
Cap5 - Tehnici de Proc Si Recun a Semnalului Vocal
22
Cap. 5 Tehnici de procesare şi recunoaştere a semnalului vocal Cap. 5 Tehnici de procesare şi recunoaştere a semnalului vocal Sistemele de recunoaştere automată a vorbirii ASR (Automatic Speech Recognition) se bazează pe modalitatea de producere, respectiv de percepţie a vorbirii în algoritmii de analiză acustică, de procesare a vorbirii şi în tehnicile de recunoa ştere pe care le înglobează (Juang et al., 2004), (Rabiner, Juang, 2006). Pornind de la modul în care este caracterizat ă forma de undă a semnalului vorbit de c ătre fenomenele fizice ce le genereaz ă au fost dezvoltate o serie de instrumente specifice de procesare a semnalelor vocale, cum ar fi cepstrum ( şi metodele ce derivă din acesta MFCC – Mel frequency cepstal coefifcient, LPC - linear predictive coding) Transformata Fourier pe timp scurt STFT - S hot Time Fourier Transform. Tehnicile LPC şi variante ale acesteia au fost create ca urmare a model ării mecanismului de producere a vorbirii umane, model ce include glota ca element de vibraţie ce conţine informaţii legate de frecvenţa fundamentală şi de tractul vocal (laringe, gur ă) ca element rezonant ce ofer ă informaţii despre formanţi. Metoda LPC face posibilă estimarea formanţilor (a caracteristicilor tractului vocal) şi respectiv eliminarea efectului acestora din semnalul procesat, astfel încât se face o separare a celor două componente: excitaţia şi r ăspunsul la impuls al tractului vocal. Secvenţele analizate au dimensiune mic ă, de ordinul milisecundelor, datorit ă variaţiilor rapide ale semnalului vocalic în timp. În tehnicile de recunoa ştere a vorbitorului este necesar ă extragerea unui vector de tr ăsături cu un grad mai mic de generalitate şi un grad mai mare de particularitate. Tehnologiile des folosite pentru recunoaşterea vorbitorului includ estimarea frecven ţelor, GMM (gaussian mixture models), potrivire de pattern-uri, arbori de decizie şi reţele neuronale (Hosom, 2004). O problemă importantă este cea de eliminare, sau de neglijare a zgomotului ambiental (Bhiksha, 2007), (Lee Y.W., 2005), (Guinness, 2005). În acest capitol se prezint ă trei metode de extragere de tr ăsături bazate pe coeficienţii de predicţie liniar ă LPC (Zbancioc, Costin 2003), coeficienţi mel-cepstrali MFCC (Costin, Zbancioc, 2002, 2003) şi coeficienţi autoregresivi (Costin, Grichnik, Zbancioc, 2003). Pentru acest set de tr ăsături s-au dezvoltat metode de recunoaştere a vorbirii folosind pentru clasificare în special arborii de decizie DT - decision tree şi reţelele neuronale MLP - Multi-Layer Perceptron (Dumitraş, 1997), (Toderean et al., 1995). 5.1. Recunoaşterea fonemelor pe baza coeficien ţilor MFCC Metoda descrisă are la bază modelul de percepţie auditivă a omului, model în care frecvenţele sunt date de o scar ă mel şi faptul că persoanele cu implant auditiv pot recunoaşte secvenţele rostite, folosind numai un set foarte redus de informaţii. Metoda calculează procentul de recunoaştere a unor foneme folosind pattern-uri extrase din benzile de frecvenţă mel, aplicând un set de opera ţii specifice celor ce se realizeaz ă în implantul cochlear (CI). Simulările realizate au vizat determinarea importan ţei specifice a unor benzi spectrale în procesul de recunoa ştere a unor foneme.
-
Upload
briciu-marian -
Category
Documents
-
view
72 -
download
0
Transcript of Cap5 - Tehnici de Proc Si Recun a Semnalului Vocal

5/8/2018 Cap5 - Tehnici de Proc Si Recun a Semnalului Vocal - slidepdf.com
http://slidepdf.com/reader/full/cap5-tehnici-de-proc-si-recun-a-semnalului-vocal 1/22
Cap. 5 Tehnici de procesare şi recunoaştere a
semnalului vocal
Cap. 5 Tehnici de procesare şi recunoaştere a semnalului vocalSistemele de recunoaştere automată a vorbirii ASR (Automatic Speech
Recognition) se bazează pe modalitatea de producere, respectiv de percepţie a vorbiriiîn algoritmii de analiză acustică, de procesare a vorbirii şi în tehnicile de recunoaştere pe care le înglobează (Juang et al., 2004), (Rabiner, Juang, 2006). Pornind de lamodul în care este caracterizată forma de undă a semnalului vorbit de cătrefenomenele fizice ce le generează au fost dezvoltate o serie de instrumente specificede procesare a semnalelor vocale, cum ar fi cepstrum (şi metodele ce derivă din acesta
MFCC – Mel frequency cepstal coefifcient, LPC - linear predictive coding)Transformata Fourier pe timp scurt STFT - Shot Time Fourier Transform.
Tehnicile LPC şi variante ale acesteia au fost create ca urmare a modelăriimecanismului de producere a vorbirii umane, model ce include glota ca element devibraţie ce conţine informaţii legate de frecvenţa fundamentală şi de tractul vocal(laringe, gur ă) ca element rezonant ce ofer ă informaţii despre formanţi. Metoda LPCface posibilă estimarea formanţilor (a caracteristicilor tractului vocal) şi respectiveliminarea efectului acestora din semnalul procesat, astfel încât se face o separare acelor două componente: excitaţia şi r ăspunsul la impuls al tractului vocal.
Secvenţele analizate au dimensiune mică, de ordinul milisecundelor, datorită variaţiilor rapide ale semnalului vocalic în timp. În tehnicile de recunoaştere avorbitorului este necesar ă extragerea unui vector de tr ăsături cu un grad mai mic degeneralitate şi un grad mai mare de particularitate. Tehnologiile des folosite pentrurecunoaşterea vorbitorului includ estimarea frecvenţelor, GMM (gaussian mixturemodels), potrivire de pattern-uri, arbori de decizie şi reţele neuronale (Hosom, 2004).O problemă importantă este cea de eliminare, sau de neglijare a zgomotului ambiental(Bhiksha, 2007), (Lee Y.W., 2005), (Guinness, 2005).
În acest capitol se prezintă trei metode de extragere de tr ăsături bazate pe coeficienţiide predicţie liniar ă LPC (Zbancioc, Costin 2003), coeficienţi mel-cepstrali MFCC(Costin, Zbancioc, 2002, 2003) şi coeficienţi autoregresivi (Costin, Grichnik, Zbancioc,2003). Pentru acest set de tr ăsături s-au dezvoltat metode de recunoaştere a vorbiriifolosind pentru clasificare în special arborii de decizie DT - decision tree şi reţeleleneuronale MLP - Multi-Layer Perceptron (Dumitraş, 1997), (Toderean et al., 1995).
5.1. Recunoaşterea fonemelor pe baza coeficienţilor MFCC
Metoda descrisă are la bază modelul de percepţie auditivă a omului, model în carefrecvenţele sunt date de o scar ă mel şi faptul că persoanele cu implant auditiv potrecunoaşte secvenţele rostite, folosind numai un set foarte redus de informaţii. Metodacalculează procentul de recunoaştere a unor foneme folosind pattern-uri extrase din benzile de frecvenţă mel, aplicând un set de operaţii specifice celor ce se realizează înimplantul cochlear (CI). Simulările realizate au vizat determinarea importanţei specificea unor benzi spectrale în procesul de recunoaştere a unor foneme.
5/8/2018 Cap5 - Tehnici de Proc Si Recun a Semnalului Vocal - slidepdf.com
http://slidepdf.com/reader/full/cap5-tehnici-de-proc-si-recun-a-semnalului-vocal 2/22
122 Cap. 5 Tehnici de procesare şi recunoaştere a semnalului vocal
Implantul cochlear generează pe baza semnalelor recepţionate, utilizând stimulareaelectrică artificială, un pattern de activitate neuronală, care permite pacienţilor cuimplant să recunoască semnalele vorbite, sau alte sunete din mediul înconjur ător.Influenţa zgomotului asupra inteligibilităţii vorbirii are efecte puternice asupra pacienţilor cu implant cochlear. La ora actuală există numeroase studii în acest senscare vizează fie îmbunătăţirea tehnicilor de filtrare, fie creşterea robusteţei la zgomota algoritmilor de recunoaştere (Bhattacharya and Zeng, 2005), (Loizou et al., 2005).
5.1.1. Extragerea de pattern-uri din benzile de frecvenţe mel
Scara mel de frecvenţe simulează modul de percepţie a frecvenţelor în urecheainternă a omului în melcul cochlear. Implantul cochlear MXM-Digisonic foloseştedoar 15 electrozi pentru stimularea terminaţiilor nervoase, fiecare electrod transmiteimpulsuri electrice direct nervului auditiv. Limitele celor 15 benzi de frecvenţe melsunt calculate după formule lui Fant sau lui Koening:
⎟ ⎠
⎞⎜⎝
⎛ +⋅=
10001log1000)( 2
f f Mel Fant ;
⎟ ⎠
⎞⎜⎝
⎛ +⋅=
7001lg2595)(
f f Mel Koening
(5.1)
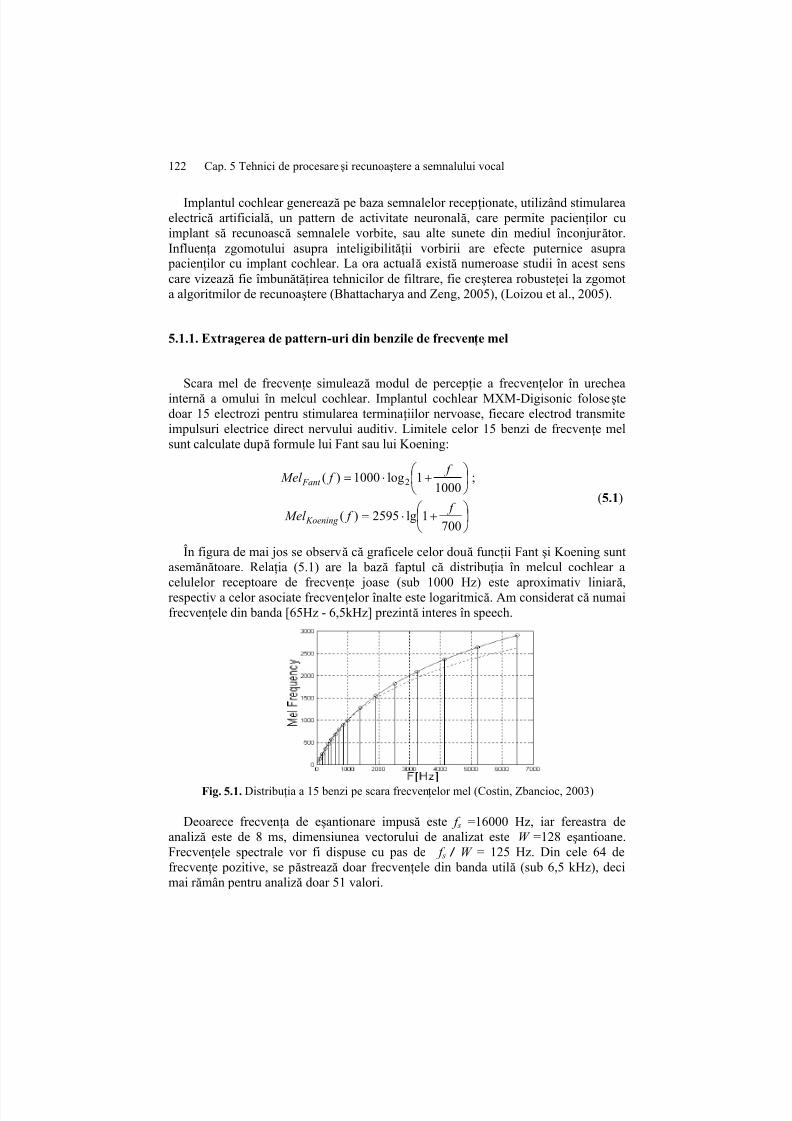
În figura de mai jos se observă că graficele celor două funcţii Fant şi Koening suntasemănătoare. Relaţia (5.1) are la bază faptul că distribuţia în melcul cochlear a
celulelor receptoare de frecvenţe joase (sub 1000 Hz) este aproximativ liniar ă,respectiv a celor asociate frecvenţelor înalte este logaritmică. Am considerat că numaifrecvenţele din banda [65Hz - 6,5kHz] prezintă interes în speech.
Fig. 5.1. Distribuţia a 15 benzi pe scara frecvenţelor mel (Costin, Zbancioc, 2003)
Deoarece frecvenţa de eşantionare impusă este f s =16000 Hz, iar fereastra deanaliză este de 8 ms, dimensiunea vectorului de analizat este W =128 eşantioane.Frecvenţele spectrale vor fi dispuse cu pas de f s / W = 125 Hz. Din cele 64 defrecvenţe pozitive, se păstrează doar frecvenţele din banda utilă (sub 6,5 kHz), decimai r ămân pentru analiză doar 51 valori.

5/8/2018 Cap5 - Tehnici de Proc Si Recun a Semnalului Vocal - slidepdf.com
http://slidepdf.com/reader/full/cap5-tehnici-de-proc-si-recun-a-semnalului-vocal 3/22
Cap. 5 Tehnici de procesare şi recunoaştere a semnalului vocal 123
Table 5.1. Distribuţia frecvenţelor spectrale în benzile mel (Costin, Zbancioc, 2003)
Numărul benzii
Frecvenţacentrală
Număr totalfrecvenţe
Frecvenţele corespunzătoare fiecărei benzi mel(se specifică şi indicele din vectorul spectral)
B1 125 1 125 (1) B2 250 1 250 (2) B3 375 1 375 (3) B4 500 1 500 (4) B5 625 1 625 (5) B6 750 1 750 (6) B7 875 1 875 (7) B8 1000 1 1000 (8) B9 1185 2 1125, 1250 (9-10) B10 1435 2 1375, 1500 (11-12) B11 1745 3 1625, 1750, 1875 (13-15) B12 2180 4 2000, 2125, 2250, 2375 (16-19) B13 2795 6 2500, 2625, 2750, 2875, 3000, 3125 (20-25)
B14 3825 113250, 3375, 3500, 3625, 3750, 3875, 4000,4125, 4250, 4375, 4500 (26-36)
B15 5500 154625, 4750, 4875, 5000, 5125, 5250, 5375, 5500,5625, 5750, 5875, 6000, 6125, 6250, 6375 (37-51)
Fereastra de analiză s-a ales de 8ms, iar pasul de deplasare este de 50% dinlungimea ferestrei.
Etapele realizate în procesarea semnalului sunt următoarele:• calculul spectrului (transformata FFT), după ce în prealabil eşantioanele din
fereastra curentă de analiză sunt ponderate cu o fereastr ă Hamming;
• Calculează energia celor 15 benzi mel;• Se realizează o preaccentuare, pentru a accentua energiile de pe benzile
frecvenţelor înalte a căror valori sunt mici, comparativ cu cel al frecvenţelor joase.
Fig. 5.2. Funcţie de preaccentuare cu variaţie exponenţială (Costin, Zbancioc, 2003)
5.1.2. Recunoaşterea vocalelor pe baza energiei benzilor mel cu RN-MLP şi DT
Clasificarea vocalelor nu ar trebui să ridice mari dificultăţi, date fiindcaracteristicile spectrale ale acestora, frecvenţa fundamentală şi valorile formanticecare au valori bine stabilite în special la nivelul primilor doi formanţi. Chiar şi persoanele cu implant nu au mari probleme în a distinge corect vocalele. Nu acelaşilucru se întâmplă însă şi cu fonemele consonantice, pentru care pattern-urile
B1*2.4, B2*3.6, B3*15,B4*38.5, B5*78.1, B6*125,B7*218.8, B8*250, B9*312.5,B10*500, B11*625, B12*791.7,B13*1562.5, B14*2187.5, B15*3062.5

5/8/2018 Cap5 - Tehnici de Proc Si Recun a Semnalului Vocal - slidepdf.com
http://slidepdf.com/reader/full/cap5-tehnici-de-proc-si-recun-a-semnalului-vocal 4/22
124 Cap. 5 Tehnici de procesare şi recunoaştere a semnalului vocal
construite doar din energiile benzilor de frecvenţă nu conduc la scoruri bune derecunoaştere.
Reţeaua neuronală MLP folosită are o arhitectur ă cu două straturi ascunse. Numărul neuronilor pentru primul strat ascuns a fost N1=60, respectiv pentru al doileastrat ascuns N2=30. Vectorul de intrare {x1, x2,..., xn} are dimensiunea de N =15(valorile energiilor benzilor mel), iar dimensiunea vectorului de ieşire este dat denumărul de foneme care se doresc a fi recunoscute. Setul de antrenare este construitastfel încât să nu avem două pattern-uri succesive ale aceleiaşi vocale.
Arborii de decizie sunt metode de clasificare automată care furnizează la ieşire unset de reguli. Am utilizat arborii de decizie See5 care folosesc o variantă îmbunătăţită a algoritmului ID3, bazat pe entropie (Quinlan, 1996).
Dimensiunea setului de antrenare şi cea a setului de test a fost aleasă egală, de 100
vectori de tr ăsături.Table 5.2. Rata recunoaşterii vocalelor {a, e, i , o , u } cu RN-MLP şi DT
Număr vorbitori
Rata recunoaştereRN-MLP
Rata recunoaştereDT- arbore de decizie
3 76% 94%
Făr ă a putea afirma că arborii de decizie sunt clasificatori mai buni decât reţeleleneuronale, a căror performanţă depinde foarte mult de arhitectura acesteia şi derelevanţa datelor furnizate la intrare, am obţinut o rată de clasificare acceptabilă de94% pentru acest set restrâns de doar trei vorbitori. Arborele de decizie este structurat pe doar trei nivele, pentru clasificare fiind folosite doar benzile de frecvenţă B7, B9,
B11 şi B14. Nu se poate face afirmaţia că energiile celorlalte benzi nu ajută în procesulde clasificare, bazându-ne doar pe faptul că utilitarul See5 a reuşit să obţină o clasificareoptimă doar pe baza a 4 caracteristici din totalul de 15 existente în vectorii de tr ăsături.Rezultatele cercetărilor au fost prezentate în (Costin, Zbancioc et al., 2002).
IF C1: (B7 > 0.04439)THEN
IF C2: (B9 <= 0.05271)THEN Vowel = ’o’ELSE Vowel = ‘a ‘
ELSE
IF C3: (B11 > 0.00976)THEN Vowel = ‘e’ELSE
IF C4: (B14 <= 0.0212THEN Vowel = ‘u’ELSE Vowel = ‘i’
Rule 1: B9 > 0.05271=> vowel a
Rule 2: B7 <= 0.04439B11 > 0.00976=> vowel e
Rule 3: B7 <= 0.04439B11 <= 0.00976B14 > 0.0212
=> vowel iRule 4: B7 > 0.04439B9 <= 0.05271=> vowel o
Rule 5: B7 <= 0.04439B11 <= 0.00976B14 <= 0.0212=> vowel u
Fig. 5.3. Regulile de clasificare a vocalelor {a, e, i, o, u} furnizate de utilitarul See5

5/8/2018 Cap5 - Tehnici de Proc Si Recun a Semnalului Vocal - slidepdf.com
http://slidepdf.com/reader/full/cap5-tehnici-de-proc-si-recun-a-semnalului-vocal 5/22
Cap. 5 Tehnici de procesare şi recunoaştere a semnalului vocal 125
Table 5.3. Matricea de confuzie a vocalelor {a, e, i, o , u} dată de See5 (Costin, Zbancioc et al., 2002)
Eroare : 1 ( 1.0%) Eroare: 6 ( 6.0%)a e i o u a e i o u
a 20 a 20e 20 e 19 1i 20 i 19 1o 1 19 o 1 17 2u 20 u 1 19
Estimarea relevanţei în cazul reţelei neuronale MLP a parametrilor folosiţi larecunoaştere este înglobată în ponderile dintre neuronii reţelei. Modul de antrenare areţelei este în mod normal transparent utilizatorului, în special în cazul folosirii unor instrumente care nu ofer ă acces la matricea ponderilor. Dacă suma tuturor ponderilor de la un neuron aflat pe stratul de intrare, la neuronii de pe stratul urm ător este nulă sau semnificativ mai mică decât sumele celorlalte intr ări ale reţelei neuronale, atuncise poate spune despre acel neuron că nu conţine informaţie utilă procesului deantrenare/clasificare. Identificarea acestor tr ăsături, eliminarea şi înlocuirea lor cu altetr ăsături poate conduce la o antrenare mai rapidă şi la o rată de recunoaştere mai bună.
5.1.3. Metodă de construcţie de pattern-uri folosind coeficienţii MFCC
Vectorii de tr ăsături construiţi cu valorile energiilor benzilor mel nu permit oclasificare a fonemelor consonantice, motiv pentru care am propus ca alternativă folosirea în locul acestora a coeficienţilor mel cepstrali MFCC. Aceşti coeficienţi suntdes întâlniţi în literatura de specialitate, în sistemele de recunoaştere automată avorbirii (Holmberg et al., 2006), (Zheng 2001). De obicei sunt folosiţi împreună cualte tehnici avansate de clusterizare/clasificare, de reducţie date (cum ar fi VQ-vector quantization), cu modele statistice etc.
Sphinx spre exemplu reprezintă unul dintre sistemele consacrate de recunoaştere avorbirii independent de vorbitor şi foloseşte coeficienţii MFCC împreună cu modeleacustice Markov (HMMs) şi un model de limbaj statistic n-gram (Lee K.F., 1989).Ultimele variante Pocketsphinx pentru platformele mobile şi Sphinx4 sunt dezvoltateîn Java, de mai multe grupuri de cercetare şi sunt un excelent suport pentru cercetare.
Metoda de extragere a coeficienţilor MFCC a fost prezentată în (Costin, Zbancioc,2003), iar etape algoritmului sunt următoarele:
Pas 1) Re-eşantionarea semnalului de intrare (dacă este cazul) astfel încât fe=16kHzPas 2) Aplicarea unui filtru de preaccentuare semnalului de intrare având funcţia
caracteristică 197.01)( −⋅−= z z H
Pas 3) Ponderarea ferestrei curente de analiză de 8ms cu o fereastă HammingPas 4) Calculul spectrului (aplicare transformată Fourier discretă)Pas 5) Determinarea coeficienţilor spectrali mel MFSC (pentru cele 15 benzi mel)Pas 6) Aplicarea transformatei cosinus discrete (DCT) la fiecare 10 ms şi calcularea
pentru fiecare vector mel a N =7 coeficienţi MFCC, ∆ MFCC (40ms şi 80ms)şi ∆∆ MFCC

5/8/2018 Cap5 - Tehnici de Proc Si Recun a Semnalului Vocal - slidepdf.com
http://slidepdf.com/reader/full/cap5-tehnici-de-proc-si-recun-a-semnalului-vocal 6/22
126 Cap. 5 Tehnici de procesare şi recunoaştere a semnalului vocal
Calcularea coeficienţilor MFCC prin aplicarea DCT se face după relaţia:
[ ] ( )( )[ ]∑=
≤≤−⋅=15
1, Nk 1 15/2/1cos
i
it t ik X k x π (5.2)
unde X t,i sunt cei 15 coeficienţi mel cepstrali MFSC corespunzători benzilor mel dinfereastra curentă de analiză (t notează indicele ferestrei). Calculul acestora se faceţinând cont de limitele intervalului benzii mel (vezi relaţia 5.1 şi tabelul 5.1) sumândtoate valorile spectrale din banda.
Vectorii derivativi MFCC şi MFCC sunt calculaţi pe baza derivatelor de ordin1 şi de ordin 2, ceea ce revine în domeniul discret la calculul diferenţelor:
( ) ( ) N k k xk xk x t t mst ≤≤−=∆ −+ 1 ,)( 2240, ( ) ( ) N k k xk xk x t t mst ≤≤−=∆ −+ 1 ,)( 4480,
N k k xk xk x t t t ≤≤∆−∆=∆∆ −+ 1 ),()()( 11
(5.3)
În relaţia 5.3 s-a ţinut cont de faptul că se calcululează coeficienţilor MFCC lafiecare 10 ms, şi că operatorul de diferenţiere se aplică pentru vectori situaţi la 40 ms,respectiv 80 ms unul de celălalt.
Fig. 5.4. Fazele de procesare a semnalului de intrare în vederea extragerii coeficienţilor MFCC(Costin, Zbancioc, 2003)
Preaccentuarea semnalului vocal are ca efect reducerea efectului componentei ceţine de modul de generare a sunetului vocal (existentă la frecvenţe joase) şiaccentuarea componentei ce ţine de modul în care rezonează sunetul (informaţia defrecvenţă înaltă corespunzătoare frecvenţelor rezonante - formanţilor).
Preaccentuare
Fereastr ă Hamming 8-ms
Transformata Fourier discretă
Filtrare trece-bandă pe frecvenţe mel
Transformata Cosinus
coeficienţi cepstrum MFCC 40-ms & 80-ms dif. MFCC dif. cepstrum de ordinul doi MFCC
Semnal vocal

5/8/2018 Cap5 - Tehnici de Proc Si Recun a Semnalului Vocal - slidepdf.com
http://slidepdf.com/reader/full/cap5-tehnici-de-proc-si-recun-a-semnalului-vocal 7/22
Cap. 5 Tehnici de procesare şi recunoaştere a semnalului vocal 127
5.1.4. Rezultate experimentale, concluzii în urma aplicării metodei MFCC
Datele de intrare furnizate sistemului sunt extrase din consoane a căror dificultateîn recunoaştere se datorează componenţei frecvenţelor înalte specifice consoanelor plozive, ’p’, ’b’, ’c’, ’g’, ’t’, ’d’.
Dimensiunea setului întreg de date este de 210 de înregistr ări (câte 35 pentrufiecare fonem), din care am ales aleatoriu 60 pentru construcţia setului de test şicelelalte pattern-uri s-au folosit la antrenare. Deoarece setul de date pe care s-a f ăcutanaliza este destul de mic, după încheierea procesul de antrenare (stabilizarea ponderilor neuronilor şi a erorii de clasificare) s-a repetat iterativ procesul deantrenare pentru un alt set de 150 valori alese aleatoriu (câte 25 pattern-uri pentru
fiecare consoană). Procesul de rulare se încheie în momentul în care aplicarea a treiseturi consecutive nu conduce la o modificare a erorii de recunoaştere (durataverificării setului este de o singur ă iteraţie). În tabelul 5.4 sunt furnizate valorile mediide recunoaştere pentru metoda bazată pe coeficienţi MFCC.
Table 5.4. Procente de recunoaştere folosind vectorii energiilor spectrale, vectorii MFCC şi vectoriiMFCC calculaţi pentru o selecţie fuzzy a benzilor mel- frecvenţelor (Costin, Zbancioc, 2003)
FFT50%
FFT75%
MFCC50%
MFCC75%
MFCCFuzzy50%
MFCCFuzzy75%
/b/ 41 42 53 56 57 59/p/ 46 45 62 61 63 67/c/ 42 47 68 67 71 69/g/ 51 53 70 72 70 74/t/ 57 55 73 75 74 78/d/ 49 48 60 60 68 65
Medie 47.7 48.3 64.3 65.2 67.2 68.7
Setul de înregistr ări conţine pronunţii de genul VCV vocală+consoană+vocală (degenul aba, apa, aca etc.), din aceste înregistr ări fiind delimitată manual zonaconsonantică ce urmează a fi analizată. Chiar şi în condiţiile în care s-a realizat oadnotare manuală a înregistr ărilor şi s-a evitat folosirea unor cuvinte care să conţină mai multe consoane alăturate (de exemplu act, apt, strict, etc.) rezultatele obţinute înurma procesului de antrenare pot fi considerate ca fiind satisf ăcătoare. Într-un procesde vorbire continuă, rata de recunoaştere cel mai probabil ar scade.
Folosirea directă a valorilor energiilor spectrale în vectorii de tr ăsături ofer ă celemai mici scoruri de recunoaştere. O suprapunere între două ferestre consecutive cu75% şi nu doar cu 50%, ofer ă mai multe cazuri de analiză şi rezultate în general mai bune. Metoda de selecţie „fuzzy” presupune calculul coeficienţilor spectrali melMFSC luându-se în calcul nu un interval strict fixat pentru fiecare bandă mel, ci uninterval variabil ale cărui limite sunt ponderate printr-o funcţie trapezoidală fuzzy. Înacest fel valorile spectrale aflate în apropierea limitei dintre două benzi mel Bi, Bi+1 vor fi utilizate în determinarea energiei spectrale mel pentru ambele benzi.

5/8/2018 Cap5 - Tehnici de Proc Si Recun a Semnalului Vocal - slidepdf.com
http://slidepdf.com/reader/full/cap5-tehnici-de-proc-si-recun-a-semnalului-vocal 8/22
128 Cap. 5 Tehnici de procesare şi recunoaştere a semnalului vocal
( )ii
l
l k
k
l l
X
iMFSC
i
i
−=
+
=∑
+
1
1
)( ,∑
∑∆+
∆−=
+
⋅
=
k
k
l
l k
k k
fuzzy
i
i
X
iMFSC µ
µ
1
)( (5.4)
Fig. 5.5. Delimitarea benzilor mel de frecvenţe prin limite variabile - calcul fuzzycoeficienţi MFSC (Costin, Zbancioc, 2003)
Utilizarea unor intervale cu prag variabil pentru benzile mel cepstrale şi asociereaunor funcţii fuzzy trapezoidale a condus la o îmbunătăţire uşoar ă a scorurilor derecunoaştere.
Rezultatele cercetărilor metodei de recunoaştere bazată pe coeficienţi MFCC aufost publicate în (Costin, Zbancioc et al. 2002), (Costin, Zbancioc 2003).
5.2 Recunoaşterea fonemelor pe baza coeficienţilor LPCC
Metodele bazate pe coeficienţi liniar predictivi LPC sunt considerate a fi metodeeficiente de analiză, în procesarea şi recunoaşterea semnalului vocal. Această metodă face posibilă reprezentarea caracteristicilor tractului vocal şi separarea celor două componente legate de: excitaţia şi r ăspunsul la impuls al tractului vocal (Juang et al.,2004), (Juang and Rabiner, 2006).
Metoda se extragere a coeficienţilor LPCC realizează o preaccentuarea asemnalului de intrare, calculul unui vector de autocorelaţie pe baza căruia suntcalculaţi prin metoda Levinson-Durbin (Press et al., 2007) coeficienţii LPC, LPCC.Vectorii de date astfel obţinuţi sunt introduşi ca set de antrenare în clasificatori de tipreţea neuronală (Reynolds and Antoniu, 2003), scopul acestui studiu fiind acela de a
compara pe baza erorilor de clasificare, eficienţa folosirii pattern-urilor LPCC în procesul de recunoaştere automată a vorbirii.În literatur ă există numeroase studii asupra eficienţei coeficienţilor LPC în
recunoaşterea vorbitorului (Naito et al., 2002), în codarea semnalului vocal (So andPaliwal, 2007), (Krishna 2001) în sinteza semnalului vocal (Nusbaum and Shintel, 2006), în sisteme adaptive fuzzy de discriminare a muzicii (Muñoz-Expósito, 2007)etc. Metoda prezentată în această secţiune a fost utilizată la studiul eficienţeivectorilor de tr ăsături ce includ coeficienţi LPCC în recunoaşterea unui număr izolatde foneme consonantice ale limbii române (Zbancioc, Costin, 2003).
Bi Bi+1l il i-1 l i+1
recven ă
l i -∆ l i +∆
µ

5/8/2018 Cap5 - Tehnici de Proc Si Recun a Semnalului Vocal - slidepdf.com
http://slidepdf.com/reader/full/cap5-tehnici-de-proc-si-recun-a-semnalului-vocal 9/22
Cap. 5 Tehnici de procesare şi recunoaştere a semnalului vocal 129
5.2.1. Descrierea generală a modelului LPC
Modelul LPC a fost dezvoltat pornind de la modul de generare a sunetului uman şiurmăreşte aproximarea unui eşantion al vorbirii la momentul de timp, pe baza unuinumăr de eşantioane anterioare conform relaţiei următoare de calcul:
∑=
⋅+−= p
k
k nuGk n san s
1
][][][ (5.5)
∑=
− ⋅+= p
k
k k z U G z S z a z S
1
)()()( ,)(
1
1
1
)(
)()(
1
z A z a
z GU
z S z H
p
k
k
k
=
−
==
∑=
−
(5.6)
S-a notat cu u sursa de excitaţie şi cu G valoarea câştigului. Sursa de excitaţienormalizată este considerată a fi un tren de impulsuri cvasiperiodice pentru sunetevocalice, respectiv o secvenţă de zgomote aleatoare pentru sunete nevocalice.
Eroarea de predicţie ][][ˆ][ n sn sne −= , unde ][̂n s reprezintă valoare prezisă a
semnalului la momentul de timp n şi va avea funcţia de transfer A( z ). Estimareacoeficienţilor predictorului se face pornind doar de la un segment scurt al semnaluluivocal, prin minimizarea erorii e[n]. Acest fapt se datorează în principal variabilităţiimari în timp a caracteristicilor semnalului vocal.
5.2.2. Metodă de construcţie de pattern-uri folosind coeficienţii LPCC
Pentru extragerea coeficienţilor LPC este necesar ă parcurgerea unui număr deetape (reprezentate în figura 5.7). Semnalul vocal de intrare a fost analizat folosind ofereastr ă glisantă de 16 ms ( N =256 eşantioane pentru un semnal cu frecvenţa deeşantionare fe=16kHz), pasul de deplasare a ferestrei fiind de 8ms (suprapunere de50% între două ferestre consecutive). Metoda de extragere a parametrilor LPCC a fost prezentată în (Zbancioc, Costin, 2003), etapele algoritmului sunt următoarele:
Pas 1) Ponderarea ferestrei curente de analiză de 16 ms cu o fereastr ă Hamming,scopul acestei ponder ări este acela de a minimiza discontinuităţile semnaluluide la începutul şi sfâr şitul fiecărei secvenţe.
)()()( min nwn xn x g Ham= , ⎟ ⎠ ⎞⎜
⎝ ⎛
−−=
12cos46.054.0)(min
N
nnw g Ham
π (5.7)
Pas 2) Preaccentuarea semnalului de intrare )(n x se face cu un filtru trece sus HPF
cu funcţia de transfer 11)( −−= az z H cu 97.0=a .
)1()()(ˆ −⋅−= n xan xn x (5.8)

5/8/2018 Cap5 - Tehnici de Proc Si Recun a Semnalului Vocal - slidepdf.com
http://slidepdf.com/reader/full/cap5-tehnici-de-proc-si-recun-a-semnalului-vocal 10/22
130 Cap. 5 Tehnici de procesare şi recunoaştere a semnalului vocal
În (Rabiner, Juang, 1993) se sugerează că na să varieze cu timpul (n) în funcţie de
criteriul de adaptare ales, de exemplu )0()1( nnn r r a = , calculată la pasul următor.
Ordinea etapelor 2 şi 3 poate fi schimbată, valorile obţinute în final fiind foarteapropiate.
a) b) c)Fig. 5.6. Reprezentare comparativă a) semnal iniţial, b) semnal ponderat cu o ferestr ă
Hamming, c) semnal după aplicare filtru preaccentuare (Zbancioc, Costin, 2003)
Pas 3. Calculul vectorului de autocorelaţie de ordin p al semnalului )(ˆ n x . Valoarea
lui p reprezintă ordinul maxim al coeficienţilor LPC şi este aleasă între 8 şi 16.
∑−−
=
+⋅=m N
n
mn xn xmr
1
0
)(ˆ)(ˆ)( , m =0, 1, ..., p (5.9)
Procesul de corelare ofer ă o bună caracterizare a semnalelor şi poate fi folosit în
algoritmi de predicţie sau estimare, el realizând şi o diminuare a nivelului de zgomotraportată la semnalul util, fapt ce ajută în procesul de recunoaştere a unei secvenţedintr-un semnal. Prima valoare din vectorul de autocorelaţie r (0) reprezintă energiaferestrei curente de analiză.
Pas 4) Extragerea coeficienţilor LPC – folosind metoda Levinson-Durbin cetransformă vectorul de autocorelaţie prin următoarea relaţie de calcul recurentă (Press et al., 2007) (Brockwell and Dahlhaus, 2004), (Shaman, 2010):
)0()0(r E = (5.10)
)1(1
1
)1( |)(|)( −−
=
−
⎪⎭
⎪⎬⎫
⎪⎩
⎪⎨⎧
−−= ∑ i L
j
i ji E jir ir k α ,
iii k =)(α , )1()1()(−
−−
−= i jiii ji j k α α α , 1≤ j < i)1(2)( )1( −−= i
ii E k E , i≤ p
(5.11)
Relaţia recurentă de calcul 5.11 se aplică pornind de la o primă valoare )0( E , până sunt determinaţi tot setul de p coeficienţi. După realizarea acestui calcul se obţin atât
coeficienţii LPC corespunzători valorilor )( pmα , cât şi setul mk al coeficienţilor de
reflexie PARCOR, m=1,…, p.

5/8/2018 Cap5 - Tehnici de Proc Si Recun a Semnalului Vocal - slidepdf.com
http://slidepdf.com/reader/full/cap5-tehnici-de-proc-si-recun-a-semnalului-vocal 11/22
Cap. 5 Tehnici de procesare şi recunoaştere a semnalului vocal 131
Pas 5) Conversia parametrilor LPC în parametri cepstrali se realizează prinurmătoarea relaţia recurentă:
20 ln σ c = , ,unde σ 2 este “câştigul” modelului LPC (5.12)
∑−
=
−⎟ ⎠
⎞⎜⎝
⎛ +=
1
1
m
k
k mk mm acm
k ac 1 ≤ m ≤ p (5.13)
∑−
=
−⎟ ⎠
⎞⎜⎝
⎛ =
1
1
m
k
k mk m ack
k c m > p (5.14)
Setul coeficienţilor LPCC, este considerat în comparaţie cu setul LPC sauPARCOR, ca fiind o mulţime de tr ăsături mai robustă, mai demnă de încredere în
procesul de recunoaştere a vorbirii. În general se alege dimensiunea vectoruluicepstral ca fiind 2/3 pQ ⋅≈ .
Fig. 5.7. Diagrama metodei de extragere a coeficienţilor predictivi liniari (Zbancioc, Costin, 2003)
Numeroase aplicaţii de recunoaştere automată a vorbirii includ în vectorii decaracteristici şi coeficienţii cepstrali. Atât prima cât şi a doua derivată au fost testate şis-au dovedit utile în sistemele de recunoaştere a vorbirii (Lee K.F., 1989), (Lee K.F.,et al., 1990). Modul de determinare a acestora este similar cu cel prezentat în metodaMFCC (vezi relaţia de calcul 5.3).
5.2.3. Rezultate experimentale, concluzii în urma aplicării metodei LPCC
Metoda cepstrală LPCC ofer ă parametri distinctivi relevanţi pentru un sistem derecunoaştere. Coeficienţii LPC realizează o bună discriminare a secvenţelor de semnalanalizate. În fig. 5.8 este reprezentată evoluţia în timp a setului celor 14 valori LPC(fereastr ă de analiza de 16 ms, deplasată cu pas de 8ms).
LPCC (cepstrum LPC)∆ LPCC pe 40-ms şi 80-ms
parametrii de putere P, dif. de P pe 40-ms
Semnal vocal
Fereastr ă Hamming pe 16-ms
Preaccentuare
Autocorelaţia (de ordinul 14)
Calcul LPC (metoda Levinson-Durbin)
Conversia LPC în LPCC

5/8/2018 Cap5 - Tehnici de Proc Si Recun a Semnalului Vocal - slidepdf.com
http://slidepdf.com/reader/full/cap5-tehnici-de-proc-si-recun-a-semnalului-vocal 12/22
132 Cap. 5 Tehnici de procesare şi recunoaştere a semnalului vocal
Fig. 5.8. Evoluţia în timp a coeficienţilor LPC pentru fonemele [a] şi [i] voce masculină (Zbancioc, Costin, 2003)
.
Fig. 5.9. Reprezentarea comparativă a coeficienţilor LPC şi a LPC cepstrali pentru două secvenţe de semnal vocal: [e] în partea stângă şi [u] în partea dreaptă (Zbancioc, Costin, 2003)
Seturile de antrenare au fost construite din setul de p=14 coeficienţi LPC şi m=21coeficienţi LPCC şi pentru aceste seturi reţeaua neuronală MLP a realizatrecunoaşterea vocalelor {a, e, i, o , u} cu un procentaj mediu de 90%.
Alegerea dimensiunii vectorilor de tr ăsături s-a f ăcut după mai multe simulări,după ce am observat că pentru vectori de dimensiuni mai mari (s-a mers până la p=32şi m=48) erorile de clasificare sunt apropiate ca valoare de cele ale cazului ( p=4,m=21), însă pentru timpi de antrenare mai mari. Pentru vectori de dimensiuni maimici, şi anume p=6, m=9 s-au obţinut diferenţe foarte mari, procentajul mediu de
recunoaştere scăzând foarte mult, până la 54%.Pentru a face un compromis între timpii de antrenare ai RN şi performanţele declasificare s-a ales dimensiunea pattern-urilor p=14 şi m=21.
De interes în acest studiu au fost erorile de clasificare pentru fonemele nevocalice(consoanele { b, p, d, t, c, g, v, f, z, ţ, s, ş }) pronunţate în context VCV vocală-consoană-vocală, erorile de recunoaştere ale reţelei sunt date în tabelul 5.5. Amconsiderat ca fiind bune erorile de clasificare de sub 30% şi după cum se poate vedeaîn medie una din patru valori nu a putut fi clasificată cu succes. În setul de antrenareal RN s-au inclus câte 20 de pronunţii diferite pentru fiecare fonem.

5/8/2018 Cap5 - Tehnici de Proc Si Recun a Semnalului Vocal - slidepdf.com
http://slidepdf.com/reader/full/cap5-tehnici-de-proc-si-recun-a-semnalului-vocal 13/22
Cap. 5 Tehnici de procesare şi recunoaştere a semnalului vocal 133
Table 5.5. Procentaje de clasificare a fonemelor nevocalice pentru vectori de tr ăsături LPC(Zbancioc, Costin, 2003)
b p d t c g v f z ţ s ş 65 75 60 65 70 65 90 75 90 80 70 85
Eroarea medie de recunoaştere pentru un vector de tr ăsături în care s-au inclus doar coeficienţii LPC, corespunzători fonemelor consonantice din tabelul 5.5 este de 25,8(procentaj de recunoaştere de 74.2%.) Am studiat procentajele de recunoaştere încondiţiile în care s-au variat datele din setul de intrare, pentru vectori de tr ăsăturimicşti compuşi din seturile AC (vectorul de autocorelaţie), LPC şi LPCC.
Table 5.6. Procentaje medii de recunoaştere pentru vectori de tr ăsături compuşi din mai multe
seturi de tr ăsături - AC, LPC, LPCC (Zbancioc, Costin, 2003)
Setul de intrare Procentaj de recunoaştereAC 67.9LPC 74.2LPCC 78.3LPC+AC 71.7LPCC+AC 75.4LPC+LPCC 81.7LPC+LPCC+AC 82.5
Deşi performanţele cele mai bune s-au obţinut pentru cazul în care în setul de dates-au introdus toate tipurile de coeficienţi, s-a preferat cazul LPC+LPCC datorită
timpului de antrenare mai mic.Rezultatele cercetărilor metodei de recunoaştere cu coeficienţi LPCC au fost
valorificate în lucrarea (Zbancioc, Costin, 2003).
5.3. Metodă de recunoaştere pe baza coeficienţilor autoregresivi
Metoda coeficienţilor autoregresivi a vizat stabilirea importanţei benzilor defrecvenţă în tehnicile de recunoaşterea a vorbirii, respectiv a vorbitorului (Costin,Grichnik, Zbancioc, 2003). Metoda curentă se bazează pe ideea că informaţia de fază a semnalului vocal are relevanţă în procesul de recunoaştere. Se continuă astfel
studiile realizate anterior pe baza energiilor din benzile mel de frecven ţă (Costin,Zbancioc et al. 2002).Metoda calculează coeficienţii de autoregresie din benzile spectrale selectate prin
două metode: o primă metodă ce utilizează frecvenţe mel fixe şi o a doua metodă cedetermină printr-un algoritm propriu frecvenţele de “tăiere” ale filtrelor trece bandă.Întrucât descrierea metodei cu frecvenţe mel fixe s-a f ăcut în prima secţiune a acestuicapitol, se va insista pe cea de a doua metoda de selecţie a benzilor.
Seturile de antrenare construite pe baza coeficienţilor AR sunt aplicate la intr ărileunui arbore de decizie C5 şi a două tipuri de reţele neuronale RBF (radial basis

5/8/2018 Cap5 - Tehnici de Proc Si Recun a Semnalului Vocal - slidepdf.com
http://slidepdf.com/reader/full/cap5-tehnici-de-proc-si-recun-a-semnalului-vocal 14/22
134 Cap. 5 Tehnici de procesare şi recunoaştere a semnalului vocal
function) şi perceptron multistrat, în final fiind realizat un studiu comparativ alrezultatelor furnizate de cele trei metode de clasificare. Se poate astfel determina“gradul de relevanţă” a fiecărei benzi de frecvenţe (a fiecărei caracteristici dinvectorul de tr ăsături) în procesul de recunoaştere. Importanţa studiului constă în posibilitatea extragerii unui set de ponderi asociate diverselor informaţii extrase din benzi de frecvenţă care să îmbunătăţească procesul decizional.
5.3.1. Descrierea modelului autoregresiv
Modelele AR sunt des utilizate în procesarea semnalului şi în statistică pentru amodela şi prezice diverse tipuri de fenomene. Conform funcţiei de transfer amodelului AR acesta este un filtru cu r ăspuns infinit la impuls IIR (Infinte ImpulseResponse Filter) sau un filtru "all pole" (Press et al., 2007). Defini ţiile modeluluiautoregresiv şi funcţia de transfer a acestuia sunt următoarele:
t
p
i
it it xa x ε +⋅= ∑=
−
1
(5.15)
ω ω
ω
jP M
j
j
eaeae H
−− +++=
...1
1)(
1
(5.16)
unde ai reprezintă parametrii modelului sau coeficienţii de autoregresie, xt estesemnalul analizat/prezis, P este ordinul filtrului (ales mult mai mic decât lungimeaseriilor aplicate la intrare) şi t ε notează valoarea reziduală (zgomot alb). Conform
formulei termenul curent este estimat ca o sumă ponderată a termenilor anteriori.Există mai multe modalităţi de calculul a coeficienţilor AR, printre cele mai
cunoscute se număr ă metoda Burg şi metoda celor mai mici pătrate (bazată peecuaţiile Yule-Walker). Asupra parametrilor modelului se aplică un algoritm decontrol adaptiv al cărui scop este acela de a minimiza eroarea de predicţie.
Fig. 5.10. Schema unui model autoregresiv AR (Costin, Grichnik, Zbancioc, 2003)
Cea mai utilizată metodă pentru obţinerea coeficienţilor de regresie ai implică rezolvarea setului de ecuaţii liniare Yule-Walker care au forma matricială dată înecuaţia (5.17). Elementele de pe diagonala principală r(0) = 1.
u(n-1)− z − z …
− z
)(1 na
)(naM
Σ Σ ΣAlgoritm decontroladaptiv
u(n u(n-M )
)(2 na
…

5/8/2018 Cap5 - Tehnici de Proc Si Recun a Semnalului Vocal - slidepdf.com
http://slidepdf.com/reader/full/cap5-tehnici-de-proc-si-recun-a-semnalului-vocal 15/22
Cap. 5 Tehnici de procesare şi recunoaştere a semnalului vocal 135
⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢
⎣
⎡
=
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
−−
−
−
∗
∗
∗
∗∗
∗
)(
)2(
)1(
)0()2()1(
)2()0()1(
)1()1()0(
2
1
M r
r
r
a
a
a
r M r M r
M r r r
M r r r
M
MM
K
MOMM
K
L
, *r a R =⋅
(5.17)
Soluţiile sistemului sunt date de *1 r Ra ⋅= − .Studiul metodei de recunoaştere cu coeficienţi de autoregresie, s-a f ăcut,
comparativ, pe două metode: metoda rapidă a covarianţei modificate (FMC FastModified Covariance) şi metoda Burg a entropiei maxime. Deoarece cele două metode sunt bine tratate în literatura de specialitate (Brockwell., Dahlhaus, 2004) nuse va insista asupra acestora sau asupra criteriilor de alegere a ordinului modelului.
Funcţiile MATLAB care realizează calculul coeficienţilor AR prin cele două metodesunt arburg şi arcov.
5.3.2 Metodă de extragere de coeficienţi autoregresivi
Algoritmul se aplică pe o singur ă fereastr ă extrasă din mijlocul semnalului deintrare (foneme). Am considerat că această regiune caracterizează cel mai binefonemul de clasificat. Algoritmul prezentat în cele ce urmează este o variantă a uneimetode de recunoaştere a vorbirii propuse de A. Grichnik, la care au fost introduseelemente proprii de selecţie a benzilor de frecvenţe în funcţie de semnalul vocal deintrare, analizându-se relevanţă benzilor de frecvenţe selectate în recunoaşterea
vorbirii şi a vorbitorului. Metoda de extragere a coeficienţilor autoregresivi a fost prezentată în (Costin, Grichnik, Zbancioc, 2003), paşii algoritmului de sunt următorii:
Pas 1) Calculul spectrului semnalului de intrare (de dimensiune N eşantioane).Semnalului complex i se aplică funcţia modul şi se păstrează doar jumătateacorespunzătoare frecvenţelor pozitive.
N
ik j N
i
ei f N
k X π 21
0
)(1
)(−−
=∑= ; )12/:1()12/:1( −=− N X N X A (5.18)
Pas 2) Determinarea benzilor de frecvenţă mel2.1. pentru benzi delimitate de frecvenţe mel fixe se utilizează formula (5.1)2.2 algoritmul propriu de selecţie a frecvenţelor de tăiere pe baza informaţiei
spectrale este următorul:- se calculează vectorul X S , în care valoarea k reprezintă suma tuturor amplitudinilor spectrale până la acea valoare. Deoarece X A este pozitivă, funcţiaobţinută este crescătoare;
∑=
=k
i
A s i X k X
1
)()( (5.19)

5/8/2018 Cap5 - Tehnici de Proc Si Recun a Semnalului Vocal - slidepdf.com
http://slidepdf.com/reader/full/cap5-tehnici-de-proc-si-recun-a-semnalului-vocal 16/22
136 Cap. 5 Tehnici de procesare şi recunoaştere a semnalului vocal
- se aproximează cu segmente de dreaptă, pornind în sens invers, funcţiacrescătoare X s după o eroare globală ε impusă (vezi fig. 5.11), limitele acestor segmente fiind asociate frecvenţelor de tăiere;
- se păstrează un număr de p=7 frecvenţe de "tăiere" reprezentative ale spectrului:din care prima şi ultima valoare sunt frecvenţa minimă şi frecvenţa maximă a benzii semnalului util [65Hz – 6,5kHz].
Dacă numărul frecvenţelor detectate este prea mare se impun restricţii legatede dimensiunea minimă a intervalului unei benzi mel şi se prefer ă eliminareafrecvenţelor de tăiere joase.
Dacă numărul este prea mic se scade valoarea erorii globale ε şi se reiaalgoritmul de căutare a frecvenţelor de tăiere.
a)
b)
c)Fig. 5.11. a) Semnalul corespunzător cuvântului “stop” b) spectrul semnalului c) selecţie benzi
de frecvenţe din spectrul sumat X s
Pas 3) Folosind frecvenţele de tăiere găsite anterior se filtrează semnalul de intrare,după metoda propusă de Grichnik ce asigur ă pierderi minime ale informaţiei defază (figura 5.12). Adaptarea frecvenţelor de tăiere în funcţie de semnalul deintrare se realizează pentru o mai bună delimitare a frecvenţelor formantice.În (Mitra, 2001) este prezentat principiul distorsiunii de fază nule (zero-phase
transfer functions), prin realizarea unei duble operaţii de reflexie (inversarestânga-dreapta) a semnalului după aplicarea filtrului şi obţinerea unui semnalnedistorsionat din punctul de vedere al modificării fazei prin filtrare.
Pas 4) Se extrag coeficienţi autoregresivi prin metoda Burg sau metoda covarianţeiFMC şi se aplică vectorii de tr ăsături unor clasificatori de tip reţea neuronală MLP, RBF sau de tip arborele de decizie See5. Procentajele de detec ţie vor stabili relevanţa informaţiilor din diverse benzi de frecvenţă în procesul derecunoaştere.

5/8/2018 Cap5 - Tehnici de Proc Si Recun a Semnalului Vocal - slidepdf.com
http://slidepdf.com/reader/full/cap5-tehnici-de-proc-si-recun-a-semnalului-vocal 17/22
Cap. 5 Tehnici de procesare şi recunoaştere a semnalului vocal 137
Fig. 5.12. Filtrarea semnalului pe mai multe benzi cu modificare de fază zero(Costin, Grichnik, Zbancioc, 2003)
5.3.3. Rezultate experimentale, concluzii în urma aplicării metodei LPCC
Setul de date a fost extras din înregistr ări provenind de la 10 vorbitori, câte 20 de pronunţii pentru fiecare fonem (10 pronunţii pentru setul de antrenare, 10 pronunţii pentru setul de test). Seturile de coeficienţi autoregresivi s-au calculat prin două metode Burg şi FMC pentru un număr de 6 benzi de frecvenţe.
Rezultatele obţinute în cazul selecţiei benzilor folosind frecvenţe mel fixe au fostmai slabe decât pentru algoritmul de selecţie adaptată la informaţia spectrală. Dinacest motiv prezentăm doar rezultatele obţinute prin selecţie adaptivă a benzilor.Frecvenţele mel fixe folosite în selecţie sunt 100-500-1050-1800-2900-4400-6500Hz.Reţeaua neuronal de tip MLP a furnizat rezultate de clasificare mai slabe decât RBF
(vezi tabelul 5.10).La fel ca şi în cazul celorlalte studii f ăcute cu metodele bazate pe coeficienţiMFCC, LPCC datorită setului relativ mic de înregistr ări s-au extras aleatoriu din bazade înregistr ări, seturi succesive de înregistr ări (câte un număr de foneme pentrufiecare vorbitor), pattern-urile rezultate fiind aplicate succesiv reţelelor neuronale.Procesul se opreşte atunci când trei seturi de antrenare consecutive nu modifică eroarea de recunoaştere. Rezultatele raportate în tabelele 5.7-5.9 reprezintă erorilemedii de clasificare pentru seturile de antrenare aplicate consecutiv la intrare.
Filtru trece jos f L= f 1
Simetrie prin reflexiefaţă de dreaptă
... ...
Semnal de intrare
Filtru trece bandă f i÷f i+1
Filtru trece sus f H = f
Simetrie prin reflexiefaţă de dreaptă
Simetrie prin reflexiefaţă de dreaptă
Filtru trece jos f L=f 1
Simetrie prin reflexiefaţă de dreaptă
... ...Filtru trece bandă
f i÷ f
i+1
Filtru trece sus f
H =f
N
Simetrie prin reflexiefaţă de dreaptă
Simetrie prin reflexiefaţă de dreaptă
... ...
... ...
Extragere AR1 Extragere AR i Extragere AR N
Utilizare reţeaneuronală RN 1
Utilizare reţeaneuronală RN i
Utilizare reţeaneuronală RN N
... ...
... ...

5/8/2018 Cap5 - Tehnici de Proc Si Recun a Semnalului Vocal - slidepdf.com
http://slidepdf.com/reader/full/cap5-tehnici-de-proc-si-recun-a-semnalului-vocal 18/22
138 Cap. 5 Tehnici de procesare şi recunoaştere a semnalului vocal
În studiul importanţei benzilor pentru recunoaşterea vorbitorului am obţinuturmătoarele procentaje ale erorii de recunoaştere:
Table 5.7. Eroare clasificator de tip reţeaua neuronală RBF în recunoaşterea vorbitorului(Costin, Grichnik, Zbancioc, 2003)
AR/RBF B1 B2 B3 B4 B5 B6Burg 15.3 18.1 20.7 25.5 28.3 20.0FMC 29.2 23.7 13.4 21.9 33.6 40.2
Table 5.8. Eroare clasificator de tip arbore de decizie C5 în recunoaşterea vorbitorului(Costin, Grichnik, Zbancioc, 2003)
AR/C5 B1 B2 B3 B4 B5 B6
Burg 12.7 21.4 22.1 31.1 31.4 12.4FMC 33.4 29.1 10.7 27.1 31.1 28.4
După cum se poate observa pentru metoda FMC am obţinut cele mai bune rezultate pentru frecvenţele centrale, iar pentru metoda Burg au fost mai importante benzile dela început (corespunzătoare frecvenţelor joase).
La o comparare a performanţelor în funcţie de clasificator, reţeaua neuronală RBFare un procent mediu de recunoaştere pentru metoda Burg de 78,68% şi de 73% pentru metoda FMC, iar arborele de decizie furnizează procentaje medii de clasificareapropiate (78,15% pentru Burg şi 73,37% pentru FMC).
În studiul importanţei benzilor pentru recunoaşterea vorbirii, valorile erorii declasificare sunt date în tabelul 5.9:
Table 5.9. Eroare clasificator de tip reţeaua neuronală RBF în recunoaşterea vorbirii(Costin, Grichnik, Zbancioc, 2003)
AR/RBF B1 B2 B3 B4 B5 B6Burg 24.4 23.3 29.6 34.1 38.7 45.2FMC 33.4 27.8 26.5 32.7 42.8 55.3
Cel mai bun procentaj de recunoaştere a vorbirii se obţine utilizând informaţia din banda 2 prin metoda Burg 76.7%, dar rata medie de recunoaştere pe toate benzile estede doar 67,45% pentru metoda Burg şi 63,58% pentru metoda FMC.
Tabelul 5.10 s-a realizat sintetizând toate informaţiile obţinute prin clasificarea cucele trei tipuri de clasificatori.
Table 5.10. Reprezentarea scorurilor RV de recunoaştere a vorbitorului şi Rv de recunoaştere avorbirii pentru fiecare tip de clasificator (Best case, Average case)
RV(recunoa ştere vorbitor) Rv (recunoa ştere vorbire) BEST AVG BEST AVG
MLP 78.4% 67,5% 69.0% 59,3%RBF 86.6% 78,7% 76.7% 67,45C5 89,3% 78,15% 83,8% 70,4%

5/8/2018 Cap5 - Tehnici de Proc Si Recun a Semnalului Vocal - slidepdf.com
http://slidepdf.com/reader/full/cap5-tehnici-de-proc-si-recun-a-semnalului-vocal 19/22
Cap. 5 Tehnici de procesare şi recunoaştere a semnalului vocal 139
Reţeaua neurală RBF (cu funcţie Gaussiană) conduce la rezultate mai bune pentruseturile de date cu coeficienţi autoregresivi, decât reţeaua cu arhitectur ă perceptronmultistrat (MLP). Pentru o antrenare mai rapidă a reţelei MLP am iniţializat la începuteroarea globală de propagare cu o valoare mai mare (ξ=0.3), urmând ca după încheierea procesului de antrenare, să se realizeze rafinări ale acesteia, valoarea eroriifiind micşorată la ξ=0.1, respectiv ξ=0.03.
În analiza influenţei unei benzi de frecvenţe Bi în procesul de recunoaştere, nu s-aueliminat toate informaţiile din celelalte benzi. S-au păstrat toţi coeficienţii AR din banda analizată Bi, şi o doar informaţie globală privind suma tuturor amplitudinilor spectrale (calculata cu relaţia 5.19) din celelalte benzi de frecvenţe.
Cu această metodă se obţin procentaje mai mari pentru recunoaşterea vorbitorului,decât pentru recunoaşterea vorbirii. Deducem din rezultatele obţinute că faza
semnalului influenţează mai mult procesul de recunoaştere a vorbitorului, decât pe celde recunoaştere a vorbirii. Această concluzie este întărită şi de faptul că rezultateleobţinute cu coeficienţii AR au fost mai slabe dacă nu s-a aplicat o procedur ă defiltrare cu caracteristică de fază zero (pentru a nu afecta informaţia de fază).
Datorită diferenţelor de la un vorbitor la altul a aceleiaşi secvenţe rostite, datorateîn principal valorilor diferite ale frecvenţei fundamentale F0 şi automat aleformanţilor, devine necesar ă introducerea în vectorul de tr ăsături a acestor caracteristici. În lucrarea (Costin, Zbancioc, 2002) se prezintă două metode dedetecţie a pitch-ului (frecvenţei fundamentale F0): metoda cepstrală şi metodaspectrală. Pornind de la aceste cercetări s-a elaborat un instrument de extragere ainformaţiei spectrale detaliat în capitolul următor al tezei.
5.4. Concluzii. Contribuţii personale
Studiile şi cercetările prezentate în acest capitol au fost desf ăşurate împreună cuCS.III dr. ing. Mihaela Costin, Institutul de Informatică Teoretică al AcademieiRomâne – Filiala Iaşi şi au stat la baza realizării unor rapoarte de cercetare, a publicării unei lucr ări într-o revistă internaţională (Costin, Zbancioc, 2002) şi a prezentării unor articole în cadrul unor conferinţe naţionale şi internaţionale. (Costin,Zbancioc et al., 2002), (Costin, Grichnik, Zbancioc, 2003), (Costin, Zbancioc, 2003)(Zbancioc, Costin, 2003)
Cele trei metode de extragere de vectori de tr ăsături bazate pe coeficienţii MFCC,LPCC şi autoregresivi au vizat evaluarea relevanţei fiecărui tip de pattern în procesulde recunoaştere a vorbirii. Cu observaţia că rezultatele statistice obţinute prinantrenarea cu reţele neuronale şi arbori de decizie au avut la bază seturi de înregistr ărirelativ mici (de doar 200-300 de fişiere de sunet, provenite de la un număr mic de persoane) şi nu de câteva sute de mii, milioane cum au studiile realizate pe un număr reprezentativ statistic de date, concluziile desprinse şi rezultatele raportate în parteaexperimentală a fiecărei metode pot suferi modificări la o extindere a bazei de date.Dificultăţile obţinerii unui set mare de înregistr ări pentru limba română provin şi dinfaptul că există puţine instituţii care ofer ă acces gratuit la bazele lor de date. Unexemplu pozitiv în acest sens îl reprezintă baza SRoL – Proiectul Sunetele Limbii

5/8/2018 Cap5 - Tehnici de Proc Si Recun a Semnalului Vocal - slidepdf.com
http://slidepdf.com/reader/full/cap5-tehnici-de-proc-si-recun-a-semnalului-vocal 20/22
140 Cap. 5 Tehnici de procesare şi recunoaştere a semnalului vocal
Române, proiect coordonat de prof. H.N. Teodorescu care ofer ă o colecţie de câtevamii de înregistr ări (foneme, cuvinte, fraze, fraze cu încărcătur ă emoţională etc.), precum şi un set de instrumente pentru procesarea automată a fişierelor de sunet(Feraru, Teodorescu, Zbancioc, 2010).
Contribuţiile personale legate de metodele de extragere de tr ăsături şi derecunoaştere sunt următoarele:- elaborare prin colaborare a unei metode de extragere a coeficienţilor MFCC;- studiu în colaborare a relevanţei energiei benzilor de frecvenţă mel în
recunoaşterea unui set de vocale ale limbii române;- studiul în colaborare a procentelor de clasificare obţinute cu vectori de tr ăsături
MFCC, MFCC, MFCC în recunoaşterea unor foneme nevocalice;- elaborare prin colaborare a unui algoritm de calcul MFSC folosind benzi cu limite
variabile, ponderate prin funcţii de apartenenţă fuzzy trapezoidale;- implementare aplicaţie software de extragere a coeficienţilor MFCC;- elaborare prin colaborare a unei metode de extragere a coeficienţilor LPCC;- studiu în colaborare a relevanţei coeficienţilor LPC, LPC cepstrali în recunoaşterea
unor foneme nevocalice;- implementare aplicaţie software de extragere a coeficienţilor LPCC;- elaborare prin colaborare a unei metode de extragere a coeficienţilor autoregresivi;- elaborare prin colaborare a unei metode adaptivă de estimare a frecvenţelor de
tăiere, a benzilor de frecvenţe pentru care se calculează coeficienţii AR, dinsemnalul sumă al amplitudinilor spectrale;
- studiu în colaborare a relevanţei coeficienţilor autoregresivi extraşi prin metodeleBurg şi FMC în recunoaşterea unor foneme nevocalice în diverse benzi defrecvenţe asupra recunoaşterii vorbitorului şi a vorbirii;
-
implementare aplicaţie software de extragere a coeficienţilor autoregresivi;- aplicarea vectorilor de tr ăsături extraşi unor clasificatori de tip reţea neuronală şi detip arbori de decizie şi analiza prin colaborare a procentajelor de recunoaştere.
Direcţiile de cercetare din acest capitol se continuă cu metode şi tehnici de detecţiea informaţiei prozodice: frecvenţa fundamentală şi valorile formantice în cadrul unui proiect prioritar al Academiei Române.
Bibliografie capitol
Bhattacharya A. and F.-G. Zeng (2005), Companding to improve cochlear implants’ speech
processing in noise, in Proceedings of Conference on Implantable Auditory Prostheses,Pacific Grove, Calif, USA, July-August 2005.
Bhiksha Raj, Lorenzo Turicchia, 2 Bent Schmidt-Nielsen, and Rahul Sarpeshkar (2007) An FFT-Based Companding Front End for Noise-Robust Automatic Speech Recognition,Hindawi Publishing Corporation, EURASIP Journal on Audio, Speech, and MusicProcessing, Vol. 2007, Article ID 65420.
Brockwell P. J., R. Dahlhaus (2004), Generalized Levinson–Durbin and Burg algorithms,Journal of Econometrics, Vol. 118, Issues 1-2, January-February 2004, pp. 129-149
Costin Mihaela, Grichnik Anthony, Zbancioc Marius (2003), “Tips on Speaker Recognition by
Autoregressive Parameters and Connectionist Methods”, International Symposium onSignal, Circuits and Systems SCS2003, IEEE Procedings, Vol. 1, Iaşi, România, p.169-172,ISBN 0-7803-7979-9.

5/8/2018 Cap5 - Tehnici de Proc Si Recun a Semnalului Vocal - slidepdf.com
http://slidepdf.com/reader/full/cap5-tehnici-de-proc-si-recun-a-semnalului-vocal 21/22
Cap. 5 Tehnici de procesare şi recunoaştere a semnalului vocal 141
Costin Mihaela, Zbancioc Marius (2002), “ Hints About Some Baseful but Indispensable Elements in Speech Recognition And Reconstruction”, Computer Science Journal of Moldova, 2002, Vol.10, No.2., pp.169.
Costin M., M. Zbancioc, A. Ciobanu, Ch. Berger Vachon (2002), “Some Attempts in Improving
Cochlear Implanted Patients Performances: Modeling and Automatic Methods”, IPMU2002 International Conference on Information Processing and Management of Uncertaintyin Knowledge-Based Systems, Annecy, France, 1-5 July, 2002, pp. 711-718.
Costin Mihaela, Marius Zbancioc (2003), “ Improving Cochlear Implant Performances by
MFCC Technique”, International Symposium on Signal, Circuits and Systems SCS2003,IEEE Procedings, Vol. 2, Iaşi, România, pp.449-452, ISBN 0-7803-7979-9 .
Dumitraş A. (1997), Proiectarea re ţ elelor neuronale artificiale, Casa Editorială Odeon,Bucureşti, 1997, ISBN 973-9008-75-5.
Feraru S.M., Teodorescu H.N., Zbancioc M.D. (2010), SRoL -Web-based Resources for Languages and Language Technology e-Learning , International Journal of Computers
Communications & Control , ISSN 1841-9836, 5(3):301-313, 2010.Guinness J., B. Raj, B. Schmidt-Nielsen, L. Turicchia, and R. Sarpeshkar (2005), A
companding front end for noise-robust automatic speech recognition, in Proceedings of IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP ’05),Vol. 1, pp. 249–252, Philadelphia, Pa, USA, March 2005.
Hariharan M., Paulraj M.P., Yaacob, S. (2009), Identification of vocal fold pathology based on
Mel Frequency Band Energy Coefficients and singular value decomposition, Signal andImage Processing Applications (ICSIPA), IEEE International Conferenc, 18-19 Nov., pp:514 - 517 ISBN: 978-1-4244-5560-7, Kuala Lumpur, 2009.
Holmberg M., D. Gelbart, and W. Hemmert (2006), Automatic speech recognition with anadaptation model motivated by auditory processing , IEEE Transactions on Audio, Speech,and Language Processing, Vol. 14, No. 1, pp. 43–49, 2006.
Hosom J.-P. (2004), Speech Recognition, Encyclopedia of Information Systems Editor-in-
Chief: Hossein Bidgoli , Academic Press, ISBN: 978-0-12-227240-0, 2004, pp. 155-169.
Juang Biing Hwang, M. Mohan Sondhi, Lawrence R. Rabiner (2004), Digital Speech Processing , Third edition, Encyclopedia of Physical Science and Technology, Editor-in-Chief: Robert A. Meyers, Academic Press, 2004, pp. 485-500, ISBN: 978-0-12-227410-7.
Juang B.-H., L.R. Rabiner (2006), Speech Recognition, Automatic: History, Encyclopedia of Language & Linguistics (Second Edition), 2006, Elsevier, ISBN: 978-0-08-044854-1, pp.806-819.
Krishna K., V. L. N. Murty, K. R. Ramakrishnan (2001), Vector quantization of excitation
gains in speech coding , Signal Processing, Volume 81, Issue 1, January 2001, pp. 203-209Lee K.F.(1989), Automatic Speech Recognition; The Development of SPHINX System, Kluwer
Academic Publisher, Boston, 1989.Lee K.H., H.Hon, R.Reddy (1990), An Overview of the SPHINX Speech Recognition, IEEE
Trans. on Acoustics, Speech and Signal Processing, jan 1990.Lee Y. W., S. Y. Kwon, Y. S. Ji, et al. (2005), Speech enhancement in noise environment using
companding strategy, in Proceedings of the 5th Asia Pacific Symposium on Cochlear Implant and Related Sciences (APSCI ’05), Hong Kong, November 2005.
Loizou P. C., K. Kasturi, L. Turicchia, R. Sarpeshkar, M. Dorman, and T. Spahr (2005), Evaluation of the companding and other strategies for noise reduction in cochlear implants ,in Proceedings of Conference on Implantable Auditory Prostheses,Pacific Grove, Calif,USA, July-August 2005.
Mitra K. S. (2001) Digital Signal Processing A Computer Based Approach, 2nd ed. McGraw-Hill, ISBN 0-07-232105-9.
Muñoz-Expósito J.E., S. García-Galán, N. Ruiz-Reyes, P. Vera-Candeas (2007), Adaptivenetwork-based fuzzy inference system vs. other classification algorithms for warped LPC-

5/8/2018 Cap5 - Tehnici de Proc Si Recun a Semnalului Vocal - slidepdf.com
http://slidepdf.com/reader/full/cap5-tehnici-de-proc-si-recun-a-semnalului-vocal 22/22
142 Cap. 5 Tehnici de procesare şi recunoaştere a semnalului vocal
based speech/music discrimination, Engineering Applications of Artificial Intelligence, Vol.20, Issue 6, September 2007, pp. 783-793
Naito Masaki, Li Deng, Yoshinori Sagisaka, (2002), Speaker clustering for speech recognitionusing vocal tract parameters, Speech Communication, Vol. 36, Issues 3-4, March 2002, pp.305-315
Nusbaum H.C., H. Shintel (2006) , Speech Synthesis, in ”Encyclopedia of Language &Linguistics – Second edition”, Editor-in-Chief: Keith Brown 2006, ISBN: 978-0-08-044854-1, pp. 19-31
Quinlan J. R.(1996). Improved use of continuous attributes in c4.5. Journal of ArtificialIntelligence Research, 4:77-90, 1996.
Press H. W. , Teukolsky A. S., Vetterling T. W., Flannery P. B., Cambridge (2007) Numerical receips in C , The Art of Scientific Computind Third Edition, Camridge University Press,ISBN 978-0-521-88068-8, 2007.
Rabiner L., B. H. Juang (1993), " Fundamental of Speech Recognition", PTR Prentice Hall 1
edition, ISBN-10: 0130151572 , pp. 496, 1993.Rabiner L.R., B.-H. Juang (2006), Speech Recognition: Statistical Methods, Encyclopedia of
Language & Linguistics (Second Edition), 2006, Elsevier, ISBN: 978-0-08-044854-1, pp. 1-18
Reynolds T. J.,. Antoniou C. A. (2003) Experiments in speech recognition using a modular MLP architecture for acoustic modelling, , Information Sciences, Vol. 156, Issues 1-2, 1 November 2003, pp. 39-54,
Shaman Paul (2010), Generalized Levinson–Durbin sequences, binomial coefficients and
autoregressive estimation, Journal of Multivariate Analysis, Volume 101, Issue 5, May2010, pp. 1263-1273
So Stephen, Paliwal Kuldip K (2007), A comparative study of LPC parameter representations
and quantisation schemes for wideband speech coding , Digital Signal Processing, Vol. 17,Issue 1, January 2007, pp. 114-137
Zbancioc Marius, Mihaela Costin (2003), “Using Neural Networks and LPCC to Improve
Speech Recognition”, International Symposium on Signal, Circuits and Systems SCS2003,IEEE Procedings, Vol. 2, Iaşi, România, pp. 445-448, ISBN 0-7803-7979-9.Zheng Fang, Guoliang Zhang and Zhanjiang Song (2001), Comparison of Different
Implementations of MFCC , J. Computer Science & Technology, 16(6): 582–589.


















