
Contributii la proiectarea aplicatiilor paralele pe ... · Universitatea Tehnic Gheorghe Asachi din...
164
Universitatea Tehnică „Gheorghe Asachi” din Iaşi Facultatea de Automatică şi Calculatoare 2011 Contribuţii la proiectarea aplicaţiilor paralele pe clustere de calculatoare ing. Cristian Mihai Amarandei - TEZĂ DE DOCTORAT - Conducător ştiinţific: prof. dr. ing. Vasile-Ion Manta
Transcript of Contributii la proiectarea aplicatiilor paralele pe ... · Universitatea Tehnic Gheorghe Asachi din...

Universitatea Tehnică „Gheorghe Asachi” din Iaşi Facultatea de Automatică şi Calculatoare
2011
Contribuţii la proiectarea aplicaţiilor paralele pe clustere de calculatoare
ing. Cristian Mihai Amarandei
- TEZĂ DE DOCTORAT -
Conducător ştiinţific: prof. dr. ing. Vasile-Ion Manta


Teza de doctorat
Contributii la proiectarea
aplicatiilor paralele pe clustere de
calculatoare
ing. Cristian-Mihai AMARANDEI
Iasi, 2011


UNIVERSITATEA TEHNICA ,,GHEORGHE ASACHI” DIN IASI
Facultatea de Automatica si Calculatoare
Comisia pentru sustinerea tezei de doctorat:
1. Conf. dr. ing. Mihai Postolache Presedinte comisie
(Universitatea Tehnica ,,Gheorghe Asachi” din Iasi)
2. Prof. dr. ing. Vasile-Ion Manta Conducator stiintific
(Universitatea Tehnica ,,Gheorghe Asachi” din Iasi)
3. Prof. dr. ing. Stefan-Gheorghe Pentiuc Membru
(Universitatea ,,Stefan cel Mare” din Suceava)
4. Prof. dr. Gheorghe Grigoras Membru
(Universitatea ”A. I. Cuza” din Iasi)
5. Prof. dr. Mitica Craus Membru
(Universitatea Tehnica ,,Gheorghe Asachi” din Iasi)


Sotiei mele, Andreia


Mentiuni
Inainte de a va invita sa cititi aceasta lucrare, se cuvine sa multumesc celor ce
m-au sustinut ın obtinerea rezultatelor ce vor fi prezentate.
Doresc sa multumesc domnului profesor Vasile Manta pentru sfaturile dum-
nealui si pentru rabdarea de care a dat dovada ın coordonarea acestei lucrari.
As dori sa multumesc ın mod deosebit domnului profesor Mitica Craus. Dum-
nealui m-a sprijinit constant pe parcursul cercetarilor ın domeniul calculului pa-
ralel si cel al sistemelor Grid. Apreciez foarte mult ıncrederea dumnealui de a
ma include ın colectivele de cercetare ale contractelor coordonate. Multe dintre
rezultatele prezentate ın cadrul acestei lucrari au fost obtinute ın urma acestei
colaborari.
Doresc sa multumesc colegilor mei: Alex, Simona, Andrei, Adi, Daniel si
Marius. Le multumesc pentru sprijinul acordat si pentru mediul deosebit creat.
Nu ın ultimul rand, doresc sa multumesc familiei pentru sustinerea necondi-
tionata si pentru rabdarea de care a dat dovada pe parcursul studiilor doctorale.
Doresc, de asemenea, sa multumesc tuturor celor care m-au sprijinit si m-au
ıncurajat ın toti acesti ani.
i


Cuprins
Cuprins iii
Index figuri vi
Index tabele viii
Index algoritmi ix
1 Introducere 1
1.1 Motivatie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 Structura tezei . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.3 Diseminarea rezultatelor . . . . . . . . . . . . . . . . . . . . . . . . 6
Partea I: PROIECTAREA APLICATIILOR PARALELE 9
2 Metodologii de proiectare a aplicatiilor paralele 11
2.1 Introducere ın proiectarea aplicatiilor paralele . . . . . . . . . . . . 13
2.1.1 Definirea problemei . . . . . . . . . . . . . . . . . . . . . . . 13
2.1.2 Modelarea aplicatiilor paralele . . . . . . . . . . . . . . . . 14
2.2 Modele de proiectare a aplicatiilor paralele . . . . . . . . . . . . . . 19
2.2.1 Determinarea paralelismului aplicatiei (partitionarea) . . . 21
2.2.1.1 Descompunerea domeniului de date . . . . . . . . 22
2.2.1.2 Descompunerea functionala . . . . . . . . . . . . . 22
2.2.1.3 Reguli de partitionare . . . . . . . . . . . . . . . . 23
2.2.2 Comunicatiile . . . . . . . . . . . . . . . . . . . . . . . . . . 24
2.2.2.1 Reguli de proiectare/verificare a comunicatiilor . . 27
2.2.3 Aglomerarea . . . . . . . . . . . . . . . . . . . . . . . . . . 28
2.2.3.1 Reducerea costului comunicatiilor . . . . . . . . . 30
2.2.3.2 Pastrarea flexibilitatii . . . . . . . . . . . . . . . . 30
2.2.3.3 Reducerea costurilor de proiectare . . . . . . . . . 31
2.2.3.4 Reguli de aglomerare . . . . . . . . . . . . . . . . 31
iii

iv CUPRINS
2.2.4 Maparea . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
2.2.4.1 Algoritmi de echilibrare a ıncarcarii . . . . . . . . 35
2.2.4.2 Algoritmi de planificare a task-urilor . . . . . . . . 35
2.2.4.3 Reguli de mapare . . . . . . . . . . . . . . . . . . 35
2.3 Proiectarea modulara . . . . . . . . . . . . . . . . . . . . . . . . . 36
2.3.1 Reguli de proiectare modulara . . . . . . . . . . . . . . . . 37
2.4 Analiza cantitativa si calitativa a algoritmilor paraleli . . . . . . . 38
2.4.1 Parametrii cantitativi . . . . . . . . . . . . . . . . . . . . . 39
2.4.1.1 Accelerarea . . . . . . . . . . . . . . . . . . . . . . 39
2.4.1.2 Eficienta . . . . . . . . . . . . . . . . . . . . . . . 40
2.4.1.3 Supraıncarcarea . . . . . . . . . . . . . . . . . . . 41
2.4.1.4 Costul . . . . . . . . . . . . . . . . . . . . . . . . . 42
2.4.1.5 Legile accelerarii . . . . . . . . . . . . . . . . . . . 42
2.4.2 Parametrii calitativi . . . . . . . . . . . . . . . . . . . . . . 45
2.4.2.1 Granularitatea . . . . . . . . . . . . . . . . . . . . 45
2.4.2.2 Scalabilitatea . . . . . . . . . . . . . . . . . . . . . 46
2.5 Problema echilibrarii ıncarcarii ın proiectarea aplicatiilor paralele . 47
2.5.1 Echilibrarea ıncarcarii ın aplicatiile paralele . . . . . . . . . 47
2.5.2 Echilibrarea dinamica a ıncarcarii . . . . . . . . . . . . . . . 48
2.5.2.1 Echilibrarea centralizata . . . . . . . . . . . . . . 49
2.5.2.2 Echilibrarea descentralizata . . . . . . . . . . . . . 50
2.5.3 Echilibrarea dinamica a ıncarcarii ın sistemele de agenti
mobili si sisteme message passing . . . . . . . . . . . . . . . 53
2.5.4 Rezultate . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
3 Model de proiectare a aplicatiilor paralele folosind proiectarea
statistica a experimentelor 61
3.1 Introducere ın tehnica proiectarii statistice a experimentelor . . . . 63
3.1.1 Analiza dispersionala . . . . . . . . . . . . . . . . . . . . . . 67
3.1.2 Analiza de regresie . . . . . . . . . . . . . . . . . . . . . . . 70
3.1.3 Modelul unui proces . . . . . . . . . . . . . . . . . . . . . . 70
3.1.4 Utilizare ın domeniu . . . . . . . . . . . . . . . . . . . . . . 72
3.2 Modelul propus pentru ımbunatatirea proiectarii aplicatiilor paralele 75
3.2.1 Analiza unei aplicatii paralele folosind modelul propus . . . 77
3.3 Analiza cu DOE a unei aplicatii paralele ce utilizeaza metoda des-
compunerii domeniului de date: sort last parallel rendering . . . . 78
3.3.1 Planul experimental . . . . . . . . . . . . . . . . . . . . . . 80
3.3.2 Analiza statistica a modelului . . . . . . . . . . . . . . . . . 81
3.3.2.1 Analiza volumului de date procesat . . . . . . . . 83
3.3.2.2 Analiza timpului de procesare . . . . . . . . . . . 84
3.3.2.3 Analiza timpilor de comunicatie . . . . . . . . . . 88
3.3.3 Interpretarea rezultatelor . . . . . . . . . . . . . . . . . . . 89

CUPRINS v
3.4 Concluzii . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91
Partea a II-a: SOLUTII DE IMPLEMENTARE A INFRAS-
TRUCTURII PENTRU SISTEMELE GRID SI A CLUSTERELOR
COMPONENTE 93
4 Clustere si sisteme grid 95
4.1 Arhitecturi de tip Grid . . . . . . . . . . . . . . . . . . . . . . . . . 96
4.2 Arhitectura clusterelor . . . . . . . . . . . . . . . . . . . . . . . . . 98
4.3 Studiu de caz - Gridul GRAI . . . . . . . . . . . . . . . . . . . . . 102
4.3.1 Implementarea infrastructurii GRAI . . . . . . . . . . . . . 105
4.3.1.1 RocksClusters - Cluster Deployment and Manage-
ment Tool in Grid Systems . . . . . . . . . . . . . 105
4.3.1.2 Suportul pentru instalarea multi-site si securitatea
ın RocksClusters . . . . . . . . . . . . . . . . . . . 108
4.3.2 Concluzii . . . . . . . . . . . . . . . . . . . . . . . . . . . . 110
5 Un nou model de optimizare a comunicatiilor ın clustere 111
5.1 Definirea problemei . . . . . . . . . . . . . . . . . . . . . . . . . . . 111
5.2 Modelul de optimizare a comunicatiilor . . . . . . . . . . . . . . . 112
5.3 Implementarea modelului . . . . . . . . . . . . . . . . . . . . . . . 115
5.4 Rezultate si concluzii . . . . . . . . . . . . . . . . . . . . . . . . . . 117
6 Tehnici de gestiune a resurselor ın clustere 123
6.1 Definirea problemei . . . . . . . . . . . . . . . . . . . . . . . . . . . 123
6.2 Arhitectura sistemului de management a resurselor . . . . . . . . . 125
6.3 Implementare . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 126
6.4 Rezultate si concluzii . . . . . . . . . . . . . . . . . . . . . . . . . 128
7 Concluzii, contributii si directii viitoare de cercetare 131
7.1 Concluzii . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 131
7.2 Contributii . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 134
7.3 Directii viitoare de cercetare . . . . . . . . . . . . . . . . . . . . . . 135
Bibliografie 137

Index figuri
2.1 Un model simplu de programare paralela . . . . . . . . . . . . . . . . 15
2.2 Metodologie de proiectare a aplicatiilor paralele . . . . . . . . . . . . . 20
2.3 Utilizarea task -urilor de date separat pentru a deservi cererile de
scriere/citire asupra unei structuri de date distribuite . . . . . . . . . 27
2.4 Exemple de aglomerare . . . . . . . . . . . . . . . . . . . . . . . . . . 29
2.5 Maparea ın problemele care se rezolva pe o plasa de procesoare . . . . 34
2.6 Work-pool centralizat . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
2.7 Work-pool distribuit . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
2.8 Work-pool descentralizat . . . . . . . . . . . . . . . . . . . . . . . . . . 51
2.9 Algoritm de selectie descentralizat . . . . . . . . . . . . . . . . . . . . 52
2.10 Echilibrarea ıncarcarii pe o topologie de tip hipercub (n=4) folosind
platforma PASIBC - Agenti de echilibrare SID . . . . . . . . . . . . . 55
2.11 Echilibrarea ıncarcarii pe o topologie de tip hipercub (n=4) folosind
platforma PASIBC - Agenti de echilibrare DASUD . . . . . . . . . . . 55
2.12 Echilibrarea ıncarcarii pe o topologie de tip hipercub (n=4) folosind
MPI - Algoritm de echilibrare SID . . . . . . . . . . . . . . . . . . . . 56
2.13 Echilibrarea ıncarcarii pe o topologie de tip hipercub (n=4) folosind
MPI - Algoritm de echilibrare DASUD . . . . . . . . . . . . . . . . . . 56
2.14 Rezultatele algoritmilor SID si DASUD cu primul set de date . . . . . 58
2.15 Rezultatele algoritmilor SID si DASUD cu al doilea set de date . . . . 58
2.16 Rezultatele algoritmilor SID si DASUD cu al treilea set de date . . . . 59
3.1 Alegerea modelului DOE . . . . . . . . . . . . . . . . . . . . . . . . . 64
3.2 Etapele ce trebuie urmate ın analiza folosind DOE . . . . . . . . . . . 67
3.3 Modelul de tip cutie neagra . . . . . . . . . . . . . . . . . . . . . . . . 71
3.4 Modelul de proiectare al aplicatiilor paralele utilizand DoE . . . . . . 76
3.5 Aplicatia paralela de randare a unei imagini . . . . . . . . . . . . . . . 79
3.6 Distributia normala a reziduurilor. a) pentru raspunsul Y2 , b) pentru
raspunsul Y3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
vi

INDEX FIGURI vii
4.1 Arhitectura Grid stratificata . . . . . . . . . . . . . . . . . . . . . . . 97
4.2 Grid departamental(Cluster Grid), de ıntreprindere (Campus Grid)
si global (Global Grid) . . . . . . . . . . . . . . . . . . . . . . . . . . . 98
4.3 Structura logica a unui cluster . . . . . . . . . . . . . . . . . . . . . . 100
4.4 Arhitectura serviciilor gLite . . . . . . . . . . . . . . . . . . . . . . . . 101
4.5 Sistem Grid generic . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102
4.6 Exemplu de configuratie hardware ce elimina prezenta unui singur
punct de defectare . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102
4.7 Arhitectura retelei GRAI . . . . . . . . . . . . . . . . . . . . . . . . . 104
4.8 Generarea distributiei RocksClusters . . . . . . . . . . . . . . . . . . . 106
4.9 Procesul de generare a unui fisier kickstart la cererea unui nod . . . . 108
4.10 Wide Area RocksClusters . . . . . . . . . . . . . . . . . . . . . . . . . 109
5.1 Modelul de optimizare a comunicatiilor ın clustere . . . . . . . . . . . 113
5.2 Dependenta latimii de banda fata de TCP window scaling . . . . . . . 118
5.3 Dependenta latimii de banda fata de valoarea TCP read buffer . . . . 119
5.4 Dependenta latimii de banda fata de valoarea TCP write buffer . . . . 120
5.5 Latimea de banda obtinuta pentru diferite valori ale bufferelor TCP . 121
5.6 (a) Timpul de transfer a unui fisier de 512MB ıntre nodurile clusteru-
lui; (b) Avantajele utilizarii modelului propus . . . . . . . . . . . . . . 122
6.1 Arhitectura sistemului de management a resurselor . . . . . . . . . . . 126
6.2 Partitionarea resurselor . . . . . . . . . . . . . . . . . . . . . . . . . . 127
6.3 Utilizarea latimii de banda pentru transferul unui fisier de catre un
singur utilizator . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 129
6.4 Utilizarea latimii de banda de catre 4 utilizatori fara restrictii asupra
ratei de transfer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 129
6.5 Utilizarea latimii de banda de catre 4 utilizatori cu restrictii asupra
ratei de transfer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 130

Index tabele
2.1 Echilibrarea ıncarcarii folosind algoritmii SID si DASUD pe platforma
de agenti PASIBC si pe platforma message passing (MPI) . . . . . . . 60
3.1 Alegerea planului experimental . . . . . . . . . . . . . . . . . . . . . . 66
3.2 Tabelul ANOVA pentru un plan bifactorial cu interactiuni . . . . . . . 69
3.3 Factorii de intrare . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
3.4 Planul experimental codificat . . . . . . . . . . . . . . . . . . . . . . . 80
3.5 Valorile furnizate de aplicatie pentru variabilele raspuns urmarite con-
form planului experimental . . . . . . . . . . . . . . . . . . . . . . . . 81
3.6 Tabelul ANOVA pentru raspunsul Y1 . . . . . . . . . . . . . . . . . . . 82
3.7 Tabelul ANOVA pentru raspunsul Y2 . . . . . . . . . . . . . . . . . . . 82
3.8 Tabelul ANOVA pentru raspunsul Y3 . . . . . . . . . . . . . . . . . . . 82
3.9 Evolutia raspunsului Y1 . . . . . . . . . . . . . . . . . . . . . . . . . . 84
3.10 Planul experimental pentru timpul de procesare . . . . . . . . . . . . . 84
3.11 Coeficientii β ai ecuatiei pentru Y2 . . . . . . . . . . . . . . . . . . . . 85
3.12 Timpii de calcul masurati si calculati cu ajutorul ecuatiei pentru Y2(6-8 procesoare) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
3.13 Valorile factorilor de intrare pentru predictia raspunsului Y2 . . . . . . 86
3.14 Timpii de calcul masurati si prezisi cu ajutorul functiei ce descrie Y2(cazul 10-12 procesoare) . . . . . . . . . . . . . . . . . . . . . . . . . . 86
3.15 Coeficientii β ai ecuatiei pentru Y3 . . . . . . . . . . . . . . . . . . . . 88
3.16 Timpii de comunicatie masurati si prezisi cu ajutorul functiei ce de-
scrie Y3 - cazul 6-8 procesoare . . . . . . . . . . . . . . . . . . . . . . . 88
3.17 Timpii de comunicatie masurati si prezisi cu ajutorul functiei ce de-
scrie Y3 - cazul 10-12 procesoare . . . . . . . . . . . . . . . . . . . . . 89
viii

Index algoritmi
1 Algoritmul de calcul a parametrilor retelei de comunicatii . . . . . . 114
ix


Capitolul 1
Introducere
1.1 Motivatie
Calculul paralel reprezinta o solutie atractiva de fiecare data cand este nevoie de
putere de calcul pentru rezolvarea unei probleme. Acest lucru este posibil datorita
scaderii continue a costurilor componentelor hardware. In timp ce masinile para-
lele sunt foarte scumpe si sunt produse de un numar mic de companii specializate,
scaderea costului componentelor obisnuite a facut puterea de procesare accesibila
institutiilor si companiilor mici, extinzand numarul domeniilor care pot benefi-
cia de aceasta oportunitate. Astfel, cercetatorii din domenii precum medicina,
chimie, biologie, fizica, arheologie sau antropologie se regasesc printre utilizatorii
si beneficiarii cei mai importanti ai sistemelor de calcul de mare performanta.
Producatorii de procesoare au renuntat treptat la obtinerea unei frecvente
de lucru a procesoarelor cat mai ridicata, adoptand o strategie noua: cresterea
performantelor prin adaugarea mai multor unitati de procesare pe un singur chip.
Aceste procesoare multicore sunt prezente ın toate laptopurile si calculatoarele
personale. Aceasta mutare a producatorilor are un impact puternic asupra pro-
gramatorilor, care nu mai pot presupune ca aplicatia secventiala va rula mai
rapid pe un procesor dintr-o generatie mai noua. In loc sa creasca, frecventa de
lucru a procesoarelor este redusa pentru a putea face fata problemelor legate de
disiparea caldurii generate de numarul ridicat de nuclee de pe un singur proce-
sor. Performanta unui singur core tinde astfel sa ısi atinga limitele fizice. Astfel,
pentru a obtine timpi de raspuns mai buni, programatorii trebuie sa paralelizeze
eficient codul aplicatiilor.
Desi este o tema de actualitate, utilizarea sistemelor de calcul paralel pentru
rezolvarea unor probleme complexe nu este o tema noua. Primele sisteme paralele
dateaza de la sfarsitul anilor ’50 cu sistemul Burroughs D-825 (sistem multi-
procesor cu memorie comuna) si sistemul PILOT al American National Bureau
1

1. Introducere
of Standards (mai multe calculatoare erau conectate prin intermediul unei retele
de comunicatii). Aceste arhitecturi sunt larg raspandite fiind reprezentate ın
momentul de fata de sistemele din primele locuri din Top 500 Supercomputer 1.
Ambele arhitecturi furnizeaza posibilitatea de a executa operatii multiple pe
procesoare independente. Mare parte din aceste sisteme utilizeaza o combinatie
a celor doua arhitecturi, interconectand noduri ce contin 2, 4 sau mai multe
procesoare prin intermediul unei retele de mare preformanta fiind cunoscute sub
denumirea de clustere. Pentru a obtine maximum de eficienta din partea clus-
terelor, aplicatiile care ruleaza pe acestea utilizeaza tehnici hibride ce includ atat
facilitatile oferite de accesul la memoria comuna cat si de sistemele de comunicatie
prin transmitere de mesaje.
Clusterele se bucura la ora actuala de o larga acceptare din partea comu-
nitatilor de cercetatori din diverse domenii, marea majoritate incluzand compu-
tere interconectate cu retele de mare viteza reprezentand majoritatea sistemelor
din Top 500 Supercomputer. Desi sunt ieftine din punctul de vedere al costurilor
de constructie (ın mod uzual clusterele sunt contruite pe calculatoare obisnuite),
clusterele au si dezavantaje (nu utilizeaza eficient spatiul, consumul ridicat de
energie si cantitatea mare de caldura disipata). Datorita faptului ca nu au com-
ponente optimizate pentru acest tip de utilizare exista si riscul defectarii acestor
componente (datorita utilizarii puternic crescute fata de scopul pentru care au
fost proiectate).
Pe de alta parte, asa cum a fost amintit mai sus, scaderea frecventei proce-
soarelor si cresterea numarului acestora pe un singur chip face atractiva solutia
oferita de clustere prin ıncorporarea sistemelor de calcul din ce ın ce mai diver-
sificate, de la statii de lucru la console de jocuri.
Aceste ultime evolutii ale sistemelor de calcul paralel duc inevitabil la prezenta
tot mai pregnanta a paralelismului ın aplicatiile software utilizate. Desi hardware-
ul ieftin este disponibil oricui, dezvoltarea de software pentru aceste sisteme de
calcul paralel constituie un obstacol pentru majoritatea programatorilor. Astfel,
producerea de software care sa foloseasca eficient un sistem de calcul paralel
ramane o problema ce se adreseaza specialistilor ın domeniu.
In dezvoltarea aplicatiilor pentru un sistem uniprocesor, programatorul se
concentreaza asupra algoritmului, luand ın considerare aspecte precum complexi-
tatea calculelor si necesarul de memorie pentru a produce programe eficiente. Mi-
grarea spre o arhitectura paralela pune noi probleme precum distributia taskurilor
pe mai multe fire de executie, partitionarea datelor si colaborarea dintre taskuri
sau optimizarea resurselor utilizate.
Pe o arhitectura paralela, aplicatiile trebuie sa aiba posibilitatea de a executa
portiuni de cod simultan, iar ın acest scop este necesara ımpartirea sarcinilor
de lucru. Acest concept de partitionare a problemelor complexe ın subprobleme
1http://www.top500.org
2

1.1. Motivatie
ce se pot executa ın paralel pe mai multe procesoare pare extrem de intuitiv.
Pentru ca o aplicatie paralela sa fie eficienta, trebuie analizate problemele legate
de granularitate (ın vederea minimizarii comunicatiilor ıntre procese), de supra-
punere a calculelor si a comunicatiilor sau reducerea numarului operatiilor de
sincronizare dintre procesoare. Mai mult, cresterea numarului de procese impli-
cate ın rezolvarea unei probleme poate duce la aparitia complicatiilor ın rezolvarea
sincronizarii.
Pe de alta parte, implementarile optimale devin foarte complexe si sunt, ast-
fel, predispuse la erori. Reducerea numarului de operatii de sincronizare poate
conduce la aparitia problemelor specifice aplicatiilor paralele: blocajele (apar
atunci cand exista concurenta asupra accesului la o resursa si unul sau mai multe
procese nu pot rula) si/sau concurenta ıntre mesaje (atunci cand ordinea livrarii
mesajelor schimba rezultatele furnizate de aplicatie). Aceste erori pot fi dificil de
prevazut si de ınteles, atat datorita faptului ca se pot manifesta doar ın anumite
configuratii de intrare cat si datorita metodelor de analiza a erorilor. Mai mult, o
aplicatie paralela trebuie analizata si din punct de vedere al performantelor. Tre-
buie avute ın vedere masina paralela pe care va rula aplicatia, resursele ocupate
si conditiile ın care ruleaza. Performantele unei aplicatii paralele sunt puternic
influentate si de ıncarcarea clusterului pe care ruleaza.
In domeniul calculului de mare performanta, ıncepand de la sfarsitul anilor ’90
se depun eforturi pentru dezvoltarea sistemelor Grid. Aceste sisteme furnizeaza
cercetatorilor accesul la resurse de calcul ce depasesc performantele unui cluster
de tip Beowulf construite din componente disponibile utilizatorilor comuni. Inca
de la ınceputuri, scopul fundamental al tehnologiilor Grid a fost acela de a realiza
sisteme dinamice ce interconecteaza facilitati distribuite geografic pentru accesul
la unitati de procesare, medii de stocare, senzori, instrumente si multe altele. Un
rol important ın cadrul sistemelor Grid ıl joaca clusterele de calculatoare si su-
percalculatoarele, acestea reprezentand principala resursa partajata. Dezvoltarea
sistemelor Grid a dus la cresterea interesului cercetatorilor din diverse domenii.
Existenta unor aplicatii ce rezolvau problemele la care acestia cautau solutii, a
impus necesitatea utilizarii noilor resurse puse la dispozitie de sistemele Grid.
Fiind eterogene prin natura lor, sistemele Grid au impus cautarea de solutii pen-
tru a putea rula aplicatii paralele scrise initial pentru un anumit tip de masina
paralela ıntr-un mediu complet nou. Cercetarile ın acest domeniu dinamic au im-
pus dezvoltarea de noi modele si tehnici de proiectare a aplicatiilor paralele, de
noi tehnici de programare, precum si la adaptarea acestora la diverse configuratii
hardware.
In acesta teza sunt prezentate solutii care adreseaza aceste probleme. Sunt
descrise metode destinate proiectarii si analizarii performantelor aplicatiilor pa-
ralele si a sistemelor paralele pe care acestea pot rula. Predictia performantelor
aplicatiei paralele ajuta la identificarea problemelor aparute ın proiectarea aces-
3

1. Introducere
teia si a factorilor ce influenteaza performantele. Performantele clusterelor pe
care ruleaza aplicatiile paralele reprezinta un factor important de luat ın con-
siderare atunci cand se analizeaza o aplicatie paralela. In lucrarea de fata sunt
tratate atat probleme legate de constructia clusterelor, cat si solutii legate de
ımbunatatirea performantelor acestora. Tinand cont de evolutia sistemelor de
calcul de mare performanta, un capitol important este adresat proiectarii si im-
plementarii unei infrastructuri Grid si a clusterelor componente.
1.2 Structura tezei
Aceasta lucrare, organizata sub forma a sase capitole, prezinta aportul autorului
adus ın cadrul temei Contributii la proiectarea aplicatiilor paralele pe
clustere de calculatoare, atentia fiind focalizata asupra dezvoltarii unei noi
metode de proiectare a aplicatiilor paralele si de analiza a performantelor de rulare
ale acestora ın clustere. Primul capitol al acestei lucrari justifica abordarea
temei propuse si puncteaza principalele obiective atinse. De asemenea, tot ın
cadrul acestui prim capitol este detaliat si modul ın care contributiile aduse temei
au fost validate prin publicarea rezultatelor obtinute.
In continuare, lucrarea este organizata ın doua parti. Prima parte trateaza
problematica proiectarii si analizei performantelor unei aplicatiilor paralele.
Capitolul 2 detaliaza problemele implicate ın proiectarea aplicatiilor para-
lele. Sunt prezentate pe rand etapele de proiectare, de analiza cantitativa si
calitativa a unei aplicatii si problema echilibrarii ıncarcarii.
In capitolul al 3-lea este prezentata o noua metoda de proiectare a aplicatiilor
paralele tinand cont de factorii care pot influenta atat performantele aplicatiei,
cat si performantele retelei, ıncarcarea procesoarelor, memoria disponibila, etc.
Analiza acestor factori este realizata utilizand proiectarea statistica a experi-
mentelor (Design of Experiments: DOE ). Sunt descrise pe scurt tehnicile folosite
ın analiza statistica: analiza dispresionala (analysis of variance: ANOVA) si ana-
liza de regresie. Utilizarea tehnicilor specifice DOE ın proiectarea unei aplicatii
paralele permite descrierea comportamentului acestei aplicatii ın functie de fac-
torii care o influenteaza. Astfel, modelul propus permite testarea riguroasa a
unei aplicatii paralele atat prin definirea setului de teste, cat si prin prezicerea
performantelor obtinute de aplicatie. In functie de numarul parametrilor de in-
trare si de raspunsul urmarit, se pot identifica mult mai usor erorile aparute ın
cadrul fiecarei etapa de proiectare. Totodata analiza statistica a permis elimi-
narea factorilor care nu au nici un efect asupra raspunsului aplicatiei analizate
si permite proiectantului sa verifice performantele pentru parametri de intrare
reali, fara a rula efectiv aplicatia. Estimarile obtinute din analiza statistica pot
fi utilizate la optimizarea gradului de ocupare a resurselor la un moment dat de
aplicatie si la ımbunatatirea acesteia ın sensul modificarii dinamice a modului de
4

1.2. Structura tezei
lucru ın functie de datele de intrare/iesire.
Partea a doua a tezei este dedicata dezvoltarii unei infrastructuri de tip Grid si
a clusterelor componente. Rularea aplicatiilor paralele pe clustere de calculatoare
sau ın sisteme Grid presupune existenta unei infrastructuri hardware si software
adecvate.
Capitolul 4 este dedicat prezentarii arhitecturii clusterelor, a sistemelor Grid
si a unui studiu de caz asupra arhitecturii Gridului GRAI, dezvoltat ın cadrul
proiectului de cercetare ”GRID ACADEMIC PENTRU APLICATII COMPLEXE”,
contract Nr. 74 CEEX-II03 (2006-2008), director prof. dr. Mitica Craus. In
cadrul acestui proiect au fost studiate tehnologiile de proiectare si implementare
a clusterelor si a sistemelor Grid. Capitolul include, pe langa prezentarea in-
frastructurii hardware si software a Gridului GRAI, si o justificare a alegerii
tehnologiilor utilizate.
Odata dezvoltata infrastructura gridului GRAI, cercetarile ulterioare s-au
axat pe ımbunatatirea performantelor clusterlor ınglobate de acest sistem Grid.
Astfel, au fost avute ın vedere optimizarea comunicatiilor si partajarea resurselor
disponibile ın clusterele membre ale gridului GRAI. Capitolul 5 este dedicat
prezentarii unui model de optimizare a comunicatiilor ın reteaua interna a clus-
terelor. Implementarea acestui model pe un cluster al gridului GRAI a condus la
reducerea timpilor de transfer a datelor ıntre nodurile din cluster. Spre deosebire
de solutiile existente, avantajul modelului propus este ca rezolva aceasta pro-
blema utilizand doar facilitatile oferite de nucleul sistemului de operare Linux.
Pentru implementarea acestui model este propus si un algoritm de analiza a
performantlor si de optimizare a comunicatiilor. Cercetarile incluse ın acest capi-
tol au fost ıncununate de obtinerea premiului Best Paper la International
Conference on Computers, Communications & Control (ICCCC) 2010.
Capitolul 6 este dedicat problemei de partajare a resurselor unui cluster.
Partajarea resurselor reprezinta o problema cu implicatii multiple ın managemen-
tul task -urilor si a retelei de comunicatii a clusterului. In mod uzual, politicile de
rezervare a resurselor utilizate de job manager -e iau ın considerare pentru fisierele
de descriere a job-ului doar numarul de procesoare, memoria disponibila si arhi-
tectura sistemului. Pentru aplicatiile de tip data intensive, timpul de acces la
fisiere/date si timpii de transfer al acestor date sunt timpi critici. Performantele
si rezultatele acestui tip de aplicatii sunt puternic dependente de acesti timpi.
In mod uzual, ın cazul unui cluster partajat de mai multi utilizatori, task -urile
sunt acceptate pentru rulare de catre un job manager daca acestea satisfac un
anumit set de restrictii. In astfel de cazuri, job manager -ele nu iau ın considerare
resurse precum latimea de banda disponibila ın reteaua clusterului sau resursele
consumate de alte aplicatii ce ruleaza ın cluster. In acest capitol sunt prezentate
o serie de tehnici alternative de management eficient al resurselor, precum CPU
si latime de banda, si implementarea acestor solutii ın clustere. Spre deosebire de
5

1. Introducere
cazurile uzuale, aceste tehnici noi permit o alocare dinamica de resurse ın functie
de politicile de rezervare ale acestora impuse de administratorii sistemului.
In capitolul 7 sunt prezentate sintetic rezultatele obtinute si sunt evidentiate
contributiile aduse pentru domeniile abordate. Finalul capitolului contine pro-
punerile de cercetare ce deriva din rezultatele obtinute.
1.3 Diseminarea rezultatelor
Articolele stiintifice ce stau la baza acestei lucrari au fost publicate ın reviste (2),
volume de specialitate (3), carti (1) sau prezentate la conferinte internationale (6).
Contributiile aduse ın cadrul temei abordate s-au conturat ın jurul urmatoarelor
directii de cercetare:
• proiectarea aplicatiilor paralele
Cristian-Mihai Amarandei, Daniel Lepdatu, Simona Caraiman.
Improving the Design of Parallel Applications Using Statistical
Methods, Journal of Applied Science, 2011 (jurnal indexat SCO-
PUS, Thomson Reuters Master Journal List)
I. Sova and C.M. Amarandei and I. Gavrila, Dynamic Load
Balancing in Tree-Topology Distributed Mobile Agents System,
Proceedings of the Eighth International Symposium on Auto-
matic Control and Computer Science, 2004
T. Teodoru and C.M. Amarandei, Load Balancing in a Mobile
Agent System, Proceedings of 9th International Symposium on
Automatic Control and Computer Science, 2007
• proiectarea si implementarea unei infrastructuri Grid
C.M. Amarandei, A. Rusan, A. Archip and S. (Caraiman)
Arustei, On the Development of a GRID Infrastructure, In H.N.
Teodorescu and M. Craus, editors, Scientific and Educational
Grid Applications, pages 13 - 23, Iasi, Romania, 2008, Ed. Po-
litehnium.
C.M. Amarandei, A. Archip, and S. (Caraiman) Arustei, Per-
formance Study for MySql Database Access Within Parallel Ap-
plications, Buletinul Institutului Politehnic din Iasi, Automatic
Control and Computer Science Section, LVI(LII):127 - 134, 2006.
A. Archip, C.M. Amarandei, S. (Caraiman) Arustei, and M.
Craus, Optimizing Association Rule Mining Algorithms Using
C++ STL Templates, Buletinul Institutului Politehnic din Iasi,
Automatic Control and Computer Science Section, LVII(LIII):123
– 132, 2007.
6

1.3. Diseminarea rezultatelor
C. Aflori and M. Craus and I. Sova and F. Leon, C. Butincu
and C.M. Amarandei, GRID - Tehnologii si aplicatii, Ed. Po-
litehnium, 2005
S. (Caraiman) Arustei, A. Archip, and C.M. Amarandei, Pa-
rallel RANSAC for Plane Detection in Point Clouds, Buletinul
Institutului Politehnic din Iasi, Automatic Control and Computer
Science Section, LVII(LIII):139 - 150, 2007.
S. (Caraiman) Arustei, A. Archip and C.M. Amarandei, Grid
Based Visualization Using Sort-Last Parallel Rendering, In H.N.
Teodorescu and M. Craus, editors, Scientific and Educational
Grid Applications, pages 101 - 109, Iasi, Romania, 2008, Ed.
Politehnium.
A. Archip, S. (Caraiman) Arustei, C.M. Amarandei and A. Ru-
san, On the design of Higher Order Components to integrate MPI
applications in Grid Services, In H.N. Teodorescu and M. Craus,
editors, Scientific and Educational Grid Applications, pages 25 -
35, Iasi, Romania, 2008, Ed. Politehnium.
• optimizarea comunicatiilor si partajarea resurselor ın clustere.
Cristian-Mihai Amarandei and Andrei Rusan, Techniques for
efficient resource management on shared clusters, Proceedings
ECIT2010 - 6th European Conference on Intelligent Systems and
Technologies Iasi, Romania, 2010
Andrei Rusan and Cristian-Mihai Amarandei, A New Model
for Cluster Communications Optimization, International Journal
of Computers, Communications & Control, Vol. 5, Issue 5, ISSN
1841-9836, Oradea, Romania, 2010 - ”Best Paper Authored
By a PhD Student” http://www.iccc.univagora.ro/ , (ISI
Impact factor = 0.373)
O parte din cercetarile si rezultatele obtinute ın aceasta lucrare au fost efec-
tuate ın cadrul urmatoarelor proiecte de cercetare:
• ”GRID academic pentru aplicatii complexe”, contract Nr. 74 CEEX-II03
(2006-2008), director Mitica Craus;
• ”Sistem de informare distribuit pe o arhitectura GRID, dotat cu agenti
inteligenti pentru constructia si actualizarea automata a fondului docu-
mentar si cu instrumente de extragere de cunostinte”, Contract de cercetare
CNCSIS cod 442 (2005 - 2006);
• ”Sisteme de calcul paralel si distribuit. Tehnologii si aplicatii.”, Grant
Banca Mondiala nr. 44058 (1998 - 2002), grant tip D.
7


Partea I: PROIECTAREA
APLICATIILOR PARALELE
9


Capitolul 2
Metodologii de proiectare a
aplicatiilor paralele
Rezumat
In cadrul acestui capitol este descris pe larg stadiul actual pentru trei
probleme implicate ın proiectarea aplicatiilor paralele: etapele de proiectare,
analiza cantitativa si calitativa a aplicatiilor si problema echilibrarii ıncarcarii.
Este prezentat si un studiu de caz privind implementarea si performantele
unor algoritmi de echilibrare a ıncarcarii pe o platforma de agenti mobili
(PASIBC1) si ın medii message passing (MPI - Message Passing Interface).
Programarea paralela este un aspect important al calculului de ınalta per-
formanta. Initial un domeniu de nisa, programarea paralela a capatat tot mai
multa importanta si a devenit un aspect important al tehnicilor de dezvoltare a
software-ului datorita schimbarilor radicale ın hardware.
Marii producatori de chip-uri au introdus pe piata procesoare cu mai multe
unitati sau nuclee de procesare pe un singur chip. Aceste unitati lucreaza inde-
pendent, beneficiaza de acces concurent la memorie si sunt eficiente din punct de
vedere al consumului de energie. Termenul de nucleu (core) este utilizat pentru
o singura unitate de procesare. Termenul de multicore a ınceput sa fie utilizat
pentru un ıntreg procesor ce contine mai multe nuclee de procesare. Dezvoltarea
sistemelor multicore a fost impusa de limitele fizice ale tehnologiei – frecventa de
lucru a procesoarelor cu din ce ın ce mai multi tranzistori nu poate fi crescuta
fara a exista riscul supraıncalzirii. Arhitecturile multicore prezente sub forme
diverse pornind de la un singur procesor multicore, memorie comuna partajata
de procesoare multicore sau clustere ce au ın componenta lor sisteme multicore
1Platforma Agent pentru dezvoltarea Sistemelor Informatice Bazate pe Cunostinte[Sova 06]
11

2. Metodologii de proiectare a aplicatiilor paralele
interconectate de retele de comunicatii de mare viteza, au un impact deosebit
asupra tehnicilor de dezvoltare a software-ului [Rauber 10].
Incepand din 2009, procesoarele dual-core sau quad-core sunt standard ın cal-
culatoarele personale, iar producatorii au introdus deja procesoare cu sase, opt
sau doisprezece nuclee. Se poate prezice conform legii lui Moore, ca numarul de
nuclee per procesor se poate dubla la fiecare 18-24 luni. Conform unui raport al
companiei Intel [Kuck 05], exista posibilitatea ca ın 2015 un procesor obisnuit sa
fie alcatuit din zeci sau chiar sute de nuclee, o parte dedicate unor sarcini ca ma-
nagementul retelei, criptare/decriptare sau procesare grafica, iar restul sa ramana
disponibile pentru aplicatii, oferind o putere extraordinara de calcul. Concomi-
tent cu cresterea numarului e nuclee al procesoarelor de uz general, producatorii
de chip-uri grafice (GPU) au crescut performantele acestora. Acest lucru a con-
dus la acordarea unei mai mari atentii asupra performatelor procesoarelor grafice
si a includerii lor ın arhitecturile supercalculatoarelor.
Utilizatorii sistemelor de calcul sunt interesati sa beneficieze din plin de per-
formantele oferite de procesoarele multicore. Daca acest lucru poate fi atins, uti-
lizatorii se asteapta ca programele lor sa fie din ce ın ce mai rapide si sa includa
din ce ın ce mai multe facilitati ce nu au putut fi introduse ın versiunile ante-
rioare ale software-ului datorita cerintelor ridicate din punct de vedere al puterii
de calcul. Pentru a atinge acest deziderat, este necesar fie suportul din partea
sistemului de operare, fie rularea mai multor programe ın paralel. Atunci cand
este furnizat un procesor multicore este necesara executia unui singur program
pe mai multe nuclee. In cel mai bun caz, pentru dezvoltatorii de aplicatii ar fi
utila existenta unor instrumente care, plecand de la codul secvential sa genereze
un program paralel ce va rula eficient pe noua arhitectura. Daca astfel de in-
strumente ar fi disponibile, dezvoltarea de software s-ar desfasura ca pana acum
[Rauber 10]. Din nefericire, experienta cercetarilor din ultimii 20 de ani ın par-
alelizarea compilatoarelor arata ca pentru foarte multe programe secventiale este
imposibila o paralelizare complet automata [Rauber 10]. Interventia programa-
torului este ın continuare necesara pentru a reorganiza corespunzator codul unei
aplicatii secventiale. Pentru dezvoltatorul de software, provocarile apar din per-
spectiva restructurarii codului existent pentru a beneficia de avantajele sistemelor
multicore. Programatorul nu se mai poate astepta ca performantele aplicatiei sale
sa creasca automat odata cu cresterea puterii de calcul a procesorului. Este nece-
sar un efort suplimentar pentru ca aceasta putere de calcul sa poata fi folosita.
Exista cercetari ın domeniul mediilor si limbajelor de programare paralela cu
scopul de a usura scrierea codului paralel prin furnizarea unui anumit nivel de
abstractizare fata de arhitectura masinii.
Stadiul actual al dezvoltarii aplicatiilor paralele poate fi descris pe scurt astfel
[Skillicorn 05]: programarea specifica unei anumite arhitecturi (masini paralele)
a ajuns la un anumit nivel de maturitate si beneficiaza de utilitare din ce ın ce
12

2.1. Introducere ın proiectarea aplicatiilor paralele
mai sofisticate; ın timp ce programarea paralela independenta de arhitectura sis-
temului de calcul este ın continua dezvoltare. Din punct de vedere al arhitecturii
sistemelor paralele, idei noi apar la un interval regulat, idei ce se concretizeaza ın
noi tipuri de procesoare si ın arhitecturi paralele cu diferite grade de parelelism
si caracteristici.
Modele de programare paralela au fost dezvoltate rapid pentru fiecare tip de
arhitectura aparuta: executii sincronizate la nivel de instructiune pentru masinile
SIMD (lockstep execution), instructiuni de tip test-and-set pentru gestiunea ac-
cesului la memorie ın cazul masinilor paralele bazate pe partajarea memoriei,
precum si mesaje si canale de comunicatie pentru masinile bazate pe principiul
memoriei distribuite [Skillicorn 05]. Limbaje, algoritmi, compilatoare si ın unele
cazuri pentru suite ıntregi de aplicatii paralele au aparut ın jurul fiecarui tip de
arhitectura paralela ın parte.
Utilizatorii sistemelor de calcul de mare performanta doresc sa beneficieze de
software-ul ce exploateaza paralelismul unei anumite arhitecturi chiar daca apar
schimbari la nivelul hardware-ului. Acest tip de software nu este portabil pe
orice tip de arhitectura. Uneori, nu este portabil nici chiar pe variante extinse
ale aceluiasi sistem [Skillicorn 05]. De aceea, aplicatiile scrise pentru un anumit
tip de sistem de calcul pot fi migrate pe alta arhitectura doar dupa un important
efort de rescriere. Uneori este necesara rescrierea completa a software-ului pentru
o anumita arhitectura. Nucleul acestei probleme ıl reprezinta legatura stransa
dintre modelul de programare si arhitectura tinta; ceea ce implica ınvatarea unor
noi metode si paradigme de programare.
2.1 Introducere ın proiectarea aplicatiilor paralele
2.1.1 Definirea problemei
Proiectarea aplicatiilor paralele si a algoritmilor paraleli introduce un plus de
complexitate fata de cazul aplicatiilor si algoritmilor secventiali. In cazul proiecta-
rii aplicatiilor si algoritmilor paraleli, trebuie dezvoltate metodologii care sa con-
duca la producerea unor coduri paralele eficiente si scalabile. Au fost propuse
mai multe astfel de metodologii, care adreseaza fie cautarea modelului de executie
paralela cel mai potrivit, pe baza descrierii problemei de rezolvat, fie parcurgerea
a patru etape pentru crearea programului paralel (partitionarea, comunicarea,
aglomerarea si maparea) [Foster 95], [Cole 89], [Hammond 99].
O prima metoda de realizare a programelor paralele a constat ın paralelizarea
programelor secventiale cu volumul de calcul cel mai mare. Aparent, toate bu-
clele din program exprima un paralelism intrinsec, care poate fi exploatat prin
ımpartirea lor ın mai multe activitati de calcul simultane. Acest lucru nu poate fi
realizat daca exista dependente de date ıntre iteratiile succesive. In plus, pentru
multe probleme, solutiile paralelele eficiente nu sunt obtinute prin simpla para-
13

2. Metodologii de proiectare a aplicatiilor paralele
lelizare a celui mai bun algoritm secvential. Astfel, se poate observa aparitia
unor compilatoare specializate care erau puternic legate de modelul sistemului
de calcul. Acest fapt a facut aproape imposibila portarea unui program de pe un
sistem cu memorie partajata pe unul cu memorie distribuita [Grigoras 00].
O alta posibilitate este de a pleca de la problema de rezolvat si de a proiecta
de la ınceput varianta paralela cea mai buna, pentru tipul de sistem de calcul pe
care se va executa. In acest caz trebuie sa se tina cont de tipul de paralelism
al aplicatiei [Hammond 99]. Un alt tip de aplicatii (numite ın literatura de spe-
cialitate aplicatii ”stanjenitor de paralele” – embarassingly parallel) constau ın
activitati de calcul complet diferite (nu necesita comunicatii intermediare) si care
pot fi alocate unor procesoare distincte.
Principala problema ın proiectarea aplicatiilor paralele, este de a obtine un
cod paralel eficient si scalabil. Nu exista o solutie unica, general valabila. In
majoritatea cazurilor, cade ın seama proiectatului sa aleaga o solutie convenabila
ın raport cu diferite criterii, precum natura aplicatiei de paralelizat si tipul de
resurse necesare, tipul masinii paralele, s.a.m.d.
2.1.2 Modelarea aplicatiilor paralele
O prima etapa ın proiectarea aplicatiilor paralele, consta ın definirea activitatilor
paralele, prin exploatarea la maximum a potentialului de paralelizare. Dupa
definirea acestor activitati paralele, trebuie sa se analizeze necesarul de comuni-
catii, pentru a se determina care este granularitatea optima a aplicatiei ın raport
cu sistemul paralel tinta, deoarece de dimensiunea optima a granulei depinde
eficienta sistemului. Se observa o contradictie ıntre tendinta de a crea cat mai
multe activitati paralele (pana la numarul maxim dat de numarul procesoarelor
din sistem) si aceea de a avea un numar mai mic de activitati paralele, dar o
granularitate mai mare (o eficienta mai buna). Urmatoarea etapa consta ın plan-
ificarea executiei activitatilor paralele pe procesoare. Spre deosebire de planifi-
carea proceselor ın sistemele secventiale, trebuie specificat atat momentul lansarii
ın executie cat si procesorul pe care se executa. Daca aplicatia are o structura
dinamica (apar noi activitati de calcul), poate deveni utila abordarea unor algo-
ritmi de echilibrare dinamica a ıncarcarii [Grigoras 00].
Conform lui [Gergel 06], dezvoltarea unei aplicatii paralele implica urmatoarele
etape:
• Analiza activitatilor de calcul si ımpartirea lor ın subactivitati cu un grad
ridicat de independenta ce pot fi procesate separat.
• Realiazarea interactiunilor dintre subactivitatile de calcul pentru rezolvarea
problemei initiale.
• Definirea sistemului de calcul necesar ce poate rezolva problema si dis-
tribuirea subactivitatilor pe procesoare.
14

2.1. Introducere ın proiectarea aplicatiilor paralele
Aceste activitati, definite la modul general, presupun ca volumul de calcule alocat
unui procesor este aproximativ acelasi, iar interactiunile dintre subactivitati sunt
minime.
Un prim model de dezvoltare a aplicatiilor paralele, propus de Ian Foster
[Foster 95], presupune crearea de mecanisme care sa permita discutia explicita
ıntre task -uri cu privire la operatiile paralele si cele locale. In Figura 2.1 sunt
reprezentate astfel de task -uri si etapele de calcule si comunicatiile aferente.
Etapa de calcul este reprezentata prin cercuri conectate prin canale de comunicatii
(sageti). Un task contine un program si memoria locala, precum si un set de
canale de comunicatii. Un astfel de canal de comunicatii reprezinta o coada ın
care pot fi introduse sau din care pot fi extrase mesaje.
Legenda:
Proces
Canal comunicaţii
Primire/Transmitere mesaje
Canale primire/transmitere mesaje
Codul procesului
Figura 2.1: Un model simplu de programare paralela (adaptare dupa [Gergel 06]
si [Foster 95])
Acest model de dezvoltare permite realizarea unor aplicatii scalabile si mod-
ulare, daca sunt satisfacute urmatoarele cerinte:
• Aplicatiile paralele trebuie sa fie formate dintr-unul sau mai multe task -
uri care se executa ın paralel. Numarul task -urilor poate varia ın timpul
executiei.
• Un task trebuie sa contina cod secvential si memorie locala (o masina von
Neumann virtuala). In plus, un task este interfatat cu exteriorul prin in-
termediul unui set de porturi de intrare/iesire.
• Un task trebuie sa poata realiza patru operatii de baza: trimitere/primire
de mesaje, creare de task -uri noi, terminare.
• Operatia de trimitere de mesaje trebuie sa fie asincrona: se termina imediat.
Operatia de primire a mesajului trebuie sa fie sincrona: task-ul se blocheaza
pana cand este disponibil mesajul.
• Porturile de I/O trebuie sa fie conectate prin cozi de mesaje numite canale
de comunicatie. Aceste canale de comunicatie pot fi create sau sterse, iar
15

2. Metodologii de proiectare a aplicatiilor paralele
referinte catre ele pot fi incluse ın mesaje. Se poate considera ca aceste
canale de comunicatie sunt create dinamic, la momentul executiei primei
operatii de comunicare pe canalul respectiv. Pentru simplificarea modelu-
lui, se presupune ca aceste canale corespund uneia sau mai multor operatii
de comunicare, pot fi canale sincrone sau asincrone, si au o capacitate ne-
limitata [Gergel 06].
• Task -urile pot fi mapate pe procesoare fizice ın mai multe moduri, maparea
nu trebuie sa afecteze semantica programului. In particular, mai multe
task -uri pot fi mapate pe un singur procesor.
Acest model furnizeaza un mecanism numit dependenta de date: pentru a-
si putea continua executia, un task poate avea nevoie de datele localizate ın
memoria locala a altor task -uri. Alte proprietati ale acestui model, identificate
de [Foster 95], sunt:
• Performanta : procedurile si structurile de date din programarea secventi-
ala sunt eficiente deoarece pot fi mapate simplu si eficient pe masina von
Neumann. Acest lucru este posibil si ın cazul task -urilor si canalelor de
comunicatie. Un task reprezinta codul care poate fi executat secvential
pe un singur procesor. Daca doua task -uri care partajeaza acelasi canal de
comunicatie sunt mapate pe procesoare diferite, atunci canalul de comunica-
tie este implementat ca o comunicatie inter-procesor. Daca sunt mapate pe
un acelasi procesor, atunci pot fi utilizate alte mecanisme mai eficiente.
• Independenta fata de maparea pe procesoare . Deoarece task -urile uti-
lizeaza acelasi mecanism (canale de comunicatie) privind localizarea task -
urilor, rezultatele furnizate de aplicatie nu depind de locul executiei task -
ului. Asadar, algoritmii pot fi implementati fara a se tine cont de numarul
de procesoare pe care se executa; de fapt, algoritmii ar trebui realizati ast-
fel ıncat sa poata crea mai multe task -uri decat numarul de procesoare. In
acest fel se poate obtine o scalabilitate crescuta: cu cat numarul de proce-
soare creste, numarul de task -uri per procesor scade, dar algoritmul ın sine
nu se modifica. Crearea mai multor task -uri decat procesoare ar putea fi,
de asemenea, utila ın ascunderea ıntarzierilor datorate comunicatiilor, prin
furnizarea altor calcule ce trebuie efectuate ın acest interval de timp.
• Modularitatea . In programarea modulara, numeroase componente sunt
realizate separat si apoi combinate pentru a realiza programul complet.
Interactiunea dintre module este restrictionata de interfete bine definite.
Asadar, modulele implementate pot fi modificate fara alterarea altor compo-
nente, iar proprietatile programului pot fi aflate din specificatiile modulelor
si din codul care leaga aceste module. Aplicata cu succes, programarea
modulara duce la reducerea complexitatii programului si faciliteaza reuti-
lizarea codului.
Task -ul, care ıncapsuleaza datele de lucru, codul care opereaza asupra aces-
16

2.1. Introducere ın proiectarea aplicatiilor paralele
tor date si porturile de comunicatii (interfata cu exteriorul), reprezinta
o modalitate de proiectare modulara a unei aplicatii paralele. Exista de
asemenea similaritati cu programarea orientata obiect. In acest caz task -
urile, la fel ca si obiectele, ıncapsuleaza date si codul care opereaza asupra
acestor date, diferenta fiind data de concurenta si de utilizarea canalelor
de comunicatie ın locul metodelor (procedurilor) pentru interactiunea cu
exteriorul. O alta diferenta notabila este lipsa mostenirii.
• Determinismul . Un algoritm sau un program se numeste determin-
ist daca executia pentru o intrare particulara produce ıntotdeauna acelasi
rezultat si nedeterminist daca pentru aceeasi intrare se obtin iesiri diferite.
Programele deterministe sunt usor de ınteles, fiind de dorit un model de pro-
gramare paralela care permite dezvoltarea acestui tip de aplicatii. Verifi-
carea corectitudinii unui algoritm/program determinist poate fi realizata
mai usor: un model determinist permite identificarea rapida a tuturor
cazurilor de executie posibile. Modelul task/canale de comunicatie fa-
ciliteaza obtinerea unor algoritmi/aplicatii deterministe.
Alte modele de programare au fost propuse, diferenta dintre ele fiind data
de flexibilitate, mecanismele de interactiune dintre task-uri, granularitatea task-
urilor, suport pentru pozitionare, scalabilitate si modularitate:
• Transmitere de mesaje (Message passing). Acest model de programare
paralela este, probabil, cel mai utilizat. Programele dezvoltate dupa acest
model, creeaza task -uri multiple si ıncapsuleaza datele conform modelului
task/canale de comunicatie. Task -urile sunt identificate de un nume unic
si interactioneaza ıntre ele prin transmitere de mesaje. Din acest punct de
vedere, modelul message passing poate fi privit ca o particularizare a mod-
elului task/canale de comunicatie. Modelul nu exclude crearea dinamica
a task-urilor, executia mai multor task -uri pe un procesor sau executia a
diferite programe de task -uri diferite. Unele versiuni ale sistemelor message
passing creeaza un numar fix de task -uri identice la pornirea programului
si nu permit crearea sau distrugerea task-urilor ın timpul rularii programu-
lui. Despre aceste sisteme se spune ca implementeaza un model de executie
SPMD (Single Program Multiple Data) deoarece acelasi program opereaza
asupra mai multor seturi de date diferite.
• Paralelismul de date (Data Parallelism). Acest model de programare
exploateaza paralelismul care deriva din aplicarea unei aceleiasi operatii
asupra mai multor elemente ale structurilor de date. Un program care
foloseste acest model consta ın secvente de astfel de operatii. Granulari-
tatea acestui model este redusa deoarece, ın foarte multe cazuri, operatia
efectuata asupra unui singur element de date este privita ca task indepen-
dent. Trebuie tinut cont si de faptul ca localizarea datelor poate fi un
impediment ın calea implementarilor eficiente ce urmaresc modelul de dez-
17

2. Metodologii de proiectare a aplicatiilor paralele
voltare ın discutie. Compilatoarele pentru acest model cer programatorului
informatii despre modul ın care datele sunt distribuite procesoarelor sau,
altfel spus, cum sunt ımpartite datele ıntre task-uri.
• Memoria partajata (Shared Memory). In acest model de programare
paralela task -urile partajeaza un spatiu de adrese comun asupra caruia
au drept de scriere/citere ın mod asincron. Pentru a controla accesul la
memoria comuna sunt folosite diverse mecanisme de sincronizare. Un posi-
bil avantaj al acestui model este absenta notiuni de proprietate a datelor
(data ownership). In acest context nu este necesara specificarea explicita
a comunicatiilor de date ıntre task -uri, simplificandu-se astfel procesul de
dezvoltare al aplicatiilor. Cu toate acestea, ıntelegerea si manipularea lo-
calizarii datelor, precum si scrierea unor programe deterministe este mai
dificila.
O sinteza a modelelor de programare paralela, ın functie de gradul de abstrac-
tizare a fost realizata ın [Skillicorn 96]. Modelele sunt grupate ın sase categorii,
dupa cum urmeaza:
1. Modele ce abstractizeaza complet paralelismul. Aceste modele descriu nu-
mai scopul urmarit de un algoritm paralel, nu si modul ın care acesta este
realizat. Programatorii nu au nevoie sa stie daca programul ce ıl scriu va fi
rulat sau nu ın paralel.
2. Modele ın care paralelismul este explicit, dar descompunerea domeniului
este implicita, ceea ce atrage dupa sine faptul ca maparea, comunicatiile
si operatiile de sincronizare sunt, la randul lor, implicite. Implementarea
acestui model presupune ca programatorul sa cunoasca tipul de paralelism
utilizat. Aplicatiile dezvoltate trebuie sa ınglobeze informatii legate de
numarul maxim posibil de entitati de procesare. De asemenea, aplicatiile
trebuie sa fie capabile de rulari adaptabile, ın functie de configuratia masinii
paralele pe care sunt lansate ın executie.
3. Modele ın care paralelismul si descompunerea sunt prezentate explicit, iar
maparea, comunicatiile si operatiile de sincronizare sunt implicite. In acest
caz, programatorul se axeaza pe descompunerea problemei ın subprobleme,
fara a fi necesar sa trateze maparea datelor sau gestiunea comunicatiilor si
a operatiilor de sincronizare.
4. Modele ın care paralelismul, descompunerea si maparea sunt explicite, iar
comunicatiile si operatiile de sincronizare sunt implicite. Programatorul nu
numai ca trebuie sa realizeze descompunerea datelor, dar trebuie sa ia si
deciziile legate de amplasarea lor pe procesoarele masinii paralele. Deoarece
localizarea datelor are impact asupra performantelor retelei de comunicatii,
programatorul trebuie sa cunoasca modalitatea de interconectare a pro-
cesoarelor. Acest model pune probleme atunci cand se ia in considerare
portarea aplicatiei pe diverse arhitecturi.
18

2.2. Modele de proiectare a aplicatiilor paralele
5. Modele ın care paralelismul, descompunerea, maparea si comunicatiile sunt
explicite, iar operatiile de sincronizare sunt implicite. Majoritatea deciziilor
sunt ın grija programatorului, cu exceptia celor legate de sincronizare care
sunt lasate ın seama sistemului.
6. Modele ın care totul este explicit. Programatorul trebuie sa precizeze toate
detaliile de implementare. Construirea de aplicatii folosind acest model este
extrem de dificila, deoarece corectitudinea si performanta poate fi obtinuta
numai prin considerarea unui numar mare de detalii.
Aceste categorii nu acopera toate modelele existente, dar includ pe cele ce
introduc idei semnificative si ofera o privire de ansamblu asupra stadiului actual
al tehnicilor de programare paralela existente.
2.2 Modele de proiectare a aplicatiilor paralele
O majoritate covarsitoare de probleme de programare pot fi paralelizate prin
intermediul mai multor metode. Sunt, de asemenea, situatii ın care solutiile par-
alele eficiente difera de paralelizarile induse de algoritmii secventiali existenti.
Metodologia de proiectare pe care o vom descrie intentioneaza sa ıncurajeze o
abordare a proiectarii ın care considerentele independentei de masina si concurenta
sa fie luate ın considerare ınaintea aspectelor legate de specificul masinii pe care
va rula aplicatia (aspectele legate de arhitectura de rulare fiind ın acest context
implicate spre finalul procesului de proiectare). Aceasta metodologie ımparte
proiectarea aplicatiilor ın patru etape distincte: partitionare, comunicatii, aglom-
erare si mapare (partitioning, communication, agglomeration, and mapping –
PCAM)[Foster 95]. In primele doua etape, se va pune accent pe paralelism, scal-
abilitate si descoperirea algoritmului care ındeplineste aceste cerinte. In etapa
a treia si a patra, se va pune accent pe performante. Astfel, pornind de la
specificatiile problemei, se realizeaza partitionarea calculelor, sunt determinate
cerintele de comunicatie, se realizeaza aglomerarea task -urilor, iar, ın final, aces-
tea sunt alocate procesoarelor (Figura 2.2) [Rauber 10].
• Partitionarea: Calculele care vor trebui realizate si datele asupra carora se
lucreaza sunt descompuse ın task -uri mai mici. Probleme practice, precum
numarul de procesoare de pe masina tinta, sunt ignorate si atentia este
concentrata asupra recunoasterii posibilitatilor de obtinere a paralelismului.
• Proiectarea comunicatiilor : Sunt determinate comunicatiile necesare pentru
coordonarea executiei task -urilor si este definita structura comunicatiilor si
algoritmii necesari.
• Aglomerarea: Task -urile si structura comunicatiilor definite ın prima parte
a proiectarii sunt evaluate luand ın considerare cerintele de performanta
si costurile de implementare. Daca este necesar, task -urile pot fi grupate
ın task -uri mai mari pentru a creste performantele si a reduce costurile de
19

2. Metodologii de proiectare a aplicatiilor paralele
dezvoltare.
• Maparea: Fiecare task este alocat spre executie unui procesor astfel ıncat
sa fie satisfacute cerintele de utilizare maxima a procesoarelor si minimizare
a costurilor de comunicatie. Maparea poate fi definita static sau determi-
nata la rularea aplicatiei prin intermediul unor algoritmi de echilibrare a
ıncarcarii.
Rezultatul acestui proces de proiectare poate fi un program care porneste si
opreste task -uri dinamic, utilizand algoritmi de echilibrare a ıncarcarii pentru
controlul maparii task-urilor pe procesoare. O alternativa ar fi un program SPMD
care creeaza cate un singur task pentru fiecare procesor. Acelasi proces de re-
alizare a algoritmului se aplica ın ambele cazuri, dar, ın cazul unui program
SPMD, actunile asociate maparii sunt incluse ın etapa aglomerarii.
Proiectarea algoritmilor paraleli este prezentata ca o activitate secventiala. In
practica, este un proces paralel, cu multe preocupari privind simultaneitatea. De
asemenea, desi se ıncearca evitarea backtracking-ului, evaluarea partiala sau com-
pleta a rezultatului proiectarii poate duce la aparitia unor schimbari ale etapelor
de proiectare realizate ın pasii anteriori.
Partiţiona
re
Aglomera
re
Comunicaţii
Mapare
Problemă
Figura 2.2: Metodologie de proiectare a aplicatiilor paralele (adaptare dupa
[Rauber 10] si [Quinn 04])
20

2.2. Modele de proiectare a aplicatiilor paralele
2.2.1 Determinarea paralelismului aplicatiei (partitionarea)
Pentru ınceput, dupa formularea problemei de rezolvat, trebuie realizata anal-
iza posibilitatilor de paralelizare. O prima etapa este evidentierea potentialului
maxim de executie paralela, fara a lua ın considerare aspectele practice. In con-
tinuare, se realizeaza descompunerea problemei ın activitati de calcul cat mai fine,
concurente (paralele), prin detectarea secventelor de operatii independente. De-
scompunerea ın activitati de calcul trebuie sa ındeplineasca urmatoarele conditii:
sa poata furniza acelasi volum de calcule ın fiecare activitate si sa minimizeze
dependenta de informatiile provenite de la alte activitati [Gergel 06]. Rezultatul
va fi un graf de executie (sau, altfel spus, un graf de dependenta), ın care nodurile
simbolizeaza activitatile de calcul iar arcele reprezinta canalele de comunicatie.
Aceste canale de comunicatie pot fi si relatiile de precedenta dintre activitatile
de calcul. Relatia de ordine ın graful de executie va fi indicata prin dependenta
de date [Almasi 89]:
• dependenta de curs (flow dependence) : exista atunci cand ıntre activitatile
a1 si a2 exista un arc si cel putin o data produsa de a1 la iesire este preluata
la intrare de a2 , deci a1 → a2;
• antidependeta (antidependance): a2 urmeaza dupa a1, iar iesirea lui a2 se
suprapune cu intrarea lui a1, deci a1 7→ a2;
• dependenta de iesire (output dependence): a1 si a2 produc (scriu) aceeasi
variabila de iesire;
• dependenta de I/E (I/O dependence): se acceseaza simultan acelasi fisier.
O relatie de conditionare suplimentara este dictata de ordinea de executie,
care stabileste ca o activitate de calcul nu poate ıncepe ınaintea terminarii unei
alte activitati de calcul. Dependente de date ıntre secvente pot fi introduse
sau eliminate prin evaluarea unor conditii ce depind de natura aplicatiei sau a
algoritmului ın discutie.
Atunci cand sunt solicitate aceleasi resurse de calcul intervine dependenta de
resurse. Fiind date doua activitati de calcul, a1 si a2 , cu datele de intrare I1,
respectiv I2 si datele de iesire O1, respectiv O2 ele se pot executa ın paralel daca
sunt independente si nu genereaza rezultate confuze, adica respecta conditiile lui
Bernstein ([Rauber 10] si [Bernstein 66]):
I1⋂O2 = � – nu exista anti-dependenta a lui a2 fata de a1
I2⋂O1 = � – nu exista dependenta prin succesiune (reala) a lui a2 fata de a1
O1⋂O2 = � – nu exista dependente prin iesire ıntre a1 si a2.
Pentru o mai buna analiza a aplicatiei paralele se pot diviza atat activitatile de
calcul cat si datele, pentru a construi un graf de executie. Pe acest graf, numarul
activitatilor paralele nu este constant, decat ın cazuri particulare, variind de la
1 la o valoare maxima, care reprezinta gradul maxim de paralelism al aplicatiei.
Acest grad maxim se poate modifica ın sensul descresterii ın etapa de modificare
a granularitatii. Nu are sens ca numarul de procesoare folosit sa fie mai mare
21

2. Metodologii de proiectare a aplicatiilor paralele
decat gradul maxim de paralelism obtinut ın final [Grigoras 00].
In general, analiza problemei si descompunerea ın activitati paralele este o
problema complicata. Exista doua abordari distincte pentru determinarea par-
alelismului aplicatiei – la nivelul datelor de prelucrat, atunci cand volumul lor o
justifica si cand asupra lor se executa aceleasi operatii sau la nivelul calculelor:
• descompunerea domeniului de date (domain decomposition) reprezinta o
abordare orientata spre date si consta ın realizarea unei partitionari adec-
vate pentru date, dupa care se asociaza acestora calculele necesare;
• descompunerea functionala (fuctional decomposition) reprezinta identificarea
activitatilor de calcul ce se pot executa ın paralel si consta ın gruparea cal-
culelor ın activitati de calcul, granule, dupa care se aloca datele aferente.
2.2.1.1 Descompunerea domeniului de date
Exista diverse metode de partitionare ın functie de structura datelor. O regula
practica este de a partitiona ıntai cea mai mare structura de date, sau structura
cel mai frecvent accesata. Daca ın cursul efectuarii operatiilor se folosesc structuri
de date diferite, sau este necesara o descompunere diferita pentru aceeasi struc-
tura, atunci fiecare faza va fi tratata separat. Ulterior, se va verifica modul ın care
se potrivesc descompunerile si algoritmii propusi pentru fiecare faza. Datele pot
fi grupate ın submultimi de dimensiuni (aproximativ) egale. Daca sistemul este
eterogen si exista diferente sensibile de performanta ıntre procesoare, domeniul
se poate descompune ın submultimi inegale. Astfel o cantitate mai mare de date
va putea fi alocata procesorului mai rapid. Apoi se partitioneaza operatiile, de
regula prin asocierea calculelor cu datele asupra carora se efectueaza. Se obtin,
astfel, un numar de activitati de calcul definite de un numar de date si operatii.
Este posibil ca o operatie sa solicite date de la mai multe activitati. In acest caz
vor fi necesare comunicatii.
2.2.1.2 Descompunerea functionala
Descompunerea functionala este o abordare complementara, obiectivul fiind acum
descompunerea calculelor ın activitati de calcul cat mai fine. Dupa crearea aces-
tora, se examineaza cerintele privind datele. Daca submultimile de date pot fi
disjuncte, partitionarea este completa. Daca, ın schimb, aceste submultimi se
suprapun ın mod semnificativ, vor fi necesare comunicatii considerabile pentru a
se evita multiplicarea datelor si din acest punct de vedere poate fi mai avantajoasa
descompunerea pe domenii. Metoda descompunerii functionale este valoroasa ca
mod diferit de abordare a problemelor si ca tehnica de structurare a programelor.
De aici poate apare o anumita structura a problemei si oportunitati de optimizare
care nu sunt evidente numai din studiul datelor si care pot reduce complexi-
tatea programului pe ansamblu. Fiecare componenta are un model propriu si
poate fi paralelizata folosind descompunerea domeniului. Aplicatia ın ansamblu
22

2.2. Modele de proiectare a aplicatiilor paralele
va deveni mai simpla daca se utilizeaza descompunerea functionala, chiar daca
ın cadrul acestui proces nu sunt produse multe activitati de calcul concurente.
Executia unei componente poate fi realizata pe mai multe procesoare (sau entitati
de procesare) [Rauber 10].
Alegerea metodei de descompunere ın activitati de calcul independente re-
prezinta o etapa esentiala ın proiectarea unei aplicatii paralele. Generarea unui
numar maxim de activitati paralele furnizeaza nivelul maxim de paralelizare pen-
tru problema ce trebuie rezolvata. Totusi, acest grad de paralelizare complica
analiza calculelor necesare. Folosirea unui numar mare de activitati paralele poate
furniza o schema de paralelizare clara, dar acest lucru poate complica utilizarea
eficienta a unui numar mare de procesoare. Combinarea celor doua metode con-
duce la alegerea acelor activitati paralele pentru care calculele sunt cunoscute sub
numele de elemente de descompunere de baza. Aceasta metoda de descompunere
a calculelor face posibila atat furnizarea unei scheme de paralelizare eficiente cat
si o paralelizare eficienta a calculelor. Activitatile astfel selectate sunt referite ca
activitati de calcul de baza elementare: indivizibile daca nu permit o partitionare
ulterioara, iar, ın caz contrar, agregate [Gergel 06].
La ıncheierea acestei faze trebuie realizata o analiza a rezultatelor obtinute.
Activitatile concurente generate trebuie sa aiba aproximativ acelasi volum de cal-
cule (sa fie echilibrate), iar numarul lor trebuie sa fie cel putin egal cu numarul
de procesoare din sistem, preferabil mai mare. Astfel, se poate obtine o gran-
ularitate optima prin contopirea mai multor granule. Un aspect important de
proiectare, care influenteaza scalabilitatea aplicatiei, este ca modificarea dimen-
siunii problemei sa conduca la modificarea numarului de activitati paralele si nu
la modificarea volumului de calcule al acestora [Grigoras 00].
2.2.1.3 Reguli de partitionare
Faza de partitionare a proiectarii poate produce una sau mai multe descompuneri
posibile a problemei. Inainte de evaluarea cerintelor de comunicatie, pentru a
putea fi siguri ca nu exista erori grave de proiectare, se recomanda parcurgerea
urmatoarei liste de ıntrebari/verificari [Quinn 04]:
• Partitionarea defineste cu cel putin un ordin de marime mai multe task -uri
decat numarul de procesoare de pe sistemul pe care se va rula aplicatia?
• Partitionarea obtinuta nu produce calcule redundante si necesitati de sto-
care suplimentare? Daca produce, algoritmul rezultat nu este scalabil pen-
tru probleme mari.
• Task -urile sunt de dimensiune comparabila? Daca nu, poate fi dificil de alo-
cat aceeasi cantitate de calcule la toate procesoarele (este dificila realizarea
unei echilibrari a ıncarcarii procesoarelor).
• Numarul de task -uri este scalabil cu dimensiunea problemei? In cazul ideal,
la o crestere a dimensiunii problemei ar trebui sa creasca si numarul de task -
23

2. Metodologii de proiectare a aplicatiilor paralele
uri, nu si dimensiunea acestora. Daca nu, algoritmul paralel nu va putea
sa rezolve probleme de mari dimensiuni atunci cand sunt disponibile mai
multe procesoare.
• A fost identificata o solutie alternativa de partitionare? Poate fi ımbunatati-
ta flexibilitatea diferitelor parti ale programului ın functie de aceste alter-
native, investigand atat descompunerea functionala cat si descompunerea
domeniului de date.
Raspunsurile acestor ıntrebari poate sugera ca, ın ciuda atentiei alocate fazei
de proiectare, solutia obtinuta nu este cea mai buna. In aceasta situatie este
riscanta trecerea la implementare si vor trebui utilizate tehnici care sa determine
daca solutia proiectata ıntruneste cerintele de performanta ın ciuda deficientelor
observate. Pentru atingerea acestui obiectiv se pot folosi parametrii de performan-
ta calitativi: accelerarea, eficienta, costul, granularitatea, scalabilitatea). De
asemenea pot fi revizuite specificatiile problemei.
Un caz particular este cel al aplicatiilor stiintifice, unde problema de re-
zolvat poate implica simularea unor procese fizice. Aplicatiile si tehnicile nu-
merice utilizate ın acest caz pentru dezvoltarea aplicatiei pot influenta dificul-
tatea proiectarii aplicatiei paralele. Frecvent, apare situatia ın care pentru im-
plementarea solutiei paralele sau secventiale folosesc tehnici diferite.
2.2.2 Comunicatiile
Activitatile, sau task -urile ce sunt generate ın urma partitionarii trebuie sa se
execute ın paralel, dar ın general nu pot fi executate independent. Calculele
aferente unui task au nevoie, de obicei, de datele calculate de catre un alt task si
vor fi necesare comunicatii pentru transferul datelor ıntre task -uri pentru a putea
permite continuarea calculelor.
Fluxul de informatii este specificat ın faza de realizare a comunicatiilor pentru
proiectarea aplicatiei. Necesarul de comunicatii dintre task -uri poate fi descris
prin canale de comunicatie: cate un canal de comunicatie dedicat pentru receptie
si, respectiv, transmisie de mesaje pentru fiecare task ın parte. Din acest motiv,
comunicatiile asociate unui algoritm trebuie specificate ın doua faze. In prima
faza, definim structura canelelor de comunicatii care leaga, direct sau indirect,
task -urile care au nevoie de date (consumatorii) de task -urile care detin datele
(producatorii). A doua faza presupune specificarea mesajelor care se transmit de
la un task la altul pe aceste canale de comunicatii. In functie de tehnologia de
implementare, este posibil ca aceste canale sa nu fie efectiv create atunci cand se
scrie codul algoritmului [Foster 95].
La definirea canalelor de comunicatii, trebuie maximizate performantele aplica-
tiei prin distribuirea comunicatiilor la mai multe task -uri si prin organizarea lor
astfel ıncat sa permita executia concurenta. In cazul descompunerii domeniului,
cerintele de comunicatii nu pot fi ıntotdeauna determinate cu usurinta, deoarece
24

2.2. Modele de proiectare a aplicatiilor paralele
descompunerea domeniului produce task -uri prin ımpartirea datelor ın sectiuni
disjuncte si apoi se asociaza datele acelor operatii care pot fi executate ın par-
alel. Aceasta parte a proiectarii pare relativ simpla, dar trebuie analizate, ın
continuare, cu atentie acele operatii care necesita date de la mai multe task -
uri. In acest caz sunt necesare comunicatii pentru a transfera datele la task -urile
care au nevoie de ele si de aceea organizarea eficienta a comunicatiilor poate
fi o adevarata provocare (cea mai simpla descompunere a datelor poate avea o
structura a comunicatiilor extrem de complexa).
In contrast cu descompunerea domeniului, cerintele de comunicatie obtinute
prin descompunerea functionala corespund fluxului de date dintre task -uri.
Comunicatiile pot fi analizate pe baza a patru criterii, care definesc natura
acestora:
• scheme de comunicatii locale sau globale - atunci cand un task comunica cu
un numar redus de task -uri vecine, se obtin scheme de comunicatii locale.
Atunci cand un task comunica cu un numar mare de task -uri, sau chiar cu
toate, se obtin scheme de comunicatii globale ce pot restrictiona operatiile
paralele [Gergel 06].
• metode de interactiune structurate sau nestructurate: atunci cand se uti-
lizeaza o topologie structurata (arbore, plasa, etc.), comunicatiile sunt
structurate; atunci cand se utilizeaza o topologie de tip graf oarecare se
obtin comunicatii nestructurate. Comunicatiile nestructurate complica eta-
pele de aglomerare si mapare din proiectarea aplicatiilor, iar ın unele cazuri
sunt necesari algoritmi sofisticati pentru determinarea unei strategii de
aglomerare si mapare care creeaza task -uri de dimensiune aproximativ egala
si minimizeaza necesitatile comunicare prin crearea unui numar minim de
canale de comunicatii. Daca cerintele de comunicare sunt dinamice, acesti
algoritmi vor fi aplicati frecvent, iar costul rularii acestor algoritmi poate fi
prea mare ın comparatie cu beneficiile aduse [Grigoras 00].
• scheme de comunicatii statice sau dinamice: atunci cand identitatea par-
tenerului de comunicare nu se schimba pe durata executiei, schema de
comunicatii este statica; atunci cand identitatea partenerul de comunicare
este determinata dinamic, ın functie de datele calculate la un moment dat,
se obtin comunicatii dinamice (exemplu: quick sort pe hipercub) [Foster 95].
• metode de interactiune sincrone sau asincrone: atunci cand partenerii de
comunicatie se asteapta unul pe celalalt pentru a realiza operatia de comuni-
care, comunicatiile sunt sincrone; atunci cand partenerii de comunicatie pot
obtine datele fara cooperarea partenerului, se obtin comunicatii asincrone
(atunci cand se folosesc buffere). Alegerea formei de comunicare a datelor,
sincrona sau asincrona, este o problema dificila. Comunicatiile sincrone sunt
simple si usor de utilizat, pe cand cele asincrone pot duce la modificarea
ıntarzierilor cauzate de operatiile de comunicatii. De asemenea este posibil,
25

2. Metodologii de proiectare a aplicatiilor paralele
datorita specificului problemei, ca algoritmul ce rezolva o anumita problema
sa forteze alegerea unei anumite metode [Gergel 06].
In cazul comunicatiilor asincrone, task -urile care au nevoie de date le pot cere
explicit de la procesul care le detine, desi acesta din urma nu poate determina
momentul cererii ın discutie. Cea mai frecventa situatie este aceea ın care cal-
culele sunt structurate ca un set de task -uri care trebuie sa citeasca sau sa scrie
periodic elementele unei structuri de date partajate. Sa presupunem ca aceste
date sunt prea mari sau accesate frecvent pentru a putea fi ıncapsulate ıntr-un
singur task. In acest caz va fi necesar un mecanism care sa permita distribuirea
datelor, pastrand suportul de scriere si citire pentru operatiile asincrone asupra
acestor date. Un astfel de mecanism poate include urmatoarele:
• Structurile de date sa fie distribuite catre toate task -urile. Fiecare task
realizeaza calcule si genereaza cereri pentru datele detinute de alt task. De
asemenea, periodic, ısi va ıntrerupe activitatea si va rezolva cererile pentru
date.
• Structura de date distribuita este ıncapsulata ıntr-un alt set de task -uri
responsabile doar de citirea sau scrierea cererilor (Figura 2.3). Task -urile
care realizeaza calculele genereaza cereri de scriere/citire catre task -urile
care detin datele. Liniile continue reprezinta cererile iar cele ıntrerupte
raspunsul. Un task de calcule si unul de date pot fi atribuite unui singur
procesor (4 ın total) pentru a asigura o ıncarcare (cu date si calcule) egala
a procesoarelor [Foster 95].
• Pe sistemele care suporta modelul de programare bazat pe memorie comuna
(shared-memory), task -urile pot accesa datele partajate fara a se lua masuri
speciale. Totusi trebuie asigurat faptul ca operatiile de citire/scriere asupra
datelor au loc ıntr-o anumita ordine.
26

2.2. Modele de proiectare a aplicatiilor paralele
Calcule Calcule Calcule Calcule
citeste(k)kscrie(a) d citeste(d)
Date
l
k
j
Date
i
hg
Date
f
e
d
Date
c
b
Figura 2.3: Utilizarea task -urilor de date separat pentru a deservi cererile de
scriere/citire asupra unei structuri de date distribuite (adaptare dupa [Foster 95])
Fiecare strategie are avantajele si dezavantajele ei, performantele fiind diferite
de la un sistem de calcul la altul:
• comutarea de la un task la altul poate fi costisitoare ın unele cazuri;
• ın situatiile ın care datele nu sunt locale, sunt necesare comunicatii pentru
operatiile de citire/scriere;
• raspunsurile aferente cererilor ar trebui sa fie imediate, nu sa se astepte
tratarea lor dupa o anumita perioada de timp.
2.2.2.1 Reguli de proiectare/verificare a comunicatiilor
Pentru evaluarea rezultatelor obtinute ın aceasta etapa se recomanda parcurgerea
unui set de verificari [Quinn 04], dupa cum urmeaza:
• Toate task -urile realizeaza aproximativ acelasi numar de operatii de comuni-
care? Un dezechilibru al comunicatiilor sugereaza o constructie nescalabila.
In astfel de cazuri trebuie reproiectate comunicatiile pentru a fi distribuite
echitabil. De exemplu, daca structurile de date accesate frecvent sunt ıncap-
sulate ıntr-un singur task, ar trebui verificat daca se pot replica sau distribui
catre mai multe task -uri.
• Task -urile comunica numai cu un numar mic de procese vecine? Daca
fiecare task realizeaza comunicatii cu un numar mare de task -uri, trebuie
evaluata posibilitatea transformarii acestor comunicatii globale ın comunica-
tii locale.
27

2. Metodologii de proiectare a aplicatiilor paralele
• Comunicatiile pot fi realizate concurent? Daca nu, algoritmul nu este nici
eficient si nici scalabil. Trebuie abordate tehnici de tip divide-and-conquer
pentru a realiza concurenta.
• Este posibil ca diferite calcule asociate unor task -uri sa fie executate con-
curent? Daca nu, algoritmul fie nu este eficient, fie nu este scalabil. In acest
caz ar trebui revazute comunicatiile si calculele sau, ın anumite cazuri, chiar
specificatiile problemei.
Aceste verificari suplimentare au rolul de a detecta cazurile ın care implementarea
(desi realizata conform specificatiilor problemei) pentru un anumit tip de masina
paralela poate, fie sa introduca ıncarcari suplimentare, fie sa nu furnizeze para-
metrii de performanta doriti pentru aplicatia paralela.
2.2.3 Aglomerarea
Schemele de calcul paralel dezvoltate pentru rezolvarea problemelor trebuie sca-
late relativ la dimensiunile sistemelor tinta. In cazurile ın care numarul de ac-
tivitati de calcul este mult mai mare decat numarul de procesoare este necesara
scaderea numarului acestui tip de activitati. Acest lucru coincide cu recoman-
dararile de la finalul etapei de partitionare [Gergel 06]. Algoritmul rezultat dupa
parcurgerea primelor doua etape este abstract ın sensul ca nu este specializat
pentru executia eficienta pe un anumit sistem de calcul paralel. In realitate ex-
ista cazuri ın care sistemele de calcul paralel nu sunt destinate executiei eficiente
a task -urilor de mici dimensiuni. Etapa aglomerarii presupune trecerea de la
modelul abstract la cazul concret de implementare. Sunt reanalizate deciziile
legate de fazele de partitionare si comunicare pentru a obtine un algoritm care
se va executa eficient pe o anumita clasa de calculatoare paralele. In particu-
lar, poate fi utila combinarea sau aglomerarea task -urilor identificate ın etapa de
partitionare, astfel ıncat sa se obtina un numar redus de task -uri de dimensiune
corespunzatoare (Figura 2.4) [Quinn 04]:
• poate fi crescut volumul task -urilor prin reducerea numarului de dimensiuni
implicate ın descompunere ( Figura 2.4 a);
• task -urile adiacente pot fi grupate pentru a produce o descompunere de
granularitate mare ( Figura 2.4 b);
• ın cazul aplicatiilor de tip divide-and-conquer, unele structuri de tip sub-
arbore pot fi reunite pe baza criteriilor de omogenitate (Figura 2.4 c);
• o alta abordare posibila pentru situatiile similare cazului anterior poate fi
combinarea nodurilor omogene din arborele solutie (Figura 2.4 d).
In functie de specificul problemelor de rezolvat, replicarea datelor si/sau a cal-
culelor poate fi, de asemenea, luata ın considerare. Foster atrage atentia asupra
faptului ca desi numarul de task -uri create dupa faza de aglomerare este redus,
acesta poate fi mai mare decat numarul de procesoare [Foster 95].
28

2.2. Modele de proiectare a aplicatiilor paralele
a)
b)
c)
d)
Figura 2.4: Exemple de aglomerare (adaptare dupa [Foster 95])
In astfel de situatii este de dorit reducerea ın continuare a numarului de task -
uri, astfel ıncat sa se obtina o mapare de un singur task atribuit unui singur
procesor (daca, spre exemplu, calculatorul paralel tinta sau mediul de dezvoltare
impun un program de tip SPMD). Daca aceasta reducere este posibila se poate
afirma ca proiectarea aplicatiei este aproape completa deoarece a fost atinsa si
29

2. Metodologii de proiectare a aplicatiilor paralele
problema maparii.
Deciziile legate de aglomerare si replicare trebuie luate considerandu-se trei
obiective tinta [Foster 95]:
• reducerea costului comunicatiilor prin cresterea volumului de calcule si a
granularitatii comunicatiilor;
• pastrarea flexibilitatii pentru a nu influenta scalabilitatea si deciziile luate
ın faza de mapare;
• reducerea costurilor de proiectare a software-ului.
Pot fi ıntalnite cazuri in care atingerea unuia dintre obiective le defavorizeaza pe
celelalte.
2.2.3.1 Reducerea costului comunicatiilor
In faza de partitionare a procesului de proiectare, eforturile sunt concentrate pe
definirea unui numar de task -uri cat mai mare posibil. Acest lucru se poate dovedi
util deoarece forteaza considerarea unui numar crescut de posibilitati de executie.
De asemenea, definirea unui numar mare de task -uri cu granularitate fina nu im-
plica ın mod necesar faptul ca algoritmul paralel rezultat este eficient. Costul
comunicatiilor devine o problema critica si poate influenta decisiv performantele
aplicatiilor paralele: vehicularea mesajelor implica oprirea activitatilor de calcul.
Considerand etapele de calcul ca fiind prioritare, se poate creste performanta
aplicatiei paralele prin reducerea timpului pierdut cu efectuarea comunicatiilor.
Acest lucru poate fi obtinut prin doua metode: se ıncearca fie reducerea volu-
mului de date transmis, fie minimizarea numarului de comunicatii necesar pen-
tru transmiterea aceluiasi volum de date (aceasta ultima metoda se dovedeste
eficienta ıntrucat un numar redus de comunicatii implica si o scadere a timpi-
lor de initializare – communication startup cost). Aglomerarea este ıntotdeauna
benefica daca analiza necesarului de comunicatii indica faptul ca unele task -uri
nu se pot executa concurent [Foster 95].
2.2.3.2 Pastrarea flexibilitatii
Este foarte usor ca ın etapa de aglomerare sa fie luate decizii de proiectare care sa
limiteze scalabilitatea algoritmului. De exemplu, se poate alege descompunerea
unei structuri de date multidimensionale pe o singura dimensiune, daca acest
lucru furnizeaza un grad sporit de concurenta relativ la numarul de procesoare
disponibile. Aceasta strategie se poate dovedi a fi imprudenta si poate conduce
la implementari ineficiente daca, ın final, aplicatia va rula pe un sistem de calcul
paralel cu un numar mare de procesoare.
Capacitatea de a crea un numar variat de task -uri este critica ın cazurile ın
care programele dezvoltate vor trebui sa fie portabile si scalabile. In plus, al-
goritmii paraleli eficienti trebuie sa fie flexibili relativ la variatia numarului de
procesoare. Flexibilitatea poate fi utila si ın cazul ın care se urmareste ajustarea
30

2.2. Modele de proiectare a aplicatiilor paralele
codului pentru un anumit calculator paralel. Daca task -urile se blocheaza des
ın asteptarea unor date aflate la alte procese, poate fi avantajoasa maparea
mai multor task -uri pe un procesor. In acest caz blocarea unui task nu im-
plica faptul ca un procesor va fi ın stare idle (fara nimic de executat), deoarece
un task blocat este imediat ınlocuit de catre un alt task activ. In acest fel
comunicatiile unui task sunt suprapuse peste calculele altuia, tehnica fiind nu-
mita suprapunerea comunicatiilor si a calculelor (overlapping computation and
communication)[Foster 95].
Un alt avantaj al proiectarii aplicatiilor astfel ıncat numarul de task -uri decat
numarul de procesoare este acela al obtinerii unui grad crescut de libertate ın
faza maparii, cand se poate realiza o mai buna echilibrare a ıncarcarii. Ca si
regula generala, se poate cere ca numarul de task -uri sa fie cu cel putin un ordin
de marime mai mare decat numarul de procesoare. Numarul optim de task -uri se
poate determina printr-o combinatie de modele analitice si studii empirice. Flex-
ibilitatea nu este o cerinta expresa daca ın urma proiectarii se creeaza un numar
mare de task -uri. Granularitatea poate fi controlata prin parametri transmisi ın
fazele de compilare sau de rulare. Un aspect foarte important este ca ın faza de
proiectare sa nu se introduca limitari inutile ın privinta numarului de task -uri
care vor fi create [Gergel 06].
2.2.3.3 Reducerea costurilor de proiectare
Pana acum, s-a presupus ca strategia de aglomerare este determinata numai de
dorinta de a ımbunatati eficienta si flexibilitatea unui algoritm paralel. O preocu-
pare suplimentara, ce poate fi foarte importanta atunci cand se paralelizeaza un
cod secvential, este costul de dezvoltare asociat diferitelor strategii de partitionare.
Din aceasta perspectiva, cea mai interesanta strategie ar putea fi aceea ın care
se evita schimbarile masive ale codului pentru a putea reutiliza unele rutine deja
scrise. Frecvent, proiectarea unei aplicatii paralele se face avand grija ca algorit-
mul paralel rezultat sa poata fi executat ca o parte integranta a unui sistem mai
mare. In acest caz, apare o alta problema a proiectarii aplicatiilor paralele: dis-
tribuirea datelor utilizate de alte componente ale programului. De exemplu, cel
mai bun algoritm pentru un program poate cere ca o structura de date de intrare
sa fie descompusa ın trei dimensiuni, ın timp ce structura datelor rezultate dintr-o
faza anterioara sa fie bidimensionala. In acest caz, fie se schimba ambii algoritmi,
fie se restructureaza datele ıntr-o etapa intermediara. In functie de solutia aleasa,
se vor obtine ın final diferite caracteristici de performanta [Foster 95].
2.2.3.4 Reguli de aglomerare
Pentru evaluarea rezultatului proiectarii ın urma etapei de aglomerare, sunt utile
urmatoarele ıntrebari/verificari, care vor deveni din ce ın ce mai importante pe
masura ce se trece de la abstract la concret [Quinn 04]:
31

2. Metodologii de proiectare a aplicatiilor paralele
• Aglomerarea reduce costurile generate de comunicatii prin cresterea volu-
mului de task -uri locale? Daca nu, trebuie examinat algoritmul pentru a
determina daca acest lucru poate fi obtinut prin alte strategii de aglomerare.
• Daca aglomerarea a dus la replicarea calculelor, s-a verificat daca beneficiile
acestei replicari depasesc costurile, pentru un numar variat de dimensiuni
ale problemei si de procesoare?
• Daca aglomerarea duce la replicarea datelor, s-a verificat daca acest lucru
nu compromite scalabilitatea algoritmului prin restrictionarea la o anumita
dimensiune a problemei sau a numarului de procesoare pentru care poate
fi folosit?
• Aglomerarea produce task -uri ce au costuri de calcul si comunicatie simi-
lare? Cu cat este mai mare task -ul creat prin aglomerare, cu atat este mai
important sa avem costuri aproximativ egale. Daca a fost creat doar un
task pentru fiecare procesor, atunci aceste task -uri trebuie sa aiba costuri
aproape identice.
• Numarul de task -uri este scalabil ın raport cu dimensiunea problemei? Daca
nu, algoritmul nu este capabil sa rezolve probleme de mari dimensiuni pe
sisteme de calcul mai puternice si cu un numar mare de procesoare.
• Daca aglomerarea elimina oportunitatile de executie concurenta, s-a veri-
ficat daca exista suficiente calcule concurente pentru sistemul existent sau
pentru dezvoltari ulterioare? Un algoritm care nu ofera posibilitati de
executie concurenta poate fi totusi eficient, daca alti algoritmi au costuri
de comunicatie excesive si pot fi folosite modele de calcul a performantei
pentru cuantificarea acestor avantaje.
• Poate fi redus numarul de task -uri fara a introduce dezechilibre de ıncarcare
si fara a creste costurile de proiectare sau a reduce scalabilitatea? Daca da,
este posibil sa fie mai simplu de creat task -uri cu o granularitate mai mare
decat sa se genereze un numar mare de task -uri cu granularitatea mica?
• Daca este paralelizat un algoritm secvential, au fost considerate costurile
pentru modificarea necesara codului secvential? Daca aceste costuri sunt
prea ridicate, trebuie luate ın considerare strategii de aglomerare care cresc
posibilitatile de reutilizare a codului. Daca algoritmul rezultat este mai
putin eficient, trebuie utilizate tehnici de modelare care sa estimeze cos-
turile.
2.2.4 Maparea
Ultima etapa a procesului de proiectare a algoritmilor paraleli, maparea, are
rolul de a specifica unde va fi executat fiecare task. Problema maparii nu apare
pe un sistem multi-procesor sau pe sistemele cu memorie comuna care furnizeaza
tehnici de planificare a executiei task -ului. Pe aceste sisteme de calcul, cerintele
de comunicatii asociate task -urilor sunt ın mod uzual suficiente pentru definirea
32

2.2. Modele de proiectare a aplicatiilor paralele
specificatiilor unui algoritm paralel, si planificarea executiei task -urilor pe proce-
soare cade ın seama sistemului de operare sau a mecanismelor hardware. In cazul
sistemelor multiprocesor, daca numarul de task -uri coincide cu numarul de pro-
cesoare si daca topoplogia de comunicare este un graf complet (toate activitatile
sunt conectate direct ıntre ele) problema este mult simplificata [Gergel 06]. Totusi,
mecanisme generice de mapare automata sunt dificil de dezvoltat pentru sistemele
paralele scalabile. In general, maparea reprezinta o problema dificila care trebuie
abordata ın fazele de proiectare a unui algoritm paralel. Scopul principal ın dez-
voltarea algoritmilor de mapare este minimizarea timpului total de executie si
pentru aceasta pot fi utilizate doua strategii:
• se plaseaza task -urile ce se pot executa ın paralel pe procesoare diferite,
pentru a creste paralelismul;
• se plaseaza task -urile care comunica frecvent pe acelasi procesor, pentru a
mentine cat mai multe comunicatii locale.
Aceste doua strategii pot intra ın conflict si ın acest caz proiectantul sa re-
alizeze un un compromis ın alegerea unei solutii eficiente. In plus, limitarile
accesului la resursele de calcul poate restrictiona numarul de task -uri care pot
fi alocate unui singur procesor. Suplimentar, trebuie notata si cerinta de mini-
mizare a comunicatiilor dintre procesoare, cerinta ce poate contrazice conditia de
mapare uniforma.
Problema maparii este NP-completa, adica nu exista nici un algoritm de timp
polinomial care sa poata evalua costurile de calcul si de comunicatii pentru cazul
general. In timp, datorita cunostintelor acumulate ın privinta strategiilor eu-
ristice si a claselor de probleme pentru care acestea sunt eficiente, au aparut
solutii acceptabile pentru rezolvarea problemei maparii. De exemplu, ın cazul
problemelor care se rezolva utilizand o plasa (mesh) de procesoare, fiecare task
executa acelasi volum de calcule si comunicatii cu task -urile vecine (Figura 2.5).
Plasa si calculele asociate sunt distribuite ıntre procesoare astfel ıncat sa sa se
obtina acelasi volum de calcule si sa se minimizeze comunicatiile pentru fiecare
procesor ın parte.
Multi algoritmi paraleli au fost dezvoltati utilizand tehnica descompunerii
domeniului de date. In mod uzual, este generat un numar fix de task -uri de
dimensiuni egale si un numar fix de comunicatii globale si/sau locale, fapt ce
implica un proces de mapare simplu si eficient. Task -urile sunt mapate astfel
ıncat sa fie minimizate comunicatiile inter-procesor, fie prin aglomerarea mai
multor task-urilor pe un procesor, fie prin crearea unui numar de task -uri, cu
granularitate mare, egal cu numarul de procesoare din sistem.
In cazul algoritmilor mai complecsi de descompunere a domeniului, cu o canti-
tate de calcule variabila per task si/sau cu comunicatii nestructurate, aglomerarea
si strategia de mapare eficienta nu este evidenta, de cele mai multe ori, pentru
programator. Sunt astfel necesari algoritmi de echilibrare a ıncarcarii pentru a
33

2. Metodologii de proiectare a aplicatiilor paralele
Figura 2.5: Maparea ın problemele care se rezolva pe o plasa de procesoare(adaptare dupa [Foster 95])
gasi o solutie de aglomerare si o strategie de mapare eficienta, cautare ce se face,
de obicei, folosind tehnici euristice. Timpul necesar pentru rularea acestor al-
goritmi trebuie sa primeze beneficiilor aduse de reducerea timpului de executie
(altfel spus, determinarea solutiei de echilibrare si aplicarea acesteia trebuie sa
obtina o reducere cat mai semnificativa a timpului de executie pentru aplicatia
reechilibrata). Metodele probabilistice de echilibrare a ıncarcarii tind sa introduca
o ıncarcare suplimentara mai mica decat cele care exploateaza structura interna
a unei aplicatii. Cei mai complecsi algoritmi de echilibrare a ıncarcarii sunt aceia
ın care atat numarul de task -uri, cat si volumul de calcule si de comunicatii se
schimba dinamic ın timpul rularii programului.
In cazul problemelor care folosesc tehnica descompunerii domeniului se pot
utiliza strategii dinamice de echilibrare a ıncarcarii: algoritmul de echilibrare
este executat periodic pentru a se determina noi solutii de aglomerare si ma-
pare. Deoarece echilibrarea ıncarcarii trebuie facuta ın timpul rularii progra-
mului, sunt preferati algoritmii care nu cer informatii despre starea globala a
calculelor. Aceste strategii vor fi discutate pe larg ın sectiunea 2.5.2. Algoritmii
ce au la baza descompunerea functionala genereaza adeseori calcule prin crearea
de task -uri cu durata de viata redusa, task -uri ce se coordoneaza cu celelalte doar
la pornire si la oprire. Se pot folosi algoritmi de planificare ce aloca task -urile
catre procesoarele libere sau care sunt pe cale sa devina libere.
34

2.2. Modele de proiectare a aplicatiilor paralele
2.2.4.1 Algoritmi de echilibrare a ıncarcarii
Au fost propuse o varietate de tehnici de echilibrare a ıncarcarii specifice unui
tip de aplicatii pentru a fi utilizate ın dezvoltarea algoritmilor paraleli bazati
pe descompunerea domeniului: metoda bisectiei, algoritmi locali, metode proba-
bilistice sau mapari ciclice. Aceste tehnici au ca scop aglomerarea task -urilor cu
granularitate fina ıntr-o partitie initiala pentru a obtine un task cu granularitate
mare pe fiecare procesor. Alternativ, aceste tehnici pot fi privite ca o partitionare
a domeniului de calcule pentru a crea sub-domenii pentru fiecare procesor ın parte
si sunt referite ca algoritmi de partitionare [Foster 95].
Subcapitolul 2.5 trateaza ın detaliu problema echilibrarii ıncarcarii ın proiec-
tarea aplicatiilor paralele.
2.2.4.2 Algoritmi de planificare a task-urilor
Algoritmii de planificare a task -urilor pot fi utilizati atunci cand descompunerea
functionala genereaza foarte multe task -uri, fiecare cu cerinte de comunicatii lo-
cale reduse. Este mentinuta o multime de task -uri (task pool), centralizata sau
distribuita, ın care sunt introduse task -urile nou create si din care sunt preluate
cele ce vor fi alocate la procesoare. Efectiv, se rescrie algoritmul paralel astfel
ıncat ceea ce a fost conceput ca un task va deveni o structura de date ce reprezinta
”problemele”. Cele mai importante aspecte legate de algoritmii de planificare a
proceselor sunt strategiile utilizate pentru alocarea acestora catre procesoare.
In general, strategia aleasa reprezinta un compromis ıntre cerinte contradictorii:
realizarea independenta a calculelor (pentru a reduce costul comunicatiilor) si
obtinerea informatiilor despre starea generala a calculelor (pentru echilibrarea
ıncarcarii) [Foster 95].
2.2.4.3 Reguli de mapare
Etapa de mapare este ultima din faza de proiectare si specifica modul ın care
sunt repartizate (mapate) task -urile definite ın etapele anterioare pentru executia
pe procesoare. Deciziile de mapare ıncearca sa echilibreze contradictiile dintre
cerintele pentru echilibrarea ıncarcarii si costul comunicatiilor. Atunci cand este
posibil, schemele de mapare statica repartizeaza cate un singur task la fiecare pro-
cesor. In cazurile ın care numarul sau dimensiunea task -urilor sunt variabile sau
nu sunt cunoscute pana ın momentul rularii, sunt, ın mod uzual, abordate doua
strategii: fie sunt utilizati algoritmi dinamici de echilibrare a ıncarcarii, fie este re-
formulata problema astfel ıncat structurile de date pentru planificarea proceselor
sa poata fi folosite pentru planificarea calculelor. Pentru evaluarea rezultatelor
etapei de mapare sunt utile urmatoarele ıntrebari/verificari [Quinn 04]:
• Daca se ia ın considerare un model SPMD pentru probleme complexe, a fost
utilizat un algoritm bazat pe crearea si stergerea dinamica a task -urilor?
35

2. Metodologii de proiectare a aplicatiilor paralele
• Daca se ia ın considerare un model bazat pe crearea si stergerea dinamica
a task -urilor, a fost luat ın considerare un algoritm SPMD? Un astfel de
algoritm poate furniza un control mai bun asupra planificarii calculelor si
comunicatiilor, dar poate fi cu mult mai complex.
• Daca se foloseste o schema centralizata de echilibrare a ıncarcarii, s-a verifi-
cat daca procesorul manager nu devine o sursa de ıntarzieri (bottleneck)? Se
pot reduce ın continuare costurile comunicatiilor ın cadrul acestor scheme
prin transmiterea unor pointeri la task -uri (fata de cazul transmiterii task -
urilor ın sine)?
• Daca se foloseste o schema dinamica de echilibrare a ıncarcarii, au fost e-
valuate costurile altor strategii? Costurile de implementare ale acestora
trebuie, de asemenea, incluse ın analiza performantelor. Maparea prin
metode probabilistice sau ciclice este simpla si ar trebui luata ın considerare
ıntotdeauna pentru a ınlatura nevoia de repetare a operatiilor de echilibrare
a ıncarcarii.
• Daca se folosesc metodele probabilistice sau ciclice de mapare, exista un
numar suficient de task-uri pentru a asigura echilibrarea ıncarcarii proce-
soarelor? Sunt necesare de cel putin de zece ori mai multe task-uri decat
procesoare.
Desi sunt terminate toate fazele de proiectare ale algoritmului paralel, nu se
poate trece la scrierea codului. Mai trebuie efectuate analize privind performantele
pentru a putea alege ıntre algoritmi alternativi si pentru a determina daca sunt
ıntrunite criteriile de performanta. O alta problema o reprezinta costul de imple-
mentare si oportunitatile de reutilizare a codului existent. Mai trebuie evaluate,
de asemenea, si posibilitatile de integrare a algoritmului paralel ın contextul mai
larg al unui program complet [Foster 95].
2.3 Proiectarea modulara
O aplicatie paralela completa include mai multi algoritmi paraleli, fiecare operand
cu structuri de date, partitionari, comunicatii si strategii de mapare diferite.
Complexitatea care apare atunci cand sunt construite aplicatii mari poate fi con-
trolata prin tehnici de proiectare modulara. Ideea principala este de a ıncapsula
aspecte complexe sau variabile ın componente separate ale programului, sau mod-
ule, cu interfete bine definite care sa indice modul ın care interactioneaza cu
exteriorul. Proiectarea modulara creste fiabilitatea, reduce costurile prin dez-
voltarea mai usoara a programelor si reutilizarea componentelor. Ideea de baza
a proiectarii modulare este organizarea sistemelor complexe ca un set de compo-
nente distincte ce pot fi dezvoltate independent si apoi asamblate. Desi pare o
idee simpla, ın practica se dovedeste a fi destul de dificil de implementat si de-
pinde de modul ın care este ımpartit sistemul ın componente si de mecanismele
36

2.3. Proiectarea modulara
utilizate pentru conectarea lor. In continuare sunt prezentate cateva principii de
proiectare utile ın programarea paralela [Foster 95]:
• Furnizarea de interfete simple: Interfetele simple reduc numarul de interacti-
uni care trebuiesc luate ın considerare atunci cand se verifica daca sis-
temul are functionalitatea dorita, si le fac usor de utilizat ın circumstante
diferite. Reutilizarea codului este un factor major de reducere a costurilor
de dezvoltare atat prin eliminarea timpului consumat cu scrierea codului,
proiectarea si testarea aplicatiei, cat si prin amortizarea costului de dez-
voltare a mai multor proiecte.
• Ascunderea informatiilor despre functionarea interna: Modul ın care un
program este descompus are o influenta determinanta asupra modului de a
implementa sau de a modifica aplicatia ın discutie. In mod uzual, un modul
poate ıncapsula informatii care nu sunt necesare pentru restul programului.
Aceasta tehnica reduce costul de reproiectare a modulelor. De exemplu, un
modul poate ıncapsula:
– functii care au o implementare comuna sau care sunt utilizate ın mai
multe parti ale programului;
– functionalitati care este posibil sa nu se schimbe ın fazele de proiectare
sau de dezvoltare ale aplicatiilor;
– aspecte ale problemei care sunt mai complicate si/sau
– cod care poate fi refolosit ın alte programe.
Trebuie observat ca nu se precizeaza daca modulul trebuie sa contina functio-
nalitati care sunt logic ınrudite, deoarece acest tip de descompunere nu
faciliteaza ıntretinerea si nici nu promoveaza reutilizarea codului.
• Utilizarea unor instrumente potrivite de dezvoltare: Modulele proiectate pot
fi implementate ın aproape orice limbaj de programare, lucru cu atat mai
usor de realizat cu cat limbajul ofera suport mai bun pentru ıncapsularea
codului si a structurilor de date.
2.3.1 Reguli de proiectare modulara
Urmatoarele reguli, identificate de Foster ın [Foster 95], pot fi utilizate la proiec-
tarea modulelor unei aplicatii:
• Proiectarea modulelor trebuie realizata ın asa fel ıncat acestea sa fie capabile
sa lucreze cu mai multe tipuri de date, fapt ce le creste gradul de reutilizare;
• Trebuie ıncorporate informatiile legate de datele distribuite ın structuri de
date si nu ın interfetele modulului. Acest lucru duce la realizarea unor
interfete mai simple si maximizeaza oportunitatile de reutilizare a codului;
• Utilizarea descompunerii secventiale atunci cand sunt realizate aplicatii
pentru un sistem de programare SPMD, precum HPF (High Performance
Fortran) sau MPI;
37

2. Metodologii de proiectare a aplicatiilor paralele
• Considerarea compunerii secventiale atunci cand componentele unui pro-
gram nu se pot executa concurent sau au nevoie de o cantitate foarte mare
de date partajate;
• Considerarea compunerii concurente atunci cand componentele programu-
lui se pot executa concomitent, costul comunicatiilor este ridicat si se pot
suprapune etapele de comunicatie cu cele de calcul;
• Considerarea compunerii paralele daca memoria este un factor cheie sau cos-
tul comunicatiilor interne, din cadrul componentelor, este mai mare decat
cel dintre componentele ın sine.
Rezultatele proiectarii modulelor unei aplicatii paralele pot fi evaluate cu urma-
toarea lista de verificari/ıntrebari (o aplicatie bine proiectata ofera raspunsuri
afirmative) [Foster 95]:
• Modulele sunt identificate corect si clar ın faza de proiectare?
• Fiecare modul are un scop clar definit? Se poate formula acest scop ıntr-o
propozitie?
• Interfata fiecarui modul este suficient de abstracta pentru a nu fi necesara
studierea implementarii pentru a fi ınteleasa? Sunt ascunse detaliile de
implementare fata de celelalte module?
• Modulele sunt descompuse ıntr-un mod cat mai util posibil?
• Au fost verificate modulele astfel ıncat sa nu aiba functionalitati similare?
• Au fost izolate aspectele complexe ale problemei, cele specifice hardware-
ului sau cele cu o probabilitate redusa de modificare?
2.4 Analiza cantitativa si calitativa a algoritmilor paraleli
O aplicatie paralela este bine proiectata daca optimizeaza timpul de executie,
cerintele de memorie, costurile de implementare si de ıntretinere, etc. Aceste
ıncercari de optimizare implica, ın mod uzual, compromisuri ıntre simplitate,
performanta, portabilitate si alti factori. Deciziile referitoare la ce metoda de
rezolvare trebuie aleasa pentru o anumita problema trebuie luate considerand
diferitele costuri implicate de fiecare metoda ın parte. In acest context devine
utila dezvoltarea unor modele matematice pentru analiza performantelor. Aceste
modele pot fi folosite pentru a face o comparatie eficienta ıntre diversi algoritmi,
pentru evaluarea scalabilitatii si pentru identificarea diverselor deficiente (un ex-
emplu de acest fel este ”gatuirea” executiei – bottlenecks) ınainte de investi un
efort substantial ın implementare. Modelele de performanta pot ajuta eforturile
de implementare pentru a indica eventualele optimizari posibile [Foster 95].
38

2.4. Analiza cantitativa si calitativa a algoritmilor paraleli
2.4.1 Parametrii cantitativi
2.4.1.1 Accelerarea
Accelerarea, notata cu Sp, reprezinta raportul ıntre timpul de executie al celui
mai bun program secvential (t1) si timpul de executie al programului paralel
echivalent (tp) pe un sistem paralel cu p procesoare:
Sp =t1tp
(2.4.1)
Daca, fie nu se cunoaste timpul de executie al celui mai bun algoritm secvential,
fie varianta paralela difera foarte mult de cea secventiala, comparatia nu-si mai
are rostul. Din acest motiv se accepta mai multe variante de definitie pentru cei
doi timpi si vom avea cinci alternative la definitia accelerarii [Sahni 4]:
• relativa, atunci cand t1 este timpul de executie al variantei paralele pe un
singur procesor al sistemului paralel; depinde de problema de rezolvat si de
numarul de procesoare;
• reala, atunci cand se compara timpul de executie paralel cu timpul de
executie pentru varianta secventiala cea mai rapida, pe un procesor al sis-
temului paralel. Este posibil ca cel mai rapid algoritm ce rezolva problema
sa nu fie cunoscut, sau un singur algoritm nu este cel mai rapid pentru toate
dimensiunile posibile ale problemei, motiv pentru care se alege ca referinta
varianta secventiala cea mai rapida;
• absoluta, atunci cand se compara timpul de executie al algoritmului paralel
cu timpul de executie al celui mai rapid algoritm secvential, executat pe
procesorul serial cel mai rapid;
• asimptotica, atunci cand se compara timpul de executie al celui mai bun
algoritm secvential cu functia de complexitate asimptotica a algoritmului
paralel, ın ipoteza existentei numarului necesar de procesoare;
• relativ asimptotica, atunci cand se foloseste complexitatea asimptotica a
algoritmului paralel executat pe un procesor.
Daca p este numarul de procesoare ale sistemului paralel, atunci, ıntr-un caz
ideal, are loc urmatoarea relatie:
tp =t1p. (2.4.2)
Utilizand 2.4.2, conform ecuatiei 2.4.1, se obtine Sp = p. Intrucat apelurile
functiilor sistem determina o diminuare a accelerarii, ın cazurile reale se obtine:
1 ≤ Sp ≤ p (2.4.3)
In [Sun 91], Sun si Gustafson considera ca accelerarea este o unitate de masura
imprecisa, ce favorizeaza procesoarele lente si codul de calitate slaba. Autorii
creeaza o unitate de masura derivata, numita sizeup, definita ca fiind raportul
39

2. Metodologii de proiectare a aplicatiilor paralele
dintre dimensiunea problemei rezolvate de un calculator paralel si dimensiunea
problemei rezolvate de un sistem secvential ıntr-un anumit interval de timp. Fie,
spre exemplu, cazul a doua calculatoare paralele, M1 si M2, pentru care costul
fiecarei operatii este acelasi. Se considera ca M1 executa operatiile paralelizabile
mai rapid decat M2. Sun si Gustafson demonstreaza ca M1 obtine o accelerare
mai slaba (chiar daca sunt ignorate comunicatiile), dar conform sizeup M1 ar
trebui considerat ca fiind mai bun.
O alta unitate de masura a scalabilitatii introdusa de Sun si Rover ın [Sun 94],
numita izoviteza, reprezinta factorul cu care dimensiunea problemei poate fi
crescuta astfel ıncat viteza medie de calcul sa ramana constanta daca este crescut
si numarul de procesoare de la p la p′. Unitatea medie de viteza a calculatorului
paralel este definita ca fiind viteza de procesare obtinuta pentru un anumit volum
de date (W ) divizata cu numarul de procesoare din sistem. Atfel, daca numarul
de procesoare este crescut de la p la p′ se va obtine:
izoviteza(p, p′) =p′W
pW ′. (2.4.4)
Utilizand ecuatia 2.4.4, dimensiunea W ′ a problemei pentru p′ procesoare este
determinata astfel: considerand cazul ideal al unui algoritm perfect paralelizabil,
fara comunicatii, se poate arata usor ca izoviteza trebuie sa aiba valoarea 1; se
va obtine:
izoviteza(p, p′) = 12.4.4=⇒ W ′ =
p′W
p
Pentru un sistem paralel real, relatiile anterioare se modifica astfel [Kumar 91]:
izoviteza(p, p′) < 1
W ′ >p′W
p
2.4.1.2 Eficienta
Eficienta masoara modul ın care sunt utilizate procesoarele din sistem:
Ep =Spp. (2.4.5)
Acest parametru exprima penalitatea platita pentru nivelul de performanta atins.
In cazul ideal acest parametru are valoare 1, dar ın cazurile reale 0 < Ep < 1.
Daca se mareste numarul de procesoare al sistemului, eficienta poate fi mentinu-
ta la aceeasi valoare prin cresterea volumului de calcule, ca o consecinta a volu-
mului mai mare de date de prelucrat [Grigoras 00]. Timpul de executie paralela se
mai poate exprima si ın functie de gestiunea proceselor paralele (creare/distrugere,
planificare, sincronizare), comunicatiile dintre ele, echilibrarea ıncarcarii si re-
alizarea de calcule suplimentare. Aceste operatii consuma un timp numit timp
40

2.4. Analiza cantitativa si calitativa a algoritmilor paraleli
de overhead, care se aduna la timpul executiei paralele si depinde de volumul de
calcule si de numarul de procesoare [Kwiatkowski 02]:
toverhead(W,p) = tp −W
p. (2.4.6)
Din relatia 2.4.6 rezulta ca:
tp =W
p+ toverhead(W,p) , (2.4.7)
ceea ce implica, conform [Grama 03], modificarea relatiei 2.4.5 astfel:
Ep =Spp
=
WWp+toverhead(W,p)
p=
W
W + p · toverhead(W,p)=
1
1 + p · toverhead(W,p)W
(2.4.8)
Considerand relatiile anterioare, volumul de calcule W , conform [Grama 03],
devine:
W =Ep
1− Epp · toverhead(W,p) = K · p · toverhead(W,p) (2.4.9)
Acest ultim rezultat este cunoscut ın literatura de specialitate sub numele de
functie de izoeficienta [Grama 03]:
W = K · p · toverhead(W,p) . (2.4.10)
Relatia 2.4.10 indica modul ın care trebuie sa se modifice volumul de calcule
W , astfel ıncat sa se mentina aceeasi eficienta, atunci cand creste numarul de
procesoare din sistem.
2.4.1.3 Supraıncarcarea
Daca eficienta este privita ca o functie dependenta de dimensiunea problemei
(n) si de numarul de procesoare (p), notata E(n, p), atunci supraıncarcarea se
poate defini ca [Petcu 01]:
f(n, p) =1
E(n, p)− 1 (2.4.11)
Supraıncarcarea (overhead) include costurile implicate de startarea unui pro-
ces, de comunicare a datelor, de diversele sincronizari si eventuale calcule su-
plimentare. In general supraıncarcarea poate fi [Petcu 01]:
• software: calcule aditionale descompunerii datelor si atribuirii acestora
catre procesoare;
41

2. Metodologii de proiectare a aplicatiilor paralele
• datorata dezechilibrului ıncarcarii : fiecare proces ar trebui sa primeasca
acelasi volum de calcule;
• datorata comunicatiilor : ın cazurile ın care este imposibila suprapunerea
comunicatiilor si a calculelor, accesarea datelor aflate la distanta poate
introduce timpi suplimentari considerabili sau ın cazul ın care volumul de
calcule dintre comunicatii succesive este redus (granularitate redusa).
2.4.1.4 Costul
Costul unui program paralel (Cp) se defineste ca fiind produsul dintre timpul de
calcul (tp) si numarul de procesoare (p). Daca se presupune ca toate procesoarele
executa acelasi numar de instructiuni, atunci:
Cp = p · tp (2.4.12)
Deoarece o aplicatie paralela poate fi simulata pe un sistem secvential, caz ın care
procesorul executa de p ori instructiunile executate de un procesor al sistemului
paralel, atunci aplicatia paralela este optima din punct de vedere al costului daca
valoarea acestuia este egala cu timpul de executie al celei mai bune variante
secventiale.
2.4.1.5 Legile accelerarii
Legea lui Amdahl
”Accelerarea este marginita superior de o valoare independenta de numarul de
procesoare si de arhitectura masinii.”
Se considera urmatoarele notatii [Shi 96]:
• tsec: timpul de procesare pentru partea secventiala a unui program (uti-
lizand 1 procesor);
• tpar: timpul de procesare pentru partea paralela a unui program (utilizand
1 procesor);
Shi, pentru a demonstra legea lui Amdahl, considera ca timpul de executie
al programului paralel (tp) poate fi considerat ca o suma ıntre o componenta
ce corespunde secventelor de instructiuni din program care nu pot fi paraleliza-
te (partea secventiala a programului) si o componenta paralela executata de p
procesoare (tparp ) [Shi 96]:
tp = tsec +tparp
. (2.4.13)
In acelasi context timpul de executie a unui program paralel pe un singur procesor
(t1) se poate defini ca fiind [Shi 96]:
t1 = tsec + tpar . (2.4.14)
42

2.4. Analiza cantitativa si calitativa a algoritmilor paraleli
Conform relatiei 2.4.1 se obtine
Sp =tsec + tpar
tsec +tparp
≤ t1tsec
, (2.4.15)
ceea ce ınseamna ca oricare ar fi p (numarul de procesoare), accelerarea este
inferioara inversului proportiei de cod serial din totalul codului[Grigoras 00].
Legea lui Amdahl modeleaza foarte bine comportarea programelor cu para-
lelism de cod, dar nu si a celor cu paralelism de date. Lee considera ca odata
cu variatia parametrului i - numar de procesoare, cu valori ın domeniul [1, p], se
modifica si proportia din program, qi, care poate fi paralelizata (executata de i
procesoare) [Lee 80]. In acest context relatiile anterioare ce descriu timpul de
executie paralel (2.4.13), secvential (2.4.14) si accelerarea (2.4.15), se modifica
astfel [Lee 80]:
t1 =
p∑i=1
qiti , (2.4.16)
tp =
p∑i=1
qiiti , (2.4.17)
Sp =1
p∑i=1
qii
. (2.4.18)
Daca qi = 1/p,∀i ∈ [1, p], se obtine [Lee 80]:
Sp ≤p
log2 p. (2.4.19)
Acest rezultat arata faptul ca accelerarea nu mai depinde de natura aplicatiei ci
de numarul de procesoare din sistem [Lee 80].
Legea Gustafson-Barsis
Gustafson si Barsis, ın [Gustafson 88], pleca de la ipoteza ca timpul total
de executie pe un singur procesor este constant: s + p, unde s este timpul de
executie al codului secvential si p timpul de executie al codului paralel pe un
singur procesor. Pentru simplitatea caluclelor se considera ca s+p = 1. In aceste
conditii accelerarea devine [Wilkinson 99]:
S =s+ p
s+ p/n=
1
s+ (1− s)/n(2.4.20)
Plecand de la acest rezultat, Gustafson si Barsis au introdus un nou factor nu-
mit factor de scalare a accelerarii SS(n). Considerand ca timpul de executie
pe un calculator paralel este format dintr-o componenta secvetiala si o compo-
nenta paralela, s+ p, ca timpul de executie pe un singur calculator va fi s+ pn,
43

2. Metodologii de proiectare a aplicatiilor paralele
unde n reprezinta numarul de parti ce trebuie executate secvential, si din nou ca
s+ p = 1, acest factor se calculeaza astfel [Wilkinson 99]:
S =s+ np
s+ p= s+ np = n+ (1− n)/s (2.4.21)
Aceasta relatie, cunoscuta sub numele de legea Gustafson-Barsis, arata ca ac-
celerarea trebuie masurata prin scalarea dimensiunii problemei odata cu numarul
procesoarelor si nu prin pastrarea unei dimensiuni fixe.
Arhitecturile microprocesoarelor integreaza tot mai multe unitati de procesare
pe acelasi cip, pentru a depasi constrangerile arhitecturilor cu un singur nucleu si
consumul de energie din ce ın ce mai mare al acestora. Aceasta abordare ofera o
alternativa la regula lui Pollack care afirma urmatoarele: cresterea performantei
microprocesoarelor este aproximativ proportionala cu radacina patrata a cresterii
ın complexitate a procesorului [Pollack 99]. Conform acestei reguli, pentru o
crestere cu 40% a performantelor unui sistem cu un singur nucleu, trebuie dublat
numarul de porti logice. In acest context, sistemele cu mai multe nuclee ofera o
alternativa eficienta din punct de vedere al costului, furnizand mai multa putere
de calcul prin procesarea paralela, consumand mai putina energie si ocupand mai
putin spatiu [Sun 10].
Pentru aplicarea legii lui Amdahl la sistemele cu mai multe nuclee trebuie
elaborat un model de cost care sa ia ın considerare numarul si performantele
nucleelor suportate de procesor [Hill 08]. ın primul rand, autorii presupun ca
procesoarele multicore pot contine n BCE (Base Core Equivalents), unde BCE
reprezinta un singur nucleu. In al doilea rand, se mai presupune caproiectantul
procesorului poate utiliza resursele a mai multe BCE pentru a un nucleu cu
performante secventiale mai bune. Daca performanta unui BCE este 1, se pre-
spune ca se pot folosi resursele a r BCE pentru a crea un procesor mai puternic
cu performanta secventiala perf(r) ( 1<perf(r)<2) Plecan de la acest model
de cost, Hill si Marty identifica trei tipuri de procesoare multicore pentru care
trebuie reformulata legea lui Amdahl: simetrice, asimetrice si dinamice.
• Procesoare multicore simetrice: se presupune ca fiecare nucleu are acelasi
cost. In [Hill 08], autorii noteaza cu:
– f – portiunea de cod paralelizabila,
– n – numarul total de BCE,
– r – resursele implicate ın cresterea performantei unui singur nucleu si,
– perf(r) – perfomanta cu care aceste procesoare folosec un singur nu-
cleu pentru executia codului secvential,
– perf(r)× n/r – performanta cu care aceste procesoare executa codul
paralel.
44

2.4. Analiza cantitativa si calitativa a algoritmilor paraleli
,In aceste conditii accelerarea este o expresie de forma [Yao 09] :
Speedupsimetric(f, n, r) =1
1−fperf(r) + f ·r
perf(r)·n, (2.4.22)
• Procesoare multicore asimetrice: presupun ca unele nuclee sunt mai puter-
nice decat altele. Astfel, formula 2.4.22 devine [Yao 09]:
Speedupasimetric(f, n, r) =1
1−fperf(r) + f
perf(r)+n−r. (2.4.23)
• Procesoare multicore dinamice: presupun combinarea a r nuclee pentru
a creste performantele componentei secventiale. In acest caz accelerarea
devine [Yao 09]:
Speedupdinamic(f, n, r) =1
1−fperf(r) + f
n
. (2.4.24)
In contrast cu Hill si Marty, ce considerau incert viitorul procesoarelor multi-
core, Sun si Chen demonstreaza ca aceste arhitecturi sunt fundamental scalabile
si nu sunt afectate de legea lui Amdahl [Sun 10] .
2.4.2 Parametrii calitativi
2.4.2.1 Granularitatea
Granularitatea (grain size) indica volumul de calcule alocate procesoarelor ın val-
ori minime acceptabile.
Granularitatea aplicatiei - reprezinta dimensiunea minima a unei unitati sec-
ventiale dintr-un program, exprimata ın numar minim de instructiuni, ın care
nu se executa operatii de sincronizare sau de comunicare cu alte procese (G =
Tcalcule/Tcomunic) [Kwiatkowski 02] Deoarece un proces este compus din unitati
secventiale de granularitati diferite, atunci granularitatea unui proces este gran-
ularitatea unitatii secventiale celei mai mici [Grigoras 00].
Granularitatea sistemului - valoarea minima a granularitatii sub care performanta
unui sistem paralel dat scade semnificativ si este justificata de timpul de overhead
(comunicatii, sincronizari) care poate fi comparabil cu timpul de calcul paralel.
Granularitatea sistemului paralel este definita ca raportul dintre timpul consumat
pentru o operatie fundamentala de comunicatie si timpul consumat de o operatie
fundamentala de calcul.
Granularitatea este folosita ın [Kwiatkowski 02] pentru a calcula eficienta si
implicit accelerarea plecand de la formula urmatoare:
E =G
G+ 1(2.4.25)
Este de dorit ca un calculator paralel sa aiba o granularitate mica, astfel ıncat
sa poata executa eficient o gama larga de programe, iar aplicatiile sa aiba o
granularitate cat mai mare.
45

2. Metodologii de proiectare a aplicatiilor paralele
2.4.2.2 Scalabilitatea
Scalabilitatea reprezinta posibilitatea de a asigura cresterea accelerarii odata cu
cresterea numarului de procesoare pornind de la ipoteza ca programul executat
are o granularitate suficient de mare. Daca se obtine o crestere liniara a ac-
celerarii, avem un sistem scalabil liniar. La nivelul aplicatiei este necesar sa fie
asigurata flexibilitatea si adaptabilitatea la dinamica arhitecturii.
Factorii ce influenteaza scalabilitatea unei aplicatii sunt legati de echipa-
mentele hardware si/sau de bibliotecile si aplicatiile folosite: dimensiunea mem-
oriei, dezechilibrele arhitecturale, performantele sistemului de I/O, accesul con-
curent la resurse, comunicatii sau echilibrarea ıncarcarii. Scalabilitatea mai este
echivalenta cu asigurarea izoeficientei si poate fi mentinuta pana la atingerea
unui numar de procesoare egal cu un Pmax. Valoarea numarului maxim de proce-
soare poate fi marita prin cresterea granularitatii. Optimizarea performantelor si
ımbunatatirea calitatii unui sistem multiprocesor se bazeaza pe exploatarea par-
alelismului la nivelul proceselor care alcatuiesc aplicatiile si ınsusi a sistemului de
programe de baza.
In [Zirbas 89], este dezvoltat un framework care modeleaza scalabilitatea unui
sistem paralel. Un algoritm paralel format dintr-o componenta secventiala Wserial
si o componenta paralela Wparalel, atunci cand este rulat pe un singur procesor
are un timp de rulare de forma: tc(Wserial + Wparalel), unde tc este o constanta
pozitiva. Timpul de executie ideal pe un sistem cu p procesoare este de forma
[Zirbas 89]:
tc(Wserial +Wparalel
p) (2.4.26)
In practica, datorita overheadului introdus de paralelism, valoarea timpului de
executie este mai mare. Din acest motiv se introduce o functie de overhead
Φ(p). Un sistem cu p procesoare este scalabil daca timpul de executie TP pe p
procesoare satisface relatia [Zirbas 89]:
TP ≤ tc(Wserial +Wparalel
p)× Φ(p) (2.4.27)
Cea mai mica valoare a functiei Φ(p) ce satisface ecuatia 2.4.27 este denumita
functia de overhead a sistemului si este definita de relatia: TPtc(Wserial+Wparalel/p)
.
Un sistem paralel este considerat scalabil daca functia de overhead ramane con-
stanta atunci cand dimensiunea problemei se modifica suficient de rapid.
Pentru orice sistem paralel, daca dimensiunea problemei creste mai repede
ca functia de izoeficienta, atunci functia de overhead Φ(p) reprezinta o con-
stanta ce face sistemul ideal scalabil [Kumar 91]. Astfel, conform definitiilor din
[Zirbas 89], toate sistemele paralele pentru care exista functia de izoeficienta sunt
scalabile. Daca Φ(p) creste ca o functie de p, atunci rata de crestere a functiei
de overhead determina gradul ın care un sistem nu este scalabil. Cu cat este mai
rapida cresterea, cu atat sistemul este mai putin scalabil.
46

2.5. Problema echilibrarii ıncarcarii ın proiectarea aplicatiilor paralele
Astfel, functia de supraıncarcare (overhead), complementara functiei de izo-
eficienta, face distinctie ıntre sistemele care sunt scalabile si cele nescalabile fara
a furniza ınsa nici o informatie cu privire la gradul de scalabilitate a unui sistem.
Pe de alta parte, functia de izoeficienta nu furnizeaza nici o informatie ın legatura
cu gradul de scalabilitate a unui sistem de calcul. O limitare a acestui rezultat
este faptul ca functia de overhead Φ(p) surprinde numai overheadul introdus de
comunicatii si nu pe cel introdus de codul secvential. Daca un algoritm par-
alel este slab scalabil datorita dimensiunilor mari ale componentelor secventiale,
Φ(p) poate avea valori mici datorita faptului ca supraıncarcarea introdusa de
comunicatii este redusa. De exemplu, daca Wserial = WS si Wparalel = 0, atunci:
Φ(p) = TPtc(Wserial+Wparalel/p)
= 1tc
= Φ(1), adica sistemul este perfect scalabil
[Kumar 91].
2.5 Problema echilibrarii ıncarcarii ın proiectarea aplicatiilor
paralele
2.5.1 Echilibrarea ıncarcarii ın aplicatiile paralele
Un rol important ın proiectarea aplicatiilor paralele cu efect imediat asupra
performan-telor ıl are echilibrarea ıncarcarii. Scopul echilibrarii ıncarcarii poate
fi formulat ın felul urmator: avand o colectie de task -uri care realizeaza un calcul
si un set de computere pe care aceste task -uri pot rula, sa se gaseasca o mapare de
task -uri la computere astfel ıncat fiecare computer sa aiba o cantitate aproxima-
tiv egala de sarcini. O mapare care echilibreaza ıncarcarea procesoarelor va mari
eficienta pe ansamblu a calculului. Marirea eficientei pe ansamblu va reduce tim-
pul de executie al calculului, care este de fapt un scop al calculului paralel. Dar
uneori o tratare simplista a echilibrarii ıncarcarii nu conduce ın mod necesar la un
calcul mai rapid. Daca aplicatia este statica (adica timpul asociat unui anumit
task poate fi determinat apriori), problema echilibrarii ıncarcarii se reduce la ma-
parea grafului aplicatiei pe reteaua de procesoare. Daca aplicatia este dinamica
(adica ıncarcarea unui procesor poate varia ın decursul unui calcul si nu poate fi
estimata ınainte), exista un numar de strategii (SID, DASUD, difuzie) care pot
fi folosite pentru a varia ıncarcarea unui procesor. Majoritatea strategiilor de
echilibrare a ıncarcarii au cel putin unul din urmatoarele neajunsuri:
• Nu se poate face o estimare dinamica a ıncarcarii. Majoritatea tehnicilor
dezvoltate pana ın prezent se bazeaza pe cunoasterea globala a volumului
de lucru.
• Eficienta lor nu poate fi analizata teoretic. Desi intuitiv, multe tehnici pot
avea un potential destul de mare, implementate practic pot genera multe
dezechilibre ın distributia sarcinilor.
47

2. Metodologii de proiectare a aplicatiilor paralele
• Sunt specifice aplicatiilor. Multe dintre aceste tehnici au fost proiectate si
implementate numai pentru anumite aplicatii
• Aplicabilitatea lor a fost studiata la o scara redusa. O parte din aceste
tehnici au fost studiate pe masini cu un numar mic de procesare sau pe
task -uri generice.
• Sunt prea complicatii pentru implementari optimale. Modalitatea relativ
complexa ın care sunt prezentati acesti algoritmi ın lucrarile de specialitate
duce la aparitia erorilor ın implementarea acestora.
• Ingreuneaza foarte mult comunicatiile ıntre procese si nu se reuseste esti-
marea costului acestor comunicatii.
• Sunt sincroni. Multe dintre aceste tehnici sunt concepute astfel ıncat toate
unitatile de procesare sa execute ın acelasi timp faza de echilibrare a ıncarca-
rii.
O solutie practica pentru problema echilibrarii ıncarcarii dinamice implica cinci
faze distincte:
• Evaluarea ıncarcarii: o estimare a ıncarcarii procesorului trebuie realizata
pentru a determina daca exista un eventual dezechilibru.
• Determinarea profitabilitatii: odata ce ıncarcarea procesoarelor a fost e-
valuata, prezenta dezechilibrului poate fi detectat? Daca costul dezechili-
brului depaseste costul echilibrarii ıncarcarii, atunci echilibrarea ıncarcarii
poate fi initiata.
• Calcularea vectorului de transfer al ıncarcarii: pe baza masuratorilor facute
ın prima faza, se calculeaza vectorul de transfer al ıncarcarii pentru a echili-
bra procesoarele.
• Selectia task -urilor: Task -urile sunt selectate pentru transfer ın acord cu
vectorul de transfer calculat ın faza anterioara.
• Migrarea task -urilor: Odata selectat, task -urile sunt transferate de la un
computer la altul.
2.5.2 Echilibrarea dinamica a ıncarcarii
In cazul echilibrarii dinamice a ıncarcarii, task -urile sunt alocate procesoarelor
ın timpul executiei programului. Echilibrarea poate fi centralizata sau descen-
tralizata. In primul caz, task -urile sunt remise dintr-o locatie centrala. Exista
o structura clara master-slave, ın care procesul master controleaza direct fiecare
proces slave. In al doilea caz, task -urile sunt pasate ıntre procese arbitrare. O
colectie de procese de lucru opereaza asupra problemei si interactioneaza, ra-
portand ın final unui singur proces. Un proces poate primi task -uri de la alte
procese si poate trimite la randul sau task -uri altor procese.
48

2.5. Problema echilibrarii ıncarcarii ın proiectarea aplicatiilor paralele
2.5.2.1 Echilibrarea centralizata
In echilibrarea centralizata, procesul master poseda colectia de task -uri care
urmeaza a fi executate. Task -urile sunt trimise proceselor slave. Cand un proces
slave termina un task, el cere un altul de la procesul master. Acest mecanism
este trasatura esentiala a abordarii denumite work-pool. Aceasta tehnica poate
fi usor aplicata problemelor simple de tip divide-and-conquer. Poate fi de aseme-
nea aplicata problemelor ın care task -urile sunt sensibil diferite si cu dimensiuni
inegale. In general, este bine sa fie trimise mai ıntai task -urile cele mai mari si
mai complexe. Daca un task mai mare este trimis mai tarziu, task -urile mai mici
pot fi terminate de catre procesele slave, care vor sta apoi inactive ın asteptarea
terminarii task -ului mai mare. Tehnica mai poate fi aplicata cand numarul de
task
task
Cerere task
Trimitere task
task
task
Procese
slavetask
Task-uri
Proces
Master
Figura 2.6: Work-pool centralizat (adaptare dupa [Wilkinson 99])
task -uri se modifica ın timpul executiei. In unele aplicatii, mai ales algoritmi
de cautare, executia unui task poate genera noi task -uri, desi ın final numarul
task -urilor trebuie sa se reduca la 0, semnalizand terminarea procesului de calcul.
Pentru memorarea task -urilor ın asteptare poate fi folosita o coada, Figura 2.6.
Daca toate task -urile sunt de dimensiune si importanta egale, poate fi acceptata
o coada simpla FIFO. Daca unele task -uri sunt mai importante decat altele (de
exemplu, pot conduce mai repede catre o solutie), acestea vor fi pasate primelor
procese slave. Procesul master poate detine si alte informatii, cum ar fi solutia
optima curenta [Wilkinson 99].
Oprirea procesului de calcul ın momentul gasirii solutiei se numeste terminare.
Un avantaj specific echilibrarii centralizate este existenta unui singur master, care
49

2. Metodologii de proiectare a aplicatiilor paralele
recunoaste foarte usor momentul terminarii. Atunci cand task -urile sunt preluate
dintr-o coada, procesul de calcul se termina cand coada este vida sau atunci
cand fiecare proces a facut o cerere pentru un nou task fara sa mai primeasca
vreunul. In unele aplicatii, un proces slave poate detecta conditia de terminare a
programului prin unele conditii locale (de exemplu, gasirea unui element cautat).
In acest caz, el va trimite un mesaj de terminare catre master, care va opri toate
celelalte procese slave. In alte aplicatii, fiecare proces slave trebuie sa atinga
o conditie locala de terminare specifica, precum convergenta unei solutii locale.
In acest caz, master -ul trebuie sa primeasca mesaje de terminare de la toate
procesele slave [Wilkinson 99].
2.5.2.2 Echilibrarea descentralizata
Desi utilizata pe scara larga, echilibrarea centralizata are un dezavantaj semni-
ficativ: procesul master poate trimite un singur task la un anumit moment, iar
dupa ce task -urile initiale au fost trimise, el poate raspunde la o singura cerere
de noi task -uri la un moment dat. De aici rezulta potentialul unui blocaj, atunci
cand exista multe procese slave care pot face simultan cereri. Echilibrarea cen-
tralizata este satisfacatoare daca exista putine procese slave si task -urile sunt
intensiv computationale. Pentru task -uri cu granularitate mai fina si procese
slave mai numeroase, este mai potrivita distribuirea volumului de lucru ın mai
multe locatii (Figura 2.7). Procesul master divizeaza volumul de lucru initial ın
task
task
task
task
task
Task-
uri
Proces M0
Proce
se
slav
e
task
task
task
task
task
Task-
uri
Proce
se
slav
e
Proces Mn-1
task Task-
uri iniţia
le
Proces Master
Trimitere task
Cerere task
Figura 2.7: Work-pool distribuit (adaptare dupa [Wilkinson 99])
mai multe paarti si trimite fiecare parte unei multimi de procese ”mini-master”
50

2.5. Problema echilibrarii ıncarcarii ın proiectarea aplicatiilor paralele
(M0 . . .Mn−1). Fiecare mini-master controleaza un grup de procese slave. Pen-
tru o problema de optimizare, procesele mini-master pot gasi un optim local pe
care sa-l trimita ınapoi la master si acesta va selecta cea mai buna solutie. Este
clar ca aceasta abordare poate fi dezvoltata astfel ıncat sa cuprinda mai multe
nivele de descompunere; poate fi format un arbore cu procesele slave ın calitate
de frunze iar nodurile interne sa divida volumul de lucru. Acesta este metoda
de baza pentru descompunerea unui task ın sub-task -uri egale. La fiecare nivel
din arbore, procesul paseaza jumatate din task -uri unui sub-arbore si cealalta
jumatate celuilalt sub-arbore, daca avem ın vedere un arbore binar.
O alta abordare distribuita ar fi ca procesele slave sa detina o portiune a
volumului de lucru si sa rezolve problema pentru aceasta [Wilkinson 99]. Odata ce
sarcinile sunt distribuite proceselor, exista posibilitatea ca acestea sa interschimbe
task -uri (Figura 2.8). Task -urile pot fi transferate prin:
proces
proces
proces
proces
proces
Cereri taskuri
Figura 2.8: Work-pool descentralizat (adaptare dupa [Wilkinson 99])
• metoda initializarii de catre receptor (receiver-initiated): un proces solicita
task -uri de la alte procese pe care le selecteaza. In general, un proces solicita
task -uri de la alte procese atunci cand are putine sarcini de ındeplinit (sau
nici una). S-a demonstrat ca metoda functioneaza bine la ıncarcari mari
ale sistemului.
• metoda initializarii de catre transmitator (sender-initiated): un proces
trimite task -uri altor procese pe care le selecteaza. Un proces cu o ıncarcare
mare paseaza unele task -uri altor procese care sunt dispuse sa le accepte.
S-a demonstrat ca aceasta metoda este potrivita sistemelor cu ıncarcari reduse.
51

2. Metodologii de proiectare a aplicatiilor paralele
O alta optiune este combinarea celor doua metode. Din pacate, determinarea
ıncarcarilor proceselor poate fi costisitoare. In sisteme cu ıncarcari foarte mari,
echilibrarea ıncarcarii poate fi de asemenea dificila datorita lipsei proceselor
disponibile. Echilibrarea ıncarcarii ın contextul metodei initializarii de catre re-
ceptor poate fi adaptata si pentru metoda initializarii de catre transmitator. Sunt
posibile mai multe strategii. Procesele pot fi organizate ca un inel, ın care task -
urile sunt cerute de la vecinii cei mai apropiati. O organizare de tip inel va fi
potrivita pentru un sistem multiprocesor care foloseste o retea de interconectare
inelara. In mod similar, ıntr-un hipercub, procesele pot solicita task -uri de la
vecinii cu care au legaturi, cate unul pentru fiecare dimensiune. Desigur, in-
diferent de strategie, trebuie sa ne asiguram ca un task primit nu este trimis
mai departe [Wilkinson 99]. Fara constrangerile (si avantajele) unui anumit tip
de retea, toate procesele sunt candidati egali, care pot selecta orice alt proces.
Pentru operatiile distribuite, fiecare proces trebuie sa aiba propriul algoritm de
selectie ca ın Figura 2.9 Cand este implementat local, acest algoritm poate fi
Listă taskuri
Alg
oritm
de
se
lecţie
loca
lă
Alg
oritm
de s
ele
cţie
locală
Listă taskuri
cereri
cereri
Proces Pi
Proces Pj
Figura 2.9: Algoritm de selectie descentralizat (adaptare dupa [Wilkinson 99])
aplicat tuturor proceselor care lucreaza la problema sau la diferite submultimi
ale sale. Unul din algoritmii pentru selectarea unui proces este roundrobin, ın
care procesul Pi solicita task -uri procesului Px, unde x este dat de un contor,
incrementat dupa fiecare cerere, modulo numarul de procese. De exemplu, daca
exista n = 8 procese, x ia valorile 0, 1, 2, 3, 4, 5, 6, 7, 0, 1, 2, 3, 4, 5, 6, 7 etc. Proce-
sul nu se auto-selecteaza, deci contorul va fi incrementat ınca o data cand este
ındeplinita conditia x = i. In algoritmul votarii aleatorii (random polling), proce-
52

2.5. Problema echilibrarii ıncarcarii ın proiectarea aplicatiilor paralele
sul Pi solicita task -uri de la procesul Px, unde x este un numar selectat aleatoriu
din intervalul 0−n−1, excluzand i. Cand un proces primeste o cerere de task -uri,
trimite un fragment din task -urile pe care le mai are de ındeplinit catre procesul
solicitant. De exemplu, sa presupunem ca avem de rezolvat problema traversarii
ın adancime a unui arbore de cautare. Nodurile vor fi vizitate ıntr-o maniera
descendenta, ıncepand cu radacina. Va fi mentinuta o lista cu nodurile neviz-
itate, iar procesul va selecta din lista o multime potrivita de noduri nevizitate,
pe care o va trimite procesului solicitant. Pot fi folosite diverse strategii pentru
a determina cate noduri si care vor fi returnate [Wilkinson 99].
2.5.3 Echilibrarea dinamica a ıncarcarii ın sistemele de agenti mobili
si sisteme message passing
Vom considera o clasa de calculatoare paralele echipate cu o multime finita de
procesoare omogene interconectate printr-o retea de interconectare directa. Pro-
cesoarele comunica prin transmiterea de mesaje. Canalele de comunicatie se
considera full-duplex, astfel ıncat o pereche de procesoare conectate direct pot
primi si trimite simultan mesaje unul altuia. In continuare este prezentat studiul
asupra algoritmilor SID (Sender Initiated Diffusion) si DASUD (Diffusion Al-
gorithm Searching Unbalanced Domains) de echilibrare dinamica a ıincarcarii
implementati pe o platforma de agenti mobili PASIBC (Platforma Agent pen-
tru dezvoltarea Sistemelor Informatice Bazate pe Cunostinte) [Sova 06] si pe un
mediu message passing (MPI) [Sova si Amarandei 04].
Algoritmul SID, propus ın [Willebeek-LeMair 93], porneste de la premisa ca
task -urile sunt infinit divizibile si ıncarcarea unui procesor este reprezentata de
un numar real. Presupunerea este valida ın programele paralele care folosesc
paralelismul ın task -urile cu granularitate mica. Pentru taskurile cu granular-
itate medie sau mare algoritmul trebuie sa poata lucra cu taskuri indivizibile.
Algoritmul DASUD descris de [Cortes 98] se bazeaza pe algoritmul SID, care a
fost ımbunatatit pentru a ıncorpora caracteristici noi, care detecteaza daca un
domeniu (toti vecinii imediati ai unui procesor) este echilibrat sau nu. Daca
domeniul nu este echilibrat, excesul de ıncarcare este distribuit vecinilor dupa
diferite criterii, depinzand de distributia ıncarcarii lor.
In mediile distribuite traditionale programele sunt proiectate astfel ıncat sa
accepte cat mai multi clienti posibili. Procesele client ruleaza de obicei pe cal-
culatoare aflate la distanta si comunica cu procesele server pentru a-si putea
ındeplini sarcinile. Aceasta abordare poate genera un nivel ridicat de trafic ın
retea si, ın functie de aceasta, pot sa apara ıntarzieri semnificative. Tehnologia
agenttilor mobili, prin procesul de migrare a codului executabil, aduce clientul
mai aproape de sursa si astfel se obtine o reducere majora a traficului necesar.
Totusi, ınlocuirea sistemelor client-server cu agentii mobili nu este ıntotdeauna o
idee foarte buna. De exemplu, agentii mobili trebuie sa transporte cu ei datele,
53

2. Metodologii de proiectare a aplicatiilor paralele
ın timp ce sistemele client-server trimit datele imediat ınapoi catre client. Astfel,
ın cazul sistemelelor client-server, se poate reduce traficul ın retea. Platforma de
agenti mobili descrisa ın [Sova 06] pe care au fost implementati si testati algo-
ritmii de echilibrare a ıncarcarii este PASIBC implementata folosind tehnologii
.NET. Platformele de agenti mobili au fost interconectate pentru a forma topolo-
gia de tip hipercub, dar sistemul poate fi utilizat ssi ın cazul altor topologii cum
ar fi, de exemplu, topologii inel, stea, mesh sau combinatii ale acestora.
In cadrul simularii pe topologia de tip hipercub cu 4 dimensiuni au fost injec-
tate 100 de unitati de ıncarcare ın nodul S00. O unitate de ıncarcare este de fapt
un agent mobil ce poate migra ıntre diferite platforme, iar injectarea unitatilor
de ıncarcare consta ın crearea agentilor task. Injectarea task -urilor poate fi fa-
cuta ın orice moment, ın orice nod al sistemului si ın oricate noduri. Pentru
topologia hipercub am ales nodul S00, deoarece alegerea oricarui alt nod nu ar fi
influentat complexitatea situatiei. Migrarea unui astfel de agent este initiata de
catre platforma agent pe care rezida acesta. Fiecare platforma PASIBC dispune
de un agent de echilibrare a ıncarcarii astfel ıncat, la nivelul nodului S00, avem
101 agenti ce trebuie distribuiti ın cadrul sistemului ca ın figurile 2.10 si 2.11.
Suplimentar am ales cazul, defavorabil, ın care este supraıncarcat nodul S00 cu
100 si respectiv 150 task -uri.
Pentru testarea implementarii algoritmilor de echilibrare a ıncarcarii SID si
DASUD folosind MPI s-a folosit acelasi set de date initiale (ıncarcarea initiala)
ca cel de la platforma PASIBC, rezultatele fiind prezentate ın figurile 2.12 si 2.13.
54
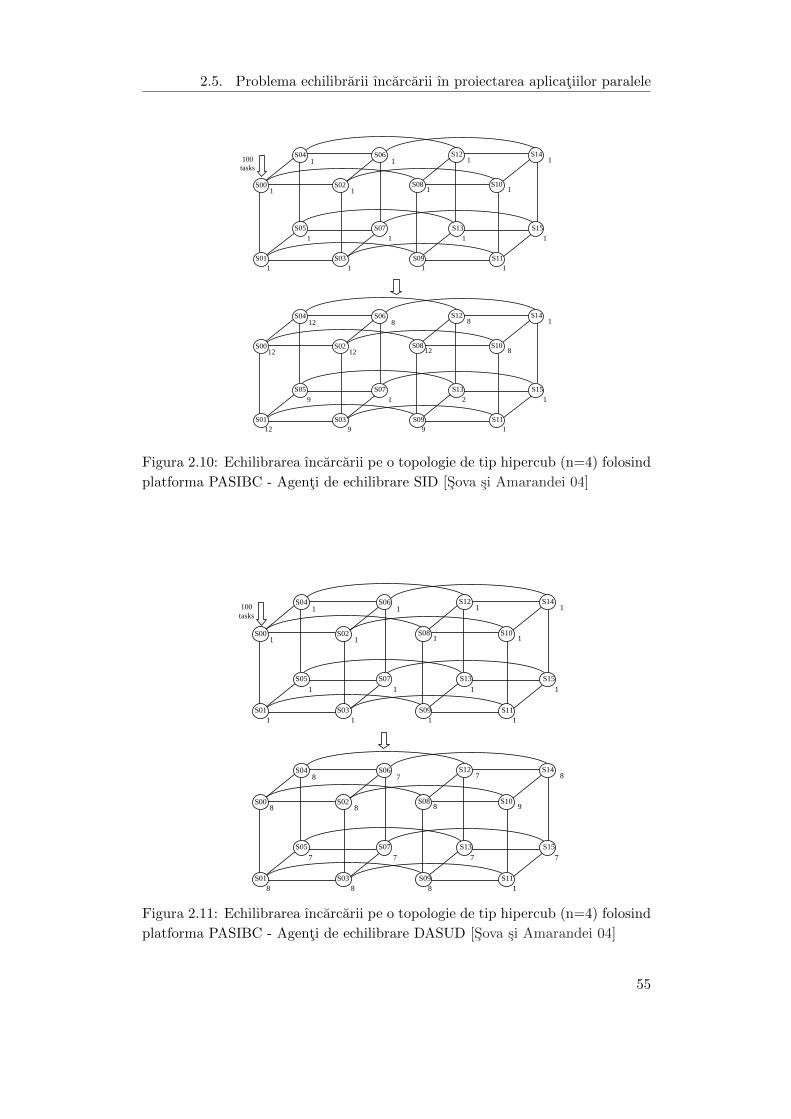
2.5. Problema echilibrarii ıncarcarii ın proiectarea aplicatiilor paralele
1 1
1 1
1 1
1 1
S01
S05 S07
S03
S00
S04 S06
S02
S09
S13 S15
S11
S08
S12 S14
S10
1 1
1 1
1 1
1 1 100 tasks
12 9
9 1
12 12
12 8
S01
S05 S07
S03
S00
S04 S06
S02
S09
S13 S15
S11
S08
S12 S14
S10
9 1
2 1
12 8
8 1
Figura 2.10: Echilibrarea ıncarcarii pe o topologie de tip hipercub (n=4) folosind
platforma PASIBC - Agenti de echilibrare SID [Sova si Amarandei 04]
1 1
1 1
1 1
1 1
S01
S05 S07
S03
S00
S04 S06
S02
S09
S13 S15
S11
S08
S12 S14
S10
1 1
1 1
1 1
1 1 100 tasks
8 8
7 7
8 8
8 7
S01
S05 S07
S03
S00
S04 S06
S02
S09
S13 S15
S11
S08
S12 S14
S10
8 1
7 7
8 9
7 8
Figura 2.11: Echilibrarea ıncarcarii pe o topologie de tip hipercub (n=4) folosind
platforma PASIBC - Agenti de echilibrare DASUD [Sova si Amarandei 04]
55
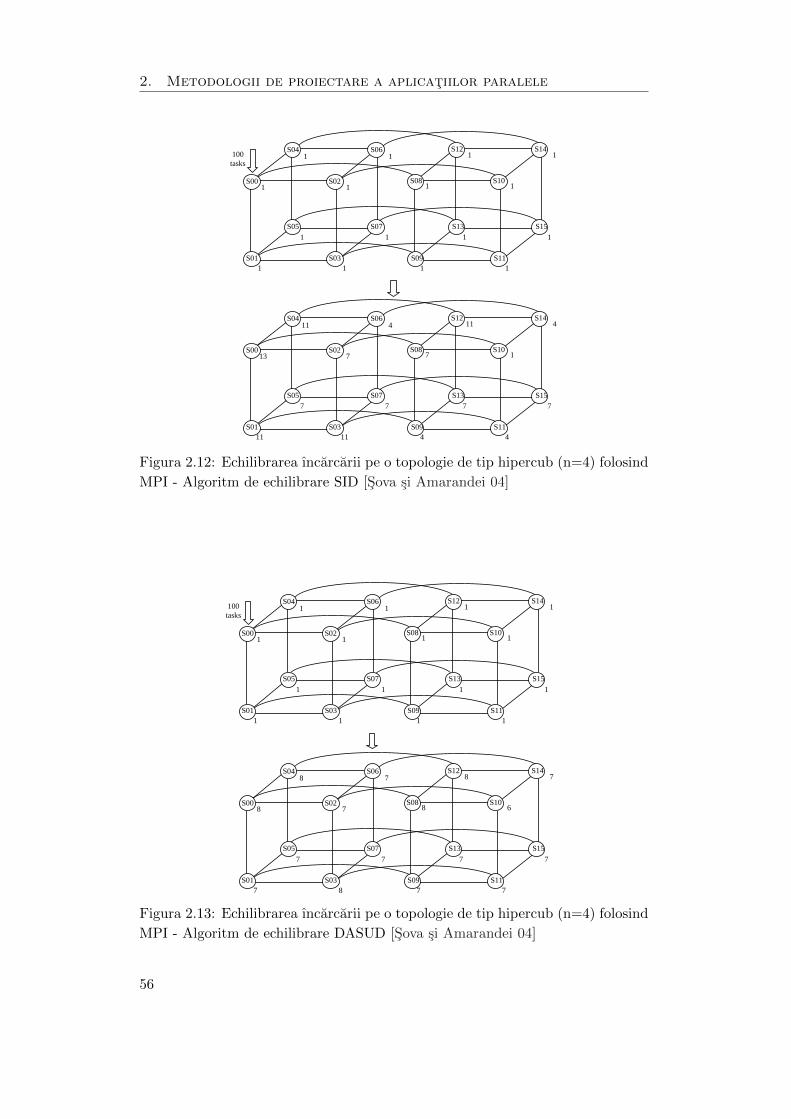
2. Metodologii de proiectare a aplicatiilor paralele
1 1
1 1
1 1
1 1
S01
S05 S07
S03
S00
S04 S06
S02
S09
S13 S15
S11
S08
S12 S14
S10
1 1
1 1
1 1
1 1 100 tasks
11 11
7 7
13 7
11 4
S01
S05 S07
S03
S00
S04 S06
S02
S09
S13 S15
S11
S08
S12 S14
S10
4 4
7 7
7 1
11 4
Figura 2.12: Echilibrarea ıncarcarii pe o topologie de tip hipercub (n=4) folosind
MPI - Algoritm de echilibrare SID [Sova si Amarandei 04]
1 1
1 1
1 1
1 1
S01
S05 S07
S03
S00
S04 S06
S02
S09
S13 S15
S11
S08
S12 S14
S10
1 1
1 1
1 1
1 1 100 tasks
7 8
7 7
8 7
8 7
S01
S05 S07
S03
S00
S04 S06
S02
S09
S13 S15
S11
S08
S12 S14
S10
7 7
7 7
8 6
8 7
Figura 2.13: Echilibrarea ıncarcarii pe o topologie de tip hipercub (n=4) folosind
MPI - Algoritm de echilibrare DASUD [Sova si Amarandei 04]
56

2.5. Problema echilibrarii ıncarcarii ın proiectarea aplicatiilor paralele
2.5.4 Rezultate
Din rezultatele obtinute ın cazul echilibrarii ıncarcarii pe platforma de agenti mo-
bili si pe sistemul de tip message-passing se observa ca ın cazul algoritmului SID
se obtine doar o echilibrare locala iar sistemul pe ansamblu este dezechilibrat. O
ımbunatatire substantiala se observa ın cazul utilizarii algoritmului DASUD - o
echilibrare locala si globala. Totusi, ın ambele cazuri apar probleme (dezechili-
bre) din cauza configuratiei hardware si software pe care au fost facute testele -
incompatibilitati cu software-ul instalat. Testele efectuate cu platforma PASIBC
a fost rulate pe o retea alcatuita din statii cu WindowsXP, iar testele folosind
MPI au fost rulate pe un cluster Linux. Implementarea algoritmilor fiind aprox-
imativ aceeasi, diferenta apare datorita modului ın care sunt implementate cele
2 sisteme de test. Mai exact, varianta de MPI ce ruleaza pe Linux beneficiaza
de modul de lucru cu procese al acestui sistem de operare; ın timp ce platforma
PASIBC fiind implementata folosind platforma .NET, nu a fost posibila folosirea
acelorasi mecanisme de comunicatii [Sova si Amarandei 04].
Pe de alta parte, utilizarea platformelor de agenti mobili ofera urmatoarele
avantaje [Teodoru si Amarandei 07]:
• reducerea traficului pe retea – numai codul agentului si datele finale sunt
mutate de pe un nod pe altul, nu si datele intermediare.
• adaptabilitate – agentii mobili au abilitatea de a-si schimba comportamen-
tul functie de mediul ın care ruleaza.
• robustete si toleranta la defecte – platformele de agenti mobili sunt mult
mai robute decat alte modele de sisteme distribuite. Daca o platforma se
defecteaza, alta poate prelua agentii cu task-urile aferente.
• arhitectura distribuita si flexibila – sistemele de agenti mobili sunt foarte
flexibile datorita posibilitatii de migrare a codului.
Performantele sistemelor distribuite ce utilizeaza agenti mobili pot fi crescute prin
utilizarea algoritmilor de echilibrare a ıncarcarii, datorita faptului ca agentii pot
utiliza mai bine puterea de procesare a sistemului [Teodoru si Amarandei 07].
57
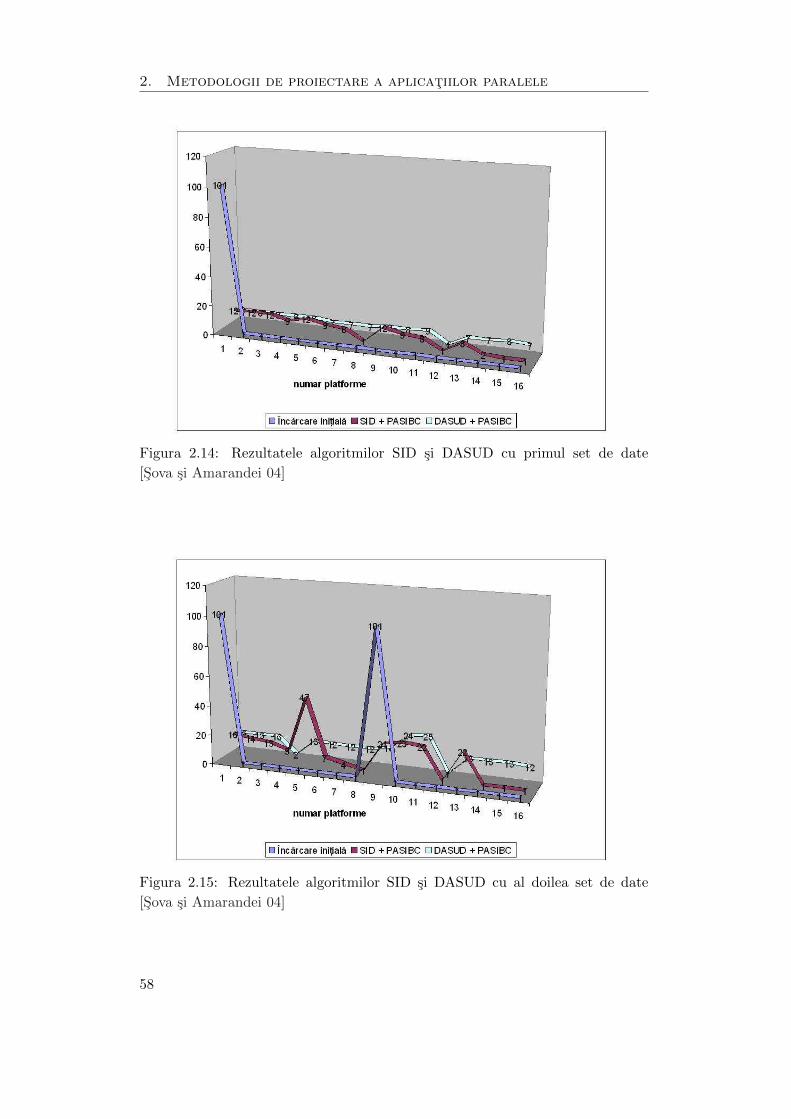
2. Metodologii de proiectare a aplicatiilor paralele
Figura 2.14: Rezultatele algoritmilor SID si DASUD cu primul set de date
[Sova si Amarandei 04]
Figura 2.15: Rezultatele algoritmilor SID si DASUD cu al doilea set de date
[Sova si Amarandei 04]
58
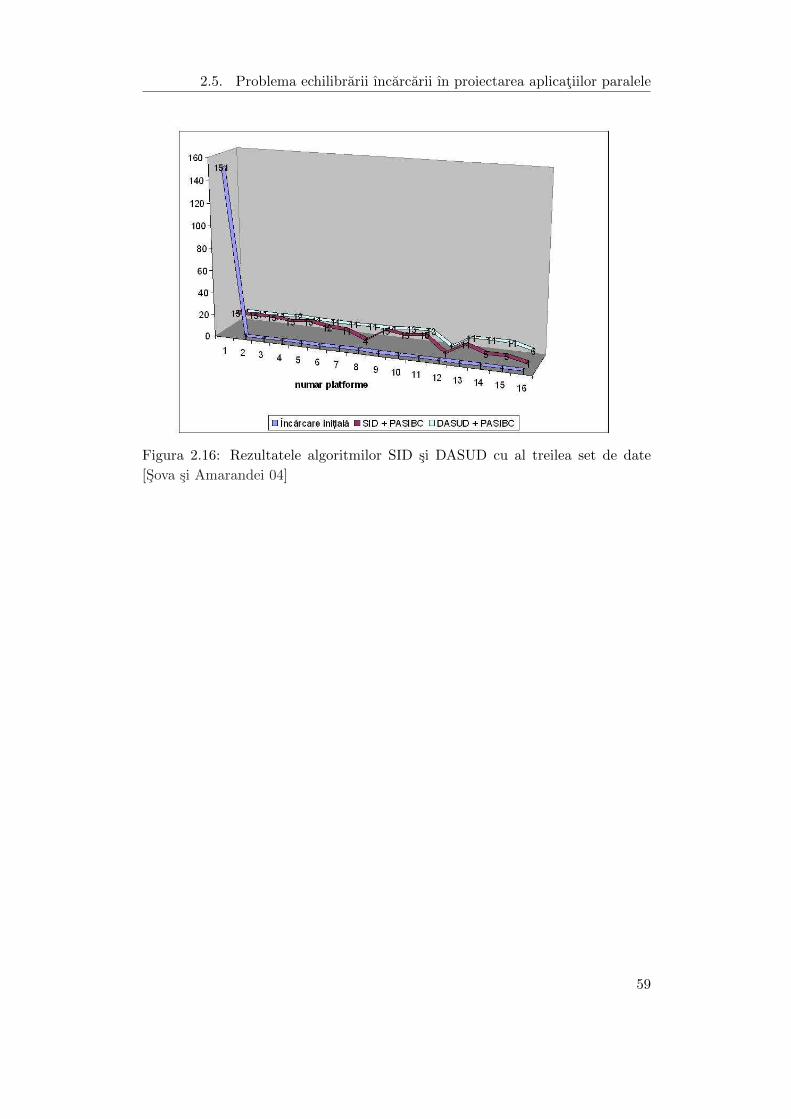
2.5. Problema echilibrarii ıncarcarii ın proiectarea aplicatiilor paralele
Figura 2.16: Rezultatele algoritmilor SID si DASUD cu al treilea set de date
[Sova si Amarandei 04]
59
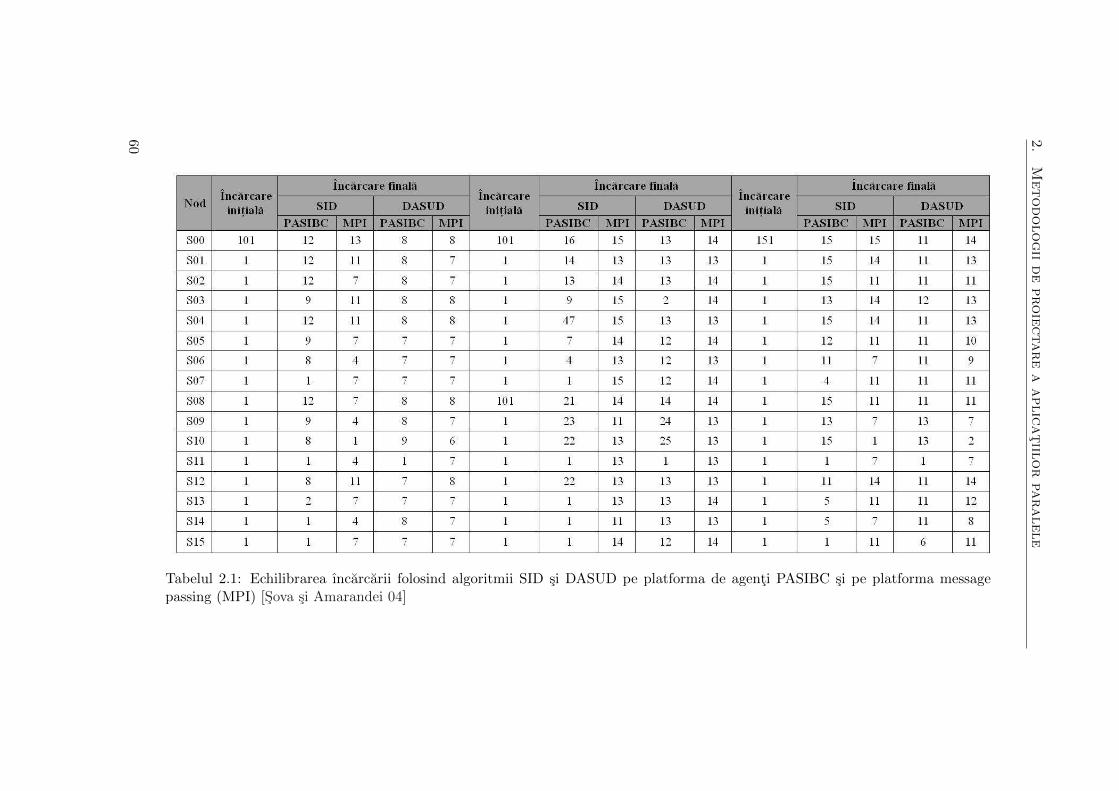
2.
Metodolog
iide
proie
ctare
aaplic
atiil
or
paralele
Tabelul 2.1: Echilibrarea ıncarcarii folosind algoritmii SID si DASUD pe platforma de agenti PASIBC si pe platforma messagepassing (MPI) [Sova si Amarandei 04]
60

Capitolul 3
Model de proiectare a aplicatiilor
paralele folosind proiectarea
statistica a experimentelor
Rezumat
Performantele aplicatiilor paralele sunt influentate de numerosi factori
dependenti de mediul de rulare, precum performanta retelei, ıncarcarea pro-
cesoarelor, memoria disponibila etc. Datele produse de o aplicatie parale-
la pot fi analizate folosind tehnici de investigatie, cum ar fi, de exemplu,
proiectarea statistica a experimentelor (DOE – Design of experiments) pen-
tru investigarea erorilor de proiectare. Pentru utilizarea acestei tehnici este
dezvoltat un model de proiectare al aplicatiilor paralele, model care per-
mite descrierea comportamentului acelei aplicatii ın functie de factorii care
o influenteaza.
Suportul disponibil pentru rularea aplicatiilor paralele (sistemele multicore,
hyperthreading, GPU etc.) precum si arhitecturile ın care sunt integrate (sis-
teme paralele, distribuite etc.) sunt din ce ın ce mai complexe. Acest lucru
face deosebit de dificila construirea de modele analitice care sa permita studiul
performantelor unei aplicatii sau predictia acestora. Prin urmare se ridica prob-
lema validarii aplicatiilor paralele propuse ca solutii pentru rezolvarea prob-
lemelor din diverse domenii. Precum ın cazul altor domenii stiintifice, raspunsul ıl
constitue validarea prin experimente. Cu toate acestea, experimentele ın dome-
niul stiintei calculatoarelor este un subiect ce ridica mai multe probleme deca
rezolva: Ce poate valida un experiment? Ce reprezinta un ”experiment bine
realizat”? Cum se poate construi un mediu experimental ce permite realizarea
unui ”experiment bun”? Cum se poate realiza acest lucru ın cazul calculului de
61

3. Model de proiectare a aplicatiilor paralele folosindproiectarea statistica a experimentelor
mare performanta? [Gustedt 09]. Realizarea unei aplicatii paralele presupune si
analiza parametrilor cantitativi si calitativi ce o descriu: timpi de raspuns, scala-
bilitate etc. Acest lucru se transpune ın realizarea unor teste de performanta pe
baza carora se pot trage concluzii privind modul ın care a fost proiectata si imple-
mentata aplicatia ın cauza. Proiectarea aplicatiilor paralele conform [Foster 95] si
[Quinn 04] presupune patru etape: partitionarea datelor, definirea comunicatiilor,
aglomerarea si maparea. Chiar daca acest model (vezi Figura 2.2) este urmarit cu
atentie ın faza de proiectare, aplicatia rezultata nu functioneaza la parametrii de
performanta asteptati. Acest lucru este posibil nu numai datorita unor verificari
superficiale ale cerintelor suplimentare propuse de Foster, cat datorita conditiilor
ın care ruleaza aplicatia. Pentru a depasi aceste neajunsuri este definit un model
analitic de investigare a performantei, model bazat pe metoda de proiectare de-
scrisa ın capitolul anterior.
Abordarile eficiente din punct de vedere al costurilor se obtin rareori avand
baze exclusiv teoretice. Acest lucru se datoreaza nevoii de flexibilitate si de
usurinta ın mentenanta software-ului pe de o parte si datorita complexitatii sis-
temelor de calcul paralel, pe de alta parte. Datorita numarului mare de strategii
de proiectare si a posibililor factori ce le influenteaza, studiile experimentale tre-
buie realizate tinand cont de urmatoarele [Amarandei 11]:
• factorii ce influenteaza anumite metrici de performanta;
• existenta interactiunilor dintre acesti factori;
• cuantificarea efectului fiecarui factor si a interatiunilor dintre acestia;
• valorile pentru care factorii furnizeaza raspunsul optim;
• limitarile impuse de conditiile de rulare asupra aplicatiei.
Un factor important, care adesea nu este luat ın considerare, este faptul ca
pe un anumit cluster nu ruleaza, ın mod uzual, o singura aplicatie paralela.
Astfel, ın functie de datele transferate ıntre noduri la un moment dat, gradul
de ocupare al retelei interne a clusterului este diferit. De asemenea, utilizarea
clusterului poate fi rezervata pentru mai multe scopuri (de exemplu academice, de
cercetare sau comerciale). O aplicatie proiectata fara a tine cont de acesti factori
poate avea variatii drastice de performanta. In timpul proiectarii nu se poate
cunoaste cu exactitate pentru ce dimensiuni ale problemei va fi rulata aplicatia
de catre beneficiar. Astfel, ın cazurile ın care proiectarea aplicatiilor paralele
se realizeaza folosind descompunerea domeniului, datele sunt separate ın blocuri
distincte ce pot fi procesate separat. Dupa stabilirea modului de partitionare
a domeniului de date este necesara definirea comunicatiilor, sarcina ce poate
reprezenta o adevarata provocare.
Pentru a veni ın sprijinul proiectantului se poate dezvolta un model statistic al
aplicatiei. Utilizand acest model, dupa implementarea unui prototip al aplicatiei,
proiectantul trebuie sa poata urmari evolutia parametrilor de calitate ai aplicatiei
si sa poata identifica mai usor eventualele erori.
62

3.1. Introducere ın tehnica proiectarii statistice a experimentelor
3.1 Introducere ın tehnica proiectarii statistice a experi-
mentelor
In realizarea testelor, ın mod deliberat sunt schimbate una sau mai multe vari-
abile (factori) pentru a observa efectul pe care aceste schimbari ıl au asupra
raspunsului. Tehnica proiectarii statistice a experimentelor (Design of ex-
periments – DOE) reprezinta o metoda eficienta de planificare a testelor astfel
ıncat rezultatele obtinute pot fi analizate pentru a trage concluzii valide si obiec-
tive [NIST/SEMATECH 06].
Metodologia DOE poate fi aplicata cu succes ın cazurile de tip blackbox, atunci
cand se cauta optimizarea unei caracteristici de calitate (raspuns al sistemului)
prin reglarea factorilor de intrare. Datele de intrare sunt cunoscute ın literatura
de specialitate cu numele de factori/variabile care pot fi cunoscuti sau controlati.
Pot exista ınsa si factori care influenteaza sistemul, dar care nu pot fi gestionati,
fiind o sursa de incertitudine – se numesc ın mod uzual factori necunoscuti sau
necontrolati. Datele de iesire ale sistemului se numesc raspunsuri sau variabile
de iesire care sunt de fapt caracteristici de calitate ce urmeaza a fi studiate si
optimizate.
Un plan experimental este o schema de realizare a experimentelor prin care
[Isaic-Maniu 06]:
• sunt organizate, desfasurate si executate experimentele;
• sunt culese si ınregistrate datele de observatie si felul ın care sunt rapor-
tate acestea, astfel ıncat sa se poata investiga influenta factorilor controlati
asupra variabilei de interes, estimand cantitativ si calitativ magnitudinea
acestei influente si stabilind care dintre factorii controlati au o importanta
deosebita;
• sunt decantate sursele de variabilitate prezente ın datele stranse – cele da-
torate factorilor controlati si cele atribuite variatiilor aleatoare provenite
din actiunea factorilor necontrolati.
Realizarea planului experimental ıncepe cu determinarea obiectivelor unui expe-
riment si selectarea factorilor ce vor fi studiati.
Un plan experimental bine ales maximizeaza cuantumul de informatii care
poate fi obtinut pentru un anumit efort depus ın realizarea experimentului. Tre-
buie precizat ca se evita folosirea termenului de ”planificare” a experimentului,
deoarece nu se planifica nimic ın sensul de a obtine ceva dinainte scontat. ”Plani-
ficarea” nu se refera decat la conditiile ın care se desfasoara experimentul, pentru
a asigura obiectivitatea acestuia [Isaic-Maniu 06].
Teoria ce sta la baza DOE are ca punct de start definirea conceptului de
model al procesului. Pasii ce urmeaza fi parcursi pentru realizarea acestui model
sunt [NIST/SEMATECH 06]:
• selectarea modelului (model selection);
63

3. Model de proiectare a aplicatiilor paralele folosindproiectarea statistica a experimentelor
• ajustarea modelului (model fitting);
• validarea modelului (model validation).
Acesti trei pasi sunt urmati iterativ (vezi Figura 3.1) pana cand se gaseste un
model ce descrie cat mai bine procesul.
Start
Selectarea modelului pe baza datelor curente sau pe baza
rezultatelor unui model anterior
Validarea modelului
Sunt necesare date noi
pentru aproximarea modelului?
Proiectează unnou experiment.
Aproximează modelul folosind metoda estimării parametrilor
bazată pe informaţii şi date ale procesului
Achiziţie date noi.
Performanţelemodelului sunt satisfăcătoare?
Stop
Nu
Da
Nu
Da
Figura 3.1: Alegerea modelului DOE (adaptare dupa [NIST/SEMATECH 06])
Exista patru arii de probleme de proiectare ın care se poate aplica tehnica
DOE [NIST/SEMATECH 06]:
• Testari comparative (Comparative): – se urmareste sa se determine ın ce
masura schimbarile efectuate asupra unui singur factor au ca rezultat mod-
ificarea/ımbunatatirea procesului ca ıntreg.
• Selectare (Screening/Characterizing): – reprezinta ıntelegerea procesului ca
64

3.1. Introducere ın tehnica proiectarii statistice a experimentelor
ıntreg ın sensul ca se doreste obtinerea unei liste cu factorii, de la cei mai
importanti la cei mai putin importanti, ce au influenta asupra procesului.
• Modelare (Modeling): – dezvoltarea unui model al modului de functiona-
re a unui proces, cu raspunsurile descrise de o functie matematica si spre
obtinerea unei estimari cat mai precise a coeficientilor acestei functii.
• Optimizare (Optimizing): – identificarea valorii optime a factorilor ce in-
fluenteaza procesul, si determinarea factorilor, sau ce nivel al acelor factori,
optimizeaza raspunsul procesului.
Alegerea unui plan experimental depinde de obiectivele experimentului si de
numarul de factori ce urmeaza a fi investigati [NIST/SEMATECH 06]:
• Analiza comparativa a factorilor (Comparative objective): Daca exista unul
sau mai multi factori ce trebuie investigati, iar scopul analizei este aflarea
unor informatii despre un anumit factor (ın pofida prezentei si/sau absentei
altor factori) si determinarea importantei acestuia, atunci trebuie realizat
un plan de analiza comparativa.
• Selectia factorilor (Screening objective): Scopul urmarit este gasirea si ex-
tragerea doar a acelor factori ce au influenta asupra raspunsului. Acest tip
de analiza este numita si plan de tip ”efecte principale”.
• Metoda suprafetelor de raspuns (Response Surface (method) objective: ın
acest caz, este utilizata ipoteza ca experimentul este proiectat astfel ıncat sa
permita estimarea interactiunilor si sa ofere informatii despre forma (locala)
a suprafetei de raspuns investigate. In general, aceste metode sunt utilizate
pentru:
– gasirea unor parametri mai buni sau chiar a celor optimi pentru un
proces;
– depanarea si descoperirea punctelor slabe;
– realizarea unui produs sau proces imbunatatit si mai robust la influenta
factorilor ce nu pot fi controlti.
• Optimizarea raspunsului: obiectivul acestui model este determinarea influ-
entei diferitelor combinari de factori asupra variabilei raspuns. Se urmareste
practic identificarea acelor combinari care, ın diferite proportii, maximizeaza
(sau minimizeaza) valoarea raspunsului primit.
• Obiective de tip adaptarea optima a modelelor de regresie: scopul urmarit
este identificarea acelui tip de regresie care aproximeaza cel mai bine pro-
cesul supus analizei.
Alegerea planului experimental se poate face conform Tabelului 3.1, descrirea
detaliata a acestuia fiind disponibila la [NIST/SEMATECH 06].
Planul experimental folosit in sectiunea 3.3.2 este cel multifactorial (full fac-
torial) cu doua niveluri pentru fiecare factor, plan care este cel mai des ıntalnit,
conform [NIST/SEMATECH 06]. Nivelul fiecarui factor poate fi ”minim” (”low”
sau ”+1”) sau ”maxim” (”high” sau ”−1”). Un plan ce contine toate combinatiile
65
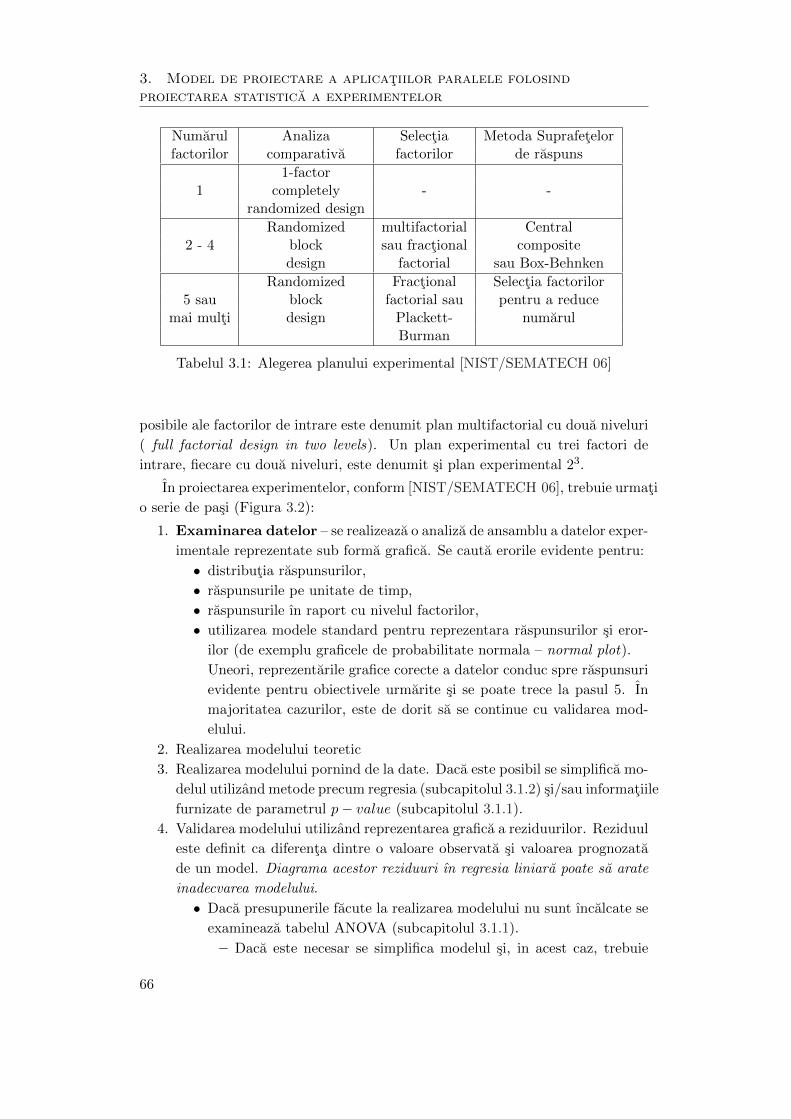
3. Model de proiectare a aplicatiilor paralele folosindproiectarea statistica a experimentelor
Numarul Analiza Selectia Metoda Suprafetelorfactorilor comparativa factorilor de raspuns
1-factor1 completely - -
randomized design
Randomized multifactorial Central2 - 4 block sau fractional composite
design factorial sau Box-Behnken
Randomized Fractional Selectia factorilor5 sau block factorial sau pentru a reduce
mai multi design Plackett- numarulBurman
Tabelul 3.1: Alegerea planului experimental [NIST/SEMATECH 06]
posibile ale factorilor de intrare este denumit plan multifactorial cu doua niveluri
( full factorial design in two levels). Un plan experimental cu trei factori de
intrare, fiecare cu doua niveluri, este denumit si plan experimental 23.
In proiectarea experimentelor, conform [NIST/SEMATECH 06], trebuie urmati
o serie de pasi (Figura 3.2):
1. Examinarea datelor – se realizeaza o analiza de ansamblu a datelor exper-
imentale reprezentate sub forma grafica. Se cauta erorile evidente pentru:
• distributia raspunsurilor,
• raspunsurile pe unitate de timp,
• raspunsurile ın raport cu nivelul factorilor,
• utilizarea modele standard pentru reprezentara raspunsurilor si eror-
ilor (de exemplu graficele de probabilitate normala – normal plot).
Uneori, reprezentarile grafice corecte a datelor conduc spre raspunsuri
evidente pentru obiectivele urmarite si se poate trece la pasul 5. In
majoritatea cazurilor, este de dorit sa se continue cu validarea mod-
elului.
2. Realizarea modelului teoretic
3. Realizarea modelului pornind de la date. Daca este posibil se simplifica mo-
delul utilizand metode precum regresia (subcapitolul 3.1.2) si/sau informatiile
furnizate de parametrul p− value (subcapitolul 3.1.1).
4. Validarea modelului utilizand reprezentarea grafica a reziduurilor. Reziduul
este definit ca diferenta dintre o valoare observata si valoarea prognozata
de un model. Diagrama acestor reziduuri ın regresia liniara poate sa arate
inadecvarea modelului.
• Daca presupunerile facute la realizarea modelului nu sunt ıncalcate se
examineaza tabelul ANOVA (subcapitolul 3.1.1).
– Daca este necesar se simplifica modelul si, in acest caz, trebuie
66

3.1. Introducere ın tehnica proiectarii statistice a experimentelor
reluat pasul 3 (folosindu-se, bineinteles, noul model simplificat).
• Daca presupunerile facute la realizarea modelului sunt ıncalcate, tre-
buie aflata cauza:
– Exista termeni ce lipsesc din model?
– Daca transformarea raspunsului ajuta, se reia de la pasul 3.
5. Utilizarea rezultatelor pentru a raspunde la ıntrebarile generate de obiec-
tivele analizei – gasirea factorilor importanti, gasirea valorilor optime ale
factorilor etc .
Pasii ce trebuie urmati ın analiza DOE, descrisi anterior si ın Figura 3.2 ,
nu trebuie priviti ca o solutie universala rapida la analiza folosind DOE. Este
posibil ca anumite experimente sa nu poata fi analizate doar cu un set simplu de
proceduri ([NIST/SEMATECH 06] si [Montgomery 07]).
Evaluarea datelor
Răspunsurilela întrebări sunt
evidente?
Dezvoltare model teoretic
Estimarea modelului folosind datele experimentale. Simplificarea
modelului dacă este posibil.
Reziduurile sunt aleatoare şi au o distribuţie normală
în jurul valorii 0?
Existăerori de aproximare
mari?
Examinare tabel ANOVA
Se încearcăprocesarea datelor
experimentale
Utilizarea reprezentării graficepentru a identifica sursa erorilor
de aproximare. Daca este fezabil, se modifică
modelul. Dacă nu, se reproiectează.
Este utilă simplificarea
modelului?
Utilizarea rezultatelor obţinute pentru a răspunde la întrebările generate de
obiectivele analizei.
Nu
Da
Da
Nu
Da
Da
Nu
Nu
Figura 3.2: Etapele ce trebuie urmate ın analiza folosind DOE (adaptare dupa
[NIST/SEMATECH 06])
3.1.1 Analiza dispersionala
Procedeul de analiza a variantei factorilor sau analiza dispersionala (analysis of
variance – ANOVA) reprezinta acea metoda ce analizeaza variatia unei variabile
ın raport cu factorii de influenta [Jaba 98]. Prin acest procedeu se pot testa
ipoteze cu privire la parametrii unui model, se pot estima componentele dispersiei
unei variabile si semnificatia factorilor de influenta asupra dispersiei.
67

3. Model de proiectare a aplicatiilor paralele folosindproiectarea statistica a experimentelor
Procedeul consta ın descompunerea variatiei totale a unui ansamblu de date
ınregistrate pentru o variabila X ın componente definite dupa sursa variatiei
(cauzele acesteia) si compararea acestora pentru a stabili daca factorii considerati
cauza au influenta semnificativa asupra varaibilei X [Jaba 98].
Metoda analizei dispersionale (ANOVA), este utilizata pentru a verifica gradul
ın care valorile reale, empirice ale unei caracteristici se abat de la valorile teoretice,
determinate ın general cu ajutorul mediilor sau al ecuatiilor de regresie. Metoda
studiaza efectul variabilei/variabilelor independente asupra celei dependente, al-
tfel spus, masura ın care variatia caracteristicii rezultative este dependenta sau
nu de factorul (factorii) de grupare. ANOVA are la baza metoda gruparii, prin
ea separandu-se influenta factorilor esentiali (determinanti) de influenta facto-
rilor considerati ıntamplatori (aleatori) asupra caracteristicii efect. In functie de
numarul factorilor ınregistrati ce-si exercita influenta asupra caracteristicii rezul-
tative (unul, doi sau mai multi), analiza dispersionala se poate efectua dupa un
model unifactorial, bifactorial sau multifactorial.
Pentru fiecare varianta/interval de variatie a caracteristicii cauzale X, se ınre-
gistreaza o distributie de valori ale variabilei efect Y , distributie pe care o putem
caracteriza, de regula, prin nivelul mediu. Daca aceste medii ale variabilei Y , pe
grupe dupa X sunt egale sau foarte putin diferite, atunci se concluzioneaza ca
variabila independenta X nu influenteaza variatia variabilei dependente Y . Cu
cat mediile lui Y pe grupe dupa X difera mai mult unele de altele, cu atat X
influenteaza mai mult pe Y .
Tabelul ANOVA pentru o variabila raspuns este utilizat la identificarea fac-
torilor si a interactiunii dintre factori ce sunt semnificative din punct de vedere
statistic (vezi Tabelele 3.6, 3.7, 3.8). Acest tabel are urmatoarele componente
[Montgomery 07]:
• prima coloana indica sursa de variatie;
• coloana a doua reprezinta suma patratelor abaterilor (Sum of squares –
SS);
• coloana a treia reprezinta numarul de grade de libertate ( d.f.)
• coloana a patra reprezinta media patratelor (Mean Squares - MS);
• ın coloana a cincea se gaseste testul statistic F (Fisher);
• gradul de influenta – P −value: reprezinta probabilitatea de aparitie a unei
erori observate din ıntamplare.
Semnificatia statistica a P−value este urmatoarea: o valoare foarte apropiata
de zero indica o importanta crescuta a factorului ın discutie asupra raspunsului
urmarit. Presupunem o familie de teste ale unei ipoteze nule (notata cu H0),
definite de valori ale nivelului de semnificatie p. Prin P − value asociata ipotezei
nule, pentru setul de date considerat, se ıntelege cel mai mic nivel de semnificatie
p pentru care ipoteza nula se respinge ın toate testele. Astfel, ıntr-un test uni-
lateral, daca X este statistica testului si notam cu xp valoarea critica astfel ıncat
68

3.1. Introducere ın tehnica proiectarii statistice a experimentelor
respingem H0 pentru X < xp, notam cu x valoarea observata a lui X, atunci
P − value pentru ipoteza nula si observatiile disponibile este cea mai mica val-
oare p ıncat x < xp. Majoritatea programelor dedicate calculelor statistice ofera,
la procedurile de testare a ipotezelor, valoarea de probabilitate. Daca P − valueeste mai mica sau egala cu nivelul de semnificatie p, atunci se respinge ipoteza
nula.
O situatie des ıntalnita ın practica este aceea ın care asupra unei caracteristici
ce trebuie studiate, actioneaza doi factori A si B, factori ce se pot influenta
reciproc. In acest caz trebuie luata ın considerare si interactiunea acestora. Este
posibil ca efectul interactiunii factorilor asupra variabilei investigate sa fie nul, dar
acest lucru nu se poate determina cu certitudine ınaintea derularii experimentului.
Acest model este numit modelul bifactorial cu interactiuni. Pentru fiecare factori
avem mai multe niveluri. Notam cu a numarul de niveluri ale factorului A, cu
b numarul de niveluri ale factorului B si cu n numarul de experimente. Pentru
acest caz, tabelul ANOVA este de forma:
Sursa de variatieSuma de
patrate
Gradele de
libertateMedia patratelor
Statistica
F
Tratamentul (A) SSA a− 1 MSA = SSAa−1
MSAMSE
Tratamentul (B) SSB b− 1 MSB = SSBb−1
MSBMSE
Interactiunea
(AB)SSAB (a− 1)(b− 1) MSAB = SSAB
(a−1)(b−1)MSABMSE
Eroarea SSE ab(n− 1) MSE = SSEab(n−1) –
Total SST abn− 1 – –
Tabelul 3.2: Tabelul ANOVA pentru un plan bifactorial cu interactiuni (adaptare
dupa [Isaic-Maniu 06] si [Montgomery 07])
Formulele cu ajutorul carora se calculeaza sumele de patrate din tabelul
ANOVA sunt urmatoarele [Montgomery 07]:
a∑i=1
b∑j=1
n∑k=1
(yijk − y···)2 = bna∑
i=1
(yi·· − y···)2
+ anb∑
j=1
(y·j· − y···)2
+ n
a∑i=1
b∑j=1
(yij· − yi·· − y·j· + y···)2
+a∑
i=1
b∑j=1
n∑k=1
(yijk − yij·)2
69

3. Model de proiectare a aplicatiilor paralele folosindproiectarea statistica a experimentelor
sau simbolic:
SST = SSA + SSB + SSAB + SSE ,
unde: y··· – reprezinta media tuturor celor abn observatii; yi·· – reprezinta media
observatiilor pentru nivelul i al factorului A; y·j· – reprezinta media observatiilor
pentru nivelul j al factorului B iar yij· – reprezinta media observatiilor pentru
nivelurile i si j ale celor 2 factori [Isaic-Maniu 06].
Daca pentru o statistica F din tabelul ANOVA, probabilitatea P −value este
mai mica sau egala cu nivelul de semnificatie ales (de obicei 0.05 sau 0.01), atunci
se respinge ipoteza nula, asa cum se va arata ın subcapitolul 3.3.2.
3.1.2 Analiza de regresie
Intelegerea comportamentului unui sistem impune studierea legaturilor dintre
variabilele ce ıl definesc prin utilizarea metodei de regresie si corelatie. Situatiile
care se ıntalnesc ın studiul legaturilor dintre variabile [Jaba 98]:
• legatura nula: cand nu exista nici o influenta ıntre variabilele considerate;
• legatura functionala: cand modificarea unei variabile antreneaza variatia
altei variabile ıntr-o masura ce ramane constanta;
• legatura statistica: cand modificarea unei variabile este rezultatul conjugat
al influentei mai multor variabile.
Studiul comportamentului a doua sau mai multe variabile poate evidentia o
relatie de dependenta functionala sau o dependenta statistica (definirea unei legi
care sa explice relatia dintre variabile). Astfel de probleme se pot rezolva cu
ajutorul analizei de regresie si corelatie.
Conceptul de regresie exprima o legatura de tip statistic cu privire la com-
portamentul unor variabile. Analiza modelelor de regresie reprezinta o metoda
statistica care permite studierea si masurarea relatiei care exista ıntre doua sau
mai multe variabile, precum si descoperirea legii relative la forma legaturilor
dintre variabile. Prin aceasta metoda se ıncearca, pe baza unui esantion, sa
se estimeze relatia matematica dintre doua sau mai multe variabile, adica sa
se estimeze valorile unei variabile ın functie de valorile altei variabile [Jaba 98].
Modelele matematice obtinute prin aplicarea analizei de regresie sunt denumite
ecuatii de regresie. Expresia generala a unui ecuatii de regresie va fi descrisa ın
paragraful urmator.
Pentru alegerea tipului de regresie se poate utiliza aceiasi metoda ca aceea
descrisa ın Figura 3.1 la alegerea modelului DOE.
3.1.3 Modelul unui proces
In mod uzual, modelarea unui proces ıncepe cu modelul de cutie neagra, ımpreuna
cu factorii de intrare discreti sau continui ce pot fi controlati si modificati de
cercetator, si una sau mai multe variabile de tip raspuns ce pot fi determinate.
70

3.1. Introducere ın tehnica proiectarii statistice a experimentelor
Variabilele raspuns se presupun a fi continue. Datele experimentare sunt utilizate
pentru a realiza un model empiric care leaga factorii de intrare de raspunsuri. De-
seori, experimentele trebuie sa determine numarul de factori ce nu pot fi controlati
(Figura 3.3).
Informatii suplimentare legate de proiectarea statistica a experimentelor si
de construirea modelelor empirice bazate pe analiza statistica pot fi gasite ın
[Jain 91], [Box 78], [Kleijnen 04], [Isaic-Maniu 06], [Jaba 98] si [Montgomery 06].
Modelul generic al unei ecuatii de regresie este de forma [Montgomery 06]:
Y = f (X1, X2, . . . , Xk) + ε . (3.1.1)
Intrări
necunoscute/necontrolate -ε
Intr
ări
contr
ola
te
(Fac
tori
) X
Ieşi
ri
(Răs
punsu
ri)
Y
Figura 3.3: Modelul de tip cutie neagra (adaptare dupa [NIST/SEMATECH 06])
Pentru un model liniar cu doi facori X1 si X2, ecuatia de regresie poate fi
scrisa [Montgomery 06]:
Y = β0 + β1X1 + β2X2 + β12X1X2 + ε , (3.1.2)
unde Y reprezinta raspunsul pentru un anumita valoare a factorilor X1 si X2,
ε este eroarea experimentala iar termenul X1X2 simbolizeaza un posibil efect al
interactiunii dintre X1 si X2. Constanta β0 reprezinta raspunsul Y al sistemului
atunci cand cei doi factori sunt nuli.
Pentru modele mai complicate, un model liniar cu trei factori X1, X2, X3 si
un raspuns Y poate fi descris prin ecuatia urmatoare [Montgomery 06]:
Y = β0 + β1X1 + β2X2 + β3X3 + β12X1X2
+β13X1X3 + β23X2X3 + β123X1X2X3 + ε , (3.1.3)
71

3. Model de proiectare a aplicatiilor paralele folosindproiectarea statistica a experimentelor
sau ın cazul general:
Y = β0 +
k∑i=1
βixi +
k∑i=1
βiix2i +
k∑i<j
k∑j=1
βij ·xi ·xj +
p∑i<j<k
βijk ·xi ·xj ·xk + . . .+ ε .
(3.1.4)
Termenii ce contin un singur factor X reprezinta efectul direct al acestora
asupra raspunsului. In cazul general, modelul expus de ecuatia 3.1.4 va lua ın
considerare toate interactiunile combinate ıntre toti cei k factori de intrare. Alt-
fel spus trebuie considerati toti factorii de forma Cik, pentru 1 < i ≤ k. Astfel,
pentru cazul a trei factori de intrare exista C23 = 3 interactiuni bilaterale ıntre
factori si C33 = 1 interactiuni trilaterale (ecuatia 3.1.3). Pentru simplitate aceasta
ultima interactiune ıntre factori este adesea ignorata. Cand sunt analizate datele
experimentale, toti parametrii necunoscuti β sunt estimati, iar coeficientii terme-
nilor X sunt testati pentru a determina care sunt valorile semnificativ diferite de
zero, conform ANOVA.
Coeficientii β mai sunt numiti si coeficienti de regresie. Acesti coeficienti
sunt estimati cu scopul de a minimiza eroarea, proces denumit si regresie. Ecuatia
raspunsului Y se poate scrie sub forma matriciala astfel [Montgomery 06] :
y = X · β + ε . (3.1.5)
unde
y =
y1y2...
yn
X =
1 x11 x12 · · · x1k1 x21 x22 · · · x2k...
......
...
1 xn1 xn2 · · · xnk
β =
β1β2...
βn
ε =
ε1ε2...
εn
In cazul general, y este vectorul raspunsurilor (n × 1), X este o matrice n × p,unde p = k + 1, ce contine nivelurile factorilor si a interactiunii dintre acestia –
matricea modelului, β este un vector de dimensiune p×1 ce reprezinta coeficientii
de regresie si ε este un vector de dimensiune (n× 1) cu erorile experimentale.
In ecuatia anterioara, deoarece se urmareste minimizarea erorii ε, coeficientii
β ai modelului predictiv sunt estimati utilizand formula urmatoare:
β =(XT ·X
)−1 ·XT · y . (3.1.6)
3.1.4 Utilizare ın domeniu
Analiza statistica folosind planul experimental ofera o cale de a determina ce con-
figuratie specifica trebuie simulata pentru ca informatiile dorite sa fie obtinute
dupa un numar redus de simulari [Law 99]. Suplimentar, planul experimental
realizat si analizat corespunzator: (1) faciliteaza identificarea efectului factorilor
72

3.1. Introducere ın tehnica proiectarii statistice a experimentelor
(variabilelor) care pot determina modifiari ale performantei; si (2) ajuta ın a de-
termina daca un anumit factor are efect semnificativ sau daca diferentele obser-
vate sunt rezultatul unor erori aleatorii rezultate din masuratori si din paramatri
ce nu pot fi controlati [Jain 91].
Ruthruff, ın [Ruthruff 06], arata ca utilizarea tehnicii planului experimental
poate ajuta cercetatorii si dezvoltatorii de software sa identifice limitarile tehni-
cilor de analiza, sa ımbunatateasca tehnicile de analiza experimentala existente
si sa creeze noi tehnici de analiza a programelor. Aceste tehnici pot fi capabile
sa creioneze concluzii despre proprietatile sistemelor software ın cazul ın care
utilizarea metodelor traditionale nu are succes [Ruthruff 06].
De exemplu, ın [Rao 08], tehnica planului experimental este utilizata pen-
tru testarea performantelor masinii virtuale Java pe sisteme embedded. Au-
torii construiesc un model de regresie care utilizeaza relatii ıntre parametrii de
performanta ai masinii virtuale Java cu diverse metrici corespunzatoare arhitec-
turilor embedded. Modelul dezvoltat este usor de interpretat si precizia este
apropiata de erorile de masurare. Prin aceasta metoda, proiectantul aplicatiilor
este sfatuit sa modifice parametrii masinii virtuale Java pentru a obtine performan-
tele optime.
Utilizarea metodei de proiectare statistica a experimentelor ın proiectarea a-
plicatiilor secventiale reprezinta o buna politica de selectare a componentelor unei
aplicatii, ce ofera cele mai bune rezultate pentru o anumita problema. O astfel
de abordare este descrisa ın [Stewardson 02] pentru selectarea unui numar redus
de combinatii de algoritmi genetici pentru rezolvarea problemelor de planificare.
Deoarece selectia trebuie sa acopere ın egala masura fiecare tip de parametru
si combinatiile acestora, autorii utilizeaza metoda planului experimental pe post
de metoda de reducere a incertitudinii si complexitatii. Tehnica planului exper-
imental este utilizata si ın [Ridge 07], unde este construit un model predictiv
al performantelor ce combina tehnicile euristice de optimizare asupra unui set
de parametri si caracteristicile problemei studiate. Alte abordari statistice de
analiza a performantelor aplicatiilor paralele au fost propuse recent de [Zheng 10],
[Barnes 08] si [Whiting 04].
Totusi, nici una din solutiile mentionate nu se adreseaza tehnicilor de cons-
truire a unui eventual model generic de proiectare a aplicatiilor paralele. De
exemplu, [Zheng 10] utilizeaza modele statistice pentru predictia performantelor
unei aplicatii paralele, utilizand performantele blocurilor secventiale. Acest lu-
cru este realizat prin simulari ale unui model de dimensiuni reduse al problemei
pentru a afla caracteristicile aplicatiei. Prin intermediul tehnicilor de ınvatare
(machine learning techniques) precum retelele neuronale, cunostintele acumulate
sunt transformate ıntr-un model statistic pentru fiecare bloc executat secvential.
Aceste cunostinte sunt apoi utilizate ın prezicerea performantelor la rularea ın
cazul real pe un simulator.
73

3. Model de proiectare a aplicatiilor paralele folosindproiectarea statistica a experimentelor
In [Barnes 08], regresia multi-variabila este utilizata pentru a prezice per-
formantele unei configuratii cu un numar mare de procesoare utilizand datele
obtinute prin rularea pe un numar mic de procesoare. Chiar daca aceasta metoda
poate fi utilizata pentru prezicerea scalabilitatii unui program paralel, tehnica nu
ofera informatii legate de factorii ce determina performantele aplicatiei parale-
le studiate. Tehnica planului experimental este utiliata de [Whiting 04] pen-
tru a evalua performantele unei aplicatii paralele ce implementeaza o problema
computationala complexa din domeniul filogeneticii. Autorii prezinta cateva
metode de realizare a planului experimental precum: multifactorial (full facto-
rial), fractional factorial (vezi Tabelul 3.1) si D-optimal (definit ın [Dykstra 71]).
Evaluarea parametrilor este realizata prin metoda planului D-optimal. Autorii
prezinta un set de concluzii cu privire la influenta spatiului de cautare, a algorit-
mului ales si a numarului de procesoare asupra performantelor aplicatiei.
Analiza comportamentului unui program prin intermediul paradigmelor de de-
sign experimental poate ajuta cercetatorii si dezvoltatorii de aplicatii sa identifice
limitarile tehnicilor de analiza, sa ımbunatateasca modelul si sa creeze noi tehnici
de analiza.Aceste tehnici sunt capabile sa creeze o imagine asupra proprietatilor
sistemului ın cazurile ın care tehnicile traditionale esueaza [Ruthruff 06].
O strategie bazata pe DOE a fost utilizata pentru analiza performantelor mo-
delului retelelor mobile ad-hoc si a protocoalelor utilizate. Rezultatele obtinute
au condus la determinarea unor concluzii obiective asupra unor arii largite de
retele si medii de comunicatii [Totaro 05].
Spre deosebire de aceste solutii, abordarea prezentata ın sectiunile urmatoare
are la baza un model predictiv al performantelor, scopul acestuia fiind deter-
minarea factorilor ce influenteaza performantele aplicatiei paralele, precum si
prezicerea performantelor aplicatiei ın diferite conditii de rulare ınca din faza de
proiectare.
Un numar semnificativ de factori si strategii de proiectare conduc la nu-
meroase ıntrebari: Care factori influenteaza o anumita metrica de performanta?
Exista interactiuni ıntre factori? Este posibila cuantificarea efectului fiecarui fac-
tor si a interactiunilor dintre acestia? Daca da, modificarea carui factor furnizeaza
performante maxime si care este comportamentul acestora? Aceste modificari
impun limitari pentru programe?
O alternativa la DOE ar fi utilizarea de tehnici euristice, dar ın acest caz
comportamentul aplicatiei nu poate fi cuantificat. Tehnicile euristice presupun
rularea repetata a aplicatiei pentru a obtine comportamente diferite. Dezavanta-
jul acestor tehnici este ca ofera rezultate aproximative, ce trebuie reevaluate ın
permanenta pentru a fi ımbunatatite [Ridge 07].
Prin contrast, avantajele utilizarii tehnicilor statistice bazate pe DOE sunt
semnificative. Un plan experimental bine construit permite proiectantilor de
aplicatii sa obtina maximum de informatii cu un numar minim de experimente
74

3.2. Modelul propus pentru ımbunatatirea proiectarii aplicatiilor paralele
[Totaro 05]. Planul experimental ofera o metoda de indentificare a configuratiilor
specifice de simulare ınaintea rularii efective. Astfel, informatiile dorite sunt
obtinute cu un numar minim de simulari [Jain 91].
Tehnici detaliate de folosire a DOE si de construire a modelelor empirice se pot
gasi ın detaliu ın [Box 78], [Jain 91], [Montgomery 06] si [Kleijnen 04]. Cateva
idei si metodologii de investigare empirica ce pot fi utilizate ın ingineria software
sunt prezentate ın [Kitchenham 02] si in [Ivan 04].
3.2 Modelul propus pentru ımbunatatirea proiectarii apli-
catiilor paralele
In continuare este prezentat un model de analiza si verificare a unei aplicatii
paralele. Modelul ia ın considerare factorii ce pot influenta comportamentul
aplicatiei, furnizand indicii asupra erorilor ce pot apare ın etapele de proiectare.
Este prezentata modalitatea ın care strategiile statistice bazate pe DOE pot fi
folosite pentru analiza performantelor unei aplicatii paralele ın scopul de a trage
concluzii obiective privind erorile de proiectare. De asemenea, se pot obtine
informatii legate de conditiile de rulare pe baza parametrilor de performanta
luati ın considerare.
Modelul propus ın [Amarandei 11] pentru proiectarea aplicatiilor paralele pre-
supune parcurgerea a trei etape (Figura 3.4).
Astfel prima etapa reprezinta pasii clasici de proiectare a unei aplicatii par-
alele, pasi descrisi ın [Foster 95]. Conform acestui model, la sfarsitul fiecarei
etape, proiectantul unei aplicatii paralele trebuie sa analizeze rezultatul obtinut
printr-o serie de verificari descrise ın cadrul subcapitolelor 2.2.1.3, 2.2.2.1, 2.2.3.4
si 2.2.4.3. Rezultatul acestei etape ıl reprezinta prototipul aplicatiei paralele sau a
algoritmului paralel. Cu acest prototip se fac masuratori legate de functionalitatea
si performantele aplicatiei: timpii de procesare, timpii de comunicatie, cantitatea
de date transferata ıntre procese, etc.
Dupa proiectarea aplicatiei paralele, un rol important ıl au modelele de perfor-
manta descrise ın [Foster 95] si mai pe larg ın sectiunea 2.4. Informatii importante
pot fi obtinute prin compararea datelor masurate si a celor prezise. Aceste valori
sunt rareori identice datorita gradului de idealizare utilizat ın timpul proiectarii.
Daca sunt discrepante majore, acestea apar fie datorita modelului incorect, fie
datorita implementarii defectuoase. In cazul unui model incorect, rezultatele
empirice pot fi utilizate pentru a determina deficientele modelului si a reevalua
compromisurile facute pentru a justifica deciziile de proiectare. In al doilea caz,
putem utiliza modelul pentru a identifica unde anume poate fi ımbunatatita im-
plementarea.
Etapa a doua presupune realizarea unui plan experimental cu efectuarea expe-
rimentelor, analiza statistica si interpretarea rezultatelor. Analiza statistica poate
75
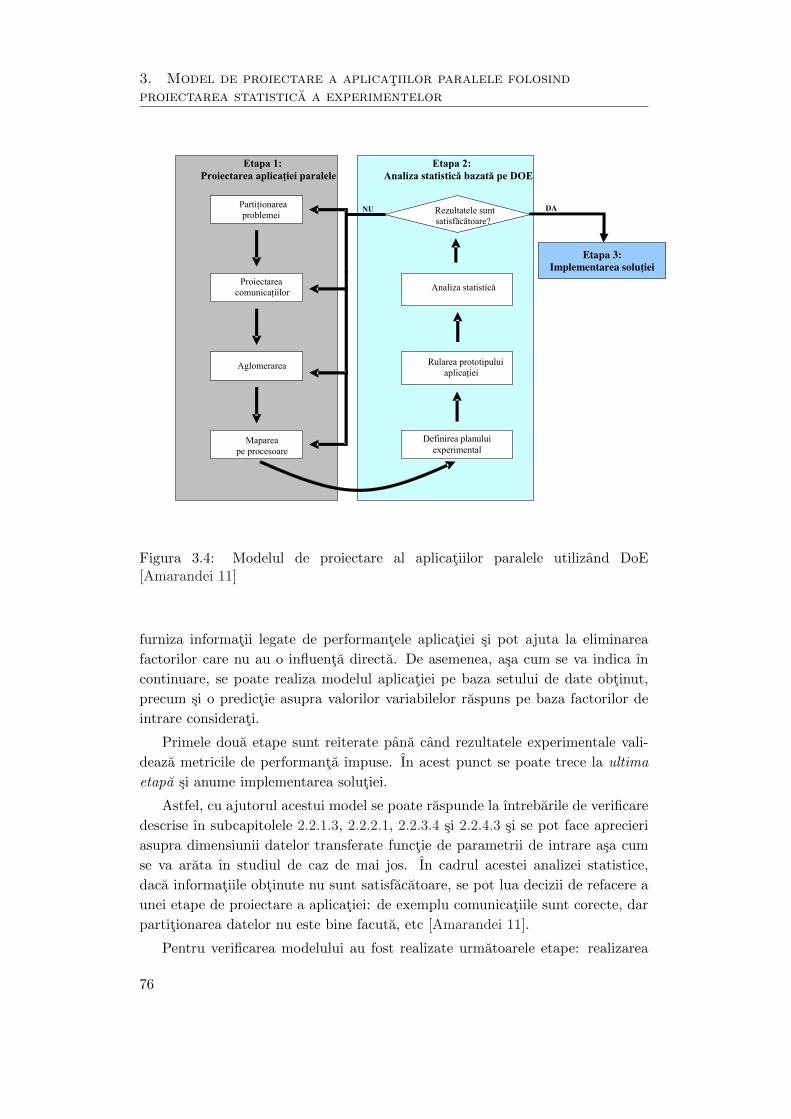
3. Model de proiectare a aplicatiilor paralele folosindproiectarea statistica a experimentelor
Etapa 2:
Analiza statistică bazată pe DOE
Etapa 1:
Proiectarea aplicaţiei paralele
Partiţionarea
problemei
Proiectarea
comunicaţiilor
Aglomerarea
Maparea
pe procesoare
Definirea planului
experimental
Rularea prototipului
aplicaţiei
Analiza statistică
NU Rezultatele sunt satisfăcătoare?
Etapa 3:
Implementarea soluţiei
DA
Figura 3.4: Modelul de proiectare al aplicatiilor paralele utilizand DoE[Amarandei 11]
furniza informatii legate de performantele aplicatiei si pot ajuta la eliminarea
factorilor care nu au o influenta directa. De asemenea, asa cum se va indica ın
continuare, se poate realiza modelul aplicatiei pe baza setului de date obtinut,
precum si o predictie asupra valorilor variabilelor raspuns pe baza factorilor de
intrare considerati.
Primele doua etape sunt reiterate pana cand rezultatele experimentale vali-
deaza metricile de performanta impuse. In acest punct se poate trece la ultima
etapa si anume implementarea solutiei.
Astfel, cu ajutorul acestui model se poate raspunde la ıntrebarile de verificare
descrise ın subcapitolele 2.2.1.3, 2.2.2.1, 2.2.3.4 si 2.2.4.3 si se pot face aprecieri
asupra dimensiunii datelor transferate functie de parametrii de intrare asa cum
se va arata ın studiul de caz de mai jos. In cadrul acestei analizei statistice,
daca informatiile obtinute nu sunt satisfacatoare, se pot lua decizii de refacere a
unei etape de proiectare a aplicatiei: de exemplu comunicatiile sunt corecte, dar
partitionarea datelor nu este bine facuta, etc [Amarandei 11].
Pentru verificarea modelului au fost realizate urmatoarele etape: realizarea
76

3.2. Modelul propus pentru ımbunatatirea proiectarii aplicatiilor paralele
unei aplicatii paralele ce utilizeaza tehnica descompunerii domeniului de date
(domain decomposition), realizarea unui plan experimental de tip multifactorial
(conform Tabelului 3.1) pentru analiza performantelor aplicatiei, interpretarea
rezultatelor din ANOVA si din analiza de regresie pentru identificarea unor even-
tuale erori de proiectare.
3.2.1 Analiza unei aplicatii paralele folosind modelul propus
Utilizand analiza statistica a datelor obtinute ın urma simularilor, prin inter-
mediul ANOVA, cercetatorii pot identifica efectele produse de factorii de intrare
precum si interactiunea dintre acestia pentru a explica metricile de performanta
[Totaro 05]. Pasii care trebuie urmati pentru realizarea experimentului sunt
urmatorii [Amarandei 11]:
1. Definirea obiectivelor: Scopul acestui model este demonstrarea eficientei
strategiei bazate pe DOE ın evaluarea performantelor unei aplicatii par-
alele si identificarea erorilor de proiectare. Pentru atingerea acestui scop,
obiectivele specifice sunt cuantificarea efectelor unor potentiali factori ce
influenteaza performantele unei aplicatii paralele. Utilizand aceste efecte, se
dezvolta un model empiric, ce poate fi folosit pentru a prezice performantele
aplicatiei paralele ın momentul rularii cu date de intrare diferite de cele ex-
aminate.
2. Selectarea factorilor de intrare: Pasul urmator ın realizarea planului
experimental este selectia factorilor de intrare potentiali ce pot influenta
performantele aplicatiei paralele.
3. Selectarea variabilelor raspuns: Dupa alegerea factorilor de intrare,
functie de obiectivele urmarite sunt selectate variabilele raspuns – ca de
exemplu timpul de procesare sau timpul de comunicatie.
4. Selectarea metodei de analiza: Exista libertate deplina ın a alege o
metoa de analiza ın functie de numarul factorilor si de obiectivele urmarite
(Tabelul 3.3 si Figura 3.1), motivarea alegerii si metodele disponibile nu fac
obiectul acestei teze, fiind prezentate pe larg ın [NIST/SEMATECH 06].
Pentru simplitatea calculelor, este utilizata o codare a factorilor folosind,
de obicei, valori +/- sau 0/1.
5. Rularea aplicatiei si colectarea datelor: In acest pas se efectueaza
testarea aplicatiei. In functie de numarul factorilor de intrare, aplicatia
trebuie rulata de n ori (la fiecare rulare pentru factorii de intrare trebuie
utilizate valorile din planul experimental si adunate rezultatele.
6. Analiza statistica: In acest pas, se analizeaza efectele principale si cele
de interactiune. Efectele principale sunt modificarile asupra unei variabile
raspuns la variatia unui factor de intrare. Efectele de interactiune sunt
efectele combinate ale factorilor de intrare asupra unei variabile raspuns.
Dupa rularea aplicatiei, pentru setul de date de intrare ales, se analizeaza
77

3. Model de proiectare a aplicatiilor paralele folosindproiectarea statistica a experimentelor
influenta acestora asupra raspunsului urmarit.
7. Construirea modelului empiric pentru raspunsurile considerate:
Dupa rularea aplicatiei utilizand factorii de intrare selectati, se analizeaza
influenta acestora asupra variabilelor raspuns. Se construieste un model
empiric pe baza datelor obtinute utilizand metoda planului experimental.
Pasii ce trebuie urmati sunt urmatorii: selectia modelului, ajustarea si vali-
darea acestuia. Acesti trei pasi sunt utilizati iterativ pana cand se obtine un
model cat mai apropiat de rezultatele obtinute. In etapa de selectie a mod-
elului, efectele factorilor si a interactiunilor dintre acestia sunt determinate
din tabelul ANOVA pentru a afla modul ın care modelul poate fi adaptat
la date. Dupa acest pas, folosind modelul selectat si datele disponibile, se
verifica daca acest model descrie cat mai bine posibil parametrii necunoscuti
ai modelului. Dupa estimarea parametrilor, modelul este evaluat pentru a
afla daca nu cumva presupunerile facute pe parcursul analizei sunt plauz-
ibile. Daca se dovedeste ca presupunerile sunt corecte, modelul poate fi
folosit pentru a raspunde ıntrebarilor care au dus la realizarea lui. Daca pe
parcursul validarii modelului sunt descoperite probleme, se repeta etapele
parcurse folosind informatiile deja obtinute pentru a selecta si/sau adapta
un model ımbunatatit.
8. Interpretarea rezultatelor: In aceasta ultima etapa se coreleaza efectele
factorilor de intrarea considerati cu analiza variabilelor raspuns ale aplicatiei
paralele pentru a valida sau invalida modelul aplicatiei rezultat din analiza
statistica ın functie de restrictiile impuse asupra parametrilor de performanta.
Dupa analiza statistica asupra factorilor ce influenteaza variabilele raspuns se
construieste un model empiric pe baza datelor colectate utilizand diverse modele
de tip regresie descrise pe larg ın [NIST/SEMATECH 06]. Acest model defineste
relatia functionala ıntre factorii de intrare si metricile de performanta urmarite.
Pe baza acestui model se pot face optimizari asupra modelului, se pot calcula si
estima performantele aplicatiei.
3.3 Analiza cu DOE a unei aplicatii paralele ce utilizeaza
metoda descompunerii domeniului de date: sort last
parallel rendering
Pentru a demonstra utilitatea modelului propus vom analiza o aplicatie de ran-
dare paralela. Operasiunea de realizarea unei imagini 3D se doua etape: proce-
sarea geometriei (transformari, decupari, iluminare etc.) si rasterizarea (transfor-
marea de rastru - umbrire, determinarea vizibilitatii). Paralelizarea geometriei
este de obicei realizata prin atribuirea unei submultimi din primitivele grafice
din scena la fiecare procesor. Paralelizarea operatiei de rasterizare se face prin
78

3.3. Analiza cu DOE a unei aplicatii paralele ce utilizeaza metodadescompunerii domeniului de date: sort last parallel rendering
distribuirea unei portiuni din calculele pixelilor la procesoarele din sistemul de
calcul paralel.
Operatia de randare are ca punct central calcularea efectului fiecarei primitive
asupra fiecarui pixel. Deoarece o primitiva se poate afla oriunde ın spatiul ecran
sau ın afara lui, randarea poate fi privita ca o problema de sortare. Pentru
sisteme complet paralele, operatia de sortare implica redistribuirea datelor ıntre
procesoare. Responsabilitatea pentru fiecare primitiva grafica si pentru fiecare
pixel este distribuita la procesoarele sistemului paralel [Molnar 08].
Proces masterDistribuţie task-uri (NP/n)
Date de intrare (NP)
IM2 IM3 IMnIM1
WP1 WP2 WP3 WPn
Procesare
date
Procesare
date
Procesare
date
Procesare
date
Proces masterAdună rezultatele şi
compune imaginea finală Imaginea finală
Legendă:
WPi – procese worker
NP – dimesciunea datelor de intrare
IMi – imaginea procesată de workerul i
Figura 3.5: Aplicatia paralela de randare a unei imagini [Amarandei 11]
Structura sistemului de randare paralela este data de locul unde are loc
operatia de sortare. Din acest motiv, principala provocare ın proiectarea unui
sistem de randare paralela o reprezinta varietatea de structuri posibile ce se pot
realiza cu resursele de calcul. Sortarea poate avea loc oriunde ın procesul de
randare: ın timpul procesarii geometriei (sortare-ınainte sau ”sort-first” - sunt
distribuite primitivele neprelucrate ınainte de li se cunoaste coordonatele ecran),
ıntre procesarea geometriei si rasterizare (sortare-ıntre sau ”sort-middle” - se re-
alizeaza redistribuirea primitivelor din spatiul ecran) sau ın timpul rasterizarii
(sortare-dupa sau ”sort-last” - sunt redistribuiti pixelii).
In randarea paralela de tip sortare-dupa, cunoscuta si sub numele de randare
paralela ın spatiul obiect, fiecare nod de procesare este responsabil cu randarea
unui bloc de date, indiferent daca acestea sunt sau nu vizibile la momentul re-
79

3. Model de proiectare a aplicatiilor paralele folosindproiectarea statistica a experimentelor
spectiv (Figura 3.5).
Aplicatia paralela analizata implementeaza modelul de randare paralela sortare-
dupa utilizand modelul de programare message passing. Implementarea aplicatiei
paralele urmareste modelul descris ın Figura 2.2. De aici, utilitatea modelului
propus ın subcapitolul anterior este imediata. Aplicatia poate suferi dezechilibre
ale sarcinilor de randare, si din acest motiv se preteaza analizei utilizand modelul
propus. Scopul acestei analize este extragerea de informatii despre performantele
aplicatiei si identificarea eventualelor erori de proiectare si/sau de implementare.
3.3.1 Planul experimental
Deoarece obiectivul nostru este ilustrarea eficientei metodei de analiza statistica
bazata pe DOE, sunt selectati doar trei factori: dimensiunea datelor de intrare
(X1), dimensiunea imaginii finale (X2) si numarul de procesoare (X3). Valorile
pe care le pot lua acesti factori sunt date ın tabelul 3.3 [Amarandei 11]:
Denumire Codificare Valoare minima Valoare maxima
Nr. puncte X1 100000 4000000
Rezolutia imaginii X2 480000 50000000
Nr. procesoare X3 6 8
Tabelul 3.3: Factorii de intrare [Amarandei 11]
Consideram urmatoarele variabile raspuns pentru aplicatie: dimensiunea da-
telor schimbate ıntre procese (Y1), timpul de procesare (Y2) si timpul de comu-
nicatii (Y3).
Pentru analiza vom utiliza un plan multifactorial (full factorial) pe doua
niveluri. Pentru simplitatea calculelor, este utilizata o codare a factorilor folosind
valori de 0 si 1.
rulare X1 X2 X3
1 0 0 0
2 1 0 0
3 0 1 0
4 1 1 0
5 0 0 1
6 1 0 1
7 0 1 1
8 1 1 1
Tabelul 3.4: Planul experimental codificat [Amarandei 11]
Mediul de testare a aplicatiei consta ıntr-un cluster al gridului GRAI ( des-
cris ın capitolul 4.3) avand urmatoarea configuratie: front-end cu procesoare 4
80

3.3. Analiza cu DOE a unei aplicatii paralele ce utilizeaza metodadescompunerii domeniului de date: sort last parallel rendering
Y1 Y2 Y37500 2.40813 0.661006
7500 20.8237 2.288
781250 177.86 65.7456
781250 199.783 66.1748
7500 3.02641 0.880815
7500 21.7683 2.55107
781250 243.713 89.9857
781250 264.943 90.3144
Tabelul 3.5: Valorile furnizate de aplicatie pentru variabilele raspuns urmariteconform planului experimental [Amarandei 11]
x 3.66 GHz Intel Xeon, 4 x 146 GB discuri si 8GB RAM ; 12 computing nodes
cu 1 x 2.33GHz Intel Core2 Duo CPU, 1 x 160GB disk, 2GB RAM interconec-
tate folosind placi de retea Gigabit Ethernet si cabluri CAT6 prin intermediului
unui switch Gigabit. Aplicatia este scrisa in C++ iar paralelismul (vezi Figura
3.5 si [Molnar 08]) este obtinut prin utilizarea implementarii LAM 7.1.2/7.1.4 a
standardului MPI-2. Chiar daca randarea este un proces de apel invers, ın cazul
nostru este urmarita posibilitatea de a analiza comportamentul aplicatiei la pro-
ducerea unor imagini foarte mari utilizand dimensiuni foarte mari ale setului de
date.
Dupa rularea aplicatiei, pentru setul de date de intrare ales, se analizeaza
influenta acestora asupra raspunsului urmarit, ın cazul de fata timpul de comu-
nicatii, timpul de procesare si dimensiunea datelor interschimbate, asa cum se va
prezenta ın continuare.
3.3.2 Analiza statistica a modelului
Pentru analiza statistica a modelului au fost realizate Tabelele ANOVA pentru
cazul cu planul multifactorial pe doua niveluri descris anterior. Pentru acest plan
tabelele ANOVA sunt o extensie naturala a Tabelului 3.2 si au fost calculate
utillizand instrumentele statistice puse la dispozitie de mediul Matlab.
In urma rularii aplicatiei paralele pe un numar variabil de procesoare (6 si 8
ın cazul de fata), s-a constatat ca raspunsul Y1 (volumul de date transferat de
aplicatie) depinde doar de factorul X2 (rezolutia imaginii finale) iar factorul X1
nu are nici o influenta (Tabloul ANOVA din Tabelul 3.6 - confirma observatia).
Este important de remarcat faptul ca acest comportament este consistent cu
analiza metodei de randare paralela din [Molnar 08].
Metoda analizei variantei (ANOVA) este utilizata pentru a testa ipotezele cu
privire la influenta factorilor considerati X1, X2, X3 si a interactiunii lor ( X1X2,
X1X3 si X2X3) asupra raspunsului. In exemplul considerat, sunt sase ipoteze ce
81
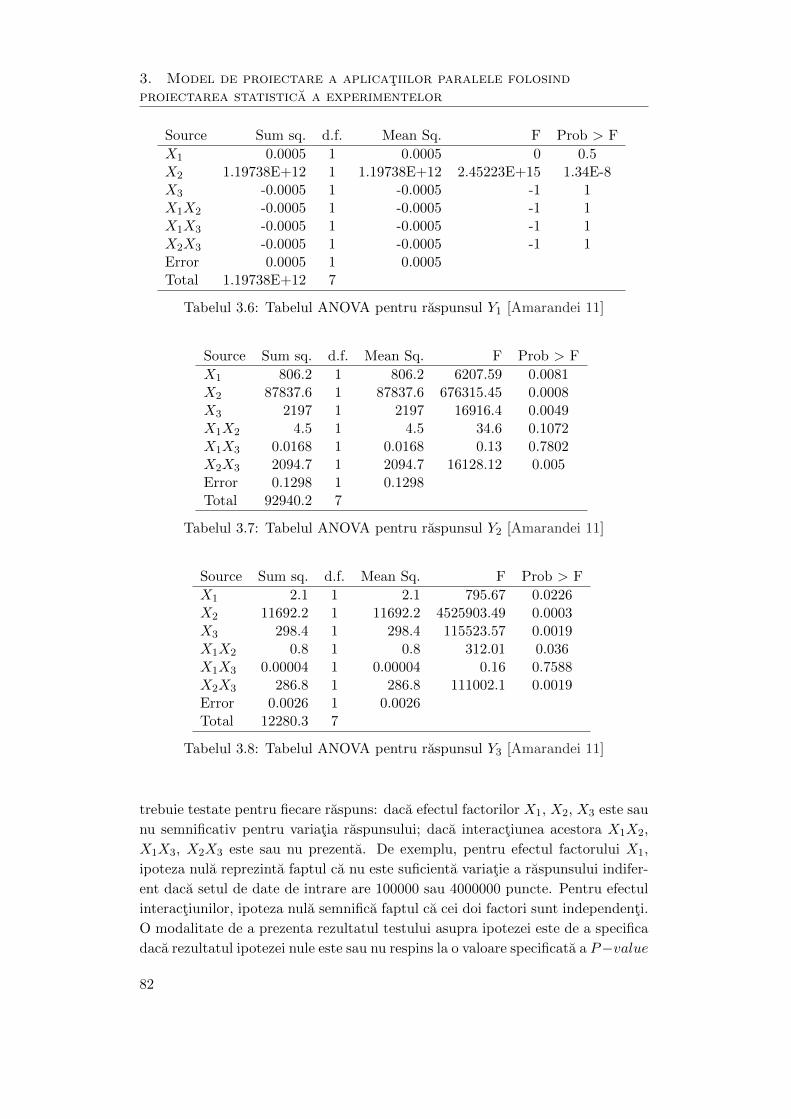
3. Model de proiectare a aplicatiilor paralele folosindproiectarea statistica a experimentelor
Source Sum sq. d.f. Mean Sq. F Prob > F
X1 0.0005 1 0.0005 0 0.5X2 1.19738E+12 1 1.19738E+12 2.45223E+15 1.34E-8X3 -0.0005 1 -0.0005 -1 1X1X2 -0.0005 1 -0.0005 -1 1X1X3 -0.0005 1 -0.0005 -1 1X2X3 -0.0005 1 -0.0005 -1 1Error 0.0005 1 0.0005Total 1.19738E+12 7
Tabelul 3.6: Tabelul ANOVA pentru raspunsul Y1 [Amarandei 11]
Source Sum sq. d.f. Mean Sq. F Prob > F
X1 806.2 1 806.2 6207.59 0.0081X2 87837.6 1 87837.6 676315.45 0.0008X3 2197 1 2197 16916.4 0.0049X1X2 4.5 1 4.5 34.6 0.1072X1X3 0.0168 1 0.0168 0.13 0.7802X2X3 2094.7 1 2094.7 16128.12 0.005Error 0.1298 1 0.1298Total 92940.2 7
Tabelul 3.7: Tabelul ANOVA pentru raspunsul Y2 [Amarandei 11]
Source Sum sq. d.f. Mean Sq. F Prob > F
X1 2.1 1 2.1 795.67 0.0226X2 11692.2 1 11692.2 4525903.49 0.0003X3 298.4 1 298.4 115523.57 0.0019X1X2 0.8 1 0.8 312.01 0.036X1X3 0.00004 1 0.00004 0.16 0.7588X2X3 286.8 1 286.8 111002.1 0.0019Error 0.0026 1 0.0026Total 12280.3 7
Tabelul 3.8: Tabelul ANOVA pentru raspunsul Y3 [Amarandei 11]
trebuie testate pentru fiecare raspuns: daca efectul factorilor X1, X2, X3 este sau
nu semnificativ pentru variatia raspunsului; daca interactiunea acestora X1X2,
X1X3, X2X3 este sau nu prezenta. De exemplu, pentru efectul factorului X1,
ipoteza nula reprezinta faptul ca nu este suficienta variatie a raspunsului indifer-
ent daca setul de date de intrare are 100000 sau 4000000 puncte. Pentru efectul
interactiunilor, ipoteza nula semnifica faptul ca cei doi factori sunt independenti.
O modalitate de a prezenta rezultatul testului asupra ipotezei este de a specifica
daca rezultatul ipotezei nule este sau nu respins la o valoare specificata a P−value
82

3.3. Analiza cu DOE a unei aplicatii paralele ce utilizeaza metodadescompunerii domeniului de date: sort last parallel rendering
sau la un nivel de importanta. Campul P − value (ultima coloana din Tabelul
3.5) este cel mai mic nivel de semnificatie ce duce la respingerea ipotezei nule.
Daca orice P-value este aproape zero, ridica ındoieli asupra ipotezei nule asoci-
ate, adica, exista influenta din partea acelui factor. Pentru a determina daca un
rezultat este semnificativ din punct de vedere statistic, trebuie alese limite pentru
valoare lui P − value. In mod uzual se considera semnificativ un rezultat daca
P − value este mai mic decat 0.05 sau 0.01 [Montgomery 06].
3.3.2.1 Analiza volumului de date procesat
Rezultatele obtinute la rularea aplicatiei paralele pe 6 si 8 procesoare arata faptul
ca raspunsul Y1 depinde doar de factorul X2 (dimensiunea finala a imaginii),
ın timp ce factorii X1 si X3 nu au influenta asupra acestei variabile raspuns.
Tabelul ANOVA anterior (Tabelul 3.6) confirma aceasta observatie: ipoteza nula
H0 : β2 = 0 este respinsa. Este important de precizat ca acest comportament
este consistent cu analiza metodei de randare furnizata de [Molnar 08]. Urmarind
aceste observatii, plecand de la formula 3.1.4, putem deduce ca Y1 este dependent
liniar de factorul X2, si poate fi definit astfel:
Y1 = β0 + β2x2 + ε , (3.3.1)
unde ε este eroarea experimentala, iar β0 si β2 pot fi determinate folosind valorile
din Tabelul 3.3, 3.4 si 3.5 ca intrari pentru factorul X2 si valorile corespunzatoare
pentru raspunsul Y1. Se obtin urmatoarele valori pentru coeficientii ecuatiei 3.3.1:{β0 = 0
β2 = 0.15625 ,(3.3.2)
ceea ce duce la urmatoarea forma a ecuatiei pentru descrierea comportamentului
raspunsului Y1:
Y1 = 0.15625 x2 , (3.3.3)
unde x2 reprezinta numarul de puncte din imaginea finala.
Astfel, asa cum era de asteptat, volumul de date tansferat este o functie
liniara de numarul de pixeli (rezolutia pe axele x si y) din imagine indiferent de
numarul de procesoare si dimensiunea datelor de intrare. In tabelul urmator este
prezentata evolutia raspunsului Y1 conform ecuatiei 3.3.3. Factorul X1 (numarul
de puncte) nu influenteaza volumul de date transferat, ci doar timpul de calcul.
83
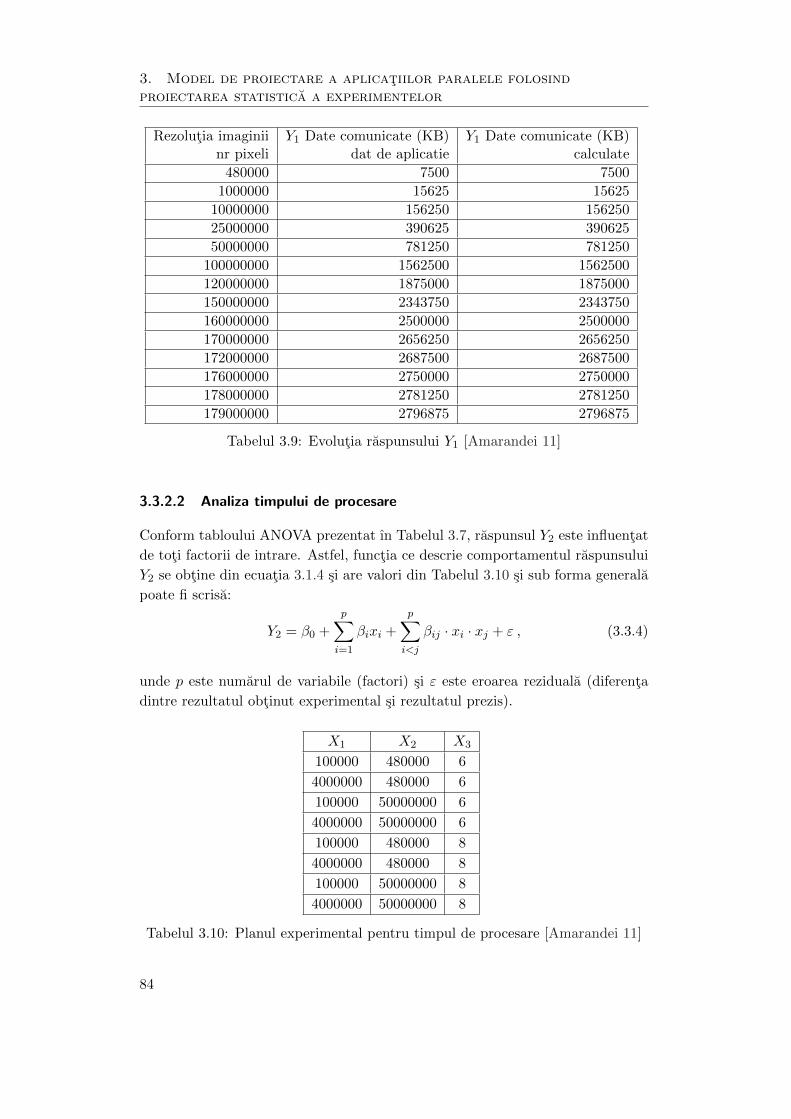
3. Model de proiectare a aplicatiilor paralele folosindproiectarea statistica a experimentelor
Rezolutia imaginii Y1 Date comunicate (KB) Y1 Date comunicate (KB)nr pixeli dat de aplicatie calculate
480000 7500 7500
1000000 15625 15625
10000000 156250 156250
25000000 390625 390625
50000000 781250 781250
100000000 1562500 1562500
120000000 1875000 1875000
150000000 2343750 2343750
160000000 2500000 2500000
170000000 2656250 2656250
172000000 2687500 2687500
176000000 2750000 2750000
178000000 2781250 2781250
179000000 2796875 2796875
Tabelul 3.9: Evolutia raspunsului Y1 [Amarandei 11]
3.3.2.2 Analiza timpului de procesare
Conform tabloului ANOVA prezentat ın Tabelul 3.7, raspunsul Y2 este influentat
de toti factorii de intrare. Astfel, functia ce descrie comportamentul raspunsului
Y2 se obtine din ecuatia 3.1.4 si are valori din Tabelul 3.10 si sub forma generala
poate fi scrisa:
Y2 = β0 +
p∑i=1
βixi +
p∑i<j
βij · xi · xj + ε , (3.3.4)
unde p este numarul de variabile (factori) si ε este eroarea reziduala (diferenta
dintre rezultatul obtinut experimental si rezultatul prezis).
X1 X2 X3
100000 480000 6
4000000 480000 6
100000 50000000 6
4000000 50000000 6
100000 480000 8
4000000 480000 8
100000 50000000 8
4000000 50000000 8
Tabelul 3.10: Planul experimental pentru timpul de procesare [Amarandei 11]
84

3.3. Analiza cu DOE a unei aplicatii paralele ce utilizeaza metodadescompunerii domeniului de date: sort last parallel rendering
Asa cum se observa din Tabelul 3.7 cel mai important efect asupra raspunsului
Y2 ıl au factorii X1, X2, X3 si interactiunea X2X3. Alegerea valorii de 0.01 pentru
cea mai mic nivel de semnificatie ce duce la respingerea ipotezei nule pentru datele
existente, modelul de regresie utilizat pentru obtinerea valorilor prezise este:
Y2 = β0 + β1x1 + β2x2 + β3x3 + β23x2x3 + ε . (3.3.5)
Utilizand valorile din Tabelele 3.3, 3.4 si 3.5, se calculeaza coeficientii de regresie
β pentru ecuatia 3.1.4, unde consideram variabila raspuns ca fiind Y2. Acesti
coeficienti pot fi calculati prin minimizarea erorii reziduale utilizand metoda re-
gresiei liniare [Barnes 08]. Valorile obtinute pentru coeficientii de regresie sunt
prezentati ın Tabelul 3.11, iar valorile masurate si cele calculate pentru raspunsul
Y2 sunt prezentate ın Tabelul 3.12.
β
-6.52E-01
4.92E-06
-3.75E-07
1.25E-01
1.60E-14
-2.35E-08
6.54E-07
Tabelul 3.11: Coeficientii β ai ecuatiei pentru Y2 [Amarandei 11]
Y2 Y2 ε εr(%)
real prezis
2.40813 2.29 0.11 4.57%
20.8237 21.49 -0.66 -3.17%
177.86 177.92 -0.06 -0.03%
199.783 197.12 2.67 1.34%
3.02641 3.17 -0.15 -4.96%
21.7683 22.36 -0.59 -2.71%
243.713 243.53 0.19 0.08%
264.943 262.72 2.22 0.84%
Tabelul 3.12: Timpii de calcul masurati si calculati cu ajutorul ecuatiei pentru
Y2 (6-8 procesoare) [Amarandei 11]
Ecuatia 3.3.5, pe baza tabelului 3.7 si utilizand coeficientii β obtinuti, devine
[Amarandei 11]:
85

3. Model de proiectare a aplicatiilor paralele folosindproiectarea statistica a experimentelor
Y2 = −6.52 · 10−1 + 4.92 · 10−6x1 − 3.75 · 10−7x2 + (3.3.6)
+1.25 · 10−1x3 + 6.54 · 10−7x2x3 + ε .
Utilizand functia ce descrie raspunsul Y2, determinam comportamentul sis-
temului (Tabelul 3.14) pentru cazul ın care numarul de procesoare se modifica
(Tabelul 3.13). Cu valorile coeficientilor β determinati folosind ecuatia 3.3.4
pentru rularea pe 6 si 8 procesoare se ıncearca calcularea timpului de procesare
pentru cazul ın care se ruleaza aplicatia paralela pe 10 si 12 procesoare folosind
datele din Tabelul 3.13. Timpii de procesare calculati pentru raspunsul Y2 si
eroarea reziduala se pot observa ın Tabelul 3.14. Validarea modelului de re-
gresie din ecuatia 3.3.5 utilizata pentru raspunsul Y2 utilizand metode standard
pentru analiza reziduurilor (Distributia de probabilitate normala sau distributia
normala) deoarece nu se observa nici o anomalie ın modelul obtinut (Figura 3.6a).
X1 X2 X3
100000 480000 10
4000000 480000 10
100000 1.79E+08 10
4000000 1.79E+08 10
100000 480000 12
4000000 480000 12
100000 1.79E+08 12
4000000 1.79E+08 12
Tabelul 3.13: Valorile factorilor de intrare pentru predictia raspunsului Y2[Amarandei 11]
Y2 Y2 ε εr(%)
real prezis
3.62407 4.05 -0.43 -11.87%
22.1726 23.24 -1.07 -4.83%
1111.68 1103.87 7.81 0.70%
1131.72 1123.06 8.66 0.77%
4.27239 4.93 -0.66 -15.45%
23.2734 24.12 -0.85 -3.65%
1359.53 1338.08 21.45 1.58%
1374.250 1357.27 16.98 1.24%
Tabelul 3.14: Timpii de calcul masurati si prezisi cu ajutorul functiei ce descrie
Y2 (cazul 10-12 procesoare)[Amarandei 11]
86
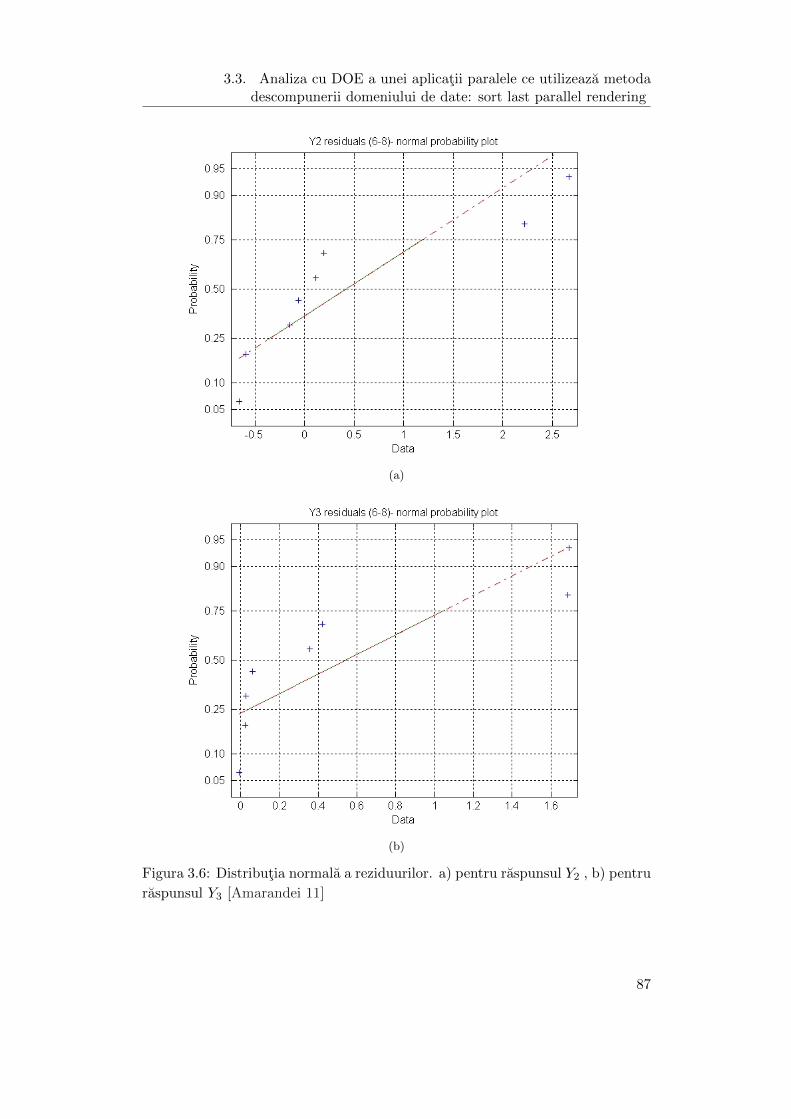
3.3. Analiza cu DOE a unei aplicatii paralele ce utilizeaza metodadescompunerii domeniului de date: sort last parallel rendering
(a)
(b)
Figura 3.6: Distributia normala a reziduurilor. a) pentru raspunsul Y2 , b) pentru
raspunsul Y3 [Amarandei 11]
87

3. Model de proiectare a aplicatiilor paralele folosindproiectarea statistica a experimentelor
3.3.2.3 Analiza timpilor de comunicatie
Pentru analiza timpului de comunicatie (raspunsul Y3), se foloseste acelasi rationa-
ment ca pentru raspunsul Y2. Din tablelul Anova (Tabelul 3.8) se poate observa
ca raspunsul Y3 depinde de factorii X2, X3 si de interactiunea X2X3. In acest
caz, urmatoarea ecuatie poate fi utilizata pentru modelarea raspunsului Y3:
Y3 = β0 + β2x2 + β3x3 + β23x2x3 + ε . (3.3.7)
Coeficientii de regresie β determinati pentru raspunsul Y3 sunt prezentati ın
Tabelul 3.15. Utilizand ecuatia 3.3.7 si coeficientii β determinati se realizeaza
predictia asupra timpului de comunicatie ın cazul rularii pe 10-12 procesoare.
Tabelul 3.16 si, respectiv Tabelul 3.17, prezinta valorile masurate si prezise pen-
tru raspunsul Y3 ın cazul rularii pe 6-8 si, respectiv, 10-12 procesoare.
β
-1.04E-01
4.52E-07
-1.35E-07
1.22E-02
-7.00E-15
-3.67E-09
2.42E-07
Tabelul 3.15: Coeficientii β ai ecuatiei pentru Y3 [Amarandei 11]
Ecuatia 3.3.7, pe baza tabelului 3.8 si utilizand coeficientii β obtinuti, devine
[Amarandei 11]:
Y3 = −1.04 · 10−1 + 1.35 · 10−7x2 − 1.22 · 10−2x3 + 2.42 · 10−7x2x3 + ε . (3.3.8)
Y3 Y3 ε εr(%)
real prezis
0.661006 0.6004 0.0606 9.17%
2.288 0.6004 1.6876 73.76%
65.7456 65.7535 -0.0079 -0.01%
66.1748 65.7535 0.4213 0.64%
0.880815 0.8569 0.0239 2.71%
2.55107 0.8569 1.6942 66.41%
89.9857 89.9584 0.0273 0.03%
90.3144 89.9584 0.3560 0.39%
Tabelul 3.16: Timpii de comunicatie masurati si prezisi cu ajutorul functiei ce
descrie Y3 - cazul 6-8 procesoare [Amarandei 11]
88

3.3. Analiza cu DOE a unei aplicatii paralele ce utilizeaza metodadescompunerii domeniului de date: sort last parallel rendering
Y3 Y3 ε εr(%)
real prezis
1.11392 1.1134 0.0006 0.05%
2.79507 1.1134 1.6817 60.17%
407.274 408.6592 -1.3852 -0.34%
408.065 408.6592 -0.5942 -0.15%
1.34075 1.3698 -0.0291 -2.17%
3.03985 1.3698 1.6700 54.94%
493.946 495.2499 -1.3039 -0.26%
494.171 495.2499 -1.0789 -0.22%
Tabelul 3.17: Timpii de comunicatie masurati si prezisi cu ajutorul functiei ce
descrie Y3 - cazul 10-12 procesoare [Amarandei 11]
3.3.3 Interpretarea rezultatelor
Pentru aplicatia de randare considerata, am urmarit realizarea unui model care
sa o descrie si cu ajutorul caruia sa verificam performantele prototipului utilizand
tehnicile DoE. Mai mult, modelul matematic obtinut ın ecuatiile 3.3.3 si 3.3.4),
permite studierea rezultatelor ın cazul rularii pe un numar variabil de procesoare
sau pe alte dimensiuni ale problemei. Astfel, predictia realizata asupra compor-
tamentului aplicatiei asa cum se poate observa din Tabelele 3.9, 3.12 si 3.14, a
fost realizata cu o eroare acceptabila.
Scopul urmarit ın analiza prezentata ın sectiunea anterioara este gasirea
combinatiei de valori ale factorilor de intrare pentru care erorarea de predictie
este mare. Astfel modelul de analiza propus permite identificarea cazurilor ın
care modelul empiric al aplicatiei nu descrie corect un anumit raspuns. Daca,
folosind planul experimental, se obtin erori mari numai pe o anumita combinatie
de valori de intrare (cazul expus ın Tabelele 3.16 si 3.17), se evidentiaza com-
parativ erorile modelului ın raport cu unul dintre parametri sau erorile la nivel
de aplicatie ın raport cu acelasi parametru. In functie de scopul analizei, trebuie
luate decizii legate de modalitatea de implementare a aplicatiei. In Tabelele 3.16
3.17 se pot observa erori foarte mari pentru o combinatie a factorilor de intrare
din planul experimental din Tabelul 3.13. Acest lucru inseamna ca, fie modelul
nu descrie corect aplicatia, fie exista probleme ın implementarea aplicatiei.
In urma analizei statistice folosind DoE, se constata ca timpul de comunicatii
si timpul de calcul se modifica odata cu cresterea dimensiunii problemei ( numarul
de puncte pentru care se face randarea) iar volumul de date transferat de aplicatie
creste liniar odata cu rezolutia imaginii de iesire conform ecuatiei 3.3.3. De
asemenea, s-a realizat si o predictie a evolutiei acestora pentru diverse conditii
de rulare. Faptul ca timpul de calcul cat si cel de comunicatii creste odata cu
89

3. Model de proiectare a aplicatiilor paralele folosindproiectarea statistica a experimentelor
dimensiunea problemei este acceptabil si era previzibil.
Relatia dintre numarul de puncte, dimensiunea imaginii si timpul de comuni-
catii este descrisa de ecuatia 3.3.3. Astfel, indiferent de numarul de puncte folosite
la randarea imaginii ( ıntre 100000 si 4 mil. puncte) dimensiunea imaginii nu se
modifica, ajungand la ordinul 2,5GB pentru o rezolutie maxima a imaginii de 17
mil. puncte. Acest maxim pentru care au fost realizate testele experimentale se
datoreaza memoriei disponibile.
Proiectarea unei aplicatii paralele nu este o sarcina usoara. In unele cazuri,
algoritmii secventiali existenti pot fi transformati ın algoritmi paraleli, ın timp ce
ın altele trebuie dezvoltati algoritmi noi. Indiferent de originea lor, majoritatea
algoritmilor paraleli introduc ıncarcari suplimentare ce nu se regasesc ın core-
spondentul lor secvential. Aceste supraıncarcari apar datorita: comunicatiilor
inter-procesor, dezechilibrelor din ıncarcarea procesoarelor, calcule suplimentare
sau redundante, cresterea cererilor legate de stocarea structurilor de date se-
cundare sau a duplicatelor. O parte din aceste concepte sunt specifice algorit-
milor paraleli ın timp ce altele (coerenta datelor, maparea din spatiul imaginii
ın spatiul obiectelor) sunt specifice problemei de randare considerate. Pentru
aplicatia de randare paralela am urmarit descrierea comportamentului aplicatiei
cu ajutorul ecuatiilor si sa utilizam aceste ecuatii pentru studierea (si prezicerea)
performantelor aplicaiei paralele atunci cand variaza numarul unitatilor de proce-
sare [Amarandei 11].
Utilizand modele empirice construite pentru cele trei raspunsuri urmarite,
observam ca timpii de procesare si de comunicatii depind de rezolutia imaginii
finale si de numarul de procesoare. Acest lucru se datoreaza faptului ca ultima
etapa a aplicatiei implica comunicarea rezultatelor locale de pe fiecare procesor
pe care s-a realizat randarea catre nodul ce compune imaginea finala. Cu cat este
mai mare rezolutia imaginii finale cu atat mai mult timp dureaza sa fie trans-
mise. Mai mult, acest lucru reprezinta o sursa de ıntarzieri (bottleneck) pentru
aplicatia paralela. O alta concluzie importanta priveste numarul de procesoare
utilizate pentru distribuirea taskurilor de randare. Utilizarea unui numar larg
de procesoare de randare nu furnizeaza neaparat un timp de procesare total mai
bun. Aceasta problema de scalabilitate poate fi ımbunatatita prin ınlocuirea
etapei de compunere finala a imaginii cu un mecanism mai eficient, de exem-
plu rutarea mesajelor ın retea utilizand topologii de tip plasa sau arbore binar,
sau o compunere planificata a imaginii. Considerand observatiile anterioare, ın
eventualitatea executarii simultane a aplicatiei de catre mai multi utilizatori sau
daca este impusa un maxim de alocare a memoriei, aplicatia devine rapid extrem
de limitata si se pot observa rezultate slabe ale acesteia daca o parte nu este
reproiectata.
90

3.4. Concluzii
3.4 Concluzii
In acest capitol a fost propus un model de testare a unei aplicatii paralele prin
definirea unui set eficent de teste. Un plus al acestui model este posibilitatea
estimarii performantelor aplicatiei la rularea ın alte conditii si cu alti parametri
fata de conditiile ın care au fost realizate testele initiale. Aceste obiective pot fi
atinse utilizand metode de analiza statistica ce permit o identificare mai usoara
a erorilor ce apar ın fiecare etapa de proiectare. Metoda propusa faciliteaza
eliminarea factorilor care nu au influenta asupra raspunsului analizat al aplicatiei,
oferind ın acelasi timp o mai buna perspectiva asupra factorilor care au cel mai
mare impact asupra performantelor aplicatiei paralele.
Tehnica planului experimental permite proiectantului unei aplicatii paralele
ce utilizeaza descompunerea domeniului de date sa testeze performantele cu
parametri de intrare reali fara a rula efectiv aplicatia. Estimarile obtinute prin
analiza statistica pot fi apoi utilizate pentru optimizarea resurselor necesare
aplicatiei ın sensul adaptarii dinamice, ın timpul executei, la dimensiunea datelor
de intrare sau de iesire. Daca mediul de programare permite, ar fi utila mod-
ificarea dinamica a numarului de procese sau procesoare utilizate de aplicatia
paralela. Utilizarea metodei propuse poate aduce o noua perspectiva asupra an-
umitor conditii de rulare ce poate fi obtinuta pe baza parametrilor considerati.
Acest lucru este util ın special pentru estimarea resurselor necesare unei aplicatii
paralele. Un considerent important, rareori luat ın considerare, este faptul ca
aplicatia nu este singura ce ruleaza pe un cluster. Astfel, ıncarcarea retelei in-
terne a clusterului variaza datorita datelor transferate de toate aplicatiile. Mai
mult, resursele unui cluster pot fi rezervate ın diverse scopuri (de exemplu: aca-
demice, de cercetare sau comerciale). Este util ın astfel de situatii ca cererile
de resurse realizate de catre aplicatii sa fie formulate considerand acest aspect
dinamic. In caz contrar, performantele aplicatiilor pot varia ıntr-o maniera com-
plet necontrolata si nu se pot obtine rezultate satisfacatoare. Modelul propus ın
cadrul acestui capitol ajuta la detectia si eliminarea acestor neajunsuri.
91


Partea a II-a: SOLUTII DE
IMPLEMENTARE A
INFRASTRUCTURII PENTRU
SISTEMELE GRID SI A
CLUSTERELOR COMPONENTE
93


Capitolul 4
Clustere si sisteme grid
Rezumat
Cunoasterea arhitecturii sistemelor de calcul de mare performanta este
un punct esential ın implementarea clusterelor si interconectarea acestora
ın cadrul sistemelor Grid. In acest context, ın cadrul capitolului curent
este prezentat un studiu al arhitecturilor de tip cluster si respectiv al celor
de tip Grid. Capitolul se ıncheie cu prezentarea unui studiu practic de caz:
proiectarea arhitecturii gridului GRAI si a clusterelor componente. Se pune,
de asemenea, accent pe justificarea tehnologiilor utilizate.
Tehnologiile Grid au potentialul de a schimba modul de utilizare a calcula-
toarelor pentru rezolvarea problemelor. Unii autori considera ca influenta aces-
tor tip de sisteme de calcul distribuit poate fi comparata cu impactul produs de
tehnologiile web asupra mecanismelor de comunicare a informatiilor. Acest tip de
sisteme de calcul distribuit au la baza cercetarile realizate ın domeniile calculului
de mare performanta, a clusterelor de calculatoare si al retelelor peer-to-peer.
Prima definitie a acestei infrastructuri apartine lui Ian Foster: ”un Grid com-
putational reprezinta o infrastructura hardware si software care furnizeaza un
mod de acces sigur, consecvent, universal si ieftin la resurse de calcul de ınalta
performanta” [Foster 98]. Ulterior, aceeasi autori, ın [Foster 01] redefinesc Grid-
ul considerand si problemele legate de institutiile care partajeaza resurse dis-
tribuite geografic. In diverse activitati si domenii din stiinta, inginerie si afaceri,
angajamentul ın procese colaborative se impune ca o necesitate. Un astfel de grup
de persoane/institutii care definesc regulile de partajare a resurselor formeaza o
organizatie virtuala (Virtual Organization – VO). Astfel Grid-ul reprezinta in-
frastructura care integreaza resurse distribuite geografic (putere de calcul, retele
de comunicatie, capacitate de stocare a datelor, informatie, etc.) cu scopul de a
furniza o platforma virtuala de colaborare, utilizata atat pentru calcule complexe
95

4. Clustere si sisteme grid
ce trebuie realizate asupra unui volum din ce ın ce mai mare de date cat si pentru
gestiunea eficientaa acestui volum de date.
Calculul pe Grid (Grid computing) implica utilizarea de programe organizate
pe componente care ruleaza pe un numar foarte mare de calculatoare. Astfel
calculul pe Grid poate fi gandit ca o forma de calcul paralel pe un cluster de
dimensiuni foarte mari conectate pe principiul rolurilor egale. Ian Foster si co-
laboratorii propun ın [Foster 02] trei criterii pentru caracterizarea sistemelor Grid
[Aflori si Amarandei 05]:
• Coordonarea resurselor : Resursele sunt coordonate, dar nu sunt controlate
ıntr-o maniera centralizata – un sistem Grid integreaza resurse si utilizatori
care apartin de domenii diferite, resurse si utilizatori ce sunt administrate
local.
• Utilizarea standardelor, a protocoalelor si a interfetelor deschise, general
valabile: Intr-un sistem Grid trebuie sa existe protocoale si interfete pen-
tru autentificare, autorizare, descoperirea si accesul la resurse. Este foarte
important ca aceste protocoale sa fie standardizate si deschise.
• Furnizarea de servicii netriviale: Conceptul de Grid presupune avantajele
resurselor de grup, dar si participare activa la dezvoltarea acestor resurse.
Din acest motiv, ıntr-un sistem Grid exista doua categorii de participanti:
consumatorii si furnizorii de servicii. Pentru ca sistemul sa functioneze,
serviciile trebuie sa fie de calitate, altfel consumatorii se orienteaza spre
alte sisteme.
4.1 Arhitecturi de tip Grid
Conform [Foster 01] ın definirea unei arhitecturi Grid se pleaca de la principiul ca
o organizatie virtuala eficienta trebuie sa poata integra noi membri, care sa puna
la dispozitie resursele proprii si sa acceseze resursele partajate. Astfel, arhitectura
Grid este o arhitectura de protocoale care definesc mecanismele prin care utiliza-
torii organizatiilor virtuale negociaza, implementeaza, administreaza si utilizeaza
resursele partajate [Aflori si Amarandei 05]. Arhitectura protocoalelor Grid este
organizata pe 5 niveluri ( vezi Figura 4.1).
Stratul de baza furnizeaza operatiile locale necesare utilizarii resurselor ın
regim partajat si include: retele de interconectare, PC-uri cu diverse sisteme de
operare, clustere de calculatoare, sisteme de management a resurselor, senzori,
sisteme de stocare si baze de date. Stratul conexiunilor contine protocoalele de
comunicare si autentificare necesare pentru tranzactiile specifice Gridului. Stratul
de resurse contine protocoalele, interfetele (API) si platformele (SDK) pentru ne-
gocierea, initierea, monitorizarea, controlul, contabilizarea si plata operatiunilor
realizate asupra resursele partajate. Stratul colectivitatilor contine protocoale,
servicii, interfete si platforme care nu sunt asociate cu nici o resursa specifica,
96

4.1. Arhitecturi de tip Grid
Stratul Aplicaţiilor
Stratul Colectivităţilor
Stratul Resurselor
Stratul Conexiunilor
Stratul de bază (Fabric)
Figura 4.1: Arhitectura Grid stratificata [Aflori si Amarandei 05]
ci vizeaza obtinerea de informatii despre colectiile de resurse. Ultimul strat ın
arhitectura Grid cuprinde aplicatiile utilizatorilor care opereaza ın cadrul unei
comunitati Grid [Aflori si Amarandei 05].
Sistemele Grid pot fi clasificate ın 3 categorii (vezi Figura 4.2): departa-
mentale (sau Cluster Grid), de ”ıntreprindere” (Campus Grid) si globale (Global
Grid). Aceste categorii ar corespunde unei firme care, initial, ısi foloseste resursele
ın cadrul unui singur grup, de exemplu departamentul de ingineri. Se extinde
apoi la resursele de calcul ale personalului ne-tehnic (pentru utilizarea puterii de
calcul nefolosite si a capacitatii de stocare), ca ın final sa se ajunga la un Grid
gobal (ceea ce implica resursele distribuite geografic ale firmei) care sa poata fi
folosit ıntr-un mod comercial sau colaborativ.
Principala resursa a unui Grid computational o reprezinta puterea de calcul
materializata prin clusterele de calculatoare. Notiunile de Cluster computing si
Grid Computing sunt notiuni complementare; sistemele Grid expun sub forma
de resurse partajate si clustere de calculatoare. De fapt, pentru un utilizator al
unui sistem Grid folosirea unui cluster de calculatoare este total transparenta,
clusterul fiind vazut ca o resursa de calcul pentru sistemele de management ale
resurselor.
In cele ce urmeaza este prezentata arhitectura clusterelor atat datorita im-
portantei acestora ın cadrul stratului de baza al sistemelor Grid, cat si da-
torita influentei pe care proiectarea acestora o poate avea asupra performantelor
aplicatiilor tinta.
97

4. Clustere si sisteme grid
Cluster Grid Campus Grid Global Grid
Figura 4.2: Grid departamental(Cluster Grid), de ıntreprindere (Campus Grid)si global (Global Grid) [Aflori si Amarandei 05]
4.2 Arhitectura clusterelor
Intr-o definitie simpla, clusterele reprezinta un grup de calculatoare interconectate
ce lucreaza ımpreuna pentru rezolvarea unei probleme. Acestea nu pot fi confun-
date cu modelele din sistemele client-server ın care aplicatiile sunt ımpartite logic
ın unul sau mai multi clienti care cer informatii sau acceseaza servicii furnizate de
unul sau mai multe servere. Ideea principala din spatele functionarii unui cluster
este de a aduna puterea de calcul a sistemelor componente pentru a furniza scala-
bilitate sau pentru a crea sisteme redundante ın scopul oferirii unei disponibilitati
ridicate (high availability). Clusterele reunesc sisteme de calcul pentru a furniza
un mediu de lucru puternic, prin crearea unei imagini unice de sistem cunoscuta
si sub denumirea de Single System Image (SSI).
In general clusterele sunt ımpartite ın doua mari categorii:
• clustere HA (High availability sau Failover Clusters) – construite pentru a
oferi disponibilitate ridicata, echilibrare a ıncarcarii, redundanta pentru un
data center ;
• clustere HPC (High Performance Computing) – construite pentru a ınlocui
supercalculatoarele si a furniza putere mare de calcul, ıncorporand si fa-
cilitati oferite de clusterele HA.
Scopul clusterelor HPC este acela de a oferi suport pentru rularea aplicatiilor
intesiv computationale. O prima abordare ın implementarea unei astfel de solutii
a fost utilizarea calculatoarelor personale, abordare ce are si avantajul unor cos-
turi reduse. Realizarea unui astfel de cluster impune furnizarea unei imagini unice
a sistemului prin mecanisme ce gestiuneaza un numar mare de noduri distincte.
98

4.2. Arhitectura clusterelor
Trebuie, de asemenea, solutionate urmatoarele probleme:
• instalarea si ıntretinerea sistemului de operare si a aplicatiilor pe toate
nodurile;
• managementul nodurilor si gestionarea erorilor hardware si software ce pot
aparea;
• accesul concurent si ın paralel la acelasi sistem de fisiere;
• comunicatiile interproces pentru coordonarea lucrului ın paralel pe nodurile
disponibile.
Anterior avantajele clusterelor sunt evidente. In ciuda acestui fapt, costurile
aferente realizarii si mentinerii ın functiune pot fi ridicate. De exemplu, pentru
a implementa cel mai simplu cluster HA (sistem complet redundant cu rezerve
pasive) se pot atinge costuri duble pentru hardware si software fata de cazul clus-
terelor simple. Pentru cazul clusterelelor HPC, se doreste minimizarea costurilor
legate de hardware si licente software. Scopul unui astfel de cluster este acela
de a oferi unui mediu de calcul cat mai simplu si eficient posibil, pentru a ex-
ploata la maxim resursele computationale ale nodurilor individuale; si a scadea
costurile legate de licentele software. Desi aproape toate nodurile unui cluster
HPC sunt identice din punct de vedere hardware, pot exista diferente – mai multe
functii logice ale unui nod din cluster pot exista pe acelasi nod fizic (Figura 4.3)
[Amarandei 08]:
In cadrul unui cluster HPC, calculele efective sunt realizate pe nodurile de
calcul (compute nodes), iar distributia task -urilor este realizata de un planificator
(SGE, Condor, PBS). Gestiunea ıntregului cluster este realizat prin intermediul
unui nod de management, nod ce ofera servicii de monitorizare individuala a
fiecarei componente a clusterului (Ganglia) si de transmidere de comenzi (C3,
GXP Shell, parallel shell). Un astfel de cluster trebuie sa includa si un nod de
control ce va furniza servicii precum DHCP, DNS, planificare, etc. In cazul ma-
joritatii clusterelor reconfigurarea sau reinstalarea nodurilor de calcul cu o noua
imagine este o actiune frecventa. In consecinta, este absolut necesara integrarea
unui nod de instalare care sa furnizeze imaginile nodurilor. Acesta trebuie sa
ofere mecanisme de instalare rapida a imaginilor de sistem pe nodurile tinta sau
a aplicatiilor necesare. Pentru o mare parte a aplicatiilor care ruleaza ın cluster,
nodurile de calcul au nevoie de acces rapid, stabil si simultan la un sistem de
stocare. Acest lucru poate fi rezolvat ın diverse moduri ın functie de specificul
fiecarei aplicatii: sistem de fisiere distribuit/partajat sau baze de date. In cazul
accesului la un sistem de fisiere se pot folosi dispozitive de stocare performante
atasate direct nodurilor printr-o interfata dedicata, separata complet de cea uti-
lizata pentru comunicatiile dintre noduri. In cazul accesului la baze de date se
poate folosi un cluster independent, capabil sa furnizeze date la o rata de transfer
satisfacatoare (MySQL Cluster, Oracle, etc.). Pentru cresterea performantei se
poate folosi acelasi tip de conectare ca la un sistem de stocare specializat. Un
99

4. Clustere si sisteme grid
Nod de management
Nod de instalare
Nod de stocare
Nod de control
Frontend
DHCP, DNS, Sheduler , etc
Noduri de calcul
Imaginile nodurilor pentru instalare
rapida
Management , power on /off, event handing , etc.
Acces rapid la un sistem de fisiere
User nodeOfera acces utilizatorilor
Cluster
Figura 4.3: Structura logica a unui cluster [Amarandei 08]
astfel de sistem de stocare poate fi de asemenea conectat si prin intermediul unui
nod specializat. Acesta trebuie sa fie capabil sa deserveasca cererile nodurilor de
calcul (un exemplu ın acest sens este MySQL Cluster: exista noduri distincte pen-
tru stocarea datelor si pentru interfatarea cu exteriorul). In mod uzual, nodurile
unui cluster sunt conectate prin intermediul unei retele interne, private, si nu
pot fi accesate direct din exterior. Interfata cu utilizatorii trebuie realizaa prin
intermediul unui nod de tip frontend. Acest nod este special configurat pentru a
furniza utilizatorilor o interfata de acces la resursele de calcul, pentru a rula un
task sau pentru a vizualiza rezultatele produse de un task ce a rulat anterior.
Din punct de vedere al administratorului, pentru o astfel de structura a unui
cluster, sunt rezolvate urmatoarele probleme:
• configurarile de securitate si mijloacele pentru managementul acestora;
• modalitati de a instala/reinstala nodurile prin intermediul unui singur nod
ce furnizeaza imaginile necesare;
• gestiunea aplicatiilor instalate ın cluster.
Structura logica a unui cluster, prezentata ın Figura 4.3, poate fi extinsa la nivelul
sistemelor Grid: noduri de control, de stocare, de management, de instalare si
de interfata cu utilizatorul situate ın locatii distincte ale sistemului Grid. Ast-
100

4.2. Arhitectura clusterelor
fel, de exemplu, pentru realizarea unei infrastructuri Grid folosind middleware-ul
gLite este necesara existenta urmatoarelor componente care vor furniza servici-
ile prezentate ın Figura 4.4: UI (User Interface), CE (Computing Element),
SE (Storage Element), WN (Working Node), WM (Workload Manager), MON
(Monitoring Services), RB (Resource Broker), LB (Logging and Bookkeping) etc.,
servicii ce pot fi instalate atat pe nodurile unui cluster, cat si pe noduri din clus-
tere aflate ın locatii diferite.
Figura 4.4: Arhitectura serviciilor gLite [gLite Documentation 11]
Serviciile furnizate de organizatiile membre ale unui sistem Grid sunt diferite,
dar software-ul care furnizeaza partea de control si management este acelasi ın
toate locatiile sau exista aplicatii specializate care ofera posibilitatea de inter-
conectare.
Gradul de adoptare de utilizator al sistemelor Grid si performanta acestora
sunt direct influentate de disponibilitatea serviciilor furnizate de site-urile mem-
bre. Deoarece clustere HPC trebuie sa includa si facilitatile oferite de clusterele
HA ca cele din figura urmatoare, acestea se extind si influeteaza sistemul Grid
din care fac parte.
Lipsa elementelor HA precum cel din Figura 4.6 din proiectarea unui cluster
poate afecta functionalitatea ıntregului sistem Grid [Amarandei 08]. In general
trebuie adoptate solutii de backup atat pentru componentele unui site Grid cat
si pentru elementele critice ale clusterelor membre.
101
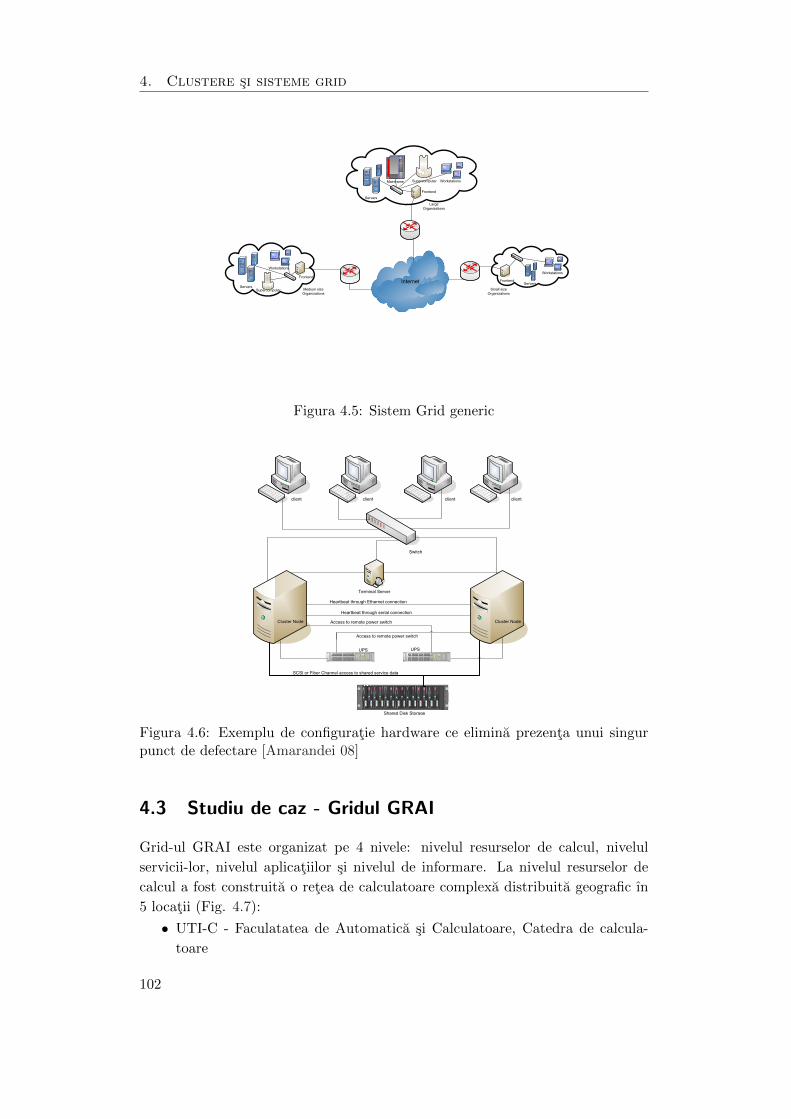
4. Clustere si sisteme grid
Internet
Workstations
Servers
Workstations
Large
Organizations
Medium size
Organizations
Small size
Organizations
Mainframe Supercomputer
Frontend
Servers
Frontend
Supercomputer
Frontend
Workstations
Servers
Figura 4.5: Sistem Grid generic3
00
GB
15k
300
GB
15k
300
GB
15k
300
GB
15k
300
GB
15k
300
GB
15k
300
GB
15k
300
GB
15k
300
GB
15k
300
GB
15k
300
GB
15k
300
GB
15k
300
GB
15k
300
GB
15k
Shared Disk Storage
SCSI or Fiber Channel access to shared service data
Access to remote power switch
Access to remote power switch
Heartbeat through serial connection
Heartbeat through Ethernet connection
Cluster NodeCluster Node
client client client client
Switch
Terminal Server
UPS UPS
Figura 4.6: Exemplu de configuratie hardware ce elimina prezenta unui singurpunct de defectare [Amarandei 08]
4.3 Studiu de caz - Gridul GRAI
Grid-ul GRAI este organizat pe 4 nivele: nivelul resurselor de calcul, nivelul
servicii-lor, nivelul aplicatiilor si nivelul de informare. La nivelul resurselor de
calcul a fost construita o retea de calculatoare complexa distribuita geografic ın
5 locatii (Fig. 4.7):
• UTI-C - Faculatatea de Automatica si Calculatoare, Catedra de calcula-
toare
102

4.3. Studiu de caz - Gridul GRAI
• UTI-E & AR-IIT - Facultatea de Electronica si Telecomunicatii si Institutul
de Informatica Teoretica Iasi,
• UAIC-I - Facultatea de Informatica,
• UMF-B - Facultatea de Bioinginerie si
• USAMV-H - Facultatea de Horticultura.
Nivelul serviciilor contine un set de servicii Grid de baza, suport pentru aplicatii,
ın urmatoarele domenii: Descoperirea de cunostinte ın baze de date, Procesare
de imagini, Platforme multi-agent, Optimizare combinatoriala, Rezolvarea prob-
lemelor de programare bazata pe constrangeri (CSP), Web semnatic, Metode ale
calculului evolutiv, Bioinformatica, E-learning.
Datorita specificului amplasarii acestor noduri, modul de conectare al acestora
s-a realizat pe infrastructura existenta, utilizandu-se retelele de comunicatii ale
Universitatii Tehnice ”Gheorghe Asachi” Iasi, ale Universitatii ”Alexandru Ioan
Cuza” Iasi, ale Universitatii de Stiinte Agronomice si Medicina Veterinara ”Ion
Ionescu de la Brad” Iasi, Universitatii de Medicina si Farmacie ”Gr. T. Popa”
Iasi, precum si reteaua metropolitana academica ieseana. Sistemele frontend
aflate ın dotarea membrilor GRAI sunt ın urmatoarea configuratie:
103
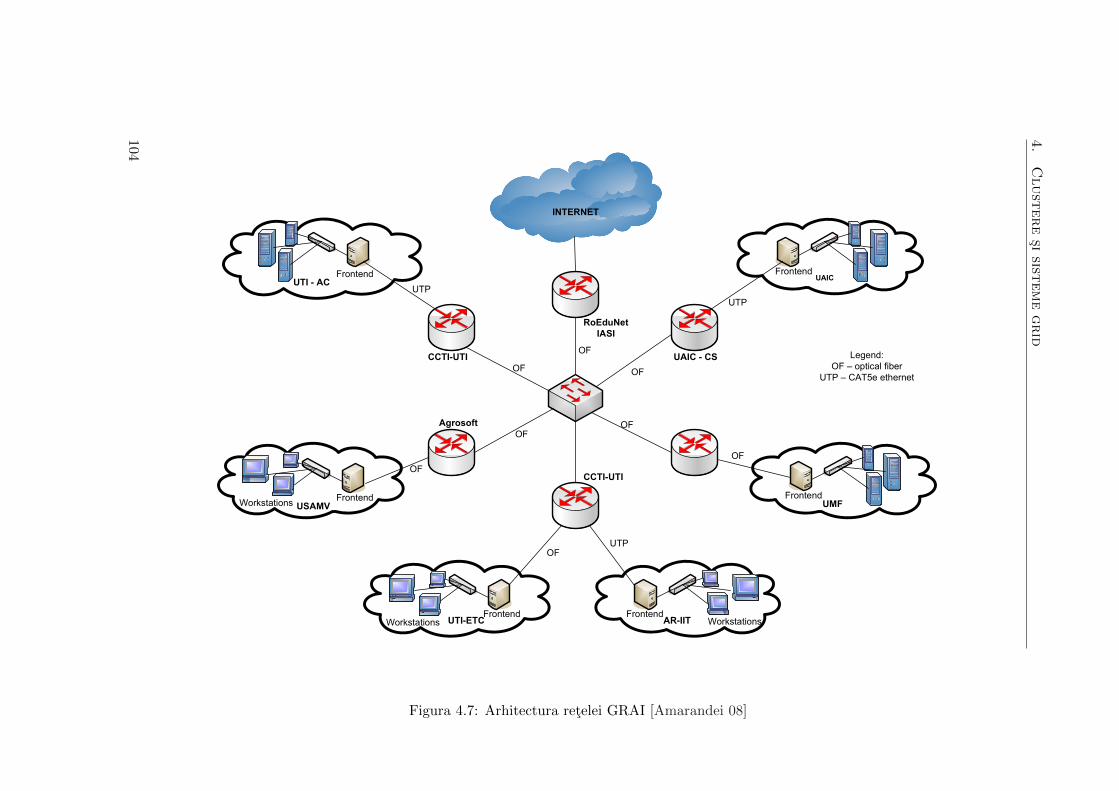
4.
Clust
ere
sisist
em
eg
rid
FrontendUSAMVWorkstations
Frontend
CCTI-UTI
RoEduNet
IASI
INTERNET
FrontendUAIC
UTI - AC
UAIC - CS
Agrosoft
CCTI-UTI
FrontendUTI-ETCWorkstations
FrontendWorkstationsAR-IIT
FrontendUMF
OF
OF
OF
OF
OF
UTP
UTP
UTP
Legend:
OF – optical fiber
UTP – CAT5e ethernet
OF
OF
OF
Figura 4.7: Arhitectura retelei GRAI [Amarandei 08]
104

4.3. Studiu de caz - Gridul GRAI
• Nodurile UTI-AC, UAIC-I si UTI-E & AR-IIT au ın dotare sisteme IBM
x3800 fiecare cu 4 procesoare 3.66 GHz Intel Xeon, 4 x 146 GB SAS HDD,
configurate ın RAID 6 si 8 GB RAM.
• Nodul USAMV-H are ın dotare un sistem: IBM x3650, 2x146GB SAS HDD,
1GB RAM
• Nodul UMF-B are ın dotare sistem: IBM x346, 4x146GB SAS HDD, 1GB
RAM.
Nodurile din clustere sunt ın urmatoarea configuratie pentru toti partenerii:
Dell Optiplex 755, Dual Core (Intel Core 2 Duo) 2,33GHz, 2 GB DDR2 Non-
ECC SDRAM 667MHz, 160GB 7200RPM High Reliability SATA 3.0Gb/s, 8MB
DataBurst Cache.
4.3.1 Implementarea infrastructurii GRAI
Software-ul de management al clusterului este un aspect deosebit de important
ce trebuie considerat de un administrator de sistem, iar solutiile disponibile
sunt numeroase: RocksClusters, Platform Open Cluster, RedHat Cluster Suite,
Linux Cluster Manager, OSCAR (Open Source Cluster Application Resources),
BOINC, ComputeMode, Clustermatic sau Perceus/Warewulf Cluster (daca sunt
utilizate statii fara disk ın constructia clusterului). In continuare, vom prezenta
solutia aleasa pentru implementarea infrastructurii GRAI cu RocksClusters.
4.3.1.1 RocksClusters - Cluster Deployment and Management Tool in Grid
Systems
NPACI Rocks reprezinta o distributie de Linux completa, avand la baza Red-
Hat Linux la care au fost adaugate aplicatii suplimentare pentru configurarea
si instalarea automataa clusterelor si sistemelor de calcul de mare performanta.
Distributia RedHat Linux a fost aleasa din cauza prezentei a doua mecanisme
cheie: sistemul de management al pachetelor (RPM) s utilitarele de instalare a
aplicatiilor ce pot descrie configuratia software pentru nodurile clusterului (kick-
start) [Papadopoulos 04].
RocksClusters funizeaza mecanisme pentru instalarea complet automata a
noduri-lor din cluster folosind RPM si fisiere kickstart pentru a asigura scalabili-
tatea instalarii. Procesul de instalare se desfasoara ın doua etape: instalarea pa-
chetelor software si configurarea pachetelor instalate. La configurarea pachetelor
software de cele mai multe ori se accepta setarile standard ın cazul unui sistem de
tip desktop, sau au diferite configuratii ce trebuie modificate ın cazul unei retele
cu diferite cerinte .
Cea mai utilizata abordare este instalarea pachetelor software si printr-un pro-
ces de introducere manuala a datelor, pachetul software este configurat. Pentru
a extinde acest proces la nivelul unui cluster, trebuie configurat un nod, creata
105

4. Clustere si sisteme grid
o imagine a acestuia si replicarea ei pe toate nodurile clusterului. Desi proce-
sul pare simplu, ın cazul unor configurati hardware/software diferite, lucrurile se
complica.
RocksClusters simplifica acest proces prin tratarea separata a etapei de insta-
lare a software-ului de etapa de configurare a acestuia. Instalarea si configurarea
pachetelor software este realizata sub forma unui pachet ce este instalat dupa
functionalul fiecarui nod ın parte si este privita ca un ıntreg si referita sub nu-
mele de appliance [Papadopoulos 04].
Pentru a veni ın ajutorul proiectatului unui cluster sa realizeze un nou appli-
ance si sa reutilizeze configuratia sistemului, RocksClusters furnizeza un frame-
work simplu ce este descris prin fisiere XML. Pentru a integra acest frame-
work cu distributiile de tip Red Hat Linux, este furnizata o aplicatie denumita
rocks-dist. Aceasta aplicatie adunainformatii legate de componentele software
din distributia Linux de baza, aplicatii dezvoltate de comunitatea Rocks si de
catre dezvoltatori independenti. Aceste informatii sunt utilizate pentru a crea o
distributie de Linux actualizata, compatibila cu Red Hat Linux (vezi Figura 4.8
[rocksclusters 02]).
Red Hat
Enterprise Linux
Red Hat Updates
Rocks RPMS
Other RPMS
eKV service
rocks-dist
Kickstart Profiles
Rocks
Figura 4.8: Generarea distributiei RocksClusters (adaptare dupa[rocksclusters 02])
Prin gestionarea pachetelor software independent de configurarea lor, aceeasi
configuratie poate fi folsita pentru diverse variante ale aplicatiilor
[Papadopoulos 04].
RocksClusters foloseste urmatoarele componente pentru a genera distributia
sistemului de operare [Katz 02]:
• Anaconda: reprezinta utilitarul de instalare folosit de RedHat Linux; uti-
106

4.3. Studiu de caz - Gridul GRAI
lizeaza un fisier kickstart (aflat pe mediul de instalare local sau ın retea),
parcurge cuvintele cheie din fisier si executa comenzile corespunzatoare pen-
tru instalarea aplicatiilor software. Dupa repornire, sistemul de calcul este
gate de utilizare.
• CGI: RocksClusters utilizeaza scripturi CGI pentru a furniza catre Ana-
conda fisierele de kickstart corespunzatoare. Pentru fiecare nod instalat,
fisierele kickstart sunt cerute folosind protocolul HTTP. RocksCluster con-
struieste pentru fiecare nod ın parte un URL ce combina informatiile din
raspunsul la cererile DHCP si informatii specifice fiecarui nod ( de exem-
plu tipul hard disk-ului si arhitectura nodului). Fisierul de kickstart este
generat de scripturile CGI astfel: se iau informatiile specifice fiecarui nod
din cererea HTTP, este interogata baza de date si sunt transmise valorile
oibtinute catre componenta KPP ce va genera un fisier XML si apoi catre
KGen, ce transforma acest fisier XML ıntr-un fisier kickstart valid ce poate
fi trimis catre nodul de instalare si interpretat de Anaconda.
• baza de date SQL: Configuratiile sistemelor si ale clusterului per ansam-
blu sunt salvate ıntr-o baza de date.
• KPP: KPP (Kickstart Pre-Processor) parcuge graful de configurare, ia
informatii legate de starea masinii din baza de date SQL si construieste un
fisier kickstart ın format XML, specific fiecarui nod din cluster.
• KGen: KGen ( Kickstart Generator) transforma fisierul kickstart din for-
matul XML ın formatul specific RedHat. Acest pas suplimentar este necesar
pentru a permite utilizarea altor formate. Intreg procesul de instalare ce
utilizeaza fisiere kickstart din [Katz 02], este prezentat ın Figura 4.9 .
107

4. Clustere si sisteme grid
Anaconda KGen CGI KPP SQL Database
Request Red Hat Kickstart File
Request Appliance Name
Appliance Name
Request XML Kickstart File
Request Configuration Variables
Configuration Variables
XML Kickstart File
XML Kickstart File
Red Hat Kickstart File
Red Hat Kickstart File
Figura 4.9: Procesul de generare a unui fisier kickstart la cererea unui nod(adaptare dupa [Katz 02])
4.3.1.2 Suportul pentru instalarea multi-site si securitatea ın RocksClusters
Urmatorul pas ın construirea unei infrastructuri Grid GRAI, este instalarea
clusterelor din locatiile partenere. Instalarea acestora a fost realizata tot cu
RocksClusters utilizand facilitatile acestuia de instalare pe WAN (wide area net-
works). Utilizarea RocksCluster presupune crearea unui server central de in-
stalare ce va stoca software-ul necesar pentru a putea fi utillizate de front-end-
uri. Deoarece acest server reprezinta o resursa critica pentru toata infrastructura
Grid, utilizarea unei configuratii de tipul celei prezentate ın Figura 4.6 este reco-
mandata. Arhitectura unui RocksClusters pentru WAN din [Sacerdoti 04], este
prezentata ın Figura 4.10:
Facilitatile WAN utilizate, permit instalarea rapida a unei infrastructuri Grid
prin instalarea ıntregii suite de aplicatii de la distanta, simplificand astfel operatiile
de administrare. Daca o anumita locatie are nevoie de configurari specifice si de
pachete software suplimentare, structura interna a RocksClusters permite ad-
ministratorului sa contruiasca un pachet de aplicatii denumit roll, pachet ce va
fi instalat pe frontend-ul corespunzator locatiei si de acolo pe noduri. Instalarea
108

4.3. Studiu de caz - Gridul GRAI
Figura 4.10: Wide Area RocksClusters (adaptare dupa [Sacerdoti 04])
aplicatiilor, a fisierelor de configurare si a informatiilor de autentificare ale uti-
lizatorilor constitue o potentiala problema de securitate pentru intreg sistemul
Grid. Pentru a evita acest tip de probleme, RocksClusters distribuie fisierele de
parole, configuratiile pentru utilizatori si grupuri utilizand un serviciu numit 411
Secure Information Service. Serviciul 411 furnizeaza un serviciu asemanator cu
NIS (Network Information Service) pentru Rocks, imitand functionalitatea NIS
la care adauga Public Key Cryptography pentru a proteja continutul fisierelor.
Serviciul lucreaza la nivelul fisierelor spre deosebire de NIS care utilizeaza RPC
(Remote Procedure Call). Deoarece nu are la baza RPC, 411 distribuie fisierele
utilizand servicii web. Principala sarcina a serviciului 411 este pastrarea si
securizarea fisierelor cu utilizatori si parole pe nodurile clusterelor. Acest lu-
cru este realizat prin implementarea unei baze de date distribuite de fisiere
[rocksclusters 02]. Frontend-urile cripteaza si furnizeaza fisiere 411 (numite si
mesaje 411 dupace sunt criptate) utilizand serverul web Apache. Nodurile clus-
terului primesc mesajele 411 utilizand HTTP, le decripteaza si salveaza fisierele
rezultate pe sistemul de fisiere local. Nodurile pot recunoaste mai multe ser-
vere 411 si ıncearca sa implementeze o echilibrare a ıncarcarii acestora. In
cazul instalarii pe WAN, functionalitatea descrisa anterior este extinsa la nivelul
frontend-urilor [rocksclusters 02].
109

4. Clustere si sisteme grid
Complexitatea unui sistem Grid aduce multe provocari administratorilor. Uti-
lizarea RocksCluster ın gridul GRAI faciliteaza stabilirea unui plan de instalare
si ıntretinere a aplicatiilor, permitand extinderea sistemului prin adaugarea de
hardware si software cu un efort minim. Pachetele software cerute de GRAI
includ: middleware, sistem de management al job-urilor si aplicatii de monitor-
izare a sistemelor. RocksClusters furnizeaza suite de aplicatii a caror instalare si
configurare este sau poate fi automatizata complet:
• GlobusToolkit 4 - middleware Grid;
• Condor, SunGrid Engine sau Torque - managere de resurse;
• OpenPBS - planificarea taskurilor;
• Ganglia, OpenSCE - utilitare de monitorizare.
Impreuna cu suitele de aplicatii furnizate de distributia RedHat Linux, Rocks
Clusters a fost ales pentru implementarea infrastructurii gridului GRAI.
4.3.2 Concluzii
In acest capitol, dupa trecerea ın revista a arhitecturii generice a unui site Grid si
a unui cluster este prezentata arhitectura gridului GRAI implementat la nivelul
universitatilor din centrul universitar Iasi.
Cerintele impuse ın implementarea conceptului de sistem Grid ın general,
si al sistemului Grid GRAI ın particular, ridica provocari pentru care exista
diverse solutii. Construirea unei infrastructurii Grid presupune combinarea ıntr-
o maniera complexa a experientelor cu diferite sisteme de operare, middleware
si instrumente de instalare si configurare. Este necesara alegerea dispozitivelor
hardware adecvate, a infrastructurii de retea, proiectarea clusterelor si instalarea
sistemului de operare si a instrumentelor de administrare, inglobarea tehnologiilor
de securitate, testarea diferitelor instrumente si aplicatii disponibile. Dezvoltarea
gridului GRAI a ınceput cu proiectarea retelei de comunicatii si a clusterelor
membre, continua cu instalarea sistemelor de operare si a softului de management
si se ıncheie cu tratarea problemelor de securitate.
In construirea clusterelor si ale sistemelor Grid, o problema importanta o
reprezinta variatia echipamentelor hardware si a retelei de comunicatii. Alegerea
cu grija a acestora se traduce ın reducerea timpului necesar mentenantei si dez-
voltarii ulterioare a infrastructurii [Amarandei 08], dar si ıntr-o exploatare efi-
cienta [Amarandei 06].
110

Capitolul 5
Un nou model de optimizare a
comunicatiilor ın clustere
Rezumat
Performantele aplicatiilor care ruleaza pe un cluster sunt influentate
de mai multi factori, ıntre care si reteaua de comunicatii. In mod nor-
mal, aplicatiile care de tip CPU intensive genereaza foarte putin trafic si
dependenta de performantele retelei de comunicatii este minima. Pe de alta
parte, o aplicatie de tip data intensive genereaza un volum mare de trafic
iar dependeta de performantele reteaua de comunicatii este semnificativa.
In acest capitol este prezentat un model de ımbunatatire a performantelor
retelei de interconectare a unui cluster prin reducerea timpului de transfer,
solutie ce ofera avantaje prin faptul ca nu presupune modificarea aplicatiei
originale.
5.1 Definirea problemei
Performantele unui cluster depind de peformantele componentelor acestuia: no-
durile de calcul si infrastructura de comunicatii. Infrastructura de comunicatii a
unui cluster este construita folosind interfete de comunicatii ale caror performante
pot fi modi-ficate doar prin modificarea echipamentelor hardware (de exemplu
ınlocuirea unui switch cu altul ce are performante superioare) si din acest motiv
aceasta componenta a clusterului este neglijata. Performanta unui nod de cal-
cul este definita de performantele hardware-ului si ale software-ului. Performanta
hardware-ului poate fi considerata o valoare constanta si depinde doar de schimba-
rile ce se pot face ın hardware. Software-ul poate fi separat ın doua compo-
nente: aplicatiile si sistemul de operare. Performantele clusterului pot depinde de
ambele componente. Imbunatatirea performantelor clusterului prin modificarea
111

5. Un nou model de optimizare a comunicatiilor ın clustere
aplicatiilor este o tinta dificil de atins, unele aplicatii ar trebui rescrise complet.
Exista si exceptii, ca de exemplu aplicatiile network-aware, construite special ın
acest scop si care nu necesita modificari. Ultima componeta care poate modifica
performantele clusterului este sistemul de operare prin configurarile kernelului
sau optimizarile la nivelul subsistemului de retea [Rusan si Amarandei 10].
Tinand cont ca un cluster contine un numar mare de noduri, ımbunatatirea
performantelor clusterului trebuie facuta cu modificari minime la nivelul sistemu-
lui de operare instalat. Aceasta cerinta este necesara pentru a usura operatiile
de mentine ıntretinere a clusterului. Solutiile existente implica modificarea fie a
sistemului de operare, fie a aplicatiilor.
Cercetarile existente, prin proiecte precum WAD (Work Around Daemon) sau
ENABLE nu ındeplinesc cerintele impuse - WAD cere kernel modificat; ENABLE
cere rescrierea aplicatiilor.
Proiectul WAD furnizeaza o serie de mecanisme care trateaza transparent
problemele legate de retea, incluzand TCP buffer size, MTU size si reordonarea
pachetelor [Dunigan 02]. Scopul proiectului este eliminarea interventiei adminis-
tratorului pentru ajustarea manuala a parametrilor retelei. Pentru aceasta, este
nevoie de un kernel modificat ce poate fi obtinut de pe site-ul proiectului Web100.
Aceasta solutie nu este aplicabila clusterelor membre ale gridului GRAI datorita
faptului ca exista patch disponibil ıncepand cu versiunea 2.6.12 a kernel-ului
Linux. Datorita unei versiuni diferite de kernel, pot apare probleme de incom-
patibilitate cu versiunile sistemului de operare instalat (CentOS 4.5), iar una din
cerintele exprese este utilizarea kernelului existent.
Proiectul ENABLE, include aplicatii de monitorizare, vizualizare, arhivare,
de detectie a problemelor etc si furnizeaza un API ce permite dezvoltatorilor de
aplicatii sa determine parametrii optimi ai retelei [Tierney 01]. Din nou, acesta
solutie nu corespunde cerintelor GRAI - nu se pot rescrie aplicatiile, sunt dificil
de modificat sau codul nu este disponibil.
In continuare este prezentat modelul de auto-optimizare a comunicatiilor din
cluster pentru a-i ımbunatati performantele prin scurtarea timpului de transfer
a datelor. Modelul propus nu presupune modificarea aplicatiilor sau a structurii
kernelului ci utilizeaza doar facilitatile oferite de sistemul de operare.
5.2 Modelul de optimizare a comunicatiilor
Modelul propus presupune calcularea celor mai bune valori posibile pentru un
set dat de parametri ai sistemului de operare. In Figura 5.1 sunt prezentate
cele trei module componente: modulul de control (Contro Logic - CL), modulul
de calcul a parametrilor (Parameter Computation - PC) si modulul de testare
a retelei (Network test tool - NTT). Prima componenta este responsabila de
transmiterea valorilor catre modulul PC si controleaza ıntregul sistem. Al doilea
112

5.2. Modelul de optimizare a comunicatiilor
modul, calculeaza seturi de valori pe baza unor date cunoscute initial si a rezul-
tatelor curente primite de la modulul NTT si le transmite kernelului pentru a
seta valorile corespunzatoare ın subsistemul de retea. Modulul NTT este re-
sponsabil de rularea testelor si de transmitere a rezultatelor catre modulul PC.
Procesul de optimizare a comunicatiilor este pornit de modulul CL, care trans-
mite valorile de start setate ın kernel catre modulul PC ti primul set de teste
prin intermediul NTT este pornit. Dupa terminarea testelor, rezultatele produse
sunt transmise catre modulul PC ce calculeaza un nou set de parametri pana la
ıntalnirea conditiei de terminare [Rusan si Amarandei 10].
Compute node Compute node
Network test
tool
Network
subsystem
Network
device
Compute node
Network test
tool
Network
subsystem
Application
Kernel
Hardware
Control logic
Parameter
computation
Network
device
Network
infrastructure
Network test
tool
Network
subsystem
Network
device
Figura 5.1: Modelul de optimizare a comunicatiilor ın clustere
[Rusan si Amarandei 10]
Modelul furnizeaza auto optimizarea parametrilor kernelului pentru subsis-
temul de retea, singura interactiune cu aplicatia fiind fisierul de configurare
ce contine valorile necesare pornirii aplicatiei. Aceste valori pot fi setate de
catre administratorul clusterului ın functie de necesitati. Pentru implementarea
functionalitaii modelului, propunem urmatorul algoritm (Algoritmul 1). Algo-
ritmul realizeaza masurarea latimii de banda si modifica parametrii kernelului
pentru a obtine latimea de banda maxima pentru fiecare caz ın parte.
Pentru l, numarul de teste ce trebuie realizate, fie N = {n1, n2, . . . , nk}setul
de noduri din cluster, T = {t1, t2, . . . , tl} setul de variabile (de exemplu tcp_rmem,
tcp_wmem, tcp_window_scalling), I = {i1, i2, . . . , il} valorile de start pentru
parametrii kernel ai subsistemului de retea si E = {e1, e2, . . . , el} setul de valori
ce trebuie calculat pentru fiecare test ti. Fiind dat m numarul de mesaje, definim
MS = {ms1,ms2, . . . ,msm} ca setul de mesaje utilizat de aplicatia de testare a
performantelor retelei, X = {x1, x2, . . . , xm} setul celor mai bune valori calculate
113

5. Un nou model de optimizare a comunicatiilor ın clustere
pentru fiecare test tt, setul de rezultate Ri = {r1, r2, . . . , rk}i pentru fiecare nod
din cluster, S = {s1, s2, . . . , sm}, unde si =∑k
j=i rij si B = {b1, b2, . . . , bm} este
setul celor mai bune valori obtinute pentru fiecare test ti. Algoritmul de calcul
este urmatorul:
foreach ti in T do1
iter=ii;2
while iter < ei do3
param = generate set(ti, iter);4
set kernel parameters(param);5
foreach ni in N do6
start remote testing program(ni);7
prepare local testing program(ni);8
end9
parallel do10
Ri = execution of local testing programs;11
end12
foreach msi in MS do13
foreach nj in N do14
si[iter] += rij ;15
end16
iter = get next iter(ti,ii,ei,iter);17
end18
end19
foreach msi in MS do20
iter=ii;21
while iter < ei do22
if xi < si[iter] then23
xi = si[iter];24
bi = iter;25
end26
iter = get next iter(ti,ii,ei,iter);27
end28
end29
best = get max count(B);30
set kernel parameters(ti,best);31
end32
Algoritm 1: Algoritmul de calcul a parametrilor retelei de comunicatii[Rusan si Amarandei 10]
Algoritmul are doua componente:
• o componenta pentru testarea retelei corespunzator modulului ”Network
test tool” din Figura 5.1 si este implementata ın liniile 3-19 ale algoritmului,
• o componenta corespunzatoare modulului ”Parameter Computation” din
114

5.3. Implementarea modelului
Figura 5.1 si implementat ın liniile 20-30.
Functiile utilizate ın acest algoritm implementeaza urmatoarele actiuni:
• generate set: genereaza un nou set de parametri utilizati ın testarea retelei;
• start remote testing program: lanseaza ın executie componenta de testare
(NetPIPE) aflata pe nodurile din cluster;
• prepare local testing program: pregateste componentele locale ale aplicatiei
de testare - functie necesara pentru a asigura acuratetea rezultatelor;
• execution of local testing programs: ruleaza aplicatia de testare;
• get max count: pentru parametrii considerati extrage valorile corespunza-
toare ratei de transfer maxime.
Linia 31 a algoritmului seteaza parametrii nucleului cu cele mai bune valori cal-
culate pe toate nodurile din cluster.
5.3 Implementarea modelului
Pentru testarea modelului propus, urmatorii parametri de kernel au fost folositi:
tcp_window_scalling, tcp_rmem si tcp_wmem. Modelul a fost testat pe un clus-
ter gridului GRAI prezentat ın Capitolul 4.3. Prima implementare a algoritmului
a fost realizata ın Bash, dar a fost rescris ın Perl datorita dificultatilor ıntampinate
la lucrul cu structuri de date. Desi nu este explicit prezentat ın algoritm, rezul-
tatele obtinute ın timpul rularii au fost salvate ın fisiere.
Protocolul TCP transmite date noi ın retea atunci cand pachetele deja trimise
destinatarului indica receptia. Rata de transmisie este depinde de dimensiunea
ferestrei glisante si este limitat din aplicatie, de dimensiunea bufferului de trans-
misie si a celui de receptie precum si de congestion window. TCP modifica di-
namic dimensiunea congestion window pentru a afla rata de transfer dintre sursa
si destinatie. Pachetele lipsa sau corupte sunt reparate prin retransmiterea din
bufferul de transmisie. Acest proces presupune ca datele se ıncadreaza ın dimen-
siunea bufferelor de receptie si transmisie. [Dunigan 02] Dimensiunea maxima a
ferestrei este de 216 = 65KB deoarece headerul TCP utilizeaza 16 biti pentru
a raporta catre expeditor dimensiunea ferestrei care o poate primi destinatarul.
Optiunea window scale a fost introdusa pentru a defini factorul de scalare implicit
pentru multiplicarea dimensiunii ferestrei din headerul TCP si a-i obtine dimen-
siunile reale [Jacobson 92]. Bufferele au valori implicite ce pot fi modificate fie de
catre aplicatie prin apeluri sistem ori prin utilizarea utilitarelor puse la dispozitie
de sistemul de operare, ca de exemplu utilitarul sysctl din Linux/Unix.
Optimizarile propuse de model au loc la nivelul subsistemului de retea al
nucleului Linux. Incepand cu versiunea 2.4 a nucleului Linux, sunt implementate
tehnici de auto reglare pentru a realiza managementul memoriei.
Aceste tehnici cresc sau reduc dinamic dimensiunea memoriei alocate buffer-
elor. Prin cresterea dimensiunii bufferelor, conexiunile TCP pot creste dimensi-
115

5. Un nou model de optimizare a comunicatiilor ın clustere
unea ferestrei, cresterea performantelor retelei fiind un efect secundar intentionat
[Tierney 01]. Pe de alta parte, acest lucru se face ın limitele memoriei disponibile,
resursa deosebit de valoroasa pe un cluster.
Subsistemul de retea al nucleului Linux trebuie reglat pentru a putea obtine
maximum de performanta. Pentru aceasta, modificari se pot face la nivelul
interfetei de retea sau la nivelul parametrilor de kernel. Parametrii de kernel se
pot regla pentru a determina schimbari ın performanta retelei prin modificarea
urmatoarelor fisiere din /proc/sys/net:
/proc/sys/net/core/rmem_max
/proc/sys/net/core/rmem_default
/proc/sys/net/core/wmem_max
/proc/sys/net/core/wmem_default
/proc/sys/net/ipv4/tcp_stack
/proc/sys/net/ipv4/tcp_timestamps
/proc/sys/net/ipv4/tcp_keepalive_time
/proc/sys/net/ipv4/tcp_mem
/proc/sys/net/ipv4/tcp_rmem
/proc/sys/net/ipv4/tcp_wmem
/proc/sys/net/ipv4/tcp_window_scaling
La nivelul interfeei de retea se pot face reglari prin modificarea setarilor legate de
viteza, modul de lucru (duplex) si a dimensiunii MTU (maximum transmission
unit). La configurarea unui cluster, trebuie tratate doua probleme:
• setarile implicite ale kernelului nu furnizeaza cele mai bune performante
pentru diverse cazuri particulare, si
• numarul cartelelor de retea ce trebuie configurate.
Deoarece soluitile care sa trateze aceasta problema lipsesc, modelul furnizeaza
valorile optime pentru fiecare nod din cluster. Folosind utilitare adecvate furni-
zate de sistemul de operare Linux, aceste valori necesare modificarii parametrilor
retelei sunt disponibile imediat, algorimtul prezentat anterior bazandu-se pe acest
lucru. Astfel, valorile pentru dimensiunea bufferele de send/receive (tcp_rmem si
tcp_wmem) pot fi modificate prin specificarea dimensiunii minime, a celei initiale
si a celei maxime dupa cum urmeaza:
sysctl -w net.ipv4.tcp_rmem="4096 87380 8388608"
sysctl -w net.ipv4.tcp_wmem="4096 87380 8388608"
A treia valoare trebuie sa fie cel mult egala cu wmem_max si rmem_max. Prima
valoare poate fi crescuta pentru retelele de mare viteza pentru ca dimensiunea
initiala ferestrei sa fie suficient de mare [NetPIPE ]. De asemenea, activarea
opinii de scalare a ferestrei (window scaling) duce la cresterea ferestrei trans-
ferate. Masurarea performantelor retelei clusterului se poate face cu o gama
116

5.4. Rezultate si concluzii
larga de utilitare ca Iperf [Tirumala ], Netperf [Netperf ] sau NetPIPE (Net-
work Protocol Independent Performance Evaluator). Deoarece trebuie testate
atat performantele pentru TCP cat si pentru MPI, a fost ales NetPIPE. Net-
PIPE foloseste pentru testare transmiterea de mesaje ıntre doua noduri. Pentru
a funiza informatii complete, NetPIPE modifica dimensiunea mesajului la un in-
terval constant de timp si masoara performantele comunicatiilor punct-la-punct
dintre noduri [Turner 03]. Deoarece se doreste determinarea setarilor pentru
diverse cazuri de utilizare, modificarea dimensiunii pachetelor utilizate este obli-
gatorie. Acesta este motivul principal pentru care este utilizat NetPIPE ın imple-
mentarea modului de testare. O descriere detaliata a acestei aplicatii se gaseste
ın [Turner 03], [Turner 02] si [Snell 96].
5.4 Rezultate si concluzii
Rezultatele testelor de performanta pentru cei trei parametri kernel utilizati
(TCP windows scaling, TCP read buffer si TCP write buffer). Pentru fiecare
parametru ın parte, graficele au pe coordonata X dimensiunea mesajului iar
pe coordonata Y , latimea de banda obtinuta. Astfel, rezultatele dupa modifi-
carea valorii parametrului TCP window scaling, sunt prezentate ın Figura 5.2a,
unde o line este pentru cazul net.ipv4.tcp window scaling = 0 si cealalta pentru
net.ipv4.tcp window scaling = 1. Pentru o mai buna ıntelegere a rezultatelor
a fost preferata aplicarea unei functii Bezier iar rezultatul se poate observa ın
Figura 5.2b.
Dependenta latimii de banda de dimensiunea bufferelor read/write este prezen-
tata ın Figura 5.3a si Figura 5.4a. In acest caz, datorita numarului mare de valori
reprezentate, utilitatea aplicarii unei functii Bezier este imediata, rezultatele fiind
prezentate ın Figura 5.3b si Figura 5.4b.
Linia rosie continua din reprezentarile grafice corespunde latimii de banda
disponibile pentru valorii implicite din nucleu. Modificarile aduse dimensiunii
buferelor si variatia latimii de banda disponibile pentru fiecare valoare ın parte
sunt prezentate ın Figura 5.5. Dimesiunea bufferelor pleaca de la 4KB si la fiecare
pas a algoritmului este dublata fata de valoarea utilizata anterior.
117
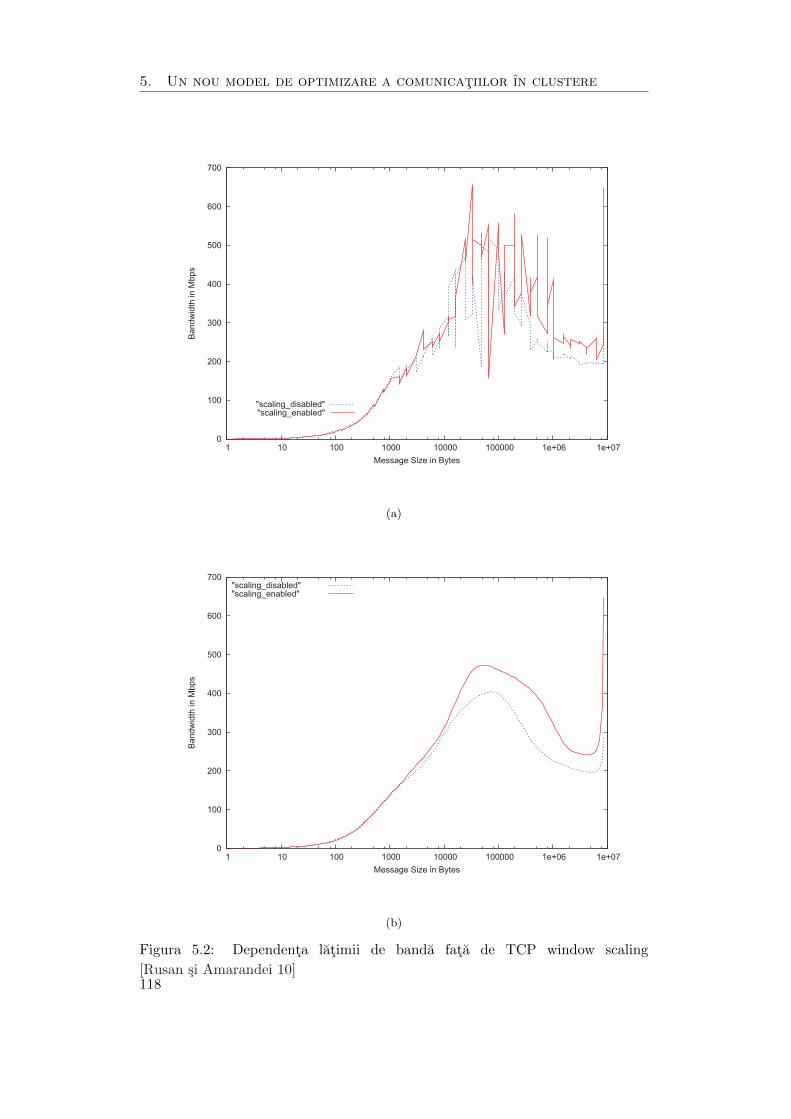
5. Un nou model de optimizare a comunicatiilor ın clustere
0
100
200
300
400
500
600
700
1 10 100 1000 10000 100000 1e+06 1e+07
Ba
nd
wid
th in
Mb
ps
Message Size in Bytes
"scaling_disabled""scaling_enabled"
(a)
0
100
200
300
400
500
600
700
1 10 100 1000 10000 100000 1e+06 1e+07
Ba
nd
wid
th in
Mb
ps
Message Size in Bytes
"scaling_disabled""scaling_enabled"
(b)
Figura 5.2: Dependenta latimii de banda fata de TCP window scaling
[Rusan si Amarandei 10]118
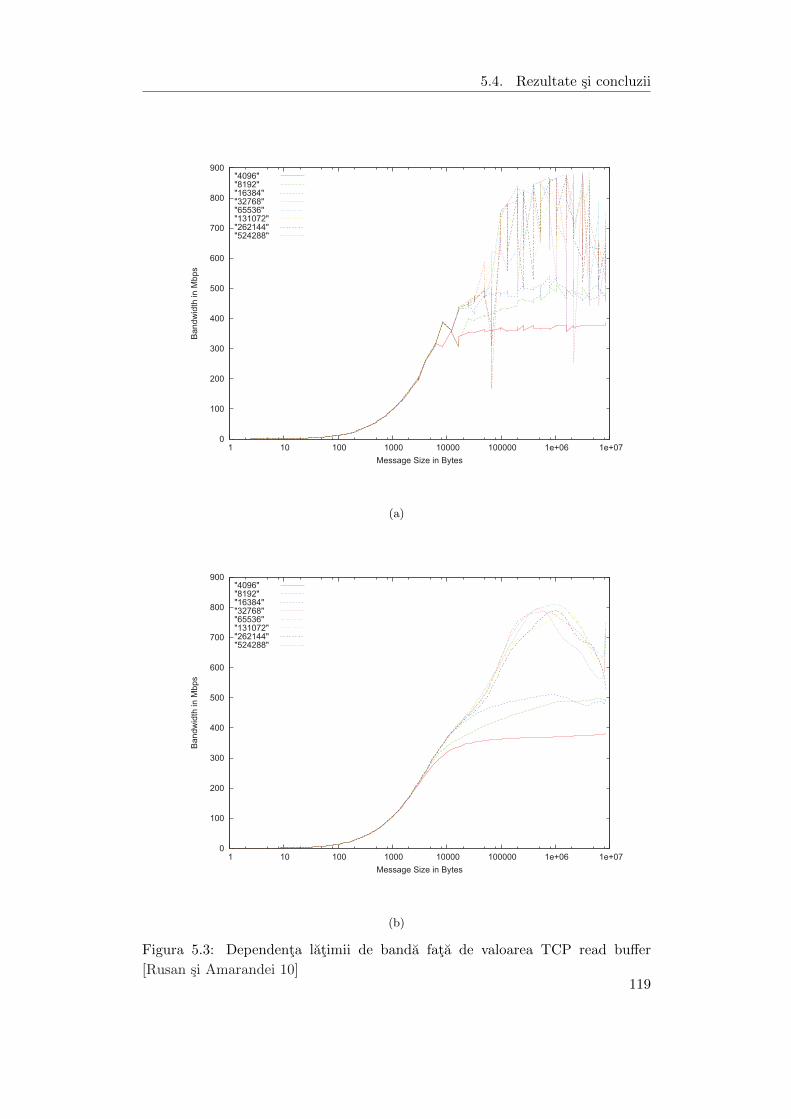
5.4. Rezultate si concluzii
0
100
200
300
400
500
600
700
800
900
1 10 100 1000 10000 100000 1e+06 1e+07
Ba
nd
wid
th in
Mb
ps
Message Size in Bytes
"4096""8192""16384""32768""65536""131072""262144""524288"
(a)
0
100
200
300
400
500
600
700
800
900
1 10 100 1000 10000 100000 1e+06 1e+07
Ba
nd
wid
th in
Mb
ps
Message Size in Bytes
"4096""8192""16384""32768""65536""131072""262144""524288"
(b)
Figura 5.3: Dependenta latimii de banda fata de valoarea TCP read buffer
[Rusan si Amarandei 10]119
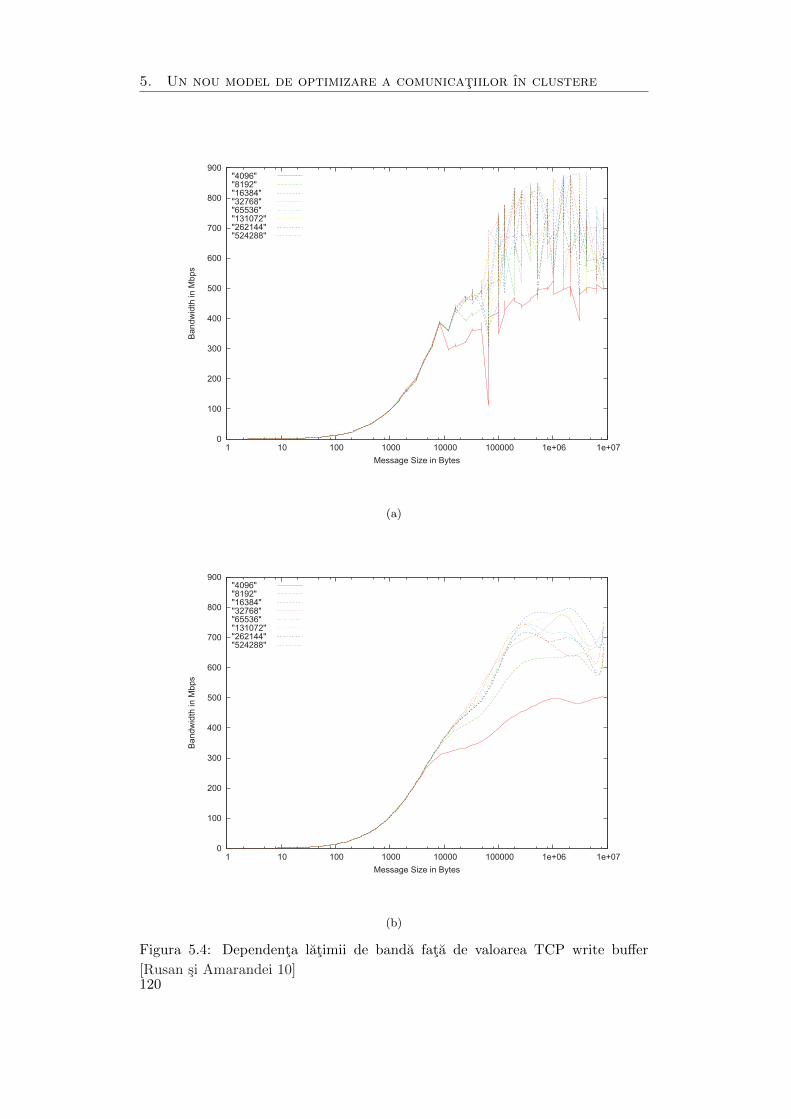
5. Un nou model de optimizare a comunicatiilor ın clustere
0
100
200
300
400
500
600
700
800
900
1 10 100 1000 10000 100000 1e+06 1e+07
Ba
nd
wid
th in
Mb
ps
Message Size in Bytes
"4096""8192""16384""32768""65536""131072""262144""524288"
(a)
0
100
200
300
400
500
600
700
800
900
1 10 100 1000 10000 100000 1e+06 1e+07
Ba
nd
wid
th in
Mb
ps
Message Size in Bytes
"4096""8192""16384""32768""65536""131072""262144""524288"
(b)
Figura 5.4: Dependenta latimii de banda fata de valoarea TCP write buffer
[Rusan si Amarandei 10]120
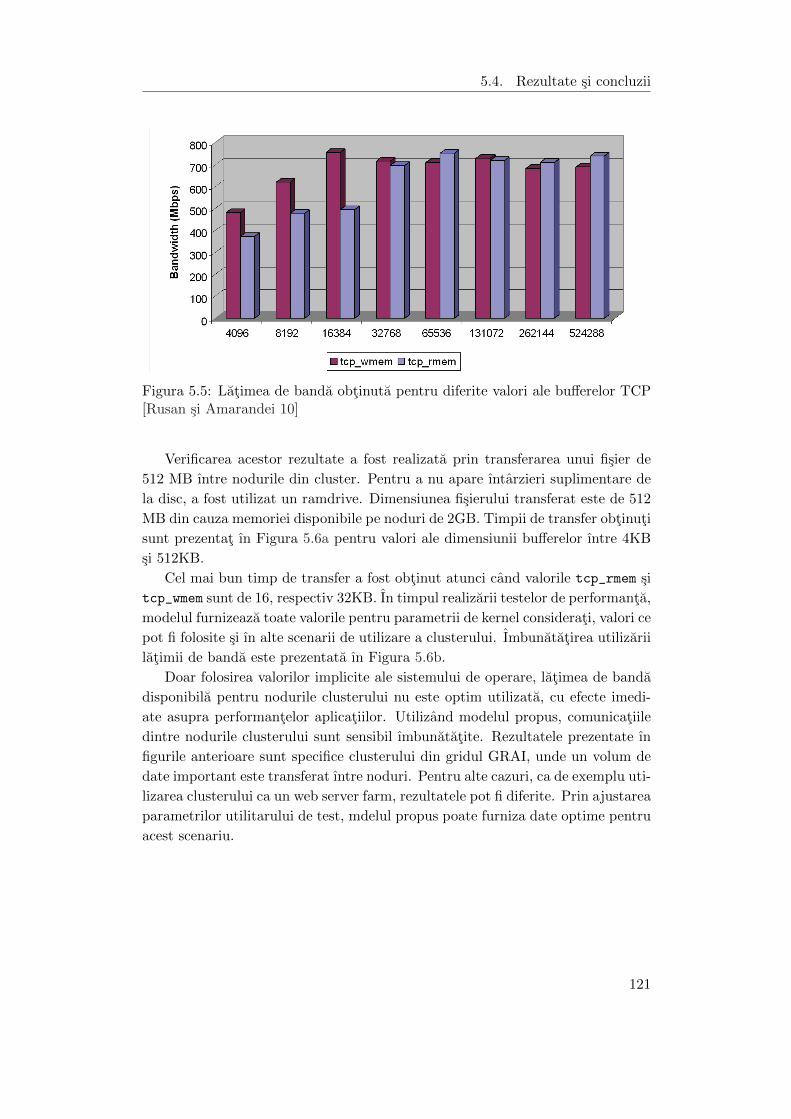
5.4. Rezultate si concluzii
Figura 5.5: Latimea de banda obtinuta pentru diferite valori ale bufferelor TCP[Rusan si Amarandei 10]
Verificarea acestor rezultate a fost realizata prin transferarea unui fisier de
512 MB ıntre nodurile din cluster. Pentru a nu apare ıntarzieri suplimentare de
la disc, a fost utilizat un ramdrive. Dimensiunea fisierului transferat este de 512
MB din cauza memoriei disponibile pe noduri de 2GB. Timpii de transfer obtinuti
sunt prezentat ın Figura 5.6a pentru valori ale dimensiunii bufferelor ıntre 4KB
si 512KB.
Cel mai bun timp de transfer a fost obtinut atunci cand valorile tcp_rmem si
tcp_wmem sunt de 16, respectiv 32KB. In timpul realizarii testelor de performanta,
modelul furnizeaza toate valorile pentru parametrii de kernel considerati, valori ce
pot fi folosite si ın alte scenarii de utilizare a clusterului. Imbunatatirea utilizarii
latimii de banda este prezentata ın Figura 5.6b.
Doar folosirea valorilor implicite ale sistemului de operare, latimea de banda
disponibila pentru nodurile clusterului nu este optim utilizata, cu efecte imedi-
ate asupra performantelor aplicatiilor. Utilizand modelul propus, comunicatiile
dintre nodurile clusterului sunt sensibil ımbunatatite. Rezultatele prezentate ın
figurile anterioare sunt specifice clusterului din gridul GRAI, unde un volum de
date important este transferat ıntre noduri. Pentru alte cazuri, ca de exemplu uti-
lizarea clusterului ca un web server farm, rezultatele pot fi diferite. Prin ajustarea
parametrilor utilitarului de test, mdelul propus poate furniza date optime pentru
acest scenariu.
121
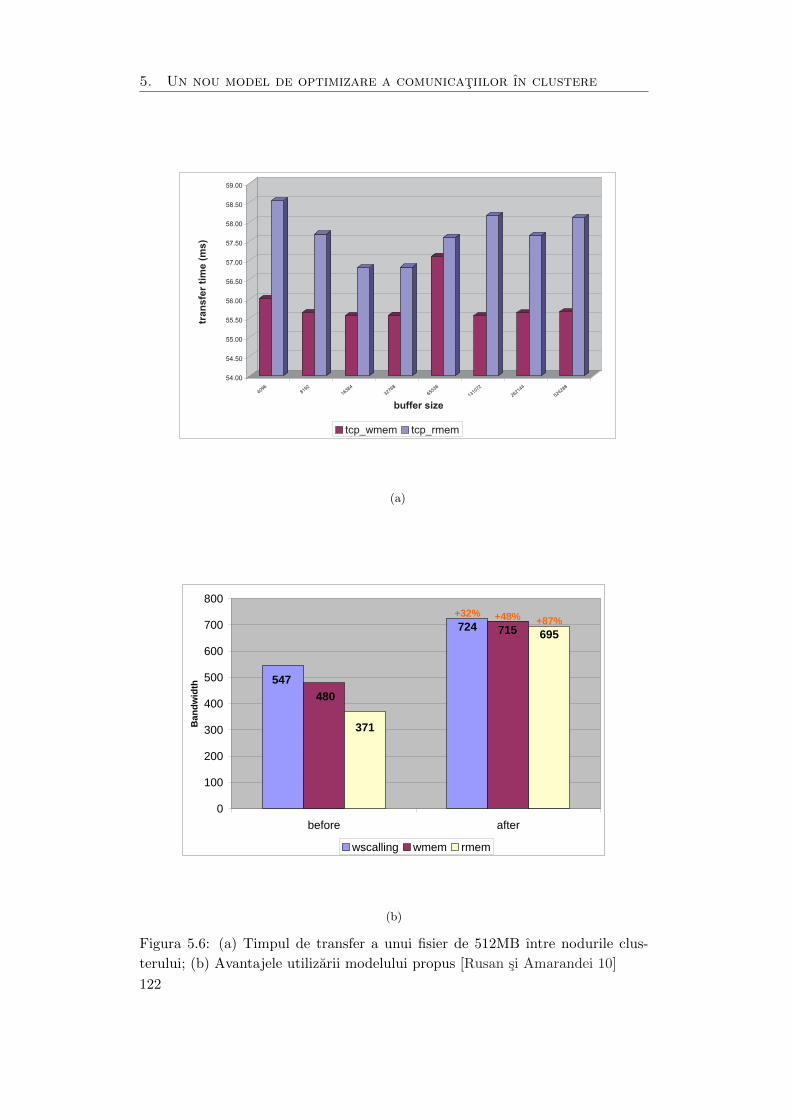
5. Un nou model de optimizare a comunicatiilor ın clustere
54.00
54.50
55.00
55.50
56.00
56.50
57.00
57.50
58.00
58.50
59.00
tra
ns
fer
tim
e (
ms
)
4096
8192
16384
32768
65536
131072
262144
524288
buffer size
tcp_wmem tcp_rmem
(a)
+32%724
547
+48%715
480
+87%695
371
0
100
200
300
400
500
600
700
800
before after
Ban
dwid
th
wscalling wmem rmem
(b)
Figura 5.6: (a) Timpul de transfer a unui fisier de 512MB ıntre nodurile clus-
terului; (b) Avantajele utilizarii modelului propus [Rusan si Amarandei 10]
122

Capitolul 6
Tehnici de gestiune a resurselor
ın clustere
Rezumat
Partajarea resurselor unui cluster reprezinta o problema cu implicatii
multiple ın managementul taskurilor si a retelei de comunicatii a clusterului.
In mod uzual, politicile de rezervare a resurselor utilizate de job managere
iau ın considerare pentru fisierele de descriere a jobului doar numarul de
procesoare, memoria disponibila si arhitectura sistemului. Pentru aplicatiile
de tip data intensiv, timpul de transfer al datelor si timpul de acces la fisiere
este critic, iar performantele si rezultatele acestora depind de acest lucru. In
cazul unui cluster partajat de mai multi utilizatori, taskurile rulate de un job
manager pot ıntruni restrictiile impuse si aplicatia poate fi pornita. Un job
manager nu ia ın considerare resurse precum latimea de banda disponibila
ın reteaua clusterului sau resursele consumate de alte aplicatii ce ruleaza
ın cluster. In acest capitol vom prezenta o serie de tehnici alternative de
management eficient a resurselor precum CPU si latime de banda si imple-
mentarea acestora ın clustere. Aceste tehnici permit alocarea dinamica de
resurse si furnizeaza politici de rezervare a acestora pentru toti utilizatorii.
6.1 Definirea problemei
Aplicatiile de management a resurselor precum Condor, SGE sau PBS sunt ori-
entate ın special pe optimizarea globala ın privinta unor metrici de performanta
precum timpul de terminare, gradul de utilizare a sistemelor etc. Pe un cluster
partajat, unde numarul de aplicatii este semnificativ mai mare decat numarul
de noduri, este necesara o partajare a resurselor ıntre aplicatii. Aceste clustere,
de obicei, sunt utilizate de grupuri de utilizatori (de exemplu un colectiv de
cercetare al unui departament dintr-o universitate) pentru a rula diverse aplicatii,
123

6. Tehnici de gestiune a resurselor ın clustere
simulari, compilari distribuite etc. Cand mai multe servicii partajeaza acelasi
server, fiecare primeste o parte din resursele disponibile. Fiecare serviciu trebuie
sa fie capabil sa-si utilizeze partea de resurse primite ca si cum ar rula singur ın
cluster [Amarandei 10].
Abordarile solutiilor de management de resurse traditionale prezinta doua
pro-bleme. Un prim neajuns ar fi faptul ca aplicatiile sunt trate ın mod egal la
realizarea optimizarilor. Aceste solutii ignora cererile variate de resurse ale uti-
lizatorilor pe baza nevoilor imediate sau a importantei acestora. Al doilea neajuns
este ca ın sistemle unde cererile depasesc resursele disponibile, probabilitatea ca
resursele clusterului sa fie suprasolicitate este ridicata [Chun 00].
Daca consideram urmatorul scenariu ([Amarandei 10]), ın care un cluster
dintr-o universitate are numerosi utilizatori, profesori si studenti, cu urmatoarele
restrictii de utilizare:
• utilizarea resurselor precum procesor si memorie trebuie alocate profesorilor
(50%), studenilor (30%) si pentru sistem (20%);
• numarul maxim de procese permise trebuie sa fie distincte ıntre grupurile de
utilizatori ( de exemplu maxim 50 procese pentru fiecare cont de student);
• utilizarea latimii de banda disponibila din reteaua clusterului trebuie repar-
tizata astfel ıncat sistemul de fisiere (NFS) partajat ın retea sa aiba alocat
ıntre 40 si 60% din disponibil, 5% sa fie alocat sistemului de operare si pen-
tru middleware, iar restul sa fie disponibil pentru aplicatiile utilizatorilor.
Daca ramane latime de banda neutilizata, aceasta trebuie safie disponibila
aplicatiilor utiliatorilor.
Implementari ale tehnicilor de alocare a resurselor includ sistemul Sharc
[Urgaonkar 04], un sistem de management proportional bazat pe cereri descris ın
[Chun 00], partajarea si izolarea ın cadrul sistemelor multiprocesor cu memorie
comuna [Urgaonkar 02] si Control Groups [cgroups ].
Sistemul proportional de partajare a resurselor propus ın [Chun 00], cere efec-
tuarea unor modificari la nivelul planificatorului sistemului de operare, modificari
ın care algoritmul standard cu prioritati este ınlocuit cu o tehnica de planificare
cu intervale mari (stride scheduling). In contrast cu aceasta solutie, modelul pro-
pus nu modifica nucleul sistemului de operare, furnizand o mai mare flexibilitate
ın operatiile de ıntretinere a clusterului.
Pe de alt parte, Control Groups furnizeaza mecanisme pentru gruparea sau
parti-tionarea seturilor de procese si a tuturor procesor fiu ale acestora, ın ierarhii
de grupuri cu un comportament specific [cgroups ]. Desi este o tehnologie relativ
noua, introdusa ıncepand cu versiunea 2.6.24 a kernelului Linux, este obligatorie
recompilarea kernelului, instalarea acestuia pe toate nodurile si repornirea clus-
terului. Impreuna cu Linuxcontainers, Control Groups furnizeaza o metoda de
management a resurselor prin intermediul containerelor si rezervarea resurselor
prin intermediul spatiilor de nume. De asemenea, scopul Linuxcontainers este
124

6.2. Arhitectura sistemului de management a resurselor
utilizarea acestor noi functionaltati pentru a furniza un obiect de tip container ın
spatiul utilizator, container care sa orefere o izolare completa si controlul asupra
resurselor folosite de o aplicatie sau un sistem [Linuxcontainers ].
Pe de alta parte sistemul Sharc prezentat ın [Urgaonkar 04] utilizeaza tot o
tehnica de tip container pentru alocarea resurselor unei aplicatii. Principalul
dezavantaj al acestei solutii este faptul ca nu poate fi aplicata pe un cluster
partajat si cere efectuarea unor modificari la nivelul kernelului.
Pentru rezolvarea acestor probleme, vom prezenta ın continuare un model
de proiectare a politicilor de rezervare a resurselor si implementarea acestora ın
clustere.
6.2 Arhitectura sistemului de management a resurselor
Modelul propus pentru managementul resurselor, descris ın Figura 6.1, are doua
componente majore [Amarandei 10]: Management Control Unit (MCU) instalat
pe nodul de management al clusterului sau pe front-end (Figura 4.3) si agentii
de control (Control Agent - CAg).
Instalarea acestor componete este realizata prin intermediul softului de man-
agement al clusterului. Management Control Unit este componenta principala a
modelului si controleaza agentii de control, politicile de alocare a resurselor prin
modulule Resource Reservation policy (RR) si Rule Management (RM), iar pen-
tru a determina latimea de banda disponibila realizeaza testele de performanta
folosind modulul de optimizare a comunicatiilor (Communications Optimization
module - CO). Acest ultim modul este prezent si ın cadrul agentilor de control
iar functionalitatea a fost descrisa in Capitolul 5.2 si ın [Rusan si Amarandei 10].
Acest modul este utilizat de fiecare data cand configuratia hardware sau scopul
ın care este utilizat clusterul se schimba.
Un modul de realizare a comunicatiilor ( Communication Module - CM ) este
prezent ın ambele componente MCU si CAg pentru a realiza comunicatiile dintre
acestea. Pentru detectarea aplicatiilor pornite de utilizatori, un modul denumit
Local Application Detection (LAD) este folosit de ambele componente.
Politicile de utilizare a resurselor sunt stocate ın fisiere de configurare si dis-
tribuite la nodurile clusterului de catre MCU. Agentii de control sunt responsabili
de implementarea acestor politici prin ıncarcarea lor din fisierele de configurare si
monitorizarea activitatii de pe noduri. MCU utilizeaza modulul Control Logic &
Agent Monitor (CLAM) pentru urmarirea starii agentilor si notificarea acestora
ın cazul schimbarii politicilor de alocare.
125

6. Tehnici de gestiune a resurselor ın clustere
Distributed/shared filesystem
Clu
ster
mid
dle
war
e
Manage filesystems
MCU
LAD module
Comm module
CLAM module
RR policy
RM logic
Cluster CO
module
Cluster management
Cluster Node(s)
User application
CAg
OS kernel
No. of processes
CPU time
Memory limit
Disk quota
Process priority
Network bandwidth
Resource reservation module
Local application detection module
Communication module
Communications optimization
module
Deploy CAg
Deploy Management Control Unit
Legend: CAg – Control Agent RR – Resource Reservation RM – Rule Management CO – Communications Optimization Comm – Communications CLAM – Control Logic & Agent Monitor LAD – Local Application Detection MCU – Management Control Unit
CA comm
Figura 6.1: Arhitectura sistemului de management a resurselor [Amarandei 10]
6.3 Implementare
Implementarea prototipului solutiei propuse ın paragraful anterior presupune
utilzarea unor tehnologii ce sunt prezentate ın cele ce urmeaza.
Un set de mecanisme este utilizat pentru restrictionarea traficului ıntr-o retea
de calculatoare si aplicarea lui ıl reprezita TC(Traffic Control). Este utilizat
cu predilectie pentru a acorda prioritate unui anumit tip de trafic, pentru a
limita rata de transfer folosita sau pentru a bloca un anumimt tip de trafic
[Almesberger 02]. O descriere detaliata a arhitecturii TC ın cadrul nucleului
Linux poate fi gasita ın [Almesberger 02], [Almesberger 99] si [diffserv ].
Pe un sistem Linux, majoritatea utilizatorilor au acces nelimitat la resurse
precum CPU si memorie. Daca nu sunt aplicate restrictii, utilizatorii pot rula
cod rau intentionat (malicious code) ce poate duce exploatarea unor brese de se-
curitate sau chiar pot provoca un atac de tip refuzare serviciu (Denial of Service).
Deoarece scrierea unor programe de acest tip nu necesita cunostinte avansate de
programare, pot cauza blocarea sistemului sau pot aduce ıntarzieri semnifica-
tive ın raspunsul acestuia la alte aplicatii. Resursele alocate utilizatorilor sau
grupurilor pot fi limitate folosind fisierul /etc/security/limits.conf dispono-
bil pe orice sistem Linux si controlat prin modulul PAM (Pluggable Authen-
tication Modules) numit pam_limits a carui descriere detaliata se gaseste ın
[Morgan 10].
Adaugarea politicilor pentru utilizarea procesorului, a memoriei si a numarului
de procese pe care un utilizator le poate rula pe fiecare nod din cluster reprezinta
126

6.3. Implementare
o tinta usor de atins. Cu toate acestea, modulele Local Application Detection,
Resource Reservation si Rule Management Logic sunt cel mai dificil de imple-
mentat datorita faptului ca aplicatiile care utilizeaza reteaua trebuie detectate ın
timp real. Acelasi lucru este valabil si ın cazul schimbarii politicilor. De aseme-
nea, este posibil ca aplicatiile care au alocate resurse sa nu suporte mecanisme de
tip checkpoint precum un transfer de fisiere. Aceste aplicatii trebuie sa ruleze ın
continuare, dar ın noile conditii stabilite de politicile de alocare [Amarandei 10].
De exemplu, daca pentru grupul studenttilor este alocata 25% din latimea
de banda disponibila, toate aplicatiile pornite de utilizatorii acestui grup trebui
sa se ıncadreze ın aceasta restrictie. Prezenta acestei restrictii seminifica fap-
tul ca utilizatorii vor obtine performante diferite pentru aplicatiile lor ın functie
de numarul utilizatorilor din grup activi si de aplicatiile rulate de acestia. Pre-
supunem ın cadrul acestui scenariu, ca administratorul clusterului schimba politi-
cile de alocare a latimii de banda pentru grupul studentilor la 20% din disponibil
cu un maxim de 30% daca este banda neutilizata. ın acest caz, aplicatiile vor con-
tinua rularea, dar ın conditiile noilor politici. Aceste politici de alocare sunt luate
ın considerare de kernelul Linux imediat, iar utilizatorii pot observa fluctuatii ale
parametrilor de performanta ai aplicatiilor pana cand noile politici devin active
ın tot clusterul [Amarandei 10].
Resource K
1st reservation y1%
Default x%
Nth reservation yn%
Inst
ance
1 (
x/n
%)
Inst
ance
n (
x/n
%)
Inst
ance
1 (
y n/n
%)
Inst
ance
n (
y n /n
%)
Resource 1
1st reservation y1%
Default x%
Nth reservation yn%
Inst
ance
1 (
x/n
%)
Inst
ance
n (
x/n
%)
Inst
ance
1 (
y n/n
%)
Inst
ance
n (
y n /n
%)
Resource 1
1st reservation y1%
Default x%
Nth reservation yn%
Inst
ance
1 (
x/n
%)
Inst
ance
n (
x/n
%)
Inst
ance
1 (
y n/n
%)
Inst
ance
n (
y n /n
%)
Figura 6.2: Partitionarea resurselor [Amarandei 10]
Pentru implementarea politicilor de alocare, resursele sunt ımpartite ın clase
de prioritati definite separat pentru fiecare utilizator. O clasa speciala, numita
Default, este creata pentru fiecare tip de resursa ın parte (CPU, memorie, latimer
127

6. Tehnici de gestiune a resurselor ın clustere
de banda etc) asa cum se poate observa ın Figura 6.2. Cererile care nu se
ıncadreaza ın una din clasele de prioritate definite explicit, sunt alocate clasei
Default. Cererile de resurse ale utilizatorilor care se ıncadreaza ıntr-o anumita
clasa, partajeaza ın mod egal resursele rezervate de clasa respectiva.
6.4 Rezultate si concluzii
Testarea modelului propus a fost realizata pe clusterul AC al gridului GRAI
descris ın Capitolul 4.3. Pe acest cluster, aplicatiile rulate de utilizatori sunt
urmarite si politicile definite sunt aplicate asupra acestora. A fost aleasa urmarirea
si limitarea accesului la latimea de banda disponibila. Se considera cazul trans-
ferului unui fisier cu dimensiunea 330MB iar utilizatorii trebuie sa partajeze ın
mod egal latimea de banda disponibila. Primul test a fost realizat cu un singur
utilizator ce transfera un fisier cu si fara aplicarea politicilor de limitare. Asa
cum se poate observa din Figura 6.3, fara limitarea ratei de transfer, aplicatia
utilizatorului ocupa cat mai mult din disponibilul latimii de banda, iar timpul
de transer este de 15 sec. Dupa modificarea politicilor de utilizare la 250Mb/sec
si aplicarea acestora, acelasi transfer dureaza 29 de secunde fara a depasi limita
impusa.
Pentru analiza modelului ın cazul unui mediu de lucru real, au fost realizate
teste cu 18 conturi pentru studensi active la un moment dat. Datorita faptului
ca reprezentarea rezultatelor pentru toate cele 18 conturi concurente active nu
poate fi citita, ın Figurile 6.4 si 6.5 sunt prezentate doar rezultatele pentru doar
4 utilizatori.
Pentru cazul ın care nu se aplica nici o politica de rezervare, timpul de transfer
este ıntre 25 si 27 secunde (Figura 6.4). Fiecare utilizator ocupa cat mai mult
posibil din latimea de banda disponibila. Dupa definirea restrictiilor si aplicarea
acestora, timpul de transfer se modifica corespunzator iar rata de transfer a celor 4
utilizatori nu depaseste 250Mb/sec (Figura 6.5). Pentru cazul celor 18 utilizatori,
rata de transfer este de aproximativ 50Mb/sec [Amarandei 10].
O alocare echitabila a resursei alese a fost obtinuta ın urma utilizarii mod-
elului propus. Politicile de rezervare, odata definite, pot fi usor aplicate ın tot
clusterul. Datorita adoptarii Control Groups ın nucleul ce este furnizat ıncepand
cu Red Hat Enterprise Linux 6, dezvlotarea ulterioara a modelului propus include
compatibilitatea cu aceasta noua facilitate.
128
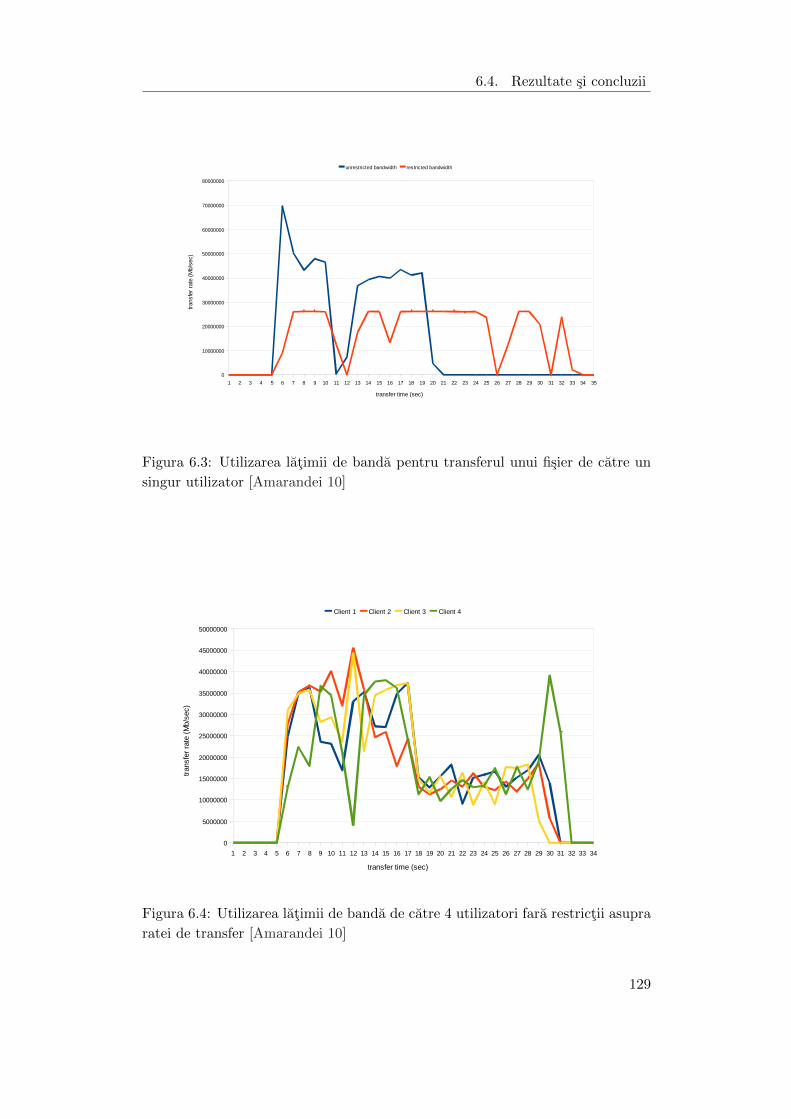
6.4. Rezultate si concluzii
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35
0
10000000
20000000
30000000
40000000
50000000
60000000
70000000
80000000
unrestricted bandwidth restricted bandwidth
transfer time (sec)
tran
sfer
rat
e (M
b/se
c)
Figura 6.3: Utilizarea latimii de banda pentru transferul unui fisier de catre un
singur utilizator [Amarandei 10]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34
0
5000000
10000000
15000000
20000000
25000000
30000000
35000000
40000000
45000000
50000000
Client 1 Client 2 Client 3 Client 4
transfer time (sec)
tran
sfer
rat
e (M
b/se
c)
Figura 6.4: Utilizarea latimii de banda de catre 4 utilizatori fara restrictii asupra
ratei de transfer [Amarandei 10]
129
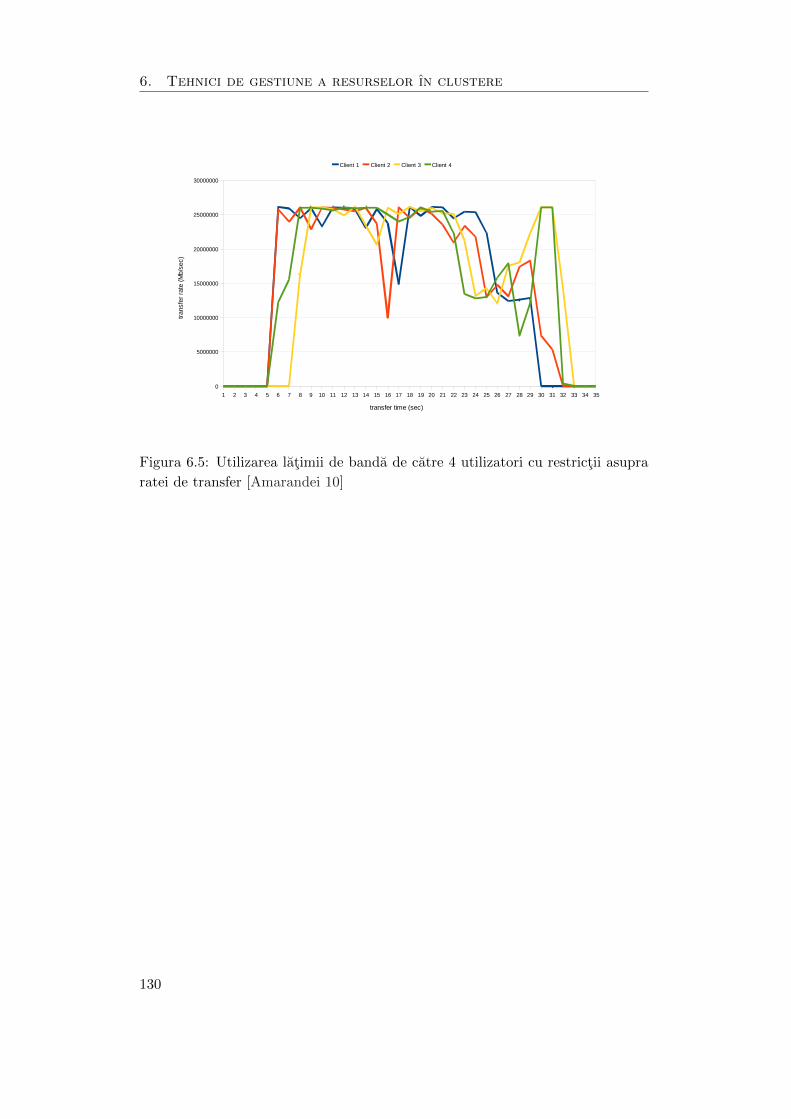
6. Tehnici de gestiune a resurselor ın clustere
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35
0
5000000
10000000
15000000
20000000
25000000
30000000
Client 1 Client 2 Client 3 Client 4
transfer time (sec)
tran
sfer
rat
e (M
b/se
c)
Figura 6.5: Utilizarea latimii de banda de catre 4 utilizatori cu restrictii asupra
ratei de transfer [Amarandei 10]
130

Capitolul 7
Concluzii, contributii si directii
viitoare de cercetare
7.1 Concluzii
Domeniul calculului de ınalta performanta vizeaza optimizarea aplicatiilor prin
adoptarea unor solutii eficiente de paralelizare/distribuire, solutii ce urmaresc
ın special reducerea timpilor de raspuns si, eventual, cresterea acuratetii ras-
punsurilor oferite. Rezultatele cercetarilor aferente acestui domeniu influenteaza
dramatic performantele celorlalte domenii ce se bazeaza pe tehnologii de cal-
cul paralel/distribuit. Reducerea timpului de calcul ın rezolvarea unei probleme
reprezinta principala motivatie ce ghideaza nevoia de paralelizare/distribuire efi-
cienta a solutiilor secventiale existente. Mai mult, odata cu evolutia tehnologiilor
hardware si software suport, apar noi oportunitati de ımbunatatire a solutiilor ex-
istente sau de dezvoltare a unor solutii noi, mai eficiente. Regasirea informatiilor
ın domeniul economic, regasirea de informatii pe Web, cercetarile ın domeniul
geneticii, procesarea imaginilor medicale, bioingineria, meteorologia sunt doar
cateva dintre cele mai importante domenii ce pot beneficia din plin de aceste
schimbari. Astfel, cercetatorii implicati ın aceste domenii utilizeaza cele mai noi
tehnologii din domeniul calculului de mare performanta pentru a rezolva prob-
leme din ce ın ce mai complexe, ın timp cat mai scurt.
Aparitia tehnologiilor suport a dus la cresterea asteptarilor privitoare la per-
formantele instrumentelor software si hardware. Se urmareste realizarea de apli-
catii care sa ofere solutii ıntr-un timp acceptabil la probleme de o complexitate
din ce ın ce mai ridicata. Pentru atingerea acestui obiectiv, nu este suficienta doar
cresterea performantelor sistemului de calcul. In mod uzual se recurge una din
urmatoarele doua abordari: fie se reproiecteaza integral aplicatia, fie, ın cazul
unor costuri foarte mari de reproiectare, se urmareste dezvoltarea unor solutii
131

7. Concluzii, contributii si directii viitoare de cercetare
destinate sistemelor de calcul paralel/distribuit. Ambele abordari solicita din
partea dezvoltatorului de aplicatii sa studierea unor tehnici noi de implementare
si proiectare. Solutiile oferite trebuie sa fie proiectate astfel ıncat sa ruleze pe
arhitecturi hardware din ce ın ce mai complexe, cu un pronuntat caracter dinamic.
Mai mult, trebuie considerata posibilitatea integrarii rapide a tehnologiilor noi,
ceea ce confera un grad ridicat de complexitate acestui domeniu.
In acest context, prima parte a Capitolului 2 este dedicata analizei tehnicilor
de dezvoltare a unei aplicatii paralele. Accentul cade pe etapele de proiectare si
pe cele de analiza cantitativa si calitativa a acestui tip de aplicatii. Modelele exis-
tente de proiectare implica parcurgerea urmatoarelor etape: analiza problemei si
a activitatilor de calcul; ımpartirea activitatilor ın subactivitati cu un grad ridi-
cat de independenta; identificarea interactiunilor dintre subactivitati si definirea
sistemului de calcul ce poate fi utilizat pentru rezolvarea problemei. Un model
descris ın acest capitol, ce permite realizarea unor aplicatii scalabile si modulare
este modelul de tip task-canale de comunicatii. Acest model furnizeaza mecanis-
mul numit dependenta de date, mecanism ce presupune ca un task, pentru a-si
putea continua executia, poate avea nevoie de acces la datele aflate ın memoria
locala ce apartine altor task -uri. O serie de alte modele de programare sunt tre-
cute ın revista: transmitere de mesaje, paralelism de date, memorie partajata.
Diferentele dintre aceste modele sunt date de mecanismele de interactiune din-
tre task -uri, granularitatea acestora, suportul pentru pozitionare si modularitate.
Pentru a putea trece de la modelele de aplicatii paralele, la scrierea efectiva a co-
dului, trebuie parcurse o serie de etape de proiectare. Metodologia de proiectare,
ın prima faza, pune accent pe paralelism, scalabilitate si descoperirea algorit-
mului ce ındeplineste aceste cerinte. Se urmareste ca, pornind de la problema
data, sa se identifice posibilitatile de paralelizare si sa determinae necesarul de
comunicatii dintre activitatile paralele rezultate. Faza a doua, este axata pe
probleme legate de performanta solutiei gasite si pe identificarea modalitatilor
de ımbunatatire a acestora. Se pune accent pe evaluarea rezultatelor obtinute
ın prima faza, considerand costurile implicate. Daca este posibil se trece la gru-
parea activitatilor de calcul astfel ıncat sa fie satisfacute si cerintele de utilizare
maxima a procesoarelor si de minimizare a costurilor de comunicatie. In fi-
nalul acestui capitol este tratata si problema echilibrarii ıncarcarii ın sistemele
de calcul de mare performanta. Sunt detaliate tehnicile existente de solutionare
a acestei probleme, precum si posibilitatile de implementare. In acest context
sunt analizate performantele unor algoritmi de echilibrare a ıncarcarii ce au fost
implementati utilizand o platforma de agenti mobili. Pentru comparatie, aceiasi
algoritmi au fost implementati si ın medii de tip message passing.
Odata ce a fost dezvoltata o aplicatie paralela, validarea parametrilor ce
afecteaza performanta aplicatiei si rezultatele produse este deosebit de impor-
tanta. O posibila solutie ın acest sens este reprezentata de validarea prin metode
132

7.1. Concluzii
experimentale. In Capitolul 3 a fost propus un model propriu de proiectare si
testare a unei aplicatii paralele, model care extinde abordarile existente prin
tehnici de proiectare a experimentelor. Un plus al abordarii propuse este posi-
bilitatea estimarii performantelor unei aplicatii ın cazul rularii ın conditii diferite
si/sau cu alti parametri fata de cazurile particulare ale testelor initiale. Aceste
obiective pot fi atinse utilizand metode de analiza statistica ce permit o identifi-
care mai usoara a erorilor ce apar ın fiecare etapa de proiectare. Metoda propusa
faciliteaza eliminarea factorilor care nu au influenta asupra raspunsului analizat
al aplicatiei, oferind ın acelasi timp o mai buna perspectiva asupra factorilor
care au cel mai mare impact asupra performantelor. Modelul prezentat permite
proiectantului unei aplicatii paralele sa estimeze performantele cu parametri de
intrare reali fara a rula efectiv aplicatia.
Solicitarile legate de performantele unui sistem de calcul au dus la apatia unor
concepte si modele noi, precum sistemele Grid sau tehnologiile de tip Cloud com-
puting. Aceste modele ofera solutii pentru rezolvarea unor probleme ce depasesc
puterea de calcul a unui calculator sau a unui cluster de calculatoare. Capitolul
4 este dedicat cerintelor impuse ın implementarea conceptelor sistemelor Grid.
Este prezentat cazul particular al gridului GRAI, ımpreuna cu provocarile ridi-
cate de implementarea acestuia. Construirea unei infrastructuri Grid presupune
ımbinarea de sisteme de operare, middleware-uri si instrumente de instalare si
configurare diferite. Problemele adresate ın cursul implementarii solutiei vizeaza
alegerea dispozitivelor hardware adecvate, a infrastructurii de retea, proiectarea
clusterelor, instalarea sistemului de operare si a instrumentelor de administrare,
ınglobarea tehnologiilor de securitate, testarea diferitelor instrumente si aplicatii
disponibile.
Sistemele Grid sunt sisteme de calcul de mare performanta eterogene, fapt
ce poate atrage dupa sine diferite probleme legate de exploatarea lor eficienta.
Nucleul acestor sisteme este reprezentat de clusterele destinate calculului sau
stocarii de date. Capitolul 5 este dedicat ımbunatatirii performantelor aplicatiilor
care ruleaza pe un cluster. Este abordata problematica legata de performantele
retelelor de interconectare interne clusterelor, scopul principal fiind reducerea
timpilor de comunicatii. In mod normal, aplicatiile intensive computational
genereaza foarte putin trafic si dependenta de performantele retelei de comunicatii
este minima. Pe de alta parte, o aplicatie de tip data intensive poate genera un
volum mare de trafic. Astfel, eficienta acestui tip de aplicatii este direct depen-
denta de performantele retelei de comunicatii. In acest scop, a fost proiectat si
implementat un model de ımbunatatire a performantelor retelei de interconectare
a unui cluster. Problema adresata de acest model este reducerea timpului de
transfer dintre noduri. Solutia oferita nu implica modificarea sau reproiectarea
aplicatiilor existente, fapt ce constituie un atu deosebit de important al modelu-
lui propus: practic sunt eliminate costurile suplimentare implicate de adaptarea
133

7. Concluzii, contributii si directii viitoare de cercetare
aplicatiei la eventualele modificari hardware ce pot aparea ın sistem.
Dupa cum a fost mentionat anterior, sistemele Grid intra ın categoria sis-
temelor neomogene de calcul distribuit. Pentru utilizatorii finali este importanta
identificarea, ın cadrul acestor sisteme, a unor resurse care sa ofere un timp ac-
ceptabil de rezolvare al problemelor. Urmarind aceasta idee, ın Capitolul 6, sunt
prezentate o serie de probleme care apar la partajarea resurselor de calcul. O
atentie deosebita este acordata tehnicilor de management a resurselor si a im-
plementarii acestora ın clustere. In prezent, solutiile existente ce rezolva aceste
probleme se bazeaza pe functii de biblioteca ce presupun modificarea aplicatiilor,
pe introducerea unor noi module de nucleu, pe utilizarea unor versiuni person-
alizate ale nucleului sistemului de operare sau pe modificarea planificatorului.
Versiunile recente ale nucleului Linux includ mecanisme noi pentru partitionarea
resurselor (Control Groups), mecanisme ce sunt utilizate cu precadere ın virtu-
alizarea resurselor de calcul, precum si ın sistemele de tip Cloud. Aceste tehnici
nu pot fi ınsa utilizate pe clustere unde nu se pot instala, din diverse motive,
aceste versiuni noi. Solutia propusa ın acest capitol se adreseaza direct acestei
situatii, destul de frecvent ıntalnita. Este introdus un sistem de management
al resurselor, implementat folosind o arhitectura de tip client-server. Utilizand
acest sistem, sunt propuse o serie de tehnici de alocare dinamica de resurse, pe
baza unor politici de rezervare, ın functie de tipul utilizatorilor. Folosirea acestor
tehnici nu implica decat simpla definire a unor politici de alocare/rezervare de
resurse. Avantajele acestei abordari deriva din faptul ca se utilizeaza software-ul
deja instalat pe cluster si nu se solicita modificari la nivelul sistemului de operare
sau al aplicatiilor.
7.2 Contributii
Contributiile aduse ın cadrul acestei lucrari s-au conturat ın jurul urmatoarelor
directii de cercetare:
1. Furnizarea unui model de proiectare si analiza a aplicatiilor par-
alele cu ajutorul metodei de proiectare statistica a experimentelor.
• Analiza metodelor clasice de proiectare a aplicatiilor paralele, de analiza
a performantelor acestora si problema echilibrarii ıncarcarii
[Sova si Amarandei 04], [Teodoru si Amarandei 07].
• In vederea ımbunatatirii metodelor de proiectare a aplicatiilor paralele,
a fost propusa o metoda de descriere a unei aplicatii si de analiza
a performantelor acesteia. Rezultatele obtinute au demonstrat atat
eficenta acestei metode ın detectarea erorilor de proiectare cat si posi-
bilitatea studierii comportamentului real al aplicatiei pe un set redus
de teste [Amarandei 11].
2. Proiectarea si implementarea unei infrastructuri Grid
134

7.3. Directii viitoare de cercetare
• Proiectarea si implementarea infrastructurii hardware si software pen-
tru site-ul grid GRAI ([Amarandei 08]).
• Analiza tehnicilor de implementare a clusterelor si diverse sisteme Grid
ın scopul realizarii infrastructurii hardware si software a gridului GRAI
([Aflori si Amarandei 05], [Amarandei 06], [Teodoru si Amarandei 07],
[Archip si Amarandei 08], [Arustei si Amarandei 07],
[Archip si Amarandei 07]).
3. Definirea unui nou model de optimizare a comunicatiilor ın clus-
terele membre ale sistemelor grid
• Definirea unui model de optimizare a comunicatiilor
([Rusan si Amarandei 10]).
• Realizarea unui algoritm ce implementeza modelul propus.
4. Definirea si implementarea unor technici eficiente de gestionare a
resurselor ın clustere
• Analiza tehnicilor de gestionare a resurselor disponibile ın clustere
([Amarandei 08], [Rusan si Amarandei 10]).
• Definirea arhitecturii unui sistem de gestiune a resurselor si partitionarea
acestora ([Amarandei 10]).
7.3 Directii viitoare de cercetare
Clusterele de calculatoare reprezinta ın continuare nucleul ultimelor tendinte ın
domeniul calculului de mare performanta. Tehnologiile de tip Grid si cloud com-
puting se bazeaza pe clustere cat mai performante pentru a putea asigura un
nivel corespunzator al serviciilor. Furnizarea unor servicii de calitate presupune
atat proiectarea corespunzatoare a aplicatiilor care vor oferi aceste servicii, cat
si utilizarea eficienta a sistemelor de calcul. Asa cum am amintit ın Capitolul 3,
ın proiectarea aplicatiilor paralele trebuie considerata identificarea factorilor care
au o influenta deosebita asupra performantlor. Simpla implicarea proiectantului
si a programatorului de aplicatii paralele nu este uneori suficienta ın realizarea
modelului ce descrie comportamentul aplicatiei. La testarea fuctionalitatii si
performantelor unei aplicatii paralele trebuie avute ın vedere si posibile influente
din partea mediului ın care aceasta ruleaza. Din acest motiv, ın modelul unei
aplicatii ar putea fi inclusi factori ce tin posibilitatile oferite de compilatoare
pentru optimizarea codului, de optimizarile ce se pot face la nivelul biblioteci-
lor utilizate (de expemplu MPI sau OpenMP) sau chiar la nivelul sistemului de
operare. In cazurile ın care rescrierea/adaptarea unei aplicatii paralele existente
implica un set suplimentar de costuri ridicate, o posibila abordare este reprezen-
tata de adaptarea dinamica a mediului ın care ruleaza aplicatia. In acest context
metodele de analiza a aplicatiilor bazate pe DoE pot fi extinse prin considerarea
unor factori externi aplicatiei ın sine. De exemplu, pentru aplicatiile MPI se pot
135

7. Concluzii, contributii si directii viitoare de cercetare
include ın modelul de analiza parametrii de configurare ai middleware-ului MPI
suport sau chiar parametrii subsistemului de comunicatii al sistemului de operare
gazda.
Asa cum s-a aratat ın Capitolul 5, performantele unui cluster sunt direct
influentate de parametrii sistemului de operare care ruleaza pe nodurile compo-
nente. Valorile acestor parametri pot fi luate ın considerare la realizarea mod-
elului unei aplicatii paralele. Sistemul de management al resurselor, prezentat ın
Capitolul 6, poate beneficia de utilizarea tehnicilor de proiectare statistica a ex-
perimentelor. Aceste tehnici pot furniza un model de performanta al parametrilor
sistemului de operare.
In cadrul Capitolului 6, a fost mentionat faptul ca sistemele de manage-
ment al joburilor iau ın considerare pentru stabilirea politicilor de rezervare a
resurselor informatii precum numarul de procesoare solicitate, memoria disponi-
bila, ıncarcarea si arhitectura sistemelor de calcul din clustere. Acest lucru poate
reprezenta o problema datorita faptului ca nu toti utilizatorii unui cluster folosesc
sistemul de management al job-urilor. Este frecvent cazul ın care utilizatorii unui
cluster au cont cu acces la shell si prefera sa utilizeze aceste facilitati pentru a rula
aplicatii ocolind job manager -ul. Aceste cazuri introduc ıncarcari suplimentare pe
nodurile unui cluster, ce pot ıngreuna activitatea planificatoarelor de job-uri. O
posibila directie de dezvoltare pentru solutia propusa ar fi extragerea informatiilor
de la job manager -ul ce ruleaza ın cluster si utilizarea lor ın rezervarea dinamica
de resurse. Majoritatea planificatoarelor de job-uri pot fi interogate prin inter-
mediul DRMAA (Distributed Resource Management Application API ). Plecand
de la acest lucru, posibilitatea de extindere este imediata. Se poate interoga
job managerul prin intermediul DRMAA pentru a extrage informatii despre job-
urile planificate si resurele socilitate. Aceste date pot fi utilizate pentru a revizui
politicile de rezervare de resurse existente. Desi metoda propusa se adreseaza
managementului clusterelor, avantajul pentru sistemele de tip Grid sau Cloud
computing sunt imediate. Administratorul poate defini politici de rezervare a
resurselor pentru clusterul pe care ıl gestioneaza si ın functie de cerintele pe care
trebuie sa le ındeplineasca ın cadrul sistemului Grid sau Cloud din care face parte.
136

Bibliografie
[Aflori si Amarandei 05] C. Aflori, M. Craus, I. Sova, C. Butincu F. Leon & C.M.
Amarandei. Grid - tehnologii si aplicatii. Politehnium, 2005.
[citat la p. 96, 97, 98, 135]
[Almasi 89] G. S. Almasi & A. Gottlieb. Highly parallel computing.
Benjamin-Cummings Publishing Co., Inc., Redwood City,
CA, USA, 1989. [citat la p. 21]
[Almesberger 99] W. Almesberger. Linux Network Traffic Control - Implemen-
tation Overview. In roceedings of 5th Annual Linux Expo,
pages 153–164, Raleigh, NC, May 1999. [citat la p. 126]
[Almesberger 02] Werner Almesberger. Linux Traffic Control - Next Gener-
ation. In Proceedings of the 9th International Linux Sys-
tem Technology Conference, pages 95–103, September 2002.
[citat la p. 126]
[Amarandei 06] C.M. Amarandei, A. Archip & S. (Caraiman) Arustei. Per-
formance Study for MySQL Database Access within Paral-
lel Applications. Buletinul Institutului Politehnic din Iasi,
Automatic Control and Computer Science Section, vol. LVI,
no. LII, pages 127–134, 2006. [citat la p. 110, 135]
[Amarandei 08] C.M. Amarandei, A. Rusan, A. Archip & S. (Caraiman)
Arustei. Scientific and educational grid applications, chapitre
On the Development of a GRID Infrastructure, pages 13–23.
Politehnium, Iasi, Romania, 2008. [citat la p. 99, 100, 101, 102,
104, 110, 135]
[Amarandei 10] C. M. Amarandei & A. Rusan. Techniques for effcient resource
management on shared clusters. In Proceedings of ECIT2010
- 6th European Conference on Intelligent Systems and Tech-
nologies, Iasi, Romania, October 2010. [citat la p. 124, 125, 126,
127, 128, 129, 130, 135]
[Amarandei 11] C. M. Amarandei, D. Lepdatu & S. Caraiman. Improving
the Design of Parallel Applications Using Statistical Meth-
137

Bibliografie
ods. Journal of Applied Sciences, vol. 11, no. 6, pages 932–
942, January 2011. http://dx.doi.org/10.3923/jas.2011.
932.942. [citat la p. 62, 75, 76, 77, 79, 80, 81, 82, 84, 85, 86, 87, 88,
89, 90, 134]
[Archip si Amarandei 07] A. Archip, C.M. Amarandei, S. (Caraiman) Arustei &
M. Craus. Optimizing Association Rule Mining Algorithms
using C++ STL Templates. Buletinul Institutului Politehnic
din Iasi, Automatic Control and Computer Science Section,
vol. LVII, no. LIII, pages 123–132, 2007. [citat la p. 135]
[Archip si Amarandei 08] A. Archip, S. (Caraiman) Arustei, C.M. Amarandei & A. Ru-
san. Scientific and educational grid applications, chapitre On
the design of Higher Order Components to integrate MPI ap-
plications in Grid Services, pages 25–35. Politehnium, Iasi,
Romania, 2008. [citat la p. 135]
[Arustei si Amarandei 07] S. (Caraiman) Arustei, A. Archip & C.M. Amarandei. Paral-
lel RANSAC for Plane Detection in Point Clouds. Buletinul
Institutului Politehnic din Iasi, Automatic Control and Com-
puter Science Section, vol. LVII, no. LIII, pages 139–150, 2007.
[citat la p. 135]
[Barnes 08] Bradley J. Barnes, Barry Rountree, David K. Lowenthal, Jaxk
Reeves, Bronis de Supinski & Martin Schulz. A regression-
based approach to scalability prediction. In ICS ’08: Proceed-
ings of the 22nd annual international conference on Super-
computing, pages 368–377, New York, NY, USA, 2008. ACM.
[citat la p. 73, 74, 85]
[Bernstein 66] A. J. Bernstein. Analysis of Programs for Parallel Process-
ing. IEEE Transactions on Electronic Computers, vol. EC-15,
no. 5, pages 757 – 763, October 1966. [citat la p. 21]
[Box 78] G. E. P. Box, W. G. Hunter & J. S. Hunter. Statistics for
experimenters: An introduction to design, data analysis, and
model building. John Wiley and Sons, New York, NY, USA,
1978. [citat la p. 71, 75]
[cgroups ] cgroups. cgroups. Website. http://www.linuxhq.com/
kernel/v2.6/24-rc3/Documentation/cgroups.txt.
[citat la p. 124]
[Chun 00] Brent N. Chun & David E. Culler. Market-based Proportional
Resource Sharing for Clusters. Technical Report CSD-00-
1092, University of California at Berkeley, 2000. [citat la p. 124]
[Cole 89] M. Cole. Algorithmic skeletons: structured management of
parallel computation. MIT Press, 1989. [citat la p. 13]
138

Bibliografie
[Cortes 98] A. Cortes, A. Ripoll, M.A. Senar, F. Cedo & E. Luque. On the
convergence of SID and DASUD load-balancing algorithms.
Technical report, Universitat Autonoma de Barcelona, 1998.
[citat la p. 53]
[Sova si Amarandei 04] I. Sova, C.M. Amarandei & I. Gavrila. Dynamic Load Bal-
ancing in Tree-Topology Distributed Mobile Agents System. In
Proceedings of the Eighth International Symposium on Auto-
matic Control and Computer Science, 2004. [citat la p. 53, 55,
56, 57, 58, 59, 60, 134]
[Sova 06] I. Sova. Aplicatii ale agentilor inteligenti ın sisteme informat-
ice bazate pe cunostinte. Tehnopress, 2006. [citat la p. 11, 53,
54]
[diffserv ] diffserv. Differentiated Services on Linux. Website. http:
//diffserv.sourceforge.net. [citat la p. 126]
[Dunigan 02] T. Dunigan, M. Mathis & B. Tierney. A TCP tuning dae-
mon. In Proceedings of the 2002 ACM/IEEE conference on
Supercomputing, 2002. [citat la p. 112, 115]
[Dykstra 71] O. J. Dykstra. The Augmentation of Experimental Data to
Maximize |X ′X|. Technometrics, vol. 13, no. 3, pages 682–
688, August 1971. http://www.jstor.org/pss/1267180.
[citat la p. 74]
[Foster 95] I. Foster. Designing and building parallel programs. Addison-
Wesley, 1995. [citat la p. 13, 15, 16, 19, 24, 25, 26, 27, 28, 29, 30, 31,
34, 35, 36, 37, 38, 62, 75]
[Foster 98] I. Foster & C. Kesselman. The grid: Blueprint for a fu-
ture computing infrastructure. Morgan Kaufmann, 1998.
[citat la p. 95]
[Foster 01] I. Foster, C. Kesselman & S. Tuecke. The Anatomy of
the Grid: Enabling Scalable Virtual Organizations. Interna-
tional Journal of High Performance Computing Applications,
vol. 15, no. 3, pages 200–222, 2001. [citat la p. 95, 96]
[Foster 02] I. Foster. What Is the Grid? A Three Point Checklist. Grid
Today, vol. 1, no. 6, 2002. [citat la p. 96]
[Gergel 06] Victor P. Gergel. Introduction to Parallel Programming.
University of Nizhni Novgorod, November 2006. https://
www.facultyresourcecenter.com/curriculum /pfv.aspx?
ID=6594&Login=. [citat la p. 14, 15, 16, 21, 23, 25, 26, 28, 31, 33]
[gLite Documentation 11] gLite Documentation. gLite 3.2 Documentation. Website,
2011. http://glite.web.cern.ch/glite/documentation/.
[citat la p. 101]
139

Bibliografie
[Grama 03] Ananth Grama, George Karypis, Vipin Kumar & Anshul
Gupta. Introduction to parallel computing (2nd edition). Ad-
dison Wesley, 2 edition, Jan 2003. [citat la p. 41]
[Grigoras 00] D. Grigoras. Calcul paralel. de la sisteme la programarea
aplicatiilor. Agora, 2000. [citat la p. 14, 22, 23, 25, 40, 43, 45]
[Gustafson 88] John L. Gustafson. Reevaluating Amdahl’s law. Commun.
ACM, vol. 31, no. 5, pages 532–533, 1988. http://doi.acm.
org/10.1145/42411.42415. [citat la p. 43]
[Gustedt 09] Jens Gustedt, Emmanuel Jeannot & Martin Quinson. Ex-
perimental Methodologies for Large-Scale Systems: a Survey.
Parallel Processing Letter, vol. 19, no. 3, pages 399–418, Sept
2009. [citat la p. 62]
[Hammond 99] K. Hammond & G. Michaelson (editors). Research directions
in parallel functional programming. Springer-Verlag, 1999.
[citat la p. 13, 14]
[Hill 08] Mark D. Hill & Michael R. Marty. Amdahl’s Law in the
Multicore Era. Computer, vol. 41, no. 7, pages 33–38, 2008.
http://dx.doi.org/10.1109/MC.2008.209. [citat la p. 44]
[Isaic-Maniu 06] Alexandru Isaic-Maniu & Viorel Voda Gh. Proiectarea statis-
tica a experimentelor: fundamente si studii de caz. Editura
Economica, 2006. [citat la p. 63, 69, 70, 71]
[Ivan 04] I. Ivan & C. Boja. Metode statistice in analiza software. Ed-
itura ASE, 2004. [citat la p. 75]
[Jaba 98] Elisabeta Jaba. Statistica. Editura Economica, 1998.
[citat la p. 67, 68, 70, 71]
[Jacobson 92] V. Jacobson, R. Braden & D. Borman. RFC1323 TCP Ex-
tensions for High Performance. Website, May 1992. http:
//www.ietf.org/rfc/rfc1323.txt. [citat la p. 115]
[Jain 91] R. Jain. The art of computer system performance and anal-
ysis. John Wiley and Sons, New York, NY, USA, 1991.
[citat la p. 71, 73, 75]
[Katz 02] Mason J. Katz, Philip M. Papadopoulos & Greg Bruno. Lever-
aging Standard Core Technologies to Programmatically Build
Linux Cluster Appliances. In CLUSTER ’02: Proceedings
of the IEEE International Conference on Cluster Computing,
page 47, Washington, DC, USA, 2002. IEEE Computer Soci-
ety. [citat la p. 106, 107, 108]
[Kitchenham 02] Barbara A. Kitchenham, Shari Lawrence Pfleeger, Lesley M.
Pickard, Peter W. Jones, David C. Hoaglin & Khaled El
Emam. Preliminary Guidelines for Empirical Research in
140

Bibliografie
Software Engineering. IEEE Transactions on Software En-
gineering, vol. 28, no. 8, pages 721–734, 2002. [citat la p. 75]
[Kleijnen 04] J.P.C. Kleijnen, S.M. Sanchez, T.W. Lucas & T.M. Cioppa.
A User’s Guide to the Brave New World of Designing Simula-
tion Experiments. INFORMS Journal on Computing, vol. 17,
no. 3, pages 263–289, 2004. [citat la p. 71, 75]
[Kuck 05] D.J. Kuck. Platform 2015 software: Enabling innovation in
parallelism for the next decade. Rapport technique, Intel,
2005. [citat la p. 12]
[Kumar 91] Vipin Kumar & Anshul Gupta. Analysis of scalability of par-
allel algorithms and architectures: a survey. In ICS ’91: Pro-
ceedings of the 5th international conference on Supercomput-
ing, pages 396–405, New York, NY, USA, 1991. ACM. http:
//doi.acm.org/10.1145/109025.109118. [citat la p. 40, 46,
47]
[Kwiatkowski 02] Jan Kwiatkowski. Evaluation of Parallel Programs by Mea-
surement of Its Granularity. In PPAM ’01: Proceedings of the
th International Conference on Parallel Processing and Ap-
plied Mathematics-Revised Papers, pages 145–153, London,
UK, 2002. Springer-Verlag. [citat la p. 41, 45]
[Law 99] Averill M. Law & David M. Kelton. Simulation modeling and
analysis. McGraw-Hill Higher Education, 1999. [citat la p. 72]
[Lee 80] R. Lee. Empirical results on the speed, efficiency, redundancy
and quality of parallel computations. In Proceedings of the
1980 International Conference on Parallel Processing, pages
91–100, 1980. [citat la p. 43]
[Linuxcontainers ] Linuxcontainers. Linuxcontainers. Website. http://lxc.
sourceforge.net/. [citat la p. 125]
[Molnar 08] Steven Molnar, Michael Cox, David Ellsworth & Henry Fuchs.
A sorting classification of parallel rendering. In ACM SIG-
GRAPH ASIA 2008 courses, SIGGRAPH Asia ’08, pages
35:1–35:11, New York, NY, USA, 2008. ACM. [citat la p. 79,
81, 83]
[Montgomery 06] Douglas C. Montgomery. Design and analysis of experiments.
John Wiley & Sons, 2006. [citat la p. 71, 72, 75, 83]
[Montgomery 07] D.C. Montgomery & G.E. Runger. Applied statistics and
probability for engineers. John Wiley & Sons, 4 edition, 2007.
[citat la p. 67, 68, 69]
[Morgan 10] Andrew G. Morgan. The Linux-PAM System Administrator’s
Guide. Website, 2010. http://www.kernel.org/pub/
linux/libs/pam/Linux-PAM-html/Linux-PAM_SAG.html.
[citat la p. 126]
141

Bibliografie
[Netperf ] Netperf. Netperf homepage. Website. http://www.netperf.
org/netperf/NetperfPage.html. [citat la p. 117]
[NetPIPE ] NetPIPE. NetPIPE. Website. http://www.scl.ameslab.
gov/netpipe/. [citat la p. 116]
[NIST/SEMATECH 06] NIST/SEMATECH. e-Handbook of Statistical Methods. Web-
site, 2006. http://www.itl.nist.gov/div898/handbook/
pri/section3/pri3.htm. [citat la p. 63, 64, 65, 66, 67, 71, 77,
78]
[Papadopoulos 04] Philip M. Papadopoulos, Caroline A. Papadopoulos, Ma-
son J. Katz, William J. Link & Greg Bruno. Config-
uring Large High-Performance Clusters at Lightspeed: A
Case Study. Int. J. High Perform. Comput. Appl., vol. 18,
no. 3, pages 317–326, 2004. http://dx.doi.org/10.1177/
1094342004046056. [citat la p. 105, 106]
[Petcu 01] D. Petcu. Procesare paralela. Editura Eubeea, 2001.
[citat la p. 41]
[Pollack 99] Fred J. Pollack. New microarchitecture challenges in the com-
ing generations of CMOS process technologies. In MICRO
32: Proceedings of the 32nd annual ACM/IEEE international
symposium on Microarchitecture, page 2, Washington, DC,
USA, 1999. IEEE Computer Society. [citat la p. 44]
[Quinn 04] M. J. Quinn. Parallel programming in c with mpi and openmp.
Higher Education. McGraw-Hill, SEPT 2004. [citat la p. 20, 23,
27, 28, 31, 35, 62]
[Rao 08] Pradeep Rao & Kazuaki Murakami. Using Statistical Mod-
els for Embedded Java Performance Analysis. International
Conference on High Performance Computing (HiPC 2008):
December 17-20, 2008 : Bangalore, India, December 2008.
[citat la p. 73]
[Rauber 10] Thomas Rauber & Gudula Runger. Parallel programming for
multicore and cluster systems. Software Engineering. Springer
Verlag, 1 edition, 2010. [citat la p. 12, 19, 20, 21, 23]
[Ridge 07] Enda Ridge, Daniel Kudenko & Yo Dd England. Analyz-
ing Heuristic Performance with Response Surface Models:
Prediction, Optimization and Robustness. In GECCO ’07:
Proceedings of the 9th annual conference on Genetic and
evolutionary computation, pages 150–157, New York, NY,
USA, 2007. ACM. http://doi.acm.org/10.1145/1276958.
1276979. [citat la p. 73, 74]
[rocksclusters 02] rocksclusters. Rocks Cluster Distribution manuals: Users
Guide, Introduction to Clusters and Rocks Overview. Web-
site, 2002. http://www.rocksclusters.org. [citat la p. 106,
109]
142

Bibliografie
[Rusan si Amarandei 10] A. Rusan & C. M. Amarandei. A New Model for Clus-
ter Communications Optimization. International Journal of
Computers, Communications & Control, vol. V, no. 5, 2010.
[citat la p. 112, 113, 114, 118, 119, 120, 121, 122, 125, 135]
[Ruthruff 06] Joseph R. Ruthruff, Sebastian Elbaum & Gregg Rothermel.
Experimental Program Analysis: A New Program Analysis
Paradigm. In Proceedings of the 2006 international sympo-
sium on Software testing and analysis, pages 49–60, Portland,
Maine, USA, 2006. [citat la p. 73, 74]
[Sacerdoti 04] F. D. Sacerdoti, S. Chandra & K. Bhatia. Grid systems de-
ployment & management using Rocks. In CLUSTER ’04: Pro-
ceedings of the 2004 IEEE International Conference on Clus-
ter Computing, pages 337–345, Washington, DC, USA, 2004.
IEEE Computer Society. [citat la p. 108, 109]
[Sahni 4] Sartaj Sahni & Venkat Thanvantri. Performance Metrics:
Keeping the Focus on Runtime. IEEE Parallel Distrib. Tech-
nol., vol. 1996, no. 1, pages 43–56, 4. http://dx.doi.org/
10.1109/88.481664. [citat la p. 39]
[Shi 96] Justin Yuan Shi. Reevaluating Amdahl’s Law and Gustafson’s
Law. Website, 1996. http://www.cis.temple.edu/~shi/
docs/amdahl/amdahl.html. [citat la p. 42]
[Skillicorn 96] David B. Skillicorn & Domenico Talia. Models and Languages
for Parallel Computation. ACM Computing Surveys, vol. 30,
pages 123–169, 1996. [citat la p. 18]
[Skillicorn 05] D. B. Skillicorn. Foundations of parallel programming,
volume 6 of Cambridge International Series on Parallel
Computation. Cambridge University Press, August 2005.
[citat la p. 12, 13]
[Snell 96] Quinn O. Snell, Armin R. Mikler & John L. Gustafson. Net-
PIPE: A Network Protocol Independent Performance Evalu-
ator. In in IASTED International Conference on Intelligent
Information Management and Systems, 1996. [citat la p. 117]
[Stewardson 02] D.J. Stewardson, C. Hicks, P. Pongcharoen, S.Y. Coleman &
P.M. Braiden. Overcoming complexity via statistical thinking:
optimising Genetic Algorithms for use in complex scheduling
problems via designed experiments. Tackling Industrial Com-
plexity: the ideas that make a difference, pages 275–290, April
2002. [citat la p. 73]
[Sun 91] Xian-He Sun & John L. Gustafson. Toward a better parallel
performance metric. Parallel Computing, vol. 17, no. 10-11,
pages 1093 – 1109, 1991. [citat la p. 39]
143

Bibliografie
[Sun 94] Xian-He Sun & Diane Thiede Rover. Scalability of Paral-
lel Algorithm-Machine Combinations. IEEE Trans. Parallel
Distrib. Syst., vol. 5, no. 6, pages 599–613, 1994. http:
//dx.doi.org/10.1109/71.285606. [citat la p. 40]
[Sun 10] Xian-He Sun & Yong Chen. Reevaluating Amdahl’s law in
the multicore era. J. Parallel Distrib. Comput., vol. 70, no. 2,
pages 183–188, 2010. http://dx.doi.org/10.1016/j.jpdc.
2009.05.002. [citat la p. 44, 45]
[Teodoru si Amarandei 07] Tudor Teodoru & C.M. Amarandei. Load Balancing in a Mo-
bile Agent System. In Proceedings of 9th International Sym-
posium on Automatic Control and Computer Science. Editura
POLITEHNIUM, 2007. [citat la p. 57, 134, 135]
[Tierney 01] B.L Tierney, D. Gunter, J. Lee, M. Stoufer & J.B. Evans.
Enabling network-aware applications. In Proceedings of the
10th IEEE International Symposium on High Performance
Distributed Computing, pages 281–288, 2001. [citat la p. 112,
116]
[Tirumala ] A. Tirumala & L. Cottrell. Iperf Quick Mode. Web-
site. http://www-iepm.slac.stanford.edu/bw/iperfres.
html. [citat la p. 117]
[Totaro 05] Michael W. Totaro & Dmitri D. Perkins. Using statisti-
cal design of experiments for analyzing mobile ad hoc net-
works. In MSWiM ’05: Proceedings of the 8th ACM inter-
national symposium on Modeling, analysis and simulation of
wireless and mobile systems, pages 159–168, New York, NY,
USA, 2005. ACM. http://doi.acm.org/10.1145/1089444.
1089472. [citat la p. 74, 75, 77]
[Turner 02] Dave Turner & Xuehua Chen. Protocol-Dependent Message-
Passing Performance on Linux Clusters. In CLUSTER ’02:
Proceedings of the IEEE International Conference on Clus-
ter Computing, pages 187–194, Washington, DC, USA, 2002.
IEEE Computer Society. [citat la p. 117]
[Turner 03] D. Turner, A. Oline, X. Chen & T. Benjegerdes. Integrating
New Capabilities into NetPIPE. In Lecture Notes in Com-
puter Science, pages 37–44. Springer-Verlag, September 2003.
[citat la p. 117]
[Urgaonkar 02] B. Urgaonkar, P. Shenoy & T. Roscoe. Resource overbooking
and application profiling in shared hosting platforms. SIGOPS
Oper. Syst. Rev., vol. 36, no. SI, pages 239–254, 2002. http:
//doi.acm.org/10.1145/844128.844151. [citat la p. 124]
[Urgaonkar 04] B. Urgaonkar & P. Shenoy. Sharc: Managing CPU and
Network Bandwidth in Shared Clusters. IEEE Transac-
tions on Parallel and Distributed Systems, vol. 15, no. 1,
144

Bibliografie
pages 2–17, 2004. http://dx.doi.org/10.1109/TPDS.2004.
1264781. [citat la p. 124, 125]
[Whiting 04] David Whiting, Quinn Snell, Rebecca R. Nichols, Megan L.
Porter, Kevin Tew, Keith A. Crandall, Michael F. Whiting &
Mark Clement. Complex Performance Analysis Through Sta-
tistical Experimental Design: An Evaluation of Parameters
Associated with Speed in Parallel Phylogenomics. Hawaii In-
ternational Conference on Computer Science, pages 615–629,
January 2004. [citat la p. 73, 74]
[Wilkinson 99] B. Wilkinson & M. Allen. Parallel programming. Prentice-
Hall, 1999. [citat la p. 43, 44, 49, 50, 51, 52, 53]
[Willebeek-LeMair 93] M. Willebeek-LeMair & A.P. Reeves. Strategies for Dynamic
Load Balancing on Highly Parallel Computers. IEEE Transac-
tions on Parallel and Distributed Systems, vol. 4, no. 9, pages
979–993, 1993. [citat la p. 53]
[Yao 09] Erlin Yao, Yungang Bao, Guangming Tan & Mingyu Chen.
Extending Amdahl’s law in the multicore era. SIGMET-
RICS Perform. Eval. Rev., vol. 37, no. 2, pages 24–26, Octo-
ber 2009. http://doi.acm.org/10.1145/1639562.1639571.
[citat la p. 45]
[Zheng 10] Gengbin Zheng, Gagan Gupta, Eric Bohm, Isaac Dooley &
Laxmikant V. Kale. Simulating Large Scale Parallel Applica-
tions using Statistical Models for Sequential Execution Blocks.
In Proceedings of the 16th International Conference on Par-
allel and Distributed Systems (ICPADS 2010), pages 10–15,
Shanghai, China, December 2010. [citat la p. 73]
[Zirbas 89] J. R. Zirbas, D. J. Reble & R.E. vanKooten. Measuring the
scalability of parallel computer systems. In Supercomputing
’89: Proceedings of the 1989 ACM/IEEE conference on Super-
computing, pages 832–841, New York, NY, USA, 1989. ACM.
http://doi.acm.org/10.1145/76263.76358. [citat la p. 46]
145











![A BUMPLESS TRANSFER METHOD FOR AUTOMATIC FLIGHT … · A bumpless transfer method for automatic flight contro l switching 5 UASSC schemes used so far, as noted in [1] and [2], stems](https://static.fdocumente.com/doc/165x107/5e57aad3b480df45561bb456/a-bumpless-transfer-method-for-automatic-flight-a-bumpless-transfer-method-for-automatic.jpg)







