
CURSUL AL VII-LEA 1. Eşantion - umfcv.ro MG - Cursul VII.pdf · CURSUL AL VII-LEA 1. Eşantion....
18
Biostatistică - Cursul al VII-lea CURSUL AL VII-LEA 1. Eşantion Indicatorii statistici calculaţi pentru un eşantion anume sunt simple aproximări pentru parametrii reali ai populaţiei din care provine eşantionul. De exemplu, coeficientul mediu de inteligenţă calculat la un eşantion de studenţi, este o aproximare foarte proastă a coeficientului mediu de inteligenţă al întregii populaţii, deoarece un eşantion de studenţi nu este reprezentativ pentru întreaga populaţie. În schimb, coeficientul mediu de inteligenţă calculat la un eşantion mare de indivizi aleşi la întâmplare din populaţie, va fi probabil o aproximare mai bună a coeficientului mediu de inteligenţă al întregii populaţii. Se pune în mod natural problema de a stabili câtă încredere se poate avea în aceste aproximări, sau cât de precise sunt ele. Să încercăm să precizăm condiţiile pe care trebuie să le avem îndeplinite pentru ca gradul de siguranţă în concluziile pe care le tragem despre o populaţie pe baza rezultatelor obţinute pe un eşantion, să fie cât mai mare. Înainte de a preciza aceste condiţii, să stabilim de ce aprecierea acestei precizii de aproximare este importantă. Deci, să plecăm de la faptul că avem media şi deviaţia standard calculate pentru un anumit parametru pe un eşantion. Dacă modul în care a fost ales eşantionul ne dă posibilitatea să afirmăm că acestea sunt bune aproximări ale mediei şi deviaţiei standard pentru întreaga populaţie, atunci acesta este de fapt singurul lucru pe care ne putem baza, în afara, eventual, a unor medii sau deviaţii date în literatura de specialiate. De exemplu, dacă pe un eşantion bine ales, vom obţine coeficientul mediu de inteligenţă 101,5 şi o deviaţie standard de 14,4, aceasta ne îndreptăţeşte să spunem că media populaţiei este aproximativ 101,5 , iar deviaţia standard aproximativ 14,4. Media reală a întregii populaţii şi deviaţia standard a întregii populaţii ne sunt chiar necunoscute de multe ori. În acest curs ne vom pune problema de a stabili cât de bune sunt aproximaţiile de acest gen. Vom încerca să stabilim cât de aproape de realitate este media aproximativă, obţinută luând în calcul doar indivizii eşantionului ales. Uneori, din surse bibliografice avem informaţii despre media unei întregi populaţii, dar în cazul în care nu avem astfel de date din surse bibliografice, sau când datele din mai multe surse nu concordă, atunci media întregii populaţii nu ne va fi de fapt cunoscută decât prin aproximările obţinute pe eşantioane. De fapt, sursele bibliografice nu ne dau nici ele decât tot aproximări foarte bune ale adevăratei medii sau deviaţii standard, obţinute tot pe nişte eşantioane extrase din populaţia respectivă. Pentru o discuţie ceva mai exactă, să introducem câţiva termeni: vom numi eşantion sau lot, o submulţime a unei populaţii statistice. Extrapolarea, sau generalizarea unor rezultate obţinute prin măsurători pe un eşantion la întreaga populaţie o vom numi inferenţă. De exemplu, dacă coeficientul mediu de inteligenţă pe un eşantion reprezentativ este 101,5, putem, în anumite condiţii foarte precise, să facem afirmaţia generalizatoare, sau inferenţa, că media coeficientului de inteligenţă al populaţiei este de este 101,5. 2. Eşantionare Şi acum să trecem la modalităţile prin care se realizează inferenţa statistică. De la început trebuie precizat că un rol central îl joacă distribuţia Gauss care de fapt nu este o distribuţie ca oricare alta ci, datorită proprietăţilor ei naturale, în special simetria, are un statut oarecum privilegiat. Pentru a ne da seama de acest lucru, să presupunem că ne aflăm în faţa unei populaţii cu un număr foarte mare de indivizi, ceea ce, din punct de vedere statistic se denumeşte ca “practic infinită”. Să presupunem pentru simplitate că media populaţiei respective în ceea ce priveşte un anumit parametru este m iar deviaţia standard este s, valori care sunt de obicei necunoscute, iar distribuţia variabilei respective este 1
Transcript of CURSUL AL VII-LEA 1. Eşantion - umfcv.ro MG - Cursul VII.pdf · CURSUL AL VII-LEA 1. Eşantion....

Biostatistică - Cursul al VII-lea
CURSUL AL VII-LEA
1. Eşantion Indicatorii statistici calculaţi pentru un eşantion anume sunt simple aproximări pentru parametrii reali ai populaţiei din care provine eşantionul. De exemplu, coeficientul mediu de inteligenţă calculat la un eşantion de studenţi, este o aproximare foarte proastă a coeficientului mediu de inteligenţă al întregii populaţii, deoarece un eşantion de studenţi nu este reprezentativ pentru întreaga populaţie. În schimb, coeficientul mediu de inteligenţă calculat la un eşantion mare de indivizi aleşi la întâmplare din populaţie, va fi probabil o aproximare mai bună a coeficientului mediu de inteligenţă al întregii populaţii.
Se pune în mod natural problema de a stabili câtă încredere se poate avea în aceste aproximări, sau cât de precise sunt ele. Să încercăm să precizăm condiţiile pe care trebuie să le avem îndeplinite pentru ca gradul de siguranţă în concluziile pe care le tragem despre o populaţie pe baza rezultatelor obţinute pe un eşantion, să fie cât mai mare. Înainte de a preciza aceste condiţii, să stabilim de ce aprecierea acestei precizii de aproximare este importantă.
Deci, să plecăm de la faptul că avem media şi deviaţia standard calculate pentru un anumit parametru pe un eşantion. Dacă modul în care a fost ales eşantionul ne dă posibilitatea să afirmăm că acestea sunt bune aproximări ale mediei şi deviaţiei standard pentru întreaga populaţie, atunci acesta este de fapt singurul lucru pe care ne putem baza, în afara, eventual, a unor medii sau deviaţii date în literatura de specialiate. De exemplu, dacă pe un eşantion bine ales, vom obţine coeficientul mediu de inteligenţă 101,5 şi o deviaţie standard de 14,4, aceasta ne îndreptăţeşte să spunem că media populaţiei este aproximativ 101,5 , iar deviaţia standard aproximativ 14,4. Media reală a întregii populaţii şi deviaţia standard a întregii populaţii ne sunt chiar necunoscute de multe ori.
În acest curs ne vom pune problema de a stabili cât de bune sunt aproximaţiile de acest gen. Vom încerca să stabilim cât de aproape de realitate este media aproximativă, obţinută luând în calcul doar indivizii eşantionului ales.
Uneori, din surse bibliografice avem informaţii despre media unei întregi populaţii, dar în cazul în care nu avem astfel de date din surse bibliografice, sau când datele din mai multe surse nu concordă, atunci media întregii populaţii nu ne va fi de fapt cunoscută decât prin aproximările obţinute pe eşantioane. De fapt, sursele bibliografice nu ne dau nici ele decât tot aproximări foarte bune ale adevăratei medii sau deviaţii standard, obţinute tot pe nişte eşantioane extrase din populaţia respectivă.
Pentru o discuţie ceva mai exactă, să introducem câţiva termeni: vom numi eşantion sau lot, o submulţime a unei populaţii statistice. Extrapolarea, sau generalizarea unor rezultate obţinute prin măsurători pe un eşantion la întreaga populaţie o vom numi inferenţă. De exemplu, dacă coeficientul mediu de inteligenţă pe un eşantion reprezentativ este 101,5, putem, în anumite condiţii foarte precise, să facem afirmaţia generalizatoare, sau inferenţa, că media coeficientului de inteligenţă al populaţiei este de este 101,5.
2. Eşantionare Şi acum să trecem la modalităţile prin care se realizează inferenţa statistică. De la început trebuie precizat că un rol central îl joacă distribuţia Gauss care de fapt nu este o distribuţie ca oricare alta ci, datorită proprietăţilor ei naturale, în special simetria, are un statut oarecum privilegiat. Pentru a ne da seama de acest lucru, să presupunem că ne aflăm în faţa unei populaţii cu un număr foarte mare de indivizi, ceea ce, din punct de vedere statistic se denumeşte ca “practic infinită”.
Să presupunem pentru simplitate că media populaţiei respective în ceea ce priveşte un anumit parametru este m iar deviaţia standard este s, valori care sunt de obicei necunoscute, iar distribuţia variabilei respective este
1

Biostatistică - Cursul al VII-lea normală. Să mai presupunem că, să aproximăm media m a populaţiei prin medii obţinute pe eşantioane de volum n, adică eşantioane cu n indivizi.
Putem chiar să ne imaginăm ce se întâmplă dacă luăm foarte multe astfel de eşantioane, poate chiar pe toate. Vom obţine foarte multe medii aproximative, aproximaţii care sunt, multe dintre ele mai departe de adevărata medie, altele mai apropiate.
Vom numi aceste medii aproximative, medii de eşantionare de volum n. Se naşte astfel o serie statistică, a acestor medii, care are o importanţă deosebită, deoarece are anumite proprietăţi pe care le vom descrie în continuare, care ne vor ajuta în a estima cât de bune sunt aproximările prin medii de eşantionare.
Fie seria statistică Mn: m1, m2, m3.........., seria acestor medii de eşantionare de volum n. Se poate demonstra că:
• media seriei statistice Mn este aceeaşi cu a populaţiei, adică m.
• deviaţia standard a seriei Mn este s snn = , adică mai mică decât a populaţiei, care este s.
• distribuţia seriei Mn este Gauss.
Afirmaţiile de mai sus s-ar traduce în termenii exemplului cu media coeficientului de inteligenţă aşa cum este descris mai jos.
Media coeficientului de inteligenţă într-o populaţie este, sa zicem, 100, iar deviaţia standard 15, dar noi nu ştim aceste valori. O serie de cercetători, dorind să o aproximeze, iau fiecare câte un eşantion, şi calculează coeficientul de inteligenţă mediu, fiecare la eşantionul pe care şi l-a ales.
Să mai presupunem că toţi cercetătorii iau eşantioane de volum egal, adică cu acelaşi număr de indivizi, de exemplu, 144. Ei vor obţine aproximaţii mai bune sau mai proaste, căci mai joacă şi întâmplarea rolul ei, unele vor da o medie de eşantionare sub 100, altele peste 100, etc.
Dacă am lua TOATE eşantioanele de câte 144 de indivizi, fiecare eşantion ne dă câte o medie aproximativă a coeficientului de inteligenţă de 100 al populaţiei. Media tuturor acestor aproximaţii va fi TOT 100!!! Cum aceste aproximaţii sunt unele mai mici, unele mai mari, unele sub media reală, altele peste, ele au şi o deviaţie standard.
Deviaţia standard va fi 25,11215
14415
144 ====nss , ceea ce ne spune că aproximaţiile ar fi destul de
bune, dacă se abat de la medie cu o deviaţie standard aşa de mică, de 1,25. În plus, aceste aproximaţii se distribuie Gauss, ca şi coeficientul de inteligenţă, care se distribuie tot Gauss.
Pentru ce este bună o astfel de teorie? Ajută să ne dăm seama cât de bune sunt aproximaţiile. De exemplu, aproximaţiile pe aşantioane de 144 de indivizi, sunt, cum se vede de mai sus, destul de bune. Pe eşantioane de 400 de indivizi, aproximarea care se obţine are o deviaţie standard de 75,0
2015
40015
400 ====nss ,
deci aceste aproximaţii vor fi probabil mai bune.
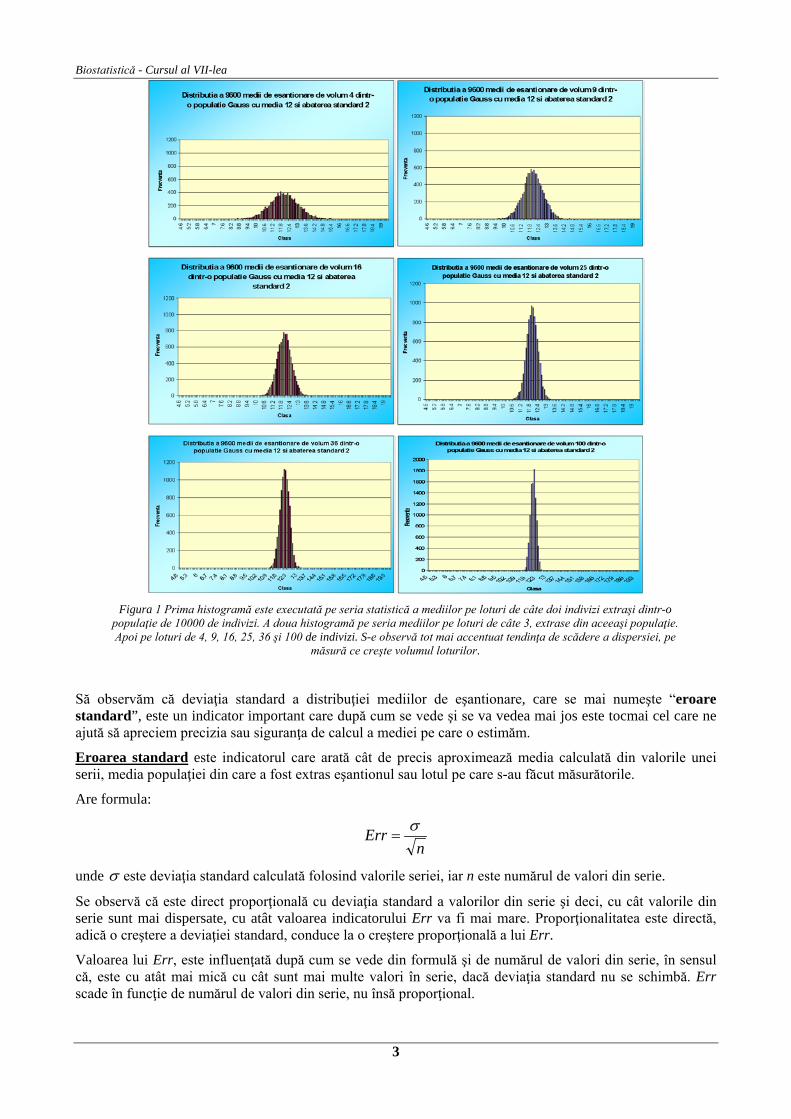
În figura 1 sunt reprezentate histogramele corespunzătoare cazurilor când luăm foarte multe medii pe loturi de câte 2 sau 3 sau 4, până la 100 (2, 3, 4, 9, 16, 25, 36, 100). Se observă toate cele trei afirmaţii punctate mai sus.
2
Biostatistică - Cursul al VII-lea
Figura 1 Prima histogramă este executată pe seria statistică a mediilor pe loturi de câte doi indivizi extraşi dintr-o
populaţie de 10000 de indivizi. A doua histogramă pe seria mediilor pe loturi de câte 3, extrase din aceeaşi populaţie. Apoi pe loturi de 4, 9, 16, 25, 36 şi 100 de indivizi. S-e observă tot mai accentuat tendinţa de scădere a dispersiei, pe
măsură ce creşte volumul loturilor.
Să observăm că deviaţia standard a distribuţiei mediilor de eşantionare, care se mai numeşte “eroare standard”, este un indicator important care după cum se vede şi se va vedea mai jos este tocmai cel care ne ajută să apreciem precizia sau siguranţa de calcul a mediei pe care o estimăm.
Eroarea standard este indicatorul care arată cât de precis aproximează media calculată din valorile unei serii, media populaţiei din care a fost extras eşantionul sau lotul pe care s-au făcut măsurătorile.
Are formula:
nErr σ
=
unde σ este deviaţia standard calculată folosind valorile seriei, iar n este numărul de valori din serie.
Se observă că este direct proporţională cu deviaţia standard a valorilor din serie şi deci, cu cât valorile din serie sunt mai dispersate, cu atât valoarea indicatorului Err va fi mai mare. Proporţionalitatea este directă, adică o creştere a deviaţiei standard, conduce la o creştere proporţională a lui Err.
Valoarea lui Err, este influenţată după cum se vede din formulă şi de numărul de valori din serie, în sensul că, este cu atât mai mică cu cât sunt mai multe valori în serie, dacă deviaţia standard nu se schimbă. Err scade în funcţie de numărul de valori din serie, nu însă proporţional.
3

Biostatistică - Cursul al VII-lea De exemplu, dacă n creşte de 4 ori, Err scade de două ori: două serii de valori, X şi Y, au aceeaşi deviaţie standard egală cu 2,3, iar numărul de valori în seria X este 25 iar cel al seriei Y este 100. Atunci erorile standard pentru cele două serii sunt:
46,053,2
25===
σXErr
23,010
3,2100
===σ
YErr
Deoarece este considerată a fi abaterea standard a mediei (calculată pe valorile măsurate pe un lot), faţă de media întregii populaţii, i se mai spune uneori «abaterea standard a mediei de la medie», ceea ce este bineînţeles un simplu joc de cuvinte şi nu trebuie luat în serios atunci când este întâlnit.
Bineînţeles că mediile obţinute pe eşantioane de volum n vor fi de obicei, cu atât mai aproape de realitate cu cât n este mai mare. Acest aspect nu trebuie neapărat demonstrat căci are un suport intuitiv evident: o aproximare a mediei unei populaţii este în principiu, cu atât mai bună cu cât eşantionul extras este mai numeros.
Acest lucru ne spune că dacă reprezentăm curba Gauss a mediilor de eşantionare, ea va fi cu atât mai “strânsă“ în jurul mediei reale, cu cât eşantioanele sunt de volum mai mare, deoarece este mai puţin probabil să avem medii foarte îndepărtate de media reală.
Pe când folosirea de eşantioane restrânse ca acelea formate din doar doi sau trei indivizi poate duce la medii foarte departe de cea reală, mediile obţinute pe eşantioane mai numeroase vor fi în general mult mai apropiate de media reală.
De altfel, formula s snn = , ne spune tocmai acest lucru, căci se vede că o creştere a lui n conduce la un
numitor mare şi deci la o eroare standard mică.
Această distribuţie, a mediilor de eşantionare, ne oferă posibilitatea de a estima siguranţa cu care este aproximată media din chiar forma ei. O distribuţie a mediilor de eşantionare foarte strânsă arată în genereal precizii bune. Dar o distribuţie “strânsă”, înseamnă o eroare standard mică.
Eşantionarea este un proces cu încărcătură pur statistică, el punând la încercare fondul de gândire probabilistă pe care fiecare îl avem prin educaţie, fără să fi învăţat neapărat probabilităţi sau statistică. Gândirea comună, sau uzuală, ne spune că este natural ca măsurători multe să ne conducă la o precizie mai bună. Există totuşi multe limite ale gândirii comune care ne pot arunca în capcane greu de ocolit.
Judecăţile de mai sus sunt valabile ca afirmaţii statistice şi nu absolute. Am fi de exemplu tentaţi să afirmăm că media de eşantionare obţinută pe un eşantion de volum mai mare este totdeauna mai precisă decât media de eşantionare obţinută pe un eşantion de volum mai mic, ceea ce nu este adevărat. Adevărată este doar afirmaţia:
Este mai probabil ca o medie de eşantionare pe un eşantion de volum mai mare să fie mai precisă decât una obţinută pe un eşantion de volum mai mic.
Este posibil ca, prin jocul întâmplării, o medie obţinută pe un eşantion mai mare să fie mai departe de media reală decât o medie obţinută pe un eşantion mai mic. Numai că această situaţie este mai puţin probabilă, cu atât mai puţin probabilă cu cât diferenţa de volum între cele două eşantioane este mai mare.
3. Intervale de încredere
Definiţie. Estimarea unui parametru printr-o valoare numerică supusă unor erori inerente. Nu există metodă perfectă de a măsura ceva şi ca urmare, orice înregistrare de date se face cu erori care se datorează în primul rând procesului de măsurare. Iar în medicină, mai intervine şi variabilitatea naturală, un acelaşi parametru fiind diferit de la individ la individ şi chiar, la un acelaşi individ, dacă măsurăm la două momente de timp
4

Biostatistică - Cursul al VII-lea difeite. De aceea, o metodă comodă de a estima media unui parametru este aproximarea ei dacă este posibil, printr-un interval în care se află adevărata medie a acelui parametru.
Din păcate, nu este posibil să găsim în general un interval finit în care să fim absolut siguri că se află valoarea medie a parametrului de estimat. Acest lucru este posibil de exemplu atunci când avem informaţii apriorice despre parametrul respectiv, de exemplu când este sigur că valoarea lui este în intervalul unitate, sau, cum este cazul coeficientului de corelaţie (vezi cursul VII), valoarea lui este cuprinsă în intervalul [-1, 1].
Tot ceea ce se poate face este să găsim un interval în care valoarea medie a parametrului pe care îl estimăm să se afle nu sigur, ci numai cu o probabilitate dinainte fixată. Dacă fixăm nivelul de siguranţă (probabilitatea) la o valoare suficientă, de exemplu 95% sau 99%, ne putem declara mulţumiţi.
Pentru a înţelege mai bine cele expuse mai jos, este bine să gândim în termenii exemplului cu coeficientul de inteligenţă: avem de estimat parametrul care se numeşte media coeficientului de inteligenţă al unei populaţii şi avem la îndemână doar un eşantion, pe care am calculat numai o medie de eşantionare care o aproximează pe cea reală, necunoscută.
DEFINIŢIE: Vom numi interval de încredere de siguranţă α% (95%, 99%, etc), un intreval de numere în care suntem α% siguri că se află adevărata valoare a parametrului pe care îl estimăm.
Dacă un parametru este repartizat Gauss, cu media m şi abaterea standard s, atunci media de eşantionare X , obţinută pe un aşantion de n indivizi, respectă formula următoare:
95,096,196,1 ≈
⋅+<<⋅−nsXm
nsXP
Această formulă se traduce astfel în limbajul obişnuit: Există o probabiltate de aproximativ 95% ca media
reală (necunoscută) m să fie cuprinsă în intervalul de la nsX ⋅− 96,1 la
nsX ⋅+ 96,1 .
Sau, altfel spus: adevărata medie m, necunoscută, se află cu o probabilitate de 95%, adică aproape sigur, în intervalul format prin adunarea şi scăderea din media de eşantionare X , a unei valori egale
cu 1,96 ns . În practică, deoarece s este necunoscut, se pune în locul lui, deviaţia standard de eşanationare
adică cea calculată folosind eşantionul de n indivizi. Această deviaţie standard, care a fost notată în cursul întâi cu σ, este doar o aproximare a deviaţiei standard a populaţiei, pe care am norat-o cu s. Se demonstrează că în acest caz, trebuie să ne referim la repartiţia Student şi să luăm în locul a 1,96 erori standard stânga dreapta, un număr de erori standard dat de 1
%95−nt , unde n este volumul lotului, iar 1
%95−nt se ia din tabelele
distribuţiei Student (vezi laborator).
Formula de calcul pentru intervalul de încredere de 95% este deci:
⋅+⋅−= −−
ntX
ntXI nn σσ 1
%951%95%95 ,
În general, pentru calculul intervalului de încredere de siguranţă α%, formula este:
⋅+⋅−= −−
ntX
ntXI nn σσ
ααα1
%1
%% ,
Exemplu de calcul: Media de eşantionare pentru o serie statistică în care am măsurat latenţa semnalului pe nervul optic, este 112,2 ms iar abaterea standard este 12,5 ms. Volumul eşantionului este de 156 de indivizi. Să se calculeze intervalul de încredere de 95%.
Eroarea standard este 149,125,12
1565,12
====n
Err σ
În tabele statistice, corespunzător la 155 grade de libertate se găseşte 96,1155%95 =t
Deci limitele inferioară şi superioară pentru intervalul de încredere sunt:
5

Biostatistică - Cursul al VII-lea
24,110196,12,112155%95 =⋅−=⋅−=
ntXInf σ
16,114196,12,112155%95 =⋅−=⋅+=
ntXSup σ
Deci, intervalul de încredere este: [ ]msms;114,110,2I 2%95 =
Putem afirma cu o siguranţă de 95% că media reală, pe care nu o cunoaştem este în acest interval.
Un interval de încredere este totdeauna centrat pe media de eşantionare, lucru care este normal, el fiind obţinut prin adăugarea şi scăderea din media de eşantionare a aceleiaşi cantităţi tαErr. Deci dacă suntem întrebaţi unde este media de eşantionare în raport cu limitele unui interval de încredere al ei, spunem simplu că este la mijloc.
Ceea ce ne interesează însă, este unde se află media reală în raport cu intervalul de incredere asociat, sau care o estimează, pentru că de fapt chiar acesta este scopul pentru care construim intervale de încredere, ca să estimăm media reală.
După definiţia intervalului de încredere, media reală se află α% sigur (95% sigur, 99% sigur, etc), între limitele intervalului de încredere. De obicei suntem tentaţi să spunem că este la mijloc, ceea ce nu este adevărat. Media reală, poate fi oriunde în interiorul intervalului de încredere, aşa cum poate să fie chiar şi în afara lui, cu o probabilitate foarte mică. Nu este corect să spunem nici măcar că este mai probabil să se afle la mijlocul sau în jurul mijlocului intervalului de încredere. Ea se află oriunde în intervalul de încredere, la fel de probabil spre mijloc sau spre capete.
TESTE STATISTICE
1. Problema testelor statistice În ştiinţă, afirmaţiile sunt adevărate sau false. Spre deosebire de ştiinţele exacte însă, în medicină şi biologie avem o interpretare relativ diferită a adevărului şi falsităţii.
În ştiinţele vieţii, nu totdeauna este cazul unor decizii clare, sigure. De exemplu, la un lot de indivizi sănătoşi am putea obţine media latenţei semnalului electric pe nervul optic 104,5 ms, iar la un lot de indivizi cu lacunarism cerebral am putea obţine o medie a latenţei de 116,4 ms. Având în vedere diferenţa destul de mare între cele două medii, ne putem gândi că cele două loturi provin din populaţii cu medii diferite. Dacă însă, facem afirmaţia că cele două loturi provin din populaţii cu medii egale, vom putea lua o decizie de genul:
„este foarte improbabil ca cele două loturi să provină din populaţii cu medii egale”.
Totuşi, nu este exclusă posibilitatea ca cele două loturi chiar să provină din populaţii cu medii egale, şi nu putem fi 100% siguri pe decizia luată. În statistică, nu are sens să se spună despre o astfel de ipoteză că este adevărată sau falsă. Tot ce se poate aprecia este plauzibilitatea ei.
În statistică, orice afirmaţie este mai mult sau mai puţin plauzibilă, şi nu neapărat adevărată sau falsă.
În mod natural, atunci când constatăm diferenţe mari între mediile a două loturi, punem diferenţa pe seama faptului că populaţiile din care provin loturile au medii diferite. Invers, când diferenţele între mediile celor două loturi sunt mici, le punem pe seama întâmplării şi considerăm că loturile provin din populaţii cu medii egale, sau, că provin din aceeaşi populaţie. Această problemă apare foarte des în practică pentru că foarte des aplicăm tratamente la loturi care trebuie apoi comparate cu alte loturi la care nu se aplică tratamentul.
Una din problemele esenţiale ale statisticii este aceea de a decide asupra unor ipoteze care se nasc în mod natural din examinarea datelor avute la dispozitie sau a indicatorilor statistici care le caracterizează.
6

Biostatistică - Cursul al VII-lea Vom considera că normalii la care s-au facut măsuratori provin dintr-o populaţie, teoretic infinită, pe care o vom denumi populaţia normală, iar ceilalţi provin in mod asemănător dintr-o populaţie pe care o vom denumi populaţia afectată. Vom avea două cazuri posibile:
a) Media latenţei la cele două populaţii este in realitate aceeaşi (necunoscută) iar diferenţele constatate la cele două loturi sunt datorate întâmplării. Dacă am continua măsuratorile, mărind cele două eşantioane, mediile recalculate vor fi mai apropiate, iar in cele din urmă vor tinde să devină egale, rolul întâmplării diminuându-se încet, încet.
b) Cele două populaţii au in realitate medii diferite, şi anume cea afectată are o medie a latenţei mai mare, caz în care dacă am continua măsurătorile, mărind loturile, încet, încet, mediile tind să se stabilizeze, adică să nu se mai modifice prea mult, dar, media la cei afectaţi tinde la o valoare diferită (şi anume mai mare) ca media la sănătosi.
Înainte de a face măsurători efective, nimeni nu poate spune care este situaţia, adică nu poate decide între cazurile a) si b). Din păcate, de obicei este greu să se ia o astfel de decizie chiar si după efectuarea de măsuratori. In practică, diferenţe destul de mari între mediile de eşantionare pot apare la loturi extrase din aceeasi populaţie dacă s-au măsurat puţini indivizi, mai ales dacă împrăştierea datelor este mare.
A trage concluzia că cele două loturi provin din populaţii cu medii diferite este, bineînţeles în acest caz nu numai riscant ci de-a dreptul greşit. Invers, diferenţe între mediile de eşantionare care la prima vedere par neînsemnate, pot să indice că cele două loturi provin din populatii diferite, dacă măsurătorile s-au facut pe suficient de mulţi indivizi, mai ales când datele au împrăştieri mici.
De exemplu, la un lot de 122 de normali s-a măsurat latenţa semnalului nervos pe nervul optic şi s-a obţinut o medie de 105,4 ms şi o deviaţie standard de 8,6 ms. Pacienţii cu o afecţiune au fost 87 şi s-a obţinut o medie de 108,7 ms şi o deviaţie standard de 9,5 ms.
După cum se vede foarte uşor, diferenţa de medie pare mică şi suntem tentaţi să considerăm că suntem în cazul a), adică diferenţa de 108,7 ms - 105,4 ms = 3,3 ms este întâmplătoare. În realitate testul Student, despre care va fi vorba în acest curs arată că este aproape sigur (p=99,52%) că cele două eşantioane provin din populaţii diferite sau că cele două populaţii din care provin (sanatoşi si afectaţi) au medii ale latenţei diferite. Acest curs îşi propune printre altele să vă iniţieze în modul de a lua astfel de decizii.
Într-un alt caz, pe un lot de 35 de indivizi sănătoşi s-a obţinut media de 105,2 ms şi o deviaţie standard de 11,6 ms în timp ce la cei bolnavi (n=21), media a fost de 109,6 ms şi deviaţia standard 13,9 ms.
În ciuda faptului că diferenţa este acum ceva mai mare (4,4 ms), şi ar trebui deci să deducem că este cu atât mai probabil ca cele două loturi să provină din populaţii diferite, din contră, testul Student arată că nu sunt suficiente dovezi pentru această concluzie, ci, mai degrabă este corect să punem diferenţa constatată pe seama intâmplării. Acest lucru se întâmplă din cauza datelor mai împrăştiate, lucru dovedit de deviaţiile standard mai mari, precum şi din cauza numărului mai mic de măsurători în cele două loturi.
Vom conveni în continuare ca, dacă ne aflăm într-o situaţie asemănătoare cu cea de mai sus, să denumim cele două situatii posibile (a si b) ca ipoteze fundamentale de lucru şi anume pe prima o vom numi ipoteza de diferenta nulă, sau ipoteza de nul, iar pe cealaltă ca ipoteza alternativă.
• Ipoteza de nul (notaţie: H0 ): mediile populaţiilor din care provin loturile sunt egale.
• Ipoteza alternativă (notaţie: H1 ): mediile populaţiilor din care provin loturile diferă.
Uneori, ca alternative se pot alege două ipoteze sau chiar mai multe. De exemplu, în cazul de mai sus, putem avea două ipoteze alternative la ipoteza de nul:
• Ipoteza alternativă H1 : media populaţiei de sănătoşi este mai mare ca cea a populaţiei de afectaţi.
• Ipoteza alternativă H2 : media populaţiei de sănătoşi este mai mică decât cea a populaţiei de afectaţi.
Definiţie:
Vom numi test statistic, o metodă care ne ajută să decidem cu un grad de siguranţă ales, dacă ipoteza de nul poate fi respinsă în favoarea ipotezei sau ipotezelor alternative sau dacă nu sunt suficiente dovezi care să justifice respingerea ipotezei de nul.
7

Biostatistică - Cursul al VII-lea Ipotezele pe care le putem supune deciziei unui test statistic sunt foarte variate. Din observarea datelor, se pot naşte ipoteze dintre cele mai diverse. Categoriile principale de ipoteze sunt:
• Ipoteze care afirmă că mediile a două populaţii sunt egale • Ipoteze care afirmă că dispersiile a două populaţii sunt egale • Ipoteze care afirmă că mediile a trei sau mai multe populaţii sunt egale • Ipoteze care afirmă că dispersiile a trei sau mai multe populaţii sunt egale • Ipoteze care afirmă că repartiţia unei variabile aleatoare este o repartiţie fixată (Gauss, Poisson, etc.) • Ipoteze care afirmă că doi factori de clasificare sunt independenţi
Fiecare dintre tipurile de ipoteze formulate mai sus, are una sau mai multe ipoteze alternative.
Se poate testa deci, dacă dispersiile unor populaţii sunt diferite, discuţia fiind în fond aceeaşi ca la cea pentru medii. În plus, există teste care testează egalitatea a mai multor medii, adică având la dispoziţie mediile de eşantionare a trei sau chiar mai multe loturi (cu deviaţiile lor standard), ne situăm în unul din cazurile:
• Ipoteza de nul H0 : Mediile m1, m2, m3 (etc), ale populaţiilor din care provin eşantioanele 1, 2, 3, sunt egale.
• Ipoteza alternativă H1 : cel puţin două dintre mediile populaţiilor din care provin eşantioanele diferă.
Un test statistic va trebui în toate aceste cazuri, să ne ajute să decidem între a respinge sau nu ipoteza de nul H0.
Testarea unor ipoteze statistice se poate face bazându-ne pe proprietăţile distribuţiei normale. De cele mai multe ori insă, ipotezele statistice sunt de aşa natura că este nevoie de cunoaşterea proprietăţilor altor distribuţii pentru a putea decide dacă sunt sau nu suficient de bine susţinute de datele pe care le avem la dispoziţie.
În continuare vom expune principalele categorii de teste folosite mai des în practica medicală.
2. Testul Student de comparare a unei medii cu media teoretică Uneori cunoaştem din literatura de specialitate care este media populaţiei din care presupunem că este extras un lot şi dorim să verificăm ipoteza că eşantionul aparţine într-adevăr populaţiei respective.
Să presupunem că 0X este media teoretică şi să presupunem că valorile măsurate pentru indivizii din lotul de
comparat dau seria statistică: nxxxX ,......., 21÷ , iar media de eşantionare este X . Atunci variabila aleatoare
ct , obţinută după formula:
n
XXtc σ
0−= , sau
σ0XXn
tc
−⋅=
are o repartiţie Student cu n-1 grade de libertate. Decizia o vom lua stabilind care este plauzibilitatea ca ct să aparţină repartiţiei Student cu n-1 grade de libertate. Vom căuta limitele dreapta-stânga între care avem
A testa ipoteza de nul H0, contra unei ipoteze alternative H1, sau a mai multor ipoteze alternative (H1, H2), înseamnă să acordăm lui H0 prezumţia de a fi adevărată, în afară de cazul că datele îi sunt potrivnice într-un înalt grad, caz în care H0, trebuie respinsă în favoarea ipotezei H1 sau în favoarea uneia dintre ipotezele H1, H2.
8

Biostatistică - Cursul al VII-lea cuprinsă 95% sau 99% din aria de sub curba repartiţiei Student. Va fi deci suficient să căutăm valoarea lui
1%95−nt , sau 1
%99−nt , dată de tabelele statistice pentru t, şi să o comparăm cu valoarea lui ct .
O interpretare, a acestui test este deci următoarea:
• Dacă 1%95−> n
c tt , atunci există o diferenţă semnificativă între media de eşantionare X şi media teoretică 0X
• Dacă 1%95−< n
c tt , atunci nu avem motive suficiente pentru a afirma că există o diferenţă
semnificativă între media de eşantionare X şi media teoretică 0X
În figura 1, este arătat motivul pentru care comparăm ct cu limita de cuprindere a 95% (99%) din repartiţie. Dacă ct este la dreapta acestei limite, este puţin probabil să aparţină repartiţiei respective şi ipoteza H0 va fi respinsă ca falsă.
Figura 1 Pragul de 95% arată că valori mai mici decât acest prag sunt plauzibile, iar valori mai mari decât acest prag sunt neplauzibile.
Exemplu practic:
• Media eşantionare X =14,5
• Media teoretică 0X =18
• Deviaţia standard σ =12,5
• Pragul teoretic tt = 1%95−nt = 83
%95t =1,998
• Volumul eşantionului n = 84
Deci, calculăm valoarea lui tc :
=−⋅
=−
=σσ
00 XXn
n
XXtc
515,275,12078,32
5,12165,95,3
5,1284)5,1418(
==⋅
=⋅−
=
Deoarece tt < tc, luăm decizia că diferenţa între media de eşantionare şi media propusă de ipoteză este semnificativă cu pragul de semnificaţie de 95%
3. Testul Student de comparare a mediilor. Cazul eşantioanelor mici şi dispersii egale Fie seriile statistice:
1,......., 21 nxxxX ÷ , extras din populaţia cu media m1 şi dispersia s2 şi
2,........., 21 nyyyY ÷ , extras din populaţia cu media m2 şi dispersia s2, ca şi la prima
Aşadar, avem două medii de eşantionare, X şi Y , două deviaţii standard de eşantionare 21σ şi 2
2σ , iar ipotezele pe care le facem sunt:
9

Biostatistică - Cursul al VII-lea • H0: m1=m2 (Mediile populaţiilor din care provin cele două eşantioane sunt aceleaşi).
• H1: m1≠ m2 (Mediile populaţiilor din care provin cele două eşantioane nu sunt aceleaşi).
Dacă populaţiile sunt de aceeaşi dispersie, atunci putem amesteca cele două eşantioane şi să estimăm s2 prin dispersia de eşantionare calculată luând în considerare ambele eşantioane:
( ) ( )2
11
21
2221
212
−+−+−
=nn
nn σσσ
Testul se bazează pe statistica
21
11nn
YXtc
+
−=σ
,
care are o distribuţie Student cu n1+n2-2 grade de libertate.
Pentru a alege între ipotezele H0 şi H1, ne folosim de această statistică. Decizia este:
• Dacă 1%95−> n
c tt , diferenţa este semnificativă la pragul de semnificaţie de 95%.
• Dacă 1%95−< n
c tt , diferenţa este nesemnificativă la pragul de semnificaţie de 95%.
Să mai amintim că am folosit tacit ipoteza că măsuratorile efectuate pe indivizii din lot sunt independente, adică nu depind unele de altele ceea ce de fapt se şi întâmplă în majoritatea cazurilor când este vorba de eşantioane de pacienţi.
Astfel, testul Student pentru loturi mici poate fi aplicat dacă sunt îndeplinite următoarele condiţii, numite condiţii de aplicare pentru teste parametrice, loturi mici:
• Repartiţiile populaţiilor din care provin loturile sunt normale
• Deviaţia standard este aceeaşi la cele două populaţii.
• Măsurătorile sunt independente.
Exemplu de calcul: Măsurând frecvenţa cardiacă la 9 pacienţi cu hipertiroidie şi la alţi 9 pacienţi cu hipotiroidie, au fost obţinute valorile din tabelul 1. Primul pas este calculul mediilor, al deviaţiilor standard şi al dispersiilor. Cum statistica testului foloseşte direct dispersiile, deviaţiile standard nu sunt absolut necesare.
Tabelul 1 Valorile frecvenţei cardiace la 9 pacienţi cu hipotiroidie şi 9 pacienţi cu hipertiroidie. Mediile, deviaţiile standard şi dispersiile sunt calculate pe ultimele trei linii.
Nr Hipertiroidieni Hipotiroidieni1 110 722 98 693 100 704 105 695 98 746 107 707 102 678 97 589 110 68
Media 103.000 68.556St Dev 5.172 4.475Dispersia 26.75 20.02777778
Calculele, decurg în felul următor:
10

Biostatistică - Cursul al VII-lea
Valoarea prag a lui t95% din tabele statistice este 2,12. Cum statistica testului depăşeşte valoarea prag, ipoteza de nul se respinge, diferenţa între cele două medii de eşantionare este semnificativă la pragul de semnificaţie de 95%.
4. Testul t Student pentru esantioane mici cu dispersii diferite Pentru acest test, vom renunţa să expunem toate calculele, deoarece în practică, aceste calcule le efectuează în mod automat un program specializat şi utilizatorul culege doar rezultatele. Testele implementate pe calculator, nu mai furnizează utilizatorului toate rezultatele intermediare ci, s-a optat pentru o modalitate mai practică: testul dă ca rezultat, un număr p, cuprins între 0 şi 1 care reprezintă probabilitatea de a comite o eroare prin respingerea lui H0.
Dacă lucrăm deci pe calculator, vom interpreta acest rezultat furnizat de program în felul următor: Dacă p>0,05 nu se respinge H0, diferenta este nesemnificativă la pragul de semnificatie
de 95%
Dacă p<0,05 se respinge H0 cu pragul de semnificatie de 95%. Diferenta este semnificativă
Dacă p<0,01 se respinge H0 cu pragul de semnificatie de 99%. Diferenta este înalt semnificativă
Nu uitaţi că scopul unui test statistic este numai acela de a respinge sau nu ipoteza de nul, iar interpretarea acestei decizii revine utilizatorului. Totdeauna vom trage concluzia astfel:
Dacă p>0,05 H0, nu a fost respinsă, nu se poate spune că loturile provin din populaţii diferite
Dacă p<0,05 se respinge H0, loturile provin din populaţii diferite (nivel de siguranţă 95%)
Dacă p<0,01 se respinge H0 loturile provin din populaţii diferite (nivel de siguranţă 99%)
Pentru acest test, suntem în următoarea situaţie: Două populaţii cu mediile m1, m2 si abateri standard s1,s2, toate necunoscute
Două eşantioane extrase din ele: X: x1,x2,....xn şi Y: y1,y2,...ym
Valorile de eşantionare: două medii de eşantionare, X şi Y , două dispersii de eşantionare 21σ şi
22σ ,
Ipotezele: H0 : m1 = m2 H1 : m1 ≠ m2
Rezultatul p, un număr subunitar, se interpretează conform cu cele expuse mai sus:
Exemplu de folosire a testului în Excel: La 27 pacienţi cu Diabet Zaharat si la 17 indivizi sănătosi, s-a măsurat latenta semnalului electric pe nervul optic (PEV)
Rezultat: media dispersia
11

Biostatistică - Cursul al VII-lea DZ: 111,11 105,93
Sănătosi: 107,44 70,61
Ipotezele:
1. H0: Mediile populaţiilor din care provin eşantioanele sunt egale
2. H1: Mediile populaţiilor din care provin eşantioanele diferă
Deoarece dispersiile sunt mult diferite, se aplică testul t pentru esantioane cu dispersie inegală. Mai jos, este arătat rezultatul aplicării testului, folosind programul Microsoft Excel. Valoarea lui p este 20,4%, deci ipoteza de nul nu se respinge, cele două medii de eşantionare nu diferă semnificativ.
După cum se observă, Excel calculează şi mediile şi dispersiile de eşantionare, precum şi alte valori care prezintă o importanţă mai mică.
Condiţii de aplicare
Măsurătorile trebuie să fie independente (valabil la orice test statistic)
Dacă eşantioanele sunt relativ mici (sub 30 de indivizi), să se ştie că provin din populaţii cu distribuţie Gauss
Pentru a decide dacă dispersiile seriilor de valori obţinute prin măsurători pe două loturi de pacienţi sau de probe, diferă semnificativ, se poate folosi testul F, al lui Fisher, de comparare a dispersiilor.
5. Testul t Student pentru esantioane pereche Se face de obicei atunci când se doreste punerea în evidentă a efectelor unui tratament sau altă
acţiune asupra pacientilor.
Eşantioanele au acelaşi număr de indivizi şi sunt dispuşi în perechi, câte unul din fiecare eşantion
Într-o pereche, cei doi pacienţi sunt cât mai asemănători (ca vîrstă, sex, afecţiune, etc), dacă este posibil singura diferenţă majoră să fie că la unul se aplică un tratament iar la celălalt nu. Uneori pacienţii sunt aceiaşi şi măsurătorile se efectuează înainte şi după aplicarea tratamentului
În rest, ipotezele, rezultatul şi interpretarea sunt identice ca la testul t anterior
12

Biostatistică - Cursul al VII-lea
În figura de mai sus, este arătat rezultatul aplicării testului, folosind programul Microsoft Excel. Valoarea lui p este mult sub 0,01) este un număr cu foarte multe zerouri după punctul zecimal). Deci, ipoteza de nul se respinge, cele două medii de eşantionare diferă înalt semnificativ.
La fel, se observă că Excel calculează şi mediile şi dispersiile de eşantionare, precum şi alte valori care prezintă o importanţă mai mică.
Condiţii de aplicare
Măsurătorile trebuie să fie independente (valabil la orice test statistic)
Dacă eşantioanele sunt relativ mici (sub 30 de indivizi), să se ştie că provin din populaţii cu distribuţie Gauss
Dispersiile de eşantionare să nu difere semnificativ
Dacă una sau mai multe din cele trei condiţii sunt încălcate, testul nu poate fi aplicat şi se caută un alt test (vezi teste neparametrice, cursul următor)
* * * Observaţie: Un test statistic poate eşua în tentativa de respingere a ipotezei de nul dacă:
• H0 este adevărată. Ea nu trebuie respinsă (mediile populaţiilor sunt egale)
• H0 este falsă. Ea ar trebui respinsă, dar datele pe care le avem la dispoziţie nu oferă suficientă evidenţă împotriva ipotezei de nul
• Dacă ipoteza de nul este respinsă, aproape sigur mediile populaţiilor diferă
• Dacă ipoteza de nul nu este respinsă, nu se poate spune nimic.
o Ori, mediile, în realitate nu diferă
o Ori, ele diferă dar nu avem date suficiente care să pună în evidenţă acest adevăr
6. Testul ANOVA – testul analizei de varianţă Compară în acelaşi timp mediile mai multor eşantioane. Dacă notăm ca şi până acum, mediile
populaţiior din care provin eşantioanele cu m1, m2, m3, m4 (pentru 4 eşantioane) H0: m1 = m2 = m3 = m4 (pentru 4 eşantioane) H1: cel puţin două medii diferă semnificativ Rezultatul este un număr p care se interpretează la fel ca la celelalte teste:
13
Biostatistică - Cursul al VII-lea Dacă p>0,05 nu se respinge H0, diferenţa este nesemnificativă la pragul de semnificaţie de 95%
Dacă p<0,05 se respinge H0 cu pragul de semnificaţie de 95%. Cel puţin două medii diferă semnificativ
Dacă p<0,01 se respinge H0 cu pragul de semnificaţie de 99%. Diferenţa este înalt semnificativă
Testul nu îşi propune să compare loturile două câte două, deoarece răspunde la întrebarea dacă medile eşantioanelor au o corelaţie cu criteriul de împărţire pe loturi. Veţi înţelege mai bine această afirmaţie dacă urmăriţi exemplul de mai jos.
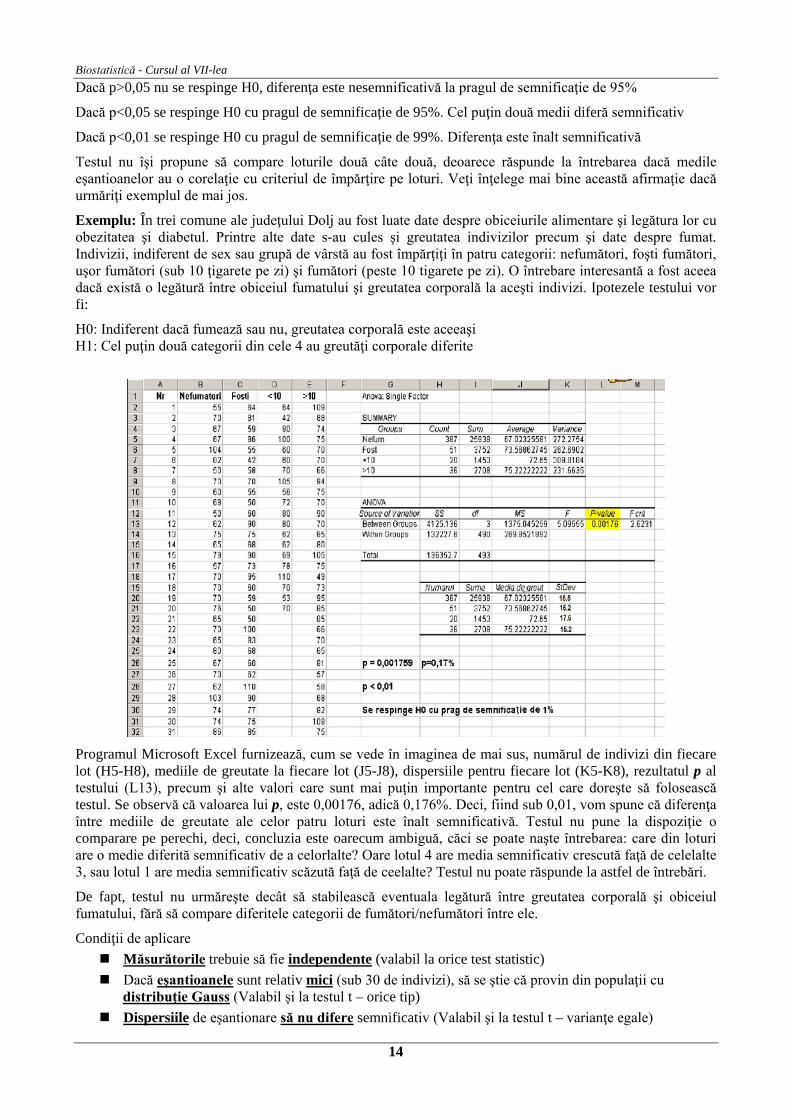
Exemplu: În trei comune ale judeţului Dolj au fost luate date despre obiceiurile alimentare şi legătura lor cu obezitatea şi diabetul. Printre alte date s-au cules şi greutatea indivizilor precum şi date despre fumat. Indivizii, indiferent de sex sau grupă de vârstă au fost împărţiţi în patru categorii: nefumători, foşti fumători, uşor fumători (sub 10 ţigarete pe zi) şi fumători (peste 10 tigarete pe zi). O întrebare interesantă a fost aceea dacă există o legătură între obiceiul fumatului şi greutatea corporală la aceşti indivizi. Ipotezele testului vor fi:
H0: Indiferent dacă fumează sau nu, greutatea corporală este aceeaşi H1: Cel puţin două categorii din cele 4 au greutăţi corporale diferite
Programul Microsoft Excel furnizează, cum se vede în imaginea de mai sus, numărul de indivizi din fiecare lot (H5-H8), mediile de greutate la fiecare lot (J5-J8), dispersiile pentru fiecare lot (K5-K8), rezultatul p al testului (L13), precum şi alte valori care sunt mai puţin importante pentru cel care doreşte să folosească testul. Se observă că valoarea lui p, este 0,00176, adică 0,176%. Deci, fiind sub 0,01, vom spune că diferenţa între mediile de greutate ale celor patru loturi este înalt semnificativă. Testul nu pune la dispoziţie o comparare pe perechi, deci, concluzia este oarecum ambiguă, căci se poate naşte întrebarea: care din loturi are o medie diferită semnificativ de a celorlalte? Oare lotul 4 are media semnificativ crescută faţă de celelalte 3, sau lotul 1 are media semnificativ scăzută faţă de ceelalte? Testul nu poate răspunde la astfel de întrebări.
De fapt, testul nu urmăreşte decât să stabilească eventuala legătură între greutatea corporală şi obiceiul fumatului, fără să compare diferitele categorii de fumători/nefumători între ele.
Condiţii de aplicare Măsurătorile trebuie să fie independente (valabil la orice test statistic) Dacă eşantioanele sunt relativ mici (sub 30 de indivizi), să se ştie că provin din populaţii cu
distribuţie Gauss (Valabil şi la testul t – orice tip) Dispersiile de eşantionare să nu difere semnificativ (Valabil şi la testul t – varianţe egale)
14

Biostatistică - Cursul al VII-lea Dacă una sau mai multe din cele trei condiţii sunt încălcate, testul ANOVA nu poate fi aplicat şi se caută un alt test (vezi teste neparametrice)
EXEMPLU: Testul ANOVA – conditii de aplicare
Dorim să comparăm nivelul bilirubinei totale la pacienţi cu ciroze şi cancere hepatice, în funcţie de prezenţa sau absenţa ascitei
Se observă că programul a făcut trei clase: “da”, “Missing”, “nu’, şi deci va face o comparare între trei loturi. Loturile “da” şi “nu”, sunt loturile cu ascită şi respectiv, fără ascită. Al treilea lot apare ca alcătuit din pacienţii la care nu s-a specificat dacă au sau nu ascită, însă valoarea bilirubinei a fost înregistrată. Şi de data aceasta vom verifica întâi dacă sunt îndeplinite condiţiile de aplicare a testuui ANOVA, şi dacă putem interpreta valoarea lui p, care se vede că este 0,0838.
ANOVA- Verificarea conditiilor de aplicare – dispersii egale - testul Bartlett
H0 – Dispersiile sunt egale
H1 – Dispersiile sunt diferite
p = 0,5196 → Ipoteza de nul nu se respinge – Dispersiile de eşantionare nu diferă semnificativ
În acest caz, ar mai trebui verificată condiţia ca distribuţiile bilirubinei la cele trei loturi (lotul cu “da”, cel cu “Missing” şi cel cu “nu”) au distriuţii Gauss. Teoria spune însă ca dacă loturile sunt suficient de mari, această condiţie nu este obligatoriu de verificat. Cu cât loturile sunt mai mari, cu atât verificarea acestei condiţii este mai puţin necesară. În cazul nostru, nu vom mai verifica această condiţie şi von interpreta rezultatul testului ANOVA.
Se observă, mai sus, că rezultatul testului ANOVA este p=0,0838, adică 8,38%. Deducem că ipoteza de nul nu se respinge, diferenţa între mediile de bilirubină este nesemnificativă.
Testul ANOVA face parte din categoria testelor parametrice, ca şi testul t-Student. Aceste teste cer ca distribuţia valorilor să fie Gauss (cel puţin la loturi relativ mici).
Deci, teste parametrice de comparare a mediilor învăţate sunt: Testul t Student pentru eşantioane cu dispersii egale Testul t Student pentru eşantioane cu dispersii diferite Testul t Student pentru eşantioane pereche Testul ANOVA al analizei de varianţă
15

Biostatistică - Cursul al VII-lea
7.Teste neparametrice Atunci când nu este posibilă compararea mediilor a două sau mai multe loturi cu ajutorul testelor parametrice, se pot folosi aşa-numitele teste neparametrice, care nu cer decât ca măsurătorile să fie independente. Nu sunt cerute condiţii ca distribuţia măsurătorilor să fie Gauss, şi nici condiţii legate de dispersia măsurătorilor. Deci, testele neparametrice:
Sunt teste care nu fac presupuneri legate de distribuţia datelor.
Se aplică în orice condiţii, dacă măsurătorile sunt independente
Se aplică atunci când nu putem aplica un test parametric
a. Testul Mann-Whitney-Wilcoxon de comparare a mediilor (se poate aplica şi la mai multe eşantioane) Două populaţii cu mediile m1, m2 şi abateri standard s1,s2. Două eşantioane extrase din ele:
Valorile de eşantionare: , , , . Ipotezele: H0 : m1 = m2 H1 : m1 ≠ m2 Rezultatul p se interpretează:
Dacă p>0,05 nu se respinge H0, diferenţa este nesemnificativă la pragul de semnificaţie de 95%
Dacă p<0,05 se respinge H0 cu pragul de semnificaţie de 95%. Diferenţa este semnificativă Dacă p<0,01 se respinge H0 cu pragul de semnificaţie de 99%. Diferenţa este înalt
semnificativă
b. Testul Kruskal – Wallis/ Friedman de comparare a mediilor (se aplica la mai multe eşantioane)
Clasificarea testelor de comparare: Teste parametrice: se ştie ce fel de distribuţie au populaţiile din care provin eşantioanele ale căror
medii sau dispersii se compară. Ex: toate tipurile de test t-Student, testul ANOVA Teste neparametrice: nu se conoaşte distribuţia populaţiilor. Ex: Testul Mann-Whitney/Wilcoxon,
Testul Kruskal-Wallis, testul Friedman
Diferenţa dintre cele două tipuri, din punctul de vedere al celui care le foloseşte este că un test neparametric eşuează de obicei mai des în tentativa de a respinge H0, atunci când ea ar trebui respinsă. Acest lucru se datorează de obicei lipsei de informaţie. Cunoaşterea distribuţiei la testele parametrice este o informaţie suplimentară foarte importantă
În afară de testele învăţate, folosite pentru compararea mediilor sau a dispersiilor, există teste foarte variate pentru testarea unor ipoteze statistice care nu se referă la compararea mediilor. De exemplu, putem încerca să verificăm dacă o serie de valori are o distribuţie Gauss şi pentru aceasta există chiar mai multe teste, printre ele şi testul Kolmogorov sau testul Anderson-Darling
4. Chestiuni de examen: 1. Pe un eşantion de 64 probe identice, un laborator a dat media concentraţiei compusului activ de 18mg/100ml, iar deviaţia standard a valorilor din seria de 64 rezultate a fost de 2mg/100ml. Din tabele, 263
%95 =t . Intervalul de încredere al mediei este în acest caz: A. ]5,18;5,17[ corect B. ]18;17[ C. ]5,19;5,16[ D. ]5,19;5,17[
16

Biostatistică - Cursul al VII-lea 2. Intervalul de încredere pentru media calculată pe o serie de valori are interpretarea: A. Adevărata medie, cea care se aproximează, este aproape sigur în intervalul de încredere B. Media de eşantionare, este aproape sigur în intervalul de încredere C. Adevărata mediană, cea care se aproximează, este aproape sigur în intervalul de încredere D. Este un interval în care de află aproape toate valorile din seria de valori
3. Intervalul de încredere de 95% pentru coeficientul de inteligenţă al unui lot selecţionat de 1000 de economişti este [114,7 ; 129,7]. Aceasta înseamnă că: A. Media coeficientului de inteligenţă al populaţiei economiştilor este aproape sigur în acest interval B. Media de eşantionare este aproape sigur în acest interval C. Media coeficientului de inteligenţă al populaţiei economiştilor este sigur în acest interval D. Media de eşantionare este sigur în acest interval
4. Valoarea lui OR, calculat pentru un tabel de incidenţă 2x2, este 2,4, iar intervalul de încredere este de la 0,8 la 4,9. În acest caz: A. Valoarea lui OR este semnificativă B. Valoarea lui OR este nesemnificativă C. Nu putem decide dacă valoarea lui OR este sau nu semnificativă
5. Pentru a găsio aproximare a mediei de greutate la studenţii UMF, doi studenţi aleg câte un eşantion extras aleator de 40 şi respectiv 60 de subiecţi, şi calculează media de greutate, fiecare la eşantionul său. În acest caz: A. Media pe lotul de 40 de subiecţi va fi sigur mai paroape de realitate B. Media pe lotul de 60 de subiecţi va fi sigur mai paroape de realitate C. Media pe lotul de 60 de subiecţi va fi probabil mai paroape de realitate D. Oricare din cele două medii obţinute poate fi mai aproape de realitate
6. Pentru a estima greutatea medie a studenţilor UMF, un student alege ca eşantion primii 100 de studenţi ai UMF din lista alfabetică. A. Eşantionul este nereprezentativ, deoarece extragerea nu s-a făcut aleator B. Eşantionul este reprezantativ, deoarece ordinea alfabetică este aleatorie din punctul de vedere al greutăţii C. Eşantionul este prea mic D. Eşantionul este prea mare
7. Următoaree condiţii sunt binevenite sau necesare pentru ca un eşantion să fie reprezentativ: A. Să fie alcătuit din subiecţi aleşi aleator din populaţie B. Să fie cât mai voluminos C. Să fie reprezentativ
8. Media calculată pe un eşantion de 100 de subiecţi este totdeauna mai apropiată de media reală decât cea calculată pe un eşantion de 60 de subiecţi, deoarece: A. Eşantion mai mare, înseamnă totdeauna o precizie mai bună B. Eşantion mai mic, înseamnă totdeauna o precizie mai slabă C. Media pe eşantionul de 100, este mai probabil să fie mai apropiată de media reală
9. Dacă dintr-o populaţie extragem în mod repetat eşantioane foarte mari şi la fiecare eşantion calculăm media, mediile astfel obţinute vor fi: A. Distribuite apropiat de o distribuţie Gauss B. Distribuite foarte diferit de o distribuţie Gauss C. Distribuţie Gauss
10. Intervalul de încredere de 99% are ca diferenţe faţă de cel de 95%, următoarele: A. Intervalul de 99% este mai larg decât cel de 95% B. Intervalul de 95% este mai larg decât cel de 99% C. Intervalul de 99% şi cel de 95% sunt la fel de largi D. Nu putem şti dinainte care din cele două intervale este mai larg
11. Dacă două loturi sunt mici, atunci pentru aplicarea testului Student, trebuie îndeplinite condiţiile: A. Repartiţiile populaţiilor din care provin loturile sunt normale B. Deviaţia standard este aceeaşi la cele două populaţii C. Măsurătorile sunt independente D. Loturile să aibă medii egale
12. Care din următoarele teste sunt teste parametrice: A. ANOVA B. Student C. Wilcoxon D. Kruskal-Wallis
17

Biostatistică - Cursul al VII-lea 13. Rezultatul p al unui test statistic se interpretează astfel:
A. Se respinge ipoteza de nul dacă p<0,05 B. Se respinge ipoteza de nul dacă p>0,05 C. Se respinge ipoteza alternativă dacă p>0,05 D. Se acceptă ipoteza de nul dacă p<0,05
14. Pentru a putea aplica testul ANOVA, trebuie verificate următoarele condiţii A. Măsurătorile să fie independente B. Dispersiile să nu difere semnificativ C. Distribuţiile populaţiilor din care provin eşantioanele să nu fie simetrice D. Distribuţiile populaţiilor din care provin eşantioanele să fie Gauss
15. Testul ANOVA este un test: A. Parametric B. Neparametric C. De comparare a mediilor D. De compaarre a dispersiilor
16. Rezultatul p al unui test statistic are intrepretare diferită de la test la test A. Da, la fiecare test avem o altă interpretare B. Nu, totdeauna ne ajută să respingem sau nu ipoteza de nul C. Rezultatul p nu se interpretează, el fiind un simplu număr D. Avem o interpretare la testele parametrice şi o alta la cele neparametrice
17. Dacă în urma efectuării unui test Student de comparare a mediilor, obţinem p=0,78656, atunci: A. Nu se respinge H0 B. Se acceptă H0 C. Se respinge H0 D. Nu putem decide
18. Dacă în urma efectuării unui test Student de comparare a mediilor, obţinem p=0,0256, atunci: A. Se respinge H0 B. Se acceptă H0 C. Se respinge H1 D. Nu putem decide
19. Dacă în urma efectuării unui test Student de comparare a mediilor, obţinem p=0,0000000000000001, atunci: A. Se respinge H0 B. Nu se respinge H0 C. Nu se respinge H1 D. Se acceptă H1
20. Dacă efectuăm testul t al lui Student, măsurători pereche: A. Loturile pot fi diferite ca volum B. Loturile trebuie să fie egale ca volum C. Loturile trebuie să aibă aceeaşi medie D. Trebuie să avem trei loturi
21. Respingerea ipotezei de nul când efectuăm un test de comparare a mediilor înseamnă: A. Cele două medii de eşantionare diferă semnificativ B. Cele două medii ale populaţiilor din care provin loturile diferă C. Cele două medii de eşantionare nu diferă semnificativ D. Cele două medii ale populaţiilor din care provin loturile nu diferă
22. Nerespingerea ipotezei de nul când efectuăm un test de comparare a mediilor înseamnă: A. Cele două medii de eşantionare diferă semnificativ B. Cele două medii ale populaţiilor din care provin loturile diferă semnificativ C. Cele două medii de eşantionare nu diferă semnificativ D. Cele două medii ale populaţiilor din care provin loturile nu diferă
23. Intervalul de încredere de 95% pentru coeficientul de inteligenţă al unui lot selecţionat de 1000 de economişti este [114,7 ; 129,7]. Aceasta înseamnă că:
A. Media coeficientului de inteligenţă al populaţiei economiştilor este aproape sigur în acest interval B. Media de eşantionare este aproape sigur în acest interval C. Media coeficientului de inteligenţă al populaţiei economiştilor este sigur în acest interval D. Media de eşantionare este sigur în acest interval
18


















