
CAPITOLUL 1 INTRODUCERE IN ALGORITMICA DE …shannon.etc.upt.ro/teaching/tart/FINAL.pdf1 CAPITOLUL 1...
208
1 CAPITOLUL 1 INTRODUCERE IN ALGORITMICA DE RETEA Scopul algoritmicii de reţea este combaterea strangulărilor de reţea cauzate de diferite implementări. Pe lângă tehnici specifice, sunt cristalizate principiile creării de soluţii pentru evitarea strangulărilor în internet, înglobate în ceea ce se numeste algoritmica de reţea sau teoria algoritmilor de reţea. Ea asigură cititorului ustensile pentru crearea diferitelor implementări, pentru anumite contexte particulare şi pentru abordarea noilor strangulări care cu siguranţă vor apărea în lumea în permanentă schimbare a reţelelor. Algoritmica de reţea sau teoria algoritmilor de reţea trece dincolo de crearea algoritmilor eficienţi pentru sarcinile reţelei, chiar dacă aceştia au un rol important. In particular, teoria algoritmilor de reţea recunoaşte importanţa majoră a abordării sistemelor interdisciplinare pentru fluentizarea implementărilor de reţea. Algoritmica de reţea este o abordare interdisciplinară deoarece cuprinde domenii ca arhitecturi şi sisteme de operare (pentru creşterea vitezei serverului), proiectare hardware (pentru creşterea vitezei componentelor de reţea cum sunt ruterele), şi proiectarea de algoritmi (pentru proiectarea unor algoritmi scalabili). Algoritmica de reţea este şi o abordare de sistem, fiind descris un set de 15 principii şi utilizarea lor, care exploatează faptul că ruterele şi serverele sunt sisteme, în care eficienţa poate fi obţinută prin deplasarea funcţiilor în spaţiu şi timp între subsisteme. Problemele algoritmicii de reţea sunt legate de performanţa fundamentală legată de strangulările de reţea/bottlenecks. Soluţiile adoptate de algoritmica de reţea generează un set de tehnici fundamentale pentru tratarea acestor strangulări. 1.1. PROBLEMA: STRANGULĂRILE DE REŢEA Principala problemă avută în vedere este realizarea unor reţele uşor de folosit, utilizând hardware-ul la capacitatea maximă. Uşurinţa folosirii vine de la folosirea unor abstractizări puternice de reţea, cum sunt interfeţele socket şi expedierea/înaintarea bazată pe prefix a pachetelor. Trebuie avut grijă însă, deoarece astfel de abstractizări pot duce la scăderea performanţelor comparativ cu capacitatea transmisiilor pe legături ca fibra optică. Pentru a putea înţelege această diferenţă de performanţă vom examina două categorii fundamentale de dispozitive de reţea, nodurile terminale/endnodes şi ruterele. Strangulări la nodurile terminale Nodurile terminale sunt punctele de final ale reţelei. Ele includ calculatoarele personale şi staţiile de lucru precum şi serverele de mari dimensiuni, furnizoare de servicii. Nodurile terminale sunt dedicate calculelor, spre deosebire de reţele, şi de obicei sunt proiectate ca să poată realiza calcule de uz general. Astfel strangulările nodurilor terminale sunt de obicei rezultatul a două cauze: structura şi scala/dimensiunea.
Transcript of CAPITOLUL 1 INTRODUCERE IN ALGORITMICA DE …shannon.etc.upt.ro/teaching/tart/FINAL.pdf1 CAPITOLUL 1...

1
CAPITOLUL 1
INTRODUCERE IN ALGORITMICA DE RETEA Scopul algoritmicii de reţea este combaterea strangulărilor de reţea
cauzate de diferite implementări. Pe lângă tehnici specifice, sunt cristalizate principiile creării de soluţii pentru evitarea strangulărilor în internet, înglobate în ceea ce se numeste algoritmica de reţea sau teoria algoritmilor de reţea. Ea asigură cititorului ustensile pentru crearea diferitelor implementări, pentru anumite contexte particulare şi pentru abordarea noilor strangulări care cu siguranţă vor apărea în lumea în permanentă schimbare a reţelelor.
Algoritmica de reţea sau teoria algoritmilor de reţea trece dincolo de crearea algoritmilor eficienţi pentru sarcinile reţelei, chiar dacă aceştia au un rol important. In particular, teoria algoritmilor de reţea recunoaşte importanţa majoră a abordării sistemelor interdisciplinare pentru fluentizarea implementărilor de reţea. Algoritmica de reţea este o abordare interdisciplinară deoarece cuprinde domenii ca arhitecturi şi sisteme de operare (pentru creşterea vitezei serverului), proiectare hardware (pentru creşterea vitezei componentelor de reţea cum sunt ruterele), şi proiectarea de algoritmi (pentru proiectarea unor algoritmi scalabili). Algoritmica de reţea este şi o abordare de sistem, fiind descris un set de 15 principii şi utilizarea lor, care exploatează faptul că ruterele şi serverele sunt sisteme, în care eficienţa poate fi obţinută prin deplasarea funcţiilor în spaţiu şi timp între subsisteme.
Problemele algoritmicii de reţea sunt legate de performanţa fundamentală legată de strangulările de reţea/bottlenecks. Soluţiile adoptate de algoritmica de reţea generează un set de tehnici fundamentale pentru tratarea acestor strangulări.
1.1. PROBLEMA: STRANGULĂRILE DE REŢEA Principala problemă avută în vedere este realizarea unor reţele uşor de
folosit, utilizând hardware-ul la capacitatea maximă. Uşurinţa folosirii vine de la folosirea unor abstractizări puternice de reţea, cum sunt interfeţele socket şi expedierea/înaintarea bazată pe prefix a pachetelor. Trebuie avut grijă însă, deoarece astfel de abstractizări pot duce la scăderea performanţelor comparativ cu capacitatea transmisiilor pe legături ca fibra optică. Pentru a putea înţelege această diferenţă de performanţă vom examina două categorii fundamentale de dispozitive de reţea, nodurile terminale/endnodes şi ruterele.
Strangulări la nodurile terminale Nodurile terminale sunt punctele de final ale reţelei. Ele includ
calculatoarele personale şi staţiile de lucru precum şi serverele de mari dimensiuni, furnizoare de servicii. Nodurile terminale sunt dedicate calculelor, spre deosebire de reţele, şi de obicei sunt proiectate ca să poată realiza calcule de uz general. Astfel strangulările nodurilor terminale sunt de obicei rezultatul a două cauze: structura şi scala/dimensiunea.

2
• Structura: Pentru a putea rula orice cod, calculatoarele personale şi serverele mari au de obicei un sistem de operare care mediază între aplicaţii şi hardware. Pentru a uşura dezvoltarea software-ului, majoritatea sistemelor de operare de mari dimensiuni sunt structurate cu grijă, ca un software pe niveluri; pentru a proteja sistemul de operare de alte aplicaţii, sistemele de operare implementează un set de mecanisme de protecţie; în final, rutinele nucleului sistemului de operare, cum sunt planificatoarele si procedurile de alocare, sunt scrise folosind mecanisme generale, orientate spre o clasă de aplicaţii cât mai largă posibil. Din păcate, combinaţia între software-ul pe niveluri, mecanismele de protecţie, şi generalitatea excesivă poate duce la încetinirea semnificativă a software-ului reţelei, chiar şi cu procesoarele cele mai rapide. • Scala/dimensiunea: Apariţia serverelor mari oferind Web şi alte
servicii duce la apariţia altor probleme, de performanţă. In particular, un server mare cum este un server de Web, va avea de obicei mii de clienţi concurenţi. Multe sisteme de operare folosesc structuri de date ineficiente şi algoritmi care au fost proiectaţi pentru o epocă în care numărul de legături a fost mic.
In figura 1.1 sunt prezentate principalele strangulări ale nodurilor terminale, împreună cu cauzele şi soluţiile lor. Prima strangulare are loc deoarece structurile sistemului de operare convenţional impun copierea pachetelor de date între domeniile protejate; situaţia se complică şi mai mult în cazul serverelor de Web prin copieri similare pentru sistemul de fişiere şi alte manevre, ca sumele ciclice de control, care verifică toate pachetele de date. Se descriu un număr de tehnici de reducere a acestor supraincarcari, menţinând ca scop abstractizările sistemului, ca protecţia şi structura. A doua supraîncărcare majoră este cea generată de control, cauzată de comutarea între firele de control (sau domeniile de protecţie) în timpul procesării unui pachet.
Strangulare Cauze Exemple de soluţii
Copierea Protecţia, structura
Copierea mai multor blocuri de date fără intervenţia sistemului de operare(ex. RDMA)
Comutarea contextului Planificarea complexă
Implemenetarea protocoalelor la nivelul utilizatorului Servere Web comandate de evenimente
Apelurile de sistem Protecţia, structura Canale directe de la aplicaţii spre drivere (ex. VIA)
Contoarele de timp Scalarea la numarul contoarelor Contoare de timp ciclice
Demultiplexarea Scalarea la numărul de noduri terminale
BPF şi Pathfinder/căutător de cale
Sumele de control/ CRC-uri
Generalitatea Scalarea la viteza legăturilor Calculul multibit
Codul protocolului Generalitatea Predicţia antetului
Figura 1.1 Prezentarea strangulărilor nodurilor terminale Aplicaţiile de reţea folosesc contoare de timp/temporizatoare pentru a
rezolva defecţiunile. Cu un număr mare de legături la un server

3
supraîncărcarea dată de contoarele de timp poate deveni mare. De asemenea, mesajele de la reţea trebuie demultiplexate/orientate pentru a fi recepţionate de aplicaţia corectă. In final, mai există alte câteva sarcini de procesare obişnuite ale protocoalelor, cum sunt alocarea buffer-elor/tampoanelor de memorie şi suma de control.
Strangulările în rutere Deşi ne axăm pe ruterele pentru Internet, aproape toate tehnicile descrise
pot fi folosite la fel de bine şi în cazul altor echipamente de reţea, cum sunt punţile/bridge, comutatoarele/switch, porţile/gateway, monitoarele şi alte dispozitive de securitate, precum si pentru protocoale diferite de IP, ca FiberChannel. De aceea, în continuare, ruterul este gândit ca un “dispozitiv generic de interconectare a reţelei”. Spre deosebire de nodurile terminale, acesta este un dispozitiv cu scop special dedicat lucrului cu reţelele. Problemele fundamentale pe care le întâlneşte un ruter sunt legate de dimensiune/scală şi servicii. • Scala: Dispozitivele de reţea se confruntă cu două tipuri de scalare:
scalarea benzii şi scalarea populării. Scalarea benzii are loc deoarece legăturile pe cale optică devin din ce în ce mai rapide, viteza legăturilor crescând de la 1-Gbps la 40-Gbps, şi deoarece traficul in Internet creşte continuu datorită unui set vast de aplicaţii noi. Scalarea populării are loc deoarece tot mai multe noduri terminale sunt adăugate la Internet odată cu conectarea online a tot mai multor întreprinderi. • Serviciile: Nevoia de viteză şi dimensiune a crescut mult faţă de
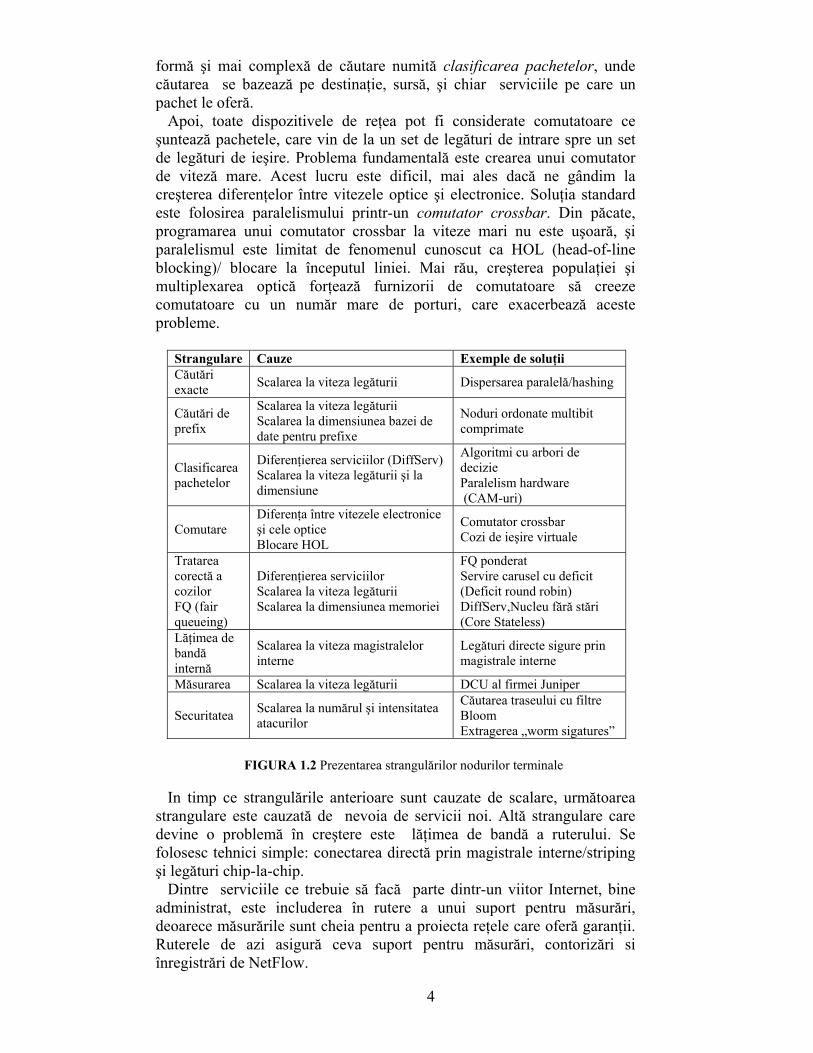
industria reţelelor din anii ’80 şi ’90, pe măsură ce tot mai multe afaceri deveneau online (de ex. Amazon), şi au fost create noi servicii online( de ex. Ebay). Dar succesul Internetului impune o atenţie deosebită în următoarea decadă, pentru a-l face mai eficient, şi a asigura garanţii de performanţă, securitate şi siguranţă. La urma urmei, dacă producătorii (de ex. Dell) vând mai mult online decât prin alte mijloace, este important să se ofere garanţii ale reţelei – întârzierea în timpul congestiei, protecţia în timpul atacurilor, şi disponibilitatea când apar defecţiuni. Găsirea unor metode de implementare a acestor noi servicii la viteze mari va fi o mare provocare pentru furnizorii de rutere în decada următoare.In figura 1.2 sunt prezentate principalele strangulări din rutere abordate aici, împreună cu cauzele şi soluţiile lor.
In primul rând, toate dispozitivele de reţea expediază pachete destinaţiei prin consultarea (looking up) unui tabel de înaintare(forwarding). Prin consultarea celui mai simplu tabel de înaintare se găseşte o potrivire exactă (exact match) cu adresa destinaţiei, ca de exemplu în cazul punţilor. Sunt descrise scheme de căutare rapide şi scalabile, pentru potriviri exacte. Din păcate, scalarea la dimensiunea populaţiei a făcut ca pentru rutere căutările sa fie mult mai complexe. Pentru a trata populaţiile mari de pe Internet, ruterele reţin o singură intrare numită prefix (analog cu codul telefonic de zonă) pentru un grup mare de staţii. Astfel ruterele trebuie să facă o căutare mult mai complexă pentru potrivirea celui mai lung prefix/the longest-prefix-match. Sunt descrise soluţii la această problemă, scalabile la viteze mari şi dimensiuni mari ale tabelelor.
Multe rutere oferă azi ceea ce este deseori numit diferenţierea serviciului, prin care diferite pachete pot fi tratate diferit pentru a oferi garanţii asupra serviciului şi a securităţii. Din păcate, acest lucru necesită o
4
formă şi mai complexă de căutare numită clasificarea pachetelor, unde căutarea se bazează pe destinaţie, sursă, şi chiar serviciile pe care un pachet le oferă.
Apoi, toate dispozitivele de reţea pot fi considerate comutatoare ce şuntează pachetele, care vin de la un set de legături de intrare spre un set de legături de ieşire. Problema fundamentală este crearea unui comutator de viteză mare. Acest lucru este dificil, mai ales dacă ne gândim la creşterea diferenţelor între vitezele optice şi electronice. Soluţia standard este folosirea paralelismului printr-un comutator crossbar. Din păcate, programarea unui comutator crossbar la viteze mari nu este uşoară, şi paralelismul este limitat de fenomenul cunoscut ca HOL (head-of-line blocking)/ blocare la începutul liniei. Mai rău, creşterea populaţiei şi multiplexarea optică forţează furnizorii de comutatoare să creeze comutatoare cu un număr mare de porturi, care exacerbează aceste probleme.
Strangulare Cauze Exemple de soluţii Căutări exacte Scalarea la viteza legăturii Dispersarea paralelă/hashing
Căutări de prefix
Scalarea la viteza legăturii Scalarea la dimensiunea bazei de date pentru prefixe
Noduri ordonate multibit comprimate
Clasificarea pachetelor
Diferenţierea serviciilor (DiffServ) Scalarea la viteza legăturii şi la dimensiune
Algoritmi cu arbori de decizie Paralelism hardware (CAM-uri)
Comutare Diferenţa între vitezele electronice şi cele optice Blocare HOL
Comutator crossbar Cozi de ieşire virtuale
Tratarea corectă a cozilor FQ (fair queueing)
Diferenţierea serviciilor Scalarea la viteza legăturii Scalarea la dimensiunea memoriei
FQ ponderat Servire carusel cu deficit (Deficit round robin) DiffServ,Nucleu fără stări (Core Stateless)
Lăţimea de bandă internă
Scalarea la viteza magistralelor interne
Legături directe sigure prin magistrale interne
Măsurarea Scalarea la viteza legăturii DCU al firmei Juniper
Securitatea Scalarea la numărul şi intensitatea atacurilor
Căutarea traseului cu filtre Bloom Extragerea „worm sigatures”
FIGURA 1.2 Prezentarea strangulărilor nodurilor terminale
In timp ce strangulările anterioare sunt cauzate de scalare, următoarea
strangulare este cauzată de nevoia de servicii noi. Altă strangulare care devine o problemă în creştere este lăţimea de bandă a ruterului. Se folosesc tehnici simple: conectarea directă prin magistrale interne/striping şi legături chip-la-chip.
Dintre serviciile ce trebuie să facă parte dintr-un viitor Internet, bine administrat, este includerea în rutere a unui suport pentru măsurări, deoarece măsurările sunt cheia pentru a proiecta reţele care oferă garanţii. Ruterele de azi asigură ceva suport pentru măsurări, contorizări si înregistrări de NetFlow.

5
Suportul pentru securitate este parţial inclus deja în rutere. Datorită sofisticării crescute, agresivităţii, şi ratei de atacuri asupra reţelei, este esenţială implementarea securităţii în rutere sau dispozitive de reţea specializate detectării/prevenirii intruziunilor. Dar dacă dispozitivul de securitate nu poate ţine pasul cu legăturile de mare viteză, pot fi omise informaţii vitale, necesare pentru detectarea unui atac.
Filtre Bloom: structură de date aleatorizată ingenios pentru reprezentarea concisă a unui set/mulţime, care suportă interogări/queries despre apartenenţa aproximativă la mulţime.Are o mare eficienţă spaţială, iar riscul/costul este de a detecta falsuri pozitive.
1.2. TEHNICI: TEORIA ALGORITMILOR DE REŢEA Vor fi discutate tehnici specifice: pentru întreruperi, copiere, şi contoare
de timp circulare/timing wheels; pentru Pathfinder şi Sting; de ce unele rutere sunt foarte încete; şi dacă serverele de Web pot să se scaleze la noile dimensiuni. Ceea ce leagă împreuna toate aceste probleme este algoritmica de reţea; algoritmica de retea admite importanţa primordială a unei abordari sistemice, necesară pentru fluentizarea implementărilor de reţea.
Internet-ul este un sistem compus din rutere şi legături; dar este mai puţin vizibil faptul că fiecare dispozitiv de reţea, de la un Cisco GSR la un server Web Apache, reprezintă sisteme, construite prin interconectarea subsistemelor. De exemplu, un ruter nucleu este compus din carduri de linie cu motoare de înaintare şi memorii de pachete, conectate printr-un comutator crossbar. Comportamentul ruterului depinde de decizii luate la diferite scale de timp, începând cu momentul producerii lor (când parametrii impliciţi sunt stocaţi în NVRAM) până la momentul calculului rutei (când ruterele calculează traseul) şi la momentul expedierii pachetelor (când pachetele sunt trimise ruterelor adiacente).
Astfel o observaţie importantă în abordarea sistemică este că deseori poate fi proiectat un subsistem eficient prin mutarea în spaţiu (spre alte subsisteme) a câtorva din funcţiile sale, sau mutarea în timp (anterior sau posterior momentului aparent în care funcţia este necesară). Intr-un anume sens, cel care practică algoritmica de retea este un oportunist fără scrupule care schimbă regulile jocului în orice moment, pentru a-l face mai uşor. Singura condiţie este ca funcţiile oferite de sistemul global să continue să satisfacă utilizatorul. Ţinând cont de constrângerile impuse implementărilor reţelei la viteze
mari –sarcini din ce în ce mai complexe, sisteme tot mai mari, memorii mici de viteză mare, şi un număr redus de accesări ale memoriei –trebuie folosit orice artificiu, orice metodă sau resursă pentru a face faţă vitezei şi dimensiunii din ce în ce mai mari ale Internetului. Proiectantul poate încerca să plaseze problema în hardware, să schimbe ipotezele sistemului, să proiecteze un algoritm nou – orice este necesar pentru a rezolva problema.
1.2.1 Exemplu: depistarea pachetelor rele (evil packets) Imaginati-va un monitor de reţea terminal/front-end, sau un sistem de
detectare a intruşilor, de la periferia unei reţele de intreprindere, ce vrea să marcheze pachetele de intrare suspecte, care ar putea conţine atacuri asupra unor calculatoare interne. Un atac des întâlnit este inundarea

6
bufferului/depăşirea capacităţii bufferului, când codul maşinii C se plasează în antetul de reţea F.
Daca staţia destinaţie alocă un buffer prea mic pentru câmpul F al antetului şi nu are grijă să verifice depăşirea/inundarea, codul C poate ajunge în stiva staţiei destinaţie. Cu un mic efort suplimentar, intrusul poate face ca staţia destinaţie să execute codul rău C. C va prelua controlul staţiei destinaţie. In figura 1.3 este reprezentat un astfel de atac, incorporat într-un câmp familiar, Web URL (Uniform Resource Locator) destinaţie. Cum poate monitorul detecta prezenţa unui URL suspect? O cale este să observăm că URL-urile care conţin un cod dăunător sunt deseori prea lungi (o verificare uşoară) şi deseori au o mare parte de caractere neobişnuite pentru URL-uri, cum este #. Monitorul poate marca astfel de pachete (cu o lungime prea mare sau cu prea multe caractere neobişnuite), printr-o examinare amănunţită.
Dar implicaţiile acestei strategii asupra securităţii trebuie gândite atent. De exemplu, pot exista programe inofensive, cum sunt scripturi CGI în URLuri, ce duc pe piste false. Fără a intra în prea multe amănunte legate de toate implicaţiile arhitecturale, să presupunem că aceasta a fost o specificare trimisă arhitectului de chip-uri, de către arhitectul de securitate.Vom folosi o problemă ca model, pentru a observa modul de lucru al teoriei algoritmilor.Având de a face cu o astfel de specificare, proiectantul de chip-uri poate folosi următoarele procese de proiectare, care ilustrează unele principii ale algoritmicii de reţea. Procesul începe cu proiectarea strawman şi rafinarea proiectarii, prin proiectarea unui algoritm mai bun, relaxarea specificaţiilor şi exploatarea hardware-ului.
FIGURA 1.3 Găsirea unui pachet dăunător, observand frecventa caracterelor nelistabile
FIGURA 1.4 Soluţia strawman pentru detectarea unui pachet dăunător: se contorizează
fiecare caracter într-un tablou contor şi apoi în pasul final se compară valorile cu cele din tabloul de praguri
Sistem de detecţie al intruşilor
AIM://depăşire # * # ! * # ...... *
Cod dăunător
2%
• •
1%
• •
5
••
3
••
Tabloul Prag
Tabloul Contor
AIM://depăşire # * # ! * # ...... *
Cod dăunător
0
#
255
Incrementează

7
1.2.2 Soluţia strawman Verificarea lungimii totale este implementată direct, deci ne concentrăm
la verificarea unor caractere suspicioase predominante. Prima soluţie strawman este ilustrată în figura 1.4. Chip-ul păstrează două tablouri, T şi C, cu câte 256 de elemente fiecare, unul pentru fiecare valoare posibilă, pe caractere de 8 biţi. Tabloul de praguri, T, conţine procentul acceptabil (ca o fracţiune din lungimea totală a URLului) pentru fiecare caracter. Dacă apariţiile unui caracter într-un URL trec peste prag, pachetul este marcat. Fiecare caracter are un prag diferit.
Tabloul de contorizare C, în mijloc, conţine contorul curent C[i] pentru fiecare caracter i posibil. Când chip-ul citeşte un nou caracter “i” in URL, se incrementează C[i] cu 1. C[i] are iniţial valoarea 0 pentru toate valorile lui i când un nou pachet este întâlnit. Procesul de incrementare începe numai după ce chip-ul analizează antetul HTTP şi recunoaşte începutul URL-ului.
In HTTP, sfârşitul URL-ului este reprezentat cu două caractere de rând nou; aşa că lungimea unui URL se poate şti doar după ce s-a parcurs întregul şir URL. Astfel, după ce a fost întâlnit sfârşitul URLului, chip-ul realizează o ultimă parcurgere a tabloului C. Dacă [ ] [ ]C j L T j≥ ⋅ pentru orice j, unde L este lungimea URL-ului, pachetul va fi marcat.
Presupunem că pachetele vin cu viteză mare în monitor şi dorim să terminăm procesarea pachetului înainte de sosirea următorului. Această cerinţă, numită procesare la viteza liniei/wire speed processing, este des întâlnită în reţele; se previne amânarea procesării chiar şi în ce mai defavorabil caz. Pentru a îndeplini cerinţele de procesare la viteza liniei, ideal chip-ul ar trebui să facă un număr mic şi constant de operaţii pentru fiecare octet al URL-ului. Presupunem că pasul principal de incrementare al contorului poate fi făcut pe durata recepţiei octetului. Dar, cele două treceri prin tablou, pentru iniţializare si verificare a depăşirilor de prag, fac această proiectare lentă. Dimensiunea minimă a unui pachet este de 40 de octeţi, incluzând doar antetele de reţea. Adăugând 768 operaţii în plus (1 scriere şi 1 citire pentru fiecare element din C, şi 1 citire din T pentru fiecare din cei 256 indici) modelul de proiectare devine irealizabil.
1.2.3 Gândirea algoritmică Intuitiv, a doua trecere prin tablourile C şi T de la sfârşit pare o risipă.
De exemplu, este suficientă avertizarea când orice caracter depăşeşte pragul. Atunci de ce să verificam toate caracterele? Acest lucru sugerează să urmărim doar cel mai mare contor de caracter c; la sfârşit algoritmul trebuie să verifice doar dacă c e deasupra pragului, ţinând cont de L lungimea totală a URL-ului.

8
FIGURA 1.5 Evitarea buclei finale prin tabloul cu praguri, urmărind doar Max, cel mai mare contor relativ la valoarea de prag, întâlnit până acum.
Metoda nu prea funcţionează. Un caracter nesuspicios cum este “e”
poate apărea destul de des, şi deci probabil că i se atribuie un prag ridicat. Dar dacă ţinem evidenţa numai pentru “e”, 20 de apariţii de exemplu, s-ar putea să nu mai ţinem evidenţa lui “#” cu 10 apariţii. Dacă pragul pentru “#” este mult mai mic, algoritmul poate duce la un răspuns negativ fals: chip-ul poate eşua la alarmarea despre un pachet care ar trebui marcat.
Contraexemplul sugerează următoarea corecţie. Chip-ul ţine într-un registru evidenţa valorii maxime a contorului relativ la valoarea pragului. Mai precis, chip-ul ţine evidenţa celei mai mari valori a contorului relativizat, Max, corespunzătoare unui caracter k oarecare, astfel încât [ ] [ ]/C k T k Max= este cel mai mare dintre toate caracterele contorizate
până acum. Dacă un caracter nou i este citit, chip-ul incrementează [ ]C i .
Dacă [ ] [ ]/C i T i Max> , atunci chip-ul înlocuieşte valoarea curentă a lui
Max memorată, cu [ ] [ ]/C i T i . La sfârşitul procesării URL-ului, chip-ul ne alertează dacă Max L≥ .
Iată de ce această soluţie e bună: dacă [ ] [ ]/Max C k T k L= ≥ , evident că pachetul trebuie marcat, deoarece caracterul k depăşeşte pragul. Pe de altă parte, dacă [ ] [ ]/C k T k L< , atunci pentru orice i, avem
[ ] [ ] [ ] [ ]/ /C i T i C k T k L≤ < . Astfel dacă Max cade sub prag, atunci nici un caracter nu va trece peste prag. Astfel nu pot exista răspunsuri false negative (vezi fig. 1.5).
1.2.4 Rafinarea algoritmului: exploatarea hardware-ului Noul algoritm a eliminat bucla de final dar încă trebuie să realizeze
operaţia de împărţire în timpul procesării fiecărui octet. Logica împărţirii este ceva mai complicată şi trebuie evitată dacă se poate– dar cum?
Revenind la specificaţii şi scopul lor, probabil că pragurile nu trebuie să fie numere reale exacte în virgulă flotantă. Puţin probabil ca proiectantul care deduce pragurile să poată estima precis valoarea; probabil că 2.78% va fi aproximat cu 3% fără a afecta prea tare securitatea. Atunci de ce să
2%
• •
1%
• •
5
••
3
••
Tabloul Prag
Tabloul Contor
AIM://depasire # * # ! * # ...... *
Cod dăunător
0
#
255
1) Incrementează 3) Dacă C[i]/T[i] > Max, Max = C[i]/T[i]
2) Citire

9
nu aproximăm pragul cu o putere a lui 2, în loc să folosim valoarea exactă a pragului respectiv? Astfel dacă pragul este 1/29, de ce să nu îl aproximăm cu 1/32?
FIGURA 1.6 Folosirea unui cuvânt lung şi un tablou compus pentru a combina 2 citiri într-una
Schimbarea specificaţiei în felul acesta necesită o negociere cu arhitectul
sistemului. Presupunem că arhitectul este de acord cu propunerea. Un prag ca 1/32 poate fi codat compact ca o putere a lui 2 – ex. 5. Această valoare de prag deplasată/shift poate fi memorată în tabloul de praguri, în locul unei fracţii.
Când este întâlnit un caracter j, chip-ul incrementează [ ]C j ca de obicei şi-l deplasează apoi spre stânga– împărţirea cu 1/ x este înlocuită cu înmulţirea lui x cu pragul indicat. Dacă valoarea deplasată e mai mare decât ultima valoare Max stocată, chip-ul înlocuieşte vechea valoare cu noua valoare şi continuă.
Astfel logica necesară pentru implementarea procesării unui octet constă dintr-o deplasare şi o comparaţie. E necesar doar un registru pentru memorarea valorii Max. Dar e necesară o citire a tabloului Prag (pentru a citi valoarea deplasată), o citire a tabloului Contor (pentru a citi vechiul contor) şi o scriere in tabloul Contor (pentru a reînscrie valoarea incrementată).
Citirea memoriei durează acum 1-2nsec chiar şi pentru cele mai rapide memorii pe chip, dar poate dura până la 10nsec pentru memoriile mai lente – deci e mai lentă ca logica. Întârzierile porţilor sunt de ordinul picosecundelor, şi logica de deplasare nu necesită prea multe porţi. Astfel, strangularea de procesare este dată de numărul de accesări ale memoriei.
Implementarea chip-ului poate combina cele două citiri ale memoriei într-o singură citire, reunind cele două tablouri Prag şi Contor într-unul singur (fig.1.6). Ideea este de a face cuvintele din memorie destul de lungi pentru a conţine şi contorul (15 biţi pentru a manevra pachete cu lungimea 32K) şi pragul (care depinde de precizia necesară, nu mai mult de 14 biţi). Astfel cele două câmpuri pot fi uşor combinate într-un cuvânt mai mare de 29 biţi. In practică, hardware-ul poate manevra cuvinte mult mai mari, de până la 1000 biţi. De altfel trebuie avut în vedere că extragerea celor două câmpuri dintr-un singur cuvânt, o sarcină laborioasă prin software, este
2%
• •
1%
• •
5
• •
3
• •
Tabloul Prag plus Contor
AIM://supraincarcare # * # ! * # ...... *
Cod dăunător
0
#
255
1) Citeşte un cuvânt lung 2) Compară şi marchează dacă e necesar 3) Scrie valoarea incrementată

10
banală prin hardware, prin cablarea adecvată a firelor între registre, sau prin folosirea multiplexoarelor.
1.2.5 Ştergerea Deşi bucla terminală a fost eliminată, nu a fost rezolvată problema
delicată a buclei de iniţializare. Pentru a trata această problemă, chip-ul are la dispoziţie un timp de iniţializare, dupa analiza URL-lui pachetului curent şi înainte de tratarea URL-lui următorului pachet.
Din păcate, dimensiunea minimă a pachetelor poate fi mică, de până la 50 bytes, inclusiv antetul HTTP. Presupunând că sunt 40 bytes non-URL şi 10 bytes URL, iniţializarea unei zone de 256 de bytes nu poate fi făcută fără un cost suplimentar de 256/40 =6 operaţii per byte, necesare prelucrării unui URL. Ca şi la bucla de procesare a URL-lui, fiecare iniţializare presupune o citire şi o scriere a zonei comasate.
O metodă este amânarea lucrului până nu e absolut necesar, în speranţa că nu va mai fi necesar. De fapt, chip-ul nu trebuie să iniţializeze [ ]C i până când caracterul i e accesat prima dată în pachetul următor. Dar cum poate să ştie chip-ul că accesează caracterul i pentru prima dată? Pentru a implementa evaluarea relaxată, fiecare cuvânt de memorie, reprezentând o intrare în zona comasată, trebuie extins pentru a include [ ]G i , numărul generaţiei. Acest număr de generaţie, pe 3 biţi, poate fi văzut ca un contor, care numară de câte ori e întâlnit pachetul, cu excepţia faptului că e limitat la trei biţi. Astfel, chip-ul are un registru suplimentar g pentru fiecare i, pe lângă [ ]G i , cu 3 biţi; registrul g este incrementat modulo 8 la fiecare
pachet intâlnit. In plus, de câte ori [ ]C i este actualizat, chip-ul
actualizează şi [ ]G i pentru a reflecta valoarea curentă a lui g. Având numerele generaţiei, chip-ul nu mai trebuie să iniţializeze zona de
numărare dupa ce pachetul curent a fost procesat. Totuşi, să considerăm cazul unui pachet cu numărul generaţiei h, care conţine un caracter i în URL-ul său. Când chip-ul întâlneşte caracterul i în timpul procesării pachetului, citeşte [ ]C i şi [ ]G i din zona de numărare. Dacă [ ]G i h≠ înseamnă că intrarea i a fost accesată anterior de un pachet şi nu a fost iniţializată în consecinţă. Astfel, logica va repune pe 1 valoarea lui [ ]C i (iniţializare plus incrementare) şi va pune pe h valoarea lui [ ]G i (fig.
1.7). Apare imediat o obiecţie.Deoarece numărul generaţiei are doar 3 biţi, iar
valoarea lui g este ciclică, pot apare erori. Dacă [ ] 5G i = iar intrarea i nu este accesată până când nu au trecut deja 8 pachete, valoarea curentă a lui g este 8. Dacă următorul pachet conţine caracterul i, [ ]C i nu va mai fi iniţializat şi contorul va număra eronat valoarea de ordine a caracterului i din pachetul curent, cu valoarea din urmă cu opt pachete.
Chip-ul poate evita această eroare printr-o buclă de filtrare separată, care citeşte tabelul şi iniţializează toate contoarele cu numerele de generaţie învechite. Pentru corectitudine, chip-ul trebuie să realizeze o scanare completă a zonei pentru toate cele opt pachete procesate. Incetinirea existentă, de 40 non-URL octeti per pachet, garantează o încetinire de 320

11
bytes non-URL pentru cele opt pachete, ceea ce este suficient pentru a iniţializa o zonă de 256 de elemente, utilizând o citire şi o scriere per octet indiferent de tipul de octet, URL sau non-URL. Se poate câştiga mai multă întârziere dacă este nevoie, crescand numărul de biţi ai numărului generaţiei, cu preţul unei uşoare creşteri a necesarului de memorare a zonei.
Fig 1.7 Soluţia finala cu numere de generaţie pentru rafinarea buclei de iniţializare
In acest caz, chip-ul trebuie să conţină două stări, una de procesare a
biţilor aparţinând URL-lui şi una de procesare a biţilor non-URL. Când un URL este complet procesat, chip-ul trece în starea de filtrare/scrub. Chip-ul dispune de un alt registru, care indică intrarea s a următoarei zone de filtrat. Dacă [ ]G s g≠ , [ ]G s este resetat la valoarea g, iar [ ]C s este iniţializat pe 0.
Deci utilizarea a 3 biti suplimentari, pentru numărul generaţiei pentru fiecare intrare de zonă, a dus la reducerea ciclurilor de iniţializare cu preţul creşterii zonei de memorare. Intrarea zonei comasate are acum doar 32 de biţi, 15 biţi pentru contor, 14 biţi pentru valoarea de prag de comutare, şi 3 biţi pentru numărul generaţiei. Verificările adăugate iniţializării, necesare în timpul procesării byte-lor URL nu cresc numărul de referiri la memorie (strangulare) ci cresc puţin logica de procesare. In plus, mai e nevoie de două registre pe chip pentru memorarea şirurilor g şi s.
1.2.6 Caracteristicile algoritmilor de reţea Detectarea un pachet malefic pune în evidenţă trei aspecte importante: a) Algoritmica reţelelor este un domeniu interdisciplinar. Datorită
vitezelor mari de procesare în reţele, proiectanul de rutere va fi presat să nu utilizeze implementări hardware.Exemplul exploatează câteva caracteristici ale hardware-ului. Astfel, se presupune că: sunt posibile, fără dificultate, cuvinte lungi de diferite dimensiuni; deplasarea este mai uşoară decât împărţirea; referirile la memorie conduc la strangulări; este fezabilă implemetarea unor memorii rapide pe chip, cu zone de 256 de elemente;este fezabilă adăugarea unor registre suplimentare; modificările aduse logicii pentru a combina procesarea URL şi iniţializarea sunt uşor de implementat.
Inţelegerea unor aspecte ale proiectării hardware poate ajuta, chiar pe un programator software, să înţeleagă fezabilitatea diferitelor implemantări hardware. Abordarea interdisciplinară poate conduce la o proiectare optimă. Sunt prezentate câteva modele hardware care oferă posibilitatea

12
soluţionării şi rafinării unor probleme de implementare. De asemenea, sunt prezentate modele simple de sisteme de operare, deoarece pentru îmbunătăţirea performanţelor, terminalele (serverele web) şi clienţii trebuie să înţeleagă problemele sistemelor de operare, după cum ruterele şi dipozitivele de reţea implică o bună cunoaştere şi adaptare a hardware-ului.
b) Algoritmica de reţea admite primordialitatea gândirii sistemice. Specificaţiile au fost relaxate permiţând praguri aproximative, ca puteri ale lui 2, ceea ce simplifică hardware-lui.Relaxarea specificaţiilor şi translatarea activităţii de la un subsistem la altul este o tehnică obişnuită, dar care nu este încurajată în sistemul educaţional din universităţile în care fiecare domeniu este predat izolat de celelalte domenii. De aceea, în zilele noastre, există cursuri de algoritmi, de sisteme de operare şi de reţele. Acest fapt are tendinţa de a promova gândirea la nivel de “cutie neagră” în loc de o gândire globală, sau sistemică.Exemplul a făcut aluzie la alte tehnici cum ar fi “evaluarea relaxata” (lazy evaluation) şi compromisul memorie pentru procesare cu scopul de a elimina zonele de contorizare.Aşadar s-a încercat sintetizarea principiilor sistemelor utilizate în algoritmică (15 principii), precum şi explicarea şi analiza implementărilor realizate pe baza acestor principii.
c) Algoritmica de reţea poate beneficia de pe urma gândirii algoritmice. Dşi gândirea la nivel de sistem este importantă pentru a rafina de câte ori este posibil, o problemă, sunt multe situaţii în care constrângerile impuse sistemelor nu permit eliminarea unor probleme. Ca exemplu, dupa sublinierea importanţei gândirii algoritmice prin relaxarea specificaţiilor, problema “ falsului pozitiv ” a condus la luarea în calcul a contorului maxim relativ la valoarea sa de prag. Alt exemplu este comutarea etichetelor/tag switching, când s-a încercat rafinarea căutării IP/lookup prin comutarea etichetelor, deşi multe rutere au recurs la alţi algoritmi eficienţi de căutare.
Deoarece modelele sunt diferite de modelele teoretice standard, deseori nu e suficient să fie reutilizaţi orbeşte algoritmii existenţi. Ca exemplu, necesitatea de a programa un comutator crossbar în 8ms conduce la luarea în considerare a potrivirii maxime prin încercări, mai simplă decât algoritmii complicaţi care duc la asocieri optimale.
Alt exemplu descrie cum implementarea BSD a procedurii de căutare (lookup) reutilizează orbeşte o structură de date denumită proba Patricia, ce utilizează un contor de omisiuni, pentru căutarea IP. Algoritmul rezultat necesită o urmărire recursivă complexă. O simplă modificare, care păstrează biţii omişi, elimină urmărirea recursivă. Dar acest lucru presupune o pătrundere în cutia neagră (algoritmul) şi aplicării sale. Algoritmul a fost mulţi ani considerat o capodoperă şi a fost implementat în hardware, în multe rutere. Dar de fapt nu este decât o implementare hardware a BSD Patricia tries with backtracking. E util de ştiut că o simplă modificare a algoritmului poate simplifica hardware-ul substanţial.
In concluzie, folosirea fără discernământ critic a algoritmilor standard poate duce la eşuarea perfecţionărilor, prin măsuri inadecvate (e.g., pentru filtrele de pachete ca BPF, introducerea unui nou clasificator duce la timpi mai mari decat timpii de căutare), datorită modelelor nepotrivite (ignorarea liniilor cache în software şi a paralelismului în hardware) şi datorită

13
analizelor neadecvate (e.g., ordinul complexităţii ascunde constant factorii esenţiali ce asigură înaintarea rapidă a pachetelor pe liniile fizice). Aşadar, un alt scop este de a urmări implementări care pătrund în esenţa algoritmilor, şi folosirea tehnicilor fundamentale algoritmice (ca de exemplu tehnica divide et impera/dezbină şi cucereşte, şi aleatorismul). Acestea conduc la următoarele concluzii.
Definiţie: Algoritmica de reţea este folosirea abordării sistemice interdisciplinare, combinată cu gândirea algoritmică, pentru proiectarea implementărilor rapide ale sarcinilor de procesare în reţea, la nivelul serverelor, ruterelor şi a altor dispozitive de reţea.
Obiectiv Motiv Subiecte simple Modele Inţelegerea modelelor
simple de sisteme de operare,hardware,reţele
Tehnologii de memorii :întreţesere, combinare SRAM/DRAM
Strategii Inţelegerea principiilor sistemelor pentru evitarea strangulărilor
Pasarea indicaţiilor, evaluarea relaxată, suplimentarea stărilor, exploatarea localizării
Probleme Practică aplicarea principiilor la probleme simple
Proiectarea unui motor de verificare(lookup) pentru monitorul reţelei
Fig.1.8 Algoritmica de reţea (cu modele, strategii şi probleme simple). 1.3 Exerciţiu: Implementarea Chi-Square. Statistica chi-square se
foloseşte pentru a vedea dacă frecvenţele caracterelor observate sunt neobişnuit de diferite (comparativ cu variaţia aleatoare normală) faţă de frecvenţele estimate ale caracterelor. Acesta este un test mai sofisticat decât un simplu detector de prag. Se presupune că pragurile reprezintă frecvenţele aşteptate. Statistica se calculează pentru toate valorile caracterelelor i prin:
[ ] [ ]( )[ ]
2
Frecventa estimata i Frecventa observata i
Frecventa estimata i−
Chip-ul ar trebui să semnalizeze dacă rezultatul final depăşeşte un anumit prag (ca exemplu, o valoare de 14,2 semnifică că sunt 1,4% şanse ca diferenţa să se datoreze unor variaţii aleatoare). Găsiţi o cale de implementare eficientă a acestei metode, presupunând că lungimea este cunoscută doar la sfârşit.

14
CAPITOLUL 2
MODELE DE IMPLEMENTARE A RETELELOR Pentru a îmbunătăţi performanţele nodurilor terminale şi a
ruterelor, un implementator trebuie să cunoască regulile jocului. O dificultate centrală este aceea că algoritmii de reţea cuprind patru domenii diferite: protoacoale, arhitecturi hardware, siteme de operare şi algoritmi. Inovaţiile în domeniul reţelelor apar când experţii din diferitele domenii conlucrează pentru a obţine soluţii sinergice. Poate oare un proiectant hardware să înţeleagă problemele legate de protocoale, iar un proiectant de algoritmi să înţeleagă problemele hardware, fără un studiu temeinic?
Se începe cu modele simple, capabile să explice şi să anticipeze, fără detalii inutile. Modelul ar trebui să ofere posibilitatea ca o persoană creativă din afara unui domeniu să poată crea proiecte, ce pot fi verificate de un expert din interiorul domeniului. De exemplu, un proiectant hardware de chip-uri ar trebui să fie capabil să sugereze schimbări de software în driver-ul chip-lui, iar un teoretician din domeniul calculatoarelor ar trebui să fie în stare să viseze la algoritmi de asociere pentru switch-uri.
2.1 Protocoale Secţiunea 2.1.1 descrie protocolul de transport TCP şi protocolul de
rutare IP. Aceste două exemple sunt utilizate pentru a asigura un model abstract de protocol şi funcţiile acestuia din &2.1.2. Secţiunea 2.1.3 se încheie cu ipoteze asupra performanţelor reţelelor. Cititorii familiarizaţi cu TCP/IP ar putea dori să sară peste &2.1.2.
2.1.1 Protocoale de transport şi dirijare Aplicaţiile se bazează pe o transmitere fiabilă, sarcină ce revine
protocolului de transport, aşa cum este protocolul TCP (Transport Control Protocol). Sarcina protocolului TCP este de a asigura transmiterea şi recepţionarea aplicaţiilor, ca şi cum ar fi două cozi de aşteptare separate, una în fiecare direcţie, chiar dacă emiţătorul şi receptorul sunt separate de o reţea cu pierderi. Aşadar, orice ar scrie aplicaţia emiţătoare în coada sa de aşteptare locală TCP, ar trebui să apară, în aceeaşi ordine, în coada de aşteptare locală TCP a receptorului şi viceversa. Protocolul TCP implementează acest mecanism prin fragmentarea cozii de aşteptare a datelor aplicaţiei în segmente şi transmiterea fiecărui segment până când s-a recepţionat confirmarea.
Dacă aplicaţia este, de exemplu, o videoconferinţă care nu necesită neapărat o garanţie a fiabilităţii, se poate alege protocolul denumit UDP (User Datagram Protocol) în locul TCP-lui. Spre deosebire de TCP, UDP nu necesită aşteptarea unor confirmări sau retransmisii deoarece nu garantează transmisia fiabilă.
Protocoalele de transport cum sunt TCP şi UDP lucrează prin transmiterea unui segment de la un nod emiţător la un nod receptor prin intermediul internetului. Sarcina actuală de transmitere a unui segment revenind protocolului internet de rutare IP.

15
Rutarea în Internet este impărţită în două părţi “forwarding and routing”, înaintare/dirijare. Inaintarea reprezintă procesul prin care pachetele sunt transmise între sursă şi destinaţie trecând prin ruterele intermediare. Pachetul reprezintă un segment TCP care are ataşat un antet de rutare care conţine adresele internet destinaţie.
In timp ce procesul de înaintare trebuie să se realizeze la viteze mari, tabelele de rutare din cadrul fiecărui ruter trebuie construite de către un protocol de rutare, mai ales în cazul unor modificări de topologie cum este cazul unor legături întrerupte. Sunt câteva protocoale de rutare mai cunoscute, cum este protocolul bazat pe vectorii distanţă (RIP), sau pe starea legăturii (BGP).
2.1.2 Model abstract de protocol Un protocol reprezintă o stare a maşinii pentru toate nodurile participante la protocol, împreună cu interfeţele şi mesajele. Un model pentru un protocol este prezentat în figura 2.1. Specificaţiile trebuie să descrie cum diagrama de stări a maşinii evoluează şi răspunde la interfeţele utilizator, la mesajele recepţionate şi la contorul de evenimente. De exemplu, când o aplicaţie face o cerere de conectare, diagrama de stări a maşinii TCP emiţătoare se iniţializează prin alegerea unui număr de secvenţă iniţial, ajunge la aşa numita stare SYN-STATE şi trimite un mesaj SYN. Ca un al doilea exemplu, un protocol de rutare cum este OSPF are câte o diagramă de stare a maşinii corespunzătoare fiecărui ruter; când un pachet de stare LSP (Link State Packet) ajunge la un ruter cu număr de secvenţă mai mare decât ultimul LSP transmis de către sursă, noul LSP ar trebui să fie memorat şi transmis către toate ruterele învecinate. In timp ce protocolul de stare a liniei este foarte diferit de protocolul TCP, ambele protocoale pot fi abstractizate de către diagrama de stări prezentată în figura 2.1. In afara protocoalelor TCP şi IP, vor fi luate în considerare şi alte protocoale, aşa cum este protocolul HTTP. Un asemenea model este prezentat în figura 2.2 fiind folosit drept referinţă.
In primul rând, (fig.2.2 jos), diagrama de stări trebuie să recepţioneze/trimită pachete de date. Aceasta implică manevrarea datelor sau operaţii de scriere şi citire a fiecărui octet dintr-un pachet. De exemplu, TCP trebuie să copieze datele recepţionate în buffer-ele aplicaţiilor, în timp ce ruterele trebuie să comute pachetele între liniile de intrare şi cele de ieşire. Antetul TCP specifică, de asemenea, o sumă de control ce trebuie calculată în funcţie de toate datele. Copierea datelor necesită de asemenea alocarea de resurse, cum sunt buffer-ele.
In al doilea rând, (fig.2.2, sus), diagrama de stări trebuie să demultiplexeze datele către unul sau mai multi clienţi. In unele cazuri, programele client trebuie activate, necesitând un transfer costisitor al controlului. De exemplu, când TCP receptionează o pagină web, trebuie să demultiplexeze datele către aplicaţiile de tip web-browser utilizând câmpurile cu numărul portului şi s-ar putea să fie nevoie să lanseze procesul rulând browser-ul. Figura 2.2 descrie câteva funcţii generice utilizate de mai multe protocoale. In primul rând, protocoalele trebuie să îndeplinească condiţia crucială de a se putea bloca la viteze mari iar uneori de a putea fi manipulate. De exemplu, un pachet TCP recepţionat face ca protocolul TCP să caute în tabela de stări a conexiunii, în timp ce

16
pachetele IP recepţionate fac ca protocolul IP să caute o tabelă de expediere.
Figura 2.2 Funcţii comune ale protocolului, folosind tabela de stări (înegrită)
In al doilea rând, protocoalele au nevoie să seteze eficient contoarele
pentru a controla, de exemplu, retransmisiile protocolului TCP. In al treilea rând, dacă un modul al protocolului gestionează mai mulţi clienţi trebuie să-i programeze eficient. De exemplu, TCP trebuie să programeze procesarea diferitelor conexiuni, în timp ce un ruter trebuie să se asigure că dominarea conversaţiilor între câteva perechi de calculatoare nu blochează alte conversaţii. Multe protocoale permit ca mari cantităţi de date să fie fragmentate în bucăţi mai mici care necesită o reasamblare ulterioară. Asemenea funcţii generice sunt uneori costisitoare, costul lor putând fi atenuat utilizând tehnici potrivite.Aşadar fiecare funcţie generică a protocolului merită să fie studiată individual.
2.1.3 Performanţă şi măsurări
Această secţiune descrie câteva măsurători importante şi presupuneri de performanţă. Se consideră un sistem (cum este o reţea sau chiar un singur ruter) unde sarcinile (cum ar fi transmiterea mesajelor) sosesc, iar după realizarea lor, pleacă. Cei mai importanţi parametri în reţele sunt

17
debitul/traficul util (throughput) şi latenţa (latency). Debitul indică numărul de operaţii realizate cu succes per secundă. Latenţa măsoară timpul (cel mai slab posibil) de realizare a unei operaţii. Posesorii sistemelor (ISP, ruterele) caută să maximizeze debitul util pentru a-şi mări câştigurile, pe când utilizatorii sistemului doresc o latenţă cap-la-cap mai scăzută de câteva milisecunde. Latenţa afectează de asemenea viteza de calcul în reţea. Următoarele observaţii legate de performanţa mediului Internet sunt utile când se iau în considerare compromisurile implementării. •Vitezele liniilor : viteza liniilor principale de tranzit (backbone) poate fi marită până la 10Gps şi 40Gbps, iar viteza liniilor locale ajunge la ordinul Gbps. Legăturile wireless şi cele de acasă sunt la momentul curent mult mai încete. •Dominanţa TCP şi Web : traficul Web reprezintă peste 70% din traficul de bytes sau pachete, iar traficul TCP reprezintă 90% din trafic. Transferurile reduse : majoritatea documentelor Web accesate sunt de dimensiuni reduse ; un studiu SPEC arată că 50% din fişierele accesate sunt de 50 kilobytes sau mai puţin. • Latenţa slabă : întârzierea în timp real depăşeşte limitările impuse de viteza luminii: măsurătorile efectuate au semnalat o întârziere de 241 msec dealungul Statelor Unite, în comparaţie cu întârzierile datorate vitezei luminii care este de 30 msec. Latenţa crescută se datorează eforturilor de îmbunătăţire a debitului, cum ar fi compresia în modemuri şi pipelining-ului în rutere. • Localizarea slabă : studiul asupra traficului din backbone-ul reţelei indică 250.000 de perechi diferite sursă-destinaţie ce trec printr-un ruter într-un interval redus de timp. Estimări mai recente indică în jur de un milion de transmisii concurente. Reunind grupurile de antete care au aceeaşi adresă destinaţie sau alte resurse comune, nu se reduce semnificativ numărul de clase al antetelor. Astfel, localizarea, sau probabilitatea de reutilizare a calculului, investit într-un pachet, pentru un pachet viitor, este mică. •Pachetele de dimensiuni reduse: aproximativ jumătate din pachetele recepţionate de către un ruter sunt pachete de confirmări de dimensiune minimă de 40 octeţi. Pentru a se evita pierderea de pachete importante într-un flux de pachete de dimensiuni minime, majoritatea producătorilor de rutere şi adaptoare de reţea ţintesc către expedierea la viteza liniilor/wire speed forwarding. •Măsurări critice : trebuie făcută distincţia între măsurări globale ale
performanţei (întârzirea cap-la-cap şi lărgimea de bandă), şi măsurări locale ale performanţei (viteza de căutare/lookup a ruterelor). Măsurările globale sunt cruciale pentru o evaluare globală a reţelei. Aici ne concentrăm numai asupra măsurărilor locale ale performanţei, şi anume performanţele de expediere (forwarding) şi resursele (logice, de memorie). • Instrumente : majoritatea instrumentelor de management a reţelelor,
cum este HP’s Open View, lucrează cu măsurări globale. Instrumentele necesare pentru măsurările locale sunt instrumente de măsurare a performanţei din interiorul calculatoarelor, aşa cum este “profiling software”.

18
Exemplele includ: Rational’s Quantify (http://www.rational.com) pentru aplicaţii software, Intel’s Vtune (www.intel.com/software/products/vtune), şi chiar osciloscoape hardware. De asemenea sunt utile programele de monitorizare a reţelelor aşa cum este tcpdump (www.tcpdump.org).
2.2 Hardware Pe măsură ce legăturile de date se apropie de viteze de 40 gigabit/s
(OC-768), un pachet de 40 bytes trebuie transmis în 8 nsec. La aşa viteze, transmisia mai departe a pachetelor este de obicei implementată hardware, şi nu de un procesor programabil. Nu se poate participa la procesul de proiectare a unui astfel de hardware, fără înţelegerea condiţiilor impuse proiectanţilor şi mecanismelor unui asemenea hardware competitiv. Câteva modele simple pot permite înţelegerea şi facilitează lucrul cu astfel de modele de hardware.
Căutările Internet sunt implementate de obicei folosind logica combinatională, pachetele Internet sunt stocate în memoriile ruterelor, şi un ruter Internet este pus laolaltă cu comutatoare şi chip-uri de căutare. În consecinţă, se începe cu implementarea logică, se continuă cu descrierea memoriilor, şi se termină cu schema bazată pe componente. Pentru detalii, dăm spre referinţa clasicul VLSI, care încă se mai foloseşte, şi arhitectura clasică a calculatorului.
2.2.1 Logica combinatorie Modelele foarte simple pentru porţile logice de bază cum ar fi:
Inversorul, SI-NU şi SAU-NU pot fi înţelese chiar şi de un programator. Totuşi, nu este necesar să ştim cum sunt implementate porţile logice de bază, pentru a avea o privire de ansamblu asupra proiectării hardware.
Primul pas spre înţelegerea proiectării logice este observaţia următoare. Fiind date porţile inversoare, SI-NU şi SAU-NU, algebra booleană arată că poate fi implementată orice funcţie booleană ( )1,..., nf I I , de n variabile de intrare. Fiecare bit al multibitului de ieşire poate fi considerat ca o funcţie de biţii de intrare. Minimizarea logicii foloseşte la eliminarea porţilor redundante şi uneori la creşterea vitezei. De exemplu, dacă “+” înseamnă poartă SAU şi “• ” poartă SI, atunci funcţia :
2121 IIIIO ⋅+⋅= poate fi simplificată la: 1IO = .
Exemplul 1: Calitatea serviciului (QOS) şi codoarele de prioritate: să
presupunem că avem un ruter de reţea care menţine pentru pachete n cozi de aşteptare per legătură de ieşire, unde coada i are o prioritate mai mare decât coada j dacă i j< . Aceasta este o problemă de QOS. Planificatorul transmisiei din ruter trebuie să aleagă un pachet din prima coadă nevidă, în ordinea priorităţilor. Planificatorul menţine un vector pe N-biţi (bitmap): I, aşa încât [ ] 1I j = dacă şi numai dacă coada j este nevidă; atunci planificatorul poate găsi coada nevidă cu cea mai mare prioritate, prin găsirea celei mai mici poziţii din I cu bitul setat. Proiectanţii hardware cunosc această funcţie sub denumirea de codor de prioritate. Totuşi, chiar

19
şi un proiectant de software trebuie să-şi dea seama că această funcţie se pretează la o implementare hardware, pentru un n rezonabil. Funcţia este descrisă mai detaliat în exemplul 2.
2.2.2 Sincronizare şi putere Pentru transmisia mai departe a unui pachet de 40 bytes la viteza unui
OC-768, orice funcţie de reţea aplicată pachetului trebuie terminată în 8 nsec. De aceea intârzierea maximă la transmisia semnalului de la intrare la ieşire, pe orice cale logică, nu trebuie să depăşească 8 nsec. In acest scop, e necesar un model al timpului de intârziere introdus de un tranzistor. In ansamblu, fiecare poartă, NU sau SI-NU, poate fi gândită ca un set de capacitoare şi rezistoare care trebuie încărcate (când se schimbă valorile de intrare) ca să se poata calcula valorile de ieşire. Chiar mai rău, încărcarea unei porţi de intrare poate determina ca ieşirile unor porţi ulterioare să încarce intrări următoare, şi aşa mai departe. In consecinţă, pentru o functie combinaţională, întârzierea în calcularea funcţiei este suma întârzierilor de încărcare şi de descărcare introduse de căile cele mai defavorabile ale tranzistoarelor. Timpii de întârziere introduşi de astfel de căi trebuie să se încadreze în timpul minim de sosire al pachetelor.
De asemenea este nevoie de energie pentru a încărca condensatoarele; energia pe unitatea de timp (puterea) este proporţională cu capacitatea, pătratul tensiunii, şi frecvenţa cu care se poate schimba intrarea fVCP ⋅⋅= 2 . Noile procese reduc nivelul tensiunii şi al capacităţii, iar circuitele de viteză mare trebuie să crească frecvenţa de ceas. Paralelism înseamnă că mai multe capacităţi trebuiesc încărcate simultan. In consecinţă, multe chip-uri de mare viteză disipă foarte multă caldură, necesitând tehnici deosebite de răcire. ISP-urile şi facilităţile de colocare sunt mari consumatori de putere. Desi nu tratăm schimbul de caldură, e bine de ştiut că chip-urile şi ruterele sunt câteodată limitate în putere. Câteva limite practice de astăzi sunt: 30 W/cm2 si respectiv 10 000 W/foot2 într-un centru de date (1 foot =0.305m).
Exemplul 2: Proiectarea codoarelor de prioritate: Să considerăm problema estimării sincronizării necesare codorului de prioritate din exemplul 1, pentru o legătură OC-768, folosind pachete de 40 bytes. In consecinţă circuitul are la dispoziţie 8 nsec să producă ieşirea. Considerând că intrarea I şi ieşirile O sunt vectori pe N biti ca [ ] 1O j =
dacă şi numai dacă [ ] 1I j = şi [ ] 0I k = pentru toate k j< . Trebuie observat că ieşirea este reprezentată în unar (de multe ori numită reprezentare 1 hot) şi nu în binar. Specificaţia conduce direct la ecuaţia combinaţiilor logice: ][]1[...]1[][ jIjIIjO −= pentru j > 0.
Acest model poate fi implementat direct folosind N porţi SI, una pentru fiecare bit de ieşire, unde cele N porţi au un număr de intrări care variază de la 1 la N. Intuitiv, din moment ce N porţi de intrare SI iau ( )O N tranzistoare, avem un model. Modelul 1, cu ( )2O N tranzistoare
care pare că iau ( )1O timp. Chiar şi acest nivel de proiectare este util deşi s-ar putea şi mai bine.

20
Un alt model mai economic din punct de vedere al suprafeţei este bazat pe observaţia că fiecare bit de ieşire ( )O j necesită poarta SI componentă a primilor 1j − biţi de intrare. In consecinţă definim rezultatele parţiale
]1[...]1[][ −= jIIjP pentru 2...j N= . Este clar că [ ] [ ] [ ]O j I j P j= . Dar [ ]P j
poate fi construită recursiv folosind ecuaţia ][]1[][ jIjPjP ⋅−= care poate fi implementată folosind N porţi SI de câte două intrări, conectate în serie. Aceasta conduce la un model, modelul 2 care necesită ( )O N tranzistoare
dar care ia ( )O N timp. Modelul 1 este rapid şi mare, şi modelul 2 este lent şi redus. Acesta este
un compromis familiar spaţiu-timp care sugerează că putem avea o soluţie intermediară. Calculul lui [ ]P j în modelul 2 seamană cu un arbore binar
neechilibrat de înălţime N. Totuşi, este evident că [ ]P N poate fi calculat folosind un arbore binar complet echilibrat de porţi SI cu 2 intrări, de înălţime log N . Rezultatele parţiale ale arborelui binar pot fi combinate în feluri simple astfel încât să avem [ ]P j pentru toate j N< folosind acelaşi arbore binar.
De exemplu dacă N=8, pentru calculul lui P[8] calculăm ]3[...]0[ IIX = şi ]7[...]4[ IIY= şi calculăm SI din X şi Y la rădăcină. Deci este uşor să
calculăm P[5] spre exemplu, folosind una sau mai multe porţi SI, calculând ]4[IX ⋅ . O astfel de metodă este foarte utilizată de proiectanţii hardware pentru înlocuirea lanţului de calcul aparent lung de ( )O N , cu lanţuri de lungime 2log N . Deoarece a fost folosită prima dată ca să grăbească lanţurile carry, este cunoscut sub denumirea de carry lookahead sau simplu look-ahead. Chiar dacă tehnicile look-ahead par complexe, chiar şi programatorii le pot stăpâni pentru că la baza lor, folosesc tehnica dezbină-şi-cucereşte.
2.2.3 Creşterea nivelului de abstractizare a proiectării hardware Proiectarea manuală a fiecărui tranzistor dintr-un nou cip de reţea, care
constă în 1 milion de tranzistoare, ar fi consumatoare de timp. Procesul de proiectare poate fi redus la câteva luni folosind blocurile constructive (vezi tehnologiile de construire a blocurilor funcţionale, ca PLA, PAL şi a celulelor standard).
Un lucru important este faptul că la fel ca şi programatorii care refolosesc codurile, proiectanţii de hardware refolosesc implementări de funcţii frecvent utilizate. In afară de blocurile de calcul comune, ca blocurile de adunare, multiplicare, comparare şi codare a prioritatilor, proiectanţii folosesc de asemenea blocuri decodoare, blocuri de deplasare cu împrumut (barrel shifter), multiplexoare şi demultiplexoare.
Un decodor converteşte o valoare log N biţi la una N biţi unară de aceeaşi valoare; reprezentările binare sunt mai compacte, dar reprezentările unare sunt mai convenabile pentru calcul. Un bloc de deplasare cu împrumut deplasează o intrare I cu s pozitii la stânga sau la dreapta, cu biţii mutaţi circular de la un capăt la celălalt.

21
Un multiplexor (mux) conectează una din mai multe intrări la o ieşire comună, în timp ce dualul său: demultiplexorul, rutează o intrare la una din mai multe posibile ieşiri. Mai precis, un multiplexor conectează unul din n biţi de intrare jI la ieşirea O dacă un semnal de selecţie S de log n biţi codează valoarea j în binar. Dualul său, demultiplexorul, conectează intrarea I la ieşirea jO dacă semnalul S codează valoarea j în binar.
FIGURA 2.3: Multiplexor cu 4 intrări cu biţii de selecţie 0S şi 1S , pornind de la trei multiplexoare cu 2 intrări (multiplexorul are simbolul standard trapezoidal).
Astfel trebuie descompusă o funcţie logică complexă în funcţii standard,
folosind recursivitatea când este nevoie. Aceasta este o reducere şi urmează principiul dezbină-şi-cucereşte fiind folosită de programatori cu uşurinţă. De exemplu, figura 2.3 arată problema tipică Lego cu care se confruntă proiectanţii hardware: construiţi un multiplexor de 4 intrări pornind de la multiplexoare de 2 intrări. Incepeţi prin a alege una dintre intrările 0I si
1I folosind un multiplexor cu 2 intrări şi apoi una dintre 2I şi 3I folosind un alt multiplexor de 2 intrări. Rezultatele multiplexoarelor de 2 intrări din primul etaj, trebuie combinate folosind un al 3-lea multiplexor de 2 intrări; singura observaţie este că semnalul de selecţie pentru primele 2 multiplexoare este cel mai puţin semnificativ bit 0S al semnalului de selecţie de 2-biţi, iar al treilea multiplexor selectează jumătatea de sus sau cea de jos, astfel încât foloseşte 1S ca bit de selecţie.
Următorul exemplu de reţea arată că reducerea este o unealtă de proiectare puternică pentru proiectarea funcţiilor de reţea.
Exemplul 3: Planificarea crossbar şi codoare de prioritate programabile: Exemplele 1 şi 2 au motivat proiectarea unui codor de prioritate rapid (PE). Un mecanism obişnuit de arbitrare de ruter foloseşte o formă îmbunătăţită de codor de prioritate numit codor de prioritate programabil (PPE). Avem o intrare I de N biţi ca mai înainte, împreună cu o intrare adiţională P de log N biţi. Circuitul PPE trebuie să calculeze o ieşire O astfel încât [ ] 1O j = , unde j este prima pozitie după P (tratat ca valoare binară) care are o cifră binară diferită de zero în I. Dacă 0P = , această problemă se reduce la un codor de prioritate simplu. PPE-urile apar natural în arbitrarea switchurilor. Deocamdată presupunem că un ruter conectează N legături de comunicaţie Presupunem că mai multe legaturi de intrare vor să transmită un pachet la legătura de ieşire L. Pentru a evita coliziunea la ieşirea L, fiecare intrare trimite o cerere la L în primul interval de timp; L alege legătura de intrare căreia îi va servi cererea în

22
slotul al doilea; intrarea aleasă expediează un pachet în al treilea interval temporal.
Pentru a lua decizia de servire, L poate să stocheze cererile primite la sfârşitul slotului 1 într-un vector R de N-biţi, unde [ ] 1R i = dacă legătura de intrare i doreşte să transmită la L. Pentru corectitudine, L ar trebui să reţină ultima intrare P servită. După aceea, L ar trebui să servească prima legătură de intrare de după P, care are o cerere. Aceasta este o problemă PPE cu R şi P ca intrări. Deoarece un ruter trebuie să facă o arbitrare pentru fiecare poziţie temporală şi pentru fiecare legătură de ieşire, este nevoie de un model PPE rapid şi eficient ca arie. Chiar şi un programator poate să înţeleagă, şi posibil să repete procesul folosit pentru a proiecta PPE-ul din Tiny Tera, un switch construit la Stanford şi mai târziu comercializat. Ideea de bază este reducerea: reducerea proiectării unui PPE la proiectarea unui PE (exemplul 2).
Prima idee este simplă. PPE este în esenţă un PE a cărui prioritate mazimă începe de la pozitia P în loc de 0. Un barrel-shifter poate fi folosit pentru a deplasa I mai întâi spre stânga cu P biţi. După aceasta se poate folosi un simplu PE. Bineinţeles că vectorul bitilor de iesire este acum deplasat; deci trebuie restabilită ordinea originală deplasând ieşirea lui PE la dreapta cu P biţi. Un bloc de deplasare cu împrumut pentru N-biti de intrare poate să fie implementat folosind un arbore de multiplexoare de 2 intrări într-un timp în jur de log N . Astfel două blocuri de deplasare cu împrumut şi un PE echivalează cu aproximativ 3log N întârzieri de porţi.
Un proiect mai rapid, care necesită numai 2 log N întârzieri de porţi este următorul. Problema se poate împărţi în două părţi. Dacă intrarea are nişte biţi setaţi la poziţia P sau mai mare, atunci rezultatul poate fi găsit folosind un PE care operează pe intrarea originală după ce au fost setaţi pe 0 toţi biţii de intrare a căror poziţie este mai mică decât P. Pe pe de altă parte, dacă intrarea nu are nici un bit setat la poziţia P sau mai mare, atunci rezultatul poate fi găsit folosind PE-ul care operează pe intrarea originală fără nici o mascare. Acest rezultat din modelul din figura 2.4, testat pe Texas Instrument Cell Library, a fost aproape de două ori mai rapid şi a însemnat folosirea unei suprafeţe de trei ori mai mică decât modelul blocului de deplasare cu împrumut, pentru un ruter cu 32-porturi.
Deci logica modelului pentru o componentă de timp critică, un switch, poate fi realizată folosind reduceri şi modele simple.
2.2.4 Memorii In punctele terminale şi rutere, înaintarea/expedierea pachetelor se face
folosind logica combinaţională, dar pachetele şi stările necesare înaintării trebuiesc stocate în memorii. Deoarece accesarea memoriilor este semnificativ mai lentă decât întârzierile logice, memoriile sunt cele care generează strangulări masive în rutere şi în puncte terminale.
În plus, diferitele subsistemele necesită memorii cu caracteristici diferite. De exemplu, vânzătorii de rutere cred că este important un buffer de 200 de msec pentru a evita pierderea pachetelor în timpul perioadelor de congestie. La, să zicem 40 Gbit/sec per legătură, un astfel de buffer de pachete necesită o cantitate enormă de memorie. Pe pe de altă parte, căutările ruterelor necesită o

23
cantitate mai mică de memorie, accesată aleator. Astfel este bine să avem modelele simple pentru memorii cu diferite tehnologii.
REGISTRE Un bistabil (flip-flop) conectează două sau mai multe tranzistoare într-o
buclă, astfel încât (în absenţa căderilor tensiunii) cifra binară să stea nedefinit de mult timp pe ieşire fără să se modifice valoarea tensiunii. Un registru este o colecţie ordonată de bistabile. Cele mai moderne procesoare au registre pe chip de 32 sau 64 biţi. Un registru pe 32 biţi conţine 32 de bistabile, fiecare pentru a memora 1 bit. Accesul de la logică la un registru, pe acelaşi chip, este extrem de rapid, în jur de 0.5-1 nsec.
SRAM O memorie statică cu acces aleator (SRAM) conţine N registre adresate cu o
adresă A, pe log N biţi. SRAM este numită astfel deoarece reîmprospătarea bistabilelor este de tipul “static”. În afară de bistabile, SRAM are nevoie şi de un decodor care decodează A, într-o valoare unară, folosită pentru accesarea registrului potrivit. Accesarea unui SRAM pe-chip este doar puţin mai lentă decât accesarea unui registru, din cauza întârzierii introduse de decodare. În momentul actual, este posibil să se obţină SRAM pe chip cu timp de acces de 0.5 nsec. Timpi de acces de 1-2 nsec pentru SRAM pe-chip şi 5-10 nsec pentru SRAM care nu este pe chip, se întâlnesc în mod uzual.
DRAM O celulă binară SRAM necesită cel puţin cinci tranzistoare. Astfel
SRAM este întotdeauna mai puţin densă sau mai scumpă decât tehnologia de memorie bazată
FIGURA 2.4: Proiectul Tiny Tera PPE foloseşte codor de prioritate 1, pentru a găsi
setul cel mai mare de biţi, dacă există, a tuturor biţilor mai mari decât P folosind o mască de codare a lui P. Dacă nu e găsit nici un bit, e validată ieşirea codorului 2 de prioritate (poarta SI de jos). Rezultatele celor două codoare sunt apoi combinate cu o poartă SAU cu N intrări.
pe DRAM (Dynamic RAM). Ideea de bază este să se înlocuiască bucla de răspuns (şi implicit tranzistoarele suplimentare) folosită pentru a memora un bit într-un bistabil, cu o capacitate care poate să stocheze bitul; sarcina se scurge, dar încet. Pierderea datorată descărcării este compensată reîmprospătând celula DRAM în mai puţin de o milisecundă. Bineînţeles, fabricarea unei capacităţi mari folosind puţin siliciu e complexă.

24
Capacitatea chip-urilor DRAM pare că devine de 4 ori mai mare la fiecare 3 ani şi tinde spre 1 Gbit pe un singur chip. Adresarea acestor biţi, chiar dacă ei sunt construiţi împreună în aceeaşi capsulă sub forma unor registre de 4 sau 32 de biţi, este dificilă. Adresa trebuie să fie decodificată de la, să zicem 20b la una din 220 valori. Complexitatea unei astfel de logici de decodare sugerează folosirea tehnicii dezbină şi cucereşte. Dar de ce să nu se folosească o decodare în doi paşi în schimb?
FIGURA 2.5: Memoriile mai mari sunt organizate pe două dimensiuni în rânduri şi
coloane. Selectarea unui cuvânt constă în selectarea mai intâi a rândului şi apoi a coloanei din acel rând.
Figura 2.5 arată că cele mai multe memorii sunt organizate intern pe
două dimensiuni, în rânduri şi coloane. Cifrele binare de adresă de sus sunt decodificate pentru a selecta rândul, şi după aceea cifrele binare de adresă de jos sunt folosite pentru a decodifica coloana. Utilizatorul furnizează mai întâi biţii de adresă a rândului şi activează un semnal numit RAS(Row Address Strobe); apoi utilizatorul furnizează biţii de adresă ai coloanei şi activează un semnal numit CAS(Column Address Strobe). Dupa un timp specificat, cuvântul dorit din memorie poate fi citit. Presupunând rânduri şi coloane egale, se reduce complexitatea porţii de decodare de la ( )O N la
)(( NO ) cu preţul creşterii întârzierii cu timpul necesar pentru încă o decodare. In afară de timpul de întârziere necesar, dintre RAS şi CAS, mai este de asemenea necesară şi o întârziere de preîncărcare între invocări succesive ale lui RAS şi CAS, timp ce permite încărcarea condensatoarelor.Cele mai rapide chip-uri DRAM au nevoie în jur de 40-60 nsec (latenţa) pentru acces, cu timpi mai lungi ca de exemplu 100 nsec, între citiri succesive (consum) din cauza restricţiilor de preîncărcare. Acesta latenţă include timpul necesar pentru a adresa liniile externe de interfaţă la pinii memoriei DRAM; inovaţiile recente permit realizarea de DRAM pe chip, cu timpi de acces mai mici, în jur de 30 nsec. DRAM va fi întotdeauna mai densă dar mai lentă decât SRAM..
Page-Mode DRAM Unul din motivele înţelegerii DRAM este înţelegerea artificiului
utilizat pentru accelerarea timpului de acces, numit page mode/modul pagină. Acest mod de acces este benefic pentru a accesa structuri de date care au o localizare spaţială, în care cuvintele de memorie adiacente sunt

25
accesate succesiv. Dar accesând un rând (fig. 2.5), se pot accesa cuvinte din rând, fără întârzieri suplimentare de RAS şi preîncărcare. RAM–urile video exploatează această structură având o citire de rând într-un SRAM, care poate fi citit serial, pentru a reîmprospăta un ecran (display) la viteze înalte. In afara de page mode şi video RAM, mai sunt şi alte idei care exploatează structura DRAM, care pot fi folositoare în reţele.
Multe chip-uri de DRAM au avantajul că adresele de linii şi coloane nu sunt cerute în acelaşi timp astfel ca pot fi multiplezate pe aceeaşi pini, reducând necesarul de pini per chip.
FIGURA 2.6: Ideea RAMBUS, SDRAM, etc., este crearea unui singur chip cu
DRAM multiple paralele, câştigând astfel lăţime de bandă de memorie şi folosind doar un set de linii de adrese şi de date.
DRAM -uri întreţesute În timp ce latenţa memoriei este critică pentru viteza de calcul, debitul
memoriei (numit şi lăţime de bandă) este de asemenea important pentru multe aplicaţii de reţea. Cu o memorie DRAM care are cuvinte de 32b şi ciclul de 100 nsec, debitul de ieşire, folosind o singură copie a memoriei DRAM este limitat la 32 biţi la fiecare 100 nsec. Debitul de ieşire poate fi îmbunătăţit folosind accesările la DRAM-uri multiple (fig. 2.6), numite bancuri de memorie, care pot avea o singură magistrală. Utilizatorul poate să înceapă o citire a bancului1 punând adresa pe magistrala de adresă. Presupunem că fiecare banc DRAM are nevoie de 100 nsec pentru a returna datele selectate.
În loc să aştepte inactiv în acest timp de întârziere de 100-nsec, utilizatorul poate să pună o a doua adresă pentru bancul 2 pe magistrală, a treia pentru bancul 3, şi aşa mai departe. Dacă punerea fiecărei adrese ia 10 nsec, utilizatorul poate alimnta 10 bancuri DRAM înainte să ajungă răspunsul la cererea făcută asupra primului banc DRAM, urmată 10 nsec mai târziu de răspunsul la cererea făcută asupra celui de-al doilea banc DRAM, şi aşa mai departe. Deci lăţimea de bandă netă de memorie folosită în acest exemplu este de 10 ori mai mare decât cea a unei singure memorii DRAM, atâta timp cât utilizatorul poate face în aşa fel încât să aibă adresări consecutive la bancuri consecutive.
In timp ce ideea folosirii de bancuri de memorie multiple este una veche, în ultimii 5 ani proiectanţii memoriilor au integrat mai multe bancuri într-un singur chip (fig. 2.6), în care liniile de adresă şi de date pentru toate bancurile de memorie sunt multiplexate folosind o reţea comună de mare viteză numită magistrală/bus. In plus, accesurile de tip “page mode” sunt de cele mai multe ori permise pe fiecare banc. Există multiple tehnologii de realizare a memoriilor folosind această idee de bază, cu diferite valori pentru mărimea DRAM, protocolul de citire şi scriere şi numărul

26
bancurilor. Exemple importante includ SDRAM cu 2 bancuri şi RDRAM (Remote DRAM)cu 16 bancuri.
Exemplul 4. Căutări/lookup de fluxuri pipeline: un flux este caracterizat de existenţa unei adrese IP a sursei şi a destinaţiei, şi de porturi TCP. Unii clienţi doresc ca ruterele să ţină evidenţa pachetelor trimise de fiecare flux de reţea, pentru contorizare. Sunt deci necesare structuri de date care să stocheze un contor pentru fiecare flux ID şi care să suporte două operaţii: Insert (FlowID) pentru inserarea unui nou ID de flux şi Lookup (FlowID) pentru găsirea locaţiei contorului de flux ID. Căutarea necesită o potrivire exactă a ID-ului fluxului – care este în jur de 96 biţi – în timpul recepţionării pachetului. Aceasta poate fi făcută prin orice algoritm de potrivire exactă, cum ar fi cel de dispersare/hashing.
Totuşi, pe măsură ce tot mai mulţi vânzători de rutere vor să limiteze timpul de lookup pentru cazul cel mai defavorabil, căutarea binară este cea mai bună. Presupunem că aceste căutări ale ID-urilor fluxurilor trebuie făcute la viteza liniei, pentru cazul cel mai defavorabil de pachete de 40 bytes la viteze de 2.5 Gbit/sec/viteze OC-48. In consecinţă chip-ul are la dispoziţie 128 nsec pentru a găsi un ID de flux.
Pentru a mărgini întârzierile de căutare, considerăm un arbore binar simetric, ca arborele B. Logica parcurgerii arborelui este uşoară. Pentru creşterea vitezei, ar trebui ca ID-urile fluxurilor şi numărătoarele să fie stocate într-o memorie SRAM.. Estimările actuale actuale în ceea ce priveşte nucleul ruterelor arată în jur de 1 milion de fluxuri concurente. Păstrarea stării pentru 1 milion de fluxuri în SRAM este scumpă. Chiar dacă folosim doar DRAM-uri, cu arbori binari cu factor de branşament de 2, ar necesita log21.000.000=20 accese de memorie. Chiar cu un timp de acces optimist al memoriei DRAM de 50 nsec, timpul necesar întregii căutări este de 1 μsec, care este prea lent
O soluţie este folosirea pipelining-ului (fig. 2.7), în care accesul logic prin pipeline la ID-urile fluxurilor stocate într-o memorie RDRAM cu 16 bancuri este ca în figura 2.6. Toate nodurile de înălţime i din arborele binar sunt stocate în bancul i al RDRAM-ului. Chip-ul de căutare face16 căutări de ID-uri de fluxuri (pentru 16 pachete) deodată. De exemplu după ce a căutat în nodul rădăcină pentru pachetul 1 în bancul 1, chip-ul poate să caute, la nodul arborelui de nivel doi, după pachetul 1 în bancul 2 şi (foarte repede dupa asta) poate să caute la nodul rădăcină al arborelui pentru pachetul 2 din bancul 1. Când firul/thread procesului de căutare a pachetului 1 accesează bancul 16, firul procesului de căutare a pachetului 16 accesează bancul 1. Deoarece RDRAM-ul direct funcţionează la 800 Mhz, timpul dintre cererile de adresare a magistralei RAM-ului este mic comparativ cu timpul de acces de citire de 60 nsec. Astfel, în timp ce unui singur pachet îi trebuie16∗60 nsec, procesarea concurentă a 16 pachete permite debitul de o găsire de ID de flux la fiecare 60 nsec.

27
FIGURA 2.7: Găsirea identităţii fluxului, cu un chip de căutare pipeline, care lucrează la găsirea a
până la 16 ID-uri de fluxuri în acelaşi timp, fiecare din ele accesând un banc DRAM independent. Chip-ul de căutare returnează un index procesorului de reţea care actualizează numărătorul ID a fluxului.
Dar, un arbore binar cu 16 nivele permite doar 216 = 64 K ID-uri de flux, prea
puţin. Din fericire RAMBUS permite o variantă de page mode, unde 8 cuvinte de 32 biţi pot fi accesate aproape în acelaşi timp ca 1 cuvânt. Astfel putem găsi două chei de 96 biţi şi 3 pointeri de 20 biţi într-un acces la memorie de 256 biţi. Se poate deci folosi un arbore cu branşament de 3, care permite potenţial 316 sau 43 milioane de ID-uri de fluxuri.
2.2.5 Tehnici de proiectare a subsistemelor de memorii Problema găsirii ID-urilor fluxurilor de date ilustrează 3 tehnici majore folosite
de obicei în proiectarea subsistemului memoriei pentru chip-urile de reţea. • Intreţeserea memoriilor şi tehnica pipeline: Tehnici similare sunt folosite
în căutarea IP-urilor şi algoritmilor de planificare care implementează QOS. Bancurile multiple pot fi implementate folosind câteva memorii externe, o singură memorie externă ca RAMBUS, sau un SRAM pe chip care contine şi logica de procesare. •Procesarea paralelă a cuvintelor lungi: Multe modele de reţea, ca schema
vectorilor binari de la Lucent, folosesc cuvinte de memorie lungi care pot fi procesate în paralel. Aceasta poate fi implementată cu DRAM si folosind page-mode-ul, sau cu SRAM şi făcând fiecare cuvânt de memorie mai mare. •Combinarea DRAM şi SRAM: Tinând cont de faptul că SRAM este scump şi
rapid iar DRAM este ieftin şi lent, este de aşeptat o combinaţie a acestora. Folosirea SRAM ca şi cache pentru bazele de date DRAM este clasică, dar sunt multe aplicaţii creative a memoriei ierarhizate. In exerciţii e analizat efectul unui SRAM mic în proiectarea unui chip căutator de ID. O aplicaţe mai neobişnuită a acestei tehnici de implementare a unui număr mare de numărătoare, este stocarea în SRAM a biţilor de rang inferior.
E mai important ca tânarul proiectant să înţeleagă aceste tehnici de proiectare (decât să stie detalii de implementare a memoriilor) ca să producă implementări hardware creative a funcţiilor de reţea.
2.2.6 Proiectarea la nivel de componente Metodele din ultimele două secţiuni pot fi folosite pentru a realiza o
maşină de stări/state machine care implementează o prelucrare oarecare. O maşină cu stări are starea curentă stocată în memorie; maşina procesează datele de intrare folosind logica combinaţională, citeşte starea curentă şi eventual memorează starea. Un exemplu de maşină complexă cu stări este procesorul Pentium, a cărui stare curentă este o combinaţie de

28
registre, memorie cache şi memorie principală. Un exemplu de maşină cu stări mai simplă este chip-ul de căutare a ID-ului fluxului (flow ID lookup) din figura 2.7, a cărui stare e dată de registrele folosite pentru urmărirea fiecăreia din cele 16 căutări concurente şi RDRAM-ul care memorează arborele binar B.
Doar puţine chip-uri cheie trebuie proiectate pentru a realiza un ruter sau o placă de reţea, iar restul proiectării este la nivelul componentelor: organizarea şi interconectarea chip-urilor pe placă şi amplasarea plăcii în carcasă ţinînd cont de factorul de formă, de putere şi de răcire. Un aspect cheie în proiectarea la nivel de componente este înţelegerea limitării impuse de numărul de pini (pin-count) care de obicei permite „verificării de paritate” rapidă a proiectelor fezabile.
Exemplul 5. Influenţa numărului de pini asupra bufferelor din rutere: considerăm un ruter cu 5 legături, fiecare de 10Gb/s. Necesarul de buffer-e va fi 200ms*50Gb/s, deci 10Gb. Din cauza costului şi a puterii se folosesc DRAM-uri pentru memoriile tampon/buffer de pachete. Deoarece fiecare pachet trebuie să intre şi să iasă în/din buffer, lăţimea totală de bandă trebuie să fie dublul lăţimii de bandă de intrare (ex.100Gb/s). Dacă presupunem o supraîncărcare de 100% pentru antetele pachetelor interne, legăturile dintre pachetele din cozile de aşteptare şi lăţime irosită de bandă de memorie, atunci este rezonabil să considerăm o lăţime de bandă de 200Gb/s pentru memorie.
Pentru o singură memorie RDRAM directă cu 16 bancuri, specificaţiile dau o lăţime maximă de bandă a memoriei de 1.6Gb/s, sau 13Gb/s. Accesarea fiecărei memorii RDRAM necesită 64 de pini de interfaţă pentru date şi 25 de pini pentru adrese şi control, deci un total de 90 pini. Pentru a obţine 200Gb/s avem nevoie de 16 memorii RDRAM, care necesită 1440 de pini în total. O limită superioară conservativă a numărului de pini per chip este de circa 1000. Chiar dacă producătorul de rutere ar construi un chip foarte rapid, personalizat conform cererii clientului, capabil să trateze toate pachetele la rata maximă, tot mai este nevoie de măcar un chip pentru manevrarea traficului în/din buffer-ul de pachete RAMBUS. În concluzie limitarea numărului de pini este o condiţie cheie în partiţionarea proiectării între chip-uri.
2.2.7 Concluzii despre hardware Din partea de hardware cele mai importante sunt tehnicile de proiectare
din &2.2.5. Următorii parametri sunt utili pentru proiectanţii de sisteme: • Scalarea complexităţii chipului: numărul total de componente per
chip se dublează la fiecare doi ani. La momentul de faţă un ASIC (Application Specific Integrated Circuit) poate conţine mai multe milioane de porţi logice plus încă 50 Mbiţi într-o memorie SRAM pe chip. DRAM încorporată pe chip este o opţiune comună, pentru a avea mai mult spaţiu pe chip chiar cu întârzieri mai mari. •Viteza chip-ului: frecvenţe de 1GHz sunt comune, unele chip-uri
ajungând până la 3GHz. Un ciclu de tact pentru un chip care lucrează la 1GHz este de 1ns. Dacă se optează pentru operarea în paralel prin pipeline-uri şi memorii cu cuvinte extinse, se pot efectua mai multe operaţii pe un singur ciclu de tact, mărindu-se astfel substanţial viteza de procesare.

29
• I/E chip-ului: numărul de pini per chip creşte de la an la an, dar deocamdată limitarea superioară este de 1000 pini per chip. • I/E seriale: sunt disponibile legături seriale între chip-uri de pînă la
10Gb/s. • Scalarea memoriei: există memorii SRAM pe chip cu timpi de acces
de 1ns, iar memoriile SRAM externe au de obicei timpi de acces de 2.5ns. Pentru memoriile DRAM avem 30ns pentru cele integrate pe chip şi 60ns pentru cele externe chipului. Desigur se pot folosi memorii DRAM întreţesute pentru a îmbunătăţi rata de transfer a subsistemului memoriei pentru anumite aplicaţii. Costul DRAM e de 4-10 ori mai mic decât SRAM la aceeaşi capacitate. •Puterea şi carcasa: consumul mare de putere a ruterelor de mare
viteză necesită o proiectare adecvată a sistemului de răcire/ventilaţie. De asemenea există şi o cerinţă de minimizare a dimensiunilor ruterelor pentru a putea fi montate în rack-uri dedicate cât mai compacte.
Valorile acestor parametri au o influenţă clară asupra proiectării de reţele de mare viteză. De exemplu, la viteze OC-768, un pachet de 40 octeţi ajunge în 3.2ns, deci este clar că toate stările prin care trece prelucrarea pachetului trebuie să fie puse în memorii SRAM integrate pe chip. Din păcate capacitatea acestor memorii pe chip nu creşte atât de repede ca şi numărul de fluxuri din ruter. Cu o memorie SRAM de 1ns, cel mult 3 operaţii de acces a memoriei pot fi efectuate spre un singur banc de memorie în timpul sosirii unui pachet.
Deci tehnicile de proiectare din &2.2.5 trebuie folosite în interiorul chip-ului pentru a obţine paralelismul în chip-uri, folosind bancuri multiple de memorie şi cuvinte extinse, şi pentru a creşte memoria utilizabilă combinând memoriile de pe chip cu memoriile externe. Dar deoarece densitatea de chip-uri şi constrângerile de putere limitează paralelismul la un factor de maxim 60, concluzia este că toate funcţiile de prelucrare a pachetelor la viteză mare trebuie să folosească cel mult 200 accesări ale memoriei şi o memorie pe chip limitată.
2.3. Arhitectura echipamentelor de reţea Optimizarea performanţelor reţelelor necesită optimizarea căilor datelor
prin nodul sursă şi prin fiecare ruter. Din acest motiv este importantă înţelegerea arhitecturii interne a nodurilor terminale şi a ruterelor. În esenţă şi ruterele şi nodurile terminale sunt maşini cu stări, dar arhitectura fiecăruia este optimizată pentru scopuri diferite. Nodurile terminale au o arhitectură mai generală pentru relizarea unor operaţii comune, în timp ce ruterele sunt specializate pentru comunicaţia de tip Internet.
2.3.1 Arhitectura nodurilor terminale Un procesor cum este Pentium este o maşină cu stări, care ia o secvenţă
de instrucţiuni şi date de intrare, după care trimite ieşirea spre anumite echipamente de I/E, precum imprimante şi terminale. Pentru a asigura programelor un spaţiu mare de memorare a stărilor, cea mai mare parte a informaţiei este stocată în memorii externe ieftine precum DRAM. În PC-uri această memorie reprezintă memoria principală şi este implementată folosind 1GB sau mai mult de memorii DRAM întreţesute, precum SDRAM. Dar memoriile DRAM necesită un timp de acces mare (60ns) şi

30
dacă stările proceselor ar fi memorate numai în DRAM, atunci o instrucţiune ar necesita 60ns pentru a scrie şi a citi din memorie.
Procesoarele mai folosesc o memorie pentru a câştiga viteză care se numeşte cache. Memoria cache este o memorie relativ mică formată din memorii SRAM, care memorează bucăţi de stări folosite des, mărind astfel viteza de acces. Unele memorii SRAM (ex. L1 cache) se află în procesor pe când altele (ex. L2 cache) sunt externe procesorului. O memorie cache este un tablou care mapează adresele de memorie ale unor locaţii şi conţinutul acestora. Cache-ul procesorului foloseşte o funcţie simplă de căutare: extrage câţiva biţi din adresă pentru a-i indexa într-un tablou şi apoi caută în paralel toate adresele care se potrivesc cu elementul din tablou. Când o locaţie de memorie tebuie citită din DRAM ea este stocată în cache şi un element deja existent din cache poate fi eliberat. Datele folosite des sunt stocate într-o memorie cache de date în timp ce instrucţiunile folosite des sunt stocate într-o memorie cache de intrucţiuni.
Memorarea in cache este eficientă dacă instrucţiunile şi datele prezintă o localizare temporală (poziţia corespunzătoare este reutilizată frecvent într-o perioadă scurtă de timp) sau o localizare spaţială (accesarea unei locaţii este urmată de accesarea unei locaţii vecine). Localizările spaţiale sunt avantajoase deoarece accesarea unei locaţii din DRAM implică accesarea unei linii R şi apoi a unei coloane din acea linie. Deci citirea cuvintelor de le linia R este mai puţin costisitoare după ce linia R a fost accesată. Astfel, procesorul Pentium extrage anticipat 128 de biţi vecini în memoria cache (mărimea unei linii din cache), de fiecare dată cand sunt accesaţi 32 de biţi de date. Accesarea celor 96 de biţi adiacenţi nu va atrage o disfuncţie în memoria cache.
Multe benchmark-uri (programe pentru testarea performantei calculelor) prezintă localizări temporale şi spaţiale, dar în cazul fluxurilor de pachete cel mai probabil se va întâlni doar fenomenul localizărilor spaţiale. Imbunătăţirea performanţelor protocoalelor nodurilor terminale necesita o analiza atenta a efectelor memoriei cache.
În figura 2.8 se prezintă arhitectura unui nod terminal:
Figura 2.8: Arhitectura unei staţii de lucru
Procesorul, CPU, este conectat la o magistrală/bus (similara cu o retea ca
Ethernet, dar optimizata prin faptul ca dispozitivele sunt apropiate), prin
Magistrală sistem
Magistrală I/E
Memorie CPU
MMU, Cache
Adaptor magistrală
Interfaţă reţea

31
care comunică cu celelalte componente trimiţând mesaje pe magistrala. Echipamentele de I/E sunt de regulă memory mapped, adică pentru procesor toate dispozitivele de I/E (placa de reţea sau discul) reprezintă locaţii de memorie. Astfel se asigură o comunicare uniformă între CPU şi orice echipament, folosind aceleaşi convenţii ca la accesarea memoriei. Cu terminologia din retele, o citire/scriere se poate vedea ca un mesaj trimis pe magistrală, adresat unei locatii de memorie, locatie la care se poate afla si un dispozitiv de I/E.
Maşinile moderne permit accesul direct la memorie DMA (Direct Memory Acces), prin care echipamente precum discul/adaptorul de reţea trimit datele de citit/scris pe magistrală, direct la memorie fără intervenţia procesorului. Dar la un moment dat doar o entitate poate folosi magistrala, motiv pentru care adaptorul trebuie să concureze pentru magistrală. Fiecare echipament care ocupă magistrala va „fura cicluri” procesorului, deoarece procesorul e obligat sa astepte pentru accesul la memorie cat timp dispozitivul trimite mesaje pe magistrala.
Tot în figura 2.8 se observă că adaptorul de magistrală este conectat la magistrale diferite (magistrala de sistem sau de memorie) iar toate echipamentele sunt conectate la magistrala de I/E. Magistrala de memorie este proiectată pentru viteze mari, şi este reproiectată pentru fiecare procesor nou. Magistrala de I/E este standard (ex. magistrala PCI) ea fiind aleasă pentru a rămâne compatibilă şi cu echipamentele de I/E mai vechi, astfel ca ea este mai lentă decât cea de memorie.
Trebuie reţinut că rata de transfer a unei aplicaţii de reţea este limitată de viteza celei mai lente dintre magistrale, de obicei magistrala de I/E. Încă şi mai rău este faptul că sunt necesare şi copii suplimentare pentru diverse sisteme de operare, astfel ca fiecare pachet transmis sau recepţionat de staţia de lucru va traversa magistrala de cateva ori.(vezi capitolul 5 pentru tehnicile de evitare a traversării multiple a magistralei).
Procesoarele moderne folosesc tehnica pipeline/seriala pentru extragerea instrucţiunii, decodarea instrucţiunii, citirea şi scrierea datelor, care sunt divizate în mai multe stări intermediare. Maşinile superscalare şi cele cu multiple fire de execuţie/multithreaded trec dincolo de tehnica pipeline prin tratarea mai multor instrucţiuni în acelaşi timp în mod concurenţial. În timp ce aceste metode înlătura congestia cauzata de calcule, ele nu îmbunătăţesc congestia cauzata de transferul de date. Se consideră următorul exemplu de arhitectura:
Exemplul 6: arhitectură de nod terminal cu comutator crossbar: in figura 2.9 magistrala nodului terminal este înlocuită de un comutator hardware programabil, folosit deseori la rutere.
Comutatorul conţine un număr de magistrale paralele a.î. fiecare set de perechi de puncte terminale disjuncte poate fi conectat în paralel prin intermediul comutatorului. Astfel, în figură, procesorul este conectat la memoria 1, în timp ce placa de reţea este conectată la memoria 2. În acest fel, pachetele care sosesc din reţea pot fi stocate în memoria 2 fără a interfera cu procesorul care citeşte din memoria 1. În momentul în care procesorul doreşte să citească pachetul de date sosit, comutatorul poate fi reprogramat pentru a conecta procesorul cu memoria 2 şi placa de reţea cu memoria 1.

32
Figura 2.9. Folosirea conexiunilor paralele într-un nod terminal pentru a permite
procesarea concurentă şi trafic de reţea printr-un comutator paralel. Acest mod de funcţionare este eficient dacă coada bufferelor de pachete
goale, folosita de placa de reţea, alternează între cele două memorii. Există propuneri recente de înlocuire a magistralei de I/E din procesoare cu tehnologia de comutare Infiniband. Ideea ce trebuie retinuta din acest exemplu este ca, nu este neaparat buna arhitectura in fig.2.9, ci schimbari simpe ale arhitecturii pot fi concepute chiar si de catre proiectantii de protocoale, conform unor modele simple de hardware si arhitecturi.
2.3.2 Arhitectura ruterelor Modelul unui ruter care acoperă atât ruterele high-end (seria de rutere
Juniper M) precum cat şi ruterele low-end (Cisco Catalyst), este prezentat în figura 2.10. În principiu, un ruter este un echipament cu un set de legaturi de intrare, şi un set de legături de ieşire. Sarcina ruterului este de a comuta pachetul de pe legătura de intrare pe legătura de ieşire corespunzătoare adresei destinaţie din pachet. În timp ce legăturile de intrari şi de ieşire sunt reprezentate separat, cele două legături în fiecare direcţie între două rutere sunt deseori împachetate împreună. Există trei congestii principale într-un ruter: căutarea adresei, comutarea şi coada de ieşire.
Figura 2.10 Model de ruter cu cele 3 congestii principale in calea de inaintare:
căutarea adresei (B1), comutarea (B2) şi planificarea ieşirii (B3).
Procesor
Comutator programabil paralel
Placă de reţea
Memorie 1
Memorie 2
Ruter B2
Comutare
Legătura de intrare i
B1 Căutare adresă
B3
Legături de ieşire
Planificare

33
Căutarea adresei (lookup)
Un pachet care soseşte pe legătura de intrare i poartă o adresă IP de 32 biţi (desi majoritatea utilizatorilor lucreaza cu nume de domenii, acestea sunt translatate in adrese Ipde serviciul DNS, inainte ca pachetul sa fie transmis). Presupunem că primii 6 biţi ai adresei destinaţie din pachet sunt 100100. Un procesor din ruter va inspecta adresa destinaţie pentru a determina încotro să dirijeze pachetul în cauză.
Procesorul consultă o tabelă de rutare/inaintare pentru a determina legătura de ieşire pentru pachet. Acest tabel mai poartă denumirea de FIB (Forwarding Information Base) – baza de informaţii pentru dirijare. FIB conţine un set de prefixe şi legatura de ieşire corespunzătoare. Un prefix poate fi privit ca fiind un „cod de judeţ/zona” de lungime variabilă care reduce substanţial mărimea tabelei FIB. Un prefix ca 01∗ (unde ∗ poate insemna oricâte alte simboluri), se potriveşte cu toate adresele IP care încep cu 01.
Presupunem un prefix 100∗ care are atribuită legătura de ieşire 6, în timp ce prefixul 1∗ are atribuită ieşirea 2. În acest caz adresa 100100 se potriveşte cu ambele prefixe şi avem o problemă de ambiguitate. Pentru înlăturarea incertitudinii, ruterele IP asociază adresa cu prefixul cel mai lung/the longest prefix matching cu care se potriveşte, astfel că în exemplul de faţă se va alege legătura de ieşire 6 pentru pachetul de date.
Procesorul care realizează căutarea/identificarea şi procesarea de bază asupra pachetelor poate să fie un procesor dedicat/partajat de uz general/chip specializat. Ruterele din primele generaţii foloseau procesoare partajate, dar acest lucru s-a dovedit a fi o congestie. Generaţiile mai noi de rutere (familia Cisco GSR) folosesc un procesor dedicat pentru fiecare legătură de intrare. La început s-au folosit procesoare de uz general, dar mai nou (Juniper M-160) se folosesc chipuri specializate (ASIC) cu un oarecare grad de programabilitate.Clientii pretind ruterelor functii noi, ca echilibrarea incarcarii Web. Ruterele mai noi folosesc procesoare de reţea (exemplul 7), care sunt procesoare de uz general optimizate pentru reţele.
Exista o serie de algoritmi folosiţi pentru identificarea prefixului. Multe rutere de azi oferă un mod de căutare mai complex numit clasificarea pachetelor, unde pentru căutare se foloseşte ca intrare adresa destinaţie, adresa sursă şi portul TCP.
Comutarea După identificarea adresei, procesorul spune sistemului de comutaţie
intern să transfere pachetul de pe intrarea i spre ieşirea corespunzătoare (ieşirea 6 din exemplu). În procesoarele mai vechi, comutatorul era o simplă magistrală, ca în figura 2.8. Acest mod de abordare s-a dovedit a fi o mare limitare de viteză, deoarece, daca comutatorul are N intrări, fiecare cu B biţi/s, magistrala trebuia să aibă o lăţime de bandă de B·N. Pe măsură ce N creşte, efectele electrice (capacitatea electrica a magistralei) vor deveni predominante, limitând viteza magistralei.
Din acest motiv ruterele cele mai rapide de azi folosesc un comutator paralel (figura 2.9). Rata de tranfer a comutatorului creşte folosind N magistrale paralele, una pentru fiecare intrare şi una pentru fiecare ieşire.

34
O intrare este conectată cu o ieşire prin comandarea tranzistoarelor care conectează magistralele de intrare şi ieşire corespunzătoare. În timp ce realizarea legăturii între magistrale este relativ simplă, partea mai dificilă este planificarea comutatorului, deoarece mai multe intrari ar putea să dorească să comunice cu o anumită ieşire în acelaşi timp. Problema planificării comutatorului se rezumă la identificarea intrărilor şi ieşirilor disponibile la fiecare interval de sosire a pachetelor.
Memorarea în coada de aşteptare Dupa ce pachetul (figura 2.10) a fost identificat şi comutat spre ieşirea 6,
ieşirea 6 s-ar putea să fie congestionată, şi deci pachetul s-ar putea să trebuiască să fie pus într-o coadă de aşteptare pentru ieşirea 6. Majoritatea ruterelor mai vechi pun pur si simplu pachetele într-o coadă de transmisie de tip FIFO. Alte rutere folosesc insa metode mai sofisticate de planificare a ieşirii pentru a asigura alocări echitabile de bandă şi întârziere.
Pe lângă căutare, comutare şi memorarea în coada de aşteptare mai există un număr de alte sarcini care trebuie efectuate, mai putin critice ca timp.
Validarea antetului şi sumele de control Este verificat numărul versiunii fiecărui pachet şi pentru opţiuni este
verificata lungimea antetului. Opţiunile sunt directive de procesare suplimentare către procesor, dar care sunt folosite rar; astfel de pachete sunt de cele mai multe ori şuntate spre un procesor special. Şi antetul are o sumă de control simplă ce trebuie validată. În cele din urmă mai trebuie decrementat contorul de timp de viata TTL (time to live) şi suma de control a antetului trebuie recalculată. Suma de control se poate actualiza incremental. Validarea antetului şi calculul sumelor de control se fac prin hardware.
Procesarea rutei Ruterele din interiorul unor domenii implementează RIP şi OSPF, în
timp ce ruterele care leagă domenii diferite trebuie să implementeze şi BGP(*). Aceste protocoale sunt implementate în unul sau mai multe procesoare de rutare. De exemplu dacă un pachet de stare a legăturii este trimis spre ruterul din figura 2.10, procesul de căutare va recunoşte că acest pachet este destinat ruterului însuşi şi va determina comutarea pachetului spre procesorul de rutare. Procesorul de rutare menţine baza de date cu starea legăturilor şi calculează drumurile cele mai scurte. După calcul, procesorul de rutare încarcă noua tabelă de rutare în fiecare dintre procesoarele de rutare, fie prin comutator, fie printr-o cale separată din afara benzii. La început CISCO procesa nu numai pachete Internet dar şi alte protocoale precum DECNET, SNA sau Appletalk. La ora actuală s-a introdus comutarea multi-protocol după etichetă (MPLS – Multi Protocol Label Switch) care este esenţială pentru ruterele core, ale retelelor de tranzit. În MPLS, antetului IP i se adauga un alt antet care conţine indici întregi simpli, care pot fi identificaţi direct fără cautarea prefixului.
(*)E posibilla achizitionarea acestor protocoale, dar software-ul trebuie personalizat conform cu noile platforme hardware. O problema si mai delicata este, in special pentru BGP si OSPF, ca multe dintre primele implementari ale acestora variaza in mod subtil fata de specificatiile actuale. Noile implementari care indeplinesc specificatiile ar putea sa

35
nu poata interopera cu ruterele existente. Astfel ca ISP-urile opun rezistenta la cumpararea noilor rutere, daca acestea nu asigura „calitatea”codului BGP, in sensul capacitatii de interoperare cu ruterele existente.
Procesarea protocolului Toate ruterele din ziua de azi trebuie să implementeze protocolul SNMP
(Simple Network Management Protocol) şi să furnizeze un set de contoare care să poată fi verificate de la distanţă. Pentru a permite comunicarea la distanţă cu ruterele, majoritatea ruterelor implementează şi protocoalele TCP şi UDP. Pe lângă acestea ele mai trebuie să implementeze protocolul ICMP (Internet Control Message Protocol) care este de fapt un protocol de transmisie a mesajelor de eroare, precum „depăşirea timpului de viata TTL”.
Fragmentarea, redirecţionarile şi ARP Este clar că procesarea rutei şi a protocolului este îndeplinită cel mai
bine de un procesor de rutare pe o aşa numită „cale înceată”, dar sunt cateva funcţii mai ambigue ale ruterului. De exemplu dacă un pachet de 4000 octeţi trebuie transmis pe o legătură cu o limită maximă a pachetelor MTU (Maximum Transfer Unit) de 1500 octeţi, pachetul va trebui să fie fragmentat in doua. Desi aceasta fragmentare este in general facuta de sursa, multe rutere fac acest lucru in calea rapida. O altă funcţie este cea de trimiteri de Redirecţionări. Dacă un nod terminal trimite un mesaj spre un ruter greşit, atunci ruterul trebuie să trimită înapoi o redirecţionare sprenodul terminal. O a treia funcţie de acest fel este transmiterea cererilor de identificare a adresei ARP (Adress Resolution Protocol). Ruterele din ziua de azi mai au şi alte funcţii care trebuie rezolvate. Multe rutere din întreprinderi manevrează pachetele pe baza conţinutului, astfel că procesarea de pachet se face în funcţie de şirurile de caractere din pachet. De exemplu ruterele care primesc traficul Web pentru mai multe servere ar putea sa doreasca sa transmita pachetele cu acelasi URL aceluiasi server Web. In plus, mai există şi funcţiile de măsurarea şi contorizare a traficului.
Exemplul 7: Procesoare de reţea: sunt procesoare programabile de uz
general, optimizate pentru traficul de reţea. Crearea lor a fost justificata de caracterul impredictibil al naturii sarcinilor ruterelor (ca livrarea pe baza continutului), ceea ce ar face riscanta crearea unor rutere implementate exclusiv hardware. Procesorul de reţea Intel IXP1200 conţine şase procesoare interne, fiecare rulând cu 177MHz, şi având un ciclu de tact de 5.6ns. Fiecare procesor recepţionează pachete de la o coadă de intrare (pachetele sunt stocate într-o memorie DRAM mare). După ce procesorul a identificat legătura de ieşire, pachetul este pus în coada de ieşire cu o etichetă ce specifică legătura de ieşire spre care trebuie dirijat.
Problema principală este că procesoarele sunt responsabile de transferul pachetelor în/din memoria DRAM. La IPX1200 mutarea a 32 de octeţi din coadă spre DRAM necesită 45 tacte şi 55 de tacte pentru mutarea din DRAM în coadă. Deoarece dimensiunea minimă a unui pachet este de 40 octeţi sunt necesare 200 cicluri de tact = 1.12μ s, ceea ce se traduce într-o rată de rutare de numai 900K pachete/s. Acest neajuns se înlătura folosind 6 astfel de procesoare paralele şi o idee numită multithreading/fire de

36
execuţie multiple. Ideea principală este că fiecare procesor lucrează pe mai multe pachete, fiecare pachet reprezentând un fir de execuţie; când procesarea unui pachet stagnează din cauza referirii la memorie se reia execuţia următorului fir de execuţie. Folosind comutarea rapidă de context între firele de execuţie şi patru contexte per procesor, procesorul IPX1200 poate obţine teoretic 6∗4∗900 = 21.4 Mpachete/s.
Procesoarele de reţea oferă şi instrucţiuni speciale pentru identificarea adreselor şi funcţii uzuale de dirijare. Unele procesoare de reţea fluentizeaza miscarea pachetelor de date folosind motoare hardware care arată procesorului doar antetul fiecărui pachet. Ceea ce rămâne din pachetul de date este transferat direct spre coada de ieşire. Procesorul/procesoarele citeste antetul, identifică legătura de ieşire şi scrie antetul reactualizat în coada de ieşire. Partea hardware concatenează antetul reactualizat şi pachetul original şi păstrează toate pachetele în ordine. Desi această metodă evită transferarea prin procesor a datelor din pachet, ea nu îmbunătăţeşte tratarea pachetelor de dimensiune minimă.
Studiu de caz 2: Memorarea in tampoane şi comutarea optică.
Legăturile pe fibră optică oferă viteze din ce în ce mai mari, dar partea implementarea electronică a logicii şi memoriile din ruterele core reprezintă o strangulare. Pachetele sosesc pe legături de fibră optică, fiecare bit fiind codat ca un impuls luminos. La receptor se converteşte lumina în semnal electric şi apoi partea electronică implementează comutarea şi rutarea. Pachetul este depus într-o coadă de ieşire din care biţii sunt convertiţi iar în impulsuri luminoase. Pentru înlăturarea congestiei se pot crea rutere total optice.
Din păcate identificarea optica a adresei IP şi mai ales realizarea unor memorii optice dense pentru pachete este încă destul de dificilă, dar comutarea luminii între diferite noduri terminale este realizabilă. Un comutator optic de circuit, conecteaza intrarea X cu ieşirea Y pe o durată relativ lungă, comparativ cu durata unui singur pachet din comutatoarele de pachete. Astfel de comutatoare de circuit sunt folosite ca rutere core flexibile din reţeaua unui ISP (Internet Service Provider) pentru a interconecta ruterele convenţionale. Dacă de exemplu, traficul dintre ruterul R1 şi R2 creşte, un operator de servicii internet poate schimba comutatoarele de circuit spre a mări banda legăturii R1–R2 (pe durata mai multor minute). Ruterele cu comutare de pachete probabil ca vor exista încă o perioadă lungă în viitor, ţinând cont de caile rezervate de fluxurile de scurta durata.
2.4. Sistemele de operare Un sistem de operare OS (Operating System) este software-ul care sta
deasupra componentelor hardware-ului facilitand sarcina programatorilor de aplicatii. Pentru cele mai multe rutere de Internet, pachetele la care timpul de transmisie este critic sunt tratate direct prin hardware (fig. 2.10) si nu sunt mediate de sistemul de operare. Coduri care sunt mai putin critice ca timp ruleaza pe sistemul de operare al unui ruter, descris mai jos (IOS Cisco). Totusi, pentru a imbunatati performantele cap-la-cap pentru navigare Web, de exemplu, un proiectant trebuie sa inteleaga costurile si beneficiile folosirii sistemului de operare.

37
Abstractizarile sunt idealizari sau iluzii pe care le inventam pentru a ne descurca cu ciudateniile lumii reale. Pentru a reduce dificultatile, sistemul de operare ofera abstractizari pentru programatorii aplicatiilor. La lucrul cu hardware-ul apar trei probleme importante: intreruperile, administrarea memoriei, si controlul dispozitivelor de I/O. Pentru a trata aceste dificultati, sistemele de operare ofera abstractizari cum sunt calculul neafectat de intreruperi, memoria infinita si I/O simple.
O abstractizare corecta creste productivitatea programatorilor, dar are doua costuri. Primul, mecanismul de implementare a abstractizarii are un pret. De exemplu, planificarea proceselor poate cauza supraincarcarea serverului Web. Al doilea cost, mai putin evident, este acela ca abstractizarea poate masca puterea, impiedicand programatorul sa foloseasca optim resursele. De exemplu, managementul memoriei la un sistem de operare, poate impiedica programatorul unui algoritm de cautare pe internet sa-si tina in memorie structura de date a cautarii pentru a maximiza performantele sistemului.
2.4.1. Calculul neintrerupt prin procese Un program nu poate rula foarte mult pe un procesor fara a fi intrerupt
de adaptorul de retea. Daca programatorii aplicatiilor trebuie sa foloseasca intreruperi, rularea unui program de 100 de linii de cod ar fi un miracol. In consecinta sistemele de operare ofera programatorilor abstractizarea unui calcul secvential neintrerupt sub numele de proces.
Abstractizarea procesului este realizata prin trei mecanisme: comutarea contextului, planificarea si protectia, primele doua fiind descrise in figura 2.11. In figura, procesul P1 are iluzia ca el ruleaza singur pe procesor . In realitate, cum se vede si pe axa timpului, procesul P1 poate fi interupt de o intrerupere de ceas, care lanseaza in lucru pe procesor planificatorul OS . Inlocuirea lui P1 pretinde OS-ului sa-i salveze starea in memorie. Planificatorul poate rula rapid si decide sa-i dea controlul procesului P2.
Figura 2.11 Programatorul are iluzia timpului continuu, neintrerupt,dar timpul
procesorului e impartit intre mai multe procese Relansarea in rulaj a procesului P2 necesita readucerea starii lui P2 din
memorie in procesor. Astfel ca actuala axa a timpului pentru procesor poate implica schimbari frecvente de context intre procese, dirijate de planificator. In plus, protectia asigura ca anumite comportamente incorecte sau daunatoare al unui proces sa nu poata afecta alte procese.

38
Figura 2.12 Procesul de primire a pachetelor de pe internet este impartit intre adaptorul
de retea, nucleu si procesul destinatie Ca agenti ai calculului, “procesele” sunt de trei tipuri – manipulatorul de
intreruperi, firele de procese si procesele utilizator – clasificate in ordinea cresterii gradului de generalitate si al costului. Manipulatoarele/handler-e de intreruperi sunt programe mici folosite pentru rezolvarea cererilor urgente, cum ar fi sosirea unor mesaje la placa de retea; ele au un numar redus de stari, folosind doar cateva registre de stare. Procesele utilizator folosesc complet starile masinii, memoria si registrele; astfel este scumpa comutarea intre procesele utilizator, la comanda planificatorului. In cadrul unui singur proces, firele de procese ofera o alternativa mai ieftina decat procesele. Un fir de proces este un proces simplu care ocupa mai putine registre de stare, deoarece firele aceluiasi proces partajeaza aceeasi memorie (si deci aceleasi variabile) . Astfel comutarea contextului intre doua fire de executie ale aceluiasi proces este mai ieftina decat comutarea proceselor, deoarece memoria nu trebuie sa fie realocata. Urmatorul exemplu arata relevanta acestor concepte pentru nodului terminale ale retelei.
Exemplul 8. Receptorul Livelock in BSD Unix. In BSD UNIX (fig. 2.12), sosirea unui pachet genereaza o intrerupere. Intreruperea este un semnal hardware care determina procesorul sa salveze starea proceselui ce ruleaza (de exemplu , un program Java). Procesorul sare apoi la codul manipulatorului de intreruperi, si evita planificatorul pentru a creste viteza. Manipulatorul de intreruperi copiaza pachetul in nucleu, intr-o coada pentru pachete IP in asteptarea servirii, si face o cerere pentru un fir de executie al sistemului de operare (numita intrerupere software), si iese. Presupunand ca nu mai apar alte intreruperi, la iesirea din intrerupere se cedeaza controlul planificatorului, care probabil va ceda procesorul intreruperii software, care are prioritate mai mare decat procesele utilizator.
Firele de executie ale nucleului fac o procesare de tip TCP si IP si memoreaza pachetul in coada de aplicatii adecvata, numita coada socket (fig. 2.12). Sa presupunem ca aplicatia este un browser cum ar fi Netscape. Netscape ruleaza ca un proces adormit in asteptarea datelor si acum este considerat de planificator ca fiind in rulaj pe procesor. Dupa ce se termina

39
intreruperea software si controlul revine planificatorului, planificatorul poate decide sa ruleze Netscape in locul programului initial Java.
Daca reteaua e foarte incarcata, calculatorul poate intra in starea numita receiver livelock, in care petrece tot timpul procesand pachetele care sosesc, numai pentru a le arunca mai tarziu deoarece aplicatiile nu ruleaza niciodata. In exemplul nostru, daca pachetele sosesc unul dupa altul, planificatorul pentru intreruperi va trata doar prioritatea cea mai mare, si este posibil sa nu mai ramina timp pentru intreruperi software si sigur nu ramine deloc timp pentru procesul de navigare. Deci se vor umple ori cozile IP ori cele socket, si pachetele vor fi aruncate, dupa ce au fost investite resurse in prelucrarea lor.
Intarzierea si debitul codului de retea din nodul terminal al unei retele depind de timpii de activare ai proceselui. De exemplu, datele actuale arata ca pentru procesoarele Pentium IV, latenta intreruperii este in jur de 2µs pentru un apel nul de intrerupere, in jur de 10µs pentru un comutator Context Process de pe o masina Linux cu doua procese, si mult mai mult timp pentru Windows si Solaris pe aceeasi masina. Acesti timpi par mici, dar in 10 µs pot ajunge 30 de pachete de dimensiune minima (40-bytes) pe o legatura Gigabit Ethernet.
2.4.2 Memoria infinita folosind memoria virtuala La memoria virtuala (fig.2.13), programatorul lucreaza cu o
abstractizare a memoriei care consta dintr-o zona liniara, in care compilatorul asigneaza diferite locatii. Variabila X poate fi stocata in locatia 1010 in aceasta zona imaginara (sau virtuala). Abstractizarea memoriei virtuale este implementata folosind mecanismul dublu, de asociere de tabele de pagini si cerere de pagini. Intelegerea ambelor mecanisme este cruciala pentru optimizarea costulului transferului datelor prin nodul terminal.
Orice adresa virtuala trebuie sa corespunda unei adrese fizice de memorie. Cea mai usoara mapare este folosirea unei deplasari (offset) in memoria fizica. De exemplu, o zona virtuala de 15.000 de locatii, poate fi mapata in memoria fizica de la locatia 12.000 pana la 27.000. Aceasta are doua dezavantaje: mai intai, cand programul ruleaza, trebuie gasite 15.000 de locatii alaturate. Apoi, programatorul nu are voie sa foloseasca o memorie mai mare decat cea fizica.

40
Figura 2.13 Programatorul are iluzia unei memorii virtuale continue; in realitate este
asociata din parti ale memoriei principale si pagini de pe discul de memorie, folosind tabele de pagini
Ambele probleme pot fi evitate prin maparea bazata pe o tabela de
cautare (table lookup). Deoarece implementarea maparii dintre orice locatie virtuala catre orice locatie fizica consuma prea multa memorie, se foloseste o mapare mult mai resctrictiva bazata pe pagini este folosita. Consideram ca pentru orice adresa virtuala, bitii cei mai semnificativi(de exemplu 20 de biti) dau numarul paginii iar cei mai putin semnificativi (de exemplu 12 de biti) dau pozitia din interiorul paginii. Toate locatiile din interiorul unei pagini virtuale sunt mapate fata de aceeasi locatie relativa, dar paginile virtuale individuale pot fi mapate la locatii arbitrare. Memoria principala este de asemenea divizata in pagini fizice, astfel ca fiecare grup de 212 cuvinte de memorie constituie o pagina fizica.
Pentru a asocia o adresa virtuala cu una fizica, pagina virtuala corespunzatoare (in exemplu, cei 20 de biti cei mai semnificativi) este asociata numarului unei pagini fizice, dar mentinand aceeasi locatie in interiorul paginii. Asocierea se face prin cautarea in tabela de pagini, indexata cu numarul paginii virtuale. O pagina virtuala poate fi localizata in orice pagina a memoriei fizice. Mai general, unele pagini pot sa nu fie rezidente in memorie (de exemplu, pagina virtuala 2 in fig. 2.13) si pot fi marcate ca fiind pe disc. Cand este accesata o astfel de pagina, hardware-ul va genera o exceptie, determinand sistemul de operare sa citeasca pagina de pe disc intr-o pagina a memoriei principale. Acest mecanism secundar se numeste cerere de pagini/demand paging.
Asocierea/cererea de pagini rezolva impreuna doua probleme: de alocare si de limitare a alocarii memoriei . In loc sa rezolve problema mai dificila de alocare a informatiilor stocate in locatii de marime variabila, OS are nevoie doar sa tina minte o lista cu paginile libere de marime fixa si sa asigneze noului program cateva pagini libere. Astfel, programatorul poate lucra cu o memorie abstracta, cu dimensiunea limitata doar de capacitatea discului si de numarul de biti de adresa ai instructiunii.
Maparea suplimentara poate incetini considerabil fiecare instructiune. O citire/Read de locatie virtuala X, poate necesita doua accesari ale memoriei principale: un acces la tabelul de pagini pentru a translata X catre o adresa

41
fizica P, urmat de o citire/Read a acestei adrese P. Procesoarele moderne evita aceasta activitate suplimentara prin memorarea cache a celor mai recente asocieri adrese virtuale-adrese fizice intr-un buffer TLB (traslation lookaside buffer), care este o memorie cache rezidenta in procesor. Translatia curenta (fig.2.8) o face o componenta hardware specializata pentru managementul unitatii de memorie, numita MMU (memory management unit).
Maparea tabelului de pagini ofera un mecanism de protejare inter-procese. Cand un proces face o citire/Read a unei locatii virtuale X, daca nu este o intrare prevazuta in tabelul de pagini, hardware-ul va genera o exceptie de pagina defecta (page fault exception). Daca se prevede faptul ca doar sistemul de operare sa poata schimba intrarile in tabelele de pagini, sistemul de operare poate asigura ca nici un proces sa nu poata citi/scrie neautorizat memoria altui proces.
In timp ce la transmiterea prin ruter se lucreaza direct cu memoria fizica, toate nodurile finale si codurile serverelor de retea lucreaza cu memoria virtuala. Dar desi memoria virtuala reprezinta un potential cost (e.g.pierderi TLB), ea ofera si o oportunitate. Astfel e posibil sa se faca mai eficienta copierea pachetelor intre sistemul de operare si aplicatii folosind tabelele de pagini (exemplul 8).
2.4.3 I/O simple prin Apeluri de Sistem Persoana care programeaza aplicatiile nu poate fi constienta de varietatea
si complexitatea fiecarui dispozitiv de I/O. De aceea sistemele de operare ofera programatorului o abstractizare a dispozitivelor ca piese de memorie care pot fi citite si scrise (fig.2.14).
Codul care asociaza apelul interfetei I/O simple unei citiri fizice a dispozitivului (cu toti parametrii completati), este numit driver de dispozitiv (device driver). Daca singura preocupare ar fi abstractizarea, codul driverului de dispozitiv poate fi instalat intr-o biblioteca de coduri comune disponibile, care pot fi “verificate” de fiecare aplicatie. Totusi, cat timp dispozitive precum discul trebuie sa fie partajate intre toate aplicatiile, daca aceste aplicatii ar controla direct discul, un proces eronat ar putea strica discul. Proiectarea unui sistem de operare securizat necesita insa ca numai aplicatiile proaste sa dea gres.
Astfel, are sens ca apelurile de I/O sa fie manevrate de catre driverele de dispozitiv care se afla intr-o portiune securizata a sistemului de operare care nu poate fi afectata de catre procesele care dau gres. Aceasta portiune securizata, numita nucleu/kernel , furnizeaza cateva servicii esentiale, ca I/O si actualizarea tabelelor de pagini, operatii pentru care nu exista suficienta incredere in aplicatii, incat acestea sa le realizeze direct.
Cand un browser, ca Netscape, vrea sa acceseze discul pentru a citi o pagina Web, trebuie sa faca un asa numit apel de sistem/system call peste granitele nucleului de aplicatii. Apelarea sistemului este o forma protejata de apelare a unei functii. Se spune ca instructiunea hardware este o “capcana” pentru a ajunge la un nivel mai privilegiat (modul nucleu), care permite accesul in interiorul sistemului de operare. Cand apelul functiei revine dupa incheierea I/O, codul aplicatiei ruleaza cu un nivel normal de privilegiu. Un apel de sistem este mult mai costisitor decat un apel de functie, din cauza ca nu mai beneficiem de avantajul implementarii in

42
hardware si sunt necesare cautari suplimentare de parametri incorecti. Un apel sistem simplu poate fi executat in cateva microsecunde pe masinile moderne.
Figura 2.14 Programatorul vede dispozitivele, ca discul sau adaptorul de retea, ca piese
disparate ale memoriei, care pot fi citite/scrise utilizand apelul de sistem, dar de fapt nucleul administreaza o gazda cu detalii specifice dispozitivului.
Relevanta pentru retele este ca atunci cand un browser doreste sa trimita
un mesaj prin retea (de exemplu procesul 2 din fig. 2.14), trebuie sa faca un apel la sistem pentru a activa procesarea TCP. Cateva microseconde pentru o apelare a sistemului poate parea putin, dar de fapt produce o incarcare foarte mare pentru un Pentium rapid. Vom vedea daca aplicatiile pot sa mareasca viteza retelei renuntand la apelurile la sistem, si in caz afirmativ, daca se poate renunta si la protectia OS.
2.5 Sumar S-a lucrat pe patru niveluri de abstractizare care afecteaza performanta: hardware-ul, arhitectura, sistemul de operare si protocoalele. Acest fapt este util deoarece viteza de procesare a pachetelor poate fi limitata: de traseele cu tranzistoare care implementeaza procesarea pachetelor, de limitarile arhitecturale ca viteza magistralei, de suprasolicitarea sistemului generata de abstractizarile OS ca apelurile la sistem, si in final chiar de mecanismele protocolului.
Proiectantii, care vor incerca sa tina cont de simultan de toate cele patru nivele de abstractizare pentru fiecare problema, se vor pierde in detalii. Totusi, sunt cateva rezultate importante referitoare la performanta si decizii arhitecturale majore pentru care intelegerea simultana a tuturor nivelelor de abstractizare este esentiala. De exemplu, modelele simple prezentate in acest capitol permit lucrul impreuna al arhitectilor, proiectantilor de circuite, de logica, de microcodoare si implementatorilor de protocoale software pentru a crea rutere de clasa mondiala. Ele permit proiectantilor de sisteme de operare, expertilor in algoritmi si celor care creaza aplicatii sa lucreze impreuna pentru a concepe un server Web de clasa. La viteza de 40 Gps pe legatura, echipele interdisciplinare devin extrem de importante.
Exista un alt aspect al creativitatii. Am vorbit despre mari contributii individuale, dar atunci cand creezi tehnologie este necesara o activitate in grup, deoarece astazi tehnologia este atat de complexa incat trebuie sa fie interdisciplinara…, in esenta, fiecare isi vorbeste propriul limbaj, chiar

43
daca despre aceleasi concepte. Stabilirea unui limbaj comun dureaza luni de zile… o tehnica pentru a face oamenii sa-si depaseasca limitele gandirii ar fi : se da o problema, de procesare a semnalelor lingvistilor, si vice versa, fiind lasati sa aplice cunostintele cu care sunt familiarizati unei probleme complet diferite. Abordarea rezultata este in majoritatea cazurilor una complet noua, la care expertii in domeniul original nici nu s-ar fi gandit. Munca in echipa da creativitatii o noua dimensiune.
2.6. Exercitii 1. Protocoalele TCP si atacuri de tip refuz de serviciu DOS (Denial-
Of-Service Attacks ). De obicei, un hacker incearca sa atace un serviciu cunoscut, precum Yahoo, printr-un atac de tip DOS. Un atac DOS simplu este cel de tip TCP Syn-flooding, in care hacker-ul trimite cateva pachete SYN catre destinatia aleasa D (ex. Yahoo), folosind adrese sursa alese la intamplare. D trimite inapoi un SYN-ACK catre presupusa sursa S si asteapta raspunsul de la S. Daca S nu este o adresa IP activa, atunci nu va primi un raspuns de la S. Din pacate, starea lui S este mentinuta in coada de asteptare a conexiunilor lui D, pana la expirarea sa. Trimitand periodic incercari false de conectare, pretinzand ca sunt de la surse diferite, atacatorul se poate asigura ca la D, coada de asteptare finita va fi intodeauna plina. Prin urmare, o cerere legitima de conectare spre D va fi refuzata.
Presupunand ca exista un monitor care supravegheaza tot traficul, ce algoritm poate fi folosit pentru a detecta atacurile de tip DOS ? Presupunem ca programul monitor realizeaza ca are loc un atac prin inundare TCP. De ce e greu sa deosebseti traficul legitim de cel prin inundare?
2. Proiectarea numerica: Multiplexoarele si Barrel Shifters (*) sunt foarte folositoare in partea hardware a retelei, deci lucrul la aceasta problema poate ajuta chiar si un softist sa construiasca un hardware in mod intuitiv.
(*) Barrel shifter este un dispozitiv hardware care poate depasa sau roti un cuvant de date cu oricate pozitii intr-o singura operatie. E implementat ca un multiplexor, fiecare iesire iesire putand fi conectata cu fiecare intrare •Creati un multiplexor cu 2-intrari cu porti primare (SI,SAU,NU). •Generalizati ideea creand un multiplexor cu N intrari din multiplexoare
cu N/2 intrari. Cu acestea descrieti un model cu log N intarzieri de porti si ( )O N tranzistoare. •Aratati cum se creaza un barrel shifter folosind o reductie catre
multiplexoare (i.e. folositi cate multiplexoare aveti nevoie). In solutia propusa, care sunt complexitatile timpului si portilor? • Incercati sa creati un barrel shifter direct la nivel de tranzistor. Care
este complexitatea de tranzistor si de timp a lui? Creatia directa e mai buna decat reducerea simpla folosita anterior?
3. Proiectarea memoriei: Pentru proiectarea schemei seriala/pipelined de cautare a ID-ului descrisa anterior, desenati diagramele in timp pentru cautarile din pipeline. Folositi numerele descrise in capitol, si schitati clar o mostra de arbore binar cu 15 noduri si arata cum poate fi inchis dupa patru cautari in patru blocuri diferite. Presupune un arbore binar nu un arbore tertial. De asemenea, calculati numarul de chei care poate fi

44
suportat folosind 16 blocuri de RAMBUS daca primele k nivele al arborelui sunt depozitate in SRAM-ul de pe chip.
4. Memorii si arbori pipeline: Aceasta problema studiaza cum sa faci un pipeline unei stive/heap. O stiva/heap este importanta pentru aplicatii precum QoS, unde un ruter doreste sa transmita primul, pachetul cu eticheta de timp cea mai recenta. In consecinta are sens sa ai o stiva aranjata dupa eticheta de timp. Pentru a o face eficienta stiva/heap, trebuie sa fie serializata/pipelined in aceeasi maniera ca si exemplul de arbore binar de cautare din capitol; totusi sa faci o stiva asa de mare este greu. Figura 2.15 arata un exemplu de P-stiva capabila sa stocheze 15 chei. O P-stiva este un arbore binar complet, ca si o stiva/heap standard, exceptand faptul ca nodurile de oriunde din stiva/heap pot fi vide cat timp toti copiii nodului sunt de asemenea vizi (ex. nodurile 6, 12, 13).
(*) colectie de obiecte, plasate una peste alta ; arbore binar cu n-noduri complet, in care toate nodurile, altele decat nodul radacina, satisfac proprietatea de ’’heap’’ .
Figura 2.15 Un exemplu de insiruire in cinci poze care se citesc de la stanga la dreapta
si apoi de sus in jos. In fiecare poza indexul reprezinta adancimea a subarborelui si pozitia este numarul nodului asa ca valoarea este adaugata lui.
Pentru urmatoarele explicatii consultati figurile 2.15 si 2.16. Considerati
adaugarea cheii 9 in stiva/heap. Presupunand ca fiecare nod N are un numarul care reprezinta numarul de noduri goale din subarbore (care pleaca din nodul radacina N). De vreme ce 9 este mai mic decat valoarea radacina 16, 9 trebuie sa fie dedesubt. De vreme ce atat ramurile dreapta cat si stanga au noduri goale in subarborii lor, am ales arbitrar sa adaugam 9 la subarborele stang (nodul 2). Indexul, valoarea si pozitia valorilor aratate in figura la stanga fiecarui arbore sunt registrele folosite pentru a arata starea operatiei curente. Astfel in figura 2.15, partea (b), cand 9 este

45
adaugat subarborelui stang, indexul reprezinta adancimea subarborelui (adancimea 2) si pozitia este numarul nodului (i.e. nod 2) la care valoarea 9 este adaugata..
Pe urma, din moment ce 9 este mai putin dacat 14 si de vreme ce doar copilul drept are spatiu in subarborele sau, 9 este adaugat subarborelui inradacinat la nodul 5. Acum 9 este mai mare dacat 7, deci 7 este inlocuit cu 9(la nodul 5) si 7 este impins in jos la nodul liber 10. Chiar daca in Figura 2.15, part(d), valoarea indexului este 4 (i.e. operatia este la adancimea 4) si pozitia este 10. Desi in figura 2.15 doar unul dintre registrii la index/adancime are informatie nevida, si tine registrii separati pentru fiecare index este permis pipelining-ul.
Figura 2.16 Inlaturarea celui mai mare element
•Consideram operatia de scoatere din coada (indepartarea celui mai
mare element). Indeparteaza 16 si incearca sa impingi in jos golul creat pana cand un subarbore vid este creat. Deci in pasul, 3 golul este mutat la nodul 2 (deoarece valoare sa, 14, este mai mare decat fratele cu valoare 10), apoi la nodul 4 si in final la nodul 9. De fiecare data cand un gol este mutat in jos, valoarea nevida de mai jos inlocuieste vechiul gol. • Pentru a face operatia de incarcare in coada sa mearga corect, trebuie
mentinuta numararea nodurilor subarborilor goi. Explica sumar cum numararea trebuie mentinuta pentru fiecare operatie de introducere/extragere din coada (structura va fi serializata/pipelined la un moment dat, deci numararea valorilor respecta scopul). • Logic este sa serializam/pipeline per nivel. Totusi, e o problema. La
fiecare nivel (sa zicem, inserarea lui 9 in radacina ) operatia trebuie sa consulte cei doi copii, de la nivelul urmator. Astfel, cand prima operatie coboara la nivelul 2, nu se poate aduce a doua operatie la nivelul 1, sau va

46
fi o coliziune de memorie. Asteptarea ca operatia sa se termina complet va functiona, dar se va reduce la procesarea secventiala a operatiilor. Care este rata maxima la care poate fi serializata/pipeline o stiva/heap? •Considera operatiile “introduce in coada 9; introduce in coada 4,5;
extrage din coada”serializte/pipelinedanterior. Deseneaza 6 stari consecutive ale arborelui in timpul acestor 3 operatii. • Presupune ca fiecare nivel de memorie este pe un SRAM pe-chip, care
are nevoie de 5 nanosecunde pentru accesarea memoriei. Presupune ca poti citi, scrie valoarea si numerota campurile, impreuna intr-un singur acces. Tine minte ca unele memorii pot fi interogate in paralel. Care este valoarea stationara a debitului stivei/heap in operatiuni pe secunda? • Poate fi imbunatatit numarul de referiri la memorie folosind un acces
de memorie mai extins si o plasare adecvata a arborelui? • Inainte de a folosind o memorie mai extinsa si arborele adecvat,
proiectarile anterioare foloseau un element de memorie pentru fiecare element din stiva/heap precum si logica aferenta. Astfel logica necesara este direct proportionala cu marimea stivei/heap, care se adapteaza prost in termeni de densitate si putere.In aceasta proiectare, memoria este proportionala cu numarul de elemente ale stivei si deci cu densitatile si puterea SRAM, dar logica este mult mai redusa. Explicati.
5. Arhitecturi, memorii-caches si functii hash rapide: Memoria cache L1 din procesor furnizeaza in esenta o functie hash rapida, care mapeaza de la adrese fizice de memorie spre continutul sau, prin memoria cache L1. Presupunem ca vrem sa invatam un caine batran (memoria cache L1) cu un nou truc (sa faca cautari de IP). Scopul este sa folosim memoria cache L1 ca o tabela hash, ca sa mapam adrese IP de 32 de biti la numere de porturi de 7 biti. Presupunem o memorie cache L1 de 16-KB, cu primii 4KB rezervati tabelei hash, si o marime a blocului cache de 32 bytes. Presupune o masina adresabila pe octet, adrese virtuale de 32-biti si marimea paginii de 4KB. Asadar sunt 512 blocuri de 32 bytes in cache. Presupunem ca memoria cache L1, este indexata direct/direct mapped. Deci bitii 5-13 ai unei adrese virtuale sunt folositi pentru a indexa unul din cele 512 blocuri, cu bitii 0- 4 identificand octetul din fiecare bloc. • In ipoteza ca paginile sunt de 4 KB si masina este adresabila pe byte,
cati bytes din adresa virtuala identifica pagina virtuala? Cati biti din numarul paginii virtuale se intersecteaza cu bitii 5-13 folositi pentru indexarea memoriei cache L1? • Singura cale de a asigura ca tabela hash nu este aruncata afara din
memoria cache L1 cand sosesc alte pagini virtuale, este marcarea la inceput a oricarei pagini, care s-ar putea pozitiona in aceiasi portiune a memoriei cache L1, ca nedepozitabila in cache. Conform cu raspunsurile anterioare si cu faptul ca tabelele hash folosesc primi 4KB a memoriei cache L1, identifica precis care pagini trebuie marcate ca nedepozitabile. • Pentru a face o cautare a unei adrese de IP de 32-byte, prima oara
convertiti adresa ca o adresa virtuala prin setarea pe 0 a tuturor bitilor exceptand bitii 5-11 (bitii 12 si 13 sunt zero deoarece doar sfertul de sus a L1 cache este folosit). Presupune ca aceasta este translatata in exact aceeasi adresa fizica.Cand se face o Citire de la aceasta adresa, hardware-ul L1 cache va returna continutul primelor cuvintelor de 32-biti ale blocului cache corespunzator. Fiecare cuvant de 32-bit va contine o

47
eticheta de 25-biti si un port numeric de 7-biti. Pe urma, compara toti bits din adresa IP, altii decat bitii 5-11, cu eticheta, si fa asta pentru fiecare intrare de 32-biti din bloc.Cat de multe accesuri L1 cache sunt necesare in cel mai rau caz pentru o cautare hash? De ce ar fi asta mai rapida decat o cautare standard hash in software?
6. Sisteme de operare si procesarea relaxata a receptoarelor lenese/lazy receiver processing: Exemplul 8 descrie cum protocoalele de procesare BSD pot conduce la receptorul livelock. Procesarea relaxata a receptoarelor combate aceasta problema prin doua mecanisme. • Primul mechanism este sa inlocuim coada de asteptare de procesare IP
unica partajata, prin cate o coada separata per socket destinatie.De ce aceasta ajuta? De ce aceasta nu ar putea fi usor de implementat? •Mecanismul secund este implementarea procesarii de protocol la
prioritatea procesului de receptie, si ca parte a contextului procesului receptionat (si nu ca o intrerupere software separata). De ce aceasta ajuta? De ce aceasta nu poate fi usor de implementat?

48
CAPITOLUL 3 PRINCIPII DE IMPLEMENTARE I- Principiile sistemelor II- Cresterea eficientei, cu mentinerea modularitatii III-Accelerarea
3.1. Motivarea folosirii principiilor Actualizarea memoriilor ternare cu continut adresabil Numim un sir ternar daca contine oricare din caracterele: 0, 1 sau *,
unde * denota un „wildcard” care se potriveste si cu un 0 si cu un 1. Exemple de siruri ternare de lungime 3 sunt: S1=01* si S2=*1*; de fapt, sirul binar 011 se potriveste si cu S1 si cu S2, in timp ce 111 se potriveste doar cu S2.
Nu- mar
Principiu Folosit in
P1 Evitarea „risipei evidente” Interfete Zero-copy P2 P2a P2b P2c
Schimbarea calcului in timp Precalculare Evaluare treptata Impartirea costurilor,a pachetelor
Canale cu aplicatie pe dispozitiv Copiere pentru scriere Procesarea integrata in niveluri
P3 P3a P3b P3c
Cerinte pentru destinderea sistemului Compromis certitudine/timp Compromis precizie/timp Schimbarea calcului in spatiu
Servirea stohastica corecta a cozilor de asteptare Comutare functie de incarcare Fragmentare IPv6
P4 P4a P4b P4c
Egalizarea componentelor sistemului Exploatarea localizarii Compromis memorie - viteza Exploatarea hardware-ului existent
Receptor actionat local Procesare; cautare de tip Lulea IP Calcul rapid al sumei de control TCP
P5 P5a P5b P5c
Suplimentare hardware Folosirea metodei de intretesere si pipeline in memorie Folosirea paralelismului extins Combinarea eficace DRAM si SRAM
Citire IP pipelined Comutare cu memorie partajata Mentinerea contoarelor
Fig. 3.1 Sumarul principiilor 1-5 – Gandirea/conceptia sistemului

49
Numar Principiu Exemple de procese in retele P6 Creare de rutine speciale eficiente Control UDP P7 Evitarea generalitatilor inutile Fbufs P8 Fii flexibil in implementare Upcalls P9 Paseaza indicatii interfetelor dintre
niveluri Filtre de pachet
P10 Paseaza indicatii antetelor protocolului Comutarea etichetelor Fig. 3.2 Sumarul principiilor 6-10 – Refacerea eficientei pastrand modularitatea
Numar Principiu Exemple de procese in retele P11 P11a
Optimizarea cazului probabil Folosirea memoriilor Cache
Predictia antetului Buffere rapide Fbufs
P12 P12a
Suplimentarea starilor pentru a creste viteza Calcul incremental
Lista de circuite virtualeVC active Recalcularea CRC- urilor
P13 Optimizarea „gradelor libertatii” Tentativa de cautare IP P14 Folosirea sortarii bucket, a bitmap-
urilor Sincronizare
P15 Crearea de structuri de date eficiente Comutarea de nivel 4 Fig. 3.3 Sumarul principiilor 11-15 – accelerarea rutinelor cheie
Prefix Pasul urmator
Liber Liber 010001* 110001* ● ●
P5 P5 ● ●
110* 111*
P3 P2
00* 01* 10*
P1 P3 P4
0* P4 Fig. 3.4. Exemplu utilizarii unei CAM ternare pentru cautari de prefixe
O memorie ternara cu continut adresabil(CAM) este o memorie
continand siruri ternare de lungime specifica, cu informatie asociata; cand i se prezinta un sir la intrare, CAM va cauta in toate locatiile sale de memorie in paralel pentru a genera la iesire(intr-un ciclu) locatie de memorie cu cea mai mica dresa, al carei sir ternar se potriveste cu cheia de intrare specicata.
Figura 3.4 arata o aplicatie de CAM ternara referindu-se la problema celei mai extinse potriviri de prefix pentru router-ele de Internet. Pentru fiecare pachet primit, fiecare router de Internet trebuie sa extraga o adresa IP destinatie de 32 biti din pachetul de intrare si sa caute potrivirea intr-o baza de date de prefixe IP pentru urmatorul nod la care sa fie trimis pachetul. Un prefix IP este un sir ternar de lungime 32, in care toate wildcard-urile se afla la sfarsit.Vom schimba notatia treptat si vom lasa *
Ruter
110001 P1 P2 P3 P4 P5

50
sa indice orice numar de caractere wildcard astfel ca 101* se potriveste cu 10100 si nu doar cu 1010.
Astfel, in fig. 3.4, un pachet trimis la o adresa destinatie care incepe cu 010001 se potriveste prefixelor 010001* si 01* dar ar trebui trimis la portul P5 deoarece expedierea pachetelor prin Internet cere ca acestea sa fie trimise utilizand cea mai lunga potrivire.Vom vorbi mai mult despre aceasta problema in Capitolul 11. Deocamdata, este de retinut faptul ca prefixele sunt aranjate intr-o CAM ternara astfel incat toate prefixele mai lungi sa fie inaintea tuturor prefixelor mai scurte(ca in fig. 3.4); CAM ternara sustine potrivirea saltului urmator intr-un ciclu de memorie.
Desi CAM-urile ternare sunt extrem de rapide in trimiterea mesajului, ele cer ca prefixele mai lungi sa apara inaintea prefixelor mai scurte. Dar, protocoalele de rutare/dirijare adauga sau sterg prefixe deseori.
Sa presupunem ca in fig. 3.4 un nou prefix, 11* , cu urmatorul nod indicat la portul P1 trebuie sa fie adaugat in baza de date a ruter-ului. Calea cea mai simpla de a-l insera ar produce spatiu in grupul de prefixe de lungime 2 prin inaintarea cu o pozitie a tuturor prefixelor de lungime 2 sau mai mare.
Din pacate, pentru o baza de date mare cu aproximativ 100000 prefixe detinuta de un router tipic, ar dura 100000 de cicluri de memorie, care ar determina o adaugare lenta a unui prefix. Am putea obtine sistematic o solutie mai buna prin aplicarea urmatoarelor doua principii(descrise mai tarziu in acest capitol, ca si principiile P13 si P15).
Intelegerea si exploatarea „gradelor libertatii” Privind tabelul din stanga fig. 3.4, vedem ca toate prefixele de aceeasi
lungime sunt aranjate impreuna si toate prefixele de lungime i apar dupa toate prefixele de lungime j>i.
Fig. 3.5 Cautarea unui loc pentru noul prefix mutand X in pozitia lui Y , ne cere repetat sa gasim un loc pentru a-l muta pe Y.
Spatiu liber
Y
Prefixe de lungime (i+1)
X
Prefixe de lungime i
Crearea unui gol aici prin mutarea lui X in pozitia lui Y

51
Totusi in figura toate prefixele de aceeasi lungime sunt si ele sortate dupa valoare. Astfel, 00* apare inainte de 01*, care apare inainte de 10*. Dar acest lucru nu impune CAM-ului sa returneze corect potrivirea de prefixe cele mai lungi; se cere numai ordonarea prefixelor de lungimi diferite, nu ordonarea prefixelor de aceeasi lungime.
Din fig. 3.4 abstractizata ca fig. 3.5, se vede ca daca vrem sa adaugam o inregistrare la inceputul grupului de prefixe cu lungime i, trebuie sa cream un spatiu liber la sfarsitul grupului de prefixe cu lungime (i+1). Astfel trebuie sa mutam inregistrarea X, care exista deja in aceasta pozitie la alta pozitie. Daca mutam X cu un pas mai sus, vom fi fortati la solutia anterioara ineficienta.
Oricum, observatia despre „gradele libertatii” ne permite sa plasam pe X oriunde intre alte prefixe adiacente de lungime (i+1). Astfel, o alta idee este sa mutam X la pozitia detinuta de Y, ultimul prefix de lungime (i+2),ceea ce ne forteaza sa gasim o noua pozitie pentru Y. Cum facem? Avem nevoie de al doilea principiu.
Folosirea tehnicilor algoritmice Problema recurentei se impune de la sine: rezolvam o problema prin
impartirea ei in etape mai mici. In acest caz, noua problema de asignare a lui Y pe o noua pozitie este „mai redusa” deoarece grupul de prefixe de lungime (i+2) este mai aproape de spatiul liber din varful CAM-ului decat grupul de prefixe de lungime (i+1). Astfel mutam Y la sfarsitul grupului de prefixe de lungime (i+3), etc.
Deoarece recursivitatea este solutia fireasca de a gandi,o implementare mai buna este sa incepem din varful CAM-ului si sa o parcurgem descendent creand un gol la sfarsitul grupului de prefixe de lungime 1, apoi creand un gol la sfarsitul grupului de prefixe de lungime 2, etc. pana cand cream un gol la sfarsitul grupului de prefixe de lungime i. Astfel, cazul cel mai defavorabil de accesari ale memoriei este 32-i, care este in jur de 32 pentru un i foarte mic.
Putem sa exploatam mai departe gradele libertatii. In primul rand, in fig. 3.5 am presupus ca spatiul liber este in varful CAM-ului. Dar spatiul liber poate fi plasat oriunde. In particular, poate fi plasat dupa prefixele de lungime 16. Aceasta reduce la jumatate cazul cel mai defavorabil de accesari ale memoriei.
Un grad de libertate mai sofisticat este urmatorul. Pana acum, specificatia algoritmului de inserare in CAM cerea ca „un prefix de lungime i trebuie sa apara inaintea unui prefix de lungime j daca i>j”. O asemenea specificatie este suficienta pentru corectitudine dar nu si necesara. De exemplu, 010* poate aparea inainte de 111001* deoarece nu exista nici o adresa care sa se poata potrivi ambele prefixe.
Astfel o specificatie mai putin exacta este: „daca doua prefixe P si Q se pot asocia aceleasi adrese, atunci P trebuie sa apara inaintea lui Q in CAM doar daca P este mai lung decat Q”. Aceasta este folosita in Shah si Gupta [SG01] pentru a reduce mai mult numarul cel mai defavorabil de accesari ale memoriei prin inserarea unor baze de date practice.
Desi ultima imbunatatire e discutabila din cauza complexitatii, ea conduce spre un alt principiu important. Noi, deseori impartim o problema mare in subprobleme si transmitem altora subproblema pentru rezolvare

52
insotita de anumite specificatii. De exemplu, proiectantul de hardware a CAM-ului poate transmite problema de actualizare a unui microcoder, specificand ca prefixele mai lungi sa fie plasate inaintea celor mai scurte.
Dar, ca si mai inainte, o asemenea specificatie poate sa nu fie singura cale de rezolvare a problemei originale. Astfel schimbarile in specificatii(principiu P3) pot oferi o solutie mai eficienta. Bineinteles, aceasta cere persoane curioase si increzatoare in fortele proprii, care inteleg problema in ansamblul ei si au curajul sa puna intrebari riscante.
3.2. Algoritmi si studiul algoritmilor Ar fi posibil sa argumentezi faptul ca exemplul anterior este o metoda
esentialmente algoritmica esentiala si nu necesita o gandire sistematica? Problema analizei securitatii judiciare. In multe sisteme de detectie de intruziune, un manager deseori gaseste ca un flux (definit prin antetul pachetelor, spre exemplu o sursa de adrese IPare o comportare necorespunzatoare, lucru constatat prin metode probabilistice. Spre exemplu, o sursa care face o scanare a unui port poate fi identificata dupa ce a trimis 100000 de pachete daunatoare la diferite masini intr-o subretea.
Desi exista metode de identificare a unor asemenea surse, o problema este faptul ca evidenta (celor 100000 de pachete trimise de sursa) a disparut in timpul in care sursa vinovata este identificata. Problema este ca, controlul probabilistic cere acumularea unor stari(sa zicem, un tabel de suspiciune) pentru fiecare pachet primit intr-o anumita perioada de timp, inainte ca o sursa sa fie declarata suspecta. Daca o sursa e considerata suspecta dupa 10 secunde, cum poate cineva sa revina in timp si sa recupereze pachetele trimise in timpul celor 10 secunde?
Pentru aceasta, in fig. 3.6 tinem un sir cu ultimele 100000 pachete care fusesera trimise de catre router. Cand un pachet este trimis mai departe, vom adauga o copie a acestui pachet (sau doar un pointer spre pachet) in capul sirului. Pentru a pastra sirul limitat, atunci cand acesta e plin, vom sterge pachetele de la coada. Principala dificultate la aceasta schema este atunci cand un flux vinovat este detectat ,pot fi multe alte fluxuri de pachete in sir(fig. 3.6). Toate aceste pachete trebuiesc plasate in rezerva judiciara pentru transmisia lor la un manager. Metoda naiva de cautare printr-un buffer DRAM mare este foarte lenta.

53
Fig. 3.6 Pastrarea unui sir cu ultimele 100000 de pachete care contine informatii judiciare despre fluxurile suspecte care fusesera trimise in trecut.
Abordarea didactica permite adaugarea unor structuri de indecsi pentru
cautarea rapida a ID-urilor fluxurilor. Spre exemplu, am putea mentine un tabel de dispersie(hash-table) cu ID-urile fluxurilor, in care fiecare flux este asociat cu o lista de pointeri ale tuturor pachetelor avand ID-ul in sir. Cand un nou pachet este introdus in sir, ID-ul fluxului este cautat in tabelul de dispersie si adresa noului pachet din sir este plasata la sfarsitul listei fluxului. Bineinteles, atunci cand pachetele parasesc coada, inregistrarile lor trebuiesc eliminate din lista, si lista poate fi lunga. Din fericire, inregistrarea ce trebuie stearsa este sigur in capul sirului pentru acel ID de fluxului.
In ciuda acestui fapt, abordarea didactica are cateva dificultati. Ea adauga mai mult spatiu pentru a mentine aceste extra-siruri per ID si spatiul poate fi crucial pentru implementari rapide. De asemenea, adauga complexitate in procesarea pachetelor pentru a mentine tabelul de dispersie si cere inregistrarea tuturor pachetelor fluxului in rezerva judiciara inainte ca pachetul sa fie suprainscris de un pachet care soseste cu alte 100000 de pachete mai tarziu. Mai degraba urmatoarea solutie sistematica poate fi mai eleganta.
Solutie. Nu incercati imediat sa identificati toate pachetele fluxului F, cand F este identificat, dar identifica-le relaxat atunci cand ajung la sfarsitul sirului de pachete (fig. 3.7). Cand adaugam un pachet in capul sirului, trebuie sa inlaturam un pachet de la sfarsitul sirului( atunci cand sirul este plin).
Daca acel pachet ( sa zicem Q, vezi fig. 3.6) apartine fluxului F care este in Tabelul de Suspiciuni si fluxul F a depasit niste praguri de suspiciune, atunci adaugam pachetul Q la Rezerva judiciara. Rezerva poate fi trimisa la un manager. Avem de facut doi pasi pentru procesarea pachetului, unul pentru trimiterea pachetului mai departe si unul pentru
Daca e stare de alerta, adauga F in tabel;
Daca F e in tabel, stare de update F
F
F
Tabel de suspiciune
Memoria judiciara
Raport catre manager periodic sau dupa detectia unui flux suspect
Pachetul P soseste pe fluxul F
Forward P
Adauga copia lui P in antet
Test rapid probabilistic de suspiciune
Şir cu ultimele N pachete
Mod căutare memorie pentru pachete trimise cu fluxul cu ID F, de adăugat la memoria judiciara
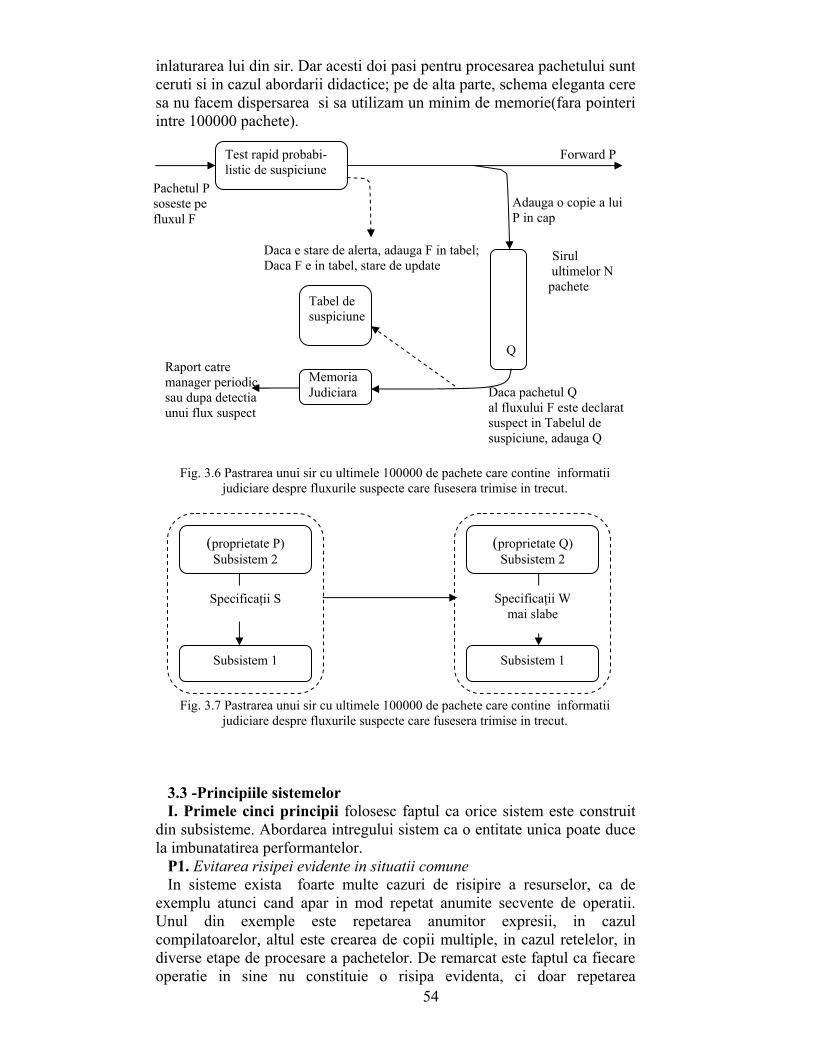
54
inlaturarea lui din sir. Dar acesti doi pasi pentru procesarea pachetului sunt ceruti si in cazul abordarii didactice; pe de alta parte, schema eleganta cere sa nu facem dispersarea si sa utilizam un minim de memorie(fara pointeri intre 100000 pachete).
Fig. 3.6 Pastrarea unui sir cu ultimele 100000 de pachete care contine informatii
judiciare despre fluxurile suspecte care fusesera trimise in trecut.
Fig. 3.7 Pastrarea unui sir cu ultimele 100000 de pachete care contine informatii judiciare despre fluxurile suspecte care fusesera trimise in trecut.
3.3 -Principiile sistemelor I. Primele cinci principii folosesc faptul ca orice sistem este construit
din subsisteme. Abordarea intregului sistem ca o entitate unica poate duce la imbunatatirea performantelor.
P1. Evitarea risipei evidente in situatii comune In sisteme exista foarte multe cazuri de risipire a resurselor, ca de
exemplu atunci cand apar in mod repetat anumite secvente de operatii. Unul din exemple este repetarea anumitor expresii, in cazul compilatoarelor, altul este crearea de copii multiple, in cazul retelelor, in diverse etape de procesare a pachetelor. De remarcat este faptul ca fiecare operatie in sine nu constituie o risipa evidenta, ci doar repetarea
Sirul ultimelor N pachete
Daca pachetul Q al fluxului F este declarat suspect in Tabelul de suspiciune, adauga Q
(proprietate P) Subsistem 2
Subsistem 1
(proprietate Q) Subsistem 2
Subsistem 1
Specificaţii S Specificaţii W mai slabe
Test rapid probabi- listic de suspiciune
Daca e stare de alerta, adauga F in tabel; Daca F e in tabel, stare de update
Q
Adauga o copie a lui P in cap
Tabel de suspiciune
Memoria Judiciara
Pachetul P soseste pe fluxul F
Forward P
Raport catre manager periodic sau dupa detectia unui flux suspect

55
secventelor de operatii. Identificarea situatiilor care conduc la risipe este mai mult o problema de intuitie, dar optimizarea poate fi facuta utilizand programe de test specializate (benchmarks).
P2. Deplasarea in timp a calculelor Sistemele pot fi abordate in timp si in spatiu. In spatiu, sistemele pot fi
privite ca fiind compuse din subsisteme, eventual distribuite geografic. In spatiu, sistemele pot fi caracterizate la momente diferite de timp, incepind cu momentului fabricatiei, momentul compilarii momentul initializarii parametrilor, respectiv momentul rularii propriu zise. Exista trei metode de baza referitoare la deplasarea in timp a calculelor:
P2a. Calculul anticipat (precalculul): anumite calcule se pot face anticipat, pentru a realiza o economie de timp la momentul in care e nevoie de ele.Un exemplu este cautarea in tabele (lookup table) precalculate. Astfel, in loc sa calculam la momentul necesar o functie f, al carui calcul dureaza mult, se creaza in avans o tabela de valori ale lui f pentru fiecare din argumentele sale. Operatia de cautare in tabela este oricum mai rapida. La retele se pot precalcula antetele IP sau TCP pentru pachetele unei conexiuni; efortul de scriere a antetelor se reduce, deoarece de la pachet la pachet se schimba doar putine dintre campurile antetului.
P2b. Evaluarea relaxata : se refera la aminarea in momentele critice, a unor operatii consumatoare de timp, in speranta ca fie nu va mai fi nevoie de ele, fie executia lor se va face intr-un moment in care sistemul nu mai este atit de ocupat.
Un exemplu de evaluare relaxata este copiere pentru scriere (copy-on-write) din sistemul de operare Mach. Presupunem ca avem un spatiu de memorie ce contine o copie la adresa virtuala A si ca mai avem nevoie la adresa B de un spatiu cu aceeasi copie, pentru o inscriere viitoare. Solutia generala ar fi sa avem doua copii si la adresa A si la B, permitind astfel inscrierea lor independenta. Metoda insa aloca pentru B o tabela care indica paginile corespunzatoare din A. Doar cand procesul lui B are nevoie sa faca o scriere intr-o anumita pagina, se creaza copia respectivei pagini pentru B si are loc operatia de scriere propriu zisa. Sunt evitate astfel copiile inutile, deoarece e de asteptat ca numarul de pagini scrise in B sa fie mai mic decat numarul total de pagini.
Un exemplu din retele este sosirea unor octeti de date in alta ordine decat cea asteptata de nodul X de destinatie.Este preferabil sa se modifice doar acele secvente care vor fi de fapt citite, si nu toate secventele.
P2c. Impartirea efortului, se refera la plasarea operatiilor cu consumuri mari in alte parti ale sistemului. Un exemplu important de operatii de mare consum este prelucrarea in loturi (batching) unde este executia comasata a unor instructiuni de consum mare este mai economica decat executia lor separata. Procesarea in loturi se practica de multa vreme in calculatoare, mai ales pe vremea calculatoarelor de capacitate si viteza foarte mari (mainframes), inainte chiar de a aplica tehnicile de divizare a timpului.
P3. Relaxarea conditiilor impuse initial sistemului Cand se incepe proiectarea unui sistem, de sus in jos, functiile se
impart unor subsisteme. Dupa ce se impun conditii sistemelor si se stabilesc interfetele, se trece la proiectarea separata a subsistemelor. Daca

56
apar dificultati la implementare, trebuie refacuta structura sistemului (vezi fig. 3.8).
Uneori dificultatile pot fi rezolvate relaxand conditiile impuse unuia dintre subsisteme. Se relaxeaza de exemplu conditia impusa subsistemului 1 (conditia S mai severa devine conditia W mai putin severa), dar in schimb conditia impusa sistemului 2 devine mai severa (P mai putin severa devine Q mai severa).
Pot fi puse in evidenta trei tehnici ce rezulta din principiul relaxarii conditiilor impuse initial sistemului.
P3a. Compromisul siguranta-timp. Proiectantii de sisteme se leagana in iluzia ca sistemele lor ofera o comportare determinista, cand de fapt comportarea este probabilista. Astfel ca, atunci cand algoritmii deterministi sunt prea lenti e bine sa apelam la metode aleatoare.
In sisteme, milioane de utilizatori Ethernet folosesc aleatorizarea pentru transmiterea de pachete dupa coliziuni. In retele un exemplu de aleatorizare este software-ul de masurare a traficului NetFlow al firmei Cisco. Daca ruteru nu are capacitatea sa contorizeze tot traficul de sosire, el va lucra cu esantioane aleatoare de trafic fiind capabile sa identifice fluxurile mari prin mijloace statistice. Al dolilea exemplu in retele este servirea corecta stohastica a cozilor de asteptare (stochastic fair queuing), in care in loc sa se urmareasca exact conversatiile care trec prin ruter, ele sunt urmarite probabilistic, folosind dispersarea (hashing).
P3b. Compromisul precizie - timp. La fel, analiza numerica ne induce iluzia preciziei calculatoarelor. Astfel am putea relaxa conditia preciziei de dragul vitezei. In sisteme, multe tehnici folosesc compresia cu pierderi prin interpolare (vezi MPEG).
Pentru a inlocui impartirile cu deplasari se folosesc praguri aproximative. In retele, anumiti algoritmi de planificare a pachetelor folositi in rutere implica sortarea pachetelor dupa termenle de timp de plecare ; in retelele de viteze mari exista propuneri de reducere a antetelor de sortare printr-o sortare aproximativa, care desi mai scade putin din calitatea serviciului QOS, reduce din timpul de procesare.
P3c. Deplasarea in spatiu a calculelor. Exemplele de pina acum se refereau la relaxarea conditiilor : esantionarea duce la omiterea unor pachete, si astfel imaginea transmisa poate sa nu mai fie identica cu cea originala. Dar alte parti ale sistemului, de exemplu subsistemul 2, trebuie sa se adapteze acestor conditii ce conduc la pierderi. De aici rezulta si ideea de deplasare in spatiu a calculului. De exemplu, recent,in retele, se evita fragmentarea pachetelor in rutere obligand sistemele terminale sa calculeze dimensiunile de pachete permise de rutere.
P4. Egalizarea componentelor sistemului Proiectarea sistemului la nivel de schema bloc presupune
descompunerea sistemului in subsisteme si proiectarea separata a fiecarui subsistem.desi aceasta abordare de sus in jos e convenabila din punct de vedere al modularitatii, in practica, anumite componente critice ca performanta sunt deseori create, cel putin partial si de jos in sus.Ca de exemplu, algoritmii sunt adapatati la hardware-ul existent. Sunt date mai jos cateva tehnici conforme acestui principiu :
-P4a : Exploatarea localizarii ; in cap.2 s-au aratat avantajele exploatarii memoriilor atunci cand datele sunt continue/succesive-de exemplu acelasi

57
sector de disc, sau aceeasi pagina de DRAM. Algoritmii de cautare pe disc folosesc acest lucruprin cautarea in arbore a radacinii superioare, ca la arborii de tip B. Algoritmii de cautare in tabele IP folosesc acelasi artificiu pentru a reduce timpul de cautare, plasind cateva chei in cuvintul extins.
-P4b : Compromisul memorie-viteza ; tehnica evidenta este extinderea memoriei, ca de exemple tabelele de cautare (lookup tables), pentru a economisi timpul de procesare. O tehnica mai putin evidenta este comprimarea structurilor de date ca sa incapa in memoria cache, deoarece accesul la cache este mai rapid decat la memoria obisnuita.
-P4c: Exploatarea facilitatilor hardware ; compilatoarele folosesc reducerea complexitatii pentru optimizarea inmultirilor in bucla; de exemplu, intr-o bucla in care adresele au 4 octeti si indexul i creste cu 1 la fiecare pas, in loc sa se calculeze produsul 4*I, compilatorul calculeaza noul index crescindu-l cu 4 fata de pasul precedent, deoarece inmultirile sunt mai lungi decat adunarile. La fel se manevreaza datele, in multiplii ai cuvintelor calculatorului, ca de ex. algoritmul sumei ciclice de control IP.
Evident ca daca se exagereaza cu aplicarea acestui acest principiu se pune in pericol modularitatea sistemului. Pentru a evita acest lucru se folosesc doua tehnici. Mai intai trebuie avut in vedere ca daca se folosesc anumite caracteristici ale sistemului doar pentru a imbunatati performantele sistemului, atunci schimbarile acestor caracteristici afecteaza doar performanta si nu corectitudinea. Apoi, aceasta tehnica se foloseste doar pentru componentele sistemului care se prevad a fi strangulari .
P5 : Suplimentarea harware-ului pentru imbunatatirea performantei
Cand totul esueaza, foloseste forta bruta. Adaugarea de hardware suplimentar, ca de exemplu cumpararea de procesoare mai rapide poate fi pina la urma mai simpla si mai economica decat implementarea de tehnici sofisticate. Pe linga abordarea de tip forta bruta, prin folosirea unor infrastructuri mai rapide (procesoare,memorii,magistrale si legaturi), exista cateva compromisuri inteligente. Dar daca hardware-ul este mai putin flexibil si implica costuri mari de proiectare, atunci este preferabil ca suplimentarea de hardware sa fie minima.Pe masura cresterii dramatice a vitezelor procesoarelor si densitatii memoriei sugereaza algoritmi noi in software si dotarea cu procesoare mai rapide pentru cresterea vitezei.
Sistemele de calculatoare abunda de compromisuri hardware-software stralucite. De exemplu, in sistemele multiprocesor, daca un procesor doreste sa scrie date, el trebuie sa informeze toate celelalte procesoare care acceseaza respectivele date din memoria cache. Aceasta interactiune poate fi evitata, daca fiecare procesor are o componenta hardware care supravegheaza magistrala pentru operatiile de scriere a altor procesoare si cand e nevoie invalideaza automat locatiile respective din memoria cache. Acest controler simplu de spionare a memoriei cache permite restului algoritmului dedicat memoriei cache sa-si pastreze eficienta software.
Descompunerea functiilor intre harware si software este insa o arta in sine. Hardware-ul ofera anumite avantaje. In primul rand nu e necesar timp de aducere a instructiilor, deoarece instructiile sunt codate hard. In al doilea rand, secvente de calcul commune (care ar necesita cateva instructiuni in software) pot fi facute intr-un singur ciclu harware de ceas.

58
De exemplu, gasirea primului bit dintr-un cuvant de 32 de biti, ar necesita cateva instructii pe o masina RISC, dar poate fi facuta cu un simplu codor de prioritati (vezi capitolul precedent). In al treilea rand, haedware-ul ne permite sa beneficiem de aplicarea paralelismului inerent problematicii.In fine, productia hardware de masa poate fi mai ieftina decat a unui procesor specializat. De exemplu un Pentium poate costa 100$ in timp ce un ASIC cu performante similare pote costa doar 10$.
Pe de alta parte, proiectarea software poate fi usor translatata spre urmatoarea generatie de chip-uri mai rapide. Hardware-ul, in ciuda folosirii chip-urilor programabile, ramine mai putin flexibil. Totusi, aparitia unor mijloace de proiectare ca VHDL pentru sintetizarea hardware-ului, face ca timpul alocat pentru proiectarea hardware-ului sa scada considerabil. Astfel, in ultimii ani, au fost proiectate chip-uri care realizeaza functii complexe, ca de exemplu compresie de imagini sau verificare de tabele IP.
Pe linga imbunatatirea unor anumite performante, noile tehnologii pot determina abordari complet noi. Un proiectant vizionar ar putea sa reproiecteze complet un sistem in vederea noilor aplicatii. De exemplu, inventarea tranzistorului si a memoriilor rapide ne-a permis sa folosim digitizarea vocii in retelele telefonice.
Cresterea densitatii chip-urilor a facut proiectantii de calculatoare sa chibzuiasca asupra facilitatilor de calcul adugate memoriilor pentru a evita strangularea procesor-memorie. In retele, aparitia liniilor de mare viteza in anii ’80, a condos la folosirea adreselor si antetelor extinse . Ca o ironie, folosirea calculatoarelor portabile in anii ’90, a dus la folosirea de banda ingusta a legaturilor fara fir, si in consecinta a aparut problema comprimarii antetelor.Tendintele tehnologice sunt oscilante.
-P5a:Folosirea pentru memorii a tehnicilor de intretesere si serializae/pipelining.Tehnici similare sunt folosite la verificarea tabelelor IP, la clasificare si in algoritmii de planificare care implementeaza QOS. Bancurile multiple pot fi implementate folosind cateva memorii externe, asu o memorie externa cum este RAMBUS, sau un SRAM pe un singur chip care contine si logica de procesare.
-P5b : Folosirea paralelismului pe cuvinte extinse. O tema comuna in multe proiectari de retele, ca de exemplu schema vectorului de biti de la Lucent, este folosirea unor cuvinte de memorie extinse, care pot fi procesate in paralel. Acest lucru se implementeaza folosind DRAM si modul page-mode, sau folosind SRAM-uri si extinzand fiecare cuvint de memorie.
-P5c : Combinarea DRAM cu SRAM. Stiind ca SRAM-urile sunt mai scumpe si mai rapide, iar DRAM-urile sunt mai ieftine si mai lente, are sens sa le combinam astfel incat sa obtinem un optim pentru amandoua. Folosirea SRAM-urilor ca si memorii cache si a DRAM-urilor pentru baze de date este clasica deja, dar exista multe plicatii mult mai creative pentru ierarhizarea memoriilor. Pe moment se analizeaza efectul unui volum redus de de SRAM la proiectarea chipurilor pentru tabelele de verificare a fluxurilor ID. In capitolul 16 sunt descrise tehnici mai non-uzuale de aplicare a acestei tehnici la implementarea unui numar mare de numaratoare, unde bitii cei mai putini semnificativi sunt memorati in SRAM.

59
II. Principii pentru modularitate si eficienta Lucrari de profil (Dave Clark) au aratat ineficienta implementarilor
stratificate si a modularitatii, dar raspunsul altora (Radia Perlman) a fost ca acest lucru nu arata decat faptul ca s-a ajuns in faza in care ne putem plinge de ceva. Ideea este desigur, ca sitemele complexe cum sunt protocoalele de retea nu pot fi implementate decat folosind stratificarea si modularitatea. Urmatoarele principii arata cum poate fi redobindita eficienta, pastrind modularitatea.
P6. Crearea unor rutine specializate eficiente si inlocuirea rutinelor cu scop general
Folosirea abstractizarilor in proiectarea sistemelor de calcul poate face sistemul mai compact, ortogonal si modular. Totusi cu timpul, folosirea rutinelor cu scop general a dus la ineficienta. In cazurile importante trebuie proiectate si optimizate rutine specializate.
Un exemplu poate fi gasit in cazul memoriilor cache pentru baze de date. Cea mai generala strategie de utilizare a memoriilor cache prevede mutarea pe disc a celor mai vechi inregistrari. Totusi sa consideram o rutina a procesului de interogare (query-processing), care proceseaza in bucla o secventa de tuple ale bazei de date. In acest caz, cea mai recenta inregistrare va fi cel mai tirziu folosita in viitor, deci e candidatul ideal pentru inlocuire. Astfel ca aplicatiile mai noi ale bazelor de date inlocuiesc rutinele sistemului de memorare in cache cu ritine mai specializate. E bine ca aceste specializari sa se faca doar pentru rutinele cheie, pentru a evita extinderea peste masura a codului. Un exemplu din retele sunt rutinele rapide de procesare UDP.
P7. Evitarea generalizarilor inutile Tendinta de a proiecta subsisteme abstracte si generale poate duce la
crearea unor facilitati inutile sau rar folosite. Astfel, in loc sa mai trebuiasca sa facem rutine specializate suplimentare (e.g. P6) cu care sa inlocuim rutinele generale, am putea sa eliminam diverse facilitati crescand astfel performanta. Ca si in cazul P3, eliminarea acestor rutine impune utilizatorilor sa se dezobisnuiasca sa le foloseasca. De exemplu, la procesoarele RISC, eliminarea instructiunilor complexe cum sunt inmultirile, implica emularea lor prin firmware. Un exemplu din retele este cazul fbuf-urilor care ofera un serviciu specializat memoriilor virtuale, ce asigura o copiere eficienta intre spatiile de memorie virtuala.
P8. Nu te incurca cu implementarile de referinta. Specificatiile sunt scrise pentru claritate, nu ca sa sugereze o
implementare eficienta. Deoarece limbajele abstracte ale specificatiilor sunt nepopulare, multe specificatii contin indicatii ferme despre care anume functie trebuie calculata si cum sa fie implementat calculul. Acest fapt are doua efecte secundare.
Mai intai exista o tendinta reala spre specificarea exagerata. Apoi, multi implementatori copiaza implementarea de referinta in specificatii, ceea ce constituie o problema cand implementarea de referinte a fost aleasa pentru claritate si nu pentru eficienta. Implementatorii sunt liberi sa schimbe implementarea de rferinta atita timp cat efectele externe ramin aceleasi. De fapt pot fi structurate alte implementari, care sa fie si eficiente si modulare.

60
In sisteme, Clark a sugerat folosirea la sistemele de operare a apelurilor spre nivelurile superioare (upcalls). La aceste upcalls-uri un nivel inferior poate apela unul superior, pentru avizare sau a cere date, incalcand apparent regulile de decompozitie ale proiectarii de sisteme. Aceste apeluri sunt astazi utilizate frecvent in implementarile protocoalelor.
P9. Paseaza indicatii interfetelor modulelor O indicatie (hint) sau o sugestie este o informatie pasata de la client la
serviciu, care poate scuti serviciul de volume mari de calcul, daca este corecta. Cuvintele cheie aici sunt paseaza si daca este corecta. Prin pasarea indicatiei in cererea sa serviciul poate evita necesitatea unei citiri asociate in tabele, necesare pentru accesul la memoria cache. De exemplu, o indicatie poate fi folosita pentru a furniza receptorului un index direct in starea de procesare. Dar, spre deosebire de memoria cache, nu se garanteaza ca indicatia este corecta, astfel ca trebuie verificata cu alte informatii a caror corectitudine este verificabila. In majoritatea cazurilor, indicatiile imbunatatesc performanta, daca sunt corecte
Din insasi definitia hint-ului rezulta necesitatea verificarii corectitudinii sale, scutind astfel receptorul de aceasta etapa. Un hint verificat se numeste tip (sfat). Sfaturile sunt greu de utilizat, tocmai din cauza conditiei de a le asigura corectitudinea. Un exemplu din sisteme este sistemul Alto-File care are fiecare bloc de fisiere dotat cu un pointer indicand urmatorul bloc de fisiere. Acest pointer este tratat doar ca hint, si este verificat cu numele fisierului si numarul blocului memorate chiar in interiorul blocului. Hinturile incorecte nu trebuie sa pericliteze corectitudinea sistemului ci doar sa scada din performante.
P10. Paseaza indicatiile in antetele protocolului Pentru sistemele distribuite, extensia logica a principiului P9 este sa se
paseze informatia ca indicatii in antetul mesajului. Acest lucru poate sa constituie un principiu separat, pentru sistemele distribuite. Pentru sistemele paralele acest principiu e folosit de arhitecti pentru a evita ineficientele in pasarea mesajelor. Una din ideile de la mesajele active este sa avem un mesaj ce transporta adresa handlerului de intreruperi pentru expedierea rapida. Alt exemplu este comutarea etichetelor (tag switching), in care pachetele transporta un indice suplimentar pe linga adresa destinatie, pentru a permite verificarea rapida a acestei adrese. Etichetele sunt folosite ca sugestii, deoarece nu este verificata corectitudinea etichetelor ; pachetele pot fi dirijate spre o destinatie gresita si acolo ele trebuie verificate.
III Principii pentru accelerarea rutinelor Principiile anterioare se refereau la structura sistemului, iar cele ce
urmeaza se refera la accelerarea rutinelor vazute izolat. P11. Optimizarea cazurilor probabile Sistemele pot sa manifeste o gama larga de comportamente, care pot fi
impartite in mici categorii, numite ”cazuri probabile”. De exemplu, chiar si cele mai bine proiectate sisteme pot functiona in regimul ” fault” sau ”exception-free”. Alt exemplu este cel al unui program care manifesta o localizare spatiala, datorata accesarii in principal a unor zone mici de

61
memorie. Astfel, merita sa facem mai eficiente comportarile uzuale, chiar daca devin mai costisitoare comportarile neuzuale.
Optimizarea euristica a cazurilor probabile nu da satisfactie teoreticienilor, ei preferind mecanisme ale caror beneficii pot fi cuantizate cu precizie, fie in medie fie pentru cazul cel mai defavorabil. In apararea metodelor euristice, trebuie spus insa ca fiecare calculator in functie astazi, optimizeaza cazurile cele mai probabile de cel putin un milion de ori pe secunda.
De exemplu, la folosirea ”paging”-ului, cel mai defavorabil numar de referiri la memorie pe care le poate avea o instructiune de PC este de patru, (extragerea nstructiei din memorie, citirea primului nivel al tabelului de pagini, citirea celui de al doilea nivel al tabelului de pagini si extragerea operandului din memorie). Dar, folosind memoriile cache numarul de accese la memorie poate fi redus la zero. In general, memoriile cache permit proiectantilor sa foloseasca structuri modulare si adresari indirecte, castigand astfel in flexibilitate si in final in performanta pentru cazurile cele mai probabile. Deci merita sa tratam si sa subliniem importanta memorarii in memorii cache.
P11a : Folosirea memoriilor cache Principiul cazului probabil are utilizari subtile, asociat cu folosirea
memoriilor cache. De exemplu, daca in editorul EMACS dorim sa schimbam bufferele, editorul ne ofera numele ultimului buffer folosit (default buffer name). Acest lucru economiseste timpul de tiparire in cel mai probabil caz, adica atunci cand se comuta mereu intre doua buffere. Folosirea predictiei antetului este un alt exemplu de optimizare in retele a cazului cel mai probabil. Costul procesarii pachetului poate fi mult redus daca se presupune ca urmatorul pachet ce va fi receptionat e strans legat de ultimul pachet procesat (de exemplu este urmatorul pachet din secventa), si nu necesita exceptii la procesare.
Trebuie precizat ca determinarea cea mai buna a cazurilor cele mai probabile se face prin masuratori si prin scheme care inregistreaza automat cazurile comune. Dar depinde de multe ori si de intuitia proiectantului. Cazul cel mai probabil poate fi incorect in situatiile speciale sau se poate schimba in timp.
P12. Adauga sau foloseste starile pentru a castiga viteza Daca o operatie este costisitoare, trebuie luata in considerare o stare
suplimentara dar redundanta, pentru accelerarea operatiei. La bazele de date, un exemplu este adaugarea unui indice suplimentar. Bancurile de inregistrari pot fi memorate si cautate folosind o cheie primara, ca de exemplu numarul asigurarii sociale a clientului. Daca mai apar chestionari suplimentare referitoare la numele acelui client (balanta de cont, etc.), se poate plati folosind un index suplimentar (de exemplu o tabela hash sau un arbore B). Dar starea suplimentara implica prevederea posibilitatii de schimbarea a sa atunci cand apar modificari.
Totusi, uneori, acest principiu poate fi aplicat fara adaugarea de stari suplimentare, doar folosind starile existente, fapt subliniat de principiul P12a.
P12a. Calculul incremental La sosirea sau plecarea unui client trebuie actualizata tabela de asteptare
pentru clienti. La fel este si in compilatoare, la siruri (vezi exemplul de la

62
P4c) unde se calculeaza incremental noua tabela de indecsi din cea veche, si nu se folosesc inmultiri pentru calculul valorii absolute a indecsilor. In retele, un exemplu de calcul incremental este calculul sumelor ciclice de control IP, unde se modifica doar o mica parte din campurile pachetelor.
P13. Optimizarea gradelor de libertate E utila la determinarea caror variabile se afla sub control si a celor care
le controleaza, precum si la determinarea criteriilor de obtinere a unei bune performante. Apoi se trece la optimizarea acestor variabile pentru maximizarea performantei. De exemplu clientii sunt inscrisi in tabele de asteptare pe masura ce apar locuri libere, dar optimizarea asteptarii se poate face prin asignarea la un set de tabele continue a fiecarui client in asteptare.
Un alt exemplu, din compilatoare, este algoritmul coloring algorithm, prin care se face asignarea registrelor in timp ce se minimizeaza depasirea capacitatii registrelor. Un exemplu din retele este algoritmul de testare multibit a tabelelor IP de cautare. In acesta un grad de libertate care poate fi prezentat este ca numarul de biti care poate fi utilizat intr-un nod de test poate fi variabil, si depinde de calea de test, si nu este fix la fiecare nivel. Numarul de biti utilizati poate fi optimizat prin programare dinamica pentru a cere cel mai mic volum de memorie la o viteza impusa.
P14: Folosirea unor tehnici specifice universurilor finite (cum sunt numerele intregi)
Cand avem de-a face cu universuri mici, ca de exemplu intregii de valori moderate, se folosesc tehnici specifice ca bucket sorting, array lookup, bitmaps, care sunt mai eficiente decat algoritmii generali de sortare si cautare.
Pentru a translata o adresa virtuala intr-p adresa fizica procesorul incearca mai intai o memorie cache numita TLB. Daca nu reuseste, procesorul trebuie sa caute in tabela de pagini.Se foloseste un prefix al bitilor de adresa cu care tabela de pagini este indexata direct. Folosirea cautarii in tabele evida folosirea tabelelor de dispersare (hash) sau cautarea binara, dar duce la dimensiuni mari ale tabelelor de pagini. Un exemplu din reteleal acestei tehnici sunt contoarele de timp,(vezi capitolul 7) unde este construit un algoritm eficient pentru un ceas de timp cu domeniu limitat, folosind zone circulare.
P15: Folosirea tehnicilor din teoria algoritmilor pentru crearea unor structuri eficiente de date
Chiar in prezenta unor strangulari majore, ca translatarea adreselor virtuale, proiectantii sistemelor resping algoritmii inteligenti cum sunt transmiterea de indicatii, folosirea memoriilor cache sau a tabelelor de cautare performante. Algoritmii eficienti pot imbunatati mult performanta sistemelor. Primele 14 principii trebuie sa fie aplicate inainte ca oricare dintre rezultatele teoriei algoritmilor sa duca la strangulari, cum se intimpla in multe cazuri.
Abordarea algoritmica include folosirea structurilor standard de date la fel ca si a tehnicilor algoritmice cele mai generale, ca de exemplu aleatorizarea sau dezbina si cucereste. Pe de alta parte, proiectantul unui algoritm trebuie sa fie pregatit sa faca fata si situatiei in care sa vada ca algoritmul sau a devenit perimat, din cauza schimbarilor de tehnologie sau de structura. Progresul real poate aparea mai degraba din aplicarea

63
gandirii algoritmice decat din reutilizarea vechilor algoritmi. In calculatoare exista numeroase exemple stralucite de folosire a unor algoritmi ca de exemplu: algoritmul de compresie Lempel-Ziv folosit in utilitarul gzip din UNIX, algoritmul Rabin-Miller de test a proprietatii de a fi numar prim din sistemele cu chei publice, si folosirea arborilor B (datorat lui Bayer-McCreight) din bazele de date. In retele, exemple deja prezentate includ algoritmul Lulea-IP-lookup si schema RFC pentru clasificarea pachetelor.

64
CAPITOLUL 4 PRINCIPIILE IN ACTIUNE În capitolul precedent s-au evidenţiat 15 principii pentru implementarea
eficientă a protocoalelor de reţea. Aici se dau exemple de aplicare a principiilor.
4.1. Validarea buffer-elor pentru canalele dispozitivului aplicaţie ADC(Application Device Channel)
De obicei, programele aplicaţiilor pot trimite date în reţea numai prin nucleul sistemului de operare, şi doar nucleul are dreptul să comunice cu adaptorul de reţea. Această restricţie previne ca diferite aplicaţii (răutăcioase sau accidentale) să citească sau să scrie în datele celorlalte aplicaţii. De altfel, comunicarea prin intermediul kernel-ului aduce supraîncărcări, sub forma apelurilor de sistem. Ideea la ADC-uri (Application Device Channels), să permită unei aplicaţii să trimită date către/dinspre retea prin scrierea directă în memoria adaptorului de reţea. Un mecanism de protecţie, în locul medierii de către kernel, este ca nucleul să seteze adaptorul cu un set de pagini valide de memorie pentru fiecare aplicaţie. Adaptorul de reţea trebuie apoi să asigure că datele aplicaţiei pot fi trimise şi recepţionate doar prin memoria din setul valid.
Figura 4.1. În APDs, adaptorul de reţea primeşte un set de pagini valide (X, Y, L, A, etc.) pentru o anumită aplicaţie P. Când aplicaţia P face o cerere de primire a datelor în pagina A, adaptorul trebuie să verifice dacă A este în lista paginilor valide, înainte de a permite recepţia lui.
În figura 4.1, aplicaţiei P i se permite să trimită/primească date din/in setul de pagini valide X, Y, ..., L, A. Presupunem că aplicaţia P încarcă în coadă o cerere spre adaptor să-şi primească următorul pachet, destinat lui P, într-un buffer din pagina A. Deoarece cererea este trimisă direct adaptorului, nucleul nu poate verifica dacă acest buffer este valid pentru P. În schimb, adaptorul trebuie să valideze această cerere asigurându-se că A
CPU
Aplicatia P
Kernel/nucleu
Memorie
Pagina X
. . .
Pagina A
Lista valida X, Y, ..., L, A pt P
ADAPTOR
RETEA
Recepţionarea următorului pachet în A

65
este în setul de pagini valide. Dacă adaptorul nu face această verificare, aplicaţia P ar putea oferi o pagină invalidă, aparţinând altei aplicaţii, şi adaptorul ar scrie informaţia destinată lui P în pagina greşită. Necesitatea acestei verificări conduce la următoarea problemă.
Problemă: Când aplicaţia P face o receptie, adaptorul trebuie să valideze că pagina aparţine setului de pagini valide pentru P. Dacă setul de pagini este organizat ca o lista liniară, atunci validarea poate costa O(n), unde n este numărul de pagini din set. In figura 4.1, deoarece A este la sfârşitul listei de pagini valide, adaptorul trebuie să parcurgă întreaga listă până îl găseşte pe A. Dacă n este mare, atunci acest lucru poate fi scump şi poate duce la încetinirea ratei cu care adaptorul poate trimite sau recepţiona pachete. Cum poate fi crescută viteza procesului de validare?
Indicaţie: O abordare bună pentru a reduce complexitatea validării este folosirea unei structuri de date mai bune decât o listă (P15). Poate fi îmbunătăţită comportarea în cazul cel mai defavorabil, şi pe viitor, şi găsiţi factori constanţi mai mici, folosind o gândire sistemică şi pasând indicaţii interfeţelor. O gândire algoritmică ar conduce imediat la ideea implementării setului de pagini valide ca un tabel de dispersie, hash table, si nu ca o listă. Acest lucru ar oferi un timp mediu de căutare de O(1). Dispersarea are două dezavantaje: (1) funcţiile perfomante de dispersie cu o probabilitate mică de coliziune sunt scumpe computaţional; (2) dispersarea nu oferă o limită bună pentru cazul cel mai defavorabil. Căutarea binara asigură un timp de căutare logaritmic pentru cazul cel mai defavorabil, dar e scumpă (necesită şi păstrarea unor seturi sortate) dacă setul de pagini e mare şi rata de transmisie a pachetelor e mare. In schimb, putem înlocui verificarea tabelei de dispersie cu o tabelă de verificare indexată, după cum urmează. Soluţie: Adaptorul va stoca un set de pagini valide pentru fiecare aplicaţie într-un tablou, (fig.4.2). Acest tablou este actualizat numai când nucleul actualizează setul de pagini valide pentru aplicaţie. Când aplicaţia face o recepţie în pagina A, transmite adaptorului un indicator. Acest indicator este indexul poziţiei din tablou unde este stocat A. Adaptorul poate să folosească această informaţie ca să confirme rapid dacă pagina din cererea de recepţie se potriveşte cu pagina din indicator. Costul validării e mărginit, dat de o căutare în tablou (verificarea că indexul e valid) şi o comparaţie.
66
Figura 4.1. În APDs, adaptorul de reţea primeşte un set de pagini valide (X, Y, L, A,
etc.) pentru o anumită aplicaţie P. Când aplicaţia P face o cerere de primire a datelor în pagina A, adaptorul trebuie să verifice dacă A este în lista paginilor valide, înainte de a permite recepţia lui.
Figura 4.2: Evitarea necesităţii actualizării tabelei de dispersie, prin pasarea manevrei
prin interfaţa aplicaţie-adaptor
Exercitii •Este ghidajul/handle o indicaţie/hint sau un tip ? să revenim la P1:
daca e un handle de ce să pasăm numărul paginii (e.g.A) interfeţei? De ce să eliminăm accelerarea uşoară a vitezei task-ului de confirmare a numărului paginii? • Pentru a găsi tabela corespunzătoare aplicaţiei P e necesară o căutare
în tabelele de dispersie, folosind P ca şi cheie. Acest lucru atenuează argumentul de a scăpa de căutarea în tabelele de dispersie ca să verificăm dacă o pagină e validă sau nu, cu excepţia rafinării căutării în tabelele de dispersie. Cum poate fi făcut acest lucru ?
4.2. Planificator pentru controlul fluxului la ATM In modul ATM ( Asynchronous Transfer Mode), adaptorul ATM poate
avea sute de circuite virtuale,VC(Virtual Circuit) care pot transmite simultan date (numite celule). Deseori, se controlează fluxul fiecărui VC, într-o formă sau alta, pentru a limita rata de transmisie a acestuia. De exemplu, la controlul fluxului bazat pe rata de transmisie, un circuit virtual VC poate primi credite, ca să transmită celulele la momente de timp fixe.
ADAPTOR
CPU
Aplicatie P
Kernel
Memorie
Page X
. . .
Page A
Lista valida X, Y, ..., L, A pt P
RETEA
Recepţionarea următorului pachet în A

67
Pe de altă parte, la controlul fluxului bazat pe credite, creditele pot fi transmise de nodul următor de pe cale când se eliberează buffer-ele.
Astfel (fig.4.3), adaptorul are un tabel care păstrează starea VC. Sunt patru VC setate (1, 3, 5, 7). Dintre acestea, doar VC1,5 şi 7 au celule de transmis. Dar VC5 e inactiv, astfel că numai VC1 şi 7 au credite pentru a transmite celule. Astfel următoarea celulă trimisă de adaptor ar trebui să fie dintr-un VC disponibil: 1 sau 7. Selecţia dintre VC disponibile ar trebui făcută corect, de exemplu prin tehnica round-robin. Dacă adaptorul alege să transmită o celulă din VC7, el va decrementa la 1numărul de credite al VC7. Cum nu mai sunt alte celule de transmis, VC7 devine acum nedisponibil. Alegerea următorului VC disponibil duce la următoarea problemă.
Problemă: Un planificator naiv ar putea parcurge ciclic tabloul cu circuite virtuale căutând unul eligibil. Dacă multe dintre VC sunt nedisponibile, atunci planificatorului îi va lua mult timp până va găsi unul disponibil, lucru care este ineficient. Cum poate fi evitată această ineficienţă?
Indicaţie: Apelăm la P12, suplimentarea stărilor pentru accelerarea buclei principale. Ce stare trebuie adăugată pentru a evita parcurgerea stărilor VC neeligibile ? Cum poate fi menţinută eficient această stare ?
Soluţie: Se ţine o listă a circuitelor virtuale eligibile, în plus faţă de tabelul de VC (fig. 4.3). Singura problemă este menţinerea eficientă a acestei stări. Aceasta e dificultatea majoră a principiului P12. Dacă această evidenţă este prea scump de menţinut, adăugarea altor stări este o calitate nu o necesitate. Ştim că un VC este disponibil dacă are atât celule de transmis cât şi credite. Astfel un VC este scos din listă dacă devine inactiv sau nu mai are credite; altfel e adăugat la coada listei pentru asigurarea corectitudinii; adăugarea se face fie când soseşte o celulă la coada de aşteptare vidă a unui VC sau când VC fără credite primeşte credite.
Exercitii •Cum puteţi fi siguri că un VC nu e adăugat de mai multe ori listei
eligibile? • Poate fi generalizată schema pentru a permite unor VC mai multe
posibilităţi de a transmite decât altora, pe baza unor ponderi alocate de manager?
4.3 Calcularea rutei folosind algoritmul lui Dijkstra Cum decide un ruter S asupra rutei/traseului unui pachet spre destinaţia
D? Fiecare legătură într-o reţea are un cost, şi ruterele trebuie să calculeze drumul cel mai scurt/de cost minim către destinaţie în domeniul local. Costul e un număr întreg, de valoare mică. Cel mai folosit protocol de dirijare intradomeniu este OSPF (Open Shortest Path First), bazat pe starea legăturilor.
În cadrul rutării după starea legăturii, fiecare ruter dintr-o subreţea trimite un pachet cu starea legăturii LSP (Link State Packet) care conţine lista legăturilor cu toţi vecinii săi. Fiecare LSP este transmis spre toate celelalte rutere din subreţea folosind un protocol de inundare. Odată ce fiecare ruter a primit câte un LSP de la oricare din celelalte rutere, atunci fiecare ruter are harta întregii reţele. Presupunând că topologia ramâne stabilă, fiecare ruter poate acum să calculeze cel mai scurt drum către

68
fiecare nod din cadrul reţelei, folosind un algortim standard de cale minimă, ca de exemplu algoritmul lui Dijkstra.
În figura 4.5, sursa S doreşte să calculeze arborele de drum minim către restul nodurilor (A, B, C, D) din reţea. Reţeaua este prezentată în stânga figurii cu legăturile şi costurile lor. În algoritmul Dijkstra, S începe prin a se plasa doar pe el în arborele de cost minim. S actualizează costul pentru a ajunge la vecinii adiacenţi (ex. B, A). La fiecare iteraţie, algoritmul Dijkstra adaugă la arborele curent, nodul cel mai apropiat arborelui curent. Costurile vecinilor noului nod adăugat sunt actualizate. Procesul se repetă până toate nodurile din reţea aparţin arborelui.
De exemplu, în figura 4.5., după ce a adăugat S, algoritmul alege nodul B şi apoi A. La aceasta iteraţie, arborele arată ca cel din dreapta figurii 4.5. Liniile continue arată arborele existent, iar cele întrerupte arată cele mai bune conexiuni curente spre nodurile care nu sunt încă în arbore. Cum A are un cost de 2 şi este o legatură de cost 3 de la A la C, C este marcat cu 5. Asemănător, D este marcat cu un cost egal cu 2 pentru drumul prin B. La următorul pas, algoritmul alege nodul D ca nod cu costul cel mai mic ce nu aparţine arborelui. Costul legăturii către C este actualizat folosind ruta prin D. În final, C este adăugat în ultimul pas.
Această soluţie necesită determinarea nodului cu cel mai mic cost care nu se află în arbore la fiecare pas. Structura de date standard, pentru a ţine evidenţa elementului de valoare minimă, într-un mediu care se modifică dinamic, este o coadă de aşteptare cu priorităţi. Acest lucru conduce la următoarea problemă.
Problemă: Algoritmul Dijkstra necesită o coadă de aşteptare cu priorităţi la fiecare din cele N iteraţii, unde N este numărul nodurilor de reţea. Cele mai bune cozi de priorităţi cu scop general, ca depozitele/heap au un cost de ( )logO N pentru a găsi elementul minim. Acest lucru
implică un timp total de rulare de ( )logO N N . Rezultă, pentru o reţea de dimensiuni mari, un timp de răspuns mare la defecţiuni şi modificări de topologie.
Indicaţie: Trebuie exploatat situaţia că legăturile au ca şi costuri numere întregi mici (P14), folosind un tabel cu costurile legăturilor. Cum puteţi găsi eficient următorul nod de cost minim pentru a-l include în arborele căilor minime?
Soluţia: Faptul că costurile legăturilor sunt valori mici întregi poate fi exploatat pentru construcţia cozii de aşteptare cu priorităţi, folosind sortarea de tip găleată/bucket sorting (P14). Presupunem că cel mai mare cost de legătură este MaxLinkCost. Astfel costul maxim al unei căi nu poate fi mai mare de Diam∗MaxLinkCost, unde Diam este diamterul reţelei. Presupunem că Diam este un număr întreg de valoare mică. Astfel putem folosi un tablou cu o poziţie pentru fiecare cost posibil c în gama 1...Diam*MaxLinkCost. Dacă în timpul algoritmului Dijkstra costul curent al nodului X este c, atunci nodul X poate fi plasat în lista indicată de elementul c alt tabloului. (fig.4.6). Acesta ne conduce la următorul algoritm.
De fiecare dată când un nod X îşi schimbă costul de la c la c’ , nodul X este scos din lista pentru c şi adăugat în lista pentru c’. Dar cum se găseşte elementul minim în tablou? Se foloseşte un indicator numit

69
CurrentMin iniţial pus pe 0 (ce corespunde costului lui S). De fiecare dată când algoritmul doreşte să găsească nodul de cost minim care nu aparţine arborelui, CurrentMin este incrementat cu 1 până este găsita o locaţie de tablou care conţine o listă nevidă. Orice nod din această listă poate fi adăugat la arbore. Costul algoritmului este ( )O N Diam MaxLinkCost+ ∗ deoarece acţiunea care dă în avans CurrentMin poate fi cel mult de dimensiunea tabloului. Aceasta este mult mai bine dect logN N ,dacă N este mare şi Diam şi MaxLinkCost sunt mici.
Factorul crucial care permite folosirea eficientă a cozii de aşteptare cu sortare prin găleată a priorităţilor este faptul că costurile nodurilor sunt întodeauna înaintea valorii lui CurrentMin. Aceasta este condiţia de monotonie. Dacă nu ar fi aşa algoritmul ar începe de la 1 la fiecare iteraţie, în loc sa înceapă de la ultima valoare a lui CurrentMin, şi să nu mai revină niciodată. Această condiţie de monotonie este evidentă pentru algoritmul Dijkstra deoarece costul nodurilor care nu aparţin arborelui trebuie să fie mai mari decât costurile nodurilor din arbore.
Figura 4.6. arată starea cozii de aşteptare cu sortarea priorităţii cu găleată după ce A a fost adăugat arborelui (cadrul din dreapta în fig.4.5). La acest moment CurrentMin=2, care este egal cu costul lui A. La următorul pas, CurrentMin va deveni 3, şi D va fi adăugat arborelui. Acest lucru duce la reducerea costului lui C la 4. Astfel C va fi scos din lista din poziţia 5 şi adăugat în lista vidă din poziţia 4. CurrentMin devine 4 şi abia atunci C este adăugat arborelui.
Exerciţii: •Algoritmul cere ca un nod să fie extras dintr-o listă şi adăugat altei
liste, precedentă. Cum poate fi făcut acest lucru eficient ? • In fig.4.6 cum ştie algoritmul că a terminat, după adăugarea nodului C
arborelui, şi să nu mai parcurgă tabloul pîna la capăt ? • In reţelele unde apar defectări, conceptul de diametru este foarte
suspect, deoarece el se poate modifica mult în caz de defectare. Considerăm o topologie circulară, unde toate cele N noduri au diametrul 2 prin nodul zis central; dacă acesta se defectează, diametrul scade la N/2. Deobicei, în practică, diametrul este mic. Acest lucru poate crea probleme în dimensionarea tabloului ? • Putem evita complet problema diametrului înlocuind tabloul liniar din
fig.4.6 cu unul circular de dimensiune MaxLinkCost ? Explicaţi. Soluţia rezultată se numeşte algoritmul Dial.
4.4 Monitor Ethernet cu o punte hardware Alice Hacker a lucrat la Acme Network cu o punte Ethernet a firmei
Acme. O punte este dispozitivul care face legătură între mai multe reţele Ethernet. Pentru a transmite pachete de la o reţea Ethernet la alta, puntea caută adresa destinaţie pe 48 biţi din pachetul Ethernet, la viteze mari.
A. Hacker a decis să transforme puntea într-un monitor de trafic Ethernet, care să asculte pasiv reţeaua, pentru a obţine statistici asupra structurii traficului Ethernet. Monitorizarea se face între perechi sursă-destinaţie arbitrare, astfel că pentru fiecare pereche activă sursă-destinaţie, ca A şi B, se reţin în variabilele PA,B numărul de pachete trimise de la A spre B, de la începutul monitorizării. Când un pachet este trimis de la A la

70
B, programul de monitorizare (care ascultă toate pachetele transmise) va prelua o copie a pachetului. Dacă sursa este A şi destinaţia B se incrementează PA,B. Operaţia trebuie facută în 64μ sec, timpul minim între pachete în Ethernet. Strangularea apare la verificarea stării PA,B asociate unei perechi de adrese pe câte 48 biţi A,B.
Din fericire, puntea hardware are un motor de căutare ce poate verifica starea asociată unei singure adrese de 48 biti în 1,4μ sec. Un apel spre hardware poate fi făcut de forma Lookup(X,D), unde X este cheia pe 48 biţi şi D este baza de date în care se face căutarea. Apelul returnează starea asociată cu X în 1,4μ sec pentru baze de date cu un număr mai mic de 64.000 chei. Problema ce trebuie rezolvată este următoarea: Problemă: Programul de monitorizare trebuie să actualizeze starea pentru AB când ajunge la B un pachet de la A. Programul are un motor de căutare care poate găsi doar adrese singulare şi nu perechi.Cum poate motorul actual să caute perechi de adrese? (figura 4.7). Indicaţie: Trebuie folosit P4 pentru a exploata puntea hardware existentă. Deoarece 1,4μ sec << 64μ sec putem folosi în proiectare mai mult de o căutare hardware. Cum poate fi redusă o căutare de 96 de biţi la o căutare de 48 de biţi, folosind trei căutări ? Soluţia naivă este folosirea a două căutari pentru a converti sursa A şi destinaţia B în indici mai mici (<24 biti), AI şi BI . Aceşti indici pot fi apoi folosiţi pentru căutare într-un tablou bidimensional care memorează starea pentru AB. Aceasta pretinde doar două căutari hardware şi un acces la memorie, dar poate implica un volum mare de memorie. La 1000 de surse posibile şi tot 1000 destinaţii posibile, tabelul trebuie să aibă un milion de intrări. In practică sunt active deobicei doar 20.000de perechi sursă-destinaţie. Cum poate fi adaptat volumul necesar de memorie proporţional cu numărul actual al perechilor sursă- destinaţie ? Soluţie: Intâi se face câte o căutare pentru a converti sursa A şi destinaţia B în indici mai mici (<24 biti), IA si IB. Apoi se foloseşte o a treia căutare pentru a face asocierea între IAIB şi starea AB. Soluţia este ilustrată în figura 4.8. Cea de-a treia căutare face compresia tabloului bidimensional din soluţia naivă. Soluţia are ca autori pe Mark Kempf şi Mike Soha.
Exerciţii • Poate fi problema rezolvată cu doar două căutări ale punţii hardware şi
fără memorie suplimentară ? • Setul perechilor sursă-destinaţie se poate schimba în timp, deoarece
anumite perechi de adrese devin inactive lungi perioade de timp. Cum poate fi manevrată situaţia fără a ţine câte o stare pentru fiecare pereche posibilă de adrese, care are de comunicat de la pornirea monitorului ?
4.5 Demultiplexarea în nucleul-X Nucleul-x asigură o infrastructură software pentru implementarea de
protocoale în staţii/gazde. Sistemul nucleului-x asigură baza pentru un număr de funcţii de protocoale necesare. O funcţie folosită este protocolul de demultiplexare. De exemplu, când IP, nivelul reţea Internet, primeşte un pachet, trebuie să folosească câmpul de protocol pentru a vedea dacă pachetul trebuie trimis la TCP sau la UDP.

71
Majoritatea protocoalelor fac demultiplexarea pe baza unor identificatori în antetul/header-ul protocolului. Aceşti identificatori pot să varieze ca lungime în diferite protocoale. De exemplu, câmpurile pentru Ethernet pot fi de 5 octeţi, iar numerele portului TCP au 2 octeţi. Astfel x-kernel-ul permite demultiplexarea pe baza identificatorilor de protocol cu lungime variabilă. Cand se iniţializează sistemul, rutina protocolului înregistrează legăturile între identificatori şi protocolul destinaţie cu nucleul-x. In timpul rulării, când un pachet soseşte, rutina protocolului poate extrage identificatorul protocolului din pachet şi apelează rutina nucleului-x de demultiplexare pentru protocolul destinaţie. Cum pachetele pot veni la viteze mari, rutina de demultiplexare trebuie să fie rapidă. Rezultă următoarea problemă.
Problemă: In medie, cea mai rapidă cale de a face o căutare este folosirea unui tabel de dispersie. Cum este prezentat în figura 4.9, sunt necesare folosirea unor funcţii de dispersie asupra identificatorului K pentru generarea unui index de dispersie, folosirea acestui index pentru a accesa tabelul de dispersie, şi compararea cheii L, reţinută la intrarea în tabelul de dispersie, cu K. Dacă se potrivesc, rutina de demultiplexare poate recupera protocolul destinaţie asociat cheii L. Presupunem că funcţia de dispersie a fost aleasă să facă coliziunile rare.
Deoarece lungimea identificatorilor este un numar arbitrar de octeţi, rutina pentru comparaţie pentru cele două chei trebuie, în general, să facă comparaţia octet cu octet. Oricum, presupunem cazul cel mai des întâlnit a identificatorilor pe 4 octeţi, care este dimensiunea unui cuvânt. In acest caz, este mult mai eficient să facem comparatia la nivel de cuvânt. Astfel scopul este (P4) să exploatăm comparaţia eficientă pe cuvânt pentru optimizarea cazului cel mai probabil. Cum putem opera, daca se manevrează diferite protocoale ?
Indicaţie: Dacă x-kernel-ul are de demultiplexat un identificator de 3 octeţi, trebuie să folosească rutina de comparaţie octet cu octet; dacă identificatorul e pe 4 octeti, şi maşina lucrează cu cuvinte de 4 octeţi, poate fi făcută comparaţia pe cuvânt. Primul grad de libertate care poate fi folosit este să avem rutine de comparaţie diferite pentru cele mai comune cazuri (comparare pe cuvânt, comparare pe cuvinte lungi) şi o rutină de avarie/default pentru compararea pe octet. Acesta este un compromis spaţiu-timp (P4b). Pentru corectitudine, trebuie ştiut care rutină de comparaţie trebuie folosită în cazul fiecărui protocol. Trebuie invocate principiile P9 de pasare de indicaţii interfeţelor şi P2a de realizare a precalculelor.
Soluţie: Fiecare protocol trebuie să declare identificatorul şi protocolul destinaţie nucleului-x când se iniţializează sistemul. Cand s-a realizat acest lucru, fiecare protocol poate să-şi predeclare lungimea identificatorului, ca nucleul-x să folosească rutine de comparaţie specializate pentru fiecare protocol. Efectiv, informaţia este transmisă între protocolul client şi nucleul-x mai devreme. Presupunem că nucleul-x are un tabel de dispersie pentru fiecare protocol client şi că nucleul-x ştie contextul pentru fiecare client astfel încât să folosească codul specializat pentru acel client.
Exerciţii •Codaţi comparaţiile octet-cu-octet şi pe cuvânt pe calculatorul vostru,
faceţi un număr mare de comparaţii şi apoi comparaţi timpul global necesar fiecărui tip.

72
• In primele soluţii ADC cautarile tabelelor hash au fost rafinate prin pasarea unui index (în loc de lungimea identificatorului, ca la început). De ce poate fi această soluţie dificilă în acest caz ?
4.6 Arbori cu prefix cu compresia nodului
Un arbore cu prefix sau arbore ordonat/trie este o structură de date de forma unui arbore de noduri, unde fiecare nod este un tablou de M elemente. Figura 4.10 prezintă un exemplu simplu cu M=8. Fiecare tablou poate reţine fie o cheie (ex. KEY 1, KEY 2, sau KEY 3 în figura 4.11) sau un pointer către alte noduri ale arborelui cu prefix (ex. primul element în nodul test cel mai de sus din figura 4.10, care este rădăcina). Arborele cu prefix este folosit pentru a căuta potriviri exacte (şi potriviri de cele mai lungi prefixe) cu un şir de intrare. Arborii cu prefix sunt utili în reţele atunci când se caută o adresă IP, o punte, şi filtre de demultiplexare.
Nu ne interesează acum algoritmul exact al arborelui cu prefix. Singurul lucru ce trebuie ştiut este cum se face căutarea în arborele cu prefix. Presupunem că c=log2M este dimensiunea unei bucăţi de arbore cu prefix. Pentru a căuta în arborele cu prefix,întâi se separă şirul de caractere introdus, în bucăţi de dimensiunea c. Căutarea foloseşte bucăţile succesive, începând cu cea mai semnificativă, indexând nodurile unui arbore cu prefix, începând cu nodul rădăcină. Cand căutarea foloseşte bucata j pentru a indexa în pozitia i a nodului curent al arborelui cu prefix , pozitia i poate conţine un pointer sau o cheie. Dacă poziţia i conţine un pointer nenul către nodul N, căutarea continuă din nodul N cu bucata j+1; altfel căutarea ia sfârşit.
Pe scurt, fiecare nod este un tablou de pointeri sau chei, şi procesul de căutare trebuie să indexeze în aceste tablouri. Oricum, dacă multe din nodurile arborelui cu prefix sunt împrăştiate, se face risipă de spaţiu (P1). De exemplu, în figura 4.10, doar 4 din 16 locaţii conţin informaţie utilă. In cel mai rău caz, fiecare nod al arborelui cu prefix poate conţine un pointer sau o cheie şi ar putea fi un factor M în memorie nefolosită. Presupunem M≤ 32 în cele ce urmează. Chiar daca M este aşa mic, o creştere cu 32 a memoriei poate duce la mărirea semnificativă a costului proiectării. O abordare evidentă este înlocuirea fiecarui nod al arborelui cu prefix cu o listă liniară de perechi de forma (i,val), unde val este o valoare nevidă (pointer sau cheie) în poziţia i a nodului. De exemplu, nodul arborelui cu prefix rădăcină în figura 4.10 poate fi înlocuit cu o listă (1,ptr);(7,KEY1), unde ptr1 este un pointer la nodul arborelui cu prefix de jos. Din păcate, acest lucru poate încetini căutarea arborelui cu prefix cu un factor M, deoarece căutarea fiecarui nod al arborelui cu prefix duce la căutarea intr-o lista de M locaţii, în locul unei simple operaţii de indexare. Asta ne conduce la următoare problemă.
Problema:Cum pot nodurile arborelui cu prefix să fie comprimate prin eliminarea pointerilor nuli fără a încetini căutarea decât cu un factor mic?
Indicatie: Deşi nodurile sunt comprimate, indexarea tabelelor trebuie să fie eficientă. Dacă nodurile sunt comprimate, cum ar putea fi reprezentată informaţia despre nodurile care au fost eliminate ? Considerăm o egalizare faptul că M este mic, respectând P14 (exploatarea dimensiunii întregilor mici) şi P4a (exploatarea localizării).

73
Soluţie: Cum M<32, un bitmap de dimensiune 32 poate uşor să încapă într-un cuvânt. Astfel pointerii nuli sunt scoşi după ce se adaugă un bitmap cu zero biţi indicând pozitia originală a pointerilor nuli. Acest lucru este arătat în figura 4.11. Nodul arborelui cu prefix poate fi acum înlocuit cu un bitmap şi un nod al arborelui cu prefix comprimat. Un nod al arborelui cu prefix comprimat este un tablou ce conţine doar valorile nenule din nodul original. Astfel în figura 4.11 nodul rădăcina al arborelui cu prefix original (de sus) a fost înlocuit cu nodul arborelui cu prefix comprimat (de jos). Bitmapul contine un 1 în prima şi a şaptea pozitie, unde nodul rădăcină conţine valori nenule. Tabloul necomprimat conţine acum doar 2 elemente, primul pointer şi KEY 3.
Având în vedere că atât nodurile comprimate cât şi cele necomprimate sunt tablouri şi procesul de căutare începe cu un index I în nodul necomprimat, procesul de căutare trebuie să consulte bitmapul pentru a converti indexul necomprimat I într-un index comprimat C în nodul comprimat. De exemplu, dacă I este 1 în figura 4.11, C ar trebuie să fie 1; daca I este 7, C ar trebui să fie 2. Dacă I este oricare altă valoare, C ar trebui să fie 0, indicând că este un singur pointer nul.
Conversia din I la C poate fi realizată uşor ţinând cont de următoarele. Daca poziţia I în bitmap conţine un 0, atunci C=0. Altfel, C este un număr de 1-uri în primii I biţi ai bitmapului. Astfel dacă I=7, atunci C=2, deoarece sunt doi biţi setaţi în primii şapte biţi ai bitmapului. Acest calcul necesită cel mult două referiri la memorie: una pentru a accesa bitmapul (deoarece bitmapul e mic, P4a) şi una pentru a accesa tabloul comprimat. Calculul numarului de biţi setaţi într-un bitmap poate fi făcut folosind registre interne (în software) sau logica combinaţională (în hardware). Astfel încetinirea efectivă este cu un factor ceva mai mare de 2 în software şi exact 2 în hardware.
Exerciţii •Cum puteţi folosi căutarea tabelelor (P14, P2a) pentru accelerarea
contorizării numărului de biţi din set, în software? Ar fi necesar al treilea apel la memorie ? • Presupunem că bitmap-ul e mare (sa zicem,M=64K). Ar părea că
contorizarea numărului de biţi din set cu asemenea bitmap mare e imposibil de lentă, în software sau hardware. Puteţi găsi o cale de accelerare a contorizării biţilor în bitmap-urile mari (P12 si P2a) ?
4.7 Filtrarea pachetelor in rutere Există protocoale care setează resursele la rutere pentru trafic care
necesită garantarea performanţelor, cum e traficul video sau audio. Astfel de protocoale folosesc concepte ca filtrarea pachetelor, numite şi clasificatoare. Astfel, în figura 4.12 fiecare receptor ataşat unui ruter poate specifica un filtru de pachete descriind pachetele pe care doreşte să le recepţioneze. De exemplu, în fig.4.12 receptorul 1 poate fi interesat de recepţia NBC, care e specificat de filtrul 4. Fiecare filtru e conform unor specificaţii ale câmpurilor care descriu pachetele video trimise de NBC. De exemplu, NBC poate fi specificat de pachetele care folosesc adresa sursă a transmiţătorului NBC din Germania şi utilizează o anumită destinaţie TCP şi numărul de port sursă.
La fel, în fig.4.12 receptorul m poate fi interesat în recepţionarea ABC-Sport şi CNN, care sunt descrise de filtrul 1şi 7. Pachetele sosesc la ruter

74
la viteze mari şi trebuie trimise tuturor receptoarelor care cer pachetul. De exemplu, receptorul 1 şi receptorul 2 pot dori ambele să recepţioneze NBC, fapt ce duce la următoarea problemă.
Problemă Fiecare pachet recepţionat trebuie încercat la fiecare filtru şi trimis la toţi receptorii care îl lasă să treacă. O scanare liniară simplă a tuturor filtrelor e scumpă dacă numărul de filtre e mare. Presupunem numărul de filtre e peste o mie. Cum poate fi grăbit un pic acest proces?
Indicaţie Ne-am putea gândi să optimizăm cel mai probabil caz utilizând cache-ul pentru memorare (P11a). Totuşi caching-ul e dificil de folosit aici, şi de ce ? Considerăm adăugarea unui unui câmp (P10) la antetul pachetului pentru a face cachingul mai usor. Care nivel de protocol ar trebui ideal adăugat ?Adăugând un câmp fix bine cunoscut pentru fiecare tip de video posibil nu e un panaceu, deoarece implică o standardizare globală, şi filtrele trebuie să fie bazate pe alte câmpuri, ca de exemplu adresa sursei. Presupunem că câmpurile adăugate de noi nu necesită identificatori standardizaţi global. Ce proprietăţi trebuie să asigure sursa acestor câmpuri?
Soluţia Folosirea memorilor cache (P11a), vechiul cal de bataie al proiectanţilor de sisteme, nu e directă pentru această problemă.In general în cache se memorează asocierile dintre o intrare a şi o ieşire oarecare f(a). Cache-ul constă deci dintr-un set de perechi de valori, de forma (a,f(a)),. Baza de date poate fi implementată ca un tabel de dispersie (software) sau o memorie cu conţinut adresabil (hardware). Având valoarea a şi trebuind să calculăm f(a), se consultă baza de date ca să vedem dacă a nu a fost deja introdus. Dacă da atunci se poate da direct, rapid valoarea lui f(a). Dacă nu atunci se va face calculul folosind o altă metodă de calcul (posibil scumpă) şi perechea (a,f(a)) este introdusă în baza de date cache. Pe urmă intrările de valoare a pot fi calculate foarte rapid.
In problema filtrării pachetelor, scopul este să calculăm setul de receptoare asociate unui pachet P. Problema e că ieşirea este o funcţie de, posibil, un număr mare de câmpuri antet ale pachetului P. Astfel pentru a folosi memoria cache, trebuie stocate o parte mare de antetele lui P asociate setului de receptoare pentru P. Memorarea asocierilor dintre cei 64 de octeţi ai antetului pachetului e o propunere foarte costisitoare.Este costisitoare în timp, deoarece căutarea cache-ului poate fi mai lungă deoarece cheile sunt vide.Este costisitoare şi ca spaţiu de memorare. Stocările masive implică un număr mai mic de asocieri care pot fi stocate într-o memorie cu o capacitate dată, adică în final un hit-rate mai prost.
Se preferă reţinerea în cache a asocierilor dintre unul/două câmpuri de pachete şi setul de receptoare de la ieşire. Acest lucru ar accelera timpul de căutare prin cache şi ar îmbunătăţi hit-rate-ul. E preferabil că aceste câmpuri să fie plasate în antetul de rutare, verificat oricum de ruter.Problema e că acolo ar putea să nu fie un asemenea câmp care să amprenteze unic pachetul P ?
Totuşi, presupunând că suntem proiectanţi de sisteme, şi avem de proiectat un protocol de rutare.Am putea adăuga un câmp antetului de rutare. Problema pare banală dacă am putea asigna fiecărui flux de pachete posibil un identificator global unic.De exemplu, dacă am putea asigna lui NBC identificatorul 1, lui ABC identificatorul 2, iar lui CNN identificatorul 3, atunci am putea memora în cache folosind identificatorul

75
ca şi cheie. O asemenea soluţie ar implica o formă oarecare de comitete de standardizare globală responsabile cu botezarea fiecărui flux aplicaţie. Chiar dacă s-ar putea face acest lucru, filtrul receptor ar putea cere toate pachetele NBC de la o anumită sursă, iar filtrul ar putea depinde şi de alte câmpuri ale pachetului.Acest lucru a condus la următoarea idee finală.
Soluţia la care s-a ajuns este modificarea antetului de rutare prin adăugarea unui identificator de flux F (fig.4.13), cu semnificaţie dependentă de sursă. Cu alte cuvinte, surse diferite pot folosi acelaşi identificator de flux deoarece este o combinaţie, a sursei şi a identificatorului de flux, care este unică. Aşa nu e necesară standardizarea globală a identificatorilor de flux (şi nici altă coordonare globală).Identificatorul de flux e doar un contor local menţinut de sursă Ideea este că la transmiţător o aplicaţie care transmite poate cere nivelului de rutare un identificator de flux. Acest identificator este adăugat antetului de rutare la toate pachetele aplicaţiei.
Ca deobicei, când un pachet aplicaţie soseşte prima dată, ruterul face o căutare liniară (lentă) pentru a determina setul de receptoare asociate cu antetul pachetului. Deoarece identificatorii nu sunt unici de la o sursă la alta, ruterul reţine în cache asocierile folosind concatenarea adreselor sursă a pachetului si identificatorul de flux ca şi cheie. Evident că corectitudinea depinde de condiţia ca aplicaţia transmiţătorului să nu schimbe câmpurile care ar putea afecta filtrul, fără să schimbe deasemenea şi identificatorul de flux din pachet.
Exerciţii •Ce poate merge prost când cade sursa şi revine fără să-şi mai
amintească ce identificatori au fost asignaţi diferitelor aplicatii? Ce poate merge prost când receptorul adaugă un filtru nou? Cum pot fi aceste probleme rezolvate? • In soluţia curentă identificatorul de flux e folosit ca un tip şi nu ca un
hint. Ce costuri suplimentare ar presupune tratarea perechii identificatorul de flux-adresa sursei ca un hint şi nu ca un tip?
4.8 Evitarea fragmentarii pachetelor de stare a legaturii Problema care urmeaza a aparut in timpul proiectarii protocoalelor de
dirijare conform cu starea legaturii, OSI si OSPF. Ea se refera la proiectarea si nu la implementarea protocolului, odata ce proiectarea a fost facuta. Se vede acum cat de tare afecteaza performanta protocolului solutiile adoptate in timpul proiectarii.
La dirijarea conform cu starea legaturii, ruterul trebuie sa transmita un pachet cu starea legaturii LSP(Link State Packet) tuturor vecinilor sai. Protocolul de dirijare conform cu starea legaturii consta din doua procese separate. Primul este procesul de actualizare care transmite pachete cu starea legaturii in siguranta de la ruter la ruter, folosind protocolul cu inundare, care aloca un numar de secventa unic fiecarui pachet de stare a legaturii. Numarul de secventa e folosit pentru a rejecta copiile duplicate ale unui LSP. De cate ori un ruter primeste un nou LSP numerotat cu x de la sursa S, el va memora valoarea x, si va rejecta orice LSP-uri urmatoare avand numarul de secventa x. Dupa ce procesul de actualizare isi termina treaba, procesul de decizie din fiecare ruter aplica algoritmul lui Dijkstra tabelei de retea formate de pachetele de stare a legaturilor.

76
Un ruter poate avea putine rutere vecine, sau poate avea vecine multe calculatoare gazda/host-uri (noduri terminale), conectate direct la ruter in acelasi LAN. De exemplu, in fig.4.14, ruterul R1 are 500 de noduri terminale vecine, E1...E500. Marile LAN-uri pot avea si mai multe noduri terminale vecine, ceea ce conduce la problema urmatoare.
Problema:La cei 8 bytes alocati fiecarui nod terminal (6 bytes pentru identificarea nodului in sine, iar 2 bytes reprezinta informatia de cost adica LSP-uri), LSP-ul poate fi foarte mare (pentru 5000 de noduri terminale, dimensiunea poate ajunge la 40,000 bytes). Aceasta valoare este mult prea mare pentru ca LSP-ul sa incapa intr-un cadru chiar si de dimensiune maxima din majoritatea legaturilor de date obisnuite. De exemplu, protocolul Ethernet are dimensiune maxima a cadrelor de 1500 bytes, iar protocolul FDDI, 4500 bytes. Acest lucru implica fragmentarea LSP-urilor mari intr-un numar mare de cadre de nivel legatura de date, la fiecare nod, si apoi reasamblarea lor de catre urmatorul nod, s.a.m.d. Pentru a determina daca toate fragmentele de LSP au fost receptionate, este necesar, din pacate, un proces de reasamblare costisitor in fiecare nod.
Figura 4.14 Pachetul de stare a legaturii a ruterului R1 (cu 500 de noduri vecine) poate
fi prea mare ca sa incapa intr-un cadru de nivel legatutra de date. Acest lucru implica fragmentari si reasamblari ineficiente, la fiecare salt.
Figura 4.15 Evitarea fragmentarii hop-by-hop impartind ruterele mari in pseudorutere De asemenea, creste latenta propagarii LSP-ului. Presupunem ca
fiecare LSP incape in M cadre de nivel legatura de date, ca diametrul retelei este D, iar timpul de transmitere pe legatura al unui cadru de nivel legatura de date este de o unitate de timp. Atunci, timpul de propagare al unui LSP, tinind cont de reasamblarea in fiecare nod va fi D M⋅ . Daca ruterele in cauza nu ar fi avut de asteptat pentru reasamblarea LSP-urilor pas cu pas, intarzierea datorata propagarii ar fi fost doar M D+ . Cand a fost proiectat protocolul pentru starea legaturii, aceste probleme au fost detectate de cei care au revizuit ulterior specificatiile.
Pe de alta parte, pare imposibil ca fragmentele sa fie transmise independent unul de celalalt, deoarece LSP-ul poarta un singur numar de secventa care este crucial in procesul de actualizare. Simpla copiere a numarului de secventa in fiecare fragment nu ajuta, deoarece duce la

77
rejectarea a fragmentelor ulterioare, pe motiv ca au acelasi numar de secventa cu primul. Rezolvarea cestei probleme aparent imposibila se face prin deplasarea calculului in spatiu, pentru a evita nevoia de fragmentare pas cu pas. Sunt permise schimbari in protocolul de rutare LSP.
Sugestie: trebuie oare ca toti cei 5000 de octeti de informatie de la nodurile finale sa se afle in acelasi LSP ? Vezi principiul P3c, deplasarea calculului in spatiu (nodurile terminale vor fi astfel proiectate incat sa calculeze dimensiunile maxime ale fragmentelor care pot trece prin orice retea si sa faca ele insele fragmentarea).
Solutie. Daca fragmentele individuale ale LSP-ului original al ruterului R1 s-ar propaga independent unul de altul, fara reasamblarea pas cu pas, atunci fiecare fragment trebuie sa fie un LSP in sine, cu un numar de secventa separat. Aceasta observatie extrem de importanta duce la o idee eleganta.
Se modifica protocolului de rutare a informatiilor de stare LSP pentru a permite oricarui ruter R1 sa apara ca mai multe pseudo-rutere 1 , 1 , 1a b cR R R (figura 4.15). Astfel, grupul initial de noduri terminale este impartit intre aceste pseudo-rutere, si in consecinta LSP-ul fiecarui pseudo-ruter va incapea in majoritatea cadrelor de nivel legatura de date fara a mai fi nevoie de fragmentare. De exemplu, daca majoritatea dimensiunilor de nivel legatura de date este de minim 576 bytes, intr-un cadru de nivel legatura de date pot incapea ≈ 72 de noduri terminale.
Cum ar fi implementat acest concept de pseudo-ruter? In propagarea initiala a LSP-ului, fiecare ruter avea un ID de 6 bytes, introdus in LSP-ul global transmis de ruter. Pentru a permite existenta pseudoruterelor schimbam protocolul si permitem ca LSP-ul sa aiba 7 bytes de ID (6 bytes ID + 1 byte pseudoruter). ID-ul pseudoruterului poate fi asignat de catre ruterul actual care contine toate pseudoruterele. Permitand 256 de pseudorutere pe un singur ruter, atunci acest ruter va putea suporta in jur de 18,000 de noduri terminale.
Propagarea LSP-urilor trateaza pseudoruterele separat, dar pentru calculul rutei este crucial ca pseudoruterele separate sa fie tratate ca un singur ruter. In exemplul nostru toate nodurile terminale sunt de fapt conectate direct la acelasi ruter R1. Acest lucru este usor de realizat, deoarece toate LSP-urile cu primii 6 bytes identici pot fi recunoscute ca provenind de la acelasi ruter.
Pe scurt, ideea de baza este aceea de a deplasa calculul in spatiu (P3c), asigurand ca procesul de fragmentare a LSP-ului original in LSP-uri independente, sa fie facut de catre sursa S si nu de fiecare legatura de date. Acest exemplu permite intelegerea gandirii sistemice. Bineinteles, implementatorii au preferat solutiei originale, aceasta solutie, inventata de Radia Perlman.
Exercitii: • Cum poate un ruter asigna noduri terminale unui pseudoruter? Ce
se intampla daca un ruter are la inceput o multime de noduri terminale (si deci o multime de pseudorutere) iar la un moment dat, majoritatea nodurilor terminale dispar? Aceasta poate genera situatia in care raman o multime de pseudorutere, fiecare avand doar cateva noduri terminale. De ce nu e bine asa si cum putem remedia situatia ?

78
• La fel ca in exemplele de reducere a severitatii conditiilor, aceasta solutie poate genera conditii incorecte neasteptate (temporare deobicei si fara sa fie foarte grave). Tinand cont de solutia gasita la exercitiul precedent, descrieti un scenariu in care un anume ruter, de exemplu R2, poate gasi (la un moment dat) eroarea in care, in baza sa de date pentru LSP-uri, acelasi nod terminal (de ex E1) apartine la doua pseudorutere, R1a si R1b. De ce nu este acest caz mai rau decat rutarea obisnuita a LSP-urilor ?
4.9 Supravegherea structurii traficului Anumite protocoale de retea pretind ca sursele sa nu transmita niciodata
datele mai rapid decat cu o rata impusa. In loc de a specifica rata medie pe o perioada lunga de timp, protocolul poate deasemenea specifica volumul maxim de trafic, B, in biti pe care sursa-i poate transmite in orice perioada de T secunde. Acest lucru limiteaza sursa la rata medie de /B T biti pe secunda. De altfel, acest lucru limiteaza si “gradul de rafala” a traficului utilizatorului la maxim o rafala de dimensiune B la fiecare T unitati de timp. Alegand, de exemplu, o valoare mica a parametrului T, se limiteaza considerabil rafalele de trafic. Rafalele fac probleme retelei, deoarece perioadele cu trafic mare si pierderi de pachete sunt urmate de perioade de inactivitate.
Daca fiecare sursa isi indeplineste contractul (nu transmite peste volumul de trafic specificat pe o perioada data), reteaua poate oferi garantii de performanta si sa asigure ca nimic din trafic sa nu fie pierdut, precum si livrarea la timp a traficului. De cele mai multe ori regulile sunt respectate, fie pentru ca sunt considerate corecte de catre unii, fie de teama penalizarilor, de catre altii. Dar acest lucru nu se intampla intotdeauna, astfel ca urmarirea traficului e foarte importanta. Fara ea, unii utilizatori ar putea profita, incorect, de banda retelelor.
Presupunem ca fluxurile de trafic sunt identificate prin adresa sursei si a destinatiei, precum si prin tipul de trafic. Fiecare ruter trebuie sa sa se asigure ca nici un flux sa nu transmita mai mult de B biti in nici o perioada de T secunde.Pentru ruter, cea mai simpla solutie este sa foloseasca un singur timer care ticaie la fiecare T secunde, si sa numere bitii trimisi in fiecare perioada, folosind cate un contor per flux. Daca la sfarsitul fiecarei perioade contorul depaseste B, ruterul detecteaza o violare de contract.
Dar folosind un singur timer pot fi supravegheate doar anumite perioade. Presupunem de exemplu, fara a pierde din generalitate, ca timer-ul porneste la momentul 0 de timp.Atunci singurele perioade verificate vor fi [ ] [ ] [ ]0, , , 2 , 2 ,3 ,....T T T T T , ceea ce nu asigura ca fluxul sursei nu violeaza
contractul de trafic in perioade ca [ ]/ 2,3 / 2T T , suprapuse peste perioadele supravegheate. De exemplu, in stanga figurii 4.16, fluxul transmite o rafala de lungime B, chiar inainte ca ceasul/timerul sa ticaie la momentul t, si trimite a doua rafala de lungime B chiar dupa ticaitul de la momentul T.
O solutie ar fi utilizarea timer-elor si contoarelor multiple. De exemplu, avem un ruter care poate utiliza un timer ce incepe la momentul 0, iar urmatorul timer, la momentul T/2. Din pacate, sursa poate viola in continuare contractul, trimitand legal, B biti in fiecare perioada

79
supravegheata, dar ilegal, mai mult de B biti intr-o perioada ce se suprapune celor supravegheate. In partea dreapta a figurii 4.16 avem o sursa ce nu se incadreaza in contract. Aceasta trimite o rafala de B bits la sfarsitul primei perioada, si o a doua rafala la inceputul celei de-a treia perioade, in total trimitand 2B biti intr-o perioada cu putin mai mare decat T/2. Din pacate nici unul dintre timer-e nu vor vedea acest lucru drept un viol. Acest lucru duce la urmatoarea problema.
Figura 4.16 Folosirea naiva a unuia sau a mai multor timer-e (pentru a verifica daca sursa nu transmite un volum de trafic mai mare decat B biti la fiecare T secunde)
T Aleator T Aleator
Figura 4.17 Daca se iau pauze aleatoare intre intervalele de supraveghere ruterele vor
detecta violarile de contract cu o probabilitate mare Problema. Folosirea timerelor multiple este scumpa si nu garanteaza ca
traficul de date va respecta contractul. Este usor de vazut faptul ca, utilizand chiar si un singur timer, sursa nu poate trimite mai mult de 2B biti in orice perioada de T secunde. Un mod de rezolvare ar fi sa consideram ca un viol de gradul 2 nu merita efortul de a supraveghea traficul. Dar in cazul in care avem o legatura transcontinentala in care banda este extrem de importanta, violul de gradul 2 este o reala problema. Cum ar putea fi prins un viol de trafic cu un singur timer?
Indiciu: Considerand exploatarea unui grad de libertate (P13), presupus fixat in solutia naiva. Intervalele de supraveghere ar trebui sa inceapa la intervale fixate de timp? Considerati folosirea lui P3a.
Solutie: Intervalele de supraveghere nu trebuie sa fie fixe, deci pot exista spatii goale distribuite arbitrar intre acestea. Cum ar putea fi localizate spatiile goale? Deoarece o sursa ce nu respecta contractul poate sa isi aleaga in orice moment inceputul perioadei de viol a contractului, o idee simpla (P3a) conduce la urmatoarea solutie (figura 4.17)
Ruterul utilizeaza un singur timer de T unitati si un singur contor, la fel ca in cazul precedent. Un interval de supraveghere se termina cu un tact de timer; daca contorul este mai mare decat B, a fost detectat un viol. Apoi, este setat un indicator sa arate ca timerul este folosit acum doar pentru a introduce un spatiu aleator. Dupa care timerul este resetat pentru un interval aleator de timp, cuprins intre 0 si T. Cand timerul indica

80
momentul, indicatorul este pus pe valoare nula, contorul va fi initializat, iar timerul resetat pentru o perioada T.
Exercitiu: Presupunem contorul initializat si mentinut in aceasta stare atat in timpul perioadelor de pauza, cat si in timpul intervalelor de supraveghere. Poate ruterul sa faca o deductie corecta in timpul unei asemenea perioade, chiar si in cazul in care perioada pauzei este mai mica de T unitati?
4.10 Identificarea celor care monopolizeaza resursele Sa presupunem ca un dispozitiv doreste sa urmareasca resursele, cum ar
fi memoria de pachete alocata diferitelor surse din ruter. Dispozitivul respectiv ar dori sa localizeze simplu sursa ce consuma cea mai mare parte de memorie, astfel incat, ulterior, sa poata recupera memoria “furata” de acest monopolizator de resurse. Figura 4.18 arata cinci surse diferite, avand fiecare propriul consum de banda: 1, 9, 30, 24 si 7 unitati. Monopolizatorul de resurse este sursa S3.
O solutie simpla de a identifica un monopolizator de resurse ar fi aceea de a utiliza o gramada dezorganizata/heap.Dar, la viteze ridicate si daca numarul surselor depaseste numarul 1000, solutia ar fi prea scumpa. Indicarea gradului de folosire al memoriei se face folosind numere intregi de la 1 la 8000, caz in care sortarea cu galeti/bucket sorting nu mai functioneaza bine, deoarece trebuie cautate 8000 de intrari pentru a gasi monopolizatorul de resurse.
Figura 4.18 Gasirea sursei care monopolizeaza resursele
Daca dispozitivul nu doreste sa gaseasca neaparat sursa cu debit maxim,
ci se multumeste si cu cea de pe locul doi (corectitudinea maxima nu este importanta in P3b), in exemplul de mai sus, raspunsul va fi S4 (24) in loc de S3 (30). Aceasta duce la urmatoarea problema.
Problema. Un modul software sau hardware trebuie sa urmareasca resursele necesare diferitilor utilizatori. De asemenea, modulul are nevoie ca, printr-o metoda ieftina, sa gaseasca utilizatorul ce consuma cele mai multe resurse. Deoarece gramezile dezordonate simple sunt de viteza mica, inginerii de protocoale de retea sunt dispusi sa mai scada cerintele de sistem (P3b) si sa se multumeasca si cu al doilea consumator d.p.d.v. ierarhic. Cum se poate ca aceasta diminuare a exactitatii cautarii sa fie transpusa intr-un algoritm mai eficient?
Indiciu: Sa consideram utilizarea a trei principii: cea a compromisului volum de calcul - in defavoarea preciziei (P3b), sortarea prin metoda galetilor si utilizarea tabelelor de corespondenta (P4b, P2a).
Solutie: Deoarece rezultatul cautarii poate fi gasit cu o inexactitate de ordinul 2, este normal sa includem utilizatorii a caror resurse consumate se afla pe locul 2, in acelasi grup de utilizatori de resurse. Acest lucru ar

81
putea fi un castig daca numarul rezultant de grupuri este mult mai mic decat numarul initial de utilizatori; deci, gasirea celui mai mare grup va fi mai rapida decat gasirea celui mai mare utilizator de resurse. Aceasta idee este foarte asemanatoare cu cea de la asamblarea din rutarea ierarhica, in care numarul destinatiilor sunt grupate sub un prefix comun; acest lucru poate face ca procesul de rutare sa fie unul mai putin precis dar poate sa reduca numarul intrarilor de rutat. Rezulta urmatoarea idee.
Figura 4.19 Agregarea utilizatorilor, cu factor 2 de consum, duce la un numar mic de
agregari, ai caror membri pot fi reprezentati folosind un bitmap Gruparea binomiala poate fi folosita (figura 4.19) toti utilizatorii fiind
plasati in grupe/galeti conform cu consumul de resurse folosit; galeata i contine toti utilizatorii a caror consum de resurse este intre 2i si 12 1i+ − . In figura 4.19, utilizatorii S3 si S4 se afla in intervalul [16, 31], deci se gasesc in aceeasi galeata.
Fiecare galeata contine o lista nesortata a inregistrarilor resurselor tuturor utilizatorilor ce intra in limitele intervalului sau. De aceea, in figura 4.19, S3 si S4 sunt in aceeasi lista. Structura de date contine si o harta/bitmap, cu un bit corespunzator pentru fiecare galeata, care este setat sa arate daca galeata asociata lui este plina. In consecinta, bitii corespunzatori galetilor [1, 1], [4, 7], [8, 15], si [16, 31] sunt setati pe valoarea 1, in timp ce bitul corespunzator lui [2, 3] este setat pe 0. Deci, pentru a gasi monopolizatorul de resurse, algoritmul trebuie doar sa caute bitul cu pozitia i aflat in pozitia extrema dreapta a hartii. Apoi, algoritmul va returna utilizatorul aflat in capul listei galetii corespunzatoare pozitiei i. In consecinta, (fig.4.19), algoritmul va returna valoarea acceptabila S4, in loc de valoarea corecta S3.
Exercitii: •Cum este mentinuta structura datelor? Ce se intampla daca un
utilizator isi reduce nivelul necesar de resurse de la 30 la 16? Ce fel de liste sunt necesare pentru o mentenanta eficienta ? •Cat de mare e fiecare harta? Cum sa gasm eficient cel mai din dreapta
bit? 4.11 Debarasandu-ne de lista de conexiuni TCP deschise Un protocol de transport ca TCP, aflat in calculatorul X, va tine seama de
absolut toate conversatiile simultane pe care statia de lucru respectiva le are cu alte PC-uri. O conexiune reprezinta starea partajata intre doua puncte terminale ale unei conversatii. Daca un utilizator doreste sa trimita un mail de pe statia X pe statia Y, atunci programul de mail de pe statia X trebuie sa stabileasca o conexiune (stare partajata) cu programul de mail

82
din statia Y. Un server ocupat, ca cel de Web, poate avea o multime de conexiuni concurente.
Starea conexiunii consta din lucruri ca numarul de pachete trimise de statia X, neconfirmate de statia Y. Orice pachet de date neconfirmat de statia Y intr-un anumit interval de timp, trebuie retransmis de X. Pentru a face retransmisia, protocoalele de transport obisnuiesc sa aiba timere periodice ce declanseaza retransmisia oricarui pachet a carui confirmare intarzie sa apara dupa o anumita perioada de timp.
Figura 4.20 Implementarea x-kernel-ului foloseste o tabela hash de asociere a
conexiunilor pentru stare (pentru expedierea pachetelor)si o lista inlantuita de conexiuni (pentru timere)
Codul TCP Berkeley (BSD), disponibil gratis, tine o lista a conexiunilor
deschise (fig. 4.20) pentru a examina, la fiecare declansare a timerului, daca e nevoie sa faca o retransmisie. Oricum, daca soseste un pachet la statia X, TCP-ul lui X trebuie sa stabileasca rapid carei conexiuni apartine pachetul, pentru a reactualiza starea conexiunii. Fiecare conexiune este identificata de un identificator de conexiune, transportat de fiecare pachet.
Pentru determinarea conexiunii careia apartine un anumit pachet, ar fi necesara cautarea lui in intreaga lista (cazul cel mai defavorabil), ceea ce ar fi prea lent pentru serverele cu multe conexiuni. In consecinta, implementarea x-kernel a adaugat un tabel de dispersie implementarii BSD (P15) pentru a asocia eficient identificatorii de conexiune din pachetele de date cu starea conexiunii corespunzatoare. Tabela de dispersie este un vector de indicatori, indexati cu valoarea dispersiei care indica spre listele de conexiuni, ce disperseaza catre aceeasi valoare. In plus, lista originala de conexiuni inlantuite a fost retinuta pentru procesari de timer, in timp ce tabela de dispersie ar fi trebuit sa mareasca viteza procesarii de pachete.
Ciudat, dar masuratorile efectuate in cazul noii implementari au aratat o incetinire a vitezei. Dupa masuratori riguroase, s-a constatat faptul ca problema ar fi stocarea redundanta, a informatiilor despre conexiuni, lucru ce a dus la reducerea eficientei memoriei cache din procesoarele moderne. Acesta este un exemplu despre cum o imbunatatire evidenta a unei anumite componente poate afecta alte parti din sistem. Trebuie mentionat ca memoria principala poate fi ieftina, dar memoria rapida precum memoria de date cache este deseori limitata. Structurile folosite uzual, ca listele de conexiuni, ar trebui sa ramana in memoria cache de date, daca sunt destul de mici ca sa incapa in ea.
Solutia evidenta este evitarea redundantei. Tabelul de dispersie e necesar pentru o gasire rapida. De asemenea, rutina de timer trebuie sa caute

83
periodic si eficient prin toate conexiunile existente. Acest lucru duce la urmatoarea problema.
Problema. Se poate scapa de pierderea cauzata de lista de conexiuni explicita, dar sa se retina si tabela de dispersie? E rezonabila adaugarea unei mici informatii suplimentare tabelei de dispersie. Cand facem acest lucru, se poate observa ca lista originala de conexiuni a fost creata cu dublu inlantuita, pentru a permite la terminare o stergera facila a conexiunilor. Dar acest lucru duce la depozitare si dilueaza memoria de date cache. Cum ar putea fi utilizata o lista simplu inlantuita, fara incetinitirea procesului de stergere?
Indiciu: Prima parte este usor de reparat, inlantuind intrarile valabile din tabela de dispersie intr-o lista. Cea de-a doua parte este mai dificil de realizat (evitarea listei cu dubla inlantuire, care ar necesita doi indicatori per intrare a tabelei de dispersie). O lista de legatura consta din noduri, fiecare din ele contine o identitate a conexiunii (96 de biti pentru IP), plus doi indicatori (sa zicem 32 biti fiecare) pentru o stergere facila. Din moment ce tabela de disperse este necesara pentru o demultiplexare rapida, lista de legaturi poate fi indepartata daca intrarile valide din tabela de dispersie sunt conectate ca in figura 4.21, iar un indicator este pastrat in capul listei. La un ticait de timer, rutina de retransmitere va scana periodic lista. Scanarea intregii tabele de dispersie are o eficienta redusa, deoarece pot exista o multime de locatii goale in interiorul sau.
Solutia implicita ar fi aceea de a adauga doi indicatori la fiecare intrare valida a tabelei de dispersie in scopul de a implementa o lista cu dubla legatura. Din moment ce acesti indicatori pot fi indecsi ai tabelei de dispersie in loc de indicatori arbitrari catre memorie, indecsii nu trebuie sa aiba dimensiunea mai mare decat dimensiunea tabelei de dispersie. Chiar si cea mai mare tabela de dispersie ce contine conexiuni, nu ar avea nevoie de mai mult de 16 bits (in general , mult mai putin). Solutia implicita da rezultate bune, adaugand cel mult 32 de bits, in loc de 160 per intrare, deci o economie de 128 de bits. In orice caz, este posibil de a face mai mult, in sensul de a adauga numai 16 bits per intrare. Considerati utilizarea evaluarii de viteza redusa (P2b) si specificatiile mai putin severe (P3).
Figura 4.21 Inlantuirea intrarilor tabelei valide de dispersie cu pointeri de inaintare si stergere relaxata. Cu linie intrerupta s-a u notat inregistrarile marcate ca sterse dar care
vor fi procesate doar in urmatoarea iteratie

84
Solutie: O lista dublu inlantuita este utila doar pentru stergeri eficiente.
Cand o anumita conexiune este terminata, ar fi indicat ca rutina de stergere sa gaseasca intrarea valida anterioara celei sterse, pentru a putea lega lista precedenta de urmatoarea. Acest lucru ar necesita ca fiecare intrare din tabela de dispersie sa memoreze un indicator catre intrarea valida anterioara din lista.
In schimb, considerati principiul P3, relaxarea conditiilor impuse sistemului. In mod normal, se presupune ca atunci cand o conexiune este terminata, locul ei din memorie este recuperat imediat. Pentru a recupera un loc de depozitare, intrarea din tabela de dispersie ar trebui pusa intr-o lista goala, din care sa poata fi folosita de catre o alta conexiune. In orice caz, daca tabela de dispersie este mai mare decat este strict necesar, nu este esential ca locul de depozitare utilizat de conexiunea ce tocmai a fost terminata sa fie reutilizat imediat.
Fiind date cerinte mai putin severe, implementarea poate sa stearga cu incetineala starea conexiunii. Cand o conexiune este terminata, intrarea respectiva trebuie marcata ca fiind libera. Acest lucru necesita un extrabit de stare, la fel ca in P12, fiind ieftin. Stergerea intrarii nefolosite din tabela de dispersie E, implica legatura dintre intrarea aflata inaintea lui E cu cea aflata dupa E. de asemenea, necesita returnarea lui E unei liste goale. Aceasta stergere poate fi facuta la urmatoarea trecere prin lista, atunci cand este intalnita o intrare nefolosita.
Exercitii • Scrieti un pseudocod pentru adaugarea unei noi conexiuni, terminarea
unei conexiuni si terminarea sa (bazata pe timer). •Cum putem face sa avem liste cu legaturi simple pentru listele de
conexiuni in fiecare lista a tabelelor dispersie? •Cineva, interesat in trucuri inteligente si care nu gandeste niciodata
pana la capat o problema anume, sugereaza o cale pentru a evita folosirea indicatorilor inapoi, in orice lista cu dubla legatura. Presupunem ca nodul X trebuie sters. In mod normal, rutinei de stergere i se indica manevra de regasire a lui X, deobicei un indicator spre X. In schimb, manevra ar putea fi un indicator catre nodul respectiv inaintea lui X in lista inlantuita (cu exceptia cazului cand X se afla in fruntea listei si manevra este un pointer nul). Acest mod va permite implementarii sa localizeze eficient atat nodul anterior lui X, cat si cel de dupa X, utilizand doar indicatoriinspre inainte ? Prezentati un contra exemplu care invalideaza acest mod de lucru.
4.12 Retinerea confirmarilor Protocoalele de transport, ca TCP, asigura ca datele sa fie livrate la
destinatie cu confirmarea (ack) primirii fiecarui fragment de date receptionat. Aceasta actiune este similara cu mailul de confirmare. Pachetele si confirmarile sunt numerotate. Confirmarile sunt, de obicei cumulative, un “ack” pentru pachetul N confirma implicit toate pachetele primite anterior, numere mai mici sau egale cu N.
Confirmarile cumulative permit receptorului flexibilitatea de a nu transmite un ack de fiecare data cand primeste un pachet. In schimb, confirmarile pot fi comasate (P2c). In figura 4.22 programul de transmisie

85
a fisierelor trimite blocuri de fisiere, unul in fiecare pachet. Blocurile 1 si 2 sunt confirmate individual, dar blocurile 3 si 4 printr-un singur ack pentru blocul 4.
Reducerea confirmarilor este un lucru bun atat pentru emitator, cat si pentru receptor. Desi confirmarile au dimensiuni reduse, ele contin antete ce trebuie procesate de fiecare ruter, de sursa si de destinatie. Mai mult, fiecare pachet primit, oricat de mic ar fi, poate cauza o intrerupere,scumpa, la destinatie. Ideal ar fi ca receptorul sa comaseze cat de multe confirmari poate. Dar care ar fi criteriul dupa care receptorul comaseaza confirmarile? Rezulta urmatoarea problema.
Problema. Retinerea confirmarilor este dificil de realizat la un receptor care nu are un software bine pus la punct. In figura 4.22, de exemplu, daca blocul 3 este receptionat primul si procesat rapid, cat ar trebui sa mai astepte receptorul dupa blocul 4, inainte de a confirma blocul 3 ? Exista sansa ca blocul 4 sa nu mai ajunga, deci retinerea confirmarii pentru blocul 3 ar cauza o functionare incorecta. Solutia clasica ar fi aceea de a crea un contor de timp pentru confirmarile retinute; la expirarea sa, va fi trimisa o confirmare cumulativa. Astfel se limiteaza timpul maxim cat o confirmare oarecare va putea fi retinuta. Dar acest contor de timp creaza anumite probleme. Unele aplicatii sunt sensibile la intarzieri. Adaugarea acestui contor de timp poate creste intarzierea in cazurile in care emitatorul nu mai are date de transmis. Daca protocolul de transport ar putea fi modificat, ce informatie trebuie adaugata pentru a evita intarzierile nedorite, permitand totusi, comasarea efectiva a confirmarilor?
Indiciu : Intr-o aplicatie ca FTP, care modul software “stie“ ca mai exista date de trimis ? Pentru retinerea confirmarilor, care modul ar fi ideal sa stie ca ar mai fi date de trimis? Considerati utilizarea lui P9 si P10.
Figura 4.22 Ack-urile cumulative permit receptorului sa confirme cateva pachete cu un singur ack.(ex : blocurile 3 si 4), dar pretind monitorizarea ack-urilor la receptor Solutie : Intr-o aplicatie ca transferul de date, aplicatia de la emisie stie
ca mai exista date ce trebuiesc transmise (de exemplu: va urma blocul 4 dupa blocul 3). Aplicatia de la emisie va fi dispusa si sa tolereze latenta datorata comasarii confirmarilor. In orice caz, trebuie ca aceasta informatie sa fie cunoscuta de nivelul transport la receptorului. Aceasta observatie duce la urmatoarea propunere.
Aplicatia de la emisie va transmite un bit catre nivelul transport al emitatorului (interfetei de transport a aplicatiei) care este pus pe 1 atunci cand aplicatia mai are de transmis date. Presupunem ca protocolul de transport poate fi modificat astfel incat sa aiba un bit de retinere. Nivelul

86
transport de la emisie poate utiliza informatia data de aplicatie pentru a seta un bit w de retinere, in fiecare pachet pe care il transmite; bitul w va fi anulat cand emitatorul doreste o confirmare imediata.
De exemplu, in figura 4.23 nivelul transport de la emisie este informat de catre aplicatia transfer de fisiere, ca fisierul de trimis are patru blocuri. Astfel, nivelul transportde la emisie va valida bitul de retinere pentru primele trei pachete, respectiv il va invalida pentru al patrulea pachet. Receptorul va trimite in consecinta, o singura confirmare, in loc de patru. Dar o aplicatie care este sensibila la intarzieri, poate sa nu trimita nici o informatie privitoare la datele de transmis. Bitul de retinere este un indiciu, pe care receptorul poate sa-l ignore si sa trimita oricum o confirmare. Desi solutia pare ingenioasa, nu e o idee buna pentru protocolul TCP actual.
Exercitii: •O tehnica de reducere a numarului de confirmari este returnarea
confirmarilor in pachetele de date dinspre receptor spre emitator. In acest scop, majoritatea protocoalelor de transport, ca TCP, au campuri suplimentare in pachetele de date pentru confirmarile in sens opus. Returnarea confirmarilor in pachete de date e compromisul clasic latenta/eficienta. Cat timp ar trebui sa astepte nivelul transport datele din sens opus? Dar, exista aplicatii uzuale in care aplicatia de la emisie cunoaste aceasta informatie. Cum poate fi extinsa solutia precedenta pentru a permite si returnarea confirmarilor prin pachete de date, si comasarea lor?
Figura 4.23 Telegrafierea intentiei transmitatorului, folosind bitul w de retinere
Exercitii: •O tehnica de reducere a numarului de confirmari este returnarea
confirmarilor in pachetele de date dinspre receptor spre emitator. In acest scop, majoritatea protocoalelor de transport, ca TCP, au campuri suplimentare in pachetele de date pentru confirmarile in sens opus. Returnarea confirmarilor in pachete de date e compromisul clasic latenta/eficienta. Cat timp ar trebui sa astepte nivelul transport datele din sens opus? Dar, exista aplicatii uzuale in care aplicatia de la emisie cunoaste aceasta informatie. Cum poate fi extinsa solutia precedenta pentru a permite si returnarea confirmarilor prin pachete de date, si comasarea lor? •Evaluarea imbunatatirilor pretinse se poate face cu intrebari de test. De
exemplu, schimbarea poate afecta restul sistemului ? De ce ar putea ca

87
retinerea confirmarilor sa afecteze alte parti ale protocolului de transport, cum ar fi controlul fluxului si al congestiilor ?
4.13 Citirea incrementala a bazelor mari de date Presupunem ca un utilizator citeste continuu o baza de date mare de pe
un site web. Continutul paginii web se poate schimba, dar cititorul doreste doar actualizarile incrementale fata de ultima citire. In figura 4.24 avem o baza de date ce contine cateva produse alimentare foarte raspandite, citite constant de catre cititorii din lumea larga, ce doresc sa fie la curent cu moda culinara. Din fericire, moda culinara variaza lent.
2pm 3pm 6pm
Figura 4.24 Schimbari lente a bazei de date cu alimente la orele 2pm, 3pm, 6pm. Cel
care urmareste baza de date vrea sa vada doar schimbarile (aici, de la 2pm la 3pm s-a schimbat pretul la bauturi nealcoolice, si de la 3pm la 6pm, la cereale)
Un cititor vrea la ora 18 sa vada doar diferenta fata de ora 14 : Coke fata
de Pepsi, Wheaties fata de Cheerios. Alt cititor vede pagina la ora 15:00 si apoi la ora 18:00 vrea sa vada ce s-a schimbat la Wheaties fata de Cheerios. Acest lucru genereaza urmatoarea problema.
Problema. Cum sa realizeze eficient baza de date asemenea interogari incrementale (incremental queries) ? Ar fi dificil ca baza de date sa-si aminteasca ce a citit fiecare utilizator ultima data, avand milioane de utilizatori.
Indiciu: Daca baza de date nu memoreaza nici o informatie referitoare la ultima citire a unui utilizator, solicitarea de citire a utilizatorului trebuie sa contina ceva informatie (P10) despre ultima sa citire. Transmiterea detaliilor despre ultima citire inseamna un efort urias si e total ineficienta. Care ar fi partea de informatie care sa caracterizeze succint ultima cerere a utilizatorului? Putem adauga o stare redundanta suplimentara (P12) la baza de date ce permite usor indexarea, folosind informatia de la utilizator pentru a facilita interogarea incrementala.
Solutie: Cererile de vizualizare ale utilizatorului trebuie sa contina o anumita cantitate de informatie (P10) despre ultima solicitare de vizualizare facuta de acesta. Cea mai succinta si relevanta informatie este timpul la care a fost facuta ultima cerere. Daca cererea utilizatorului contine timpul ultimei citiri, atunci baza de date trebuie organizata astfel incat sa-si actualizeze eficient continutul la intervale date de timp. Memorarea unor copii ale bazei de date din momentele anterioare este o metoda ineficienta, si poate fi evitata daca se memoreaza doar modificarilor incrementale (P12a). Acest lucru duce la urmatorul algoritm.
Se poate adauga bazei de date o lista a actualizarilor, care are in capul listei ultimele actualizari. Cererile de citire contin momentul T al ultimei

88
citiri, deci cererea poate fi procesata prin scanarea inceputului listei, pentru a gasi toate actualizarile ulterioare lui T.
De exemplu, in figura 4.25 in capul listei de actualizari se afla ultimele modificari (comparati cu figura 4.24) la ora 18:00 de la Wheaties la Cherios, si modificarea precedenta, de la ora 15:00 de la Coke la Pepsi. Consideram o cerere de citire efectuata la ora 17:00. Cand scanam lista din varf, procesarea cererilor va gasi actualizarea de la ora 18:00 si se va opri cand va ajunge la actualizarea de la ora 15:00, deoarece 15:00 < 17:00, deci cererea va returna doar prima actualizare.
Figura 4.25: Rezolvarea problemei reactualizării incrementale folosind o listă de
reactualizare Exercitii: •Daca o intrare se modifica de mai multe ori, atunci modificarea acelei
intrari poate fi memorata redundant in lista, dar cu costuri suplimentare de timp si spatiu. Ce principiu poate fi folosit pentru a evita redundanta? Presupunem că baza de date este doar o colecţie de înregistrări şi se doreşte ca fiecare înregistrare să apară cel mult o dată în această listă incrementală.
Dacă numărul înregistrărilor este mare sau metoda de mai sus nu este aplicată, atunci dimensiunea listei incrementale va creşte foarte mult. Sugeraţi o metoda de reducere periodică a dimensiunii listei incrementale. •Dacă numărul înregistrărilor este mare sau metoda de mai sus nu este
aplicată, atunci dimensiunea listei incrementale va creşte foarte mult. Sugeraţi o metoda de reducere periodică a dimensiunii listei incrementale.
4.14 Cautarea binara a identificatorilor lungi Generaţia viitoare de Internet (IPv6) îşi propune să folosească adrese pe
128biţi pentru a putea găzdui mai multe terminale. Dacă se doreşte identificarea unei adrese pe 128 biţi, şi algoritmul rulează pe un procesor cu 32 biţi pe cuvant, atunci fiecare comparaţie a două adrese lungi va dura 128/32=4 operaţii În cazul general presupunem că fiecare identificator este compus din W cuvinte (în exemplu W=4), atunci căutarea binară naiva va avea nevoie de logW N comparaţii, ceea ce e scump. Dacă toţi identificatorii au identice primele 1W − cuvinte, atunci sunt suficiente doar log N comparaţii. Problema e de modificare a algoritmului de căutare binară a.î. să se ajungă la un număr de log N W+ comparaţii. Strategia este de a lucra pe coloane, începând cu cel mai semnificativ cuvânt şi efectuând căutarea binară în acea coloană, până când se gaseste o egalitate în acea coloană. În acest punct, algoritmul trece la următorul cuvânt din dreapta şi continuă căutarea binară de unde a rămas.
cuvinte de dimensiune W
A C E
Actualizarea listei
Wheaties Cheerios 6 pm
Coke Pepsi 3 pm
Ultima reactualizare 6 pm
Pepsi Mere
Placinte Cheerios

89
A D C
A Testul 3 M Testul 4 W B M W
Testul 1 B Testul 2 N X B N Y B N Z C N D
Figura 4.26 Cautarea binara a identificatorilor lungi poate duce la un factor de multiplicare W (numarul de cuvinte din identificator). Metoda naiva, de reducere la un factor aditiv
prin mutare la dreapta in egalitate, esueaza. Generaţia viitoare de Internet (IPv6) îşi propune să folosească adrese pe
128biţi pentru a putea găzdui mai multe terminale. Dacă se doreşte identificarea unei adrese pe 128 biţi, şi algoritmul rulează pe un procesor cu 32 biţi pe cuvant, atunci fiecare comparaţie a două adrese lungi va dura 128/32=4 operaţii În cazul general presupunem că fiecare identificator este compus din W cuvinte (în exemplu W=4), atunci căutarea binară naiva va avea nevoie de logW N comparaţii, ceea ce e scump. Dacă toţi identificatorii au identice primele 1W − cuvinte, atunci sunt suficiente doar log N comparaţii. Problema e de modificare a algoritmului de căutare binară a.î. să se ajungă la un număr de log N W+ comparaţii. Strategia este de a lucra pe coloane, începând cu cel mai semnificativ cuvânt şi efectuând căutarea binară în acea coloană, până când se gaseste o egalitate în acea coloană. În acest punct, algoritmul trece la următorul cuvânt din dreapta şi continuă căutarea binară de unde a rămas.
În figura 4.26 se consideră W=3, şi se doreşte căutarea identificatorului BMW. Se consideră că fiecare literă este un cuvânt. Comparaţia începe cu elementul central de pe coloana din stânga (Testul 1). Deoarece cuvântul din coloană este identic cu cel căutat se trece la coloana următoare din dreapta. Testul 2 identifică N>M şi se continuă testul în jumătatea jumătăţii de sus a coloanei (Testul 3) unde se identifică M. Apoi se trece la coloana următoare unde se găseşte W (Testul 4), dar din nefericire pe această linie s-a identificat AMW şi nu BMW, înseamnă că există o problemă.
Problema: Găsirea unei condiţii care adăugată algoritmului de mai sus asigura log N W+ comparaţii.
Indicatie: Problema apare din cauza ca, atunci cand cautarea binara se muta la pozitia a patra din coloana 2, se presupune ca acea pozitie incepe cu B, ipoteza in general falsa. Ce stare trebuie adaugata pentru a evita aceasta ipoteza falsa, si cum se modifica cautarea in aceasta ipoteza ?
Soluţia: Artificiul consta in adaugarea unei stari fiecarui element al fiecarei coloane, care impune cautarii binare sa ramina intr-un interval de
cuvinte de dimensiune W
A C E A D C A Testul 3 M Testul 4 W B M W Testul 1 B Testul 2 N X B N Y B N Z
C N D

90
garda (fig.4.27) Trebuie limitat domeniul de căutare. Pentru fiecare cuvânt B din coloana cea mai semnificativă se adaugă un pointer care indică limitele liniilor celorlalte cuvinte care conţin B pe prima poziţie. De data aceasta, în figura 4.27 se ţine cont şi de domeniul de gardă, care include rândurile 4 – 7. Acest domeniu este memorat la prima comparaţie a lui B.
Atunci când căutarea trece la coloana 2 şi se găseşte N > M, algoritmul va încerca să înjumătăţească domeniul de căutare şi deci va încerca să compare rândul 3. Dar cum 3 < 4 (limita inferioară a domeniului de gardă) nu se va efectua comparaţia, şi algoritmul va încerca să înjumătăţească din nou domeniul de căutare binară. Acum se încearcă rândul 4, care e în domeniul de gardă, se identifică M şi se trece spre coloana din dreapta, indentificându-se corect BMW.
W cuvinte A C E A D C A Tentativă 3 M W *B Testul 4 *M Testul 5 W Testul 1 B Testul 2 N X B N Y *B N Z C N D
Figura 4.27: Adăugarea unui domeniu de gardă fiecarui element din coloana, pentru
căutarea binară corecta la schimbarea coloanelor
În general fiecare intrare a unui cuvant multiplu 1 2, ,..., nW W W va memora un domeniu de gardă precalculat. Domeniul pentru iW indică domeniul care conţine 1 2, ,..., iW W W în primele i cuvinte. În acest fel se asigură căutarea pe coloana i+1 doar în domeniul de gardă. Folosind această strategie se asigură 2log N W+ comparaţii daca avem N identificatori. Costul suplimentar este adăugarea a doi pointeri de 16 biţi pentru fiecare cuvânt iW . Cum majoritatea cuvintelor sunt pe cel puţin 32 biţi înseamnă ca vor trebui adăugaţi doi pointeri pe 32 biţi pentru ficeare cuvânt, ceea ce înseamnă dublarea memoriei folosite. O a doua idee pe lângă limitarea domeniului de căutare este folosirea preprocesării (P2a) care permite obţinerea unor căutări mai rapide (ideea lui Butler Lampson).
Exerciţiu: Actualizarea structurii de căutare binară necesită reconstruirea întregii structuri. Totul poate fi reprezentat ca un arbore binar de căutare, fiecare nod având un pointer „<”, „>” dar şi „=”, care corespunde trecerii la următoarea coloană din dreapta. Subarborele format din pointerii „=” reprezintă domeniul de gardă. Folosiţi această observaţie şi tehnicile de actualizare standard pentru arbori binari echilibraţi şi obţineţi timpi de reactualizare logaritmici.
4.15 Videoconferinţă prin ATM (Asynchronous Transfer Mode) În ATM reţeaua stabileşte un circuit virtual, printr-o serie de switch-uri,
înainte ca datele să fie transmise. Standardul ATM permite realizarea unor circuite virtuale (CV) de la o sursă la mai multe receptoare. Datele

91
transmise de sursă sunt multiplicate şi transmise fiecarui receptor prin circuitul virtual unu-la-mai mulţi.
Chiar si fara standardizare, e relativ uşor sa avea circuite vituale de la mai mulţi la mai mulţi, în care fiecare terminal poate fi atât sursă cât şi receptor. Principala problemă a CV mai mulţi la mai mulţi este atunci când mai multe staţii vorbesc în acelaşi timp. În acest caz datele de la cele două surse vor fi întreţesute în mod arbitrar la receptor şi se va naşte confuzie.
În figura 4.28 se prezintă un sistem de videoconferinţă care conectează N staţii prin intermediul unui comutator. Soluţia din figură foloseşte N circuite virtuale unu-la mai mulţi, conectând astfel partea audio si video a fiecărui utilizator cu ceilalţi utilizatori. Stiind care e banda minimă video Bmin şi banda switch-ului ATM (B) se poate determina numărul maxim de staţii participante la videoconferinţă: B/Bmin. Nu cumva există o soluţie mai buna ?
Figura 4.28: Sistem de videoconferinţă via ATM
Soluţia este folosirea circuitelor virtuale de la mai mulţi la mai mulţi, care să înlocuiască cele N circuite unu-la-mulţi. În acest mod se poate scala banda switch-ului la mai mulţi utilizatori.
Dacă considerăm o singură conexiune mulţi la mulţi pe care o numim C, atunci o soluţie ar fi folosirea unui protocol de tipul round-robin care asigură ca la un moment dat doar o singură staţie să-şi conecteze ieşire video la conexiunea C. Un astfel de protocol necesită coordonare şi deci va introduce întârzieri. Proiectanţii sistemului au observat, că ar fi suficient ca doar interlocutorul curent să fie afişat. Din acestă cauză a fost introdus un detector de voce (P5) la fiecare staţie. Dacă se detectează activitate la o staţie X, atunci detectorul va conecta intrarea video la conexiunea C. În caz contrar intrarea video nu este conectată la C. Deoarece această componentă hard era destul de ieftină, creşterea numărului de utilizatori conectaţi a implicat un preţ rezonabil al terminalelor.
În continuare s-a observat că dacă se păstrează şi imaginea ultimului interlocutor se păstrează o continuitate vizuală mai bună, şi deci s-a propus
Switch ATM
N CV 1-la-mai mulţi
92
folosirea a două conexiuni virtuale mulţi la mulţi, una C pentru interlocutorul curent şi una L pentru ultimul interlocutor ca în figura 4.29
Figura 4.29: Folosirea a două CV mulţi la mulţi
Exerciţii: • Scrieţi pseudocodul părţii hardware a fiecărei staţii care actualizează
conexiunile la C şi L. Se presupune că detectorul de voce este o funcţie. •Ce se întâmplă daca mai mulţi utilizatori vorbesc deodată? Ce
componentă hard se poate adăuga staţiei a.î. aplicaţia să afişeze ceva rezonabil? De exemplu, nu ar fi rezonabil ca imaginile celor doi interlocutori să fie combinate?
Switch ATM
2 CV mulţi-la- mulţi
Interlocutorul Interlocutorul anterior

93
Tratarea nodurilor terminale
Algoritmii de nod terminal sunt o aplicaţie a algoritmilor de reţea, pentru a construi implementări de protocoale rapide în nodurile terminale, mai ales în servere. Aceştia pot fi priviţi ca tehnici de construire a serverelor rapide, aplicate cu precădere în software. O mare parte dintre ele evită structurile sistemelor de operare, pentru a permite transferuri de date de mare viteză. Vom vedea cum să reducem antetele implicate de: copiere, controlul transferului, demultiplexarea, timerele, şi alte sarcini de baza din procesarea protocoalelor.
CAPITOLUL5
COPIEREA DATELOR
Intr-un birou, fiecare scrisoare primită este mai întâi trimisă la transport
si recepţie, unde scrisoarea este deschisă şi se decide cărui departament îi este adresată şi se face o fotocopie pentru îndosariere.Este apoi înmânată departamentului de securitate care verifică fiecare linie a scrisorii căutând semne de spionaj industrial. Departamentul de securitate face si el o fotocopie a scrisorii, pentru o eventuală utilizare ulterioară. Situaţia pare ridicolă, dar majoritatea serverelor Web şi calculatoarele în general, fac un număr de copii suplimentare ale mesajelor recepţionate şi transmise.Spre deosebire de fotocopii, care consumă doar o mică cantitate de hârtie, energie şi timp, copierea suplimentară în calculator consumă două resurse preţioase: lăţimea de bandă de memorie şi memoria în sine. În cele din urmă, dacă sunt k copii implicate în procesarea unui mesaj într-un server Web, ieşirea serverului Web poate fi de k ori mai înceată.
Deci se trateaza aici eliminarea pierderilor (P1) generate de copiile inutile. O copie este inutilă dacă nu este impusă de hardware. De exemplu, hardware-ul cere copierea, biţilor recepţionaţi de un adaptor, în memoria calculatorului. Totuşi, acesta nu este un motiv esenţial (în afara de cele impuse de structurarea sistemelor de operare convenţionale) pentru copierea între bufferul aplicaţie şi bufferul sistemului de operare. Eliminarea copiilor redundante permite software-ului să se apropie de capacitatea hardware-ului, unul din ţelurile algoritmilor de reţea.
Sunt expuse pe scurt alte operaţii (ca sumele de control şi criptarea) ce se referă la toate datele din pachet şi alte tehnici pentru a unifica conditiile impuse de software-ul protocolului si cele impuse de hardware, ca lăţimea de bandă a magistralelor şi memoriei cache.Sunt revăzute sistemele de operare mai reprezentative şi arhitecturile relevante, precum şi tehnicile de

94
reducere a costului manipulării datelor, păstrând modularitatea şi fără schimbări majore în proiectarea sistemului de operare. În & 5.1. se arată de ce/cum apar copii în plus ale datelor, &5.2 descrie o serie de tehnici de a evita copiile prin restructurări locale ale sistemului de operare şi ale codului reţelei la un nod final (endnode). In &5.3 se vede cum să se evite copierea şi suprasarcinile din cazul transferurilor mari, utilizând DMA la distanţă, care implică modificări de protocol. In $5.4 se extinde problema pentru sistemul de fişiere dintr-un server Web şi se arată cum să se evite copiile inutile dintre memoria cache pentru fişiere şi aplicaţie. In &5.5. sunt discutate operaţii care includ toate datele (ca suma de control şi criptarea) şi se introduce tehnica procesării integrate pe niveluri (integrated layer processing).În &5.6 se extinde discutia dincolo de copiere, şi se arată că fără analiza atentă a efectelor memoriei cache, efectele instrucţiunilor cache pot eclipsa efectele copierii pentru mesaje mici.
Număr Principiul Utilizat în P13 Localizarea memoriei(in adaptor) ca grad de
libertate Afterburner
P2b Copiere înceată utilizând copierea-la-scriere Mach P11a P7
Asocierea unei memorii cache virtuale per cale Uniformizarea pe procese a bufferelor rapide fbuf
Solaris fbufs
P10 Pasează în pachet numele buffer-ului şi a deplasării
Sisteme RDMA
P4 Asociere de memorie virtuala pentru a evita copiile din cache şi în aplicaţii
Flash
P11a Asocierea unei memorii cache virtuale per cale
Flash-lite
P6 Noi apeluri la sistem îmbinate cu I/O Sendfile() P1 Evitarea accesului repetat la memorie
în timpul manevrării ILP
P13 Dispunerea codului pentru a minimiza ratările de I cache
x-kernel
P13 Ordonarea pe niveluri a procesării (grad de libertate)
LDRP
Figura 5.1. Tehnici de evitare a copierii şi eficienţa cache discutate în acest capitol, împreună cu principiile corespunzatoare 5.1. Necesitatea copierii datelor. In figura 5.2. se arată secvenţa transferurilor de date implicate în citirea
fişierelor de date de pe disc (în cazul cel mai defavorabil) la trimiterea segmentelor corespunzătoare prin adaptorul de reţea. Principalele componente hardware din figura 5.2. sunt procesorul, magistrala de memorie, magistrala de I/O, discul şi adaptorul de reţea. Principalele componente software sunt aplicaţia de server Web şi kernel-ul. Sunt implicate două subsisteme principale ale kernel-ului, sistemul de fişiere şi sistemul de reţea. Pentru simplitate e dat doar un CPU (multe servere sunt multiprocesor) în server şi se pune accent doar pe cereri cu conţinut

95
static(multe cereri sunt pentru continut dinamic fiind servite de un proces CGI, computer-generated imagery).
Intuitiv, problema este simplă. Fişierul este citit de pe disc în buffer-ul aplicaţiei printr-un apel la sistem, read()de exemplu. Combinaţia dintre răspunsul HTTP şi buffer-ul aplicaţiei este trimisă apoi reţelei prin conexiunea TCP către client printr-un apel de sistem, de exemplu write(). Codul TCP din subsistemul pentru reţea al kernel-ului împarte datele răspunsului în segmente de câte un bit şi le trimite adaptorului de reţea după ce adaugă fiecărui segment o sumă de control TCP.
Figura 5.2. Copii redundante implicate în manipularea unei cereri GET la un server
Detaliile reale sunt mai dificile. În primul rând fişierul este citit într-o
regiune a memoriei kernelului numită file cache (copia 1). Ideea este bună deoarece cererile succesive la un fişier des utilizat pot fi servite din memoria principală fără operaţiile lente de I/O la disc. Fişierul este apoi copiat de serverul Web din file cache în buffer-ul aplicaţiei (copia 2). Deoarece bufferul aplicaţiei şi file cache sunt în zone diferite a memoriei principale, copierea se poate face doar de CPU, care citeşte datele din prima locaţie de memorie şi le scrie în cea de-a doua, prin magistrala de memorie.
Serverul Web face apoi un apel write() la socketul corespunzător. Deoarece aplicaţia îşi poate reutiliza bufferul în orice moment (sau chiar să-l dezaloce) după apelul write(), subsistemul de reţea din kernel nu poate să retransmită pur şi simplu din buffer-ul aplicaţiei. Software-ul TCP poate avea nevoie să retransmită unele părţi din fişier după un anumit timp, timp în care aplicaţia poate reutilizarea buffer-ul în alte scopuri.
Astfel, UNIX şi multe alte sisteme de operare, oferă semantica copierii. Buffer-ul aplicaţiei specificat în apelul write() este copiat într-un buffer socket (un alt buffer din kernel la o adresă de memorie diferită atât de file
Kernel
CPU
Aplicatia server-ului Web write() read()
TCP/IP Sist. de fisiere
Buffer-ul server-ului
Buffer-ul socket
Buffer-ul fis. cache
Adaptor de retea
Retea
Copia 4 Disc
Copia 1
Magistrala de memorie
Magistrala I/O
Copia 2
Copia 3

96
cache cât şi de buffer-ul aplicaţiei) (copia 3). În final, fiecare segment este transmis reţelei (după ce au fost adăugate antetele de nivel legătura de date şi IP-ul) copiind datele din buffer-ul socket-ului în memoria adaptorului de reţea (copia 4). Înainte de transmisia la reţea software-ul TCP din kernel trebuie să parcurgă datele pentru a calcula suma de control TCP, pe 16 biţi, pentru fiecare segment.
Fiecare din cele 4 copii şi suma de control consumă resurse: lăţimea de bandă a magistralei de memorie. Copierile între locaţiile de memorie (copiile 2 şi 3) sunt mai dezavantajoase decât celelalte, deoarece necesită un read şi un write pentru fiecare cuvânt transferat prin magistrală. Suma de control TCP necesită doar un read pentru fiecare cuvânt şi un singur write pentru a ataşa suma finală. Copiile 1 şi 4 pot fi la fel de costisitoare ca şi copiile 2 şi 3 dacă procesorul face o copiere folosind o I/O programată; totuşi dacă dispozitivele fac singure copierea (DMA), costul este un singur read sau write per fiecare cuvânt ce trece prin magistrală.
Copiile consumă şi lăţimea de bandă a magistralei de I/O şi lăţimea de bandă de memoriei. O memorie care furnizează un cuvânt de W biţi la fiecare x nanosecunde are o limită fundamentală la ieşire de W/x biţi/ns. Chiar şi dacă folosim DMA aceste copii folosesc magistrala de memorie de 7 ori pentru fiecare cuvânt al fişierului trimis de server. Astfel ieşirea server-ului Web nu poate depăşi T/7, unde T este cea mai mică dintre vitezele memoriei şi a magistralei de memorie.
Mai important, copiile suplimentare consumă memorie. Acelaşi fişier (figura 5.2.) ar putea fi stocat în memoria cache pentru fişiere, buffer-ul aplicaţiei şi buffer-ul socket. Deşi memoria este ieftină şi multă, ea are unele limitări şi server-ele Web vor să folosească cât mai multă memorie cache pentru fişiere ca să evite operaţiile lente de I/O cu discul. Astfel, exitenţa a trei copii pentru un fişier poate reduce de trei ori memoria cache de fişiere, care la rândul său poate reduce rata de bit a cache-ului şi deci performanţa globală a server-ului.
În concluzie, copiile redundante afectează performanţa în două moduri fundamentale disjuncte. În primul rând, prin utilizarea unei lăţimi de bandă a magistralei şi a memoriei mai mare decât strictul necesar, server-ul Web rulează mai încet decât viteza magistralei chiar şi când trimite documente care sunt în memorie. În al doilea rând, utilizând mai multă memorie decât ar trebui, server-ul Web va trebui să citească mai multe fişiere de pe disc în loc să le citească din file cache. A fost descris doar scenariul în care este servit un conţinut static. În realitate, testele cu SPECweb afirmă că 30% din cereri sunt pentru conţinut dinamic. Acesta este de multe ori servit de un proces CGI separat (altul decât aplicaţia server) care comunică acest conţinut server-ului prin intermediul unor mecanisme de comunicare inter-proces cum ar fi UNIX pipe care implică de multe ori încă o copie.
Ideal, aceste traversări în plus ale magistralei ar trebui eliminate. Copia 1 nu este necesară dacă datele sunt în cache. Copia 2 pare inutilă: de ce nu pot fi trimise datele direct la reţea din locaţia de memorie file cache? Copia 3 pare inutilă. Copia 4 nu poate fi evitată.

97
5.2. Reducerea copierii prin restructurări locale Copia 3 este copia principală făcută de aplicaţie în buffer-ul kernelului
(sau vice versa) când un mesaj este trimis/primit pe reţea. Aceasta este o problemă fundamentală a reţelelor, independentă de problemele sistemului de fişiere. Soluţiile generale de eliminare a copiilor I/O redundante se bazează pe tehnicile prezentate în secţiunea &5.4. Se presupune că protocolul este fix dar implementarea locală poate fi restructurată (cel puţin kernel-ul). E de dorit un numar minim de restructurări pentru a echilibra sarcinile software-ului de aplicaţie şi ale kernelului. In & 5.2.1. sunt descrise tehnici bazate pe o exploatare mai buna a memoriei adaptorului. &5.2.2. descrie ideea principală pentru evitarea copiilor (prin reasocierea paginilor fizice comune) şi pericololele sale. & 5.2.3. prezintă optimizarea reasocierii paginilor utilizând pre-procesarea şi cache-uri pentru fluxurile I/O, tehnici ce implică însă modificarea API (interfaţa programabila de aplicaţie). & 5.2.4. descrie o tehnică ce utilizează memorie virtuală dar nu modifică API.
5.2.1. Exploatarea memoriei adaptorului Ideea este folosirea unui grad de libertate (P13) stiind că, într-o
arhitectură cu memorie asociată, memoria poate fi localizată oriunde pe magistrală. Asocierea memoriei/memory mapping presupune că procesorul “vorbeşte” cu toate dispozitivele, ca adaptorul şi discul, prin citirea/scrierea unei locaţii fizice, din spaţiul de memorie alocat dispozitivului.
Deşi memoria kernelului se află deobicei rezidentă pe subsistemul de memorie, nu există nici un motiv ca o parte din ea să nu fie plasată în adaptor, care conţine şi el memorie. Prin împartirea echitabilă a memoriei adaptorului şi folosind acest grad de libertate putem plasa memoria kernel în adaptor. Asa că, după ce datele au fost copiate din aplicaţie în memoria kernel, ele se află deja în adaptor şi nu trebuie copiate din nou pentru transmisia în reţea (fig. 5.3).
Comparând figura 5.3.cu 5.2, observăm că în figura 5.3 nu apare nici un transfer de la disc la memorie. Copia 3 inutilă (fig. 5.2) e acum combinată cu copia 4 care este esenţială şi formează o singură copie (figura 5.3).
Ideea principală la suma de control (&5.5), este aplicarea principiului de partajare a efortului P2c. Când datele sunt mutate, din buffer-ul aplicaţiei în memoria kernel rezidentă în adaptor, de către procesor (printr-o I/O programată sau PIO, care este o operaţie de I/O sub controlul procesorului), oricum procesorul citeşte fiecare cuvânt al pachetului. Deoarece astfel de citiri ale magistralei sunt laborioase, procesorul ar putea îmbina calculul sumei de control cu procesul de copiere, ţinând un registru care să acumuleze sumele cuvintelor pe măsură ce acestea sunt transferate.
Ideea, numită metoda Witless (sau gândirea-simplă), dar expusă prima dată de Van Jacobson, nu a fost implementată niciodată. Mai târziu Banks şi Prudence au aplicat-o la laboratoarele Hewlett-Packard creând adaptorul Afterburner. În abordarea afterburner procesorul nu transferă datele din memorie în adaptor. Acest transfer este realizat de adaptor utilizând accesul direct la memorie sau DMA. Dar pentru că procesorul nu mai participă la procesul de copiere, adaptorul ar trebui să facă suma de control. În acest scop, adaptorul afterburner are un hardware specializat simplu, care face suma de control în timpul transferului DMA.

98
Ideea, deşi bună, are trei defecte. În primul rând adaptorul de reţea ar trebui să aibă multă memorie pentru a manevra mai multe conexiuni TCP, iar suplimentarea memoriei pate creşte preţul adaptorului prea mult. În al doilea rând, în metoda Witless, unde CPU calculează suma, copierea pachetului recepţionat în buffer-ul aplicaţiei în timpul calculării sumei, poate duce la scrierea unor date eronate în buffer-ul aplicaţiei. Deşi aceasta poate fi descoperită la sfârşit când suma de control nu corespunde, ea cauzează dificultăţi în prevenirea citirii de date incorecte de către aplicaţii. A treia problemă cu confirmările întârziate este studiată în execiţii.
Figura 5.3. Metoda Witless (afterburner) elimină nevoia copierii din kernel în adaptor
plasând buffer-ele kernelului în adaptor
5.2.2. Folosirea copierii- la- scriere La metoda Witless ideea de bază este eliminarea copiei kernel-adaptor,
dar în următoarele trei paragrafe ideea este eliminarea acestei copii prin reasocierea memoriei virtuale. Unul din motivele copierii separate era posibilitatea ca aplicaţia să vrea să modifice buffer-ul încălcând astfel semantica TCP. Al doilea motiv e că aplicaţia şi kernel-ul utilizează spaţii diferite de adrese virtuale.
Unele sisteme de operare (Mach) oferă o facilitate numită copiere-la-scriere, COW(copy-on-write) care permite unui proces să duplice o pagină virtuală în memorie la un cost scăzut. Copia trebuie să indice pagina fizică P originală din care a fost copiată. Aceasta implică doar actualizarea unori descriptori (cuvinte de memorie) şi nu copierea întregului pachet (1500 bytes de date). Remarcabil la COW este că, dacă proprietarul datelor originale modifică datele, sistemul de operare detectează această condiţie automat şi generează două copii fizice separate P şi P’. Proprietarul original pointează acum către P şi poate face modificări asupra lui P;
Aplicatie write()
TCP/IP Kernel
CPU
Buffer-ul server-ului
Retea
Magistrala de memorie
Magistrala I/O
Buffer socket
Memorie
Adaptor de retea
O singura copie

99
proprietarul paginii copiate pointează către vechea copie P’. Treaba merge bine dacă majoritatea paginilor rămân nemodificate (sau se modifică doar câteva pagini) de către proprietarul original.
Astfel, în sistemul cu copiere-la-scriere, aplicaţia ar putea face o copie COW pentru kernel. În cazurile rare în care aplicaţia îşi modifică buffer-ul, kernel-ul face o copie fizică (scumpă), dar asta nu se prea întâmplă. Evident, se utilizează o evaluare înceată (P2b) pentru minimizarea încărcării pentru cazurile cele mai probabile (P11). În figura 5.4. suma de control poate fi returnată fie într-o copie spre/dinspre memoria adaptorului, fie folosind circuite specializate pentru calculul CRC, aflate în adaptor.
Din păcate, multe sisteme de operare, precum UNIX(*) şi Windows nu oferă copiere-la-scriere. Totuşi, rezultate asemănătoare se pot obtine sesizand ideea care sta la baza COW si anume utilizarea memoriei virtuale.
(*) Ssistemul V-UNIX foloseşte COW când apare un fork; paginile partajate de procesele părinte şi fiu sunt partajate folosind poziţionarea unui bit.
Implementarea serviciului copiere-la-scriere Majoritatea calculatoarelor moderne utilizează memoria virtuală.
Programatorul lucrează cu abstractizarea unei memorii infinite, adică un şir liniar în care el (de fapt compilatorul) asignează locaţii variabile; de exemplu, locaţia X va fi locaţia 1010 în acest şir imaginar sau virtual. Aceste adrese virtuale sunt apoi asociate cu memoria fizică (rezidentă pe disc sau în memoria principală) utilizând un tabel de pagini. Pentru orice adresă virtuală biţii de ordin superior (20 în exemplu) dau numărul paginii şi biţii de ordin inferior (12 în exemplu) dau poziţia în pagină. Memoria principală este divizată şi ea în pagini fizice astfel încât fiecare grup de 212 cuvinte de memorie formează o pagină fizică. Asocierea adresă virtuală-adresă fizică se face asociind pagina virtuală-pagina fizică, printr-o căutare în tabelul de pagini indexat cu numărul paginii virtuale corespunzătoare. Dacă pagina dorită nu este rezidentă în memorie, hardware-ul generează o excepţie, care face ca sistemul de operare să citească pagina de pe disc în în memoria principală.
Supraîncărcarea apărută prin citirea tabelelor de pagini din memorie poate fi deobicei evitată folosind TLB(translation look-aside buffer) (*), care este un cache rezident în procesor.
(*)TLB este o tabelă folosită în sistemele cu o memorie virtuală, care conţine lista cu numerele paginilor fizice asociate numărului fiecărei pagini virtuale. TLB este folosit împreună cu o memorie cache având indicii bazaţi pe adresele virtuale. Adresa virtuală este simultan prezentă la TLB şi la cache, astfel că accessul la cache şi translatarea adresă virtuale-adresă fizică se face în paralel. Dacă adresa cerută nu se află în cache atunci data se încarcă într-o adresă fizică din memoria principală. Tabela cu translaţii ar putea fi plasată şi între cache şi memoria principală, ca să poată fi activate simultan când adresa nu se află în cache.
Schema de copiere-la-scriere se bazează pe memoria virtuală. Presupunem că pagina virtuală X pointează la o pagină P rezidentă în memoria fizică, şi că sistemul de operare doreşte să duplice conţinutul lui X într-o nouă pagină virtuală, Y. Calea mai grea pentru a face aceasta ar fi alocarea unei noi pagini fizice P’, copierea conţinutului lui P în P’ şi apoi asociind pe Y cu P’ în tabelul de pagini. Calea mai simplă concretizată în copiere-la-scriere este asocierea noii pagini virtuale Y tot cu vechea pagină fizică P, modificând intrarea din tabelul de pagini. Deoarece majoritatea

100
sistemelor de operare moderne utilizează pagini lungi, modificarea unei intrări în tabelul de pagini este mai eficientă decât copierea dintr-o pagină fizică în alta.
În plus, kernel-ul setează şi un bit de protecţie COW ca parte a intrării, în tabelul de pagini, pentru pagina virtuală originală X. Dacă aplicaţia încearcă să scrie în pagina X hardware-ul va accesa tabelul de pagini pentru X, va observa bitul de protecţie setat şi va genera o excepţie, care apelează sistemul de operare. În acest moment sistemul de operare va copia pagina fizică P într-o altă locaţie P’, şi va face ca X să pointeze spre P’, după ce a modificat bitul COW. Y continuă să indice către vechea pagină fizică. Desi fiecare bit e la fel de costisitor ca şi copierea unei pagini fizice, ideea e ca acest cost apare doar în cazurile când aplicaţia scrie într-o pagină COW.
Figura 5.4. Utilizarea copierii-la-scriere
Modul de funcţionare al COW oferă o şansă şi acelor sisteme de operare,
ca UNIX sau Windows, care deşi nu au COW au memorie virtuală. Memoria virtuală prezintă o indirectivitate care, pentru a evita copierea fizică, poate fi exploatată prin modificarea intrărilor tabelului de pagini. Trebuie găsită o altă soluţie, decât la COW, de protejare la tentativele de scriere ale aplicaţiei.
Kernel
CPU
Aplicatie write() TCP/IP
Server +buffer socket
Magistrala de memorie
Magistrala I/O
Retea
Buffer socket
Memorie
Adaptor de retea
O singura copie (cu suma de control calculata prin hard/soft)
Copiere la o pagina libera doar daca aplicatia scrie

101
5.2.3. Fbufs: optimizarea reasocierii paginilor
Chiar dacă ignorăm aspectul protecţiei împotriva scrierilor aplicaţiei, figura 5.5. implică faptul că un buffer mare poate fi transferat din aplicaţie în kernel (sau vice versa) cu o scriere în tabelul de pagini. Această viziune simplistă a remapării paginilor este cam naivă şi greşită.
Figura 5.5. arată un exemplu concret al remapării paginilor. Presupunem că sistemul de operare doreşte să facă o copie rapidă a datelor procesului 1 (aplicaţia) din pagina virtuală (VP10) într-o pagină virtuală (VP 8) din tabelul de pagini a procesului 2 (kernel-ul).Aparent, ar fi necesară doar modificarea intrării corespunzătoare lui VP 8 (din tabelul de pagini a procesului 2), să indice spre pachetul de date la care deja indică pagina virtuală 10 (din tabelul de pagini a procesului 1). Apar câteva încărcări suplimentare, nespecificate încă:
• Tabele de pagini multinivel: majoritatea sistemelor moderne folosesc asocieri pe mai multe niveluri ale tabelelor de pagini, deoarece este nevoie de prea multă memorie pentru asocierea tabelelor de pagini cu 20 biţi de pagină virtuală. Astfel, maparea reală poate cere modificări ale mapărilor în cel puţin primul şi al doilea nivel al tabelului de pagini pentru portabilitate. Există deasemenea atât tabele independente de calculator cât si dependente de calculator. Astfel, sunt implicate câteva scrieri, nu doar una. •Obţinerea blocărilor şi modificarea intrărilor tabelului de pagini:
tabelele de pagini sunt resurse comune şi deci trebuie protejate folosind blocări care trebuiesc obţinute şi eliberate. •Folosirea TLB-urilor: pentru a economisi timpul de translaţie,
asocierile pentru tabelele de pagini utilizate mai des sunt memorate în TLB. Când este scrisă o nouă locaţie de pagină virtuală pentru VP 8, orice intrare TLB pentru VP 8 trebuie găsită şi eliminată sau corectată. •Alocarea VM în domeniul destinaţie: deşi s-a presupus că paginii
destinaţie i s-a alocat locaţia 8 din memoria virtuală, trebuie făcute, înainte să aibă loc copierea, calcule de găsire a unei intrări libere în tabelul de pagini din procesul destinaţie. •Blocarea paginilor corespondente: anumite pagini fizice de pe disc pot
fi înlocuite, ca sa faca loc altor pagini virtuale. Pentru a preveni înlocuirea, paginile trebuie să fie blocate, ceea ce reprezintă un cost suplimentar.
Toate aceste suprasarcini cresc foarte mult în sistemele multiprocesor. Rezultatul net este că, deşi asocierea tabelelor de pagini pare foarte bună
Pachet date
Procesul 2 Tabel pagini
Procesul 1 Tabel pagini
VP 8VP 10
Scrie
Figura 5.5. Operaţiile de bază implicate în copierea unei pagini utilizând memoria virtuală

102
(asocierea pare că dureaza un timp constant, independent de dimensiunea pachetelor de date), factorii constanţi (Q4) generează o suprasarcină mare. Această supraîncarcare, sesizată deja la începutul anilor ’90 (Druschel şi Peterson) a crescut permanent de atunci. Ei au propus o facilitate a sistemului de operare numită fbufs (fast buffers), ce elimină majoritatea celor 4 surse de supraîncărcare în cazul asocierii paginilor.
Fbufs Ideea principală în fbufs este că: dacă o aplicaţie trimite prin kernel mai
multe pachete de date reţelei, atunci probabil ca un buffer va fi reutilizat de mai multe ori, şi astfel sistemul de operare poate precalcula în avans (P2a) toată informaţia de asociere a paginii pentru buffer, evitând astfel mare parte din suprasarcina asocierii paginii din timpul transferului de date. Sau, asocierile pot fi calculate mai încet (P2b) când este pornit transferul de date pentru prima oară (generând o suprasarcină pentru primele câteva pachete) dar care poate fi memorată (P11a) pentru pachetele următoare, eliminând supraîncărcarea pentru cazurile obişnuite.
Cea mai simplă cale de implementare a acestui mod de lucru este prin folosirea memoriei partajate. Se asociază simultan un număr de pagini P1,...,Pn în tabelele de memorie virtuală ale kernel-ului şi simultan se transmit aplicaţiile A1,...,Ak. Deşi ideea e tentanta, s-ar putea ca aplicaţia A1 să trebuiască să citească pachetele trimise de aplicaţia A2. S-ar încălca astfel securitatea şi separarea greşelilor.
Mai sigură ar fi rezervarea (sau stabilirea lentă) paginilor partajate mapate pentru fiecare transfer aplicaţie-kernel, şi vice versa. De exemplu, ar putea fi un set de buffer-e (pagini) pentru FTP, unul pentru HTTP, şi aşa mai departe. Mai general, unele sisteme de operare definesc multiple subsisteme de securitate, pe lângă kernel şi aplicaţie. Proiectanţii fbufs-urilor numesc cale o secvenţă de domenii de securitate. In exemplul anterior, e suficient să gândim o cale kernel-aplicaţie si alta aplicaţie-kernel (FTP-kernel, kernel-HTTP). Căile sunt unidirecţionale, deci aplicaţia are nevoie simultan de două căi, câte una în fiecare direcţie.
Figura 5.6. arată un exemplu mai complex de căi, unde software-ul Ethernet este implementat ca un driver la nivelul kernelului, stiva TCP/IP este implementată ca un domeniu de securitate la nivelul utilizatorului, iar aplicaţia Web este implementată la nivelul aplicaţie. Fiecare domeniu de securitate are propriul set de tabele de pagini. Căile receptoare sunt Ethernet, TCP/IP, Web şi Ethernet, OSI, FTP.
Pentru a implementa ideea fbuf, sistemul de operare ar putea lua câteva numere din paginile fizice P1,...Pk şi să le premapeze în tabelul de pagini al driver-ului Ethernet, codului TCP/IP şi aplicaţiei Web. Aceeaşi operaţie ar putea fi realizată cu un set de pagini fizice diferite pentru Ethernet, OSI şi FTP. Astfel, folosim P2a pentru a precalcula mapările. Rezervarea paginilor fizice pentru fiecare cale poate fi o risipă serioasă, deoarece traficul este în rafale; o idee mai bună este P2b, maparea lentă doar când o cale devine ocupată.
P2b evită supraîncărcarea cauzată de: actualizarea multinivel a tabelelor de pagini, obţinerea blocărilor, eliminarea TLBurilor şi alocarea memoriei virtuale de destinaţie după sosirea si expedierea primelor câteva pachete. Această treabă se face odată, la începutul transferului. Pentru a face fbuf funcţional, este crucial ca la sosirea unui pachet, driver-ul de nivel minim

103
(sau chiar adaptorul însuşi) să fie capabil să realizeze rapid calea completă pe care pachetul va fi mapat (demultiplexare anticipată). Intuitiv, (fig. 5.6) aceasta este realizată examinând toate antetele pachetelor pentru a determina (pe moment) dacă un pachet, cu un antet Ethernet, IP şi HTTP aparţine căii 1.
Driver-ul/adaptorul va avea atunci o listă cu buffer-ele libere pentru acea
cale, care vor fi utilizate de adaptor pentru a scrie pachetele în ele; când adaptorul termină, va transmite descriptorul buffer-ului următoarei aplicaţii de pe cale. Un descriptor de buffer este doar un pointer spre o pagină partajată, şi nu pagina în sine. Când ultima aplicaţie din cale termină cu pagina, o retrimite primei aplicaţie din cale, unde devine din nou un buffer liber, ş.a.m. d.
În acest punct, se pune problema de ce căile sunt unidirecţionale. Căile sunt făcute unidirecţionale deoarece primul proces de pe fiecare cale este presupus a fi scriitor şi procesele rămase sunt presupuse a fi cititoare. Acest lucru poate fi impus în timpul premapării prin setarea unui bit de permisiune-scriere pentru prima aplicaţie în intrarea tabelului său de pagini, şi un bit doar-citire în intrările tabelelor de pagini ale celorlalte aplicaţii. Apare asimetrie între sensuri şi necesitatea căilor unidirecţionale. Dar se asigură astfel un anumit grad de protecţie. In figura 5.7. sunt doar două domenii pe o cale. De observat că scriitorul scrie pachetele în nişte buffere (descrise de o coadă de fbufs libere) şi apoi pune descriptorul scris într-o coadă de fbufs scrise, care vor fi citite de următoarea aplicaţie (în figura 5.7. este arătat doar unul).
Mai departe, este posibil ca pagina 8, premapată unei căi în prima aplicaţie, să fie asociată paginii 10 în a doua aplicaţie. Lucrul e neplăcut, deoarece când a doua aplicaţie citeşte un descriptor pentru pagina 8 trebuie să ştie cumva că el corespunde cu propria sa pagină virtuală 10. Dar proiectanţii au evitat a generalizările inutile (P7) şi au insistat ca fbuf-ul să fie mapat în aceeaşi pagină virtuală în toate aplicaţiile de pe cale. Aceasta se poate face prin rezervarea unui număr iniţial de pagini în memoria virtuală a tuturor proceselor, pentru a fi pagini fbuf.
Web FTP
IP OSI ?
Ethernet
Calea 2 Calea 1
(Domeniu 0)
(Domeniu 2)
(Domeniu 1)
Calea 2 Buffer cache
Calea 1 Buffer cache
Figura 5.6. Preasocierea paginilor buffer in tabele de pagini ale fiecarui domeniu intr-o cale evita costul remaparii paginii in calea de timp real dupa setarea initiala
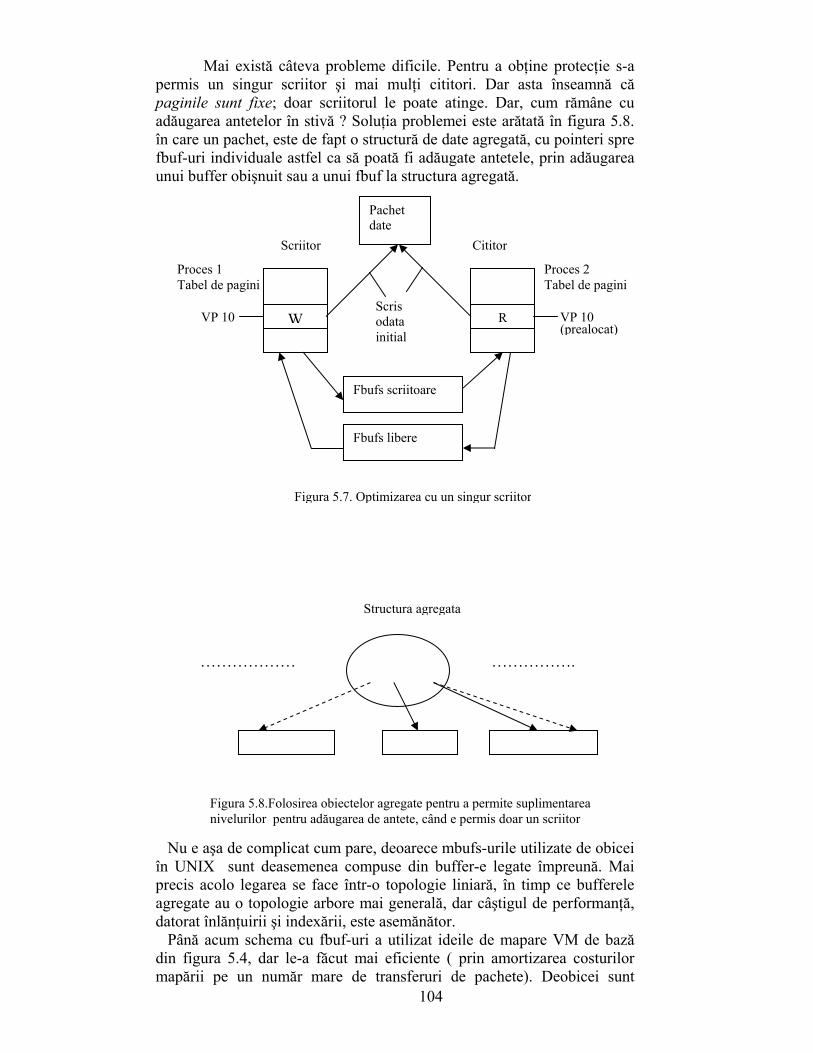
104
Mai există câteva probleme dificile. Pentru a obţine protecţie s-a permis un singur scriitor şi mai mulţi cititori. Dar asta înseamnă că paginile sunt fixe; doar scriitorul le poate atinge. Dar, cum rămâne cu adăugarea antetelor în stivă ? Soluţia problemei este arătată în figura 5.8. în care un pachet, este de fapt o structură de date agregată, cu pointeri spre fbuf-uri individuale astfel ca să poată fi adăugate antetele, prin adăugarea unui buffer obişnuit sau a unui fbuf la structura agregată.
Nu e aşa de complicat cum pare, deoarece mbufs-urile utilizate de obicei
în UNIX sunt deasemenea compuse din buffer-e legate împreună. Mai precis acolo legarea se face într-o topologie liniară, în timp ce bufferele agregate au o topologie arbore mai generală, dar câştigul de performanţă, datorat înlănţuirii şi indexării, este asemănător.
Până acum schema cu fbuf-uri a utilizat ideile de mapare VM de bază din figura 5.4, dar le-a făcut mai eficiente ( prin amortizarea costurilor mapării pe un număr mare de transferuri de pachete). Deobicei sunt
Structura agregata
……………… …………….
Figura 5.8.Folosirea obiectelor agregate pentru a permite suplimentarea nivelurilor pentru adăugarea de antete, când e permis doar un scriitor
Pachet date
R
W
Fbufs scriitoare
Fbufs libere
Proces 2 Tabel de pagini
Proces 1 Tabel de pagini
Scriitor Cititor
VP 10 VP 10 (prealocat)
Figura 5.7. Optimizarea cu un singur scriitor
Scris odata initial

105
eliminate actualizările tabelelor de pagini, lucru făcut în sistemele de operare obişnuite. De fapt, Thadani şi Khalidi au extins ideea fbufs şi au implementat-o în sistemul de operare al lui Sun Solaris. Dar cum se păstrează semanticile copiilor standard? Ce se întâmplă dacă aplicaţia face o scriere? Un sistem de operare standard ca UNIX nu poate depinde de copierea-la-scriere (figura 5.4).
Răspunsul este că nu se păstrează semanticile copiilor standard. API este schimbat. Aplicaţiile care scriu trebuie să fie atente să nu scrie într-un fbuf când acesta a fost alocat kernel-ului până când fbuf-ul este returnat de kernel listei de buffere goale. Pentru a proteja împotriva unui cod ce contine erori sau este rău intenţionat, kernel-ul poate activa bitul de scriere când un fbuf este transferat de la aplicaţie la kernel; bitul este setat din nou când fbuf-ul este returnat. Dacă aplicaţia face o scriere fara să aibă permisiunea de scriere, este generată o excepţie şi aplicaţia eşuează, lăsând celelalte procese neafectate.
Deoarece activarea biţilor de scriere necesită o activitate suplimentară pe care fbufs încearcă să o evite, facilitatea fbuf permite şi o altă formă de fbufs numită volatilă. De observat că, dacă procesul care scrie este o entitate de încredere (cum ar fi kernel-ul), nu are rost să fie impusă protecţia la scriere. Dacă kernel-ul are o eroare (bug), care îl face să realizeze scrieri neaşteptate, sistemulse va defecta oricum.
Schimbarea API-ului în acest fel sună dramatic. Ar trebuie rescrise toate aplicaţiile software ale UNIX–ului? Pentru a evita aceasta, există soluţii. API-ul existent poate fi completat cu noi apeluri de sistem. Extensiile Solaris adaugă un apel uf_write() în plus faţă de apelul standard write(). Aplicaţiile performante pot fi rescrise utilizând aceste noi apeluri.
Apoi, pot fi folosite extensiile în implementarea substraturilor I/O comune (ca biblioteca UNIX stdio) care sunt părţi ale mai multor aplicaţii. Aplicaţiile legate de această bibliotecă nu trebuie să fie schimbate, dar le creste totuşi performanţa.
Problema nu este modificarea API-ului, ci cât de greu este să modificăm aplicaţiile pentru a beneficia de schimbările din API. Thadani şi Khalidi, respectiv Pai au prezentat câteva aplicaţii la care modificările, necesare ca respectivele aplicaţii să folosească un API cu fbuf, au fost mici si locale.
5.2.4. Emularea transparentă a semanticilor copiilor Pentru noul API cu fbuf aplicaţia poate fi modificată pentru a-şi creşte
performanţa. Deşi modificările pot fi simple şi locale, se modifică drastic conceptia programatorului despre buffer. În API-UNIX standard, aplicaţia asignează adresele de buffer-e; în fbufs buffer-ele sunt asignate de kernel, din spaţiul de adrese fbuf. În API-UNIX standard, programatorul poate proiecta buffer-ul cum doreste, inclusiv folosirea buffer-elor succesive. În fbufs datele recepţionate de la reţea pot fi dispersate în părţi, legate între ele prin buffer-ul agregat, şi programatorul aplicaţiei trebuie să lucreze cu noul model de buffer ales de kernel. Beneficiile fbufs pot fi obţinute fără modificarea API-UNIX ? Teoretic software-ul aplicaţiei va rula neschimbat, şi s-ar putea obţine performanţe fără rescrierea aplicaţiilor.
Un mecanism inteligent de copiere-la-scriere rapidă este TCOW (transient copy-on-write). Teoretic se păstreaza API-ul neschimbat si aplicaţiile vor avea performanţe mai bune, dar propunerea nu e verificată

106
experimental. In practică, probabil că aplicaţiile vor trebui modificate, mai mult intuitiv, pentru a profita de schimbările fundamentale ale implementării kernel-ului.
API standard trebuie să permită oricând unei aplicaţii să scrie sau să dezaloce un buffer pasat kernel-ului. Proiectarea fbuf modifică API interzicând unei aplicaţii să facă asta. Dar, pentru a păstra API cand se fac doar mapări de memorie virtuală, sistemul de operare trebuie să lucreze cu cele două ameninţări posibile (scrierea/dezalocarea aplicaţiei), timp în care buffer-ul este utilizat de kernel pentru a trimite/retransmite un pachet. În sistemul Genie maparea VM e utilizată la fel ca în fbufs, iar cele două ameninţări sunt tratate după cum urmează.
Contorizarea ameninţărilor de scriere prin modificarea managerului de erori VM: când o aplicaţie face mai întâi o scriere, buffer-ul este marcat în mod special, ca Read-Only. Astfel, dacă aplicaţia face o scriere, este invocat managerul de erori VM. În mod normal, acest lucru ar trebui să genereze o excepţie dar, dacă sistemul de operare păstrează semanticile copiilor, nu ar trebui să fie o eroare. Genie modifică handlerul de excepţii astfel. În primul rând pentru fiecare pagină/buffer Genie urmăreşte dacă există transmisii de rezolvat (transmisii spre reţea) utilizând un numarător, incrementat când începe transmisia şi decrementat când transmisia este completă. În al doilea rând, handlerul de erori e modificat ca sa facă o copie separată a paginii pentru aplicaţie (care conţine noul Write) dacă există un Send nerezolvat. Desigur, performanţa este afectată, dar se păstrează semanticile copiilor standard ale API, ca în UNIX. Această tehnică numită protecţie tranzitorie la COW e folosită doar la nevoie – când buffer-ul este citit si de subsistemul de reţea.
Contorizarea ameninţărilor de de-alocare prin modificarea Pageout Daemon: într-un sistem standard de memorie virtuală, există un proces responsabil pentru punerea paginilor dezalocate într-o listă liberă, din care paginile pot fi scrise pe disc. Acest Pageout Daemon poate fi modificat sa nu dezaloce o pagină, când e folosită pentru a trimite/recepţiona pachete.
Aceste două idei sunt exemple ale principiului P3c, deplasarea calculelor în spaţiu. Acţiunea de verificare a scrierilor neaşteptate este pasată handlerului de erori VM, şi acţiunea de dezalocare este pasată rutinei de dezalocare a paginii. Cele două idei sunt suficiente pentru a trimite un pachet dar nu şi pentru recepţie. La recepţie, Genie trebuie să se bazeze, la fel ca fbufs, pe suportul hardware din adaptor, ca să despartă antetele pachetelor într-un buffer, şi datele rămase într-alt buffer de dimensiunea unei pagini, care poate fi schimbat cu buffer-ul aplicaţiei.
Pentru ca această acţiune să nu implice şi o copiere fizică, buffer-ul de date al kernel-ului trebuie să înceapă la acelaşi offset din pagină ca şi buffer-ul de recepţie al aplicaţiei. Pentru un buffer mare, probabil că ar fi mai eficient ca pentru prima şi ultima pagină (care pot fi parţial completate) să fie făcută o copie fizică; totuşi, paginile intermediare care sunt pline pot fi simplu schimbate de la kernel la aplicaţie printr-o mapare corectă a tabelelor de pagini. Există şi optimizarea numită copiere reversă.
Datorită complexităţii remapării tabelelor de pagini, nu e clar cum se face eficient remaparea paginilor în Genie. O posibilitate este că Genie foloseste aceeaşi idee fbuf a memorării mapărilor VM bazată pe căi, pentru a evita supraîncărcarea prin eliminarea TLB, când avem mai multe

107
tabele de pagini, etc. Experimentele Genie au fost făcute pe reţele ATM, unde cu identificatorul căii virtuale remaparea căii se face rapid.
Cum poate TCOW să beneficieze de implementarile anterioare? Nu există confirmări experimentale ale acestei idei, deoarece experimentele au folosit un simplu banc de test de copiere şi nu o aplicaţie cum ar fi un server Web. Pare dificil pentru o aplicaţie existentă să beneficieze de noua implementare a kernelului cu API-urile existente.
Considerăm o aplicaţie ce rulează TCP, care-i dă un buffer TCP-ului. Deoarece nu există o reacţie spre aplicaţie (ca la fbufs) aplicaţia nu ştie când poate reutiliza buffer-ul în siguranţă. Dacă aplicaţia rescrie prea devreme buffer-ul pe care TCP îl ţinea pentru retransmisie, atunci nu este compromisă siguranţa, ci doar performanţa, datorită copiei fizice implicată în copierea-la-scriere. E puţin probabil ca o aplicaţie nemodificată să-şi poată sincroniza momentele modificării buffer-elor cu momentele transmisiilor TCP, şi ar trebui să-şi poată alinia buffer-ele sale destul de bine pentru a permite un schimb de pagini corect.
Astfel, aplicaţiile trebuie modificate pentru a beneficia de sistemul Genie. Chiar şi atunci, ar trebui să ştie când să reutilizeze un buffer, deoarece lipseşte reacţia. Aplicaţia ar putea monitoriza erorile TCOW şi să îşi modifice, funcţie de acestea, modelul de reutilizare. Dar dacă aplicaţiile trebuie modificate subtil, pentru a beneficia de noul kernel, nu e clar ce beneficiu au obţinut din păstrarea API-ului.
5.3. Evitarea copierii utilizând DMA la distantă (RDMA)
Fbufs oferă o soluţie rezonabilă pentru evitarea copiilor redundante aplicaţie-kernel, dar există o soluţie mai directă de eliminare a suprasarcinii cauzata de control. Dacă un fişier de 1MB este transferat între două staţii de lucru pe Ethernet, e divizat în părţi de 1500-byte. CPU tratează fiecare parte de 1500-byte pentru a face procesarea TCP şi copierea fiecărui pachet (posibil printr-o interfaţă zero-copii cum ar fi fbufs) în memoria aplicaţiei.
Dar CPU poate face un DMA între disc şi memorie pentru a transfera să zicem 1MB. CPU setează DMA, spune discului zona de adrese în care datele trebuiesc scrise şi îşi vede de treburile sale. După transfer, discul întrerupe CPU pentru a-i spune că a terminat. Procesorul nu controlează în detaliu transferul, ca in cazul anterior al transferului în reţea.
Această analogie sugerează execuţia unui DMA prin reţea, RDMA (Remote-DMA). Această soluţie de reţea a fost propusă în VAX Clusters, de proiectantii de calculatoare. Intenţia este ca datele să fie transferate prin reţea între memoriile celor două calculatoare, fără intervenţia celor două procesoare la fiecare pachet. Cele două adaptoare cooperează la citirea dintr-o memorie şi scrierea în alta. La DMA prin reţea trebuie rezolvate două probleme: (1) cum ştie adaptorul receptor unde să plaseze datele – el nu poate cere ajutor calculatorului fără a compromite ideea; (2) cum este menţinută securitatea. Nu e discutata posibilitatea pachetelor solitare care sosesc de pe reţea şi rescriu părţi cheie de memorie. 5.3.1.Evitarea copierii în cluster
În ultimii ani, clusterele de staţii de lucru au fost acceptate ca înlocuitoare mai ieftine şi mult mai utile decat calculatoarele mari. Multe

108
servere Web sunt compuse dintr-o reuniune de servere. Deşi tehnologia pare recentă, DEC (Digital Equipment Corporation) a introdus acum 20 de ani un produs comercial de succes numit VAX Clusters, pentru a asigura baza unor operaţii scalabile (aplicaţii cu baze de date). Inima sistemului a fost o reţea de 140-Mbit numită CI (Computer Interconnect) având un protocol asemănător cu Ethernet. Clienţii puteau conecta la CI, un număr de calculatoare VAX şi discuri ataşate reţelei. Copierea eficientă a fost cauzată de necesitatea transferului unor mari cantităţi de date între discul îndepărtat şi memoria VAX-lui. Asa a aparut RDMA.
RDMA impune ca pachetele de date, conţinând părţi dintr-un fişier mare, să ajungă la destinaţia finală odata sosite în adaptorul destinaţiei. Lucrul este mai greu de facut decât pare. În reţelele tradiţionale, pachetul sosit obligă CPU să-l examineze si sa-i decida destinatia. Chiar dacă CPU se uită la antete, el poate specifica doar coada bufferelor de recepţie (bazat pe aplicaţia destinatie).
Presupunem că aplicaţia de recepţie memoreaza in coada aplicaţiei 1 de la adaptorul de recepţie, paginile 1, 2 şi 3. Primul pachet soseşte şi este trimis la pagina 1, al treilea pachet soseşte în afara secvenţei şi este pus în pagina 2, în loc de pagina 3. CPU poate întotdeauna remapa paginile la sfârşit, dar remaparea tuturor paginilor la sfârşitul transferului, pentru un fişier mare, poate fi dificilă. Datorită pierderii de pachete, sosirile în afara secvenţei pot apărea întotdeauna, chiar şi într-o legătură FIFO.
La VAX-Clusters ideea este însă este ca mai întâi aplicaţia destinaţie să blocheze un număr de pagini fizice (paginile 11 şi 16 din figura 5.9.) pentru memoria destinaţie de transfer a fişierului. Logic ar fi ca bufferul, B să zicem, să aibă pagini consecutive (paginile 1 şi 2 din figura 5.9.). Numele acestui buffer B este pasat la aplicaţia de transmisie. Sursa pasează acum (P10 pasarea informaţiei în antetele de protocol) numele buffer-ului şi decalajul cu fiecare pachet trimis. Astfel, când trimite pachetul 3 în afara secvenţei din ultimul exemplu, acesta va conţine B şi pagina 3 şi deci, nu poate fi memorat în pagina 2 a buffer-ului chiar dacă soseşte înaintea pachetului 2. Astfel, după ce toate pachetele sosesc, nu mai este nevoie de o remapare a paginilor.
Pentru ca procesorul să nu mai fie ocupat la fiecare sosire de pachet luate nişte măsuri. În primul rând adaptorul trebuie să implementeze protocolul de transport (şi să verifice toate duplicatele,etc.) ca în procesarea TCP. În plus, adaptorul trebuie să fie capabil să determine unde se termină antetul şi unde încep datele, astfel ca în buffer-ul destinaţie să fie copiate doar datele.
În sfârşit, să permitem fiecărui pachet, care transportă ID–ul buffer-ului de la reţea, să fie scris direct în memorie, ar putea fi o lacună în securitate. Pentru a evita acest lucru, ID-ul buffer-ului conţine un şir aleator, greu de ghicit.Astfel, clusterele VAX sunt utilizate doar între gazdele de încredere din cluster, ceea ce evident că ar fi mai difícil pentru transferul de date la scala Internet-ului.

109
Figura 5.9 Realizarea DMA prin reţea
5.3.2. RDMA actual.
Clusterele VAX au introdus foarte devreme ceea ce se numeşte reţea cu zonă de stocare SAN (storage area network). SAN sunt reţele “în culise” (back-end) care conectează mai multe calculatoare care partajează memoria, adică discurile ataşate reţelei. Câţiva succesori recenţi ai clusterelor VAX care folosesc tehnologia SAN sunt: canalul pe fibra optică (Fiber Channel) mai vechi, sau mai modernele InfiniBand şi iSCSI(Small Computer System Interface) Fiber Channel
În 1988 ANSI Task Group X3T11 a început să lucreze la un standard numit FiberChannel. Unul din scopurile FiberChannel era să ia standardul SCSI dintre o staţie de lucru şi un disc local şi să îl extindă pe distanţe mari. Astfel, în multe instalaţii FiberChannel, SCSI este încă utilizat ca protocolul care rulează pe FiberChannel.
FiberChannel merge la fundamentele reţelei mai departe decât clusterele VAX, utilizând tehnologii noi de reţele, cum ar fi legăturile punct-la-punct pe fibră conectate cu switch-uri. Aceasta permite viteze de până la 1Gb/sec şi distanţe mai mari decât în reţeaua clusterelor VAX. Switch-urile pot fi chiar conectate la distanţă, permiţând unei firme de comerţ să aibă pe un site îndepărtat o memorie de rezervă a tuturor tranzacţiilor. Utilizarea switch-urilor trebuie să aibă în vedere controlul fluxului, care trebuie făcut cu grijă pentru a evita pierderea de pachete pe cât posibil.
FiberChannel face mai multe concesii asupra securitaţii decât clustereleVAX, unde orice dispozitiv cu un nume potrivit poate scrie în memoria oricărui alt dispozitiv. FiberChannel permite reţelei să fie virtualizată în zone, si nodurile dintr-o zonă nu pot accesa memoria nodurilor din alte zone. Produse mai recente merg mai departe si propun chiar tehnici de autentificare ; dar ideile de bază sunt aceleaşi. Infiniband
Infiniband porneşte de la faptul că PCI, magistrala internă I/O utilizată în multe staţii de lucru şi PC-uri, e învechită si trebuie înlocuită. Cu o lăţime de bandă maximă de 533 Mb/sec, magistrala PCI este inundată de perifericele moderne de mare viteză, ca plăcile de interfaţă Gigabit Ethernet. Deşi există câteva alternative temporare cum ar fi magistrala
B1 B2
Pagina 11
Pagina 16
ADAPTORUL DESTINATIE
B, 2
B, 1
Numele buffer-ului B

110
PCI-X, magistralele interne din calculatoare trebuie redimensionate ca să ţina pasul cu modificări de genul de la 10-Mbit Ethernet la Gbit Ethernet.
De asemenea, observăm că există trei tehnologii de reţea diferite într-un calculator: interfaţa de reţea (ex.Ethernet), interfaţa de disc (ex.SCSI prin FiberChannel) şi magistrala PCI. Principiul lui Occam,cea mai bună cale este cea mai simplă, sugerează substituirea acestora trei cu o tehnologie de reţea unică. Astfel, Compaq, Dell, HP, IBM şi SUN au format Infiniband Trade Association. Specificaţiile Infiniband utilizează multe din ideile tehnologiei FiberChannel. Interconectarea se face cu comutatoare şi legături punct-la-punct. Infiniband are câteva schimbări: adresare IP pe 128 biti pentru Internet-ul de generaţie următoare, virtualizarea legăturilor fizice individuale sub formă de căi, facilităţi pentru calitatea serviciului, multicast si RDMA pentru evitarea copiilor.
iSCSI FiberChannel pare să aibă un cost mai ridicat la viteză echivalentă,
pentru scrierea între părţi decât scrierea între părţile Gigabit Ethernet. Dat fiind faptul că IP a pătruns în numeroase spaţii de reţea cum ar fi voce, TV şi radio, natural ar fi să pătrundă şi în spaţiul de memorare. Aceasta ar trebui să scadă preţurile (deschizând noi pieţe pentru furnizorii de reţele).Pe mai departe, se extind FiberChannel şi Infiniband să conecteze prin Internet centre de date distante. Aceasta implică folosirea de protocoale de transport care nu sunt neapărat compatibile cu TCP, în ceea ce priveşte reacţia la congestie. De ce să nu adaptăm TCP în acest scop, în loc să modificăm celelalte protocoale ca să fie compatibile TCP?
Cel mai interesant lucru la iSCSI este modul de emulare a RDMA prin protocoale IP standard. La RDMA, adaptorul gazdă implementează în hardware protocoalele de transport ale Internet-ului. Protocolul de transport din Internet este TCP. Deci adaptoarele trebuie să implementeze TCP în hardware. Chip-uri care realizează TCP, fără a creşte efortul de calcul, sunt pe cale să devină accesibile pe scară largă.
Mai dificile sunt următoarele părţi. În primul rând, TCP este un protocol orientat pe flux. Aplicaţia scrie octeţii într-o coadă, şi aceşti octeţi sunt segmentaţi arbitrar în pachete. RDMA, pe de altă parte, este bazată pe mesaje, fiecare din acestea are un câmp “nume buffer”. În al doilea rând, RDMA prin TCP necesită un antet pentru numele buffer-elor.
Propunerile RDMA rezolvă ambele probleme stratificând trei protocoale peste TCP. Primul protocol, MPA, adaugă un antet care defineşte limitele mesajelor în fluxul de biţi. Al doilea şi al treilea protocol implementează câmpurile antetelor RDMA dar sunt separate dupa cum urmeaza. Când un pachet transportă date are nevoie doar de numele bufferului şi deplasarea. Acest antet este abstractizat prin antetul DDA (Direct Data Access) împreună cu o comandă (read sau write).
Protocolul RDMA, stratificat peste DDA adaugă un antet cu câteva câmpuri în plus. De exemplu, pentru o citire RDMA la distanţă, cererea iniţială trebuie să specifice numele buffer-ului de la distanţă (de citit) şi numele bufferului local (de scris). Unul dintre numele acestor două buffer-e poate fi plasat în antetul DDA, dar celălalt trebuie plasat în antetul RDMA. Astfel, cu excepţia mesajelor de control, cum ar fi iniţierea unei citiri, toate datele transportă doar un antet DDA şi nu un antet RDMA.

111
În evoluţia de la clusterele VAX la RDMA, o generalizare interesantă a fost înlocuirea buffer-ului cu nume cu un buffer anonim. În acest caz antetul DDA conţine numele unei cozi şi pachetul este plasat în primul buffer liber, din capul cozii de la recepţie. 5.4. Extinderea la sistemul de fişiere
Până acum s-a tratat doar evitarea copiilor redundante ce apar cand se transmit date între o aplicaţie (ca serverul Web) şi reţea. Dar (fig.5.2) şi după îndepartarea tuturor antetelor redundante datorate copierii prin reţea, încă mai sunt copii redundante care implică sistemul de fişiere. Tehnicile de evitare a copierii, discutate până acum, sunt extinse si la sistemul de fişiere. Pentru a procesa o cerere pentru fişierul X (fig.5.2), serverul trebuie să citească X de pe disc (copia 1) într-un buffer kernel (reprezentând fişierul cache) şi apoi să facă o copie din cache în buffer-ul aplicaţiei (copia 2). Copia 1 este eliminată dacă fişierul este deja în cache, o presupunere corectă pentru fişierele cu utilizare intensivă dintr-un server cu memorie suficientă. Principalul scop este eliminarea copiei 2. Intr-un server Web dublarea inutilă a numărului de copii înjumătăţeşte lărgimea de bandă efectivă şi înjumătăţeşte cache-ul serverului. Aceasta reduce performanţa serverului, crescând rata de pierderi, adică mai multe documente sunt servite la viteza discului şi nu la viteza magistralei.
Sunt prezentate aici trei tehnici pentru îndepărtarea copiei redundante a sistemului de fişiere (copia 2): maparea memoriei partajate care poate reduce copia 2, dar nu este bine integrată în subsistemul de reţea; IO-Lite, o generalizare a fbufs extinsă la sistemul de fişiere; I/O splicing, utilizată de multe servere Web comerciale. 5.4.1. Memoria partajată
Variantele moderne de UNIX oferă un apel de sistem convenabil mmap() pentru a permite unei aplicaţii (un server) să mapeze un fişier în spaţiul său de adresare a memoriei virtuale. Şi alte sisteme de operare oferă funcţii echivalente. Când un fişier este mapat în spaţiul de adrese al unei aplicaţii, este ca şi cum aplicaţia ar fi făcut o copie cache a fişierului în memoria sa. Operaţia pare redundantă, deoarece sistemul de fişiere reţine fişierele şi în cache. Dar folosind memoria virtuala (P4, egalizarea componentelor sistemului), fişierul cache este doar un set de mapări, pentru ca alte aplicaţii şi cache-ul serverului de fişiere să acceseze în comun setul de pagini fizice pentru acel fişier.
Serverul Web Flash evită copia 1 şi 2 (fig.5.2) impunând ca aplicaţia server să mapeze în memorie fişierele des utilizate. Dar, fiind limitate atât numărul de pagini fizice ce pot fi alocate paginilor fişierului, cât şi mapările tabelului de pagini, serverul Web Flash trebuie să trateze aceste fişiere mapate, ca un cache. În loc să memoreze în cache fişierele întregi, el memorează doar segmente din aceste fişiere şi foloseşte o politică LRU (Least Recently Used) pentru a demapa fişierele nefolosite de ceva vreme.
Funcţiile de mentenanţă cache sunt dublate prin cache-ul sistemului de fişiere (care are o evidenţă mai precisă asupra resurselor, cum ar fi paginile libere, fiind rezident în kernel). Totuşi, aşa se evită copiile 1 şi 2 (figura 5.2). În timp ce Flush utilizează mmap() pentru a evita copierea sistemului de fişiere, el rulează în UNIX API. Astfel că Flush e obligat să

112
facă o copie suplimentară pentru subsistemul de reţea (copia 3, figura 5.2.). Chiar când s-a reuşit eliminarea copiei 2, reapare copia 3 !
Copia 3 poate fi evitată combinând emularea copierii, făcută de TCOW, cu mmap() (desi TCOW are unele dezavantaje, menţionate anterior). Deasemenea, nu este o soluţie general valabila pentru evitarea copierii la interacţiunea cu un proces CGI prin intermediul unui canal/pipe UNIX . 5.4.2. IO-Lite: o vedere de ansamblu asupra buffer-elor
Deşi combinarea copiere emulată-mmap() elimină copierea redundantă, lipsesc totuşi câteva optimizări. În primul rând, nu se face nimic pentru a evita copierea între orice aplicaţie CGI (care generează conţinut dinamic) şi serverul Web. Acest tip de aplicaţie se implementează deobicei ca un proces separat, care-şi trimite conţinutul dinamic procesului server printr-un canal/pipe Unix. Dar pipe-urile şi alte comunicaţii interprocese similare presupun copierea conţinutului între două spaţii de adrese.
În al doilea rând, nici una din schemele de până acum nu a rezolvat problema sumei ciclice de control TCP, care este o operaţie costisitoare. Dacă acelaşi fişier indică mereu memoria cache, în afară de primul răspuns care contine antetul HTTP, toate pachetele succesive, care returnează conţinutul fişierului, rămân aceleaşi pentru oricare cerere. De ce nu s-ar putea memora în cache suma de control TCP? Asta ar presupune o memorie cache care să poată cumva asocia conţinutul pachetului cu suma de control, treabă ineficientă într-o schemă de memorare convenţională.
Schema de memorare IO-Lite generalizează ideile fbuf şi la sistemul de fişiere. IO-Lite nu numai că elimină toate copiile redundante din figura 5.2, ci şi copierea redundantă între procesele CGI şi server. Ea are o schema specializată de numerotare a buffer-elor care permite unui subsistem (ca TCP) să realizeze eficient că retransmite un pachet anterior.
IO-Lite derivă din fbufs, dar extinderea la sistemul de fişiere adaugă mai multă complexitate. Spre deosebire de TCOW, fbufs nu pot fi combinate cu mmap(), deoarece în mmap() aplicatia alege adresa şi formatul buffer-ului aplicaţie, în timp ce în fbufs kernel-ul selectează adresa şi buffer-ul rapid (fbuf). Astfel, dacă aplicaţia a mapat un fişier utilizând un buffer în spaţiul adreselor virtuale al aplicaţiei, buffer-ul nu poate fi trimis utilizând un fbuf (spaţiul adreselor kernel) fără o copie fizică.
Deoarece fbufs nu pot fi combinate cu mmap, IO-Lite generalizează fbufs pentru a include sistemul de fişiere, făcând mmap inutil. IO-Lite este implementat şi într-un sistem de operare de interes general (UNIX), spre deosebire de fbufs. Dar IO-Lite împrumută toate ideile principale de la fbufs: noţiunea partajării read-only prin buffer-e invariabile (numite felii/slices in IO-Lite), utilizarea buffer-elor compuse (numite buffer agregates), şi noţiunea unui cache creat relaxat pentru o cale (numit I/O stream in IO-Lite).

113
IO-Lite trebuie să rezolve problema dificilă de integrare în sistemul de
fişiere. În primul rând, IO-Lite trebuie să se ocupe de modelele complexe de partajare, unde mai multe aplicaţii pot avea buffer-e care pointează la un buffer IO-Lite, împreună cu codul TCP şi cu serverul de fişiere. În al doilea rând, o pagină IO-Lite poate fi în acelaşi timp o pagină de memorie virtuală (returnată de fişierul de pagini de rezerva de pe disc) sau o pagină de fişier (returnată de copia actuală de pe disc a fişierului). Astfel, IO-Lite trebuie să implementeze o politică complexă de înlocuire, care integrează împreună regulile standard de înlocuire a paginilor şi cele de înlocuire a fişierului cache. În al treilea rând, ca să rulăm pe UNIX trebuie găsită o cale de a integra IO-Lite fără operaţii majore asupra UNIX.
Figura 5.10. arată paşii pentru a răspunde la cererea GET din figura 5.2. Când fişierul este citit prima dată de pe disc în memoria cache a sistemului de fişiere, paginile fişierului sunt memorate ca buffer-e IO-Lite. Când aplicaţia face un apel de citire a fişierului, nu se realizează nici o copie fizică, dar este creat un buffer agregat cu un pointer spre buffer-ul IO-Lite. Când aplicaţia trimite fişierul TCP-ului pentru a fi transmis, sistemul reţelei primeşte un pointer la aceleaşi pagini IO-Lite. Pentru a preveni apariţia erorilor sistemul IO-Lite păstrează un contor de referinta, pentru fiecare buffer, şi realocă bufferul doar când toţi utilizatorii au terminat.
Figura 5.10. arată încă două optimizări. Aplicaţia ţine o memorie cache de răspunsuri HTTP pentru fişierele comune, şi deseori poate adăuga pur şi simplu răspunsul standard cu modificări minime. În al doilea rând,
Aplicatia server-ului Web write() read()
TCP/IP Sistem fisiere Kernel
Buffer server Buffer socket Buffer fisier cache
Buffer IO-Lite
Adaptor de retea
Retea
CPU Memorie
Copia 2
Bus memorie
Bus I/O
Disc
Copia 1
Figura 5.10. IO-Lite elimină toate copiile redundante din figura 5.2. pasând efectiv pointeri (prin mapări VM) la un singur buffer IO-Lite. Presupunând că fişierul, suma de control TCP şi
răspunsul HTTP sunt toate memorate în cache, server-ul Web nu trebuie decât să transmită aceste valori din cache într-o singură copie la interfaţa de reţea.
Cached checksum
Cached response header

114
fiecărui buffer îi este dat un număr unic (P12, adaugă stări redundante) de către IO-Lite, şi modulul TCP ţine un cache al sumelor de control indexate cu numărul buffer-ului. Astfel, când un fişier este transmis de mai multe ori, modulul TCP poate evita calcularea sumei de control, după prima transmisie. Aceste modificări elimină toată redundanţa din figura 5.2 care măreşte viteza de procesare a răspunsului.
IO-Lite poate fi utilizată şi pentru implementarea unui program pipe modificat, care elimină copierea. Când acest mecanism IPC este utilizat între procesul CGI şi procesul server, toate copiile sunt eliminate, fără a compromite siguranţa şi izolarea defectelor, oferită de implementarea celor două programe ca procese separate. IO-Lite permite deasemenea aplicaţiilor să-şi particularizeze strategia de memorare-cache a buffer-elor, permiţând strategii de memorare-cache mai deosebite, pentru serverele web bazate pe dimensiunea şi frecvenţa accesului.
Este important de remarcat că IO-Lite realizează aceste performanţe fără a elimina complet kernel-ul Unix şi fără a lega strâns aplicaţia de kernel. Serverul Web Cheetah, cu sistemul de operare Exokernel, e şi mai radical, permite fiecărei aplicaţii (inclusiv serverului Web) să îşi individualizeze complet reţeaua şi sistemul de fişiere. Mecanismele Exokernel permit astfel de individualizari, pentru fiecare aplicaţie, fără a compromite siguranţa. În virtutea acestor modificări, serverul Web Cheetah poate elimina toate copiile din figura 5.2. şi deasemenea poate elimina calcularea sumei de control TCP utilizând un cache.
În timp ce Cheetah permite câteva artificii suplimentare, enorma provocare în ingineria software de proiectare şi menţinere de kernel-uri individualizate pentru fiecare aplicaţie, face mai atractive abordările ca IO-Lite. IO-Lite se apropie de performanţa kernel-urilor individualizate ca Cheetah avand de rezolvat mult mai putine probleme de inginerie software.
5.4.3. Evitarea copiilor sistemului de fişiere prin I/O Splicing Server-ele Web sunt apreciate prin teste comerciale: SPECweb pentru
serverele Web şi poligraf-Web pentru proxy-ul Web. În spaţiul proxy, există un raport de recurenţă anual în care toate dispozitivele sunt măsurate împreună pentru a calcula cea mai mare rată de găsire a fişierului dorit în cache, normalizată la preţul dispozitivului. Testerele SPECweb utilizează un sistem diferit în care producătorii îşi înregistrează propriile rezultate experimentale la sistemul de teste, chiar dacă aceste rezultate sunt verificate. În testele poligraf Web, la vremea scrierii, tehnologia unui server Web bazată pe ideile IO-Lite era printre cele mai avansate.
De altfel, în testele SPECweb mai multe server-e Web prezintă, deasemenea, performanţe impresionante. Aceasta se datorează şi unui hardware mai rapid (şi mai scump). Totuşi, există două idei simple care pot evita nevoia de schimbări complete ale modelului ca în cazul IO-Lite.
Prima idee este de a plasa complet în kernel aplicaţia serverului Web. În acest fel în figura 5.2., toate copiile pot fi eliminate deoarece aplicaţia şi kernelul sunt părţi ale aceleaşi entităţi. Problema majoră cu această abordare este că astfel de servere, Web aflate în kernel, trebuie să se ocupe de rezistenţa la schimbări de implementare a sistemelor de operare. De exemplu, pentru un server popular de mare performanţă care ruleaza pe

115
Linux, fiecare modificare internă a Linux-ului poate invalida ipotezele software-ului serverului, şi cauza o blocare a sistemului. De menţionat că un server convenţional din spaţiul utilizatorilor nu are această problemă deoarece toate modificările implementării UNIX păstrează API-ul.
A doua idee menţine aplicaţia server în spaţiul utilizator dar se bazează pe o idee simplă numită I/O splicing pentru a elimina toate copiile din figura 5.2. I/O splicing arătat în figura 5.11. a fost introdus pentru prima data în Fall şi Pasquale. Ideea este de a introduce un nou apel de sistem care combină vechiul apel de citire a unui fişier cu vechiul apel (P6, rutine specializate eficiente) de trimitere a unui mesaj în reţea. Permiţând kernel-ului să îmbine aceste două sisteme de apel, separate până acum, putem evita toate copiile redundante. Multe sisteme au apeluri de sistem cum ar fi sendfile () care acum sunt utilizate de câţiva producători comerciali. În ciuda succesului acestui mecanism, mecanismele bazate pe sendfile nu pot fi bine generalizate pentru comunicaţia cu procesele CGI.
5.5. Extinderea dincolo de copii Clark şi Tennehouse, într-o lucrare de referinţă, generalizând ideea lui
Van Jacobson (descrisă mai înainte), au sugerat integrarea sumei de control şi a copierii. Mai detaliat, ideea Jacobson a pornit de la următoarea observaţie. Când se copiază un cuvînt de pachet dintr-o locaţie (de exemplu W10 în memoria adaptorului din figura 5.12.) într-o locaţie de memorie (de exemplu M9 din figura 5.12.), procesorul trebuie să încarce W10 într-un registru şi apoi să memoreze acel registru în M9. Tipic, cele mai multe procesoare RISC cer ca, între o încărcare şi o memorare
Aplicatia sesver-ului Web sendfile()
CPU
Adaptor de retea
Retea
Copia 2 Disc
Copia 1 Magistrala de memorie
Magistrala I/O
Figura 5.11. În I/O splicing, toate indirectările cauzate de copierea în şi din buffer-e din spaţiul utilizator sunt îndepartate printr-un singur apel de sistem care “îmbină” fluxul I/O de la disc cu fluxul I/O de la reţea. Ca de obicei, copia 1 poate fi eliminată pentru fişierele din cache.
Kernel Buffer fisier cache
Memorie

116
compilatorul să insereze un aşa numit slot de întârziere, sau ciclu gol, pentru a asigura ca pipeline-ul să functioneze corect (aici nu motivăm de ce). Acel ciclu gol poate fi utilizat pentru alte operaţii. De exemplu, el poate fi folosit pentru a adăuga cuvântul tocmai citit într-un registru care conţine suma de control curentă. Astfel, fără cost în plus, bucla de copiere poate fi deseori complementata să fie şi buclă de sumă de control.
Dar există alte manevrări de date intensive cum ar fi criptarea de date şi conversiile de format. De ce să nu integrăm toate aceste manevre în bucla de copiere ? au susţinut Clark şi Tennehouse. De exemplu, în figura 5.2. CPU ar fi putut citi W10 şi după aceea să decripteze W10 şi să scrie cuvântul decriptat M9 decât să facă asta într-o altă buclă. Ei au numit această idee integrated layer processing, sau ILP. Ideea esenţială este de a evita pierderile evidente, (P1), la citirea (şi posibil la scrierea) biţilor unui pachet, de mai multe ori pentru operaţii de manevrare multiplă a datelor aceluiaşi pachet.
Astfel, ILP este o generalizare a integrării copiei sumei de control şi pentru alte manevrări(de exemplu, criptare). Totuşi, ea are câteva cerinţe. • Cerinţa 1: Informaţia necesară manevrărilor e specifică fiecărui nivel (criptarea la nivelul aplicaţie, verificarea sumei de control la nivelul TCP). Integrarea codului în nivele e dificilă fără sacrificarea modularitaţii. • Cerinţa 2: Fiecare manevrare poate opera pe felii de diferite mărimi şi pe zone diferite ale pachetului. TCP lucrează pe 16 biţi pentru o suma de control de 16 biţi iar criptarea DES lucrează pe 64 biţi. Astfel, în timp ce lucrează cu un cuvânt de 32 biţi, bucla ILP trebuie să se ocupe de două cuvinte de sumă de control TCP şi o jumătate de cuvânt DES. • Cerinţa 3: Unele manevrări pot depinde una de cealaltă: nu ar trebui ca un pachet să fie decriptat, dacă suma de control nu este verificată. • Cerinţa 4: ILP poate mări rata de pierderi a cache, deoarece poate reduce localizarea printr-o singură manevrare. Dacă TCP şi DES au fost făcute separat, şi nu într-o singură buclă, codul care ar fi fost folosit la fiecare etapă este mai redus pentru cele două bucle luate separat decât cel pentru o singură buclă. Aceasta face mai probabil ca, într-o implementare mai naivă, codul să fie găsit în cache-ul instrucţiunii. Creşterea integrării,
Stocare M9, R0 (adaugare R0 la suma de control) Incarcare W10, R0
M9
W10 Memoria adaptorului
CPU
Figura 5.12. Integrarea sumei de control şi a copierii

117
dincolo de un anumit punct poate distruge localizarea codului într-o asemenea măsură încât, poate avea efectul opus.
Primele trei cerinţe arată că ILP este greu de realizat. A patra sugerează că integrarea a mai mult de câteva operaţii odată, poate chiar reduce performanţa. În sfârşit, dacă pachetul de date este utilizat de mai multe ori, ar putea fi rezident în cache-ul de date (chiar şi într-o implementare naivă), făcând inutil tot deranjul pentru integrarea buclelor. Posibil din cauza acestor motive, ILP a rămas doar o idee tentantă. Înafară de combinarea copierii cu verificarea sumei de control, au fost puţine manevrări care au mai fost integrate în sistemele academice sau comerciale. 5.6. Extinderea dincolo de manevrările datelor
Până acum scopul a fost reducerea lărgimii de bandă a memoriei (şi a magistralei) cauzată de operaţiile de manipulare a datelor. În primul rând, a fost problema eliminării copierii de date redundante între reţea şi aplicaţie. Apoi a fost tratată copierea redundantă dintre sistemul de fişiere, aplicaţie şi reţea. În final, s-a pus problema eliminării citirilor şi scrierilor redundante în/din memorie, utilizând procesarea integrată pe niveluri când mai multe operaţii de manevrări a datelor operează asupra aceluiaşi pachet. Comun acestor tehnici este încercarea de a reduce presiunea asupra memoriei şi a magistralei I/O, prin evitarea scrierilor şi citirilor redundante. Dar odată realizată, mai sunt alte surse de presiune care apar într-o arhitectură endnode (fig.5.2). Aceasta se referă la următorul extras dintr-un e-mail trimis după lansarea etapei alpha a serverului rapid Web Linux de nivel utilizator.
Cu un transfer de fişier cu zero copii, deplasarea datelor nu mai este o problemă, reteaua I/O asincronă permite o planificare cu adevărat necostisitoare, şi invocarea apelului de sistem adaugă un antet neglijabil în Linux. Ce ne rămâne acum sunt doar ciclurile de aşteptare, CPU-urile şi NIC-urile, care rivalizează pentru lăţime de bană de memorie şi de magistrală.
În esenţă, odată ce se are grijă de efectele de ordinul întâi (cum ar fi eliminarea copiilor), performanţa poate fi îmbunătăţită doar având grijă la ce ar putea fi considerat ca efecte de ordin doi. Două astfel de efecte arhitecturale cu impact mare asupra utilizării lărgimii de bandă a magistralei şi a memoriei sunt utilizarea eficientă a cache-urilor şi alegerea DMA versus PIO. 5.6.1. Utilizarea eficientă a cache-urilor Modelul arhitectural din figura 5.2, nu prezintă două detalii importante. Reamintim că procesorul păstrează una sau mai multe cache-uri de date (d-caches) şi una sau mai multe cache-uri de instrucţiuni (I-caches). Cache-ul de date este un tabel care mapează de la adrese de memorie la conţinutul de date; dacă există citiri şi scrieri repetate la aceeaşi locaţie L din memorie şi L este în cache, atunci aceste citiri şi scrieri pot fi servite direct din cache-ul de date, fără a implica lăţime de bandă de memorie şi de magistrală. Similar, reamintim că programele sunt stocate în memorie; fiecare linie de cod executată de CPU trebuie adusă din memoria principală dacă nu se găseşte în cache-ul de instrucţiuni.

118
Acum, pachetul de date beneficiază puţin de un cache de date, deoarece datele sunt puţin reutilizate şi copierea implică scrierea într-o nouă adresă de memorie, spre deosebire de citiri şi scrieri repetate din aceeaşi adresă de memorie. Astfel, tehnicile deja discutate de reducere a copiilor sunt inutile, în ciuda prezenţei în procesor a unei memorii cache de date mari. Totuşi, există două alte elemente stocate în memorie care pot beneficia de pe urma memoriei cache. În primul rând, programul, care execută codul de protocol pentru procesarea unui pachet, trebuie extras din memorie, dacă nu este stocat în I-cache. În al doilea rând, starea necesară pentru a procesa un pachet (tabelele de stări ale conexiunilor TCP) trebuie extrasă din memorie, dacă nu este stocată în d-cache. Din aceste două posibile concurente pentru lăţimea de bandă de memorie, codul de executat este o ameninţare mai serioasă. Aceasta deoarece starea (în bytes), necesară pentru procesarea unui pachet (de exemplu intrarea într-un tabel de conexiuni, sau într- un tabel de rutare), este în general mică. Totuşi, pentru un pachet mic de 40 bytes până şi aceasta poate fi semnificativă. Astfel, evitarea de câte ori este posibil, a utilizării unor stări redundante (care tinde să polueze d-cache),poate îmbunătăţi performanţa.
Codul necesar pentru executarea întregii stive de reţea (legăturile de date, TCP, IP, nivelul socket şi intrările/ieşirile kernel) poate fi mult mai mare. Masurările la Blackwell arată un cod de 34 KB utilizând implementarea TCP NetBSD din 1995. Ţinând cont că, chiar şi pachetele Ethernet mari au maxim 1,5 KB, efortul de a încărca codul din memorie face să pară nesemnificativ efortul de a copia pachetul de mai multe ori.
Dacă, de exemplu, I-cache are 8KB (tipic pentru sisteme mai vechi, cum ar fi sistemele alpha utilizate în Blackwell) înseamnă că cel mult un sfert din stiva de reţea poate intra în cache. Rezultatul e că toate codurile, sau cea mai mare parte a lor, trebuie aduse din memorie, de fiecare dată când un pachet trebuie procesat. Sistemele moderne nu şi-au îmbunătăţit semnificativ dimensiunea I-cache. Pentium III utilizează 16 KB. Astfel, utilizarea eficientă a I-cache poate fi o soluţie pentru îmbunătăţirea performanţei, în special pentru pachetele mici.
Sunt descrise două tehnici care pot îmbunătăţi eficienţa I-cache: aranjarea codului şi procesarea pe nivele
Aranjarea codului Este greu sa-ti dai seama când scrii un cod de reţea, că plasarea codului în memorie (deci în I-cache) are un grad de libertate (P13) care, cu puţin efort, poate fi exploatat. Ideea este de a plasa codul în memorie pentru a optimiza situaţiile comune (P11): codul utilizat frecvent să fie în I-cache pentru ca efortul de încărcare a I-cache să nu fie risipit.
Aparent, nu e necesar un efort suplimentar. Cache-ul ar trebui să favorizeze codul frecvent utilizat fată de cel utilizat mai rar, deci operatia ar trebui sa fie automată. Acest lucru nu se întîmplă însă din cauza modului de implementare a I-cache-ului.
• Maparea directă: Un I-cache este o mapare a adreselor de memorie la conţinutul lor; maparea este de obicei implementată de funcţie hash simplă optimizată pentru accesul secvenţial. Astfel, majoritatea procesoarelor au I-cache-uri mapate direct, unde biţii de ordin inferior ai unei adrese de memorie sunt utilizaţi pentru a indexa zona I-cache. Dacă biţii de ordin superior se potrivesc, conţinutul este returnat direct din cache; altfel, se
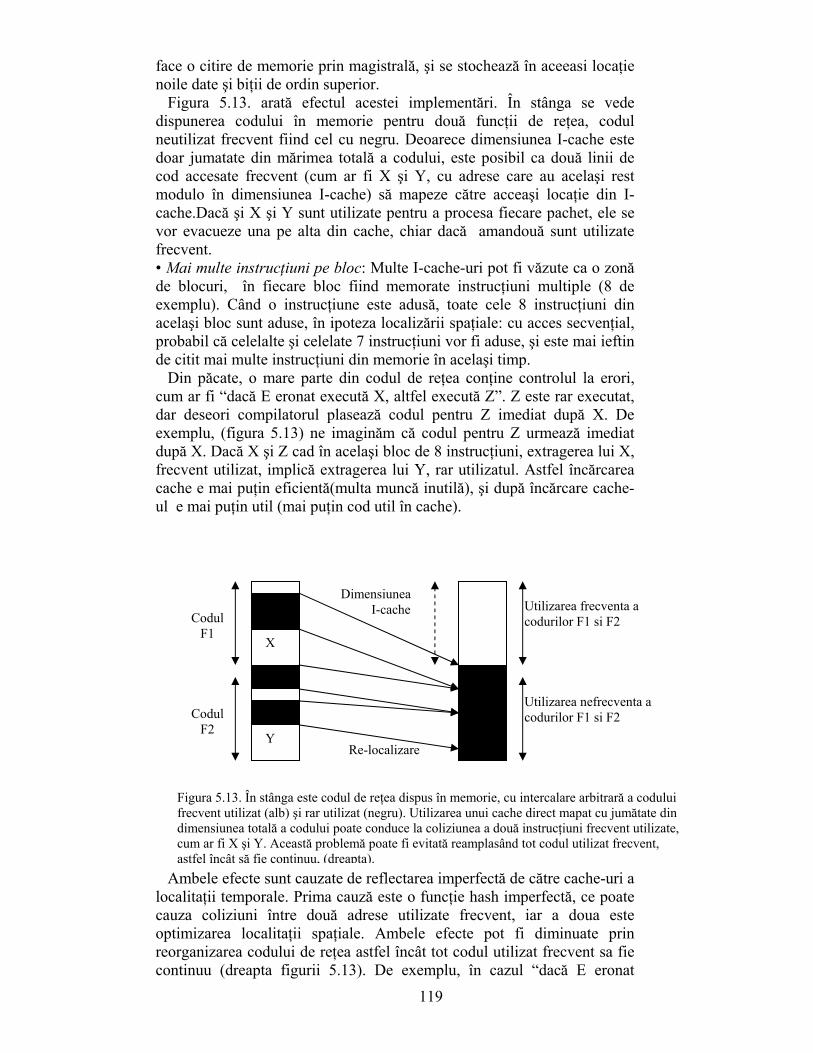
119
face o citire de memorie prin magistrală, şi se stochează în aceeasi locaţie noile date şi biţii de ordin superior.
Figura 5.13. arată efectul acestei implementări. În stânga se vede dispunerea codului în memorie pentru două funcţii de reţea, codul neutilizat frecvent fiind cel cu negru. Deoarece dimensiunea I-cache este doar jumatate din mărimea totală a codului, este posibil ca două linii de cod accesate frecvent (cum ar fi X şi Y, cu adrese care au acelaşi rest modulo în dimensiunea I-cache) să mapeze către acceaşi locaţie din I-cache.Dacă şi X şi Y sunt utilizate pentru a procesa fiecare pachet, ele se vor evacueze una pe alta din cache, chiar dacă amandouă sunt utilizate frecvent. • Mai multe instrucţiuni pe bloc: Multe I-cache-uri pot fi văzute ca o zonă de blocuri, în fiecare bloc fiind memorate instrucţiuni multiple (8 de exemplu). Când o instrucţiune este adusă, toate cele 8 instrucţiuni din acelaşi bloc sunt aduse, în ipoteza localizării spaţiale: cu acces secvenţial, probabil că celelalte şi celelate 7 instrucţiuni vor fi aduse, şi este mai ieftin de citit mai multe instrucţiuni din memorie în acelaşi timp.
Din păcate, o mare parte din codul de reţea conţine controlul la erori, cum ar fi “dacă E eronat execută X, altfel execută Z”. Z este rar executat, dar deseori compilatorul plasează codul pentru Z imediat după X. De exemplu, (figura 5.13) ne imaginăm că codul pentru Z urmează imediat după X. Dacă X şi Z cad în acelaşi bloc de 8 instrucţiuni, extragerea lui X, frecvent utilizat, implică extragerea lui Y, rar utilizatul. Astfel încărcarea cache e mai puţin eficientă(multa muncă inutilă), şi după încărcare cache-ul e mai puţin util (mai puţin cod util în cache).
Ambele efecte sunt cauzate de reflectarea imperfectă de către cache-uri a
localitaţii temporale. Prima cauză este o funcţie hash imperfectă, ce poate cauza coliziuni între două adrese utilizate frecvent, iar a doua este optimizarea localitaţii spaţiale. Ambele efecte pot fi diminuate prin reorganizarea codului de reţea astfel încât tot codul utilizat frecvent sa fie continuu (dreapta figurii 5.13). De exemplu, în cazul “dacă E eronat
X
Y
Codul F1
Codul F2
Dimensiunea I-cache Utilizarea frecventa a
codurilor F1 si F2
Utilizarea nefrecventa a codurilor F1 si F2
Re-localizare
Figura 5.13. În stânga este codul de reţea dispus în memorie, cu intercalare arbitrară a codului frecvent utilizat (alb) şi rar utilizat (negru). Utilizarea unui cache direct mapat cu jumătate din dimensiunea totală a codului poate conduce la coliziunea a două instrucţiuni frecvent utilizate, cum ar fi X şi Y. Această problemă poate fi evitată reamplasând tot codul utilizat frecvent, astfel încât să fie continuu, (dreapta).

120
execută X, altfel execută Z”, codul pentru Z poate fi mutat departe de X. Aceasta necesită adăugarea unei instrucţiune de salt la cod lui Z pentru ca acesta să poată reveni la codul ce urma după Z în versiunea neoptimizată. Cum saltul se face doar în caz de eroare nu reprezintă un cost mare.
Deci localizarea codului în memorie (P13) permite prima optimizare, a doua optimizare fiind a cazului cel mai probabil(P11), prin lungirea codului rar utilizat. Procesarea pe nivele
Reorganizarea codului poate ajuta până la un anumit punct, dar dă greş dacă zona de lucru (setul de instrucţiuni accesat pentru aproape fiecare pachet) depăşeşte dimensiunea I-cache. De exemplu, în figura 5.13. dacă dimensiunea albului, adică a instrucţiunilor frecvent utilizate este mai mare decât I-cache, reorganizarea codului va fi încă de folos (sunt necesare mai puţine încărcări din memorie, deoarece fiecare încărcare aduce instrucţiuni utile). Totuşi, fiecare instrucţiune va mai trebui adusă din memorie.
Dacă zona de lucru al stivei reţelei poate încăpea într-un I-cache modern (care este din ce în ce mai mare) e posibil ca protocoalele mai complicate (ce rulează TCP/IP ) să nu încapă. Ideea procesării pe nivele este utilizarea efectivă a I-cache cât timp codul fiecărui nivel al stivei reţelei încape în I-cache. Procesând repetat codul aceluiaşi nivel pntru mai multe pachete, costul încărcării I-cache-ului este împărţit pe mai multe pachete(P2c). În figura 5.14, la reprezentarea în timp a procesării convenţionale, toate nivelurile reţea ale pachetului P1 sunt procesate înainte celor ale pachetului P2. Dacă două pachete P1 şi P2 sosesc la un server, într-o implementare convenţională, se termină toată procesarea lui P1 începând cu nivelul legătură de date şi terminând cu nivelul transport, şi doar apoi se începe procesarea pachetului P2.
Ideea principală în procesarea localizată pe niveluri este de a exploata un alt grad de libertate (P13) şi de a procesa toate codurile unui nivel, pentru cât mai multe pachete posibil, înainte de a trece la nivelul următor. Astfel,
P1 P1 P1 P2 P2 P2 Legătura Reţea Transport Legătura Reţea Transport de date de date
Procesare convenţională
Timp P1 sosire P2
P1 P2 P1 P2 P1 P2 Legătura Legătura Reţea Reţea Transport Transport de date de date
Figura 5.14 Reprezentând în timp procesareaconvenţională, toate nivelurile de reţea ale pachetului P1 sunt procesate înaintea celor pentru pachetul P2. Într-o procesare
localizată pe niveluri a receptorului, codul fiecarui nivel este executat de mai multe ori, pentru pachetele multiple recepţionate, înainte de a trece la nivelul următor.
Procesare localizata pe niveluri.

121
după ce codul de nivel legătură de date pentru P1 este terminat, CPU trece la executarea codului de nivel legatură de date pentru P2 şi nu la codul de nivel reţea pentru P1. Corectitudinea ar trebui să nu fie afectată, deoarece codul unui nivel n-ar trebui să depindă de starea nivelurilor inferioare.Totuşi, procesarea integrată pe niveluri are câteva dependenţe subtile şi deci cazuri de eşec.
Astfel, dacă codul pentru fiecare nivel încape în I-cache (de exemplu codul nivelului legatura de date) dar nu încape codul pentru toate nivelurile, atunci această optimizare amortizează costul încărcării I-cache pentru mai multe pachete. Se utilizează procesarea pe loturi (P2c): cu cât lotul este mai mare, cu atât I-cache este utilizată mai eficient.
Implementarea poate adapta dinamic dimensiunea lotului. Codul poate procesa o serie de până la k pachete, din coada de pachete sosite( k este un parametru care limitează latenţa). Dacă sistemul este slab încărcat, atunci un singur mesaj va fi procesat la un moment dat. Dacă sistemul este puternic încărcat, se creşte dimensiunea lotului, crescând astfel când e nevoie, eficienţa utilizării lărgimii de bandă a memoriei.
Consideraţii de inginerie software Optimizările de gen restructurarea codului (figura 5.13.) şi procesarea
localizată pe niveluri(figura 5.14.) trebuie evaluate şi ţinând cont de efectele lor asupra modularităţii codului şi mentenanţei. S-ar putea rescrie kernel-ul şi toate aplicaţiile, utilizând un limbaj de asamblare pentru o optimizare perfectă a utilizării lărgimii benzii memoriei. Dar ar fi greu de a face codul să ruleze corect sau să fie uşor de întreţinut.
Restructurarea de cod este cel mai bine realizată de un compilator. De exemplu, codul ce manevrează erorile, poate fi adnotat cu indicii care să sugereze ramificaţiile cele mai frecvente (evidente, în general, pentru un programator) şi cu un compilator completat special, care poate restructura codul pentru localizarea I-cache.
Pe de altă parte, procesarea localizată pe nivele păstrează modularitatea în interiorul nivelurilor. Comunicarea între niveluri trebuie modificată după cum urmează. Dacă fiecare cod de nivel pasează un pachet către codul unui nivel superior cu o procedură de apel, acest cod trebuie modificat să adauge pachetele pentru nivelul superior într-o coadă. Similar, când un nivel este apelat, el scoate pachete din coada sa de citire până când aceasta este terminată; după procesarea fiecărui pachet, îl plasează în coada pentru următorul nivel superior. Această strategie funcţionează corect când fiecare nivel poate reutiliza buffer-ele de la alte niveluri, aşa cum este cazul mbuf-urilor UNIX. În ansamblu, modificările codului ar putea să nu fie majore. 5.6.2. Accesul direct la memorie DMA versus I/O programate
Secţiunile anterioare au afirmat că schema Witless utilizează I/O programate, sau PIO (procesorul este implicat în transferul fiecărui cuvânt între memorie şi adaptor), în timp ce alte scheme, cum ar fi VAX Clusters utilizează DMA (unde adaptorul copiază datele direct în memorie). Poate părea că DMA este întotdeauna mai bună decât PIO. Totuşi, comparaţiile

122
între DMA şi PIO sunt complicate deoarece fiecare metodă are implicaţii subtile pentru utilizarea per total a lărgimii de bandă de memorie.
De exemplu, PIO are avantajul că datele circulă prin procesor şi astfel ajung în cache-ul procesorului, prevenind pierderile de lăţime de bandă a memoriei la accesul secvenţial. Deasemenea, cu PIO e mai uşoară integrarea altor funcţii, cum ar fi verificarea sumei de control, fără să fie necesar un adaptor hardware care să facă aceeaşi funcţie.
Totuşi, unele studii au arătat că dacă datele sosite sunt utilizate mult mai târziu de către aplicaţie, atunci plasarea datelor în d-cache prea devreme este o risipă a d-cache şi mai degrabă scade decât creşte rata de succes a cache. Pe de altă parte DMA poate fura cicluri de la CPU şi necesită deasemenea o atentă invalidare a cache-ului când datele sunt scrise într-o locaţie de memorie(care poate fi tot în cache). Alegerea se face de la caz la caz, din considerente arhitecturale şi de aplicaţie . 5.7. CONCLUZII
Pe măsură ce reţelele devin mai rapide legăturile, cum ar fi Gigabit Ethernet, sunt deseori mai rapide decât magistralele interne şi memoriile din calculatoare sau servere. Astfel, lărgimile de bandă de memorie/magistrale sunt resurse cruciale. Au fost descrise tehnici de optimizare a utilizării lărgimii de bandă de memorie/magistrală pentru procesare de pachete IP şi Web, care reprezintă traficul Internet dominant. S-a arătat cum să înlăturăm copiile redundante implicate în procesarea unui pachet IP utilizând memoria adaptorului sau remaparea memorie virtuale. Apoi s-a arătat cum să îndepărtăm copiile redundante implicate în procesarea cererilor Web la un server, prin generalizarea remapării memoriei virtuale, pentru a include sistemul de fişiere sau prin combinarea sistemului de fişiere şi reţelei I/O într-un singur apel de sistem. Apoi s-a arătat cum să combinăm diferite manipulări de date simultan. Toate aceste tehnici necesită schimbări în aplicaţie şi kernel dar schimbările sunt destul de localizate şi majoritatea păstrează modularitatea.
În final s-a arătat că, dacă nu se are grijă, procesarea protocolului poate face nesemnificativă suprasarcina datorată copierii şi au fost descrise tehnici de optimizare a cache-ului de instrucţiuni. Serverele Web moderne pot fi deja optimizate pentru implementări zero-copii utilizând apeluri de sistem de tipul sendfile (). Totuşi, astfel de servere încă consumă cicluri de processor aşteptând memorie. Astfel, tehnici de îmbunătăţire a eficienţei I-cache pot oferi următoarea etapă de optimizări pentru serverele Web. Figura 5.1. prezintă un sumar al tehnicilor utilizate în acest capitol, împreună cu principiile majore implicate.
Dar nu au fost eliminate toate problemele de performanţă implicate în construirea unui server Web modern. Site-uri Web complexe, cum ar fi amazon.com utilizează adesea mai multe niveluri de procesare pentru a răspunde cerinţelor Web (un server aplicaţie, un server Web şi un server bază de date). Serverele Web bază de date introduc noi constrângeri care pot necesita noi tehnici în afară de cele descrise aici. Totuşi, principiile de bază ar trebui să rămână aceleaşi.
Referitor la principii, capitolul se ocupă cu utilizarea repetată a P1, de evitare a pierderilor evidente, ca citiri şi scrieri inutile consumatoare de

123
lăţime preţioasă de bandă de memorie/magistrală. La prima privire, principiul P1 pare stupid . Ceea ce face acest principiu mai profund este că pierderea devine vizibilă doar dacă analiza este extinsă la întregul sistem, sau la cea mai mare parte din el.În interiorul fiecărui subsistem local (de exemplu aplicaţie-kernel, kernel-retea, disc-sistem de fişiere) nu există risipă de lăţime de bandă de memorie. Doar atunci când se urmăreşte traseul unui pachet recepţionat se descoperă redundanţa dintre copiile aplicaţie-kernel şi kernel-reţea. Doar atunci când se extinde vederea şi mai departe pentru a observa distorsiunile implicate în răspunsul la o cerere Web se observă redundanţele care implică sistemul de fişiere. Doar atunci când se extinde şi mai mult vederea se văd toate manipulările implicate în procesarea unui pachet şi citirile inutile din memorie. În sfârşit, doar atunci când se examinează încărcarea instrucţiunilor se vede posibilitatea alarmantă ca codul protocolului să fie de câteva ori mai mare decât dimensiunea pachetului.
Astfel, utilizarea primului principiu al algoritmilor de reţea necesită o vedre sinoptică a întregului sistem, de la http şi anteteele sale la sistemul de fişiere şi la cache-urile de instrucţiuni. Deşi complexitatea pare descurajantă, s-a argumentat deja că modelele simple de hardware, arhitectură, sisteme de operare şi protocoale pot face posibilă o astfel de vedere globală. De exemplu, I-cache-urile au câteva variante complexe, dar un model simplu, de mapare directă I-cache cu multiple instrucţiuni per bloc, e uşor de ţinut minte de proiectantul unui sistem de operare.
Comparate cu eleganţa şi complexitatea tehnicilor teoretice, cum ar fi algoritmul elipsoid pentru programarea lineară şi teoria lanţurilor Markov cu mixaj rapid, tehnicile de sistem, cum ar fi evitarea copierii, par lipsite de strălucire şi superficiale. Totuşi, se poate argumenta că complexitatea sistemului nu se referă la profunzime(complexitatea fiecărei componente în parte) ci la ansamblu(relaţiile complexe dintre componente). Poate că gradul de înţelegere (HTTP, sistemul de fişiere, codul de reţea, implementarea cache-ului de instrucţiuni) necesar pentru a optimiza lăţimea de bandă de memorie într-un server Web pledează pentru această lucrare. 5.8. EXERCIŢII
1. Memorii cache de date şi copii: o memorie cache de date normală mapează de la o adresă de locaţie de memorie la o piesă de conţinut. Cand conţinutul e accesat frecvent, atunci poate fi accesat direct din cache, în loc sa se faca un acces la memorie. Presupunând că memoria cache este de tip write-back, chiar şi scrierile pot fi facute în cache în loc de memorie şi sunt scrise în memorie doar când cache-ul e supra-încărcat. Un bloc cache modern e destul de mare (128 biţi), cu mapari de la adrese de 32 de biţi la 128 de biţi, de date începând cu acea adresă.
Abordăm problema copierii, unde diferite module(inclusiv reţeaua şi sistemul de fişiere) copiază date prin intermediul buffer-elor care devin curând supra-încărcate (de exemplu, buffer-ul socket, buffer-ul aplicaţie). lucru făcut pana acum cu modificări software. Analizam acum dacă schimbarea arhitecturii hardware poate ajuta, fără modificări software ca IO-Lite, fbufs şi mmap.

124
• Chiar şi un cache de date obişnuit poate ajuta la îndepărtarea unor supraincarcari când copiem date de la locaţia L la locaţia M. Explicaţi de ce. (Presupunem că locaţia M este un buffer temporar care este în curând supraînscris, ca si un buffer socket. Presupunem că dacă un singur cuvânt este scris într-un bloc cache mare, cuvintele rămase pot fi marcate ca invalide.) Intuitiv, problema e dacă există un echivalent al copierii-la-scriere (utilizată pentru a reduce copierea între spaţiile adreselor virtuale) folosind cache-uri de date. • Acum presupunem o proiectare diferita a cache-ului de date, unde un
cache este o mapare de la una sau mai multe adrese la acelaşi conţinut. Astfel, un cache s-a modificat de la o mapare unu-la-unu la o mapare mai multe-la-unu. Presupunem un cache unde două locaţii pot pointa către acelaşi conţinut. O intrare cache poate fi (L,M,C), unde L şi M sunt adrese şi C este conţinutul comun al lui L şi M. Un acces la memorie la oricare L sau M va returna C. Care este avantajul faţă de schema precedentă ? • Totul e foarte ipotetic si ciudat. Comentaţi dezavantajele ideii din
cazul precedent. Multe cache-uri utilizează tehnica numită asociativitatea multimilor/set associativity, unde o simplă funcţie hash (de exemplu biţii de ordin inferior) este utilizată pentru a selecta un set mic de intrări cache, pe care hardware-ul le parcurge în paralel. De ce ar putea adresarea multiplă per intrare cache să interacţioneze slab cu căutarea prin asociativitatea multimilor ?
2. Optimizări de nivel aplicaţie pentru servere Web: sisteme de operare ca Exokernel permit aplicaţiei să particularizeze kernelul in beneficiul său, fără a compromite securitatea altor aplicaţii. O optimizare interesantă este combinarea TCP final FIN cu citirea ultimului segment de date (optimizare permisă de TCP). • De ce această optimizare ajută transferurile Web mici, obişnuite? • De ce este această optimizare greu de realizat într-un server Web
obişnuit şi mai uşor de realizat dacă aplicaţia este integrată în kernel, ca în Exokernel? • Cum poate fi deplasată această optimizare într-un server Web obişnuit
pasând informaţie prin interfaţă (P9) fără a compromite siguranţa? 3. Copiere inversă: emularea copierii-la-scriere are un grad de libertate
interesant (P13) pentru copiere paginilor-aliniate de date între două module (să zicem, sistem şi aplicaţie). Imaginaţi-vă că doriţi să copiaţi o pagină parţială dintr-o pagină de aplicaţie, X, într-o pagină de sistem,Y. Dacă pagina este plină presupuneţi că puteţi schimba cele două pagini eficient. Presupuneţi că pagina parţială are date utile D şi o rămăşiţă R. • Dacă volumul de date D este mic comparativ cu R e mai simplu să
copiem D în pagina destinaţie Y. Dar dacă D e mare (aproape toată pagina) comparativ cu R, imaginaţi o strategie simplă pentru a minimiza copierea. De reţinut că dacă pagina destinaţie Y are alte date în restul de pagină aceste date trebuie să rămână şi după copiere. • Care e criteriul de alegere între aceste două strategii?

125
CAPITOLUL 6 CONTROLUL TRANSFERULUI
Într-o companie plata unei facturi durează 6 luni. Factura ajunge prima dată în poştă, petrece ceva timp pe biroul secretarei, ajunge pe biroul celui care ia principalele decizii şi ajunge în sfârşit la contabil. La procesarea facturii, fluxul de control îşi urmează calea prin diferite straturi de comandă, fiecare adăugând un antet semnificativ. Un consultant de management sugereaza scurtarea procesarii facturii elimininand straturile intermediare când e posibil, şi facand fiecare nivel cât se poate de selectiv. Totuşi, fiecare nivel are câteva motive de a exista. Camera de poştă îmbină serviciul de livrare a poştei pentru toate departamentele companiei. Secretara protejează şeful de întreruperi şi elimină cererile nepotrivite. Şeful trebuie eventual să decidă dacă factura merită plătită. Detaliile de alocare a banilor sunt decise de contabil.
Un CPU modern, care procesează un mesaj de reţea, trece prin nivele similare de mediere. Dispozitivul (un adaptor Ethernet) întrerupe CPU, solicitand atenţie. Controlul este pasat la kernel, care comasează întreruperile cand e posibil, face procesarea pachetului la nivelul reţea şi planifică să ruleze procesul aplicaţie (un server Web). Recepţia unui singur pachet oferă o vedere limitată a contextului global de procesare. De exemplu, un server Web va analiza cererea din pachetul de reţea, va căuta fişierul şi va iniţializa extragerea fişierului de pe disc. Când fişierul este citit în memorie, este trimis înapoi un răspuns conţinând fişierul cerut, adăugând un antet HTTP.
A fost analizata reducerea supraincarcarii creata de operaţiile cu date (copiere, verificarea sumei de control). Va fi analizata reducerea supraincarcarii creata de controlul implicat în procesarea unui pachet (trimiterea/recepţia unui pachet) si apoi la aplicatia de reţea, serverul Web.
Număr Principiu Utilizare P8 Trecerea dincolo de apelurile de sosire
utilizate în specificaţii Apel de plecare
P8 Procesare pe mesaj, nu pe nivel x-Kernel P13 Protocol de legătură implementat cu cod
utilizator Potrivirea variantelor
P13 Proces per acces la disc Flash P13 Modularizare pe sarcini, nu pe clienţi Server Web Haboob P4 Mapări VM pentru evitarea copiilor
în cache şi aplicaţie Flash
P15 Arbore bitmap ufalloc() rapidă P12a P9 P12
Calculul incremental al vectorului de interes Pasarea indiciilor de la protocol la select() Reţinerea intereselor de-a lungul apelurilor
select() rapidă
P3c P2
Mutarea protecţiei din kernel în adaptor Autorizarea adaptorului de către Kernel la iniţializare
ADC-uri
P13 Intreruperi comasate de procese Majoritatea OS P2b Executarea protocolului în contextul
procesului de recepţie LRP
Figura 6.1. Tehnici de reducere a antetelor de control si principiile corespondente

126
6.1 Suprasarcina generata de control Capitolul precedent a analizat suprasarcina cauzata de copiere într-un
server web (arătând potenţialele copii implicate în răspunsul unui server la o cerere get, fig.5.2). Figura 6.2 arată potenţialele suprasarcini generate de controlul dintr-un server Web mare care deserveşte mai mulţi clienţi (sunt ignorate aspectele transferului de date). E prezentata o vedere arhitecturală simplificată, axată pe interacţiunea controlulului dintre adaptorul de reţea şi CPU (prin intreruperi), între aplicaţie şi kernel (prin apelul de sistem) şi între diferite procese de nivel aplicaţie sau thread-uri (prin apeluri la planificator). Pentru simplitate e dat doar un CPU în server (multe servere sunt multiprocesor) şi un singur disc (unele servere utilizează discuri multiple şi discuri cu capete multiple). Serverul poate servi un număr mare /mii de clienţi concurenţi.
Pentru a înţelege posibilele suprasarcini generate de control, implicate in deservirea unei cereri GET, presupunem că clientul a trimis o cerere TCP SYN, care soseşte la adaptor, de la care este plasată în memorie. Kernelul este apoi informat de această sosire prin intermediul unei întreruperi. Kernelul anunţă serverul Web prin deblocarea unui apel de sistem anterior; aplicaţia serverului Web va accepta conexiunea dacă are resurse sufiente.
În pasul 2 al procesării, unele procese ale serverului parcurg cererile
Web. Presupunem că cererea este GET fisier1. În pasul 3, serverul trebuie să localizeze fişierul pe disc, navigand prin structurile de directoare, care pot fi deasemenea stocate pe disc. Odată fişierul localizat, în al 4-lea pas, procesele server iniţiază un Read spre sistemul de fişiere (alt apel de sistem). Dacă fişierul este în cacahe-ul de fişiere, cererea Read poate fi satisfăcută repede; altfel, subsistemul de fişiere iniţiază o căutare pe disc pentru a citi datele de pe disc. După ce fişierul este în buffer-ul aplicaţiei,
TCP/IP Sistem fisiere
Client 1...Client 50 Client 51...Client 74 Client 75
Adaptor de retea
Retea
DiscMemorieBus
Pachet receptionat
CPU
write() read() FindActive()
Proces per grup; grupuri definite de structura aplicatiei
Aplicatia serverului Web
Kernel
Figura 6.2. Antetul de control implicat in manipularea unei cereri GET la un server

127
serverul trimite răspunsul HTTP, prin scrierea conexiunii corespunzătoare (alt apel de sistem).
Pînă acum, singurele suprasarcini generate de control par să fie apelurile de sistem şi întreruperile, dar asta deoarece nu au fost examinate îndeaproape structura reţelei şi codul aplicaţiei.
În primul rand, pentru un cod structurat naiv, cu un singur process per nivel în stivă, atunci suprasarcina generata de planificarea proceselor (de ordinul sutelor de microsecunde) pentru procesarea unui pachet, poate fi cu uşurinta mult mai mare decât timpul de sosire al unui singur pachet. Această potenţială suprasarcina generata de planificare este arătată în figura 6.2 cu linie punctată spre codul TCP/IP din kernel. Din fericire, cele mai multe coduri de reţea sunt structurate mai mult monolitic, cu un antet de control minim, deşi unele tehnici mai inteligente pot face si mai bine.
În al doilea rând, descrierea procesării web s-a axat pe un singur client. Deoarece presupunem un server Web mare ce lucrează concurent pentru mii de clienţi, nu e clar cum ar trebui structurat acesta. La o extrema, fiecare client este un process separat (sau thread) rulând codul serverului Web si concurenţa este maximizată (pentru că atunci când clientul 1 aşteaptă pentru o citire de pe disc, clientul 2 ar putea trimite pachete de reţea) cu costul mare al suprasarcinii generata de planificarea procesului.
Pe de altă parte, dacă toţi clienţii sunt serviţi de un singur proces lansat de evenimente, pierderea datorată schimbării contextului este minimizată, dar procesul unic trebuie să-şi planifice intern clienţii, pentru a maximiza concurenţa si trebuie să stie când sunt gata citirile fişierului şi când au sosit datele de reţea.
Multe sisteme de operare oferă un apel de sistem in acest scop, numit generic FindActive () în figura 6.2. In Unix, numele sau este select (). Dar daca un apel de sistem gol e costisitor din cauza depăşirii limitei kernel-aplicaţie, o implementare select() ineficientă poate fi si mai costisitoare.
Dar raman intrebări provocatoare ca structurarea reţelei şi a codului serverului în ideea minimizarii suprasarcinii generata de planificare şi maximizarii concurenţei. Din acest considerent, figura 6.2 arată clienţii partiţionaţi în grupuri, fiecare din acestea fiind implementat într-un singur proces sau thread. De remarcat ca suprasarcina generata de planificare tuturor clienţilor într-un singur grup determina abordarea lansata-de-evenimente, iar plasarea fiecarui client într-un grup separat determina abordarea proces/thread -per-client.
Astfel, o implementare neoptimizată poate implica suprasarcini considerabile datorate comutării proceselor (sute de sμ ) dacă aplicaţia şi codul de reţea sunt prost structurate. Chiar dacă este eliminata suprasarcina structurării-proceselor, apelurile-sistem pot costa zeci de sμ , iar întreruperile sμ (la o legătură Ethernet de 100 Gbps un pachet de 40 bytes poate sosi la PC la fiecare 3,2 sμ ).
Dat fiind faptul că legăturile de 10 Gbps se raspandesc, trebuie acordată mai multă atenţie suprasarcinii generata de control. Dar, desi procesoarele au devenit mai rapide, suprasarcina generata de control asociata cu comutarea contextului, apelurile-sistem şi întreruperile nu s-au imbunatatit in acelasi ritm. Unele progrese au fost făcute cu sisteme de operare mai eficiente, ca Linux, dar progresul nu este suficient pentru a ţine pasul cu vitezele pe legătură crescânde.

128
6.2. Evitarea suprasarcinii generata de planificare în codul de reţea. Una din marile dificultăţi în implementarea unui protocol este de a
echilibra modularitatea (să implementezi un sistem mare pe părţi şi să faci fiecare parte bine, independent de celelalte) şi performanţa (să faci să funcţioneze bine intreg sistemul). Să considerăm exemplul simplu de implementare a unei stive de reţea. “Modularitatea evidentă” ar fi implementarea ca procese separate a protocolului de transport (TCP), a protocolului de rutare (IP), şi a aplicaţiei. In acest caz, fiecare pachet recepţionat ar trece prin cel puţin două comutari de context a procesului, care sunt costisitoare.
Există totuşi alternative care permit si modularitate şi eficienţă. Fie o aplicaţie simplă (fig.6.3) care citeşte date de la tastatură şi le trimite în reţea, utilizând un protocol de transport. Când acestea sunt recepţionate de un receptor din reţea sunt afişate pe ecran. Pe verticala sunt arătate diferite nivele de protocol, sus fiind protocolul aplicaţie, apoi protocolul transport şi jos protocolul de reţea. O implementare naiva a acestui protocol ar fi să avem un protocol per secţiune, adica trei procese şi două schimbări complete de context per pachet primit/trimis.
Pot fi utilizate doar două procese la transmiţător şi două la receptor (pe verticala) pentru a implementa stiva protocoalelor de reţea. Procesele receptorului sunt in stânga, iar procesele transmiţătorului in dreapta. Astfel, transmiţătorul are un proces de manevrare a tastaturii/Keyboard Handler care capteaza datele in/din tastatura, si cand are ceva date, apeleaza transport-arm-to-send, care este o functie de nivel transport, exportata spre procesul de manevrare a tastaturii si executata de acesta. In acest moment, procesul de manevrare a tastaturii se poate autosuspenda (comutarea contextului). Transport-arm-to-send spune protocolului de transport ca acea conexiune doreste sa transmita date, dar el nu transfera date.
Procesul transmisie-transport poate să nu transmită datele imediat, din cauza limitărilor impuse de controlul fluxului. Dacă dispar condiţiile impuse de controlul fluxului (datorită sosirii unor confirmări/ack), procesul de transmisie, SendProcess va executa rutina transport-send pentru această conexiune. Apelul send va chema mai intâi protocolul aplicaţie care va exporta rutina display-get-data care furnizează de fapt, aplicaţiei datele. Acest lucru este avantajos, deoarece e posibil ca aplicaţia să fi recepţionat mai multe date de la tastatură în timp ce protocolul de transport este pregătit pentu a trimite, şi se pot trimite deodată mai multe date, câte incap într-un pachet. In final, în contextul aceluiaşi proces, protocolul transport adaugă un antet de nivel de transport şi apelează protocolul de nivel reţea pentru a transmite efectiv pachetul.
La partea de receptor, pachetul este primit de către handlerul întreruperilor de recepţie care, folosind o rutină de reţea numită net-dispatch, trebuie să găsească cărui proces să-i expedieze pachetul. Pentru a afla procesul, net-dispatch apelează portul-primire-transport, care de fapt este o rutină exportată de către nivelul transport, care citeşte numerele portului din antet pentru a-şi da seama care aplicaţie (de ex. FTP) trebuie să manevreze pachetul. Apoi se comută contextul şi handlerul de recepţie

129
recâştigă controlul şi atenţionează procesul de recepţie, care execută funcţiile de reţea-transport, şi în final codul aplicaţiei pentru afişarea datelor. De menţionat că un singur proces execută toate nivele protocolului.
Ideea a fost neobişnuită la acel timp din cauza prejudecăţii că nivelurile ar trebui să folosească doar serviciile oferite de nivelurile inferioare; apelurile între niveluri se numeau downcalls (cerute de specificaţiile protocolului). Dar nu sunt singurele alternative pentru implementările protocolului. In exemplul prezentat, pentru obţinerea datelor sunt folosite apelurile de tip upcalls (apeluri pentru afişarea datelor, display-get-data), respectiv upcalls-uri pentru avizarea nivelurilor superioare (upcalls-uri spre transport-get-port).
Deşi upcalls-urile sunt de obicei folosite în implementări reale, probabil nu este nici o diferenţă între upcalls-uri şi procedura standard de apel, cu excepţia noutăţii în contextul implementării reţelei pe niveluri. Ideea mai importantă, este a folosirii doar a unul/două procese pentru procesarea unui mesaj, fiecare proces constând din rutine a două sau mai multe niveluri de protocol. Ideea a fost folosită în sisteme ca x-Kernel şi în folosirea reţelor la nivelul utilizatorului, descrisă în secţiunea următoare.
Ideea folosirii structurilor alternative de implementare, care conservă modularitatea fără să sacrifice performanţa, este un exemplu al principiului P8. Fiecare nivel din protocol poate fi implementat modular, dar rutinele de tip upcall pot fi înregistrate de nivelele superioare când sistemul porneşte.
6.2.1. Aplicarea implementării protocolului la nivel de utilizator. Majoritatea maşinilor moderne nu implementează fiecare nivel de
protocol în procese separate. In UNIX, toate codurile de protocol (transport, reţea, legătură de date) sunt manevrate ca parte a unui singur
afisare-date primite transport-date primite retea- receptie
transport-alocare port retea- expediere
afisare-date transport-transmisie retea- transmisie
manipulator tastatura transport-pregatit de transmisie
Proces de receptie
Manipulator de receptie intreruperi
Proces transmitator
Manipulator tastatura
Figura 6.3. Implementarea unui protocol utilizand apeluri de transmisie
Intrerupere

130
“proces” nucleu/kernel-ul. Când un pachet soseşte prin intermediul unei întreruperi, handlerul de întreruperi notează sosirea pachetului, posibil îl memorează într-o coadă şi apoi planifică un proces nucleu (printr-o întrerupere software) pentru procesarea propriu-zisă a pachetului.
Procesul nucleu execută codurile de nivel legatură de date-reţea-transport (folosind upcalls-uri); citind numerele porturilor de transport, procesul nucleu află aplicaţia şi o lansează. Astfel, fiecare pachet este procesat, prin cel puţin două comutări; una de la contextul întreruperii la procesul nucleu manevrând protocolul, şi una de la procesul nucleu la procesul care rulează codul aplicaţiei (ex. Web, FTP).
Figura 6.4 Demultiplexarea unui pachet spre procesul destinaţie final, folosind un proces intermediar de demultiplexare, este costisitoare
Implementarea protocoalelor la nivel-utilizatorul e arătată în procesul de
primire (fig.6.3) unde handlerul de protocol rulează în acelaşi process ca aplicaţia şi poate comunica folosind upcalls-uri. Implementările la nivel-utilizator pot avea două avantaje. Putem să nu folosim nucleul şi să trecem de la handlerul de întreruperi direct către aplicaţie, economisind o comutare de context. Codul protocolului poate fi scris şi depanat (debugged) în spaţiul-utilizatorul (programele de depanare functionează bine în spaţiul utilizatorului şi nu prea bine în nucleu).
Solutia extremă aparţine lui Mach, care a implementat toate protocoalele în spaţiul utilizatorului, iar protocoalelor au fost create mai generale decât în fig 6.3. Astfel, când un handler de întreruperi de recepţie primeşte un pachet, nu poate spune cu uşurinţă care este procesul spre care să fie trimis pachetul (deoarece implementarile la nivel-reţea din procesul final conţin codul de demultiplexare). In particular, nu se poate face doar un apel-transport pentru a examina numerele portului (ca în exemplul din fig 6.3) deoarece putem avea o mulţime de protocoale de transport/reţea posibile.
Initial, metoda naivă (fig 6.4) implica un proces de demultiplexare separat, care să primeasca toate pachetele şi să le examinaze determinând procesul destinaţie final, spre care să expedieze apoi pachetul. Dar noul proces de demultiplexare adaugă de fapt comutatorul de context lipsă.
Ideea simplă de remediere a acestei situaţii, este de a transmite o informaţie suplimentară (P9) prin interfaţa aplicaţie-nucleu, ca fiecare aplicaţie să poată informa ce fel de pachete doreşte să proceseze (fig. 6.5). De exemplu, o aplicaţie de e-mail doreşte toate pachetele cu câmpul Ethernet-IP, al căror număr de protocol IP specifică TCP, şi având numărul portului TCP destinaţie 25 (aplicaţie de mail implementează IP, TCP şi mail). Pentru a face aceasta, nucleul defineşte o interfaţă, care de obicei este o formă de limbaj de programare. De exemplu, primul a fost CSPF (CMU Stanford Packet Filter), care specifică câmpurile pachetelor

131
folosind un limbaj de programare bazat pe stive. Mai raspandit este BPF (Berkeley Packet Filter) care foloseşte un limbaj de programare bazat pe stive; un limbaj mai eficient este Path Finder.
Trebuie să fim atenţi la transmiterea informaţiei de la o aplicaţie la nucleu, ca aplicaţiile greşite sau maliţioase să nu poată distruge nucleul. Trebuie evitate acele aplicaţii care generează coduri arbitrare nucleului, ce duc la dezastre. Din fericire, există tehnologii software care pot încapsula codurile străine, în “sandbox”, astfel încât să poată face rău doar în spaţiul de memorie alocat lor (sandbox-ul propriu). De exemplu, un limbaj bazat pe stive poate fi pus să lucreze pe o stivă cu mărime specificată cu graniţe controlate în fiecare punct. Această formă de tehnologie a culminat recent în executarea applet-urilor Java arbitrare primite din reţea (applet-ul este un program scris în Java, ce poate fi integrat în alt program, fiind independent de limbajul de programare în care se integrează appletul)
Dacă pachetele sunt expediate de la handlerul de întreruperi al nucleului (folosind o serie de filtre de pachete) către procesul de recepţie, acesta ar trebui să implementeze stiva protocolului. Repetarea codului TCP/IP în fiecare aplicaţie ar genera foarte mult cod redundant. Astfel, în asemenea sisteme, TCP este implementat ca o bibliotecă partajată cu legături (este folosită o singură copie, spre care aplicaţia are pointer, dar codul este scris în modul reentrant, pentru a permite reutilizarea).
Aceasta nu e atât de uşor cum pare deoarece există unele stări TCP comune tuturor conexiunilor, chiar dacă majoritatea sunt stări TCP specifice unor conexiuni. Există şi alte probleme, deoarece ultima scriere făcută de o aplicaţie ar trebui să fie retransmisă aplicaţiei de către TCP, dar aplicaţia ar putea sa-şi termine procesul după ultima scriere. Oricum, aceste probleme pot fi rezolvate. Au fost scrise implementări la nivel utilizator cu performanţe excelente, care exploatează gradul de libertate (P13) adică protocoalele nu trebuie implementate în nucleu.
6.3. Evitarea în aplicaţii, a suprasarcinii comutarii contextului A fost tratata evitarea suprasarcinii dată de planificarea proceselor, la
procesarea unui singur pachet primit din reţea, prin limitarea procesării la domeniul întreruperilor (care poate de asemenea fi eliminată/diminuată când se prelucrează mai multe pachete) şi expedierea pachetului către procesul final aplicaţie (care procesează pachetul). Daca procesul destinaţie rulează în acel moment, nu va exista o supraîncărcare cauzată de

132
planificarea proceselor. Astfel, după toate optimizările, nu va apărea o suprasarcină dată de controlul procesării pachetului, asemanator cu procesarea unui pachet primit, cu zero copii. Dupa analiza procesării complete a aplicaţiei, vom vedea că apar alte copii redundante, cauzate de interacţiuni cu sistemul de fişiere.
Acum extindem analiza dincolo de procesarea unui singur pachet, pentru a vedea cum procesează pachetele o aplicaţie. Considerăm din nou un server Web tipic, important în practică (fig 6.2), care trebuie făcut mai eficient. El manipuleaza un număr mare de conexiuni: un server proxy TCP→UDP de telefonie poate manevra 100 000 de conexiuni concurente.
Cum ar trebui structurat un server Web? Inainte, trebuie să înţelegem concurenţa posibilă dintr-un singur server Web. Chiar cu un singur CPU şi un singur disc e posibilă concurenţa. Presupunem că într-o procesare apare o citire a fişierului 1, care nu se află în memoria cache. Astfel CPU initiază o citire a discului, care necesită câteva milisecunde. Dar pentru CPU, care poate rezolva o instrucţiune aproape la fiecare nanosecundă, timpul ar fi irosit dacă ar aştepta terminarea citirii. O posibilitate este comutarea procesării spre un alt client, în timp ce are loc citirea discului pentru clientul 1. Aceasta permite ca procesarea discului pentru clientul 1, să fie suprapusă cu procesarea CPU pentru clientul 2.
Un al doilea exemplu de concurenţă CPU/dispozitiv (tipic pentru un server Web) este suprapunerea dintre operaţiile I/O ale reţelei (realizată de adaptor) şi CPU. De exemplu, după ce serverul acceptă o conexiune, poate face pentru clientul 1 o citire a conexiunii acceptate. Citirea conexiunii poate dura câteva milisecunde, deoarece clientul distant trebuie să trimita pachetul, care trece prin reţea, şi în final e scris de adaptor pe socket-ul din server corespunzător clientului 1.Comutarea la un alt client, face ca procesarea reţelei pentru clientul 1, să se suprapună cu procesarea CPU pentru alt client. La fel, când se face o scriere către reţea, scrierea poate fi blocată din cauza lipsei de buffer-e la socket. Buffer-ul poate fi eliberat mult mai târziu, cand sosesc confirmari ACK de la destinaţie.
Pentru creşterea eficienţei unui server Web, trebuie exploatată orice posibilitate de concurenţă. CPU–ul serverului Web trebuie să comute între clienţi, când un client este blocat în aşteptarea unei I/O.
6.3.1. Procese per client Pentru un programator, cea mai simplă cale de implementare a unui
server Web este să structureze procesarea fiecărui client ca un proces separat, adică fiecare client se află singur într-un grup separat (fig 6.2). Planificatorul sistemului de operare comută între procese, repartizând un proces nou CPU-ului, când procesul curent este blocat. Majoritatea sistemelor de operare moderne pot lucra cu mai multe CPU-uri, şi să le planifice astfel încât toate CPU-urile să aibă o activitate utilă de câte ori este posibil. Astfel, sistemul de operare jongleaza între clienti, în contul aplicaţiei, şi nu aplicaţia serverului Web. Dacă de exemplu, clientul 1 este blocat în aşteptarea controlerului de disc, OS poate salva în memorie tot contextul procesului-client 1, şi să permită procesului-client 2 să ruleze prin restaurarea contextului său din memorie.
Această simplitate costă. Comutarea între contextul şi restaurarea procesului este dificilă, deoarece necesită citiri/scrieri din memorie în

133
registre pentru salvarea/restaurarea contextului. Contextul include schimbarea tabelelor de pagini care sunt folosite (deoarece tabelele de pagini sunt per proces); astfel, fiecare translatare a memoriei virtuale, (memorată în memoria cache TLB), trebuie incarcată în cache. Si conţinutul memoriei cache de-date/de-instrucţiuni era cel util procesului rezident anterior, astfel că aproape tot conţinutul acestora e inutil noului proces. Când toate apelurile la cache eşuează, performanţa iniţială a comutării între procese poate fi slabă.
Dar este dificilă şi naşterea unui nou proces la sosirea unui nou client, aşa cum s-a făcut iniţial în serverele Web. Din fericire, supraîncărcarea dată de distrugerea/crearea unui proces când un client vine/pleacă poate fi evitată prin precalcul şi/sau ştergerea relaxată a proceselor (P2 deplasarea în timp a calcului). Când un client termină sarcina de procesare şi conexiunea este terminată, în loc să distrugem procesul, el e returnat stocului de procese în aşteptare. Apoi procesul poate fi alocat următorului client nou, ca să supravegheze cererea acestuia către server.
A doua problemă este asocierea clienţilor nou sosiţi cu procesele în aşteptare din stoc. Calea naivă trimite fiecare client nou la un proces de asociere cunoscut, care-l asociaza cu un proces liber oarecare din stoc. Proiectanţii sistemelor de operare au realizat importanţa asocierii si au inventat apelurile de sistem (apelul Accept din UNIX) pentru a face asocierea cu alt cost decat cel al comutării contextului proceselor.
Când se desfasoara un proces din stoc, el face un apel Accept şi aşteaptă la rând într-o structură de date a kernel-ului. Când apare un nou client, socket-ul său este trimis primului proces inactiv din rand. Astfel, kernel-ul furnizează direct serviciile de asociere.
6.3.2. Fire de proces per client Procesele sunt o solutie scumpă, chiar şi după eliminarea supraîncărcării
produsă de crearea la cerere a unui proces şi de asociere a proceselor. Conexiunile lente pe arii extinse către servere sunt obişnuite şi sosirile la un server Web cunoscut depaşeste uşor 2.000/sec, e obişnuit ca un server Web să aibă 6000 de clienţi concurenţi serviţi simultan.
Chiar dacă procesele sunt deja create, comutarea între procese include TLB-uri şi pierderi în cache şi necesită efort pentru salvarea şi restaurarea contextului. In plus, fiecare proces necesită memorie pentru stocarea contextului, care poate lua din cea necesară cache-ului de fişiere.
O solutie intermediară este folosirea firelor de proces/thread sau procese uşoare. Ele au încredere unele în altele, cum şi trebuie în cazul în care ele procesează clienţi diferiţi în serverele Web. Putem înlocui procesarea fiecărui client cu un fir de proces separat per client, toate protejate de un singur proces (fig 6.6). Firele de proces folosesc aceeaşi memorie virtuală, deci intrările TLB nu trebuie şterse între firele de proces.
In plus, partajarea memoriei intre firele de proces implică faptul că toate pot folosi un cache comun pentru a partaja şi translatarile numelor fişierelor şi chiar fişierele. Pe de altă parte, cu un proces per client, adesea cache-urile de fişiere nu pot fi partajate eficient de procese, deoarece fiecare proces foloseşte un spaţiu separat al memoriei virtuale. Astfel, cache-urile de aplicaţii pentru serverele Web vor suferi la capitolul

134
performanţă, deoarece fişierele comune multor clienţi sunt replicate. Serverul Web Apache e implementat în Windows cu cate un fir per client.
Suprasarcină generata de comutarea între firele de proces e mai mică decât comutarea intre procese, dar este totuşi considerabilă. In esenţă, sistemul de operare trebuie încă să salveze/repună contextul per fir de proces, ca stivele/registrele. De asemenea, memoria necesară pentru stocarea stării per fir de proces sau per proces ia din cache-ul pentru fişiere, care duce probabil la o rată de erori mai mare.
Fig 6.6 Două alternative simple pentru structurarea unui server Web:(1) folosirea unui singur proces (sau fir) per client; (2) implementarea unui proces unic care foloseşte un manager de evenimente pentru a raporta procesului starea I/O a fiecărui client.
6.3.3. Planificatorul lansat de evenimente Daca facilităţile unui sistem de operare cu scop general sunt prea
scumpe, trebuie evitate. Daca planificarea firelor de procese, care permite jonglarea între clienţi fără o programare ulterioară, este prea scumpă, aplicaţia poate jongla ea însăşi.
Aplicaţia trebuie să implementeze propriul său planificator intern care să jongleze cu stările fiecărui client. De exemplu, s-ar putea ca aplicaţia să trebuiască să implementeze o maşină care să ţină minte că, clientul 1 este în stadiul 2 (procesare HTTP) în timp ce clientul 2 este în stadiul 3 (aşteptând o I/O la disc), şi clientul 3 este în stadiul 4 (aşteptând un buffer de socket liber pentru a trimite următoarea parte a răspunsului).
Kernel-ul are un avantaj faţă de un program aplicaţie, deoarece vede toate evenimentele I/O care se încheie. Dacă într-o implementare per fire de proces, clientul 1 este blocat aşteptând o I/O, când controlerul de disc întrerupe CPU ca să-i spună că datele sunt acum în memorie, kernel-ul poate să planifice firul de proces al clientului 1.
Astfel, dacă aplicaţia serverului Web îşi planifica singură clienţii, kernel-ul trebuie să paseze informaţie (P9) către API, pentru a permite aplicaţiei per un singur fir de proces să vadă încheierea tuturor operaţiilor de I/O pe care le-a iniţiat. Multe sisteme de operare oferă această facilitate,

135
FindActive() (fig. 6.2). De exemplu, Windows NT 3.5 are un mecanism IOCP (I/O completion port), de verificare a terminării I/O şi UNIX furnizează funcţia select() de apel la sistem. Aplicaţia stă într-o buclă care apelează funcţia FindActive(). Presupunând că tot timpul este ceva de făcut la partea clientului, apelul va returna o listă de descriptori I/O a activităţii respective (în exemplu datele fişierului 1 sunt acum în memorie, conexiunea 5 a primit date). Când serverul Web procesează aceşti descriptori activi, revine cu un alt apel FindActive().
Dacă există mereu cate un client care necesită atenţie (tipic pentru un server aglomerat), nu trebuie să abandonam invocand costurile comutării contextului când se jonglează între clienţi. Asemenea jonglări necesită ca aplicaţia să aibă o maşină de stări care să-i permită să comute singură contextul între numeroasele cereri concurente. O astfel de planificare internă specifică aplicaţiei e mai eficientă decât apelarea planificatorului extern de uz general, deoarece aplicaţia ştie setul minim de contexte care trebuie salvat cand se mută de la client la client.
Serverul Zeus şi serverul original Harvest/Squid proxy cache folosesc modelul lansat de evenimentele unui singur proces. Fig. 6.6 arată arhitectura serverelor multiproces (şi fire de proces multiple) comparativ cu arhitectura lansată de evenimente.
6.3.4. Serverele lansate de evenimente, cu procese ajutătoare In principiu, un server lansat de evenimente poate să extragă tot atâta
concurenţă din fluxul de operaţii a clientilor ca şi un server multiproces sau multifir. Dar multe sisteme de operare, ca UNIX, nu au suportul adecvat pentru operaţii de disc care nu se blochează.
De exemplu, dacă un server lansat de evenimente vrea să fie eficient, când dă o comandă read() pentru un fişier care nu este în cache, ar vrea ca funcţia read() să răspunda imediat că nu este disponibil, astfel ca funcţia read() să fie fără blocare, ceea ce ar permite serverului să se mute către alţi clienţi. Mai târziu, când se termină operaţia de I/O a discului, aplicaţia poate fi regăsită folosind următorul apel FindActive(). Dar dacă apelul read() se blochează, bucla principală a serverului va aştepta milisecundele necesare incheierii operaţiei de I/O a discului.
Dificultatea este că multe sisteme de operare ca Solaris şi UNIX permit operaţii de read(), write() nonblocante pentru conexiunile reţelei, dar care se pot bloca când sunt folosite pentru fişierele de pe disc. Aceste sisteme de operare permit alte apeluri sistem asincrone pentru I/O cu discul, dar care nu sunt integrate în apelul select() (echivalentul în UNIX a FindActive() ). In asemenea sisteme de operare trebuie să se aleagă între pierderea concurenţei, prin blocarea operatiei de I/O a discului, şi trecerea dincolo de modelul cu un singur proces.
Serverul de Web Flash merge dincolo de modelul cu un singur proces pentru maximizarea concurenţei. Când trebuie citit un fişier, procesul principal de pe server întâi testează dacă fişierul este în memorie, folosind fie un apel standard de sistem, fie blocand paginile fişierelor cache, pentru ca procesele serverului să ştie întotdeauna care fişiere sunt în cache. Daca fişierul nu este în memorie procesul principal din server instruieşte un proces ajutător/helper pentru a face citirea de disc, posibil blocantă. Când

136
procesul ajutător a terminat, comunică cu procesul principal de pe server, printr-o formă de comunicare interprocese, precum pipe.
Spre deosebire de modelul mutiproces, procesele ajutătoare sunt necesare doar pentru fiecare operaţie concurentă pe disc, şi nu pentru fiecare cerere client concurentă. Modelul exploatează un grad de libertate (P13), observând că mai sunt şi alte alternative interesante între un singur proces şi un proces per client.
In afara de citirea fişierelor, procesele helper mai pot fi folosite la căutări în directoare pentru localizarea fişierelor pe disc. In timp ce Flash menţine un cache, care face legătura între numele căilor directoarelor şi fişierele de pe disc, dacă există cumva o greşeală a cache-ului, atunci trebuie căutat prin structurile directoarelor de pe disc. Deoarece asemenea căutari de directoare se pot bloca, sunt de asemenea necesare proceselor helper. Crescând cache-ul pentru numele de căi, creşte de asemenea consumul de memorie, dar reducerea ratei de erori a cache-ului poate reduce numărul de procese ajutătoare necesare şi să scadă necesarul global de memorie.
Procesele helper ar trebui să evite întârzierea creării unui proces, de fiecare dată când un process helper este invocat. Câte procese helper trebuie să fie? Prea puţine cauzează pierderi de concurenţă şi prea multe cauzează pierderi de memorie. Solutia în Flash este crearea dinamică şi distrugerea proceselor helper în funcţie de încarcare.
6.3.5 Structurarea bazată pe sarcini/task-uri In figura 6.7 sus, e descrisa abordarea lansata-de-evenimente îmbogăţită
cu procese helper. E similara cu manevrarea simplă lansata de evenimente, figura 6.6 jos, cu exceptia proceselor helper. Există câteva probleme la arhitectura lansată de evenimente cu procese helper.
•Complexitatea: proiectantul aplicaţiei trebuie să ştie să folosească maşina de stări pentru manevrarea cererilor clientului fără ajutor. •Modularitate: codul pentru server e scris ca un singur modul. Serverele Web sunt foarte răspîndite, dar sunt şi multe servicii Web care pot utiliza părţile de cod similare (ca de exemplu cele pentru acceptarea conexiunilor). Abordarea şi mai modularizată permite reutilizarea codului. •Supraîncărcarea cauzata de control: producătorii serverelor Web
trebuie sa facă faţă variaţiilor considerabile a sarcinilor provenite de la numărul imens de clienţi, fiind esential ca serverul să-şi continue activitatea în suprasarcina (fără să piarda date), tratând corect toţi clienţii.
Ideea principală în arhitectura multinivel a proceselor acţionate de evenimente este exploatarea gradului de libertate (P13) în descompunerea codului. În locul descompunerii orizontale de către client în fire de execuţie, ca la arhitectura cu fire multiple, sistemul serverului este descompus vertical de către sarcini, la fiecare ciclu de cerere a clientului (fig. 6.6, jos). Fiecare nivel poate fi controlat de unul sau mai multe fire. Astfel, modelul pe niveluri poate fi considerat o rafinare a modelului simplu a proceselor lansate de evenimente, deoarece el atribuie un fir principal şi un fir posibil fiecărui nivel de procesare a serverului. Apoi, nivelurile comunică prin cozi de aşteptare şi, la fiecare etaj, poate fi făcut un control mai rafinat al supraîncărcării.

137
Fig. 6.7 Două propuneri de arhitecturi Web ( diferite de cele din fig. 6.6) : (3) procese lansate de evenimene (event-driven) si procese ajutatoare; (4) arhitectura pe niveluri a proceselor lansate de evenimente
6.4 Selecţia rapidă Pentru a justifica problema selecţiei rapide, se prezintă o problemă de
performanţă din literatură, apoi e descrisa utilizarea şi implementarea in UNIX a apelului select(), se face o analiză a supraîncărcării, şi se aplică principiile de implementare sugerând diverse imbunătăţiri. E descrisă o îmbunătăţire, în ideea că API nu poate fi schimbat si se propune o soluţie mai bună care implică însă multe schimbări ale API.
6.4.1 Probleme ale serverului Evitarea supraîncărcării generată de planificarea proceselor este o
problemă importantă într-un server Web. De exemplu, un server „event-driven” reduce complet supraîncarcarea dată de planificarea proceselor prin utilizarea unui singur fir pentru toţi clienţii, după care se utilizează un apel FindActive() la fel cu select(). Acum, proxy-ul Web CERN utilizează un proces per client, iar serverul Web Squid utilizează o implementare „event-driven”. Măsurătorile făcute într-un mediu LAN au arătat că proxy-ul Web Squid e mai performant decât serverul CERN. Testele într-un mediu WAN au arătat că aici nu există nici o diferenţă între performanţa serverelor CERN şi Squid. De ce ?
Problema a fost elucidată dupa ce s-a remarcat că la acelaşi trafic(ca număr de conexiuni pe secundă) cu cât întârzierea tur-retur dintr-un mediu WAN e mai mare, cu atât e mai mare numărul de conexiuni concurente din WAN. Fie un mediu WAN cu un timp mediu de 2 secunde per conexiune şi un server Web cu traficul de 3000 conexiuni pe secundă. Legea lui Little (teoria cozilor de aşteptare) spune că numărul mediu de conexiuni simultane este dat de produsul acestora, adică 6000.

138
Dar într-un mediu LAN, cu ciclul de întârziere de 2 msec, numărul mediu de conexiuni simultane scade la 6. Dacă numărul de conexiuni pe secundă rămâne la fel, în WAN o mare parte din conexiuni trebuie să fie în starea „idle”(aşteptând răspunsuri) în orice moment.
Două cauze principale de supraîncărcare au fost apelurile de sistem folosite de către serverul event-driven: • select(): serverele event-driven rulând pe UNIX utilizează apelul de
select() pentru apelul FindActive(). Experimentele făcute arată că mai mult de jumătate din CPU este utilizat pentru kernel şi funcţii nivel-utilizator select() cu 500 conexiuni; • ufalloc(): de asemenea, serverul are nevoie să repartizeze cel mai mic
descriptor nealocat pentru socket-uri sau fişiere noi. Acest apel simplu consumă a treia parte din timpul CPU.
Performanţele ufalloc() pot fi uşor explicate. In mod normal, găsind un descriptor liber, acesta poate fi uşor implementat utilizând o lista liberă de descriptori. Din păcate, UNIX cere alegerea celui mai mic descriptor neutilizat. De exemplu, daca lista curentă de descriptori nealocaţi are elementele (nesortate) 9, 1, 5, 4, 2, atunci nu poate fi găsit 3, ca fiind cel mai mic număr nealocat, fără parcurgerea întregii liste nesortate. Din fericire, o simplă schimbare în implementarea kernel (P15 utilizarea unor structuri de date eficiente) poate reduce aproape la zero suprasarcina.
6.4.2 Utilizarea select() şi implementarea existentă Presupunând ca supraîncarcarea generată de ufalloc() poate fi
minimizată uşor prin schimbarea implementării kernel-ului, este important să ameliorăm strangulările rămase, cauzate de implementarea select() într-un server event-driven. Deoarece cauzele problemei sunt mai complexe, sunt revăzute utilizarea si implementarea select() pentru a înţelege diferitele surse de supraîncarcare.
Parametri Select() este numită: -Input (de intrare): o aplicaţie cheamă select() cu trei bitmap-uri de
descriptori (unul din care se citeste, unul în care se scrie şi unul din care se extrag excepţiile) şi o valoare de timeout.
-Interim (provizorie): aplicaţia e blocată dacă nu e nici un descriptor pregătit.
-Output (de iesire): când apare ceva de interes, apelul returnează numărul descriptorilor pregătiţi (transmis ca valoare de întreg) şi lista specifică a descriptorilor fiecărei categorii (transmisă ca referinţă, prin supraînscrierea bitmap-urilor de intrare).
Utilizarea într-un Server Web După parametrii apelului select(), este important să înţelegem cum poate
fi acesta utilizat de către un server Web lansat de evenimente. Un exemplu de utilizare este prezentat în cele ce urmează. Firele aplicaţiei serverului stau într-o buclă cu trei componente majore:
•Iniţializare: primele zero-uri ale aplicaţiei sunt scoase în afara bitmap-urilor şi se setează bitii pentru descriptorii de interes în vederea scrierii/citirii. Aplicaţia serverului ar putea dori să citească din descriptorii fişierului şi să scrie/citească socket-urile reţelei deschise clienţilor.

139
•Apel: apoi aplicaţia apelează select() cu bitmap-urile construite la pasul anterior, şi se blochează dacă nici un descriptor nu e pregătit în momentul apelului; dacă expiră timpul (timeout), aplicaţia face o procesare de excepţie.
•Răspuns: după ce apelul revine, aplicaţia trece liniar prin bitmap-urile returnate şi invocă antetele de citire şi scriere adecvate, pentru descriptorii corespunzători poziţiilor cu biţi setaţi.
Costurile construirii bitmap-urilor, din pasul 1 şi scanării lor din pasul 3, sunt suportate de către utilizator, deşi ele sunt atribuibile direct costurilor de pregătire a răspunsului la apelul select().
Implementare Este important să înţelegem implementarea select() în kernel-ul unei
variante tipice de UNIX. Kernel-ul face următoarele (adnotat cu surse de supraîncărcare): •Curăţare: kernel-ul începe cu folosirea bitmap-urilor, transmise ca
parametri, pentru a construi un sumar cu descriptorii marcaţi în cel puţin unul din bitmap-uri (numit setul selectat).
Acest lucru necesită o căutare liniară printre bitmap-urile de dimensiune N, indiferent de numărul de descriptori de care aplicaţia este interesată. •Verificare: apoi, pentru fiecare descriptor din setul selectat, kernel-ul
verifică dacă descriptorul este pregătit; dacă nu, încarcă ID-ul firului aplicaţiei în coada de aşteptare selectată a descriptorului. Kernel-ul pune în adormire firul aplicaţiei apelante, dacă nu există descriptori pregătiţi.
Acest lucru necesită investigarea tuturor descriptorilor selectaţi, indiferent de câţi sunt pregătiţi de fapt. Acest pas este mai costisitor decât simpla scanare a bitmap-ului. •Reluare: când descriptorul devine pregătit din cauza unei operaţii de
I/O (de exemplu, un pachet soseşte la un socket, de la care serverul aşteaptă date), modulul de I/O al kernel-ului îşi verifică coada de aşteptare selectată şi „trezeşte” toate firele care aşteaptă un descriptor.
Acest lucru implică o supraîncărcare cauzată de planificare, care pare inevitabilă fără un apel selectiv sau aşteptare de ocupat. •Redescoperire: in final, select() redescoperă lista descriptorilor
pregătiţi făcând o scanare a tuturor descriptorilor selectaţi pentru a vedea care a devenit pregătit în timpul în care select() fusese pus în adormire şi „trezit” apoi. Aceasta necesită repetarea aceloraşi verificări costisitoare de la pasul 2.
Verificările se repetă deşi modulul de I/O ştie care descriptori devenisera pregătiţi, dar nu informează implementarea select().
6.4.3 Analiza operaţiei select() Se descriu posibilităţile de optimizare a implementării operaţiei select()
existente, şi apoi se sugereaza strategii de îmbunătăţire a performanţei folosind principiile.
Risipa evidenta în implementarea select() Principiul P1 urmăreşte înlăturarea risipei evidente, dar pentru aplicarea
lui trebuie găsite sursele risipei evidente în implementarea select(). Pentru fiecare sursă de risipă, căutăm o cauza.
1.Recreerea interesului pentru fiecare apel: acelaşi bitmap este folosit pentru intrare şi ieşire. Aceasta supraîncărcare determină aplicaţia să reconstruiască bitmap-urile din zona de lucru (scratch), deşi poate o interesează în majoritate aceiaşi descriptori la apelurile consecutive spre

140
select().De exemplu, dacă doar 10 biţi se schimbă la fiecare apel într-un bitmap de dimensiune 6000, aplicaţia tot trebuie să treacă prin cei 6000 biţi pentru a seta fiecare bit dacă e nevoie. Trebuie învinuită fie interfaţa API, fie lipsa calculului incremental in aplicaţie.
2.Reverificarea stării după fiecare reluare: nici o informaţie nu trece, de la modulul protocolului (care trezeşte un fir adormit de pe socket) spre apelul select() invocat când firul îşi reia activitatea. De exemplu, dacă modulul TCP primeşte date pe socket-ul 9, pe care doarme firul 1, modulul TCP se va asigura mai întâi ca firul 1 s-a trezit; dar nici o informaţie nu-i e dată firului 1 la trezire. Astfel firul 1 trebuie să reverifice toate socket-urile selectate pentru a stabili dacă socket-ul 9 are într-adevar date, deşi modulul TCP ştia sigur acest lucru când l-a trezit. Trebuie învinuită implementarea kernel-ului.
3.Kernel-ul reverifică disponibilitatea descriptorilor anterior nepregătiţi: aplicaţia server-ului Web e interesată de un socket până la eşecul/sfârşitul conexiunii. Atunci de ce se repetă testele pentru disponibilitate dacă nu s-a observat nici o schimbare a stării? Presupunem de exemplu, că socket-ul 9 este o conexiune spre un client distant, cu o întârziere de 1 sec pentru trimiterea/ recepţia pachetelor. Presupunem că la timpul t este trimisă o cerere la un client prin socket-ul 9 şi serverul aşteaptă răspuns, care soseşte la t+1 secunde. Presupunem că în intervalul dintre t şi t+1, firul serverului apelează select() de 15000 ori. De fiecare dată când e apelată select(), kernel-ul face o verificare laborioasă a socket-ului 9 pentru a determina dacă au sosit date sau nu. In schimb, kernel-ul poate deduce aceasta, din simplul fapt ca socket-ul era verificat la timpul t şi nici un pachet din reţea nu a fost recepţionat de la acest socket de la momentul t. Astfel 15000 de verificări nefolositoare şi costisitoare pot fi evitate; când pachetul soseşte în sfarsit, la timpul t+1, modulul TCP poate transmite informaţia pentru a reporni verificarea acestui socket. Trebuie învinuită implementarea kernel-ului
4.Bitmap-uri liniari în raport cu dimensiunea descriptorului: Atât kernel-ul cât şi utilizatorul trebuie să scaneze bitmap-urile, proporţional cu dimensiunea descriptorilor posibili, şi nu cu volumul de muncă utilă. De exemplu, dacă sunt 6000 de descriptori posibili, un server Web ar trebui să trateze un vârf de sarcină, bitmap-uri cu lungimea 6000. Presupunem că în timpul unei perioade oarecare sunt 100 de clienţi concurenţi, din care doar 10 sunt pregătiţi în timpul fiecărui apel select(). Atât kernel-ul cât şi aplicaţia scanează şi copiază bitmap-uri de dimensiune 6000, deşi aplicaţia este interesată doar de 200 de biţi si doar 10 biţi sunt setaţi la revenirea fiecărui select(). Trebuie învinuită API.
Strategii şi principii pentru a repara select() Odată stabilite cauzele risipei, pot fi aplicate strategii simple, utilizând
principiile algoritmice: •Recrearea interesului pentru fiecare apel: Consideră schimbarea API-
ului (P9) pentru a utiliza bitmap-uri separate pentru intrare şi ieşire. Sau menţine API-ul şi foloseşte calculul incremental (P12a). •Reverificarea stării după fiecare reluare: Pasează informaţia între
modulele protocolului care ştiu când un descriptor este pregătit şi modulul selectat (P9).

141
•Să ai reverificări kernel a disponibilităţii descriptorilor ştiuţi a fi nepregătiţi. Kernel îşi menţine starea în timpul apelurilor, asfel încât nu trebuie să reverifice descriptorii ştiuţi a fi nepregătiţi (P12a, utilizează calculul incremental) •Să foloseşti bitmap-uri liniari în raport cu mărimea posibilă şi nu cu
mărimea descriptorului: Schimbă fundamental API-ul pentru a evita necesitatea interogării asupra stării tuturor descriptorilor reprezentaţi de bitmap-uri (P9).
6.4.4 Accelerarea select() fără schimbarea API Vom vedea cum să eliminam primele trei, din patru, cauze de risipă,
prezentate anterior. 1.Evitarea reconstruirii bitmap-urilor din scratch-uri: Codul aplicaţiei
este schimbat pentru a folosi doua bitmap-uri de descriptori, de care este el interesat. Bitmap-ul A este folosit pentru memorarea pe termen lung, şi bitmap-ul B este folosit ca parametru curent transmis ca referinţă la select(). Astfel în bitmap-ul A, dintre apelurile spre select(), doar câţiva descriptori care s-au schimbat trebuie să fie actualizaţi. Inainte de a apela select(), bitmap-ul A este copiat în bitmap-ul B. Deoarece copierea se face per cuvânt este mai eficientă decât inspecţia laborioasă bit cu bit a bitmap-ului. In esenţă, noul bitmap este calculat incremental (P12a).
2. Evitarea reverificărilor tuturor descriptorilor când select() se activeaza: Pentru a evita aceasta supraîncărcare, implementarea kernel-ului este modificată astfel încât fiecare fir păstrează un set de indicaţii H, care înregistrează socket-urile care au devenit pregătite de la ultima dată când firul a apelat select(). Protocolul sau modulele de I/O sunt modificate astfel încât atunci când sosesc date noi (pachete din reţea, terminarea unor operaţii de I/O cu discul), indexul descriptorului corespunzător este scris în setul de indicaţii al tuturor firelor, aflate în coada de aşteptare selectată pentru acel descriptor. In sfârşit, după ce un fir se trezeşte în select(), doar descriptorii din H sunt verificaţi. Esenţa acestei optimizări este pasarea de indicaţii interfeţelor dintre niveluri (P9).
3. Evitarea reverificării descriptorilor ştiuţi a fi nepregătiţi: Observaţia fundamentală este aceea că un descriptor care aşteaptă date nu trebuie să fie verificat până nu apare o notificare asincronă (de exemplu, descriptorul este plasat în setul de indicaţii H descris anterior). Este clar că, orice descriptori proaspăt sosiţi (de exemplu, socket-uri nou deschise) trebuie verificaţi. A treia idee mai subtilă este ca aplicaţia poate citi doar 200 bytes, chiar şi după ce datele din reţea au sosit la un socket (de exemplu, 1500 bytes). Astfel, un descriptor trebuie verificat pentru disponibilitate, chiar după sosirea primei date, până când nu mai rămân date (de exemplu, aplicaţia citeşte toate datele) pentru a declara disponibilitatea.
Pentru a implementa aceste idei, pe lângă setul de indicaţii H, implementarea kernel-ului mai păstrează încă două seturi. Primul este setul de interes I, cu toţi descriptorii de care firul este interesat. Al doilea este un set de descriptori R cunoscuţi a fi pregătiţi. Setul de interes I reflectă interesul pe termen lung; de exemplu, un socket este plasat în I când este menţionat prima dată într-un apel select() şi este înlăturat doar când socket-ul este deconectat sau refolosit. Să notăm cu S setul transmis

142
la select(). Atunci I este actualizat la Inou=Ivechi∪ S. Acesta incorporează descriptorii proaspăt selectaţi fără a pierde descriptorii anterior selectaţi.
Apoi, kernel-ul verifică doar descriptorii care sunt în Inou , dar sunt fie: (i) în setul de indicaţii H fie (ii) nu sunt în Ivechi sau (iii) în setul vechi de descriptori pregătiţi Rvechi. Aceste trei afirmaţii reflectă cele trei categorii discutate în urmă cu două paragrafe. Ele reprezintă fie activitatea recentă a fiecăruia, interesul proaspăt declarat sau datele neconsumate rezultate dintr-o activitate prioritară. Descriptorii găsiţi a fi pregătiţi în urma verificării sunt înregistraţi în Rnou. La sfârşit, apelul select() returnează utilizatorului elementele din Rnou∩ S. Acest lucru se întâmplă deoarece pe utilizator îl interesează doar disponibilitatea descriptorilor specificaţi în setul selectat S.
Ca exemplu, socket-ul 15 poate fi verificat când e menţionat pentru prima dată în apelul select() şi deci intră în I; socket-ul 15 poate fi verificat apoi, când un pachet de 500 bytes soseşte din reţea, ceea ce face ca socket-ul 15 să intre în H; în final, socket-ul 15 poate fi verificat repetat ca parte a lui R până când aplicaţia consumă toţi cei 500 bytes, punct în care socket-ul 15 părăseşte R (P12,suplimentarea stărilor pentru a creşte viteza) stă la baza acestei optimizări. Optimizarea menţine starea peste apeluri (P12) pentru a reduce verificările redundante.
6.4.5. Accelerarea procedurii select( ) schimbând API Tehnica descrisă îmbunătăţeşte considerabil performanţa prin eliminarea
din select() a primelor trei surse (principale) de supraîncărcare. Oricum, funcţionează asa, prin păstrarea unei stări suplimentare (P12) sub forma a încă trei seturi de descriptori (H, I si R) care sunt menţinuţi, de asemenea ca şi bitmap-uri. Aceasta, împreună cu setul selectat S transmis la fiecare apel, necesită scanarea şi actualizarea celor patru bitmap-uri, separat.
Situaţia în care sunt prezente un număr mare de conexiuni, dar doar câteva sunt active la un moment dat, implică o mică supraîncărcare, proporţională cu numărul total de conexiuni şi nu cu numărul de conexiuni active. Aceasta este a patra sursă de “risipă” enumerată anterior şi pare inevitabilă cu API-ul existent.
Mai mult, precum am văzut anterior, chiar şi procedura select() rapidă modificată verifică un descriptor de mai multe ori pentru fiecare eveniment, ca sosirea unui pachet (dacă aplicaţia nu consumă toate datele odată). Asemenea controale adiţionale sunt inevitabile deoarece select() furnizează starea fiecărui descriptor.
Dacă ne uităm mai îndeaproape la interfaţă, ceea ce aplicaţia cere în esenţă, este să fie informată de fluxul evenimentelor (terminarea unei I/O, sosirea unui pachet de reţea) care-i schimbă starea. Notificările lansate de evenimente apar pentru a putea înlătura neajunsuri evidente ce rezultă din utilizarea anterioară.
• Notificare asincronă: dacă aplicaţia este anunţată imediat ce un eveniment apare, ar apărea încărcări suplimentare, şi ar fi dificil de programat. De exemplu, atunci când o aplicaţie serveşte socket-ul 5, un pachet ar putea sosi la socket-ul 12. Intreruperea aplicaţiei, pentru a o informa de noul pachet, poate fi o idee proastă.

143
• Rata excesivă a evenimentelor: aplicaţia e interesată de evenimentele care cauzează schimbarea stării, nu de fluxul lor neprelucrat. Pentru un transfer Web mare, mai multe pachete pot ajunge la un socket şi aplicaţia ar dori să obţină o notificare pentru întregul lot, nu câte una pentru fiecare pachet. Suprasarcina generată de fiecare notificare este echivalentă cu memorarea fiecărei notificări, în termeni de costuri de comunicaţie(CPU).
Principiul P6 sugerează proiectarea rutinelor specializate eficiente pentru a evita strangulările.
● Interogarea sincronă: ca şi în cazul apelului select() original, aplicaţia poate interoga evenimentele în curs. Spre exemplu, în exemplul anterior, aplicaţia continuă să servească socket-ul 5 şi toate celelalte socket-uri active înainte să întrebe (şi să i se spună despre) evenimente ca de pildă sosirea pachetului la socket-ul 5.
● Comasarea evenimentelor: dacă, în timp ce un prim eveniment a fost introdus într-un şir pentru notificare, apare un al doilea eveniment pentru descriptor, cea de-a doua notificare este omisă. Astfel per descriptor, acolo poate fi cel mult o notificare de eveniment important.
Utilizarea noului API este directă dar nu prea conformă cu stilul aplicaţiilor ce foloseau vechiul select() API. Aplicaţia stă într-o buclă, în care are nevoie de sincronizare pentru setul următor de evenimente, şi intră în repaus în caz contrar. Când apelul revine, aplicaţia trece prin fiecare notificare de eveniment şi invocă antetele potrivite de scriere sau citire. Implicit, setarea registrelor unei conexiuni interesează descriptorul corespunzător, în timp ce deconectarea conexiunii înlătură descriptorul din lista de interes.
Implementarea: fiecărui fir îi este asociat un set de descriptori de care este interesat. Fiecare descriptor (socket de exemplu) păstrează o lista de mapare inversa a tuturor firelor interesate de descriptor. In activitatea de I/O (de exemplu, sosirea datelor la un socket), modulul I/O utilizează propria sa lista de mapare inversă, pentru a identifica toate firele posibil interesate. Daca descriptorul este în setul de fire interesat, un eveniment de notificare este adăugat şirului evenimentelor în curs al acelui fir.
Un bitmap per fir simplu, un bit per descriptor, este utilizat sa înregistreze faptul că un eveniment este în aşteptare în şir şi să evite multiplele notificări de evenimente per descriptor. In final, când aplicaţia cere următorul set de evenimente, acestea sunt returnate din şirul de aşteptare.
6.5 Evitarea apelurilor de sistem Omitem discuţia referitoare la select(), şi reluăm discuţia despre lucrul
cu reţeaua la nivelul utilizatorului. Se pare că am eliminat kernel-ul din tablou prin recepţia şi trimiterea unui pachet, dar din păcate nu e aşa. Când o aplicaţie vrea să trimită date, trebuie cumva sa anunţe adaptorul unde se află acele date.
Când o aplicaţie vrea să primească date, ea trebuie sa specifice buffer-ele unde se vor scrie pachetele de date primite. In Unix acest lucru se face utilizând apelurile de sistem, în care aplicaţia comunica kernel-ului despre datele pe care ar vrea să le trimită şi buffer-ele pe care ar vrea să le primească. Chiar dacă implementăm protocolul în spaţiul utilizatorului,

144
kernel-ul trebuie să servească aceste apeluri de sistem (care pot fi costisitoare) pentru fiecare pachet trimis sau primit.
Acest lucru pare a fi necesar deoarece pot fi câteva aplicaţii care primesc şi trimit date de la un adaptor comun; din moment ce adaptorul este o resursă partajată, este de neconceput pentru o aplicaţie să scrie direct în registrele dispozitivului unui adaptor al reţelei fără ca kernel-ul să verifice utilizarea eronată sau răuvoitoare.
Sunt posibile şi alte soluţii. In figura 6.8 vedem că dacă o aplicaţie
vrea să seteze valoarea unei variabile X la 10, nu face de fapt o chemare a kernel-ului. Dacă ar trebui să facă asta, atunci fiecare citire si scriere s-ar face foarte lent. In loc de asta, hardware-ul găseşte pagina virtuală a lui X, o translatează într-o pagină fizică (sa zicem 10) prin intermediul TLB, şi apoi permite accesul direct la ea atâta timp cât aplicaţia are pagina 10 mapată în memoria sa virtuală.
Dacă pagina 10 nu este mapată în memoria virtuală a aplicaţiei, hardware-ul generează o excepţie, care determină kernel-ul să intervină, stabilind de ce este un viol al accessului la pagina acolo. Kernel-ul a fost implicat în setarea memoriei virtuale pentru aplicaţie (doar lui i se permite sa facă asta, din motive de securitate) şi poate fi implicat dacă aplicaţia violează accesul la paginile sale setate de kernel. De altfel, kernel-ul nu este implicat în orice acces. Putem spera la o abordare similară în cazul accesului aplicaţiei la memoria adaptorului, pentru a evita apeluri inutile la sistem (P1) ?
Pentru a vedea dacă acest lucru este posibil trebuie să examinăm mai atent ce informaţie trimite şi receptionează o aplicaţie, de la un adaptor. Sigur că trebuie să prevenim ca aplicaţii incorecte sau rău intenţionate să defecteze alte aplicaţii sau chiar kernel-ul însuşi. Figura 6.9 arată o aplicaţie care doreşte să primească date direct de la adaptor. Tipic, o aplicaţie care face asta trebuie să puna în coada de aşteptare un descriptor. Un descriptor este o bucată mică de informaţie care descrie buffer-ul din memoria principală, unde ar trebui înscrise datele din pachetul următor

145
(pentru această aplicaţie). In consecinţă ar trebui să considerăm cu atenţie şi separat memoria descriptorului şi memoria actuală a buffer-ului.
Putem lucra uşor cu memoria descriptorului, ştiind că memoria adaptorului este o memorie mapată. Presupunem că adaptorul are 10.000 bytes de memorie, considerată memorie pe magistrală, si că pagina fizică a sistemului este de 1000 bytes. Rezultă faptul că adaptorul are 10 pagini fizice. Presupunem că alocăm câte 2 pagini fizice fiecărei aplicaţii dintr-un set de 5 aplicaţii de mare performanţă (ex.Web, FTP), aplicaţii care vor să folosească adaptorul pentru a transfera date. Presupunem că aplicaţia Web primeşte 2 pagini fizice, de exemplu nr.9 si 10. Kernel-ul mapează paginile fizice 9 şi 10 la tabela de pagini a aplicaţiei Web, iar paginile fizice 3 şi 4 le mapează la tabela de pagini a aplicaţiei FTP.
Acum, aplicaţia Web poate scrie direct în paginile fizice 9 şi 10, fără nici un pericol; dacă va încerca să scrie în paginile 3 şi 4, hardware-ul memoriei virtuale va genera o excepţie. Astfel (P4c) exploatăm hardware-ul existent sub forma TLB, pentru a proteja accesul la pagini. Presupunem acum că pagina 10 este o secvenţă de descriptori de buffer-e libere, scrise de aplicaţia Web; fiecare descriptor de buffer descrie o pagină din memoria principală (presupunem că avem la dispoziţie doar 32 biţi), care va fi folosită pentru a recepţiona următorul pachet descris pentru aplicaţia Web.Spre exemplu, pagina 10 poate conţine secvenţa 18, 12 (fig.6.9). Aceasta înseamnă că aplicaţia Web are în coada curentă paginile fizice cu numărul 18 şi 12 pentru recepţionarea următoarelor pachete. Presupunem că paginile 18 şi 12 se află în memoria principală şi sunt pagini fizice blocate, atribuite aplicaţiei Web de către kernel, la pornirea aplicaţiei Web.
In momentul în care soseşte un nou pachet pentru aplicaţia Web, adaptorul va demultiplexa pachetul către pagina 10, folosind un filtru de pachete, iar apoi va scrie datele din pachet (folosind DMA) în pagina 18. După ce a realizat aceasta, adaptorul va scrie descriptorul 18 într-o pagină dedicată descriptorilor de pagini scrise (exact ca la fbufs), spre exemplu pagina nr.9, pagina pe care aplicaţia Web este autorizată să o citească. Este apoi sarcina aplicaţiei Web să termine procesarea paginilor scrise, şi să pună periodic în coada adaptorului noi descriptori de buffer-e libere.
Totul pare frumos, dar există o problemă de securitate. Presupunem că printr-o eroare/rea intenţie, aplicaţia Web scrie în pagina descriptorilor secvenţa 155, 120 (lucru pe care-l poate face). Presupunem în continuare ca pagina 155 este în memoria principală, şi că în această pagină kernel-ul işi stochează structurile de date. Cand adaptorul primeşte un nou pachet pentru aplicaţia Web, va scrie datele pachetului în pagina 155, suprascriind structurile de date ale kernel-ului. Aceasta va cauza probleme serioase, cel putin eşuarea sistemului.
Dar de ce nu poate detecta hardware-ul memoriei virtuale acest tip de problemă? Motivul este ca hardware-ul memoriei virtuale (observaţi pozitia TLB în fig.6.8) oferă protecţie doar împotriva accesului neautorizat a proceselor care rulează pe CPU. TLB interceptează fiecare acces de tip READ (sau WRITE) făcut de către procesor şi poate face verificari; însă adaptoarele care fac acces de tip DMA, ocolesc sistemul memoriei virtuale şi accesează memoria direct.

146
In practică, acest lucru nu reprezintă o problemă deoarece aplicaţiile nu pot programa dispozitivele (precum discuri, adaptoare) să citească sau să scrie la o anumită locaţie, la comanda aplicaţiei. Insă, accesul este mediat mereu de către kernel. Dacă nu implicăm şi kernel-ul, trebuie să ne asigurăm că instrucţiile pe care aplicaţia le-ar putea da adaptorului au fost atent verificate.
Soluţia folosită la canalul dispozitivului aplicaţie ADC (application device channel), este ca (P9, pasează indicaţii la interfaţă) kernel-ul să trimită adaptorului o listă de pagini fizice valide, pe care fiecare aplicaţie care foloseşte adaptorul, să le poată accesa direct. Acest lucru poate fi făcut doar după ce aplicaţia a pornit şi înainte de a începe transferul de date. Cu alte cuvinte, calculul implicat în autorizarea paginilor este decalat în timp (P2), de la faza transferului de date la faza de iniţializare a aplicaţiei. Spre exemplu, în momentul în care începe aplicaţia Web, aplicaţia va cere kernel-ului 2 pagini, de exemplu 18 şi 12 iar apoi va cere kernel-ului să autorizeze utilizarea acestor pagini de către adaptor.
Kernel-ul este apoi transpus în regim normal de operare de date. Daca în acest moment aplicaţia Web pune în coadă descriptorul 155 şi apare un nou pachet, adaptorul va verifica mai întâi dacă numarul 155 este în lista autorizată a aplicaţiei (care conţine 18 şi 15). Deoarece 155 nu este în listă, adaptorul nu va suprascrie structurile de date ale kernel-ului.
In concluzie, ADC-urile deplasează în spaţiu funcţiile de protecţie (P3c) de la kernel la adaptor, folosind informaţii prelucrate anterior (lista paginilor fizice autorizate, P2a) trimise de la kernel către adaptor (P9) şi la care s-a adăugat hardware-ul memoriei virtuale (P4c).
In ultimii ani a fost promovată utilizarea mesajelor active pentru scopuri similare. Mesajul activ conţine adresa procesului de nivel utilizator care va manevra pachetul.Un mesaj activ evita intervenţia kernel-ului şi stocarea temporară în tampoane, prin folosirea tampoanelor prealocate sau a mesajelor de dimensiune mică, răspunsuri directe ale aplicaţiei, ajungându-se astfel la o latenţă mică. Latenţa mică permite o suprapunere a calculului şi comunicaţiei în maşinile paralele. Implementarea cu mesaje active permite doar transferul mesajelor scurte sau a blocurilor mari. Implemetarea mesajelor rapide merge mai departe şi combină interfeţele de dispersie-regrupare la nivel-utilizator cu controlul fluxului, pentru a permite o performanţă ridicată uniformă, atât pentru mesajele scurte cât şi pentru cele lungi.
La ce folosesc kernelurile? Problema este importantă deoarece ADC-urile şi mesajele active ocolesc
kernel-ul. Nucleele sunt bune pentru asigurarea protecţiei (protecţia sistemului şi a utilizatorilor bine intenţionaţi, de programe rău intenţionate şi erori) şi pentru planificarea resurselor între diferitele aplicaţii. Dacă scoatem nucleul din funcţie, aceste servicii vor trebui îndeplinite de altcineva. Spre exemplu, ADC-urile oferă protecţie folosind hardware-ul memoriei virtuale (pentru a proteja descriptorii) şi constrângerea adaptoarelor (pentru a proteja memoria tampon).
Trebuie de asemenea să multiplexeze legătura fizică de comunicare (în special în partea de emisie) între diversele canale ale dispozitivelor aplicaţiei şi să asigure un oarecare grad de corectitudine. Pentru aceasta

147
codul kernel-ului ar trebui replicat în fiecare dispozitiv; unele dispozitive însă, precum discul sau adaptorul de reţea sunt mai speciale, în sensul că necesită performanţă mai ridicată, şi trebuie tratate special. Există o iniţiativă prin care se doreşte ca toate aceste idei să aibă şi o formă comercială, bazat pe ideea ADC şi pe soluţia UUNet de la Cornell (asemănătoare cu ADC şi propusă în paralel cu aceasta). Această propunere, cunoscută sub numele de arhitectura interfeţei virtuale VIA (Virtual Interface Architecture)este descrisă în cele ce urmează.
6.5.1. Propunerea de arhitectură a interfeţei virtuale (VIA) Arhitectura interfeţei virtuale este un standard comercial, care
înglobează ideile legate de ADC. Termenul de interfaţă virtuală are sens, dacă considerăm că un canal al unui dispozitiv al aplicaţiei poate oferi fiecărei aplicaţii câte o interfaţă virtuală proprie, pe care o poate manevra fără intervenţia nucleului. Interfeţele virtuale sunt desigur multiplexate către o singură interfaţa fizică. VIA a fost propusă de un consorţiu industrial care include Microsoft, Compaq şi Intel.
VIA foloseste următoarea terminologie: •Memoria înregistrată: Acestea sunt regiuni de memorie folosite de
aplicaţie pentru a trimite/recepţiona date. Aplicaţia e autorizată să citească/ /scrie din/în aceste regiuni; regiunile sunt îmbinate pentru a evita paginarea. •Descriptorii: Pentru a trimite/recepţiona un pachet, aplicaţia foloseşte
o bibliotecă la nivel-utilizator (libvia), pentru a construi un descriptor care este o structură de date ce conţine informaţii despre tampon (de exemplu un pointer). VIA permite unui descriptor să se refere la mai multe tampoane din memoria înregistrată (pentru dispersie/regrupare) şi permite folosirea de diferite etichete de protecţie a memoriei. Descriptorii pot fi adăugaţi unei cozi de descriptori. • Soneriile (doorbells): Reprezintă o metodă nespecificată prin care
interfeţei de reţea i se comunică descriptorii. Se poate face fie prin partea de scriere a interfeţei cardului de memorie, fie prin declanşarea unei întreruperi pe card; variază de la implementare la implementare. Sunt de fapt pointeri către descriptori, conducând la nivelul doi de indirectare.
Standardul VIA are câteva probleme : •Performanţa mesajelor mici: trimiterea datelor necesită urmărirea unei
sonerii care este pusă în legătură cu un descriptor (destul de mare, în jur de 45 bytes), care indică spre date. In cazul unor mesaje mici, aceasta reprezintă un cost suplimentar mare (un mod de a elimina această problemă este de a combina descriptorul şi datele pentru mesajele mici). •Memoria soneriei: La fel ca la memoriile înregistrate, şi soneriile
trebuiesc protejate. Specificaţia VIA cere ca fiecare sonerie să fie mapată la o pagina de utilizator separată, ceea ce reprezintă o risipă a spaţiului adreselor virtuale pentru mesaje de dimensiune mică (un mod de a elimina această problemă este de a combina mai mulţi descriptori cu o singură pagină, însa aceasta presupune mecanisme suplimentare)
Specificaţiile VIA sunt destul de vagi.

148
6.6. Reducerea intreruperilor Deşi supraîncărcarea datorată întreruperilor este mai mică decât cea
apărută la planificarea proceselor sau apelurile sistem, ea poate fi totuşi destul de substanţială. De fiecare dată când soseşte un pachet, apare o întrerupere care are ca efect înteruperea procesorului şi o comutare de context. Nu pot fi evitate de tot întreruperile, dar se poate reduce supraîncărcarea datorată întreruperilor prin următoarele artificii. • Intrerupere doar pentru evenimente importante: de exemplu, în
soluţia ADC, adaptorul nu trebuie să întrerupă procesorul la fiecare recepţie a unui nou pachet, ci doar la recepţionarea primului pachet din fluxul de pachete (presupunem că aplicaţia va verifica pachetele recepţionate) şi când coada descriptorilor de tampoane libere este goală. Aceasta poate reduce supraîncărcarea datorată întreruperilor, la un singur pachet din N pachete recepţionate, presupunând că cele N pachete se recepţionează într-o rafală. •Polling/anchetarea: Procesorul (CPU) verifică dacă au apărut noi
pachete iar adaptorul nu întrerupe niciodată. Acest lucru poate duce la o supraîncărcare mai mare decât în cazul procesării acţionate de întreruperi, dacă numărul de pachete recepţionate este scăzut, dar metoda poate fi eficientă pentru volume de trafic mari. O altă variantă a acestui concept ar fi întreruperile de ceas: CPU verifică periodic, la expirarea unui timer. •Controlul prin aplicaţie: Transmiţătorul poate determina momentul
când se întrerupe receptorul, setând un anumit bit din antetul pachetului. De exemplu un transmiţător FTP poate seta bitul de întrerupere, doar în ultimul pachet de date din cadrul unui transfer de fişiere (P10, pasează indicaţii în antetele protocolului). Ideea este probabil prea radicală pentru a putea fi folosită, însă a fost propusă o implementare care are la bază o rafinare a acestei idei, într-un chip ATM, fabricat deja.
In general, folosirea simultana a mai multor metode funcţionează destul de bine în practică. In unele implementări cum cum este “first bridge”, utilizarea polling-ului este foarte eficace. De aceea, ideile mai radicale precum întreruperile de ceas sau cele controlate de aplicaţie au devenit mai puţin folositoare. Trebuie menţionat faptul că ideile RDMA au marele avantaj de a înlătura, pentru transferurile de date de mari dimensiuni, necesitatea apelurilor de sistem per pachet şi a întreruperilor per pachet.
6.6.1. Evitarea blocării Livelock la nivelul recepţiei Pe lângă ineficienţele datorate costurilor de tratare a întreruperilor,
întreruperile pot interacţiona cu planificarea sistemului de operare, reducând la zero debitul nodurilor terminale, fenomen cunoscut sub numele de receiver livelock. In BSD UNIX, recepţionarea unui pachet generează o întrerupere. Procesorul face un salt la rutina de tratare a întreruperii, trecând peste planificator, pentru a câştiga viteză. Rutina de tratare a întreruperii face o copie a pachetului, pe care o pune într-o coadă a nucleului, care conţine toate pachetele IP ce aşteaptă să fie “consumate”, face o cerere de atribuire a unui fir de execuţie către sistemul de operare (întrerupere software) şi îşi termină activitatea.
Daca reţeaua este foarte încărcată, calculatorul poate intră în starea de receiver livelock, stadiu în care calculatorul procesează toate pachetele care ajung la el, doar pentru a le distruge ulterior, deoarece aplicaţiile nu

149
rulează niciodată. Dacă se receptionează un tren de pachete, doar rutina de tratare a întreruperilor de prioritate maximă va rula, şi probabil nu va mai fi timp pentru întreruperile software şi nici atât pentru procesul browser. Astfel, se ajunge la momentul în care cozile IP sau cozile socket-urilor vor fi pline, şi la pierderea pachetelor în a cărei procesare s-au investit resurse.
O tehnică, care pare necesară în astfel de situaţii este dezactivarea întreruperilor, când procesarea la nivelul aplicaţiilor este foarte redusă. Acest lucru se poate face urmărind timpul de rulare a rutinelor de întrerupere aferente unui dispozitiv, iar dacă timpul respectiv depăşeşte un anumit procentaj din timpul total, atunci dispozitivul respectiv va fi mascat. Aceasta va duce însă la pierderea pachetelor care ajung în momentele de supraîncărcare ale calculatorului, printre care vor fi şi pachete importante sau care nu ar genera întreruperi.
Se apeleaza la două mecanisme. In primul rând ar trebui folosite cozi separate pentru fiecare socket destinaţie şi nu o singură coadă utilizată în comun. La recepţionarea pachetului, prin demultiplexare timpurie se va plasa fiecare pachet în coada asociată socket-ului. In acest fel, dacă se întamplă ca o coadă a unui socket să se umple, pentru că aplicaţia respectivă nu citeşte pachetele, celelate socket-uri vor putea progresa, neinfluenţate de această problemă.
Al doilea mecanism este implementarea procesarii protocolului la nivelul de prioritate a procesului receptor şi ca parte a contextului proceselor recepţionate (şi nu ca o întrerupere software separată). In primul rând se înlătura practica neechitabila, în care se transferă procesarea de la aplicaţia X la aplicaţia Y, ce rula în momentul recepţionării pachetului pentru aplicaţia X. In al doilea rând, dacă o aplicaţie rulează încet, coada soclului respectiv se va umple iar pachetele recepţionate pe acest socket vor fi pierdute, permiţând însă procesarea celorlalte pachete. In al treilea rand, şi cel mai important este faptul că deoarece protocolul de procesare este făcut la un nivel mai scăzut (procesarea aplicaţiei), se înlătură problema livelock cauzată de procesarea parţială (de exemplu, procesarea de protocol) a multor pachete, fără ca procesările aplicaţie aferente să fie obligate să scoată pachetele din coada de socket.
Acest mecanism, denumit lazy receiver processing (LRP), foloseşte în principiu procesarea înceată, nu atât de mult pentru eficienţă, cât pentru echitate şi pentru a evita apariţia livelock.
6.7. Concluzii Pe lângă restructurarea principală referitoare la evitarea copierii,
controlul supraîncărcării este o problemă foarte importantă, care trebuie tratată când e vorba de aplicaţii de reţea. Serverele rapide trebuie să reducă supraîncărcarea cauzată de planificarea proceselor, de apelurile la sistem, şi de întreruperi. Sistemele de operare mai noi, precum Linux se străduiesc enorm să reducă costul inerent pe care îl implică controlul supraîncărcării. Arhitecturile moderne devin tot mai rapide în procesarea instrucţiunilor, folosind date din memoria cache, fără o accelerare sensibilă a comutării contextului sau a procesării întreruperilor.
Au fost trecute în revistă, pentru aplicaţiile de reţea, tehnicile de bază pentru reducerea supraîncărcării cauzată de planificarea proceselor. Cu

150
greu se poate face ceva ieşit din comun, ca structurarea fiecărui nivel ca un proces separat, fără apeluri la nivelurile superioare. Din fig.6.3 trebuie desprinsă ideea profundă a procesarii la nivelul utilizatorului. Proiectarea de reţele la nivel de utilizator, împreună cu canalele dispozitivelor de aplicaţie fac posibilă existenţa unor tehnologii precum VIA, care vor face parte în curând din sisteme reale, pentru a evita apeluri de sistem la trimiterea/recepţionarea pachetelor.
Pe de altă parte, arta procesării structurate în contextul aplicaţiei, de exemplu un server Web, s-a bucurat de tot mai multă atenţie în ultimul timp. In timp ce serverele conduse de evenimente (împreună cu processele ajutătoare) echilibrează maximizarea concurenţei şi minimizarea încărcării datorată comutării de context, aspectele legate de ingineria software lasă încă multe întrebări fără răspuns. Va fi suficientă abordarea lansată-de -evenimente în mediul de producţie, cu modificări şi depanări frecvente? Un pas inainte îl reprezintă abordarea condusă de evenimente, pe nivele, însă ingineria serverelor Web mari va necesita cu siguranţă mai mult efort.
Abordarea condusă de evenimente se bazează pe implementarea rapidă a apelului select() sau a funcţiilor echivalente cu acesta. Abordările Unix au probleme fundamentale de scalabilitate ; sistemele de operare mai populare, precum Windows, au API-uri mult mai eficiente
Ideea foarte importantă privind standardul VIA o reprezintă faptul că se permite aplicaţiilor să comunice direct cu dispozitivele de reţea, folosind o interfaţă virtuală protejată. Ideal, adaptorii sunt astfel proiectaţi încât să permită funcţionarea mecanismelor de tip VIA sau similare. Intreruperile sunt evident de neevitat, această problemă poate fi însă ameliorată folosind amestecul şi polling-ul în medii potrivite.Figura 6.1 listează tehnicile discutate în acest capitol şi principiile corespunzătoare.
6.8. Exercitii 1. Filtre de pachete şi apeluri : La descrierea apelurilor (fig.6.3)
sistemul şi-a dat seama pentru care aplicatie era destinat un anumit pachet, prin faptul că apela o rutină de transport. De ce mai e necesară filtrarea pachetelor? Ce presupuneri implicite au fost făcute aici?
2. Compararea modelelor de structurare a serverelor Web : au fost comparate diferite mecanisme de structurare a serverelor prin intermediul unor metrici simple ca eficienţa planificării şi concurenţa CPU. Considerati şi celelalte două metrici în procesul de comparare. •Concurenţa la disc : Unele sisteme au discuri multiple şi există o
planificare a discurilor. Intr-un asemenea mediu se pune întrebarea dacă la o abordare condusă de evenimente ar putea apare probleme, în comparaţie cu abordarea multiproces. Vor apare probleme şi la abordarea condusă de evenimente care dispune şi de procese helper? •Acumularea statisticilor: Serverele Web trebuie să deţină informaţii
statistice referitoare la structurile de utilizare pentru a ţine evidenţa. Vor fi aceste statistici mai complexe la arhitecturile proces-per-client şi fir de execuţie-per-client? De ce este mai simplu într-o arhitectură condusă de evenimente?
3. Algoritmi versus algoritmică în reimplementarea ufalloc(): Se determina modul cel mai eficient de reimplementare a funcţiei
ufalloc(), pentru a găsi cel mai mic descriptor nealocat.

151
• Se folosesete o stivă/heap binară. Pentru N identificatori, câte accese la memorie sunt necesare? Cât spaţiu este necesar, în biţi? • Presupunem că maşina este pe W biţi (la Alpha W=64) şi că există o
instrucţiune (sau un set de instrucţiuni) pentru a găsi cel mai din dreapta zero într-un cuvânt de W biţi. Presupunem că descriptorii alocaţi sunt reprezentaţi ca un set de biţi de dimensiune N. Cum poate fi completat setul de biţi cu o stare suplimentară (P12), pentru a calcula eficient cel mai mic descriptor nealocat ? •Care sunt costurile de spaţiu şi timp ale acestei scheme, în comparaţie
cu o stivă simplă? Se poate face stiva simplă mai rapidă folosind un artificiu prin care se măreşte baza stivei, astfel încât să avem K>1 elemente în fiecare nod al stivei?
4. Implementarea modificată a unui fast select(): Textul explică modul în care elementele sunt adăugate setului I, H şi R, dar nu specifică în totalitate modul în care ele sunt scoase din set. Explicaţi modul în care elemetele sunt scoase din set, în special la setul de indicaţii H.
5 Implementarea modificată a unui fast select(): Se consideră următoarele modificări ale implementării fast select:
(a) Inew este egal cu S (şi nu cu Iold ∪ S). (b) Rnew este calculat ca şi înainte. (c) Utilizatorului i se returnează Rnew (şi nu Rnew ∪ S).
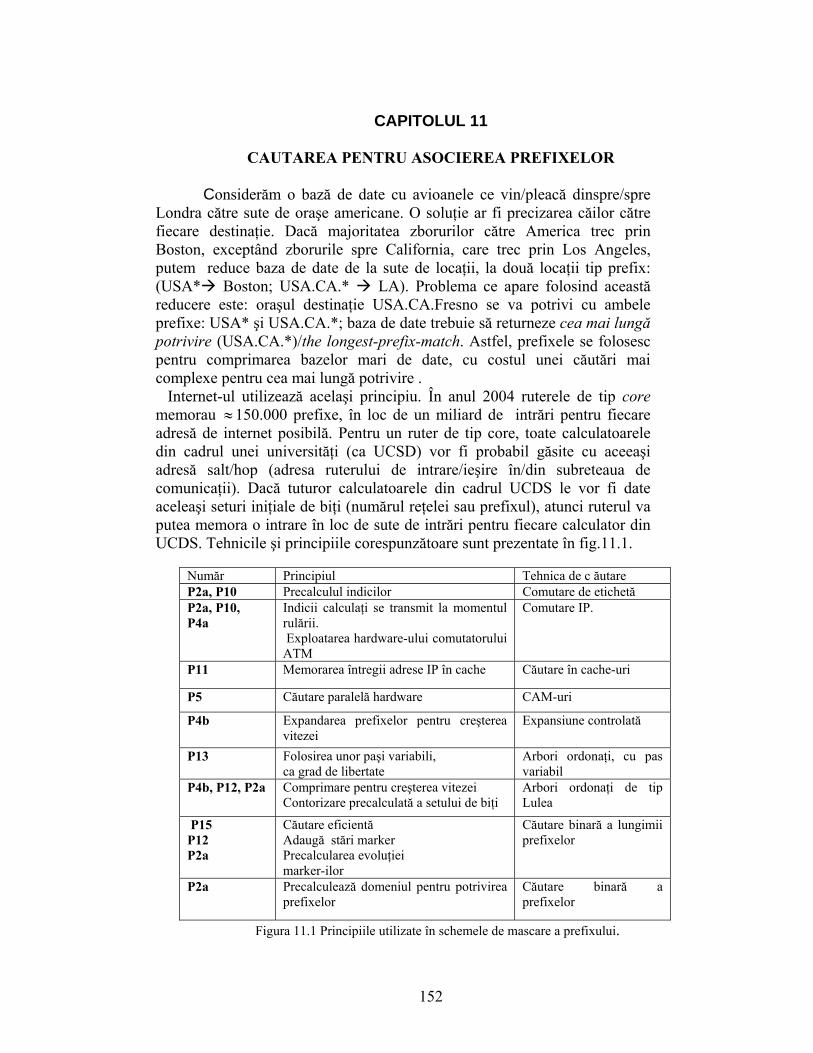
152
CAPITOLUL 11
CAUTAREA PENTRU ASOCIEREA PREFIXELOR
Considerăm o bază de date cu avioanele ce vin/pleacă dinspre/spre
Londra către sute de oraşe americane. O soluţie ar fi precizarea căilor către fiecare destinaţie. Dacă majoritatea zborurilor către America trec prin Boston, exceptând zborurile spre California, care trec prin Los Angeles, putem reduce baza de date de la sute de locaţii, la două locaţii tip prefix: (USA* Boston; USA.CA.* LA). Problema ce apare folosind această reducere este: oraşul destinaţie USA.CA.Fresno se va potrivi cu ambele prefixe: USA* şi USA.CA.*; baza de date trebuie să returneze cea mai lungă potrivire (USA.CA.*)/the longest-prefix-match. Astfel, prefixele se folosesc pentru comprimarea bazelor mari de date, cu costul unei căutări mai complexe pentru cea mai lungă potrivire .
Internet-ul utilizează acelaşi principiu. În anul 2004 ruterele de tip core memorau ≈150.000 prefixe, în loc de un miliard de intrări pentru fiecare adresă de internet posibilă. Pentru un ruter de tip core, toate calculatoarele din cadrul unei universităţi (ca UCSD) vor fi probabil găsite cu aceeaşi adresă salt/hop (adresa ruterului de intrare/ieşire în/din subreteaua de comunicaţii). Dacă tuturor calculatoarele din cadrul UCDS le vor fi date aceleaşi seturi iniţiale de biţi (numărul reţelei sau prefixul), atunci ruterul va putea memora o intrare în loc de sute de intrări pentru fiecare calculator din UCDS. Tehnicile şi principiile corespunzătoare sunt prezentate în fig.11.1.
Număr Principiul Tehnica de c ăutare P2a, P10 Precalculul indicilor Comutare de etichetă P2a, P10, P4a
Indicii calculaţi se transmit la momentul rulării. Exploatarea hardware-ului comutatorului ATM
Comutare IP.
P11 Memorarea întregii adrese IP în cache Căutare în cache-uri
P5 Căutare paralelă hardware CAM-uri
P4b Expandarea prefixelor pentru creşterea vitezei
Expansiune controlată
P13 Folosirea unor paşi variabili, ca grad de libertate
Arbori ordonaţi, cu pas variabil
P4b, P12, P2a Comprimare pentru creşterea vitezei Contorizare precalculată a setului de biţi
Arbori ordonaţi de tip Lulea
P15 P12 P2a
Căutare eficientă Adaugă stări marker Precalcularea evoluţiei marker-ilor
Căutare binară a lungimii prefixelor
P2a Precalculează domeniul pentru potrivirea prefixelor
Căutare binară a prefixelor
Figura 11.1 Principiile utilizate în schemele de mascare a prefixului.

153
11.1 Cautarea prefixelor Această secţiune introduce notaţia prefix, explică de ce e folosită căutarea
prefixelor şi descrie principalele metrici pentru evaluarea schemelor de căutare a prefixelor.
11.1.1 Notarea prefixelor. Prefixele utilizate pe internet sunt definite prin biţi şi nu prin caractere
alfanumerice, având o lungime de până la 32 de biţi. Confuzia e creată de faptul ca că prefixele IP sunt scrise deseori cu notaţii cu punct zecimal. Astfel, prefixul de 16 biţi pentru UCDS, se scrie 132.239. Fiecare din cifrele zecimale dintre puncte reprezintă un octet. Deoarece în binar 132 este 10000100 şi 239 este 11101111, prefixul UCDS în binar poate fi scris şi ca 1000010011101111*, unde caracterul “*” arată că biţii rămaşi nu contează. Toate adresele IP de 32 biţi ale staţiilor UCSD încep cu aceşti 16 biţi.
Deoarece prefixele pot avea lungime variabilă, alt mod de notare a prefixelor este de forma A/L, unde A e o adresă IP de 32 biţi în virgulă zecimală şi L lungimea prefixului. Astfel, prefixul UCDS poate fi scris şi ca 132.239.0.0/16, unde lungimea 16 indică faptul că doar primii 16 biţi (132.239) sunt relevanţi. Al treilea mod de a scrie prefixele este utilizarea unei măşti în loc de o lungime explicită de prefix. Astfel prefixele pot fi scrise în următorul mod: 128.239.0.0 cu masca 255.255.0.0. Deoarece masca 255.255.0.0 are 1 pe primii 16 biţi, se indică o lungime implicită de 16 biţi.1
Din aceste trei modalităţi prin care se poate nota un prefix (binar cu asterix la sfârşit, cu notaţie ”/ ” slash, şi prin intermediul măştii), ultimele două sunt mai compacte şi deci mai potrivite pentru scrierea prefixelor mari. Din motive pedagogice este mai simplu să se utilizeze prefixe mici pentru exemple şi scrierea în binar. În acest capitol se va utiliza 01110* pentru a indica un prefix ce se potriveşte cu toate adresele IP de 32 de biţi care încep cu 01110. Este uşor de convertit această notaţie spre notaţiile slash sau mască. Majoritatea prefixelor au lungimea minimă de 8 biţi.
11.1.2 De ce prefixe cu lungime variabilă? Înainte de a considera abordarea temei complexe de potrivire a prefixelor
cu lungime variabilă, să vedem de ce prefixele Internet-ului au lungime variabilă. De exemplu pentru un număr de telefon 858-549-3816, e uşor de extras codul zonei, adică primele trei cifre zecimale (858). Dar dacă prefixele cu lungime fixă sunt uşor de implementat, care este avantajul celor cu lungime variabilă?
Răspunsul general e că prefixele cu lungime variabilă sunt mai eficiente ca spaţiu utilizat pentru adresare. Zonelor cu multe terminale li se asociază prefixe scurte, iar celor cu puţine terminale prefixe lungi.
Răspunsul specific vine din istoria adresării pe Internet. Internetul a început printr-o simplă ierarhie în care adresele de 32 de biţi erau divizate în adresă de reţea şi număr de staţie gazdă; ruterele doar memorau intrările în reţele. Pentru alocarea flexibilă de adrese, adresele de reţea vin cu dimensiuni variabile: Clasa A (8 biţi), Clasa B (16 biţi), Clasa C (24 biţi). Pentru a face faţă epuizării adreselor de clasă B, schema CIDR (Classless Internet Domain
1 Notaţia cu mască este de fapt mai generală din cauză că se pot folosi măşti neînvecinate,
la care 1-urile nu sunt neapărat consecutive pornind de la srtânga. Astfel de definiţii ale reţelelor sunt din ce în ce mai puţin folosite şi nu există în tabelele de prefixe ale ruterelor core.

154
Routing) asignează noilor organizaţii adrese multiple continue din Clasa C ce pot fi agregate cu un prefix comun. Se reduce dimensiunea tabelului ruterului core.
Lipsa spaţiului de adresare, a determinat ca înregistrările Intrenet să fie foarte conservative în asignarea de adrese IP. Unei organizaţii mici i se poate aloca doar o mică parte a adreselor Clasă C, poate a 30-a parte, care permite folosirea a doar patru adrese IP în cadrul organizaţiei respective.Multe organizaţii rezolvă problema prin împărţirea adreselor IP între mai multe calculatoare, utilizând scheme ca translatarea adreselor reţea, NAT(Network Address Translation).
Astfel, CIDR şi NAT au ajutat la manevrarea creşterii exponenţiale a Internet-ului cu un spaţiu finit de adrese de 32 de biţi. Eficienţa NAT pe termen scurt şi complexitatea lansării unui nou protocol au determinat o dezvoltare lentă a IPv6 care are adrese de 128 biţi. Dar, într-o lume nouă cu miliarde de senzori fără fir, interesul pentru IPv6 va reveni.
Decizia de dezvoltare a CIDR a salvat Internetul, dar a introdus complexitatea metodelor de verificare a potrivirii celui mai lung prefix.
11.1.3 Modelul de căutare/lookup Un pachet care soseşte pe o legătură de intrare poartă o adresă2 de Internet
de 32 biţi. Procesorul consultă un tabel de expediere/forwarding care conţine un set de prefixe cu legătura de ieşire corespunzătoare. Pachetul se asociază cu prefixul cel mai lung, care se potriveşte cu adresa destinaţie a pachetului, şi este retransmis către legătura corespunzătoare de ieşire. Sarcina găsirii legăturii de ieşire numită şi căutarea adresei /address lookup, este subiectul acestui capitol, care expune algoritmii de căutare şi arată că aceste căutări pot fi implementate la viteze de gibabit şi terabit.
Înainte de a căuta soluţii pentru căutarea IP, trebuie să ne familiarizăm cu câteva probleme legate de distribuţia traficului, tendinţele memoriilor, şi dimensiunile bazelor de date (fig.11.2), care justifica schemele de căutare.
Studii asupra traficului în reţelele de tranzit/backbone (1997), arată ≈250.000 de fluxuri concurente de scurtă durată, cu o măsurare destul de conservativă a fluxurilor. Numărul fluxurilor este în creştere, deci memoriile cache nu funcţionează bine.
Aproximativ jumătate din pachetele recepţionate de către ruter sunt pachete TCP de confirmare de lungime minimă. E posibil ca un ruter să primească un şir de pachete de lungime minimă. Ca să putem căuta prefixul în timpul retransmiterii unui pachet de lungime minimă, trebuie evitată necesitatea unei cozi pe legătura de intrare, ceea ce ar simplifica proiectarea sistemului.
Al doilea motiv este comercial: mulţi vânzători pretind transmisii la viteza /firului: transmisia unui pachet de 40 byte la viteza liniei nu ar trebui să dureze mai mult de 320ns la o viteză de 1Gbps, 32nsec la 30Gbps (vitezele OC – 192), şi 8nsec la 40Gbps (OC - 768).
Cea mai importantă metrică a schemelor de căutare/lookup este viteza căutării. A treia observaţie arată că, deoarece costul computaţional e dominat
2 Deşi majoritatea utilizatorilor lucrează cu nume de domenii, trebuie menţionat că acestea sunt translatate în adrese IP de către serviciul DNS, înainte de transmiterea pachetelor

155
de accesările memoriilor, cea mai simplă măsură a vitezei căutării este numărul de accesări ale memoriei în cazul cel mai defavorabil. A patra observaţie arată că deoarece bazele de date ale reţelelor backbone au prefixe cu lungimea între 8 şi 32, schemele naive vor avea nevoie de 24 de accesări ale memoriei în cel defavorabil caz, pentru a testa toate lungimile posibile de prefix.
A cincea observaţie susţine că în timp ce bazele de date au în jur de 150.000 prefixe, posibila utilizare a rutelor pentru calculatoarele gazdă (cu adrese de 32 biţi) şi a rutelor multicast, înseamnă că ruterele backbone viitoare vor avea baze de date de prefixe cu 500.000 -1.000.000 de prefixe.
A şasea observaţie se referă la viteza de actualizare a structurilor de date pentru căutări, pentru adăugarea/ştergerea unui prefix de exemplu. Implementările instabile ale protocoalelor de rutare pot duce la actualizări de ordinul milisecundelor. De observat că, indiferent dacă sunt de ordinul secundelor sau a milisecundelor, sunt cu câteva ordine de mărime sub necesarul căutării/lookup, permiţând astfel luxul precalculării informaţiilor (P2a), sub formă de structuri de date, pentru accelerarea căutării, cu costul creşterii timpilor de actualizare.
A şaptea observaţie se referă la memoriile standard ieftine, DRAM cu timpi de acces de ≈60 nsec, şi memoriile de viteză mare (off/on-chip SRAM, 1–10nsec) ce trebuie folosite la viteze mari. DRAM sunt teoretic nelimitate, dar SRAM şi cele on-chip sunt limitate de costul mare şi nondisponibilitate. Astfel a treia metrică este utilizarea memoriei; aceasta poate fi scumpă şi rapidă (cache la software, SRAM la hardware), sau ieftină şi lentă (DRAM, SDRAM).
O schemă de căutare care nu face o reactualizare incrementală, va avea nevoie de două copii ale bazei de date de căutare/lookup, astfel încât în prima să poată face căutarea, şi în cealaltă asocierea. Astfel actualizarea incrementală reduce la jumătate necesarul de memorii de mare viteză..
A opta observaţie se referă la lungimea prefixelor. IPv6 foloseşte prefixe de 128 biţi, iar lookup-urile multicast necesită asocieri pe 64 biţi (adresa de grup şi adresa sursă pot fi concatenate în 64 de biţi). Este discutabila generalizarea Ipv6 şi a multicast-ului, asa că lookup-urile IP pe 32 biţi rămân actuale. Schemele descrise se scalează bine şi la prefixe lungi.
Pe scurt, metricile importante în ordinea importantei sunt: viteza lookup-ului, memoriile şi timpul de actualizare. Ca exemplu, o proiectare buna on-chip, folosind o memorie on-chip de 16 Mbiţi, poate suporta orice set din 500.000 prefixe, face un lookup în 8 nsec pentru a permite o expediere la viteza firului la ratele OC-192, şi permite actualizarea prefixului în 1msec.
Datele sunt conform cu baza de date disponibilă pentru proiectul IPMA, folosită pentru a compara experimental schemele de mascare. Cea mai mare dintre acestea Mae East, e un model rezonabil pentru un suport larg de ruter.
Următoarea notaţie este utilizată în mod repetat pentru raportarea performanţelor teoretice ale algoritmilor de mascare IP. N reprezintă numărul de prefixe (150.000 pentru baze de date mari, în prezent ), iar W reprezintă lungimea adresei (32 pentru IPv4) .

156
Observaţii Inferente 1)250000 de fluxuri concurente în backbone Memorarea cache lucrează slab în ruterele
backbone 2)50% sunt confirmări TCP Pentru pachetele de 40 biţi e necesară
căutarea cu viteza liniei 3)Căutare dominată de accesările memoriei Viteza căutării măsurată de numărul de
accesări ale memoriei
4)Lungimea prefixelor 8 - 32 Schemele naive cer 24 de accesări ale memoriei
5)150.000 prefixe actuale şi rute multicast şi gazdă
În urma creşterii 500.000 -1.000.000 prefixe
6)BGP instabil, multicast Actualizare în timp de milisecunde-secunde
7)Vitezele mari necesită SRAM Duce la minimizarea memoriei 8)Ipv6, întârzieri multicast Decisiv e lookup pe 32biţi FIGURA11.2 Date curente despre problemele de lookup şi implicaţiile asupra soluţiilor În final două observaţii pot fi exploatate pentru optimizarea cazului utilizat. O1: Aproape toate prefixele au 24 biţi sau mai puţin, în timp ce majoritatea
au prefixe de 24 biţi şi următorul vârf e la 16biţi. Uneori vanzătorii utilizează aceasta pentru a prezenta cel mai slab caz pentru metodele de căutare cu 24 biţi. Viitorul poate să aducă baze de date cu un număr mare de rutere gazdă (32 adrese de bit) şi integrarea memoriilor ARP.
O2: Sunt rare prefixele ce sunt prefixele altor prefixe (ca 00* şi 0001*). Numărul maxim de prefixe ale unui prefix, conţinute într-o bază de date, e 7.
Ideal ar fi să facem faţă şi celui mai defavorabil caz de căutare din punct de vedere a timpului, dar este de dorit să găsim scheme ce utilizează observaţiile precedente pentru creşterea performanţei medii de stocare.
11.2 Evitarea căutării Pornirea instinctivă a proiectantului de sistem este nu să rezolve
problemele complexe (ca potrivirea cea mai lungă a prefixelor), ci să le elimine. In reţelele cu circuit virtual, ca reţelele ATM, când o sursă doreşte să transmită date către o destinaţie, stabileşte un apel, asemănător cu stabilirea unui apel telefonic. Numărul de apel (VCI) este pentru fiecare ruter un întreg cu lungime moderată, uşor de căutat. Stabilirea apelului duce la creşterea întârzierii tur-retur, suplimentară faţă de timpul necesar transmisiei datelor. In reţelele ATM comutatorul precedent trimite un index (P10, trimite informaţii în antetele de protocol), către următorul comutator. Indexul este calculat (P2a) chiar înainte ca datele să fie trimise, de către comutatorul precedent (P3c, realizează deplasarea calculului în spaţiu). Aceeaşi idee poate fi utilizată în reţelele de tip datagrame, ca Internetul, pentru a evita căutarea prefixului. Vor fi descrise două metode ce au la bază această idee: comutare cu etichetă şi comutarea circuit.

157
11.2.1 Şiruri de indici şi comutarea etichetelor La folosirea şirurilor de indici, fiecare ruter pasează un indice tabelului de
retransmisie a următorul ruter; se evită astfel folosirea căutării prefixelor. Indecşii sunt precalculaţi de către protocolul de rutare/dirijare de cate ori se schimba topologia retelei. În figura 11.3, sursa S trimite un pachet către destinaţia D prin primul ruter A; antetul pachetului conţine un index i spre tabelul de retransmisie al lui A. Astfel, ruterul A precizează calea spre D prin ruterul B, care la rândul lui conţine indicele j către destinaţia D. Astfel A trimite pachetul spre B şi precizează indicele j al acestuia. Procesul se repetă în fiecare ruter din reţea prin utilizarea indexului din pachet pentru căutarea in tabelele de transmisie spre destinaţie.
Diferenţele majore între şirurile de indici, şi indicii circuitelor virtuale sunt următoarele: şirurile de indici sunt per destinaţie, nu per perechea activa sursă-destinaţie ca indicii circitelor virtuale tip ATM. Cea mai importantă diferenţă este aceea că şirurile de indecsi cu sunt precalculate de către protocolul de rutare de fiecare dată când se schimbă topologia. In figura 11.4 se prezintă topologia unui ruter ce utilizează protocolul Bellman – Ford pentru găsirea distantelor spre destinaţie.
Cu protocolul Bellman–Ford (folosit de protocolul intradomeniu RIP, Routing Information Protocol), un ruter R calculează calea cea mai scurtă spre D, prin retinerea celui mai mic dintre costurile spre D, prin fiecare vecin. Costul spre D printr-un vecin ca A, este costul lui A spre D (5 in cazul nostru) la care se adună costul de la R la A (3, in exemplul nostru). În figura 11.4, costul cel mai scurt de la R spre D este prin ruterul B, cu costul 7. R poate calcula aceste costuri deoarece fiecare vecin al lui R, (A si B aici) paseaza costul propriu de la D spre R, cum se arată în figură. Pentru calcularea si a indicilor, se modifică protocolul de baza astfel încât fiecare vecin isi reportează indicii spre destinaţie in plus cu costul propriu spre destinatie. În figura 11.4, A trimite pe i şi B pe j; astfel, cand R alege pe B, ii foloseste si indexul j a lui B in intrarile tabelului de dirijare pentru D. Deci, fiecare ruter utilizează indexul vecinului de cost minim pentru fiecare destinatie, ca sir de indecsi pentru acea destinatie.
Cisco a introdus mai târziu comutarea etichetelor, a cărei concept se aseamănă cu conceptul înşiruirii indecsilor, dar comutarea etichetelor permite unui ruter utilizarea unei stive de etichete (indici) pentru ruterele multiple care urmeaza. Cu toate acestea, ambele scheme nu lucrează bine cu structurile ierarhice. Se consideră un pachet ce ajunge de la backbone la primul ruter al domeniului de ieşire. Domeniul de iesire este ultima retea condusa autonom traversata de pachet, sa zicem o retea de intreprindere careia ii apartine destinatia pachetului.
Singura cale de evitare a căutării/lookup in primul ruter R, din domeniul de ieşire, este sa avem un ruter inafara domeniului de ieşire care sa trimita (pentru subreteaua destinatie) mai devreme un index către R. Acest lucru este imposibil, deoarece ruterele backbone anterioare ar trebui să aibe doar o intrare agregata de rutare către intreg domeniul destinaţie şi, astfel, poate trimite doar un indice spre toate subretelele din acel domeniu. Soluţia este fie adăugarea unor intrări suplimentare ruterelor din afara domenuilui (ceea ce e nefezabil), sau sa se pretinda o cautare IP banala la punctele de intrare in domeniu(soluţia folosită). Comutarea etichetelor s-a dezvoltat azi sub o

158
formă mai generala numită comutare de etichete multiprotocol (MPLS MultiProtocol Label Switching). Totusi, nici comutarea de etichete nici MPLS nu evita complet cautarea IP ordinara.
11.2.2 Comutarea fluxurilor O altă metodă de evitare a căutării este comutarea fluxurilor. Se utilizeaza
un ruter de salt precedent care trimite un indice următorului ruter de salt, dar spre deosebire de comutarea etichetă, acest index este calculat la cerere, atunci când ajung datele la ruter, si apoi e memorat in cache.
Comutarea fuxului începe cu ruterele care conţin un comutator ATM intern(posibil lent), şi un procesor capabil sa realizeze retransmisia IP şi rutarea. În figura 11,5 sunt prezentate două astfel de rutere R1 şi R2. Cand ruterul R2 trimite prima data un pachet IP spre destinaţia D, care ajunge la
A, i
D i B,j
D j B, -
D -
S A B D
Fig. 11.3 Căutarea destinaţiei prin utilizarea de către fiecare ruter a unui index de trecere în tabelul de transmisie a următorului ruter
Nod ATabel rutareTabel rutare
D, 5
D, 5, i
D, 6
Nod A Nod B
D, 5, j D, 5, j
Nod D
Cost 3
Cost 6Cost 5
Cost 1
Nod R
Tabel trimis de A
Tabel trimis de B
i j
Fig 11.4 Setarea indicelor înşiruirii, sau modificarea înşiruirii prin rutarea Bellman Ford

159
intrarea din stânga a ruterului R2, portul de intrare trimite pachetul procesorului sau central. Aceasta este o cale lenta. Procesorul face o căutare IP şi comuta intern pachetul spre legatura de iesire L. Mai departe nimic nu e iesit din comun.
La comutarea IP, daca R1 doreste sa comute pachetele transmise spre D
destinate legaturii de iesire L, R1 alege un circuit virtual liber I, plaseaza asocierea I,L in portul sau de intrare, si apoi trimite pe I inapoi la R2. Daca acum R2 trimite lui D pachete cu eticheta VCI I, pachetul va fi comutat direct spre legatura de iesire, fara sa mai treaca prin procesor.
Daca insa, daca momentan e un volum mare de trafic spre D, nodului R1 ”ii vine idea” sa ”comute” pachetele ce merg spre D, situatia devine ciudata.In acest caz, R1 alege mai intai un circuit virtual liber I, plaseaza asocierea I L in portul sau hardware, si apoi trimite I inapoi la R2. Daca acum R2 trimite spre D pachete cu eticheta VCI I , spre portul de intrare a lui R1, portul verifica asocierea lui I cu L si comuta pachetul direct spre legatura de iesire L fara sa mai treaca prin procesor. Desigur, R2 poate repeta acest proces de comutare cu ruterul precedent de pe cale, s.a.m.d. Eventual, inaintarea IP poate lipsi complet in portiunea comutata a secventei de rutere cu comutarea fluxurilor.
Comutarea fluxurilor, desi eleganta, probabil ca nu functioneaza prea bine in retelele de tranzit/backbone, deoarece fluxurile backbone au o viata scurta si o localizare slaba. Unii autori, Molinero-Fernandez si McKeown au o parere contrara, si argumenteaza in favoarea unei reveniri a comutarii fluxurilor bazata pe conexiunile TCP. Ei considera ca actuala folosire a comutatoarelor optice cu comutarea circuitelor in ruterele de tranzit/core, subutilizarea legaturilor de tranzit/backbone care lucreaza la 10% din capacitate, si cresterea latimii de banda optce vor favoriza simplitatea comutarii de circuit la viteze mari.
Ambele metode de comutare (IP şi etichetă), sunt folosite pentru evitare a cautarilor IP prin pasarea de informatii in antetele protocoalelor. Ca şi la ATM, ambele trimit indici (P10); dar comutarea etichetă precalculează indicii in avans(P2a) (topologia se modifica in timp), spre deosebire de ATM (chiar inainte de transferul datelor). Pe de alta parte, la comutarea IP indicii sunt calculaţi la cerere (P2c, evaluare relaxata) după ce datele încep să fie trimise. Cu toate acestea nici comutarea etichtelor nici comutarea IP nu evită
I,L
R2 R1
ProcesorSlow path
Fast path
L
M
Fig. 11.5 Comutarea IP
I
D

160
complet căutarea cu prefix şi fiecare adauga un protocol complex. Sa vedem acum cum e cu presupusa complexitate a cautarii IP.
11.2.3 Situatia comutării etichetelor, comutarii IP şi comutării
multiprotocol a etichetelor Desi comutarea etichetelor şi cea IP au fost initial introduse pentru
creşterea vitezei căutării, la comutarea IP s-a renuntat. Dar comutarea etichetelor s-a reinventat sub forma mai generală a comutarii multiprotocol a etichetelor (MPLS), pentru a diferentia fluxurile in scopul asigurarii calităţii serviciilor. Asa cum un VCI indică o etichetă simpla pentru distingerea rapidă a fluxului, eticheta permite ruterului să izoleze rapid un flux pentru servicii speciale. De fapt, MPLS utilizează etichetele pentru a evita clasificarea pachetelor, ceea ce este o problema mult mai dificila decăt căutarea prefixelor. Asa ca, desi asocierea prefixelor este necesara inca, metoda MPLS este utilizată actualmente in ruterele de tranzit/core.
Pe scurt, inaintarea/expedierea rapida MPLS a pachetelor se desfasoara astfel. Dacă este identificat un pachet cu un antet MPLS, este extras din acesta o etichetă de 20 biţi si eticheta este cautata intr-o tabela care asociaza eticheta cu regula de inaintare/retransmisie. Regula specifică următorul nod/hop şi operaţiunile ce vor fi efectuate asupra setului curent de etichete din pachetul MPLS. Aceste operaţiuni pot include renunţarea la etichete (”extragere din stiva etichetelor”)sau adăugarea de etichete (”introducere in stiva etichetelor”).
Implementarea ruterelor MPLS trebuie realizată impunand anumite limitări procesului general, pentru a garanta retransmisia la viteza liniei. O limitare posibila se refera la impunerea unui unui spatiu dens pentru etichete , care suporta un numar de etichete sub 202 (ceea ce permite un volum mai mic de memorie pentru lookup, si evitarea tabelului hash), si limitarea numarului de operatii cu stiva de etichete care pot fi efectuate asupra unui singur pachet.
11.3 Tehnici nonalgoritmice de asociere a prefixelor Se prezintă aici alte două tehnici de căutare a prefixelor, nelegate de
metodele algoritmice: memorarea in cache-uri şi CAM ternar. Memorarea in cache-uri se bazează pe localizarea referinţelor adreselor, iar CAM ternar pe paralelismul hardware.
11.3.1 Memorarea in cache-uri Căutarea/lookup poate fi mai rapidă prin utilizarea memoriilor cache,
(P11a) care mapează adresele de 32 biţi spre următorul salt/hop. Cu toate acestea rata de utilizare a acestor memorii in backbone-uri este destul de mică din cauza lipsei localizării prezentata de fluxurile din backbone. Utilizarea unei memorii cache mari necesită folosirea unui algoritm de asociere precis pentru cautare. Au aparut propuneri inteligente de modificare a algoritmului de lookup pentru cahe-ul CPU, in acest scop. În esenta, memorarea in cache-uri poate fi de folos dar nu elimină necesitatea unei căutări rapide a prefixului.
11.3.2 Memorii ternare adresate prin conţinut. Memoriile ternare adresate prin conţinut (TCAM) care permit biti ”care nu
conteaza” ofera o căutare paralelă printr-un singur acces la memorie. CAM-

161
urile actuale pot face căutarea si actualizarea/update intr-un singur ciclu de memorie (10 nsec de exemplu) si manevreaza orice combinatie a 100.000 de prefixe. Dar CAM-urile au următoarele probleme: • Scalarea densitatii: un bit în TCAM-uri are nevoie de 10, 20 tranzistoare, pe când un SRAM necesita doar 4, 6 tranzistoare. Astfel TCAM-urile vor fi mai puţin dense decât SRAM-urile, adica vor avea o suprafaţă mai mare, iar suprafaţa plăcilor este o problemă critica pentru rutere. • Scalarea puterii: TCAM-urile consumă o putere mai mare din cauza comparării paralele. Dar furnizorii de CAM-uri evita problema, gasind cai de eliminare a unor parti ale CAM-ului, pentru a reduce puterea. Puterea este o problema cheie in ruterele mari de tranzit/core. • Scalarea timpului: logica de asociere intr-un CAM cere ca toate regulile de asociere/matching sa lucreze astfel incat sa castige cea mai lunga potrivire.Vechile generatii de CAM-uri aveau nevoie in jur de 10nsec pentru o operatie, dar produsele anuntate actualmente se pare ca vor necesita doar 5 nsec, probabil prin pipelining-ul din partea de intirziere a asocierii. •Chip-uri suplimentare: avand in vedere faptul ca multe rutere, ca CISCO GSR si Juniper M160, au circuite integrate dedicate ASIC (Application Specific Integrated Circuit) expedierii pachetelor, e tentanta integrarea algoritmilor de clasificare cu cautare, fără adăugarea interfeţei CAM si chip-urilor CAM. Tipic, CAM-urile necesita o punte ASIC in plus pe langa chip-ul CAM de baza, iar uneori neceista chip-uri CAM multiple.
În concluzie, tehnologia CAM se îmbunătăţeşte rapid şi pot inlocui metodele algoritmice în ruterele mai mici. Dar, pentru ruterele de tranzit mai mari ce vor avea in viitor baze de date cu milioane de rute, ar fi mai bune soluţiile care se scaleaza la tehnologiile memoriilor standard ca şi SRAM. Probabil ca tehnologia SRAM va fi mereu mai ieftină, mai rapidă şi mai densă ca şi CAM-urile. Desi e prea devreme sa prezicem rezultatul acestei competitii dintre metodele algoritmice si cele TCAM, chiar si producatorii de semiconductoare furnizeaza ambele solutii: algoritmice si cu CAM-uri.
Fig. 11.6 Baza de date cu prefixe.
11.4 Arbori ordonati unibit Trie sau prefix tree este o structura de date ordonata de tip arbore pentru
memorarea tabelelor asociative la care cheile sunt siruri. Spre deosebire de binary search tree, nici un nod din arbore nu memoreaza cheia asociata nodului, dar in schimb, pozitia sa in arbore arata care este cheia asociata.Toti descendentii oricarui nod au un prefix comun al sirului asociat acelui nod, iar radacinii ii este asociat un sir vid. In mod normal, nu se asociaza valori fiecarui nod, doar frunzelor (leaves) si anumitor noduri interne (inner nodes) care corespund cheilor de interes.
P1=101* P2=111* P3=11001* P4=1* P5=0* P6=1000* P7=100000* P8=100* P9=110

162
Termenul trie deriva din retrieval. Din cauza etimologiei sale unii sustin ca ar trebui pronuntat ca si ”tree”, dar altii sustin varianta ”try”, pentru a face distinctia fata de termenul mai general ”tree”.
Este utila trecerea in revista a tehnicilor algoritmice (P15) pentru căutarea prefixelor printr-o tehnică simplă: arborii ordonati unibit / unibit tries. Se va considera o bază de date (fig 11.6), pentru ilustrarea soluţiile algoritmice din acest capitol, cu 9 prefixe, P1-P9, cu sirurile de biţi ca in figură.
În practică, exista un hop/salt urmator asociat fiecărui prefix (omis in figura). Pentru evitarea confuziei, numele prefixelor sunt folosite pentru precizarea următorului hop. Astfel o adresă D ce începe cu 1 şi continua cu 31 de zerouri se va potrivi cu P6, P7, P8. Cea mai lungă potrivire este P7.
In fig.11.7 este prezentat un arbore ordonat unibit pentru exemplul de baza de date din fig.11.6. Arborele ordonat unibit e un arbore la care fiecare nod e un tabel/array care contine pointer-0 si pointer-1. La radacina toate prefixele care incep cu 0 sunt memorate intr-un subarbore ordonat indicat de pointerul-0 si toate prefixele care incep cu un 1 sunt memorate intr-un subarbore ordonat indicat de pointerul-1.
Fiecare arbore ordonat este apoi construit recursiv, intr-un modul asemanator, folosind restul de biti ai prefixului alocati subarborelui ordonat.De exemplu, in fig.11.7, P1=101 e memorat intr-o cale parcursa urmarind pointerul 1 ca radacina, pointerul 0 ca si copilul din dreapta al radacinii, si pointerul-1 la urmatorul nod al caii.
Mai trebuie remarcate doua probleme. In unele cazuri, un prefix poate fi un subsir al altui prefix. De exemplu, P4=1∗ este un subsir al lui P2=111∗ . In acest caz, cel mai mic sir, P4, e memorat in interiorul nodului ordonat, pe calea spre sirul mai lung.De exemplu P4 e memorat la copilul din dreapta a radacinii; calea acestui copil din dreapta este sirul 1, care e acelasi cu P4.
La sfarsit, in cazul unui prefix ca P3=11001, dupa ce urmam primii trei biti, naiv ne-am putea astepta sa gasim un sir de noduri corespunzand ultimilor doi biti.Dar deoarece nici un alt prefix nu partajeaza cu P3 mai mult decat primii trei biti, aceste noduri ar contine doar un pointer de fiecare.Un astfel de sir de noduri ale arborelui ordonat cu cate doar un pointer e numit ramura cu cale unica. In mod clar, ramurile uni-cale pot creste spatiul pierdut de memorare, folosind intregul nod (ce contine minim doi pointeri) cand de fapt ar fi suficient doar un bit. O tehnica simpla de a elimina aceasta risipa evidenta (P1) este sa comprimam ramurile uni-cale.
Figura 11.7 Arbore ordonat unibit pentru baza de date din fig.11.6 In fig.11.7 acest lucru e facut folosind un sir text (de ex.”01”) pentru a
reprezenta pointerii care ar urma in ramura unicale. Astfel, in fig.11.7, doua noduri ale arborelui ordonat (continand fiecare doi pointeri) din calea spre P3, au fost inlocuiti de un singur sir text, de 2 biti. Dar nu s-a pierdut informatie prin aceasta transformare (ca exercitiu, determinati daca mai e vreo cale prin arbore care poate fi comprimata asemanator).
Pentru cautarea celei mai lungi potriviri a prefixului addresei destinatie D, se folosesc bitii lui D pentru a trasa calea prin arbore. Calea incepe cu radacina si continua pina ce cautarea esueaza prin terminare la un pointer vid ori la un sir text care nu se potriveste complet.In timp ce urmareste calea, algoritmul tine evidenta ultimului prefix numarat la un nod de pe cale. Cand cautarea esueaza, acesta este cea mai lunga potrivire a prefixului si e

163
returnata.De exemplu, daca D incepe cu 1110, algoritmul porneste urmarind pointerul-1 la radacina ca sa ajunga la nodul ce-l contine pe P4.Algoritmul isi aminteste pe P4 si foloseste urmatorul bit al lui D ( un 1) pentru a urmari pointerul -1 la urmatorul nod. La acest nod, algoritmul urmareste valoarea (P4) prin prefixul (P2) gasit mai nou.In acest punct se termina cautarea, deoarece P2 nu are pointeri de iesire.
Pe de alta parte, consideram ca facem o cautare pentru destinatia D’ ai carui primii 5 biti sunt 11000. Inca odata, primul bit de 1, e folosit pentru a ajunge la nodul ce-l contine pe P4. P4 este tinut minte ca ultimul prefix contorizat, si pointerul 1 e urmarit pentru a ajunge la nodul cel mai din dreapta de adincime 2.
Algoritmul urmareste acum al treilea bit din D’ (un 0) spre nodul sirului text care contine ”01”. Astfel ne amintim ca P9 a fost ultimul prefix contorizat. Al patrulea bit a lui D’ este 0, care se potriveste cu primul bit din ”01”. Dar, al cincilea bit a lui D’ este 0 (si nu 1 cum e al doilea bit din ”01” ). Astfel cautarea se termina cu P9 ca cea mai lunga potrivire.
Literatura despre arborii ordonati nu foloseste sirurile text pentru a comprima ramurile cu cale unica (fig.11.7).In schimb schema clasica Patricia trie / testul Patricia, foloseste un contor de omisiuni / skip count. Acest contor memoreaza numarul de biti din sirul text corespunzator, si nu bitii in sine.De exmplu, ”01” din exemplul nostru va fi inlocuit cu contorul de omisiuni ”2” in testul Patricia.
Algoritmul lucreaza bine atata timp cat testul Patricia e folosit pentru pentru potriviri exacte, pentru care a si fost initial creat.Cand ajunge cautarea la la un nod cu contor de omisiuni, omite numarul de biti potriviti si urmareste pointerul nodului contorului de omisiuni pentru a continua cautarea. Deoarece bitii omisi nu sunt comparati pentru potrivire, Patricia pretinde ca la sfarsitul cautarii sa se faca o comparare completa dintre cheile cautate si intrarile gasite de Patricia.
Din pacate, algoritmul lucreaza foarte prost pentru potrivirea prefixului/ prefix matching, pentru care Patricia nu a fost proiectat la inceput. De exemplu, la cautarea lui D’, ai carui primii 5 biti sunt 11000 in echivalentul lui Patricia a figurii 11.7, cautarea ar trebui sa omita ultimii doi biti si sa o ia spre P3. In acest punct compararea va gasi ca P3 nu se potriveste cu D’ .
Cand se intampla acest lucru o cautare in arborele Patricia trebuie sa revina inapoi si sa retesteze arborele pentru o posibila potrivire mai scurta. S-ar parea ca in acest exemplu, cautarea ar trebui sa-si aminteasca P4. Dar daca P4 a fost de asemenea contorizat pe calea care contine nodurile contoarelor de omisiuni, algoritmul nu poate fi chiar sigur de P4. Astfel el trebuie sa revina ca sa verifice daca P4 este corect.
Din pacate, implementarea BSD a inaintarii IP a decis sa foloseasca arborii Patricia, ca baza pentru cea mai buna potrivire de prefix. Astfel, implementarea BSD a folosit contoarele de omisiuni; de asemenea implementarea memoreaza prefixele umplandu-le cu zerouri. Prefixele au fost depozitate in frunzele arborelui, in loc sa fie in interiorul nodurilor, cum e aratat in fig.11.7. Rezultatul e ca potrivirea prefixului poate, in cel mai rau caz, sa duca la o reluare/ backtracking a arborelui pentru cazul cel mai defavorabil de 64 de accesari ale memoriei (32 in josul arborelui si 32 in susul arborelui).

164
Avand alternativa simpla a folosirii sirurilor text pentru evitarea backtracking-ului, contoarelor de omisiuni sunt o idee proasta; in esenta, deoarece transformarea contoarelor de omisiuni nu conserva informatia, in timp ce transformarea sirurilor text o conserva. Totusi, din cauza influentei enorme a BSD-ului, unii producatori si chiar algoritmi au aplicat contoarele de omisiuni in implementarile lor.
11.5 Arbori ordonaţi multibit Majoritatea memoriilor mari folosesc DRAM-uri; acestea au latenta
mare(≈60 nsec), comparativ cu timpul de acces la registre (2-5 nsec). Deoarece la arborii ordonati unibit testarea poate necesita 32 de accesari ale memoriei pentru un prefix de 32 de biti, timpul de cautare in cazul cel mai defavorabil la arborii unibit e de minim 32 60 1,92 secμ∗ = , ceea ce motiveaza cautarea in arborii ordonati multibit.
Pentru a face cautarea cu pasi/strides de 4 biti, principala problema este de a lucra cu prefixe ca 10101∗ (cu lungimea 5 ), a caror lungime nu e multiplu de 4 lungimea aleasa a pasilor. Cum putem fi siguri ca nu omitem prefixe ca 10101∗ , atunci cand la un moment dat cautam 4 biti ? Problema se rezolva cu expansiunea controlata a prefixului, prin transformarea bazei de date de prefixe existenta intr-o baza de date noua, cu mai putine prefixe dar posibil cu mai multe prefixe. Eliminarea tuturor lungimilor care nu sunt multipli de lungimea pasului ales, expansiunea permite o cautare multibit mai rapida, cu pretul cresterii dimensiunii bazei de date.
Figura 11.8 Expansiunea controlata a bazei de date de prefixe originala (stanga, cu cinci
lungimi de prefixe 1,3,4,5,6) la o baza de date expandata (dreapta, cu doar doua lungimi de prefixe 3 si 6).
De exemplu, extragand prefixele impare vechi se reduce numarul de
prefixe, de la 32 la 16, ceea ce ar permite cautarea in arbore a cate doi biti la un moment dat. Pentru a extrage un prefix ca 101∗ de lungime 3, se observa ca 101∗ reprezinta adresele care incep cu 1010∗ sau cu 1011∗ . Astfel 101∗ (de lungime 3) poate fi inlocuit de doua prefixe de lungime 4 (1010∗ si 1011∗), ambele mostenind intrarile de inaintare spre nodul/hop urmator 101∗ .
Dar prefixele extinse pot intra in coliziune cu un prefix existent care are noua lungime.In acest caz se renunta la noul prefix expandat, si se da prioritate vechiului prefix deoarece el a avut de la inceput lungimea mai mare.
In esenta, expansiunea face un compromis memorie/timp in favoarea timpului (P4b). Aceeasi idee poate fi folosita pentru a indeparta orice set ales de lungimi, cu exceptia lungimii 32. Deoarece cautarea in arbore depinde liniar de numarul de lungimi, expandarea reduce timpul de cautare.
Consideram mostra de baza de date din fig.11.6, cu noua prefixe, P1-P9. Aceasta e trecuta si in stanga figurii 11.8. Baza de date din dreapta figurii 11.8 este o baza de date echivalenta, construita prin expandarea bazei de date originale, pentru a contine doar prefixe de lungimea 3 si 6. De

165
mentionat este faptul ca prin expandarea lui P6=1000∗ de la patru biti la sase biti, se intra in coliziune cu P7=100000∗ si astfel se renunta la P6.
11.5.1 Arbori ordonati cu pas fix In fig.11.9 e prezentat un arbore ordonat pentru aceeasi baza de date ca cea
din fig.11.8, folosind un arbore expandat cu pas fix, de lungime 3. Astfel fiecare nod al arborelui foloseste 3 biti. Intrarile replicate in nodurile arborelui din fig.11.9 corespund exact prefixelor expandate din dreapta figurii 11.8. De exemplu, P6 din fig.11.8 are trei expandari ( )100001,100010,100011 .
Aceste trei prefixe expandate indica spre pointerul 100 a nodului radacina din fig.11.9 (deoarece toate cele trei prefixe expandate incep cu 100 ) si sunt memorate in intrarile 001,010,011 ale copilului din dreapta nodului radacina. De mentionat este ca intrarea 100 in nodul radacina are prefixul memorat P8 (pe langa faptul ca pointerul indica spre expansiunea lui P6), deoarece P8=100∗ este el insusi un prefix expandat.
Figura 11.9 Arbore ordonat expandat (care are doi pasi de cate 3 biti) corespunzator bazei
de date de prefixe din fig.11.8. Astfel, fiecare element al nodului arborelui e o inregistrare continand doua
intrari: prefixul memorat si un pointer. Cautarea in arbore proceseaza 3 biti la un moment dat de timp.De fiecare data cand e urmat un pointer, algoritmul isi reaminteste prefixul memorat (daca are). Cand se termina cautarea la un pointer vid, este returnat ultimul prefix memorat din cale.
De exemplu, daca adresa D incepe cu 1110 , cautarea pentru D incepe la intrarea 111 a nodului radacina, care nu are un pointer de iesire ci doar un prefix memorat (P2). Astfel, cautarea pentru D se termina cu P2. O cautare pentru o adresa care incepe cu 100000 urmareste pointerul 100 in radacina (si-si reaminteste P8). Acesta indica spre nodul de mai jos din dreapta, unde intrarea 000 nu are pointer de iesire ci doar prefix memorat(P7).Astfel cautarea se termina cu rezultatul P7. Atat pointerul cat si prefixul memorat pot fi regasite printr-un singur acces la memorie folosind memorii mari ( P5b).
Un caz special a arborilor ordonati cu pas fix,foloseste pasi ficsi de 24,4 si 4.Autorii, Guptas.a., observa ca DRAM-urile cu mai mult de 242 de locatii devin accesibile, astfel ca devine fezabila si cautarea cu pas de 24 de biti.
11.5.2 Arbori ordonati cu pas variabil In figura 11.9, nodul frunza cel mai din stanga trebuie sa memoreze
expandarile lui P3=11001∗ , iar nodul frunza cel mai din dreapta trebuie sa memoreze P6 (1000∗ ) si P7 (100000∗ ). Astfel, dincauza lui P7, nodul frunza cel mai din dreapta trebuie sa examineze mai mult de 2 biti, deoarece P3 contine doar 5 biti, si oasul radacinii eate de 3 biti. Exista un grad de libertate suplimentar care poate fi optimizat (P13).
In arborii ordonati cu pas variabil, numarul de biti examinati de fiecare nod al arborelui poate varia, chiar si pentru noduri de acelasi nivel. Pentru a face acset lucru, pasul nodului arborelui e codat cu un pointer spre nod. Figura 11.9 poate fi transformata inlocuind nodul cel mai din stanga cu un tabel cu

166
patru elemente si codand lungimea 2 cu pointerul spre nodul cel mai din stanga. Codarea pasului necesita 5 biti. Dar, arborele ordonat cu pas variabil din fig.11.10 are cu patru intrari in tabela mai putine decat arborele din fig.11.9.
Exemplul motiveaza alegerea pasilor pentru minimizarea volumul de memorie al arborelui. Deoarece expandarea face un compromis memorie-timp, de ce sa nu minimizamnecesarul de memorie prin optimizarea gradului de libertate (P13), pasii folositi in fiecare nod ? Pentru alegerea pasilor variabili, proiectantul trebuie sa specifice mai intai numarul de accesari ale memoriei in cazul cel mai defavorabil.De exemplu, cu un pachet de 40 de octeti la 1 Gbps si un DRAM de 80 nsec, avand bugetul de timp de 320 nsec, sunt permise doar patru accesari ale memoriei. Acest lucru conditioneaza numarul maxim de noduri in orice cale de cautare (patru pentru exemplul considerat).
Daca inaltimea arborelui este data, pasul poate fi ales pentru a minimiza memoria. Acest lucru poate fi facut in cateva secunde folosind programarea dinamica, chiar si pentru baze mari de date de 150.000 de prefixe. Un grad de libertate(pasii), e optimizat pentru minimizarea memoriei folosita pentru o inaltime data cea mai defavorabila.
Un arbore ordonat se spune ca e optimal pentru o inaltime h si o baza de date D, daca arborele are cel mai mic spatiu de memorare dintre toti arborii ordonati cu pas variabil pentru baza de date D, si inaltimea nu mai mare decat h. Se arata usor ca arborele din fig.11.10 e optimal pentru baza de date din stanga figurii 11.8 si inaltimea 2.
Problema generala a alegerii pasul optim poate fi rezolvata recursiv (fig 11.11). presupunem ca inaltimea arborelui trebuie sa fie 3. Algoritmul alege mai intai o radacina cu pasul s. Cei 2sy = pointeri posibili din radacina pot conduce spre y subarbori nevizi 1,..., yT T . Daca multimea de s pointeri indica spre subarborele iT , atunci toate prefixele din baza de date originala D care incep cu ip trebuie memorate in iT . Numim setul de prefixe iD .
Presupunem ca putem gasi recursiv iT optimal pentru inaltimea 1h − si baza de date iD . Avand un acces la memorie folosit la nodul radacina, au ramas doar 1h − accese la memorie pentru a parcurge fiecare subarbore iT . Notam cu iC necesarul de spatiu de memorare, numarat in locatii de tabele, pentru iT optimal. Atunci, pentru un pas s al radacinii fixat, costul arborelui optimal rezultat ( )C s este 2s (costul nodului radacina in locatii de tabel)plus
1
y
ii
C=∑ . Astfel, valoarea optimala a pasului initial este valoarea lui s , unde
1 32s≤ ≤ , care minimizeaza s. O folosire naiva a recursivitatii duce la subprobleme repetate. Pentru a
evita subproblemele repetate. Algoritmul construieste mai intai un arbore ordonat 1-bit.De mentionat este ca oricare subarbore ordonat iT (fig.11.11) trebuie sa fie un subarbore N al arborelui 1-bit. Apoi, algoritmul foloseste programarea dinamica pentru construirea costului optim si pasii arborelui pentru fiecare subarbore N din arborele original 1-bit, pentru toate valorile 1-h ale inaltimii, construind de jos in sus, de la subarborele de cea mai mica

167
inaltime spre subarborele de cea mai mare inaltime. Rezultatul final sunt pasii optimi pentru radacina (subarborelui 1-bit) cu inaltimea h.
Complexitatea finala a algoritmului este ( )2O N W h∗ ∗ , unde N este numarul prefixelor originale din baza de date originala, W este latimea adresei destinatie, iar h este ponderea dorita pentru cazul cel mai defavorabil. Aceasta este deoarece exista N W∗ subarbori in arborele 1-bit, fiecare din ei trebuie rezolvat pentru inaltimi in gama 1-h, si fiecare solutie implica o minimizare fata de cel mult W alegeri posibile, pentru pasul initial s. Complexitatea este liniara fata de N (numarul cel mai mare cunoscut actual fiind de 150.000)si h, (care ar trebui sa fie mic, maxim 8), dar patratica ca functie de latimea adresei (32, in mod curent). In practica, dependenta patratica de latimea adresei nu e un factor major.
De exemplu, pentru o inaltime de 4, baza de date optimizata Mae-East necesita 432 KB, fata de 2003 KB a variantei neoptimizate. Varianta neoptimizata foloseste pasii „naturali”de 8,8,8,8 . Programul dinamic ia 1,6 sec timp de rulare pe un Pentium Pro de 300 MHz. Programul dinamic poate fi chiar mai simplu pentru arborii cu pas fix, rularea durand doar 1msec, dar necesita 737KB in loc de 423 KB.
Dar 1,6 msec este mult prea mult ca programul dinamic sa ruleze la fiecare actualizare si mai permite actualizari de ordinul milisecundelor. Cu toate acestea, instabilitatile backbone sunt cauzate de patologii de genul in care acelasi set de prefixe S sunt inserate repetat si sterse de ruterul care e temporar suntat. Deoarece a trebuit sa se aloce memorie pentru intregul set, inclusiv S, oricum, faptul ca arborele este suboptimal la folosirea sa a memoriei cand S este sters, este irelevant. Pe de alta parte, rata la care noile prefixe sunt sterse sau adaugate de manager, pare ca e mai probabil ca acest lucru sa fie facut in ordinea zilelor. Astfel, un program dinamic care ia cateva secunde timp de rulare, e rezonabil sa fie rulat zilnic, si nu va afecta timpul pentru cazul cel mai defavorabil de inserare/stergere, permitand arbori optimali rezonabili.
11.5.3 Actualizarea incrementala Pentru arborii ordonati multibit exista algoritmi simpli de inserare/stergere.
Consideram adaugarea unui prefix P. Algoritmul simuleaza mai intai cautarea unui sir/string de biti in noul prefix P, pina la si inclusiv ultimul pas complet din perfixul P. Cautarea se termina fie prin terminarea cu ultimul pas (posibil incomplet) sau prin ajungerea la un pointer vid/nil.Astfel, pentru adaugarea lui P10=1100∗ bazei de date din fig.11.9, cautarea urmeaza poiterul 110 si termina la frunza cea mai din stanga a arborelui ordonat a nodului X.
Pentru scopul inserarii/stergerii, pentru fiecare nod X a arborelui ordonat multibit, algoritmul mentine un arbore 1-bit corespondent, cu prefixele memorate in X. Aceasta structura auxiliara trebuie sa nu fie in memoria rapida. Astfel, pentru fuecare element al tabelului de noduri, algoritmul memoreaza lungimea celei mai bune potriviri ale sale prezenta.Dupa ce se determina ca P10 trebuie adaugat nodului X, algoritmul expandeaza P10 spre pasul lui X. Orice element al tabelului spre care P10 este expandat (care este etichetat curent cu un prefix avand o lungime mai mica decat P10) trebuie suprascris cu P10.

168
Asfel, la adaugarea lui P10=1100∗ , algoritmul trebuie sa adauge expansiunea lui 0∗ inspre nodul X. In particular, intrarile 000 si 001 in nodul X trebuie actualizate sa fie P10.
Daca se termina cautarea inainte de a atinge ultimul pas in prefix, algoritmul creaza un nou nod al arborelui ordonat. De exemplu, daca prefixul P11=1100111∗ e adaugat, cautarea esueaza la nodul X, cand se gaseste un pointer vid/nil la intrarea 011. Algoritul creaza atunci un nou pointer la aceasta locatie, care e facut sa indice spre un nou nod al arborelui care contine P11. Apoi P11 este expandat in acest nod nou.
Stergerea este similara adaugarii. Complexitatea inserarii si a stergerii este data de timpul de realizare a unei cautari ( )( )O W plus timpul de reconstruire
completa a nodului ( )(O S , unde S este dimensiunea maxima a nodului arborelui). De exemplu, folosind noduri ale arborelui de 8-biti, acest al doliea cost va necesita scanarea a aproximativ 82 256= intrari de nod ale arborelui. Astfel, pentru a permite actualizari rapide, e crucial sa limitam de asemenea dimensiunea oricarui nod din programul dinamic descris anterior.
11.6 Arbori ordonati comprimati pe nivel, LC(Level-Compressed
Tries) Un arbore ordonat LC este un arbore comprimat cu pas variabil in care
fiecare nod al arborelui contine intrari nevide. Un arbore ordonat LC e construit gasind mai intai pasul celei mai mari radacini care permite intrari non-vide si apoi se repeta recursiv procedura in subarborii copii. Un exemplu al acestei proceduri e dat in figura 11.12, pornind cu un arbore 1-bit in stanga si rezultand intr-un arbore LC in stanga. P4 si P5 formeaza cel mai mare subarbore cu radacini complete posibil – daca pasul radacinii este 2, atunci primele doua intrari de tabele vor fi goale. Motivul este evitarea elementelor goale de tabel, pentru a minimiza spatiul de memorare.
Arborii cu pas variabil pot fi perfectionati in continuare, permitand ca memoria sa fie tratata pentru viteza. De exemplu, reprezentarea arborelui ordonat LC folosind baza Mae-East (1997) are o inaltime de arbore de 7 si un necesar de 700 KB de memorie. Prin comparatie, un arbore ordonat cu pas variabil are o inaltime a arborelui de 4 si necesita 400 KB de memorie. Reamintim deasemenea ca pasul variabil optim calculeaza cel mai bun arbore pentru o inaltime tinta, si astfel ar putea intr-adevar produce un arbore ordonat LC daca arborele LC ar fi optimal pentru inaltimea sa.
Figura 11.12 Schema arborelui ordonat LC descompune recursiv arborele 1-bit in
subarbori completi/full de cea mai mare dimensiune posibila. (stanga). Copiii din fiecare subarbore complet (cu linie punctata) sunt apoi plasati in nodul arborelui pentru a forma un arbore cu pas variabil specific bazei de date alese.
Figura 11.13 Reprezentarea tabelului arborelui ordonat LC In forma sa finala, nodurile arborelui ordonat LC cu pas variabil in ordinea
de pe prima latime (prima data radacina, apoi toate nodurile arborelui si nivelul secund de la stanga la dreapta, apoi nodurile din al treilea nivel, etc.), ca in fig.11.13. Asezarea tabelei si conditiile impuse pentru subarborii completi fac ca actualizarea sa fie lenta in cazul cel mai defavorabil. De exemplu, stergerea lui P5 din fig. 11.13 cauzeaza schimbari in

169
descompunerea in subarbori. Si mai rau este ca face ca aproape fiecare element din reprezentarea tabelului din fig.11.13 sa migreze in sus.
11.7 Arbori ordonati comprimati de tip Lulea Desi arborii ordonati LC si arborii ordonati cu pas variabil incearca sa
comprime arborii ordonati multibit variind pasul la fiecare nod, ambele scheme au probleme. Desi folosirea tabelelor complete permit arborii ordonati LC sa nu iroseasca de loc memoria cu locatii vide, ele cresc inaltimea arborelui ordonat, care nu poate fi potrivita. Pe de alta parte, arborii ordonati cu pas variabil pot fi potriviti sa aiba o inaltime scurta, cu costul irosirii memoriei datorata locatiilor goale din tabel in nodurile arborelui ordonat. Abordarea Lulea, descrisa acum, este o schema de arbore ordonat multibit care foloseste noduri de arbore cu pas ficsi mari, dar si o compresie bitmap pentru a reduce considerabil necesarul de memorie.
Sirurile cu repetitie (e.g. AAAABBAAACCCCC) pot fi comprimate folosind un bitmap care denota punctele de repetitie (i.e.10001010010000) impreuna cu o secventa comprimata(i.e.ABAC). Similar, nodul radacina din fig.11.9 contine o secventa repetata (P5,P5,P5,P5) cauzata de expandare.
Schema Lulea evita aceasta irosire evidenta comprimand informatia repetata folosind un bitmap si o secventa comprimata, fara o penalizare mare la timpul de cautare. De exemplu, aceasta schema foloseste doar 160 KB de memorie pentru a memora baza de date Mae-East, ceea ce permite ca sa fie memorata intreaga baza de date intr-o SRAM on-chip scumpa. Costul platit este timpul mare de inserare.
Unele intrari de arbore expandate (e.g. 110 intrari la radacina din fig. 11.9) au doua valori, un pointer si un prefix. Pentru a face compresia mai usoara, algoritmul porneste facand ca fiecare intrare sa aiba exact o valoare, prin impingerea informatiei de prefix jos in frunzele arborelui. Deoarece frunzele nu au pointer, avem doar informatia despre urmatorul hop la frunza si doar pointerii la nodurile non-frunza. Acest procedeu se numeste leaf-pushing.
De exemplu, pentru a evita prefixe memorate in intrarea 110 a nodului radacina din fig.119, prefixul memorat P9 este impins spre toate intrarile nodului arborelui, cu exceptia intrarilor 010 si 011(ambele continua sa contina pe P3). Similar, prefixul memorat P8 in intrarea 100 a nodului radacina, este impins in jos spre intrarile 100,101,110 si 111 ale nodului cel mai din dreapta a arborelui. Odata realizata aceasta etapa, fiecare intrare de nod contine fie un prefix memorat, fie un pointer.
11.10 Căutarea binară a lungimii prefixului
Aici se adaptează o altă schemă clasică de potrivire perfectă, dispersarea/hashing-ul, la potrivirea celui mai lung prefix. Căutarea binară asupra lungimii prefixului duce la găsirea celei mai lungi potriviri utilizând 2log W dispersări, unde W reprezintă lungimea maximă a prefixului. Aceasta poate asigura o soluţie scalabilă pentru adresarea pe 128 biţi de tip IPv6. Pentru prefixele de 128 de biţi, acest algoritm utilizează 7 accese la memorie spre deosebire de 16 accese la memorie dacă se utilizează un arbore multibit ordonat cu pasul de 8 biţi. In acest scop, în prima fază, algoritmul sortează prefixele după lungime, în tabele separate de dispersare. Mai precis, utilizează o zonă L de tabele de

170
dispersare, astfel încât [ ]L i e un pointer spre tabela de dispersare care conţine toate prefixele de lungime i. Considerăm acelaşi tabel mic de rutare din figura 11.17, cu doar două prefixe, P4 = 1* şi P1 = 101*, de lungime 1 şi respectiv 3. Acesta este un subset al figurii 11.18. Zona tabelelor de dispersare este orizontală, în partea de sus (A) a figurii 11.18. Tabela de dispersare de lungime 1, conţinând prefixul P4, este verticală, în partea stângă şi indică spre poziţia 1 din tabel; tabela de dispersare de lungime 3, conţinând prefixul P1, este în partea dreapta şi indică spre poziţia 3 din tabel; tabela de dispersare de lungime 2 este vidă, deoarece nu există nici un prefix de lungime 2. O căutare naivă a adresei D începe cu tabelul de lungimea cea mai mare (3 în exemplu), extrage primii l biti din D în lD şi apoi caută lD in tabelul de dispersie de lungime l. Dacă cautarea are succes, a fost găsită cea mai bună potrivire; dacă nu, algoritmul ia în considerare lungimea imediat mai mică (de ex. 2). Algoritmul caută, decrementând lungimea posibilă a prefixului, până când găseşte o potrivire în mulţimea prefixelor posibile, sau până când epuizează lungimile. Schema naivă realizează o căutare liniară a lungimilor de prefixe distincte. Analogia sugerează un algoritm mai eficient: căutarea binară (P15). Spre deosebire de căutarea binară a domeniului/gamei de prefixe, aceasta este o căutare binară asupra lungimii prefixelor. Diferenţa este majoră. Cu 32 de lungimi, căutarea binară asupra lungimii durează 5 accesări în cel mai rău caz ; cu 32000 de prefixe căutarea binară asupra gamei de prefixe durează 16 accesări. Căutarea binară trebuie să inceapa de la lungimea mediana a prefixelor si fiecare dispersare trebuie sa împartă în două lungimile posibile ale prefixelor. O căutare poate da doar două rezultate: găsit sau negăsit. Daca s-a găsit o potrivire la lungimea m, atunci lungimile strict mai mari decât m trebuie căutate pentru o potrivire mai lungă. In mod corespunzător, dacă nu s-a gasit nici o potrivire, căutarea trebuie sa continue printe prefixele de lungimi strict mai mici decât m. De exemplu, în figura 11.18.A, presupunem că începe căutarea la lungimea medie-2 a tabelei hash, pentru o adresă care începe cu 101. Evident că această căutare nu duce la găsirea unei potriviri. Dar există o potrivire mai lungă în tabelul de lungime 3. Din moment ce doar găsirea unei potriviri duce la translatarea căutării la jumătatea din dreapta, trebuie introdusă o “potrivire artificială”sau marker/indicator care să forţeze căutarea în jumătatea din dreapta în cazul în care există posibilitatea unei potriviri mai lungi. De aceea în partea B se introduce o intrare de marcare 10 reprezentată îngroşat, care corespunde primilor doi biţi ai prefixului P1= 101 din tabelul de lungime 2. In esenţă, starea a fost adaugată pentru creşterea vitezei (P12).Markerul permite eşecuri de testare în zona mediană pentru a exclude toate lungimile mai mari decât cea mediană.

171
Căutarea unei adrese D care începe cu 101 se face corect. Căutarea pentru 10 în tabelul de lungime 2 (fig.11.18.B) duce la găsirea unei potriviri ; căutarea continuă mai departe în tabelul de lungime 3, se găseşte o potrivire cu P1 şi se încheie căutarea. In general, trebuie plasat un marker pentru un prefix P, la toate lungimile prin care va trece căutarea binară pentru găsirea lui P. Se adaugă doar un număr logaritmic de marcatori. Pentru un prefix de lungime 32, markerii necesari sunt doar la lungimile 16, 24, 28 şi 30. Din păcate, algoritmul este încă incorect. In timp ce markerii duc la prefixe posibil mai lungi, pot de asemenea să ducă la o căutare pe piste greşite.Se consideră căutarea unei adrese D’ (fig.11.18.B) ai cărei primi trei biţi sunt 100. Deoarece mijlocul tabelului conţine 10, căutarea în tabela hash mijlocie conduce la găsirea unei potriviri. Acest lucru forţează algoritmul să caute 100 în continuare în al treilea tabel ceea ce va duce la eşuarea căutării. Cea mai bună potrivire corectă a prefixului se află în primul tabel (P4 = 1*). Markerii pot cauza deraierea căutarii. Dar, o revenire a căutării în jumătatea stângă duce la un consum liniar de timp. Pentru a asigura un timp de căutare logaritmic, fiecare nod marker M va conţine o variabilă M.bmp, unde M.bmp reprezintă cel mai lung prefix care se potriveşte cu şirul M. Această variabilă este precalculată când M este introdus în tabela hash. Când algoritmul urmareşte markerul M şi caută prefixele de lungime mai mare decât M, dacă eşuează în găsirea unui asemenea prefix mai lung, atunci răspunsul este M.bmp. In esenţă, cel mai potrivit prefix asociat fiecărui marker este precalculat (P2a). Acest lucru evită căutarea tuturor lungimilor mai mici decât lungimea medie dacă potrivirea se face cu ajutorul markerului.

172
Versiunea finală a bazei de date ce conţine prefixele P4 şi P1 este prezentată în fig.11.18.C. A fost adăugat un câmp bmp markerului 10 care indică spre cea mai bună potrivire de prefix a şirului 10 (ex. P4 = 1*). De aceea, când algoritmul caută 100 şi găseşte o potrivire în tabelul median de lungime 2, îşi aduce aminte valoarea bmp corespunzătoare intrării P4, înainte de a căuta în tabelul de lungime 3. Când căutarea eşuează (în tabelul de lungime 3), algoritmul returnează câmpul bmp al ultimului marcator întâlnit (ex. P4).
Un algoritm banal pentru construirea unei căutări binare a structurii de date din memoria de lucru/scratch este următorul. Prima dată se determină lungimile de prefix distincte; se determină astfel secvenţa de lungimi de căutat. Apoi se adaugă fiecare prefix P tabelei hash corespunzător lungimii P, length(P). Pentru fiecare prefix, se adaugă de asemenea un marker fiecărui tabel corespunzător lungimilor L < lungimea (P) pe care căutarea binară le va parcurge (dacă nu există una deja). Pentru fiecare astfel de marker M se utilizează o testare suplimentară 1-bit pentru determinarea prefixului cu cea mai bună potrivire a lui M. In timp ce acest algoritm de căutare utilizează cinci căutări în tabelele hash, în cel mai defavorabil caz pentru IPv4, în cele mai probabile cazuri majoritatea căutărilor ar trebui să aibă două accesări ale memoriei. Aceasta se datorează observării cazului aşteptat O1 care arată că majoritatea prefixelor sunt de lungine 16 sau 24 de biţi. De aceea căutarea binară la 16 iar apoi la 24 de biţi va fi suficientă pentru majoritatea prefixelor. Utilizarea hashing-ului face căutarea binară asupra lungimii prefixelor să fie într-o oarecare măsură dificil de implementat hardware. Oricum, scalabilitatea tehnicii la lungimi mari de prefixe, cum sunt adresele IPv6, a făcut-o suficient de atractivă pentru anumiţi producători.
11.11 Alocarea memoriei în scheme comprimate Cu excepţia căutării binare şi a arborilor cu prefix/ordonati multibit cu pas fix, multe din schemele descrise necesită alocări de memorie de diferite dimensiuni. De aceea, dacă un nod al arborilor cu prefix comprimat creşte de la două la trei cuvinte de memorie, algoritmul de inserare trebuie să dezaloce vechiul nod de dimensiune 2 şi să realoce noul nod de dimensiune 3. Alocarea memoriei în sistemele de operare este oarecum euristică, utilizând algoritmi cum sunt best-fit si worst-fit (cea mai bună/proastă potrivire) care nu garantează propietaţile cazului cel mai defavorabil. De fapt toate metodele standard de alocare a memoriei pot avea un caz cel mai defavorabil, în care raportul de fragmentare a memoriei este foarte rău. Este posibil ca locatorii şi delocatorii de memorie să conlucreze pentru a fragmenta memoria în petice de zone goale şi blocuri de memorie alocate de dimensiuni reduse. Dacă Max este dimensiunea maximă de memorie a unei cereri de alocare, cazul cel mai defavorabil apare când toate spaţiile libere de memorie au dimensiunea Max – 1 şi toate blocurile alocate au dimensiunea 1. Această situaţie poate să apară prin alocarea întregii memorii utilizând cereri de alocare de dimensiune 1, urmate de dealocările corespunzatoare. Rezultatul

173
final este că doar 1/Max din memorie este utilizată sigur, deoarece toate cererile de alocare viitoare pot fi de dimensiune Max.
Utilizarea locatorului de memorie o translatează direct în numărul maxim de prefixe pe care un chip de căutare o poate suporta. Presupunem că, ignorând locatorii, 20MB de memorie on-chip poate suporta 640.000 de prefixe în cel mai defavorabil caz. Dacă ţinem seama de locator, şi Max = 32, chip-ul poate garanta suportarea a doar 20.000 de prefixe.
Nu ajută la nimic că vânzătorii avertizau asupra celui mai defavorabil caz de 100.000 de prefixe cu un timp de căutare de 10 nsec şi un timp de actualizare de o microsecundă. Aşadar, având în vedere că algoritmii de căutare a prefixelor comprimă frecvent structurile de date pentru a încăpea într-o memorie SRAM, aceşti algoritmi trebuie şi să proiecteze o alocare rapidă a memoriei şi cu o fragmentarea minimă.
Exista o limită care spune că: locatorii care nu compactează memoria
nu pot avea un raport al utilizării mai bun decât Max2log
1 . De exemplu,
acesta este 20 % pentru Max = 32. Deoarece această valoare este inadmisibilă, soulţiile algoritmice ce implică structuri comprimate de date trebuie să utilizeze compactarea memoriei. Compactarea memoriei constă în mutarea blocurilor de memorie alocate, astfel încât să se mărească dimensiunea spaţiilor libere din memorie.
Compactarea este puţin folosită în sistemele de operare din motivul următor. Dacă o porţiune de memorie M este mutată, atunci trebuie corectaţi toţi indicatorii care indică spre M. Din fericire, majoritatea structurilor de căutare sunt structuri de tip arbore, în care oricare nod este indicat ca vecin a cel mult unui nod. Menţinând un nod părinte pentru fiecare nod al arborelui, nodurile care indică spre un nod M al arborelui pot fi modificate corespunzător când M este realocat. Din fericire, indicatorul părinte este necesar doar pentru actualizare si nu pentru căutare. Deci, indicatorul părinte poate fi memorat într-o copie externa chip-lui, a bazei de date utilizată pentru actualizări în procesorul de dirijare, fără a ocupa memoria SRAM internă chip-lui. Chiar după rezolvarea aceastei probleme, este necesară existenţa unui algoritm simplu, care să decidă când să se compacteze o anumită porţiune a memoriei. In literatura de specialitate există tendinţa de a utiliza compactori globali, care pot scana toată memoria într-un singur ciclu de compactare. Pentru a limita timpii de intercalare trebuie să existe o formă de compactare locală, care compactează doar o mică porţiune de memorie, din jurul regiunii afectate de actualizare.
11.11.1 Compactarea pe cadre
Pentru a arăta cât de simple pot fi schemele de compactare locale, e descrisă mai întâi o schemă foarte simplă care, deşi face o compactare minimă, acoperă totuşi 50% din cele mai defavorabile cazuri de utilizare a memoriei. Apoi se va urmări îmbunătăţirea utilizării memoriei până la o valoare cât mai apropiată de 100%.

174
In fuzionare cadrelor se presupune că toate cele M cuvinte de
memorie sunt divizate în MaxM cadre de dimensiunea Max. Fuzionarea
cadrelor caută să păstreze utilizarea memoriei la cel puţin 50%. In acest scop toate cadrele nevide ar trebui să fie cel putin 50% pline. Fuzionarea cadrelor păstrează urmatoarea invarianţă : toate cadrele neumplute cu excepţia unuia singur sunt cel putin 50% pline. Dacă
lucrurile stau în felul acesta şi MaxM este mult mai mare decât 1, atunci
utilizarea garantată va fi de aproape 50%. Cererile de alocare şi dealocare sunt realizate cu ajutorul etichetelor
ataşate fiecărui cuvânt, care ajută la identificarea blocurilor de memorie libere şi ocupate. Singura restricţie suplimentară este că toate spaţiile libere să fie continute în interiorul cadrelor; spaţiilor libere nu li se permite să se extindă înafara cadrelor.
Un cadru este imperfect/defect dacă nu este gol şi are utilizarea mai mică de 50 %. Pentru a se menţine invarianţa, fuzionarea cadrelor conţine un indicator suplimentar care să urmareasca cadrele curente imperfecte, daca există. Acum, o alocare poate face ca un cadru anterior gol să devină un cadru imperfect dacă alocarea este mai mică decât
2Max .
Similar, o dealocare poate face ca un cadru plin mai mult de 50% sa devină plin mai puţin de 50%. Se consideră un cadru care conţine două blocuri alocate de dimensiune 1 şi respectiv Max – 1 şi deci are o
utilizare de 100%. Utilizarea s-ar putea reduce la Max
1 dacă blocul de
dimensiune Max – 1 este dealocat. Acest lucru ar putea face ca cele două cadre să devină imperfecte, fapt ce ar încălca regula de invarianţă.
In continuare e dat un artificiu simplu pentru a păstra invarianţa. Se presupune că există deja un cadru imperfect F şi că apare un nou cadru imperfect F’. Invarianţa este păstrată prin fuzionarea conţinutului cadrelor F şi F’ într-un nou cadru F. Acest lucru este posibil deoarece ambele cadre F şi F’ au fost ocupate într-o proporţie mai mică de 50%. De reţinut este faptul că singura compactare utilizată este cea la nivel local şi este limitată la două cadre imperfecte F şi F’. Asemenea compactare locală duce la obţinerea unor timpi mici de actualizare.
Gradul minim de utilizare în cazul fuzionării cadrelor poate fi îmbunătăţit prin creşterea dimensiunii cadrelor la kMax şi prin schimbarea definiţiei cadrelor imperfecte, astfel încât utilizarea acestor
cadre să devină mai mică decât 1+k
k . Schema descrisă anterior este un
caz special în care k=1. Crescând valoarea lui k se imbunătăţeşte utilizarea, cu costul creşterii compactării.
11.12 Modelul chip-lui de căutare Având în vedere creşterea vitezelor la cele din standardul OC-786, schemele de căutare vor fi probabil implementate mai degrabă on-chip decat în procesoarele de reţea, cel puţin la viteze ridicate. Figura 11.19

175
descrie un model al chip-lui de căutare/lookup care realizează căutarea şi actualizarea. Chip-ul are un proces de Căutare şi unul de Actualizare, amândouă accesând o memorie comună de tipul SRAM care poate fi încorporată în chip sau poate fi plasată în exteriorul acestuia.
Procesul de Actualizare permite actualizări incrementale şi posibil, realizarea alocării/dealocării memoriei, şi o compactare locală redusă pentru fiecare actualizare. El poate fi implementat fie complet on-chip, fie parţial /complet prin soft. Dacă o companie producătoare de semiconductori doreşte să vândă un chip de căutare care utilizează un algoritm complex de actualizare (de ex. pentru schemele comprimate), ar fi de recomandat să furnizeze şi un algoritm de actualizare implementat hardware. Daca chip-ul de căutare face parte dintr-un motor de expediere/forwarding, ar fi mai simplu să se retrogradeze complet procesul de actualizare pe un CPU separat.
Fiecare acces la memoria SRAM poate fi destul de mare dacă e
nevoie, chiar până la 1000 de biţi. Acest lucru este posibil de implementat în zilele noastre utilizându-se o magistrală extinsă. Logica de căutare şi actualizare poate procesa cu uşurinta 1000 de biţi în paralel într-un singur ciclu de memorie. Accesul la cuvinte de dimensiuni mari poate fi de folos, de exemplu, în căutarea binară, pentru a reduce timpii de căutare.
Timpii de Căutare şi Actualizare sunt multiplexaţi pentru a se împărţi accesul la memoria comună SRAM care conţine baza de date de căutare. Aşadar procesului de Căutare i se permit S accese consecutive la memorie, iar apoi procesului de Actualizare i se permit K accese la memorie. Dacă S este 20 iar K este 2, se permite ca Actualizarea să “fure” câteva cicluri de acces de la procesul Căutare prin scăderea vitezei de căutare pentru o fracţiune din timp. De notat o creştere a latenţei în cazul căutării de k ori în cel mai defavorabil caz. Deoarece procesul Căutare este proiectat în tehnica pipeline, această întârziere poate fi considerată o mică întârziere pipeline suplimentară.
Chip-ul are pini pentru semnalele de Căutare şi Actualizare şi poate furniza rezultatele căutării la ieşiri. Modelul poate fi proiectat pentru diferite tipuri de căutări, inclusiv căutarea IP, căutarea adreselor fizice (adresele MAC pe 48 biţi ca şi chei şi porturile de ieşire ca rezultate) şi

176
clasificare (de ex. antetele pachetelor ca şi chei şi regulile de potrivire ca rezultate).
Oricare adăugare sau ştergere a unei chei poate duce la cererea unei dealocări a unui bloc şi de alocare a unui bloc de dimensiune diferită. Fiecare cerere de alocare poate fi în domeniul 1 la Max cuvinte de memorie. Sunt în total M cuvinte de memorie care pot fi alocate.Memoria actuală poate fi incorporată în chip, în exteriorul chip-lui sau ambele cazuri.Chiar dacă se utilizează opţiunea de memorare off-chip, primele niveluri ale oricărui arbore de căutare vor fi memorate în interiorul chip-lui. Memoria on-chip este mai atractivă din punct de vedere al costului şi al vitezei. Din păcate, memoria on-chip este limitată de procesele concurente la aproximativ 32 Mbiţi. Acest lucru face dificilă suportarea unei baze de date de 1 milion de prefixe.
Intern, chip-ul va utiliza din plin tehnica pipeline. Structura de date de căutare este partiţionată în câteva bucăţi, fiecare din aceste bucăţi fiind prelucrată concurent de către niveluri diferite ale logicii. Deci memoria SRAM va fi probabilîimpărţită în câteva memorii SRAM mai mici care pot fi accesate independent de către fiecare etapă a pipeline.
Exista o problemă referitoare la partiţionarea statică a memoriei SRAM între nivelurile pipeline, datorită faptului că necesarul de memorie pentru fiecare nivel poate varia pe măsură ce prefixele sunt inserate şi şterse. O soluţie posibilă este aceea de a împărţi memoria SRAM într-un număr mare de bucăţi care pot fi alocate dinamic nivelurilor, prin intermediul unui switch crossbar de partiţionare. Proiectarea unui asemenea switch crossbar care să lucreze la viteze mari este dificilă.
Toate schemele descrise pot utiliza metoda pipeline, deoarece toate se bazează pe structuri de date de tip arbore. Toate nodurile de la acelaşi nivel a arborelui pot fi alocate aceluiaşi nivel pipeline.
11.13 Concluzii Situaţia actuală din domeniul căutarii/lookup şi principiile de bază utilizate:
Starea actuală a lookups. Schemele de căutare au apărut din cauza ruterelor de tranzit (core) la care cresc rapid atât dimensiunile tabelei (până la 1 milion de prefixe) cât şi viteza (până la 40Gbps). MPLS (Multi Protocol Label Switching) s-a considerat ca fiind o modalitate de finisare a tehnicilor de căutare, iar în momentul de faţă este utilizat pentru evitarea clasificării pachetelor din ingineria traficului. CMS-le sunt înlăturate chiar şi din nucleele ruterelor, dar costurile ridicate, puterea consumată a CAM-lor de dimensiuni mari rămâne o problemă. Asa ca mulţi producători de rutere încă utilizează şi proiectează algoritmi de căutare. Desi e ciudat, după ce o bogăţie de algoritmi au fost exploraţi în acest capitol, arborii simpli cu prefix unibit împreună cu memoria SRAM şi tehnica pipeline lucrează bine chiar şi la viteze de 40 Mbps. Lucrul se datorează faptului că arborii simpli cu prefix unibit cu comprimarea căii sunt relativ compacti; timpii mari de căutare pot fi deplasaţi prin pipeline împreună cu o zonă de căutare iniţială. Folosirea pipeline este dificilă deoarece necesită partiţionarea memoriei între niveluri.

177
La viteze de până la 10 Gbps, arborii simpli simpli cu prefix multibit ce utilizează extinderea controlată a prefixelor, lucrează bine cu memoriile de tip DRAM. Memoriile DRAM sunt mai încete, dar sunt ieftine şi uşor de găsit. Tehnicile RAMBUS pot permite utilizarea pipeline în căutări/lookup chiar şi cu procesoare de reţea. Simplitatea acestor scheme s-a dovedit atractivă pentru mulţi producători. Unii producători utilizează căutarea binară a cărei viteze şi utilizare a memoriei sunt rezonabile, în mod special în cazul arborilor-B cu memorie extinsă pentru a se reduce înălţimea arborilor. Schemele de căutare binară a gamelor nu sunt patentate. La viteze mai mari, numărul de niveluri pipeline poate fi redus de la 20 la 5 utilizând arborii simpli cu prefix multibit. Arborii simpli cu prefix multibit trebuie comprimate pentru a putea fi memorate într-o memorie SRAM on-chip sau off-chip. Compresia la Lulea este remarcabilă, dar se pare că algoritmul poate fi utilizat astăzi numai în soluţiile personalizate per client oferite de o companie numită Effnet. Schema Lulea are de asemenea o actualizare înceată. Schemele bitmap de tip arbore au actualizări rapide şi pot fi tolerate de o gamă largă de setări hardware.De asemenea pot exista patente ce pot restricţiona folosirea lor. E utilizat în prezent în ruterul Cisco CRS-1. In concluzie, căutarea binară asupra lungimii prefixelor este atractivă datorita proprietăţilor de scalabilitate la lungimi mari ale adreselor. Din păcate, utilizarea tehnicii de hashing face dificilă obţinerea unor timpi buni de căutare. In mod similar, introducerea adresării IPv6 şi multicast ce cresc importanţa căutării adreselor lungi, au făcut ca această schemă să fie puţin atractivă. Schema este utilizată de anumiti producători in implementări software. Soluţiile algoritmice împreună cu pipeline pot ţine pasul cu vitezele legăturilor atât timp cât memoriile SRAM pot respecta timpii de sosire a pachetelor. Toate schemele studiate pot fi pipeline pentru a asigura o căutare/lookup per timp de acces la memorie. Alegerea între CAM şi schemele algoritmice va fi greu de cuantificat şi probabil alegerea se va face ad hoc în funcţie de fiecare produs. Dacă schemele cu arborii cu prefix comprimate pot utiliza mai puţin de 32 de biţi per prefix atunci arborii cu prefix comprimaţi par a utiliza mai puţine tranzistoare şi o putere mai mică decât CAM. Acestea se datorează faptului că în CAM, logica de căutare/lookup este distribuită în fiecare celulă N de memorie, în timp ce într-o solutie algoritmica logica de căutare, deşi mai complicată, este distribuită de-a lungul unui număr mai mic şi constant de niveluri. O analiză VLSI atentă a celor două implementări ar fi foarte utilă. Deşi capitolul e dedicat tehnicilor de căutare, in concordanta cu tendinţele curente ale pieţei, să nu se uite că la baza acestora stau anumite principii. Este plauzibil ca toate ruterele din viitor să utilizeze comutarea şi procesarea optică chiar şi în cazul căutarii. In acest caz, algoritmii specifici descrişi ar putea fi depaşiţi, dar principiile de proiectare vor rămâne valabile. Schemele descrise în acest capitol necesită într-o anumită măsură gândirea algoritmică precum şi alte principii ce au fost prezentate. Schemele utilizează precalcularea, care scurteaza timpii de

178
inserare/ştergere. Schemele se folosesc de asemenea de anumite caracteristici hardware cum ar fi memoria extinsă, utilizarea dupa caz a memoriilor rapide sau lente şi optimizarea gradului de libertate într-o proiectare data (vezi fig. 11.1).

179
COMUTAŢIA
În primii ani ai telefoniei, operatorul de telefonie a ajutat la realizarea structurii sociale într-o comunitate. Dacă X a dorit să vorbească cu Y, a apelat operatorul şi a întrebat de Y; operatorul a trebuit să introducă manual un fir într-un tablou de comutaţie care conectează telefonul lui X cu al lui Y. Tabloul de comutaţie permite desigur şi conexiuni paralele între perechi disjuncte, iar 'X a putut vorbi cu 'Y în acelaşi timp. S-a putut întâmpla ca fiecare apel nou să fie întârziat pentru un interval de timp scurt, timp în care operatorul finalizează tratarea apelului anterior.
Când a fost descoperit tranzistorul în laboratoarele Bell, faptul că fiecare tranzistor era de fapt un comutator controlat în tensiune a fost imediat exploatat în realizarea comutatoarelor electronice utilizând o matrice cu tranzistori. Operatorul de telefonie a fost folosit pentru funcţii care necesită intervenţia omului, ca de exemplu colectarea apelurilor. Utilizarea electronicii a crescut cu mult viteza şi fiabilitatea comutaţiei telefonice.
Un ruter este de fapt un oficiu poştal automat pentru pachete. Ruter are sensul generic de componentă generală de interconectare, ca de exemplu gateway sau comutator SAN. In esenţă ruterul este o cutie care comută pachete între legăturile de intrare şi de ieşire (figura 13.1). Procesul de căutare (B1) determină linia de ieşire la care un pachet va fi comutat. Trebuie facuta planificarea pachetelor la linia de iesire (B3). Esenta ruterului este sistemul intern de comutaţie (B2), descris în acest capitol.
Literatura în domeniul comutaţiei este vastă, şi acest capitol s-a axat pe comutatoarele analizate în literatură, utilizate în prezent în industria reţelelor. Comutatoarele descrise, Gigacomutatorul DEC, GSR-ul lui Cisco, seriile T ale lui Juniper, TSR-ul lui Avici, reprezintă o introducere în problemele teoretice şi practice implicate în structurile de comutatoare pentru ruterele de viteză. Tehnicile de comutaţie şi principiile corespunzătoare invocate sunt rezumate în figura 13.2.
Număr Principiu Comutator P5b Acces extins la memorii
pentru viteză de lucru Datapath
Comutaţie
RUTER B2
Linie ieşire B3
Planificare
B1Căutare adrese
Linie intrare i
FIGURA 13.1. Modelul ruterului
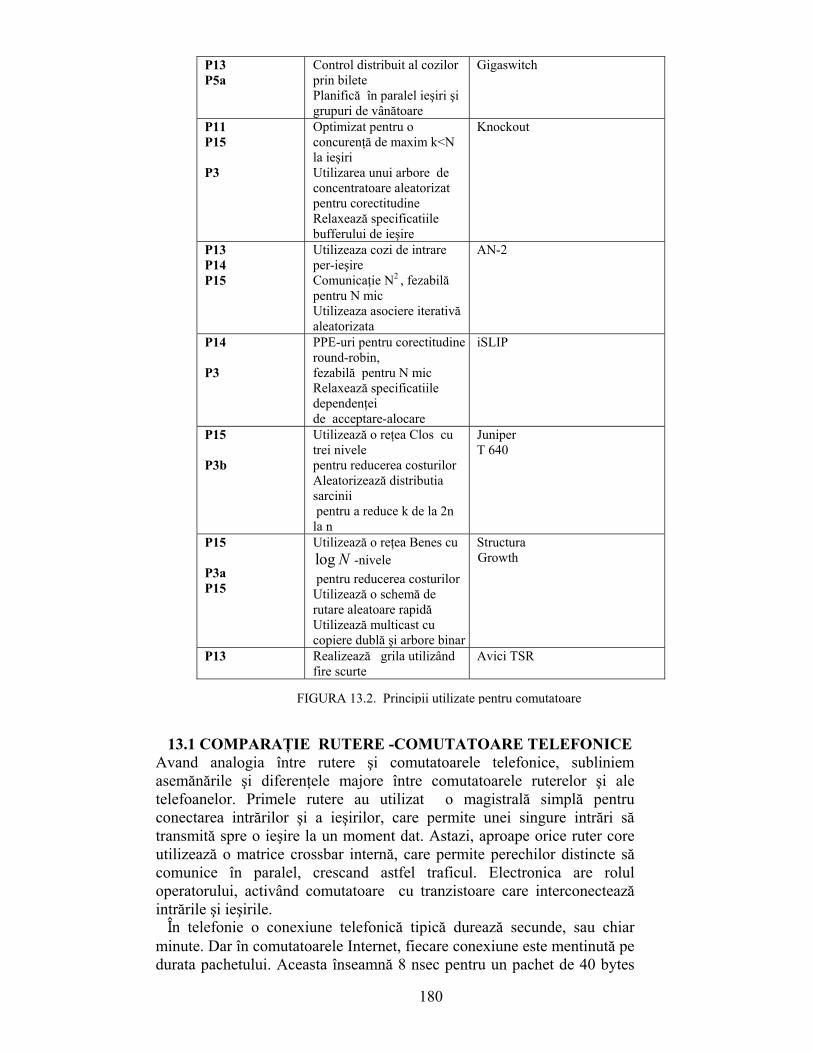
180
P13 P5a
Control distribuit al cozilor prin bilete Planifică în paralel ieşiri şi grupuri de vânătoare
Gigaswitch
P11 P15 P3
Optimizat pentru o concurenţă de maxim k<N la ieşiri Utilizarea unui arbore de concentratoare aleatorizat pentru corectitudine Relaxează specificatiile bufferului de ieşire
Knockout
P13 P14 P15
Utilizeaza cozi de intrare per-ieşire Comunicaţie N2 , fezabilă pentru N mic Utilizeaza asociere iterativă aleatorizata
AN-2
P14 P3
PPE-uri pentru corectitudine round-robin, fezabilă pentru N mic Relaxează specificatiile dependenţei de acceptare-alocare
iSLIP
P15 P3b
Utilizează o reţea Clos cu trei nivele pentru reducerea costurilor Aleatorizează distributia sarcinii pentru a reduce k de la 2n la n
Juniper T 640
P15 P3a P15
Utilizează o reţea Benes cu log N -nivele pentru reducerea costurilor Utilizează o schemă de rutare aleatoare rapidă Utilizează multicast cu copiere dublă şi arbore binar
Structura Growth
P13 Realizează grila utilizând fire scurte
Avici TSR
13.1 COMPARAŢIE RUTERE -COMUTATOARE TELEFONICE Avand analogia între rutere şi comutatoarele telefonice, subliniem asemănările şi diferenţele majore între comutatoarele ruterelor şi ale telefoanelor. Primele rutere au utilizat o magistrală simplă pentru conectarea intrărilor şi a ieşirilor, care permite unei singure intrări să transmită spre o ieşire la un moment dat. Astazi, aproape orice ruter core utilizează o matrice crossbar internă, care permite perechilor distincte să comunice în paralel, crescand astfel traficul. Electronica are rolul operatorului, activând comutatoare cu tranzistoare care interconectează intrările şi ieşirile.
În telefonie o conexiune telefonică tipică durează secunde, sau chiar minute. Dar în comutatoarele Internet, fiecare conexiune este mentinută pe durata pachetului. Aceasta înseamnă 8 nsec pentru un pachet de 40 bytes
FIGURA 13.2. Principii utilizate pentru comutatoare

181
la 40 Gbps. Memoriile cache nu reduc căutările, datorită rarităţii secventelor de pachete de mari dimensiune in aceeaşi direcţie. De asemenea, este improbabil ca două pachete consecutive la un port de intrare al comutatorului să fie destinate aceluiaşi port de ieşire. Aceasta îngreunează echilibrarea sarcinii de comutaţie pentru pachetele multiple.
Deci, pentru a opera la viteza liniei, sistemul de comutaţie trebuie să decidă intrările şi ieşirile ce trebuie asociate, în timpul minim de sosire al unui pachet. Astfel, partea de control a unui comutator de Internet (care stabileşte conexiunile), e mult mai greu de realizat decât în cazul unui comutator telefonic. O altă diferenţă importantă între comutatoarele telefonice şi cele de pachete este necesitatea conexiunilor multicast pentru comutatoarele de pachete. Multicastul complică suplimentar problema planificării, deoarece unele intrări vor să transmită spre ieşiri multiple.
Pentru a simplifica problema, majoritatea ruterelor segmentează intern, pachetele de dimensiune variabilă în celule de dimensiune fixă, înainte de a fi transmise spre structura de comutaţie. Matematic, comutaţia ruterului este redusă la rezolvarea unei probleme de asociere bipartita: ruterul trebuie să asocieze cât mai multe linii de intrare (la cât mai multe linii de ieşire), în limita posibilităţilor, într-un timp fix de sosire a celulelor. Deoarece algoritmii optimali pentru asociere bipartită rulează într-un timp de ordinul milisecundelor, rezolvarea acestei probleme la fiecare 8 nsec necesită gândirea unor sisteme. Soluţiile descrise în acest capitol realizeaza un compromis precizie/timp (P3b), utilizeaza paralelismul hardware (P5) şi aleatorizarea (P3a), şi exploateaza faptul că comutatoarele tipice au 32-64 porturi, pentru a face operaţii rapide cu cozi prioritare utilizând bitmap-uri(P14).
13.2. COMUTATOARE CU MEMORIE COMUNĂ Înainte de-a descrie comutatoarele cu magistrale, respectiv crossbar,
analizam una dintre cele mai simple implementări de comutator, cea cu memorie partajată. Pachetele sunt scrise in memorie de pe linia de intrare si citite spre linia de iesire. Acest tip de proiectare a fost utilizat in comutatoarele cu interschimbarea diviziunilor de timp din telefonie. Funcţionează bine şi pentru reţele de date în cazul comutatoarelor de dimensiuni mici.
Principala problemă este latimea de banda a memoriei (viteza de lucru). Dacă chip-ul are 8 linii de intrare şi 8 linii de ieşire, va trebui sa citeasca/ scrie fiecare pachet/celulă. Deci memoria trebuie să ruleze la o viteza de 16 ori mai mare decat viteza fiecărei linii. Până la un punct, problema se poate rezolva cu o memorie cu viteza mare de acces. Biţii sosesc serial la o linie de intrare şi sunt memoraţi întru-un registru de intrare cu deplasare. Cand toată celula a fost memorată, ea poate fi încărcată într-o memorie cu dimensiunea unei celule. Apoi aceasta poate fi citită în registrul de deplasare de ieşire al liniei corespunzătoare şi transmisă pe linia de ieşire.
Comutatorul Datapath utilizează o memorie centrală de 4 Kcelule, care evident nu asigură memoria tampon adecvată. Totusi, această memorie poate fi implementată uşor într-un singur chip si mărită, utilizând controlul fluxului şi memorii tampon de pachete externe chipului. Dar proiectarea acestor memorii partajate, ca aceasta, nu se scaleaza peste memoriile de dimensiunea unei celule, deoarece pachetele de dimensiune minimă pot

182
avea cel mult dimensiunea unei celule. Un comutator care trimite mai multe pachete de dimensiune minimă înspre diferite destinaţii poate împacheta mai multe asemenea pachete într-un singur cuvânt, dar nu e sigur că le poate extrage în acelaşi timp.
In ciuda acestui fapt, comutatoarele cu memorie partajată pot fi relativ simple pentru un număr mic de porturi. Marele lor avantaj este că pot fi optimale ca memorie şi putere, deoarece datele sunt stocate/extrase in/din memorie o singură dată. Comutatoarele hard sau crossbar, aproape întotdeauna necesită memorarea pachetelor de două ori dublând potenţial costurile de memorie şi de putere. Este posibilă extinderea ideii de memorie partajată la comutatoarele de dimensiuni mai mari, folosind întreţeserea aleatoare DRAM.
13.3 RUTERELE: DE LA MAGISTRALE LA CROSSBAR Comutatoarele pentru rutere au evoluat de la cele mai simple
comutatoare cu mediu partajat (magistrale sau memorii), (fig.13.3a) la comutatoarele crossbar mai moderne (fig.13.3 d). Un card de linie într-un ruter sau comutator conţine logica interfeţei pentru o legătură de date (linie pe fibră optică sau un Ethernet). Primele comutatoare au conectat intern toate cardurile de linie, printr-o magistrală de viteză mare (asemanator cu o reţeea locala LAN interna) pe care numai o pereche de carduri de linie pot comunica simultan. Astfel dacă cardul de linie 1 a transmis un pachet înspre cardul de linie 2, nici o altă pereche de carduri de linie nu mai poate comunica.
MA
GIS
TRA
LĂ
Card de linie 1
Card de linie 2
Card de linie N
Pachet
CPU
a) Magistrală, CPU comun
MA
GIS
TRA
LĂ
Card de linie 1
Card de linie 2
Card de linie N
Pachet
CPU 1
b) Magistrală, CPU-uri comune
CPU M
MA
GIS
TRA
LĂ
Card de linie 1
Pachet
c) Magistrală, CPU-uri pe fiecare card de linie
CPU 1
CPU 2 Card de linie 2
CPU N Card de linie 2
CPU (uri) de rutare
Card de linie 1
Pachet
d) Crossbar, motoare de înaintare pe fiecare card de linie
FE 1
FE 2Card de linie 2
FE NCard de linie 2
CPU (uri) de rutare
FIGURA 13.3. Evoluţia comutatoarelor pentru reţele, de la comutatoarele cu magistrală comună cu un CPU comun, la comutatoarele crossbar cu un motor de înaintare pe fiecare
card de linie

183
Mai rău, în ruterele şi comutatoarele mai vechi, decizia de înaintare a pachetelor a fost dată unui CPU cu scop general, partajat. CPU-urile cu scop general au un software de înaintare mai simplu şi uşor de modificat. Dar ele erau lente, datorită nivelurilor suplimentare de interpretare a instrucţiunilor cu scop general. Le lipsea capacitatea de lucru/control in conditii de timp real la procesarea pachetelor, din cauza nedeterminismului cauzat de mecanisme ca memoriile cache. Fiecare pachet traversează magistrala de două ori, o dată pentru a ajunge la CPU şi o dată pentru a ajunge de la CPU la destinaţie, deoarece CPU se află pe un card separat, accesibil numai prin intermediul magistralei.
Deoarece CPU a fost o strangulare, pasul urmator a fost adăugarea unui grup de CPU-uri comune pentru înaintare, dintre care fiecare poate expedia un pachet. De exemplu un CPU poate înainta pachetele de pe cardurile de linie 1 până la 3, cel de-al doilea de pe cardurile de linie 4 până la 6 şi aşa mai departe. Aceasta creşte eficienta totală, sau reduce cerinţele pentru fiecare CPU individual, conducând potenţial spre o variantă cu un cost mai scăzut. In orice caz, fără o atenţie corespunzătoare se poate ajunge la o ordonare greşită a pachetelor, ceea ce nu este de dorit.
Cu toate acestea, magistrala rămâne o strangulare. O singură magistrală partajată are limitări de viteză, datorită numărului de surse şi destinaţii distincte care trebuie tratate de o singură magistrală comună. Aceste surse şi destinaţii adaugă sarcină electrică suplimentară, înrăutăţind timpii de crestere ai semnalelor, şi în final viteza de transmitere a biţilor pe magistrală. Alte efecte electrice includ conectorii multipli (de la fiecare card de linie) şi reflexiile pe linie.
Metoda clasică de-a evita această strangulare este comutatorul crossbar (fig. 13.3.d) care conţine în esenţă 2N magistrale paralele, o magistrală pentru fiecare card de linie sursă, şi o magistrală pentru fiecare card de linie destinaţie. Matricea de magistrale sursă (orizontale) şi destinaţie (verticale) formează crossbar-ul.
Teoretic viteza pe o magistrală creşte de N ori, deoarece în cel mai bun caz toate cele N magistrale vor fi utilizate în paralel, simultan pentru a transfera date, în locul unei singure magistrale. Bineînţeles pentru a obţine această creştere de viteză este necesară găsirea a N perechi distincte sursă-destinaţie in fiecare diviziune de timp. Apropierea de această margine reprezintă probema majoră de planificare studiată acum.
O altă modificare a comutatoarelor crossbar, produse in perioada 1995-2002, este utilizarea de circuite integrate speciale dedicate (ASIC) şi a motoarelor de înaintare, în locul CPU-urilor cu scop general, deşi asocierea nu e obligatorie. Dezavantajele acestor motoare de înaintare ar fi costurile de proiectare ale ASIC-urilor, şi lacunele de programabilitate (ceea ce face ca eventuale modificări să fie dificile sau chiar imposibile). Aceste probleme au condus din nou la procesoare de reţea rapide, dar programabile .
13.4. PLANIFICATORUL CROSSBAR „IA-ŢI UN BILET” Cel mai simplu crossbar este o matrice cu N magistrale de intrare şi N
magistrale de ieşire (fig.13.4). Atunci cand cardul de linie R doreşte să transmită date cardului de linie S, magistrala de intrare R trebuie să fie conectată la magistrala de ieşire S. Cea mai simplă cale de-a face această

184
conexiune este aducerea unui tranzistor în stare de conducţie (fig.13.5). Pentru fiecare pereche de magistrale de intrare şi de ieşire, la fel ca la R şi S, există un tranzistor care, în conducţie, conectează cele două magistrale. O astfel de conexiune este cunoscută sub denumirea de punct de conexiune/crosspoint. Un crossbar cu N intrări şi N ieşiri are N2 puncte de conexiune, iar fiecare dintre acestea necesită o linie de control de la planificator, pentru a-l aduce în stare de conducţie şi pentru a-l bloca.
Desi N2 pare mult, implementările VLSI simple cu tranzistoare fac ca limitarile în realizarea comutatoarelor de dimensiune mare sa fie impuse mai ales de numărul de pini, tehnologiile de conectare a cardurilor, etc. Majoritatea ruterelor şi comutatoarelor dinainte de 2002 utilizează comutatoarele crossbar simple ca suport pentru 16-32 porturi. Multicastul se face prin conectarea magistralei de intrare R la toate magistralele de ieşire care doresc să recepţioneze de la R. Dar planificarea multicast e complicată.
In practică numai variantele mai vechi de crossbar utilizează tranzistoare pentru conexiuni (capacitatea totala creşte cu numărul de porturi). Aceasta duce la creşterea întârzierii la transmisia unui semnal, ceea ce devine o problemă la viteze mai mari. Implementările moderne utilizează pe ieşiri arbori mari de multiplexoare, sau buffere cu 3 stări. Sistemele performante utilizează, pentru trecerea fluxului de date prin crossbar, nişte memorii (de ex. o poartă) la punctele de conexiune.Astfel considerentele de nivel fizic fac proiectarea comutatoarelor crossbar moderne complicată.
Va fi tratata doar partea de planificare a comutatoarelor. Pentru corectitudine controlul logic trebuie să asigure conectarea fiecărei magistrale de ieşire la cel mult o magistrală de intrare (pentru a preveni mixarea intrărilor). Pentru performanţă, partea logică trebuie să
Intrare 1
Intrare 2
Intrare 3
Ieşire 1 Ieşire 2 Ieşire 3
FIGURA 13.4. Comutatorul crossbar fundamental
Intrare R
Ieşire S
Se setează la adevărat pentru a conecta intrarea R la ieşirea S
FIGURA 13.5. Conectează intrarea de pe cardul de linie R la cardul de linie S, prin aducerea tranzistorului în stare de conducţie. La modelele moderne de crossbar această variantă simplă este înlocuită cu arbori de multiplexoare pentru a reduce capacitatea.

185
maximizeze numărul de perechi de carduri de linie care comunică în paralel. Deşi paralelismul ideal asigura că toate cele N magistrale de ieşire sunt ocupate în acelaşi timp, în practică paralelismul este limitat de doi factori. In primul rând s-ar putea să nu existe date pentru unele carduri de linii de ieşire. Apoi e posibil ca două sau mai multe caduri de linii de intrare să dorească să transmită date aceluiaşi card de linie de ieşire. Dar o singură intrare poate câştiga la un anumit moment dat, si astfel se limitează traficul pentru intrările care au pierdut si nu pot transmite date.
Astfel, în ciuda paralelismului extins, concurenţa majoră are loc la portul de ieşire. Cum poate fi soluţionată concurenţa pentru porturile de ieşire în acelaşi timp cu maximizarea paralelismului? O variantă simplă şi elegantă de planificare a fost pentru prima dată inventată şi utilizată în Gigacomutatorul DEC. Un exemplu al aşa numitului algoritm „ia-ţi un bilet” utilizat de DEC este dat în figura 13.6.
Ideea este ca fiecare card de linie de ieşire S să menţină o coadă distribuită pentru toate cardurile de linie de intrare R care aşteaptă să transmită înspre S. Coada pentru S este memorată in cardul liniei de intrare (în loc de S) utilizând un mecanism simplu cu numere de bilet. Dacă cardul de linie R doreşte să transmită un pachet spre cardul de linie S, mai întâi trimite o cerere printr-o magistrală de control separată înspre S; S trimite apoi un număr de coadă înspre R pe magistrala de control. Numărul de coadă este numărul poziţiei lui R în coada de ieşire pentru S.
Apoi R monitorizează magistrala de control; când S termină acceptarea unui nou pachet, S trimite pe magistrala de control numărul de coadă curent pe care o serveşte. Dacă R observă că numărul său este „servit”, R îşi plasează pachetul pe magistrala datelor de intrare pentru R. In acelaşi timp S se asigură că punctul de conexiune între R şi S a fost activat.
In fig. 13.6 se vede algoritmul în acţiune ; cadrul de la cardul de linie A conţine trei pachete destinate ieşirilor 1, 2 şi 3, B are 3 pachete destinate aceloraşi ieşiri, iar C are pachete destinate ieşirilor 1, 3 şi 4. In acest exemplu pachetele au aceeaşi dimensiune (acest lucru însă nu este necesar pentru ca algoritmul „ia-ţi un bilet” să funcţioneze).
Fiecare port lucrează numai pentru pachetul din fruntea cozii sale. Deci algoritmul începe cu fiecare intrare transmiţând o cerere, printr-o magistrală de control înspre portul de ieşire căruia îi este destinat pachetul din fruntea cozii de intrare. Astfel, în exemplu, fiecare intrare trimite o cerere înspre portul 1 pentru permisiunea de-a transmite un pachet.
Numărul de bilet este un întreg mic care depinde de, şi este eliberat în ordinea sosirii. Presupunem că cererea lui A ajunge prima pe magistrala de control serială urmată de B, iar apoi de C. In figura din stânga sus aparent cererile sunt transmise în mod concurenţial, nu secvential. Deoarece portul de ieşire 1 poate servi un singur pachet la un moment dat, el pune cererile în ordine serială şi returnează T1 lui A, T2 lui B, şi T3 lui C.
Astfel, în figura din mijloc în rândul de sus, portul de ieşire 1 difuzează numărul de bilet curent care este deservit (T1) pe o altă magistrală de control. Când A observă că are un număr corespunzător pentru intrarea 1, în figura din partea dreaptă sus, A conectează magistrala sa de intrare la magistrala de ieşire a lui 1 şi îşi trimite pachetele pe magistrala sa de intrare. Deci la sfârşitul primului rând de imagini, A a trimis pachetul din fruntea cozii sale de intrare la portul de ieşire 1.

186
Al doilea rând din figura 13.6 începe cu transmisia unei cereri de către A pentru pachetul care este acum în fruntea cozii sale înspre portul de ieşire 2. Lui A i se returnează un număr de bilet, T1, pentru portul 2. În imaginea din mijlocul rândului 2, portul 1 anunţă că este pregătit pentru T2, şi portul 2 anunţă că este pregătit pentru biletul T1. Aceasta rezultă din figura din partea dreaptă a celui de-al doilea rând, unde A este conectat la portul 2 şi B este conectat la portul 1 şi pachetele corespunzătoare sunt transferate.
Al treilea rând de imagini din figura 13.6 începe similar cu transmisia de
către A şi B a unei cereri pentru porturile 3 şi 2, respectiv. Numai C mai este încă blocat în aşteptarea pentru numărul său de bilet T3, care este obţinut cu două iteraţii înainte pentru a fi anunţat la portul de ieşire 1. Astfel C nu mai trimite alte cereri până ce pachetul din fruntea cozii sale de aşteptare este deservit. Lui A i se returnează T1 pentru portul 3 şi lui B i se returnează T2 pentru portul 2. Apoi portul 1 difuzează T3, portul 2 difuzează T2, şi portul 3 difuzează T1. Aceasta duce la ultima imagine din partea stângă a rândului 3, unde comutatorul crossbar conectează A cu 3, D cu 2 şi C cu 1.
Varianta „ia-ţi un bilet” este avantajoasă în starea de control necesitând doar două numărătoare de 2log N biţi la fiecare port de ieşire pentru a reţine numărul de bilet curent care este deservit şi cel mai mare număr de bilet dispensat. Aceasta a permis să se ajungă la o dimensiune de 36 porţi la Gigacomutatorul DEC chiar şi în anii ’90 când dimensiunea memoriei pe chip a fost limitată. Varianta a utilizat un planificator distribuit, iar arbitrarea fiecărui port de ieşire a fost realizată de un aşa numit chip GPI pe fiecare card de linie; chip-urile GPI comunică printr-o magistrală de control.
Chip-urile GPI trebuie să arbitreze magistrala de control (serială) cu scopul de-a prezenta o cerere la un card de linie de ieşire şi de-a obţine un număr de ordine în coadă. Deoarece magistrala de control este o magistrală
AB C
A A
A A A
AA A
B B
B B B
B B BCCC
CCC
CC
3 3 2 4 3 1
3 3 2 4 3 1
3 3 2 4 3 1
3 2
4 3 13 2 1 3 2 1
3 2
4 3 13 2 1 4 3 1
3 2
3 2 1 3 2 1 4 3 1
3 2 13 2 1
4 3 1 4 3 13 2 13 2 1
3 3 3
3 3 3
3 3 3
2 2 2
2 2 2
2 2 2
1 1 1
1
1 1 1
1 1
4 4 4
4 4 4
4 4 4
Etapa 1
Etapa 2
Etapa 3
Cerere
Cerere
Cerere
Acordare bilet
Acordare bilet
Acordare bilet
Conectare
Conectare
Conectare
T1 T2 T3
T1
T1
T2
FIGURA 13.6. În mecanismul de planificare „ia-ţi un bilet”, toate porturile de intrare au o singură coadă de intrare care este etichetată cu numărul portului de ieşire căruia fiecare pachet îi este destinat. Astfel în primul cadru, intrările A, B şi C trimit cereri înspre portul de ieşire 1. Portul de ieşire 1 (sus, mijloc) îi acordă primul număr lui A, cel de-al doilea lui B, etc., şi aceste numere sunt utilizate pentru a stabili o ordine serială pentru accesul la porturile de ieşire.
T2 T1
T3 T2 T1

187
de difuziune, un port de intrare îşi dă seama când îi vine rândul observând activitatea acelora care au fost înaintea lui, şi apoi poate instrui comutatorul să realizeze o conexiune.
Pe lângă simplitatea de realizare a controlului, varianta „ia-ţi un bilet” are avantajul de-a fi capabilă să opereze direct cu pachete de dimensiune variabilă. Porturile de ieşire pot difuza asincron numărul următor de bilet în momentul în care acestea finalizează recepţionarea pachetului curent; porturi distincte de ieşire pot difuza numărul lor de bilet curent la momente de timp arbitrare. Astfel spre deosebire de toate variantele care vor fi descrise mai târziu nu există antet şi trafic de control pentru împărţirea pachetelor în „celule” şi reasamblarea lor ulterioară. Pe de altă parte în cazul „ia-ţi un bilet ” paralelismul este limitat de „blocarea în fruntea liniei”, fenomen analizat în următoarea secţiune.
Un alt avantaj al variantei „ia-ţi un bilet” se numeşte grupuri de vânătoare. Orice set de carduri de linie (nu numai cardurile de linie învecinate fizic) pot fi agregate pentru a forma o legătură cu banda mai mare, numită grup de vânătoare. Astfel 3 legături de 100 Mbps pot fi grupate într-o singură legătură de 300 Mbps.
Implementarea ideii necesită doar mici modificări ale algoritmului de planificare original, deoarece fiecare dintre chip-urile GPI din grup poate observa mesajele trimise unul altuia pe magistrala de control şi astfel să păstreze copii locale ale numărului de bilet (comun). Următorul pachet destinat grupului este servit de primul port de ieşire liber din grupul de vânătoare. In timp ce grupurile de vânătoare de bază pot reordona pachetele transmise spre legături diferite, o mică modificare permite ca pachetele de la o intrare să fie transmise spre un singur port de ieşire într-un grup de vânătoare, printr-o dispersare deterministă simplă. Modificarea evită reordonarea cu preţul reducerii paralelismului.
Gigacomutatorul fiind o punte, a trebuit să trateze LAN-ul multicast. Deoarece mecanismul de planificare „ia-ţi un bilet” utilizează planificarea distribuită, prin chip-uri GPI separate pe ieşire, este dificil să se coordoneze toate planificatoarele pentru a asigura ca fiecare port de ieşire să fie liber.In plus aşteptarea ca fiecare port de ieşire să aibă un bilet liber pentru un pachet de multicast ar duce la blocarea unor porturi care au fost gata de-a servi pachetul mai înainte, pierzându-se debit util. Aşadar multicastul a fost tratat de către un procesor central prin software, şi în consecinţă a fost asociat ’’stării de clasa a doua’’.
A
B
C C
CBA
BACBA1
2
3
4
Timp (conform cu durata pachetelor)
3 1 2
3 1 2
4 1 3
FIGURA 13.7 Blocare „în fruntea liniei” cauzată de variante de algoritmi „ia-ţi un bilet”. Pentru fiecare port de ieşire, o scară de timp orizontală este etichetată cu portul de intrare care trimite un pachet către acel port de ieşire în perioda de timp corespunzătoare sau cu un pătrat gol dacă nu se transmit pachete. Se observă numărul mare de pătrate goale, ceea ce denotă o risipă de oportunităţi, ceea ce limiteaza paralelismul .

188
13.5 BLOCAREA ÎN FRUNTEA LINIEI (HOL) Facand abstractie de mecanismul intern din figura 13.6, se observă că în
3 iteraţii au fost 9 posibilităţi de transmisie (3 porturi de intrare şi 3 iteraţii), dar după ultima imagine, cea din dreapta jos, rămâne un pachet în coada lui B şi două pachete în coada lui C. Deci au fost transmise numai 6 din 9 pachete posibile ; rezultă că paralelismul este limitat.
Această concentrare doar pe comportamentul de intrare-ieşire este ilustrată în figura 13.7, care arată pachetele transmise în fiecare durată de pachet la fiecare port de ieşire. Fiecare port de ieşire are o linie de timp asociată, etichetată cu portul de intrare care transmite un pachet în durata corespunzătoare de timp ; pătratele albe au semnificaţia că nici un port de intrare nu transmite pachete în acel interval de timp. Este continuat exemplul din figura 13.6 pentru încă trei iteraţii, până ce toate cozile de intrare sunt goale.
In dreapta figurii se observă că doar aproximativ jumătate din posibilităţile de transmisie sunt utilizate (9 din 24). Bineînţeles nici un algoritm nu o poate face mai bine pentru anumite scenarii. Totuşi, alţi algoritmi ca de exemplu iSLIP (figura 13.11) poate duce la un paralelism mai bun, finalizând aceleaşi nouă pachete în patru iteraţii în loc de şase.
In prima iteraţie, (fig.13.7), toate intrările au pachete în aşteptare pentru ieşirea 1. Deoarece numai una singură (de exemplu A) poate să transmită un pachet către ieşirea 1 la un anumit moment de timp, întreaga coadă la B (şi C) este blocată aşteptând finalizarea transmisiei lui A. Deoarece întreaga coadă este blocată de progresul pachetului din fruntea cozii, aceasta se numeşte blocare în fruntea liniei HOL (head of line). ISLIP şi PIM ocolesc această limitare permiţând pachetelor din spatele pachetului blocat să progreseze (de exemplu pachetul destinat portului de ieşire 2 în coada de intrare a lui B poate fi transmis înspre portul 2 în prima iteraţie a figurii 13.7) cu preţul unui algoritm de planificare mai complicat.
Pierderea de debit util prin blocarea HOL poate fi descrisă analitic cu un model simplu, uniform de trafic. Presupunem că în fruntea fiecărei cozi de intrare este un pachet destinat unei ieşiri din N cu probabilitatea 1/N. Astfel, dacă două sau mai multe porturi de intrare transmit către acelaşi port de ieşire, toate cu excepţia unei intrări sunt blocate. Intregul trafic al celorlalte intrări este „pierdut” datorită blocării în fruntea liniei.
Considerăm pachetele de dimensiune egală şi o încercare iniţială unde un proces aleator asociază un port destinaţie fiecărui port de intrare, uniform de la 1 la N. In loc sa ne concentrăm atenţia asupra porturilor de intrare, ne concentrăm asupra probabilităţii că un port de ieşire O este nefolosit, care e de fapt probabilitatea ca nici unul dintre cele N porturi de intrare să aleagă portul de ieşire O. Deoarece fiecare port de intrare nu alege O cu probabilitatea 1 1/ N− , probabilitatea ca toate cele N porturi de intrare nu vor alege O este ( )1 1/ NN− . Această expresie converge rapid înspre 1/ e . Deci probabilitatea ca O să fie ocupat este 1 1/ e− , adică 0,63. Deci debitul util al comutatorului nu este N B∗ (ideal atins doar dacă toate cele N intrări ar fi ocupate, operând la B bps). El este 63 % din această valoare maximă, deoarece 37 % din legături sunt nefolosite.
Analiza este simplistă şi presupune (incorect) că fiecare iteraţie este independentă. In realitate, pachetele selectate să nu fie transmise într-o

189
iteraţie, trebuie luate în consideraţie în iteraţia următoare (fără o altă selecţie aleatoare a destinaţiei). O analiză clasică, care elimină prezumţia de independenţă, arată că debitul util se apropie de 58 % .
Dar sunt realiste distribuţiile uniforme de trafic? Analiza depinde de distribuţia traficului, deoarece nici un comutator nu poate funcţiona bine dacă tot traficul e destinat unui singur port. Analiza arată că efectul HOL poate fi redus utilizând grupuri de vânătoare, mărind viteza comutatorului crossbar comparativ cu a legăturilor, şi lucrând cu distribuţii mai realiste, la care un număr de clienţi transmit trafic către câteva servere.
Există insa distribuţii pentru care blocarea în fruntea liniei poate afecta grav traficul. Să ne imaginăm că fiecare linie de intrare are B pachete spre portul 1 urmate de B pachete spre portul 2 şi aşa mai departe, şi în final B pachete spre portul N. Aceeaşi distribuţie de pachete este prezentă la toate porturile de intrare. Dacă planificăm pachetele destinate portului 1 în grupul iniţial, blocarea în fruntea liniei va limita comutatorul, fiind posibilă transmisia unui singur pachet pe intrare în fiecare interval de timp. Astfel, comutatorul reduce traficul la 1/ N din traficul total posibil, dacă B este destul de mare. Pe de altă parte vom vedea că variantele de comutatoare care utilizează cozi de ieşire virtuale (VOQ) pot atinge în situaţii similare aproape 100 % din debitul util, deoarece fiecare bloc de B pachete se distribuie în cozi separate la fiecare intrare.
13.6 EVITAREA HOL PRIN COZI LA IEŞIRE Pentru evitarea blocării HOL s-au propus cozi de aşteptare la ieşire în
locul cozilor la intrare. Presupunem că pachetele pot fi trimise oricum către un port de ieşire fără coadă de aşteptare la intrare. Un pachet P destinat unui port de ieşire ocupat, nu poate bloca un alt pachet care-i urmează, deoarece pachetul P, trimis în coada de aşteptare a portului de ieşire, poate bloca doar pachetele destinate aceluiaşi port de ieşire.
Cea mai simplă cale de-a realiza acest lucru ar fi de-a face comutaţia de N ori mai rapidă comparativ cu viteza liniilor de intrare. Atunci chiar dacă toate cele N intrări transmit către aceeaşi ieşire, într-un anumit timp de celulă, toate cele N celule pot fi trecute prin comutator spre a fi introduse în coada de aşteptare la ieşire. Deci, pentru a realiza cozi de aşteptare la ieşiri e nevoie de comutatoare cu viteze de N ori mai mari. Soluţia e scumpă sau irealizabilă.
O implementare practică a cozilor de aşteptare la ieşire este comutatorul „knockout”. Presupunem că recepţia a N celule pentru aceeaşi destinaţie, în orice interval de timp de celulă, este rară şi că numărul aşteptat este k, iar k N<< . In acest caz (P11) este necesar să se proiecteze un comutator doar de k ori mai rapid decât viteza liniei de intrare, nu de N ori. Aceasta duce la economii substanţiale pentru comutator, şi se poate realiza prin paralelism hardware (P5), folosind k magistrale paralele.
In afara de varianta „ia-ţi un bilet” toate celelalte variante, inclusiv varianta knockout, se bazează pe divizarea pachetelor în celule de dimensiune fixă. Se va folosi noţiunea de celulă nu de pachet, dar se subînţelege faptul că exista o etapă iniţială de segmentare a pachetelor în celule, şi apoi de reasamblare la portul de ieşire.
Pe langa un comutator mai rapid, varianta knockout necesită o coadă de aşteptare la ieşire capabilă să accepte celule cu o viteză de k ori mai mare

190
decat viteza liniei de ieşire. O implementare naivă ar fi cu un FIFO rapid, dar costul e ridicat. De altfel ideea unui FIFO rapid este exclusă, deoarece bufferul nu rezistă la un dezechilibru pe termen lung, între viteza de intrare şi cea de ieşire. Astfel specificarea bufferului poate fi relaxată (P3) permiţându-i-se să opereze astfel doar pe perioade scurte, în care celulele sosesc de k ori mai rapid decât sunt transmise mai departe. Aceasta se poate rezolva prin intreţeserea memoriei şi folosirea a k memorii paralele. Un distribuitor (care rulează de k ori mai repede) împarte celulele ce sosesc la k memorii, în ordine round-robin, iar la ieşire celulele sunt extrase în aceeaşi ordine.
In final trebuie tratat corect şi cazul în care nu este respectată condiţia impusă, şi N k> celule sunt transmise la aceeaşi ieşire, în acelaşi timp. Pentru a înţelege soluţia generală expunem trei cazuri mai simple.
Doi concurenţi, un câştigator: In cel mai simplu caz dacă k=1 şi N=2, arbitrul trebuie să aleagă echitabil o singură celulă din două variante posibile. Aceasta se poate face prin realizarea unui echipament elementar de comutaţie 2x2, numit concentrator care selectează aleatoriu un câştigător si un necâştigător. Ieşirea câştigătoare este celula selectată. Ieşirea necâştigătoare este folositoare în cazul general în care sunt combinate mai multe concentratoare elementare 2 x 2.
Multi concurenţi, un singur câştigător: Acum considerăm k=1 (numai o singura celulă poate fi acceptată) şi N>2 (sunt mai mult de două celule între care arbitrul trebuie sa facă o selecţie echitabilă). O strategie simplă se bazează pe varianta dezbină şi cucereşte (P15 structuri de date eficiente) pentru a crea un arbore knockout de concentratoare 2x2. Celulele sunt grupate două câte două utilizând / 2N copii ale concentratorului elementar 2x2. Acestea formează primul nivel al arborelui. Câştigătorii primei runde trec la runda a doua unde sunt N/4 concentratoare şi aşa mai departe, pînă se ajunge la un singur concentrator (root) care stabileşte câştigătorul. Se observă că ieşirile necâştigătoare au fost ignorate pană acum.
Mai mulţi concurenţi, mai mult de un castigator: In final, consideram cazul general in care k celule trebuie selectate din N celule posibile, pentru valori arbitrare ale lui k si N. O idee simpla este de-a crea k arbori knockout separati pentru a calcula primii k castigatori. Pentru corectitudine, celulele necâştigătoare la arborii knockout de nivel inferior trebuie trimise la urmatorul nivel pentru locurile urmatoare. Aceasta este posibil deoarece concentratorul knockout 2x2 are doua iesiri, una pentru castigator si una pentru necâştigător, nu doar una pentru castigator. Iesirile necâştigătoare sunt direcţionate înspre arborii pentru poziţiile următoare.
Dacă trebuie selectate 4 celule din 8 candidaţi, cea mai simplă variantă va atribui cei 8 candidaţi (în perechi) la 4 concentratori knockout 2x2. Acestea logic vor selecta patru câştigători, cantitatea dorită. Aceasta variantă este mult mai simplă faţă de utilizarea a patru arbori separaţi, dar poate deveni inechitabilă. De exemplu presupunem două surse care transmit continuu informaţie, S1 si S2 şi întâmplarea face ca aceste două surse să formeze o pereche, în timp ce o altă sursă cu debit mare S3 formează o pereche cu o sursă cu debit mic. In acest caz sursele S1 si S2 vor obţine aproximativ jumătate din traficul pe care îl obţine S3. Trebuie evitate aceste situaţii inechitabile prin utilizarea a k arbori separaţi, unul

191
pentru fiecare poziţie.Implementarea naivă a arborilor este: se începe rularea logicii pentru arborele din poziţia j, strict după ce s-a terminat rularea logicii pentru arborele din poziţia j-1. Aceasta asigură că toti necâştigătorii eligibili au fost colectaţi. Echitatea este dificil de implementat.
Inţelegerea comutatorului knockout e importantă datorită tehnicilor pe care le introduce, dar implementarea lui este complexă şi face presupuneri asupra distribuţiei de trafic. Presupunerile nu sunt valabile pentru topologii reale, unde mai mult de k clienţi concurează frecvent în cazul transmisiilor către un server foarte mult accesat. Dar cercetătorii au găsit căi simple de a evita blocarea HOL fără utilizarea cozilor la ieşire.
13.7.EVITAREA HOL CU ASOCIERE PARALELĂ ITERATIVĂ Ideea principală la PIM, asocierea paralelă iterativă, este de-a
reconsidera cozile de aşteptare la intrare, adaptându-le să evite blocarea în fruntea liniei. Unui port de intrare i se planifica nu doar celula din fruntea cozii sale de intrare, ci şi toate celelalte celule ce pot progresa când prima celula este blocată. Pare foarte dificil: pot fi o sută de mii de celule în fiecare coadă si chiar cu un singur bit de planificare a stării fiecărei celule rezulta prea multa memorie pentru stocare şi procesare.
Prima observaţie e că celulele din coada fiecărui port de intrare pot fi destinate numai pentru N porturi de ieşire posibile. Presupunem că celula P1 este situată înaintea celulei P2 în coada de intrare X, şi ambele P1 si P2 sunt destinate aceleiaşi cozi de ieşire Y. Cu FIFO, P1 trebuie planificată înainte de P2. Deci, nu se obţine nici un câştig din încercarea de-a planifica P2 înainte de P1. Risipa evidentă poate fi evitată (P1) prin planificarea doar a primei celule destinate fiecărui port de ieşire distinct, iar restul celulelor raman neplanificate.
Primul pas la fiecare port de intrare, este descompunerea cozii unice de intrare din fig.13.6 în cozi de intrare separate pentru fiecare ieşire numite cozi virtuale la ieşire (VOQ) (fig.13.8) ; in stânga sus sunt aceleaşi celule de intrare ca şi în fig.13.7, dar plasate în cozi separate.
Pentru comunicarea planificării porturilor de intrare e nevoie de un bitmap de doar N biţi (N este dimensiunea comutatorului). Un 1 in poziţia i a bitmap-ului arată că există cel puţin o celulă destinată portului de ieşire i. Astfel dacă fiecare port de intrare, din N, comunică folosind un vector de N biţi pentru descrierea planificării necesare, planificatorul trebuie să proceseze numai N2 biţi. Pentru N<32, nu sunt prea mulţi biţi de transmis pe magistralele de control sau de depus în memoriile de control.
Comunicarea cererilor e în stânga sus in figura 13.8. Se observă că A nu transmite o cerere portului 4 deoarece nu are celule destinate portului 4. De asemenea portul de intrare C transmite o cerere pentru celula destinată portului de ieşire 4, deşi aceeaşi celulă este ultima în coada de intrare C, în cazul scenariului cu o singura coadă de intrare din figura 13.6.
E necesar acum un algoritm de planificare ce asociază resurse nevoilor. Deşi inteligent, adevăratul progres îl constituie evitarea blocării HOL utilizând VOQ la intrare. Pentru a menţine analogia între exemplul din fig.13.8 şi fig.13.6, presupunem că fiecare pachet din fig.13.6 e convertit într-o singura celulă în fig.13.8.
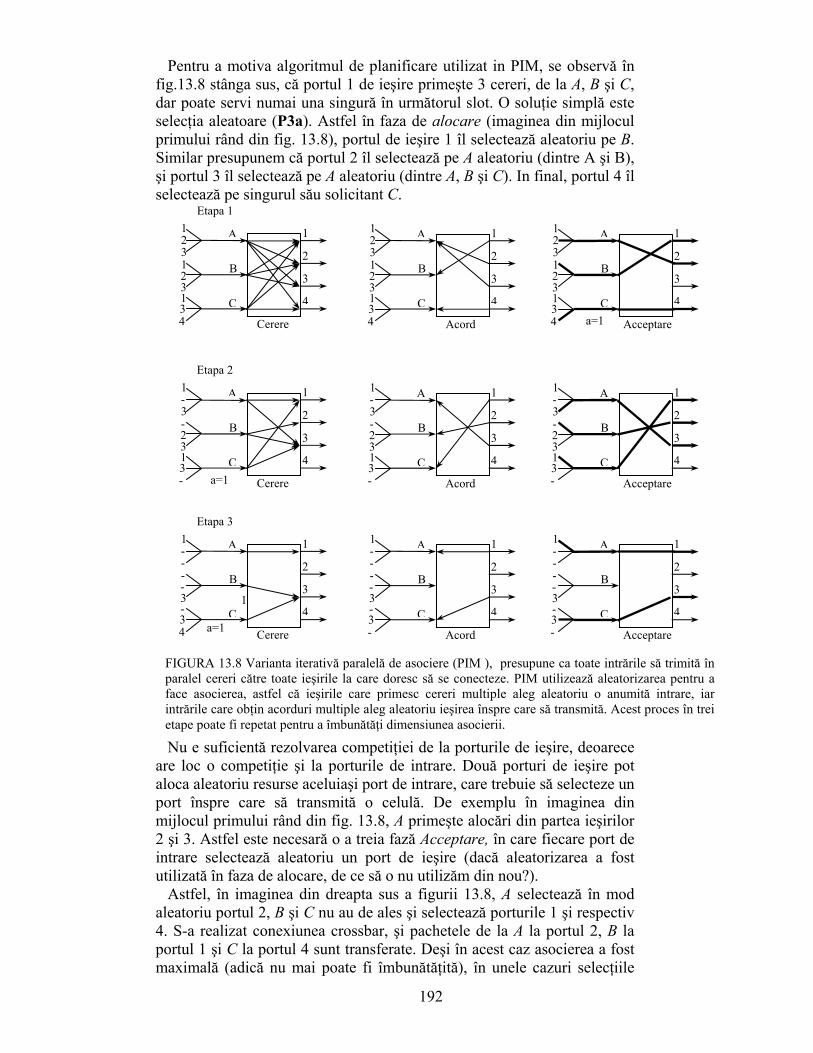
192
Pentru a motiva algoritmul de planificare utilizat in PIM, se observă în fig.13.8 stânga sus, că portul 1 de ieşire primeşte 3 cereri, de la A, B şi C, dar poate servi numai una singură în următorul slot. O soluţie simplă este selecţia aleatoare (P3a). Astfel în faza de alocare (imaginea din mijlocul primului rând din fig. 13.8), portul de ieşire 1 îl selectează aleatoriu pe B. Similar presupunem că portul 2 îl selectează pe A aleatoriu (dintre A şi B), şi portul 3 îl selectează pe A aleatoriu (dintre A, B şi C). In final, portul 4 îl selectează pe singurul său solicitant C.
Nu e suficientă rezolvarea competiţiei de la porturile de ieşire, deoarece
are loc o competiţie şi la porturile de intrare. Două porturi de ieşire pot aloca aleatoriu resurse aceluiaşi port de intrare, care trebuie să selecteze un port înspre care să transmită o celulă. De exemplu în imaginea din mijlocul primului rând din fig. 13.8, A primeşte alocări din partea ieşirilor 2 şi 3. Astfel este necesară o a treia fază Acceptare, în care fiecare port de intrare selectează aleatoriu un port de ieşire (dacă aleatorizarea a fost utilizată în faza de alocare, de ce să o nu utilizăm din nou?).
Astfel, în imaginea din dreapta sus a figurii 13.8, A selectează în mod aleatoriu portul 2, B şi C nu au de ales şi selectează porturile 1 şi respectiv 4. S-a realizat conexiunea crossbar, şi pachetele de la A la portul 2, B la portul 1 şi C la portul 4 sunt transferate. Deşi în acest caz asocierea a fost maximală (adică nu mai poate fi îmbunătăţită), în unele cazuri selecţiile
FIGURA 13.8 Varianta iterativă paralelă de asociere (PIM ), presupune ca toate intrările să trimită în paralel cereri către toate ieşirile la care doresc să se conecteze. PIM utilizează aleatorizarea pentru a face asocierea, astfel că ieşirile care primesc cereri multiple aleg aleatoriu o anumită intrare, iar intrările care obţin acorduri multiple aleg aleatoriu ieşirea înspre care să transmită. Acest proces în trei etape poate fi repetat pentru a îmbunătăţi dimensiunea asocierii.
Etapa 1
A
B
C
3
2
1
4
Cerere
1 2 3 1
4
3 1 3
2
A
B
C
3
2
1
4
Acord
1 2 3 1
4
3 1 3
2
A
B
C
3
2
1
4
Acceptare
1 2 3 1
4
3 1 3
2
Etapa 3
A
B
C
3
2
1
4
Cerere
1 - - -
1
4
3 - 3
-
A
B
C
3
2
1
4
Acord
1 - - -
-
3 - 3
-
A
B
C
3
2
1
4
Acceptare
1 - - -
-
3 - 3
-
Etapa 2
A
B
C
3
2
1
4
Cerere
1 - 3 -
-
3 1 3
2
A
B
C
3
2
1
4
Acord
1 - 3 -
-
3 1 3
2
A
B
C
3
2
1
4
Acceptare
1 - 3 -
-
3 1 3
2
a=1
a=1
a=1

193
aleatoare pot da o asociere ce mai poate fi îmbunătăţită ulterior. De exemplu în cazul improbabil ca porturile 1, 2 şi 3 să selecteze toate A, vor fi asociate doar două.
In aceste cazuri, neprezentate în figură, algoritmul poate fi îmbunătăţit prin mascarea tuturor intrărilor şi ieşirilor asociate, după care se fac mai multe iteraţii (pentru acelaşi interval de timp care urmează). Dacă asocierea în cazul iteraţiei curente nu este maximală, o iteraţie următoare va îmbunătăţi asocierea cu cel puţin 1. Iteraţiile următoare nu pot înrăutăţi asocierea, deoarece asocierile existente se păstrează de la o iteraţie la alta. Deşi cel mai defavorabil caz pentru a atinge o asociere maximală pentru N intrări este de N iteraţii, se arată că numărul cel mai probabil de asocieri este mai apropiat de logN. Implementarea DECAN 2 a utilizat 3 iteraţii pentru un comutator cu 30 de porturi.
Exemplul din fig.13.8 utilizează o singură iteraţie pentru fiecare asociere. Rândul din mijloc arată a doua asociere pentru al doilea timp de celulă, în care, de exemplu A şi C ambele transmit o cerere pentru portul 1 (dar nu şi B deoarece celula dinspre B înspre 1 a fost transmisă în ultimul timp de celulă). Portul 1 îl selectează aleatoriu pe C şi asocierea finală este A-3, B-2 şi C-1. Al treilea rând arată a treia asociere, de data aceasta de dimensiune 2. Dupa a treia asociere numai celula destinată portului 3 în coada de intrare B nu este transmisă. Astfel în patru timpi de celulă (din care al patrulea nu e utilizat optimal şi nu poate fi utilizat pentru a se transmite mai mult trafic) s-a transmis întreg traficul. Varianta aceasta e mai eficientă decât cea cu bilete din figura 13.6. 13.8 EVITAREA ALEATORIZĂRII CU iSLIP
Asocierea paralelă iterativă, PIM este extrem de importantă, deoarece introduce ideea că blocarea HOL poate fi evitată, cu un cost hardware rezonabil. Dar PIM are doua probleme. Utilizează aleatorizarea, şi e greu de creat o sursă acceptabilă de numere aleatoare la viteze foarte mari. Apoi, e necesar un număr logaritmic de iteraţii pentru a obţine rezultate maxime. Dar fiecare iteraţie necesită trei faze, iar decizia de asociere trebuie luată în timpul minim de sosire al pachetelor, aşa că ar fi mai eficientă o variantă care se apropie de asocierea maximă într-una sau două iteraţii.
ISLIP este o variantă foarte răspîndită, care „dezaleatorizează” PIM, astfel ca se obţine un rezultat foarte apropiat de asocierile maxime într-una sau două iteraţii. Ideea este extrem de simplă. Când un port de intrare sau de ieşire recepţionează cereri multiple, el va selecta cererea „caştigătoare” în mod uniform până la aleatoriu pentru echitate. Ethernet asigura echitatea folosind aleatorizarea, iar token-ring prin utilizarea unui pointer round-robin, implementat prin tocken.
ISLIP asigura echitatea, alegând următorul câştigător dintre multiplii competitori, în maniera round-robin, utilizând un pointer circular. Deşi pointerii round robin pot fi iniţial sincronizaţi şi dau ceva asemănător cu HOL, aceştia tind să devină liberi şi, pe termen lung, dau asocieri maximale. Deci, subtilitatea în iSLIP nu este utilizarea pointerilor round-robin, ci aparenta lacună de sincronizare pe termen lung între N pointeri ce rulează în mod concurent.

194
Mai precis fiecare port de ieşire/intrare menţine un pointer g, setat iniţial spre primul port de intrare/ieşire. Daca un port de ieşire trebuie să selecteze multiplele cereri de intrare, el va selecta cel mai mic număr de intrare egal sau mai mare ca g. Similar dacă un port de intrare are de ales între multiple cereri provenite de la porturile de ieşire, el alege cel mai mic număr de port de ieşire mai mare sau egal cu a, unde a este pointerul portului de intrare. Cand un port de ieşire este asociat unui port de intrare X, atunci pointerul portului de ieşire este incrementat la primul număr de port mai mare decât X, în ordine circulară (de ex. g devine X+1 în afară de cazul în care X a fost ultimul port, caz în care g se va afla în jurul primului număr de port).
„Prioritatea rotitoare” permite fiecărei resurse (port de ieşire, port de intrare) să partajeze destul de echitabil toţi competitorii, cu preţul a 2N pointeri, de dimensiune log2N, suplimentari fata de N2 stări de planificare necesare fiecărei iteraţii.
In figurile 13.9 si 13.10 se prezintă acelaşi scenariu ca în figura 13.8 (şi figura 13.6), dar cu doua iteraţii iSLIP. Dacă fiecare rând este o iteraţie a unei asocieri, fiecare asociere este prezentată utilizând două rânduri. Deci, cele trei rânduri ale figurii 13.9 prezintă primele 1,5 asocieri ale scenariului. Figura 13.10 prezintă celelalte 1,5 asocieri rămase.
FIGURA 13.9 O etapă şi jumătate a unui exemplu de scenariu iSLIP
Etapa 1, iteratia 1
A
B
C
3
2
1
4
Cerere
1 2 3 1
4
3 1 3
2
A
B
C
3
2
1
4
Alocare
1 2 3 1
4
3 1 3
2
A
B
C
3
2
1
4
Acceptare
1 2 3 1
4
3 1 3
2
Etapa 2, iteratia 1
A
B
C
3
2
1
4
Cerere
- 2 3 1
-
3 1
-
A
B
C
3
2
1
4
Alocare
- 2 3 1
-
3 1
-
A
B
C
3
2
1
4
Acceptare
- 2 3 1
-
3 1
-
Etapa 1, iteratia 2
A
B
C
3
2
1
4
Cerere
1 2 3 1
4
3 1 3
2
A
B
C
3
2
1
4
Alocare
1 2 3 1
4
3 1 3
2
A
B
C
3
2
1
4
Acceptare
1 2 3 1
4
3 1 3
2
a=1
a=1
a=1
a=1
a=1
a=1
g=A
g=A
g=A
g=A
a=2
a=1 g=A
g=A
g=A
g=B
a=2
a=1
g=B
g=A
g=A
g=A
a=1
a=1
a=2
g=B
g=A
g=A
g=A
a=3
a=2
a=1
g=C
g=B
g=A
g=A

195
Imaginea din stânga-sus a figurii 13.9 este identică cu figura 13.8, fiecare port de intrare transmiţând cereri spre fiecare port de ieşire pentru care are celule destinate. O diferenţă este că fiecărui port de ieşire i se asociază un pointer de alocare g, iniţializat pentru toate ieşirile la valoarea A. Similar, fiecărui port de intrare i se asociaza un asa-numit pointer de acceptare a, iniţializat la valoarea 1 pentru toate intrările.
Determinismul în iSLIP cauzează o divergenţă, imediat în faza de Alocare. Compară imaginea din mijloc sus a figurii 13.9 cu imaginea din mijloc sus a figurii 13.8. De exemplu dacă ieşirea 1 recepţionează cereri de la toate cele trei porturi de intrare, portul selectat va fi A, deoarece A este cel mai mic număr de intrare mai mare sau egal cu g1 = A. In figura 13.8, portul 1 selectează aleatoriu portul de intrare B. In această etapă determinismul la iSLIP se dovedeşte a fi un dezavantaj real deoarece A a trimis cereri şi înspre porturile 3 şi 4. Deoarece 3 şi 4 au de asemenea pointerii de alocare g3 = g4 = A porturile 3 şi 4 îl vor selecta deasemnea pe A ignorând pretenţiile lui B şi C. C fiind singurul care trimite o cerere înspre portul 4 va primi alocarea din partea portului 4.
Daca A a primit trei alocări din partea porturilor 1, 2 şi 3, A îl acceptă pe 1, deoarece 1 este prima ieşire egală sau mai mare ca pointerul de acceptare a lui A, aA, care a fost egal cu 1. Similar C îl alege pe 4. Acestea fiind făcute A îl incrementează pe aA la 2 si C incrementeaza aC la 1 (incrementarea circulară a lui 4 este 1). Numai la aceasta etapă ieşirea1 incrementează pointerul său de alocare, g1, la B (cu 1 mai mare decât ultima alocare ce a avut loc cu succes) iar portul 4 în mod similar face incrementarea la A (cu 1 mai mare decat C în ordine circulară). Se observă că celelalte porturi care au dat alocări portului A, adică 2 şi 3 nu îşi incrementează pointerii de alocare deoarece A a refuzat alocările lor. Dacă aceştia ar fi făcut incrementarea, ar fi fost posibilă construirea unui scenariu în care porturile de ieşire menţin incrementarea pointerului lor de alocare, dincolo de un anumit port de intrare I dupa alocări fără succes, astfel înfometând continuu portul de intrare I. Asocierea are doar dimensiunea 2; dar spre deosebire de figura 13.8 acest scenariu poate fi îmbunătăţit printr-o a doua iteraţie prezentată în figura 13.9. La sfarşitul primei iteraţii intrările şi ieşirile asociate nu sunt conectate prin linii îngroşate (însemnând transfer de date), ca în dreapta sus la figura 13.8. Acest transfer de date va aştepta sfârsitul ultimei iteraţii (iteraţia a doua).
A doua iteraţie (rândul din mijoc al figurii 13.9) începe cu intrările care nu au fost asociate într-o iteraţie precedentă (aceasta înseamnă B) adresând cereri numai porturilor de ieşire neasociate până acum. Astfel B trimite cereri lui 2 şi 3 (şi nu lui 1 deşi B are de asemenea o celulă destinată lui 1). Ambele porturi de ieşire 2 şi 3 trimit alocări portului B, iar B îl selectează pe 2 (cel mai mic număr de port care este mai mare sau egal cu pointerul său de acceptare). Pentru evitarea înfometării, iSLIP nu-şi incrementează
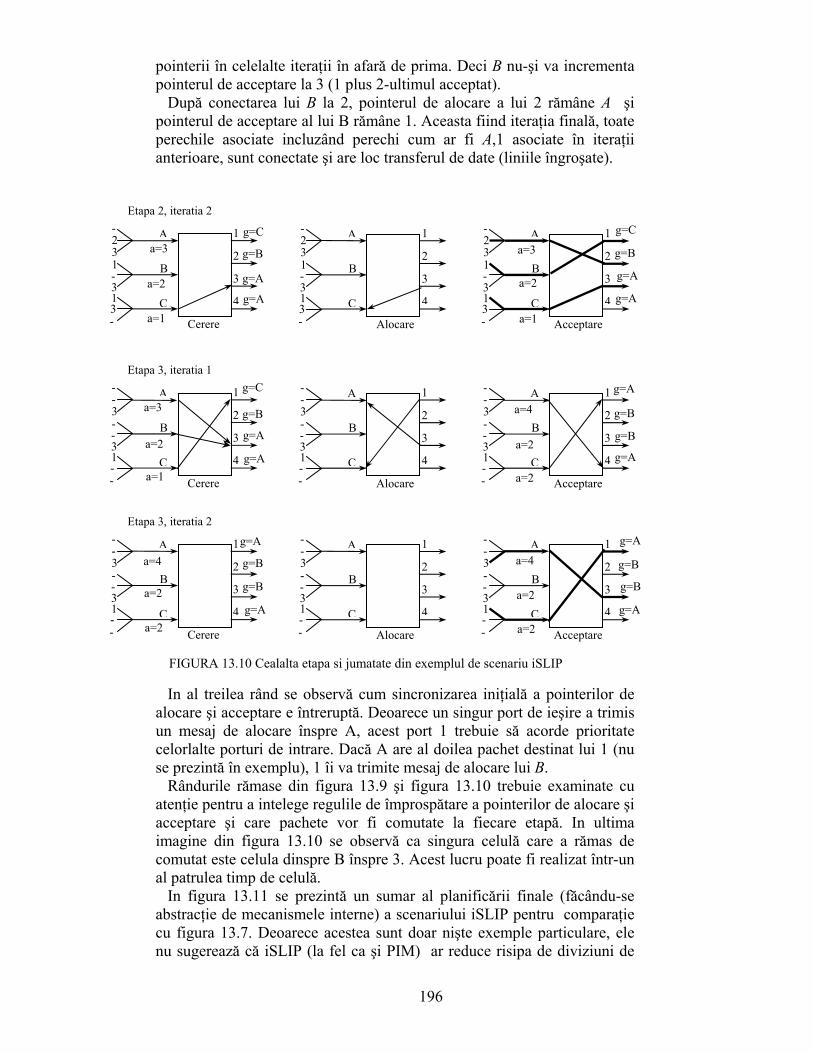
196
pointerii în celelalte iteraţii în afară de prima. Deci B nu-şi va incrementa pointerul de acceptare la 3 (1 plus 2-ultimul acceptat).
După conectarea lui B la 2, pointerul de alocare a lui 2 rămâne A şi pointerul de acceptare al lui B rămâne 1. Aceasta fiind iteraţia finală, toate perechile asociate incluzând perechi cum ar fi A,1 asociate în iteraţii anterioare, sunt conectate şi are loc transferul de date (liniile îngroşate).
In al treilea rând se observă cum sincronizarea iniţială a pointerilor de
alocare şi acceptare e întreruptă. Deoarece un singur port de ieşire a trimis un mesaj de alocare înspre A, acest port 1 trebuie să acorde prioritate celorlalte porturi de intrare. Dacă A are al doilea pachet destinat lui 1 (nu se prezintă în exemplu), 1 îi va trimite mesaj de alocare lui B.
Rândurile rămase din figura 13.9 şi figura 13.10 trebuie examinate cu atenţie pentru a intelege regulile de împrospătare a pointerilor de alocare şi acceptare şi care pachete vor fi comutate la fiecare etapă. In ultima imagine din figura 13.10 se observă ca singura celulă care a rămas de comutat este celula dinspre B înspre 3. Acest lucru poate fi realizat într-un al patrulea timp de celulă.
In figura 13.11 se prezintă un sumar al planificării finale (făcându-se abstracţie de mecanismele interne) a scenariului iSLIP pentru comparaţie cu figura 13.7. Deoarece acestea sunt doar nişte exemple particulare, ele nu sugerează că iSLIP (la fel ca şi PIM) ar reduce risipa de diviziuni de
FIGURA 13.10 Cealalta etapa si jumatate din exemplul de scenariu iSLIP
Etapa 2, iteratia 2
A
B
C
3
2
1
4
Cerere
- 2 3 1
-
3 1 3
-
A
B
C
3
2
1
4
Alocare
- 2 3 1
-
3 1 3
-
A
B
C
3
2
1
4
Acceptare
- 2 3 1
-
3 1 3
-
Etapa 3, iteratia 2
A
B
C
3
2
1
4
Cerere
- - 3 -
-
3 1 -
-
A
B
C
3
2
1
4
Alocare
- - 3 -
-
3 1-
-
A
B
C
3
2
1
4
Acceptare
- - 3 -
-
3 1 -
-
Etapa 3, iteratia 1
A
B
C
3
2
1
4
Cerere
- - 3 -
-
3 1 -
-
A
B
C
3
2
1
4
Alocare
- - 3 -
-
3 1 -
-
A
B
C
3
2
1
4
Acceptare
- - 3 -
-
3 1 -
-
a=1
a=1
a=2
a=3
a=2
a=1
g=C
g=B
g=A
g=A
a=3
a=2 g=A
g=A
g=B
g=C
a=3
a=2
g=C
g=B
g=A
g=A a=2
a=2
a=4
g=A
g=B
g=B
g=A
a=4
a=2
a=2
g=A
g=B
g=B
g=A
a=2
a=4
g=A
g=B
g=B
g=A

197
timp prin evitarea blocării în fruntea liniei. Se observă că iSLIP la fel ca şi PIM comută acelaşi trafic de intrare în 4 timpi de celulă, si nu 6.
Comparand figurile 13.9 şi 13.8, iSLIP pare să fie inferior lui PIM, deoarece sunt necesare două iteraţii pe asociere la iSLIP pentru a obţine acelaşi număr de perechi asociate pentru care la PIM este nevoie de-o singură iteraţie pe asociere. Aceasta ilustrează mai degrabă penalizarea pe care iSLIP trebuie s-o plătească la pornire şi nu o penalizare pe termen lung. In practică, pe moment ce pointerii iSLIP se desincronizează, iSLIP functioneaza foarte bine cu o singură iteraţie şi unele implementări comerciale utilizează doar o singură iteraţie: iSLIP este extrem de popular.
Foarte sumar, iSLIP se deosebeşte de PIM prin înlocuirea aleatorizării
cu o planificare folosind o planificare circulară (round robin) folosind pointeri de intrare şi de ieşire. Acestei caracterizări îi lipsesc două aspecte subtile ale iSLIP. • Pointerii de alocare sunt incrementaţi numai în faza a treia,
după acceptarea alocării Intuitiv, daca O acordă o alocare portului de intrare I, nu există nici o garanţie că I o va accepta. Dacă O şi-ar incrementa pointerul de alocare se poate ajunge la o înfometare permanentă a traficului între I şi O. Şi mai grav, Mc Keown a arătat că această variantă round-robin reduce debitul util la numai 63 % (pentru sosiri Bernoulli) deoarece pointerii tind să se sincronizeze şi să se ajungă la blocaj. • Toţi pointerii sunt incrementaţi numai după recunoaşterea
acceptării primei iteraţii: regula previne înfometarea, dar scenariul este mult mai subtil decât exerciţiul prezentat.
Asocierile realizate în iteraţii, altele decât prima din iSLIP, sunt considerate un bonus crescând debitul util fără a fi contorizate în dezavantajul cotei unui port.
13.8.1 Extinderea iSLIP la multicast si priorităţi LIP poate fi extins pentru a trata trafic multicast şi pe bază de priorităţi.
PRIORITĂŢI Priorităţile sunt utile pentru a transmite traficul critic sau de timp real
mai rapid prin comutator. Cisco GSR permite traficului voice over IP, să fie planificat cu o prioritate mai mare decat restul traficului, deoarece are o rată limitată şi deci nu poate înfometa alte categorii de trafic.
A
B
CC BA
B ACBA1
2
3
4
Timp (in sloturi de celula)
3 1 2
3 1 2
4 1 3
FIGURA 13.11 Evitarea blocării HOL de către iSLIP creşte debitul util din scenariul din figura 13.7
C

198
Implementarea Tiny Tera manevrează patru niveluri de prioritate. Fiecare port de intrare are 128 de cozi virtuale (una pentru fiecare combinaţie de 32 de ieşiri şi 4 niveluri de prioritate). Deci, la planificator, fiecare intrare are 128 de biţi pentru controlul intrărilor.
Algoritmul iSLIP este modificat foarte simplu pentru a trata priorităţi. Pentru început fiecare port de ieşire păstrează un pointer de alocare separat gk pentru nivelul de prioritate k, şi fiecare port de intrare păstrează un pointer separat de acceptare ak pentru fiecare nivel de prioritate k. In esenţă se aplică algoritmul iSLIP, astfel încât fiecare entitate (port de intrare, port de ieşire) să aplice algoritmul iSLIP la cel mai mare nivel de prioritate existent la intrări.
Fiecare port de ieşire face alocarea doar pentru cererea cea mai prioritară recepţionata. Un port de intrare I poate face o cerere la nivelul de prioritate 1 pentru ieşirea 5, şi o cerere la nivelul de prioritate 2 pentru ieşirea 6, deoarece acestea sunt cererile de cea mai înalta prioritate pe care le-a avut portul pentru ieşirile 5 şi 6. Daca ambele ieşiri 5 şi 6 fac alocări pentru I, I nu va face selecţia bazându-se pe pointerii de acceptare deoarece cele două celule au priorităţi diferite, ci o va selecta pe cea de prioritate mai mare. La o acceptare, în prima iteraţie, pentru prioritatea k, între intrarea I şi portul de ieşire O, pointerul de acceptare a priorităţii k la I şi pointerul de alocare corespunzător priorităţii k la O, sunt incrementaţi.
MULTICAST Datorita aplicaţiilor (videoconferinta) şi protocoalelor (IP multicast) in
care ruterele transmit pachetele înspre un număr de porturi de iesire mai mare ca unu, multicast în comutatoare, ca entitate de prima clasă, a devenit importantă. Algoritmul ia-ţi un bilet a tratat multicastul ca o entitate de clasa a doua, prin transmiterea întregului trafic de multicast la o entitate/entităţi centrală, care apoi va transmite traficul de multicast pachet-cu-pachet ieşirilor corespunzătoare. Mecanismul ia-ţi un bilet iroseşte resurse de comutatie (lăţime de bandă de control, porturi) şi asigură performanţe mai scăzute (latenţa mai mare, trafic mai scăzut) pentru multicast.
Pe de alta parte, figura 13.4 arată că multicastul este suportat cu uşurinţă pe calea de date a unui comutator crossbar. De exemplu dacă intrarea 1 (fig.13.4) transmite un mesaj pe magistrala sa de intrare şi punctele de conexiune sunt conectate astfel încât magistrala de intrare a lui 1 este conectată la magistralele de ieşire verticale ale ieşirilor 2 si 3, atunci ieşirile 2 şi 3 recepţionează o copie a pachetului /celulei la acelaşi moment de timp. Dacă pachetele au lungimea variabilă, mecanismul distribuit de control al variantei ia-ţi un bilet, trebuie să aleagă între a aştepta eliberarea simultană a tuturor porturilor, şi transmiterea pachetelor unul după altul.
Extensia iSLIP pentru multicast, numită ESLIP, acorda multicastului aproape acelaşi statut ca şi unicastului. Ignorând priorităţile pentru moment, există o coadă suplimentară pentru multicast pentru fiecare intrare. Pentru evitarea blocarii HOL, ar fi ideal să existe o coadă separată pentru fiecare subset posibil de porturi de ieşire, ceeace ar duce la un număr impracticabil de cozi (216 pentru 16 porturi). Astfel se utilizează o singură coadă pentru multicast şi poate apărea blocarea HOL, deoarece nu

199
se poate începe procesarea unui pachet pană ce pachetele de multicast anterioare lui nu sunt transmise.
Presupunem că intrarea I are pachete destinate ieşirilor O1, O2 si O3 în fruntea cozii de multicast a lui I. Se spune că I are un fan-out de 3. Spre deosebire de cazul unicastului, ESLIP păstrează un singur pointer de alocare comun pentru multicast si nici un pointer de acceptare pentru multicast. Utilizarea pointerilor comuni implică o implementare centralizată, diferită de planificatorul ia-ţi un bilet. Pointerul comun permite întregului comutator să favorizeze o intrare particulară, încât să-şi poată completa întregul fan-out mai repede decât daca ar fi mai multe porturi de intrare, care transmit porţiuni mici din fanout-ul lor de multicast în aceleaşi momente de timp.
In exemplu, I va transmite o cerere de multicast înspre O1, O2 si O3. Dar porturi de ieşire cum este O2 pot recepţiona cereri de unicast de la alte porturi de intrare, de exemplu J. Cum va decide un port de ieşire între pachete de unicast şi de multicast? ESLIP acorda traficului de multicast şi de unicast prioritate mai mare în sloţi alternanţi de celulă. De exemplu în sloţii impari O2 va selecta unicastul iar in sloţii pari multicastul.
Pentru a continua exemplul presupunem un slot impar şi presupunem că O2 are cereri de unicast în timp ce O1 şi O3 nu au cereri de unicast. Atunci O2 va transmite un mesaj de alocare de unicast în timp ce O1 şi O3 vor transmite alocări de multicast. O1 şi O3 aleg pentru alocare intrarea corespunzătoare primului număr de port mai mare sau egal faţă de pointerul comun de alocare G. Presupunem că s-a selectat I şi astfel O2 şi O3 vor trimite alocări de multicast înspre I. Spre deosebire de unicast, I poate accepta toate alocările de multicast.
Spre deosebire de planificarea unicast, pointerul de alocare la multicast e incrementat doar după ce I şi-a completat fanoutul. Astfel în următorul slot de celulă, când multicastul are prioritate, I va putea transmite la O2. Acum fanout-ul e completat, pointerul de alocari multicast se incrementeaza la I+1, si planificatorul transmite inapoi lui I un bit prin care-i spune ca s-a terminat transmisia din capul cozii sale multicast, deci poate fi luat in lucru urmatorul pachet multicast.Un multicast nu trebuie terminat intr-o singura diviziune de celula(ceea ce ar presupune ca toate iesirile implicate sa fie libere), dar prin folosirea fanout splitting pe mai multe diviziuni.
Desigur ca iSLIP poate induce blocarea HOLpentru multicast. Daca pachetul P1din capul cozii multicast este destinat iesirilor O1si O2 si ambele sunt ocupate, atunci urmatorul pachet P2, destinat lui O3 si O4 libere amandoua, trebuie sa astepte dupa P1. Ar fi mult prea dificila implementarea fanout splitting-ului pemtru alte pechete decat cele din capul cozii si asta deoarece nu ne putem permite cate un VOQ separat pentru fiecare combinatie posibila de porturi destinatie.
Algoritmul final ESLIP care combina patru niveluri de prioritate si multicastingul este implementat in ruterul CISCO GSR.
13.8.2 Implementarea iSLIP Inima hardware-ului ce implementeaza iSLIP este arbitrul care alege
intre cele N cereri (codate ca bitmap), cautandu-l pe primul mai mare sau egal cu un pointer fix ; acesta este codorul programabil de prioritati. Planificarea comutatorului poate fi facuta cu un arbitru de alocari similar,

200
pentru fiecare port de iesire (pentru arbitrarea cererilor) si un arbitru de acceptari pentru fiecare port de intrare (pentru a arbitra intre alocari). Prioritatile si multicastul sunt reintroduse intr-o structura de baza prin adaugarea unui filtru la intrari, inainte de arbitru ; de exemplu, filtrul de prioritati va anula toate cererile cu exceptia celor de prioritate maxima.
Desi, in principiu, planificatoarele unicast pot fi proiectate folosind cate un chip separat per port, starea este suficient de redusa ca sa fie manevrata de un singur chip planificator cu fire cablate de control spre/dinspre fiecare port. Algoritmul multicast necesita un pointer multicast partajat per nivel de prioritate, care implica si el un planificator centralizat. Centralizarea implica insa intarzieri sau latenta, pentru a trimite cererile si deciziile de la cardurile liniilor de port spre/dinspre planificatorul centralizat.
Pentru a tolera aceasta latenta, planificatorul lucreaza cu un pipeline de m celule (8 in Tiny Tera), de la fiecare VOQ si n celule (5 in Tiny Tera) de la fiecare coada multicast.Acest lucru presupune ca fiecare card de linie in Tiny Tera trebuie sa comunice 3 biti per unicast VOQ, care inseamna dimensiunea VOQ , maxim pina la 8. Cu 32 de iesiri si patru nivele de prioritate, fiecare port de intrare are de trimis 384 de biti de informatie unicast. Fiecare card de linie isi comunica si fanout-ul (32 de biti per fanout), pentru fiecaredin cele cinci pachete multicastdin fiecare cele patru nivele de prioritate, ajungandu-se la 640 biti. Cei 32 1024∗ biti ai informatiei de intrare sunt memorati intr-un SRAM pe chip. Dar pentru accelerare, informatia despre capul fiecarei cozi (stari mai mici, de exemplu, doar 1 bit per VOQ unicast) e memorata in bistabile, mai rapide dar mai putin dense.
Consideram acum manevrarea ieratiilor multiple. Faza de cerere apare doar in prima iteratie si trebuie modificata in celelalte iteratii prin mascare a intrarilor associate.Astfel, K iteratii apar ca au nevoie de 2K pasi de timp, din cauza ca pasii de alocare si acceptare necesita fiecare cate un pas de timp. La prima vedere pare ca faza de grant a iteratie k+1 incepe dupa faza de acceptare a iteratiei k ; si acest lucru, deoarece e nevoie sa stim daca un port de intrare I afost acceptat in faza k, astfel incat e permisa o alocare pentru acea intrare in iteratia k+1.
Urmatoarea observatie face partial posibil pipelining-ul: daca I intrari receptioneaza orice grant in iteratia k, atunci I trebuie sa accepte exact una, si deci este nedisponibila in iteratia k+1. Astfel pot fi relaxate specificatiile implementarii (P3) pentru a permite fazei de grant din iteratia k+1 sa inceapa imediat dupa faza de grant din iteratia k, si deci sa se suprapuna cu faza de acceptare din iteratia k. pentru a face acest lucru, folosim un Sau intre toate granturile intrarii I (la sfarsitul iteratiei k) pentru a masca toate cererile la I (in iteratia k+1). Se reduce astfel timpul total cu un factor apropiat de 2 pasi de timp pentru k iteratii, de la 2k la k+1. De exemplu, la implementarea iSLIP Tiny Tera sunt trei iteratii in 51nsec (≈viteza OC-192) cu un ceas de 175 Mhz ; fiecare ciclu de ceas fiind de ≈ 5,7 nsec, iSLIP are 9 cicluri de ceas pentru a termina. Deoarece fiecare pas de grant si acceptare necesita doua cicluri de ceas, pipelining-ul e crucial pentru manevrarea a trei iteratii in 9 cicluri ; implementarea naiva ar avea nevoie de minim 12 cicluri de ceas.
13.9.2 Scalarea la switch-uri mai mari Pana acum au fost tratate switch-urile mici care necesitau rutere cu pana
la 32 de porturi, categorie in care intrau si actualele rutere Internet. Deocamdata construirea codurilor cablate tinde sa limiteze numarul de oficii care pot fi servite de un dulap cablat. Astfel, switch-urile pentru

201
LAN-uri plasate in dulapuri cablate sunt bine deservite de porturi de dimensiuni reduse.
Dar in general, retelele telefonice foloseau cateva switch-uri foarte mari care pot comuta 1.000-10.000 legaturi. Folosirea switch-urilor mari tinde sa elimine legaturile switch-la-switch, reducand astfel latenta si crescand numarul de porturi diponibile utilizatorilor. Astfel unii cercetatori pledeaza pentru switch-uri mari, dar pana recent nu a existat suportul industrial pentru ele.
Exista trei tendinte recente in favoarea proiectarii switch-uri mari: 1. DWDM: folosirea multiplexarii cu diviziune prin lungimea de
unda, pentru a asocia multiple lungimi de unda in legaturi optice intre ruterele core, care va creste numarul de legaturi logice comutate de ruterele core.
2. Fibra la domicilii: e o sansa reala ca in viitorul apropiat conexiunile intre switch-uri si case/oficii sa fie cu fibre optice .
3. Rutere modulare multisasiu: exista un interes crescut in dezvoltarea clusterelor de rutere, formate din rutere interconectate prin retele de mare viteza. De exemplu, multe puncte de acces in retele conecteaza ruterele prin legaturi FDDI sau Gigaswitch-uri. Clusterele de rutere sau ruterele multisasiu cum mai sunt numite, sunt de interes deoarece permit dezvoltarea incrementala.
Tipic, timpul de viata al unui ruter core e estimat la 18-24 de luni, dupa care traficul creste, determinand ISP-urile sa renunte la vechile rutere si sa se orienteze spre unele noi. Ruterele multisasiu pot prelungi timpul de viata al unui ruter core la 5 ani sau mai mult, permitand ISP-urilor sa inceapa cu rutere mici si apoi sa adauge altele clusterelor, conform cu necesarul de trafic. Retelele Juniper au creat seria T de rutere, care permit asamblarea a pana la 16 rutere unisasiu (fiecare cu pana la 16 porturi), formand astfel un ruter cu 256 de porturi. In inima unui ruter multisasiu se afla un sistem de comutare scalabil 256x256. CRS-1 este versiunea Cisco a unui astfel de ruter.
13.9.1 Masurarea costului switch-ului Inainte de problema scalarii, este importanta intelegerea principalelor
metrici de cost ale switch-ului. La inceputul telefoniei, punctele de interconectare erau realizate cu switch-uri electromagnetice, si astfel cele
2N puncte de interconectare ale comutatorului crossbar reprezentau un cost major. Chiar si astazi acesta este principalul cost pentru ruterele foarte mari, de dimensiune 1000. Dar fiind vorba de interconectari cu tranzistoare, dimensiunea lor e redusa.
Limitarea reala a switch-urilor electronice este data de numarul de pini al circuitului integrat. Limita curenta este de 1000 de pini, dintre care o mare parte sunt alocati altor functii, alimentare/pamintare, si e imposibil de pus pe un singur chip chiar si un switch de 500x500. Desigur ca s-ar putea multiplexa cateva intraride crossbar pe un singur pin, dar asta ar incetini viteza fiecarei intrari la jumatate din viteza posbila de I/O a fiecarui pin.
Cele 2N puncte de interconectare ale comutatorului crossbar, constituie o problema pentru N suficient de mare, dar pentru N<200, majoritatea complexitatii interconectarii e continuta de chip. Astfel ca implementarea

202
numarul mari se fac fac prin interconectarea chip-urilor care contin comutatoare crossbar mici. Costul dominant ramine numarul pinilor si numarul de legaturi intre chip-uri. O masura mai rafinata a costului tine cont si de tipul de pini, fiecare avand un cost diferit.
Alti factori care limiteaza constructia switch-urilor monolitice mari este incarcarea capacitiva a magistralelor, complexitatea planificarii, spatiul in dulapuri si puterea. Daca se construieste un switch 256x256 de tip crossbar cu 256 magistrale de intrare si iesire, incarcarea acestora va duce la scaderea vitezei. Apoi, un algoritm de planificare centralizat ca iSLIP, care are nevoie de 2N biti de planificare a starii, nu se adapteaza prea bine la valori mari ale lui N.
O alta limitare este conditia, in multe rutere, de a avea putine (de preferinta unul singur) porturi pe un card de linie. Situatia e la fel, din condsiderente de putere disipata, si pentru numarul de carduri de linie ce pot fi plasate intr-un dulap. Solutiile multirack si multisasiu sunt logice.
13.9.2 Reţele CLOS şi rutere multişasiu Pentru switch-urile VLSI e important numărul total de comutatoare şi de
legături care le interconectează. Costul comutatoarelor realizate in tehnica VLSI e constant indiferent de numărul punctelor de intersecţii. Firma Juniper foloseşte o reţea Clos pentru a realiza un ruter multişasiu 256x256 interconectând 16x16 rutere T în primul etaj. O reţea Clos standard ar avea nevoie de 16 rutere în primul etaj, 16 în etajul al treilea şi k=2*16-1=31 comutatoare în etajul mijlociu. Costul acestei configuraţii s-ar putea reduce dacă s-ar impune k=n, dar atunci reţea Clos se va putea bloca.
Reţeaua Clos poate deveni neblocabilă prin rearanjare dacă oricare intrare i poate fi conectată cu oricare ieşire o atâta timp cât există posibilitatea rearanjării unor conexiuni din etajul mijlociu.Folosind k=n în loc de k=2n-1 se reduce aproape de două ori numărul total de comutatoare de pe etajul mijlociu, dar creşte complexitatea alogoritmului de rearanjare. În cazul apelurilor telefonice se presupune că toate apelurile sosesc la intrare în acelaşi timp. Când soseşte un nou apel, convorbirile existente trebuie rearanjate.
Pentru a profita de complexitatea redusă si pentru a permite tratarea apelurilor telefonice problema se poate rezolva elegant dacă mai întâi se înlocuieşte fiecare apel cu pachete şi fiecare pachet cu celule de dimensiune fixă. In fiecare interval de celulă, apar celule la fiecare intrare destinate fiecărei ieşiri: fiecare celulă nouă are nevoie de o aplicare nouă a algoritmului de potrivire, care să nu fie restricţionat de celulele precedente. In loc rularii unui proces lent, ce foloseşte tehnica edge coloring, se redistribuie traficul fiecarei intrari pe comutatoarele de pe nivelul mijlociu (echilibrarea încarcarii, deterministă sau aleatoare).
Divizând pachetele în celule şi apoi distribuindu-le peste întreaga structură Clos se obţine acelaşi efect ca prin manevrarea conexiunilor în reţeaua cu comutare de circuit, deoarece toate căile sunt folosite simultan. Afirmaţia este parţial adevărată deoarece pot apărea comutatoare congestionate pe nivelul mijlociu.

203
Mai există posibilitatea de folosire a unui algoritm aleator, prin care fiecare comutator de pe nivelul de intrare alege aleator un comutator de pe nivelul mijlociu, pentru fiecare celulă care trebuie transmisă. În acest caz, d.p.d.v. probabilistic fiecare comutator de pe nivelul mijlociu va recepţiona N/n celule, numărul de ieşiri ale comutatorului de pe nivelul mijlociu. Astfel, dacă avem un flux de celule care merg spre ieşiri diferite vom avea un debit de 100% pentru algoritmul aleator.
Dar algoritmul de aleatorizare e greu de realizat, existând şi probabilitatea de coliziune, când mai multe comutatoare de intrare doresc să folosească acelaşi comutator de ieşire. Acest fenomen va reduce debitul şi va impune folosirea bufferelor.Scăderea debitului poate fi compensată prin cresterea vitezei de operare internă a comutatoarelor.
Un algoritm de aleatorizare relativ uşor de implementat şi cu eficienţă crescută este generatorul de numere aleatoare Tausworth compus din trei registre de deplasare cu reacţie care apoi sunt insumate SAU-EXCLUSIV.
Algoritmul de reasamblare a celulelor în pachete este mai complex dacă se foloseşte echilibrarea aleatoare a încărcării, decât dacă se foloseşte metoda deterministă de echilibrare a încărcării. În ultimul caz, logica de reasamblare ştie de unde tebuie să sosească următoarea celulă.
13.9.3 Reţele Benes pentru rutere mari Având în vedere faptul că switch-ul No.1.ESS pentru telefoane comută
65.000 de legături de intrare, Turner susţine faptul că Internet-ul ar trebui să fie construit cu ajutorul a câtorva rutere mari în locul de mai multe rutere mici. Aceste topologii pot duce la reducerea legăturilor risipite pentru realizarea conexiunilor ruter-la-ruter între ruterele mici, reducându-se costul; aceste topologii pot deasemenea reduce lungimea terminal-cale cele mai defavorabile, reducând latenţa şi îmbunătăţind timpul de răspuns al utilizatorului.
În esenţă, o reţea Clos are o dimensiune de aproximativ NN , din punctul de vedere al complexităţii punctelor de intersecţii, folosind doar 3 nivele. Experienţa algoritmicii generale sugerează faptul că o reţea ar trebui să aibă o complexitate a puctelor de intersecţii de logN N∗ , în acelaşi timp mărind adâncimea de comutare la logN. Astfel de reţele de comutare pot exista şi au fost cunoscute ani de-a rândul în telefonie şi în industria de operare paralelă. Alternative precum reţelele Butterfly, Delta, Banyan şi Hypercube reprezintă o concurenţă bine cunoscută.
Acest subiect este foarte vast, astfel ca acest capitol se va concentra doar asupra reţelelor Delta şi Benes. Asemenea reţele sunt folosite în multe implementări. Spre exemplu switch-ul Gigabit de la Universitatea din Washington foloseşte o reţea Benes, care poate fi considerată ca 2 copii a unei reţele Delta. Cea mai simplă modalitate de a înţelege o reţea Delta este prin recursivitate. Să presupunem că avem N intrări în stânga, iar această problemă trebuie redusă la problema construirii a două reţele Delta mai mici, de dimensiune N/2. Presupunem că există un prim nivel de 2 x 2 comutatoare.

204
Figura 13.14: Construirea recursivă a unei reţele Delta Dacă ieşirea este în jumătatea superioară (MSB al ieşirii este 0), atunci
intrarea este direcţionată către reţeaua Delta N/2 superioară, dacă însă ieşirea este în jumătatea inferioară (MSB=1) atunci intrarea este direcţionată către reţeaua Delta N/2 inferioară.
Pentru a economisi la primul nivel 2 comutatoare de intrare, trebuie grupate intrările în perechi consecutive, fiecare pereche făcând uz de acelaşi comutator cu 2 intrări, cum se vede în fig.13.14. În acest fel, dacă cele 2 celule de intrare dintr-o pereche merg către 2 jumătăţi de ieşire diferite, atunci ele pot fi comutate în paralel, altfel una va fi comutată iar cealaltă va fi abandonată sau stocată într-un buffer. Bineînţeles, acelaşi proces poate fi repetat în mod recursiv pentru fiecare dintre reţelele Delta de dimensiune N/2, unde din nou există un nivel de 2 x 2 comutatoare, apoi 4 N/4 comutatoare e.t.c. Extinderea completă a unei reţele Delta este vizibilă în prima jumătate a figurii 13.15. Se poate observa cum construcţia recursivă din fig.13.14 se regăseşte în conexiunea dintre primul nivel şi cel de-al doilea nivel din fig.13.15.
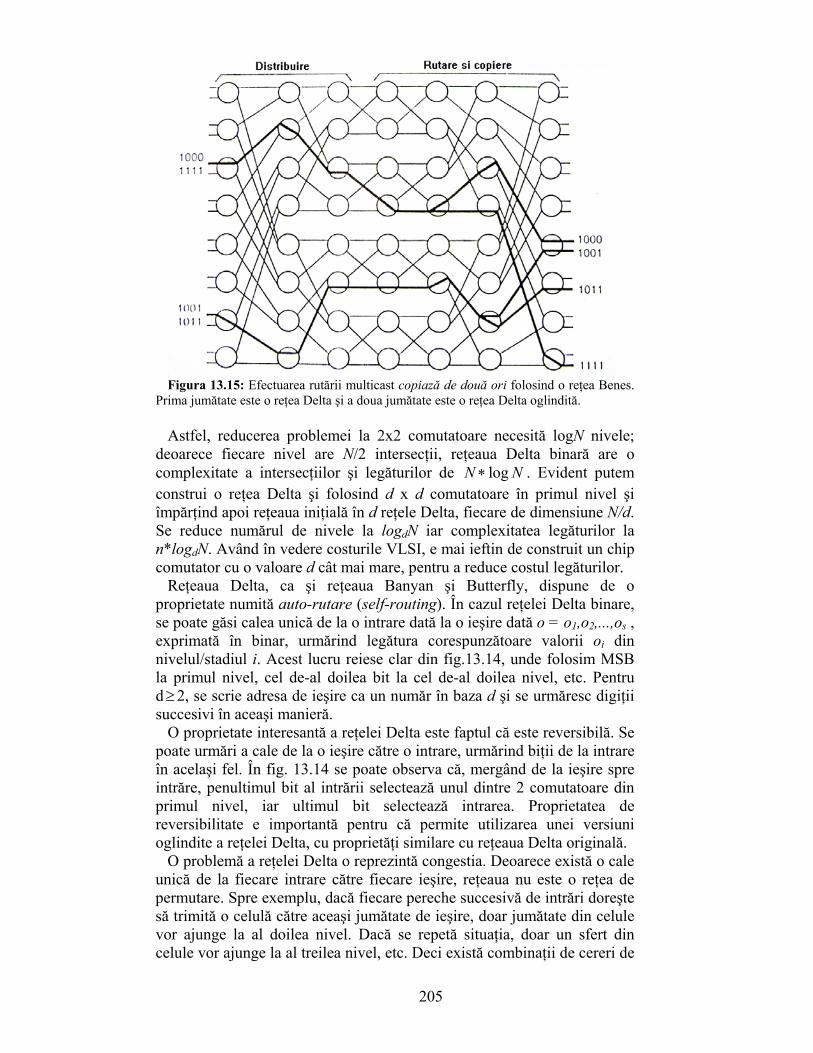
205
Figura 13.15: Efectuarea rutării multicast copiază de două ori folosind o reţea Benes.
Prima jumătate este o reţea Delta şi a doua jumătate este o reţea Delta oglindită. Astfel, reducerea problemei la 2x2 comutatoare necesită logN nivele;
deoarece fiecare nivel are N/2 intersecţii, reţeaua Delta binară are o complexitate a intersecţiilor şi legăturilor de logN N∗ . Evident putem construi o reţea Delta şi folosind d x d comutatoare în primul nivel şi împărţind apoi reţeaua iniţială în d reţele Delta, fiecare de dimensiune N/d. Se reduce numărul de nivele la logdN iar complexitatea legăturilor la n*logdN. Având în vedere costurile VLSI, e mai ieftin de construit un chip comutator cu o valoare d cât mai mare, pentru a reduce costul legăturilor.
Reţeaua Delta, ca şi reţeaua Banyan şi Butterfly, dispune de o proprietate numită auto-rutare (self-routing). În cazul reţelei Delta binare, se poate găsi calea unică de la o intrare dată la o ieşire dată o = o1,o2,...,os , exprimată în binar, urmărind legătura corespunzătoare valorii oi din nivelul/stadiul i. Acest lucru reiese clar din fig.13.14, unde folosim MSB la primul nivel, cel de-al doilea bit la cel de-al doilea nivel, etc. Pentru d≥2, se scrie adresa de ieşire ca un număr în baza d şi se urmăresc digiţii succesivi în aceaşi manieră.
O proprietate interesantă a reţelei Delta este faptul că este reversibilă. Se poate urmări a cale de la o ieşire către o intrare, urmărind biţii de la intrare în acelaşi fel. În fig. 13.14 se poate observa că, mergând de la ieşire spre intrăre, penultimul bit al intrării selectează unul dintre 2 comutatoare din primul nivel, iar ultimul bit selectează intrarea. Proprietatea de reversibilitate e importantă pentru că permite utilizarea unei versiuni oglindite a reţelei Delta, cu proprietăţi similare cu reţeaua Delta originală.
O problemă a reţelei Delta o reprezintă congestia. Deoarece există o cale unică de la fiecare intrare către fiecare ieşire, reţeaua nu este o reţea de permutare. Spre exemplu, dacă fiecare pereche succesivă de intrări doreşte să trimită o celulă către aceaşi jumătate de ieşire, doar jumătate din celule vor ajunge la al doilea nivel. Dacă se repetă situaţia, doar un sfert din celule vor ajunge la al treilea nivel, etc. Deci există combinaţii de cereri de

206
ieşire pentru care debitul reţelei Delta se reduce la o legătură, spre deosebire de N legături.
O cale de a face reţeaua Delta mai puţin susceptibilă la congestionare în cazul permutărilor arbitrare a cererilor de intrare, este adăugarea mai multor căi între o intrare şi o ieşire. Generalizând ideile discutate la reţeua Clos (fig.13.12), putem construi o reţea Benes (fig,13.15), care constă din 2 reţele de adâncime logN: jumătatea din stânga este o reţea Delta standard iar jumătatea din dreapta este o reţea Delta inversată prin oglindire. Dacă privim invers la jumătatea din dreapta, mergând de la ieşiri spre stânga putem observa că conexiunile dintre ultimul nivel şi penultimul nivel sunt identice cu conexiunile dintre primul şi cel de-al doilea nivel.
Se poate privi reţeaua Benes şi recursiv, adăugând la fig.13.14 al treilea nivel de comutatoare 2 x 2, conectând acest nivel la cele 2 reţele de dimensiune N/2 din mijloc, în aceaşi manieră în care comutatoarele din primul nivel sunt conectate la cele 2 reţele de dimensiune N/2 (fig.13.16). Această procedură recursivă poate fi folosită pentru a creea direct schema din fig.13.15, fără a crea 2 reţele Delta separate.
Figura 13.16: Construirea recursivă a unei reţele Benes Există asemănări între versiunea recursivă a reţelei Benes din fig.13.16
şi reţeaua Clos din fig.13.12, care pot fi folosite pentru a demonstra faptul că reţeaua Benes poate ruta orice permutare de cereri de ieşire, similar cu proprietatea de rearanjare fără blocare a reţelei Clos.
În fiecare din două iteraţii se caută o potrivire perfectă a primului şi ultimului etaj din figura 13.16, ca mai înainte, şi se alege una din cele două comutatoare de pe nivelul mijlociu. Dar algoritmul nu se opreşte aici ci urmăreşte recursiv acelaşi algoritm de rutare în reţeaua Benes de dimensiune N/2. Alternativ, întreg procesul poate fi formulat folosind metoda edge coloring. Mesajul final este că rutarea permutărilor arbitrare într-o reţea Benes este posibilă; dar metoda e complexă şi greu de obţinut ieftin într-un interval minim de sosire a pachetului.
La reţeaua Clos se putea alege aleator comutatorul din etajul mijlociu; se poate alege şi aici o destinaţie aleatoare pentru fiecare celulă în prima jumătate. Apoi în a doua jumătate se poate folosi metoda de rutare Delta inversată, pentru rutarea de la comutatorul intermediar aleator la destinaţie.

207
Ca şi la reţelele Clos, se poate arăta că dacă se foloseşte un algoritm aleator, nici o legătură internă nu devine congestionată atâta timp cât nici o intrare sau ieşire nu devine congestionată. Intuitiv: jumătatea responsabilă de împărţirea încărcării preia traficul destinat oricărei ieşiri de la oricare intrare şi îl distribuie în mod egal spre toate cele N legături de ieşire ale primei jumătăţi. În a doua jumătate, datorită structurii simetrice, tot traficul este dirijat spre legătura de ieşire destinaţie.
De exemplu, considerăm că legătura de sus ajunge la primul comutator de pe etajul final din figura 13.15. Această legătură de sus va purta jumătate din traficul legăturii de ieşire 1 (deoarece legătura de sus transportă tot traficul destinat ieşirii 1 din jumătatea de sus a nodurilor de intrare şi datorită proprietăţii de împărţire a încărcării se obţine jumătate din traficul destinat ieşirii 1). Tot aşa se poate observa că legătura de sus poartă jumătate din traficul destinat ieşirii 2, etc.
În timp ce unele dintre aceste proprietăţi erau cunoscute dinainte, Turner a extins aceste idei pentru traficul multicast. Problema nu a fost tratată la ruterele multişasiu bazate pe reţeaua Clos. Tratarea multicast este bazată pe modelul server ca în schema de acordare a unui bilet („take a ticket”).
Pentru a extinde ideile de rutare Benes şi pentru multicast, Turner a elaborat o formă mai simplă de multicast numită „copiază de două ori”. În această formă, fiecare intrare poate specifica două ieşiri. Mai departe este treaba reţelei să trimită două copii ale celulei de la intrare spre porturile de ieşire specificate. Dacă acest lucru este posibil şi legăturile de ieşire pot fi reciclate spre intrare, atunci cele două copii create la prima parcurgere pot fi extinse la 4 copii în parcurgerea a doua şi la 2i copii la parcurgerea i prin reţeaua Benes.
Spre exemplu în figura 13.15 se observă faptul că cea de-a cincea intrare are o celulă care este pusă în legătură atât cu 1000 (adică ieşirea 8) cât şi cu 1111 (adică ieşirea 15). În prima jumătate, celula este rutată în mod aleator către ieşirea 7 a celei de-a doua jumătăţi. În cea de-a doua jumătate, se urmăresc biţii ieşirii reale, întâi MSB, până se ajunge prima dată într-un loc în care cele două adrese de ieşire diferă. Deobicei, dacă bitul curent are valoarea 0 se comută în sus, iar dacă are valoarea 1 se comută în jos. De aceea, la primul nivel al reţelei copiate, celula este rutată spre legătura de jos, pentru că ambele adrese de ieşire încep cu un 1.
Lucrurile se complică la nivelul doi, deoarece la poziţia a doua dinspre dreapta adresele diferă. Astfel, comutatorul din nivelul doi (adică comutatorul al patrulea de la vârf) trimite celulele în două direcţii. Cele două căi de ieşire s-au despărţit la primul bit care diferă. Din acest moment, fiecare dintre cele două celule urmăreşte adresa corespunzătoare ieşirii sale. În figura 13.15, dacă se iau în considerare ultimii 2 biţi ai 1000 şi 1111, se observă faptul că cele 2 celule ajung la ieşirea 8 şi 15.
Se poate demonstra că dacă copierea se face la nivelul primului bit care diferă, aceasta nu duce la nici o supraîncărcare a vreunei legături interne, dacă legăturile de intrare şi ieşire nu sunt supraîncărcate. Rezultatul e valabil şi la reţele copy-3 (reţea capabilă să producă 3 copii la o trecere).
În momentul în care o celulă ajunge la un comutator, ea poartă un specificator multicast cu legătura de ieşire, care trebuie transformat în 2 sau mai mulţi specificatori unicast pentru fiecare parcurgere. În mod similar, fiecare celulă trebuie să poarte cu ea 2 sau mai multe adrese pe

208
parcursul drumului. Utilizarea unui număr mic, precum 2 limitează complexitatea operaţiei de mapare a porturilor şi dimensiunea antetului. Utilizarea unor numere mai mari va duce la micşorarea numărului de parcurgeri necesare pentru a replica o celulă muticast.
O proprietate îmbucurătoare a proiectării multicast a lui Turner este faptul că fanout-uri cu valori mari, de tip multicast, pot fi prelucrate în mai multe iteraţii. Acest lucru poate fi vizualizat ca un arbore binar multicast, din cadrul mai multor reţele Benes conectate în serie. În realitate, este refolosită aceaşi reţea Benes, astfel reducând costul. Imaginea demonstrează eficienţa adăugării de noi conexiuni multicast. Aceasta presupune de fapt adăugarea unei frunze la arborele existent, cauzând o perturbare minimă la nivelul celorlalte noduri existente ale arborelui şi celorlalte conexiuni.
În consecinţă, comutatorul Turner tinde să folosească resursele în mod optim datorită reciclării. Proiectul permite o scalabilitate a resurselor de
logN N∗ , poate trata orice configuraţie de trafic unicast şi multicast şi poate adăuga sau şterge un punct terminal dintr-un arbore multicast într-un interval de timp constant. Alte arhitecturi de comutatoare nu îndeplinesc aceste condiţii, iar în practică pot face faţă doar la un trafic multicast de dimensiune limitată. În prezent importanţa traficului multicast este limitată, însă având în vedere creşterea importanţei videoconferinţelor prin Internet se poate spune că va exista un viitor, în care comutatoare multimedia de mari dimensiuni vor avea un rol cheie.
În concluzie trebuie menţionat faptul că la fel ca la comutatorul Clos, simplitatea conceptuală a unei strategii de echilibrare aleatoare a încărcării pentru o reţea Benes aduce o complexitate de implementare. În primul rând, deoarece echilibrarea aleatoare a încărcării nu este perfectă, comutatorul Turner necesită buffere şi controlul fluxului. În al doilea rând, aleatorizarea trebuie facută corect. Primul prototip al comutatorului de la Universitatea Washington a folosit echilibrarea simplă a încărcării, bazată pe un numărător, însă atunci când a fost reproiectat la compania Growth Networks, comutatorul a folosit un circuit de aleatorizare mult mai sofisticat, care să poată rezolva chiar şi cele mai patologice modele de intrare. În final, o resecvenţiere eficientă a celulelor a necesitat un doesebit efort în această arhitectură.

















