita regiuneR pe baza masuratorilor facute in n locatii din aceasta regiune. Sa presupunemca aceste locatii sunt x1, x2, . . . , xn. Deoarece aceste puncte sunt planare, pentrua determina exact fiecare locatie este nevoie de cate doua coordonate. Vom notageneric prin (xi1, xi2) coordonatele locatiei xi, pentru fiecare i = 1, 2, . . . , n. Dorimsa prezicem valoarea variabilei Z intr-o locatie generica x din R, tinand cont devalorile cunoscute z(x1), z(x2), . . . , z(xn). Presupunem ca pentru locatia x avemcoordonatele (x1, x2). In general, valoarea prezisa de o suprafata de raspuns va fi deforma:
z(x) := z(x1, x2) = f (x1, x2)+ εx, (7.1.2)
unde f (x) este o functie de coordonatele spatiale ale locatiei investigate si εx esteo eroare de masurare. Aceasta eroare este presupusa a fi normala, de medie 0 sideviatie standard σ . Mai mult, se presupune ca erorile observate in diferite locatii safie independente intre ele.Exemple de suprafete de trend:
• (trend liniar, adica un plan):
f (x1, x2) = β0 +β1x1 +β2x2.
• (trend cuadratic pur):
f (x1, x2) = β0 +β1x1 +β2x2 +β3x21 +β4x2
2.
• (trend cuadratic cu interactiuni):
f (x1, x2) = β0 +β1x1 +β2x2 +β3x1x2 +β4x21 +β5x2
2.
• (trend cubic):f (x1, x2)= β0+β1x1+β2x2+β3x1x2+β4x2
1+β5x22+β6x2
1x2+β7x1x32+β8x3
1+β9x32.
Pe baza masuratorilor deja facute, se estimeaza parametrii βi, obtinandu-se astfelsuprafata de raspuns care se apropie cel mai mult de datele observate. O metoda deestimare a acestor parametri este metoda celor mai mici patrate (se minimizeaza supapatratelor erorilor de aproximare). De indata ce acesti coeficienti (se mai numesc

7.1 Metode deterministe de interpolare spatiala 81
si coeficienti de regresie) sunt determinati, vom cunoaste forma exacta a functieif (x1, x2), si astfel putem estima valoarea variabilei in locatia x = (x1, x2) prin
z(x) = f (x1, x2).
Spre exemplu, in cazul unui trend liniar cu β0, β1, β2 cunoscuti, estimam z(x) prin
z(x) = β0 +β1x1 +β2x2.
De indata ce functia de regresie f este determinata si parametrii sunt estimati pe bazaobservatiilor, se poate folosi modelul de regresie in predictii in locatii de unde nus-au facut masuratori. Insa, aceste predictii trebuie folosite cu mare atentie, deoareceestimarile pot fi total neadecvate in cazul in care locatiile sunt din afara regiunii(ariei) acoperite de observatii.
6. Metoda functiilor spline
O functie spline este o functie definita pe portiuni, iar in fiecare portiune avem unpolinom. Daca toate polinoamele au grad unu, vom spune ca avem o functie splineliniara, daca toate polinoamele au gradul doi, atunci avem o functie spline patraticaetc. Pentru un set de locatii, putem determina o functie spline care interpoleazaaceste valori. Pe baza acestei functii putem estima valoarea unei variabile intr-olocatie x0 prin valoarea functiei in x0. Interpolarea cu functii spline a fost introdusade matematicianul roman Isaac Jacob Schoenberg care a sustinut teza sa de doctoratla Universitatea din Iasi in 1926.
Figura 7.4: Functii spline


8. Procese stochastice spatiale
Pentru o regiune R, dorim sa caracterizam varabila de interes Z. In acest scop, se consideraun set de locatii x1, x2, . . . , xn. Valorile variabilei in aceste locatii sunt masurate, obtinandu-se valorile z(x1), z(x2), . . ., z(xn). In realitate, aceste masuratori sunt facute cu anumiteerori, fapt care ne indreptateste sa consideram variabilele aleatoare Z(x1), Z(x2), . . . , Z(xn).In mod generic, prin Z(xi) intelegem variabila Z in locatia xi, iar z(xi) este o valoareobservata a sa. Pentru fiecare locatie x din campul R, variabila Z(x) este o variabilaaleatoare care are o anumita repartitie care poate sa difere in functie de locatie.Sirul de variabile aleatoare Z(x); x ∈R se numeste proces stochastic sau câmp aleatorsau functie aleatoare.Acesta este un sir infinit, deoarece exista o infi-nitate de locatii x intr-o regiune. O realizare afunctiei aleatoare (sau variabila regionalizata)este formata din multimea valorilor obtinute inurma unei masurari a fiecarei variabile in parte.Este cunoscut faptul ca valorile observate in lo-catii apropiate sunt apropiate iar cele observatein locatii indepartate sunt diferite, aceasta insem-nand ca aceste variabile Z(xi) sunt corelate intreele. Acest aspect nu este comun Statisticii cla-sice, unde variabilele ce corespund selectiei suntindependente intre ele si, mai mult, identic repar-tizate. In Figura 8.1 am reprezentat 5 realizariale unui proces stochastic.
Figura 8.1: 5 realizari ale unei functiialeatoare
Un camp aleator este cunoscut in totalitate daca pentru orice configuratie de loca-tii, z(x1), z(x2), . . ., z(xn), s-ar cunoaste repartitia variabilei vectoriale n−dimentionaleV (x) = (Z(x1), Z(x2), . . . , Z(xn)), lucru care este practic imposibil. In unele cazuri sepoate presupune ca repartitia vectorului V (x) este normala n−dimensionala, caz in care

84 Capitolul 8. Procese stochastice spatiale
cunoastem mediile, dispersiile si corelatiile dintre componentele vectorului. Insa, din nou,acest caz este doar un un caz particular. In cazul general este greu de prezis repartitia exactaa acestui vector, dar putem face anumite presupuneri legate de momentele variabilelor ce-lcompun.
Presupunem ca variabila de interes, Z, admite valoare medie in orice locatie x. Pentru adescrie relatia intre doua variabile Z(xi) si Z(x j) (unde locatiile xi si x j sunt diferite), vomutiliza conceptele de covarianta si corelatie. Reamintim aceste doua concepte in cazulvariabilelor spatiale.
Pentru doua locatii x1 si x2 din R, definim covarianta variabilelor Z(x1) si Z(x2),notata prin cov(x1, x2), cantitatea
cov(Z(x1), Z(x2)) = E[(Z(x1)−µ(x1))(Z(x2)−µ(x2)], (8.0.1)
unde µ(x1) si µ(x2) sunt mediile variabilelor in locatiile x1, respectiv, x2.Covarianta detecteaza doar dependente liniare între doua variabile aleatoare. Daca cele
doua locatii coincid (scriem ca x1 = x2 = x), atunci obtinem varianta a priori a procesului:
cov(Z(x), Z(x)) = E[(Z(x)−µ)(Z(x)−µ)] = E[(Z(x)−µ)2] = σ2Z(x).
O masura (adimensionala) a corelatiei dintre doua variabile este coeficientul de corelatie(sau corelatia, in unele carti). Acesta este utilizat ca fiind o masura a dependentei liniareîntre doua variabile. Se numeste corelatie a variabilelor Z(x1) si Z(x2) cantitatea
ρ =cov(Z(x1), Z(x2))
σ1σ2,
unde σ1 si σ2 sunt deviatiile standard pentru Z(x1), respectiv, Z(x2).Un estimator pentru covarianta variabilelor Z(x1) si Z(x2), bazat pe un set de n obser-
vatii perechi, (z1,1, z2,1), (z1,2, z2,2), . . . , (z1,n, z2,n), este:
cov(x1, x2) =1n
n
∑i=1
[(z1,i− z1)(z2,i− z2)],
unde z1 si z2 sunt mediile pentru fiecare selectie in parte..Dupa cum se observa din relatia (8.0.1), pentru a evalua covarianta variabilelor Z(x1) si
Z(x2) avem nevoie de mediile acestor variabile. Din pacate, aceste valori nu sunt cunoscute.Pentru a simplifica formula, trebuie sa facem presupuneri suplimentare. Una dintre acesteaeste legata de invarianta mediei µ(x) de locatia x, pe care o tratam in cele ce urmeaza.
8.1 Procese stochastice stationareStationaritatea este o presupunere fundamentala in Geostatistica. Un proces stochastic(functie aleatoare) Z(x); x ∈R se numeste proces stationar daca repartitia variabileiZ(x) nu depinde de locatia x. Cu alte cuvinte, daca pentru orice configuratie de locatii, x1,x2, . . ., xn, repartitia variabilei vectoriale n−dimentionale V (x) = (Z(x1), Z(x2), . . . , Z(xn))este independenta de locatii. Aceasta inseamna ca pentru orice locatie x, variabila Z(x)urmeaza aceeasi repartitie. O consecinta a acestui fapt este ca media µ(x), dispersia σ2(x),

8.2 Functia de covarianta 85
dar si momentele de ordin superior (daca ele exista!) sunt independente de locatie. Scriemasta astfel: µ(x) = µ, σ2(x) = σ2, pentru orice locatie x. Daca procesul aleator Z(x) estestationar, atunci putem scrie ca
Z(x) = µ + ε(x),
unde ε(x) sunt erori normal repartizate, ε(x)∼N (µ, σ), pentru orice x din regiune.Totusi, stationaritatea procesului este o ipoteza prea restrictiva in Geostatistica, de-
oarece in general repartitia variabilei Z depinde de locatie. Pentru a indeparta acestinconvenient, vom face o presupunere mai putin restrictiva (mai slaba), si anume caprocesul aleator sa admita doar momente de ordinul 1 si 2 independente de locatie.
Suntem in cazul in care procesul stationar admite momente de ordinul intai si doi (adica,medie, dispersie, covarianta). Un proces stochastic (functie aleatoare) Z(x); x ∈R senumeste proces slab stationar sau stationar de ordinul doi daca media procesului, variantasi covariantele nu variaza cu locatia, iar covariantele depind doar de distanta dintre valori(lag) si nu de valorile in sine. Valoarea lag este un vector care reprezinta distanta si directiadintre doua locatii. Matematic, scriem astfel:
µ(x) = µ, σ2(x) =σ
2, cov(Z(xi), Z(x j)) =C (xi−x j), pentru orice locatie x∈R,
unde C (xi− x j) este o functie ce depinde doar de xi− x j si pe care o vom preciza lamomentul potrivit. Aceasta functie ne va spune cum sunt corelate valorile din doua locatiiale variabilei Z.
8.1.1 ErgodicitateDupa cum am vazut mai sus, un set de date statistice este doar un set de masuratori pe carele-am observat dintr-o infinitate de posibile realizari ale unei functii aleatoare. Pentru aavea o idee cat mai fidela despre functia aleatoare, ar fi necesar sa avem foarte multe astfelde realizari (variabile regionalizate). In practica poate fi imposibil de obtinut, asa ca vatrebui sa ne multumim doar cu o singura variabila regionalizata.
Un proces stochastic se numeste proces ergodic daca proprietatile sale statistice (e.g.,media, varianta, momente) pot fi deduse dintr-o singura realizare (variabile regionalizate),de volum suficient de mare. In Geostatistica, ergodicitatea este doar o presupunere si, ingeneral, nu poate fi testata.
8.2 Functia de covariantaUn rezultat important ar fi sa descriem covarianta dintre variabilele Z(x1) si Z(x2) macarintr-un caz restrictiv, dar nu foarte simplist. Sa presupunem ca functia aleatoare Z(x) estestationara de ordinul al doilea si, pentru doua locatii x1 si x j din R, sa notam variabila lagcu h = xi− x j. Deoarece functia aleatoare este slab stationara, covariantele vor depindedoar de lag si nu de pozitii. Pentru o locatie x generica, vom scrie ca:
cov(Z(x), Z(x+h)) = E[(Z(x)−µ) · (Z(x+h)−µ)]
= C (h).

86 Capitolul 8. Procese stochastice spatiale
Functia C (h) se va numi functia de covarianta. De multe ori, i se atribuie denumirea defunctie de autocovarianta, deoarece in calcularea covariantei apare aceeasi variabila, desiin diverse locatii. Aceasta functie descrie legatura dintre valorile variabilei Z atunci candse schimba locatia. Unitatea de masura a functiei de covarianta este unitatea de masurapentru variabila Z. Pentru un proces stationar, functia de covarianta define
C (h) = E[(µ + ε(x)−µ) · (µ + ε(x+h)−µ)] = E[ε(x) · ε(x+h))].
Pentru a adimensionaliza relatia dintre valorile variabilei Z in diferite locatii, se folosestevaloarea urmatoare:
ρ(h) =C (h)C (0)
=C (h)σ2 ,
unde prin C (0) am notat covarianta pentru valoarea de lag h = 0. Functia ρ(h) se numestefunctie de corelatie sau corelograma.
8.3 Variograma
O alta notiune fundamentala in Geostatistica este variograma. Aceasta va reprezentavariabilitatea (continuitatea) variabilei spatiale in functie de variabila lag h. Este posibilca doua variabile, sa le numim Z1 si Z2, sa aiba parametrii teoretici foarte apropiati sauchiar identici (vezi Tabelul 8.1 pentru aproximarile parametrilor respectivi si Figura 8.2pentru o reprezentare cu histograme a datelor observate), si totusi repartitiile lor sa aratecomplet diferit. Dupa cum se poate observa din Figura 8.3, repartitiile celor doua variabilesunt complet diferite. Se poate observa ca reprezentarea variabilei Z2 este mai "grosiera"decat cea reprezentata de variabila Z1. Variabila Z1 se modifica mai rapid in spatiu, pecand, pentru a doua variabila, exista regiuni mai vaste in care valorile variabilei par a fineschimbate. Totodata, nu putem spune ca Z2 are o variatie mai mare decat Z1, deoarecevariantele sunt egale. Mai mult, deoarece mediile sunt egale, atunci si coeficientii devariatie sunt egali.
valori numerice variabila Z1 variabila Z2media x 101 101
mediana Me 100.73 100.80varianta s2 400 400
prima cuartila q1 87.3 87.93a treia cuartila q3 116.3 116.78
volumul n 15625 15625
Tabela 8.1: Valori numerice pentru douavariabile spatiale

8.3 Variograma 87
Figura 8.2: Reprezentarile cu histograme pentru cele doua variabile
Figura 8.3: Reprezentarile 2D pentru variabilele Z1 si Z2
In acest caz, valorile numerice asociate celor doua seturi de date nu pot identifica variabili-tatea celor doua caracteristici. Daca am fi luat o decizie doar bazandu-ne pe valorile dinTabelul 8.1, am fi cochis ca Z1 si Z2 au aceeasi repartitie, concluzie care este evident falsa.
Pentru a putea descrie (explica) aceasta variabilitate, este nevoie reprezentarile vario-gramelor asociate celor doua variabile. In Figura 8.4, se observa ca variogramele asociatecelor doua variabile difera.
Figura 8.4: Reprezentarile variogramelor empirice si teoretice pentru variabilele Z1 si Z2

88 Capitolul 8. Procese stochastice spatiale
Vom discuta aici despre 3 tipuri de variograme: variograma teoretica, variograma regionalasi variograma empirica. Variograma teoretica este variograma bazata pe toate realizarileposibile ale unei variabile spatiale. Cum o variabila spatiala are, in general, o infinitatede realizari, aceasta variograma este imposibil de obtinut in practica. Variograma empi-rica este cea construita pe baza masuratorilor observate. Este o estimare a variogrameiteoretice. Plecand de la variograma empirica, vom face inferente referitoare la variogramateoretica. Variograma regionala este variograma formata cu o anumita realizare a proce-sului stochastic intr-o regiune finita, daca am avea acces la toate informatiile legate deacea regiune. Variograma teoretica este o medie a tuturor variabilelor regionale legate deprocesul stochastic studiat.
Daca procesul stochastic Z(x) nu este stationar, atunci E(Z(x)) = µ(x) depinde delocatie si Var(Z(x)) poate creste fara limita in cazul in care regiunea este mare. GeorgesMatheron a cautat sa rezolve aceasta problema prin considerarea unor ipoteze simplifica-toare. Cel putin pentru valori mici ale valorii lag |h|, media variatiei procesului stochasticintre doua locatii x si x+h este 0, iar dispersia acestei variatii este dependenta doar de h,independenta de locatie. Cu alte cuvinte, procesul stochastic se comporta ca un processtationar de ordinul al doilea. Matematic, vom scrie astfel:
E[Z(x+h)−Z(x)] = 0; (8.3.2)si
E[(Z(x+h)−Z(x))2] = 2γ(h), (8.3.3)
unde γ(h) este o functie ce depinde doar de h. Aceasta functie se numeste variograma.Prin definitie, formula pentru variograma este:
γ(h) =12
Var[Z(x+h)−Z(x)]. (8.3.4)
Deoarece E[Z(x+h)−Z(x)] = 0 si
Var[Z(x+h)−Z(x)] = E[(Z(x+h)−Z(x))2]− (E[Z(x+h)−Z(x)])2 ,
gasim va variograma poate fi exprimata si astfel:
γ(h) =12E[(Z(x+h)−Z(x))2]. (8.3.5)
Daca variabila Z(x) este 1-dimensionala (x = x, h = h), atunci formula din definitie sescrie astfel:
γ(h) =12
Var[Z(x+h)−Z(x)]. (8.3.6)
Daca variabila Z(x) este 2-dimensionala (x = (x1, x2), h = (h1, h2)), atunci formula dindefinitie se scrie astfel:
γ(h) =12
Var[Z(x1 +h1, x2 +h2)−Z(x1, x2)]. (8.3.7)
Daca variabila Z(x) este 3-dimensionala (x = (x1, x2, x3), h = (h1, h2, h3)), atunci formuladin definitie se scrie astfel:
γ(h) =12
Var[Z(x1 +h1, x2 +h2, x3 +h3)−Z(x1, x2, x3)]. (8.3.8)

8.3 Variograma 89
Datorita termenului 1/2 din fata, se mai foloseste si termenul (in unele carti) de semivario-grama. Legatura sa cu functia de covarianta este urmatoarea:
γ(h) = C(0)−C(h). (8.3.9)
Legatura variogramei cu corelatia (sau it corelograma) este data de:
γ(h) = σ2[1−ρ(h)]. (8.3.10)
In Geostatistica, o variograma poate fi caracterizata de urmatorii parametri:1. sill, care este valoarea asimptotica a variogramei, adica valoarea dupa care nu mai
exista crestere. Este egala cu C(0). Matematic, scriem ca C(0) = limh→∞
γ(h). In
cuvinte, pentru doua locatii foarte indepartate, covarianta este aproape 0.2. range, sau prima valoare (daca exista!) pentru lag (h) pentru care variograma atinge
valoarea sill. Aceasta valoare reprezinta, de fapt, distanta dupa care valorile variabileispatiale nu mai sunt autocorelate. Asadar, valorile variabilei sunt autocorelate doarpentru un lag h mai mic decat valoarea range. Zona ce contine locatia x si pentrucare valorile lui Z sunt corelate cu Z(x) se numeste zona de influenta a locatiei x.
3. nugget (sau efectul nugget), ce reprezinta valoarea variogramei pentru h foarteapropiat de zero, dar nu 0. Aceasta valoare reprezinta eroarea de masurare a variatieispatiale. Valoarea nugget poate aparea atunci cand nu exista masuratori culese dinlocatii foarte apropiate, care ar putea dovedi continuitatea in h = 0. In cazul in carelimh0
γ(h) = 0, atunci variograma va pleca din origine.
Figura 8.5: Variograma si covarianta
Variograma este o unealta importanta in studiul corelatiei datelor spatiale, de aceea este im-portanta aproximarea acesteia. Dupa cum vom vedea, exista diverse modele de aproximarepentru variograma teoretica definita prin formula (8.3.4).

90 Capitolul 8. Procese stochastice spatiale
8.4 Modelarea variogramei teoretice
8.4.1 Proprietati ale functiilor de corelatie spatiale
Prezentam mai jos proprietati ale covariantei, corelogramei, sau variogramei:
• γ(0) = 0.• Cand h creste suficient de mult, γ(h) tinde sa devina constant. Aceasta insemna lipsa
de corelatie intre valorile variabilei din locatii indepartate.• Variograma γ(h) poate sa nu fie continua doar in h = 0 (origine). In acest caz, saltul
discontinuitatii se numeste efect nugget. Efectul nugget este r =C(0) = Var[Z(x)] =σ2 > 0.
• C(h) = C(−h) si γ(h) = γ(−h) pentru orice lag h, adica functia de corelatie sivariograma sunt functii pare.
• Corelograma are intotdeauna valori intre 0 si 1. Pentru h = 0, gasim ca ρ(0) =C(0)C(0) = 1.
• Functiile C(h) si γ(h) sunt functii continue de h, mai putin, eventual, in origine.• Matricea de covarianta
C(x1, x1) C(x1, x2) · · · C(x1, xn)C(x2, x1) C(x2, x2) · · · C(x2, xn)
...... . . . · · ·
C(xn, x1) C(xn, x2) · · · C(xn, xn)
este pozitiv definita, in sensul ca toti determinantii minorilor principali sunt nenega-tivi. Astfel, variograma este negativ semidefinita.
• Este posibil ca variatia spatiala sa se modifice in functie de directia dintre locatiile xsi x+h, fenomen numit anizotropie. Un exemplu de anizotropie este mineralizarea.
Daca x = (x1, x2, x3) (regiune 3−dimensionala), atunci h =√
h21 +h2
2 +h23 si γ(h)
va reprezenta o familie de variograme γ(|h|, α), unde α este directia.• Ca functie de variabila lag h, variograma creste mai incet decat creste h2. Daca
ar creste mai rapid decat aceasta functie, aceasta ar indica prezenta unui trend incampul aleator.

8.4 Modelarea variogramei teoretice 91
Figura 8.6: Diverse tipuri de variograma: (a) nemarginita (procesul nu este slab stationar); (b)constanta (nu exista corelatii spatiale), (c) fara efect nugget, (d) fluctuanta.
8.4.2 Comportamentul variogramei in jurul originii
Cand variabila lag h se apropie de 0, forma variogramei poate fi una dintre cele reprezentatein Figura 8.7. Putem avea un comportament liniar care trece prin 0. In acest caz, pentruh suficient de mic, variograma are forma γ(h) = a|h|. Este posibil ca variograma sa aibao forma aproximativ liniara cand h este suficient de mic, insa sa nu treaca prin 0. Estecazul figurii (b), in care se observa efectul nugget. In cazul (c), variograma are o formaparabolica pentru h suficient de mic, de forma γ(h) = a|h|2. In figura (c), variograma treceprin 0, dar exista cazuri in care se poate observa un efect nugget si pentru forma parabolica.O variograma cu un comportament parabolic in jurul originii sugereaza existenta unuitrend in variabila spatiala Z(x).
Figura 8.7: Diverse tipuri de comportament in jurul originii unei variograme:(a) liniar; (b) efect nugget; (c) parabolic.

92 Capitolul 8. Procese stochastice spatiale
8.4.3 Modele de variograma
Nu orice functie care se apropie suficient de mult de variograma empirica poate fi ovariograma teoretica. O variograma teoretica va trebui sa satisfaca anumite conditii, dupacum urmeaza:
• functia ia doar valori pozitive (mai putin, eventual, in cazul h = 0);• functia trebuie sa fie crescatoare in h;• pentru h suficient de mare, functia atinge un maximum (sill);• uneori, aceasta functie nu porneste din 0, caz in care valoarea γ(0) se numeste efect
nugget;• exista cazuri in care functia fluctueaza periodic (apar zone numite holes);
Modelele de variograma prezentate mai jos sunt modele izotropice, astfel ca functiiledepind doar de h = |h|. Putem construi modele marginite sau nemarginite. Un exemplu demodel nemarginit este urmatorul:
γ(h) = uhα , cu 0 < α < 2,
si u este un numar real ce reprezinta intensitatea variatiei. Constanta α reprezinta curbura.Pentru α = 1 avem o variograma liniara; pentru 0 < α < 1 avem o variograma concava sipentru α > 1 avem o variograma convexa.
Exista o clasa de modele de variograma teoretica care garanteaza existenta unei solutiiunice. Acestea se numesc modele valide de variograma si sunt urmatoarele:
• modelul exponential, pentru care
γ(h) = c
1− e− h
ar
, daca h > 0.
• modelul sferic, pentru care
γ(h) =
c
[3h2r− 1
2
(hr
)3]
, daca 0 < h≤ r;
c , daca h > r.
• modelul Gaussian, pentru care
γ(h) = c
1− e−1
a
(hr
)2 , daca h > 0.
Aici, am notat c = s−n, s = sill, n = nugget si a este o constanta folosita cu diferitevalori in carti. O valoare des folosita este a = 1/3.

8.4 Modelarea variogramei teoretice 93
Figura 8.8: Modele valide de variograma
Alte modele de variograma:• modelul liniar marginit, folosit doar pentru variatii intr-o singura dimensiune. Vario-
grama corespunzatoare este:
γ(h) =
c(
hr
), daca 0 < h≤ r;
c , daca h > r.
• modelul circular, pentru care
γ(h) =
c
[1− 2
πarccos
(hr
)+
2hπr
√1− h2
r2
], daca 0 < h≤ r;
c , daca h > r.
• modelul pentasferic, pentru care
γ(h) =
c
[158
hr− 5
4
(hr
)3
+38
(hr
)5]
, daca 0 < h≤ r;
c , daca h > r.
• modelul cubic, pentru care
γ(h) =
c
[7(
hr
)2
− 354
(hr
)3
+72
(hr
)5
− 34
(hr
)7]
, daca 0 < h≤ r;
c , daca h > r.
• modele compuse;

94 Capitolul 8. Procese stochastice spatiale
Acestea pot fi compuse din doua sau mai multe modele de mai sus. Sunt folosite mai alescand avem multe date si variogramele par a fi mai complexe. Sunt folosite in special atuncicand variograma prezinta efect nugget. Exemple: modelul exponential cu nugget, modeluldublu sferic, modelul dublu exponential etc.Pentru modelul exponential cu nugget, variograma (cea desenata cu albastru in primulgrafic alaturat) este:
γ(h) = c0 + c
1− e− h
ar
, daca h > 0.
Pentru modelul dublu sferic cu nugget (format din compunerea a doua modele sferice plusun model nugget) desenat in al doilea grafic, variograma (cea desenata cu albastru) este:
γ(h) =
c0 + c1
[3h2r1− 1
2
(hr1
)3]+ c2
[3h2r2− 1
2
(hr2
)3]
,0 < h≤ r1;
c0 + c1
[3h2r1− 1
2
(hr1
)3]
,r1 < h≤ r2;
c1 + c2 ,h > r2.
Figura 8.9: Modele compuse
• modelul pure nugget, pentru care
γ(h) =
0 , daca h = 0;c , daca h > 0.
Este modelul desenat in Figura 8.6 (b).• modele cu functii oscilante (vezi Figura 8.6 (d)), e.g.:
γ(h) = c(
1− sinhh
).

8.4 Modelarea variogramei teoretice 95
8.4.4 Estimator pentru variogramaIn practica, un geostatistician are la indemana un set de date spatiale (masuratori), pe bazacarora doreste sa creeze o harta a regiunii de unde au fost facute aceste masuratori, care saindice variatia variabilei de interes. Determinarea variogramei este unul dintre lucrurileimportante pe care trebuie sa le intreprinda pentru a-si atinge scopul. Folosind acestemasuratori, el poate estima variograma procedand astfel.Presupunem ca valorile masurate (x1, x2, . . . xn):
z1 = z(x1), z2 = z(x2), . . . , zn = z(xn).
orice pereche de locatii (xi, x j) (exista n(n−1)2 astfel de perechi), se calculeaza (semi)variantele:
γ(xi, x j) =12[zi− z j]
2.
Reprezentarea grafica a acestora in functie de lag se numeste norul variogramei.Deoarece este dificil (daca nu imposibil) de examinat variatia spatiala din aceasta
reprezentare, se va face o medie a tuturor variantelor pentru fiecare valoare de lag h,obtinandu-se variograma empirica.
Figura 8.10: Semivariantele in functie de lag (norul variogramei)
Pentru a ne face o idee despre cum sunt corelate datele pentru diferite nivele de lag, sepot construi asa-numitele h−scattergrame. Acestea sunt reprezentari grafice ale valorilorz(x+h) versus z(x) (vezi Figura 8.11).

96 Capitolul 8. Procese stochastice spatiale
Figura 8.11: Exemple de h−scattergrame
Pentru un nivel de lag h, calculam
γ(h) =1
2|N(h)| ∑(i, j)∈N(h)
[zi− z j]2, (8.4.11)
unde N(h) reprezinta multimea tuturor perechilor de observatii i, j care satisfac conditiade lag, |xi− x j|= h si |N(h)| este numarul acestor perechi. In general, valoarea lui h esteadmisa cu o anumita toleranta.
Pentru fiecare nivel de lag h, valorile γ(h) le scriem in ordine crescatoare, obtinandastfel variograma empirica (sau variograma experimentala). Formula (8.4.11) este cu-noscuta sub numele de estimator obtinut prin metoda momentelor si a fost introdus de (G.Matheron).
Variograma empirica este un estimator nedeplasat pentru variograma teoretica γ(h).Daca Z(x) este ergodic, atunci γ(h)→ γ(h) cand n→ ∞. Un analist nu poate trage conclu-zii despre variabilitatea spatiala doar bazandu-se pe variograma experimentala, deoarecevariograma experimentala nu poate prezice valorile variatiei spatiale in locatiile nemasuratea priori. Aceste valori pot fi prezise doar dupa ce o variograma teoretica este potrivita; pebaza acesteia se utilizeaza metode de kriging pentru predictie.
8.4.5 Pasi in estimarea variogrameiConstructia unei variograme presupune urmatorii pasi:

8.4 Modelarea variogramei teoretice 97
• Determinam pasul lag, h. Un pas h este practic daca pentru aceasta valoare avem celputin 30 de perechi (xi, x j) care sa se situeze la aceasta distanta. Este de dorit ca hsa fie mai mic decat jumatate din range-ul datelor observate.
• Stabilirea unei tolerante pentru determinarea lui h. Aceasta valoare va precizaacuratetea cu care o anumita distanta este aproximata cu h. Cu alte cuvinte, tolerantadetermina latimea clasei h stabilite.
• Stabilirea numarului de pasi h pentru care vom calcula variograma experimentala;• Stabilirea unui unghi si determinarea unei tolerante pentru unghi;
Figura 8.12: Construirea variogramei experimentale
• Pentru un h fixat si pentru fiecare pereche de noduri (x, x+h) ale retelei de locatii,calculam valoarea
γ(h) =1
2|N(h)| ∑(x,x+h)
[Z(x)−Z(x+h)]2,
• Pentru toate valorile lui h, sa spunem ca acestea sunt h1, h2, . . . , hm, vom obtinevalorile corespunzatoare γ(h1), γ(h2), . . . , γ(hm).
• Reprezentam valorile (hi, γ(hi)) intr-un grafic si obtinem astfel variograma experi-mentala (empirica).
• Daca se observa anizotropie, se va repeta procedura pentru un alt unghi, construindu-se astfel o noua variograma.

98 Capitolul 8. Procese stochastice spatiale
Figura 8.13: Variograma experimentala (puncte albastre) si cea teoretica (cu linie rosie)
Exemplu: Variograma pentru o singura dimensiune spatiala
Intr-o singura dimensiune, toate locatiile de unde se fac masuratori sunt situate pe odreapta. Presupunem ca locatiile masuratorilor, x1, x2, . . . , xn, sunt cele din Figura 8.14(a). Cerculetele goale reprezinta lipsa de masuratori din respectivele locatii. Figurile 8.14(b), (c) si (d) arata cum se formeaza perechile pentru valorile de lag 1, 2, respectiv 3. Incazul 1 dimensional, formula 8.4.11 devine:
γ(h) =1
2(n−h)
n−h
∑i=1
[zi− zi+h]2. (8.4.12)
Pentru h = 1, calculam valoarea γ(1) pentru toate perechile care se afla la o distanta deo lungime, folosind formula 8.4.12. Similar, pentru h = 2, 3, . . . , n, calculam valoarileγ(2), γ(3), . . . , γ(n), pentru toate perechile care se afla la o distanta de, respectiv, 2 lungimi,3 lungimi, etc., n lungimi. Reprezentam grafic valorile γ(1), γ(2), . . . , γ(n) intr-un grafic,obtinand astfel variograma experimentala 1-dimesionala.

8.4 Modelarea variogramei teoretice 99
Figura 8.14: Variograma experimentala 1−dimensionala (cerculetele goale sunt locatii neselec-tate)
8.4.6 Sfaturi practice pentru construirea unei variograme
• Priviti in ansamblu datele observate. Pot aparea unele erori de masurare, virguleomise, alte tipuri de date etc;
• Observati orice tip de clustere in date. In caz ca sunt prezente, trebuie indepartate;• In cazul in care datele par a nu fi observatii normale, o transformare a lor ar fi
necesara (e.g., logaritmare);• Variograma ar trebui determinata in cel putin 3 directii diferite;• Detectati daca este prezent vreun trend in varianta experimentala. Daca este posibil,
determinati variograma fara trend;• Verificati prezenta izotropiei.
8.4.7 Indicatorul Akaike
Tendinta unui analist este de a crea modele statistice cat mai apropiate de datele observate.Pentru a realiza acest deziderat, se poate folosi, spre exemplu, metoda celor mai mici patrate.Daca modelul este prea simplist (modelul contine putini parametri necunoscuti), rezultatulpoate fi unul nesatisfacator. De aceea, de multe ori in practica suntem tentati sa introducemnoi parametri in model, imbunatatind considerabil apropierea datelor de modelul teoretic.Insa, odata cu cresterea numarului de parametri, apare problema urmatoare: modelul astfelobtinut va avea performante foarte slabe in a face predictii. Un model prea complex va”memora” valorile caracteristicii in locatiile observate pentru a le reproduce cu precizie,insa nu va avea capabilitati de a prezice valori pentru date neobservate, nefiind ”antrenat”sa o faca. Daca modelul ar fi fost mai putin complex, s-ar fi folosit de valorile observatepentru a prezice eventuale valori pentru variabila cercetata.
Indicatorul Akaike realizeaza un compromis intre complexitatea unui model (care, deobicei, este reprezentata de numarul de parametri; mai multi parametri implica un modelmai complex) si cea mai buna potrivire a modelului (determinata de metoda celor mai micipatrate). Acest indicator se defineste astfel:
AIK= 2p−2lnL, (8.4.13)

100 Capitolul 8. Procese stochastice spatiale
unde p este numarul de parametri din model si L este functia de verosimilitate a modelului.Pentru un model statistic, o functie de verosimilitate (in engleza, likelihood) este o functiede parametrii modelului, care este egala cu probabilitatea de a observa datele masuratepentru parametrii dati. Un estimator pentru indicele teoretic AIK este urmatorul:
AIK= 2p+2ln(MSE)+
n ln(
2π
n
)+n+2
, (8.4.14)
unde n este numarul de puncte de pe variograma si MSE este media patratelor erorilor deaproximare (mean squared error).
8.4.8 Metode de estimare a variogramei teoretice
Pentru a stabili un model teoretic de variograma care se potriveste cel mai bine datelormasurate, este nevoie de a estima parametrii modelului teoretic. Spre exemplu, daca dorimsa determinam o variograma teoretica exponentiala, atunci avem de estimat 2 parametri, sianume: c (lungimea de variatie) si r (range). In cazul in care modelul include si o valoarenugget, atunci mai avem, in plus, un parametru de determinat, si anume c0. Exista douametode uzuale folosite in estimarea acestor parametri: metoda celor mai mici patrate simetoda cu ponderi a celor mai mici patrate. In cazul metodei celor mai mici patrate, secauta sa se minimizeze suma patratelor erorilor dintre valorile estimate pentru variogramasi cele masurate a priori. Matematic, problema se scrie astfel: determinati acea valoarepentru vectorul de parametri, θ , care este solutia problemei de optim:
minθ
∑i[γ(hi, θ)− γ(hi)]
2.
Pentru metoda cu ponderi a celor mai mici patrate, se determina acea valoare pentruvectorul de parametri, θ care este solutia problemei de optim:
minθ
∑i
[γ(hi, θ)− γ(hi)]2
Var(γ(hi)),
unde
Var(γ(h))≈ 2|N(h)|(γ(h, θ))2.
Astfel, ponderile sunt
wi =1
Var(γ(hi))≈ |N(hi)|
2(γ(hi, θ))2 .
8.4.9 Anizotropia
In multe cazuri, variograma empirica difera in functie de directia spatiala, fapt ce senumeste anizotropie (geometrica). Cu alte cuvinte, anizotropia este variatia variogrameicu directia spatiala a observate. In caz de anizotropie, se pot observa diferite pante alevariogramei in diferite directii spatiale. In multe cazuri insa este posibil de a modela

8.4 Modelarea variogramei teoretice 101
anizotropia printr-o transformare liniara de coordonate carteziene.
Figura 8.15: Directii spatiale diferite Figura 8.16: Variograme pentru directii dife-rite


9. Kriging
9.1 IntroducereDupa cum am discutat anterior, un teren pentru care un geostatistician doreste sa studiezeproprietatile unor anumite variabile are o infinitate de locatii. Masuratorile pe care acesteale poate efectua sunt in numar finit. De fapt, din consideratii practice si economice, el vaconsidera doar cateva locatii unde va efectua masuratori. In restul de locatii, el va dori safaca predictii pe baza datelor deja culese. O metoda de baza in Geostatistica folosita inpredictia valorilor in locatiile neselectate pentru masurare se numeste kriging. Kriging esteo forma (generalizata) de regresie liniara prin care se determina un estimator (predictor)spatial. In contrast cu regresia liniara multipla, metoda de kriging tine cont de volumulobservatiilor si de corelatiile dintre aceste valori. Metoda functioneaza cel mai bine intr-undomeniu convex (un domeniu in care, odata cu doua puncte, va contine si segmentul ce leuneste). In mod uzual, rezultatele unei interpolari de tip kriging sunt: valoarea asteptata(media de kriging) si dispersia (varianta de kriging), estimate in punctul dorit din regiune.Numele de kriging deriva de la numele inginerului minier Danie Krige, nume atribuitde G. Mangeron. Exista atat metode liniare, cat si neliniare de interpolare spatiala degen kriging. Fiecare dintre aceste metode face presupuneri diferite relativ la fluctuatiilevariabilei. Dintre aceste metode, amintim urmatoarele: kriging ordinar, kriging simplu,kriging lognormal, kriging cu drift, kriging factorial, cokriging, kriging indicator, krigingdisjunctiv, kriging bayesian etc. Metoda generala de kriging este urmatoarea.
Presupunem ca dorim sa prezicem valorile caracteristicii Z(x) intr-o regiune R. Aceastaregiune poate fi 1−, 2− sau 3− dimensionala. Se efectuaza observatii asupra acesteivariabile in locatiile x1, x2, . . . , xn ale regiunii R. Pe baza acestor masuratori, dorim saprezicem valorile lui Z in celelalte locatii din regiune. O formula generala a unui estimatorpentru valoarea variabilei Z intr-o locatie generica din R, sa zicem x0, este:
Z(x0) =n
∑i=1
λiZ(xi), (9.1.1)

104 Capitolul 9. Kriging
unde λi sunt ponderile ce trebuie determinate.
9.2 Kriging simplu
Este cea mai restrictiva metoda kriging. In cazul unei metode de interpolare geostatisticade tip kriging simplu se fac urmatoarele presupuneri relativ la variabila Z:
• valorile observate formeaza o realizare partiala a procesului aleator generat de Z(x).• variabila Z(x) se considera a fi stationara de ordinul al doilea (slab stationara), i.e.,
E(Z(x)) = µ si cov(Z(x), Z(x+h)) = C (h), pentru orice locatie x din R.
• valoarea constanta µ si covarianta C (h) sunt presupuse a fi cunoscute a priori.
Predictiile metodei kriging simplu sunt ba-zate pe urmatorul model de camp aleator:
Z(x) = µ + ε(x), (9.2.2)
unde µ este o constanta cunoscuta si ε(x)este partea aleatoare a variabilei, reprezen-tand eroarea de aproximare a variabilei cuvaloarea µ . Aceasta eroare este presupusaa fi normala, de medie 0.
Figura 9.1: Variabila Z(x) pentru kriging simpluIn cazul unui kriging simplu, se prezice valoarea variabilei Z in locatia necunoscuta x0
folosind relatia:
ZSK(x0) = µ +n
∑i=1
λi (Z(xi)−µ) , (9.2.3)
unde λi sunt ponderile asociate erorilor masuratorilor obtinute in locatiile selectate. Putemrescrie relatia precedenta sub forma echivalenta:
ZSK(x0) =n
∑i=1
λiZ(xi)+
(1−
n
∑i=1
λi
)µ.
Pentru simplitate, putem presupune ca media cunoscuta este µ = 0. In caz ca aceasta estediferita de zero, efectuam calculele pentru µ = 0, obtinem valoarea prezisa, dupa careadaugam µ la final. Obtinem ca
ZSK(x0) =n
∑i=1
λiZ(xi). (9.2.4)

9.2 Kriging simplu 105
Vom determina ponderile λi astfel incat sa minimizeze varianta estimatorului ZSK . Aceastaeste:
Var[ZSK(x0)] = Var
[Z(x0)−
n
∑i=1
λiZ(xi)
]
= Var[Z(x0)]−2n
∑j=1
λ jcov(Z(x0), Z(x j))+n
∑i=1
n
∑j=1
λiλ jcov(Z(xi), Z(x j))
= C (0)−2n
∑j=1
λ jcov(Z(x0), Z(x j))+n
∑i=1
n
∑j=1
λiλ jcov(Z(xi), Z(x j))
Pentru a determina ponderile λi ce realizeaza minimumul lui Var[ZSK(x0)], se cauta punc-tele critice in raport cu λi, adica rezolvam sistemul de ecuatii:
∂
∂λ jVar[ZSK(x0)] = 0, pentru orice j = 1, 2, . . . , n.
Se va obtine sistemul de ecuatii algebrice (n ecuatii cu n necunoscute):
cov(Z(x0), Z(x j)) =n
∑i=1
λicov(Z(xi), Z(x j)), pentru orice j = 1, 2, . . . , n. (9.2.5)
Cu solutiile λ SKi astfel obtinute, se estimeaza valoarea Z0 folosind formula (9.2.4). Disper-
sia de kriging va fi data de:
σ2SK(x0) = C (0)−
n
∑i=1
λSKi cov(Z(x0), Z(xi)).
Estimarile obtinute prin kriging simplu sunt nedeplasate. De notat faptul ca valorileponderilor λi depind doar de locatii si de covariante, dar nu si de datele observate. In cazulmetodei kriging simplu, suma acestor ponderi nu este neaparat egala cu 1.
Dupa ce prezicem prin kriging simplu valorile variabilei Z in toate locatiile regiuniide interes, se pune problema urmatoare: Ce se intampla cand prezicem valoarea intr-unpunct unde avem deja masuratori?Cand un punct x0 in care prezicem valoarea variabilei se apropie de un punct x0 +h in caream masurat deja valoarea lui Z, si daca variograma este fara nugget (i.e., este continua),atunci
C (h) = cov(Z(x0), Z(x0 +h)) h→0−→ cov(Z(x0), Z(x0)) = C (0) = 0.
Astfel daca punctul x0 este foarte apropiat de punctul xi (din selectie), putem aproximacov(Z0, Zi) prin cov(Z0, Z0) = C (0). In acest caz, dispersia pentru kriging simplu devine
σ2SK(x0) = C (0)−
n
∑i=1
λSKi C (0) =
(1−
n
∑i=1
λSKi
)C (0) = 0. (9.2.6)
Mai mult,lim
x0→xiZSK(x0) = Z(xi).

106 Capitolul 9. Kriging
In cazul in care nu exista efect nugget, atunci metoda kriging simplu pastreaza valorilemasurate (i.e., Z(xi) = Z(xi): valorile estimate prin kriging simplu in locatiile stabilite apriori sunt chiar cele masurate). Pentru doua locatii apropiate, aceasta metoda va prezicevalori apropiate ale variabilei Z.
Figura 9.2: 5 simulari ale variabilei Z(x) ce pastreaza cele 4 valori masurate initial
Exercitiu 9.1 (preluat din [olea]) Pentru o variabila Z s-au observat valorile sale in loca-tiile precizate cu buline rosii in Figura 9.3 de mai jos. Pe baza acestor valori, se cere sa seprezica valoarea variabilei Z in locatia x0 si dispersia pentru aceasta valoare. Se cunosc:µ = 110 si γ(h) = 2000(1− e−h/250) pentru h > 0. (model exponential de variograma).
Figura 9.3: Locatii intr-un camp aleator
Figura 9.4: Tabel cu date observate
Solutie: Distantele di j dintre locatiile masurate, calculate cu formula
di j = d(xi, x j) =√
(xi1− x j1)2 +(xi2− x j2)2,
sunt
d11 d12 d13 d14d21 d22 d23 d24d31 d32 d33 d34d41 d42 d43 d44
=
0 260.8 264 364
260.8 0 266.3 366.7264 266.3 0 110.4364 366.7 110.4 0

9.2 Kriging simplu 107
Distantele d0i de la x0 la xi sunt:
[d01, d02, d03, d04] = [197.2, 219.3, 70.7, 180].
Din formula γ(h) = C (0)−C (h), gasim covariantele. Aici, C (0) = 2000 si
C (x0, x1) = 2000e−d01/250 = 2000e−197.2/250 = 908.78,
C (x0, x2) = 2000e−d02/250 = 2000e−219.3/250 = 831.89,
C (x1, x2) = 2000e−d12/250 = 2000e−260.8/250 = 704.65 etc.
Sistemul de ecuatii (9.2.5) care determina ponderile λi devine:
λ1C (x1, x1)+λ2C (x2, x1)+λ3C (x3, x1)+λ4C (x4, x1) = C (x0, x1);λ1C (x1, x2)+λ2C (x2, x2)+λ3C (x3, x2)+λ4C (x4, x2) = C (x0, x2);λ1C (x1, x3)+λ2C (x2, x3)+λ3C (x3, x3)+λ4C (x4, x3) = C (x0, x3);λ1C (x1, x4)+λ2C (x2, x4)+λ3C (x3, x4)+λ4C (x4, x4) = C (x0, x4).
Inlocuind valorile covariantelor, obtinem:
2000λ1 +704.65λ2 +695.68λ3 +466.33λ4 = 908.78;704.65λ1 +2000λ2 +689.31λ3 +461.32λ4 = 831.89;
695.68λ1 +689.31λ2 +2000λ3 +1286.01λ4 = 1507.34;466.33λ1 +461.32λ2 +1286.01λ3 +2000λ4 = 973.50.
Dupa rezolvarea sistemului, obtinem ponderile:
λSK1 = 0.1847, λ
SK2 = 0.1285, λ
SK3 = 0.6460, λ
SK4 =−0.0013.
Folosind formula (9.2.2), determinam estimarea valorii lui Z in x0:
zSK(x0) = µ +λSK1 (z(x1)−µ)+λ
SK2 (z(x2)−µ)+λ
SK3 (z(x3)−µ)+λ
SK4 (z(x4)−µ)
= 110+0.1847 · (40−110)+0.1285 · (130−110)+0.6460 · (90−110)−−0.0013 · (160−110)
= 86.6560.
Dispersia estimatorului in acest punct poate fi calculata cu formula (9.2.6). Obtinem:
σ2SK(x0) = C (0)−
n
∑i=1
λSKi cov(Z(x0), Z(xi))
= 2000−0.1847 ·908.78−0.1285 ·831.89−0.6460 ·1507.34+0.0013 ·973.50= 752.7744.
In cazul in care valoarea µ din formula (9.2.2) nu este cunoscuta, avem doua posibilitatide a prezice valorile variabilei Z in celelalte valori decat cele masurate:
• Estimam valoarea µ pe baza observatiilor prin µ =n
∑i=1
zi, apoi folosim metoda
kriging simplu. Insa, aceasta metoda nu tine cont de variabilitatea valorilor zi inprezicerea lui µ .
• Folosim o alta metoda de kriging, numita kriging ordinar.

108 Capitolul 9. Kriging
9.3 Kriging ordinarEste cea mai uzuala metoda de kriging (interpolare geospatiala). In cazul unui krigingordinar, campul aleator este considerat a fi tot de forma (9.2.2), insa de aceasta dataconstanta µ este necunoscuta si va trebui estimata. Valoarea prezisa a lui Z in x0 este
ZOK(x0) =n
∑i=1
λiZ(xi), (9.3.7)
unde ponderile λi satisfac constrangerean
∑i=1
λi = 1. Aceasta constrangere asigura ne-
deplasarea estimatorului ZOK , in sensul ca valoarea asteptata este E[Z(x0)−Z(x0)] = 0.Dispersia estimatorului este:
Var[ZOK(x0)] = E[(
ZOK(x0)−Z(x0))2]= Var
[ZOK(x0)−Z(x0)
]= Var
[n
∑i=1
λiZ(xi)−Z(x0)
]
= Var[Z(x0)]︸ ︷︷ ︸= C (0)
−2n
∑i=1
λicov(Z(x0), Z(xi))+n
∑i=1
n
∑j=1
λiλ jcov(Z(xi), Z(x j))
= 2n
∑i=1
λiγ(x0, xi)−n
∑i=1
n
∑j=1
λiλ jγ(xi, x j),
unde γ(xi, x j) sunt (semi)variatiile intre valorile campului aleator Z observate in locatiilexi si x j si γ(xi, x j) sunt (semi)variatiile intre valoarea observata a campului aleator Z inlocatia xi si valoarea lui Z in locatia de estimat x0.
Scopul este de a determina ponderile λi ce realizeaza minimul lui Var[ZOK(x0)] cu
constrangerean
∑i=1
λi = 1. Metoda de lucru este metoda multiplicatorilor lui Lagrange. Se
considera functia
F(α,λi) = Var[ZOK(x0)]+α
(n
∑i=1
λi−1
),
unde α este o constanta ce urmeaza a fi determinata, numita multiplicator Lagrange. Seconsidera sistemul format din anularea derivatelor functiei F(α,λi) in raport cu α si λi,i.e.,
∂F(α,λi)
∂λ1= 0;
∂F(α,λi)
∂λ2= 0;. . .
∂F(α,λi)
∂λn= 0;
∂F(α,λi)
∂α= 0.

9.3 Kriging ordinar 109
Vom obtine sistemul :
cov(Z(x0), Z(x j)) =n
∑i=1
λicov(Z(xi), Z(x j))+α, pentru orice j = 1, 2, . . . , n.(9.3.8)
n
∑i=1
λi = 1. (9.3.9)
Aceste sistem de n+1 ecuatii si n+1 necunoscute, si anume λ1, λ2, . . . , λn, α . Solutiileλ OK
i ale acestui sistem sunt ponderile cautate. Folosind aceste ponderi, determinam estimaavalorii lui Z in x0 prin:
ZOK(x0) =n
∑i=1
λOKi Z(xi).
Dispersia pentru kriging ordinar se calculeaza similar ca in cazul metodei krigingsimplu si are formula:
σ2OK(x0) = C (0)−
n
∑i=1
λOKi cov(Z(x0), Z(xi))−α. (9.3.10)
Observatii:• Ponderile λ OK
i vor avea valori mai mari pentru punctele apropiate lui x0. In general,cele mai apropiate 4 sau 5 valori contribuie cu cca 80% din ponderea totala inprezicerea valorii lui Z in x0, iar urmatoarele 10 puncte invecinate cu cca 20%.
• In general, σ2OK(x0) este un pic mai mare decat σ2
SK(x0) din cauza incertitudiniilegate de valoarea reala a lui µ .
• Daca variograma prezinta efect nugget, atunci cresterea dispersiei pentru nugget vaconduce la o crestere a dispersiei pentru valorile prezise prin kriging.
• Daca locatiile masuratorilor nu sunt regulat raspandite, atunci punctele izolate au ingeneral ponderi mai mari decat cele adunate in palcuri (clustere).
• Punctele care sunt ecranate (mascate) de alte puncte din regiune pot avea ponderinegative.
• Am vazut ca, pentru un punct x0, doar o multime mica de puncte vecine vor aveaponderi nenule semnificative, restul ponderilor fiind aproape egale cu 0. Din acestmotiv, am putea reduce sistemul de kriging (implicit formula (9.3.7) doar la punctelevecine. Daca numarul acestor puncte vecine este semnificativ mai mic decat n, atunciprocedeul numeric de calcul al ponderilor se va desfasura intr-un timp mult mai mic.Este posibil ca, pentru un n mare, ponderile calculate sa prezinte erori mari, dincauza complexitatii sistemului de ecuatii care au ca solutii aceste ponderi. De aceea,se recomanda calcularea ponderilor doar pentru o multime mica de vecini ai lui x0.
• Pentru a determina vecinatatea lui x0 pentru care este practic sa calculam ponderile,se poate proceda astfel:
– Pentru o variograma marginita si date dense in jurul lui x0, aceasta vecinatatepoate avea dimensiunea range-ului de la variograma. Oricum, punctele care iesdin acest range aproape ca nu sunt corelate cu x0.
– Daca datele sunt rarefiate, atunci punctele indepartate pot avea ponderi impor-tante, asa ca ar fi necesara o vecinatate care sa le includa.

110 Capitolul 9. Kriging
– Pentru un efect nugget mare, punctele in-departate vor avea ponderi semnificative,deci vecinatatea lui x0 ar trebui sa le in-cluda.
– Pentru o retea neregulata de date selectate,numarul minim de puncte din vecinatateaunui x0 este 3 si numarul maxim nu artrebui sa depaseasca 25.
– Daca datele din selectie sunt foarte neregu-late, atunci este utila impartirea spatiuluidin jurul lui x0 in octanti si sa fie alese celemai apropiate 2 puncte din fiecare octant(vezi Figura 9.5).
Figura 9.5: Impartirea in oc-tanti pentru determinarea veci-nilor
Exercitiu 9.2 Folosind metoda de interpolare geostatistica kriging ordinar, determinati opredictie si dispersia acesteia pentru valoarea in locatia x0 din Exercitiul 9.1.
Solutie: Valorile pentru distante sunt aceleasi ca in Exercitiul 9.1. Sistemul de ecu-atii (9.3.8)&(9.3.9) care determina ponderile λi si multiplicatorul Lagrange α este:
λ1C (x1, x1)+λ2C (x2, x1)+λ3C (x3, x1)+λ4C (x4, x1)+λ1 = C (x0, x1);λ1C (x1, x2)+λ2C (x2, x2)+λ3C (x3, x2)+λ4C (x4, x2)+λ2 = C (x0, x2);λ1C (x1, x3)+λ2C (x2, x3)+λ3C (x3, x3)+λ4C (x4, x3)+λ3 = C (x0, x3);λ1C (x1, x4)+λ2C (x2, x4)+λ3C (x3, x4)+λ4C (x4, x4)+λ4 = C (x0, x4);
λ1 +λ2 +λ3 +λ4 = 1.
Inlocuind valorile covariantelor, obtinem:
2000λ1 +704.65λ2 +695.68λ3 +466.33λ4 +α = 908.78;704.65λ1 +2000λ2 +689.31λ3 +461.32λ4 +α = 831.89;
695.68λ1 +689.31λ2 +2000λ3 +1286.01λ4 +α = 1507.34;466.33λ1 +461.32λ2 +1286.01λ3 +2000λ4 +α = 973.50;
λ1 +λ2 +λ3 +λ4 = 1.
Dupa rezolvarea sistemului, obtinem ponderile λi si multiplicatorul Lagrange α:
λOK1 = 0.1971, λ
OK2 = 0.1410, λ
OK3 = 0.6506, λ
OK4 = 0.0113, α =−42.6936.
Folosind formula (9.3.7), determinam estimarea valorii lui Z in x0:
zOK(x0) = λOK1 z(x1)+λ
OK2 z(x2)+λ
OK3 z(x3)+λ
OK4 z(x4)
= 0.1971 ·40+0.1410 ·130+0.6506 ·90+0.0113 ·160= 86.576.

9.4 Kriging lognormal 111
Dispersia estimatorului in acest punct poate fi calculata cu formula (9.3.10). Obtinem:
σ2OK(x0) = C (0)−
n
∑i=1
λOKi cov(Z(x0), Z(xi))−α
= 2000−0.1971 ·908.78−0.1410 ·831.89−0.6506 ·1507.34−−0.0113 ·973.50+42.6936
= 754.60.
9.4 Kriging lognormal
Daca datele observate z(x1), z(x2), . . . , z(xn) sunt pozitive dar nu par a fi normale (acestfapt se poate observa dintr-un indice de skewness mai mare decat 1), atunci o practicautila este logaritmarea datelor. Vom obtine astfel setul de date y(x1), y(x2), . . . , y(xn), cuy(xi) = ln(z(xi)). Cu alte cuvinte, in loc sa analizam variabila initiala Z(x), vom lucracu variabila transformata Y (x) = lnZ(x). Daca presupunem ca procesul aleator generatde Y (x) este stationar de ordinul al doilea (slab stationar), atunci putem aplica metodeleanterioare (kriging simplu sau kriging ordinar) pentru valorile transformate. Vom obtineastfel valori prezise pentru Y in locatiile neconsiderate in selectie si dispersii pentru acestevalori. Dupa aceasta, aceste valori se vor transforma inapoi in valori prezise pentru variabilaoriginala, Z(x).
Sa notam prin YSK(x0) si σ2SK(x0) estimatori punctuali pentru, respectiv, valoarea
prezisa si dispersia sa obtinute prin kriging simplu in x0. Similar, notam prin YOK(x0) siσ2
OK(x0) estimatori punctuali pentru, respectiv, valoarea prezisa si dispersia sa obtinuteprin kriging ordinar in x0. Atunci, estimatorii corespunzatori pentru variabila Z sunt:
ZSK(x0) = eYSK(x0)+12 σ2
SK(x0) pentru kriging simplu
si
ZOK(x0) = eYOK(x0)+12 σ2
OK(x0)−α(x0) pentru kriging ordinar,
unde α(x0) este multiplicatorul Lagrange. Dispersia pentru variabila originata poate fiestimata doar pentru metoda kriging simplu, pentru care µ este cunoscut. Aceasta este:
VarSK(x0) = µ2eσ2
SK(x0)[eσ2SK(x0)−1].

112 Capitolul 9. Kriging
9.5 Kriging universal (sau kriging cu drift)
Este posibil ca valoarea µ din relatia (9.2.2) sanu fie nici cunoscuta, nici constanta, indicandprezenta unui trend (sau drift). In acest caz,
Z(x) = u(x)+ ε(x), (9.5.11)
unde u(x) este o functie determinista si ε(x) estepartea aleatoare a variabilei, reprezentand eroa-rea de aproximare a variabilei cu valoarea µ .
Figura 9.6: Variabila cu trend neliniarAceasta eroare este presupusa a fi normala, de medie 0 si variograma γ(h). Cantitatea
ε(x) = Z(x)−u(x) se mai numeste si reziduu de trend. Expresia lui u(x) este de obicei unpolinom de coordonatele geografice, de forma:
u(x) =m
∑j=0
β j f j(x),
unde β j sunt niste numere reale necunoscute si f j(x) niste functii necunoscute. Acest trendpoate fi estimat pe baza observatiilor z(x1), z(x2), . . . , z(xn). Spre exemplu, un trend liniar2−dimensional arata de forma
u(x) = β0 +β1x1 +β2x2.
Un trend neliniar parabolic 1−dimensional care ar putea fi un model pentru cel din Figura9.6 este de forma
u(x) = β0 +β1x+β2x2.
Coeficientii β0, β1, β2 pot fi obtinuti prin metoda celor mai mici patrate (regresie liniaramultiple).
In prezenta unui trend, G. Matheron a sugerat estimarea variabilei Z in x0 prin
ZUK(x0) =n
∑i=1
λiZ(xi),
cu λi verificand constrangerean
∑i=1
λi = 1. Valoarea medie a acestui estimator este
E[ZUK(x0]) =n
∑i=1
m
∑j=0
λiβ j f j(xi)
Conditia de nedeplasare a estimatorului este:
n
∑i=1
λi f j(xi) = f j(x0), pentru orice j = 0, 1, 2, . . . , m.

9.6 Kriging indicator 113
Folosind metoda multiplicatorilor lui Lagrange, se pot determina ponterile λUKi si parame-
trii necunoscuti β j. Astfel, un estimator pentru valoarea lui Z in x0 va fi
ZUK(x0) =n
∑i=1
λUKi Z(xi),
iar dispersia acestui estimator este
VarUK(x0) = C (0)−n
∑i=1
λi C (x0, xi)−m
∑j=0
β j f j(x0).
9.6 Kriging indicatorAceasta medota de kriging este folosita pentru variabilele de tip binar (Bernoulli), adicaacele variabile discrete care pot lua doar doua valori: 1 (prezenta) sau 0 (absenta). Este utilain practica atunci cand pentru variabila de interes se doreste sa se estimeze probabilitatea caaceasta sa depaseeasca o anumita valoare prag, notata aici prin zc. Spre exemplu, am dorisa determinam probabilitatea ca, intr-o anumita regiune, apa de baut sa aiba o concentratiede nitrati sub pragul critic zc = 50mg/l. Un alt exemplu este determinarea probabilitatii caintr-o regiune solul sa aiba o valoare pH sub o valoare critica.
Fie Z o variabila de interes. Pentru aceasta variabila construim functia indicatoare
χzc(x) =
1 daca Z(x)≤ zc;0 daca Z(x)> zc.
Aceasta functie indicatoare este o variabila binara. Valoarea medie a acestei variabile estechiar probabilitatea ca valorile variabilei Z(x) sa nu depaseasca pragul critic zc, care estetotuna cu functia de repartitie a acestei variabile in valoarea zc. Matematic, scriem astfel:
E[χzc(x)] = P(Z(x)≤ zc) = FZ(x)(zc).
Pentru variabila indicatoare se poate estima variograma teoretica
γzc(h) =12E[(χzc(x)−χzc(x+h))2
]pe baza unei variograme experimentale:
γzc(h) =1
2|N(h)|N(h)
∑i=1
[(χzc(xi)−χzc(xi +h))2
].
Pe baza variogramei teoretice se pot prezice valori ale variabilei Z in punctele neselectate.O metoda de kriging indicator bazata pe n observatii χzc(xi)i=1,n are la baza formula deestimare:
χzc(x0) =n
∑i=1
λiχzc(xi). (9.6.12)

114 Capitolul 9. Kriging
Pentru estimare se poate proceda ca in metoda kriging simplu. Ponderile pot fi obtinute casolutii ale sistemului de n ecuatii si n necunoscute:
n
∑i=1
λiγzc(xi, x j) = γzc(x0, x j) pentro orice j = 1, 2, . . . , n,
unde γzc(xi, x j) sunt semivariantele calculate in punctele xi si x j. Dupa ce se determinaponderile λ IK
i , se estimeaza valoarea
χzc(x0) =n
∑i=1
λIKi χzc(xi).
Valoarea prezisa χzc(x0) va fi o valoare intre 0 si 1, reprezentand probabilitatea ca, pentrudatele observate, variabila Z(x) ia valori sub pragul critic zc. Matematic, scriem ca
χzc(x0) = P(
Z(x)≤ zc |zi, i = 1, n).
9.7 CokrigingAceasta metoda ofera posibilitatea de a prezice simultan valorile a doua sau mai multevariabile pentru un acelasi domeniu. Se mai numeste si coregionalizare. Nu este necesarca toate variabilele sa fie masurate in aceleasi locatii, insa ar fi indicat sa fie un minim devalori observate perechi in aceleasi locatii din regiune de interes. Aceasta metoda poate fiutila atunci cand una dintre variabile, variabila primara, a fost observata in putine locatii,insa corelatia sa cu alte variabile (secundare) de interes in regiune poate duce la o preciziemai mare a estimarilor celei dintai variabile.
Presupunem ca Z1(x), Z2(x), . . . , Zp(x) sunt p variabile ce se doresc a fi masuratepentru un acelasi domeniu. Putem crea matricea aleatoare:
Z(x) = [Z1(x), Z2(x), . . . , Zp(x)].
Vom nota prin Λi matricea ponderilor corespunzatoare fiecarei valori a fiecarei variabile.O vom scrie sub forma:
Λi =
λ i
11 λ i12 . . . λ i
1pλ i
21 λ i22 . . . λ i
2p. . . . . . . . . . . .λ i
41 λ i42 . . . λ i
pp
Scopul principal al metodei cokriging este de a determina (prin metoda celor mai micipatrate) ponderile Λi pentru estimatorul:
ZCK(x0) =n
∑i=1
ΛiZ(xi),
cu constrangerean
∑i=1
Λi = In matricea identitate de ordin n.
Modelul cokriging va furniza un numar de p estimatori liniari in x0, cate unul pentru fiecarevariabila in parte, si p dispersii corespunzatoare estimatorilor. Metoda este asemanatoarecu metoda kriging ordinara, insa executata pentru p variabile simultan.

9.8 Cross-validare (validarea incrucisata) 115
9.8 Cross-validare (validarea incrucisata)Cross-validarea este o metoda de verificare sau de a alege dintre mai multe modele dekriging pentru aceleasi date observate. Precizam mai jos detaliile validarii incrucisate:
• Se calculeaza variograma experimentala si apoi se potrivesc diverse variogrameteoretice potrivite;
• Se scoate un punct dintre cele n initiale si se estimeaza valoarea in acest punct pebaza celorlalte n− 1 puncte. Aceasta valoare prezisa este comparata cu valoareamasurata initial. Se repeta procedura pentru toate valorile observate.
• Diagnosticarea se face fie prin grafice sau prin masurarea erorilor de predictie.Graficele sunt de forma valori prezise versus valori masurate. Pentru opredictie cat mai buna, valorile prezise trebuie sa fie cat mai apropiate de celemasurate, aceasta observandu-se in grafic daca punctele rosii sunt apropiate dedreapta 1:1.
• Pentru a face un diagnostic numeric al preciziei estimarii, se folosesc urmatoarelemasuri ale erorilor de interpolare:
• Eroarea medie (Mean error in ArcGIS):
ME=1n
n
∑i=1
[z(xi)− z(xi)].
• Eroarea medie standardizata (MeanStandardized error in ArcGIS):
SME=1n
n
∑i=1
[z(xi)− z(xi)]
σ(xi).
• Eroarea medie patratica:
MSE=1n
n
∑i=1
[z(xi)− z(xi)]2.
• Radacina mediei erorilor patratice (Root-Mean-Square error in ArcGIS):
RMSE=
√1n
n
∑i=1
[z(xi)− z(xi)]2.
• Eroarea standard medie (Average Standard error in ArcGIS):
ASE=
√√√√√ n
∑i=1
σ(xi)
n.
• Radacina mediei erorilor patratice standardizate (Root-Mean-Square Standardizederror in ArcGIS):
RMSSE=
√1n
n
∑i=1
[z(xi)− z(xi)
σ(xi)
]2
.

116 Capitolul 9. Kriging
Figura 9.7: Compararea a doua metode kriging.
Pentru o precizie foarte buna este de dorit ca primele erorile ME, SME si MSE sa fie catmai apropiate de valoarea 0, eroarea RMSSE va trebui sa fie apropiate de valoarea 1, iarerorile RMSE si ASE sa fie similare. Figura 9.7 contine doua grafice pentru doua metodede interpolare kriging ordinar; prima metoda este fara trend iar a doua cu trend. Fiecarefigura reprezinta valorile prezise vs. valorile masurate. Pentru o apropiere cat mai buna,punctele rosii ar trebui sa fie cat mai apropiate de dreapta 1:1 (prima bisectoare). Pentru adetermina care dintre cele doua metode este mai buna, ne uitam la erorile afisate si cautammetoda ce da erorile cele mai mici.
9.9 Simulare stochasticaDupa cum am vazut mai sus, metodele kriging sunt utilizate pentru a estima valorileposibile ale unei variabile in locatiile neobservate. Estimarile obtinute sunt optimizateastfel incat in acele locatii variantele sunt minime. Totusi, nu este nicio garantie ca o hartaobtinuta printr-o metoda kriging va avea aceeasi variatie (sau variograma) ca si dateleobservate initial. Daca se doreste a construi o harta care sa pastreze intocmai caracteristiciledatelor observate, atunci trebuie considerate metode alternative la metodele kriging. Oastfel de metoda este simularea stochastica.
Simularea stochastica ofera posibilitatea de a crea valorile uneia sau mai multorvariabile care sa aiba aceleasi caracteristici ca si datele observate in realitate. Variabilelepentru care putem obtine simulari pot fi atat discrete cat si continue.
Presupunem ca z(xi)i=1,n sunt valorile observate pentru variabila Z(x). Dupa cumam discutat anterior, putem privi Z(x) ca fiind un proces stochastic. Daca acest proceseste stationar de ordinul al doilea, atunci el poate fi descris prin media si functia de

9.9 Simulare stochastica 117
covarianta. Acesti parametri ii putem estima cu statistici specifice obtinute pe baza datelorobservate. Principiul simularii stochastice este simularea pe calculator de valori posibilepentru variabila Z(x) ce au media si functia de covarianta stabilite. Se pot astfel creaoricate (o infinitate) simulari se doreste, toate realizarile avand aceeasi probabilitate deaparitie, aceeasi medie si aceeasi functie caracteristica. Din punct de vedere teoretic,valoarea medie a unui numar mare de simulari va arata similar cu harta obtinuta prinmetoda kriging. Simularile stochastice ofera posibilitatea de a obtine predictii realiste alevalorile unei variabile, pe cand estimarile obtinute prin metoda kriging se preocupa maimult de acuratetea statistica a predictiilor.
In concluzie, metoda kriging ofera estimari locale de varianta minima, fara a se preo-cupa de distributia in ansamblu a valorilor prezise. Pe de alta parte, simularea stochasticaare ca scop reproducerea distributiei datelor observate, fara a se preocupa de acuratetealocala a valorilor prezise.
Simularile stochastice pot fi facute in doua moduri: neconditionate si conditionate.O simulare stochastica neconditionata nu are alte constrangeri asupra valorilor simulate
decat faptul ca media si o functia de covarianta a acestor valori sa fie cea specificata apriori. O simulare stochastica conditionata are, pe langa constrangerile de medie si functiede covarianta, cerinta ca valorile observate pentru variabila aleatoare sa fie pastrate in urmasimularii. Cu alte cuvinte, o simulare conditionata este o procedure ce reproduce valorilesi locatiile tuturor datelor observate, pe cand una neconditionata nu are aceasta cerinta.
In cazul unei simulari stochastice neconditionata, metoda de simulare este metodaMonte Carlo. Exista diverse software care pot simula valori aleatoare ce au media si functiade covarianta specificate.
In cazul unei simulari conditionate, varianta valorilor simulate este dublul varianteivalorilor estimate prin metoda kriging. Asadar, daca scopul este o precizie mai buna avalorilor simulate, metoda kriging este mai buna. Daca scopul este realizarea unei hartipentru care caracteristicile observatiilor sa fie pastrate, atunci metoda de simulare este ceapotrivita.
Exista mai multe tipuri de simulari stochastice, si anume:• simulare gaussiana secventiala (fiecare valoare este simulata secvential in concor-
danta cu functia sa de repartitie conditionata normala, care se determina in fiecarelocatie simulata);
• metode de descompunere LU (bazata pe descompunerea Cholesky a oricarei matricepozitiv definite C in produs de doua matrice triunghiulare, inferior si superior, i.e.,C = LU .);
• simulare annealing (bazata pe algoritmi de optimizare);• metode orientate pe obiect;
Metoda de simulare gaussiana secventiala este cea mai folosita. Pasii de implementare ametodei sunt:
• Asigurarea ca datele sunt normale. In caz ca nu sunt normale, datele ar putea fitransformate in date normale standard;
• Se determina un model de variograma;• Se formeaza un grid cu punctele in care urmeaza sa determinam simulari;• Se determina ordinea (o secventa) locatiilor xi in care vom obtine simulari.• Pentru fiecare locatie xi se determina Z(xi) si σ2
K(xi) prin metoda kriging simpla.Apoi, se va genera aleator o valoare normala ce are media Z(xi) si varianta σ2
K(xi).

118 Capitolul 9. Kriging
Aceasta valoare simulata se va adauga la setul de date observate, apoi se trece lasimularea urmatoarei valori. Se repeta procedeul de kriging (incluzand in setul dedate toate valorile simulate anterior) pana ce toate valorile pentru punctele din gridau fost simulate.
• Daca datele originale au fost transformate, se va aplica transformarea inversa pentrua determina simularile valorilor variabilei de interes.

9.9 Simulare stochastica 119
Figu
ra9.
8:E
tape
pent
ruin
terp
olar
eapr
inkr
igin
g


10. Anexe
10.1 Tabele cu cuantile pentru repartitii uzuale
α 0.9 0.95 0.975 0.99 0.995 0.999zα 1.282 1.645 1.960 2.326 2.576 3.090
Tabela 10.1: Cuantile pentru repartitia N (0, 1). Pentru un α , tabelul afiseaza cuantila zα pentrucare P(Z ≤ zα) = α , unde Z ∼N (0, 1). De remarcat faptul ca: z1−α =−zα .

122 Capitolul 10. Anexe
n\α
0.90.95
0.9750.99
0.9950.999
n\α
0.90.95
0.9750.99
0.9950.999
13.078
6.31412.706
31.82163.657
318.31321
1.3231.721
2.0802.518
2.8313.527
21.886
2.9204.303
6.9659.925
22.32722
1.3211.717
2.0742.508
2.8193.505
31.638
2.3533.182
4.5415.841
10.21523
1.3191.714
2.0692.500
2.8073.485
41.533
2.1322.776
3.7474.604
7.17324
1.3181.711
2.0642.492
2.7973.467
51.476
2.0152.571
3.3654.032
5.89325
1.3161.708
2.0602.485
2.7873.450
61.440
1.9432.447
3.1433.707
5.20826
1.3151.706
2.0562.479
2.7793.435
71.415
1.8952.365
2.9983.499
4.78227
1.3141.703
2.0522.473
2.7713.421
81.397
1.8602.306
2.8963.355
4.49928
1.3131.701
2.0482.467
2.7633.408
91.383
1.8332.262
2.8213.250
4.29629
1.3111.699
2.0452.462
2.7563.396
101.372
1.8122.228
2.7643.169
4.14330
1.3101.697
2.0422.457
2.7503.385
111.363
1.7962.201
2.7183.106
4.02432
1.3091.694
2.0372.449
2.7383.365
121.356
1.7822.179
2.6813.055
3.92934
1.3071.691
2.0322.441
2.7283.348
131.350
1.7712.160
2.6503.012
3.85236
1.3061.688
2.0282.434
2.7193.333
141.345
1.7612.145
2.6242.977
3.787038
1.3041.686
2.0242.429
2.7123.319
151.341
1.7532.131
2.6022.947
3.73340
1.3031.684
2.0212.423
2.7043.307
161.337
1.7462.120
2.5832.921
3.68650
1.2991.676
2.0092.403
2.6783.261
171.333
1.7402.110
2.5672.898
3.64660
1.2961.671
2.0002.390
2.6603.232
181.330
1.7342.101
2.5522.878
3.61080
1.2921.664
1.9902.374
2.6393.195
191.328
1.7292.093
2.5392.861
3.579100
1.2901.660
1.9842.364
2.6263.174
201.325
1.7252.086
2.5282.845
3.552∞
1.2821.645
1.9602.326
2.5763.090
Tabela10.2:
Cuantile
pentrurepartitia
Studentt(n).Pentru
unα
siunn,tabelulafiseaza
cuantilatα,n
pentrucare
P(Z≤
tα,n )
=α
,undeZ∼
t(n).D
acan
estem
aimare
de100,se
poateutiliza
tabeluldela
repartitianorm
ala.

10.2 Exemplu de date statistice spatiale 123
1 Table des quantiles de la v.a. Chi-Carre
Fournit les quantiles xp tels queP(X≤xp)= ppour X ∼ χ2
n
n / p 0,005 0,010 0,025 0,050 0,100 0,250 0,500 0,750 0,900 0,95 0,975 0,990 0,995n1 0,00 0,00 0,00 0,00 0,02 0,10 0,45 1,32 2,71 3,84 5,02 6,64 7,882 0,01 0,02 0,05 0,10 0,21 0,58 1,39 2,77 4,61 5,99 7,38 9,21 10,603 0,07 0,11 0,22 0,35 0,58 1,21 2,37 4,11 6,25 7,82 9,35 11,35 12,844 0,21 0,30 0,48 0,71 1,06 1,92 3,36 5,39 7,78 9,49 11,14 13,28 14,865 0,41 0,55 0,83 1,15 1,61 2,67 4,35 6,63 9,24 11,07 12,83 15,09 16,756 0,68 0,87 1,24 1,64 2,20 3,45 5,35 7,84 10,64 12,59 14,45 16,81 18,557 0,99 1,24 1,69 2,17 2,83 4,25 6,35 9,04 12,02 14,07 16,01 18,48 20,288 1,34 1,65 2,18 2,73 3,49 5,07 7,34 10,22 13,36 15,51 17,53 20,09 21,959 1,74 2,09 2,70 3,33 4,17 5,90 8,34 11,39 14,68 16,92 19,02 21,67 23,5910 2,16 2,56 3,25 3,94 4,87 6,74 9,34 12,55 15,99 18,31 20,48 23,21 25,1911 2,60 3,05 3,82 4,58 5,58 7,58 10,34 13,70 17,28 19,68 21,92 24,72 26,7612 3,07 3,57 4,40 5,23 6,30 8,44 11,34 14,85 18,55 21,03 23,34 26,22 28,3013 3,57 4,11 5,01 5,89 7,04 9,30 12,34 15,98 19,81 22,36 24,74 27,69 29,8214 4,08 4,66 5,63 6,57 7,79 10,17 13,34 17,12 21,06 23,68 26,12 29,14 31,3215 4,60 5,23 6,26 7,26 8,55 11,04 14,34 18,25 22,31 25,00 27,49 30,58 32,8016 5,14 5,81 6,91 7,96 9,31 11,91 15,34 19,37 23,54 26,30 28,85 32,00 34,2717 5,70 6,41 7,56 8,67 10,09 12,79 16,34 20,49 24,77 27,59 30,19 33,41 35,7218 6,27 7,02 8,23 9,39 10,87 13,68 17,34 21,61 25,99 28,87 31,53 34,81 37,1619 6,84 7,63 8,91 10,12 11,65 14,56 18,34 22,72 27,20 30,14 32,85 36,19 38,5820 7,43 8,26 9,59 10,85 12,44 15,45 19,34 23,83 28,41 31,41 34,17 37,57 40,0021 8,03 8,90 10,28 11,59 13,24 16,34 20,34 24,94 29,62 32,67 35,48 38,93 41,4022 8,64 9,54 10,98 12,34 14,04 17,24 21,34 26,04 30,81 33,92 36,78 40,29 42,8023 9,26 10,20 11,69 13,09 14,85 18,14 22,34 27,14 32,01 35,17 38,08 41,64 44,1824 9,89 10,86 12,40 13,85 15,66 19,04 23,34 28,24 33,20 36,42 39,36 42,98 45,5625 10,52 11,52 13,12 14,61 16,47 19,94 24,34 29,34 34,38 37,65 40,65 44,31 46,9326 11,16 12,20 13,84 15,38 17,29 20,84 25,34 30,43 35,56 38,89 41,92 45,64 48,2927 11,81 12,88 14,57 16,15 18,11 21,75 26,34 31,53 36,74 40,11 43,19 46,96 49,6428 12,46 13,56 15,31 16,93 18,94 22,66 27,34 32,62 37,92 41,34 44,46 48,28 50,9929 13,12 14,26 16,05 17,71 19,77 23,57 28,34 33,71 39,09 42,56 45,72 49,59 52,3430 13,79 14,95 16,79 18,49 20,60 24,48 29,34 34,80 40,26 43,77 46,98 50,89 53,6740 20,71 22,16 24,43 26,51 29,05 33,66 39,34 45,62 51,81 55,76 59,34 63,69 66,7750 27,99 29,71 32,36 34,76 37,69 42,94 49,33 56,33 63,17 67,50 71,42 76,15 79,4960 35,53 37,48 40,48 43,19 46,46 52,29 59,33 66,98 74,40 79,08 83,30 88,38 91,9570 43,28 45,44 48,76 51,74 55,33 61,70 69,33 77,58 85,53 90,53 95,02 100,4 104,280 51,17 53,54 57,15 60,39 64,28 71,14 79,33 88,13 96,58 101,9 106,6 112,3 116,390 59,20 61,75 65,65 69,13 73,29 80,62 89,33 98,65 107,6 113,1 118,1 124,1 128,3100 67,33 70,06 74,22 77,93 82,36 90,13 99,33 109,1 118,5 124,3 129,6 135,8 140,2
1
Tabela 10.3: Cuantile pentru repartitia χ2(n). Pentru un α = p si un n, tabelul afiseaza cuantilaχ2
α,n pentru care P(Z ≤ χ2α,n) = α , unde Z ∼ χ2(n).
10.2 Exemplu de date statistice spatiale

124 Capitolul 10. Anexe
Figura10.1:
Exem
plude
datestatistice
spatiale.

10.3 Tabel cu intervale de încredere 125
10.3 Tabel cu intervale de încredere
Param. Alti param. Interval de încredere cu nivelul de semnificatie α
µ
(X− z1− α
2σ√
n , X + z1− α2
σ√n
)σ2 (
X− z1−ασ√
n , +∞
)cunoscut (
−∞, X + z1−ασ√
n
)
µ
(X− t1− α
2 ; n−1s√n , X + t1− α
2 ; n−1s√n
)σ2 (
X− t1−α; n−1σ√
n , ∞
);necunoscut (
−∞, X− tα; n−1s√n
)
σ2
(n
χ21− α
2 ;ns2, n
χ2α2 ;n
s2
)µ
(n
χ2α;n
s2, +∞
)cunoscut (
−∞, nχ2
1−α;ns2)
σ2
((n−1)
χ21− α
2 ;n−1s2, (n−1)
χ2α2 ;n−1
s2
)µ
(n−1
χ2α;n−1
s2, +∞
)necunoscut (
−∞, n−1χ2
1−α;n−1s2)
p n(
p− z1− α2
√p(1−p)
n , p+ z1− α2
√p(1−p)
n
)mare
µ1, µ2σ2
1 /σ2
2
(s2
1
s22
fn1−1,n2−1; α2,
s21
s22
fn1−1,n2−1;1− α2
)necunoscuti
µ1−µ2 σ21 , σ2
2
X1−X2− z1− α2
√σ2
1n1
+σ2
2n2
, X1−X2 + z1− α2
√σ2
1n1
+σ2
2n2
cunoscuti
µ1−µ2 σ21 6= σ2
2
X1−X2− t1− α2 ; N
√s2
1n1
+s2
2n2
, X1−X2 + t1− α2 ; N
√s2
1n1
+s2
2n2
necunoscuti
σ21 = σ2
2µ1−µ2
(X1−X2− t1− α
2 ; n1+n2−2 d(X1, X2), X1−X2 + t1− α2 ; n1+n2−2 d(X1, X2)
)necunoscuti
p1− p2 n1, n2
(p1− p2− z1− α
2
√p1 (1−p1)
n1+ p2 (1−p2)
n2, p1− p2 + z1− α
2
√p1 (1−p1)
n1+ p2 (1−p2)
n2
)mari
Tabela 10.4: Tabel cu intervale de încredere.

126 Capitolul 10. Anexe
Mai sus, prin d(X1, X2) am notat:
d(X1, X2) =√
(n1−1)s21 +(n2−1)s2
2
(n1 +n2−2
1n1+ 1
n2
)− 12
.

Bibliography
[1] David Brink, Statistics compendium, David Brink & Ventus Publishing ApS, 2008.
[2] Jay L. DeVore, Kenneth N. Berk, Modern Mathematical Statistics with Applications(with CD-ROM), Duxbury Press, 2006.
[3] Clayton V. Deutsch, Geostatistical reservoir modeling, Oxford University Press,2002.
[4] ESRI, Introduction to the ArcGIS Geostatistical Analyst Tutorial (online tutorialnotes)
[5] Pierre Goovaerts, Geostatistics for natural resources evaluation, Oxford UniversityPress, 1997.
[6] T Hengl, A Practical Guide to Geostatistical Mapping of Environmental Variables,JRC Scientific and Technical Research series, Office for Official Publications of theEuropean Comunities, Luxembourg, EUR 22904 EN, 143 pp, 2009
[7] Peter K. Kitanidis, Introduction to Geostatistics, Applications in Hydrogeology,Cambridge University Press, 1997.
[8] Marius Iosifescu, Costache Moineagu, Vladimir Trebici, Emiliana Ursianu, Micaenciclopedie de statistica, Editura stiintifica si enciclopedica, Bucuresti, 1985.
[9] K. Johnston, JM Ver Hoef, K. Krivoruchko, N. Lucas, Using ArcGIS GeostatisticalAnalyst, 2001
[10] S. McKillup, M Darby Dyar, Geostatistics Explained. An Introductory Guide forEarth Scientists, Cambridge University Press, 396 pp, 2010

128 BIBLIOGRAPHY
[11] Georges Matheron, Principles of Geostatistics, Economic Geology 58, 1963, pp.1246-1266.
[12] Georges Matheron, Les variables régionalisées et leur estimation, Masson, Paris,1965.
[13] Gheorghe Mihoc, N. Micu, Teoria probabilitatilor si statistica matematica, Bucuresti,1980.
[14] Ricardo A. Olea, Geostatistics for Engineers and Earth Scientists, Kluwer AcademicPublishers, Boston, 1999
[15] MJ Smith, MF Goodchild, PA Longley, Geospatial Analysis. A Comprehensive Guideto Principles, Techniques and Software Tools, Second Edition, Matador, TroubadorPublishing Ltd., online version: http://www.spatialanalysisonline.com/
[16] Iulian Stoleriu, Statistica prin MATLAB. MatrixRom, Bucuresti, 2010.
[17] Richard Webster, Margaret Oliver, Geostatistics for environmental scientists, JohnWiley and Sons, Ltd., 2007.
[18] David Williams, Weighing the Odds: A Course in Probability and Statistics, Cambri-dge University Press, 2001.

Glosar
amplitudinea, 28
box-and-whiskers plot, 30
caracteristica, 14clasa mediana, 33clopotul lui Gauss, 51coeficient de aplatizare, 29, 47coeficient de asimetrie, 29, 47coeficient de corelatie, 84coeficient de corelatie teoretic, 48coeficientul de corelatie empiric, 26coeficientul de variatie , 27colectivitate statistica, 13corelatia, 28corelatia teoretica, 48cuantile, 47
date continue, 16date discrete, 16densitati de frecventa, 22deplasarea unui estimator, 56deviatia standard, 27diagrama cuantila-cuantila, 26diagrama probabilitate-probabilitate, 26dispersia, 27dispersia teoretica, 45distributie empirica de selectie, 18
eroare în medie patratica, 56estimator nedeplasat, 56eveniment aleator, 39eveniment aleator compus, 39eveniment aleator elementar, 39evenimente dependente, 49evenimente independente, 49experienta aleatoare, 39
frecventa cumulata, 20frecventa absoluta, 18, 41frecventa cumulata, 18frecventa relativa cumulata, 18frecventa relativa, 18frontierele unei clase, 24functia de probabilitate (de frecventa), 43functie de repartitie (cumulata), 44functie de repartitie empirica, 28
histograma, 22
indicatori statistici, 26interval de încredere, 58ipoteza statistica, 63
kriging, 103, 104kriging ordinar, 108kurtosis, 29, 47
media, 27

130 GLOSAR
media teoretica, 45metoda celor mai mici patrate, 100modul, 48momente, 27momente centrate ale unei v.a., 46multime de selectie, 39
nivel de semnificatie, 59, 64
ogiva, 25
P-valoare, 64populatie statistica, 13probabilitate, 40, 41probabilitate de risc, 59
recensamânt, 15regula celor 3σ , 46repartitia χ2, 53repartitia normala standard, 51riscul beneficiarului, 64riscul furnizorului, 64
scatter plot, 73selectie, 14serie de timpi, 18simulare stochastica, 116simulare stochastica conditionata, 117simulare stochastica neconditionata, 117skewness, 29, 47Statistica, 12stem-and-leaf, 21
tabel de frecvente, 17test bilateral, 65test de concordanta, 68test statistic, 65test unilateral dreapta, 65test unilateral stânga, 65
UMVUE, 57
variabila aleatoare, 42variabila aleatoare standardizata, 46variograma, 86variograma empirica, 88, 96variograma regionala, 88variograma teoretica, 88



![Mobil : 0722 373 625 Email : syscom02@gmail.com PORTABIL GAZE SYWA550L 06... · Caracteristici tehnice Valori masurate Concentratie de oxigen [O2] in gazele arse Afisaj % din volumul](https://static.fdocumente.com/doc/165x107/5e0d7ba5a3510d0d262dfd9c/mobil-0722-373-625-email-syscom02gmail-portabil-gaze-sywa550l-06-caracteristici.jpg)